#data-science-and-ml
1 messages · Page 303 of 1
Literally the same logic, I'm just picking the cheapest courses with the biggest names
Hey all, I am trying to figure out a way that I can update subsequent dataframes that are created based on an original dataframe. So if I change the original dataframe, I would want the later dataframes to take that change.
import pandas as pd
old = pd.DataFrame({'A' : [4], 'B' : [10], 'C' : [100], 'D' : [30]})
# Function to Add a Row to Old
def add_row(A,B,C,D):
global old
data = {'A': A, 'B': B, 'C': C, 'D': D}
old = old.append(data, ignore_index = True)
new = old[['A', 'C', 'D']] # New DataFrame to Grab Columns A, C and D only
add_row(1,2,3,4)
print("Old: \n", old)
print("New: \n", new)
This code will print out the following:
Old:
A B C D
0 4 10 100 30
1 1 2 3 4
New:
A C D
0 4 100 30
As you can see, in line 13 I added a new row using the add_row function to the old dataframe. However, the line did not append to the new dataframe. What can I do to ensure if I make a change to the original dataframe, the child dataframes also get updated?
why do you want to do this?
@velvet thorn I have created multiple new dataframes out of the original where I filter it by a specific column, count them and then plot them.
and
But I want the ability to filter by date range
So I figured if I filter the original dataframe by date the subsequent ones would update too. But that is not the case.
indeed it is not
okay
so...
How do I work around this?
pandas DataFrames
are backed by numpy arrays
which have fixed sizes.
so when you "append" to a DataFrame or, in general, change its size in any other way, a new array is allocated
and the relevant data copied over.
in certain specific cases
you can have a view into a DataFrame:
!e
import pandas as pd
df = pd.DataFrame([[1, 2], [3, 4]])
sub = df.iloc[:1]
print(df)
print(sub)
df.iloc[0] = [5, 6]
print()
print(df)
print(sub)
@velvet thorn :white_check_mark: Your eval job has completed with return code 0.
001 | 0 1
002 | 0 1 2
003 | 1 3 4
004 | 0 1
005 | 0 1 2
006 |
007 | 0 1
008 | 0 5 6
009 | 1 3 4
010 | 0 1
011 | 0 5 6
you can see here that the sub-dataframe is a view into the original
and changes propagate.
however, in general, you cannot reliably create a view of pandas DataFrames (and if you're performing complex filtering, that'd be more or less impossible because of memory layout)
also, once you add or remove rows/columns, a new array is allocated, which means your views are into the old array anyway.
I would suggest
some sort of observer pattern?
build an abstraction around your original DataFrame and have all access flow through it
I dont completely follow. Any chance you have an example?
which part?
building an abstraction around the original df
Like 10 columns and 250 rows
Not super big
But the df does grow as im pulling the data from an API
instead of
having sub-dataframes that you pass around
have, for example
methods in a class
that you call every time you want a specific subset
Ah I see what you're saying
That makes more sense actually
@velvet thorn Does the dataframe need to be defined within the constructor or outside of the class in a case like this?
what do you think would be more appropriate?
@velvet thorn I think making the class for the dataframe might be the way to go
do you know any good resources for a cycle gan?
guys i am planning to start machine learning , just ml not data science
anyone have a good roadmap on where should i start and continue from it ?
When I was looking to learn i was just trying different resources, for me the best one was fast.ai deep learning course.
But everyone will have different goals and learning styles ...
For me for example ML is Data science

I'm doing the Stanford Machine Learning one which is by far the best certificate I've come across so far in terms of teaching
yes i am looking that one too , by andrew right ?
i see
Yeah, he has a few courses outside of Stanford, not that great for CV padding but his teaching style is great
deep learning comes after ml and ai , so ill do that after i finish this
i see
@mild totem does the hotel earn money the day people check in or check out?
Hey ! I'm new to python.
Need to plot stick data using Mplfinance with some delay(Animation) in plotting.
Code given by library.
https://github.com/matplotlib/mplfinance/blob/master/examples/mpf_animation_demo1.py
I'm not able to run the animate function and the chart get plotted out till the end period without animation function hitted.
It will be very helpful if anyone can help
GitHub
Financial Markets Data Visualization using Matplotlib - matplotlib/mplfinance
cool
nice library for the some finance specific plots. thanks for sharing
if anyone could help with some keras in #help-broccoli i'd be super thankful
hey guys i have a question about decision tree regression modelling
if my dataset is all numerical. In my instance it is
temp | windspeed | humidity | bike_rent_count
where bike_rent_count is my target and the rest are predictors. how would you calculate the STD reduction? My goal is to find the best predictor for the root node in this case.
@glossy trellis feel free to ask and post the link here. I think it's very fitting here.
Hello everyone, I've project to do. It's about login with sign recognition . for example I'll show to camera 1-2-3-4 and the programme should tell me you logged in successfully...
can someone help me?
Sure
I can build it
For you
I will charge though.
Jk i cant man sorry
🥴
better?

Does anyone have any good resources for learning NER for NLP project? I'll be using Spacy and have read through their documentation, but am looking for tutorials on youtube or a class on a platform like coursera/pluralisight to get me started. If you know something, please reach out!
I need a good project idea, could anyone land me a hand?
technically, if you let a deep-learning ai machine read through history of the server (and simultaneously learn), will it have a perfect understanding of python?
(if say it can somehow comprehend all of the articulated questions, answers and conversations with all grammar)
maybe you already found something, but if not I would recommend ray's rllib. It supports quite a few RL algorithms out of the box and the ray ecosystem has a lot of tools to help you out
How would i create something like this? https://vm.tiktok.com/ZMePCTByV/
im not even sure what he's trying to do, he kinda just said a bunch of flashy words
this sums it up pretty well 😄

he sounds like he doesn't know what he's talking about
this is like the people who think AI/ML is going to cure cancer or something
he's joking right
I hope he's joking
it just sounded like a bunch of buzzwords to me
psuedoscience?
the point is the idea not the video smh
🥴
the idea doesn't make any sense
its tiktok ofc theres buzzwords
the idea isn't feasible dude
elaborate
I like the like 3d space room thing clip but it's probably just like blender or smthing
how is he going to get his memories into an artifical neural network?
answer that
pictures ffs
I don't know what part of this idea makes sense to you
all of it
ill simplify it
bc you're doing an excellent job
images merged together to create something unique
🥴
so scanning + mapping 3d space?
yuh
im sure it's possible but you'd have to get your network to 1) understand depth (assuming you're not feeding in depth maps or actual 3d files) and 2) understand how space works + how to create it
idek how you'd approach that/if you can
ill find a way ty
i could
attemp giving orthographic views of the place
because im not rly basing it off memories
more like photos
never would have guessed
if you give it 2d photos and figure out the second point I mentioned, it'll give you back a 2d photo tho?
it helps if you deal with reality 🤷♂️
true true
i dont know if there is the right place, but i'm working on a simple anthill, i'm trying to create a smooth random movement for the ant ai
does anyone have a good solution?
ok thx
What are you working on?
what kind of movement do you want? you could do something like the brownian process and smoothen it by averaging over several ticks
mhm, may be a good way, but i'm kinda "noob" with this stuff, may you explain "how"?
hello, I've problem with my project. When I show to the camera 1 sign with my hand, it gives me infinite 1 on console. How can I fix it. I can share my codes btw.
hello, I have an assignment about Genetic Algorithm and I couldn't understand the Crossover Probability..How can I decide the Pc based on this description ?

hey, does anyone know about an active machine learning server or forum? I wanna find some people to work together with
im looking for one too, though it is for stock trading
I'm interested in a lot of things, but I know nothing about economics haha
what kind of project are you thinking of?
The r/algotrading discord isn't completely quiet. Have you found that one yet?
yeah, but it doesn't seem to be active
i have found some resources but no one to communicate and talk with
wsb? /s
What?
Maybe someone from wallstreetbets can help
when BERT is applied towards NER, does it predict each token in isolation?
is there a way to add black borders around each bar?

edgecolor
I read a few tutorials and started writing my first AI. I came to multivariate linear regression and using the sklearn library. Everything worked as expected and I saw how it simply detects mathematical patterns to generate a prediction, the more data I added, the more accurate. (code: https://paste.gg/p/anonymous/71402a14eee8434d968b5b9001af5d1f )
However, that was solely with numbers. If I wanted to detect patterns in strings, and I don’t mean anything that can be accomplished using lexical analysis, regex or a set of grammar rules. I mean patterns such as expecting a certain character after another or identifying grammar set.
If I wanted to do this, should I use a different method (i.e not regression), and how would I do it? Would I assign a numeric key for every allowed item?
Note that the patterns will not be numerically related to the place in the alphabet or the key. To exemplify: "Hello"," W" would expect that there is likely orld! after the W. (although that is a terrible example)
Maybe a manual algorithm? (i.e string and grammars might not be great for an AI)
what yo are talking about is NLP, which is a branch of ML itself.
Common NLP models are SVMs, Naive Bayes Multinomial / Bernoulli, etc
from what I'm understanding (reading the Wikipedia page), it seems ‘medical’ or ‘talks’/‘understands’ languages somehow.
what I mean is for example, I can give it a few strings of a programming language and it can generate a grammar set for use with an error handler or such.
is that NLP?
Hey everyone (idk if it's the right place to ask), do you guys think that this is a good start on data science (still relatively new to python tho) if i want to learn quickly for a possible ML/Fluidmechanics PhD ? https://www.udemy.com/course/the-data-science-course-complete-data-science-bootcamp/
yes, that does sound in the scope of NLP. Basically you want something like Intellisense I think
Hi guys,
If I want to play a little bit with the WAYMO dataset (computer vision), would you recommend using PyTorch or TensorFlow? Does it matter? (Personally I prefer PyTorch)
Can someone help me please?
Any cheap platform for text labelling? I'm looking at products like monkeylearn and the pricing is killing me
I know the formula, but I couldn't find Pc (Crossover Probability) value based on the description given in the question.
Can someone help me please?

Can someone explain in layman's terms what a hilbert space is of a given feature map?
hilbert space is a vector space that has an inner product (and is complete but dont pay attention to that)
that means that this space has a concept of orthogonality and direction
i cannot go in any further detail without first knowing your background potentially burning your brain
A vector space already has concept of direction, inner product is mostly orthogonality and induced distance
direction requires inner product
but i wont argue on that since it matters not
a vector space only "knows" how to add two vectors and multiply a scalar
you just confuse it with Rn spaces which are already hilbert spaces (probably)
since you tried to use intuition
Yeah it's worth digging into axiomatic definitions of abstract vector spaces and building up the algebraic structures and abstract properties you can build on top
Really important concepts that lead into some very important applied fields (signal proc, quantum mech, etc)
wait
u were right
u can have a direction aka a scalar multiplied by a vector
its just that any span of those wont span the whole space
so yeah there is a direction
even on non hilbert spaces
Indeed. Direction is a bit underspecified, but linear independence and whatnot can be a good indicator of different directions
Makes sense given the intro definitely of vectors as "a magnitude with a direction"
Depends if you consider orientation to be part of "direction", some people distinguish between the two. There is always a direction, but there may not be orientation.
Sometimes in math it's better to just say the full definition of the word you are using (how you define it), rather than just saying the word because (at least at this abstract level) things can get confusing about the semantics, especially when people with different language backgrounds try to interact.
(And in the case of ML, there are different definitions for words thrown around all the time in papers and people just assume you are on the same page)
new_data = pd.DataFrame(dicts).set_index("Month")
##df_predict = pd.DataFrame(transform, columns=["predicted value"])
response = make_response(new_data.to_csv(index = True, encoding='utf8'))
response.headers["Content-Disposition"] = "attachment; filename=result.csv"
labels = [d['Month'] for d in dicts]
values = [d['Predictions'] for d in dicts]
colors = [ "#F7464A", "#46BFBD", "#FDB45C", "#FEDCBA",
"#ABCDEF", "#DDDDDD", "#ABCABC", "#4169E1",
"#C71585", "#FF4500", "#FEDCBA", "#46BFBD"]
line_labels=labels
line_values=values
return render_template('graph.html', title='Time Series Sales forecasting',
max=17000, labels=line_labels, values=line_values, filename = response)
@app.route('/download/<filename>')
def download(filename):
filename = filename
return send_from_directory(filename=filename, as_attachment = True)
Hi community, I m currently deploy a machine learning model in web using flask python, Does anyone excel in send_from directory, please share me how to return my send_from directory correctly? cause I want to pass my response to serve a download route, currently I only can return my plot graph
Error I got >> TypeError: send_from_directory() missing 1 required positional argument: 'directory'
<a href="{{ url_for('download', filename=filename) }}">Download</a>
Hi does anyone here? please help~
how to create this equation in LATEX Overleaf?

i dont think it's the right topic
yeah, not really for this server. Also, the answer is "with quite a bit of work", not sure what you're asking about(specific symbols? it uses no weird ones, I don't think).
@last nest thanks for letting me know, is there an Overleaf channel?
but you can find all syntax about it on google, it's not that hard , or on latex reddit
oh okay thanks
Just search online for things like "latex subscript", etc.
yeah just focus term by term and you'll do it
Thanks for the explanation. I'm in the middle of a theoretical MSc in Data Sci/Computer Sci, so I could handle a semi complex explanation.
Do I understand it correctly that the RKHS is basically a higher dimentional representation of the map which is implied by the kernel, but not actually calculated (since that's the whole point of the kernel), which is basically just the dot product of the feature in higher dimensions?
I understood that if two features have a close norm in the RKHS, they're probably pointwise close as well
Sorry for my dumb question, I'm making right now a course about data analytics, and I don't understand a few term, because (I think) they use a lot of time like synonyms. Can you help me, please?
Can you show me on a diagram what's the hierarchy and what's the relation between: data science, data analytics, data analysis, data scientists, machine learning, statistics, analytics, data ecosystem?
I would say: statistics -> the rest are applications of it
though machine learning is technically its own thing
But other than that, I don't really know of a great way to put it in a hierarchy, it's more of a loose cloud.
In terms of machine learning:
Statistical learning theory is used as a tool in order to improve machine learning models (how they should learn, what loss functions to use, what optimizers to consider, how to choose good values for hyperparamters considering the estimation/approximation error etc)
So statistics would be a tool for machine learning, and machine learning is a tool for solving problems such as classification or complex regression problems
\
In general, when should I use ROCAUC instead of accuracy for my optimization metric, just when classes are imbalanced, or in general when I care about true/false positive ratios?
and data science vs data analytics?
Data analytics is arguably more specific, and usually focusses on the 'applied' side of things (very loose definition), e.g. BI tools
Data analytics is more specific and concentrated than data science. Data analytics focuses more on viewing the historical data in context while data science focuses more on machine learning and predictive modeling. ... On the other hand, data analytics involves a few different branches of broader statistics and analysis. ^google.
Data analytics are the people showing nice graphs to important people in meetings. Data Scientists usually aim to improve their ML models while AutoML is running in the background and beating them anyway
heh
(assuming this data scientist is building ML models, and not just data engineering, etc.. or anything else which is done in the field)
Data science can involve switching hats ^
for me the confusing part is that data science is the biggest one (I guess) but who do it we call data scientist. Same with data analytics (analysis?) and analyst
so a data scientist could make data analysis as well, so its higher in the hierarchy?
ROC is for the true/false positive ratios as the threshold changes, it can be computed with the CDF.
Assuming youre not calibrating your threshhold, why would I choose ROCAUC over Accuracy?
i.e., cost of false positive = cost of false negative
It's for calibrating threshold.
(And yes equal cost)
If the cost difference is too big, it's kind of useless.
I mean, imagine I have a neural network, and I compile it like py network.compile(loss='categorical_crossentropy', optimizer='rmsprop', metrics=['accuracy'])
is there a difference if I use ROCAUC instead of accuracy then?
So ROC is for binary classification.
I actually use a binary classification here
and not strictly, you can weigh the classses to still get ROC for multiclass problems
softmax plus cross entropy or categorical cross entropy is typically used for multi-class
I guess you could
If you use ROCAUC you get more detail than accuracy is the where i'm gonna leave it at.
Basically it gives you what it says it gives you, if you don't care about that information then don't use it.
where you guys run your ML code?
in jupyter notebook?
but i already installed tensorflow 2.2+ and reloaded kernel, wtf x_x

hi, anyone using tensorflow-gpu with ATI ?
wow, google colab and jupyter notebook are so slow for training models
colab a bit faster but anyway its slow
it's best to just ask your question, rather than ask if anyone knows about an unstated question.
which free cloud platforms are you guys using for compile ML models?
possible, but at the very edge (not to mention narrow focused, domain dependent) and won't give good results without serious research (as in actual academic one)
Rocm?
I understand all evaluation metrics but for Gods sake i still dont get what the hell ROCAUC is meant to represent
Hello everyone! I have a data set but I dont know how to format it into a workable manner. I need to compile the data the days into monthly averages but I dont know how to proceed or where to look. Any advice?
what does the data look like currently?

what is the file format?
csv
have you heard of pandas?
yes
import pandas as pd
data = pd.read_csv('that_file.csv')
that would be the first step.
okay done
so each column is a date?
that sounds like a good next step. columns should be types of data, whereas rows should be instances. it looks like this dataframe is backwards from that
okay thanks!
jesus, i set up cuda installation to disk F:, but cuda installed in somewhere i can't find now
TBH i dont like working with datetime . rather work with 3 int fields (year , month, date)
Instead of transpose it might be better to restructure ur data with a melt (unpivot) instead.
This might help @ruby magnet https://www.javaer101.com/en/article/19693997.html
Into Numbers I'm having troubles with grouping a
Ill look into this
Feel free to ping me if u need any help o/ do ur research first tho 🙂
finally i get gpu support for tensorflow🤕
I unstructured the data but I have no idea how to make it workable 😦
I only needed dining data, so I dropped the other values
this is what it looks like rn

df=df[df["Type"]=="<dining string here>"]
^filter
Something went wrong on ur code
2nd column has date and type together
I used this:
df_melt=pd.melt(df,id_vars=["Name"])
But i think it just seperated it based on Name
df=pd.read_csv(path here)
df=df[df["Type"]=="Dining Data"]
del df["Type"]
df=df.melt(id_vars="Name",var_name="date",value_name="value")
@ruby magnet try this
also whats the next plan - average on month?
Yeah, the average % per month for each state
mm/dd/yyyy?
yeah
ROC AUC is the 'Area Under Curve" for a ROC plot, where you plot the FPR and TRO
TRP*
@ruby magnet
df[["month","year"]]=df["date"].astype(str).str.split("/",expand=True)[[0,2]]
df["month"]=df["month"].astype(int)
df["year"]=df["year"].astype(int)
df["value"]=df["value"].astype(str).str.replace("%","").astype(float)
df1=df.groupby(["month","year"])["value"].mean().reset_index()
I know what the letters mean and how to build it; but I still dont get what exactly it describes
Meaning: if you have a higher AREA under the curve of FPR and TRP, you essentially predict the labels of your data better
The middle line is just random guessing

Therefore: if your ROC AUC is 0.5, it is basically as good as a random guess.
CLoser to 1: closer to 'perfect' (overfitting? ;)) model.
For all others is easy:
Recall? how often your true labels are predicted correctly. (How many times you said a real value was false, false negatives)
Precision? How often your predictions were right (how many predicitions wer real=
and so on.
I think my confusion is because i feel ROC is very close to precision
I'm not sure about that.
On a different note: why is it that RandomForest doesn't need cross validation (how come it has standard OOB?)
I mean, the TPR is literally precision lol
Thank you so much! Been struggling with this for a while now. Any idea on where I could learn what you just wrote so I can do it myself again if need be?
pandas documentation
Well the TPR is a rate, and this is an area showing a tradeoff between false positives and true positives
is pretty good
got it
which comes bacl to my point that i still can't quite materialize it mentally, because TPR itself contains false positives.
I think i'll need to read it AGAIN lol
also stack overflow and pandas docs together solves issue 😄
Pandas documentation is the most beautiful thing ever changfe my mind
lol, not sure how to help with that 😉
Use your head! think for me! heavy breathing rant

Would if I could, but gotta study for my ML exams 😉
hey guys i am trying to plot financial data from alpha vantage using matplotlib, with date field being the x axis and the closing price of stock being the y axis
i am not able to parse it, as data['date'] is not working..
how to parse the date as a column?
also i am using pandas as the output format
nvm figured it out... to anyone wondering; https://samanamp.medium.com/fetching-live-stock-market-data-with-python-and-alphavantage-7d0ff8a8d2e4
Medium
These days accurate data is most precious asset for financial market participants. Recently I was working with a not so old python code…
Hey guys, sorry to interrupt, i'm a fluid mechanics graduate, didn't do much python (some projects so i'm quiet new), willing to do a possible PhD in ML/Fluid mechanics, do you guys know if this https://www.udemy.com/course/the-data-science-course-complete-data-science-bootcamp/ a good course for data science and ML on python ?
if you have time i would recommend exhausting your free options before spending any money
FreeCodeCamp has a good course on data analysis awa machine learning
kaggle also offers free lessons
i dont really have time, in fact there's a big discount on this course from more than 50 to 12 euros, so i thought may be it was a good opportunity
i'll check those too , thanks 🙂
udemy always gives discount so dont worry about missing the discount. they have a really wierd marketing strategy of changing course prices wildly but there are always discounts atleast ones a month. i wouldnt rush about it if that was your only concern
No Problem
you're right i saw that weird discounts over time finishing in 5 hours, then the same the next day etc
not to mention the bid difference in price based on your location
I generally do not believe in paying to learn code
i didnt try it but it might be cheaper to buy courses using a vpn in india
can you recommend me one
oww is that from coursera
i heard he uses matlab instead
never heard of that
is it free to use
matlab isnot free unless you have a university licence
yes octave is free to use
but I wouldn't get into the MOOC if you don't have the math recommended for it
how much math are we talking about
i already have done the FCC course and it doesnt seem to require advanced math,
but it required logic
is it that advanced math, cause i already graduated so may be it's already ok on this level
idk what the FCC course is
it's on coursera right
but you need stats, linear algebra, calculus, and discrete maths for Ng
FreeCodeCamp
andrew ngs course? yes
Idk if the FCC course was as math-intensive
FreeCodeCamp is the best resource imo
i agree but if you dont have patience it can be offputting as they dont teach you everything you need in order to pass the projects
but i can see why?
they want to encourage us to go research ourselves but still...
if i get a good price for a mooc like course i'll take it and add fcc and others free to complete, thing is i need to know these subjects for physics application idk if i have to go deep in details into data scince, idk YET
this might be relevant for you

oh okay on fcc , ok that could be helpful , thanks !
i'll check all this , thanks guys
anytime
personally, if i get everything on a silver platter i cannot learn at all.. so it works well for me
Anyone saw IBM's call for code? I am suprised AF that all they expect is to deploy web apps
tbh I thought it would focus more on actual solutions than just a geek cringe-fest with idiots trying to show coding can solve any problem in the world
Where would you use MatLab over Python/R?
you're going to trigger a lot of CS grads and "code-bros" lol
I'm not sure if this still falls in "ML and AI" but network theory is pretty interesting. Specially these thing aout Power Laws in networks
dummyboi comin in with a dummyboi question. I was initially concerned the validation loss and loss were so spread. But they do start to converge...and since val_loss < loss it isnt an indication of overfitting and this general shape doesnt indicate there is something wrong? Is that correct?

But I guess on the flip side, if I cant get them to converge...I would have an issue
If you're into fluid mech, best to just do a more rigorous ML course. Start reading Bishop, etc.
Depending on what you're into, there's other more specific resources on what to learn
Eg Fluids people who are there to speed up fluid simulations with ML are different from fluid people learning non-linear modes of oscillatory phenomena using techniques like Koopman operators and dynamic mode decomposition
No overfitting yet, keep training. Maybe lower the learning rate a bit
Always stops early and no noticeable convergence. But will try the learning rate, thanks for the suggestion
im trying to take a df and return a different one with columns [opening_eco, dt] (dt being last_move_at - created_at)
def create_time_delta(df: pd.DataFrame) -> pd.DataFrame:
_df = pd.concat([pd.DataFrame([row["opening_eco"], row["last_move_at"] - row["created_at"]],
columns=["opening_eco", "dt"]) for _, row in df.iterrows()],
ignore_index=True)
return _df```
this raises `ValueError: Shape of passed values is (2, 1), indices imply (2, 2)` an I've got no clue whyI have data with dst_bytes, src_bytes, record ID etc and I want to cluster it using KMeans
df = pd.read_csv(f_path, names=["record ID", "duration_", "src_bytes", "dst_bytes"], header=None)
# X = ?
kmeans = KMeans(n_clusters=2).fit(X)
What exactly do I need to put as X? I'm a little confused on what n_samples and n_features are

In this series, we'll explore the complex landscape of machine learning and artificial intelligence through one example from the field of computer vision: using a decision tree to count the number of fingers in an image. It's gonna be crazy.
Become a Patron for exclusive perks: https://www.patreon.com/welchlabs
Supporting Code: https://github...
is that average loss or something like total? because it sounds really weird to me to have val_loss lower than training loss, ever.
What do you mean stops early?
Just train for more epochs
Is keras installed as part of tensorflow2 or do you install separately
Seems like a fairly common problem from my earlier google searches. Seems since val_loss always comes after the training session during that epoch, it has already adjusted weights and such and is typically lower
I have an early stop on, so if no improvements over 10 epochs the training will terminate
that seems to me like it can justify the test loss being as good as the training loss of the next epoch, but here the difference is massive.
Do learning rate scheduling
Either decay or a strict schedule where you reduce learning rate explicitly

@dapper halo
well then, thanks
oh I see it does use non-AI algorithms such as lexical analysis
I'm trying to machine-learn string. I finished using a ‘vectorizer’ with a ‘bag-of-words’ model and it seems like it works. I think it’s generating unique numeric keys for lexical items.
But how would I actually use them? Which models can I use and how would I write these [a b c x y z]-looking keys as string for the model?
Here's my working code so far:
https://paste.gg/p/anonymous/01bf343d27ae45eba8debaa4fb5a77b1
hi
Anyone here have experience with chess engine development? if so please DM me
hello again friends
im wondering if anyone has experience with uploading projects onto github
ive got a gan project ive finished but instead of uploading the IPYNB, because it seems that most professionals separate the files into different py files, e.g. test py, model py etc etc.
im not sure how i should divide my project up if that makes sense
yeah I'm not sure. Been at it for a few hours. Managed to cut the difference between val_loss and loss by 50% but its still pretty large. I will say that I am injecting 0 points into the data when I clean it as I expect the user would not be able to always obtain all the metrics I am training on. While all random, I assume many more of these masks get put into the training set which causes it to have a harder time evaluating the loss as opposed to the validation loss??
Outside of that I'm at a loss
ok thx i'll check that
i have a heatmap that looks like this

all_corr = np.corrcoef(all_features.T)
plt.figure(figsize=(14,14))
all_mask = np.triu(np.ones_like(all_corr, dtype=bool))
sns.heatmap(all_corr, cmap="coolwarm", xticklabels=all_cats, yticklabels=all_cats)
I only want to show the columns poly1 through poly10 and rows RSCI through AST/TOV
how do i change what's shown?
thanks!
You probably need to index on the labels. You can 'pull apart' the all_cor into x and y, then index on the final [-10:] for y, and the first [:9] for x.
Keep in mind that your xticklabels need the same size as x, and same goes for y.
On another note: Why are layered neural networks easier to train than large non-layered networks?
for i in range(X_FUTURE):
curr_date = curr_date + relativedelta(months=+1)
dicts.append({'Predictions': transform[i], "Month": curr_date})
new_data = pd.DataFrame(dicts).set_index("Month")
##df_predict = pd.DataFrame(transform, columns=["predicted value"])
new_data.to_csv(os.path.join("downloads", index = True, encoding='utf8'))
labels = [d['Month'] for d in dicts]
values = [d['Predictions'] for d in dicts]
colors = [ "#F7464A", "#46BFBD", "#FDB45C", "#FEDCBA",
"#ABCDEF", "#DDDDDD", "#ABCABC", "#4169E1",
"#C71585", "#FF4500", "#FEDCBA", "#46BFBD"]
line_labels=labels
line_values=values
return render_template('graph.html', title='Time Series Sales forecasting', max=17000, labels=line_labels, values=line_values, filename = filename)
@app.route('/download/<filename>')
def download(filename):
return send_from_directory("downloads", filename, as_attachment = True)
<a href="{{ url_for('download', filename=filename) }}">Download</a>
Hi community, I m trying to save my to_csv into os.path.join and return the csv file from download button in HTML page, currently I m getting this error TypeError: join() got an unexpected keyword argument 'index', Does anyone excel in flask python, please correct me ~ Appreciate
hello, I've problem with my project. When I show to the camera 1 sign with my hand, it gives me infinite 1 on console. How can I fix it.
hello, I'm a beginner at ML, and the field of ML/AI seems very overwhelming to me. I am so confused about how deep does one have to dive into each topic in order to cover the overall ML field? If one wants to he/she can spend months on learning just one kind of model, there is just so much to learn, so many parameters and stuff that affect your model. I just can't figure out when to stop studying a particular model/algorithm. I wish there was a certain "threshold" that says like "ok you've done enough of this, you can move on to the next topic.". So yeah, how deep am I supposed to go? how can i figure that out? It would be nice to find out how deep the advanced ML users go. 🙁
You could always go in the wanted depth, but if you want the practical answer just learn enough to do the projects you're interested in completing.
hmm, thanks for the advice @primal tulip 👍
learn as much as you like; if you get bored or find something interesting, move on
this is a common conception that for example, if you want to compete in an AI competition, you need to know everything about it. this is actually not a realistically feasible approach to learning something. the best motivation is what comes from within
im getting this error while running openai cartpole environment: GLXInfoException: pyglet requires an X server with GLX
im not sure what to do
more trials to decrease the score @analog cave
its the epochs
sorry for the misuse of words
but yea its the epochs
👍
do u know if there is an AI that given an input (a picture), or more than 1, outputs u the picture from different perspectives?
there are plenty of that from 2-minute papaers
hmm
i remember seeing some thing that makes ur face visually three dimensional and you could drag it around
forgot what it was called
Ruler always coming up with the based comments
To add to this. ML/AI has in many ways become a buzzword, almost like blockchain, people want kt everywhere even if they dont wth it does and this puts too many expectations on learners.
Dont pressure yourself with unreleastic expectations. Find a problem you are interested in, and try to solve it, thats all.
Most of the time, even if the project is dumb basic stuff, you have something to show that proves you have a clue and more importantly, that you have hands on experience.
I'm using quadratic features to train a model, but the issue is I have about 5000 of these features to choose from. What type of feature selection should I do to make sure that I choose as diverse a featureset (in terms of they're not all heavily correlated with each other) as possible while still keeping the model accurate?
The issue I've had before is that feature selection chooses, say 10 quadratic features which happen to be extremely similar to each other, making it so there's basically no point in having 10 features, and agglomerating features together made them basically indistinguishable from each other as well. I'm interested in choosing the features which have the most impact on the model while being independent from the other ones
thanks and cheers!
@exotic maple hey, trying to implement the advice you gave. refresher: the script isn't printing rows that have a combination of integers and letters ex. "1889AM" but will print either "TEST" or "1889" on separate tests. raw_input would've worked if i wasn't using python3 i think. what do i need to do? below is a segment of the script but it's with the Alert ID not Acronym, feel like this is an easy fix but just lost
while True:
variable = input(f"{bcolors.WARNING}Search by Acronym / Parent / Alert ID / Account? {bcolors.ENDC}")
if variable == "Exit":
sys.exit(0)
if variable not in df.columns:
print(f"{bcolors.FAIL}Error: Invalid Input{bcolors.ENDC}")
continue
if variable == "Acronym":
while True:
input1 = input("Please provide an Acronym: ")
result1 = df.loc[df[variable] == input1]
if input1 == "Back":
break
if len(result1) == 0:
print(f"{bcolors.FAIL}Acronym not found. Please try again{bcolors.ENDC}")
else:
print(tabulate(result1, headers='keys', tablefmt='psql'))
continue```I see that there's a dataframe but I'm not seeing how this is a data science question
@serene scaffold i'm using pandas referencing an excel sheet with 4k rows of data
so you're trying to map user inputs to pandas operations?
no i'm trying to use user input to search the excel file, initial question is to determine which column it needs to search in. acronym (which is all letters) works, parentid and account id all integers - works, but alert ID is a mixture and it won't print 100% integers but will print either 100% letters or a mix
anyone know a fix? @exotic maple @iron basalt
is anyone familar with control variates as a variance reduction technique?
Don't ping me for your questions.
didn't, i mentioned u
Don't @ me
Does anyone know much about signal processing? any resources with personal preference that aren't math-intensive, or just use logic?
ok @iron basalt
Signal processing is all the math.
that isn't particularly encouraging - anyways, that's why I asked some resources you might know which use logic more
how hard would you rate the math?
Anywhere from linear algebra to does not exist / needs more math to be invented.
Maybe this will help: https://en.wikipedia.org/wiki/Signal_processing

Signal processing is an electrical engineering subfield that focuses on analysing, modifying, and synthesizing signals such as sound, images, and scientific measurements. Signal processing techniques can be used to improve transmission, storage efficiency and subjective quality and to also emphasize or detect components of interest in a measured...
scroll down to mathematical methods applied
are you seriously recommending wiki to a newbie?
It gives a list of applied mathematics
perhaps then I would be expected to know just the basics then
does anyone know any modules that could be used to draw borders around the shapes in this image?

You'd have to write a workaround to exclude the white inside of those objects, but my first thought would be to use something like cannyedge
opencv
I tried using opencv's cannyedge but it gave this

i'm wondering if this might be easier if I get rid of all the noise first
Brings back schlieren image processing nightmares. All I can say is have fun haha

any ideas?
sorry haha kinda got buried
many automl tools do them (pycare, MLjar) they would usually output the most important one and how you can use them to construct "golden features"
i'm trying to implement this project: https://stackoverflow.com/questions/42203898/python-opencv-blob-detection-or-circle-detection
but how do I make cv2 show the contours?
what do I put in the arguments for cv2.imshow()

Stack Overflow
I am having problems detecting circle areas.
I tried it with the HoughCircles function from opencv. However even though the images are pretty similar the parameters for the funtion have to be diffe...
hello guys, how can we load tensorflow to opencv?
Signal processing is a 3rd year subject in a maths intensive EE degree. There's literally no way to do signal processing without maths
I TA it at University and the maths is too heavy for 3rd years, much less some high schooler.
Yeah worked, why
figures, they prob expected me to learn some bare-bones basics
Not sure what's involved in barebone basics of sigproc
me neither - it's something related to raw audio and they did say they used signal proc
but not explicitly mention that
hello
i am new here
and i have made an enviroment
but i am having a biiig trouble geting my tensorflow sequential to read my input
or to crating my reinforce agent
i passed 5 days reading the doc from start to finish
still cant get past some problems
how can i share my code here????
i made a small version with my problems
!code
Here's how to format Python code on Discord:
```py
print('Hello world!')
```
These are backticks, not quotes. Check this out if you can't find the backtick key.
the docs aren't very compherensive, so reading them doesn't provide a much deep idea
thanks
Here's how to format Python code on Discord:
```py
print('Hello world!')
```
These are backticks, not quotes. Check this out if you can't find the backtick key.
import pyautogui
import time
import cv2
from PIL import ImageGrab
from pynput.keyboard import Key, Controller
import numpy as np
import keyboard
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
from tflearn.layers.core import input_data, dropout, fully_connected
from tf_agents.networks import actor_distribution_network
fullscreen = [110,130,710,570]
screenpil = ImageGrab.grab(bbox=fullscreen)
showprint = np.array(screenpil)
grayscreen = cv2.cvtColor(showprint, cv2.COLOR_BGR2GRAY)
screenrect = cv2.cvtColor(grayscreen, cv2.COLOR_GRAY2BGR)
print(tf.data.Dataset.from_tensors(screenrect))
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(filters=25, kernel_size=40,padding="valid", activation="swish", input_shape=[ 440, 600,3 ]),
tf.keras.layers.MaxPool2D(pool_size=2, strides=5, padding='valid'),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(units=50, activation='swish'),
tf.keras.layers.Dense(units=25, activation ="swish"),
tf.keras.layers.Dense(units=15, activation ="relu"),
])
initial_learning_rate = 0.0005
lr_schedule = tf.keras.optimizers.schedules.ExponentialDecay(
initial_learning_rate,
decay_steps=6000,
decay_rate=0.95,
staircase=True
)
model.compile(
optimizer=tf.keras.optimizers.Adam(learning_rate=lr_schedule),
loss=tf.keras.losses.SparseCategoricalCrossentropy(),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()]
)
reshapedData = screenrect.reshape((440, 600, 3))
rereshaped = np.expand_dims(reshapedData, axis=0)
rereshaped = rereshaped.reshape(len(rereshaped), 440, 600, 3)
model.fit(rereshaped) ```this is my basic model witch returns this erro
Tried to squeeze dim index -1 for tensor with 0 dimensions.
it is suposed to recive a "screenshot" as input
can you post your full error?
InvalidArgumentError: Tried to squeeze dim index -1 for tensor with 0 dimensions.
[[{{node metrics/sparse_categorical_accuracy/Squeeze}}]]
the full traceback
ooooooooo
Hey @willow quarry!
Uh-oh! It looks like your message got zapped by our spam filter. We currently don't allow .txt attachments, so here are some tips to help you travel safely:
• If you attempted to send a message longer than 2000 characters, try shortening your message to fit within the character limit or use a pasting service (see below)
• If you tried to show someone your code, you can use codeblocks
(run !code-blocks in #bot-commands for more information) or use a pasting service like:
put it here https://paste.pythondiscord.com/
and share the link
there
what does putting print(rereshaped.shape) before model.fit output?
WARNING:tensorflow:From C:\Users\Watso\AppData\Local\Programs\Python\Python38\lib\site-packages\tensorflow\python\compat\v2_compat.py:96: disable_resource_variables (from tensorflow.python.ops.variable_scope) is deprecated and will be removed in a future version.
Instructions for updating:
non-resource variables are not supported in the long term
curses is not supported on this machine (please install/reinstall curses for an optimal experience)
<TensorDataset shapes: (440, 600, 3), types: tf.uint8>
Train on 1 samples
i belive its <TensorDataser shapes: .....
how much data are you giving?
one image
i tried that in other sample
grayscreen = grayscreen.reshape( 440, 600, 1)
print(grayscreen.shape)
Tfdata = tf.data.TFRecordDataset.from_tensors(tf.expand_dims(grayscreen, axis=0))
#grayscreen = numpy.asarray(grayscreen)
print(Tfdata)
model.fit(Tfdata)
<TensorDataset shapes: (1, 440, 600, 1), types: tf.uint8>
witch returned that
give it multiple images, so that the shape looks something like this:
(x, 440, 600, 3)
wait what's the label lol?
no avail
what is your Y value? what are you trying to do?
so it plays retroarch games
sparsecategoricalcrossentropy needs a non-sparse array to calculate loss
there is no y exactaly
...what?
that's not how you do RL
that is my actual first atempt
but i also ran into mutch errors
like
now i am stuc at
InvalidArgumentError: cannot compute Conv2D as input #1(zero-based) was expected to be a int32 tensor but is a float tensor [Op:Conv2D]
In call to configurable 'ReinforceAgent' (<class 'tf_agents.agents.reinforce.reinforce_agent.ReinforceAgent'>)
my recommendation is to follow some tutorial that solves the game you want
for solving above error, you can just cast it to int32
i did 4 tutorials
and?
yeah, without full knowledge, trying to make something custom sucks
for a virtual xinput controller
and the input for some darn reason always crashes stuf
but tell me more about cast it to int 3
int32
Again, I recommend trying to solve some simple games then moving to your own problem
google "how to cast a tensor to a dtype"
i would looooove to
most of your issues can be solved via a bit of research
but that is my project to finish my full stack formation
i have 10 days to present
something
then i will polish stuf
"full stack formation" what is that?
data and some more stuf formation
are you in college?
what did the course teach?
why, if you don't mind me asking?
i changed country
tried colege here but need to worck to eat
actualy i am at work right now
night receptionisgt
i have lots of fre time at night
use that to study
that is indeed very good 👍
yes
but trust me, start with the absolute basics first - learn good amount of python, then move to data science
that is true
yes
it doesn't take a lot of time if you do it properly
you have us right?
so i ned at least that the car is able to turn by it self
what is the environment?
can i show you my screen???
yes, a screenshot would be good
year cus i made some wrong thing and it only runs in one of my pcs
will take 3h to fix it
and time is something i dont have now
a sec please
here an example

it analizes the pos of the players trough its faces moving in the mile and return points
did they teach reinforcement learning in the course?
with this config i can train 4 agents at once and in the future even use a ai x ai pontuation method
no
kkkkkkkkkkk
well, then what did they teach?
in ai they teach randon forest
those basic
and then some tensorflow to recognise paterns and images
basicaly basic keras
so how did you jump from that to rl?
i always loved rl
so i watched lots of videos
and i had an idea about enviroments
rl is very complicated
I recommend you do something about the basics you learn, do project related, then learn more, do something more complex and so on
I too tried to learn RL at first 😅
I quickly dropped it after I realized the amount of coding needed to do the theory - I still find it intriguing though.
again, do some image recgnition with keras first using the code in course
if i am able to present this project my idea is to pass sometime working in a real enviroment to retroarch
maybe even a custom version alowed to return framerates in an internal way readable for python
that way i can acelerate without losing sync
all in good time, my man. first, learn the basics and then start implementing complex stuff.
I know it is not easy to do something that may be boring/you do not like - but it is the best way to learn
if i am able to make nuice inviroments i would like to make a twitch to host ai x ai tournaments
its not boring
even the basics are awesome
man is a self learning algoritym
then why aren't you doing a project related to Random forest/ tensorflow image recognition?
cus there is everione in my course doing it
ignore those idiots, focus on what is appropriate
yeah, it looks simple but is actually not
its not hard tooo
it is
i just realy realy suck at tensorflow at the moment
and even if i understand the llogic behind
there is always an int32 in the way
there is; that's why I told you to learn basic python first
leave that project for a moment
i do games in c# for years
my problem is wen you drop tons of lbraries
i am used to do my code so i know its flaws
i started programing at 12
well, then it's pretty hard to direct you since solving all those errors would take months
kkkkkkkk
i have just one last question
tf_agent = tf_agents.agents.ReinforceAgent(
time_step_spec = time_step_spec,
action_spec = Tensod_spec,
actor_network=actor_net,
optimizer=lr_schedule,
normalize_returns=True,
train_step_counter=train_step_counter
)
at this part in the code
what exactaly i am supodes to place at action_spec
i undertud how to create specs
yea, it would look something like this action_spec = BoundedTensorSpec(....)
year
i made an array 14 bounded tensor
but my actor didn't liked it
so i made it a tensor spec
no, it has to be bounded
iit is
no tensor spec, only bounded tensor spec
wen we convert it keeps the bounds doesn't it???
no, that's not how it works
TF_Ximput_specs = tf_agents.specs.BoundedArraySpec(
(15,), dtype=np.float32 , minimum=[0,0,0,0,0,0,0,0,-32768,-32768,-32768,-32768,0,0,0], maximum=[1,1,1,1,1,255,1,255,32767,32767,32767,32767,15,1,1], name="XimputSpecs"
)
TF_ScreenRead_Specs = tf_agents.specs.BoundedArraySpec(
[1 , 440 , 600 , 1], dtype= np.int32 , name="ScreenSpecs"
)
Tensod_spec = tf_agents.specs.tensor_spec.from_spec(TF_Ximput_specs)
Tensod_spec2 = tf_agents.specs.tensor_spec.from_spec(TF_ScreenRead_Specs)
print(Tensod_spec2)
print(Tensod_spec)
this code
BoundedTensorSpec(shape=(1, 440, 600, 1), dtype=tf.int32, name='ScreenSpecs', minimum=array(-2147483648), maximum=array(2147483647))
BoundedTensorSpec(shape=(15,), dtype=tf.float32, name='XimputSpecs', minimum=array([ 0., 0., 0., 0., 0., 0., 0.,
0., -32768., -32768., -32768., -32768., 0., 0.,
0.], dtype=float32), maximum=array([1.0000e+00, 1.0000e+00, 1.0000e+00, 1.0000e+00, 1.0000e+00,
2.5500e+02, 1.0000e+00, 2.5500e+02, 3.2767e+04, 3.2767e+04,
3.2767e+04, 3.2767e+04, 1.5000e+01, 1.0000e+00, 1.0000e+00],
dtype=float32))
this output
some how it keeps bounded
oh, then it would remain bounded
year
I thought you have changed the whole object
i thought it would unbound to
it would crashh all cus its already a weard array with 'ints' and axes limits and all
BoundedTensorSpec(shape=(15,), dtype=tf.float32, see the dtype? you change tf.float32 to tf.int32 to get it in integers
sorry, have to go. talk to you later
does anyone know how to make a bot embed
This is mostly a pandas question, trying to figure out how to conditionally drop rows based on a list of values. I have data that looks like this:
COL1|COL2 1| 1 1| 2 1| 3 2| 2 2| 3 2| 6 2| 7 2| 8
And I have another dataset like this
KEEP_NUM|DROP_LIST 1|[2,3] 6|[7]
The goal is if the number in KEEP_NUM is in COL2, and any of the DROP_LIST are also in COL2 for the same COL1, drop those in the DROP_LIST, so the above would look like
COL1|COL2 1| 1 2| 2 2| 3 2| 6 2| 8
Since for COL1=1, 1 was in there so it dropped 2 and 3. For COL1=2, 7 existed with 6 so 7 was dropped, however neither 2 or 3 were dropped since there was no 1
I know I could do this reasonably easily with just a few for loops, but that's horribly inefficient.
about my question
the problem on the agent build was the conv layer that was buging every thing
but it would be advisable to have a nice conv2d layer since my main read data is image
i will try to make that on my actor_distribution_network
preprocessing_layers
not sure if this exactly belongs here, but do you guys have any idea why
my dataframe is unshuffling itself?
y_data = pd.concat([Dataframe.pop(x) for x in ['Metallicity', 'Density']], axis=1)
maskedData = feature_mask(Dataframe)
normalizer = preprocessing.MinMaxScaler()
transformed = pd.DataFrame(normalizer.fit_transform(maskedData))
transformed['Metallicity'] = y_data['Metallicity']
transformed['Density'] = y_data['Density']```the first line (.sample) definitely shuffles it, but once I put the y_data back into the dataframe to save it, it unshuffles it.
scratch that. Still confused, but idk why I didnt just shuffle again afterwards. Problem resolved
I take that back. It screws up my labels. Ya im so confused why this unshuffles it. Maybe I just need to reset the index?

you need to change the format of your second dataframe
actually
hm
you can do it without
but I would do it with
like spread it out
so it’s in the same format as the first one
how do i access the contrib library of tensorflow
tf.compat.v1.contrib doesn't work
is this valid forward pass?
inputs --> layer 1--->layer 2--->softmax_activation-->cross_entropy-->MSE(Mean square error)
layer1 = sigmoid((input x weights1) +bias1)
layer2 = sigmoid((input x weights2) +bias2)
x = iris[(iris['sepal.length'] > 5) and (iris['variety'] == 'Virginica')]
is my code
Python
pinned
a message
to this channel.
See all the pins.
Today at 1:10 PM
SREESANKAR — Today at 1:10 PM
ValueError Traceback (most recent call last)
<ipython-input-24-55b181a65cd7> in <module>
----> 1 x = iris[(iris['sepal.length'] > 2) and (iris['variety'] == 'Virginica')]
C:\Anaconda\lib\site-packages\pandas\core\generic.py in nonzero(self)
1327
1328 def nonzero(self):
-> 1329 raise ValueError(
1330 f"The truth value of a {type(self).name} is ambiguous. "
1331 "Use a.empty, a.bool(), a.item(), a.any() or a.all()."
ValueError: The truth value of a Series is ambiguous. Use a.empty, a.bool(), a.item(), a.any() or a.all().
it is giving me the above error
👆 👆
i'm using pandas
please help
try replacing and with & (bitwise and), currently using and tries to evaluate the truthyness of the entire data frame produced by (iris['sepal.length'] > 5), before it would move onto (iris['variety'] == 'Virginica'), the issue being that pandas data frames don't like being cast to a boolean (hence the error) and instead have their own methods for this (as it says in the error message), using a bitwise and (&) should instead compare each element of both data frames produced (for indexing) and then the result should be that it returns the positions in the iris data frame that meet both of your conditions
>>> import pandas as pd
>>> df = pd.DataFrame({"a": range(7), "b": [5] * 5 + [2] * 2})
>>> df
a b
0 0 5
1 1 5
2 2 5
3 3 5
4 4 5
5 5 2
6 6 2
>>> x = df[(df["a"] >= 3) & (df["b"] == 5)]
>>> x
a b
3 3 5
4 4 5```Hi all, I was wondering if anyone can help me. I have used skimage to detect some 'blobs' on an image. I know have the x, y location and radius of thse blobs. There are thousands, and they are detecting what I want. I would like to get the average R, G, B value in each blob. I have tried masking in CV2 but that has issues. Can anyone speak me through this or have another solution (perhaps in skimage?)? Thanks in advance
what issues?
when i import my image in cv2 it is really dark
image2 = cv2.imread('./data/18b.jpg')
img = cv2.cvtColor(image2, cv2.COLOR_BGR2RGB)
plt.imshow(img)
when i import like this it is really dark
so i have no idea
also some of my ROI, are returning as NaN in one channel
basically, i have this: https://scikit-image.org/docs/dev/auto_examples/features_detection/plot_blob.html
and i want to measure the mean RGB in each blob
Im trying to read data from sql to python but got a
ProgrammingError: ('42000', '[42000] [Microsoft][ODBC SQL Server Driver][SQL Server]Must declare the scalar variable "@ID". (137) (SQLExecDirectW)')
@ID is one of the column in the sql table. Im getting error in while using
query = pd.read_sql_query("""SELECT col_name, @ID, col_name FROM dbo.table_name""", conn)
Is the error due to "@" and how do i solve this?
you can try using quotes around the name :
query = pd.read_sql_query("""SELECT col_name, "@ID", col_name FROM dbo.table_name""", conn)
Easiest way to save a tf 2.4.1 Tensor to file? I need to take some tensors from insinde my NN to apply manual operations for debugging purposes
I used [ ]and that fixed it. Thanks anyways
I'm trying to train a model on BERT features calculated from texts, and starting with a simple linear regression model to see how it works. But my R^2 metric is getting out of hand for my testset (it's minus billions for some cross-validation folds). What could be going on? Could it be that my trainset is too small (500-1000) or that BERT embeddings have too many features (768)? Also the LinReg coefficients are huge.

Hi guys, how can I add here to display the time spent in the voice chat https://pastebin.com/maXTbxcX
Pastebin
Pastebin.com is the number one paste tool since 2002. Pastebin is a website where you can store text online for a set period of time.
@next ibex what do you mean by "add to display"? Where did you calculate the time spent? (And could it be that this is not a #data-science-and-ml question?)
Well, I also want to add counting and display to this function
But nowhere can I find a solution to this
Apparently, no one knows how to do this 😦
But if you want to display 'time spent', you'll need to calculate it. You need a 'time opened' and a 'time closed' for example. Do you have these?
I think you should either ask this in #discord-bots or claim an unused help channel such as #help-potato
As you can see he is not there, and about this I came to ask for help here)
I do not know how to do that
Just look at the left sidebar. Under 'AVAILABLE HELP CHANNELS' you can see three channels. Right now they are #help-candy #help-dumpling #help-coconut . If you click one of these and just type something, you claim it 🙂
Hopefully somebody will come along and answer your question
what is your task?
what is your data preprocessing and emebdding size?
@grave frost I want to classify transcribed conversations. I split them up in sentences, every time the speaker changed is a new sentence. The conversations are labeled 0 or 1, the individual sentences get scores between 0-0.5 when the conversation is labeled 0, or 0.5-1 when the conversation is labeled 1, in both cases dependent on a word list occurring in a sentence, and those scores are smoothed afterwards for each conversation. The sentences are fed to BERT, which returns a vector of 768 floats. These features need to go into a new model.
The BERT features are completely meaningless for a human reader, but should have a low cosine distance when the sentences are similar.
I used the BERTje model actually, a Dutch variation on the original BERT model. But that's a detail.
hmm...I think you are rather constructing useless processes to encourage what can automatically be mapped by the model
So each sentence in the transcribed conversation has a labelled value - and you are approximating the overall score of the sequence by averaging?
how did you get the word list? was it hardcoded?
I'm not sure yet how I'd aggregate the sentences back to a conversation score. The word list was hard-coded, manually extended using WordScores, which scores words based upon co-occurrence.
so in the dataset, your X is sequences and Y a corresponding score?
X --> src data | Y --> Target data
and even if your Y is numeric, you could bin it into categories and fine-tune BERT as a classification task on n labels
Yes that's right! I'm done working for today so tomorrow I'll try to implement the classification of the sentences in BERT itself tomorrow. Thanks a lot for your help!
Hello,
I have this Dataframe:
id another other actors. other
-
~ ~ A, B ~ -
~ ~ C ~ -
~ ~ A ~ -
~ ~ F, G ~ -
~ ~ A, B, F ~ -
~ ~ C, F ~
What I want to do is graph the number of times each actor appears.
So what I see I have to do is:
Have a list of the actors (A, B, C, F, G) and then go looking in each row how many times each actor appears.
I want to know if there are methods in Pandas to do that, or do I have to implement it from scratch with numpy?
Thanks
the actors attr is comma-separated?
you could create a list from that column (via pandas) and explode it, then groupby / plot
Yes
Thanks
Hi. I want some help to decide which course i should stick up with.
The problem begins with me choosing ML topic as graduation project, but i have no experience with it. Only know how to code in python. So our plan is to work on "Image colorization" problem and there 2 methods to do the required job; One using Convolution neural network the other using auto encoders. So to get through the scientific paper i have to know what are these topics. After searching i found two suitable courses that covers topics from the beginnings to advanced levels that might make you able to go through scientific papers about the colorization problem.
The courses:
- UC Berkeley CS 182: Deep Learning.
- Udemy - Deep Learning A-Z™️: Hands-On Artificial Neural Networks
So which one do you recommend? And any advice?
PS. I'm a CS/Math student so i have the programming and the mathematical maturity that would make me and my team able to go through these stuff quickly. Thanks
Does dask or vaex have an equivalent to pandas.merge_asof?
https://pandas.pydata.org/docs/reference/api/pandas.merge_asof.html
I'm trying to refactor a function to be analogous between pandas/ dask/ vaex to test performance differences
hello
so i was trying to use policies
i am trying with a random policy and actor policy
but i always get
AttributeError: 'TensorDataset' object has no attribute 'shape'
fullscreen = [110,130,710,570]
screenpil = ImageGrab.grab(bbox=fullscreen)
showprint = np.array(screenpil)
grayscreen = cv2.cvtColor(showprint, cv2.COLOR_BGR2GRAY)
screenrect = cv2.cvtColor(grayscreen, cv2.COLOR_GRAY2BGR)
grayscreen = grayscreen.reshape( 440, 600, 1)
grayscreen = grayscreen.astype(int)
print(grayscreen.dtype)
Tfdata = tf.data.Dataset.from_tensors(grayscreen)
#grayscreen = numpy.asarray(grayscreen)
print(Tfdata)
arg = torch.from_numpy(grayscreen)
time_step = tf_agents.trajectories.time_step.TimeStep(
step_type = "FIRST",
reward = 0 ,
discount = 1 ,
observation = Tfdata
)```that is the input
ok
i got an idea
i hadn't gave a batch zise to the polocy
ut i am doing my own enviroment
how can i make my own "batch_size"
for neural networks for binary classification do the labels need to be one hot encoded or is using label encoder enough?
looks no pros online today
i am having touble to feed my agent with data
and cant run even random_policy
have 10 days to finish project
2 weeks reading docs no stop
witch library you use??
i think i found my problem
pil_img = tf.keras.preprocessing.image.array_to_img(img)
i didn't know there was tf.image
Hello here. I have a pandas dataframe. One on the column contains arrays. How would you get the top n common items of thoses arrays ?
oh i could do with an accumulator or something
so the column is of dtype object, and each cell in it is an array?
yes. I got it with a df['xxx'].str.split()
I'd just make a Counter from each and add them all up. If that's too slow, use a faster multiset library.
Oh, so you mean lists, not (numpy) arrays.
i was about to say it an iterator is always helpful
hey confused do you undestarnd about tensor specs??
not sure what you mean
I got it wrong, i thought you were talking about the column, while you were talking about the column elements
each column of a DataFrame is a numpy array, but if it's storing something like lists or numpy arrays, that can only be done by making the column's dtype object, which essentially gives up most of numpy's vectorized operations
which means in that case you can just iterate over the column - there isn't really a faster vectorized way.
ok no point in trying to optimize here, unless i go to a different lib to parse my csv. Thanks you for the help 🙂
I'll go the slow way and sleep on it if it's too long
Hi, i'm working on a neural network (to establish a link between RGB values & wavelength/purity) but it seems my loss is way too high (i expected to get 0.005 for 50 epochs, and i get something like 0.25 (globally the same result with 50 epochs & 100 epochs). Any idea to reduce the loss please ?
Here's the code :
Regarding the datas :
F=np.load('data/data_RGB_Train.npy')
#Normalisation de F['lambda']
Flo=F['lambda']
Flm=np.min(F['lambda'])
Flo-=Flm #Flm < 0
FlM=np.max(Flo)
Flo/=FlM
#Normalisation de F['pure']
Fpure=F['pure']
Fpm=np.min(F['pure'])
Fpure+=Fpm #Fpm > 0
FpM=np.max(Fpure)
Fpure/=FpM
R=F['R']
V=F['G']
B=F['B']
L=np.array([R,V,B]).T
X_t=copy.deepcopy(L)
X_test2=np.random.random((len(Flo),3))
y_t=np.zeros((len(Flo),2))
y_test2=np.random.random((len(Flo),2))
for i in range(len(Flo)):
y_t[i,:]=[Flo[i],Fpure[i]]
Regarding the network :
model=km.Sequential()
model.add(kl.Dense(20,activation='tanh',input_dim=3))
model.add(kl.Dense(10,activation='tanh'))
model.add(kl.Dense(5,activation='tanh'))
model.add(kl.Dense(3,activation='tanh'))
model.add(kl.Dense(1,activation='linear'))
model.compile(optimizer='Adam',loss='mse')
model.output_shape
model.summary()
history2 = model.fit(X_t, y_t[:,0],
batch_size=32,
epochs=50,
validation_split=0.3,
verbose=0) # % of data being used for val_loss evaluation
ev = model.evaluate(X_test2, y_test2[:,0])
print(ev)```
```Output : 1024/1024 [==============================] - 1s 1ms/step - loss: 0.2475
0.24748222529888153```
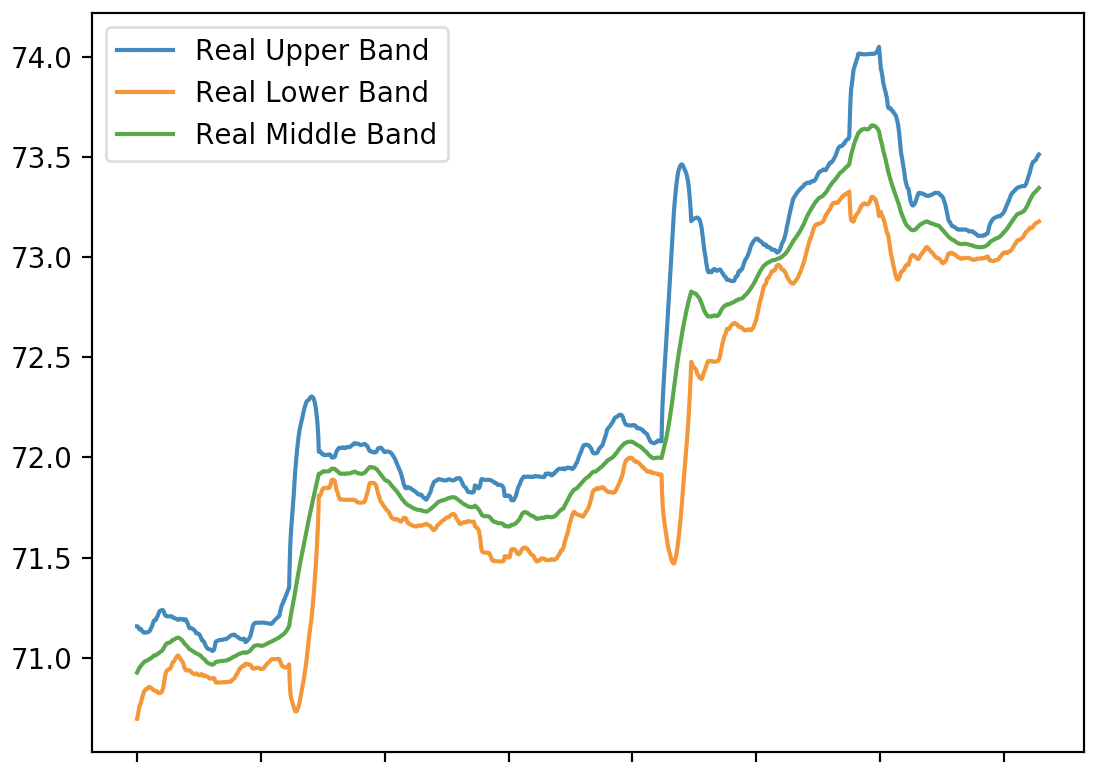
the pic is the loss/val_loss plot (for 50 epochs)
@echo orbit how did you decide on that specific architecture? maybe try something simpler with fewer layers and add regularization
and why is validation loss lower than training loss? that's odd
That was an architecture suggested by one of my teachers
And yes it's odd and i couldn't figure out what was wrong
is it the way i initiated ? (reversing X_train with X_test, same with Y_train & Y_test ?)
your code is a bit hard to follow...
your test data is random?
that doesnt make sense to me
Well i'm kinda new to neural network so it's highly possible i made a mistake when initiating
also, does normalization between 0 and 1 actually make sense for this data? i don't think normalization is a good idea unless the inputs are actually bounded
certainly randomized data is not a suitable alternative for out-of-sample validation data
however i think its a great idea to fit your model on simulated data before you start trying to fit it on real data. if it performs badly on simulated data that you know has a strong relationship, then your model has a bad architecture for the problem
to establish a link between RGB values & wavelength/purity
do you have a theoretical physics/optics model of some kind that describes this relationship? if so, you could (and should) generate fake data using that relationship and fit the model on that fake data, to make sure your architecture and model fitting procedure is good
To sum up i have datas (called in the F variable) which are vectors with R, G, B ,wavelength and purity each (around 32.5K points, so 32.5K vectors), there is no explicit formula that links RGB with wavelength & purity and i was asked to make a neural network & verify if it does find a formula/relation between these parameters
The previous notebook had a similar issue but the formula was known so that wasn't an issue
i see.. i guess i am willing to take that network architecture at face value from your teacher. but at least add regularization to it, and use a proper train/test split, or better yet cross validation, to estimate out-of-sample error
it looks like you randomly generated X's and Y's that have no relationship to each other for the test data
which doesn't make any sense
I was looking at the problem that way :
- i have generated datas in a .npy file that i set in a variable
F. I extracted the parameters of interest in different variables (X_train&y_trainthen normalized (so i can at least take a look at them).
-for the neural network, i was thinking i should generate completely random X & Y values that i'd use to test on the network withX_train&y_trainas datas for training, then evaluate the loss & val_loss so i can compare them & verify if the network works correctly or not
At least that's what i was understanding till now
I was thinking earlier about finding a relation between each of these parameters but i couldn't find any (& that surely was intended), so i went with purely random values to see how it works
you should find 0 relationship between X_train and Y_train if they're totally random
so the loss should be approximately the same as randomly guessing Y_train values
im not sure there is any benefit in doing this
however if you can randomly generate X and Y that have some known relationship, you should be able to compare the function learned by the machine to see if the machine is able to learn a relationship
I don't see what i can do then
well there is no explicit relationship
as mentioned before
(though there are obvious relationships between wavelength & colors)
right, but the point is that you want to see if your model can find any relationship right?
so try making up a few possible relationships to see how well the model does
use that to debug your code and your cross validation pipeline etc
also like i said, you will definitely want to add regularization to the model
i think also you're conflating two needs: 1) "make sure the model works", and 2) "evaluate the model on out-of-sample data"
for the former, use simulated data. for the latter, use a train/test split or cross-validation.
hello! new-ish to pandas and wrecking my brain over this one... any help would be greatly appreciated
import pandas as pd
prices = pd.DataFrame({
'slot': ['1', '2', '3'],
'price': [10.0, 20.0, 30.0],
})
balances = pd.DataFrame({
'slot': ['1', '2', '3'],
'val_a': [2, 3, 4],
'val_b': [3, 1, 6],
})
incomes_eth = balances.set_index('slot').diff().reset_index()
# Doesn't work
# prices['price'] * incomes_eth
# Works but is hard-coded
print(prices['price'] * incomes_eth['val_a'])
print(prices['price'] * incomes_eth['val_b'])
also, please butcher my code - i'm trying to learn
Income_eth becomes a dataframe no? I'm not sure you can operate Dataframe X Dataframe
you can do DF * Series because its ndim * a single column / row
why not merge both dataframes before operating?
you can concat on columns and create a single df
First off, thanks for responding! 🙂
I mean, the end goal is to have a dataframe saying the income in USD for a validator at a given slot. e.g
incomes_eth = pd.DataFrame({
'slot': ['1', '2', '3'],
'val_a': [NaN, 20.0, 30.0],
'val_b': [NaN, -40.0, 150.0],
})
Would merging the dataframes help with that?
lambda???
So I'm assuming this isn't a super common operation? I wonder if I'm going about this wrong
a lambda might do, but it wouldnt be my first choice
so with lambda you can make operations that will be done in every row
I'd rpefer to merge dataframes and operate as vectors. A lambda might do it iteratively
BUT if this is some kind of script and its memory constrained or permission restricted, i guess he could do a lambda
tbh id prefer a function
i am not good with the ins and outs of libraries so i like to stick to basic logic kkkkkk
like this
hey warden are you good with tensorflow agents???
def func(df1, df2):
extract relevant columns here
operate
reform in desired format
and specs
ive never used tensorflow
This is meant to run on a larger-ish dataset... So definitely not a one-off small dataset.
So I figure staying with pandas best practices would be best?
you have no idea how luck you are
there's probably a lot of ways to do what you want
merging dataframes might not be good idea
print(prices['price'] * incomes_eth['val_a'])
print(prices['price'] * incomes_eth['val_b'])
what is the problem with that though?
it's not "hard" coded from what i see?
or do incomes_eth columns vary in number?
have you tried to create a 3 dataset and make it row by row??
Exactly... On actual data the columns are expected to vary depending on certain inputs.
then you can loop through the columns list
Just curious if there's an elegant one-liner or do I need to build it in a for loop.
Wouldn't that be less performant though?
for column in list(df.column):
df1 * df2[column]
I mean that's exactly what you want
you're not doing a matrix operation
Right, but lets say I have 10k columns, wouldn't it be better to let pandas handle all that iteration of parallelism or whatever internally?
pandas would only do the df1 * df2[column]
it would be around the same milisecond time diference
i belive
I dont think pandas has a ethod for that
its the same operation you're trying to do
and tbh 10k vector operations dount sound too largfe
It does if you're trying to do them fast 🙂
But you're right - this does work
import pandas as pd
prices = pd.DataFrame({
'slot': ['1', '2', '3'],
'price': [10.0, 20.0, 30.0],
})
balances = pd.DataFrame({
'slot': ['1', '2', '3'],
'val_a': [2, 3, 4],
'val_b': [3, 1, 6],
})
incomes_eth = balances.set_index('slot').diff().reset_index()
incomes_usd = pd.DataFrame({
'slot': incomes_eth['slot']
})
for c in incomes_eth.drop(columns=['slot']).columns:
incomes_usd[c] = prices['price'] * incomes_eth[c]
incomes_usd
thanks for the tip, that's probably fine for now...
if i were you id do the loop
Like the above?
and research more. persnoally ive never encountered that situation
Just to confirm, the above snippet is the solution you were suggesting, right?
Honestly, I come from Go and people complain about that being hard but Panda's been kicking my butt these last few hours 😄
I'd very impressed if you figured pandas out in a cuouple of hours lol
Hehe I will stick around so that you can witness the years it takes me 😄
also, looks like this'll do the trick as well (thx @willow quarry for the lambda tip)
incomes_eth.apply(lambda x: x if x.name == 'slot' else prices['price'] * x)
you can test which solution is faster
to me it looks like it would be the same either way
hi i've created a DCGAN, and the generator loss is gradually increasing throughout each iteration, any ideas what could cause this..? any help would be greatly appreciated, thanks.
and in that case readability is better
has anyone encountered the issues that a softmax layer outputs totally wrong values? TF Version 2.4.1
i am here to help
and also to make questions and talk about
so i just encountered a complicated situation
and i have no idea how to do about it
with tensorflow to make Reinforcement Learning wee have steps to folow
1 make an enviroment
2 get enviroment specs
3 create actor (neural network)
4 create agent (manager to the neural)
5 make data with polices
6 train agent
ok
but my model starts with an image on screen
so the logic is to go with convolutional network
if i use conv with int32 dtype my agent says
Cannot convert -0.012009611535381534 to EagerTensor of dtype int32
if i use float
cannot compute Conv2D as input #1(zero-based) was expected to be a int32 tensor but is a float tensor [Op:Conv2D]
i would like to try other actors
but i dont know how to set them up
soooooooo
i realized one thing
with that code in the actor
conv_layer_params = [(5, 2, 0)] ,
TypeError: Cannot convert -0.5 to EagerTensor of dtype int32
In call to configurable 'ReinforceAgent' (<class 'tf_agents.agents.reinforce.reinforce_agent.ReinforceAgent'>)
is anyone good at pandas here?
i have the simplest problem but i can't figure it out
for instance, if i have 2 dfs
both have the same columns -> x, y, z
if df1 has rows, NA, NA, 3
and if df2 has rows 3, 3, NA
I wanted my merged df to be 3, 3, 3
is there a way to do this? thanks in advance!
mmm
The first thing that comes to mind is
df1.iloc[:2] = df2.iloc[-1]
Basically, set those rows to be exactly equal as is
obviously this isn't scalable or foulproof
is that NA an np.nan? or string?
uhh it's actually NaN
actually slight change in the desc
so df1 has cols -> x, y, z
df2 has cols -> x, y, a
i want to merge these two dfs but i want them to be one in one row because cols x and y are guaranteed to be the same
so df3 (merged) should have cols x, y, a, z
and if df1 has 1 row and df2 has 1 row, then df3 should have 1 row as well
currently, what is happening when i merge with outer, is i get df3 with the 4 cols but 2 rows
so x, y, z, a
5, 5, NAN, 5
5, 5, 5, NAN
i want it to be 5, 5, 5, 5
def signal(df):
'''
1 = Expansion: Above mean and Positive slope
2 = Downturn: Above mean and Negative slope
3 = Slowdown: Below mean and Negative slope
4 = Recovery: Below mean and Positive slope
'''
slope = df['3MA'] - df['3MA'].shift(1) > 0
if df['Cycle'] >= 0 & (slope >= 0):
return 1
elif df['Cycle']>= 0 & (slope < 0):
return 2
elif df['Cycle'] < 0 & (slope < 0):
return 3
elif df['Cycle'] < 0 & (slope >= 0):
return 4
else:
return np.nan
return signal
i keep on getting a AttributeError: 'numpy.float64' object has no attribute 'shift' and ive tried to lookup how to fix it but they havent been helpful
any idea on wtf i should do
@glad mulch I would print out what df['3MA'] is and see if it's what you expected
it looks like it isn't a dataframe
I would print it out and see

that isn't necessarily the same data
ah that was a good catch. i have a 3m ma and a 12ma so i had some nan values
but it still doesnt work
I would make print df the first line of the function you provided
here is the original df


here is the printed df
in the function
it gets to here and shits the bed
so df['3MA'] is an individual number
it's not a series or a dataframe
looks like it's actually a series
that is, df appears to be a series and not a dataframe

what is the .shift for?
essentially for each date i want to check if the cycle is above 0 and that the difference in the 3ma is positive
I don't think I have enough energy at the moment to think through that but I wish you the best of luck