#data-science-and-ml
1 messages · Page 318 of 1
and for each sample
multiple readings are taken over time
so you have an array of shape (n_patients, n_reading_types, n_timesteps)
such that the data pertinent to any single patient
is a 2D array
representing readings over time
yup
TimeDistributed
is something that helps you work with timesteps
or something analogous
it applies a layer
across each of the time steps?
to each timestep (slice in the 2nd dimension)
wait so
it assumes
data is formatted like so?
like the 2nd dim is always the time step?
yes
hey im new and i wanted to test something i made up in 1 and a half hours
what happens when theres a 3rd dim?
Every input should be at least 3D, and the dimension of index one of the first input will be considered to be the temporal dimension.
there has to be, right
no like for a single sample

if someone's on pc can you test pls im sure its not a virus or anything it just redirects you to google with youtube link (3)
what happens if you apply 2D convolution to a 3D sample (image)
vs a 4D sample (video)?
same concept here
try it 🙂
How to implement backward pass in relu
hey, i am stuck scraping something using xpath, can anyone helo me out
yo yo yo
Has anyone here worked with python-aiml?
Guys, do anyone have any ideas on how to predict the right candidate's for a job? I have a previous data-set of previous job postings, and people who got selected/rejected and their skills, location, experience etc... I'd appreciate any ideas on how to do this.
I recommend you don't do it on your own, if you are actually going to use it in production
Oh, I'm assigned to work on this use-case. Any reason for saying this?
because its probably going to be biased
True...
so I'm working on face detection using the face_recognition python library, I'd like some tips on what some changes might do to the algorithm.
https://colab.research.google.com/drive/1n5m_ptYS86R5oYjOjaE7-FPCn2T-S841?usp=sharing
this is the link, I've left instructions to run on the notebook.

I was wondering if I should add the matched faces from the unidentified test group into the training data later.
if the encodings of the test data faces are unique, they could be added to the face_encoding list and perhaps improve accuracy the more matches it gets.
I'm using scipy.optimize.least_squares() to fit function variables based on measured data. Unfortunately it seems like my function is sensitive to initial values and choosing the wrong ones can make or break the fitting. I could loop over a TON of initial values and see which work and which don't, but it might take days to run. Is there a clever way of finding the global minimum using that method if I know the bounds of the variables?
Hello, I'm trying to use mediapipe for hand tracking but it's raising this error that I'm not sure how to solve: WARNING: Logging before InitGoogleLogging() is written to STDERR W20210608 18:19:09.910010 8004 tflite_model_loader.cc:32] Trying to resolve path manually as GetResourceContents failed: ; Can't find file: mediapipe/modules/palm_detection/palm_detection.tflite INFO: Created TensorFlow Lite XNNPACK delegate for CPU. W20210608 18:19:09.924013 7944 tflite_model_loader.cc:32] Trying to resolve path manually as GetResourceContents failed: ; Can't find file: mediapipe/modules/hand_landmark/hand_landmark.tflite I'm using pipenv and I checked the path it's raising error for, the file is there

AIML files anyone?
when using a pre trained model, should u use the preprocess_input function of that model?
Generally preprocessing should be considered part of the model
But it might not be relevant in any particular specific situation
i mean, that function exists cuz the model has been trained with data like that, right?
like, this may make sense for me
i was having an issue where resnet wasnt increasing accuracy. I read docs and reset wants BGR values between 0-255
i was giving BGR 0-1
so all picture were black for it
i think it should still train and increase acc, but slower than if i give the correct values for inputs
Hello everyone,
I have a few basic questions regarding inputs for (deep) Q-Learning. Let's assume I want to train an agent on a 2D game like pacman.
The agent needs the actual score and the frame (2d array) of the game right? Has someone a minimal example how this frame could look like? If this game has 30 fps, how many frames do you process?
Could the array look like:
|0000000000|
|0000000100|
| 0002000100 |
|---|
Where 2 is the player, 1 is an object (that leads to a game over). The 0 are basically fillers
wouldn't it be better to just input the position of the pacman?
rather than giving it an image
Like the coordinates of the pacman and the objects?
yes
so like player[0][1] and object [0][5]?
Yeah this sounds way more perfomant
So all I need is the player state, the collision objects and the score right?
Anyone here have experience or interested in OpenCV/Tensorflow image processing, such as fixing white balance, contrast, sharpening, etc.? I'm looking for someone to partner up with for a project
Is there a github repository?
Would this be a good place for a pandas question?
hi. i am trying to install pytorch but it wont work
its telling me to run that command

but
ERROR: Could not find a version that satisfies the requirement torch==1.8.1+cu111 (from versions: 0.1.2, 0.1.2.post1, 0.1.2.post2)
ERROR: No matching distribution found for torch==1.8.1+cu111
i get this error
and this warning
do you have 64 bit python
if you start up the repl it'll tell you
you need 64
I've got the below code:
buyouts is a sorted pandas series of floats. I want to take at least the 1st 15% of elements from the series, up to 30% - stopping if there is a 20% jump in value.
It looks gross but works - but surely there is a better way? haha
for _index, _buyout in enumerate(buyouts):
if (
_index <= num_buyouts * 0.15
or (_index <= num_buyouts * 0.3 and _buyout < buyouts.iloc[_index - 1] * 1.2)
):
filtered_buyout_count += 1
else:
break
RoCm still isn't on windows?
if there's a 20% jump between consecutive elements, or between the first and current element?
consecutive
one moment
experimenting with pct_change atm but I am relatively new to pandas heh
Yes but it's pretty much empty, just starting with it
series.pct_change() > .2 will tell you when there's an increase greater than 20%
but I'm not sure how to drop all the values after the first True.
Go ahead and share the repo
I used a multi-layer perceptron classifier to investigate data about a machine breaking. It classified between "break" and "no break"
These were the results:

So because the precision and recall are basically 50/50 for machines 1-3, I've said that the model is only as good as a coin at predicting whether a machine breaks or not
Database may be too small
But for data from the fourth machine, it looks like it's worse at predicting whether the machine breaks. Couldn't you say that you could ignore what the model is saying and therefore it's actually an ok predictor of whether machine 4 breaks?
Database had like 2000 rows
It might just be that the input parameters did not correlate to whether a break happened or not, that's fine
Just wondering about the above is all
nope
i don't even think theres a plan to port it to windows
I'm learning AI too and I need help cus BOT all the time closing my ticket
Is there an easy way to make muliplie object detection and localization using my camera, with keras model and opencv?
I'm not sure what should I do next and how... https://github.com/CresixU/Machine-Learning/blob/main/cam.py
It's private
You can't recruit for closed-source projects here. Sorry!
when you report data like this, you should also include the number of records from each machine
you might as well include the accuracy too, it's not a proper scoring rule but it's intuitive
also yes i think it's safe to say that, on the instances where the machine is broken, the model is no better than random guessing. but keep in mind that neither precision nor recall takes the "no" cases into account
precision/recall/f1 are great, but they don't tell the full story
these model results would have different interpretations depending on the rarity of each machine breaking
Oh as in what percentage of the times does the machine break?
I should find that out actually, yeah. Let me do so
@desert oar So i've got this:

So this is the percentage of times that it either broke or did not break
basically they're all breaking around a third of the time
and you trained the model 4 separate times, once on each machine?
ok, so that is 4 separate models
yeah
so... ideally you'd apply some kind of probability calibration to the model (like temperature scailng) and then evaluate the model using a proper scoring rule
but for now you can at least look at the accuracy; for example, you should be able to get 62% accuracy on machine 1 by always guessing "no break". so if your accuracy is lower than that, your model is worse than guessing
recall of 0.50 means that, in the cases where the machine did break, you predicted that it breaks half the time
so yes, in that subset of cases, your model is no better than flipping a coin
So if my model's purpose was to be able to predict when a break happen and then run some code to contact someone to fix it, it would be no better at flipping a coin?
wait no
not necessarily! it might be worse 😛
oh that's even better
as long as it's not a good model that's fine
my conclusion was essentially "this data doesn't correlate to whether breaks happen or not"
So say it had a recall of 10%
That's pretty terrible
But you could ignore what the model says right? In the case of a classification problem
Thereby kind of making it a good model no?
you can say that half of the model predictions would be wrong, and the model would miss half of the cases where the machine is going to break
i wouldn't say "doesn't correlate" - you could use actual correlation for that
but correlation is valid to compute on binary data and it could be a good idea to compute it here
not sure what you mean by this, if you're ignoring the model then why have a model?
or are you saying that you can just flip the model predictions and then have 90% recall
oh I put it through a regressor as well and it gave essentially close-to-zero R^2 values.
yeah, this!
not sure why regression would make sense in this case, if it's a classification problem
that'd give bad R^2 even in a good situation
i mean, compute the correlation between the predicted 1,1,0,0,1,... and the actual values
I can't explain why without going into a painful amount of detail, but I formulated the data in such a way that it became a classification problem so that I could use a classifier
So i also used a regressor on the data before simplifying it
Essentially "how many times it broke today" got turned into "did it break at all today"
hello, could someone potentially help me / point me in the right direction. I desperately need help with some optimisation theory, I need to apply branch-and-bound to a knapsack problem
@twin fiber you might get help more efficiently in #algos-and-data-structs . but please keep in mind our homework/exam policy.
ok, that's a reasonable thing to do
okay thanks so much
oh wow you think so?

my supervisor was confused so this feels good
Just got one more Q if that's ok Salt Lamp ?
it makes sense if it makes sense
if it doesn't make sense then it doesn't make sense
as in, do you care if the machine breaks twice vs just once in a single day?
if you don't care about the difference, then maybe yes/no binary classification is correct and you shouldn't even be using the regression model
not really, we wanted to use ML to explore why it might be breaking at all. So how many times it broke wasn't relevant until we understood what was making it break in the first place
if you do care about the difference, then maybe the classification version is still suggestive but certainly not the full story
This was exactly the same line of thinking I had
ah, this is somewhat of an exploratory project then
yeah it is
yes, i think you can say that this is not a good model, certainly not one that i would look to for explanatory power
and you are using a neural network in the hope of extracting higher-order features that could potentially be informative?
well the model was actually fine, I checked to see what would happen if I put in a feature that directly correlated with whether a break happened or not. It trained perfectly fine and managed to make good predictions. That lead me to conclude the data wasn't correlating to a break or not
I used it to investigate whether the input features were responsible for causing the machines to break
Any advice on courses to take for someone interested in going data science (for context I have a business background)
I have narrowed down the list to:
[ ] Python for Data Science, AI & Development (Coursera)
[ ] Introduction to Data Science in Python (DataCamp)
[ ] Programming for Data Science with Python (Udacity)
yes that's a very good practice - compare the model on real data to a model on idealized data
i would caution that you can't rule out these features as being relevant
Yeah exactly, I needed a reference essentially
but you can rule this particular combination of features and this particular arrangement of those features in a model as relevant
probably datacamp. i would focus more on the "data science" and less on the "python", at least at the beginning.
The dataset was from data taken over the past decade so i felt confident in saying that. But I also reduced the number of features and their placement to no avail to check if that would have an effect
you can also do stupider things like compute the mutual information of every feature with # of breaks or yes/no breakage
At this point I've finished off all the "experimental" side of things, I'm just preparing for a presentation where I justify the paper I wrote for this
So i'm just trying to make sure I understand my results completely basically
@grave frost has also suggested that autokeras (https://autokeras.com/) can be really good for building models automatically, so it could be helpful in this case where you don't have any "theory" for your model and a bunch of features that might or might not be useful
Documentation for AutoKeras.
Oh i'll look into that, thank you. I could suggest it for further work for the next poor sod who has to look at this
Hi ,is anyone here has good knowledge of scikit learn for machine learning. I need some help
understood. hopefully you feel more confident with interpretation; when in doubt, look at the confusion matrix
also, you might as well compute the correlation between the predicted and actual from each model
Oh i did, it was this:
and show accuracy even if it's not a "good" metric
no progress after all these years 😞

ayy, its great for testing whether ML would even work on your problem or not
yeah that's so bad it's actually good if you flip the slope on the line lol
No amount of fiddling with hyper parameters could bump it above 0
it might also be that the neural network model is garbage
did you try basic linear regression?
an OLS algorithm or something?
Nah, but again I input a fake correlation into the input data
an OLS algorithm or something?
you're an engineer, aren't you
heh
hey OLS is as simple as it gets
yeah, plain linear regression
the situation is so complex, i doubt anything is linearly correlated
ah
That's why i used an MLP
and frankly if the model is that bad it's not like some other model is going to suddenly be amazing
also just because "neural network" would get my assessor hot and bothered and my grade would go up ;)
yeah exactly
yeah it's been on my short list of things to try, after you suggested it
wish I'd known about it half a year ago hahahahaha
But this is great for future experiments I'll do, so imma definitely look into it
ikr - I keep trying to keep up with AutoML, but I find that transfer learning is the best in all cases
for your dataset, it would def work very well
Autokeras tends to get SOTA accuracy a lot - its system of blocks is pretty novel imo
SOTA?
[state of the art] accuracy
gotchaaa
I'm probably gonna end up using ML for my PhD so stuff like this will be useful to test if all that effort is worthwhile
Not that "import sklearn" is particularly difficult ;)
fwiw i've never worked on a problem that even had an established "state of the art"
i consider you lucky if you do
wouldn't it be arbitrary anyway?
yea, that's a lot of trouble to know what you haev produced is good enough or not
yes, but an externally-validated baseline can save a lot of time and effort
I went nuts in one task, had to spend a couple of days poring over papers to even get a rough score
Just to check @desert oar Machine 4's model having a worse recall means... what exactly?
If i can flip the predictions because it's a classification problem, could that mean that the machine is more faulty as a result of inputs?
like there's a large correlation?
Has anyone here worked with AIML files? I need some help with predicates fast 🥺
Normalise dataset
Classifier:- Random Forest (supervised learning)
1.no of estimators increasing accuracy or not.
2.Heatmap
any one can help me with it
bruh, its based off xml
ik, but it is not that easy haha
May somebody help me with video object detection?
Opencv + keras
I'm stuck
this works!
buyouts = buyouts.loc[
(buyouts.index <= num_buyouts * 0.15)
| ((buyouts.index <= num_buyouts * 0.3) & (buyouts.pct_change() < 0.2))
]
YAY!
if you wanted an automl solution...what features would you want it to have?
I am mining data from Twitter and every tweet I mine is returning the current date as created at parameter
What could be the problem here ?
Hi, I have a question: Why I can't plot a columns of 'Country' and 'TotalCost'?

Hey man, can you please show the full snippet of code and the complete error msg?
You're perhaps overwriting the variable twice.

guys, if i am using ImageDataGenerator, when should i call preprocess_input?
i mean, all examples use the preprocess_input function to make inference. But i guess to train it must be done aswell, no?
do you know how to so solve it?
Note: each Keras Application expects a specific kind of input preprocessing. For Xception, call tf.keras.applications.xception.preprocess_input on your inputs before passing them to the model. xception.preprocess_input will scale input pixels between -1 and 1.
Idk if it means for training or only inference
Is that the full error? It doesn't show at which line YOUR program is failing. It only shows where the library is failing.
There should be something more just above.
yes, that's only full error
Weird. Either way, you've got a TypeError. Somewhere is trying to apply a mathematical operation with text strings and it's failing because of it. For example, if you try to get the .mean() of a country name it will give an error for example.
what should i do?
the column of 'Country' just assigned this time to plotting
Check what are you doing with the text columns and confirm that the type of the other columns is ok. Review the methods and operations then and hopefully you'll find where is the issue.
I don't understand type of error as " unsupported operand type(s) for -: 'str' and 'str' "
the column of 'TotalCost' just plotting of sum with another column like 'Months, Day, Hours, InvoiceNo, ect.."
"Text" + " chain"
results in
"Text chain"
However if you try to do
"Text" * " chain"
will result in an error. Python doesn't know what to do when you're multiplying 2 strings of text. Hence, the "invalid operand with 2 strings"
and I so confuse why when I plotting column of 'Century' and 'TotalCost' it's doesn't works
I'm not change anything in that columns. I just calculate the value of column
Show the exact code of what are you doing with the columns. It's really hard to pinpoint the error and help you otherwise.
before it, i just plotting like this

guys, the preprocess_input function, what is for?
Note: each Keras Application expects a specific kind of input preprocessing. For Xception, call tf.keras.applications.xception.preprocess_input on your inputs before passing them to the model. xception.preprocess_input will scale input pixels between -1 and 1.
For train or inference?
All examples use it for inference
but since it is given for inference, it means the train has been done with that preprocessing, right? so if i wanna fine tune, should i preprocess images like the function sais?
and if so, how do i use it when loading data with ImageDataGenerator object from keras?
I need helpe 😢
Hello, my problem consists of classifying short texts (59 average words) whose vocabulary is very small, I mean that the unique tokens are few because they all deal with the same topic. I need to vectorize it and the conventional methods doesn't work well, I tried with word2vec, doc2vec and tf-idf vectorizer with and without n-grams but nothing work well.
- Is there a way to extract features without vectorizing the text?.
- Do I have to resort to neural networks?.
P.D.: I have 30k of shorts text approximately
Are you talking about importing data from word documenets, word2vec?
nope
@mortal pendant I got my own autoencoder working, so I figured out some stuff regarding your issues. First, you can totally have multidimensional inputs and outputs for images in your model, you just have to flatten/reshape at the start and end.
Secondly, image_dataset_from_directory, if called with labels=None, only returns inputs, but no target outputs. This is what causes the no gradients provided issue. So what you can do is make a new dataset where the input is also the target like so: py x_train = image_dataset_from_directory(...) x_train = x_train.map( lambda x: (x / 255., x / 255.) ) This takes the single input element provided by the dataset turn into an input, target tuple, which is what fit expects. (Also, I normalized the input to change 0-255 RGB into 0-1 for the model)
Finally, since the batch size is already provided by the dataset, you shouldn't specify it in fit. My own code just does this: ```py
autoencoder.fit(x_train, epochs=epochs)
Then I don't understand where your tokenization problem lies
you can totally have multidimensional inputs and outputs for images in your model, you just have to flatten/reshape
Ye I realised that much 😂 The images are multi-dimensional, but to make them an input I have flattened them, it's the reshaping part I was stuck on
Oh ye... I had that before, but must have accidentally removed it when switching to the BatchDataset. Maybe assumed it did this for me. Thanks so much! I'll try it 😄
Finally, since the batch size is already provided by the dataset, you shouldn't specify it in fit. My own code just does this:
Makes sense 🤔 Thanks!
my model did the flatten/reshaping like this ```py
input_img = layers.Input(shape=size)
augment = layers.Flatten()(input_img)
encoded = layers.Dense(encoding_dim, activation='relu')(augment)
decoded = layers.Dense(shape, activation='sigmoid')(encoded)
output_img = layers.Reshape(size)(decoded)
autoencoder = Model(input_img, output_img)
hmm, can you explain your problem more fully?
I'm lost 🙁 I've tried my best to replicate this in my code https://paste.pythondiscord.com/uvelasuzum.py but I get the following error https://paste.pythondiscord.com/jeqemiwezo.sql Any ideas where I've gone wrong?
guys, the preprocess_input function, what is for?
Note: each Keras Application expects a specific kind of input preprocessing. For Xception, call tf.keras.applications.xception.preprocess_input on your inputs before passing them to the model. xception.preprocess_input will scale input pixels between -1 and 1.
For train or inference?
All examples use it for inference
but since it is given for inference, it means the train has been done with that preprocessing, right? so if i wanna fine tune, should i preprocess images like the function sais?
and if so, how do i use it when loading data with ImageDataGenerator object from keras?
that's regarding your encoder model definition, the first parameter should be inputData, not input_flattened (as input_flattened is not an input layer)
Cause the input of classifier need vectors or matrix of short texts
How's that the case if the error is occurring on the line before that?
the error is on this line encoder = Model(input_flattened, encoded)
Oh wait- I must have ran the code then edited it so it showed the wrong line before haha. It was showing it was on the autoencoder line before. This error makes more sense 😂
basically my text is very redundant, I need to recognize, for example, with which part a car collides in a story of a traffic accident
This is giving my a right headache lol. Current code is https://paste.pythondiscord.com/oqopojowoz.py but for some reason, at least from what I can tell, it's saying that my conversion from the encoded data to the output data should be the same, which to me sounds like it ruins the point of the encoder altogether so I must be missing something https://paste.pythondiscord.com/jogaqirole.sql You can tell I really don't understand Keras's/Tensorflow's modelling system 😂
lol, that's regarding your decoder now
I think your autoencoder is fine
because we have the reshape layer now, you actually need to get autoencoder.layers[-2]
for the decoder
and then, if you want the decoder to output a 2d array you have to add a reshape layer to it too
I did this for the decoder ```py
decoder_input = layers.Input(shape=(encoding_dim,))
decoder_layer = autoencoder.layers-2
decoder_layer = layers.Reshape(size)(decoder_layer)
decoder = Model(decoder_input, decoder_layer)
Once I have this working I'm going to move everything into classes so that I can have less confusing variable names, there's too many and my instinct is just to name them inputData since they're all inputs for the next thing lol
Ah ok, that makes sense 👍
i haven't actually used encoder or decoder though so I can't guarantee those work lol
Yes!Defining model Training model Found 2485 files belonging to 1 classes. Using 1988 files for training. Found 2485 files belonging to 1 classes. Using 497 files for validation. 11/249 [>.............................] - ETA: 9:55 - loss: 0.6935Now I should probably code it to save the models to a file, because I do not want to wait 10 minutes every time I test it lol
yeah, good idea
also, does it also take your code like 30+ seconds to actually start the fitting?
hi, I was wondering how to count the number of occurrences of a state per state if that makes sense
for instance, this has 3 floridas, so it means count of 3 for florida
for delaware, it would be zero

If we were to create a research bot what kind of data/ knowledge are required?
Like using Artificial Intelligence to do research for you and return the results to you, for example research for; Fossil fuels vs Nuclear energy sustainability.
I don't believe that is currently possible.
You'd be putting academia out of work.
I would also be helping a lot of industries grow at a much faster rate than it is now.
And if the research process (takes roughly 9 hours) for some people - if this was to be taken out, I believe we can achieve much more by investing our time in more human stuff such as creativity
I'm about to submit a paper on how to better help computers identify which words and phrases in a document relate to certain aspects of patient treatment, and I can assure you, we're not about to be able for computers to be able to identify all experimental parameters.
What about if it were to be done for one narrow field; ie Computer Science
btw, I'm curious where it got 249 from. I assumed I had messed up the validation split, but I tried changing that to 0.8 and it lowered to 63 instead, but I would have thought it would do 2160 since there's 2700 in my dataset?
See if there's a domain for named entity recognition that's under researched.
how about instead of that, you can make some web scraping bot to get the data then rather than having an ai do the research you can just have the ai find key points or summarize it
Yeah this is what I am talking about essentially
What do I need to know of to be able to do that?
web scraping isn't that big a deal. Which documents are or are not of interest is a more interesting question.
Yeah, that's where I am stuck on.
You're talking about natural language processing.
Instead of students having to read a huge pdf from google scholar
Look into different algorithms for document classification.
what if i could create a bot to extract important bits
Alright
I've been researching that for three years.
Sheesh
if it's something of interest to you
why not work together
competition for what?
that is the number of batches, so it's going to be roughly number of images in the set / batch size
to get this out into the market
Oh wait yeh, that makes sense
I thought people either haven't thought of this or who have, have thought that it probably would be impossible.
If you increase the scope to "automating all of research", then that is not currently possible. But automating specific steps is an ongoing topic of inquiry, yes.
I see.
Another interesting topic is "literature based discovery"
and seeing if automatically crawling through existing papers can discover that certain topics are interrelated.
this isn't web crawling
probably captchas
I'm using that term loosely
Probably. But I'm an impostor, so I wouldn't know.
I'm unsure how to properly save the decoder. I currently have this https://paste.pythondiscord.com/soyutacuxo.py but when saving, it warned about the decoder not being trained. Am I supposed to get the decoder from the autoencoder model? If so, any ideas how?
This is my testing code https://paste.pythondiscord.com/egelopoqab.py and it gives me this warning aswellWARNING:tensorflow:No training configuration found in save file, so the model was *not* compiled. Compile it manually. Loading testing datathen I get this error https://paste.pythondiscord.com/mepoqisaku.sql
I think there's a point at which there are discoveries waiting to be made, and if you're actively involved in research, it's sort of random if you end up being the one to stumble upon a "game changer".
It's alright if I fail too cause at least I fail trying something that I love doing and that could potentially add value to humanity
right
guys, the preprocess_input function, what is for?
Note: each Keras Application expects a specific kind of input preprocessing. For Xception, call tf.keras.applications.xception.preprocess_input on your inputs before passing them to the model. xception.preprocess_input will scale input pixels between -1 and 1.
For train or inference?
All examples use it for inference
but since it is given for inference, it means the train has been done with that preprocessing, right? so if i wanna fine tune, should i preprocess images like the function sais?
and if so, how do i use it when loading data with ImageDataGenerator object from keras?
hm, this seems to work for me ```py
autoencoder.save('autoencoder.h5')
encoder.save('encoder.h5')
decoder.save('decoder.h5')
Maybe it’s because I’m using the wrong file format- I didn’t know Keras used hdf5
it's the older format, the other one is the recommended one actually
also, I realized that the "no training configuration found in save file" warning isn't really accurate, the models loaded just fine
I think because the training wasn't performed on exactly those models, keras gets a bit confused and doesn't notice that the weights were, in fact, trained elsewhere
hey
can anyone suggest any good resources and project ideas for machine learning and ai?
@lapis sequoia speaking of that, tonight I'm working on handwriting recognition of years of drawings of sunspots! Try using ML for this...

It's for helioseismic research, just putting all of this into a database. But the thing is, we only need numbers and OpenCV/pytesseract keeps interpreting the numbers as letters
For example, when trying to detect the UT time: "Zolb, Saturday, the 20 of Februar, I$:00 UT. Seeiny= 25S, SP."
Anyone happen to know how to tell it to only try interpreting the characters as digits? If I could simply exclude I and $, then it would have gotten 18 right! Thanks!
OH. Sorry, I just found that there's a character whitelist!
pytesseract.image_to_string(question_img, config="-c tessedit_char_whitelist=0123456789abcdefghijklmnopqrstuvwxyz -psm 6")
ooo
thats a nice project
Yeah! Absolutely no idea how I'd even start going about interpreting the active region's coordinates though lol
Darn, with the whitelist it's excluding letters, not doing best effort to interpret what it sees as letters as numbers
2020 1:0UT25
I need to figure out how to just train it using the handwriting but I'm using command line only on an HPC and would really prefer to avoid GUI apps. Photoshop to make an image would be fine though
Guys... How to detect and classify multiple object on video? I want to classify there for example carrots between healthy and rotten.
Every tutorial includes HAAR ready to use template with faces or peoples...
Any other way?
why is it impossible for me to understand the usage from api doc.......even when there are examples in them?
hello guys ! is there someone who can explain me which argument I should use in scipy.stats.lognorm.ppf ? I already tried to use it myself but the result I obtain isn't good :/
hello guys Anyone scraping google maps data?
that's kinda complex. what do you mean by which part a car collides? like the exact quotations, or would the sentence/para work?
YoLo
How do i create machine learning model with python?
hey I am stcuk in NLP data tokenizer stuff please refer a good resource
what are you trying to make this model do
create a Machine Learning/Deep Learning Model which will predict the categories on the basis of the various inputs in the form. Data Preprocessing and Exploratory Data Analytics
were you instructed to do EDA or modelling?
I recommend watching a few videos or taking a course rather than jumping in
Okay man i will do that 👍🏼
you can checkout the pinned resources on the top for a starting point
Where is it ?
clik the pin on top
Okay bro 👍🏼
guys, the preprocess_input function, what is for?
Note: each Keras Application expects a specific kind of input preprocessing. For Xception, call tf.keras.applications.xception.preprocess_input on your inputs before passing them to the model. xception.preprocess_input will scale input pixels between -1 and 1.
For train or inference?
All examples use it for inference
but since it is given for inference, it means the train has been done with that preprocessing, right? so if i wanna fine tune, should i preprocess images like the function sais?
and if so, how do i use it when loading data with ImageDataGenerator object from keras?
using pandas? excel? something else?
simple question and im too lazy to browse stack overflow
how can i save plt.savefig(r"bar_line_scatter.png") to a certain place in my files?
nvm i got it
i can't install autopy module can anyone help me out ?
is that a data science thing? if so, go ahead and ask
i actually work on a virtual mouse project, learning from a youtube channel, there he install the autopy module
but i can't ,
it based on AI thats why i asked that here
Have any of u ever wrote a custom data generator for data augmentation? if so, could u lend me a hand pls?
Hi anyone is planning to work in beginner python project.
I want to learn more about Python through live project.
which kind of project
beginner project like Data visualization, regression, prediction model something like this.
i have learned almost everything required and going to start a project
Hello, Anyone working on topic modelling using VAE? Need some help in getting the probabilities of the words. I feel like i am not getting how to do that. Let me know if any one could help me on that. I can give more details on how and what i am trying to do. im using basic variational inference to do the task.
@lapis sequoia you're using pyro?
not sure if this is a code question or math/theory question
GitHub
PyTorch implementation of AVITM (Autoencoding Variational Inference For Topic Models) - vlukiyanov/pt-avitm
this is what im using... its a coding question i would say.
and just so i know, this is a standard LDA topic model where the probability of a specific word in a specific position is conditional on the "topic" in that position?
that appears to be the case as in https://arxiv.org/abs/1703.01488
arXiv.org
Topic models are one of the most popular methods for learning representations
of text, but a major challenge is that any change to the topic model requires
mathematically deriving a new inference...
i have no idea how to do it either but i might be able to help figure it out
yes, thats absolutley right!!
This is great. let me know when you have time and we could discuss.
Great, can we take any used case project so it will help us a lot.
i will dm you
Hi, can anybody suggest a Good Machine Learning course?, I don't want one with 6 months of ML
week or less is ok
machine learning is a big topic and takes a long time to learn. 6 months is maybe even too short... it takes years to get good
in a week you will barely learn basic statistics
I know that it takes long to cover all the things and take a step by step, all I want is a good course that gives me a brief look into ML
Do you mean I can't learn all of it except if I was learning it in college?
you can learn it on your own, but it might take longer and you might struggle more without guidance
#data-science-and-ml message see here (and the messages below by myself and Squiggle)
there are fine "boot camp" types of courses too, but those still take months
Actually Computer Science and machine learning is where I will be heading after HS
it also depends on your personality type and your prior background
i see. if you're young and full of energy you might be able to get pretty far on your own.
cool
i am old and slow and my brain is partially turned to stone in some places and turned to mush in others.
i can self-teach because i already know a lot of things, but i don't know if i'd be able to learn it all again from scratch 😛
Old is Gold 😏
do you know what the "features" referenced in the documentation are supposed to be?
Can I ask an NLP Question here?
yes, this is the right channel for it
how do you calculate the frequency of a word using the zipfian distribution?
if the most popular word rank 1 occured n times
how would you calculate for something like for the rank 10 word
i know f = 1/r
but still don't see how they calculate it
what do you mean calculate the frequency using the distribution?
you wouldn't use the probability distribution as such
but zipf's law states the approximate frequency of the k'th rank word
it can't be 1/r because then the 1st rank word would be the entire document 🙂
so if the most frequent word occured 150 times would the rank 3 word occur apporx. 50 times?
so you would want the rank number x frequency ~= the frequency of the rank 1 word?
Hi guys! Is there someone who have experience in building a recommender system?
zipf's law is freq = c * (1 / rank), for some constant c
so if you want to get the ratio of frequencies, you can do c*(1/rankA) / c*(1/rankB) = rankB/rankA
ok thanks
@lapis sequoia it looks like each element of the resulting vector corresponds to a "topic", but it's not a probability distribution over topics. i'm not sure if it's an un-normalized probability distribution or something else.
@lapis sequoia aha, .transform just performs the encoding step of the autoencoder but not the decoding step.
After finally getting all this to actually give an output, some of my images kinda look like they have text but are extremely corrupted and I can't seem to figure out why.
Code for generating model: https://paste.pythondiscord.com/tiyaqifola.py Code for producing output: https://paste.pythondiscord.com/agigeficuz.py (saves loads of images showing the resized image and it's autoencoded version next to each other)
Rough expected output: https://i.imgur.com/2FACBVm.png Actual output: https://i.imgur.com/qQ9l3gL.png
I assume it's likely just an issue with the resizing of the image, as if the resized image had issues, the output inherently would too. I can't see anything I could have done wrong though. Any ideas for where it could be stemming from would be great!
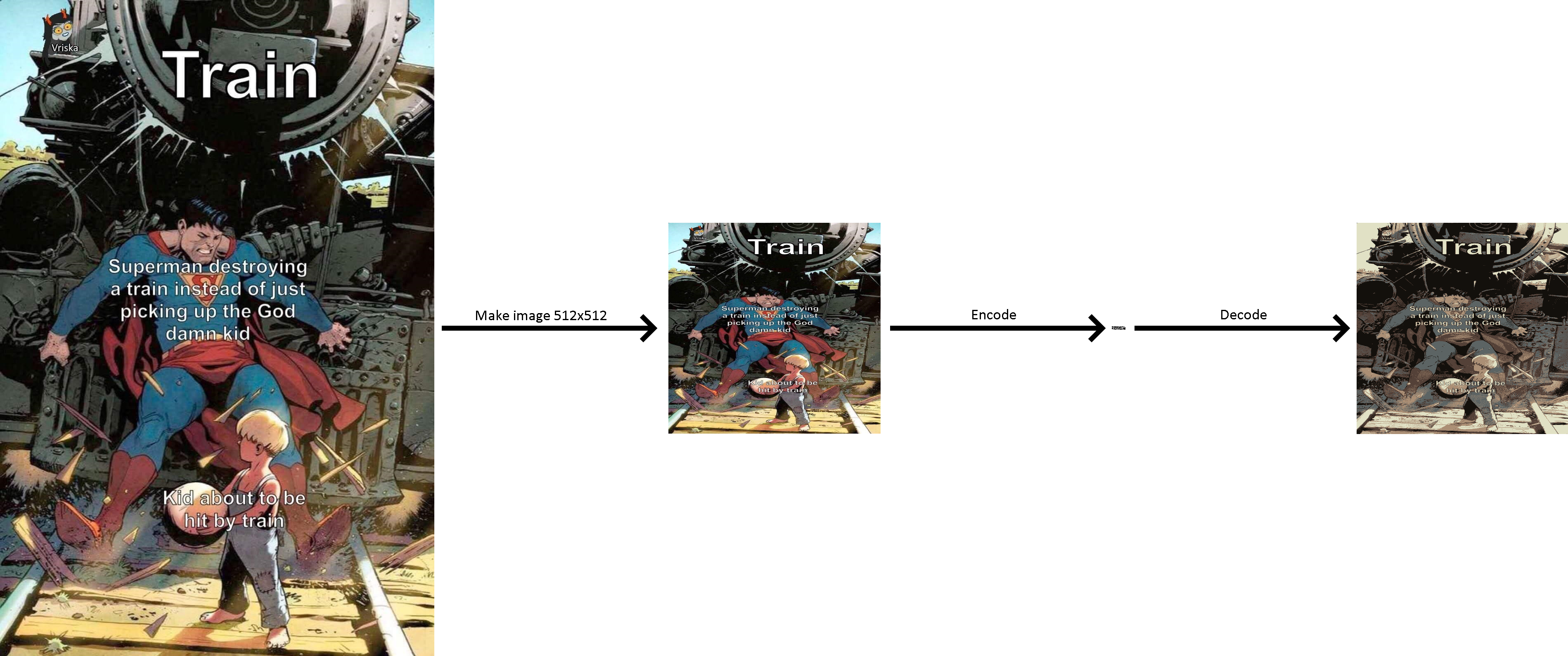
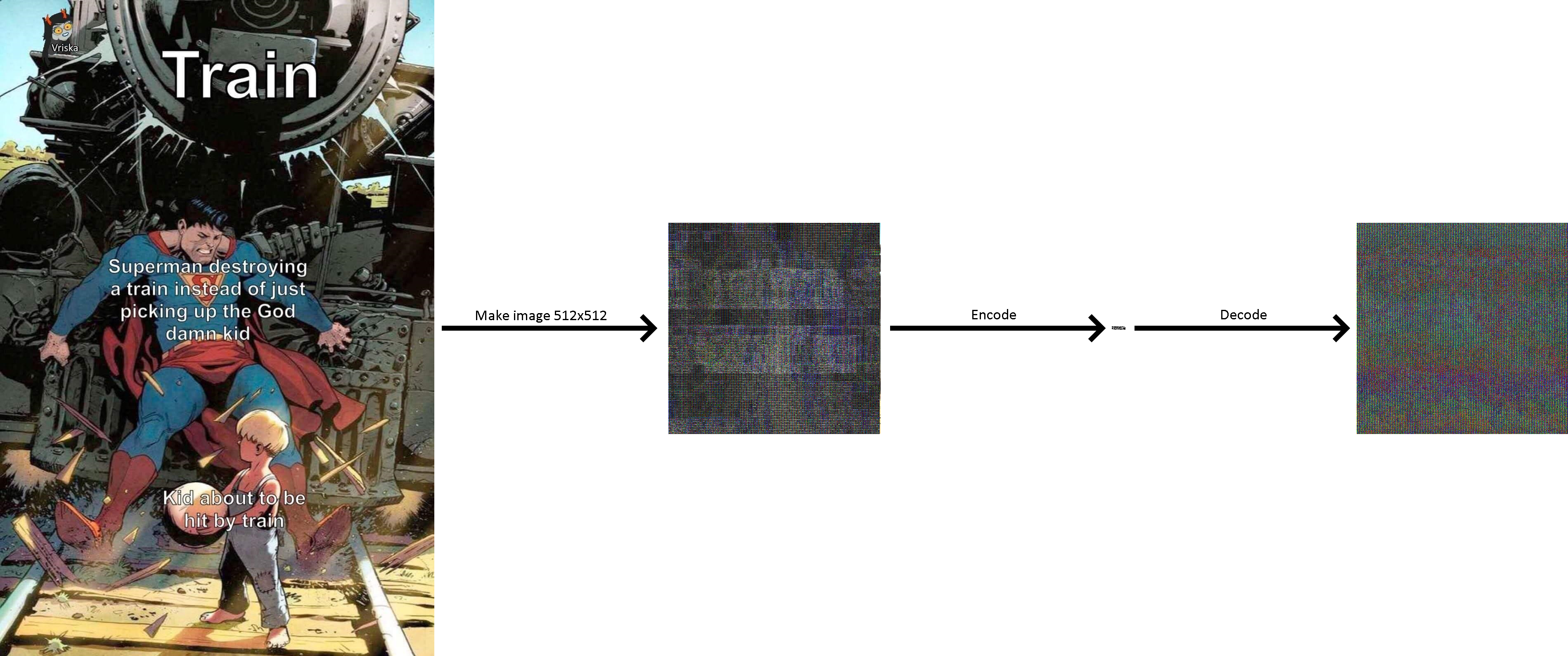
How would an issue with the decoder result in the resized image being corrupted? The resized image is before it enters any of the model at all afaik
It's worth noting, by the way, that it could be that the entire model is working and it's just saving the results where the issue is happening
yeah, i'm reading your code now to see what's going on
Also- wait- I have just realised that the autoencoded image is the same on all the results
In some of the results, the text is really obvious though. My best guess is that it's taking loads of chunks from the images and overlaying them ontop of each other

you could be right!! im not sure how to get the probability at the decoding step. Here's the result i get after running the model with News20 data
i think perhaps the parameters are supposed to be read from the encoded values
i'm looking into the AEVB technique to see if there's a straightforward way to do that
ah.. so I need to check the parameter values?
That would be great. Thank you so much for taking the time to have a look

i ran the code in the readme and got a matrix with 1 row per input document, and 1 column per topic
ah. how and where did you run?
I ran the example , news20 from the example folder.
https://github.com/vlukiyanov/pt-avitm#usage the example here
GitHub
PyTorch implementation of AVITM (Autoencoding Variational Inference For Topic Models) - vlukiyanov/pt-avitm
result.shape is (11314, 50)
you saved that code in .py file and ran it?
i pasted it into ipython, same thing
you could file an issue on the github repo and ask
you want the probability of a specific word w in each document?
yes
also, if I pass some word, I want to know the probability of it....
Also, in the paper they have mentioned about the PRODlda, can we use something from this link to get the probabilites? https://pyro.ai/examples/prodlda.html
although im not sure what in this link would fetch me that information.
that's pretty much a restatement of the paper + a demo implementation
Hello everyone. If you train a reinforcement learning agent on a game, what is the optimal fps in your opinion?
hah, i think there's a bug in their code @lapis sequoia
when you run predict with encode=False you get an error
it looks like they didn't test this code properly, they used a lot of mocking but never ran anything end-to-end
universities should keep programers on staff to assist researchers with this stuff, imo
would be money well-spent
professional on-call code-unfucker ml engineer for researchers, i'd do that job
their forward function returns a tuple of tensors, which is allowed by pytorch, but their predict() function assumes it's a single tensor
More precisely. How many updates per second/minute/whatever do you expect from the game with the actual state and score of the game?
can someone please look over my voice assistant code (it works but its just not accurate)
True that!!!
ahhhh! okay. I feel like im lost with this.. I will try to analyse it.
@lapis sequoia https://github.com/vlukiyanov/pt-avitm/issues/35

GitHub
Hello! And thanks for publishing this repository. Problem I noticed that the predict function is broken with encode=False. This is because the code assumes that the output from ProdLDA.forward is a...
i just filed this bug report
oh great!!
Im going to run some tests too...
with the correction you mentioned in the bug#
ah, the first issue is the format PIL expects the arrays in. The keras format isn't going to work. You should import from keras.preprocessing.image import array_to_img and use array_to_image to convert the numpy array to an image
instead of using Image.fromarray(...) manually
with that correction, you get what i believe is a probability distribution over the vocabulary, for each input document
by doing what?
if you re-wrote predict w/ that bugfix, and called it yourself
anyone free to help with some data wrangling? I am doing a project to showcase some comparisons over time wit solar panels and renewable energy in residential USA sector
can someone please look over my voice assistant code (it works but its just not accurate)
i trained it 200 times (epochs 200)
do u know how to know if an image is RGB or BGR?
Ask the person who gave you the data... or look at one in RGB, and see if it looks right, then try BGR if it doesn't
i cant return the db_avg ..

chipotle2 is not defined 
instead of doing one by one line as chipotle1, i tried to do it as function for chipotle2, but it is not working

you have a couple non-data-science Python issues there, I suggest you try getting a help channel
okok 
ok, will try this, thank you so much 🙂
anyone familiar with geoplotlib?
is there any popular alternative library for geoplotlib?
so i think api doc doesnt suck but tensorflow's is an exception.......
First issue?
hey this is a long shot but could anyone help me find a paper in the field of biology with applies optimisation / mathematical modelling techniques?
Hey I am trying to load in a keras model I've created. I have saved it has .h5 but when im trying to load it in with keras using load_model I get the following error OSError: SavedModel file does not exist at:./neural_models/RNN_100000.h5/{saved_model.pbtxt|saved_model.pb}
Can someone tell me how to plot a scatterplot from two Pandas DataFrame columns?
You can always use matplotlib directly, but from pandas it's I think something like df.scatter("Name of column to use as X", "Name of column to use as Y")
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.plot.scatter.html
Thanks a lot!, can you also let me know how to find correlation between the same?
Has anyone here worked with aiml python predicates before? I want to know, how to store the predicated permanently, so that they don't get deleted when I restart the bot
anyboby know how to convert the tensor graph file (.pb) into tflite?
I wanna use it for raspberry pi

regarding research methodology/methods - these things short circuit my brain, but I have a question. Broadly a paper that takes a dataset and applies algorithm x and evaluates it + compares with other papers on the same dataset/problem is experimental research (methodology) and conducts an experiment, right? What about papers that suggest a new implementation or an improvement on an existing technique?
I have Excel files with different columns that need to be merged. How do I convert them to a dataframe and merge them so that the headers are intact?
Look up pd.merge()
perhaps you can give an example of the data (print(df.head().to_csv())) and explain what transformation you want to do. "merge" has a specific meaning in the context of pandas, but it might be that you want to concatenate, or something.
Is random weight init done on every layer of NN or just the first hidden layer?
you have to initialize all the weights to something, so some kind of initialization procedure is used for all weights. random is one of several techniques for initializing them.
So all neurones, be it hidden or not, are init, right?
it's better to think of the weights as being initialized
talking about "neurons" is kind hand-waving over the math
I have a dataframe with 110 rows, and each group of ten consecutive rows are about the same experiment. How can I add a multiindex to that?
0,DoseUnits,0.957,0.629,0.759
1,SampleSize,1.0,0.167,0.286
2,Sex,0.958,0.742,0.836
3,Species,0.952,0.927,0.94
4,Strain,0.939,0.848,0.891
5,TestArticle,0.733,0.695,0.714
6,TestArticlePurity,0.6,0.75,0.667
7,TestArticleVerification,0.0,0.0,0.0
8,TimeAtFirstDose,0.0,0.0,0.0
9,system,0.844,0.721,0.767
10,DoseUnits,0.698,0.604,0.648
11,SampleSize,0.333,0.2,0.25
12,Sex,0.922,0.887,0.904
13,Species,0.916,0.929,0.923
14,Strain,0.884,0.781,0.829
15,TestArticle,0.754,0.577,0.654
16,TestArticlePurity,0.667,0.533,0.593
17,TestArticleVerification,0.0,0.0,0.0
18,TimeAtFirstDose,0.0,0.0,0.0
19,system,0.777,0.663,0.713
give your indexes names!!
Should be indexed by (n, tag) where n is in [0, 10]
experiment_size = 10
n_experiments = df.shape[0] // experiment_size
df['experiment'] = np.repeat(
np.arange(n_experiments), experiment_size
)
df.set_index(['experiment', 'tag'], inplace=True)
Yo
kinda confusing but it worked!
so I'm using the face_recognition library.
and I get this

encoding = face_recognition.face_encodings(image)[0] it's a face encoding
because arange gives you [0, n), I guess
anyone know how they create those encodings tho? I looked up auto encoders and variation auto encoders but i don't understand the values in the library
this is the black box i used https://pypi.org/project/face-recognition/

it sorta works but for some reason it sucks with ethnic minorities
I'm planning on retraining it to better detect facial features of ethnic minority groups.
it thinks these 3 are the same guy 

when clearly they are distinct individuals who are not even remotely similar
first question is what's creating the bias
training data probably didn't have enough people in it who look like that
pretty embarrassing result for that library author
sorta did the same thing here.

also black/people of color people are actually some of the hardest people for AI to learn ((why that is i'm not sure but it's like an actual thing which has caused issues with things like false identification by police cams))
that's racist
yea I figured that was the issue which is why I want to create my own set of minority faces
interesting, i wonder if it has to do with distinguishing dark skin from shadows
i got these values from
encoding = face_recognition.face_encodings(image)[0]
but I want to know what they mean

how did the author of the library come up with these values
you could try "fine tuning"https://www.tensorflow.org/tutorials/images/transfer_learning
he refrenced Deep Residual Learning for Image Recognition in his paper.
the author presumably has a trained model in the source code somewhere
@desert oar i'd assume so! but yeah it's an interesting but def a problem and a big one sense it's a huge issue for even like professional companies
indeed. one of many good reasons not to proclaim ai victory yet (or any time soon)
AI is amazing but yeah it's got weird quirks and stuff lol
in regards to my question any idea what he's using to encode?
i assume that's output from a model of some kind
you might have to read the source code to find out exactly how it's being created
so the library I am using can run through 2 models
hog and CNN
the author used hog in the tutorial, sentdex used a cnn
any reason to pick one over the other?
my current results are using the cnn model
They don't. That's what an auto-encoder does- it converts a high dimensional image into a lower dimension of values from 0 to 1, where the first values are what it thinks are most distinctive from the training data (usually lighting)
so it's not a variational autoencoder? just an auto encoder
auto encoder is just a form of compression tho?
Probably not if it doesn't provide the key
No. It's mostly used for automatically providing a basis of generating images, or you can manually identify what each of the values changes, atleast from what I know
Also for denoising
hm... guess I have to research this topic more.
that and find out what a euclidean distance exactly is 
https://youtu.be/NTlXEJjfsQU Here's my favourite usage of it (I'm biased though cos I just like carykh lol)

Check out Brilliant.org for fun STEMmy courses online! First 200 people to sign up here get 20% off their annual premium subscription cost: https://brilliant.org/CaryKH/
Part 2: https://www.youtube.com/watch?v=L0kmDiJ68CA
GitHub Repo: https://github.com/carykh/alignedCelebFaces
ooooOOOooooOOOOOHHH! I'm probably going to upload the source code...
Each of the sliders is just a different dimension that the autoencoder came up with
ahh perfect, I'ma check it out.
I actually like sentdex videos
easy to follow thru in regards to this topic
cary's video doesn't explain how it works very well, it's just showing a common usage of it
i see, well that's a start.
I can't find any use for image recognition other than security tbh.
Finding images containing a celebrity is one that comes to mind
But yeh security is the most obvious haha
StyleClip might interest you 😛
It worked! Off course, since I didn't train it much and the encoding_dim was fairly low, the output was mostly just brown blobs, though there was a pattern of them being in a grid on the left, which fits with my dataset, so better than nothing. Now to just figure out why it's displaying the same output for all inputs
Oh that looks really cool!
if you enjoy generating images from machine l;earning, we are in really interresting times
openAI released a model named clip that is able to grade how much an image matches a text, and it is used a lot for open ended generation
eh, another AI bias problem
I would argue the problem is not with the author at all - and shouldn't be taken seriously
its a random repo, and unless the repo is sponsored by corporation, it shouldn't be a problem
Found out why- forgot to take j into account. It was only every group of 8 images that was the same!
guys ive followed this tuto to make a custom data generator

Step Up AI
Learn how to implement your custom preprocessing function and integrate it into Keras data augmentation pipeline. Follow along on the Colab notebook.
The thing is, if i want the color (hue) to be a random value between 0 and 1
how can i make it?
I mean, once i create an instance of this class, the hue remains the same. I wanted to, after calling flow, which returns a kind of an iterator, each next() call to have a random value of the hue
Now I need to reshape this so folds are columns and tags are row
precision ... f1
tag DoseUnits SampleSize Sex Species Strain TestArticle TestArticlePurity ... Species Strain TestArticle TestArticlePurity TestArticleVerification TimeAtFirstDose system
fold ...
0 0.957 1.000 0.958 0.952 0.939 0.733 0.600 ... 0.940 0.891 0.714 0.667 0.0 0.000 0.767
1 0.698 0.333 0.922 0.916 0.884 0.754 0.667 ... 0.923 0.829 0.654 0.593 0.0 0.000 0.713
2 0.879 0.786 0.940 0.921 0.831 0.716 0.600 ... 0.915 0.862 0.703 0.600 0.0 0.000 0.797
3 0.836 0.722 0.971 0.942 0.770 0.608 0.000 ... 0.942 0.814 0.713 0.000 0.0 0.000 0.793
idk
University
I figured it out btw.
Okay, can anyone suggest an ML and Ai course, NON VISUAL(No Video tutorials )
What i mean is
I want someone to guide me
and say
'okay read these docs'
and try this project
please :3
post your solution!
The original dataframe looks like this:
precision recall f1
fold tag
0 DoseUnits 0.957 0.629 0.759
SampleSize 1.000 0.167 0.286
Sex 0.958 0.742 0.836
Species 0.952 0.927 0.940
Strain 0.939 0.848 0.891
... ... ... ...
10 TestArticle 0.675 0.719 0.689
TestArticlePurity 0.543 0.497 0.507
TestArticleVerification 0.000 0.000 0.000
TimeAtFirstDose 0.225 0.051 0.069
system 0.775 0.761 0.760
So instead of going though that intermediate step in my previous example, it's simply df.unstack(0)
it's almost like I XY-problemed myself 😄
also I wasn't being very precise earlier. They were folds, not experiments 😄
if you use dropout layers, does that mean that some nodes will not contribute to the overall fitting of the model at all? if that's the case, how can you find the weights for those nodes that were dropped?
or, is it that in each epoch, some nodes randomly are dropped out meaning in the end all of the nodes actually have contributed to the fitting of the model - it's just that in some epochs some were ignored to prevent overfitting?
I'm learning 
Can someone tell me how to find the correlation between 2 Pandas Dataframe columns ?
some nodes will not contribute to the overall fitting of the model at all?
yes
if that's the case, how can you find the weights for those nodes that were dropped?
can't, they're just 0
in each epoch, some nodes randomly are dropped out
one set of nodes is dropped across the entire network; it's not per-epoch
thanks for the elaboration. the more I learn about ML, the more I think results are more random, what if the nodes that are dropped out are quite important for the final classification? (but I guess if we're using neural networks, the relationship between features and the classification is complex so individual nodes have a very small influence on it individually)
Anyone? Please?
yeah, and also that other neurons can compromize in the loss of those neurons too
true that
does anyone know why exporting tensorflow google teachable machines always break
or is there any good alternatives to google teachable machine
side note: this is why it's important to set all random seeds before doing any serious work, otherwise your output isn't reproducible
set all random seeds? what does that mean?
computers can't really generate random numbers - they use an algorithm called a "psuedo-random number generator" (PRNG) to generate random-looking numbers. typical PRNGs must be "seeded" with a starting value, usually an arbitrary number. if you set the same seed value in a given PRNG, you will get the same psuedo-random number sequence out from the PRNG.
if you don't provide a seed in your program, software libraries usually make up a seed using some other data like the system clock. if you run your model without setting the seed explicitly, then you don't have the ability to re-create your model from scratch, because you can't re-create the random number sequence that was used to things like dropout, train/test splitting, etc.
ah that makes sense. I've seen seeds be used with train/test splits but I never actually knew what it was for. I'll have to read about PRNGs, sounds interesting.
Doing TF-IDF for the first time. When I wanna predict something, do I turn the thing I'm predicting into a TF-IDF matrix as well?
Cannot find any good resources on how to predict stuff after I've trained my models with TF-IDF data
yes, but don't re-fit the TF-IDF part on the prediction data
are you using scikit-learn?
I am, yeah
I am a bit at a loss. Cause my model is running EXTREMELY slow
For some reason
Essentially, I have trained my model on a list of sentences (which I did TF-IDF on). Now, I have a dataframe that contains lists of sentences. I want to predict if these lists contain positive (1) or negative (-1) sentences. Then I wanna get an average of these lists and finally get a score between 1 and -1
But it's running so slow
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
from sklearn.pipeline import make_pipeline
pipeline = make_pipeline(
TfidfVectorizer(),
LogisticRegression()
)
train_documents = ...
train_labels = ...
test_documents = ...
test_labels = ...
pipeline.fit(train_documents, train_labels)
train_pred = pipeline.predict(train_documents)
train_acc = accuracy_score(train_labels, train_pred)
test_pred = pipeline.predict(test_documents)
test_acc = accuracy_score(test_labels, test_pred)
this is basically the pattern you'll follow
if you provide example code i can help more specifically
Thanks a lot!! I will try to modify your code and hopefully I can make my code run quicker
i bet your slow code is because you're doing something weird with your data processing
show it anyway
also state how big the dataset is
Man, it's so difficult to explain what I'm doing though. Essentially, I am trying to do sentiment analysis on vaccine article data. In this data, I have identified a number of "relevant" sentences (so we don't use the whole article, as it could contain other irrelevant stuff). Now, I have taken some of these sentences, put them into another dataset to manually label them as positive and negative and trained a RF model to predict whether a sentence is positive or negative.
Now back to the first dataset, I have a column that says "Relevant sentences". Each row of this column contains a list of 0 to n sentences (I think max is probably 7/8 sentences). Now, I wanna predict the sentiment for each of these sentences and get the average sentiment.
Does it make sense so far?
from sklearn.feature_extraction.text import TfidfVectorizer
def clean(text):
tokens = nltk.word_tokenize(text)
lower = [word.lower() for word in tokens]
no_stopwords = [word for word in lower if word not in stopword]
no_alpha = [word for word in no_stopwords if word.isalpha()]
lemm_text = [wn.lemmatize(word) for word in no_alpha]
clean_text = lemm_text
return clean_text
def vectorize(data,tfidf_vect_fit):
X_tfidf = tfidf_vect_fit.transform(data)
words = tfidf_vect_fit.get_feature_names()
X_tfidf_df = pd.DataFrame(X_tfidf.toarray())
X_tfidf_df.columns = words
return(X_tfidf_df)
tfidf_vect = TfidfVectorizer(analyzer=clean)
tfidf_vect_fit=tfidf_vect.fit(X_train)
X_train_vec=vectorize(X_train,tfidf_vect_fit)
X_test_vec=vectorize(X_test,tfidf_vect_fit)
note: tfidf_vect_fit is the same object as tfidf_vect. fitting is done in-place on the object, unlike in R where fitting returns a new thing that describes the fitted model
but this looks very reasonable so far
the clean function is going to be slow
use generator comprehensions instead of list comprehensions
Generator comprehensions?
they're "lazy" - they don't build up a new list in memory each time
def clean(text):
tokens = nltk.word_tokenize(text)
lower = (word.lower() for word in tokens)
no_stopwords = (word for word in lower if word not in stopword)
no_alpha = (word for word in no_stopwords if word.isalpha())
lemm_text = (wn.lemmatize(word) for word in no_alpha)
clean_text = list(lemm_text)
return clean_text
should reduce some overhead from constantly re-allocating more memory
yes, but only converting to list once at the end
def clean_gen(text):
tokens = nltk.word_tokenize(text)
for token in tokens:
word = word.lower()
if word in stopword or not word.isalpha():
continue
yield wn.lemmatize(word)
def clean_list(text):
return list(clean_gen(text))
you could write it like this too if you wanted, the yield makes the entire clean_gen() function a generator
then use analyzer=clean_list
import numpy as np
def compute_mean_sentiment(sentences_list):
if len(sentences_list) == 0:
return np.NaN
sentiment = [rf.predict(vectorize([sentence],tfidf_vect_fit))[0] for sentence in sentences_list]
#mean_sentiment = np.mean(sentiment)
return sentiment
#manufacturers = ["Pfizer", "Moderna", "Johnson & Johnson", "Astrazeneca"]
#for i in manufacturers:
# c_df[f'{i}_mean_sentiment_rf'] = c_df[f'{i}_relevant_sentences'].apply(lambda x : compute_mean_sentiment(x))
Because that would give me one score (either 1 or 0) right? For every sentence list
And then the score would always be exactly 0 or exactly 1
sentiments = rf.predict(tfidf_vect_fit.transform(sentences))
sentences is a list of sentences. vectorizing will return a big matrix, one row per sentence. then predict will return a vector of class predictions.
same behavior as during training
Oooh!
Of course!
There's my issue
Yeah, that greatly improved speed! Thank you so much!
looping in python is much much slower than letting numpy/scipy do it, which is mostly what scikit-learn uses internally
Yeah, I really should get a better grip on numpy/scipy
Err, now everything is getting labelled as 0.66666 - Are you able to see what I did wrong based on this snippet?
import numpy as np
def compute_mean_sentiment(sentences_list):
if len(sentences_list) == 0:
return np.NaN
sentiments = rf.predict(tfidf_vect_fit.transform(sentences))
translations = {"Positive":1, "Negative":0}
sentiments_translated = [translations[i] for i in sentiments]
mean_sentiment = np.mean(sentiments_translated)
return mean_sentiment
manufacturers = ["Pfizer", "Moderna", "Johnson & Johnson", "Astrazeneca"]
for i in manufacturers:
c_df[f'{i}_mean_sentiment_rf'] = c_df[f'{i}_relevant_sentences'].apply(lambda x : compute_mean_sentiment(x))
0.66666 for everything is impossible, as there are many cases where we have way more than 3 sentences
Otherwise, I can probably figure it out. It was just if you immediately spotted something that seemed off 😛
.apply seems weird here, this function returns a single number
Yeah, I want this function to return the average
Argh, I need to do axis=1
ah yeah, axis=0 can be surprising sometimes. i forget about it too
Kinda crazy the function ran then
it's easier if you think of it as the axis that will be "consumed" by the operation
the one you're iterating over in the innermost part of the loop
Ah wait, the apply was working - Cause of the lambda I think.
The error I get is this now
ValueError: Iterable over raw text documents expected, string object received.
Error occurs on this line
import numpy as np
def compute_mean_sentiment(sentences_list):
if len(sentences_list) == 0:
return np.NaN
print(sentences_list)
**sentiments = rf.predict(tfidf_vect_fit.transform(sentences_list))**
translations = {"Positive":1, "Negative":0}
sentiments_translated = [translations[i] for i in sentiments]
mean_sentiment = np.mean(sentiments_translated)
return mean_sentiment
manufacturers = ["Pfizer", "Moderna", "Johnson & Johnson", "Astrazeneca"]
for i in manufacturers:
c_df[f'{i}_mean_sentiment_rf'] = c_df[f'{i}_relevant_sentences'].apply(lambda x : compute_mean_sentiment(x))
Ah, bold doesn't work in code snippets
sentiments = rf.predict(tfidf_vect_fit.transform(sentences_list))
Ah, just added [ ] around sentences_list
Seemed to work
Ah shit, guys. I have a column that contains lists of strings. However, pandas understands lists as strings. Therefore, I have a rows like this
r = "['Blablabla, blab lba', 'This is another string bla bla']"
How can I convert these to actual lists that I can loop over? When I do this
list(r)
>>> ['[', "'", 'B', 'l', 'a', 'b', 'l', 'a', 'b', 'l', 'a', ',', ' ', 'b', 'l', 'a', 'b', ' ', 'l', 'b', 'a', "'", ',', ' ', "'", 'T', 'h', 'i', 's', ' ', 'i', 's', ' ', 'a', 'n', 'o', 't', 'h', 'e', 'r', ' ', 's', 't', 'r', 'i', 'n', 'g', ' ', 'b', 'l', 'a', ' ', 'b', 'l', 'a', "'", ']']
This is obviously not what I want. And I cannot split on the commas, since the strings may contain commas
hello everyone
i have used teachable machine to train and export model , so i exported it as tflite bcz i want to use it in a real time object detection app
so when i export the model it has a name "mode_unquant.tflite" but in the most of the flutter apps the model used is ssd_mobilenet
so the question is there's a different between these models or nah ?
Thanks a lot!
@acoustic forge i called it sentences_list for a reason 🙂
oh dear, you put raw python code into your dataframe
you will have to eval() those to get lists back
data_transforms = {
'train': transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
'val': transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
}
data_dir = 'data/hymenoptera_data'
image_datasets = {x: datasets.ImageFolder(os.path.join(data_dir, x),
data_transforms[x])
for x in ['train', 'val']}
dataloaders = {x: torch.utils.data.DataLoader(image_datasets[x], batch_size=4,
shuffle=True, num_workers=4)
for x in ['train', 'val']}
dataset_sizes = {x: len(image_datasets[x]) for x in ['train', 'val']}
class_names = image_datasets['train'].classes
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")```why are these being treated like a dictonary?
is it to link everything between train and val?
@acoustic forge in the future use json.dumps, or save your data in parquet format where array-of-strings is a valid data type
Also for the transforms.Normalize how were those values choosen?
can someone explain me how does keras ImageDataGenerator class to get a random transformation for each image on the batch?
yep, but... mmm my issue is a bit harder
i made my own function to preprocess images, but idk how it takes a random value each time
If I have a list within a list, eg:
((a, b, c), (1, 2, 3)), is there a way to delete the first element (a, b, c) given a and b?
I know I can create a for-loop to iterate through the list's lists, but is there a one-liner that can do the similar thing?
you can't modify a tuple - only a list
you would have to convert first
oh wait you wanted it deleted, lol
!e
l = [(9, 8, 0), (1, 2, 3)]
a = 9 #a value you want to remove
b = 8 #b values you want to remove
output = [i for i in l if not i[0]==a and not i[1]==b] #list comphrension
print(output)
@grave frost :white_check_mark: Your eval job has completed with return code 0.
[(1, 2, 3)]
A bit hacky, but can't be that bad imo
Use != instead but there isn't another sensible way to do it
ay that works lol
good enough
tyty
Could someone help me with a program I'm doing using GeoPy with Pandas?
I need to take the longitude and latitude from the .csv file and turn it into something like (lat1, lon1), but I have no idea how to do this because there are more than 300 cities in the file
The number of instances in the file shouldn't matter as long as you know how the problem is solved for one of them
Can you show what the data in the CSV looks like (as text, no screenshot)?
ofc, its something like that
codigo,nome,telefone,logradouro,numero,latitude,longitude
1;RODOVIÁRIA;"3221-9371 ";LG VESPASIANO JULIO VEPPO ;"0";-30,02399616;-51,2194512698
458;AV. DAS INDÚSTRIAS X AV. SEVERO DULLIUS; ;AV. DAS INDÚSTRIAS ;"1344";-29,9872776651;-51,1698367788
great, so the latitude and longitude are given. So what do you need to do?
i know how to pass both values to python, but i don't know how to compare all cities to see which one is closer to my latitude
I didn't need to create 1 variable per street to compare with my location?
if you know your own latitude and longitude, you just have to apply the distance formula to each row and take the minimum.
oh, just to your latitude?
yeah, compare all the streets to see which one has the shortest distance compared to mine
so, shortest distance, not just the closest latitude?
because those are different calculations.
If you just need to find which location is closest to you, you don't need to compare them to each other.
i mean, i need the distance that is less kilometers from my house, for example
the distance between what two locations?
the first location would be my home, the second would be based on the .csv file, which I believe would have to go through a loop to see which one has the shortest distance based on the first location
So are you trying to find which location is closest to your house?
yeah, that is it
Okay. So you don't need to compare the locations to each other. You only need to figure out how far your house is from each location, and then take the row with the minimum distance.
You don't need to do a comparison sort, or something like that.
Do you know how to apply the distance formula for coordinates?
i was using the geopy to do that, but without it i don't know how i could do
you can use geopy
>>> from geopy.distance import geodesic
>>> newport_ri = (41.49008, -71.312796)
>>> cleveland_oh = (41.499498, -81.695391)
>>> print(geodesic(newport_ri, cleveland_oh).miles)
538.390445368
from their docs
ok, but do i need to create 1 variable for each street?
No. You can use .apply
It should be pretty simple. Let me know if you don't figure it out and we can go over it.
thanks dude
I'm really having difficulties doing that, the most I could do was print the latitude and longitude on the console, but even so, they are not separated by a comma and are not even inside parentheses, if you could help me when it's possible I would be very grateful
I have a nasty bug with the module Numba. I've isolated the bug down to the exact point, and I think it's a bug within Numba. I need some help:
def total_distance(solution, distanceMap):
"""
Calculate the total distance among a solution of cities.
Uses a dictionary to get lookup the each pairwise distance.
:param solution: A random list of city tuples.
:distanceMap: The dictionary lookup tool.
:return: The total distance between all the cities.
"""
totalDistance = 0
for i, city in enumerate(solution[:-1]): # Stop at the second to last city.
cityA = city
cityB = solution[i+1]
buildKey = str((cityA, cityB))
totalDistance = totalDistance + distanceMap[buildKey]
return totalDistance
The exact bug occurs at buildKey = str((cityA, cityB)). Without numba decorator, this code runs perfectly. With the numba decorator, it does not know how to convert a tuple into a string.
I've separated every single piece of that line. Numba can build a tuple (cityA, cityB). Numba can convert an int like 1234 into a string with str('1234'). However, numba crashes when trying to convert a tuple into literal string.
what are the skillset that i would need to become a data scientist in india
For anyone in the future: I figured out my issue. It requires an insane line of code.
distanceMap = Dict.empty(key_type=types.UniTuple(types.int64, 2), value_type=types.int64)
Hello
I was trying to do a mini project using linear regression
Project name: Full Battery time prediction
What this project does is
It will collect the battery level for 2 mins with 5 sec interval
And linear regression with gradient descent is applied for getting the equation of the line that is fit to the data
Equation: time=m*batteryLevel + b
Here m and b is found using linear regression
I could plug in batteryLevel value as 100 and get the time it takes for completing the charging
I ended up collecting the data in this format.
X=[0.55,0.56,0.56,0.56,0.56,0.56,0.56,0.56,0.56,0.56,0.56,0.56,0.56,0.57,0.57,0.57,0.57,0.57,0.57,0.57,0.57,0.57,0.57,0.57,0.58]
Y=[0,5,10,15,20,25,30,35,40,45,50,55,60,65,70,75,80,85,90,95,100,105,110,115,120]
- Can I apply linear regression for the X and Y directly and get the value of m and b
Or I need to scale the data such that both are in same decimal places? - The data in X is quite repeating. Can I add 2 more decimal values using some math techniques? Like since 0.56 is repeated so can I change the data to 0.5612,0.5622,0.5632,0.5642,0.5652...... Will this affect the learning??
Please @ me
I have seen in many code snippets, that most people tend to write array[i, :] instead of array[i] (for numpy arrays).
Although, both lines produce the same outcome.
Is it some kind of agreed convention? The common way to type numpy indexing?

Hello everyone, I just wanted to share my first kaggle notebook. I analysed the solar panel dateset. Please upvote if you find interesting and leave any feedback: https://www.kaggle.com/kristiandilov/eda-of-solar-panel-data

Explore and run machine learning code with Kaggle Notebooks | Using data from Solar Power Generation Data
a stupid question please, how can i get ssd_mobilenet model ?
Hello, please help to define the mathematical model that is used in this project: https://github.com/MioPoortvliet/COP-Population-Dynamics
Population dynamics model, there is an assumption that this is a very complicated Lotka-Volterra model, but it's not very clear how it looks like here.

GitHub
Contribute to MioPoortvliet/COP-Population-Dynamics development by creating an account on GitHub.
In querries, what does <> mean?
different i think
so does it mean the same as != ?
yes
Please don’t look at my status
hey anyone knows any resource on how to set up a remote jupyter server? want to use my main computer when I am out in the park
on google colab
from google.colab.patches import cv2_imshow
this cv2_imshow
behaves the same way as the cv2.imshow from opencv?
i imagine it's there because the standard cv2.imshow doesn't work right, based on the fact that it's called "patches"
yeah, but what i mean is, opencv reads images as BGR
so if u convert BGR to RGB, and display it, it is displayed wrongly

{kind=link}
{kind=link}
probably bgr then, but when in doubt consult the docs
so i guess this function needs the img to be bgr in order to display it correctly
i'm sure there is a documentation page for these google colab patches
idk where are the docs for this custom function lol
you can also type ?cv2_imshow into a new code cell
oh
i believe cv2_imshow? also works
a : np.ndarray. shape (N, M) or (N, M, 1) is an NxM grayscale image. shape
(N, M, 3) is an NxM BGR color image. shape (N, M, 4) is an NxM BGRA color
image.```? is an ipython feature, help() is built into python
You most certainly dont know an answer to that, but why does openCV use BGR > RGB?
idk :D
XD
i have been wondering the same since i used opencv for the first time
"The reason why the early developers at OpenCV chose BGR color format is probably that back then BGR color format was popular among camera manufacturers and software providers. E.g. in Windows, when specifying color value using COLORREF they use the BGR format 0x00bbggrr.
BGR was a choice made for historical reasons and now we have to live with it. In other words, BGR is the horse’s ass in OpenCV."
:D

Stack Overflow
Can any one explain why OpenCV using BGR colour space instead of RGB. We all know that RGB is the convenient colour model for most of the computer graphics and also the human visual system works in...
but idk why the changed, cuz now, a file is stored as rgb on the computer
like, png jpg etc have RGB order
so opencv has to do some extra operations
seems like we read the same article and you were faster
but it sucks actually
aren't most computer monitors RGB? it probably works better with computer hardware
cuz, if u wanna be fast, to display 9 images on a 3x3 grid, u could use matplot lib
but since images are bgr, matplot will display them wrongly
u will have to convert them if u wanna use matplotlib
or use np.concatenate if u wanna use imshow
i think keras reads on rgb, pillow rgb
i am pretty sure everyother image lib reads on rgb
opencv is the black sheep :D
Or use moveaxis/transponse
yeah, this too. hardware needs rgb info, so opencv, on the imshow, will have to convert from bgr to rgb too xD
Man, I should have started using pipeline a long time ago. What have I been doing
@acoustic forge pipeline is pretty great. however there's no pipeline for the labels, i ended up building my own at one point but i kind of lost track of the code when i left my previous job
huh ive never used those
i had intended to submit patches to sklearn but never got around to it. i should probably make that a priority, i think it'd benefit a lot of people
Can you elaborate on what you mean by pipelines for labels?
Stack Overflow
I have an ndarray such as
arr = np.random.rand(10, 20, 30, 40)
arr.shape
(10, 20, 30, 40)
whose axes I would like to swap around into some arbitrary order such as
&...
!e ```python
import numpy as np
x = np.arange(234).reshape((2,3,4))
print(x)
print(x.transpose())
print(x.transpose((1, 0, 2)))
@desert oar :white_check_mark: Your eval job has completed with return code 0.
001 | [[[ 0 1 2 3]
002 | [ 4 5 6 7]
003 | [ 8 9 10 11]]
004 |
005 | [[12 13 14 15]
006 | [16 17 18 19]
007 | [20 21 22 23]]]
008 | [[[ 0 12]
009 | [ 4 16]
010 | [ 8 20]]
011 |
... (truncated - too many lines)
Full output: https://paste.pythondiscord.com/zogonifiri.txt?noredirect
there's no equivalent functionality if you need to apply transformations to "y"
Ah, makes sense. Yeah
i will take a look at those funcs, seems faster than concatenate xd
also, i though about using reshape
is the same?
no, they're different
mmm
transposing a matrix is also a pretty fundamental linear algebra operation
you should definitely know what transpose is and does, at least for 2d matrices
if i had an array with shape (9,160,160,3) which are 9 images, couldnt i reshape into (3,3,160,160,3)?
so i have a grid of 3x3 with images?
i know what is the transpose, but the transpose of an image doesnt make any sense (?) it will rotate (?) the image?
it will flip it around the primary diagonal.
yes this is what .reshape would do
you wouldn't need to transpose for that
so the reshape would do what i want? idk, never tried to
how much data science do i need to know to learn ai
i'll make an example @cedar sun , give me a bit
not needed salt, really, thanks ^^ i will take a look at locs, they usually have examples ^^ but if u really tho, thanks very much :D
anyone?
or is ai basically data science
im not sure how it works tbh
more than data science a bit of maths
what do you mean?
well, what are u interested on?
machine learning
how a neural network works?
yeah
yeah, maths
not much of data science?
ai is kind of a separate field, but it uses a lot of machine learning and other general principles from data science, and it shares a lot of the math in common
i can get away with basic data science?
the data science is to process inputs to make the neural network learn faster
in broad sense, data science includes a lot of hats
that is: (some of) the core techniques in modern data science are also (some of) the core techniques in ai
if you want to become a data scientist, then you would want to know all the things
that includes visualizations, plotting, basic algos, ML etc.
do i need to learn everything or just some chapters for machine learning

if you want to do something simpler, then you can chose data analytics or sometthing
everything at some point
since the book that igot on machine learning said to read it i need to know numpy and pandas
all these things build up on basic concepts
@desert oar do you know if it's possible to get most informative features from a pipeline? Normally I can get it from randomforest, but what about if the classifier is in the pipeline?
yea, you can use youtube or some course for that
i see
you can use .steps or .named_steps to get the pipeline steps, if you've fitted the pipeline then the pipeline will contain the fitted individual models
Ahh, perfect
oh it looks like they do have the "y" transformer now, nice!
ah yes i remember this
there's a problem in how the scoring functions are handled for multi-label classification
if that hasn't been fixed, i should submit my patch still
I haven't run into any issues as of yet
anyway, you will want these:
https://scikit-learn.org/stable/modules/classes.html#module-sklearn.compose
https://scikit-learn.org/stable/modules/classes.html#module-sklearn.pipeline
ColumnTransformer, TransformedTargetRegressor (note they don't support classification for the reason i stated above), FeatureUnion, and Pipeline itself are very useful
Thanks! Will add these to the list of resources I gotta check out
Just finishing my report, to be handed in in a couple of days
Just wondering, has anyone even tried to train Huggingface models on TPU?
A guy's notebook I found had something like this:
def train_nli(model_name='bert-base-uncased'):
import datasets
from transformers import Trainer, TrainingArguments
from transformers import AutoModelForSequenceClassification, AutoTokenizer
from sklearn.metrics import precision_recall_fscore_support, accuracy_score
nli_data = datasets.load_dataset("multi_nli")
train_dataset = nli_data['train'].select(range(20000))
# limiting the training set size to 20,000 for demo purposes
dev_dataset = nli_data['validation_matched'].select(range(20000))
tokenizer = AutoTokenizer.from_pretrained(model_name)
tokenizer.model_max_length = 256
def tokenize(batch):
return tokenizer(batch['premise'], batch['hypothesis'], padding='max_length', truncation=True)
train_dataset = train_dataset.map(tokenize, batched=True, batch_size=64)
dev_dataset = dev_dataset.map(tokenize, batched=True, batch_size=64)
#device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=3)
model.train()
epochs = 10
#total_steps = (epochs * len(train_dataset)) // batch_size
#warmup_steps = total_steps // 10
warmup_steps = 200
training_args = TrainingArguments(
output_dir='./results',
num_train_epochs=epochs,
warmup_steps=warmup_steps,
evaluation_strategy="epoch",
weight_decay=0.01,
logging_dir='./logs',
load_best_model_at_end=True,
metric_for_best_model="f1",
)
results = []
trainer = Trainer(
model=model,
args=training_args,
compute_metrics=compute_metrics,
train_dataset=train_dataset,
eval_dataset=dev_dataset,
)
trainer.place_model_on_device = False
trainer.train()
trainer.save_model("nli_model/")
tokenizer.save_pretrained("nli_model/")
so he used the whole (weird) function and used torch_xla's spawn method to put it on TPU
the question is why would you need to have the imports, tokenization etc. all in the function?
doesn't make sense that you would execute all your code on TPU - some ops would be on CPU etc.
Wow
holy shit, when did we start to get 20-core CPUs on Colab? RAM 35Gb?
Soo many threads lol

When google strategically decided to try and become indispensable to the ai/research community in order to offset it abusing everyone else on the internet
That's my conspiracy theory anyway
Same reason Microsoft puts so much money into VSC
no matter what the core corporate agenda is, Pichai's aim is to stop all the shit at google and that involves getting out of the adsense business. hence their dominant position in AI and other niche areas
he has repeatedly tried to reform the company. I think he is getting quite a good amount of leverage by the AI approach, since GCP is now being used more
his long-term plan is kinda clear
What, to move away from ads?
yeah, that's his goal - atleast if we trust pichai anyways
Now that I think about it, they are probably envisioning the ad business getting regulated out of existence in the next 5 years
he has iterated it multiple times. the bad PR google gets from ads is not worth the revenue which would diminish
yea, smart
That's probably a win-win for society anyway so I'm OK with it
good for us, we get more funding 
I am really not a fan of this EEE stuff going on with chromium though
what stuff? I dunno
I kind of like the idea of MS Amazon Google exerting competitive pressure on each other
Oh, they've just been abusing their dominant browser market share
they've been abusing a lot of things lol
The reason they haven't crushed firefox is because the existence of firefox helps them avoid anti-trust regulation lol
but atleast now they are recognizing what's gonna happen
I don't think so really
the people who use firefox just want a lighter version of browser
it has quite many missing features from Chrome
well yeah, mozilla has been pretty badly mismanaged over the years
I wouldn't say it has quite many missing features though, if anything chrome is relatively feature deficient
I think its the intergration - mozilla has great integration when migrating, but bad with existing products
like casting, google home etc.
plus it requires some extensions to run... ahem different "content" websites
pirated movies sites mostly
it doesn't work for me in some sites
prime video is shaky too - can't use bluetooth speaker or cast
haven't tried with nflx tho.
it has quite many missing features from Chrome
I am still waiting for tree style tab to come to Chrome 😮
oh, that sounds like a nice feature for my 50 concurrent tabs
Hi Everyone,
I am currently an intern at a company trying to create a documentation diagram for my team who is building a chatbox for the companies website/mobile app. One of my tasks is trying to help them understand what models do what and who is in charge of that model.
I created a few questions myself, but I don't know what else I should be asking. I have never done something like this in class before so I wanted to come here and see any tips you have?
They are using Python, Hadoop, Apache Spark, Google Dialogflow, and SQL.
Thank you all and I appreciate your help!
what do you mean by "questions" in this case @silver sun ?
questions to ask other people at the organization?
Any reason in particular for choosing datacamp?
compared to the other two options it seemed the most "data"-oriented
"python for x" versus "x that happens to be with python"
i prefer the latter mindset
i have not tried any of them, no
Yes I have to talk with Data Scientists and ask them questions and I created some but dont really know if im asking the right stuff.
- What does this model do?
- What business purpose does it serve?
- What data was used to train the model? What features and input data processing were used?
- What kind of model is it? Regression, neural network, etc.
- How is model performance evaluated?
- How often is the model re-trained, if ever?
- Who is responsible for monitoring model performance over time?
- Who is responsible for maintaining the source code for: the model, input data processing, and output processing?
just some stuff off the top of my head
Hello I am using Pandas and am wondering how I can iterate through my dataframe grabbing the value in a column while changing other values in the same row?
@toxic urchin instead of thinking about how you're going to do it, can you explain what you ultimately want to get?
What data transformation do you actually want?
Omggggg thank you so much man. I didnt have alot of these only a few basic ones.
Sure, sorry about that
So I realized that while I was building my dataframe I had an issue with the code that was supposed to fill in a cell on the row.
So for me to fix this mistake, I need to go through my dataframe using the value in one cell to query my endpoint to fix the other cell.
Can you provide an example as comma separated values (no screenshot)?
So I'll need a way to grab the cell value on one column use this value on my endpoint and then use the output to fix.
Sure, one sec.
Row1 Row2 Row3 Material Price
ABC NaN
CBD NaN
I'll be back in a little bit
I'm looking to grab the value from Material and then change price
@toxic urchin so you're trying to replace the nan values. But with what?
With values that my endpoint will provide
But in the body of my request
I need to pass in my material, hence why I'll need the value
So I'm basically stuck on how I can create a loop to work by the row of the df
Like
for i in range(len(df)):
cur_material = ???
I'm stuck on how to get the material for the index i'm iterating