#data-science-and-ml
1 messages · Page 174 of 1
might u be talking to me?
non-native english speaker just trying to have a conversation haha
sorry if unclear.
I am big fan of doing some RICE scoring
It helps frame problems with a specific goal and can be done as a team
I didn’t know of this, I’ll check it out thanks a lot
And in terms of orgs/groups/teams, I do like giving problems with KPI, so it's about converging towards solving a problem that is crisp to everyone
It's as important to know what to work on as it is important to know what to not work on. It avoids a lot of issues with respect to engineers being annoyed or wondering about why we ain't working on that shiny thing
We rarely formulate this stuff because most people on my team have great “instinct”
Sure and that's great! But I find that having great instinct going in the same direction has its benefits
Yup, it’s not an excuse
Lastly, when it comes to data and Python one thing I notice a lot is that classic DS/DA profiles are highly specialised to the point where it becomes annoying
can you please elaborate?
Sometimes the solution isn’t building a new data thing or model but just rethinking the business process and maybe putting a small app in the middle
Most of the people that use Python in my company are fully siloed to pandas, spark stuff
Well as DAs you should have a say in those processes/apps or additions that would solve that problem

Hi
I am trying to train a model with tensorflow/keras and get this error:
UserWarning: Your input ran out of data; interrupting training. Make sure that your dataset or generator can generate at least
steps_per_epoch * epochsbatches. You may need to use the.repeat()function when building your dataset.
self._interrupted_warning()
2025-09-20 22:35:46.493184: I tensorflow/core/framework/local_rendezvous.cc:407] Local rendezvous is aborting with status: OUT_OF_RANGE: End of sequence
[[{{node IteratorGetNext}}]]
[[StatefulPartitionedCall/ArgMax/_6]]
2025-09-20 22:35:46.493207: I tensorflow/core/framework/local_rendezvous.cc:426] Local rendezvous recv item cancelled. Key hash: 1198440015494271145
I preprocessed my training data and saved it to .npz files. When I try to just loop infinitely over the .npz files, training never advances from "1/15 epochs". How do I resolve this? What am I missing and how do I trouble shoot it?
I'm fitting the model like this:
def train(
model: keras.models.Model,
training_data: Iterable[tuple[np.ndarray, np.ndarray]],
steps_count: int,
validation_data: Iterable[tuple[np.ndarray, np.ndarray]],
batch_size: int,
output_directory: Path,
) -> keras.Model:
typer.echo("Training model")
model.compile(
loss="categorical_crossentropy", optimizer="sgd", metrics=["accuracy"]
)
model.fit(
batches(training_data, batch_size),
validation_data=batches(validation_data, batch_size),
epochs=15,
steps_per_epoch=steps_count,
verbose=2,
callbacks=[BackupAndRestore(output_directory, delete_checkpoint=False)],
)
return model
My code is here: https://github.com/codeguru42/gobot/blob/steps_count/src/train.py
GitHub
AI for playing Go. Contribute to codeguru42/gobot development by creating an account on GitHub.
Hey a rookie question but is there a way I can see how cnn is extracting features from an image
Because it's not able to capture patterns on my dataset but it memorize a sample when I train it on same like 2-10 sample for 500 epochs but when I train on like 12000 samples it's not able to capture patterns
Your CNN might not be complex enough
Or your hyper parameterd are badly tuned
Do you have a plot epoch x error or epoch x loss ?
That you would have furing training
Hi there! I want to share a GitHub project about artificial intelligence: https://github.com/Julien-Livet/ai. I am currently thinking about natural language learning step by step, after composing numbers, expressions and dealing relationships with Python standard types (bool, int, float, numpy.ndarray, Sympy and OpenCV functions). I am open to any constructive feedback about my work 🙂 .
Hi
sup guys
no, none of us have seen your script or know what it's supposed to do or what the current results are. you have to say all of that for us to be able to help you.
I know I just wanted to see who would respond first
Click here to see this code in our pastebin.
please never do that. always give all the information people would need to start helping you right away.
yes. you also have to say what the current results are.
I'm actually heading out, but hopefully someone will take a look.
Alr
The current resutls are... amazing
I got a 300% return within a 3 month period on BTCUSD
simulated on previous data
but its the same thing as it would do if it were live other than latency
that could be an issue but the model is pretrained
This only wastes time. Just ask your question.
I DID
are you listening???
https://paste.pythondiscord.com/KELBSCU7W4S2PQIUXO4IIXZLRE
I NEED FEEDBACK
that's not a question
Can you please give me feedback?
Can you be more specific? Maybe take some time to explain the purpose of your code. Then describe what the current results are. Is there any problems with the code that you need help with? Or are you just looking for a general code review?
Can you say what the PDF says? PDFs aren't safe to share.
I added a test with the Syracuse suite 🙂 . Here is the associated graph. Enjoy!

Hi, I’m Francis 👋
Aspiring Data Engineer learning Python & SQL, currently building my first projects.
Excited to learn & connect 🚀
Hello Francis, I am Ivan. 🙂
I am open to contact too
what is manim used for ?
math animations
it's written and used by the 3blue1brown YouTube channel
hi i am sparkling
i am exited to connect with you guys.🙂
ok tanks
hello there, sparkling!
sup
heeeeeeeeeey guys
yo im gay
This channel is for talking about data science and AI. You're welcome to participate, but don't just say "hi" or anything like that. Say something about the topic that can contribute to meaningful@warm flame @crude escarp @marsh iron @hot otter conversation. @mystic heron
do we know of any Time-Series adjusted Random Forests or Neural Networks?
What's your actual question?
i need to estimate some nuisance functions in the DML framework, but i need time series adjusted methods
hello i'm sheiza,nice to see you guys
Hello! Please read this: #data-science-and-ml message
hello sheiza
Please stop just writing greetings without saying anything about data science or AI. These messages will be treated as intentional spam!
in pandas, how do you set a negative number to NaN
usually you'd just use numpy for that, np.where(series < 0, np.nan, series)
(series being a pandas series)
series[series < 0] = float('nan') also works but I'd recommend against using in-place operations if you can avoid it
Cheers
You can use .where in pandas https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.where.html
hey guys please let me out from this error

I'm trying to get jupyter notebooks to work in Pycharm, I've run the pip install notebook command, but I can't find the way to create a jupyter project the way the website shows it.
https://www.jetbrains.com/help/pycharm/editing-jupyter-notebook-files.html
I don't even see the sidebard on the right in the first image shown.

PyCharm Help
hello, please always show the code and the whole entire error message as text. it's difficult to read all this, and some of the error message is cut off.
!code
what's the specific issue that you'r ehaving?
I cannot confirm that jupyter is working as intended, and if it is how to work with it in pycharm.
can you show a screenshot of what you're currently seeing in pycharm?
are you still there, @latent heath?
I am, sorry.
I was walking, I need a moment to get set up.
That's the new project screen, and the options for enviroments I have.

the tutorial is using Conda, which you do have in the list?
any of them should work though, it's just that conda contains binaries for some annoying to build packages
I normally just use the first. I'm in an ai course and the prof has given us a .ipynb to work with, so I'm just going through setting it up.
oh you meant the templates?
I don't recommend using conda, unless you know that you have a dependency that requires it (this is getting increasingly rare) or your professor says you must do it.
Conda isn't required, but the rest of the instruction is on that file.
what do you mean "that file"?
does it shows anything if you just try to open the jupyter notebook in it?
The .ipynb file he's given us to work on.
just clicking "Create" with this menu as-is should be sufficient.
Welp. When I tried to at the start, it gave me some apps to try, but I was still under the impression at the time that jupyter was an app and not a package, so I haven't retried it since correcting that idea and installing it.
I remembered having jupyter lab. Now that I have a new laptop, I just have Visual Studio Code.
jupyter is a python package that can be used to run the jupyter notebook browser app, which is a way of editing jupyter notebooks.
I remembered taking a class based on Jupyter Lab. If I one day decide to complete the course, I suppose I could perhaps do so. Afterwards, given that I had experience in cv2, I could then apply for a job with that udemy certificate
And it does just open as it should. Welp. One of the dumber mistakes I've made. It says community edition only supports read only, but I should just be able to do it in any browser?
if your only credential is a udemy certificate, you will not be able to out-compete degree holders.
I thought udemy certificates plus experience I gain from that Computer Vision certificate program could guarantee a job
if you have a python environment with jupyter installed, doing python -m jupyter notebook in a terminal will start the juptyer notebook browser app
Like I believe it isn't just the certificate itself that guarantees the job, but also the knowledge I gained/retained while working toward that certificate
Neat. Thanks. Now hopefully this is straightforward enough.
No, if there's a job listing for an AI/ML job, and more people with relevant degrees apply to that position than they can interview (which will happen), they won't bother interviewing anyone who doesn't.
yes. this won't stop being the case in the forseeable future.
a masters is usually required for these positions.
Well, if I were to get a masters, I must not have a social life if possible
Well, I should try not to socialize with anyone outside of my career interest
uh, what?
Why's that? I'm only in my undergrad rn, but I'm considering a masters in some area of discrete math, but generally wouldn't it be better to have collegues with varied backgrounds?
So people with different career interests?
I mean, if you're doing data science and ml, who are you doing it for? Like somewhere along the way you're gonna encounter people in different fields and have to work with them.
I see
Also, just make friends with cool people? I can't speak on the purely utilitarian aspect of how you pick your friends, but I don't see a reason to just aim for people who want the exact same career as you. You'll find those anyway.
I see. So social skills are important?
Correct.
If you want it for utilitarian purposes, modern science and professions are rarely solo or signle discipline endevours. You are a social being. Be social.
I will try
👍
there's more to life than your career. it's a good thing to have varied interests and to have friends who share those interests
So I shouldn't try and graduate as fast as possible?
this is a non sequitur.
Like, should I take my time in getting the degree I need for my career?
what country is this? in the US, a bachelors degree usually takes four years. so do it in four.
Alright. Once I get the finances needed for my degree, I will go the four years
what country are you in?
The US.
so it's pretty much impossible to pay for a degree up-front. when you say "get the finances you need", what are you talking about?
I mean, I'm not. Between work and not being able to confirm that there won't be scheduling conflicts, I dropped my course load and have seen my grades go up for it. Something to think about if you want a masters.
This is a good point. I lived with my parents for the first 3 years of my degree, and only paying tuition and textbooks I'm still over 24k.
has anyone got access to WRDS CRSP data via an institution subscription and would be willing to share the AAPL series?
I've been trying to reproduce the "Tidy Finance with Python" beta calculations, and my attempts are close but not quite the same.
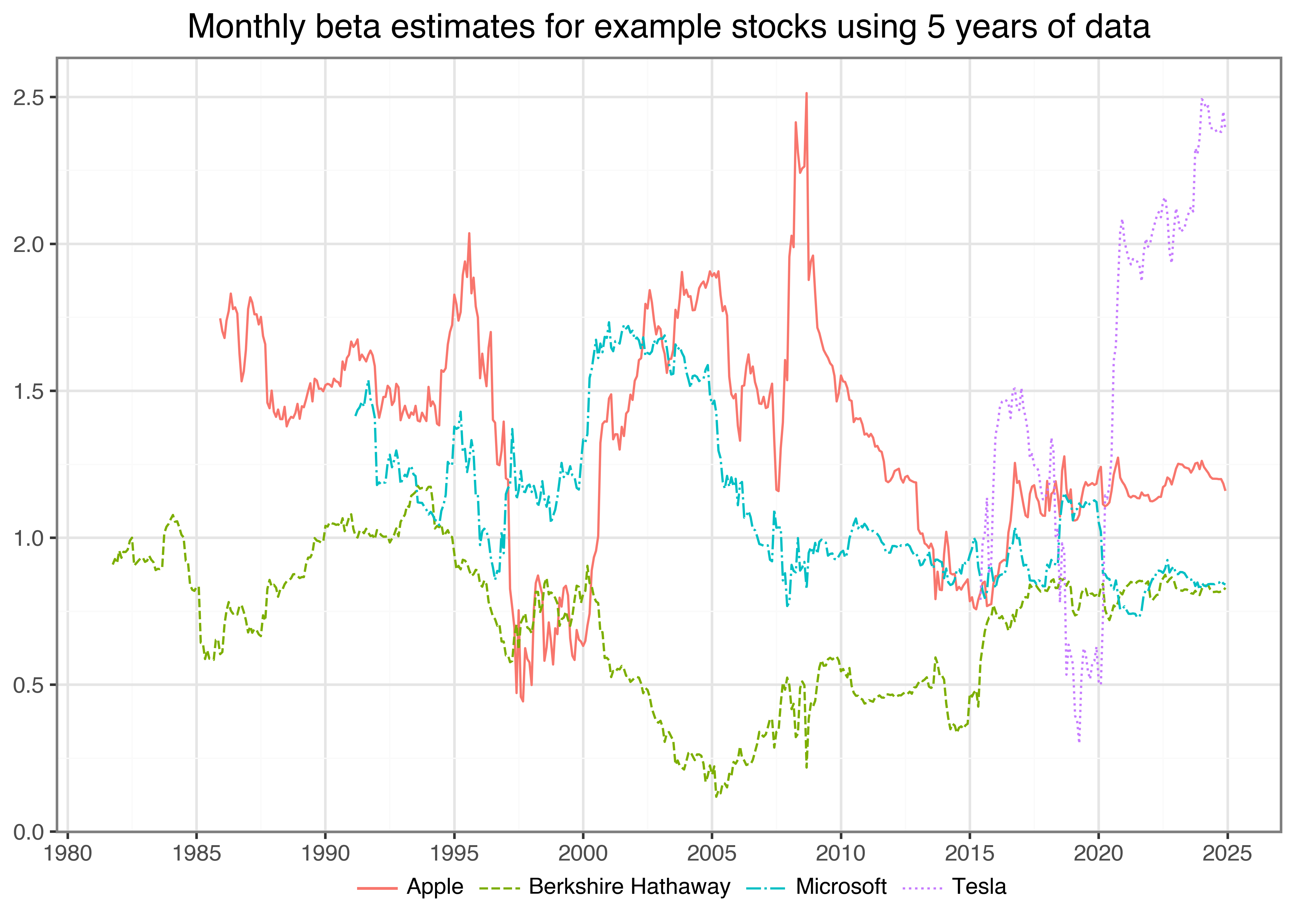
Tidy Finance
An opinionated approach on empirical research in financial economics
My colab notebook is here: https://colab.research.google.com/drive/1UIIBMfx-BHro_MAX2ZwZ7tA1Zd4EZNbG?usp=sharing
with yf data i get Intercept 0.009941 and beta 1.376236 , however the article is quoting Intercept 0.010093 and beta 1.387103 , which is very close but not quite. I am interested to know whether CRSP is doing something additional when making adjustments to prices, or whether I missed something

I'd like to compare the outpuit of this:
crsp_monthly_query = (
"SELECT msf.permno, date_trunc('month', msf.mthcaldt)::date AS date, "
"msf.mthret AS ret, msf.shrout, msf.mthprc AS altprc, "
"ssih.primaryexch, ssih.siccd "
"FROM crsp.msf_v2 AS msf "
"INNER JOIN crsp.stksecurityinfohist AS ssih "
"ON msf.permno = ssih.permno AND "
"ssih.secinfostartdt <= msf.mthcaldt AND "
"msf.mthcaldt <= ssih.secinfoenddt "
f"WHERE msf.mthcaldt BETWEEN '{start_date}' AND '{end_date}' "
"AND ssih.sharetype = 'NS' "
"AND ssih.securitytype = 'EQTY' "
"AND ssih.securitysubtype = 'COM' "
"AND ssih.usincflg = 'Y' "
"AND ssih.issuertype in ('ACOR', 'CORP') "
"AND ssih.primaryexch in ('N', 'A', 'Q') "
"AND ssih.conditionaltype in ('RW', 'NW') "
"AND ssih.tradingstatusflg = 'A'"
)
to the yahoo data for AAPL, so see where the discrepency arises
How can I train a multi-model?
What going take catastrophic forgetting even if it has a large data set?
I am trying to build a movie recommendation system, and i don't have much knowledge about RecSys apart from the basics of SVD and came across criticker , it looks like a good interface and close to what i want to do, are there any specific resources that will come in handy or any tips to start with the project will be highly appreciated..
Hey folks, is anybody willing to do a neutral evalution of a Data Science B.S. degree program I am looking at? I have some personal biases here that I would like to calibrate out.
If so: https://datascience.fsu.edu/students/combined-pathways
Specifically, what you get when you click on BS in Computer Science (BS-CS to MS-IDS)
The program director is an old friend of mine, and I can't really expect myself to not have some rose tint when I review his choices etc.
The base-level Comp. Sci. B.S. flow this uses is here: https://www.cs.fsu.edu/files/Course_Flowcharts_2024/2020_CS_BS_Updated_2024.pdf
Has anyone looked at my work on GitHub? I'd love to hear some feedback on it 🙂 .
Im here to learn data science and AI. I'm a biomedical engineering student
(re: the above, feel free to @ me if you end up taking a look, many thanks.)
Computer Security Fundamentals for Data Science sounds a bit weird?.. shouldn't that be part of the "base-level Comp. Sci. B.S."?
You’re right, that is weird. Conway’s Law suggests that means there is some org chart weirdness
I'm working on a project where I integrate all the standard stuff I think should be in any Pytorch project: MLFlow, Optuna, seperation between settings and logic using config files, cross validation, and making the core training script as generic as possible while supporting multiple model repo's like huggingface,ollama,monai. Are there any other projects that attempt writing a similar unified "template" code?
Hello I want to start to do Machine learning and AI can anyone tell me how i do it im kinda a begginer in python
Me too , I'm a begginer
Nice
beginner* 🙂
Hi, in my opinion start with learning python basis, (loops arrays and functions)
After that move to the analasis (EDA and data engineer)- master pandas and seaborn.
After you finish that you can move to machine learning and start learn the basic models (such as knn and lenear regression) and use them for your data with sklearn
focus on strong python bases, then array manipulation, linear algebra and statistics, with numpy and pandas
i need to learn, alot of my 12th marks depends on it and i hope to make a career in AI engineering which requires atleast basic python knowledge
ok? do you need help with anything ?
i need python teacher
oh why? is there a rule against it?
!res
Resources
The Resources page on our website contains a list of hand-selected learning resources that we regularly recommend to both beginners and experts.
so you think, that i am playing the games?
what ?
i am serious about this python stuff dude.
if you wanna learn, check the resources and ask when you have specific questions
but we don't do teaching/tutoring here
wheres the rule against it
(and if you plan to have someone doing it for free, you'll simply don't find anyone)
it is not against the rules, but nobody has time to teach you personally
you can ask questions and whoever's available may reply, but we are not home tutors
do you think, i am son of jeff bezos?
No one will spend hours for free to teach you
@delicate trench i have a tutor for you... https://www.youtube.com

Enjoy the videos and music you love, upload original content, and share it all with friends, family, and the world on YouTube.
do you think, we have nothing else to do with our time?..
again, you can ask questions here, but we don't do 1:1 tutoring
Why would I spend hours doing it for free when I could be paid by someone to do so
See, it seems you are entitled
You dont speak for 400k people in this server sir
Thats your choice, i respect whatever decision you make
Thats your decision and not mine to make
but dont try to force others
been here for 5 years mate my friend, good luck finding anyone who will help you regularly and reliably for free, you will be much better off research on stack, github, youtube etc.
dude, dont speak for the 400k people here. Dont be entitled. i respect your choice if u dont wanna do it
Yeah really, I never saw someone accept such a thing here, everyone always share the resource page
bc that's how developers learn
you're entitled expecting people to give you their time and effort for free to teach you things you can very easily teach yourself
tbh if you wanna go into dev and Data science, you'll need to learn to use resources
better starting now
Dude like i said. I wont listen to you but I RESPECT your decision
I only listen to parents, God, teachers, and then whoever i want to listen to
ok?
And surely, i wont be paying a money to anyone. So no server rules are being broken
so chill out, and dont play the games with me
With your attitude, I would be very unlucky to have you as a student
because i know my rights and dont bend to your will>?
the ego is insane
It's not about rights and will, it's about people telling you it's gonna happen
<@&831776746206265384> can we perhaps get someone to tone this guys attitude down a bit, fresh addition to the server and already being combative/rude
I mean, we can simply stop talking and wait that hopefully someone come and accept, but you'll better start using the resources we gave you or you'll never learn anything
bc noone is coming to teach
realistically, noone will
i just want to be left alone
Yes, lets do the first one. We can stop talking and hopefully someone come and accept.
Thats the best option
!shh
✅ silenced current channel for 4 minute(s).
I need a few minutes to get caught up
@delicate trench in all my years here, I've never seen anyone commit to an ongoing mentor-student relationship with another user. if someone wants to do that (for free), they absolutely can, but that's so unlikely to happen that the best way to learn and get help is to use self-guided resources and ask specific questions in this server when you have them. there are lots of people here who are excited to answer one-off questions.
✅ unsilenced current channel.
we can now put that to bed
thankyou good sir 🙂
can you please ask the others to stay out of my business tho?
They think they are slick man.
yeah, I said we're done talking about that, so they will.
alright thanks man!
i will use resource, but i still will continue search the master
there is no master

dude i just said chill out lets mind our own business
especially in AI. everyone is running around acting ike they know what they're doing, but everyone is trying to figure out what's going on
!res
Resources
The Resources page on our website contains a list of hand-selected learning resources that we regularly recommend to both beginners and experts.
assalamualaikum guys
I'm learning AI but the problem is machine compatibility can someone share information for it except Cloud Computing Paid virtual machines or any method
What OS do you have
How hard would it be to train a model to convert speech to text?
Not very difficult, considering you could just download one from huggingface.
How much would the cost be to run it locally and is it free for comercial use?
Good question, let me look.
Sorry, I am new to the space and I am asking as a complete beginner
I need to find out if this would make sense for me to do

whisper should not be free for comercial use IIRC
Ohh that's right...
Wait could be free for commercial use
No, it is not.
But this version is! https://huggingface.co/openai/whisper-large-v3-turbo

MIT license!
Nice
And it only has 800M params
However does it make sense to train the model?
I don't want it to think I am saying the wrong words
Probably not.
You could if you wanted, but it would be a lot of work.
Hm..
It does not even have to understand a lot, it is just supposed to convert speech to the correct letters. If it sounds right its already enough for me
That's the hard part. 'Converting speech to the correct letters'
That """just""" is a giant hurdle
it would be fine if he thinks: "apple" is "abble" but not fine if it thinks its "train"
@coral hollow Do you want me to write a script for whisper v3 large for you?
no no
just wondering about the expected accuracy
assuming that the input is clear, fluent and loud enough, it is pretty good (comparable to assistants like Siri or Alexa)
Essentially what I need is whatever google is using to convert spoken words to text, like the small microphone button to talk
which then just converts whatever language is spoken to letters
What do you mean 'letters'?
i wonder how they are doing it
Ok, I've made a small script:
import torch
from transformers import AutoModelForSpeechSeq2Seq, AutoProcessor, pipeline
from datasets import load_dataset
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32
model_id = "openai/whisper-small"
model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_id, dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True
)
model.to(device)
processor = AutoProcessor.from_pretrained(model_id)
pipe = pipeline(
"automatic-speech-recognition",
model=model,
tokenizer=processor.tokenizer,
feature_extractor=processor.feature_extractor,
torch_dtype=torch_dtype,
device=device,
)
result = pipe(["audio_1.mp3"], batch_size=1)
print(result["text"])
Make sure there is a mp3 file labeled 'audio_1.mp3' in the same directory.
It's from the website 😜
You can see I've chosen the small version so it can download faster. It's almost downloaded and I can see how it works.
@coral hollow It looks like it has an accuracy of 'up to 99% in some cases'!
that sounds hard to believe but yea lets see
I'd test it with music in the background, speaking quitly and like somone who dropped out of school
Then we'll see how good it really is
Good idea. Remember to replace whisper-small with whisper-large-v3-turbo
sure
Try talking while eating
At this point its trolling the ai though
I am not at home, so I can't test it myself rn
@jagged jasper did you test it?
@coral hollow I'm having a problem with ffmpeg right now; I'm not on my main computer. You can try it yourself; it's not a big download.
You'll need to get a particular version of ffmpeg, ffmpeg 7 I think.
ok
@coral hollow I've tested it, and it seems really good!
I recorded a few clips with a poor mic and it translated perfectly.
One small mistake I made, you need to make this change to the definition of model:
model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True
)
Anyway, this definitely seems like a good idea for your project.
Window 10
I want to learn RAG I have seen a few tutorials on YouTube but they uses , langchain mostly , is there any resources where they make a RAG FROM scratch, especially Retriever part.
Any good documentation for statistics used in data science
Where can i find MIMIC-III and MIMIC-IV datasets?
Need these datasets for NLP model.
Hey im looking for recommendations on the best LLM for generating ML code, specifically for a computer vision task. My goal is to train a facial expression recognition model that beats an old paper's accuracy by at least 1%.
I'm a novice and initially used DeepSeek Coder R1, which performed well but didn't meet the target accuracy. Are there any other powerful LLMs you guys can suggest? Im currently torn between Claude $20 a month, Expanse Ai or Open router.
Claude write better code try to generate code from Claude use perplexity to refactor according to your requirements.
You have to ask your actual question to get help
My bad bro
hloo
does anyone know a good website where i can download datasets? Im working on a homework where i need to find a real-world data set and create a plot to display it
Kaggle?
i was thinking of that, but my professor recommends not to use kaggle
why?
you can also find a bunch in Hugging Face, https://datasetsearch.research.google.com/, government websites, and random places around the web though
edit; also public data in Google BigQuery though that is a bit of a pain to work with
some examples of government websites where you can find data:
- Brasil: https://dados.gov.br/home
- Europe: https://data.europa.eu/en
- USA: https://data.gov/
I honestly don’t know
Thank youu
overall just remember to check the size, scope and license of any dataset before you download it
you don't want to try to download something larger than your computer's available storage space by mistake,
you probably don't want something that only covers things you are unfamiliar with,
and some datasets require attribution (and while not applicable for this, may also restrict commercial usage and redistribution)
got it, thank you so much
@small wedge so how would i add the weitghts first so i have a better understanding on how they can influence my ants
i know that the weights multiplied do something
that's up to you as the person designing the sim, if you want to do it with a neural network like you're describing then you need to do two things, first is decide how to turn your inputs the ants will get as a vector of numbers, and then decide how you want to interpret the output of the nn, which will also be a vector of numbers
for example one of my projects taught some ai's to aim at a moving target, the numbers they were given as input were the position and velocity of the target, their outputs were the x,y coordinate to aim their shots at
like use the output of the numbers as a sort of way to determine what the program wants to do next based on what happens?
yes
then you score the different ants (assuming you want them all to be agents and do a genetic sim), the best ones survive and cross over then their children mutate a bit
neat part about this is you can kind of avoid all the math of gradient descent etc that you would need in a policy gradient method like deep q learning or ppo
should i store their decisions somewhere in the program so that the ants remember previous decisions so they know how to work next
nah, there are algorithms that do that like q-learning where you score actions and then your agent basically picks the best actions based on their q-scores, but that would be seperate from this
another simple way of doing this that doesn't require a neural network at all is like a string genome, you could represent actions as just plain letters like L for left and R for right, you can run the same process here with choosing the best and crossing over their brains without any sort of actual weights
there are an infinite number of ways to do it really, you could add as many extra things as you want
alright that makes more sense ive made a kind of AI program a while ago that had a memory factor i might try and use it in a differnt way i used it so it can apply to this project
all the program did was store each response or prompt i gave it to a list named memory and it output responses based on what was in its memory
As another beginner i can let you know its a complete pain in the ass
Can anyone recommend me between claude opus and gpt-5 in improving competent ML code
Hello, can someone explain what moving average is, how is it calculated and how it differs from "normal" average pls. I know it's a maths stuff but I don't have that knowledge, would really appreciate if someone can explain.
I did google but all I'm seeing is application of it, like for forecasting etc but they aren't explaining why it's used there, what is it's benefit and why not use just normal average
In real word analysis, what can moving average demonstrate to us that normal average can't pls
Also, if we need to plot the moving average on a graph, this average is for multiple years, so which year do we choose? I read that's it's the middle year which is chosen, would really appreciate if someone can explain why
An average is great at representing data where the distribution doesn't change over time... but, how many things in the real world are stable?
But, take global warming, for instance. Is the average temperature of the earth over past 1000 years useful?
You could chop the period into fixed intervals chunks, and compute 100 year averages, sure
That would produce a discontinuous graph, almost appearing like the average jumps around every 100 years
A rolling average would produce a more intuitive view of the changing temperature: showing how the average is changing over time
If you're plotting rolling average, you'd plot it for each year, with the average over that year and the preceding N values
There's also ways to 'weight' the more recent averages higher, so a weighted average but one where the older events are given less significance (Google 'EWMA')
yepp, I see, question though, when we plot the graph of moving average, since we are using multiple years, how do we choose which year correspond to the computed average?
I mean, we just take the middle year?
No, the moving average is for (as of) the last date.
For example, a 3 day moving average for past three days would be wed-fri for Friday, thur to sat for sat, and fri-sun for Sunday
how do you mask out noise before calculating the silhouette score for DBSCAN?
I don't know about your professor but I've noticed Kaggle has had more and more low-quality synthetic datasets that don't make for good analysis projects recently
some of them disclose they're synthetic, but a lot of them don't, and you won't really know anything is wrong until you try to do anything useful with the data
also I didn't see anyone post the UCI Machine Learning Repository, it's a little older but I think they do more vetting of the datasets https://archive.ics.uci.edu/
Discover datasets around the world!

did you open that course to check its description before asking?
It has that on the linked page

and yes, I'd also recommend that course
I built Data-Cent because I often need to explore CSVs quickly without firing up pandas or writing custom code. It’s a Streamlit-based web app where you can: • Upload CSV files (no setup) • Auto-filter and explore the data • Create interactive charts (line, bar, scatter, etc.) • Run quick stats (mean, median, std) • Download a PDF/HTML report of your analysis
Live demo: https://data-cent.streamlit.app/ Source: https://github.com/data-centt/Data-Analytics
Would love feedback on performance and UI/UX — especially from folks who explore data often or build Streamlit apps.
If you find it interesting please help me star the repo. TY


GitHub
Contribute to data-centt/Data-Analytics development by creating an account on GitHub.
it just means you always calculate average of x time periods (e.g. 5 minutes) while you always get new points
Normal average is a calculation which is not getting updated
why did no one tell me how hard ML actually is i thought i could do this without other libraries like pytorch or numpy
im starting to get it now but what was i thinking last night where i could make a machine learning project by myself
also using cursor code editor
ML jobs pay well precisely because they're difficult to train for
You can, but you need to be pretty comfortable with programming new ideas from scratch in general to do that. And that is a skill most acquire over a decade or so.
That is in addition to the mathematical knowledge needed and then specific ML knowledge.
Cursor can't do that for you, it will only accelerate you if you already know what you are doing (almost all time is spent debugging, and you can't do that without understanding it all).
yeah, i hope they do because so far most of my time has been spent making prototypes simulations without RL/ML not to mention the notetaking and document reading but i'm slowly understanding this more because the formulas are surprisingly easy to read
the hard part so far which is what i didnt expect to be hard is make the program make decisions on its own first before adding the machine learning aspect to it but other than that im making decently good progress in numpy its just a matter of can i understand pytorch libraries and documents
my first project is training a ant colony to maintain a good healthy state over time by making good decisions
let me know how that goes
i'll let you know how it goes by the end of the week because i still have to go to school unfortunately
i just asked Claude Opus to generate ML code and bro costed $2.5 for the single prompt
how many tokens were the input and the output?
500 input and around 6000 output
Anyone knows a way to make f strings format as normal string in newer versions of jupyterlab?
I don't like that colour

!e unless you meant R$2.5 or some other currency that sounds off```py
from decimal import Decimal
input_cost = Decimal("15") / Decimal("1_000_000") # USD per Million tokens
output_cost = Decimal("75") / Decimal("1_000_000") # USD per Million tokens
cost = 500 * input_cost + 6000 * output_cost
print(cost)
:white_check_mark: Your 3.13 eval job has completed with return code 0.
0.457500
but yeah Claude is ridiculously expensive
you should be able to change the Theme under Settings, not sure if you can change that in specific or if you would need to create a new theme and modify it though
Hi
Could I ask for some input, please?
How could one develop a AI tool that shows me gaps or trends, for example with cooking recipes. Let's assume there are databases with public API and no API (this would mean webscaping)
Now I would like to aggregate data in a structured way, I could query the data bases (or maybe later web scraping).
But then what is next? Maybe I want to find a trend in pasta recipes, are currently ingredients more popular then others ?
My question is if I have the data , I would need first to develop rules when something is popular, missing, trending? Am I right?
you'd need of some structured way of determining what each recipe covers, then you can create some simple models to identify what "normal" looks like for each ingredient and look for outliers (values significantly above or under the normal)
Hi etrotta, thank you for the reply. For example, cooking utentils,number of ingredients, preparation time, type of ingredients maybe ?
When I thought about it, I arrived to the conclusion that I would to structure my data.
My introductions to ML showed me often the IRIS dataset, several properties, and finally a label for y. Based on those properties it was possible to sort the petals.
But with the recipes, the story is different? I don't have this "y" parameter.
there are a lot of different 'tasks', I'd guess that most of what you have seen falls under supervised learning like regression and classification, but there are also a lot of techniques for unsupervised learning, in which you don't have clear labels
take a look at https://scikit-learn.org/stable/unsupervised_learning.html - specially https://scikit-learn.org/stable/modules/outlier_detection.html
scikit-learn
Gaussian mixture models- Gaussian Mixture, Variational Bayesian Gaussian Mixture., Manifold learning- Introduction, Isomap, Locally Linear Embedding, Modified Locally Linear Embedding, Hessian Eige...
scikit-learn
Many applications require being able to decide whether a new observation belongs to the same distribution as existing observations (it is an inlier), or should be considered as different (it is an ...
a clause is a database query that is a command to get something out of a database?
is brocode's pandas 1h video solid?
Guys i got a question, i'm currently 15 and interested in ML. I know the math behind ML algos, Neural Networks and more. And working on personal projects. And i'm using Python for that, but got a question. On university, are they only going to teach math behind this? Or also teach libraries like Pytorch? Also if i'm graduated from university, is it easy to find a job in this field?
It depends what courses you follow, but you will probably learn how to use the libraries too
Any decent DL course will explain how to use pytorch or tensorflow
also bc practicing things is part of the learning process
I'm doing this like 2 years
Wanted to start 4 years ago but my math couldn't handle it.
For the job, it's hard to answer, as it's hard to predict what the job market will be once you graduate
in like, 6-7 years....
Today I would not call it easy, because you need to have good grades and show a strong interest, but the job market is (for now) quite open in this field, at least it's what I feel, where I live. That will depend on where you live too
I'm interested in math and programming but the university exam in my country is a bit hard. I can speak english like a usual person does. Also thinking to go abroad. (Sorry if took a bit long to write)
I you think you can't pass the exams in your country, idk what to suggest. Believe in yourself, if you are interested enough, and know how to study right, you'll get it !
If it doesn't work for you, studying abroad is also a great opportunity
there is a lot of pros and cons for all decisions, at the end it's for you to make them
If the exams are hard and you succeed where most people fail, you won't have any issue finding a job
I'd strongly recommend reading the official User Guide above anything else
is brocode's pandas 1h video solid?
seems mid
see https://pandas.pydata.org/docs/user_guide/index.html instead
Hello, can someone explain how image processing works in general pls.
I need to answer these questions using pullow in python:
b. Swap Red and Blue → how does the image change?
c. Extract the Green channel and compute its average value.
d. Convert image to grayscale by averaging R, G, B.
e. Image cropping – cut out the center 100×100 region.
f. Blurring – apply Gaussian blur.
But I first wanted to understand the theoretical aspect of how images are processed. I know that images are sequences of bits and are made up using multi-dimensional matrix/vectors.
I know we need to use libraries like numpy so that we can upload the image to be processed.
First question, when we upload the image into that array, do we have pixels to work with?
I know images are made of 3 colors, RGB, how do they work?
Like if I need to swap red with blue, what's the idea behind that, convey all bits holding blue into red?
The colors have an average value, what does that mean pls
First question, when we upload the image into that array, do we have pixels to work with?
Basically yes, you get either a 2D (mapped/palettized values or grayscale) or a 3D (RGB(A) values) array where the innermost dimension typically represents a particular pixel's color
I know images are made of 3 colors, RGB, how do they work?
You can think of them as color components, you have a bit of red, a bit of green, a bit of blue and when you mix them together you get a new color (and the value of a component tells you how much it contributes to the resulting color)
Like if I need to swap red with blue, what's the idea behind that, convey all bits holding blue into red?
with swapping you'd essentially write the original value of the red pixels to the blue pixels and then write the original value of the blue pixels to the red pixels, as in, overwrite those values with the original values of the color you're swapping with
if you work with an array interface, you'd essentially just extract all values of a particular color channel and then inject them into the other color channel, though there might be a method with pillow that already abstracts this away from you
The colors have an average value, what does that mean pls
In the context of grayscale, you take any single pixel and calculate the average value of its 3 components (RGB), just an arithmetic mean, for example if the pixel's value is [128, 64, 120], you get (128 + 64 + 120) / 3 = 104, so you just replace the pixel's value with [104, 104, 104]
in the context of blurring, you take the average of each color channel for all pixels in a certain area around your center pixel and then replace all of those pixels' color channel values with that single average for that channel (and this is a weighted average in the case of something like a gaussian blur)
Could be
Enough to get the ball rolling
There's Udemy courses for more in-depth
Or more on youtube
what do u think he's missing?
ty
There's more in pandas than this

And just watching a couple of minutes of these won't help u know about all the other cool functions that exist in pandas
What is the common practice for pushing data-manipulation jupyter notebooks to github? Do you just push it as is or do you convert it to a python script first ? I have had some weird problems when pulling an .ipynb from a github repo.
just push them as is
what kind of problem are you getting when pulling one?
Sometimes im having issues with the cells loading. Some take very long to appear properly. Tried this with multiple IDEs.
how complex is it? will the cells load if its something as simple as print("hello world")?
I'm basically working with local datasets via pandas an NumPy. Also in the github repository the cell-outputs are cleaned so it does not automatically load the outputs when i pull the notebook.
What is in the cell? 'Long to appear properly' could be any number of things.
im loading a dataset from a json file, normalizing it, and building a relational scheme. In another Cell im using the featuretools library to extract custom features via dfs from my relational data scheme. With "long to appear properly" i mean in VSCode for example the notebook is completely blank after pulling from the repo and the cells only appear one by one very slowly. Simmilarily to when youre loading a web page with a really bad internet connection. That's why i was wondering if it's even common practice to push jupyter notebooks to github instead of converting it to a python script, which fixes all these issues with a loss of control ofc.
it varies, some projects rather keep the outputs such that users can preview it without running anything, others just clear the outputs, others always convert to Python
some alternatives to Jupyter (namely marimo) use .py files with slightly custom syntax (e.g. decorators or comments) instead of json-based files
For me, I 'strip' notebooks before committing them to GitHub. My repo is just the notebook code, because I can regenerate what I need fairly cheaply. Anything 'expensive' gets saved separately, ie: to a parquet file or a model file
I use a precommit to do this, so I don't forget
yeah in my case the usage of this is more like a script. Im modifying a json file, building a new dataframe with more complex features and then saving the "clean" data to a parquet file. The actual use-case for it would be to just run it once on a raw-data-lake to convert it into a clean dataset. The notebook format is more like a debugging thing to inspect dataframes etc.. so i guess im going to convert this into a python script for the final version of my project.
I'd just be curious what step is slow though, it could be that it's loading js assets for rendering/etc. Are you opening it in Jupyter directly or via vscode? I usually open my notebooks in vscode
I open it in vscode
I couldn't find 1 GPU of H100/A100 on AWS, only the 8 GPUs of it so does anyone know an alternative I could use?
how much VRAM do you need?
what about kaggle's course on pandas?
or what about this? https://github.com/Asabeneh/30-Days-Of-Python/blob/master/25_Day_Pandas/25_pandas.md
GitHub
30 days of Python programming challenge is a step-by-step guide to learn the Python programming language in 30 days. This challenge may take more than100 days, follow your own pace. These videos m...
yepp I see, thanks for the explanation !
One thing, how does "blurring" occurs? I mean when we see a blurred picture, under the hood, we have multiple "center pixels" and the neighbouring pixels intnesities / values are decreased?
also one thing :c, this is more of a general question, why would we represent images using multidimensional arrays, like 2D arrays? What flexibility does it gives us? Is it because of the row x col structure? (if so, what is special with that)?
Hey everyone, I need some help with running an older ML project called ECINN (Electrochemical-Inspired Neural Network).
I’ve been trying to run the example code (main.py) for Fe ion detection, but I keep running into compatibility issues with TensorFlow, Keras, and Python versions.
Here’s what I’ve tried so far:
-
Environment: WinPython 3.12.4.1
-
TensorFlow version: 2.20.0
-
Keras: the one bundled with TF
-
The codebase was originally written for TensorFlow 2.3.0 (2020 era).
-
On Windows, I keep hitting errors like:
TypeError: unsupported format string passed to list.__format__(fixed manually)ValueError: by_name only supports loading legacy '.h5'- DLL load failures for TensorFlow on WinPython
- Pandas: "Invalid file path or buffer object type: <class 'list'>"
I even tried Colab, but it doesn’t support TF 2.3.0 anymore (only ≥2.16).
Question: What’s the best way to get ECINN running in 2025? Should I:
- Use Docker with an old TF 2.3.0 image?
- Patch the code fully for TF 2.20.0 (new Keras saving/loading API, etc.)?
- Or is there a smarter way to emulate the old environment?
Ultimately, I just want to run the Fe ion example (ECINN-BV for Fe Ion on GCE) and get the trained weights + plots it should output.
Any advice or working setup instructions would be amazing 🙏
Zenodo
Comparisons with brute force finite difference fitting, Tafel region analysis and Randles-Sevcik equation are added.
docker with the original version is probably your best bet as far as compatibility goes
I have tried everything else except that
i will do that and see if it works
if it doesnt ill probably have sit and make the whole thing again
if anybody wants to work on modeling the economy within hypixel skyblock (minecraft), please dm me.
Hi, can someone explain how pre-processing techniques like gaussian blur and grayscale make images reduce "noise" pls
Things like Gaussian blur filter/dampen out large variations (for example neighboring pixels with very different grayscale values
These large variations often relate to noise, but of course some of it is part of the image so it comes out blurry if you use it too aggressively.
High frequency details are lost during blur.
I think you can change that
There's some extension or something I remember in GitHub that make notebooks look cleaner and shows output clearly with diffs too.
yo anyone learned bayesian networks Probabilistic graphical modelling
I am about to do research with my professor about it and i started to learn a bit but i feel like i am not yet comfortable w the math side of it the probability and side of it is just so weird any advice
I hear there is a good course on Coursera about it

Coursera
Offered by Stanford University. Probabilistic Graphical Models. Master a new way of reasoning and learning in complex domains Enroll for free.
yea this is the one i am doing right now
when it comes to the tests i fail it
i feel like it doesn't help much and it just expects us to already be familiar with it
I see 🙁
Good evening fellas
This looks pretty good at first glance https://mmids-textbook.github.io/
hi, quick question, say I loaded a RGB image, I only show the Red channel, when I open the copy of the image, the image is now white/blackish, is there a reason for that pls


well, apparently you just essentially got rid of the other color channels (green, blue), but you should have set them to 0 instead if what you wanted to see was like a very red image
oh ok I see, if I only use the red channel (which I did), why our image becomes kind of grayscale? is there a reason for that pls
well, that's similar to taking the average of all channels to convert it to grayscale(ish), but you only used the value of one of the color channels (red in this case)
like you went from some pixel value like [128, 64, 120] to [128, 128, 128] instead of [128, 0, 0] (or [128, 255, 255])
when I only use r, like consider this:
r,g,b = cat_img.split()
Normaly, we have 3 instance of an image? Each r,g and b would each have 3 channels? Displaying r will show the average intensities across each channel? Like [128,128,128]?
You can check this by comparing the first few pixels of the original with your modified 'red' one. Then it will become clear what happens.
Can someone say how I'd collect column headers from polars? atm I'm using column_list = list(headers_lf.collect_schema().names())
collect_schema is throwing a bunch of warnings at me
show which warnings
it's somewhat discouraged overall as it can be expensive depending on your query though, i.e. if you can avoid it just use expressions/selectors instead
Could I ask you if you heard about SPECTER2? https://huggingface.co/allenai/specter2
To the best of my understanding, this is an encoder for scientific text. Are there maybe better ones out there?
I would like to fine-tune this on a scientific domain.
What I have not yet full understand, I couple this with a LLM like LLama and somehow I can query with this help on my embeddings?
And how would I couple this with scikitlearn functionality, e.g. clustering?

I know, i know this is python based discussioons but is there a server to discuss how ot get into ai? Besides just youtubing it and being a drift on what is right and wrong approach? Tutorial hell. T-T, is that a better place toi ask this? JUST to start bc idk wnywhere to start with it, and I guess learn to use it, no mak stuff i guess..yet.
lots of resources in the pinned messages for this channel, in general things go better here if you come with a specific question about a problem you're having
hi
hi
heeey
I’m still absolute beginner & still learning Python, my dad was like learn ai. Which again broad af. But I did like the concept of data analyst when I picked this up years ago, just dunno how I could use ai to help with that.
no, RGB are the 3 channels
I opted to use readline(), though I have no idea how it compares, I read that it's lazy.
collect_schema may or may not need to load some data and execute parts of the query depending on the query
for example, ```py
import polars as pl
lz = pl.LazyFrame({'x': [1, 2, 3]})
unknown_schema = pl.col('x').map_elements(print)
informed_schema = pl.col('x').map_elements(print, return_dtype=pl.Int64)
No need to run any parts of the query (it can determine without running the query itself)
lz.select(informed_schema).collect_schema()
Schema({'x': Int64})
It needs to run it for a part of the query to know what the final schema will be (unknown return_dtype for map_elements)
lz.select(unknown_schema).collect_schema()
1
1
Schema({'x': Int64})
(not sure why it is printing 1 twice though)My aim was to cast everything to float64 by looping over the headers.
It worked with collect_schema().names() which now that I think about it, worked when inferring the datatypes failed before, so it must not be terribly expensive (vertically)
yeah I see, when I display only the image with channel r, this mean channel g and b have a bunch of 0s? Didn't understand why we have the gray image and not the red though, what is the maths here pls
Chat, I'm fed up of web development it's boring just designing and making it real. Resources that I have learned gives me edge fir machine learning and AI like python ..... So can anyone provide me a roadmap or structured plan on how to become a ML engineer to land a job at MAANG companies????
jobs in AI development require a lot of specialized training for you to be valuable to a company. You would probably need to go back to university to get a masters degree in CS that's focused on AI.
I'm still in uni doing bachelor's but focus is on core cs but yeahh I'm making a lot of projects like Netflix recommendation system and AI chatbots.
Are there some video/course to help with general knowledge how to just get started?
Assuming you want ml
If you're just looking for like the most basic surface level intro
Id recommend the 3 blue 1 brown series on neural networks
I have a project name NCl or can be called: SSC 🙂 I'm working on its parser/lexer:
There was an error uploading your paste.
So I'm at a fork, altair or plotly? Until now I've used mostly matplotlib and I hate it.
Tempted to just flip a coin.
1000 times (naturally)
Hello everyone, im a bs data science student, i just completed a 12 hours python course and learnt basic stuff and also did some basic projects as well. now i just want to ask what should be the next thing to work on for me. related to data science.
Pytorch or TenserFlow?
Pytorch.
Tensorflow is only used in outdated tutorials
Thanks a lot!
I needed that..
if plotly express works with minimum configuration use it
otherwise (if it lacks in performance or customizability) consider altair
i wanna make a AI chatbot with python using torch library
Don't start with a chatbot. Those are so challenging that you'll give up before making any progress
A classifier would be more approachable to start. By orders of magnitude
alright
Is that Florida State?
Yep
I thought the did it with FAU or something.
Hi, can someone suggest where I can get an image data set containing at least six of the following office items pls:
chair, bin, mug, bottle, book, keyboard, mouse, stapler, notebook, phone
There are a lot of overall engineering connections to FAMU, but this is the Math department basically so not here
I graduated from UCF, but does FSU still have the Actuary Department? I just remembered that.
Looks like it! https://www.math.fsu.edu/~paris/actmath.math
Welcome to the Department of Mathematics. Our mission is to preserve, expand, and disseminate mathematical knowledge. Pursue a degree in the fields of Financial, Pure, Applied, Biomathematics, and Data Science.
Never run into it but cool.
I’m aiming to do their “Interdisciplinary Data Science”
!rule 6 | We're not a job board. Your message has been removed.
suggest me things I can improve in this programs
Please react with ✅ to upload your file(s) to our paste bin, which is more accessible for some users.
Hey I have a doubt what's the difference between training model for 200 epochs and training model for 100 epoch and then fine-tuning it with same data for 100epochs
those are equivalent
"fine tuning" is just "more training, possibly for a different task"
Got it
So like optimizer momentum, learning rate schedule will be lost right in case of fine tuning
As we are starting again ?
When compared to going for 200 epochs on one go or saving all this info while saving the best model
In these cases both will be same?
yeah
yeah, I guess so
what I'm getting at is that "fine tuning" isn't a fundamentally different thing from training
Usually you finetune something that has been trained for a different task
Or with different data
This is equivalent, with very little difference if you reinitialize the optimzer and hyperparameters
What would the architecture for a multi model look like?
what do you mean by multi model?
A multiple model that can generate text and object detection
it varies, if by text you mean arbitrary LLM-like text messages, at one extreme you could have a ""normal"" multimodal llm trained to do object detection via tool calling, representing the detection as normal text formatted as JSON
another case could be having a shared base model, then one head that predicts the text and another head that predicts the bounding box for the object
(this second case making more sense for classification with fixed text labels)
Hi Guys.
I built an automated data analysis using Python and its open-source.
Check it out; https://github.com/data-centt/Data-Analytics
Open to contributions
GitHub
Contribute to data-centt/Data-Analytics development by creating an account on GitHub.
Hi, i am new to ML and from non-tech bg. I have a doubt. When working with outliers and resampling , do we work with the entire dataset or just training data
there are probably different opinions about this, but I wouldn't remove outliers from the test set. the outliers are still part of the data and we need to be honest about what consequences that will have.
you can remove outliers from the training data to help the model train more easily.
Got it. Thank you
Im planning to buy ISLR I only know python but should I buy the R or python version?
Some say to buy the R version while you build it in python so you can also pick up R comprehension along the way.
seems like the Python version is more recent so I'd go with it
looks like both are available for free as PDF downloads on the official website though? so you can download both and check before purchasing
Does someone use GitHub Education?
always ask your actual question. what would you ask someone who does?
Do I have to use my university email address to gain access to GitHub Education? Is it only part of the verification step?
Hello, quick question, I saw the word epoch quite frequently when we talk about training, what is that?
a full pass over the training data
usually when you train, you let the model train on each instance in the training set once.
every time you do that, that's an epoch
oh ok, so let's imagine I have 1000 images. I need to train my model to classify those images, let's say between cats and dogs.
1 epoch means "looking" at the dataset only once? ML algorithm try to infer some features during that first pass but this 1 epoch might not be sufficient to deduce all underlying features, so we try to increase the number of epochs?
(But if more epochs means better accuracy, does that mean, it should be as big a possible? )
more epochs just means more training. that doesn't automatically translate to better performance.
are you familiar with loss?
ah ok, loss, loss function? Yeah heard that term, I know we use backpropagation and gradient descent to minimize the loss
ideally, the average loss will decrease over each epoch. but eventually you'll get a diminishing rate of return, at which point additional epochs won't really make a difference.
yeah exactly, at this point, we don't really need to do more training, we assume it's a compromise and that adding more epoch will just increase accuracy by only a very little amount?
it's not a forgone conclusion that a lower loss translates directly to better performance. but in either case, if the loss is decreasing by a very small amount between epochs, that might not make a noticable difference at all.
like, if your test set has 1,000 instances, a loss change of 0.00000001 probably won't influence the model's decision for any of those 1000.
yeah I see
a lower loss translates directly to better performance
like overfitting you mean?
you quoted that in a way where it sounds like I'm saying the opposite of what I said
is this how politicians feel?
anyway, if a model performs poorly despite gradually decreasing loss, that would mean that the model overfit to the training data.
yep I see, thanks !
Hello quick question. Say someone understood the basics of how ML/DL works, like the theoretical concept but now this person needs to apply it. While the later knows the concept, he still needs to implement that through code.
So my question is, what is a correct approach here? How does that person decide which library/framework to use?
Say we pick a library/framework. Now, in order to understand, for e.g, how to implement an RNN in tensorflow, we would expect tensorflow documentation to talk about that?
Always pick pytorch over tensorflow. That part is easy.
You can usually look at code that implements similar architectures and figure it out from there
alright noted, thanks !
by the way is there a reason why pytorch is prefered over tensorflow?
The community has coalesced around pytorch and no one uses tensorflow except the authors of outdated tutorials.
I've never seen a coworker use tensorflow a single time for anything
yep noted, thanks !
Hello, quick question, how do we know that a model we have trained is ready? Like it's not overfitted etc and we can actually use it to do real stuff?
depends on the task, for many you'll want to keep track of some metrics like its accuracy in addition to the loss, then stop training a bit after it stops improving
for some cases it could never become good enough to do 'real stuff' depending on what it is, or you could need to retrain it a few times using different data & hyperparameters configurations
yep I see, question though
when I was doing a project for uni, the teacher said that we should split our data into 80% trainint and 20% testing I think. But I read recently that we have training, validation and testing set
I'm confused, validation and testing set are different things?
with the 3 sets, you split some data that will only be used after your entire project is over - you never evaluate with it until right before you decide whenever or not to put it into production / publish your results
if you 'retrain it a few times using different data & hyperparameters configurations' too much, some configurations may be better on your test data by chance, similarly to over-fitting to the train data
the separation of test & validation data helps to avoid overoptimistic results which then fail in production
I see validation as a way to check on progress, and testing as a way to check outcomes, lemme know if anyone thinks that is crazy.
Maybe it means something different in the data science context.
yeah I see, hmm I will read a bit on hyperparameter tuning and came back, but with the validation data set, this also is unseen, no?
ah it's used indirectly with hyperparameters tuning?
with the test set, we don't do anything with that, no hyperparameters tuning etc?
I didn't specify which is which because I sometimes get confused and swap them 
yeah, you only run the later a single time after it's done training, no more tuning after you get your score on it, ideally no selecting which model to use based on it, just "this is your expected score with real data" after picking the final model
course materials are the training set, past year exams are the validation set, to-be-taken exam is the test set
yep I see, thanks !
https://youtu.be/UYq7KY90i4M?si=-PBWWJRVjjIrsjup
What would the code for this type of simulation look like

The first 500 people to use my link https://skl.sh/cozmouz05251 will receive 20% off their first year of Skillshare! Get started today!
This video is sponsored by Skillshare. Thanks a lot for the support!
2nd Channel: https://www.youtube.com/@cozmouzlabs
Discord: https://disc...
they literally explain it in the video?
Is this an ad?
Has anyone worked with RAG base memory for a llm
Instead of maintaining the last 5-6 queries as conversation history we can use the Rag based approach for memory.
No but I have tried to understand and I'm confused
which part specifically?
The reward function and the agent it's self
what about it?
The very small reward and how does the AI use the joints of the model
Hello, quick question, why are histograms vital in image processing? For example say we are plotting frequency against pixel values, what can we infer?
If say we have different histograms with R,G,B colors, if we draw 3 bell curve on them, we can try to deduce the tendency which pixel is more dominant?
import matplotlib.pyplot as plt
import numpy as np
plt.rcParams['text.usetex'] = True
fig = plt.figure()
ax = fig.add_subplot(projection="3d")
ax.view_init(elev=-21, azim=153, roll=-79.5)
ax.set_box_aspect((1, 1, 1), zoom=0.95)
x, y, z = np.array([[-1,0,0],[0,-1,0],[0,0,-1]])
u, v, w = np.array([[1,0,0],[0,1,0],[0,0,1]])
ax.quiver(x,y,z,u,v,w,arrow_length_ratio=0.1, color="black", length=5)
ax.text(3.9, 0.1, 0, '$x$', size='x-large')
ax.text(0, 3.9, 0.1, '$y$', size='x-large')
ax.text(0, 0.1, 3.9, '$z$', size='x-large')
ax.plot([0, 1], [0, 2], [0, 3], marker='o')
ax.set_axis_off()
plt.savefig('Figure-4.svg', bbox_inches='tight')
plt.show()
Why does my code above produce arrows of different lengths?

That is what ax.quiver produces
Or do you mean the main axes themselves?
It is likely to do with the default projection and rotation
it does seem like the scale of each axes itself changes
even if I comment out my code for setting the default view angle, one of the axes is still noticeably longer than the rest

Hmmm.
Could be the way you are passing parameters to the quiver function
From the docs:
quiver([X, Y], U, V, [C], /, **kwargs)
I think that's for 2d
So for 3D I would guess [X, Y, Z]

The plot thickens
as if it wasn't thick enough already
judging by how the text placements relative to the arrows are correct, I'd say the scale of each axis is what's changing
so in other words, the actual space is warping
🤔

import matplotlib.pyplot as plt
import numpy as np
# plt.rcParams['text.usetex'] = True
fig = plt.figure()
ax = fig.add_subplot(projection="3d")
# ax.view_init(elev=-21, azim=153, roll=-79.5)
ax.set_box_aspect((1, 1, 1), zoom=0.95)
x, y, z = np.array([[-1,0,0],[0,-1,0],[0,0,-1]])
u, v, w = np.array([[1,0,0],[0,1,0],[0,0,1]])
ax.quiver(x,y,z,u,v,w,arrow_length_ratio=0.1, color="black", length=5)
ax.text(3.9, 0.1, 0, '$x$', size='x-large')
ax.text(0, 3.9, 0.1, '$y$', size='x-large')
ax.text(0, 0.1, 3.9, '$z$', size='x-large')
ax.plot([0, 1], [0, 2], [0, 3], marker='o')
ax.set_axis_off()
plt.savefig('Figure-4.svg', bbox_inches='tight')
plt.show()
?

Does the saved figure look different from your shown figure?
the same
import matplotlib.pyplot as plt
import numpy as np
# plt.rcParams['text.usetex'] = True
fig = plt.figure()
ax = fig.add_subplot(projection="3d")
ax.view_init(elev=-21, azim=153, roll=-79.5)
ax.set_box_aspect((1, 1, 1), zoom=0.95)
x, y, z = np.array([[-1,0,0],[0,-1,0],[0,0,-1]])
u, v, w = np.array([[1,0,0],[0,1,0],[0,0,1]])
ax.quiver(x,y,z,u,v,w,arrow_length_ratio=0.1, color="black", length=5)
ax.text(3.9, 0.1, 0, '$x$', size='x-large')
ax.text(0, 3.9, 0.1, '$y$', size='x-large')
ax.text(0, 0.1, 3.9, '$z$', size='x-large')
ax.plot([0, 1], [0, 2], [0, 3], marker='o')
ax.set_axis_off()
# plt.savefig('Figure-4.svg', bbox_inches='tight')
plt.show()
ohhhhh
from that view angle it looks fine
but moving it around you realize the z axis is absurdly longer than the other axes
x axis I mean
That is odd, but I gotta run

{kind=link}
there goes my one ray of hope
time to go back down the google/stack overflow rabbit hole
ax.set_xlim3d(0, 5)
ax.set_ylim3d(0, 5)
ax.set_zlim3d(0, 5)
adding this seems to work
import numpy as np
import matplotlib.pyplot as plt
# Parameter
a = 0.1
# Time array
t = np.linspace(0, 50, 400)
# Compute X and Y
X = np.sin(t * a)
Y = np.cos(t * a)
# Create 2D grid for contour plot
X_grid, Y_grid = np.meshgrid(X, Y)
# Define function F(X, Y)
F = X_grid + Y_grid
# Plot filled contour
plt.figure()
contour = plt.contourf(X_grid, Y_grid, F, levels=8, cmap='plasma')
# plt.colorbar(contour, label='F(X, Y)')
# plt.title('Filled Contour plot of F(X, Y) = X + Y')
# plt.xlabel('X = sin(t*a)')
# plt.ylabel('Y = cos(t*a)')
plt.show()
``` I think matplotlib has some bugs
Multi-Agent Game 🎮 Generation and Evaluation via Audio-Visual Recordings 📹
Indeed, especially love the exploration away from LLMs
Play 47 images of cast would be good data set of cat images

for which task ?
Image recognition of animals I still have dogs and gerbils
I think you would need a at least few thousand images per class to get decent accuracy
I could apply transforms to all the images to test the model to robustness plus I this is why I could get from scouring both the internet and some of discord
yes but still
Right and get more images for the price of 47
But truly it would also train the ai for robustness
48, you have 48 images
also 48 images is how you overfit the model
have you considered getting a dataset from somewhere like huggingface?
Well, no
it will train it to recognize 48 images of cats, and some very similar images
remember that cat vs dog vs gerbils are very similar, it may be hard to spot differences even for a human if low-resolution or bad lighting
Yes but I'm going to go to college for AI so might as well make a dataset from scratch because it may be a requirement
it won't
a requirement for what?
I don't think you realize how many samples are required to train ML/DL/AI algorithm
and what does "from scratch" mean anyway? are you going around with a camera, to people's houses and taking photos of their cats?
No I mean is from scratch taking photos that people have shared I'm putting them in a folder labeled cats and naming each file
And to answer your statement 2x tanguy
I do realize how many images are needed I tried to make a image scraper (mindful dev) took me off of that route because he said it was against a sites policy I know but I can go to hugging face or kaggle but if I need to understand why is so hard to train my as well learn a little bit of it right
ifyou do realise you wouldn't be saving a few dozen random pics from the internet
I'm going to add more
I don't exactly sleep and when I do I don't exactly want to get up so might as well use that to my advantage aim to get by the next two days scrape enough images that are not AI made to make my own dataset
You can 100% use some AI-made images
of course not 100% of the dataset should be made of it, but you can have some
I'm trying to use as much pure data as I can
any good resources for data science?
- The reward is cumulative. They use two parts: the alignment and matching with the target and then increment the reward each time the robot touches a target.
- It's all done in unity and unity provides such capabilities
Hello, Im thinking about doing a project that would involve training an ai model. Im a beginner still, but a cs student so in any case it will be a good learning experience. Now because Im a beginner, I dont really have an idea where to start and I was thinking about using GPT, not to code for me, but to point me in the right directions to start with, perhaps what I need and must do and generally just sets me up to go? Im not asking out of ethical concerns, but purely for if Language models like GPT are in a state sufficient enough to do that.
you can use ChatGPT for that, yes.
great to hear! thank you ❤️
Been going over pl.LazyFrames, working toward a memory cheap pipeline. I have it written from csv (-> to parquet) though the preprocessing operations and am at a point where I need to import it into pytorch. I'm not quite sure where to start, I'm compelled to .collect for everything in torch but I sus there's a cheaper method to load batches.
polars 1.34 added a collect_batches() method, either use it, consider map_batches(), or really just collect into memory
What about train_test_split? I googled it but everything is eager
either take the head and tail, or do it for each batch after collecting into memory
oh, duh! that's perfect, I just need to work a shuffle in somewhere, thanks!
shuffling in lazy mode is also awkward, but if you can do it after collecting each batch that should work
find solution by yourself and never ask here again
Check out the "Guided Learning" modes; that's what Gemini calls theirs, can't remember what it's termed in ChatGPT.
Instead of giving you the answer, they explain the context and then ask you a question etc.
this kind of "humor" isn't really appropriate for this server, if you wouldn't behave that way in a library it's probably not a good idea, someone who wants help might be turned off to the server by your behavior and that is basically the opposite of what we want here. Everyone is trying to be helpful.
They won't be able to reply
anybody help me develop an ai
Check this out, this is the jam IMO https://alexiajm.github.io/2025/09/29/tiny_recursive_models.html
Recursive Reasoning with Tiny Networks
no like a proper medical chatbot ai
Yep, that's how I would build that.
as we said in #python-discussion , check out #❓|how-to-get-help and perhaps open a thread in #1035199133436354600 .
Hello, quick question, what's the purpose of thresholding in image processing? Like I was told to apply "otsu" thresholding, what it is its purpose, how does that benefit image processing techniques pls
My understanding is that there are two main reasons: To reduce the amount of data you are processing, and to "converge" similar images into the same result if they differ in ways that just seem "noisy".
But I'm not an expert, hopefully someone can improve on that.
Hey 👋 , I need 1-2 team members for Amazon ML Challenge urgently ( registration closing in 4 hours ) : https://unstop.com/hackathons/amazon-ml-challenge-2025-amazon-1560375
Eligibility: participiants should be from India, pursuing PhD/ M.E./M.Tech./ M.S./MS by Research/B.E./B.Tech. full-time degree, with graduation in 2026-27
I'm pleased to share with you the final results of my approach on the ARC AGI benchmark, which are as follows:
- Total number of tasks solved: 446/1000
- Success rate: 44.6%
- Total execution time (on a CPU with 12 logical processors): 15 hours
- Data size to analyze: 170 MB
someone from Indonesia?
https://github.com/SusanBhattarai/StringableInference-py
im just a beginner, any suggestions guys?

GitHub
Free Python client for the StringableInference API, supporting chat completions and model retrieval - SusanBhattarai/StringableInference-py
hey all, is this a good place to ask a question about data science specifically (no relation to Python) or are there better places for it?
I like discord or other chatroom-like apps over something like stackoverflow because it's easier to make conversation
Im pretty sure its fine to talk about data science. It will eventually gets translated to Python afterwards probably. Whats on your mind?
there's a pretty cool statistics overview about Japanese travel: https://statistics.jnto.go.jp/en/graph (official numbers by a Japanese organisation) and I was wondering if the given data is enough to get a sense of the "average" itinerary of a tourist

Japan Tourism Statistics | 日本の観光統計データ
specifically, given the "breakdown by length of stay" and "overnight stays by region/prefecture" would it be possible to make any meaningful inferences about how many regions the average tourist visits over the course of their trip
probably but it also depends on the flight, no? I have booked a family trip to Japan for early Jan 2026 and the return flight wont happen for a week. So we're basically forced to fill up our itinerary for a week (I have to admit that is too short to truly enjoy Japan but we'll make the most of it). So flight availability returns may influence the stats somewhat
interesting stats nevertheless
yeah and that info isn't available, I imagine it's very challenging to collect
I bet so too
a few people I know have gone between 10 days and two weeks, they did get around a bit more but I'm sure that for business purposes it's entirely plausible that some people stay in the same city for months on end
Skimming the data briefly, and to answer your original query, yes, it does look like you can get a very good general sense of average itinerary of a tourist from this dataset. Really nice find
how would you go about it? I'm not a stats guy myself personally
Me neither. Still a noob at it. But here's my take. Start by a question like "how many tourists would go do Osaka by end of the year and what would they be doing" or something. Then I would dive into each stats and find correlation that may help answer that question. Organize and sort. And that should answer that question. Another hypothetical question might be, "I want to go when its not peak tourist season but still has events to attend". Then find the relevant data that shows and answers that.
hmm I see, that sounds like an interesting approach yeah
I tried ChatGPT but obviously it's not gonna teach me data science from a few questions
If you wanted a course on Data Analytics, theres a lot of resource on that. Like from Google is one way: https://grow.google/certificates/data-analytics/

The Data Analytics Certificate, developed by Google, can help you learn how to use AI to process, analyze, and visualize data.
oh nice, I'll check that out, thanks
Greetings. If anyone here is familiar with the img2table library, I'm getting an error that I need to install img2table[paddle] (despite it being installed). I found an issue for it here- https://github.com/xavctn/img2table/issues/243 - but I don't understand the solution. Can anyone provide some direction here?

GitHub
Hello, I got this error: Missing dependencies, please install 'img2table[paddle]' to use this class I created a virtual environment to navigate through the files, and I’m 100% sur I install...
PaddlePaddle installs itself with setuptools if setuptools is not installed the error will be raised. I think it would make sense to add setuptools to the requirements.txt file
assuming that is right, you can try installingsetuptoolsbefore you install it
I have done that, and I still get the error. Part of why I assume there's something here I'm not understanding.
odds are it's just broken then
damn. Aight, thanks. o7
for random sampling for train/test split, the method gpt is suggesting is hashing
test_lazy = (
lazy_df
.with_columns((pl.col("id").hash(seed=42) % 10).alias("bucket"))
.filter(pl.col("bucket") >= 8)
)
just wondering if this reasonable
It clearly works but gpt's advice is about the last place I'd take advice from if I have a choice
I guess it works? not sure if I'd really recommend it though
I feel like splitting into different files makes more sense
it's not unreasonable though
hmmm
that's not a bad idea
Thinking I might polish this for my portfolio if I can get it streaming straight from parquet into the data loader
you could also take the head/tail or every Nth row instead of doing it based on the ID
Hi,
I wanted to know what kind of projects I can make in order to secure a summer internship for a data scientist role
By the way I'm a beginner; currently working on a credit card fraud system; but I'm unsure if it would be enough
Building a classifier like that is a good start IMO
Alright thanks
I've learned a lot
If I have enough time I was thinking building a regressor next
Hi, just wondering, is there any resource that explains us how to train a multi-classification models using recommended ai/ml frameworks pls. Like from data cleaning, data split, hyperparameters tunning, metrics, model evaluation etc
https://kaggle.com/learn is usually a good place to start. If you're looking into deep learning, then check fast.ai course
Practical data skills you can apply immediately: that's what you'll learn in these no-cost courses. They're the fastest (and most fun) way to become a data scientist or improve your current skills.
Hi, quick question, when it comes to LLMs, how are they keeping track of latest things? For instance, say there is a new article published or a new technology released, what happens?
I know that LLMs learn from us, from our data, but question. Do they learn from anything we type in the LLM itself? Is there some kind of filtering before storing somewhere like in a vector database? Do the AI engineers actually have time to filter those info? Seem unrealistic, no?
I know there is the concept of RAG, but even, that database used is updated at some point no?
in the offensive language dataset based, the one from twitter tweets, is the point of it that it lacks context severely? Like, the word "yellow" without attention, will be classified as neutral, because it will more than likely be interpreted as a color, when it means something else based on the context(which is ignored). Is that kind of the reasoning for that dataset?
Yes.
hmm yes in the sense that filtering does occur?
an LLM only "knows" things that are stated in its training data, which is always going to be somewhat outdated. If you use ChatGPT and you see "Searching the web..." on the screen, it's doing RAG.
training on dialogues with users would be risky, because users could just enter a bunch of nonsense, and that would mess up the model's understanding of how converstaions work.
yeah so basically, each time we see "searching the web", it's using an AI agent behind the scene to scrap the web and look for the info?
no, go ask something to chatgpt like : """ answer the follwoing question based on the following pieces of context without crawling the entire internet: {context} Question: when did Hulk Hogan die? Answer:""" You should get something like this.

ohhh ok
its RAG
it depends on the documents being fed. ChatGPT is taking a snapshot of the internet for any data regarding the prompt that it was not trained on or is not common knowledge.
no, it depends on the quality of data. if you are using chatgpt on the openai site, it is ok. LLMs in general make up stuff or just go on forever and spew nonsense if it doesn't know the answer. LLM's with direct docuements on your PC through a api key are pretty great if you know what you doing.
what is the {context} part for?
I know, just a habit. It had no context to go from.
fellow devs. anyone having experience working with pyspark to resolve deeply nested XML? I have XML files of different schema which are both nested and deeply nested (struct array stuct), I would be using a mapping csv to resolve the data. But I have not been able to do so far.
I wanted to know if I can use deepface to train an AI
any of you do RL?
When working with a dataframe, how do you deal with incorrect data points? For example a column 'age' having values such as -1 and 225, while ordinal columns like 'Thalassemia' have values outside the range of 3, 6, 7?
Like how can you set those out of range values to NaN for each column
Hey I am trying to educate myself. Can someone explain to me what are
Gradient decent
loss function
learning rate
I am so confused rn. I just know they are used to optimize an algorithm but how
Ok I’m gonna use an analogy that’s so old, it’s probably older than me even. Imagine you are hiking on some mountains, but it’s suddenly really foggy, and you can barely see. You want to find your way down to the lowest point, the valley in between the peaks or whatever…
The loss function is the mountain. Your altitude is how “wrong” your current position is. High means you are not close to your goal, low means you might be.
Gradient descent is how you find your way downhill. You stop, check out the ground where you are standing, and then figure out which way slopes down and go that direction.
Learning rate is how long the steps you take are. A long stride means you travel faster, but you also might step over an edge if you’re not careful. A short stride means you are shuffling forward and it might be slow, and you might not make it down before nightfall, when the ice weasels come out.
Thank you sire can you bless my soul further by enlightening me about their mathematical relation
Have you studied any calculus? In particular differential calculus is really super related, it’s the same kind of “incremental” approach it seems to me.
If you think about a curving line drawn on a 2D plot, the process of using calculus to find the lowest point is exactly what is going on with “gradient descent”
Gradient descent is just the “extension” of that idea to more dimensions, like you end up with in machine learning
The “slope” of the higher dimensional “curve” is called the “gradient vector”
So I think the intuition of running your hand over a surface to find the lowest point is pretty ok to use
Just remember occasionally that it’s a bunch of dimensions not just three
Beyond that it’s just learning what the “update” formula looks like, but all it’s doing is the stuff described above.
The curving line is the loss function right?
Will the loss function always be a declining curve?
The Y value of the curving line is the loss function
the gradient vector is the slope at any given point
the loss function isn't the declining part, that's the gradient vector. the loss function is just a value, in this case 'how high off the ground are you'
This paper/book is the best explanation of LLMs I've seen so far, if you want to see how the full catastrophe is currently put together: https://arxiv.org/abs/2501.09223
arXiv.org
This is a book about large language models. As indicated by the title, it primarily focuses on foundational concepts rather than comprehensive coverage of all cutting-edge technologies. The book is structured into five main chapters, each exploring a key area: pre-training, generative models, prompting, alignment, and inference. It is intended f...
(To be clear I'm not saying you were asking about LLMs, just that they certainly use these ideas.)
Another way to look at this stuff is as an application of this: https://en.wikipedia.org/wiki/Free_energy_principle
The free energy principle is a mathematical principle of information physics. Its application to fMRI brain imaging data as a theoretical framework suggests that the brain reduces surprise or uncertainty by making predictions based on internal models and uses sensory input to update its models so as to improve the accuracy of its predictions. Th...
The "least surprise" idea here is useful etc.
Correct me if I am wrong:
So we start with OUR weights and a fixed technique of the loss function(eg the sum of sq diff)
We then calculate the Gradient (derivative)of the loss function wrt the weights used.
This tells us the side of the slope we should move(increase or decrease our weights, And the learning rate tells us by what extent we will change the weights).
And we continue this until we reach the weight that gives us the least value of the loss function
And now just have to apply this in a multi dimensional world
100% yes
Start with the weights, calculate the gradient, update the weights, repeat
You got it
Thanks! I plan to run unopposed though when the time comes. 
where to find models? i dont wanna do the ml
i just want the model
im a swe
you want a model for what exactly
hugging face maybe
im trying to find the right type of chart for displaying the proportion of a groups subcategories
wow that actually sounds like gibberish
its probably easier to just show what i mean

i found that a sankey diagram kinda works but only if i have the subcategories have different names which is doesnt look great
so like if i remove the prefixes it joins the categories together

Maybe this is a situation for a "Sunburst Chart"? You're right that Sankey isn't great at hierarchies

or a Treemap maybe
both are designed for nesting
plotly can just do px.sunburst(df,...) on a dataframe from pandas or similar.
What about a network
assuming your data was like:
data = {
'group': ['Adult', 'Adult', 'Child', 'Child', 'Child', 'Child'],
'gender': ['Male', 'Male', 'Male', 'Male', 'Female', 'Female'],
'speed': ['Fast', 'Slow', 'Fast', 'Slow', 'Fast', 'Slow'],
'value': [4, 2, 1, 3, 3, 3]
}
plotly.sunburst would just "eat" that etc
With nodes being names and the number of instances from a set to another is written on the edges ?
Yeah, the numbers could be weights of the connections etc I guess.
But I think a Treemap kinda "just does that"? Not sure if they are totally equivalent.
Yeah i think works too
basically im wanting to show the proportions of each subcategory
let me try and word this right
I think I get what you're saying, and IMO both Starburst and Treemap do it
with the 'pie wedge size' and the 'rectangle size', respectively
i looked at treemaps and i dont think they do
i might be looking at bad example tho
How not? a treemap view of your hard drive for example makes each box sized to the file

(bad-looking example but you get the idea)


area of labeled section = size/value/whatever
It's old:

Yeah, might have to play with the 'style' a lot
oh yeah it probably helps if i share what this is actually for
but I think it can clearly represent what you've got schema-wise
im making a crowd crush simulator and i was using this chart as an example of how you might set the statistics of the crowd
basically recursively setting how different properties are distributed
splitting the categories into smaller subcategories
where can i learn mathematics for AI and i have no background
These words (recursively setting, splitting categories) are like EXACTLY the reason Sunburst was developed, as far as I can tell. I think it's gonna work great, once you pick a 'style' to make it look pretty and readable.
The sunburst chart is perfect because it directly maps to the nested properties of a crowd.
imagine you have "age group", "temperament", "goal", and "count" (number of people in each sub-category)
plotly.sunburst(
your_df,
path=['age_group', 'temperament', 'goal'], # The hierarchy
values='count',
title='Crowd Distribution Sim'
)
and whammo
Use everything but the thing you want to have control the size of the section be part of the 'path', and then use the thing that should map to area be the 'values'.
just do a "college algebra, with python code" by freecodecamp, and practice with "Hall and Knight"
Hi, quick question, I started learning n grams in nlp. I did scraped 9 wikipedia pages e.g. one on algorithms and software engineering etc, I just wanna ask after I have 1 gram - 5 gram, does the n grams need to be ordered by frequency (which is most common appearing)? Is it important if I need to make visualisations of each extracted gram e.g 1 gram, 2 gram etc?
what do you mean by that do they need to be ordered by frequency ?
Like the word that appears the most in a page e.g. artificial is on the top
can anyone help me with model selection for a time series forecasting. I have 20 time series with an upward trend and with a seasonality.
I tried using LSTMs , but the error is still too high
the evaluation metric is RMSLE
hello
Instructor is normalizing the entire dataset in a course I'm following, does this result in a leak from the testing set?
He hasn't included a validation set at any point yet, I wonder if he's just loosely combining them for simplicity's sake. I should probably just complete the course before I go crazy writing a pipeline
was thinking it might be cool to write a train_test_split suite with marimo ui elements, as lazily as possible, I'd love to hear peoples thoughts on that
Yes
It probably doesn't matter, but practically yes
That's what I was thinking, was nice to normalize it on the fly but it's not that hard to set some stats aside
What is usually done is to normalize both datasets woth the stats of the training one only
But in practice, if you get both subsets from the same dataset, they should have the same distribution
So you would get the same result
the random seeds have a pretty noticeable impact on the toy sets I'm using but I imagine that isn't an issue with larger sets
https://github.com/brentleythegreat13694/basic-python-bot rate my basic python bot please

GitHub
Hello! My name is Brentley, I'm 13, and I love computers. I know a bit of C, C++, and Python. My dream college is MIT, and I also plan to make more projects! If you want to contact me, my D...
I’m looking for someone who knows machine learning and deep learning for a few coaching sessions. I’m currently learning and need help with a few things, as well as someone to review my code. If anyone’s interested, hit me up in the DMs.
it would be great if someone volunteers to do this, but it's pretty unlikely--you're more likely to get help if you ask specific questions or post the code that you want to have reviewed.
I will pay
Thanks, where should I post the code?
It is not allowed to offer payment in this server.
You can post it in a paste bin or link to the github
!paste
Pasting large amounts of code
If your code is too long to fit in a codeblock in Discord, you can paste your code here:
https://paste.pythondiscord.com/
After pasting your code, save it by clicking the Paste! button in the bottom left, or by pressing CTRL + S. After doing that, you will be navigated to the new paste's page. Copy the URL and post it here so others can see it.
Oh im sorry I didnt know that
Hey I was trying to implement a Multilayered Perceptron from scratch using numpy on Iris dataset but I can't implement the back propagation part so need help
Are there some video or course to help with general knowledge how to just get started with ai? I don’t think machine learning. But ya probably have to know the basics of that too. I’ve also heard the term ai agent thrown around too.
Check out AI tracks on roadmap.sh
Also there is plenty of good courses available for free from Google, Nvidia, and Intel. Although, if you are just looking for high level AI integration on apps, most YouTube courses will fulfill your needs
Hello everyone, I wrote some optimizers for TensorFlow. If you're using TensorFlow, they should be helpful to you.

GitHub
This project implements optimizers for TensorFlow and Keras, which can be used in the same way as Keras optimizers. Machine learning, Deep learning - NoteDance/optimizers
Hello, quick question. I need to work on a multi-image classification ML project.
I need to do some preprocessing with my dataset, I wanted to know how should I proceed.
So first, I should perform some data cleaning, like normalizing categories to numbers, removing nan values if any etc...?
Then after that, say I have my images. My question is:
I need to perform image augmentation/preprocessing, how should I proceed?
I should perform image rotation, transformation, grayscale, blurr? All of these operations or some specific pls, how do I choose which one?
Then after that, I would need to do my data split, say 80 10 10.
Then train, validate and test my model.
At the very end, I would need to calculate some metric to my model? What kind of metrics should we use for such task, the confusion matrix thing?
the metrics you'd want to use are precision, recall, and f1
at an aggregate level, you'd want to do the micro and macro averages of all three.
yeah heard of these, I will need to read on that, will do so and come back
concerning the image processing, is there anything I should cater about?
I've never actually done image processing.
ahh, no problem :c, I was wondering, normally in a dataset, should we have grayscale image/blurred image or these come down to the pre-processing
I think it comes to the pre-processing, no?
idk
:c, hopefully someone may have an answer
I'm looking for resources online for these but it's very limited 🥲
Look for LangChain courses
Hello, can someone explain why when it comes to model evaluation, we can't only rely on accuracy, what would this imply if we did so?
it varies a lot based on which kind of model you're working with, but for starters
- are some classes over/under represented in the training data & in evaluation?
- does it generalises for unseen data?
for example, if a model trained to detect rare problems just says everything is OK 100% of the time it may still get >99% of the results right, but is completely useless
small question, I just had a look at the evaluation metrics, normally f1 score would be an aggregate of precision and recall, no?
yes
you'd want to do the micro and macro averages of all three.
What do you mean the micro and macro averages pls :c
look into it and tell me what you find
yep will do so
from what I've understood, macro average treats all class size equally and so we perform the average on precision/recall and f1 separately.
On the other hand, for micro average, we sum up all individual fn/tp/fp then calculate the mean for each metrics, I didn't understand quite where this is used though, when we need an overall metric for our model ? But we can achieve same with macro average, no? Why micro?
Anybody used "Google Vertex AI Studio" for anything yet? I'm considering doing a thing with it, because it lets you directly get feedback about the "perplexity" of your prompts. The setup is a bit tedious though so I figured I'd ask first before going through the checklist.
looks like you pretty much understand it.
From which creator/s??? like idk anything & still learning.
Hello, can someone explain the difference between evaluation and regression metrics and where to use them pls.
From what I've read, evaluation metrics is used when we have built our model entirely, while, regression metrics can be used for each epoch? See how to minimize loss for e.g?
Trying to write some lazyframe code to return mean and standard deviation of the frame, it seems really clunky to produce a 1 row frame with alternating columns for the values.
Hey how these big models are train? Like gpt models,stable diffusion and all?
How do they decide which arch is best as it takes so much time to train
So trying different combinations will take lots of time and resources
you could either select two frames then collect together
import polars.selectors as cs
mean_lz = lz.select(cs.numeric().mean())
std_lz = lz.select(cs.numeric().std())
mean, std = pl.collect_all([mean_lz, std_lz])
or suffix/prefix the columns
stats = lz.select(
cs.numeric().mean().name.suffix('_mean'),
cs.numeric().std().name.suffix('_std'),
).collect()
oh neat, i haven't looked at selectors. was trying to work out how to make
train_mean, train_std = aggstats_lf.mean(), aggstats_lf.std()
play with my data nicely
still wrapping my head around dataframes tbh, everything was a vlookup during my years as an excel spec
Does anyone over here has the Machine Learning Specialization and Deep Learning Specialization course by andrew ng?
I honestly don't think they do, it's just try to make your best educated guess and hope that it works
otherwise we wouldn't get massive flops like llama4 400b / 2T (whose release was literally walked back, presumably due to it underperforming)
stable diffusion 3 also had issues on release; if you've seen the "woman lying on grass" abominations yeah that's sd3.
3.5 did fix some of those issues, but by then the community has moved on to flux
hi guys nice to meet everyone
hello nice to meet you too
helows , whats up?
I've been doing a soft robot simulator xd but sometimes it's hard to concentrate while working alone in a project
that's why I joined this server
what's the project about? seems interesting
yeah this is a good server. Glad you joined
it has helped me couple of times here and there
I have a video ... is it possible to share here videos? , its a little language built with python that lets you prototype and test voxel based robots
its very hard to sell something like this so my goal is to make it super fun to work with xd almost like a game
i am not sure if its possible to share vidoes here. You could give it a try 🙂
love it!
his name is fernando , he likes to walk but never gets too far : P
hahah I have another video with the IDE but I don't want to spam so I will share later
its very easy to do shapes because the shapes are defined by scalar fields , so you can do any implicit shape , I wanted to do this one first because it was the easiest
oh wow!! this is so cool
thank you!! uwu
so cool
the robot behaves like this because of different material properties , and the oscillations I defined owo
you can change the frequency for example and that can make it move twice as fast
when I get something more stable I will share it so people can write their own robots (its opensource), I wanna make a contest to see who can write the best bots for specific tasks uwu
this is a really nice presentation @cedar veldt looks fun. Hopefully it will be open source some day. 😎
it is already opensource
I haven't shared yet because I'm embarrassed of my messy code 😛
Hi, @tropic edge
Do you find LangChain developer?
I am senior AI/ML engineer.
What have you made?
oof, I just traced what I thought was a bug in my data preprocessing code to a couple of bad blocks on the drive storing my data
Yeah it always surprises me or they got like insane Resources
Using which they can speed up and try different archs
Hello quick question, I know that both standardization and normalization are part of the feature scaling process in data preparation. My question is, why do we use one over the other?
Their main goal is just to convert some values into some other numerical values, like 0 and 1.
I read that normalization is preferred when we know that our dataset doesn't follow the gaussian distribution, so maybe when there are lots of outliers/skewness?
But what abour standardization when do we use it and why pls.
scikit-learn
Feature 0 (median income in a block) and feature 5 (average house occupancy) of the California Housing dataset have very different scales and contain some very large outliers. These two characteris...
I want to learn the maths associated with gradient descent and stochastic gradient descent, anyone knows where I can get a reference to pls. I know it's just basic thing like y= mx + c but I don't really know which parameter represent what

I'm trying to understand the problem of vanishing and exploding gradient and I wanted to have an overview of the maths related to gradient first
what part of it troubles you?
i'd say wikipedia offers a pretty good introduction, but the notation is already a little technical
https://en.wikipedia.org/wiki/Gradient this is a good starting point
The thing is I know the theoretical concept but not really how the maths work
yup will give it a go, ty !
https://en.wikipedia.org/wiki/Chain_rule this is also probably going to come in handy, then
vanishing and exploding gradients are usually something that pops up in the context of using the "chain rule"
yup noted, I have some knowledge of the chain rule I think, I will have a look how this give rise to these problems, ty !
if you want to try this out yourself by hand, something like khan academy should have simple examples with a step-by-step on how it works
Hi, has anyone ever use YOLO for image recognition and classification? I don't understand, under the hood it uses ResNet or ResNet is completely another CNN architecture?
I need to train a multi class classification model both for image recognition and classification, am confused which framework/library to use. I was told to use YOLO though, don't know the reason though, anyone here has experience with it pls
Hey, i am new to deep learning and i am confused which library should be the best to start? I started with tensorflow but i also read abt pytorch and now I am confused
https://arxiv.org/abs/2001.08361#openai check this out
arXiv.org
We study empirical scaling laws for language model performance on the cross-entropy loss. The loss scales as a power-law with model size, dataset size, and the amount of compute used for training, with some trends spanning more than seven orders of magnitude. Other architectural details such as network width or depth have minimal effects within ...
Start with pytorch
Hello everyone..
I havs finished python tutorial video and i have done some exercises of all topic and my end aim is either data science or ai enginner.
Now I am planning to do DSA in python but people are saying don't do DSA with python.
What should I do? I would be pleased if someone share their insight on my problem.
sounds like a question for #algos-and-data-structs, but I disagree with the people saying not to do DSA in python.
Yeah, DSA isn't about micro-performance issues like language choice, it's about different orders of efficiency.
micro-performance is Progamming Language Theory territory, not DSA
What should i do?
whatever you want. we're both telling you that you can do DSA in python if you want.
Dsa is used everywhere
You can do in python as well if you are gonna use python in your career ahead
Acquire this book and grind through it, emerge as a true warrior: https://webperso.info.ucl.ac.be/~pvr/book.html
A comprehensive programming textbook that
covers all important programming paradigms in a unified framework
that is both practical and theoretically sound.
Special attention is given to concurrent programming and data abstraction.
The textbook uses the Oz multiparadigm programming language for its examples.
And yeah logic stays same between the languages
this channel is for talking about data science and AI. not general python or DSA.
resources page: https://www.pythondiscord.com/resources/
We're a large, friendly community focused around the Python programming language. Our community is open to those who wish to learn the language, as well as those looking to help others.
hello quick question, say I have a system that takes as input multiple images but these images are all of different resolution and now I need to standardize them, say I need to make them 500 by 500pixels.
Now my question is, does the new size of the resolution we want matter, like if I want to use 300 by 300 or 400 by 400?
Now, I was wondering we would need to keep aspect ratio the same, no?
Now, all images might not have same aspect ratio so, in code we can't hard-code to keep aspect ratio of say 16:9, maybe I would need to find aspect ratio of original image for each sample of my data set then for that aspect ratio use pixel say 500 by 500, no?
it varies
you can just crop or expand (e.g. add black borders) to adjust the aspect ratio, then scale up or down to a fixed resolution like 512x512 or whatever is the most common for your dataset
the new size does matters, you'll want to minimise artefacts caused by scaling if possible, but larger inputs = more operations (although the difference could be small depending on how you model it)
ImageMagick's CLI tools can do this in a one-liner
(depending on the settings you want etc)
oh ok, will investigate about what you said and come back, ty !
didn't know about that, will have a look, thanks for the tip !
Actually lemme see if I can just craft that example
Assuming you've installed the base ImageMagick package for your OS (which has various differently-named CLI entry points)...
mkdir -p ./conform_output
mogrify -path conform_output -resize '800x800>' -background black -gravity center -extent 800x800 *.png
``` (example uses 800x800 as max size, pick whatever you need.)
I think that's right?(would work for *.jpg also etc)
The -resize syntax is advanced, you can do lots fancier stuff than that, which is just saying "limit max dimension to 800 pixels"
montage is great too, I used this recently to lay up a directory of pngs into 4-column posterboard style:
montage *.png -tile 4x -geometry +10+10 posterboard.png
(+10+10 says all-around 10px spacing between each)
oh ok, will have a look at that, seem really powerful and useful, ty !
hello may i ask a small question?
i am trying to start learning robotics and automation but i am confused about what content should i follow like which topic to be focused on and what will be a fun way to keep progressing while learning.
I'm not in robotics (yet?) but I have friends who are (massively, at NASA, etc) and it seems SO BROAD, there's SO MUCH to learn.. so maybe just pick some part that seems interesting to you and start diving into it?
my buddy Trey's title at NASA before his recent promotion was:
The Solver-in-Residence (SiR) program is a one-year detail position with the chief technologist in NASA’s Office of Technology Policy and Strategy. The program enables a NASA civil servant to propose a one-year investigation on a specific technology challenge and then work to identify solutions to address those challenges.
"AI and Autonomy Solver-in-Residence"
crazy smart kid
My main responsibility is conducting a study I formulated on how Modular Open Systems Approaches could be used at NASA, both broadly and with a focus on how autonomy and robotics software interoperability could be improved using the Space Robot Operating System (Space ROS) framework. Conducting the study involves meeting with a broad range of experts across government, industry, and academia, organizing workshops, managing technical investigations, and briefing findings to senior NASA leadership.
Learning Robot Operating System stuff might be a good place to start actually.
this warning about column names is bugging me, I recall now that collect_schema.names appears to do what I need but this code is really verbose and it feels wrong ```py
lf = lf.select([(pl.col(c) - mean_df[c][0]) / std_df[c][0] for c in lf.HeresWhereTheNamesAre])
something like
(lf - mean_df) / std_df
would be so much prettier
Do I need more imports
Looks like that url is incomplete. But you don't just "need imports".
Import * from *
Got it to working and I need to know what imports I might need to add so I can train an AI to do all of abilities above
are you a pytz enjoyer or a zoneinfo embracer?
hello, quick question
say I have train an image classification model. During the standardization process, I converted my images into 512 x 512 pixels.
Now say I build some interface that require us to upload the image we want to process. Now behind the scenes, we must first convert this image into 512 x 512 pixels then process it, right?
Check out what I said above re: imagemagick and its “mogrify” command.
yep so basically I can apply a vast range of transformations using that command but the thing is I would use imageMagick on images that are already on disk, right?
Say I have a website and a user decided to upload its own image, I would still need to do that processing... hmm do you think there are some sort of api that would allow me to write code to interact with imageMagick (I should investigate). For example the idea is:
User upload picture.
Picture goes into /images folder or something like that.
Before verifying/classifying which image it is, runs the imageMagick commands for that image.
Overwrite that image and classify the new image based on what was trained.
You can apply it before training no need for overwriting the image
no but, I will do so, I will apply them on my dataset, but my system will be like a website where we can upload images and these uploaded images are not preprocessed
yeah you must pre-process it identically to how you process training images