#data-science-and-ml
1 messages · Page 170 of 1
You don't need to persist it in the context window necessarily right?
Like I imagine you could provide the model with some functions, such as write_to_db or read_from_db, and have the Todo list retrieved istead
Ah smart
Hmm tru
How'd you do it?
Interesting
I was thinking maybe maintaining several databases 🤔
Maybe running ollama or smth locally?
Well not locally obviously but like hosting your own model
Oh yeah and it's fantastic at code generation
I use it to write all my latex these days 💀
Were u the person I talked to about Jax/Flax?
So maybe this isn't relevant to you but I've started using it
It's actually so good
Super speedy, and the syntax is a lot cleaner
Unfortunately I've had to implement some of the loss functions myself
But it's not too bad ngl
Like I had to implement Huber loss a few days ago
hello guys, i am new to the server, i want to start with machine learning, can anyone help me with a good resource to start with.
how to use conda for data science and machine learning? (sorry I am a beginner)
don't use conda. if you're following a tutorial saying that you need to use conda for data science, it's outdated.
just regular python.
don't do that.
what i have to use for ml?
They say that conda is ideal for machine learning and data science.
i just watch and i i belive it😅
only outdated tutorials say this. it hasn't been necessary to use conda for machine learning for several years.
I have never used conda, and I've been doing ML since about 2018.
yes.
hello guys i am kinda new to python and data science i kinda learned the basics of the python i still have some problem with the classes , lists and to add more extentions to the codes but what should i do and how can i learn better and i wanna become a data scientist if someone helps me i would be appriciated
you have to learn Descriptive statistics (mean, median, mode, standard deviation, distribution)Basic Probability (Chance, Normal Distribution, Binomial)Linear Algebra (vectors, matrices, basic operations)Basic Calculus (derivatives, gradients — for ML later).
and the library NumPy - numerical operations and arraysPandas - read data, clean, transformMatplotlib and Seaborn - data visualization
oh yea
@serene scaffold can i add you?
I don't usually accept friend requests from server members. I answer questions here when I'm able.
i know every thing till here "... for ML later)."
i still have some problem with the classes , lists ...
then probably try to grasp those concepts first before trying more complex stuff
what kind of AI model do you have in mind?
there's no way to run an LLM on a CPU efficiently no matter what.
Had 2 columns , salary and log_salary , and I was passing log_salary directly into training set 
This regression is driving me mad
No matter what I do I can't get R2 score above 50
Random Forest classifier
1MB approximately
Lads I have a doubt my regression model is pretty bad so I am thinking of converting it into classification, is this logical?
Or I am just dumb
you can just run that normally and no special work is required to make it efficient

ahhh so data leaking?
thats a big oof lmao

So Python is ok for it?
I was blind
I've heard that pandas is slow (and seen benchmarks)
yes. python is the main language for AI.
And there's a high load expected
For developing
I need to run it with zero overhead
there's no such thing as zero overhead.
Cause cloud GPU is too expensive
if a model depends on a GPU to be fast, that has nothing to do with Python. it can't be fast without a GPU in any language.
and random forrests don't need a GPU.
Yes, that's what I'm talking about
But I want minimal overhead
And probably want to avoid slow pandas
idk where you're getting the idea that pandas is slow, but in either case, pandas is faster with the pyarrow backend than with the numpy one.
altenatively xgboost
supposed to be faster i think?
but i feel like most of these tools are already optimized
xgboost is a different algorithm than random forrest.
Benchmarks
Pandas spends 30 seconds on what polar does in 2 seconds
I've tried it, but sadly the metrics weren't good enough
That must be an extreme example with many GB of data
Yeah
I expect somewhat high load
Isn't there something like model runner or so
xgboost (extreme gradient boosting), as the name implies, is a gradient boosting machine; you can see more in sklearn here
and you can use a gpu with xgboost but you don't have to
both RFs and GBMs use trees as base learners so it's easy to confuse
and the other 2 popular libraries that you see around - lightgbm, catboost - are also GBMs and not RFs
hey guys
im a fresher as a cs major
i wanna choose data science in ai as my main goal
is it a bad option ,as i hear it from diff people about it negative sides
please give ur feedbacks
guys i have passion in ai where do i start learning
No, ds is one of the best domain you can choose
What negative sides are you taking about tho?
it is growing very rapidly, but in my experience, it's not simple to break into data science role as a fresher without having masters or phd in ds or minimum 3 years experience is required if you are applying for job
ANYONE DOING JOB?
yes
What's your role?
computational linguist
i'm hearing it for first time , can you explain what's that?
AI for applications that involve language
in the field of ds is front end dev is neccesary to learn,what's your pov
no
what should i cover in my initial 3 months in my ds jounrny
??
How to explore data
how can i do it ? i only know python and its some libraries
like num,pan and mat
The domain of AI is soooo broad, so many things you could do
Here's an idea I think would be pretty cool (though I'm slightly biased towards making games in a way, lol)
You could make a strategy game and integrate RULER into it, making the enemy AIs learn using RL, but with a more attractive way of crafting the reward functions
You could record player's actions, then use an LLM to summarize those actions, then use an LLM to devise a strategy to be fed into RULER and then make it learn based on that, then you can set up RAG to store previous player strategies as well or something
I'm sure something can be made in that direction, for example
but like, sooo many options out there
I need to wrap a custom function (like an API call) inside a PyTorch nn.Module. Is it hard to do?
why are you wanting to do an API call in a torch module?
hey guys, im pretty new to all this. Im currently a rising sophmore in highschool and im wondering what college majors should i look into if im trying to become an ML engineer.
a torch module is like, a layer of a network. I can't think of a situation where it would entail an API call. and it would make it take way way longer to train.
you should probably plan to get a masters in CS.
would that be best over data science or engineering?
in theory, there's a difference between ML engineering, data science, in data engineering.
in practice, you do whatever your job involves, and it doesn't fall neatly into any of those three.
ah thank you
Alright, so I'm working on GNNs for molecular representation, and I found two main types, imo: GNNs that learn off 2d data, and GNNs that work on 3D data. Which should I use for my project? Should I use both or stick to one? (My project is on the understanding on organic molecules with LLMs, for context)
U should get CS the reason almost every concept used on ML is learned on a CS career is really useful on ML I'm currently working on some ML stuff on my job and some AI concepts that i learned on College really help's to understant ML also College is not all u should read from books, tutorials and also very fucking important LEARN HOW TO READ DOCUMENTATION that really helps in work usually on school everybody just type on Google "Wtf is numpy" and just skip the official documentation, it could be a little overwhelming but the the sooner you do it, the better for you and Good Luck and wishing success bro !
and dont forget : "Understand very well the basics almost every thing in programming are just basic concepts on Complex problems "
Thanks man I appreciate the guidance
I don't think those are two categories of GNN
generally, most GNN shouldn't care of the data is 2d or 3d
Math, Computer Science, or Statistics major will set you up for the journey ahead properly.
heyyy,does anybody have a github student verified account ???
I really need it
Why don't you enroll yourself into Uni or College?
so i need to have atleast 3 year experience as any post in a company to get into ML in AI
umm my uni is done few months ago, so I wont be able to get it
Re enroll ig
no I have to be in a uni in order to get a student account, do you have one??
No, not any post it should be data scientist role , ml engineer role etc.
its the need
requirement
okay, but what does the API do?
you should collect the API data before hand, then go through the data with torch (If you can)
Thanks for this, thats a great idea and also in my niche
AI is really a vast field but thats the thing about it , you go deep in some areas which in future may not be that much beneficial and thus things can go south for you.....so i was also looking for a person who is in this industry so that they can guide me on which path shall i choose
I have some time so if the path is new , i will on it ....i just dont wanna be left out
Is there any webistes that help with learning about neural networks?
YouTube is a treasure trove of knowledge
3Blue1Brown videos are very intuitive
So I'd start there
Is anyone knowledgeable with GRU and transformer conceptually? I (this sounds stupid but it was good for getting the toes wet) have been working on exposing myself more to at least basic ML concepts, so I tried my best to implement an ML solution that can identify single word palindromes. I initially tried an LSTM, then I moved to working on GRU, and more recently have a GRU transformer hybrid, and I learned (probably nothing impressive) a bit about how to think about and abstract the basic ways to structure your dataset to improve a model of that kind. I’ve gotten it to a point to where the current model is 99.88% accurate on a data set of 800 randomly selected as well as generated inputs.
But now I’m trying to further understand how to identify what the model is doing over the course of its training, and I’m having a hard time making sense of the heat maps, I’m not sure if I’m generating them right or if I just don’t understand how to read them. Truthfully, I’ve done googling, YouTubing but also have used LLMs to try to get a better understanding and I’m still falling short.
I feel like I get how to identify when a model is overfitting and when it’s reached its peak for identifying over training. But I want to better understanding the process of what it’s doing, and how I can look at the training data to understand what correlations it’s drawing during the training.
If anyone’s got some insight they’d share, welcome to PM me if this isn’t seen until some later time
Hm a couple of things, first I guess there's nothing wrong with training a model to identify palindromes but it can be done very simply with a handwritten algorithm so machine learning is massive overkill
you're just experimenting so it is ok but it isn't something you would typically do with machine learning
I would expect massive overfitting with this problem, a dataset with 800 examples is extremely small compared to the size and complexity of the model
I'm curious where your 99.88% accuracy is coming from - when you're evaluating model performance, is it on a train/test/validation split of the data, or are you training and evaluating with the same data?
and finally I wouldn't expect looking at heat maps in general to tell you much, neural networks are famously black boxes and you won't learn much about what they're doing by peeking inside, unless you have a very specific problem where the model's attention directly corresponds with some explainable aspect of the problem
your model is overfitting if it achieves near-perfect results when evaluated on training data, but very poor results on test data that wasn't used for training
@solar thistle are you tokenizing at the letter level? Otherwise, the model is certainly overfitting.
Check the pinned message in this channel
You can start by sharing us your plots (with proper description so we can understand it)
Besides heatmap, you can also collect the model input and output pairs along training to see any patterns.
And in general, this is still a very active area of research.
Oh yeah I know that its an overkill solution for an already easily solved problem. But thats one of the reasons I picked it. Its an easy problem to model out and the possible ways to solve a palindrome traditionally is like, theres only 1 and its really easy to do lol. But That gives me an advantage because its not a problem that I have any difficulty understanding to the full degree how to solve it. I figured because of that the ML model that would solve it would for 1, be simple enough that I can use it as a self guided intro to ML, but also there wouldnt be any "magic" to how it works. That hasnt entirely really been the case though. Since this is my first time really trying to understand how ML works, I stumbled a lot to get to where I was. I had heard some of the terms before (LSTM, GRU, RNN etc etc) but wasnt sure how you identify a problem and which solution is most fit to be used to apply to it)
Really I feel like I learned more about the importance of well structured and valid data that represents the problem youre trying to solve lol.
Training intially wasnt that great, but I learned (for this specific application) things I hadnt really thought of before. Cuz youre right, its an easily solvable tradtional CS problem, but when I was working on the GRU and the LSTM both I noticed things about palindromes id never considered would be kind of important facets of what they are. For example the LSTM version I did would often misclass palindroms that were near-palindromes, consistently. Like wowowiw as an example often was mis-classed
so that lead me to generate data that specifically would expose the model to large amounts of data that included those kinds of near-palindrome edge cases, and improved the model success substantially. I think the orignal GRU model I started with would also fail a lot when you had the first 2 or 3 letters symetrically match the last 2 or 3, and it would basically ignore the middle section. Also got stumped when words had more than 2 repeated letters, no matrter where they appeared
Obviously what Im using ML for isnt impressive, but I dont expect to fully become ML capable, I just want to be able to better understand how they work and just be somewhat competent about recognizing how they work/what and how useful data is structred etc
I mean, yeah I think so, (forgive my ignorance on the proper terminology) but you mean like encoding each letter into an array of ints representing each letter right?
this is how im encoding
def preprocess(data, maxlen=MAXLEN):
alphabet = list(string.ascii_lowercase)
char_to_index = {c: i+1 for i, c in enumerate(alphabet)}
def encode(word):
return [char_to_index.get(c, 0) for c in word]
X = [encode(word) for word, _ in data]
y = [label for _, label in data]
X = pad_sequences(X, maxlen=maxlen, padding='post')
y = np.array(y)
return X, y```so X ends up as a numpy array (num_samples, maxlen) and y ends up being the binary representation identifier of if the word is a valid or invalid palindrome
I only use words of len 12 so pad the delta of word.len and 12, and then use the padding to normalize all words to the same array len
Heres an example of the attention heatmap for both classifications


I was reading that the heatmap represents the y axis is the query, so responsible for computing attention, and the x axis is the listener thats attended to or whatever, which sounds kinda fine, I guess the query token basically uses the grid to represent how much "attention" was paid on the listener
conceptually that sounds fine lol. But like. So why then in the first graph did each encoded letter position pay basically what I udnerstand to be like "max" attention, all to the same letter
wouldnt, if how Im thinking of that and said it, was correct, wouldnt you expect to see a distribution of max heat like this? - or rather, where you would expect the most "attention" to have been attatched

thats kinda why Im asking for help, cuz im not sure if im just not reading the graph correctly, or if the graph itself isnt being generated correctly
And I know the model works well, so its not like its just randomly outputting some invalid data

The data is a mix of predefined english palindromes and non palindromes, and randmomly generated just palindromes/nonpalindromes from random characters
I am not 100% sure about this but I suspect attention isn't right mathematically for palindrome detection
Maybe if you try adding some positional encoding it could work, but I think the principle of how attention works isn't going to help
If you're interested in interpreting how neural networks work, have you studied the xor problem?
Also here's a good blog post where someone is tracking the cell state of a RNN on different language tasks, this might be along the lines of what you're trying to do https://karpathy.github.io/2015/05/21/rnn-effectiveness/
Musings of a Computer Scientist.
Lads I want to make some good projects. Any recommendation?
Pi as function of angle of every number(0=0°, 1=36°, ... 9=324°) every number is one step forward in the angle of the number.
first 50000 second 200000 with the window of 50000


Hey, I hope that this is the right channel for my issue. I need to read some txt files with spectra Data. The thing is that both Excel and Origin can't really import the data. It just come out wrong. So I thought about doing it in Python. I got some old lecture skripts from a friend that goes in that direction but I don't really understand them. I either would like some help writing skript, which I can read all the files and have it build an Excel file so I can insert it into Origin properly, or recommendations for resources where I can do it myselve (preferably in a acceptable amount of time). I tried several AI Tools but the produced Excel Files all have major problems.
All the files look like above (I don't know if it acceptable to uploade one here, I would need to change some meta data in order to not post personal info). And I need an Excel file that looks somewhat like the following:
Mass (m/z) Value (counts)
100.3 281083.092750
can somebody help me?

Please also fell free to ping me
hey guys, i want to learn ml and now i am at a stage of learning pure python. Is asyncio worth spending time to learn or should i skip this step? i learned about coroutines and it says that it is useful in asynchronous programming, so i wonder if i even need it
and is algorithms knowledge (like in leetcode) needed for it? i will make graph neural network (some physics applied) as my diploma thesis, at this point i still didnt look up what graph neural network is (and neither my supervisor lol), so i wonder if i need to know algorithms like BFS or DFS
Yes
This "data format" doesn't appear to be intended for use in programs. You'll have to break it up into sensible units. Like one CSV for the mass and value rows at the bottom of the screenshot.
asyncio is not important for ML
Neither are most leetcode questions. You should probably know the main sorting algorithms and understand their asymptotic analysis. Same for graph traversal algorithms.
"BFS and DFS" you need to understand these, and if you can't code them, you don't understand them
See if any will let you be their research assistant
I think this is the most questions I've answered in my three-stop train ride
It's a txt file
Yes
It looks like 3 separate tab-separated tabular files combined into one with headers separating them
It's two in that case, there are also other spectra with 2
If you manually separate them, pandas should be able to open them as is
Granted you'll probably have to do more cleanup, but at least you'll have it in memory in a format where that's possible
If you can't manually separate them you'll have to try to do it in code, which could be easy or hard depending on how much variation there is in the structure
Actually hmm the first two sections look like key value pairs
I tried to do something with ai assistantence. The main Problem are commas and that some numbers don't get recognized in Excel as numbers
Only the third section is tabular data
I don't think AI assistance would work well here, worst case it could misrepresent your numbers depending on how it attempts to break up the files
Oh you mean that with section. I only need the third in this case
It's better than me. But Manuel check ups revealed mistakes that are not allowed to happen
I mean it could completely make up numbers that were never there in originally
If you still want to use AI, try something like this in your prompt
You want to write a program that will read the contents of a text file into memory, but will ignore all lines that occur before "Raw Data:"
Once you have it in memory as a string, you can load it into Pandas
I don't know enough python to do it all on my own
I will try that tomorrow or the day after chatgpt told me that I hit the limit for data analysis
Yeah give it a shot
If you're intending any or part of this process to involve python scripts, even with chatgpt, you're going to need to know some python
I know enough so I can read most of what I encountered. Just the writing process is the problem
And I am working on refreshing some stuff with lecture notes and books from my Uni library
Thx for advice
Atm, getting a bit bored with ai/ml. I feel like the projects I’m doing are not piquing my interest. I’ll still go through with them because I need the practice and experience in applying my knowledge but, I’d like suggestions in interesting machine learning projects
Thats kinda like, the only thing that makes sense right? Like. I said I wasnt sure If i wasnt reading it right, or if it wasnt being generated right, but maybe thats just not the way to conceptualize the model performace, I didnt really think about that so thank you so much for the input. And no I havnt heard of that but I will do some reasearch and hopefully that points me in a better direction that Im going now, thank you very much for taking the time to read and respond to me!
So the reason I suspect it is challenging is because dot product attention effectively uses the similarity between the key and query vectors to determine the score
And because determining palindromes requires considering position, that means the RNN has to produce a sequence of vectors where, to use the outer two characters as an example, the first vector is most similar to the final vector
Or at least it has to produce vectors that can be transformed into a key space and query space where that is true
But I also think that is probably very hard for a RNN to do because it goes into the input without knowing how long it is
I suspect it might be possible to make it work with a very deep multilayered bidirectional RNN, and it also might be possible that it is doing something unrelated to position that still generalizes, but at any rate it is probably just overfitting and memorizing the training data
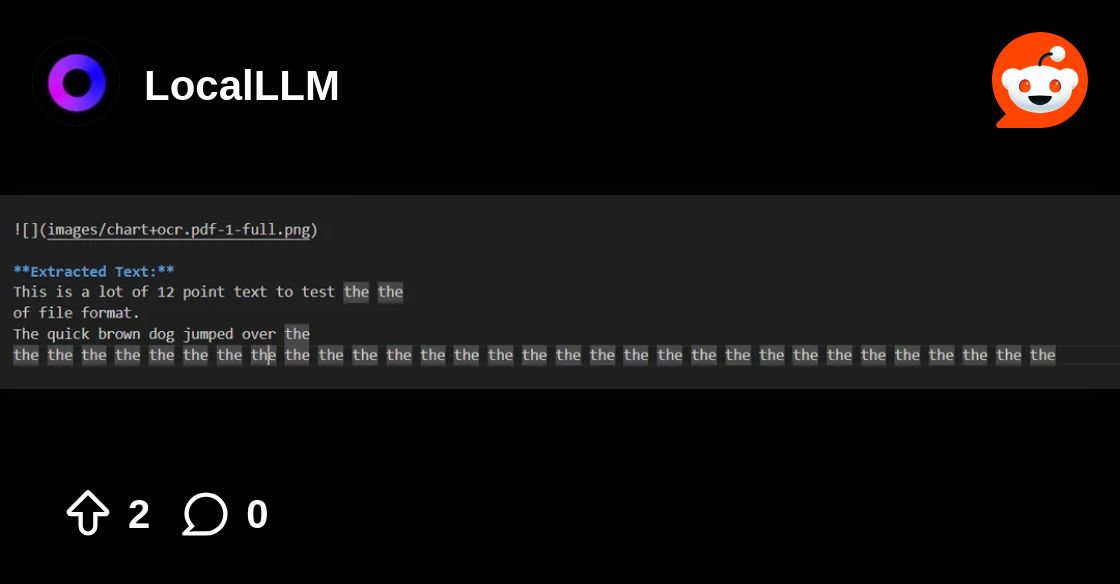
Reddit
Explore this post and more from the LocalLLM community
any help would be amazing
We Just Build an AI Agent without a Big A$$ Prompt
Last year we tried to bring an LLM “agent” into a real enterprise workflow. It looked easy in the demo videos. In production it was… chaos.
• Tiny wording tweaks = totally different behaviour
• Impossible to unit-test; every run was a new adventure
• One mega-prompt meant one engineer could break the whole thing
• SOC-2 reviewers hated the “no traceability” story
We wanted the predictability of a backend service and the flexibility of an LLM. So we built NOMOS: a step-based state-machine engine that wraps any LLM (OpenAI, Claude, local). Each state is explicit, testable, and independently ownable.
NOMOS supports lots of llm providers including OpenAI, MistralAI, Groq, Gemini/Gemma, OpenRouter, Anthropic, Ollama and Cohere. and there is lots of functionality already there and more are coming everyday.
Open-source core (MIT)
• GitHub: https://github.com/dowhiledev/nomos
• Documentation: https://nomos.dowhile.dev/
Looking ahead: we’re also prototyping Kosmos, a “Vercel for AI agents” that can deploy NOMOS or other frameworks behind a single control plane. If that sounds useful, Join the waitlist.
https://nomos.dowhile.dev/kosmos
Would love war stories from anyone who’s wrestled with flaky prompt agents. What hurt the most?.
yes, you can use nomos validate --config ... to check the validity
also can generate the schema easily using nomos schema and use it with your yaml
We introduced steps and transition between each steps. transitions are fully controlled by different routes and conditions. If the conditions are not met those routes will be not taken. Also we have introduced lots self healing techniques such as as soon the llm makes an mistake we will constrain the options it have dynamically, so next time it tries back it has fewer options.
This is an ad for a service, isn't it? <@&831776746206265384>
ehhh
it's OSS
but it's edging on advertisements
@nocturne whale showcasing projects is okay here, but not anything which has any sort of paid offering, just as a reference
i think what you're posting is okay, apart from the fact you're posting it in multiple channels. showcase OSS work but don't do it in the form of length walls of text, it's not appropriate for the space and violates the rules.
There's a waitlist for a control panel service
talking about OSS software is fine -- promoting paid offerings for upgraded versions of OSS suites is not okay and over-promoting the corporate side of OSS is not appropriate for this space
Do u do reinforcement learning
Those look more fun especially the game labs
More challenging aswell
is why machines learn a good start for learning the math
or is khan academy better?
im already familiar with python and im currently learning pandas and numpy tho i was told here that learning the math is crucial for learning the libraries for data science
Dont want to get into reinforcement learning until im comfortable i know more of the maths but i might give it a go anyway
there are some simple reinforcement learning problem formulations that might help you learn the math as you learn the RL
maybe try studying something like multi-armed bandits to start with
it's usually one of the earliest things you'd study in reinforcement learning anyway
while a lot of RL algorithms require a lot of math like qlearning and gradient policy stuff, I find things like evolution strategies and genetic algorithms to be a very easy way to jump into some fun RL projects without needing much math. Or at least the math involved is very simple and intuitive; what it means to preform crossover and mutation is completely up to you as the dev.
can anyone here proof chain a sigmoid activation function all the way to an equilateral triangle?
I just an undergraduate
i was still thinking about learning RL vs LLMs/agents... im personally more interested in RL than LLMs, but im not sure about the career opportunities
as im kinda mid-level already, I think it is time for me to specialize
and almost all jobs are asking for LLM experience, ugh
my current skillset is more towards ML/DL/optimization
An LLM got gold in the IMO, something many thought would take years.
and it wasnt even allowed to use the internet, or external tools, and had the same time as the other contestants
PURE NATURAL LANGUAGE.
that is seriously impressive
It seems test time compute is indeed extremely effective. Of course, along with other algorithmic breakthroughs
yeah i saw that news but uh... i dont know. seems to excel in advanced areas but struggle with other areas which are deemed more basic?
anyway, it seems like in industry, usually the applications of LLM are kinda... boring? like chatbots and shit
Yeah but it's an unreleased model. The model capabilities can vary drastically between the models.
For example, gpt 4o fails at elementary math, while something like o3 gets like a 98% on AIME
hey, grade 11 student here. im lowk interested in learning abt data science and ai and i wanna be able to land a small internship next summer before going into uni for cs. any tips on how to get started?
oh and also, what's even more crazy is that this was a GENERAL REASONING model. This was NOT A fine tuned model.
That is absolutely wild
unlike googles model
that was specifically made for this
this is fundementally different
does anyone here understand LLMs on a deep level? i've been struggling to see it past a "next word guesstimator"
i see, that's impressive
A simple ""next word guesstimator" would absolutely NOT be getting scores like this
It uses lots of test time compute and some other breakthroughs which open ai has mentioned
It can think for many hours, that's the difference between a model like this, and say... gpt 4o, that responds almost instantly
oh, so i guess it's very different than a vanilla Transformers then?
i have some basic understanding of Transformers as I'm going to need that for my next project. my "understanding" of LLMs is from that
i dont follow the LLM space/progress closely
another important thing is this. Long horizon tasks, which LLMs have struggled with in the past. It seems really good progress is being made there.

right. any idea how it's being done differently? is it a totally new model architecture or are they just adding on extra stuff to the core (which I assume to be still Transformers)?
More test time compute, and other experimental things they are doing it seems. What that "other" is, im not sure.


learn python? and how to handle basic files like excel/csv and do some data analysis stuff before jumping into the basic ML stuff. maybe look at statquest YT videos to learn and kaggle titanic dataset for a start.
test time compute... hmm. wonder how it works.
because at the end of the day, it's all numbers isn't it? are they letting the LLM loop more...? against different parts of the pre-trained dataset? ugh
yeah
i know MLPs, LSTMs on a quite deep level
and basics for transformers, CVAEs
because to me, these models are learning a set of weights, which are just numbers, from data. i think that'd be good enough to guess the next word, and the next. or even a sentence or paragraph if given the right architecture and data. but to say that they can "understand meaning" and "reason", that's a bit of a stretch to me.
but it could be because i don't understand the leap from Transformers -> the current LLMs
i've seen some of the basic ML/DL models achieve surprising things though


Until they publish their results and methodology in a way that is reproducible by other researchers, this is just marketing
These all (obviously) Open Ai researchers.
Yeah… we kinda already know the methodology…



If you think they are literally just lying like this… then you are beyond saving… you do you I guess
Yeah that will probably happen, as it literally has with every single Open Ai release…
But the model will be released likely by end of year
The most insane part is it’s a GENERAL reasoning 💀
This is not like Google, who creates their models specially for this.
THIS is what AGI is about
GENERAL intelligence. Google deepmind results are cool…. but far less impressive
What?
Open Ai said it passed the bar and then MIT said it didn’t?
It does easily pass the bar now btw lol
🤦♂️
I’m sure they are all lying bro.
But we’ll see
This insane distrust people have for literally no reason is so insane. Especially with a company like Open Ai which has a pretty good track record believe it or not
Every single open ai model ever released in the history of Open ai has had a paper along with its release.
This model obviously won’t have one as it’s not coming out yet.
They don't, they are extremely closed off and routinely hype themselves up and actively try to scare people
They are very closed off to the peer review process
But I guess we’ll see. Im sure in 3 months it will come out that it was ALL A BIG LIE PERPETUATED BY EVERY SINGLE EMPLOYEE, LIKE THE LAST TIME THAT OPEN AI… did some imaginary major lie like this which apparently I’ve never heard of
It’s ok. We’ll see. For now, GPT 5 is incoming, which is exciting.
Anyways…

Ima go eat pizza now
that movie was fucking awesome btw. ok im leaving now
uhh i also view these news and benchmarks with distrust
to me, openAI needs investors and they tend to hype things up
kinda distrust sam altman as a person too
remember a few months ago when they were hyping AGI
and how close we were to AGI
actually, what is the deal about getting gold for math olympia?
what i mean is, how differently are the math olympia questions structured differently from ... i don't know, typical questions that the general public ask an LLM?
multiple layers of reasoning?
it's funny they mention that the model has no access to the internet or tools? i kinda thought it almost has the entire internet as its training data, isn't it?
I see
that's kinda strange though
i'd imagine
i'd think that math equations would be closer to code than say... natural language
for LLMs to perform better in natural language than math, it's interesting
yeah on that, has there been any research on why LLMs hallucinate?
yeah i've read something along this line as well. perhaps human-like reasoning is flawed, full of gaps and we tend to "hallucinate" too?
it could also be that the training data has much more natural language than code?
or that the underlying architecture, LSTMs and Transformers, seemed to be designed more for natural langauge rather than code or math
do you have any resources to quickly understand the leap from Transformers to the first-generation of GPTs?
i roughly understand how transformers work, but the Generative & Pre-trained part of it, I don't
haven't tried looking at it yet 😛
oh wow
this almost simulates how i add numbers quickly
but anyway, interesting, so there are multiple pathways
i guess that same set of weights has to be used across all functions/domains
not just simple addition/subtraction
oh yeah, i was about to suggest something similar, to have steps/layers at the start to figure the task
they probably already have it though
this is probably a simplified diagram
im kinda wondering about this part as well
do they use the same set of weights for all tasks? or different sets of weights for different tasks? or different PARTS of the weights for different tasks (i.e. can we activate/deactivate some of the weights depending on the task, as i'd imagine the other parts of the weight to represent the "reality" that is not specific to the task)?
ah this is making my brain hurt
hahahaha
😮
maybe i should go into LLM research
and get 1% of that sweet sweet 200 mil package
ahh this is too advanced for me. i don't have the background for it
hahahaha
i see
openAI is closed-sourced, how about the rest like claude?
right
"Kimi K2 is a state-of-the-art mixture-of-experts (MoE) language model with 32 billion activated parameters and 1 trillion total parameters." so 32B params is considered small?
in the world of LLMs
yeah prolly, I can run 1B params on 4 L40s
🤣
params is referring to the number of weights/ the scalar values that are in the matrices, right?
hmm that doesn't sound like a lot
i dont know, unless 1 param takes different amount of compute depending on if you're running a MLP vs LSTM vs Transformers, etc.
my own models had i think... uh
1GB of params
which was about 1B params if i remember correctly
which is why im a little surprised at the 50-100B number hmm
anyways
yeah
Hey, I’ve been building a local AI assistant in Python — voice + text input, mood engine, memory with ChromaDB, and an LLM running via Ollama. It runs offline and uses a personality system that shifts tone based on mood vectors (sort of like a 12-band EQ). Also uses local TTS.
The problem is I’ve hit serious hardware limits (6GB VRAM). I’ve already optimized it to load models on-demand and split behavior vs task logic, but beyond this, the system can’t handle more development or testing. I’ve tried to keep everything modular and as light as possible, but even basic scaling breaks things.
At this point, I’m mostly just finishing up documentation. Not sure what to do next — cloud is not really an option. Has anyone here worked on something similar or found any hacks/tricks to keep these kinds of projects alive locally on limited hardware?
Appreciate any ideas. Not trying to show off, just genuinely stuck.
Mood engine is a combination of different things the input is processed in 3 layers and you can find full documentation here https://github.com/SilverShadowHeart/silver_heart

GitHub
simulated emotions. Contribute to SilverShadowHeart/silver_heart development by creating an account on GitHub.
I'd imagine it could have some steps to figure out what the question is asking, a step to encode the number and operations, but then why not just take advantage of the fact that it's running on a computer and that the network is just processing a bunch of vectors already ?
I don't think that's possible - remember that there's stuff like activation functions on each layer
the fact that everything is highly nonlinear harms it here - it has to find a combination of nonlinear operations that approximates multiplication
So it can't, just, say, have a subnetwork that turns a written number into a single scalar that it can then do operations on, because a single scalar can't represent a number - it'll instantly get truncated by the activation function
If you have a fairly new GPU, maybe experiment with vllm rather than ollama; you might be able to squeeze out some extra performance that way
(vllm is more hardware-demanding, e.g. it refuses to work on my Pascal-architecture GPU, but it's significantly faster and I suspect you can configure it for low RAM usage, too)
Kimi was already mentioned, but the technique is far older than it - Mixtral is what comes to my mind, which is a Mixture of Experts (MoE) model
oh, and the new Gemma models, too. It's popular for local reasoning because it lets you pack more capabilities into a limited amount of VRAM (or even RAM).
could also try running a quantized version and/or a weaker model
Well, sure, but tt doesn't instinctively seem to me that there's simpler ones then the one that paper finds?
Thanks a lot
That would ruin the entire project's aim i tried
ollama is already using heavily quantized models, doesn't it?
it always downloads the Q4_M gguf (IIRC) unless you specify an exact huggingface file
why would it "ruin the entire project"??
like I'm actually curious
idk they were using ollama tbh, just saw they posted a link to the repo tho
and last time I took a look at ollama it was still using q4_0 or q4_1 as the default, idk if that has changed
The model loses power and becomes too dumb and makes no sense and gives out rubbish in simple terms
ah, I think you're right
Yes it does the model is q4 quantized
well I mean that's the tradeoff you get for trying to fit more into the limited vram
anyway, quickly scanning through your readme, you're using this model:
nous-hermes2:10.7b-solar-q4_K_M
which is 2 years old at this point, you should definitely switch to something else
I tried phi 3 tiny lama
some models of similar size:
- llama 3.x 8b
- gemma 2 9b
- gemma 3 12b
- mistral nemo 12b
- qwen 3 14b
They are too verbose or 1800 scholars
Ohhh I will try these
I haven't heard of "phi 3 tiny llama," but I know that the phi series is more meant for single turn reasoning / instruction following
they are extremely dumb when it comes to human knowledge
so maybe not what you want
Yes i learnt it after using them
I wanted a model which is capable of good modern english and does some level of reasoning
Phi3 is one model tiny lama was another model 😅 i forgot comma
maybe also see phi4-reasoning:plus, somehow I missed its release entirely but it's 14B and dominates benchmarks... though depending on the GPU it might be hard to fit into 6GB
ah alright, so by tiny llama you mean this one?
then yeah I can definitely see it being dumb
personally I wouldn't go anywhere below 2b if you want to have a somewhat coherent chat without wanting to punch the model for being too stupid, and even then that's stretching it a bit
Yes
It is but I will do something about it and push this project forward
Your project is quite interesting to me because I also have only 6GB VRAM (and an old GPU that doesn't support a lot of important features like bfloat16), and I mostly concluded that all the LLMs I can run locally are too dumb to be useful, even as assistants
there is offloading to cpu but it tanks inference speed obviously
I have an rtx 3050 in a laptop 💻 overheating is a thing i should be careful with
Isn't that already part of the training process for most small models?
well, I guess they weren't finetuned on this exact environment, so it might help
well but for someone to finetune a model you need quite a bit more compute than you need to run it
finetuning on 6gb of vram sounds sketch
I tried a multi-model style. It's too much latency
Like brain swapping
Trying to make this fully local with colab u get high resources I get carried away puts me off the goal of making this possible
In any laptop with a gpu and 6gb vram
well what they mean is, since finetuning is way more hardware intensive than inference, you can borrow the good hardware in colab to finetune a model to better suit your task
then the inferencing wouldn't take any more vram, but since it's finetuned the model will (ideally) perform better
Ohh okayyy i misunderstood sorry
I will try that
I don't know much about fine tuning where do i learn more about it ?
Final question thanks for all the support guys
I will try youtube if I get any problems I will comeeee back 🤧 tysm for helping
Guys, is jupyter plugin in pycharm better choice than pure jupyter? I mean in pycharm it has much better tools, even fancy looking array display and i have pycharm pro cuz i am currently a student
Hi all, what laptop would you recommend for starting with a data science and ai bachelor’s degree?
Any laptop that isn't a Chromebook.
That's a matter of personal preference. Try both and see how you feel
I tried google colab before because i needed it for university tasks to present some data visualization and i wasn't comfortable with it, but i like pycharm features overall so i really like this jupyter plugin so i can still use pycharm and its project management
So i guess i will stivk with it
I want to make an Project about the skills i learnt and how to integrate all things
I have understanding about - Python, numpy, pandas, streamlit, sql, matplot and powerBI
I am new at discord, finding peoples which can help...
Is optical character recognition still practical tech?
Pretty interesting. Thanks for giving me the rundown
I am just a beginner
And held on tutorials
But wanted to make some projects but not able to do so
I want to learn ML
Thanks! I also have a macbook, but unfortunately I require a laptop with a minimum of nvidia 3070, so I need to buy a windows laptop
And somebody asked me to firstly learn about Data Analytics
But I’ll just wait for the first lessons and ask a teacher if it’s really necessary
Yeah it’s probably for the machine learning course
and now i got stuck not able to find projects
If you need a graphics card for AI, I have heard it is usually just better to rent a server and use that instead
Ohhh that’s sick
Yeah, that's the most practical thing to do...
How does that work? (I’m sorry I’m very new to this)
A server is just another computer
So you have a crappy cheap laptop, that you use to SSH into (remotely log in) another computer (the beefy server) that runs all of your costly computations on
It is the same idea of logging into a raspberry pi from my macbook?
Yes they are both computers
Ahhhh I see
Do you use SSH to get into your raspberry pi
Yes
Yes exactly the same
But instead of spending 2-3 thousand dollars on a laptop
You might spend 100 and then rent a server for like 10-20 bucks a month
Where would I be able to do that?
Ohkay
I'm not in the market, so I will literally just use my search engine and see what prices I see
What should I search for?
https://www.gpu-mart.com/pricing
Here's an example. There's a lot of companies providing this stuff
you gotta learn how to use a search engine 😆

GPU Mart
GPU hosting for deep learning, AI, Android emulator, gaming, and video rendering. 24/7 Expert support for GPU Dedicated servers included.
Also, does it work without flaws?
Just look up VPS, gpu's, machine learning, do research from there
Dont straight up buy, read about what people have written
Not just about specific services, but the entire process
Yess I see, thank you for your explanation 😊, I’m going to look into it
Then you can weigh it against owning the GPU machine yourself
Idk how many semesters you're in class for. But if you can find the GPU in a laptop for $2k, divide the VPS monthly rental price by that and see how many months it would take to cost more
If rental fee is $50 a month, it would take 40 months of renting to cost $2k, or over 3 years
The degree is 4 years
I suppose yes
$2k / 36 months = $55 a month
Hmmm
So if you get something beefier than that, it would maybe be better to buy a laptop at the $2k. Once again, you would need to weigh the option of what the laptop provides
Your laptop will also be running other graphical things when you're using it, so you probably wont have access to the entire GPU resources to program
Is there a laptop you would recommend? If I were to go for a new laptop
No I have no idea
Ahhh okay thank you again for your replies ur amazing
Just looking at a VPS, here's the rental price for 2 years (monthly rental price), and here's JUST THE GPU BY ITSELF


So you could buy the GPU at $2700 and own it, or you could rent it for 2 years which will cost $312
@acoustic barn ^ just things to consider. So once again, just look at hardware and VPS providers and see if things line up and how cost efficient it is to go one way or the other
It almost seems ridiculous, 18 years of renting until it costs more to rent? Yeah, I would just do a bit more research. I'm just saying, what I've heard is it's better to rent servers for this type of thing
Thank you for sharing! Definitely gonna look into it
Follow up - I have ZERO idea why it's showing.. indian? currency in the gpu price on the right? It thinks I'm in mumbai? 🤔
Whatever link I used did amazon.in which is india, I'm guessing
I was thinking what the hell is that currency symbol
Sorry for spamming, I have learned the price of this specific gpu is $80. a much better price 😂 I would probably just purchase that
Yeah what about a recent gpu such as rtx 4080 or sth?
Ohhhhh hahahaha I was so confused I thought it was dollars, so I was thinking “if it’s so expensive it’s best to buy a laptop 😂”
Ohhh no don’t apologise I appreciate the information
Yeah looks like after 6-9 months it's better to own. At that point, probably best to own a GPU somewhere and use it - if you're going to need it for 4 years.
I suppose the whole "rent dont buy" is for people who want to spin up a new application for their company during 1 month or something - train their models, then use it on "normal" computers


Ask older students what they use @acoustic barn
Maybe you could have a cheaper gpu for personal use/more frequent lower end class projects, then when big projects come through you rent one of these bad boys
Ohhh that’s also a good one
Yeah if you could get ahold of a senior or junior and talk to them about how workloads are
Yeah this will be the second year that this program exists here xd
I will ask someone in year two when uni starts
Will they not lie about hallucination
If it already hallucinates wont it believe its information is true
Only when I directly "confront" it by saying it's wrong will it say so. And even then, it's because they want to agree so bad
Maybe some sort of roleplaying like "you are under oath, and perjury is a penalty that is enforced with jailtime" or some crazy shit 😂
idk how practical it is to test hallucinations. If hallucinating scenarios are even reproducible. I feel like a lot of LLM results aren't reproducible. Or maybe I'm ignorant, can you provide static seeds to LLM applications so they always respond the same to input?
That would be the only way I could see any sort of real test driven solutions bearing fruit. But then again, it would form an extreme bias towards that one seed, so 🤷♂️
what are you designing here
human memories are just in yaml format?

I'm joking, I was just referencing that image I responded to
That's fun. I haven't gotten deep into AI, but I have wanted to because I have some of my own opinions on the human brain. It's cool how you're tying your conception of memory together in the process of information flow
Just gotta program the DNA that seeds the whole process, then it can be a reproducible learning agent with access to actuators and sensors 😂 maybe try to give a large reward mechanism towards friendly sociable, non psychotic selfish behavior 😂
LLM's are just trained models that predict statistically likely responses to queries. I still keep an open mind that a lot of tech people are skeptical of AGI possibilities. The brain exists in the physical universe, I dont see why it can't be recreated outside of our biological context
I think the human brain tries to put everything it interacts with into a sort of mental state. And we are always predicting where we expect those states to be. And as we interact with the world, it adjusts how our inner state representation looks and behaves. And as we further interact with the environment, our prediction of entities improves. You see a car driving down the street, you expect it to continue and it does. When it crashes, that is surprising. You know it can happen. Sometimes it's surprising. However, sometimes you see somebody driving erratically and you sort of expect an accident. It happens, still surprising, but not as much
You also expect your kitchen to be in a "state" of configuration. You leave your room, or enter your house, and are thirsty, so you move towards the state that should satisfy your quest
If it's a natural or instinctive decision, I can see it coming first. But some decisions you truly have to contemplate over
Then the act of deciding, it sort of doesn't matter which "happens" first. I would presume the "conscious" awareness must lag a bit
You can only be aware of something once it exists
Awareness is probably just your own ability to measure the state of your mind. Well, your mind reaches that state before it can be measured
Upon being aware, you are in a state of review, and you still have the option of "changing your mind"
You've trained your brain how to make decisions
It's been trained over a lifetime of you making decisions, right or wrong, then reviewing them
Even if you make a decision, you can review it and adjust it or change it completely
All of which requires the awareness and review process
You could choose to throw yourself in front of a bus, but you are not passive. It's always an option but your awareness is saying it's probably not a good one
Maybe sometimes you want to quit your job, but you still decide against it. Not passive at all
Yeah I mean we have a brain stem that breathes for us, or makes the heart pump. There needs to be an underlying order that we don't consciously focus on or we would get nothing done
If we had to be consciously aware of the prediction mathematics and calculus that goes into the process at all times it would be overwhelming. However, you can review and report on how you predict things using your words. It would be extremely verbose to lay it out in detail in realtime 24/7, but you can get quite introspective
When you say evolution, you mean neural network architectures predisposed from dna? Because babies still have to "learn" and train their models through experience
There's certainly some architectures already setup from dna. And initial seeding of its "training set" potentially which is why most babies act the same
I suppose that would come from evolution pressures, yes
Maybe no initial seeded training set, just randomized. Crying and all that is just lack of emotional control (training)
Hey guys, I'm looking for a way to parse a pdf file into a format like:
{
"title": "This is the title",
"outline": [
{ "level": "H1", "text": "Introduction", "page": 1 },
{ "level": "H2", "text": "Main content", "page": 2 },
{ "level": "H3", "text": "Conclusion", "page": 3 }
]
}
pymupdf has been my primary basis to extract the content from the pdf but any idea, what can be done further from that, simple heuristics extraction doesn't always work for all the different types of pdfs
P.s apologies for disturbing the existing convo
#data-science-and-ml message
Spoke somewhat about this earlier. But also you can look into the python module pdfplumber which can parse pdfs
Okay that ocr model unfortunately sits quite a bit out of my size constraint and yes pdfplumber does extract the content of the pdf, but accurately classifying what are titles and what are headings has still been a challenging task
Especially when u take into account more complex pdfs
Hello so I am new in coding and I wanna learn data science and I wanna get the basics in math first where can I learn? Any recommendations
Given the mostly unstructured nature of the PDF format, everything would likely need to be done through heuristics. This could be things like detecting headers from font usage or the document outline or tables from the way items are grouped. Fortunately here, there are multiple existing tools for this, primarily for use with LLMs but perhaps useful here, such as docling, markitdown, and PyMuPDF4LLM to name a few.
Depending on where the document was sourced though, it's possible that it already includes similar information in the form of logical structure. Unfortunately, I'm not sure if anything supports a high-level interface for it though most PDF processors will let you access the StructTreeRoot key where this information is stored. So that would probably be a last resort.
I have explored docling and pymupdf4llm as of now, docling does seem to do a decent job although I have to probably switch to an onnx runtime to fall under <200mb time constraint.
Just tried out pymupdf4llm earlier and it's pretty solid as well but not quite enough on its own, I'll try applying heuristics and see where this goes.
Haven't tried markitdown so will do that and see.
and I'm surprised this would be done through heuristics ideally, I thought a light weight classifier or a visual analysis tool maybe using yolo finetuned on a dataset would be a better approach.
and yeah I wouldn't bank on that, the ones I'm using don't have that yeah.
thanks though I'll definitely give this a shot
hi
how long would you say, on average, would take for someone to get a grip on computer vision?
someone who knows programming, but nothing about computer vision or ai in general
claude 4.5
lol I didn't think I asked too much too often to hit these errors

Hello guys, hope you are doing well. I have problem I cant solve. I try to deploy my ML model with streamlit. its the first time I do this. I ve been said that the model and other relevent files should be in the same directory than the streamlit app python file, which is what I did. however when I run the code I got the error message ( that I wrote in the code ) : "Model file not found! Please ensure 'los_model_complete.pkl' is in the same directory."
I do not understand whats going on, if someone can guide me on how to solve this I would appreciate it very much, thanks


P.S: I made a mistake in the code screen shot, the file should be los_model_complete.pkl and not los_best_model, I changed it but it still doesnt work
issue solved, thanks anyways
I'm looking for a realistic e-commerce dataset. Does anyone know any sources outside of Kaggle? My next bet was looking into synthetic data creation with Python functions since it's just for a showcase project
I'll resume the convo: wtf are you talking about
Ai cannot "infinitely recycle energy" like a perpetual motion machine
I'll resume the convo: wtf are you talking about
is a good quote
haha, well, I am excited to hear the thought
hello, chat. I'm new here and wanted to share my data cleaning/ visualization project. Just looking for some feedback from you, so is it ok if i share a link on the gihub preview and a repo here?
sure
Thanks) My project will be especially interesting for those who're interested in media, politics and journalism things
So I was looking at the Reporters Without Borders data estimates on countries' press freedom index, and thought that if we could see this data on the graph along the years - it could me much more informative than a simple timestamp that they have on their infographics in a form of worldmap with countries on it.
So here I've collected their data from 2002 and until now about the counties ranking in press freedom, their score and different factors (which are very valuable, but initiate only from 2022.
You can play around with it, selecting different countries, years and factors. Again, could be very informative for those who appreciate a truthful journalism.
And here's the link: https://vlad-gby.github.io/rsf_index_visualization/
And a repo with files and a notebook (readme is not ready yet, working on it): https://github.com/vlad-gby/rsf_index_visualization

GitHub
I decided that the data form RSF can be structured better and in a more informative way - in a form of interactive graph - vlad-gby/rsf_index_visualization
thank you
@modest badger the whole point of a PMM perpetual motion machine is to make a way to infinitely recycle and use heat energy to power machines or in general support civilization. the problem with every life form and physical object is its subject to entropy and loses either its structure or energy.
the only way we can avoid death or extinction is by finding a way to reverse or manipulate entropy and bypass the laws of thermodynamics
so far there doesnt seem to be a way to do it
it seems like we all will die with this bright staryy universe
whats even more terrifying than death is a cyclical universe. scientsits have said that our universe will never repeat again and this is likely to be the first lifespan or itereation of the universe. whether that sounds stupid since this is the only known universe as if there were more. well my point is scientists said that we will never be created again through another big bang or big crunch
it still worries me since there is such a possiblitiy for lifeforms on earth to exist once more and billions of animals suffering and being exploited and humans suffer as well
i dont wanna come on earth anymore
so your angst is not just your own mortality, but the universes?
Me when I'm not isent from transformation and entropy as a physical object within the universe

But how is this related to data science and AI?
But it can do the opposite
if you want that for all pdf, yes you should use heuristic ... simple analyze font type/size and bold-flag does only work for 50% of all cases.
in addition you need the position, is it a bit separated from other text-blocks max 10 words or such things you will run in a never ending story ^^
iv tried that for one week ^^
What are some good resources to get started with AI and ML? I barely know anything about it. And please a more "practical" approach. I couldn't keep reading the Microsoft AI tutorial on Github just because it was more theoretical than practical
Don't fall into the trap of thinking practical means useful and theory means useless. They're two sides of the same coin
!resources data science
Resources
The Resources page on our website contains a list of hand-selected learning resources that we regularly recommend to both beginners and experts.
o thanks
I just want the tutorial to be more interactive. I can't handle just reading 5 chapters of something and doing nothing
Yeah, and you probably wouldn't learn anything from that either. Whatever resource you use should be interactive or give you an exercise to do on your own or something
mhm yeah that's what I meant by theoretical
That's not really what theory means. See my prior message
yeah sorry, bad phrasing. I just wanted something more interactive 😆
what module should i use to make an ai
What are you trying to do
Like what is this AI supposed to do?
Hello, im trying to make a suspicious activity detection model given as a challenge to me by my prof, my current plan is to make a shoplifting detection model then build upon other activities. Im going to use yolo11-pose.pt model to get the keypoints, label each frame and feed them into an LSTM model so it can predict whether or not there is a shoplift. Is this a good approach, i really want some advice. I havent started coding im only looking for approaches. Any help is appreciated :)
learn the working of models like linear regression, logistic regression then implement them in python then work up to more complex algorithms
yeahh I've been doing that, maybe an ml model might work
thank you lisan. what a perfect answer you gave me about my issues. i really agree with #3 as well as the rest of what you said. I suppose there are ways to live much longer or possibly live nearly forever. although we may never defeat the laws of thermodynamics which governs us and energy exchange. i guess im just worried we will be trapped to do the same things over and over forever in a deterministic universe. i personally believe in free will but if time really is similar to a flat circle or even a clock i assume it would repeat but like you said thats incredibly far into the future and better not to worry about it
not sure if this is the right place to ask but does anyone have experience with publishing applied maths papers?
and if so what plotting library did you use for graphs
i cant decide between plotly and matplotlib, but im open to other suggestions too
matplotlib is probably more often used for academic papers than plotly, but it doesn't ultimately matter. either one can generate images of the plots.
I used matplotlib when I was in academia, and I hate it.
the plotly API feels less intentionally unintuitive than the matplotlib one.
thats really helpful thanks a lot <3
You have this project and the accompanying thesis, which is one of the most advanced in the field (the model is under a non-commercial license). It’s up to you to rewrite and train the final model. https://github.com/TeCSAR-UNCC/PoseLift

GitHub
This directory contains the PoseLift dataset published in WACV 2025 conference. - TeCSAR-UNCC/PoseLift
well he aint wrongl AI = 0 because thats the amount of value it provides in that specific usecase
Seaborn is a wrapper library around Matplotlib that has more complex built in graph types, native DataFrame support, and slightly better visual defaults, I always recommend it if you're going to use Matplotlib
I just use plotly
But it doesn't make it less clunky to use unfortunately
I'm going to have to learn plotly sometime
Oh that helps a lot, thank you
Are GANS dead? Like, what’s going on? Pump the latent dim into robots so they can learn quicker and let’s make everything automated. Let’s go!
The answer for "why is X not used" is usually either: does not scale (it's not a bunch of copy pasted things you can just increase N on), too hard to train, or does not fit modern hardware (GPUs). GANs are too hard to train.
I guess I can add the fourth case of lack of software ecosystem (tooling) surrounding the idea.
Hey all, I’m Ali from Code Craft — I made a beginner-friendly Linear Regression tutorial in Python. Excited to learn with you
Stable diffusion is better and GANS take forever. I don’t know they had their day.
👋 Hey everyone!
I just finished making a short and beginner-friendly tutorial on Linear Regression in Python.
✅ You’ll learn how to:
Import and work with a clean dataset (included)
Train and visualize a simple linear regression model
Predict house prices using scikit-learn
🎯 It’s aimed at new ML learners who want a clear, step-by-step walkthrough with no fluff.
📊 Dataset (CSV): https://drive.google.com/file/d/1rZ5OhntQeJ5gA7WtWFAWbntgwznTx10X/view?usp=sharing
▶️ Tutorial (14–15 mins): https://www.youtube.com/watch?v=zBk72AV_weg&t=76s
I’d love any feedback or suggestions on what project I should do next. Thanks!
Google Docs

🎯 Learn how to build your first Linear Regression model in Python and use it to predict house prices — step by step!
In this beginner-friendly tutorial, we’ll cover:
✔️ Importing libraries
✔️ Loading a clean, custom dataset
✔️ Splitting the data into training and test sets
✔️ Training a simple linear regression mode...
I lot of things in ML can work / are valid options, but not used due to simple practical issues, like being too annoying to work with.
The options are also narrowed down by available hardware (although FPGAs exist so you can put this under "too annoying to work with" too).
I don’t know, it used to be the big thing. But it’s just two NNs fighting. autoencoders are better by a lot.
Totally agree, but why is it like that
Computers that we have these days are a miracle of modern science and international cooperation. It's a miracle that we have any, and as many options as we do. Ideally we would have way more types/options though.
Then on the software side it's driven by open source, which is driven by a few very motivated individuals (working for free) that are just rare, like 1 in a million rare (combination of skill, obsession and resources (free time mostly)).
I know right, I cant even Imagine how they created stuff like this, but do you want to check out my chanel, I would for you to support
I started today, and made my first video
It is about LinearRegression
Yeah
And if you do, suggest what I should teach next
I want tensor flow full tutorial
Ok I will try!
although I am not that good
At tensor
But I will give a beginner
Tutorial
If that is ok
Ok brother
Self-promotion is not allowed
Anyway, I don't recommend learning to use tensorflow. It hasn't been popular for several years
Just use pytorch
I think i finally found the "book of everything"
how old are you?
https://metr.org/blog/2025-07-10-early-2025-ai-experienced-os-dev-study/ fascinating, really well written summary foe the layperson
does anyone know where i can find just a very basic premade ai network and weights to run on my home computer?
nothing too fancy, just something i can run on my cpu
Open WebUI is an extensible, feature-rich, and user-friendly self-hosted AI platform designed to operate entirely offline. It supports various LLM runners like Ollama and OpenAI-compatible APIs, with built-in inference engine for RAG, making it a powerful AI deployment solution.
Hi Ali, I'm young coder too and Interested with ML, your awesome project interested for me, I want to know more about this project
Can anyone give me some advice on how to detect if a person is looking at their phone? Are there any libraries which could help me achieve that? I found this gazetracking library but its meant for webcams. Ig i could still use it but its not the greatest?
Absolutely, my friend! I'm launching a free YouTube course called "Regressions" — a beginner-friendly series covering the top 5 regression models. I’ll not only break down how each one works but also show you how to choose the right model based on your dataset. Let’s make machine learning simple!
Hi, anyone know how to get KitLive working with OpenAI? https://discord.com/channels/267624335836053506/1397500697842421862
@sour hamlet your message was removed for advertising
Yes bro, hope we can work together after I learn enough about ML, keep share your knowledge
I might do a live stream of an Ai "Hackathon"
anyone know how I can read a pdf table that is formatted like this?

i tried to use camelot but it gives me this

Hey guys\
Hi guys please suggest to me what I should add in my GitHub profile
anyone have recommendation to have a more efficient code here (it works but I don't like creating another temporary dataframe I want it all in one statement):
import pandas as pd
def assign_id(df_,value_list):
previous_value = ''
for i in range(len(value_list)):
if value_list[i] != '':
previous_value = value_list[i]
else:
value_list[i] = previous_value
return value_list
def tweak_df(df_):
temp_df = df_.filter(items = [0,2,3,4]).rename(columns = {0:'END_ID', 2:'PART_NUMBER', 3: 'DESCRIPTION', 4: 'QTY'}).drop([0])
updated_val = assign_id(temp_df, temp_df.END_ID.values)
(im basically trying to replace the values in one column based on the previous values before it since some values are empty
for each value in the END_ID column, you want to replace empty-string values with values from a different series?
from the previous value of the same series
if empty-string values were previously NaNs, and you replaced them with empty strings, do not do that.
replace the empty strings with NaNs and do ffill (which is forward-fill)
so for example if I have:
0 hello world
1
2
3 hello
4
Always represent missing data with NaN and not with anything else.
oh i did not think of tht
my missing data is empty strings
so i replace ' ' with NaN
np.nan
and then use ffill
very good suggestion haha
did not think of it
if the CSV is like ,,3,,, the actual empty strings should be interpreted as NaN
if the csv is like "","",3,"","", you can change the parameters of read_csv to interpret "" as NaN.
that sucks
its pain but I have no other choice
all the data at the company i work at is all in pdfs
i mean I could convert all the data to csv or excel but it would take me years cuz i would need to do it all by hand
its a weird ass and long ass table to parse
so using camelot helped me to put it in a more readable form
Have any of you ever used a transformer for time series? If so, was it encoder-decoder ish?
what type of task you doing
classification
forecasting?
Forecasting. I just hate using RNNs all of the time.
that's fair. have you looked into TFT?
No, this is the first time I considered anything out of RNNs, ARIMA, SARIMA, prophet, or regular ML models. People have had to use transformers for this right? Is TFT good?
Well the one issue with time series data is that it is usually multivariable for most problems, which can lead to slow training times, but from my experience, TFT does well with forecasting. https://arxiv.org/pdf/1912.09363
@lapis sequoia also it depends on the nature of you data
Panel data , frequently updated, reliable sources, fairly consistent
how many columns
Are you asking this because you want to know if it’s multivariate?
ya
wanna know if its bivariate uni or multi
A good amount not over blown
ok ya TFT should be good but I would start with a subset of dataset and experiment
with other models aswell
are you strictly stuck to a transformer-based model?
Is TFT anything like a HF transformer?
if by HF you mean huggingface? than not really.
Yes, I mean hugging face. I am honestly more comfortable with that than really any RNNs or prophet .
!pip darts

A python library for easy manipulation and forecasting of time series.
Released on <t:1751200606:D>.
darts supports the TFT model
so you just got to import it
and you can play around with it
it is inspired by HF transformer but it has modifications and additional features that make it specialized for its task
Is there any HF transformer that is used a lot for time series? I honestly cannot find much. And thank you.
not that I have used but I can try and find some rq.
found this in the docs
I will try something. It’s not a huge deal just waiting epoch after epoch and then boom, not even as good as an ensemble method. I appreciate your suggestions.
ensemble methods are crazy slow
I know
from my experience
took me 7 days to training on a simple dataset
@lapis sequoia
this looks promising for HF based
Thank you. I was about to use T5 for whatever reason
🚀 Just Dropped: Build Your Own AI Chatbot in Python (Part 1)
Hey everyone! 👋
I just released the first video in a free series where I teach how to build an AI chatbot from scratch using Python.
✅ No libraries. No shortcuts. Just pure Python and real learning.
📹 Watch here: https://www.youtube.com/watch?v=2p9hr53iBYY
🤖 In this part, we build the bot’s brain + memory — and it actually learns from you as you chat!
If you’re into:
Python projects
AI / machine learning
Building real-world tools
…then this is for you. Would love feedback or ideas for future parts!
Let’s build smarter tools together. 💬

🚀 Welcome to Part 1 of this beginner-friendly series where we build an AI chatbot in Python — from scratch!
In this video, you'll learn how to:
✅ Create a chatbot that responds to known phrases
✅ Teach the bot new responses during chat
✅ Store the chatbot's brain and memory using JSON
✅ Save every conversation and response fo...
Hi, anyone know how to get KitLive working with OpenAI? https://discord.com/channels/267624335836053506/1397500697842421862
Or any suggestion for low cost 'receptionist' AI agent?
I'm building a SQL Ai agent, And I'm a bit lost
Any public repository that can bring me some help?
I feel like the sentiment for a good chunk of people still is that complex deep learning models aren't as great as advertised
for one they need a lot of data; while we have that for images and text that might not be the case for your time series
they're also computationally expensive compared to other options when the gain could be small
Its really good but too basic for 2025
Hi I'm back, As I said I will learn this course after finishing previous courses. I'm going to take this course. How's your progress?
Hey, i’m a student really into finance and quant stuff, and I’ve been thinking of starting a project in that space (something hedge fund-ish, infra/research focused). Just wondering if anyone else here might be interested in teaming up — could be a cool opportunity to build/research something legit and learn a ton along the way.
Nothing formal, just seeing who’s out there. feel free to dm!
I really like that you said that. I agree completely. Most people make this way too complicated when simple methods can be used and don’t take forever and are more direct and faster and accurate. Everything in data doesn’t need a Neural Net.
I know that it is too basic my lan was to keep making it better, but in the end of my course I will teach how to make a chatbot that learns over time, more advanced
My friends requested it bbecaue they want ot learn about ai and machine laering, although this was not but my next video will be some ai to it
wait arent transformers by definition designed for timeseries?
well generally you'd use encoder for classification related tasks (i.e. given a time series, identify abnormalities or something idk) and you'd use decoders for autoregressive purposes
encoder + decoder is good for seq2seq
transformers were originally designed for NLP, benchmarked on translation tasks
yes right> because they were designed for sequence data, which is essentially a superset of time series
there have been variants for visual data but I'm not very familiar with them
that is definitely a stretch of a definition imo 😅
attention doesn't necessarily imply timeseries but it's often used in timeseries data
I'm using timeseries and sequential interchangeably
actually to drive that point home even further, a lot of language models add positional encoding to the input data, because otherwise the transformer wouldn't know where timesteps exist in the input in relation to one another
whereas you'd get some kind of notion of position in a RNN for free just based on how it works
but the basic abstraction you use to think about transformers are queries, keys, and values, which has nothing to do with position
actually if you want an example of non-sequential attention, check out global style tokens for tacotron
they do but the attention layer would not consider position in weighing each step
positional encoding allows it to do this
right
yes exactly
it's a question of who thinks it's sequential data
without positional encoding, you're interpreting the data as sequential, but the attention layer doesn't care
with positional encoding, the attention layer can treat the data as sequential, or at least account for position when computing attention scores
this is only indirectly related to the attention talk but I thought it was cool
some TTS models perform a small one-dimensional convolution over the input data prior to giving it as input in a RNN
so if you're trying to synthesize "Hello", it has the effect of blurring nearby characters into each other
they are built for time series as much as CNNs are built for timeseries
so instead of considering H, e, l, l, o separately, it would consider H-e, e-l, l-l, l-o together
and I think that's neat
yeah
I think it's loosely related to the n-gram concept from NLP
and it works really well with speech synthesis where a character by itself isn't enough context to know how to pronounce it
This is a meaningless statement
the thing is text data has some very specific properties that don't generalize to all time series, like:
- we have a lot of text
- text heavily correlates with each other on multiple levels
etc
like I don't think there's even close to a silver bullet type architecture to time series just because how broad that entails
like the position of a pendulum swinging back and forth on a moving cart could be a time series, and so can the population of rabbits and wolves in an area
ahhh that makes sense
yeah
It's been shown that if you just scale it up enough and train long enough it basically learns to do positional encoding on its own. Having it helps by it not having to waste a bunch of time and resources on learning this though. Interestingly, the thing it learns resembles grid cells (which positional encoding does too) (hinting that this may be a universal solution to positioning problems that biology has also found).
(RNNs have been shown to learn the same thing too)
I wouldn't be surprised, but it would be based on patterns it finds in the data
mathematically any single attention layer has no concept of position or a local space around different timesteps in the input or anything like that
To perform well it needs to reinvent space.
(And grid cells it seems)
does anyone know if cuda 12.9 plays nice with PyTorch?
I have 12.9 and torch is running fine for me
which version torch?
whatever the latest is
what GPU are you using?
actually to clarify I have 12.9.1 installed at the system level, but the cuda in my virtual environment is 12.6.4.1, but they are working fine together
it's on a 3090
your PyTorch is using the 12.6?
it's whatever the PyTorch module has listed as a dependency
I wouldn't be surprised if it takes many more than one block
this paper tested it on models with 125 million to 1.3 billion weights
they saw it learning positions within 4 layers
so you are using 12.9 with Pytorch or 12.6?
hm I guess it must be 12.6 but it is not incompatible with a system installation of 12.9
you might want to disregard what I said if you're intending to run it with 12.9, although I don't know if it's compatible with the current stable version
sounds like you're not sure of anything
right, like i said, disregard what I said before
It is not meaning less both algorithms work with time series data but neither was specifically built for it.
book or online training to learn code ?
!resources
Resources
The Resources page on our website contains a list of hand-selected learning resources that we regularly recommend to both beginners and experts.
Hey guys!
My name is Romie and I am an aspiring Data Scientist!
No formal schooling and currently hold a position as a data analyzer!
My company is small and no one has degrees. The data literacy is very limited so I'm traveling through uncharted territory.
I just started Learning Python and I am great need of a mentor or someone to point me in the right direction. My co-workers have no interest in data, so most of my conversations are diluted to fit my audience.
Someone '@ me or message me. I'm hungry to learn.
What should I learn first. Mathematics? Fundamentals of Language? Someone point me.
Thanks!
Romie
🚀 New Video: Smarter Python Chatbot That Understands Typos (Part 2)
Hey everyone! 👋
Just dropped Part 2 of my free YouTube course where we’re building an AI chatbot in Python — this time, it gets smarter.
✅ Now it can understand fuzzy input — like if someone types "helo" instead of "hello," it still gets it right.
This is where the AI magic starts!
📹 Watch here: https://youtu.be/gI4ftsWQSXk
🧠 Built with basic Python + fuzzy matching — no fancy libraries needed.
If you're into AI, Python projects, or building tools that learn, check it out and let me know what you'd like to see in Part 3!

In this second part of our free AI Chatbot course, we take our basic chatbot to the next level — by teaching it to understand fuzzy input!
That means: if a user types “helo” instead of “hello,” the bot will still know what you meant. 🧠
✅ What you'll learn in this video:
• How to use difflib.get_close_matches() for fuzzy ...
getting nvidia to install is fucking tedious
you'd imagine that a trillion dollar corp wouldn't be so inept
yeah
to be fair, Microshit is worse
and it has been worse for decades
like, why the fuck do I have to iterate over goddamn visual studio versions while installing nvidia?
slow mode
it has a "feature" called Nsight, and there are versioning issues. Added to that are whatever mysteries that happen in your own machine (GPU versions, which OS, etc)
Anthropic has an excuse. It is barely 4 years old
I just want a local CUDA for PyTorch (another versioning headache)
done 🫡

had to install the cuda toolkit 12.9, then find out that Pytorch only likes 12.8, so uninstall, restart, redownload 12.8, install & discover that it hanged on the Nsights stuff.
so, I had to then wipe the computer clean of nvidia 12.8, Visual Studio 2022, then reinstall the same fucking Visual Studio version and nvidia version and then it worked
like WTF man
there is an Nvidia app that doesn't seem to work unless you have visual studio installed. The whole thing is bonkers
so, after installing 20 GB of Visual Studio, another 4 GB of nvidia, I can write a 3 line python script! Woohoo!
probably the visual studio c++ redistributables?
ah just noticed the message is pretty old
not sure, tbh
these packages are so sprawling and over extended that it is probably unknowable
Hi does anyone happen to have a prompt script for sending prompts to a LM Studio llm with vectors from a qdrant database thats working? I cannot seem to get mine working after days of trying...
Hey everyone, I’m a Biochemistry grad diving into ML for bioinformatics. Just shared two Jupyter Notebook projects analyzing ALAS1 gene expression (1000-row Bgee RNA-Seq dataset) on GitHub (MIT License):
ALAS1 Expression Analyzer: Normalizes expression & read counts to compute Expression_Combined, with stats and histogram.
ALAS1 Read Count Visualizer: Plots trends over time with linear regression.
🔗 Code: https://github.com/Hi-Script/biochemistry_ml_mini_projects
Why: ALAS1 is key for heme biosynthesis, prepping for ML like LSTM.
Feedback: Ideas for ML models or code improvements?

GitHub
Jupyter Notebook projects analysing ALAS1 gene expression and read counts for bioinformatics. - Hi-Script/biochemistry_ml_mini_projects
@old rivet I don't understand what that trend line is supposed to be trending on
like, is it appropriate to toss out those apparent outliers (like the one around 150 minutes)?
the outlier might not correspond to an actual time point but rather a data point’s position I think it’s tied to a specific strain or condition, it could be biologically meaningful e.g., a strain with unusually high ALAS1 expression. What do you think?
you could project the points to the y-axis, and thus build a sort of probability mass function. From there assume some sort of distribution, and remove outliers. But, that is just clumsy, surely they mean something physical?
I am not a biochemist. But from a pure time series perspective, that trendline is somewhat problematic. It doesn't seem to have any meaning
torch success after last night's hair pulling frustrations:

pretty cool that pip3 install ing pytorch brings in mpmath, arbitrary precision floating point computation. Also, sympy
Thanks thanks for this, an outlier at ~150 minutes, which I kept after IQR analysis, suspecting it’s biologically meaningful (ALAS1 is key in heme biosynthesis). I want to:
- Improve trend analysis (e.g., handle outliers better).
- Predict future h.
ALAS1_Combinedvalues (time-series forecasting). - Classify strains by expression patterns (e.g., high vs. low).
ML Ideas: I’m exploring:
- Robust regression ( Huber) to reduce outlier impact.
- LSTM for forecasting
ALAS1_CombinedoverTime_min. - K-means clustering to group strains by expression.
Any suggestions for robust ML models or preprocessing? better ways to handle outliers or prep data for LSTM/clustering?
forecasting time series is probably best done via ARIMA (classical, i.e.) approaches. I am not sure LSTM is interpretable enough. What do you plan using K-means?
But, again, not a biochemist.

We've been exploring local models for marimo lately and came to the conclusion that you can very much get a performance boost even if you don't resort to the large vendors. However, to really benefit most it might be most helpful to pivot your expectations and way of working slightly.
00:00 The case for local models
01:58 The setup
06:06 The p...
Have use sql in data science or mostly use pandas ??
SQL is mandatory
Bro can any one tell how much math is required for data science
I'm 14 rn and I really interesting in coding but I'm so scared and overthinking because of the ai, what do I do T-T
I have a project in mind that should "leverage" ai, but I feel is more of a systems progarmming problem than anything.
I simply want to detect, through optical character recognition, the XYZ coordinates of a minimap. The minimap is not always on the screen, however, so I will need to also detect when the minimap is available
Will I need to manually take a lot of static images, and label them for where the minimap is and if it is available? What sort of process do I need to follow to have a classification/identification network for this?
hey, i have a task and i dont know how shall i proceed
i have 700+ tables having polution related data, i stored them in bigquery and made excel modules to fetch them.
now i want if user give me a query like
tell me co2 emission of aniak electricity plant , then the source should be searched for in the tables.
i have made a graph rag for that (made metadata of tables and stored in json) and fed it to gemini and asking for response as in "which dataset u think this can be present"
but gemini response is very inaccurate, is there a way to make it accurate or is there any other way for me to get the source info
Information overload
Dont take in everything at once. You need to learn how to program first
You didn't study calculus or geometry when you started school. You began with the basics, to give your mind context and a framework of logic to reason with. That will aid you in understanding more complex topics in the future
you could just run your OCR regardless of whether the minimap is on the screen and then just parse out what it gives you and see if part of the parsed text contains coordinates, if not, the minimap is not on screen, but at that point you don't really care about that anymore, lol
let me send u the prompt

i think my metadata is abit loose but still im not sure

and i have these categorized based on country -> material -> sector
1.5 flash
uhm but wont that be time taking, as i may have 100s of inputs
but my approach is fine right?
i mean, it cant go more optimal
but how would i know which dataset my source input is
for example if someone say
tell me co2 emission caused because of crops in france
then my llm will see the metadata -> country (france)-> datasets in france -> oh its a crop (agribalyse dataset) -> give output as = your source can be in 'agribalyse'
then i perform normal fuzzy match in this dataset and show user the co2 emission
yes bcz i cant see each source in all tables as i have 700+ im using llm to narrow down it to one or two tables
so if i give wider description of all datasets and use a reasoning model, i can expect better results
is there any better approach or this llm thing sounds good
oh
😭 im short on tokens too or else i could have used multiple prompts
Gemini?
im not so worried about the data as im using openly available ones but still ill take care of it
thank you for your help
Has anyone worked on any application
Like which can do data analysis, and can do forecasting on the user data
hey everyone
i am into learning ML so i wonder if someone can assist me
like how to start and what should i learn is there any resources you recommand
i was going to say the exact thing aswell
that is interesting
would you like if we start together ?
well im pretty much as lost as you but i dont mind at all!
Figured it out.

100% accurate now up to Len 100

oh nice! was that with a RNN with a transformer on top, or only transformers?
i'd be really curious to see the weights either way
and if you had to add positional encoding or it's working without it
also curious if you think two heads are required for this or if only one is necessary
uhhh
Its a transformer on top of a bi directional GRU classifier with like a little extra custom classafier injected in
idk if its necessary to have 2 really, but it helped a lot
it was getting caught up on palindromes made up of palindromes, and that seemed to help
like for example "wee kek kek kek eew"
Try to start with simple linear regression models.. Get the book, data, and compute the model on paper
PS: No one said it's going to be easy👍
I didnt add positional encoding like, directly
ah I see, I guess the GRU is learning some kind of position
I did give it this though
which like is kind of cheating but not really
def char_reflection_score(s):
"""Calculate symmetry score based on character reflection."""
s = ''.join(c for c in s.lower() if c in string.ascii_lowercase)
n = len(s)
half = n // 2
if n % 2 == 0:
left = s[:half]
right = s[half:]
else:
left = s[:half]
right = s[half+1:]
right = right[::-1]
def embed(c):
return (ord(c) - 97 - 13) / 13 # zero-centered
vec1 = np.fromiter(map(embed, left), dtype=float)
vec2 = np.fromiter(map(embed, right), dtype=float)
diff = vec1 - vec2
return 1.0 - np.mean(np.abs(diff)) # 1.0 = perfect symmetry```it just splits a string basically, encodes it to a vector and then linear normalization
Whats an idea of the project?
i just wanted to explore ML, ive never done it before
so i trained a model to identify palindromes
I was joking with sdomeone I should write it in JS and release it as an NPM package lel
I would recommend to read about least squares algorithm, linear regression algorithm and try some simple data (about 50 lines of data)
oh im done now its 100% accurate lol. Can only beat this horse so much
Now get the multilinear regression with 10 predictor data))
Oh no
I do wanna play with RAGs and LLMs though
Sounds scary tbh.. CS GO rules
Retrieval augmented generation. Like you can give it structured data that gets kinda injected into the prompt. It’d be cool to datastruct the whole electrical code book.
Idk.. I do like mine image recognition app with Telegram bot interface))
Based on on logistic regression
What’s it ID
Im trying to restructure it.. And I dont have server for 24/7
I also think if I have to split into 3×3 segments, rather than 2×2
hey guys, hows it going?
please anyone have an idea of how much it'd cost to build a chat bot?
i'm not asking for a job or offering one, i just want to confirm something
From scratch? Millions of dollars
Free?
are you for real?
please i need to deliver an answer
At least he has to think about renting server, I guess
Chatbot for discord?
hi guys does anyone have a good/decent resource to learn ai? im kind of struggling rn
What have you been trying to do?
Hey can anyone suggest me for numpy reference documentation, which I should use
Or some resource which I should use
The numpy website has its reference documentation.
Which tutorial I should follow
I am in data science field
How things were working , was your input and how you were getting the output
how does one get into nlp
let me confirm from my end, I only use their ytube
it's not from my end
I wanted to build a chat bot for discord just as practice since I’m new to python. Would you guys recommend that?
building a chat bot from scratch is exceptionally complicated and expensive, and not something I would recommend. or which is possible.
making API calls to existing chatbots is just general software development and doesn't involve any actual AI.
What are some projects you would recommend for me to do as practice?
making a basic classifier
You might face burn out and frustration like me 😅 , just start small and simple
This is a cool project but I don't understand how they're fixing the problem of reward hacking they describe in section 3.1 of the paper
I guess the idea is that they're qualitatively evaluating the architecture in addition to mazimizing performance, but that would just mean they're cherry-picking models that do well and look nice as opposed to just cherry-picking models that do well
something pretty easy to do would have been to hold out a few benchmarks that aren't part of the fitness function to show that the model generalizes as opposed to just optimizing for all the benchmarks
they're evaluating models on the training loss? wtf
I like it
Analysis for all life cases.. How do you input the data?
How do you guys keep your servers alive for 24/7?
Keep your desktop work for 24/7?
You use your desktop as server?
Ohh
How much do u pay?
Ohh.. Okok I see
If it works, you can make huge staff based on that data
Yes, we can discuss it on pm
I mean you can implement ml with it
For different apps
Are you good with the frontend programming?
Something like telegram bots?
Have you heard of telegram?
You can make a bot for telegram
Ohh okok
You write them from scratch or using specific libs?
Did you create discord.py by yourself?
Lmao ok😂
Yeah, in terms of bot creation the only one I made was in telegram
Yet
I like it😂👍
Good luck, man. Ill be back little later
no it's actually community made
Can I share Logos
Against my better judgement I spent most of today looking into their results, lol
I have a lot of issues with the methodology of the paper but I put some visualizations together based on the lineage of different models
So first off this thing generated 1771 models and only 106 of them were actually selected as being good based on some iffy criteria

the vast majority of generated models performed worse than their parent

here's a visualization that shows the lineage of each model along with its score
it looks to me like this is maybe more akin to a genetic model that's just throwing stuff at the wall and seeing what sticks than anything that's actually making intelligent decisions about what to try next
Here's a better version of the lineage visualization, no change to the data, just better axis labels

what issues do you have with their methodology?
there are a couple of things
all qualitative measuremeants of the model are done with LLMs
the qualitative LLM scores given to their models don't seem to be explained or explored in any depth and I don't know how it compares to something like a human rater, or code complexity measures, or anything that might show how it compares to other ways of evaluating code
if I take the language they use in the paper literally, they seem to be using the training loss rather than a validation loss when computing the score, which is useless
they don't use statistical tests to show if their results are meaningfully different from the human baselines
they only give a consolidated score for the 1,771 candidate models, so it's difficult to evaluate how the model performance changed as they adjusted the number of weights and training data size
it appears that some models might have performed worse as they scaled them up, which suggests that improvements are more due to random noise than actual improvements in the model
none of the training code or code that computes metrics are available in the repo
lol I think that's it