
#data-science-and-ml
1 messages · Page 320 of 1
@sly salmon in one-hot encoding, you can always drop 1 of the columns and still unambiguously represent the data
encoding yes/no to 1 and 0 in a single column is equivalent to one-hot encoding then dropping the no column
Yeah. But in my case I have a single column - gender - being 0 or 1.
I don't need to one-hot encode that right?
almost.

@sly salmon i'd encourage you to drop the distinction in your mind
you don't need to use sklearn OneHotEncoder, but are you one-hot encoding? "kind of" i think is an appropriate answer
@desert oar what do you mean by that?
the following are equivalent:
[(1, 0), (1, 0), (0, 1), (1, 0)]
[(1,), (1,), (0,), (1,)]
[1, 1, 0, 1]
if they're equivalent, are they different?
- "one-hot encoding" applied to 2 categories
- above, but with the last column dropped
- "binarization"
only the 0th index maters here?
[(1, 1), (1, 0), (0, 1), (1, 0)]
[(1,), (1,), (0,), (1,)]
still equivalent?
@thorn bobcat no. they all matter except the last one
in this particular case, there are only 2
[(1, 0, 0), (0, 0, 1), (0, 1, 0), (1, 0, 0)]
[(1, 0), (0, 0), (0, 1), (1, 0)]
these two are equivalent
you're only taking a section tho
using your logic these 2 should be equivalent then?
what do you mean by last one by the way? last digit out of the tuple containing 2 digits or the last tuple itself?
in the the one-hot encoding of N categories, you can remove 1 of the encoded columns without losing information
this is like softmax?
when you turn a 2 x 2 matrix into 1 value
it's similar in that you can remove 1 of the elements without losing information
Hey, I made an easier wrapper for OpenCV if any of you would like to use it
I made it mainly to learn how to make a library but it's proven to be useful
so
base_model = load_model('model.h5')
base_model = Model(base_model.input, base_model.layers[-2].output)
x = GlobalAveragePooling2D()(base_model.output)
predictions = Dense(len(pokemons), activation='softmax')(x)
model = Model(inputs=base_model.input, outputs=predictions)```ValueError: Input 0 of layer global_average_pooling2d is incompatible with the layer: expected ndim=4, found ndim=2. Full shape received: (None, 1024)
Why tho?
these are the last layers of base_model
__________________________________________________________________________________________________
global_max_pooling2d_1 (GlobalM (None, 2048) 0 mixed10[0][0]
__________________________________________________________________________________________________
dense_1 (Dense) (None, 1024) 2098176 global_max_pooling2d_1[0][0]
==================================================================================================
Total params: 23,900,960
Trainable params: 0
Non-trainable params: 23,900,960```afaik global average pooling 2d expects following shape: [batch_size, height, width, feature_dim] and outputs [batch_size, feature_dim]. And it looks like you are using some sort of imagenet model with already applied pooling and dense layer, so it produces [batch_size, feature_dim]. Maybe you should use base model without global average pooling. Just apply dense layer directly to base_model outputs.
ha
so instead of base_model.layers[-2].output do base_model.layers[-3].output
?
but no, it is not a model with imagenet weights
it is a pretrained model
but what i wanted to do i removing the last layer
which is a dense of x classes
i wanna remove that and add a dense with my own number of classes
so the problem is that global average pooling im adding
by mistake
Yep, that might work too, with -2 you are using global_max_pooling2d_1 outputs
isnt this?
[-3] doesnt work too
hey guys
i just want to show you a basic record i made of my reinforcement learn project
i am making an enviroment to work with old game emulators
can i share links here??
I have this video feed which I applied image recognition on using face_recognition library, I found over 400 encodings in this video.

Is there a way I can keep my current sensitivity to find the maximum number of encodings but have a way of compiling similar encodings together?
I'm training a model using sampled videos
it's easy with 1 person in the video but becomes nearly impossible when there's more than one person
I need an algorithm that would look at my encodings and put all the encodings of the same face in one folder.
I assume there should be a small difference between encodings of the same face, the algo should be able to tell that difference.
hi folks i'm trying to find trending items from the list of items mentioned in my app and came across this repo on github https://github.com/anadaf/trending/blob/master/trending.py#L57
trending.py line 57
data['diff']=(((data[interaction_time] - pd.datetime.now().date()).dt.days) / self.int_days).astype(int)```line 57 is failing with error TypeError: unsupported operand type(s) for -: 'DatetimeArray' and 'datetime.date'
could you point me in the right direction please?
hey guys
can anyone tell me how to split data from 1 column in to multiple rows and columns? im having a issue with a csv read from an excel sheet... all the data in the excel file is in one cell

tell excel to split by tab
what is this algo detecting in this frame?

ahh the thing is its a project my teacher has done this so i have to split it hahha
like i know ive to for loop it some how and split the data but im unsure what to do as im new to programming an bit lost
may i know the relation between the paper referenced and my problem?
I am using face_recognition library
What are you trying to do?
stated in the abstract
will check it out, thanks for the response.
really appreciate it.
I think line 57 is trying to subtract todays date from all dates in the rows
what version of numpy were you using when you got the error?
nm, figured it out
changed to data['datetime'] = pd.to_datetime(df[interaction_time]) data['diff']=(((data['datetime'] - datetime.datetime.now()).dt.days) / self.int_days).astype(int)
sadly the author didn't specify package versions in the repo
hey guys, i´m currently working with data that has 14 layers of 7x7 matrixes and the numbers in one particular matrix are either -99999 or in beetween [0,1]. Should I scaled it or leave it like that?. And if I have to scaled it, any scaler recommendation?
I can't seem to find a way to do df.rolling(5).max() if I wanted a window like "two before and three after". It only appears to support symmetrical windows.
sounds like -99999 is "missing"
what does this data represent?
i think you are right, i remember someone else asked about this a while ago and i couldn't find anything about it
you'd have to generate a sequence of (start,stop) pairs, and slice with iloc
maybe could implement efficiently with numba
at least, you could implement certain routines like min max mean etc. efficiently
pandas does a lot of index bookkeeping w/ those methods but it wouldn't be that hard to implement it all yourself, maybe a bit fussy
pd.concat(
(
df.rolling(5).max(),
df.iloc[::-1].rolling(2).max().iloc[::-1],
), axis=1
).max(axis=1)
what have I done
that is definitely one way to do it
@true cypress you could do that...
Given a list of face encodings, compare them to a known face encoding and get a euclidean distance for each comparison face. The distance tells you how similar the faces are.
 this is what i need in my lifee
this is what i need in my lifee
Yes, cool!
pd.concat is pandas concatinate?
ye
figured without reading the docs!
the rest looks like a dice roll but i could be very wrong
correction >> this is what df.rolling does Contrasting to an integer rolling window, this will roll a variable length window corresponding to the time period.
@serene scaffold https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.rolling.html#pandas.DataFrame.rolling
If a
BaseIndexersubclass is passed, calculates the window boundaries based on the definedget_window_boundsmethod. Additional rolling keyword arguments, namelymin_periods,center, andclosedwill be passed toget_window_bounds.
Use this to implement asymmetrical rolling windows
I'd have to figure out how it works
Why are you telling me to learn stuff
lol, i'm learning things too
i just found this. might be relatively new
or it was just well-hidden before
https://github.com/pandas-dev/pandas/blob/v1.2.4/pandas/core/window/indexers.py#L69-L96 could use this as a base

GitHub
Flexible and powerful data analysis / manipulation library for Python, providing labeled data structures similar to R data.frame objects, statistical functions, and much more - pandas-dev/pandas
i can't say i understand where this num_values comes from
hello for anyone interested in reinforcement learn here is the start of my new enviroment https://github.com/watson1423/Retrogame-Reinforce-Companion

GitHub
RRC is still under development the end goal is to make a reinforcement learning enviroment for simple games reading screen sownd memory all you decide is important for a determined game and then ge...
ok, num_values is supposed to be the length of the thing you're computing the windows over
https://github.com/pandas-dev/pandas/blob/v1.2.4/pandas/core/window/indexers.py#L39-L55 x-files lost episode: everyone time you use kwargs this way, barbara liskov astral projects in her sleep and breaks your computer
GitHub
Flexible and powerful data analysis / manipulation library for Python, providing labeled data structures similar to R data.frame objects, statistical functions, and much more - pandas-dev/pandas
!otn a barbara liskov's astral projection
:ok_hand: Added barbara-liskov’s-astral-projection to the names list.
In [41]: y.rolling(FixedForwardWindowIndexer(window_size=0)).max()
zsh: segmentation fault ipython
nice
In [41]: y.rolling(FixedForwardWindowIndexer()).max()
zsh: segmentation fault ipython
oopsie!
i'm actually not sure where or why that segfault even happens
@serene scaffold https://paste.pythondiscord.com/adezifeqiw.py
Hey, so I'm wondering if there's any way to make pytorch think several steps ahead? I'm doing my first pytorch project as a snake game and it keeps running itself into a circle
Doing Deep Q learning, using Adam compiler
you have to do all that to get the desired behavior?
fucks sake
not necessarily, i tried to make a nice-ish api around it
you should put it on pypi
is this something people often want to do?
idk, but I want this and normalization to be part of pandas, but this is the normalization and asymmetric window at home
if i can figure out a way to test it i would put it on pypi
testing is work
the normalization i'm not sure about, it might not be possible to implement "efficiently" so it's not worth their time maintaining a helper for it
you ultimately need to make 2 passes over the data: once to get the min and max, and once to normalize
T(n) = 2n \in O(n)
makes sense
it's weird, this is something that you'd want in a big library, but they probably won't do it due to mainentance burden, but on its own it's "too small" and might be a left-pad type of situation
what happened with left pad
it was a tiny npm package that left-padded a string
and something happened where the maintainer randomly pulled it off npm or something like that
and it turned out that it had a huge number of dependents and a bunch of stuff broke unexpectedly
and everyone used it as an example of how stupid and lazy javascript programmers are ha ha!

Quartz
A man in Oakland, California, disrupted web development around the world last week by deleting 11 lines of code.
if left-padding a string is that verbose in javascript, then I don't even blame them for being "lazy"
right
the reality is that this is not something that everyone should have to add to their utils.js and write tests for
(also strings have a padding method now)
as a response to that fiasco?
oh btw, I have two interviews for data scientist positions tomorrow
I'll sprinkle myself with salt before the interview for good luck.
 🧂
🧂
i'm sure you'll do very well
the second interview is for a job I actually want, so the first one will help me warm up
the first interview is for a job at a location that I can only get to by crossing one specific bridge, and that would ruin my fucking life.
can anyone help with R ?
Political_Affiliation Total_Income
1 Conservative 54794016
2 Liberal 58860890
3 New_Democrat 30839697
4 Other 18334826
i have this table and want to return max name with max income
which.max() returns index 2
Hi, i have a question: What the meaning of hyperparameters? how we can deciding a value of hyperparameters?
how much ML experience do you have
are you familiar with linear regression?
and regularisation?
I'm a beginner
is that a no to my other 2 questions
Now, i'm learning about that
1 month
okay, long story short
2 weeks i mean
you can use certain techniques
to build machine learning models.
which are basically mathematical techniques to predict some output, given some input.
the "parameters" of the model are what lets it perform that prediction
Alright I've never seen ml before what's the most basic example of machine learning?
and we say it "learns" those parameters based on exposure to training data.
hyperparameters are the things that control how it learns.
you're really just starting out so this might be hard to get right now
but for linear regression, the individual coefficients are parameters
and regularisation strength is the canonical example of a hyperparameter: as it changes, so will the coefficients learnt, even if the training data is the same
How to deciding a value of hyperparameters?
a lot of it is actually educated guessing
well, there are advanced ways
but the simplest principled way is
random search
say, specify a range from 0 to 1, and choose random values in that range
another very simple way is grid search, where you take steps from one end of that range to the other
remember that there may be multiple hyperparameters, and as their number increases, so too does the count of possible combinations
I'm so confuse why the value of hyperparameters on 'gamma' is 0.1 until 0.9
and why 'c' value is 0.25 until 1

i really don't understand about that
whether it's just a random value what i want to choose?
hm I'm not sure about those choices tbh
seem a bit weird
this comes with experience
it's hard to identify a general principle
but
I would say
at this point
since you're new
don't worry so much about the exact values
focus more on the concepts
I so confuse because when i change the hyperparameters higher than that, the accuracy is better and better than that
it's from udemy
i still learning about that

Stack Overflow
import random
import json
import pickle
import numpy as np
import nltk
from nltk.stem import WordNetLemmatizer
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import D...
help plz
Hi, can someone tell me if there is a way to obtain all urls in this nested structure using beautiful soup?

These are all hyperlinks
Hello, I was doing some array indexing with numpy, specifically trying to find all values not in a given index array, and for some reason I remember it being possible to do something like:
n=100
rg = np.arange(n)
idx = np.random.choice(rg, int(n*0.1), replace=False)
rg[~idx]
However, I just realized ~idx negates the content of the (currently integer) array, so now I wonder what kind of code I used to use to select values not in the array. I can use Pandas' isin() function to do the same, s.loc[~s.isin(idx)], but how can I do this using only numpy?
Also, has numpy has always behaved in this way, and I somehow managed to never notice, or is it something that came up in a recent update and that I didn't notice? (please ping me)
I believe so. According to https://stackoverflow.com/questions/27824075/accessing-numpy-array-elements-not-in-a-given-index-list, you can achieve what you want by doing the following:
mask = np.ones(arr.size, dtype=bool)
mask[indexes] = False
result = arr[mask]
Is there anything specific I have to do to install pytorch through conda? I'm using the install command that the pytorch website gives, but it just gives a "Found conflict" error.
It's on a fresh virtual environment with python 3.9.5
Thanks for the reply and the snippet, for some reason I was convinced that simply negating the array would be enough, but I guess I must have confused array indexing with pandas loc
Did you read the comments?
ya thnk u
did you try googling it yourself?
problem solved thnx
share the command you used and the error message, usually the instructions on their webpage works well
I found a lot of recent posts about the same issue. Seems to be a common problem with conda.
Managed to install it just fine using pip.
can you share the posts?
I found a problem with qt and torchvision, I wonder if its that
fwiw here's the error
Solving environment: failed with initial frozen solve. Retrying with flexible solve.
Solving environment: failed with repodata from current_repodata.json, will retry with next repodata source.
Collecting package metadata (repodata.json): done
Solving environment: failed with initial frozen solve. Retrying with flexible solve.
Solving environment: |
Found conflicts! Looking for incompatible packages.
This can take several minutes. Press CTRL-C to abort.
Examining @/win-64::__cuda==11.2=0: 25%|████████████ | 2/8 [00:05<00:17, 2.90s/it]\failed
UnsatisfiableError: The following specifications were found
to be incompatible with the existing python installation in your environment:
Specifications:
- torchaudio -> python[version='>=2.7,<2.8.0a0|>=3.5,<3.6.0a0']
- torchvision -> python[version='>=2.7,<2.8.0a0']
Your python: python=3.9
If python is on the left-most side of the chain, that's the version you've asked for.
When python appears to the right, that indicates that the thing on the left is somehow
not available for the python version you are constrained to. Note that conda will not
change your python version to a different minor version unless you explicitly specify
that.
The following specifications were found to be incompatible with each other:
Output in format: Requested package -> Available versions
Package vs2015_runtime conflicts for:
torchvision -> numpy[version='>=1.11'] -> vs2015_runtime[version='>=14.15.26706|>=14.16.27012,<15.0a0|>=14.27.29016|>=14.16.27012']
torchaudio -> vs2015_runtime[version='>=14.16.27012|>=14.16.27012,<15.0a0']
pytorch -> vs2015_runtime[version='>=14.16.27012,<15.0a0']
......
It goes on for a while about various conflicts
https://discuss.pytorch.org/t/not-being-install-pytorch/122630
https://discuss.pytorch.org/t/package-pytorch-conflicts-during-installation-with-conda/122896
None of them seem to have been answered yet, so I'm just using pip for now
Haven't encountered that, seems to be a problem with python 3.9 :S
Hi guys, I have a problem to solve and that is to find the similarity between two names. For example, 'John Doe' and 'D. John' should have a very high similarity score, whereas, 'John Doe' and 'William Cross' should have a very less similarity score. I have explored algorithms about Jaro-Winkler, Levenstein, etc... Any other approach towards solving the above problem given that names are in varying natures.
Please help me with any approaches you can think of for solving this problem.
convert names to set of letters, encode numerically and then use some sort of set metric that matches the letters that are similar in both sets, cluster as needed
Thank you!
Or even encode them into sets of n-grams (of letters)
Hey can someone tell me how many states Flappy Bird in a Q table has? The Q-table has the dimension m x n where m is the number of states and n the number of actions.
Flappy bird has only 1 action (jump) but how many states? oO
is numpy faster in conda enviroment?
@near gust I made this a while ago :

GitHub
A replica of the famous Flappy Bird game with Pygame and the neat-python module for an AI to play the game perfectly - HerbeMalveillante/flappybirdAI
I'm not sure about what you mean about Q table but I feeded the algorithm with three inputs
that's a basic application of the tech with tim tutorial
Thanks for the repo. Yeah I currently try it by hand. The q table is a matrix where the q values are stored which determine the action of the agent depending on the current state and the future reward (if I'm not completely wrong).
I'm currently building my own agent in Rust but I don't know the actual states so far... Therefore I don't know the size of the Q table,.... 😄
Well, I'm afraid i'm not knowledgable enough to help you more than that, sorry ! Good luck tho :)
Thanks :>
Yes, go ahead and ask, then someone can see if they can help.
Any of you know what is the ratio of
True length to apparent length of a square based pyramid??
I mean like True Lenght/Apparent length = ?
For the slanted part
it depends on the states you use
Q-learning is literally just a table. you can use the distance of the bird from the midpoint of the line joining the spaces b/w the pipes as a state
the more states you have, the more complex it gets
Currently I have the distance between the Bird and the Pipes with normalized values and the score itself.
This is how my array looks from the game:
{
"player": 0.1953125,
"score": 0,
"pipes": [
[
[0.6435185, 0.49414062],
[0.6435185, -0.38476562]
],
[
[0.9328703, 0.359375],
[0.9328703, -0.51953125]
],
[
[1.2222222, 0.2890625],
[1.2222222, -0.58984375]
]
]
}
those sound like weird metrics, but ig if you want to use them 🤷 . what's the problem here? The Q-table would be quite large, but you wouldn't want to grow it further if it gets decent accuracy
what is "apparent length"?
is this a homework question?
Ah so instead the top and bottom of the pipes you just use the center? Make sense.
The problem is that I don't know the size of the q table. You say that the q table would be quite large but what's inside the q table?
I'm trying to use vanilla SQLAlchemy and I'm lost. Is there any way to instanciate the tables you just created in a row, through your Base classes?
this is a #databases question, but you might want to clarify your question before asking there
I have another data science interview in an hour, but I want this job more than the other one
what do I do? think about neural nets?
hmm
what's the job?
how did the first one go?
don't need to know the company, but what "flavor" of data science would be helpful
computational linguist
i always like to think of data science as problem-solving first
prime yourself with problem-solving techniques
"how would i approach X?"
"what worked for me when i did Y in the past, and what didn't?"
with weapons
i don't know much of anything about computational linguistics, but you do
maybe look at some equations too
basic stuff that you might blank on during an interview
neural networks and backprop, eigenvalue stuff, whatever math you think might be relevant
or even just google around on topics you know that you know but that you don't think you have perfect recall for
again just to keep it fresh in your mind
Methodology question. I have a survey, with about 110k responses. Survey has about 13 IV and about 4 dependant variables I want to analyze. Looking to use random forest for feature selection. But I need to remove nulls. If I remove all nulls I am left with about 30% of my surveys where each question was answered....:( My values are binary, 0 and 1. Yes or No. What issue would I run into if I convert the nulls to 0?
Why would I ask my homework here -_-
Apparent length is the length are the slanted sides of turtle and real length is the length is the length you get when you assume that slanted side is at 90 degrees
If that makes sense -_-
Each IV has only 2-5k nulls but one IV has over 50k nulls because not everyone should answer it. I can't drop IVs.
Why would I ask my homework here --
lots of people just drop homework questions in this server expecting people to do their homework them. that said, i still don't know what you're asking, but maybe someone else does
random forests can handle nulls
if you convert all nulls to 0 then you are assuming that all nulls are 0
so you're basically making an arbitrary choice that might or might not be true
For feature selection, it errors out with nulls. Infinite error
what do you mean by using random forest for feature selection?
are you planning to fit a random forest model, then select the most important features for use in a 2nd model?
Yes
RF for feature selection to then using those IVs in a regular decision tree/ log reg.
I'm getting a very low acc for my tensor flow model, what are the common cases?
@hearty token what is that model designed to do, and are you using accuracy specifically? There are a lot of performance metrics.
I have an intents file that has a few tags, patterns and responses. I'm using it to make a chat bot
I'm not sure what you mean by "using accuracy specifically"
and out of curiosity, is there a reason you're not just using the random forest model as-is? there's no guarantee that the feature importance scores have any meaning outside of that particular model, because the scores are computed directly from the tree splits, so if you use different splits the scores would necessarily be different
model is bad or insufficient, data is bad or insufficient, model code is buggy, data processing code is buggy
i.e. "anything"
Can you describe what kind of data is bad?
weak or no relationship between features and target, or not enough data to for such a relationship to be apparent if it exists
ah okay, ill see if i can get the data sorted
there are some good sorting algorithms for that, classic ones
I don't know if this is the correct channel but I'll take my chances.
In regards to presentation, what is the best way to present your code in data science? I have made a Tweepy system and in 7 days gonna explain the code to my supervisor.
Panda is one of the libraries I have used. If you were in my position how would you talk about pandas?
So far I am pointing out the advantages and disadvantages we had but are there any other important pointers to have in mind?
I'm sorry if it's a trivial question and if it sounds like I am trying to have someone else do it for me, I just wanna hear your thoughts about it because I am new in the area.
good question
Thanks, matplotlib is also one of the libraries I have used. It's just that it's easy to just explain "Pandas does this etc and combining with matplotlib is the given results... etc"
Just wanna hear if any of you could point me in other directions
know your audience
if your supervisor already knows what pandas and matplotlib are, maybe they need no explanation
Hey guys, I'm looking for some pretty advanced help regarding the use of loss functions in the context of variational autoencoders
Is this a channel suited for that?
yes but i think you might be already on the advanced end for even asking
Specifically, I have modified my data for categorical loss, but I want to use ELBO in order to maximize the log loss (using KL divergence)
Well we have an external examiner. Our supervisor told us that in regards to data science he is a greek god because he is from Greece lol
However, normally I would use crossentropy loss (just the default pytorch implementation) to go from probabilities/classes -> loss, but this doesn't seem to be working in the context of ELBO
It's a longshot, but I'm looking for advice on categorical loss for ELBO basically
wdym categorical loss @jade chasm ?
I'm creating a VAE in order to reconstruct images from MNIST based on their approximated distributions
normally I would just have a float value for the pixel values, i.e. an image would be [1,28,28] in shape
now , instead, I'm using one hot encoding to bin the float values
for instance, I could have [5,28,28] for a single image, indicating 5 'channels' for the brightness value of a cell
cross entropy would usually work for this, but I need to use ELBO since I'm approximating a distribution, and not neccesarily just classifying.
categorical loss is meant for this
Yes
Normally, I'd use ```py
log_p = -0.5 * torch.sum(np.log(decoder.var * 2 * np.pi) + d2 / decoder.var)
KL = -0.5 * torch.sum(1 + torch.log(torch.tensor(decoder.var)) - mu_x**2 - decoder.var)
where d2 is the distance between my true image and the output of a decoder (which samples from a latent space + estimated distribution of my input)
but obviously, that d2/loss wouldn't work for categorical
i see
so how do you compute the loss/distance between the true image and the decoder output?
well that depends
let me get you some working code which gives a logical output
imgstemp = torch.argmax(imgs, dim=1).view(-1, 28, 28)
#tmp = nn.functional.one_hot(imgstemp).view()
mask = imgs.bool()
probs = mu_x[mask]
log_probs = torch.sum(torch.log(torch.clamp(probs, min=0.005)))
so that would work pretty well
As the input images imgs are one hot encoded, I can use it as a mask in order to get the probabilities of the predicted true class from mu_x (mu_x is basically my prediction)
then I can just sum the log likelhoods (clamp is for preventing inf values for p=0) to get a logical value
This will not converge or learn.
Same issue with built-in cross entropy.
Yeah, it's basically a different version from:
which can go over N dimensions and C classes
This might be too specific for this channel :), sorry for that
heh, it's on topic, but i don't know that there are many people here who can help
i personally haven't messed with variational inference much, i know the concepts but not how to derive my own models from scratch
They're a mess
i can DM you the link to the data science and statistics servers i'm in. some phd students hang around those, you might get better help there.
you can also ask on https://stats.stackexchange.com or https://datascience.stackexchange.com (or apparently also https://ai.stackexchange.com)

Cross Validated
Q&A for people interested in statistics, machine learning, data analysis, data mining, and data visualization

Data Science Stack Exchange
Q&A for Data science professionals, Machine Learning specialists, and those interested in learning more about the field
would love the link. I'm interested in some more advanced discsussions 🙂
sent
I have huge data samples with people conversing in them, how can prepare this data for a deep learning model? (for potentially a AI chat bot)
If i have questions regarding data engineering, is this the place or maybe the channel databases? 🙂
can you distill what you want the chatbot to be able to do?
this is the channel for that.
@serene scaffold thanks!
I want it to respond properly to major small talk questions.
does the data you have contain examples of that?
Yeah, over a hundred thousand.
what does the data look like?
(author identifier):(content)\n
(author2 identifier):(content)\n...
They are grouped in order
Author 2 presumably is replying to author
is it always author 1, author 2, author 1, author 2, etc?
It's not always the case that author 2 is replying to author though, the roles will be reversed.
Not particularly, sometimes author 1 can show up multiple times as well as author 2
so are there always exactly two participants?
Yes
For entry level positions in data engineering, do you think i would have to know apache spark/airflow or, better with a good foundation of python/SQL?
definately need one of those univarsity parpers
I've been interviewing for data scientist positions, and I know Python and SQL. I don't even know what spark or airflow are, though.
the latter, but it can be valuable to know some of the former
@serene scaffold they are more specific tools in the data engineering stack
I figured as much. You would probably need a degree in computer science or statistics.
@serene scaffold i'm surprised you've never heard of them. spark is a distributed computing platform that runs on hadoop. airflow is basically a DAG-based task runner but somewhat oriented for ETL-like jobs.
@candid pulsar the more of the basics you know, the more of the complicated stuff you will find that you can learn efficiently
@serene scaffold hmm i'm from economics but i think i have easier to grasp technical stuff than finance to be honest
I see hadoop in job listings, yet no one ever asks about it
you don't need to care about it unless you're trying to be a data engineer
you might encounter it at some of your jobs but you won't have to administer it
maybe you might have to use spark
@desert oar that was helpful, yeah makes sense i guess, "if you know one programming lang, it's easier to pickup another one" due to you already having the knowledge of the basics of programming 😄 I liked it!
note that spark will stretch your understanding of "programming"
the computation model is quite different from python
plus if you want to use scala you're also learning a different language
@desert oar haha so maybe wait with spark until necessary
it depends on your current skill level
airflow i think you can just start messing with
Well i've studied data science, and now i have mixed feelings, i would like to lean more towards building stuff and automation. Hence i'm starting to gain interest in data engineering or even web development
spark too, really. maybe there's a free databricks tier you can use
there are probably good data engineering courses
i wish i knew less data engineering, i feel like my spark knowledge is a battle scar more than a trophy
the world needs more good data engineers
@desert oar are you working with data engineering at the moment?
no, i took a break from the industry
okay but you have experience from that field then?
yeah, i did write some ETL jobs in pyspark and attempt to do some machine learning there too
He's the best salt data scientist 😄
oh that's cool! what did you enjoy the most about working as a data engineer? And if you want to answer, maybe what was the worst things about it?
i was a data scientist, not a data engineer. but the worst thing about being data scientist was when i had to be a data engineer 😉
that said, the data engineering that i did was not all that different from the software development i do now. it's a constant ongoing problem-solving exercise. the problem with data engineering is that everything is potentially big, slow, and expensive.
there are a lot of possible solutions to any given problem, and many of them are either extremely expensive enterprise-grade systems, or totally-unsupported-you-fix-it-yourself open source systems
from what i saw, is no "just do X" in data engineering
@desert oar even more interesting so you went from data science to software development, what made you change path?
almost everything requires care and forethought
my job fucking sucked and i was burned out
@desert oar oh i'm sorry to hear that!
life lesson: try to build up a savings account as quick as you can. that way if your job sucks you can quit without going broke
that's some advise!
Is there a way to make pytorch think several steps ahead?
Hi, is that channel "open" to questions?
in the the discussion channels we don't have restrictions like in the "help" channels. go ahead and ask your question if you have one
I have huge data samples with people conversing in them, how can prepare this data for a deep learning model? (consists of 2 users chatting with each other -- for potentially a AI chat bot)
hi guys, beginner here. I wrote a script which scrapes a website and generates a json file. I'd like to visualize the data a bit. Basically it contains the words in the headlines of a news portal and also how many times the words occur in the news. My question is: which library do you recommend for a beginner to get a bit familiar with diagrams?
I need to modify the types of curves accepted by openMotor (a GitHub sourced program that i'm using), because it only accepts closed curves (standard) with geometries derived from arcs, lines, and circles. In a way that i don't know, it's saying that my geometry is made out of splines (but it is made of the types that the program should in theory accept).
seaborn :D
the input is one person and the output the other :D
if u say to the bot "hello my name is aza"
bot should reply "hi aza, i am a bot"
and so on
If a model that has all the firsts layers frozen doesnt improve its acc, may i unfreeze more?
Hey guys, im trying to solve a linear program with python, (artificial constraint method) and i don't why the first function is not running
can you be more specific? did you try something and you got an error message? or you are just asking about if something is possible?
I can't send the code is too long
!paste @kind totem
Pasting large amounts of code
If your code is too long to fit in a codeblock in discord, you can paste your code here:
https://paste.pydis.com/
After pasting your code, save it by clicking the floppy disk icon in the top right, or by typing ctrl + S. After doing that, the URL should change. Copy the URL and post it here so others can see it.
I tried to input a test geometry a little bit different than the one (that is working) sent to me (by the main developer of the program) than, the program showed an error message, saying that the geometry type wasn't supported by the program (the developer said that he didn't had time to make the program compatible with splines, the unsupported type of geometry). And after that, i'm trying to edit the class CustomGrain (in grain fille) so that the program will be able to run simulations with that types of geometries. But, as i said, i don't know some of the libraries he used, and i needed this code to work with splines so the results would confirm or regret what alternative do i have to follow in the project of a very important protype i'm working.
GitHub
An open-source internal ballistics simulator for rocket motor experimenters - reilleya/openMotor
this is the link of the GitHub repository that better explains the function of the program
it's a large bunch of information, an for sure it won't fit in the chat hahahah
How to assign more then three different values to a new column based on values in the row in a dataframe

hello guys
sorry daddy, i will wait for you '
your porject looks so much like mine
So you did try md_genres3 (the dropped duplicated) in the scatter function?
this is more opencv but is there any best practice method for pattern matching a camera position?
My goal is to detect when a specific spawnpoint is onscreen. The lighting may change, and there may be some objects preventing exact matches, but the majority of the landscape should be identical when in this location, so I feel its possible.
I was thinking some sort of averaged edge-detection threshold?
I'll handle capture with MSS or whatever, I'm just interested in what algorithm or implementation would be best for this
when making a conv2D layer, do we actually specify the filters that we use? Or does it handle it automatically?
the filters are learned during training
I tried to make Live Speech to Text IBM but gives me the same error Handshake status 403 Forbidden my api key and url are correct
even their server's are up, no outage
Hey @olive jackal!
It looks like you tried to attach file type(s) that we do not allow (.zip). We currently allow the following file types: .gif, .jpg, .jpeg, .mov, .mp4, .mpg, .png, .mp3, .wav, .ogg, .webm, .webp, .flac, .m4a.
Feel free to ask in #community-meta if you think this is a mistake.
probs just something weird with plotly
i think my last plotly graph bugged a bit too but it also fixed on restart

i have always used test_train_split in all of my code up until now since my testing and training dataset would be within the same file
for the first time i'm doing something where the training dataset and testing dataset are different files
how should i go about the x_train, x_test, y_train, y_test
i have done it for x_train, x_test, y_train
but how should I initialise the target variable that is y_test
can i just initialise y_test as an empty pandas series
will that work?
I mean, all test_train_split does is split the data into variables, and optionally shuffle it. You can do that yourself with a function.
i got this
this is what i used to do when both my training and testing data were in the same csv file
what changes do i have to make when i take the test data set from a different file
Are there any resources for weighted n-gram vectors for sentence similarity? Or something similar to the implementation in the paper? I found a paper that makes use of it but I'm confused about the implementation:
https://www.cicling.org/2019/intranet/papers/paper_315.pdf
Hi guys, I'm analysing some eshop data. Do you have any links or algorithms that may help me doing this logic: people who bought product A in the first purchase bought B in the second and so on. So I want to just get products that led to another in the next purchase
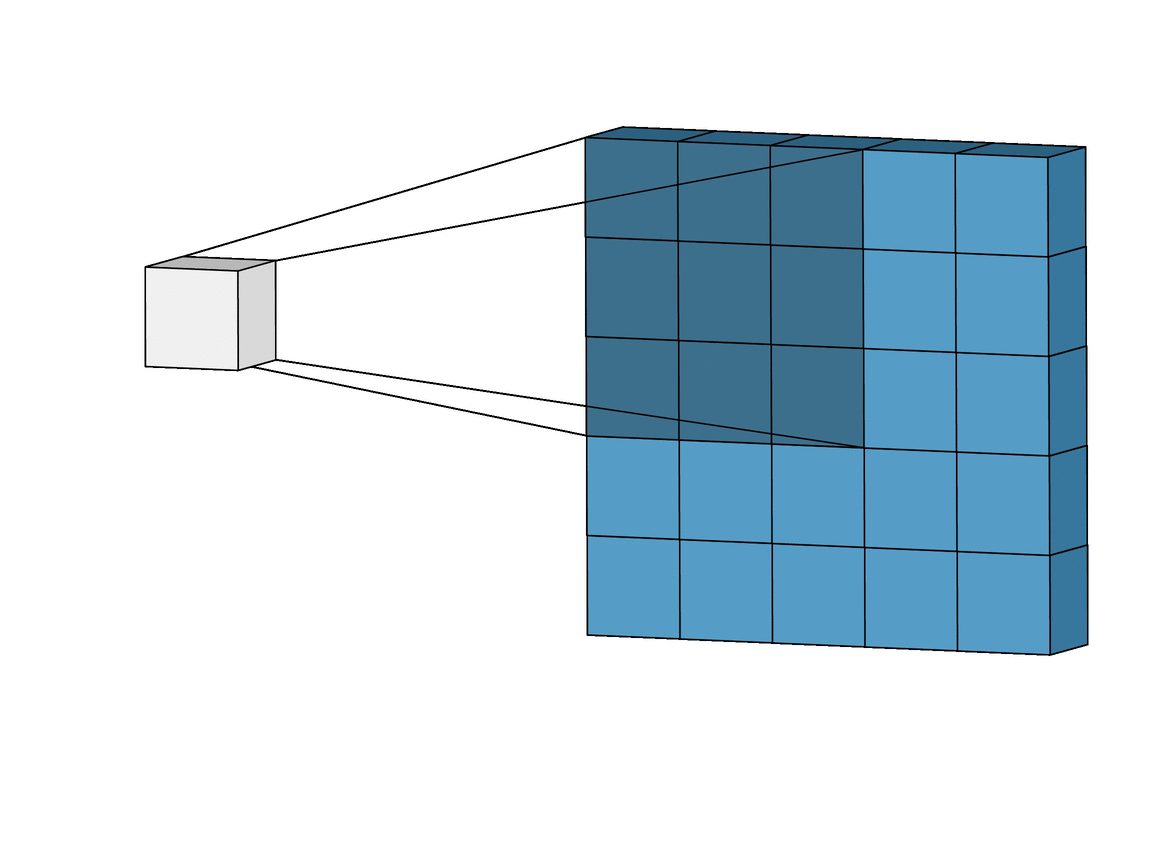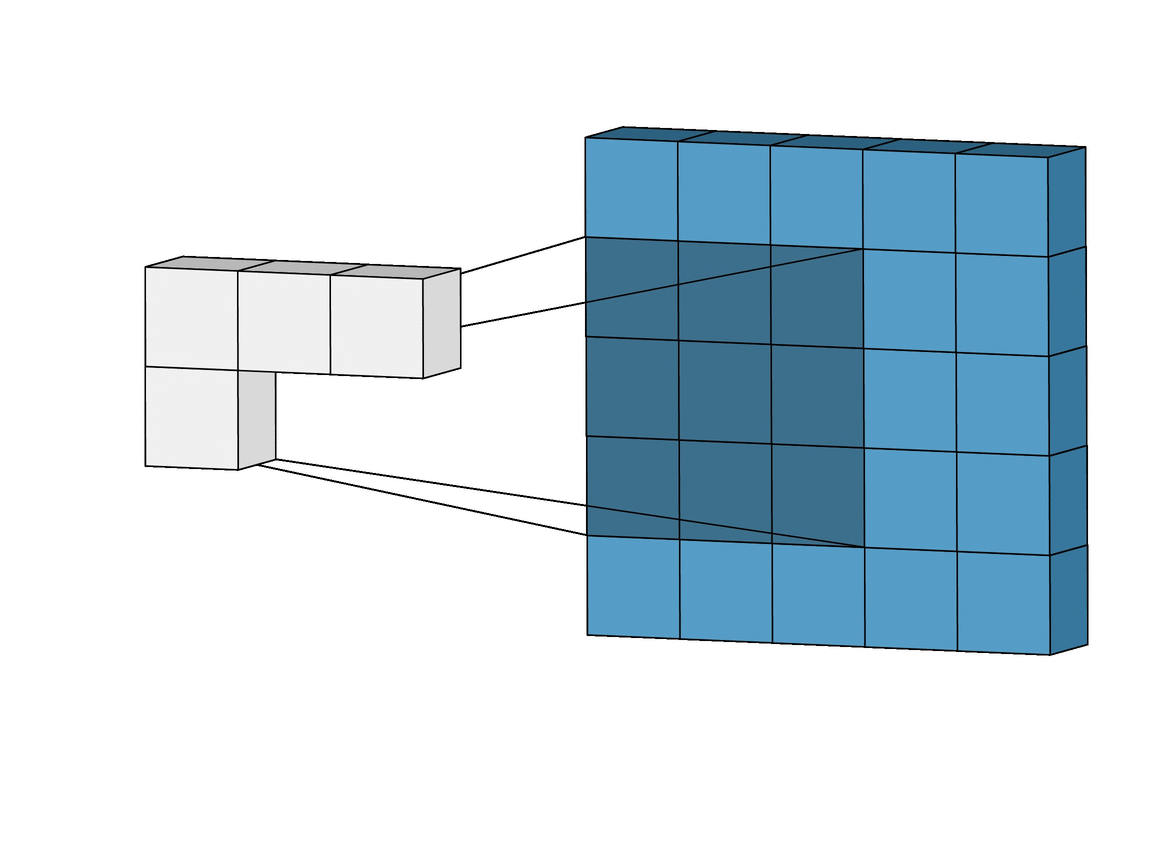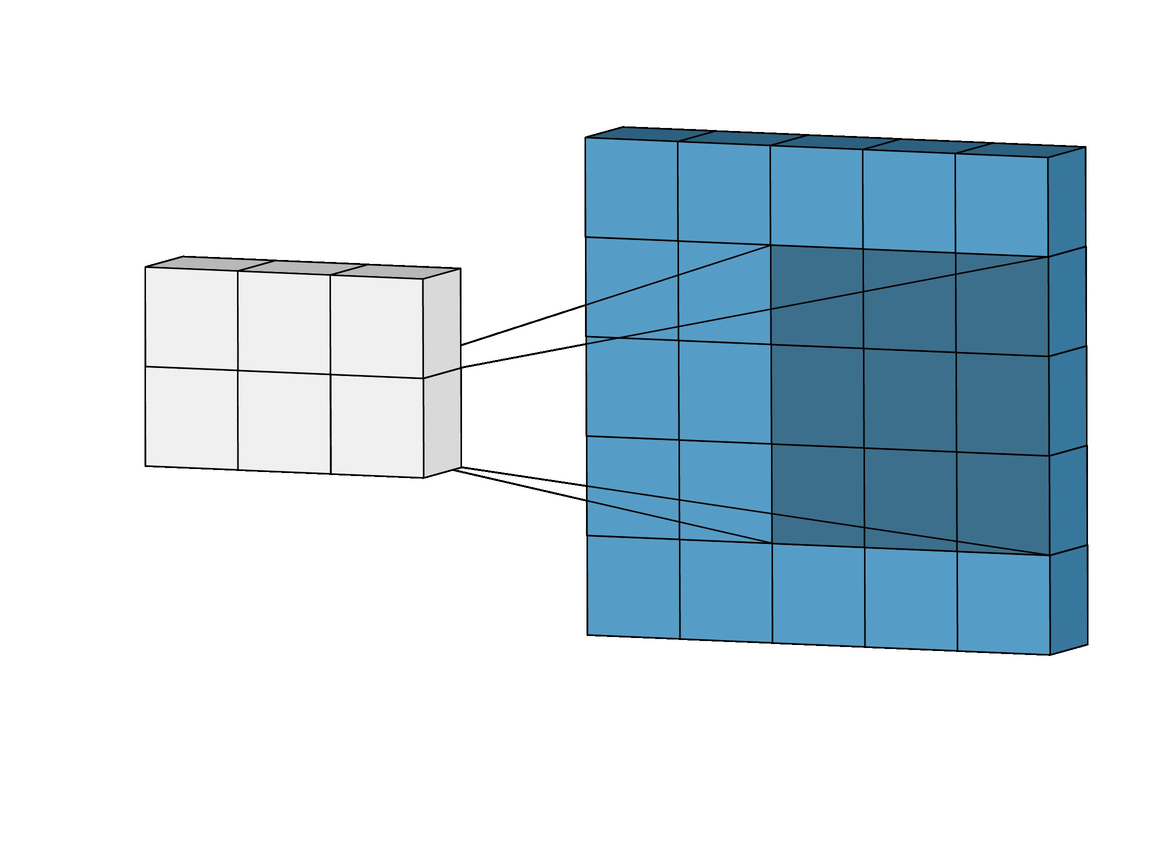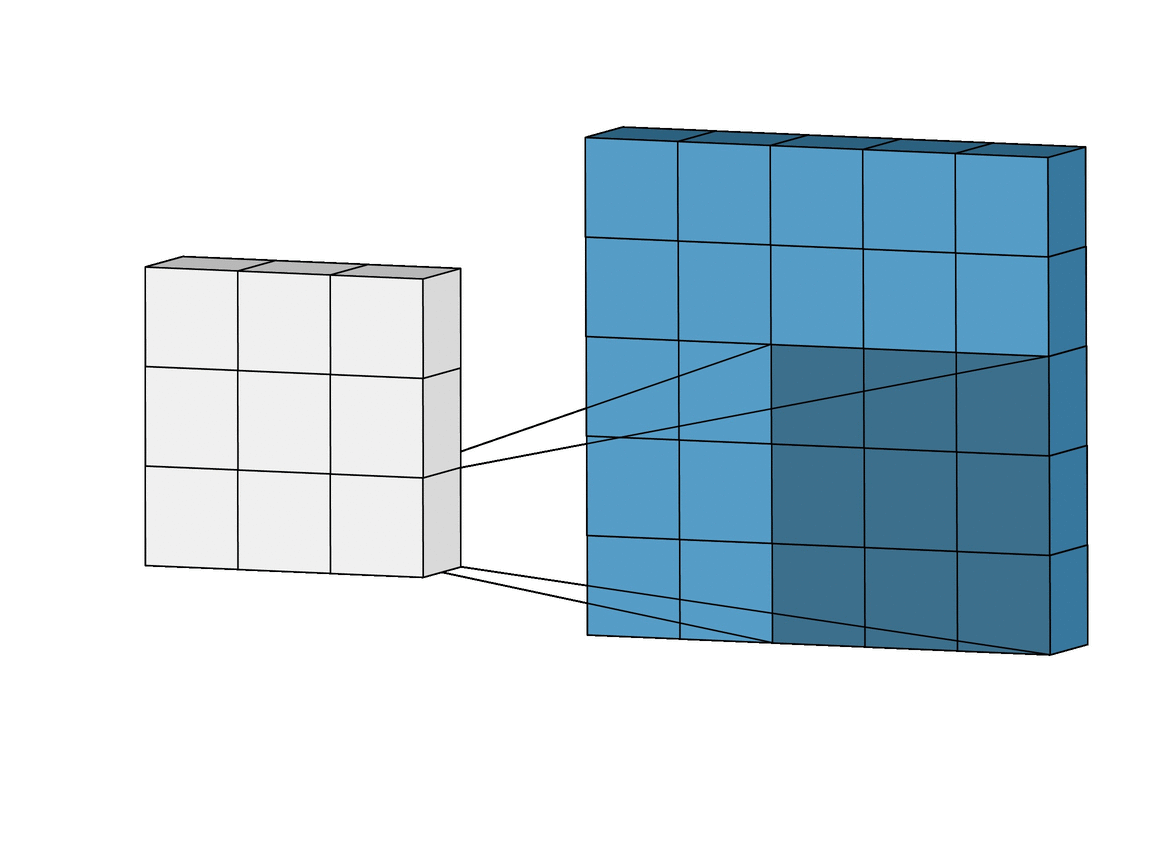
Q about layers in Conv2D layers.
The number of layers is a parameter. Firstly, say we had 3 layers which for an input pixel, returned the values 1, 2, and 3.
Does this mean that the first pixel of our output is [1, 2, 3]?
Also, what actually is the layer in a Conv2D layer? There's specific ones for detecting edges, but it doesn't seem that we specify the layer to use, so what is used?
you can watch jay alammars visualization on how convolutions work
its has some pretty good gifs there
#help-broccoli i need some help with selenium, would be very nice if someone can take a look please
Thank you
this?

AI/ML has been witnessing a rapid acceleration in model improvement in the last few years. The majority of the state-of-the-art models in the field are based on the Transformer architecture. Examples include models like BERT (which when applied to Google Search, resulted in what Google calls "one of the biggest leaps forward in the history of Se...
Can someone help me understand how they are loading the data to the model here? https://github.com/vlukiyanov/pt-avitm
GitHub
PyTorch implementation of AVITM (Autoencoding Variational Inference For Topic Models) - vlukiyanov/pt-avitm
its quite confusing for me to understand. If i understand how they are loading the data, I can load the data without the stop words and find the probability of each word. So that I can know how much of influence each word has.
just confused on which filters Conv2D layers use, because we're not specifying the matrix/filter that they use. Unless they have a list of the most common filters to detect edges
anyone know anything about data handling in machine learning
thx dude
Hey guys, all good? Does any one here knows how to customize mplfinance graph, like background color etc...?
mpf.make_mpf_style(
base_mpf_style="yahoo",
facecolor="black",
style_name="My_Style",
rc={'font.size': 12},
)
mpf.plot(df, type='candle', style='My_Style',
title='',
ylabel='',
ylabel_lower='',
volume=True,
mav=(12,26),
tight_layout=False,
# addplot=apds,
)
Does anyone know of any deeplearning datasets with information a lot of small talk tags and patterns?
why do we have to make the testing images and training images divide by 255 why cant we leave it like thaat btw new to machine learning and neural network
i mean, you can
people just tend to do that so that the pixel values will be scaled from 0-1 instead of 0-255
does that like decrease the efficeny ?
Does anyone have a good resource on GPU memory management (preferably with PyTorch)? I use a batch size which puts me just under the memory limit. I now added a parameter to allow me to skip certain operations, which should in theory use less memory, but then it gives me a CUDA out of memory error.
You're not allowed to need help. You gave that up when you became an admin.
Is supervised approach good for a time series prediction problem?
Yeah, I don't see why not. You use unsupervised when you don't have labeled data, or when you're not sure what you're looking for.
In this stock prediction problem, there is a target column "close" that needs to be predicted from training data and this column is missing from the test data.. and needs to be appended after predicting.
I'm not sure how should i choose the input variables
Does anyone know of any deeplearning datasets with information a lot of small talk tags and patterns?
Using supervised learning on time series data needs re-structuring data and i don't completely understand it..
That's the problem
the competitions on kaggle... is making the best model that achieves the task?
yo
weird question but a junior was asking me
can a machine learning engineer apply for a data scientist job
and the other way around
@upper spade of course, but the skillset isn't a 1:1 overlap
i see
depends on the specific applicant, job, and company
can a data scientist apply for a ml engineers job?
oh i see
example: an ml engineer might need to know stuff about cuda programming, but a typical data scientist doesn't or shouldn't have to worry about that in their day-to-day work
even "data scientists" vary tremendously in their skills
oh i see
a lot more variation than in software engineering i think
but that's my subjective take
its probably not true also
like, an embedded systems engineer has a wildly different skill set from a front-end web dev
they share common fundamentals, and mastery thereof gives you flexibility
data science is the same way
but at some point you're going to specialize in this or that, whether you like it or not
don't hold me accountable here, i don't know any details
if you fit the job description then you apply, if you don't fit then don't apply
i don't think it's any more complicated than that
either you know you can do the work or you don't
would you hire a frontend dev to do backend work? sure, if they had the right skills and/or you could accommodate their skill gaps until they learned
years of experience is just a signal for accumulated expertise
I'm doing a binary classification and my f1 score for my hold out is higher than my training (.98 vs .94). I don' t don't have an imbalanced dataset and I'm not aware of any feature leakage. Is graphing both classes using a box plot for each feature the best way to see if there's a feature that's distinct to one class?
no worries dude
hes just looking for a career options
fresh out of high school
I'm stuck at the formulation step
so here is what the train and test sets contain
Train set: (2017-2019)
Date, Open, High, Low, Close (Target Column), Adj Close, Volume
Test set: (2019-20)
Date, Open, High, Low
Because there's a target column i think i should go with a supervised learning model...can anyone help me with deciding the input variables for the model??
Hi, I need some help with deciding how to visualise some data. Currently this is the data frame that I have:

There are 32 different boroughs in London an I am looking for a visualisation technique that would allow for an easy see the trend for borough. I thought a line graph would be a good idea but it turned out to be an absolute mess. If anyone could help it would be appreciated
how can i run an AIML code with python at command prompt
perhaps you can change the scale of the line graph so it's easier to read?
guys, this is the best i can achieve 3200/3200 [==============================] - 798s 249ms/step - loss: 1.3253 - accuracy: 0.6762 - val_loss: 1.2971 - val_accuracy: 0.6932
Any tips to improve it a bit?
anyone recommend a good resource to learn databricks?
model = Sequential()
model.add(InputLayer(input_shape=(28, 28, 1)))
model.add(Conv2D(filters=3, kernel_size=3, strides=2, activation='relu', input_shape=(28, 28, 1)))
model.add(MaxPooling2D(pool_size=(2, 2), strides=2, padding='valid'))
model.add(Conv2D(filters=3, kernel_size=3, strides=2, padding='valid'))
model.add(MaxPooling2D(pool_size=(2, 2), strides=2, padding='valid'))
model.add(Flatten())
model.add(Dense(32, activation='relu'))
model.add(Dense(10, activation='softmax'))
I'm getting the error ValueError: Input 0 of layer conv2d is incompatible with the layer: : expected min_ndim=4, found ndim=3. Full shape received: (None, 28, 28)
Really not sure why. Using the mnist dataset and each input is a 28x28 gray-scale image. I think my input shapes are correct.
hmm - well, I just reshaped my inputs into my "supposed" correct shape. That worked.
is there any standard for the number of hidden layers in the neural network? At the moment the number of layers / type of layers isn't really informed when I make a model...
I am a beginner , what should I do learn it in better and faster way?
I am doing artificial intelligence and data science engineering
I am in first year
Can anyone guide me please?
When we are given the task of developing a "good" image recognition solution - as a study project. What does good mean? Can it be determined on the basis of accuracy? For example, if it reaches 90% or can we also use speed as a measurement criterion? How fast the software is for "n" pictures?
Is it doing multi or binary classification?
no, that's for transformers
couldn't find his video on it
Medium
Exploring the strong visual hierarchies that makes them work
thanks! 🙂
90%+ or near-SOTA
I would say 95+ for real world use
we start with a binary one
your image shape needs to have a batch size too; the shape to be expected is (batch_size, 28, 28, 1) if Grayscale. you need to pass a 4-D tensor
Doesn't keras do that for you under-the-hood anyways?
as in, add the batch_size to the shape
Hmm..some time I used convnets in Keras, but I do remember that Keras doesn't do that
the Generator you construct supplies a 4D tensor, but the input shape for first layer should be correct
otherwise it just removes the dimension, implicitly (apparently)
like he doesn't incorporate it, so either it should be in tuple, or some other external argument
# Normalize pixel values within images
image_augmentation = ImageDataGenerator(rescale=1/255)
# Training data iterator
training_data = image_augmentation.flow_from_directory(directory="../datasets/Covid19-dataset/train",
target_size=(256, 256),
class_mode="sparse",
color_mode="grayscale",
batch_size=10)
# print(np.array(training_data).shape)
# Testing data iterator
testing_data = image_augmentation.flow_from_directory(directory="../datasets/Covid19-dataset/test",
target_size=(256, 256),
class_mode="sparse",
color_mode="grayscale",
batch_size=10)
# Early stopping to reduce computation and over-fitting.
early_stopping_callback = EarlyStopping(monitor="accuracy", mode="max", patience=5)
# Create model
model = Sequential()
model.add(InputLayer(input_shape=(256, 256, 1)))
model.add(Conv2D(filters=12, kernel_size=3, strides=2, activation="relu"))
model.add(MaxPooling2D(pool_size=(3, 3), strides=2))
model.add(Conv2D(filters=8, kernel_size=2, strides=2, activation="relu"))
model.add(MaxPooling2D(pool_size=(3, 3), strides=3))
model.add(Flatten())
model.add(Dense(12, activation="relu"))
model.add(Dense(3, activation="softmax"))
model.compile(optimizer="adam", metrics=["accuracy", AUC()], loss=SparseCategoricalCrossentropy())
model.fit(training_data, validation_data=testing_data, epochs=40, callbacks=[early_stopping_callback], verbose=1)
I'm getting the error:
ValueError: No gradients provided for any variable: ['conv2d/kernel:0', 'conv2d/bias:0', 'conv2d_1/kernel:0', 'conv2d_1/bias:0', 'dense/kernel:0', 'dense/bias:0', 'dense_1/kernel:0', 'dense_1/bias:0'].```I don't know where I'm going wrong.
I read that the error arises when you don't pass in any labels. But my data iterators contain both the features and the labels...
oh... uhm, the error was here:
model.compile(optimizer="adam", metrics=["accuracy", AUC()], loss=SparseCategoricalCrossentropy())
I changed it to
model.compile(optimizer="adam", metrics=["accuracy"], loss="sparse_categorical_crossentropy")
and it worked.
Does anyone know why this is the case?
guys, how many models for average the outputs of them? like, i was willing to train different models with the same dataset, and then average the predictions
idk. The object i pass to the loss function is from keras.losses
this is how i compile
model.compile(loss=keras.losses.categorical_crossentropy,
optimizer=keras.optimizers.Adam(learning_rate=0.001),
metrics=['accuracy'])```oh, I see what I could've done wrong here
SparseCategoricalCrossentropy was imported from keras.metrics instead of keras.losses
haha! thanks for your message though, without it I wouldn't have realized
just created a model for classifying x-rays to classifying them as a result of a disease: such as covid-19, viral pnemonia, or being normal
i'm really liking ML right now, but I feel like a lot of it is an abstraction or "black-box" per-se, and that abstraction is so much greater than fullstack dev.
Hi, I am relatively new to machine learning and I'm looking to solve an optimization problem using ML
Tensorflow seems to be the most prominent of all resources, however, their tutorials mainly seem to focus on larger data like images and audio
well, ML isnt rlly a black-box. I mean, u can perfectly know whats going inside. It is just done automatically. U need some maths to understand whats going on the hidden layer, but basically is "i give u this and i want this. fit ur weights to make it happen"
the last part is all maths
I have already solved my problem by making use of an Integer Linear Programming model
look for keras examples
My issue is that all the examples have images etc.

Great, I'll have a read
Sure, you can "know" to a certain extent what's going on, but still a lot of it is abstracted and a black-box. At least for beginners like me. I'm going to look into the maths of CNNs a bit more because I had so many questions learning about em.
Like, I'm using adam's optimizer knowing the general premise and maths of gradient descent, without really knowing what it does
u can manually tho an small nn tho. Like, make a network with only 1 hidden layer of 3 neurons, and u can do it by hand
By the way, when would one choose to use solely tensorflow rather than using the tensorflow.keras library?
to expect too much from a nn like that, but u could probably calculate square roots with a nn like that
idk :) i started with keras and i use keras. But since keras is built over tf, i guess tf gives u more control of the things
i dont know cuz ive never used tf
alright, I'll just stick to keras for now and than probably find out along the way
!e ```python
import numpy as np
from collections.abc import Sequence
print(isinstance(np.arange(5), Sequence))
@desert oar :white_check_mark: Your eval job has completed with return code 0.
False

range is a generator, right?
range is its own class
i read it is a generator
it implements Iterable but not Generator or Sequence
ah, numpy arrays don't implement index or count
why the hell are those part of the core Sequence protocol?
If it's not indexable, isn't it just an iterable that isn't a sequence?
list.index returns the first index w/ the requested value
basically a linear scan for a value
oh i see, those are mixins
i thought it'd be a Sequence if it implements __getitem__ and __len__ which afaik np.ndarray does
Sequence.register(np.ndarray) fixes it
interesting, i assumed it'd use __subclasshook__ to check, but i guess they just use abc registration
why is it ndarray, anyway? is this a relic of an older system? (as opposed to just array)
"n-dimensional array"
ndarray is the type, array is the top-level function that constructs them
yeah but aren't vectors and matrices just arrays with exactly one or two dimensions, respectively?
why treat them differently?
wdym? np.matrix has been deprecated for years
so yes they are just arrays
and no they aren't treated differently
so my question is, why isn't the class just named array, since vectors and matrices are just names for specific cases of arrays?
given that np.matrix is deprecated, my assumption is that vectors, matrices, and arrays with >=3 dimensions used to be treated differently, and that design was deprecated.
no they weren't, afaik
np.matrix was some kind of convenience layer over np.ndarray
the "n" in "n-dimensional" could always be 0, 1, or 2 🙂
as well as 3+
or like, 42, yes?
!e ```python
import numpy as np
x = np.arange(42).reshape((-1, 42))
print(x.shape)
@desert oar :white_check_mark: Your eval job has completed with return code 0.
(1, 42)
!e ```python
import numpy as np
x = np.arange(42).reshape((*(-1 for _ in range(41)), 1))
print(x.shape)
@desert oar :x: Your eval job has completed with return code 1.
001 | Traceback (most recent call last):
002 | File "<string>", line 2, in <module>
003 | ValueError: maximum supported dimension for an ndarray is 32, found 42
I just found that out as well and my day is permanently ruined.
granted I've never legitimately wanted more than four dimensions.
same
can a cubic array have a determinant? 😮
why not? :D
do u know what a determinant is? it is actually all sort of products
i guess on 3D it can happen too lel
huh, now that i read the definition, i dont think so
I'd assume it's possible
to get better results, i may use albumentations on the train, train different models, and do TTA?
i dont think so
I can think of a way to determinant a 3D.
to get up there, first, baby steps
The only 1d matrix you can determinant is a... 1 sized matrix
det([2]) = 2
it exists for n=1; therefore we can assume it exists for n=k.
2d, 2x2:
| 2 1 |
| 1 0 | = 2*0 - 1*1 = 1
there it's clear which way to do operations, ad-bc
2d, 3x3:
| 1 1 2 | = 1*(1*1-4*10) - \
| 0 1 4 | 1*(0*1-4*3) + \
| 3 1 1 | 2*(0*1-3*1) = -33
here we have a clear +i -j +k alternating pattern at the top, and each number at the top multiply by the determinant of the matrix not covered by covering the row and column of the current number at the top.
This is a recursive algorithm, allowing this to happen for nxn sixed squares.
but can we do 3D?
2x2x2
A = [[2 1] [0 1];
[1 1] [4 3]]
so which way's the top?
we'll assume the left side of the above is the "front", hence top view:
_Top_ Under
[0 1] [4 3]
[2 1] [1 1]
Now that my head is wrapped around three dimensions,
det(A) = 0*1-1*1-2*3+1*4 = -3
this time, the top square
[ i j ]
[k l ]
was multiplied by the underneath submatrices (1x1)
[m n]
[o p]
like such:
i*p - j*o - k*n + l*m
following the alternating signs pattern:
[+ -]
[- +]
3x3 would start off looking like this:
A = [[1 1 1] [2 1 2] [0 3 0];
[4 1 2] [0 0 1] [4 1 1];
[1 2 1] [1 1 5] [3 2 3]] %this is gonna be a lot of math
top = [[1 1 1] % + - +
[2 1 2] % - + -
[0 3 0]]% + - +
det(A) = 1*det([[0 1],[1 1];[1 5],[2 3]]) - 1*det(...) + ... % yeah too much math for this early in the morning
Theoretically it's also possible in 4D
In which case the "top" is a cube
2x2x2x2
A(:,:,:,1) = [[1 1] [1 2];
[3 1] [3 3]] % "top" cube
A(:,:,:,2) = [[5 3] [0 0];
[4 0] [1 2]]
det(A) = 1*2 - 1*1 - 3*0 + 1*0 - 1*0 + 2*4 + 3*3 - 3*5
= 0
I am not gonna even try 3x3x3x3
TL;DR any s**(n dimensions) matrix has a determinant
I...don't think so?
like one of the properties of the matrix determinant is that it is nonzero if and only if the matrix is invertible
and I think if you wanted to generalise that concept, you'd need to define the analogue of matrix inversion, and therefore matrix multiplication, for 3D and above arrays
I haven't heard of anything that lets a 3D matrix-equivalent exist in its own right, as opposed to a stack of identically-sized matrices
but I'm not a mathematician @ all so YMMV
by matrix inverse you mean like
A*A¯¹ = I
?
multiplication in higher dimensions should be possible, it's just a lot of dot products
so we define the 3D identity in 2x2x2 as
I₂³ = [[1 0] [0 0];
[0 0] [0 1]]
and 3x3x3 as
I₃³ = [[1 0 0] [0 0 0] [0 0 0];
[0 0 0] [0 1 0] [0 0 0];
[0 0 0] [0 0 0] [0 0 1]]
Just for bonus,
4d 3x3x3x3 sparse Identity matrix
I₃⁴(:,:,:,1) = [[1 0 0] [0 0 0] [0 0 0];
[0 0 0] [0 0 0] [0 0 0];
[0 0 0] [0 0 0] [0 0 0]]
I₃⁴(:,:,:,2) = [[0 0 0] [0 0 0] [0 0 0];
[0 0 0] [0 1 0] [0 0 0];
[0 0 0] [0 0 0] [0 0 0]]
I₃⁴(:,:,:,3) = [[0 0 0] [0 0 0] [0 0 0];
[0 0 0] [0 0 0] [0 0 0];
[0 0 0] [0 0 0] [0 0 1]]
yes
matrix multiplication.
We're only interested in cubics (and tesseracts) as they have identities, but we might show a few skinny matricies this time around
Let's build up from basics again
[2]*[3] = [6]
[2, 2, 2]*[3; 3; 3] = 18
[2 2] * [3 3] x
[2 2; * [4; = [2*4 + 2*1; = [8;
1 2] 1] 1*4 + 2*1] 6]
so how do we do 3D?
let's throw some 1s behind that last example
i'll change the 3d notation a little, to have less brackets
[2 2, 1 1; * [4, 1; = ?
1 2, 1 1] 1, 1]
so how would you go about it?
it would be a 1x2x2, as
2x2x2 * 1x2x2
multiplying a 2d matrix boils down to vector products, there's no reason 3d would be a any different
i'm gonna say
[2*4 + 1*1, 1*1 + 1*1;
1*4 + 2*1, 1*1 + 1*1]
thus
[2 2, 1 1; * [4, 1; = [7, 2;
1 2, 1 1] 1, 1] 6, 2]
numpy can do it
https://www.geeksforgeeks.org/numpy-3d-matrix-multiplication/

GeeksforGeeks
A Computer Science portal for geeks. It contains well written, well thought and well explained computer science and programming articles, quizzes and practice/competitive programming/company interview Questions.
so how it's done there i need coffee
did someone say coffee 
also matrix multiplication is cool stuff
thanks for the mini-lesson

as long as i never have to do it by hand again i will be satisfied 
do you need to study linear algebra to understand matrices right?
i dont suppose anyone in here is good with matplotlib and keen on helping a little bit?
Go ahead and ask your question. Even if there's someone around who knows about matplotlib, they would first have to know the question.
(And someone who doesn't think they know matplotlib might still be able to help somehow)
you can learn basic matrix and vector math without really knowing linear algebra, but you won't really understand why anything is the way it is without knowing linear algebra
I was taking linear algebra when covid started and everything after the determinant is a blur. What even is linalg if not matrices?
linear transformations, ultimately
fine, my linear algebra book really worth 30 BRL which is 6 USD I guess 🙏🏽
you can do linear algebra without ever doing matrix arithmetic
A blog about math by Nic Ford
a matrix an unambiguous way to represent a linear transformation for a particular choice of basis
btw, calculus 2 too? I finished calculus 1 (in brazil is limits, derivatives and integrals), starting LA but idk if Calculus 2 is really necessary
what is calculus 2?
give me a second just to see the book
Differential equations, parametric equations and polar coordinates, infinite and finite series, vectors, vector function, parcial derivative, multiple integrals, vetorial calculus and 2nd order differential equations
idk if this is the correct translation, sorry
maybe I need to ping you idk
linalg is, as far as i know, a library of maple XD
I attempted calc 2 at two different institutions, and there were a few differences, but it was mostly integration and sequences and series.
apparently brazilian calc 2 is quite different!
but yeah that was mine too
i guess that's the north american way
i did integration and fourier on calc 3 lel
fourier is calc 3 here too
The syllabus also had parametric equations and polar coordinates, but my section was fucked and it took forever to teach us the other things I mentioned
hmm so to AI I just need calc 1?
u need algebra
it is that easy? 
i'm working on it
I would plan to get linear algebra and statistics in there. I wish I had taken a better statistics class.
then thats all. u may need differentiation but nothing that hard
why you don't try to learn by yourself?
diff eq - mostly not relevant in day-to-day work
parametric equations and polar coordinates - mostly not relevant in day-to-day work
infinite and finite series - foundational to pretty much all "interesting" math, you need this
vectors, vector function - necessary
partial derivative - necessary
multiple integrals - necessary for probability and stats
vector calculus - gradient and hessian is necessary, the rest is not relevant in day-to-day work
I do.
thanks lamp
oh nice
python for AI is hardcore?
the growth of a population is modelated with diff eqs
for example
rabits and foxes :D
u dont want infinite rabbits, but u also dont want 0 rabbits xD
@cedar sun right, i should have clarified that this is "day-to-day work on typical prediction problems"
ah okey uwu
parametric functions might also be very useful in some specific fields
ye ye, on ML world not very relevant
interesting that they teach integrals before sequences and series
hmm wait
integrals before fourier. the SUM of expo series, geometrics, etc, are on calc 2
before integration
at least where i live
I know riemann and Arithmetic/geometric progreesion if is just this
maclaurin and taylor too
some projects ideas for data science/data engineering ?
i am currently doing a loan_status_problem
wherein i have to train a model
with a dataset and then predict whether a certain profile will have its loan request rejected or accepted
but i have used train_test_split whenever i have done analysis like this
now since i have two different files for training and testing data
i don't know how the code should be


these photos are in order
this is the link to the notebook

Explore and run machine learning code with Kaggle Notebooks | Using data from Loan Prediction Problem Dataset
could anyone help why does its fall to 62,62 after 64,64

2 questions related to data science from a 14 year old:-
1- Do i need to study DSA for data science or it will be helpful
2- Will data Scientist's job will be extinct till 2030
- Not really 2. Kinda, it will be merged with general software engineering
i disagree strongly about 2
Question regarding image processing:
How do I selectively pre-process the images? How will my code know if the image needs to be processed or not?
I am doing text detection
Hi, I had a question for anyone that can help me with image colorization using deep learning. I am helping a friend with a project and he wants the implementation using tensorflow
I have a model but the results aren't as good as I would like. I am not sure if it's my data, model or etc.
If anyone has suggestions, please ping me
Rule of thumb: it's the data!
alright, any recommendations on the data I should use


this is the output of the model
What is it trained on? (I don't have any image colorization experience)
a random dataset that I found of random rgb pictures
I then convert the RGB to LAB and then extract L and predict ab.
what are the common ways to ensemble nns?
For 2, I am of the strong opinion - yes. ultimately, software written has gone down, only to glue up pre-existing services for applications. So has quite a lot of CS jobs (especially in 3rd world countries).
I am of the opinion that programming is the low hanging fruit of automation - simple functions that are efficient can be used to build a large variety of applications; and applications can easily be tested what's lacking and whether it runs at all/works efficiently. SWE is gonna be extinct sooner or later, as well as Data science which is already just done by AutoML (you would do data cleaning and engineering most of the time).
You can check out DreamCoder which is a pretty interesting (new) paper about having neurally guided search to build a library of primitives to solve applications. its fascinating how with its Dream and Wake cycles, such a primitive method is able to solve medium-complexity problems - and it hasn't been scaled yet, like GPT3 was in NLP
Many people don't realize how simple their jobs are, until they are automated. A big example is self-driving cars. No one could have thought that cars would be navigate the complex environment that we all thought only a human could. Now we know its not the case. Same with DS/SWE


I don't know whether this is the right channel to ask
I am trying to implement Stereo Rectification
I don't know how to rotate a 2D image in 3D
given a 3D rotation matrix

I tried using the rotation matrix Rz as a Homography for
cos_theta = np.sqrt(3) / 2 # theta=30 deg
sin_theta = 0.5
rotate_z = np.array([[cos_theta, -sin_theta, 0], [sin_theta, cos_theta, 0], [0, 0, 1]])
warped = cv.warpPerspective(pool_img, rotate_z, pool_img.shape[1::-1])
But the result looks weird
This is the result

This is the original image

Hey,
Please how to add a row in matrice class in python
Maybe you're looking for
np.vstack
a = np.array([[1,2,3],[4,5,6]])
np.vstack((a,[7,8,9])

Yup
you can simply append a row
a : List[List[int]] = [[1,2,3],[4,5,6]].append([7,8,9])
i want to build a ai chatbot (open source or from scratch, but i choose open source) with the help of rasa
but after i installing rasa module using pip install rasa, i cant run rasa commands in my terminal
Just had to ask, the results given by USE are all normalized, right?
me ?
just a general question, my bad
oh kk
try python -m rasa
oh ok
i am not on my linux machine atm
can i tell u the results in some time
@austere swift i am getting this
No module named rasa
Hello, everyone. I loaded an image dataset using the tf.keras.preprocessing.image_dataset_from_directory class. Now I'm trying to view some images from the train dataset generated but it's not working. I used the take method from image_dataset_from_directory but it's not working.
I have 2 classes and I want to view like 2 images each from the classes folders' using matplotlib pyolot. Thanks.

just browse r/machinelearning everyday and read papers which you find interesting
https://papers.labml.ai/papers/recent/ is also great for seeing the most famous papers
Find latest and trending machine learning papers
Lots of parts automated away != extinct. DS is surely going to change, but I see no possibility that the need to understand data, statistics, modeling will be gone in 10 years or that it will be subsumed into general SWE
ds will just spend less time doing stupid bullshit and more time solving problems
"analytics guy wants you to predict Y by 5 pm"
"nope sorry ask the robot to do it"
Hello, I was learning about bias and variance. And according to most articles on the web, "high error on test set is a sign of high variance", also the definition of variance is more or less : "a measure of how far off each prediction is from the average of all predictions for that testing set record." So, can it ever be that the test set error is high but the variance turns out to be low?
imagine you re-ran your train/test split 1000 times, and did your fit-and-score procedure on each of those splits. the "variance" is the variance of those scores
as for the statement, high error on the test set could mean either high bias or high variance
https://en.wikipedia.org/wiki/Bias–variance_tradeoff#Bias–variance_decomposition_of_mean_squared_error this might be enlightening
ohh
thanks
Hi, I had a question for anyone that can help me with image colorization using deep learning. I am helping a friend with a project and he wants the implementation using tensorflow
I have a model but the results aren't as good as I would like. I am not sure if it's my data, model or etc.
If anyone has suggestions, please ping me
does anyone know how i can sum all under the curve of type 1?

Z-score normalization is also known as standardization?!
you are standardizing the data

this allows you to compare different distributions
even if they have start with different numbers
standardizing or normalizing allows you to do this
so, standardization can be an umbrella term for normalization? It's just normalization if it falls within the range 0-1?
how would you say it?
is this correct x = np.linspace(0,4,100) print(np.sum(x))
why does one-hot-encoding have to be on a 2D array, instead of a 1D array?
it's not really normalization at all
"normalization" usually implies scaling to unit norm, or sometimes is misused to imply scaling to [0,1]
standardization is a much more correct term for centering around the mean and scaling by standard deviation
it's the same "standardization" as in "standard normal"
statistics terminology sucks
have u ever used albumentations?
if so, for this method
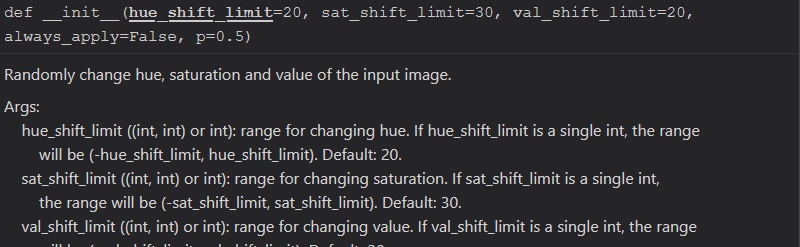
What is the hue limit XD
i mean, hue goes from 0 to 360?
or what?
docs do not say anything
Anyone got some good things to read as sort of a starting thing? I understand the basics of AI with Q-Learning and the Bellman equation and what not, but there's a lot of things that try to explain other stuff and it just makes me more confused
Let's say I'm trying to classify credit card fraud.
My training data consists of 80% non-fraudulent transactions, and 20% fraudulent transactions.
Wouldn't that mean that my model is "better" at classifying non-fraudulent transactions rather than fraudulent transactions?
If so, how can I fix this?
Should I be looking for a 50:50 split between classes to remove this bias or am I completely wrong?
I used codecademy for learning about ML, going along with the projects. I also quite often found myself reading blog posts on https://machinelearningmastery.com/ and watching youtube videos here and there.
Just focus on one algorithm at a time, make some notes while you go through and you should be good!

It's only codecademy pro that has ML though right?
But I do think now I need to go back and delve into the maths aspect a bit more
yeah, I can give you an account to borrow
Nah it's all good, I'll try the free trial of it and see how it is
Hi all 🖖🏻
hiya 🙂
that's because programming itself would be largely automated.
You misunderstand - I don't speak of a world where there are no programmers, just that a large part of it automated heavily leading to smaller teams (+++ profit for companies) and lesser available jobs
That is a big reality - if more parts of your job are being automated, and an intern can call the same model.fit with similar results or upload data to AutoML, why would they pay you so much for doing statistics work that can be automated?
Auto-EDA tools produce far better graphs and visualizations. And programming itself is going to be automated. its not a "gambling" level prediction, but an educated one. If we do come close to replicating AGI (which we will) CS/Programming would be the first thing to be automated
hey guys i have 2 dataframes a and b with the column date in each of them: so i want to merge both dataframes with a key but also with the date column: so the date of column "a" should has the closest date of column b
I agree that there will be many things that will be automated away and that people are generally bad at identifying what parts of their job are in for automation. I also agree that we will need fewer people and the skill level to be in the game will be much higher.
On the other hand, you seem to be conflating programmers and data scientists, conflating statistics and the model search that AutoML does, and vastly underestimating the timescales.
But, yes, if your value is fully replaceable by an intern calling model.fit, your job is going away.
On the other hand, you seem to be conflating programmers and data scientists, conflating statistics and the model search that AutoML does, and vastly underestimating the timescales.
Well, then give me an example of a task a normal data scientist does in a company (most of the times) that can't be replaced/made easier by automation?
on what timescale?
🤔 ...any, I guess?
Properly interpreting and explaining the results to people
Also replaced and made easier are VERY different
and why can't that be automated, if I may ask?
Everything will be made easier. Some things won't be entirely replaced
I don't see how hard its for an analyst to interpret a decision trees
you guys don't do model.fit? damn, I have a long way to go
this is a silly argument, it applies to literally all work anywhere ever performed by humans or beasts
the question should be: what can we reasonably expect will be fully automated by 2030 (as in the original question)
and the answer is: some of the day-to-day drudgery, not the actual hard stuff
with a decent enough AI? the whole job id expect
(unless you guys would be retiring by then, which is from a different perspective)
this
timescale obviously matters
I am talking about pretty intelligent AGI by 2030
lol there's no way you will have "pretty intelligent" AGI by 2030
there is no principled reason AI cannot surpass humanity
the way research ramps up? funding?
this seems kinda unrealistic to me
I can quote about a million researchers whose timescales are in decades
unless there's some kind of super amazing unprecedented moonshot project
HTM 😏
I may be doing quite conflation. and humans have been know to incorrectly predict
but
you know how the manhattan project was an amazing scientific achievement? it took 1000s of scientists untold thousands of hours over several years. but you know what? the underlying principles were gradually in development over decades prior
there is not a single major scientific advancement that did not have decades of precedent and/or took decades to materialize
Google is getting on Neurologically similar models too, so has all major institutions too (MIT/CSAIL/FAIR/MS). It has already demonstrated remarkable similarity to human brains
by 2050, maybe we could be seeing some really cool AI shit
lol that's what they said about perceptrons in the '50s
we don't know shit about brains
we do lol
we know more about neural networks than brains
that's what literally every DS person says on the net
well, it depends on what we’re talking about, right
the basic physical mechanisms are fairly well mapped
just because its not heavily researched into, doesn't mean we don't know much about it
yeah, only we need a unifying framework - like relativity
anyway: by 2030, i think there will be much more significant efficiency gains to be made due to better project management, better tooling, better/bigger/faster computers, and 10 more years of lessons learned, than due to automation of high-level knowledge work
and HTMs ticks all the boxes, so its close
see
Numenta and a lot of other insititutions were doing small baby steps; just like in old DL
computer vision and related fields will continue to improve, i predict we will have a war fought entirely by drone before data science is fully automated
it wasn't uptil a lot of companies got interested, then we started to see autoencoders, and all the RL +cool shit we see today in AI
in 5 years, we have taken unprecented huge leaps in DL
unless we don't
right now, every AI researcher knows they are f*ked, if imma be frank
because DL can't go much futher
you can't get from a universal approximator to high level thinking
Hello, you can make a python online tool?
...and that's entirely unrelated to the automation of professional data science
so they need an alternative theory framework - that's neurologically similar models. as more people come - the more growth we gonna see. its always played out in history, and it will play out again
but you predict that this will happen by 2030?
that's basically a black swan event in science
deep learning wasn't even a "revolution" as such, a few researchers figured out some new shit and computers got good
everything else was a corollary
but it all depends on how popularized its gonna be
and right now, its aleady becoming HUGE
also i don't think DL is hitting its limits, maybe in computer vision it is
but computation will continue to get cheaper and it will start finding its way into a wider range of tasks
Function approximators in the end
yield nothing to any higher level thinking
but there's a lot of function approximation left to do
yes
care to elaborate on this
man I’ve been away from ML for too long
I would like to become an MLE again
if you take 2 minutes and think about all the things you can do, and what DL can't you know how far we are
it’s been almost 2 years
i think the idea (and i am tempted to agree) is that the human mind is probably a lot more complicated than "a function" so a "universal function approxmator" can only do so much to emulate human-like intelligence
idk, AI has never been about just training a neural network
its a shitton more complicated, that's for sure
simple example
I would say it’s more a question of whether it’s the right abstraction
everything is a function if you scale up enough
well maybe it's a relation, maybe the brain is fundamentally nondeterministic
yeah
any idiom I give you would not be parsed literally - like its "raining cats and dogs". it would be a refernce frame to memories and emotioons of a wet day
I was about to add that caveat
its not even static
the structure
right
as opposed to the original DL hypothesis
all this is precisely why i am not expecting the next big revolution in the next 10 years
too much foundational work doesn't exist
well, that would be a parameter of the hypothetical function too
because you are in the wrong theory - that DL would work
no?
you know what
this is both easily falsifiable and unprovable
like
i agree that DL alone will not beget AGI
we’ll see in 10 years.
I mean - we can do soo much more as humans that's more than functions.
for example
There's someone who's a programor?
well, one of the biggest example is our learning capability. A 5-year old know a lot about the world - it knows how balls bounce, how to manipulate them, learn new thing quickly, how to adjust with different situations, etc. its not just multi-modal. our brain can do so many tasks in parallel that mix CV/NLP/RL, process so much information at a time and understand things from an extremely complicated environment whose aim is to not just survive.
our consciousness itself is dervied from our intelligence. the ability to think philosphically, to intuit towards tasks is really not a function.
how it is not a function?
making your brain a function serves as a very raw representation.
as a pure abstraction
everything you do is a function of immediate input and wider context
how good is ensembling models?
DL doesn't understand anything, only a statistical technique that produces statistically closer results
does it matter?
the nature of understanding is philosphical
yes, it does matter
its not really
its as scientific as newton's laws
it’s epistemology
which is philosophical
unless we have differing definitions of understanding
intelligence and consciousness are just byproducts of our brain, an illusion that can quickly perceive our environment
do we, as humans?
yes
it’s not something that is falsifiable
if you read any literary work, you'd be surprised
and therefore is not scientific
of how much work and intelligence goes behind poetry for instance
uh
I’m not really sure what you’re insinuating here…?
it was more meant to be put at a /s
my point is this
the point being the high level thinking we do can't be replicated as a function
“understanding” is not falsifiable because actual comprehension cannot be distinguished empirically from being sufficiently good @ faking it
and the scientific method is premised upon falsifiability
anyone know why my DataFrame.groupby() call is returning another dataframe instead of a groupby object? docs say it should and so does most stuff on the internet, but for some reason i get a df
therefore it doesn’t matter if an AI “truly” understands like we think we do or seems like it
show your code
as long as it produces the right responses, it can be said to understand the problem
literally just this result = df.groupby(['shape', 'dev_fac', 'spd_fac']).agg({'time':['mean', 'std'], 'deviation':['mean', 'std']})
but that's not true AI then. something that is not conscious can't replace use at all
you have .agg at the end
that means “perform these aggregations”
why not?
or rather
replace in what sense?
in the full sense, to create another human in short
ok yeah that was dumb, thanks
it can't be put as a sum of many actions under a fn if the function itself doesn't exist
yw 👋
our brain is a prime testimony of that
every prediction (assuming the universe is deterministic) can be cast as a function of present and past
bold assumption
in this specific case, of immediate real-world context and memory