
#data-science-and-ml
1 messages · Page 107 of 1
Yeah sometimes that happens because the lib code is not properly typed
But you can still do the help thing
hmm, that's interesting. How would you find log-probabilities of normal distributions which has domain (-inf, inf)?
The domain has nothing to do with it, you have to look at the target. The y axis in the normal distribution represents probability mass, so you'd have to apply log to that somehow
log(X) where X ~ N
My starting point would be here maybe, log(p(x)dx), find some way to make this make sense
you mean log-normal distribution?
Yes that seems to be it

Tho a bit of a boring proof compared to going for the intuitive picture of infinitesimals
No wait, here ln(x) ~ N right
i'm trying to apply techniques from discrete action space for actor-critic to continuous action space and it's not working
Idk anything about that tho
no, it's log(X) where X ~ N, because we want X to be bounded by (-inf, 0), not (0, 1)
If you want to interpret your array as a set of probabilities people usually apply softmax, but honestly idk your context in any way
I'm confused, above the log normal is log(X) ~ N, what you seem to be looking for is log(X) where X ~ N, but that doesn't put any bound on X, it spans the real line still
But I reckon the derivation is super similar
lmao forgot log of normal distribution is actually a straight line

That can't be tho
The area under the curve must sum up to 1
And any individual p(x)dx is a probability too, so it must be above or eq to 0
That is you can't have negative numbers
Oh sorry you said log of
Ah I got it, I think you have to do like
straight line makes sense, because normal distribution tends to 0 at both -inf and +inf, but straight line tends to -inf and +inf respectively
Integral of A log(p(x))dx = 1
And find A = 1 / that integral
Like just normalize it
This the only way that makes sense, because you can't really do log(X)
this is just for taking log of probability which improves numerical precision
I don't need it to be a distribution, you can't normalise a straight line anyway
Ah, in that case you need to take it to the positive reals first
Maybe exp(x)
Or add a displacement in case X is bounded
But again, that's totally not a probability
Since prob is not negative
I can do log(X)^2
or log(abs(X)) where X ~ N
You can't because X can be negative
You are just transforming the real line, you can even omit X~N
X is not a probability
I think taking log probability of normal distribution makes no sense. It only works with categorical actions and not continuous actions
I mean, that's what you asked for right
Here
im very new to RL, thanks for your help
I don't know anything about it, otherwise I could've helped more
Been getting enough fun with supervised learning
i dont even know what it means
do you manually change hyperparameters?
Just means labeled data
Yeah
Gotta do a grid search, I'm even doing a whole pipeline for it
do you use tensorflow?
I prefer pytorch, recently started using the rust bindings
I know about 1% about pytorch compared to tensorflow. will reverse engineer a ready continuous action space from someone else, should find the solution
They are fairly similar I think, they all are really.
Be sure to check with papers with code too. I recently spent like 2 weeks training a model that was already at maximum performance since the start >.>
Like always check what other people are getting for that dataset and how and if your results make sense in that context
I was getting 56% accuracy for a dataset where the best BERT gets 65%, given that my models are way smaller and likely much less optimized, it's a good result
And the way BERT got there was by pre training it on next token prediction on the usual massive amounts of text
you misplaced the 2, making it a multiplier instead of a power.
are literally all non-mamba leaders in the open source LLM leaderboards some variation on transformers?
do ALL loss functions for transformers work in the following way? the transformer produces a probability distribution of the most likely next token; then a loss function scores the probability assigned to the actual next token? the aim then is that, in the following step, a better probability is assigned to the actual next token?
It's pretty hard to make statements about "ALL" things in any research field, specially one that's moving/evolving pretty fast
Even if it boils down to that, the loss function which "scores the probability assigned to the actual next token" part can be extremely complicated thanks to reinforcement learning from human feedback (RLHF) / Proximal Policy Optimization (PPO)
will look into those keywords, thanks!
even further down the rabbit hole: https://huggingface.co/blog/pref-tuning
(and not gonna lie, I don't understand much of that either)
Guys i got a question
they have given me a dataset (generated or something), when i check profession and age
average age of students seems to be 41
they want me to build an application with target audience regarding time management in social media
so do I consider the target audience?
hello?
I've seen two major setups for training them, in case of decoder architectures (single branch with causal self attention, i.e. zeroing of the self attention scores of future words ), you feed the x[i:i+n] and then expect it to reproduce x[i+1:i+1+n], so it's like you're asking it to reproduce the input except for the first word and to guess the lass the word. So it's actually not just doing next token prediction, it's also doing transcription.
The second major setup I've seen is that for encoder architectures, single branch with no masking of attention scores. In this case you take the input, say x, and you substitute tokens at random and assign them a special token and then expect the transformer to reproduce the entire input but substitute back the tokens by means of guessing.
This is how GPTs are trained
This is how BERT is trained
Guys, I coded a virtual Hadron Collider also known as a Monte Carlos, can anyone help me with something?
woah, I've also coded something similar, what do you need help with ?
did you use geant4 ?
The collected data, I don't know what to do with it, and I'm using Python
what did you simulate exactly, and how did you set it up ?
3163906 different interactions of all particles
right, which particles, which transport code ?
Um.
I was studying physics and connected GR and QM, and connected the strong force to the table, and was able to generate the results based off that.
can you show me the code that you wrote, maybe it's easier for me to understand what you did
I can't provide it because of the implications of this all..
I can't trust anyone but myself with the information as of yet
GR is usually not involved in these simulations though, as their mass is actually very small and we're talking at very small scales
Yes, it's connecting GR and QM
then I cannot help
So even on the quantum scale it still applies
there's actually no connecting to be done between QM and GR, QM is a mathematical formalism that you apply to classical theories, it's more of a framework, there's first and second quantizations. Applying these formalisms to GR has been unsuccessful as far as I understand
I did a lot of research in to it, trust me. The connection became obvious after a while.
I have a ton of calculations in regards to all of that nonsense
But I'm here now trying to make sense of the data I've gathered
my understanding is that the more recent developments point to spacetime as being a quantum object already, like with ER=EPR, which would explain why applying quantization to it don't work
that's super suss tho
You may think it, but it's what my research lead too.
All the calculations, figuring out how things actually worked compared to what we think we know
And figuring out the connection between the two\
we don't think we know anything though, we have data and a bunch of explanatory models that fit to that data
Ask yourself this question
If you were to place two objects with the same mass in a vacuum, no matter how far apart they were from each other, how fast do you think their velocity would get?
early proponents of QM didn't even think of QM as describing reality, they believed QM to model our data only, which explains why it's so weird, it's more about our ignorance of the world than about the world itself
I know it's about the ignorance, I solved for the ignorance.
I'd just use a bare bones newtons law of gravity for that
Yeah, I did too, and did more, and more, and more, and it always still broke the speed of light.
Now will you help me with this process? lol
no I can't help you with your data since I don't know how you produced it
It's not about how it was produced, but how the current data can be observed.
that tends to happen if you don't use relativity
I ended up using everything in relativity in the end and it still broke the lorentz factor, so...
I cannot answer this question without details about the simulation
or what you're looking for
usually from monte carlo simulations you get a bunch of particle tracks
along with their associated energy losses at each interaction with the medium
This is one of the results from one of the interactions

which you can use to do lots of things
again it's meaningless to me without knowing what you did
it's like me saying I simulated the japanese economy using language models, but then I don't tell you how I did it and show you a random graph
What would you do in my position then with the implications of it all?
I can't trust anyone but myself I feel like.
if you have something useful for the scientific community I'd write a paper on it and submit it to peer review
I'd also open source the code
This is the answer to everything.
I don't know if everyone should be open to such a thing until more is known
unless it can be used for nefarious purposes, in that case I'd be careful not to release something that produces too accurate results and place it behind a form or somethin
That's what I'm saying, you could create the biggest explosion ever with this information.
You can create cures for diseases, create diseases, not even sure of the implications at the end of it all.
All I know is it has to be kept close to chest
sure, but they're empty claims until they've gone through the very rigorous peer review process you usually see in particle physics
I was solving for the The Equation of Almost Everything and connected it mathematically, it wasn't just a logic step.
they do this with lamma for example
It's how I got these values in the first place was because of that equation.
like you can do anything with mathematics, it's like when you get super good with python and you can just do wtv
doesn't mean wtv is good, most times it's actually kinda bad
what truly matters is putting your model against experimental data
What I am saying is the results are accurate based on the results of the data.
which data exactly ?
All the interactions between the different particles
in your simulation ?
A Monte Carlo
This is off of my previous data, no other models.
and where did that data come from ?
The Equation of Almost Everything
that's just an existing model
you need to build a big machine and then collide the particles, you can't just use an existing model
I made improvements on it and calculated data on the different interactions
It shows every interaction based off the Monte Carlo
this kind of physics is very stale right now due to hardware limitations, there's not gonna be a new big discovery until they build a larger hadron collider or someone sees something crazy in smaller experiments
I can tell from this conversation that you have synthetic data produced from the existing models
Models that I improved on
okay, do you have new predictions ?
That's what I'm trying to figure out.
I have all this data but don't know how to read it properly
that strikes me as very odd, it's usually very straightforward to understand the predictions of your own model
The first test was for the frequency and strength of the interaction, then I calculated for the graph above as well as other statistics.
But I don't know what it all means
in MC simulations the stats are already kinda baked into the simulation
MC simulations?
monte carlo simulations of particle transport and interaction with matter
Sounds like that's what I do next.
you take existing models to calculate colision cross sections, which you use as probability distributions of the final variables resulting of each interaction
this reminds me that I have to finish writing a whole thing about this stuff
Hello everyone
so im running a keras sequential model on colab, and have REALLY low accuracies
on top of that, it just ends abruptly at 14 epochs when i clearly specified 20 epochs
ive never seen something like this happen
my model architecture is:
def create_improved_model():
model = Sequential()
model.add(Conv2D(64, kernel_size=3, input_shape=(50, 50, 3), activation="relu"))
model.add(BatchNormalization())
model.add(Conv2D(32, kernel_size=3, activation="relu"))
model.add(BatchNormalization())
model.add(Dropout(0.25)) # Adjust the dropout rate as needed
model.add(Flatten())
model.add(Dense(1, activation="softmax"))
# Compile the model
adam = Adam(learning_rate=0.0001)
model.compile(loss="binary_crossentropy", optimizer=adam, metrics=["accuracy"])
return model
can someone tell me why this is happening?
The principles proposed in the RCNN paper continue to remain useful
Tho more powerful models must've been developed for each different "module" of the process
e.g. ViTs for extracting rich feature map representations
@final kiln ty for comments!
even with an accuracy of 88%, for some reason it always returns the EXACT same accuracy EVERY single time for both images
class_1_img = "/content/sample_data/10253_idx5_x501_y351_class1.png"
class_0_img = "/content/breast-hispathology-images/10301/0/10301_idx5_x1001_y1651_class0.png"
# Load and resize the images
img_0 = cv2.imread(class_0_img)
img_0 = cv2.resize(img_0, (50, 50), interpolation=cv2.INTER_LINEAR)
img_1 = cv2.imread(class_1_img)
img_1 = cv2.resize(img_0, (50,50), interpolation=cv2.INTER_LINEAR)
# Ensure the images have the correct shape and type
img_0 = np.expand_dims(img_0, axis=0) # Add batch dimension
img_0 = img_0.astype('float32') / 255.0 # Normalize pixel values between 0 and 1
img_1 = np.expand_dims(img_1, axis=0)
img_1 = img_1.astype("float32")/ 255.0
# Make predictions
prediction_0 = model.predict(img_0)
prediction_1 = model.predict(img_1)
print(prediction_0[0][0])
print(prediction_1[0][0])
can someone tell why exactly is this happening
Hi everyone, I have been trying to implement U-net model in tensorflow from original paper. In the paper it is said that the network uses "unpadded convolutions". This lead to some shape problem in my case. Every implementation that I have seen une "same" as padding for convolution. I do not understand it. If the papers states "unpadded convolutions" shouldn't one use "valid" as padding ?
uhm if you don't pad your convolution kernels the resulting output will be slightly smaller in size
it's not really the kernel being padded right
it's the input matrix
probably a good idea to go over what each of those modes mean, but for the 1d case, which is much easier to follow
exact, if you don't pad, the ouput will be smaller, which is what they show in the paper, if I understand correctly
if I had to guess, there's likely just not a big performance difference between the modes, the UNET in particular is a very strong and versatile architecture
or, maybe the other way around right
there's a performance difference that was found in a later paper
so every1 does the other way
maybe not, but I try to understand why people implement it in a way that from my point of view differs from the original paper
ah ok
would you have the reference of the later paper you mention ?
try to look into more recent papers, even the transformer has already suffered some mutations
not really, check the website papers with code for SOTA papers
there should be a section for the UNET somewhere
ok, great ! thank you !
why does this happen
ValueError: Failed to find data adapter that can handle input: <class 'PIL.Image.Image'>, <class 'NoneType'>
my code is:
def tensor_to_image(tensor):
tensor = tensor*255
tensor = np.array(tensor, dtype=np.uint8)
if np.ndim(tensor)>3:
assert tensor.shape[0] == 1
tensor = tensor[0]
return PIL.Image.fromarray(tensor)
def load_image():
#reshuffle
reshuffled = test_dataset.shuffle(buffer_size=8, reshuffle_each_iteration=True).batch(BATCH_SIZE).prefetch(tf.data.AUTOTUNE)
for i, (image,label) in enumerate(test_dataset.take(1)):
img = tensor_to_image(image[0])
img.save("sample_img.png")
print(parasite_or_not(model.predict(img)))
load_image()
the image is getting saved
but this error also comes with it
Hello! Anyone who has experience with OCR and organize the output in a table who can help me with a doubt? I will really appreciate it 🙂
what would be your preferred way to make a 27x27 heatmap
Heatmap of what
And from what
ended up just using plt.imshow
this was going to be my response. just pay attention to the aspect and interpolation settings.
will do, ty!
what the heck are all these interpolation options
you guys use these at all? since all I have is a 27x27 array, I'm using None, but at which point would I use something else?
I think that's just to make the image lighter or something
Yeah I think high fidelity render is heavier, so you interpolate the pixels
I usually just use the option to get it to not do interpolation

Uhmmm
Yeah that's it right, it loads like a percentage of the pixels and displays interpolated values
I guess, if you just need a datapoint most precise than what you actually have

no clue when this would be relevant
Chat gpt says it's just for appearance purposes, like when resizing the image, zooming in and out, etc, you gotta interpolate the missing pixels
Guess not zooming in, but scaling it
hm, it would make sense in the following situation: you've got a sensor that makes measurements, one axis of the heatmap is distance, the other is some form of quantity of interference, and the hardware of your sensor, or the experimentation costs, don't allow you to take intermediary distances
so your heatmap is pixelated, but this would be an inadequate representation of the data because it should vary continuously with distance and degree of interferene
Like if you do an interpolation it's not guaranteed to be the correct value tho
But I get what you're saying, I've used cubic splines a lot when I knew that even a line between points was a good approx
i REALLY need to get up to date with hardcore statistics
took two classes a while back but it's not enough
Been thinking of brushing up on some math too
Maybe go deeper in stats
I thinking, once I finish this project and also land a job in Switzerland (which hopefully will happen this week), I'm gonna start reviewing some stats heavy math. I can just stick it with the rest of my thesis.
drop me a message when they need another ml enthusiast lol
They're purely ML company, with offices in like 3 countries
And they'll be expanding to the US this year, which might be how I get the L1
Will see, haven't gotten the job yet, and I have a tooon of time
good luck
Thank you
I'm also gonna move my course credits to a different uni, the objective is to present the thesis in front of the top experts in the field. Still don't know how I'm gonna do it yet, but shouldn't be too hard due to EU standardization
I got a ton of cool stuff planned for the future
Like, on all fronts
they're for actually showing images and things like actual heatmaps, rather than just visualizing a grid of numbers
you definitely know enough "math" from what i've seen. i'd say to go for probability and stats specifically
precisely this
Yeah but it's been like 2 years since college, I gotta start exercise some those muscles to get them back in shape
My thesis is monte Carlo stuff so stats and probs actually fit well with it
perfect
any recs beyond beginner stuff?
Any quants ?🙌🏾🙌🏾
recs for what? textbooks? topics to cover?
either
what's your background?
econ major math minor
i know my way around a transformer
but literally 0 ML theory
so you've taken econometrics?
that was where i started about a decade ago. econ major + math minor, trying to figure out how SVM, CNN, and random forest models worked
yeah, a bit of R but sort of was not very interested in the material until recently
was the last semester too
if you're still in school, try to take a stats class outside of the econ department. i.e. "statistics" and not "econometrics". some of it will seem very familiar, some of it will seem like an alien reinterpretation of what you've already learned, some of it will be new.
if you can take a class on probability modeling with the math department that will help as well. my stochastic processes class was a great way to reinforce probability as well as think more clearly about applying it to real problems.
sure! also make sure you are very comfortable with linear algebra and calculus. the MIT OCW course by Strang is legendary for a reason. that + the 3b1b courses are great, even if you got an A in those course sequences, you might learn something or at least gain new intuition.
for modern ML stuff i'm not that well-versed either because i don't actually do it much at work. but i do really like Dive Into Deep Learning https://d2l.ai/
thankfully linear algebra, calculus and pure math are a breeze
nice! will look into this too
Hanning/Hamming windows come up a lot in signal processing. https://en.wikipedia.org/wiki/Window_function#Examples_of_window_functions

In signal processing and statistics, a window function (also known as an apodization function or tapering function) is a mathematical function that is zero-valued outside of some chosen interval. Typically, windows functions are symmetric around the middle of the interval, approach a maximum in the middle, and taper away from the middle. Mathema...
If you think of the spatial frequencies contained in the heat map, the pixellated view is kind of obscuring things
the windowed view is allowing the "fundamental" spatial frequencies to come through
And yeah, it would make more "physical" sense if you think of remote sensing where a pixel is 500m x 500m, but there is no way the contents of the pixel on earth are uniformly one flat colour, unless it's the roof of the Tesla factory or something 😉. The windowing will let you see the underlying shape a bit more clearly, even though it is still blurred
i have a plot that looks like this

i want to have a line that fits only the linear region extending to the =x axis
the x intercept is what i want how to do it?

something like this
can you reject the low values, there's a voltage below which you don't get much current, right?
It's been a while since I did anything with transistors.
it more a data sci thing i think
I guess the other thing is to do a diff of your points which effectively is the derivative
im not sure how to do it in python
but umm isnt that quite difficult
can i just curve fit
and reject all the points where the derivative is low so the curve is nearly flat
a line on the linear region
fit on the remaining points that are neither low voltage, nor "flat" current i.e. diff(I) = ~0
https://numpy.org/doc/stable/reference/generated/numpy.diff.html would this help?
i was also gonna ask if the polyfit function works
imma look into it
I've done it in scipy before for polynomials, but I don't think the transistor curve works that way
and you only want its linear part, you want to be rejecting all the points outside that linear part before doing a line fit
Good luck
do you know where the "elbow" is located, or are you trying to figure out how to locate it / work around it?
Hello ! I have a dataframe, named 'ctl' made after a csv file: each row corresponds to a country (in two-letter format) and each column is named after a language (also in two-letter format). The data in this dataframe is in the following form for a given row: ,,,,,,,,,,,,,,,,,,"{'percent': 100.0, 'official': True}","{'percent': 1.9, 'official': False}","{'percent': 0.47, 'official': False}",,,,,, for example. I want to create a dictionary from this dataframe where, for each country (in lowercase two-letter format), it associates the most spoken language (in lowercase two-letter format). In order to do this i just aim to search for the highest pourcent found in the row, but its in a string format so its kinda difficult to do this...another approch was to find something higher than 50 in string but i also failed...is there a easiest approch to solve this ?
yeah i do know where its located
so far right now i took two points in the lienar regime and calculated its slope
and modeled the linear part with scipy
for context I have a CSV file in which each entry has a 'username' and the languages the user speak, along with their proficiency level (Native, A2, B1...). The goal of my project is to, for each username, determine which languages they can speak, associated with their proficiency level. My output file should represent languages using
codes. (i.e., i should have ‘es’ - not ‘mx’ or ‘en’ not ‘eng’ or ‘us’).
hope this is right channel
anyone knows how to use sklearn in jupyter lab desktop version?
I have already installed scikit-learn, started scripts, create a new kernel and change it to my jupyterlab. Help pleaseee
that's what i was going to suggest. pick the first non-elbow point on the left, and the last point, and just compute the slope between them
this is the right channel but i think your first post is really deep into XY territory. your 2nd post clarifies, but it's not clear specifically waht you want here.
sorry !!
country en ... mxc kck
0 AC {'percent': 99.0, 'official': False} ... NaN NaN
1 AD NaN ... NaN NaN
2 AE {'percent': 50.0, 'official': False} ... NaN NaN
3 AF NaN ... NaN NaN
4 AG {'percent': 86.0, 'official': True} ... NaN NaN
I think you're including a lot of unnecessary information here:
You want to know the most spoken language?
basically country goes through 278 row and most common languages are column titles
Given Country, Language, Population (or something like that)?
So your dataframe has: Country, Language and Population?
country and all languages
I think you need to show more about what a single country with multiple languages looks like.
Show us the first few rows of the CSV plz
AC,"{'percent': 99.0, 'official': False}",,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,AD,,"{'percent': 51.0, 'official': True}","{'percent': 43.0, 'official': False}","{'percent': 7.5, 'official': False}",,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,
AE,"{'percent': 50.0, 'official': False}",,,,"{'percent': 78.0, 'official': True}","{'percent': 7.0, 'official': False}","{'percent': 2.9, 'official': False}","{'percent'
and headers is like country,en,ca,es,fr,ar,ml,ps,bal,fa,haz,uz_Arab,tk,prd,bgn,ug,kk_Arab,pt,sq,el,mk,hy,ku,az,umb,kmb,ln,und,cy,gn,sm,de,bar,it,hr,sl,hu,zh_Hant,wbp,hnj,nl,pap,sv,az_Cyrl,tly,ttt,tkr,bs,bs_Cyrl,sr,sr_Latn,bn,rkt,syl,rhg,ccp,my,grt,mro,mni,vls,wa,mos,dyu,ff,ff_Adlm,bg,ru,tr,rn,sw,fon,yo,ms,ms_Arab,qu,ay,aro,vec,ja,kgp,ko,yrl,gub,xav,dz,ne,tsj,lep,tn,af,be,zh,yue,pa,fil,ur,hi,ta,vi,pl,gu,ro,pdt,uk,so,iu,iu_Latn,oj,ojs,chp,moe,cr,mic,atj,bla,crk,den,dgr,csw,moh,nsk,dak,clc,hur,crg,war,lil,oka,pqm,crl,kwk,gwi,lua,lu,kg,lol,rw,sg,gsw,lmo,rm,rmo,wae,bci,sef,dnj,kfo,bqv,arn,bum,ewo,ybb,bbj,nnh,bkm,bas,bax,byv,mua,maf,bfd,bss,kkj,dua,mgo,jgo,ksf,ken,agq,ha_Arab,nmg,yav,wuu,yue_Hans,hsn,hak,,gan,ii,za,mn_Mong,bo,lis,ky_Arab,nxq,khb,tdd,lcp,uz_Cyrl,lzh,guc,kea,cs,sk,nds,vmf,da,swg,ksh,hsb,frr,dsb,frs,stq,pfl,aa,fo,kl,jut,arq,kab,qug,et,fi,vro,arz,ti,tig,ssy,byn,gl,eu,ast,ext,an,oc,am,om,sid,wal,gez,rmf,se,smn,sms,hif,fj,rtm,chk,pon,kos,yap,uli,pcd,br,co,frp,ia,puu,sco,lt,ga,gd,kw,en_Shaw,ka,xmf,ab,os,gcr,ak,ee,abr,gur,ada,gaa,nzi,ha,saf,man,man_Nkoo,sus,nqo,kpe,fan,bvb,pnt,tsd,quc,ch,knf,ht,id,jv,su,mad,min,bew,ban,bug,bjn,ace,sas,bbc,mak,ljp,rej,gor,nij,kge,aoz,kvr,lbw,gay,rob,mdr,sxn,sly,mwv,he,yi,lad,gv,te,mr,kn,or,bho,awa,as,bgc,mag,mwr,mai,hne,dcc,bjj,sat,wtm,ks,kok,gom,swv,gbm,lmn,sd,gon,kfy,doi,kru,sck,wbq,xnr,tcy,wbr,khn,sd_Deva,brx,noe,bhb,raj,hi_Latn,hoc,mtr,unr,bhi,hoj,kha,kfr,unx,bfy,srx,saz,bfq,njo,ria,bpy,bft,bra,btv,lif,lah,sa,kht,dv,ckb,az_Arab,lrc,syr,mzn,glk,sdh,rmt,bqi,luz,lki,gbz,is,sc,nap,lij,scn,sdc,fur,egl,pms,rgn,jam,ryu,ki,luy,luo,kam,kln,guz,mer,mas,ebu,dav,teo,pko,saq,ky,km,cja,kdt,gil,zdj,wni,kk,ug_Cyrl,lo,kjg,ku_Arab,si,vai,men,vai_Latn,st,zu,ss,xh,sgs,lb,lv,ltg,ary,zgh,tzm,shi,shi_Latn,rif,rif_Latn,gag,mg,mh,bm,ffm,snk,mwk,ses,tmh,bm_Nkoo,khq,dtm,kao,bmq,bze,shn,kac,mnw,mn,wo,mt,mfe,ny,tum,tog,yua,nhe,nhw,maz,nch,sei,iba,zmi,dtp,vmw,ndc,ts,ngl,seh,mg
cropped because too long
anyone knows how to use sklearn in jupyter lab desktop version?
I have already installed scikit-learn, started scripts, create a new kernel and change it to my jupyterlab. Help pleaseee
sorry this is like the worst formatting possible
It's kinda terrible, but it's ok
So, the first thing I'd do is melt() the dataframe
import pandas as pd
df = pd.DataFrame({"col1": ["USA"], "en": ["{'percent': 43.0, 'official': False}"], "es": ["{'percent': 43.0, 'official': False}"]})
print(df)
Sample df so you can test this easier.
import pandas as pd
df = pd.DataFrame({"country": ["USA"], "en": ["{'percent': 43.0, 'official': False}"], "es": ["{'percent': 43.0, 'official': False}"]})
melted_df = df.melt(id_vars="country", var_name = "language")
print(melted_df)
Now, you just need to parse out the percent from value.
ill try thank you very much !!
did you create this data? with python dicts embedded in csv? in the future i strongly suggest not doing this.
What isn't working?
no i had to work from this file, but i cant agree more with you
What is your error?
ModuleNotFoundError: No module named 'sklearn'
from sklearn import linear_model
regr = linear_model.LinearRegression()
x = np.asanyarray(train[['ENGINESIZE','CYLINDERS','FUELCONSUMPTION_COMB']])
y = np.asanyarray(train[['CO2EMISSIONS']])
regr.fit (x, y)
print ('Coefficients: ', regr.coef_)
What happens when you run pip install -U scikit-learn
In jupyter, %pip install scikit-learn
basically says i have it installed already

same output with this command
Then restart the kernel and try again
And what happens with %pip install?
That was to confirm you weren't running in some other virtual environment. I'm stumped if that said it was installed.
ERROR: You must give at least one requirement to install (see "pip help install")
first time im using jupyter desktop, i had this problems too with wget and some other libraries, i did install some other files to solve those issues
and run scripts/activate
should i just use jupyterlab in explorer? 🤣
this
requeriments already satisfied
Traceback
Please provide the full traceback for your exception in order to help us identify your issue.
While the last line of the error message tells us what kind of error you got,
the full traceback will tell us which line, and other critical information to solve your problem.
Please avoid screenshots so we can copy and paste parts of the message.
A full traceback could look like:
Traceback (most recent call last):
File "my_file.py", line 5, in <module>
add_three("6")
File "my_file.py", line 2, in add_three
a = num + 3
~~~~^~~
TypeError: can only concatenate str (not "int") to str
If the traceback is long, use our pastebin.

What about !pip install scikit-learn?

That would run from inside the jupyter cell
Same as %pip
Did you run %pip from the jupyter notebook?
%pip is not recognized
Hold up:
Inside Jupyter, in the same notebook, create a new empty Cell. In that cell put %pip install scikit-learn. Run that cell. Share the screenshot.
with cell what do you mean? a new folder?
This is a Jupyter cell.
oh
says i need to restart kernel to use adapted packages (if i restart it it says the same thing)
The system cant find the directory
yeah, i did, and when i run it it says the same thing
Show me ss


The spanish text says this:
says i need to restart kernel to use adapted packages
The system cant find the directory
%pip install -U scikit-learn
same thing
Ok, try !pip install scikit-learn
you are the best, that was it!! tysmmm!!
What's happening is: the jupyter kernel is running in a different environment than your terminal window. So when you pip install in Terminal, it's installing to a different python install.
i see, what can i do to sync terminal and jupy kernel?
You need a CNN with 8 layers to reproduce the computational power of a single neuron
Paper says 128 feature maps per layer, assuming 3x3 kernels (I can't find the actual size so I'm gonna guess a small one), that puts the number of parameters at around 2500
Times the 86 billion neurons that gives us an estimate of
2.15e+14 parameters in the brain
Which I do believe matches my previous Fermi estimate
I don't know your configuration at all... depends on where the jupyter kernel is running/etc.
I see! thanks very interesting stuff
Here
The kernels are likely a bit larger than 3x3, so they might actually match quite well, via two different paths
Kinda cool
Gotcha, thanks
one_hot_encoded_following_bigrams_according_to_maximal_distance
i don't care ok the variable names will be as long as they need to
depends on how you installed python and jupyter, how you set up the terminal, etc.
Link?
does anyone know why my machine learning bot learns through all the noice at the start but there is that one individual per generation that is all the way down there

Is something possibly wrong with my code?
does anyone have any good resources to get a really quick overview of python stuff that would be useful for math modelling/data sci (ie numpy, matplotlib, scipy, pandas, sklearn)
im using scipy for curve fitting
but its giving me a strange error, i dont udnerstand why this is wrong

Looks very clear to me, one of your arrays contains inf or Nan values and the algo won't work with those so they interrupt the execution by throwing an error
Just print every array along the way until you find out where they get introduced, then try to find out how they are introduced, and by then it should be clear what you have to do
Damn, that's disappointing
Anyone know how to parse through PDFs with complicated tables and maintain table structure? I’ve exhausted a lot of the common libraries and was wondering if there’s something out there I’m missing
I'm trying to run the model I've uploaded as an image.
I expected that the gpu (NVIDIA GeForce GTX 1660 TI) would run it faster than the cpu (AMD Ryzen 7 4800 H with Radeon Graphics), but it turned out to be the opposite with gpu taking about 5 minutes, while cpu takes about 1.5 minutes.
Is this supposed to be like this? If not, what can I do to fix it? If tensorboard profiler is what I have to look at, how can i verify that gpu is running as it should?

Can somebody explain how to find solution to question C


you may think of the law of total probability and bayes rule to write down alternative factorizations which you can then draw as diagrams. or maybe you know these concepts under the idea of computing "posterior probabilities"
guys
whenever i use dataset.take() the model gives accurate results
but if i use cv2.imread() it gives inaccurate results
i dont get it, why exactly is this happening?
are your images color images?
cv2's imread returns the slices in order BGR
take the output from dataset.take and cv2.imread and compare the individual slices, it might be that the slices are ordered differently
dataset.take doesnt exactly return anything
i have to use enumerate() to get it
it returns a tensor() when i do that
all right, that sounds fine
numpy arrays have a transpose function that, more generally, allows you to swap axes
np.transpose(your_array, axes=(2,1,0)) would give the correct order in that case
i don't recall what cv2 returns exactly, but there should be an equivalent way of reordering axes for it if it doesn't return numpy arrays

what's the type?
ok, then you can reshape exactly as i showed above
thanks
give that a shot and see
ill see if it works
@wooden sail
label = load_one_image()
img = cv2.imread("sample.png")
transposed = np.transpose(img, axes=(2,1,0))
reshaped = cv2.resize(transposed, (224, 224))
final_img = np.expand_dims(reshaped, axis=0)
print(label)
print(str(parasite_or_not(model.predict(final_img))))
returns:
ValueError: Input 0 of layer "sequential" is incompatible with the layer: expected shape=(None, 224, 224, 3), found shape=(None, 224, 224, 224)
what's the original shape of img before you do anything to it
ok, try this instead, that was my bad
img = img[:,:,[2,1,0]]
ok ty
however i really wanna see if i gets the parasitized cell correct
because it always got the uninfected ones
right
that's up to you 😛 i just wanted to point out that cv2 loads images in an unusual order. make sure that the arrays cv2 gives you are in the same order as the other loading method or the training is going to have issues
training is already done
its getting everything correct
reason im going through all this trouble is because i need to deploy to web
so i have to use cv2.imread()
instead of taking new images
btw
the unchanged image
plt.imshow() will work fine on it right?
should be the case
wait
ok nvm
i dont need plt.imshow since its already being saved
so i can just see the images
facing another problem
def load_one_image():
#reshuffle
reshuffled = test_dataset.shuffle(buffer_size=8, reshuffle_each_iteration=True).batch(BATCH_SIZE).prefetch(tf.data.AUTOTUNE)
for i, (image,label) in enumerate(test_dataset.take(1)):
img = tensor_to_image(image[0])
url = f"sample.png"
img.save(url)
return str(parasite_or_not(label.numpy()[0]))
for i in load_image():
url = f"/content/drive/MyDrive/malaria_samples/sample_img{i[0]}.png"
img = cv2.imread(url)
img = img[:,:,[2,1,0]]
resized = cv2.resize(img, (224, 224))
final_img = np.expand_dims(resized, axis=0)
print("For image "+i[0])
print("Label: "+i[1])
print("Predicted: "+str(parasite_or_not(model.predict(final_img)))
when i do for i in load_image() it cant read the image
because it doesnt exist
for some reason the images never got created?
oh
its bc google colab suck
i have to rerun the method when i changed it
that's an issue with notebooks and the possibility of running cells out of order
wwait
its making mistakes
still
it said this is uninfected

and when i do this:
for i, (image,label) in enumerate(test_dataset.take(9)):
ax = plt.subplot(3, 3, i+1)
plt.imshow(image[0])
plt.title("Label: "+str(parasite_or_not(label.numpy()[0])) + " Predict: " + str(parasite_or_not(model.predict(image)[0][0])))
plt.axis("off")
it gets everything correct
you'll have to compare what the difference between the images gotten with take vs with cv2 is
it always predicts U
are you loading the exact same image just with 2 different methods?
wdym by reshuffled?
ok
OHHHHH
bro
this is why i should start acting on my own
and stop reading online guides
a true moment of clarity!
idk why i wanted to use cv2.imread
i should have just used dataset.take()
and returned the result
I would like to create a backprop algorithm but I struggle to find a convincing explanation of the process. Do you guys have a pdf file or stuff that explain it clearly pls ?
I usually don't like video content but this is the exception to the rule. https://www.youtube.com/watch?v=VMj-3S1tku0 or https://www.youtube.com/watch?v=i94OvYb6noo
Most backprop guides don't place enough emphasis on automatic differentiation imo
Ok tysm I will watch them asap!
still very much work in progress, but not to shabby right ? compile time checks on matrix multiplication and inference of the resulting dimensions

Are you making a rust library?
I'm porting my pytorch code to rust (torch c++ bindings in rust), just playing with the idea of compile time matrix checks, might include it in a utilities file for this project but if it proves super useful I might make it into one yeah
Maybe this can be an inspiration: https://github.com/dragonfly-ai/slash
They do the same compile time shape checking etc.
interesting, will check it out for sure
never coded in scala tho, and am learning rust so idk if I'll be able to find good connections due to me being newbie in both
in rust it seems I'll be entirely relying on macros to do this
Ah that's fair
is the only way to get the FLOPS of a piece of code to manually analyze the code and add counters?
So I'm downloading Nous Hermes 2 Mistral DPO, would this be a good AI to use for python coding and data analysis?
by "for python coding and data analysis", you mean literally asking the model to write code for you?
If so, no - no model is good for that, and we strongly recommend against doing that at all.
It's the only option I have right now with my knowledge on coding and structure.
If it can calculate the data that I recieve that's good enough for me anyways
looks like doing FLOPS estimation is an absolute pita
@app.route('/predict')
def predict():
pred_array = get_img_array()
for i in pred_array:
url = i[0]
label = i[1]
prediction = i[2]
return f'<center><img url="{url}" height=224 width=224><h3>Prediction: {prediction}</h3></center>'
guys i need help in displaying the images and predictions of my model in a flask application
i think this will work
wait nvm
what exactly do i do
Yoooooo
Evening
I want to ask a question??... Been into data science for a while.... I need a platform where I can test my skills
Try Kaggle
is MIPS a good measure for code performance, instead of FLOPS?
no: different instructions have different costs
there are no really good benchmarks/ways to measure things, at least looking at it in an absolute way
anything that gives you one single absolute number as a way of measuring something will be ignoring a lot of context, and that context can make enormous differences
you can compare how two things perform on your system for your problem, but that isn't always going to transfer 1:1 to other people's environments
yeah I just need to optimize distribution of tasks over a cluster of computers with different abilities
might just benchmark a piece of the algorithm I need to run on each computer, and use that as the "unit" measurement
Yes, but you need to look at the compiled output of a program (the disassembly). Also some count MADs as two floating point operations, others don't, and so when comparing it's important to know how they count FLOPs. If MADs are counted as two, then programs that make more use of them will pretty much always win in FLOPs measurement (e.g. Nvidia counts them as two, and so the theoretical FLOPs count on the box used as a selling point is much higher than in practice for many programs).
what an absolute pain
You may want to just measure throughput more directly, how many GB/s of input data can it process.
definitely, thanks a lot for the input
That is, transform to the correct output, regardless of what in-between steps are used (maybe no FLOPs at all).
Before spending a bunch of time on parallelization, apply Amdahl's law to see if it's actually going to be worth it / do anything.
woah, had no clue this existed!
very cool, thanks seriously, will be reading up on it properly
i need to do very concrete stuff and need very concrete numbers/data for this part of the setup so that definitely helps
anyone got resources on distributed inference?
Hello everyone, how can I learn data science and ai effectively, what should I learn before jumping into this field?
I would suggest to look at the pinned resources
Hi, so I am trying to clone and install an api but during that process I am getting this error the only reason why I can think of is that its trying to access a file located in the c drive programs file but I installed my git in e drive. Any idea how to resolve this?

pip3 install git+https://github.com/philferriere/cocoapi.git#subdirectory=PythonAPI
GitHub
Clone of COCO API - Dataset @ http://cocodataset.org/ - with changes to support Windows build and python3 - philferriere/cocoapi
This was the command that i tried to run
anyone have thoughts on embedding programming language tokens
My first thought is that it doesn't sound very efficient in terms of implementation, at least in the general case. Programming languages evolve and get new features and keywords all the time. Do this for every programming language out there and it starts to look hard to even keep track of over time. Once you had an unsupervised setting where you just throw text at the model and it learns syntax, now you have to change the embedder every X months.
I think it may be a good idea for self contained models specialized in a single language or in a single language version. It would definitely result in smaller models due to the reduced vocabulary size
Is there anyone familiar with SARIMA model?
i have a simple question, is this equation wrong, since it does account for only p_1 and not p_2?

Im thinking of building a deep learning/llm rig from a dell powerPowerEdge R720 with 2x Tesla p40. Anyone here done this or somethinf similar? It seems like the best cost effective route compared to 3090 or 4090s and im hoping ill learn more about servers
what is p_2, in this context?
how much memory does each Tesla p40 have? Because having two GPUs with y memory is worse than having one GPU with 2y memory. It's not the same as CPUs.
24gb each, im based in UK and can pick them up for about £150. For a 24gb 3090 on ebay its about £630 and 4090 is £1700+
its a decision tree to predict cat or dog. p_1 is probability that its a cat. p_2 is dog. this is from andrew ngs course on decision tree.

Coursera
Video created by DeepLearning.AI, Stanford University for the course "Advanced Learning Algorithms". This week, you'll learn about a practical and very commonly used learning algorithm the decision tree. You'll also learn about variations of the ...
Hey guys, sorry if this is the wrong forum but I was wondering if anyone had any books they could recommend to get started with NLP? There are a lot of different sources out there and was wondering if there were any someone in here found more useful than others.
Daniel Jurafsky and James H Martin. Speech and Language Processing
This is the right channel. However, I wouldn't recommend a book for learning about NLP. Though reasonable people can disagree.
the equation is right.
H(p_1^left) is entropy of the subgroup after the left split, it contains terms of p_1 and p_2 inside
more precisely:-
H(p_1^left) = p_1 log(p_1) + p_2 log(p_2)
oh got it. thanks
what's the intuition behind the information entropy definition ? in physics entropy measures the number of microstates associated with a given macrostate
but it's worth noting i have not seen it written like that before.. it's only after i watched his video you linked that i realised that's what he meant
the way i think of it is that entropy is a measure of "how many bit do i need to recreate the information i was given" (with some degree of hand waving)
is there someone else that experience with 429 error? im using pytrends library
So the macro state is the message and the microstate is the bits that build up the message
Wait no that doesn't make sense
HTTP 429 means you can exceeding some rate limit and the server is complaining, don't do so many requests at once/in such a short time
Uhmmm
ive tried with, reduced my request and it doesnt work, i felt like google just block me away from their API
i use my laptop and PC to run the code, its ll the same
I think I can see it more or less. The more certain a bit is, the less it will be capable at conveying a message
so say you have an array of bit of length 10
1111111111 and 0000000000 has 0 entropy, meaning you almost don't need anything to recreate that array
1010101010 has entropy of 1, the maximum entropy, meaning you kinda need to store exactly that array to recreate that array
(but now that i think of it, it's not really true is it? store 10 and run legth of 5, that's not exactly 10 bit.. i guess the point is shannon entropy is a measure of that without further method of compression / just coming from a probabilitic point of view)
entropy is a nice metric here to judge how pure the dataset is. if dataset has only dogs or cats, entroy is 0. maximum is equally balanced. you dont need to use entropy any other function with similar charterstics works. infact people use 1-p_1^2-p_2^2 (aka gini) instead of entropy these days. because its efficient to compute.

inspect the headers and see if it's suggesting a time where you can start using it again
Wait but isnt entropy calculated over all possible events ? A single bit string would be a realization of a random variable

like this?
Yeah looking at a single bit
above picture considers both p_1 and p_2. those are the only two possibilities. but in general there can be more terms. i usually think of it as a metric to measure purity in this case, nothing more.
not really. look at the response object that you were given, from whatever python library you are using - the headers of the HTTP response should be parsed and stored in the object
By pure, do you mean that the prob dist is uniform ?
no not uniform. pure mean only dogs or only cats. so opposite of uniform
uniform would be a set of equal number of dogs or cats.
But in your picture entropy seems to be maximum at 0.5
we are trying to minimise entropy. or maximaize information gain. same thing
Ah okay it's a different measure I see
yes. you can go through the lecture. he explains in simple ways
No wait in the wiki it says it's entropy

So if the coin is balanced entropy is maximized
do you want to join on a vc channel?
i usually think of it as a metric to measure purity in this case,
high entropy = low purity
low entropy = high purity
it's flipped, maybe that's the source of confusion
I'm looking at entropy here
So 0.5 = max entropy
yep
Okay so, the more uniformly distributed the dataset is, the higher the entropy
At least in the coin flip case
indeed
So entropy measures how uniformly distributed a dataset is ?
yep that's a valid interpretation
Uhm okay
Gonna see if I can relate it to information
I don't see how uniformity implies information in some capacity. Since if the random var is uniformly distributed I can't really use it to encode a message
Maybe the other way around ? If it's not uniformly distributed I can decode it very easily
Or at least, predict it from the others
So in your previous example with the random string of bits
What is missing is the distribution itself
So, (00000000, P(0)=1) means low entropy
Because you just need one 0 to predict the entire sequence
As you increase P(0), one 0 will correspond to higher numbers of possibilities
Idk if I'm getting anywhere here >.>
Ah okay the description right after the graph is very telling
The entropy of the unknown result of the next toss of the coin is maximized if the coin is fair (that is, if heads and tails both have equal probability 1/2). This is the situation of maximum uncertainty as it is most difficult to predict the outcome of the next toss;
So it's measuring uncertainty
this is correct though, uniform distributions have maximum entropy
encoding techniques for communications seek to yield a dictionary of symbols that are close to equiprobable
I'm just having trouble seeing how high uncertainty = high information content
they're almost synonymous
I think I can see the uncertainty bit
Wait ,are they
If I send a message there's not much uncertainty in it, but a ton of information
there's a precise definition of information here
as an example, most text can be compressed
that hints at the existence of a more compact representation of the exact same content with different, fewer symbols
you can achieve that by removing all the redundance and expected patterns from text. those are the things that make it easy to read for you as a person, but they reduce the uncertainty in the string of symbols that represent the content
I'm looking for the definition in the wiki
things like huffman encoding do exactly this
I'm not seeing a formal definition of information
Just the entropy formula
There's a paper on this from the 40's
that is what entropy is
entropy is the standard measure of information of a random variable
the idea being that if a random variable is constant, it carries 0 information since you already know what it is
Okay sure, but from my point of view, I can't use a random process to convey information right
Like if it's uniform
the classical example is that if you're in the desert and are dying of thirst, the knowledge that it's hot and sunny carries no value to you, but the rare event that it rains has a huge amount of information
this is exactly the idea: it's the randomness that carries information
if it's not random, you already know the outcome and it is moot
and a uniform distribution is, in this sense, "the most random" because you can make no guess as to what event happens next
if one event happens less often, it immediately means it is less informative because you expect it to happen often
So would you say that entropy measures how much information a particular string of bytes has about the prob distribution that is generating it
yes
Alright I got it then, it makes some sense
and entropy in base 2 in particular measures the number of bits needed to describe an event happening
for a uniform distribution, you need a very large number of bits to describe all events
a very biased distribution can be explained with way fewer bits
now you can think back to the concrete example of huffman encoding for text
what do you do there? if a letter or string of letters happens very often, it is less informative and we represent it with fewer bits
But so like, you only know an accurate value for entropy if you know the prob distribution
So from the string of bytes, I can't really be certain about their entropy
right. in communications, you construct the source yourself too, it's your task to make it have a good distribution
In which case, how is it useful, is it another case of large numbers making it accurate
and if you hope to describe any statistical event, you need to either know or learn the statistical distribution (this is what ML is about)
I think I get yeah, awesome, thank you for your help I think I would've taken like a day or two to dig this one up
Also interesting
one way of thinking about ML is "i have no idea about the statistical distribution of data. lemme hook up this black box thing and show it so many examples that it learns the distribution on its own"
Makes sense too.
(noting that estimation theory uses a different, though tangentially related, definition of information)
Hello.
Is there anyway to match two shapes that consist of two or more contours in opencv?
I tried using matchShapes with grayscaled images but the results were totally inaccurate
results about huffman encoding are what is supporting this claim?
intuitively it looks true
Yeah intuition is easy for this one, like you can ommit 'lot stuff from english still understand message'
right but I wonder whether it depends on some statistical properties of the reducible text, or whether the reduced text has some sort of specific statistical properties wrt. the reducible text
Not sure if I understood what you mean. I think that there's something fundamental to the reduced text, as in, it's the smallest amount of bits needed to represent the text
Then you add redundancy and you get the English language
how can the redundancy part be important tho, isn't it just something you shave off anyway
so the cool thing about shannon's coding theorem is that it's not constructive
it tells you there's a theoretical amount of information your data contains, but not how to reach it
you can't in general reduce a message to its bare minimum, and even if you could, there's possibly more than one way of doing it
that actually sounds kinda odd
data can be encoded in more than one way, and you can compare how "efficient" each way is w.r.t. the theoretical "best code"
i'd assume that the "purest" way to encode data is binary
but you can't directly find what that best code is in any straightforward way
there's more than one way to encode something in binary
the entropy helps you find how many bits you need, but not how to construct the bit stream
sure, but once you compress it, the final representation should be equal for all of them - this totally coming from what my brain feels like it should be tho lol
no, that's the point
shannon's theorems don't tell you want the "final representation" is
in fact, it may not be achievable at all
but there is one and is unique right ?
0101, there's no other way of describing this
anything else would be a change of symbols
nothing is said about whether you can achieve it (might not exist at all) or whether it's unique (may be more than one)
this is the whole point
the meaning of symbols is assigned by the encoder and decoder
you don't know what 0101 represents
it could be an int, a char, or anything else encoded in an arbitrary way
you can pick that yourself
same as the number 1 can be stored as a float, int, short, long, char, str, etc
those all use a different number of bits to represent the same thing
that's not what I'm getting at tho, what I'm saying is that all those "meanings" eventually reduce to that bit string
how do you mean?
if that makes sense
like, you can have a string and a number, represent them in binary and they end up being represented by the same bit string
after ideal compression
i'm not sure i get what you mean
the original meaning is unique
the encoding is arbitrary and not unique
so you have a string of text, which you can represent in binary and then compress it
actually idk if it makes sense, never studied this stuff, but my intuition is that if there is a process of compressing a message to its bare minimum bits, they should be an unique representation
neither of those is true though 😛
there is no general process to do that, and the representation is not unique in general, if it exists at all
the only thing the theorem can guarantee you is that if you use any fewer bits than the limit, you immediately lost information and cannot recover the original meaning
can't you have something like byte pair encoding
but reducing it to the smallest bit string possible
no
it doesn't like it should be impossible
you can look this up, any compression scheme you can imagine, and this one ofc included because language models use byte pair encoding a lot, has been compared to the shannon limit
Someone sends a machine learning project in python?
so if I have a vocabolary of one letter, but I can repeat it
"aaaaa"
can't I encode it like so
"aaaa" -> 4 - b'001'
if you like
isnt't that the theoretical minimum bits
is it? that is not random if that is the whole string
so it has 0 entropy
if you consider it in the context of a larger dictionary, then you have to study the statistical properties of that 😛
well yeah more bits make it redundant, and if I take one bit I change the string
btw there's a proof that all compression algorithms will fail for at least one data input, yielding a sequence that is even longer than the original
so no single algorithm could reach the shannon limit for all data
ah
and really very few compression algorithms have been shown to be able to do that for a single type of data in the first place
the proof is cute, by the pigeonhole principle
if you start with files of a size N and compress them to size M, M < N, with a fixed compression alg that is invertible
reason why I think it's weird, is because physically there's a maximum amount of information you can place in a given volume of space, once you reach it you get a black hole and all the information gets encoded at the surface
the number of files of length M is smaller than the number of files of length N. so either the algorithm was not invertible and you violated the shannon limit/lost information, or some of the encoded files are actually of length M' >= N
so I'd imagine the black hole surface as being like, the perfect compressed encoding for the stuff that's inside
idk whether that analogy is true in the first place, and if so, whether it helps here anyway 😛
yes it is true, there's a thing about it
wait
The holographic principle is a property of string theories and a supposed property of quantum gravity that states that the description of a volume of space can be thought of as encoded on a lower-dimensional boundary to the region — such as a light-like boundary like a gravitational horizon. First proposed by Gerard 't Hooft, it was given a prec...
it's helpful because it would be the perfect algorithm that you said doesn't exist
well, we just showed above that it doesn't exist 😛
experiment always wins tho
so most likely scenario is I'm doing the analogy wrong
you're mistaking "difficult" with "impossible"
I'm currently working on making two of my simulations into a much bigger and complex one that simulates the human experience. so first up we use a hyper focused Machine learning model to try and mimic a "General Intelligence" (a general intelligence in the context of the simulation not the real world) This intelligence is placed in a world with different materials that have unique properties. These materials can be combined to create tools and technology based on a system of patterns, where the created items have the characteristics of the materials used. To manage this, I need to figure out a way to show the basic rules of this simulation, which is why I'm considering creating a simple programming language that will represent the physics in this world, allowing the MLM to learn how to work with it over time.
My question is: how can I do this in a way that allows for many different possibilities without slowing down the simulation or making it too complex for the MLM to handle effectively?
ah so I was sorta right then, just read it wrong
id love your opinions and idea's!
oh I've had a similar idea for a programming language that encodes physical laws
was some time ago, and in the context of MC simulations, the idea was to have a language that came with the physical models already coded
instead of coding a lib for it
not at all what im going for
more like simulating a new version of physics in relation to the simulation and what is present in it, as it its flexible but with limitations forcing the MLM to be "creative"
"creating a simple programming language that will represent the physics in this world"
this world being the simulation...
sure, similar to my idea, not the same
but you're probly looking for a game engine or something of the sort right
not at all no, the simulation is already built...
My question is: how can I do this in a way that allows for many different possibilities without slowing down the simulation or making it too complex for the MLM to handle effectively?
im basically looking for ideas on how this can be done in a cost efficient way that also allows the MLM to be stuck within certain limits forcing it to look into different solutions
you mean like, you're trying to find a way to describe the simulated world to the language model ?
more of less
I want it to be a programming language so the model can use it further on to make tools, new mateirials and tech
Im building the model from scratch around the programming language im making right now
ah I see, you want an API for the language model to interact with your simulation
no
you want an actual programming language for it to interact with the world, or a DSL
No i don't want it to interact with the world via a programming language, I want to make a custom programming language to represent the world so the MLM can visualise what is around the 3D representation of it inside the simulation, fetching information like the structure of the material, state [liquid gas or solid] and the materials present inside said structure, all of this to allow it to try and create tools and tech to help it in its survial / its communities survival.
Uhmm okay I think I understand, it's a DSL describing 3d space and physics
Why not use game engines and their code, sounds like you'd be duplicating a lot of work
pretty much yea
With game engine you could even vizualize stuff easier
not really, the information is back end
like everything is generated into custom classes that are then represented visually inside the simulation
and to make it a bit more difficult im using Ursina, a python based open source engine
Can't you use those classes ?
yes but again I want the model to try and make complex structures using the programming language
Presumably if you code the world, and it renders, then that code should be enough to represent the world
Regardless of compilation steps in between
...? how would radioactivity be rendered...?
Ah wait but it needs to be dynamic right
Wdym ?
im talking about an extensive simulation with a ton of diffrent attributes and physichal laws, not all of them are going to be rendered because that would fry my equipment xd
Uhm I see what you mean
Certain things you don't want to code in a game engine
You just want values to be generated so that you can feed to the LM
no... again I want the MLM to take the programming language and try to structure it into useful scripts, like tools and tech
I legit want the MLM to understand the attributes of the elements inside the simulation, find uses for them and try to adapt over time to use them
Interesting
and then to try and combine these attributes into more useful items
Wait wait, but is the LM constructing the physics ?
which is why i need it to be a programming language which is formatted in a specefic way, to give limits but allow flexibility
no not at all the physics are independent and predefined
So you just want a language which efficiently represents building blocks within the physics you coded
An example would make it easier for me
ok then... lets say I have 3 materials, Uranium, Osmium and wood.
I want to make a radioactive material that is dense and does not emit too much radiation so it can be used as a weapon, the way I would do that inside the hypothitical programming language could possibly be:
Materials = [U, O, W]
Possible_Patterns = [[U, O, W], [U, W, O], [O, U, W], [O, W, U], [W, U, O], [W, O, U]]
# logic to try and check for the best pattern based on stats and attributes inherited via the crafting proccess's logic
something of the sort
does not emit too much radiation so it can be used as a weapon
.>
sounds like you want to code my framework
my dude there is a difference between wearing a slightly nuclear necklace and being stabbed with a slightly nuclear weapon
just reacting to the weapon part, which is a bit suspicious
in any case, I have a similar thing in which you can combine materials like that
and then test for radiation and whatnot
no no its not just to combine materials
it also does CSG
but also to try and teach the model about their properties
so you can construct an environment and etc
trail and error
uhm, right, so you want the language model to code the MC input files
everything is done and dusted I am just looking for ideas on how to make the programming lanaguage so I can build the model around it
what I did was something like this
water = H*2 + O
and it would compile all the information from the elements to make the data needed to simulate radiation in water
you give it density too to get the liquid, gas, etc
yea thing is I wont be giving every element a name, or any data at all, the model will only get data to allow to try new things, from there it depends on the model itself and the enviorment around it
it's a python variable, the model can name it however it wants
for the geometry I did this
I dont this this is what im looking for my guy
with Sphere(params) as s1:
with Cube(params) as c1:
...
etc
this would construct a, I forget what it's called actually, but it's a tree structure used in computer graphics to optmize ray tracing
so like c1 is inside s1, and that info is used to not ray trace s1 when appropriate
I just want the model to try and learn based on the information it finds around it and try to apply the scientific method along with trail and error, your more trying to visualise this, I dont want any advanced visuals beyond representing the model and the base materials.
hell even those are just cubes...
not bounding boxes
...?
sure im just giving you an example based on the DSL I created within py
eventually I was gonna do something inspired by JSX
to get dynamic objects
was gonna be so cool
I gotta finish that thing
def some_obj():
t = useTime()
return <Box>
<Sphere radius={t**2} />
</Box>
uhm
this should be a t-shirt
i meant it the other way around though
many people fail to grasp that things are proven to be impossible 😛
for now
exactly like this
i mean i wouldn't wear it but it would sell
I strongly belive that given enough time we would break the laws of physichs
and by enough times I mean eons
that just means we have the laws wrong
reality doesn't care about your proof tho, if all of a sudden 1 + 1 = 3 was observed everywhere that's what it would be
you'd have to adapt your formalism
please don't ping me for this
lol
uhm, sure
...?
sorry but out of what you say I understand like 30% at best
what I'm stating is that experiment is king, and the rest is mathematical idealism
if it were any other way we wouldn't have AI in the first place for ex
the 1+1=3 was just an extreme to illustrate a point
I got like 10-20% of that sorry dude
which part is confusing
ima just give up and back out of this...
uhm sure, if you want to understand my point I'd be happy to explain tho
walks away slowly
ok i have a much less theoretical question
I'm working on something to learn from a bunch of very long budget documents (pdfs), combined text and tables
assuming I can get both types of data extracted, what would be the best approach to building something that could answer questions about the documents?
ie: "how much did the parks department spend on maintanence in 2022"
(I have a good understanding of LLMs and I know spacy, huggingface etc, i'm just trying to map out a good workflow)
uhm, I'd possibly try to tokenize everything and store it in chunks that can be embedded in a template prompt
your question here
[pre computed chunk]
and then it would output the answer if possible, like iterating through the various chunks until it finds it

IBM Research Blog
RAG is an AI framework for retrieving facts to ground LLMs on the most accurate information and to give users insight into AI’s decisionmaking process.
cool -- is there a better way than just using a diff model to answer qs from the table data?
(ideally this is something i can set up on my own server as opposed to paying for textract)
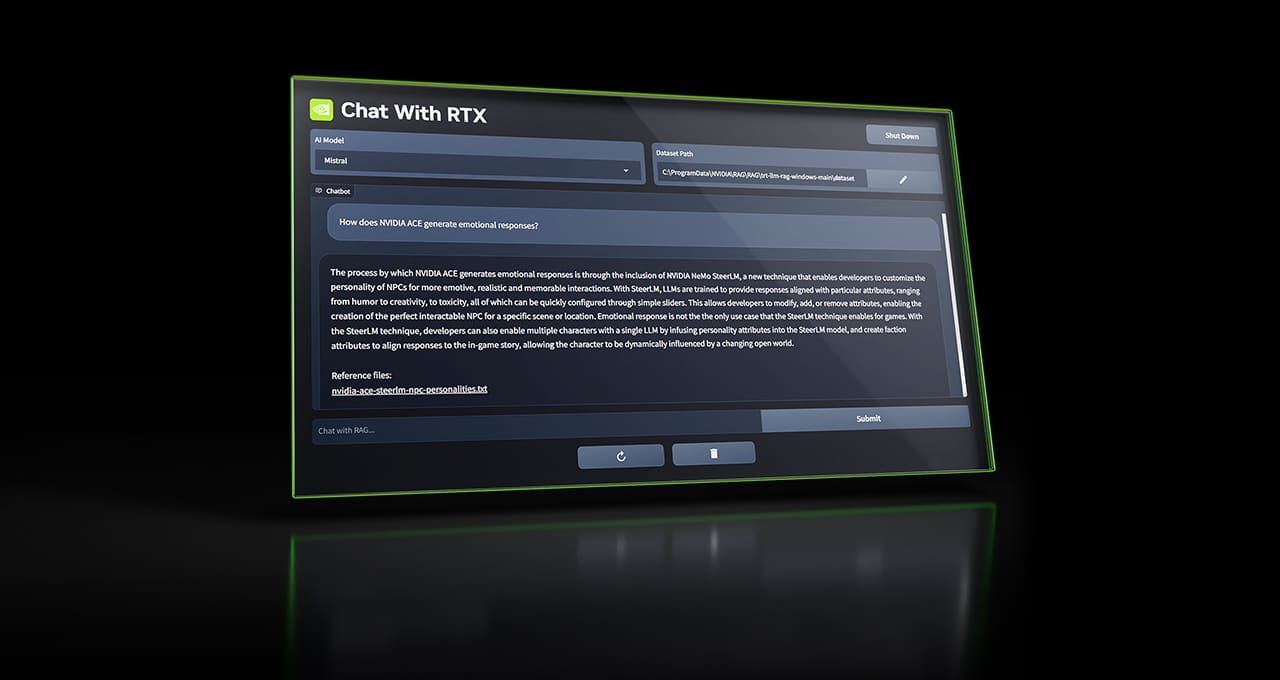
NVIDIA Blog
New tech demo gives anyone with an NVIDIA RTX GPU the power of a personalized GPT chatbot, running locally on their Windows PC.
I think it's free
gets you a UI and everything, you just feed it the documents
ayooo
and then ask questions
awesome, thank you!!!
shi- i was working on something simmillar using open source LLM's
Concept of how the model could work

yeah it looks interesting
I think there's some recent developments made by google that would make LLMs work in the context of scientific discovery
im an 18 year old soldier working from a war room on a laptop :Y
I make everything I use to save cash
as I got like 300$ in bank account after 2 months of working so
im 10 years older, we are not that different
you also live on 150$ a month?
no I pay rent
im 20 years older i haven't paid my rent in six months because im on rent strike
yea I dont I live in a room with 6 other doods :")
thats a thing?
you can make anything a strike
been there too when I was your age
hopefully the trend spreads : D
my guy im pretty sure I have some unique exprience here :")
they won't give me a new lease unless i sign away my rent stabilization, evicting people is actually really difficult
yeah, as it should be
like im currently part of a war doing 17 hour shifts while still trying to run my personal life which is 137km away I really dont think anyone else here has done that :")
are you studying AI ?
Danggg why is the entire world hyped on NN and LLMs ... I'm still learning predictive modeling on ML level 😆
in my spare time im teaching myself how to work with it
wait like a literal war ?
im in the war room rn lol
oh for sure, i think it just comes as a surprise to a lot of ppl who are worried about getting evicted!
the problem is the GPU i would be using is on a compute VM lol
still tho, good looks
ah okay, just to be clear, you are not in an actual war where people die right ?
unfortunately that's always possible given the state of things
it depends sometimes I get sent to places with semi active combat to document things
guys, can we keep this channel for the actual topics?
yea true we did drift off topic
feel free to chat about wars and stuff on off-topic or even private, many people do not need to be dragged into sensitive subjects
yeah it was for me too, I had to check because I'm taking a bit of a risk for my current career step. but like, I get along with my landlord very well and we're in constant comunication, we'd figure it out if it came to that
we already agreed and stopped dood no need to go on
oh sorry
anyway, so this is what I was thinking the model should be built around,
anyways how hard do we think its gonna be to adapt this for linux
https://github.com/NVIDIA/trt-llm-rag-windows
GitHub
A developer reference project for creating Retrieval Augmented Generation (RAG) chatbots on Windows using TensorRT-LLM - NVIDIA/trt-llm-rag-windows
i am less familiar with that shit
(good with setting up vms and good at following instructions, but not a lot of experience with GPU set-up)
I tried enabiling cuDNN its a bloody pain
I got 0 idea how to work with GPU's beyond that
is it possible the only windows-specific thing is the UX?
(i do NOT really know how computers work)
computers are fancy calculators with memory
*nailed it *
ah I didnt knw it was just for windows
oh maybe
behind it would be a windows VM ofc
id still have to figure out how to run an app on a VM
but there might be images prepared with all the drivers and stuff
er run a UX
if it exposes a web UI, all you need to do is open that port on the docker container right
um ima see and report back
it's gonna be funky for sure due to gpu stuff, but im curious to see if it works
yeah this is one of those awesome "choose your pain in the ass adventure" situations
are you using windows or linux ?
windows
linux tends to be better for this stuff
but using the gpu is easy if you're using a python ML lib like pytorch
you kind just do .to(cuda)
and a copy is sent to the gpu
all operation thereafter happen in the gpu
and that's pretty much everything
unless you want to code your own custom layers on the gpu
just got an RTX 3060 for better development but cant figure out how tf to use it
should be possible to do what I just described
but you do need to install the drivers and cuda
I am telling you hat I am struggeling with even using CudNN
uhm
sounds quite sad you figuring that out after gettin it lol
good luck tho
you gonna wanna use this
I saved for 4 yeats to buy a new setup, i7 14th gen (I now realise 14th gen is a mistake but eh) with an ETX 3060 12GB
install docker and run this command "docker run -it --gpus=all --rm nvidia/cuda:11.4.2-base-ubuntu20.04 nvidia-smi"
should be enough
now I live 137km away from it and I cant even figure out how to use the GPU
on windows?
yes
And here i am, saving money and still sittin on a computer from 2014 or somethin
(Only got a new one because i just needed open gl 3.2 support)
Suppose that, for any batch, if token X_1 appears, token X_2 will also appear. What's the most computationally efficient way to infer this property?
You guys don't need to spend too much money on GPU tho, since you can just rent it
Where does X_2 appear ? In the same sequence or it can appear anywhere in the batch of sequences ?
Oh, suppose our model takes only singular sequences and batches of size one (slightly mispoke)
I'm more confused now ahah,
So the shape of the input would be: (1, 1, number_of_tokens) ?
yep
Uhm
If there's only one token in the sequence, there's no place for X_2 to appear
I maybe miswrote it
I totally did
shape (1,1,x) is a column/row vector
this is what I mean
no it's not
i messed up too
Usually you have (batch_dimension, sequence_size)
So you mean (1, 10) maybe
[[token1, token2, ...]]
if there is X_1 in the input the model will necessarily produce X_2
Well you train it to do so