#data-science-and-ml
1 messages · Page 315 of 1
@rose cipherAs for linear algebra, it has the basics:
https://www.khanacademy.org/math/linear-algebra
but not any of the more advanced stuff - eigenvalues, etc.
nah
What do I have to know to learn calculus and linear algebra?
why dont u search on youtube for videos like "coding my first neural network for scratch"
or something
I am afraid of math right? I have this shit.
they might as well enroll in https://www.coursera.org/learn/machine-learning then 🙂

Coursera
Offered by Stanford University. Machine learning is the science of getting computers to act without being explicitly programmed. In the past ... Enroll for free.
I saw a video that the guy said that´s possible to learn ML without math, but it´s harder
^ this course teaches you the linear algebra involved in the process
I love geometry as long as its not in the exam 😛 becoz then it's just memorization of thereoms
I don't remember if it teaches you calculus or if it's assumed knowledge
of algebra... u need gauss (?) and idk if something else. Normalization and such things, which are easy
and calculus, to differentiate
and solving linear equations
flashbacks to nightmares of 80+ thereoms to memorize
one day before the exam
this course covers, say, SVD, which has eigenvalues involved
this is probably true just because ML frameworks exist, so you don't need to write any of the algorithms yourself and so don't necessarily need to know how they work
THANK GOD! So, I do not have to learn advanced topics of math?
but it'd be "learn" as in "able to use to solve problems", not as in "able to use cutting-edge stuff" and certainly not "be an ML researcher"
not really, but you should actually
The problem is that takes a lot of time
i mean, u can code a nn without knowing anything for maths. Thats why frameworks exists
I don't know the math either 🤷
(I mean, you wouldn't be learning advanced math anyway, only linear algebra and calculus 😛 )
I do not have much time
u are using discord without knowing whats behind, so same for ML
but then what would I be doing in college if not the math?
so im just chillin and procrastinating on the fundamentals 😛
These are advanced stuff
Let me be honest with you guys, I was learning some algebra stuff to help me improve my habilities in programming. But then I realized that I was not using nothing at all
some by any grammar mistakes, I from Brazil
I'm study in this course now https://www.coursera.org/learn/machine-learning with a little math knowledge
Coursera
Offered by Stanford University. Machine learning is the science of getting computers to act without being explicitly programmed. In the past ... Enroll for free.
yeah, that course is nice, it tries to teach you all the math required if you don't know it
when you suddenly realize that you don't know how exactly pre-training works in NLP
and not a single article explains it 😡
https://paste.pythondiscord.com/hufixafeka.sql
friend says:
you need to update torch so it updates mkl (the intel libs)
how is this done?
😅 I'm bad at updating conda when it isn't explicitly called for. still a newb. what do?
Algebra and geometry are fundamentally linked. "Geometry without algebra is dumb! - Algebra without geometry is blind!" - David Hestenes
You will only use as much math as your problem that you are solving demands.
If you have not used any of your algebra skills then you have not been solving programming problems that require it.
There are many different flavors of programming depending on which problem is being solved. Some of these are almost exclusively algebraic solution implementations.
While something like making a GUI layout in HTML or having some javascript fetch some data when a button is pressed has no math involved (that you directly see, at the very low level there is some networking insanity happening).
Can you tell me how many algorithm & data structure to use in ML?
Uncountable, several thousand are made each day (probably, idk the exact number of course).
If you mean fundental data structures that can be often re-used, then something like numpy.
The "ndarray".
Or as pytorch and others like to incorrectly name them: "tensors".
So not directly in ML, but an obvious use case of something like a B-tree would be in the database that you're fetching data from to train your ML agent.
Well, trees in general show up yes.
Their are quite a lot of machine learning algorithms
I mean, they call them a different name because they're a different class. Pytorch tensors keep track of the compute graph when you do operations on them so that they can then run backpropagation on it.
True that
Decision trees are an obvious case (it's in the name).
Graphs show up in the form of computation graphs like in Tensorflow.
A lot of programming can be boiled down to "how do I represent this problem as a graph?"
Can you elaborate on this a bit ?
I think it's best shown by example, but if you want a longer explanation, the CS course on brilliant.org teaches this (not sponsored, I just think it's actually pretty good).
Ohh
So let's say you have this problem (it's a good example): https://en.wikipedia.org/wiki/Wolf,_goat_and_cabbage_problem
The wolf, goat and cabbage problem is a river crossing puzzle. It dates back to at least the 9th century, and has entered the folklore of several cultures.
true
This can be solved by a brute force search algorithm that tries all sequences of moves.
The search space is not too big so a computer has no problem brute forcing it.
true
So to find the correct sequence of moves you can represent each "state" of the world as a single vertex.
Then connect each vertex with an edge if you can make a single move that brings you from state A to state B.
Label that edge with the move.
Now solving the problem is equivalent to finding a path that goes from the start state to the win state.
This can be done by something like (standard school taught algorithm) https://en.wikipedia.org/wiki/Dijkstra's_algorithm
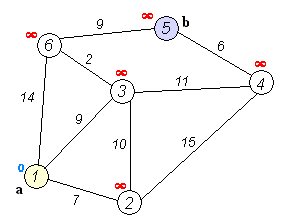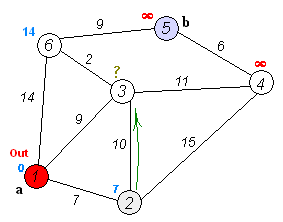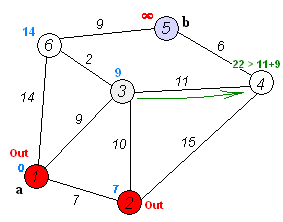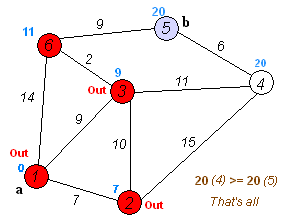
To reduce the time spent searching you can also delete any of the "lose" state vertices since you never want to get to those anyhow.
Others examples of using graphs to represent problems / solve them are any recursive algorithms or dynamic programming algorithms (pretty much everything).
The structure of your program itself (the architecture, what talks to what). NN diagrams are just that.
conda create --name DLnotes_env
conda install pytorch
pip install pdf2image
conda install -c pytorch torchvision
pip install opencv-python
was numpy included?
❯ pip install opencv-python
Collecting opencv-python
Downloading opencv_python-4.5.2.52-cp39-cp39-manylinux2014_x86_64.whl (51.0 MB)
|████████████████████████████████| 51.0 MB 213 kB/s
Collecting numpy>=1.19.3
Downloading numpy-1.20.3-cp39-cp39-manylinux_2_12_x86_64.manylinux2010_x86_64.whl (15.4 MB)
|████████████████████████████████| 15.4 MB 4.4 MB/s
Installing collected packages: numpy, opencv-python
Attempting uninstall: numpy
Found existing installation: numpy 1.19.2
Uninstalling numpy-1.19.2:
Successfully uninstalled numpy-1.19.2
Successfully installed numpy-1.20.3 opencv-python-4.5.2.52
ModuleNotFoundError: No module named 'matplotlib'
conda install -c conda-forge matplotlib
ModuleNotFoundError: No module named 'seaborn'
conda install -c conda-forge seaborn
ModuleNotFoundError: No module named 'pytesseract'
conda install -c conda-forge pytesseract
/mnt/d/Code/DLnotes/ocr.pytorch master !2 ?17 13s Py DLnotes_env
❯ python3 detect_recognize.py
[W NNPACK.cpp:80] Could not initialize NNPACK! Reason: Unsupported hardware.```Fuckguys any good course or youtube channel where I can learn abot NLP?
I have a library of resources fopr ML / DL, but nothing like tha for NLP. only basic info
GitHub
Acceleration package for neural networks on multi-core CPUs - Maratyszcza/NNPACK
what kind of calculus and linear algebra is needed for ml?
i only know differential equations
I mean at that point you should be good.
If you know diff eqs you know how to derivate, integrate and probably vector calc
oh cool
think "college level"
Yeah they just needed some name. Naming is hard and it's kind of whatever as long as everyone gets it (also not too much typing / single word).
i do wonder why they went with the name "tensor"
n-dimensional arrays are special cases of tensors, right?
Because when doing computations involving tensors, ndarrays are involved for holding the actual values.
(From a computation and physics POV, from math POV is just for doing some proofs)
so is there a 1:1 relationship between tensors and multidimensional arrays?
are there tensors that can't be represented as multi-d arrays?
No, tensors are an abstract thing.
well a vector in a vector space over the field of real numbers pretty much is a tuple of real numbers
a linear transformation in the same context is a matrix (there's a theorem for this)
Fairly sure n-dimensional arrays are exactly tensors, unless you distinguish between lower and upper indexes, in which case... still n-dimensional arrays, but with some stuff involved to lower/raise indexes
but that's not a problem unless you're considering tensors over a vector space with a metric with a non-all-ones signature, e.g. Minkowsky with its 1,-1,-1,-1
It's more something like saying that a vector is an array of numbers.
It can be represented by an array of numbers.
right, im not saying they are the same, but that there's an unambiguous correspondence
a bijection between (certain kinds of) tensors and multi-dimensional arrays
that's true I suppose, a tensor in a certain basis is a specific multidimensional array
like how if you choose a basis for a linear operator you get a matrix
yeah, it's close enough for sure. I don't think people get too confused unless they start digging too deep.
right
in the very general sense, a tensor is a multi-linear map?
i don't know any theory for those
just linear maps from undergrad-level linear algebra
To quote wikipedia "A tensor may be represented as an array (potentially multidimensional). Just as a vector in an n-dimensional space is represented by a one-dimensional array with n components with respect to a given basis, any tensor with respect to a basis is represented by a multidimensional array."
makes sense, im reading that page now
Found this great gem for basic implementation of models: https://nn.labml.ai/

LabML Neural Networks
That's pretty well made.
ive been meaning to spend some time with "coordinate-free" linear algebra
ikr. best way to study new architectures - they've even got FNET
it's not full, but it does give an idea as to what ops they're doin
can i somehow work with colab with files from my local machine without uploading them?
I have a really stupid question based on what we learned and not learned in the school.
I Should do a project for Picture recognition and a task is, that we should take pictures from google etc. - All good. Now - I'm at the point where i want to use K-Means to cluster those pictures but my point is. How do I load my local dataset into Jupyter Notebook? Because our teacher always came up with those
"from sklearn.datasets import blablabla" ^^
And our task is clear to create an own dataset. And I'm confused about my point i don't get it (or I don't see it)'^^
Guys, I'm having a little issue. I'm trying to use the ImageDataGenerator to create the train, valid, and test dataset.
The target labels is binary (0, 1) but my validation dataset is only seeing one class (0). Shuffle is set to True when I use the flow_from_dataframe
How can I ensure my ImageDataGenerator sees the 2 classes in the dataset as it's only seeing one.
Of course not 😁
a "dataset" could be as simple as a list of numpy arrays and a list of corresponding labels
allright what can i do
not sure. for all i know, there's a bug in your model code
can you post the code for your model, a description of the data, and maybe a plot of loss vs epochs
maybe there's nothing wrong and the optimizer has reached convergence


@lament stag I think we're facing the same issue. Probably, the reason you're getting a constant accuracy of 50% is cause your model can only see one of the labels in the validation dataset.
That's the same thing I'm experiencing. I confirmed it by using pd.unique on my validation dataset and I got only 0, instead of (0, 1)
The train and test dataset gave me (0,1) when I checked for unique labels, only the validation gave me just 0.

Btw activate windows
I used the ImageDataGenerator class, it returns the X and Y together as a tuple.
Yes, but can u show?
You mean the code?
Nah, images
Whem u do flow from dir
The images on each subfolder belong to the class of that subfolder
Main folder
--- f1
------- imgs1
--- f2
------- imgs2
If u pass "main folder"
U will have 2 classes, f1 and f2
I'm chatting from my phone, I already shut my laptop and on my way home.
I'll send you a link to the code, and a link to the task.
Just read me
Also, on the datagenerator class, there is an argument called validation_split
U can use that
Read the docs, there are examples
And idk ur optimizer. I always use adam lol
I also used Adam
I actually did split the dataset.
I already did a project last week, facemask recognition, and everything went on fine.
I'll continue checking it out on Monday , when I get back.
u have to give access
I set validation split = 0.20
Okay, Lemme do that
Any idea how open it up?

Compete and show case your skills by solving Data Science & A.I Challenges that simulate real-world problems. Organize A.I Challenges and invite the best Data Scientists across the globe.
Here's the challenge
I'll try to open up my code.
can libs like tensorflow, pytorch and such work on those nvidia jetson boards for e.g. model training, or can models only be deployed there with prior conversion?
cannot import name 'image_dataset_from_directory' from 'keras.preprocessing' (/usr/local/lib/python3.7/dist-packages/keras/preprocessing/__init__.py)
huh?
keras no longer having some methods?
guys any good course or youtube channel where I can learn abot NLP?
I have a library of resources fopr ML / DL, but nothing like tha for NLP. only basic info
@cedar sun what's your keras version?
what are you trying to do with nlp?
i have a question
base_model = keras.applications.Xception(weights='imagenet',
input_shape=dimensions,
include_top=False)
base_model.trainable = True
x = GlobalAveragePooling2D()(base_model.output)
predictions = Dense(len(pokemons), activation = 'softmax')(x)
model = Model(inputs = base_model.input, outputs = predictions)
This is how i was making my model
But currently i have another model a bit trained, but with more classes than mine. How can i load the pretrained model but change it last layer to match so it has the same amount of classes than me?
I guess i need to start with a load_model, right? XD
Learn. From scratch. I just recommendation for a good starting point
So.. what happens if we fourier transform on a signal twice?
Keep in mind that NLP isn't a monolithic thing that one learns. However the first assignment in the NLP class I just finished TAing was to make a program that reads in a document and uses ngram modeling to generate random sentences.
how do we actually get our cost function? do we hardcode / specify it within models?
I'm just wondering how the model knows what formula to partially differentiate for gradient descent.
Damn, everyone is implementing models in JAX. poor pytorch, RIP Tensorflow
So for example, extracting n-grams from a document, and using those n-grams to create random sentences?
yes 
no. pos tagging was the second assignment, actually
All right! i'll try both with a few documents, see if I can generate random babbling sentences lol
thanks 😄
NLP is the easiest field for beginners imo
beginners to DL that is - their concepts are quite intuitive
if you have general idea of NNs and DL then it shouldn't be much of a roadblock - the most different aspect is simply that your approach changes
hey
i'm trying to store image features in a database and then later do a search to find similar images using an image
what's the best way to go about doing this
TypeError: Cannot convert a symbolic Keras input/output to a numpy array. This error may indicate that you're trying to pass a symbolic value to a NumPy call, which is not supported. Or, you may be trying to pass Keras symbolic inputs/outputs to a TF API that does not register dispatching, preventing Keras from automatically converting the API call to a lambda layer in the Functional Model.
Whats this
It happens here
predictions = Dense(len(pokemons), activation = 'softmax')(x)
base_model = tf.keras.applications.Xception(weights='imagenet',
input_shape=dimensions,
include_top=False)
base_model.trainable = True
x = GlobalAveragePooling2D()(base_model.output)
predictions = Dense(len(pokemons), activation = 'softmax')(x)```Wtf keras changed a lot lmao
i get the estimating functions part, but how does a markov chain "resemble" a particular probability distribution at a certain point? and how do u even construct it?
that's what the various mcmc algorithms are for. it's a bit complicated, but very much worth exploring how they work if you're interested. metropolis hastings in particular isn't that complicated, but it's clever.
So
can someone tell me whats wrong with fkin keras? XD
That error was cuz Dense layer came from keras
and not from tensorflow.keras
and also, why cant i do
import tensorflow as tf
from tf.keras.layers import Dense```?
it sais ``tf.keras`` is bad@cedar sun the tensorflow team decided to make things as confusing as possible. keras is the name of a software library that popularized a certain programming style for building neural networks and other models by building them out of pre-existing layers. tensorflow decided to be helpful and basically copy the keras library into tensorflow, which would be very helpful, except they called it "keras" and in the documentation they mostly pretend that the standalone keras library doesn't exist.
i know tensorflow exists and keras exists
also that tensorflow.keras exists
but why keras doesnt wotk anymore?
Like, nothing from keras works?
Not even the layers, not even image_dataset_from_directory
i am not sure. maybe you're not supposed to mix tensorflow-keras and standalone keras?
Now everything has to come from tf?
https://keras.io/ on their website they tell you to use tensorflow.keras
Keras documentation
so sad
so it's tensorflow.keras.applications now
not necessarily sad, but very confusing for people like me who don't use this stuff frequently
good for the keras team, the developers built something that turned out to be good enough for google to eat them
AttributeError: module 'keras.applications' has no attribute 'Xception'
yeah
from tensorflow.keras.applications import Xception
does that work?
yes, the keras by itself doesn't exist anymore apparently
everything has to be from tf
but layers are created as they were on keras even they come from tf????????
asdkfjhasdkflasdhlf
https://github.com/keras-team/keras
In the near future, this repository will be used once again for developing the Keras codebase. For the time being, the Keras codebase is being developed at tensorflow/tensorflow, and any PR or issue should be directed there.
are you saying that a model which used to work no longer works?
it sounds like you are expected to not import keras anymore, and you are expected to import tensorflow.keras instead
No, i mean that keras had its own way to build layers, and tensorflow its own
GlobalAveragePooling2D()(base_model.output) this is from keras
and this syntax isnt valid for tensorflow
Or at least it wasnt
yep
okey, ty for the clarification q,q
the english word is "clarification" 🙂
and do u know something about this?
:)
import tensorflow as tf
from tensorflow.keras.layers import Dense
this works fine
yeah but, then why import as tf? :c
if u import as is for abreviation
and then u cant use it q.q
that's just how python works. you need to use the full name of the module in from ... import
the former is just a graphics processor, the latter is google's proprietary machine learning specific processor
graphics processors happen to be really good at doing lots of arithmetic in parallel, which is why they turned out to be good for machine learning
and tpu?
something google invented
ah shit okay. ill go read up a bit more
purpose-built hardware for doing matrix arithmetic and other math required for machine learning models
it's enlightening imo. basically the idea with the metropolis algorithm is that you bounce around a known probability distribution (e.g. gaussian), rejecting bounces with some probability determined by the probability you're trying to sample from
cool stuff
how do u know the probability ur sampling from if you dont know the probability distribution
heh, good question
you still need to know a function that's proportional to the density function
this is very very useful in sampling from probability distributions that arise in bayesian statistics
because you often have a tractable numerator with an intractable denominator
holy shit bruh this is screwing with my head
think about what bayes' theorem gives us for an unknown parameter t and some data y: p(t | y) = p(y | t) * p(t) / p(y). we can assume some functional form for p(t) (prior) and p(y|t) (likelihood), but we have no sensible way to compute p(y), which means we don't know the normalizing constant for the pdf (i.e. to ensure that if we integrate from 0-1 we get a total of 1), which means we can't sample from it directly because we can't derive its exact form. but we can use mcmc instead because we know p(y|t) * p(t) which is proportional to the true pdf we want to sample from.
if you're interested in bayesian statistics, you will depend heavily on mcmc, much in the same way that traditional stats depends on newton methods for fitting generalized linear models with maximum likelihood, and deep learning depends on sgd for fitting neural networks
you don't need to understand it at a deep level because it's somewhat of an implementation detail, but you definitely would benefit from wrapping your head around how it works at a high level
i have so many questions. can i dm you?
i'd rather not. but i am also not the best person to ask.. i can try to dig up some learning resources
thats good too
i dont have a "professional level" knowledge of this subject myself
wait i dont really get how bayes theorem works in conjunction with the prior/likelihood/posterior thing
like why is likelihood = p(y|t)? isnt it independent of the prior
awesome, thanks
neat
oh god the math 😭
the reason is
you can only import from modules
so say you had this:
import tensorflow as tf
tf = 1
# should you be able to do "import keras from tf" here?
remember you can't import from names
(well, not using the import statement, anyway)
Hey guys, can someone help me with this?
I have a python data frame and would like to select the whole row from the data frame if the value of a column in that row is between a particular interval.
Id Hobbies Age Labels
0 Id-1 {Arts, Shopping} 15 {C1, C2}
3 Id-4 {Sports, Shopping} 15 {C1, C3, C2}
4 Id-5 {Sports, Arts, Shopping} 15 {C2}
8 Id-9 {Sports, Shopping} 15 {C1, C3, C2}
1 Id-2 {Sports, Arts} 17 {C2, C3}
7 Id-8 {Arts, Shopping} 18 {C1, C3}
9 Id-10 {Shopping} 18 {C2}
5 Id-6 {Sports, Shopping} 25 {C1}
2 Id-3 {Arts} 28 {C3}
6 Id-7 {Sports} 28 {C2, C3}
If I have this data, and if my intervals = [(14.99, 15), (15.01, 18), (18.01, 25), (25.01, 28)]
Now, for each interval, I would want to filter out a few rows from the dataframe.
I tried doing this -
branches = [] for interval in intervals: selected_rows = data.loc[(data.iloc[:,attribute] >= interval[0]) & (data.iloc[:,attribute] <= interval[1])] return branches
But my selected rows contains the header
branches = [] for interval in intervals: selected_rows = data.loc[(data.iloc[:,attribute] >= interval[0]) & (data.iloc[:,attribute] <= interval[1])] branches.append(selected_rows) return branches
But my selected rows contains the header of the columns, and when I print out branches - my output looks like this

branches is a list of DataFrame objects, thats why its printing the headers (for each dataframe). You can use pd.concat to put them in a single DataFrame object
btw, you can use the between function:
branches = []
for a,b in intervals:
selected_rows = data.loc[data.iloc[:,attribute].between(a,b)]
branches.append(selected_rows)
return pd.concat(branches)
Suggest good Regression based project ideas,to practice and also put in the resume
Thank you so much Renato 😄
Hi Dru! Thank you for your help but my validation gave me [0,1] . Do you know any other way?
and output

I hope you reply
why does research in TF2 rely on v1.compat? aren't functions as exposed in TF2?
I think I remember reading in the book I'm reading that if you're gonna use Batchnormalizao, you should add the activation as a separate layer after the Batchnormalizao and maxpooling.
Model.add(Keras.... activation ('relu:) should be a layer.
Yes. I added before
Also, try using categorical loss when you compile the model and set the last layer to 2 outputs instead of 1.
I already got up to 80% accuracy on what I'm currently working on, but I felt it wasn't good enough. It's gotten worse.
Later today, DM me the dataset and your code. We can work on it together but that will be tomorrow.
Model.add(Dense(1,activation="sigmoid")) Is it?
Change it to
Model.add(dense(2, activation='softmax'))
Then change the loss in the compile to categorical cross entropy, let's see if that works, while you make other adjustments.
You could also try using a pretrained model.
Alright man, 👍🏿

I can't get how to import packages in different file
I am trying absolute import but its not working
in pandas how can I select for rows that do not meet BOTH condition
test = test[(test["ABC_cluster"]!="C") & (test["XYZ_cluster"]!="Z")]
```
this excludes both all C and Z instances but I want to exclude only rows that meet both condtion (e.g. C for the abc column and Z in xyz columns)Use == instead of !=
and then ~ in front?
what did you just call me? 😠
jk
so I have to specify all isntances I want to keep?
is there no way to do it in one line?
I could use drop tho no?
For indexes yes, but there's not much reason to
c
df.drop(df.index[cond], inplace=True)
test = test.drop(test[(test["ABC_cluster"] == "C") & (test["XYZ_cluster"]=="Z")].index)
test = test.drop(test[(test["ABC_cluster"] == "C") & (test["XYZ_cluster"]=="Z")].index)
``` so this should workit did work
thanks @desert oar (I hope that's your @ is not drug talk!)
Hi all, I'm trying to find the best way to run some Tensorflow code, I have an ATI gpu 😦 Tried spinning up some GPU instances in both Azure & AWS but I need a quota increase before I can do anything.
Any suggestions please?
i need some help with matplotlib in my project
so i have a bot which gets info from an api which tells prices of some crypto coins
i want to make a graph from that
i was able to make a simple graph and wanted to try out formatting
i wanted the color and the fade to be something like this

but cant get it working myself
heres the code of what i tried
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.path import Path
from matplotlib.patches import PathPatch
xx = np.arange(0, 11)
yy = [0, 1, 2, 3, 4, 5, 5, 4, 3, 2, 1]
yy = np.array(yy)
print(xx, "\n", yy)
path = Path(np.array([xx,yy]).transpose())
print(path)
patch = PathPatch(path, facecolor='none')
plt.gca().add_patch(patch)
im = plt.imshow(xx.reshape(yy.size, 1), cmap="Blues", interpolation="bicubic",
origin='lower', extent=[0, 10, -0.0, 0.40], aspect="auto", clip_path=patch, clip_on=True)
# im.set_clip_path(patch)
plt.plot(xx, yy, color="blue")
plt.show()```i tried putting my own values in but the fade fill just doesnt work
Today is 5 hours for training my model :D easy peasy
If any of u has a 3090 i appreciate 😝
I think I should have asked here the question.... my bad. didn't realize it in time. if anyone works with imgaug here for Image Augmentation, could you help here? <#☕help-coffee message> (it's on #☕help-coffee)
i know about imageaug
but never used
how are u augmenting the data?
if only noise changes the color
i bet is due to open cv :))
i think it sucks, but is usefull
idk how noise works, but i know open CV reads images as BGR
instead of RGB
maybe the noise changes the image to RGB and opencv still thinks it is BGR
so colors get wrong
if not, u can always read the docs for blur
no no. rotating changes the color to darker color (and brown to blue - wtf???). putting noise gets it back into the original colors
hmm. then I'll try with showing the pictures before writing them to the disk and see if they are different than what cv writes 🤔. good idea
should have read all the messages first 😄. ok, BGR.... weird. thanks!
yep, it's working now! real colors! thank you!!
im glad
Can someone help me in this
in colab u have to do
!pip install ur_module
if it is not a common module
like that one. Never heard of it
make a cell doing !pip install module
Hi guys any tips for outlier detection? I'm currently working on my data set after scraping it from the web. And I figured that many of the features contain extreme outliers. From 1,000 observations I'm down to around 300. And I would look to the other features and some will still have some outlier to them. Is there any guideline to how many minimum observations I need for a non-parametric hypothesis test? Or am I missing out on a statistical concept that determines the minimum sample size needed for one?
If I have a bunch of dataframes with identical sets of rows and columns (all representing the same type of data), is it a better data model to stack the frames vertically or horizontally?
how do I show lambert w function?
Isn't long format more ideal than wide?
yeah probably. I figured out how to do it with multiindex
If you're dealing with generators. A for loop will help.
Depends on what you are doing with them. Otherwise a dict or list could suffice
what does this mean
3200/3200 [==============================] - 1103s 345ms/step - loss: 2.3130 - accuracy: 0.5238 - val_loss: 3.9021 - val_accuracy: 0.2877
That it will never be able to classify correctly?
the diff between acc and val_acc is big
it performs worse than random guessing on the validation set
im not sure what you mean by that
how many classes do you have? with 2 classes, accuracy < 0.5 means it's worse than randomly guessing a class, which is bad
is this epoch 3200? or epoch 10 with 320 batches?
if it's significantly less than .5, doesn't that mean that it's just learning the classes in reverse? 😄
possibly yes!
epoch 10
and 898 classes
and batches are of 16
ok, so that's a lot of classes
in which case 25% accuracy is still better than guessing
ah u mean like saying this pokemon is this randomly
it is not
if 25% of the pokemon are blastoise, you can be right 25% of the time by guessing blastoise every time
hum, hi
one thing xD
i hate google colab
it closed session
after 3 hours training model
and it wasnt saved :)
you hate free things?

that sounds like bad checkpointing on your part
is this considered imbalanced?
i didnt think it will close XD
how can i use callbacks?
no, that does look pretty good
don't you save it to a file or something?
yeah but only after train is done
:)
i forgot google decides to close ur session by the face
without warning
and losing everything
hihihihihi
well yes you are using their compute resources for free, it makes sense
tf.keras.callbacks.ModelCheckpoint(
filepath,
monitor="val_acc",
mode="max"
)
This?
but i have a question
Even if i do that
make a check point
if google decides to reset my session
i will also lose the checkpoint
may i go with few epochs and manually download the progress?
does colab save your data somewhere in the cloud?
locally
if not, then yeah you might have to download and re-upload
apparently you can use google drive for it

Medium
Not all people have a Deep Learning Rig or lots of credits in cloud services to have hardware accelerated computing. Google Colabaratory…
https://stackoverflow.com/q/49322072/2954547 this is an example of doing it with upload/download

Stack Overflow
How do I store my trained model on Google Colab and retrieve further on my local disk?
Will checkpoints work? How do I store them and retrieve them after some time? Can you please mention code for ...
thats the other way arround
so it looks like your options are: 1) mount google drive, or use upload/download
and where is it downloaded? lel
the drive is mounted already
so how can i copy a file from colab to my drive?
just copy command?
%cp colab_path drive_path?
this is a very wide question i know, but i need to know this as i need to kinda work on implementation of a paper.so.
question.
if we email authors of research papers for further info on paper, do they reply?(generally)
you can just go to that place by cd(i think !cd) on colab after mounting drive, and just access file the way we do in python
if you need more detail i can share, i did it once.
what's the harm in trying?
i did that. i hope i get it. the topic is a lil bit advanced for me.
Anyone know why I cant output all my headerse in a conccurent line?
I have a csv with 10 colums but python outputs 5 and then once my 45 "dummy users" are displayed it does another set ?

hi guys! im in grd 11 and i’d like to pursue in data science! i’m not sure if this is true but i was told to take data management (as a grd 12 math course in school) since my interest line involves those concepts but i’m not sure whether to take it or not bc i already have a busy course package for grade 12. it would be great if i could get some advice 🙂 feel free to ping me if you have any
it probably depends on how you write your email and how busy the authors are. be respectful/polite and understand that they're busy people. but they might respond!
I have question. I know how to count words in Python, but how i count words , based on more other colums? I have a datafram (example) after split the sencenses
Like
Peter | England | hello | 2
Peter | china | alot | 34
Krillen | china | morealot | 343
What you see is, there a lot of krillins, in china but also peter and they count 34 times the word 'alot' and morealot 343 times. p.s: | = split
Hey everyone! I'm looking for small team (3-4 members) to set learning targets, discuss and code in Python on Leetcode/Codechef and maybe codejams/hackathons on weekends. I am a Data Scientist and have around ~4yrs of experience in coding in python so looking for like-minded people. Please ping me separately/ reply in thread without spamming group if it interests you.
Hi I am trying to make a self driving car in a 2D simulation I am using double deep q learning I am graphing my results using weights and biases and seem to get this. My neural network has an input layer which consists of the distances of the sensors(7) then 2 dense layers(512,256) and an output layer with 3 outputs (move forward,forward right,forward left) my learning rate=0.00045 batch size =516 and my memory is 100,000, gamma = 0. I implemented prioritized replay memory(sum tree) and epsilon greed. Please ping me if you know how to solve thing issue or need more information. I am new to pytorch and ai so iam not sure if I wrote the model correctly so i attaches the code too.

class QTrainer:
def __init__(self,model,target,lr,gamma):
# self.lr = lr
self.gamma = gamma
self.model = model
self.target = target
self.optimizer = optim.Adam(self.model.parameters(),lr=lr)
self.criterion = nn.MSELoss()
def train_step(self,state,action,reward,next_state,done,memory,tree_idx):
global counter
state = torch.tensor(state, dtype=torch.float)
next_state = torch.tensor(next_state, dtype=torch.float)
action = torch.tensor(action, dtype=torch.long)
reward = torch.tensor(reward, dtype=torch.float)
if len(state.shape) == 1:
state = torch.unsqueeze(state,0)
next_state = torch.unsqueeze(next_state,0)
action = torch.unsqueeze(action,0)
reward = torch.unsqueeze(reward,0)
done = (done, )
targetV = self.model(state)
target_old_clone = targetV.clone()
target_old = target_old_clone.detach().numpy()
target_next = self.model(next_state)
target_val = self.target(next_state)
if counter%12 == 0:
self.target = copy.deepcopy(self.model)
self.target.eval()
print("target changed")
wandb.log({"target_counter":counter})
counter+=1
for i in range(len(done)):
if done[i]:
targetV[i][action[i]] = reward[i]
else:
a = torch.argmax(target_next[i])
targetV[i][action[i]] = reward[i] + self.gamma * (target_val[i][a])
idx = np.arange(516, dtype=np.int32)
target_V_clone = targetV.clone()
targetV = targetV.detach().numpy()
absolute_errors = np.abs(target_old[idx, np.array(action)]-targetV[idx, np.array(action)])
memory.batch_update(tree_idx,absolute_errors)
self.optimizer.zero_grad()
torch.autograd.set_detect_anomaly(True)
loss = self.criterion(target_old_clone,target_V_clone)
loss.backward()
self.optimizer.step()
wandb.log({"loss":loss})
thats a good one, i want know too
whats a good call back for early stopping?
i have a question on colab
I am doing !cp command, and the copy is inside a try except block, just in case the file im trying to copy from google drive does not exists, so it executed the except
but actually it doesnt. Maybe cuz !cp is special command, but how can i make it do other thing if !cp fails?
If you decide to write, do not waste their time with long intros. Get to the point, keep it short.
That can get you replies. Long emails will usually be ignored.
For what it's worth, I can say that people with no data science specific courses can get into data science as well (though it may be slightly harder) . So essentially decide your courses based on what you prefer in school, and your own workload , honestly your choices will be trumped by your course choice in college anyways.
oo gotcha! thank you so much for the advice 😊
i realiced i was doing something really bad :)
class CustomDataGenerator(ImageDataGenerator):
def __init__(self, hue=False, **kwargs):
super().__init__(preprocessing_function=self.augment_color, **kwargs)
self.hue = None
if hue:
self.hue = random.random()
def augment_color(self, img):
if not self.hue:
return img
img_hsv = cv2.cvtColor(img, cv2.COLOR_BGR2HSV)
img_hsv[:, :, 0] = self.hue
return cv2.cvtColor(img_hsv, cv2.COLOR_HSV2BGR)
Can u see the mistake? x)
are you just overwriting the whole image with a single color?
also you should really use a single random seed
make sure to call random.seed with some seed value, to make sure your results are reproducible
that i never have an image non-colored
xD
so my model will never train with a original pokemon ajdasd
And no :/ i forgot to set the seed for the random lib
but why do i wanna reproducide?
like, is not on my plans reproducing a 12 hours training :)
the only seed i have is on flow_from_directory method
i modified the code like this
def augment_color(self, img):
if not self.hue or random.random() < 1/3:
return img```so only 1/3 of the times the image will be painted
HOLY HOLY HOLY
@desert oar bro bro bro bro bro
I am at 0.60 val acc
asdasads
whats this black magic
yeah something weird going on
3200/3200 [==============================] - 1097s 343ms/step - loss: 2.1622 - accuracy: 0.5474 - val_loss: 1.7149 - val_accuracy: 0.6089
val_acc > acc
pretty normal
rlly?
yea
@rare tundra The question is a little unclear. It might be helpful to give additional information about what each column represents and what you are trying to achieve. Without knowing this, one approach would be to load the data into Pandas using a dataframe (read_csv, etc.), use https://pypi.org/project/pandasql/ , and then use some type of sql count in order to achieve your objective.

i'm using opencv i'm trying to compare two histograms using compareHist formatted in ndarray and its throwing this error
error: (-215:Assertion failed) H1.type() == H2.type() && H1.depth() == CV_32F in function 'cv::compareHist'
if anyone else stumbles across this error the problem was one histogram was float 32 and the other was float 64
convert the float64 to float32
Guys I am trying to detect hands through the webcam with OpenCV and MediaPipe; However, this error spits out:
[ WARN:0] global C:\Users\runneradmin\AppData\Local\Temp\pip-req-build-m8us58q4\opencv\modules\videoio\src\cap_msmf.cpp (388) `anonymous-namespace'::SourceReaderCB::OnReadSample videoio(MSMF): async ReadSample() call is failed with error status: -1072875772
[ WARN:1] global C:\Users\runneradmin\AppData\Local\Temp\pip-req-build-m8us58q4\opencv\modules\videoio\src\cap_msmf.cpp (1021) CvCapture_MSMF::grabFrame videoio(MSMF): can't grab frame. Error: -1072875772
Traceback (most recent call last):
File "c:\Harshit\Programming\Python\Learning\Real-Time-Hand-Tracking\Hand-Tracking.py", line 16, in <module>
imgRGB = cv.cvtColor(img, cv.COLOR_BGR2RGB)
cv2.error: OpenCV(4.5.2) C:\Users\runneradmin\AppData\Local\Temp\pip-req-build-m8us58q4\opencv\modules\imgproc\src\color.cpp:182: error: (-215:Assertion failed) !_src.empty() in function 'cv::cvtColor'
[ WARN:1] global C:\Users\runneradmin\AppData\Local\Temp\pip-req-build-m8us58q4\opencv\modules\videoio\src\cap_msmf.cpp (438) `anonymous-namespace'::SourceReaderCB::~SourceReaderCB terminating async callback
This is my code:
import cv2 as cv
import mediapipe as mp
import time
cap = cv.VideoCapture(0)
mpHands = mp.solutions.hands
hands = mpHands.Hands()
mpDraw = mp.solutions.drawing_utils
pTime = 0
cTime = 0
while True:
success, img = cap.read()
imgRGB = cv.cvtColor(img, cv.COLOR_BGR2RGB)
results = hands.process(imgRGB)
if results.multi_hand_landmarks:
for handLms in results.multi_hand_landmarks:
for id, lm in enumerate(handLms.landmark):
h, w, c = img.shape
cx, cy = int(lm.x * w), int(lm.y * h)
print(id, cx, cy)
if id == 0:
cv.circle(img, (cx, cy), 25, (255, 255, 255))
mpDraw.draw_landmarks(img, handLms, mpHands.HAND_CONNECTIONS)
cTime = time.time()
fps = 1/(cTime-pTime)
pTime = cTime
cv.putText(img, str(int(fps)), (10, 70), cv.FONT_HERSHEY_PLAIN, 3, (255, 255, 0), 2)
cv.imshow('Hand Detector', img)
key = cv.waitKey(1)
Hey Guys, im using Pandas and trying to get two cells ex a1 | a2 to be bound together as a dic
ex: Employee ID: UserName (or UserName: Employee ID), anyone know how to do this in Pandas?
yes indeed, that actually work, I put it short and simple and they replied 😄
Thanks for help @ripe forge and @desert oar
hey guys does anyone known what a live json file is
hey guys , i want to know how linear regg model in sklearn is calculating the score , is it using R^2 ??
if you want to merge two df then pd.concat(df1,df2)
is there something like mainDataFrame[mainDataFrame["Best Pos"].contains "D"]?
I mean i need to see all rows which "best pos" column contains letter "D"
.str.contains
thank you 😉
Is log_softmax just log(softmax) ?
What should the axis parameters be for ndarray ?
how do I calculate z score in python @ripe forge
i googled zscore in python and got scipy stats.zcore. i'd perhaps start with that
if you use scipy
scipy.stats.zscore(a, axis=0, ddof=0, nan_policy=’propagate’) where a is array like object containing data
this thing returns me an array of nan values @stoic tiger
(x - mean) / std
My professor gave me some exercise to solve based on matplotlib, one of the question was

why does the details in the charts differ from each other even when done with the same code?

reset your notebook and clear outputs. then run one cell at a time, only once. does the problem fix itself?
nah I tried everything
what does z(a&b) mean
Where ?
Only the axis labels are different. Could be something as subtle as different versions of matplotlib or different dpi settings
I was looking at some no-code ML plattorms after attending a webinar. How will this no-code tech impact ML professionals. I am just curious to know your thoughts on this.
a good amount id say
most companies don't like to use cutting edge stuff anyways, unless it's interpretable which NNs are not
I guess dpi's are 100 by default?
basic algos and simple networks are easy to implement on their own
so the only part the companies would want to pay is data cleaning (primary)
Maybe your browser windows have different sizes and it's choosing different figure sizes. I wouldn't worry about this. If you need precise control over tick labels, set them yourself @tame sleet
rest even other AutoML tools (liek google) can do full data pre-processing and feature generation and end-to-end deployment all in one step
granted, they are expensive - but they would always be less than a single data scientist's salary
That's so depressing 😭
the things daily ML people use are not sophisticated - tho I expect companies (like tesla, aapl, amz, Goog) who use cutting-edge stuff can never use AutoML tools
They also aren't necessarily good yet
It's still relatively new and relatively unproven
says who?
As someone who has used Google's AutoML thrice, I am more than impressed by it's data engineering capabilities
sure, if you want to squeeze out that 1-2% go ahead
but most AutoML tools (even OSS like AutoKeras) are outstandingly well-performing
most companies just like to use AI as a buzzword. perfect for them incorporating basic models, not paying for a dedicated ML engineer, and getting your local SWE guy to get it to press 2 buttons in the cloud in his spare time
even if AutoML used like 10,000$ on running NASNET-large, it honestly doesn't matter compared to a team of data scientists who would probably charge more
yooo this server is fking cool af
hey guys, i think my model is stucked at 0.66 val acc. Can u give me some tips i could try to improve it?
If youre using keras try using the keras-tuner tool
automatically tunes ANN, RNN, and CNN stuff
guys i have one doubt , i was easily able to get the m and b for linear regg line by using m and b formula ```
m = (xy - xny) / (sqxm - mxsq)
b = ym - (m * xm)
I had two dataframes with equivalent sets of indices and columns, and I passed them both to scipy.metrics.ttest_ind. Unsurprisingly, the scipy function didn't appear to acknowledge what pandas thought like elements should be. I guess you have to make sure the rows and columns are in the same order before passing them to non-pandas functions?
what is a tunner for?
Hello 🙂 In Numpy, is there a nifty way to get a rectangular view on a 2d array, given the coordinates of the top-left corner (as a 2 element 1d array) and the dimensions of the rectangle (also as a 2 element 1d array)?
Here's what I came up with, but I was thinking that there might be a built-in way? 🤔
!eval ```py
import numpy as np
a = np.arange(0, 20).reshape((4, 5))
print(a)
pos = np.array([1, 2])
dim = np.array([2, 3])
print(a[tuple(map(slice, pos, pos+dim))])
@atomic tide :white_check_mark: Your eval job has completed with return code 0.
001 | [[ 0 1 2 3 4]
002 | [ 5 6 7 8 9]
003 | [10 11 12 13 14]
004 | [15 16 17 18 19]]
005 | [[ 7 8 9]
006 | [12 13 14]]
Basically it tests the parameters in your hidden layers across a bunch of iterations and returnes the ones with the highest CCR, precision, sensitivity, MSE (other ANN metrics)
Ive played around a little in machine learning and am now doing audio recognition. The problem is that the training files are too long and have a lot of silence in them, any ideas on what libraries to use to identify and cut those parts out?
people can you help me with free courses of ML from a good site so that my CV doesn't stink?
Not any Youtube courses
Unfortunately I don't think employers will care about free online courses themselves, though if you learn from them and apply that knowledge towards a project, they'd probably be interested in the project.
yeah but to mention what platform i learnt it will make it a stronger point, like a certificate would be of great help but shady sites don't provide you with that
The certificates are what I was referring to.
aight, any good site names pop up for ML then do lemme know!
cause i gotta hop onto ML
and YT videos ain't good
We're working on a project to improve our resource recommendations, so keep an eye out
sure thing! Thank you.
@grave frost i haven't tried anything like automl in a few years. last i checked (using the tpot package) it did "okay" but wasn't something i felt comfortable relying on. if they're at a point now where you can dump in a csv of 50k records and get a decent model back, then that's really good and i'm happy to give it another shot.
@atomic tide 👇
!e ```python
import numpy as np
a = np.arange(0, 20).reshape((4, 5))
row_inds = np.array([[1, 1, 1], [2, 2, 2]])
col_inds = np.array([[2, 3, 4], [2, 3, 4]])
print(a[row_inds, col_inds])
@desert oar :white_check_mark: Your eval job has completed with return code 0.
001 | [[ 7 8 9]
002 | [12 13 14]]
ah, i see you're basically constructing that
there might be some way to use built-in broadcasting here
you can use np.broadcast_arrays maybe
but the slices i think make sense
salt
val_acc is stucked at 0.66
do u know what things can i do?
i can share u my colab
if u wanna see what am i doing
is that for training or testing?? check for both and if the training score is more than testing score then your model is suffering from high variance if so then try to get more data samples or if the testing score is higher then try to get more features . this can improve the score little bit , or try using diff model/algorithm
@cedar sun i am a beginner , ask others too just to be sure
>>> a = np.arange(0, 16).reshape((4, 4))
>>> a
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11],
[12, 13, 14, 15]])
>>> coords = np.array([1, 1])
>>> size = np.array([2, 2])
>>> a[coords[0]:coords[0]+size[0], coords[1]:coords[1]+size[1]]
array([[ 5, 6],
[ 9, 10]])
TPOT is still a tinker toy for AutoML tools. it has traditional algos only, doesn't do basic pre-processing and can't handle many records. You might want to try AutoKeras sometime - it gives quite good accuracy much faster than other AutoML tools out there
Sure, I can give it a try on some social science data
yeah gradient decent for solving linear regression doesn't make sense, you can solve it with matrices is O(n^3) time (maybe a better algorithm exists that I don't know about)
it might be that sklearn is optimizing for huge datasets where O(n^3) is too slow, and you want an approximate solution though

it says it wants a tensor

are you passing it a numpy array?
you need to convert it to a tensor
my instructor run the same thing without error
can you show the code?
I see thanks , it would be cool if others shared their thoughts on this
this is upper part: (runs fine no problem)

this is lower part(runs fine for instructor only lol)

i can run upper part correctly but lower part shows up that error
so idk the problem but have you tried changing x to be a tensor instead of a numpy array?
i will try now....first time using tensor so no didnt knew....
you don't seem to pass it to tensorflow so idk how it could cause a problem but it might fix it
but instructor ran it ....it doesnt make sense how he was able to
maybe he used a different version of tensorflow?

are you using the gpu or cpu for this?
try with cpu?
disable cuda?
yeah temporarily
how to?
to see if it fixes it
Stack Overflow
Is there a way to run TensorFlow purely on the CPU. All of the memory on my machine is hogged by a separate process running TensorFlow. I have tried setting the per_process_memory_fraction to 0,
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "-1"
import tensorflow as tf
try putting this at the top of your code
this is a random guess that prolly won't fix it though
you should tell your instructor about your problem

@mint palm try changing x to a list instead of a numpy array

x[i] is a numpy.int64 which idk if it could cause problems but who knows
cudnn is a separate install
if you read it, it says it could not load cudnn
which indicates theres no cudnn
or that cudnn is installed incorrectly
i think its not cuda too cuz i remember faintly running it before and still having some error

what i'm saying is, your code is likely fine, the error is saying it couldnt find cudnn
so, you need to install cudnn

are you on windows or linux
hello, I want to make an assistant with artificial intelligence, but how can I do it with only artificial intelligence?
can you be more specific? what do you want your assistant to do? how will it get inputs? etc
I want to chat with him first and then I want to do something in the computer.
@austere swift
there is literally only one link that says windows lmao
cudnn library for windows
its x86
yeah
i am x64
so if you wanna chat with it you'd first need to have a speech recognition algorithm
so it turn what you're saying into text
then some language model to understand what the text means
then you'd need some output from the language model to say what you want it to do based on what your input is
nice project topic
I made in speach reconition but its not be a ai
yeah
why do you need everything to be ai?
some things are better done with other methods
the only thing you'd probably need some ai for is the language model for the text
which, in some cases, it may still be better to just look for keywords in the text rather than making a whole model for it
I dont know python succesfully
i checked the assignments tensorflow version correspondinto video......its this

in my pc i have 2.4.x
if you don't know python then how do you plan on making an ai
2.3-2.4 isnt really much of a difference
it would only be a big difference if it was tf 1 in the tutorial or something
is there a way to know cuda version also from jupyter?
guys, can u help me plotting the confusion matrix of my model?
of thier pc
easy
if your model has 898 classes then your confusion matrix will be 898x898
there isnt really a way to shrink that down
y_true is your labels
and y_pred is the output from the model
you basically put y_true and y_pred into that function, and it'll return a 2d numpy array which is the confusion matrix
but how do i get the y_pred?
you use the model
looping through all my images?
yes
@austere swift hey
Hi, I have a question: Why I get an error like this?

I think your computer just ran out of memory
I have problems loading a tensorflow model using tensorflow 2.0
I am using tf.io.gfile.GFile to load the file but I keep getting the error: "module 'tensorflow._api.v2.io.gfile' has no attribute 'Gfile'"
Any ideas help, thanks all!
huh idk how to load model with tf
u can do
tf.keras.models.load_model
i think u will be able
my computer have 1 TB memory
I have to represent about 60,000 unqiue values with preferably alphabetical values
like 0 --> AA, 2 --> AB, ......
what do you think I should use?
Not that kind of memory. Look up on google memory error and it will get you more details
When I run that code, I get a long time to see the result, and eventually the result giving an error. What's happened?
before this, i has running that code and it's fine at all. but why when i open my notebook second time i get an error?
Because your memory is full
memory remaining so much

I tried that too but it seems like that way of loading models is not compatible with the files that I have.
I think tf.io loads the model is the format that it was saved, but if i try to use tf.keras.models_load_model, it gives me a "missing file error"
I'am trying fine tune a bert model. I think I have to use tf.io.gfile
What's happened?

what do you think the error means
there’s a difference between RAM and disk storage
@velvet thorndo u know by chance some tricks that can improve the acc?
what?
I mean
you have no guarantee I know anything about your problem, right
🥴
anyway
like I said
it depends on what you’ve done
what you’re trying to model
the characteristics of your data
model architecture
preprocessing
etc.
do u have time to take a look at my colab?
my_callbacks = [
tf.keras.callbacks.EarlyStopping(patience=2),
tf.keras.callbacks.ModelCheckpoint(filepath='model.{epoch:02d}-{val_loss:.2f}.h5'),
tf.keras.callbacks.TensorBoard(log_dir='./logs'),
]
model.fit(dataset, epochs=10, callbacks=my_callbacks)
This is from keras page
KeyError: 'Failed to format this callback filepath: "model-scrap-{val_acc}.h5". Reason: \'val_acc\''
check_points = tf.keras.callbacks.ModelCheckpoint('model-scrap-{val_acc}.h5', mode='max', monitor='val_acc')```Why it isnt working for me?
filepath: string or PathLike, path to save the model file. e.g. filepath = os.path.join(working_dir, 'ckpt', file_name). filepath can contain named formatting options, which will be filled the value of epoch and keys in logs (passed in on_epoch_end). For example: if filepath is weights.{epoch:02d}-{val_loss:.2f}.hdf5, then the model checkpoints will be saved with the epoch number and the validation loss in the filename. The directory of the filepath should not be reused by any other callbacks to avoid conflicts.```umm is that just the filename shouldnt have brackets?
nvm ive literally never used collab before lol
I save my models as h5
And extension of a file shouldnt matter tho
Also, load_model loads the model as h5
no it doesn't; read the docs first before asking
Where is that said?
Have you tried logistic regression for hyperparameter optimization?
It only works for regression, not classification models.
What model are you trying to train?
a pokemon classifier
Try to build the model from scratch by yourself. Don't rely too much or copy code from tutorials.
Go line by line and understand what they are trying to do; that's really the best way to learn.
It's painful, I know, lol. I have been stuck in the same problem for 2 weeks but I'm learning plenty!
read the docs first before answering. The error was {val_acc} instead of {val_accuracy}
1 1/23/2021
2 1/31/2021
Name: Date:, dtype: object]```
how can i stop the data being printed like this?
this is my code```py
df = pd.read_excel(Log)
row_vals = [df['Date:']]
print(row_vals)```don’t put it in a list
not really my thing, sorry
do you have specific questions?
sounds like you’re doing image classification
yeah, but not a particular question
so like this row_vals = df['Date:']?
i mean, idk, neither my accuracy nor validation accuracy are increasing passed certain point
so seems im stucked
but is weird not even overfitting the model works
@grave frost what file format is it? If it's hdf5 then why don't people use the h5 extension?
It's saveModel format I beleived - im p sure they dropped h5 due to it saving only the weights and biases, while requiring the optimizer state to be saved seperately.
they decided to remove it and simplify everything by the new one, which is a folder not a file (dunno the technical reason why)
ahh, I may be incorrect actually - it was just for the special case for custom objects
If you are using the SavedModel format, you can skip this section. The key difference between HDF5 and SavedModel is that HDF5 uses object configs to save the model architecture, while SavedModel saves the execution graph. Thus, SavedModels are able to save custom objects like subclassed models and custom layers without requiring the original code.
To save custom objects to HDF5, you must do the following:
Define a get_config method in your object, and optionally a from_config classmethod. get_config(self) returns a JSON-serializable dictionary of parameters needed to recreate the object. from_config(cls, config) uses the returned config from get_config to create a new object. By default, this function will use the config as initialization kwargs (return cls(**config)). Pass the object to the custom_objects argument when loading the model. The argument must be a dictionary mapping the string class name to the Python class. E.g. tf.keras.models.load_model(path, custom_objects={'CustomLayer': CustomLayer})
I think you mean something different from "overfitting"
that suggests underfitting, actually
well, depends on the problem too
Then the model has converged
but why even repeating epochs doesnt increase train acc???
Why cant i overfit the model?
Because that's not how it works
Eventually you hit a local minimum in the loss function
yes, but that doesnt mean it is the only minimun
how can i find others?
make the lr higher or lower?
higher, right?
@desert oarif my images are on a directory like
class1
-- img1
-- img2
class2
-- img1
-- img2
class3```Can u tell me how could i plot confusion matrix?
didnt you ask this earlier?
and i gave you an answer
For transfer learning on multi class image classification...vgg16 is giving 80% test accuracy...is there any other way to improve on the test accuracy?
try a different model, different optimizer, different loss function, etc
just test out a bunch of different hyperparameters and see what gets you the best accuracy
Hi
who can help me with yolov3?
i need to add custom object and import this ai into project on my computer. I need to ai search custom object on screen. Please help me idk how it work.
your model might not have enough power
you can only overfit if your model has the capacity to overfit in the first place
just install tensorflow-gpu with anaconda
Hey guys, please help me with this if you can! 🙂
I have a dataframe consisting of these records

And I have a set of unique_values = {'Arts', 'Sports', 'Shopping'}
Now, I want to select records whenever a unique value in the above is in a row at this attribute (column)
So my code looks like this
def partition_for_categorical(self,data,attribute,unique_values): branches = [] for row in data.values: selected_rows = [] for value in unique_values: if (value in data.iloc[:,attribute]): selected_rows.append([row]) branches.append(selected_rows) return branches
But somehow the records don't get selected
Please help me out 🙂
So, it should basically be like for Arts, both the records should get selected, and for Sports only the second record should get selected, and for Shopping both the records should get selected
Yes, attribute is my column name and unique values are what has to be searched for (matched with the column in that row), and if that values exists, it should append the whole row to selected rows.
are you using it in pandas dataframe ?
I don't understand why something so simple doesn't work, and I'm helpless
Yes, it is a pandas dataframe
the 'data' is a pandas dataframe
y r u storing values in sets ?
I would but it takes a lot of time :/
And how can i give it more power?
increase complexity
I don't want duplicate values in my list, so I am storing it in a set
because your are using set there
the elements wont be treated as string
just have look on it
elements aren't in quotes
Are you familiar with the way confusion matrices work?
You literally cannot make a confusion matrix without doing predictions on all of the images
The folders in the zip file correspond to folders in your CUDA directory
You’ll need to manually place the files from those folders into the corresponding locations in CUDA
You can find CUDA in your program files folder under nvidia gpu computing toolkit
you can apply this ..
def attrib_map(list_, search):
for search in search:
if search in list_:
return True
else: False
# attribute is column, value in column is considered as set
# unique_values are also considered as list
result = data[data[attribute].apply(attrib_map, args = (unique_values,)) == True]
it won't matter much by those hyperparameters. Just focus on your model arch (like gm said) and tune your learning rate for starters
then if you have achieved your best accuracy, you can experiment with different optimizers, loss functions etc.
in my expereince, those adjustments yield relatively less benefits than what model architecture tuning can do
Hello everyone, I'm using python from some long time, since beginning i have done a little in django, write from scratch basic for mmorpg 2d game, write few simple programs like scrappers, I was still looking for new python learning opportunities and I find out about Data sience on udemy courses, I am best learner in live project, for now i know basic of jupyter nootebook and pandas, but can someone help me to understand how i can make some proper(from data-sience worker view site) project? I found some ideas like : Climate Change Impacts on the Global Food Supply
But i don't know how to start with it, just found some API to get climat changes data, and make some spracer to look for food prices, and take how many % incrased both? Please someone lead me the way to proper start learning data science
Hey, I'm studying about logistic regression and I'm seeing 2 different definitions of the logit fucntion. Some say it's the log of odds, while some say its the log of the odds ratio. The formula for logit however favors the 1st definition i.e :

So which one is it?
there are some pinned resources to the top
Thank you! 🙂
worked for you ?
got it i am trying
pls help me with zvalue and pvalue
No 😦
But, I'm unable to get that result thing working
Why is there only one parameter but in the function we mentioned 2 params?
im little confused 
df[attribute].apply(attrib_map)
apply send columns value one by one to attrib_map,
to add extra parameter you need to pass tuple of args
?
log of the odds ratio
can you quote where? AFAIK the eq. in the photo is the correct one

This video is a bit more "mathy" in that we somehow have to bridge our independent variables and our dependent variables...which are 1's and 0's. So in this video we learn about the logit, inverse logit, and the estimated regression equation. Nothing harder than basic algebra which leads us to being able to interpret logistic regression output. ...
at 4:24
oops, the video isn't playing on discord
Here's a screenshot

How is that?
Never done one srry
But the guy further proceeds to use the logit function as given in the photo i just send.
Whats the model arch? Sorry i dont know some terminology
must have made a small mistake then
Ah. Using Xception
its a small detail anyway, if you write ratio after odds - its just one word
try different nets then
yeah, i guess so. Thanks though 👍
Also, btw, does the odds ratio play any role in logistic regression?
i mean, like i said. it takes a lot of time to train it. i rather using that as last option
i will try to plot the confusion matrix, sec
Logistic regression coefficients are log odds ratios
btw, u should try this ^^ https://colab.research.google.com/drive/1go6YwMFe5MX6XM9tv-cnQiSTU50N9EeT

what, no. logistic regression coefficients are equal to log of odds i.e logit.

Also... one thing
I have 100k images for training and 25k for validation
the random split is always the same cuz i set a seed
May i change the seed so model can see different images?
Hey @spring seal!
It looks like you tried to attach file type(s) that we do not allow (.ipynb). We currently allow the following file types: .gif, .jpg, .jpeg, .mov, .mp4, .mpg, .png, .mp3, .wav, .ogg, .webm, .webp, .flac, .m4a.
Feel free to ask in #community-meta if you think this is a mistake.
You're right 🙂 I shouldn't drive-by respond to messages like this
Hey @spring seal!
It looks like you tried to attach file type(s) that we do not allow (.csv). We currently allow the following file types: .gif, .jpg, .jpeg, .mov, .mp4, .mpg, .png, .mp3, .wav, .ogg, .webm, .webp, .flac, .m4a.
Feel free to ask in #community-meta if you think this is a mistake.
Wait hold on
Hey @spring seal!
It looks like you tried to attach file type(s) that we do not allow (.csv). We currently allow the following file types: .gif, .jpg, .jpeg, .mov, .mp4, .mpg, .png, .mp3, .wav, .ogg, .webm, .webp, .flac, .m4a.
Feel free to ask in #community-meta if you think this is a mistake.
The logit is log odds
Hey @spring seal!
It looks like you tried to attach file type(s) that we do not allow (.csv). We currently allow the following file types: .gif, .jpg, .jpeg, .mov, .mp4, .mpg, .png, .mp3, .wav, .ogg, .webm, .webp, .flac, .m4a.
Feel free to ask in #community-meta if you think this is a mistake.
The coefficient is an odds ratio
It's a difference in log odds
Ergo, odds ratio
@late shell
The overall linear component is log odds
Im on my phone let me find a blog post or something for you
umm, could you break that down into noob language please.
ahh, thanks
@late shell the w.x part id log odds
now increment one element of x by 1
What's the difference between those two expressions?
That's a difference in log odds
yes
Difference in logs is a ratio of non-logs
yes
Ergo, difference in two log odds -> log odds ratio
Happy I could help after all!
mmm okey, i got the y_true and y_pred
How can i plot the confusion matrix?
okey, nothing is seen. I got too many classes
i mean, 900x900 is too big xd
that is 1 pixels per class
on my monitor tho
Im trying with inception anyway
But one more thing. I have an already pretrained model for this pokemon classification
if i load the model as load_model
How can i remove the last layer, add my own, and train that one?
I want this because this model has 928 classes, while i have 898
confusion matrix is always 2x2
I don't know how good this article is, but the first graphic might be useful to you

What is Confusion Matrix and Advanced Classification Metrics? After data preparation and model training, there is model evaluat...
which algorithms are important to know for data science and ai?
You can take a cross tab of predicted vs actual with any number of classes
it is not (?)
Not many from the traditional computer science world. Dynamic programming can be a useful technique but otherwise I wouldn't stress about "algorithms". Learn linear algebra, probability, and stats instead.
You should know dot product and matrix multiplication, and you would benefit from knowing about "algorithmic" things like nearest neighbors, k-means, decision trees, eigendecomposition/svd, sgd, least squares, et al
Reversing a linked list is relatively useless knowledge for this field
Depends on what you want to do, but I would start by learning regularized linear and logistic regression. Then learn K nearest neighbords, SVM and clustering.
Fair point, but if you have >900 classes I would stick to the 2x2 version 😉
Eh
that's only for binary tasks
I think they're using it to mean a cross tab of correct/incorrect somehow?
You'd need a 2x2 crosstab for each class
They being elitegamr?
ig yea, can do that then
You can do 2x2 for multiclass problems still. TPR can be measured across multiple classes.. same for FPR etc. But you're right that "always" was too strong a statement
Well yeah but those are calculated using the underlying 900x900 table
There's no "actual negative", there are 899 of them
You're right about the calculations I'm just talking about the resulting visualization
guys i have one doubt regarding linear regression . i tried to find the slope(m) and the y-intercept(b) for one independent feature using their formula m = (xy - xny) / (sqxm - mxsq) b = ym - (m * xm) where, xy - mean of x*y xny - mean of x * mean of y xm, ym - x mean, y mean sqxm - mean of squared xs mxsq - square of x mean
using the above formula i got the weight and bais and i also tried sklearn linear regg which uses gradient descent to minimize the cost func until it iterates n times . after that i tried to predict and both gave me the same r^2 score and predicted the same values . now my question is why is gradient decent is used if that simple m and b formula itself working ??
i mean, confusion matrix shows u what % of all the images of a class are from that class, and which arent
the 2x2 matrix u are saying is just the val_acc
@somber prism sgd is not necessary unless you have billions of data points and/or many thousands of features
i dont need a matrix for that
sgd ?
Also @somber prism the general formulas for regression with more than one variable are more complicated to compute
SGD, stochastic gradient descent
It doesn't have to though. True positive rate can be generalized to true for the observations respective class. It's not the same measure as splitting it up on a class-by-class basis but if you have to choose between a 2x2 or a 900x900 matrix I'm going to go with the 2x2
So you put TPR, FPR, etc in the 2x2 across all classes?
Yeah
I have done that before but I don't think I've ever presented it as a confusion matrix. It's a good idea
the formula i showed you isnt sgd , i am not picking some random x sample and reducing the cf
Maybe we can call it an aggregated confusion matrix 😉
a 2x2 isnt usefull
Still, if you plot the big heat map and use seriation, you can possibly identify clusters of misclassification
Of course it's useful, it's different information. It's a summary
cuz the point of the confusion matrix is knowing what classes have the worst learn ratio
Well you're right it wouldn't help with that
so u can emphasize on them more. By grabbing more images or what ever
There are other things you might want to see in the matrix and other things you might want to do
It's not a good attitude to assume things that other people find useful are not useful
the 2x2 matrix u are saying is like if i eat chicken and u dont. On average, we both ate half chicken, but the reality is u are hungry af xd
Ask why it's useful, don't state that it isn't useful
Idk if I'm tracking with that one Aza haha