#data-science-and-ml
1 messages · Page 312 of 1
rest is correct
also before it was 6 frames and adding steps_per_epoch made it 5
@serene scaffold you there?
yes. one moment
ok cool
what is train_ds?
training dataset
what class does it belong to?
what type of object is train_ds?
yes. that function returns an instance of tf.data.Dataset
and that should work right?
which one is import - creation of model,compile or fit?
rephrase: what type is image_learner?
Sequential
okay, and what is the import statement for Sequential?
i am not very sure i understood this but i think this is what you are asking for
image_learner = Sequential([
data_augmentation,
layers.experimental.preprocessing.Rescaling(1./255, input_shape=(img_height, img_width, 3)),
layers.Conv2D(16, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(32, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(64, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Dropout(0.2),
layers.Flatten(),
layers.Dense(128, activation='relu'),
layers.Dense(num_classes)
])```!code
Here's how to format Python code on Discord:
```py
print('Hello world!')
```
These are backticks, not quotes. Check this out if you can't find the backtick key.
here
I got it already, thanks for your help!


the edited one is ok right?
The table used in ques 7 is above it
@dusky granite I noticed that you don't pass a y argument
well i don't have a y argument
does it not work without one?
Looks like you don't need one when x is a tf.data instance of some kind
hmmmmmmmmm
also it worked as a gpu model
btw I'm pretty sure you didn't share the whole error message
what should be the steps_per_epoch?
InvalidArgumentError: Unable to parse tensor proto appears to be cut off
no that is the full thing
i can send an ss if you want
Did you look into what "InvalidArgumentError: Unable to parse tensor proto" might mean?
it can mean a lot of things
like wrong input something missing


the screenshots
it was 6 frames earlier
adding the steps_per_epoch made it 5
i believe these 5 are based on the first one
I don't think I have any ideas other than to check out how you're interacting with the GPU
it is able to connect to a tpu
here
Pastebin
Pastebin.com is the number one paste tool since 2002. Pastebin is a website where you can store text online for a set period of time.
is there a different way to use TPU?
I'm not sure.
do you know what is currently wrong?
No


Why am i wrong in question 7
I think my friend is right💯
The given answer is option a
did you try readin the TF docs?
the model isn't supposed to be in the strategy.scope
I tried to where there were no other guides
take out an hour, read about TPU and solve accordingly
go through the whole guide, even if it's not for your case
Even that says this
model = create_model()
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['sparse_categorical_accuracy'])
Ok will do tonight
I mean, can you see any other line in there except create and compile???
Mine is also the same just that. I don't have create_model() and it is all there
you place your layers there too
Practically, I think your choice is a reasonable conclusion, but here are some other things to consider: there's pretty much always a higher error in validation/test splits (is 5% acceptable?). There's also a large gap between train error and human-level performance, which could indicate that the model itself may be a poor choice. Finally, a high discrepancy in train/val error doesn't necessarily mean validation samples are harder; they could simply belong to a separate distribution
I will read the docs once and understand what I am doing wrong and then ask any remaining questions if I have. Currently I am just confused
cool
can someone explain me about dummy variable trap , it is defined as the variables are highly correlated to each other but how , i mean arent the features are independent and the output variable dependent ?
I'm not sure about the trap, but often the statement "features are independent" is an assumption rather than a reality 🙂
I took a quick look at this page (https://www.algosome.com/articles/dummy-variable-trap-regression.html) which seems helpful. The gender example makes it clear in my opinion
Algosome Software Design.
Hey, can someone enlighten me regarding the parameters that can help me know if a sample of a dataframe is fair representative of the original dataframe please ? I'm thinking about bayesian inference but i don't really know how i could make it work (as my datas are hashtags (and not values), i don't think i can work with mean values & std)
To sum up : i have multiple dataframes of different sizes (from 5m rows to 67m rows) and i, for example, took only 500K rows of each dataframe. Are there ways to verify if such samples' properties can be applied to the original dataframes ?
Hi guys. I don't know how relevant this is for Python but I am using Python to do this so I might as well just ask it here. My plan is to use images of a well-known object (a painting in a museum for example) and then use those to query some online database to retrieve the correct name for that painting.
I know this will involve AI but I was hoping someone here can point me in the right direction. Is there already some Python library to do this?
that online database could be a wikidatabase
google reverse image search
@grave frost i figured most of the stuff out
just one thing
how can i put my own dataset here?
as_supervised=True, try_gcs=True)```i currently use this for my datasets
tf.keras.preprocessing.image_dataset_from_director
Compare distributions of sample and population over parameters you care about. Do sensitivity analysis by resampling and measuring variance in your procedure.
Hmmm
I think my issue is that i don't really understand what comparing distributions of sample and populations over parameters mean when my "values" are strings
If i had numerical values i could probably understand how to do it (with mean, std, etc...) but i really can't see how to make a distribution of strings
What type of analysis are you planning to do? At some point the strings get turned into numbers.
I think i'll go with a statistical analysis
though i wouldn't mind going with a bayesian analysis if that can help me verify if the sample's properties represent the original dataframe's properties as well
But like simple frequency of each hashtag? Or an embedding like bag of words? What is the question about the data you are trying to answer
Yeah it seems i forgot to give the context :
-My main objective is to study how the COVID-19 crisis has been lived by Twitter users using hashtags more or less related with COVID-19.
-To do that, i downloaded a dataset on github containing CSV files of tweet/thread IDs with the hashtags (https://github.com/lopezbec/COVID19_Tweets_Dataset/tree/master/Summary_Hashtag)
-As these are hourly datas, i concatenated them so they become monthly datas & applied some edits (lowercap, delete NaN, etc...)
-Since there is an enormous amount of data, i decided to sample the dataframes so it becomes easier to study them
-My final objective is to use networkx to plot networks of the hashtags & to observe how they are linked to each others (2 hashtags mentioned in the same tweet/thread means they are linked).
However there is not a single analysis there : i need to figure out what would be the best parameters to sample the dataframes so i can tell if any property/result found in the samples would still be accurately found on the original dataframes.
Sorry if my english is kinda bad, please tell me if anything isn't clear
@near cosmos

GitHub
COVID-19 Tweets Dataset. Contribute to lopezbec/COVID19_Tweets_Dataset development by creating an account on GitHub.
The dataframes look like this (that was for ex after taking 500K rows) :
Index Tweet_ID Hashtag
5 5 1219774023246192640 #cdc
15 15 1219775789270351873 #coronavirus
21 21 1219778666877448192 #coronavirus
30 30 1219781023023685633 #cancer
32 32 1219781023023685633 #ourmoment
43 43 1219784288687792128 #chinapneumonia
57 57 1219788195799302144 #coronavirus
60 60 1219789360725483520 #coronavirus
67 67 1219794180274151424 #cdc
73 73 1219794987451158528 #wuhanvirus
79 79 1219797876127215616 #corona
127 127 1219807844599336961 #coronavirus
132 132 1219808345713868800 #coronavirus
146 146 1219811459200249856 #sb276
153 153 1219811598845349888 #us
154 154 1219811697176612867 #wuhancoronavirus
156 156 1219811935765483520 #wuhanpneumonia
176 176 1219815212607594506 #coronavirus
193 193 1219817193241751553 #jesussaves
197 197 1219817448083464192 #breaking
205 205 1219818433165946880 #china
209 209 1219818516473270273 #wuhancoronavirus
210 210 1219818516473270273 #wuhanpneumonia
229 229 1219821014735118337 #publichealth
236 236 1219821518718406658 #wuhancoronavirus
238 238 1219821744724369408 #coronavirus
242 242 1219822045367656449 #wuhan
249 249 1219823148998119425 #coronavirus
256 256 1219823683092566016 #coronavirus
257 257 1219824203454529536 #chinapneumonia```So a simple first check then is to calculate your network over several resamples and see if it varies too much for your purposes
In that case is there a parameter i can look at to verify if my networks are sufficiently accurate ?
You can also look at cross-validation techniques, which are essentially aimed at the same question (is my sample good)
Also is there another parameter that can evolve with the sample size so i can see at what exact/approximative value my sample size starts to be good enough ?
I'd say the parameter you care about and what is "good enough" is specific to your question/domain. That is, there isn't one right technical answer: You have to think about what you care about and what matters to your problem. But what I would tend to look at is, say, variance in the linkage strengths
I see
There is still something i don't understand : iirc cross-validation needs an estimator, however i don't think i have any estimator to use (as i'm not trying to make predictions on the datas)
In that case how should i define my cross-validation method ?
I'd say it this way: you are calculating some statistic (edge strengths in a network) and you want to estimate the variance. Resampling, bootstrapping, cross-validation, etc all give techniques for creating new samples so that you can measure variance.
Then i can just make new samples using the DataFrame.sample function
(Or in Bayes world, you are estimating the posterior distribution for linkage strength)
In that case what would be the objective ? Get the variance as low as possible ?
Yes, if your goal is to show that your sample doesn't alter your conclusions
I may be dumb but i don't see how i can establish a link between the sample size & the accuracy of the network
Like even if i get a pretty low variance (which will tell me i get similar results regardless of the samples (of the same size ?)), how does that tell me that my sample is sufficiently large to correctly represent the original dataset without being too large so i can work on it with satisfying execution times ?
I accept the fact that they can belong to different distribution but i choose last option cuz it says "probably" lower than dev/test set
Oh totally, it's a bunk question 😛
Is it just to be ignored or
Ya
I am just asking cuz instructor specified 30 times to go through questions in detail
I hv one more mind f question

I got this wrong too
Does anyone have an idea of how many GCN layers shoule be stacked when using GCNs?

I think we are just talking basic sampling theory now. How do you know your sample is a good representation of the population you care about? In this case, you are treating your original dataset as the population (it is also a sample), and then subsampling and trying to show that the subsample accurately captures the features you care about
That's right
If you increase your subsample size, your uncertainty about the actual value of the sample will go down. You can demonstrate that by subsampling a bunch of times, perhaps sweeping the sample size and showing you converge
If I did 1000 repeat experiments on the real world and showed that my uncertainty on my stats were very small, wouldn't you say that was good evidence I am appropriately sampling reality?
We are using the same logic here to show that your subsampling is appropriate
So i should, let's say take multiple subsamples (10%,20%,30%, etc...), plot the network for each subsample then notice a convergence in the network constitution (similar links, same nodes, same nodes size, etc...) & conclude my model is accurate at whatever sampling coefficient i notice the convergence ?
Where would the bayesian analysis interfere then ?
Yes, but also you do many subsamples at each subsamole size. That gives you a distribution
Then i plot the variance as function of the sample size (in % for ex)
And take the sample size at which the variance is minimal ?
Well, it's going to always be smaller as your sample gets bigger, so look at it first like you are characterizing the behavior and demonstrating that your choice is reasonable
But yeah, you've got the basic idea. Give it a go
Alright
Just in case : where would the bayesian inference/analysis come in please ? Like where in the advices you gave me can i see a bayesian reasoning please ?
A gentle nudge to the Bayesian way to think through the problem is to think in distributions. Every parameter and outcome is a distribution and you are trying to characterize it.
That's a bit hard to imagine ngl
Frequentist: there is one true linkage strength + error in my ability to measure it. Bayesian: there is a family of linkage strengths, some more likely than others
From what i understand, i have a distribution of sample size correlated with a distribution of results & i want to find what sample size maximize the probability to get the correct result
(With apologies for discussing complex topics over chat)
I think i start to understand what is the difference between both
hello can someone help me involving finding the Exponential Moving Average from a list of prices
Signal Processing people - what is the technical term for the specific frequency of an audio file that occurs most of the time? (for ex. say I have a bass song and a lot of frequencies are near 2khz - what would be the technical term for it?)
Are you thinking about normalized (relative) frequency?

whats this app called?
import pandas as pd
from sklearn import linear_model
app = Flask(__name__, template_folder='template')
@app.route("/")
@app.route("/home")
def home():
dataset = pd.read_csv("diabetes.csv")
df = pd.DataFrame(dataset, columns=['Gender', 'AGE', 'Urea', 'Chol', "BMI"])
X = df[['Gender', 'AGE', 'Urea', 'Chol', 'BMI']]
Y = df['CLASS']
regr = linear_model.LinearRegression(n_jobs=-1)
regr.fit(X, Y)
X_TEST = [['F', 24, 4.5, 4.2, 21]]
predicted_val = regr.predict(X=X_TEST)
return render_template('index.html', data = predicted_val)
if __name__ == '__main__':
app.run(debug=True)```this giving me indent error : X = df[['Gender', 'AGE', 'Urea', 'Chol', 'BMI']]
^
IndentationError: unindent does not match any outer indentation level
it worked
Can someone tell me how to start learning machine learning Im beginner at AI field I love this field so much so I wanted to get into but im not beginner at data analysis and visualization field so i believe that will help
because that's not how overfitting works. you can still overfit within one class even if you are reasonably confident that you have a representative sample of other classes
have a look at its graph its quite straight forward
The range of cosine function is [0, 1]
Defintion: cosine(theta) is the x coordinate of the point on a unit circle at angle theta.
It depends, actually - https://docs.scipy.org/doc/scipy/reference/generated/scipy.spatial.distance.cosine.html uses a definition by which it's from 0 to 2.
As for why, well: dot product of two vectors divided by the product of their norms is the cosine of the angle between vectors. That's from -1 to 1. Then you take 1 minus that, and get a value from 0 to 2.
With 0 achieved by collinear vectors, and 2 by antiparallel ones.
why isnt anyone answering my simple question
and not only this question , another question since days and not answered
Reads the pins
Ask in #web-development
isnt matplotlib and ChartJs data science related ?
They are related to data science in the same way that knowing how to open a window is related to game development. Data science is also a buzz term and therefor related to everything. The question is like asking if math is related to physics. Also the previous question was web stuff so it's better suited for the web dev channel.
why remove it from the negative range tho?
I don't think it makes sense computationally - and we have a mathematical foundation for the negative range
ah, right oops. range is [-1, 1] not [0, 1]
what do you want to do with ML?
Because it is intended to be used as a distance function.
distance functions with negative values are kinda bad. Though even the 0-2 cosine distance isn't positively determined (or whatever that property is called) - cosine(a,b)==0 means a || b, but not necessarily a==b, so it's not a metric unless your vectors are normalized.
There are signed distance functions that have great use, but in this case (assumption) you don't care about the sign (and very often don't).
I want to learn it for a lot of things like chat bot using machine learning , I wanna learn a lot of it
there are unlimited projects to do with ML
hmmm..alright, that does make sense
Basically, you need to ask yourself: "What does the sign mean?" and "Do I want/need it to be taken into account (or be invariant to it)?"
how long should is the learning curve from beginner to coding ai
depends on factors - efforts, time, consistency, IQ
Hi people! I'm an undergrad that wants to make the best of his summer, and I'm looking for good courses to learn skills in Data Science/ML/AI. I'm not really sure where to start, but I've been suggested to look at PyTorch as a starting point (since I'm already decently fluent in Python), and then make my way up to SQL. Can somebody suggest any good online courses/bootcamps/online resources to use over the summer? Thanks.
Why are neural networks not used for everything?
Like, why would you choose to use a statistical model like a Random Forest over a neural network?
possibly lower variance
lower computational complexity
higher interpretability
access to software
so generally just for computation?
would big tech companies generally always use NNs then?
since they have the resources
no
interpretability and variance matter
NNs aren't better @ solving all problems
example
Amazon SageMaker Random Cut Forest (RCF) is an unsupervised algorithm for detecting anomalous data points within a data set. These are observations which diverge from otherwise well-structured or patterned data. Anomalies can manifest as unexpected spikes in time series data, breaks in periodicity, or unclassifiable data points. They are easy to...
also
with high enough time complexity and dataset size, nobody has enough resources
Makes sense, thanks
@velvet thorn
You helped me 2 days ago on Numpy array broadcasting. I've been studying array broadcasting, but I'm still stuck. I rewrote my code snippet (https://paste.pythondiscord.com/inoyecifax.py) and I've included the necessary utility functions to convert image files to integer matrix for testing purposes.
There's a useful tutorial on calculating 'pairwise distances' which is close to what I'm doing... https://www.pythonlikeyoumeanit.com/Module3_IntroducingNumpy/Broadcasting.html#Pairwise-Distances-Using-Broadcasting-(Unoptimized)
Topic: Numpy array broadcasting, Difficulty: Medium, Category: Section
Does anybody use MatLab anymore
Its coursera
I heard in video, instructor specifically mentioned that when synthesizing new sample from something if one set in very small as compared to another then algo may overfit to repeated pattern of that set cuz small set will have to be repeated multiple times to synthesize with big set
If we take fog example:
If we Use 1000 fog sample on 100,000
One fogs texture would be repeated 100 times
qq decision trees use binary trees as a structure/support?
what type of regularisation is used for linear classifiers?
@app.route("/home", methods=['GET', 'POST'])
def home():
form= DataForm()
if form.validate_on_submit():
gender = float(form.gender.data)
age = float(form.age.data)
urea = float(form.urea.data)
cr = float(form.cr.data)
hba1c = float(form.hba1c.data)
chol = float(form.chol.data)
tg = float(form.tg.data)
hdl = float(form.hdl.data)
ldl = float(form.ldl.data)
vldl = float(form.vldl.data)
bmi = float(form.bmi.data)
else:
pass
DATA = [[gender, age, urea, cr, hba1c, chol, tg, hdl, ldl, vldl, bmi]]```Error: gender = float(form.gender.data) TabError: inconsistent use of tabs and spaces in indentation
you have some indents with tabs and some with spaces
what shall i do?
Redo your indents, check your whitespace if your text editor has that
that worked, but now it is giving the error DATA = [[gender, age, urea, cr, hba1c, chol, tg, hdl, ldl, vldl, bmi]] UnboundLocalError: local variable 'gender' referenced before assignment
Hi, I'm looking for help with seaborn/matplotlib - How can I put many stripplots on same figure, with (categorical) axis common for all plots?
I tried to do it like this:
sns.stripplot(y="Project", x="DUT_result", data=df[df['Test_result']=='Pass'], hue='Country', marker = 'o')
sns.stripplot(y="Project", x="DUT_result", data=df[df['Test_result']=='Fail'], hue='Country', marker = 'X')
but the second plot changes the y axis, as the rows with Test_result==Pass contain different Project names than ones with Fail.

Hi, I would like to know if let's say I'm going to train a machine learning model based on a stroke dataset from kaggle, is it possible if I create a form asking for some stuff using a form or data from another file and it can predict if the patient has a stroke? I'm not too sure if it's possible, googling doesn't give me any info if it is
Sure, possible. Why wouldn't it be. As long as the data from the form can be converted (which, yes it can. You're the programmer you're in control) then that model can make a prediction on it
And is the conversion via hot encoding?
That depends entirely on how the train data was prepared.
You follow the same steps you took
@ripe forge but would it be possible if let's say I'm doing it on an application, and I've already prepared the trained data and have already did the application? Because what I'm doing is basically the user entering the data from the form and afterwards there'll be a result of whether the patient has a stroke or not
sorry for ping
are there any libraries which can implement OCR on a screen that is being scrolled live?
like for example if i want to make a program which constantly watches my screen and keeps converting text on the screen to like a dictionary and if a certain word pops up on the screen, it needs tro detect it and then shut the program off
its kinda like u have a screen recorder(like obs) and u are implementing ocr at the same time
off topic question here, but are there any university professors specializing in mathematical modelling/statistics or economics here?
I'm making a discord bot to play card games and was wondering if the best way to make an AI for this would be to have it "cheat".
If you know of a better way, please tell me.
Noob Question: why can't the attention mask have values between 0 and 1 (rather than only 0 and 1)? Kind of thinking them as weights for instance, then if I want the model to have partial attention to a token, can't I use something like [0, 0.5, 0.8, 1, 1]??
aye. a model would be pretty useless if you couldn't use it after training it. Your ask is literally the bread and butter of what makes a model useful - the ability to run it on new data. you do need to have a record of the actual steps you took to prepare the data. run the same steps on the new data, and there should be a .predict method of some sorts on your model.
So, you need to save the steps, and the model. and then re-do the dataprep steps on the new data, and load the model, and run a predict on the data
then re-do the dataprep steps on the new data
That's kinda discouraged now. it's recommended you keep pre-processing as custom layers in the model itself to keep it simple and quick
figured some more stuff out
i need help creating this type of dataset
as_supervised=True, try_gcs=True)```i generally do this type
```tf.keras.preprocessing.image_dataset_from_directory```I have a use case where I will have a central model which needs to be trained and will deliver predictions. My data is harvested in real time from multiple clients across the internet. I originally thought of making a system where each time a client collects a data point, it sends it to the server with an API and is added to a queue which will contain data which will be batched and trained on. However, this data is sensitive and as far as possible, I would like to avoid it traversing the internet.
Then I came across PySyft which would allow me to train on data remotely. However, can PySyft be used in a way where there is one model and innumerable data sources, instead of multiple models sharing one data source? Also, my use case requires that data clients can come online and offline randomly so it should be possible to add and remove data sources while training.
I appreciate that this is probably a niche use case but would greatly appreciate any guide on the matter.
Please tag in responses
data is sensitive and as far as possible, I would like to avoid it traversing the internet.
what?
I have a binary image with some features in it, but sometimes they touch and I want to get individual contours for each. Is there a "more proper" way to go about this than just using cv2.drawContours() to draw a black outline around each directly onto the binary image, thereby shrinking them, and then contour it again?
It feels like such a hack but like ... it does work perfectly
Try morphological open https://docs.opencv.org/master/d9/d61/tutorial_py_morphological_ops.html
I don't need noise got rid of, so I don't need the dilate afterwards, and if anything the dilating would just put me right back where I started. I guess it would just be erosion that I want on reflection
Also I need the inside of the contours not to be eroded, there are pretty erosion-sensitive contours inside of those boxes that I need to remain untouched. I guess I could erode it, find those outer contours, then look inside the region of each on the original mask to find those details but at that point it's so much more work than just shrinking with a drawContours()
It's useful for splitting features also, especially if you define the kernel in a way that favors the shape you care about.
Yeah erosion and opening are both handy tools but it's just a bit too destructive for this purpose, sadly. I'm fine with my hacky solution I just wasn't sure if there was a "proper" one. Though I guess erosion is that proper solution, I'd just need to also retain the un-eroded mask so I could use that for getting the contours within these other ones
Seems pretty normal to me to do those different things (get the inner contours, define outlines) in different steps. In any case, it sounds like you are doing contouring twice as a way to erode then contour. You could also try adding a watershed like step if you can find centers https://docs.opencv.org/master/d3/db4/tutorial_py_watershed.html .

By providing the positional argument "units"
Dense() apparently needs to be given units, either by name or by position ahead of the named arguments
But when I redo the contouring I want to be able to maintain the parent/child relationship between the contours in the hierarchy because it's useful, so having a second step where I take a small section of the image and then contour it means I lose that / have to define it manually.
Appreciate all the thoughts though :)

Sounds like you provided 6 logits and only 1 label, rather than one for each
does anyone here have experience making a webcrawler
My data seems to be overfitting, how can I do regularisation?


At the bottom of the error message it says what the problem is. You are trying to convert Florida directly into a number... Not sure if that's possible.

Florida doesn't float? Better hope those sea levels don't rise
hello, somebody know if it is possible speech-to-text conversion with speech recognition but in the output audio?
right. the question said little risk of overfitting, which would be wrong
btw, what are differences in algorithm between object detection and grad cam?
Hey @limpid saddle , that's quite a broad question. There are many regularization techniques available, but your choice of which technique to use will depend on the data modality (e.g. tabular, imagery, text, etc) and modeling approach. Folks might be able to help more if you could describe the problem, data, and model :)
For example, @uncut barn asked this morning about regularization with linear classifiers. In that case, L1 and/or L2 regularization are typically used
But if you're working with a neural network and imagery, it's typical to use Dropout layers, batch normalization, and data augmentation
!e what should I add? ```py
#LVL 0
mean=avg=lambdaa,n=1,sigma=0,_:sum(a)/len(a or[()])if a else sigma/(n or 1)
sqrt= lambda n:n0.5
_p_m= lambda a,b:(min([a+b,a-b]),max([a+b,a-b]))
c = lambdaa:a
def sd(*a,**k):
mean = k.get('mean',avg(a,n=k.get('n',len(a))))
return sqrt(avg([abs(i-mean)**2 for i in a]))
#LVL 2
def SE(*a,**k):
s = k.get('s',sd(*a))
n = k.get('n',len(a))
return s/sqrt(n)
def z(x, *a, k):
mean = k.get('mean',avg(*a))
s = k.get('s',sd(*a,({'mean':mean}|k)))
return (x-mean)/s
def raw_score(z, *a, **k):
k['mean'] = k.get('mean',avg(a))
s = k.get('s',sd(a,**k))
return zs + k['mean']
#LVL 3
s2=lambdaa,**k:k.get('s',sd(*a,**k))**2
def t_stat(*a,mu0=0,**k):
mean = k.get('mean',avg(*a))
se = k.get('SE',SE(*a,**k))
return (mean-mu0)/se
def conf_int(*a,T,**k):
se = k.get('SE',SE(*a,**k))
return _p_m(k.get('mean',avg(a)),Tse)
#LVL 4
def summary(*a,**k):
k['mean']=k.get('mean',avg(*a,**k))
k['s']=k.get('s',sd(*a,**k))
k['SE']=k.get('SE',SE(*a,**k))
k['t']=t_stat(a,**k)
if'T'in k:
k['confidence_interval']=conf_int(a,**k)
_01 = [k['t'] <- k['T'], k['t'] >+ k['T']]
k |= {'H0':'reject'if any(_01)else'accept','Ha':['mu < mu0'](_01[0])+['mu > mu0'](_01[1])+['mu != mu0']if any(_01)else'reject'}
k['Z-score']=z(k.get('mu0',0),*a,**k)
for n,v in k.items():print(n,'=',v)
data = {'n':40,'mean':172.55,'s':26.33}
summary(**data)
data |= {'mu0':166.3,'T':2.021}
print(summary(**data))
@jolly nest :white_check_mark: Your eval job has completed with return code 0.
001 | n = 40
002 | mean = 172.55
003 | s = 26.33
004 | SE = 4.163138539611671
005 | t = 41.44709534842795
006 | Z-score = -6.5533611849601225
007 | None
008 | n = 40
009 | mean = 172.55
010 | s = 26.33
011 | mu0 = 166.3
... (truncated - too many lines)
Full output: https://paste.pythondiscord.com/sufijoxodi.txt?noredirect
actually, how do you get p-value?
I see it everywhere, but no clear way to get it algorithmically
just modules and ambiguous formulae
hello
am interested in machine learning and ai
i just figuered web development wasnt for me
i hope you dont need any form of html/css or js for machine learning and ai 😞
Not really, no. Though those are useful things to know if you ever need to deploy stuff yourself
Even basic knowledge is enough
anyone know how to do early stopping in pytorch?
Pytorch you write the model in a loop yeah? Just add a logic for checking validation data in the loop and keeping track of last validation
If the score becomes worse, break


hello every one
I have one python code which generates .csv as output,but I want to share as link where, when user hit url csv should be downloaded at user side
please help
how advanced math do i need for ai
this week assignment sure is nasty
the library is not installed properly
I have a code from about 3 years ago, and i don't know how can i fix it
I guess it's code for older versions of keras and tensorflow, and there are some bugs inside
can someone fix this for me? it's a CNN code
if you guys want to help, text me, I can send the code and data set
Anyone have any recommended texts for data science and ai?
You could try "Data Science from Scratch". It's an O'Riley book.
I want to make a Gantt chart for different phases of a space mission. I'm using matplotlib atm (not adverse to using bokeh). Trying to add more entries along the y-axis and it's not displaying for whatever reason. The timeframe I want to do it over would be over years.
nvm
Does it make sense to do cross validation on undersampled data?
Thanks @serene scaffold, I'll check it out 🙂
and any recommendations on a data analytics book? I've heard of 'python for data analysis' from Wes McKinney but I think it's kind of outdated as for today
Is it correct that with the right training, I can setup a tensorflow AI with python that will solve captchas with 90%+ accuracy?
Hi Anyone know if we have anything to figure out difference between figures and text? Something that would mark figures and text seperatly in an Image?
Hi everyone! Can someone help me "Natural Language Processing"(nlp) in "word level tokenization"?
Can someone help me "Natural Language Processing"(nlp) in "word level tokenization"?
Hi everyone! What you can recommend to learn for noob, who want to learn ml. Have knowledge of python.
Hey @lapis sequoia!
Uh-oh! It looks like your message got zapped by our spam filter. We currently don't allow .txt attachments, so here are some tips to help you travel safely:
• If you attempted to send a message longer than 2000 characters, try shortening your message to fit within the character limit or use a pasting service (see below)
• If you tried to show someone your code, you can use codeblocks
(run !code-blocks in #bot-commands for more information) or use a pasting service like:
Ok this is driving me crazy, can someone confirm something about neural networks:

These neurons/nodes... do they ALL have summation and activation functions in them?
This is how i thought a single layer perception looked:

Where the circle and box are the summation and activation functions respectively
But this confuses the "input layer" and "output" layer terminology.
(please ping me!)
yes. Break down the whole diagram and try doing it layer by layer.
Yep, you can try something like an image captioning model to start with.
Hello, I'm learning about regression algorithms, and I'm having trouble understanding the Support Vector Regression. I don't understand why we want to minimize the coefficients vector w? Also how does C play a role in affecting the model? I read this explanation of C on youtube : How much should an SVM/SVR care about getting everything right vs getting the things that it gets right very right. But I don't really get it. Can someone please explain it in noob language. Thanks

@kindred radish the terminology is indeed confusing, for the reason you mention: the idea of a "layer" doesn't make sense when you think of a neural network as a sequence of data transformations
Hi, there are many ways to do it, if you use tensorflow, you can take a look at tokenizer().
@kindred radish maybe it's best to think of a "layer" as "the data resulting from a transformation", if that helps at all. Also, not all "layers" are neatly divisible into "linear component" and "elementwise activation", cf. convolutional layers, attention units, softmax output layer, etc.
C is basically inverse of alpha/lambda(in logistic regression) it does the opposite here in SVMs.
I'm sorry, I've not yet read about logistic regression. I'm a beginner.
The course I'm following instructs us to study about SVR before SVM, that doesn't make sense to me though.
Oh, I recommend you start with logistic regression before moving on to SVMs.
SVMs are tricky compared to Logistic regression.
oh
okay
alright, thanks @fading thunder
You can check for Andrew Ng's Machine learning playlist in youtube or coursera.
And follow it until you reach SVMs
This is a technique called "regularization". The very general idea is that if the weights are "small", then our estimates are closer to a common "baseline" estimate, and we aren't making wildly strong predictions and/or making wildly large changes in predictions for small changes in the input data.
This helps prevent overfitting, at the cost of "shrinking" our predictions towards a baseline and potentially reducing the sensitivity of the model to variation in the inputs. In the extreme case, an over-regularized model might predict the same output for every input.
By adding the total size of the weights into the objective function, we are telling our optimization process penalize bigger weights and prefer smaller weights. We control the strength of the penalty by adjusting C.
On the math side of things, this technique is an application of something called "Lagrange multipliers" that you will learn about in university-level calculus courses.
The technique of regularization by penalizing the "size" of the weights is quite general and you will see it appear in different types of machine learning models.
Edit: specifically in the context of an SVM, the optimization problem is not possible to solve without this weight penalization thing... there are other mathematical interpretations for what is happening here.
somebody here can help me get all plugins i need in pycharm for an own voice asisstented i cannot download them and i dont know why
Thank you for this, I think the second diagram that I made is correct then according to what you're talking about?
The "input layer" are nodes that provide data
The middle layer (or hidden layers in the case of MLPs) are nodes that contain AFs
The "output layer" are nodes that contain the output layer?
Actually, this means this line from: https://scikit-learn.org/stable/modules/neural_networks_supervised.html#regression
Class MLPRegressor implements a multi-layer perceptron (MLP) that trains using backpropagation with no activation function in the output layer, which can also be seen as using the identity function as activation function.
Doesn't make sense?
Like, i guess the "output layer" is the "outer-most hidden layer"?
according to that diagram i made?
I'd rephrase it as, the output layer is just the last layer. And the input layer is a special case where the data flows in from "outside", rather than resulting from a computation.
Right I think that clears that up nicely? Lemme sketch something quick
A "layer" itself is a computation with inputs and outputs. The idea of a layer as "a bunch of nodes" kind of breaks down once you get away from fully-connected multilayer perceptron models.
Wow, that was so informative, thank you very much sir. 🙌
Noob Question: why can't the attention mask have values between 0 and 1 (rather than only 0 and 1)? Kind of thinking them as weights for instance, then if I want the model to have partial attention to a token, can't I use something like [0, 0.5, 0.8, 1, 1]??

Would this be right?
each circle represents a node that contains AFs and the like
I'm trying to detect the circle of the wheel and draw its shape on the image

this is what I have but it's not working
img = cv2.medianBlur(img, 7)
circles = cv2.HoughCircles(img, cv2.HOUGH_GRADIENT, 1, 300, param1=30, param2=45, minRadius=0, maxRadius=0)
for c in np.uint16(np.around(circles))[0, :]:
a, b, r = c[0], c[1], c[2]
cv2.circle(img, (a, b), r, (0, 255, 0), 2)
plt.imshow(img, 'gray');
how can I adjust the parameters?
try maxRadious something else than 0

well, it's a progress, better more than none, amirite? apparently it's seeing everything else but the one circle in the middle 😂
exactly hahaha
do I have to apply more filters? reduce more noise?
that would be the next step, yea
With Wasserstein GANs, how easily comparable are Critic outputs as metrics? I understand that the Critic doesnt output a 0-1 probability of the data being fake/real and instead is more of an abstract score reflective of 'real-ness', but I am not sure if a battery of Critic outputs are 'comparable' between runs?
I have a WGAN model that at the end of training runs the original dataset through the Critic and records the output for every datapoint and im trying to see whether or not by repeating this many times to produce many runs I can take the mean of each run for each datapoint as a means of aproximating a score of normality for the purposes of outlier detection
Anyone know anything about that sort of thing?
its actually so funny to see nn mistakes for the first time in vision
this gets me excited for upcoming computer vision lectures
😆
Honestly... I think you are overthinking the whole nodes and layers things
But yes, that diagram looks fine
Oh? What's the topic?

Home page: https://www.3blue1brown.com/
Help fund future projects: https://www.patreon.com/3blue1brown
Additional funding for this project provided by Amplify Partners
An equally valuable form of support is to simply share some of the videos.
Special thanks to these supporters: http://3b1b.co/nn1-thanks
Full playlist: http://3b1b.co/neural-netw...
A neural network diagram is just a computation graph, but specific to processes which very loosely mimic neural networks.
Hi all I currently trying to write program to scrape numerical data from a website, but I am having a hard time finding any tutorials on finding some reference material or code to extract the: Date, Volume & Short Volume from a table


Can anyone help or point me in the right direction? can't seem to figure out how to get the table
Hello, I have a numpy question ( likely a matrix operation )
I have 2 arrays, A and B, with sizes 2,3 and 3,3
I want to subtract A - B in a way that I would have a result with the shape 3,2,3 or 2,3,3 with all the results
is this possible?
@tidal bough is it better?
Hmm, not quite clear what your result should be. Like, if C is the result, what would be the formula for C[i,j,k]?
(like how, for example, for elementwise multiplication C[i,j] = A[i,j] * B[i,j])
you might be looking for np.subtract.outer, but that would be an array of shape 2,3,3,3 with formula C[i,j,k,l] = A[i,j] - B[k,l].
will look into that, thanks!
but basically I want every element of A iterate through every element of B and return the results
when the arrays have same size, I use a for and np.roll
like this:
A = [...]
for i in range(A.shape[0]):
B_shifted = np.roll(B, i, axis=0)
C = A - B_shifted
but since they don´t have same size, I can´t do that
this outer thing is really cool, I think it will work! thanks
@serene scaffold i think i forgot to share this the other day, this was that pd.concat thing we were doing, but in hy:
(require [hy.contrib.walk [let]])
(import [pandas :as pd])
(setv df1
(pd.DataFrame {"x" [1 2 3]
"y" [4 5 6]}
:index ["a" "b" "c"]))
(setv df2
(pd.DataFrame {"x" [11 22 33]
"y" [44 55 66]}
:index ["c" "b" "a"]))
(defn myfunc [v1 v2]
"Silly function for demo purposes"
(/ (+ (get v1 "x")
(get v2 "y"))
2))
(setv result
(let [myfunc2 (fn [row] (myfunc (get row "x")
(get row "x")))]
(doto
(pd.concat {"x" df1 "y" df2} :axis 1)
(.apply myfunc2 :axis 1))))
(print result)
scheme-like language that compiles to python 🙂
ah, i seem to be using doto wrong, but this works:
(require [hy.contrib.walk [let]])
(import [pandas :as pd])
(setv df1
(pd.DataFrame {"x" [1 2 3]
"y" [4 5 6]}
:index ["a" "b" "c"]))
(setv df2
(pd.DataFrame {"x" [11 22 33]
"y" [44 55 66]}
:index ["c" "b" "a"]))
(defn myfunc [v1 v2]
"Silly function for demo purposes"
(/ (+ (get v1 "x")
(get v2 "y"))
2))
(setv result
(let [myfunc2 (fn [row] (myfunc (get row "x")
(get row "x")))
df (pd.concat {"x" df1 "y" df2} :axis 1)]
(.apply df myfunc2 :axis 1)))
(print result)
Why have you done this
^
why not?
in fact, why wouldnt everyone do this
ive actually written datascience code like this, its not that bad
although i think lisp is better left as an application dev language style, too verbose to comfortably express "math" in lisp
I would definitely write ETL code this way though
run it on pypy for extra zoom
it even supports type annotations
but do you get an optimization if you use them?
a quick question folks, jus to make sure I have to idea right.
In general, cross_validation is performed to estimate the classifier / regressor performance on the training set (and skips the need for a validation split). Cross_val doesn't train a model, but only provide a estimation of performance.
Grid_search is used for hyperparameter tuning the selected model; grid search finds and remembers the "best" parameters for the scoring selected. A grid CAN be used for predictions.
Is this correct?
Not as of this version but theoretically they could add tail call elimination, peephole optimizations, etc
But sometimes it's better to let the runtime do its own optimization. Although TCO would be really cool
It's probably better that the generated python easy to reason about and mostly 1:1 with the hy code
Sorry to bother... It might be a dumb question but...
Does anyone know why I got different Coefficient with sklearns's LinearRegression and statsmodel's OLS ?
This is sklearn's result

while OLS's result like this...
only Year's coef same

@dapper swan what's the .intercept_ of the sklearn model?
-88254.65075453684
maybe something is different in how the categorical State feature is expanded. can you show your code for both?
Cost benefit analysis of a new programming language: Benefits: a syntax that you prefer | Costs: More code = more problems, you need to now learn a new language, everyone else that you work with needs to learn a new language, the language needs to be maintained, new programmers at the company need to learn this language making the hiring process a nightmare. Overall, more technical debt with no gain other than "I like it".
Not to misunderstand though, I like the idea of trying new programming languages and making them, but one must always be honest with oneself about the costs and benefits. Making a language worth adopting is hard since it requires some extreme benefits.
This is sklearn's code (I just made a little modify)

(The benefits for many actually comes through the standard library, not the language itself (it's why a language tends to take off (see ruby on rails, jquery, etc)).
And here is statemodel's

(Or in the case of something like python, a giant distributed globally accessible library pool via pip)
To be clear, Hy is entirely a "because i like it" project
Yeah, that's totally alright. I just want to clarify why some programmers might be like "why?". They are typically expecting some killer feature (or library).
Or some more subtle "restrained" approach, like Rust in which the goal is to make things more safe or stable, etc.
I have snuck into into a couple script at work but
The main advantage that something like Lisp has is that it's easy to implement, so back in the day when you were stuck in assembly and you wanted to quickly get out of assembly, you could quickly make Lisp.
I do think that lisp like languages can express certain kinda of ideas and programs very elegantly
"Real" lispers seem to treat lisp as a kind of smalltalk style all-encompassing environment
I don't feel that way about it
But i do think there are some advantages to lisp and it certainly has its joys, although I don't believe any lisp will ever gain adoption at the level of python
@dapper swan do you mind sharing your code as text and not as a screenshot?
!code-block
Here's how to format Python code on Discord:
```py
print('Hello world!')
```
These are backticks, not quotes. Check this out if you can't find the backtick key.
(Also back then, Lisp's macros and meta-programming ideas were new-ish (in terms of popularity), but these days there is nothing stopping someone from making something like python or C but with Lisp-like macros or even cleaner).
ahem Julia
+1
(Crystal and Nim also have strong syntactic macros, OCaml has its macro PPX thing, Idris has elaborator reflection, et al)
I am currently awaiting a bunch of C++ replacements to have such strong macros, Rust has some pretty ok ones.
Does D have good macros?
IDR, but D has kind of fallen off in favor of Rust, Zig, etc in the systems software space. Garbage collection has no place there.
Anyway the pandas and numpy apis do not work that well with Hy and you'd want to work up some nice macro DSL for it
Kinda, but i think maybe focus on the concepts rather than the sklearn implementation thereof. Cross validation is a technique for estimating out of sample performance by slicing up your data and training the model on different slices of the data. Grid search means defining a grid of model parameters and fitting the model at each point on the grid, picking the best performing model. The standard "intro to ML" approach is to use grid search with cross validation at each point in the grid
The scikit learn implementation of grid search does give you the convenience of keeping the best-performing model for you and letting you make predictions from it
to use them together I can use the CV parameter of sklearn?

if im not mistaken the "folds" would CV -1, no?
I'm not sure what you mean by that
thanks! 🙂 I feel like i've gotten most of these things but im still missing some important bits of the basics >.<
ignore that i was reading something else and it got mixed on my head lol
I have problem when try to extract face with MTCNN library. I put my mtcnn as function:
face_detector = MTCNN()
detected = face_detector.detect_faces(img)
return detected```
and run it with this:
from skimage import io as ios
from mtcnn.mtcnn import MTCNN
...
img = ios.imread(images)
detected_faces = face_detector(img)
if len(detected_faces) > 0:
k = detected_faces[0]
...
it raise error: ```ValueError: Input 0 of layer conv2d_3444 is incompatible with the layer: expected axis -1 of input shape to have value 3 but received input with shape [None, 272, 507, 4]``` which I know something wrong with the model.Hello guys so I have a pretrained Pix2Pix GAN (pytorch) model that takes an input edge drawing and from one folder and output the drawing colored in essentially. Im currently trying to build a web application that would allow for users to upload there own drawings and receive the generated results.
What would be some technical solution to implement this?
use flask to build the api that receives the file and returns the generated image
How do the depth and width of a deep neural network play into the mean and variance
do i need external GPU or i can run with my intel UHD 620 graphics card to learn deep learning ?
the better the GPU, faster the training... and I´m not sure you can use intel´s gpu to train
I know tensorflow only supports nvidia ( AFAIK )
edit: tensorflow supports AMD too https://medium.com/analytics-vidhya/install-tensorflow-2-for-amd-gpus-87e8d7aeb812

Medium
AMD has released ROCm, a Deep Learning driver to run Tensorflow-written scripts on AMD GPUs. However, many owners and I have encountered…
TensorFlow
You can use streamlit

Streamlit is an open-source app framework for Machine Learning and Data Science teams. Create beautiful data apps in hours, not weeks. All in pure Python. All for free.


You need to transform all values to numerics via standard scaling or whatver fits so... and then train... Strings aren't interpteted by models, we need convert and transform them into numerics 😃... Normalize them from what i think
do you use early stopper... it seems you have achieve 0.98 acc but still retrain again
Apache Hadoop or Spark which one should i preffer. I'm a junior in college and i'm interested in data analytics.
Hello has anyone worked with databases before please someone DM or anything i need help 🙂 thanks hope someone helps me
Hi guys I scraped some e-commerce dataset and posted it in kaggle. There's product, shop, and text data. I would like to see how an experienced data analyst/scientist would approach the dataset and its shortcomings etc. I would really appreciate it if someone can give a minute or two to see this dataset.. https://www.kaggle.com/jaepin/shopeeph-koreantop-clothing thanks

E-commerce Dataset, Sales & Reviews
It's about using machine learning to improve industrial practice. I'm a physics student so this whole paper is going to go over my supervisor's head lmao. So if i can explain everything as concisely and clearly as everything I should hopefully do well
Obvious first steps would be to impute missing data, like in the "Brand" col of shopee_ktops_main.csv.
You could try to find/come up with some questions you would like answer, then try to answer them (in this order). For example: does Brand influence average likes, prices, etc
Another question would be the interaction of comments and ratings. You could try some sentiment analysis, but I think your translations would need some love for that first 🙂
Thanks for your reply. I'm actually working the translations, rather than trying to feed it to nltk with no language support for tagalog.
Recently i'm doing a lot of work on sequential data like for example log-files. I would like to maken a comparison of LSTM vs. CNN on generating and separately classifying those samples. Can you recommend a setup, an architecture or anything to compare both types of networks to get meaningful results? Would be awesome to let me know your thoughts
am I missing something or why arent you using something like google translate?
I actually did. The googletrans package was really unstable. It wouldn't detect the source language, and got buggy along the process. I translated it via deep-translator module. It was more stable, but still had some issues.
Can anyone recommend a startup related to data science ?
Do you have any recommendation?. I was planning on using spacey because it has language support. I would probably remove the translated column and just go ahead with the native language.
Hi, I have a question: what of condition to build a training set and test set in Decision Tree Regression?
For regression things there's no something specific dataset structure for what's in your dataset, the different is the target is something that you want to predict is not a class.
its also same as how to built the dataset for the classifier task too
oh anyway... i have specific question about storing preprocessed datasets. I have let say a 2*n array of feature and 1 class of data which will i used for classification in CNN. The feature taken from a quantized soundwave (so it must be array) with two channel (that's why the dimension is 2 times n when n is the length of the signal). Since pandas are not design to store this kind of data structure , is there the alternative to store the data? so it will have structure like this:
record|min|data |class
--------------------------------------------------------
0001 |1 |[[0.011,...,0.01],[-0.1010,...,-0.001]]|1
since as far my experience Pandas cannot store data like this so i looking for other alternatives.
You can put arrays as values in a DataFrame or Series. And the parquet file format supports array valued columns, although not multidimensional arrays. Unsure if pandas can store and recover array dimensions for you in parquet, you might have to flatten the array and store the shape in a separate column
Another option is a nested list of lists https://stackoverflow.com/a/56288696

Stack Overflow
I'm trying to save a pandas dataframe to a parquet file using pd.to_parquet(df).df is a dataframe with multiple columns and one of the columns is filled with 2d arrays in each row. As I do this, I
Or write your own routine with pyarrow https://mungingdata.com/pyarrow/parquet-metadata-min-max-statistics/
This post explains how to create a Parquet file with PyArrow and how to read Parquet footer metadata like the compression algorithm and min / max column statistics.
Hey, how do I know if each value in a Series is a number and, if so, divisible by 10?
I've tried (df[1].str.isnumeric() & df[1].astype(int).mod(10) == 0) but it will stop at any non-numeric value as it can't convert it.
(Don't know if I can ask this here or it has to be on the help channels)
Yeah, it's fine in this channel.
I'd do:
inds = df[1].str.isnumeric()
inds2 = df[1][inds].astype(int).mod(10) == 0 # check only the numerical ones
# and then combine them, which I think would be
inds = inds[inds2]
inds = inds[inds2] does not work (IndexingError), but inds = inds & inds2 does the job. Thanks!
If I were to get multiple conditions out of a Series is that approach acceptable? Say there was an inds3 or inds4
How would the depth and width of a deep neural network play into the mean and variance?
not sure the latter does the right thing, hmm
because I think inds2 would be shifted compared to inds
true, just noticed
like, say inds is [1,3,5], and df[1][3] is the only one that's 0 mod 10. Then inds2 would be [1], I think, meaning that only the second element of inds fullfills it
maybe inds = np.array(inds)[inds2] or something
I just tested, it skips over indexes so while it has less elements it's still the same indexes
x = pd.Series(['1', 'data', '3', '5'])
inds = x.str.isnumeric()
inds2 = x[inds].astype(int).mod(5) == 0
inds = inds & inds2
works and outputs False, False, False, True
Anyone can tell me what the meaning of first line in that cell?

This creates X_grid.
as for how it works, well:
!docs numpy.arange
numpy.arange([start, ]stop, [step, ]dtype=None, *, like=None)```
Return evenly spaced values within a given interval.
Values are generated within the half-open interval `[start, stop)` (in other words, the interval including *start* but excluding *stop*). For integer arguments the function is equivalent to the Python built-in *range* function, but returns an ndarray rather than a list.
When using a non-integer step, such as 0.1, the results will often not be consistent. It is better to use [`numpy.linspace`](https://docs.scipy.org/doc/numpy/reference/generated/numpy.linspace.html#numpy.linspace "numpy.linspace") for these cases.I mean what is correlation on plot in graph? Can you explain to me how the first line in that cell can visualizing the plot?
it doesn't; it create a bunch of evenly spaced points
they are later used as the X values for the plot
huh?
What?
I don't really get what you're asking
I mean if i count a grid for X --> len(X_grid) I get 900
And my question is, Why in that plot has only 10 dots?
wait...
Oh I know
900 for Position level, right?
that is for drawn of scale on axis, right?
X_grid is for drawing the blue line
the red points are placed separately
there's 900 points in the blue line (but they are too close to see where the line passes through them)
Yeah I understand now. Thank you!
But, can u explain me what the meaning of 1 in that cell? What is impact to visualization of Decision Tree Regression?

This reshapes the input from (900,) to (900,1) - from 1d to 2d
that's required for the input to the model
basically, the input needs to be 2d, even if each sample is just 1 number.
Can u explain to me how the logic can be visualizing from 1d to 2d?
Sorry, I still don't understand about that
Because I'm beginner in Machine Learning
no real visualization here, it's just that 1d arrays are considered different from 2d arrays with a second shape of 1
even though they are laid out the same way
Why if I change a number of 1 to 2 the result is error?
Why'd that array be reshapable into len(X_grid),2? It'd imply that len(X_grid) == len(X_grid)*2, not really possible 🙂
Whether that's mean an array to be vertical sequence?
Can someone help me find module that helps calculation of variogram 2D?
If you formalize it, and your professor did not skip his maths classes - I don't see why it would go over his head as long as the models are relatively simple (which to me seems MLP you are using)
he won't be an expert, but atleast he would have a decent idea
that's pretty optimistic
professional scientists in hard fields absolutely can be totally ignorant about computers, sadly
hi I'm supposed to find a model for the data provided and plot it, can someone help me take a look and see if its alright


not mathematics surely 😮
if a physician doesn't know maths/calc/lin algebra how do they do physics?
Im pretty convinced they can get atleast a basic and rough idea of how MLP works from the formalization
Hi, i'm working with pandas, I was wondering if there was a way to group data and count according to column value? Here is an example of my dataframe and what I would want.

Hi everyone.
I'm currently working on a news aggregator and I want to group same-topic news. As my dataset will be continuously increasing, so I want to use Incremental Clustering.
Q 1: Is "Incremental Clustering" a name of some algorithm or is it a way of clustering?
Q 2: If "Incremental Clustering" is not an algorithm but an approach, then tell me what specific algorithms will help me.
Request: Please suggest some good tutorials (Python preferred).
I'm using 'gray' as argument when plotting because the image is in grayscale but I need the circle to be displayed in color, how can I do that
img = cv2.medianBlur(img, 5)
img = cv2.GaussianBlur(img, (5, 5), 0)
img = cv2.medianBlur(img, 5)
circles = cv2.HoughCircles(img, cv2.HOUGH_GRADIENT, 2, 1000, param1=10, param2=10, minRadius=0, maxRadius=0)
for c in np.uint16(np.around(circles))[0, :]:
a, b, r = c[0], c[1], c[2]
cv2.circle(img, (a, b), r, (0, 0, 255), 2)
plt.imshow(img, 'gray');```
Stochastic gradient descent is pretty simple for a physicist so it's not that which will go over his head. I've spoken about spectral clustering which uses node networks which definitely could.
Part of it as well is I don't want to bore them
Because they might not be interested in
Stack Overflow
I have a simple image that I'm showing with imshow in matplotlib. I'd like to apply a custom colormap so that values between 0-5 are white, 5-10 are red (very simple colors), etc. I've tried follo...
ah... you are actually adding the circle to the image
in pyspark, what's the best way to run some function over each row of a dataframe and map them to a new row with a different schema?
im a data science noob
Why is extend replacing the previous array with the new one, instead of adding the new array to a list of arrays? ```if file.endswith("_MID-R1-ECG.1D_hrv.txt"):
full_name = pathlib.Path(root) / file
try:
read_fname = full_name
data = np.loadtxt(read_fname)
data_list = data.tolist()
data_list.extend(data_list)
c = np.array(data_list) ```
it seems to be just one single [x,x,x,x,x,x,x,x] array instead of [[x,x,x,x,x,x,x,x],[x,x,x,x,x,x,x]] which is what I would want
currently it replaces the first array with the second, as I just have two files in the folder to test it out
i thought extend would combine the separate arrays into a list of arrays
you should be using append not extend
extend (merges) the two lists and creates a single longer list
append would "add" the 2nd list to the first one
what you should do is create a 3rd, upper lñevel list
and then append your data to it
so initialize a new list for them all?
no...
something like this
list_of_arrays = [] # master list to store the lists/arrays
if file.endswith("_MID-R1-ECG.1D_hrv.txt"):
full_name = pathlib.Path(root) / file
try:
read_fname = full_name
data = np.loadtxt(read_fname) # im assuming you're creating an array from text here
data_list = data.tolist()
list_of_arrays.append(data_list) #this will append the list-like array to the end of the master list
if for some reason you want to set those lists back to array you can do some list comprehension
list_of_arrays2 = [np.array(element) for element in list_of_arrays]
ah ok, that is working
and setting it back to arrays would allow to me to np.mean them im guessing
that depends on whatever you want to do
I'm not sure why you're converting them to list after reading them thou
but i'll leave your logic to you :p
originally thought I had to as I thought combining lists was easier than arrays
You can append any kind of object to a list.
I want to do the following:
If a user misspells a command or input or whatever my programm gives an output with relevant commands (based on the input and the using history) that are available
how would i do that?
can u dm me if u know how?
yup
maybe we have to research it on google or somthin because the ppl on this server dont seem to know how this works
already went there
hmm I tried np.mean on the both versions, the list and array and I get the error ''function' object is not subscriptable'
maybe also look up the keyword fuzzy python package
seems to have something todo with this subject
yep
first think exactly of what you want to do and then shape your data in accordance to it. You want to store the mean of each array in the list, NOT the arrays?
I want the mean of [x1,x2,x3,x4,x5] and [y1,y2,y3,y4,y5] like [x1+y1/n,x2+y2/n,etc]
np.mean with axis= 1 i thought would do that
yes, but they would need to be in a single array for that to work
I think @serene scaffold once showed me a way to compute the mean of a row/axis across many np.arrays, but I can't quite remember which function it was
!docs numpy.mean
numpy.mean(a, axis=None, dtype=None, out=None, keepdims=<no value>, *, where=<no value>)```
Compute the arithmetic mean along the specified axis.
Returns the average of the array elements. The average is taken over the flattened array by default, otherwise over the specified axis. [`float64`](https://docs.scipy.org/doc/numpy/reference/arrays.scalars.html#numpy.float64 "numpy.float64") intermediate and return values are used for integer inputs.so I just need to make [[47.634249643827026, 48.707791774949484, 44.958609806628594, 46.17740725913995, 38.02733794748916, 38.1356384904845, 35.35533905932738, 35.68120160740313, 38.23956264058725, 40.523534677334084, 36.66523725058259, 31.91423692521127, 39.82019774119848, 40.08918628686366, 33.96831102433787, 59.219460014799566, 43.164887897106965, 44.69394835554186, 40.131993759056165, 75.0, 72.50760609188853, 28.4045450908509, 22.941573387056174, 26.28287415189234, 30.525697073419664, 37.17810563304078, 32.21390769615825, 23.27373340628157]] [[356.22258666457407, 349.47877856411634, 256.22921201710994, 251.57835094989127, 393.43572113709587, 204.17516989095418, 108.25317547305482, 109.66546927595373, 156.7907310185565, 215.62248388226018, 76.82953714410739, 131.98240351921797, 107.11309110334874, 100.0, 155.02932273957373, 267.6284738214527, 342.3813663153998, 289.35272592460575, 319.09348500700077, 277.6278189993808, 261.0439415001608, 229.46949688357273, 313.3243843228943, 250.97033910625996, 194.7798480058684, 326.25957840345467, 235.80044921893565, 140.24663149986463]] into one [.........] then?
you're trying to get the average of all the elements, regardless of the shape?
average of 47.6+356/n (for now n=2), 48.7+349.5/n, etc
they should all be the same shape
so given [[a, b, c], [d, e, f]], you want [(a+d) / n, (b+e) / n, (c+f)/n]?
yeah
for linear regression, is the "weight" of a feature the same as the variance between our outcome and our feature?
but it will be much larger, x+y+z+..etc./n
just testing it out with these two files for now
np.sum(arr, axis=0) / n will take the "vertical sum" (I just made that up) of your array
and then divide each element by n
seems to almost do it but it summing strangely
[47.63424964 48.70779177 44.95860981 46.17740726 38.02733795 38.13563849
35.35533906 35.68120161 38.23956264 40.52353468 36.66523725 31.91423693
39.82019774 40.08918629 33.96831102 59.21946001 43.1648879 44.69394836
40.13199376 75. 72.50760609 28.40454509 22.94157339 26.28287415
30.52569707 37.17810563 32.2139077 23.27373341]
[[356.22258666457407, 349.47877856411634, 256.22921201710994, 251.57835094989127, 393.43572113709587, 204.17516989095418, 108.25317547305482, 109.66546927595373, 156.7907310185565, 215.62248388226018, 76.82953714410739, 131.98240351921797, 107.11309110334874, 100.0, 155.02932273957373, 267.6284738214527, 342.3813663153998, 289.35272592460575, 319.09348500700077, 277.6278189993808, 261.0439415001608, 229.46949688357273, 313.3243843228943, 250.97033910625996, 194.7798480058684, 326.25957840345467, 235.80044921893565, 140.24663149986463]]
[356.22258666 349.47877856 256.22921202 251.57835095 393.43572114
204.17516989 108.25317547 109.66546928 156.79073102 215.62248388
76.82953714 131.98240352 107.1130911 100. 155.02932274
267.62847382 342.38136632 289.35272592 319.09348501 277.627819
261.0439415 229.46949688 313.32438432 250.97033911 194.77984801
326.2595784 235.80044922 140.2466315 ]```[47.63424964 48.70779177 44.95860981 46.17740726 38.02733795 38.13563849
35.35533906 35.68120161 38.23956264 40.52353468 36.66523725 31.91423693
39.82019774 40.08918629 33.96831102 59.21946001 43.1648879 44.69394836
40.13199376 75. 72.50760609 28.40454509 22.94157339 26.28287415
30.52569707 37.17810563 32.2139077 23.27373341]
[[356.22258666457407, 349.47877856411634, 256.22921201710994, 251.57835094989127, 393.43572113709587, 204.17516989095418, 108.25317547305482, 109.66546927595373, 156.7907310185565, 215.62248388226018, 76.82953714410739, 131.98240351921797, 107.11309110334874, 100.0, 155.02932273957373, 267.6284738214527, 342.3813663153998, 289.35272592460575, 319.09348500700077, 277.6278189993808, 261.0439415001608, 229.46949688357273, 313.3243843228943, 250.97033910625996, 194.7798480058684, 326.25957840345467, 235.80044921893565, 140.24663149986463]]
[356.22258666 349.47877856 256.22921202 251.57835095 393.43572114
204.17516989 108.25317547 109.66546928 156.79073102 215.62248388
76.82953714 131.98240352 107.1130911 100. 155.02932274
267.62847382 342.38136632 289.35272592 319.09348501 277.627819
261.0439415 229.46949688 313.32438432 250.97033911 194.77984801
326.2595784 235.80044922 140.2466315 ]```after converting back to element to array
there's too many numbers for me to ascertain what the problem is.
what is the shape of the array you're passing to np.sum?
hmm says list object has no attribute shape
data has a shape of 28 which is what I Want, but once I list_of_arrays.append(data) it has no shape
if file.endswith("_MID-R1-ECG.1D_hrv.txt"):
full_name = pathlib.Path(root) / file
try:
read_fname = full_name
data = np.loadtxt(read_fname) # im assuming you're creating an array from text here
data_list = data.tolist()
list_of_arrays.append(data) #this will append the list-like array to the end of the master list
list_of_arrays2 = [np.array(element) for element in list_of_arrays]
print(list_of_arrays)
n = len(list_of_arrays)
s = np.sum(list_of_arrays, axis=0) / n
print(s)```and getting [array([47.63424964, 48.70779177, 44.95860981, 46.17740726, 38.02733795, 38.13563849, 35.35533906, 35.68120161, 38.23956264, 40.52353468, 36.66523725, 31.91423693, 39.82019774, 40.08918629, 33.96831102, 59.21946001, 43.1648879 , 44.69394836, 40.13199376, 75. , 72.50760609, 28.40454509, 22.94157339, 26.28287415, 30.52569707, 37.17810563, 32.2139077 , 23.27373341])] [47.63424964 48.70779177 44.95860981 46.17740726 38.02733795 38.13563849 35.35533906 35.68120161 38.23956264 40.52353468 36.66523725 31.91423693 39.82019774 40.08918629 33.96831102 59.21946001 43.1648879 44.69394836 40.13199376 75. 72.50760609 28.40454509 22.94157339 26.28287415 30.52569707 37.17810563 32.2139077 23.27373341] [array([356.22258666, 349.47877856, 256.22921202, 251.57835095, 393.43572114, 204.17516989, 108.25317547, 109.66546928, 156.79073102, 215.62248388, 76.82953714, 131.98240352, 107.1130911 , 100. , 155.02932274, 267.62847382, 342.38136632, 289.35272592, 319.09348501, 277.627819 , 261.0439415 , 229.46949688, 313.32438432, 250.97033911, 194.77984801, 326.2595784 , 235.80044922, 140.2466315 ])] [356.22258666 349.47877856 256.22921202 251.57835095 393.43572114 204.17516989 108.25317547 109.66546928 156.79073102 215.62248388 76.82953714 131.98240352 107.1130911 100. 155.02932274 267.62847382 342.38136632 289.35272592 319.09348501 277.627819 261.0439415 229.46949688 313.32438432 250.97033911 194.77984801 326.2595784 235.80044922 140.2466315 ]
oops, also replacing list_of_arrays in the final few lines with list_of_arrays2 gives same output
Traceback (most recent call last):
File "<ipython-input-333-83ca99a6c7b8>", line 1, in <module>
list_of_arrays2.shape
AttributeError: 'list' object has no attribute 'shape'```list_of_arrays.shape
Traceback (most recent call last):
File "<ipython-input-334-637c734ee8f5>", line 1, in <module>
list_of_arrays.shape
AttributeError: 'list' object has no attribute 'shape'```no...I mean the actual arrays inside
how much Python do you know?
because it seems your struggles come a bit more from the fundamentals
try this:
for array in list_of_arrays:
array.shape
for array in list_of_arrays:
array.shape
array.shape
Traceback (most recent call last):
File "<ipython-input-336-270abd9e5a99>", line 1, in <module>
array.shape
AttributeError: type object 'array.array' has no attribute 'shape
im still learning definitely
(list_of_arrays[0])
Traceback (most recent call last):
File "<ipython-input-337-c9ed6307f273>", line 1, in <module>
(list_of_arrays[0])
IndexError: list index out of range
ok this is a bit frustrating
(list_of_arrays2[0])
Out[340]:
array([356.22258666, 349.47877856, 256.22921202, 251.57835095,
393.43572114, 204.17516989, 108.25317547, 109.66546928,
156.79073102, 215.62248388, 76.82953714, 131.98240352,
107.1130911 , 100. , 155.02932274, 267.62847382,
342.38136632, 289.35272592, 319.09348501, 277.627819 ,
261.0439415 , 229.46949688, 313.32438432, 250.97033911,
194.77984801, 326.2595784 , 235.80044922, 140.2466315 ])
ok this is an array. So do the following now
for array in list_of_arrays2:
array.shape
for array in list_of_arrays2:
array.shape
array.shape
Out[344]: (28,)
28 is good for each individual, but I wanted to combine the two individual files (arrays out of those files) into one so I can find the mean easily
hello, noob question : I was training a Support vector regression model when I realized that scaling the target variable significantly boosted the accuracy as opposed to where I only scaled the predictors. Can someone please explain the reason behind this? Why should scaling the target variable help in training the model in any way?
What I would do is:
Create individual arrays fo each file or whatever you're reading.
concatenate those arrays across an axis
calculate your resulting array across the desired axis
Someone knows a good article explaining about facial recognition with python and could share with me please?
I think data exploration, plotting, and anything from the statistics (vs comp sci) wing of modeling and analysis is better in R
assuming use of tidyverse
IME, a lot of research is still done in MATLAB. My sense is this is partly because of legacy/familiarity and lower incentives to learn new tools vs get work done, and partly because there really is good support and documentation for things like data acquisition and optimization. That's kind of mind-reading though--I'm not a fan of MATLAB
I used to use R as my main language for work, pretty much this
I was blown away the first time i saw someone doing regression in matlab while they also had university access to stata
As silly as stata is, there is zero reason to use matlab over stata for just doing basic regression analysis
People are really weird when it comes to the tools they like
For a lot of users, the work of learning enough to be productive in one environment was tremendous. So they'll go through incredible pain to keep using that environment.
Also, "the last postdoc wrote it in matlab and gave me the script"
which we use for time series prediciton?
sparse categorical crossentropy or categorical crossentropy
Any sample code for reading training data set of pdf containing scan image of restaurant invoice, and using nlp based model to extract total amount from receipt?
hey i'm trying to learn RNNs
and they say you define one in keras like so?
*:
keras.layers.SimpleRNN(1, input_shape=[None, 1])
the thing is, where do we specifify the number of times it's passed through?
uh....none? I can't see how you can predict categories in a time series
But I can be extremely wrong as well
almost in every predictions, they use Dense(1) without any activation.
what should y choose for?
I'm assuming you mean some kind of binary classification problem?
I'm surprised...I've used sigmoid activation at the last layer for that kind of problem (kill me)
for cost function you may use...binary cross entropy i think its called
a single neuron layer can also be used as the output layer if you are doing regression, especially when they don't use any activation after it
oooh ive never done regression thats why
hey i'm trying to learn RNNs
and they say you define one in keras like so:
keras.layers.SimpleRNN(1, input_shape=[None, 1])
the thing is, where do we specifify the number of times it's passed through?
better not use activation?
if you are doing regression, don't use a activation at the end
So I've been thinking about learning how to do object detecting and stuff with opencv... However, I have no clue where I might start with that. Are there any resources for this type of stuff? (or maybe even just a list of relevant concepts that I can use to piece something together)
im not an expert, but learning about filters and region of interest is generally useful
and on the model side, you could learn some R-CNNs or yolo models
I should maybe mention that I've got almost no prior knowledge about any of this
yeah, so learn about filters in image processing
and when you get an idea about that, you can move on to the other stuff
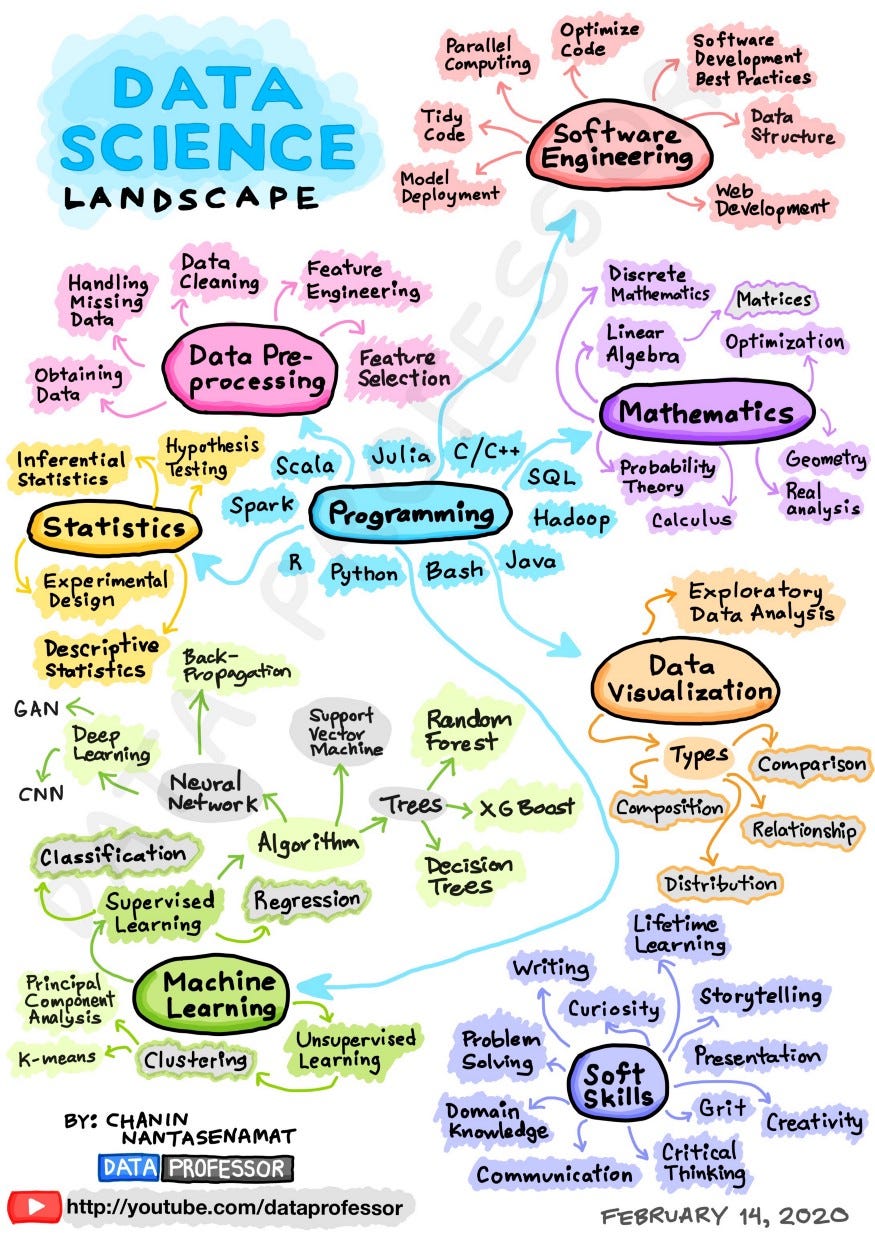
Hello Guys, I have written my first article on @Medium "A Guide On How To Become A Data Scientist - (Step By Step Approach)" for people who are either ... 10 comments on LinkedIn
Maybe try pyimagesearch
anyone know if there is a way to reduce memory usage from scipy sparse matrices? trying to run a classification model with a pretty big dataset and it is way to expensive to run in terms of memory
Just a check about the precision and recall metrics
if i were to get a precision and recall of 50%, that implies the classifier is as good as a coin flip in making predictions?
(would reallllly appreciate an answer my dissertation is due soon!!)
that depends how you are computing them because there are multiple ways
macro or micro?
uhhhhhhhh wdym
you are using precision_score() function right?
aye and recall_score()
so in these functions you can implement different ways of calculation
ohhh yeah i see them

I've been using 'binary'
as i'm using a binary classifier
ie. the output is either 1 or 0
maybe try out different ones to see the difference
oh in that case maybe it doesnt make a difference
but in general if you have an equal number of samples in each class then it will result in the same score (i think)
wait really, wouldn't that make them bad metrics then?
sorry i mean macro and micro will result in same score
oh jesus that scared me hahahahaha
Otherwise my entire conclusion for my dissertation would have been fucked lmao
so yeah it really depends on what the distribution is
okay, y see.
so how about loss?
probably mean squared error since its regression
even to non linear regression in time series prediction?
yeah, since the neural net itself is non linear
okay y see.
thx for helps!
Hi was wondering if it was possible to do a linear regression
with multiple categorical variables
Can anyone help me out with Incremental Clustering?
I want to group same-topic news but I seem to find either too advanced stuff, or just theoretical resources.
I want to ask about Siamese NN implementation. According to the behavior of the model, it need 2 image to compare if both are similiar. In real world case, let said i have 1000 person in db and I need to compare a probably same person.
Is the better way to loop 1000 times and summarize the result (the minimum distance is the similar person), or is there way to parallelized the process?
should compare the images 1 by 1
but i need loop rights? it will cost much if we talk about time and money cost, especially if i using API such AWS Rekognition or similar one
i have read and examine this git https://github.com/tensorfreitas/Siamese-Networks-for-One-Shot-Learning and it said the evaluation using N-Way one shot task to evaluate the class. Could i can use it to predict the class or which image has nearest similarity to the inserted person?

GitHub
Implementation of Siamese Neural Networks for One-shot Image Recognition - tensorfreitas/Siamese-Networks-for-One-Shot-Learning
or should i use usual classification tasks for my case?
just siamese, count the limit classification
🤣 🤣

Autocompletion, where an application predicts the next item in a text input, has become a convenient and widely used tool in contemporary messaging and other writing tasks. It is also one of the most important features of an integrated development environment (IDE) for computer programming. Recent research has shown that autocompletion can be po...
the research is that pre-training code on large models works better? how is that research???
if nobody has actually tried pre-training LM on code before, I am going to go and hang myself
Hey guys, does anyone have any idea how to use monte carlo simulation for a continuous variable in python?

I've been breaking my head over this. This should be insanely easy
np.random usually deals with discrete probability density functions
I could calculate the CFD, but that wouldn't really help here, would it?
obviously, the CFD is just a straight line from 0 to 2.
my previous monte carlo esimates were among the lines of:
M = (3*(math.e**4))/103
p = lambda k: M * (((4 ** k) * (math.e**-4)) / math.factorial(k))
probs = [p(k) for k in range(5)]
print(probs)
sample_space = [k for k in range(5)]
# samples = np.random.choice(sample_space, size = 1000000, replace = True, p = probs)
# print((np.mean(samples)))
solution = {}
N=0
cumsum = 0
while N < 100000:
N += 100
counts = 0
samples = np.random.choice(sample_space, size = 100, replace = True, p = probs)
cumsum += sum(samples)
solution[N]= cumsum/N
``` for different parts.If you have an idea, please @ me as I'll be alt-tabbing in a bit. You're a god if you give me the tip which helps me solve it, because I'm all out of idea's.
Can you pass me your database and for me to study it please
You can find in google with keyword: Position_Salaries.csv
can anyone tell me what went wrong here?

missing ) for imshow function
ah thanks
should be view(18, 28))
is there good source to study transformation of non-normally distributed data? I'd like to understand when to chose standarscaler, log transform, or boxcox etc.
I think you already said it-- the CDF is a straight line from 0 to 2... conversely, it's hence easy to compute the inverse CDF, so now you just sample from a uniform distribution (np.random.rand) and pass those values through the inverse cdf and you have samples from your desired distribution
Any Natural language processing expert who can help me?
@jade chasm take a look at https://en.wikipedia.org/wiki/Inverse_transform_sampling
I'm not sure how that would work, I'll take a look at your link
thanks for your insight by the way
i need some help with dash from plotly
does anyone have experience with this library here?
im using for a school project
Hi. Required for word level tokenization to use Train / Val / Test splits?
what are you trying to do?
now I just try discover word level tokenization
dummy question...how can you reset a dataframe index without dropping out any duplicates.
Trying to append data to end of a dataframe and at the end would just like to reset index so its sequential. But it always removes the additional rows I've added onto it
I guess reset is supposed to take it back to the original indexing....doesn't seem any of the commands lets you just overwrite the ordering
you need to tokenize for any NLP task where work boundaries are important, but that's a separate consideration from splitting your data for training and evaluation. I don't see the connection.
Hi everyone! What you can recommend to learn for noob, who want to learn ml. Have knowledge of python.
anybody knows how can i search for a specific face on opencv like when i will show my face it will say jack when i show any other person it will say human
i want to make my own haarcascade file
you should learn the basics of linear algebra and how to manipulate data with pandas.
there's also a lot of possible directions with ML, so you should look into what those are and pick one.
- linear algebra: vector/matrix math and how to interpret matrices as systems of equations
- calculus: derivatives, convex optimization, at least conceptually know what an integral is (riemann sums)
- probability: random variables, mean / expected value, variance / std dev, conditional probability (bayes' theorem & law of total probability), law of large numbers, central limit theorem, bernoulli/binomial and gaussian distributions
- statistics: sample vs population, bias-variance tradeoff, cross validation, classical null hypothesis testing, linear regression, logistic regression
off the top of my head, those are probably the fundamental tools that you will use on a regular basis in machine learning
you don't have to learn all of it at once
imo the best place to start is basic data analysis (estimating mean and median, data visualization basics) and play around with real datasets using pandas and matplotlib.
you will build intuition and experience working with real world data
you'll start learning some of the core statistics vocabulary, and you'll gradually start to encounter things you don't understand from probability and stats
when you have a bit of comfort in that area, you can move on to more advanced problems. basically, start by getting hands-on with real data, while gradually expanding your sphere of understanding
but you absolutely need to be comfortable working with, visualizing, talking about, and thinking about data
how to insert a dataframe in an sql database\
!d g pandas.DataFrame.to_sql
DataFrame.to_sql(name, con, schema=None, if_exists='fail', index=True, index_label=None, chunksize=None, dtype=None, method=None)```
Write records stored in a DataFrame to a SQL database.
Databases supported by SQLAlchemy [[1]](https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.to_sql.html#r689dfd12abe5-1) are supported. Tables can be newly created, appended to, or overwritten.
Why filter has -1
Arent rgb for 0 to 255
And even if we only use grey scale ...isnt it 0 to up
@mint palm often in machine learning we like to normalize data to the -1,1 or 0,1 range when we know it is bounded
here they normalized 255->1 and 0->-1
While plotting will we have to take extra care for affects of normalization
all closed intervals of real numbers are isomorphic 🙂 meaning you can always rescale an interval without losing any data
Forming image i mean
in matplotlib you should probably set the Z range manually
Ok thank you
https://matplotlib.org/stable/api/_as_gen/matplotlib.pyplot.imshow.html use the norm= parameter
default is 0,1 so if your data is -1,1 use norm=Normalize(-1, 1) https://matplotlib.org/stable/api/_as_gen/matplotlib.colors.Normalize.html#matplotlib.colors.Normalize
Currently theory ...will see practical in weekend thank you though

that does not help in saving the data frame. I dont just want to operate on it
that method does nothing but write a dataframe to a table
you can also manually iterate over rows with .itertuples and run an INSERT for each row
yes but I am automating a script of datamining, so I need it to store it too
I tried this but where does it store data. The only path given to engine is SQLite
sorry I am automating for the first time
did you read the docs?
yeah
it says that you need to use the sqlalchemy library to create an "engine" object
then you pass the engine
yes, I got that working.
if you use sqlite you can use the sqlite connection object directly, as a special convenience case
can I retrieve the data later when my complier has stopped working or reset?
I requested permission @desert oar
.
oh i didnt know you needed permission
of course, that's what saving to the database does
it's stored in the database
try again @mint palm i unrestricted it
exactly where, on SQLlite as its not stored locally
Ok
i dont understand. do you have a database that you are connecting to?
are you using sqlite?
its possible that you need to commit after saving if you are using the sqlite3 library
no I m using
create_engine('sqlite://', echo = False)
df.to_sql('table_name', con= engine, if_exists='append')
you don't need to create an engine if you're using sqlite
Got it so we normalize it setting max 1 and min -1
no check the path of create engine
also it looks like that won't save to a file since you didn't provide a filename. so this database might be in-memory only
Thank you
i am saying that pandas specifically lets you use a plain sqlite connection without sqlalchemy
this is a specific case for sqlite, for convenience
I think I missed something in documentation. I will go over it again
You may restrict it again if you want
@mint palm i will try to make it read only but i dont care if its publicly viewable
i believe it already is read-only actually
I was editable i guess it felt so
are you sure?
can you try to add and run a new cell?
@flint mason sqlite has the ability to save the database "in memory", which means it doesn't create a database file, and the database disappears when the python process exits
So I did a course of a kinda sketchy website. (sketchy in terms that the course did not even mention tensorflow, only sklearn) and I got a certificate of completition. So I wanted to know if the certificate was hot garbage or is it worth something?? the website is https://www.sololearn.com
and on a side note, after doing another course on ML from freecodecamp I see tf.estimators.LinearClassifier() ans sklearn LinearClassifier(), what are the key differences
between them?
Join Now to learn the basics or advance your existing skills
certificates generally aren't worth much
p sure
there's no sklearn LinearClassifier?
show me
the TensorFlow one is a logistic regression I believe
I meant sklearns's Linear classifier
don't exactly remember the module its imported from
yeah sklearn.linear_model.LinearClassifier
@velvet thorn
@tiny flax where did you write your code? on their IDE or your own computer
somewhat on their IDE and some on my computer
ahhh
are you sure?
because LinearRegression is a regression model
the LinearClassifier from TF is a classifier
so my next question is
why are you comparing the two?
okay so assuming
thats why I was repeatedly going on about sklearn's LinearClassifier
you meant
LogisticRegression
they may differ in terms of implementation?
possibly TF's uses the GPU
yeah like if one's better than other
in terms of implementation or something
I doubt it matters that much
I'd suggest looking @ the source
I found sklearn is a bit simpler atleast as much thats covered in the course and tensorflow seems to be a bit more complicated
syntax and usage wise
that's because Sklearn is supposed to be simple and light, while TF is a part of a bigger framework for heavy DL computation on multiple devices.
I mean I couldn't initially download the tensorflow package using pip over wifi( 456 MB ) It took long enough for the mirror to close the connection,
I thought it was a problem with Jupyter
My wifi is kinda slow
sklearn is comparatively lightweight
hello, what is the Pre-processing Data?
depends on the task in question
I don't want to print the "ali", but also that "0",how can i do this? Shortly: string --> decimal literal

Hello everyone i have a question, currently im creating a program for classification and prediction disease using diagnosed dataset.
500 datasamples (imbalanced)
9 predictor class
1 Target class (450 class a, and 50 class b)
On predictor attribute, mostly data samples is in categorical type, "Yes" or "No"
I tried to balanced the dataset using SMOTE, and the result of my program is always on 100% accuracy. The question is, how can my accuracy always on 100%? Even tho I'm using SMOTE to balanced the dataset.
maybe you have some columns high correlated to your y class label
you have to know what types of data are in a given dataframe to understand what the operations with it are doing.
guys, how do i train a time series model(scikit or other), with chucks of data(all dataset = 20 GB) how i make it free space, and advance in traing/fiting, like model.fit(df1) than model.fit(df2)... and in the end i have only one model fited
i have only 8GB of ram to use
have you looked into collab?
its not a option, there is a way to do this in chunks or parts?
in either case, what library are you using to train?
i hope this will help you: https://docs.dask.org/en/latest/array-chunks.html

dask is a common library, so if you don't mind having it as a dependency
i thonth to use just scikit LinearRegression
ok, i have chunks of data, but can i fit with chunks?
you can use partial_fit instead of fit for each chunk
nice, partial_fit is like = fit df1 , than fit df2 ... ?
you use partial_fit normally as you would fit, but on each minibatch
for x_chunk, y_chunk in chunks:
model.partial_fit(x_chunk, y_chunk)
like dis
nice, thank, i think this solve my problem!
cool
do look into dask, it was made for handling large datasets
and it has some lazy evalution features
i try usin vaex, but it has so many bugs 😦
i've heard MODIN is better as it can implement more pandas operations
GitHub
Modin: Speed up your Pandas workflows by changing a single line of code - modin-project/modin
It seems to work as a wrapper around Dask
and simplifies a lot of its operations
statistics: how to do chi squared thingy in python without imports.
https://medium.com/analytics-vidhya/pearsons-chi-squared-test-from-scratch-with-python-ba9e14d336c
scratch is the word you need to use on google

Medium
After having discussed Fisher‘s exact test and its implementation with Python in my last article, I now want to dedicate myself to another…
if you dont want to use np, good luck, but i think you will find some guides
just marking
ah thank you
We start by importing some Python libraries:
XD
they abstract away what im trying to learn!
he build with numpy, he just use scikit to compare

Anybody got any good resources to learn computer vision?
Coursera seems fine
Deep learning. Ai course 4 of specialization
Also i have been doing this.....
https://www.unschool.in/courses/deep-learning/
This gives pretty basic intro to CNN
Ohh thanks
And intro to Tensorflow and RNN too
If you think of choosing unschool course then DM me, i may have something awesome for you.
guys
when should i learn data science
i just finished the basics
what should i read
to go down data science and ai road
@upper spade Finishing basic python is enough to continue with data science
really???????????
damn
okay man
ill go on the hunt for my first book
you will learn advanced stuff along the way of learning data science anyways
Many people recommend to start with Machine Learning course on Coursera (even I did) ... It's in Octave but the concepts are very useful ... also a lot of syntax is similar like slicing and stuff
free?
The content is entirely free ... but the certificate isn't
You can try for financial aid though if you want certificate ... it is usually quite easy to get
it would be nice if i can get some financial aid
okay man
thanks so much for your help
really appreciate it man
After that you can do two specializations on Coursera "Applied Data Science with python by UMich" and "Deep Learning by deeplearning.ai"
this is what you took?
Yeah I did
okay me too then
After doing that you will have enough knowledge to participate in kaggle contests and boost your skills
kaggle is like codeforces for data scientists ... there are various data science contests, expert notebooks to learn from, and datasets to experiment on
Also, do follow some medium sites like Towards Data Science, Analytics Vidhya, etc.
all the answers of quizzes of coursera are available in gihub . cerificate can be obtained within week of free trial .
so no money has to be spent for it
just focus on skills . Certificate means nothing
They updated the course and certificate....atleast for deeplearning.ai u cant get cetification in just trials now
Haha hard way is the only way left
Github answer key is useless now
ohh
can anybody teach me python
Buy a book 🙂
does anyone know how i can teach objects to opencv
like it comes with face eyes car plates
but i want to add other things too
how can i train it
how can I visualize numpy arrays? I'm having a hard time understanding the concept of 1D, 2D, 3D arrays.

that doesn't do it for me, to be honest
ok
uh
line, square, cube?
yeah
it gets complicated after 3D
yeah I can wrap my head around the 1D and 2D arrays, but building and visualizing 3D or higher with numpy is a bit of a headache
technically I could have a 2D array with many different features, which represent coordinates to make a n dimensional graph - that makes sense
but it's just a minor hiccup
hopefully it’ll come with experience