#data-science-and-ml
1 messages · Page 152 of 1
model is of type Blip2ForConditionalGeneration. Here is the code that imports it: ```py
model = Blip2ForConditionalGeneration.from_pretrained(
"Salesforce/blip2-flan-t5-xl-coco", device_map="auto", low_cpu_mem_usage=True
)
that's the code that defines model, but it's not an import statement. but I was able to find the documentation for that class without it.
oh I'm sorry
from transformers import Blip2Processor, Blip2ForConditionalGeneration, AutoModelForSeq2SeqLM, AutoTokenizer, BitsAndBytesConfig
this person got a similar error: https://github.com/huggingface/transformers/issues/22563

GitHub
System Info Issue When setting ignore_mismatched_sizes=True in Blip2ForConditionalGeneration, a KeyError is raised. Who can help? No response Information The official example scripts My own modifie...
Im kinda lost on how I can go about in getting into either the space industry or healthcare w ml/ai. For health, I found some courses online by Stanford to get some certifications. Do you guys think I’m on the right path? I currently only have my bachelor’s in ml and 2 years of experience as a research assistant/data analyst.
Is anyone here in either industry?
your best bet might be to get a masters.
@gleaming osprey try setting ignore_mismatched_sizes=False when you call Blip2ForConditionalGeneration.from_pretrained and see if you get a different error
also, the problem is arising when trainer tries to save the model.
there's also something about shard. I wonder if device_map="auto" is the problem. do you have the whole model on one device?
in either case, I have to run. I hope this was more helpful than nothing.
is that the standard I'm holding myself to now? wow.
I would do that but it’s too expensive 🤡🤡😢
Can anyone recommend a resource for self study? I can already code since I've been doing Web Dev for some years now (but in Java and React mostly)
Thanks for the help nonetheless! The issue is with Checkpointing and sharding and offloading some of the model (purpose of module map), how do i know?
- I looked through the transformers source code for clues
- If i disable checkpointing i get no errors
Thing is, i want checkpointing.
i coded a neural network and when i train it he values come out as inf
weights and biases
what do i do
the first thing would be to play around with the learning rate. try making it smaller
did that
did you make everything yourself from scratch or are you using something like pytorch? cuz another issue might be just using the wrong derivatives
and you're sure the math is correct?
if you want i can send the formulas i used but idk if you can understand it
i followed this video wait
Help fund future projects: https://www.patreon.com/3blue1brown
An equally valuable form of support is to share the videos.
Special thanks to these supporters: http://3b1b.co/nn3-thanks
Written/interactive form of this series: https://www.3blue1brown.com/topics/neural-networks
This one is a bit more symbol-heavy, and that's actually the point. ...
i mean, the math and formulas are easy, the question is whether they are coded correctly 😛 have you tried some small scale toy scenarios that you can verify by doing the math on paper?
what does small scale toy scenarios mean
like just one layer with few parameters
currently self learning ML using Hands On Machine Learning but Im on Chapter 2 and Im not really enjoying it as I don't fully understand the functions I'm using when I go along with the guided projects. What 3 ML techniques should I focus for now as a beginner? I know linear regression is one of them but what other 2 should I work on?
something you can realistically do on a piece of paper
did it on paint does that count
if you did the full math with numbers and used it to corroborate the results your code spits out
you can verify every number in your code vs calculations you make on paper
the problem seems to be in my sigmoid deriv function
i tried without it and it works
not true values but no inf or nan
lemme send that function rq
def sigmoidDeriv(x):
return x*(1-x)
that's not the correct derivative of a logistic sigmoid, is it?
i dont think so
shouldn't it be f(x) * (1 - f(x))? where f(x) is a sigmoid
i copy pasted it from somewhere since i had more stuff to do
yea bro im questioning that too lol
it should include sigmoid too
lemme fix that
@wooden sail sorry for the ping but i wanna ask something
how much should it take in an average pc to train with 60000 img dataset
depends on what size the images are, how big the network is, and how good your computer is
mnist
60k isn't that many, anywhere from like 10 minutes to "it's not worth it" depending on if you have a gpu or not
its an average pc
oh ok
oh ok
can someone help me with a python project in data mining. plz dm me
Hello, people won't want to dm you to figure out if the question is something they can help with. Please ask your whole question in this channel.
nvm i got it
guys, what do you think about applyting ML/DL into cybersec?
I need help. I am currently studying Multimodal RAG: Chat with Videos
https://www.deeplearning.ai/short-courses/multimodal-rag-chat-with-videos/
In the course, there is a use of bridgetower-large-itm-mlm-itc using predictionguard. When I want to try it on a local laptop, following all the examples in the course, I am currently working on the chapter L4_Multimodal Retrieval from Vector Stores. I am having trouble with bridgetower-large-itm-mlm-itc using predictionguard, which I do not have an API KEY for. So I searched for information on huggingface and found https://huggingface.co/BridgeTower/bridgetower-large-itm-mlm-itc. But the next problem I encountered is how do I make a function to solve this problem?
# helper function to compute the joint embedding of a prompt and a base64-encoded image through PredictionGuard
def bt_embedding_from_prediction_guard(prompt, base64_image):
# get PredictionGuard client
client = _getPredictionGuardClient()
message = {"text": prompt,}
if base64_image is not None and base64_image != "":
if not isBase64(base64_image):
raise TypeError("image input must be in base64 encoding!")
message['image'] = base64_image
response = client.embeddings.create(
model="bridgetower-large-itm-mlm-itc",
input=[message]
)
return response['data'][0]['embedding']
Can you suggest how I should modify the function to successfully use bridgetower-large-itm-mlm-itc locally?

Build an interactive system for querying video content using multimodal AI
Q5. Write a program to filter count vowels in the below-given string.
string = "I want to become a data scientist"
..
!e
string="Text goes here"
count = sum(c in 'aeiou' for c in string.lower())
:white_check_mark: Your 3.12 eval job has completed with return code 0.
12
!e ```py
string="I want to become a data scientist"
count=sum(map(string.count, "aeiou"))
print(count)
ooo
forgor the +1
?
no
i see what's wrong
!e ```py
string="I want to become a data scientist"
count=sum(map(string.lower().count, "aeiou"))
print(count)
:white_check_mark: Your 3.12 eval job has completed with return code 0.
12
OH WAIT, nevermind i forgot to make it lower as well lmao
lmao, i thought it was just from off by one or smthn
im confused on how to use yolo for training, what do i write in the .yaml file??
Guys I am trying to train a model to respond with a structured json response
specifically:
import json
from datasets import load_dataset
from transformers import (
AutoTokenizer,
AutoModelForSeq2SeqLM,
Seq2SeqTrainer,
Seq2SeqTrainingArguments,
DataCollatorForSeq2Seq,
)
# Load Flan-T5 model and tokenizer
MODEL_NAME = "google/flan-t5-large"
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
model = AutoModelForSeq2SeqLM.from_pretrained(MODEL_NAME)
# Load dataset
dataset = load_dataset("json", data_files={"train": "train.jsonl", "validation": "validation.jsonl"})
# Preprocess the dataset
def preprocess_function(examples):
inputs = examples["input"]
outputs = examples["output"]
# Convert output to a string if it's a JSON object or list
outputs = [json.dumps(output, ensure_ascii=False) for output in outputs]
# Tokenize inputs and outputs with padding and truncation
model_inputs = tokenizer(inputs, truncation=True, max_length=512, padding="max_length")
labels = tokenizer(outputs, truncation=True, max_length=512, padding="max_length")
# Add labels to model inputs
model_inputs["labels"] = labels["input_ids"]
return model_inputs
# Tokenize the dataset
tokenized_dataset = dataset.map(preprocess_function, batched=True)
# Data collator to handle dynamic padding
data_collator = DataCollatorForSeq2Seq(tokenizer=tokenizer, model=model)
# Training arguments
training_args = Seq2SeqTrainingArguments(
output_dir="./flan-t5-greek",
evaluation_strategy="epoch",
learning_rate=5e-5,
per_device_train_batch_size=1, # Reduce batch size for memory efficiency
per_device_eval_batch_size=1,
num_train_epochs=3,
weight_decay=0.01,
gradient_accumulation_steps=4, # Simulate larger batch size
save_steps=5000,
save_total_limit=2,
predict_with_generate=True,
fp16=True, # Use mixed precision for speed
logging_dir="./logs",
logging_steps=500,
report_to="none",
)
# Trainer
trainer = Seq2SeqTrainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset["train"],
eval_dataset=tokenized_dataset["validation"],
tokenizer=tokenizer,
data_collator=data_collator,
)
# Train the model
trainer.train()
# Save the model and tokenizer
trainer.save_model("./flan-t5-greek")
tokenizer.save_pretrained("./flan-t5-greek")
the train.jsonl contains such data as:
{"input": "ΠΛΗΡΗΣ\nΚΥΡΙΟΣ (ΠΟΣΟΣΤΟ:100/100 )\nΟνοματεπώνυμο Φυσικού Προσώπου: REDACTED\nΟνοματεπώνυμο Πατέρα: REDACTED\nΟνοματεπώνυμο Μητέρας: REDACTED\nΗμερομηνία & Τόπος Γέννησης: 99/99/9999 Α.Φ.Μ.:99999999\nΔιεύθυνση: REDACTED, TK: 55555 REDACTED, Νομός: ΑΤΤΙΚΗΣ\nΑ.Δ.Τ.: Σ999999 99/99/9999 Α.Τ. REDACTED\nΑιτία/-ες Κτήσης: ΧΡΗΣΙΚΤΗΣΙΑ\n\n", "output": [{"full_name": "REDACTED", "father_name": "REDACTED", "mother_name": "REDACTED", "date_and_place_of_birth": "99/99/9999", "tax_id": "99999999", "address": "REDACTED", "postal_code": "99999", "location": "REDACTED", "municipality": "REDACTED", "adt": "Σ999999 99/99/9999 Α.Τ. REDACTED", "percentage_ownership_land": "100/100", "ownership_state": "ΠΛΗΡΗΣ"}]}```tag me if anyone wants to help 😭
I have posted to https://discord.com/channels/267624335836053506/1310574647498117120, (I show the channel later)
3B1B!!!!
3b1b + chatgpt for your questions
better than any free/paid course imo
can't disagree with ya mate
ChatGPT is not exactly reliable though
there's a considerable risk of it hallucinating and giving you incorrect answers, so you must double check nearly everything it says
Yeah if you're already studying it's common to study from multiple sources
you should like read a book then like ask chatgpt for clarification
if thats the case im cooked
hey there guys
I'm looking for some basic information on training AI models
I have 5 days to make an inventory management and automatic reordering system, which takes in a bunch of data points such as:
- current stock amount
- rate of usage
- time to receipt of a new order of supplies
- reliability of specific suppliers (i.e. how long they take to actually deliver supplies versus their delivery estimation)
- historical data about the usage rate of specific items around certain times of year
and make a system that automatically decides how much of a stock to order, and when to order it, to ensure optimal storage costs and no shortages
it seems to me like it would be difficult to manually model a relationship between these variables in a way where I can write an algorithm for it
I'm not looking for anybody to solve my problem, I've just never messed around with AI before and I don't know up from down
If someone could point me in the general direction of the type of AI model that is optimal for this sort of work, I can learn everything myself from there
I just don't know where to start
@wild storm thank you for explaining what you want to do. this is a great amount of detail for a beginner question.
have you heard of forecasting?
making predictions about future data using the data you have?
right.
Start out with exponential smoothing or similar
Why? It's very very easy to explain to stakeholders and very easy to implement as well
Afterwards you can gradually add new variables and try different models
You can also get quite far with saying "demand yesterday will be the demand tomorrow"
5 days to come up with this is pretty much impossible though, at this point I'd focus on managing expectations lol
Hello guys, can someone tell me a site where I can make my AI recognise open eyes/closed eyes by showing him a video/picture?
also, i dont know if the tutorial you follow will have everything but make sure you learn about MovingAverage
hello everyone
i'm working on this loan dataset i saw online, where the goal is to identify individuals who are most likely to repay loans while reducing the risk for financial institutions.
going through the data, i dont know how they arrived at Total_Income and its not the summation of ApplicantIncome and CoapplicantIncome.
when i checked the description of the features, they didnt include Total_Income.
could the Total_Income feature be there to throw me off or it means something im not seeing because i think its an error.
Thank you 🙏


Hi all, I'm sorry if this is not the right sub for this question- but I'm looking for some good yt resources that explain python from scratch from a credit risk standpoint. Google search gave me a few courses but they are too expensive for me right now and yt vids I came across so far are not that helpful. Any suggestions would be appreciated as i have no experience in python or programming. However I have done FRM so I do have a basic level understanding of stats.
https://youtube.com/playlist?list=PL-osiE80TeTt2d9bfVyTiXJA-UTHn6WwU&si=oaXo1vh7t6zMp8dt
Corey is good. I didn't use Corey but the few I've learnt from him are alright. straight to the point, audible and visible enough.

YouTube
Python Tutorials. An in-depth look at the Python programming language. Learn about Python development, tips and tricks, walkthroughs, and best practices.
Thanks
Hey guys!
I'm doing my Master's in mechanical engineering with applied computer science, and I've got the basics of ML and AI from 2 courses I took during my masters, I also have basic programming skills in python.
Can someone please recommend resources ( Books, papers....etc) to learn PINNs and their programming? I need them for my thesis.
Thanks
What have you used in the past?
I'm not following, what do you mean?
https://benmoseley.blog/my-research/so-what-is-a-physics-informed-neural-network/ this has a pretty clear explanation and some references

Machine learning has become increasing popular across science, but do these algorithms actually understand the scientific problems they are trying to solve? In this article we explain physics-informed neural networks, which are a powerful way of incorporating existing physical principles into machine learning.
@crimson raft wendigo is a beginner. if you've taken two ML courses, you probably know more than them.
I don't know anything about PINNs--sorry
the paper on SIRENs is also fairly clear IMO
https://arxiv.org/pdf/2006.09661 this one
those two were enough for me to set up a PINN for the 1D wave equation on a string
can someone possibly explain this to me?

cause i cant understand shit from this
(the formula)
do you know about derivatives in general? do you know the derivative of f(x) = x^2 + 3x?
no :(
okay. put everything you're trying to do with ML on the shelf and learn derivative calculus.
I know that's a big diversion, but it's critical.
okay
khan academy and 3b1b are your friend.
yea im looking at 3b1b's channel rn
you need to learn how to calculate the derivative of functions with one variable, and functions with multiple variables (but with respect to one variable at a time)
what you're looking at isn't as complicated as the notation makes it look, once you know what the notation means.
Thanks, appreciated.
Nice suggestion, but I'd rather recommend cal 1 & 2 Mit opencoourseware on YouTube
Nice.
Have you worked on anything else? Are you an engineer/ physicist?
with pinns or in general? i'm an engineer, one could say
my grad studies went in interesting directions, but engineering at the end of the day
Nice to meet a fellow engineer.
Since you worked on wave equation, I guess you are mechanical engineer.
Pinns just wanna get a heads up before I get involved 😅
so that's where it gets interesting
i did telecom for my bsc, communications and signal processing for masters, and doing ultrasound sigproc for phd
i only have tangential knowledge about the physics. just enough to build a not-so-wrong model for the approximate propagation of ultrasound in "well-behaved" solids
i'd say my bread and butter is more the estimation part
but pinns work well for inverse problems/estimation, so
if you close both eyes and wave your hands, sound kinda works like electromagnetism
Wow, that really is an interesting turn.
I love electromagnetism and communication, never had the time to dive deep into it
does anyone know how to get tensorflow with gpu (cuda) to work ive tried literally everything. i have the right tensorflow cuda toolkit and cudnn versions installed and wsl and nothing recognizes my gpu
i dont mind. at the end im learning the math still to understand ai
What math do I need to learn to make a neural network sorry
if I tell you, are you going to learn it, or are you going to suddenly go in a different direction again?
How much is an array is important for data science student
how can i add more images to a cvat task?
Please give me an example for losting data because of encoding
a lot
pretty much everything is represented as an array.
aka yes its very important lmao
Greetings everyone
I'm assigned a binary classification problem and I was wondering if someone can help in the modeling part.
If someone is interested helping me, please let me know 💗
you can just say the problem you have
Oh ok thanks.
wdym by model? what are you trying to model exactly?
e.g. are you thinking that in a fail, fail, fail, ..., fail, success sequence, the more times it fails consecutively, the more likely that the next time will be a success or something?
Yeah exactly
also, isn't this just visit_id?
Yes
then... just put it in as a feature?
if there is such a relationship, then the model will pick up on it
e.g. if you have a tree, then the splits will contain something like
if visit_id > 2:
... move to a subtree with higher success rate overall
well, what is it?
I'm also not exactly sure what you mean by "in a node level"
But what if we can make it more clear
so what you really want is a way to emphasize specific features to the model?
I'm not aware of such methods if they exist tbh, if anything the model should pick up on these relationships on their own if these relationships indicative enough
your visit_id already encodes the information of how many times a specific task failed to complete
well, given a task with visit_id == 2, can you ensure that you'll have access to the same task, but when it was visit_id == 1 and visit_id == 0?
not only for the training data btw, any future data you need to perform classification on as well
2nd thing to consider, if you know for sure that engineers in previous attempts always have lower engineer_lvl, then including any feature regarding this is just redundant
e.g. a column is_previous_engineer_lower_level will always be True 100% of the time if the above assumption holds, thus providing no valuable information
sure, the question is do you have it?
given a task with visit_id == n, will you have access to data that details what happened before that?
Yes if only this wasnt the very first attempt
then what you're doing is a pretty nice approach already
include features from previous failed attempts
Nice talk btw.
ig you might run into trouble where
| visit_id | prev_1_eng_lvl | prev_2_eng_lvl | ...
| 2 | 5 | 3 |
| 1 | 7 | ??? |
```one way I could see it working is set it to `0`, and let the model pick up on the fact that `0` means there's no oneYeah you can do a bunch of things. That;s another approach as well
or if you really want to emphasize, include binary columns like
| visit_id | prev_1_eng_exists(binary) | prev_1_eng_lvl | prev_2_eng_exists(binary) | prev_2_eng_lvl | ...
```probably have to test what works best😂
sure
Food for thought
whats the time complexity for lookup in csv by pandas?
lets say i have a column with unique values called "id", and i do a lookup like this dataframe[id]["unique_id_value"]
is it O(1)?
To be O(1) it should use a hashtable. Let me check
Its O(n)
With an index is O(1) :
dataframe.set_index("id", inplace=True))
i read somewhere that with index, it is O(logn) due to B-trees, i maybe wrong though
B-trees are for certain kinds of actual databases, whereas pandas is all in-memory.
if you do df.loc[row_index, column_index], that's O(1). you should never have expressions that look like df[ ][ ] in pandas.
thank you for the insight, im actually building a search engine based on files, i've chosen a dataset of 1M+ docs
what could be the better format for storing files? json or csv? im gonna be dealing with roughly ~500K-1M doc files
JSONL
which is slightly different from JSON. you'll want to look into it.
and if you need to be able to quickly look up subsets of the document set (the whole document set is a corpus), you'll need to put it in a search engine like elasticsearch.
More than 150% important because if you use a regular list python it takes a while for it to take every object out of the list but if you assign it as an array it'll make it so that it's in a format that's more of an integer most likely sorry
we have to actually build a search engine from scratch so i need to look for a format for fast retrievals and less memory consumption
can anyone help me with python ML?
not if you don't ask a concrete question
i have to make a program that get a sound of person talking and it needs with background vs foreground to find the seconds the person talks
and it wants me to create an ML from the begining no ready dataframes.
that's not a DS/AI question anymore.
by "ready dataframes" do you mean training data?
Hello, What would be the best path to get big in the AI and make it big
I don't have the resources for college till yet
get a PhD in computer science with a research focus in a niche area of AI.
I want to build up my skills, learning and hopefully make something in AI, but I can't afford the have a education in US till yet
you can start learning about AI whenever you want. but you almost certainly won't be able to have a career in AI unless you get at least a bachelors--and probably a masters--in a scientific field with focus on AI.
Are you interested to learn about AI anyway? Or do you need to be able to "get big and make it big"?
are the same any good books that teach creating AI using python? Geared towards a beginner
!resources data science
Resources
The Resources page on our website contains a list of hand-selected learning resources that we regularly recommend to both beginners and experts.
also this: #data-science-and-ml message
Ty
I want to be able to get into AI from a problem solving standpoint, i.e. learning and hopefully finding a problem which I could then be able to solve and contribute that way.
I am not saying he's good, but Sam Altman like didn't have a degree, but still runs OPenAI
Sam Altman like didn't have a degree, but still runs OPenAI
you need connections and an insane amount of luck for that to work.
So are there no practical path for something like me in the AI?
if you can't get a job or funding through connections, and you can't get a degree, then there is not.
it might work out anyway because of luck, but if you don't get lucky, you will have wasted time that you could have spent preparing for a different career.
Does this applies to AI or with other paths in prgraming as well?
AI is the most degree-requiring path within programming. Web development is the least.
Also, Sam Altman was in university, but he dropped out to found a company with a classmate. Which meant that he needed to have an idea that he knew how to implement, and which he could convince investors to give him money to do, and then it had to actually work.
Should I focus on my current skills like Web Dev and Game Dev and be able to save up enough money to afford education in AI eventually?
and it looks like 90% of AI startup companies fail.
I wouldn't plan that far out. No one knows what the AI landscape will look like by then.
Thats what I am confused with, I want to do something in Game Dev, Web Dev, App Dev and also in AI, but don't have a practical path on which one to choose as the future
game development has some of the worst working conditions in all of programming.
you can start practicing web development and app development at any time.
Game Dev is something that I find fun and something as a hobby. I currently am a web developer.
But problem with web dev and apps is that, those are kind of saturated and I am not sure I would be able to actually contribute in them
And overall what should I aim in terms of carrer
if you want a specific job start building a portfolio for that job, if you have a passion the job will fix itself
That last book, “dive into deep learning”, does it explain concepts start to finish in python? If you’ve read it
Very new to this so looking for something with actual code that can help me build networks myself
How does regularisation make any sense
So you find the best line fit and then you decrease the slope for some bs reason
“My model doesnt perform well, ill randomly adjust the weight”
the idea behind regularization is preferring simpler models over complex ones in order to avoid overfitting
i'm not sure what you mean by "decrease the slope"
Looking for some thoughts on this
Ive been writing a few of different agentic rags I’ve seen online on Jupyter notebook and I kinda thought it would be neat to go straight from Jupyter to api server so I can give it to a buddy to test out. Like have him hit certain functions
Thought it was clever enough to share lol
Notebooks are for human consumption. You'll have to copy the relevant functionality into a py file and wrap the functions with flask or something
If you find game dev fun, do it as a hobby instead of a career
hi, any one familiar with aws glue with terraform. need one help pls.
Hello, please remember to always ask your actual question. Never ask if someone knows about the topic of your unasked question.
pyspark_data_transform_code.py
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
# Get job arguments, get datalist https://www.datablist.com/learn/csv/download-sample-csv-files
# args = getResolvedOptions(sys.argv, ["JOB_NAME"])
# Initialize SparkContext, GlueContext, and SparkSession
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
# Create Glue job
job = Job(glueContext)
job.init("pyspark_glue_job")
# Script generated for node AWS Glue Data Catalog
AWSGlueDataCatalog_node = glueContext.create_dynamic_frame.from_catalog(
database="crawler_output_db",
table_name="customers_csv",
transformation_ctx="AWSGlueDataCatalog_node",
)
# Script generated for node Change Schema
ChangeSchema_node = ApplyMapping.apply(
frame=AWSGlueDataCatalog_node,
mappings=[
("index", "long", "index", "long"),
("organization id", "string", "organization id", "string"),
("name", "string", "name", "string"),
("website", "string", "website", "string"),
("country", "string", "country", "string"),
("description", "string", "description", "string"),
("founded", "long", "founded", "long"),
("industry", "string", "industry", "string"),
("number of employees", "long", "number of employees", "long"),
],
transformation_ctx="ChangeSchema_node",
)
# Script generated for node Amazon S3
AmazonS3_node = glueContext.write_dynamic_frame.from_options(
frame=ChangeSchema_node,
connection_type="s3",
format="csv",
connection_options={
"path" = "s3://${aws_s3_bucket.destination_data_heidi.id}",
"partitionKeys": []
},
transformation_ctx="AmazonS3_node",
)
job.commit()
glue_job.tf
resource "aws_glue_job" "pyspark_script" {
glue_version = "4.0" #optional
max_retries = 0 #optional
name = "pyspark_script" #required
description = "This script will transform the catalog data" #description
role_arn = aws_iam_role.glue_role.arn #required
number_of_workers = 2 #optional, defaults to 5 if not set
worker_type = "G.1X" #optional
timeout = "60" #optional
execution_class = "FLEX" #optional
command {
name = "glueetl" #optional
script_location = "s3://${aws_s3_bucket.pyspark_script_heidi.id}/pyspark_data_transform_code.py"
}
default_arguments = {
"--class" = "GlueApp"
"--enable-job-insights" = "true"
"--enable-auto-scaling" = "false"
"--enable-glue-datacatalog" = "true"
"--job-language" = "python"
"--job-bookmark-option" = "job-bookmark-disable"
"--datalake-formats" = "iceberg"
"--conf" = "spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions --conf spark.sql.catalog.glue_catalog=org.apache.iceberg.spark.SparkCatalog --conf spark.sql.catalog.glue_catalog.warehouse=s3://tnt-erp-sql/ --conf spark.sql.catalog.glue_catalog.catalog-impl=org.apache.iceberg.aws.glue.GlueCatalog --conf spark.sql.catalog.glue_catalog.io-impl=org.apache.iceberg.aws.s3.S3FileIO"
}
}
pls ask me for any additional details / screen shots.
it's been 2 days on this.
Destination bucket is getting created where the script output should get stored. However the data is not getting created inside it.
On the debugging process, i found that input data bucket is getting properly & input data is loading into it properly.
And then the glue job is running on that input data.
Are there people that get into computational linguistics with a degree in linguistics? Or is a degree in compsci better? I'm new to IT so I don't know a whole lot about industry demands these days
I am a computational linguist. I was a linguistics major but switched to computer science. One of my coworkers has a degree in linguistics and a minor in computer science.
Note that computer science is not IT.
Oh I see, what's the difference between the two?
in principle, IT is just "information technology", but it's generally understood to refer to degrees in information technology and the occupations that those with that degree have, which are not scientific.
a degree in IT is going to be a business degree, and if you have a degree in IT, you'd be filling technical support roles. not developing software or AI.
Is it a good field for someone who likes programming and linguistics? I guess that question is subjective, but I guess the linguistics aspect of it might be different from what I would think?
it's the only field in linguistics that pays well, for one thing.
when I was in high school, one of my teachers had a phd in linguistics, and I told her that I wanted to go into historical linguistics. and she said "you should go into computational linguistics. they make bank."
she actually wasn't my teacher. she was my friend's teacher.
but she taught me the most important thing I learned in high school, so I guess she was my teacher.
I didn't actually do what she said to do until like 7 years later.
I'd probably do linguistics with a minor in compsci. I really find language interesting, and that'd be my biggest focus. Do you know where I'd find good resources to get into it? Is open source contributing a good way to dip my toes into the field to see if I like it?
I don't know of any open source projects that are approachable for beginners and which actually involve theoretical linguistics
linguistics with a minor in compsci
do it the other way around.
especially in the age of deep learning, your explicit awareness of theoretical linguistics won't be as helpful as it probably would have been 10 years ago.
I have this chart on a poster in the room where I work. if I didn't, I probably wouldn't think about pure linguistics most days.

It's a shame that I wasn't on the computational linguistics grind when I was 8 years old. But jokes aside I see what you mean
my advice to all fetuses is to get a law degree and adopt an extreme political ideology so that they can get on the supreme court when they're born.
I think that’s what I’m alluding to, build some kernel commands that make a cell an api I can share. Totally bypass the flask thing
Thoughts on that?
Every tech guru ever
I don't even want to think about how a notebook could be turned into a web app without switching back to normal py files. not everything needs to be a notebook.
whatever solution you come up with, you're not "bypassing flask". you're just replacing it with something that's "flask for notebooks".
Yeah the sales pitch sounds more like bypassing flask. The engineering hack would just hide the complexities of flask or a web framework from your notebook
flask isn't that complicated.
I haven't used it in years, but from what I recall, it would be a challenge to make it less complicated.
It’s more like it’s a pain to do every time for every iteration of notebook I do.
I.e im on a dedicated AI team tweaking various versions of our RAG and agent workflows and I do NOT want to make flaks endpoints for every tweak/version etc. which I currently do.
I would rather have certain cells be my handler functions automatically
you know when the US adopted a containment policy to stop the spread of communism? I'm like that with use cases for notebooks.
Big mr. I don’t like thinking outside the box I see 😉
I use IPython every day and notebooks most days. But I see their limitations and don't try to expand their scope.
AWS glue job is producing output files like run-1732763023996-part-r-00000.
can we get them in .csv format?
What was this out of curiosity? The recommendation of what to study?
Yes. Though I was being facetious
Regularisation like laso and rigid apply penalty on trainable parameters. I was referring to regularisation on linear regression, it adds penalty the slope
Loss: mse + alpha * |m|
Where m is the learnable parameter in y = mx + b
where did you get this formula? this is not correct
I'm new to python and data science. Can you guys suggest some good projects with source code
How so
What exactly js not correct
ah. misread. yeah, the idea is to penalize larger coefficients unless it is a lot better than a smaller coefficient
scikit-learn
The following are a set of methods intended for regression in which the target value is expected to be a linear combination of the features. In mathematical notation, if\hat{y} is the predicted val...
its confusing
hello friends... i am a master's in AI but i am unable to land a job. i have been contemplating on doing a certificate course online but cannot decide which one to opt for ?? Shall i got for Google Cloud or AWS Cloud ??? Please guide me 😄


You decrease the slope for good reasons.
You find the line of best fit on the data you have at hand.
A good assumption is that your data might not be perfect.
For example, there might be some variable there that shouldn't have any correlation, but because you have limited data and bad luck, the line of best fit shows some correlation when there is actually supposed to be none.
In other words, the gradient is supposed to be zero, but coz your dataset is not perfect, you got some gradient.
some regularization counteract this by decreating that graident
But how does it decrease some gradients by a lot and others by just a little?
I assume it depends on how much decreasing the gradient would result in increase in mse
Correct me if i am wrong
Now that i am thinking of it, it would make sense that it would cancel out the gradient which has no correlation with the label instead of the other way around
not sure what you mean exactly
if you have a model that optimizes some function objective(), then adding regularization can be thought of as optimizing objective() + regularization()
and we can design the regularization() function to encourage specific behavior; e.g. L1 = sum(abs(weights)) encourages the absolute values of each weight to be small
not sure where the "random" is coming from
Below is the script executed as part of glue job
# ------------------------------------------
# Bioler plate code
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
sc = SparkContext.getOrCreate()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
# ------------------------------------------
# Read data in CSV From AWS S3
s3_path = "s3://source-data-heidi/"
customer_table = glueContext.create_dynamic_frame_from_options(
connection_type="s3",
connection_options={"paths": [s3_path]},
format="csv",
format_options={"withHeader": True, "optimizePerformance": True},
)
# ------------------------------------------
# Write data in CSV into AWS S3
s3_path = "s3://destination-data-heidi/"
glueContext.write_dynamic_frame.from_options(
frame=customer_table,
connection_type="s3",
connection_options={"paths": [s3_path]},
format="csv",
format_options={"separator": "|"},
)
# ------------------------------------------
# Display schema and first 5 records
customer_table.printSchema()
customer_table.toDF().show()
# ------------------------------------------
job is getting failed & when i verify the logs, it says
An error occurred while calling o93.getSink. No usable value for path. Note: This run was executed with Flex execution. Check the logs if run failed due to executor termination.
could not understand what is this error message trying to say.
any help pls.
hello i want to create a model that compares actual result with expected result and flag it as positive or negative. but problem is i cant find this type of dataset. can someone help me on what to do in such case
L1 = sum(abs(weights))
Hi, quick question. I'm given a dataset were 1 column is called
engineer_note: A summary note left by the engineer after this visit. The note
is already tokenized, so all words are replaced with numeric ids. Each word is
always associated with the same numeric id. For example, 106 might always
refer to the word ‘wire’.
How can I use such information to build external features even though I dont have access to the dictionary ? I can think of just 1 hot-encoding. A word2Vec has no meaning and also any mapping from LLMs to get the embeddings has no meaning cause the dictionary might be different.
this is random, you could perform any other operation
how do you know that you have to decrease gradients? maybe we need to increase the gradients?
this is random, you could perform any other operation
sure, you can make up some other strange complicated function and use that as the regularization function and get another result
L1 and L2 have quite a bit more history though (see lasso and ridge, MAE and MSE), and have been studied more not only in ML but statistics
the reason they're chosen involves errors being normally distributed or something... I'm not well versed in stats enough to explain thoroughly
how do you know that you have to decrease gradients?
uhh... sorry? walking down the gradient would decrease the value of the function(the objective) being evaluated, which is what we want?
ig as a not-very-rigorous reasoning, it's not hard to reason that if we penalize sum(abs(weights)), then the model would prefer a solution with smaller weights, which makes it more stable (e.g. similar inputs would have similar outputs), which ideally means it generalizes better
is there any way i can make ultralytics yolov11 to reuse the runs folder? i just have trained it and forgot to export, it took me very long
walking down the gradient would decrease the value of the function(the objective) being evaluated, which is what we want?
it decreases the output, why would you want to decrease the output.
If i have a data set, and i find the line of best fit (linear regression with mse or mae) why would i willingly go against my data and enforce it to decrease the output by penalizing the gradients? It seems absurd.
this is confusing me
no, we're not decreasing the output, we're decreasing the objective function, which is a measure on how good / bad the model is (usually defined in terms of lower = better)
originally the objective function F is just objective(), e.g. mse. we can find a best fit for it, which is the model that minimizes F
then we add regularization, and now the new objective function F' is objective() + regularization(), e.g. (mse + l1), which we now again find a best fit, which is the model that minimizes F'
this new model that minimizes F' may not be one that minimizes F, but due to how regularization() was set up (say l1, which penalizes weights with big absolute values), we can expect the model to have better stability
we wouldn't need to do this if the original data is very good, such that the best model for it just so happens to be the best model in general
but that's usually not the case
the standard statistical formulations for L1 and L2 regularization of a least squares cost function is superficially along the lines of: the least squares cost function corresponds to "maximum likelihood estimation" under gaussian noise. L2 regularization comes in when the parameter you're looking for is also gaussian distributed and you now do "maximum a posteriori estimation". L1 shows up when the parameter is instead laplace distributed (the values are 0 with high probability), and again doing maximum a posteriori.
the deterministic formulation for L2 reg has to do with improving the condition number of (almost) singular matrices, and for L1 it has to do with the convex relaxation of L0 regularization so that the solution is sparse (explains the data with as few parameters as possible, or "in a simple way")
Hi, quick question. I'm given a dataset were 1 column is called
engineer_note: A summary note left by the engineer after this visit. The note
is already tokenized, so all words are replaced with numeric ids. Each word is
always associated with the same numeric id. For example, 106 might always
refer to the word ‘wire’.
How can I use such information to build external features even though I dont have access to the dictionary ? I can think of just 1 hot-encoding. A word2Vec has no meaning and also any mapping from LLMs to get the embeddings has no meaning cause the dictionary might be different.
I am new to AI, I want to build a application which reframes videos from 16:9 to 9:16 using dynamic cropping, subject detection. How do I do this? Any suggestions?
Ping me while replying
Because, usually, in the design of your pipeline, you usually risk overfitting, by throwing in more parameters than neccesarry.
From experience, it is seems what work best is to make your model slightly more complex, and then fix it using regularisation.
also remember, we usually standardise the data 1st
like, the best way to understand this is from the perspective of the bias variance tradeoff
this depends only on whether you formulate your task as an optimization or a minimization problem
the gradient always tells you the direction in which, locally, the function increases the most
oops wrong reply
this was for you
one usually writes ML problems in terms of the "error", "cost", or "loss". these are all things you want to reduce to 0 if possible
so you want the negative of the gradient. otherwise you make the error bigger and your model becomes worse
Any idea in this NLP task ?
I think part of the confusion may be that you are viewing the minimization process as “going against the data.”
I have a question about Experience Replay and Reinforcement Learning. Is there some paradigm where you adjust all rewards of any given measured episode at the very end using some form of discount? I know the standard Bellman equation already does similar iterative math with adjusting Q-values. However, I'm thinking about an episode where rewards are only calculated on the final cycle. And the reward is either very positive/negative (depending on how the system evolved). Well, given Experience Replay, obviously rewards are not going to be present on any random sampling. So I wonder if I can post-process my experience when an episode ends and give some sort of discount factor to all the steps? Maybe this is a horrid approach.
First thing that came to mind similar to what you describe were the concept of fixed Q targets, however, a quick search brought up a concept of delayed rewards which might be worth checking out, though I'm not particularly familiar with it.
more generally the fortran code people use to optimize things only works in one direction so even if you want to maximize something you just negate it first
that's the real reason it's always minimizing lol
case in point: minimizing the negative log likelihood
it would seem to be more straightforward to just maximize the log likelihood but the convention is to minimize the negation because that's just the code we have available to use
and everyone uses it
I think yoiu misunderstood his question lol. He is not talking about the backprop gradient, he is talking about the model weights, and calling it gradient, making anologies to linear models.
ah well i didn't read the whole convo. can't do anything if a technical term is used wrong :p
how do i make yolo auto export upon exit while it's training? i've tried with a try finally and model.export but got TypeError: 'IterableSimpleNamespace' object is not subscriptable
the regularization() makes no sense, it could be anything.
L1 regularization is alpha * |slope| (where slope refers to the trainable parameter in linear regression), why dont we use the opposite of that and make regularization() be - alpha * |slope|
so regularization attempts to make the model more complex to avoid overfitting? how does making the model more complex help with overfitting? it seems quite the opposite, it would make more sense to make a model more simple.
For example, if a neural network is overfitting the data, decreasing the number of neurons or layers could solve the issue instead of increasing it.
i should have clarified, i was referring to the slope in y = mx + b where m is the slope and the trainable parameter
not the loss function gradient
honestly, the entire concept of regularization is confusing me. I might have to skip this part for later, maybe ill understand it better when get to deal with bad dataset
what part of it troubles you?
understanding why we add + alpha * |slope| to the loss function instead of - alpha * |slope|
what do you want the regularization to do?
Hi, would someone mind helping me with an issue I've had with my neural network?
I've been stuck at 76% accuracy and realisitcally want to get it to 95% for my school project
the way i understand it, regularization makes the model less prone to overfitting
have you tried adding regularization?
I don't think so
i prefer interpretting it as giving the parameters "structure"
the question is what structure do you want to give to the parameters
how does it structure the parameters?
if you have a loss function that you're minimizing involving the equation a line, and you add alpha * abs(slope) to that loss, then clearly the overall loss function is larger if the slope is big
so now you have forced the model to limit itself to smaller values of slope
the structure here would be "use small slope values"
if you subtract alpha * abs(slope) from a cost you are minimizing, then obviously this is useless. the minimum overall cost is minus infinity, which you achieve by making the slope infinitely large
by adding max leaf and max sample
so the negative version is useless
i've never worked with decision trees so i can't comment
Would you mind helping me with that?
I see
idk how i didnt think of that, its was just used as an example anyways
honestly this makes a lot of sense now
thanks
something super important to keep in mind: the minimum of a cost function and the minimizer of a cost function are completely different things
the minimum is the value the cost function reaches. the minimizer is the parameter needed to achieve that minimum
so always play with the two. that's how we concluded that + was the correct regularizer here
it's the same distinction between min and argmin
in ML one should technically always write argmin cuz we care about the params. the shorthand for this is min, with the minimizer variable as a subscript. so it's actually argmin
.latex e.g. [
\argmin_{\bm{x}} \Vert \bm{y} - \bm{Ax} \Vert_2^2
]
sigh
the minimizer is the parameter needed to achieve that minimum
I assume you are refering to hyper parameters, correct me if i am wrong
you are wrong
why
hyperparameters are a different discussion still
the actual value of alpha here is a hyperparameter, for example
or how many layers you will use, or number of iterations in an iterative algorithm
the parameters are the slope m and offset b
got it
share more details, i would like to look at the issue and hopefully learn from it
Should I share my model code?
yes, if its a lot of code, put it in pastebin
Pastebin
Pastebin.com is the number one paste tool since 2002. Pastebin is a website where you can store text online for a set period of time.
Pastebin
Pastebin.com is the number one paste tool since 2002. Pastebin is a website where you can store text online for a set period of time.
1sec
np
i expected a simple neural network, this is a large cnn (for me at least). I dont think i can help you with improving the model

ok np, that's fine
do you mind sharing the training/testing data? I would like to tweak it and test somethings out
The folders are quite large so it may be better if I just link the dataset I downloaded
Since I used a python program to split the picture roughly in a 10:90 ratio of validation to training data
Awesome
I think it was this one: https://www.kaggle.com/code/utkarshsaxenadn/celebs-face-recognition-facenet/notebook#About-the-Dataset

Explore and run machine learning code with Kaggle Notebooks | Using data from multiple data sources
Hello did anyone here try running torch / tension with PyPim and can share the experience?
By PyPim I mean in memory processing package, not the networking one, as in utilise the RAM for computation instead of gpu / cpu
The link to repo
https://github.com/oleitersdorf/PyPIM
I've tried reading this article
https://arxiv.org/html/2308.14007v2
But it goes way in depth and my knowlage base isn't good enough to fully understand what are the benefits / preformance gains vs gpu computation
GitHub
Contribute to oleitersdorf/PyPIM development by creating an account on GitHub.
im trying to write a siamese network that uses yolo as its sub-networks how would i make one?
Yes.
limiting the number max number of leaf and samples ARE regularisation methods as well.
guys, I want some help with reinforcement learning problem
don't wait for someone to engage. describe the problem in enough detail that someone can jump in.
Sure,
The RL problem is defined as follows:
- The agent has one action to take from a continuous action space, the agent chooses a float between 0.2 and 0.7
- The environment is taking this action and calculating some values to end up with a target value "SPEED"
- The state is defined with 5 parameters, SPEED and 4 more that goes in the calculation of the SPEED
- After each step, only SPEED is affected by the action that the agent took, the other 4 parameters come from a database and change and the start of each episode.
The main idea of the problem is we want the agent to be able to find the optimal number that achieves 8 < SPEED < 9
The problem is that most of the time the agent tends to keep choosing 0.2 and 0.7 even thought this action is heavily penalized, and even when the agent convergence after 800k steps it doesn't converge to the optimal solution
I tried PPO and TD3 with different exploration parameters and different learning rates
Hello there I want to build a real time sign language translator having continuous video prediction I have tried Mediapipe with BiLstm the results are good on dataset but soon as I deploy it for real time footage the model sucks and it shows random predi toon
I have an dataset of 256 labels but currently I am just using 8 labels for initial testing
Thanks
that's called overfitting
when model sucks for new data
try to flexible while training ( what does that mean now?)
use different types of data
I tried with generating different types of video augmenation but the results are not much better
Initially there was no testing accuracy so i figured it is overfitting but after augmentation the testing accuracy improved.
So is it still possible to have overfitting even though i have good testing accuracy?
And my dataset consists of complex signs not just static images for alphabets.
I want it to be somewhat usable in real world sceanrios.
that's the sign of overfitting
when your testing loss is less on trained dataset
but at the same time model doesn't perform well for new type of data
can you share what you are using for training
and for real world
Yeah i can,
Can I DM them?
👍
This is an example for the training dataset
In the real time one i recorded my own videos containaing multiple signs for testing it in real time using opencv
First the video is fed to the mediapipe to extract the keypoints lh, rh and the pose (All total 258 keypoints)
Then after collecting this data from each video
I train the model using the below architecture in tensorflow
Input(shape=input_shape),
# Bidirectional LSTM layers
Bidirectional(LSTM(64, return_sequences=True)),
Bidirectional(LSTM(128, return_sequences=True)),
Bidirectional(LSTM(64, return_sequences=True)),
Flatten(),
# Fully connected layer : ANN
Dense(128, activation='relu'),
Dense(num_classes, activation='softmax')
])```The data extracted from mediapipe is first stored in the form of an numpy array which later laoded to be trained by the rnn
stop using GPT btw!
if you want to understand the dataset more thoruogly i can send the sources of the datset
NO I use it rarely
when i have no option
the code says it all
The base was originaly from there because i had no idea first how this worked then i modified it accordingly
can u share , what features the mediapipe is extracting
before converting it to np
Sure
First i extarct the kepoints in form 3 numpy arrays first one being the data for poseture then the left hand and right hand and then concatenate it all
If a detetction is missed the array send 0 instaed of leaving it empty
def extract_keypoints(results) -> np.array:
pose = np.array([[res.x, res.y, res.z, res.visibility] for res in results.pose_landmarks.landmark]).flatten() if results.pose_landmarks else np.zeros(33*4)
lh = np.array([[res.x, res.y, res.z] for res in results.left_hand_landmarks.landmark]).flatten() if results.left_hand_landmarks else np.zeros(21*3)
rh = np.array([[res.x, res.y, res.z] for res in results.right_hand_landmarks.landmark]).flatten() if results.right_hand_landmarks else np.zeros(21*3)
return np.concatenate([pose, lh, rh]) ```I basically extarct all the x,y and z coordinate
always add "py" after back ticks
do you have any video on test data?
how model is deriving features
Do you mean how the model is tracking ?
this is your data extraction part which is fine
but I need what type of model you are using
yup on test data
Ok i will record the tracking and send it over
This is the recording for tracking on real time data
Do you mean mediapipe's model ?
Then it is mp.solutions.hollistic
What is your recommendation for the solution of my problem
tf happen to recording
after extracting data from video and converting it to np.array , then on what model you are training it?
BiLSTM
model = Sequential([
Input(shape=input_shape),
# Bidirectional LSTM layers
Bidirectional(LSTM(64, return_sequences=True)),
Bidirectional(LSTM(128, return_sequences=True)),
Bidirectional(LSTM(64, return_sequences=True)),
Flatten(),
# Fully connected layer : ANN
Dense(128, activation='relu'),
Dense(num_classes, activation='softmax')
])```ohh my bad
why LSTM?

Stack Overflow
I am a newbie trying out LSTM.
I am basically using LSTM to determine action type (5 different actions) like running, dancing etc. My input is 60 frames per action and roughly let's say about 120 s...
read second answer from here
Becuase of its ability to relate with older data in NN so my though process was in videos model should be able to make sense with its older frames so and LSTM would be good
update this first of all
can't see video here
So basically i have to ditch Mediapipe here and just directly feed the video in this architecture?
yeah!
CNN are capable to directly extract features! but they need lot of data to be more accurate
That's the problem here i don't exactly have a lot of data available with augmentation on average I have 60 videos here for a single label
wait!!
this approach is also good
just confused why it is overfitting
That's what I am trying to figure out for past 4 days
okay so for now!!
lets do some testing
-> keep the same model you have trained
-> don't test on your own video ( your PC camera )
-> just download random video from online and test
let's see what it does
it's okay don't worry
Ok i will try the random videos
But by random vedios you are saying videos with same label set or any random signs
you must clarify the signs which you are trained
if that random video has that signs then its okay
can u share how the model is responding to that videos
How can i make a siamese model?
The idea is you take a standard neural net, output N neurons in the final layer
It takes two or three inputs when predicting
And then you compute some distance metric for your loss
what are you going to do with that information if I give it to you? because you shouldn't try to learn machine learning in terms of a framework/library.
after learning how the machine learning work im not gonna do a big project with numpy
there's more to machine learning than neural networks, but you should use pytorch if you want something more practical, or JAX if you want less abstraction. don't use tensorflow as it's dying.
i typed wrong i was gonna say machine learning
you did say machine learning; did you mean to say neural networks?
i edited it 😭
when you do your big project, what is the model that you create intended to do?
do i need 2 subnet or just 1?
i dont have anything in mind
one, that's the tricky part when trying to understand siamese nets
Basically: 1 net, send in the first input, get the embedding, send in the second input, get the embedding and then calculate the similarity metric between both
Hey there! I'm trying to create the following fourier transform:
f0 is given, f is known and sBB(t) is known. I can use np.ftt.ftt(sBB) to get the fourier transform of it, but I need it moved ( (f-f0) and (f+f0) )

responded in #1312458387832705035
what was for second test video?
the model predicts accurately for first test video I guess
The first one was quiet which gives sad as a prediction
and second vedios was for sad
for how many epochs you trained?



how much time it took? for 15
I have an gpu so it hardly takes a minute
And its just the extracted coordinated instead of images so yeah it takes very less time to train
okay so from all this things
-> the data points ( np arrays ) which are extracted either lacks the info for the model
-> of the model size needs to be changed
haven't you look for some papers on this?
which approach are they following
hi.. kinda off topic.. but can anyone with pika pro generate one dissolve effect for me? I really need it >(
Hi, Im pretty new to AI and Im currently trying to train a vanilla DQN with a prioritized replay memory buffer for a pretty simple task.
Its a small 2d football game and im doing a multicurricular approch where I start off very simple and then later add in more complex task with harder to get rewards. For the first phase I just wanted the ai to learn to walk towards the ball and pick it up, for this im giving a negative reward of -0.2 for every step and a positive reward of 10 for touching the ball. When the agent touches the ball I also end the episode. Now Ive been training my ai for around 200k training steps with a minibatch size of 24 and a learning rate of 0.025 and I literally see 0 progress at all. The AI is pretty much still walking around randomly. Now I know that vanilla dq learning is pretty slow but I feel like at this point there has to be something wrong with something in my code or approach since there is truly no visible progress at all.
This is the link to the pastebin of the code, if anyone with more knowledge and expertise could take a look at it I would appreciate it a lot!
https://paste.pythondiscord.com/APLQ
Who here works as an AI developer?
I have and they all are following somewhat similar architecture but none of them mentioned about testing on live feed even the people who published the dataset recommended an dataset but that didn't work that well if you want I can send there recommended architecture too
Some have even tried Gru and lstm
I could try them but I doubt it will have any difference
The thing of np arrays the problem could be with tracking
As if the frame dozens track the hand I pass an zero array instead of coordinates
And my another concern/question is can models learn this quickly
it depends on data you passed
e.g -> raw images which gets passed to CNN takes lot of time
where are textual data learn quickly
ok so what could be tthe problem here
I tried GRU here results are better but not much better
I'm trying to use a GAN model to try and generate spectrograms. I'm stuck on this issue where it seems like the generated images are limited by their resolution. The original shape of the sample images were 128 x 128, and while the output images are not that size (they're much larger), the image is limited to 128 by 128 rectangles (i went through the trouble of counting). I'm not sure why this is or how to counteract this.

I wasn't sure if this is really classified as the checkerboard pattern that I've encountered before or something else.
Does anyone have experience with FSDP+QLoRA? Looking for help on this problem. I have spent 10+ hours and still can't come up with a solution 😢 .
https://discord.com/channels/267624335836053506/1312775104664571995
Can anyone tell me how to get started with data science/ml, i know python and basics of algebra and probability. any tips for what i should learn next etc...
CS50 Artificial Intelligence
but i love using tf with keras
https://www.youtube.com/watch?v=tIeHLnjs5U8
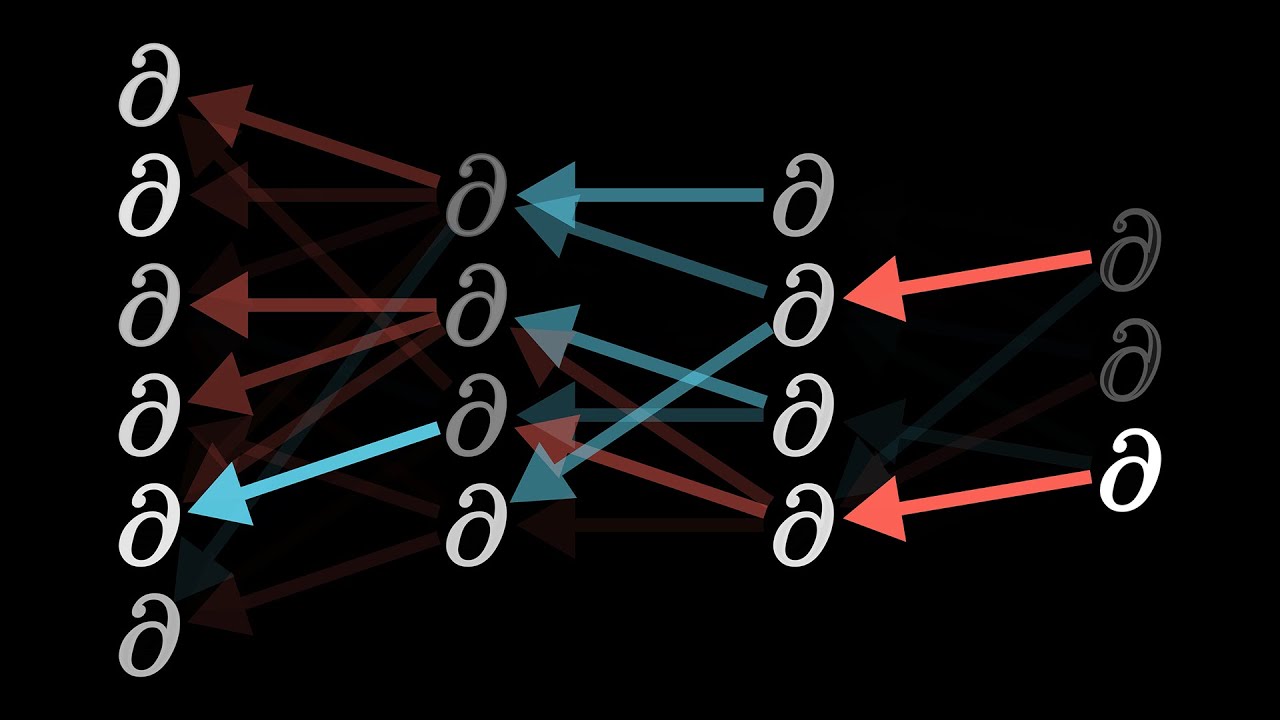
can someone (if possible) explain to me how backpropagating the error works based on this video?
Help fund future projects: https://www.patreon.com/3blue1brown
An equally valuable form of support is to share the videos.
Special thanks to these supporters: http://3b1b.co/nn3-thanks
Written/interactive form of this series: https://www.3blue1brown.com/topics/neural-networks
This one is a bit more symbol-heavy, and that's actually the point. ...
Can you describe in your own words what the error is? This isn't a test. I need to know what you currently know
cost
(current - desired)^2 as i know
Can you describe what this value represents?
@weary timber do you understand how a neural network is like a function? when you put a value into the neural network, the result is a function of that input and all the weights of the network.
i know that the neural network is a function but i cant really understand what you said at tthe end
the weights of the function are an inherent part of the neural network, right?
but the instance that you put into the network (such as to train it) is not
yep
sorry for the late replies i translate some words to understand well
that's alright.
the whole point of training the network is to change the weights until you minimize the loss. right?
yep
and for that as i know you calculate how sensitive the cost function is to the weights and biases so you can change the values of them correctly
aka derivatives
so when you write (current - desired)^2, you're hiding a key consideration: current is the result of a function
suppose your neural network is f, and the input is x, and the weights are w. then the result is f(x; w). do you understand how I wrote that?
what is the ; for
to indicate that w is an inherent part of f, but x is not.
oh ok makes sense
yes
you can also say loss(x, desired) = (f(x; w) - desired)^2
the next thing. w isn't a single value. each weight is its own value
when you look at a neural network diagram, each line between nodes is its own weight
still with me?
yeye i dont wanna interrupt
I want to make sure you understand what I'm saying at each step
if you don't understand, then it's my job to find a different way to explain it
how can I teach ai to play games?
i understand it to this point
yes
I said how
sorry
need help
you should start from scratch and learn how ai's work for that
@weary timber this is where the calculus starts: when you do back propagation, you're calculating the derivative of (f(x; w) - desired)^2 with respect to each individual weight in w
how can I learn it
any links?
@vestal mirage I'm in the middle of an in-depth explanation for memo; I'll try to help you next.
do you understand this?
sure thanks
yes
and then you multiply the result by the learning rate, and subtract that much from the individual weight.
ye i can do that part
the part i struggle is when it comes to going to other layers
from there you will calc the error (cost ) for each layer as you go
you don't need to think of backpropogation as an iterative process
the neural network is ultimately one big function
when you write it out as one big function, individual weight variables might appear multiple times, but that's okay
you just take the derivative of the big function with respect to that weight
@wooden sail what I'm saying is accurate, right?
so i dont calculate the cost for each layer and just use the output layers cost for all weights
?
well, keep in mind that the whole point of this is that the computer is doing it for you. but mathematically, you don't have to think of it as something that cascades through the layers.
what
which part are you confused about?
all the message
when you train a neural network, you don't have to do any math, because the computer is doing it. right?
i mean i write it one time and thats all so yeah
@weary timber you want to understand how the math for backpropogation works. specifically, how it "moves" between the layers. right?
YES EXACTLY
@serene scaffold can you help me now?
do you know the chain rule from calculus?
I'm not done helping memo.
yes
@weary timber the reason it's called "backpropogating" is that when you calculate the derivatives for the weights in one-layer, you can re-use those calculations to calculate the derivative of the layer before it.
well, the error more so than the derivatives
@vestal mirage you want to start small with this kind of thing. what game do you want your AI to play? connect four?
Like snake game.
wait let me change my username xd
@vestal mirage look into reinforcement learning
but I dont want to make it working for my own games
I want to make auto play for other games like google snake game
one last thing. can you say this sentence again simpler my english isnt englishing
I know Turkish @weary timber
please speak Turkish in your DMs
sorry sorry
it's okay
so i use the calculations i did to find the cost at output layer for the layers before that?
yes
ohhhhhhhhhhhhh tysm
you are welcome 💚
any links
No; I've never done reinforcement learning. sorry
Read about basic RL
DQN, Q-network
Agents and all that stuff
Then play with openai gym library
RL needs time to learn remeber this
Hi guys, what are the best online tools that you guys have used to learn the python skills
For data science

It's the DP solution to the problem.
(When you are doing math on paper, substituting in the values for variables, you are always doing a table-filling (DP) algorithm by having written down the resolved values on paper (except not in a table, maybe just written all over the place) and reusing that over and over in other places (you could not do this, but it would take forever by hand and so people tend to do DP naturally))
I find myself needing to store a lot of (30G+) multiline text, as well as a variable-length header describing the data, so I need a dataset format that is streamable and performant. Which combination of dataset libraries/formats are the best for this?
it's behind http, but oh well: https://incompleteideas.net/book/RLbook2020.pdf
JSON Lines seem perfect for this except, I need to store which classes and there and such
Why are Encoder-Decoder neural networks stacked with two LSTM layers that are independent of each other
Ty
I wonder if I'd understand it at this point without you and @past meteor
Certainly no thanks to my deep learning "instructor"
Controversial but I think maybe they should just teach backprop with auto differentiation in mind from the get go
not found
Every time people want to do neural nets from scratch they’re “hard coding” the derivatives etc. instead of making something small like micrograd
GitHub
A tiny scalar-valued autograd engine and a neural net library on top of it with PyTorch-like API - karpathy/micrograd
as mentioned it's not an "https site", so, perhaps, your browser just doesn't want to let you view the resource
but also take a look at the pinned messages in this channel
Understanding compute DAGs (dependency graphs) in general can make understanding a lot of stuff in math easier (and also often results in the optimal algorithm (DP)). I agree that this should be covered.
Can anyone solve my doubt related toCopy-Move Image Forgery Detection gaussian model?
Here this code, after resizing images and feeding them to the model with combined masks, it gives the error: ValueError: Arguments target and output must have the same shape. Received: target.shape=(1, 256, 256), output.shape=(1, 2048, 2048) for the below code:
# Assuming the input images are of shape (256, 256, 3)
# and the masks are of shape (256, 256)
# Combining the masks for training
def combine_masks(masks_copy, masks_paste, masks_forged):
print(np.array(masks_copy).shape)
print(np.array(masks_paste).shape)
print(np.array(masks_forged).shape)
# resizing
masks_copy = cv2.resize(masks_copy, (256, 256))
masks_paste = cv2.resize(masks_paste, (256, 256))
masks_forged = cv2.resize(masks_forged, (256, 256))
# checking shapes
print(np.array(masks_copy).shape)
print(np.array(masks_paste).shape)
print(np.array(masks_forged).shape)
print("-----------------")
combined_mask = np.maximum(masks_copy, masks_paste) # Take union of copy and paste masks
combined_mask = np.maximum(combined_mask, masks_forged) # Add forged regions
return combined_mask
combined_masks = [combine_masks(copy, paste, forged) for copy, paste, forged in zip(masks_copy, masks_paste, masks_forged)]
print(np.array(combined_masks).shape) # shape of combined masks
resized_images = [cv2.resize(image, (256, 256)) for image in original_images]
# Train the model
# model.fit(np.array(original_images), np.array(combined_masks), epochs=10, batch_size=1, validation_split=0.2)
model.fit(np.array(resized_images), np.array(combined_masks), epochs=10, batch_size=1, validation_split=0.2)
how should I resolve this error?

There is a mismatch between the shape of inputted mask (256x256) and the predicted mask from the model. The model outputs a mask of shape (1, 2048, 2048), while the target mask is of shape (1, 256, 256)?
Gaussian model code: https://paste.pythondiscord.com/N65Q
You should make it so the model outputs a tensor of shape (1, 256, 256)
Because that is what you are trying to predict
BlazeChat - Fast CPU-Powered Chat & Image Generation: https://github.com/SanshruthR/CPU_BlazeChat

GitHub
Generate text and images using the CPU. Contribute to SanshruthR/CPU_BlazeChat development by creating an account on GitHub.
Hello. I want to start course on data science. So I was thinking of either getting the DL or ML course by Andrew Ng on coursera. Can anyone tell me which course i am supposed to watch first? The DL one or ML
I made the Final Layer Adjustment in model -> Changed the final Conv2D layer to output a single channel with a sigmoid activation function. Ensures that the final layer of model outputs a tensor with the desired shape (1, 256, 256).
Still the same error I am getting.
Could you please look once into the updated model code?
https://paste.pythondiscord.com/5FJQ

I am working on a Copy-Move Image Forgery Detection DL model. I can give you full context of the code if u want for reference so u can understand the model little bit clearer.
I mean access to the code

@serene scaffold How can I start off with AI and machine learning from scratch? I have foundational python skills, and i kinda like maths and statistics, so what could be the roadmap??
tell me if im wrong. i saw in 3b1b's video that you can calculate how the previous neurons activation should change in order to lower the cost at output. dont we use that value as desired and calculate the cost for that layer like we did at output? (current - desired)^2
if not please explain to me how exactly we do it im really stuck
i can calculate all but stuck at this
Look at zestar's message in the pins
@serene scaffold maybe you can help me with this. (sorry if im bothering too much tell me if i at any point)
This is what we talked about yesterday. It seems that you understand it
What is your question?
@serene scaffold im asking if everything i said here is correct
There isn't a "cost for each layer"
so i just use the cost at output everywhere?
Anyone?
can you (if you have time) explain to me how that actually works im so confused
in one video it says you propagate the error back
now you say this my mind is mixed
that's correct. there is one cost evaluated with the final output of the network. you propagate that cost back through the chain rule
can you tell me or provide me some resources over how i do that?
cuz shit im stuck
thanks i will check it out
Can someone make an basic script so I can see how I can start making AI
Can someone provide a link to all the available transfer learning models?
like from tensorflow hub
am struggling to find that particular link
"AI" is a very general concept. What kind of AI do you want to make? (Don't say "Jarvis")
I just want to make an AI for my website as support
What does "AI" mean to you?
are you talking about a chat bot? because that's a very small subset of what AI is.
That's okay. What kind of website is this?
What is the point of the website
Sorry if this is advertising, but you can check website here: https://noctyrium.online
@hidden fable so it's a website for people to learn about your business and potentially establish a working relationship, and the bot should answer questions about what your business does?
Its like they can use our services to upgrade their company. But I want to make an AI which will make them bot so they don't need to wait
They don't need to wait for what?
For me to give them bot and that
Like AI can do it with python (discord.py)
And I actually need chatbot too
So your company is about making discord bots for clients?
And websites too
And it is for hosting others websites but it is not still available
And you want to use generative AI to produce the source code for the bot or website?
Yes, but it will be worse than ChatGPT, so you shouldn't bother.
hey, what can i do if my image segmentation model training has become super slow?
it was initially fast, but as the model got better and better the training going slower
what do you mean by training slower, like the actual epochs are taking longer or the model is getting diminishing returns on its accuracy/other metrics increases?
no the epochs run pretty fast (i run it on x2 rtx4090 and the dataset isnt super large, 7.5 images) but improvements are super slow
and minor at that
are you doing any kind of hyperparameter scheduling like learning rate decay?
its my first time training a model, i've been writing in python for over a year but pytorch is nothing like anything ive done before so im not super fimilar with all the terms, used alot of googling, samples from github and (shamefully) GPT as well
thats my scheduler
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='max', patience=3, factor=0.5, verbose=True)
i will reduce it and try to run again
beyond the fact that models will tend to plateau in performance as they approach convergence just by the nature of needing to make smaller adjustments to fit into a local optimum, the lr being cut early might be causing the model's updates to be "too careful" slowing down the convergence, or forcing it into a suboptimal local minimum
umm im not sure what that means to be completely honest
do you have a geometric intuition of gradient descent?
like a ball rolling down a hill
im making sure to not save the model unless theres an improvment over the baseline model from which point it has started
no
can i share the entire code here and get some suggestions on points to improve?
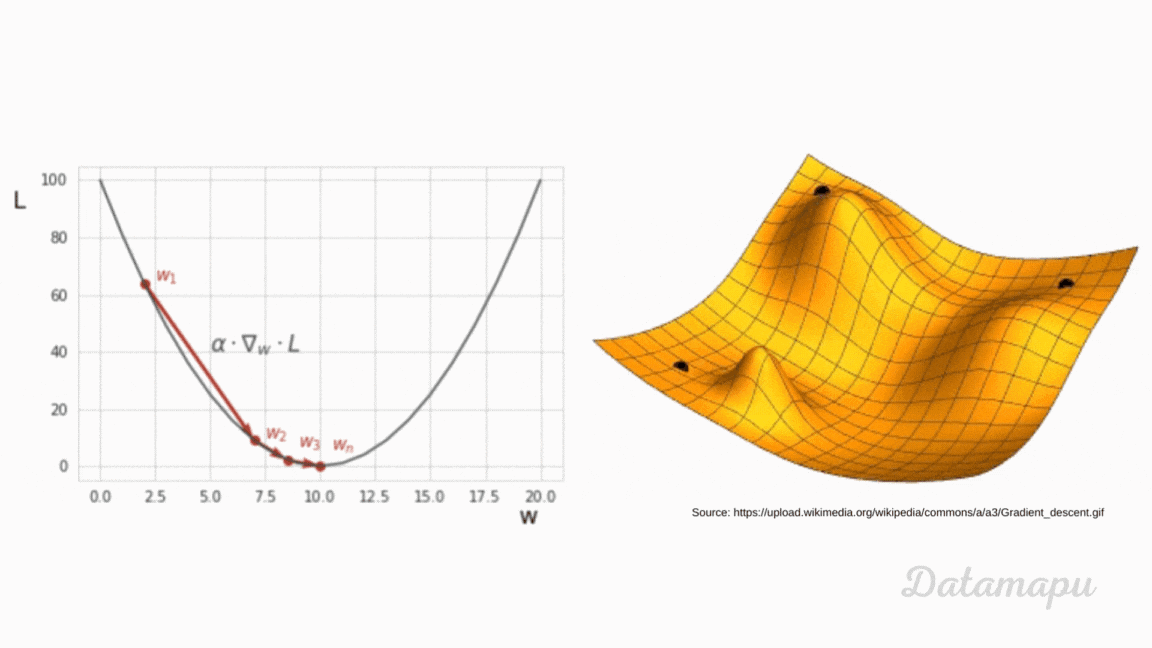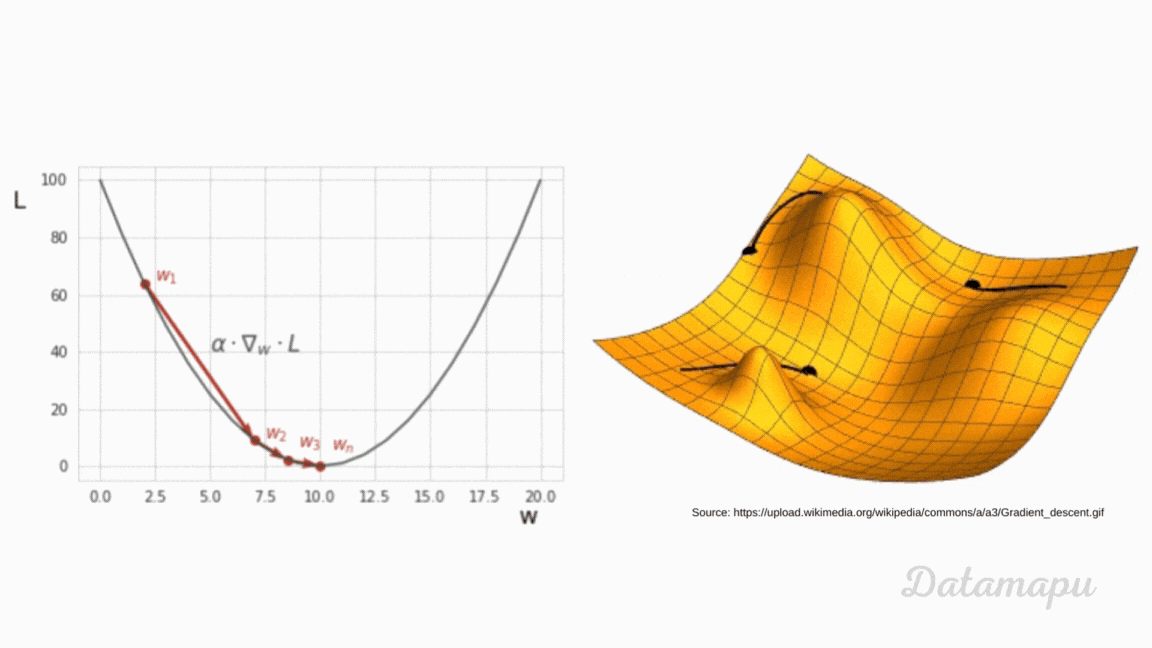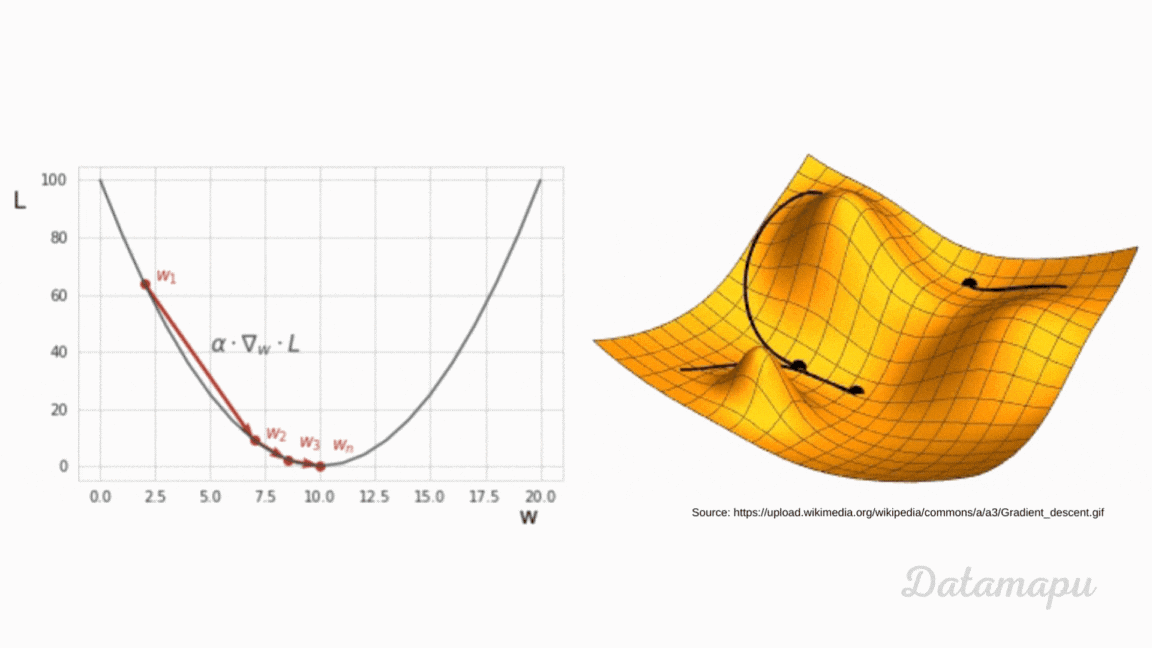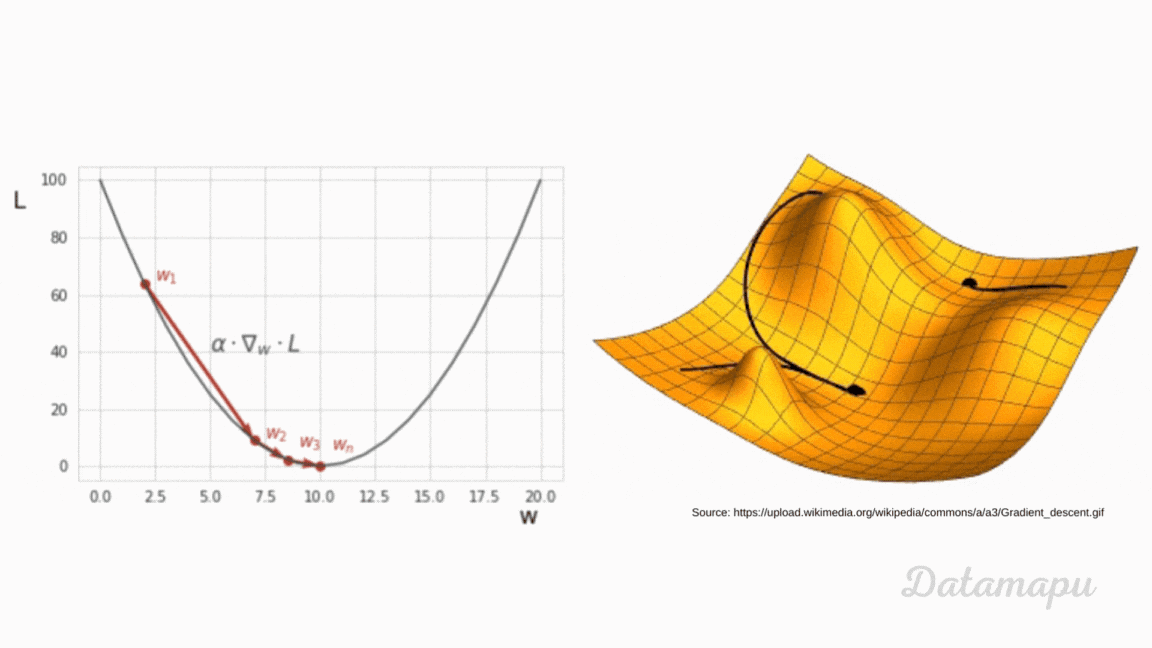
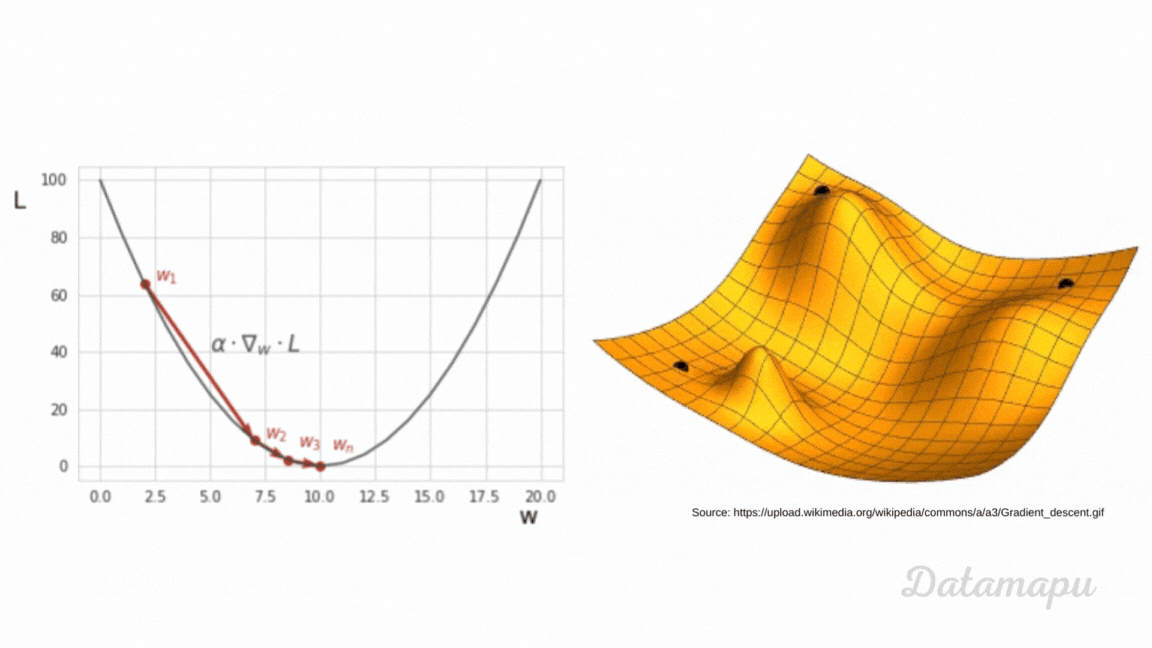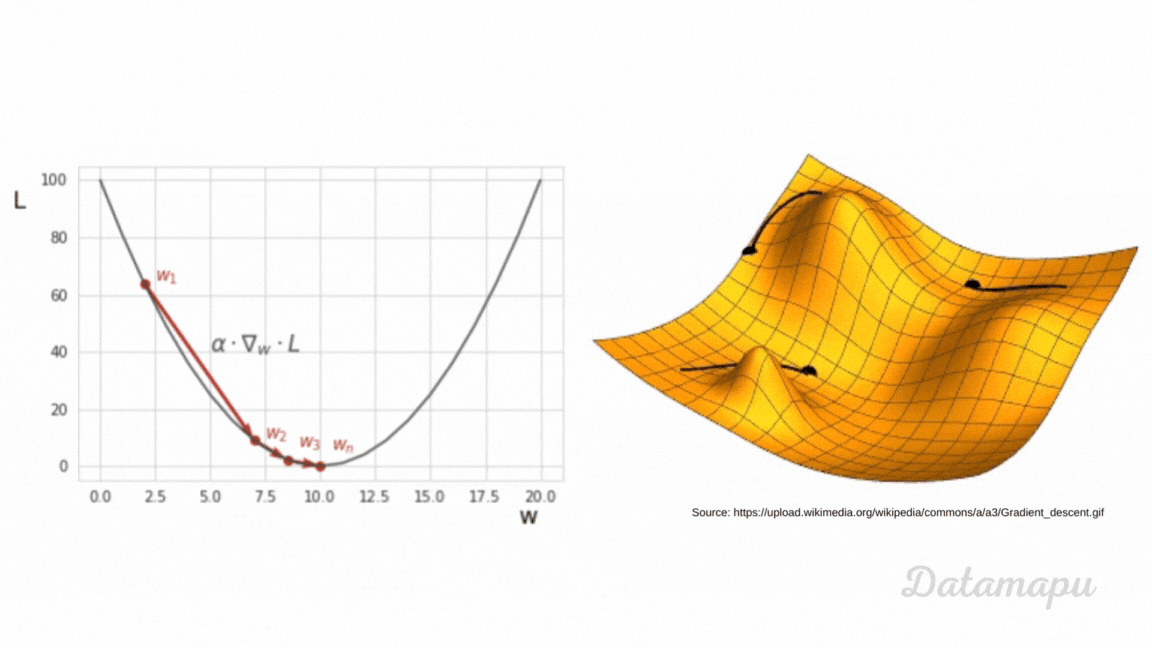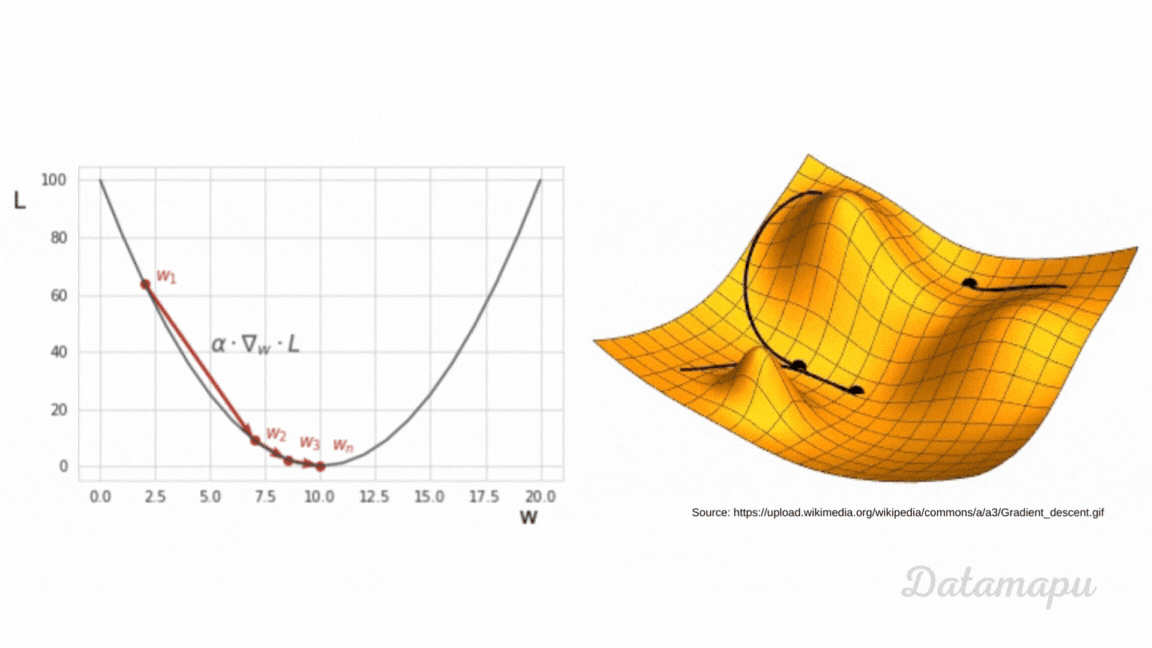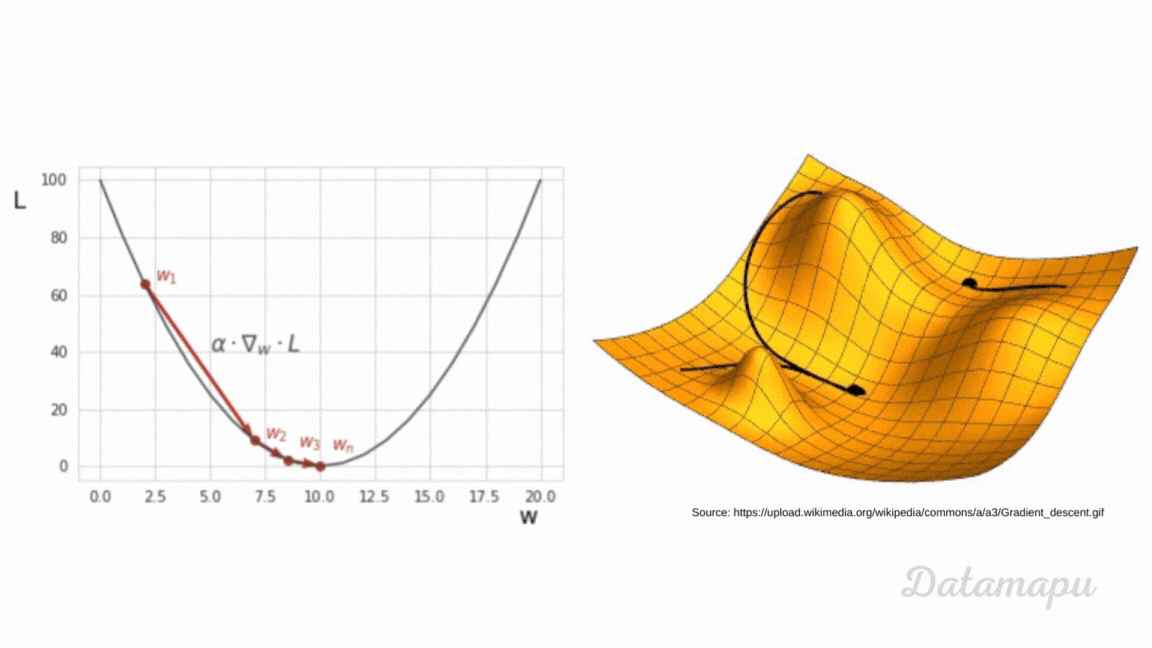{kind=link}
sure
!paste
Pasting large amounts of code
If your code is too long to fit in a codeblock in Discord, you can paste your code here:
https://paste.pythondiscord.com/
After pasting your code, save it by clicking the Paste! button in the bottom left, or by pressing CTRL + S. After doing that, you will be navigated to the new paste's page. Copy the URL and post it here so others can see it.
you can imagine the little black balls as being the model, on the yellow landscape that represents the negative gradient
each update the model moves a step down the gradient in a direction
please keep in mind that my first ever ML related code
how far that ball moves is dependant on your learning rate
wdym by layers
by moving a step down, do you mean removing layers in the image?
ive read online the the decoder does that (?)
no, I mean adjusting the model to make its outputs have a lower cost
the landscape is representing the cost of the average guess a model would make
so if it's really high on the landscape any guesses it makes will be pretty bad
and vice versa
yeah gradient descent is the basis of optimizing most neural nets
my issue isnt with time is i rent cloud gpus and can basically let them run for days, but the issue is even with LOTS of time it still barely improve
another thing I'm noticing that you could mess with is your batch size
you have it set to 8 which is very low for most problems
for example for the last 2 hours it isnt improved at all
this would suggest you're stuck in a local minimum
thats the default argument but i pass to it 30
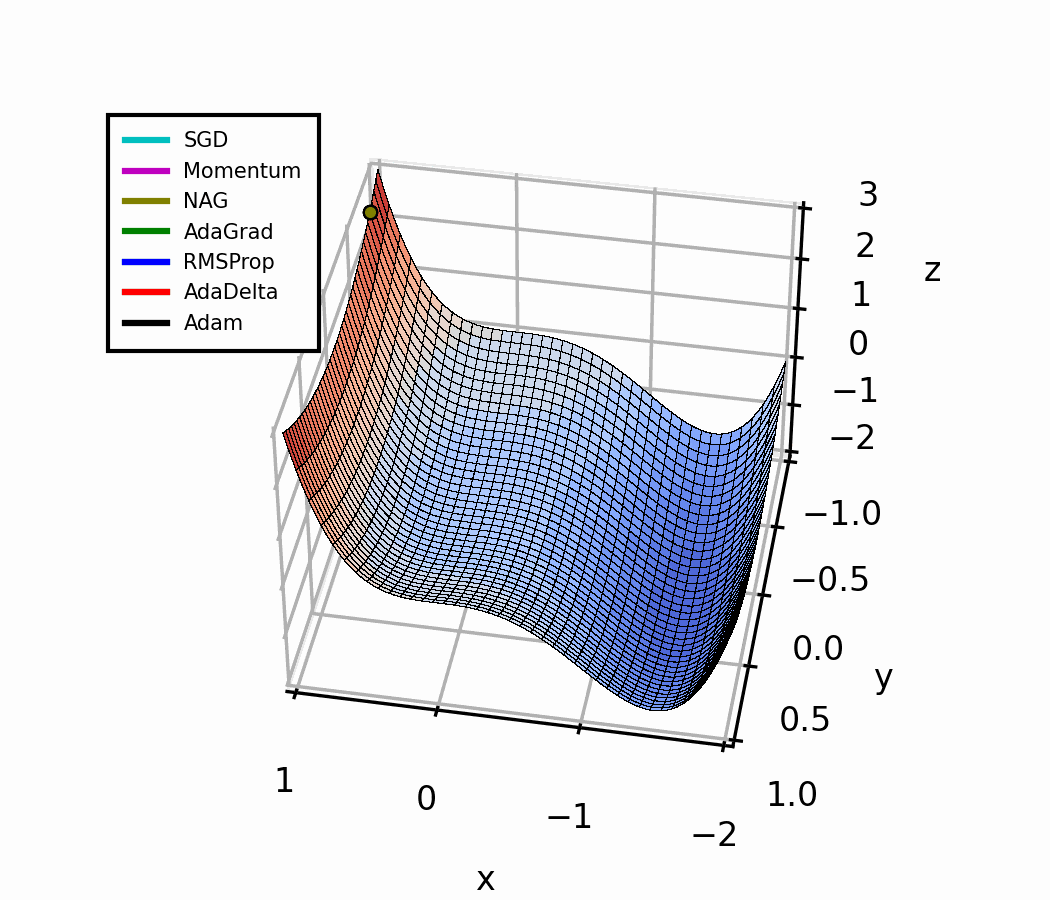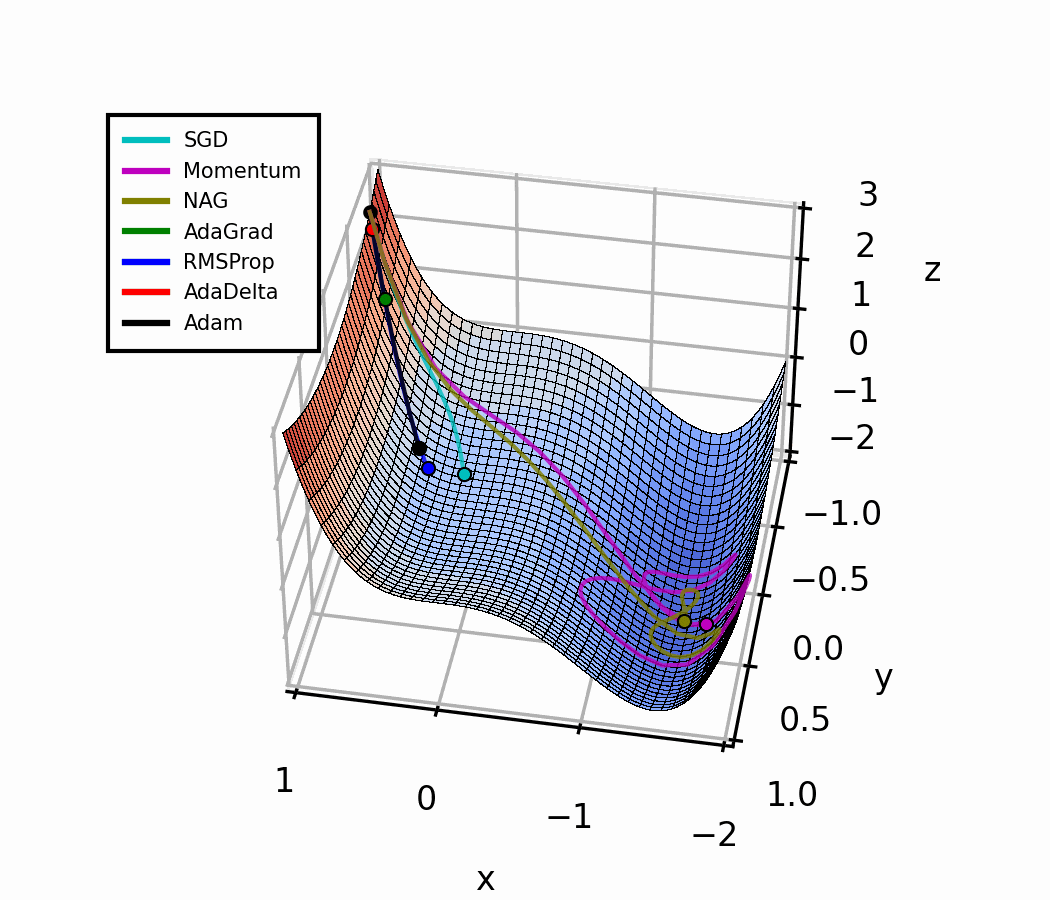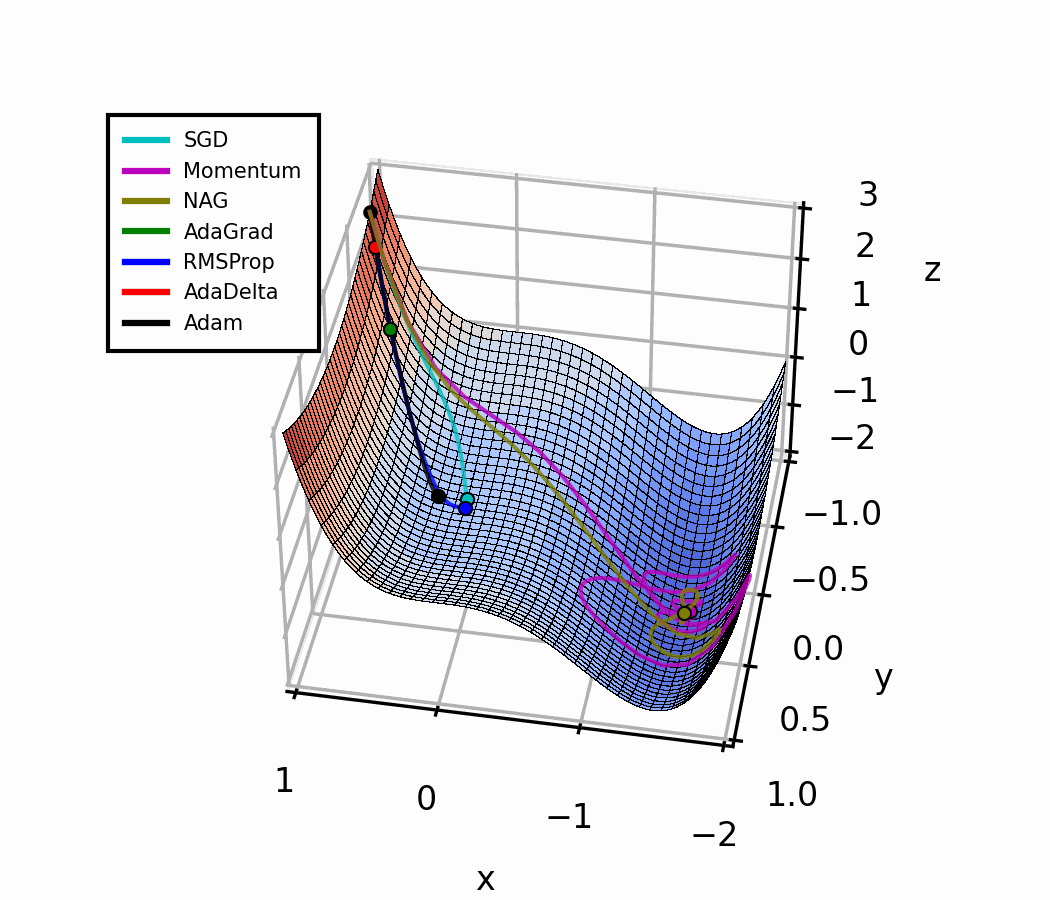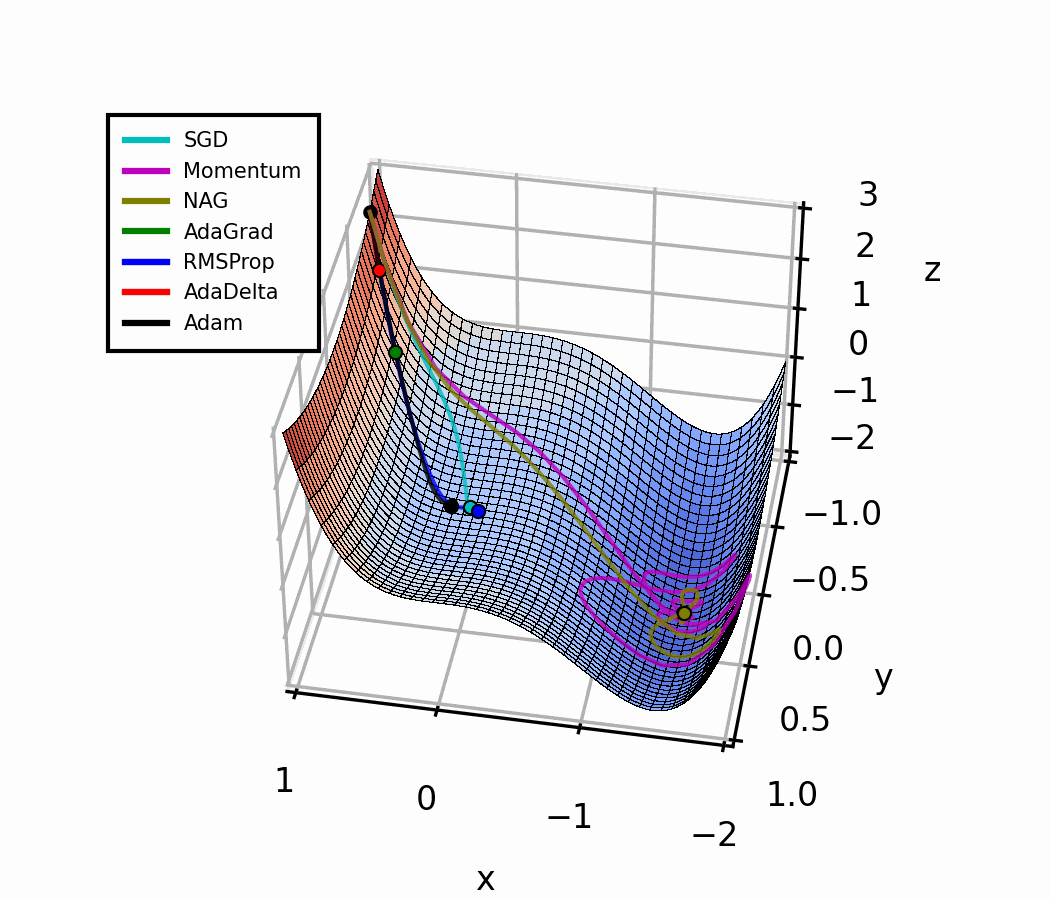{kind=link}
I see, 30 should be fine
i made it 8 by default as i ran tests on my laptop (rtx 3090, not exactly super strong)
here you can see the balls on the left don't take very big steps and end up getting stuck in a little ridge
this can represent what a low learning rate could do
batch size on the other hand determines how well your model actually estimates what the landscape looks like
a true gradient would be calculated by passing every single sample in your dataset and finding the average cost
so higher batch size = better predictions ?
but we take a shortcut in minibatch gradient descent where we only feed the model a number of samples equal to the batch size before assuming the gradient is good enough and making an update
yeah basically
i noticed that too hence i upped it to 30
but bigger batch size also means slower training (less actual updates per epoch)
tried 50, it ran out of memory xD
yikes lol
maybe i should hire someone to do this for me, im too clueless at ML, i usually do web related stuff (django)
this is way complex and require actual scientific knowlage
yeah training them can be tricky
plus you seem to have jumped in the deep end with your first model
its no joke! harder than any python stuff ive done before, even C extentions are easier
most people do a simple mnist classifier for their hello world model
well im trying to train a model for background removal and publish it for free under MIT license, and keep it lightweight
most existing models are heavy, and are not free for commercial use
quantization could be an avenue to look down in that case, although that will require diving even deeper into the science rabbit hole
basically you can take really big models trained with standard float precisions (ex. 32) and then once they are trained convert their weights to small precisions like 1, 2, 3, 4, 8 bit float/integers
and you only lose a few percent of preformance on benchmarks if done right, but reduce the size and compute required to use the model by many fold
mine currently get around 0.9763% accuracy (where 1 being the highest) and weights only 50mb but its a super slow progress in the past 2 days
thats seems even more complex than what im doing now xD
yeahh
maybe i should just increase the dataset from 7.5k images to 20k
although getting good datasets is a pain
oh you only have 7.5k?
yep
the dataset is the foundation, no matter how good your model is without a good dataset you will get shit results
well its not even that bad now
maybe thats the main issue then, the dataaset
lol yeah some transform stuff
actually almost an alarming amount, another thing is to be 100% sure that none of those features you're adding noise to could be useful to the model
well i do need the end model to handle any quality, zoom, crop, color image as the end user will upload whatever
say for example I'm classifying a picture as either an apple or a banana, it's okay for me to rotate those images because the model should be able to tell the difference no matter the orientation, but say I now randomize all the colors on screen; I'm taking away a large portion of what makes apples and bananas easily distiguishable by adding noise there
yeah it might be unavoidable in your case, the only real solution to what I'm mentioning would probably be more real samples
But the model doesn't classify an object type
It just classifies what's the main object and what's the background
yeah I gotchu, I'm just giving an example
saying you have to be sure that all of ```
A.Resize(512, 512),
A.HorizontalFlip(p=0.5),
A.VerticalFlip(p=0.5),
A.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1, p=0.5),
A.RandomRotate90(p=0.5),
A.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)),
It gives decent results, I'll show ya

That's not super bad is it? And keep in mind that's an image he was not trained on
remember that if you post images, they should be closely cropped around the part of interest.
looks pretty good to me
And it only weights 50mb, comparable models weight north of 1gb and are not under MIT license
I'll keep that in mind, cheers!
Yeah so I think I got a good shot to actually do somthing good here and produce an actual free and open source background removal model / tool, just getting stuck on the last bit of model training which is frustrating
Hi guys. I need some help. I've one-way multi-layer neural
where i need y_t as function y_t=sin(PI*x1 *x2)
for x1,x2 = <-1,1>. And i need these graphs drawed while my "AI" is learning, but don't know why it isn't working

import numpy as np
import nnet as net
import matplotlib.pyplot as plt
x = np.array([[-1, -0.9, -0.8, -0.7, -0.6, -0.5, -0.4, -0.3, -0.2, -0.1, -0.0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0]])
y_t = np.array([[1.2246467991473532e-16, 0.5620833778521305, 0.9048270524660195, 0.9995065603657316, 0.9048270524660196, 0.7071067811865476, 0.4817536741017153,
0.2789911060392293, 0.12533323356430426, 0.03141075907812829, 0.0, 0.03141075907812829, 0.12533323356430426, 0.2789911060392293, 0.4817536741017153,
0.7071067811865476, 0.9048270524660196, 0.9995065603657316, 0.9048270524660195, 0.5620833778521305, 1.2246467991473532e-16]])
max_epoch = 200000
err_goal = 1e-50
disp_freq = 1000
lr = 0.01
L = x.shape[0]
K1 = 13
K2 = 7
K3 = y_t.shape[0]
SSE_vec = []
w1, b1 = net.nwtan(K1, L)
w2, b2 = net.nwtan(K2, K1)
w3, b3 = net.rands(K3, K2)
# hkl.dump([w1,b1,w2,b2,w3,b3], 'wagi2w.hkl')
# w1, b1, w2, b2 ,w3, b3 = hkl.load('wagi2w.hkl')
for epoch in range(1, max_epoch + 1):
y1 = net.tansig(np.dot(w1, x), b1)
y2 = net.tansig(np.dot(w2, y1), b2)
y3 = net.purelin(np.dot(w3, y2), b3)
e = y_t - y3
d3 = net.deltalin(y3, e)
d2 = net.deltatan(y2, d3, w3)
d1 = net.deltatan(y1, d2, w2)
dw1, db1 = net.learnbp(x, d1, lr)
dw2, db2 = net.learnbp(y1, d2, lr)
dw3, db3 = net.learnbp(y2, d3, lr)
w1 += dw1
b1 += db1
w2 += dw2
b2 += db2
w3 += dw3
b3 += db3
SSE = net.sumsqr(e)
if np.isnan(SSE):
break
SSE_vec.append(SSE)
if SSE < err_goal:
break
if (epoch % disp_freq) == 0:
print("Epoch: %5d | SSE: %5.5e " % (epoch, SSE))
plt.clf()
plt.plot(x[0],y_t[0],'r',x[0],y3[0],'g')
plt.grid()
plt.draw()
plt.pause(1e-2)
print("Epoch: %5d | SSE: %5.5e " % (epoch, SSE))
fig = plt.figure(figsize=(8,8))
ax = fig.add_subplot(111, projection='3d')
surf = ax.plot_surface(x, y_t, x, cmap='viridis')
plt.ioff()
plt.figure()
plt.plot(SSE_vec)
plt.ylabel('SSE')
plt.yscale('linear')
plt.title('epoch')
plt.grid(True)
plt.show()
trying to train a neural network is like trying to play golf but you only know the general direction of the hole, and you have to guess how much power to use, what type of club to use and the conditions of the field
Well I'm increasing the dataset to 40k let's see if that helps 😂
From 7.5k to 40k, that hopefully will do the job
Before trying to go on to a larger and probably more complex dataset, see if you can overfit a much smaller dataset of a few select examples so you can train much faster and see if its a dataset issue, this also makes it easier to find good hyper-parameters
there may be bad examples in your dataset especially if it's self labeled
I am beginning to machine learning or coding in general? My apologies
you should defintely learn the fundamental ideas of ml
here's some videos that helped me learn:
https://www.youtube.com/watch?v=aircAruvnKk&list=PLZHQObOWTQDNU6R1_67000Dx_ZCJB-3pi
https://www.youtube.com/watch?v=hfMk-kjRv4c
https://www.youtube.com/watch?v=Lakz2MoHy6o
then learn the frameworks like tensorflow or pytorch for actually programming these models, start with the simplest of models with an XoR, then i'd reccoment move on to a mnist solver and then from there wherever you want

What are the neurons, why are there layers, and what is the math underlying it?
Help fund future projects: https://www.patreon.com/3blue1brown
Written/interactive form of this series: https://www.3blue1brown.com/topics/neural-networks
Additional funding for this project was provided by Amplify Partners
Typo correction: At 14 minutes 45 seconds...

Exploring how neural networks learn by programming one from scratch in C#, and then attempting to teach it to recognize various doodles and images.
Source code: https://github.com/SebLague/Neural-Network-Experiments
Demo: https://sebastian.itch.io/neural-network-experiment
If you'd like to support me in creating more videos (and get early acce...

In this video we'll create a Convolutional Neural Network (or CNN), from scratch in Python. We'll go fully through the mathematics of that layer and then implement it. We'll also implement the Reshape Layer, the Binary Cross Entropy Loss, and the Sigmoid Activation. Finally, we'll use all these objects to make a neural network capable of classif...
https://pytorch.org/docs/stable/index.html my apologies
How far should I read into pytorch?
completely stop reading pytorch docs until you figure out what you're trying to do.
MNIST
If my pre-trained model is trained on images with the size 224, 224 for example, will i be forced to stick with that size or i can adjust it to be for example 150,150?
I don't specialize in image-related AI, but I imagine you'd need adapter layers, or something
okok
For MNIST , there are lot of articles to start out
So read them
some help me to make this data beutiful like data would be aligned in sigle rows rather then a huge screen and rows should be in black and white background colour

sorted out alhamdulillah

Hey, I was wondering after learning pandas and numpy, how should I start building real world projects?
I am new to the field so I would like a some sort of guidance
Do you have something you are into that you would like to apply your newfound knowledge on? I would start with something tangential or maybe something that relates to the industry you are trying to get into
Well not really, but I’ve done a quick research and results were to practice and apply what I know with kaggle
But I don’t have something particular in mind I want to get into
Kaggles not a bad place to start either, it's got a pretty bright community and you'll learn lots of cool things reading other peoples code while competing.
Participating in any of those competitions is pretty cool on it's own. I've personally have been able to use past competitions in job interviews even if I didn't place super high on any of the leaderboards
I don't see why not
Kaggle projects done through competitions
Just be ready to speak to your work
I am still a high schooler 😂😭
Hey the earlier the better! Right on.
Anyone here familiar with pyspark? I'm starting out a new project for work and having troubles finding resources on project structures and organizational patterns.
I've kinda defaulted to the typical project structure. Where my main.py runs code in each of my packages.
foo/
-src/
--package1/
--package2/
--main.py
I don't love having to use magic commands to run code as I'm finding it causes issues with imports and variables being changed inadvertedly.
Anyways, just looking for resources on how to structure projects, I would also eventually love to implement unit tests in my codebase. So will take any suggestions!
Hey, any recommendations for courses or resources to learn pandas and xarray, from basic to advanced ?
Here is a youtube small course I watched to get rather good in pandas, covers a lot of things: https://www.youtube.com/watch?v=8xUgesdShE8

Complete course explaining how to use Python Pandas for data wrangling. You should have a basic understanding of Python and NumPy prior to taking this course.
0:00 - promo
1:26 - 1.1 introduction
2:15 - 2.1 Series creation
8:48 - 2.2 Series basic indexing
19:38 - 2.3 Series basic operation
22:51 - 2.4 Series boolean indexing
26:19 - 2.5 Series ...
Does anyone know what is the size of the tensorflow gpu and pytorch gpu libraries?
oh thanks a lot ! I can't return the favor for the ai field sorry 😦
Haha, it is fine, I ll hope someone else can cover that
Hello can someone explain what cost function is? and how it is represented in 3d?
I get that the formula is y-hat(prediction) minus target value(actual value). So is it how wrong or the error between the prediction and target value for the same input?
most of the time when you see something represented in 2d / 3d, that's an oversimplification
the cost function is what tells the model how wrong it is, and that value is used to determine how much it needs to change its parameters (as well as which parameters to change in which direction)
quoting https://developers.google.com/machine-learning/glossary#loss-function
(cost function and loss function are synonyms)
During training or testing, a mathematical function that calculates the loss on a batch of examples. A loss function returns a lower loss for models that makes good predictions than for models that make bad predictions.
The goal of training is typically to minimize the loss that a loss function returns.
Many different kinds of loss functions exist. Pick the appropriate loss function for the kind of model you are building.
Hello I want to get into the AI field, but dont know were to start. Does anyone have a good roadmap towards learning machine learning and AI? However, I have heard that Andrew NG has a good course on corsea, but should I take any courses before that, or anything after that course - and how long do you think it would take to complete that course? Btw, I know a lot in pandas and numpy already. Or do you guys have a completely other roadmap you can recommend for a noobie like myself?
Had the same question. I just started AI. 😆
I would suggest look at pins in this thread, Look at where you stand. Try the free courses first and then get the andrew course on coursera. I did the mistake of getting DL course first, You are supposed to learn ML first and then DL.
Hello, i am trying to scrape several data on the brand "Polene", i'm still a beginner in python. i tried with reddit and get the error : raise ResponseException(response)
prawcore.exceptions.ResponseException: received 401 HTTP response, you can see my code on the screen

!code
Please copy the code, don't post a screen shot...
401 means authorization error/failure. Your tokens are probably wrong (I'm guessing, no experience with that lib). Check the examples for that library and check your keys/etc.
Open a #❓|how-to-get-help help thread if you need more help, this isn't really on topic for this channel.
ok!
should i give up on trying to create a neural network without looking at any code if my brain isnt functioning and i have been stuck for the past 1 week?
@weary timber When I started working with neural networks, at the start I had lots of trouble to understand what was going on. What worked to me what to take a step back, research how neural networks work and I created an entire Neural Network training algorithm from scratch on my own. That helped me a lot to understand how they worked. I think doing something similar can help you a lot.
who tf reacted to this lol
i cant seem to understand the part where we have to propagate the error backwards.
What I mean is that you might be stuck because you are trying to understand complex stuff before understanding properly the basics.
So understanding everything from the lowest level might help you
can you provide me a resource that made you understand?
https://youtu.be/bfmFfD2RIcg?si=FHD5e6T5QrcSn28N and https://youtu.be/aircAruvnKk?si=--BkVmGDgjwQKucV

🔥Artificial Intelligence Engineer (IBM) - https://www.simplilearn.com/masters-in-artificial-intelligence?utm_campaign=bfmFfD2RIcg&utm_medium=DescriptionFirstFold&utm_source=Youtube
🔥IITK - Professional Certificate Course in Generative AI and Machine Learning (India Only) - https://www.simplilearn.com/iitk-professional-certificate-course-ai-machi...
What are the neurons, why are there layers, and what is the math underlying it?
Help fund future projects: https://www.patreon.com/3blue1brown
Written/interactive form of this series: https://www.3blue1brown.com/topics/neural-networks
Additional funding for this project was provided by Amplify Partners
Typo correction: At 14 minutes 45 seconds...
These two helped me a ton
i have already watched the 3b1b so i will look at the first one
The first one is very simple and a bit childish, but it was my first step and it built a great base for me
docker or kubernotes for a beginner in ml ?
What problem are you trying to solve? Kubernetes uses docker (most of the time). You probably don’t need either until you get into some serious ML
Don’t worry about k8s or docker for a while. Most of your day to day will not be using either. The infrastructure team will handle that
it will help for the resume
But you should know docker before k8s or learning k8s will be way harder
Learn docker, then k8s. But there are a lot of other things that are more important in a DS/ML resume imo.
yeahhh
do i type the hyperlinks to my notebooks in github or kaggle ?
in my resume
or the project names and details or both
which area do u work in ?
Basic docker isn’t hard. You can get a decent grasp in a week or so. Advanced docker can be brutal. You get into some deep Linux networking and kernel level stuff.
I don't think there's any reason for a person to learn docker while getting into machine learning
I definitely agree with this. You could learn docker and k8s if you have been applying for jobs for months with no responses and you want something extra to standout. But it is very unusual for a DS person to do any infrastructure like that. There are normally teams who handle it.
That being said… docker makes development and production deployment much easier even for example projects. I HATE when people try and give me Jupyter notebooks.
there are a lot more careers in ML than just DS to be fair. an mle for example might frequently use docker. but when just starting in ML, docker is not really relevant
Exactly
is Cuda a programming language? How come GitHub lists it as a programming language
if it is, it's not one that you need to know
Cuda is c
CUDA is just the API for the GPU as hardware. you don't really have to think about it except for when you install the CUDA drivers or when you update pytorch, jax, etc.
Well GitHub lists it as a language which misleads my belief in what Cuda actually is
😂
i said programming language idk im sure the programming community can chime in on that
It's the Nvidia Graphics API/SDK and also a language (both under the same name "CUDA"), which is very similar to C++.
The implementation of that language is really ugly, it kind of high-jacks the C++ compiler.
You don't need to know it unless you want to write compute shaders (programs that run on the GPU).
Usually there are a bunch of these programs (kernels) written for you and wrapped by a library, e.g. pytorch.
(Or generated as needed by some libraries for you)
(There are other options too, such as OpenCL, Vulkan (but on Nvidia GPUs, CUDA will always have priority on new features))
When should I use DRL vs Deep Learning?
I've looked it up and genuinely there are mixed answers and I really could go either or with my project on sports prediction. The way im looking at this is I have 10 years of data. I implemented Deep Learning which is fairly ok. But is it worth pushing to do Deep Reinforcement Learning? I can just use all those years to try to see if it can learn on its own. But again Im not sure what to do
Hey guys so I have a doubt with NLP, I am working on text classification (it's binary classification) and I'm using BioBert for the text embedding and it seems that LSTM has less to no learning rate, the predictions are all stagnant i.e there's no variance in prediction. However when I use the Bidirectional layer on LSTM the results are great with a 90%+ accuracy and a confidence level (0.9) of 90%. Is having a bidirectional layer a must for bert embeddings?
I think it depends on your project
so tell more about your sports prediction project
How can I improve the images? So far I've done this -- Is it possible to refine the images any further than this?
Here's what my model does:
def build_text2image_model():
encoder_inputs = Input(shape=(max_query_length, len(unique_characters)))
encoder = LSTM(256, return_state=True, return_sequences=False)
encoder_outputs, state_h, state_c = encoder(encoder_inputs)
decoder_inputs = RepeatVector(max_answer_length)(encoder_outputs)
decoder_lstm = LSTM(256, return_sequences=True)
decoder_outputs = decoder_lstm(decoder_inputs)
decoder_dense = TimeDistributed(Dense(7 * 7 * 64, activation='relu'))
decoder_outputs = decoder_dense(decoder_outputs)
decoder_reshape = TimeDistributed(Reshape((7, 7, 64)))
decoder_outputs = decoder_reshape(decoder_outputs)
# add Conv2DTranspose layers with batch normalization and activations
decoder_deconv1 = TimeDistributed(Conv2DTranspose(64, (3, 3), strides=(2, 2), padding='same'))
decoder_outputs = decoder_deconv1(decoder_outputs)
decoder_outputs = TimeDistributed(BatchNormalization())(decoder_outputs)
decoder_outputs = TimeDistributed(Activation('relu'))(decoder_outputs)
# upsample to 28x28
decoder_deconv2 = TimeDistributed(Conv2DTranspose(32, (3, 3), strides=(2, 2), padding='same'))
decoder_outputs = decoder_deconv2(decoder_outputs)
decoder_outputs = TimeDistributed(BatchNormalization())(decoder_outputs)
decoder_outputs = TimeDistributed(Activation('relu'))(decoder_outputs)
# final output layer
decoder_deconv3 = TimeDistributed(Conv2DTranspose(1, (3, 3), activation='sigmoid', padding='same'))
decoder_outputs = decoder_deconv3(decoder_outputs)
text2image_model = Model(encoder_inputs, decoder_outputs)
text2image_model.compile(optimizer='adam', loss='binary_crossentropy')
text2image_model.summary()
return text2image_model



ahh interesting
so what are your inputs?
numbers or images
like, to get that output image as "113" are you using images or just numbers for addition operations?
is this a good place to ask about numpy?
it's the best place
right, so I wrote this little piece
def part2(self):
floor = 0
position = 0
# self.instruction is a ndarray
for step in self.instructions:
floor += step
position += 1
if floor == -1:
break
return position
I feel like there should be a better way to utilize the numpy array to get the position, but I'm not terribly familiar with numpy's idiosyncrasies to know if that's the case
heh what is instruction array?
just give a small example
it's an array of ints with 3 different values: 1, -1 and 0, like [1, 1, -1, 0]
is this aoc? don't you just want to sum the entire array?
ah sorry. you want to do a cumulative sum and find where it gets to -1
yes
well, how exactly do I use it? don't see a conditional for when the sum reaches -1
why are you using numpy for this?
used it for the first part, because it was just that, a sum of the whole thing
yes, its like query in integers and output is images. I made some improvement, does it look promising than the last?





what's the operation called for numpy, when you have 2d array, and each subarray consists of n elements and each element needs to be multiplied with another?
example:
[2, 5, 6] -> [2*5, 2*6, 5*6] -> [10, 12, 30]
You just do normal * and you get that behavior automatically
Wait, you need to multiply every combination of two elements?
yes, so you get from [2, 5, 6] to [10, 12, 30]
yeah, what improvements do you make?
I added Conv2DTranspose layers with upsampling and residual connections instead of batch normalization and activations, and converted grayscale to RGB for VGG16 perceptual loss then finally I reducded nooise
Also, I think this is good because last time when I put this in the supervised training model it yield only 47% accuracy now I got 85%
Look in the pins
Keep in mind that data science is an academic subject unto itself. You have to think of yourself as learning data science, and using python to implement what you're doing. The code is not the objective.
Hmm good question. I’m actually stumped. Besides here, anyone know? Coursera has really good certificate programs. Tho they are a couple months long. Tho I believe there are shorter term certificate courses
But it is not free to be transparent. Maybe some are?
Should I use multiple targets in training to get all predictions at once or seperate them by each target? Im not sure if this affect accuracy in any way or not
I have 10 inputs and 10 targets.
U wanna classify the 10 targets?
That’s pretty much a multiclass classification task no?
mb it’s multioutput classification
I am trying to improve the validation accuracy of this model but I am not sure where I am wrong.
loss: 0.0119 - accuracy: 0.9976 - val_loss: 4.7028 - val_accuracy: 0.3508
This is what I did so far.. is it even possible to improve validation accuracy?
def build_image2text_model():
input_shape = (X_img.shape[1], X_img.shape[2], X_img.shape[3], 1)
image2text = tf.keras.Sequential()
image2text.add(
ConvLSTM2D(
filters=64,
kernel_size=(3, 3),
activation='relu',
input_shape=input_shape
)
)
image2text.add(Dropout(0.2))
image2text.add(Flatten())
image2text.add(RepeatVector(max_answer_length))
image2text.add(LSTM(256, return_sequences=True))
image2text.add(Dropout(0.2))
image2text.add(TimeDistributed(Dense(len(unique_characters), activation='softmax')))
image2text.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
image2text.summary()
return image2text
image2text_model = build_image2text_model()
image2text_model.fit(
X_img, y_text_onehot,
epochs=40, batch_size=128,
validation_split=0.1
)
anyone have tried tensorflow object detection API?
I am trying to to fine-tune the model but getting version issues, although tried every possible way I guess
Seems like you might be overfitting, how big is your dataset?
!code
def backpropagation(output,desired,learning_rate):
dZ2 = cache["A2"] - desired.T
dW2 = np.matmul(dZ2,cache["A1"].T)
dB2 = np.sum(dZ2,keepdims=True,axis=1)
dA1 = np.matmul(params["W2"].T,dZ2)
dZ1 = dA1 * sigmoid(cache["Z1"],True)
dW1 = np.matmul(dZ1,cache["A0"])
dB1 = np.sum(dZ1,keepdims=True,axis=1)
params["W1"] -= learning_rate*dW1
params["W2"] -= learning_rate*dW2
params["B1"] -= learning_rate*dB1
params["B2"] -= learning_rate*dB2
this uses the backprop equations everyone uses but i somehow get an error, can this be fixed?
the error says that dz2 and a1 cant be multiplied since they are different sizes
@serene scaffold sorry for ping
@wooden sail
thank you for showing the code. be sure to always show the full error message as well.
ok wait
sorry for the wait i deleted the training data so im loading again to get error
Traceback (most recent call last):
File "c:\Users\mehme\OneDrive\Desktop\neural network\nlfromscratch.py", line 40, in <module>
feedforward(x)
File "c:\Users\mehme\OneDrive\Desktop\neural network\nlfromscratch.py", line 21, in feedforward
cache["Z1"] = np.matmul(params["W1"],cache["A0"].T) + params["B1"]
~~~~~~~~~~~~~~~~~~~~~~~~~~^
File "C:\Users\mehme\AppData\Local\Programs\Python\Python312\Lib\site-packages\pandas\core\ops\common.py", line 76, in new_method
return method(self, other)
^^^^^^^^^^^^^^^^^^^
File "C:\Users\mehme\AppData\Local\Programs\Python\Python312\Lib\site-packages\pandas\core\arraylike.py", line 186, in add
return self._arith_method(other, operator.add)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "C:\Users\mehme\AppData\Local\Programs\Python\Python312\Lib\site-packages\pandas\core\frame.py", line 7910, in _arith_method
self, other = self._align_for_op(other, axis, flex=True, level=None)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "C:\Users\mehme\AppData\Local\Programs\Python\Python312\Lib\site-packages\pandas\core\frame.py", line 8141, in _align_for_op
right = to_series(right)
^^^^^^^^^^^^^^^^
File "C:\Users\mehme\AppData\Local\Programs\Python\Python312\Lib\site-packages\pandas\core\frame.py", line 8133, in to_series
raise ValueError(
ValueError: Unable to coerce to Series, length must be 70000: given 64
im using mnist from sklearn
@weary timber look at the shapes of params["W1"] and cache["A0"].T
they are not matching
but the thing i dont understand is i checked 2 codes and everyone uses the same as i do without an error
do you know what the rule is for what matrix shapes can be multiplied
idrk
you should look into that.
i understand the rules but how do i come up to a fix with them
what is the rule?
the number of columns on first matrix's should be equal to the second matrix's row number
a(m,n) b(n,p)
can be multiplied
okay, and what are the snapes of your two matrices?
W1 is 64x784 and A0 784
784 by what?
1
and is that before or after you transpose it?
what is transpose?
the .T. if you have a matrix of shape (m, n), then it's transpose is where it's (n, m). the values are the same, just rearranged.
rows become columns, columns become rows.
ohhh no its before
if the shape of A0 is (784, 1) then what is the shape of its transpose?