#data-science-and-ml
1 messages · Page 127 of 1
Your fixes last time worked well though 😄
I'm glad ^^
:incoming_envelope: :ok_hand: applied timeout to @meager prairie until <t:1718739446:f> (10 minutes) (reason: duplicates spam - sent 4 duplicate messages).
The <@&831776746206265384> have been alerted for review.
while installing torch!!
should I change the directory where it all install
because I have created venv for this project so just confuse about this
If you have a venv active it will automatically install it to the venv
You don’t need to worry about location
but why storage issue?
/dev/nvme0n1p3 237G 136G 100G 58% /
devtmpfs 4.0M 0 4.0M 0% /dev
tmpfs 2.9G 141M 2.8G 5% /dev/shm
efivarfs 128K 33K 91K 27% /sys/firmware/efi/efivars
tmpfs 1.2G 1.8M 1.2G 1% /run
tmpfs 2.9G 2.6G 332M 89% /tmp
/dev/nvme0n1p3 237G 136G 100G 58% /home
/dev/nvme0n1p2 974M 360M 548M 40% /boot
/dev/nvme0n1p1 599M 20M 580M 4% /boot/efi
tmpfs 583M 180K 583M 1% /run/user/1000
in project dir!
What partition is that on
hey all the packages of venv gets stored in tmpfs which is full now
dunno about this
Find the partition tmpfs is and increase it
lemme search
but is this okay?
to increase storage for this?
becaues it then runs on RAM, and I have only 8gb
I mean 5.7 to exact
and I always open bunch of tabs so I don't want lag
The packages are stored on physical storage and not ram
Tmpfs (Temporary Filesystem) is a Linux filesystem that stores files in virtual memory, typically on RAM
what about this? searched on google
Uh I don’t know Linux well enough, try asking in python general or a help chat. They are more active than this chat and your issue isn’t directly related to PyTorch
I have linux server for this!
I dont think it should be trying to install on tmpfs but I don’t know how to fix that
No don’t mess with python files by hand
Python won’t know where they are
His packages are being installed outside the venv
Idk how but they are he said
I am installing on venv
Cwd?
home/Projects/Pong and then venv!
then there is not option ? I guess because limited RAM!!
8gb
That is plenty
I don't think so because browser eats half
But not on ram
no because available is 5.7
Also should be plenty
pip install torch
and then it downloads
2 files of nearly 700 mb
I think so, but hey all the venv packages get downloaded on tmpfs
how to see what is in tmpfs
yeah!!
Try
pip —no-cache-dir install torch
tried!!
if I close all the chrome tabs and run only terminal ( for venv ) it still takes 2 to 3 gb
The error has nothing to do with memory
It says storage
Which is caused by it trying to install to the wrong location
Huh
I mean screen gets restarted not fully restarted but just place me into login page
100gb
Yeah that happens when it runs out of swap
Increase swap
then it will hurt to ram
You should have led with that
Agreed, PyTorch says it takes 2gb of memory to install
tmpfs 2.9G 2.6G 332M 89% /tmp
first of all , what if /run?
yeah with that pytorch vision
I think I need add hard drive now !!
currently on ssd of only 256
Plenty
heh? how to?>
increase RAM?
I said swap not ram
I know commands
It’s in settings somewhere
no it's not I have keep that smooth
till now!! atleast!!
that's the reason
hmm!!
wait lemme ask to this in linux servers
🥲
You aren’t an expert though 🥸
I think I need to run the whole program ( whole folder ) on google colab now
Bruh
which OS?
bruhh come on ? what distro?
but you have more ram than me!!
docker !! yeah I need to learn that
so how does it work for this things?
it create image space!!
currently learning in clg now , but seems to be boring because of way of teaching
our sir litterally spends 2-3 days for explaining basics on linux and all those stuff , which I know ( but others dont because they use windows) and then when it comes to docker , he just speeds up
after using docker?
I don't need to worry about this thing then?
installin pytorch and this?
btw our lane dataset is ready , I spend some time seeing images, but now currently doing RL stuff so I will start that later
and what about running programs on docker , it need installing packages?
one guy in linux server told me , to increase space of swap but hey, it will then slow down pc
How much of the gpu can torch utilize and why not 100%?
okay so new task is to learn docker now!!
@final kiln what kind of ML do you work with
just give me some freelancing tips I need to earn for buying this things now!
Do you know if it’s possible to tell torch to just obliterate the GPU’s power usage in favor of performance?
gpu, ram
I find that most of the time my gpu is basically idle while running deep learning
4090 TI, 128 Gb DDR5
seriously ohh god!
Meme answer cause he didn’t ask an answerable question
Hey people, I'm having error when trying to use pytorchlightening trainer to train a model
Stack expects each tensor to be equal size, but got [73482, 4, 72] at entry 0 and [73482, 1] at entry 1
Do you've any idea how can I overcome this error?
You have to show code for that. We have no way of knowing why your tensors are mismatched size
So the thing is I am tyring to feed 4,72 data in order to predict one value, in that case how can I make this same size?
they are mismatched on purpose
hey, freelancing tips?
That’s not allowed, as the error says
then only job?
Be better than your competition
that's what all are doing !! lol
I need to predict 1 value based on 4x72 values, do you know any workarounds?
Have a good day
bye
Anyone had this problem before in chat? The data is tabular. I need to predict value based on values, but for some reason lightining freaks out..
The thing is I can't move to colab , as the code structure will change because colab has different functions for cv2, so I need to atleast go with docker or increase swap!
docker seems to be correct
Sure I will do it rn, though I was wondering if anyone had this problem before posting.
so all my python files will run on local? right but with docker containers or what so called stuff
!paste
Pasting large amounts of code
If your code is too long to fit in a codeblock in Discord, you can paste your code here:
https://paste.pythondiscord.com/
After pasting your code, save it by clicking the Paste! button in the bottom left, or by pressing CTRL + S. After doing that, you will be navigated to the new paste's page. Copy the URL and post it here so others can see it.
Anyone who used pytorch lightining before, and also familiar with pytorch are welcome to check. Basically I'm trying to do forecast on time series dataset. Where each 4x72 data are the 4 different columns and 72 measurements are being used to predict 72 + 1 = 73 values of one column. But I cannot do that on pytorch lightining why is that?
https://paste.pythondiscord.com/EU5Q
hey but will this problem occur in windows?
with same specification for installing pytorch?
No windows dynamically allocates swap
ohh, that's why it's slow lol
not for your specification
Got absolutely nothing to do with it
True
So basically I tried to tidy up the code using lightining. Therefore I was asking if anyone had this problem in lightining
not on pytorch
hm yeah I can but I think it does not even reach to train step
it fails in DKASCDataModule here
okay let me try
where exactly you are suggesting me to add debug line?
still same
the worst thing PyTorch has ever implemented is letting people use __call__ and not forcing .forward 
True but it does not even come this point. Therefore I've not noticed the error there
I've added print statement to the first line of each method, nothing prints..
The 2nd epoch results are in are look very interesting.

yeah, have no money for local setup unfortunately..
Aws is fairly cheap
kaggle is free mate
Oh I thought you were talking about computing power
no I do not need tbh, model is only 21k params
btw, that self.gru(y)[0] looks a bit sus, why the first item? 
it's something from pytorch. They send hiddenstate and output together
I need only output
I'm a beginner just trying to finish my master thesis lol
sorry for the ugly code guys
What’s your thesis?
I had a friend do 9000 lines of code changes pushed to production in a day because he was tired of terrible error handling
Trying to forecast solar panel output based on a few params, then use the trained model for predicting in newly established fields, basically a renewable energy engineer trying to learn ML haha
Why does that need ML?
That's a good question, but I've no answer to it. I've found the topic to graduate from master
was being advertised, took it
Don’t you have to present to a board? They might ask that question
this is part of a big project, I am just trying to answer if TL can be used to predict solar energy output whenever there is no to little data available
A ML prediction with no data?
Sounds good, have fun 
I am actually wondering if TL is appleciable to the regression problems..
Ive seen so much on classification problems being improved by tl but rarely regression tasks..
tabular dataset with deep learning is a terrible decision.
100%
Deep learning is not for tabular data in my humble opinion.
but I've to do something and pressure to have successfull results... I dunno man..
Lying is tempting haha.
And I think it is what so many people does in their academic work
100%
Any lightining expert here?
Could you please check it out?
No wonder best papers are coming from company researches not university

In this tutorial, we'll show you how to "Dockerize" your Python applications by building and running a Python app in a container.
Docker is an open-source platform that makes it easy to build, ship, and run distributed applications. With Docker, you can create lightweight, portable, and self-sufficient containers that can run on any system.
We...
wait I am asking question
so for that WORKDIR , what should be naming convention, I guess I can named as any suitable nams
what about root?
that guy specified as /app
it does not really matter
need to learn first
The thing is I have done all this steps in college, but now understanding more with self-study
then need to install docker first
workdir is where your commands will run
yeah so I will use /root
yeah , it keeps me familiar
so what you named it as?
I think I should first create test dir, and then create docker file there just to try installing pytorch
Hey, I would like to learn AI but don't know where to start, is this roadmap good? https://roadmap.sh/ai-data-scientist
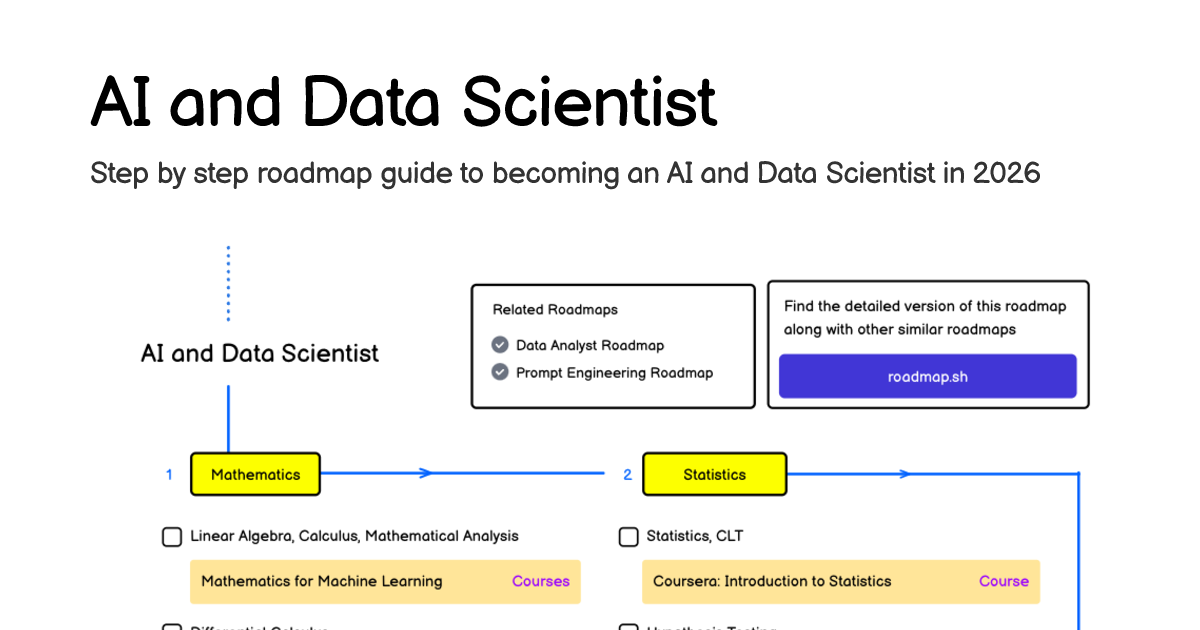
roadmap.sh
Learn to become an AI and Data Scientist using this roadmap. Community driven, articles, resources, guides, interview questions, quizzes for modern backend development.
any roadmap is good, unless it doesn't bother your field of interest!!
then /app
I would like to do be able to do stuff like this https://www.youtube.com/watch?v=hCmrMOzx5VA, what should I aim for?

AI vs AI Playing Game of Tag!
https://brilliant.org/AIWarehouse/
If you want to learn more about AI and deep reinforcement learning (how Albert is trained), there are amazing courses teaching those exact concepts on Brilliant! You can use my link to get a free 30 day trial with 20% off! I've personally gone through the course "Introduction to Ne...
it's reinforcement learning!!
My enemy
you need to learn basics first !!, about types of ML and algo in ML
but it is what attracts you the most !
all types of AI have the same basics I suppose
Indeed
first ML!!
okok
you seem to be familiar with pygame!!
I have seen your comments on general chat!
You would be surprised
😂 lol
how the hell you can directly categorized me in this way !! lol
and you are supporting him!!😂
hey is it necessary to run the .py with that docker run command?
because I have .ipynb file , so the canvas of my env should support that
Just watch a video on how to use python with docker instead of asking about every step
I am watching
but he is not dealing with .ipynb
Then you did something differently. ipynb is for a notebook idk if that’s what you wanted
The reconstructed images seem to align with the metrics, Still looks like crap, but its an improvement from the 1st one.


@small wedge i cant even explain this

Guys is it a good idea to put a project of hand gesture recognition using a fine-tuned vision transformer on my resume?
yes
I also capture on real time a video with my laptop camera and the predictions the person do are shown on screen
cool
how is it possible my results converged after the random exploration chance was 0
and why did it take so damn long
trained that mf for 3 days
can the model start to fail if my PC gets hot enough?
the model itself should not care
your hardware will literally melt if it gets hot enough (like anything else IRL), but usually has sensors to shutdown before it gets to that point
hardware doesnt melt
yes it can
if the pc turns off your model can fail
didnt turn off but the fans started to go insane at some point and after that the predictions worsened
those had nothing to do with eachother
it was done on real time. i was making gestures
eh potentially the qualiy of the camera data decreased
it could be also because of the background? since it's based on vision transformer i've noticed it makes better predictions on background with light color and with a varieties of objects. On a plain white background it's quite bad or at least that's what happened to me. it could be because of the size of the training too idk so many variables
right but none of those have anything to do with your pc overheating
that's sort of the point, first you do a breadth-first search, then over time as the chance of random moves decreases, you go in depth on the best solutions found so far
Does your random chance get reset each cycle or over the entire simulation?
If it gets reset each cycle that would explain the results
Good models being forced to randomly kill themselves and make bad moves until the randomness dies out
Guys but the predictions kinda suck? Like it predicts the label alright but the probabilities are around 20% to 50% or even 60% in some cases. Sometimes it struggles to identify which one is which
Hello, I have an idea for an application of ai, anyone here with some general programming experience, preferably in Texas. I think I came up with a pretty good roadmap of how to implement ai into businesses that rely on stored physical texts like lawyers and doctors. If anyone wants to work on a project with me hmu, if this is breaking a rule or something I'm sorry.
Man if I had a penny for every time I heard that 😅
- Yes it does break the rules as we don't allow ads or recruitment
- Some feedback for your idea:
** Ideas are cheap. Everything is in the execution
** As such, no one want to partner with "the idea person". So you must bring something to the table beyond ideas
it decreases over the entire training
but i dont understand how it converged so late or why it took so long
a bread what
whats its benefit to the area its gonna be used in
breadth first
bread
if the model has 0% chance of randomness it has no chance of getting better
yet it still converged way after
are you applying the epsilon randomness thingy to a policy gradient? or to DQN?
no
i didnt think that would help
where are you applying the randomness then?
after every action
but what are you applying it to?
the chance for the model to choose a random action instead of predicting
so, the epsilon randomness thingy
yeah, so, epsilon greedy policy
anyway
as I said, at first you do basically a breadth-first search where you explore a bunch of options randomly and over time that randomness decreases and you instead start exploring the best options found so far in depth
the model automatically does that?
yes
I have no idea, there could be dozens of factors at play here and you don't have a ton of samples to learn from anyway
i would think this simple of a model could converge in a few hundred or maybe a few thousand
not this many
is it reasonable to set the random value to 0 after it achives the highest score
I couldn't tell you, but you can always set a limit to how low the epsilon value can go, to always preserve some randomness
yk, think of it as exploring alternative options every once in a while after you have started going in depth
why would i want some randomness
so you dont know of anything that i can do to decrease the iterations
this kind of performance doesnt scale
imagine you stumble across a vein of gold while mining just because you decided to randomly explore a different direction than you were currently going
wdym? just train more agents in parallel
this agent eats my cpu
and that number of iterations seems way too high for a simple model
i ran my pc like a space heater for 3 days straight
I have no idea what your model or your environment or the rewards for certain actions or what actions there are or what are the inputs for your model or really anything and how many agents were you running in parallel and how many episodes did it take, how many max steps there are
!paste
Pasting large amounts of code
If your code is too long to fit in a codeblock in Discord, you can paste your code here:
https://paste.pythondiscord.com/
After pasting your code, save it by clicking the Paste! button in the bottom left, or by pressing CTRL + S. After doing that, you will be navigated to the new paste's page. Copy the URL and post it here so others can see it.
https://paste.pythondiscord.com/ODJA
long code for reference and ill summarize it in a second
2 berry pushes in a 1 dimensional plane. bear can go left, go right, eat, or kill itself
score increases as it survives and when it eats a berry. Very simple
are you doing Q-Learning or DQN?
i dont know
dqn
ah, I see, DQN, yeah
Try to decrease the randomness a bit, from .999 to .99
oh
are you calculating the average over all agents that ever exist in the simulation?
yes but i wasnt really paying attention to that i was paying attention to the average of the last 100
well there's your answer
All Time Average Score: 24.1825
Average of last 100 bears: 34.62
Highest Score: 48
Total Bears: 8000
the last 100 is a moving average
8000 bears
why
I'd still wanna see the actual scores in those hundred that are being averaged to see if there are outliers or all the models are doing mid
let me get that for you
your batch size is 8, your memory is 10k, that's kiinda horrible IMO, how do you expect it to sample favourable states with those odds?
Guys what free cloud platforms do you suggest to run ML models because it got heavy on my laptop
Google Colab
but I would suggest Paperspace, it's not exactly free, though occasionally there are free machines available, but it at least has a rather transparent pricing model and you don't need to like actually develop there, develop locally and then just run the model itself there, the cheapest paid machines are ~$0.55/hr there
oh noted!
horrible? can you explain why
im not defending them i just want to know why
alright, well, is that priority replay? cuz I'm not familiar with those torch types
priority replay?
alright, doesn't seem to be (by default anyway), so it's even worse then
the chances of picking states that you would want to learn about with those odds are miniscule
why
because you only pick 8 states from the 10k at every learning step
the number of samples used to calculate the gradient estimation
yeah, but if you only pick 8 from the 10k you have in memory, the chances of those 8 being something you actually want to learn about are very slim, like, there's nothing really interesting going on in most of those cases
The caption creation is cracking me up. But its trying to create captions for images now. Its pretty interesting though. I really likes its trying to grasp the images though.

hmmm what if the bear dies at 1? wouldnt it error because not enough tasks
samples would be a set of transitions from replay memory
in torch's official tutorial they use 10k memory and 128 batch size
you don't start sampling from the memory until you have enough states saved up in memory, say once your memory size reaches half of the total capacity
@spring field Did you here about kaggle?
128 isnt that far off of 8
kek
ill try 128
it's like 16 times more
also, I'm not exactly sure on how complex is your environemnt, but reducing the complexity of the model might also help it converge faster, basically say reduce the hidden size to 64 instead of the 128 you have now
niiice
same for randomness scaling
less randomness will mean faster convergence assuming there's enough for it to find maximum score transitions
and also the learning rate, perhaps, you could increase it a tiny bit to say 1e-3 or 5e-4
surely the lr param means something for it as well
that would stand to reason lol, think it's just the starting value
the complexity is very low as this was a proof of concept
right, well, reduce it more
lower complexity models will be less compute so faster convergence, and less likely to overfit
yes but this one is sufficiently simple
and yet it took 3 days? I mean, honestly, the replay batch might have played a huge role here, lol, but still
replay sample 128 doesnt seem to be doing anything
the goal should be to find the minimum size/depth model that can still generalize the task, you can scale it up for more complex tasks as necessary
oh also
in the tutorial they are sampling randomly from the memory
dunno if that class you're using automatically does that but if not you should try that as well
also, another thing is fixed Q targets, that helps to sort of anchor the model at a certain point and make it take actions relative to that anchor
otherwise you have a lot of fluctuations during the learning process because you move the anchor and then make a decision based on the current anchor position, but then you move the anchor to that new position and try to go from that again, so you continuously carry it around as opposed to having a fixed anchor for a couple steps and then basically moving it to the best position found
ill try to add those 2 things
im also creating a log of all the bears with scores
ack its too big

but it is 😭
fine ill re run it with 10x less data
although it did converge relatively fast
Average of last 100 bears: 47.99
Highest Score: 48
Total Bears: 23000```@spring field @small wedge thank you
I made a new version , made a lot of changes started the training over this chart looks much more typical now.

Im confused what this means, huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks... To disable this warning, you can either: - Avoid using `tokenizers` before the fork if possible - Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)
heres the 2nd epoch .. Any type of feedback would be welcomed.

Alright heres the visuals.


Honestly I dont think gpt 2 is doing me any justice I need something with multihead attention mechanism that would aling with my project like Roberta
you guys are all I got, is there like a donation jar? lol
I would be surprised if GPT 2 were good enough to be useful for anything ever.
There are decently OK small models like the Phi series and perhaps even Google's PaliGemma
some big tech companies actually do provide sponsorships, research grants and alike at times, but you'd probably need to be affiliated to an university or startup to be elligible for most of them
anyone know how to use rocm hip sdks with pytorch? I already installed cudo and the hip sdks but this still returns no gpu.
if torch.cuda.is_available() and torch.version.hip:
print("hip version:", torch.version.hip)
elif torch.cuda.is_available() and torch.version.cuda:
print("cuda version:", torch.version.cuda)
else:
print("no gpu")```You would seem to be right
If anyone is interested. Im going to start the Roberta implementation soon.


Hi!
I want to understand the end of the pipeline of teaching a simple NN or even just a machine learning model. I kind of understand the steps leading up to encoding the data as numerical values, train/test splitting, creating a model with layers and even reading the results in the classification report and the confusion matrix.
What I don't understand is the most important part of why I'd be teaching the model in the first place - how can I then get REAL data, and plug it into my model? When I'm making the model, I'm transforming all the categorical data into numbers through various kinds of encoding. When I get new raw data, it's in its original format with the categorical variables, dates and so on.
Example - I want to predict whether the response to an official letter from a client will be on-time or overdue. I have the branch responsible for the response, the manager, the client, the dates (incoming, due-date, actual response date). When I train the model I encode all those. Say I get a new letter, how can I input all these variables to know if the response is going to be overdue or not according to my model?
Also, since everything is encoded, how can I understand which of the parameters have the most influence on the response being overdue? Which variables actually matter? All the information I'm currently finding online just skim over this most crucial part.. They just go - oh, here accuracy_score(y_test, y_predict) - which just gives a percentage with 0 insights.
I aint touching that. Smells to much like attorneys and insurance. Two things I dislike, nite!
https://scikit-learn.org/stable/data_transforms.html# would you say this part of scikit is good to learn, or commonplace? I seem to be seeing sklearn.preprocessin a lot in notebooks I'm guessing it'll be good to know and not handcraft these in my own work. I'm not so sure about Pipelines, it seems interesting but is it commonly used? I'm not sure if it's worth learning
Just browsing that site, yes, very important elements to check out. I'm more of a torch guy myself. Haystack is my goto for NLP
Pipelines and preprocessing all included.
This ones interesting, anyways off to bed nite


is the recon, vq, and clip loss the one that contributes to the training loss or the validation loss?
it doesn't seem to contributing to training loss I guess
Hello All, I'm having an issue with my pipeline. I made a pipeline with the intention of carrying out all my data preprocessing steps, however I'm faced with a major challenge.
The pipeline incorporates an outlier removal using zscore, if I apply this pipeline to my test its going to remove some rows which is not desirable, since my intention is to make predictions on the test without removing any of the data.
If I choose to fit the pipeline on my features df only without including the target, it would lead to a data mismatch between the features df and the target df.
I am trying to fix an error in deep fake AI and I am getting this error:
res1 = cv2.bitwise_and(cv_correct, cv_correct, mask = green_mask_inv)
cv2.error: OpenCV(4.6.0) D:\a\opencv-python\opencv-python\opencv\modules\core\src\arithm.cpp:230: error: (-215:Assertion failed) (mtype == CV_8U || mtype == CV_8S) && _mask.sameSize(*psrc1) in function 'cv::binary_op'```Code:
def create_maskref(cv_mask, cv_correct):
#Create a total green image
green = np.zeros((512,512,3), np.uint8)
green[:,:,:] = (0,255,0) # (B, G, R)
#Define the green color filter
f1 = np.asarray([0, 250, 0]) # green color filter
f2 = np.asarray([10, 255, 10])
#From mask, extrapolate only the green mask
green_mask = cv2.inRange(cv_mask, f1, f2) #green is 0
# (OPTIONAL) Apply dilate and open to mask
kernel = np.ones((5,5),np.uint8) #Try change it?
green_mask = cv2.dilate(green_mask, kernel, iterations = 1)
#green_mask = cv2.morphologyEx(green_mask, cv2.MORPH_OPEN, kernel)
# Create an inverted mask
green_mask_inv = cv2.bitwise_not(green_mask)
# Cut correct and green image, using the green_mask & green_mask_inv
res1 = cv2.bitwise_and(cv_correct, cv_correct, mask = green_mask_inv)
res2 = cv2.bitwise_and(green, green, mask = green_mask)
# Compone:
return cv2.add(res1, res2)
type(cv_correct) and type(green_mask_inv) is numpy.ndarray
(337, 191, 3) = cv_correct.shape
(336, 192) = green_mask_inv.shape
it is on windows
How about cv_correct.dtype ?
Should be (unsigned) 8 bit integer
Oh actually, look at the shapes
It does not match
width and height need to be the same (for image and mask)
Well I tried resizing and somehow it gave value error. I think I am just bad at AI.
├── ball.py
├── Dockerfile
├── main.py
├── __pycache__
├── requirements.txt
├── RL
├── striker.py
└── venv
4 directories, 5 files
this is current dir!
You probably change the mask size with dilation
Check mask size before and after dilation
I have done it green_mask = cv2.dilate(green_mask, kernel, iterations = 1)
haven't I?
You have done what?
cv2.dilate on the green_mask
Could you show the mask size before and after dilation
Best course for learning fundamentals of deep learning and neural networks?
Should we go for tensorflow or pytorch?
I wish I knew a good course, but every course I see they just code away and don't explain why or just say "you can look it up on the documentation".
What are the shapes of the arguments you supply to the function?
😧🙁
For example they create a few classes and say that should do this. They don't explain why or how. It just needs to do it.

What are the neurons, why are there layers, and what is the math underlying it?
Help fund future projects: https://www.patreon.com/3blue1brown
Written/interactive form of this series: https://www.3blue1brown.com/topics/neural-networks
Additional funding for this project provided by Amplify Partners
Typo correction: At 14 minutes 45 seconds, th...
This is a good start btw
cv_mask.shape = (336, 192, 3)
cv_correct.shape = (337, 191, 3)
Tysm
No code in here. Just teory.
yes
Ohhh
What sources did u personally follow?
I have no idea.
It is just theory yeah, but it does explain the "How" and not just how to implement it practically.
I don't. I really want to learn it, but I haven't found a good free one yet, so I gave up. Text me if you find something.
ML shouldn't really be learned by coding it immediatly imo, I would start with theory anyways.
I ment the code. How he coded it and why.
Well shouldn't the mask and the image match? 😛
I started with theory as well, but after 5 videos of just theory I think I know how it learns and how it preforms. The differend types of data and learning algos.
Yeah
Actually I explored the course by Andrew a little bit... It was some collaborative course... Two instructors...
But it was similar to what u said...
He explained a few things then said that we can look up to docs bla bla bla
🥹 Who's gonna tell them that we can't always directly look at the docs if it is about ml
The docs often refer to the paper on which the algortihm/model is based.
Yes, but I don't know how to reshape them without damaging the qulity.
Why reshape them, how did you obtain them orignally?
The original mask and image should already match
The problem is not the code, but the data
Well what image should I give?
I gave like 3 images. It didn't worked with all of them.
Were the image and mask the same width and height for one of them?
they are ndarrays.
(337, 191, 3) = cv_correct.shape
(336, 192) = green_mask_inv.shape
Gemini made this code for reshaping
def create_maskref(cv_mask, cv_correct):
# Create a total green image with the same dimensions as cv_correct
green = np.zeros_like(cv_correct) # This ensures green has the same dimensions as cv_correct
green[:,:,:] = (0,255,0) # (B, G, R)
# Define the green color filter
f1 = np.asarray([0, 250, 0]) # green color filter
f2 = np.asarray([10, 255, 10])
# From mask, extrapolate only the green mask
green_mask = cv2.inRange(cv_mask, f1, f2) #green is 0
# (OPTIONAL) Apply dilate and open to mask
kernel = np.ones((5,5),np.uint8) #Try change it?
green_mask = cv2.dilate(green_mask, kernel, iterations = 1)
#green_mask = cv2.morphologyEx(green_mask, cv2.MORPH_OPEN, kernel)
# Create an inverted mask
green_mask_inv = cv2.bitwise_not(green_mask)
# Cut correct and green image, using the green_mask & green_mask_inv
res1 = cv2.bitwise_and(cv_correct, cv_correct, mask = green_mask_inv)
res2 = cv2.bitwise_and(green, green, mask = green_mask)
# Combine
return cv2.add(res1, res2)
but it gave the same error.

So this is your situation. The mask is not the same size as your image, so how would you be able to mask the image. Opencv sees the difference in size, and says NO.
Resizing it could work, if the images were the same size, but one was resized for some reason.
It may be cropped though, so maybe you need to recrop one of the images.
I can;t know without knowing how you obtained the original data, what you could do to fix this data.
So I guess I have to eather make the mask resize itself acording to the image shape or just accept only one why shaped images.
Imo if the image is not the same size as the mask, the function should give an error, which is what it is doing. You need to find out why the image is a different size from the mask, and change one of them correctly based on that (if that is even possible).
512x512 is the dementions of an image I just tested.
and it worked.
why can't the mask reshape?

So in this case, reshaping would fix it
The mask is too thin

But here the mask is too thin as well, but reshaping would not fix it
I don't know which situation you have
To be honest. I got the code from github and I wanted to test some AI imaging, but got that error.
@final kiln
need help with docker
just completed Dockerfile
no
sudo docker run pytorch?
in project dir?
Unable to find image 'pytorch:latest' locally
and yeah I need sudo for this
docker: Error response from daemon: pull access denied for pytorch, repository does not exist or may require 'docker login': denied: requested access to the resource is denied.
already!
but still this!!
and also my main.py is running but where is pygame window??
Unable to find image 'pytorch:latest' locally
docker: Error response from daemon: pull access denied for pytorch, repository does not exist or may require 'docker login': denied: requested access to the resource is denied.
See 'docker run --help'.
now it is!
also I have .ipynb file where my RL environment is so how can I run that too?
and yeah why I am downloading this pytorch image?
no god!!, I am doing it on .ipynb extension with vs code
I think I will need another Hard drive , because only 100 gb is remainig now!
okay done all!
yeah , half of the saving is done!! need to save more now!
I am new to this as you know!
then docker-compose!
done!
so I downloaded whole pytorch on my pong-game image,
and now again it is downloading again some 4 gb!!
and all this whole project dir is allowed to uploaded on github??
can I upload all files including this docker-compose.yml on github?
yeah that's noob question
wait what this does?
wait leeme share my tree first
├── ball.py
├── docker-compose.yml
├── Dockerfile
├── main.py
├── __pycache__
├── requirements.txt
├── RL
├── striker.py
└── venv
4 directories, 6 files
and again I have bunch of .py files in RL
wait that pytoch downloading process is still in process
yeah!
remote development?
wait that process is still in process
wait wait another noob question
so in RL/environment.ipynb
there is custom environment so when I run this whole file in vs code only it results into popping up window and then all RL stuff continues
so the question is will it able to run in the same way in docker?
whatever is good just need to apply!
Hey @final kiln
demand is increasing !! lol
ive been working on this geo spatial segmentaion project, I want to how can i create a early warnning system for my project, like if there is a time series images my model will segment them to that label and warn the user
Ive trained multiple models

these so far
all of them have different IoU score
so far what i;ve learned is that there is no best or worst they just depend on the type of data you are working on
but Yolo and DeepLab seem to give good result in most casues
Like a warning system, i cant thing of an implement
kind of
like it warns people about a disatrer
disaster
nice project idea!!
like image of the same place withtin a range of time
so i would say time series image
okay let me explain
consider images of a locatio for month 1, moth 2, month 3
the characteristic of the image change and the model detetcs that change
consider it an image
so bunch of recurrent images right?\
time series image, where images of the same location are taken over different time intervals (e.g., monthly), and a model detects and segments changes in the characteristics of the location over time
yeah series of images
someone's about to suggest transformers
yeah i was just giving an eaxamples
😂 lol
I... sigh
i thought he ain't going above CNN!
ViT + TokenLearner
and form where the heck you are getting this much of data?
hacking satellites or what!
the dataset is small < 1500 images
but ive been able to train the models well
Yes
Sentinel 2 Images
do you have something in mind?
no just rgb iamges nothing extra, RBG IMAGES + THEIR MASKS
😂
- images: optical images (*.png)
- labels: ground truth segmentation RGB masks (*.png)
- labels_1D: ground truth segmentation labels (*.png)
RGB Masks:
Black: Background
White: Lake
RGB Values:
Black: (0,0,0)
White: (255,255,255)
1_D Labels:
0: Background
1: Lake
we are getting closer then!
hmm okay
😂 🙃
yeah now focus on me!
pytorch is downloaded
ahh huh!!, okay anyways!
yeah I am unclear about that, we will continue this after some time!!
so what to do with this
ohhh!!
where to put this?
.yml?
okay done
then what?
how deep of a network do i need to fit a curve like this

discontinuous and piecewise linear
im happy if it can handle 2 jumps at least
i tried sthn random like 1 -> 3 -> 2 -> 1 with relu but its struggling
e.g. this one sometimes works if I get lucky with the random state:
model = MLPRegressor(
(5, 10, 5),
"relu",
solver="lbfgs",
max_iter=20000,
max_fun=10**5,
tol=1e-7,
alpha=0,
)

is that from sklearn
to be more precise, here's me training 1000 models with these settings. great results are quite rare.

if you only want 2 jumps, why not just fit a linear spline?
i guess i could
its not linear in the general case but i havent decided if i want to care about that
well i never experienced with ai in my life, i cannot find any useful information about neural networks, could anyone briefly explain the concept of a neural network to me?
they perform a series of mathematical operations on a given input, trying to approximate an unknown function that will give your desired output
I'd recommend just looking an introduction up on YouTube, visuals can help a lot to get a grasp of what's going on
currently watching 3blue1brown's introduction
I need to get my EDA down to a drill for a coding test I'm going to take for a job interview. Any suggestions?
I'm thinking we do the correlation grid plot, try some PCA, do an Andrews plot
surely at some point it is cheaper to use a $4 VPS and just run it like a normal webserver
😅 Yes
Tbh at work I've spent the last 6 months distinctly going back to the old monolithic ways rather than 50 billion micro services and aws services everywhere
makes life so much easier
I mean that sort of thing works
until you care about cost and scale
or you have slow running tasks behind load balancers that assume low latency
easy until it isn't
Can somebody help me with an exam question please??? Or at least try the question
Do u know how to do this?
not much readable
When you click on the picture it doesnt come up bigger?
I even opened in new tab
Best-first seearch new word!
yes
No of course not
This iss just a sample paper
But the guy said it will be similar to tomorrows paper
which subject?
Computer science (AI module)
which university?
Its in the UK (England)
What is better RMSE or MAE?
RMSE is better with outliers!
but in general MAE gives more accuracy, if outliers are not there!
Anyone have experience with google colab? I've got an llm that gets trained on some data (a driving manual pdf) and I can get it to run on my local machine, but the second I change to colab it gives me one of two different errors each time: ReadTimeout: timed out and ConnectError: [Errno 99] Cannot assign requested address. If anyone has any ideas that would be great! My code is ```py
Define system prompt and query wrapper prompt
system_prompt = "You are an instructor teaching people driving lessons about the rules of the road. Your goal is to answer questions as accurately as possible based on the instructions and context provided. Make sure to reference the document and explain how you got your answer"
query_wrapper_prompt = PromptTemplate("{query_str}")
Initialize the Llama model
llm = Ollama(
model="phi3",
#Changes how much it's allowed to generate
context_window=320,
max_new_tokens=100,
generate_kwargs={"do_sample": True},
# Give it the prompts from before
system_prompt=system_prompt,
query_wrapper_prompt=query_wrapper_prompt,
tokenizer_kwargs={"max_length": 100},
)
Set the LLM and other settings
Settings.llm = llm
Settings.chunk_size = 512
Create a vector store index from the documents
index = VectorStoreIndex.from_documents(documents)
Create a query engine from the index
query_engine = index.as_query_engine(include_text=False, response_mode="tree_summarize")
Define the predict function
def predict(input_text):
# Querys the engine from input
response = query_engine.query(input_text)
return str(response)
prediction = predict("What are signals used for?")
print(prediction)and it consistently errors on
response = query_engine.query(input_text)```
you might need to explicitly enable internet access to download the model
what exactly do you mean
How would I stop that from happening, or how would I get around that?
No, that one looks like it works
Serving HTTP on 0.0.0.0 port 8000 (http://0.0.0.0:8000/)
if this is my current matplotlib gridspec with this code:
gs = fig.add_gridspec(2, 3)
l_up = fig.add_subplot(gs[0, 0])
r_up = fig.add_subplot(gs[0, 1])
l_dwn = fig.add_subplot(gs[1, 0])
c_dwn = fig.add_subplot(gs[1, 1])
r_dwn = fig.add_subplot(gs[1, 2])```
how can i center the upper row's two boxes such that their midpoint lines up with the midpoint of the bottom row?
so that it looks like this:

nvm lol i figured it out
Guys how do I enable my GPU for tensorflow?
now tell me how can I run .py file which has torch module!!
I wanna test my model code
oops, I am so noob !!
but we didn't installed pytorch on venv sir!
we installed it on docker
don t you know this you recommend this, because of that swap file issue
I wrote that code on docker-compose
and then?
I am on venv right now , should I deactivate?
Cannot connect to the Docker daemon at unix:///var/run/docker.sock. Is the docker daemon running?
sry I didn't started docker
no I started now it is runnig something
✔ Network pong_default Created 0.1s
✔ Container pong-pytorch-1 Created 0.1s
Attaching to pytorch-1
yeah
yeah
downloaded !
wait how to got remote extension?
through search bar?
yeah find that it's logo

same output
wait step by step all new things to me now!
in new terminal?
because one is runnignthat docker compose up
groupadd: group 'docker' already exists
yeah done
now restart whole pc?
till then explain why we do this
Hey people, does anyone knows the reason of extensive memory usage associated with pytorch lightining?
It's layers of shit tbh.
I am having problems from yesterday
I've kind of solved the problem tensor shape with padding, though now I've another problem which is memory crashes
trainer = pl.Trainer(max_epochs=20, limit_train_batches=1, limit_val_batches=1, limit_test_batches=1, callbacks=[RichProgressBar()])
My current trainer is this. Even with 1 batches I am having memory issues..
back now!
but there is nothing in dev containers!
already
what
vs code? or docker compose

same as it is

from containers?
this are dirs...
okay wait wait you mean from Containers/pong/pytorch

or from individual containers?
there is a option of connect to vs code for pong/pytorch
attach vs code
but you said individual
now new vs pops up
installing server
ohh miracle for me thanks
so whenver I comes to code
I should open terminal
start docker
then docker compose up
then go to vs code and start all this
lol I don't have GPU
so should I start venv?
what is this btw?
then directly python .py ? on terminal?
what to do of that docker compose up , should I keep that as it is running ?
and for git push?
can I directly do that?
hey I am getting error for pygame now for module!!
but have limited time!!
we do for pytorch , but what about other libraries
I need GPU, but I don;t have that
I am runnig code which has pygame (import pygame)
now it is throwing error as no module found
yeah!
hey but I install all the packages on venv!!
so now where to install this all on local?
ohh that's interesting
so whatever I do pip install
it will get installed in container?
that's nice thing then!!
also one thing , should I buy used hard disk or get new one?
because they are offering on half prices
one guy litterally offering 2 hard disk on one hard disk price , but used !
wtf?? we installed this!!
what?
I didn't do anything wrong!
ohh god , how to check
no such dir
how to go in right?
I clicked on torch and attach to vs !
how to restart this now
just close the vs code?
yeah but of
Pong/torch
not of individual/torch
look here the name is pytorch-1
this is output of docker compose up
wait leeme stop this docker compose and again do that
what is volume now?
module not found
now what?
how to troubleshoot this thing
pytorch:
image: pytorch/pytorch
command: sleep infinity
working_dir: /app
volumes:
- ./:/app```yeah it is same
it's correct path!! for current working dir
because there is no /app in Pong!
docker-compose.yml main.py requirements.txt striker.py
only this
home/user/Projects/Pong/RL
yeah I think so
why?
yeah
now on vs code terminal but still same
running
docker compose up
On vs code terminal?
okay
wait we first did
docker compose up
and then went to vs code remote extension and then connected it
so now how can I run again docker compose up on vs code ?
which I did
so my pc terminal is running that
docker compose
ls: cannot access '/app': No such file or directory
again
and same for pwd
should I reopen whole thing from begining?
here is my terminal
and then on that terminal I run ls /app
and got that output
should I send ss of that also?
because it's boring
which thing?
now here is new thing in dev container

on that pong right?
of dev containers
I did this also
on that attach new window type the it asked, new or current
now project dir gone
currently on something else
yeah got that now
all the files!
working fine
yeah now got it !!!
I was opening through local my bad!
not paying attention that there was /app
thanks for this!!
maybe will try that later
it is recommending to download git now!!
I have already on local shit!
automatically?
so nice that I learned about container in just few minutes!
yeah lol!, but this will same will take days for my college
what's the curse part?
whole pytorch is installed now that's heaven now without accessing swap files
now what if I wanna share this container?
how can I?
and then image will eventually have my container?
can someone help me here? https://discord.com/channels/267624335836053506/1253077065784102942
then what is shareable?
I don't care I am only using this because of pytorch
and only because it is running on local!
will try that later!!
now have to focus on RL
btw , what about your interviews?
how's that gooing?
application cycle?
does that related to scrum and all those things
3 offers?
then? on what third
ohh and what about this time? did they accept for interview?
for which position you are applying?
what about tech stack?
with python?
how the hell this command is working I have fedora
there is dependency issue for opencv
which uses ubuntu?
wazup guys can someone help me with 2048 code?
pygame?
yep
create thread on #1035199133436354600
in python-help last message in the morning, but rn is night and there is now answer on bros queshtion
did you created thread in night?
nah, someone
someone created!! on what topic?
ok im try post it
yeah!
I think I finally got Roberta to start creating captions for the images! Haven't gotten this far before, but had to restart the test, I forgot to add something . The max length of sentance transformer and clip model have to have the same size though, It took me forever to figure this out
Feature shape: torch.Size([512]), Input IDs: tensor([[ 0, 22710, 106, 14304, 1363, 12, 2]], device='cuda:0')
I have not, what is it?
having trouble using VCS for my AI Agentic Design Patterns with AutoGen course
Whats the issue you're having with VCS?
That's what I use
Is this what you are looking for? https://microsoft.github.io/autogen/docs/Getting-Started/
AutoGen is a framework that enables development of LLM applications using
wait that actually helps a lot thank you

im just following along a course
but i thinj its better i just use that to learn how to use autogen
No it seems like its not loading properely
check your enviroment, make sure its correctly installed/updated and make sure you are working in the same enviroment if you used something like miniconda or python venv
whats the entire error message?
im not entirely sure how to do that
im very new to all this. I installed VSC today
do you think you could call?
@rich moth
Dude I think its working lol says 5 hours, use to take like 20 minutes. Evaluation: 1%|▋ | 6/582 [03:43<6:00:43, 37.58s/it]
looks like your processing it via a juypter notebook, maybe the service your are connected to doesnt have that pip package instaleld.
I imagine you are connecting remotely. The server you have access to need to have the package installed im guessing
oh, trying !pip install autogen
Inside a cell .
In a code cell, type !pip install <package_name> and run the cell. Replace <package_name> with the name of the package you want to install.
uh
I think I got it. You pade a new pyton file, not a juypter file

!pip install autogen

Install packages from within code
Released on <t:1638381260:D>.


You got maybe tyle different enviroments, the virtual one, and then I dont know Where /Users/cryusvakii looks like in windows
You need to point you VCS enviroment to you virtual python one, not the windows one
im on mac
how do i do that
Whats /Users/ point too? whats the entire line? Maybe try excluding that, or adding the virtual env to your settings in VCS
its the folder i think
Show the entire line

Hmm maybe you need to !pip uninstall autogen, then %pip install autogen.
[{
"resource": "/Users/cyrusvakil/Visual Studios/Python/Experimental/L2_Sequential_Chats_and_Customer_Onboarding.ipynb",
"owner": "workbench.notebook.cellDiagnostics",
"severity": 8,
"message": "ImportError: cannot import name 'ConversableAgent' from 'autogen' (/Users/cyrusvakil/Visual Studios/Python/Experimental/.venv/lib/python3.12/site-packages/autogen/init.py)",
"source": "Cell Execution Error",
"startLineNumber": 1,
"startColumn": 1,
"endLineNumber": 1,
"endColumn": 37
}]
Whateve ryou showed me does seem to be using % maybe thats what seperates it
what i deleted?
or this

okay
i did that
it got rid of the !pip install error
but the conversable agent error is still there

hmm
thats for the juypter one
but if i wanted to just use straight python
i have the exact code in this test file

and when i run it this happens
type this is a cell ```import autogen
print(autogen.file)
like in line 1?
sure

oh lol your not in cells



do this one in another cell ```import os
autogen_dir = os.path.dirname(autogen.file)
print(os.listdir(autogen_dir))

does it have ConversableAgent in there?
nope
maybe its agentchat?
You could be on a old or newer version that doesnt have it, or its called something else now
no like from autogen import agentchat
that workeds
so its agent chat instead of conversable agent
is that the same thing?
so i have to define it i think
try ```from autogen.agentchat import ConversableAgent


looks just like an API issue now, you fixxed it
no u fixed it ..
pretty sweet, well we learned it together.
https://paste.pythondiscord.com/2U2Q
why GPU run it 3x slower than CPU
do u know how to fix this

OpenAIError: The api_key client option must be set either by passing api_key to the client or by setting the OPENAI_API_KEY environment variable
Output is truncated. View as a scrollable element or open in a text editor. Adjust cell output settings...
your neural network probably only accounts for extremely little of what the program is doing?
it's relatively small, and you are doing a lot in between iterations
then what is it doing
taking 45 seconds
the entire while True: loop (+ in the case of GPU, moving data into it and outside of it)
the majority of the while True is logic statements that are basically instant
so is one pass of your neural network
so 15 seconds on cpu is as fast as it gets and the only benefit to gpu is working with big neural nets?
How long does one iteration takes? As in, calling choose_action once?
1.0013580322265625e-05
9.775161743164062e-06
9.775161743164062e-06
1.239776611328125e-05
9.5367431640625e-06
1.0013580322265625e-05```approximately 1/10000 of a second? 0.1ms?
ye
yeah, at this point the overhead from moving the data to a different device might as well be more of a hassle than it helps
iirc typically you should not be doing things one iteration at a time
next_state = get_state(bear, berries)
bear.remember(state, choice, score_per_action, next_state, bear.hp <= 0)
bear.learn()
print("bunga bunga", time.time() - b)``` this also only takes 8 e-05wym
in short, run things in parallel
you are running one agent, one step at a time
yes
run multiple agents or multiple "steps" at a time instead of one continuous simulation
if i run multiple agents at the same time is it not going to slow them all down because its still on the same cpu and still average be the same speed
it can be more efficient to do some sequence of operations [A 100 times] -> [B 100 times] -> [C 100 times] than [A -> B -> C] 100 times
so if i do a batch size of 10 i run the choose action for all 10 agents. collect the scores in a list then run the get_state, remember, and learn for each of the scores. Why is that faster?
compare ```py
import numpy as np
1)
for _ in range(10_000_000):
A = np.random.rand(100)
B = np.random.rand(100)
something = np.mean(A * B)
2)
for _ in range(100):
A = np.random.rand(10_000_000)
B = np.random.rand(10_000_000)
something = np.mean(A * B)
hmmm
the majority of it is done within numpy instead of normal python which makes it faster
but how does that apply to what im doing
because it increases the amount of work your gpu can do before it gives back the data to the cpu
if you have 1000 calls of 1 operation on the gpu, your cpu has to tell your gpu to do the calc then it's passed back 1000 times
if you have 1 call of a thousand operations you have the cpu asking for data once and the gpu doesn't have to wait to be asked a thousand times
one line error from onnxruntime
Segmentation fault (core dumped)
from
sess_options = onnxruntime.SessionOptions()
sess_options.intra_op_num_threads = 1
self.session = onnxruntime.InferenceSession(path, sess_options=self.sess_options)```I don't think this will ever execute faster on the GPU than CPU as is, most of your time is probably spent just copying data to and from the GPU before it even thinks about executing
i managed to crash the debugger

Segfaults will do that
how do i debug it
!paste
Pasting large amounts of code
If your code is too long to fit in a codeblock in Discord, you can paste your code here:
https://paste.pythondiscord.com/
After pasting your code, save it by clicking the Paste! button in the bottom left, or by pressing CTRL + S. After doing that, you will be navigated to the new paste's page. Copy the URL and post it here so others can see it.
You can use that for reference how to implement it
Gradually remove code till it stops doing so
i found the line that causes it
but no explanation as to why
what line?
this one
ooo i will check this out once i get the onnx working
I suspect it isn't that
I suspect it is the MMap
but that optimizer line was the last line the debugger saw before it died
Because it is a segfault
i.e. the program did something so bad the OS killed it
loosely
I would start by trying to remove memmap and seeing if that fixes it
but thats a core part of the program
the memmap isnt
the replay is, but I am sure that libary has more than just LazyMemmapStorage as an option
although with a size of I assume 10_000 you could hold the entire buffer in memory anyway... Idk why you need a memmap there
removing lazymemmap doesnt fix it
Rip, welp that is one line down
i have a working file if that helps
yes
!paste
the difference is i removed most of the training stuff with the intention of the failing file to just visualize the agent from a premade model
The things I would do for us to support diffing two different paste links...
Try adding some exception blocks around the areas you think its affecting. Maybe from the save_brain?
Only sus thing between the working and non-working example is on the working one you set self.device = "cpu"
what is sus about that
Code Diff - #import pygame
import sys
#import onnxruntime
from tensordict import TensorDict
import torch
from
if the os kills the app no exception block will be hit
Well you are changing what pytorch is trying to execute on
Thats a cool website
i dont think this is the issue because i was doing it earlier in the other file for testing
Do you have a GPU?
yo, for RNNS, for the input dim in the embedded layer, does it have to be the max length after "tokenizer.texts_to_sequences" max sequence is found? Is the input_dim= (len(word_index + 1))), and what goes in the output layer and units for LSTM? do the units for the LSTM have to be between two(if it is categorical) and the input length? Really, what goes in the output dim for the Embedded layer of the RNN LTSM?
If you add that line back to the non-working example does anything change?
no
The output dim is the embedding layer the model returns
oh i found it
what was it?
#screen = pygame.display.set_mode((screen_width, screen_height))
for some fucking reason
🤨 What
yup
i undid all the changes to the new file and made the one line at a time
this one fails when its uncommented
-_- But why is that line commented out in your non-working example then