#data-science-and-ml
1 messages · Page 123 of 1
and it doesn't even work on kaggle when i tried to put it there
like this code
let me try putting it on kaggle again
Is this assignment from an online course, or a uni, or?
The wording and terminology is just really confusing and ambiguous.
I'm not in uni, this one is just scientific data analysis which i need to apply for some physics related context
it's an elective in school
😭 well this was like a "speedrun" of pytorch
i have no idea what any of this is but okay wait give me a second

okay yeah it's these things; eventually itjust errors
i've been fiddling with this for hours

but it works on my system though but out of let's say 7 files
only like 3 downloads
the rest like doesn't even exist lol
cuz i tried to manually download them too, and only 3/7 or maybe 3/6 of the links work

actually 4, it's all the ones i've manually downloaded
is this thing deprecated or smth?
Hmm, okay that sucks. I don't know, but you should be able to find MNIST dataset somewhere, it's probably the most popular computer vision dataset.
Oh, then maybe it's my fault
If that code is given to you like that it wouldn't be your fault.
yeah that code is given to me
i tried to manually do the loading but i think that's advanced
i had chatgpt do it but ofc that never worked

like replacing this line by just loading my files in or smth
well okay, i think that shouldn't be an issue right? it works on my system so hmm
for what it's worth
If the data is in the correct format (a folder for each class, each folder containing the images, the label being the folder name) then it should be easy to load with a DataSet class.
no idea if "ubyte" is the correct format tbh
But concerning the initial question:
If there is no additional information, I would just train the model with whatever batch size you want (100 was already used in the code, so stick with that), and then make another dataloader that has a batch size of 600 (call it dl_question1). At the end of a training epoch, pass a single batch of thedl_question1 data loader to the model, calculate the loss (MSE), and store it in a list.
I just stole the link from everytime it ran "downloading <link>"
btw i think batch_size = 600 and batch_size = 100 gives me the same "answer" for q1)
is that like normal?
it takes 20 mins per run :V
And the total loss I assume would be the sum of all losses, or the final MSE, this is ambiguous imo.
It should be approximately the same yes
And 20 mins is quite slow, did you install the CUDA version of pytorch
i don't have a graphics card
well not one that's nvidia
Then it might be slow depending on your hardware and model, yes.
that's why i wanted to try kaggle but that specific "block of code" 😭 doesn't allow me to continue
# Define a data transformation to convert digit images to tensors
transform = transforms.ToTensor()
# Load the MNIST datasets for training and validation
# images are 28x28 pixel images of handwritten digits in a greyscale
train_dataset = torchvision.datasets.MNIST(root='./data', train=True, download=True, transform=transform)
valid_dataset = torchvision.datasets.MNIST(root='./data', train=False, download=True, transform=transform)
# Create a data loader for training data with a batch size of 100
train_dl = torch.utils.data.DataLoader(train_dataset, batch_size=100)```so just carry out the process like twice for different dataloaders (one with batch size of 100 and one with a batch size of 600)?
Well at the end of updating the model for a single epoch (which is trained with batches of size 100 f.e.), you pass a batch of the other dataloader (with size of 600 images), and store the resulting MSE of this batch.
For question 3 you do not the train the model, And you make a set number of batches of size 1, so you pass a single image each time, calculate the loss, and add this loss to a list. Later you can then plot the losses (with a boxplot, or a frequency plot or wahtever), and take the average of these losses to answer the question (which would simply be the MSE before epoch 0).
right makes sense yeah i think i get that
This would give a higher value than for question 1 though, which doesn't seem to make sense looking at the values from the multiple choice answers.
Yep 😭
I did something wrong by deleting the "trainign" section or whatever u call it
The "average" clearly didn't match
So that's why I think the question probably wants something else, but the terminology just sucks ass, and the teacher can't clarify what they actually mean with their words.
btw

GitHub
🐛 Bug I'm getting a 403 error when I try to download MNIST dataset with torchvision 0.4.2. To Reproduce ../.local/lib/python3.6/site-packages/torchvision/datasets/mnist.py:68: in init self....
I think the MNIST issue is a thing
but none of their solutions work :V
or maybe i'm misunderstanding
Btw thanks, i think i'll just ask clarification for this assignment
I would ask the following:
- After each epoch the "total loss" for a batch of 600 images is stored. Do we just create a random batch of 600 images after training and calculate the MSE for this random batch?
- Should we use a batch size of 600 for training, or keep the batch size of 100 supplied in the code?
- What is meant with "total loss after 100 epochs"? (Q.1) Is this simply the MSE of epoch 100, or the sum of MSEs over all 100 epochs.
- Is question 3 simply asking for the MSE for a random batch of images before training the model?
I think all these points are ambiguous in the question.
Okay thanks!! Btw while i'm asking, do you think this question is ambiguous too?

Like would i be asking for this too?
This would be the MSE over a batch of N "random" images. I think it should be pretty straight-forward.
Just create a random batch of images like
N = 100
random_batch = torch.randn(N, 1, 28, 28)
Pass it to the model, then calculate the MSE.
They probably mean torch.randn()*, torch.rndn() does not exist.
Okay fair enough, thanks! I'll just about the 1 and 3 then
If the answer isn't clear, feel free to ask me or someone in this server.
btw the answer to 3) should just be MSE of epoch 100 right ( the sum is too large right?)
epoch 100 was 22.5 or something
the sum would be too large or i just don't know what i'm talking about? 😭
Right thanks!!
The MSE of epoch 0 (Q.3) would be higher than the MSE of epoch 100.
Because at epoch 0 it is untrained, so higher loss.
Yes i agree, i think i plotted it and it decreases
So that is why I suspect with "total loss" they mean the sum of MSEs over the 100 epochs, otherwise this loss must be lower than the ones for question 3.
but the sum of 100 epochs would be at least 2000 if epoch 100 is 20ish right?
But all answers for Question 3 are lower than question 1, so this does not make sense.
Yeah anything i choose for 1

It will at least be 100x the MSE of epoch 100
Yes, so with total loss they don't just mean MSE of epoch 100
unless the MSE of epoch 100 would be about 2, and the MSE of epoch 0 is about 3.6, then it could make sense I guess.
But probably not the case.
this is rough 
The wording of the questions, the grammar, and the general english is just very poor, so ask for clarification.
Mhm right, thanks for the help
I'll be back if i get a response 😭
If i don't then welp i'll just skip this bit
The important part is that you yourself understand the meaning of MSE, total loss, etc. and whatever this teacher expects is just important for you to get a good grade.
I'm done with the actual "assessment" (like the actual test)
they don't test pytorch and stuff
only scipy and the things we kinda did last time and the like
This one is an "optional" thing but yes 😭 i think i'll try to better understand total loss vs MSE for now
Maybe with total loss they mean the Sum of squares errors, instead of MSE, since coincidentally 22/600 is about 0.03666...
But anyways, I'm gonna sleep. Gl though
wow interesting
okay okay good night maybe i'll look at the sum of squares errors
and see if it matches
i am using jupyter lab and whenever i use vpn it does not open for me even though i switched default browser to split vpn connection it does not work.
searched it online but could find any helpful solution.
if anybody finds anything please tag me or ping.
thanks
I have a set of images that are unlabeled and I will be using resnet to classify those images into 4 categories how do i label them or prepare them to train the model or to fine tune the model to my needs
The images are basically 2D representation of TMT bars and must be classified into 4 categories normal, circular (has curved bends) , intersecting ( 2 bars pass over each other which might make it look like a bend) and overlapping (can hide any underlying bends)
I've already completed the code to find the bends in the 3 categories but i must develop a model that classifies the set of images in the mentioned categories and run the specific bend detection codes for respective categories.
Hey there, I need help with pyspark.
Facing an ValueError: Cannot Serialize object size larger tharn 2G.
Does anyone know about it's fix?
Should i use l1loss or mse loss for a simple linear regression model?
I have a field with list of strings, I'm creating additional field that will contain subset of existing list.
For e.g.: A, B, C, D (these ABCD are some large string)
Subsets:
A
A, B
A, B, C
A, B, C, D
So,I have dataframe with 3935 records and there's record with array size of greater than 10K and one with 17K.
What do you think I should be doing here to make object smaller other than string encoding..
Are you using sklearn? If so I'd always go for RidgeCV over flat LinearRegression
i use pytorch
MSE and add weight decay
Which corresponds to L2 regularisation / ridge regression
Now we have that out of the way, why are you doing linear regression with Pytorch?
oh im just watching some pytorch tutorial on youtube
pytorch ppl like how we can decorate a function with @torch.no_grad() is the similar possible if we decorate classes with it? how does it behave in such a case?
aight ty
hmm can we decorate some bound method to a class
or does it have to be a static method
right
cool ty again
where is the series currently? in a dataframe?
Oops you did it again...
sorry for crossposting, but does anyone here have thoughts on this? #1246146113086685194 message
basically getting an inhomogenous error within a tensorflow helper, and was wondering if anyone had experience w/ it + a solution
i was creating a fresh series
just started learning Pandas
It's not different from making variables in general
i was doing as
ingredients = pd.Series(['4 cups', '1 cups', '2 large', '1 can'],
index=['Flour', 'Milk', 'Eggs', 'Spam'],
name='Dinner')
but answer was incorrect
The answer to what?
Create a variable ingredients with a Series
Your code does that, so if it's wrong, the question must have more requirements than that

You wrote 1 cups
yes that was the mistake
sorry
why sorry
do you guys agree with the 10,000 hours statement?
the one that it takes 10k hours to master something?
well, what it means to master something is going to vary by what that thing is. and even then, you probably can't have objective standards for at what point one becomes a master.
the point is that learning and gaining skill is a life-long thing.
I put probably like 6000 hours into this. No, talent is defintely a thing. Like outliers, when their averages are better than the majority of the populations best. Everyone at one point will experience diminsihsing returns no matter how many hours you put in.
6000 hours into what
@serene scaffold ML
over how long have you done that? how many years?
@serene scaffold a little over a year
,,,you worked 8+ hours on ML a day, every day, for more than a year?
@tidal bough yes. Barley slept
@agile cobalt You were right about my zipped data being the problem, so i did a flat zip and added this workaround before passing it to fit:
trainer, valer = tf.keras.utils.split_dataset(batched, 0.7)
trainer = trainer.map(lambda f,w,l: ((f,w), l))
valer = valer.map(lambda f,w,l: ((f,w), l))
it's a bit jank, but everything's happy
uh, just be careful about using .map, .apply and similar methods, it shouldn't make too much of a difference when your bottleneck is training a giant neural network, but they're usually considered bad practice as they're not very efficient compared to built-in methods
what do you do during all that time?
what do you mean?
if you say you're spending so much time learning about AI that you aren't sleeping enough, you're probably studying ineffectively.
No, I mixed it pretty well. It was, since February 2023
looking for someone who can make a AI paraphraser that can paraphrase off of human written essays
What do you guys make of this I created



what is a good level?
I just have not really messed with pytorch, keras or NLPs until about two weeks ago. I wanted my groundings in other things to be firm first
how much time did you put into actual practice?
no matter what subject you were learning, you had to practice it
anyway, what is your level then? what did you learn during this time?
hi guys, i am performing customer segmentation/clustering analysis, and i am currently doing feature selection. the image above shows the distribution of age in years by the different unique values in 'Number of existing credits in the bank'. i am unsure how to analyse this and would like to know whether this particular feature has high variance or not? and i would also want to learn about how to determine high or low variance in such plots

an optimization algorithm in the adaptive gradient family
idk what an adaptive gradient family is
it calculates a learning rate for each weight/bias based on second order statistics instead of you setting a learning rate manually
Wait
thats actually fire
idk what any of those words mean
learning rate is how much you update the model based on your gradient calculations
if I wanna update my weight I do weight -= cost w.r.t weight * learning rate
what if they roll from the opposite corner?
any good resources for intro into structure for motion (SFM) in python
all inputs are much appreciated, thank you
can you try from the other corner that's close to the global minimum
Hmmm
I'm gonna make a RAG on my code this weekend. Download everything, embed it and have a basic UI so people can "chat" with all I have on GitHub.
Haven't done a Python project outside of work for a while so I'm stoked 👀
I use sveltekit + tailwind because I'm fastest at that
I don't like htmx
It feels like it's the tool people use that are scared to learn JavaScript
but... can I see it 😁
On top of that, there's SPAs that can work without any backend. HTMX automatically needs you to run one etc.
Anyway, I'm getting off topic. I think I can crank this out by tomorrow evening latest, I'll share if/when it's done
looking forward to it
I've coded in so many strange languages I believe Python, C#, JS, Java, ... are all the same with different syntax. JS has some strange semantics as well but in a week you know and avoid the rough edges.
hi
hi
How I should choose which is best?
Ok then I will start with pytorch
One more thing
YouTube
This is a complete course on linear algebra for machine learning. It is also the first quarter of my broader ML Foundations series, which details all of the ...




Is this playlist good for learning Linear algebra?
Is this good?
Can you send me link?
I have to learn numpy, pandas, matloib, pytorch and linear algebra
right?
can you give me a order to learn these things?
I have learned the basics of python and some pandas and now I am learning linear algebra and numpy
Is this right?
@final kiln What I should select for linear algebra?

Ok thanks


From where I should learn numpy?
I'm on the train for some hours 😩 but I guess it's time I have to get the architecture right
@past meteor plz tell me
I'm gonna use dagster to make a schedule that reads my private repos daily. I'm on the fence of storing the actual source code in minioDB or simplifying my architecture and not doing that
someone? It should be a video
I can tell you that I learned it mostly from practice and then oftentimes I have some intuitions (like having seen the functions in the past) on what to google for specific to numpy
other times I just google for something roughly specific I want to do
but like, generally it's been largely just applying numpy
Is this using pydantic?
I learnt it from reading the numpy documentation. I did a project with it. Writing a genetic algorithm from scratch (it was for uni)
Don't do videos. Videos aren't great. Read docs and do projects
So I should mess with numpy to learn it?
If you need inspiration for projects, I can give you projects you can do
application beats memorization and understanding, so yeah, sth like that
I dont understand docs
Ok give me
well, that's another skill to pick up along the way then
That's a hurdle you'll have to get over. You read docs, if you don't understand words then google those words recursively, or ask us here "What does X mean"
Ok
btw, zestar, have you heard about Bloom's Revised Taxonomy?
I like it, I've done this myself with dataclass
What is it? 😮
it's levels of learning
Ok
I looked at it for a second and it makes sense
My trick is to never put myself in a situation where I need to learn 2 things at the same time
So I have to read the docs and Implement the things in code as I go
Otherwise you get into a situation called cognitive overload. Let's say I want to learn Julia to do operations research stuff. I'd learn Julia syntax first coding things I've already implemented exclusively to get familiar with it, then review operations research and then do the algos in Julia
Too many people just go for the big leap at once and it becomes a mess imo
Try doing things like coding linear regression, decision trees, logistic regression, ... with numpy
The code is pretty simple and it'll get you thinking about the math too 😄
Ok
Start with linear regression using gradient descent and then try linear regression with QR decomposition (you may use scipy for this)
Then make it stochastic gradient descent, then add L2 regularisation to make it ridge regression and so on
docs tend to have some quick start guides and tutorials you can look at to sort of get your feet wet and see what the library offers, but then you decide what you want to implement and then look up the docs as needed, occasionally you can just surf the docs in case you come across something interesting or new you'd like to learn more about, you don't have to immediately memorize it and learn and such, just at least take a look, read the description, see examples if there are any just so you can revisit it if you need it
It's 5-10 lines of code
Make your own data at random with numpy too
I assume you want to learn about ML, this is good practice if you want to dive deeper there as well 😄
Ok
also Feynman Algorithm:
- write down the problem
- think real hard
- write down the solution
I can do this with only knowing python basics?
uhh, might want to practice those a bit first
In my opinion, no. Because of this
But if you did high school tier mathematics (partial derivatives) this is actually quite a basic way to learn python
So I should learn python better?
The genetic algorithm thing was the first "big" python project I did after a huge break
So it can work, ig
??
Yes, now just go out and code something 😄
Code tic tac toe
That's a project you can do 😎
snake is not simple 
and rock, paper and scissors
I'm gonna move on, you should too. Code some more until you feel confident.
!kindling
Kindling Projects
The Kindling projects page on Ned Batchelder's website contains a list of projects and ideas programmers can tackle to build their skills and knowledge.
Other then these?
Hi i am currently learning python and would like to use it to analyse images from my multispectral camera and turn the into NDVI maps. Does anyone know some books or courses that could help me learn this field using python.
Thanks
I didn't do that in uni. I skipped classes and did them sequentially so I could immerse myself (as opposed to 5 classes concurrently)
Does anyone here ever build onnx ACL execution provider? https://onnxruntime.ai/docs/build/eps.html#arm-compute-library
onnxruntime
Learm how to build ONNX Runtime from source for different execution providers
Those instructions are so bad and so unclear that i dont know what to do and im looking for someone who maybe tried it befroe
I need that to make my ARM device run faster object detection
Does anyone know an api marketplace or somewhere can i can acces an chatgpt api without linking a creditcard (cause i don't own one), somewhere i can maybe top up balance on the website it self
what are you even doing?
would it be useful if i started learning how to use python with sql now or carry on using pandas for now until i have a good understanding of them?
i have read online sql would be vital to know. only used a sql for a bit during secondary school for a gcse project and i did like using it
simple to learn, simple to use yet a very powerful tool (if thats the right term to use) for storing and sorting data
Hi
I wish to know from you folks that before beginning to build my own model, how much math experience should I have?
For reference, I have taken a course in linear algebra and calculus-1, wherein I've somewhat learnt how to make a jacobian (just that, i didn't learn what it actually is and what's it used for, we were kind of rushing with the syllabus in my uni) and I know multivariable calculus to a good extent.
What I don't know but I think I should for AIML->
Tensors
Probability Distribution functions
Statistics in regression and bayes classifier
of course, there is more but these were just what I felt important
See, I have two books
one is very popular, Hands-on implementing deep AI algorithms with extensive math and tensorflow
it has decent amount of math, but I am very impressed by the fact that I can actually understand the main idea of how the algorithms are working, and even understand the math behind it thanks to its easy wording.
the other one is practical math for deep learning
this was takes a huge dive into every nook and corner of math required for AIML
I had to search up a whole playlist of tensor calculus for this.
A bit of my situation-> I am having a vacation of 2 months and I want to "learn" AIML
that means I don't want to compromise on math, but I also don't want to keep studying theory and not build any projects
I haven't even built the handwritten digits classifier yet which makes very disappointed in myself.
So, to improve from hereon
I need your wise advice
Judging by the books I am using and my background
please tell me what would be the best course of action for me,
do the theory in math
or start with the hands-on book
please this is very important for me 🙏
A good exercise is to do the same data processing in both pandas and sql. I find myself alternating a lot beteeen dataframes and sql.
Ill give it a go once im done with my current project. Got an interview for an engineering appreticeship next week. Hopefully i get in
anyone here done anything with physics informed neural nets?
i'm learning about them and i did it for the logistic equation successfully, but my model for simple harmonic motion isn't quite converging
Hello, it's best if you ask your question in a way that assumes a domain expert is reading it. That maximises your chances of getting an answer.
ah sorry
i'm playing around with the number of iterations, updating learning rate, batch size, and the weights on each term of my loss function (dif eqn itself, boundary condition on function, boundary condition on first derivative of function) and no matter what i do, i can get it close-ish but not really properly on the solution - i'm not sure what other sorts of things i can try, basically
best result i've gotten looks like this

which is close, but when i weight the boundary condition on the function more in the loss function, it tends to get worse, not better, even though as far as i can tell the only issue with the solution it's finding here is that it's phase shifted from the correct one
(and also, i can't help but feel there must be a better way, since there's no way to validate changes in weights in the loss function without knowing the solution to the equation already!)
they are "validated" by gradient descent
also can you plot your loss across epochs?
could you clarify what you mean by 'validated by gradient descent'?

latest loss plot; i achieved this with a much better fit using gelu instead of tanh for my activation function - before this strategy my loss plot looked like a much more standard decay without the spikes
ah just that switch got it to fit honestly, it's looking pretty good now - i'm still not sure about how changing the weights within the loss function we're optimizng on is validated by gradient descent
Can anyone give me some tips I just started Ml a week ago
Keep reading books and doing more projects and it'll make more and more sense along the way
Hey, Im an Ml Enginner and would like to know in your opinion what makes an exceptionally good mle?
I'm biased but I believe knowing how to monitor and evaluate models is what separates the good from the exceptional
I see too many people think their job is to make good models. It's not. it's to accurately estimate the performance of models so you don't deploy 💩
If this isn't your priority, sooner or later you'll
A. leak data because you think the goal is "making the best model possible".
B. Deploy something like gemini that tells people to add glue to pizza 😩
~~you sound like a hater who's never tried glue on their pizza  ~~
~~
Which would be?
hello .... i am a beginner in data science ..i had a question... if

i am working on a skew dataset .... to remove the outliers is this the correct method
here i manually selected the range of data which i would be using
you would need to ensure that you are calculating your IQR using only the training dataset (i.e. after you have performed your train/test split) or you are at risk of data leakage
so i know the baisics in python but how do i make a website
so can yall help me on that
You want to make website with python?
Sure, you can code the backend in python and do the frontend in HTML,CSS and JS
okay thanks
How would I go about comparing similarities between two audio files, one that's already recorded and one that's being recorded in real time via a mic?
hey maybe try the #media-processing channel too , not sure how many of the data science people here are into audio.
Fair, thank you stelios!
@agile cobalt, idk if you're up but do you have any pros and cons I need to take into consideration for langchain vs. just raw openAI client if I'm making a basic RAG
I was thinking of doing everything on the side of embedding in an ETL without langchain and doing the actual RAG stuff with it
it is 1PM for me 
I mess up my sleep schedule really hard at times...
lang chain's advantages are its integrations with a lot of tools and different providers
What do you do? Do you use it or just go raw (this sounds bad)
raw should be fine unless you want flexibility to swap between different providers
it's a bit like using SQLAlchemy versus using a connector specific to one database
the tools part is more useful if you're messing with agents
Nah my use case is very basic. I'm making a RAG on top of all my github code
whats your fav codeing lan\gage
I don't need agents, I think
code huh... I would be a bit concerned about all the imports missing context it might end up with
I'm curious as well, I'll be able to tell you how it turns out in a few days tops
It failing is also interesting
tbh I'd actually recommend using LangChain to be able to try models like CodeLlama or Codestral without having to change everything
and adding a simple additional agent-like reasoning step like "Think about the imports you'll have to consider" could make a difference
I already bought the credits so I'll only use openAI
oh
I mean, I could get other credits
the two I mentioned are open source, a few dozen of billions of parameters iirc
I think I'll just finish it like this (using the client). Worst case I'll need to refactor a bit
It's not a lot of code, neither hard code, so that's okay
just be careful about system prompt, special tokens and such (esp. open source, not as much openai)
Yup, I'll "slow down" for that part
The hardest part is persisting all of the github code/having the ETL to do so and that stays the same across models
just how much code are you working with?.. a few thousands of files shouldn't be too bad
effort wise, switching to another model is fine considering I won't have to refactor that part.
You gave me a good tip though, I'll make my DB schema a bit more flexible so I can accommodate different embedding models
Not a lot. I have like 40 repos
I filtered out stuff I contributed to and forks because huge projects would weigh the thing down yeah
tsym for the tips!
speak of which, how are you planning to build the embeddings rn?
naively - using "text-embedding-3-large" and adding some extra stuff (maybe a readme). I'll mull it over
At the very least I'll add the file path to each code file
one embedding for each entire files or breakdown like separate functions/classes?
tbh I have no idea if there are embedding models more suited for code
To the beginning and end I'll add respectively file_path\n and \nfile_path
entire files 😎
that might work if your files are all <100 lines, but I would strongly consider breaking down if you have >1000 lines files
I rarely have 1000+ LoC files
rarely means there are?
like 5-6
And those that are that long are half comments (docstrings)
I feel like slicing the files will only make sense depending on the questiosn that are asked
If the questions are more "high level" they'll span multiplle documents
perhaps as a future step, but you could break down into functions/classes then perform retrieval (search) based on that and use the metadata to retrieve the entire file during 'augment', before passing to the generate part
Yeah, that's fair. I think what next should/will be added really will depend on how good (or bad) the PoC is based on some testing
Breaking arbitrary code into functions and/or classes will be very hard though
if it's just python, ast should make that fairly simple?
if it involves multiple languages idk
I'm known to do this
def fn1():
def local_fn():
...
local_res = local_fn()
return local_res
When I want a private function sometimes I do that
I'd just keep it as part of fn1 without splitting further
just splitting on top level class and def
only top level means it's now context-sensitive parsing and becomes hard
some very simple heuristics like line.startswith('class') line.startswith('def') line.startswith(' ') (without stripping) could be a descent approximation
maybe I'm resisting too much
this is a good one
what is the best why to code and make am app
But honestly, I think this all depends on the level of detail people ask, no?
"Can you show instances of where zestar75 demonstrated testing" versus "How did zestar75 implement X in project Y"
yeah, I guess you cannot make a system without taking into consideration how it is going to be used
sounds obvious when you put it like that, but I frequently tunnel vision myself 
If I slice on the function/class level one becomes very hard and the other easier
I'm like that too 😂 but for this project I decided to put my "deliver value" hat on and rush to an MVP + do it in Python as opposed to Rust or Scala so it'd be done faster
did you see the GraphRAG paper and coverage around it?
in particular the cases normal RAG does not covers that it tries to cover
No, I'm totally out of the loop with RAG stuff. I'm just going off of the intuitions I have from my information retrieval coursework
things like "show instances of where zestar75 demonstrated testing" are pretty much just failure cases of rag
Which probably gets me "far enough" but 100 % not to the sota
you could throw in an agent step to try and create a more relevant query, but if you perform similarity search directly with that question, it'll give you completely irrelevant documents
Yeah - I need to actually play around empirically with how this stuff is embedded + retrieved
I strongly recommend taking a look around it later to see some RAG limitations + workarounds for them
When I played with bedrock I did this - I just had a rewrite step before the retrieval to verbosify and do some other goodies (using a cheaper model)
Honesty, when I'm done with the e2e I'll just play around with embedding questions and looking at the top-k
Together with the paper
If I get in research mode now I won't deliver anything 😂
I think that some frameworks even recommend using a LLM model to generate a more relevant embedding like https://docs.llamaindex.ai/en/stable/module_guides/models/embeddings/#custom-embedding-model
really, thanks for all the help!
I've been trying to keep up with gen ai news, but haven't used it in practice as much as I wish
I ignored all of it in favour of "regular" ML/DL
But as I was looking at job postings, many of the ML eng stuff is really gen AI focused now 😩
like anything else, >90% of all applications are destined to fail, but whoever finds the 1% actually useful things will probably make $$$
I'm curious how hard it'll be to get fully up to date there. It should be OK since I have a background
Hence why I wanted to bust out this project
hi,what is the best source for learn the machine learning?
practice
also check the pinned messages in this channel
It's actually a nice project I'm doing. Spans many domains. So much so it was too ambitious to do in a weekend that was already busy
At least I have the ETL with an orchestration tool set up + dockerized that downloads all of my code, embeds it and stores it in pgVector
also all the boring stuff like db migrations, ... 🥴
Honestly, it's a workaround for the limit context window or the fact we don't have giga embeddings
If we could reduce an arbitrary length piece of data into a dense vector that contains the signal and not the noise then there's a lot we can do, not just RAGs
That's the prototypical problem
Hi guys what environment do you use to type and implement your code
Me personally, I use PyCharm
but I also use vscode, just not for Python (usually)
and then sometimes I also use Notepad++
first time seeing someone using notepad++
I've recently noticed that I don't use it as often now
mostly for C stuff really
but at this point it's just for quick views and things like that
not the weirdest IDE ive seen used
I once knew someone using Microsoft word to code (not a joke)
Notepad++ is not an IDE
and as I said, I rarely use it nowadays
yeah I know
idk why I called it one
@abstract wasp so you're studying both ML and neuroscience? What are your thoughts on the term "neural network"?
Yeah, it’s cognitive science but I specialize in ML and neural computation.
I think it’s fitting to some extent. The neural net is biologically inspired by the way neurons in the brain transfer their signals and such but actual human neural networks and computer neural networks, will definitely differ due to their own unique complexities.
Hey y'all, first message here. Just made my 1st year as a DE but its a hybrid role and they have me developing models as well. Recently graduated last December & been writing my DL models in TF for the last 2 years and recently started realizing I was living in a bubble lol.
Just made the decision to switch my models to PyTorch after seeing how prevalent it's become, as well as a better supported ecosystem for loading datasets from delta table format in Databricks.
Been focusing lately in multivariate timeseries forecasting and signal processing. But I just wanted to introduce myself and say what's up.
how do you save the file into py extension with microsoft office
I think I'll use agents for the RAG. I'll use one to transform my initial query into a list of topics and then query each of them separately or so
The more I think about it, the more it's clear that this is such a crude technique
Slicing a collection into multiple documents and then hoping the query doesn't span several...
I'm curious how would you guys approach open set object tracking today.
Optical flow, yolo-based, point tracking, transformer based, or something else?
We used Yolo recently
We considered optical flow for a long time
I forgot the details but we used a thing built on top of Yolo that does a lot of other things like Kalman filtering and so on
But I'd say I was proved wrong, my money was on optical flow being the right bet for my use case 🤷. Someone went the other route and it worked really well
I'm think optical flow would be a neat, fitting solution for many cases.
But in some it doesn't seem to be accurate enough.
would yolo work well when the classes are not pre-determined?
As in, you want to track arbitrary objects?
There's also a recent paper called sam-pt but that will obviously be very heavy
Yes
Yeah, I was thinking of sam as well but I can't vouch for it because I've never used it on non-toy problems (and it came out after we did our project)
They're just tracking prompt points you give for Sam input, doing a Sam segmentation using those prompts for every frame, and getting the bbox from that
We also had hard constraints of running it on an edge device
Problem is it'd be very heavy
Yup, this makes sense, I thought it'd be something like this
Would yolo work well for this
Honestly, I wouldn't know. I'd think about optical flow, but I was proved wrong last time as well lol
There's a bunch of transformer based papers also recently, their advantage being superior image understanding of the model helps it perform very accurate tracking where that's a need
But I haven't tried them out yet
What would the approach be? Take an image detection dataset, make all bboxes be a single class and fine-tune on that?
I see. I'm also on optical flow for open set tracking, but I was wondering if I'm being too tunnel visioned and I should explore more
I think a segmentation dataset might work better
That would be one approach ig
The goal would be to add to the model's image understanding capabilities some information about the dynamics and how these image portions flow in subsequent frames
Because an object detection dataset is biased towards only recognising a set of the objects in the scene
True but that would then need segmentation input at inference too I think
Since it would learn to track in association with these dense annotations
(all these bunch of pixels close by)
True
I'll try and find out from my colleague what post processing was used with Yolo and ping you if I do
That would be amazing, thank you!
Seems like still a tricky problem. I thought we'd have been further along with this as a field at this point.
Yes and no, I'm pretty sure this has been solved somewhere in industry potentially without publishing
Are you in the computer vision discord?
That's a great place you could ask imo
oh well yes, what can we do 😔
Hopefully one day we have a true openAI
No I'm not. Do you have a link?
Joined, thank you!
anyone know how to do stratified cross validation for an image classification task?
Thanks for sharing, that is also of interest to me.
Are there discord channels for materials science or for remote sensing? I mean I just found out about this one by chance.
do you know what cross validation is, in general?
People really cross validate neural networks because training a single one takes too long, let alone K-1 nets
But in general, you can do stratified splitting with sklearn
Haha this brings me back to uni. We had to do "all" of them with pen and paper
Which one did you implement?
Ah yes, we did this one
Which linkage did you use?
If you're clever about it you can do it in one pass afaik
In statistics, single-linkage clustering is one of several methods of hierarchical clustering. It is based on grouping clusters in bottom-up fashion (agglomerative clustering), at each step combining two clusters that contain the closest pair of elements not yet belonging to the same cluster as each other.
This method tends to produce long thin ...
This is a better link
https://www.google.com/amp/s/www.geeksforgeeks.org/ml-types-of-linkages-in-clustering/amp/
GeeksforGeeks
A Computer Science portal for geeks. It contains well written, well thought and well explained computer science and programming articles, quizzes and practice/competitive programming/company interview Questions.
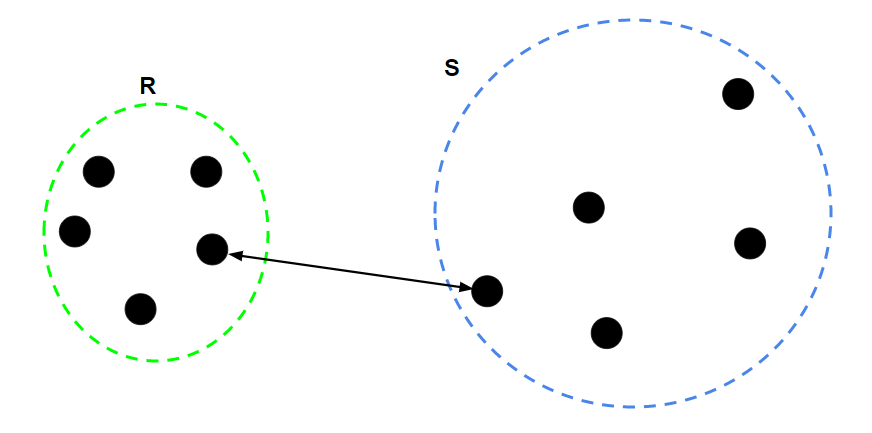
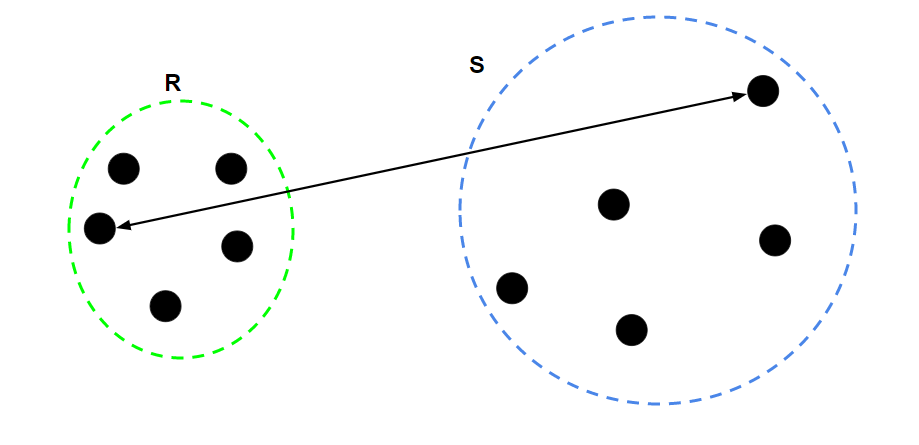

It can make your clustering algos garbage
Single linkage
Or the furthest
All 3 have different properties
scikit-learn
This example shows characteristics of different linkage methods for hierarchical clustering on datasets that are “interesting” but still in 2D. The main observations to make are: single linkage is ...
single linkage is fast, and can perform well on non-globular data, but it performs poorly in the presence of noise.
if you find this interesting you could look at http://mmds.org/
Well, I'd recommend any ML professional to look at the table of contents and at least use it as a reference on those topics
but maybe it's getting a bit old
I think it's all stuff you already know
and they want SWEs to all implement hierarchical clustering, That's interesting
My search slowed down a little, I should go hard on it again myself
I started texting my preferred connections in order of preference today
I'll stagger it by like 2-3 days
You know what I noticed? There's so many more data engineering roles
The premier ML company I interviewed at Friday has a 2-1 ratio of cloud/data engineering vs ML engineers
Yeah, I answer this one by saying it's a means to an end for me and not something I'd want to do full-time
Odds are they're looking at how you implemented it and not just what
Do you all think the mit 6.036 ocw lecture on intro to machine learning is relevant to study now? Or should I try to get my hands on a more recent set of lectures? Been pretty hard to find
Im having a lot of problems and misunderstandings with building onnx ArmNN interface wheel packages, does anyone every did that before? Refernign to this: https://onnxruntime.ai/docs/build/eps.html#armnn
onnxruntime
Learm how to build ONNX Runtime from source for different execution providers
what does it mean PCA ??
I have issue I cannot get it very well
I mean why do I use it and when ?
Ye but the controler which i use doesnt have access to GPU
And someone send me ArmNN exectuion provider here
So i investigated but building process is so unclear documented
Has anyone worked with pvlib library
Hello, be sure to always ask your actual question. Don't ask to ask, or wait for a commitment from a supposed expert.
can anyone help me in YOLO ? model please am stuck at 1 point.
my custom trained model is predicting the doctor, patient, nurse (making it blue in the sample video) but its not drawing the Boundry boxes around the persons please help me.
Pls does anyone know how to Quantize LLM with LLMWare and Quantized Dragon
what shall i take i changed many things like increasing the width of the boundary walls walla etc many things but still not working
if you can help can i dm ?
hey anyone have tried deeplabv3_resnet50 model??
I mean, suppose someone has, what then?
I am having trouble in segmenting
you're gonna need to elaborate
okay
how can I create paste for .ipynb ??
so that I can share code also!
I am having trouble segmenting images , for front dash cam pictures
you can copy each cell individually, or run python -m jupyter nbconvert --to script the_notebook.ipynb
hey I am on google colab
try showing the part of the code that you're having trouble with, and explain in more detail what the problem is
!code
file > download > .py
okay got it!!
just take a look at code
I mean I can't share ( plt images)
so try to imagine!
wait lemme share pictures then

final output
here's what I'm gonna implement now
Variational AutoEncoder Generative Adversial Network
VAE + GAN
it just seems so funny to me when it's expanded like that
what's the rationale behind that architecture?
I'll look it up because in my mind they're different architectures that do the same and I haven't seen them combined
what is kwd??
I just want to label my entire dataset which consist of 1000 images of car's front dash cam
and then I will create my own model for lane detection
so what should I do?
okay !!
wait I am trying changing few parametrs
and now that model is not predicting one truck
take a look now , it is predicting that left truck

but what's next now?
will it able to detect lane??
then it's good !!
what should I change in existing parametrs so that model can predict correctly
because now I am chaging with transforms
yeah
from
transforms.Resize((256, 256)),
to
transforms.ReCrop(256)
but then hey, it didn't work
so I remove this parameters
and then it predicts
preprocess = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean = (0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)),
])
this was the code
so I should change this now?
output_predictions = torch.argmax(output, dim=0).cpu().numpy()
ohh then which?
sounds interesting though
torch.cpu().numpy()
correct?
sorry but didn't understand , I am litterally new to this!
okay so
yeah sorry about that!
hmm, I read this in docs
that''s why the output image is black and white
and what about my transform ??
should I keep same as it is
preprocess = transforms.Compose([
transforms.Resize((512, 512)),
transforms.ToTensor(),
transforms.Normalize(mean = (0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)),
])
is it good?
okay
so changes are to made on that below predictions function
output_predictions = torch.argmax(output[0]).cpu().numpy()
what about this?
yup because I just want to label my dataset
but is it correct?
sry about I am asking dump questions because I just recently read about CNN in a blog and find interesting
like for example it returns max value
from tensor!
this needs to be googled
hmm
trying now thanks
output_predictions = torch.cpu().numpy()
so here? what we can do?
I am getting confused reading docs
yeah I missed the whole thing
library
so now I am reading whole code from start to end with docs
thanks for waking me up
I was just changing parameters not understanding what it does
suppose a module has a function and we have to call that then we use that .
like here we are doing this with torch.
but hey I feel docs have very short explaination why so?
because I read some dataCamp blogs and some medium they explain it well like in longer words
what you think for this CNN fundamentals what should I read first?
because I just randomly visited a site and then got interest
thruogh docs and then understanding each words how it works right!?
I am from commerce background so litterally learning maths parallelly
but yeah it's good
hey need to go I will start this after some time!!
thanks for the time that teaches me a lot
can I ping you here in this channel if I need some clarification
all the best then!
okay!!
I didn't exactly look into that 😐
it was suggested here https://github.com/soumith/ganhacks?tab=readme-ov-file#7-dcgan--hybrid-models and I just have to implement a couple of these suggestions for an exercise so, this one seemed fun, so imma try it, see how it goes, I did find a couple pictures describing it too, so ig it's not exactly something super novel
mmm
now thinking about it, it could allow you to generate images similar to another image
though it would be kiiinda deterministic then
guess you can add random noise to your inputs then
yeah lmk how it goes
VAEs can do this too
Send an image through the GAN, get the latent vector and use it to sample and generate more from that
Hence why I'm confused of the combo
Which one is better, diffusion or GAN+VAE?
depends on what you want to do, but it's pretty easy to tell which one the industry is using more lately
Just on the basis of how good the end result looks like I'd say diffusion
but this is specifically for image generation. I'll admit I haven't looked deeply enough on the pros and cons of diffusion models
well, they include a VAE in there
or like, Unet
Either way, some sort of autoencoder. Mostly the training process / loss that is different
I’m trying to train a model for stock prediction but would that be too demanding to train for hundreds of stocks over a couple of years?
Hello, be sure to always ask your actual question. Don't ask to ask.
oke
in tensorflow
do you need the env if you use only the model ?
in tensorflow ?
so currently am using YOLO V8 and i did labelling of data manually like nearly 30 images. but its all good when am running with an video the Doctors, patients , nurse are blue in colour but the main thing is this that its not showing th boundry boxes.
Hey- I know ive asked this before, but i'm here to ask again. After i've learnt the Data Science Libraries, how do I proceed with ML?
learning DS/ML in terms of libraries is already the wrong approach.
try following along with a resource that teaches you concepts (not libraries) and how to apply those concepts using the libraries.
I've already done a course about the concepts, but I'm unable to find a course that will apply those concepts using the libraires, do you know any good ones?
What resources would you guys recommend to get a solid foundation of math, algorithms, models, etc.., for Data Science?
look in the pins
Oh I see, thanks! @serene scaffold
this tells a lot!
do you know how I can implement the concepts using the libraires? Thats what im stuck on right now
Seems like the right time to try building a project to apply what you learned
but i dont know what project to build it, or how to go about it really
I think I solved a problem I've been facing, but I wouldn't mind getting a second opinion if it's not too much trouble
#1247620747891839118 message
feels jank
Guys is preceptron same as logistic regression , practically wise?
I just watched this video : https://youtu.be/O5xeyoRL95U?si=IYzG_jYHATXx9m8-

An introductory lecture for MIT course 6.S094 on the basics of deep learning including a few key ideas, subfields, and the big picture of why neural networks have inspired and energized an entire new generation of researchers. For more lecture videos on deep learning, reinforcement learning (RL), artificial intelligence (AI & AGI), and podcast c...
I love it, gives you a great overview of what the dl is capable off
Gave me a motivation to look into gans, as I have not used it so far
but they are extremely intresting
well, perceptrons technically use only step activation function
model.py line 78
class MLP(nn.Module):```meh, the terminology just stuck from back when, soooo, yeah, but I do my best to make it change (idk to what though, lol, MLN? MLAN?)... mby it'll happen... someday 
same, I've been calling them that as well
Is it general chat for data science ai with python?
that's what this channel is for.
Ok then, I wanna know how to start as a beginner in this field. I have an intermediate understanding of python. Should I go and start learning ml frameworks such as TensorFlow or Pytorch.
you can start learning about neural networks and apply what you're learning by writing code with pytorch. don't think of it as "learning pytorch".
though I would start with something non-neural.
I think it will be easier to learn to use tensorflow at the beginning
The syntax of pytorch is more complex and cumbersome
Thanks for the suggestion bud.
Then you need to use keras of tensorflow
Can you recommend any specific YT playlist for the learning purpose?
The problem with tensorflow is that it is more trouble to install cuda on windows.
YouTube
Welcome to TensorFlow Tutorials with the goal to build a strong foundation so we can start building our own projects! I have tried to make these videos very ...




YouTube
In this playlist we'll learn A.I. Deep Learning with Pytorch and Python. If you're new to Artificial Intelligence, this is for you!




You can look at them all and choose the one you like
Usually it is better on linux system
i use linux..and my laptop is backdated. It doesn't have any dedicated gpu. I think that'll just work for me now.
Without a GPU, it will run very slowly. It is recommended to use one with a GPU.
it has built in Intel 5000 series hd gfx
Or you can use Google colab first
I love doing it locally.
Will it be enough for small projs
Me too
which sort of projects are you thinking about?
if you want to train/fine-tune nearly anything non-trivial at all, you'll need of a GPU
if you want to use large models like LLMs or diffusion based image generation models, you'll need of a GPU
But deep learning usually requires GPU or TPU, NPU
Yes I want to learn generating images for now.
Ah that's a lotta terms hope I don't bump into them very soon.
all of them are <something> Processing Unit, they're specialized types of hardware made to do certain operations more efficiently
(as opposed to CPUs, which are general and versatile, but less efficient)
You can first take a look at what AutoEncoder is
and GAN
Is there a way to cut the model weights to rotate into the GPU for inference when working with large models
Will this further reduce GPU memory usage?
ok Let me try
man, these papers just keep on using phrases like "it is noticeable" and "it is easy to see" when, in fact, it is not 
anyone care to review this, based on this paper: https://arxiv.org/pdf/1609.05158
class PixelShuffle(torch.nn.Module):
def __init__(
self,
in_channels: int,
out_channels: int,
hidden_size: int,
hidden_layers: int,
scale: int = 3,
kernel_size: int = 3,
stride: int = 1,
padding: int = 1,
):
super().__init__()
# currently supports only a single output channel
assert out_channels == 1
assert kernel_size % scale == 0
#
assert kernel_size % 2 == 1
assert kernel_size // 2 == padding
self.scale = scale
def conv2d(in_ch, out_ch):
return torch.nn.Conv2d(
in_channels=in_ch,
out_channels=out_ch,
kernel_size=kernel_size,
stride=stride,
padding=padding,
)
layers = [
conv2d(in_channels, hidden_size),
torch.nn.BatchNorm2d(num_features=hidden_size),
torch.nn.Tanh(),
]
for _ in range(hidden_layers):
layers.extend(
[
conv2d(hidden_size, hidden_size),
torch.nn.BatchNorm2d(num_features=hidden_size),
torch.nn.Tanh(),
]
)
layers.append(conv2d(hidden_size, scale**2 * out_channels))
self.layers = torch.nn.Sequential(*layers)
def forward(self, x_bchw):
height, width = x_bchw.shape[-2:]
y_prim_br2hw = self.layers.forward(x_bchw)
y_prim_bchw = (
y_prim_br2hw.view(-1, self.scale**2, width * height)
.mT.reshape(-1, height, width, self.scale, self.scale)
.transpose(2, 3)
.reshape(-1, 1, height * self.scale, width * self.scale)
)
return y_prim_bchw
personally, this bit is a bit... janky IMO (frankly I was just throwing stuff at it until it worked how I wanted it to), but probably faster than a for loop (I hope)
y_prim_bchw = (
y_prim_br2hw.view(-1, self.scale**2, width * height)
.mT.reshape(-1, height, width, self.scale, self.scale)
.transpose(2, 3)
.reshape(-1, 1, height * self.scale, width * self.scale)
)

yeah, I mean, while this at least tells you what shape to expect (roughly because actually it's the scaled up width and height here that I didn't notate differently, I was considering using capital H and W, but...), it's not exactly readable when you look at the RHS... 
import IPython.display as ipd
from IPython.display import clear_output
import time
def get_detections(frame_idx):
return []
video_path = 'icu3.mp4'
cap = cv2.VideoCapture(video_path)
if not cap.isOpened():
print("Error: Could not open video.")
exit()
display_rate = 0
last_display_time = time.time()
frame_idx = 0
try:
while True:
ret, frame = cap.read()
if not ret:
break
detections = get_detections(frame_idx)
for (x1, y1, x2, y2, label) in detections:
cv2.rectangle(frame, (x1, y1), (x2, y2), (255, 0, 0), 2)
cv2.putText(frame, label, (x1, y1 - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.9, (255, 0, 0), 2)
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
if time.time() - last_display_time > display_rate:
ipd.display(ipd.Image(cv2.imencode('.png', frame)[1].tobytes()))
clear_output(wait=True)
last_display_time = time.time()
# time.sleep(display_rate)
frame_idx += 1
finally:
cap.release()
print("Video processing complete.")```mmm, I'm yet to explore that possibility
I see
I was considering it, but... oh well
@final kiln
sure brother just write me on DM may be because i dont open the server its a request please.
To follow up on gans ydays, do u think gans application is possible in also tabular type of data?
Are there any good text-to-speech models which are open source? I tried using Coqui-TTS and was having a problem installing it as it needed Visual Studio C++ which my computer cannot handle anymore :(
So i'm just brushing up my pandas knowledge, and here I have a dataset that has names of a bunch of pokemon, and I want to rename the Type of the pokemon from 'Fire' to 'Inferno', I run that command but it doesnt seem to work, any suggestions?

you have a comma in your 'Fire,'
that is the valid otherwise
🤦🏻 i totally missed that- Thank you!!
Why doesnt the groupby() work?

hm I can't see the error from your ss but I would have to assume it's because you're trying to take a mean on an object/string dtype
Can someone help me? kaggle isnt using more than 3% gpu and taking long time
Hey guys , just let me know if what I studied is right?
Perceptron is a line which can help us divide the linear dataset into 2 regions, more like a binary classifier. Now in order to get the best line to classify the points , we find out the loss function . Our objective is find out the values of W1, W2 and b in such a way that the loss function is minimum . In order to find the values of W1, W2 and b , we use the gradient descent function which partially differentiates the loss function with W1, W2 and b respectively . This is done in 1000 epochs , so that we get the best value of W1 , W2 and b , for which the loss function is minimum . Hence we get the best fit line using this.
Am I right?
couldn't one consider that operator to be a function?
a function that returns the gradient
it's an optimization algorithm. it might be correct to characterize aspects of its implementation as a function.
though maybe I'm just pouring more water into the sea of confusion.
I've spent last like 3m+ feature engineering + gathering data + building neural nets for both classification and regression model. Achieved descent accuracy. Decided I will give a try with XGB lib and achieved almost the same acc results with it! And SHAP is insanely powerful
Yes
A function is something with a domain and codomain etc
why is it so hard to display the numbers with thousand seperators as integers from a pandas df
is there a straight way to do this?
using lambdas makes it complicated for no reason and turns the integer to a string so definitely not the answer
don't change the data itself to change how the data is displayed
pd.options.display.float_format = '{:,}'.format
try that.
Nobody really answered your question yeah, the gradients are a vector of partial derivatives. They give the direction of steepest descent/ascent. The perceptron is indeed a linear classifier.
thanks for the quick response. this didn't work

if it makes any difference I tried putting the options display both before and after reading the df
try pd.set_option("styler.format.thousands", ","). Don't run pd.options.display.float_format = '{:,}'.format again (remove it if you have to run that cell again)
If your dataset is tabular then xgb is typically the way to go
any global pandas options that you set are in effect for the rest of the interpreter session, or until you overwrite them.
It's not a panacea though, tree based models have some oddities
They famously cannot extrapolate
Aside from xgboost they're also a bit bad at online learning
restarted the kernel. only wrote the new part. still nothing?

Yeah, thing is that I had a problem to solve, didn't have the initial dataset. I went from scratch, gathered some data, impute missing value, had a meeting with domain specific knoweledgeble people, created a list of features, prioritize them
Xgb can do online learning by adding trees which is stupid but possible
With tabular I meant, no sequences or images
I guess images are sequences too 😄
I have a meeting now, unfortunately. look into how to add thousands separators for integers only
Lessson I learnt is that you dont have to use big guns for small problems
I gathered like 40k records dataset
xgb performed insanely good
Thanks for the answer
was looking online for about 20 minutes tbh but can't find answer. thanks though. if by chance u figure it out tag me lol
and it gave me the confidence that for 99% of tabular problems xgb is sufficient
Yeah another way to look at it is that training neural networks is an absolute pain in the ...
If your use case can be solved by not training them, do it (which is the case when you don't have text, images, sequences)
i loved the whole process tbh, from start to finish
Even tho starting with neural nets was a inefficient start, i learned a lot
by making mistakes
im going to say that my uni didnt prepare me for this real world problems 😄
however i found myself in ml/dl
Yeah, I guess using them even if it doesn't make sense is a learning opportunity
I have learnt SGD and SGD is made of loss function and regularization , I need to learn regularization
There's also SGD without regularisation
So that woul be just equal to the loss function?
It's optional but you should probably always add it
There's reasons why you wouldn't but those mostly matter from a statistical inference pov.
Equal to minimising the loss function yes (without adding a penalty term)
With inference I mean, not just caring about the prediction output but actually looking at how each variable influences the target (like what you do in econometrics)

Here loss would be = 1/n Summation of L(Yi,f(Xi))
where Yi is the actual output value and f(Xi) = W1X1 + W2X2 + W0 , consider this for a dataset for 2 input columns
By using gradient descent , we have the algo
for i in epochs :
W1 = W1 - Learning Rate*(partial derivative of loss with respect to W1)
W2 = W2- Learning Rate*(partial derivative of loss with respect to W2)
W0 = W0- Learning Rate*(partial derivative of loss with respect to W0)
and now we have the best possible of the weights WO,W1,W2 for the best line
Is my intuition correct?
Yes
Yes so lets assume that i draw a function of L versus w1

Lets assume this
Or wait

How do I do that then
I keep getting this error while implementing gradio

Does the same goes for scikit learn module too?
I know what is one-hot encoding but not able to understand how labels are converted into this tensors
https://pytorch.org/tutorials/beginner/basics/transforms_tutorial.html
consider this
I am confuse in this line
target_transform=Lambda(lambda y: torch.zeros(10, dtype=torch.float).scatter_(0, torch.tensor(y), value=1))
I mean , I am confuse in scatter_ function!!
rest is clear to me
You could use scikit learn for this
hmmm, I am learning pytorch now sir!
but now I am asking this to chatgpt he is explaining well
but why scikit learn??
You can do one hot encoding with its help better
okay I will give a look at that then!
Guys I'm so enthusiastic about contributing to open source. But wondering how. What skills should I possess if I want to contribute to ML related projects?
depends on which kind of project exactly do you have in mind
some projects would appreciate improvements to the documentation or translations, but actual changes to the source code may be complicated unless you have a formal background and a good understanding of whichever languages that projects uses beyond just python
making open source models more user friendly or fine-tuning them is also an option though
(e.g. UIs for generative models like llama and stable diffusion)
As of now, I know python, Java, git, numpy, pandas etc
you should just find a project (say on GitHub) you're interested in and browse what issues have been opened, especially ones labeled "Good First Issue", then go from there, see what you'd like to tackle and do it
Yeah I know this part. But the thing is, I can't figure out which one I should be working on. I don't understand what skills I would require
Aside ML Research where you basically try to figure out the unknown by doing lots of digging and running experiments, I think you already possess a good requisite skill to contribute to many open source ML project; so long as you know python and ML.
Start from a library you use all the time. It's easier that way, especially if there's a bug, a warning message, a documentation etc you think could be better improved on.
Can someone pls help I’m trying to connect mysql to power bi but it keep showing me this error

Have any of you been invited to do data set labeling / verifying LLM output work before?
A recruiter, who was surprisingly human, invited me to do some at an okay pay rate. A colleague in my department got the same offer and he said he did okay for himself there but online discussions about these kind of operations imply it’s a nightmare.
@final kiln have you seen
just to get back to you on this. it turns out both your solutions work, this was the step missing. the column was of type int so after converting to float it worked

what did tool you use to visualize the function like this
matplotlib does not create 3d grapgh like that
cool
has anyone worked with geo-spatial data, making prediction and calssficaiton etc
IEEE DataPort
Glacial lake outburst floods (GLOFs) are a major threat to the local communities and important infrastructures in the high mountain regions. Early detection of glacial lakes can prevent these disastrous events. Towards this end, we collected Sentinel 2 true color scenes of High-Mountain Asia (HMA) region using glacial lakes inventory of this reg...
trying to work on this, and maybe train DeepLabv3+ or something similar for Flood detection
Does anyone know of a similar dataset to this one? I can't access it without my advisor's permission, and I'd like to find a comparable dataset to start working with. If I manage to get this dataset later, I'll simply add it to my model.
@final kiln do you have experience with geo-spatial bro?
it requires a formal request from the advisor to the dataset owner, which takes time
and i just want to make sure i can do it so when i have the dataset i would just change some code and fit the model
just explain the problem !!
so actually the probelm is this that am not getting boundry boxes around the video and even a single image am giving. and also i did many steps like asking from gpt , changing the size of same
its an yolo v8 model actually i cannot say anything much about that because i have not studied about that
yes did that yesterday by asking from gpt but in image too the doctors, nurses, patients all were showing blue in color
i can explain you better with screen share.
am giving my ipynb file
uff i cannot share here
i know brother am just tired and am new to the YOLO thats why hanged into this
gpt told me same but it was saying same cannot draw boxes cannot detect etc etc
SW?
ok fine i will tag you when i will run it again and will show you the o/p.
well btw I have started learning pytorch again , but now with docs and not things are becoming clear!!
what docs ??
thats what am suffering from TBH
idk bruh its all done by some friends and gpt.
see i also watched some yt videos for custom training model.
I labelled using roboflow like they did in videos. after that whatever they did i followed same steps and i can see yes its detecting the things.
@final kiln @spring field
The RAG thing on my GitHub code I spoke about works and its pretty cool
curl -X 'POST' \
'http://127.0.0.1:8000/' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"query": "Give examples of where he applied software testing in his projects please."
}'
gives me a detailed answer like so:
Yes, I can provide an example of where dependency injection (DI) is used in <my name>'s GitHub repositories. One such example is in the Scala-based <repo-name>.
In the file src/environment.scala, we can see how the application configuration is set up. Dependency Injection is applied to inject configuration and logger instances into the application components.
Here is a snippet of the relevant code:
it was very easy to set up tbh
Dagster data pipelines to draw in all of the data / populate pgvector and building a rag with openAI's api is not a lot of code
I think I do need agents here tbh
I think the RAG can't answer basic questions so I need more "juice"
I'm actually surprised it answers "What programming languages does zestar75 use" somewhat correctly
Because you need knowledge of my entire git for that, not just the top 5 matches
Honestly, what bothers me the most is cost.
Did you do anything fancy with the embeddings and retrieval part or just embed entire files without any sort of preprocessing or extra prompting?
Not yet. I'll do that with gpt3.5-turbo later but as of now I just wanted the e2e thing to work
Is it actually using knowledge of the entire git, or just guessing based on random matches?
It isn't using the knowledge of the entire git because it doesn't have access to it ofc
but that's a question I expected to be very difficult with just top 5 but it did it really well
yeah idk if you logged which pieces you sent as part of the prompt but I'd expect for that to just match random files and return based on them
wdym? The retrieved documents?
yes
I store them
I meant for debugging what the model used to generate the response
Yes, I add them to the bottom
ah
And they make sense, in the context of answering that question correctly
I wrote about my stack on my website
I guess it might've been too easy because of that
im learning pandas now. Is it important that I remember the names of the functions? or should i just know that there exists a function which can do some 'x' job
you don't need to memorize everything. just keep the docs handy.
ummm, you mean i have to refer to the docs every now and then?
more like every time you use pandas.
at least for a while
The key to learning pandas is to avoid writing loops or using .apply as much as you possibly can, and keep looking in the docs to find a solution that involves neither.
umm so basically i studied all the math that is required for machine learning in my last semester
so you know how to calculate the derivative wrt each weight in a neural network?
no
then you haven't. but that's okay.
i thought i was going to study that when i learn deep learing
isn't it how it works?
well, I guess you mean "all the math that is required to start learning ml" rather than "all the math that machine learning requires to work"
my mistake
tensorflow or o lama?
I don't think those are interchangeable. but use pytorch.
pytorch
can we train it easily?
train what
i need some help in the #❓|how-to-get-help channel
how-to-get-help has instructions. if you have a question in a thread, link to your specific thread.
How can I know if there is a bias in the dataset?
You can see from the graph that ther are more who transported (the label) more than not transpoted on the people who slept. Is this a bias?


What is does the y-axis count mean ?
or benchmarks on cherry picked data to achieve good results
The count of the people who sleep
you have a bias in numbers of data on CryoSleep with summed up - 4500, and on True with 2500
Its just a guess
good idea tbh, especially for validating claims
Folks I need advice. I've tried learning Python for DA/DS on my own and somehow the discipline just doesn't stick. Learning the theory isn't the problem, consistently practicing with coding is very much the problem. Any tips for what I can do?
current meta is that they overuse buzzwords without proper validation metrics
Theory is for DS more important. good coding skills come with expierence
my tutor said you have to know the algo and the math, and then coding.
Our neural network uni professor was insanely obssesed with that part of the research, so I catch some ideas out of it
Yup
transperancy is the key word
is the real issue in accessibility or academic journals middlemen
normie cant post on https://arxiv.org?
?
What I mean is, actually doing coding every day, is what I don't do. The discipline to code is missing.
theres no magic pill man or secret loss functions, at the end of the day you just need to put the work in
I'm currently using a sequence2sequence model to create suggestions for shortened urls such as https://pyga.me/docs/ref/font.html#pygame.font.Font.point_size being converted to https://pyga.me/go/point_size
What models would you guys suggest?
go to hugging face and select text-to-text
Then code. Its more important to know the basics in python f.e. and then just the theory. (But I am talking only about DS) I also think that Python in DS is that hard, especially with AI.
by simply googling it something like t5 or bart might be good fit
i ussually dont use nor finetune models
but u are looking for some sequence-to-sequence models
theres not right or wrong answer, it is very iterative process
go try it out and evaluate the resutls
ehh, it's a bit tricky with URLs tbf, they're not exactly regular data that a seq2seq model would be trained on
what one could try is provide either additional textual context as a description along the URL or sth like that
and then use that shortened text by just appending it to the end of the short url
is there a way to create custome special type of tokenizers that understands url patterns?
probably? you could make the model learn those patterns itself as well
yeah like explicitly say domain, path, parameters and everythingelse he needs in his use-case
would that be an overkill
probably
yeah, but when has overkill not been fun?
also I'm not sure still though, like, fine, you can tokenize a URL in a different manner, but then you still need to train a model to learn these different tokens
this is honestly not a simple task at first glance IMO
I agree
Back in the days when i was grinding leetcode for job interviews
i came across some url shortner problem
can u get away with something like this
not every problem requires big guns
(I think what he wants is something more human-readable)
Hey- for python and matplotlib and stuffs, I've been doing the
pd.read_csv("xyz.csv"), which basically displays me a table of data. This has got me wondering, how does one collect all this data and make them into a csv? What are the process(es)?
Depends on the situation. Surveys will store the results in some structured way. Or government agencies.
you dont know about database do you?
I should add my LinkedIn data to the RAG as an additional data source 😮
I'm gonna add a small feature to store the questions, answers and retrieved docs in the DB then deploy
Any suggestions on understanding and learning foundations for ML/Ai?
check out the pinned messages here
Can do, thanks for the suggestion
New here, i can do question about Jupyter Notebook here ?
Yes
Guys can someone guide me . I am thinking about learning machine learning
please check out the pinned messages in this channel
I can export it with the gdpr thingies
Should i use torch.reshape or torch.Tensor.view on pytorch?
Guys i have a doubt can someone tell me how did they get started with ML and their journey throught it
i am thinking about getting started and help is appreciated 🙏
Use view if you can, if your tensor isn't contiguous (you'll get an error saying so) fall back to using reshape
.view(...) if you can, otherwise you can't not use .reshape(...), unless you do .contiguous().view(...)
someone help me?
I started through uni
i mean
how did u build foundation or what resources
University stuff. Things are graded properly. You have maths, stats, ... first and then ML courses later on
a specialized course/program
I think a good question is "how would you approach it if you'd have to start again?"
I'd probably focus on building things first and see if I'm willing to stick with ML, if it interests me
And especially, to what extent. Then I'd make the trade-off and see how much math and so on I'd have to learn to do what I find interesting
Agreed, but that's not the essential part of what I mean 😄
Like, when I was learning functional programming I wasn't in uni anymore. I started out, read some books and got proficient. Then I realised to go to the "next level" I'd have to start doing mathematics I don't enjoy (category theory) so I decided not to go to that level
You can apply the same strategy to learn ML, start building things, going 1 level "deeper", learning the math necessary to go there until you find your sweet spot
ah
btw, I apparently found a cool resource on Bloom's Revised Taxonomy some while ago https://potentialplusuk.org/wp-content/uploads/2018/06/S306-Higher-Order-Thinking-Skills-180611.pdf
the crucial bit is this
Applying the knowledge depends on at least some Understanding being in place and helps to
cement a learner’s comprehension of the subject. Once a learner can apply the knowledge, he/she
is ready to think in a more complex way about the topic and to start thinking critically and
creatively.
which basically supports what you said about starting to build, then learn as you go as I understand it
because obviously you need to like understand how to write code to some extent or some simple math to some extent, but after that you apply and then learn more as you go
pretty much yes
I'm also afraid that when people say "start with math, stats" we gatekeep them from finding it fun and having the energy to learn it to do more things you find fun etc
very true
also because the math portion of neural nets (i.e., gradients) is largely covered in hs already (well, at least derivatives, but gradients are not far off)
Ik maths is a bit boring we all like the coding part
What happens if tensorflow encounters multiple languages while training? I want to train a model of my friend and I's conversation but we occasionally send estonian and russian text

Is there anything else that I should have mentioned? I faced this problem like few weeks ago when I was finetuning my neural net and this is how I approached it
Optuna has neural net support as well? I used it last week with xgb random forest
Chatgpt recommended me her
Which literature you use? At my uni we didnt have hardcover book, rather just some slides that were half coppied from tehnische universitat Munchen
Hello i have a question about quality assessments of two or more data sets. If i have some data base that has been in use and i get few more data sets that are similar to the one in use but not the same what would be best way to assess quality of those new data sets?
I have very abstract views on the tuning, you know when to tune what, and then brute force it if u have comp power else random search
for example tuning layers structure vs tuning lr, dropout and other anti - overfiting params
what keywords do u use for searching for academic stuff
"Hyperparameters tuning"
or is there anything that querries better
Imma look into it
Very nice
Cool, thanks man!
I think quality could generally be anything you're trying to prioritise in this case.
Are you interested in quality of dataset in terms of its structure, cleanliness, richness (content-wise), richness in terms of coverage (a.k.a domain-wise) , quality of features captured in the data, kind of distribution the data follows, contribution of the said new data on your model performance, etc.
To better quantify or measure quality, I think it depends on what you're prioritising at the moment because that's what will determine how to approach quantifying quality.
However, the straightforward way is to compare and contrast old data vs new data on some task. How to do that would then depend on what quality measure you're prioritising.
Thanks for the answer!
Still don't work on the model so i can't define precise interest but while reading i saw that quality assessment is important, so this is how i got this question. I was wondering was there more general rule/steps to be followed and adapt if needed or to always be created unique for every set i have.
Again thanks for the answer it got me on the right track.
Hello,everyone, I wrote a machine learning library based on TensorFlow. Here is the project's repository.
https://github.com/NoteDance/Note

GitHub
Easily implement parallel training and distributed training. Machine learning library. Note.neuralnetwork.tf package include Llama2, Llama3, Gemma, CLIP, ViT, ConvNeXt, BEiT, Swin Transformer, Segf...
https://pytorch.org/tutorials/beginner/basics/intro.html
I have done understanding each concepts from all chapters of this , so what's next?
what should I do read now?
https://pytorch.org/tutorials/beginner/introyt.html
should I start this docs along with yt video?
Hi, im looking for the way of converting distance on img to distance in real life:
thats how i calculate distance on img:
camera_center = np.array([img_width // 2, img_height // 2])
plate_center = np.array([(x1 + x2) // 2, (y1 + y2) // 2])
distance = np.linalg.norm(plate_center - camera_center)``` And im wondering how can i get that distance value to be in some real world units to make it easy to setup.guys i really need to learn EDA for data analysis
does anyone here understand EDA even a lil bit?
becuz i am not able to understand how to start learning it
If you dont understand what does function do, thats how they look on "paper" math

mainly for Lane detection , and all that stuff related to autonomous driving
I didnt know this actually

I think he means normalizing, not scaling
But I do preffer them normalized, feels better
Any reason not to do it?
Definitely! Good quality data almost always gives birth to good model performance. Hence the reason it's optimal to ensure the data is of good quality even before model training part.
A more general step like you mentioned would be, the data cleaning and preprocessing part.
Some part are unique, like taking care of missing values while some are however, determined by the kind of project you're working on.
Check the EDA part on https://kaggle.com/learn
More so, you can also check the notebook section on Kaggle for more practical examples on EDA.
Practical data skills you can apply immediately: that's what you'll learn in these no-cost courses. They're the fastest (and most fun) way to become a data scientist or improve your current skills.
It's same. Some people call it normalizing, some call it feature scaling.
To save some keystrokes and your time 😃 `cos those algorithms are robust enough to perform well even without scaling your numeric features.
idk, scaling is a bit of a different operation tbf
afaik sth like batchnorm can speed up training, so in that sense it's more likely to save your time, yeah, it likely won't affect accuracy at the end of the training session, but rather how soon you finish that training session with satisfactory accuracy
Anyone know of a Python package that does an integrated ARIMA-GARCH model or should I build one
Hello! Newbee here!
Hello folks, I'm looking for TF agnostic data pipeline as a replacement for tf.data, which is scalable horizontally and vertically. I consider Dask, Ray and Spark. Would you recommend something else?
yes:
https://www.statsmodels.org/stable/index.html or https://pypi.org/project/pmdarima/
or even statsforecast https://github.com/Nixtla/statsforecast
I meant specifically something that fits the variance and the mean models simultaneously so mean variance correlation can be captured while taking into account heteroskedasticity. I don't think those arima packages include garch for heteroskedastic variance prediction
Aha! I see what you mean. No, I don't think that's somewhere off-the-shelf in Python. This is where I'd reach for R or heck even Stata
Have you used numba? I think you have
Might be an option if you're building it from scratch and want to make it fast 🚀
yeah that's what I was going to do if I did it
I get really frustrated with the untyped stats libraries
they are good but some are borderline unusable in forecasting loops
good point
Yes, technically, both operation do different things..
Hey guys, anyone here who uses polars? can someone explain how to make a correlation matrix and heatmap using polars?
the easiest way? honestly probably just turn it into pandas
df.select(cs.numeric()).to_pandas().corr().abs()
ahaha, fair enough. but I am trying to learn using polar so I didn't wanna do this on purpose. The problem is that all the examples I found weren't working, I assume cause the polars had some syntax updated. I was able to do it with numpy, but this way I had the problem of not having variable names on y scale as well after ploting since I cant use indexes. The example I found basically resulted in a df with 3 column. 1st variable, second variable and correlation between them, this is super easy to plot but I cant seem to get the same result.
(
df_pl.corr()
.with_columns(index = pl.lit(df_pl.columns))
.melt(id_vars = "index")
.filter(pl.col('index') != pl.col('variable'))
)```
this is the closest thing I found fromstackoverflow but I cant make it worklearn using polars
i see... honestly I just dug that line of code up from one of my notebooks
I think I also did make a confusion matrix in polars only, but it didn't work nice when I threw it intosns.heatmap
I really like using interactive plots from polars with df.plot.heatmap(), its with hvplot. They look super good. Unfortunately I got stuck at making the correlation matrix
I would love it more, if my pc wasn't bad and it took like 20 seconds to import hvplot instead of 2 seconds to import matplotlib+sns
lemme try to code up something anyways
I'm working on a gaming pc so it works great xd
actually, just the correlation matrix?
why doesn't df.corr() work for you?
and actually, I remember my problem now, I couldn't get index to show the name instead of a number

oh, let me try, I think I misunderstood how this function works, let me check
yes, that is also my problem