Cell In[90], line 9
7 model.train()
8 y_pred = model(X_train)
----> 9 loss_score = loss_fn(y_pred, y)
10 optimizer.grad_zero()
11 loss_score.backward()
File , in Module._wrapped_call_impl(self, *args, **kwargs)
1551 return self._compiled_call_impl(*args, **kwargs) # type: ignore[misc]
1552 else:
-> 1553 return self._call_impl(*args, **kwargs)
#data-science-and-ml
1 messages · Page 150 of 1

hmmm weird
oof
Is there a way to use matplotlib without all the global state?
@wooden sail
Is there any any simple implementation of maximal marginal relevance ? I am trying to fetch similar texts with diversity
LF pytorch expert, welling to contribute in a Computer vision project idea
I am clustering a dataset of tweet like post which contains million of text but each text is less than 300 character . I am trying to cluster it but i don't know how many cluster should i use . How do i find out how many groups should i cluster . elbow ? silhouette ?
anyone know a good resource on open cv? I'm trying to get a model to identify the word killed on screen but for some reason and getting anything but that so I would like to learn more about making custom models in open cv

applying data science on valorant is crazy
I'm trying to make a sentiment analysis model for a project and i was wondering if a 60% accuracy rate is a reasonable goal. I have no prior experience with machine learning and want to use this as a way to learn plus get an extra qualification.
I want to train my own model to be able to take a piece of text (like a review on a product) and be able to tell if its a positive or negative review.
I mean, it is more like an art right? Just try it out?
hard code some dumb baseline, and then beat it http://karpathy.github.io/2019/04/25/recipe/
Musings of a Computer Scientist.
alright thanks
How to be, one of the greats.
good project i believe
import tensorflow as tf
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
from sklearn.preprocessing import OneHotEncoder
Guys, I have tenserflow installed but line 2 and 3 have a missing module error. Anyone knows what to do?
Idk if this is the right channel, but I’m learning data science in python, specifically data structures and algorithms, and I’m having trouble implementing the concepts into python for projects and stuff
It’s stressing me out and I just want some general advice on how to better problem solve and to implement concepts into python
Can you give a simple example that you had trouble with?
In one project, I had to build a binary search tree. Then, I had to build two functions for that binary search tree. One for inserting a value and the other for deleting a value
I understood the concept of both
Which way was confusing you because problems like this have 100 approaches. Did you have specific rules you had to follow?
anyone know anything about creating simple AIs for games
specifically in a fighting game like street fighter
Reinforcement learning is perfect for this but the environment is very hard to interact with
whats that?
I don't think unless you intense experience that you will be able to do this
but like a very very simple one
Google it it's an agent that interacts with your environment
There sadly are no very simple ones that are effective
i was thinking using random
Google reinforcement learning the descriptions will be very good for you and you will realize it's really the only way of solving this problem
I mean there are PLENTY of simple?-ish? RL algorithms but you need to work your way up
can i send you guys the code ive done so far
at the rate python is getting module updates, one of these days it'll be
import learn
game.learn()
No simple ways for solving your desired problem tho because interaction with the environment (street fighter) is extremely complicated
sure but use the pastebin
its super super simple and just uses random
ahhh ok
I wouldn't say that just using some sort of package that learns? an environment will be anything close to what you need
But once again there are lvls to this and I'm not so sure what you are trying to achieve
I took what you said quite literally
just using random , and like when the characters are in distance the ai will randomly some times throw attacks
thats the thought anyway
Try writing out the process of inserting a value for that BST in plain English (writing things is important, don't try to do it all in your mind).
Oooooo ok I misinterpreted and thought you wanted something much more complex
nooo no something simple
Yeh that's not what I would call "a.i." (which has turned into a throw around word nowadays)
Which is why I was slightly confused
oh haha
sorry
No yeh what you want is completely achievable with no huge effort
Definitely
ok perfect
No no problem at all I was thinking you wanted to build an agent that plays the ENTIRE game for you
me too lol
not at that level yet haha
And I was like this is a very difficult problem -> achievable for sure but extremely difficult
The python syntax for making the Binary search tree functions are very confusing to me.
Who says you need to use a module
trying to make it as complex as possible but within a range that i can understand it , cause its for a coursework project
Just define the conditions under which you want the "ai" to take an action and set the chances for each possible action. The reason it's not an ai is because it doesn't learn from better or worse actions, but just has a lower chance of performing rarer actions.
You don't need to do that at all, for example, all trees can be topologically mapped to arrays where you are instead constructing an N long integer that implicitly holds your tree construction
to get an A i need to implement some sort of complex algorithms and i was kind of depending on this 'ai' for this
Lets go to #algos-and-data-structs . Try writing the process of inserting into a binary search tree there in plain English.
Actually I do research into discrete structures so to me these may be more obvious but I understand why they may not be. My suggestion is you try and do things WITHOUT some package first
ah ok
Chat, i am just downloading articles from wikipedia to train my GPT on it, is it cool ?
do you think this would count as a complex enough algorithm
.
Interesting but you need to account for a lot of things like text parsing for example is difficult because the text behind a Wikipedia document is quite loaded
As long as you have done this and don't really care about the details/correctness? of your responses then sure it's totally fine
Dont worry i got that covered, its being copied nice and clear and ready for my purposes 👍
Welp as long as your preprocessed correctly then sounds good to me
Tasks like text analysis and stuff tend to be more difficult because of preprocessing not actually the underlying structure of a learning agent
I am using the model_name = "gpt2-medium" model as pretrained cs it would take a lot to just learn grammar i am just training it on info from wiki and i am interested in what happens you know.
Even tho it takes forever i love it.
(While listening to music of course)
Does anyone know I can compare two different objective functions in an optimization problem? In particular the value being returned from cvxpy? I am looking at quad vs sum of squares so it should be a very similar problem - not sure if I can treat it like MSE in a model
thanks.... In your bio is written ask me about my research. so i ask, what is your research or what you up to rn in python ?
Sorry king dont expect anything from teen like me, i hope someone has the strengt to help you. 👍
depends on what the task is asking for
I do research in multi agent reinforcement learning problems and I am developing a massive software package right now for optimally traversing tree structures in constant time
https://paste.pythondiscord.com/BDTQ can anyone tell me how i can fix this? once the 'ai' attacks it doesnt stop and starts spamming them forever, seems very simple but i have no idea what to do
But if you're in school I would say definitely
Thats cool! Do you enjoy it ?
It includes applications in RL trainings, neural network construction, scheduling and transportation problems, option pricing, discrete state space control system problems etc
I like it, it's fine it's part of my PhD
OOoh maan, how are here so many smart people on this python server ?
I am happy for you.
🤷
Thanks dawg
PhD is a tough 5 years if u don't like what you do
Or at least dont hate it
I am so fascinated by computer science idk how anyone can not enjoy it
🙏 😭
I've looked but honestly can't tell what's wrong
9 more minutes and 1000 articles from wiki will be downloaded right into my txt file... i mean it should finish.
oo ok thank you
would you like to see the whole code?
maybe that will explain a lot more
My PhD is in applied math actually not CS
I just do a lot of CS stuff by nature ig
🙏
But one thing, you said distance = self.x-character_select.x
but distance only = self.x-character_select.x if the self.x > character_select.x
otherwise you get negatives
I mean.... when i open the link it says 404 err
same
oh wait
it happens
Surely impressive
taking way too long
and got my deadline in like 3 weeks😭
still need a whole user interphase made like a menu and stuff
🥶
am i cooked😭
Sorry man i am too dumb and cooked to help.😭
no worries😭
this is always the case though cause the left character cant pass the right character in my game
Man, why did you requested a game here ? I thought there is another topical channel for that.. i mean i dont care but... i just wonder....
I mean they could help you there, no ?
someone told me to go here haha
i did say it was an ai so thats probably why
I am so dumb for programming but using AI always helped me, bro everything i programmed {almost} is by chatgpt
i mean i programed the easy stuff by myself
but if yk yk
Thats unlucky
And what does even your function do ? like loop or sum ?
the function calls the movements
so like when it calls left the character moves left innit
ive called it in the main loop so its constantly being run
idk if that might be the problem
but feel like it should be ok
Oh... i mean if you can do something better... i am just asking couse i want to sound important i dont actully know how to help you, so sorry if waste your time
its cool😭
Woah you have done it, no ?
done it !!!!!!
Woah
oh no
I am the mental support
Damn
no like itll work smoothly
for like 5 seconds
and then start bugging out again and spamming the attacks
dont you have some variable that goes up super exponentialy fast or sum ? that likes multiplies ?
I would check what could trigger the function in the code
and look into that part a bit maybe places some print("ok") functions to see if its going there, yk and show some data maybe could help you ?
yeah ill do that now
I mean you can give it a shot
hello guys
Hello ?
are you smart
Oh he looks smart as heel
yes ofc
vamos
vamoos
vamos a la playa ?
i love python language
you know how to fix this?
I mean i think everyone loves python who are on this server...
making an 'ai' for a street fighter game
no Vamos Real Madrid
and doing simple like mechanics for it but its bugs out and spams the attacks
yes ofc man but I'm a web developer i use Laravel
have you ever worked with python Selenium?
nope whats that
it's an automation tool in python
Google says its for web development... do you think it will help with pygame ?
how..
it's very powerful
How much on scale from -100/100 ?
what is pygame?
i think 70/100
Thats a library in python used to develop games in python. i think its most used ? and too cmplex for me
aah like Pyglet
have you looked at my code?
it is a library for develop games
no
nice
do you think you might have time to have a look😭 🙏
been stuck on this fir way too long
problems in the mechanics method in the ai class
okey i will look up
thank you !!!
any ideas?
I'm in progress can you explain more the problem?
ill attach a video that will definitely explain it😭
okey
the right one is the ai
😭
Alright, I’m kind of losing my mind rn with langchain. Can someone help me conceptually understand how the heck I’m supposed to use RunnableWithMessageHistory to have a conversation that I can extract structured data from? Like, I am just trying to have it ask a few questions and at the end of it all I want to have access to the extracted data. ie:
ai: hey, what’s your favorite color?
human: it’s blue.
{ favorite_color: “blue” }
ai: what’s your favorite animal?
human: purple
{ favorite_color: “blue”, favorite_animal: null }
ai: That’s not an animal, can you try again?
human: it’s a dog
{ favorite_color: “blue”, favorite_animal: “dog” }
As soon as I try to extract structured data from the responses, I lose the ability to persist my messages in my message_store table. I don’t get why 😭.
Can you share your code?
@indigo wing looks like this is a #user-interfaces or #web-development question.
it's easier for everyone to help you if you post your code in the server. not DMs.
Hi I need some help in Lstm Univariate exogenous time series prediction. If anyone has expertise in this, please DM me. or we can make a private thread here
Hello, We do not have private threads on this server. it's easier for everyone to help you if you post your code in the server. not DMs.
class neuralnet (object):
def __init__(self, layer_sizes):
self.sizes = layer_sizes
self.weights = [np.random.uniform(-0.5, 0.5, (layer_sizes[i], layer_sizes[i+1])) for i in range(len(layer_sizes) - 1)]
self.biases = [np.random.uniform(-0.5, 0, (layer_sizes[i+1])) for i in range(len(layer_sizes) - 1)]
self.learning_rate = 0.01
self.loss = 0
def fprop(self, inputs):
self.activations = [inputs]
for w, b in zip(self.weights, self.biases):
inputs = activationfunction(np.dot(inputs, w) + b)
self.activations.append(inputs)
return self.activations
def backprop(self, target):
deltas = []
output = self.activations[-1]
delta = (output - target) * activation_derivative(output)
deltas.append(delta)
for i in reversed(range(len(self.weights) - 1)):
delta = np.dot(deltas[-1], self.weights[i+1].T) * activation_derivative(self.activations[i+1])
deltas.append(delta)
deltas.reverse()
return deltas
def update_parameters(self, deltas):
for i in range(len(self.weights)):
self.weights[i] -= self.learning_rate * np.dot(self.activations[i].T, deltas[i])
self.biases[i] -= self.learning_rate * np.sum(deltas[i], axis=0)
def train(self, inputs, target, epochs=1,epoch=0):
inputs = np.array(inputs)
target = np.array(target)
for i in range(epochs):
self.fprop(inputs)
deltas = self.backprop(target)
self.update_parameters(deltas)
self.loss = np.mean((target - self.activations[-1]) ** 2)
def predict(self, inputs):
self.fprop(inputs)
return self.activations[-1]
i hand coded a neural network in python using numpy
oH MY GYAT that looks nice
wats an ideal Cloud storage solution to store extremely large datasets exceeding 400 GB?
Following up on the einsum performance discussion, I did a detailed investigation on the topic as a follow-up post: https://dev.to/kylepena/investigating-the-performance-of-npeinsum-22ho

DEV Community
A reader of my last blog post pointed out to me that np.einsum is considerably slower than slicewise...
nice
also keep in mind this is like a degenerate scenario, since there are operations you can do with einsum that at least off the top of my head are not possible with vanilla numpy operations without using for loops and/or nesting several calls/operations
you might see different behaviors there
Agreed. I first learned einsum when I was implementing Grad-CAM and I couldn't wrap my head around what sequence of tensorflow operations would actually be required to implement the math. That one didn't boil down to any kind of numpy op known to man
I'm thinking the post might have been better off with that as an example, but I couldn't find my notes from like 8 years ago and LLMs are way more topical
There's really two reasons why optimize is faster. The first (and original) reason is it tries to find an optimal contraction path. The second (and newer) reason is that the code path that uses the contraction path is also the only codepath that calls tensordot, which uses BLAS
Therefore, even in the two operand case, where optimize really shouldn't matter, the trivial contraction path calls out to tensordot instead of c_einsum, and therefore you get a siginficant (20x) speedup
I'm following a tutorial what's the number for being able to see in color and not just black and white sorry I'm just wondering so I can write it down so when I think I might be ready after falling a few tutorials and learning how it's supposed to work
Did you type this message manually, or did you use speech recognition?
If you represent an image with a 2d array, then the two dimensions represent height and width, and the values are the intensity of that pixel. that can only encode greyscale images.
If you represent an image with a 3d array, then each dimension can be height, width, and color channel. there are three color channels: red, green, and blue.
Yes
did I answer your question?
Yes
#===[imports]===#
from torch import nn, save,load
from torch.optim import Adam
from torch.utils.data import dataloader
from torchvision import Datasets
from torchvision.transforms import ToTensor
#===============#
train = Datasets.MNIST(root="data", download=True, train=True, transform=ToTensor())
dataset = dataloader(train, 32)
# image clasifire
class Image_clasifier(nn.Module):
def __init__(self):
self.modle = nn.Sequential(
nn.Conv3d(3, 23, (3,3)),
nn.ReLU(),
nn.Conv3d(32, 64, (3,3)),
nn.ReLU(),
nn.Conv3d(64, 64, (3,3)),
nn.ReLU(),
nn.Flatten(),
nn.Linear(64*(28-6)*(28-6), 10)
)
def forward(self, x):
return self.modle(x)
clf = Image_clasifier().to('cuda')
opt = Adam(clf.parameters(), lr=1e-3)
loss_fn = nn.CrossEntropyLoss()
#training flow
if __name__ =="__main__":
for epoch in range(10):
for batch in dataset:
x,y = batch
x,y = x.to('cuda'), y.to('cuda')
yhat = clf(x)
loss =loss_fn(yhat, y)
#apply backprop
opt.zero_grad()
loss.backward()
opt.step()
print(f"epoch:{epoch} loss is {loss.item()}")
with open('modle_state.pt', 'wb') as f:
save(clf.state_dict(), f)

I haven't been able to get a message that shows me that it's trained I made sure to get all the imports working but it's still giving me an error that I didn't import them correctly
what do you think the solution is?
I went to my terminal downloaded everything maybe I have to uppercase the t an v because I made sure it was installed
take a look at some examples.
https://youtu.be/mozBidd58VQ?feature=shared
Here's the video that was i following.

What's happening guys, welcome to the third episode of CodeThat!
In this ep I try to build my first neural network in PyTorch...seriously the first time I even dug into their documentation was yesterday! Anyway you know the rules I have to get it done in 15 minutes, no doco or stack overflow and a gift card to you guys if I fail.
Will I make ...

DEV Community
The Rise (Return?) Of Specialized Computing Environments Isn't it interesting that the key...
How can I create a database for my neural network ?
what is the database intended to do?
databases aren't a thing that neural networks are intrinsically required to have.
An animal detector
how is a database part of that?
I mean a library like the MNIST sorry got them mixed up


This for example would be the difference from bluefin tuna and a fox I want to make a convolution that can say with a print statement fish or mammal
@unkempt wigeon can you explain the difference between a database and a dataset?
Databases are for large scales of data such as criminal and crime
While a dataset is a small collection of data or numbers pertaining to a subject
dataset is a set of data, database is a service to maintain data.
a dataset can be stored in a database, a dataset can also be stored in a csv file or something else
Creating a database for a neural network depends heavily on how you intend to use the database. There's no single "best" approach; the optimal solution depends on your specific needs and the size and complexity of your neural network.
how to use the data
how to maintain the data
what is the data
how to assess the data
how to evaluate the data
what is the criteria
Anyone know how a Trump win might benefit the Python community?
We're not even going to discuss this.
Is this how I would label images for my data set?

no
No. you need to have it in like a CSV or something which images have which labels.
I can understand why you thought this is what is meant by "labeled data", since that is what a labeled image is in the colloquial sense
but the fact that you thought to ask this indicates that you're not comprehending the material that you're trying to learn from.
Have you considered following a tutorial? There’s great ones on the PyTorch website and they cover things like this
Could you say as a simplified way that labelled data is classified data and unlabelled data is unclassified?
that's not really simplified. that's just using synonyms.
but I've never heard anyone refer to labeled data as "classified data".
I have Chinese open CV or something else using py torch?
I’d put your project on hold and just try and follow along with google Colab on this project
https://pytorch.org/tutorials/beginner/basics/data_tutorial.html
what is it called when I have a times series only ranging from say 10am - 2pm for each day, and I want to predict data for 2pm-3pm? (mainly looking for terms I can search)
and, any cool techniques on dealing with these? I assume fitting an autoregressive model won't very well (cause there'd be sudden jumps of time, like from day1 2pm to day2 10am)
Does anyone here have experience with Autoencoders (not LLM related)?
I've got a doubt in flask inorder to render template the html file it should be inside teh template folder right? what about css file how to get it
don't worry about css file as the path is included in html file itself
although you can also keep css files in template/ if your project is small
but if you want good example then this is it
/static/
/main.css
/templates/
/base.html```thanks very much
Thank you and what is Google collab?
Google collab is google platform app, like google docs or sum. its used to run python or other code that is a bit computative expensive, the google gives you some free space and you can test some things that your computer may not handle well. Its super useful.
I can't open a new notebook in the site so I just use regular python
Yes
how can I make my own dataset?
For image classification? You don't want to do that. It would take weeks.
do i need png for data to be lerned?
hello, trying to parse some text files with pyspark in windows environment. when the files are local, all is well, but then the files are on a server and I need to access them with //server/path/type/file.dff it errors out. any hints on why that is the case? thanks
Format doesn't matter
@unkempt wigeon are you following a tutorial? You seem lost again
for a univariate time series prediction / forecasting using transformers, does it expect the date / timestamp to indicies to not repeat (be unique)?
color image file am I doing this correctly I just need somebody to point me into the right area I'm going to label them I just need to be pointed in the right direction sorry

is this right
I’m looking for collaborators to make this repo better! If you find it useful, please consider ⭐ starring the repo and contributing.
This project showcases real-time object detection using the YOLOv5n6 model, balancing speed and quality by running inference on low-resolution frames while displaying results in high resolution.
https://github.com/SanshruthR/CCTV_YOLO

GitHub
Fast Real-time Object Detection with High-Res Output https://x.com/_akhaliq/status/1840213012818329826 - SanshruthR/CCTV_YOLO
Hey smart people
I have some questions about skip connections
Specifically in an autoencoder/unet
This might seem a bit dense, but if the goal is for the encoder to learn an accurate representation of an image in a lower dimensional space, wouldn't skip connections essentially be "cheating," and giving the network an easy way out instead of actually learning a representation?
im dead going nuts this stupid agent just never choosing the correct actions
I want to make a style transfer unit which doesn't just try to replicate line style and color palette and such. I want to be able to actually redraw an image in another style, modifying the shapes of the eyes or giving a character noodle arms or whatever
The only tool I know of that can do this is a diffusion model, by the way. My original idea was to train two encoders - a style encoder trained to align the latents of images in the same style (screenshots from TV shows/cartoons/anime/etc), and a content encoder trained using mutual information loss against the style encoder as well as orthogonalization and consistency loss.
A big problem with this is image quality though. Especially but not exclusively because of my computational constraints, training a model with enough power to autoencode 512x512 images with any decent level of detail is tough. As the latent becomes more abstract (and the resolution drops), more layers and features are required to adequately reconstruct the image. Getting pixel perfect quality or even close to it would require a much strong machine then I have even after a single downscaling.
So I thought, skip connections! But as someone I spoke to said, U-Net architectures seem to be more suitable for situations where the encoding produced is used to essentially "color" the finer details that are provided by the skip connections. The latent is an augment, not a true representation. I might be able to work around this though.
My latest thought is this: diffusion models can produce high quality images with much less power. What if I were to use a U-Net to train encoders for style and content, and then used those encodings in place of text prompts to train a diffusion model. Assuming the latents were appropriate, one describing style and the other describing content (both at a high level, like a text prompt), the attention layers in the diffuser should be sufficient to enable high level transfer
Any thoughts? XD
does anybody here tried or knows how to train in SSD (object detection)?
not necessarily have to actually know how, i just have some questions about the code from this https://github.com/pierluigiferrari/ssd_keras

GitHub
A Keras port of Single Shot MultiBox Detector. Contribute to pierluigiferrari/ssd_keras development by creating an account on GitHub.
forecasting, but imputation might also return some technique you can use.
Auto regressive model would work, but if you do it naively, it won't work for reasons you mentioned.
You can use positional encoding so that the model know that there is a gap. You can only input contigous inputs.
positional encoding
I'll look into that, ty
forecasting
ig I worded it poorly; I more meant that is there a special name for this type of time series forecasts where it's... discontinuous (see I don't know the term)? as opposed to say I have data for every day, and I want to forecast also in days
Maybe you can show us examples of the results?
What I mean is, I think most techniques that would work for regular forecasting, would also work in your discontious setup as well.
alright, thanks for your input
would you mind sharing how you train this model?
its quiet interesting
also how long did it take to train the model? on which gpu?
@visual sage your message was removed for containing advertising.
Ah that's a shame - I'm not really advertising anything. I thought it would be interesting for ai enthusiasts here. Where should I post this sort of project?
I'm not sure. Not on this server.
Thanks for your help... 👍
Hi, I'm using the pretrained weights and looking to expand its functionalities. Please DM me and let's work on that together
I was actually thinking about adding point tracking to it tbh
can you tell me some important things to learn i learned the basics the kotlin basics jetpack compose etc but for things like databases auth, integration of fe to be what should i learn graphQL, firebase, dependancy injection?
this is the data science channel. It sounds like you're asking about something else.
ok
Firebase and OAuth work the best.
nice
ahhh, interesting
have you tried the encoder way ?
I think first go with very basic level understading such as -> GAN with U-Net
so will train model on style images and then maybe apply it on output image
@rich moth can understand this better
Hello, anyone know what version of blis & thinc library is compatible with numpy 1.26.4? because currently gensim is not compatible with numpy 2.0
need some advice rq
finished a data analysis course and dont know what to do now, i wanna just practice but have no idea where to start and what projects to start on. Any ideas ??
If some1 can recommend some projects or what they did to imrpove that'll be great
hey everyone, i want to learn nlp, can someone provide me best free resources?
what kind of nlp do you want to learn
fundamentals

For more information about Stanford's Artificial Intelligence professional and graduate programs visit: https://stanford.io/3w46jar
This lecture covers:
- The course (10min)
- Human language and word meaning (15 min)
- Word2vec algorithm introduction (15 min)
- Word2vec objective function gradients (25 min)
- Optimization basics (5min)
- ...
wow, thanks
Do I use cv2 for labeling?
What tutorial are you following?
I found a couple of videos if I want to know if there's a specific in pytorch for labeling
You should pick a specific tutorial and follow it exactly. Don't try to follow more than one at the same time.
You should use a dataset that's already labeled.
Does Microsoft LightBGM support repeating indicies - dataset (for time series prediction)?
why does openai api keep saying Expected either ('model' and 'prompt') or ('model', 'prompt' and 'stream') arguments to be given
storeFile = request.files["file-upload"]
file_name = storeFile.filename
first_file = client.files.create(
file = storeFile.read(),
purpose = "assistants"
)
print(first_file)
print(f"file name is {file_name}")
print(f"file id is {first_file.id}")
myprompt = f"Please read the contents of the file with ID {first_file.id} and summarize them into clear, concise study notes. Focus on the key concepts, important details, and any relevant information that will help in studying."
completions = client.completions.create(
model="gpt-4",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": myprompt}
],
max_tokens=150
)
print(completions.choices[0].message.content)
Hey Stelercus! I know you work in NLP domain and I have a question for you. What would you recommend doing when you have imbalanced dataset when you do sentiment analysis
Sentiment
neutral 3130
positive 1852
negative 860
Name: count, dtype: int64
This is my dataset
just continue as normal and wait to find out if the imbalance appears to be an issue.
make a confusion matrix and see what you can infer from it.
you could try training on a set that's more balanced, but make sure your test set reflects the true distribution.
precision recall f1-score support
0 0.48 0.28 0.35 175
1 0.59 0.51 0.55 372
2 0.68 0.81 0.74 622
accuracy 0.64 1169
macro avg 0.58 0.53 0.55 1169
weighted avg 0.62 0.64 0.62 1169
what I get with logistic regression
so I did text preprocessing, lemmatization and stop words
and used Glove as word embeddings
you mean undersampling the majority?
is this the confusion matrix?
nah the classification report
sure, you could put it that way.
okay
class_0 = data[data['Sentiment'] == 0]
class_1 = data[data['Sentiment'] == 1]
class_2 = data[data['Sentiment'] == 2]
min_size = min(len(class_0), len(class_1), len(class_2))
class_0_downsampled = resample(class_0, replace=False, n_samples=min_size, random_state=42)
class_1_downsampled = resample(class_1, replace=False, n_samples=min_size, random_state=42)
class_2_downsampled = resample(class_2, replace=False, n_samples=min_size, random_state=42)
something like this I assume
https://youtu.be/9b5g-smg5Mo?feature=shared
Is this good for making bounding boxes for the neural network sorry

This video titled "Annotate Videos for Machine Learning Model | Label Videos for Object Detection Model | YOLOv4" explains the steps to annotate or label videos in order to make it as dataset for machine learning model training. Models such as Classification, Object Detection, etc. If someone wants to build your own custom YOLO V4 object detecti...
you were trying to do image classification. why the sudden change?
I thought this was used for labeling?
No.
What do I need for training and labeling because I have all the images to train it on colors I just need to know if I didn't the labeling right which I have provided earlier
weren't you trying to train it to classify animals? what's this about colors?
I'm starting colors because it seems easier to do colors to identify an animal within the image because some animals might have a toxic counterpart very hard to tell apart but for a computer it needs data and if you crunch all that data for color you can give it a way of seeing between all the different types and if one's a little too Orange then it can be poisonous etc
you don't need to train neural networks to recognize colors. the color of a pixel is self-evident by its RGB values.
omg much better now
Accuracy: 0.5872093023255814
precision recall f1-score support
0 0.58 0.62 0.60 172
1 0.62 0.51 0.56 182
2 0.57 0.64 0.60 162
accuracy 0.59 516
macro avg 0.59 0.59 0.59 516
weighted avg 0.59 0.59 0.59 516'
did you keep the class distribution in the test data "real"?
df['Sentiment'] = df['Sentiment'].map({'positive': 1, 'negative': 0, 'neutral': 2})
data = df.dropna(subset=['Sentiment'])
min_size = data['Sentiment'].value_counts().min()
balanced_data = data.groupby('Sentiment').sample(n=min_size, random_state=42)
X_balanced = balanced_data['Sentence']
y_balanced = balanced_data['Sentiment']
this is what I did
how do i keep it real in test data?
X_train, X_test, y_train, y_test = train_test_split(X_balanced_vectors, y_balanced, test_size=0.2, random_state=42)
what I use
if the distribution of the three classes in the whole data is (for example) .6/.3/.1, then it needs to be .6/.3/.1.
how you achieve that is up to you.
do you understand why that needs to be?
yeah so this is what I did 😄
X_balanced_vectors = np.array([sentence_to_vector(sentence, glove_embedding, embedding_dim) for sentence in X_balanced])
X = np.array([sentence_to_vector(sentence, glove_embedding, embedding_dim) for sentence in df['Sentence']])
y = df['Sentiment']
X_train_orig, X_test, y_train_orig, y_test = train_test_split(X, y, test_size=0.2, random_state=42, stratify=y)
X_train_balanced, y_train_balanced = X_balanced_vectors, y_balanced
I got a little bit more improvement actually
!paste
Pasting large amounts of code
If your code is too long to fit in a codeblock in Discord, you can paste your code here:
https://paste.pythondiscord.com/
After pasting your code, save it by clicking the Paste! button in the bottom left, or by pressing CTRL + S. After doing that, you will be navigated to the new paste's page. Copy the URL and post it here so others can see it.
Heres what I did
So how Cheyenne go ahead and make a data set for my network?
don't make a dataset. use one that already exists.
#===[imports]===#
import torch
from torch import nn, save, load
from torch.optim import Adam
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision.transforms import ToTensor
#===============#
train = datasets.MNIST(root="data", download=True, train=True, transform=ToTensor())
dataset = DataLoader(train, 32)
# image clasifire
class Image_clasifier(nn.Module):
def __init__(self):
super().__init__()
self.modle = nn.Sequential(
nn.Conv2d(1, 23, (3,3)),
nn.ReLU(),
nn.Conv2d(32, 64, (3,3)),
nn.ReLU(),
nn.Conv2d(64, 64, (3,3)),
nn.ReLU(),
nn.Flatten(),
nn.Linear(64*(28-6)*(28-6), 10)
)
def forward(self, x):
return self.modle(x)
clf = Image_clasifier().to('cpu')
opt = Adam(clf.parameters(), lr=1e-3)
loss_fn = nn.CrossEntropyLoss()
#training flow
if __name__ =="__main__":
for epoch in range(10):
for batch in dataset:
x,y = batch
x,y = x.to('cpu'), y.to('cpu')
yhat = clf(x)
loss =loss_fn(yhat, y)
#apply backprop
opt.zero_grad()
loss.backward()
opt.step()
print(f"epoch:{epoch} loss is {loss.item()}")
with open('modle_state.pt', 'wb') as f:
save(clf.state_dict(), f)
like this?
Not too shabby

I tried I'm having a problem though
GitHub
Deep learning for dummies. All the practical details and useful utilities that go into working with real models. - EleutherAI/cookbook
if the dependencies needed for the ssd model are:
Dependencies
Python 3.x
Numpy
TensorFlow 1.x
Keras 2.x
OpenCV
Beautiful Soup 4.x
what versions should i install in my anaconda environment?
Anyone can suggest me how I make a model for detecting spam emails using SVM model with both types linear and multiple. Any YouTube or any blog that I can learn from it.
I'm a beginner in it
Any reference also can be helpful to my project
Please suggest
Depends on what it’s been tested on. Either stated in a paper or GitHub repo.
Hey smart people! Question for you
How would you all approach distilling an image into a vector?
Here's the gist: I'm building an encoder and adversarial classifier to take batches of images in the same style and distill them into vectors. The goal is to generate a unique and consistent vector encoding for each unique style.
One option is to execute a convolution, downscale, execute another, downscale, and so on until the image has been reduced to 1x1. The second option is run convolutions on the image without ever downscaling, and then use a global max pool to convert the final feature maps into a vector. Or, maybe a combination of both.
Thoughts?
I'm leaning towards the second option because (a) you lose a lot of detail when you downscale, (b) you can capture larger and larger features simply by expanding the kernal size, and (c) most of what defines a style is exists on the small scale
the first approach is the standard. you never go down to 1x1 though, that's ofc not invertible and you lose all info
the second is computationally inefficient when used on large images. natural images are expected to be smooth and structured, so you don't lose (much) info as long as you downsample reasonably
Excellent! Thank you
I'm not trying to create an autoencoder though
doesn't matter
I'm trying to build vectors (in a smooth embedding space) which represent a style, and I'll be using these vectors as control signals in a later entity
if you plan on using the vectors for anything, you better hope they represent the original image in some way
What, in your mind, is "reasonable" downsampling?
that depends on the processing that comes after, you'll have to try and see
1 sample is not reasonable though
As an aside
Does anyone know how to make it so that every item in a batch comes from the same subdirectory?
class DataFinder(datatools.Sampler):
def __init__(self) -> None:
root = pathlib.Path('/Users/lucasyoung/Desktop/MELD')
self.styles = []
self.styles.extend(filter(pathlib.Path.is_dir, (root / 'Public Domain').iterdir()))
self.styles.extend(filter(pathlib.Path.is_dir, (root / 'Cartoon').iterdir()))
self.styles.extend(filter(pathlib.Path.is_dir, (root / 'Anime').iterdir()))
self.styles.extend(filter(pathlib.Path.is_dir, (root / 'CGI').iterdir()))
self.styles.extend(filter(pathlib.Path.is_dir, (root / 'Other').iterdir()))
def __iter__(self) -> typing.Iterator[typing.Any]:
return iter(self.styles)
I'm not really sure what I'm supposed to be doing here
The sampler is supposed to be giving indices back, right? Through the iter function?
So, what, if I have x styles, then the length of my dataset is x * batch_size?
So, what, should I make a range of digits of x * batch_size, break them into batch_size chunks, and return chunks of indices
How do I compute the cosine similarity (or similar) of all embeddings in a single batch?
More saliently, how do I compute how different two embeddings are from each other in terms of both magnitude and direction?
Cosine similarity is direction only. The difference in magnitude is just the difference in magnitudes i.e. the difference in the vectors' norms
Re: construction of vectors, you could use something old school like PCA if for whatever reason you don't want to use an autoencoder
I'll look into this!
From the name, a quick glance seems like it's appropriate to the task
I'm doing something wrong
My encoder is producing tensors of shape torch.Size([8, 128, 1, 1]). It's supposed to be a batch of vectors, one for each image in the batch, and each vector with entries. I'm calling torch.cdist(embeddings, embeddings).mean() to compute the average distance between pairs of vectors in the batch. I'm doing something wrong though because I'm getting 0.0 as the mean distance
Am I supposed to transpose the embedding or something?
I forgot to flatten the tensor into vectors XD
so you copied the model and added tracking functionality? I dont know enough to work on this project yet, was just curious how it was trained.

So, the majority of models and frameworks use pre-trained models since training from scratch is quite costly. ViTs are generally used nowadays for real-time tracking and analytics, but they are very computationally expensive to run. However, YOLO models can infer things quite quickly and work with cpus
Like there’s some loss in accuracy but it still works
No, worries mate 😊
Hey guys i am new here
import numpy as np
sorts = np.array([[3,4,2], [1,3,2], [2,3,4]])
bigs = np.array([[5,4,2], [1,4,2], [8,9,0]])
max_values = np.argsort(sorts)[:, -1]
sorts[[:], max_values] ```
Can someone please explain to me, why it does not work to use the column (:) when trying to slice in numpy? It is so weird, beacuse it works in other type of slicing or indexing to use (:). So my last line with sorts[[:], max_values] is fucking my code up because of the column sign.But I have been working on a ai project for a year now but I do not a the divece that can run applications to test it ro see if it actually works or not I will appreciate if someone tested it out for me and give me feedback
Here it is: https://paste.pythondiscord.com/XAVQ
See if this works https://paste.pythondiscord.com/CBXQ
Yea, thx alot mate! Very nice code ( :
No problem brother
Does hi Wednesday how come I'm getting a shape error too
what does hi Wednesday mean?
Hello, be sure to ask your actual question. don't ask if anyone will answer a question you haven't asked.
this is the data science channel, so your question needs to be about that.
Okay
I've done make this code last mounth, and don't work this time
this code use for image clasification with roboflow platform, if a new file (video or image) have been add in some directory "C:\ALARM" then its will process "a new file" to roboflow platform and turn to image clasification
sample


hey im new to this topic , where would you suggest me to start ? my goal is to make my own food recognizer
Sorry darn auto correct
Autocorrect
Is there a way to return bounding box coordinates using sklearn?
I'm training a person detector model and I want to draw bounding boxes around the person
Here is the code I have right now
import cv2
import os
import numpy as np
from sklearn.svm import SVC
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
import pickle
winSize = (64, 128)
blockSize = (16, 16)
blockStride = (8, 8)
cellSize = (8, 8)
nbins = 9
hog = cv2.HOGDescriptor(winSize, blockSize, blockStride, cellSize, nbins)
def load_data(data_dir):
data = []
labels = []
for label in ["0", "1"]:
folder_path = os.path.join(data_dir, label)
for filename in os.listdir(folder_path):
img_path = os.path.join(folder_path, filename)
img = cv2.imread(img_path, cv2.IMREAD_GRAYSCALE)
if img is not None:
img = cv2.resize(img, winSize)
features = hog.compute(img)
data.append(features.flatten())
labels.append(int(label))
return np.array(data), np.array(labels)
data_dir = "data"
X, y = load_data(data_dir)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
svm = SVC(kernel='linear', probability=True)
svm.fit(X_train, y_train)
y_pred = svm.predict(X_test)
print("Accuracy:", accuracy_score(y_test, y_pred))
with open('svm_people_recognizer.pkl', 'wb') as f:
pickle.dump(svm, f)
with open('scaler.pkl', 'wb') as f:
pickle.dump(scaler, f)
Hi how do i create a learning system from scratch with no imports but numpy
That would be pretty challenging--you'd need to implement differentiation and gradient descent
I assume you're talking about a neural network
Yep
A machine learning craftsmanship blog.
Hey data science peeps - I could really use help making a Gaussian Mixture Model if anyone is available! I have a csv with my data and don't really know how to code, I had a friend helping but he gave up.
I recommend spending a few days/weeks getting used to the basic functionality of Python.
How does one get better at sentiment classification with Bert and PyTorch?
Get insipiration from the latest research? https://paperswithcode.com/task/sentiment-classification

Thank you
Are transformers through torch advanced and harder than GANS?
You can start by learning how to code.
Maybe you are not aware, but this like asking doctor to do a surgery on you, or a lawyer to represent you, or an accountant to fill in your taxes. This is not something that people do in 5 mins. This will take few weeks (to do it properly, making sure GMM is the right model for your data in the first place) and people do this professionally for a good amount of money.
I'm not saying you won't get such help here, you might, but I won't be counting on it.
Maybe if you do have money and you are willing to pay. I suggest that you contact consulting firms such as:
- accenture
- IBM
- BCG
- Deloitte
- Bain
You can also dm me with your offer, I might be cheaper than them lol.
I don't think so
Are transformers all the final frontier? And I just bugged my pc like crazy from scrapping a bunch of news article for trying to make a game, like a game theory game with players through text corpus. I need articles to scrape what are some hot topics with a winner and a loser or two people competing? Go!
The final frontier of what? Machine learning? No shot
if a column has over 1000 unique categorical values how can i encode it?
!rule paid
Check Karpathies yt tutorial
He has a from scratch video series, where you build the whole autograd engine yourself
hey guys,
https://github.com/ArnavTamrakar/Ufc-Data-Scraping-and-Cleaning
this is my first pandas project. can u have a look and give me feedback?

GitHub
Contribute to ArnavTamrakar/Ufc-Data-Scraping-and-Cleaning development by creating an account on GitHub.
@ruby maple
- It's annoying to scroll past the output of
print(soup.prettify()). Notebooks are for human consumption, so don't display more than you need. # ## Initialize an empty DataFrame for Ilia Topuria's fight statistics-- When you use pandas idiomatically, you'd almost never initialize an empty dataframe.illia_topuria = pd.concat([illia_topuria, pd.DataFrame({this is incredibly inefficient, because it repeatedly copies all ofillia_topuriainto a new object. So it's O(n^2). It could quickly start to take up minutes of wall-clock time.- Your string-cleaning stuff is fine, though you can do all of
# Drop original columns that are no longer neededwith one call todrop, ieillia_topuria.drop(columns=['Knockdown', 'Strikes', ...])
## Initialize an empty DataFrame for Ilia Topuria's fight statistics -- When you use pandas idiomatically, you'd almost never initialize an empty dataframe.
can u elaborate on this?
usually you pass a list of dicts where each dict represents a row, or a dict of lists where each index of the lists represents a row, and it creates the whole dataframe all at once.
okayy thanks for the feedback. Will implement them on my future projects.
you can also update your currrent project
okayy
https://discord.com/channels/267624335836053506/1304768366866599998
anyone know to successfully convert a model to coreml or tflite without mismatching?
basically im tryingn to make it small to put into mobile
i quantized it successfully but havent been able to compress it properly to coreml
this is the repo if you want to take a look: https://github.com/Prakhar998/Food-Classification
i need help with the classic unet
I was just a joke, I thought it is clear from context.
Hey guys, I am trying to add Gaussian noise to a tensor in Pytorch, but when I do, I always get an error about the input and noisy tensor being on different devices, and that being an issue.
class AddGaussianNoise(object):
def __init__(self, mean=0., std=.3):
self.std = std
self.mean = mean
def __call__(self, tensor):
tensor=tensor.to(device)
return (tensor + torch.randn(tensor.size()) * self.std + self.mean).to(device)
def __repr__(self):
return self.__class__.__name__ + '(mean={0}, std={1})'.format(self.mean, self.std)
ex=AddGaussianNoise().__call__(path_mnist_train[0][0])
Here is the code so far
@dry raft Do you know what they mean by devices
Hi guys, I am looking for someone who could help me learn simple data analysis using python - it is basically using Pandas to extract data from a txt file, and do some calculations on them. I am happy to discuss details in DM if anyone would be interested. I have got detailed instructions of what needs to be done for my example problem (Uni course) but I need to learn how to do all of it.
Like the GPU and cpu
I moved my pytorch model to the GPU, aka cuda
And I am having trouble moving the images and noisy images to cuda, whenever I try, the same error keeps popping up 😭
See what you can do and come here when you have specific questions
I think the problem is that the randn tensor is on the wrong device. Not the input tensor.
You can use this to figure out what device the input tensor is on and go from there.
So I am supposed to move the randn tensor to cuda before I return a noisy image?
Right. Because your input tensor is presumably on the GPU
Yup, colab is a bit buggy though 😭
Idk what you mean by that.
When people say "I get errors" or "there are bugs" that doesn't communicate anything about what the problem is
No, I meant that my computer has a bit of trouble connecting to the Internet, yk just running slow after a bit of use. I usually get this so don't worry about it too much
how hard would it be to make a food, weight recognition based on image im new to machine learning and that would be the goal for me to make.
food should be possible, and relatively simple, albeit you would need of a lot of images of each food you want to identify... but weight recognition?
Estimate the weight of an arbitrary thing from an image?
Just don't. It will be extremely inaccurate no matter what you do.
for food, you could either train a classifier, or just create a database with embeddings then search for similar images later
well im doing an app in react with calories track and i saw the app called CalAI and they have this feature. i wanted to add aswell
but i dont think it would be a problem to just recognize the object and make the user input the ~ weight
I highly doubt that it'll be accurate
idk how trustworthy this is, but sounds like some apps use LiDAR which might be able to get slightly more accurate results than just normal images, but you would need of millions of lidar+image & weight pairs for training that
yeahh bcs of the density and volume makes it almost impossible, also i wanted to ask any reliable sources for the images of food? maybe kaggle or i should make my training materials from google or something?
Kaggle and HuggingFace are good places to start
if you need to scrape data, you could try looking for some recipes website or even just places in social media where people post images of food they've cooked, but make sure the platform allows it before you try to scrape anything
alright thank you very much etrotta i hope you have a nice day ;)
this might be useful https://github.com/qdrant/demo-food-discovery/

GitHub
Source code of the food discovery demo built on top of Qdrant - qdrant/demo-food-discovery
for example, instead of a recommendation api, you could just upload an image then retrieve the most similar embeddings to use it for classification
(well, training an actual classification model should be way more accurate though)
to be completely honest i dont understand the most similar embeddings method but i want to try making my own model to have it on my portfolio i would say thats required these days..
😔 Guys, does anyone have any good links for understanding how array strides can be derived from array shape... And how to use those to broadcast arrays to new shapes without the mem copy
it is messing my brain up trying to scrap it out with python scripts
you mean like by chaining divmods?
I've managed to gas light myself into now having absolutely zero clue how to go about it
fully working out a few examples in 2-way and 3-way arrays should help
imagine we have a matrix of size m x n stored in memory in row major order, so that elements of a row are contiguous in memory
[[[0. 1.]
[2. 3.]
[4. 5.]]]
shape: (1, 3, 2) strides: (24, 8, 4)
😅 Well you see, that is how I've ended up gaslighting myself into being completely dumb
Now I understand all the byte sizes and memory ordering
I just cannot work out how (1, 3, 2) becomes (24, 8, 4) or if we just work in terms of elements rather than bytes (6, 2, 1)
let's see. the first dimension is of size 1, so that means that in memory you have all 6 elements of the matrix adjacent to each other
you need to jump 6 items to reach the next matrix
then inside a matrix, you have 3 rows
i'm not sure what exactly is being show there tbh, dunno where the 8 and 4 come from
ok
right, ok, this makes sense
so we established dim 1 contains matrices of six elements, so the 24 makes sense
the second index goes inside a matrix and indexes the rows
because your rows have 2 elements, you need to jump 2 elements to move from one row to the next, hence the two
then rows are inherently memory adjacent cuz numpy is row major
so the last dimension should be 1 by default unless you specify a different memory layout
the outermost level holds 3 x 2 matrices. the next level holds vectors of size 2. the final level is the scalar elements of the vectors
at each level you multiply by the number of objects, from the inside out
1 for scalars. 2 scalars per row. 3 rows per matrix
3 * 2 * 1 elements at the outermost level
you compute the indices in the same way by divmodding
Question about the inner most then, the outermost makes sense
but do we end up just hard coding that the inner most is always 1 ?
(assuming row major)
numpy probably has an if-else tree based on the order parameter
since you can e.g. specify fortran (column major) order
that'd make the second to last stride always 1
yeah, for simplicity sake should probably just pretend column major doesnt exist
😅 At least, that I am pretending it doesn't exist
then you can set the last stride to 1 if you stick to row major memory layout and build n-way arrays inside out, like we did just now
so at each level you go out, you multiply by the number of elements in that dim. the innermost level is always 1. (everything multiplied by the dtype size in the end)
Okay, so let me try and digest this:
input_shape: (1, 3, 2)
to_get_strides:
strides = [0, 0, 0]
strides[0] = fold(input_shape[1:], |a, b| a * b) % input_shape[0]
strides[1] = fold(input_shape[2:], |a, b| a * b) % input_shape[1]
strides[2] = fold(input_shape[3:], |a, b| a * b) % input_shape[2]
return strides
I haven't actually tested this, but this is what my monkey brain is current thinking
idk what fold and |a, b| do
Nvm 😅 I realise I am wrong
i would again look at 2-way and 3-way cases, because the order of vectorizing immediately translates into the stride
so let's go back to our m x n matrix. say the memory layour is row major and we want to vectorize the matrix
where does the divmod come into play, that is the bit I am cofused at
it comes right now 😛
we want a vector v made out of the elements of a matrix M. we need to assign the elements M[r, c] to v[k], so k and r and c are somehow related. but how?
well, we need the following. i want to increase k so that it goes along the rows of M. but once i reach the end of the row, k somehow needs to roll back the value of the column to 0, but move to the next row
this means that c = k mod n, and r = floor(k, n)
or alternatively, that k = c + r*n
i had done that backwards, i meant n instead of m, sorry. it's fixed now

!e
m = 3
n = 2
for k in range(m*n):
row = k // n
col = k % n
print(f"{row=}, {col=}")
``` something like this:white_check_mark: Your 3.12 eval job has completed with return code 0.
001 | row=0, col=0
002 | row=0, col=1
003 | row=1, col=0
004 | row=1, col=1
005 | row=2, col=0
006 | row=2, col=1
this would be what numpy does for the example you gave above
OH
minus the extra nesting level cuz you put it inside another bracket
So this is how it does the broadcasting behaviour when it needs to loop back to the start
so we said k = c + r*n, yeah? and what if we now add the new nesting level you described? let's call this the slice number s. then we would have k = c + rn + snm
and each extra level gets multiplied by the size (number of elements) of the previous level. the bigger the multiplier, the "slower" the index
i think what might help you is what is normally referred to as "tensor unfolding" or "tensor unrolling", since that's how one translates indices of an arbitrarily shaped, arbitrarily big array into a different shape... on paper, at least
ok, wikipedia's article is not gonna be very helpful unless you eat kronecker products for breakfast. one sec
i would normally call these "n-way arrays" instead of tensors, and "n-mode unfolding" for a particular reshaping
kinda like this

Hmm
idk if that helps you
😅 I'll confess it is kind of blurring into one, but let me do a couple tests to see if I actually am understanding
try the matrix example again, but this time if the memory layout were column-major
and then try a 3-way array. grab a pen and paper and take it easy. the first time is difficult, but it's really like riding a bike. it clicks once and then you're enlightened for life
(i actually forgot how to ride a bike after like 15 years)
Okay, so, effectively we apply this, and the number of 'steps' becomes our strides right?
wdym by steps here?
So shape (1, 3, 2)
Our inputs m: 3, n: 2 ends up with 6 'steps'/elements
then we get m: 2, n: 1 ends up with 2
then we get m: 1, n: 1 ends up with 1
Yes? no?
i actually wouldn't modify the m and n at all
the product just excludes them
the outermost level is 1 * 3 * 2
one level in, the 1 disappears because we're now looking at 1 specific matrix. that leaves 3 * 2
if you go inside the matrix, you now have rows. each row is of size 2
and if you go inside the row, you have scalars, which have a stride of 1
.latex it's more like \prod_{i = 1}^{\text{chosen level}} \text{number of elements at level} i
ugh
So we effectively calculate (1*3*2, 3*2, 2*1, 1) and drop the outer most?
Right, and 1*3*2*1 represents the whole thing
Ok, that makes sense
Just to check, then with these strides, if we want to broadcast say a array of shape (1, 3, 1) to (3, 3, 3) we work from the inner most dimension out, and can repeat effectively the elements defined by the stride for that dimension
Probably not wording that right, but if our strides are (3, 1, 1) we can see we just need to repeat the 1 elements 3 times for the inner most dimension
yeah, right
i would kinda look at it as saying that, wherever a dimension is 1, you can replace the index with the index mod 1
okay, I think I get it now 😅
Thank you for the help, I've been bashing my head into this issue for ages
you caught me when i've just written a cursed amount of reindexing for toeplitz matrices, so my memory was fresh
I think at some point I just started over thinking it when trying to visualise it across arrays with more than 2 dimensions
oh yeah past 3 dims you can only do it algebraically unless you come up with some intricate pictorial representation
which is possible, but past like 5 dims you'll get tired of grouping cubes together
convince yourself you have it right in one 3-way example and then trust the heart of the cards
Yeah, I have been making a matrix lib for a while now and this was one of the main blockers I had left to do
Now I just need to write it in a way that doesn't confuse the compiler
I've done small ETLs before and it was rather simple. But this time around, I'm having trouble designing a smart way to aggregate 9 data sources, APIs, spreadsheets, sql etc, into 1 or more target systems. anyone know of a book or course that can tell me the best etl/data engineering practices or etl model design ? I feel like my code it so random and has no structure. and a pain to update if anyone whims a column change
can somebody tell me why i get only 2 values with this: for *xyxy, conf, cls in result.boxes.xyxyn: and when i remove * from xyxy and remove also conf and cls i get 4?
What are you struggling with specifically? Schema changes? The codebase? Scalability?
What stack are you using as well? Maybe I can find something tailored to your stack 🙂
my code just looks like a rat's nest. but I don't know how to make it more manageable. or flexible when people chang eteh source data
no particular stack. just python, pandas, sqlalchemy, odbc connections etc
nothing like s3 or cloud storage, and the data size isn't very large. it's just lots of operations to clean update and do quality checks on it
I'm solo
my plan is to convert it to apache airflow, as soon as I get teh base code working
Disclaimer, I'll use some buzz words here and there, just so you can Google them afterwards. I'll try and explain them along the way but ask away if I'm not clear
sure thing - go ahead
The current "best practice" way to do data transformations is called the medallion architecture. It's a fancy way to say you store the data 3 different times:
- Bronze: You store the raw data as-is on s3. This means jsons from your APIs, and exports from DBs in a format like Parquet or even better: Delta
- Silver: You do minimal cleaning but NO business logic yet
- Gold: you model and do all the business logic, cleaning, validation that is necessary
Why? This kind of solves an issue you have. If your source changes your copy to bronze is untouched, what you must change is silver -> gold
That's the first part explained, all clear so far?
easy peasy - got it
You can even organize your codebase like this, you can have a "ingestion" folder that manages source -> S3, another one that does bronze -> silver and another that does silver -> gold
You should carry this division over to S3 and organize your data that way
In terms of compute, things like dbt (data build tool) can make things very easy. In ETL setups you typically have three parts, one where you define the schema and another one where you define your transforms and finally actually moving the data (you can do this in a number of ways, like truncating and inserting, merging, ...)
All that you have to do if you use these tools is the transforms, the rest is more or less handled for you
If you're using Pandas and have low volume (as you mentioned) consider just truncating silver and gold at each new run. Saves a lot of time having to think through merging logic. You also need to write your ETL once, to do a full load. Each load you do afterwards is de facto a full load because you're deleting silver and gold. This is called "truncate/insert"
I get bronze, and I might consider minio for storage. I will have to do silver because the source data is horrible., and gold because well, we're basically inventing a new process
Oh you're not on the cloud. What are you using storage-wise?
I misread you
It's not a requirement btw 😄
data sources are spreadsheet, cloud ERP, on-prem MES and WMS, and sql dbs in various places. it's also part of a busines mergers and acquisitions, where both sets of primary keys overlap each other
And where will you store the things you're using for your data engineeirng stuff
the merging is complicated, because it's dealing with duplicate primary keys like part codes, and also, merging of part thats are identical in real life, but have different part codes
So this stuff is going to happen between silver and gold
That's where you should position this
storage, it's up to me - I'm doing this because nobody else can, and I dont' have a budget. I'm on the fence about minio or even using postgres
At my previous job I used minio and postgres
good question, I forgot 😓

Data Engineering Wiki
A medallion architecture is a data design pattern, coined by Databricks, used to logically organize data in a lakehouse, with the goal of incrementally improving the quality of data as it flows throu…
welI was just curious if you keep up with it in youtube or books or podcasts
I looked up etl through youtube and this is the first I've heard about medallion.
I go to meetups and stuff to see what other people are doing in industry 🤓
any well known industry groups ?
You'll have to check wherever you're living
ok, I thought there was something lik eieee ir siam etc
Reddit is also OK but it can be an echo chamber
thanks for the big tip. imma go read up
Lemme think, is there anything else I should mention
when you add airflow don't mix orchestration and compute
Your airflow should just be this:
- For all tasks, ingest
- For all tasks, run bronze
- For all tasks, run silver
- For all gold tables, run silver to gold
Is there a way to return bounding box coordinates using sklearn?
I'm training a person detector model and I want to draw bounding boxes around the person
Here is the code I have right now
https://paste.pythondiscord.com/D3LA
Why? It's good software engineering practices to compartmentalize stuff. The reason to do all this ceremony is that 1 real world change means you need to change 1 specific thing in your code, not that you need to change a little bit of everything everywhere
zestar75 - exactly my issue currently
Then start with the approach I detailed. It might be overkill for what you need
But by trying it and gaining experience you'll learn to think for yourself and you can trim it down where necessary in following projects
true, and the project it's for will be 3 years minimum and I'll need to reuse parts of this data organization for different purposes, instead of remaking it from stratch
What is the end goal? What will be done with your data?
my company and another company merged. and at the same time, we're replacing both of our ERP systems from on-prem to cloud.
several hundred interfaces are being rewritten to accomodate, and we'll roll out, in phases for a few dozen locations over a year or so
all never stopping production (manufacturing)
So you're not using it for analysis/reporting/ML, you're using it for operational tasks?
for now. it'll transform into analysis and ML later, after this project is over
Like, is the end product of your use case a dashboard or a database people are using it on the shop floor to see where the parts are
the first use case is to load the systems MES systems will the brand new data from the new ERP system.
So is this running in real-time?
no, we're building the system now, so it's batch only. real time is for later if I can convince people that the supply chain needs to be smarter, then it's analytics and ML
So MES needs input from ERP1 and ERP2 so you convert and match the data and supply it it in a format it understands
Correct?
well, ERP1 and ERP2 is being restructured to go into ERP3. my data load is taking ERP1 and 2, MES 1 and 2, WMS 1, 2, 3, and a few spreadsheets, and loading into MES 3. MES3 will also report productionback to ERP3
and it's pulling master data from ERP3
And this happens once per day?
right now, it's once per 4-6 months
but after we start teh first phase of go live, all sets of systems will need to talk to each other, in the way that you hop from a sinking ship to the new ship.
Alright, interesting use case. I understand what you're doing a bit better now
along the way, there will be changes to the source data of all 3 sets, and so need to include that in the next phase of go-live
Bronze - silver - gold should work. Gold is just whatever MES 3 takes as input
Once you're ready to do ML and analytics you can use exactly the same silver as a starting point
🙂 I'm counting on it. at that point, we'll have visibility from earth to store shelf, definitely need analytics and ml
I was in manufacturing for a bit in the past, I like the idea of it
Our data was terrible and to get things done it had needed EU, US and India
then you understand how horrible the source data can be. lol
A lot of the data came from manual input
It was a pointless exercise in my case imho
The brother of the previous CEO made the ERP a decade ago 🤦
lol yeah...
The ERP's "database" was a network drive with xlsx files
With some screens that mapped directly to fields in the xlsx file
that's horrible ...
I hope yours is better 👍
I'm still trying to squash a system that uses a cascading set of excel sheets in power query
they power query each other! lol
A healthy way to look at things like this is: "it's bad, I want to change it. What's in it for the person that owns it and authorizes the change."
Often times I find things that are objectively bad and I can't formulate an answer to the question and I just let it rest then
A lot of this is just dealing with people 😄
true - just curious, is there any money in this kind of work ?
cleaning and moving data around etc. and is it lucrative ?
Are you doing this as a volunteer? It's not your job?
it's my job, I took it on as a challenge and opportunity to learn. but if I switch to this data stuff completely, is it worth it..
Either way, I think all sexy data initiatives only work if the "data engineering" side of things is in place
So it's important at the very least
Is there money in it? Sure
Where I live it's a pretty easy subdomain to get a job in
Do you guys like C? 😃
I haven't used C since I was doing hardware development. long time. but there's a news story about it that might make people move away from C

InfoWorld
Biden administration calls for developers to embrace memory-safe programing languages and move away from those that cause buffer overflows and other memory access vulnerabilities.
I don't know what exactly it means
C/ C++ will always be bae
Nasty C++ code dominates Python code. Not hating on Python
anyone know
isnt rust good with memory
ok I just played with duckdb and parquet and I'm loving it. pandas and sqlite seems outdated now
and the speed... woohoo!
Sqlite is literally perfect
@left tartan you will like
now just add dbt
almost there!
Hey, Bert advice and torch advice dood.
When you add it, try to remember what problem it solves
I read somewhere that I need dbt.core, not dbt.cloud
I don't have generic BERT and torch advice that is broadly applicable to all possible scenarios.
Oh
Your select statements turn into (materialised) views
the medallion architecture I was reading that it's more of a guideline and that I can split each medallion into multiple steps if required
Meaning, you just write transforms and it does everything else
It’s hard
I'm rewriting the bronze/ingestion stage at the moment. I think I can use the duckdb instead of minio
For NoSQL?
You’ll need both
You should look at DuckDB as compute
wiat, you're right. I also need to ingest jsons from api
You still need to store the data somewhere
No. sorry. NoSQL is just so bad
Yes, it’s compute you use to move or transform stuff but you land the files in minio
Or similar
I forget, can I create buckets in buckets with minio ?
Yes
Maybe the name duckDB isn’t intuitive
Because it should be a 1 to 1 replacement for Pandas
And Pandas isn’t a database, look at it from that perspective. Both are compute
I'm focusing on the csv imports at the moment - way easier with duckdb, and errors handling and error reporting - failed lines etc
FYI, their discord is pretty active if you get stuck
thanks for the tip!
I like dbt-DuckDB.... gives me externalized parquet files as a materialization option
woohoo, minio deployed on k3s cluster.
Sqlite is for a very different application
reject pandas embrace polars
I think I'm doing this wrong. for each step, like landing, verified schema, cleaned, etc steps, I'm uploading and downloading files from the minio storage. I know this is wrong and inefficient, but how am I supposed to save and read files from minio without having to upload and download the files for each step ?
!paste
Pasting large amounts of code
If your code is too long to fit in a codeblock in Discord, you can paste your code here:
https://paste.pythondiscord.com/
After pasting your code, save it by clicking the Paste! button in the bottom left, or by pressing CTRL + S. After doing that, you will be navigated to the new paste's page. Copy the URL and post it here so others can see it.
I use something similar to this for my intergrating datasets into my DB. https://paste.pythondiscord.com/IGEQ
To anyone who joins that discord for vermin money and not to stand on the shoulders of giants, are thy looked at in vain if one proceeds to the gates with vermin thoughts in their minds and souls?
Maybe caching can help ?
Should Bert take an unreasonable amount of time to run?
well, I download the entire csv file, which is a few GBs. then I uploade it to minio. then I download csv from minio, then do one simple transform, then upload entire csv to a new file to save the transformations. if the file or data set was in the TBs, this workflow doen'st make sense so I'm doing something wrong...
No, not for hardware you're using at least meets the requirments, but it depends on how tokens are being generated and your input. Theres a lot of factors to that question.
Thanks
Anytime. If I see what you're working with maybe I can help more.
But it sounds like you got it figured out
Yeah, I will get it down. Thank you very much.
Hastebin is a free web-based pastebin service for storing and sharing text and code snippets with anyone. Get started now.
Wondering if I can get a critique on the architecture. I've only run it a little bit - I'm taking a little sidetrack to expand the dataset
The goal is this: every batch of images comes from the same artist. The encoder's job is to learn to build a vector encoding for every style. The classifier's job is to consume the encoding to try to predict which style it encodes - mainly just to "keep the encoder on it's toes," hopefully to produce better encodings and encourage convergence
I'll be using these encodings in a couple of ways - I'll be feeding them as control signals to a U-Net to try to implement style transfer, and as control signals for a small diffusion model in place of a text prompt also as part of a style transfer experiment
Anyway, it's just the encoder and classifier right now. I'm pretty new to machine learning, so any insight y'all might have is welcome
I've got a weird coding style, I know XD But I'm happy with it
It sounds stupid but this is genuinely what people do in this medallion architecture
They call it the separation of compute and storage. Minio and s3 are “dumb” storage, unlike traditional DB servers they don’t have tightly coupled compute.
To move data means to bring it to your compute and then to bring it back to storage. Downloading and uploading.
what is the benefit of doubling your I/O processing time for everyone using the data set ? I guess there is no other way really.
Being able to scale storage and compute independently
ok, I guess I haven't worked on huge datasets yet, gotcha
I despise (cloud) tools that couple them
Want more storage? Move into a tier that also provides expensive compute you don't need at all so you overpay
does the medallion arch break down when the data is larger than waht the computer can store retain in memory. like where chunking isn't helpful either
At that point you can use spark or so
installing spark over kubernetes looks intense...
For your dataset size polars or dbt is perfect
what is your preferred file format when sending to s3 ? I think I made a mistake sending the duckdb over. I'm considering parquet
can anyone recommend a good local model for text summarization of terms and conditions? i have tried bart large cnn and pegasus but i mainly get a short phrase of the original text instead of a more relevant breakdown of the main ideas
Is there a way to return bounding box coordinates using sklearn?
I'm training a person detector model and I want to draw bounding boxes around the person
Here is the code I have right now
https://paste.pythondiscord.com/D3LA
`import numpy as np
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
data = ([[58,236,13.2,21.2],
[48,263,10.0,44.5],
[80,294,8.1,31.0],
[50,190,8.8,19.5],
[91,276,9.0,40.6],
[78,204,7.9,38.7],
[77,110,3.3,11.1],
[72,238,5.9,15.8],
[80,335,15.4,31.9],
[60,211,17.4,25.8],
[83,48,5.3,20.2],
[54,120,2.6,14.2],
[83,249,10.4,24.0],
[65,113,7.2,21.0],
[57,56,2.2,11.3]])
es = []
for i in range(1,15):
model = KMeans(n_clusters=i,max_iter=300)
model.fit(data)
es.append(model.inertia_)
plt.plot(range(1,15),es)
plt.xlabel("n_clusters")
plt.ylabel("elbow")
plt.show()
#with elbow the best numer of cluster is 3
from sklearn.metrics import silhouette_score
sc = []
for i in range (2,15):
model = KMeans(n_clusters=i)
model.fit(data)
sc.append(silhouette_score(data,model.labels_))
plt.plot(range(2,15),sc)
plt.xlabel("n_clusters")
plt.ylabel("silhouette")
plt.show()
#with silhouette the best numer of cluster is 2
why the in silhouette and in elbow , cluster's are not same ?
For neural network do I have to normalize it And denoises and s sharpen the image?
If I have a classifier in an adversrial setup
And I'm using BCE to compute how close it's guess is to the truth
How do I compute the complement/negation/inverse to be used by it's adversary?
Any deep learning champions wanna help a newbie with improving his embedding model?
!starify @zealous brook "one day"
:incoming_envelope: :ok_hand: applied superstar to @zealous brook until <t:1731281818:f> (1 hour).
Superstarified!
Your previous nickname, Small penis, big heart ❤, was so bad that we have decided to change it. Your new nickname will be Darude.
You will be unable to change your nickname until <t:1731281818:f>. If you're confused by this, please read our official nickname policy.
delta
it's a file format that builds over Parquet. The main issue with parquet is that in order to delete a single row you must delete the entire file and create a new one without that row. Delta ... stores the delta(s). Also gives you tons of cool features like schema evolution, time traveling, rollbacks and so on
Meanwhile I am stuck with HIVE and parquet only 😔
Which can also be fine 😄
I've spoken with a lot of people recently that use delta in a way where it buys 0 over just regular parquet
True, for our application Delta isn't actually that useful
Iceberg would be though with the compaction features etc...
However, we use Athena a lot and that seems to just hate Iceberg
Like, at my previous job we put it in a SQL DB. Say it was parquet, each time I ran my data pipeline I did truncate -> insert
My delta log would be 2 entries: truncate and then insert all 🥴
whoa... delta what's the pip install ? delta-spark ?
Q: I have a continuous variables for binary classification, what do you guys think would be a better analysis tool to analyze feature importance relative to the target feature? I've tried correlation matrix, but it doesn't seem intuitive enough to make an analysis out of it.
I'm having a total brain fart
My brain isn't cooperating. I've got a classifier designed to consume an encoding of an image and predict from which (mutually exclusive) class the encoded image belongs to.
What loss function do I use? Then, how do I "invert" or "negate" that loss for use in the encoder? I'm aiming for an adversarial setup.
I'm trying to understand the readings, but it's all explanations of the math when all I really need is to see the code required for the loss functions XD
what is the dataset you're working with? have you made initial analysis of the dataset? And 2ndly have you deduce what preprocessing steps should you take?
and what is the problem You're facing currently? I'm not fully aware
Well when you want to decide what "functions" to use for any machine learning model, usually you should do initial analysis of the data, but for the case of image classification, it really depend on the model, you might just want to look around for answer, even if the answer is depends. you'll just have to take it with a grain of salt and make a list of functions that you'll then input into a pipeline for training and testing, after that you'll rely on the comparative result to determine which function work best for your scenario.
I think one analysis that is still imperative to any SOP of building a ML model is class-label distribution, since you want to see if the dataset is imbalanced, since imbalance dataset does affect the accuracy, think of it like that one question you thought wouldn't be in the test, but in reality it's in the test.
😛 Well, the problem isn't exactly complicated, and I understand the theory. There's a broader context, but in a nutshell I'm training an encoder on batches of images where each batch (of 8) all come from the same artistic style. The encoder's job to build consistent and distinct encodings for each style, and the adversary's job to push the encoder to work harder to do this - and also to prevent the encoder from trending towards the zero vector for all styles
So yeah, a pretty simple setup. The classifier just consumes the embedding from the encoder, passes it through a bunch of connected layers, and spits out a vector.
And I know I can use binary cross entry, or some variation thereof, to measure the classifier's predictions against the ground truth - what I can't figure out is how to invert/negate this loss to train the encoder to better fool the classifier
In a nutshell, as the classifier's loss goes down, the encoder's loss should go up
And vice versa
As for the dataset, I think that's immaterial
And the problem you're facing is?
"what I can't figure out is how to invert/negate this loss to train the encoder to better fool the classifier"
How do I compute the inverse/negation/complement of binary cross entropy? ChatGTP is no help, and neither has been google
But I'll reiterate, my brain is kinda filled with fog today
Put a bit more correctly - what is the standard/appropriate way to compute the losses for both the generator and the adversary based on the adversaries predictions
Do I just negate the classifier's loss? Or do I somehow compute it's complement?
Hmm still looking into it hold on
Whenever I google it, I'm only ever met with the theory and the math. I just need to know which functions to invoke XD
Wait have you not seen this?
There's also this article
https://link.springer.com/article/10.1007/s10462-024-10897-x
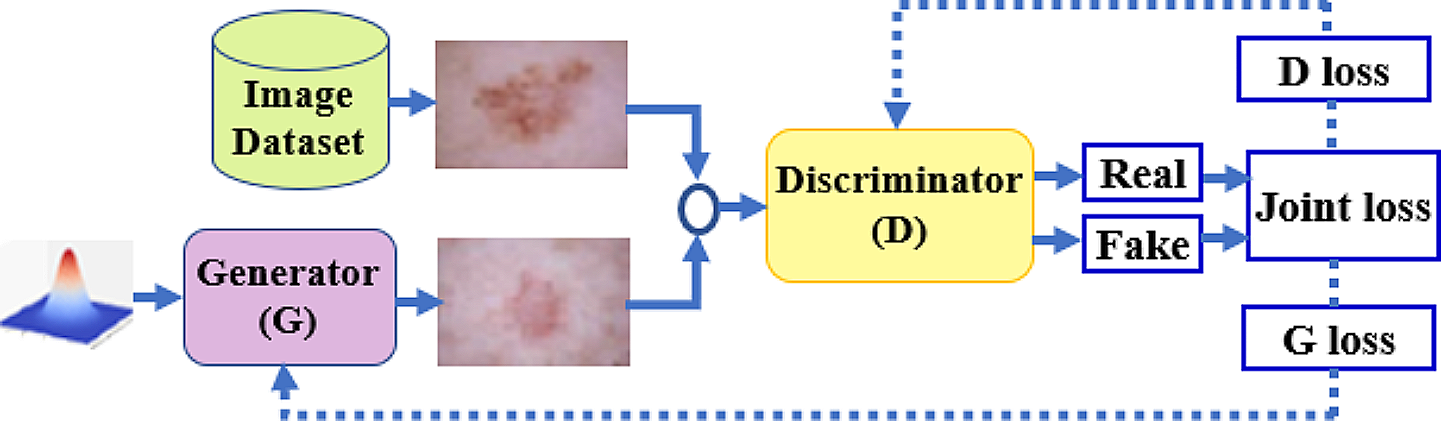
SpringerLink
Artificial Intelligence Review - Dermatology is the most appropriate field to utilize pattern recognition-based automated techniques for objective, accurate, and rapid diagnosis because diagnosis...
I think that is not the right one, I just search up "adversarial", which might be confused with GAN
Polars and duckdb can read and write to delta. On top of that you can use this as well if you want:
well anyone can teach me how to create an Ai
as Data Scientist or Machine Learning Engineer?
Hmm student?
Computer Science Student?
Nope
If so then it's Data Science, but if you're self-taught for industry related job then ML Engineer
Well
let me ask it like this, What motivation do you have to learn AI? @spiral plume
Im just a beginner u can say
Well so it can help me a lot of things
If you want to land a job in "hot-topic"/"all-the-buzz" of the current century, go for ML Engineer. but If you want to be a part of scientific community then Data Science.
No no i want it for myself not as job
Ahh ok
well sorry for wasting ur time
Regardless, I think it's best to start learning through experience, you might want to get involved with the community on Kaggle, there's a lot like-minded people
I'm also part of it
Ohh i see
Well i think i will start by creating simple one
I can create simple chatbot
But that's not ai
Ohh I see
well thanks for the help
Since you're specific on the type of AI you want to learn, then the magic keyword for you is Natural Language Processing, Large Language Model, Text Pre/processing.
Hmm did miss anything else?
yea ik about then
Oh yeah also if you want to jump in asap you might also want to look into HuggingFace community
Ohh yea still tensorflow and pytorch too
I think i need to learn a lot
what road map should i follow to be a good data science enthusiast? ve seen on a lot of places as well as its confusing.
i know i shouldnt ask to ask for help but are images allowed in here? i want to send a screenshot from scikit-learn website followed by my question
images are allowed in this channel, but if the image is of text, it's easier for people if you copy and paste the actual text directly.
alright thank you.
i want to learn scikit-learn by reading the docs, following YouTube is ok but sometimes it just doesn't come with the right juice.
so this is the pattern i saw at the scikit learn website
Release Highlights
Biclustering
Calibration
Classification
Clustering
Covariance estimation
Cross decomposition
Dataset examples
Decision Trees
Decomposition
Developing Estimators
Ensemble methods
Examples based on real world datasets
Feature Selection
Gaussian Mixture Models
Gaussian Process for Machine Learning
Generalized Linear Models
Inspection
Kernel Approximation
Manifold learning
Miscellaneous
Missing Value Imputation
Model Selection
Multiclass methods
Multioutput methods
Nearest Neighbors
Neural Networks
Pipelines and composite estimators
Preprocessing
Semi Supervised Classification
Support Vector Machines
Tutorial exercises
Working with text documents
is the a proper start to intermediate or advance way?
Don't try to "learn scikit-learn".
Focus on learning data science concepts, and use whatever tools from whichever libraries you need to apply that concept.
Your replies are always on point. Thank you.
I recommend downloading a tabular dataset and doing some basic manipulations with it (this will involve a small subset of pandas), and then training a classifier on that dataset (this will involve a small subset of sklearn).
how do i start with this?
with what?
Can anyone help me in a 2d floor plan generator project
I am going through this github repo https://github.com/LengSicong/Tell2Design?tab=readme-ov-file
GitHub
[ACL2023 Area Chair Award] Official repo for the paper "Tell2Design: A Dataset for Language-Guided Floor Plan Generation". - LengSicong/Tell2Design
All of these require a graduate lvl understanding of mathematics. If you are at that lvl, then yes
not even close? an undergrad statistics course would cover most of the stat you need, and up to calc 3 will cover almost everything else
to use sklearn, I think it's less about knowing the math and more about knowing the data science concepts (which includes math). sklearn has tools to help you do k-fold CV, but it doesn't do anything to help you learn why you should want to do that.
okay, I guess it sort of does https://scikit-learn.org/dev/modules/cross_validation.html
scikit-learn
Learning the parameters of a prediction function and testing it on the same data is a methodological mistake: a model that would just repeat the labels of the samples that it has just seen would ha...
but the arrangement of the user guide is still by feature set, not anything that's pedagogically intentional.
right. it's designed for people that already know what they want to use. they have explainers, but the docs for each model are telling you the syntax, not how they work
how do i start with data science and ai
whats the starter pack i need for ai
pip install numpy and pandas.
The docs actually tell you how the models work. You can learn a lot of (tabular) data science by reading them and the papers they link to
That's how I did it at least 🙂
i mean like this page: https://scikit-learn.org/1.5/modules/generated/sklearn.svm.SVC.html. you won't be able to understand what they're talking about without reading more into it. though they do link to a lot of explainers, which is nice
It's the user guide
scikit-learn
Support vector machines (SVMs) are a set of supervised learning methods used for classification, regression and outliers detection. The advantages of support vector machines are: Effective in high ...
That's where it's at 😄
yeah
E.g., here they go over the math briefly https://scikit-learn.org/1.5/modules/svm.html#mathematical-formulation
Hi, I'm a sixth form (high school) student who needs some help with starting a facial recognition programme
i recommend checking docs reading them
So, reading the user guide front-to-back for those that have (too much) time is actually great
you can get a basic from of how to do it
The plan is to basically use tensorflow, keras and opencv to make a simple log in system
ⓘ This user is suspended for being a part of an terroristic organization. Report any illegal activity to https://support.discord/
ⓘ This user is suspended for being a part of an terroristic organization. Report any illegal activity to https://support.discord/
!ban 1283907958597619765 Persistent spam.
:incoming_envelope: :ok_hand: applied ban to @warm flint permanently.
Geez, thats not something you see everyday. Terroristic organization?
I could use some input on this. Not a code review, except maybe the PyTorch specific parts since I'm still learning, but rather a review of the architecture
Hastebin is a free web-based pastebin service for storing and sharing text and code snippets with anyone. Get started now.
The goal is this: Feed the encoder batches of images all from the same style, and attempt to force it to generate the same encoding for each image. Feed those to the classifier which will try to predict which style is being encoded - this is to force the encoder to work harder, and to keep it from generating the same vector for every style
Specifically, I'm not sure if I've done the cloning and detaching correctly
Beyond that, I was thinking of adding a variational component to the loss, for the encoder at least, since a smooth embedding space seem natural to me for encoding style
Sure if you don't care how they work then you can write the same spaghetti code that every other comp sci kid writes. If you want to know how to write stuff correctly the you need to learn the math. Half those topics are not "just linear algebra" and more importantly the ones that are linear algebra are far beyond what is covered in an undergrad linear course
i didn't mention linear algebra. what graduate level math is required for, say, decision trees?
MDP's? this would include stochastic processes, discrete control system theory, etc
once again that list of topics was very good, just needs a graduate lvl understanding of mathematics if you actually want to learn and write code that isnt just a copy and paste of some openAI environment or filling in parameters on scikitlearn function calls
which si not writing machine learning
I want to progress/ make a LLM Inferencer, does anyone have any resources that I could use to make an LLM inference. Or any guides that could teach me about how LLMs work behind the scene.
A powerful and user-friendly AutoML application built with Streamlit and H2O.ai. It allows users to easily upload datasets, train machine learning models, and make predictions, all through an intuitive web interface.https://github.com/SanshruthR/AquaLearn

GitHub
Upload CSV data, get predictions and save models. Contribute to SanshruthR/AquaLearn development by creating an account on GitHub.
thank you, will do
will steady youtube help?
Hi guys, how can I tell my shareholders that the POC and MVP stages are relatively close in scope? I’m pitching some DL solution that will realistically need about 4-6 months for development, plus an additional 1-4 weeks to encapsulate it in a basic UI. Thanks
hey, will this do?
"
good day everyone, the proof of concept and minimum viable product stages for this project are actually similar in scope. the poc will illustrate the core functionality of the solution and the mvp will acually build on that and add a simple user interface. these stages focus on confirming the key features and the timeline for this project development will be within 4-6 month and also an additional 1-4 weeks to finish it up in a simple ui. there will be lots of testing, feedback getting all while we stay on track.
"
Hey, thanks for the reply and effort for putting it! Might have caused a bit of confusion in my question. Rather than just focusing on phrasing, I want to know from ML standpoint how to help them to get into perspective—that the POC phase typically requires much mroe workload than other phases in SE
Ah, lol, I see. Well, sorry, I’m still picking up the pieces of ML/DL. I hope you find what you’re looking for.🙂
No worries, good luck!
hi people
Getting to the point of a working proof-of-concept is more of a research project than a software development project. That's why it takes so long.
Machine learning isn't just a matter of writing down code. It tends to be hard to tell if something will work until you try it, even if it seems like it should work based on literature, prior experience, and domain knowledge. This is even more true in deep learning specifically, where the models can take a long time to train, so there is a relatively long feedback loop, and there is a large number of small design decisions that might or might not be consequential depending on the task.
Moreover, gathering and cleaning input data tends to be a slow, tedious, labor-intensive process. And sometimes even the way that we put the input data together can affect the deep learning model itself. So the R&D iteration loop potentially covers a large portion of the pipeline.
TLDR: ML/DL is heavy on the "R" in "R&D", and that means each attempt has some uncertainty in it. Moreover, each attempt can also take a while to see if it works. The result is that a working PoC can take a long time to put together, but from there it's relatively easy to build a simple product around it.
For my current employer this is actually quite different. We only do a handful of things and we’ve done them so many times it shifts closer to the D of R&D than the R
It’s less sexy but there’s a lot of merit in that approach
How do I organize a data set?
Very well said. You just made my life way easier. Thank you so much for this
Yeah, I think that's true for a lot of established data teams, within a particular business domain, but it sounds like this is a greenfield deep learning project
Would anyone mind helping me write some code for a neural network for facial recognition using tensorflow and opencv?
It's for a school project which contributes to my final grade and I basically don't know how to set one up
My plan was to use a mobilenetv2 model which has been pre-trained to detect faces and I basically have to train it correctly extract features and recognise individuals
Any help at all would be greatly appreciated
Hello, what have you done so far?
Not much tbh, I've struggled to understand how to piece things together
For now though I have managed to code this:

Please only show code as text
!code
that's the link for the whole paste bin. not your paste.
Yh, sorry, I fixed it now
I've sorted all of my images into a test and validation folder using a script I found online
Lmk if you have any suggestions

do you have a question?
i mean math is hard to learn like this and i obviously dont recommend it but if this is your only avenue, and you are willing to be super critical of where u r as you learn, then yes it is possible