#data-science-and-ml
1 messages · Page 108 of 1
I don't know how I helped, but happy I did
I still need idea's on how to make the programming system
like what do you think should I do it via specific classes that correspond to attributes and physical laws? for example
CHECK-ATTRIBUTE -> (Material) [Corrosponding attribute] returns T/F
OBJECT-DENSITY -> (Material) returns object density
... so on...
would this be too simple? too complicated?
I think an object oriented language, when it comes to physics makes a lot of sense
class Material:
density: float
state: Literal["gas", "solid", "liquid"]
def to_liquid(self):
...
the objects are in python, the way this will work is that the model will decide when to check for materials based on its proximity to other objects in the simulation, it needs to learn how to check properly and how to craft properly
You see a stream of cars drive by in front of you. They are all the same green car. Then after a long period of time, you finally see a red car. If you count how many green cars you have seen and how many red, red has a low probability of being seen, yet seeing the red car told you a lot more about what kinds of cars there are than seeing yet another a green car, seeing a green car is not special / common and does not tell you anything new.
If you are trying to hack a program and seeking information on its behavior, are you looking for common / normal / not rare behavior or rare behavior? Which tells you more about all the possible ways the program can behave given random inputs?
yea that makes sense
What does this imply about how you can train an agent to exploit an environment?
I want to use this as the programming language the MLM uses to learn, it should be complex enough to create a learning algorithim and custom behaviour in relation to materials.
1. CHECKATTRIBUTE -> TOOL(OPTIONAL), (Attribute) Material
2. ALLOYING -> [Material, Material, Material…]
3. GASBLENDING -> [Material, Material, Material…]
4. BLENDING -> [Material, Material, Material…]
5. FOR (CONDITION-A) OPTIONAL [&&, || (and, or) (CONDITION-B)] …
6. WHILE (CONDITION-A) OPTIONAL [&&, || (and, or) (CONDITION-B)] …
7. IF (CONDITION-A) OPTIONAL [&&, || (and, or) (CONDITION-B)] …
8. ELSE-IF (CONDITION-A) OPTIONAL [&&, || (and, or) (CONDITION-B)] …
9. ELSE
10. MATERIALSTATE(Material) returns the state of the material as a string.
11. MATERIALSTAT -> (Stat), (Material) returns the current value of the material
hello, i am trying to integrate a model into android app and i am getting this error
java.lang.RuntimeException: Error occurred when initializing ImageClassifier: Input tensor has type kTfLiteFloat32: it requires specifying NormalizationOptions metadata to preprocess input images.
i didnt have much knowledge about ml
can anybody help??
i think i have to add metadata to the tflite model.
But i didnt have any idea about it
god bless the SPAADIA corpus
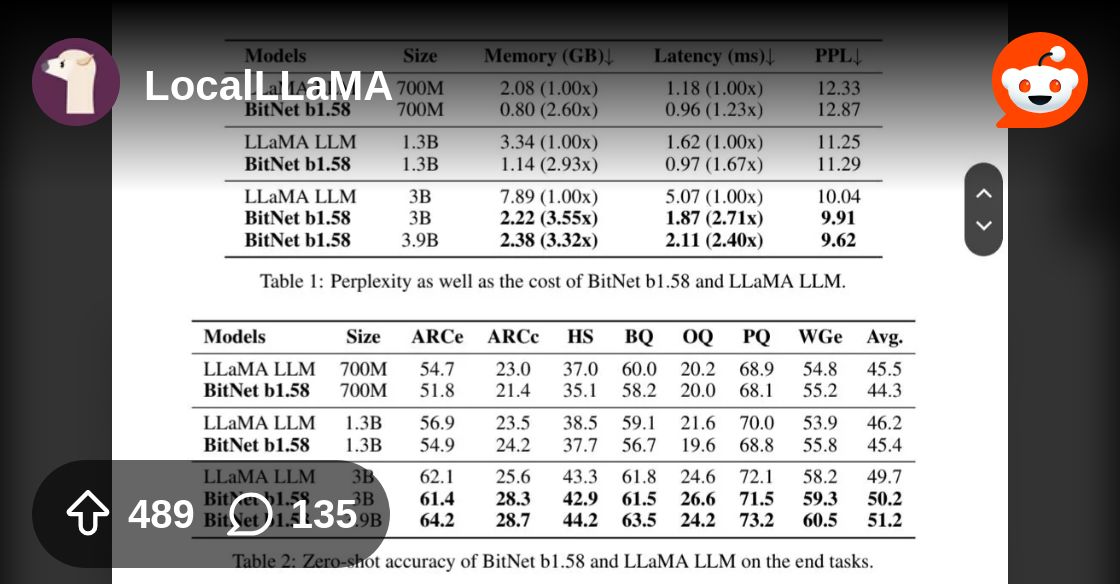
https://arxiv.org/pdf/2402.17764.pdf
thoughts on this paper? looks lowkey incredible to me
extremely rough guesses but I'd imagine either
- their model is overfit and the performance wouldn't hold up in practice, in particular I'd be very sceptical of its reasoning capabilities
-
- might've just have been out of scope for their research, but there being no "instruct" model nor open source weights at all reinforces that for me
- if you can get that much better with smaller models, then normal LLMs are ridiculously underfit to the point that we should be able to get x10 better performance with the current parameter 7~13B ish counts
these benchmarks also look pretty sus imo
where did they even take that "llama llm" 3b parameters model from? the official llama2 models are 7, 13 and 70b
We compared BitNetb1.58 to our reproduced FP16 LLaMA LLM in various sizes.
To ensure a fair comparison, we pre-trained the models on the RedPajama dataset for 100 billion tokens.
if I'm understanding this correctly, they only trained the big LLM for 100 billion tokens?
no wonders it sucks
the comparison with StableLM might be a bit more fair, but iirc StableLM is so bad nobody even uses it in first place?
yo big claim
trying to find a github link
honestly the fact that this can even be done without resulting in straight non-sense is pretty amazing to me
just to see if I understood correctly

every weight is now -1, 0 or 1
the implications of this, if it works, are really big I think, cuz this is great for electronics right
yes, I'm using python because I like to think in python, like then you can translate to any language you want or make a new one
this also makes a ton of sense to me, I think I need to chew on this concept for a bit, I've gotten a ton of good tips here I'm sure I'll be able to piece it all together and even connect it back to the entropy you see in physics (very very likely connected, formulas are v similar)
???
Entropy in information theory is directly analogous to the entropy in statistical thermodynamics. The analogy results when the values of the random variable designate energies of microstates
I'm using python as pseudo code to come across an idea
gotcha
so I decided I want the languages structure to be like this:
CHECKATTRIBUTE -> TOOL(OPTIONAL), (Attribute) Material;
MATERIALSTATE -> (Material);
MATERIALSTAT -> (Stat), (Material);
ALLOYING -> [Material, Material, Material…];
GASBLENDING -> [Material, Material, Material…];
BLENDING -> [Material, Material, Material…];
FOR (CONDITION-A) OPTIONAL [&&, || (and, or) (CONDITION-B)] … {LOGIC}
WHILE (CONDITION-A) OPTIONAL [&&, || (and, or) (CONDITION-B)] … {LOGIC}
IF (CONDITION-A) OPTIONAL [&&, || (and, or) (CONDITION-B)] … {LOGIC}
ELSE-IF (CONDITION-A) OPTIONAL [&&, || (and, or) (CONDITION-B)] … {LOGIC}
ELSE {LOGIC}
FUNC -> (Param-1, Param-2…) {LOGIC}
VAR -> (VariableName), (int/str/float/list/set);
VAR = Value;
RETURN VARTYPE(VAR)
its clear enough, flexible while also allowing for complexity and limitations
if anyone got any ideas on how I can make an interpeter for this without costing too much preformance wise im all ears!
ok I'm gonna try to use this as a starting point and walk back to information theory and then ML
- for a given microscopic system we have a state space that is the tensor product of the state space of each of its particles
- from my point of view, all I can observe are averaged out variables, such as average momentum, average energy, etc
- a given combination of these averaged out values (macro states) that I can measure experimentally, a partitioning of state space occurs, there's N micro states for each macro state
- for a given macro state, entropy is the logarithmic measure of the number of possible micro states
- in a sense then, entropy kinda measures the probability of a macro state, which is why systems evolve to higher entropy, a bit of a circular thing really
- so the analogy here is that the macro state is the random variable (from which I can extract average values), and the micro states are the various realizations of the random variable
I think I'm getting somewhere
microstates here would then be like, the number of things I have to write in order to fully describe the random variable,
tho I think that in statistical mechanics you have the assumption that each micros tate is equally probable, idk how that affects this picture
I'm joining in this discussion quite late, but what are you hoping to do with such a model? The structure of the language seems fine, I'm no expert on language structure nor am I very familiar with condensed matter physics, but the basic operations are there and can be fleshed out in the future. However, why do you feel like you need a new programming language? This process can be described well in OOP or functional programming. In terms of performance, I don't believe making a new language vs doing this in an existing language will really matter.
I see we're working our way towards shannon entropy and classifiers
trying to >.>
has been a struggle
I'm gonna try to pick it from the other side
I just want the model to have a very specific and limited set of tools which will force it to mix and match them trying to make the best possible results, this in my opinion needs to be done in a controlled environment where all of the outcomes and possible matches can be predicted relatively easily, with a larger more fleshed out language it would be way more difficult to look at its limitations and try to force the MLM to "innovate", so yea this is all in my own opinion ofc and i could be wrong
I suppose my confusion is you're basically describing OOP. The first step in OOP is to collect all the objects that you want to manipulate and their relationship to each other. You then label these objects as classes which describe how they can be manipulated. Imo, you've basically describe the problem that OOP was designed for. There's a known number of material properties (if I'm understanding your project correctly), and known ways materials can interact with each other to potentially create those properties.
omg this only works when p_i = 1/N where N is the number of microstates
To explain my thoughts, this programming language isn't going for computation. Its describing processes for your model to evaluate. In this case where you're essentially trying to describe a process graph to an ML model, your language of choice really won't matter, and you shouldn't need to really care about performance. (I could be completely misinterpreting your project since its 4 am in the morning for me and I haven't had my morning coffee)
https://www.youtube.com/watch?v=0GCGaw0QOhA
this all makes sense, until you need to generalize to biased coins
for a fair coin, sure, I need one bit to communicate an outcome, but that's exactly the same thing as for a biased coin, it's either heads or tails, so I only need one bit regardless of how improbable it is, as long as it's not p=0
unless like, we're interpolating between communicating between zero bits and communicating a bit ? if that even makes sense, which it doesn't because even if I would consider "not sending a bit" as a communication, that's still exactly the same as sending a bit
(im dead >.<)
Reddit Agrees To $60M Deal That Allows Google To Train AI Models On Its Posts Xd
I get the feeling that they are gonna lose so many users over this
And they would be like so what
At this stage mega 'influential' companies are not doing what consumer wants Xd
sad thing is that that's their exact attitude, how reddit still exists is beyond me
They are about to IPO, pension funds ect will buy shares. They have got AI training data Xd
i am aware, i received the invite thing
since im not a us citizen I can't participate, and not sure if I would tbh
Well people like to socialise - and are simply letting themselves to be corralled to reddit like funnels Xd
even unis are selling their students data it's insane
Reddit - people could like posts. Posts could not be liked on IRC Xd
IRC ?
Lettings themselves to be corralled to online where estimating people emotions are hard, higher insecurity, yearning for likes
internet relay chat Xd
that's before my time
history repeats
Like why would one interact in moderated online environment mostly
Well many proverbs are simply made. Like discord is bad tea is good Xd
or Joe is cool, sun is cool, rain is wet, cold is cold Xd
I am asking local AI model how would AI AGI enslave humans, would it even be interested
Humans are by far more interested in being an AI slaves than AI is in been a master
how is this even topic related???
Given that there are billions of humans and that the nature of consciousness escapes even the best minds for the past thousands of years, I find this statement too strong
Which part?
All of it, you're making a statement about the interests of billions of people.
And what AI wants, if it wants or ever will want, is unknown
eh personally I believe consciousness to be a physical force like gravity, would explain quantum superposition and help create a theory of everything
I agree that whatever it is, it must be rooted in something fundamental like physics
Well - AI that knows humans can not delete it . It may simply ignore humans. If you listen to Elon he claims AI wants to control. Elon wants to be controlled maybe
I don't listen to Elon.
Why are we talking about AI as though its not just an equation at the moment
This channel isn't really a place for grandiose speculation about apocalyptic AI.
I've considered, I got some spot quota for them
The specs on the chips seem to suggest they have some enormous compute power for 16bit floats and int8 models
but for me to test would involve quite a bit of work to use 😅 So just asking around before hand
Well AI regulation is debated now in most countries
What is needed to run on those chips ?
I would be planning to run our inference engines on them
which deploy fine tune BERT type models
However it seems they simply want some limited AI AGI that will enslave humans. AGI itself is like meh
Right now I usually just pull the Nvidia docker container and set it up to have GPU access right, would it be similar for TPU ?
It is more similar to onnx
Model compiles to their instructions -> Tranium chips execute those instructions
Interesting
Neuromorphic computing is an approach to computing that is inspired by the structure and function of the human brain. A neuromorphic computer/chip is any device that uses physical artificial neurons to do computations. In recent times, the term neuromorphic has been used to describe analog, digital, mixed-mode analog/digital VLSI, and software s...
move on gpu
as someone who works with neuromorphic computing, its not going to replace gpus, its just another way to compute
how come?
They have an AMI for it, so there's no need to pull docker
Well for one, the technology is not quite there yet. It's still pretty much an arms race between memcomputing, neuromophic, or quantum computing to see which one will become viable. In addition, the specific computing tasks that they have an advantage over classical computing in, is very specialized. This area of computing, I've generally seen referred to as alternative computing, is essentially computing at scale. It'll most likely end up being another specialized component like a gpu rather than completely replacing it as they serve different purposes.
Just the challenges of making a useful memristive material still haven't been solved yet
If by neuromorphic engineering, you're referring to snns, that's potentially viable in the next couple of years. The main challenge with snns is that their performance is often just comparable to anns rather than being a generational advantage. From the research I'm done with recurrent spiking neural networks, they have a similar roc curve as their ann counterparts, but are better at general cases and fail more often for edge cases. The biggest issue is why spend 2 weeks implementing stuff like neurogenesis when you could train an lstm much faster?
I'm gonna coin a new term, "evolution envy", which describes the tendency for humans to try to replicate the systems that evolution has come up with over billions of years
I think it's appropriate because it's hard not to envy the engineering marvel you see all over nature
There's definitely a lot to learn there. I believe vanadium oxide is the closest thing we have to neurons, and they don't come close
And you're just actually replicating the perceptron right ? Like the artificial neuron you see in AI.
Because the actual neuron is way more complex, it's not a simple linear separator
I saw this recently
The goal is to mimic the nonlinear behavior of actual neurons, rather than the simple linear behavior of perceptions
Yeah that would be cool
But well, we're not quite there yet. We have some cool random number generators last I checked lol
But also very complicated I would imagine
I think my math is all over the place lol, but stuff works out to more or less the same order of magnitude
Yup, the main barrier is we don't have a material at room temperature that behaves the way we want. Its currently a material hunt on the experimental side, while people try to figure out how to create a new theory of computing that's turing complete.
Why do that though, can't we use actual neurons
I believe the most accurate physical model of a neuron is coupled magnetic oscilators.
I don't know enough to really say. I'm sure there's biophysicists out there working on actual neurons, but I'm computational physics so all we mostly care about is mimicking biological behavior.
My knowledge of the mechanical side of things is because most of the physicists I interact with work on it. My own research is in physics informed machine learning, for high energy physics.
Oh interesting, that was likely gonna be a PhD path for me, I was doing monte carlo stuff in my masters
My supervisor at the time talked about physics informed ML, tho at the time I didn't have much interest in ML tbh
Looks insane if real
I saw it
With a rapid expansion of AI ability to spot connections yes tech explosion
Question is do most people want AGI to do most so people can relax, enjoy or people want limited AGI dictators
🤣 For me, a dive into general relativity led me to machine learning, and I somehow ended up working at a lab that focuses on physics ml
gonna be working on an implementation in the coming weeks, crazy if true
it would speed up inference like crazy
Yes
Forget about phd
Now when person ai communication is free substandard ways of learning are obsoleting
I'd be very interested in the results, I'm a bit skeptical of this paper, as airxiv isn't exactly peer reviewed, and the paper doesn't go into too much detail.
I just entered the market as a software engineer and eventually GPT came out, was hard to ignore, now I'm doing ML, I see the fascination
Well what do you like doing? Or its chasing latest trends?
i just need cheap inference, queries on whole codebases currently cost 1 USD lol
I've done enough frontend to know not to chase trends
Yeah it's not peer reviewed yet
That was my plan until the ML explosion. That and operator models have always interested me since there's a surprising lack of recent research on toeplitz matrices.
But has Microsoft stamp on it I think
For many in past access to uni, professors was costly. Their place was full of backward people. Now people can and do talk to AI direcly and privately. It is also changing ways people act
Yup it has the microsoft stamp, I'm just skeptical. I don't think its a scam, but I definitely think their data is pretty crazy.
If we can have bit models, do we really need quantum computing for ex
QC has very limited usage as it is
Maybe its a bit too much to ask. However after talking to AI did you change the way your behave?
Yup, the goal of quantum computing is to avoid the exponential cost of algorithms.
Avoidances of exponential costs - nice
I don't think its a realistic goal, but if its possible, then it has a lot of potential applicability
At least that's the reason why so much money gets thrown at it
Not really I guess, even if something on me changed from talking to gpt, I think that it would be something that would can be changed from a mundane Google search
It saves me a lot of time when coding, but that's pretty much it.
Yeah it saves a ton of time for sure
It's allowed me to focus more on what I care about instead of learning a new api pretty much
Well maybe effect is more pronounced in kids - teens people who still actively question ways of expressing
And yes it saves a lot when it comes to code
Also writing the boring stuff, I can make it write my docstrings and stuff
Just needs me to audit it and make changes here and there
Ah and emails. Automating email writing has been the best contribution of gpt to my life for sure
My main issue is there's other approaches, that imo are more promising than quantum computing.
This is an interesting one for example https://arxiv.org/pdf/2309.08198.pdf
They claim to find prime factorizations in polynomial time
paul_mk1
Fun to see ternary weights making a comeback. This was hot back in 2016 with BinaryConnect and TrueNorth chip from IBM research (disclosure, I was one of the lead chip architects there).Authors seemed to have missed the history. They should at least cite Binary Connect or Straight Through Estimators (not my work).Helpful hint to authors: you can...
AI can be used for thinking too. And inventing
Very cool
0.68 bit
Yeah you can use it as a rubber duck
It can simply decide what to do and that is a relief
hi
anyone here using a tesla p40 in their deep learning / LLM rig?
No, we run rtx Quadro cards
thats crazy
Honestly they're chronically underused and were an investment from before my time
As much as I dislike non fixed price cloud services I think they're the way to go for GPUs
will a p40 be able to locally run LLM
24GB vram right? You can run certain things
yeah but im a little confused, a youtuber was saying theres two cards each at 12
Honestly, I don't know the specs by heart. Your odds are higher going through Reddit and whatnot to find someone with exactly your (envisioned) setup
Thanks ill try that
A100 is the way. Changed my life lol
(don't actually buy one though. Just if you have access to one, don't bother with multi gpu setups unless you really need more than 80gb)
Which cpu is better suited for LLM: i5 12600k or ryzen 7 5800x
we need an encoder/decoder architecture for a transformer when the "form" or "type" of the input is different than the output, right?
take this with a grain of salt, but you can't really train a truly large language model on consumer hardware
it might be wiser to pay for usage of a compute cluster online than to build an expensive computer that will anyway not be great at it
spot on
Holy
I hadn't realized they were such a big flex 🤷
Can i get ur hiring managers number
the CPU that you use for LLM training is much less important than the GPU. And it might have been possible to work with LLMs on consumer GPUs 4 years ago, but not these billions-of-parameter models
I was reading a paper yesterday, and it just said "language models (LMs)" and I don't think they ever said LLM in the paper. And that made me happy.
You can quantise them pretty hard but I have no sense of how good they are afterwards
I think quantized models are generally "pretty good, but not necessarily worth the tradeoff of using a natively smaller model."
hello i need help with understanding image classification model 🙂
I read something along the lines of "bigger + quantized > smaller unquantized"
CIFAR-10
Go for it--when you want to ask a question, just ask it. don't wait for a commitment.
idk if you're saying the opposite or not - don't have a frame of reference for LLMs' performance wrt size
ask here?\
yes, just ask your specific question please
Yes, this is the data science and AI channel. Ask a complete question all at once.
I'm saying the opposite. But it's based on a comment at NeurIPS rather than a thorough review.
okay so coming from a person who's just done basics of python
now we are given a task to perform LSH on images and design an image retrieval system
so initially we are given 50,000 images in a folder that we are suppose to load and pre process them
so i have no clue where to start or load the data (we are restricted to use pytorch or tensorflow) so i want basically 2 things
- how should i load the data? and in what data structure should i store it?
- if only someone could give overview about what features to extract from data/images?
Have you read the Pytorch or Tensorflow documentation yet?
i havent? we have never used pytorch /tensorflow
That's a great place to start because they directly answer question 1
For 2) how well you do understand the role of convolutional layers in a CNN architecture?
anyone attempt implementing the 1bit paper?
(if being honest - none) (cuz the only thing they taught us is lsh (just thoeratically) and ask us to implement this code))
it came out ... yesterday?
which is already 24 hours where are my results
I'm going to be honest and say I'm not entirely familiar with LSH
this work is like challenge for us (even they told most of us wont be able to do this) )
!zen now
The Zen of Python (line 14):
Now is better than never.
But, what I can say is that the role of the conv layers in a CNN are extracting features from raw input
Features that should carry some (domain) semantics
A good place to start is likely taking an pretrained CNN (resnet, xception, ...) without the fully connected layers and giving your image as input to that
If none of this makes sense (and you're in it for the long game - not just to complete your assignment) I'd have a look at understanding (C)NNs first 🙂
😥
@past meteor


Q1? Tasks? What's that, homework or some take-home assignment?
a group based assignment where we have no clue
- pre-processing: any computer vision tutorial at all should explain it
- meaningful features: Try a bunch of different things - Which sort of features easy to compute would you use to manually divide these into different classes? (even if very broad)
- LSH: See this for a high level explanation but if they're asking for you to implement it you should be able to figure it yourselves / find resources explaining it more technically
- querying against it should be trivial after implementing it
- for the metrics, literally look up their names to see how they work and how to implement them (or find which method to use from a library you're allowed to use)
The feature extraction can be done with a multitude of ways, such as the CNN approach I mentioned but also traditional methods in open-cv like ORB/SURF/SIFT/BRIEF/...
https://docs.opencv.org/4.x/db/d27/tutorial_py_table_of_contents_feature2d.html
tbh the way they worded the second point (Extract meaning features) sounds a bit weird
like... the way they're wording it, it's not clear to me if you are supposed/allowed to use a deep neural network at all or if you're supposed to do it manually
though I guess that if they're telling you to use pytorch/tensorflow you probably should use one?
hey are RTX GPUs so powerful I couldn't run code for them on the less fancy GPUs available on compute engines?
They also mention color histograms
someone adapted the NVIDIA RAG thing @final kiln posted yesterday for linux ...
https://github.com/noahc1510/trt-llm-rag-linux

GitHub
A developer reference project for creating Retrieval Augmented Generation (RAG) chatbots on Linux using TensorRT-LLM - GitHub - noahc1510/trt-llm-rag-linux: A developer reference project for creat...
So I'm expecting traditional methods (surf, brief, ...) are also on the table 🤷
but im having issues with installation
But features from a pretrained cnn are just better

they told us not to use pytorch or tensorflow to load data , nothing more
At least, that's what I noticed empirically
oh
wait, what?
Oh you're not allowed to use Torch or TF?
Seems strange
that first "not" is confusing me
not allowed to use torch or tf to load data , rest we can
how are you supposed to load then? PIL?

exactly 🙂
cv2.imread
🫥
50k images with that?
and even if i open it how am i suppose to get imp data out of it and how am i suppose to store it AHHHHHHHh
def read_from_folder(path: str) -> list[np.ndarray]:
images = []
for file_name in os.listdir(folder):
img = cv2.imread(os.path.join(path,file_name))
images.append(img)
return images
smth like this presumably
or PIL
can be anything
so a list of all images hmm
Hello guys, Is learning data structure and algorithm relevant to become an data scientist?
I actually made something vaguely something to that a little while ago but using an existing open source model for embeddings + an open source vector database for querying instead of implementing it myself, the overall idea is
- user submits image
- create a vector out of it
- query against saved vectors
- retrieve similar records
with open source tools and no limitations the first prototype was done and working in 1 day but took a while to polish, create embeddings for all of the data, and put online
?
I never took a course in DSA, you can be fine without
you'll want to have a high level understanding of the basics concepts, but nothing too much in detail
statistics on the other hand...
having a general idea of what computational complexity means is sort of important
Knowing how to work with most non-exotic data structures (what their performance characteristics are like) is something I'd say most people that code should know
But it's something you can learn over a weekend
@median drift I don't respond to DMs sorry
or openCV
Installing OpenCV can be a pain
If you can avoid it in its entirety that may be nice
Then you could just use that
.
I don't think it's really all that important to become a data scientist.
Learn it because you really want to know it or perhaps you have an interview with Meta, Instagram, Tik-Tok, or one of those companies obsessed with LeetCode.
there is one part of DSA that does overlap with your duties in data science... depending on your definition of data science
tasks involving discrete optimization overlap with DSA and dynamic programming. being able to recognize them can save you a lot of heartache, since they're often combinatorial and scale very poorly
no need to implement the algs yourself, but you need to be able to recognize the problems to know how/where to look up the solution
depending on what you do in your data science work, you might really benefit from a basic understanding of data structures and algorithms to the extent that it benefits any code where you might be working with large(r) amounts of data
e.g. being able to rewrite multiple linear scans over a dataset with a single loop using dynamic programming, or being able to reason through an accidentally-quadratic algorithm that's exploding your cloud costs
knowing broadly what kind of access and insertion time complexity to expect from a hash table, things like that
basically why I mentioned this as well
One of my friends has the opinion that everyone should write at least 1 program in C, it can be fairly simple even
Goes hand in hand with this, you don't need to master it but knowing some of this stuff at a super high level at least makes you stop and think a little bit more 🙂
Hi Guys, does anybody know how to install python Box 2D using pipenv?
I have python 3.11.0, but box2d-py 2.3.8 refuses to be install into pipfile
are there any possible alternatives to box2d-py 2.3.8?
We don't have so many people from Africa here, but if by chance you reside or generally from Africa, and you're interested in attending a computer vision summer school in Kenya, please do apply
The African Computer Vision Summer School (ACVSS) 2024 application closes on 15th March.

The African Computer Vision Summer School (ACVSS) unites outstanding African students and researchers with leading computer vision and AI experts. The location will vary annually within Africa, and the inaugural occurrence will be held in Kenya.
📆 July 14-24, 2024
🌍 in Nairobi, Kenya at
There's funding as well. (T&C applies)
is it free
This but I'll add that: probably don't prepare as intense as you would for an algorithms interview, but having an understanding of the common ds and algorithms will be helpful, you will see this reappearing in seemingly unrelated areas of CS.
Because in principle most data structures and algorithms are just a manner of breaking down a problem into mathematically composable parts, which is a widely applicable skill, in CS and beyond.
Idk about International applicants (would have to ask my friend. He's one of the organisers) but there's funding (which usually covers flight and accommodation) for Africans whose application got accepted.
Always use a pre made docker image for the driver stuff
Surprised they don't have a Docker file in their repo
I am starting to see why rust's borrow checker exists and why it don't let me do certain stuff, every time it bothers me it means I was gonna hit myself in the foot
Can avoid most problems by not doing fancy pointer stuff
I'm setting up a config file that can be read by all processes, otherwise it's gonna be mayhem

And the rust binary is going to be reading data from the same file, it reads it, deletes it, waits for the next. This way I have a complete separation of concerns, the pipeline decides everything related to data and the binary just takes data, batches it and performs gradient descent, it doesn't care which epoch or slice it is or anything else
This is something I'm gonna be able to edit in the prefect UI
So the workflow will be, I hit a button on GitHub actions, it finds me a suitable spot instance, deploys prefect there. Then I manually trigger the training loops that I want
When I'm done I bring it down, or leave an automation that brings the spot instance down after all pipelines are done
Hi guys I have been self-learning to code for 2 months, I went from not even defining functions and not knowing what pep8 was to my current state. I have tried to follow SOLID principles, this example is a simple webscraper, the code works. What would you do different as someone with more experience, what parts look like bad code, or newbie behavior ?
from selectolax.parser import HTMLParser
from webscraper import WebScraper
import re
import json
def get_data_container(html):
tree = HTMLParser(html)
cars = tree.css('form div.d-md-none')
return cars
def process_title(title):
_, rest = title.split('&', 1)
brand, model, year = rest.split('.')
return brand, model, year
def extract_number(text):
match = re.search(r'\d+', text)
return match.group() if match else None
def extract_car_data(car):
data = {
'title': car.css_first('td.brandtitle-sm > a').attrs['href'],
'passengers': extract_number(car.css_first('td.brandtitle-sm > span').text().strip()),
'price': int(extract_number(car.css_first('span.precio-sm').text().replace(',', ''))),
'details': [item.strip() for item in car.css_first('div.transtitle').text().replace('|', '').strip().split('\n') if item.strip()]
}
data['brand'], data['model'], data['year'] = process_title(data['title'])
return data
if name == "main":
URL = 'URL'
scraper = WebScraper(URL)
html = scraper.get_html()
cars = get_data_container(html)
data = [extract_car_data(car) for car in cars]
with open('cars.json', 'w') as f:
json.dump(data, f, ensure_ascii=False, indent=4)
scraper.close()
from playwright.sync_api import sync_playwright
class WebScraper:
def __init__(self, url):
self.playwright = sync_playwright().start()
self.browser = self.playwright.chromium.launch(headless=True)
self.page = self.browser.new_page()
self.page.route('**/*.{png,jpg,jpeg}', lambda route, _: route.abort())
self.url = url
def get_html(self, selector = None):
self.page.goto(self.url)
if selector:
self.page.wait_for_selector(selector)
html = self.page.inner_html('body')
return html
def close(self):
self.browser.close()
self.playwright.stop()
I factorized this one with the intention to add subclasses or different capabilities as navigation and stuff
BY THE WAY SOME UNDERSCORES DISAPPEAR WHEN COPYING THE CODE, nervermind that
Try using ```
So you get
Abc
from webscraper import WebScraper
import re
import json
def get_data_container(html):
tree = HTMLParser(html)
cars = tree.css('form div.d-md-none')
return cars
def process_title(title):
_, rest = title.split('&', 1)
brand, model, year = rest.split('.')
return brand, model, year
def extract_number(text):
match = re.search(r'\d+', text)
return match.group() if match else None
def extract_car_data(car):
data = {
'title': car.css_first('td.brandtitle-sm > a').attrs['href'],
'passengers': extract_number(car.css_first('td.brandtitle-sm > span').text().strip()),
'price': int(extract_number(car.css_first('span.precio-sm').text().replace(',', ''))),
'details': [item.strip() for item in car.css_first('div.transtitle').text().replace('|', '').strip().split('\n') if item.strip()]
}
data['brand'], data['model'], data['year'] = process_title(data['title'])
return data
if __name__ == "__main__":
URL = 'https://crautos.com/autosusados/searchresults.cfm?c=02281'
scraper = WebScraper(URL)
html = scraper.get_html()
cars = get_data_container(html)
data = [extract_car_data(car) for car in cars]
with open('cars.json', 'w') as f:
json.dump(data, f, ensure_ascii=False, indent=4)
scraper.close()
class WebScraper:
def __init__(self, url):
self.playwright = sync_playwright().start()
self.browser = self.playwright.chromium.launch(headless=True)
self.page = self.browser.new_page()
self.page.route('**/*.{png,jpg,jpeg}', lambda route, _: route.abort())
self.url = url
def get_html(self, selector = None):
self.page.goto(self.url)
if selector:
self.page.wait_for_selector(selector)
html = self.page.inner_html('body')
return html
def close(self):
self.browser.close()
self.playwright.stop()
Thanks !!!
In physics, the von Neumann entropy, named after John von Neumann, is an extension of the concept of Gibbs entropy from classical statistical mechanics to quantum statistical mechanics. For a quantum-mechanical system described by a density matrix ρ, the von Neumann entropy is
S
=
−
tr
...
(Note they use natural log instead of base 2 in physics, but they could use base 2 (and do depending on what they are doing))
(When base e, it's "nats" (natural unit of information) instead of "bits")
Unsure if QM is where I'm gonna get my intuitive understanding 😭


In statistical mechanics, Boltzmann's equation (also known as the Boltzmann–Planck equation) is a probability equation relating the entropy
S
{\displaystyle S}
, also written as
S
B
{...
This is just classic statistics gas stuff.
Yes they have that equivalence, but in statistical mechanics you assume every micro state is equally probable, so it's like looking at the fair coin only, whose case I already find intuitive
So what most people probably think of with the classic idea of entropy.
Calculation of the entropy for the biased coin is what I don't find intuitive
I get it's talking about an average number of bits
Because it wouldn't make sense to talk about 0.5bits for ex
What average it is, idk
But I think this is literally restating <ln W> but using bracket notation
So lets say you have a set of things you want to send over a wire encoded with bits: {red, green, blue, orange, purple, pink, yellow, brown}. You could use a simple encoding with 3 bits per message: {000, 001, 010, 011, 100, 101, 110, 111}. So on average you are sending 3 bits over the wire. So lets say this encoding instead: {1, 01000, 01001, 01010, 01011, 01100, 01101, 01110}. The other colors now use 5 bits and if they were all equally likely this would use an average of 4.625 bits, so it's worse. But what if all the messages are not equally likely? What if read is really likely and the rest almost never happen? Then this would be close to an average of 1 bit. Btw as a detail on the receiver side, if the first bit it receives is a 0, then it knows it needs to read 4 more. So it would be nice to have a formula to compute this average required number of bits to encode these messages...
Wait how did the likelihood change the amount of bits set in this case
Don't matter if red is super likely, you're still sending the same number of bits unless you decide on a more clever encoding
Ah that's exactly it
You're sending 1
1=red in your other encoding
Yeah, and you can measure the difference between the encodings, and then you get the KL.
Basically abusing the probabilities to send less, on average.
Yeah I get it makes sense.
Okay it makes sense in this setup of two people or computers trying to communicate, but what is about it that makes it appear in so many places like other than message sending, like in physics and ML
I assume that in physics it's gonna tell me (if I use base 2), the number of bits on average that I need to write down the current micro state of a given macro state
Ok yeah I think I get it, it's the average number of bits I need to describe an outcome, given that I can use knowledge of the dist itself to minimize that average
"In short, the Boltzmann formula shows the relationship between entropy and the number of ways the atoms or molecules of a certain kind of thermodynamic system can be arranged. "
They use natrual log though, so they don't use bits.
Except now they sometimes do.
Usually in physics log=log10, maths log=loge and CS log=log2
In the past, pre-shannon, natural log just made sense, because it makes the math easier.
Euler's constant makes calculus stuff easy.
This is a pretty crude way to look at it tho
You either live in a pre-Shannon world, or a post-Shannon world.
Idk what that means but I assume post Shannon is better
Yeah. It's a paraphrase, I can't find the source anymore, but Shannon's work affected physics too, and it really changed everyone's perspective on things.
It at first might seem like it's just about efficient communication over wires, but applies far beyond that.
Yes that's easy to see given how in SOTA physics they like to throw the word information around
The original paper is easy to follow, worth a read.
Some dude wrote a NN in ps

Now next time someone says "X bits," you can say "X Shannons."
well the first problem im having is that you cant get RTX GPUs on compute sooooooo
You can just rent it on Amazon using spot
I can see how this abstract diagram can be applied in many situations
the idea of a signal travelling through a channel is key in many control theory, communications, signal processing, and optimization problems
ah ok
well the second issue was apparently my huggingface login expired so i have to wait to get approved again to download Llama
Waaaat, I never did get approved
but yeah i guess i can just set up a Dockerfile to do most of this and let er rip
maybe i never did? iuno i think it did it years ago and i hadn't had an issue until today
No like for downloading lamma, they never let me
hmm guess we'll see!!
Information source could be some physical system, the transmitter would be something that somehow couples with the quantity I want to measure, the receiver would be the actual display, like a needle thingy pointing to a scale, and the destination is my brain
Or, the information source could be my body, the transmitter a black hole, the signal the black hole radiation emitted after I'm absorbed by it, the receiver a measurement apparatus and the destination is someone trying to decode my age
Wait no, in that case I'm the message
The information source is whatever bumped me into it
Or am I the transmitter since all that's being decoded is my age ?
I'm gonna read the paper tomorrow, I think I'm getting all of them wrong
Btw note how the rare events have high information concept plays nicely with the encoding stuff. It's basically telling me to use many bits for rare events, and few for common events (which gives a better average number of bits sent over the wire).
(Also it should pretty straight forward to make the connection to compression now)
Hi, I read a book that said RandomForest is the most popular multi classifier on Kaggle, but the author did not cite the source, I wonder if this is true?
you could try determining it based on the classes used in https://www.kaggle.com/datasets/kaggle/meta-kaggle-code but it wouldn't be 100% accurate and may take a while
in practice, RandomForest is a good pretty good place to start when working with tabular data though ; you might want to try something fancier like gradient boosting, but random forest is about as 'safe' as it gets when it comes to avoiding pitfalls and getting a baseline

Kaggle's public data on notebook code
An untuned GBM is usually what performs best for me in a diverse set of problems
It could also be an implementation issue on sklearn's side but GBMs typically are faster to train for me as well on CPU
Hey peeps, does anyone mind taking a look at #1212891108418256936 if they get a chance, i know it looks daunting to read but I've tried to include as much context as possible to hopefully alleviate the number of questions I receive. I don't there will be no questions
faster than RF? that's very surprising to me since RF is trivially parallelizable but GBM isn't
anybody using Hugging Face or NLTK? are you able to design complex chatbots with any?
of course
huh weird, mine got approved within a day I thought they were approving everyone
Within a day... Maybe it was my email domain, which is my personal domain and not a known host like Gmail or outlook
I requested it again using Gmail
Ah I already got it ._.
That was it
Like it took a couple minutes
Perf
Yup, even with using multiple cores on RF. The algo is embarassingly parallel yes, but maybe the implementation is just lacking
Hi, in PyTorch I’m so confused on how to get the output channels for that first conv2d layer (the 6… is that just a random number that was chosen?). I’m also confused on how to figure out what to put in for that fc1, can someone pls explain thanks

Also, how can I check size of the image as I build the network?
Heyo. Anyone has experience working with Whisper? Facing some weird issues with the transcription.
Whisper not predicting end of sequence token properly. Will like to discuss if you have encountered similar issues 🙂
:incoming_envelope: :ok_hand: applied timeout to @lapis sequoia until <t:1709295520:f> (10 minutes) (reason: duplicates spam - sent 4 duplicate messages).
The <@&831776746206265384> have been alerted for review.
do you have any examples?
the lamma2 models are not too shabby
I wonder if it's worth it to get a serverless setup for the 70B model
perhaps save me from the chat gpt subscription + a lot more privacy
I've not used whisper a lot, but I'm planning to make heavy use of it at a later stage, can you describe your issue in more detail ? I can try to help
Im new to python.. is it possible to make a tool integrated with chat GPT where it has a pre loaded question and just simple input is required? For example:
The tool would say “Enter city:”
You’d enter the city name and press enter, and it would feed back the temperate in that city.
Example:
Enter city: New York
Response: The tempature in new york is **
This is just an example, i’d use it for multiple purposes.
<@&831776746206265384> ad
!pban 1141814750808903720 seems like you're just here to advertise
:incoming_envelope: :ok_hand: applied ban to @random summit permanently.
Hey!
Figured I'd ask here, as I don't see a reason to open a help channel for this.
What is the best LLM library/framework for Python which supports AMD GPUs?
Thanks 🙂
I have used Pycharm for all of my python needs. I am starting to learn ML and Jupyiter Notebook is recommended for that. Can I set up pycharm so that it has the same features or should i learn how to use Jupyiter?
There's likely some sort of extension/plugin thing in pycharm, jupyter notebook will likely be one of them
In vs code there's an extension for it
Yes, as I looked deeper it looks like pycharm can just act like jupiter notebook.
I think if there's a framework specific for LLMs, it will likely build on top of pytorch, tensorflow or paddle. All of them support AMD as far as I understand (not sure about paddle)
Scientific project is what i need. It is a pycharm profesinal only feature, but I have it
I think the extension will simply open Jupyter inside Pycharm if I'm not mistaken
Yeah, it creates the jupyter server but uses pycharm UI
heyy
i am a student that has worked in python and c and done some wbdev along with ml and ai
i have an interview at a "neo bank " startup for the position of data analyst
what should i expect
and what should i prepare for
Nice
Hi could anyone that does data analysis help me out? I have a project for predictive analysis and I’m really confused on where to start https://discord.com/channels/267624335836053506/1213159563654598688
Im new to python.. is it possible to make a tool integrated with chat GPT where it has a pre loaded question and just simple input is required? For example:
The tool would say “Enter city:”
You’d enter the city name and press enter, and it would feed back the temperate in that city.
Example:
Enter city: New York
Response: The tempature in new york is **
This is just an example, i’d use it for multiple purposes.
This is old school chat isn't it? Why do you need gen ai for this?
Again integrating with chat gpt and old school chatbots are just api calls.
let's gooooooo

the second blue one is already using a rust binary
and training a model
now would be nice to have a flow chart for it, and logs
ok so I went offline for a few days sorry about that, but I decided to cut down some of the work and just use python to allow the MLM to try make tools and such
now I just gotta figure out how the MLM will take that information decide on its use, how I would actually apply theuse in the simulation and how the MLM will pass on the information to their offspring.
is 42k rows 17 columns high dimentionality ?
so any idea's are welcome...
it's 2 dimensions if you're looking at the whole dataset, or 17 dimensions if you consider each row to be coordinates in 17-dimensional space
which is to say, it's 17 dimensions, the rules for doing math in 17-dimensional space is the same, regardless of how many points you have in it. Be it 10, or 100, or 42,000
To answer "is 17 dimensions high?", this is a matter of perspective. but I've seen 2048 dimensions
Hello everyone is this a good place to ask about a pandas dataframe question?
Yes, there’s a few places, here or in #python-discussion , or in a help thread. #❓|how-to-get-help
Ah nice.
I have a main df with a location column and another df which has a ledger of locations with corresponding postcodes. I want to add a new postcode column with the correct postcodes for the locations in the main df. Where im tripping up is the main df has duplicate locations. Both df locations spellings are the same
so you want to use the second df to append a column to the first dataframe based on the location. you're keying 2nd dataframe's postcodes (the one of the one-to-many relationship) to the first dataframe's postcodes (the many of the one-to-many relationship)
df2 postal codes to df1 where df1 location = df2 location
ChatGPT gave me this
`# Assuming df1 and df2 are your DataFrames
df1 is the DataFrame you want to add information to
df2 is the DataFrame containing the lookup table
Create a dictionary from the lookup table
lookup_dict = df2.set_index('key_column')['value_column'].to_dict()
Use map() to apply the lookup
df1['new_column'] = df1['key_column'].map(lookup_dict)`
so I think key-column would be location, and value column the postal codes ( @supple inlet )
I don't see why that wouldn't work. I'd also look at pandas' Merge function
you could splice out what you want from the original dataframes, if there's more, then merge it accordingly.
yeah gpt also gave me Merge, but that seems to be adding the full df2 to df1, but i guess it has options
Hope that helps!
coming from the SQL side of things, I would merge this outside of Python honestly, but might be a great moment to learn it with pandas
What are the pros and cons of data loading, wrangling, cleaning outside of Python, likely with SQL, and then store it in a db table specifically for ML? As opposed to wrangling/cleaning within Python?
Anyone have any idea this won't work?
Youd enter the two basketball teams, and chatgpt would tell you who has better statistics overall.
Example:
Enter two teams separated with a comma: Philadelphia 76ers, Miami Heat
Response: According to sources, the team with better overall statistics is ----
This is just an example, i’d use it for multiple purposes.
you might want to cover up your key 😉
I dont really use chatgpt for anythig important
is there a channel for dat engineering questions or does this serve as such?
I have a pyspark issue I wanted to learn about
ok I want to make my own python back end using flask and pytorch weight that is already trained dataset on some project I have and I just can't seem to understand how to make it so it can read the live camera feed from my nginx server or how to even pair the 2 togetherI need help with it, if anyone knows what to do please help!
@dusty forge @peak jackal Thanks for your help, ill give your suggestions a go. At first i did use gpt and bard for help and it suggested merge which didnt work great but perhaps thats down to my bad prompt.
This is going to sound stupid and i totally would but IT at work is refusing giving me access to the DB. So what im stuck with is downloading raw data (excel) from a web portal and making do with that. Im a data analyst (2 months in) and its my first job out of uni and the IT department sucks. They refused to let me download python and said its a security risk but my machine already had it installed lol.
i feel that
data analysts/scientists embedded in the non-IT team seem to be in an awkward position in these things so often
2¢: I understand if you just want to get what you need to get done. But if you had "I use Python to do data analysis!" in your resume, or in your interviews... lean on that. Let them know that you were hired for a reason. You're going to need to communicate effectively with the IT team, and this is a reason to start a conversation with them.
with SQL you use the computational power of the database, with Python you use the computational power of your own machine. If the database is something like Google BigQuery, but even a well provisioned PostgreSQL instance etc., your own machine probably can't compete
Get your manager on the case. They presumably hired you to do Python. Maybe IT has a particular solution like giving you a separate "developer laptop" that is not the same as the "corporate laptop", or a virtual machine hosted by them, or on the cloud
Yes, you can pick the number of output channels you want. Hopefully, this long post provides you a little bit of clarity.
Suppose we have 1 input channel and 3 output channels, it would look like the attached image (see image 1). So here, I'm using the @ symbol to denote the number of channel(s)
- On the left, we have an input represented by a 12x12 image with a single channel.
- On the right, our output is a feature map that is 10x10 in size and has three channels.
To consider concrete example, let's assume again we have an input image 5. (see image 2)
Now the convolution operation for this first output feature map is exactly the same convolution operation you're probably familiar with. I modified the notation a bit here in order to include the channel reference.
The @ symbol followed by 1 refers to the first output channel. (see 3rd image). Then we'll also perform the same convolution operation for the 2nd and 3rd output channel respectively (see 4th image)
In fact, we are using the same convolution operation across all three output channels. The only distinction here is that, each output channel uses a different set of weights; in other words, we use different feature detectors for each channel to produce different outputs. However, the convolution operation itself remains exactly the same for each output channel.
=================================
Suppose we have 3 input channels and 5 output channels. Now if we have 5 output channels, we need 5 kernels, and since we have 3 input channels, each of the kernels has to have three channels as well. (see image 6)
if I want to code this now in PyTorch it'll be
import torch
import torch.nn as nn
layer = nn.Conv2d(in_channels=3, out_channels=5, kernel_size=2)
layer.weight.shape
This configuration will generates a four-dimensional weight tensor. Therefore, the resulting weight tensor will have the dimensions of 5x3x2x2 shape.
Hopefully this clarifies things a bit for you.







In that 1st fully connected layer, we're simplying flattening the image (tensor) in order to perform the last arm of the work (MLP) where the classification happens.
The CNN part is the 1st arm which is used to extract features from the image before it's passed to the last arm (MLP part)
So the last convolutional layer has 16 output channels × 5 (input image width) X 5 (input image height)
120 is the number of output features from the fc1.
anyone know to what extent loss functions are convex?
Uhm, I'm guessing that if they can't go below 0 they gotta always curve back up right
Yh i took it to my manager who escalated to the IT director and so i had to write a BRD (Business requirements document) outlining every detail of why i wanted it and what i was going to do with it. IT Director denied it and basically said its out of thier scope and because of that its a security risk. Then told me to work with their legacy systems because "well documented"
we're talking convex in N dimensions
What's the difference ?
Idk if this is correct but, if 0 is a point, the hyper surface tends to infinity, and is continuous
Then it's gotta be convex at least on avg
no guarantee and we need regular enough convexity to apply convexity algorithms
we don't even know if we can reach 0
Wait convexity is a global thing from what I'm seeing now. Uhm I think that it's always gonna be a funnel shape with local minima here and there and tending to infinity cuz the model not modelling the data is the easy thing
But a pure convex shape almost looks like an idealized case right
Not sure tbh
I think this looks realistic

And this looks artificial

Just tried this and it worked perfectly. Thank you 🙂
the thing is i'm thinking if I should use something like PCA
You don't lose anything by trying it 🙂
or I should select the columns manually
Either you use a method with regularisation, most popular ML algorithms do this, or you do a PCA with hyperparemeter tuning
most aren't, convexity is a rare property of "easy" problems
convexity in general also doesn't mean there's a unique solution, either
for nonlinear cost functions, you can safely assume they're non convex. ml in general has no guarantee of optimality
Short q: why do the x values get stored in 2D, and the y values in 1D? Why not both in 2D by default?

Hi, 2-3 months ago there was a post on reddit about an alternative to jupyter notebooks, but I couldn't quite remember the project name
you edit it like a regular python file, but it can be executed interactively like jupyter,
it also says that it guarantee the flow of code execution (top to bottom), so it can be run like a regular python file
because of how you read the data
you used iloc to take all rows, and then a number of columns, from a dataframe. then you used values to get a numpy array representation of that
for y, you said "all rows, 1 column". that's 1d
for x, you specified a range of columns, even if the range is a singleton
try and see
think carefully about the ranges
what do you expect 1:-1 to do? what about -1:-1?
you should leave the dimension empty to specify "up to the last element"
i think you'd benefit from reading these https://realpython.com/lessons/indexing-and-slicing/ https://python-reference.readthedocs.io/en/latest/docs/brackets/slicing.html
for y I only want to have the last column, hence trying -1:-1 to force a range selection even though it's only one column
because -1:-1 is an empty slice
it contains nothing
leave it empty or write None if you want to let the slice go "to the end"
!e
import numpy as np
x = np.array([[1,2,3],[4,5,6]])
print(x[:, -1:])
print(x[:, -1:None])
@wooden sail :white_check_mark: Your 3.12 eval job has completed with return code 0.
001 | [[3]
002 | [6]]
003 | [[3]
004 | [6]]
do take a chance to read through those links on slicing
numpy has docs on it as well https://numpy.org/doc/stable/user/basics.indexing.html
How would you select only the last column, without the need to reshape in a later step?
Basically the second part of my original question, how can I read the data and store the y, in the same way as storing the X, immediately as a 2D array?
that'S exactly what i did in the demo above... there is no reshaping
oke so
-1:-1 as in, last column up to last column = does not work as it's an empty slice
-1: as in, last column up to the end = does work
selecting the last column as the 'start' confused me
Thanks, yeah that worked, not sure why the course is not using that, I guess they want us to learn the reshape method
[-1] might be clearer
though that guarantees a copy, which may or may not be desired (probably won't matter)
also .values is sad code nowadays, cool people use .to_numpy()
.values doesn't always give a NumPy array whereas .to_numpy() as its name suggests does, though the instances where .values is not giving back a NumPy array but instead, e.g., pandas array is super rare but still
lastly, some APIs might as well accept pandas stuff, so chances are you don't need to go to NumPy's domain at all maybe
Ok understood, will keep this in mind. I'm following an Udemy course where they use .values, but I'm also reading the pandas (and numpy) book by Wes McKinney as an additional source, just to have a more complete view
The course starts with Regression and it might be possible that they will change the code along the way to teach us other (and perhaps better) ways to code for similar purposes, that's what I'm hoping for anyways.
I've been trying to learn data analysis all by my own from few months
I see it's getting tougher for me.
Thinking about buying a course
Can anyone recommend a good one?
Jupyter Lab? Or the alternatives that requires connection to internet... Binder? Colab? Deepnote?
For solely Data Analysis, I highly recommend Maven Analytics, they offer both on Udemy and their own platform. Very clear and clean explanation, course comes with their own dataset, and you 'play' the role of the analyst on different topics depending the course. I have several of their courses, Power BI, Power Excel/Pivot/Query. They explain the theory, then followed by the practical exercise, followed by you getting a virtual message by one of your colleagues asking for an analysis (this is the actual exercise to check if you understand what to do), then the solution.
Can you send it on my DM please
Check the pricing of https://DataCamp.com or https://DataQuest.io
You can also check Udemy
Learn Data Science & AI from the comfort of your browser, at your own pace with DataCamp's video tutorials & coding challenges on R, Python, Statistics & more.

Dataquest
97% of learners recommend Dataquest for learning AI and data skills. Better teaching = better outcomes. Take a free lesson now >>
K
Also idk why I think that data analysis would not be a cool job for a girl like me
Holy moly this code, I tried to write down my notes as comments but how close or wrong am I here?

sad heheh.... any sort of work gone into studying general properties of loss functions?
thanks for the answer btw
there's no such thing
you study each one individually and group them by how nice they are
convexity, smoothness, etc
currently wondering whether % linearity of total layers could play a role in how nice they are
you can't assume anything about a function, it's your job to show it belongs to a family or to recognize at a glance it has a special form
you usually don't need any linear layers other than at input preproc or output
linear funcs associate into a single linear func
MLP feedforward is all linear no?
It's worth writing this out to see it
All things considered, gradient descent is a pretty crude algorithm that assumes very little about the search space, just that it is first order differentiable.
If we're using it then I'd assume most inputs will not have nice properties.
it's not just gradient descent though, ML also relies on the gradients being stochastic
all of the gradients are wrong at each iteration due to noise and batching, but the error averages out through the training
you reap the benefit of being able to escape saddle points this way
scheduling of the step size can also help you escape local minima
Yeah you're working with the wrong surface at each iteration
that's where all the momentum and what not comes in. you almost never use GD or SGD directly
I learned that one early, an entire afternoon just to find out every1 is using Adam and such
Was trying to train a GAN with the SGD optimizer, as soon as I changed to Adam it worked
that's cuz GD actually has fairly strict conditions go guarantee convergence to a stationary point
either a step size that decreases quickly enough, or lipschitz continuity, along with starting close enough to a stationary point
adam adaptively uses momentum to make a step size schedule
Btw my intuition here is that the right batch size will be somewhat representative of the data, so the surface actually ends up somewhat resembling the true one
Interesting, I haven't looked into so much detail yet, but looks useful knowing these things
are there special fine-tuning algorithms, or is it just doing more training on a special dataset?
What I think it says in the line is: arrange the X-axis values in decimal steps, specifically 0.1. But what does the reshape in second line do, or perhaps, why is this second line needed? And in line three, why do I need to predict on X_grid instead of X? Wouldn't changing the actual values of the data, and showing the data be separate? To me this looks like I'm changing the values of the data just to show it nicer in the graph.

What I mean is, when I have values like 15, 33, 71 for example, those are the true values. Changing them to 15.0, 33.0, 71.0 so the graph looks smoother feels wrong. As opposed to only changing the axis' intervals from 0 to 10, to 0.0 to 10.0.
That's how I interpret this part

No its not a online platform like that,
In the demo they show a plain text format, not cell based like jupyter
what is the way to find correlation between a numerical feature & a categorical target variable
there are 17 columns and they can be segregated as demographic, call and one more (3 columns)
Hi
17 columns in total, so the last one is the y?
I've been only learning Regression so far but in every model the courses taught me to encode the categorial values to numerics
You also want to look if you need all the 16 other columns as Xn or able to ignore some of those if you think it won't add value
Well, idk. Perhaps it's Spyder.
Is there any particular reason you're searching for this platform?

Not cell-based? So I guess it would be one of the many IDE's? PyCharm, VSCode?
the promise is interesting for me,
its interactive, but saved as plain python file (git friendly)
they also said that you can rerun the file/notebook as a script,
they somehow managed the notebook state so that you dont have to deal with "which cell should i run first to make this code work"
all I can remember is that their website was green 😂
That reminds me of Spyder
You can select the parts you want to run
Ig the disadvantage was that the graphs weren't neatly displayed after the code
spyder IDE? I know this program but its not it
It's as if you ran it as a script or in the terminal
Yes I used it for a while, them changed to sublime and eventually vs code
Now I want to get into neovim so that I can tell everyone I use neovim
Jk, I think it's really good, looking at how fast people are with it
I was following a tutorial and the histogram for one of the columns was like this image. The tutorial then said that we should use the log function to modify that column so that it had more of a bell curve.
Why is that needed? Does it just yield better results and should be done on all skewed columns? Or is it more specific to the needs later on?
Wdym ?
MLOps is a lot of work, idk how much they're paid but it ain't enough ._.
so it's a yes?
No, I'm asking for clarification
What do you mean by scope in 3 years
You mean like, will it still be relevant ?
exactly
I don't see much reason for it to disappear. As long as you need infrastructure to do ML, you need MLOps
ohk
What I’ve heard from several big (really big) firms is: MLOps is an area they are struggling, like DevOps, it’s a complex topic that requires serious engineering and planning and oversight.
Just talked with a large firm last week and they specifically called out mlops as their biggest challenge/gap
Reddit
Explore this post and more from the LocalLLaMA community
Log transform is one of the popular transformation techniques applied to a skewed data whose distribution isn't Gaussian in a bid to make it one.
Aside transforming skewed data to approximate normality, these are other reasons why log transform is useful:
- Reducing the impact of outliers
- Linearizing relationships between variables
- Stabilizing variance in heteroscedastic data
- Simplifying complex relationships
Ok thank you, but why is it better for a distribution to be gaussian?
Because most ML algorithms especially the linear-based model have this underlying assumption of data being normally distributed.
So, training a linear-based model with a data whose distribution is guassian yields better result in most cases.
Thanks!
I have no idea. Do let me know the name when you remember.
I'm trying to make forecasting to a signal that have same pattern everyday using SARIMA model but the forecasting become close to zero. is there anyone know how can I improve the forecasting result?
This is why I love quant financenobody cares if the data isn’t Gaussian 🙂
:x: failed to apply.
Tbh, I think lamma2 7B is gpt 3.5 level. Can talk and do basic tasks if well instructed, but also not very intelligent and will easily misunderstand context
It can also run in the CPU, not that slow
I'm running a discord bot on a private server to test it out during the day
Lamma paper mentions AdamW
hm nanoGPT also uses AdamW
in the image below, z_j^l is the pre-normalization activation of the jth neuron in layer l, C is the cost function, and delta is the neuron's error

is there a case where delta is NOT defined this way?
Uhm, that's not the error, it's the slope in the z direction
The error would be the cost function itself
In gradient descent you use the directional derivative to ascertain the direction towards the minima
But like, it doesn't really give any info about how much distance to travel
ah right, that's the l,j parameter's net instantaneous contribution to the error
Uhm, also no, it's the velocity at which the error is increasing in the direction of increasing z

Uhm, do you have anything useful to add? I don't mind being corrected if I said something wrong.
no
just a meme
like im amazed
"Wooooow"
Oh. I'm finding it hard to interpret the facial expression
I do have a minor correction here, it's the velocity at which it is changing when you increase z. Cuz it might actually be negative right.
So like if increasing z, also increases the error, then what you want is to decrease z
And if increasing z decreases the error, then what you want is to increase z
The full gradient gives you the relative values between the changes in the various z's so that the resulting vector points in the direction of greatest ascent.
This is why force of gravity = - gradient ( gravitational potential )
pytorch is computationally optimized right? i.e., it's as fast as if we do a manual implementation in numpy right?
it is probably going to be faster
Numpy is a good tool
but it is not specialised for the things PyTorch can do
this may not be the right answer but it has many different backends, opencl, cpu, cuda, ...
ty
there are more than this list
I'm using AWS cuz I have a lot of free credit. Otherwise I think I'd use vast.ai, seems to have the best prices
on AWS do you just make VMs?
Yeah, you select your machine type, the OS and the AMI. The AMI is like a Docker image
ah makes sense ok ty
If you use it try using Spot, which will give you the best pricing in exchange for letting them take the machine away with a 2min warning
oh nice
hm, might make sense to learn to use their API to quickly make VMs and deactivate them right?
get some MLOps skills on the way
I think there's clients that can be used for all cloud providers, can help minimize vendor lockin
sky something i think i heard of this
skypilot
Perhaps, terraform falls in this category I think
Haven't used it yet
My MLOps setup is a GitHub actions workflow that brings up a spot instance and does a prefect deployment. Which itself is a pipeline that coordinates a rust binary that performs the actual training and a python task that fetches data from a hosted parquet file, processes it and gives it to the rust program
neat!
Hey I'm having trouble with color detection for open CV regarding HSV values, and was wondering if I could get some help on it
They'll also register data to be read by MLFlow
And finally ofc, Ill eventually have the attention mechanisms coded in custom CUDA kernels
So that I can benchmark their performance
any clue what vLLM does?
First time I've heard of vLLM
seems like it does some of this MLOps stuff
Isn't it like just faster inference
MLOps you have automation




Any ML/Vision genius have a quick 10-15 mins to chat about drawing recognition
Any time series ML models expert can have 10 mins of quick discussion about model performance?
I found it !! @odd meteor https://marimo.io/

Explore data and build apps seamlessly with marimo, a next-generation Python notebook.
It works as it said, plain python file.
each cell is just a method with its dependencies specified, very readable.
vim keybind works out of the box too!!
🥳 but for those who missed the excitement yesterday, what are the pros over Jupyter or Python in an IDE?
its offer the same interactivity as jupyter, but underneath its just a python file
on jupyter you can run any cell anytime you want, its good for prototyping
but its a pain when you have to figure out in what order does the cell need to run in order to make the code works
on marimo, they figure out each cell dependencies by itself
sounds cool. It shouldn't be that hard in jupyter though, it's supposed to run in order 🙂
And you can use jupytext have jupyter notebooks as plain text python (just how vscode also does it)
what do you guys use for hyperparam tuning?
That's nice. I've not heard of it before. I'll check it out.
Optuna
will check that out, ty!
I use the pipeline itself, which sends the data to MLFlow
how so? do you mod your hyperparams after the data is sent to MLFlow?
No, I decide on the hyper parameters that I want to test and schedule a series of runs, one for each
oh I see
the scheduling is a custom script?
No, in case of GitHub actions (which I deprecated) I set concurrency to 1 in the matrix strategy thing.
With prefect, very similar, I set concurrency to one in the deploy parameters
In case of GitHub actions, you can write matrices and it computes the various possible combinations
In case of prefect, it's a bit more manual but the UI is good enough because the form caches the values from the previous run
I'm still seeing how this will go down tho, I might need to write a script or code it to behave like GitHub matrices
But I don't think a script will be needed
thanks for the answer!
just so you get an idea
the form is created directly from a pydantic model

very cool
I've been exploring a lot of things, trying to find the best ways of doing this or that
it's a lot of work overall, but I'm hoping that once I get to a good pattern I'll never have to have so much work with it
I'll just keep some boilerplate code on some repo so I can reuse it
yeah it would be nice if there were some mlops libraries that would help out w/ this stuff
I think github is in a very good position to solve many of these problems, at least from where I stand
if they enabled gpu runners for github actions, with competitive pricing to aws
and with drivers ready and all that good stuff
I think they'd be more likely to do that with Azure
but Azure already has some pretty good CICD integration for GPU runners
For AWS runners, idk if you already use it. But CML makes it like a 1 line setup to spin up instances on AWS and attach them as runners automatically
and can do things like reuse idle instances, etc...
Does it do AWS spot ?
Seems like it
yeah
But my point is that most code is already on GitHub, and GitHub actions is already used a lot
deploy-runner:
runs-on: ubuntu-latest
if: "!startsWith(github.event.head_commit.message, '[skip')"
steps:
- uses: iterative/setup-cml@v2
- uses: actions/checkout@v3
- name: Deploy runner on EC2
shell: bash
env:
REPO_TOKEN: ${{ secrets.CRAWLER_GH_TOKEN }}
AWS_ACCESS_KEY_ID: ${{ secrets.AWS_ACCESS_KEY_ID }}
AWS_SECRET_ACCESS_KEY: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
AWS_CML_REGION: ${{ env.AWS_CML_REGION }}
run: |
cml runner launch \
--repo=https://github.com/my/repo \
--cloud=aws \
--cloud-region=$AWS_CML_REGION \
--cloud-type=g5.8xlarge \
--cloud-hdd-size=100 \
--labels=cml-runner-large \
--reuse-idle \
--idle-timeout=1200
model-training:
if: "!startsWith(github.event.head_commit.message, '[skip')"
timeout-minutes: 5000
needs: [deploy-runner]
runs-on: [self-hosted, cml-runner-large]
Example CI config
cut out the company specific stuff
but that is about all you need to do really, and then just tell CI to run what ever script starts the training
It's similar to my setup, I have a single step which gets the instance and runs the self hosted runner there
Are you running the training thing directly or are you deploying something ?
My previous setup was a self hosted runner in which I passed the training parameters via env, which I would get by defining a matrix strategy.
It was great, except that it took a long time to start the self hosted runner and that slowed me down quite a lot.
So now I'm deploying a prefect thing, which exposes a UI that I can use to start runs dynamically. I can set the training parameters there and everything will get recorded on MLFlow.
I also couldn't selectively stop runs. Or start new ones. Apart from the very good version control (hyper parameter search strategy got written directly in the commit), it was very clumsy and slow
what's this fed into?
Prefect is promising to solve all my problems tho.
They have a managed solution
I can create work pools, turn them on and off, once deployed they know to reconstruct the pipeline from the correct commit
And it seems to support spot
And handles the fault tolerance, tho not sure if it will workout neatly when GPU is involved
So like, I'm just gonna have a CD pipeline on GitHub, and a bunch of deployments that I can trigger manually on the UI
Input is easily written via pydantic models
If the spot work pools work as I imagine it, this is awesome
are top university college courses on ai pre chatgpt release worth studying or is the material too old to be considered good enough to spend hours on? had someone hook me up with a bunch of old lectures from a few places and im seeing if it would be worth it to study them alongside my current school lectures
Hi does anyone that does data analysis know what the best way to analyse timesheet data would be? Thank you
Well most things remained the same I think. Gradient descent hasn't changed and transformers were making waves before 2022, even in vision with stuff like the swin transformer
excellent, i'm so glad to hear this! and if some of the intro lectures are from 2015, would those also still be good or should i find something more up to date?
2015 is getting to be a bit ancient tbh, but really, it depends on what stuff you're studying. For example the stuff 3blue1brown shows in his ML videos has not changed and I don't think it will
When you're getting to more recent models it's best to check the time when they came out I think. For ex transformers appeared in 2017, so the more mature material will be at least a couple years after that
Yah, if you take an AI course like I did in grad school (multiple decades ago)... that stuff is terribly outdated. God, what a waste of time.
Are you saying that AI courses are chronically outdated, or that the one you took wasn't outdated at the time, but is now?
Hmm. Interesting. I don’t know. Only that the content 20ish years ago is laughably irrelevant
But im not sure if it was irrelevant at the time, or that AI in general was at a real low point in that era.
was it during (one of?) the AI winter(s)?
Oh it was probably around 2003 or so
So yah?
I think nearly half the course was on rules driven nonsense/expert systems

At least from a historical review. Absolutely nonsense, and we knew it
constructing knowledge bases has a bright future
it is the replacement of 1d written natural language
1d as in text flow in one direction, word, sentence, paragraph, chapter, document
and the ability to refer to any point in your knowledge base at any other point, automatically infer differences between viewpoints, so much
automatic detection of contradiction in ones logic, detection of self justifying logical systems
in addition this improves the agency of human actors instead of constructing things external to conscious bodies which conducts thought
AI is good and bad at a same time. If citizens can no longer replace governments - wont govs simply become openly dictatorial? Xd
directly speaking this is one of the few courses my friend gave me that are that old, and it's a UC berkley course intro to ai from 2015, I think some of the others are more recent
hi
format1 = ff.FortranRecordReader('(F8.4,F9.4,ES12.4, F8.4, 1x, 1x, 1x, I3, I3, ES12.4, F8.3, F8.3, 1x, ES12.4, 1x, ES12.4, ES12.4, 1x, ES12.4, ES12.4 1x, ES12.4, 1x, 1x,I3,I2,I3,I2,I3,I2)')
Im trying to read a fortran formatted output file using this command but I get the following error
InvalidFormat:
Token: type=ED7, value=ES has invalid neighbouring token
at first I had this error but with value=x, I fixed it by putting a 1 in front of every x. But when I try this fix with ES, I still get the same error
anyone know what Im doing wrong?
Some of my profs were pushing this till the very end
You know we need? More rules!
It has use cases but they're slim
I don't think it's healthy to trim down AI to ML and ML to NLP and NLP to LLMs
Tbh, I think to most people AI = ChatGPT rn
ML gives approximate answers and the rule based stuff gives you exact answers
ML needs data and rule based stuff needs ... rules
if people actually work in the industry/tech then I don't think there really is any bad slimming
it is just to people who aren't techy, the only AI they see are the likes of ChatGPT or deep fake Talyor Swift nudes
I think it holds for AI professionals to a certain extent as well
How many people could set up a rule based system when it's appropriate (or recognise that it is for that matter)
!mute 1181398920358789120 1d this behavior is clearly not appropriate. Read our #rules
:incoming_envelope: :ok_hand: applied timeout to @raven brook until <t:1709583921:f> (1 day).
Bro needed fortran
Oh, there were other msgs.
Too real
Senior/older academics that are not in entirely cutting edge research groups are often like this. They know what they know, and they keep working on what they know.
There's a lot of educational material to choose from tho, so there's not a lot of need to constrain yourself to older stuff
Depends what we mean by AI, things like linear regression and even basic classifiers are ancient
And it is worth dipping into the history of computer vision and speech recognition if you are working in those fields, it's a long history
I'm assuming basic knowledge of undergrad math, tho I probably shouldn't assume
Have any of you guys tried to access the Shapenet dataset?
am currently living thedistilbert life
torch.cat((torch.ones(len(datalist1)), torch.zeros(len(datalist2))), dim=0) is there a nicer way to write this
Yes, by expanding it out into variables named in a self-documenting manner
Probably also by pre-allocating the array with zeros and incrementing the ones you want to be ones
Guys, cv2.imread is not reading all the png files in a path, what can be the reasons ? specifically stops after reading 446 files

I have a server sending objects of data to another server through an mqtt.
According to predefined parameters, the data should run through some filters and ml models and return to a user results.
What are the best practices, architectures and technologies/frameworks I should use considering that I use python as a server language.
Example, if I have a data parcel that is 1 second of ECG samples, and pre-defined param states that I want to fetch heart rate results, I should by default filter the ECG samples and reduce noise, and if the parcel doesn't include any R peaks, I should use another filter and set R peaks for this second of data. Only then the ml heart rate model can run. Another parameter is the rate of samples. Some devices have different rates and should be included within the inputs.
This is one example. Consider having multiple filters while sometimes needed and sometimes not. Consider having some models that require A buffer of 10 seconds to run a ml model to produce results. In my head, it looks a bit like a branch with nodes. If there is some resources you recommend or reviewing that seem similar, I'll be more than happy to check them out. 8 just really don't know what to search for
I want to study EDA, but I need datasets with some missing values for learing the handling of missing part better. But the datasets that I want to use don't have missing values. Is there any efficient way to generate missing values, lets say 12%? But it should be random. I tried bruteforcing but the dataset has around 40k entries. Pls help
You could just start with a complete dataset then remove some values
Yeah I wanted some efficient solution, brute forcing is not worth it
What do you mean? Unless we're not thinking the same thing, what I proposed should be pretty quick and efficient
>>> import pandas as pd, numpy as np, seaborn as sns
>>> df = sns.load_dataset('iris')
>>> df
sepal_length sepal_width petal_length petal_width species
0 5.1 3.5 1.4 0.2 setosa
1 4.9 3.0 1.4 0.2 setosa
2 4.7 3.2 1.3 0.2 setosa
3 4.6 3.1 1.5 0.2 setosa
4 5.0 3.6 1.4 0.2 setosa
.. ... ... ... ... ...
145 6.7 3.0 5.2 2.3 virginica
146 6.3 2.5 5.0 1.9 virginica
147 6.5 3.0 5.2 2.0 virginica
148 6.2 3.4 5.4 2.3 virginica
149 5.9 3.0 5.1 1.8 virginica
[150 rows x 5 columns]
>>> rng = np.random.default_rng()
>>> mask = rng.random(size=df.shape) < 0.12
>>> df[mask] = np.nan
>>> df
sepal_length sepal_width petal_length petal_width species
0 5.1 NaN 1.4 0.2 NaN
1 4.9 3.0 1.4 0.2 setosa
2 4.7 3.2 1.3 0.2 NaN
3 4.6 NaN 1.5 0.2 setosa
4 5.0 3.6 NaN NaN setosa
.. ... ... ... ... ...
145 6.7 3.0 5.2 2.3 virginica
146 6.3 2.5 5.0 1.9 virginica
147 NaN 3.0 NaN 2.0 virginica
148 6.2 3.4 5.4 2.3 virginica
149 5.9 3.0 5.1 1.8 virginica
[150 rows x 5 columns]
>>>
Yeah but will it work on a dataset with more than 40k values?
Iam concerned about the time
uh... yeah? I don't see why not
It should be really fast because all I'm using is np/pd's vectorized functions and not loops
So how exactly does it work? I would like te learn the intricacies of it
Is there a specific part of the code that you don't quite understand?
I understand the code, I am more interested in how does the function actually works on the dataframe. Like what makes it faster, and what mathematics goes behind it
There's no fancy math
It's just that python (loops in this case) is comparatively slow, and using vectorized functions means that the looping happens in a faster language like C
Okay, thanks
I have a neat-python project but my issue is that the agents have the same-ish behaviour with a minority of the population showing variation in behaviour... What am I doing wrong (I know it's not enough info but if someone's willing to help, I'll share repo / provide any more info)
Hello all! I had an open question that went unresolved. Trying to get into the transformers library from HuggingFace but I keep hitting a dependency error on distutils. Can anyone in this group tell me what I'm doing wrong? Would love to explore the topic of ML and AI here with everyone but this bump is popping up for some reason; recent install of transformers where the requirement is supposedly not there anymore since distutils has been deprecated?
create a virtual environment and download your packages there
fml, rocm docker image is frigging huge
55 GB lol
 Yup, which is why we use onnxruntime aha
Yup, which is why we use onnxruntime aha
Nvidia Cuda with pyTorch is also insanely big
huh on an amd gpu?
onnxruntime can support multiple execution platforms
rocm and migraphx are two of them for AMD gpus
I think the docker image size with them enabled tends to be < 1GB if I remember right
woah incredible
does involve converting your model to onnx first though
any performance loss wrt rocm/cuda?
but it is well supported by pytorch and TF
right
shouldn't be
very cool, thanks a lot for the reference
For us we actually get faster times, but that is because onnxruntime has some specialised handling for transformers
but yeah, if you are unfirmiliar with it, highly recommend
incredible stuff, tyvm!
Hi can anyone recommend predictive models for timesheet data? I want to separate by employee, the month and the project if this is possible
what could be said about the prediction bias in random forest & decision trees algorithms on imbalanced dataset ?
if you want to answer this, go to #1214238334415671357
this sounds like a homework question. what is "prediction bias" according to your understanding?
they perform really well and give high accuracy on imbalanced dataset but that leads to overfitting
It's a nightmare, every time I try to get AMD to do the thing it don't do it and I spend countless hours to then have Nvidia do the thing in less than an hour
no it's not a hw ques, bias means the model learns more about majority class and less about minority class
I think you can't train it like that tho, I've had this problem before, don't know if I missed something at the time
Oh I think you can
you can definitely train it
What you can do is train with onnx, export model waits to like safetensors, then import back to pytorch if needed
Might've been something specific to the model I guess
I was exploring models from all the frameworks, ended up only being able to do inference with them
uh is your entire screen supposed to freeze when you run pytorch with cuda?
Paddle in particular was a bit troublesome, also tf
That is my normal experience 🤣
For real though, if it is using most of your GPU memory, and the actual cores itself, then yeah your display is going to start suffering
If you CPU allows it, you may find it temporarily benifitial to switch the display to be rendered with the CPU's inbuilt iGPU
No idea I don’t use python often 🤣
That question wasn't directed at you. But the question is about ML, not Python.
Ohh sorry
nice i see thanks again
what do you say ?
If I make a numpy array somewhere in between, gradient wont flow through them, right?????
do u know any background remover model?
idk if they are technically called saliency object detection
Check paddleseg, they have a nice zoo of models
Uhm, that's simple enough to manage with the for loop I think
yeah i'm figuring out it's just advanced pandas-fu
heatmap analysis
This is one of the ways I like to set it up; #data-science-and-ml message
It keeps your training loop details hidden from the code you use to send data to your logger
A recent one I'm using is to have one process that doesn't care about which epoch it is rn, it just reads the data from the disk and applies gradient descent, this inside a while True
And then another that keeps generating data and storing it to the disk
This way one process trains, the other pre processes the data, and there's 0 down time for each
what's the reasoning behind yielding the entire model? seems interesting
to work in a REPL-like environment?
There's no inherent cost since in python everything is a reference, I yield it in case the logger wants to save the model
hm right I see
nice code
Thank you
Still looking for the best ways to do stuff
Tbh, I think compiled languages will have their place in my workflow.
For experimentation, jupyter and python for sure, but for a full implementation I think the compilation step is crucial, there's a ton of useful stuff that can be done there like checking if the matrix dimensions make sense
Not even the full code, just the model code, it's super helpful
GitHub
Type annotations and runtime checking for shape and dtype of JAX/NumPy/PyTorch/etc. arrays. https://docs.kidger.site/jaxtyping/ - patrick-kidger/jaxtyping
There's this tho
Hi guys if anyone that knows about predictive analysis would you be able to help me out on this please? Thank you https://discord.com/channels/267624335836053506/1214326780861620354

hello people, bit of a conceptual question for my understanding
what are the hidden layers supposed to do? so I understand it's basically linear transformations and sigmoid functions (or some other function like ReLU) all the way through and the linear transformations make sense as a means to go from more inputs to less outputs via those linear transformations, like if you have 3 separate parameters and 1 value as the prediction, you need to at some point or over the course of the hidden layers transform those 3 into 1, alright, so that makes sense and like you then also put them through those sigmoid functions or whatever
but, how do you decide on what transformations you're gonna do exactly? because you could for example expand the inputs via linear transformations and then compress them again to the output dimensions and like how do you figure out that you need to expand the inputs to more dimensions for example?
and more generally, how do you figure out how many hidden layers you need for a particular thing?
I'd also appreciate some resources if you can throw some my way 😁
I'm sort of reading this rn: http://neuralnetworksanddeeplearning.com/
these are mostly determined statistically
we don't have a good understanding of why particular settings work better than others
the best way to gain intuition in this area is to begin from what works and from the performance these models are already able to achieve, and then begin to think architecturally only after you're already familiar with these
alright, thanks, currently I feel like I have a rough understanding (being at the peak of Dunning-Kruger's effect be like) of like the sort of whole process and how like you try to reach a local minimum and such, I just don't quite get the layer configuration if you can call that, I feel like I could throw something random together and it would work, it just doesn't seem quite right, but yeah, I am practicing this ofc, so ig it's mostly time that will tell 😁
with small models it's often really easy to quickly test a couple of settings
wrt layer configuration
yeah, that's what I'm currently sort of working with
but yeah, layer configuration is literal magic atm.; what's worth knowing in these is their different types. convolutional, recurrent, feed forward, attention, etc. etc., and the very general idea of what purpose they tend to work for
but also, I was wondering, not planning to do it right now, but like I see being able to use this to sort of "predict" statistical outcomes of certain parameters by minimizing the loss, but, for example, are these sort of neural networks also used for something like game AI or do they use different models altogether? I just sort of wanted to eventually practice this by implementing a somewhat "sentient" npc in a game, but currently at a bit of a loss for how to even approach it, especially with these linear/sigmoid/relu models
alright, I see, I'll look into those, thanks a lot
in case of the same sort of idea (input layer + hidden layers + output layer) being used for networks used to train such things, I assume I'd be looking for some different types of those layers like you mentioned
the way I see it is machine learning solutions produce statistical distributions with determinate properties
if you're able to reduce your problem to generating a statistical distribution, you'll be able to use ML for it
I see, that makes sense then, it also seems rather complicated, but I guess that's the fun part 😁
wrt. sentient-like game AI: at a given point in time, a distribution of sentient-like behaviours that are likely to make a human consider the agent somewhat sentient
I suppose I'd have to read some actual research into such uses for AI at that point
overall exciting though
definitely!
What does that mean
Gradient
Gradient descent?
Yes, it's the original use case of ML.
I can suggest this video (Khan Academy - Gradient) on that topic and a couple of the following ones, but you should probably have a bit of an understanding of the previous topics as well and some calculus knowledge as well, although the concept on its own is fairly simple
https://www.youtube.com/watch?v=tIpKfDc295M&list=PLSQl0a2vh4HC5feHa6Rc5c0wbRTx56nF7&index=19
making sentient npcs for games?
A checkers bot.
(Also made by one of the first computer game developers)
(Coined the term "machine learning")
can that even be considered ML? isn't it just follow these rules and these and brute force this stuff... I mean, I guess it could be considered AI (as outlined by one of the pinned messages), but ML? well, maybe, I haven't looked into that work
Yes, it's brute force, but the trick is memorize certain routes and cache them (memoization), this is the "machine learning."
Later some extra heuristics added.
alright
(Also this was on the first computer implementation of checkers that he wrote too)
One way to see it is to view a function and look-up table as the same thing (the move / reward cached values). And those layers / neural networks as big functions with many configurable parameters.
You can imagine that a plain old table would not scale well, the memory usage would become ridiculous, and it has no ability to deal with things it has not stored previously (exact same) (if it's not in the table we just go full brute force again (with some heuristics)).
You can use Model Checkpointing to achieve this. You can use it to do stuff like: get me model weights in epoch 8 or best model weights after completing training on the whole epoch etc.
If you are using Lightning it comes even much easier
yeah i've started doing this with native pytorch
will look this up
looks interesting, thanks a lot!
IDK what sentient means, but for NPCs in a game they tend to be most interesting via emergent behavior caused by lots of simple rules interacting with each other and/or the environment. You could have them be small neural networks, or make use of them in part. Something like a language model to interact with does not really work in practice, it's something a lot people are trying but from a game design POV it does not really make sense unless you just want random stuff / interactions to happen, which makes it less of a game and more of a simulation to mess around in.
so, uhh, sth that would at least to some extent resemble a human (ish) player in a 1st person shooter is how I'd go about describing the result I'm sort of looking to achieve eventually
computationally this isn't possible atm
dont know if theyve been mentioned but i remember reading about perceptrons and it seemed to be some theory about the choices in regards to layer configuration
nooo, my hopes and dreamssss... shattered in the snap of the moment
It is possible, but question is why exactly, from a game design POV.
well, hope dies last, so at least I got some of that still left now...
I mean, fair, from a game design POV, I can't really imagine anything particularly impressive to come out of this experiment, but I'd like to practice with it that way
offloading 7b models to some cluster i guess, but still expensive stuff
Maybe to act as a shadow-boxing like bot, for high level competitive play practice, but other than that, not sure. When NPCs in a game become too good, or too unpredictable they become impossible to design a game with.
This is not a language model, just a first person shooter agent.
Standard RL agent, has been done before, runs on a PC easily.
!otn a this is not a language model it's a shooter
:ok_hand: Added this-is-not-a-language-model-it’s-a-shooter to the names list.
honestly, I have no issue with it becoming too good, besides I suppose it could be possible to somewhat revert it to previous revisions where it wasn't as good? by using weights and stuff from those previous generations or whatever?
:ok_hand: Removed this-is-not-a-language-model-it’s-a-shooter from the names list.
they did mention sentience
!otn a this isn't a language model it's an fps
:ok_hand: Added this-isn’t-a-language-model-it’s-an-fps to the names list.
i think large "action" models use exactly the same idea as llms, they just have actions as tokens
Yeah, you can totally use this approach. But making the game will be more difficult. You can have different ones with different personailities based on different data sets.
do llms use the same concept of input layer + hidden layers + output layer ?
Usually this is done with classic game AI, like hierarchical portfolio search or something.
pretty sure in fact that the tokenization of actions is how bipedal humanoid stability stuff has been implemented lately
Technically, HPS can make use of neural networks in it, since it allows mixing of AI methods.
And hard coded stuff.
something being a language model is a description of what it does, not how it's constructed. but most things that we call (large) language models are "neural". but they have a cyclic computation graph.
yep, but there's a special layer called the attention block that's sort of the magic sauce
I'm afraid I have no clue what that means. yet.
as I said, not planning on doing it right away, but I was wondering how to even approach this because it seemed pretty hard to accomplish using a model that just does transformations here and there 😁
don't worry--as you progress in your understanding of ML, you will be able to confidently use all of these terms, but you still won't know what they mean.
Highly recommend looking at HPS when you get to game AI.
There are many types of NNs, here are a few:

(Note, it's not "mostly complete" at all)
is this a poster for ants
alright, but like, is all machine learning/ai/whatever other buzzwords pretty much using this idea of input layers + hidden layers + output layers as the sort of base for everything? sure it can be cyclic somewhere along the hidden layers and such, but can it be something other than this (and possibly rules, so like, obviously it could be like a couple if statements here and there and such, but yeah)
yes that's all it is
Click on it and open in browser.
yeah, this is sort of what I was asking for, thanks, well, they do mostly seem rather similar
oh neat ty
This is a small subset.
yep so regarding the question about choosing hidden layers, in classifiers, there is theory about how the neurons relate to the ability to properly catagorise input data
the ability of a multilayer perceptron to draw boundarys may be a good search term
however this is something i just looked into so i cant provide info
we don't have the results yet
i have been doing a literature review (of abstracts, like a real researcher)
there are no results
we have no clue
neurons are just numbers that, in the context in which they're used, can amplify or silence relationships between properties of the input.
ok
the statement has been accepted
cool and I thought people had a lot of this figured out already, guess I couldn't have been further from the truth, lol
it is pretty nice to be learning about this also because it's sort of demystifying the concept of ai for me
thanks for the valuable information everyone, I'll probably hang around here more often from now on 😁
this was also in reference to how to pick the number of layers and number of neurons
It's just math (mathematical optimization). With some biological and psychological inspiration.
i feel like there are better determenistic optimisation techniques out there which dont exist yet, in an attempt to slay the rng gods :D
if you find something tag me lol
/just/
i have a non linear optimiser without constraints that doesnt work for all cases i made, but not in researchy enough circles to know where ( it/ the approach) sits on the scale of ( easy peasy did it at age 10 -> meh -> cool and fresh)
what hyperparams does it take
is it just a general nonlinear optimizer?
its not really neural net pilled, yh just general
but it would seem ( without exploration) that general opt could be applied to some nn
compare against adamW and such, you will obtain your scale
ah cool ty, was gonna set up some test environment to compare against those on https://nlopt.readthedocs.io/en/latest/
but adamW is new to me i think, so yh that too
adam and adamw are the heavyweights
ok to picture a nn in typical human optimisation form there is some function which takes all weights of the net as input and produces some single real num which represents the error for that training data
and that can be minimised
no constraints
is this linear could it be done w simplex
idk i sleepy
gnight
We learning from this one 🗣️🗣️🔥