#data-science-and-ml
1 messages · Page 106 of 1
Is JSON very important?
JSON is, for better or for worse, the de facto data exchange format nowadays yes
It used to be XML, but it's been replaced by JSON
It's also used for configuration, but there I'd say YAML, TOML etc are a bit more popular
I have this following data
which I am trying to plot by
plt.plot(options['wavelength']*1e9, results_RCWA_Matrix[0].R[0], 'b-', label='R')
plt.plot(options['wavelength']*1e9, results_RCWA_Matrix[0].A_prof[0]+results_RCWA_Matrix[0].A_bulk[0]+results_RCWA_Matrix[0].A_interface[0], 'r-', label='A')
plt.plot(options['wavelength']*1e9, results_RCWA_Matrix[0].T[0], 'g-', label='T')
plt.plot(options['wavelength']*1e9, results_RCWA_Matrix[0].A[0], 'r-', label='A')```
Though I can see A_prof and A in the dataset, I think I am not indexing it correctwhich is why I get the following error
AttributeError: 'Dataset' object has no attribute 'A_prof'
Can someone help me index it properly
is there a humaneval leaderboard somewhere?
guys I don't understand the concept of a loss function. Imagine I train an actor-critic model, what exactly is being lost?
I know there is a reward function, but what does loss function mean?
Imagine this is the reward function, what would the loss function mean in terms of concept?

I tried installing tensorflow, but when I checked for the available gpu lists, it keeps coming out as having no available gpus. Running the command "nvidia-smi" in terminal shows the following image. Can anyone tell me what I've done wrong and what I should do to enable tensorflow to use gpu?

more loss: bad
less loss: good
lossless: audio format
is loss function the difference between sampled outcomes and optimal policy?
How does it know what the real outcomes are if they are unknown? If the model knew real outcomes, it would immediately set its state to optimal policy at the next step
loss = current reward + (discount rate) * (estimated value of new state) - value of current state
bad comparing to what?
absolute badness, pure evil
pure not-want
this is as much as you need to think about it because there are arbitrarily many loss implementations
there is no "The Loss Function"
you make a forward pass, you check what your loss fuction tells you, you modify your weights, you pass forward again, then you check your loss function again. if it increased, your weight mod is not a good one
i know there are different implementations
so loss function is the difference between the desired outcomes from the already sampled ones and the random guess, like in linear regression?
yes but only insofar as an increase in the loss function is bad, otherwise it's not called a loss function but a gain/value/reward function
and it's not linear regression
i repeat: you decide what your loss function is
so would I use a reward function, a gain or loss function in an actor-critic model?
can you modify your model? if you created the model, whatever you want. otherwise, you need to check how the model was programmed
thanks, will try this
I am now meeting rusts borrow checker
Unsure if happy about it
im kinda new to AI, but why isnt glob returning anything?

absolutely nothing is happening
when i run that second cell
how deep should i learn mathematics to learn machine learning?
should i be like perfect in the concepts or is it enough to know basic definitions and formulas?
It depends how far you want to go in ML
And how you want to do it
ohh
i still dont have any idea how far i might go
i am just learning cuz i am curious, interested and for my career
i got the course material and videos
If ML is "for you" you'll fall in a rabbit hole and you'll voluntarily learn the math
I assume you're not yet in university?
some of the math is being taught in the college soo
freshman
With a standard linear algebra and calculus course you can get far
I'm not from the US so I don't know what all those calc 1, 2, 3 things are but
i am not from the US too
Basically, if you have a solid notion of linear algebra and multivariate calculus you're fine
with fine I mean, fine for applied ML. If you want to work on designing new paradigms you need more math
But I wouldn't worry about that
they taught us linear algebra in the first semester, i am good at it, i scored perfect in exams, but idk if those topics are enough
ik eigen values, eigen vectors, curve fitting, etc
is that enough for linear algebra should i move on to calculus??
i also know partial differentiation and some integration
Then you know enough math to get started
fr?
yes
Yes
My philosophy is that you should only learn 1 really new thing at a time
So do Python and "just" Python until you're comfortable with it and then move on to descriptive statistics / data visualisation and then ML
my plan was to learn math first then python and then ML
now since u said my current math knowledge is enough
i will learn python then
what binary classifier for text architecture should i look into if i'm looking to optimize either for performance or for resource efficiency? (it's probably a different one for each)

Text Classification is the task of assigning a sentence or document an appropriate category. The categories depend on the chosen dataset and can range from topics.
Text Classification problems include emotion classification, news classification, citation intent classification, among others. Benchmark datasets for evaluating text classifica...
NICE! thanks a lot

The current state-of-the-art on Yelp-2 is XLNet. See a full comparison of 4 papers with code.
very neat, thanks a lot
Hi, need some clarification. In this course we replaced the 'State' column with two additional columns to get rid of the categorical values. He calls them Dummy Vars. Then he mentions to always use only one Dummy (in this example of two values), because if it's not 1, it must be Cali.
The part I'm confused about, in another course we replaced a column 'Countries' with additional columns, but we called it Vectors. To be fair, in that example it were three countries, but we used all columns.
How is this situation different than the one where we call them Vectors and use all the columns?

it's no different, it's just that in the case where you have only two categories, using two columns requires twice the amount of variables as using only 1 but does not give you any advantages at all. you already have all of the information in a single column
since there are only two classes, saying class a or class b is the same as saying class a or not class a
guys can someone help me in building a dataset
for training a sequential model
i have 2 LISTS of images with labels of 2 different classes
but idk how to make a dataset out of these
My deploy is gonna be a rust binary and a single python file that deploys the pipeline.
Ah ok cool. Any idea why one would call them Dummy Vars and the other call them Vectors? It can't be that arbitrary right?
the name doesn't really matter. both are correct: since you made up variables and assigned them a meaning, they are dummy vars. you made the variables be in the reals, so they automatically form a vector space and are therefore vectors, too
you could also say it's a vector of dummy vars, or that the dummy vars are vector-valued
and even that each entry of the dummy vars, which are vectors, is a scalar dummy var
where would you guys go for code datasets?
it's all true, you can pick the nomenclature that helps you most
make my own I guess? but are there some that have already been somewhat processed? labels?
ok thank you, very clear
guys
can someone tell me
test = cv2.imread("breast-hispathology-images/IDC_regular_ps50_idx5/8863/0/8863_idx5_x51_y1251_class0.png")
print(test.shape)
model.predict(test)
why this return error?
Invalid input shape for input Tensor("sequential_2_1/Cast:0", shape=(32, 50, 3), dtype=float32, device=/job:localhost/replica:0/task:0/device:CPU:0). Expected shape (None, 50, 50, 3), but input has incompatible shape (32, 50, 3)
test.shape gives
(50, 50, 3)
Hi I have something I want to implement using PySpark's pandas UDF but I cannot figure out how, can someone help me out please
Don't ask to ask. Give enough information that someone who knows how to help can start helping.
You're missing the batch dimension, throw in a test.unsqueeze(0)
AttributeError: 'numpy.ndarray' object has no attribute 'unsqueeze'
Also be careful with cv2.imread, it reads BGR instead of RGB, so you might need to permute the dimensions
oh
Ah right, also turn it into a tensor first
torch.Tensor(test) should work
torch.tensor(np.array([[1, 2, 3], [4, 5, 6]]))
From the docs
array([[9.999566e-01, 4.341068e-05]] my classes are 0 and 1
so which one is the actual prediction?
What am I looking at ? Is it the output of the model ?
Do sum(output) and see what you get


Awesome, it's a bit above one
wait wtf
But that's due floating point awkwardness
They are probabilities
For each of your classes

its CLASS 0
WHY IS IT GIVING 1
wait let me try with class1
its giving 0.9999
for class 1
sum() was for debugging
You have to use argmax to get the actual result
so how do i know which class it is?
ohh
what do i do argmax on?
Look up how Logistic Regression works, it sounds like you did not read up on how the model you are using works at all before trying to use it?
when i did the same thing on Malaria, the prediction was just model.predict(resized_image)
so i assumed the same
and got stuck
i used CNN on Malaria
and im pretty sure this is also a CNN
This explains the sort of output of the model you're using: https://www.tensorflow.org/tutorials/keras/classification#make_predictions
i never had to do that in my previous projects
If you were always doing binary classification before, it might have only had one output, but if you need to work with three or more classes that approach won't work
ohh my bad
I have this dataframe that I have converted into a spark dataframe

<tf.Tensor: shape=(2,), dtype=int64, numpy=array([0, 0], dtype=int64)>
thats what happens when i do argmax of the result
def get_article_details(article_id: int, article_url: str):
agent = UserAgent()
try:
article = Article(article_url, headers={"User-Agent": agent.random})
article.download()
article.parse()
article.nlp()
if len(article.text) > 0 and len(article.summary) > 0:
return (article_id, article.text, article.summary)
else:
print(f"article with url -> {article_url} extracted with 0 length text or 0 length summary\n")
except(ArticleException, OSError) as e:
print('***FAILED TO DOWNLOAD***', article_url, "\n")
print(e, "\n")
return (None, None, None)
not required
i just did x[0][1]
I have trouble converting this function into a pandas UDF, can I get some pointers on how to do so?
and that seemed to give accurate results
Anyone knows data analysis, here
When do we use linear classfiers and non linear classifiers?
the main issue is that I have found out (I may be wrong here), the output of a UDF is a single column or a pandas series. but I want to output two columns or two series. I can't really figure out how to do it. read some stack overflow questions on this and the workaround is using nested types and then selecting the individual columns from the nested types but all those answers were using normal python UDFs in spark and not the pandas UDF. so yeah links to these stack overflow posts:

Stack Overflow
I'm using pyspark, loading a large csv file into a dataframe with spark-csv, and as a pre-processing step I need to apply a variety of operations to the data available in one of the columns (that
@agile cobalt when i try to mass predict its making mistakes
can you tell me why pls
oh its coz the accuracy is 78%
nvm i gotta do more epochs
I'm studying Actor-Critic models using tensorflow, in particular CartPole-v1 from gym.
I kind of understand what a policy is = it's a Categorical distribution of the most likely benefitical outcomes. However I do not understand what a state value means
state value is tf.Tensor([[-0.11380462]], shape=(1, 1), dtype=float32)
policy is tf.Tensor([[0.42239672 0.5776033 ]], shape=(1, 2), dtype=float32)
Does anybody understand what the state value of -0.11380462 means in layman terms for Cartpole-v1 environment?
I know policy shows the best estimates for how likely pushing cartpole left or right is, hence it's a categorical distribution with 2 values. Model thinks 0.42239672 is chance of having reward +1 by pushing left, and 0.5776033 is chance of having reward +1 when pushing right
However I have no idea how to explain the state value of -0.11380462. I know this is the approximation of value function in current state from a critic
Borrow checker was easy to avoid, kept it at bay for now
Otherwise, rust is really good
Auto docs, good type system, builtin test features
ok I spoke to chatgpt4 and apparently this -0.11380462 number is only an estimate of all expected future rewards starting from the current state, which can be imroved since critic is itself a neural network. Does that mean that Actor-Critic neural network is simply a Markov chain with estimated value assigned to current state and estimated probabilities going in all possible adjacent states according to the list of possible actions?
Which language did you use to communicate to chatgpt? assembly language? 😃
Seems you're still working on the Actor-Critic model. I hope you are making progress.
All the best in your work! ✌️
nah i asked bing copilot what a value function is in actor-critic method
progress is slow, beause most implementations are heavily outdated, so I have to reverse engineer code
Don't ask to ask. Provide enough information that'll prompt people to respond right away without having to pry
but yeah thanks very much for reassurance. I don't know what level you are on, but good luck to you in your endeavors sir!
You're welcome. And, Danke schön!
Idk much about Reinforcement Learning. Hopefully you'll brave the storm on this one soonest.
Question about One Hot Encoding. Before the encoding, the column it will be applied to is at [3], after it was moved to [0][1][2], why is this?

https://stackoverflow.com/questions/54160370/how-to-use-sklearn-column-transformer could this be what you are looking for?
Almost, I understand what it does, but why did it move it to the front instead of replacing it at the end where the original feature is?
There's really no rule of thumb to this. Usually, most people use a linear-based model as baseline model and benchmark its performance against the non-linear based models (Tree-based classifiers (Decision Tree), Distance-based (KNN), Ensemble, Probability-based (Naive Bayes), Kernel-based (SVM), Neural Network etc)
Hi I have a question about Jypter Notebook: Do I need all of the code for a given thing in one cell or can I spread code across multiple cells and refrence them like I would normal .py files in a directory? Say if I had a cell specfically for defining dataclasess and other classes and then a different cell for reading and formatting my csv data and then yet another cell for tying the other two together.
you need to run cells in order of which code you need executing first, so you can spread them out
hm, do we have a clue of any relative merit? like is there truly good reasons to choose one over another depending on some particular property you need?
Perhaps, this could be because you're applying the ColumnTransformer directly on a numpy array instead of a pandas df.
i.e., none of these are strictly superseded, right?
interesting, so it could be possible that if I were applying this to a df, it would respect the original order? this means that a np array affects how the results of the encoder will 'store' it back to the array ... will try to read into this, thanks 😄
To the best of my knowledge, there's no special reason.
"All models are wrong, some are useful.”
So, I guess it depends on what you're optimising for.
For example, if you're optimising for speed, then you need to steer clear from SVM cos it takes much time to finish training compared to many algorithms; especially if you're not using its linear kernel.
hm i see, so it's really a case-by-case, hands-on, let's try it out for this particular dataset kind of thing
thanks a lot for the answer, am still working up to the RAG articles you shared btw
does anyone know of any alternatives to Plotly?
I want to have interactive 3d plots, but plotly is sooo slow 😦
pyvista
interesting, I will check it out. Thank you!
by any chance, do you know how to assign a specific color to each point according to some 'rule'?
Trying to plot a complex function and can't find anything in the docs
Uhm, can you describe what you're looking for ? Like, are you encoding phase in color magnitude in height ?
Like, are you encoding phase in color
yeah, in hue
I know there are separate packages for that. For example, cplot. But I just want to have more control over plots
Right, but what is the shape of the function, is it R to C, R2 to C, etc
C -> C, so the height will be the magnitude and the color will represent the phase
Let me see then
It's certainly possible
Stack Overflow
I need a way to make a 3-dimensional surface plot using millions of datapoints, so I began checking into pyvista which is supposed to do this well.
However, pyvista is a bit difficult for me to gra...
hm, but the problem with that, is that they don't show how to make custom coloring
You can also try Cufflinks and Bokeh
hmmmmmm. but it seems to be that it still colors based on height. altho now we just redefine those colors
Yeah but it's a custom condition
# Define the colors we want to use
blue = np.array([12 / 256, 238 / 256, 246 / 256, 1.0])
black = np.array([11 / 256, 11 / 256, 11 / 256, 1.0])
grey = np.array([189 / 256, 189 / 256, 189 / 256, 1.0])
yellow = np.array([255 / 256, 247 / 256, 0 / 256, 1.0])
red = np.array([1.0, 0.0, 0.0, 1.0])
mapping = np.linspace(mesh['values'].min(), mesh['values'].max(), 256)
newcolors = np.empty((256, 4))
newcolors[mapping >= 80] = red
newcolors[mapping < 80] = grey
newcolors[mapping < 55] = yellow
newcolors[mapping < 30] = blue
newcolors[mapping < 1] = black
# Make the colormap from the listed colors
my_colormap = ListedColormap(newcolors)
You can edit the newcolors array as you wish, doesn't need to be based on the mapping height
Oh wait it's doing custom ranges, oops
# create an image using numpy,
xx, yy = np.meshgrid(np.linspace(-200, 200, 20), np.linspace(-200, 200, 20))
A, b = 500, 100
zz = A * np.exp(-0.5 * ((xx / b) ** 2.0 + (yy / b) ** 2.0))
# Creating a custom RGB image
cmap = get_cmap("nipy_spectral")
norm = lambda x: (x - np.nanmin(x)) / (np.nanmax(x) - np.nanmin(x))
hue = norm(zz.ravel())
colors = (cmap(hue)[:, 0:3] * 255.0).astype(np.uint8)
image = colors.reshape((xx.shape[0], xx.shape[1], 3), order="F")
# Convert 3D numpy array to texture
tex = pv.numpy_to_texture(image)
# Render it
curvsurf.plot(texture=tex)
Seems to be this, create a texture based on the phase and apply it
https://www.vtabbott.io/mixtral/ will be parsing this with another ML enthusiast tomorrow, let me know if you're interested in joining us (we're just gonna VC)
I forget how amazing this lib is

btw, i recall you being interested in video ML, check out the appendix to this: https://openreview.net/forum?id=RyZB4qXEgt&ref=vtabbott.io
some neat diagrams for video architectures
Looks cool, but I gotta finish this research project first before moving to other stuff

Tho this looks a bit too heavy
yeah it's literally a full visual specification
i.e. you can fully replicate the model component from this picture
It's too heavy for what it is, scaled dot product is fairly simple
Honestly just having the equations laid out would've helped a lot streamline that paper
heheh

beautiful
It looks cool, but idk if it makes it easier for me to understand
problem is, the equation doesn't tell you how to implement it
picture does
but yeah it's a bit heavy
the first parts of the paper go into the symbology
It's a small fix, you can just use subscripts to indicate the dimensionality
heheh yeah
Tho not really cool that they don't tell you which direction to apply the softmax for ex
hmmmm
I've been using index notation in my writings and code
nice yeah that works

best stuff is whatever works
I wonder if GitHub will be mad at me if I use the attachments feature of the releases as a dataset store
Likely not right, Im sure their traffic completely overshadows anything I might do with duckdb and parquet
And they probably rate limit this stuff automatically
you probably should use HuggingFace Datasets instead?
Why ?
I like having stuff in one place
Anything else interesting they should look at?
argh i need myself some interns
actually meant to be used for large files instead of effectively abusing another service in a way it's not meant to be used as
didn't know about goose.ai though, seems like really good pricing
They do set a limit for the size of the files
We have 80GB vRAM but it's more cost effective to have them use a LLM service than getting them access to our compute
how much compute do they have access to?
And I'm not sure I'll be doing worst than what the most popular libs get naturally
Well, I think our wallet is decently deep and their experiments are small
But it's more expensive to go through IT to get them SSH access to our servers than paying for credits if you feel me?
I'm going to have 1 qualitatively guage the perf differential on all of these models
Ig I'll just push the parquet files to S3 then, still keep a copy in the releases
hahahaha christ i need to get some interns
If quality doesn't not matters a lot, you can run something like Phi2, Gemma, Llama2 or Mistral using relatively little compute (a single good GPU)
It's all gonna happen inside AWS so it shouldn't cost that much extra for the movement of data
With LLMs I don't have a good feeling on size vs quality (unlike with say CV)
heard good things about Phi2 for low param work
Hence why I need this intern to find it for me 😂
has anyone tried anything with parallelizing small models? because i'm thinking of some pipelines with multiple small LLMs that could get work done better than throwing a single request at a huge model
It's also relative to the task we're solving
yeah makes sense
iirc the biggest difference is in reasoning/logic, so if it's for something trivial like re-formatting text a small model works fine, but for solving logical problems it has to be fairly big
All I can say rn is that it's related to education
Reasoning is required
It'll have to be a big model then yeh
you can also test Gemini and Mistral's non-open source models they offer via API
and not even sure if it was worth looking into, but Stability.ai also has a model (Stable Text)
oh nice their lib can draw surfaces now
Yes. The answer to anything in ML involving "lots of parallelized smaller things" is probably yes.
heheh
Didn't google.just release some open source models, maybe they're good
seems like they're mostly about video right? stability.ai I mean
breiman did it in the 80s 😉
They like Gemini lite or something
Gemma
Gemma is English only
They're not very good at naming things
Maybe I need to just scope them better
But there's the issue of ideally having EN + FR + DE + NL
I think that Gemini was supposed to be pretty good at multi-lingual tasks
Uhm, can't you stick a model that does translation for you on top of Gemma
Not for this use case
Unless I scope it, but it gives me stuff to think about ofc
They're more or less prepping next ~ sept's grant submission
gotta get that grant money
not everything needs to be done so I could tell them to focus on just English to have a working PoC sooner
I think even chat gpt decreases in quality if you speak in a language other than English
a bit in quality, a lot in safety
Our scope is education which means it's bound to be at least 4 langs
6 if you add latin/ancient greek
there is no way in hell you're getting a LLM to understand these well lol
I'll keep the latter 2 out of scope for sure
manim
would be interesting to see how far one could get with the limited corpora we have in these languages
But fundamentally, some tasks are literally translation so if I translate the text to EN it will not work properly
i assume at some point you hit the p >> n problem
Latin will fail but I'm very curious to see how well it'll do, but that's post grant money research
That's actually a curious use case for LLMs right, preservation of language
Guys can you suggest fully local ai models - that can be run on cpu
There's many dying rn
Ancient Greek is a no-go
hello everyone, any resources you recommend for supply chain and logistic data for buuilding forecast and optimisation models and just visualising in general.
check what latest is on hugging face, falcon 7b was pretty good like 6 months ago
we've probably got some decent ancient greek data sets though. especially given the literal centuries of scholarship
we have quite a lot of latin text. classical latin is somewhat limited but still a bigger corpus than most humans would be willing to read in a lifetime
Ive got a data science bsc and comfortable with python.
Prompt engineering can change a lot depending on which model you are interacting with, not to mention translating stuff being full of complexities even when you are not talking about AI at all
Worst case scenario, making something for an English only model then trying to swap to a completely different model + trying to adjust the prompt for new languages could take as much work as building it without having made the PoC in first place
Tbh, keeping it out of scope for funding round #1 is nice because I can ask for more money to research the classics 😂
I'm very confused about the use case ngl
This is great advice I'll keep in mind
Mainly looking for something built on leaked Llama - unrestricted. With a possibility to plug it into a browser so it can browse internet
it's because I haven't explained what I'm doing, but that's really by design
heheh
for supply chain specific data, im not sure best approach
What can it do?
Do you know such models?
I'm not the resident LLM guy at work either, I'll summon them when the time is right
Lleaked lama can intake and output docs, images, audio?
I have played with tloen ai
For example
The llama 2 - on its own does it comes with guard rails of any kind?
Just in case you haven't checked it yet, papers with code might have a nice list for these things
Leaked one had none
hmm yeah I should check it in my spare time
The cursed thing is that grant writing + "pre"research isn't budgeted
So I effectively have 0 work hours do read papers for this project before it gets money 🥴
There's many cursed things in academia
The whole paper publishing mechanism is wrong and unethical, researchers are not fairly compensated for their work
the easiest way to explain it is that I'm kind of on the R&D side of academia
No pressure to publish and a decent salary
Sounds like a nice compromise
do a phd and convince people you're not wasting your time
Theres industry sponsored PhDs, if I ever go back that's the avenue I'm taking.
fine tuning does remove some of built in bias (restrictions) however its easier if main model is free
Ai can make discoveries
That's not the scary part
If you go for PhD, better make it be something you really love, cuz it's 3 to 4 years of being overworked for little to no money
That's a good question ig, when is a PhD necessary
Like, if you're not going into research
are you looking for advice about datasets? other than looking around on kaggle, there might be some data published by industry groups or various government organizations. otherwise it's not exactly a hot AI field so you aren't likely to find anything resembling a benchmark dataset that's ready to use for machine learning.
Is it worth it to spend almost half a decade ? I'd still do one because I like spending time acquiring knowledge, but idk if it would further my career
There might be a lot of nuance in there, what would happen if you filter for people in the software industry ?
AI is obsoleting phd
Ai is replacing most research job
If you need money - there is zero need for a PHD
experience is also highly valued, a PhD might be paid less than a BSc cuz he junior level
Ai even now does discover and fast
Imagine, you enter the industry right after finishing your BSc, you'll have 6 more years of experience than the person who went for PhD
Ai is cheaper, more efficient, replacing researchers
Not just google ai
Ai s in general

The problem is the journals, the whole thing should be more like GitHub you know, maybe not the same thing but in the same spirit
It's a possibility, but it might be super hard for these centuries old institutions to disappear
Direct communication with software capable of high level novel connections discovery, induction, deduction and coming self learning
Those who refuse to think - their choice
At this point in time, I wouldn't use GPT4 to learn the hardest subjects like physics and math
But I strongly believe in their potential for education
Mass education like that will be a revolution for sure
Like up to some level, it just doesn't work well yet
But it's a matter of time ig
no moreso than today with search engines
Ai is a teacher
So unis are evaporating
Furthermore many AI models have zero guard rails - pure logic

Some thoughts on teachers, students and the Future of Education.
If there's a bookish child in your life, you should get them a copy of The Way Things Work: http://goo.gl/QdreH
Also I don't think that the idea of Digital Aristotle is sci-fi, but if you do want to read the sci-fi version, I highly recommend The Diamond Age: http://goo.gl/uvb...
That's from 2012
In uni some professors disliked direction of my research. AI simply researches
Removing asking biased humans
It's thrilling that ML Research allows one to explore the unknown, however I wouldn't wanna do that in academia.
I'll always priortize places like Cohere, StabiltyAI, Brain, or DeepMind over Academia.
Idk for sure if PhD is for me either. Maybe I'll know once I get my Msc (if I don't get offer for PhD before Msc.)
Also, I think some schools allow people to drop out of PhD after 2 years and settle for an Msc. Certificate if they discover midway they don't wanna continue PHDing
The thing is that those places ask for PhD
dunno, startups go with whatever looks promising
Most of my learning happened outside classes, I'm not sure how much value my uni added tbh
it's mostly about the fact of socially organizing learning
Well, people with PhD usually gun for places like OpenAI, DeepMind, Anthropic, HuggingFace etc. And those company priorize PhD holder
Yeah I see the value in having your group of friends and a study group.
Still not the uni tho
That seems to be the only section of the industry that highly values PhD
If you can show (provably) that you have the skills, you can still get in. But you need something to substitute the PhD, that can be verified like a PhD can.
(The most important / obvious thing being experience (in a job))
Mostly, they priorize skill-based hire over traditional certificate hire
It depends on the learning style, Im best suited for project settings for ex, and that was always where I got my best grades, or when I didn't show up for classes and appeared on the exams
Uni is obsoleting
What would be a substitute ?
Papers published, projects made (note that if you show your Github, it should probably have all green squares in the commits over time part), work experience, connections.
Ai is better at research
Not that bad actually.
Contributing to an existing project that is not yours is also a pretty good one, shows that you can work with other people and their stuff / ways of doing things.
Ai is allowing China to close semi conductors tech gap
(Can you adapt to the company)
Should note that startups are very different, it's all skill there. In a larger company things like getting along with everyone else / fitting in starts to outweigh the skill the larger the company is.
As do degrees, and certifications, since they have a hiring at scale problem.
Companies using AI cutting workforce nrs
Would Open AI and anthropic fall into the startup category ? I'm guessing the company size is the determining factor here
No
OpenAI is a dominant company, they have massive wealth now and want to protect that. They will be very picky about who they let in. When a company is large enough it becomes more like an exclusive club in the higher paying positions.
To enforce this the hiring will often become more convoluted, take longer, and have somewhat arbitrary steps / requirements.
Which ai models are you using?
Yeah I'm guessing it's not worth the hassle then. There's a ton of cool companies out there. + I can always eventually make one
Also there will just be a lot of competition for those companies, so you will probably not get in just by chance.
And since the hiring process takes so long / is convoluted, it just wasted a lot of your time (low probability of getting in).
There are lots of companies to work at, don't have to go to the most popular ones just because everyone wants to.
I do really like open ai tho, they're doing the coolest stuff rn
A talking ML model
And open ai models well you can prompt hack them however by virtue of been public facing - restricted
Knowledge is knowledge
yh they have a python lib for all the visuals in the videos
Ai demands human rights Xd
How do you publish papers if you haven't gone through the PhD route? I mean you can be a genius and do important enough work during an MSc to be published as a paper but even so, papers are kind of part of the "uni" world, and R&D departments made of PhDs.
Do we need Phds? What for?
What's even more crazy and funny at the same time is trying to get into PhD program without research experience 😀😀

You just do. Many of the most cited works in ML were published by undergraduates / no degree at all.
Yep
You don't need be a genius either, there are so many threads to tug on in ML that there are many simple but unexplored areas waiting for something to try them.
Universities give some undergraduate research opportunities e.g, some summer projects. And every project report or lab report (depending on what you are studying) is sort of structured in a similar way to a paper or a thesis, you know, introduction, method, results, discussion etc. Most degrees will involve a hefty final year project, at that point you will be reading some research papers and not just textbooks
There must be so many people submitting to journals that getting published is not so easy
I recommend taking inspiration from the Wright brothers, start making things, explore, just "wing it." Don't just do what is currently popular. If you do similar things you can expect similar results, if you do different things you can expect different results.
You certainly can publish research papers even before going for PhD. If you're lucky your paper could get accepted in top AI conferences. It's not that easy but it's doable.
I don't have PhD yet but I have a couple of published papers.
It's very possible with communities like Cohere, ML Collective (they helped me get started)
(Not even a high school diploma btw)
+1 on the ML communities, there are many now, some have their own tests to get in, but some are more loose, just anyone that is interested.
This goes for non-ML stuff too, for example, if you hang around on robotics related discords you will find some very interesting people making their own unique things, and some of those might even land you a job, or want to work with you on a project / paper.
But please do not go into it trying to explicitly get a job, just only if you are actually interested in making things, be genuine.
Those are usually the best in my opinion although it comes with its own special stress (which is worth it most times)
Sure, there are people doing interesting things that are up there with university work, outside typical ML. I'm thinking of e.g. https://gpsjam.org/ which is one guy's pet project, but gets quoted by Stanford papers.
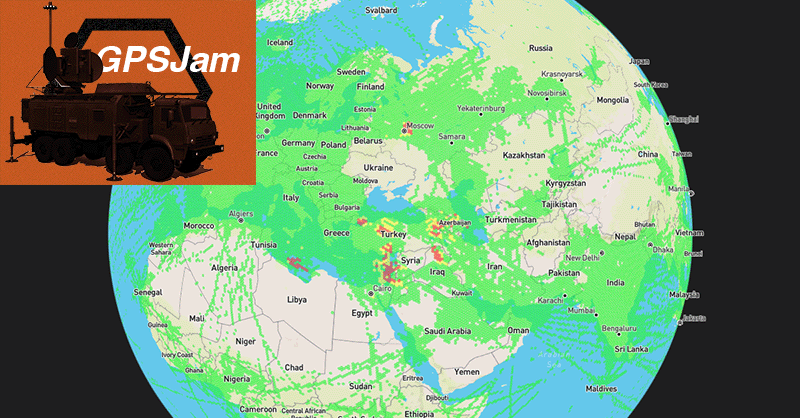
Maps showing daily possible GPS interference.
ML, being part of software has the unique advantage that you really just need a computer, and maybe some cloud, both are relativly easy to get compared to other hobbies / fields (you don't need buy a $50,000+ scanning electron microscope for whatever things you are doing).
Exactly! It's easier to also find collaborators therein. The idea doesn't even have to be something spectacular, it could literally be, for example, benchmarking different LLM performance on a VQA dataset that's native to your culture / country.
I'm tryna get published with the stuff I'm doing rn
It's not fancy stuff, but it's worth the publish if I get good results
Good luck!
Ty
Never underestimate hobbyists, they can come up with the most crazy hardware solutions. And these days even hardware can be cheap, unless we are talking about serious specialist stuff like electron microscopes 😛
Yeah, super computers are everywhere now, and cheap.
Oh, about electron microscopes tho
Also in other fields, often the best thing to buy old hardware that would be thrown out. Ebay.

Vote for me here: http://mytektronixscope.com/videos/
I am using my Tektronix 2246 analog oscilloscope to show the image generated by my DIY electron microscope. The 2246 is operating in X-Y mode, with the channels connected to a raster scan generator. The vertical scanning frequency is about 30Hz and the horizontal frequency is about 10KHz...
When I was at university I had a friend who would look through the skips to rescue random bits of dead kit
Just do it ✅
The beauty of research is, it also allows room for failure. You can literally publish a paper highlighting what you tried, the result, and how it fall short of your hypothesised outcome.
Yeah. You can find people making their own microproccessors at home and such, self-made tools or old repaired ones like the microscope.
The days before they became serious about recycling
where can i follow your stuff?
i mean, do you put up links when you publish?
+1, please also publish things that don't work (given that you tried), so we know they don't work, maybe can be picked up later and made to work.
I'm not sure if I can get published w/ bad results, at least that's not what we were taught at my faculty
Like, it's that known issue that journals refuse to publish falsification of hypothesis, thus corrupting the whole process
Someone has to do it, this is where personal principles come into play. The scientific process.
Sure, all my work is open source. Just don't know if a journal will want it.
You can always just try.
Most are on Arxiv. I intend to stay incognito for now. But this is one of my works https://arxiv.org/abs/2304.09972
arXiv.org
African languages are severely under-represented in NLP research due to lack of datasets covering several NLP tasks. While there are individual language specific datasets that are being expanded to different tasks, only a handful of NLP tasks (e.g. named entity recognition and machine translation) have standardized benchmark datasets covering se...
I will ofc, like, I don't mean to be cynical, but this is a real issue.
Can try some conferences too, not the super popular ones everyone tries to get into, but any really, your local ones.
Yeah I have a couple already
Also a talk at a workshop
But not ML stuff yet
Stuff from my previous field
Oh, a note about conferences, some are more business oriented, you want to find one that is about what you actually care about or you will be bored.
Tbh I don't think there's a "bad result" in research. When exploring the unknown, you either unravel something spectacular or you learn your approach didn't yield the expected outcome.
Either way, you gain a new insight.
Publishing failed attempt is also laudable because it provides clear perspective as regards what was explored, how it was explored, and how to possibly approach the same work differently.
cool thanks for the link!
I'm not arguing against the value of falsification, I'm just stating the bias that journals have towards positive results.
I'd swallow my words if you showed me a nature article about a failed hypothesis
Idk about journals (acceptance there might even be more crazy.)
You can always put your work on Arxiv or even submit to workshops in AI conferences like TinyPapers workshop at ICLR etc but not main conference itself cos reviewers can also be salty and brutal with such paper.
I think I can definitely get conference or workshop. I have also let it evolve into a pretty safe research question so it's actually unlikely for me to get bad results. In a sense, this is more of a reproduction study than anything else, and the surprising thing would be for it to not work.
I have way more crazier stuff planned for later.
I just need this as a stepping stone to gain experience.
ICLR 2024 decisions are now public, and it's confirmed that the recent (pretty high-profile) Mamba paper was rejected.
Sometimes I do wonder what those reviewers are smoking.

guys, how is it possible that after 100+ epochs and with an accuracy of 0.99, this is happening?


only 74.5 accuracy
did i overfit?

how come train data the accuracy is so high
The loss over epoch?
This is overfitted
The model is not complex to capture all the details
when i did the same with 20 epochs
the same thing happened

how many do i need to do
What is it trying to do?
detect cancer from 50x50x3
images
def create_model():
model = Sequential()
model.add(Conv2D(64, kernel_size=3, activation="relu", input_shape=(50,50,3)))
model.add(Conv2D(32, kernel_size=3, activation="relu"))
model.add(Flatten())
model.add(Dense(2, activation="softmax"))
adam = Adam(learning_rate=0.0001)
model.compile(loss="binary_crossentropy", optimizer=adam, metrics=["accuracy"])
return model
This is like experimenting, keep adding more layers, dropouts etc till something works
The norm nowadays would be retraining an existing model like resnet, because they're unbeatable
since im kinda new to deep learning i used an article as an guide https://www.analyticsvidhya.com/blog/2021/06/breast-cancer-classification-using-deep-learning/

In this article we are going to build an automatic breast cancer classification system using convolutional neural network in python.
they somehow got a different accuracy
and thats what im trying to figure out
I can't read this without singing in, why do blogs have to be so scummy 😐
ill explain
my code is mostly the same as theirs
the part where im confused with

is that strategy.scope part
it was never defined
so i assumed it would be Mirrored Stratefy
but since they are getting different accuracy
while everything else is the exact same
i assume the problem is with strategy.scope
for this model what strategy would you reccomend
Are you running it on a multi GPU setup btw?
nah
Then this is irrelevant, you can just remove it
Not that I'm aware of, the default parameter could have changed from the time the blog was published and the one you're using now
That could be why the results are different
which default parameter
For any of the classes or function in the code
I'm just speculating really
But are they training it in GPU?
That could make a difference, like a GPU could look at more batches of samples at the same time
so do i activate gpu accel then
wait lemme check if its already active
yes its on
Moreover, try looking into increasing the complexity of the model
From the graph it seems like it's overfit and not generalizing
so add more layers
You could try the dropout layer between the conv ones
k
but rn it seems to be different
its starting with 0.80 accuracy
on the validation
after a bit of research
is this fine?
def create_model():
model = Sequential()
model.add(Conv2D(64, kernel_size=3, input_shape=(50, 50, 3)))
model.add(BatchNormalization())
model.add(Activation("relu"))
model.add(Conv2D(32, kernel_size=3))
model.add(BatchNormalization())
model.add(Activation("relu"))
model.add(Flatten())
model.add(Dense(128, kernel_regularizer=l2(0.01)))
model.add(BatchNormalization())
model.add(Activation("relu"))
model.add(Dropout(0.5))
model.add(Dense(2, activation="softmax"))
adam = Adam(learning_rate=0.0001)
model.compile(loss="binary_crossentropy", optimizer=adam, metrics=["accuracy"])
return model
model = create_model()
model.summary()
What's the performance of your model with this new architecture?
You should, imo, nearly always start benchmarking with existing architectures like resnet/xception
Then when you roll your own architecture you can compare your performance vis a vis what you got out of those two
You should also consult papers with code to see what results SOTA is getting with this dataset. You might be getting close to the best possible and not realize it.
very important insight as well
i changed the model a bit, but i am facing a problem
def create_simple_model():
model = Sequential()
# Convolutional layers
model.add(Conv2D(64, kernel_size=3, input_shape=(50, 50, 3), activation="relu"))
model.add(BatchNormalization())
model.add(Conv2D(32, kernel_size=3, activation="relu"))
model.add(BatchNormalization())
model.add(Flatten())
model.add(Dense(128, activation="relu", kernel_regularizer=l2(0.01)))
model.add(BatchNormalization())
model.add(Dropout(0.5))
model.add(Dense(1, activation="sigmoid"))
adam = Adam(learning_rate=0.0001)
model.compile(loss="binary_crossentropy", optimizer=adam, metrics=["accuracy"])
return model
model = create_simple_model()
model.summary()
early_stop = EarlyStopping(monitor='val_loss', patience=5, restore_best_weights=True)
mixed_precision.set_global_policy('mixed_float16')
tf.config.optimizer.set_jit(True)
model.fit(x_train, y_train, validation_data=(x_val, y_val), batch_size=64, epochs=20, verbose=1)
model.save("cancer.keras")
for some reason
it is showing 1 epoch as 8 hours???
Are you training on CPU?
no i have gpu accel activated
After that I really think you need to look at my and propagation's advice
i interrupted training to make some changes and now its 8 hours
i dont know how to use resnet
but right now the problem is why it is taking so long
This is keras ye? https://keras.io/api/applications/ scroll down to https://keras.io/api/applications/#finetune-inceptionv3-on-a-new-set-of-classes

Uh well see, our teacher took all the examples once in one question to calculate Z but then in the next question he took only 1 example at a time. Why is that

All exmaples at once in first ques
But in this ques he asked us to take one example at a time

I don't wanna talk about how I learned that one 😭
we all have hahaha
I've been there, even recently
It's good advice to pass on imho

Question about Linear Regression and encoding categorical columns. Suppose I have 5 distinct categorical values, one-hot encoding would replace this column with 5 columns, for each distinct value. No biggie. But what if I have 30 distinct values, or 100, or 10.000? Is one-hot encoding still the solution? For example, I'm doing a revenue forecast on 1000 stores across the country and I have a column with the city, am I still suppose to use one-hot encode?
This encoding scheme is useful with categorical features with high cardinality, where one-hot encoding would inflate the feature space making it more expensive for a downstream model to process. A classical example of high cardinality categories are location based such as zip code or region.
Does that answer your question?
it might, will look into it, thanks
how is it possible that even with such a simple model.. i am gettign 1 epoch as 10+ hours
I think it did. If you don't mind looking at the results, this is the dataset I practiced with

I used the TargetEncoder
and this is the result

Now I'm a full beginner, but these results are not bad right? 😅
for a parquet file, is it better to have one table with everything or to split it into various tables and use the relational database thing, for example, is it better to do
CREATE TABLE test (
id INTEGER,
sentiment_id INTEGER,
sentiment VARCHAR CHECK (sentiment = 'pos' OR sentiment = 'neg'),
rating INTEGER CHECK (0 <= rating AND rating <= 10),
);
CREATE TABLE train (
id INTEGER,
sentiment_id INTEGER,
sentiment VARCHAR CHECK (sentiment = 'pos' OR sentiment = 'neg'),
rating INTEGER CHECK (0 <= rating AND rating <= 10),
);
or
CREATE TABLE dataset (
id INTEGER,
sentiment_id INTEGER,
sentiment VARCHAR CHECK (sentiment = 'pos' OR sentiment = 'neg'),
rating INTEGER CHECK (0 <= rating AND rating <= 10),
split VARCHAR,
);
@final kiln doesn't it depend? if storage is expensive and compute (joins) is cheap, you split into tables and do a relational database. If storage is cheap and compute is expensive (think terabytes/petabytes on S3 etc.) then you keep one table
Aaah that makes sense but I already started splitting. I want to keep the schema as close as possible to how the original files are laid out
test and train in different tables? why?
Thinking about it, you are not really joining on a unique key here, so not sure my answer is relevant to your particular scenario
the columnar compression should work better in the single table scenario than the two tables scenario though
this is very close to how the files and folders are laid out
--- a positive review has a score >= 7 out of 10
CREATE TABLE template_pos (
id INTEGER,
review VARCHAR,
score INTEGER CHECK (score >= 7),
);
--- negative review has a score <= 4 out of 10
CREATE TABLE template_neg (
id INTEGER,
review VARCHAR,
score INTEGER CHECK (score <= 4),
);
CREATE TABLE test_pos AS FROM template_pos LIMIT 0;
CREATE TABLE test_neg AS FROM template_neg LIMIT 0;
CREATE TABLE train_pos AS FROM template_pos LIMIT 0;
CREATE TABLE train_neg AS FROM template_neg LIMIT 0;
DROP TABLE template_neg;
DROP TABLE template_pos;
I think during training I'll be sampling randomly from train_pos and train_neg
is there a query that selects randomly, I havent done a lot of sql
If you were on Big Query https://cloud.google.com/bigquery/docs/table-sampling
Google Cloud
probably generate random numbers for each row and pick a sample from that
that's what I was thinking yeah
I'm using duckdb
still wondering why the data split into different tables 👀
found this: https://duckdb.org/docs/sql/query_syntax/sample

DuckDB
The SAMPLE clause allows you to run the query on a sample from the base table. This can significantly speed up processing of queries, at the expense of accuracy in the result. Samples can also be used to quickly see a snapshot of the data when exploring a data set. The sample clause is applied right after anything in the FROM clause (i.e., after...
duckdb has this feature where you can select tables directly using the HTTP url to it
so I'm hoping that getting them into different tables also means less bandwidth usage
like it uses some headers called range headers or something of the sort
haven't really used duckdb, but these are tables in memory and don't persist?
DuckDB
With the httpfs extension, it is possible to directly query files over the HTTP(S) protocol. This works for all files supported by DuckDB or its various extensions, and provides read-only access. SELECT * FROM 'https://domain.tld/file.extension'; For CSV files, files will be downloaded entirely in most cases, due to the row-based nature of the f...
I don't know the details yet, it's possible that it'll do some sort of caching
For Parquet files, DuckDB can use a combination of the Parquet metadata and HTTP range requests to only download the parts of the file that are actually required by the query.
ok so its like, sqlite but for analytical purpose, the tables are are just in memory for the duration of the runtime
no no, it can do parquet, sqlite, mysql, postgre, csv, json, it's a whole thing
ya but the tables are not persisted to disk if understand it correctly
you can output the result back, thats another thing
for some reason, everytime i attempt to train with GPU accel, its 7+ hours per epoch
the way im gonna set it up the files are gonna be in some remote, so it won't need to use up disk
nvidia?
ya which gpu though
only like 30k-40k params
makes sense
my gpu on my computer is intel (r) uhd (it sucks i know but its only 30k params)
check the gpu utilization during training, if its pinned at 100%, then can't do much
which os btw?
windows
currently im re running the pre processing to see if there is an issue there

performance section in the left
wait wtf
i think it was a pre processing error
becaues now it shows 3 mins
in that case
def create_simplified_model():
model = Sequential()
model.add(Conv2D(64, kernel_size=3, input_shape=(50, 50, 3), activation="relu"))
model.add(Conv2D(32, kernel_size=3, activation="relu"))
model.add(Flatten())
model.add(Dense(1, activation="softmax"))
# Compile the model
adam = Adam(learning_rate=0.001)
model.compile(loss="binary_crossentropy", optimizer=adam, metrics=["accuracy"])
return model
is there a better way to improve this model because last time i did this it gave incorrect results
you have to add and remove layers if you're experimenting, and form an understanding of what you intend to do
the norm now is to use and existing arch and upgrade and modify it
use this, since you're using keras/tf
https://paste.pythondiscord.com/2T2Q
Guys does anybody know why my optimal policy reward converges to 49 instead of 50?

I made reward function to be (1/100)*x*(100-x) which has a maximum at (50,25)

@final kiln this is how you work with duckdb?
having mixed feelings about mixing python and sql together :\

facing the same issue again
7 hour for 1 epoch
gpu is as 9%
its fluctating between 8 and 15
can you take a screencap and put it

vs code tajing 95% of memory
def create_improved_model():
model = Sequential()
model.add(Conv2D(64, kernel_size=3, input_shape=(50, 50, 3), activation="relu"))
model.add(Conv2D(32, kernel_size=3, activation="relu"))
model.add(Flatten())
model.add(Dropout(0.5)) # Adjust the dropout rate
model.add(Dense(1, activation="sigmoid"))
# Compile the model
adam = Adam(learning_rate=0.001)
model.compile(loss="binary_crossentropy", optimizer=adam, metrics=["accuracy"])
return model
model = create_improved_model()
model.summary()
mixed_precision.set_global_policy("mixed_float16")
tf.config.optimizer.set_jit(True)
early_stop = EarlyStopping(monitor='val_loss', patience=5, restore_best_weights=True)
model.fit(x_train, y_train, batch_size=64, epochs=20, validation_data=(y_val, y_val), verbose=1, callbacks=[early_stop])
model.save("cancer.keras")
current code
and gpu accel is on

so how is it possible that 1 epoch is 5+ hours
What is a train test folds?
this is vsc setting to use gpu accelerated ui rendering bruh
Only works for VScode
try this to list devices which tf can see
https://www.tensorflow.org/api_docs/python/tf/config/list_physical_devices
TensorFlow
Return a list of physical devices visible to the host runtime.
cpu
bruhhh
does tf even support intel gpu btw? not sure
i have amd cpu/gpu at the moment
how do i actually activate gpu accel
try this
then its not able to see a supported gpu unfortunately
from this intel gpu is not supported 😕
https://www.tensorflow.org/install/pip#hardware_requirements
TensorFlow
....
im sure it would work fine on google colab
but for some reason i cant even get the files there
in colab the usual pattern is to put files in gdrive or some bucket store and get it from there
What's the issue
iirc for gdrive the it gives the required code
the zip file doesnt unzip properly in colab
mhm and if you don't want to/can't attach the gdrive to the colab instance (e.g. not your gdrive acc)
You can just wget it
What do you mean but doesn't unzip properly
if i try to transfer from local to drive
its missing so many files
yeah that's pretty much how I'm gonna use it, with a bit more type checking perhaps
I'm not sure if this is a colab issue
wait let me show

i tried unzipping a zip file from kaggle
and its missing tons of files
And when you unzip the same file on your local machine / pc it's fine?
Using the same method to unzip?
Check the paths and the compatibility of unzip tool you're using with the archive(zip) format
This is a quick question, but how much difference should a tensorflow training process running on AMD Ryzen 7 4800H with Radeon Graphics compare to the same process being run on NVIDIA GeForce GTX 1660Ti? When I tried both, one with cpu took 11 hours while gpu takes 10 hours
You need Nvidia gpu in order to leverage CUDA. From this picture, you don't have the kind of GPU that'll allow you accelerate model training on your local machine.
I know this is sad news. I've been there. Blame Intel & AMD for allowing Nvidia monopolize the market unopposed.
You can't even train a deep neural nets with CIFAR-10 using a small model like ResNet-18 on a PC with Iris Xe GPU in < 4 hours. Now, imagine how long it'll take a pc with UHD GPU.
You should move your work to Colab or Kaggle if you'd want to use a free-tier GPU.
Or better still, if your pc has thunderbolt port and supports eGPU, you might wanna buy your own external GPU and just connect it to your pc.
check the gpu utilization during training
i did with tf.config.list_physical_devices('GPU'), and it detected a gpu
would this be more of a model issue?
that list the gpu, you have to use nvidia-smi or task manger if you're on windows

i will try that out
wait a bit while please
- would a model with about 500,000 params take this long for one epoch when done with 64 batches with about 1490 datapoints?
mfw you've been training on CPU all this time
eh no idea, is this some llm thing?
yeah

i mean, training doesn't seem to have started but gpu is being used up
iirc tf allocates all memory during initialization
someone correct me if i'm wrong
that's the default behavior, you can set limits and/or have it allocate vram as needed too. that's usually slower
Can anyone help me with this please? https://discord.com/channels/267624335836053506/1211270314605150228
I want to get the top k similar sentences from a corpus of senteces to each sentence in another list.
I'm really struggling with learning the high level view of which ML is part of. Made a Linear Regression model, happy with the scores and results, but now what? How do I save this model, where do I save it, how do I make it part of a pipeline for future use?
Every tutorial, course, and blog so far, focus on the experiment part, training, testing, hooray you made your first model ... that stuff. But once I have, not a single source I found so far talks about what I'm suppose to do with this model.
If anyone can point me to the proper direction, that would be great. Just to clarify, I have this model on colab, yes I can download both the notebook and the py files ... but what the heck do I need to do with it? 😅
that's really up to you. do you wanna make it part of a bigger product? make it so that it is automatically applied to a specified dataset? have the trained parameters be frozen and used for inference in a less powerful device like a phone?
there's no one direction, the question is more "what do you want to do with it?" which depends entirely on the problem you wanted to solve and why
maybe this
https://roadmap.sh/ai-data-scientist

roadmap.sh
Learn to become an AI and Data Scientist using this roadmap. Community driven, articles, resources, guides, interview questions, quizzes for modern backend development.
ideally you want to look for problems which can be solved with data and compute
then decide what to do next
I want to make it into a permanent solution. For example, if I make a model to predict procurement prices, I want to 'run' the model every quarter so our managers can have a fresh prediction every quarter to use for their decisions. This means that every quarter, the model receives new data from the quarter before this, retrains and predict. Of course, I will also review the model every quarter to check on data drift and other errors/issues. Does this makes sense?
there are typically three types of use cases
- realtime
- streaming
- batch
yours likely goes into batch
yeah, then you want a way to keep training the model with new data in the future, and also a way of "deploying" it. will it always be you that runs it, or do you want other people to also be using it, possibly without needing to know how it works behind the scenes?
the most simplest way would be to create a cron job and schedule it
you could achieve this as easily as having a jupyter notebook and storing a history of the trained parameters somehow, or e.g. make it into an easily deployable container
a batch makes sense, it would be a fixed periodical thing, and let's assume that my dataset is large but not in the millions that it requires the batch to be broken up in pieces
i meant batch jobs, not batching data
I followed the tensorflows' guide for tensorboard and this is what I got for results of the test code that they wrote. not quite sure if this means anything

this is not the right metric, this is about the layers in the model
oh its profiler not tensorboard
ideally yes, I would be the person doing all that, with the extra note that for deployment, it would likely be with assistance from IT, but surely I need to tell them how it needs to be deployed? I mean, if it can be as simple as a graphical representation of the pipeline that enables me to click run, that would be fine
then that requires you to automate the process of training and inference. that means automatically preparing and batching data, for example, and storing the results in a desired way
yeah this is exactly what I mean when I struggling haha, can't find anythinh (likely because I googled on the wrong keywords?) on moving it from experiment to production
how to do that depends on what infrastructure and software you have at hand
there's no one size fits all 😛
i guess this falls under MLOps, as someone pointed out above
you can read about that to get a feel for it, but the specific implementation really depends on the software you want to use for it
I think this is what people mean when being asked what the most valuable skills are ... putting it in production 😄 I can see this in job descriptions and finally know what it means, now that I'm struggling with it myself even if it's a practice model (small scale, nothing fancy, nothing complex)
thanks for this, looks useful to have as an anchor
mle/mlops engineer here, there is no generic strategy for this
each one depends on the company, use case and limitations
Oke so right now I'm doing this in my free time at home, to develop my skills for future jobs (currently in data analysis/management). Let's say I want to simulate the entire pipeline on my local computer. Basically, data is stored on csv, csv goes in the py file, model training and testing. How do I get the data that is loaded in, to be refreshed with new data? My gut says something called orchestration plus Edd mentioned automation. And then after the model did it's thing, I somehow need to store it in a way, that my Power BI can access it so I can make a dashboard.
how do you decide if the data is new?
there are to be something which tells the data is new
Because my colleagues will tell me on one hand, and give me the new data to upload in the ERP on the other hand
so new data is coming in regularly
i guess from powerbi would connect to data sources like a database, so it makes sense to dump the results into a database
correct, so that is probably the least challenging part
correct what does new means? it could be a like a column in the tables or an event
I think what I'm struggling with is how to 'make' the pipeline itself
pipeline could be anything really, its a sequence of step, could be functions, modules etc
I meant in terms of software, what software I need to make the pipeline
you want to something fancy, you can look at some pipelining tools like prefect, airflow, dagster etc
the use case you describe is very simple, you can put the whole thing into one .py file and call it a day 😛
I'm using prefect for pipelines
schedule it via cron, and we're done
Ahhh someone mentioned Prefect the other day, is that the type of tool that I need? I can make the steps you mentioned and in each step it's a piece of code, ranging from loading data, cleaning it up, and my actual ML model, all the way to storing it in a database so Power BI can access it?
Yeah
It boots up a fancy UI and everything if you want
With a flow chart showing all the tasks being executed real time
And you can also do it in deploy mode, so you can manually trigger stuff
Like in the UI
Flow chart, oke now you speak my language haha, I love flow chart as it makes things easier to understand.
basically all of the pipeline tools helps us in creating something called a DAG (directed acyclic graphs), you should really not be limited by what tool you pick
I'm coding one rn let me see if I can show you
some are geared towards data engineering and some towards ml
Agree, but I'm not an data engineer so wanting to make permanent solutions pushed me in that territory where everything is new 😉
just try out some, see which you like
dagster is the new shiny toy, its more geared towards DE i'd say

Luigi is simple, Airflow is powerful, and Argo is Kubernetes-based. This post offers a detailed description and comparison of workflow orchestration tools.
Hey everyone, I have a question which kind of laptop should i buy for machine learning and data science
Which one would you say is very beginners friendly? I'm on Windows and command line is not my best friend 😄
actually dont have a good one yet cuz im stil coding it, but it looks like this

prefect is easy
and you can start/stop every node seperately, or all in sequence if you wish?
I think you can only stop and start manually if you're in deploy mode, like if your run the pipeline from the command line, you cant stop it or pause it, but if you run it from the ui, you can do wtv you want
what type of models are you going to work on?
I am a begineer
@flow
def imbd():
conn = duckdb.connect()
slice = []
for split in [TRAIN_POS, TRAIN_NEG]:
data = ( x[0] for x in conn.sql(f"SELECT review FROM '{split}';").fetchall() )
for review in data:
slice.append(encode_text(review))
and i have very slow laptop running right now
and it's literally just a wrapper, "flow"
currently replacing my laptop so going for future proof
just get a decent one, don't think about ml right now
colab, kaggle provides some free gpu usage per month
I think I can understand this, it looks partially like SQL
oh nevermind, didn't see the sql method being called haha
print("Accuracy: {:.2f}%".format(accuracies.mean()))
could someone explain this line of code
the {:.2f} part just means "print the floating point number with two decimals"
looks like you're following an old tutorial. most people would write
print(f"Accuracy: {accuracies.mean():.2f}%")
I am thinking of learning pytorch and LLM's along side python how should i proceed???
Yo if anyone uses or plans to use the GPT-4 API (Turbo or Vision or whatever) please dm me, I have an opportunity for you
@autumn acorn messages such as these are not allowed.
!rule 9 6
6. Do not post unapproved advertising.
9. Do not offer or ask for paid work of any kind.
just was wondering something abt openai pricing
"I have an opportunity for you"
sry sir
anyone hear of anything involving pure function classification? classifying code into pure vs. non-pure functions?
easy enough in haskell lol, but python?
Ah okay so I run Cell A then Cell B then cell C, but I can call the functions from Cell A from inside Cells B and C?
yes, but anything in Cell A that depends on Cell B and Cell C won't run properly the first time you run Cell A
I assume you run them in this order Cell A -> Cell B -> Cell C -> Cell A. Do you mean this?
fml sometimes i hate python
I'll recommend this MLOps Roadmap https://marvelousmlops.substack.com/p/mlops-roadmap-2024
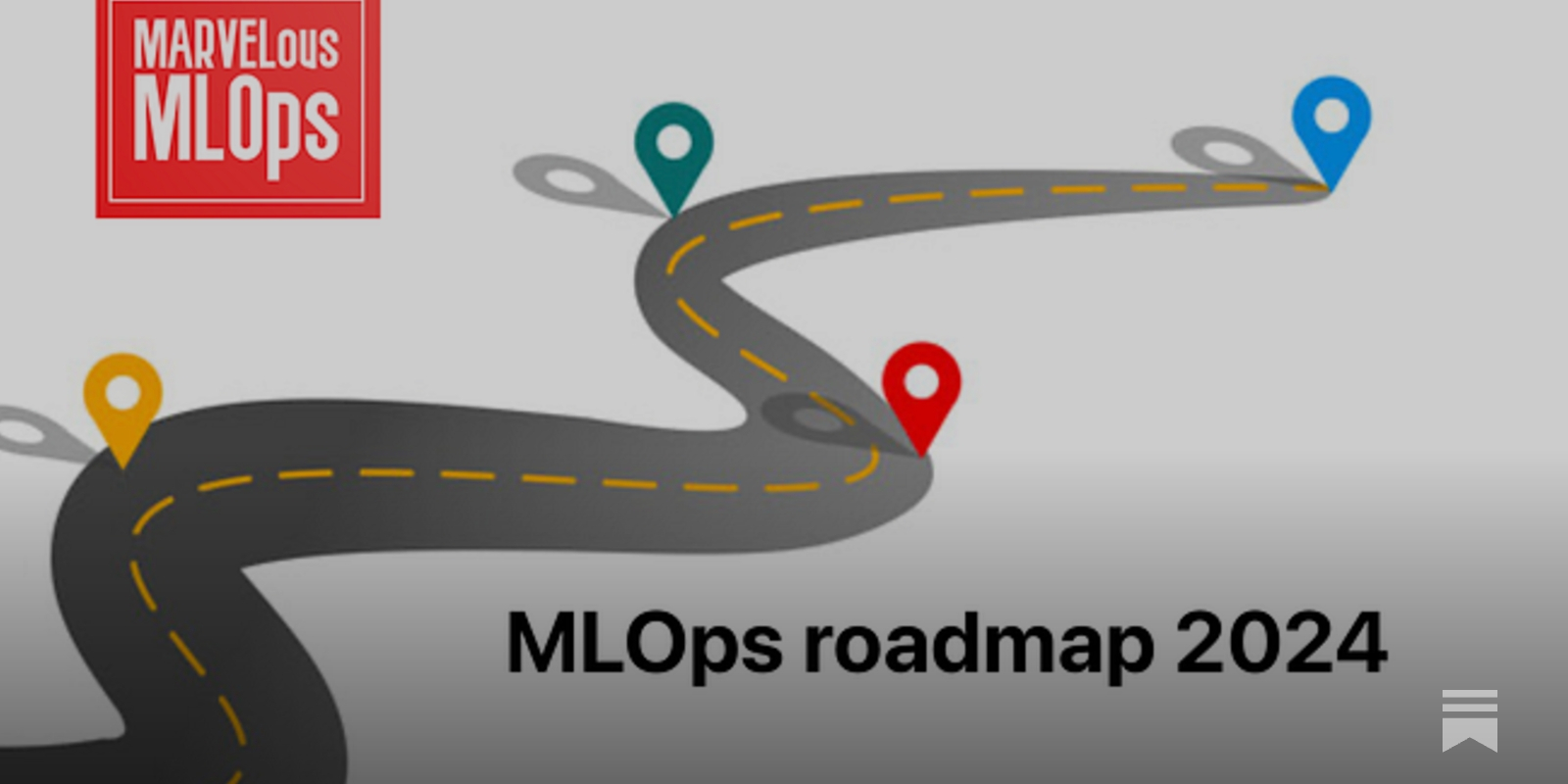
The MLOps engineer role is different from an ML engineer role. Even though the role varies from company to company, in general, ML engineers focus more on bringing individual projects to production, while MLOps engineers work more on building a platform that is used by machine learning engineers and data scientists.
Whatever brand of pc you decide to purchase, ensure it comes with Nvidia GPU (at least 8GB)😃
Python
ML
PyTorch
Deep Learning
LLM
In that order
Maybe it's because I'm more used to py, but now that I'm back to py I'm noticing how easy it is for me to produce code that is hard to test
bookmarked, will read into thhis as well, thanks
Im trying to get the profile for tensorboard to work, but it says that it failed to load libcupti, although I have installed nvidia toolkit. How can i fix this error?
hey guys what if i combine many machine learning models together, like llama2 with falcon, etc. . what is the problem i am gonna face while doing this?
Define combine
Can you brief why should I go in that order??
I think you can't do attachments, only pictures and links
Anyone can help me?
They are in order of pre requisites, you need one to understand the next
I meant: Cell A -> Cell B -> Cell C, no looping back to Cell A.
Thanks for explaining how to works to me
Ohh
but will be there a big difference in accuracy or just small difference, i mean is it worth to combine it?
I was asking if you could be more specific about what you mean by combining
I'd throw in studying the math too, like linear algebra and calculus
Yeah I am doing that also..
i mean combining many machine learning models
Any source you would recommend for llm and pytorch
That can mean many things
I haven't tried it but I've heard of it from a co-worker. I believe a research paper called model soups or something revealed how to perform weight sharing across different LLMs.
arXiv.org
The conventional recipe for maximizing model accuracy is to (1) train multiple models with various hyperparameters and (2) pick the individual model which performs best on a held-out validation set, discarding the remainder. In this paper, we revisit the second step of this procedure in the context of fine-tuning large pre-trained models, where ...
Pytorch I learned via the documentation, LLMs I learned by just implementing the stuff from papers and online diagrams
Learning this stuff is fairly easy if you get your foundations right
Thanks for the help
For math I recommend Khan academy, you can start at whatever level you are and build up
I think I can go with maths on my own , I just wanted to know how should I approach pytorch and llms..
If you know your linear algebra pytorch shouldn't be any trouble
I guess the only way to know the possible problem(s) you'll encounter is to try it first or read the research paper.
Alternatively, I found this blog/ tutorial on implementation of model soups.
https://lightning.ai/lightning-ai/studios/efficient-linear-model-merging-for-llms

Model merging is a technique for combining multiple pretrained or finetuned LLMs into a single, more powerful model. This approach is particularly useful when individual models excel in different domains or tasks, and merging them can create a model with a broader range of capabilities and improv…
I am at basics of Python at what level would you recommend I should start learning them??
First become good at python, you should be fluent in it, you should be able to write python as easily as you write English
You can also totally parallelize learning here
Like implementing math algorithms using python and numpy, helps you learn the math, py and preps you for pytorch cuz the indexing magic is similar to numpy
Ok so I learned that saving and loading a model, either in the same file/notebook or across files/notebooks, can be done easily with joblib. Has the community accepted a naming convention that I can use? Pretty sure something like 'final_model-25-2-204_version2_realfinal_withupdatedparam-002' will not be liked? 🤣
So I shouldn't go for parallel approach in learning Python and neural networks??
Uhmmmm, not if you don't have the math yet
nvm
Pytorch hides a lot of details of what's happening
When I say implement it's you writing very barebones algorithms
support ar ?
Wrong channel I believe
Sorry
Try #web-development maybe
Idk if there is a specific one for django
bro like half of my files are just not there when i unzipped my dataset
in google drive
i did it from google colab
I was thinking of applying for internship during may-june and most of them requires experience of 3 month in Python , 3 Mounty in py torch , 3 mounth in llms...
is there an easy way to unzip a huge file (like my dataset) to google drive
Not sure if I get your point tho
Like, if youre not proficient with any, that's the path, py, pytorch and then llm
Actually I am at 2 sem at uni , and thinking of applying for internship during fall break , and to be prepare ahead I read the requirements for same internship during summer and the requirements were 3 month of experience In Python , pytorch , llms....
So that's why I was asking for If I could go for parallel learning
I'm guessing they won't expect you to have any sort of in depth experience in LLMs or even pytorch, I'd go for strong python skills, working knowledge of pytorch and qualitative understanding of LLMs, perhaps building a simple CLI chatbot with one of the open source models
3 months of each is really asking for just surface level knowledge
Yeah I though that too I will get good at Python and maybe a basic level knowledge at pytorch and LLMs will do
Thanks for your time will keep you updated on my process and let you know if I needed help during learning
I'm having a hard time with SQL because I can't get variable queries unless I do templating
I wanted to avoid templating since I have every info I need in my shells env
anyone work with einsum? if so, any good tutorials?
looks like it really is something you should get used to
guys
i downloaded a dataset w kaggle in colab
colab
but i cant find a way to unzip all the files to the cloud
i can do it locally
but it wont let me tranfer it
Like I really need a for loop ._.
In SQL select query?
yes I need to execute this statement N times
ALTER TABLE dataset ADD COLUMN epoch1 FLOAT DEFAULT random();
for name in ["epoch1", "epoch2"]
SQL is meant to be declarative vectorized operations at column level
that makes it fairly useless tho, I can't do anything ; /
When you want to do element level operations you should stick with python
within the context of my application, it would be very nice to keep all these operations here
I guess you could use f strings in a loop for this
Something like
for epoch in epochs:
f"""ALTER TABLE dataset ADD COLUMN {epoch} FLOAT DEFAULT random();"""
yes that's what I'm trying to avoid
Can't have everything lol
perhaps I can find a midterm using jinja
I think im gonna go with something like this yeah
This is an unnecessary dependency, use fstrings or vanilla jinja
yeah im going for vanilla jinja
{% for epoch_name in epochs %}
ALTER TABLE dataset ADD COLUMN {{ epoch_name }} INTEGER DEFAULT trunc( {{number_of_partions}}*random() );
{% endfor %}
dont know why sql doesnt support this
trunc is needed because casting uses weird rounding rules
templates you mean? eh never need it i guess
no I mean just basic control flow, i don't really see much of a reason for it to not be supported by sql
plsql might be what you're looking for
udfs or procedures are used for custom functions, but i guess at this point we should stick with a real programming language
It’s one of the big annoyances: not being able to parametrize table names nor column names.
It has already automated a lot of stuff for me tho. This dataset is also pretty small so I'm literally just doing a select from a link to the repository, didn't need to move any files around, just committed them to the repo and that was it
I completely regret splitting the data like this tho, just gonna do a single table >.>
plsql?
Duckdb and jinja
I meant plsql is a possible solution in terms of what you're looking for
Oh interesting
Instructor said the model is overfitted a bit, but it's oke for this use. I haven't had the theory about over/under fitted yet, but am I close when I guess that the line following the dots so tight is what he means with overfitting? And that it's ok for this use since the predictions will be nicely 'on par' with the rest?

The only real way to check for overfit is to plot the line against unseen data
You can imagine that your data has been generated by an underlying fundamental law, but due to the nature of measurement, it will always contain some level of noise. Overfitting means that the model has memorized the details of the noise instead of the underlying law
Tomorrow I'm gonna finish this pipeline. One additional thing In adding to the mix is that I'm computing the random splits a priori and saving them to S3 with MLFlow. This basically lets me do fault tolerance, if AWS takes away my spot instance, I know where to start from without losing the splits.
Altho, I'm guessing that just saving the seed oughta be enough.
Yeah nevermind I'm just gonna keep saving the seed.
AI is becoming a professor
A bit off topic - Is universal income coming
Like using gpt3.5 for some of the prompts to 4
There are tons of open local ais
Good thing about rust is that I can't do a @contextmanager that yields a closure that returns a generator over the data
Oops I pinged someone
Like I know all the abstraction is bad for me, but I do it anyway cuz I'm tired and I need to get this done
SENTIMENT_TO_INTEGER = {
'pos': 1,
'neg': 0
}
def set_seed(conn, seed):
raise NotImplementedError
def create_table(conn):
conn.sql(f"""
CREATE TABLE dataset AS
SELECT id
FROM '{DATASET_LINK}';
""")
def add_epoch_column(conn, epoch_idx, number_of_partitions):
conn.sql(f"""
ALTER TABLE dataset
ADD COLUMN epoch_{epoch_idx}
INTEGER DEFAULT trunc( {number_of_partions}*random());
""")
def select_partition(conn, epoch_idx, slice_idx):
return conn.sql(f"""
SELECT sentiment, review
FROM '{DATASET_LINK}' as remote
JOIN dataset ON (dataset.id = remote.id)
WHERE dataset.epoch_{epoch_idx}={slice_idx};
""")
@contextmanager
def dataset_partitioning(number_of_epochs, number_of_partions, seed = 0.5):
with duckdb.connect() as conn:
set_seed(conn, seed)
create_table(conn)
# note: sampling is pre-computed here, data is fetched on demand with "fetch_data"
for epoch_idx in range(number_of_epochs):
add_epoch_column(conn, epoch_idx, number_of_partions)
def fetch_data(epoch_idx: int, slice_idx: int):
sentiments, reviews = [], []
for sentiment, text in select_partition(conn, epoch_idx, slice_idx).fetchall():
sentiments.append(SENTIMENT_TO_INTEGER[sentiment])
reviews.append(text)
return sentiments, reviews
yield fetch_data
if __name__ == "__main__":
with dataset_partitioning(number_of_epochs=2, number_of_partions=5) as fetch_data:
sentiments, reviews = fetch_data(epoch_idx=0, slice_idx=3)
it's not so bad im guessing
much better
I think I'm gonna start placing my test cases in the same file, like how it's done in rust
simple implementations of the self-attention algorithm consider the K, Q, V objects to be matrices, i.e., 2-dimensional tensors. when does self-attention operate on higher dimensional tensors?
all implementations use bidimensional Wq, Wv, Wk. the resulting K, Q, V have 3 dimensions because the the first one is the batch dimension
b = batch dimension, c = context window, d = vector embedding dimension
input_bcd * Wq_dk = output_bck
forgot k, k = projection dimension
batch dimension, will look into that thanks
there's not much to it, you stack multiple inputs in that dimension. only pitfall is that pytorch has a rule for matrix multiplication when you have multiple dimensions like this, important to look that up
features are your input variables, f(x1, x2, x3) - x1 x2 and x3 are your features
ive seen people call the output of the layers features too
hm, noted thank you!
guys I'm stuck, can anybody help with this?
log_prob = action_probs.log_prob(self.action) # gives error
# action_probs = tfp.distributions.Normal("Normal", batch_shape=[1, 1], event_shape=[], dtype=float32) <class 'tensorflow_probability.python.distributions.normal.Normal'>
# self.action = tf.Tensor([[-0.00545995]], shape=(1, 1), dtype=float32) <class 'tensorflow.python.framework.ops.EagerTensor'>
# log_prob = tf.Tensor([[nan]], shape=(1, 1), dtype=float32)
Why does this line output [[nan]] instead of a proper number?
You gotta print inputs and outputs at each step until you find the faulty step
log_prob = action_probs.log_prob(self.action) this is the faulty step, but I don't understand why
Have you printed self.action ?
tf.Tensor([[-0.00545995]], shape=(1, 1), dtype=float32) <class 'tensorflow.python.framework.ops.EagerTensor'>
You're applying the log right
it's all in the comments. I printed every single input
did I mess up the batch dimensions?
No, you're applying a log operation on a negative number

isn't log being applied to action_probs?
I don't know, but it really looks like it's being applied to that negative number, given that the input and output dimensions match
looks like it, I'm not sure what the 1st argument is (self.action) for .log_prob(). do you happen to know the answer or where to get the answer?
I don't know as I have very little context, but usually the first line of help is doing something like
help(self.log_prob)
That will print the docstring of the function, but your IDE should probly show it too
thanks, will try
Second line of help is the libraries documentation
Which sometimes are even compiled from the docstrings anyway
my tfd.distributions docstrings are completely broken