#data-science-and-ml
1 messages · Page 412 of 1
C has a very roundabout way of doing iteration, since it doesn't really support abstract data structures. C++ and Java inherited that approach.
I thought of it as 0 1 2... going to n-1, n being the number of elements in the list
Even though Java in particular doesn't have that limitation in the first place
It's been a long while since I've written python
I wrote "for i in range" the the first time I wrote it
in Java terms, there's a for loop interface that any Python class can implement, so the use cases for for i in range(len(...)) are actually quite few.
if you ever feel temped to do it, do some digging to see if there's a more Pythonic way to do it, and you'll often find that there is.
thank you!
Are you actually 6 years old?
hi guys, I'm looking into learning a cloud service for ML deployment, but I still can't figure out which one to go for. I see that the job listings contain mostly AWS, GCP and Azure. Is there any you guys would suggest to learn first or whatever I pick will be fine? I read some articles but none of them seemed decisive.
they're saying that their name is six.
my company uses our own infrastructure or AWS, but I'm not in charge of making that decision or setting up the AWS environments.
oh nice to know, tyty!
Oh, okay.
what are some good courses for these
That are long
And free
The andrew ng one for free doesnt have enough more advanded stuff
The ones where you learn Scikit
But I already understand the data science modules numpy, pandas, etc.
aws is pain
literally me struggling with lambda all day today

people who are Data scientist, do you remember all those major python library functions??
well, yes. you start to remember things after a while if you keep using them.
I remember by heart like 5-10 functions of each library I frequently use
how would you decide whether to create a mathematical model of a real life problem abstracted or to use machine learning for the simulation of events, is it based solely on what your trying to simulate?, for example a simple simulation on the population of rabbits and foxes on an island can be modelled by creating arbitrary values for the chances of survival for the rabbits depending on the number of foxes and the birth rate of each, but for more complex problems would it make more sense to use AI for example, these researches used AI to model an optimal tax policy (https://www.youtube.com/watch?v=Sr2ga3BBMTc). Please correct me if stated something confusing or wrong.
That's called model-based and model-free learning
well, not really - that's the difference between having a ML model that has an idea of how the environment works (as in, it has a builtin simulator of the environemnt it can play with) vs having it learn everything from scratch. You seem to instead be describing using ML at all vs using just simulation.
right, can you point me to an article or video going into more detail about the advantages and use cases of each?
For physics simulations they are hand-crafted. But these days they are starting to use ML to do it faster (deep learning is winning out). Both are approximations.
i realize that both create approximations because at the end of day they are abstracted from real life
Google and others are building physics engines specifically designed to make training these networks easier / better.
i am wondering whether it would be necessary for me to learn machine learning for a project
The answer with simulation is that you want to know everything (because you could be simulating anything), just pick and choose.
I have an idea of the model that i want to create a simulation for
But just like ML, math is the foundation.
Population of rabbits and foxes on an island can be represented by a single differential equation, or an entire complicated 3D physics simulation with neural networks.
It's however extreme you want to go (or it's whatever your budget and time frame is).
How to generate a single random number given a continuous PDF in Python?
I have a given PDF of the number that needs to be generated: p(z) = N (1 + (1-z)^2) /z
where z is restricted from some minimum z0 to 1 and proper N for normalization.
I need to generate single numbers which follow this distribution and I have no idea where to even start. I have searched around but only found solutions where PDF is for discrete values, not continuous ones.
I have searched for already implemented methods in numpy and scipy but I have failed to find anything useful, but I might have missed something.
I always use it
you always use for i in range(len(...))?
for idx, _ in enumerate(...)
yes
alot
of the time at least
why do you deliberately write worse code...?
hello, is there a good python cheat sheet available for data science that i could print?
what kind of information do you want it to have?
not deliberate, its just used in 99% of leetcode questions
so i dont know any beter
im trying to learn a bit of data science on my own, before doing concordia univeristy's bootcamp. so i'd guess the most used stuff for numpy, pandas and all the other things that are good to know for a "solid base"
It's public, sure, but you have to pay a lot of money
thats what i read when i have free time, its for generic python tho https://www.pythoncheatsheet.org/
Anyone can forget how to make character classes for a regex, slice a list or do a for loop. This cheat sheet tries to provide a basic reference for beginner and advanced developers, lower the entry barrier for newcomers and help veterans refresh the old tricks.
i was wondering if there is something similar for "data science python"
Been trying to install pytorch for a summer research project in neural networks, and it was working earlier before I made any conda environments
I uninstalled pytorch to fit it into a virtual environment, and it hasn't been working at all - every time I try to use "import torch" I get a "no module named torch" error
I've searched for solutions online and many people have had similar problems, but none of the solutions work or seem related
Any advice?

what model to generate speech or TTS?
tacotron
that's not a joke. that's really the name of it.
so, what is it and can it be implemented in pytorch?
a model that can be trained to map text to speech audio. the X values are text and the y values are audio of a person saying the words in that text.
yes.

how does that make you feel?
it is good
but i don't know how to change it into man voice
lol
if they don't provide a model that's a man voice, you'd have to find one somewhere else or train it yourself. but I wouldn't recommend using your own voice.
yes, maybe it needs to be fine tune
if all the models they provide are of a woman's voice, you probably can't make it sound like a man with fine tuning.
needing some help with tensorflow...
image_gen_train = ImageDataGenerator(preprocessing_function=find_item, rescale=1./255)
train_data_gen = image_gen_train.flow_from_directory(
batch_size=BATCH_SIZE,
directory=TRAIN_DIR,
shuffle=True,
target_size=(IMG_SHAPE, IMG_SHAPE),
)
it seems that target_size resizes the image before it is augmented. I have a preprocessing function that selects a certain part of the image and returns it in the size of 32x32. If I specified the target_size as (32, 32), my function would not work as intended given that the image is too small for processing. On the other hand if I don't specify the target_size I receive the error could not broadcast input array from shape (32,32,3) into shape (256,256,3). Is there anyway to achieve this?
I also have problem with the rescale parameter. Specifying rescale = 1./255 makes my images completely black when I plot them with matplotlib. As I remember in a course about machine learning rescaling didnt make the image black. Am I missing something?
guys I am new to ML (and pretty beginner with python in general) and I have no idea what these bits of code do
os.makedirs(housing_path, exist_ok=True) #makedirs makes directories that don't exist, ok=True means leave dir way it is
tgz_path = os.path.join(housing_path, tgz_path) #merge housing_path with tgz_path
housing_tgz = tarfile.open(tgz_path) #open joint dirs
housing_tgz.extractall(path=housing_path) #extracts all (figure out rest)
housing_tgz.close() #closes file
mainly tgz_path = os.path.join(housing_path, tgz_path); is that just assigning the datasets of housing_path into tgz?
you couldn't find it because this isn't really a coding question, it's a math question. based on how integration by substitution works, you wanna solve a simple differential equation to transform random numbers from a distribution you CAN generate (e.g. a uniform distribution, which python already brings) into the one you want. the tl;dr formula is
.latex g(z) = f(x(z)) \frac{dx}{dz}
.latex $g(z) = f(x(z)) \frac{dx}{dz}$

there we go
here, if we start with a uniform distribution in the domain [0,1], f(x(z)) = 1. then we get, for your case
.latex $N \frac{1 + (1-z)^2}{z} dz = dx$

that's the differential equation, which luckily is separable. all you need to do is integrate. based on the domain of your desired pdf and the value of N, you can find the constant of integration
after that, you'll have to simplify the expression to find z in terms of x. this one looks like it could have several branches, so you'll have to figure out which one works. once you have that, this gives you a function of the form z(x), or in other words, a function into which you input numbers that are uniformly distributed in the domain [0,1], and the output is a random variable z that follows the distribution you wanted
that's why numpy and scipy instead take in a histogram 😛 this requires some symbolic manipulations
Thanks, I never thought about it like that.
it's good to keep in mind that, at the end of the day, the computer has limited precision
that means the uniform distribution it uses is more or less the same as using a histogram with a number of bins equal to 1/machine epsilon. that's quite a large number though
but it does lend validity to making a histogram on a very fine grid
@serene scaffold tryign to move from keras to pytorch, 10x the amount of code to write, any tips?
just start out with pre determined model strucutre first?
Hey guys, where can i learn prediction of time series, which would help me predict stock market values
heya, I wanted to get values with the same value in the second column and get the mean of their values in the first column, then organize the data from smallest to the largest number (the numbers in the second column)
I wanted to ask how I would be able to get all the rows that have the same values in the second column, even if they are not back-to-back
this week i get to find out if our model can be deployed using aws lambda
and if the latency is low enough

who wants to take bets that it will not be
💀
Hi guys
if someone has some free time can he explain to me what is one hot encoding
Hi everyone! do you think tensorflow is on the decline? 🤔
Yesterday I read this post on Linkedin. https://www.linkedin.com/posts/matthew-lynley-74089011_google-is-quietly-replacing-the-backbone-activity-6942133101573648384-YQcl/

Google, despite being a trailblazer in machine learning development with TensorFlow, has ceded stewardship to Meta and the now-preferred developer framework...
could be inds = my_array[:,2] == some_value. then you get an array of booleans for all rows that satisfy the condition. then you'd simply use np.sum(my_array[inds, 1])/np.sum(inds)
so, this does seem to be a trend. tensorflow isn't dead by any means, but it seems researchers are moving over to pytorch to a considerable extent. i would also point out that moving from tensorflow to jax is more of a change in API rather than backend, since the idea is still to use google's XLA
Here we can see that trend 🤔 https://paperswithcode.com/trends
Papers With Code highlights trending Machine Learning research and the code to implement it.
i would just note that percentages mean nothing if you don't know the absolute numbers too
ah they do have them if you hover, gotta look again
hi, I am trying to make a heatmap using the "tips" dataset from seaborn. I have loaded the dataset, but I don't know what should I do to create a correlation matrix while only using the values from the column "total bill" and "tip". What I managed to do is getting the correlation between the variables. What did I miss?

what exactly is your question? the correlation matrix for total bill and tip is a submatrix of the one you computed, you could just keep the entries you need
well I was trying to do this

mhm
the heatmap I am trying to create needs to have total_bill on one axis and tip on the other right?
do you think the question is worded wrongly?
for reference, the correlation matrix is usually computed for a matrix M of size m x n, with m variables as the rows and n examples of each variable as the columns, as 1/n (M M^T), so to me, it sounds like they're asking for a 2x2 matrix
idk what nomenclature they use in your course, but if it's not this one, it's also not standard
yeah if a 2x2 matrix is the answer, it doesn't make sense to have two different colors for the matrix given the results
well, you didn't know ahead of time whether there would be a positive or negative correlation
well if I just want a 2x2 matrix from the results i get, what should I do? how do i specify which variables I want?
i see, but it is just that the results isn't that exciting xd
Hey folks! Good Evening.
I got some cleaning related issues
Hey @hoary wigeon!
You either uploaded a .txt file or entered a message that was too long. Please use our paste bin instead.
https://paste.pythondiscord.com/osajobuyux
Is there any possible way to group the similar title??
depends on your definition of similar
You'd need to define that
Using regex or something
problem its too large somewhat 11K unique titles, which looks alike
I'm trying to run this code on windows 10
https://github.com/NVlabs/eg3d
but when I run the gen_videos.py file I get this stack trace
FAILED: bias_act_plugin.pyd
"C:\Program Files (x86)\Microsoft Visual Studio 14.0\VC\bin/link.exe" bias_act.o bias_act.cuda.o /nologo /DLL c10.lib c10_cuda.lib torch_cpu.lib torch_cuda_cu.lib -INCLUDE:?_torch_cuda_cu_linker_symbol_op_cuda@native@at@@YA?AVTensor@2@AEBV32@@Z torch_cuda_cpp.lib -INCLUDE:?warp_size@cuda@at@@YAHXZ torch.lib /LIBPATH:C:\Users\Alex\AppData\Local\Programs\Python\Python310\lib\site-packages\torch\lib torch_python.lib /LIBPATH:C:\Users\Alex\AppData\Local\Programs\Python\Python310\libs "/LIBPATH:C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.7\lib/x64" cudart.lib /out:bias_act_plugin.pyd
Creating library bias_act_plugin.lib and object bias_act_plugin.exp
MSVCRT.lib(loadcfg.obj) : error LNK2001: unresolved external symbol __enclave_config
MSVCRT.lib(loadcfg.obj) : error LNK2001: unresolved external symbol __volatile_metadata
bias_act_plugin.pyd : fatal error LNK1120: 2 unresolved externals
ninja: build stopped: subcommand failed.```any ideas for how to fix this?
Hella nostalgia making heatmap outta a dataframe
Hi, I have a question regarding productionalizing a dataframe manipulation pipeline I am building: the idea is to take as input a bunch of dataframes and do a bunch of aggregations and join-like operations on them and output a dataframe as a result. While I can do this in pandas without much troubles in a development environment, I have been told that these kind of setups are a bit flimsy, and can break easily in production environments, specially considering errors would be caught at runtime. Does anyone have any advice on how to approach this problem, as in, creating robust pipelines that manipulate data for a production environment?
Has anyone here used dedupe?
Ive wanted to get rid of duplicates string from my source. I used one of the example code from the website and when i try to run, at the clustering step, it says permission error and the file is already in use.
if i have a dataframe with 2 columns like
columnn1 column2
same_entry same_entry
other_entry diff_entry
... ...
how do filter out the same_entry. same_entry being the one which have same value for c1 and c2
so you want to drop all the rows where the values in each column are the same?
because you could do it with .loc, where you instead select the rows where each column is different (ie !=)
Hi
I'm trying to make a system that automatically bypasses captchas
The captcha uses images that look like this:




I have tried a lot of things to filter out the text, none of which provided very good results.
Any ideas?
i have no experience in this, but you can look up text detection python tensorflow model, although you'd have to have a pretty big set of images
How to apply optical flow on fixed area of image instead of complete image???
I have used opencv for optical flow
you are not allowed to ask for help with this on our server, regardless of your intentions. please do not ask about it again.
@dusty valve for your awareness, you are also not allowed to help with this question.
Why exactly is my question problematic?
captchas are intended to keep out bots, so we will not help anyone do anything that is intended to get around that. bypassing captchas breaches the terms of service of whatever website you are using
!rule 5
5. Do not provide or request help on projects that may break laws, breach terms of services, or are malicious or inappropriate.
while I'm sure you aren't intending to be malicious, your intentions do not matter, in this case.
That rule is no fun!
I'm sure that providing help with questions of this nature doesn't put the server at risk.
I have changed my nickname to reflect your opinion
It's against our rules, which you agreed to when you joined the server. If you have any additional questions, you can ask us via @sonic vapor
Right, but I'm debating the substance of the rule, not whether or not I agreed to follow it. 😆
Unless questioning these things are against the rules. Haha.
I understand that it's disappointing to learn that a way you wanted to utilize our server is against the rules, but I've made our position clear. If you want to talk to us over ModMail, you can, but any further discussion in public channels is off-topic. This is the data science channel.
I'm impressed by how quickly you typed that.
I hope that your next message is about data science.
so i’m a little bit confused by how this doesn’t have a .fit

scikit-learn
Examples using sklearn.linear_model.LinearRegression: Principal Component Regression vs Partial Least Squares Regression Principal Component Regression vs Partial Least Squares Regression, Plot ind...
it looks like it goes against the documentation
it may be that it’s bc this is actually from a 2016 book
so the syntax doesn’t line up anymore?
actually no idk
Oh kek
are these a lot of params?

how exactly? im not familiar with pandas, i just need to for scraping a table from website
It really depends on what you're doing. "A lot of parameters" is subjective 😊
Do you have idea on how to perform logic and comparison operation in pandas?
If you're familiar with that, you could write a code to grab the row where c1 and c2 have same information.
Use this for quick reference
https://www.statology.org/pandas-loc-multiple-conditions/
This tutorial explains how to select rows from a pandas DataFrame based on multiple conditions using the loc() function.
hi, can anyone help me on this? ``` Input In [46], in loss2(y, y_hat, sig)
1 def loss2(y,y_hat,sig=0.03):
----> 2 if abs(y - y_hat)>sig:
3 l=abs(y-y_hat)-(sig/2)
4 else:
RuntimeError: Boolean value of Tensor with more than one value is ambiguous
are y and y_hat of the same shape?
unless you compare an n-d array to a scalar, you need to use special functions to achieve what you (probably) want - an elementwise comparison
Your result is a tensor where for any index (i, j, k, ...), the corresponding element result[i, j, k, ...] = (y - y_hat)[i, j, k, ...] > sig
If you want to get a single boolean value to use in your if statement, you'll have to figure out how to combine them together, e.g. using numpy.any() and numpy.all() (or equivalent functions in your framework of choice)
If you need to apply the if-else logic to each element, you can make use of boolean masking or use the numpy.where function (or the equivalent function in your framework of choice)
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2,random_state=4)
Can u lplease tell me the meaning of last line?
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2,random_state=4)
this one
have you not used sklearn before?
that line basically just splits the data into train/test sets
you can read more about it in the documentation
for each positional argument passed to that function, two outputs are given (train, test)
does that help?
funtion means train_test_spilt and positional argument is x and y?
yes
thnx brooooo
np
yeah I tried all it works
Hey,
I made a simple game in python using pygame and now I want to implement reinforcement learning on it. Any tips/suggestions on how to implement deep RL?
github: https://github.com/Baka-14/Afloat-Game

GitHub
Applying DRL to a Basic Retro Game that we created - GitHub - Baka-14/Afloat-Game: Applying DRL to a Basic Retro Game that we created
Have you tried computer vision properly
Not sure what a captcha is though… this for a modern art project?
You could quite easily with a large train dataset segment those letters
Though the artist may have purposefully made the letters never repeat shape enough to be predicted
You could achieve suboptimal accuracy, maybe 80%
A lot of noise
anyone familiar with tf 1.x happen to know why I cant execute a graph and view a tensor?
import nls
import batching
with tf.Session() as sess:
data_obj = nls.MyDataset('train')
inp, out = batching.batch_inputs(data_obj, train=False, batch_size=1, num_preprocess_threads=8, num_readers=4)
a = out[0]
sess.run(tf.Print(a, [a]))
try as I might, I can't get the value of a to print out
either it hangs, or it prints nothing to stdout
well, im training a text gen
and its taking so damn slong
and its overfitting
Hello. I want to build a structure. will learn the existing data and determine if there is a structure that is incompatible with the incoming data. such as outlier detection. but it will be large scale and run in real time. I think I can do this with reinforcement learning. but I couldn't create a schema about how to do it. do you have an idea?
You want a outlier detection system? @sonic jetty
Don't think you need reinforcement learning, just a Dense network will work fine probably
yes, and I want to do it with reinforcement learning. I want it to learn the general structure and catch an outlier structure in the flowing data.
and no labeled data
Well reinforcement learning requires a reward function, so you want to have some way to reward the system for certain outputs
Which kinda implies that you would need to know which data samples are outliers
Imo it just seems unfitting to use RL for this problem, but the specifications are still a bit vague, so it might be that I don't understand exactly what you want
I'm going to create an agent to monitor a few computers and there is a lot of data. It will track gpu, cpu usages etc. For example, when it sees a higher gpu usage than in general, I want to detect it. How can I do what algorithms should I research?
This seems to have some good suggestions
Clustering algorithms seem to be used for anomaly detection
That way you can keep it unlabeled
But what you describe here might be simple enough to not need ml
You could just track the temps and usage, and give a signal if they are too high f.e.
Hello im making a prediction using LSTM but somehow its prediction way off what it meant to. and its loss stuck around 40ish.. any suggestion?
already trying a lot of way but i dont know what to do.. even changing to 1dcnn and simplernn but its still way to far..
yes, I have an algorithm that works this way, and actually I'm currently working towards developing this structure. I will work a little more on ml algorithms to develop it then
yooo heyy, do u know anything about RNN ??
like do they help with prediction say .. in the medical field
oh you're struggling urself xD
sorry I just saw the word LSTM and Im like oh thank God someone knows hhhhh
depends on what the data is, and what are you trying to predict
ok
anything really xD *
I m just gonna take a random data fromm Kaggle
Lstm to do what
I’m working on lstm rn for my uni assignment 🫢
im using it to predict something, the data input is 3d array and for output that has 1 value, my model works somehow but i dont get the value that i hoped for
i guess bcs from what i hear its better when the data is an array?
Have u tried xgboost
no i havent
Or regular models
Ok rly do them first
U don’t need a neural network for 300 rows
It won’t work well
What’s the data
my data is 3d array that why im choosing that
bcs i read about LSTM many to one
Use scikit learn to model with xgboost random forest and another classifier or regressor if this is a regression task
U will get good result
What’s the data?
What are x and y
ill pm you what the data looked like, is it ok?
I mean what’s the data from
its an array
its a pixel value (R,G,B) for like 200x200px image
Are you trying to classify a pixel?
not a pixel but a value
I don’t understand what ur task is
Why are u clarifying pixel values
Classifying
Did you lose a pixel and wana file it in?
im trying to predict heart rate using ROI's pixel value
What’s roi
region of interest
face, yeah thats why im trying to do that
Heart rate from face photo?
But ur classifying each pixel as what?
That’s the most strange project I’ve ever heard
What are ur classes
Unless u want the workload of a faang research team ur gona need to just use white people portion of face is red and call it a day
You have to segment facial features and classify those as high heart rate too
I'm pretty sure I've heard of detection of heart rate/stuff like that from face pictures, at least.
how hard it is to replicate, no idea
Sounds insanely hard
"Remote Heart Rate Measurement From Face Videos Under Realistic Situations", say, from 2014
not sure this is even ML, actually, might be classical computer vision
yup

they literally just get the frequency of changes in illumination (or something like that) of the face due to heartbeat
from static photos, though? hmm
ftp://cmp.felk.cvut.cz/pub/cvl/articles/franc/Spetlik-VisualHeart-BMVC2018.pdf here's a 2018 article about CNN-based heart rate estimation from a sequence of images (link to a PDF served via FTP, because I guess some research organizations are firmly in the 90s)
https://www.sciencedirect.com/science/article/abs/pii/S1746809417301362 a review of heart rate from video papers.
So yeah, I can't find anything about estimating heartrate from a single image.
should i increase size for my layers or increase training epochs for my text gen model? when i increase layer sizes i suspect it's starting to overfit
well, it can overfit also by training for more epochs 😄
oh no
welp, time to train for 500 epochs
You could always try adding stuff to reduce overfitting
How many photos do u have labelled with heart rate
huh i just realize that i only told you that im using image not images, actually it was 200 frame-ish for 5 video that i extract its image pixels for input data
so more or less 1000 images
because my dataset hr is not matching with its frame
im sorry im not that clear
this project really takes toll on me
this is what i want to study
200 images then
Oh 1000 and each image has a heart rate right
yes
i already get some prediction but it just off like 20 points
Shud be easy to feed it test data and get a estimate of heart rate
1dcnn?
Well that’s the best u can do really because u don’t have good enough data it’s not ur fault
20 bpm off
Not that had
Bad
this is what i need to hear omg hahahahah
So it’s a 200 frame video in one video
So like 5 seconds long?
Dude who tf gave u this project
Lmao
yes, its more or less 5s
What exactly is the point of such a project
Any serious project would have a heart rate monitor plus take thousands facial photos so u get like 100,000 photos and 100,000 beat per minute measurements to match it
U cud do that in a day
5 seconds is not enough
Ur not gona have variation in someone’s face lol
im actually searching for another dataset, but somehow its just doesnt match up ecg is not that frame-friendly
Is this for school
yea this is one of its problem
yes uni
I think they’re not expecting good results just the method
So don’t worry too much that’s hard
5 second video won’t have enough change in someone’s face
Or heart rate
If they’re just running
i know but i get stressed out easily haha
thanks a lot dude
ill try cnn and other method
hi guys i'm trying to scrap some data from a directory but when i get the html content form the website i dont see the information i need but when i look i inspect it the data is clearly there. Would anyone be able to help?
Ur data is in ur hard drive as html??

I’m sure there’s a python parser for that
That looks similar to xml and u can easily parse xml
Download data as xml ?
Or just how it is u can search for a field
And return any sub field
hi, I am trying to run an ML training code on my uni's GPU clusters and it shows that CUDA capable devices are busy or unavailable even though there are 8 GPUs 0 processes running. Tried solutions on stackoverflow and nvidia forum but no dice
yeah thats correct but for some reason when i get the "soup" what i need isnt there
but its clearly on the website so thats what making me confused
perhaps this might give more details



Maybe one of your class mates have had the same problem and knows the solution?
well, it's a research project that only I am working on
plus the uni has recently purchased the GPUs so I doubt anyone had the chance to try it out

so there's nothing I can do?
# Split-out validation dataset
array = dataset.values
X = array[:,0:4]
Y = array[:,4]
validation_size = 0.20
seed = 7
X_train, X_validation, Y_train, Y_validation = train_test_split(X, Y,
test_size=validation_size, random_state=seed)
i'm so confused by this syntax
# Load dataset
filename = 'iris.data.csv'
names = ['sepal-length', 'sepal-width', 'petal-length', 'petal-width', 'class'] dataset = read_csv(filename, names=names)
there's 4 columns here so it slices up to the 4th column
and then the Y is the 4th column
so Y is class
what about it troubles you? or did you already figure it out?
it's as you said, just that technically array[:, 4] is the 5th column
idk anything about pandas, so i can't say if this is equivalent
welp it looks like it works for the author so i guess that’s the format i’ll stick to
Good day! Is anyone here has a source code for breed identification for animals? We badly need it for our thesis
I have a dataframe which contains timestamps. how can I convert datframe into list without converting datetime into seconds
0 2022-06-22
1 2022-06-22
2 2022-06-08
3 2022-06-22
4 2022-06-22
5 2022-06-22
6 2022-06-22
7 2022-06-22
8 2022-06-22
9 2022-06-22
10 2022-06-22
11 2022-06-22
12 2022-06-22
13 2022-06-22
14 2022-06-22
15 2022-06-22
16 2022-06-22
17 2022-06-22
18 2022-06-22
19 2022-06-22
20 2022-06-22
21 2022-06-22
22 2021-11-17
23 2022-05-25
24 2022-05-25
25 2022-06-22
26 2022-06-22
27 2022-06-21
28 2021-12-24
29 2022-06-22
30 2022-06-22
31 2022-06-22
32 2022-06-22
33 2022-06-22
34 2022-06-22
35 2022-06-22
36 2022-06-22
37 2022-06-15
38 2022-06-22
39 2022-06-22
40 2022-06-22
this is my dataframe
Can someone help me with StreamLit
you should get a list of pd.Timestamp objects. is that wrong?
you have to ask your actual question, not if someone will commit to answering once you ask.

!code
Here's how to format Python code on Discord:
```py
print('Hello world!')
```
These are backticks, not quotes. Check this out if you can't find the backtick key.
I know, i just try to figure it out how to ask
How to install package with anaconda?
import yfinance as yf
import streamlit as st
# import pandas as pd
st.write("""
#Simple Stock Price App
Shown are the stock closing price and volume
""")
tickerSymbol = 'AAPL'
tickerData = yf.Ticker(tickerSymbol)
tickerDf = tickerData.history(period='1d', start='2010-5-31', end='2021-5-31')
st.line_chart(tickerDf.Close)
st.line_chart(tickerDf.Volume)
it should give me a visualization in streamlit but im stack with importing
[[datetime.date(2022, 6, 22)], [datetime.date(2022, 6, 22)], [datetime.date(2022, 6, 8)], [datetime.date(2022, 6, 22)], [datetime.date(2022, 6, 22)], [datetime.date(2022, 6, 22)], [datetime.date(2022, 6, 22)], [datetime.date(2022, 6, 22)], [datetime.date(2022, 6, 22)], [datetime.date(2022, 6, 22)], [datetime.date(2022, 6, 22)], [datetime.date(2022, 6, 22)], [datetime.date(2022, 6,
22)], [datetime.date(2022, 6, 22)], [datetime.date(2022, 6, 22)], [datetime.date(2022, 6, 22)], [datetime.date(2022, 6, 22)], [datetime.date(2022, 6, 22)], [datetime.date(2022, 6, 22)], [datetime.date(2022, 6, 22)], [datetime.date(2022, 6, 22)], [datetime.date(2022, 6, 22)], [datetime.date(2021, 11, 17)], [datetime.date(2022, 5, 25)], [datetime.date(2022, 5, 25)], [datetime.date(2022, 6, 22)], [datetime.date(2022, 6, 22)], [datetime.date(2022, 6, 21)], [datetime.date(2021, 12, 24)], [datetime.date(2022, 6,
22)], [datetime.date(2022, 6, 22)], [datetime.date(2022, 6, 22)], [datetime.date(2022, 6, 22)], [datetime.date(2022, 6, 22)], [datetime.date(2022, 6, 22)], [datetime.date(2022, 6, 22)], [datetime.date(2022, 6, 22)], [datetime.date(2022, 6, 15)], [datetime.date(2022, 6, 22)], [datetime.date(2022, 6, 22)], [datetime.date(2022, 6, 22)]]
Im getting this
how is that different from what you want?
'''py
from datetime import datetime, date
import pandas as pd
import openpyxl
from openpyxl import load_workbook
import numpy as np
from mysql.connector import (connection)
cnx = connection.MySQLConnection(user='root', password='PASSWORD',
host='ACPLPIIOT001',
database='acpls_iiot_cameras')
#cnx.close()
df1 = pd.read_sql('SELECT updatetime FROM imagetemptable', cnx)
df1['updatetime'] = df1['updatetime'].dt.date
print(df1)
print(df1.dtypes)
timestamp = df1.values.tolist()
'''
this is my code
need to get rid of datetime.date
so you want tuples of three ints? or what?
because remember that what you're representing is an actual moment in time.
Ill give you overview of what Im trying to do. Basically I have pulled this column from data base and converted into df1 which is datetime object. Now I want to parse through this dataframe and compare every entry with present date.
the solution to what you're trying to do probably doesn't involve any of the steps you've described so far.
what do you mean by "compare every entry with present date"? compare in what way?
I want to match the date in dataframe with current date and check if they are match or not
so you just need to do this
import datetime as dt
is_today = df1['updatetime'] == dt.datetime.today().date()
and is_today will be a Series of bools.

Thanks It worked !!!
Can someone give me a tip with sns FacetGrid (or other options) ? I am trying to show many sns barplots for each row/index/year I got on this dataframe:

would like to get many barplots, one for each col I have there
(maybe skip some if possible but no prob if not possible)
I mean have as x the year for every col
Try using CUDA version 10.x instead of 11.x or a newer version.
Can someone send me a good resource to learn GPU parallel programming with CUDA? I need it for my research but the resources online are very limited…
there's nothing to learn, really. if you're using tensorflow or pytorch, and you have a GPU, you just tell it to use the GPU and that's about it.
you do need to look at stuff like tf distribute to parallelize over gpus though
or maybe i misunderstood the scale of parallelization
How?
cuda = torch.device('cuda')
t = some_tensor.to(cuda)
and if you have a GPU and you have the cuda driver installed, it just happens.
there are some caveats, like you can't do operations involving tensors on different devices (like the GPU and the RAM)
How can I do this w bumpy?
Numpy*
you can't. there's a separate library, cupy, that is "numpy with cuda".
I see
How do I downgrade the cuda version through commandline?
Which operating system?
most likely ubuntu (I am on Mac but this is a server that I am connected through ssh)
what I do is, connect through ssh, docker run image, run jupyter
Ubuntu is Debian based which uses Apt as its package manager.
There are many tutorials.
ahhh so I can downgrade through apt?
Yes you can manage your installed software through the package manager.
I'll try that, thanks!
There are GUIs for the various package managers, but it's on a server so I guess that is not an option, but it's pretty straight forward.
You can see if what packages are available with apt search <keyword>, if you can't find CUDA stuff then you may need to update your list sudo apt update (commonly done after a fresh install of the OS).
does anyone know if there is a more recent repo of style transfer like this?

GitHub
Style transfer, deep learning, feature transform. Contribute to NVIDIA/FastPhotoStyle development by creating an account on GitHub.
e.g.

this code relies on deprecated functions and I can't figure out how to make it work

regex it
how do you downgrade cuda via windows command terminal?
Let's say i have a DataFrame with 10 columns and 1000 rows. The values in this DF are either 1 or 0. If i want to choose a random number between 0-5 if the value 0 and 6-10 if the value in the array is 1. Anyone have any tips on how to accomplish this?
anything faster than a linear scan through each column
are the random numbers going to be integers or floats
they can be floats
for a more realistic example, i was going to do x plus or minus a std
so if the value is 1, the value could be 50 +- 5%
make one (1000, 10)-shape array that's just random floats between [0, 5), and then another (1000, 10)-shape array that's just [5, 10), and then use boolean masking to put those values in the dataframe
so if the value (i, j) in the dataframe is 1, then it takes the (i, j) value in the first array
make sense?
yeah that makes sense.
let me see your solution once you've solved it. or, let me know if you can't solve it.


I won't look at screenshots of text, sorry
!code
Here's how to format Python code on Discord:
```py
print('Hello world!')
```
These are backticks, not quotes. Check this out if you can't find the backtick key.
ah
i gotchu
def bernoulli_trial(winrate, num_trials, experiments, index):
print('bernoulli trial started')
experiments[index] = bernoulli.rvs(p=winrate, size=num_trials)
print("completed experiment {} which has {} trials with a winrate of {}".format(
index, num_trials, winrate))
def generate_experiments(winrate, trials, num_experiments, experiments):
for i in range(1, num_experiments+1):
bernoulli_trial(winrate=winrate, num_trials=trials,
experiments=experiments, index=i)
def generate_df(data, start, gain,gain_std, loss,loss_std):
df = pd.DataFrame.from_dict(data)
df.iloc[0] = start
df = generate_pnl(df,gain,gain_std,loss,loss_std)
print(df)
df = df.cumsum()
return df
def generate_pnl(df,gain,gain_std,loss,loss_std):
for col in df.columns.values:
df.loc[df[col] == 0,col] = df[col].apply(lambda x: -truncnorm.rvs(0,loss+loss_std,loc = loss, scale = loss_std,size = 1))
df.loc[df[col] == 1,col] = df[col].apply(lambda x: truncnorm.rvs(0,gain+gain_std,loc = gain, scale = gain_std,size = 1))
return df
unless your actual problem was considerably more complicated than the question you presented, this looks like overkill

glad it worked, at least!
how would i make the graph less compressed?

its all squished right now and i want it to be more clear
- Convert to time series by converting the date column to datetime with pd.to_datetime and set it as the index of the df (or the index of a new series/df with the data to be plotted), then resample the time series to a lower frequency (e.g decade) before plotting.
- Plot a Rolling statistics instead.
sorry, i'm really new to data science projects. i have dates = pd.to_datetime(global_data['dt]) done
how do i set this to a lower frequency?


Something like this. You'd have to set the index to the dates
Hi, just wanted to ask how good were the deeplearning.ai specialisations. I plan to complete most of them and wanted to know how much they’ll help me.
To anyone who's following the project, my ai chat bot got an update today. It had a issue with being unresponsive and being "too nice", so now they're tweaked to be more responsive and kinda rude.
How to analyse weather report of next 30 days using 2yrs of data
hello
expect arvix,researchgate,paperwithcode , does anyone know another website to get paper new or project application about ML/DL :(( , it's to hard to find
😦
Hi, I'm so confused about how to join the transactions column to df_train with the same date? I have already tried to 'merge' it but the result date is only on 2013

In particular ln [38]
Did U first make it bigger
how would i do that?
I was learning a bit about Pytorch, but it seems like it's more designed with neural nets in mind than reinforcement learning
Are there any particular reinforcement learning libraries you all would recommend?
pytorch is specifically about making neural networks, but you can have neural networks that do reinforcement learning
Hello, How to Add Multiple Locations using LeafletJS ? + How to draw a Path using LeafletJS ?
inb4 deep reinforcement learning

jk
i know thats a big field
one of my profs think theres going to be some breakthroughs in deep RL
next
With the way researchers have been shunning out ground breaking discoveries in AI, they'll probably discover fossil hydrocarbons (pun intended) if they keep digging deep 😀
Say for example I am performing linear regression to predict target variable Y
and I have a set of features x1,x2 and xn..
do they need to be independent of each other?
independent as in no correlation with each other?
but have some relation with the target value Y
if so why can't we use internally correlated features?
cos ultimately its just x1w1+x2w2+....=y
They don't need to be independent, but you'll get better results from features that are not strongly correlated with each other. There's no point in fitting to variables that have almost the same effect on your target.
off the top of my head, you might run into the problem that the fisher information matrix is not invertible or has a poor condition number
you'd expect the gradient of the estimator to behave "not very nicely" with small changes to small changes in the parameters or in the observed data
or alternatively your model matrix may not be invertible. not that big of a problem in itself as long as the data your care about is the image of parameters that are not in the null space, just that the solutions won't be unique
going back to the fisher info, you'd expect an increase in parameters to worsen the lower bound on the achievable variance of the estimator, and you would have done this for no reason if the extra parameters were unneeded (in the case of one of the predictors being linearly dependent on the others, for example, you'd now have extra parameters that don't give you any additional "predictive power")
Why does it get different lengths in the date column? Isn't it placed in the same dataframe?

like the determinant of the matrix might be zero i.e. having two or more same rows/columns
yeah this appears to be a simpler explanation
I'm saying the same thing Edd is, in more colloquial words
this appeared a bit tough to understand, can you link me to some article which can explain a bit more
your matrix is probably not invertible to begin with, but this would make it also not invertible from the left, or if it is invertible, it would be numerically difficult to do so (which translates into what aurendil said)
so it is recommended to remove correlated features right?
i think most books on statistical signal processing should discuss this on chapters regarding "maximum likelihood estimation", "score functions", or "cramér-rao bounds"
yeah, that's the end conclusion. they won't necessarily break what you're doing, but they never help
they can only make things more difficult 😛
do I need to study such detailed statistic as of now
or am I fine with what I am doing
I do have basic understanding of statistics but these days I have been seeing a lot more which I don't understand lol
there is a good chance you will never need something as in depth as what i mentioned now, i only brought it up because i was talking about it with a colleague just a bit ago lol
oh lol
it's more of an fyi that you can really precisely describe what problems can arise, both deterministically and statistically
anyways I will try to look into deeper portions of statistics once I feel I m ready to dive in
Thanks alot!
In image classification, can I create a model that predicts between two different objects, then add a third object to be predicted but maintaining the accuracy in predicting the former two?
Make a larger graph


Does it mean start=min and end=max will take the data according to the real dates?
Use the sample code
Newbie question here. I have a dataset with a few NaNs. I want to remove all rows that have more than 20% of the NaNs. For example if I have 6 missing cells in a row, I want to drop that row, but when I have only two missing cells I want to keep that row. Does anyone have some code on how to do this?
It is survey data so not all questions are answered
There’s prob a really easy way to do this but my first instinct would be to loop thru ur array and for each sub list Nan count / total count
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
df = pd.read_excel('data_change.xlsx')
# get NA count
print(df.isna().sum(axis="columns"))
print(len(df.columns))
for row in range(len(df)):
if len(df.row) > 0.2*len(df.columns):
df.drop()
This is what I have
if anyone wants to work on a side project with me let me know!
please don't make vague statements that are guaranteed to require follow up questions. what project?
def bernoulli_trial(winrate, num_trials, experiments, index):
print('bernoulli trial started')
experiments[index] = bernoulli.rvs(p=winrate, size=num_trials)
print("completed experiment {} which has {} trials with a winrate of {}".format(
index, num_trials, winrate))
def generate_experiments(winrate, trials, num_portfolios, experiments):
for i in range(1, num_portfolios+1):
bernoulli_trial(winrate=winrate, num_trials=trials,
experiments=experiments, index=i)
def generate_df(data, start, gain, gain_std, loss, loss_std):
df = pd.DataFrame.from_dict(data)
df.iloc[0] = start
df = generate_pnl(df, gain, gain_std, loss, loss_std)
df = df.cumsum()
return df
def generate_pnl(df, gain, gain_std, loss, loss_std):
for col in df.columns.values:
start_time = time.time()
print("Generating PNL values for portfolio {}".format(col))
df.loc[df[col] == 0, col] = df[col].apply(lambda x: -truncnorm.rvs(0, loss+loss_std, loc=loss, scale=loss_std, size=1)[0])
df.loc[df[col] == 1, col] = df[col].apply(lambda x: truncnorm.rvs(
0, gain+gain_std, loc=gain, scale=gain_std, size=1)[0])
end_time = time.time()
print("Completed generating PNL values for portfolio {} in {} seconds".format(
col, end_time - start_time))
return df
any have any recommendations on how to make this run faster
the forloop can take 2secs per portfolio and gets up to 20secs if you increase the number of trials
Sorry. I am interested in doing something utilizing a library like pandas and or pytorch, something that involves scraping then analyzing and possibly training data. Unsure of the scope yet which is why it was vague
lambda x: -truncnorm.rvs(0, loss+loss_std, loc=loss, scale=loss_std, size=1)[0] doesn't actually use x, it looks like. see if you can make a 2d array with this truncnorm thing so that you don't have to call this lambda repeatedly
also, use fstrings instead of .format
!fstring
!fstrings
Creating a Python string with your variables using the + operator can be difficult to write and read. F-strings (format-strings) make it easy to insert values into a string. If you put an f in front of the first quote, you can then put Python expressions between curly braces in the string.
>>> snake = "pythons"
>>> number = 21
>>> f"There are {number * 2} {snake} on the plane."
"There are 42 pythons on the plane."
Note that even when you include an expression that isn't a string, like number * 2, Python will convert it to a string for you.
No, because the point is that with a 2d array, you can write values in any column of the DataFrame with one statement.
Here, you're iterating over the columns, which are essentially one dimensional arrays, and overwriting them one by one
And that's probably what's slowing you down
what statement is that?
are torch.backward and .grad fucntions linked?
for epoch in range(2):
model_output = (weights*3).sum()
model_output.backward()
print(weights.grad)```sums twice
I never even changed weights
Maybe your backward function repeat the sum function
but how does backward alter set variables for grad to work
withotu specifying it in code
# X=1, y=2, loss function calculated as follows
# yhat = X*y
# loss = (yhat - y)^2
x = torch.tensor(1.0)
y = torch.tensor(2.0)
w = torch.tensor(1.0, requires_grad=True)
#forward pass
y_hat = w * x
loss = (y_hat - y)**2
print(loss)
#backward pass
loss.backward()
print(w.grad)```-2 as expected
but how does .backward on loss impact my w variable
breaks every law of python ive learnt
Hi
is anyone here familiar with anaconda spyder coding environment
I need some help

I'm trying to update the python version and I don't know if this will break everything
I have 3.8.3
I want to update to latest
so 10 something
Do you know how to do it? I'm a bit of a noob
Hello. I am attempting to make a chatbot with chatterbot and Id like to ask if theres a good chatterbot corpus, lightweight that i could use ?
I just downloaded pycharm. I was getting an error with a library and I think it's not supported in python 3.8 so i'm going to use pycharm for this only.
Hey - I have 2 text datasets - one of them is corrupted and I am looking for a way to numerically quantify the difference between them - any ideas?
levenshtein distance or something?
distance? right - im not familiar with the name - but is this somethign to do with like distance between the tokenized vectors or something?
In information theory, linguistics, and computer science, the Levenshtein distance is a string metric for measuring the difference between two sequences. Informally, the Levenshtein distance between two words is the minimum number of single-character edits (insertions, deletions or substitutions) required to change one word into the other. It is...
It's some formal way to measure distance between strings/words
oh sweet, allow me to take an earnest ponder
I'll be sleeping now, so I can't respond any further, but feel free to ask questions in this channel
pleasant slumber my g
Hi there, I had a question on Matplotlib, been having trouble with my legend
Here is the short and sweet version:
I made this graph, but want to change the legend label names from 0,1 to yes,no:
scatter = plt.scatter(test[:,0], test[:,1], c=data_train['Cancer_type'], cmap='viridis')
plt.legend(*scatter.legend_elements(), title='Cancer Type', labels=['yes', 'no'])
But whenever I include labels=yes,no, I get this figure

Super lost
My solution...
scatter = plt.scatter(test[:,0], test[:,1], c=data_train['Cancer_type'], cmap='viridis')
legend = plt.legend(*scatter.legend_elements(), title='Cancer Type')
legend.get_texts()[0].set_text('No')
legend.get_texts()[1].set_text('Yes')
I can't say this is the most efficient but just am unsure on how else to approach

I'm going for a certain fit but code isn't giving it.
import matplotlib.pyplot as plt
import numpy as np
from scipy.optimize import curve_fit
def func(timefit, a, b, c, d, e, f):
return -a*np.exp(-b*timefit+c)+d*np.exp(-e*timefit)+f
time = np.array([0, 3, 28, 33, 87, 177])
edge = np.array([23/32, 23/32, 25/32, 25/32, 24/32, 24/32])
plt.figure()
plt.scatter(time, edge, label= 'recorded measurements')
plt.tick_params(axis='x', which='both', bottom=True, top=True, labelbottom=True, labeltop=False, direction="in")
plt.tick_params(axis='y', which='both', direction="in", left=True, right=True, labelleft=True, labelright=False)
plt.tick_params(length= 3, width=2)
plt.tick_params(which='minor', width=2)
plt.minorticks_on()
guess = [100, 1, 100, 10, 100, 0.7]
parameters, covariance = curve_fit(func, time, edge, p0=guess, maxfev=100000)
fit_a = parameters[0]
fit_b = parameters[1]
fit_c = parameters[2]
fit_d = parameters[3]
fit_e = parameters[4]
fit_f = parameters[5]
timefit = np.linspace(0,180, 300)
bestfit = func(np.linspace(0,180,300), fit_a, fit_b, fit_c, fit_d, fit_e, fit_f)
plt.plot(np.linspace(0,180, 300), bestfit, c='darkorange', label='fit')
plt.legend()
plt.xlabel('Time [minutes]')
plt.ylabel('Creep [inches]')


looking for something like this

Bro u need to crop off ur axis
y axis?
i dont know if that helped

ok you got that point down there between the first two
i dont understand what you mean
You have a point between your two points bro
Don’t start at that point
U need to start ur line at x axis
Then merge those points to one point
I'm sorry I really don't know what you mean by "that point" and starting at the "x axis" and "merging those points". There are several points on that screen and I'm not understanding what you want me to do
Why does ur graph drop to zero
because thats the line of best fit attempting to make a fit that doesnt accurately fit the data

Stack Overflow
How do you calculate a best fit line in python, and then plot it on a scatterplot in matplotlib?
I was I calculate the linear best-fit line using Ordinary Least Squares Regression as follows:
from
Does that work?
Ok dude wait
Ur linspace it’s creating points from zero
?
And ur plotting those
I don’t think linear linspace between your two points would create the effect u want
im now getting
ModuleNotFoundError Traceback (most recent call last)
~\AppData\Local\Temp/ipykernel_2768/2220477731.py in <module>
1 import numpy
2 import matplotlib.pyplot as plt
----> 3 import multipolyfit as mpf
4
5 data = [[0,23/32],[3,23/32],[28,25/32],[33,25/32],[87,24/32],[177,24/32]]
ModuleNotFoundError: No module named 'multipolyfit'
i tried starting at 1 instead and the line still doesnt fit
What is the meaning of 1,0 within np.where in that case?\

If anyone is getting an error in using any libraries in python. The error should not be w general one(like it if I search it on stack over, I should not get the solution). Then contact me.
I'm trying to iterate over some pages and parse the title but for each page i'm getting playwright._impl._api_types.TimeoutError: Timeout 30000ms exceeded. Even when i set timeout to for example 70000 It seems te be some other kind of problem. Any ideas?
from doctest import testmod
import scrapy
import requests
from scrapy import Spider, Request
import json, requests
from monitors.helpers import safe_strip
from scrapy_playwright.page import PageCoroutine
class MySpider(scrapy.Spider):
name = 'example'
def start_requests(self):
urls = [
"https://www.example.com"
]
for url in urls:
yield Request(url=url,
meta= dict(
playwright = True,
playwright_include_page = True,
slow_mo = 500,
playwright_page_coroutines = [
PageCoroutine('wait_for_selector', 'div.c-text-field__wrapper')
]
)
)
def parse(self, response):
items = response.xpath("//article[@class='c-lot-card__container']")
for item in items:
product_url = item.xpath(".//a[@class='c-lot-card']/@href")
yield response.follow(product_url.get(), callback=self.parse_product,
meta= dict(
playwright = True,
playwright_include_page = True,
playwright_page_coroutines = [
PageCoroutine('wait_for_selector', 'div.be-lot-bid-status-section__bid-amount u-typography-h2')
]
)
)
async def parse_product(self, response):
title = response.xpath("//div[@class='be-lot-bid-status-section__bid-amount u-typography-h2']/text()").get()
yield {
'title': title
}
thank you

any suggestions for visuals that involve current/previous month revenue, existing/new customers and/or products?
import pandas as pd
import numpy as np
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import PolynomialFeatures
from sklearn.metrics import mean_absolute_error
from sklearn.model_selection import train_test_split
file = pd.read_csv('C:\Users\shaur_a3hetsk\OneDrive\Documents\Code\Learning Code\Machine Learning\melb_data.csv')
features = ['Rooms','Bathroom', 'Landsize', 'BuildingArea', 'YearBuilt', 'Lattitude', 'Longtitude']
panda_X = file[features]
panda_y = file.Price
x = np.array(panda_X).reshape((-1,1))
y = np.array(panda_y)
print(type(x),type(y))
train_X, val_X, train_y, val_y = train_test_split(x,y,random_state=0)
train_X = PolynomialFeatures(degree=2, include_bias=True).fit_transform(train_X)
val_X = PolynomialFeatures(degree=2, include_bias=True).fit_transform(val_X)
model=LinearRegression().fit(train_X,train_y)
y_pred = model.predict(val_X)
print(mean_absolute_error(val_y, y_pred))
can anyone tell me why my code isnt working
format it as code and tell us what error you get


show more from the error...

...
???
what's the valuerror
the whole thing is huge
jus a sec
ValueError Traceback (most recent call last)
Input In [99], in <cell line: 14>()
12 y = np.array(panda_y)
13 print(type(x),type(y))
---> 14 train_X, val_X, train_y, val_y = train_test_split(x,y,random_state=0)
15 train_X = PolynomialFeatures(degree=2, include_bias=True).fit_transform(train_X)
16 val_X = PolynomialFeatures(degree=2, include_bias=True).fit_transform(val_X)
File ~\AppData\Local\Programs\Python\Python310\lib\site-packages\sklearn\model_selection_split.py:2417, in train_test_split(test_size, train_size, random_state, shuffle, stratify, *arrays)
2414 if n_arrays == 0:
2415 raise ValueError("At least one array required as input")
-> 2417 arrays = indexable(*arrays)
2419 n_samples = _num_samples(arrays[0])
2420 n_train, n_test = _validate_shuffle_split(
2421 n_samples, test_size, train_size, default_test_size=0.25
2422 )
File ~\AppData\Local\Programs\Python\Python310\lib\site-packages\sklearn\utils\validation.py:378, in indexable(*iterables)
359 """Make arrays indexable for cross-validation.
360
361 Checks consistent length, passes through None, and ensures that everything
(...)
374 sparse matrix, or dataframe) or None.
375 """
377 result = [_make_indexable(X) for X in iterables]
--> 378 check_consistent_length(*result)
379 return result
File ~\AppData\Local\Programs\Python\Python310\lib\site-packages\sklearn\utils\validation.py:332, in check_consistent_length(*arrays)
330 uniques = np.unique(lengths)
331 if len(uniques) > 1:
--> 332 raise ValueError(
333 "Found input variables with inconsistent numbers of samples: %r"
334 % [int(l) for l in lengths]
335 )
ValueError: Found input variables with inconsistent numbers of samples: [95060, 13580]
wdyt?
meaning?
you have 95k x for 13k y's
no the issue is here:
panda_y = file.Price
x = np.array(panda_X).reshape((-1,1))
y = np.array(panda_y)```the reshape function is shortening X
why?
because with shorter arrays its not changing it
how do I stop reshape from changing the size of the array
your reshape arguments are wrong i think
you are creating an array of arrays with 1 value
you have 7 columns that's why your x is 7 times larger than y in the end
What's difference between cell 1 and cell 2?

Why do both get a different result?
you are missing a ']' in the 2nd
sorry, can you explain it? I think I already correct to write that code
or can you write the correct code in here?
sorry I'm blind - that's not the case
as I said, actually I ask the reason of why it gets a different result 😁
check:
oil.dcoilwtico.isnull()```
and
oil[oil.dcoilwtico.isnull()]
by themselvesthese return different results
1st returns series, 2nd returns df
of course, but can you explain to me why both get different values as result? and why in the 2nd each of results is repeated?
and the length in 2nd cell is twice from 1st
can you tell me the correct code?
@gilded kestrel
so I was planning to keep a code block for all regression based algorithms from sklearn and other imp libraries
lr=LinearRegression()
br=BayesianRidge()
sgdr=SGDRegressor()
en=ElasticNet()
gbr=GradientBoostingRegressor
svr=SVR()
kr=KernelRidge()
xgb=XGBRegressor
cgb=CatBoostRegressor()
lgbm=LGBMRegressor()
apart from these do I need to add any others?
or does anyone a good code gist to avoid the hassle of importing and writing these one liners again and again
It’s almost as fast to just type the model u want
Clearly u don’t have it
is there any easy to use Photoclinometry (Shape-from-shading) algorithms or python code i can use?
i tried looking online, but i can't find anything that would work for me..its all...so confusing
Are there any packages or libraries with an emphasis or algorithms on continuous valued reinforcement learning? I'm doing some research on continuous valued reinforcement learning but all the algorithms for packages I've seen are discrete
What is discrete about the algorithms that needs to be continuous @obsidian pumice
Eh, it's just a somewhat different class of algorithms
I'm reading through this paper
Want to do some implementation
Generally for reinforcement learning algorithms on continuous functions, spaces, or time scales you have to discretize the variables, which can cause performance issues on a variety of scales
Too coarse and you can't maximize as well, too fine and you get combinatorial explosion
When/why would I normalize my variables instead of standardizing?
Coming from econ I just always standardized everything
normalize as in "squish everything between 0 and 1"?
Yes!
you would do that when the upper and lower bound for a given feature is known. it's easier for the model to learn that way. and then you can convert the result of the model back to the actual value.
Is there any situation where it would be preferred over standardization or just a preference thing?
Can't we have a predefined function which also gives the cv accuracy and the training accuracy along with it.
Wouldn't that be more convinient?
normalizing and standardization change the data in different ways, so some algorithms might be affected differently
It depends on what you are planning to use the data for
Standardization is squeezing it so that the mean is 0 and the standard deviation is 1, right?
jup basically
Yeah, plus you can read coefficients in a pretty simple way "a 1sd increase in X will increase it by <coefficient size>"
I have a feeling standardization might perform better if you have a couple data points that are way outside the standard deviation. But maybe you should just throw those points away anyway.
But basically this, you'd have to check what others recommend for the algorithm
Yeah with huge outliers, and no outlier removal, normalization sucks..
Cool got it, ty @mild dirge 🙂
is there something that im missing or what, sometimes when im making prediction using lstm its predict value is always the same even when the test data changes, but sometimes its not.. any idea why this is happend?
well not just lstm.. 1dcnn and simple rnn make this output too
Does anybody know why my pytorch doesnt want to use cuda? I have cuda 11.3, torch 1.11.0, torchaudio 0.11.0 and torchvision 0.12.0, but torch.cuda.is_available() returns false. This is the link to my stackoverflow question: https://stackoverflow.com/questions/72745566/pytorch-not-being-able-to-use-cuda-for-some-reason
Stack Overflow
I want to use CUDA in PyTorch and torch.cuda.is_available() returns false.
All of my installed stuff:
hey guys, how do you treat value with meaning that's labelled as NA?
ie. as pandas convert them into Nan values

Hello. I am attempting to make a chatbot with chatterbot and Id like to ask if theres a good chatterbot corpus, lightweight that i could use ?
I don’t understand?
interesting

any plotting/data viz experts know what graph is called, which looks like a speedometer but the needle is 90 degree when at 0 value, tilting left for negative values and right for positive ones
bonus points if it can be done in plotly
sounds like you want a polar plot in clockwise orientation. idk if plotly can transform your data for you. you can normalize it by hand to the range [-1, 1] and scale that up from -90° to 90° to get the type of plot you want
ah, it seems there's also a thing called gauge chart as well, which does what you want more directly
https://plotly.com/python/gauge-charts/ check it out
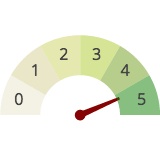
Detailed examples of Gauge Charts including changing color, size, log axes, and more in Python.
ye, but how do we modify that gauge chart to start the arc from 90 degrees, and go left/righ depending upon the signed value?
presumably by playing with the domain
theres a parameter called axis in which you specify the range
if your range goes from - some_value to +some_value, the midpoint occurs at 0
or more generally, if it goes from center - range/2 to center + range/2, whatever you specified as the center will occur at 90°
hmm... that gets close, but if you look at this

the red bar doesn't start from 0
you can read through the docs in the link i shared :p i know as much as you do
ah cool, thanks for your help though!
how are some people just on another level man
graduating with like 99% scores straight to faang or s9ome shit
how do u even learn coding nevermind deep learning at like age 19 while doing seperate degrees
respecty
Hi guys, I have a question.
When I countplot a variable, it doesn't show me the missing ones ):

I'm supposed to have 3k something missing values
u want NaN?
maybe u have to convert from type pandasNaN to string or number?
Oh..
i think seaborn countplot ignores nan, the quickest would be if you give your nan some value just for plotting
https://stackoverflow.com/a/46415931
Stack Overflow
I was given a huge file with some data we had to classify by hand, so, using Excel we placed a column that should be filled with "Y" or "N" (mainly, there are other values), if the row fits certain
hi, quick question, since tf.keras.preprocessing is deprecated, how can I now perform a shear on my image dataset as a augmentation step?
Oh, I'm hella annoyed
Thank you so much
guys is there any way to figure out what changes are done in col and rows in csv file that is available on s3 bucket. to interact s3 i am using boto3
anyone wana help me backward substution of matrix system
you doing a little gaussian elimination?
i need help..
i suck
3 2 1
2 1 2``` 15
28
23```im supposed to end up w uhh
5, 7
and
3
3 5 7
So
how
i convert the vector right?
Is that supposed to be 28, and not 26?
.latex $\begin{bmatrix} \end{bmatrix} 1 & 1 & 1 \ 3 & 2 & 1 \ 2 & 1 & 2 \begin{bmatrix} x \ y \ z \end{bmatrix} = \begin{bmatrix} 15 \ 28 \ 23 \end{bmatrix}$ like so?
each time fails
oh boy, i give up on using the lancebot for latex
ye
ive spent 1 hour on paper trying ot make it work
i ekep getting 15 255 22
111,012,001 as the echelon
first row, doesnt need to be changed surely
!e
import numpy as np
mat = np.array([
[1, 1, 1],
[3, 2, 1],
[2, 1, 2]
])
vec = np.array([3, 5, 7]).T
print(mat @ vec)
@mild dirge :white_check_mark: Your eval job has completed with return code 0.
[15 26 25]
So [15, 26, 25] then right?
no
You go to the shops on Monday and buy 1 apple, 1 banana, and 1 carrot; the whole transaction totals €15. On Tuesday you buy 3 apples, 2 bananas, 1 carrot, all for €28. Then on Wednesday 2 apples, 1 banana, 2 carrots, for €23.

right?
So then 3, 5, 7 wouldn't be correct prices?
3, 7, 5 seems like the right answer
Because that gives different totals

not [3, 5, 7]
!e
import numpy as np
mat = np.array([
[1, 1, 1],
[3, 2, 1],
[2, 1, 2]
])
vec = np.array([3, 7, 5])
print(mat @ vec)
@mild dirge :white_check_mark: Your eval job has completed with return code 0.
[15 28 23]
Yeah that makes sense Edd
then transform row b so that it begins with 0,1
so you could do rowB - 3rowA to make the first 0
?
the first row is in the form 1, 1, 1, which is very nice for getting to row echelon form. the first step would be to subtract 3x the first row from the second, and 2x the first row from the third
that was literally my method
i ended with -17
for row b
wait as ec
28-45
-17
u need to do same operation do the vector dont u
that looks correct so far
ok then i did for some reason
Yeah you need to do the same for the vec
that's just the first step though
WAIT
hold up
look dude
I thoight u have to convert the 2 in row B to a 1
manually
does that auto set?
what?
so i then went and i did row2' x. - -row 1 so that the value 2 became a 1
what you have to do is set the leading entry to 0 first, and then (if you want, it's not really necessary) set the first nonzero entry to 1 by dividing the whole row
in row B we have 3 2 1
so after setting 3 to 0, i thought i have to set the -1 to 1

what do you mean by "fix the second term"
can you see the new second row is 0 -1 -2
then -17
3 - 3 * 1 = 3
2 - 3 * 1 = -1
In [7]: M
Out[7]:
array([[ 1, 1, 1, 15],
[ 3, 2, 1, 28],
[ 2, 1, 2, 23]])
In [8]: M[1,:] = M[1,:] - 3*M[0,:]
In [9]: M
Out[9]:
array([[ 1, 1, 1, 15],
[ 0, -1, -2, -17],
[ 2, 1, 2, 23]])
this is what we have after the first operation
exactly
then we follow up on the 3rd row
as u can see in mine i have the same, however i thought before moving forward we nee to change the -1 to a 1
in second row!
In [10]: M[2,:] = M[2,:] - 2*M[0,:]
In [11]: M
Out[11]:
array([[ 1, 1, 1, 15],
[ 0, -1, -2, -17],
[ 0, -1, 0, -7]])
stahp
we can do that if you want, by multiplying by -1
do u do third row first, or stick on 2nd and fix the -1
doesn't matter
In [12]: M[1:3,:] =- M[1:3,:]
In [13]: M
Out[13]:
array([[ 1, 1, 1, 15],
[ 0, 1, 2, 17],
[ 0, 1, 0, 7]])
so we're here
right, now we take 1x 2nd row from the third
ok but cant u do a variety of operations
or is that one specific one u found after staring at it?
i mean, the final goal for back substitution is to get to echelon form
one times the oriignal second row or the updated second row?
In [14]: M[2,:] = M[2,:] - 1*M[1,:]
In [15]: M
Out[15]:
array([[ 1, 1, 1, 15],
[ 0, 1, 2, 17],
[ 0, 0, -2, -10]])
are you allowed to use updated rows in the operation?
you look at it and realize that doing the exact same thing we did to eliminate the leading entries of rows 2 and 3, we can remove the next entry from row 3
you NEED to
otherwise you're not simplifying anything
what are you doing?
i didnt touch it yet
that gets you nowhere
when you subtract the first row later, the 0 entry you get now will no longer be zero
so remove 2 but we cannot afford to remove the other 2 as making both 0 gets nowhere
what???
bump
we can just multiple row2' by row 3
i have no idea what you're trying to do
gaussian elimination is an algorithm that always works if you just follow it, idk what you're trying to do lol
u said eliminate first nonzero in row 3
i turned 2 to 0 by multiplying by the updated second row
which was 0 1 2
please just look at the operations i've sent you so far
there are only 2 operations that are allowed
scale a row by multiplying it with a number
and adding rows together
so u cant multiply rows together
i just look at the leading entries and scale them so that when i add then, they cancel out
this operation is not well defined for vectors
?
your teacher hasn't taught you to "multiply vectors" because there is no canonical way to do it
o_O
look it up in your book and you'll notice it isn't there
it's not that it doesn't work, it's that it means something different, and there is no unique way to do it
if you think about solving systems of equations, which is what you're trying to do
the kind of multiplication you're doing 1.) doesn't make sense 2.) even if it did, it doesn't help you solve the problem
but adding and subtracting things to cancel them out does work
for example if you know that x + y = 3, and x - y = 2
if you add up those 2 equations, you get that x + x + y - y = 5 -> 2x = 5
now you know the values of x, and can substitute it back in any of the original 2 equations to solve for y
cant u add scalars to everything either then
sure, that's valid. just not useful
makes sense as its just a type of equation in the end
yeah
you're just representing a large system of equations via matrices
but gaussian elimination is exactly equivalent to what i did above there
now take the example x + y = 5 and 2x + 3y = 1
i can take the first equation and write 2x + 2y = 10 instead
Yo, for the last step that you just did, what if i already have positive 1 for the second row, so instead it would give me 0,0,4 28
now if i subtract this from the second equation, i get 2x + 3y - 2x - 2y= 1 - 10
at any rate, here's the summary
In [7]: M
Out[7]:
array([[ 1, 1, 1, 15],
[ 3, 2, 1, 28],
[ 2, 1, 2, 23]])
In [8]: M[1,:] = M[1,:] - 3*M[0,:]
In [9]: M
Out[9]:
array([[ 1, 1, 1, 15],
[ 0, -1, -2, -17],
[ 2, 1, 2, 23]])
In [10]: M[2,:] = M[2,:] - 2*M[0,:]
In [11]: M
Out[11]:
array([[ 1, 1, 1, 15],
[ 0, -1, -2, -17],
[ 0, -1, 0, -7]])
In [12]: M[1:3,:] =- M[1:3,:]
In [13]: M
Out[13]:
array([[ 1, 1, 1, 15],
[ 0, 1, 2, 17],
[ 0, 1, 0, 7]])
In [14]: M[2,:] = M[2,:] - 1*M[1,:]
In [15]: M
Out[15]:
array([[ 1, 1, 1, 15],
[ 0, 1, 2, 17],
[ 0, 0, -2, -10]])
In [16]: M[2,:] = M[2,:]/-2
In [17]: M
Out[17]:
array([[ 1, 1, 1, 15],
[ 0, 1, 2, 17],
[ 0, 0, 1, 5]])
what if i made row2 positive before looking at row 3
wouldn't change anything
if you multiply one row, do u have to do all rows
the first update to row 3 involves only row 3 and 1, not row 2
second update
you'd need to change the sign, then, or more generally scale the row by a different amount before adding it to another row
there's really no special reason to turn the leading entries to 1, other than avoiding working with fractions in the leading element
i still failed because i made the rows positive 1's instead of -1
and ended up with 004 28
using ur steps
so now im at
there are literally infinitely many ways of doing gaussian elimination for the sample problem, as long as you don't mess up your arithmetic
012 17
0-10 -7```can I share my kaggle notebooks to get some feedback in here?
I just attempted a few "getting started" competitions
where'd you get 0 2 1 17 from
so 1 1 1 15
0 1 2 17
0 -1 0 -7
if u do that same operation u did
yes
bUt
the first thing i did
was make it positive
so i times row3 by -1
to get 0 1 0 7
but we ned 001
mhm
Hello
what if we minus row2 from it
sounds good
yeah, that was what i did as well
then its -7-17 = -24
wiat
no
7 - 17
-10
0 0 -2. -10
now x by -0.5 to get 0 0 1 5
WAOW
good
now you're done
you can check you could've gotten the same result without multiplying by -1 first
or also if you shuffle the rows
going back to what we said before. 4 vector products that are commonly used are the dot product, the cross product, the outer product, and the hadamard product. you were trying to do a hadamard product, which doesn't help us in these problems
well
now recall what the matrix multiplication means
wiat a second
so that z = 5, and we have found our first variable
x + y + z = 15?
yes