#tools-and-devops
1 messages · Page 15 of 1
https://pypi.org/project/qoin/ doesn't seem taken
Yeah, I'm gonna do the name updating, and then re-attempt, and if there are still issues, apologies in advance for bothering you.

I think it worked!
Quick question, can I delete the build and dist folders from my vscode (which is basically the repo)?
I understand that everytime you update you have to rebuild and redo again, so can I just delete and whenever I want to update just make and re-delete?
How do I update the pypi?
Hi guys. Sometimes last week, I had some issues with serving some web page using gunicorn and Nginx. And @rapid sparrow was very helpful in getting through this.
I have a large part of resolved. Web page is served almost fine, both locally and on the web.
Persisting issue: The served webpage does not include my dynamic resources from MySQL db.
Image 1 is what the webpage looked like prior to serving with Nginx and gunicorn
oluwaseyi@oluwaseyi:~/Documents/AirBnB_clone_v4$ HBNB_MYSQL_USER=hbnb_dev HBNB_MYSQL_PWD=hbnb_dev_pwd HBNB_MYSQL_HOST=localhost HBNB_MYSQL_DB=hbnb_dev_db HBNB_TYPE_STORAGE=db python3 -m web_dynamic.2-hbnb
Image 2 is what the webpage looks like after serving with Nginx and gunicorn to IP address.
ubuntu@289442-web-01:~/AirBnB_clone_v4$ gunicorn --bind 0.0.0.0:5003 web_dynamic.2-hbnb:app
Image 3 is a CURL-ed version of the webpage, which shows that the db is not being access.
oluwaseyi@oluwaseyi:~/Documents/AirBnB_clone_v4$ curl -s 18.204.13.162 |tail -n 40
I have the following suspects: web_dynamic/2-hbnb.py and web_dynamic/static/script/2-hbnb.js below.
web_dynamic/2-hbnb.py
#!/usr/bin/python3
""" Starts a Flash Web Application """
from models import storage
from models.state import State
from models.city import City
from models.amenity import Amenity
from models.place import Place
from os import environ
from flask import Flask, render_template
app = Flask(__name__)
import uuid
@app.teardown_appcontext
def close_db(error):
""" Remove the current SQLAlchemy Session """
storage.close()
@app.route('/2-hbnb/', strict_slashes=False)
def hbnb():
""" HBNB is alive! """
states = storage.all(State).values()
states = sorted(states, key=lambda k: k.name)
st_ct = []
for state in states:
st_ct.append([state, sorted(state.cities, key=lambda k: k.name)])
amenities = storage.all(Amenity).values()
amenities = sorted(amenities, key=lambda k: k.name)
places = storage.all(Place).values()
places = sorted(places, key=lambda k: k.name)
return render_template('2-hbnb.html',
states=st_ct,
amenities=amenities,
places=places,
cache_id=str(uuid.uuid4()))
if __name__ == "__main__":
""" Main Function """
app.run(host='0.0.0.0', port=5000)
web_dynamic/static/scripts/2-hbnb.js
$(document).ready(function () {
const selectedAmenities = {};
$('.checkbox').on('click', function () {
const amenityId = $(this).data('id');
const amenityName = $(this).data('name');
if (Object.prototype.hasOwnProperty.call(selectedAmenities, amenityId)) {
delete selectedAmenities[amenityId];
} else {
selectedAmenities[amenityId] = amenityName;
}
$('.amenities h4').text(Object.values(selectedAmenities).join(', '));
});
// getting the status of API
$.get('http://18.204.13.162/api/v1/status/', function (data) {
if (data.status === 'OK') {
$('div#api_status').addClass('available');
} else {
$('div#api_status').removeClass('available');
}
});
});
try to load static url for loading static asset web_dynamic/static/script/2-hbnb.js
it should give an error
because gunicorn should not be serving static assets, and u probably did not write Nginx config for assets serving



- Call url related to
web_dynamic/static/script/2-hbnb.jsdirectly from browser - Check browser console for errors (open it in dev tools), when u open regular pages
Both actions should clarify source of errror
For some reasons, pastebin.com isn't available.
Nginx configuration to server /airbnb-onepage
server {
listen 80 default_server;
listen [::]:80 default_server;
# root /home/ubuntu/AirBnB_clone_v4/web_dynamic;
# Server information
add_header X-Served-By $hostname;
# Config to serve /
location / {
include proxy_params;
proxy_pass http://127.0.0.1:5003/2-hbnb;
proxy_set_header X-Served-By $hostname;
# Uncomment the following line to serve static assets
include /etc/nginx/mime.types;
root /home/ubuntu/AirBnB_clone_v4/web_dynamic/static;
}
# Config to seve /airbnb-onepage/
location /airbnb-onepage/ {
include proxy_params;
proxy_pass http://127.0.0.1:5000/airbnb-onepage/;
proxy_set_header X-Served-By $hostname;
}
# Config to serve .airbnb-dynamic/number_odd_or_even/<int:n>
location ~ ^/airbnb-dynamic/number_odd_or_even/(?<n>\d+)$ {
include proxy_params;
proxy_pass http://127.0.0.1:5001/number_odd_or_even/$n;
proxy_set_header X-Served-By $hostname;
}
# Config to serve /number_odd_or_even/<int:n>
location ~ ^/number_odd_or_even/(?<n>\d+)$ {
include proxy_params;
proxy_pass http://127.0.0.1:5001/number_odd_or_even/$n;
proxy_set_header X-Served-By $hostname;
}
# Config to serve /number_odd_or_even/<int:n>
location /api {
include proxy_params;
proxy_pass http://127.0.0.1:5002/api;
}
# Config to serve /number_odd_or_even/<int:n>
location /web_dynamic {
include proxy_params;
proxy_pass http://127.0.0.1:5003/web_dynamic;
proxy_set_header X-Served-By $hostname;
}
location /static/ {
alias /home/ubuntu/AirBnB_clone_v4/web_dynamic/static/;
}
}
Odd config. why not to serve everything in a single proxy?
Allow me cleanup the config
# Nginx configuration to server /airbnb-onepage
server {
listen 80 default_server;
listen [::]:80 default_server;
# root /home/ubuntu/AirBnB_clone_v4/web_dynamic;
# Server information
add_header X-Served-By $hostname;
# Config to serve /
location / {
include proxy_params;
proxy_pass http://127.0.0.1:5003/2-hbnb;
proxy_set_header X-Served-By $hostname;
# Uncomment the following line to serve static assets
include /etc/nginx/mime.types;
root /home/ubuntu/AirBnB_clone_v4/web_dynamic/static;
}
# Config to serve /web_dynamic/
location /web_dynamic {
include proxy_params;
proxy_pass http://127.0.0.1:5003/web_dynamic;
proxy_set_header X-Served-By $hostname;
}
location /static/ {
alias /home/ubuntu/AirBnB_clone_v4/web_dynamic/static/;
}
}
The removed parts are not related to the issue.. So which other proxies did you suggest serving through a single proxy?
location / {
proxy_pass http://localhost:5003;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header Host $host;
proxy_redirect off;
}
for all addresses?
designing web site to manage routing on its own
location ~* ^.+\.(ttf|js|css)$ {
alias /path_to_static/; # with or without end slash.
}
those instructions could be repurposed to serve static assets ony 🤔
server {
server_name _;
root /var/www/site;
location / {
try_files $uri $uri/ @proxy;
}
location @proxy {
include fastcgi_params;
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
fastcgi_pass unix:/tmp/phpcgi.socket;
}
}
https://www.nginx.com/resources/wiki/start/topics/tutorials/config_pitfalls/
this is nice page with recipes
This page outlines some of the NGINX configuration issues that we see frequently and then explains how to resolve them.
looks liks simpliest choice
Service static assets first, if not discovered, then go to proxy
if we repurpose for gunicorn purposes we get
server {
server_name _;
root /var/www/site;
location / {
try_files $uri $uri/ @proxy;
}
location @proxy {
proxy_pass http://localhost:5003;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header Host $host;
proxy_redirect off;
}
}
Nothing happens when I try to run any kubectl command. Even kubectl --help does nothing, the terminal just hangs. I have to ctrl c to regain control. I'm on WSL2 with ubuntu 22.04.3. Any ideas on what's happening?
what happens if you pass -v10 to --help for verbosity
alternatively i would try running it under strace and seeing if it hangs on some network call
did you mean me?
I'm still having problems with kubernetes. There was a brief moment where I could run kubectl with no problems, but now it's crashed again but in a different way. running kubectl get pods -A gives me:
E0131 17:50:03.303917 5550 memcache.go:265] couldn't get current server API group list: Get "http://localhost:8080/api?timeout=32s": dial tcp 127.0.0.1:8080: connect: connection refused
The connection to the server localhost:8080 was refused - did you specify the right host or port?
Running docker ps shows me there are no containers running, but from what I understand there should be a kube-apiserver container, is that right?
I'm thinking of doing a completely clean install of kubernetes on my machine, but I'm not sure how to do that
why don't many open source projects use poetry? they seem to be using setuptools mostly
Why do you think they should be using Poetry?
Dependency resolution and pinning I guess?
Can’t you do that in setuptools?
lock file lets you lock all transitive dependencies while allowing only the required deps to be specified as variable versions in the dependency file which makes updating seamless
For some perspective, there are 52481 packages on PyPI using setuptools, and and 35852 packages using Poetry
They’re the #1 and #2 backends, respectively
I use setuptools and I create lock files with pip-compile
Setuptools is old. Over 20 years old. Most projects using setuptools were using it long before Poetry even existed
Okay that makes sense... yeah and I gotta figure if packages only have a few dependencies it doesn't really matter
It also supports dynamic generation of metadata with the setup.py, something that most other backends don’t really support, as the community tries to move away from it because it’s a giant security hole
People put malware in the setup.py so it executes when your computer tries to install the package, for example
so why do you use it over poetry / are there downsides of poetry?
- Poetry is not standards compliant, and they refused to be a team player for a while, and now they’re trying but they’re playing catch-up
- I was having lock files get corrupted or taking over 20 minutes to lock on a daily basis
- I don’t remember the details anymore, and it’s fixed now, but when I was using it years ago, I had a lot of trouble getting it to build and publish my packages correctly
awesome thanks for deets
I needed something that worked, and Poetry didn’t work
what standards?
It’s much more stable now, from my understanding
But it’s the only major player that’s not standards compliant, and I just don’t like that 
!pep 621
Status
Final
Created
22-Jun-2020
Type
Standards Track
!pep 517
Status
Final
Created
30-Sep-2015
Type
Standards Track
Disclaimers:
Poetry used the pyproject.toml file before PEP 621 came out, but they use their own format which is incompatible with PEP 517
They do have a PEP 517 package out now, but it parses their own custom format, not PEP 621’s format like it’s supposed to
whoa, thanks so much for the info, I didn't know about all that
does anyone uses PDM?
Lots of people
Do you have a question about it?
oh well, I am looking for some example projects
Anything in particular?
Looking for something that builds with CMake
Python with CMake?
Do you understand what they mean by missing usable build-time dependency declaration? I define what my package depends on when I build a wheel.
Can you be a bit more specific
Oh sorry. Sure I was reading the pep 517 that you shared. And the 1st paragraph is justification for moving away from distools and setup tools seems misleading about dependencies. But setup tools have the ability to include dependencies. setuptools.setup(install_requires = ['requests==2.*'],
ah
The key here is build time
install_requires, somewhat contradictory to it's name, defines what's required to run your package
There's no way to differentate a dependency that's only required to build your package but not to run it
Now, with PEP 621, you declare your run time with dependencies = [...] in the [project] section, and with PEP 517, you declare your build time dependencies in the requires = [...] in the [build-system] section
That differentiation didn't exist before these PEPs, so if you, for example, needed some C library available to build your code, you had to force your users to install it too, even though they didn't actually need it just to use your code
I see. Thank you for that explanation. That's clear now.
Hi any recommendation for CLI framework? Not really complicated use cases. It would be nice if it was easy to use. I am trying with Click but maybe there are better options
argparse is inbuilt std framework, nothing is required to install for its usage
Hi folks I want to build a project can anybody help me find a small project where I can build the project for portfolio
Is there a dashboard/graphing tool that is completely static e.g. frontend-only, no backend? Like can load data from CSV/JSON/Parquet files?
Something like Grafana except I don't have to run a Grafana process on a server?
https://datasette.io/ for displaying CSVs
No graphs though AFAIK
Not really understanding what you're looking for
!projects
Kindling Projects
The Kindling projects page on Ned Batchelder's website contains a list of projects and ideas programmers can tackle to build their skills and knowledge.
This is a server and has no graphs, seems unrelated
Maybe I'm not being clear, especially if you haven't used Grafana before. I want a web app that will graph time series, allowing one to select different time periods (zoom/pan), that loads from static data files directly without a server component (e.g. loads from S3 or GitHub Pages or similar)
Have you taken a look at streamlit? It has its limitations, but pretty easy to set up
You would need to code the graphs yourself though (with something like plotly)
So it has a server component (streamlit) and doesn't have graphs (I have to make them with plotly)
I don't know how to make it clearer that those are my two requirements
You'll have to build a JS-based solution then
Something using d3.js or the like
Yeah that's what I'm starting to realize, after looking far and wide for 2 hours
there's so many solutions but none of them frontend-only
https://perspective.finos.org/ seems pretty close
Yo guys I need help with this script (I want to troll friends that I made a hacking program)

also how do I change colors
use multi-line string """ ... """
Damn that helped tysm
You know how to change the colors?
I want to maked it half red-blue-purple
yep, however that would depend on the terminal
for example on windows, when using cmd it wont work (because windows sucks)
but with terminal (from ms store) it will
and on linux most terminals support it
you will need to use ANSI codes
ANSI escape sequences are a standard for in-band signaling to control cursor location, color, font styling, and other options on video text terminals and terminal emulators. Certain sequences of bytes, most starting with an ASCII escape character and a bracket character, are embedded into text. The terminal interprets these sequences as command...
there are a couple of libraries that will colorze text properly on all platforms -- termcolor and colorama iiuc
pls I want job elon, I can change colors
Use colorama pip to give color.
Like example:
In terminal:
pkg install colorama
pkg install Fore
pkg install Style
exit
Then:
In python script:
import colorama
from colorama import Fore
R=Fore.RED
B=Fore.BLUE
G=Fore.GREEN
print(f"""Hi Guys {R} How Are {B} You? {G} Bye""")
i love that kids are still doing this. i remember writing scary-looking batch scripts on my parents' windows 98 PC and scheming about ways to prank my family with it
guys, do you know where the mapping between a python project version (say 1.3.2-alpha0) and the package filenames (in this case 1.3.2a0) I need to be able to call this programatically
there might be something in https://packaging.pypa.io/en/latest/index.html
@tawdry needle thanks a ton, the issue i'll have to deal with is mapping normalization https://packaging.python.org/en/latest/specifications/version-specifiers/#pre-release-spelling between different part of our build pipeline (thanks again)
yeah, apparently https://packaging.pypa.io/en/latest/utils.html#packaging.utils.canonicalize_version is what i'm after
is this a good place to ask questions about setting up venvs, dealing with conda and the like? I've been trying to get something set up for several days and it's not working out
so i want to setup CI on github. as I understand it, I can setup CI for individual branch.
my plan is to have a master branch, and a release candidate rc0 branch. rc0 would have the build & test CI, as for the master branch, im not quite sure yet but maybe more test?
what is the 'sane' workflow usually?
i think usually release works with tags u have a workflow which checks for v* tags and if present a release is made
Hi friends! I'm trying to hack a little bit on the packages resolution, need a flexible resolver with some escape hatches, maybe caching of metadata for packages so it's faster. I don't think a thing that I'm looking for exists, but I'd love to learn about existing art in this space.
I'm aware of:
- pip resolver (legacy, backtracking)
- rip
What else should I know about before trying to write my own thing from the ground up lol?
noted, will read more
pdm, poetry? u mean python packages right?
yes
hmm our local pypi server rejects twine upload because package name does not include the program version
libmabma which wraps libsolv
foo-1.2.3_foo-bar-py2..whl not including foo-1.2.3-foo-bar
so annoying that names are being mangled by different tools
ideally they would all use the actual standard format
they all should, otherwise twine would reject
i use official python build, then twine, and target devpi
they say naming is hard
but naming across a stack is even more so
gotta find a coherent mapping from version to package to docker tag
These are the saddest of possible words:
Version to package to tag
hi offby1
now that's a name i haven't heard in a long time
(intersect 'version-scheme 'package-scheme 'tag-scheme) ;;; > nil
I'm here all week! Be sure to tip your waitresses
hello guys, does anyone knows an API to get data from flights? Like to get a dataset or at least a way to get the data so that i can put them into a dataset.
What kind of data?
Google comes up with https://aviationstack.com/
Free, powerful REST API for real-time flight status and tracking information. Live data for flights, airports, schedules, timetables, iata codes, and more.
FlightAPI
Flight API provides you with flight price api, flight schedule api, airport schedule api and autocomplete api.
etc
Looks like this is common
At the moment only flights, maybe airports and so on
Thanks I'll see
pricing is going to cost you $$$
maybe historical pricing is cheaper. but if you want current flight availabilty and prices (like kayak, google flights, etc) you're going to have to shell out to a GDS
for ADS-B location data you can probably get that from several places
and i think there are US government agencies and industry groups that track things like arrival and departure times
i believe ICAO sells data like that but they charge crazy high prices for their stuff
What are your guys thoughts about the Poetry package manager? were plannig to use it as our defualt package manager at work. the type of code we write is just for qa test automation
I'm a fan; it works nicely
been using it at work and on personal projects, the cli is nice and it sure beats working with pip
a low bar 🙂
not sure if this is the right channel for this Q:
does anyone know a way in python to compile a python file with all the imports compiled/defined inside of it? What I mean by is e.g. we have a function
def func_a():
print('hello')
in file file_a.py, and I am using it in file_b.py like:
from file_a import func_a
func_a()
is it possible to create file_c which would be equal to
def func_a():
print('hello')
func_a()
so the import would be defined inside file_c
but do this in an automated way
like compile it. something like webpack for javascript
hello! I would like to know if I can change the sufix (release+build) for dev versions of my packages, I was reading https://peps.python.org/pep-0440/#developmental-releases and looks like i can't but I'm curious if anyone try it - my dev version wants to have pr number like 1.1.0-dev0-prnumber
Python Enhancement Proposals (PEPs)
there isn't a tool like that which i'm aware of, but i'm not sure why you'd want to do that either. javascript there are good reasons to cram all your code into a single file, python less so. it should be possible, especially if you make some assumptions and restrict the kinds of import statements you're willing to support (e.g. no dynamic imports), but i'm not aware of any tool that does it.
pyinstaller can do it. To single file
yes
nice, i'll try it out
As far as I know it makes invisible Venv under the hood (probably)
Not exactly what he described, but same appearance
well that's not what they wanted. it might be what they actually need, but it's not what they asked for 😉
well basically i'm trying to run a glue job, and I don't know how to (it's practically not possible due to some restrictions) set up a docker image at my company in order to run it locally with aws resources, so the only way to test the glue job with real aws resources is to copy paste the whole code into the glue console. this was possible with like 500-800 loc, but now i'm going to have a project with maybe 1500+ lines, and i'd like to know how to do it
Well no, pyinstaller will not work for this
In my company when I need using AWS resources... I just assume necessary role for environment
And then use our port forwarding server to make resources at my localhost
Then I debug stuff locally with AWS resources
Optionally we have dev friendly alternative to open tmate shell to container launched in our ecs
yeah that's possible with lambdas/api at my co, but for Glue jobs, it's slightly different, and we have restrictions which make it impossible to do it. We can't install Docker locally, only on a virtual IDE 😦
can you spin up an amazon linux ec2 instance, install docker on it, and ssh in to do your dev work?
i've done things like that to get around ridiculous work restrictions before...
does glue not support any way to read files from s3?
maybe a .zip of python modules
it supports it, but that's not a problem.
not sure what you meant by that
well, can you upload a zip of your files to s3, instead of trying to inline it all and paste into the glue console?
that's interesting but probably way more overhead than just compiling. I'll see if that's possible though
oh that's interesting
yeah that's actually probably how other teams develop at my co. I'll have to ask them
that's a fine alternative to port forwarding 😄 or getting assumed locally aws roles
just going into server inside that opens us accesses
assuming aws access locally and port forwarding is still more comfy though
there are vscode extensions allowing to work comfortably over remote connections
makes vscode working like it is opened locally

that could make very smooth experience out of this option
that's if i spin up an ec2 + docker ?
and then ssh from vs code into ec2?
that's if u spin up ec2 with ssh access, then u can connect to it via ssh with vscode
docker option is available there too, but it requires connection over daemon (usually used through local socket, but sharing docker daemon over network is an option too)
it's a one-time setup vs. needing to continuously do something weird and hacky
well, i thought having ssh access should be within hacky setup
and connecting vscode over ssh and just using system python/venv directly
no docker stuff necessary
thanks guys. will try it out!
i suggested docker because that was the whole point. they can't install docker on their work machine to develop a docker image, so i suggested a way to get access to a machine that can run docker.
Oh. That is ridiculous limitation
Not having ability to install docker at dev machine
Hey there, I'm trying to automate release creation though I'm having issues with how GitHub uses "tags". I don't know if they're created automatically, if they should be created for each version, etc.
This is how the release should be created, though I get Validation Failed every time, so I can only assume the problems is tags. yml - uses: XAMPPRocky/create-release@v1.0.2 id: create_release env: GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }} with: tag_name: ${{ github.ref }} release_name: ${{ github.ref }} # Draft should **always** be false. GitHub doesn't provide a way to # get draft releases from its API, so there's no point using it. draft: false prerelease: true
git certainly doesn't automatically create tags. I doubt github or gitlab do either
should they be created for each version? I dunno. What problem are they solving for you?
It seems that to create a release, it must have a tag_name
github can create tags automatically on Release actually
a matter of Github Actions code though
although for creating Release u need to tie tag...
...okay... this does not make sense doing from Release. only from on push/pull request strategies
name: 'Associate the tag with the commit'
branding:
icon: github
color: white
inputs:
tag:
description: 'Name of the tag'
required: false
default: ${{ github.run_number }}
prefix:
description: 'Prefix to associate before the run number'
required: false
default: t
runs:
using: "composite"
steps:
- name: Create tag
uses: actions/github-script@v5
with:
script: |
github.rest.git.createRef({
owner: context.repo.owner,
repo: context.repo.repo,
ref: `refs/tags/${{ inputs.prefix }}${{ inputs.tag }}`,
sha: context.sha
})
Yeah the release should be created on every push
For context, I stole this from tokei. Though looking through all the code and commit history, it makes no sense how they get the tag name
Feel free to ignore this, found out that they use cargo workspace
Can anyone help me install llvm with all default targets enable?
How can I easily squash and merge a git branch while preserving authorship?
The end result should be a single commit on my checked out branch like if the person writing the feature branch just commited directly to my checked out branch.
There are multiple approaches, but in any case, you have to partially rewrite the final resulting commit, like re-adding author information (very tedious, when you're merging code from a lot of different contributors!).
Example:
git checkout local_branch
git merge --squash remote/remote_branch
git commit --author="Original Author <original_author_email@example.com>"
I feel like there must be a better way.
You could probably automate the extraction of the author from a commit and throw all that into a git alias.
https://opensource.com/article/20/3/lazygit
https://github.com/jesseduffield/lazygit/blob/master/docs/keybindings/Keybindings_en.md
I think it is part of lazygit functionality. There are key shortcuts for actions with authorship in its interactive rebase

Opensource.com
If there's one word people use to describe Git, it's "powerful." Nobody can deny that Git is indeed a powerful be

GitHub
simple terminal UI for git commands. Contribute to jesseduffield/lazygit development by creating an account on GitHub.
Optionally u could just make Git Alias for some of your solutions
Hi, nice to
What release bots you guys use to combine with Slack?
I would like some advice, so I'm quite new to python and I'm looking into have a better practices, as I like to be organized?
I mostly write scripts/automations, and I want to ask how you deal with env variables and secrets/credentials. Those I am storing in an .env file when working on the machine and once happy, deploy in Azure Automation and I use the credentials and variables from that resource. Is it possible to somehow retrieve those directly from same place, I would assume I need to re-authenticate and then retrieve those every time I run the code? Curious how you guys manage this and what your experience and best practices are :D
- for simple cases i just get secrets from os.environ["SECRET NAME"]
- for complex scripts and programs, i get them from pydantic settings management https://docs.pydantic.dev/latest/concepts/pydantic_settings/
how do i set them?
- in dev env i use docker-compose
- or just assign in .vscode as env variables
in production: - i extract those secrets from AWS SSM manager or AWS Secret manager and assign to my application env vars (there are equvalient services in azure) (Assignment happens automatically by terraform)
- in some cases productional code can be having as env vars ARN of secret manager and extracting variables on its own from Secret Manager
Support for loading a settings or config class from environment variables or secrets files.
forgot to clarify that in case of using secret managers, i assign them as a code automatically by terraform for my deployments (pulumi could be used too)
that makes sure that secrets are... not git commited, yet, they are fully documented as a code how to be applied to deployment automatically
that helps me not keeping track of any secrets pretty much, and they will always survive past server destructions/recreations
I have error in docker i use mac, after run this command in terminal git clone https://github.com/PacktPublishing/Attacking-and-Exploiting-Modern-Web-Applications.git and after install them, I go to this directory cd Attacking-and-Exploiting-Modern-Web-Applications/Chapter03 after this i run this command docker-compose up, I got this error failed to solve: ubuntu:bionic: error getting credentials - err: exec: "docker-credential-desktop": executable file not found in $PATH, out:
There are two considerably different things we call Docker today
https://docs.docker.com/engine/install/ubuntu/
Docker Engine that I use at dev machine directly at my Linux OS, and all people use at end servers for deployment
It uses directly current OS kennel, and very lightweightly launches its containers
It has CLI only interface by default
Your docker client is connected via Linux daemon sock directly to server part present at same OS
At Mac u can probably try dual boot, or use some Virtualization program to get normal docker in Linux VM
If u have used this version, u would not have current problem
==========
Second version of Docker is called Docker Desktop. At any OS it creates secret Virtual machine under the hood.
It makes your Docker clients (CLI and GUI) accessing over network Docker server daemon in this VM.
Without launched Docker Desktop this version will not function, because VM is offline
Docker Documentation
Jumpstart your client-side server applications with Docker Engine on Ubuntu. This guide details prerequisites and multiple methods to install Docker Engine on Ubuntu.


So... U have incorrect installation of Docker Desktop or docker desktop is not launched. Sounds like first thing
Recommendation to revisit Docker Desktop installing instruction
(or installing proper Docker Engine without Desktop)

https://docs.docker.com/desktop/install/mac-install/
Try to check official docker desktop instruction for missing things
Or reinstall in this way if u used different installing
Docker Documentation
Install Docker for Mac to get started. This guide covers system requirements, where to download, and instructions on how to install and update.
Hey, is it possible to trigger a google kubernetes pod using cloud functions.
Trigger in what way?
Create a Job/Pod? Sure, as long as you have the right perms
If you want to do it in a schedule, a k8s CronJob is probably better
Sure. it is possible for sure.
we do similar in AWS Step functions
they execute AWS lambdas (Alternative to cloud functions)
and execute some jobs as task run in our AWS ECS clusters as single task run 😅
that will be very similar action to do in GCP or Azure.
just K8s instead of ECS, and "Insert name of this cloud provider Lambdas" instead of AWS lambdas
@rapid sparrow my setup on hetzner works. I went with ansible to automate everything from 0 to a caddy instance running on Docker and then I have CI/CD pipeline to deploy static files with SCP and another one for apps using docker compose 👍
😊 do u save to docker registry in between?
I do
Awesome 😎
We use workflow Id of repository for meaningful enough auto tag.
We get it like t0884, t0885 slowly enumerated further with numbers of pipeline runs for this repo
oh wow that's a good idea
I just discovered Helm and it's such a neat way to organize K8s manifests
By the way, is it true that k8 pods aren't designed for expensive computations?
define how much expensive.
Anyway.. as long as those pods are in Deployment resource that autoheals them back to life in its Replica Set, then it should be by default fine in my opinion
And if u defined soft and hard limits for CPU/RAM properly.
Like huge Deep Learning computations
Heyy I want to create automm bot but i don't know which wallet provide free apis or cheap APIs for doing transaction, anybody know which one can i use !?
Ergh... there are options to go with Kubernetes having even videocard resources
But this option is tricky and this field has other specialized services that are meant to simplify such stuff
Kubernetes is indeed not best default option here.
Kubernetes can work for this though, and serve as autoscheduler of all those Deep Learning computations, but it will require a lot of... effort and learning
Once configured properly Kubernetes could be working just awesome... Just not out of the box as other other more ML specialized services exist.
So it's better to use AWS solutions for ML and calculations as such?
I was afraid that hypervirtualization might hinder computation abilities.
today containerization/docker is main way to go as alternative to hypervirtualization.
containers are very lightweight thing, they reuse current OS kernel.
containers are basically... having inside only an "illusion" of OS inside, with its own filesystem, but its hooked to same Linux OS
So.. they remain very lightweight (on Linux only) solution for isolation and uniform scaling
better than what? 😅 ML is very expensive.
In general though AWS/GCP/Azure are interchangable solutions with very similar qualities.
Also we can say for sure that they all are bloody expensive.
u can rather minimize costs though depending on workflow, with using serverless solutions for rare runs
or using cheap hosts power through spot requests for ultimate standy resources. That will still require a lot of tuning though for such custom solution (hello AWS ECS and EKS, the mentioned kubernetes including for custom stuff)
AWS is great because u just... scale and don't maintain this stuff though
We don't have any hardware management
We don't have long processes to buy new servers / remove somewhere no longer operational one
we just run / recreate stuff as infra code
So, at least we saved money on salaries for all the hardware operational personal and personnel that buys/delivers/accounts stuff
I've heard extremely bad feedback about azure. DevOps engineers from my team rate them as:
AWS > GCP > Azure
Well, azure is M$soft. Nothing surprising I guess.
What are my options for running a GUI application in a container?
Intended for containers:
- buliding GUI interface as web interface, using web frameworks, from back to front. (Intended and supported way)
- Using TUI framework. In theory it should make result as GUI application without problems for docker https://textual.textualize.io/
Result should be still fully well integrating with containers
not intended for containers, but still possible:
WARNING. those options are really not intended for containers. Really not intended, but still possible.
- going dark magic and forwarding current OS GUI socket (X11 or whatever) into container
- using remote connectable containers with fully fledged desktop inside
Textual Documentation
Textual is a TUI framework for Python, inspired by modern web development.
u can build rather nice results with textual https://github.com/Zaloog/dotenvhub TUI

yeah I've been using a VM for this, but my usecase requires resetting the VM repeatedly so I'm seeing if I can gain a bit of speed with a container
to cut off a bit from the boot time
explore a choice of using vagrant
yep am using vagrant
okay.
i guess u seek just forwarding x11 or whatever gui u a using into container then
not really intended way to operate containers
try to go with web/tui solution if possible ^_^ way more intended
noted ty
I heard AKS refused to use Docker build on their clusters
And my team uses Azure
I hate Azure Devops when it comes to documentation
That's the feedback I received too
It's too dense + I'd rather find complete use cases that I can modify.
How can I get the following cached?
RUN git clone ...
RUN ./cloned_dir/install_script.sh
the above is especially a pain when I need to do multiple builds the same day and the github repo won't have undergone any changes
Clone outside of the Dockerfile and COPY the cloned repo instead?
hm, so make a bash build script that calls docker build. I see I will try this, thanks for the tip
Yes, exactly
I also suggest using COPY --link if possible
That way the COPY is not invalidated when something before it changes in the Dockerfile
never head of --link, will read up on it. thanks a lot!
Hey all. I'm looking at a helm chart and I'm having trouble understanding the comment my colleague left. Here's the snippet with the comment:
image:
repository: <repo url>
# Overrides the image tag whose default is the chart appVersion.
# For insights on why we choose to use the image digest rather
# than it's tag, check out the reference below:
# https://kubernetes.io/docs/concepts/containers/images/#image-pull-policy
tag: f901e8...
I dont understand how the info in the link relates to this config. Can anyone help me understand what this is about?
you could read documentation how it relates
https://helm.sh/docs/chart_template_guide/variables/
There is even very small O'reilly book if desired
But in general it uses almost Golang text/template and Golang default json marshaling under the hood... so it strongly inherited stuff from it how it looks like
The values u have above are translated to
{{ .Image.Repository }}
{{ .Image.Tag }}
Just check where/how they are inserted and u will understand code logic of your colleague

Using variables in templates.
the book youre referring to is this one? https://www.oreilly.com/library/view/learning-helm/9781492083641/

O’Reilly Online Learning
Yup. It is rather small tool, yet i am too fan of reading book for everything
thanks for the suggestion!
Hi guys. Wrong channel, I know but no response on the main discussion channel. So I'm here again.
I've been working on a project that requires login. I'm using flask_login for the login (don't know if there are other modules). But I've been sort of confused with this callback method.
@login_manager.user_loader
def user_loader(id):
return users.get(id)
I have seen some other resources use user_id instead of id
Flask-login documentation (https://flask-login.readthedocs.io/en/latest/) vs README.md from Github (https://github.com/maxcountryman/flask-login/blob/main/README.md)
Can someone please clarify where the id or user_id is gotten from. User model or flask-login module?

GitHub
Flask user session management. Contribute to maxcountryman/flask-login development by creating an account on GitHub.
There's an emacs container I use a lot, but the emacs command is not available when I run it using distrobox. How come?
I'm a big Emacs fan, so I'd love to answer, but I have no idea what "distrobox" is.
a container-vm hybrid
ok I just glanced at their home page on github and ... I have no idea.
seems awfully complex.
Do you like the package overall?
I'm thinking about writing it myself versus using a package out-of-thebox
how exactly do the docker exec -i and -t options work?
do they intervene where docker relates to the terminal?
talking about emacs, anybody managed to emulate devcontainers with it ?
what's an alternative image to alpine that shares similar characteristics? for some reason alpine versions really are not working out for this particular build
Docker is based on a bunch of namespaces (process, filesystem, network, ...). Linux let's you run a program inside specified namespaces. For more info I recommend the man page of nsenter.
i remember this page but i got confused.. gonne re-read it
@sick dawn @timber umbra Thanks for the advice. Ended up being pretty quick to convert and implement.

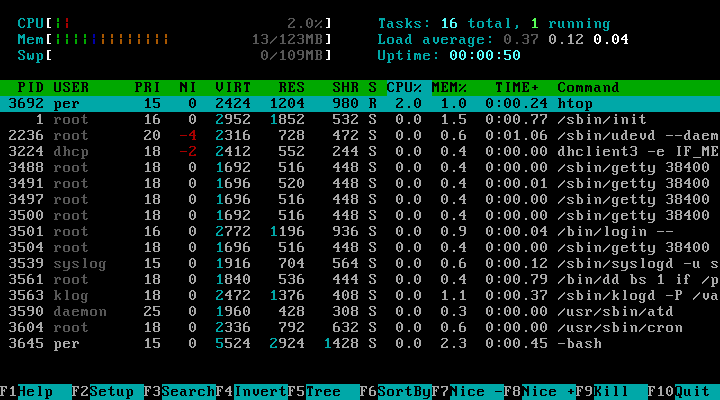
Bashtop
How do you fix problems with OS server upgrade?
I securely deployed a django app on AWS EC2 with Gunicorn, Nginx and HTTPS using Let’s Encrypt months ago. Everything was working fine. The EC2 instance was on stopped state.
There has been many updates/upgrade/software changes since and I cannot get the app to work unfortunately. Is there an easier way to to fix this than creating a new EC2 instance, new django project and re-implmenting everything again?
the minimal way to learn the better way will be learning Docker + Compose
https://www.amazon.com/Docker-Deep-Dive-Nigel-Poulton/dp/1916585256 here is structured learning for that
it lightweightly decopoules application configuration to raise it from OS server

Docker Deep Dive
once u make it that way, raising application will become simple as docker-compose up -d
and u will be able confidently reraise it again at any quickly recreated server that just has Docker installed
it is not obligatory, but there are several extra actions u could make for achieving extra points of deployment quality:
learn saving build docker image to Docker Registry (AWS ECR), or Docker hub.
then u will be able raising application as docker-compose up -d with using already saved images.
it will not be building app during this moment, u will already use saved image with all dependencies confidently frozen
also make sure to bind your database to localhost, if u will use it inside docker-compose to, and to change default passwords 😅 make sure to remember that default docker port publishing, publishes to 0.0.0.0:port, and bypasses OS firewalls (AWS Security Groups is external firewall that is not having this problem). So it is very wise binding to localhost by default
Once u learn Docker/compose, raising any app/or database/or letsencrypt, will become an effort of 1 minute for you
most of which will be finding to copy yaml file from another project and writing command docker-compose up
===============================
there are other ways available, including letting AWS taking care of certificates for you but it involves a wider array of tech and knowledge in order to make it in a sane way
so that's why i will stop on just recommending docker-compose as universal tool for development environment and simple production. It is the most manually versatile tool to fit any usage case locally and at single server.
extra hint: your CI like Github Actions could be running command to reraise new app version in docker-compose at target server on push to master for you automatically
@rapid sparrow I already know docker and docker compose. I can created Integration workflow with GitHub Actions and Release worflow and deploy it to docker hub.
great. then just put your app into docker-compose and then problem of OS upgrades will be taken care of you.
U will be able applying all OS upgrades just by selecting specific AMI version of EC2
Tbh for long time running u could have just used same AMI version for raising EC2 and things would have worked fine for you too
u just needed to know exact AMI version of EC2 u used before
that is solvable by infrastructure as a code and other tooling (Terraform / Pulumi) 😅 or just making a note into README and hoping it will not get outdated
(lightweight more dummy way could be just using recorded script for aws cli or cloud...formation. that could fit good enough i guess for single server. that will have recorded your EC2 server configuration for raising)
So you will create a service for the app in docker compose, another service that's for the OS running Ubuntu with Nginx?
exactly. all your Nginx, LetsEncrypt and Gunicorn can be into simple single Docker-compose
their service_name will be network addresss to communicate with each other
Docker-compose declared services are automatically put into a single Docker bridge network that have aliases for easy communications between each other
Okay. I understand. When you do that how do you assoicate the domain name to the webapp? Will you be targeting the service OS running ubunutu or another EC2 instnace wheere the image is going to be copied to?
When you do that how do you assoicate the domain name to the webapp?
Will you be targeting the service OS running ubunutu or another EC2 instnace wheere the image is going to be copied to?
not clear to understand question, could u rephrase it?
provide simple example what u mean, from where to where u mean to make networking requests
I'ts a little confusing I know.
My old setup was a django app running on Ubuntu AWS EC2. My domain name is with Google Domains. I had an Elastic IP Address from AWS that's assoicated with Google Domain DNS (A record, www) ....
Now with docker compose I'll have Ubuntu -Nginx inside docker compose. I meant how I get the domain name setup correctly.
service OS running ubunutu
or another EC2 instnace wheere the image is going to be copied to?
could u clarify what is the difference?
I thought lets say your EC2 instance with running ubuntu is already OS?
okay. for simple choice you just make sure your EC2 instance is having public IP
feel free optionally using or not using attached permament IP, whatever
then u point your A record onto this IP
at server u just bind your app to 0.0.0.0 (docker does it by default silently) and some its port, exposed by ports 80/443
that's it?
Domain will resolve to public IP of your EC2 machine
request will come in and will be accepted by 0.0.0.0 all listening address
of course due to AWS extra config stuff u will need to make sure your have... valid Security Groups allowing connections to those ports though (External AWS firewall we can it is)
As long as you use Public networks that allow just asigning public IP to your EC2, things will be rather simple
Right 'cause of port mapping
If I setup HTTPS/ Let's encypt on docker-compose will it still be visiable on the public domain
just for note, AWS has its own Domain controlling stuff called Route53, just in case. it has event Certificate auto generating features... but from the usage of infra code it looked rather not super simple 😅 Letsencrypt in docker-compose going to be way simpler i think
Yes I tried both Let's enctpt is the way to go
i like luxury of Cloudflare. it works out of the box. i just point IP with A record and it works even without lets encrypt to have valid certs
as long as i have any dummy self signed certs applied to 443 port and utilize Cloudflare IP A record without direct proxy mode. it auto replaces my invalid self signed certs with valid
I'll create AWS EC2 instance running ubuntu with Elastic IP address. Then assoicate the Elastic IP with my domain name. Set everything on docker-compose multiple services as you recommended. get the image on the EC2 and run docker-compose with port mapping.
yup. sounds like a good plan.
docker-compose can pull the image automatically, as long as it is available to it and specified explicitely as image:smth_tagged
easy plan validatable in local dev env 😉 as long as u have docker locally, hehe.
I did that earlier created a relase workflow wit GitHub Actions that pushes the docker image to docker hub. Then I created a new AWS EC2 ubunutu instance ... installed docker on ubuntu. Then authenicate docker using my credentials and got all my images . It took me time to learn all these 😃
CI/CD isn't easy.
it can be easy. with Dokku. fully self hosted Heroku with preconfigured GitOps out of the box (powered by Docker)
not the best way for long term running though. more or less plausable though
makes for you CI/CD at server side pretty much
and has inside letsencrypt too
Now to upgrade/update things for CI/CD. AWS EC2 ubuntu you just create a newer EC2 instance install docker on it. and copy the image. for docker-compose ... just pull newer image from docker and update Nginx same for Django, Python exc.
copy the image? it should pull itself automatically from being stored in Docker registry
in any docker 😅
u can build locally too though, but pulling is a bit nicer for long term. because it is frozen in docker registry
Sorry I was thinking about create a new AWC EC instance running newer version of Ubuntu.
with new setup it should be just:
- Create newer EC2 instance with installed docker (there are AMI versions with already preinstalled docker)
- run
docker-compose up -dcommand 😅 manually or by CD
that's it. it will auto configure the rest.
Okay. I didn't know that.
Thanks man. I got the big picture now. Just gotta implment it.
Docker on Debian 11 (Bullseye); Docker on Ubuntu 20 ; Docker on Ubuntu 22 .... Is there additional cost for using these AMIs? or the cost is the same as normal AWS EC2 instance.
Never mind. There's additional cost to it: $8.935/Hr 🙂

https://aws.amazon.com/marketplace/pp/prodview-2l3oufmhdyhrg
u could use ECS optimized AMI image

Amazon Linux AMI amzn-ami-2018.03.20240201 x86_64 ECS HVM GP2
we use them for ECS clusters that operate through docker
they have docker installed too
and they are free
payment only for hardware resources
https://aws.amazon.com/marketplace/pp/prodview-2l3oufmhdyhrg#pdp-pricing
yup. payment is not changing with different sizes

Amazon Linux AMI amzn-ami-2018.03.20240201 x86_64 ECS HVM GP2
How is the rate? Is that expensive like AWS RDS?
AWS RDS is a lightweight abstraction allowing at the level of AWS/terraform/pulumi directly deploying images to those servers
with already provided GUI interfaces and simplications. abstracted away host.
No payment at all for AWS ECS. Payment is only for hardware resources
AWS ECS can be operating on serverless fargate (most expensive)
on EC2 on demand (medium price)
and EC2 spot requests (cheapest price)
we just have autoscaling fleet of auto raisable spot requested EC2 instances
that makes sure we have the most hardware power for us at the cheapest price
it requires a lot of infrastructure configurations though
not recommending utilizing AWS ECS unless u learn terraform/pulumi
only infrastructure as a code will make sane situation to configure it simply
just using ECS AMI image as AMI for docker-compose running EC2 looks like a legit solution too to me ^_^ As a funny compromise
besides using ECS AMI image, there is always an option to build your own with stuff like Packer
https://developer.hashicorp.com/terraform/tutorials/provision/packer
we use it to make our own AMI images
Provision infrastructure with Packer | Terraform | HashiCorp Developer
Create an image with Packer, containing SSH keys, a new user, and a demo webapp, and deploy it with Terraform.
with anything we want on it
data "aws_ami" "ubuntu" {
most_recent = true
filter {
name = "name"
values = ["ubuntu/images/hvm-ssd/ubuntu-jammy-22.04-amd64-server-*"]
}
filter {
name = "virtualization-type"
values = ["hvm"]
}
owners = ["099720109477"] # Canonical
}
resource "aws_instance" "web" {
ami = data.aws_ami.ubuntu.id
instance_type = "t3.micro"
tags = {
Name = "HelloWorld"
}
}
So you use Terrafrom to create ECS container instead of EC2 and then move the image to ECS?
Thanks for the info. I'll look into. I feel more comfortable with the first setup.
.... That's the thing. There's so many different ways to do things.
Hi everybody
who can help me : self.write_log('[Err] '+(os.path.basename(file).replace('%4',''))+": Erreur d'envoi vers "+self.elk_index+":"+e.args[0]+" "+e.args[1][0]['index']['error']['type']+" "+e.args[1][0]['index']['error']['reason'],False)
print(colored('[Err] '+os.path.basename(file).replace('%4','')+": Erreur d'envoi vers "+self.elk_index+":"+e.args[0]+e.args[1][0]['index']['error']['type']+" "+e.args[1][0]['index']['error']['reason'],"red"))
the error is : TypeError: can only concatenate str (not "dict") to str
Does anyone have experience with websockets, flask and celery? I would love some help
So I have a K8s cluster setup on a Ubuntu Server Locally. Im trying to access it from another machine on the same local network. Ive setup Kubectl, Minikube, and Helm. When I use the kubectl portforward command it works. However when I set it up the NodePort way I cant connect. I feel like Im missing a step, any pointers?
hi
how to revert windows 11 so that when you uninstall a program it opens control panel and not settings/installed apps, because settings is slow asf
have you considered linux?
anyone here dislike/like/love poetry?
best to use bulkuninstaller to also clear registry values
Poetry is not listed in the official Python packaging tutorial because it’s the only one that doesn’t implement any of the backend spec (PEPs 621,517,etc)
If you’re looking for a backend for your next project, don’t choose the weird kid that does everything completely different from everyone else
That said, Poetry is bad for several reasons
It’s very slow
[My] lock files were constantly breaking
One huge thing that made a lot of devs lose faith in it was — they decided to “deprecate” their main installation method, and to get the word out they gave it a random percentage chance to fail in CI
So now your PR has a big red ❌ on it, even though you didn’t do anything wrong, and if you just run to again it will work

innovative strides in deprecation policies!
==========
twitch: https://twitch.tv/anthonywritescode
dicsord: https://discord.gg/xDKGPaW
twitter: https://twitter.com/codewithanthony
github: https://github.com/asottile
stream github: https://github.com/anthonywritescode
I won't ask for subscriptions / likes / comments in videos but it really hel...
What would you recommend instead?
I've been using poetry for the last couple of years and been reasonably happy with it. I certainly don't want to go back to whatever I was doing before with flit, but I'm open to well-designed alternatives.
pdm looks decent
Thanks, that looks indeed like a decent replacement at first glance. I'll try it out with my next project. (I find the "$tool doesn't use standard!" arguments moot tbh, these tools predate the standard.)
true standards evolve develop over time poetry has still served me pretty well imo
uv from astral also looks nice for package installation and management iirc its pretty new
Yeah, uv looked promising, but I'll wait until the dust settles around that
Aren't you a bit unfair here? Poetry added the features described in PEP 621 before it was standardized. As I understand it, the Poetry team also aims to support PEP 621 eventually.
With that said, there are nice alternatives to Poetry today such as PDM, Hatch and Rye.
i think it's understandable to not want to include a non-standards-compliant tool in a document maintained by the body that considers itself responsible for maintaining those standards and the reference implementations thereof
rye seems very interesting. i was working on something very similar and of course someone scooped me on the idea, with a more-complete and better implementation.
reminds me of opam or ghcup. imo all programming languages benefit from tooling like that
uv is also interesting. faster is better.
Rye seems nice, it uses Hatch as a the build backend by default. I have tried them both out during my open source tooling work and like the way Hatch solves the thing with source code (the force-include feature in particular).
I hate this about using powershell from wsl.
dos2unix() {
sed 's/\r\n$/\n/'
}
get_cisco_vpn_dns_servers() {
powershell.exe 'Get-DnsClientServerAddress |
Where-Object AddressFamily -eq 2 |
ForEach-Object ServerAddresses |
Select-Object -Unique' | dos2unix
}
powershell outputs crlf and sh doesn't like it
printing it only prints the first line without dos2unix
Would this be the correct channel for a hadoop mapreduce with python question(s)?
I'm using zsh (oh-my-zsh more specifically) and want to shorten git branch names. I found this github issue: https://github.com/ohmyzsh/ohmyzsh/issues/7525 but I've never made changes to zsh related files. can anyone help me figure out exactly how to incorporate this?

GitHub
I sometime work with very long branch names which make a new line in my prompt. Is there a way to trim down the branch_name to only show maybe: bugfix/XX-3145 instead of: bugfix/XX-3145-monkeys-are...
oh-my-zsh allows overrides of the themes, described here: https://github.com/ohmyzsh/ohmyzsh/wiki/Customization#overriding-internals
thanks
powershell and line endings make a huge mess. it's the one thing i really do not like about pwsh above all other complaints
@gentle solstice https://github.com/orgs/PowerShell/discussions/16569

GitHub
Summary of the new feature / enhancement I work with source code and files for cross-platform projects that are standardized to all UNIX line endings (LF) instead of "historical Windows" ...
Unfortunately I'm targeting powershell 5.2 for some reason
i'm so sorry
In case I want to share this script, I'd want it to work for as many people as possible.
I'm also using #!/bin/sh
Care to learn what this script is supposed to do?
get_cisco_vpn_dns_servers nope 😆
wsl dns is broken when using the cisco vpn client
so you have to manually set it
it gets the dns servers and search domains from powershell, then sets them in wsl via resolvectl
that sounds just as horrible as i imagined
doubt you'll get any help with that, since downloading youtube videos probably violates their terms of service
!rule 5
5. Do not provide or request help on projects that may violate terms of service, or that may be deemed inappropriate, malicious, or illegal.
!ytdl
Our youtube-dl, or equivalents, policy
Per Python Discord's Rule 5, we are unable to assist with questions related to youtube-dl, pytube, or other YouTube video downloaders, as their usage violates YouTube's Terms of Service.
For reference, this usage is covered by the following clauses in YouTube's TOS, as of 2021-03-17:
The following restrictions apply to your use of the Service. You are not allowed to:
1. access, reproduce, download, distribute, transmit, broadcast, display, sell, license, alter, modify or otherwise use any part of the Service or any Content except: (a) as specifically permitted by the Service; (b) with prior written permission from YouTube and, if applicable, the respective rights holders; or (c) as permitted by applicable law;
3. access the Service using any automated means (such as robots, botnets or scrapers) except: (a) in the case of public search engines, in accordance with YouTube’s robots.txt file; (b) with YouTube’s prior written permission; or (c) as permitted by applicable law;
9. use the Service to view or listen to Content other than for personal, non-commercial use (for example, you may not publicly screen videos or stream music from the Service)
We have a special one just for that
heh
Any suggestions on profiling execution time for hot paths in Python applications?
I added a lazy @timed decorator to hook into my structlog instance and output rough times
But it's far from a perfect solution
On Windows atm so I can't (easily) utilize Memray :/

Python documentation
Source code: Lib/profile.py and Lib/pstats.py Introduction to the profilers: cProfile and profile provide deterministic profiling of Python programs. A profile is a set of statistics that describes...
and for viewing profiler output: https://jiffyclub.github.io/snakeviz/
SnakeViz is a browser based graphical viewer for the output of Python's cProfile module.
py-spy works on Windows, too
It outputs nice flame graphs you can view in a browser
Ahhhhhh 
Thank you 🧡
Seems like I have quite a few options to choose from
Thanks guys!
Darn, seems like there are issues with 3.10+ on Windows atm
https://github.com/benfred/py-spy/issues/498
I built a new version of my docker image and it’s 5 times the size of the original. Does anyone have a blue why that might be? It’s the same Python application
E) Not enough information
without seeing the dockerfiles there's really no way to tell
Setting up Nginx Webserver with letsencrypt on Docker using docker-compose. Which pathway is easier for CD? Setting up HTTPS (443) on a docker-container in my localhost computer and then deploy the container to AWS EC2 Ubuntu or Do all of the configurations on the EC2 Ubuntu server so that the Elastic IP address and domain name be mapped on the DNS? I’m just a little confused with implementing HTTPS on a docker container … certbot and nginx are separate images and there’s just too many layers here.
dive shows in most details to dig this information https://github.com/wagoodman/dive

specialized tool to navigate through built multi layers of an image for finding where is the problem with overweights
pretty cool
optionally lazydocker can show quick overview about all docker stuff.
But its not detailed regarding layer sizes, just overview which layer which size takes.
It is more generic TUI navigating over docker in general. It has fun stuff like seeing in real time CPU/memory diagrams of containers runs


Nice to have under your belt too just in case in addition
Did you install any packages on the new version? If no. Why not just delete the new version and re-created it.
Hello. I have an application that is running on a kubernetes cluster. When I hit a certain node the application doesnt seem to function as quickly. Is there a way in python to get the node name and IP of the kubernetes node. I know I can get the POD info using sockets, but not sure how to get the Node info. Any suggestions?
https://kubernetes.io/docs/concepts/scheduling-eviction/assign-pod-node/#affinity-and-anti-affinity
kubernetes has anti-afinity feature to deselect certain nodes from being desirable for scheduling app

You can constrain a Pod so that it is restricted to run on particular node(s), or to prefer to run on particular nodes. There are several ways to do this and the recommended approaches all use label selectors to facilitate the selection. Often, you do not need to set any such constraints; the scheduler will automatically do a reasonable placemen...
Is there a way in python to get the node name and IP of the kubernetes node.
there is, by quering kubernetes API directly with http requests or with connected tools (it is mentioned in The Kubernetes book i think / should be covered in official docs)
as long as security permissions allow
but u don't need that i think
I am just trying to figure out which node is causing me the issue.
i see. u wish to log information, name of the node from python?
yeah, then makes sense 🤔
let me find a better source of material how to do that
technically Logging solution should be btw having already attached tags, at which K8s node, logs were emitted.
It is solvable without python, without application seeing the node info
just by having properly enough configured logging / quering from it
like... Loki in k8s configured mode should be having at least
datadog should be having it
probably any logging solution integratable with k8s should be having it
anyway, if u still wish quering this info from python, in The Kubernetes book, chapter 14 is all about it
This information is accesable over GET request there from certain address

Nice I took a PluralSite Kubernetes course from Nigel.
ok I will try to get it from the logs. Thx
u a welcome.
Last but not least, if your logs amount is small and u able to find the error over kubectl logs command
U could just query logs not from service, but from specific pods and finding at which ones it happened exactly
mmm....
this can be simplified with using https://k9scli.io/

K9s provides a terminal UI to interact with your Kubernetes clusters. The aim of this project is to make it easier to navigate, observe and manage your Kuber...
Simple TUI to navigate over kubectl pretty much
this solution does not require having configured any logging for cluster, it works over kubernetes API without having anything installed in cluster
Hi, do you know if there is some package/framework that would essentially act like gitlab pipelines/github actions/jenkins/openshift pipelines BUT it would be a local utility (I don't want huge deployments) that could also pass data between jobs? All I can see is pretty big projects for AI/ML, like Kedro, or pipeless for computer vision, but I am looking for a more generalized solution. Basically it's the difference between running a sloppy script or jupyter notebook vs having a solid framework that could visualize and inspect separate jobs.
Yeah my docker image file size keeps multiplying everytime I make a new version
my Dockerfile
# Use the official Python base image
FROM python:3.9-slim
# Set the working directory inside the container
WORKDIR /app
# Copy your application files into the container
COPY . /app
# Copy the requirements.txt into the container
COPY requirements.txt /app
# Install project dependencies
RUN pip install --no-cache-dir -r requirements.txt
# Copy the rest of your project files into the container
COPY . .
# Set the command to run your Python application
CMD ["python", "main.py"]
COPY . . was giving me over 2 GB
well, what are you copying
I removed COPY . .
My docker image file is now 3.41 GB
My entire project
your project is 2 GB? something's not right
Yeah I know
so, what are you copying
You mean what’s in my requirements.txt file?
i mean, what is ls -Alh
My local machine is windows
that's not the point 😔. find out what you're copying that makes the size big
Btw I had a tar file in my python project which was 1GB lol. Now my docker image is down to 2GB
Docker desktop doesn’t independently show the size for each dependency it copies
just go to . and look at what's there
I needed to make a .dockerignore file
maybe figure out why your git folder is so big. are you tracking that archive?
Ahh yes. Docker image is such shorter now. Holy shit
My docker image file is 387.23 MB now
What do you mean? I never look in there. I just use it to push the project to a GitHub repository
are you tracking the 1 GB archive you mentioned
Yeah it’s in my local machine so I guess it’s archived
🤔 in python language, or in yaml?
either is fine, Python one would be great for my python projects, but if it's some generic runner it's fine too
https://taskfile.dev/usage/ i can offer this in yaml.
As a very lightweight yamlish thing, ultimate to build/test projects. it can chain jobs for this purpose
auto generated cli interface/documentation for offered list of commands. Makefile in yaml
https://docs.celeryq.dev/en/stable/getting-started/introduction.html i can offer in python celery
It is very horizontal scalable and testable solution. good to go. but it is meant more to run single jobs and not chaining them
But celery provides actually some framework functionality to build easier multi job chained jobs too
https://tekton.dev/docs/getting-started/pipelines/ there is literally executable locally Github/Gitlab/and etc CI
powered by kubernetes. u just need microk8s/microk8s for its runs, then u will be able locally triggering its pipelines for executions.
Since it is powered by k8s, it is very horizontally scalable by design.
writable in yaml similar to github/gitlab stuff

We can mention honorably, ability to run Github Actions locally
https://github.com/nektos/act
We can mention honorably monstrocity called Apache AIrflow for building data engineering pipelines in python
https://airflow.apache.org/docs/apache-airflow/stable/tutorial/taskflow.html
i recommend trying celery by default.
otherwise see if may be tekton was exactly u desired, it describes exactly what u wrote (tekton does ask for k8s knowledge though)
I didn’t know tekton could be run locally (at least not without a huge k8s cluster that would eat all my ram)
I work with k8s often so it’s okay I have some knowledge for that
https://kind.sigs.k8s.io/ kind is the most recommended and said to be comfortable experience raising and cleaning up k8s locally
otherwise, known default is {Minikube!} meant for local runs too with easy abilities for quick wipes in between
microk8s is more for server deployments already, fully fledged running in a lightweight build
Also the task file looks kinda nice I’m gonna try that
https://cdk8s.io/docs/latest/
u could explore an idea using Golang, Typescript, Python or Java to write Tekton workflow runs then perhaps

not recommending python too much for this unless u use strict mypy/pyright mods
in golang it should flare pretty well due to uniformness of a code with low syntax varierty
it all really a bastard way to achieve this stuff tbh, with a lot of level of abstractions... 😅
but well, could be fun (as long as no colleague will be forced to maintain it)
although could fit well very kubernetes... heavy using company
in their usage case any way to do this with k8s, may be could be preferable default 🤔 since all infra is arleady configured for job runs in such companies
Celery is very nice pythonic way to approach it 😅 k8s scalable option too, but usable without k8s too
Lots of interesting tools here, thank you very much, it’s gonna take some time to try them all out 😅
Yeah celery is fine but I’ve never tried to use it to create pipelines, only with a broker to execute different but independent tasks
yeah.. it is not super meant for pipelines, more for single tasks 🙈 but it can do it and offers entire own section of framework for that
Wow that’s a whole part of celery I didn’t know existed
Maybe luigi could also work
wow. Terrific thing. exactly for pipeline built stuff in python 🤔
i do like for a first glance what it offers in terms of syntax
it looks like built with static type safety in mind
so in case of your code changes, u will be able to see with strict moded mypy/pyright code incorrectness before code run
for a first glance, code connections not a hacky some syntax working on black voodoo magic
but proper connections utilizing language itself
definitely putting into my book to try
looks like really sick solution
that could be helpful refactoring one certain code mess i inhereted, that works in AWS Step functions 🤔
ergh, too late refactoring it though, we are all too much AWS attached in terms of those solutions to step away from it probably
hmmm.. what if.
what if this Luigi could flare very well as programmatic CI runner 😅
writing CI piplines not in yaml, but in Luigi. with proper unit tests to the code
Yeah it does look promising, just found it by chance. I’m gonna take a look tomorrow when I have some spare time.
luigi the old data pipeline tool?
you might be interested to see what airflow can do. luigi is considered outdated for the kinds of tasks that people usually want to accomplish with airflow. but it might be interesting as a kind of local CI thing.
i actually started writing a tool for this. never finished it but you might find it interesting: https://github.com/gwerbin/dagrun.py
GitHub
Mirror of https://sr.ht/~wintershadows/dagrun.py/. Contribute to gwerbin/dagrun.py development by creating an account on GitHub.
@opaque totem there is a gigantic world of "workflow" tools out there as well. for whatever reason bioinformatics people love reinventing that wheel. heck, you could consider make a workflow tool depending on what you actually want to do. snakemake is one of many examples that might be relevant to whatever you want to do here.
heck arguably ansible falls into this category
I enjoy at a first glance syntax Luigi offers. I see it compatible with mypy perhaps
Airflow syntax looks extremely hacky in comparison
Yeah I’m looking mainly for local pipelines, I don’t know if airflow can achieve that but I’m gonna give it a try
I actually tried to put something together and it’s conceptually similar to your code 😅
airflow would be extreme overkill. it's a scheduler, a database, workers, etc.
if you want to try it, it technically works, it's just very unpolished 🙃 i put two small examples in https://github.com/gwerbin/dagrun.py/tree/main/dags
GitHub
Mirror of https://sr.ht/~wintershadows/dagrun.py/. Contribute to gwerbin/dagrun.py development by creating an account on GitHub.
but it's missing features like "don't run a dependent task if its upstream dependency fails" so i wouldn't exactly call it production ready yet
my goal was somewhat specific: use only the python standard library and be simple enough that you can just fetch it as a standalone .py file
@opaque totem of possible further interest here https://www.commonwl.org/
Common Workflow Language (CWL)
The Common Workflow Language (CWL) is an open standard for describing analysis workflows and tools in a way that makes them portable and scalable across a variety of software and hardware environments, from workstations to cluster, cloud, and high performance computing (HPC) environments. CWL is designed to meet the needs of data-intensive scien...
which syntax? its OO interface was similar to luigi from what i remember of luigi from ~2016
lets start with Luigi first
class MyTask1(luigi.Task):
x = luigi.IntParameter()
y = luigi.IntParameter(default=0)
def run(self):
print(self.x + self.y)
class MyTask2(luigi.Task):
x = luigi.IntParameter()
y = luigi.IntParameter(default=1)
z = luigi.IntParameter(default=2)
def run(self):
print(self.x * self.y * self.z)
if __name__ == '__main__':
luigi.build([MyTask1(x=10), MyTask2(x=15, z=3)])
I see some easy syntax out of OOP stuff, with ability declaring in static type safe connections to other tasks
def requires(self):
return OtherTask(self.date), DailyReport(self.date - datetime.timedelta(1))
luigi basically operates on classes 🤔
https://airflow.apache.org/docs/apache-airflow/stable/tutorial/pipeline.html
import datetime
import pendulum
import os
import requests
from airflow.decorators import dag, task
from airflow.providers.postgres.hooks.postgres import PostgresHook
from airflow.providers.postgres.operators.postgres import PostgresOperator
@dag(
dag_id="process-employees",
schedule_interval="0 0 * * *",
start_date=pendulum.datetime(2021, 1, 1, tz="UTC"),
catchup=False,
dagrun_timeout=datetime.timedelta(minutes=60),
)
def ProcessEmployees():
create_employees_table = PostgresOperator(
task_id="create_employees_table",
postgres_conn_id="tutorial_pg_conn",
sql="""
CREATE TABLE IF NOT EXISTS employees (
"Serial Number" NUMERIC PRIMARY KEY,
"Company Name" TEXT,
"Employee Markme" TEXT,
"Description" TEXT,
"Leave" INTEGER
);""",
)
create_employees_temp_table = PostgresOperator(
task_id="create_employees_temp_table",
postgres_conn_id="tutorial_pg_conn",
sql="""
DROP TABLE IF EXISTS employees_temp;
CREATE TABLE employees_temp (
"Serial Number" NUMERIC PRIMARY KEY,
"Company Name" TEXT,
"Employee Markme" TEXT,
"Description" TEXT,
"Leave" INTEGER
);""",
)
airflow is on decorators/decorated functions
it looks somewhat...messy for a first glance 😅
i can see myself being able probably bending mypy for luigi to operate well
but airflow syntax looks like not easily mypy friendly essentially
too much decorated magic
🙈 i need probably both to try first to conclude for sure which one will work better
i also liked coming somewhere as part of lib GUI with Luigi. it is a nice touch

monitoring IS important for such stuff a lot
for a first glance Luigi is more complete solution working out of the box with everything needed and operatable locally
Totally off the CI/CD and Pipeline topic tonight.
I have a server, a domain and two projects, one of which already being served to the "/" route of the server.
I would love to host my project and test it out he performance on the same server. Ideas popping in my head is to create a subdomain and configure Nginx to serve my new project to the subdomain.
Is this technically possible?
yes it is in basic abilities of nginx, routing/redirecting to different Reverse proxies (local host binded different ports) based on different incoming (listened) domains
https://www.nginx.com/resources/library/complete-nginx-cookbook/ this recipe should be mentioned in nginx cookbook

With new and updated recipes for 2024, this free O'Reilly eBook is better than ever. Get how-to advice and sample NGINX configurations for load balancing, cloud deployment, automation, containers and microservices, service mesh, security, and more.
it is a free book
Again, thank you. I'll work on it and come back here if I face any technical roadblock. 🙂
oooh kitty
Hey, I have access to read and write a repo, have been assigned an issue and have the changes ready to create a PR for it. My changes are not in a fork, as I had just git cloned the repo, made a new branch and made my changes there locally (haven't pushed anything).
What would be the best way of making this a PR?
I assume I would just push my local branch to the repo, and create a PR from the PR tab, but I don't know how to link this new PR to the issue assigned to me
so if you have read and write you should be able to push your branch. what does git remote -v give you?
once you find the "make a new PR button" you mention something like "Closes #111" in the PR message body and github will link your PR to the issue. when the PR is merged the issue will get closed
there are several keywords you can use to link your PR to issues https://docs.github.com/en/issues/tracking-your-work-with-issues/linking-a-pull-request-to-an-issue#linking-a-pull-request-to-an-issue-using-a-keyword
Tyvm, git remote -v gives me fetch and push :)
On the note of GitHub, how do people test their workflows before pushing them, i.e. how would you be sure that a test flow you write would run? Is it as simple as try your best, if it fails, amend it, repeat until it works?
look into nektos act i believe
wait a sec lemme look up the repo
GitHub
Run your GitHub Actions locally 🚀. Contribute to nektos/act development by creating an account on GitHub.
usually you have something like pre commit which defines same commands as your workflow
what i see here is doing more than 2x the work in airflow using only about 2x the code. seems like an improvement to me
luigi is basically Make
so yes if all you need is something like Make it's fine
but airflow is a powerful flexible orchestration engine, and it's built around the assumption that you want scheduling
if you don't want that, then you don't need airflow
For simple scheduling could also work just Celery Beat ^_^
yeah, lots of options there
airflow actually uses celery internally for scheduling
rather, it supports celery as one of a few options
It takes so long to scp a tar file of a Docker image 😕
have you tried compression
however you want to do it. pick your favorite algorithm
have u tried uploading to Docker Registry and pulling from it instead?
https://hub.docker.com/ offers unlimited amount of public repos and one private for free
That is intended way to scp docker image 😉
i think that was discussed before
This is exactly why I directly send my Docker image files to the virtual machine now
Uploading an unlimited amount to the public repository is a red flag
Having only access to one private repository is a problem now
Now my company wants me to develop two projects
If u are uncomfortable with public, just get private repo
They are offered in cloud providers
Also self hostable
Of course it’s uncomfortable. These are company projects
We use AWS ECR for example for private ones
You don’t want the public to access confidential information
Then get private docker registry, it is not hard
why is there confidential info in a docker image
other than code, i guess. but i doubt you're developing any state of the art algorithms or something
PyFlunt v2.0.0
Hey, everyone! I wanted to inform you that I've just released version 2.0 of PyFlunt, the Pythonic version of Flunt, originally created by Andre Baltieri in C#! The best part is, we've already surpassed the mark of over 9k downloads!! Fantastic! Thank you all for the support!
If you haven't already, I invite you to access our repository, give it a star to show your support, so we can reach over 100!
Open your Issue and contribute to the library; we have plenty to do: Documentation, coding, translation, etc...
Feel free!
Oh, the idea is to get as close as possible to the implementation in C# and bring some new features! I'm leaving some Issues for the community to participate in development as well! Send your PR!!
PyPi Link: https://pypi.org/project/flunt/
Repo Link: https://github.com/fazedordecodigo/PyFlunt
PyPI
Python implementation of Domain Notification Pattern based in Flunt (.NET) developed by @andrebaltieri
GitHub
Python implementation of Domain Notification Pattern based in Flunt (.NET) developed by @andrebaltieri - fazedordecodigo/PyFlunt
GitHub gives you a free one
Docker Hub does that too 😅
Free private repos*
DockerHub doesn’t have that, does it?
🤔 it gives only one private free
How is a wrapper made?
API wrappers? afaik usually with care and a good understanding of the API you're wrapping, including knowledge of the protocols it uses like HTTP/websockets, and how to use the endpoints offered by the API
in some cases you can have a code generator produce a wrapper for you, particularly if the service has an OpenAPI spec
it also depends on what features you want to provide to the users of your library, for example if you have a REST service with various data models to deal with, you might parse those models into classes and offer convenient ways to interact with them, such as methods to make certain API requests, or having your own cache (as simple as lists/dicts) so your users don't need to manually store everything from the API
btw #software-architecture is probably a more suitable place for this question
Hmm, that is a very interesting topic, thanks for the information, I'm gonna head to the channel :D
@molten forge there was mentioned "usually"...
...I built my own wrapper that offers to Django Rest Framework executions of its view actions with integration to Celery and some company permission lib.
From my experience I can tell that all necessary knowledge can be learned in the process of building the lib
Regretfully depending on chosen functionality integrating yourself further into DRF architecture, u may find more and more becoming depended on inner workings of a framework and in those terms DRF is rather awful foundation to wrap around.
Fastapi built itself around Starlette which is pretty amazing in terms of code. U could have found more enjoyment there.
Tldr: required knowledge of framework inner workings totally depends on desired functionality u wish to bring with wrapping. For some functionality u will require no knowledge of framework u wrap, for some functionality it will require a deep reading into its working for understanding how to bend it towards desired direction
Have goals/ established functionality u wish to make
Write unit tests towards desired features
https://www.amazon.com/Test-Driven-Development-Kent-Beck/dp/0321146530
https://www.amazon.com/Unit-Testing-Principles-Practices-Patterns/dp/1617296279
Learn especially how to use visual debug with making steps thorough third party libraries too.
For making wrapper it took me some significant time of just traveling with visual debug through third party libs during written unit tests in order to explore how they work and how to bend them to my will
Well and eventually desired functionality will be written

Test Driven Development: By Example

Unit Testing Principles, Practices, and Patterns: Effective testing styles, patterns, and reliable automation for unit testing, mocking, and integration testing with examples in C#
All right, thanks for the information, I'll check them right away
Current server config
sudo vi /etc/nginx/sites-available/hbnb
server {
listen 80 default_server;
listen [::]:80 default_server;
# Server information
server_name phoenixhub.tech;
add_header X-Served-By $hostname;
# Config to serve /
location / {
include proxy_params;
proxy_pass http://127.0.0.1:5003/2-hbnb;
proxy_set_header X-Served-By $hostname;
include /etc/nginx/mime.types;
root /home/ubuntu/AirBnB_clone_v4/web_dynamic/static;
}
# Config to serve /api
location /api {
include proxy_params;
proxy_pass http://127.0.0.1:5002/api;
proxy_set_header X-Served-By $hostname;
}
location /static/ {
alias /home/ubuntu/AirBnB_clone_v4/web_dynamic/static/;
}
}
Subdomain config
sudo vi /etc/nginx/sites-available/wellnourish
server {
listen 80;
listen [::]:80;
# Server information
server_name wellnourish.phoenixhub.tech;
add_header X-Served-By $hostname;
# root /home/ubuntu/wellnourish/web/static;
# Config to serve /wellnourish
location /wellnourish {
include proxy_params;
proxy_pass http://127.0.0.1:5004;
proxy_set_header X-Served-By $hostname;
include /etc/nginx/mime.types;
root /home/ubuntu/wellnourish/web/static;
}
# Config to serve /api
location /api {
include proxy_params;
proxy_pass http://127.0.0.1:5005/api;
proxy_set_header X-Served-By $hostname;
}
location /static/ {
alias /home/ubuntu/wellnourish/web/static/;
}
}
How I have been serving the websites using gunicorn
ubuntu@289442-web-01:~/wellnourish$ gunicorn --bind 0.0.0.0:5004 web.app:app
ubuntu@289442-web-01:~/wellnourish$ python3 -m api.v1.app
Main domain fine. Subdomain comes with 403 - Forbidden error. Screenshot attached.

you don't have a location / block in the subdomain config
so yeah, there's no location definition for / with the server name wellnourish.phoenixhub.tech, so nginx returns 403 by default
I thought I could only have one location / block per domain, as in root
I will look into this.
these are completely separate server blocks, right?
Yes.
then from the perspective of nginx they don't affect each other. nginx matches server name first, then locations once server name is chosen. so location blocks in two distinct server blocks shouldn't conflict. https://nginx.org/en/docs/http/request_processing.html
did you try it?
oh i see, the subdomain thing
Not yet. On transit.
yeah just try it first. i think there might be an issue where nginx might match a server name suffix under certain situations, but at least try it first
This is after adding the location / block.

Is that what you wanted?
Yes, it is. Cheers and thanks!
Hi,
Our platform is an online form builder site. The forms are visible at www.formbuilder.com/form/form_id
Our architecture is as follows AWS Route53 -> Cloudfront -> ALB -> .....
People using our site want to use their own domain so that the forms will be displayed on their domain on the following url that is forms.mydomain.com/form/form_id
https://www.typeform.com/help/a/custom-domains-for-enterprise-plus-accounts-4404606584852/
We are trying to this do the same thing for our platform the way typeform does it.
Typeform
Your typeforms connect you directly to your customers, so why not put your brand front and center? If you’re on an Enterprise plan, read on to lear...
!rule 6 , not the best place for advertisements. <@&831776746206265384>
#software-architecture message multi channel spam
Is there a question here? Not clear to me why you posted this.
But definitely don't cross-post. Please ask a question if you have one.
How to do it
@peak wraith How to do it.
I have another domain I'm trying to do it. But it is not happening
Hi,
We have this form builder site "www.formbuilder.com" which points to a cloudfront distribution.
We have added this subdomain "customdomain.formbuilder.com" which points to a cloudfront distribution.
Our form url is "www.formbuilder.com/form/form_id"
We want other people to be able to show our forms using their domain. For example our client owns the domain "coinplanet.in" we want them to be able to show our form on this url "forms.coinplanet.in/form/form_id".
How can we do it?
In our Route53 record 👇
https://pasteboard.co/iCCp4fIYI1WU.png
In Client's Route53 record 👇
https://pasteboard.co/oncFzEFb4u0k.png
But the thing is it is not working

Simple and lightning fast image sharing. Upload clipboard images with Copy & Paste and image files with Drag & Drop

Simple and lightning fast image sharing. Upload clipboard images with Copy & Paste and image files with Drag & Drop
Howdy folks!
I'm looking for an elegant solution to storing a project's pip requirements without having to manually write >= for every single pip package.
I've seen pipchill, pipreqs, and pigar, but I'm not fully sure any of those are real solution :/
How are you building your requirements automatically for your Python projects?
pip freeze > requirements.txt is not enough to make a package / library shareable and work because of the hard set versioning.
(if you respond please reply to the message so I get notified. Thanks! 🙏)
Basically an elegant solution to package versioning. It feels way too complicated right now.
@old meadow https://python-poetry.org ; https://pypi.org/project/poetry/
Python dependency management and packaging made easy
Does poetry make it to where you no longer use a requirements.txt file and have to use poetry?
also not sure this did it

Sorry Screenhot fonts too small.
(accounting-app-i5I1ONfM) C:\Users\zackp\Desktop\accounting-app>poetry export --without-hashes
Warning: poetry-plugin-export will not be installed by default in a future version of Poetry.
In order to avoid a breaking change and make your automation forward-compatible, please install poetry-plugin-export explicitly. See https://python-poetry.org/docs/plugins/#using-plugins for details on how to install a plugin.
To disable this warning run 'poetry config warnings.export false'.
annotated-types==0.6.0 ; python_version >= "3.11" and python_version < "4.0"
pydantic-core==2.16.3 ; python_version >= "3.11" and python_version < "4.0"
pydantic==2.6.2 ; python_version >= "3.11" and python_version < "4.0"
typing-extensions==4.9.0 ; python_version >= "3.11" and python_version < "4.0"
Thanks
I haven't used poetry in a min to be honest. But to answer your question. You won't need the requriments.txt file. Instead Poetry uses a lock-file. "Poetry is a tool for dependency management and packaging in Python. It allows you to declare the libraries your project depends on and it will manage (install/update) them for you. Poetry offers a lockfile to ensure repeatable installs, and can build your project for distribution. " You need to set it up.
Does anyone knows how to do it( if brute force possible)

Thanks for what? haha
Hmm, but what if I'm not wanting to use poetry for another project that I want to import this project into 🤔
@old meadow Just make sure you set it up correctly and it should work: https://python-poetry.org/docs/managing-dependencies/
Managing dependencies Dependency groups Poetry provides a way to organize your dependencies by groups. For instance, you might have dependencies that are only needed to test your project or to build the documentation.
To declare a new dependency group, use a tool.poetry.group. section where is the name of your dependency group (for instance, te...

There's also "pipenv" that I was using. But I think "Poetry" is better than "pipenv".
Hi guys when i do python to exe and it opens console it shows me path but i want only name of the script how i can fix that?
@limber grail can help? Thanks
So I just learned a bit more about it and poetry is pretty neat
I use pipenv for most of my projects
@late gull I don't understand your question. Can you restate it in a different way?
That path c:/users/user/desktop...... i want it to be only exe file name without path only python script name

Like this for example
Sorry I don't understand. I used VS Code. Looks like your using IDLE.
@limber grail there's a package called pipreqs that seems to do what I was looking for.
pip install pipreqs
then
pipreqs --force --mode gt
my concern would be that you dont already know what dependencies are required for your project beforehand, but generally trying to auto-generate a requirements file based on existing code can be a bit flawed due to package names on PyPI not always corresponding to the actual modules available for import
So the thing is, I've tried making my own Python packages before and hosting them only on github.
Everytime I tried to pip install from my github project, it would downgrade already installed 3rd party packages on the projects I pip installed my packages into.
So if my old script used selenium for example, it'd downgrade whatever new project I was using to the older version and break something
Do u know solution for my problem?
.
Are you struggling with pyinstaller?
No
I think I'm missing some step in this whole setup and package management process to keep from breaking dependencies in new projects from my old projects lmao. Maybe it's a setup.py issue.
expanding the version specifiers could help, but you also risk your projects breaking due to changes in newer packages (especially major updates, but technically minor/patch updates can break stuff too), so i highly recommend installing each project in a virtual environment so their dependencies are isolated from each other
if you find managing venvs too inconvenient, you can use pipx to install your applications
https://pypi.org/project/pipx/
I mean, I get that part, but if 2 projects have the same dependencies but different versions, how would you make them work together?
selenium 4.1 vs 4.2 or something like this haha. Don't want the newer package to use 4.1 :/
I feel like there should be a simple solution here 😅
looks like auto-py-to-exe/pyinstaller cant do that for you, you'll need to make the appropriate system call to change the console title
https://stackoverflow.com/a/67003965
unfortunately not, python's package management cant allow different versions to coexist in the same environment
But then how does any 3rd party project do it?
Like pydantic, pandas, etc.
They might have the same dependency as another package
That I'd be using in a project
But I don't think I've ever seen a downgrade there.
for libraries, its a good idea to use >= specifiers to allow greater compatibility, only adding exceptions once its discovered that a particular version breaks their library and there isnt an easy solution to support that newer version
for applications (packages that wont be used as dependencies), pinning your requirement versions helps in reliability/reproducibility which can save you some unexpected bugs
you know I only learned that ^^ in the last few months
libraries and apps are very very different when it comes to how they specify their dependencies
@thorny shell @willow pagoda Are there any good and simple guides on this topic?
It seems like something that should be known more but many people I know don't really know how this works lmao.
I know there are a ton of tools for this but I don't see any standard, I only see it being used in practice by bigger projects.
packaging has been such a mess that I've basically ignored it as much as I can get away with. And I've been using python professionally for ... uh ... 20 years or so
so, no: I don't know of any good guides.
there's https://packaging.python.org/en/latest/, which I imagine is the Official Word®
presumably if you took six months off and studied that deeply, you'd be an expert. Also all your hair would have turned gray.
Can confirm
I now look like 👴
pyproject.toml is probably the most relevant standard, with most tooling like PDM, hatch, setuptools, etc. adopting the [project] table format (poetry excepted), but im not sure of any guide that covers best practices for dependency specification
wow haha
I'm trying to run a fastapi server with docker. Works fine on my mac but for some reason it's not able to find uvicorn while deploying on a linode server.
- Error
Error response from daemon: failed to create task for container: failed to create shim task: OCI runtime create failed: runc create failed: unable to start container process: exec: "uvicorn": executable file not found in $PATH: unknown
- Dockerfile
FROM python:3.10-slim as builder
RUN apt update
RUN pip install poetry
RUN apt install python3-dev libpq-dev gcc -y
WORKDIR /app
COPY . .
RUN poetry install
FROM python:3.10-slim as base
COPY --from=builder /app /app
RUN apt update
RUN apt install libpq5 -y
WORKDIR /app
ENV PATH="/app/.venv/bin:$PATH"
CMD [ "uvicorn", "server.main:app", "--host", "0.0.0.0", "--port", "8000" ]
what could be wrong cause I don't see anything problematic
i don't see uvicorn being installed in this code
as well as installations of your app requirements
it's installed by poetry
[tool.poetry]
name = "echo-chess-server"
version = "0.1.0"
description = "Server for echo chess game"
authors = ["avilabss <contact@avilabs.net>"]
license = "UNLICENSED"
readme = "README.md"
[tool.poetry.dependencies]
python = ">=3.10.0,<3.11"
numpy = "^1.22.2"
urllib3 = "^1.26.12"
pandas = "^2.0.3"
scikit-learn = "1.2.2"
xgboost = "^1.7.6"
joblib = "^1.3.1"
fastapi = "^0.109.2"
uvicorn = {extras = ["standard"], version = "^0.27.1"}
pydantic-settings = "^2.2.1"
imblearn = "^0.0"
sqlalchemy = "^2.0.27"
alembic = "^1.13.1"
psycopg2 = "^2.9.9"
twilio = "^8.13.0"
pyjwt = "^2.8.0"
[build-system]
requires = ["poetry-core"]
build-backend = "poetry.core.masonry.api"
poetry by default installs to .venv, that u did not activate
u need to install with --system or smth like that flag so that it would have been installed without .venv directly
or change univcorn activation from venv too
I believe:
ENV PATH="/app/.venv/bin:$PATH"
this should activate venv?
ENV PATH="/app/.venv/bin:$PATH"
CMD [ "uvicorn", "server.main:app", "--host", "0.0.0.0", "--port", "8000" ]
well... to be fair u did actiate. 🤔
yup
shrugs. just build it locally on your machine and debug from it
docker run -it imaage_name bash
enter shell and check what's wrong
builds and works fine locally 😄
then do same at linode server
docker run -it imaage_name bash
enter and debug from within by using commands like ls and etc
docker exec enters existing container
docker run -it spawns new containers for running and applies requested command to it
😉 u can just run your building commands manually from within container and debug where they went wrong ^_^
feel free to comment some of them away for the purpose of debugging away
adding ENV POETRY_VIRTUALENVS_IN_PROJECT=true did the trick
hello, would this be the right place to ask for help with build?
I don't get why?
python3 -m api.v1.app
* Running on all addresses (0.0.0.0)
* Running on http://127.0.0.1:5005
* Running on http://10.247.60.7:5005
curl -sI 0.0.0.0:5005
127.0.0.1 - - [26/Feb/2024 09:56:03] "HEAD / HTTP/1.1" 404 -
curl -sI 0.0.0.0:5005/api/v1/recipes
127.0.0.1 - - [26/Feb/2024 10:08:49] "HEAD /api/v1/recipes HTTP/1.1" 200 -
Also these:
ubuntu@289442-web-01:~/wellnourish$ curl -sI 127.0.0.1:5005/api/v1/recipes/
HTTP/1.1 200 OK
Server: gunicorn
Date: Mon, 26 Feb 2024 11:05:39 GMT
Connection: close
Content-Type: application/json
Content-Length: 999783
Access-Control-Allow-Origin: *
# Config to serve recipes API
location /recipes {
include proxy_params;
proxy_pass http://127.0.0.1:5005/api/v1/recipes;
proxy_set_header X-Served-By $hostname;
}
ubuntu@289442-web-01:~/wellnourish$ curl -sI 127.0.0.1/recipes
HTTP/1.1 502 Bad Gateway
Server: nginx/1.18.0 (Ubuntu)
Date: Mon, 26 Feb 2024 11:09:14 GMT
Content-Type: text/html
Content-Length: 166
Connection: keep-alive```seems like a good place. just be sure to state your question in full, so it can get answered asynchronously amid the cross-talk

Stack Overflow
Stack Overflow | The World’s Largest Online Community for Developers
does your python app have any logging? can you see if the python app is actually receiving the request and returning a response?
@spare stratus Don't post spammy messages here please.


@wary relic Please state your question clearly and provide a context as code text for people to read and understand. Many Thanks. https://stackoverflow.com/help/how-to-ask
Stack Overflow
Stack Overflow | The World’s Largest Online Community for Developers
i already had the context for this, just so you know. also they did post a partial nginx config snippet above
i'm a little confused, it looks like you're running both your python app and gunicorn. also i don't see where nginx is involved here
i was saying that you should try making the request through nginx, but see if a request appears in the python app log
I'm running a Python app but when I curl the URL locally, I don't get the response(s) (I think) I should get.
python3 -m api.v1.app
* Running on all addresses (0.0.0.0)
* Running on http://127.0.0.1:5005
* Running on http://10.247.60.7:5005
curl -sI 0.0.0.0:5005
127.0.0.1 - - [26/Feb/2024 09:56:03] "HEAD / HTTP/1.1" 404 -
curl -sI 0.0.0.0:5005/api/v1/recipes
127.0.0.1 - - [26/Feb/2024 10:08:49] "HEAD /api/v1/recipes HTTP/1.1" 200 -
So wait, what's the problem exactly? is the URL structure not what you're expecting?
i'm confused. before you said you were getting 503 from nginx. now you're asking a completely different question
i guess i no longer have context, and i echo @limber grail 's recommendation to assemble more information about your actual question
Actually I tried both. And I intended to get the response right from curl, before Nginx. That should help me know the right proxy_pass for Nginx location /api
I'm still confused, what is the issue? ie. what do you expect from your setup and what behaviour do you actually observe? and how do they diverge?
You can look at the log files to see what’s happening in the Nginx Server:
NGINC Access Logs and Error Logs:
By default, NGINX writes its events in two types of logs - the error log and the access log. In most of the popular Linux distro like Ubuntu, CentOS or Debian, both the access and error log can be found in /var/log/nginx, assuming you have already enabled the access and error logs in the core NGINX configuration file.
Just " nano /var/log/nginx/access.log "
Also, Chrome DevTools and Firefox DevTools - Network Tab
Alright. I was having issues with serving through Nginx earlier. And I was here to ask the questions.
I was serving a Python web app via gunicorn to Nginx (works fine) and an API - python3 -m api.v1.app (which didn't).
python3 -m api.v1.app
* Running on all addresses (0.0.0.0)
* Running on http://127.0.0.1:5005
* Running on http://10.247.60.7:5005
And while troubleshooting, I found that curl 127.0.0.1:5005 returns 404 error while curl 127.0.0.1:5005/api/v1/recipes returned a status code of 200 OK
And that's surprising, and I thought to understand why. And I hope that understanding this would help me configure Nginx location /api {...}
By the way, I had some issues with Discord earlier, not sure if was general issue. Responses weren't sent immediately, and that I think compounded the issue more.
Hi All,
I was going through the tutorial for packaging my code as a lib https://packaging.python.org/en/latest/tutorials/packaging-projects/#a-simple-project
I have a following dir structure
- pose_estimation_lib
- pyproject.toml
- src/
- __init__.py (empty)
- pose_estimation_lib/
- __init__.py (empty)
- estimator.py
I can build it successfully as suggested via the docs, but when importing the lib on the Python shell I get the following error
(backend) ubuntu@devlab:~$ python
Python 3.10.12 (main, Nov 20 2023, 15:14:05) [GCC 11.4.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> from pose_estimation_lib import estimator
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/ubuntu/workspace/venv/backend/lib/python3.10/site-packages/pose_estimatio
n_lib/estimator.py", line 8, in <module>
from src.pose_estimation_lib import factory, utils
ModuleNotFoundError: No module named 'src'
Any suggestions?
You're not supposed to import from src
setuptools installs your package without the src folder
Use relative imports inside your package
Thanks this sorted the issue
I'm having trouble with tox not finding my pyenv versions. Tox can find 3.9 but not 3.7 or 3.8. I've specified the versions I want to test with
[tox]
envlist = clean,py{37,38,39}
and when I run pyenv versions
I get
3.6.14
3.7.11
3.7.12
3.8.11
3.8.12
3.9.0
3.9.5
3.9.17
so 3.7 and 3.8 are clearly there. Does it literally have to be 3.7.0 and 3.8.0?
So you want curl 127.0.0.1:5005 to succeed, ie. want nginx to rewrite the request URL to 127.0.0.1:5005:/api {something...} ??
not sure this is the right channel but i feel like this is the most correct place to post it
im getting a weird google cloud error that i just cant seem to squash
ModuleNotFoundError: No module named 'main'
ModuleNotFoundError: No module named 'main'
at ._find_and_load_unlocked ( <frozen importlib._bootstrap>:1004 )
at ._find_and_load ( <frozen importlib._bootstrap>:1027 )
at ._gcd_import ( <frozen importlib._bootstrap>:1050 )
at .import_module ( /layers/google.python.runtime/python/lib/python3.10/importlib/__init__.py:126 )
at .import_app ( /layers/google.python.pip/pip/lib/python3.10/site-packages/gunicorn/util.py:371 )
at .load_wsgiapp ( /layers/google.python.pip/pip/lib/python3.10/site-packages/gunicorn/app/wsgiapp.py:48 )
at .load ( /layers/google.python.pip/pip/lib/python3.10/site-packages/gunicorn/app/wsgiapp.py:58 )
at .wsgi ( /layers/google.python.pip/pip/lib/python3.10/site-packages/gunicorn/app/base.py:67 )
at .load_wsgi ( /layers/google.python.pip/pip/lib/python3.10/site-packages/gunicorn/workers/base.py:146 )
at .init_process ( /layers/google.python.pip/pip/lib/python3.10/site-packages/gunicorn/workers/base.py:134 )
at .init_process ( /layers/google.python.pip/pip/lib/python3.10/site-packages/gunicorn/workers/gthread.py:95 )
at .spawn_worker ( /layers/google.python.pip/pip/lib/python3.10/site-packages/gunicorn/arbiter.py:609 )
Anyone here a docker expert?
essentially I have a running palworld server within a docker steamcmd container that I cannot connect to. And I lack the experience to know where to look currently.
I am on a rocky 9 image, and I was trying to spin up a palworld server for some friends. The issue is that there is no steamcmd download for rocky, so I am using the docker steamcmd image.
I ran docker run -d --restart=unless-stopped -p 8211:8211 --entrypoint /bin/sh -it steamcmd/steamcmd:latest to map the ports and have port forwarding set up on my host. When I get the server up and running, which it seems to do in the container, I am unable to connect to it. So far I am running out of things to google.
No error messages, everything seems to run fine on the host, I just am not sure if how I set up the container was the correct way.
I do not have a /var/lib/docker dir also. I have a /var/lib/containers dir
docker ps get container I'd
docker exec -it {containerID} bash (or sh)
To enter for debug
docker attach can be used for attaching to current running process there. Useful for game servers having stdin interactions
I did a yum install docker but I seem to be missing all the files and dir that all the troubleshooting states to use for setting up port mappings.
Neither of these dir exist for me
/var/lib/docker/containers/[hash_of_the_container]/hostconfig.json or /var/snap/docker/common/var-lib-docker/containers/[hash_of_the_container]/hostconfig.json
I think I know the issue...
I have podman-docker installed.
apparently that not what I need?
U could install just a regular Docker Engine
https://docs.docker.com/engine/install/debian/
With instructions specific to your distro
Docker Documentation
Learn how to install Docker Engine on Debian. These instructions cover the different installation methods, how to uninstall, and next steps.
Docker Engine, and not Docker Desktop
Most providers offer docker servers where it is already installed (Hetzner provider for example)
yeah, i just added the docker-ce.repo and installed docker.ce
Context: We use pip in many places to install Python packages. We have a pip.conf that points at our private repos as well as public pypi. Equivalent to pip install <package> --extra-index-url=private.repo/pypi --extra-index-url=pypi.python.org/simple.
Access to these private repos is provided by connecting to org VPN but not all users need to connect to the VPN at all times. Which means that when pip installing a package (even public ones) but not on VPN, it hangs before timeout occurs for the private repos, and it defers to the public repo. For long requirements lists, this can cause excessive time wasted as each package is requested and then will timeout.
I'm looking for a way to add a check to pip that will validate connection to this private repo when attempting an install, and inform the user of this with an error message or something. I can't see a feature like this in the pip docs, so maybe a wrapper around pip is a better idea. Any ideas?
have u tried an option of specifiying your private repositories as Main pypi url --index-url
and only after that specifying extra pypi urls? (including default one)
That's functionally the same in pip's eyes no?
https://pipenv.pypa.io/en/latest/indexes.html
u man find interesting that modern package manager wrappers already offer installing package from specific index
and locking from which pypi they came
so during pipenv sync command to install stuff it should be already automatically achived failing to install if pypi is not available
so you are potentially going to reveinvent a wheel
we use pipenv, other popular solution is poetry.
I understand that. The problem though isn't in lack of specifying index sources, it's in the way that pip errors when some of the indexes supplied to it aren't accessable.
So even if I specified indexes for every package in reqs.txt, the same issue would occur for every package specified to our private repo, if the user doesn't have their VPN switched on.
are your users your company developers or third party users not associated with your company directly?
Which is usually fine because we inform users that NewConnectionError == make sure you're on the VPN. But...
Tools like pipx hide this error output, so to the end-user the issue is not visible. Which is why I'm looking for a way to wrap around this behaviour and stop it earlier.
yep company devs
well, then i think it is fine solution to just suck it up and having as it is continued 😅
or at least... i could think of a cool solution atttempting to give the error at the server side instead of client side
it could be returning
https://packaging.python.org/en/latest/guides/hosting-your-own-index/
If you wish to host your own simple repository [1], you can either use a software package like devpi or you can simply create the proper directory structure and use any web server that can serve static files and generate an autoindex.
In either case, since you’ll be hosting a repository that is likely not in your user’s default repositories, you should instruct them in your project’s description to configure their installer appropriately. For example with pip:
if your pypi index is just a static assets server, it can be returning meaningful useful error if access is forbidden.
Like, "Turn on VPN for access" forbidden 403 error 😅
if clients will be able to catch it, it will be universal solution
Problem with that is there's no communication with the server, as the VPN is down. So it's simply a host resolution failure on client side via pip
Sucking it up has worked until we've found scenarios where the issue is hidden to the user and pipx install seems to be installing but will hang for hours
I realise this issue is complex and niche so appreciate your thoughts
Mm yeah.
I guess vpn locked private pypi is just not practical may be.
We have public access protected by tokens.
Each token has granular permissions to libraries specific to current app
I am using pip and poetry during a Docker image build.
I have the situation that in the environment there are the following libraries:
poetry 1.7.1 /usr/local/lib/python3.12/site-packages pip
poetry-core 1.8.1 /usr/local/lib/python3.12/site-packages pip
poetry-plugin-export 1.6.0 /usr/local/lib/python3.12/site-packages pip
Is this okay, or should these three version align, i.e. all three rather be 1.7.1?
Okay... interestingly if in an environment without poetry installed in it I do a pip install poetry the following combination of versions gets resolved and installed:
cachecontrol-0.14.0 poetry-1.8.1 poetry-core-1.9.0 poetry-plugin-export-1.6.0
So it seems to be fine.
We’re moving to to gitlab soon so maybe auth access rather than VPN will make this issue simpler
🤔 there is also funny alternative. Protection not by VPN, but by Firewall (we utilize AWS WAFv2 for such stuff).
depending on incoming ip of user, it can allow or deny access, with writing some meaningful error for denial
that what we do for all our dev services meant to be semi public
allows us having easy access by whitelisting office ips
at the same time when our dev users work from home and turn on VPN, they have VPN ips whitelisted and they get their access once VPN was turned on too.
in this usage case pip should be quickly getting 403 denying error
with option to customize easily error for its domain/path to be more specific if desired
Open Source Django Admin Dashboard - Sneat:
https://themeselection.com/item/sneat-dashboard-free-django/

Check out the Sneat dashboard free Django 5—one of the most powerful & comprehensive Django admin dashboards for developers.
What do you guys do when VSCode stops correctly changing the colors of code? I think it's called syntax highlighting.
Here's an example of what I'm talking about.

Funny
Any way to have Docker's various stuffs installed to a non-C: drive? My C drive is dead low on free space
Found the switches at https://docs.docker.com/desktop/install/windows-install/#install-docker-desktop-on-windows > Install from the command line

Docker Documentation
Get started with Docker for Windows. This guide covers system requirements, where to download, and instructions on how to install and update.
I think there's a setting, or group of settings, called "resources", and you can tell it where to put the virtual machine's disk.
I have a problem where it thinks code is commented out, which is not. It happens when I use _db as variable 🤣
From my experience, the reasons can be:
- You have the wrong language selected for the file. To fix this, press Ctrl + Shift + P and select
Change Language Mode, then select your programming language (see screenshot below): - Some of your extensions don't work correctly. Check your extensions, especially code linters etc.

How do I use tox with pyenv? tox doesn't seem to be finding the python versions I install with pyenv nvm, needed to use "Set up your shell environment for Pyenv" section in pyenv for it tox to see the version
Would docker be used for one thing that I Don't want the user to be able to run commands on?
or some other tool on my vps?
it can be secured to this level, it is just significantly difficult.
by default it is not secure.
takes effort and knowing docker in depth in order to do that
I see
easier just to use VM i guess. Vagrant for example
going to be considerably secure out of the box, at the cost of nastier to work with.
but if it is pet project, it could work fine
I also been told non-root is much safer
but others say that's not needed
FROM python:3.11
COPY . .
RUN pip install -r requirements.txt
CMD ["python", "bot.py"]
env_file:
- .env
yeah, non root can make safer.
...you know, i could direct you to reading 1-2 chapters regarding containers security to understand full overview of necessary actions if u want
ergh, or i could just quote stuff from that. a moment
 I read docker stuff a while ago
I read docker stuff a while ago{kind=link}
{kind=link}
{kind=link}
okay next stuff is actually from kubernetes, but it is about same thing, abou container security:
You can make it considderably secure by locking filesystem to read only, and allowing only specific sections for writing if necessary

secondly, using non root.

thirdly, making restriction to escalate access in child processes. By default it can apperently create processes with higher level of access

fourthly docker/containers support setting its Linux Capabilities allowed
having them restricted to nothing by default

fifthly, scanning docker image for vulnerabilities can be made
six: using firewalls/security groups stuff to restrict container from accessing anything in your network / network isolation to bring essentially.
probably some other stuff, lets end it here
consider just using Vagrant raised with mapped volume/disk for this part
and forwarded ssh port for access depending on needs
Vagrant is CLI as a code way to raise VM
^_^
that can be a small amount of effort i think
you said vagrant would be hard to setup
easier just to use VM i guess. Vagrant for example
going to be considerably secure out of the box, at the cost of nastier to work with.
but if it is pet project, it could work fine
i said it will be easier
vagrant is not scaling for corporate needs and introduces bad... patterns?, but if u need sharing just one server for some personal needs, then i guess why not. it should work pretty fine
there will be a problem of exhausting all your resources of the server potentially
i just don't want them to acess main server stuff
it would be interesting to check if vagrant can set quotas to CPU/memory usage
that sounds sound really bad
use Vagrant ^_^.
it will be easy as vagrant up for having written file of config

users-abusers can do everything ^_^
may be u could consider a different form of sharing files? sftp for example
what is reason for sharing to those users
https://www.theregister.com/2024/03/01/github_automated_fork_campaign/
https://vxtwitter.com/stephenlacy/status/1554697077430505473 (2022)

Cloned then compromised, bad repos are forked faster than they can be removed

I am uncovering what seems to be a massive widespread malware attack on @github.
- Currently over 35k repositories are infected
- So far found in projects including: crypto, golang, python, js, bash, docker, k8s
- It is added to npm scripts, docker images and install docs
💖 19.49K 🔁 7.81K
seems more appropriate for #cybersecurity
Oh right, I didn't see it when I looked
Feel free to remove the above message if you think it's warranted
you can also remove it yourself :)
Personally I'd leave it up for better awareness due to the seriousness. ;)
Hey! Could use suggestions:
I am developing two packages concurrently. A library and an application that uses said library. I have currently set the library as a dependency of the application using pyproject.toml (PDM). The directory is:
workspace/
library/
app/
Everything works, but whenever I make a change to library code I have to call pdm update to copy the changes to app's virtual environment.
What's the most elegant way of NOT having to copy changes whenever library changes?
I understand I could hack it to become:
workspace/
app/
library/
And include library directly from application. Is there a nicer way though?
You could add the path of the library as a (dev) dependency. That should do an editable install.
That is exactly what I'm looking for, thanks! Sometimes the answer is very obvious, but doesn't click unless I know what termin I'm looking for.
im new to coding........someone please suggest me a free text editor for python
you can install themes for Thonny
ok im downloading it
like the One Dark theme
thanks i will try now
Vscode
Hey guys I need a some help 🙂
what's your problem?
Hello, whenever I attempt to install notebooks on one of my anaconda dev enviroments it will load the instilation and then not install


also not sure if its relavant but i had to downgrade to python 3.55 to get tensorflow to work
When installing a package with Python 3.12: $ pip install -e ., I get this error (truncated)
Getting requirements to build wheel ... error
error: subprocess-exited-with-error
× Getting requirements to build wheel did not run successfully.
│ exit code: 1
[ ... ]
register_finder(pkgutil.ImpImporter, find_on_path)
^^^^^^^^^^^^^^^^^^^
AttributeError: module 'pkgutil' has no attribute 'ImpImporter'. Did you mean: 'zipimporter'?
[end of output]
When googling the error, this happens because importutil.ImpImporterwas removed in Python 3.12. People claim updating pip will solve it (and indeed the issue comes from within pip).
However, I'm running in a clean virtual environment with the newest pip (24.0).
Is this a known issue? What can I do to solve it?
dunno 😐 Can you post the complete error?
[I'm thinking: maybe the fault is in the package that you're installing]
The full error can be found here: https://gist.github.com/jakobnissen/cb6ce96ac9d7eb75bad45d82fec1c607
(it is too long to post)
nothing leaps out at me 😐
Old version of pip on new version of python
Usually due to an old virtualenv
Oh this is old setuptools
it looks like setuptools is outdated rather than pip, and seems to have been fixed with 69.0.0
pkg_resources/__init__.py lines 2229 to 2230
if hasattr(pkgutil, 'ImpImporter'):
register_finder(pkgutil.ImpImporter, find_on_path)```I am running setuptools 69.1.1 though 🤔
What's in your pyproject.toml
https://gist.github.com/jakobnissen/a246780adefe725619d382e0aef1fa02
The relevant part is:
[build-system]
requires = [
"setuptools ~= 69.1",
"setuptools-scm >= 8.0",
"Cython ~= 0.29.5"
]
an older setuptools to retrieve the build system's requirements that declares the newer version of setuptools?
Nah pip doesn't use site-packages setuptools to install build-system requirements
the traceback would imply its using a pre-existing setuptools though, given get_requires_for_build_wheel() was part of it
or is that separate from retrieving the build backend?
Yep two phases to support setup_requires
Can you reproduce this in Docker?
oops, this was fixed earlier in 66.1.0, not 69.0.0
https://github.com/pypa/setuptools/commit/6653e747c3815b140156249205397ef3719581ee
I don't really know Docker, or have it installed :/
Or maybe you could make a VM image with your issue?
Guys I want to develop a SAS product so help me out to get the best tools or frameworks to develop the product
And let me know. what requires and what are the best tools for development
Do you mean SaaS?
Tools to choose depend on requirements of a product.
Describe what u wish building for a start
If this isn't the right place, lmk...
Let's say you're using Azure Repos and you have a connection from Azure Repos to terraform cloud. In tf cloud, you create a project for your repo and workspaces for the dev/test/prod branches.
What are the best automation approaches in this scenario?
Currently I'm using a terraform module. We allow devs to add a resource block to this module which describes their repo. After the changes are pushed, the project, etc, is then set up in terraform cloud, and the repo is created in Azure Repos. The issue with this approach is that the module is getting too large and slow to run. Any suggestions for a better approach?
Having defined reusable terraform module template in repository with shared code. Release it under git tag.
Use the imported module in specific repositories to apply their settings
It solves terraform size growth because u will have terraform across small repos
Now u face another problem. Ensuring code is everywhere applied, and needing to change many repos for same stuff 😅
I see. So would the repo creation happen manually in this sense? It would need to be already created if one wishes to import the module to specific repos, right?
How would one automate the repo creation itself?
Yeah, repo would be first created manually usually and imported into repo env.
Or u just be one creating repo as a cods
Ah gotcha! Makes sense, thanks 
Is anyone familiar with Selenium? I am unsure if I am in the right chat group for python
this channel is OK, but you might also want to consider #web-development or a help channel (#❓|how-to-get-help ) depending on the nature of your question. this channel is focused more on tooling related to python, than on programming in python and using python libraries.
Anyone using yapf? And what's your preferred base style?
And does any formatter support surrounding operators with spaces depending on precedence? For example
a[42-x : y**3]
b = BASE + offset*10
rather than:
a[42 - x:y ** 3]
b = BASE + offset * 10
Oh, yapf has that 😁
https://github.com/google/yapf?tab=readme-ov-file#arithmetic_precedence_indication
GitHub
A formatter for Python files. Contribute to google/yapf development by creating an account on GitHub.
i use it as extra tool for quickly fixing 98% of flake8 errors when submitting PRs 😅
Yapf has execellent ability to format only selected RANGE of code lines
thus heping greatly in fixing majority of stuff without touching formatting for the rest of code base
That's nice! Do you specify any style rules?
nope 😅 i will not be able to guess correctly what flake8 stuff wants anyway
Anything i can eliminate in bulk with default yapf for fixing flake8 stuff is already great
yapf in those terms is unique formatter
only this one is very... rich in functionality and supporting selected lines formatting :/
Why the sad face?
Flake8 should be similar to pep8, and yapf has a pep8 base style that can probably be used. Oh, that's the default!
i work across dozens of code repositories, which having in sum more than a million code lines
configuring... formatting details in such situation is meaningless and plus i have no rights anyway
i keep formatting enforced by my own rules only in repositories that belong to me
and in them i prefer way more simple strategy of just enforcing black formatting
it has no need for configuration, it formats everything Automatically on its own
and has even --dry check for CI that stuff was formatted
best formatter to use. Check + Autoformatting in same instrument.
I hate flake8 for not having automated ways for fixing its own errors 😅 it is very annoying to deal with
black for the win
but since black is not possible to enforce at most of other repos i need to deal with, i use yapf to fix flake8 stuff
I'm on the other side of the fence. I really don't like black so I need something to defend myself with 😂
black is purrfect.

nothing needed to be fixed, everything is just auto formatted (optionally on file save)
Everything is auto-messed 😛

Hey all, I'm having an issue with github. I'm trying to sign up to a site with my github account but it says I don't have a public verified email attached to my account. Looking in Settings > Access > Emails, my primary email is not unverified, there's no "resend verification email", and the "keep my email address private" checkbox is unchecked. Am I missing something?
(unrelated but is there a channel for server suggestions? I cant find it)
what kind of server suggestions?
I'd like to be able to favorite channels. I've seen this option in other servers
when they're favorited they show up at the top of the channels list
any tools that allow us to make ec2 instances aross multiple cloud providers with a unified API?
may be u a speaking about this option
Interesting! it's not quite what I meant, since the channels arent listed anymore, but it's very helpful
Kubernetes is kind of used for such deployments.
Kuberenetes abstracts away what is Server, and gives... more or less uniform unterface for deployment
Not really raising instances themselves though 🤔
this is what I meant

Can anyone help me code an discord tools? I can pay if your intrested
For raising in uniform way EC2 instances themselves u could write for example terraform module that would be doing that for you.
under the hood having switch, depending on chosen cloud provider which one to use for our "EC2 instance"
hm terraform seems to be coming up a lot, i'll check into that
thanks for the comments!
yeah, for raising servers themselves people today like the most Terraform OpenTofu and Pulumi
pulumi for python I guess? never head of OpenTofu thanks a lot for the ref
woah opentofu is opensource terraform
Terraform recently made a dick move with switching open source license into business license and adding multiple limitations/payments for all people after the last open source version 1.5.x
OpenTofu is open sourced fork as replacement to original terraform
forget terraform, long live opentofu
Pulumi can do same in regular programming languages
nice nice thanks a lot for the comments
Ah, I found where I should post my suggestion: #community-meta
and u cleared my confusion regarding which kind of server suggestions 😅
u was writing in a channel meant for other types of servers
infrastructure servers
oh my bad!
What type of tools?
Hello, I have a complex excel file. I am putting it into a dataframe and using Panera to validate the data. Is there a way for Pandera to print exactly the Sheet_name, Column and row number? the SchemaErrors failure_cases just tells me that there is an error. Which is good, but I need more info than that to be able to fix the error.
i originally had 30 gigs allocated in disk then i scaled it to 64 gigs (microsoft azure)
now it does show the newly allocated space when i do lsblk, but how do i allocate this extra space to root where its running low?


ok so figured it out had to run the following commands
sudo pvresize /dev/sda2
sudo lvdisplay
sudo lvextend -l +100%FREE /dev/rootvg/rootlv
sudo xfs_growfs /dev/rootvg/rootlv
I'm having some problems with git that are hard to explain. Yesterday, a PR was merged that had some incorrect code. we rolled back and I fixed the code from the local branch I had. Now, I pulled the main branch to merge with this fixed branch, but it seems the old, reverted code overwrote the actual new code, as if the reverted changes were newer. I solved merge conflicts, but entire pieces of code were rolled back without showing up as merge conflicts. Is there a way for me to merge, but force the code on this new branch to overwrite the code from the reverted main,even if it's not a merge conflict?
did you use git revert?
---o---o---o---M (main)
/ \
---A---B | (bad-pr)
\ \
C---D (tabris-fixes)
this is the situation, right? where M is the bad commit, and C and D are your fixes?
or something else?
Yeah I think that's it actually
well, when you say "reverted", what do you mean exactly?
did you use git revert on the main branch?
---o---o---o---M---R (main)
/ \
---A---B | (bad-pr)
\ \
C-----D (tabris-fixes)
is it this? where R is a git revert commit?
Sorry, I'm not good with these git diagrams. It would be something like this:
---o---o---o---M------R (main)
/ \
---A---B \ (bad-pr)
\ \
---------C-D (tabris-fixes)
Because C and D were comitted without R in its history
The revert was made via github, and from their documentation
Reverting a pull request on GitHub creates a new pull request that contains one revert of the merge commit from the original merged pull request.
So by merging this new revert PR, it sounds like the revert documentation (this one is from atlassian bc I found it easier to understand):
The git revert command can be considered an 'undo' type command, however, it is not a traditional undo operation. Instead of removing the commit from the project history, it figures out how to invert the changes introduced by the commit and appends a new commit with the resulting inverse content.
If I'm understanding this correctly, R had the same code as M, but was actually another entry on the history. When I tried to push C and D, R was "newer" bc the hash didn't exist in tabris-fixes history. Is that right?
wait, im gonna redo the diagram
C and D happened after R in terms of time
I don't understand why R was applied on top of D though, since it was made after R
I feel like I'm making this worse. I did manage to solve things manually so the code on main is updates correctly
pretty much, yeah. git revert is a new commit that acts the same as if you manually undid the changes and committed that
i think this could be an artifact of git not recognizing the "hunks" as being the same. so from git's perspective it was just merging in new lines of code with no conflicts
what i would do is git reset --hard your branch to before your merged the revert into your branch. then you can redo the merge with git merge --no-commit and carefully work through the changes to make sure they are what you expect them to be
you can use things like git reset --patch and git add --patch as well as git restore --ours / --theirs / --source
alternatively you could make a new branch that reverts the revert commit, and work off of that
and that should (i think) merge cleanly back into main, but should check because this stuff gets complicated. the result of a 3-way merge depends on what git sees as the common ancestor
pandoc app installed to Windows user profile, pandoc python module to virtual environment (created with vent). Latter operation using ‘pip install pandoc’ in v. env. If to attempt subsequently the Save and Export Notebook as PDF it completes in error “nbconvert failed, pandoc wasn’t found. Check that pandoc is installed”. Notebook was started in v. env.
%PATH% points to pandoc binary location on file system properly.
What may I still miss?
how did you configure PATH? if you only did it in the windows console, that doesn't affect programs started outside the console
Good point, I did it in Windows settings, the user profile scope
Terminal open from jupyter session started in virt env, then $env:PATH is listing pandoc binary path as expected - the installation point in Windows user profile. These are conditions under which problem is to observe. Conditions for good case still not known, this why I come here.
What follows is a CProfiler output
Profile stats for: [Strategy]DDPStrategy.validation_step rank: 0
21239 function calls (10163 primitive calls) in 72.883 seconds
Ordered by: cumulative time
ncalls tottime percall cumtime percall filename:lineno(function)
4 0.000 0.000 72.883 18.221 strategy.py:401(validation_step)
...
24 0.027 0.001 72.758 3.032 modeling_distilbert.py:496(forward)
148 0.002 0.000 71.335 0.482 linear.py:115(forward)
148 71.333 0.482 71.333 0.482 {built-in method torch._C._nn.linear}
24 0.000 0.000 47.561 1.982 modeling_distilbert.py:465(forward)
24 0.001 0.000 47.561 1.982 pytorch_utils.py:165(apply_chunking_to_forward)
24 0.003 0.000 47.543 1.981 modeling_distilbert.py:468(ff_chunk)
24 0.015 0.001 25.148 1.048 modeling_distilbert.py:201(forward)
48 1.214 0.025 1.214 0.025 {built-in method torch.matmul}
4 0.001 0.000 0.071 0.018 module.py:371(log)
So, the total time spent in the built-in method torch._C._nn.linear is 71.33 seconds. But how come we have 20 second bumps in the cumulative time at modeling_distilbert.py:201 and modeling_distilbert.py:468? should we understand that these are locations where torch._C._nn.linear is being called? there has to be a better way to organize this lol
the cProfile output doesn't tell you the call tree
you'd have to use a different profiler to see that
ah I see. is there a profiler that combines call tree and cumulative time?
you can try py-spy

GitHub
Sampling profiler for Python programs. Contribute to benfred/py-spy development by creating an account on GitHub.
thanks a lot!