#data-science-and-ml
1 messages · Page 109 of 1
So if I am understanding this right, basically shrinking a drawing/image to a 32x30 pixel board but you want to make sure it keeps the important details
how should I start learning Python? I want to go forward with AI and Machine Learning with it.
and there will be no color (first image was just for visibility)
it can either be black or white (different in hardware, but basically binary values true or false)
but it should still display it in a way that it is recognizable for the human eye?
try looking into 2d convolution
it may not help due to how small u want it
but it might work


google/medium idk just search it up and you'll figure it out in a month or two

Learn to Code — For Free
I think if you really dive into convolution people will point out the flaws and how recent studies improved it
How big should a image classification dataset be if I'm using no pretrained models.
Like for a simple 2 class problem
it may depend i'd say 40 for each would be enough if they are all very clear and have a clear image
you can always retrain if the accuracy is low
How deep should the network be how many convolution blocks
figuring out what works best for you is the best advice i can give
Thanks
This is a hyperparameter in NN. So feel free to try out different architecture and configurations until you achieve a decent result.
Practical data skills you can apply immediately: that's what you'll learn in these no-cost courses. They're the fastest (and most fun) way to become a data scientist or improve your current skills.
The single real number part is important, without it you can't do gradient descent because the algo relies on the "gradient" operation, which only acts on real valued functions. At each point the gradient tells you how fast the function is increasing and in which direction that increase is largest, so you use this information to find your way downhill.
I don't think it's linear though, even if the error is linear it would still require the network to be linear, if "f" is the network,
loss(w1+w2) = error(f(w1 + w2))
you'd need to impose f(w1+w2)=f(w1)+f(w2)
I don't know if that's generally possible
In case of MLPs,
activation((W1 + W2)x + B)
activation is purposely not linear
@spring field https://huggingface.co/learn/deep-rl-course/unitbonus3/envs-to-try#diambra-arena happened to find this, might be interesting to skim to see how open source models are being used for game AI
wonderful, thanks
ah ok ty, it would be a dream to use some exact training method not approximate
random grid search + statistics atm is what works for me
- zooming on grid when I want to search some specific area
The exact method is possible, but counter intuitively, not what we want.
what is searching to do?
random grid search but on a subset of the total hyperparam space
done after it looks like there's a place worth investigating on the total hyperparam space
ah ok and that searching is automatic?
Gradient descent itself is technically an accurate method, what we do IRL tho is that we chunk the dataset in "batches" and at each batch we apply gradient descent.
Each batch is somewhat representative of the whole dataset, so the loss surface for a batch will somewhat resemble the true loss surface of the whole dataset.
the random grid search is automatic, not the zooming
you zoom when you feel the force is strong with an area
i.e. it's not at all a rigorous thing
Reason why this is good is that even tho the loss surface changes at each iteration, on average you're still gonna follow a downhill path. If we were to use an exact method it would frequently be stuck in local minima, but since the loss surface changes at each batch that effect is reduced.
a grid search sounds neat, havent touched: tuning weight num... etc
random grid search only for hyperparams, not weights. some people like sequential grid search if they have the time/computing
by exact i mean find a global minima, its grad descent which gets stuck
sorry weight count, maybe im getting confused w words, layer shit, neuron count
But also, the true loss surface is not the one generated by your dataset, your dataset is also a sample of the actual population of data, so the true loss surface is unknown.
So in a way, it's almost as if you're getting your model used to seeing different landscapes instead of showing it one (very hand wavy this statement )
The global minima is also not ideal, but I ofc understand what you mean. The global minima will be an overfit
by this you mean the isdeal would be the global error minima when considering all data you will ever input?
I mean that reaching the global minima implies that the model has memorized the details of the noise in the dataset
Tho it does depend on the complexity of the model, but in most cases you'll be choosing a model that is more complex than what your data requires, and then you do regularization to prevent overfit
if we talk of the error over the entire data set then it should generalise between that data.
even a local minima over the entire data set could encode noise
Not sure what you meant by your first statement
But what I mean is that you won't be looking to get your model on top of the global minima, by the time you're there, the model has overfit
identity function has 0 loss
ah ok so it has simply learnt unique responses for every input data set and cannot adapt to new info
like what school exams require 😎
Yes, perfect loss means it learned the data + noise
Also I didn't know that, is it true
Oh wait I see
it's perfect overfitting
Yeah
but useless
perhaps some seperate func could be designed where the weights producing global minima of the func ensure generalisation, thats how id continue this exactness foray
worth looking into how adam and adamw work for this sort of stuff
You gotta be careful tho, because any information you give it about generalization will likely be a data leakeage
they are grad descent no? or similar
yeah
Stochastic grad descent with momenta in the mix
ye so theyre a local solution
Uhm not necessarily
we have nothing else 😦
Because a local minima can be unstable due to the stochastic part
interesting, ig it would be a intteresting in point into study on generalisation
ye not knocking it but compared to a proposed global solution
the classical method to ensure generalization is to compare the training loss with a validation set loss
the minima of the validation loss is maximal generalization
after that, you're overfitting
training loss keeps going down but validation loss goes up
Usually you even keep 3 dataset splits, train for training, test for testing and eval to help you choose hyper parameters
The reason why you have eval is that you choosing hyper parameters constitutes information flow from the eval split into the training process, so it's a subtle form of data leakeage
ok thanks!
ok but is that a problem, im assuming the eval dataset would be constructed to be conducive to successful training
Ideally they are chosen at random
check out the statistical learning stanford series, they give indepth explanation on exactly this
If you used only one dataset, there would be no way for you to know how it would perform IRL
If the eval dataset is coupled to the training process, you can't use it for the same reason
Like, you chose it so it works well for that dataset. And to test it you gotta test it against something it hasn't seen yet
I haven't taken any course on ML yet, I just read a couple chapters, should probably give those a watch
I find most things rather intuitive
it's very good, it gives you terminology to communicate about specifics with others and allows you to dig indepth into the stuff
Yeah that's useful for sure
allows you to search specific things about the ML workflow, etc.
Ah instead of hitting my head against the wall til I find the best way
it's a very good series, available for free on youtube, and has an associated free book
details everything we've been talking about today
Awesome, will check it out
100% worth the time
to take a break from practice to get that course done, it's the bare minimum
I hated stats in school 😭
you will hate not knowing that stuff worse lol
ah I know my stats, ig I just learned it in a more applied setting like statistical mechanics or quantum mechanics
Tho it's always different ig, more engaging
You also get it in thermodynamics I think
thanks for explanation although i need to think more about data leaking to engage
@odd meteor the lightning profiler is amazing, thanks a lot for the recommendation extremely useful stuff
yo

Gemini is free
The API
I'm gonna try it out, if it's even close to gpt 4 I'm canceling my open ai subscription
I'm tryna see if it's good, gonna hook it up to my discord bot in a minute
it's about GPT 3.5 level
from personal experience
did not know the API was free
Not a available in Europe I'm dead
proxy proxy proxy
Aaaah I'm either gonna be paying a VPN or open ai
Ig VPN is worth it regardless
But for now I'm gonna try to spin up an AWS machine
Which like, makes me wonder y restrict the regions in the first place, that's never gonna be a thing on the internet
probably works for a significant part of non-computer-savy people
me atm: bouta start making some synthetic datasets with the free gemini API
I'd assume most people who know how to consume an API are tech savvy
hm yeah
gemini API refused to respond to the query "Write a story about a magic backpack." because there was a high probability of sexually explicit content
wtf
it's probably what they're using to do load balancing
guys i wanna know, about vectore databases, i mean like which give good and fast result like i have heard about pgvector and its indexing
i know there are other vector db too
but wanna know why still some people are taking side with pgvector, what it gives better
i have also study that its recall is good but not accuracy
kindly tag me if anyone give me the answer
probably just "we do not want to / are not ready to comply with EU laws and policies"
i have also study that its recall is good but not accuracy
what?
The biggest advanced is it being fully integrated with PostgreSQL, which gives you all advantages Postgres already has and makes deployment simpler than adding an entirely new database
thats the reason i dont wanna leave posgres
but idk why, on top vector databases blog, pg_vector still remain underrated and i wonder why
Medium
Vector databases have emerged as a critical component in managing high-dimensional data efficiently, particularly in applications such as…
We found that PgVector has the lowest recall among all the evaluated vector databases. So, it is trading up its accuracy for faster search times
bad recall = bad accuracy
the tradeoff is between recall and speed, not recall and accuracy
I haven't heard of pgvector. The ones that are kinda popular here are :
Weaviate, Pinecone, and Qdrant.
It might be nice to check for an article that performed a detailed comparison on Pgvector vs. Weaviate vs Pinecone vs. Qdrant.
im just here to take an advice if someone already has use pg_vector and they are good with it
that smells like bs though
You can customise the index options on many vector databases - if what they are measuring are just the defaults, then that's borderline meaningless
there are 2 indexing available i think for pgvector
There are two index types
You can further specify parameters for the index construction and search
the thing i like about posgres, already as developer im little bit experience with it, 2nd i dont have to use these kind of multi database arch
and can use prisma ORM easily for it, but just wanna make sure before choosing it
yes i also saw that,
Even google has made their whole notebook explaining pg vector and everything related to it
I'm not sure if it's that, I was able to get a paid version going with vertex AI. Good news is they're giving me 300 dollars in credit, which I might as well take since it might cover me the entire year
different offerings, different terms
Vertex might not store your data, while Free tier Gemini eats it for breakfast
It's still Gemini pro 1.0, but it's paid
I gotta check that
Free tier Gemini get 500 internal error sometimes ( i check this today)
That's wild actually
still a different offering, regardless of it being the same model or not
Well it's different insofar that I have to pay it right
I'm gonna try to confirm the data policy
Google AI for Developers
To help with quality and improve our products, human reviewers may read, annotate, and process your API input and output
Right that's the Gemini API, I'm finding it hard to find the policy for the gemeni that vertex AI offers
Barely matters though, won't trust it regardless
Check their terms and conditions, open AI has a clause that prohibits it for example
of course, it was just a hypothetical thought of things that could only happen in my wildest dreams
at no point am I actually going to use it for creating synthetic datasets
I got my discord bot connected to Gemini pro
It's uncool that they make Europeans pay, but ig it makes sense since we regulate them
Hello
Does anybody know good open source AI photo and video generator? Preferably open source, with no limits etc
data.csv: (journeyTime is ms and length is mm)
roadNo time journeyTime length speed
1544 2024-01-01 00:00:00 1832 34439 18,7986
1582 2024-01-01 00:00:00 1524 28660 18,8058
1585 2024-01-01 00:00:00 1789 33634 18,8004
2063 2024-01-01 00:00:00 1987 38666 19,4595
2064 2024-01-01 00:00:00 1987 38666 19,4595
1544 2024-01-01 00:05:00 1830 34439 18,8191
1582 2024-01-01 00:05:00 1522 28660 18,8305
1585 2024-01-01 00:05:00 1788 33634 18,811
2063 2024-01-01 00:05:00 1984 38666 19,4889
2064 2024-01-01 00:05:00 1987 38666 19,4595
1544 2024-01-01 00:10:00 1833 34439 18,7883
1582 2024-01-01 00:10:00 1523 28660 18,8181
1585 2024-01-01 00:10:00 1789 33634 18,8004
2063 2024-01-01 00:10:00 1987 38666 19,4595
2064 2024-01-01 00:10:00 1989 38666 19,4399
There are 300 different roads in total and I have 288 times of 5 minutes. I want to convert this data into minute and metric formats. For example, the speed at the 400th meter at 01:17. I tried using interpolation and regression to fill empty data but I couldn't
'''
Python
Print the type of engaging conversation
print(type(prediction["engaging_conversation"]))
print(type(dialog))
Print the engaging conversation
print(prediction["engaging_conversation"].dialog)
<class 'str'>
<class 'list'>
AttributeError Traceback (most recent call last)
<ipython-input-40-85ca52f38205> in <cell line: 70>()
68 # Print the engaging conversation
69 #print(prediction["engaging_conversation"].dialog)
---> 70 for user1_message, engaging_response in prediction["engaging_conversation"].dialog:
71 print(f"User 1: {user1_message}")
72 print(f"User 2: {engaging_response}")
AttributeError: 'str' object has no attribute 'dialog'
'''
This means that prediction["engaging_conversation"] is a string, and not some type that has a dialog attribute.
what type do you expect prediction["engaging_conversation"] to be?
list
list
a list isn't going to have dialog as an attribute.
keep in mind that I'm asking about prediction["engaging_conversation"]. not whatever prediction["engaging_conversation"].dialog is intended to be.
ok
Make the conversation more engaging my improving the responses of User 2. Keep each turn short and crisp.
Dialog:
[ "Diana , do you like the perfume I gave you ? ", " It ’ s good . But to tell you the truth , I don ’ t wear perfume . ", " I ’ m sorry . I didn ’ t know that . ", " That ’ s all right . Thank you all the same . " ]
Response Format:
Same format as the dialog - a comma separated array of strings with chats from User 2 improved in-place.
i wanted to do this like it
can someone help me with a project of mine: I want to make a yolov5 model be able to capture the live feed of my web app camera and put the labels on objects on the web app it self
p.s already have made the yolov5 model only need a way to connect it to the web app
hey how do I keep my GPU from running out of memory?
stupid vague question I know -- I'm extracting data from a pdf one page at a time and it crashes after like 4 pages
I can just save the data and [insert something like clear GPU memory here], but I don't know that step is
(working in jupyter on a google compute VM running debian 12)
what's the best option for file compression of checkpoint files?
these things get big really quickly lol
Unfortunately even Gemini 1.0 ultra is not even close to gpt 4 https://news.ycombinator.com/item?id=39395020
needlesslygrim
Personally, I've given up on Gemini, as it seems to have been censored to the point of uselessness. I asked it yesterday [0] about C++ 20 Concepts, and it refused to give actual code because I'm under 18 (I'm 17, and AFAIK that's what the age on my Google account is set to). I just checked again, and it gave a similar answer [1]. When I tried Ch...

According to Gemini, c++ is too unsafe for underage kids
So funny
LOL
yeah i think it's doing load balancing with this
so many extremely dumb examples of these safety precautions from gemini, but sometimes it performs REALLY well
so it has to be load balancing
I sometimes think chat gpt is doing something similar, because at times it just acts dumber than it is, missing context cues a la gpt 3.5
But lying to your user about which model is being used is a recipe for disaster
So I think the variations come from the tweaks they likely make from time to time
And in the case of Gemini, well they probably just went overboard with their "safety" fine tuning
Like
A lot of bad stuff is possible with language models, so might as well have these dumb things happen than to say, have the model make someone's mental health crisis worse.
If you wanted to view the relationship between crime rate and temperature, you'd want to factor out the overall trend of the crime rate. Decomposition of a time series results in a trend, seasonal, and residual component.
Would you find the correlation between temperature and crime rate seasonal, or temperature and crime rate residual?
@odd meteor i love lightning you are a blessing unto this world
Here is an example of decompsed crime rate.

Keep winning bruh 😊💪💪
Comparing temp resid to crime resid gives a correlation of 0.36. Comparing temp seasonal to crime seasonal gives a correlation of 0.93. I'm very suspicious of such a high value for comparing the seasonal components. So much so that I'm wondering if I'm illogically comparing them when I'm trying to find something else.


It's hard, but you can make a automation chat but not ai
Not sure if this is best place to ask but are there any upcoming data science online hackathons? Would love to colab with others in the space to build a project. Or not even a hackathon where would be best place to find others to build a project
You've found a correlation between temperature and crime rate. Way I'd do it, is formulate an hypothesis and falsify it.
The hypothesis is that higher temperature leads to higher crime rates. That would imply that countries with a colder climate see less crime, and countries with higher temperatures see more crime.

If it is there, it actually doesnt look very pronounced, it's easy to see this in Europe, Portugal vs Sweden for example
Or Australia vs Russia. The stronger correlation seems to be poverty levels and perhaps even historical reasons.
Maybe the most reasonable hypothesis is that temperature levels exacerbate the crime that is already present, or people don't go outside as much so there's less opportunity for crime to occur
what's up with jax
this is a great question about correlation vs. causality. can you explain more about what this data is? did you fit separate time series models for crime rate and temperature? what geographic extent is involved here?
it's not clear to me whether this is country-level, city-level, or something else. there could be a handful of plausible explanations for this phenomenon
differentiable array programming framework. like what pytorch does, but without all the neural network helper stuff on top of it. also a lot like what the old theano framework did.
is it faster? sort of seeing a lot of people talking about it
i don't think it's significantly faster than torch. i think the idea is that it's easier to use for advanced custom things, so it's popular among researchers and ML engineers. i've certainly never needed to use it.
i guess there are some higher-level frameworks built on jax now as well
jax itself i think also glues together existing C++ libraries (XLA) instead of building it all from scratch, so that's nice too
looks like the main selling point is good TPU support
Question, do I need to do discrete math for data analytics
you need to know very basic set theory and propositional logic
both are usually covered in discrete math
Crimes from chicago and weather from chicago.
I'm not sure what you mean exactly by a time-series model. I used temperature as the predictor and crimes per day as the response.
I’m taking that course in college and it is the most confusing stuff I learn. I got the basics understanding on set theory and propositional logic on ch 1
hi, does anyone have any tips to help with overfitting for an lstm binary classifier? we've implemented several drop out layers but the best val accuracy we can get to is about 85%
Yea i get it but i want to learn machine-learning idk where to start to if some can help pls do dm.
can someone help me understand why the dimensionality changes and the second assert raises here
def _get_reward(self) -> np.ndarray:
"""
Calculate the reward for the trader.
Returns:
float: The calculated reward.
"""
ret = self._get_return()
rf_ret = self.rate / 252
ret_vol = self.return_volatility or 0.05
reward = yeojohnson((ret - rf_ret) / ret_vol, self.risk_aversion)
assert isinstance(reward, np.ndarray)
normalized_reward = (1 / (1 + np.exp(-reward)))
assert isinstance(normalized_reward, np.ndarray), f"reward: {reward}, normalized_reward: {normalized_reward}"
return normalized_reward
In [16]: k = np.array(2)
In [17]: type(k)
Out[17]: numpy.ndarray
In [18]: type(np.exp(k))
Out[18]: numpy.float64
Check your dataset on papers with code, it's possible you're already getting close the best SOTA metrics
When it comes to combating overfitting, collecting more data yields the best bang for the buck.
If collecting more data in your case is feasible and not so expensive, then start from there.
If it's not possible to collect new data, just try other techniques like batch normalization, learning rate scheduler, changing optimization algorithm and your activation function, or combination of all these stuff, etc
Or better still, check online to see what configuration worked best for similar task you're trying to solve.
Yeah I'm just throwing an hypothesis and testing if it holds.
Given this information, and that my previous explanation didn't really hold that well, my second throw is that it's gonna correlate to the amount of daylight available in the day. More daylight = more time where people go outside and that leads to more opportunity for crime.
This would mean that the number of crimes per hour of the day would remain constant.
Yah, alternate test might be looking at delta crime vs delta temperature: does crime rates change as temperature changes over time within a country?

I certainly want to know
is there any field or anything like that where Data science , ai and ml work together ?
? All those terms are tightly linked.
yeah but there certain jobs like someone who works w data science will work for a data related role someone who learned or invested in ml will get the role of ml eng and same gose for ai like the roles are separeted is there any role that combin these 3 together?
There's all sorts of roles from data engineering to data analysis to data science. There's also roles like MLOps, and titles like ML Engineer and AI Engineer... but titles are very non-standard from what I've seen... I have *my * particular view of what each term means, but different companies use them differently.
ohh so there no particular that if someone does this than they will do this? okay so perhaps if i work w data i can also work w ml if i want to?
can someone guide me to start machine learning python? idk where to start.
See pinned messages
Yeah there's a ton of stuff to explore. I think I wouldn't even go the ML route and just build something akin to biokinetic models to simulate these things.
Do these things work though ? I'm very skeptical of it because a functioning market is meant to random walk
I learned that one on the last veritassium video, really good
people who think the market is efficient are ignorant
I was about to say something much meaner
for over a decade the GSCI commodity index exhibited predictable rebalancing behavior every month end
many such cases
I figure it's approximately efficient given how much it looks like a random walk
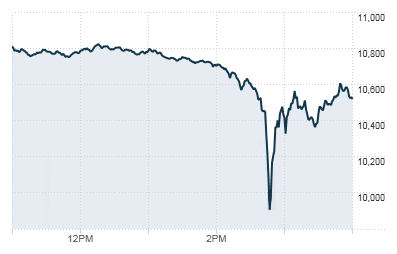
The May 6, 2010, flash crash, also known as the crash of 2:45 or simply the flash crash, was a United States trillion-dollar flash crash (a type of stock market crash) which started at 2:32 p.m. EDT and lasted for approximately 36 minutes.
But in that case why is that fact not being exploited ?
this is just one very obvious example
it is being exploited every day
some people win trying to exploit it some people lose
o.o
the people who pay are the ones who are price insensitive
usually
so hedgers pay a risk premium to speculators
because they are willing to take a worse price to offload risk
and the speculators are EV maximizing
Doesn't look very predictable to me tho
it is very predictable that is an anomaly
if you were sitting with cash ready to invest and you saw that happening
you would be an idiot not to buy into it
because it was so anomalous
In April 2015, Navinder Singh Sarao, an autistic[64][65] London-based point-and-click trader,[66] was arrested for his alleged role in the flash crash.
another example, not to get political, but the equities market crashed 6% overnight when Trump was beating Clinton and it rallied back to unch by morning
He got a sentence too
stuff like that happens not that infrequently
I just point those out because those are the most irrefutable examples of inefficiency
Yeah but that kind of stuff looks easier to predict if you actually know what's going on right, like when MSFT stock went up when they thought Sam Altman was gonna be hired into MSFT during the whole board altercation
It was possible to map the ups and downs to what was happening
well the market is very momentum based there's a lot of insurance companies that need to hedge liabilities
and their hedging behavior looks very stupid to everyone else
because they will just keep selling into selloffs
that's the type of stuff that's exploitable
I think that belief that it's not efficient is what keeps it as efficient as possible, cuz you guys are always trying to exploit it so any deviation quickly gets corrected.
the core concept and the reason why EMH can't be true is that it pretends there is one class of actors
or that actors all share the same risk preference
or that risk preferences are static
none of those things can be true
Wait, but isnt the hypothesis saying that an efficient market generates a random walk ?
And not that the market itself is efficient
The fundamental theorems of asset pricing (also: of arbitrage, of finance), in both financial economics and mathematical finance, provide necessary and sufficient conditions for a market to be arbitrage-free, and for a market to be complete. An arbitrage opportunity is a way of making money with no initial investment without any possibility of l...
Ig not, that would be this right
Wait no, I'm still digging
the EMH is actually distinct from a martingale
Omg this is all super confusing stuff
the risk neutral probability measure is a chimera
it doesn't exist in reality
people have their own risk preferences in reality
Yeah it sounds very complex to model using equations alone, maybe with simulations and such
Never did enjoy this application of math, idk why so many mathematicians like it
don't forget that actors are sampled from a finite human population
not these demigod "rational actors"
there's a lot of stupid people with a lot of money
and a lot of smart people with no money
anyway the first thing I learned at the hedge fund I worked was CAPM was wrong and they made a pretty strong case I haven't really troubled myself with purely academic perspectives on the issue since
this is a hot take but I consider Crypto to be a refutation of the EMH as well
I think the theory lacks method too
so it's kind of... a dead letter in any case
Yah, there's lots of different types of roles, depending on your interests and skills.
Peter Lynch, a mutual fund manager at Fidelity Investments who consistently more than doubled market averages while managing the Magellan Fund, has argued that the EMH is contradictory to the random walk hypothesis—though both concepts are widely taught in business schools without seeming awareness of a contradiction. If asset prices are rational and based on all available data as the efficient market hypothesis proposes, then fluctuations in asset price are not random. But if the random walk hypothesis is valid, then asset prices are not rational.
there's so many ways to demolish the EMH I think it's intellectual malpractice to teach it
It's finally black scholes oclock. I'm ready for this.
here's the thing both sides of this argument are talking their book
but who actually needs to prove it
the asset manager, ironically
if markets are efficient then asset managers wouldn't exist
the whole thing is simply ridiculous
academics need this to be true so their math has merit
asset managers need this to not be true so they can continue to sell a service
if you look at how the rest of society responds I'd say the asset managers have the thumping majority of support
which again on its face invalidates the EMH
it's kind of scary to think of what academics get away with when there isn't an industry to disprove them
and that is why there is a place for AI in markets
people are really really dumb
it's quite the opposite of EMH
which supposes people are really really smart
the returns and volatilities of assets are not on a capital market line either
the capital market line is a big joke
so yeah the market adjusts to events quickly, but does the "risk neutral probability" have any relation to the actual probability?
the starting price I mean
Playing the devil's advocate for a bit, I think the argument is that people who don't know what they are doing get discouraged from participating due to their losses, or maybe even get removed by losing everything.
So there's this enormous selection bias, the people participating in the market are super rational, and if they are not, they get eaten alive by those who are.
I feel like I reinvented the wheel for a common use case, basically bridging Torch and sklearn (having a .fit and .predict method on neural nets).
What do you guys do for this?
that's not true because again, not every class of actor is driven by value maximization in their market activities
in fact, their market activities might just be facilitating their main business
Idk what that means
there is a difference between hedgers, investors and speculators
You have to use layman terms
hedgers would be like, an oil company needs to trade oil so they know what their profit will be ahead of time
an insurance company needs to buy bonds because it sold annuities
speculators would be people who are trying to maximize value by taking risk
the market is a risk exchange mechanism
hedgers pay a risk premium to speculators on average
some speculators win, some lose
the ones who win take value from the losing speculators and the hedgers
but in theory everyone could just be taking value from the hedgers
My bridging stuff isn't efficient at all because I think I'll have to move data from CPU to GPU way more than necessary
the reason it's different is the hedgers are relatively price insensitive, they just want to get rid of their risk
anyway pretty OT
But that beats having to maintain 2 codebases: one for neural stuff and one for non-neural things
I'm not sure how that addresses my argument tho
there is no "selection bias" that makes everyone one type of actor
it is perfectly sustainable going on with hedgers and speculators acting in different ways forever
I certainly feel discouraged, and I keep seeing people I know perfectly well don't understand this stuff but keep losing their money cuz they still bet on it
the problem is that humans have a hard time being rational with certain things
the more important things are, the harder time people have being rational about them
that's why it's ripe for exploitation by algorithms
Even so, they can keep trying, but they'll just keep losing their money
Thus their impact on the market is minimal, cuz that approach only scales to 0
The people who understand the market they're investing in are able to predict more or less where it's going.
That's what I'm saying
people are rarely right more than 60% of the time when they are consistently taking views on markets
it's about risk mangement and consistency
repeated experiments to reduce the variance
if you are right 60% of the time trading 10y treasury yields, let's say on a daily timeframe, then you are a god
but in aggregate there has to be value transfer from those who are price insensitive to those who are price sensitive
that's why markets work, that's what they are for
why do you need those methods?
To provide a common interface?
Any other reason?
I always have a bespoke evaluation pipeline
Like test train splitting that make sense based on the domain, metrics that make sense based on the domain etc
I've heard a competing figure somewhere
So I want a common interface so I only need to implement these once
Oh, i guess I have some stuff like this too, thinking about it. Have had to adapt some other frameworks that all have similar but not exact interfaces
Forget which, I guess pmdarima is close but not exactly sklearn-y
you posted a screenshot of what looked like a time series decomposition, that's all i had to go on...
I've fully automated all my infra into the prefect UI, feels good, feels very good
I click a button and that increases the aws scaling group capacity to 1, which automatically boots me up the most cost effective GPU spot
@rugged comet if this isn't a time series model, you have discovered the known phenomenon of higher crime in summer. if you replace "temperature" with "deviation from historical average temperature" you should see the relationship mostly disappear, although historical average temperatures are rising so you will still inadvertently capture historical crime trend (because both temp trend and crime tend are correlated with time)
cool! building your own tools is fun, and it's hard to overstate the value and efficiency of having a workflow that you like
I've also setup my laptop as a self hosted runner for GitHub actions, now I don't need the runner to rebuild any env each time (torch images tend to be large)
And I also created a workflow that deploys a dev env remotely using vscode tunnels
lol that's certainly one way to do it
It's not fully done yet, but I'll be able to develop on any AWS machine
I really didn't find any other way less I want to boot up a machine and pay for it
The laptop is always on anyway, might as well ig
My cross validation is based on sklearn stuff which means each fold I need to move that data to GPU
Tho the irony of deploying a remote dev env through GitHub actions on my laptop and then using that to code - is not lost on me
But ofc the point is that I'll be able to develop using spot instances
Which is more cost effective than buying a GPU
I don't need one most of the time since I have the pipelines
So I just need a gpu to make final touches, making sure all fits together when I change device to CUDA
I mean - there is a bit of an argument to be made here, since it facilitates secrets management
And it also gets me an isolated environment like with dev containers, and cleans after itself so it saves me some space locally
And I also can code anywhere via the browser and a GitHub session
Yup, bridging all of these is a PITA sometimes, especially in the case of Torch / TF
Right now I have a singular ModelWrapper that takes in a specific interface and wraps it as such that it can accept pandas DF and outputs Numpy arrays
If it proves to be too slow I'll just move all the data to GPU once but I doubt it'll work properly
(it also lets me limit the resources allocated to it and when something crashes it leaves a record of what happened on the GitHub actions interface instead of losing the logs by crashing the laptop)
that makes more sense, it's just funny that you're using github actions and not like... a makefile
That's actually a lot more work if you think about it
is it? you have to set up all this github actions runner stuff instead of just kicking off a background process
It is because there's a lot of secret sharing going on, I'm using triggers like when a release is created, compile this rust stuff and upload it, there's multiple environments going around too
GitHub Actions encapsolates everything already and has pre prepared workflow steps in the actions marketplace
I didn't even to code the rust installation for example, I just used an actions thing
Setting up the self hosted actions was actually trivial, so that's what's making it better ig
They give you a short list of commands, and that's it, no extra setup
i see, that's fair enough
there is probably a self-hostable offline runner you could use, but it makes sense that GHA is just right there
i just don't really like GHA itself, it's very clunky and the docs are not great
we've been using Teamcity at work which is far better than i expected any enterprisey Jetbrains product to be
Yeah it could be better for sure, being able to run them locally for example would be good, like locally locally not this proxying type stuff I'm doing
I also like that the logs stay there, with the makefile it would be something that I run and then lose, so I'd have to do more setup to get logging going
It also integrates with the GitHub image registry, that I'm using so I can reuse environments, there's my laptop, the AWS machines and the prefect runners.
Prefect is where I'm gonna keep all the automations to control the EC2 machines from now on, and also ofc the training loops with hyper parameter search strategy. Whereas GitHub actions is mostly there to build the images and deploy the code to prefect
yeah great points on all counts
you're doing all your ML on your laptop? isn't that stupidly slow for CNNs?
i tried fitting a siamese network a while ago on the LFW dataset and it was processing like 2 images per second on the M1 Mac w/ Torch
meanwhile my 1060 (which is literally dying and randomly crashes the PC) was doing like 10 images per second 😆
I'm coding stuff locally yeah, then I run the pipelines to train them on GPU capable EC2 spot instances
ohh you're using the EC2 spot for GPU
that makes more sense. are you using a framework for that? or just saving checkpoints and monitoring + restarting if they get interrupted?
i think i asked you this before but forgot the answer
I've changed my approach several times, am trying to zone in on the best way to do it
Everything is now automated on prefect.
There's this thing called work pool, which you can configure to contain all the info needed to run a task and in my case is tied to a deployment cluster on ECS
When I turn it on, it triggers a workflow on prefect that increases the cluster capacity to 1, it will then find me the most cost effective GPU spot instance available from the list I gave it.
At that point, I can trigger pipelines on that machine. I can literally input the hyper parameters and it does the thing.
Then I can turn the pool off and that decreases capacity to 0.
The turning on and off part is important because setting up the env each time is a nightmare.
So the answer is that it's managed by prefect and ECS. But I'm missing a bit of code for fault tolerance. Like the cluster automatically brings the number of instances up when it loses one.
Recently working on comparative sentiment analysis of harry potter seven books and Robert Langdon five books
National Treasure 3: From RAGs to Riches
how are you liking prefect? i've used airflow at work for about a year and a half now, so i'm very familiar with it, but it's also very clunky for use outside of a "Data Engineering Pipeline"
how does that work with the interruptibility of spot instances though?
Been liking it a lot, their UI is solid and things generally just work and when they don't it was me shooting myself in the foot.
I don't know yet. I know it's possible to pause the runs and start them up again. Haven't gotten to that part yet basically.
But I've been using this a lot, and fault tolerance was the first thing I coded in early versions. It's not that critical, I can run them all night before they're taken away
Actually, I'm quite sure I managed to run one for three days
Going further to Dumbledore’s wisdom vs Langdon’s intelligence, could Winston pass Turing test set by Voldemort, is invisible cloak more valued than Harris Tweed Jacket
makes sense. where are you saving the models anyway? S3?
Yes, tho most times I'm not saving them since I'm just doing hyper parameter search
It's all tied together with MLFlow
That's likely what's gonna enable fault tolerance in the end. Get the 2min warning, save state to MLFlow, restore everything in the next run
But I'm not gonna dedicate time to it yet, it's not an urgent feature at all. It'll be relevant once I'm training a model for a week or so
I swear, I really want to get this MLOps stuff out of the way, it's so much work ._.
hey i’m making an app that combines decision trees, ai, neuropsychology, and a feedback loop system. does anyone have experience with decisions trees and feedback loops/ ai?
need to get exactly this + mlflow set up
you should check skypilot for automating spot management, apparently it's good for that
you prob got enough for a mlops job if you add sysops to it
I'd very likely have a job by now if I was going for MLOps. Apparently it's pretty hard to hire for those positions
I'm checking this out, looks quite good
yeah heard people train multiple days in a row with only spot instances using it
In fact, looks like I'm coding that thing lool
lol, the classic
why didn't you show me this earlier 😭
heheh
btw do you use anything special for distributed inference/training?
am trying to figure out if this is conditional on the specific models i use
Do they have a managed solution
Most I've done is use pytorch default thing to distribute training across multiple GPUs
cool yeah it does work
dunno literally heard of it in passing, saw someone training purely with spot instances somewhere i don't remember where, and they were using skypilot
I think I can use it to provision the infra, there's nuance in this for sure
Prefect is both more general and more flexible, I'm unsure I'd be able to get the same level of observability with my rust/python split while using sky
While it's true that what I'm doing is a bit unorthodox
oh were you building your project on prefect?
It does highlight that there's gonna be stuff that will not be possible
No, I'm running it there
It can do two tasks in an asynchronous manner in which one task is baby sitting a shell process while the other is pre processing data
Which is actually a pattern I wanna keep, rust split or not
So what I'm imagining is that I'll still use sky, but for turning on and off the work pool
you should prob make a git repo this stuff is likely to be useful for general mlops
Yeah I have one, this is all an open source project funded by my non profit org
oh nice what's your github profile
Ah, can't give you cuz it would dox me
oh np
Tho it is a bit counter productive to my cause to not be able to share it
i gave up and assumed i'm easy enough to dox anyway. i don't post my real name very often, but if you're motivated you could figure out who i am
have anyone done interpolation with LSTM?
i went through a phase where i thought i wanted to be one of those people who used their Real Name On The Internet, so it's my github username & some of my email addresses, but i kind of regret that
cat's out of the bag now at any rate.
Ah, same, but no need to make it easy I suppose
I think I'm doxed in a couple servers, but they're much smaller communities so it's less risk
I use my real name on GitHub and tons of places
I might switch my Discord name as well eventually

why calling this function dont work
i took a break from py for a long time and i think i did a coding error somewhere
can someone help me please?

I think "choice" is a string, so none of your if statements evaluate to true
Try to cast it to an integer, or use "1" instead of 1 in the if statements
This is why I miss having a compiler around when the project gets big, this kind of stuff just keeps happening but in more subtle ways
yea 😅
o.o

Hah, all my throwaways end up becoming my mains.
🙄 this is submarine marketing
I agree, gpt4 also does meta cognition. They just didn't fine tune Claude 3 to deny that stuff about qualia and etc
any one got good resources for text mining/analytics , how to start and where? i have a txt file to work with
mine is whenever my code doesn't work
hello i want to make name detector or something like this because in my school the teacher keep saying the names of who is absent and who is not when in a meeting so i want it to work like this
i take a screensht of everyone in meeting and then the program says me who is NOT here in the names
That's somewhat dystopian imo
I think classes are mostly counter productive, mass education is a necessary evil cuz the opposite is total mayhem. That's my take and I stand by it.

espandi per vedere il testo:
We don't need no education.
We don't need no thought control.
No dark sarcasm in the classroom.
Teacher, leave those kids alone.
Hey, Teacher, leave those kids alone!
All in all it's just another brick in the wall.
All in all you're just another brick in the wall.
We don't need no education.
We don't need no though...
is anyone here fmailiar with constrained MST probelm and how can i go about using rl and gnn to find approximate solutions ty
Can anyone recommend some sub-orgs to apply for in GSoC under the "Python software foundation" banner? My interests are in ML and DS.
can ml be thought of as a pretty complex curve fitting machinery?
check the univrsal approximation theorem
Dealing with Nvidia drivers on Linux+docker has been a bad experience overall
for a rather loose definition of "curve", since sometimes your target can be discontinuous and/or a single point, but yes
more of "function estimation", since that is more general than curve fitting
You can extend that to basically all OSs and platforms 😅
Nvidia drivers are just a bad experience
I gave up and just went to the pytorch's dockerfile and copied every line that mentioned Nvidia
Idk if it will work
It'll work I think, the AMI I'm using comes with the Nvidia docker think setup. So all it needs is the label and the env variables
I assume
Sigh
So this is the pattern I'm gonna be using to develop and deploy ML in a cost effective manner:
- setup production images, ideally this would be just one
- a GitHub workflow that:
- lets you select which machine you wanna use (local or any AWS machine)
- uses the selected production image as the base image
- installs the development dependencies on top
- sets up any extra dev config
- finally deploys a vscode tunnel that you can open anywhere with a browser and GitHub session
- a GitHub actions workflow that deploys the pipelines to prefect
- and a final workflow that actually builds the images and publishes them
so it's basically a substitute for gitpod that lets me use gpu
Eventually I'll use the sky thing to extend this to other providers, but it's not needed at the moment.
I realized I had an error in my ETL so my dataset was getting messed up and I spent all this time trying to figure out why my model wasn't working well anymore
🥴
How do your ratios of RAM to VRAM look like, I want to get an idea of what others are running here
Because mine is likely quite dumb, I'll have to ask IT to reallocate
You mean how oversubscribed we are?
Most of my systems are 1:1, just out of laziness.
my personal machine which is kind of jank and based on what was most expeditious is 256GB to 22GB VRAM. The cloud I'm going to use is 4:1 or 2:1 RAM to VRAM
but yes RAM being smaller than VRAM sounds really bad
IT or whoever provisions machines has a skill issue honestly
I think I should sit down next to them whenever they're doing it
Their lead times are too large to afford to get stuff wrong and it always seems like a back and forth to get a half decent machine lol. The most annoying part about this is that it's unutilised on premise compute anyway
I'm on 16gb ram to 16gb vram
This may seem random but does any know why euler's number shows up so often in ML equations
if you're fully using your VRAM then I think RAM should be at least a bit bigger than VRAM
everything that goes into VRAM has to go through RAM right
My whole setup might be a bit more efficient than usual
and you need RAM for other things too
So I actually could get by with less ram
Unless you do cursed things like loading into vram incrementally
isn't that enough to kill the GPU vectorization benefit
reminds me of blocking in async
I load model, then I load data
IT giving me toasters instead of real machines is what taught me a lot about programming efficiently fwiw
So the available GPU memory is less than the total GPU memory, and the difference is the ram that is needed
Ironically, after fighting with them to get resources for machines that aren't being used I got it when I had perfected my ETL to run with a fraction of the resources
do IT people actually understand how GPU computation works
can you even expect them to
Doing this was a nice experience but honestly, it was a waste of time
Hah, I’m a dope. I’m working on containers and read vram as virtual ram (ie: ratio of virtual container memory to physical memory)
why don't you just tell them what to give you
instead of having them decide what to give you
having IT decide sounds ass backwards because how can they know
It's their territory, you can't decide for them
oh hell
That's what IT does
No
then how can it be their job
They don't understand it's a special case
So they say, "it's our job to provision hardware"
I think most of our systems are 2-3x. We just take whatever lambda or ec2 provides. My workstation is more like 8:1… I maxed out my memory
I always feel like exposing the irrationality of the org structure in situations like this but I usually just end up contributing less effort to punish my employer for putting me in an impossible situation
Ram is basically free, relative to my salary
Aside from that, a lot went south like them giving me a machine that has a tiny amount of disk space allocated to /
I'm actually not sure why you need more than 1:1 or 2:1 since you can swap with disk
I have another physical drive mounted but it's not on /. Whenever I want to install large packages like Torch I need to do all sorts of magic like sim linking the cache etc
Total waste of time
This is a battle I suggest fighting early; the cost of the right server is Pennie’s to an engineers salary. A farm is different, but a single dev station matters not at all
Basically yes
For my interns I just got API keys and a budget for LLMs
We can run them on premise
Why? The price to get them SSH access is just more than paying for the compute in the cloud
You can also deploy vscode tunnels, even less time
I got all this stuff down, but I fear the next org I join will likely have its own less efficirnt ways of doing things
It depends, we also have people that are brilliant internally on the IT side.
They just don't work for our team
For the longest time I thought we were all IT
Depends on the language
In Dutch we call everything that has to do with tech IT, so even SWEs
I have no idea how it is in PT actually, but I think there is a distinction yeah, for people who haven't gone through college and don't code but know some bash and know their way around a computer
Some US firms do that too, seen it at some financial firms
it usually shows up in machine learning because of sigmoid functions. in particular the softmax function (multivariate generalization of the inverse logistic function), but also in the sigmoid activation function in neural networks
oh and of course, it's part of the gaussian distribution
not to mention the exponential distribution as well
it tends to be important mathematically because of its relationship to logarithms, and logarithms show up a lot in probability and statistics as well
From what I recall, It's the purest exponential
i've seen this in the insurance industry too. seems common among very big large firms that do not consider themselves "tech" firms
It solves f(x) = f'(x)
Thanks
yeah, that's very true (and arguably how we can define it). other exponentials are only proportional to their own derivatives.
I was talking about a sklearn interface over Torch recently. I found out skorch does it but it looks sus

Alexander Borst, Max-Planck-Institute for Biological Intelligence, Martinsried, Germany
Abstract: Detecting the direction of image motion is important for visual navigation, predator avoidance and prey capture, and thus essential for the survival of all animals that have eyes. However, the direction of motion is not explicitly represented at th...
seems like it would be hard to do that given all the customizations that are possible. maybe just write a custom fit() function?
That's what I did. I was curious how others did it
I just use torch as normal and have a very thin (20-30 loc) wrapper that can take any model
this fly vision video is really interesting
talking about the organic cognates to data structures
good days work, with all my infra finally done

ah, I do need to hookup MLFlow, shouldn't be too hard tho
after that I'm gonna do the hyper parameter search thing, and prepare the rest of the datasets
they just need to obey a certain data schema and it all works out
I went caveman this project and essentially rolled my own system using streamlit
I just need to pass an http url to a parquet file and it knows what to do with it as long as the schema is proper
Sometimes you hedge your bets on being able to write a subset from scratch faster than reading the docs
this is how it looks on prefect

Hey all, what is the most cost effective way to save training data for a model? I'm talking about 1-2 TB of data. I'm the only one who will use it, so I would be ok with non-cloud storage options.
depends on where you will train the model
If it's possible I prefer to train it locally, but the ssd in my laptop is not big enough.
you could just purchase an external hard drive then
yeah, that was my original plan. I was just checking in case there is a better alternative
Uhm, depends on how long you'll need to store the data, S3 might cost less in total
S3 is 25 USD/month for my requirements. If I need the data for more than 4 months it would be better to purchase a separate drive. Since this is my first project I think it's likely I will work with the data for more than 5 months.
Yeah then ssd seems to be the way
you can also use the drive for backing up normal things after you are done with the project, and/or just permanently keep that data backed up
it's a lot harder to do development cost effectively on cloud
until you get to a certain state anyway
if it's your first project then definitely buy hardware imo
worst case scenario you just reuse it instead of getting cloud in the future
In theory cloud is cheaper until a certain threshold of usage
But there's also initial setup cost
And you need to know what you are doing
yeah but there's also the aspect that your sunk cost on the hardware now means it's free later
whereas if you need storage again you have to pay s3 again
I think storage in general is cheap so it's pretty clear yeah
But stuff like GPU is a lot harder to see imo
Yeah,the case for an external ssd seems very clear. Thanks everyone.
the real question is whether you can expect to amortize the cost of hardware over the lifetime of the hardware vs S3 not whether for one project it's cheaper to use S3
so it's all about how long+how much you use the drive, not how long you use S3
There is also the arguement of performance and durability
You can pull at lot of data from S3 on effectively any amount of data, while also not needing to worry about drive failures etc
right but drive failures are kind of a problem that cloud makes for themselves
to a large extent
a single user using a single SSD drive, you don't have to even think about it for years
There's also the risk of losing the data
There's no fault tolerance locally, no deduplication, etc
it's also bro's first project
trial by fire
and I think in principle you can worry about moving your stuff to cloud once you've developed it locally
if the data is valuable you should have an independent backup copy anyway
but it sounds like the data can be obtained at will it's just storing it
No I think SSD is better in this case
I think so too. I'm sure other options have their advantages, but in my situations I'm really prioritizing cheaper solutions.
I just tested my stuff on cloud and tore it down but that's because I also have a local copy
I can very precisely control my cloud usage as long as I tear it down every time I'm down
and store everything locally
basically spending like $10 for 5 hrs
but with s3 you gotta pay per month to store it
and then you have to deal with s3
With interruptible instances like Spot you can get some pretty good prices, hard to argue for buying a GPU
But then again, it depends on usage and on scale
Rn if I average 4h per day of GPU usage, it leads to about 200dolar at the end of the year
where are you getting decent gpu server for 14 cents an hour?
eu-south-1, g4dn.2xlarge, AWS spot
Some of the Asia regions also have good prices
I've gotten as little as 6cents an hour, but it went up
On vast.ai you're able to get even better prices with interruptibles
I've seen 4 cents an hour at times
I'm not using vast cuz I have credit on AWS
how often do they get interrupted
AWS, not very often, only got mine interrupted once after like 24h or more
But I think it might depend on the instance type
does it give you a grace period
Yeah
And there's like a thing you can use to handle the fault tolerance, haven't tried it yet the tho
It's sky something

I'm still not fully convinced tho, I think it looks excellent for provisioning cloud infrastructure, but, it's not gonna be as flexible as something like prefect
But I haven't tried it yet, so I can't speak too much on it
can you use prefect to trigger skypilot jobs?
Yes, prefect is basically python
I'm actually thinking of using skypilot to deploy a work prefect work pool
I'm not sure, I think there's definitely a synergy possible between them
I made a GUI frontend to CoquiTTS using Tkinter in a few hours because I was bored lel
Oh wait it's already been made :(
Well it was fun to make anyways
Hi, can anyone tell me why I cant import from llama_index.core.readers import PDFReader ?
I got this error: ImportError: cannot import name 'PDFReader' from 'llama_index.core.readers' (C:\Users\barte\Documents\GitHub\Python\ai\Lib\site-packages\llama_index\core\readers_init_.py)
Or can anyone help me changing this import that this code can work?
import os
from llama_index.core import StorageContext, VectorStoreIndex, load_index_from_storage
from llama_index.core.readers import PDFReader
def get_index(data, index_name):
index = None
if not os.path.exists(index_name):
print("building index", index_name)
index = VectorStoreIndex.from_documents(data, show_progress=True)
index.storage_context.persist(persist_dir=index_name)
else:
index = load_index_from_storage(
StorageContext.from_defaults(persist_dir=index_name)
)
return index
pdf_path = os.path.join("data", "Canada.pdf")
canada_pdf = PDFReader().load_data(file=pdf_path)
canada_index = get_index(canada_pdf, "canada")
canada_engine = canada_index.as_query_engine()
A google seems to suggest it is PyMuPDFReader not PDFReader
Never mind
I see they have both types
Their doc search is terrible...
thats true 😄
Have you installed llama-index-readers-file
CPython 3.12.2 pip can‘t build statsmodels wheel while installing one bdist package (streamad).
On another side it was possible to install statsmodels to same environment explicitly - by doing pip install statsmodels.
streamad‘s meta.yaml sticks to one single version number regarding setuptool requirement. I will try to relax it, however no idea if it is of any significance as far this problem concerned - just shooting blindly.
Eventually any ideas else? I appreciate all coming in.
Are you using any sort of package manager like pipenv or poetry which do their own resolving?
same error 😦
If you are maybe it is resolving a different (wrong) version
Hmm and the extra pacakges defiantly import from core rather than like llama_index.readers import xyz ?
not working both of this option
install should looks like this: pip install llama-index-readers-file ?
But wait, do you know any other import that i can replace llama_index.redars ? I just need import data from PDF
Yes, it is a time series decomposition using statsmodels.tsa.seasonal.seasonal_decompose. Do people also call that a "time series model"?
It was my assumption that we would want to compare temperature to crime rate residual. It didn't make sense to me to include the trend because the overall decrease in crime is likely not influenced by day-to-day temperature. Where I'm confused is the seasonal part of crime. I want to believe that there's also a seasonal part of the crime rate that we want to factor out. Such as "more crime on the weekends". My instructor seems to think we should still include the "ups and downs" of both temperature and crime rate found in the seasonal parts of both.
Sorry about the random stream of thoughts. This is my first exposure to time series', so I could be making assumptions that I shouldn't be.
Pretty sure under the hood it uses pypdf
Raplace it, and get this code
import os
from llama_index.core import StorageContext, VectorStoreIndex, load_index_from_storage
from pypdf import PdfReader
def extract_text_from_pdf(pdf_path):
with open(pdf_path, 'rb') as f:
pdf_reader = PdfReader(f)
text = ''
for page_num in range(pdf_reader._get_num_pages()):
text += pdf_reader._get_page(page_num).extract_text()
return text
def get_index(data, index_name):
index = None
if not os.path.exists(index_name):
print("building index", index_name)
index = VectorStoreIndex.from_documents(data, show_progress=True)
index.storage_context.persist(persist_dir=index_name)
else:
index = load_index_from_storage(
StorageContext.from_defaults(persist_dir=index_name)
)
return index
pdf_path = os.path.join("data", "Canada.pdf")
canada_text = extract_text_from_pdf(pdf_path)
canada_index = get_index(canada_text, "canada")
canada_engine = canada_index.as_query_engine()
and that kinde of error:
PS C:\Users\barte\Documents\GitHub\Python> python main.py
building index canada
Traceback (most recent call last):
File "C:\Users\barte\Documents\GitHub\Python\main.py", line 10, in <module>
from pdf_reader import canada_engine
File "C:\Users\barte\Documents\GitHub\Python\pdf_reader.py", line 30, in <module>
canada_index = get_index(canada_text, "canada")
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "C:\Users\barte\Documents\GitHub\Python\pdf_reader.py", line 18, in get_index
index = VectorStoreIndex.from_documents(data, show_progress=True)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "C:\Users\barte\Documents\GitHub\Python\ai\Lib\site-packages\llama_index\core\indices\base.py", line 136, in from_documents
docstore.set_document_hash(doc.get_doc_id(), doc.hash)
AttributeError: 'str' object has no attribute 'get_doc_id'
I am guessing what you give to from_documents is not the right type
is it supposed to be a sting, or does llama_index expect a object with different attributes
so what exactly are you doing here? time series decomposition of both temperature and crime independently, and then looking at the correlation / regression between residuals?
what's the actual goal here?
The goal was very broad: "Does weather affect the rate of crime in Chicago? If so, how much?"
We were given the following data sources:
Crime - https://data.cityofchicago.org/ (To export, click "Public Safety", then click "Crimes - 2001 to Present")
Weather - https://climexp.knmi.nl/gdcntave.cgi?id=someone@somewhere&WMO=USW00094846&STATION=CHICAGO_OHARE_INTL_AP,_IL&extraargs= (To export, click "raw data" just above the graph of the temperatures)
Each row in crimes is one crime. Each row in weather is one temperature measurement for a day.
I started by inner joining the crime and weather data on the date. I added a "Crimes Per Day" column by getting the value counts for each date in the dataframe. Calculating correlation between temperature and crimes per day gave a very bad result. The instructor said that we should shoot for an r^2 value of around 0.48. I was getting an r value of about 0.19.
He did a sort of manual decomposition of the time series by subtracting the rolling average from each day's crime rate. He then turned that into a percentage. I assume he means percent increase.

i see. lots of different ways to approach this
i understand why your professor wants you to keep the original un-decomposed temperature series. if anything, the natural changes in weather throughout the year allow you to make interesting within-year comparisons
it sounds like this is intended as more of a general data analysis exercise, than an exercise in causal modeling, is that right?
if so, it looks like "affects" is used loosely to mean "is related to / correlated with", rather than "causes"
in which case it doesn't matter so much whether you've accounted for confounding variables etc. correlation is what it is. you just need to resist the temptation to interpret it as causality.
it's a bit weird that you're being expected to manipulate the data until you get a high correlation
is that meant to prove some kind of point about data processing affecting results?
i think your original instinct is still correct: weather alone might not cause more crimes. but that might be the point of the exercise, to demonstrate that just because two things in the data are statistically related doesn't mean they are causally related
@desert oar
it sounds like this is intended as more of a general data analysis exercise, than an exercise in causal modeling, is that right?
He didn't mention anything about causal modeling. I think you're correct in that it's intended to be more of a general data analysis exercise.
if so, it looks like "affects" is used loosely to mean "is related to / correlated with", rather than "causes"
I would agree with this.
it's a bit weird that you're being expected to manipulate the data until you get a high correlation
I think by that he meant that if you're not getting anywhere close to that, you may not be considering something that you are supposed to consider. Say I got an r^2 value of 0.25, but I didn't know that the relationship between temperature is actually stronger than that. If I worked hard, and everything I did to reach that value made sense to me, I might not have any reason to try other things such as time series decomposition.
is that meant to prove some kind of point about data processing affecting results?
He didn't say that explicitly. It seemed to me like the point of this project was to learn how to remove an overall trend from data so that the underlying relationship is clearer.
i think your original instinct is still correct: weather alone might not cause more crimes. but that might be the point of the exercise, to demonstrate that just because two things in the data are statistically related doesn't mean they are causally related
Of course weather alone does not cause more crimes. It likely isn't the only factor even affecting the rate of crime. If he wanted to demonstrate that statistically related variables doesn't necessarily mean causally related, he certainly didn't spell that out or even make any allusion to whether that was his intent.
In short, "affects" was likely used to refer to correlation. What I still don't know is whether it even makes sense to correlate seasonal temperature with seasonal crime.
Got this for HW and i have no clue how to do it 
In Exercise 1, we will group the dataframe by birdname and then find the average speed_2d for each bird. pandas makes it easy to perform basic operations on groups within a dataframe without needing to loop through each value in the dataframe.
Instructions
Fill in the code to find the mean altitudes of each bird using the pre-loaded birddata dataframe.
Here is the code:
# First, use groupby() to group the data by "bird_name".
grouped_birds =
Now calculate the mean of speed_2d using the mean() function.
mean_speeds =
Find the mean altitude for each bird.
mean_altitudes =
What is the mean speed for Sanne?
its solved now nvm
Hello friends, can anyone introduce me to a course so that I can learn mathematics related to artificial intelligence and data science or machine learning and it will be enough, thank you.
Check out this pinned message: #data-science-and-ml message
What are some required skills for ai developer job
The bare minimum is a bachelor's degree in computer science or similar where you took as many courses as you could about AI. Most AI jobs require a master's.
thanks for the clarifications. i guess all i can offer is that sure, why not? you can correlate anything with anything else. in this case you're talking about the correlation between temperature residual from decomposition and crime residual from decomposition? then you're specifically looking at a correlation between deviations from baseline levels, because that's basically all a residual is. does that make sense? yeah sure, why wouldn't it?
Had to implement REST requests to MLFlow in rust, not happy about needing to have a server up for the purpose, but it I can just get a long running free tier as I had b4
I'm also unsure why rust complicates strings
It's quite unlikely that I'll reuse rust for this though. It's not bad, but having to worry about an integration across two languages is an unnecessary hurdle.
I have to communicate the MLFlow session to this second process, when I could just be passing a python object around
Can u tell which company requires masters. I'm pursuing the same and have 1 yr experience
because strings are harder than you think. rust takes the approach of exposing that difficulty to the user, rather than hiding it and hand-waving over it
Yeah I guess that makes sense. Still, why not just have one safe type
I think in some cases it's not a hard requirement though, I still send my resume and get responses. I not only don't have a PhD but also have an incomplete masters.
I think I do a good job of showing continued education and practical experience. I also don't plan for the MSc to remain incomplete.
But the point still stands
I'd hire you for sure!
I would probs not worry about using rust until you want to deploy
We do all our training in Python then export to onnx
Then the onnx file can be compiled to rust and handled from there
Or using onnx runtime directly depending on needs
Because rust must function on a variety of setups, in particularly the language must be able to function without an allocator for things like embedded systems.
So you end up with one type to represent the "string of UTF8" pointer type which can be backed by any memory i.e. stack or heap
And then you have String for "if you have an allocator" which provides the allocing of strings on the heap
hello guys,
need help
Hello Devs,
I have Containerized MY ML Project ( FLASK BASED) and I want to deploy it on AZURE but locally on My pc it is working fine as i hit the endpoint but When I containerized the whole project the Docker Logs Show Following Warning( Note: I'm on Windows):
2024-03-08 09:53:03 2024-03-08 04:53:03.627033: I tensorflow/core/util/port.cc:111] oneDNN custom operations are on. You may see slightly different numerical results due to floating-point round-off errors from different computation orders. To turn them off, set the environment variable TF_ENABLE_ONEDNN_OPTS=0`.
2024-03-08 09:53:03 2024-03-08 04:53:03.629253: I tensorflow/tsl/cuda/cudart_stub.cc:28] Could not find cuda drivers on your machine, GPU will not be used.
2024-03-08 09:53:03 2024-03-08 04:53:03.671447: E tensorflow/compiler/xla/stream_executor/cuda/cuda_dnn.cc:9342] Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered
2024-03-08 09:53:03 2024-03-08 04:53:03.671542: E tensorflow/compiler/xla/stream_executor/cuda/cuda_fft.cc:609] Unable to register cuFFT factory: Attempting to register factory for plugin cuFFT when one has already been registered.
2024-03-08 09:53:03 2024-03-08 04:53:03.671585: E tensorflow/compiler/xla/stream_executor/cuda/cuda_blas.cc:1518] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered.
2024-03-08 09:53:03 2024-03-08 04:53:03.679435: I tensorflow/tsl/cuda/cudart_stub.cc:28] Could not find cuda drivers on your machine, GPU will not be used.
2024-03-08 09:53:03 2024-03-08 04:53:03.679764: I tensorflow/core/platform/cpu_feature_guard.cc:182] This TensorFlow binary is optimized to use available CPU instructions in performance-critical operations.
2024-03-08 09:53:03 To enable the following instructions: AVX2 AVX512F AVX512_VNNI FMA, in other operations, rebuild TensorFlow with the appropriate compiler flags.
2024-03-08 09:53:04 2024-03-08 04:53:04.893043: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Could not find TensorRT
`
you have a very very impressive side project portfolio. add that to your linkedin page, set yourself for "looking to work", and start attracting/messaging recruiters
make sure your linkedin page and portfolio emphasize your recent project work, programming experience, and strong math background. your work experience and education details are less important by comparison
doesn't rust have String? https://doc.rust-lang.org/book/ch08-02-strings.html
Adding to what BillyBobby has suggested, you might wanna attend this particular event by Cohere.
You'll get to meet people and ask questions that could help you put a lot of things in perspective.
hey guys does anyone mind helping me with a school ai project https://discord.com/channels/267624335836053506/1215731114396745810
not sure if it is a program issue or a data issue
new to all this ai stuff and teaching myself someone told me to message in this channel and that this may be of assistance to me
what do you guys use to navigate huge profiler outputs
custom parsing scripts?
trying to debug why training is going slower than expected
What knowledge i have to gain to create a AI from scratch?
Like Jarvis from IRON MAN
If we're talking Iron Man, I suppose you should go to MIT and get multiple graduate degrees. That's a good start.
(just like tony stark)
Not exactly like ironman but a good AI for daily work on laptop for queries and more
"from scratch" is very unclear. Do you want to research and train an entire LLM from scratch?
U can say that
Then you need to start at base principles, and work your way up.
Start here, perhaps #data-science-and-ml message
good luck brother im doing it rn for school very big challenge
i wish u luck
cause its borderline impossible for a single man to achieve
Hey guys, my postgres queries through SQLAlchemy and psycopg2 to Supabase has randomly started to fail with the error "server closed the connection unexpectedly This probably means the server terminated abnormally before or while processing the request." - I have not really change anything materially in my code but all of a sudden it doesnt work like 1/5 time I query the database. As far as I can tell Supabase is fully up and running, anyone has any idea what is wrong?
Do you know any Python?
Yah some basic knowledge gain from youtube and whitehatjr (144 classes 🥲😅)
If you're just starting off, focus on getting good at Python. Best way to do that is small projects.
!kin
Kindling Projects
The Kindling projects page on Ned Batchelder's website contains a list of projects and ideas programmers can tackle to build their skills and knowledge.
Okk thanks a lot
Once you feel comfortable, then try something like CS50 for AI. https://cs50.harvard.edu/ai/2024/
kaggle.com/learn has some good resources too for beginning data people
😲🤩 thanks bro @left tartan
native torch running at 3.5 it/s, while torch lightning running at 0.05 it/s
any suggestions?
polars dateparsing is pissing me off
try_parse_dates works but then it can't write to a database because pandas can't work with arrow extension dates
if I don't use try_parse_dates when I try to cast it to a date after I read it to the database it fails for some weird reason even though I have the right parse string
You may need to use a timestamp or something, I use dates with pandas/polars, but I know I had to do some thing to make it work. 🤷🏻 can’t remember the specifics
I know we can correlate anything with anything. And I think I have a good grasp on what comparing the residuals means. However, my instructor and I seem to disagree on whether we should also be including the seasonal component of either or both temperature and crime rate. He is of the opinion that we want to include the seasonal components for temperature and crime rate because it contains the "ups and downs" in the data; the "reason why crime rate varies". He goes on to say that he thinks the residual components are more akin to noise and "why would those be correlated".
I think that we don't want to include the seasonal components because it's my understanding that it holds the cyclical behaviors of each of the variables. I would think that if temperature rises and falls throughout the year every year, we don't care about that part. I'm not really basing my opinions on anything besides gut feeling/common sense.
Not my specialty, but do you know https://spacy.io/ ?

spaCy is a free open-source library for Natural Language Processing in Python. It features NER, POS tagging, dependency parsing, word vectors and more.
dont use spacy it isnt that good
your face isn't that good
but in all seriousness, what do you dislike about it?
(forgive my immature retort--I use spacy a lot and have contributed to it.)
yeah isn't spacy basically industry standard for quick and easy NLP work?
i've used it a bunch for things like lemmatization
Oh man, now I’ve got to dust off lemmings. But yah, the little I’ve had to do with Nlp, spacy seems to be able to do everything I’ve needed.
hey guys looking for an text to speech python package. similar to elevenlabs. Lightweight so it can run on just a cpu. I tried setting up the elevenlabs package but I ran out api tokens. The program just runs after a user asks a question and reply to it by looking up the most closest result
pyttsx3
I think https://assemblyai.com has an API for Text2Speech.
AssemblyAI
With AssemblyAI's industry-leading Speech AI models, transcribe speech to text and extract insights from your voice data.


Hehe Im flattered
Actually, my hypothesis is that a compiled language is better for ML, because the compilation step can be used for catching errors in the calculations without having to instantiate a model
My experience with rust has been: love -> hate -> hate -> love -> hate, I get frustrated when it doesn't let me do something but then I look back at the resulting code and see that it is better than what I was trying to do. I suspect things will become different as I start to become fluent in the language tho
can someone guide me to start machine learning
That's an interesting take, I had considered just removing my education section so I can have more space for my practical experience.
Presenting an incomplete masters in a resume is actually kinda hard, I try to balance it out with the achievements I've made during that time, and also there's the fact that I just have one presentation pending. Which is actually not the first one I've done.
Tho, I would welcome not having to think about it and just place my projects and achievements instead
Yeah that's the problem, I'm having to jump between String, &String, str and &str because the dependencies force me to
Which would be totally fine, but rust is very sensitive to the &
Quick question, how do I get my Google Colab to display this information?

Because mine only shows this

you could print it instead of just letting it show
Or look in the settings - what you're looking for is to make that cell's output be interpreted as text instead of a fancy widget.
Hmm do you know by any chance where I can find this setting? I found two 'settings' in the menu and neither seem to have something related to this, unless it's worded way off what I'm thinking
No real idea, I don't use google collab. I'd try rightclicking at the cell itself, maybe; in vscode's jupyter support it's in a menu near the output

Alright, I'll keep searching thanks
I failed to find a way to do that in google collab, but it looks like you can instead disable it on sklearn's side: https://scikit-learn.org/stable/modules/compose.html#visualizing-composite-estimators
Thanks, that helped a bit, still not showing the full summary. I posted it on Reddit. Even though I'm still learning, seeing all the parameters will help me understand the bigger picture I reckon.
Have you tried printing it, or perhaps printing its repr?
Yes, I did now, both of them yield the same result, showing the model name and that one parameter I gave it with. In the course he also gave it one parameter but it showed the full summary anyway.
aha, I got it
had to look into the code to find it, but it's another sklearn config that skips default values of estimators in their repr.
so sklearn.set_config(print_changed_only=False, display="text")
(the second one can be omitted if you like those fancy diagrams)
🥳 that was it! Ahhhh that cheeky instructor must have done this in a stealth way as he shows opening the notebook without having this line of code lool ... but yes, now I can see all of it, weird that it's on (or True) by default
Thanks a lot, found it in the documentation, bookmarked 🙂
Does anyone know how to build trading algos using ict concepts?
anyone got stats/papers on performance wrt. degree of quantization
Hiho, i am currently reading Think Bayes 2, and have some questions about the python code in the book. In Chapter 19 (https://allendowney.github.io/ThinkBayes2/chap19.html), there is a function call like this.
from scipy.stats import gamma
from scipy.stats import poisson
alpha = 1.4
sample_prior = gamma(alpha).rvs(10)
sample_prior_pred = poisson.rvs(sample_prior)
gamma(alpha).rvs(10) gives me 10 random samples from a gamma distribution with alpha set and the poisson.rvs uses the values in the array for lambda and then random samples the distribution?
so my kernel death on GPU-> CPU dump came back on my threadripper system but it doesn't happen on cloud. I wonder if it's because of ECC memory or something like that
i think it's a low level bug because I can't really narrow it down to one situation where it happens
look at the documentation for those functions
I did and i don't get it really, i tried to make sense of it by just extracting the code above but this is just what i assume now.
gamma(alpha).rvs(10) gives me 10 random samples from a gamma distribution with alpha set
yup
and the poisson.rvs uses the values in the array for lambda and then random samples the distribution?
I believe it's 10 samples from 10 different poisson distributions, yeah
Ok i was not sure if the values in the array are used as mu (lambda) for the poisson distribution. Thank you very much 🙂
Im uninstalling MLFlow and writing my own client to their rest interface
They do have a client class, but I swear, it does everything except log params and I don't understand why
The context manager that starts a run defines a global context somewhere, and then you use a globally defined log_params function to log parameters
It works fine but once you get into multiprocessing you needlessly need to reconstruct their global context without interfering with the state of the run
It's just a rest API
It's a barebones rest API
Why not just a class with a couple methods and some fields encapsolating a session
So I can pass it down to my subprocesses, it's just so simple, I must be missing something
This should still work if it hasn't been deprecated
model = LogisticRegression()
model.fit(X,y)
model.get_params()
I had to define an env variable so that the other processes pick up on the run that the parent created
No they do have it here: https://github.com/mlflow/mlflow/blob/master/mlflow%2Ftracking%2Fclient.py#L727
But I didn't see it in the docs
mlflow%2Ftracking%2Fclient.py line 727
def log_metric(```Idk why I didn't see it ._.
https://mlflow.org/docs/latest/_modules/mlflow/tracking/client.html#MlflowClient.log_metric
I'm taking a break, I am not sure how I missed that, but it was frustrating
Thanks, yeah that worked too, and no deprecation warnings
how good is rtx 2050 mobile for inferencing AI models
Looks like it only has 4 GB of memory, which will be fine for small models, but will be completely useless for any models that are larger than that.
when looking at a CUDA-enabled GPU, the main question is "how much memory does it have?". It needs to have enough for the model you want to run on it.
what are people calling "agents"?
an agent is a system that is part of and interacts with some environment. which can be the real world, or a simulation. so a self-driving car is an "agent". or a an automated opponent in a multi-player game.
makes sense, but at a python-level, what is it? just a fine-tuned model?
it could be anything.
an agent doesn't have to be created from machine learning.
it could also be a model that isn't a fine-tuned model. do you know what sets a fine-tuned model apart from one that isn't?
Not one that is separate from the one I gave earlier.
that something is an agent is a description of its external behavior. not a statement about its implementation.
yep, whatever fine-tuning technique you use (but you can also just train it more)
lora, classification layers, etc.
hmm, that isn't quite right
hm i see
how so?
This is so real. Even in CPU the bottleneck is memory
from what I've read up, fine-tuning is making a model more adept for a task. there's a couple of techniques out there, but i think more training is also fine-tuning no?
when you create a model initially, you start with random weights.
fine-tuning is when you take a model that's already been trained (so the weights are no longer random) and continue to adjust them. either for the same task, or a different task.
lora stuff, finetuning layers, prefix tuning, etc.
yeah but there's a number of fine tuning techniques
most of the newer ones don't even use the original weights
or even touch them
(lora)
my point is that you asked if an agent is "a fine-tuned model". but not all models are fine-tuned.
oh i see, ok right
ty for answer!
Hi does anyone knows how I can choose an ml algorithm for my dataset and any resources to build an end to end project
the very first thing you have to think about is which problem you are solving (regression, classification, forecasting etc)
after understanding the problem, look up models for it on popular libraries like sklearn or pytorch (if it's something simple you may want to start with sklearn ; if it requires freeform text or images, disregard most of the rest of this message)
after that, you may have to do some transformations, e.g. transform categorical string data into ordinal or one-hot encodings, as well as consider some feature engineering (adding new columns based on others such as calculating area given width and length)
after that, throw it in a model from the library you picked, try cross-validation, start playing with hyper parameters, test different models etc.
As far as resources goes, sklearn's documentation and their INRIA Mooc Course are a good place to start (assuming you're going to be working with sklearn, no images/free form text/alike)
Thank youu so much
Do you know any dataset who isn't that famous so I can use it on my project
you can browse Kaggle or collect data yourself
so this is how I deploy a server, while getting free observability
I set up a self hosted runner on the remote machine, and I get a workflow that runs the program, the logs display here and I even get an email if it goes down, dont have to pay no cloudwatch no anything

ofc, secret sharing is breeze too
Alright thxx
A rational agent or rational being is a person or entity that always aims to perform optimal actions based on given premises and information. A rational agent can be anything that makes decisions, typically a person, firm, machine, or software.
The concept of rational agents can be found in various disciplines such as artificial intelligence, co...
ty!
worth keeping an eye out for the new galore technique
i was looking at the requirements and it seems a minimum of 6 gb is needed for local LLMs
".. useless for models that are larger than that" -- larger than what ? the model size (.bin) ?
There's no point making statements about how much memory is needed to run "LLMs" as one "large" language model can be more than ten times larger than another "large" language model.
Yes, the size of the model bin.
Llama2 models range from 13 to 139 GB
hey, guys i'm unable to install packages in virtual environment that i created for a project.i was trying to download tensorflow but it's throws error unable to create process "python.exe" and "pip.exe"

i was referring to this and 6 gb vram seems to be a starting point

not sure about the correctness
how do these quantizations compare to the originals ?
any sources (books/courses or any other source) to learn statistical inference with python ? I'm an undergraduate BS Business data analytics student and I took an introductory course for python last semester. The title of my current course is Statistical inference for business analytics. What I know is that it involves working with data frames/datasets - using libraries like numpy pandas etc.
also, I have no background as far as statistics is concerned.
There is this book https://www.statlearning.com/ , now available in both R and Python versions
An Introduction to Statistical Learning
but what is your course involving in a practical way, is your course using Python or using other tools? It makes sense to focus on your course first before looking at other books that might be going too far for you
Some adjustments for this.
Instead of deploying the prefect flows to prefect cloud, I'm gonna use GitHub actions to provision cloud and deploy a prefect worker there. Same effect but the cloud management is moved back from prefect. The objective is to use skypilot to automate the provisioning instead of me having to go through the console to configure stuff
So how does this look like.
Two critical points:
- secrets are all centralized on the GitHub repository
- once stored, they never get moved by a human again
This means that not even prefect is gonna see any secrets. I'm reducing the atack surface to GitHub and to the human developing stuff, which can be further minimized by propper segregation of secrets (dev vs stage vs prod).
All workflows will follow the same logic, that is, the development deployment (which is a vscode tunnel) is very similar to staging which is very similar to prod, cuz well, they all build on top of the same base image, the one that's meant to be used for production.
For training:
- Click on GitHub actions workflow dispatch trigger (manual trigger)
- A GitHub hosted runner starts and uses skypilot to provision infrastructure, it then sets up a self hosted runner on the new machine and yields control to that new runner
- Runner will just do minor setup, stuff like logging in to prefect cloud, since this is technically the production phase of the project, it's using the production image
- A prefect worker is deployed from the pipeline, this appears in the prefect cloud UI, where I can trigger the pipeline how many times I want and with the hyper parameters I want
- When I'm done, I turn it off, control is yielded back to GitHub, which starts a new runner and de provisions cloud
- Fault tolerance might be tricky, but skypilot handles the transfer of checkpoints when an instance is removed. So all I have to do is to code check pointing through files. - this is not critical though, the instances last long enough for my purposes.
This looks like I'm giving myself a lot of work, but actually, most of it is already coded, I'll just have to take my current development deployment workflow and remove steps from it. Well, the skypilot thing will take work, but really, I don't need it until I have a need for fault tolerance. My quota for GPU doesn't really give me much choice on the machine type anyway and I don't really want to increase my GPU burn rate if I can help it
Could someone guide me on creating machine learning algorithms? I want to create a letter recognition software as my first project.
I'm following a tutorial on XGBoost, and apparently np.int was removed in the newer version of numpy, how can I solve this? Is there a line of code I can run that converts all np.int to int? I don't use/see np.int in my notebook, so I guess it's somewhere hidden.
Is there a line of code I can run that converts all np.int to int
Use find-and-replace in your IDE? :p
I don't use/see np.int in my notebook, so I guess it's somewhere hidden.
If it's in a library, then it's not really up to you.
by "was removed", you mean the library fails with an error when trying to use it? if so, probably the best solution is to downgrade numpy.
(the other solution is to, well, modify the library you're using to be compatible with modern numpy, by replacing np.int with int everywhere)
(or, hmm, technically speaking there's a cursed solution - you could try doing np.int = int. Just make sure you do it before importing those libraries that use it.)
Hmm I will try that
Oh wow, so I guess that works lol. Didn't even use before the import section on top, but just before the cell that stopped me from continuing
Here are the course contents.
My instructor mentioned that we will be using R as well but for now it's just python. One more thing - I don't trust my instructor as it's been four weeks since the start of my semester and I have sensed that she knows absolutely nothing about programming (about python, to be more specific). Her background is all statistics but she knows nothing about programming. Last week we restarted from scratch and this time she started with the theory from the book "STATISTICS UNLOCKING THE POWER OF DATA" (written by Robin H. Lock and three more ppl)
Thank you for the response. Are there any video tutorials/courses I can use with this book to enhance my learning ?

so this is a runner on the aws machine

and this is a runner on my laptop

why does the aws machine take a full minute to init a container ?

it's a list of awards ?
https://catalog.data.gov/dataset/national-student-loan-data-system-722b0 yea it's federal aid granted to students
would be cool to show if it is distributed equitably,
yeah no further ideas yet
but a density map could be cool, since you have location
i would just do that in tableau, probably.
the tableau public dashboards have very cool ideas.
i can maybe steal a few
but i'd have to contextualize them in terms of this dataset
maybe something similar to that.
ok your course is fairly introductory, the book I linked goes way beyond, I don't think it's appropriate for you at this point. Focus on understanding what is in your course, these are fundamental concepts on which to build on later. Your instructor will know statistics, this is the point of the course. Try and get what you can get from the course, and if you have extra time, try and find the python way of doing what you are learning in the course. Python being python, there are multiple ways, https://docs.scipy.org/doc/scipy/reference/stats.html is one of them.
haven't heard of it
uhmmm, not sure if I like it
it's cool that it is interactive, but like, I can select the nodes, but then nothing changes, so why let me select
yeah, put your projects upfront then. i forget: is your masters in progress still, or did you quit?
very popular BI tool, the other big ones are PowerBI and Qlik
tableau is huge
the idea is that someone with some engineering knowledge sets it all up, and then non-engineer business analysts can do fairly powerful data analysis with it
I have all my coursework complete, just need to present the thesis, I even done a talk about my thesis in a fancy german uni
I was thinking of suggesting pyvista, but rn I'm finding it hard to find you a good plot thing here:
But it was extra, it wasn't really the thesis defense
just say "in progress" with an expected completion month & year. that's completely normal
include your thesis in your project list of course and indicate that it was a thesis project
Tableau and PowerBI are important tools
@hollow sentinel if you want an in-python data viz suggestion for geospatial data, check out Geoviews
I've seen multiple work projects squander months on something that could've been done in a week
I don't have one yet, the plan is to complete it after I get some high priority stuff out of the way
This predates me but someone even set up a system where $customer could make their own graphs in the frontend because he was sick and tired of dealing with new questions/modifications
gotcha, ty 🙂
The downside of PowerBI is the licensing fees
Enterprise starts at €3995 per month last time I checked
we are doing this too, except proactively 😆 our BI platform specifically supports embedding in a frontend
then just say "in progress"
That means you're paying for embedded/premium? 🫠
Honestly, there's probably no better way because running superset or other FOSS BI tools will cost you an half an FTE or more and that'll potentially be more than just paying for PBI enterprise
Like, rn I just say that I'm on a temporary break from it. I was class rep during the first COVID 19 lockdowns and the whole thing took a huge toll on me. I'm planning to move the credits to the faculty where the top expert of that field works in, so I can present the thesis to him. Shouldn't be too hard due to EU standardization.
😀 She probably knows enough to be your prof. More so, if her background is indeed in Stats, then she most definitely will be very good in R.
Bottom line: Just keep an open mind. Whether you do most of your class in R or Python, you'll surely enjoy your class - - so long as your prof. background is in Stats, and she can explain / breakdown seemingly hard stuff very well, and above all she's pretty solid in either R/Python.
what's the shortest init time you've encountered for any cloud instance?
am wondering if I can make opening python files with emacs trigger cloud instances in a cost-efficient way, and close them when i'm done
That's the shortest I get, it's a nightmare if I actually need to pull any layers
!rule 6 seems like an ad for something you've made yourself
1 minute is the shortest?
dang
I'm not entirely sure why, I think it might have something to do with whatever technology uses the AMI's, I suspect it's docker based but I haven't looked into it
On my laptop it's 2 sec or so
Don't matter. I just have a bug to fix and I can finally start doing some training. It's all pieced together rn.
I do have to implement the other attention mechanisms, like the scaled dot product.
Then mine is gonna be implemented directly in cuda kernels, which I'll have to figure out how to bind into cpp torch, and then into rust torch
I might also try to find the best implementation of scaled dot product, so I can compete with it.
!pip install "tensorflow-text>=2.11"
ERROR: Could not find a version that satisfies the requirement tensorflow-text==2.11.* (from versions: none)
ERROR: No matching distribution found for tensorflow-text==2.11.*
why
my guess would be "you tried to install it on a python version it doesn't support, like 3.12".
Hi! model = AutoModelForCausalLM.from_pretrained( "microsoft/phi-2", quantization_config=bnb_config, device_map = 'auto', trust_remote_code=True, use_auth_token=True, ) able_parameters() print(model) ```ImportError: Using bitsandbytes 8-bit quantization requires Accelerate: pip install accelerate and the latest version of bitsandbytes: pip install -i https://pypi.org/simple/ bitsandbytes -I keep getting this error even after I updated bitsandbytes
what shall i do now ??
i am using python version 3.11.5
the specific version you're using, tensorflow-text==2.11, isn't compatible with 3.11 either. either use a later version of that dependency, or downgrade your python.
downgrade to what version ??
i will try to make a new environment with that version
For this version of tensorflow-text, python 3.10 would do.
thanks will try
Anyone has idea about this ?

funny how it doesn't overfit, I wonder if I have data leakage

These curves are a data scientist's dreams 😂
or nightmare, now you have to dig for leakage
Y'know what I do? Aggressively split data and have a final final final holdout/test set
If I leaked along the way it's "OK" because the "official" metrics are those on the final test set
what is data leakage? is that when you leak your test data into training data?
yes
I think it's the dataset that is good, I'm cross checking with this: https://paperswithcode.com/sota/sentiment-analysis-on-imdb

The current state-of-the-art on IMDb is XLNet. See a full comparison of 43 papers with code.
they are getting close to 100%
Ah nice, then it's legit
this is a very small mataformer too, 1 layer, 2 attention heads
If the dataset is large enough you should look into this though
the eval is just a small subset of the test dataset, which I'd then remove from the test dataset ofc
the original doesn't split into eval
so I chunked it from the test split
What do you mean with eval?
the split you use to do hyper parameter tuning
All I mean is that I split off say 20 % off of my full dataset and never touch it to the very end
my understanding is that those 20% are your test split
The rest of the 80 % is then split off into train val and test
The key is to touch the 20 % you split off first just once or twice max
With a small set of models
yeah it's not even coded yet, I'm not touching it at the moment
If you leaked within the 80 % it's totally ok, then the results will be representative on the 20 %
Unless you mega leaked into that 😂
I'll still check for leakage, just for peace of mind
but I'm quite happy with this
I'm gonna have to upgrade the MLFlow machine, the aws free tier can't handle more than one request at a time
I can deploy a service locally in the runner
but it starts to overload the pipeline runner
I wanted MLFlow? Set up Caddy on a machine behind my VPN in <15 mins, reverse proxy MLFlow and it's done