#data-science-and-ml
1 messages · Page 327 of 1
how negative are we talking? like -0.0000000352 or -10?
we are all delusional sometimes
oh great bro...the loop is working and a new dict is created for every 50k values but the pearsonr is not executed in remaining sets

oh yeah, do range(0, n_rows + step, step):
still same result bro. the personr is not reflected
what do you mean
can you clarify
also this should work with just range(0, n_rows, step)...
the values are the same. the pearsonar is not initiated for the second and other sets

show your code
oh, i know why
you copied my code verbatim without reading or understanding it 🙂
i made a mistake in my code
do you see the problem here?
for start in range(0, n_rows, step):
end = start + step
results[(start, end)] = pearsonr(x_np, y_np)
it's a good exercise to figure out the problem and try to fix it
i'm not sure i want to encourage people asking strangers for help and expecting that it will be 100% right the first time
it's like driving, if you rely too much on the gps you never learn how to actually get anywhere
its true. i will try bro...thanks for the help 😅
Goodmorning. I was wondering if any of you had any helpful advice or a source to help me learn how to make a dataset. Im trying to make an ai with tensorflow and numpy. I got it to work(very very basic) with numbers. Only thing is im trying to get it to save its weights and mainly work with words.
But words didnt work with an array, and i read that a dataset would be the best way to go, but i know nothing of how to do so.
hi, i am not sure will this help but you can scan this link https://towardsdatascience.com/how-to-use-dataset-in-tensorflow-c758ef9e4428

that's NLP - look up basics like one hot encoding and n-grams then move up the chain to RNNs/LSTMs
guys i have a question , if i have labels like this in a column 'N', 'VAR', 'W', 'SSW', 'SSE', 'NNW', 'NE', 'E', 'West', 'S', 'Variable', 'WSW', 'SW', 'ESE', 'South', 'ENE', 'Calm', 'NNE', 'CALM', 'NW', 'East', 'North', 'WNW', 'SE' how i do i simplify them and also explain me whats the reason for going for that method.
whats nlp and such?
is this a homework assignment?
also i just want the reason to do that so it can be helpful in future
nope
i am just practicing with some dataset
this is the dataset - https://www.kaggle.com/sobhanmoosavi/us-accidents

A Countrywide Traffic Accident Dataset (2016 - 2020)
@desert oar
natural language processing
do u know about any pretrained model that extracts the main object from an image? Like returning the mask or something
not sure about the 'main' object
but the YOLO models do object detection and can easily be trained on custom data
YOLOv5 is the latest believe, its open source
however it draws a bounding box and will not decide which is the 'main' object if it recognizes multiple in an image, so this may be irrelevant
if there is only 1 object it will extract only one, right?
so that would be the main xd
but thanks
sorry then yolo is not appropriate
googling 'object detection mask' yields some promising results though

predicting pixel level masks instead of bounding boxes
hold up
supervised or unsupervised?
like, image segmentation gives me all the objects it can detect on an image
supervised
okay wait
if you’re talking about the aspect of
pixel level mask
vs bounding box
then no
but if you’re talking about the aspect of “main” object vs “secondary” objects
then yes
is this img segmentation? https://gyazo.com/26d2852563172f9b72cfeb616f3d5007

yeah, well, i only want like the main object
like here
?? then why were you considering YOLO
someone suggested lel
here
if you want to identify an arbitrary “main object”
then that is saliency detection, yes
but you said this
which is kind of confusing
if you want to identify an ARBITRARY main object, then yes
thanks, and do u know any pretrained model loadable with keras?
hello people
can somebody pleae tell me a topic in bioinformatics that has something to do with Econ
I am going to buy a new laptop and was asking for suggestions for a processor. Almost all of them suggested me to get one with more cores. However, my use case is mostly single threaded. I will be using sklearn, Jupyter and VS code. In that case, should I be aiming for more cores or more clock speed?
@rugged crypt it sounds like you've answered your own question, though you might consider that some sklearn models can use more than one core.
CUDA 11.4 should work fine with TensorFlow 2.5.0, right?
imo both are pretty important but if I were to choose one then it would be more cores. The more cores the better generally. Im not an expert, so someone else can confirm this or tell me that I'm wrong.
ValueError: Input 0 of layer lstm is incompatible with the layer: expected ndim=3, found ndim=4. Full shape received: (None, 32, 24, 7)
hello, until now i cant resolve this.
Can someone explain what does valueerror: lengths must match to compare means?
@brisk lintel you'll need to share the whole error message and probably the relevant code
import altair as alt
import streamlit as st
import pandas as pd, numpy as np
df2= pd.read_excel('owidvac.xlsx')
subset_data=df2
country_name_input = st.multiselect(
'Country name',
df2.groupby('location').count().reset_index()['location'].tolist())
st.subheader('Comparision of infection growth')
total_cases_graph = alt.Chart(subset_data["location"]==country_name_input).mark_line().encode(
x=alt.X('date', type='nominal', title='Date'),
y=alt.Y('new_cases', title='New Cases'),
).properties(
width=1500,
height=600
).configure_axis(
labelFontSize=17,
titleFontSize=20
)
st.altair_chart(total_cases_graph)
ValueError: ('Lengths must match to compare', (34004,), (0,))
Traceback:
File "C:\Users\m\anaconda3\lib\site-packages\streamlit\script_runner.py", line 349, in _run_script
exec(code, module.dict)
File "C:\Users\m\Downloads\covid-choro-map-master\testing\test.py", line 15, in <module>
total_cases_graph = alt.Chart(subset_data["location"]==country_name_input).mark_line().encode(
File "C:\Users\m\anaconda3\lib\site-packages\pandas\core\ops\common.py", line 65, in new_method
return method(self, other)
File "C:\Users\m\anaconda3\lib\site-packages\pandas\core\arraylike.py", line 29, in eq
return self._cmp_method(other, operator.eq)
File "C:\Users\m\anaconda3\lib\site-packages\pandas\core\series.py", line 4978, in _cmp_method
res_values = ops.comparison_op(lvalues, rvalues, op)
File "C:\Users\m\anaconda3\lib\site-packages\pandas\core\ops\array_ops.py", line 223, in comparison_op
raise ValueError(
hello guys i have a weird problem regarding some data, i have a batch of satellite measurements for sea level rise from 1992 to 2020 and when i plot a line graph there is a big chuck of data missing between 2010 to 2013. What i have noticed from that period of time is that the satellites Jason-1 and 2 are heavily alternating between each other in the data set.
here's the graph

the code i used
`import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
csv_file = "slr_sla_pac_free_all_66.csv"
read_file = pd.read_csv(csv_file ,comment='#')
display(read_file)
plt.title('Sea Level rise')
plt.plot(read_file.year,read_file['TOPEX/Poseidon'])
plt.plot(read_file.year,read_file['Jason-1'])
plt.plot(read_file.year,read_file['Jason-2'])
plt.plot(read_file.year,read_file['Jason-3'])`
also you can find the data file here https://www.star.nesdis.noaa.gov/socd/lsa/SeaLevelRise/LSA_SLR_timeseries_regional.php

NOAA / NESDIS / STAR website
STAR translates raw satellite data into critical information needed to inform the public and safeguard the environment across the country and around the world.
the 4th csv file from the Pacific Ocean

Would it matter that much for training process if, say out of 6000 values id have a few duplicates
I don't know why though it seems fair to avg them and plot that instead.
read_file['avg'] = read_file[['TOPEX/Poseidon', 'Jason-1', 'Jason-2', 'Jason-3']].mean(axis=1)
plt = read_file.plot(x='year', y='avg') #, color="DarkGreen")
fig = plt.get_figure()
fig.savefig('slr_sla_pac_free_all_66.png')
I was looking into seeing if what you had was a color / styling issue though I couldn't get it to work like that.
i think il just email the profesor and tell him about the issue
What is this error how to fix it

Yooo I tried AI and ML and FAILED lolololol
i just failed my tensorflow certification exam. could someone enlighten me on how to solve the question below?
I been thinking about it whole day
I'm developing an AI based model which will help in preventing food wastage. I need collect data for that. Please fill this form accurately on individual basis.
https://docs.google.com/forms/d/e/1FAIpQLSfqcF1icI7SJYbz1IJy74wWUzM-WVVYh4MZxNIUP6OQ0h6wXg/viewform?usp=sf_link
Share it with others as much as possible.
Please React with a 👍 if you fill it!
It will be a great help.Thanks!

Google Docs
In hotels and restaurants and eateries, we witness a lot of food being wasted on a daily basis which includes the food we leave on the plates and also the extra food prepared. This food is of no use as it cannot be given away to the needy. It is moral responsibility to realise that we need to reduce the wastage of food. In order to create an AI ...
I need to get data from xml which is in website
First use requests library and then xml library
Take a look at this:

Stack Overflow
I like very much the requests package and its comfortable way to handle JSON responses.
Unfortunately, I did not understand if I can also process XML responses. Has anybody experience how to hand...
Depends on the labels you want
i know but u already said the same thing about labels, and u dont need labels
For instance segmentation you need
and if u read the conv, u will see i dont need img segmentation
I wanna start datascience and ai
@cyan drift "How much" math do you know?
Class 10th
Europe, USA, Russia?
By the way
I suggest you first to start studying calculus
Then study statistics so that you can pass reading the Hands-On Machine learning book
And if you want to get more experienced about neural networks, I suggest you the Deep Learning from scratch book
Then, if you want to know a bit more about deep learning in general, I suggest you to read this (free)
It even contains some math basics for deep learning
@cyan drift
This is if you want to master the concepts, if you just need to learning AI but you don't have time, or you just need it for a practical usage
Check out https://www.fast.ai/

Making neural nets uncool again
Even this contains math basics

is this the right place to ask about machine learning?
can someone explain why this happens on first epoch?
551/551 [==============================] - 420s 690ms/step - loss: 3.1702 - accuracy: 0.2863 - val_loss: 1.2984 - val_accuracy: 0.6414
its just printing information about the first epoch.. what about it?
that's the playground. https://playground.tensorflow.org
check pins for some links on where to learn
LOL
the pinned is all about machine learning
0 about stats
0 about data science
acc and val acc
at the end of each epoch, you get the information about both the train set and the test set. that's accuracy and accuracy on test set
well, why not?
you can have a val acc higher than train accuracy
depends entirely on the points in the validation data. for example, if your train test splits are not that great, then the validation data can be overrepresenting a certain type of data points
those could be learnt by the model during the first pass
the split is a shuffle
sure, but that doesn't mean that it can't happen.
if you want to get a better sense of what's doing on, don't try to analyse on just one epoch. what happens as you train this for more epochs, what are the trends like, etc

India
Ik statistics :D
Oh i see thank you headcrab: D
trial and error really.
out of curiousity, what's your number of data points, and what's your split ratio
is the tuner an option?
Awesome
By the way, what I linked you was just sort of a "big" path to follow
It's just to link you all resources
I don't think you need to read any single one of the book
I was watching this video on youtube by andrew ng, basics of neural network. The equation he wrote for calculating z1 is z1 = W1 * X + b1, but given the neural network (the one that's at the bottom), W1 will be a vector of shape (1,9) and X.shape would be (3,m) where m is the number of training samples, right? I don't get how these 2 matrices, W1 and X are supposed to be dotted? Their shapes won't allow matrix multiplication.

W1 should be a matrix of weights - so of shape (layer_1_size,input_size), so that it can transform (input_size,m) into (layer_1_size,m)
actually the formula is z = w^T x + b by the picture, so W's shape is (input_size,layer_1_size) then.
oh, so w^[1].shape must be (3,3), Is this correct?
I think so
cool, thanks a ton @tidal bough & @indigo stone
Good morning guys!
I want to plot different datasets with a drop down menu. I am using pandas and plyplot for graphics and data
Can anyone point me in the right direction?

Thanks! 🙂
"Machine Learning is mathematics first, and programming second. "
oh shi
how can a not very good looking website like this https://home.work.caltech.edu/telecourse.html contains a lot of useful info
guys
are this augmentations good? or too aggresive?
augs = [A.Compose([
A.Transpose(),
A.VerticalFlip(),
A.HorizontalFlip(),
A.RandomBrightness(limit=0.2),
A.RandomContrast(limit=0.2, p=0.75),
A.OneOf([
A.Blur(),
A.MedianBlur(),
A.GaussianBlur(blur_limit=5),
A.GaussNoise(var_limit=(5.0, 10.0)),
]),
A.OneOf([
A.OpticalDistortion(distort_limit=1.0),
A.GridDistortion(num_steps=5, distort_limit=1.0),
A.ElasticTransform(alpha=3),
]),
A.ISONoise(color_shift=(0.05, 0.1), intensity=(0.1, 0.4)),
# A.HueSaturationValue(hue_shift_limit=10, sat_shift_limit=20, val_shift_limit=10),
A.ShiftScaleRotate(shift_limit=0.1, scale_limit=0.1, rotate_limit=20, p=0.85)
])]```trying to classify pokemons
you can use a pretrained network
I don't think there are enough images of pokemons on the internet to train a classifier from scratch
Use transfer learning

Explore and run machine learning code with Kaggle Notebooks | Using data from multiple data sources
I don't think pokemos have consistent features to train a model.
Some of them look like lizards and or some others look like turtles, feature extraction will be hard.
But i might wrong! I dont know much about DL yet
20k img for almost 1000 classes
i think that model sucks
yeah, it sucks, i already downloaded it
i think what i dont know is a good architecture
im using eff net
but i think all prebuilt models are for realistc imgs
Hahaha I have not done image classification in a while
Any specific reason why you want to do a pokemon classifier?
not rlly
but i achieved 0.89 for gen 1 pokemons. I just... need to clean the rest generatiosn q.q
Have you tried using CLIP ? I' m unsure if it could classify more rare pokemons though
clip?

OpenAI
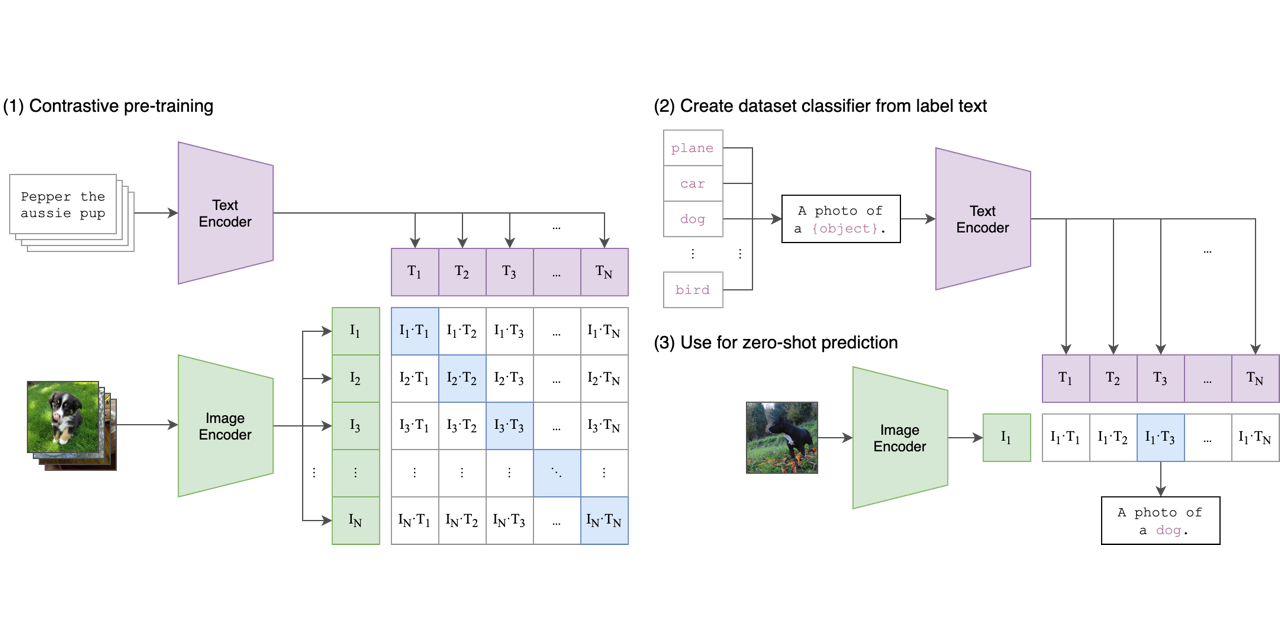
We’re introducing a neural network called CLIP which efficiently learns visual concepts from natural language supervision.
It can classify lot of stuff out of the box
how can i use this?
GitHub
Contrastive Language-Image Pretraining. Contribute to openai/CLIP development by creating an account on GitHub.
import torch
import clip
from PIL import Image
device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = clip.load("ViT-B/32", device=device)
image = preprocess(Image.open("CLIP.png")).unsqueeze(0).to(device)
text = clip.tokenize(["a diagram", "a dog", "a cat"]).to(device)
with torch.no_grad():
image_features = model.encode_image(image)
text_features = model.encode_text(text)
logits_per_image, logits_per_text = model(image, text)
probs = logits_per_image.softmax(dim=-1).cpu().numpy()
print("Label probs:", probs) # prints: [[0.9927937 0.00421068 0.00299572]]
well I thought you were trying to classify pokemons images ?
yeah i am
CLIP (Contrastive Language-Image Pre-Training) is a neural network trained on a variety of (image, text) pairs.
it would be a pretty bad classifier if it needed the class written in the image
"A picture of a Pikachu" or juste the name yeah
yeah
then you make an array with the name of all pokemon
and ask clip which one it is
ah for training u mean?
There is no training
import clip
from PIL import Image
device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = clip.load("ViT-B/32", device=device)
image = preprocess(Image.open("a_pokemon.png")).unsqueeze(0).to(device)
text = clip.tokenize(["a Pikachu", "a Squirtle", "a mew"]).to(device)
with torch.no_grad():
image_features = model.encode_image(image)
text_features = model.encode_text(text)
logits_per_image, logits_per_text = model(image, text)
probs = logits_per_image.softmax(dim=-1).cpu().numpy()
print("Label probs:", probs) # prints: [[0.9927937 0.00421068 0.00299572]]
like this, it will give you a probability for each pokemon
I put just 3 differents pokemon for the example though
and how does it know what pokemon is a_pokemon.png?
I am not sure about the network architecture, or how it works internally
I can just say that it does work very well for many tasks
u arent understanding
on ur snipper, why would it print those numbers?
how does the model, or whatever, knows what img is
if it hasnt been trained
it has already been trained
xD
You are not expected to train it yourself
There are likely pikachus in the training dataset
ViT-B/32
You can probably find the vocabulary of the text encoder yeah
it has been trained with imagenet
I think it' s like ~72K words
No it has not been trained on imagenet
I think it has been trained on this
and there are pikachus inside
is there a better way of doing this to reduce cpu-gpu overhead
def predict(self, board):
board = torch.FloatTensor(board.astype(np.float64))
if args.cuda:
board = board.contiguous().cuda()
with torch.no_grad():
board = board.view(1, self.board_x, self.board_y)
self.nnet.eval()
pi, v = self.nnet(board)
return torch.exp(pi).data.cpu().numpy()[0], v.data.cpu().numpy()[0]
if i'm calling this on parallelized mcts agents
for every unknown state
okey, but other pokemons arent
only other thing i read is that if i'm instantiating the tensor, i can just create it on cuda directly like torch.FloatTensor(board, device=torch.device('cuda'))
matplotlib python file that I did in atom. im new to coding in text editors. so i dont know why the matplotlib window isnt showing up when i run this cmd. fixes...

!paste @lapis sequoia show your code, see below 👇
Pasting large amounts of code
If your code is too long to fit in a codeblock in discord, you can paste your code here:
https://paste.pydis.com/
After pasting your code, save it by clicking the floppy disk icon in the top right, or by typing ctrl + S. After doing that, the URL should change. Copy the URL and post it here so others can see it.
@lapis sequoia put
plt.show()
at the end of the file. otherwise python doesn't know that you want to actually show the plot. jupyter notebook/lab helpfully shows you the plot anyway, under certain circumstances. but that is only in jupyter notebook or jupyterlab.
also, get in the habit of showing your code, data, etc. it's easier to help someone if the helper can see exactly what you are doing

Oh ok
Hello, I just studied about logistic regression through the probability approach i.e maximizing the Log Likelihood function using MLE. Now I'm studying the same thing, logistic regression but through a Neural Network. Andre Ng explains it really well but I don't get a few things. The traditional way i.e using MLE to calculate logistic regression seemed intuitive i.e the sigmoid function applied to z = w1x1 + w2x2 + b, (if only 2 features present) and I could understand what w1,w2, and b implied, and how they're related to the log odds. But its really hard to wrap my head around how a neural network learns this relationship because traditionally, the logistic regression model has 3 parameters (considering 2 features), right? but even a simple NN will have around 9 weights and 4 biases or so. How am I to interpret these 9 weights and 4 biases? This is really confusing, I can understand small pieces of the puzzle but I'm not able to put together the whole picture and see how each piece fits in the puzzle.
CLIP wouldn't work with that kind of things, and training a clip for this task is nonsense
CLIP works by correlating the meaning of a text to an image
Forcing the CNN to extract the meaning instead of a simple prediction
A normal CNN would work better
Why would you need so many parameters? That neural network with no hidden layer literally has the same equation as traditional logistic regression

That model isn't equivalent to logistic regression
It has an extra layer
You can use it in lieu of logistic regression, but it's not the same thing. It's certainly not an exponential family GLM anymore
But the general question of "how to interpret these weights" is a good one
I think the general answer is somewhat unsatisfying, they don't have a nice interpretation as log odds ratios or anything like that
You can think of the outputs from the hidden layer as a representation of the data that is learned by the model, and will be optimized for the classification problem
guys wat is the best lap for coding
mac or win
which one will ya suggest
Can this model be considered as a good model?
I'm asking this because. This is my first model that I have built with help of sklearn.
I have transformed the X, y data

what is the model predicting for?
It is a regression based problem
I have took a kaggle dataset of Car Price
And applied RandomForestRegressor
link to the data?
This is my first time of building the ML model

Used Cars data form websites
I have took
CAR DETAILS FROM CAR DEKHO.csv
As dataset
@serene scaffold
If you figure out something.
Please @ me
can you elaborate?

what do the 1s and 0s mean?
initaially | trouble | and | like
1 | 1 | 1 | 0
0 | 0 | 1 | 1
0 | 0 | 0 | 1
something like this
!docs sklearn.preprocessing.MultiLabelBinarizer
class sklearn.preprocessing.MultiLabelBinarizer(*, classes=None, sparse_output=False)```
Transform between iterable of iterables and a multilabel format.
Although a list of sets or tuples is a very intuitive format for multilabel data, it is unwieldy to process. This transformer converts between this intuitive format and the supported multilabel format: a (samples x classes) binary matrix indicating the presence of a class label.Multilabel ?
@hoary wigeon keep in mind that you'd end up with as many columns as the number of words in your vocabulary, and that will probably become very sparse
yes. so you should probably decide how many words you want to be of interest
like, the top 100, or something
you can tokenize the reviews.text column and then make a list of all the tokens (including duplicates). then you can count them
i did not understand this
do you know what tokenizing is?
nope
it's where you break the text down into discrete units, which are basically words

I don't think you tokenized the text, so it did something other than what you expected.
can u pls write a code or pseudocode ?
do you know about the string manipulation methods for dataframes?
yes
so you need to split up all the sentences into individual words
mmm..
In [21]: s
Out[21]:
0 Hello world!
1 I like cake
2 Pie is good
dtype: object
In [22]: s.str.split()
Out[22]:
0 [Hello, world!]
1 [I, like, cake]
2 [Pie, is, good]
dtype: object
In [23]: mlb.fit(_)
Out[23]: MultiLabelBinarizer()
In [24]: mlb.classes_
Out[24]: array(['Hello', 'I', 'Pie', 'cake', 'good', 'is', 'like', 'world!'], dtype=object)

i have three lists of 1D-arrays (training & validation), representing three different categories and i'd like to use keras Sequential to identify the different cases, how can i feed them into a model.fit call? i'm also looking at keras Dataset, but can't figure out how to use those lists of arrays as labeled data..

yeah, str is an accessor
now im using multilabelbin. after learning SVM i will try with vectorizer
which one is good method to create a review rating prediction ?
this sounds like a variation on sentiment analysis. which is known for being annoyingly difficult
but look into approaches for sentiment analysis with product reviews.
i still have a doubt
even if i train model and test it
how can i test from out of samples
you can find another dataset with similar data and see how it goes
the binarizer will ignore tokens it's not familiar with
i still dint get this
there are 15754 cols
for testing i will need array with size 15754cols
but user input may be like This was a great product i ever had.
i never deployed a model before this
i want to deploy this one
@hoary wigeon Let's assume there are only 3 words
"Hello", "I" and "am"
"Hello" would be
{1, 0, 0}
"I" would be
{0, 1, 0}
And "am" would be
{0, 0, 1}
That means that your sentence will become
{{1, 0, 0}, {0, 1, 0}, {0, 0 ,1}}
(Ignore the curly braces, just used to another programming language)
Did you got it now?
but how am will become {0,0,1} ?
when i pass it from gui
Let's suppose these are your words {"Gabe", "Hello", "I", "am"}
In order to represent a word we create a vector with the same lenght (usually one more, but ignore in this case) as our words
So, if our words are {"Gabe", "Hello", "I", "am"} we will create a vector with 4 items
If we want to represent the name "Gabe"
Since Gabe is the first element in the list
We will do
{1, 0, 0, 0}
yeah i understand this
but
my question is
my model has vector record of 15754 items
Ok
and i will pass some random text from browser
suppor , this is is a good product
how to convert it into same vector length
: )
then you turn the text into a list of word
then you create a blank array, that will contains your vectors
for every world in the array containing words you append the corresponding vector to the new array
So you have your vectorized text
If you need to represent meaning for better results
use something like GloVe or Word2Vec (even bert, but it's too heavy for your needs I guess)
ok
bert is prohibitively expensive without a GPU, unfortunately
try doing df.sum(axis=1). It should correspond to the number of tokens in each sentence. If that's the case, then you're on the right track in terms of how you described your solution.
the best models to learn what, exactly?
like, if i want a model that plays pacman, for example, a genetic one?
to do one task alone
most models do one task. for playing a game, you might try reinforcement learning.
why not genetic ones?
i mean, one task alone, not training, where u need data etc
just, play
I don't really know what those are. but one of my coworkers used reinforcement learning to train an AI to play a game and it worked really well.
if u die, punish
the genetic ones are models that start with random values
and u penalize them and reward them
so imagine, driving a car
the longer the car moves, the more rewards
sounds a lot like reinforcement learning to me.
so weights of that model will have more chances to be transmited to the next generation
but they all have random weights
u initialize like 10 models with random weights, and every generation, u get new weights, randomly, but those who achieve higher scores on previous generation will be more likely to keep some wegiths

An AI that learns to walk on its own after several generations.
Program written using python and the OpenAI Gym framework
This is the Bipedal Walker v2 Environment
Link to Code and Presentation : https://gym.openai.com/evaluations/eval_ujFWHmoqSniDh8cErKCVpA
so i didnt want to tell the model how to play pacman
i want it to discover on its own
ofc lol
how's disk storage involved? this error is about lacking RAM for your big array
@cedar sun Try Deep Q-Learning
But if you're a beginner I suggest you to start learning from the cross-entropy method
For gradually learning math and theory for DQN
my my drive c was having 9Gb free and after this error there was 7 gb free
after running the notebook again from start
there was 8.5 free storage space
Just use StackOverflow
Stack Overflow
I'm facing an issue with allocating huge arrays in numpy on Ubuntu 18 while not facing the same issue on MacOS.
I am trying to allocate memory for a numpy array with shape (156816, 36, 53806)
with...
perhaps you're using a pagefile as virtual memory and this allocation caused it to get filled somewhat
yeah
@hoary wigeon Based on what they said on stackoverflow
It's something related about OS configuration
You should run a command
But I don't think you would have access to it on a remote instance
Just run it on your local device
(Try)
?
Try running it on your pc, just to see if it works
So you can understand if your problem is the same as the guy on stack overflow

i can resize it
Usually, remote instances works on POSIX operatives systems
do i need to reduce the amount ?
ok
No
Increasing page file size may help prevent instabilities and crashing in Windows. However, a hard drive read/write times are much slower than what they would be if the data were in your computer memory. Having a larger page file is going to add extra work for your hard drive, causing everything else to run slower. Page file size should only be increased when encountering out-of-memory errors, and only as a temporary fix. A better solution is to adding more memory to the computer.```@lime berry Please don't try to ping @everyone or @here. Your message has been removed. If you believe this was a mistake, please let staff know!
i have data in form of snippets of shape (100000,), labelled for 3 categories (currently i have 3 arrays containing those snippets). i'd like to use keras to categorize them, so i built a sequential model, but i am not sure what the input parameters should be to make this work or whether i need to reshape the date somehow.. any advice?
so you have 3 arrays, and the sum of the 3 array lengths is 100_000?
no, each array is 100 snippets long
what are the snippets? code snippets?
oh, each one is already a vector of... 100k elements? what the heck?
multi electrode array
so effectively you have a (300, 100_000) dataset and 300 labels, right?
3 labels
yes, but the label vector has 300 elements
yes
i want to make a piano tiles ai but i need help i got the clicking part done using win32api code = def click():
win32api.mouse_event(win32con.MOUSEEVENTF_LEFTDOWN,0,0)
time.sleep(0.001)
win32api.mouse_event(win32con.MOUSEEVENTF_LEFTUP,0,0)
while keyboard.is_pressed('esc') == False:
click()
@lapis sequoia this is better asked in a help channel, because it's more about win32api than about "AI" as such. see #❓|how-to-get-help for instructions
ok thanks
or are you asking about "the rest of it"?
im new to this server
i.e. not the windows part?
as in, you need help building a reinforcement learning agent or something like that?
cnn_model.add(Conv1D(filters=16,
kernel_size=80,
padding="same"))
i need help with these parameters
ah, wrong one
cnn_model.add(
Conv1D(
input_shape=(100000, 1),
strides=2,
filters=16,
kernel_size=80,
padding="same",
)
)
that's my first one
input_shape should be (300, 100000) or something else?
i think (100_000, 1) makes sense
"100k time steps, 1 vector"
that's how the docs says it should be interpreted
hmm.. okay, let me try
cnn_model is a keras.Sequential right?
yeah
it gets into the first epoch, but raises a ValueError: Input 0 of layer sequential is incompatible with the layer: : expected min_ndim=3, found ndim=2. Full shape received: (None, 100000)
@desert oar any idea?
ive got a question in machine learning
so the sigmoid function compresses the values of the sum into the range 0 to 1
but you can use other activation functions, such as ReLU or tanh, whos ranges are (0, inf), and (-1,1) respectively
how do you factor for this different range?
do you normalise for example in ReLU by dividing by the largest activation in each layer
and like (A+1)/2 for tanh, to bring it into the (0,1) range
i think that depends strongly on what the data mean
where they are from
imagine your largest activation in your training data could be tiny compared to what "RL input" might cover, your whole assumptions could be invalid if you don't account for the full range (sensor data maybe)
(somehow that makes me think of autism sensory overload..)
"inside" the NN, between hidden layers, the model would learn different weights to adjust for the different activations
batch normalization is also used to help control the gradients "inside" the model
maybe you need (100_000,) as the conv1d input shape then
could you explain that to me plz salt rock lamp
because theres nothing limiting an activation of being >1 right
if ReLU is used
yeah, that in and of itself isn't a problem
you could just continue, and then normalize at the end?
wdym?
so continue the process with those activations being >1, and only normalising once you get to the output layer?
yes, even if you normalize between every layer you still need to apply sigmoid or softmax to the output layer, if the output needs to be in a certain range
could the strides=2 parameter cause the issue?
doubt it @eager imp
afaik the stride is just the "step size" between convolution passes right?
you seem like a very intelligent fellow, any nice resources for learning more about NN and machine learning?
i know strides from numpy, but i'm a bit at a loss with keras
@lapis sequoia we have a bunch of resources in the pinned messages

Machine Learning Mastery
The convolutional layer in convolutional neural networks systematically applies filters to an input and creates output feature maps. Although the […]
ty
thanks ❤️
Is torch or tensorflow Faster for cpu
none
for training models, CPU is pretty bad
if you talking about CPU ops, they are rarely a bottleneck and don't really differ in any significant perf
I am trying to use Cpu because my Gpu (GT 1030) Is pretty slow, I dont think I can use the gpu version
@sleek dagger https://medium.com/@samnco/using-the-nvidia-gt-1030-for-cuda-workloads-on-ubuntu-16-04-4eee72d56791 it will technically work but the low GPU memory will be limiting for "big" workloads
Medium
Recently nVidia released a new low-end card, the nVidia GT1030. Its specs are so low that it is not even listed on the official CUDA…
I imagine that it would still perform better than CPU
I see, Thank you! This info is a really big help
But it looks like even a toy model will be close to maxing out the VRAM
Might be better than nothing, and for all we know newer versions of TF are a lot more optimized
I see
I was wondering because in blender when rendering. Using cpu it is way faster than gpu on optix or Cuda. So I was thinking the same would apply
I guess you can try it, idk!
I will have to download drivers and see
Thank you for the info though this will help alot
How in the word do I install PyStan?
are you stuck at some point on the instructions?
anyone here has experience with streamlit and altair charts?
what should i learn for data science?
Same Question (How can i get started and make career in data science)
But my python basics are strong
Have been doing web dev from some months in django and flask
I have capability to handle pressure (i mean to struggle those 10-15 days when we start something new)
I code in double digit hrs
Buy my maths is weak
you might need ood maths in data science
like calculus is needed
but you can learn that in like a week or so
most of the people use python , r and mysql or sql for data science
I'm 16 umm
tehn take maths in 11th and 12th
Ik databases stuff too
it will be enough
Took
for data science to start with
noceee tha maths is enough
Of school
maths you will need
speificall the calculus
part it is very imposrtabt
do it overall , anything will be needed
Ohh
but mostly it will be limits and stuff , stats and probability
Stats
Prob
Calcus
And?
in 12th you will have 5 chapters on calculus so just keep your 11th basics strong
that will cover major maths for data science
rest I am also not sure , I am also learnign about it so
looks like you didn't study past few years cuz the amout of stuff you have written in bio
give it time , it will be fine
you can do it rn also
if you want
there are videos on internet
but for data science you can start ai or doing ml
which stream you have chosen btw
Pcm + cs
(I'm not good in studies 60-70% student ) but love tech so even my parents told to take commerce i took science i code whole day
@snow hearth
I would say stop and keep coing at side
if you really love tech you can take arts also
there are a lot of opportunities with that too
no it is not the only thing , you have to explore it
but if you can try changing it to arts or commerce
cuz with pcm you cannot code
you need to give time to pcm
I also have the same combination so ik how hard it is
I am going to college this year like taking admission
not leave but it will be very less cuz pcm need a lot of time
Ohh
like it is not easy to do pcm and code alot
you cange to arts or commerce rn I think cuz it is very easy in 1th
Rip Passion
do pomodoros
Now i have choosen
I won't step back now
like do 50 min sessiona dn then 10 min break
Ohh
your wish , but I like the spirit
yeah , like start doing pomodoros techniques it is awesome ngl
you will study and will not get tired also
I use that mostly to study or work
Umm
How much should i study in a day
I dont want to clear jee or stuff
Not that interested
Just need a btech clg
like study 2 to 4hrs a day to start with ( except classes or tutions)
for that you need good 12th marks or jee
both are needed
atleast good 12th marks are
Umm
but it will be easy for you cuz your syllabus is splitted in half
What if i study 5-6 hrs a day
Is that valid for class 12th. Next session too cez now i just entered 11th
amazing , but be consistent, discipline is what is important , start is easy but to keep it going is difficult
I am not sure but for this year 12th it is valid
I am not the ont th lol
no , it is hard cuz e don't have any idea about our marks
and I need to get good for clg
Ohh
your 10th ones didn't really matter tbh
it is only for you to get the stream in 11th rest no one ask for them
yess make todo ist also
if you want I can help you with softwares and stuff
Ik few good ones and also minimal cuz i am a minimalist
I wanted to learn that but I didn't from day after tomorrow I will start
Nice I'll help u
Ik python like coding it for past 2 years but due to 12th didn't make much projects, now I am gonna get back
sure i will ask if I need help , tho I have found resurses already
I know html and css also jsut gonna get then together and make projects for fun
That's what the problem is
I dont want to do this
I want to make progress in my code Also
Cez in clg i want to be different
Cez if i leave to code rn
So after 2 years i have to do concepts again and then again django
My efforts and many months wasted
don't leave just do it side by side and reduce time
I cannot say like if you good at cod you will be different cuz people really don't care how much you good at it if you only do it to look cool and be different.I really don't understand that thinking
I just do cuz I love tech tbh. I only get better than myself eveyday rather than comparing myself to others
I do cez i love to code
I don't have one tbh. It will be different for everyone and for your scheddule
then don't do it for hte sake you wanna be different. everyone is different in their own way not different in what tehy do
it looks very unprofessional or very silly to read that
Ohh
I wanna be different by doing coding
it is good , you just choose the wrong stream
And yes
I can't blame them
It's my fault why I'm not dedicated towards studies
they way you love code , you should have gone with arts
you can still get good jobs at fang companies with a btech degreee
if you want
Ohk i have chance still
yeah you can change even when you enter 12th
like alot of people change streams
you just have to research and discuss with your family
I can only suggest it to you
your choice, it is not leaving everything thing , it is just managing time according to your priority
5-6 hrs study
4 hrs code
That's it
I was managing life with code
Now I'll manage studies+ code with life
talking and having gf or frinds is alo important otherwise you will burnout
that is too much for your brain
make coding 2hrs and chat with your gf
you will feel more normal and relax everyday
6hrs of pcm is very hard buddy and the you cannot code 4hrs . you will burnout in a day or two
Start slow and after a mnth when you comfortable with this time table
change your time according to yur priorities that time
Yes cez coding in that high lvl django Databases logical thinking also needs my energy
yess , take it slow , and relax your mind also
and dang you hav a gf also at 16yrs age
no I am not intersted in any gf and things
I never have one and I am not interested in making one also
That's better
rn like for atleast this year
11th pcm books ?
Yes
download it online lol
I dont have books too rn
wait I willl suggest you something
Ohk
try doing the online videos from youtube
or maybe take physiswallah
they are very affordable and very good
like it is just 5K for whole year
I always say to everyone to go for yt
I'm gonna but it
you can learn eveyrhing fo rfree
Today
My friend too took that lmao
then you don't have to join any institute
it is very good
Yes self study is best
and you will save lacks of money
yeah
also watch maths videos from neha mam's channel on yt
you will find playlist
Ohh
I will send you link wait
Until i ace it
niceee , just don't burn out
can anyone tell me frm where do i have to learn AI ???i mean which course is best for AI
When I try to create model inside of
with strategy.scope():
it wont show me metric and loss during training
1/1 [==============================] - 61s 61s/step - loss: nan - accuracy: nan
Is it ok or is it some problem?
Is it ok to use binary features for continous regression target ?
Are theano similiar to tf?
Ik they diffrent but if i want to learn tf but i learn theano instead is that good?
Not really?
For one, theano is abandoned, I believe.
But also, I'm not sure it supports autograd for backpropagation, which is about the biggest feature of PyTorch and TF.

Explore and run machine learning code with Kaggle Notebooks | Using data from English Premier League(2020-21)
hey can someone suggest me ideas for projects i really cant find any
i know
RNN
CNN
and Autoencoders

what else would someone use it for then?
Theano? For optimizing chains of operations on arrays, as far as I know
like, the way I understand it, it's smart enough to figure out that a*2+b*2 is better evaluated as (a+b)*2, and more complex cases. In general, it I believe compiles the expression you are evaluating into a single optimized function that it then runs on the arrays
yeah, looks like it's capable of user-defined arbitrary graph optimizations even: https://theano-pymc.readthedocs.io/en/latest/extending/optimization.html
hmm 
tbh some sections of theano docs make me interested in it, like supporting sparse matrices
scipy.sparse IIRC has let me down at times
whoa, jax also has their own scipy https://jax.readthedocs.io/en/latest/jax.scipy.html
Search kaggle. You will get a lot of projects
No, I just can’t install it



Depends, what is your level of experience?
Very low
Study first
Yes i will
does anyone know about the Google lens API? I have some questions about it.
Is there a way to get it? Is it a machine learning framework?
I've used it myself in my day-to-day, and because I'm interested in OCR I'd like to know more about it.
also it seems fairly fast.
another thing I think is cool about it is it can see math equations, so I'm curious what's at work there that's allowing it to do that.
You can buy access to it throught Google Cloud
I'm not familiar with that. Can you share a direct link? Also is this on github?
Google Cloud
Enables you to train machine learning models to classify your images according to your own defined labels.
You can buy access to pretrained model
Google Cloud
@keen prism Otherwise, if you're not willing to pay, you can access Google free yet less powerful models

Google Developers
Google Developers
interesting. are those models stored locally?
or in other words, can i subscribe to google cloud, download the model, and unsubscribe?
The two models that I linked you (I think) are
But never used that
I don't think you can use them outside a mobile app
i have no idea how big a ml model like this is
so with nltk
if i have a tokenized list such as [('adjectives', 'NNS'), ('adjoin', 'VBP'), ('adjoined', 'VBN')].
how would i convert it to a CFG?
They're small
hmm. ok...
But I suggest you the paid google services
The big one is the dataset 
how can i use nasnet to see which architecture fits better for my problem?
wait, i thouigh nasnet is an ai that makes archs
Just study and make the architecture by yourself
Mate, by searching shortcuts for everything you won't learn anything
If you wish I can tell you wich direction to go, so you can learn the subject
learn to answer what ppl ask, and stop telling them what to do
if u are not gonna answer, stay quiet
then im gonna block u
chill
@short heart Hi
How's going with the project?
I think I've found a very straightforward YOLO implementation that you can use
You just have to feed the data in
And then pass to the model

GitHub
YOLOv5 🚀 in PyTorch > ONNX > CoreML > TFLite. Contribute to ultralytics/yolov5 development by creating an account on GitHub.
GitHub
YOLOv5 🚀 in PyTorch > ONNX > CoreML > TFLite. Contribute to ultralytics/yolov5 development by creating an account on GitHub.
Dm me if you need some help
horrible, i get headaches trying to figure out the only good code i found on kaggle on this task, right now im doing something but ill come back to this project later
When you're back send me the link to the code that you found
So maybe I can help you
i sent it
already
As a general rule, do you train a model for less time when the training loss starts plateauing?
just block him; I had done so ages ago when he started randomly pinging and DM-ing. if he's too rude, report to modmail
You need to chill out, man. That behavior is going to get you kick out of this channel and trust me, ML is going to get waaaay harder without a community to help you.
Does anybody know what is the "formal name" of the formula to make data into a supervised learning problem for regression?
I'm talking about the process of shifting data and turn features into targets for regression
Like this
time, measure1, measure2
1, 0.2, 88
2, 0.5, 89
3, 0.7, 87
4, 0.4, 88
5, 1.0, 90
into this:
X1, X2, X3, y
?, ?, 0.2 , 88
0.2, 88, 0.5, 89
0.5, 89, 0.7, 87
0.7, 87, 0.4, 88
0.4, 88, 1.0, 90
1.0, 90, ?, ?
Just need to know the name of the "formula" so I can add it to my paper
So is AI pretty much data. You have data and then you use that data to determine what the likelihood of something happening would be?
I don't understand the question very well but, yeah. That's pretty much what machine learning is\
I'm working on a time series project
So I shifted data to train the model. The problem is that I don't know what the formal definition ot formula is called and I need to type the mathematical expression of basically shifting data to train a model
It's for school
You mean like lag in time series ?
No, not lag. Its just data shift to train a model
Here, I have a data set time 5 timestamps and 2 features.
My data preprocessing for the model includes data shift like this because I want to train a regressor
I want to predict measure 2, so I shift my data 1 timestamp and turn the variable 2 into a target
Remove the first row and the last row and now it's a time serie.
What is the formal name of this practice?
I found it, they call it "sliding window"!
Sorry for the spam
how can i do model.predict for a tensorflow model that classifies images?
it looks like you might be pivoting the table, but I can't tell exactly what the transformation is.
oh no, I see
Sorry, I'm not familiar with a name for that.
here's how you can express it in code, I guess
In [6]: pd.concat((df.iloc[1:], df.iloc[:-1]), axis=1)
Out[6]:
time measure1 measure2 time measure1 measure2
0 NaN NaN NaN 1.0 0.2 88.0
1 2.0 0.5 89.0 2.0 0.5 89.0
2 3.0 0.7 87.0 3.0 0.7 87.0
3 4.0 0.4 88.0 4.0 0.4 88.0
4 5.0 1.0 90.0 NaN NaN NaN
It's just "lagged features" or time series features. I don't think you'll need to describe it further.
Guys I have problem with nltk nltk.CFG.fromstring(pre_model) and nltk.parse.generate.generate(self._cfg). So basically my problem is that its not generating any sentences on call. It keeps returning an empty list everytime I call it
Yeah, it's just the professor wants the math written in the paper lol
Thanks, I'll call it lagged features.
how can i convert a column in my df from printing my values as "[value]" to "value"
I don't know... maybe he deserves a second chanche
As more data you give as more your model will be flexible
Even tough you the loss will stay pretty much the same, your model will learn to generalize better
Hello everyone. For example, I need to write a program that will detect the roads in this photo and take actions accordingly. Is opencv library suitable for this job?

Search for datasets on kaggle, it might help.
hello
you are too soft 🙂
Does anyone know how to filter a csv file based on a certain entry in Pandas? I want all the data except for the column Name that has Test User.
Load it in memory. Then filter.
Could you explain sorry?
Basically read the csv into a dataframe first. As is.
Then your question changes to "how do I use all data except for column name that has Test User from a df"
So, that's a simple filter step. Something like df[df[colname]!="Test User"]
(ps. I'm on phone. Typing code is a pain. Forgive the spacing)
Thank you so much!
One more thing can I delete multiple data this way? Like if I have additional names other than Test User.
Yep. Think of it in terms of filtering
There's an .isin method that let's you compare against multiple names at once.
The road seems to be of an unique color
Use it
Or, use an edge detection algorithm
But, what I suggest is
Use its color to get only the rows, then use the "thinnification" algorithm to get just a list of points
And then maybe fit a line on those
# importing the library
import numpy as np
import matplotlib.pyplot as plt
import math
def diff(x,y,cx,cy,txt,list,dict):
for i in range(len(x)):
diffrence=math.sqrt((x[i]-cx)**2+(y[i]-cy)**2)
dict[x[i],y[i]] = diffrence
# 2.23606797749979
#
# data to be plotted
y = np.array([-2,2,4,0])
x = np.array([-2,4,2,0])
k=[-2,1]
k1=[3,1]
print(k)
l1=[]
l2=[]
dictionary2={}
dictionary1={}
# plotting
plt.title("K Means")
plt.xlabel("X axis")
plt.ylabel("Y axis")
c1=plt.scatter(k[0],k[1], color="black")
c2=plt.scatter(k1[0],k1[1], color="black")
plt.scatter(x, y, color='b')
diff(x,y,k[0],k[1],txt="1 ",list=l1,dict=dictionary1)
diff(x,y,k1[0],k1[1],txt="2 ",list=l2,dict=dictionary2)
plt.show()
help me
what is wrong
did y'all see that machine learning aimbot?
any thoughts?
literally undetectable by current anti-cheat software
If it act like human then they neef a human mod to detect it
Good idea
I actually built my own aimbot with object detection, tracking inside ROI, and automatically changed my cursor value to follow the objects, I only tested that in old offline fps game though
it would be amazing if I can make it works in latest or maybe online fps games but Im not that great at making undetectable anti-cheat program
Hi everyone, I have a quick question. How do you convert between csv file toward json. Thanks a lot
you can load the CSV in pandas and then write it back to file as a json
pd.read_csv(...).to_json(...)
let me try
Speaking of, how efficient is DataFrame.query as compared to doing the same operations in the main environment?
tbh I havent do query for a while and today I was tasked to do with athena
I was able to get some data, but the issue is athena only spit out csv somehow
My question about DataFrame.query was a general question and was not directed specifically at you. It's unrelated to your csv -> json question.
what should I put inside the to_json( ..... )
!docs pandas.DataFrame.to_json
DataFrame.to_json(path_or_buf=None, orient=None, date_format=None, double_precision=10, force_ascii=True, date_unit='ms', default_handler=None, lines=False, compression='infer', ...)```
Convert the object to a JSON string.
Note NaN’s and None will be converted to null and datetime objects will be converted to UNIX timestamps.
Similar names: pandas.pandas.DataFrame.to_json
thank you so much I'mma try it
how'd it go?
it quite well, @lapis sequoia has show me other way. My Pc cant handle your way. it crashed 3 times some unknown reason
i'm a bit stumped on ways to approach this.
i'm trying to convert a large number of proprietary survey data to a python-compatible format (namely pandas). At the same time, i want to be able to retrieve each participant's data (such as their responses) I'm thinking about using either inheritance/composite OOP and then somehow converting it to a pandas dataframe -- would you say this is an alright way to go about this?
I'm not following. Is this data in a database or something?
not a database, it's thousands of sheets of paper
literal sheets of paper that have to be scanned?
so, in what format will the data be? text files (.txt or otherwise) with a predictable format?
simplest would be csv files - index by the participant identifier and the rest of the columns being their responses
if the data is already in a CSV, you are good to go.
So again I ask, what format is the data in currently?
none, just sheets of papers with responses
So, literal sheets of paper? If you want to manually enter them into excel (or any other common spreadsheet software), you'll be fine. Pandas can open those.
cheers 
@royal crest generally speaking, what was your plan for using "inheritance/composite OOP" for this problem?
generally, I think OOP is intended to make large systems more maintainable. Data science stuff tends to be declarative.
well since i'm new to OOP thought it'd be good practice. I was thinking about making a base class named Respondent with composite classes for each attributes and their manipulation thereof
In hindsight that sounds incredibly inefficient for this particular task
Q8. Subtract the mean of each row of the given 2D array, “arr8”, from the values in the array. Set the updated array in “transformed_arr8”.
ans : arr8 = np.random.rand(3, 10)
transformed_arr8 = arr8 - arr8.mean(axis=1, keepdims = True)
how is this valid?
for rows axis = 0 , but the above solution is shown right how ?
anyone
Has anyone read Deep learning by Ian Goodfellow ?
As I understand it, the question asks you for the mean of all columns in that particular row, so axis=1 makes sense to me
It has said that " Subtract the mean of each row
that means we have to calcute mean of each row and subtract it with the values in array
right?
Ye when i read it again you are right, you should email whomever made the assignment
hello, I have a 1GB dataframe of all the projects on pypi.org, their dists (filenames) and their hashes and I'm looking to filter it by any filenames that don't start with their project name: but I'm getting this Traceback: https://gist.github.com/graingert/9a74f1a9d605caa37e078e33ef0e3091#gistcomment-3819689

>>> df
date name filename hash
3154138 2005-03-21 15:59:25+00:00 ZConfig ZConfig-2.2.tar.bz2 d394f3b3574dbe4b9ca564b078d54dede5dbd3c47b8cfd...
739804 2005-03-22 22:19:10+00:00 roundup roundup-0.8.2.tar.gz 7e4ea1cce7a1148b5843519134f1722f7d566257143e5d...
802124 2005-03-22 22:48:40+00:00 pygenx pygenx-0.5.3.tar.gz 473c10ea014b2da31405acfccc0ae141bf31dc148c2eb4...
739805 2005-03-24 18:52:12+00:00 roundup roundup-0.8.2.win32.exe adbefd79254f103dad5385e34707b29f22e47e84fd4df2...
3024342 2005-03-30 16:50:07+00:00 rlcompleter2 rlcompleter2-0.96.tar.gz a69241a3a21cbca2c1c57870e4aac620841c3f013577aa...
... ... ... ... ...
3373212 2021-07-19 07:27:31.247181+00:00 proguard-rate proguard_rate-0.0.6-py3-none-any.whl 4e93ac1ad615dbe123f0f730ffc1b9faa4e252271a4809...
3373213 2021-07-19 07:27:32.341999+00:00 proguard-rate proguard_rate-0.0.6.tar.gz bb67428728825bb0cfc6193673658fad81646d0d664ed4...
4205003 2021-07-19 07:28:27.967307+00:00 bridgecrew bridgecrew-2.0.281-py3-none-any.whl c96034720fb65d3ec10d4b55b4d1c2d686069578232126...
4205004 2021-07-19 07:28:30.409115+00:00 bridgecrew bridgecrew-2.0.281.tar.gz 5c35831ee859889e4f8364e4f09fe66bb9696832cd6dcd...
3834333 2021-07-19 07:31:41.385804+00:00 MachineData MachineData-0.1.2.tar.gz e3b342bd6c50e511887fe761c4ec4e6c5013f20c85a417...
oh that looks terrible on discord
traceback here though:
>>> df[~df.filename.str.startswith(df.name)]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/graingert/.virtualenvs/testing39/lib/python3.9/site-packages/pandas/core/generic.py", line 1529, in __invert__
new_data = self._mgr.apply(operator.invert)
File "/home/graingert/.virtualenvs/testing39/lib/python3.9/site-packages/pandas/core/internals/managers.py", line 325, in apply
applied = b.apply(f, **kwargs)
File "/home/graingert/.virtualenvs/testing39/lib/python3.9/site-packages/pandas/core/internals/blocks.py", line 382, in apply
result = func(self.values, **kwargs)
TypeError: ufunc 'invert' not supported for the input types, and the inputs could not be safely coerced to any supported types according to the casting rule ''safe''
>>>
thank you
@wispy wolf that is... weird
The only debugging step i can imagine is to write df['filename'] instead of df.filename
@desert oar is there a way to send you a sample of this DF?
>>> dfs = df.sample(100)
>>> dfs[~dfs.filename.str.startswith(dfs.name)]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/graingert/.virtualenvs/testing39/lib/python3.9/site-packages/pandas/core/generic.py", line 1529, in __invert__
new_data = self._mgr.apply(operator.invert)
File "/home/graingert/.virtualenvs/testing39/lib/python3.9/site-packages/pandas/core/internals/managers.py", line 325, in apply
applied = b.apply(f, **kwargs)
File "/home/graingert/.virtualenvs/testing39/lib/python3.9/site-packages/pandas/core/internals/blocks.py", line 382, in apply
result = func(self.values, **kwargs)
TypeError: ufunc 'invert' not supported for the input types, and the inputs could not be safely coerced to any supported types according to the casting rule ''safe''
>>>
it breaks on a sample
I've attached a sample.csv now https://gist.github.com/graingert/9a74f1a9d605caa37e078e33ef0e3091#file-sample-csv