#data-science-and-ml
1 messages · Page 155 of 1
a while back, someone i know asked similar questions regarding indexing and slicing subarrays on stack overflow. maybe my answer helps you some https://stackoverflow.com/questions/76627832/understanding-the-behaviour-of-advanced-multi-dimensional-indexing-on-a-4d-ndarr

Stack Overflow
Scenario
I have a 4D ndarray consisting of multiple 3D images/voxels with dimensions (voxels, dim1, dim2, dim3), let's say (12 voxels, 96 pixels, 96 pixels, 96 pixels). My goal is to sample a range...
thank you 🙂
thank you 🙂
Its a great explanation! I've also learned that on ISLP, so I say I'm on a good path of learning data science
ah, is that a good thing or a bad thing? sorrys i want to clarify what are you trying to convey
I'm saying that's a hard example to understand for a beginner
So it's ok to be confused
yey 😄 im sure there is no more things to be confused of
Hi. Stelercus. What do you work on?
I can't really go into specifics, but it often involves fine-tuning interactive LLMs from huggingface and creating pipelines for them to complete specific tasks.
How long have you been coding?
seven years, I guess?
Hey guys, I'm a new member,, I'm a beginner in the coding world, I was looking for some guidance from you guys. Where do I begin from?
!resources
Resources
The Resources page on our website contains a list of hand-selected learning resources that we regularly recommend to both beginners and experts.
@serene scaffold @serene scaffold Thanks 😊
Starting to see some really strange learning dynamics. It learns in like three phases from what I can tell. First, it quickly learns basic patterns (epoch 0-50), then adapts its quantum "inspired" features to tackle more complex stuff (epochs 50-100). Then seems it stabilizes and dynamically transitions between states based on market complexity looking for an optimal balance. But I thought you guys might be interested to see it, I don't think I've run into intersecting lines like that before. I had an idea for visualizing the plots, I was gonna to save them every epoch and combine them in chronological order to make like a "flip book" of the animation. Or does anyone know if their any modules forr this?

Does being stupid cracked at game theory, like, being the actual best response to all responses help with GANs and reinforcement learning? Pic related, it was years ago, but still, does game theory help a lot with RL and GANS?

from where can i start learning DS+AI?
I mean a GANs system is literally a two player zero sum game where the goal is to reach the Nash Equilibrium where the discriminator cannot tell the difference between the generated images and the real images.
You could employ strategies for optimization based off of
game theory like having alternating updates to the gradient descent to prevent oscillations within the system
it is really annoying there are CPU tensors and cuda tensors
hello, short question here,
Auto_re.loc[lambda df: df['year'] > 80, ['weight', 'origin']]
how does python knows that df takes argument from Auto_re?
its property specific 😑

these python lab chapter is almost done !!!!

Are rnn only able to have 3 unique weights in 1 layer?
no
I cant think of a way of fitting more weights
w1. w2 and w3

they are the same just unrolled
an RNN is just "a neural network with a cyclic computation graph and a hidden state". any architecture that does those things is an RNN.
it's less broad than "neural network".
you don't need to know about all possible RNNs.
hey, just trying to start out with learning ML
would it be better to go through a course like what Andrew NG taught or read through something like "Dive into Deep Learning"?
between those two, I would start with Andrew Ng's beginner course.
and if the course says that you need to know something before taking the course (like some kind of math), they mean it.
yeah I'm familiar with undergraduate level math
cool thanks, and also I saw in the pinned messages here that Columbia's course is better than Andrew Ng's, what would you recommend?
which pinned message is that? I don't have a preference between the two.
that was ages ago  I don't even know that person
I don't even know that person
ah lol okay
but I hope they're doing great, whoever they are.
Stelercus, have you tried doing kaggle competitions
No.
Okay. i hope ill make you interested in kaggle
I hope you, too. refers to a corrected typo
noooo 😱 i misclicked
I have a full time job and I'd rather spend the rest of my time doing other things, including helping people on this server.
alrighty, im glad you have time to help people 😁 including me of course
I used to do Kaggle's tabular playground series
It's good fun but imo Kaggle is far from representative of data science / ML
is it because they only deal with predictions?
That's one reason, the other one is more stuble and harmful
probably that the problems you're solving on kaggle are very artificial and neat.
how does your validation loss keep on decreasing while training loss stay pretty much fixed (the end) ?
I'll give you the technical definition because it's more concise 😄
Say you have a training distribution and a testing distribution.
For the training set you have access to
X ~ P(X), the distribution of the independent variables
Y ~ P(Y), the distribution of the dependent variables
P(Y|X), their relationships.
For the test set you have access to:
X ~ P(X) <----------- this is the problem (!)
In the real world you totally do not have access to the independent variables you will be predicting for in the future a priori. Kagglers abuse this information a lot by doing stuff like a PCA on the entire dataset instead on just the training set etc.
Also, lots of models in the real world fail because of concept drift, this is precisely when P(X) is changing over time
Basically, in all of the competitions I did you had to leak to get ahead
so how someone who is fresher ,create protfolio for entry level job?
Or in the real world you have a different issue where you introducing the model will actually influence P(X) and send you to places you've never trained on etc.
You can do Kaggle, just don't think of it as a panacea 🙂
ah, so in the real world, the data is messier and need to be cleaned up
It's actually by design. The training loss stabilizes because the model has learned the basic patterns, but the validation loss keeps improving because the model is still refining its uncertainty estimates and complexity handling. The negative validation loss isn't an error - it's a feature of how the loss function rewards both accurate predictions and well-calibrated confidence estimates.
Personally, I learnt a lot from doing tabular playground so I'd recommend doing a bit of Kaggle
What's the good way to learn datascience?
As for portfolios? I had one, nobody ever asked in interviews, ever 😄
university + books (check the pinnned thread, I recommend a bunch)
...oh... thats why some competitions with prize pool hide their test dataset to avoid abuse, even making the leaderpoint point based only a fraction of the test dataset
I heard nowadays some competitions have you submit a model instead of predictions, that effectively solves this problem
And then they run inference against your model without ever giving you samples of the test set => a lot fairer
i see
ah, yes, i see some competitions do that instead of submitting csv files
so it is purely from rewarding more simplistic patterns?
Anyway, if you want to learn ML/AI and you have the ability to just go to uni that's my recommendation
common if you use dropout for example
uni student but pursuing or!
operations research? That's a good choice
dropout? how is it common? algorithm minimizes validation loss more than training loss while backpropagating on training loss?
Not quite 🙂 it's basically because depending on the implementation neurons are zero'd out in the forward pass for training but not in eval mode when the validation loss is being computed
okay, ill try finishing ISLP before going to uni
You're still in secondary school?
yeah
That means you're miles ahead of where I was when I was your age, keep it up ❤️
thank you 🥲
although honestly i can pursue the math aspects of data science since i am lucky enough to experience competitive math and programming beforehand
No, it's more sophisticated than that. It isn't just learning simpler patterns, it's actually learning to balance prediction accuracy with uncertainty estimation. The decreasing validation loss shows the model getting better at both predicting AND knowing how confident it should be in each prediction. That V-shaped error pattern in the plots shows its learning proper market behavior. It's understanding that larger moves inherently have more uncertainty.
hey sorry just confirming
you're talking about cs229 right?
Idk

YouTube
Led by Andrew Ng, this course provides a broad introduction to machine learning and statistical pattern recognition. Topics include: supervised learning (gen...
If that's his most entry-level ml course then go for it
There’s no way to objectively define an answer as this is a subjective question. What are your goals and what kinds of things are you trying to build
I think it's probably gonna be less annoying if you look at it this way 😀
By default, when we create a tensor, it'll reside in the CPU. However, you have the liberty to relocate this tensor to a new residence (GPU) if you wanna optimize for speed since GPU usually have more cores than CPU.
It's pretty much easy to move a tensor back and forth from GPU to CPU. You just have to do that with keen attention to avoid performing operation on two tensors that resides in different locations.
hi everyone
i am new to this server
does any one know about the gguf
what is the system requirements for this
hi
is this the right channel for pandas questions?
how do I make a reward system with ai learning system I saw a mario kart vid on a person making an ai that impoves the longer it plays and I wondered how it works
I want to see if it's possible to make one for a 2d fighting game and see if it can beat actual people
Yep! Go ahead and ask your question as specifically as you can, and please also put an example of the dataframe in the paste bin. do print(df.head().to_dict('list'))
!paste
Pasting large amounts of code
If your code is too long to fit in a codeblock in Discord, you can paste your code here:
https://paste.pythondiscord.com/
After pasting your code, save it by clicking the Paste! button in the bottom left, or by pressing CTRL + S. After doing that, you will be navigated to the new paste's page. Copy the URL and post it here so others can see it.
While the number of ML job openings has exploded in recent years, the number of applicants has grown even x10 times.
This means landing an ML job today is WAAAY harder than it was five years ago.
If this makes you feel anxious or triggers that "I’m not good enough" thoughts, just take a deep breath cos everyone has it. E-V-E-R-Y-O-N-E.
Grab your favorite drink and shift your perspective:
- What are companies hiring ML engineers trying to solve?
These companies face overwhelming noise in the AI space, and they desperately need technical experts (like you) to cut through it. They need people who can design and build ML systems that turn raw data into smart decisions.
What does this mean for you?
You need to demonstrate that you can take a real-world business problem, frame it as an ML problem, and solve it by:
- Building a feature pipeline (feature engineering).
- Creating a training pipeline (training or fine-tuning models).
- Serving predictions (inference pipeline).
Package this solution into a Docker container and deploy it to a compute platform like AWS Lambda or Kubernetes.
This is the essence of real-world ML engineering—no more, no less.
How do you show this? Build a professional side project.
What makes it professional?
Gone are the days when a polished Jupyter notebook on GitHub was enough to land a job. Today, you need to go further.
Solve a specific business problem by:
- Picking a real-world problem that excites you.
- Using a data API to ingest and transform data into ML features.
- Training a model (e.g., an XGBoost model, an LLM agent, or fine-tuning a base LLM).
- Building an API to serve the model’s predictions.
Finish it with a clear, professional README file in your repo.
This is what hiring managers need to see—and it’s absolutely within your reach.
Remember:
You don’t learn first and then build. You learn by building.
To your success 🥂✌️
My question is: I have a dataframe with three columns. I want to use these values to calculate a new value for every row in this dataframe. The formula is seen in the image above, and n = 3 just like the three columns. I have the values for x[i0] as a tuple of 3 double tuples. I want to use these values later as the x-axis of a plot. Would it be better to make this new column into a series or to add it to the dataframe as another column?

values = confirmed_exoplanets.loc[:, ["koi_period", "koi_teq", "koi_prad"]]```confirmed_exoplanets is a subset of a larger dataset
can you show samples of the dataframe(s)?
{'koi_period': [9.48803557, 54.4183827, 2.525591777, 11.09432054, 4.13443512], 'koi_teq': [793.0, 443.0, 1406.0, 835.0, 1160.0], 'koi_prad': [2.26, 2.83, 2.75, 3.9, 2.77]} is the sample of values
@random dune I would organize it like this.
In [75]: koi
Out[75]:
period teq prad
0 9.488036 793.0 2.26
1 54.418383 443.0 2.83
2 2.525592 1406.0 2.75
3 11.094321 835.0 3.90
4 4.134435 1160.0 2.77
In [76]: coef
Out[76]:
0 1
period 365 1
teq 254 2
prad 1 4
In [77]: koi * coef[1]
Out[77]:
period teq prad
0 9.488036 1586.0 9.04
1 54.418383 886.0 11.32
2 2.525592 2812.0 11.00
3 11.094321 1670.0 15.60
4 4.134435 2320.0 11.08
note how I changed the names of the columns in koi, and also how doing koi * coef[1] multiplies the teq values by 2 and the prad values by 4.
i see, can this be extended into a full expression like the equation i sent? so pow(1 - abs((koi[0] - coef[0][0])/koi[0] + coef[0][0])), coef[1][0]/3)
or something of the sort, ofc
@random dune idk if this is what you want
In [81]: (koi - coef[0]) / (koi + coef[1])
Out[81]:
period teq prad
0 -33.896907 0.677987 0.201278
1 -5.604307 0.424719 0.267936
2 -102.812359 0.818182 0.259259
3 -29.262138 0.694146 0.367089
4 -70.283401 0.779690 0.261448
In [82]: np.prod(1 - np.abs((koi - coef[0]) / (koi + coef[1])))
Out[82]:
period -3.019632e+07
teq 2.269543e-03
prad 2.024582e-01
dtype: float64
also I know it's missing the exponent. idk what w is.
oh, well the x[i0] in the equation would be the first column of your version of coef, and each w is the second column
@random dune this?
In [93]: coef
Out[93]:
0 w
period 365 1
teq 254 2
prad 1 4
In [94]: koi
Out[94]:
period teq prad
0 9.488036 793.0 2.26
1 54.418383 443.0 2.83
2 2.525592 1406.0 2.75
3 11.094321 835.0 3.90
4 4.134435 1160.0 2.77
In [95]: np.prod((1 - np.abs((koi - coef[0]) / (koi + coef[0]))) ** (coef['w'] / len(koi)))
Out[95]:
period 0.047383
teq 0.201104
prad 0.071537
dtype: float64
is there a way to get the product for each individual row in koi? or rather what is prod multiplying?
In [98]: np.abs((koi - coef[0]) / (koi + coef[0])) ** (coef['w'] / len(koi))
Out[98]:
period teq prad
0 0.989654 0.766755 0.467436
1 0.941685 0.593324 0.553862
2 0.997236 0.864048 0.543507
3 0.987912 0.777785 0.657297
4 0.995479 0.836896 0.546142
np.prod does the product of all the elements along whichever axis gets collapsed.
You can do axis=1 instead
In [100]: np.prod((1 - np.abs((koi - coef[0]) / (koi + coef[0]))) ** (coef['w'] / len(koi)), axis=1)
Out[100]:
0 0.278978
1 0.400076
2 0.159780
3 0.204347
4 0.187055
I see! so this is a list of those values! thank you very much, now I know operations like this can be executed on dataframes and series
In [55]: coeffs_df = pd.DataFrame.from_dict(coefficients, orient="index", columns=["x0", "w"])
In [56]: df.sub(coeffs["x0"]).div(df.add(coeffs_df["x0"])).abs().rsub(1).pow(coeffs_df["w"].div(3)).prod(axis=1)
Out[56]:
0 0.000074
1 0.000034
2 0.000028
3 0.000093
4 0.000015
5 0.000031
6 0.000000
7 0.000016
dtype: float64
pandas has methods for its objects to perform your formula, sub for subtraction, abs for absolute value, pow for power etc.
you can chain them to build it
s.rsub(1) does 1 - s
all element-wise, except for .prod which is an aggregator
Oh okay!
we say to collapse each row by taking the product over columns belonging each row (1 means that; 0 is the default axis, collapses other way)
as an aside, numpy's aggregators by default aggregate the entire thing, i.e., give back a scalar; however, when passed a pandas object, since they implement appropriate numpy dunders, the default axis=0 is in action
what is the df here? thats the dataframe with the 3 columns right?
yes your main dataframe
it's assumed to have column names same as the keys of coefficients' dictionary; period etc.
so that the alignment will work as intended
Ok, so the chaining follows PEMDAS correct?
it follows your formula from inner to outer side
- subtract x0 first
- then divide that by x + x0
- then take absolute value etc.
operations are element-wise so they happen to every element of the frame
and the x0 and w values will be "broadcast" appropriately to happen to each row as intended
because frame is of shape (N, 3), x0 and w (3,) each
it's as if x0 and w are repeated N times to have (N, 3), then operations are done
and which coefficient goes to which column is determined by matching their names
both broadcasting and alignment happen automatically for us
and by N you mean the length of the frame not the n in the formula, which we take as 3?

Python documentation
This chapter explains the meaning of the elements of expressions in Python. Syntax Notes: In this and the following chapters, extended BNF notation will be used to describe syntax, not lexical anal...
yes
N = 8 in the example above
that link is a wrong answer
so the resulting series should have a length of N too, right?
indeed
coeffs = pd.DataFrame.from_dict(values, orient="index", columns=["x0", "w"])
exoplanets = confirmed_exoplanets.loc[:, ["koi_period", "koi_teq", "koi_prad"]]
print(exoplanets.sub(coeffs["x0"]).div(df.add(coeffs["x0"])).abs().rsub(1).pow(coeffs["w"].div(3)).prod(axis=1))
``` using this code, i get the following output: ```0 1.0
1 1.0
2 1.0
3 1.0
4 1.0
...
9559 1.0
9560 1.0
9561 1.0
9562 1.0
9563 1.0
Length: 9564, dtype: float64
which is weird, since it seems it tripled or even more
it probably is due to some misuse
you have "df" in the code what is it
the exoplanets would be that, since it is the subset of the main dataframe but only taking those 3 columns
so you have df = exoplanets or something
because code shared uses exoplanets and df both
also these have ["koi_period", "koi_teq", "koi_prad"] koi_ in front
coeffs don't, so there is a mismatch
you can do coeffs = pd.DataFrame....add_prefix("koi_") to remedy that
can i also just add koi_ manually to the values set?
that also works
Okay! it works finally! So as a last question, when i will want to plot using this new series as the x and another column as the y i can extract y and just plot it correct?
yes absolutely
you can even do df.plot(x="teq", y="something")
or you can use whichever plotting library tou want to use by passing df["stuff"] to them as x/y values
okay so the x is the series from that formula, just named that way yes? and y would be my extracted other series
or no?
oh wait i see df there
yes
well if everything is in a dataframe as columns, we access them using df[col_name] syntax right?
then you can do, e.g., plt.plot(df["some_col"], df["some_other"])
the first one was a convenience function of dataframes to plot "quickly" as calling a method
ah i see so df is the combined x and y
then you pass column names as strings there and it knows which dataframe to look at because that's what it's called on
yes df is still exoplanets
i kind of assumed this newly calculated thing also went into this as a new column
it doesn't have to
Okay! i have decided i will keep them as series and just plot them using this method
so i used plt.plot(star_mass, exoplanets_similarity) (star_mass is a series) and got this. I assume its because star_mass being the index and not sorted has caused this mess

i guess ill have to combine the two series into one and then sort it?
by star_mass ofc
scatter plot maybe?
plt.scatter
sorting also works if it's reasonable to do for the quantities
star_mass = confirmed_exoplanets["koi_smass"]
plot1 = pd.concat([star_mass, exoplanets_similarity], axis=1)
plot1.sort_values(by=["koi_smass"])
print(plot1)``` and the result is ``` koi_smass 0
0 0.919 0.119111
1 0.919 0.217223
4 1.095 0.047048
5 1.053 0.070895
6 1.053 0.061181
... ... ...
8817 0.169 0.245184
8956 0.169 0.160354
9014 0.892 0.889360
9083 1.010 0.109329
9181 0.698 0.235039
which seems unsorted still
and when i added plot1.sort_values(by=["koi_smass"], ascending=True, inplace=True) i got ``` koi_smass 0
6020 0.096 0.192808
3043 0.096 0.241544
655 0.132 0.127794
652 0.132 0.118477
653 0.132 0.071698
... ... ...
1633 2.646 0.008439
519 2.736 0.001650
5968 3.573 0.004942
2210 NaN 0.626638
8571 NaN 0.332637
because sort_values returns a new dataframe, leaving the current one unaffected
unless you pass inplace=True
another way is re-assign, i.e., df = df.sort_values(...) (df generic frame here)
is the NaN a result of some rows being left null or just a number range issue?
that may be due to pd.concat([star_mass, exoplanets_similarity], axis=1)
if star_mass and exoplanets_similarity don't have the exact same index, then for the nonexistent indexes in one another, NaN will be put to the missing one
and the resultant index is the union of that of passed Serieses
if they have the same index, then NaN is coming from somewhere else
inherent
could it be because exoplanets_parameters = confirmed_exoplanets.loc[:, ["koi_period", "koi_teq", "koi_prad"]] uses loc and star_mass = confirmed_exoplanets["koi_smass"] doesnt? they are both a column subset of the same dataframe, it seems
if not then it seems it would be inherent
two are different way of selecting columns, achieveing the same, so that wouldn't be the root cause yeah
might need to look at smass' source to see if it was there to begin with
formula may give NaNs too, e.g., 0/0 is NaN
Yep, turns out the dataset doesnt have it, weird, ill have to redownload it
Does anyone have a code for a real time object detection program using a custom yolo11n model? The frames are from my screen. It would be perfect if i can get like 10-15 fps (ips). Please help. @ me if you answer
Anybody has any idea why does my training loss seem to systematically dip?

What dataset your using
It's most likely learning rate (lr) related. A well-choosen learning rate allows for steady movement towards global minima w/o getting trapped in local minima or experiencing bumpy fluctuations.
-
If lr is too high, the loss will jump erratically (yours isn't so crazy though,)
-
if lr is too low, your model get stuck in local minima or take too long to converge.
If you have the time for further experiments, try to figure out if it's really a lr issue. You could use
-
Good old manual strategy (start from using a lr that's too large, say, lr= 1.0, then lower it until it's too small, say, lr= 1e-4 then compare and contrast with the resulting learning curve from your experiments)
-
Look for a paper that solved similar task, then use the same learning rate they used (a shortcut that works like charm)
-
If you don't wanna take the shortcut in #2, then try using automatic learning rate finder (Lightning framework has this cool option that helps one automatically find an optimal learning rate).
You can as well try other advanced concepts like:
-
Learning rate schedulers like StepLR, Decay on Plateau, and Cosine Annealing.
-
Adding
momentumparameter in your optimizer to help dampen those oscillations.
Learning rate would be a good start. I suggest optuna. Set some parameter ranges and it make a study , let it run for a while and check your results.
I suggest a two stage optimization apprroach using optuna. Start with an intial broad search followed by a refined search around the best parameters.
This is my go to strategy
!paste
Pasting large amounts of code
If your code is too long to fit in a codeblock in Discord, you can paste your code here:
https://paste.pythondiscord.com/
After pasting your code, save it by clicking the Paste! button in the bottom left, or by pressing CTRL + S. After doing that, you will be navigated to the new paste's page. Copy the URL and post it here so others can see it.
Something like this. https://paste.pythondiscord.com/ABYA
there are too many operations to be done like .cuda(), .cpu() and I have to ensure the tensor being operated are on the same device
hi guys, i am just starting data science and ai, can someone give me like a mindmap to follow?
Thanks for advice! Great Advice!

10000 exoplanet candidates examined by the Kepler Space Observatory
Hi guys I'm comfortable coding in python but would like to start creating an ai but i do not know where to start so could anyone dm how did you guys start
I've completed harvard's course CS50 Python
I've always preferred verbosity over elegance. It helps me a lot to understand better when I'm learning new stuff. So if that helps, add comments on your code especially around areas that aren't looking 100% "customer friendly" yet.
You'll get used to it soon trust me 😀
You're welcome
I usually recommend starting from https://kaggle.com/learn you can also check the pinned post.
Practical data skills you can apply immediately: that's what you'll learn in these no-cost courses. They're the fastest (and most fun) way to become a data scientist or improve your current skills.
so i made a working first order ODE solver
(for orbits)
now im trying to do Runge-Kutta 4th order and its just not working. i understand the math but i dont understand why its not working
thanks for the tips among what you wrote i am using cosine annealing. I have yet to implement gridsearch to iterate through lr's
hELP
With no knowledge of your code or what you’re working with a good place to start is considering your step size and if what’s you’re seeing could be caused by that (error per step should be on order h5 cumulative order of h4)
[test smaller dt and try to see if that helps, if so try and find a good or optimal balance between compute time and error reduction]
Also depending on what you’re doing you could consider an implementation like this https://www.sciencedirect.com/science/article/abs/pii/S0378475420300604
yet again very not sure without seeing your code or what ODE’s or system of ODE’s you’re working with
unrelated to above
I’m looking to start working on some new techniques for hyperparameter optimization in GANs and I wondered if anyone has any interesting papers I should consider, I am familiar with optuna, but I’m looking to do some paper implementations for practice and experimenting
SIGIR 2025 is happening in Europe as well. If you work on low resource languages or information retrieval, you can submit a 2-pages proposal to this venue and go present your work.

SIGIR 2025
The 48th International ACM SIGIR Conference on Research and Development in Information Retrieval | July 13-18, 2025 in Padua, Italy
poll_question_text
What should I learn (fyi -i learnt python very qell before)
victor_answer_votes
2
total_votes
4
Context? What are you trying to do and JS and ML just to clarify what do they stand for? (I'm assuming javascript and machine learning but don't want to assume)
Also, I have a question. When you're trying to diagnose a model to see if getting more training data will help, what do you do?
My first thought would be to do a learning curve, train the model on subsets of your training set and look at your cross validation and training set error to determine if new data helps. But that can be computationally expensive so I understand that it's not done in practice. So how would you determine if expanding your data set would help? (I've worked in fields where it was exorbitantly expensive to acquire more data, so would only do it if it could be proven to help beforehand)
Hey, I finally got a chance to go back and review this, thank you!
My only question is what do you mean by training multiple output layers? I thought there was only a single output layer? Or am I mising something?
Ok. So I feel pretty qualified to answer this as a current PhD student. I started from scratch, about 2 years ago, with a very rudimentary math background (basic calc).
What I did was I tried to learn and understand everything in the Sci-Kit learn library. Just go through watch videos and look at examples. Then in your own code, I would practice regression (linear, logit, and maybe fixed/random effects time series) -> then I would go to classification (learn random forest, logit, svm, other advanced versions you find interesting) -> then I would go to clustering and dimensionality reduction (k-means and PCA; you could go deeper, but I dont find this stuff as important/interesting personally) -> then I would learn some basic preprocessing (return to previous regressions or whatever, and learn imputation, feature extraction, and normalization techniques)
Once you have learned all this, I feel like you can now stand up within the machine learning space. Everything else you want to learn, should come easier. Personally, from this point, I directed all my time into learning natural language processing stuff. But if you find video/audio/image stuff more interesting you could do that. The nice part about these more advanced techniques, is that a majority of them run on the same 1-2 model architectures and therefore can be understood relatively easy.
From a natural language processing perspective what I did was I specialized with PyTorch (I dont like Keras/tensorflow libraries). Then, I implemented my first model to classify my text dataset by positive/negative sentiment using a base model included in PyTorch. Once I learned the math and architecture behind these base models, I dedicated a ton of time into the older (2017) BERT models (not generative AI/LLM). I taught myself using PyTorch documentation to build RoBERTa from scratch, and implemented all the code for the tokenizer, attention mechanism, feedforward, dataloader, etc. This was the most informative project I did for sure. In the process, I made sure to understand all the function parameters to the best of my ability, which was definitely a really good thing. From here, I would say you are more than qualified to start reading research papers and digging into all the nascent advancements.
Sorry, this was a very long post, but I wish I had this when I started learning. The biggest thing I would say I learned about machine learning in general, is that it is a ton of different fields working together. You have to be an effective statistician, mathematician, programmer, data analyst, and data scientist to truly understand all the intricacies/complexities the field is moving to.
Obviously this was my experience as a research focused individual, other's may have had different experiences
I would also HIGHLY recommend that you work with data you find interesting and intriguing. You can answer any question about the data, and to really engage with the learning, I think it's super important you choose datasets you have questions about. Kaggle is a good website for this as is Nature's database, or Harvard Dataverse for academic papers.
You could perhaps bootstrap the data and see how the test error looks-- if it's far off the training accuracy, I would say that indicates a need for more data
Would be slightly more computational feasible. I'm not sure of any other interesting methods, but there probably are some new advancements
You're welcome.
Yeah, we have just 1 output layer. What I meant by "multiple output layer" is, the MLP part, say, updating the last 2 or 3 layers, that is, going beyond fine-tuning just the last layer.
What do you mean by bootstrapping the data in this context?
Using the dataset you have, and creating an extra amount of rows. Maybe (20% more) if it's a few thousand.
I think that would be a good method for survey methodologists or social scientists to predict cost/benefit
I did some reading
I guess you could also just cross-validate on your set and look at the variability between folds
Yeah I suppose
A learning curve still seems to be the ideal way, but... I suppose it can sometimes be hard to justify the computational resources
or you could be in a field where it's cheaper to get more data than it is to do the learning curve
(I worked in neuroscience and more data meant conducting an expensive study that costs like 40k per patient)
Happy new year guys. I’m a sixth form student in the Uk and am confident in my basic Python codeing skills I would js like some advice on how to get stated with my ai journey, my aim by the end of next year is to build a chat bot that helps with finance, well thats the end goal😓. Can you guys direct me to some courses or smth that’ll help me learn how to implement my skills into Ai and start my journey, it would be great to receive advice from u guys who have been doing this for a while.
Can you give some examples of what you might want it to do?
My first thought is to think of it as two separate projects. A chatbot interface then a finance model/algorithms for specific financial problems
Unless you want it to just give generic/general finance advice I suppose
It’s fro my NEA and want it to be based around investing stocks (because i have a lot of prior knowledge abt that field) and choosing the best etfs to invest in over a long term, but initially i just want to start learning how to code and actually make a chat bot, can you give me a starting point such as a course or a video that’ll help me
I’ve done a decent amount of game dev and got kinda bored of it so i wanted to move over to something i find more interesting such as AI
pivot according to my course slides 💀

I feel like I am losing my mind
can someone confirm that this is in fact not pivot
i think of pivot as changing from wide or long, but I guess you could argue there is like "pivot" "pivot_wider" and "pivot_longer"
? maybe idk lol
definitely feels confusing though
I am honestly looking at it and, like this isn't actually doing anything but then it's in the slides
Happy New Year to Everyone ✨💫
If I just read that definition without context, I'd think it's about transposing
That said, I'd have to concentrate to come up with a good definition of pivoting that's easy to understand
it's not pivot though, right?
I might still have to write it as pivot on the answer sheet but still
The terms used in this space aren't absolute
yeah, but it's supposed to mean a database pivot I think. idk
like a group by, I guess??
Uh no
What is the question?
When the rows become columns and the columns become rows, that's called transposing. And then pivoting is a specific thing that is completely different from that.
But if your instructor uses those words differently than everyone I know, I can't make them stop.
what are the possible operations in an OLAP? and the oeprations are drill up, down, slice, dice and pivot
Idk what olap is
ahh. okay
Sounds like it's a certain way of conceptualizing large stores of structured data
I'm thinking that too. but there's no mention of what exactly the operation is supposed to accomplish or what's the possible use case.
I think it's just to display the information to a viewer differently in an eventual table or something
Is HuggingFace good for dataset gathering and NLP libraries such as NLTK?
Learn more about OLAP, a core component of data warehousing implementations to enable fast, flexible data analysis.
It's basically an implementation detail for databases that want to support operations that affect a lot of the data, not transactional.
Example database that supports OLAP: https://duckdb.org/

DuckDB
DuckDB is an in-process SQL OLAP database management system. Simple, feature-rich, fast & open source.
Basically, OLTP oriented is lots of small (and simple) queries (that often edit state). OLAP oriented is a few very large (and complex) queries that are for analysis (often read only). Technically you can have some database that can do both well.
All the table libraries used in data science would usually fall under OLAP or OLAP adjacent (OLAP is a specific thing (the cube) (but maybe also not so specific, it's a bit hand wavy), but either way these libraries are for analysis, not doing a bunch of transactions).
(However, its specific terms for stuff like pivot mean something else (internal terminology))
(This is for a text based ai that can respond to a user)
(Like how you don't need to care about what ACID is, the database just does the thing you want without knowing that)
yeah for sure, a lot of the datasets used in current research articles are uploaded to huggingface
Are there are better choices? Or do you have any suggestions...?
The best datasets that are used to train current models are on huggingface
if you want like "fun" datasets, you could look at Kaggle
if you want social science datasets like political information you could try Harvard Dataverse
Ya, idk about history exactly, but probably on Harvard Dataverse
if you are interested in like the history of wars or something, there is correlates of war which is a dataset you can find
here is some other history ones too
Thanks. One more thing, according to Claude AI, I should use spaCY over NLTK for Natural Language Processing. Is that a good choice in my case, based on what it seems I'm using?
I actually havent used either, I have only used PyTorch and HuggingFace
It looks like NLTK has more options and may be a bit more customizable
!paste
Pasting large amounts of code
If your code is too long to fit in a codeblock in Discord, you can paste your code here:
https://paste.pythondiscord.com/
After pasting your code, save it by clicking the Paste! button in the bottom left, or by pressing CTRL + S. After doing that, you will be navigated to the new paste's page. Copy the URL and post it here so others can see it.
Hey is there any tutorial to train auto encoder on custom dataset?
My Input shape is 453,958
And it always comes out as 456,960
As output
Do you (or anyone who can answer this) believe this dataset: https://huggingface.co/datasets/HuggingFaceFW/fineweb-edu can be processed on a high-end household computer at decent speed (if it has the storage space and cpu for it)?

No, I think you would need multiple GPU's and like 1tb of RAM lol
its 9.45 TB of harddrive space
I'm aware...
Dang, alright.
You could try and see if there is a subset, or you could random sample the data
What do you mean exactly?
Like randomly select 1 million rows out of the 1 billion, so that you have a smaller dataset to work with
Is there anything you like about that dataset in particular? I could try and help you find a more reasonable one for home compute
Reddit
Explore this conversation and more from the LocalLLaMA community
I would recommend trying this
So they import the dataset with huggingface and they are selecting specific keywords in the rows
it would probably take a long time to process, but you could get a few million rows to play with
just replace the keywords with stuff that you are interested in
I'm looking for a dataset that's good enough to be able to give the model enough data to be able to answer most daily questions.
And questions with specific grammatical words
And also questions for programming, math, and history.
(Not all of those in one though. I'm okay with multiple small datasets that can accommodate those.)
As far as academic stuff goes, the dataset you found would be good. You can use that code and replace the keywords with history or math questions
I think for more daily stuff, yoiu would want to use this dataset, which is just FineWeb but not trained on Google Scholar stuff:
https://huggingface.co/datasets/HuggingFaceFW/fineweb

And for programming, there are seperate datasets like: https://huggingface.co/datasets/Programming-Language/codeagent-python

This python dataset would probably not take an obscene amount of time to model, the train is 300k rows

GitHub
Learn Generative AI with PyTorch (Manning Publications, 2024) - markhliu/DGAI
I found this book too, it looks like the end chapter (chapter 16) teaches you how to "use the LangChain library to combine pre-trained large language models (LLMs) with Wolfram Alpha and Wikipedia APIs to create a zero-shot know-it-all personal assistant."
which seems kinda like what you want
If you are interested in this book, i would recommend doing chapter 8 through 12, then 16 if you want to converge your models
I already looked at that one... and I'm not using it because you should probably check how much space it uses...

yeah, its crazy
I think with the huggingface library though you can import the dataset iteratively so you don't have to download it or anything
if you wanted to skim through all the rows to get the data you want it would take forever of course
Ah. Seems interesting. I'll check out that one as well. I'm going to most likely use a pre-trained model, but I was thinking about using that to make a zero-shot.
I already found some good wikipedia datasets that are cleaned
Nice. Yeah, I would start with that. You can always just replace the dataset if you find a better one. The model architecture would stay basically the same
Yeah... 😂
Have you done any implementation of pre-trained models before?
Yea, once.
Cool. If you need any help or have questions about the basic premises of the math behind neural nets you can @ me
I used BERT to pre-train a model with some medium datasets
cool, I did that over the summer for a polling firm I was working for
BERT is a great way to learn neural nets for sure
Nice, man. I haven't tried this yet, but can I pre-train this using multiple models?
What do you mean
Like train multiple models for classification and linking them together? Or something else
Essentially, yes.
I think you can do that. I haven't done it personally. But it appears the LangChain library is what you would want to research
I know they use LangChain to make the multi-modal models that have image, chat, and other technologies all in the one
Not entirely sure about classification models though
Alright, thanks, I think I've got enough answers for now. Is it okay if I dm you next time to not use up the chat?
yeah 👍
Please can someone help me understand the chain rule because i swear I have spend forever, like a few months, and I still don't understand it 💢 ‼️
do you understand recursion?
also, can you tell me the derivative (wrt x) of 4x^3?
hi
is there any place to start learning tokenization and neural networks
more on fundamental or mathematical level

YouTube
Statistics, Machine Learning and Data Science can sometimes seem like very scary topics, but since each technique is really just a combination of small and simple steps, they are actually quite simple. My goal with StatQuest is to break down the major methodologies into easy to understand pieces. That said, I don't dumb down the material. Instea...
this guy is REALLY good if you need visuals like I do
tokenization isn't mathematical. it's just "what is considered a word in this context, and where are the word boundaries?"
i meant for neural networks
I know.
you don't really need to "learn tokenization". you just use an existing tokenizer. making your own tokenizer is very advanced and unusual.
but it is hard to tokenize things in other languages
what are you trying to do?
it's not that hard to make a tokenizer
and I maintain that you do not need to "learn tokenization". you can look for a Japanese tokenizer.
i see
by the way understanding a tokenizer as a function that converts a string into a nth dimension vector is good?
where there are 'n' words in entire dictionary
and less than 'n' words in the string
Right, for older models. For newer models there is text embedding which adds some more complexity
Looking for some feedback on this idea , what am I missing here? I’ve been brainstorming a generalized phase encoding system that adapts to different data types and computes a complexity score. The core equation is Φ(x) = x + A * exp(iθ(x)), where θ(x) captures intrinsic structure depending on the data type:
Time Series: θ(x) = ω * t + φ(volatility, trend_strength) (e.g., trends, seasonality).
Images: θ(x) = Σ(spatial_frequency * position + texture_density) (patterns + textures).
Text: θ(x) = semantic_embedding * syntactic_structure (word embeddings + grammar).
Tabular: θ(x) = Σ(feature_importance * value_normalization) (relationships between columns).
but there should be also something like order of words?
so how can i preserve the order of words into a vector if i use it?
So I think methods like word2vec keep an order of words, but to reduce computational costs they reduce the words to a lower dimensional vector
so if your vocab was 1000 words, you can set a cap on word2vec to minimize it to the 300th word
so you are left with a vector of 300 length, that still preserves order of words, just is more efficient
what the vector consists of btw?
I also think the vectors are grouped by context with the embeddings, so they arn't necessarily in the same order they came in on
No, that's an incorrect understanding. At its core, a tokenizer just splits something into individual words (tokens). what you're describing is a one-hot representation of a token.
i see, so i just get a list of words from a string
in the same order
pretty much. if you want the tokenizer (as an object in your code) to return those tokens as one-hot vectors, you can do it like that, but that's extra functionality in addition to the actual tokenization.
right, so the current method is embedding which looks like this:

so you can limit to the nth dimension, instead of the vocab size
it sounds like you're conflating unrelated concepts
and vectors incorporate context by having values similar to each other
sorry i don't get it, i meant like how to convert strings to vector preserving the order of words
if you have a vocabulary of m words and you want to represent them as n dimensional vectors, m and n are unrelated.
for example, the sentence is "This is a cat."
are you asking specifically for purposes like translation?
tokenizer will convert it into ["This", "is", "a", "cat."]
yes
no, i am asking for generative models
it would probably have the "." as its own token, because you don't want "cat" and "cat." to be different
i see
["This", "is", "a", "cat, "."]
so i got this output ig from tokenizer
and it might also treat "This" and "this" as the same token
now i assign them numbers?
i see
["this", "is", "a", "cat, "."]
for generative models like the GPT family, you have you use the tokenizer that comes with the model.
yeah I think GPT uses RoPE for its embeddings
but other models use different things
Sometimes words like unbreakable will get split
["un," "break," "able,"]
i see
thats called lemetization? or stemming?
I've heard it called subtokenization. when a word is composed of individual parts that have their own meaning, those parts are called morphemes.
yeah that makes sense
if my dictionary contains the following words.
- a
- an
- the
- this
- that
- these
- those
- is
- are
- am
- cat
- dog
- .
- ,
Stemming appears to be removing common suffixes and lemmatization reduces words to their root form
so i use 14th dimension vector?
most of those words are considered "stop words". which are words that don't carry any intrinsic meaning.
you're assuming that you're going to one-hot encode each token. which isn't a foregone conclusion.
so models play a very important role in what input they take
i was thinking to convert string into some form which won't lose any information and is computational so that any model can use it
models don't "decide" what input they take, if that's what you mean. the structure of the input is something you have to decide when you decide on the model architecture.
that's not possible, no.
i see
when you map tokens to integers (like assigning "cat" to 42069), that mapping is arbitrary--it's only significant for the model inasfaras you always use the same integer for the same token.
so after doing that, i need to prepare a neural network which can take that list of integers which are coverted from tokens
yeah, for RoBERTa specifically the "main" steps are encoder -> word embedding -> position embedding -> attention -> encoder
other models are different ofc
what is word embedding now?
word being converted to a dense vector
["I", "love", "coding"]
[[0.1, 0.3, 0.4], [0.5, 0.2, 0.7], [0.8, 0.1, 0.6]]
then does similar for position embeddings
then it adds the two together to get the full embedding
then that value goes to the attention
are these values pre assigned or?
when you create the tokenizer you train it on a dictionary of words I think
so yeah I think it is trained and knows what to give each word
but tokenizer just converted strings into a list of words?
i have dictionary, and i have assigned a number to each word, and converted the token into integer
after that i don't get what word embedding is representing here
yes, my understanding is you do that in the initial encoding block, then the word embedding creates the dense vector
def forward(self, prompts):
if isinstance(prompts, str):
prompts = [prompts]
encoded = [self.tokenizer.encode(prompt) for prompt in prompts]
max_len = max(len(seq) for seq in encoded)
padded = [seq + [self.tokenizer.get_pad_token_id()] * (max_len - len(seq)) for seq in encoded]
input_ids = torch.tensor(padded, device=self.device)
if input_ids.dim() == 1:
input_ids = input_ids.unsqueeze(0)
word_embeds = self.word_embedding.get_embeddings(input_ids)
pos_embeds = self.positional_embedding(input_ids.size(1))
embeddings = word_embeds + pos_embeds
attention_mask = (input_ids != self.tokenizer.get_pad_token_id()).float()
extended_attention_mask = attention_mask.unsqueeze(1).unsqueeze(2)
extended_attention_mask = extended_attention_mask.to(dtype=next(self.parameters()).dtype)
extended_attention_mask = (1.0 - extended_attention_mask) * -10000.0
encoder_outputs = self.encoder(embeddings, attention_mask=extended_attention_mask)
sequence_output = encoder_outputs[0]
pooled_output = sequence_output[:, 0, :]
logits = self.classifier(pooled_output)
return logits
code helps me visualize

that looks inaccurate to me
i see
at least with bert models
i think they are conflating multiple steps into the word embedding
it doesn't just go word to perfect, there is multiple steps as you can see in the above code
any recommendations for docs or video to learn word embedding first?
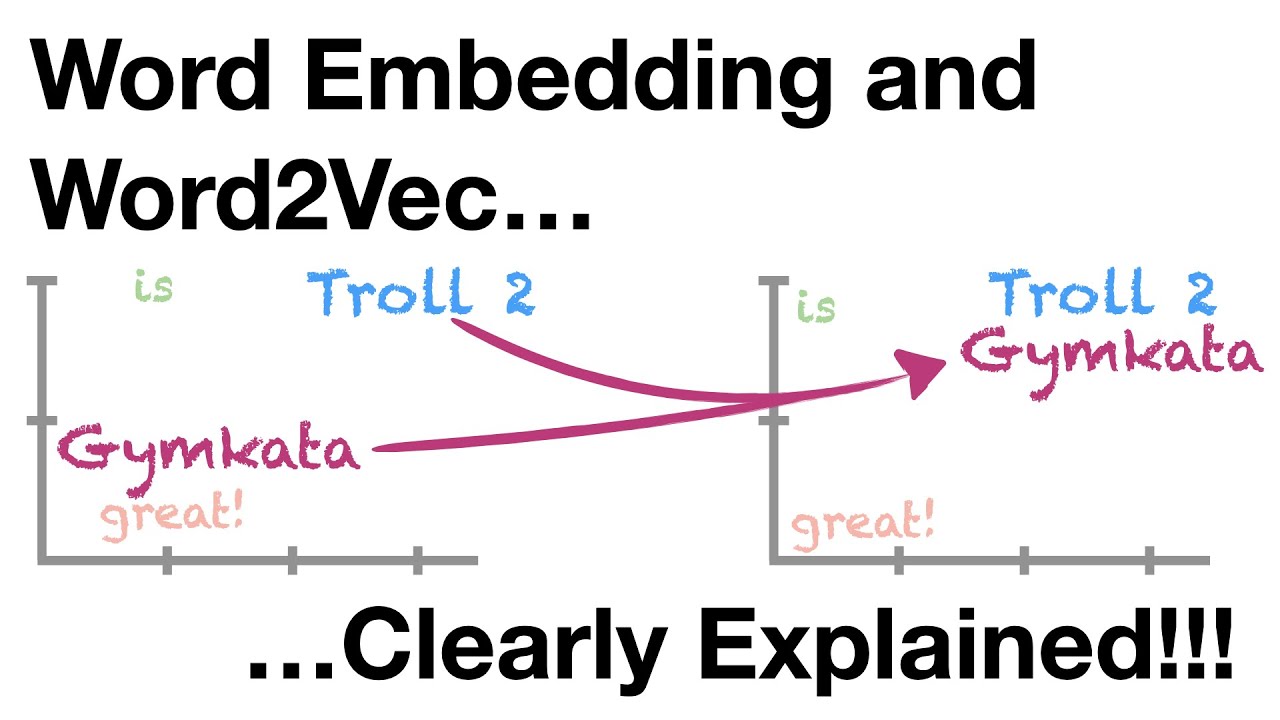
Words are great, but if we want to use them as input to a neural network, we have to convert them to numbers. One of the most popular methods for assigning numbers to words is to use a Neural Network to create Word Embeddings. In this StatQuest, we go through the steps required to create Word Embeddings, and show how we can visualize and validat...
thanks
at 5:55 in this video, just want to ask if the activation function is nothing but just a value assigner to each category
Lexicographical encodings are legitimate but it is not bijective so you can't guarantee you can recover what you sent in originally
like f_noun("cat") = 1
f_noun("is")=0
where f_noun is an activation function???
I think its just a value assigner yeah
or perhaps a selector is a better description
Just use an existing tokenizer.... I read through this and I don't why you can't.
Okay, this is pretty cool, guys. You can actually see the model shifting between using the base dimensions, and expanding its dimensions as the complexity changes. This is what I hoped would happen, adapting on the fly. I think the quantum-inspired is still the key to all this but adaptive dimensions stuff is something else. It seems to be learning really well, and only uses the extra capacity when it needs it, and chills out when it doesn't. Check these out




This one is indeed my highest score -256 . What is pretty amazing is the base dimension is only 64, but its modified with a expansion factor. I think I found it ideal to allow it to be small or modest, big isn't necessary as its highly more optimized, the vector space that is. Like switching between its dims doesn't seem to affect its accuracy at all. I believe this could be foundation for time series data or other data that's chronological organized.
@wheat merlin It's a custom job, not a library. Basically, I've got this "Market Complexity Detector" that checks out the market's vibe - you know, volatility, trends, that kinda stuff. Then, based on that complexity score, the transformer blocks can "expand" or "compress" their dimensions.
Thank man, its been a labor of love so long it feels like
It all started with an idea trying to perdict prime numbers
Obviously didnt have the compute capaticy to see it through but learned some cool stuff hehe
I believe it's proprietary in the sense that I didn't base it off any specific paper or implementation. I'm sure there are papers out there with similar ideas, its a big field hehe. But my friends did give me the idea in our ML chat channel but I just theorized the rest.
Didint happen over night though and I stumbled upon a lot of stuff just through experimentation more than anything.
Yeah im kinda looking into similar papers, it looks like this stuff kinda started getting implemented around 21-22
But you may have done something unique idk... could be worth looking to see if you could write a publication if you are interested in that
Cool idea though, definitely going to look into it more in regards to Graph theory
Thank you it worked
Thanks, dude. I appreciate that. I’m just an old UPS driver who loves tinkering with this stuff in my spare time. Writing a paper sounds cool, but honestly, kind of intimidating, and I've read my fair share. But the whole academic process Is a whole another beast, you know? I found my secret sauce in life is brainstorming and tinkering. I guess like problem solving one a whole, but everyone is a problem solver I guess lol. But with that said I have started trying to compile a lot of this data into a report which I can hope to refine and use the visuals I've gathered along with other metrics I'm sure I can eventually tackle that.
Zapbot is a beast.
Is opencv good for image augmentation? I would like to create random faces with various perspectives like for example: looking right, looking left, etc.
this is not an augmentation task. you would need a generative model that is itself trained on real pictures from various perspectives
Can you give me such example/s?
stylegan2 is one that comes to mind, but this is old by now. i'm sure nvidia must have something for this task as well
Alright, thanks
https://research.nvidia.com/labs/nxp/lp3d/ here's one from nvidia
but yeah my main point is that that is not an augmentation task, it's a very difficult modeling/inversion problem
if you use this to train another network, you now have several points of failure because the new images cannot be trusted (you have a dirty training set)
i understand recursion and it is 12x^2
the chain rule is usually applied recursively, which is why stelercus asked you that
what about the chain rule is troubling you?
guys i want to compare rows in my feature df and see which ids have a high unity.
col_0 col_1 col_2 col_3 col_4 col_5 col_6 col_7 col_8 \
412788399 0 0 1 1 55 41351 1 47333 1
412763015 0 0 1 1 62 92000 99 47999 5
col_9 ... col_37 col_38 col_39 col_40 col_41 col_42 col_43 \
412788399 0.0 ... 1.0 1.0 0.0 0.5 0.5 0.5 1.0
412763015 0.0 ... 1.0 0.0 0.5 0.5 0.5 0.5 1.0
col_44 col_45 col_46
412788399 1.0 1.0 21.0
412763015 1.0 1.0 12.0
currently i use the last col (sum of features) but i would love a better approach, not sure how that would look tho :D.
I did feature dist., corr and relationship plots already.
Any ideas?
what does it mean for two IDs to have high unity?
i would hope to see similar samples having a high unity
I'm asking what unity means.
share similar feature set
@young granitefor each pair of rows x, y, you can calculate the elementwise |x - y|, I guess
i think the result would be similar to my sum approach, wont it?
Also i would love to visualize it directly
it wouldn't be the same as the sum approach.
look into manhattan distance.
but then i would have to do that for each row, thought of a more direct approach
taking the sum of each row and comparing that sum to other rows, is not the same as the manhattan distance. [1, 2, 3] and [3, 2, 1] have the same sum, but their mahattan distance is 4.
and [2, 2, 2] also has the same sum, but manhattan([1, 2, 3], [2, 2, 2]) < manhattan([1, 2, 3], [3, 2, 1])
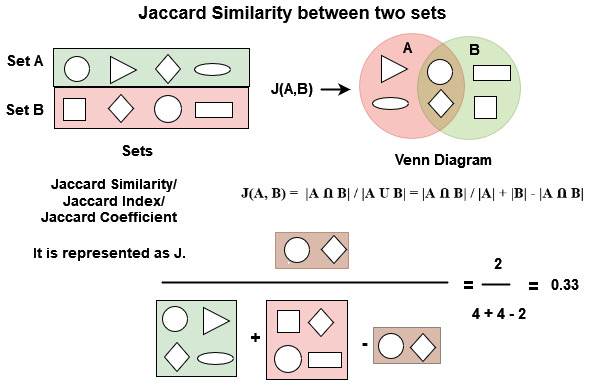
You could look at pairwise similarity using cosine or jaccard similarity
you could also use graph theory with those pairwise similarity meaures to visualize the ids close to each other
jaccard? they're not sets
GeeksforGeeks
A Computer Science portal for geeks. It contains well written, well thought and well explained computer science and programming articles, quizzes and practice/competitive programming/company interview Questions.



crazy they are used for recommendation systems... with data that looks exactly like what he is working with...
jaccard is used for calculating the similarity of two sets of discrete items. it doesn't work for continuous values like the ones Greenleek has.
(or you can use jaccard anyway, but you'll get something meaningless)
I recommend not using greeksforgeeks--their information is almost always questionable, and there are so many free resources out there.
yeah you are right that is for binary data; there would be a better approach for sure
but there is a fuzzy jaccard index that can take continuous data if you were really bent on using jaccard
I don't really know I think it is the notation but then again I don't really understand it conceptually well. Sorry, I just said a bunch of very loose things.
have you tried with some simple examples and then build up from there?
maybe an illustrative example for you is that x^6, for which you already know the derivative is 6 x^5, can be written as (x^3)^2, where we can think of f(x) = x^3, and g(z) = z^2, and then take g(f(x)). applying the chain rule should yield 6x^5, so you can check yourself if you did it right
and similarly for polynomials with higher powers, say x^8, noticing that x^8 = ((x^2)^2)^2
hey guys
I am trying to use a vision transformer for binary classification
however, at some point, it keeps guessing "1" and gets stuck at this
how can i fix this(broad tips)
what model are you using and how much data do you have?
I think there are a lot of potential options:
Make sure your class balance is good, try changing learning rate, try regularization
The model is known as TinyViT and I am using something called pneumoniaMnist from MedMNIST
There are GitHub repositories for this by the way
Ok I can look at it, I only have used one ViT before though
have you tried using a different size of the model, it looks like they have 5m, 11m, and 21m parameters models
but I would also look at: class balance, learning rate, and regularization
similar in what sense?
is (1,1,1) and (1.1, 1.1, 1.1) similar? since they are close in magnitude away from 0
or just (1,1,0) and (1,1,1) ? since they share the 2 preceeding 1s
ive been trying to make a neuronetwork combined with a sort of macro mixed into it where it would scan a group images and click on a specific one for a set period of time and if it doesnt see the images it would skip to the next set of pictures, ive been using pytorch with cuda and anaconda and i was confused on how i can give my network pictures to learn from if im confined to a terminal
Ale
Alr
Well how do you read the pictures in your code?
Hey, does anyone have a course reccomendation for ML
never did it but maybe https://www.kaggle.com/learn
Practical data skills you can apply immediately: that's what you'll learn in these no-cost courses. They're the fastest (and most fun) way to become a data scientist or improve your current skills.
During the validation in seq 2 seq , what if the decoder outputs an output sequence shorter than the true output sequence. How is the loss calculated in such cases. will categorical cross entropy work in such cases.
Im pretty sure models pad sequences as the first step
to standardize lengths
at least in the models im familiar with that's the process, I can't speak for generative models necessarily
Stack Overflow
To handle sequences of different, I would like to know.
Why do we need padding the sequence the word to the same length?
If the answer is "Yes, you need padding.". Can I set the padding in other
in translation sometimes a word is made of 2-3 words how they process in encoder?
I think that's part of the tokenizers function
you would train the tokenizer on a dictionary, it is able to then assign values to words
so multiple word words would be known if it was in the tokenizer dictionary when it was trained
I could be wrong on that last part
it may just treat each word as seperate, and it wouldn't matter much because the word and positional embeddings would still find similarities
but in sum, it's part of the tokenizer's function to make sure it's processed correctly
If you have an NLP model that processes sequences (such as sentences) of varying length, and it can do more than one sequence in a batch, you have to pad all but the longest one, so that the array/tensor is "rectangular"
But it's not the model that does this. "You" have to do it before passing the tensor into the model.
You are right. I was defining model as the whole ipynb file. The padding would be part of the preprocessing before the data is sent to the attention head of the actual model
what if we use ohe?
That's a very... Expansive definition of "model". Be sure to banish it from your vocabulary.
yeah generally a model is the layer definitions and/or it's weights
a jupyter notebook isn't really a model
we call BERT a model right
but when we say that, we know it has it's own unique tokenizer and preprocessing steps
a model in my mind is the preprocessing, tokenizer, embedding, attention, and encoder outputs
if we say that the model is only the attention onwards, that's also misleading, because you could make an entirely different "model" with a new tokenizer and preprocessing steps
.
not sure exactly, but ohe is rarely used now in nlp models
That’s what I’m trying to figure out, how do I get my code to read pictures
https://pytorch.org/vision/0.19/generated/torchvision.io.read_image.html or whatever else too you use, scikit etc. image is just an array resp. RGB tensor
Anyone here trained smaller language models? I'm looking for advice on making something small enough to run offline on ordinary machines. Project background for context:
https://bitplane.net/log/2025/01/uh-halp-data/
I'm looking for advice on what to train on top of, how much data I should be generating, and how small I can expect to get it. And if anyone wants to join in and help, that'd also be cool
If I want to start studying for ai technology where should I start still kinda confused me
it's really challenging to get your bearings. every resource makes different assumptions about what you already know.
what I would avoid for sure are "tutorials" on websites like Medium. They're not written to be helpful--they're just portfolio fodder for the authors.
what is your goal for learning about AI?
I always have been very interested in programming but with no specific topic but lately I have been very invested into ai. I am planning to take my major in AI
I have really basic knowledge on python and planning to expand on it
are you in the US or where?
Indonesia
Southeast Asia
However taking a university somewhere else
I know where Indonesia is. Are you used to talking to people who don't?
I usually recommend that people start by learning how to manipulate data with pandas. (or you can try using polars, I guess.)
that doesn't actually involve AI, but it's important to get a sense for what "data" is like.
Sorry but wdym by talking to people who don't
you specified that Indonesia is in southeast asia, so I thought you thought I didn't know.
Ah i see mb
And yes ppl usually don't know where that is
wtf
The problems that I am having is that school does not teaches comp science sadly so I need to study it myself. On top of that I have very little time so ye. Btw rq what is manipulating data with pandas
Searched it up and not 100% sure that I understand it
tabular data is where you have rows and columns of data
manipulating it is where you change it or aggregate it or spread it out to get different perspectives
I see
like, if you have sales data where each row represents one transaction, you can transform it so that each row represents a month and each column represents a year. and then you can see if there are annual trends.
Ah alright then. Welp ig I'll be learning from scratch again lol. Any web recommendations of vids to study this
ML is basically all about finding trends/patterns in data (or rather, making the computer figure out what the pattern is)
What do you think "AI" is? And what do you want to make?
A tool that will most likely help with like efficiency and figuring out small errors that can adjust the machines. What I want to make with it? I just really like automation in addition i always been very interested in it how it works. (I probably want to make like chatting bots or automation bots)
Idk if that is a good answer or not so ye
There is no wrong answer to this. I just wanted to know what you know. And what you want.
I see
have you got a decent gfx card? or money?
I would say so
not everyone is trying to fine-tune llama.
'cause both of those things will help you if you want to run long jobs
loll fair. I really don't want to 😦
I wanna find a tiny model that will work with my data
What you are looking for is sounds like machine learning (ML). Which is heavily used in AI too. Being able to mess around with data as was already suggested is a good starting point.
Alrighty
sentdex has a pretty good youtube channel for doing ML from scratch in python, he's a good guy too
Well I tried kinda a pain to find books in my area and I have joined a course before which was very underwhelming it taught me basically nothing...
Probably my best bet is to find a eBook
There are online courses too.
You will need two things in general for machine learning. You need to be very comfortable with programming, being able to make small to medium sized practical programs (manipulating files and such, a good resource for this is https://automatetheboringstuff.com/ ), and also the basics of data structures and algorithms (only really need to the basics here, but if you like it, you can dig further, it will only make you better). The second thing you need is mathematical knowledge, the usual recommendations are calculus, linear algebra, and statistics.
Also additional for programming is data manipulation / analysis with stuff like Pandas as was already mentioned.
(tabular data)
Calculus my favourite.. Teacher taught us it about 1 week and gave us a test with horrible results in it. For the whole class
I really enjoyed this video as a high level overview: https://youtu.be/0QczhVg5HaI

A video about neural networks, how they work, and why they're useful.
My twitter: https://twitter.com/max_romana
SOURCES
Neural network playground: https://playground.tensorflow.org/
Universal Function Approximation:
Proof: https://cognitivemedium.com/magic_paper/assets/Hornik.pdf
Covering ReLUs: https://proceedings.neurips.cc/paper/2017/hash...
If you can find some book online then I would go with that.
I don't really know of a good recommendation for calculus books.
Maybe someone here has one.
spivak 💀 (don't. it's a greak book, but it's more meant for people going down the maths route)
Khan Academy goes all the way up to calculus and beyond, it's interactive
Alternative to books would be these new online tutor-like methods.
This includes Khan Academy or brilliant.org.
I personally think the "learn by play" is the best way to learn anything, and the new LLM methods of exploring knowledge are really powerful too
There are additional materials that can help, but I would treat them as additional. https://www.youtube.com/watch?v=WUvTyaaNkzM&list=PLZHQObOWTQDMsr9K-rj53DwVRMYO3t5Yr

What might it feel like to invent calculus?
Help fund future projects: https://www.patreon.com/3blue1brown
An equally valuable form of support is to share the videos.
Special thanks to these supporters: http://3b1b.co/lessons/essence-of-calculus#thanks
In this first video of the series, we see how unraveling the nuances of a simple geometry que...
When I learn a new programming language or technology I want to understand, I get ChatGPT to take the role of personal tutor. First constrain it by making it come up with a plan. Then give me examples, get me to explain what I think is going on, then have it correct me while I ask questions
then once I've covered the topic, get it to move on to the next stage. It worked really well for learning golang
Kk
a quick search reveals that george simmons' calculus with analytic geometry seems to be used in MIT for engineering courses. stewart's calculus books are also standard engineering books
that's around the level to aim for imo, for the sake of practicality
I'm going to give a some more random resources, so you have options. https://www.youtube.com/watch?v=TjZBTDzGeGg&list=PLnvKubj2-I2LhIibS8TOGC42xsD3-liux&index=2

MIT 6.034 Artificial Intelligence, Fall 2010
View the complete course: http://ocw.mit.edu/6-034F10
Instructor: Patrick Winston
In this lecture, Prof. Winston introduces artificial intelligence and provides a brief history of the field. The last ten minutes are devoted to information about the course at MIT.
License: Creative Commons BY-NC-SA
...

Artificial Intelligence: A Modern Approach (Pearson Series in Artifical Intelligence)
there's also the python one, i think it's in the pins
https://www.statlearning.com/ intro to statistical learning with applications in python
An Introduction to Statistical Learning
Alright tysm also sorry for late reply
Btw would you say the 12 hour python course by brocode is a good yt vid for like reviewing the whole python language

Improve your English fluency with personalized feedback based on your real speech. Refine your accent, perfect your grammar, and expand your vocabulary.
check this i really like the ai of this i want to create something like this can anyone tell me how can i create! or anyone want to collabrate?
whats the best llm to run locally?
(using rtx 4070super)
currently looking at hugging face leaderboard

its quite odd that mistral or llama isnt on the list
is falcon3 really the best option?
Hii
My friend work in APD bank
task dependent but i hear good things about qwen2.5
using llm!
download ollama, run it, then pick a model. then do prompt-hacking and requests to call the API
Can u elaborate a bit
.
Got a decent GPU in your machine?
you have a BEAST with you
it will be excellent for learning and running a decently large model
idk how large coz i dont do llms
but yea @gray slate and @fickle shale might tell you that
but you can start working
Same as my laptop I think. 16GB? Should be good enough yeah. Here's an example:
https://asciinema.org/a/696998
basically, to configure it you set the system prompt, either:
- edit the default system prompt by editing the manifest file (I haven't tried this)
- or send in the system prompt like I did in the
curlcommand
to use it, you can either:
- chat with it directly on the command line, after running the model
- pipe data into it from a script (doesn't work well in Windows, adds junk on the end for some reason), like
echo hello! | ollama run modeland capture the output, or - use
requestsorcurllike I did, and join theresponsebit together. (usejson.loadson each line as they come back fromrequests.post, so you get the typing out effect if you need it)
Unfortunately 16GB isn't really enough. quantized mixtral will just about run, but it's dog slow. It's a pretty clever model though. llama3.3 hasn't been quantized on ollama.com yet, and that is slow as hell on my 64GB Orin too. but it's a pretty powerful model.
Damnn
llama3.2 is fast enough, and good enough for most tasks though
And if you ever need to use something smarter, you can run a larger model on vast.ai for 10 cents an hour
Thank you so much for your time brother
You're welcome 🙂
If it helps, here's an example in Python. It isn't doing a line by line approach though:
https://github.com/bitplane/uh-halp-data/blob/master/scripts/02.popularity_contest.py
I'm basically using the LLM to say "order these 10 commands by likelihood of a user typing them into a terminal", and I loop over them until all 40,000 commands have been sorted by "what the LLM thinks are the most useful commands"
steal the function from line 71 and hack it to do whatever you need 🙂
lol just ran mixtral and qwen locally, same GFX card:
https://asciinema.org/a/FKOrYUoebjXJOxJ0FNWXc2uO8
You need to do some serious prompt hacking if you want to get them to work for you!
^ @warped harness same gfx card as yours
anyone have experience with graph neural nets
stuck on a loss of .693 which is just random guessing basically lol
nope but interested to learn. how do you evaluate?
so what im doing is im trying to predict edges between nodes
which is a binary classification
so it uses binary_cross_entropy_with_logits for loss
my understanding is a loss of .693 with this function is just as good as 50/50 guessing
yeah sounds like it. does it not shift at all?

starts insanely high and gets down over the 100 epochs
for my model I HAD to add gradient clipping
how big is your data and your model?
only 1300 edges, which is probably the problem
I have been using event history analysis with a network component, it's called NEHA, but wanted to try with neural net
yeah, it can't generalize if your model isn't way smaller than your data. from what I understand anyway -- i'm no expert
can you augment your data to make realistic fake stuff and pass in a load?
yeah actually, that's part of the data preprocessing
i've never heard of negative_sampling before but it's super cool
like you said, it just makes fake networks so the model can classify between true and fake
nor me, what's that?
I'm a noob really, lots of software experience not much ML experience
But, if you take the "every weight and bias is just a line y = mx + b style, and every activation function is just a way to crop it so you get line segments rather than a linear slope and offfset", then all you're doing is fitting a function to some points... getting data right should be mostly about getting the fake data on the same line as the real stuff
chatgpt reckons that if your F1 score isn't moviing even a tiny bit, then your model probably isn't getting both of the binary classes
yeah im thinking I need to mess with the data before I mess with the model anymore
it is imbalanced and not scaled
so with a graph network, do the graphs all have to be the same depth? or do you like.... truncate them or something?
im doing edge classification, so I don't think I have to deal with graphs of different sizes
but from what I understand, GNN's can handle graphs of varying sizes when it comes to classifying the graph or nodes
oh cool, okay yeah I was confused and thinking "how the hell do you feed different length graphs into a network" - but looks like you don't, you feed stats about nodes or edges in, so it's a data formatting thing rather than a network architecture?
yeah, I think its essentially an edge list with node attribute data columns
so for me, im looking at US states
so it would be like:
receiver sender GDP %White etc.
ah okay and you're building a good ole fashioned discriminator lol
is that legal?
I worked at a loan company doing devops for linear regression models and they (data scientists) had to be really careful about that sort of thing
yeah, im not doing anything crazy lol. Im not trying to predict like crime rates and blaming it on a certain demographic or something
basically im taking a developed theory from my field and using a different method
not really changing the question or anything
stuff like "when we predict chance of a default by geographical location, the location often encodes ethnicity as a by-product"
yeah I could see stuff like that being problematic
thats why theory is so important, cuz you have to be able to explain and understand the relationships you are modeling
it's harder than it looks! I enjoy the data thing and reasoning about data but I've never actually built a full end to end model, keep getting stuck overthinking the feature engineering part, or failing to generalize
I highly recommend running through PyTorch if you are interested. PyTorch would probably be pretty easy to code with a devops background
people and companies love to use pretrained models now and just importing them from huggingface
but imo the most fun part is building the architecture and stuff with torch
I've played with other people's models and that, trained tacotron 2 models, and I tried to make a model that predicted "distance by road" given geographical locations, but never made it out of the workbook
currently I'm generating data for my uh tool (pip install uh-halp) - I want to fine tune a tiny model and have it run locally
that's cool, haven't heard of that before
when I get a house, im totally going to get a server rack and run models locally and stuff
the computer engineering stuff is so cool and fun to play with
I think the uh-halp thing should have small enough data that it can run locally. at least I think so anyway. I mean, a few hundred MB maybe?
rn im running python through Google colab. I have pro, so im using a Nvidia A100. It runs so fast that I thought my code was broken lol
nice! does it still disconnect you?
haven't had any problems recently
colab annoyed the crap out of me, deleting my data and progress every few hours
I was running a model, and it was running at 50gb of ram for 17.5 hours lmao
and then google shutdown my runtime
I shifted to vast.ai, which has its own problems but it's a docker container you run yourself
ooo ill check that out
i mean you run it on other people's computers for money, pay by the hour
my workplace has a cluster where I can get a gpu, 12 cores, and 250gb of ram. But it wasn't working earlier, so that's why im running on colab
but it's like 5 cents an hour for something like my laptop and not set my legs on fire or need to leave it open
yeah that sounds really nice
I bought an Orin too, lots of RAM but not the fastest thing
I have a question about Orin and the related small computers
my uncle is a penetration tester and does all the cybersecurity for a fortune 500 company
so he uses a lot of data and stuff
but he was looking to get a small workstation like an orin
it's 64gb shared between CPU and GPU but the CPU is 8 cores ARM and the GPU is Tegra... so .. yeah, not the fastest
do you have any recommendations? I think it would need a good cpu as opposed to a good gpu
I tend to rent boxes when I need speed, and use a lightweight gaming laptop as my daily driver
but in work we have macbook pro laptops, they're surprisingly good. 30GB of RAM on them, again, shared between CPU and GPU. battery life is insane
yeah im looking at upgrading my laptop to the new base m4 macbook
the battery life is insane
my uncle swears by the macbook cuz the terminal is really easy I guess for devops stuff
yeah it's nice to have a BSD shell. not as nice as Linux IMO, but it's usable unlike Windows
They're fast enough to run Linux in a VM and run Kali and stuff as images I think
but the CPU architecture stuff can be a bit of a pain if people haven't published aarch64 binaries
yeah
my uncle has the macbook with the intel cpu
and he was saying that to upgrade he couldn't transfer his vm's and stuff or something
so he had to remake all the stuff he was using
yeah, or ... 🐌
I dont know a ton about terminal stuff lol
I barely use the GUI! only for the web really
do you do fullstack stuff or what kinda work do you do usually
lifelong developer, games and stuff, c/c++, python back-end, did years in load testing, bit of full stack and devops, currently doing SRE work
I basically live in tmux. Use vscode sometimes, but vim mostly
what a giga chad
building my own conversational AI with open source libraries is my latest obsession
cool whatya building?
Can i add you as freind? Like if I need help in future so i can just contact you directly. Will that be alright?
broo im so obssessed with ml rn, im working like 80 hour weeks lmao
yeah go for it 🙂
status: coding in R
shudders
my job isn't in tech its in dominos delivery driver, no college education, been job hunting and starting my own AI company in my free time
never touched R
I wrote a Pydantic to R object conversion thingy for a client, and... well, R really upsets me
I don't wanna touch R unless there's no better alternatives
I highly recommend R for data transformation, visualizations, and regression stuff
but for ML definitely use python or use the python in R thing
you've got keywords that make it so parameters don't get dereferened unti they're inside the function. and all the modern R code with the filters and stuff is slow as hell because it's basically mixing compiled and interpreted code
the dplyr tidyverse stuff? yeah I was told it is really bad on ram
yes
there is a package built by Apache called Arrow
it just masks all the dplyr functions and makes it significantly faster
oh wow didn't know about that. I filed a bug with dplyr saying "hey every function is slow" and they basically said "yeah, not fixing"
GitHub
Apache Arrow is the universal columnar format and multi-language toolbox for fast data interchange and in-memory analytics - apache/arrow
spent about 3 days trying to figure out how to optimize it but it needed a partial rewrite. ended up just replacing aggregation functions with R ones
yeah it's really cool, it has the same feature that datasets from huggingface in python has
where you can load part of the data but it doesn't go the ram somehow
idk exactly how it works but its pretty cool
the state we were in is, we had data scientists who knew databases, and they wrote their extract code in SQL-flavoured R, big rectangular chunks of data. then train their models on it
then they wanted to do it live rather than on a batch job
so naturally when prepping data coming into the system, you need to run it through the same aggregation pipeline, fastapi -> R and back again
the R part wasn't threadsafe, didn't perform, the data types are a free for all, and the model ran in Python lol
but the only way to do it safely was to have the in and out of R step, "it's okay if it takes a second" and I was like my code runs in < 40ms and I'm disgusted by how slow it is!
shakes fist at dplyr
lmao
no one in my field cares about speed, it's pretty funny
we don't usually use super big data, but all the replication data and stuff is always so inefficient
ouch
I'm just anal about it because of the games programming stuff I think. in batch jobs I commit all the sins though
yeah, that makes sense
(although no modern game developers seem to care about optimization lol)
that was the best bit for me, the optimization
oops my "emojis as bullet points" trick has messed up my site
inspired by total recall's "you make me wish i had threeee hands"
No one has seen this yet, but its part of my dissertation. I'm not going to say what im modeling, but ill say that its related to state level policies

need to share it cuz I think it's super cool lol
wow yeah looks nice
the thing with R is it has all the network stuff, python really lacks in that department
it does? I thought it was mostly for rectangular SQL-like data
though I guess I only did one project in it!
@wheat merlin do you use any sort of runner to run your data creation stuff? Makefiles are grating on me
it'd be really nice if there was a docker/make style hash(inputs) cached job thingy I could use and run things on other hosts by just adding scripts and output names, and spinning up a runner with tags on it
I don't, no. Don't really know what makefiles are exactly; I don't do any model deployment for businesses or anything.
I just have everything in my rscript and press play
have a working directory set and stuff
and my data is small enough that I just write to csv and import the csv in my model execute file
im kinda just now learning git, forking, and pull request stuff; so that's where I am at with data management lol
is Malmo for reinforcement learning dead?
Never heard of Malmo
Hello everyone, I wrote optimizers for TensorFlow and Keras, and they are used in the same way as Keras optimizers.
GitHub
Optimizers for TensorFlow and Keras. Contribute to NoteDance/optimizers development by creating an account on GitHub.
fun times

I need some help; I'm trying to download a parquet dataset from hugging face, ds = load_dataset("lighteval/natural_questions_clean", split="train"). I've been trying to figure out for most of the day why the script is always only downloading the ReadMe.md file and then logging a 'tags' error no matter what dataset I use. I'm sure it's just a really easy fix but I can't quite figure it out. I've looked through documentation and videos aswell.
damn its like an environment in Minecraft for training AI agents
Using deep learning to optimize political demarcations to avoid excessive gerrymandering. There are a few people who model this is a massive convex optimization problem and solve it as an LP. I think there is a guy at Penn and a guy at UNC doing it
Hey everyone I wanted to ask how can I add temporal features in auto encoder?
I have multiple events and from each events I am taking first 10 time steps
So shape of my data comes to
There are 45 batches
And each batch is of size ([1,10,453,958])
And whole dataset
Is of shape ([450,453,958])
Am like progressing correctly?
I am trying to train auto encoder
But want it to capture temporal features as well
Try use liquid time if your varying the time step
It requires some minor modification to the keras library but keras LTC NPC works great
How to extract clothes from images? For example, imagine a picture of a person wearing a T-shirt and I want to isolate every pixel of the shirt and save it as its own image. How can I do that? I know that opencv can do this but with things like faces and maybe animals but how can you train it to detect things like say guns or any object?
I have CC-ed this question in #media-processing in case that channel would be a better place to ask this.
Thats cool. Do u do poli sci?
Segmentation
It's called semantic segmentation. It's where you classify each pixel into one of several classes (such as clothing, weaponry, etc.)
Yes there are varying time steps will look into this
from ncps import wirings from ncps.tf import LTC as LTC ncps is sparse wiring libary
its very quick
Thanks @silent @gray slate and @silent @mild dirge
Can I ask one more thing? I always get like shape mismatch for unusual shapes of images like currently I am using 4,1,10,453,958 dimensions
Batch size 4 1channel 10 time steps 453 height 958 width
But in out put I am getting always different shapes
well sadly thats the issue with nural networks
you need to specify in and out

my best advice to you is to load up tensorboard so you can see the NN and what its doing
one of the first thing to do with images is to reshape the input using image processing layer
https://www.kaggle.com/code/zeeshanlatif/image-processing-basics-with-opencv-for-beginners good thing to look at

Explore and run machine learning code with Kaggle Notebooks | Using data from No attached data sources
In this article for understanding LSTM networks, it says "forget" gates can decide when to forget some information for future propagation. Is this really what happens or this is just a naive attempt to interpret these networks?

return_sequences=True is what i think it means
its a tensorflow option
but essentual a forget gate just resets its state randomly
its another random behaviour you can add
Why would you continue to randomize the weight matrix, if you have already initialized with random values?
another thing to prevent overfitting most likly
and tbh that sounds almost exactly like the dropout feature
Really? Dropout feature initialize percentages to see how these weights are relevant to the output, and based on the output result during back propagation they are updated based on the p or 1-p probabilities. Sounds very different to me
If you do not set explicit metric, how can you track its effect?
i have been known to be wrong, and am also learning this stuff too 😉
you use a tool like tensorboard to track the optimization
IDK but this COULD be related to preventing exploding or vanishing gradients? if im understanding correctly
Lstm solved vanishing gradients problem!
randomize weight matrix for finding better local minima best soln may be!
that could be it, good thought
Guys, the name of the gate is "forget", not randomize. It uses sigmoid activation function ( codomen [0,1] ) previous cell state to see what is retained or discarded from previous memory cell context
LSTM solves vanishing gradients with cell memory context and GRUs
I am asking wether we can introduce some intuition of how we pick those things what we want to forget
maybe that's the thought behind it when it was designed
if you look at the implementation it's just some coefficients that the internal states get modified by
it determines which part is relevant from previous state!
they trained with lot of data lstm is not always correct it learns
it trains with lot of traning data then it knows which words is relevant for ur problem so it predicts correctly(not always) next word!
No PhD in applied Mathematics
are there any agent libraries that offer a wide range of models TTS, STT, VAD and other models like this for example

a bunch of models that can be stacked on one another to perform tasks
this picture is from livekit agent https://github.com/livekit/agents
but it uses this architecture, so i cant just make a script and run agent locally

Turns out that was an easy fix. I just needed to update the hugging face and datasets modules with pip install
Tell me about your research!
im working on a paper that is almost finished for the journal of algorithms which is basically the optimal traversal of n-nomial tree structure path generation that solves an open problem of how to algorithmically generate all the combinations of n-long integer with no permutations. I also work on 2 problems in DMARL (deep multi agent reinforcement learning) and the control of multi agent aquatic rover systems
im also fooling around with a problem in K-theory and another problem in stochastic path generation as a solution for monte-carlo convergence failures but those aren't really serious pursuits yet just stuff im fooling with
What deep multi agent reinforcement learning ?
So instead of single agent we will have multiple agents and then there experience will be combined together?
combined....not exactly. this problem can be super multi-faceted but in my case i consider that yes there experiences can be shared, but they still are naturally destructive agents because there are external force vectors acting on all the agents
and the construction of my environment is critical becuase if i don't reflect this none of the agents can learn at all
however multi-agent RL can also be something where agents cannot share experiences but must still interact within the same system
or the system may become a POMDP (partially observable* markov decision process) where not everything is known about the system except for what is observed at your current time step, all past time steps, and maybe some amount of n < \infty time steps in the future (i.e. maybe you know 3 time steps or maybe 10 in the future, but you dont know all of them)
and these agents need to learn to work together given this
so there are a lot of different ways in which DMARL can be formulated it's just a use case thing i would say

and this is what this would look like in a holding pattern with M agents
Half of stuff is going up my head
But it's interesting
Any papers regarding this?
That you would suggest
Google control of stochastic multi agent systems
And then you can deep learning to any of those things
To learn how to apply the math to deep learning
Will check it out thank you
It's a direct multiplicative filter on the previous state. Without it, it can only be modified through addition in the next part.
This makes its control of the cell state more powerful.
With just addition it could struggle to forget things (quickly).
Imagine that you have some problem that requires you to modify the cell state only slightly based on the current input or it will explode. So maybe the added values are around 0.01 in magnitude. But you want to forget something instantly based on the current input you just got. So maybe you have some cell state value of 1.0 and you want it instantly to go to 0. With just the addition you can't do that without breaking this whole "small added value from the input" requirement. But multiplication can do so. It can be like 0.0001 (near zero) and is separate from the addition part. So basically it gives the network better flexibility / options on the cell state control. Just addition is pretty limited and may not work at all for certain problems.
(Just multiplication would not work due to being 0 to 1 (only same or decreasing))
What book for pytorch do I need so I can put it in my cart
If you prefer a free resources, checkout https://d2l.ai

Machine Learning with PyTorch and Scikit-Learn: Develop machine learning and deep learning models with Python

Manning Publications
Learn how to create, train, and tweak large language models (LLMs) by building one from the ground up!
In Build a Large Language Model (from Scratch) bestselling author Sebastian Raschka guides you step by step through creating your own LLM. Each stage is explained with clear text, diagrams, and examples. You’ll go from the initial design and c...
I'd really like some kind of learning that has insights rather than the mathematics. Like why do they use "mean squared distance from prediction" rather than "absolute distance from predicted value".
Is it for algorithmic performance (no sqrt call), because of the tradition of std deviation, or because it's the output of a multiplication, so squared distance is the natural thing to use because it's on the same scale? Why not "absolute cubic distance from prediction"
It's like ML is filled with algorithms that seem arbitrary, or work because they have been tested empirically, or have complex mathematical reasons for why they work but not a reason you can just grock
Probably my mathematical illiteracy talking here, but I find that maths in general has a kind of... uh... it's like it's a way to logically deduce far deeper than humans are capable of understanding. It searches for proofs, not understanding, like an exploration of a tree in what is essentially a tautology-space.
So the outputs of it tend feel opaque, like circular reasoning, and process-based faith. Dunno if it's easier if you're a mathematician, but I'd guess it isn't based on the outputs.
Apologies for the unprompted philosophical noise lol
There's a nice explanation of why mean squared error is common in statistics in Koks "exporations in mathematical physics" (the arithmetical mean forms a natural pair with the sum-of-squares and with the normal distribution, whereas the sum of absolute distances is associated with the median rather than the mean), and in general you might enjoy that book to get some deeper insight into the math. Here's a few pages (note: f(x)=1 is probably a typo and should be f(x)=x).




(It's not the first time I encountered this idea though, just a recent one, but I'm not sure I can remember where I originally read about it)
the sum of absolute distances is associated with the median rather than the mean
That's interesting. So if you want to measure distance from median you'd use the sum of absolute distances from it, but the mean you'd multiply, and so have to then do the sqroot to bring it back to the same scale?
(I'm not actually sure if anything goes wrong if you use mean-absolute-distance as your error metric in ML, though. In 1d it would cause the problem that there'll be an entire region where the gradient is 0, but I think not in any higher dimension)
So if you want to measure distance from median you'd use the sum of absolute distances from it
Sort of. What I mean is that if you try minimizing∑ |x_i-m|over a 1d dataset, you'll get that the optimal solution is the median (specifically, for an odd number of points it's the middle point and for an even number of points it's the entire region between the two middle points). Whereas for the MSE (Σ (x_i-m)^2), the optimal solution is always the mean.
cool thank you. though I'm reading those pages and find it pretty mentally exhausting as my math-fu is pretty weak!

A simple explanation of physics vs mathematics by RICHARD FEYNMAN
Feynman is a pretty good example of someone who valued understanding!
This is kinda how I feel about comp.sci as someone who started out in procedural, imperative programming. I kinda have that (steps, processes, operations) baked into my intuition (rather than relationships etc)
This video is missing the last line where he says "and later it always turns out that the poor physicist has to come back and say excuse me, when you wanted to tell me about the 4 dimensions..."
As for ML, it's in its 'Babylonian' phase. We know certain parts and how they are connected, but not the whole thing from which it can be built (like axioms). And this is why most ML papers feel like loosely connected guesses that are only somewhat mathematically justified (this varies, but those that seem most immediately applicable probably are like this). https://www.youtube.com/watch?v=YaUlqXRPMmY

Richard Feynman explains the main differences in the traditions of how mathematical reasoning is employed between mathematicians and physicists.
Re: dimensions, I've spent the past year or so trying to wrap my head around what the hell a dimension even is. And I kept coming back to pi and sine, and became convinced that rather than being this "infinitely long, transcendental number" it was "a simple process where you start off with something and collapse back to some ratio"
Then I discovered that "playing pool with pi" thing and was blown away by it
The 'Babylonion' phase always comes first in new inventions, because it's the fastest way to make progress and the most natural process of randomly poking at things that humans do.
I honestly don't think that mathematics actually produces understanding, it's kinda orthogonal to proof. From a philosophical perspective I always go back to the "try to write a simple program that implements Pythagoras theorem, and would pass code review"
I can't do it yet. One day I hope to be able to
It does produce understanding, but only after it has been reduced via special case, as when it's applied to the real world.
This is a limitation of humans with complexity.
What we can "understand" is a small subset.
any idea what is a "good" mse for depe learning?
We understand the simple cases, and then we take a leap of faith on process to generalize.
With careful rigor.
But also the process, right? Like, if you optimize for proof alone, and you have this tree-search that goes really deep and narrow, and you can keep going indefinitely. But if you don't use that tool, you can't go very deep - you have to go to the next level, invent concepts then pull those back out to the level above. You get understanding that way, but it's a much less precise and efficient way of working, takes generations to change language and so on
i think my moder is overfitting, but is working great on test data
so i really got no idea how much i trust it
esp as it get there in 3 epocs
This is where heuristic search comes in or "intuition." However it's very limited for humans, but we still try. And it can go decently far after much practice and exposure, but math is endless, so you have to give up at some point.
We then have computers (machines), which can also use heuristics and are much faster. We have automated provers and such, which have already done much that humans seem to not be able to (in a reasonable amount of time).
{
"train_mse": 0.0037,
"test_mse": 0.0057,
"train_rmse": 0.61,
"test_rmse": 0.75,
"train_mae": 0.50,
"test_mae": 0.53,
"test_mape": 3500687731287.13
"train_r2": 99.95,
"test_r2": 99.93
}```these are % btw
and i have no idea how much i sould trst results like these in 3 epocs
I think maybe not having the ability to use heuristics, by being somewhat blind to it and leaning much harder on method and symbolic reasoning, many lifetimes were spent chasing things that are essentially arguing over how many angels can dance on the head of a pin
what's your data and what you're trying to solve? I'm a ML noob but have a decent nose for data and stuff
I think for ML regression problems people mostly use just MSE. I've seen fancier loss functions like Huber loss but not sure they're used in deep learning.
A block collision simulation based on a 3Blue1Brown video.
Well the neat thing about math is that even if it's not where you wanted to end up, as long as you have rigor, you did prove something. And so some progress was made. Who knows if it's useful or not.
time serise data, predicting a specifc column,
This is in contrast to physics, where you could have wasted a lifetime on something not real (e.g. string theory).
thats LTSM ive got another model with random drop and its still over 95% accuracy
honestly i just feel suspecious when i get any corrolation this good
99.93% test accuracy? IMO that means that either your dataset is trivial, or something is wrong and your test dataset leaks into the training
(or your training process implicitly does this, if you're doing something unusual like genetic algoritms)
its a month of stock data at 1m trade incraments
Well a lot of it is framing and is built into the assumptions. Like take Cantor's diagonal argument, he was proving the infinite infinity of the king of kings. When he could have been disproving the possibility of the reals
I think the problem with stock data is you're always gonna have other people's prediction models built into it, and they'll have more parameters than you, right?
Yes, you need to state your assumptions. That is the game you are playing. Mathematicians are interested in playing such games, regardless if they apply to reality. It's an art form, and needs no use case like other art forms.

for 500 diffrent stocks and 500 trainings the validation goes to under 0.5% loss in 3 or less epcos
hmm, 0.5% of what?
its ltsm MSE, adam as the optimizer
Note that in math, you just state the rules. But in physics, the entire point is to try to figure out what they are, and you can never be sure that your guesses are correct, only that they are not shown wrong yet.
so the val loss is MSE evaluator per epoc
The other way famously worked out quite fine for Einstein :p
Yeah you have a huge number of possible axioms, and the space of questions you can ask is.. I dunno, factorial of that? then you have cultural leanings and fashions that lead you into the space, much of which is a psychological trap
but this is honestly why i am deeply suspious, its a standard 80% split for data and seed 42
so nothing unusaual ther
80:20
Yeah, I'd be suspicious too. Maybe try graphing real vs predicted prices for one stock, to see if maybe the loss is higher than you think
are you gonna use it for trading? 'cause it might be better to try to predict Elliot Wave or something rather than raw price
i can hit month 4 with the model trained on 3 months of data and see if thats going ok
not yet no, i am evaluatiing diff models for effeincy
and accuracy
if they really do match, then it's somehow training on the test data- huh, wait a minute. This is an LSTM, right? Possibly you need some special way of splitting the data for LSTMs, since otherwise your "training" set might accidentally cover the entire dataset (just not all possible subsets of it)
Yeah, you still guess the rules, but unlike math where that is what it is (these are the rules I feel like playing with), in physics you need to check it against reality.
(Experiments)
def pipeline_1d(input_file, model_creation_func):
data = pd.read_parquet(input_file)
X_train, X_test, y_train, y_test = split_train_test(data, 'Close')
model = model_creation_func(X_train)
tensorboard_cb = tensorboard_callback(input_file, model.name)
model, history = fit_model(X_train, X_test, y_train, y_test, model, input_file)````
Physicist Richard Feynman explains the scientific and unscientific methods of understanding nature.
(All of this in the same lecture btw, covers a lot)
Does split_train_test make sure not to shuffle the points?
it really shoudnt be using the testing data in training, given its not being passed that way
y_train_pred, y_test_pred = model.predict(X_train), model.predict(X_test)
(note that current ML feels a lot more like this than math in many cases)
def split_train_test(data, target_column):
X, y = split_features_target(data, target_column)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Reshape X_train and X_test to 3D (samples, timesteps, features)
X_train = X_train.values.reshape((X_train.shape[0], 1, X_train.shape[1]))
X_test = X_test.values.reshape((X_test.shape[0], 1, X_test.shape[1]))
return X_train, X_test, y_train, y_test
Einstein worked in the patent office and had the idea that patent time registration was relative due to speed of communication - that insight was a real-world intuition right?
did i fuckup?