#ot1-perplexing-regexing
1 messages · Page 104 of 1
I should try that more often.
It's actually nap time for me now~
They don't make sense, they make dolla dolla bills 
but humans are these feeble mortals like any other being on earth that needs time to recoup
oh wait why am i talking like this
.uwu
but humans awe these feebwe mowtaws wike a-any othew b-being on eawth t-that n-needs time t-to wecoup
bwut h-humons ar dweese f-feebwe mowtawls wike a-any othewr b-beiwng on e-eawthh t- dat nweed time t-to wec- wecouwp... >~<
stop
:incoming_envelope: :ok_hand: applied timeout to @strange blade until <t:1717374089:f> (10 minutes) (reason: duplicates spam - sent 4 duplicate messages).
The <@&831776746206265384> have been alerted for review.
wha-
ok
what happened
:incoming_envelope: :ok_hand: pardoned infraction timeout for @strange blade.
You sent duplicate messages
where
Bot deletes them after it mutes
yea
enter key by itself doesn't work though..?
Bot should get off its high horse
on my lag it will
oh.
🐴 🛫
get that horse off the airplane
theres motherfucking horses on this motherfuckkng plane
😔
Apparently that’s an actual thing

um yea?
“Air Horse One”
lmfao
NON_)N_-

badumtss
Is that horse made of air? because that's what it implies in my head
It also implies that there is a president of horses 
Haven’t you met Mister Ed?
Only horse ever to be a mister
palaminos are the horse upper class
Mister Ed ==> horse equivalent of Mr President? 
The trajectory of ot1's discussion is going 🐴 🛫
 8 sided dice!!
8 sided dice!!
imaginary dice
I've seen the vsauce short with the different die
You've got d2s, d4s, d6s, d8s, d10s, d12s, d20s and I've seen a d100, but it's a bit impractical.
I've seen a d1
A...sphere?
Oh, one of those things that always settles on one side?
a gömböc
d1, d2, d3, d4, d5, d6, d7, d8, d9, d10
http://www.CuriosityBox.com CODE "1"
Right right.
Michael!
Code "1" 💀

hey guys
there is an all night meme fest it is tech themed
(https://twitch.tv/finndolf)

Hurm.... so if I have an Azure Web App (postgres flavor of DB), what's the best way to connect to the DB to do some one-time loading/schema creation?
I guess the most reliable is having a one-time initialize folder with data and scripts, then shell connecting in browser to run that accessible code once and/or run some manual SQL commands to COPY in the data I need....
the people in #databases might have ideas
the sticky part is that the DB is only accessible on the deployed virtual network and I don't really want to open it up to external connections if I can avoid it
I usually just throw it into a database script section of the code. I do mostly serverless work so there is a lambda that just runs those scripts behind a feature flag or a deployable, one-time, cron trigger.
Is it part of your "main" code or is it sectioned off elsewhere in your codebase?
Running a bit with the feature flag thing, is that an env var or do you implement it in a different way?
It's a part of the main codebase. My pattern at work is to have a /handler module which is all the lambda entry points. Normally those are super small modules. Just accept the trigger event and pass it to the controllers asap. For the database stuff most the logic lives in that handler since we'd need a different solution for a different deployment.
The feature flag is probably in-house solution for me. Our CI updates the deployment platform's run-time variables. Then, during deployment, those are pushed to the Parameter Store in AWS. The cron kicks the lambda off, the flag is set to True, the database scripts run, the handler sets the flag to False.
In most of my apps, we'll build an internal admin query interface (ie: a form to execute arbitrary or preloaded scripts). Obvious security considerations
Yeah, there's a lambda that runs every 15 minutes and does nothing. It costs us a penny a month (if that) 
One of our apps has this setup. I'm frantically trying to level up my nodejs skills so that I can build more off the existing interface.
Though I hesitate on the arbitrary script part. All manual actions to the database (query or otherwise) should be version controlled and tracked.
Yah, the query accounts have somewhat restrictive permissions and it's not truly arbitrary in all cases.
And tbh, it's usually more for arbitrary selects for reporting/etc
(Again, except for certain tables)
We have an "export database" button which dumps the entire thing to file. But the largest table anything I work in has is only roughly 2 million rows. Orders of magnitude larger than any other table in the database.
I hope I get to drop that table this next two weeks. 
It's interesting how dismissive people can get as soon as they get the help they ask for.
discord runs on elixir right?
You're thinking Electron
but nothing in the actual discord client can run on elixir right? it is all backend
huh?
i dont think so
electron is a js framework for apps right?
elixer is part of discord's tech stack, yeah
if there was any elixir as part of the actual discord client, they would have to ship the erlang vm with it under the hood right?
since elixir can only compile to .beam and an only run on the erlang vm
Really good blog on them using elixer (and a few other things) to support stuff: https://discord.com/blog/using-rust-to-scale-elixir-for-11-million-concurrent-users

The Backend Infrastructure team at Discord was hard at work improving the scalability and performance of our core real-time communications infrastructure.
yeah, the discord client is straight electron

rust 🔛🔝
you are very likely to find multiple languages as the company grows

GitHub
Fast batch message passing between nodes for Erlang/Elixir. - discord/manifold
Sometimes, it's more of a reflection of HNN or popularity than purely being the best tool for the job too
I guess if you want to attract impressionable young developers you have to use impressionable new technologies.
it's more of a reflection of HNN
real
Just keep the break room refrigerator stocked with kombucha.
kind of funny to see blog posts like "How we rewrote our backend in Go". Then after rust became popular: "How we rewrote our backend in rust". And then as graphql was hot: "how we migrated our frontend to graphql"
graphql my belothed
GraphQL is great technology... if you are in the problem domain that graphql solves.
$foo technology is great technology if you are in the problem domain that $foo technology solves.
News at 11
so what's your AI strategy?

need to find miles dyson
I like using AI to 'interrogate the common case'
As an alternative to google
great strategy
Maybe. I also bought that stupid brilliant AI poetry alarm clock
I guess that makes me an early adopter!!11!!11
This is how I use Copilot:

I use mistral with logseq
I have a laptop RTX 3060 (only 6 GB) so I'm not running any LLM.
What do you like about logseq versus other solutions? (like obsidian)
I suppose I could try to learn about Google Colab.
it's OSS and works great for me
you can run them on CPU too

at like 2 tokens per second maybe
don't use it for autocomplete
How does logseq make money?
Probably vc funded with the goal of making an enterprise project and eventually selling it out to a big corp
?
ah
I use my own nextcloud though
oh you are missing out
it's great for groupware type
I wonder if I'm curmudgeonly because I'm wary of cloud services.
I think it’s fine to be wary of cloud services
I don’t know if I’d call it curmudgeonly
😩 Just as I get home and can finally sleep .... someone lights furniture outside my apartment on fire so now the fire department is involved and loud and I am so tired
Well now you know your neighbors are arsonists.
you should join them
its fun
more so than me definitely
more like arsholists
I'm trying to do a git rebase but there is one file with conflicting history that I want to ignore to the power of infinity. I really don't care what's in it, it will get overwritten anyway, just give me the rest without making me resolve the conflicts. what's the magic word?
move it out, rebase, move it back in?
idk i'm not a git expert
if it's overwritten and doesn't matter, why is it even tracked? 
they want "their" changes i think 🤔
it's an API spec that is fetched from the backend whenever the backend is updated
nobody cares what its history is
senior dev was expecting it to be in gitignore
then maybe fix the issue and untrack and gitignore it
I have gitignored it but that doesn't seem to be retroactive
git restore --cached or something
are people just doing git add . or whatever blindly? 🥴
when I was using git I didn't rely on gitignore for correctness
ya
(in jj I do, but there it's more natural since everything gets auto staged)
git add -p gang
Chaotic neutral
Aren’t you?
god no
jiery jrumpy jenix
git add -u and then manually add any new files with git add file/to/add
git status
git add -A
Adding things interactively has been great and helped me catch stuff left in the code and other nonsense
bot/exts/fun/trivia_quiz.py line 400
if question_dict["id"] not in done_questions:```done_questions should be a list of strings with the question text
.xkcd
If you draw a diagonal line from lower left to upper right, that's the ICP 'Miracles' axis.
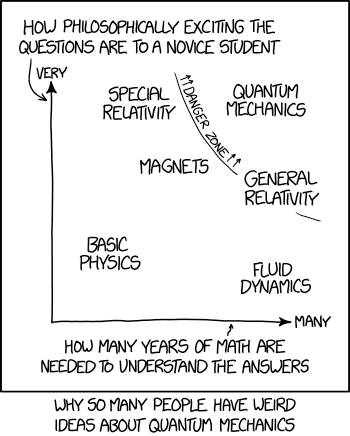
2017/7/10 - #1861, 'Quantum'
I've been very happy with vcs that mostly get rid of the staging area

If it works it works
it's not my code anyway :P
and that's why i rizzed up ice spice
Wdym its all the same thing
Lame, no
Do you think i work for 8h every day
Lmao
28
🤨
Im literally in my prime
Fully developed brain and everything
No
Work takes about 2-3h maybe
The rest is just faking it
doesn't the average person have it kinda crappy?
I dont mind it either but its boring tech wise and boring domain wise
And can be done in a few hours
So i rush it and get on my chosen steam game for the week
Fallout 4 currently
Skibdi bop bop bop yes yes
what the hell is happening here

!rule advertising
<@&831776746206265384>
@solemn tulip damn bro worked on pyrival
lol, not much
Work load is low at my job today
How does a software developer keep themselves busy when the workload is low?
import pygame
import shapes
pygame.init()
GRAVITY = shapes.Coordinates(0, 9.81)
screen = pygame.display.set_mode((800, 600))
ball = shapes.Circle((255, 0, 0), 10, 5, shapes.Coordinates(400, 300), shapes.Coordinates(0, 0))
clock = pygame.time.Clock()
running = True
while running:
for event in pygame.event.get():
if event.type == pygame.QUIT:
running = False
screen.fill("cyan")
if ball.status:
drag = shapes.Coordinates(1/2 * 1.2 * (ball.velocity.x ** 2) * 0.47 * (3.1 * (ball.radius / 1000 ** 2)), 1/2 * 1.2 * (ball.velocity.y ** 1) * 0.47 * (3.1 * (ball.radius / 1000 ** 2)))
net_force = shapes.Coordinates(ball.mass * GRAVITY.x - drag.x, ball.mass * GRAVITY.y - drag.y)
accel = shapes.Coordinates(net_force.x / ball.mass, net_force.y / ball.mass)
ball.velocity = shapes.Coordinates(ball.velocity.x + accel.x * (1/60), ball.velocity.y + accel.y * (1/60))
ball.position = shapes.Coordinates(ball.position.x + ball.velocity.x, ball.position.y + ball.velocity.y)
if ball.position.y > 600 - ball.radius and not round(ball.velocity.y):
ball.status = 1
ball.position.y = 600
elif ball.position.y > 600 - ball.radius:
ball.velocity.y = -ball.velocity.y
ball.status = 1
pygame.draw.circle(screen, ball.colour, (ball.position.x, ball.position.y), ball.radius)
pygame.display.flip()
clock.tick(60)
pygame.quit()
for some reason the ball sinks into the ground on the 5th bounce
i cant figure out why
and also shapes.py is :
class Coordinates:
def __init__(self, x, y) -> None:
self.x = x
self.y = y
class Circle:
def __init__(self, colour, radius, mass, position, velocity) -> None:
self.coefficient = 0.42
self.status = 1
self.colour = colour
self.radius = radius
self.mass = mass
self.position = position
self.velocity = velocity
can anyone guess why?
i should ask this on #python-discussion actually now that i think about it

fix tech debt

Build a rewarding career in our restaurants or in one of our global corporate offices. Search open jobs and apply today!
They're lovin' it.

🤨
everyone has hobbies
You wouldnt stay in a relationship if you werent satisfied 100% of your waking time, would you
I thought they just said they didn't have many tasks
but also...100% satisfaction is kinda unreasonable don't you think
Youre not trying hard enough
You're*
Youre mom*
hello son
I just talked somebody out of making a mobile Python app. Woo.
woo
My manager keeps asking me about Power BI training. Power BI is honestly not that complicated
I already made data visualizations of our finances for projects
To what end?
That’s what my manager wanted lol. I am just doing my job
Then to answer your earlier question of how to some keep busy when workload is low: We don't just do our job. We find other things to do that align with it.
Take the training and learn how to leverage Power BI into finding value adds that nobody has considered yet. Dig into tech debt and start resolving issues that always wait "for when we have time". Invest the time in yourself while adding value to the company paying you for that time.
From what I am researching about tech debt. It’s technical mistakes in the sense of poor software design and architecture?
Tech debt is anything left for another day. Mistakes, bugs, version updates that happen on a regular cycle, that one feature that would have been super nice but didn't fit in scope, improvements, exploration, etc.
tech debt so deep my nickname is Mariana
Some of the teams at my workplace like to use different names for keeping versions up to date, vulnerabilities patched, and such. "Engineering Experience" is one. It's all just tech debt. Stuff you need to do, can do, or might do on deployed software that isn't new implemention.
huh, this seems broader than the usual definition I see. not that it matters, it's all in the backlog 😩
Yeah. I'm guilty of using a broad brush against it. I've seen teams use more granular terms to break the backlog up. All they do is end up pushing the tech debt lower on priority by focusing on busy work that could actually wait a cycle because it's got a different name.
I'm starting an ~initiative~ to make our docs more approachable for new members (me). we'll see how it goes 😩
but also I want to code stuff. so basically I am dooming my own ticket to the backlog
It's a valuable initiative. So easy for a team's knowledge to fall into silos and "common knowledge". Fresh eyes help and it's cool that you can actually start to make some improvements.
ya. it took a whole day for me to figure out that "disco api" was short for ||"discovery api"||
discovery inferno?
Abbreviations are the bane of knowledge. 😠
real
I don’t abbreviate
My docs are also many times longer than they could be
I remember last year my team gave both senior devs on the team three days of "offline" time to just work the lowest tickets on the backlog. We closed up 40+ tasks with 10 of them being bugs that had existed for a year or more.
abbreviation is fine if you are restating the full in every "section"
We should do that again. 
Sometimes I wonder what would happen if CPython did that
I want to sort CPython’s issues to oldest first and see what’s actually still an issue
Your doctors?

Cant ever work on tech debt
If you ran out of tasks you should talk to your manager, not work on random things you think should be worked on
That leaves you vulnerable to getting dunked on
You're very defensive.
If you ran out of tasks and want to do work*
It makes sense not to work on whatever you think is appropriate but ask your manager
Its part of their job to deal out tickets, isnt it?
Without more context this should be the generic advice
Ask your manager
(if you want work)
You could always stretch out current tasks and do other things
Not so advised
If your manager is asking about power bi training then do that
Its good for you
Goes on the CV, first of all
Could also benefit the company, its a win win
> Hello.
C++ is so confusing like
you have multiple package managers that targets multiple build systems that targets multiple compilers
... like pip and poetry targetting setuptools and hatchling targeting cpython and pypy?
never thought of it that way
but still, way too complicated to include libraries unlike pip install xyz
you have to deal with cmake
Python definitely has multiple package managers, multiple build systems, and multiple compilers/interpreters 🤷♂️
and these compilers may not even target your environment
yeah, cross-compiling is a real big difference
but also, don't cross compile unless you have no other choice
especially if you need to build stuff that uses autotools, since conftest can't run programs to check OS behavior when you're cross-compiling
the difference is that the python ecosystem hides these details from you
whereas in C++ it's not that simple
the choice of package manager and compiler/interpreter is directly up to the user
the choice of build system is up to the library author, though
you're right that that's abstracted from the end user of the library
they have to know what package manager they're using and what interpreter they're installing the package for, but don't have to know how the package gets built
in practice there's not many common build systems for C++, though, either. Pretty much everything I see uses cmake, autotools, or bespoke hand-maintained makefiles
if you're just learning, you should probably only be installing packages from your distro's package manager
beyond that... yeah, C++'s package management story isn't anywhere near as good as more modern languages, or even Python's, but it's not too much of a problem in practice. If you learn how to build a CMake project (mkdir build && cd build && cmake .. && make install) and how to build an autotools project (./configure && make install) and how to build a project that just uses a Makefile (probably just make install), you're pretty much set.
the bigger problem is that every project might have a different way of controlling where it installs to, plus you might have to do extra work telling other packages how to find the one you just installed
distro package managers take care of all of that for you
oh. use WSL
unless you're specifically doing Windows-specific projects that can't be run on other OS's, at least
arent you supposed to say how easy its going to be on windows insteda off how painful?
micro soft
guys, is there a way to execute an executable from one of its symlink in win?
just run the symlink?
i tried
but it didn't even detect it
whats the error? i'm probably not smart enough to solve it though

that's not a symlink 😭
dont run it like that
that's a shortcut
do ./chdman
yeah
i did run mklink chdman "path to original chdman" and all it gave me is a shortcut
ah yeah my bad
bro this is wendy's (win)
its the linux terminal not not windows
shortcuts look like symlinks
??
chdman wont work, do ./chdman
this is the issuue
......................
ok it does run as expected in linux (wsl)
but not in cmd?
so what i saiud worked?
have you tried powershell? cmd is kind of old at this point
mayve you are in the wrong dir?
run dir to check that in cmd, since you are using that
i tried powershell
but im not even getting the output for the -h (help page) in it
atleast i got that in wsl
im in the right dir
checking with ls or dir doesnt hurt though
i did do that
and the symlink is in that dir
as expected
after being sure that im in the right dir, i tried to execute the symlink
but its not working in cmd
how exactly? what was the command?
u mean the executable that im trying to link?
what did you write in the terminal to run the symlink?
just the name of the symlink
i even tried [name].exe
give me the exact command, dont paraphrase please
its chdman
i'm sorry if i come of as rude
no no its ok
maybe try ./chdman?
it says . is not a command
you mabe have to invert the slash
with this, it says ,\chdman is not a command
theres a comma there instead of .
try the following cmd /K "[path to symlink]"
add file extension to the path as well, if your symlink for some reason has one
or you could also try start chdman[and file extension here if necessary]
same outout
its not even recognizing the symlink as an executable
ok nvm
i think im trying to solve this in the most complicated way
i could just make permanent aliases in pwsh, cmd, and bash
perhaps
windows cmd is a pain
i can never go back to it from linux
windows in general is a pain
yea, but the terminal is especially painful, along with the ram usgae and the design choices
i just decided to do this cuz my PATH list is getting bigger
why is that issue?
cuz i cant just shove every path of the executables into PATH
there's a limit for that
one app looks likw windows 10 another like a webapp and anotther like it came from goddamn win xp
i mean..... 👀
b- but backwards compatibility
i will blow up your favourite compainie's hq if you keep this up
@thick ore whats the quiz about?
i was gonna add some questions to the sir lancebot quiz game
dont talk about quizes
.quiz cs
Quiz game Starting!!
Each game consists of 7 questions.
Rules :
1: No cheating and have fun!
2: Points for each question reduces by 25 after 10s or after a hint. Total time is 30s per question
Category : cs
Question #1
What standard provides the basis for Wi-Fi networks?
ummm
20s left!
LAN
802.11
@thick ore got the correct answer :tada: 75 points!
You got it! The correct answers are **`802.11, IEEE 802.11`**
Let's move to the next question.
Remaining questions: 6
Score Board
interrrp: 75
Question #2
Name a universal logic gate.
and
nand
@brittle void got the correct answer :tada: 100 points!
You got it! The correct answers are **`NAND, NOR`**
Let's move to the next question.
Remaining questions: 5
Score Board
ghost.ops_: 100
interrrp: 75
Question #3
Why is a DDoS attack different from a DoS attack?
(A. because the victim's server was indefinitely disrupted from the amount of traffic, B. because it also attacks the victim's confidentiality, C. because the attack had political purposes behind it, D. because the traffic flooding the victim originated from many different sources)
@thick ore got the correct answer :tada: 100 points!
You got it! The correct answer is **`D`**
Let's move to the next question.
Remaining questions: 4
Score Board
interrrp: 175
ghost.ops_: 100
distributed
if @drowsy rose hears of it he will torture us with more quizes and absurd typing speed
Question #4
What is an interpreter capable of interpreting itself called?
metainterpreter
@small coral got the correct answer :tada: 100 points!
You got it! The correct answer is **`metainterpreter`**
Let's move to the next question.
Remaining questions: 3
Score Board
interrrp: 175
ghost.ops_: 100
krowten024nabru: 100
BRUH
Question #5
What does the 'B' in 'B-Tree' stand for?
b
@thick ore got the correct answer :tada: 100 points!
binary
You got it! The correct answers are **`Nothing, B, Unknown`**
Let's move to the next question.
Remaining questions: 2
Score Board
interrrp: 275
ghost.ops_: 100
krowten024nabru: 100
noooo
Question #6
Given that January 1, 1970 is the starting epoch of time_t in c time, and that time_t is stored as a signed 32-bit integer, when will unix time roll over (year)?
okay
not again
2083
20s left!
2038
@small coral got the correct answer :tada: 75 points!
You got it! The correct answer is **`2038`**
Let's move to the next question.
Remaining questions: 1
Score Board
interrrp: 275
krowten024nabru: 175
ghost.ops_: 100
Question #7
What does HTML stand for?
hypertext markup language
@thick ore got the correct answer :tada: 100 points!
You got it! The correct answer is **`HyperText Markup Language`**
Remaining questions: 0
Score Board
interrrp: 375
krowten024nabru: 175
ghost.ops_: 100
hypertext markup language
The round has ended.
@thick ore Congratulations on winning this quiz game with a grand total of 375 points :tada:
HA
brain hiccup =-='
ril
guys, im having long path issues
its not like windows is complaining about it, but its not looking good for my eyes, so i've decided to do smth to solve it
which way would be better here?
a. just leave it as it is
b. create a file that has a mapping of a name to the path of the executable, and create a startup script in .ps1, .bashrc, etc to have those aliases in every terminal
aliases can be set in the profile script. no need to make another script.
alternatively, move/copy the binaries to a single location and add that location to the shell's PATH
this statement is pretty interesting 💀

Instead all of my research had shown me nothing but enthusiastic support for a rematch To the general public, the problem with the Great War wasn't the senseless loss of human life and productive capital. The problem was that we'd lost.
death
- is just a statistic
--by the General Public
.quiz cs
Quiz game Starting!!
Each game consists of 7 questions.
Rules :
1: No cheating and have fun!
2: Points for each question reduces by 25 after 10s or after a hint. Total time is 30s per question
Category : cs
Question #1
On Linux systems, the fork system call returns what value in the parent process?
pid
@drowsy rose got the correct answer :tada: 100 points!
You got it! The correct answers are **`PID, child PID`**
Let's move to the next question.
Remaining questions: 6
Score Board
somehybrid: 100
Question #2
Name a universal logic gate.
nand
@drowsy rose got the correct answer :tada: 100 points!
You got it! The correct answers are **`NAND, NOR`**
Let's move to the next question.
Remaining questions: 5
Score Board
somehybrid: 200
Question #3
What are the components of digital devices that make up logic gates called?
sup
i dont think anybody is here rn
transisto
@drowsy rose got the correct answer :tada: 100 points!
You got it! The correct answer is **`transistors`**
Let's move to the next question.
Remaining questions: 4
Score Board
somehybrid: 300
Question #4
HTTP/3 is built on which Transport Layer Protocol?
@drowsy rose got the correct answer :tada: 100 points!
You got it! The correct answer is **`UDP`**
Let's move to the next question.
Remaining questions: 3
Score Board
somehybrid: 400
Question #5
What kind of characters are needed in UTF-16 to encode unicode codepoints outside the BMP?
@drowsy rose got the correct answer :tada: 100 points!
You got it! The correct answers are **`surrogates, surrogate`**
Let's move to the next question.
Remaining questions: 2
Score Board
somehybrid: 500
Question #6
How many bits are in a TCP checksum header?
16
@drowsy rose got the correct answer :tada: 100 points!
16
You got it! The correct answers are **`16, sixteen`**
Let's move to the next question.
Remaining questions: 1
Score Board
somehybrid: 600
Question #7
What does HTML stand for?
@drowsy rose got the correct answer :tada: 100 points!
You got it! The correct answer is **`HyperText Markup Language`**
Remaining questions: 0
Score Board
somehybrid: 700
The round has ended.
@drowsy rose Congratulations on winning this quiz game with a grand total of 700 points :tada:
i type slower than a monkey
skibidi toilet 🚽 boiii
what the sigma
skibdi toilet...........gyatt
Monkeys are actually pretty fast at tapping things.
they are fast at tapping not typing
the error rate is probably 70%
"enough time", meaning they are slow
and bogo sort would proably be more effective
just apply bogosort on the entire alphabet and wait for shakespeare to be returned
i wonder why space is needed though
they could fill up an indeterminate amount of space before completing the task
whether it be paper or digital storage
ohh i didnnt get that you meant memory
I thought you meant physical space
i read in my school book that python uses the datatype char to store characters data. but whenever i type it out in the repl in gives me a error
i know they meant exactly char since it was syntax highlighted
they even mentioned that the char type in python is defferent from C's char type
There was some kind of website where you have a "library" of randomly selected characters. That's not full random, of course, like any digital random, it's provably seeded and generated in certain manner - because there's search there, to find fragments that include text you want.
They were formatted as "books" and "pages" to see only part of the whole thing at once and easily reference it to other people... And also to look cute (it was actually displayed as open book on the website)
library of babel?
Yep
what char type?
Python doesn't have char type tho
.
this char type
when you index a str, you get a str
thats what i know
and there's no char
but my book insists otherwise
when you index bytes/bytearray, you get int
that's a misinforming book if i've ever heard of one
Maybe in C source you'd find something to store it, but it's not really in python code itself
And yes, python's string is not an array of char because it can store whole Unicode and the length per character is adjusted - if you store ascii-only text, each character will take single byte. If at least one character is 2-byte, then the whole string stores all characters as 2 bytes per character. Emoji in the string? 4 bytes per character, baby! It keeps the length uniform (even if the rest of characters are ascii, so 1-byte) so that we can index it fast
theres a shit load of mistakes in this book,
- Calling "+=" the "increment operator" and that in can only be used to increment a variable by 1
- Saying that
raw_inputis included in python 3.7 and including it in execises - Saying that
tuplesare constructed with parenthesis and not with commas - Saying that charecter data is stored in the
chardata type - Saying that C is outdated and OOP is inherently better than procedural
And probably many more.....
i'm afraid of what i'm gonna do on theh exams
3rd point is true
5th point is semi true
theres a chance my correct answers are gonna be cut because i didnt follow the book

students dont need or want partially true staements in school books
42,
the 5th point depend on the programmer
if the exams depend on what the book says, disregard everything we say regarding that when studying :P
3rd poin isnt true as parenthesis are optional and only ","s form tuples
3rd is true only for empty tuple, in any other case it's the comma that makes a tuple, see 1-element tuple
it was edited
yea, its sad. I've been studyin python on my own for 3 years now. And now i've to write wrong answers to get marks in a exam
if the second clause was added when i answered i would've changed it
i edited it after you mentioned it as clearly my 3rd point was unclear
you would think that a school book would focus more on accuracy than whaever this is
As for the "char", in C source wchar_t is used. But that's still in C source (it's a C type) and in no place char type is used to denote anything related directly to python strings.
yea, thats what i was wondering. They syntax highlighted char so they obviously think its a python data type
Wait, no, I lied... The struct itself, because of the varied bytes length, stores some stuff as char. But it's not really made to be visible "outside" as char
example?
chr is a function char is a name
I read the header and top of the c file first, but now I scrolled to the struct itself...
They mean in the book they have to use for their class, look above for other weird shit in that book
and also
But, char in Python is not the same as char un C or C++.
They obviously thinkcharis a python type
how would i send a example for that? let me descrbe it instead, the word "char" is highlighted blue by the book in text
a screenshot, perhaps
its a physical book
picture
and i'm on a laptop.
it will take some time to email it, wait a sec
let me get a pic
@young shoal see here
The += thing seems like someone learned c basics and only used ++, didn't know += also exists in C...

I read that
why isnt my email showing the pic i included

yea
not too uncommon
fuick wrong reply
not too uncommon
i've found that emailing yourself is an ineffective strategy to transfer an image
email others maybe
i got it @thick ore and @young shoal

i just learnt i cant upload jpgs for some reason
i emailed it to my laptop email account from my mobile email account
and theres the exact pic for char if anybody was interested
what is a char in python 💀
partially not for python 2, but wrong for python 3
nvm
"all text" so it's wrong either way
i'm really worried about the exams 💀 .
They will probably deduct points for correct answers since it would be different from the book
its 3.7 in the book
besides, its the one and only school textbook, it has to adhere to a certain level of quality
most unicode text is probably representable in 16-bit characters
but there's still 32-bit versions and also 8-bit ASCII
so even the size of the hypothetical char is wrong 💀
for some cases yes
in fact
if the program never uses unicode
there's a simply high likelihood it doesn't use the hypothetical char
unless the python implementation is weird or something
a datatype to contain a len 1 string, in a world where python used curly braces. What a nice dream
you're giving me ideas.
a high level C?
https://github.com/thatbirdguythatuknownot/cpython4 already has curly braces in python
GitHub
CPython. Basically. Contribute to thatbirdguythatuknownot/cpython4 development by creating an account on GitHub.
now the next thing to do is return char for a len 1 string
||(i'm not gonna do that it's too time consuming)||
the writers are probaly gonna pay you a decent amount of money to justify their shitty text
i think you can do that in Python tho
just use fishhook or smth
yea but that's not fast :<
who cares about fast
python isnt supposed to be
everything must run in 500ms
this hurtss ><
fine i'll do it myself

Here’s how to construct an argument explained simply:
1. Make your claim
2. Provide your reasoning why you’re making that claim
3. Make a statement or statements that supports your claim
If only debating was this easy

ad hominem always eventually works
unless your opponent is a major pacifist
Can someone provide me any resources for PowerBI training?
Microsoft learn..
Mentioning doesn't technically count as providing
@quasi blaze https://learn.microsoft.com/en-us/power-bi/fundamentals/power-bi-overview This is probably as good as their is for now

Overview of Power BI and how the different parts fit together: Power BI Desktop, the Power BI service, Power BI Mobile, Power BI Report Server, and Power BI Embedded.
Power BI time?

Wait what was that N Sync song...
🎶 I know that I can't take no more
It ain't no lie
I want to see you out that door
Baby 🎶
Eh, I tried
@vale raven where do you put your fixed blade knife when you go swimming?
A whole lot of clenching
Don't clench too hard though..
Fires out like a speargun
it doesn't have a lot of supports but its nice
what did you contribute in
combi?
idk if I even contributed code, most of the authors were in the same discord server discussing impls and whatnot
would you mind providing the link
updated my arch upstream rn 2 gigs
to the discord server? it's kinda useless unless you are CM or higher on codeforces
most channels are gated on that
you register your user with the bot we wrote, you only have access to the bulk of channels if you're highly rated enough
theres one server which only allows ioi delegates to avoid spammers yeah that is sensible
it does filter out a lot of noisy beginner stuff
ah great fair
it was one of the more well known codeforces related server for a long time, though it's been kinda in decline since a lot of people driving things ended up doing other stuff (like working)
the TLE bot was one thing that made the server known I think
they grew up 😭
(a disturbing amount of people who were admins or worked on the bot ended up in the same place work-wise)
not too surprising if you think about it
people tend to hire people like them
and if they were friends before
yeah, it was just getting silly when it was a majority of the admins for a bit
no, all people who met in the server
some of the people who joined the server really early on
yeah I mean before working/hiring process
plus rewards for referrals. I get like 300 for a hired referral
I didn't even know some others were starting around the same time as me
what if big companies scouted talent like sports teams
||4500CHF||
You should get a referral bonus but your pay should be docked if that employee turns out to be a dud.
pyramid scheme
make people sweat
stats are kept I think
so if you refer a lot of bad candidates your referrals will probably start getting ignored
and it's not in your interest to refer bad candidates anyway (unless you're doing something...shady)
I've had one successful referral I think
🦵🏼🔙
though shouldn't the bonus depend on the position?
so it's kinda funny, a group of people who liked to game together broke off into our own small server, the most regular group who plays is 4/5, and the 5th got rejected and did a phd instead
based
you know those discussions about how companies don't pay for open source and just use it for free
actually nevermind
There are hidden costs.
no no, go on
He accidentally closed the website he was reading from.
I realized I should not expose my team
did smalls tv act like monitors?
did your team sponsor some open source project?
no
They sabotaged OSS projects?
did your team reject your proposal to sponsor one?
I knew you were a villain.
yeah, they added malware
D:
to bro
what's bro?
bro
what coding moment could be perfectly explained by this video
brotli
that looks like a small safety hazard
pub added malware to brotli?
bro
who would've thought?

bro
how dare you add malware to a bun?
Hey if psvm made code that works
things would just be far more expensive than they are today
which would mean we would have a far lower growth and far less advances
free is not always free
I suspect the people know what this is referring to is like...zero
nothing is free
Everything is free, now.
brötli is swiss for small bread buns
there is a cost to develop, maintain, deploy and keep up
no such thing as free lunch software?

why are memes using the ubuntu font?
why not?
I'm confus
I didn't even know there was an Ubuntu font
What's a font? What year is it?
it's 1984


This is a fan made official music video for the greatest punk band who ever lived. The Dead Kennedys California Uber Alles.
see, I'm not crazy
sez u
fonts matter 😔
I've never used Ubuntu with a head
a what
a head

You paid the hipster price.
what funky language is that supposed to be?
it's just showing symbols stuff off
I would be surprised if &| is valid operator in any sensible programming language
I think bash/zsh has |&
The "I'm sitting in the coffee shop wearing my Vibram toe shoes and drinking a soy latte while complaining about the ubiquity of Helvetica" price
I also said sensible 🙃
🗿
says the person who paid $75 for a font
can you deny it looking good though?
Absolutely.
😔
just say how much it costs and I'll say how bad it looks
it's fine though
oh also my company does not publish the referral bonus amount
It's made for people with the disposable income to spend on a $75 font.
I mean it's basically just 15 more than a typical video game. and you're looking at it all the time
if you spend hours a day looking at text...
it averages out pretty fast
yeah. it's why IDEs are seemingly expensive but are quite cheap all things considered
Yes, it's pretty average.
who can say no to this at sign

me
me too
you monsters
also jj ||hipstery||

conform 👍🏼


you know what's better than a switch case?
a switch case nested in a switch case
because yes
I once wrote a nested piece of crap at work because I couldn't get itertools to work as I wanted, but when I went to bed I was so ridden with guilt that I had to wake up and rewrite the code
u got scammed, brother
that means the conditioning worked
It was one of the strangest feelings I have ever experienced. Like I couldn't face my colleagues with the garbage piece of shit code I just wrote.
I wish some particular people at work felt this
shame is a good improvement motivator
something something PR reviews
real
Nowadays you just ask chatgpt and feel superior when it cant figure out itertools stuff
It is, but so is positive feedback

@thick osprey 
I'm struggling with architecture design...
I have a scheduled task to download records from a proprietary upstream and then upload them to my own application.
I've wrapped the proprietary crap in an HTTP API, so right now my scheduled task is literally:
data = httpx.get("https://upstream.com/get-data")
httpx.post("https://downstream.com/update-data", data=data)
I'm now being asked to also bring in multiple layers of related records, and I can't decide how to handle that.
Part of me wants to query the list of of IDs that need updating, and handle everything for a single record and it's relations all together, one at a time. Part of me wants to ingest the entire table(s) and then organize on the receiving end.
Business has listed a "would be nice to have" of having a button to update a single record [and it's relations], so I'll probably end up at least supporting the former, even if it doesn't end up being my primary method of ingestion.
So many little things spinning in my head....
Upstream doesn't support soft deletes, so... if I don't see a record again, I guess I just have to assume it's gone.
What if a relation disappears in the middle of the relational hierarchy? I know cascade deletes are supposed to be super simple, but I've never gotten them to work. (though I haven't tried in several years)
IDEK what to ask you for
I'd ask you for advice on my implementation, but I can't pick an implementation
It sounds like what you have, in function, is a cache. Instead of talking to the source directly, you are polling and filling your local copy for any operations. That's fine, but it comes with some of the tradeoffs for not working with live data.
You could design it so that you have your large, filled data from the scheduled polls. Asking to look at, or update, an individual record could just proxy to the source (update your cache on success as you come back).
From another view: Hold as much data from a scheduled poll as you can for reports. Mark on the reports how old the data is. Don't work updates through a cache. Go direct to the source for the live data displayed before, during, and after the update as safely as possible.
The rest rides on that upstream source. If you tell it to update a batch of entries and one of those entries doesn't exist, what happens? That would need to be handled by your API whether it's retry the request removing the failed item or pulling the batch to validate success (and update your cache).
Those are my initial thoughts, anyway. Dozens of ways around the path with these things.
Yeah, I’m caching, with the idea of being able to support additional functionality that the current app doesn’t support.
Don’t work updates through a cache.
It’s not particularly feasible for me.
The MVP didn’t have a cache, it just always fetched live data.
One day I get a ticket — “I didn’t get my report”
Then I get an angry phone call from my boss — “user needs this data to be able to do their job!!”
Few minutes later I get an email from Sentry — “function regressed 25,000% from 30s to 17m” (made up numbers)
No code change, just time spent spinning waiting on the upstream to respond with the requested data
Bossman says “this is unacceptable!!! It MUST be faster!!”
Also taking the oppertunity to fix some absolutely GODAWFUL design
See this image: https://cdn.discordapp.com/attachments/464905259261755392/1222587259090505778/WX4IitH7Bx2dYGGJ.png?ex=6660961d&is=665f449d&hm=02d20a680bbb0741a8846990a4cf76c2339aefb0e53196517da88511df6787a3&
And this issue: impressdesigns/charlie#72
I'm blocked in multiple places just because I can't layer enough SQL to get the data I need to come out in the right order


Reports from cache, that's a solvable challenge. Single or Batch updates, you don't want to work that through a cache.
Getting slightly stale data to the user in speedy time is great.
Reporting something is done when it actually takes much longer, not so much.
And at some point you do reach the "we move at the speed of the vendor".
What happens when business says that the speed of the vendor isn’t good enough and tells you to figure it out?
Reporting something is done when it actually takes much longer, not so much.
I’m failing to compute this sentence. Shouldn’t I always be behind on updates, because I’m waiting for the cache to be updated?
When will I have an update ahead of time?
User submits an update to 10 items.
Working through a cache:
- Take the request
- Update the cache / or stage the update in a new cache?
- perform the action
- record the result
- deliver the result
Working without a cache:
- Take the request
- perform the update
- deliver the result
If it takes 10 second, they wait ten seconds. If it takes 10 hours you deliver the success after 10 hours. Same result, but you don't have a cache to juggle at the start, middle, and end.
sigh
I’m not following
Race condition?
If the user’s update gets fresher data than the cache update?
Slow doggos don't get the bone
Sounds like I get to learn about etags
It was funnier before the edit
Meanwhile your scheduled polling job does it's thing.
standard disclaimer: I've never talked with your stakeholders or worked on your system.
I think we’re on different pages.
The update is the caching.
I’m building a copy of the data, and then users are generating reports on demand from my copy of the data.
And then eventually I’ll be adding extra columns to my copy of the data.
So users will create records in the upstream, then wait for me to ingest them, then go to my app to fill in the rest of the data.
Updating my copy (the “cache”) is the only update that’s happening — during the batch job at least
So you report updates or additions as a pending status?
I don’t have my own status
I just report the data as-is
Am I worried that you are reporting data that isn't represented in the source for no reason?
Wdym?
The data you are keeping is from a proprietary upstream. Does it not need to return to that upstream?
Ah. Well I truly misunderstood.
You poll, fill your data store, then collect updates. Reports should be faster. But the next poll needs to reconcile as well? You mentioned a record could just be deleted upstream.
Upstream has records
I take a copy of those records and stick them in my DB
Then the user requests a report, I generate it from my DB and send it via email
I’ll add extra columns in my DB to add additional data to the email
But this extra context just sits in my DB
It doesn’t go back upstream
Yea, reports are quite literally “25000%” faster (according to Sentry)
And yea, records, and their relationships, can spontaneously disappear, so I will have to continuously reconcile over time
Thanks for teaching me how to explain
Would it be worth doing a soft delete on your side? Holding onto the stale record but not propagating it to a report normally?
Might simplify the relation cleanup, give you a report of "hey, where'd it go", and even make recovery possible. Just random thoughts.
Yeah
That’s something I want to do
I don’t trust the upstream to clean up after itself correctly
Good choice. Never trust input, even if you wrote it yourself.
You want a fun story about an amazing feat of development?
So… the upstream is 82 “low code” “apps”, each one complete with their entirely unique UI, DB, et all
Their names are prefixed by type
The apps starting with data_ are only used for their DB, the apps starting with int_ are “internal”, I’m assuming just business logic, the apps starting with ui_ are, well, UI
Then the frontend has a bunch of tabs, and each time you click on a different tab, you’re pulling UI from a different ui_ app.
So, you may be asking yourself, when you have 82 apps, how do you perform updates?
Well
They send you another low code app, and when you run it, it —
- makes a copy of the apps that need to be updated
- deletes the originals
- extracts the new updated ones
- iterates over each [updated]
data_*app and copies the records from the backup app to the updated app, applying migrations along the way.
When I took over the IT work, updates hadn’t been applied for a couple years, so there were a few outstanding ones.
My boss said “MAKE VERY VERY SURE YOU APPLY THOSE IN ORDER”
Okay…. I mean, I planned on it. How else would you expect me to do them?
To which he said— “You don’t understand — when they first sent me updates, they didn’t specify that you had to apply each one in order, so I only applied the latest one, so I [missed a bunch of database migrations], and now all of our data is all fucked up and not even their support can fix it”
Sounds about right in the world of software engineering. smh
My new app?
Each test runs up migrations, then builds the necessary fixtures, then runs the tests, and then runs down migrations.
I’m finally learning about tests, and I’m loving it
I can prove that moving shit around won’t break your instance
It’s great
I wish I could hire you. haha
I wish I was good like you
this sounds like a major disaster to happen
I'd look for another job asap.
That level of legacy stupidity isn't worth it IMO.
...so that's why my cpu temps were reaching 95C

that'd be so satisfying to clean tho ngl
show cleanup video
Cleanup was just me running it under water lol, no r/oddlysatisfying for you
loll
I'm facing a weird issue. some specific features on a handful of apps don't work as they should in my network: uploading images on discord has a 5 min delay, images on twitter don't load, etc
i found out that using a vpn (proxy) fixed all the issues. the weird part is it didn't necessarily have to be an external proxy; i could host one on my home server and it would still fix the issues. these issues also only happen on mobile android, haven't seen it happen on my desktop
luckily one of the apps that broke is open source so i got to debug it. it's not DNS (yay!!), instead requests mysteriously hang for a long time with no response
i have tailscale installed on all my devices. i set up my homeserver as an exit node and tested the affected apps without the exit node (just dns and whatever else tailscale does) and with it. same as above; with the exit node on, the apps worked normally. does anyone have a clue what this could be?
I'm thinking my router is doing something weird - but then why would it treat phones, desktops and my server differently?
Bro is that your dryer lint rack
How the hell
I am writing an online test and it requires me to get a 100 percent to pass 😞
if x is a function, then x() is a function call, so if x was a class, what would x() be called?
instantiation
thanks
btw, does anybody know if there is a list of all the keybindings in nvchad?
i checked their doc but couldnt find it
and the config file mappings.lua didnt have all of them either
for example, pressing ctrl + n to open the file explorer was not listed there
Can you resubmit?
I had a class where all the assignments were like that, everything was out of 1 point and you had to have it meet the requirements set by the instructor, otherwise you'd keep working on it
Yeah I have infinite tries
a pull is a fetch, followed by a merge
A pull isn't a merge. Two different actions.
you're asking the repo owner to fetch the commits from your remote, and merge them into their branch - which is a pull
A pull could include a rebase, which isn't a merge.
by pull request I mean the act of requesting a repository to merge their branch with my branch
The action (verb) is from the viewpoint of the upstream. They are pulling your changes in.
and ye, git workflows have changed, so you usually wouldn't merge a pull request
oo
you would need to merge if their branch had changes while you worked on your changes on that branch?
no?
which happens most of the times
You could merge, rebase, or even fast-forward
rebase would be the usual step these days, since it makes the entire history linear
which makes many operations easier
but for example at my workplace, we do use merges
is it possible to use other actions like rebase from github?
like what happens when you 'accept' a pull request in github
I believe there is a dropdown which merge, rebase, squash and rebase
the default is merge
unless you change it
ok thx for the info
def on_hear_rumour(person, rumour):
person.tell_rumour(person.friend1, rumour)
person.tell_rumour(person.friend2, rumour)
it's exponential growth
thats a good example
the alpha rumour needs to tell more people so it would have better chances of spresding
the aplha rumour spreader would have told a lot of his friends, so its pretty unlikely for all of them to say nothing
thats going to be the maximum saturation for the rumour
rumours spread on closed groups usually so it doesn't matter
it doesn't die down it will approach the amount of people in the closed griup
depends on the rumour
@halcyon locust
So i'm from india and im just starting like you prob know that session start b/w august or sep
how old are you , what education are you pursuing ?
and i really want guidance regarding that
I just passed out my 12th grade
cse
so you will start pursuing your b.tech degree in CSE from this aug, correct ?
ye
what college did you opt for ? what about its placement records ?
is it a tier 1 , tier 2, tier 3 , tier 4 college ?
that's what i haven't decided yet
Is it possible if we can discuss all that in dms
I just don't prefer discussing here
i dont need a college name if thats what you are worried about
just what tier is it
nah
Like some of the ppl irl ik here and i don't prefer discussing in public
i dont know what to say then 😅
as i said i am not really good at 1 on 1 talking , so i basically dont do DMs with pretty much anyone. (except in some cases obv)
there are other people in the server who are from india and would be happy to guide you , maybe you can ask them for guidance ?
but rn i can't find any
okay fine , lets go DMs
but remember i dont normally do this
I really appreciated that dude
What are the best options these days for self-hosted LLMs, specifically chatGPT type stuff
alpaca
Since I haven't been keeping up with the field so much, not even sure what exactly I'm looking for.
self hosting anything decent is going to be hard
unless you have some really powerful hardware
model or tooling? ollama is pretty convinient for running stuff
Alpaca seems to have fairly reasonable recommend specifications. I've got a rig coming up with a 5800x, 64GB RAM and a GTX 1070 - I'm not looking to do any training so I'm fairly confident this will suffice.
I'm using Ollama. I haven't tried any other one yet. I've had nothing but great experience with Ollama.
I'm not looking for performance or exceptionally good results. Just something chatgpt-like I can run locally so my expectations are pretty tempered
I'll look into Ollama as well
Dammit. I ended up using a word as a verb when it should be used as noun
Parts of speech should be one or the other. It simplifies things
embrace noun verbification
Yeah, go and verb all the nouns!
Stay the hell away from my nouns.
You've been nouned
Pronouned!
oh like "part of speech" and "part ways"?

{kind=link}
{kind=link}
{kind=link}