#data-science-and-ml
1 messages · Page 317 of 1
ill try installing
if you dont mind using v1.8.0 use: pip install torch==1.8.0+cpu torchvision==0.9.0+cpu torchaudio==0.8.0 -f https://download.pytorch.org/whl/torch_stable.html
Collecting torch==1.8.1+cpu
Downloading https://download.pytorch.org/whl/cpu/torch-1.8.1%2Bcpu-cp38-cp38-win_amd64.whl (190.5 MB)
Collecting torchvision==0.9.1+cpu
Downloading https://download.pytorch.org/whl/cpu/torchvision-0.9.1%2Bcpu-cp38-cp38-win_amd64.whl (845 kB)
Collecting torchaudio===0.8.1
Downloading torchaudio-0.8.1-cp38-none-win_amd64.whl (109 kB)
Looking in links: https://download.pytorch.org/whl/torch_stable.html
ERROR: Could not find a version that satisfies the requirement torch==1.8.0+cpu
ERROR: No matching distribution found for torch==1.8.0+cpu
Download them manually then
i tried like 5 but they all say
ERROR: torch-1.8.0+cpu-cp38-cp38-win_amd64.whl is not a supported wheel on this platform.
@blissful nymph can you screen share by any chance?
Join <#764232549840846858 >
uggh
Im in Code/Help 1
Scroll down in left pane and see
its says not permission to speek
ok just accept friend req xD
it's often much easier to use conda when installing machine learning libraries
download anaconda and use the anaconda prompt instead of the regular windows command prompt
i believe so, yes. at least, that's what i've done when i've used torch. see https://pytorch.org/tutorials/beginner/basics/data_tutorial.html#creating-a-custom-dataset-for-your-files and https://pytorch.org/tutorials/beginner/basics/data_tutorial.html#preparing-your-data-for-training-with-dataloaders
Hello! I'm reading a piece of code written way back in 2013 with Python2. Here is the code:python I = np.resize( np.array([0,1,2,1,2,3], dtype=np.uint32), (n-1)*(2*3)) I += np.repeat( 4*np.arange(n-1), 6) if I run this piece of code I get the error below:```
Traceback (most recent call last):
File "/tmp/sessions/b1d0dbc9bba9adb6/main.py", line 143, in <module>
I += np.repeat( 4*np.arange(n-1), 6)
TypeError: Cannot cast ufunc add output from dtype('int64') to dtype('uint32') with casting rule 'same_kind'
can you make everything int64?
I don't know what you mean by that. I'm not familiar to the language, and the code isn't mine, it is from a paper. These two lines are but pieces of a much bigger puzzle.
TypeError: Cannot cast ufunc add output from dtype('int64') to dtype('uint32') with casting rule 'same_kind'
One of the arrays consists of 64 bit integers, whereas the other is "uint32", which I actually haven't heard of, so my guess is that it's an older system.
Exactly, it is written in Python2 with an older version of numpy.
This is my first experience in python and numpy, so I don't know what to do 😄
any reason you're working with python 2 in your first project?
im not
this is from a paper im reading
im porting the code to another language
but i don't understand the syntax so I run it to see what it does to the input
try deleting dtype=np.uint32 from the code
and I do the same operation in a different language
and just have I = np.resize(np.array([0,1,2,1,2,3]), (n-1)*(2*3)) for that line.
it runs, but now the question is how do i make sure it produces the correct output?
unsigned 32 bit int
which is narrower
hmm
positive int64 = uint32?
i won't need negatives since these are indexes to an array
i believe this is done to save memory space by the author?
I = np.resize( np.array([0,1,2,1,2,3], dtype=np.uint32), (n-1)*(2*3))
I += np.repeat( 4 * np.arange(n-1, dtype=np.uint32), 6)
this works for me
!e ```python
import numpy as np
n = 3
I = np.resize( np.array([0,1,2,1,2,3], dtype=np.uint32), (n-1)(23))
I += np.repeat( 4 * np.arange(n-1, dtype=np.uint32), 6)
print(I)
@desert oar :white_check_mark: Your eval job has completed with return code 0.
[0 1 2 1 2 3 4 5 6 5 6 7]
is that what you want? no idea. does it work without an error? yes.
hmm, but you added dtype=np.uint32 to the second line 🤔 I'd rather have the code unchanged to avoid any unforeseen bugs 😦
nope
a uint32 has enough space (-1) to store the positive numbers you could contain in a hypothetical signed int33
powers of 2.
is it really necessary…?
i would
i have no problems with that
im trying to figure out why the author didnt
otherwise it’s a narrowing conversion which is rightfully rejected
was it significant to use uint32? or did he just felt like it?
could have been a mistake
uint32 and int64 are very different in the way they are typed tho
no like
a planning mistake
and then
sometime along the way numpy started disallowing implicit narrowing conversions
@desert oar I figured out how to do that transformation without using any for loops: df.values.reshape((24, 3, 10)).transpose((1, 0, 2)).
I found this: https://github.com/numpy/numpy/issues/7225, in the link they talk about the same problem and it is fixed by writingpython np.add(I, np.repeat( 4*np.arange(n-1), 6), out=I, casting="unsafe") instead of python I += np.repeat( 4*np.arange(n-1), 6)

!e import numpy as np n = 3 I = np.resize( np.array([0,1,2,1,2,3], dtype=np.uint32), (n-1)*(2*3)) I += np.repeat( 4 * np.arange(n-1, dtype=np.uint32), 6) I2 = np.resize( np.array([0,1,2,1,2,3]), (n-1)*(2*3)) np.add(I2, np.repeat( 4*np.arange(n-1), 6), out=I2, casting="unsafe") print(I) print(I2)
how do i run this?
yes, it is as I said
The behavior Gizeh depends on has been deprecated since 1.7.
but why wouldn't you just make the original array bigger?
unless you actually get a memory error...
well, it doesn't really matter. I only want to see the output of the original code.
and since the experinced people say the two lines I wrote are the "same"
i finally start porting it
did it. 🙂
i didn't know transpose accepted arguments
good trick
😁
also good call on the reshape
i didn't use it because i wasn't sure what order it would reshape in
how do i bookmark that
.bm 850167557101060096 using reshape + transpose to replace a for loop with groupby and pd.concat
You have to stop.
@desert oar, please enable your DMs to receive the bookmark.
if you have time for a follow-up: I just fiddled around with the orders of numbers (I knew it had to be 24, 3, and 10), and for the next operation where I needed to specify an axis, I tried 0, then 1, then -1, etc, until I got an output with the right dimensions. Is there a good resource for understanding all this dimensionality and axis stuff?
the linalg class I took only had up to 2-d matrices
yeah it gets a little mind-bending when you try to generalize row-major/c-order and column-major/fortran-order to 3+ dimensions
honestly, i don't (yet)
it's something i've been working on understanding better myself
that, and einsum
https://www.labri.fr/perso/nrougier/from-python-to-numpy/
is a very decent guide on the basics of numpy's internals and some examples of how to vectorize stuff in different ways
An open-source book about numpy vectorization techniques, based on experience, practice and descriptive examples
it kinda covers shapes and the like
thanks, this looks great
i always get tripped up because the visual display kind of doesn't follow the order you might expect
!e ```python
import numpy as np
print( np.arange(30).reshape(5,3,2) )
@desert oar :white_check_mark: Your eval job has completed with return code 0.
001 | [[[ 0 1]
002 | [ 2 3]
003 | [ 4 5]]
004 |
005 | [[ 6 7]
006 | [ 8 9]
007 | [10 11]]
008 |
009 | [[12 13]
010 | [14 15]
011 | [16 17]]
... (truncated - too many lines)
Full output: https://paste.pythondiscord.com/metahademo.txt?noredirect
!e ```python
import numpy as np
print( np.arange(30).reshape(5,3,2).ravel() )
@desert oar :white_check_mark: Your eval job has completed with return code 0.
001 | [ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23
002 | 24 25 26 27 28 29]
@light aurora :white_check_mark: Your eval job has completed with return code 0.
hello world!
i'll have to read through that numpy document
@light aurora use #bot-commands to test the bot 🙂
that's the name of a channel
feel free to head back here if you want to talk about data science (and not fight club)
Will do!
ughh how to make a new column = class and assign all the value that i already locate as food

i tried to use assign it is not working at least for me
here's one way to do it
bank_statement['class'] = None
is_atm_withdrawal = bank_statement['Transaction Details'] \
.str.contains('ATM WITHDRAWAL')
bank_statement.loc[is_atm_withdrawal, 'class'] = 'food'
another, slicker but less easy to read i think
is_atm_withdrawal = bank_statement['Transaction Details'] \
.str.contains('ATM WITHDRAWAL')
bank_statement['class'] = is_atm_withdrawal.map({True: 'food', False: None})

it’s good to think of it in terms of actual memory layout I think
that helped me
i'll have to ponder that. i know that "raveling" runs across rows by default, and that this corresponds to row-major/c-order
is it that F-order runs "along" the outermost (leftmost) dimension first, and C-order runs along the innermost (rightmost) dimension first?
x = np.arange(30).reshape(5,3,2)
x.ravel(order='C') # 0 1 2 3 ...
x.ravel(order='F') # 0 6 12 18 ...
I am trying to graph a log function with a given base value
it is giving the error
File "D:\programs\program (1).py", line 52, in __init__
y= math.log(b,x)
TypeError: only size-1 arrays can be converted to Python scalars
Is there any other way I could write this?
That's a Friday for every programmer
working with matplotlib in tkinter. both new to me
okay how I think about this is...imagine memory is linear:
0, 1, 2 ... n-2, n-1, n
no matter how many dimensions you have, in C-order, for any two values, the distance between them will depend most on the first axis, and then the second, and so on, and the reverse is true for F-order.
in other words, for all arrays a, a[0, 0, ..., 0, 0, n - 1] and a[0, 0, ..., 0, 0, n] will always be next to each other in memory, in C-order, and a[n - 1, 0, 0, ..., 0, 0] and a[n, 0, 0, ..., 0, 0] for F-order
and individual axes can be thought of as sub-arrays
for which this rule applies recursively
honestly I don't think that answered your question, sorry
no that does actually help
in F-order, these are contiguous:
a[n - 1, 0, 0, ..., 0, 0]
a[n , 0, 0, ..., 0, 0]
i'll try to think of it in those terms
does this site help?
https://numpy.org/doc/stable/reference/generated/numpy.isfortran.html

In computing, row-major order and column-major order are methods for storing multidimensional arrays in linear storage such as random access memory.
The difference between the orders lies in which elements of an array are contiguous in memory. In row-major order, the consecutive elements of a row reside next to each other, whereas the same hold...
ty
For 2D: i = col + num_cols * row
yep, 2d is the easy case
For N-D you just repeat the pattern
In row-major order, the last dimension is contiguous
[[1, 2, 3],
[4, 5, 6]]
the "last dimension" is what in this case?
the shape is (2, 3), so the "last dimension" would be "across rows", and each row is length 3?
3D: i = x + num_xs * (y + num_ys * (z))
so the last number in the numpy shape is the "size" of the dimension
So technically, the last dimension can be anything, row major and column major only refer to memory layout, but you could have that abstracted away. One should access elements in order of the memory layout for speed reasons (cache prediction).
numpy is row major by default, so im using that convention
It's the C convention, so under that.
Your 1D actual memory looks like this: [1, 2, 3, 4, 5, 6]
right, that much i understand
when you now are looping over this 2D array you have 2 indices: [0, 0]
(0, 0) -> 0, (0, 1) -> 3, etc.
To loop over this 2D array you want to start with the last index, since counting it up loops in-order in the actual 1D array.
From i = col + num_cols * row
col is indices[1]
ahhh
row is indices[0]
it's about which dimension gets incremented
now that makes a lot of sense
so in row major 2d, you move "across rows" by incrementing the column
if you loop by increasing the first dimension first, you will skip N items with each increment which is out of order memory access and your cpu may not be able to predict your movement resulting in a cache miss.
generalized to 3d, you could call the dimensions "layer", "row", and "column" - in row-major order, you still increment the "column" first
You can go in any order, but if you are doing say, elementwise addition, you want the fastest ordering.
yeah, i'm assuming that's what we are doing
yes numpy will do this
since this ordering is also contiguous
it can make use of the cpu's vector instructions, fetching say, 4 elements at a time
Numpy makes heavy use of vector operations
!e ```python
import numpy as np
x = np.ascontiguousarray([[1,2,3],[4,5,6]])
y = np.asfortranarray([[10,10,10],[100,100,100]])
print( x * y )
@desert oar :white_check_mark: Your eval job has completed with return code 0.
001 | [[ 10 20 30]
002 | [400 500 600]]
something like x3 to x5 performance increase from just the vector ops (not including the gains from in-order which are VERY big).
so that * operation up there will be significantly slower than normal, because numpy has to traverse y in non-contiguous order
In general the CPU likes contiguous homogeneous data and a predictable access pattern (just moving up by one is very predictable (with no if statements either to change this pattern)).
Both C and Fortran style are contiguous, but the complete opposite ordering
holy shit that is very much slower
In Fortran style, the first index increments the fastest.
x = np.ascontiguousarray([[1,2,3],[4,5,6]])
y = np.asfortranarray([[10,10,10],[100,100,100]])
In [7]: %timeit x*y
1.44 µs ± 220 ns per loop (mean ± std. dev. of 7 runs, 1000000 loops each)
versus
x = np.ascontiguousarray([[1,2,3],[4,5,6]])
y = np.ascontiguousarray([[10,10,10],[100,100,100]])
In [9]: %timeit x*y
490 ns ± 31.8 ns per loop (mean ± std. dev. of 7 runs, 1000000 loops each)
@iron basalt right, so when the arrays don't have the same memory layout, numpy has to traverse one of them out of order
yes, also anything that makes it not contiguous will be a lot slower, like say a slice with a non constant stride (random indices picked is probably the worst case).
In [10]: x = np.asfortranarray(x); y = np.asfortranarray(y)
In [11]: %timeit x*y
500 ns ± 33.2 ns per loop (mean ± std. dev. of 7 runs, 1000000 loops each)
In [12]: x = np.ascontiguousarray(x)
In [13]: %timeit x*y
1.39 µs ± 141 ns per loop (mean ± std. dev. of 7 runs, 1000000 loops each)
Well even with a stride > 1, it will not be as good
Elementwise operations of same shaped, some ordering arrays is the ideal scenario for speed.
(Same dtype)
Funnily, on the GPU, the time it takes to transpose a large matrix is not very big and so matrix multiply algorithms will first transpose the memory layout of one of the two matrices before doing the multiply.
So both can be accessed in order when doing the multiply.
(GPU have other quirks like loving powers of 2 for matrix sizes so if you want faster NN you can try making your weight matrices round to the nearest power of 2 for their sizes (depending on the matrix multiply algorithm impl, but the really fast ones check if you have a power of 2 and then do their fastest version))
np.arange(7*3*10).reshape((7,3,10)).reshape((7,3,5,2), order='F')
array([[[[ 0, 5],
[ 1, 6],
[ 2, 7],
[ 3, 8],
[ 4, 9]],
[[ 10, 15],
[ 11, 16],
[ 12, 17],
[ 13, 18],
[ 14, 19]],
...
i was not expecting this
i was expecting something like
array([[[[ 0, ?], ...] ,...],
[[[ 1, ?], ...], ...]])
IDR, but numpy may also check the size of the last dimension to see if it's a multiple in size of the vector operation size on your cpu and if it is, it can do a faster loop. So if your final dimension (C contiguous) is a multiple of say 4, it would not surprise me if numpy has a faster loop for it.
In my code I check for this.
It looks right to me. If look at just the last two dimensions
and imagine the rest did not exist.
5 rows, 2 columns
right, but that's not "column major" then, is it?
The memory layout is separate.
i expected order='F' to mimic the column-major memory layout
If you have 5 rows and 2 columns, this does not change no matter the memory layout
If you are thinking that the indexing order should change, numpy may keep them the same for both so the layout is abstracted away from you
https://numpy.org/doc/stable/reference/generated/numpy.reshape.html?highlight=reshape#numpy.reshape
‘F’ means to read / write the elements using Fortran-like index order, with the first index changing fastest, and the last index changing slowest.
So with reshape
The order here actually specify the order it reads from the array being reshaped.
right, i had to think about that
Not the memory layout of the array itself
Read the elements of a using this index order,
It could have the other memory layout in reality, but they are overloading/reusing the terminology to explain which order it will read from a.
>>> a = np.arange(10).reshape((5, 2), order="F")
>>> a
array([[0, 5],
[1, 6],
[2, 7],
[3, 8],
[4, 9]])
>>> b = np.arange(10).reshape((5, 2), order="C")
>>> b
array([[0, 1],
[2, 3],
[4, 5],
[6, 7],
[8, 9]])
>>> a[1]
array([1, 6])
>>> b[1]
array([2, 3])
Hey
Anyone here very experienced with NLP?
I would even pay a little fee for some assistance/guidance.
ahhh
ok this is good stuff
In [63]: np.arange(10).reshape((2,5)), np.arange(10).reshape((2,5)).reshape((5, 2), order="F")
Out[63]:
(array([[0, 1, 2, 3, 4],
[5, 6, 7, 8, 9]]),
array([[0, 7],
[5, 3],
[1, 8],
[6, 4],
[2, 9]]))
i still have a hard time generalizing this to 3+ dims in my brain
let me try a bigger example
>>> a = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]], order="C")
>>> a
array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
>>> b = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]], order="F")
>>> b
array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
>>> a[1]
array([4, 5, 6])
>>> b[1]
array([4, 5, 6])
>>>
Numpy arrays can have a different memory layout but will always be indexed in the same way (row, col). Or in N-D (..., w, z, y, x).
np.arange(24).reshape((6,2,2)), np.arange(24).reshape((6,2,2)).reshape((2,3,4), order='F')
np.arange(24).reshape((6,2,2)), np.arange(24).reshape((6,2,2)).reshape((2,3,4), order='C')
this is example is helping me (not posting output due to length)
It's always a bit hard to tell what numpy is doing due to it having so many cases and its dynamic nature.
I have read a lot of its C code, but it's a lot of stuff added over time.
At the way bottom is does a simple loop (stuck in a C macro) in which it has an array of indices and it adds one to the current dimension and if that dimension overflows (reaches the end) it sets that index back to zero and moves up a dimension and repeats.
right
A sort of multi-dimensional "i += 1"
i think reshaping is best expressed in those terms too, now that im coming to understand it in higher dimensions
i think this is what the docs are trying to say
Reshaping is just changing an array which holds lengths along each dimension (the shape array) and also the strides array (how much do you move along the 1D array for this given dimension).
Changing the memory layout would require allocating more memory and copying over the elements in the new order (this becomes the new data pointer).
yeah that much i get. the trick is knowing which i,j,k coordinate points to which element after the reshape
x = np.arange(24).reshape((6,2,2))
y = x.reshape((2,3,4), order='F')
this means
y[0,0,0] <- x[0,0,0]
y[1,0,0] <- x[1,0,0]
y[0,1,0] <- x[2,0,0]
y[1,1,0] <- x[3,0,0]
etc.
Yeah that's pretty hard to think about because it's both reshaping and doing a different ordering at the same time.
whereas
x = np.arange(24).reshape((6,2,2))
y = x.reshape((2,3,4), order='C')
means
y[0,0,0] <- x[0,0,0]
y[0,0,1] <- x[0,0,1]
y[0,0,2] <- x[0,1,0]
y[0,0,3] <- x[0,1,1]
y[0,1,0] <- x[1,0,0]
etc.
so the "order" refers to both the "source" and "target" arrays in this case
hard to wrap your head around what that means until you work through it one element at a time
It's pretty annoying / difficult to think about the other ordering when having worked in another for a long time.
i can imagine
The C ordering has some pretty good reasons as to why one pick it over Fortran, but IDK maybe there is some kind of internet war about it and I don't want to start anything.
Hey what's the difference between RidgeCV, LassoCV and GridSearchCV
?
isn't it just easier to use GridSearchCV?
it makes sense in terms of specification on the model, but isn't Grid much more flexible?
you can think of GridSearchCV as a more general form
yo
Ridge and lasso both allow for much more efficient computation than naive grid search
So it is basically computational aspect?
can someone give me some good resources for understanding backpropogation, gradient descent and cost functions?
I'm just getting into Neural networks and was trying to complete a book about it http://neuralnetworksanddeeplearning.com/chap1.html but I'm stuck not understanding the non feed - forward part of the code and book.
Yes.
In LASSO you can actually compute the entire "path" of regularization from no regularization until all weights are 0 without refitting the model at each step.
And in ridge regression, you can compute an approximation to leave-one-out cross validation without actually re-fitting the model N times.
Cost functions should be pretty straightforward. For any set of model parameters (eg weights in a neural network), it tells you how well the model performs. The core technique of machine learning, and more broadly the core technique of model fitting, is to find the parameters that minimize a cost function on your dataset.
Gradient descent is an algorithm for finding the minimum of a function. It is often used to minimize cost functions in machine learning because it can be performed on a wide variety of functions, and it does not require you to load the entire data set into memory at once, which is essential for training huge models on huge amounts of data.
Backpropagation is a technique for computing the gradient of the cost function, which is a necessary step in most optimization routines, including gradient descent. The gradient is a basic topic in multidimensional calculus; it's a multidimensional extension of the derivative. Backpropagation more or less amounts to using the chain rule for finding derivatives. If you don't know what the chain rule is and you don't know what gradients are, you would benefit from learning about those topics in calculus.
well I'm not sure if I understand this correctly but the cost function is [output - expected output ]^2 as a vector of all the outputs - expected outputs?
Kind of. That is the cost or loss "at each data point". You would need to collect them together (usually just summing them) to get the total loss for the model
also for gradient descent aren't we calculating the slope between our points trying to find the lowest point basically the negative gradient to somehow find the point that achieves the greatest change in our results.
And that is one possible loss function. There are others
sum over number of inputs right?
Yes
That is the intuition yes
hm.. I don't understand the math behind it, think a calculas course would help?
Yes, definitely
or should I just do practical work and tf, kiras , tutorials.
Both, if you have time!
like this makes no sense to me as a cost function

why 1/2n?
is there some sort of resources that just gives me the calculas needed to pursue common Neural networks
or should I study calculas from scratch?, I've studied it before but I haven't used it for so long it's like I am a fresher..
You don't need to start from scratch but this is a great opportunity to re-learn things
If you remember what the power rule is, try applying it to that expression and see what happens to the 2 in front
like the neural networks and deep learning book is a great resource, looking for something like that but with more focus on explaining the math.
I think that would be a great resource, I don't know if one exists
I think a lot of the machine learning books out there assume you already know the math
ahh guess I gotta do calculas.
I was hoping to jump into Object detection within a month.
trying to build a CNN to detect civilians and military personnel in CCTV footage.
there's alot of object detection tutorials out there but I feel like if I just follow the tutorials, I'll lose out on the educational experience of building it myself or understanding how it works on a lower level
Any web scraping legends here? :))
I have a question on how I could achieve something. Essentially, I need to scrape this site https://emm.newsbrief.eu/NewsBrief/searchresults/en/advanced.html?lang=en&sourceCountry=US&source=ABCnews%2Ccnn%2Cfoxnews%2Cnytimes%2Chuffingtonpost-us-en&atLeast=vaccine&dateFrom=2021-01-12&dateTo=2021-05-31&queryType=advanced
However, there is a short delay between the actual articles are loaded, which means scrapy doesn't pick it up in its initial response. Does anybody have an idea on how I could work around this, so I can get scrape the articles?
I don't see how this is a data science question
ok cheers!
you still can, but you have to accept that you might not understand all the math yet. i think it's a good thing to do both concurrently
get the feel for the code, working with the data, and the intuition of building models
while also gradually learning or re-learning the underlying math
it becomes an interactive exploratory process
Hello fellows. Is some one working with ML classifiers using preferably PyTorch ? I have a question regarding transfer learning between to similar problems on text classification with different number of classes of each model.
More over, I have used a pretrained BERT model and I have fine-tune it using a big dataset with 3 classes [dataset_size * 3]. I am wondering if I can load it's states or the full model and change the output size from e.g. [classifier_size * 3] του [classifier_size * 9] and fine-tune with a [dataset_size * 9] dataset. Is that even possible ?
Hello, I'm trying to plot the probability curve from logistic regression for binary classification using just 1 feature. Following is my code :
y_pred_probs = log_reg.predict_proba(X_test)
y_pred_probs = y_pred_probs[:, 1]
plt.scatter(X_test, Y_test)
plt.plot(X_test, y_pred_probs)
plt.grid()
plt.show()
But I'm getting some crazy graph, not the S-curve.

I know it sounds a bit weird, but someone is familiar with good python IDE for m.l that runs on ipad?
is it possible to group certain classes together for the purposes of transfer learning?
It could be possible if I wanted to go from 9 to 3 but I need the opposite. To final classifier must be of 9 classes. And I cant split them *
I wonder if that way is possible. Steps:
- Load Pretrained BERT model
- Fine-tune it using the 3-class dataset (as a 3-class classifier) and save the hidden layer weights
- Re-load Pretrained BERT model
- Load saved weight on BERT (as a 9-class classifier)
- Fine-tune it using 9-class dataset (as a 9-class classifier) and save model state
it can't lol
what is exactly your task/dataset?
The first large dataset consists of [[text, label (3 sentiment classes)]] whereas the other small dataset consists of [[text, label (9 emotions classes)]] . I guess that I can transfer learning from the large sentiment dataset the a similar problem for which I have a small dataset for fine tuning and testing. I will fine-tune a pretrained BERT model and the final classifier will predict emotions (multi-label) from text
aight, you can try
doesn't gurantee a good accuracy toh
Their is also an other solution, is to use 9+3 outputs and train different part of the model each time. Its called multi-task learning. The thing is that I haven't done any of those before. In the first case I might need to save the weights in an order not to conflicts with the different output size weights. So I am looking for some one how might have done it before.
Or else I get something like this
RuntimeError: Error(s) in loading state_dict for BertClassifier:
size mismatch for classifier.2.weight: copying a param with shape torch.Size([3, 30]) from checkpoint, the shape in current model is torch.Size([9, 30]).
size mismatch for classifier.2.bias: copying a param with shape torch.Size([3]) from checkpoint, the shape in current model is torch.Size([9]).
This when I load 3-class model saved weights on a 9-class classifier
Which makes absolutely sence
you load a 3-class weights file onto a 3-class model, remove the relevant layers in the end, convert it to 9-class and then train
One of the profs in our uni EE department wants to order a new multi-GPU server for ML/DL, "faster than" his current quad-2080ti system.
But the RTX 30x0 series is sooo backordered everywhere. The just-out RTX 3080Ti looks promising for this build, but its sooo overbought - people camping outside BestBuy overnight. Are we doomed?
I'm kind of hoping that system integrators will get some inventory sequestered from the retail shopping mania / bots / scalpers
I didn't get you. Here I loaded 3-class weights into a 9-class classifier and normally returned an error. What are you suggesting exactly ? If I understand you are suggesting to change the classifier's architecture/design, the output layer specifically, between loading previous states and fine tuning on the new set ?
I don't think you get it - if you load 3-class weights on 9-class classifier, the only thing different is the output softmax layer. if you just remove that layer, you can load the 3-class weights, and then add another layer for constructing a 9-class classifier
the output layer specifically, between loading previous states and fine tuning on the new set ?
exactly
anyone who can help me with confusion matrix ?
@lapis sequoia I can, whats up?
👍

haha
Ah, I've had a few beers, give me a break 😄
anyways have a good rest of your day
good job @atomic tide
props to the mod team
Alright, let's get back to data science and AI

what's happening here lol
Quick Pytorch question: collate_fn is NOT supposed to be a generator, right? I have a IterableDataset which would yield a single value - the collator function is supposed to unify those samples into a batch (like a single 2-Dim tensor), right?
I thing I get it. I am not actually using a softmax layer but a sigmoid with argmax on top to get the highest probability. I forgot to mention the in the first case I have a 3 -lass multi-class classifier where in the second case I have a 9-class multi-label classifier, so I dump the argmax for multiple labels. So that serves me well I guess. So what I need to do is change the classifier mid way. Now I get why people use notebooks instead of python classes. They are easier to play with.
using softmax or sigmoid; doesn't matter
No it doesn't, I am just talking too much I guess. Thank you for your help
Hey! I'm having a hard time understanding the np.dtype function. For example, what is the type of dash_phase? python utype = np.dtype( [('color', 'f4', 4), ('translate', 'f4', 2), ('dash_phase', 'f4', 1), ('dash_period','f4', 1), ('dash_index', 'f4', 1), ('dash_caps', 'f4', 2), ('closed', 'f4', 1)] )
what does 'f4' mean? what does 1 mean?
That seems to be a dtype of a Structured Array
https://numpy.org/doc/stable/user/basics.rec.html
Each tuple has the form (fieldname, datatype, shape) where shape is optional. fieldname is a string (or tuple if titles are used, see Field Titles below), datatype may be any object convertible to a datatype, and shape is a tuple of integers specifying subarray shape.
so the color field here is a subarray of 4 f4 values, say
(f4 seems to mean f32, a single-precision float)
yup, if I'm reading it right
but how is this possible? dash_pattern is a stringpython if self.dash_atlas: dash_index, dash_period = self.dash_atlas[dash_pattern] U['dash_index'] = dash_index ... dash atlas defined as:```python
class DashAtlas(object):
def __init__(self,shape=(64,1024,4)):
self['solid'] = (1e20,0), (1,1)
self['densely dotted'] = (0,1), (1,1)
self['dotted'] = (0,2), (1,1)
self['loosely dotted'] = (0,3), (1,1)
...```
dash_index is a single float, yet it takes two floats?
where does it take two floats here?
yeah, but why is dash_index two floats?
Quick Pytorch question: collate_fn is NOT supposed to be a generator, right? I have a IterableDataset which would yield a single value - the collator function is supposed to unify those samples into a batch (like a single 2-Dim tensor), right?
it gets two floats from dash_atlas's [] operator
It looks like whatever self.dash_atlas[dash_pattern] returns is unpacked into two variables
if it's an array of 2 elements, then dash_index ends up assigned the first of them
for example self.dash_atlas['solid'] is (1e20,0), (1,1)
dash_index gets (1e20,0)?
it is two floats
ah, I see now
how is this possible?
not sure. My next step would be using a debugger to see what dash_index and U['dash_index'] are here, at runtime
raise ValueError("Target size ({}) must be the same as input size ({})".format(target.size(), input.size()))
ValueError: Target size (torch.Size([21334])) must be the same as input size (torch.Size([21334, 2])``` anyone have any idea how to fix this?We would need to know more about what you're trying to do. However it looks like you're trying to do a mathematical operation that isn't possible.
nah i figured it out took forever
it has to do with the fact that the BCE loss functions wants the same dim as input and output
so I have to just have one at the end which makes sense
We auto-matically compiled a list of 640 abuse terms by recursively traversing the WordNet hierarchy for all the hyponyms of the root phrases“tobacco”for tobacco,“alco-holic drink”for alcohol, and“sedative”,“narcotic”, and“controlled substance”for drugabuse. There were 46 terms for tobacco (e.g., cigarette, cigar), 324 terms for alcohol(e.g., wine, porter, scotch), and 270 terms for drug (e.g., heroin, cocaine).
I am trying to replicate the task above. Can anyone help me?
Should I learn Tensorflow or Pytorch?
look up stemming in python
starting with Tensorflow is much easier
why
because you have to write a minimal amount of code
If I have an (a, b, c) shaped array, and I do a calculation along the third dimension, why is the shape of the resulting array (b, a)?
actually it's not. nevermind 😄
Can anyone tell me why I'm getting this random error? (My code was working fine last time I checked...)
Error:
line 113
except:
^
IndentationError: expected an indented block
your indentation is wrong somewhere
it never is
but I suppose you knew that already 🥴
I forgot that I had transposed it and that my actions had consequences.
if you are going to write minimal code @serene scaffold go with fast ai its much better
class dataset(Dataset):
def __init__(self,x,y):
self.x = torch.tensor(x,dtype=torch.float32).unsqueeze(1)
self.y = torch.tensor(y,dtype=torch.float32).unsqueeze(1)
self.length = self.x.shape[0]
def __getitem__(self,idx):
return self.x[idx],self.y[idx]
def __len__(self):
return self.length
trainset = dataset(train_x,train_y)
trainloader = DataLoader(trainset,batch_size=21334,shuffle=False)
class Net(Module):
def __init__(self):
super(Net, self).__init__()
self.nn = nn.Sequential(
nn.Conv2d(1, 1, kernel_size = 4, stride = 1),
ReLU(inplace = True),
nn.MaxPool2d(kernel_size = 4, stride = 1),
nn.Conv2d(1, 1, kernel_size = 3, stride = 1),
ReLU(inplace = True),
nn.MaxPool2d(kernel_size = 6, stride = 2),
nn.Conv2d(1, 1, kernel_size = 2, stride = 2),
ReLU(inplace = True),
nn.MaxPool2d(kernel_size = 2, stride = 2),
ReLU(inplace = True),
nn.Flatten(),
nn.Linear(16,1),
)
def forward(self, x):
x = self.nn(x)
return x
model = Net()
optimizer = SGD(model.parameters(), lr = .01)
criterion = nn.BCEWithLogitsLoss()```does anyone see any glaring errors with that code?
the net does not seem to be working at all
trying to predict gender
can you show your training loop?
Does anyone know of an easy way to take data from a CSV and then plot that onto a normal curve?
What's a normal curve?
Have you tried matplotlib? There are a lot of examples you can just modify. So no need to do a tutorial or something.
A normal curve, like when you plot data that is something like, age or height, it follows a general "normal curve" with standard deviations and such
Bruh
like your nickname mate
hello i am working on Logistic regression problem
i am getting this error python ValueError: could not convert string to float: 'Test Type' when i do python fitted_model = clf.fit(X, y) this
can anyone help me in this ?
data = pd.read_csv(r"C:\Users\birha\OneDrive\Desktop\test_geak_minds/ml_classification.csv")
print(data)
le = preprocessing.LabelEncoder()
x_2 = data.apply(le.fit_transform)
X = data.columns[0:3]
print(X)
y = data.columns[-1]
print(y)
# Fit (train) the Logistic Regression classifier
clf = linear_model.LogisticRegression()
fitted_model = clf.fit(X, y)
# Predict
prediction_result = clf.predict([("upload",1135, -105)])
print("prediction_result:", prediction_result)``` my code this wayyou need to encode the field. ML models do not automatically encode or preprocess categorical fields
¯_(ツ)_/¯
uhh, most models do have custom pre-processing layer tho
but I follow your reasoning
Is anyone good with the os system and knows how to find specified paths?
I have a win error 3 and I have no idea what the actual name of the path is.
I am trying to use jupyter notebook for a convolution neural network
and I am trying to use the os system to get the pictures and mutate the folders within the notebook
yea
go to kaggle
search for the data
look at the file name
even then it should appear in the downloads folder
regaardless of os'
I downloaded a couple singular zips
for example:
C:\Users\spart\Downloads\cheetah_train_resized.zip
The actual name on kaggle is cheetah_train_resized but I moved all of the pictures I need into a new folder with multiple animals
My folder is C:\Users\spart\OneDrive\Desktop\cheetah-vs-hyena-vs-jaguar-vs-tiger
It has a subfolder called train and it has the thousands of images
\

use print
how can i transform rectangular form numbers into real ones? Please help
what do you mean "rectangular numbers"?
my error python ValueError: could not convert string to float: 'upload'
my code python Traceback (most recent call last): File "E:/task/log_reg_1.py", line 33, in <module> logmodel.fit(X_train, y_train)
@dull turtle There must be more to it than this. What values are X_train and y_train?
(like, what literally are they, rather than what purpose they serve)
can i share my full code ?
I would just share what print(X_train, y_train) display.
when i do X_train, y_train.. ```python
Test Type Data Speed(kbps) Signal Strength
154 upload 6420 -90
56 download 2035 -79
1875 upload 3748 -90
208 download 15617 -107
2719 download 2176 -82
... ... ... ...
2763 upload 5374 -85
905 upload 8575 -102
1096 upload 10233 -95
235 upload 13229 -94
1061 upload 3176 -97
154 4G
56 3G
1875 4G
208 4G
2719 4G
..
2763 4G
905 4G
1096 4G
235 4G
1061 4G
``` this i get
You'll need to come up with a different way to encode Test Type
You'll probably need to do that for y_train as well
see i am doing one-hot-encoding ```python
le = preprocessing.LabelEncoder()
encoded = data.apply(le.fit_transform)
print("encoded...")
print(encoded)
X = data.drop("Technology", axis=1) #independent variable
y = data['Technology'] #dependent variable
#split data in 70% training
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.3, random_state = 1)
print("X_train, y_train..")
print(X_train, y_train)``` plz check
I don't see you using encoded after you make it
encoded... python Test Type Data Speed(kbps) Signal Strength Technology 0 0 1650 49 0 1 1 311 49 0 2 0 398 10 1 3 0 488 2 1 4 0 428 7 1 ... ... ... ... ... 3246 0 253 35 0 3247 1 176 37 0 3248 1 197 39 0 3249 1 209 23 0 3250 1 469 37 0 plz cehck
so i need to use python X = data.drop("Technology", axis=1) #independent variable y = data['Technology'] encoded here
?
data.apply doesn't modify data. encoded is separate from data.
X = encoded.drop("Technology", axis=1) #independent variable
y = encoded['Technology'] ``` this way?
try that
this worked @serene scaffold
Great work!
!pastebin
Pasting large amounts of code
If your code is too long to fit in a codeblock in discord, you can paste your code here:
https://paste.pydis.com/
After pasting your code, save it by clicking the floppy disk icon in the top right, or by typing ctrl + S. After doing that, the URL should change. Copy the URL and post it here so others can see it.
can u plz check my output https://paste.pythondiscord.com/elimesulin.yaml here @serene scaffold
my code here https://paste.pythondiscord.com/icinefuxom.py
Looks like your confusion matrix didn't print out
confusion_matrix..
accuracy_score..``` both are empty..Yeah, you have to print them
print("confusion_matrix..")
confusion_matrix(y_test, predictions)
print("accuracy_score..")
accuracy_score(y_test, predictions)
How Does calculus and linear algebra relate to machine learning?
i get python confusion_matrix: [[ 71 58] [ 26 821]] accuracy_score: 0.9139344262295082 this plz check
the ML modules re written by taking help of mathematics as well as statistics
Machine learning is turning real-world problems into math problems
(to oversimplify)
exactly
that's looking pretty good!
how i can pass user input to it ?
Try explaining more specifically calculus https://cdn.discordapp.com/emojis/788882232441307154.gif?size=64

to test more
what do you mean to test with a user input?
you want the user to add more training instances?
How Does calculus and linear algebra relate to machine learning?
Specifically when is calculus and linear algebra used and statistics too...
For example answer:
We use linear algebra to make multiply the nested list
i mean how i can give some inputs to it and it will predict wether it is 0 or 1 ?
what is the best chart to display this type of data?

that's usually taught in schools. how old would you be, if you don't mind me asking?
obviously bar chart is the worst choices
throw it onto an actual world map
heat map to represent greater values
tableau is your friend for this

models fit method is deterministic, right?
@cedar sun No, not always. That's usually fixable though by setting the seed (import random; random.seed(some_value), or the numpy equivalent).
logmodel.predict
if anyone is looking for activations coded from scratch the check this: https://github.com/M-Salim-I/Other-Projects/blob/main/Theory/Activation_functions_from_scratch.ipynb

GitHub
Projects involving deep learning, computer vision, computational mathematics etc. - M-Salim-I/Other-Projects
i mean, with the seed set
training twice a model from 0 with same dataset, will give the same result?
how do i start with Machine Learning using Python? I am not aware of the abstract idea of how Machine Learning works in general... Can anyone suggest me a course or a book that starts with Machine Learning from scratch?
one sec
sure
if you want to get into data science in general, try "Data Science from Scratch", published by O'Riley.
okey i have a question. im not understanding something
I have tried training Xception with imagenet weights. Within 3 epochs it starts working
thank you very much
I have tried with Inception/resnet50 and... 10 epochs? 15? val_acc stucked at 0.0011
why tho? i dont understand
I just hate huggingface - their library is just so fookin complex
this is my 3rd time training a model from scratch, and it seems the API changes every time
Although with heat-maps you always have to be careful that you don't end up just making a population density map.
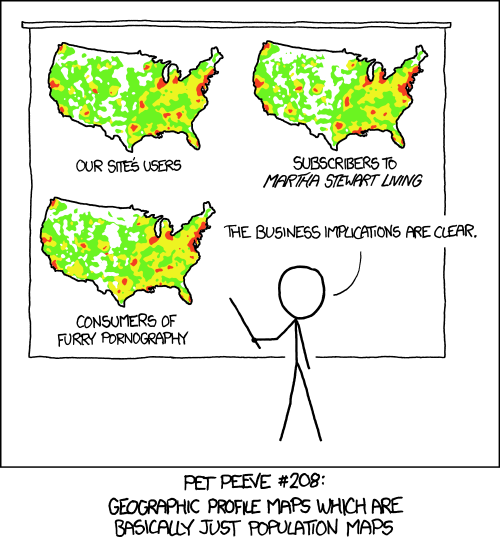
There are also a lot of global versions of this map showing traffic to English-language websites which are indistinguishable from maps of the location of internet users who are native English speakers.
from this information i believe that our site is causing users to watch furry porn
statistics disprove the amount of people watching furry - especially someone from every area
Ok maybe I should have thought twice before linking to that xkcd 😄
i can already tell you that that one guys highest value in his data is most likely united states so idk how helpful that dataset actually is.

is tableau a module of py?
tableu is a standaloe program
Tableau isn't free either
Is this the best channel regarding python pandas and data analytics? Anyone taking the udacity Data Analytics nanodegree ?
^
yes to the first
i mean to say that how can user pass some inputs and check what prediction it gets ?
i tried python X_test = (0, 1011, 30) predictions2 = logmodel.predict(X_test) print("predictions2:", predictions2) this way
i get python ValueError: Expected 2D array, got 1D array instead: array=[ 0 1011 30]. Reshape your data either using array.reshape(-1, 1) if your data has a single feature or array.reshape(1, -1) if it contains a single sample.
cant clear this value in excel

that doesn't have to do with python

is there a physical limit of neurons which can be assigned to a model layer?
like can i declare 225 neurons as my last layer and the previous layers being bigger than 225
you have to try every time
there is no fixed rule of layers
i mean it is safe for my hardware right?
i am trying to make a meme generator but if i consider the whole database it has over 6000 words so my last layer has to have 6000 neurons
if you are using more layers your hardware should capable of processing it
i am not talking about layers i am worried about amount of neurons
sorry bro, no idea
is any meme generator labrary in python?
no there is no library i am training a model with LSTM to do so
technically you can put as many neurons as you want
its just the issue of can your hardware process it and store all the data in memory
theres no hard limit
exactly
and if it does its not like you're gonna light your pc on fire, just lower the number of neurons and try again
depends on what your definition of average hardware
i have i5 GTX 1650 4gigs vram 8gig ram
and theres also a lot of other considerations
like how many layers, the size of the dataset, the way you're structuring your training loop, and other parameters
its mostly just educated trial and error
ohk
and is it a hard and fast rule to have more neurons in the previous layer than the current layer?
its mostly just educated trial and error
like mostly if its binary crossentropy and lets say 4 layers most people go with
128,64,32,2
theres not really any rules on how many neurons in each layer
also read docs for same
ohk thanks @austere swift @dull turtle
some structures work well on some applications, some work well on others
like i said earlier, its just educated trial and error
yes
the educated part is knowing not to make complete stupid moves aka 1024, 1, 512
np :)
Do you understand the error message?
i fixed it thanks
I have 2 columns A and B, column B has some missing values.
for eg:
colulmnA columnB
A1 B1
A1 B1
A1 B2
A2 B2
A2 B2
A1
When i use a simple imputer(most_frequent) , what i want for the missing cell is
the result to be dependent on what's inside columnA
I want the result:
colulmnA columnB
A1 B1
A1 B1
A1 B2
A2 B2
A2 B2
A1 B1
like instead of taking the most frequent value in columnB which is B2
It takes the most frequent value in columnB where ColumnA = A1
Do you know about groupby?
i am unable to use it though
i am basically lost on how to use groupby in the imputer
where it replaces the whole row with the the mostfrequent value in each column whenever it finds a NaN value in any cell of that row instead of just filling that particular cell
You can join #799641437645701151 in a few minutes, but you'd still have to copy and paste code into the chat any time I need you to
it sounds like you need to be using fillna though
I'll be back in a few
ok
Anyone familiar with photo processing?
I need help in creating a project my is to enter the exposure time and amount of photons and see the changes in the picture
?
Anyone knows how can I access these variables in the picture?
Pls
I have tried with Inception/resnet50 and... 10 epochs? 15? val_acc stucked at 0.0011
why tho? i dont understand
Is there anyone here who have subjected themselves to the hell of Huggingface🤗 ?
if so, would you know any idea how we can use a custom tokenizer with this?
I am writing a research project on American news channels opinions on different vaccines. Does anybody know of a sentiment analysis framework that could be used to extract the sentiment of different vaccines from articles? So for example, the article could contain multiple vaccine types, and the sentiment framework would tell me the sentiment score of each of them
I can't seem to come up with a good recipe for conditional mode imputation in pandas. groupby.DataFrameGroupBy.transform supports mean but not mode.
you can fine-tune a pre-trained BERT
Hi, anyone knows how to build Pytorch from source? I'm trying for a couple of months and it doesnt work for me.
"C:/Program Files (x86)/Microsoft Visual Studio/2019/Enterprise/VC/Tools/MSVC/14.29.30037/bin/Hostx64/x64/cl.exe"
is not able to compile a simple test program.
That seems to be the first problem
you probably need a lambda function here
something like df.groupby(...)[col].transform(lambda x: x.mode().iloc[0])
and then use that with df.fillna
Do you have any resources on BERT that could be useful? I haven't worked with BERT before
Strikes me as inelegant that there's no vectorized solution. Thanks!
it's partially vectorized
x.mode() is really just pd.Series.mode which I would hope/expect to be vectorized
it will be vectorized within the groups, just not across groups probably
What's interesting is that you can do fillna on a groupby series, but it won't be reflected in the original dataframe
check out huggingface library - it has plenty of stuff there
@grave frost thanks! I will check that out 🙂
Hello everyone! I am working on transfer learning. I am using resnet50. When I am trying to fit the model, i get this error. ValueError: Input 0 of layer conv2_block1_3_conv is incompatible with the layer: expected axis -1 of input shape to have value 64 but received input with shape (128, 30, 30, 256).
My input shape for resnet50 is (120,120,3) and then I added a classification layer at the end. Does anyone have any idea about that problem and how to solve it? Can you help me?

.
I have a value, and want to see after a multiplication where does this value plots on my graph. Im using dash and plotly this is possible?
i dont know if i explain well but i dont have a dataframe
just one value and a function tha depending of the time (argument of the function) returns diferrent values
so i want to se in my graph during time this variation
hope someone can help
if i didnt maked clear let me know
this is what i came with

fig = go.Figure(data=px.line(y = [1000,0], x = [0.100,0])) # or any Plotly Express function e.g. px.bar(...)
fig = go.Figure(data=fig.update_xaxes(title_text='Tempo'))
whti this code
so should i place bin, library, include of cdnn with the bin, compute sanitizer etc of cuda?
Are you trying to build PyTorch too ?
ok
had some cdnn issues(missing)
I don't understand anything of that :/
easier then pytorch i guess
Idk, I'm trying to build it for over 3 months or so
wow thats some dedication
i hope same for you
hello guys,im noy sure if its the right place but i wanted to know if any of you knows what its the tech behind a volumetric scanner?.I didnt find any particular info in this regard but i think its bassed on a AI,still im not quite sure.
like a Lidar scanner?

It looks like 2 Lidars to me with a bit of software to estimate the full volume.
i think seeing how iphone lidar compile a big surrounding area from small pieces of scans(by performing ceertain calculation obviously) would give you an idea of how to measure dimensions of object from similar input and then you may work on volume estimations
Any BERT experts here?
thx for the commend
There’s some stuff that goes into bin, include, and lib/x64
The cudnn zip is structured just like the CUDA folder
So everything corresponds
i just try to place bin etc(of cdnn) in folder where bin etc (of cuda) are ther
but it gave rename error
so i tried placing it(cdnn) just beside cuda
heres what i have.....i think cdnn not opening is sorted....

but the error is as it is

@austere swift
You move the files in the bin folder from cudnn into the bin folder of CUDA
And the files from the include folder into the include folder
Etc
i mean the main error was that.....we just assumed cdnn may be causing it
.
i just did this

That’s wrong
Take the files that are in the bin folder in cudnn
And move it into the bin folder in CUDA
for include and bin it says "already there"
Ok so you installed cudnn already
for x64 i cant find corresponding folder
It’s in lib
ya that wasnt there i had to paste it
and what to do for folder "NVIDIA_sla_ cdnn_support"
I found out that dash accept px.line as
and t and v1 are both arrays that were fullfulied with my function, now works well
Does anybody have any idea on how they would programatically determine whether these two sentences are connected? Essentially, I want only sentences which are related to Pfizer. So one could argue, that due to Pfizer and vaccination being in the first sentence, the 2nd one is also related to the first one
(Below is a snippet of an article)
Walgreens is shifting its Pfizer COVID-19 vaccination scheduling after federal health officials noted the pharmacy chain quietly decided to space doses apart over a longer-than-recommended period, according to a report. Federal guidelines call for the two-dose series to be administered at least 21 days apart, but Walgreens pushed the spacing to four weeks for easier logistics, the New York Times reports.
You could however, have sentences in an article that are not related to Pfizer directly. Therefore, I only want to extract the related sentences
Has anyone here tried using GPT 2 with Python or something?
i've worked with gpt3 a bit
Oh. And what about aitextgen?
I think the build is working but it stops at
[1/1088] Linking C shared library bin\torch_global_deps.dll
With
LINK : fatal error LNK1102: out of memory
ninja: build stopped: subcommand failed.
well, how much memory do you have?
12gb
do you know how to see how much memory a process is using?
then you will probably have to use a different computer

GitHub
how large the capacity of memory is needed when compiling pytorch from source ? I've got about 5GB available when compiling in ubuntu 18.04. Each time I compile with python setup.py install...
this person gives a similar suggestion: https://discuss.pytorch.org/t/high-memory-usage-while-building-pytorch-from-source/64129

PyTorch Forums
How can I reduce the RAM usage of compilation from source via python setup.py install command? It automatically spawns many threads and I don’t want that!
set MAX_JOBS=1 ?
yes
Hey @umbral zodiac!
Uh-oh! It looks like your message got zapped by our spam filter. We currently don't allow .txt attachments, so here are some tips to help you travel safely:
• If you attempted to send a message longer than 2000 characters, try shortening your message to fit within the character limit or use a pasting service (see below)
• If you tried to show someone your code, you can use codeblocks
(run !code-blocks in #bot-commands for more information) or use a pasting service like:
oh i forgot to ask. do you have the csv file for this. i want to try something in tableau
hey I want to learn AI where to start
what do you know about probability, statistics, and matrix algebra?
I am in 12th class I am studing for JEE so I know till that. that is studied in Indian Schools before Entering universities
I'm not sure what JEE is
First you learn what's is data, data environment, what is data analysis, how to mining data, how to visualise data in better manner. In sort you have to fit in role for data analyst then after learn mathematics fundamental, then comes AI algorithms


seems like 🧰 too much
It is, so Start with data analyst or I can say start with excel first, the most useful and beginners tools for data analyst good luck. ;)
No, for AI you must have. Knowledge about data analytics, and for data analytics you must have knowledge about excel
so I have to learn things of a data scientist
Start with base, don't be a full 🌝
Yes, first comes data analyst then data scientist then after machine learning and then comes AI
For AI you must have good knowledge and experience about this stream also 🥱😉
the prblm was i had swapped x and w......

might be better to define the function with better function parameter names
That way confusion happens less
i was just trying to imitate my instructor ......ended up wasting 4 days setting up cuda cdnn etc
Anyone here willing to answer this question? https://stackoverflow.com/questions/67866596/training-an-ai-by-chatting-with-aitextgen
i only have pre-process json file which some data doesn't have place value
nto able to reshape my tensor......even after reshape function its still (4,) instead of (4,1)

output:

Tf.reshape is not an in place operation
It returns the new tensor
So you need to do one_hot = tf.reshape …
any resources for learning data science?
I recommend DataCamp if you don't know anything about Data Science or Machine Learning
can you guys recommend me some good video series to start learning ML frameworks, deep learning and stuff?
Hi! What platform do you guys use to code python for data analysis? I usually use Jupyter but am wondering if there's a more suitable platforma
i code in vscode
do you already have the math background and at least a basic understanding of how it works?
if so, you can start by looking through the tensorflow guide, that gives some basic keras examples and walks you through the usage of it
TensorFlow
Complete, end-to-end examples to learn how to use TensorFlow for ML beginners and experts. Try tutorials in Google Colab - no setup required.
Jupyter notebook is the best option in my choice
why

try reinstalling numpy
Have you studied the documentation linked above for further help?
yup! I'll check it out
and btw could you guys please give me an oversimplified version of what is an optimizer and activation function?
an activation function is basically just a function that modifies the output of a layer
theres different ones that are used for different things, most common are relu and sigmoid
relu will basically make any negative value 0, and keep positive values unchanged
sigmoid puts everything between 0 and 1, so like +inf would be 1, -inf would be 0, 0 would be 0.5
and then optimizer functions basically take the computed gradient and perform the gradient descent
Thank you @austere swift
So am new to all this, and wanted to know. How can I make a chatbot AI and train it by chatting with it?
hello guys, I have written this short article on how to start learning Data science. Do share it with others if u find it helpful. Thanks https://www.kdnuggets.com/2021/05/guide-become-data-scientist.html
KDnuggets
Becoming a Data Scientists is an exciting path, but you cannot learn data science within one year or six months—instead, it’s a lifetime process that you have to follow with proper dedication and hard work. To guide your journey, the skills outlined here are the first you must acquire to…
how can i see what type or preprocessing do some pretrained models need?
rip. json is not my favorite
I haven’t watched many but abhishek thakur on YouTube has some good videos
import re
text = 'hello I am happy . Are you ?'
tokens = re.split(r"\s+", text) # splits string on space
print(f'step : {tokens}')
what does \s+ do?
is it just splitting the string based on 1 or more whitepaces?
after each word
/ punctuation
the left of it
think so?
yes, \s is whitespace and + means "one or more"
note that in most cases this is equivalent to text.split(), although i think in python the regex \s handles various non-ascii whitespace characters while str.split only handles spaces, tabs, and newlines
note that you can use https://regex101.com to test and debug regular expressions (make sure to use "python" mode on the left side)

regex101
Regular expression tester with syntax highlighting, explanation, cheat sheet for PHP/PCRE, Python, GO, JavaScript, Java. Features a regex quiz & library.
@desert oar thanks
however I'm confused on this reg exp
text = re.sub(r"(\S)\1\1+", r"\1\1\1", text)
as it looks for non white spaces but it says to the first group which doesnt make any sense to me
@uncut barn \S is a single non-whitespace character
in the pattern, \1 means "whatever was matched by the first group
basically this pattern means "3 or more of the same non-whitespace character"
regex101
Regular expression tester with syntax highlighting, explanation, cheat sheet for PHP/PCRE, Python, GO, JavaScript, Java. Features a regex quiz & library.
How can I make an AI with brainshop/aitextgen, which I can train by chatting with with?
why don't you train your own
I wish I knew haha
anybody with some experience in c in vscode?
look it up ¯_(ツ)_/¯
I did haha
just use some repo
@teal wadi
like?
chose your model, then look it up 🤷
oof ok
you can use Huggingface - they have got every single NLP model there
but I absolutely HATE that piece-of-shit lib, but ig its good for beginners
oh ok
I'm a bit confused as to why DataFrame.join and DataFrame.merge are two different things. .join appears to be a wrapper around .merge, but all of the functionality of .merge seems like joining operations to me. Maybe it's just the way I was taught database stuff.
I couldent figure out how to fine tune the hugging face models
I wanted to fine tune them to my emails and have an email writer with gpt-2 or another model
Wish they had better documentation and examples
I spent a fair amount of time 😭😭😭trying to figure it out
yeah, if your model has a sperate PT repo (which I think it does) then that's easy sailing
for people trying to use custom stuff, not so much
Yea I wanted something a little more complex than a onehot vector chat bot
Which maybe could do email writing decently well idk
Probably not
What framework do you reccomend I am working on something with keras / tf now but its kinda convoluted the way the old keras stuff and tensor flow stuff come together seems more complicated than it needs to be
@grave frost
use pytorch tbh
Thanks @desert oar
Any good place to learn PyTorch? i've found dozens of excellent TF tutorials and guides, but not a single PyTorch one 😦
check out the one from the official pytorch site
you honestly don't need any tutorials
because you can just google like, how to make an input pipeline in pytorch and just see their intro page
much of abstraction in TF is similar in PT - so its a smooth ride 👍
people talk a lot about using pytorch lightning 🤔 but I just find it pretty meh. its just feels like TF, but you import torch
How do I know if the build was sucsessful ?
what build?
pytorch
It ended like this
reading manifest file 'torch.egg-info\SOURCES.txt'
reading manifest template 'MANIFEST.in'
warning: no previously-included files matching '.o' found anywhere in distribution
warning: no previously-included files matching '.so' found anywhere in distribution
warning: no previously-included files matching '.dylib' found anywhere in distribution
warning: no previously-included files matching '.a' found anywhere in distribution
warning: no previously-included files matching '*.swp' found anywhere in distribution
writing manifest file 'torch.egg-info\SOURCES.txt'
Copying torch.egg-info to C:\Users\Maximo.conda\envs\pytorch\Lib\site-packages\torch-1.10.0a0+gitc51abf8-py3.8.egg-info
running install_scripts
Installing convert-caffe2-to-onnx-script.py script to C:\Users\Maximo.conda\envs\pytorch\Scripts
Installing convert-caffe2-to-onnx.exe script to C:\Users\Maximo.conda\envs\pytorch\Scripts
Installing convert-onnx-to-caffe2-script.py script to C:\Users\Maximo.conda\envs\pytorch\Scripts
Installing convert-onnx-to-caffe2.exe script to C:\Users\Maximo.conda\envs\pytorch\Scripts
so..
how do I add it ?
are u intentionally using the rc version of pytorch
from source
why don't you just use conda?
Im building it with conda
so you entered
conda install pytorch torchvision torchaudio cudatoolkit=11.1 -c pytorch -c conda-forge
in the terminal?
one way to check is to go to your IDE then import torch
I have a old gpu
.
this was the output from python setup.py install?
so try importing torch then
k
just try in the repl and see if that works
if it does then test torch.cuda.is_available()
to see if it detects gpu
Type "help", "copyright", "credits" or "license" for more information.
import torch
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "C:\Users\Maximo\building\pytorch\torch_init_.py", line 135, in <module>
raise err
OSError: [WinError 126] Não foi possível encontrar o módulo especificado. Error loading "C:\Users\Maximo\building\pytorch\torch\lib\backend_with_compiler.dll" or one of its dependencies.
:/
pretty sure they cut support for CUDA 3.0 a long time ago
3.0 is the compute capability of the gpu
not the cuda version
ah mb misunderstood
this is what happens after importing torch
https://stackoverflow.com/questions/63187161/error-while-import-pytorch-module-the-specified-module-could-not-be-found simple copy-paste error into google and i found this

Stack Overflow
I just newly install python 3.8 via anaconda installer and install pytorch using command
conda install pytorch torchvision cpuonly -c pytorch
when i try to import torch, I got this error message.
it says to try downloading the visual c++ redistributable
I tried
so I will have to build it again for it to work o only installing and restarting?
not sure, try only installing first and see if that works
if it doesnt, rebuild
Im felling hopeful 🙂
just so I know
after doing **python **
how can I go back to the environment
exit() or ctrl z
yeah but if you read the error it also says "or one of its dependencies"
so it could depend on something else that is missing
😭 It will take till tomorrow
it shouldn't take a day to install the redistributable
no, I mean I already installed it. same thing
here
(pytorch) C:\Users\Maximo>python
Python 3.8.10 (default, May 19 2021, 13:12:57) [MSC v.1916 64 bit (AMD64)] :: Anaconda, Inc. on win32
Type "help", "copyright", "credits" or "license" for more information.
import torch
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "C:\Users\Maximo.conda\envs\pytorch\lib\site-packages\torch_init_.py", line 135, in <module>
raise err
OSError: [WinError 126] Não foi possível encontrar o módulo especificado. Error loading "C:\Users\Maximo.conda\envs\pytorch\lib\site-packages\torch\lib\backend_with_compiler.dll" or one of its dependencies.
both the .dll and .lib are there
I don't know if I should build it again :(,
i've had nothing but headaches on windows
linux is nice
pytorch works fine on windows, it's just building from source isn't the best
May '20
Well, I reproduced it locally. Looks like it could not find our internal DLLs because it relies on AddDllDirectory which is not built-in in Python 3.7. There are two workable solutions:
Update to Python 3.8.
Apply https://github.com/pytorch/pytorch/pull/37763 340 manually. Replace your local copy with https://gist.github.com/peterjc123/bcbf4418ff63d88e11313d308cf1b427 227 (e.g. C:\Users\Grace Wu\torchenv\lib\site-packages\torch_init_.py)

GitHub
…n Windows
Without this PR, the OS try to find the DLL in the following directories.
The directory from which the application loaded.
The system directory. Use the GetSystemDirectory function to g...

Gist
Modified init.py for PyTorch 1.5.0. GitHub Gist: instantly share code, notes, and snippets.
Im trying that
the running joke is that the windows build never works lol
windows bad lmao
I did it a few years before, and after a couple of weeks I switched to linux
but why are you building from source?
old gpu, compute capability 3.0
i mean imo just use colab at that point
wait, what has that got to do with TF?
it just works as long as there is CUDA
it doesn't, theyre building pytorch from source
technically no, even TF requires a minimum compute capability of 3.5

{kind=link}
tbh i'm not sure that building from source would fix that
I mean, ... i dunno really
yeah i've never used a gpu that old
but building from source is not the way to fix incompatible software, is it?
it could just be that they havent built wheels for anything lower
but i'm not sure
🥴
if the TF require CC >= 3.5, I don't see how you can get it to work properly
not that people haven't tried
cuz I beleive that GT 1030 falls in that
TensorFlow
but its usually a shitshow that has bugs in almost every method
under the part where it says supported compute capabilities it also says:
For GPUs with unsupported CUDA® architectures, or to avoid JIT compilation from PTX, or to use different versions of the NVIDIA® libraries, see the Linux build from source guide.
which implies that if the gpu has an unsupported architecture you should be able to build from source to fix it
couldnt find anything on pytorch that explicitly states that
well, what's the technical reason for that then?
it could be that they don't want to make prebuilt packages for anything lower since it would be rare for someone to use something that old anyways
3.0 is like gtx 600 series
Take the GT 610 for example. It has 48 CUDA cores. But you just can’t install CUDA Toolkit
. No amount of messing around will help. Believe me I tried on a friend’s desktop.
some rando on quora
gtx 600s, not gt
I doubt it works
more than the issue being pre-built packages
the highest gpu i can see with 3.0 capability is the gtx 770
getting CUDA to work is the most problematic part
expecting TF to work on that too
🥴
cuda 10.1 goes down to compute capability 3.0 iirc
when using a pre trained model, should u call the preprocess_input function from that model?
nah I'm using cupscale
dunno really, murky waters for hardware here. getting stuff on normal hardware is already pain - on old and deprecated?
it doesn't seem worth the effort tbh
do u know more somethings?
yeah, that and kaggle kernels are waaay more superioir than smthing CC 3.0
like any model's even gonna fit in there
well, id be willing to have a new one
I don't even have a working laptop lol
colab and kaggle are equivalent to a million of your GPUs
and I am not even joking how powerful and useful they are
that and you can rent really good gpus for very cheap as well if you need long term training jobs
since colab and kaggle will time out eventually
most models can be trained in the 24 hours limit, if you buy Pro
https://gpu.land rents V100s for $0.99/gpu/hour
and you can always checkpoint and come back tomorrow
It already was hard to get this old thing as before I didnt had anything
Surely I wont complain
sell it again
😂 .
use OLX if you are in India lol
it won't sell for the same price as a new one lol
it's extremely similar, the only difference is that .join joins the index of the first df with either columns or indexes of the other df. whereas with .merge you're joining columns together for both dataframes
Yeah, it looks like join is just a simplified way of calling merge when you plan to merge/join on the index.
Looks like they call it merge because of R.
so
they say keras.layers.TimeDistributed "wraps any layer and applies it at every time step of its input sequence"
what
what does this even mean
have you worked with RNNs?
i'm actually reading about the rnns rn
okay
so basically
say you represent your data as 2D
each row is a sample
each column a feature
right?
now imagine that each sample is taken over n timesteps
say, 60 seconds of tracking a stock’s price
what now
that would give you 3D data
a sample is an instance in time...?