#data-science-and-ml
1 messages · Page 140 of 1
but when i try any X beyond 12, things get really weird.
am i doing something very wrong, that the most simple third degree polynomial is not being correctly found using regression?
may simply not have enough data points ?
wikipedia says that you may have issues is your dataset is too small
but the perfect fit is weird ngl
the testing im doing is this:
did you look at the extracted coeffs ?
model = Model("data/perfect_fit_heat_capacity.csv", "data/perfect_fit_resistivity.csv")
trained_x_test = PolynomialFeatures(degree=3, include_bias=False).fit_transform([[1],[2],[3],[4],[5]])
trained_y_test = [1, 8, 27, 64, 125]
assert model.heatCapacityModel.score(trained_x_test, trained_y_test) == 1
untrained_x_test = PolynomialFeatures(degree=3, include_bias=False).fit_transform([[0], [13],[1000]])
untrained_y_test = [0, 2197, 100000]
assert model.heatCapacityModel.score(untrained_x_test, untrained_y_test) == 1
the first assert succeeds
the second assert fails comically, with the first x mapping to like -1million y
havent done polynomial regression before, but might be worth a try
these are the coefs:
material_test.py .Coef: [ 5.26907445e-14 -4.39378140e-15 1.00000000e+00]
seems like overfitting again
try bumping up to 150 samples or so
overfitting it is
unfortunately, i only have like 20 samples
but i know that im mapping a third degree polynomial
hmmm
my samples are based on some published material science articles
and they only have like 20 data points
try going oldschool if you are absolutly sure that it is in fact a cubic
https://math.stackexchange.com/questions/2655178/finding-the-equation-of-a-cubic-when-given-4-points

Mathematics Stack Exchange
I am asked to find the equation of a cubic function that passes through the origin. It also passes through the points $(1, 3), (2, 6),$ and $(-1, 10)$.
I have walked through many answers for simi...
ok im not like positive it will always be
the function is the heat specifity of a metal wrt temperature
ah
and for one specific metal it is
lemme try plotting your coeffs
but i dont think it is for all metals
your code has gone awry somewhere

wait, shouldn't your cubic have one more coeff ?
material_test.py .coef: [ 5.26907445e-14 -4.39378140e-15 1.00000000e+00]
how tf is this giving a 1.0 fit for [[1],[2],[3],[4],[5]]
im just doing: print("coef: ", model.heatCapacityModel.coef_)
oh wait lol a score of 1.0 is the worst possible
a score of 0.0 is the best
sorry im pretty new to python data science. ok well i fucked up this very simple linear regression
lol, its fine
I'm banging my head against trasformers myself
give it a few more tries !
none of us are born clever : D
hrm, python is doing something weird when converting my y values to floats
this is my csv:
temp,specifity
1,1
2,8
3,27
4,64
5,125
6,216
7,343
8,512
9,729
10,1000
11,1331
12,1728
im just printing out the parsed values from the results of genfromtxt:
temps: [ 1 2 3 4 5 6 7 8 9 10 11 12]
specificity: [1.000e+00 8.000e+00 2.700e+01 6.400e+01 1.250e+02 2.160e+02 3.430e+02
5.120e+02 7.290e+02 1.000e+03 1.331e+03 1.728e+03]
looks right to me ?
also, why floats ?
because actual metal heat capacity is reported as floats in kelvin
consider just multiplying your inital data by 1k or so to get inits
called a kernel trick iirc
you can just divide your predicted values by 1k too to get the right values
floats can be painful to debug with their inaccuracy
ok ill try it. but yeah the input vectors to my polynomial regression look right

ok wtf
this is the perfect fit

#use model to make predictions on response variable
y_predicted = poly_reg_model.predict(poly_features)
#create scatterplot of x vs. y
plt.scatter(temps, heatCapacity)
#add line to show fitted polynomial regression model
plt.plot(temps, y_predicted, color='purple')
plt.show()
seems like best lol
but this doesnt look at all like the graph you plotted
got absolutely no clue ¯_(ツ)_/¯
print(poly_reg_model.intercept_, poly_reg_model.coef_)
1.7053025658242404e-13 [-4.84333615e-14 1.28108132e-16 1.00000000e+00]
that wasnt what you sent before either
im bouta lose my mind lmao
alright well thanks for helping rubber duck, if i get this working ill come back
plot a few more out of dostribution man
ah good idea
ye !
stares into my unchanging f1 scores
like wtf
this is from a total of ~25 epoaches or so (restarted from checkpoints a few times)
oversampling time ig


Looking at doc's for instructor. But can't find a way to use custom model or hosting API. Is it possible?
https://python.useinstructor.com/

A lightweight library for structured outputs with LLMs.

A lightweight library for structured outputs with LLMs.
idk if it supports passing a custom client, but some of the clients it supports allow for you to use a custom hosting API (like how that example uses OpenAI's library for interacting with a model hosted under localhost)
Thanks yeah. Where I work they use their own wrapper for openai API. Which complicates things. Can't use lang chain, instructor without customizing it ...
anyone here familiar with the RK45 api in scipy?
what is the shape of this curve called? and what type of sklearn regression model best fits it?

ive tried linear polynomials of various degrees and none fit it very well
looks kinda sigmoid to me? or maybe log
worth noting, this is unrelated to any coursework, im a 32 year old trying to relearn practical diffeq
Just curious has anyone seen documentation on forward/back buttons in plotly animations opposed to pause and play?
Or has anyone implemented it
Just curious I may post a thread on this later or if i succeed on implementation I'll share
you can try applying a non-linear transformation before trying to fit a linear model to it
isnt that what i did by performing a linear regression with varying polynomial degrees?
oh wait youre saying map the values in the scatter plot to logs of themselves, then regress on that?
im dumb, if the x axis is multiples of e^-7 the x axis is not logarithmic right. so this relationship is actually linear?

Yes, that'd be linear... same as: y = (1e-7)ax+b
Perhaps its labeled wrong?
nah
i probs made a mistake with my runge kutta formulation or something
i hate math
@fallow plume are you familiar with matplotlib? in particular 3d plots?
a little y?
magnet = Magnet(material, validated_config)
accumulator = []
for current in validated_config.current_densities_to_plot_A_per_m2:
(times, temps) = magnet.computeTemperatureEvolution(current)
accumulator.append([[current]*len(times), times, temps])
this results in an accumulator with N entries
where the entries represent time vs temperature time series data of my model of a metal at different currents
they are definitely not the same length
i cant figure out what matplotlib plot to use
nah doesnt work
Man, I've been using pandas for a couple weeks, still cant figure out some basic stuff....
Pandas works pretty differently from the rest of python. Avoid loops and the apply method, and keep a tab open for the docs. Eventually you'll get it.
Things like...
I've got a super-big dataset, and I want to just update "things that match whatever" with a lambda.
I can use
df = df.loc[whatever, 'colname'] = df[whatever].apply(mylambda, axis=1)
But can't see how to chain something like that...
If you use apply, you're not reading the docs to figure out how you're "supposed" to do it
Apply is only there as a fallback if there's no way to do it with existing methods.
who need free recaptcha slover api key
So have a nice
result_df = (
something
.groupby(..).agg(...)
.rename()
.whatever()
)
# then
result_df= # like above
There are also cases where you just can't chain whatever you're trying to do
I couldn't figure how to chain "update some of the rows with a lambda"
because df is pretty large, and running the lambda for every one is super slow.
Right, because you're only supposed to use lambdas as a last resort.
Always assume that there's a solution that doesn't involve loops or apply (including lambdas), and only give in to using either when you're sure the docs don't have a solution.
How else to do:
if record.type == 'something' then record.id = f'xxxx{record.a} : yyyy{record.b} : zzzz{record.c}'
I have no loops. And try and use ... uh the arrayish things when I can
The replace method might help, but I can't do a deep dive right now
is this considered ok?
df.loc[df.SOMETHING.str.startswith('xxx-'), 'status'] = 'this is an xxx'
Yes, though I don't recommend ever looking up columns with the dot operator
it's the same as df['SOMETHING']
Right. I recommend you always do that and never use the dot operator.
hmmmm.
It's an unholy mixing of namespacing that pandas shouldn't support.
Is there any way to chain a "select and update" .loc like that?
Not that immediately comes to mind
ok thanks
Could you parameterize it with a loop?
Note that it wouldn't be a loop over the dataframe, which is what you want to avoid
# not parameterized
thing['a'] = b + c
thing['d'] = e + f
thing['g'] = h + i
# parameterized
for letter, x, y in [
('a', b, c),
('d', e, f),
('g', h, i),
]:
thing[letter] = x + y
so you only have df.loc[df['col'].str.startswith('xxx-'), 'status'] = 'this is an xxx' once, but with loop variables for all the parts that change.
anyway, I'm going to log off now
good luck
thanks 🙂
Any recommendations on a good book for learning pandas? Or is the website the best?
The kaggle pandas tutorial
the official User Guide is very good imo
Geeksforgeeks or their official docs
Note that if you spam, you will get moderated
Yeah I am not spamming I want to talk about a problem im facing with azure functions
I'm sorry if that's spam
Hi there, I have a question around date / time data for ML training. If this is something that might interest you / know the answer to, here is a link to my help post 🙂
https://discord.com/channels/267624335836053506/1271445530307727446
Does anyone have any good resource to understand SVM time series? and how to use it
if youre using python to perform numerical analysis of very large decimal numbers, what operators do you use for things like exponeniation, and what primitives do you use to represent the numbers?
probably just the decimal lib

Python documentation
Source code: Lib/decimal.py The decimal module provides support for fast correctly rounded decimal floating-point arithmetic. It offers several advantages over the float datatype: Decimal “is based...
yeah, if you need of perfect accuracy decimal ; if you need of speed and don't mind trading off accuracy you could use numpy's int64 or float64
 seems like
seems like polars supports Decimals, might be faster without trading off precision, but doesn't supports pow (it does supports * so you can do pl.col("X") * pl.col("X") for ** 2 and alike, but if you try to .sqrt() for example it just casts to float64)
edit; disclaimer: still considered "unstable" and there are some nasty sounding issues related to Decimals open in their github
past a certain point you'd wanna consider using sage or mathematica
Hi, I want to do Machine learning to get started. Can anyone suggest me any?
You can use sympy: https://docs.sympy.org/latest/modules/evalf.html
There is also gmpy2, which is faster.

Learn how to install and deploy LLaMA 3 into production with this step-by-step guide. From hardware requirements to deployment and scaling, we cover everything you need to know for a smooth implementation.
20GB of VRAM required ..
that's relatively low for post-ChatGPT LLMs.
the highest-performing models require the highest-end hardware.
what is 50 tokens generated in 1 second?
each token is similiar to word ( according to inference )
so 50 words in 1 sec?
Gemma 2 has a 2B parameters model
that article is from before Llama 3 405B and Gemma 2 models were released I think?
Gemma have 7B _I think _
Huh 27B since when
yeah, it was suggested by reddit post! for 7B model
Yup I saw it, interesting
Realistically, what's the difference between Gemini and Gemma
Except the size of the model itself of course
Is the architecture similar, I wonder
people used to hate gemini so they release gemma to distract!😂
I mean, Gemini is proprietary and Gemma is open source (ish?)
"token" is basically MLspeak for "word". a token is the primary unit of language that models deal with.
should be extremely similar if not the same, perhaps excluding multi-modal changes though
Isn't technically, a token is part of a word?
Like wordpices
yeah sort of !
a token size could be anywhere from a single letter to an entire sentence, and there are some special tokens that don't correspond to text but rather special instructions
most of the time it should be part of a word though
"wordpiece" is another ML term that isn't from linguistics. but a wordpiece is smaller than a token.
the reason "token" and "word" are separate is that "words" are a linguistic concept, and token boundaries for ML purposes might not be what linguistics consider to be word boundaries.
from single letter to whole sentence (combinations of letters) then how can we define token size?
Oh, I see, is the definition of a token manually defined by human?
No I mean Google's WordPices tokenizer
It separates some word into parts from what I know
I know what wordpieces are. that's what I'm talking about.
Sorry then, I misunderstood, but don't wordpices turn sentences into tokens, each token can be a word, but it can also be part of a word?
and this is how we invent recurssion! lol
iirc most models are trained on a vocabulary created by another program - I forgot the details about how that's generated but Stel should know?
You can manually define/overwrite some tokens though, that's somewhat frequently used for fine tuning (e.g. fine tuning Stable Diffusion to recognize a person, or a LLM to perform a new task)
Oh I see
no, the wordpiece tokenizer turns a string into a sequence of wordpieces.
Sorry I might've mixed it up with sentence piece, is it also like wordpices?
wordpieces are basically "subtokens".
note that "wordpiece" and "wordpiece tokenizer" are separate things.
Thanks for the explanation, but I am still a bit confused
I'll have some more look into it

Doesn't wordpices break sentences down to smaller part
Then the word get tokenized or something?
Is this correct?
it sounds like you think "a wordpiece" is a thing that does something
a "wordpiece tokenizer" is a thing that does something.
"wordpiece tokenization" is the process of splitting a unit of text (such as a word or sentence) into wordpieces.
Oh, I see what you meant
wordpieces and tokens are both units of text; wordpieces are smaller than tokens.
May I ask why wordpices are smaller than token?
that's just how wordpiece is defined. originally, "token" referred to the smallest units of text used in ML.
Oh
I thought number of token was the size of the input to the algorithm?
Is that an incorrect assumption?
If tokenizer turn test->1 try>2 ing->3 then testing would be 1,3 so 2 token, this is my understanding is it correct?
depends on the model and what you are doing. neural networks are inherently numeric, so the input to a network is often an array/tensor of integers, where each integer represents a token from the input
or it might be that the integer represents a subtoken from the input.
Oh, I automatically assume each float/integer in a array is a token, but they can also be a sub token?
Sorry for the stupid question
Thanks for having the patience to answer said question
They could be sub tokens.
It depends on the model architecture
I see, thanks!
Generally speaking, tokens correspond to "words" in pure linguistics, and sub tokens/word pieces correspond to morphemes. https://en.m.wikipedia.org/wiki/Morpheme
A morpheme is the smallest meaningful constituent of a linguistic expression. The field of linguistic study dedicated to morphemes is called morphology.
In English, morphemes are often but not necessarily words. Morphemes that stand alone are considered roots (such as the morpheme cat); other morphemes, called affixes, are found only in combinat...
Oh I see
So to check my understanding: a word is a token, wordpices which is part of a word is subtoken
Is that correct?
So word pieces tokenizer break word such as "unbreakable" into un, break, able
Each of them is a subtoken?
Yes!
Is that correct? Thanks!
Thanks!
yeah nice
Thanks for explaining this to me! And thanks for the tolerating stupid question!
so you put that model onto your website right?
that chatbot which tells about you?
yeah but it needs whole GPU clusters
then what is your monthly cost?
how? only ec2 is free right?
which one are you using?
1 year for free tier right?
so it is not completely free>
okay so that means I can play with llama on free tier? for completely free no additional plugins stuff require?
uhh ohh
heh, why total is 0.00?
100 dollars? for credit
okay
Hey guys I got a question:
Before choosing the model, you have to prepare the data. How do you select columns are important for the model?
I have like 79 columns
that's kinda the hardest task, you have to explore and there is no general answer, you can for example drop column that have too much missing values, low variance (and it's obvious if the column have the same value every time) , maybe sometime the column have low data quality, then there is stats, you look associations between you target and the columns with stats, correlations, anova... depends,
sometimes theres is more practical aspects like how easy is it to have this variable or "does it makes sense to make a model with this variable"
some test: correlation,anova, chi2
also make some visuals
some associations might be non linear and you have to do log transform to a variable etc... the tools goes on
pca
best way is domain knowledge, but this is also the hardest obv
take ideas from stats as mentioned by gabigabgob, e.g. mutual information, (k)pca
use other models to assist, e.g. lasso, trees
Pca is a tool?
is RNN foundation for LLM?
I mean do I need to care about gru, lstm before transformers etc?
my focus is on nlp and text
no, but it was a predecessor to transformers in the field of nlp
I mean, wouldn't be a bad thing to know about them anyway
Guys i am getting an error while using transfer learning
Only instances of `keras.Layer` can be added to a Sequential model. Received: <tensorflow_hub.keras_layer.KerasLayer object at 0x00000280F44756D0> (of type <class 'tensorflow_hub.keras_layer.KerasLayer'>)
encoder = OneHotEncoder(sparse_output=False)
one_hot_encoding = encoder.fit_transform(data[['Old/New']])
encoded = pd.DataFrame(one_hot_encoding, columns=encoder.get_feature_names_out(['Old/New']))
combined_encoded = pd.concat([data.drop(['Property', 'Type', 'Old/New'], axis=1), encoded_df, encoded_df_two, encoded], axis=1) # Combine with the original data, dropping the original 'Property' & 'Type' column
#Table visualization
#pd.set_option('display.max_rows', 40)
pd.set_option('display.max_columns', None)
pd.set_option('display.max_colwidth', None)
#sorted_data = data.sort_values(by=['Revenue'], ascending=True)
print(combined_encoded)```
why is it returned in float instead of interger?

GitHub
Issue type Bug Have you reproduced the bug with TensorFlow Nightly? No Source source TensorFlow version v2.15.0-rc1-8-g6887368d6d4 2.15.0 Custom code No OS platform and distribution Kaggle Mobile d...
ho
also does the fact that its returned in float instead of interger, does it would efct the model prediction performance?
ok I read it I need lstm and/or transformers for llm
so its base
ok I now read your response, ok so good to know
guys, can anyone suggest me a tutorial or book or a doc related to machine learning. it should cover the basic ML, THE problem is that IDK high school maths cause i am only 13. idk calculus and other maths stuff, I am just learning. so please suggest.
start by coding, then move to simple frameworks like fast ai @lyric furnace
then you'll already have an idea if you wanna do the math part.
learn the language you wan to learn first while learn linear algebra
to do ML youre dealing with data you hv to do data cleansing which involving data manipulation
pandas ?
understand how the system execute the code
ive learn that a bit
@proper crag sorry but I am a beginner IDK much about the programming world
tbh , at 1st im like you didn know where to go but just learn python as much as you can
while learn the math
thx bro
i've learned a bit in khan acardemy
[[1,1,0]
[0,1,0]]
Ive remeber somethign like above
Keep learning Python, keep learning math, both of those will serve you well
since you're here...i wan to ask something
ahh'
@final kiln

i ve encoded them
but why its in float?...does wether its in float or interger would efect the model performance ? @final kiln
it can do both
@final kiln Thx alot bro, you helped me alot, thx !!!
encoder = OneHotEncoder(sparse_output=False)
one_hot_encoding = encoder.fit_transform(data[['Old/New']])
encoded = pd.DataFrame(one_hot_encoding, columns=encoder.get_feature_names_out(['Old/New']))
combined_encoded = pd.concat([data.drop(['Property', 'Type', 'Old/New'], axis=1), encoded_df, encoded_df_two, encoded], axis=1) # Combine with the original data, dropping the original 'Property' & 'Type' column
#Table visualization
#pd.set_option('display.max_rows', 40)
pd.set_option('display.max_columns', None)
pd.set_option('display.max_colwidth', None)
#sorted_data = data.sort_values(by=['Revenue'], ascending=True)
print(combined_encoded)``` this is the code[1,2][2,3] => [1,3]
[2,3][3,1] => [2,1]
im using SK Learn
in finite dimensions at least
Old/New....i've encoded them and its give the result in float
in infinite dims, the operation of taking the dual is not an involution
so it's not enough to just say something like "i'll just treat the dual space as a vector space and let the original vector space be its dual"
Also it's cool to use a tree model with relatively low depth and visualize the decisions and check the used variables
in linear algebra
wow ray tune seems powerful
what make almost feel stuggl is scalar
i mean like how to satsify vextor x from the given 2 vectors
and diffenrental calculus
it's quite neat that kaggle gives you 2 gpus
Hello, everyone, this is my project, it allows you to easily train agents.

GitHub
Machine learning library, Distributed training, Deep learning, Reinforcement learning, Models, TensorFlow, PyTorch - NoteDance/Note
Is there any reason why pytorch is more popular than tensorflow/keras?
It looks like keras is easier to use
||Any why is JAX not that used? It's suppose to preform better than both of those 3? Right?||
I see, but it looks like keras abstract away the training loop with fit too, so even less code needed?
It might be, that makes sense
I know
Fair enough
Intresting
pred = model(X)
loss = loss_fn(pred, y)
# Backpropagation
loss.backward()
optimizer.step()
optimizer.zero_grad()
I don't understand, loss.backward calculate the gradient, but how do optimizer.step updates the parameter of the model?
I've only tried jax before, and it's functional, so this is weird
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=1e-3)
Right, python is pass by reference, forgot that for a second
keras still allows custom loops
Oh I see
I see, I was expecting something like w = w - learning_rate * w_grad, but it seemes like pytorch don't do reassignment(?) often
i think the main reason why torch is more popular is that it's easier to run
i.e has more hardware support, and less bugs of that sort
not bc of the api
That makes more sense, the API is really similar
you can see people stuck installing tf for months
Yeah I've seen them in help channel
I understand, but I was surprised at the fact that in pytorch when you use optimized.step() it automatically updated the parameters
I thought it'll return a new parameter, then I'll update my model with the new parameters
Either way, if it works it works
in tf weights are variables, and they can be mutated
Understandable, there's many layer with lots of neuron
That's the formular for regression
I was expecting something similar
I suppose you can create your own class for optimizer? (Not that I can do that)
i meant the weights themselves
but yeah you can create or just extend it rather, since it's a large pile of inherited stuff
Thanks everyone @final kiln @lapis sequoia (apologies for pinging)
I guess I'll play with pytorch (and Jax) and see
some of the current rationale is to map after batch i think this makes it faster, im unsure whether prefetch/cache order matters here.
one tricky thing with training using iterators is that you may run out of data, so sometimes it requires .repeat(n)
how do you handle outlier?
data_quantile_1 = data['Revenue'].quantile(0.75) #31050500.0
data_quantile2 = data['Revenue'].quantile(0.25) #9021375
data_min = data['Revenue'].min() #2336000
data_max = data['Revenue'].max() #100083000```the comment is the output of the method
like you all see, its have outlier
would it be better to just use matplotlib or should i use it in combination with seaborn for ease of mind? Ive used matplotlib by itself and it pissed me off
I prefer plotly. I think it's a matter of preference
isnt matplotlib, from what ive read up, more extensive compared to other modules of its type?
Ill probably move onto other sorts of graphing modules but for now, I want to stick with whats most commonly used and has the most features
They are both widely used
what i supposed to do ?
i wan to implemet the data for Logistic Regression
Matplotlib is mainly better for scientific graphic and simple/sober graphics, with plotly its easier to do sexier graphics
Is that the target?
i have encoded all the object type ..okay im actual beigner ..i didn know anything regrding feature engineering
It's easier to see what's going on with a boxplot tbh
okay what is this target you're talking about?
pls bare with me
im complete beginer in ML
however, ihave all the object type/string data encoded

Em, if you want to do a ML model that means you want to determine a target variable with other variables, is revenue what you want to determine
(might be a good idea to read about basics)
so i heard about feature engineering and like outlier could efct the model performance
so, what i need to do regarding that step
then i would read anything i need just right this process which i need to get through bfore start to code my model
I think you have check for really the 101 of ML on really easy data, you should know what is the target and what the "explicative column" means, I think that would be a slightly better start
bcuz the data have outlier
im using logistic regression model is bcuz i wan to predict the pattern which then i could classify what might could be the peoples factors influencing market competitiveness and consumer interest using
yeah, its the target...the revenue have outlier and is the target since i can undesrtand the revenue column as the output of the input ...thats what tartget mean right?
class CNN(eqx.Module):
layers: list
def __init__(self, key):
key1, key2, key3, key4 = jax.random.split(key, 4)
# Standard CNN setup: convolutional layer, followed by flattening,
# with a small MLP on top.
self.layers = [
eqx.nn.Conv2d(1, 3, kernel_size=4, key=key1),
eqx.nn.MaxPool2d(kernel_size=2),
jax.nn.relu,
jnp.ravel,
eqx.nn.Linear(1728, 512, key=key2),
jax.nn.sigmoid,
eqx.nn.Linear(512, 64, key=key3),
jax.nn.relu,
eqx.nn.Linear(64, 10, key=key4),
jax.nn.log_softmax,
]
def __call__(self, x: Float[Array, "1 28 28"]) -> Float[Array, "10"]:
for layer in self.layers:
x = layer(x)
return x
Do anyone know why it's eqx.nn.Linear(1728, 512, key=key2), 512 is more or less abitory, but do anyone know how they figure out the size of the activation when it's ravel(ed)? (where do 1728 come from?)
hey whats a good book for math for data science
quick i need to order
with explanations and stuff
nd solved examples
may i ask a question?
-
The book by Ian Goodfellow
https://www.deeplearningbook.org/ -
Statistical Learning
https://www.statlearning.com/ -
Mathematics for ML book
Mathematics for Machine Learning
https://mml-book.github.io
- Check pinned post for more
An Introduction to Statistical Learning
Mathematics for Machine Learning
Companion webpage to the book “Mathematics for Machine Learning”. Copyright 2020 by Marc Peter Deisenroth, A. Aldo Faisal, and Cheng Soon Ong. Published by Cambridge University Press.
thankyou
It's gotten from the image you're working with.
To build intuition, imagine you're working with a grayscale image with 14 x 14 pixels (14x14-dimensional image. That is, you have a matrix of pixels with the shape 14 rows by 14 columns )
Now, when we shrink (flatten) this image (matrix of pixels) to a row vector, you'll get a 196-dimensional row vector (14 x 14 pixels = 196 pixels)
This is what they calculated on the image you're working with to arrive at 1728, which was then passed to the 1st hidden layer.
The activation function doesn't have a size, I think you mean, the configuration of the hidden layers (number_of_input_features, num_of_output_features)
But why is it 1728?
Oh, my apologies
11818 is the image, the "channel" (?) is 1 because it's grayscale
But I don't see where 1728 is derived from
What am I missing?
Thanks!
may i ask a question?
Don't ask to ask, just ask
how could i create a neral network?
can anyone help me with python?
Gotta pick what kind first- (Convolutional Neural Network, Generative, Recurrant NN)

Once you've gotten the dimension of the image you're working with, you can compute that value.
number of channel x image height x image width.
In my cooked up explanation, we assumed we're working with a grayscale image with 14 x 14 dimension.
1 (channel) x 14 (height) x 14 (width) = 196
https://www.youtube.com/watch?v=VMj-3S1tku0&list=PLAqhIrjkxbuWI23v9cThsA9GvCAUhRvKZ
this is one of the best tutorials to learn
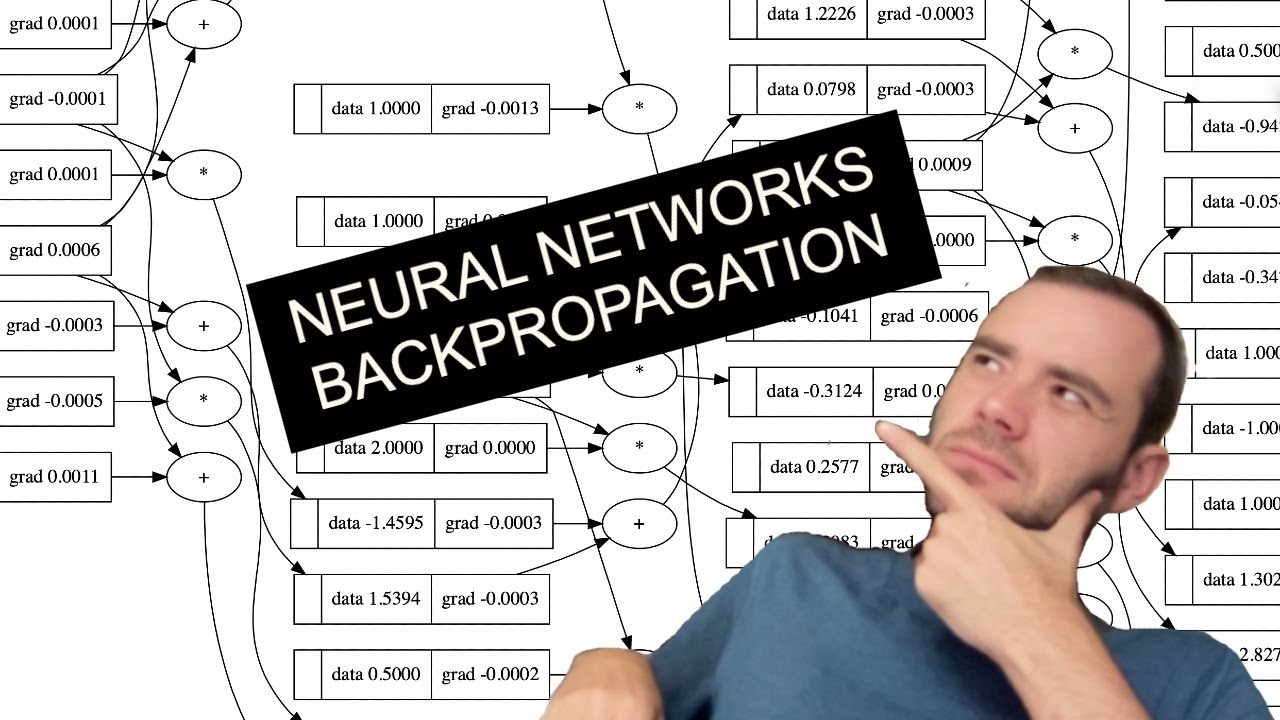
This is the most step-by-step spelled-out explanation of backpropagation and training of neural networks. It only assumes basic knowledge of Python and a vague recollection of calculus from high school.
Links:
- micrograd on github: https://github.com/karpathy/micrograd
- jupyter notebooks I built in this video: https://github.com/karpathy/nn-z...
I understand 196 but why 1728
What is the dimension of your image data?
Check the shape
It's a MINST data set
Let me check
*MNIST
28*28*1
784
DeepLearning.AI - Learning Platform
Enroll in 'AI Python for Beginners' by DeepLearning.AI and learn Python programming with AI assistance. Gain skills writing, testing, and debugging code efficiently, and create real-world AI applications.
Yeah MNIST is 28x28, it should be 784 not 1728. Or am I missing something 👀
It's convolutional, and there's down sampling (?) with MaxPool2d maybe?
what can learn to find people in a photo or from a live feed??
my apoliges
Called Facial Recognition. Just a piece of Computer Vision. Learn Computer Vision and you will get to it after a couple of chapters of applied study
My intuition is that it's your MLP outputs, but I'm kindof doing a few things at once
Oh I see... 1728 is the result of flattening the output of the final feature map after the convolution and max pooling layers, leading to a total of 1728 elements which was then passed to the 1st hidden layer in the MLP.
I want to make sure I'm getting RL down correctly so I'm going to give a general description of RL and if I'm missing something or it's incorrect would you guys correct me. Thank you in advance.
RL uses an agent to take some action in an environment based upon that state that it's in. The agent will either receive a positive reward or negative reward and the agent wants to obtain the highest reward possible.
The foundational model of RL is called the Markov Decision Process which contains states, actions, rewards, the transition probabilities between states, and the policy.
RL can be broken up into two categories, model-based and model-free. Model-based uses the environment to take predictions (policy iteration and value iteration or non-linear dynamics) based upon the environment. Model-free uses 'trail-and-error' to compute a gradient and if you know the gradient you can use some mathematical formula, otherwise, you'll use gradient-free methods mostly and they're broken up into either value-based or policy-based methods.
Value-based methods take value functions and iterate through it (value iteration) and it uses a bellman function to help determine the optimal policy (policy iteration). Policy-based methods just takes the next best action with just one step.
I've been getting confused on the value-based and policy-based methods the most. I'm not sure at all if my definiton is correct on those.
There's some slight mistakes but you're largely on the right track
For instance, model based vs model free isn't the only way you can categorize RL algorithms. There are many.
For model based algorithms you can be more specific, they specifically try to make a world model and use that model, by means of unrolling to find the best actions
Supervised RL models actively influence their own data distribution.
The model-free part can be more specific too. I'd definitely talk about the distinction between monte Carlo and temporal difference learning.
If I remember correctly value and policy based was basically if you're learning Q values or V.
Finally, I'd definitely spend some time talking about on policy and off policy.
^ I'm just saying it matters for an RL model if it's supervised or unsupervised.
Unsupervised ones were the algorithms that mostly seek novelty yeah?
That use some kind of novelty signal as the reward in lieu of actual rewards
Or wdym exactly @severe hare
Gotcha. Is there anything wrong with my value-based and policy-based def at the bottom?
Yes, it's not as complicated as you present it
I should learn MC and TD before learning about value-based and policy-based methods?
Value based simply learns the value of each state, V(S). You can easily derive the behaviour policy from that. Take the action that leads to the highest V(S+1). Policy based learns Q(S, A), it learns the value of a state action pair. It's also trivial to find the behaviour policy from this


The Berkeley Artificial Intelligence Research Blog
The BAIR Blog
Yup, I read a lot about this in the context of offline RL
Yes it won't use intrinsic rewards; that's correct
But it's been a while and I'm rusty
Your knowledge is good.
I've really never done Temporal Difference; maybe I should try that. MCs and Bayesians yeah
You really want experience with both MCs' ; because there is two
So the only real difference between those two is that one calculates it alongside the action while the other one doesnt. Otherwise it'll still get the max reward.
I actually made a mistake here sorry, it's been a while
Both MCs?
Policy based is stuff like policy gradient, it doesn't learn Q or V at all.
Oh so it basically looks at the gradient and determines its next move like that?
Policy-based vs. Value-based In Policy-based methods we explicitly build a representation of a policy (mapping π:s→a) and keep it in memory during learning.
In Value-based we don't store any explicit policy, only a value function. The policy is here implicit and can be derived directly from the value function (pick the action with the best value).
Think about it more abstractly, forget about gradients for a second
Monte Carlos, and Markov Chains which also can be paired together,
You have a function π: s -› a, basically something that maps a state to an action
Policy based methods are able to update this function directly
Just to keep it confusing; there is such a thing as the Markov Chain Monte Carlo: that combines them
https://en.wikipedia.org/wiki/Markov_chain_Monte_Carlo
In statistics, Markov chain Monte Carlo (MCMC) is a class of algorithms used to draw samples from a probability distribution. Given a probability distribution, one can construct a Markov chain whose elements' distribution approximates it – that is, the Markov chain's equilibrium distribution matches the target distribution. The more steps that a...
The others update Q or V and simply derive π: s -› a from that
Make sense? @shut shoal
OHHH
Basically policy-based only looks at the current state to compute an action while value-based looks at values to get some action based on a state.
Well, maybe π: s -› a takes into account future states, we don't know that
All we know is that it doesn't need to estimate the value of states or state action pairs
Oh gotcha
Also from what I'm understanding, the value-based functions determine the values (Q or V) by using the Bellman equation.
Yup, and to be sure just look at it this way: the value of a state is the immediate reward and the discounted future states
And you can expand the latter term etc.
This makes much more sense. Thank you @past meteor @severe hare
I think of it that, the computer wants to be 'led to' a solution for the value of Q, even if your model never reaches it
Glad to help
Same
Try implementing as many of these algorithms as possible. The basic ones rarely exceed 25 loc and in my experience those small experiments teach you a lot

GitHub
I custom library I made for training neural networks from scratch, using numpy and scipy - TheonlyIcebear/Neural-Net-Framework
Can you tell us more? Why would one use this instead of pytorch?
I guess the answer is "no one, this is just a demonstration of concept"
simple answer dont

its probably way slower and doesnt have many features like pytorch
from utils.layers import *
from utils.schedulers import *
from utils.network import Network
from utils.optimizers import Adam
from utils.functions import Activations, Loss
import matplotlib.pyplot as plt
import numpy as np, pickle, time
if __name__ == "__main__":
model = [
Input(2),
Dense(3),
Activation("lrelu"),
Dense(2),
Activation("softmax"),
]
print(model)
network = Network(model, loss_function="cross_entropy", optimizer=Adam(momentum = 0.9, beta_constant = 0.99))
network.compile()
training_percent = 1
batch_size = 4
save_file = 'model-training-data.json'
xdata = [[i % 2, i // 2] for i in range(4)]
ydata = [[(i % 2) ^ (i // 2), 1 - ((i % 2) ^ (i // 2))] for i in range(4)]
costs = []
plt.ion()
start_time = time.perf_counter()
for idx, cost in enumerate(network.fit(xdata, ydata, learning_rate=0.01, batch_size = batch_size, epochs = 1000, threads=4)):
if idx % 10:
save_data = network.save()
# network = Network()
# network.load(save_data)
end_time = time.perf_counter()
print(end_time - start_time, "time")
costs.append(cost)
print(cost)
plt.plot(np.arange(len(costs)) * (batch_size / (len(xdata) * training_percent)), costs, label='training')
plt.legend()
plt.draw()
plt.pause(0.1)
plt.clf()
start_time = time.perf_counter()
heres an xor solver using it
do i need to identify outliers by distributing data points from the minimum to the maximum value, and whether to use the actual data points themselves or to use the frequency (count) of those points for the y-axis in my visualization or analysis ?
im srry if i'm perhaps ovethink that its bcomes so complex when it isnt
i wan to use SVR for my dataset
and this is how my dataset looks like

is it possible to make an iterative language model ?
If I have a dataframe with a columns (say): A,B,C,status
And I want to group-by A,B,C with a new column saying "number of times status=X" and "total number of items"
Feels like something .groupby().agg() <=== not sure what to put here
What would it mean for it to be iterative
do you mean like recurrent? like it plugs the output of the model back into the model
Hey so I am currently trying to use a transformer to predict the next human generated "random" number from 1-100 inclusive. I'll drop some info about it and see if anyone has any suggestions on how to potentially improve it.
Transformer:
lr: 1e-3
L2: 1e-6
dropout: 0.2
feed forward size: 32
Embed size: 32
Attention heads: 7
num classes: 100
num features 43
features:
number itself
number mod 2
number mod 3
number mod 5
number mod 10
number of divisors
Digit sum
ranking in occurance
each digit as it's own feature (2 digits. We treat 100 as 99 which ik isnt the best but is better than having an optional feature)
x3 (We do encode the previous number and the number even before that with all the same features into this number as well)
Plus an additional difference feature for the numbers preceeding it (2 features)
And also an additional quotient feature for the numbers preceeding (2 more features)
All of these values are normalized correctly I ensured as well
Lmk if there is anything I can do better
Hi everyone! Hope you all are doing great today.
I am a beginner in Python and graduated high school this year. I am having a lot of difficulities in my Python learning journey.My elder brother, who is in his last year of college and is a web developer, guided me to explore the field of machine learning and recommended the Machine Learning Specialization course by Andrew Ng (Stanford University) on Coursera. Since it consists of many difficult concepts like linear regression, Gradient Descent, Supervised learning, e.t.c. I found the course quite tough and challenging and couldn't understand much. I have asked this server for guidance many times, but they usually respond as if I were an advanced programmer
Can You please guide me step by step. What and from where should I learn.
I have also started exploring Python libraries like Numpy and pandas.
If you are alrdy good with python, like as in understanding simple concepts well enough, you should revise some of the mathematical concepts u have learnt in highschool like linear algebra, probability and statistics and familiarising urself with concepts like differentiation and integration. You should also get comfortable with data handling, for example understanding numpy and pandas. Datasets are a core part so i would say you should experiment with them (kaggle is one of my fav platforms for datasets), practice loading and cleaning them, experiment with augmentation. Aftr all these you should start with the basic concepts of ml, use sckit learn at first then move on to pytorch or tensorflow, start experimenting with mnist datasets. And like your brother said, Andrew Ng's course is a great source for understanding all the fundamental concepts.
Start with simple networks like cnns and rnns then move on to more advanced topics like rl, GANs, hybrids or NLP. Start a github repo(for documanting ur progress), join communities like stackoverflow and r/Machinelearning, and most important of all participate in competitions (competitions are held in sites like kaggle, they can range from small to large)
////
Btw someone help me with this: My training of a multiclass img model is done, validation is done too got an f1 of 85(20- test, 80 - train). However I want to test the model on another dataset, I was thinking of using the 2017, 2018 or the ham dataset but later I found out that the isic2019 is an extension that also contains all the imgs of all those sets. So which dataset should I use for another test?
I cant find one on Google and I have been searching for too long
For context: the isic2019 is an imbalanced dataset with 25k images for dermatology (also known as skin related issues). The model is an ensemble hybrid rf
Btw forgot to mention, please learn how to handle imbalance, its really important. I regret not learning it before: accuracy can be significantly impacted by imbalance
So should I quit Andrew Ng course for now or should continue with these other stuffs
Well, if you believe your still not ready for it, yeah sure
But that course is really good, so I recommend u follow it
After you are more confident ofc
But I want to know how it's calculated, I've tried different calculations but I can never get that specific value

24*24*3
In this case (W-K) + 1 gives you the result; (width and kernel size.)
first it's 28-4 + 1 = 25
then its 25 -2 +1=24
then goes 24*24*3
may help: https://cs231n.github.io/convolutional-networks/
feel free to ask
Course materials and notes for Stanford class CS231n: Convolutional Neural Networks for Visual Recognition.
What do you mean?
how to find outlier in a dataset ?
im asking this bcuz i wan to find outlier
in my dataset which i got from kaggle
do i need to identify outliers by distributing data points from the minimum to the maximum value, and whether to use the actual data points themselves or to use the frequency (count) of those points for the y-axis in my visualization or analysis ?
im srry if i'm perhaps ovethink that its bcomes so complex when it isnt
does this also applies when you train a model across epochs?
im not asking in technical perspective, rather in perspective of analysis of how it might efect the model performance...i alr have target column and 2 features
I mean the memory accumulation, cause I see that you mean the jupyter saves the variables in the memory
Until you explicitly free them
Depending on the concrete dataset
One common approach is to do dimensionality reduction and try to plot it within 2d/3d
Yeah, I get what you mean. But would you call that pitfall or just a feature 😄
the features is originally a categorical column but i already encoded them
But this is school example for gc
You lose reference to it - > gc should be activated
ok that means it is unfixable
well knowing that why would you use car for floating on water, when by default it is not intended for that use-case?
okay you can use for EDA
but create a script for training, no
right
people are spoiled
118 rows x 7 columns is considered small?
 this is a bold quote
this is a bold quoteI trained an ML model of my own that classifies brain tumor with about 92% accuracy. I unfortunately am not sure how I can integrate the .h5 file of the trained model in a simple web application or desktop application where I can upload an image and the model classifies the tumor based on the scan image. Please give me a step by step guide on how I can do that
what is the best solution to handle with outlier
when the target column which hv outlier?
How extreme are the outliers, how much outliers, are you using a robust model, does it make sense to have such outlier in the context?
how so
Is a library to do basic python data app
There's some best practices around managing notebooks, and ensuring reproducibility. Such as only committing stripped notebooks, using something like papermill to populate notebooks for 'production' use, etc. Some devs local notebook is just a sandbox.
you can convert models with onnx and use them on the web, but i'd recommend models < 50Mb, if they run on the client.
i decide to use SVR
The model is 100mb, is there any workaround for that
Yeah pretty terrible
yes, quantisation
you may be able to do it when exporting (onnx export) or within the library you use for training/saving.
depends on many things, but it's possible.
for example, if you have float32 weights, you'll get to 50mb a bit less precision (normally you don't notice.) with float16, and 25mb with uint8s (that sometimes isn't as good, since the error increases substantially.) if you already have done that, then idk..XD
I think I used float64
Im relatively new to this so if you can tell me some resources where I can learn from that'd be pretty great
search deep learning model quantisation
i think chatgpt can give you a decent introduction
you can check this but it's more complex https://newsletter.maartengrootendorst.com/p/a-visual-guide-to-quantization

Exploring memory-efficient techniques for LLMs
Thanks
yeah but numpy seems to shit itself when you have mixed float precision
and certain functions just fail like np.var with float32
...
That's a simple solution I somehow haven't came up with
Thanks!
I though I have to do some trick as MaxPolling downsample the data
Oh and
When should sigmoid be used over relu in hidden layer?
24 (height) * 24 (width) * 3 (out channel of relU)
I though it would be 23 * 23 as conv2d have stride of 1
Does the MNIST handwritten digit generalize badly?
(my own handwritten image)

Epoch 449 loss: 0.10526546835899353 accuracy: 0.9675506353378296
How can I improve this
when you feel like it 🥴
generally you just look at what various papers implement and when or just experiment
MNIST is a dataset... it doesn't do anything except exists as a dataset
your model OTOH can either generalize or overfit/(specialize?) (if those are opposites)
your model accuracy is about where one would expect it to be though
are the MNIST digits anti-aliased as well?
but yeah, I don't think your model is really capable of generalizing well because it's literally just a single convolutional layer with an MLP at the end (technically it's not an MLP, but oh well, I hate that term, no one ever uses MLPs anymore, but the term stuck, smh, anyway...)
If I want to count the number of a particular value in a series, is there a better way than
def somefunc(blah: pd.Series):
return (blah == 'running').sum()
Yes. Use value counts
unless that's precalculated and cached, feels like that's doing a bunch of work I wouldn't care about? (for the other values?)
It's not precalculated, but both involve essentially the same amount of work.
and are you suggesting: blah.value_counts().get('running', 0)
I would probably keep the value count series as a variable
As it happens, i'm using this in an agg() from a groupby. Would that suggest a better way?
df2 = df.groupby(['ACCOUNT_NAME', 'REGION', 'TYPE', 'ID', 'Name']).agg(
RunningHr=('STATE', lambda x: (x == 'running').sum()),
NotRunningHr=('STATE', lambda x: (x != 'running').sum())
)
Think I'm going to replace NotRunningHr with a total (count).
That's fine. I'd use the eq and ne methods, though.
OK, eq/ne is for style?
Right, so you don't need parens for == and !=
Yup I just removed those 🙂
Optimal?
df2 = df.groupby(['ACCOUNT_NAME', 'REGION', 'TYPE', 'ID', 'Name']).agg(
RunningHr=('STATE', lambda x: x.eq('running').sum()),
TotalHr=('STATE', 'count')
)
I'm probably over-obsessed with chaining stuff, rather than keeping lots of temporary variables.
Sure
Thank-you
Not creating references means fewer opportunities for memory to be waiting for garbage collection.
I had a related question, and I think I've seen it somewhere, but don't know the words to search.
How can I add a "filter" to a series of chained calls?
Like if I have the code above, in a function called "summarise" how can I do:
result = pd.load_csv()...
.rename(this,that)
._CALL SUMMARISE
.other_thing()
Is there a "chain" or "call" thingy?
Ahh... "pipe" ?
Yeah, I think you have to use pipe so you can pretend that you have a variable for the dataframe at that stage
Pandas is weird
What's a good way to update all values in a column (in a dataframe) with a lambda? I want to remove a substring (which is in another column)
The IDE suggested
all_resources['ACCOUNT_NAME'] = all_resources.agg(lambda x: x['ACCOUNT_NAME'].replace('-' + x['REGION'], ''), axis=1)
But I dont understand why it used agg() and not .... .assign() or .apply() ?

"what's a good way to do x in pandas with a lambda" is self contradictory
A lambda is almost always the wrong way to do anything in pandas
Looks like you should make a new string column with str.replace that applies the desired string transformation.
yessir, how can I do that with not-lambda 🙂
can I use str.replace on a vectory thing? when the text to be replaced is actually another column?
Thoughts on how to create "pretty reports" using pandas? Presumably need some kind of templating engine....
I used matplotlib and just wrote out graphs to a pdf for presenting pandas data at my job
although in hindsight making a blank graph and a custom method to position text as I wrote it was a waste of time
This is then passed to the policy function to calculate the next possible action.
^^
||
This last sentence is a guess. Is this a correct guess?
Does this sound right?
just for completeness, this isn't quite right. if you have a fixed architecture and use different data sets to train it, the data sets will determine how well the model learns and whether it generalizes well too
it's fairly difficult to tell whether the data or the model is responsible without extensive testing, which is why one would do a lot of cross validation and play with removing some layers and reevaluating
I forgot to say thanks.
By the way, I took some classes from Andrew Ng's course yesterday and decided to pause the course for a while to focus on more practical work
I will consider taking your help on my journey with Python. I hope you don't mind.
😊
ReLU tends to perform better for various reasons, including that it's got no vanishing gradient problem. (probably especially true for leaky relu though.)
it's also simpler to compute the gradient.
here is a standard argument https://stats.stackexchange.com/questions/126238/what-are-the-advantages-of-relu-over-sigmoid-function-in-deep-neural-networks

Cross Validated
The state of the art of non-linearity is to use rectified linear units (ReLU) instead of sigmoid function in deep neural network. What are the advantages?
I know that training a network when ReLU is
nice, yes, also silu (idk what it is.) and leaky relu, which has got a small (adjustable) negative slope
im experimenting with hyperparameter tuning libraries and it's a neat way to test those,
I really need some help in this kaggle competition I am taking part in so please hop on the voice chat 0 if you know a thing or two about about kaggle or ai in general. (it is my first competition)
random blogpost conclusion...
So which one should you use?
It depends on your application and what works best for your network. In general, ELU or GELU may be better choices than ReLU if you’re worried about dead neurons, while SILU may be a good choice if you’re using batch normalization.
Also GELU seems to be the SOTA for transformer models and SiLU is use mostly in computer vision models.
(E: exponential, G: gaussian, S: sigmoid)

/*! elementor - v3.21.0 - 30-04-2024 */ .elementor-widget-text-editor.elementor-drop-cap-view-stacked .elementor-drop-cap{background-color:#69727d;color:#fff}.elementor-widget-text-editor.elementor-drop-cap-view-framed .elementor-drop-cap{color:#69727d;border:3px solid;background-color:transparent}.eleme...
yeah
The main reason these functions are used is that they're easy (fast) to compute right? The derivative is very straightforward
they need a couple of attributes: must be non linear, simpler is better indeed (but not too simple), have (or 'produce') non exploding or vanishing gradient...
its fun
idk tbh
interesting!
lol yeah I guess
i may compare on mnist those for fun
the point of these functions is to introduce non-linearity, so less linear -> easier to fit to real world (non-linear) data?
oh that's dan, he seems smart, one of the authors
dan hendrycks is one of the ones passing (or helping to write or smth) the bill to regulate ai i think
is on the 'imminent extinction' side iirc
fn is that one right?
the siren part is pretty cool
erf is a gaussian like fn i think
erf is the integral of a gaussian
you usually get it as the CDF of the gaussian, i.e. the probability of a gaussian distributed event happening. it's called error function because it describes the probability of making errors when transmitting signals under gaussian noise
looks like a sigmoid :-(
a lot of stuff looks like a sigmoid
no wait, but in the paper that's \Phi(x)*x I think
so it's like a probability times a weight in a way
We perform an empirical evaluation of the GELU nonlinearity against the ReLU and ELU activations and find performance improvements across all considered computer vision, natural language processing, and speech tasks.
same paper, ig that's not a proof, but interesting.
I am facing an issue in the ML models I have created. Please dm me if you know a thing or two about AI and ML
i only partially agree with that; the paper you included says:
But as networks became deeper, training with sigmoid activations proved less effective than the non-smooth, less-probabilistic ReLU (Nair &
Hinton, 2010) which makes hard gating decisions based upon an input’s sign.
sigmoids are non linear
the introduction is very neat
there's this one talk from ICASSP 2020 or 2021 that i never found again, but discussed that if you learn the activation function, piecewise polynomials (like relu) are in some sense the optimal choice
but there is leaky relu as well
the discussion also is very nice
Across several experiments, the GELU outperformed previous nonlinearities, but it bears semblance to the ReLU and ELU in other respects. For example, as σ → 0 and if µ = 0, the GELU becomes
a ReLU. More, the ReLU and GELU are equal asymptotically. In fact, the GELU can be viewed
as a way to smooth a ReLU.
yeah, there's a handful of smoothing approximations to the relu. the problem is that it isn't differentiable at 0, only subdifferentiable. as a result, different ML libraries and implementations of autodif make different, arbitrary choices of what to do for the derivative at 0
i see
the x in their formula turns to relu ig x*Phi(x)
idk what u and sigma are here (i mean the role in the network); the weights?
mean and variance of a gaussian distribution. it's not really a pdf here though, so it's better to say they're the "shape parameters" of a "bell curve"
they are tunable though, i guess?
sure
How does log(n) can centralized skewed graph?
it could also be the u and sigma of a batchnorm on x i think
so not tunable
actually (this may be incorrect) but i think x is just the output of a linear transformation; but that's assumed to be normally distributed
(formula just for discussion.)

there are good arguments to be made for x being normal distributed if you got it from a large enough matrix, sure
the original paper discusses it only very loosely though
i was wondering how they use that function since it does not have an actual expression
but they use tanh in replacement apparently
oops, they do say this though:
We could use the CDF of N (µ, σ2) and have µ and σ be learnable hyperparameters, but throughout this work we simply let µ = 0 and σ = 1.
which im assuming means the data comes from batchnorm
it really depends on what interpretation you want to give to the activation function
even though they called it a cdf, by leaving it fixed it pretty much detaches the function from the data, so it's not really a cdf
just a function that looks like a relu but is everywhere differentiable
it's a bit like x*sigmoid conceptually (in my mind at least.)
it's exactly that, because sigmoid is an umbrella world describing any roughly s-shaped function
like the logistic function, which is what people usually mean, or the hyperbolic and inverse tangents, or the error function
those are all sigmoids
you can
i wonder whether x*logistic would work well
yes
in my work we do this all the time, since the activation functions should mimic some other algorithm
so you chuck the hyperparams into the training
just realised that's exactly silu

yep
How does it differ from a skip connection
so they propose a whole family of activation functions, that's quite beautiful
Seems pretty similar

yeah all sigmoid-type actually
is that like or same as dropout?
Different. You multiply theta(w, x) * x
i'm not sure what exactly you mean by "having it depend on previous outputs"
through composition and the usage of iterative optimization methods, all of the parameters depend on the initial guess, all of the previous parameters in the network, and all of the previous guesses of the optimal parameters
all gradient based optimization methods are recurrent
you can do arbitrary graphs, does that relate?
i.e 1 activation takes 2 prev layers as input
oh, skip connection as in resnets
i didn't know the name
i think i more or less suggested the same as @past meteor if i understood correctly
skip connections are one way to make that prev-output dependency using graphs, but you may have asked smth else
so this may be wrong but in my mind all the paths forward have a gradient backwards
then i thought that'd give a state in the sense you wrote (using just +complex graphs), but ig it does not
is the last representing y what you want, or what i meant?
does this match the description?

XD sorry
my current activation default stack sigmoid < ReLU < ELU < x * sigmoid (includes GeLU, SiLU,..)
according to some papers it's not for large networks
arXiv.org
We study the connection between the highly non-convex loss function of a simple model of the fully-connected feed-forward neural network and the Hamiltonian of the spherical spin-glass model under the assumptions of: i) variable independence, ii) redundancy in network parametrization, and iii) uniformity. These assumptions enable us to explain t...
there is also the regularisation parts, chatgpt returns a neat summary with what is a regularizer in deep learning networks?
idk whether regs matter that much either. actually dropout and batchnorm are regularisers
they say somewhere that large neural networks get to similar local minima disregarding of initialisation (since it's random and all get to the min.)
not to the same parameters, but to minima of similar quality (error.)
btw one of the authors is lecunn, worth reading him
lol, i take it
ill take a look
that's my read of this part at least:
However, several researchers experimenting with larger
networks and SGD had noticed that, while multilayer
nets do have many local minima, the result of multiple experiments consistently give very similar performance. This suggests that, while local minima are
numerous, they are relatively easy to find, and they
are all more or less equivalent in terms of performance
on the test set
(it could be they all tuned the init, im assuming they didn't to some extent)
is kernel in kernel method is the OSes kernel?
yeah but their "experiments" for example say...
We performed an analogous experiment on a scaled-down version of MNIST, where
each image was downsampled to size 10 × 10. Specifically, we trained 1000 networks with one hidden layer
and n1 ∈ {25, 50, 100, 250, 500} hidden units (in the
paper we also refer to the number of hidden units as
nhidden), each one starting from a random set of parameters sampled uniformly within the unit cube. All
networks were trained for 200 epochs using SGD with
learning rate decay.
(it certainly does matter for small networks though.)
maybe i should add the remaining bit:
(...)
We obtained less than 2.5% drop in accuracy, which
demonstrates the heavy over-parametrization of neural
networks as discussed in Section 3.
yeah seems possible, this says smth similar https://ai.stackexchange.com/questions/40495/what-is-the-impact-of-the-initialization-of-weights-in-the-performance-of-a-neur

Artificial Intelligence Stack Exchange
In my own experience, weight initialization matters for model convergence.
Theoretically, can different weight initialization methods eventually converge to the same optimal solution? Are their we...
i was likely stretching that original model too far, it's not even meant to explain inits.
Hello, I hope this is the correct channel for the question I have. I would like to to create an animated bubble chart, similar to https://cryptobubbles.net/ . Is there a package or framework in python I can use or is this only possible with D3.js ?

Crypto Bubbles
Explore the dynamic world of cryptocurrencies with Crypto Bubbles, an interactive visualization tool presenting the cryptocurrency market in a customizable bubble chart. Dive into the latest market trends and gain valuable insights effortlessly. Crypto Bubbles serves as an independent data aggregator, offering a comprehensive view of the crypto ...
bc it reduces to a gaussian process
they want to prove that neural nets reduce to a gaussian process; using a recent advance that the spin-model is equal to a gaussian process
i may be wrong, it's in the limit of my understanding
uhmm i think they assume a random input vector, but would need to re-read
also it's about the training, and the finding of the weights; actually the gaussian process is the loss there.
yes, that's quite interesting
it's structured data (not just noise), but can be modelled statistically and hence has randomness (i assume.)
i spent quite some time understanding that equation, i can't do it algebraically though
both are a feed forward, second one is a different way of writing it
since the sigmas are relus here, it's the same as multiplying specific paths by 1 or 0
you can think of a single weight and how it moves in the network
it ends up multiplied by every other weight, in the following layers
so write that down for all weights added up, and it's just another description.
XD
well, a large enough network is a universal approximator
the only thing they require for those first 2 equations is that the activation is a relu, as far as i can see
no
you'd have to analyze other architectures separately to show whether the result applies to them
general results of that kind are in general not tight and don't provide as much insight though
e.g. there are papers explaining the conditions under which special architectures will always reduce the training loss to 0, but you can't really make that conclusion for general networks since it would be a general statement about nonconvex opt that has eluded researchers for several years
the universal approx theorem is pretty much the starting point
which means you don't have even that for general architectures
that's a steep slope to fight against if you want to show any general results
that was kinda my point
you start with a general nonconvex, possibly nondifferentiable function you want to optimize, and have almost nothing to go off of
you'll find that theoretical guarantees of any kind are made only for special families of functions
and those are the special families of functions
if you go broader, you have pretty much nothing
nonconvex opt is a PITA
https://github.com/samratsb/QueryDB
Hey I want to further my project to be able to talk with documents and dockerize it and upload it to cloud, what do I do?
GitHub
RAG with chromadb embedding and huggingface model. Contribute to samratsb/QueryDB development by creating an account on GitHub.
Anyone interested, please contribute
does seem like nice project to experiment with activations, since they are easy to implement;
that paper by hendrycks is not too hard imho
has anyone used duckdb for logging metrics where there are a lot of metrics and they get logged ultra quickly
or has anyone used duckdb at all just wanted to know what people use it for and how fast it is in real tasks
so quickly that after I debugged the logging takes 40 seconds
not that quickly actually but there are so many metrics that it each logging event is very small amount of time from previous one
can someone contribute to my project, I have created a semantic search. it adds querys, and does a semantic search
I want to use it to do more, I feel like this is not enough
I just read that it is fast but I can't find any benchmarks and dont know if it is worth trying to implement
but also I want to learn it anyway
I use duckdb all the time. It's a great analytical engine. Not what you'd use for logging tho: you might use it for log analysis tho.
this is my current logging, just dicts
{
"metric1":{
1: 100,
4: 200,
7: 300,
},
"metric2":{
2: 15,
3: 25,
},
}
and I thought it could be faster if I have a table for iterations, and table of metrics, and table of metric per iteration
Why not one table?
idk, I'm not sure what would be faster, I would need to benchmark all of it
Faster at what?
faster at saving the metrics per some iterations
Fastest is to stream a csv to a text file.
Appending to a single table will also be fast.
So will writing to a log store or time series db
The 'trick' to speed is to aggregate (buffer) writes... one big write is faster than many small
I'll do more benchmarking
some metrics are logged every second iteration some like every 128 iteration which is why maybe multiple tables will be faster
What difference would that make to the tables?
How many metrics and how many iterations per second are we talking?
that's a cute request, i've no knowledge about that, but keep trying :-)
Dan Hendrycks on Reddit, interesting story about SiLU


this video seems promising, terence tao about the potential of ai in mathematics (for automatic proofs etc.) https://www.youtube.com/watch?v=_sTDSO74D8Q

Terry Tao is one of the world's leading mathematicians and winner of many awards including the Fields Medal. He is Professor of Mathematics at the University of California, Los Angeles (UCLA). Following his talk, Terry is in conversation with fellow mathematician Po-Shen Loh.
The Oxford Mathematics Public Lectures are generously supported by XT...
I need to do so much on this project, can someone help me please
add KNN, similarity check, eval downstream tasks, model fine tuning, making it work on pdfs (I am currently creating chunks from .md files and finally I want to use this project to further it and make it into a complete RAG, that is, make it ans from what it is not trained on, using what it is trained on
And I have no idea how to implement this all, including dockerizing, what tech to use etc. I am suffering.
maybe up to 100 per second, and about 100 metrics, but only to are logged per iteration, other ones are once per few iterations
I mean for logs analytics if this is for a service click house or quickwit are better solutions
But I guess your scale is probably a bit small for those systems to really be super useful
may i ask a question
llama%2Fmodel.py lines 218 to 219
def forward(self, x):
return self.w2(F.silu(self.w1(x)) * self.w3(x))```can a rrecurent networks learn if you give it data?
yes
no teaching requierd?
well, you need backprop I guess
interesting !

Backpropagation, short for "backward propagation of errors," is an algorithm for supervised learning of artificial neural networks using gradient descent. Given an artificial neural network and an error function, the method calculates the gradient of the error function with respect to the neural network's weights. It is a generalization of the d...
you can shut down the machine that is running the neural network.
well i want to make a code just encase sone takes a copie of the network and train it to be dangerous or if it becomes dangerous on it's own i can reset it or shut it of in esence a time out
my apologizes
great idea. good luck!
but could the network break the shut down code?
that would depends on the network, and the shut down code
a code decrypting neural network and image identifyer
so
what do what do you think
I want to integrate a model to some existing system. What should I pay attention to other then current infrastructure to ensure that my model wrapper complements their style
Hey guys, quick question
The last time I finetuned a ml model (xlm-roberta), my model basically learned to always predict the majority class - like ALWAYS, regardless of the input
Even if I used oversampling, the same issue occurred (it predicted the majority class in that epoch) : /
Do you guys have any ideas on what went wrong and how to solve it ?
these questions are hard to answer. you probably need to adjust the hyperparameters
did you use dynamic loss weighting like focal loss?
hmm I wonder should I choose NLP with LLM or 3d deep learning path?
goal is to help people rather than do projects
or 3d deep learning is rather research?
hey guys has anyone here worked with the zero-shot-classification pipeline from transformers library? is it supposed to take so long to process a small string even when it is accelerated by a gpu? and yes i asked help on #1035199133436354600 but it was locked before anyone could answer
Dunno what that means, but what I did was simple cross entropy
Would love to know what you are talking about
It should warn you of you have a GPU that it detects and is not using
focal loss is related to focal length?
Prob not lol
yes you can do focal loss for cross entropy ..it's a special formula that counts the numebr of classes and dynamically adjusts the weights of the observed batch
How many parameters ?
from transformers import pipeline
# Use a model specifically fine-tuned for zero-shot classification
classifier = pipeline('zero-shot-classification', model='facebook/bart-large-mnli', device=0)
res = classifier(
"I am kinda sad today",
candidate_labels=["happy", "sad"],
)
print(res)
this is all, and it doesn't show a output on pycharm

Medium
Focal loss is said to perform better than Cross-Entropy loss in many cases. But why Cross-Entropy loss fails, and how Focal loss addresses…
ill give it another try with this, thanks a lot
np 🙂
I'll send the colab link next time lol
Like no output whatsoever ?
wait could my internet speed be the bottleneck? because now that i think about it, how would it access teh model without locally caching it
nope it just runs and runs and i get no output
Should show you a progreebar lol
so like loop forever?
Add prints to know where it is stuck lol
where do i add prints in a 10 line code 😭
The nine in between : P
did you move the tensors to gpu?
Huggingface takes care of that for you
if you mean adding the device = 0 parameter then yes i did
this the script
Try removing that parameter
And actually try the prints lol
ahhh didn't see that
Again, how many parameters does that model have
Like if it's in the high billions, it'll take time
And what gpu

Ah, I think I get it
The pycharm term seems to not support progress bars lol
The model is dl'ing
Use Windows terminal or kitty depending on your os
should i try running in the terminal?
alright
in pycharm u can enable emulate the terminal btw
yeah i think it works now

lmao it was at 99% all this time
That too works lol
It'll time out
Read the error then
you can make it run with terminal like this instead of going to terminal

okay i will set it up, thanks!
they've got a neat site https://www.vincentsitzmann.com/siren/
Implicit Neural Representations with Periodic Activation Functions
bro wtf! my device crashed while processing the stuff so i had to do a force restart and now it doesn't show that i have a gpu
in what environment?
i was working in a conda env, but not even my task manager recognizes my gpu
so it's on your computer, and not something like google colab?
you can try rebooting, I guess.
there are some interesting criticisms of siren here as well https://www.reddit.com/r/MachineLearning/comments/hd6tu1/d_paper_explained_siren_implicit_neural/

Reddit
Explore this post and more from the MachineLearning community
How to know if feature is linear?
Thank you. So there is nothing on Python side that can be used instead?
Great thank you! 🙏
my gpu shows up again after restarting but the code has stopped working for some reason, even though it had worked earlier
how do you know that it "stops working"? what does that mean in this context?
Oh right, let me share it, one sec
https://arxiv.org/pdf/1710.05941 "Searching for activation functions"
can i just share the repo?
you can, but that won't tell us how you know that it "doesn't work".
was there an error message?
right so essentially, it a review summarizer which scrapes reviews of product parses it and extracts reviews and then sends it over a zero shot classification pipline to classify the reviews by their degree of positivity or negativity, so the code returns an error while it creates an object for the class which does the classficaiton work
the code returns an error
If you need help in relation to an error message, always show the whole error message
from driver_init import SeleniumDriver
from review_scraper import ReviewScraper, parse_reviews
from review_classifier import ReviewClassifier
def main():
url = "https://www.amazon.in/Number-Backpack-Compartment-Charging-Organizer/dp/B09VTDMRY7?pd_rd_w=giCzt&content-id=amzn1.sym.ec5c60c1-ae3d-4950-9707-1e49240719bc&pf_rd_p=ec5c60c1-ae3d-4950-9707-1e49240719bc&pf_rd_r=Y3MSH92QWBEKYCN9ATGK&pd_rd_wg=ZzwV4&pd_rd_r=8e0c7a40-a11e-4573-9b38-15ab13f59a8c&pd_rd_i=B09VTDMRY7&ref_=pd_hp_d_btf_unk_B09VTDMRY7"
# Creating object of the class SeleniumDriver
selenium_driver = SeleniumDriver()
# Setting up the webdriver
driver = selenium_driver.get_driver()
try:
# Creating object of the class ReviewScraper
review_scraper = ReviewScraper(driver)
page_sources = review_scraper.navigate_to_reviews(url)
# Check if we have the required page sources
if len(page_sources) >= 2:
# Parse reviews
positive_reviews = parse_reviews(page_sources[0])
negative_reviews = parse_reviews(page_sources[1])
# Combine positive and negative reviews
reviews = ([review for review in positive_reviews] +
[review for review in negative_reviews])
print("Reviews:")
for i, review in enumerate(reviews, start=1):
print(f"Review {i}:")
print(f"Review: {review['review']}")
print(f"Date: {review['date']}")
print("-" * 40) # Separator line
# Create and use the ReviewClassifier
review_classifier = ReviewClassifier(reviews)
review_classifier.classify_reviews()
else:
print("Not enough page sources available.")
except Exception as e:
print(f"An error occurred: {e}")
finally:
# Close the driver
selenium_driver.close_driver()
if __name__ == "__main__":
main()
the main file
if your code "doesn't work", but you got an error message, you don't need to say that the code doesn't work. you only need to show the error message.
print(f"An error occurred: {e}")
as far as i understand e should send error message, but it gives only '0'
show your whole terminal output from when you start the program to the end of the error message
!paste
Pasting large amounts of code
If your code is too long to fit in a codeblock in Discord, you can paste your code here:
https://paste.pythondiscord.com/
After pasting your code, save it by clicking the Paste! button in the bottom left, or by pressing CTRL + S. After doing that, you will be navigated to the new paste's page. Copy the URL and post it here so others can see it.
alright
this is it

okay. make it so that none of the code is in try-except, so that when an exception is raised, you get the exception.
okay give me a sec
:incoming_envelope: :ok_hand: applied timeout to @flat plaza until <t:1723481327:f> (10 minutes) (reason: duplicates spam - sent 4 duplicate messages).
The <@&831776746206265384> have been alerted for review.
i hope that i used that right
"sequence": sequences[0],
~~~~~~~~~^^^
KeyError: 0
do you see what this error message is telling you?
not quite... i don't understand what is under the pipelines that well
do you know what keys are in Python?
yes
so if you got a key error from doing sequences[0], then what type of object is sequences?
a list?
you are mixing up indices and keys.
am i sending a list of dictionaries instead of a list of string to the classifier?
sequences is apparently a dict.
for which 0 is not one of its keys
what types are the keys and values of sequences? I do not know.
i do not have a dictionary named sequences, in my code
the code where the error occurs is C:\Users\Rikhil Nellimarla\.conda\envs\NLP_env\Lib\site-packages\transformers\pipelines\zero_shot_classification.py
yes... but that is inside a package tho
i wouldn't edit the python files inside an imported package
just went on a rabbit hole reading about sirens, if i understand correctly those can't model the probability distribution of a dataset of signals, just overfit a single signal sample.
still, it is extremely cool!
i think i got it! i
positive_reviews = parse_reviews(page_sources[0])
negative_reviews = parse_reviews(page_sources[1])
# Combine positive and negative reviews
reviews = ([review for review in positive_reviews] +
[review for review in negative_reviews])
here both positive and negative reviews are a list of dictionaries with the review of the product and the date, so when only isolating reviews i need to write
reviews = ([review['review'] for review in positive_reviews] +
[review['review'] for review in negative_reviews])
instead so that i can take only string assigned to the key of reviews
@serene scaffold see

@brave yew sorry, I have like four coworkers asking me to do stuff
no its okay, i just wanted to say my issue got solved, thanks!
you can just do reviews = positive_reviews + negative_reviews and it's the same thing
oh? but the positive reviews and negative reviews are lists of dictionaries
sure, but if you're just concatenating two lists, you just + them. you don't need the list comp part.
[x for x in y] is pointless if y is already a list.
(note that for arrays, this would do elementwise addition, so don't use "list" and "array" interchangeably)
oh okay, i will do it like that then, thanks
from langchain_chroma import Chroma
from langchain_openai import OpenAIEmbeddings, ChatOpenAI
from langchain.chains import RetrievalQA
import os
openai_api_key = "sk-"
K_RESULTS = 3
SIMILARITY_THRESHOLD = 0.5
SYSTEM_PROMPT = "I have an AI informational website. " \
"You should check the user's prompt and recommend the best tool as per it. " \
"Reply with the tool names in a Python list."
def ask_question(query):
embeddings = OpenAIEmbeddings(api_key=openai_api_key)
vector_store = Chroma(persist_directory="./chroma_db", embedding_function=embeddings)
llm = ChatOpenAI(api_key=openai_api_key, model_name="gpt-3.5-turbo",
messages=[
{"role": "system",
"content": "I have an AI informational website. You should check the user's prompt and recommend the best tool as per it. Reply with the tool names in a python list."},
])
retriever = vector_store.as_retriever(
search_type="similarity_score_threshold",
search_kwargs={"k": K_RESULTS, "score_threshold": SIMILARITY_THRESHOLD}
)
chain = RetrievalQA.from_chain_type(llm=llm, chain_type="stuff", retriever=retriever)
response = chain.invoke({"query": query})
if 'source_documents' in response:
for doc in response['source_documents']:
print(f"Source Document: {doc.metadata['source']}, Section: {doc.metadata.get('section', 'N/A')}\nContent: {doc.page_content}\n")
return response.get("result", "No result found.")
if __name__ == "__main__":
query = "i need to build a website and i need tts features"
print(ask_question(query))
when i added the system message in the ChatOpenAI, my code wont run properly and gives me
Sure! Please provide me with the user's prompt so I can recommend the best tool accordingly.
instead i wanted to print the tool name
how do i make a network library?
what type of network
what type of library?
so what do you want to make
a library that does the image detection? Or library to train new models for image detection?
do you just need a model or more than that
@lapis sequoia
Is this the correct formula/terminology to calculate accuracy in a scenario where I have 10 categories and want to classify my input into one of them?
For example, referring to the 10k instances that were classified as abusive, where 95% are truly abusive and 5% were classified as abusive but are actually good instances , should I use the formula: TP / (TP + FP) to calculate accuracy? Or thats for like binary
Accuracy works the same
You can do things like precision/recall per class or averaging them over all the class to get one metric
#===[imports]===#
import sys
import numpy as np
import matplotlib
#===============#
#===[neuron network]===#
np.random.seed(0)
X = [[1, 2 ,3,2.5],
[2.0,5.0,-1.0, 2.0],
[-1.5, 2.7, 3.3, -0.8]]
class Layer_Dense:
def __init__(self, n_inputs, n_neurons):
self.weights = np.random.randn(n_inputs, n_neurons)
self.biases = np.zeros((1, n_neurons))
def forward(self, inputs):
self.output = np.dot(inputs, self.weights) + self.biases
layer0 = Layer_Dense(4,5)
layer1 = Layer_Dense(5,2)
layer0.forward(X)
print(layer1.output)
is this ok?
It should be matmul not dot in forward
Dot product returns a scalar
Also the end bit doesn’t make sense. layer1.output is going to be undefined
this is only true for 1d arrays.
@unkempt wigeon
- There is no reason for importing
syshere. It's not clear if you plan to usematplotliblater. Xshould probably be an array.- You should name the class
LayerDenseorDenseLayer. Don't use Upper_Snake_Case in python. - you made the
def forwardblock part of thedef __init__block. - The
forwardmethod should return the output, not assign it to self. - You don't do anything to make the output of layer0 go into layer1.

Neural Networks from Scratch book: https://nnfs.io
NNFSiX Github: https://github.com/Sentdex/NNfSiX
Playlist for this series: https://www.youtube.com/playlist?list=PLQVvvaa0QuDcjD5BAw2DxE6OF2tius3V3
Neural Networks IN Scratch (the programming language): https://youtu.be/eJ1HdTZAcn4
Python 3 basics: https://pythonprogramming.net/introduction-...
His forward function is not inside of __init__ and also making X(data) into a numpy array will make operations faster and easier because you will be able to leverage the functions associated with the np.ndarray type
yes
asarry()?
import numpy as np
np.random.seed(0)
X = np.array([[1, 2, 3, 2.5],
[2.0, 5.0, -1.0, 2.0],
[-1.5, 2.7, 3.3, -0.8]], dtype=np.float32)
class LayerDense:
def __init__(self, n_inputs, n_neurons):
self.weights = np.random.randn(n_inputs, n_neurons)
self.biases = np.zeros((1, n_neurons))
def forward(self, inputs):
self.output = np.dot(inputs, self.weights) + self.biases
layer0 = LayerDense(4, 5)
layer1 = LayerDense(5, 2)
layer0.forward(X)
# print(layer0.output)
layer1.forward(layer0.output)
print(layer1.output)
@unkempt wigeon
the exact code showed in the video
idk If I would structure my nn like this but that just me
does array have indexing or something else
yes
a np.array works
like a list just has certain operations that are faster
asarray()
GeeksforGeeks
A Computer Science portal for geeks. It contains well written, well thought and well explained computer science and programming articles, quizzes and practice/competitive programming/company interview Questions.
!d numpy.asarray
numpy.asarray(a, dtype=None, order=None, *, device=None, copy=None, like=None)```
Convert the input to an array.I see
[0.1 0.2 0.3 0.4]

Stack Overflow
What is the difference between NumPy's np.array and np.asarray? When should I use one rather than the other? They seem to generate identical output.
?
#===[imports]===#
import numpy as np
#===============#
X = [0.1, 0.2, 0.3, 0.4]
converted_data0=np.asarray(X)
print(converted_data0)
@lapis sequoia
I would avoid geeksforgeeks entirely. They have bad quality control.
that was a artical i found im sorry
how could i get the dat from the array?
@serene scaffold
use
import numpy as np
lis = np.array([1,2,3,4])
wdym?
lis is the same as converted_data0
in your example
take what is in the array and make it where I can add all of the numbers in the array
!e
import numpy as np
print(sum(np.array([1,2,3,4])))
:white_check_mark: Your 3.12 eval job has completed with return code 0.
10
just a warning: this creator stopped making tutorials the moment before he got to the actual complicated stuff needing of tutorials