#data-science-and-ml
1 messages · Page 136 of 1
how can i start a ml concept without a base (like pytorch library)..
ViT
Im not creating a model here
Im training on a predefined model
a transfomer
class ViTForImageClassification(nn.Module):
def __init__(self, num_labels=8):
super(ViTForImageClassification, self).__init__()
self.vit = ViTModel.from_pretrained('google/vit-base-patch16-224-in21k')
self.dropout = nn.Dropout(0.5)
self.classifier = nn.Linear(self.vit.config.hidden_size, num_labels)
self.num_labels = num_labels
pretrained model already
forget that pytorch (and tensorflow, and jax) exist for at least a month.
there's more to machine learning than just neural networks and deep learning. and you'll find beginner concepts easier to grasp if you learn them in terms of more elementary models.
@past meteor
Im not training on my own model
Im feeding my dataset on a pretrained model
looks like you've added additional layers--presumably for fine-tuning
what do u mean by saying "elementary models"
models like k nearest neighbors and support vector machines.
theres a difference between training your own model on your own architecture and training a data on a pretrained architecture
u mean like trying to understand prewritten ml models
Not really.
Try reading about k nearest neighbors and find a dataset that you can use to train a k nearest neighbors model.
i dont understand what do u mean by k nearest neighbors
look it up
I'm not trying to be dismissive. that's the concept I think you should learn about.
also accuracy is the metric here
per my professor's note. He wants the images to be accurately tagged on validation dataset
he said the higher accuracy the better
Im not doing an anomly detection here where it is more of an unsupervised learning
where you don't have labels given to you
then you need to focus more on recall
that was the case with my anomly detection project for phishing detection
it was more about the recall rather than the accuracy
low recall value and high accuracy value is bad in anomly detection
you also need your recall value to be high
or you are flooded with false positives
and false negatives
so watch out your precision too
so I dont think if I say this on an interview it will be over
it is over
This is one of the first things they teach in a rigorous ML/AI class
Im not using my own model
It doesn't matter if you're finetuning
Or training from scratch or doing unsupervised learning
i thought that its a Figuratively speaking , but i found that it s a ml concept , sry for the confusioon and i will take a look on it soon
The point of ML/AI is generalization
Accuracy on what
on validation!
okay so why are you talking about training loss then
Im not
you literally said it here bro
I said lower the training loss better the model fits
and I just checked my accuracy on validation set and it was 99 percent
the better it fits the training data
yeah
But that's orthogonal to what you're trying to do
Which is fitting unseen data
aka generalization
yeah I know that
and my validation accuracy is really high
99 percent is a great accuracy on validation
Did you miss this?
that was in 2018
so what?
Its not bad to learn these things
the professor was amazing too
I think you are being too cocky
calling my learning shit
and that I dont know anything
then lets not go to college
that's not my intention and I'm very sorry if I gave you that impression
I'm trying to help but you get so so defensive
and now we're here
I'll know not to in the future because my advice isn't well received by you and that's on me
instead of being supportive you said who uses stepwise regression
knowing niche stuff is good
thats not a good advice
thats implying you know better than anyone else
You insisted I shouldnt be focusing on accuracy in my project where the teacher speficially asked us to focus on the accuracy
and then you called my professor bad
because he is teaching stepwise regression in 202x
I said many times that Im using a pretrained model. Im just changing the hyperparameters. Learning rate, Epoch and batch size
and you keep telling my model may not work on unseen data in the wild. I know that too
Im using a dataset on a pretrained model. Im not creating a model or an architecture that will work on various datasets to make predictions
now I understand your concern if I created a transformer architecture myself but I didn't to begin with
https://www.datacamp.com/tutorial/building-a-transformer-with-py-torch now over here, the person builds a transformer from scratch

Learn how to build a Transformer model using PyTorch, a powerful tool in modern machine learning.
i didnt even do that
all i did was feeding my data to pretrained transfomer architecture and check its performance on the data I fed into
I was not aiming to make any generalization
it will definitely not be giving the same results for every dataset fed into the architecture
I can feed it with fruit dataset and may get different results with the same hyperparemeters
do you guys have any recommendations for books to learn ML (using pytorch) for someone who already has a good foundation in Python and calculus
and linear algebra?
nah I don't know too much linear algebra
that's the most important part of dl
oh
do you know what a matrix is at least?
yeah i know matrix multiplication
then you may be fine, just need to learn a few extra things
imho the best place is coursera's andrew ng intro to deep learning
what specifically in linear algebra would I need to know
do you have any free resources
coursera costs money now
i emailed them and got it for free
there is the chance to do that when you register i think
i don't know of a book, and haven't read one to get started,
i mean what would you even email
there are many pinned here at the top of the chat
i already have an account but idk how i would email them to get it for free
i said hi i don't have money, and I am learning, etc etc
oh alr
just the truth unless you have money
yeah i see
alr thanks!
they'll be too hard likely, i don't know better than the course i suggested
(and the forum linked to the course.)
ur welcome ! feel free to ask here as you go learning
is a FNN the same as a perceptron?
@fiery escarp I think the materials for andrew ng are uploaded on a github repo
You mean feed forward neural network? People typically abbreviate it as ANN 😄
Yes
oh sorry , I am new to this xd
Okay I'll start by saying that a single neuron in a neural network is sometimes called a perceptron but out of experience I can tell you that drawing parallels isn't that interesting (but maybe you should to come to the same conclusion as I have haha)
Noted
A single perceptron follows the basic structure of a neuron, it's an affine transformation of the input and then the output is sent to a non-linearity (in this case a step function, Google how it looks).
A neuron in a neural network is the same, affine transformation of the input and then a non-linearity.
The parallels stop here though, perceptrons can only fit linear functions, they're missing the juice associated with neural nets. On top of that the training algorithm is different.
Ty , I will google the step function
To top it off, the reason why they're mentioned in the same sentence as neural networks is largely historical. The Perceptron is more similar to linear support vector machines and logistic regression than it is to neural networks.
Noted!
You can also Google the XOR problem

Explore the XOR problem in neural networks—unveiling challenges and solutions with multi-layer perceptrons and backpropagation.
I think I did some course in uni that showed the XOR problem with Perceptron and then motivated neural networks on the basis of that
Spending a lot of time on this one because it's the foundation of like half of ML. If you understand that affine transformation + activation function / link function (what statisticians call it) results in a linear decision boundary you have a basis to understand most methods.
After that you just need to know how to achieve non-linearities:
- "Manually" transforming input features
- Kernel functions
- Neural networks
- Non-parametic methods (decision trees, nearest neighbours, gaussian process, ...)
And you have a nice high level overview of most of ML
@deep sleet
Noted
yes
same as MLP (multi layer perceptron), to be precise
I am trying to google what you mean with non-linearity
Tysm for the roadmap tho!
like from a linear algebra definition ?
Ah that makes sense then
Yeah, feel free to ask any and all questions. My explanation was very dense with a lot of jargon so you could Google stuff afterwards.
For non-linearities let's first look at the Perceptron algorithm. After you do your affine transformation you have a real number, the Perceptron is a classifier. You want an output of 0 or 1. The step function is used to get it down to that
This is an exercise you should do for classification first btw so you can get an intuitive understanding
the step function here is also the activation function right?
Oh please send it my way
But the idea is, if you add the non-linearity at the end of an affine transformation you end up with something that is linear in its inputs (I'm generalizing because the cool thing is that it applies to ALL models, Perceptron, linear regression, logistic regression, ...)

You need something more
And the term non-linearity in this context, I think, was coined by neural network people. If you stack several of these units doing affine transformations followed by non-linearities you end up with something that in its totality is not linear in its input wrt. the output
And this is something we absolutely want. We don't want a model that is unbelievably biased. You can interpret bias here like how humans do it. Those basic units have a preconceived notion of the output being an affine combination of the input which is sometimes untrue. You can manually transform your input with log, linear, exponential transformations and so on but it's time consuming. We want a model that can find these patterns out of the box, then we arrive at neural networks
the output will still be a linear combination of the inputs
I'm sure there's some nuance I'm probably missing but for now let me say yes.
oh
Noted boss
I kinda get it now
Maybe @wooden sail can fill in the blanks I'm undoubtedly leaving 😅
not fully but will get there
that was pretty good
Dw about it, I think this is an insight that took me a couple of years to get
But when you get it, ML gets simpler
Because it becomes a bunch of variations of the same
Gotcha
Tysm man!
I will go through what you said again then check the problem you sent
what was the classification excercise tho?
Oh, it was a thought exercise
oh lol xdd
So, in the pinned posts I have a math book listed right? If I could go back to the beginning I'd probably read that if I were getting into ML
By the end of it you'll surely have gotten this insight
Yeah I am reading the book , I need to get more consistent with it tho
I always approached it from a practical POV which can also work, it depends on your interests ofc
I am not used with alot of the notation so it takes me a bit of time to get something done with it
Like, knowing how to solve problems with ML, knowing and contributing to some libraries, ...
Yeah Ig I kind of prefer that too
Understandable
I am actually learning because I want to try and work on a forex prediction model for fun xd
and they all use LSTMs
so that's why I jumped to neural networks for a bit , I still have alot of stuff to cover in basic Ml xD
That's better than what I did
I didn't touch them for a couple of years because I believed they were a complex beast
Oh
I actually thought it was bad that I didn't try to do the same
That's a bit relieving to hear
Slightly off topic but I have a strong love hate relationship with neural networks
I love them because you can get really creative and assemble a fit for purpose architecture in a way that feels like stacking Lego bricks
On the other hand, actually training them isn't fun. Too many hyperparameters and selecting them is effectively gatekept behind expensive GPUs
For a lot of computer science I feel like it's egalitarian, the better engineer solves the problem best but for neural stuff the size of your wallet is a massive factor 😂
i agree
xd
im considering buying by parts, with cheap gpus but many, didn't research much yet
a motherboard, good amonut of ram, ok processor, and 2 not very new gpu models
you've got colab otherwise, or linode (paid, but cheap apparently.)
but when you work for a company they provide you with the resources right?
yes, either the infrastructure or they pay for it
but you may need to find a good provider etc in the second scenario.
Yeah makes sense
This is a random question to ask at this stage but is the ai space oversaturated similar to other fields in tech
I think it is unless you have some background apart from AI
background it doesn't necesarily mean a degree right?
no, not necessarily, but some experience with a wide range of tools
oh I thought you meant like domain expert
Can you use yourself as an example here?
you can take a look at job requirements in some areas
i know dl reasonably well, and only had to use it as a side in a project
that's what i mean in a way
HOLY
the tools i most commonly use are typescript, python, bash, git/github,...
i don't know what's others' take, that's mine, yes it's hard.
I am sure also having proficiency in a db is also a must
Got it
yes, it depends on the area
it's advisable to look at the jobs you'd aim for early in your path
in the end, you don't need all the skills they list, but gives you an idea i guess.
you are welcome. take it with a grain of salt, im currently unemployed lol. better to get many peoples' input @deep sleet
Gotcha
Guys i will soon start my first sem in cs but i am a bit worried , is there any points to remember and things to avoid and some common mistakes that i should not make in my 4 years of uni
this channel is specifically about data science. but don't worry too much.
i see
So the main activation func are Relu , tanh and sigmoid, what is the usages for each 1?
or a resource to read more
all that matters is that they're non-linear. I don't think there are intuitive explanations for why one works better than another in a given context.
so really which one I use don't matter
Thx
there is some logic for when to use them in output layers though
it matters more for the output layer.
for example, the softmax function turns an array into a probability distribution between 0 and 1
by the mouth of two shall every word be established.
:-)
Oh so more about how you want the output shape to be like for your usage
!e
import numpy as np
def softmax(x):
e_x = np.exp(x - np.max(x))
return e_x / np.sum(e_x, axis=0)
x = np.array([1.0, 2.0, 3.0])
y = softmax(x)
print(y)
:white_check_mark: Your 3.12 eval job has completed with return code 0.
[0.09003057 0.24472847 0.66524096]
I know about softmax from 3b1b video , I just watched it xd
it's not necessarily about the shape. but you do need to be mindful of the shapes of your arrays/tensors at each point in the network.
Got it
ReLU has also important performance benefits and you'd rarely see sigmoid in middle layers.
But conceptually, it does not matter.
Noted
So all this AI hype is just... Machine Learning?
yes
I just googled machine learning and.. my god... it is overwhelming.
How do people manage to learn all this stuff?
Is it necessary to learn all of that if I just want to build a specific app?
no, it is only for understanding it.
no, not much
Oh okay.
I am doomed then 💀
Why?
Nothing , I am a beginner and I see him answering alot of questions that's why I said that
You're learning machine learning?
I hope to at least
What resources are you using?
What channel?
they are pinned here
Yeah xd
what is required to implement GPT, GAN or else?
its about translating theory?
i see GAN is 2 networks so its about implementing network
hmm GPT is transformer
Hey guys can u recommend me a good maths book which has good basic and advance topics
For machine learning?
Ds meaning derivatives?
data science
I found these on Google.

do u hv any free source where i can download these
In the google search bar type the name of the book followed by either doctype:pdf or filetype:pdf.
thnx bro
You might be able to find pdf versions of them.
it means a lot
The reason is vanishing gradients
Let me walk you through it
So, you obviously know what a derivative is right? Let's simplify it to the geometric, intuitive interpretation. It's the slope of a function at any given point
The logistic function tails off at the end. The slope at the very end is near 0, agree?
Remember that we're doing an affine transformation. We may have very large numbers (in the positive and the negative sense)
These large numbers are squished to somethign [0, 1] for sigmoid and [-1 , 1] for tanh. Therein lies the issue. It doesn't really make a distinction between very large numbers, specifically because of the use of a logistic function. This is the whole idea between vanishing gradients.
ohh
RELU is basically min(0, affine_output). It's clearly a non-linear function, great. We needed that to satisfy the fact that neural networks can fit any type of function. Additionally, the slope is exactly the same as the number. It's a straight line. We're not losing out on our gradient for very large numbers
Lastly, the debate between tanh and sigmoid (you should use neither for hidden layers) is simple. tanh being centered around 0 (it's range is [-1, 1]) means you're less likely to have "drift", basically the numbers in the network becoming larger as you go deeper and deeper, which has negative consequences for .... reasons I forgot
oh xd
I want to graph these functions to get a better grasp
yeah, google them. Also google what a derivative is again
Is RELU the most commonly used one nowadays?
and it'll all make sense, potentially reread the explanation several times
I know what a derivitaves not alot but the basics
Will do

Visually, try imagining drawing the tangent line close to 0 and 1, can you see it's going to be pretty much flat (so, derivative of 0)

ohh
Yeah I see the graph for them now
so ReLU makes more sense for hidden layers but does it face the same issue for output layers?

if you're in doubt, look back at this picture. It's the slope of the tangent line. Don't overthink it 😄
Can you manage or are you lost? @deep sleet
oh sorry I was drinking
no you're spot on
What is the derivative when it's 10 million?
(not a trick question)
10 million
Ah I get it now
so every value is treated correctly
but what about output layers?
let's do it here, what's the derivative (approximately when it's 6)
and when it's 10m
let's wrap this up and then I'll answer the other questions 😉
it's very close to 1
actually 0, because the tangent is a flat line, the slope is 0 but you get the idea
don't worry about it, you absolutely get my point here
so the neural network treats them the same
So this phenomenon is exactly what is meant by vanishing gradient
which makes it useless
And you see how RELU doesn't have it
For the output layer I'll simplify and say we have 2 cases:
- classification
- regression
You pick the activation of the output layer depending on your task. If it's regression you use a linear layer (which is just an affine transformation) and when it's classification you pick sigmoid
But yeah, in theory you could have vanishing gradients if you pick sigmoid for classification. But you're jjust having it in one layer so it's ... okay?
Sorry to butt in, I don't understand the derivatives well, so here the slope is constant as long as x is above zero right? So the derivative is constant? Or am I missing something?
ohh yes
but what about multi class
will you use something like softmax
you pick softmax, which is basically 1 sigmoid per class
gotcha
and the sum of the sigmoid outputs needs to be 1
Yeah I just learned how softmax work a bit earlier
I think I am getting ahead of myself here but
while I was doing research it said the issue with Relu
is dead neurons
That's one you can ignore for now 😄
there's stuff like LeakyRelu that don't have this problem
to explain dead neurons we'd have to delve (a bit) into how backpropagation works
so for regression you don't really use an activation function
but basically, you can say that when the output of the affine transformation <0 you pass no gradient down
that's the very basic version
oh I know a bit about it but I need to dive a bit into calc more because it had some calc stuff in there and deep derivatives
Got it
math seem to be a very constraining factor
Typically no, but I think there's valid use cases if you're a statistician that does ML (most are coming from comp sci backgrounds)
Gotcha
They're not that mainstream so you can definitely definitely ignore them
But, to give you an idea
Many things in the world are whole numbers ([0, 1, 2, ..., ])
A basic linear layer gives you real numbers
If you're doing sales forecasting you absolutely don't want negative numbers or fractions etc. If you're ordering jeans you don't want to order -3.2 jeans, it makes no sense right?
Yep
but then if that's the prediction then something is wrong with the network (I am talking about the negative number not decimals)
There's ways you can do this with neural nets. I know this because I know (some) statistics, but I see no comp sci ML people talk about it so you can safely ignore this and run with the assumption that regression => linear 😂
Noted xd
I think I can now start checking RNNs and LSTMs and see if there's anything that I am stucl with
go for it
I'll answer this in a sec 😄
Tysm man
I really appreciate the help and I know your time is valuable
idk how long it would have took me to figure this out
or if I would have really understood
You really are similar to 3b1b in terms of your ability to teach
it's constant, it's 1 yes
I goofed, the derivative is actually 1 all over
Ah, thanks
when it's >0
because yes when it's >0 it's f(x) = x and f'=1
but you got the point
now I got to google derivatives fr xd
but yeah I get it , it still is multiplied by 1 during back propagation so it helps to learn efficiently
The last paragraph in the image says "Such automatic search method is capable of getting well-shaped bedroom layouts that are very close to real cases", but no reference is given to this. Can anyone recommend an example repository from github?
paper: Decorating Your Own Bedroom: Locally Controlling Image Generation with Generative Adversarial Networks
paper link:https://arxiv.org/pdf/2105.08222

But I feel betrayed
i want to interject briefly on the relu and its derivative
it's not differentiable at 0, but it has a so-called "subdifferential"
without going into details, there is more than one way of deciding what to do exactly at 0, and so you might find that if you try to reproduce a network and the training procedure identically on, say, tf vs pytorch, you might get different results
(Some do 0 at 0 (torch) and some 1 at 0, the difference between the two is amplified at lower precisions)
Be sure to always ask your actual question. Don't ask to ask.
sorry
my internet died
i am using pyspark and i did the flitering and everything i want to save it as csv now
i am unable to do it i did the whole winutils but i still cannot do it
what do you mean unable to do it? do you get an error?
yes

can you share the code where you save

and which one is the one that crashes? the first one?
Like from the first one itself it crashes 🧍
there's someone in https://community.databricks.com/t5/data-engineering/how-to-solve-py4jjavaerror-an-error-occurred-while-calling-o5082/td-p/24028 who had the same issue, you should give the proposed fix a try
Did this no avail
Error still persists I tried every version of winutil too
I found this video too tried that still does not work I am at loss of what should I do here now
Hey 🙂
I have a torch tensor representing the time evolution of 17 3d points. Its shape is (T, 17, 3)
I want to z-score normalize it per point, such that the mean and variance is computed separately for every point. How can I do that using torch's builtin normalizers? How is this specific type of normalization called? I have been over the different types of normalizers in the docs but they're pretty confusing and all seem similar. (I've usually been using the docs and they're great, it's the first time I struggle with them)
anyone use mamba instead of conda
Why do you ask
My opinion is that you should use standard virtual environments and pip unless you know exactly why an alternative is better for your purposes
I'm processing data by one hot encoding it. Currently I'm using pandas and I have a column thats like OneHotVariableXYZ and each row in it is a list of a one and zeros... Do you do this for processing data, or do you make multiple pandas columns like OneHotVariableXYZ_index0, OneHotVariableXYZ_index1... where each row is just a zero or one.
Or do you do something different? It's a bit hard to manage I'm finding
won't you get an error if you try to give that df to... basically any ml module?
usually you should have the latter, ending up with a lot of OneHotVariableXYZ_indexX columns
won't you get an error if you try to give that df to... basically any ml module?
ya that was the issue I hit was wondering if I was missing something like a cleverDataLoader... kinda glad if no one does that it seems hard
It seems we may have misinterpreted.
steps_per_epoch: DefaultNone. Total number of steps (batches of samples) before declaring one epoch finished and starting the next epoch.
i.e each epoch runsceil(n_samples/batch_size)batches, and sees all the training data.
If you pass a number (n), each epoch finishes afternbatches (i.e does not see all the training data on each epoch.)
TensorFlow
A model grouping layers into an object with training/inference features.
one reason for that parameter may be that training speed and accuracy depends on the batch size. (and seeing all data each time may not be needed.)
anyone whos just starting off or interested in data science as a career?
Why do you ask
my buddy and I were launching a bootcamp next month to help people out if they're thinking of data science as a career option. it'll be free
that's an interesting idea, but you can't promote that here
@serene scaffold why not?
it is almost an invitation to a coding jam imho
im not interested but others may
we don't allow that either.
WAIT I DON'T HAVE TO CODE THE ML ALGORITHMS MYSELF?
Depends on the situation.
What do you mean?
What do you mean?
What caused you to suddenly declare that you don't have to code ML algorithms?
I watched this YouTube video about machine learning (because I'm new and wanted to learn about it), and it said that I don't have to code Machine Learning algorithms from scratch.
It sounds like you aren't far enough along to understand what difference that will ultimately make.
What?
You will see
That's insanely ominous, but okay.
Yes
How long did it take you to learn machine learning?
Good god.
How long does it take to learn how to build a machine learning app that can analyze images?
Never have
I do language technology
I feel like that's the most common application of it, I might be wrong though.
So you learn how ChatGPT works?

I sort of know how it works. I've fine tuned interactive language models to do additional tasks.
Wait real quick, is a Mac or Windows computer better for coding?
Kinda depends
if your not experienced with linux using Windows for GPU compute is probably going to be more friendly
That's a matter of personal taste for which there is no objective answer.
Most deployments are on Linux.
but other than that there isn't really a difference, although some things are linux only. Most tools during development wont care
also as Stelercus says, when deployed it is in reality always linux
Use whatever computer you already have. But if it's windows, I recommend getting a bash terminal like cmder
Imo, beginners should seek the most linux-like experience possible
I thought Macs were insanely expensive for the same computing power.
Just like iPhones.
M1/M2 laptops in reality pack a lot of compute for the price
but for ML/AI generally speaking a GPU becomes important for larger training tasks
If you have a windows computer and you don't have a Mac, don't buy one.
Also if you're learning about deep neural networks, you probably won't be able to run it on any consumer hardware anyway
I kind of agree, but I think correctly setting up and managing all the nvidia drivers to do GPU compute on linux is still a very non-beginner friendly thing, or even just trying to debug why a drive you installed didnt work etc...
same sort of thing with AMD ROCM
hey I'm new in this coding thing
can someone tell me where to start from which class to join
Last gpts model are not open source also just for saying, ml/Ai isn't only LLMs and image
It was just the first thing that came to my head.
i would appreciate if someone replied please
Google Machine Learning on YouTube, that's what I'm doing.
and how to start with python is there a class or smth
W3 schools.
thank you buddy, is udemy class worth
Just saying, because the hype is big on LLM but really there is a lot of potential applications with """"just""" classical ML and time series, which is what most people were doing and are still doing beside the LLM hype (which is out of scale for me but this is just an opinion)
I haven't tried it.
To complete the answer, implementing them one time for learning is good tho, even if most of the time for tabular data you won't implement every model in real life scenario, and there's time especially in deep learning where you have to implement things yourself
Hey guys could y'll suggest me like a website where I can learn CNN to advanced?
Course materials and notes for Stanford class CS231n: Convolutional Neural Networks for Visual Recognition.
if that's known to you then there are more advanced by those people
Anyone knowledgable in web scraping?
just start.
Google Machine Learning on YouTube.
I have to ask - do all machine learning enthusiasts use Jupyter notebook?
it is extremely practical, so it is very popular to test small pieces of code for data exploration, cleaning, modelling etc... you'll still need to writte .py scripts modules
I test things in my notebooks, then write functions and put it in a .py even if it doesn't apply somewhere else than my notebook, so it makes it cleaner, too long notebooks are painfull to read
What do you mean by modules?
Do you mean that I also need to write actual python scripts instead of just small jupyter test cases?
i recently learned simple linear regression and want to try out some project in it
How long did it take you?
3 days ig
That's it? I thought it would be much more.
i had some idea about the maths behind it
Are you in high school or college?
yup
I meant are you in high school or are you in college?
Oh that would make more sense.
How often are these two lines used in Machine Learning?
import pandas as pd
from sklearn.tree import DecisionTreeCLassifier
A lot of beginners seem to like the CS50 course from Harvard if they prefer videos: https://www.youtube.com/watch?v=LfaMVlDaQ24

Learn the basics of computer science from Harvard University. This is CS50, an introduction to the intellectual enterprises of computer science and the art of programming. The course is taught live every year and this is the 2023 version.
💻 Slides, source code, and more at https://cs50.harvard.edu/x.
⭐️ Course Contents ⭐️
⌨️ (00:00:00) Lectur...
It does more than just Python, and serves as an overall introduction to computer science.
(Scratch, C, Python, SQL, HTML, CSS, Javascript, data structures and algorithms, explaining a lot of the things you might encounter randomly)
^I would also be interested in beginner projects like this
Is using Kaggle datasets a good place for this kind of practice? Because Kaggle seemed kind of advanced to me the last time I looked
Is this good for machine learning too?
Knowing some programming / computer science is prerequisite knowledge. You should be comfortable with Python, and understand the basics of data structures and algorithms, being able to code many simple things easily.
Okay.
You want to be able to focus on the machine learning, not get stuck on the code.
Can you please tell some beginner friendly machine learning projects based on real life scenerio...
handwriting recognition is a classic, imo
https://nanonets.com/blog/handwritten-character-recognition/

Nanonets Intelligent Automation, and Business Process AI Blog
How to recognize handwritten text using machine learning handwriting recognition methods. Implement handwriting OCR or handwriting recognition.
unrelated to that, if anyone wants a possibly-interesting dataset to play with, I recently found a site that can convert a debug info copy/paste from a YouTube ad and give you the link to the ad's video, and they have a list of all the vids they've collected from this method (7,297 as of this writing)
https://benjaminaster.com/yt-ad-to-link/links/
Can you give an example use-case of that dataset?
hadn't thought that far into it, personally I just like to poke around at stuff; like with that maybe I'll dig into the YouTube API and see what I can find, group by channel/advertiser, etc.
not a really useful dataset I guess, just possibly interesting as I said
and nice profile pic @umbral blaze , I used to use an ancient MacOS 8.6 machine in middle school
Thanks, I recently read Steve Jobs' biography and got inspired to do it.
nice! I've meant to read that and watch the Ashton Kutcher movie of him but haven't gotten around to it yet
I like the "the crazy ones" quote from him, think that's on the logo for Notes still in macOS
typicaly you writte a "data_cleaning.py" with useful functions and you import in your notebook
jk, apparently not a quote from him
Often misattributed to Steve Jobs, the poem was a part of Apple's iconic Think Different ad campaign developed in the late 90s.
https://basicappleguy.com/basicappleblog/heres-to-the-crazy-ones#:~:text=The poem itself was developed,one by Steve Jobs himself.

Basic Apple Guy
A short history of this iconic poem and the many Easter eggs embedded across macOS.
Oh that's cool.
I really liked it. It was the first book that I read 200 pages of in one week.
wow, nice
I haven't read that much in that little time in ages
I remember reading for hours on end as a kid
never thought I'd be into non-fiction but I've read Snowden's book and Mitnick's (rest in peace) books in the past few years
Honestly, I only read it because I wanted to prepare for AP Lang over the summer (because my English teacher told me to read biographies), so I googled "best biographies to read" and found his.
Oh nice.
those are also good reads if you're looking for other tech bios
Ghost in the Wires - Kevin Mitnick
Permanent Record - Edward Snowden
Ghost in the Wires almost reads like a thriller, since he told the story of evading the FBI and eventually getting captured
I might check that out.
I like books that are either inspiring or tell a good story without using every complicated word possible.
Most I read in school last year were so boring.
fair enough
I like my Kindle for that reason, even offline can look up word definitions
and taking up less space than physical books is a pro as well
does the part of ml in k nearest neighbor consist of choosing the right k
The results will be different based on the value of k that you pick
yeah so the role of ml comes to choosing the best k
I don't know what you mean by "the part of ML comes to"
That construction doesn't have an established meaning in English.
how can i choose a specific k
4
?
Just pick 4 and see what happens
.
but i can do this with a simple code
increasing the k every time i have an equal values like having 2 neighbors red and 2 green
Okay. Are you going to code it?
yeah
tell me about more ml concepts to study them after that
K fold cross validation
i think that the best way is trying different k values , and using the one that gives the highest rate of accurency
pick the square root of the amount of the data that you’d like to predict it’s usually the normal choice
alternatively if you’d like to figure out what’s the optimal ones you could make a dictionary that would handle each value of k and its accuracy / recall whatever you want and sort it by its value (not keys) so that you’d find the optimal k
so that you could predict each iteration with another k that exists and then find the optimal ones…. keep in mind that it may take a lot of time
What do you mean with "the part of ml"
KNN in an of itself is already ML
Selecting "the right" K is called hyperparameter tuning
what is the issue here ?????

Wait, your environment isn't activated, you are using the base environment I think.
Do you know how to use conda (miniforge3) and why do you need it? I'd guess your base env has an old python version or smth. So you need to activate your env and use the right python version.
@ember pawn
Hello. Im trying to extract prices, quantity and item names from flyers like this one. Any suggestions on how to do it optimal? I was thinking about using yolo for box detection of whole item and then extracting text with ocr. Any suggestions? Thanks

What you are thinking of is a good approach @chrome pagoda .
I liked Yolox in the past https://github.com/Megvii-BaseDetection/YOLOX but there are many

GitHub
YOLOX is a high-performance anchor-free YOLO, exceeding yolov3~v5 with MegEngine, ONNX, TensorRT, ncnn, and OpenVINO supported. Documentation: https://yolox.readthedocs.io/ - Megvii-BaseDetection/Y...
hi
i am new to ai and machine learning and i want to learn computer vision but i dont know where to start. any free course recommendation?
Thank you, ill check it out
what is the best ocr in python?
basically i want to get text off newspaper segments and was using pytesseract since it had segmentation modes as well which gave proper results for columns.
Paddle OCR has a better ocr on ads and stuff where tesseract sucks being an older model but doesn't have segmenatation support and its nonsensical for columnar text...
any idea what might fit my use case and give good ocr results with page segmentation mode support?
try ddddocr
Elbow method.
that's for the K in k-means 😄
For KNN you just cross validate
What's the most popular library for object detection in python?
detection as in classification, image bounding boxes, video tracking or what exactly?
depending on what exactly you're trying to do, you can try using OpenCV, hugging face or https://github.com/roboflow/supervision

GitHub
We write your reusable computer vision tools. 💜. Contribute to roboflow/supervision development by creating an account on GitHub.
@umbral blaze ^
Namaste everyone ,
i am currently working in YOLOv7 and getting this issue while model training
Transferred 552/566 items from /content/yolov7/yolov7.pt
Scaled weightdecay = 0.0005
Optimizer groups: 95 .bias, 95 conv.weight, 98 other
train: Scanning '/content/YOLOv7dataset/YOLOv7_dataset/train.cache' images and labels... 0 found, 0 missing, 0 empty, 42 corrupted: 100% 42/42 [00:00<?, ?it/s]
Traceback (most recent call last):
File "/content/yolov7/train.py", line 616, in <module>
train(hyp, opt, device, tb_writer)
File "/content/yolov7/train.py", line 245, in train
dataloader, dataset = create_dataloader(train_path, imgsz, batch_size, gs, opt,
File "/content/yolov7/utils/datasets.py", line 69, in create_dataloader
dataset = LoadImagesAndLabels(path, imgsz, batch_size,
File "/content/yolov7/utils/datasets.py", line 403, in __init
assert nf > 0 or not augment, f'{prefix}No labels in {cache_path}. Can not train without labels. See {help_url}'
AssertionError: train: No labels in /content/YOLOv7_dataset/YOLOv7_dataset/train.cache. Can not train without labels.
My folders hierarchy in google colab is
YOLOv7_dataset
YOLOv7_dataset
├── images
│ ├── CaptainAmerica
│ │ ├── train
│ │ └── val
│ ├── IronMan
│ │ ├── train
│ │ └── val
│ └── Thor
│ ├── train
│ └── val
├── labels
│ ├── CaptainAmerica
│ │ ├── train
│ │ └── val
│ ├── IronMan
│ │ ├── train
│ │ └── val
│ └── Thor
│ ├── train
│ └── val
├── classes.txt
├── train.txt
└── val.txt
i have checked my train.txt and val.txt they have corresponding images txt files but still getting the issue
Oupsie indeed
Too fast-read
hello, is it the good place for image processing question with opencv ?
depending on the question it might fit in #media-processing, but if it's ai or numerical computing related yeah here is the right place
i try to explain my problem, i have to recognize handwritten digits in images, when digits are not attached, i manage to extract the shape, clean it and pass it to a model i trained. but i encounter problems when digits are attached. see this example with 6 and 8 attached. i cannot extract them.

thanks etrotta, i will also post in #media-processing. do you have any suggestion for this problem ?
yes i'm sure it is. thank you for your answer anyway !
that s my own k_nearest_neighbor application https://github.com/kuger12/projects/blob/main/k_nearest_neighbor.py
the dataset used is https://github.com/kuger12/projects/blob/main/flowers.data
What if I were to try and detect skin cells that have some sort of problem with them? What would be the best library for that?
Hello. I am new to ML. I am using jupyter notebook for the first time in vscode. However, I am unable to visualise the progress of my training. Something wrong with the kernal?
You can't print something?
so like a progress bar? how do you know that the code is even trying to show a progress bar?
Yes I can print. But it doesnt work while im training a model. I cant see the progress of my training.

I have made the code to show the progress. Earlier it did show it. But today, it suddenly stopped showing.

Currently none of it shows.
Check your dms.
why do you want them to check their DMs? it's easier if you just say stuff in the channel.
any help? How to fix it?
I wasn't trying to scam them or anything I was just asking for resources.

By the way, is PyTorch a good framework to get started with? Especially for image analysis?
yes
Yes, but you probably need to learn more basic ML concepts before you do anything that involves neural networks
yeah, pytorch is a little more complicated but thats because there is a lot more control over the internals and workings of the network your building itself
Is this course good enough to explain the basics?

I'm not sure.
What did you use?
My initial learning was a clusterfuck of different experiences while I was a CS student
I guess I'll just stick to the Stanford course, especially considering I'm not even in college yet.
Are you in high school or what
Yeah.
What year? And what math are you taking?
Going into junior year, I'm taking AP Calculus AB this year.
Good
I'm guessing AP Statistics is helpful too?
I'm taking that senior year.
Yes
Any fixes for jupyter kernel? Being trying to fix it for an hour now. Cant get through it.
@wispy nacelle I recommend using Jupyter lab instead of any ide integrations

if you share screenshots, make sure they're tightly bounded around what you're trying to show. And don't do screenshots of code/error messages.
What did you do that was intended to start jupyter lab?
Sorry about that . I typed - jupyter notebook in vscode terminal. and it redirected to this page.
Thanks I seemed to have fixed this issue. It redirected to a wrong page for some reason.
try python -m jupyter lab
a bit of a dumb question but is each layer in a LTSM network consists of 1 neuron only?
you might want to look at this diagram that talks about the different gates in an LSTM cell. https://towardsdatascience.com/the-lstm-reference-card-6163ca98ae87
Medium
Introducing The LSTM Reference Card
there are a few places in the cell that have trainable parameters.
Ty
You keep asking about meta learning like which course, which that, just, start.
You don't need aprobation
Else you'll be asking things still in 6 month
There is no absolute best course and ressources
I understand it the structure of the cell , at least vaguely but my question does a LTSM neural network look like this? where each layer is limited to neuron?


that diagram is not particularly understandable
LSTMs wouldn't be of much use if they were only a neuron in width.
Check rnn first it's plenty enough to understand at first
you can look at e.g. https://pytorch.org/docs/stable/generated/torch.nn.LSTM.html for the formulas - each layer involves a matrix multiplication and some activations, as a normal dense layer, plus terms related to the cell state.
also note that the weights are shared across the entire sequence
Yeah , seems like I am getting confusing stuff a bit
Will do
Hey guys,
Im trying to calculate the distance of an object from the camera which has been detected by my model
I have been trying to use the MiDas model but am having a really hard time working with it as the values are off the charts and I dont even know if I did it right
Link to my question - https://stackoverflow.com/questions/78780498/trying-to-implement-the-midas-model-for-monocular-depth-estimation-in-tensorflow

Stack Overflow
Downloaded Tflite MiDas model from Kaggle.
Looked at a few articles for MiDas and Monocular Depth Estimation(Basically finding the distance of an object from the camera using pixels)
This is for ob...
hot take but the math behind nn for the most part r trivial
like if u know how chain rule and what convexity means, intuition is super clear
Did you try asking an AI model like Perplexity or ChatGPT?
interestingly, training nns is mostly nonconvex opt
Even then in terms of theory, u can def get started with torch api if u just know very basic concepts
I don’t think it’s necessarily super hard to learn
I am training a CNN model with a dataset of 70k images. However, the loss is not reducing. It is not going below 3. How do I fix it? What should I look for?
please show the whole code
!paste
Pasting large amounts of code
If your code is too long to fit in a codeblock in Discord, you can paste your code here:
https://paste.pythondiscord.com/
After pasting your code, save it by clicking the Paste! button in the bottom left, or by pressing CTRL + S. After doing that, you will be navigated to the new paste's page. Copy the URL and post it here so others can see it.
Trying to query a kinesis shard for the past 15 minutes worth of records, having a lot of trouble counting the records in that period. If anyone knows about kinesis with pyspark let me know
Guys is it best to learn opencv from their documentation?
i tried but it didnt help
Did you train it or is it a pre-trained model? @unique spoke
The github repo for the original architecture, and a colab of yours that we can execute, would be useful.
yo
Pretrained model
@lapis sequoia
colab would be hard to do considering that all files would have to be moved to be accessed by colab and then also webcam features
However I can send outputs and code
This is when I am right infront of the camera
Outputs: Min depth value: 56.30779266357422, Max depth value: 798.6359252929688 Depth value at (109, 127): 714.80 meters Min depth value: 53.4724006652832, Max depth value: 842.5797119140625 Depth value at (110, 127): 716.33 meters Min depth value: 53.12974548339844, Max depth value: 842.8057861328125 Depth value at (110, 127): 718.45 meters Min depth value: 54.4995231628418, Max depth value: 835.9800415039062 Depth value at (110, 127): 694.55 meters Min depth value: 52.12834548950195, Max depth value: 826.98974609375 Depth value at (110, 127): 694.30 meters Min depth value: 56.68858337402344, Max depth value: 849.092041015625 Depth value at (110, 127): 728.20 meters Min depth value: 63.134300231933594, Max depth value: 856.208740234375 Depth value at (110, 127): 691.71 meters
code can be found here
too long to send in discord
all my stuff is there
@lapis sequoia
Hi guys, I'm building a machine learning project for food stock optimization to sell to supermarkets in order for them to waste less food and money. Anybody willing to join me in order to make things faster?
you can ask questions in this channel as they arise. it's not very likely that anyone will commit to an ongoing student-tutor relationship.
Hey guys while running this command ```py
midas = torch.hub.load('intel-isl/MiDaS', 'MiDaS_small')
midas.to('cpu')
midas.eval()
I get this error : ```py
SSLCertVerificationError Traceback (most recent call last)
File /Library/Frameworks/Python.framework/Versions/3.11/lib/python3.11/urllib/request.py:1348, in AbstractHTTPHandler.do_open(self, http_class, req, **http_conn_args)
1347 try:
-> 1348 h.request(req.get_method(), req.selector, req.data, headers,
1349 encode_chunked=req.has_header('Transfer-encoding'))
1350 except OSError as err: # timeout error
File /Library/Frameworks/Python.framework/Versions/3.11/lib/python3.11/http/client.py:1303, in HTTPConnection.request(self, method, url, body, headers, encode_chunked)
1302 """Send a complete request to the server."""
-> 1303 self._send_request(method, url, body, headers, encode_chunked)
File /Library/Frameworks/Python.framework/Versions/3.11/lib/python3.11/http/client.py:1349, in HTTPConnection._send_request(self, method, url, body, headers, encode_chunked)
1348 body = _encode(body, 'body')
-> 1349 self.endheaders(body, encode_chunked=encode_chunked)
File /Library/Frameworks/Python.framework/Versions/3.11/lib/python3.11/http/client.py:1298, in HTTPConnection.endheaders(self, message_body, encode_chunked)
1297 raise CannotSendHeader()
-> 1298 self._send_output(message_body, encode_chunked=encode_chunked)
File /Library/Frameworks/Python.framework/Versions/3.11/lib/python3.11/http/client.py:1058, in HTTPConnection._send_output(self, message_body, encode_chunked)
1057 del self._buffer[:]
-> 1058 self.send(msg)
1060 if message_body is not None:
1061
...
166 f"repo could not be found in the cache ({get_dir()})"
167 ) from e
168 return repo_owner, repo_name, ref
RuntimeError: It looks like there is no internet connection and the repo could not be found in the cache (/Users/xxx/.cache/torch/hub)
I dont understand how this is happening.
I do have an internet connection
and im just following a tutorial
so in a LTSM network with for example 1 input layer , 2 hidden layers with 3 cells each and 1 output layer , now in the first layer each neuron processes the data independently
and then the output for each of them is concated and passed down to each neuron in the next cell as input , my question is how exactly is it concated?
before you continue, can you explain what you think a neuron is?
an ltsm cell with a cell state , hidden state , forget gate , input gate , cell state update gate and an output gate
That's not right.
oh
that isn't really anywhere close to what a neuron is, so banish it from your mind.
let me find a diagram
Ty

The concatenate basically means, you have several matrices/tensors that you basically put behind each other to create a new tensor
@deep sleet all the x values are the inputs. they get multiplied by their respective w value and summed up in the neuron. and then you add the bias
Let's simplify to vectors, if you have a vector of 2 long, 3 long and 5 long, concat basically means you get a new vector of 10 long that consists of the original 3
That's a basic perceptron tho right?
ohh
Forget the idea of Perceptron. Stick to the thing I told you, affine transformation + non linearity
"neuron", "Perceptron" are poor analogies for something simple
oh ok
this is the formula for what that diagram is saying

Yeah I get the basics of that from 3b1b series
but doesn't the same happen in a ltsm just in a more complicated way? I read the link you sent yesterday
LSTMs are really explained in a bad way that makes it more complicated than it is
Learn how vanilla RNNs work and just accept the RNN parts as magic
sometimes it feels like everyone who explains neural network stuff don't know what it's like to not understand it.
Yeah I tried to read about it but I didn't really find an explanation on how a network works
Everything mentions only how a cell would work
What's a "cell" in this context?
LSTM cell
Agreed, but the LSTM explanations are more evil than usual
I can explain it in the evening, I'm out today
Tysm man
In the meantime just start understanding vanilla RNNs
Will do
i'm in the camp that RNNs and LSTMs (and most ML stuff, really) is a lot easier to understand through equations than with weird diagrams
yes but you're a nerd.
yeah, well

what would be your math term for it
i thought you were gonna hit me with something fancier. i agree, but you have to admit that "neuron" and "layer" roll off the tongue nicer than " composition of an affine/linear transformation with a scalar function"
if you will repeat the same object several times, sure
I agree for LSTMs specifically
Sadly, whenever I try to make a diagram that is easier to process it becomes exactly like the clusterfuck they have
It's one strange instance where you can only understand the diagram if you already understand the idea
whenever this happens, i strongly reconsider whether the diagram is worthwhile at all
Is 80k samples in a dataset is too much for a simple CNN model used for recognizing captchas?
There is never too much especially if it has good quality
I have been getting terrible results. Loss is at 0 and the evaluation model gives an accuracy of 5%
if the captcha is like this, do you convert it to grayscale?

Are colors a usefull info here?
can someone help me run a file in this program? https://github.com/RasmusRPaulsen/Deep-MVLM
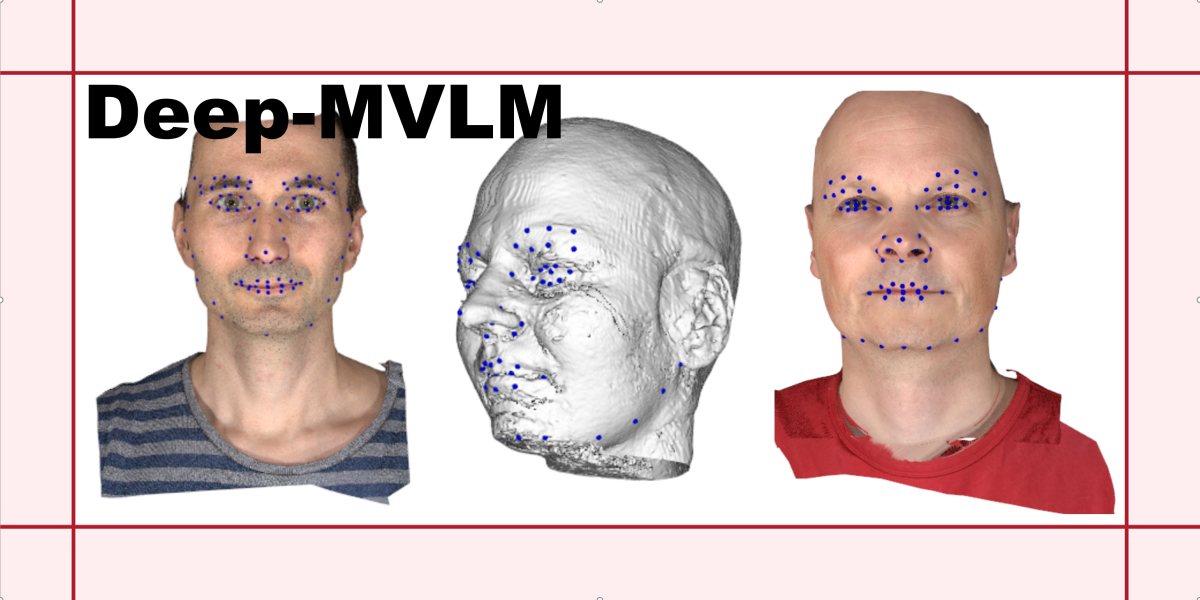
GitHub
A tool for precisely placing 3D landmarks on 3D facial scans based on the paper "Multi-view Consensus CNN for 3D Facial Landmark Placement" - RasmusRPaulsen/Deep-MVLM
Log in to iCloud to access your photos, mail, notes, documents and more. Sign in with your Apple ID or create a new account to start using Apple services.
given that recognizing captchas is pretty much only useful for bypassing restrictions sites place onto bots, we don't help with that here
Also check if captcha can have rotations, like if letters can be mirrored or something, that way you can think of data augmentation
no but is that the problem?
but it is purely for learning purposes. I am not doing it for bypassing the security
That mean you have to ask yourself this question to answer
So yeah, pbby better
but i dont understand the limitation of my model. It has 0 loss and very low accuracy. What could possibly be the issue. Is my model properly training ?
"0 loss and very low accuracy" should be literally impossible, perhaps something's wrong with your loss function?
unless you mean "low loss on the training set but bad accuracy on the test set", which is overfitting.
sorry for the mistype. yes 0 loss on the training set and bad accuracy on the validation set
@deep sleet
Okay, I have time to write it out now. You understand the basic idea of recurrent neural networks right?
Basically, you have 2 sets of weights.
Let's give them non-standard names. The first one is the input weights. They take both the hidden state (more on that later) and the input at a given time point and produce a new hidden state.
The second pair of weights you have are the output weights, they take a hidden state and transform it to an output. This pair of weights are the standard affine transformation with activation function I've been drilling you with
Let's talk about the hidden state for a second
True. It is severely overfitting. val accuracy is 7% 😦 . How can i overcome this? data augmentation? batch normalization?
What you really have to understand for this is the idea of something being Markovian.
This is something where you have a process that has a "time axis" and the next point is fully determined by the previous state. Aside from that you need no memory.
Going a bit slower, take a Fibonacci sequence for instance, if you know the previous two numbers you know the next one. We can say this is a Markovian process.
Why does this matter for recurrent neural networks? Because in the real world oftentimes it's not just the last point that determines the next, but a whole bunch of them. We can summarize all of them into a single tensor. This tensor can then be used to produce the next output. Basically, we're modelling something that follows this Markovian principle and the hidden state is a latent variable that contains all the information of the previous points.
You asked about what the concat is. To produce a new hidden state you need to consider the previous hidden state and the input. You concatenate both tensors into a new tensor and push that through the input weights to create a new hidden state. This should summarize the dataset of all points up until that point
RNNs are nice because you can use them on arbitrary length sequences. You only need parameters to process one timestep. Doing predictions with them is basically a for loop. You start by creating a new hidden state from the previous hidden state and input, produce an output and you loop until the end. For feed forward networks you need to create lagged variables. The architecture can only handle a specific amount of previous inputs
I think of Markov Chains as the analysis of 'two steps forward, one step back' ; the hardest and truest way to live, probably
Bayesians are not super different,
For now I'll just say LSTMs are a solution to the vanishing gradient problem. If you have a very long sequence and you calculate the error and the loss it's very hard to update the weights correctly @deep sleet .
The LSTM architecture has a lot of "anthropomorphization" in it with the forget gate, cell state and so on. My personal opinion (but you can disregard this!!) is that it's BS and the reason why it works is likely because it just has more parameters and it solves the vanishing gradient problem. Try digesting how RNNs work from my "blog post" above first and then we can talk about the role of those gates. It's not hard once you see it 😄
Sure you can but GANs are definitely higher on the scale of "painful to train"
And recurrent models are already high on that scale
Hi everyone!
I have been taking the Machine Learning Specialization course by Stanford (instructor: Andrew Ng) on Coursera. This specialization is a collection of three courses. After completing the first week, I am now on the second week of the first course.
I have a few doubts that I want to clear.
First of all, the first week was filled with different difficult concepts like linear regression, cost function, gradient descent, etc. Honestly, I couldn't understand much. Are these concepts really important for machine learning?
Secondly, is this course worth it? Have you taken it?
Thirdly, is this course suitable for beginners? Although it is mentioned in the description that it is.
Fourthly, is this course just theoretical or practical as well?
And lastly, if you have any suggestions for other courses that might be better than this one, please let me know.
Thanks!
i haven't taken the course so i can't address most of your points, but i can tell you that stuff like linear regression gradient descent and cost functions are things you NEED to understand at least intuitively, since these are at the core of almost everything you'll do in ML
First of all, the first week was filled with different difficult concepts like linear regression, cost function, gradient descent, etc. Honestly, I couldn't understand much. Are these concepts really important for machine learning?
Yes. That's about as fundamental to machine learning as 2+2=4 is to math.
Fourthly, is this course just theoretical or practical as well?
Depends on where you draw the line? iirc it has a few exercises but no capstone project
Secondly, is this course worth it? Have you taken it?
Depends - could be for many but perhaps not you (nothing personal, really just varies)
Thirdly, is this course suitable for beginners? Although it is mentioned in the description that it is.
it is mentioned in the description that it is.
Different perspective. I think nowadays there's a lot of room for software engineers that use AI that know little to no math. Try building stuff first to see if you enjoy the applied side. If you enjoy it you can try the other side as well (the more theoretical side)
I also think you need surprisingly little math to understand most methods. The math I learnt in high school is sufficient. The thing is, most people forgtot that math and need a refresher
(in practical terms, 'enjoy the applied side' is pretty much: stick with consuming models via APIs and don't try to create new models yourself - which is also a valid choice)
if you consider cost functions and linear regression to be difficult, the only thing I can recommend is either:
- study more
- do not bother any course that teaches you to build ML models
It's not like you would never understand it, anyone can learn it if they put enough time and effort into it, though how much that is can vary from person to person.
Which one is best for you depends - nobody has enough time to learn about everything in the world, so it's fine to prioritise other things
Do you use cross Val tho?
It's easy to overfit
I am looking for mentors in data science. Any tips on how to reach out to people? I have tried LinkedIn but no lucks yet
If anyone is interested please DM me. Thanks in advance
To a plethora of people I've had this discussion with, Andrew Ng's course happen to be the best thing since slice bread; in their ML journey of course.
I looked at myself then and I was like "Why do I find this course boring? Is there something I'm not doing right?"
I've always found myself dosing off a couple of times when I tried learning from that course.
I made significant progress when I dropped the video and started all over with a Udemy video. I think the top-down approach helped me understand better.
I later came back to Andrew Ng course after using Udemy video and it started making sense, surprisingly I didn't sleep off nor find it boring anymore.
If it's any consolation, I just wanted to tell you that nothing is wrong with you, you just haven't stumbled on the learning material your spirit finds alluring 😄.
Whenever you're learning something new and the material isn't doing it for you, please don't hesitate to drop it and try another material. Repeat this until you find that material your spirit aligns with, with ease.
That way, you'll make quick progress. That's kinda how I figure out things when I started.
is anyone familiar on how you'd go about creating a plotly animation if you have an array of figures or something similar? making static plots with plotly is simple but their animation documentation from what i found is a little bad
or if anyone knows alternative documentation I'd appreciate that, the matplotlib animation docs we're pretty good
https://plotly.com/python/animations/
You can try using go.Frame
The parameters for px are not explained very well in this page, but the API reference explains them:
animation_frame (str or int or Series or array-like) – Either a name of a column in data_frame, or a pandas Series or array_like object. Values from this column or array_like are used to assign marks to animation frames.
animation_group (str or int or Series or array-like) – Either a name of a column in data_frame, or a pandas Series or array_like object. Values from this column or array_like are used to provide object-constancy across animation frames: rows with matching `animation_group`s will be treated as if they describe the same object in each frame.
Detailed examples of Intro to Animations including changing color, size, log axes, and more in Python.
yea i've been attempting to use Frame and check those docs out earlier I may take a break then reattempt
It's nice of you to post here. You can also try posting in ML & Data Science subreddit as well.
More so, If you are interested in applying to graduate school soon, application to Fatima Fellowship & Black-In-AI mentorship program is open now.
Once you're selected, you'll be assigned a mentor. You can give it a shot if it's something you are interested in.

Black in AI is a place for sharing ideas, fostering collaborations and discussing initiatives to increase the presence of Black people in the field of Artificial Intelligence.
Fatima Fellowship
https://x.com/fatimafellowshp/status/1811098858262278330?t=Mhy2GC5kMBbVOfOJ-TrCfQ&s=19
The moment you've been all waiting for is finally here ⌛️💥
📢 We have officially opened up applications for 2024 Fellows!! 📢
Get the chance to be mentored by world-class CS researchers 💫
Apply today: https://t.co/1DAS2uM5hh

Do you have the link for the Udemy video?
It was a long time ago. I used a friend's account. Can't even remember the creator's name.
However, I can recommend checking Jose Portilla or Andre Nagogie Udemy content.
Okay.
If I made a basic logistic regression with gradient descent in numpy, how do I get the boundary programmaticlly (without solving equation manually), is this possible?
nvm
I will probably have to do it manually
Your code honestly looked scary.
I've never seen anything like it.
My fault, type annotation gone rogue
I was trying to learn how to use jaxtyping
it might've made my code less readable, which is kinda not what I expected
It's likely because I'm new to machine learning.
You cranked out all that as a beginner?
Well, I think I am 1 or 2 week in
Goddamn, you're either just copy or pasting code or just a really fast learner.
I'm still lost.
I can't find any Jax code to copy, ngl
I've done a bunch of this before, let me know if you get stuck.
Oh I forgot to mention, I'm not a python beginner, just a ml beginner
Can I see that code again?
Forgot which part, but here's some of it
@jaxtyped(typechecker=typechecked)
@jit
def logistic_cost(
w: Float[Array, "feature_size"],
b: Scalar,
x_train: Float[Array, "data_count feature_size"],
y_train: Float[Array, "data_count"],
) -> Scalar:
y_predict = vmap(lambda x: logistic_predict_all(x_train, w, b))(x_train)
return jnp.mean(
-y_train * jnp.log(y_predict) - (1 - y_train) * jnp.log(1 - y_predict)
)
@jaxtyped(typechecker=typechecked)
@jit
def mean_squared_error(
w: Float[Array, "feature_size"],
b: Scalar,
x_train: Float[Array, "data_count feature_size"],
y_train: Float[Array, "data_count"],
) -> Scalar:
y_predict = linear_predict_all(x_train, w, b)
return jnp.mean((y_train - y_predict) ** 2)
@jaxtyped(typechecker=typechecked)
@partial(jit, static_argnames="cost_function")
def grad_descend(
w: Float[Array, "feature_size"],
b: Scalar,
x_train: Float[Array, "data_count feature_size"],
y_train: Float[Array, "data_count"],
learning_rate: Scalar,
cost_function: CostFunction,
) -> tuple[Float[Array, "feature_size"], Scalar, Float[Array, "feature_size"], Scalar]:
w_grad = jacfwd(lambda w: cost_function(w, b, x_train, y_train))(w)
b_grad = grad(cost_function, argnums=1)(w, b, x_train, y_train)
temp_w = w - learning_rate * w_grad
temp_b = b - learning_rate * b_grad
return temp_w, temp_b, w_grad, b_grad
Ignote the type annotation, really, I don't know what I'm doing
Oh, it's really not that hard to understand now that I look at it. I don't know some of the values in the variables but it's pretty easy to digest.
Why not? I can try and understand it?
I think
Is it something like autograd? Where it can be implemented, but very hard to do so?
I don't know how (un)feasible it is
Oh I guess I'm wrong; I was gonna say "use an SVM in Numpy" but that won't work on Gradient Desscent
GitHub
Contribute to kailau02/machine-learning-from-scratch development by creating an account on GitHub.
Huh?
gradient_descent
this is gradient descent?
It runs a Gradient Descent as the last calculation- paragraph 14
xx = xlim
yyn = (-1 - b - (w[0] * xx)) / w[1]
yym = (-b - (w[0] * xx)) / w[1]
yyp = (1 - b - (w[0] * xx)) / w[1]
Looks like an manual calculation?
(for the decision boundary)
Is it?
I mean realistically you can't plot a graph with more than 2 feature easily anyway
So manually calculating will do
It's because you're using Numpy and Matplotlib
idk- idk what I would use- I think Keras or Tensorflow would have very immediate direct solutions for Grad-Descent
But like you said; you can do some of the calculations manually, so that's not bad
You said you're using Jupyter? Is it not running that cell? Is that what you're asking about
No, that cell showed that guy calculated a formula for decision boundary directly
I am not using Jupyter notebook
I think he calculated it direcly
Not that cell, but somewere around that cell
Right?
appreciate it I'm still trying some stuff, i've been transitioning the code from matplotlib to plotly, the regular plots were simple but it seems the way that animations are constructed in plotly are a little weird?
In matplotlib i was using FuncAnimation which basically allowed you to chain plots but seems there's nothing like that in plotly I may need to consider refactoring or something into a weird dataframe that can handle all the usecases
sorry if thats poorly explained I'm still looking through the plotly docs albeit its very short, i might just be having a skill issue tho I come from a R/matlab background so that may make plotly weird
In plotly, the easiest way to do it is to have one dataframe with all your data, with one column (ie: date) being the thing you're animating over.
yea i've been slowly realizing that, allow me to pick your brain to reduce my trouble shooting, in plotly trying to chain a bunch of Figures together for an animation isn't viable without immense workarounds i assume?
Yah, that's not their model... you don't "chain Figures", you have a Figure with frames.
ahh makes sense its on me for trying to write that way
I'll spend some time trying to process a data frame 🙏 then see if i can work some magic lol
appreciate the input (also succeeded)
Are most of the people in this channel college students?
If collage means university, I'm younger than most people here
I'm a dropout personally, just trying to learn this stuff by myself
Why’d you drop out?
Health issues
idk if most people are but alot of people i've met are that and/or workig
So I've been trying to plot the decision boundary
w.x+b=0
x1 = jnp.arange(0, 3.5)
x2 = ((-b) - x1 * w[0]) / w[1]
plt.plot(x1, x2)
what am I missing?
I think I am stupid
Wait
Is my algebra correct?

Is my equation correct in the first place? I'm trying to get the boundary equation of logistic regression
The equation seemes to be correct, but it break?

Maybe my implimentation of logistic regression is wrong?
I am stupid
The line is different
Because I trained the data on a normalized set of data
Why did it took me 2 hour to figure that out
Happens
Ok, more accurately, the w and d I had is trained with a normalized dataset
But I was plotting with a dataset that isn't normalized
So I thought it was broken and tried to fix it for 2 hours
At least you figured it out
Does anyone here have experience using OCR on handwritten forms and, if so, did you find any particular library to be more or less effective?
Hello, I'm currently running 100 or so models on the free version of Google Colab and I'm trying to see what I can do to accelerate the process. I'm currently trying a few methods, such as cuda and sklearnex, and I believe I used up my usage of the T4 GPU. Does anyone have any tips on what else I can do to speed up the process?
Surya is one of the most effective OCR libraries I've worked with.
GitHub
OCR, layout analysis, reading order, line detection in 90+ languages - VikParuchuri/surya
If you've used up your alloted free GPU on Colab, you just have to wait it out or pay for the premium version. Another alternative would be using Kaggle (you'll get 30hrs free GPU for 1 week)
Meanwhile, did you notice any remarkable improvement in speed when you used sklearnex? I honestly haven't seen any myself.
It's really inconsistent, so I'd have to make some graphs to get a better visual on whether or not it actually works. However, I did notice a decent difference whenever I used sklearnex along with using the T4 GPU runtime and setting my models' device to cuda.
So I have a question regarding LLMs
As far as I know, previously ChatGPT 4 only predicted the next token in text, and to generate or recognize "other modalities" (images/audio/video) it had to use a separate model with those capabilities
Now people talk about "multi-modal" LLMs (like gpt4o I think it's called) that have those capabilities by themselves without a separate model they turn to
What does that entail? Is this just marketing hype BS or is there a significant difference between those previous LLMs and ones that are "natively multi-modal"?
It's not BS. Here is a overview https://arxiv.org/html/2401.13601v4
Wow, it's a paper from this year.
Very cool to see this kind of advancement!
I'll take a look, thanks!
Is there a tutorial or guide that describes the basic folder structure of an sql project for data science / analysis? Would this be an accurate and generally used representation? Or are there any conventions or it is just personal preference?
sql-data-analysis-project/
├── data/
│ ├── raw/
│ ├── processed/
│ └── external/
├── database/
│ ├── schema/
│ │ └── create_tables.sql
│ ├── seeds/
│ │ ├── seed_users.sql
│ │ ├── seed_products.sql
│ │ └── seed_orders.sql
│ ├── migrations/
│ │ └── V1__initial_schema.sql
│ ├── queries/
│ │ ├── joins/
│ │ │ ├── inner_join_employee_demographics_salary.sql
│ │ │ └── left_join_users_products.sql
│ │ ├── aggregations/
│ │ │ ├── total_sales_per_product.sql
│ │ │ └── avg_salary_per_gender.sql
│ │ ├── string_functions/
│ │ │ ├── query_with_string_functions.sql
│ │ │ └── query_using_custom_string_functions.sql
│ │ ├── temp_tables/
│ │ │ └── create_temp_employee_salary.sql
│ │ └── reports/
│ │ ├── monthly_sales_report.sql
│ │ └── employee_performance_report.sql
│ ├── functions/
│ │ └── string_manipulation_functions.sql
│ ├── triggers/
│ │ └── update_stock_trigger.sql
│ ├── views/
│ │ └── employee_summary_view.sql
│ ├── indexes/
│ │ └── create_indexes.sql
│ └── inserts/
│ ├── insert_users.sql
│ ├── insert_products.sql
│ └── insert_orders.sql
├── notebooks/
│ └── exploratory_analysis.ipynb
├── scripts/
│ ├── seed_database.sh
│ └── run_queries.sh
├── results/
│ └── sales_report.csv
├── reports/
│ └── monthly_sales_report.pdf
├── docs/
│ └── project_overview.md
└── .env
Hi, I got this error: TypeError: LinearRegression.fit() missing 1 required positional argument: 'estimator' for the command I wrote: lineer_model.fit(X=ad_expenses,y=sales), can you help me for it?
Personal preference. Personally I just think the folders and filenames should explain exactly what your project is doing. Your directory structure is a form of documentation in and of itself. Organize it in a way that a random person can pick it up and based on that know what you're doing and where to find stuff
wait, don't you need to do LinearRegression() instead of LinearRegression
that's called initialising the class. not always needed but maybe there it is.
ıts like that: ad_expenses=ad_expenses.reshape(-1,1)
ad_expenses
lineer_model=LinearRegression
but I still got same error
you are not adding the parens yet, () @covert cave
Yes,thank you so much, I see it now
np :-)
Hi, I am trying to change locale in powerquery but it isnt changing. I need US date format but it does give me UK data format only.
Hey guys
Been using the midas model for depth estimation
just wondering how I can convert a depth value to an absolute distance
Most videos about the midas model converting the depth value to distance dont really give an answer
Was hoping some of you guys could hel

GitHub
A "prediction" gives the following: [[2496.0127 2495.973 2495.9888 ... 855.7698 855.57666 856.0468 ] [2495.9575 2495.9158 2495.9329 ... 855.4036 855.20917 855.68256] [2495.9797 2495.9387 ...
TL;DR
You'd need to know the absolute depth of at least two pixels in the image to derive the two unknowns.
in other words, it seems you can only (easily) get relative proximity (what's closer), but an absolute distance is more complex.
you'd need to know something like, 'the closest point is 2 meters away, the farthest is 17 meters'
GitHub
i have got midas depth but i need to convert this into distance like meter and centimeter. Can anyone help me?
yea
easily got the relative proximity
might have to just work with that
But thanks dino
Got the depth map working out
Works well on video
https://github.com/isl-org/MiDaS/issues/268
They say:
The best approach may be to try using the ZoeDepth models which are built to give metric distances as an output.
GitHub
i have got midas depth but i need to convert this into distance like meter and centimeter. Can anyone help me?
GitHub
Metric depth estimation from a single image. Contribute to isl-org/ZoeDepth development by creating an account on GitHub.
Hey bro
yea i was just looking at this
lol
I was just about to ask a question on it
# From URL
from zoedepth.utils.misc import get_image_from_url
# Example URL
URL = "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcS4W8H_Nxk_rs3Vje_zj6mglPOH7bnPhQitBH8WkqjlqQVotdtDEG37BsnGofME3_u6lDk&usqp=CAU"
image = get_image_from_url(URL) # fetch
depth = zoe.infer_pil(image)
# Save raw
from zoedepth.utils.misc import save_raw_16bit
fpath = "/path/to/output.png"
save_raw_16bit(depth, fpath)
# Colorize output
from zoedepth.utils.misc import colorize
colored = colorize(depth)
# save colored output
fpath_colored = "/path/to/output_colored.png"
Image.fromarray(colored).save(fpath_colored)
In this code
where its using a url
i dont understand how it works
what exactly?
so basically
what is it even finding
the distance for
how is it choosing what to find the distance for and where is it getting the depth from
Did it do all the code i did and made it into a function or what?
and when does it actually get the distance from the depth
i dont see a comment on that
@lapis sequoia
You have to read their documentation, and then ask imho.
i did..
idk if im reading the right thing or not coz it doesnt seem to give info on my questions
Im just reading the README.md
Do you mean something else? or did i just miss the info
Out of curiosity: Have skipped learning the python or ML basics' before running complex projects? @unique spoke
(That may be the reason why it seems overly complex)
I got pinged here?
actually, i do know the basics of ml and computer vision and done some courses as well but I have never heard of this depth estimation or depth_map really. Knowing the basics of ML (which I am aware of ) wouldnt really help me understand this. However , it is worth mentioning that I am a beginner started about a month or 2 ago
this doesnt really have much to do with ml basics or computer vision (basics atleast).
I do still have a lot to learn tho
and would appreciate any help or resources you have which you think could benefit me
Heya quick question I am sending my out of network expensive to my insurance. I sent this to chatgpt to analyze what they paid.
I got this So, the insurance is paying approximately 91.89% of the total claim amount.
Is thier a better way to get this

I am not sure if it means that they paid 91%
wdym by 'a better way'?
that's the correct %, and it's calculated fine.
i don't quite have, the way i learn is using wikipedia/books/chapters/papers/read code, and rather chaotically for the most part
so it's difficult to give you an intro resource for me
Hello everyone, I have developed ai, it is good now, but it takes up a lot of space, how can I make it give better results by taking up less space?
My 2nd question: How can I make it learn the questions and answers, that is, only from datasets?
Hey dino would you be able to help me
I'll just quickly summarize my problem
Basically, I read that distance = 1/depth or smth and basically it just needs to pass a certain threshold
So i used a measuring tape and measured 1M and checked what values it gave and
it was something like 0.00135
and when I use that value it varies so much that Im not sure where to put the threshold. I think it might be easier to place one by converting it to metric units
Would it matter if I used pytorch with tensorflow in my code considering that Zoedepth seems to use that
Or is there some sort of clash and I can only use 1
What ai, what space memory? What algo? Bro this is outrageously vague
Is it ml, is it DL
Don't make us guess everything we are not in your head
Like, you can say oh I have that much weights on my model and it takes much memory space, but here what do we know about your problem?
not sure really, but you can try adding the problem with nice descriptions and code on #1035199133436354600
2 google nq dataset = 40gb memory
I have 80gb memory in my pc
Hey guys, I wanna implement a PyTorch model from a paper in TensorFlow(maybe even get a paper from it?), but it seems so complex because I don't do PyTorch. How do I start?
can you show the paper?
i'll dm u
I will not read the DM; please use this channel.
it's easier for everyone if you ask questions in the server, so that other people can jump in as needed.
oh ok
can you also give the link to the reference implementation?
They have the PyTorch model here: https://github.com/YubiaoYue/MedMamba/blob/main/MedMamba.py

GitHub
This is the official code repository for "MedMamba: Vision Mamba for Medical Image Classification" - YubiaoYue/MedMamba
pg 5 seems useful as it shows the architecture of the model though
is there a reason you want to translate it to tensorflow? pytorch is more widely used in industry.
I just want to see how it would be if it was implemented in tensorflow(i'm just curious tbh so it's ok)
see all the subclasses of nn.Module? I would first figure out how to translate a given Module from torch to TF. https://github.com/YubiaoYue/MedMamba/blob/main/MedMamba.py
yeah, rn i'm trying to do that, but it looks hard because i'm sorta new to ml
currently, I just mess with image classification models
it will be very hard if you don't already know about array/tensor arithmetic and how neural networks compose array/tensor operations
I recommend that people who are new to ML not even touch neural networks for a few months.
yeah, currently developing my linear algebra and calc skills

when you're learning, it's important that you feel yourself making progress, or you'll get exhausted and give up. I think that people who immediately start with neural networks get exhausted and give up.
alright, i'll work on my linear algebra skills then
maybe during the school year, I can do some real stuff
there are simpler models you can implement to learn foundational concepts and how to use numpy, pandas, etc.
thank you for pointing me in the right direction man
yw
maybe then, I can finally understand NN more
I am very sorry man
I had issues with my wifi
Yes I got what you said about RNNs and I understood that also from other resources
my problem is I don't get how RNN layers interact with each other

When you don't always have the same amount of data, like when translating different sentences from one language to another, or making stock market predictions from different companies, Recurrent Neural Networks come to the rescue. In this StatQuest, we'll show you how Recurrent Neural Networks work, one step at a time, and then we'll show you th...
https://alexlenail.me/NN-SVG/LeNet.html
I wanna visualize my CNN structure using this website ( to upload on readme )
so current structure looks like this
conv1 = (3, 32)
conv2 = (32, 64)
and then fc layers
fc1 = (64 * 32 * 32, 256)
fc2 = (256, 128)
fc3 = (128, 3)
I am confuse for first layer ( on that website ) ,should I directly start with (3, 32)??
also max_pool with 2 as kernel size
Hello everyone, I am developing a real-time streaming platform
I am having some trouble at gathering data from the API via python
Could anyone check out if there is any big error in my kafka-producer.py ?
I'm trying to upload the script but Discord is erasing it haha