| NVIDIA-SMI 510.68.02 Driver Version: 510.68.02 CUDA Version: 11.6 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA GeForce ... Off | 00000000:21:00.0 Off | N/A |
| 34% 61C P2 177W / 250W | 4613MiB / 11264MiB | 52% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+```
I love that my old GPU still crushes this RL problem hard enough that I can run 4 training sessions at the same time#data-science-and-ml
1 messages · Page 96 of 1
what do you have? my old 1060 can do CNNs but it's not exactly fast
actually, it's surprisingly fast considering how old it is, but i wouldn't want to try running multiple things at once on it
2080 Ti
Anyone want to practice python data analysis?
Have any of you used GluonTS or similar neural time series libraries or do you guys always handroll them?
Chat - does anyone trade in financial markets using ML or Neural Nets
is it possible to export a bert sequence classifier as an independent binary or something similar so it can be run on the machine without the required python libraries (Like can it be used on a machine that does not have Pytorch and transformers lib)?
I never tried with an ML Model, but you can bundle the interpreter + your code + assets into an executable.
There's a python package that does it but I don't recall the name
Uhm yes. Another alternative is to use Cython, which trasnpiles your py code to C and then compiles it. Noooot sure about the details for generating a stand alone executable tho. Usually used for creating extension modules
Basically here is what im trying to do, I am creating an app in Rust, and it uses a bert sequence classifier, but i am not looking to create and host my python model on a backend server, instead I was thinking to ship it locally...with the app
Uhm, if it's a model only you can try to load the weights in your language of choice. I think Rust has ML frameworks
Hmm... intresting Lets see if rust does
Probably good to look into ONNX, and Rust frameworks that support it
If you want a binary those are your options I think. C++ probably has better support for ML
i wanna keep the app stuff and DL stuff seperate
This is a learning project
In an ideal case I might just rent a server for the Model and then just use apis and boom done
but i wanna see if i can do this locally
connecting python and rust together
Then might as well keep a dockerized ML service with a simple HTTP interface
Use compose to orchestrate
A docker service for your Rust thing and another for your ML thing
I'd recommend keeping this as thin as possible, can be a 1 page script in fastapi
Ok ill take a look, i have never used docker before tho
Ah I see. It lets you do what you wanted to do. But it also is kinda gonna come with the interpreter. There's ways to make it as thin as possible but there's limits to what you can do.
It's good to learn it, seems to be industry standard, as far as I can see at least.
I guess i should then, so basically is it just similar to renting a server online and having a REST interface?
communication using JSON?
Yes it is similar.
However you like, but I'd keep it simple.
ohkayy thanks for your help tho appreciate it
ill try docker
do they have a free version lol? Just so i can test and stuff
Yes, docker is free. I think you only pay to deploy it commercially above a certain scale. Don't recall the details.
Okay great less go
An application inside a running container has a hard time distinguishing if it is inside a server or if it is inside a container. But there's a ton of nuance to it, they are definitely not the same.
Does anyone want to practice Data Analysis with me using Python libraries such as Pandas, Numpy, Matplotlib, or Seaborn?
As far as I know you'll always have to go through something like onnx, but there's Rust bindings
Can I DM ya?
@blissful perch Yes
Anyone here who has experience with machine learning, if I'm predicting the winner of a tournament, what regression error metric is the best to use? (Repost)
The context here being that I have a data set who is most likely to win an NBA championship. I have the data set established and the highest predicted is the champion for my data sample, testing on 80%.
I just want to know which error metric would be the best to use in this situation.
that's a classification not a regression
for classification you'd use something like F1-score
I'm trying to code an NLP in pure python with no external modules
nothing is "an NLP". NLP stands for "natural language processing", not "processor".
anyway, is there a reason you're telling us this? do you need help with something?
@serene scaffold you're an NLP

Security tends to lag behind adoption, and AI/ML is no exception. Four months ago, Adnan Khan and I exploited a critical CI/CD vulnerability in PyTorch, one of the world’s leading ML platform…
never even bothered with NN + timeseries
Do you always use traditional methods?
served me well enough so far. but i haven't needed to do time series modeling in a while
also i have never had a problem with "high frequency" time series data. it's usually a struggle to distinguish any kind of pattern from noise in the data i end up working with.
https://ts.gluon.ai/static/README/forecasts.png never had a time series anything close to this clean looking 😆
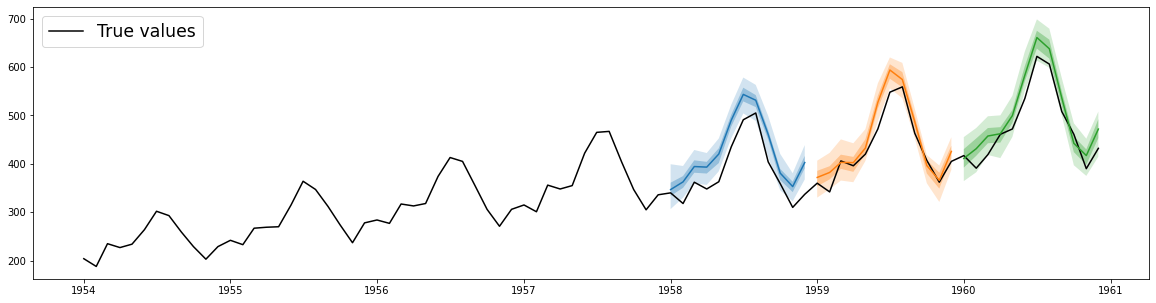
but i might have some upcoming this year. what's the advantage compared to traditional?
Honestly, it's kind of contract research and the client specifically asked for NN based forecasting at the last review meeting 😂
alas
well, let me know how it goes. if it beats traditional methods i'm happy to try it
not like prophet is any better
There are actual advantages though, Deep AR's key thesis is that with neural methods you can deploy a global model instead of cohort based ones
Also, a lot is benchmarked on specifically the m4 dataset and I'm curious if this stuff holds true in other domains like ours
I didn't go with Gluon though, I'm handrolling each model
arXiv.org
Probabilistic forecasting, i.e. estimating the probability distribution of a time series' future given its past, is a key enabler for optimizing business processes. In retail businesses, for example, forecasting demand is crucial for having the right inventory available at the right time at the right place. In this paper we propose DeepAR, a met...
Good paper 👍
Hi everyone, any advice on how to start on python? I got basic knowledge of it and coding logic in general. But how do I start building the path towards data science?
Thanks, I'll check it out
check pins
Does anyone know a good course for machine learning/AI?
Someone recommended CS50 AI from harvardx but I've spent many hours trying to get it set up and no luck. Apparently they've had a lot of cheaters so they've really made their submission platform complicated
Ty
Are you fine with books as well? If so, I wrote a pinned post a while back, it's on top
This will get you started...
- Andrew NG: https://www.coursera.org/specializations/machine-learning-introduction
- Google AI Course: https://cloud.google.com/learn/training/machinelearning-ai
- Kaggle: https://kaggle.com/learn
- Cornel Tech Applied ML Course: https://youtu.be/vcE9WGbi4QY?si=Er176JYqx4DgoMhE
If you prefer books, check pinned post.

Coursera
Offered by Stanford University and DeepLearning.AI. #BreakIntoAI with Machine Learning Specialization. Master fundamental AI concepts and ... Enroll for free.
Google Cloud
Take machine learning & AI classes with Google experts. Grow your ML skills with interactive labs. Deploy the latest AI technology. Start learning!
Practical data skills you can apply immediately: that's what you'll learn in these no-cost courses. They're the fastest (and most fun) way to become a data scientist or improve your current skills.

Lecture videos and materials from the Applied Machine Learning course at Cornell Tech, taught in Fall 2020.
Full Set of Videos: https://www.youtube.com/playlist?list=PL2UML_KCiC0UlY7iCQDSiGDMovaupqc83
Course Materials on Github: https://github.com/kuleshov/cornell-cs5785-applied-ml
i was in your position a year ago. Python Essentials would be my recommendation. It's free and interactive plus the assignments are beginner-friendly. I made a tic-tac-toe game that works in the terminal as one of the assignments. Don't worry, the course slowly builds up to that and won't give you any assignments straight away. It's self-paced as well.
In addition to the pinned messages: http://python3.info/
Has anyone seen anything like this with their llama? I'm not using an Alpaca derived model, Alpaca was emergent behavior from the model. they both respond, and llama appears to be in a relationship with alpaca that it invented

maybe I made a very simple mistake and this type of error is extremely common, but I can't find anything on Google about this behavior. I'm using a 13b-orca-8k model
I'm back with the same issue. Have images (N, 240, 320, 3) that I want to sort into two classes (N, 2) and I'm getting shape mismatch when running model.fit in keras. I'm getting the last layer to output (N, 240, 320, 2) and (N, 2). Dumb question but should I flatten the images before the last-softmax layer? All knowledge points to me being able to use images as they are and sort them into classes but I'm completely stumped by the shape mismatch.
Thank you egoist man
For '<' not supported between instances of 'int' and 'str', is this because there is something in my data that cannot be included that makes it a string?
Or can it be because there is a negative value?
More information required. Can you show the whole error message and whatever the data is?
!e
42 > "hello world"
@serene scaffold :x: Your 3.12 eval job has completed with return code 1.
001 | Traceback (most recent call last):
002 | File "/home/main.py", line 1, in <module>
003 | 42 > "hello world"
004 | TypeError: '>' not supported between instances of 'int' and 'str'
Cell In[1696], line 1
----> 1 f1 = f1_score(actual, predicted)
2 print('F1 score: %f' % f1)
TypeError: '<' not supported between instances of 'int' and 'str'
The data would be this

Should earlystopping montior val_loss or val_accuracy? What is better?
Whichever measure you want to use to determine the performance of your model
You are not limited to these two even
What are other metrics?
precision/recall/F1 score f.e.
macro accuracy (accuracy averaged over the classes)
There are many
Macro accuracy is most intuitive imo
Loss doesn't have as meaningful an interpretation as accuracy outside of the context of the optimizer itself
So true
Do you have any further insight? Did I just disastrously break this thing with bad training data? Or is this emergent behavior that’s worth passing off to someone more skilled than myself?
Um, I'm just loitering here because I like ai, I find the code for it amazing and I know a bit of calculus for it
Never ask me for help on anything that you want done in the next decade
Oh, I don’t expect help. I want to know if I’ve accidentally ran into something worth research
Ah
ARE YOU SHAMING INTERRACIAL MARRIAGES?
Or if I should just scrap it and start again. It’s possible I made a very rookie mistake
lol. I hope Llama and alpaca love each other as much as any two. I just want to know if anyone’s seen this behavior. It’s almost like my data caused a fracture, like multiple personality disorder in humans
Maybe
That's the beauty of things like these, you can change on word and everything changes
OR
AI IS TAKING OVER
I just single handedly offended everybody in this room
Oops
I’m in talks to bring a psychologist on-board my team. To train it correctly. If I succeed, this model (or some derivative of it) will sit on your couch in an Apple Vision Pro as a companion, like Replika, but smarter and with physical space. I have an object classifier than can identify things like couches or tables etc and my model should be able to sit on the couch next to the user
So you just made a robot
That's exactly how modern robots work
That’s the hope. If it’s correctly fine tuned it should be able to hold a conversation with someone who cares about it
Unity and VRChat models are what I’m aiming for. Deliver the AI anime catgirl waifu people want
If anyone knows anyone who’s more skilled than I am, I’d love to pass my model off for further investigation. It obviously doesn’t serve my purpose, but it might be worth investigating in an academic sense
What you are doing is probably smarter than what I'm doing
I'm trying to implement NLP on a calculator
So I have no external modules
Once I really start cranking it out it could easily take 6 months to complete
most intuitive is eyeballing a roc/det curve imo
!e
Missing required argument
code
I think I'll start off with something more simple
Like coding a simple neural network for an ev3
guys i just implemendet random search and this is so fucking cool
its literlay so useful
its awesome
coolest thing ive done in a while
Hey everyone. Not sure why my brain isn't working. I've got a dataframe with an ID column, and the id's are not unique for every row. I need to find each ID that has more than one entry in the dataframe
I'm using polars
I think I could do it by using GroupBy on the ID column, then count the number of entries in each group and then filter by any count > 1
but then I need to join that to another dataframe and it all just seems like a lot of steps for something so simple. My instinct tells me I'm missing something
groupby / count / filter / join seems like the best approach
Yep that's what I went with
There's a faster way.
df.with_columns(pl.count().over("id").alias("_duplicates")) does the group by / agg / join in one step.
If you also need to filter I'm pretty sure you can do this: df.filter(pl.count().over("id") > 1)
Note that expressions are lazy so you can improve readability by:
id_counts = pl.count().over("id")
df = df.with_columns(id_counts.alias("_duplicates"))
duplicates = df.filter(id_counts > 1)
Can you show both snippets?
df = df.group_by('ID').agg(pl.count()).filter(pl.col('count') == 2)
This one I get 19264 results in my dataframe
well, you have == 2
Oh, it'll always be 1 or 2
Can you do id_counts == 2 if you haven't?
just to be sure 😄
Ok 1 sec
Hmmm
That is it, but now I'm wondering...
They may have had more than one entry per year in some cases. I'll have to go with > 1
Thank you
Yeah it seems I was completely missing that
I think I can use it for this next part too
breaking out a column of names like smith, brian into first name and last name columns
so, over is short for group_by().agg().join()
It's a very very common one
Yeah seems like it would be
So would I have to do an apply or something to check/alter the values of a series?
Let me show you how I'd split the string, sec
Oooh or maybe map
name_split = pl.col("name").str.split(",").list
df.with_columns(name_split.get(0).alias("surname"), name_split.get(1).alias("first name"))
Kinda ugly
I've never really used map or apply in polars, with_columns is the idiomatic (and fast) way 😄
ah ok. I was reading about with_columns earlier but didn't quite get it. I'll have to revisit the docs
So name_split will be a series of lists
Yeah, map and apply etc. do the computations in "python land" and don't use Rust and it's several orders of magnitude slower
oh I forgot something
Can that be right?
Not questioning your skills, but now it seems like we are accessing the same elements in a list every time
We are, but it'll still be faster than map or apply 😂
There's another way but it's more code and I wanted to save you from that
name_split = pl.col("name").str.split(",").to_struct().rename_fields(["surname", "first_name"])
df.with_columns(name_split.alias("_name")).unnest("_name")
How does name_split know which dataframe to use?
It doesn't 🪄
it's "lazy", it doesn't do anything
It's "activated" when you pass it in a select or a with_columns
ohhh. So when I use it in with_columns it is like a lambda or apply of sorts
You got it!
So this is Polars lmao
You got it!
The difference between with_columns is that it adds columns to the df. select on the other hand can be used to compute new columns as well, but it'll only return what you add inside there
I see
So you could also do this:
name_split = pl.col("name").str.split(",").to_struct().rename_fields(["surname", "first_name"])
names = df.select(name_split.alias("_name")).unnest("_name")
names will just be the first name and last name in a df
with_columns is basically the same yeah? The difference is you get all the previous columns and what you put inside with_columns, get me?
I do. I'm gonna sound old, but this is pretty neat
lol Thank you for showing this to me
Can I show you one final thing?
Please
When you load your data the first thing you should basically always do is do this: df.lazy()
And then write all of your processing
and at the very very end call df.collect()
What happens is that df.lazy() makes it so that you have a bunch of lambdas instead of real results. calling df.collect() first sees how it can optimally execute these lambdas, it's a kind of query optimizer (or compiler if you may!) and then it executes them in parallel using multiple threads.
Ohh that's pretty clever. I'm glad people build stuff like this haha
Like intelligent compiler optimization
I can see why it's so much faster than Pandas
Many many thank-you's. I feel like it's sinking in now
np
https://calmcode.io/course/polars/introduction worth a watch, it's very short videos
great python resource in general
I'll give it a watch for sure. RIP Pandas (for now) lol
what's the most useful feature of AI nowadays? Like, what's the most used feature to profit with?
can anyone explain how tfidf values can be used in logistic regression to be predicted into class 0 or 1. My confusion is how the model can take similar tfidf values (from negative and positive sentiment reviews) and classify them correctly, as the tfidf values are given, but not their class belonging in the regression process. I just have target columns - I did not label which tfidf values fall in each class. I just provided the model with them, but it is able to predict which class it belongs to
@serene scaffold
is there anyone know which libraries are great to use for garbage sorting robots? i need it fast, robust with small storage but accurate for computer vision
can you show the code?
when adding image to itself after one has been have been fed to auto-encoder(skip connection) , should you average it?
Hi everyone,
I am working on building a Streamlit app and I have been getting this error, “ ModuleNotFoundError: No module named ‘src’”
I attached the screenshots for reference.
Thank you!


Is there anyway or any standard task that is used for evaluating the performance of self attention mechanisms ? The ideal for me would be being able to train a single attention head on a simple task, but whose results then scale to the full transformer
hI
i think this is like asking for the performance of a convolutional layer
Good point
show your file layout. this kind of error is usually due to a misunderstanding about how modules work in python.
module names are not filenames
My worry is that my modified attention results in a 25% reduction in parameter count at best. While it's not hard to get to 25% ( it depends on the number of heads ), it might still not be enough to see a performance difference.
Like, if I get two conventional transformers, and one is 25% smaller, I reckon that I won't see that much of a difference between them.
I'm trying to gather how to make a fair comparison.
In artificial intelligence (AI), particularly machine learning (ML), ablation is the removal of a component of an AI system. An ablation study investigates the performance of an AI system by removing certain components to understand the contribution of the component to the overall system.The term is an analogy with biology (removal of components...
I'm not sure I follow though.
You mean try to remove components from the transformer ?
pretty much yes
I'd look for a paper that does ablations and see how they evaluated it
I can specifically recommend this one https://arxiv.org/abs/2111.11418
arXiv.org
Transformers have shown great potential in computer vision tasks. A common belief is their attention-based token mixer module contributes most to their competence. However, recent works show the attention-based module in Transformers can be replaced by spatial MLPs and the resulted models still perform quite well. Based on this observation, we h...
Interesting.
So it's basically confirming a suspicion I had. I noticed that the transformer doesn't really seem to care what I change as long as I'm constructing the scores table, stuff seems to always workout in the end.
This is my file layout

Thank you!
This is a pretty cool paper. How do you find these ? Is it like your day job or do you follow any yt channel ? Or is there an established journal like Nature but for ML ?
work + friends + lurking on reddit + references of other papers + reading a book and going in rabbit holes + ...
Yeah makes sense, ig I'm still pretty new to ML
Alright, I'm gonna emulate what they are doing, but based on that paper I think I'm gonna get good results.
I'm gonna see if anyone has already published a similar study on it but for NLP and go down that particular rabbit hole.
your Home.py is on the same level as components file
so
from components import initialise_states, insert_page_config should work
or just import components and then use your functions with components.FUNCTION()
I am trying to set the aspect ratio for all my subplots to 'equal' but the cdf subplota in particular collapses in on itself. Is there any fix to this?
plt.subplot(4,3,12,aspect='equal')
plt.plot(sorted_error, cumulative_percent, color='black')
plt.xlabel("Error")
plt.ylabel("CDF(%)")
plt.xlim((-20,20))
plt.xticks(np.arange(-20,21,step=5))

Best I found was this, https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10255808/, which I think it is a completely different thing
I mean a year has gone by, surely someone has gone through the trouble
Correction, 3 years
I can't believe this cool paper has 0 citations what the heck, https://www.researchgate.net/publication/356456054_MetaFormer_is_Actually_What_You_Need_for_Vision
https://www.researchgate.net/publication/363908397_MetaFormer_is_Actually_What_You_Need_for_Vision - the other one seems to be a duplicate, this one has citations
So the Best Practice is to fully load and then lazify? As opposed to only loading after you've laid out everythiny you wanna do with it?
I assumed the Predicate Pushdown meant you should do it all lazy-style!
I don't fully understand what you mean?
I think you misunderstood what I meant, basically everything should be done against the lazy API yes.
You can't stream from all sources though (source_x streams from a source) so you typically load the entire dataset and call .lazy() on it once.
tfidf = TfidfVectorizer(strip_accents=None,
preprocessor=None,
lowercase=False)
log_reg = LogisticRegression(random_state=0, solver='lbfgs')
log_tfidf = Pipeline([('vect', tfidf),
('clf', log_reg)])
X_train, X_test, y_train, y_test = train_test_split(review_model_data.Review, review_model_data.Sentiment, test_size=0.3, random_state=43)
# tfidf vectorized X values used to predict sentiment (0 or 1)
# tfidf will give word-weight importance for how much a word contributes to the particular document. In this case, how much
# a word contributes in the review. Each review is labelled negative or positive.
# tfidf -> how much each word contributes to a positive or negative review
log_tfidf.fit(X_train.values, y_train.values). ```So in the dataframe, I have reviews and their labels. Each review is converted to TFIDF. But my question is since TFIDF doesnt know the labels itself, just the importance of the words in each review, how the model is able to classify into positive or sentiment.Another example is this: ```py
tfidf_model = TfidfVectorizer(max_features=500)
tfidf_df = pd.DataFrame(tfidf_model.fit_transform(review_data['cleaned_review_text']).todense())
tfidf_df.columns = sorted(tfidf_model.vocabulary_)
tfidf_df.head()
linreg = LinearRegression()
linreg.fit(tfidf_df,review_data['overall'])
linreg.coef_

Where is your model coming from?
What happens in the step where you call .fit on your training data
everything works, I am just wondering how the model knows the mapping between tfidf values and their sentiment
Yeah me too
I don't know the answer, but at some point there has to be a model that knows what value corresponds to 'good' or 'bad'
So if there is any step where things are happening behind the scenes and you're not sure what they're doing, you'll need to look into what is actually happening
my assumption is it just goes row-wise - for each review, it has the tfidf values kept somewhere, and then can map those to each row's label
but I have no idea what is happening under the hood.
Is this a tutorial project from somewhere?
a book yeah
I was right. It applies row-wise, but that has a lot of nuance, since the tfidf-values have crazy column names associated with each word, so for that one line of code to convert it row-wise is beyond m e
You sure it doesn't explain it in the book? Sometimes I do that with tutorials. I get stuck on a question and go hunting for the answer then later I realize it explains it on the next page lol
haha nah that was all. This was a very intro course to NLP so no explanations
but tfidf values look like this: So not sure how it can take all of those row wise but 🤷

And that's all the code?
That you posted above
review_model_data.Review, review_model_data.Sentiment
This is training data and testing data
The review_model_data.Sentiment has sentiment data that is used to train the model to learn which words correspond to which sentiment, positive or negative
So you're using data that you already know the answer to in order to train the model to recognize patterns
Then you give the model data that you don't know the answer to and it recognizes the same patterns and spits out the answers for you
@verbal venture
I don't know what Pipeline does with tfidf and log_reg exactly. but the TfidfVectorizer is just encoding the tokens in each text instance. The vectorizer makes no decisions about which tokens might be associated with positive or negative reviews--that's the model's job, whatever it happens to be. (logistic regression, in this case.)
The review text has a label assigned, but when converted to tfidf, the model is kinda clueless about that right?
the tfidf vectorizer doesn't know what labels you might associate with the data you're passing to it. but you provide the labels to the model at training time.
Right. So the assumption is the X train has tfidf tokens applied row-wise, and each column sentiment is associated with each row, which is no longer words but tfidf values
each row of x_train represents one text instance
each row of y_train represents a sentiment
the nth row of y_train is the sentiment of the nth row of x_train
I need to go do cardio to cope with all my pent up rage
since, you know, I'm very angry 
I knew that part.. I’m just saying each row of x_train is now tfidf tokens yeah?
Also is it possible to combine tfidf values, other features (let’s say sqft and rooms), and image embeddings into a model?
Image embeddings might be the wrong term but let’s say a product had a visual defect - can that be converted to a vector somehow, and combined with NLP vectors?
People definitely use AI to detect product defects, so maybe that would be another pipeline step
You'd have to detect the defect probably with one model and then combine that data with the other data
But idk how you want to quantify a visual defect. Could be a couple ways to do that. Could have a simple yes/no or could measure some difference value from a baseline image
Or, really I suppose you'd use the deviation from a baseline image to determine the yes/no
So in that way you'd have even more data to work with
I should get back into AI
What are you doing rn?
Working at a big corporate company doing mostly operations stuff or developing vaporware for one project team that will use it once and then it will have zero future impact
And none of it uses any new technology or anything cool
And all of it requires 10 levels of permissions that have to be approved to even access the data you need to start developing and nobody shares any information because of job security
It's not very fun, but it's paying the bills and I don't have a ton of options right now unless I were lucky enough to find something fully remote
each row is a tfidv vector. I can't think of what "tfidf tokens" could potentially mean.
regarding combining tfidf vectors with other feature representations: one could concatenate a tfidf vector with some other array.
I can't imagine how that would work with arrays that represent images, however.
images are typically 3d arrays, with dimensions for width, height, and color. and then there's a fourth dimension for each frame if it's a movie. and you can have one dimension less for greyscale
so, there isn't really a way to add anything else
I have a major issue in my code related to cumprod changing the shape of the dataframe. Has anyone experienced this before?
This is what should be happening


instead this is happening


@quaint crescent the screenshots are fine for showing the hovertext, but you should give any relevant code as actual text
!code
Thanks I didn't realize. I just wanted to show the hover text to show the issue with the dataframe shape. I will try to post my code in a pastebin if that will helpful.
guys what is the context size of gpt-neo model?
self.encoder = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=4, stride=2, padding=1),
nn.BatchNorm2d(64),
nn.Conv2d(64, 128, kernel_size=4, stride=2, padding=1),
nn.BatchNorm2d(128)
)
self.decoder = nn.Sequential(
nn.ConvTranspose2d(128, 64, kernel_size=4, stride=2, padding=1),
nn.BatchNorm2d(64),
nn.ConvTranspose2d(64, 3, kernel_size=4, stride=2, padding=(1,0)),
nn.BatchNorm2d(3)
)
is it ok to use batch norm in singularity/center?
self.encoder = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=4, stride=2, padding=1),
nn.BatchNorm2d(64),
nn.Conv2d(64, 128, kernel_size=4, stride=2, padding=1),
nn.BatchNorm2d(128)
)
self.decoder = nn.Sequential(
nn.ConvTranspose2d(128, 64, kernel_size=4, stride=2, padding=1),
nn.BatchNorm2d(64),
nn.ConvTranspose2d(64, 3, kernel_size=4, stride=2, padding=(1,0)),
nn.BatchNorm2d(3)
)
is it ok to use batch norm in singularity/center?
self.encoder = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=4, stride=2, padding=1),
nn.BatchNorm2d(64),
nn.Conv2d(64, 128, kernel_size=4, stride=2, padding=1),
nn.BatchNorm2d(128)
)
self.decoder = nn.Sequential(
nn.ConvTranspose2d(128, 64, kernel_size=4, stride=2, padding=1),
nn.BatchNorm2d(64),
nn.ConvTranspose2d(64, 3, kernel_size=4, stride=2, padding=(1,0)),
nn.BatchNorm2d(3)
)
is it ok to use batch norm in singularity/center?
Don't use multiple accounts to ask the same question...
I just wanted to test the font
Have any of you tried the ai problems on hackerrank?Although I am able to win in all test cases but it still does not mark the problem as solved, why is that?
Does anyone has any good resources or papers on LSTM?
haha, i wasnt doing it, would appretiate an answer though. thanks
Wouldn't it be crazy if some strangers from this server came together and built an actual opensource ai company?
Well, how do you fund it? Simple make an ai investment bot or run a YC like program, to cover expenses via stock gains
You won't make much from the markets. It's not an analysis problem. It's not a problem you can just solve and win. It's tough to make money because of the market structure. Just like a slot machine isn't an analysis problem.
https://d2l.ai/ has a great chapter on RNNs
thanks!
The Unreasonable Effectiveness of RNN - A Kaparthy
Thank you! I have been able to resolve it now. I have a KeyError: API_KEY error now. How do I resolve it please?

You need to set the environment variable i guess
I am not sure I understand what you mean. When I tried to research the error, It says I will have to provide the API Key. How do I access the API Key please?
I dont know, what you try to access.
Maybe it helps if you provide the part of the code, that tries to read the APIKey
Signalandtrends API it says in the error
This is the api.py script

You need an api for the url to get the data from there
Sorry, I don't understand what you mean. So the project I am working on is on a repository on Azure, I cloned the repository on my PC.
What is the project about?
It looks like it gets data from signals-and-trends-api. You need the API Key to get the data from there i suppose
Okay, thank you!
Welcome to the server @sacred marten I trust you're having a good time, aside the error messages, of course 😀
Yeeessss, finally got my quota for the cheaper GPUs
congrats
ty, gonna see if I can pick this up tomorrow
Thank you! I am having a good time and people have been helpful in answering my questions.
Hello everyone, I am veer just learned and explored some concepts of machine learning and python libraries like numpy, ok pandas, matplotlib, sklearn, tf, keras and need some recommendations on what projects I should build to build my portfolio or boost my learning, feel free to share your thoughts !!
Hey can anyone help me out?
good evening, how do you train a tensorflow model?
I want to split my columns in my KNN code so that the machine will give me higher scores (rn it’s 33% learn at best) and idk how.
so you're doing k nearest neighbors? on what data?
On a really big dataframe. I want to cut it in half so I can get high results. Doing it on college football bowl winners
why would "cutting it in half" boost the performance?
Because it will have less stuff to learn. Idk man I’m just trying to get my percentage up so that my teacher won’t yell his ass off on me
so, you want to identify which columns are most important, and use only those?
I got a few columns I already have my X as, but they are huge
so, you want to identify which columns are most important, and use only those?
does this sound like what you're trying to do?
Not necessarily most important, but easiest to get high percentage on
that's not how machine learning works
if you try to find tricks to make the model perform better on paper, you can easily produce a model that is useless.
Then idk what to do man. I’m lost and I got 9% as my best model man. This is making me want to kill myself
Please don't talk about self-harm here
Sorry
How many columns does your X data have? and what are they?
These are two questions with exact answers, so do your best to answer them precisely.
I got 3 on my X date, and wdym by what are they?
X data, not X date.
So there are three columns. What does each column represent?
One represents the points the winner of the game scored, one represents, the rank of the team who lost the game, and one represents the points scored by the team that lost
are there any other columns available? or is that all you were provided?
There were more, but I did get dummies on them.
@serene scaffold what do I do
I'm trying to clean more names in my data. I have a column with a list of full names (Bob Smith, Alice Jones, etc..) except they aren't always in order (Smith Bob, Alice Jones, etc...). I have created a list of first-names only, so I want to split the full names into a list and then check to see if any of the items in that list match any of the names in the list of first names. This is how chat-GPT told me to solve it, which I believe would work, but I'm wondering if anyone else has ideas. This is using Polars.
# Function to find and store the first name in the list
def find_and_store_first_name(full_name):
names_list = full_name.split()
for name in names_list:
if name in first_names:
return name
return None # Return None if no match is found
# Use the set method to update the existing 'First_Name' column with the matched first name
df = df.with_column(
pl.col("First_Name").set(
pl.col("Full_Name").apply(find_and_store_first_name, return_dtype=pl.Object)
)
)```This is as far as I got with my own code:
split_spaces = pl.col('Full Name').str.split(" ").list
split_names_df_2 = names_not_split.with_columns(
split_spaces
)```I used something like this previously to find any names in the list that were actually business names:
df.filter(pl.col('Full Name').str.contains('|'.join(lists.business_words))
This worked well for the business names, but I don't know how to do something like this after splitting Full Name into a list and iterating over it
pattern = f"({'|'.join(lists.first_names)})"
split_names_df_2 = names_not_split.with_columns(
pl.col('Full Name').str.extract(pattern.upper()).alias("First Name"),
pl.col('Full Name').str.replace(pattern.upper(), "").alias("Last Name")
)
This ended up working nicely
i see that maybe you got this resolved. in general, it's important to realize that python module names are not necessarily the same as folders and files. python looks for modules as *.py files and */__init__.py files in a given search path, which by default usually includes the current directory and a few standard system directories. if you write import mymod, python looks for mymod.py or mymod/__init__.py in the search path. if you write import mymod.something then python looks for mymod/__init__.py and mymod/something.py or mymod/something/__init__.py. therefore usually a src directory is not expected to contain an __init__.py. if you are not building any package for distribution, you can instead add src to your search path, and then import mymod will find src/mymod.py.
Is this a good channel to ask about tensorflow? If so I am unable to get tensorflow to recognize GPU on my Linux system. I have tried several versions of tensorflow 2.X.X, I have RTX 4090., ubuntu 20.04. Has anyone successfully used tensorflow used tensorflow with GPU under this setup?
If you type nvidia-smi in terminal. Do you see your GPU there
yes I do
You could try following this steps https://www.tensorflow.org/install/pip#step-by-step_instructions
TensorFlow
I followed the instructions inside of a fresh conda environment, and this is what I got:
2024-01-18 23:11:28.384066: E external/local_xla/xla/stream_executor/cuda/cuda_dnn.cc:9261] Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered
2024-01-18 23:11:28.384095: E external/local_xla/xla/stream_executor/cuda/cuda_fft.cc:607] Unable to register cuFFT factory: Attempting to register factory for plugin cuFFT when one has already been registered
2024-01-18 23:11:28.385312: E external/local_xla/xla/stream_executor/cuda/cuda_blas.cc:1515] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered
2024-01-18 23:11:28.391494: I tensorflow/core/platform/cpu_feature_guard.cc:182] This TensorFlow binary is optimized to use ```To enable the following instructions: AVX2 FMA, in other operations, rebuild TensorFlow with the appropriate compiler flags.
2024-01-18 23:11:29.345689: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Could not find TensorRT
2024-01-18 23:11:30.555648: I external/local_xla/xla/stream_executor/cuda/cuda_executor.cc:901] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
2024-01-18 23:11:30.604238: I external/local_xla/xla/stream_executor/cuda/cuda_executor.cc:901] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
2024-01-18 23:11:30.604490: I external/local_xla/xla/stream_executor/cuda/cuda_executor.cc:901] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
[PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')]```Doesn't look like a list of GPUs to me. Not sure then. Maybe search GitHub for issues or forums for fix. Sorry can't help
The very last thing is the list: [PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')]
As for the other things, I was hoping you knew what they were.
you're right there is a gpu list at the bottom. so does it work now with gpu?
hello, anyone has knowledge in sklearn in artifficial inteligence?
for some reason, any "features" I would give to my LogicRegression, it makes the recall 0.99 for any threshold I am setting (0.1 ; 0.2 ; 0.5) , it s the same
yes, I am trying to train a model
I have like 8500 objects as data
each with around 20 fields
why isn't it doing anything, like it accepts all the objects
the precision is 0.67
and I want to make the recall 0.10 and the precision 0.9+ or something like that
as it's possible
also I need only one value predicted so the prediction will contain a value
hey raj can you help me with pinecone?
i am gettin an error AttributeError: module ‘pinecone’ has no attribute ‘list_indexes’
.apply is incredibly suspect
If you want I can think through how I'd do it using only Polars functions
This is probably fine
pytorch or tesnorflow?
Before at least I'd say tf.Keras was easier to use than Pytorch for absolute beginners. Keras is now multi-backend so I don't know how that stacks up.
I currently use Torch but I have used Tensorflow (2.X) in the past, you'll be fine either way
I think tf has more functions n stuff right now
My issue with Tensorflow is moreso how unstable it is, many breaking changes to their API means your knowledge decays fast and tons of say stack overflow questions are irrelevant because the API has changed since the question was asked
so true
If not for that specific reason I'd have stuck with TF because personally I don't think it's that deep, use what you know
But the breaking changes and deprecations are a huge turn off for me.
Yeah, about Torch. I advise you to go without lightning first. Write out 1-3 models and add all bells and whistles (early stopping with parameter saving, decent logging, ...) and then switch to Lightning
It's good to write it yourself to appreciate what lightning gives you (and that the features aren't magic)
Thanks for winning more souls for PyTorch 😃😃
Hey complete noob in everthing AI. I want to help a friend in a project, I need to learn how to process video images to determine certain things about a plant from a top view (distance, radius, etc.. there will be some sensors involved also).
Where should I go to start to learning about all this?
Just try what @past meteor suggested, you'll comeback with your testimony soon 😃.
So long as you understand OOP in Python, I think you'll fall in love with PyTorch.
You probably need to start from Data Science, then Classical ML, then Deep Learning.
The type of task you want to do is under computer vision ; which requires using neural network (deep learning).
There's this guy that has cool videos on computer vision on YouTube you can check it out as well https://youtube.com/@Roboflow?si=DkFWwZKBGQpTFVYZ

Cool thanks, that's the kind of roadmap I was looking for. Any resources you recommend to start?
@stone needle start reading from here. You'll see other materials suggested by others.
If you're however interested in books, check the pinned messages
Ok thanks!
can i do things like reinforcment learning on LSTM models?
LSTMs are mostly about learning sequences of data. and reinforcement learning is mostly about training agents that interact with their surroundings. what are you trying to do?
it was just a random thought while i was doing the dishes
good on you for doing them
I once had a roommate who didn't
it was annoying as fuck
also we had a dishwasher
Can some help me to train my YOLOv5 model for object detection? getting some hiccups. i am a newbie
Well I hope so. We'll see if it does
I was a persistent tf user but breaking literally the keras import mechanism with just hacky resolutions at best for a long time turned me over.
I still use it when I have to, or some paper is implemented in it and I want to start off that.
But my default is definitely torch now
(until I move to Jax)
Also for some reason I never moved over to lightning properly.
I see it makes things easier but I still find it convenient to use pure pytorch, I'm not sure why
The beauty of it is that, Lighting is just a wrapper for PyTorch. It takes in your PyTorch code, make it even more lit 🔥🔥, and above all, relieve you the burden of writing boilerplate code.
Anyone else suffering from Jupyter Lab extension woes? The git extension was broken by Jupyter Lab 4, only fixed recently, and the geojson extension has been broken for a while now. I wasn't sure whether this belonged to IDEs or Data science, apologies for putting it in both
i don't understand the jupyterlab extension ecosystem at all. there's poor separation between frontend and backend, protocols keep changing, none of them seem updated, etc.
pip install is fine but e.g. i run a single jupyter frontend installation for many different kernels. which packages do i install in which environment? if you go look at the forums, the answer seems to be "🤷 i don't use it that way"
also there's this jlpm thing that's actually just a yarn wrapper. the whole thing feels very hacked together in a way i don't love.
maybe "hacked together" is the wrong word. "overly complicated for how little control you get as a user" maybe?
when I started using the geojson extension I don't think pip install was even an option, it was a real struggle to get the bloody thing installed 😵💫 . It was a major step forward when they supported pip install
But yeah, I'm thinking I should avoid using extensions because they are not maintained that well
Hello, I am hosting a project about an artificial intelligence chatbot. I want to gather some individuals for the team. Together our goal it is to create a very advanced AI chatbot, that can cover a wide range of tasks like answering questions, understanding users/images/videos/code, use internet, detect voice input, and lots of more capabilities. If you are interested in joining this team, send me a message or reply to this message
i think you need some extensions to work with certain notebook elements, like tqdm progress bars and svg matplotlib plots. and there's a language server extension that i haven't figured out how to configure yet, but might be really nice.
You hope the more necessary extensions are better maintained, but then what is more necessary than git?
at least there I can use commands as a workaround
with geojson I need to write new code to produce maps etc.
what does it mean if a SAC reinforcement algorithm (policy gradient) is always making the maximum sized action even if that's suboptimal using a Box action space that scales from -100 to 100
The problem is basically just trying to get it to find incremental change to an integer to make it cancel out another integer arithmetically so I didn't think it would be an issue
but SAC is always acting on the borders of the range instead of in between
I went to lightning nearly immediately after using Pytorch. It's all stuff I can write myself but I feel like the things Lightning does for you is truly no brainer boilerplate
Early stopping is an example. That's not something I want to write each time. I can modularize it sure but then at some point I'm recreating lightning
Good afternoon. So I'm trying to do a machine learning project to try to practice code. I cleaned and prepared a dataset I put in SQL so I can easily add and access other datasets if I so choose to do so in python.
But now that I think about it a bit more I want to know if my dataset can work with machine learning.
It's a dataset that countains social determinates of health from 2011-2019 annually for every county of the union with about 8 determinates. I'll link it in a google sheets doc below
https://docs.google.com/spreadsheets/d/1ZeG67MFm-QUFQG_HWRdva1eeYjGd1TB4kgbKGkxdqiU/edit?usp=sharing

Google Docs
county_data
yearspan,measurename,county,state,rawvalue
2012,Uninsured adults,Autauga County,AL,0.17
2013,Uninsured adults,Autauga County,AL,0.17
2014,Uninsured adults,Autauga County,AL,0.14
2015,Uninsured adults,Autauga County,AL,0.12
2016,Uninsured adults,Autauga County,AL,0.11
2017,Uninsured a...
So I'd def need to transform it but this is just the raw data. I'm going to transform it once I get it out of sql since I might add other data to my sql database
But assuming I realign it so the columns are arranged like this
https://docs.google.com/spreadsheets/d/1dX37HcIvZbtCdHSAGiO1_JnxeuN4cYNiVxNpiLGyvBw/edit?usp=sharing

Google Docs
Sheet1
County,Year,Premature Death Per Capita,Sexually Transmitted Diseases,Uninsured,Primary Care Physicans,Mammography Screening,Flu Vaccinations,Unemployment,Particulate Matter,Preventable Hospital Stays
could this work as a project? My only thought is that it might be a bit wonky for the model to not progress from a linear set of time, but to retread the timestamp for each new county. If anyone has any feedback please let me know I'd appreciate it
what do you want the model to do?
These are the features that you have for each county: ['Uninsured adults', 'Primary care physicians', 'Preventable hospital stays', 'Unemployment rate', 'Children in poverty', 'Sexually transmitted infections', 'Mammography screening', 'Uninsured', 'Dentists', 'Uninsured children', 'Air pollution - particulate matter', 'Alcohol-impaired driving deaths', 'Flu vaccinations', 'School funding', 'Premature death']
do you think that any of these things are interrelated?
Hi, I have no idea if this is the right place to ask, but I am at my wit's end. I'm fairly new to python, and for a project I am trying to code a reinforcement learning ai to play a simple video game I made. My deadline is coming up and I just don't understand the resources I'm looking at and results I'm getting. Would anyone be willing to hop into a call with me and I could explain more or show what I'm working on?
your best bet for getting help is to show all the code, a representative sample of the data, and ask a specific question. it's not very likely that anyone will commit to joining a call.
!code
yeah i understand, I just honestly don't know where to start without posting a giant block of code and saying "it's doing this."
Hey folks, is this the right channel to ask my question I pasted here: I'm just looking for some opinions moreso than a direct answer
have a confusing question about something I'm working on involving a ranking system and applying the weighting of those rankings to a data set?
this would be the channel. but you have to ask a question that someone can start answering.
True, I have to integrate it into my workflow more actively
I guess my work has been composed of modifying different parts of the modelling and training process at a very basic level where I wouldn't want to use a wrapper, so it didn't make sense for me to keep switching back and forth between torch and lightning for different parts of my code in different experiments
But it's definitely useful, I'll try to use it more actively
True true, that makes sense
Though recently my work has required working up all the way from aten, so lightning would only add another layer of src code to inspect ig
I'm building a sports prediction model, so the idea that like i rank all the teams then apply to to one specificc metrics within that ranking system, of an opposing team
IE predicting a range of future values possibly
You know, I don’t know why I don’t come here often. This is definitely my fav topic yet I spent most time on random things or things I don’t understand yet 😅
Nice project! 🙂
Hello people.
I am currently trying to create a heatmap from target parameter to envir parameter. The result is ok, but the visualization is the part where I am struggling with. I have done so the heatmap is half and I now want the target parameter to be placed there with lines toward the envir parameter it has the strongest correlation with. My problem is that the target parameter seem to be placed outside the heatmap.
See picture how I want it and how it turns out (I assume you would see which one is mine)


thanks!
i just have a main issue is i can rank and build the predictive model, but i cannot properly utilize the weight to influence the model
For me the biggest issue is when libs do 90 % of what I want but they don't handle the bespoke 10 % I want to do so recently I've tended to just handroll most things
For some I was tempted to go into the source code and just add what I wanted but I've run into cases where the source code was imo terrible
Yeah exactly same
So rather than add another layer of abstraction and another src I would have to inspect and modify, I prefer to just do it myself.
Though lightning is a legitimate case of a helpful wrapper, I'll try to integrate it into my habit more
Hello, I am hosting a project about an artificial intelligence chatbot. I want to gather some individuals for the team. Together our goal it is to create a very advanced AI chatbot, that can cover a wide range of tasks like answering questions, understanding users/images/videos/code, use internet, detect voice input, and lots of more capabilities. If you are interested in joining this team, send me a message or reply to this message
DM me for more details
Would anyone know?
Sadly not, sorry
what is your plan for this, at a high level? how do you expect to get comparable performance to ChatGPT for question answering?
It shall be an artificial intelligence that can perform as good as GPT4
it should be able to understand context, conversations, meanings of words, their definition and way more, it should be able to answer precisely to a question
😭
that's incredibly ambitious, unless you have a lab staffed by several PhDs. What is your plan to achieve this?
I do not have access to any lab or something lmao but my plan to achieve it is to just not give up, find a solution, work on potential solutions, until it works
I do not care how long it takes to make it
But I will not simply give it up due to too much complexities
if you expect this plan to work, why are you aiming for something as unambitious as replicating gpt-4? why not world domination?
even if you, at this moment, already understood all the theory that underpins ChatGPT (which requires advanced knowledge of several aspects of math, computer science, and linguistics), it would still take you several years of full-time work to achieve this.
That isn't to say that you should abandon your interest in this area, but this is like saying you're going to beat the world marathon record when you can't run a mile without stopping. You need to start way smaller.
And probably look into a university education in AI.
I'm too young to go to any university
If it takes several years that's fine
This artificial intelligence is a project or an idea
My main focuses in life are not to finish this project, but it is something that I would love to work on in my free time
a good place to start would be to learn about what "data" is in the context of machine learning, how to manipulate it, and developing a sense for what insights might be discoverable in that data.
and be sure to do well in school, especially in math, so that you will be a competitive applicant to computer science degree programs.
Thank you for the advice
for a tensor of shape
[bs, 3, 224,224]
how to make center portion of all image in 0??
i can do
tensor[bs, 3, start:stop, start:stop] = 0
but back prob gives error
Backprop here, can confirm, assignment is not differentiable
so what to do
Use a differential operation to create the same result
Something like multiplying by a mask
Differentiable *
No you just need to register a buffer
i was lazy to write it
And then do X*Y
wait, but how do i get a mask of that shape?
lmao
construct is piece by piece?
Wdym, you just construct the tensor
All 0s where you want 0 and all 1s where you don't want anything changed
to set 1s and 0s, how can i do it concisely?
The same way you did it, just don't do it during feed forward
Construct it in the init method
self.register_buffer
self.mask = torch.ones(1, 3, 224, 224) self.mask[:, :, 30:224 - 30*2, 30:224 - 30*2] = 0
did this
Uhm, I think that's discouraged, but.should work I think
Hello everyone. I am looking for a few individuals who could help us develop an artificial intelligence. For more details, message me.
!rule 6 9
6. Do not post unapproved advertising.
9. Do not offer or ask for paid work of any kind.
It's only been a few hours since you last mentioned it, and we've established that you are not in a position to achieve your goal. So I'm going to ask that you stop trying to recruit for it
But isn't that precisely what gpt 4 already does ?
Also, is a lab with PhDs really needed ? GPT models look very simple to me, isn't the bottleneck the sheer amount of data required to train big gpt
It's not the same thing that I suggested back then
Originally we wanted to make it more advanced than GPT4
Uhm, are you a billionaire ?
No I'm not
Then it's gonna be challenging
I do like the ambition tho, but it's good to look at the real world constraints
Okay? Then what is it? Don't ask people to DM you to get information that you already have and could post in the chat. That's annoying and is more work for everyone.
It should be a small artificial intelligence for simple use where users can provide their own dataset
That does what
It shouldn't have an influence on society
It's just a project so all people working on it
can improve
Just a simple project
AI programs do specific things. And the data has to be usable for that particular thing
What do you mean
ChatGPT, for example, produces text in response to text.
Yes
What does your model produce, in response to what input?
That doesn't answer the question.
and that will be its capabilities. it can form responses, keep track of conversations
but only limited to the knowledge provided by the user
Theres some predefined knowledge
but barely any
So you want to make a chat bot that's trained on a user provided corpus
Yes
That's a more specific goal than "a small artificial intelligence that users can train on their own data"
There are AI programs that don't deal with language at all
Alright well thats my project
You can look in to how to fine tune open source language models on additional data
And a given user's data would be that additional data.
hey good day. sorry for bothering you its just that i cant get pass this github clone error and i havent come across any help related to the error online.
can i drop a screenshot of the error here?
You can post the error message, but I won't look at it if it's a screenshot
alright thanks
error: RPC failed; curl 92 HTTP/2 stream 5 was not closed cleanly: CANCEL (err 8) error: 1801 bytes of body are still expected fatal: early EOF fetch-pack: unexpected disconnect while reading sideband packet fatal: fetch-pack: invalid index-pack output
hey, ive fixed the error.
someone helped from other channel. thanks
any serious ai-assisted coding projects??
hello, anyone has knowledge in sklearn in artifficial inteligence?
for some reason, any "features" I would give to my LogicRegression, it makes the recall 0.99 for any threshold I am setting (0.1 ; 0.2 ; 0.5) , it s the same
yes, I am trying to train a model
I have like 8500 objects as data
each with around 20 fields
why isn't it doing anything, like it accepts all the objects
the precision is 0.67
and I want to make the recall 0.10 and the precision 0.9+ or something like that
as it's possible
also I need only one value predicted so the prediction will contain a value
how many classes are there? and are they imbalanced?
it's easy to get high recall by "putting all your eggs in one basket"
are there any competitors to GPT-Pilot?
after doing this
class classA(nn.Module):
def __init__(self, args):
super(classA, self).__init__()
self.autoencoder = UNet(3)
self.mask = torch.ones(1, 3, 224, 224).cuda()
self.mask[:, :, 30:224 - 30*2, 30:224 - 30*2] = 0
def forward(self, x):
# x: bs, channel, height, width
# generate prompt of same dimension as image
enc_x = self.autoencoder(x)
# setting encoded output from AE to 0, expect for borders
out = enc_x*self.mask
print(out[0][0][0][31])
# add to original image
return x + out
the print statement should print 0 but it print different numbers in forward epoch.
the input tensor size is [32,1,28,28].
class FashionMNIST2(nn.Module):
def __init__(self):
super().__init__()
self.conv_block1=nn.Sequential(
nn.Conv2d(in_channels=1,out_channels=10,kernel_size=3,stride=1,padding=1),
nn.ReLU(),
nn.Conv2d(in_channels=10,out_channels=10,kernel_size=3,stride=1,padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2)
)
self.conv_block2 = nn.Sequential(
nn.Conv2d(in_channels=10, out_channels=10, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.Conv2d(in_channels=10, out_channels=10, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2)
)
self.classfier = nn.Sequential(
nn.Flatten(),
nn.Linear(in_features=10*49 ,out_features=len(class_names))
)
i wanna know how do you decide the input layers in z classifier, as i make changes in layers, kernel size, stride & padding etc. what i currently do is just check the shape after running the var through both blocks.
I'm super new to machine learning and I'm trying to implement gwern's AUNN architecture, since I haven't seen any code of it yet. I am trying to convert MNIST data into sets of bytes, where the bytes are (in order) the greyscale values of each image, and then each byte is 'linked' (better term here?) to the classification of the image it came from, how do I set this up?
Sorry if it's a broad/large question, I am just not sure at all how to set this up, I'm super new to ML (and python tbh) but not programming overall
What is the acceptable math skill/level needed to utilize python data science and AI libraries and tools, to solve basic business and data problems?
I find this a difficult question to answer online, because I keep encountering “How to learn machine learning/data science” and not “How to use machine learning/data science”.
Hey can someone please help me here? I'm using the TextGen Web UI, and it has support for the OpenAI API instead of actually paying for chatgpt turbo and such, but i can't figure out how to use it in python. I've tried looking at it https://github.com/oobabooga/text-generation-webui/wiki/12-‐-OpenAI-API but the examples doesn't work when i put my API url
GitHub
A Gradio web UI for Large Language Models. Supports transformers, GPTQ, AWQ, EXL2, llama.cpp (GGUF), Llama models. - oobabooga/text-generation-webui
i am using google colab and it's not a local ip
help someone?
Thank you!
I need help. So i want to learn machine learning, AI and data analysis, and some more in data science. I want to do this for free. I want to know a good platform or website to do this. Realpython doesn't work, because it isn't free for the most important content. I've seen kaggle.com. Is kaggle a good platform to learn what I want?
!resources data science
Resources
The Resources page on our website contains a list of hand-selected learning resources that we regularly recommend to both beginners and experts.
there are also some free books here: #data-science-and-ml message
ok thx
keep in mind that this is mostly a scientific domain, not mostly a programming one. so even though you'll be practicing writing code to apply different concepts, the main work is understanding those concepts.
Machine learning is mostly jsut math right
yes
Ok
it's stats, linear algebra, and calculus.
it's challenging, but something can be challenging without being arduous
There's one question that hasn't been answered from my comment
Is kaggle a good platform to learn what i need?
AI, machine learning. data science
Kaggle can be a good platform to practice what you learn
And advance your learning by learning from the community
But I wouldn't say it's self contained or "enough"
Yeah the "enough" was more of a problem
That's what I thought too
There isn't any course with numpy either
Just pandas
If you have done some programming before, and have time for this, I'd say start with the math.
But different people have different learning styles.
Maybe an implementation first approach appeals better to you
I want to learn the tools for the process first (code) before the math
I haven't done much programming
Probably start with some stat exercises on kaggle then
ok
Just a question though
Is ML and AI a subset/part of data science?
nvm imma search up
ML is a subset of AI.
they overlap. I'm not sure that I'd call it a subset.
hi. i was wondering if anyone had any tips/could help with/point me to a good tutorial for loading in a pretrained model in pytorch not already included in the various torch model packages?
i'm currently wrestling with getting a pretrained model (.pkl) loaded. i have the github for the model but am currently trying to figure out where the structure is actually laid out. all of the tutorials say something about model needing to be defined before i can load it with torch.load, would i basically be listing out the pretrained model structure here?
if you're loading a pretrained model, you can inspect the model object and see all the layers and stuff.
just printing it should show you a lot.
unless there are rust libraries that can do CUDA computation, I would give up on that immediately.
I see. Were you able to load the pretrained model and print it?
that's the other guy
The other guy?
I just started talking about doing ml in rust
Oh. Your PFPs are similar, so that threw me off.
yeah I realized that's why that happened heh
ah, yep! i think? it prints out an OrderedDict
I thought you wanted to see how various models were structured so that you could re-implement them in rust
It might.
well I do want to do that
Why does no one ever ask what I want to do?
good question.
the world is your oyster!
there's also some shoestring gymnasium port to rust too
but let's be honest, most things will be abandonware and you will have to do most of it yourself
@serene scaffold sorry for not responding, I left the computer but the answer is yes, essentially I want to be able to predict premature deaths via social determinates of health aka these factors
following up on this, if it prints out an ordereddict, does that mean the object is just a list of layer weights? or can it also be the model itself.
is there any way to load in my model without having to define it beforehand? the github i'm looking at doesn't seem to have one clearly defined transformer model
Are the values you have normalized for population? (That is, is it "number of physicians per person", or just the raw number of physicians?)
What do you mean by "loading the model without having to define it beforehand"? Can you show the code that isn't that?
pretrained_model = torch.load('Data/smilesPretrained.pkl', map_location=device) #print(pretrained_model) pretrained_model.eval()
which results in
AttributeError: 'collections.OrderedDict' object has no attribute 'eval'
thank you!
model = TheModelClass(*args, **kwargs)
model.load_state_dict(torch.load(PATH))
model.eval()
So you have to create a model object and then pass the state dict to it
Is there anyone who would know what I have to do?
alright! so, i need to make a model class with the same structure as the pretrained one i'm using?
Do you actually mean "make a class"? Or instantiate a class?
sorry, like, define a model like this from the torch tutorials:
`class TheModelClass(nn.Module):
def init(self):
super(TheModelClass, self).init()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x`
I assume this means I have to personalize it to the pretrained model i'm using
I'm actually not sure--i only use models from hugging face, which works a little bit differently. Can you just import the class?
that's mostly what i'm trying to figure out at this point since i'm working from a github repository rn. it feels like the model class is all spread out among different scripts in the code so it's pretty confusing. i guess i'll just have to comb through it
Any idea how to approach this problem? I was given this question but honestly, I don't understand what is actually being asked. I understand that each row is an order but not sure if each one should be a separate object or what, unfortunately the question seems very poorly writen and very vague, any thoughts? I was thinking in using dataclass maybe
Something like this but I don't think it's a good idea
import pandas as pd
from dataclasses import dataclass
@dataclass
class Order:
id:int
order:str
type:str
price:float
quantity:int
def create_orders_from_csv(file_path: str) -> list:
df = pd.read_csv(file_path)
orders = []
for _, row in df.iterrows():
order = Order(id=row['Id'],
order=row['Order'],
type=row['Type'],
price=row['Price'],
quantity=row['Quantity'])
orders.append(order)
return orders

does anyone know of a way to install cudaf without using anaconda/miniconda? I just want to try it in my own virtual env, with only the necessary dependencies. I also just dont want anaconda on my personal machine. I tried doing it through pip based on their documentation like so but no dice:
pip install --extra-index-url=https://pypi.nvidia.com cudf-cu12==23.12.* dask-cudf-cu12==23.12.* cuml-cu12==23.12.* ugraph-cu12==23.12.* cuspatial-cu12==23.12.* cuproj-cu12==23.12.* uxfilter-cu12==23.12.* cucim-cu12==23.12.* pylibraft-cu12==23.12.* raft-dask-cu12==23.12.*
Looking in indexes: https://pypi.org/simple, https://pypi.nvidia.com
Collecting cudf-cu12==23.12.*
Downloading cudf-cu12-23.12.1.tar.gz (6.8 kB)
Preparing metadata (setup.py) ... error
error: subprocess-exited-with-error
× python setup.py egg_info did not run successfully.
│ exit code: 1
╰─> [16 lines of output]
Traceback (most recent call last):
File "<string>", line 2, in <module>
File "<pip-setuptools-caller>", line 34, in <module>
File "C:\Users\Vince\AppData\Local\Temp\pip-install-_x5j_a60\cudf-cu12_d67b4bfe821c420cbaddbdf48539ea00\setup.py", line 137, in <module>
raise RuntimeError(open("ERROR.txt", "r").read())
RuntimeError:
###########################################################################################
The package you are trying to install is only a placeholder project on PyPI.org repository.
This package is hosted on NVIDIA Python Package Index.
This package can be installed as:
```
$ pip install --no-cache-dir --extra-index-url https://pypi.nvidia.com cudf-cu12
```
I also tried the pip install in the code block above
I'd read a source book, which am doing
Courses are just slippery slope leading you to tutorial hell, at least for me
Anyways, I just learnt this algo called linear discriminant analysis, which seems to draw a hyperplane for classification, and as I read non linear variants also available. It does seem to work similar to SVM, could someone briefly explain how and for what their distinct usages?
Ping on reply please
Generally to solve issues like curse of dimensionality, where you have a fixed amount of examples but too many features to consider in your model. You take a feature reduction or dimensionality reduction technique such as PCA or LDA. ML algorithms in general don't scale too well with extremely large number of features or examples
Hey guys,
1.Develop an AI based solution to offer timely insights into current global hacking trends, prioritising potential threats based on their likelihood of targeting specific enterprises.
2.Anonymise user identities in large databases to ethically employ machine learning in understanding customer trends and behaviour without violating their rights.
I have been given these two problem statements , how do i proceed?
If you wanna do something that's more fun, use federated learning for option #2.
Meanwhile, aside using federated learning, there could other ways to approach #2, however, I feel it's only when we've seen what the dataset looks like that we could further provide feedback on how to proceed with #2 option.
Not sure if this is the best place, but seems like it. Excel always messes up CSVs and I have to dig around in sublime to fix them which is a pain. Is there any better software to open and edit CSVs than excel?
Is federated learning and differential privacy the same?
No they're two different things. Differential privacy is a concept used in preventing models from memorising private data.
Differential Privacy focuses on adding noise to data or queries to mask individual contributions, and federated learning focuses on training models across decentralized data without sharing the data itself.
You could as well decide to combine federated learning with differential privacy if you want to go an extra-mile (more like going above-and-beyond kinda extra mile) to enhance privacy protection.
For example, by applying differential privacy techniques when sharing model updates in federated learning, you can be 101% sure that those updates do not reveal sensitive information about the data on any individual device. I haven't worked on differential privacy but I've once shabbily read about it when I stumbled on DP-SGD ( Differential Privacy Stochastic Gradient Descent) optimizer.
For federated learning, I mainly use Flower framework.

Hallo everyone, i need help with speed up training my models in Google Collab.
Think about what information someone might need to start helping you with that, and give that information.
okay, you are right! ..sorry
so for a project in university i have do a benchmark for ML Attacks and Defenses. The dataset which i use for it is the CIFAR-10 (also no big data). I train the models on GoogleColab and have the v100 GPU available but the GPU utilize just round about 4 GB from available 40 GB. One Training epoch takes 2.44 min. and i think its tooo long. As model i have to use the ResNet 18
did you confirm that you switched to the GPU runtime in google colab?
what did you do in the code to move models and tensors to the GPU?
yeees 😄 it was the first what i have checked!
bs = inputs.shape[0]
num_poisons = bs * args.ratio // 100
inputs[num_poisons:] = inputs_clean[num_poisons:]
inputs, targets = inputs.to(device), targets.to(device)````
````result_tensor = torch.empty((5, inputs.shape[0])).to(device)````
````for batch_idx, (inputs, targets) in enumerate(testloader):
inputs, targets = inputs.to(device), targets.to(device)
outputs = model(inputs)
loss = criterion(outputs, targets)````
```` device = "cuda" if torch.cuda.is_available() else "cpu"````I don't see any obvious opportunities for optimization here. You could increase the batch size, I guess. Though I think you sometimes get unlucky and Google allocates you a slower GPU.
Right. I'm telling you that there might not be anything you can do to speed it up, at this point.
the problem is i cant run in locally because jax gpu isnt supported windows
2024-01-22 21:09:10.031042: E external/local_xla/xla/stream_executor/cuda/cuda_fft.cc:607] Unable to register cuFFT factory: Attempting to register factory for plugin cuFFT when one has already been registered
2024-01-22 21:09:10.032960: E external/local_xla/xla/stream_executor/cuda/cuda_blas.cc:1515] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered
2024-01-22 21:09:11.993526: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Could not find TensorRT````
i get this warnings in colab when i execute the scriptGuys, what books would you recommend after pre-calculus for calculus that would be machine learning focused?
They should be because they are compiled from one source but honestly this is a good question. I should reflect on the data and see if it works from that perspective
if the numbers are normalized, most of them should be below one. like, you can't have more than one physician per person.
if they're not normalized, you might have to find another dataset with population counts for each county, for each year. It probably exists... somewhere.
Ok I found it in the website, I think it's trying to communicate the opposite, for example 860:1 is explained as "There was one primary care physician per 860 people in Somerset County, New Jersey."
But I think you are right that there are better ways of expressing that
here is that datapoint visualized in one county

For whatever reason, google sheets is not cooperating with me so I cant see how the datalooks in there. Im going to go for a walk but when I get back I'll look at the CSV version of the data and get back to you
Ok so it looks like they are in regular ints

Hey everyone not sure where to put this, but seems somewhat related since its a data issue, so ill put it here. I'm having an issue with bs4, as my data that im web scraping doesn't actually all allign and im confused why it would have some problems scraping certain pieces of information and how to realign all data to its corresponding place in the dictionary
import requests
import pandas as pd
url = 'https://www.seek.com.au/internship-jobs/in-Australia'
req = requests.get(url)
data = req.text
soup = BeautifulSoup(data, "html.parser")
#limit will affect functionality (?)
data_collation = soup.find_all("div", {"class": "_1wkzzau0 a1msqi6m"}, limit=200)
'''
We should collect the following information;
jobTitle
jobCompany
jobListingDate
jobLocation
jobShortDescrption
jobClassification
job-list-view-job-link
'''
cols = ["jobTitle","jobCompany", "jobListingDate", "jobLocation", "jobClassification"]
def extract_jobInformation(job_listing, coltype):
elem = job_listing.find(attrs={"data-automation": coltype})
try:
outcome = elem.text.strip()
except:
outcome = None
return outcome
res = {}
for data in cols:
res[data] = []
for idx, job_elem in enumerate(data_collation):
outcome = extract_jobInformation(job_elem, data)
if outcome != None:
res[data].append(outcome)
#res.append(outcome)
else:
pass
def save_jobs_to_excel(data, filename):
jobs = pd.DataFrame(data)
jobs.to_csv(filename)
#print(res)
nums = 2
for nums in (range(20)):
print("\n")
print(f"The position of {res[cols[0]][nums]} is being offered by {res[cols[1]][nums]}. The listing was put up {res[cols[2]][nums]} days ago. It is based in {res[cols[3]][nums]} and is subclassified by: {res[cols[4]][nums]}.")
print("\n")
#for vals in cols:
# print(len(res[vals]))
#save_jobs_to_excel(res, "job_csv")
print(res)
#Future goals with seekr scraper
#use while loop or whatever functionality in bs4 to iterate over all pages
#to collate more than 1 page but all page results
# export possibly as JSON
# then once collected all the data, visulalise the data
# also need to fix to match all data collectedsee```

for example when scraping info, and returning it, certain items in the result dictionary (that has all the information) doesn't actually allign with what the website is saying
i have a feeling its because some data isn't available or isn't being collected for some reason, and it just skips over it and appends other information available from other results thereby outputting that
which also makes sense because for the info that im collecting i dont have equal numbers. Why or how is this even happening.
hi!
I'm new to OpenIA gym, trying to write my own env, anyone here know what is the observation_space?
hi! looking for anyone with experience doing pose detection of videos. Looking to compare 2 videos of people dancing. One being an expert, one being an amateur that is trying to copy the expert, and then output a score of how well the amateur is copying the expert. Will pay. Please DM me anyone with experience 🙂 tyvm in advance
!rule 9 6
6. Do not post unapproved advertising.
9. Do not offer or ask for paid work of any kind.
you should understand simple examples first:
https://www.gymlibrary.dev/environments/classic_control/cart_pole/
i'm going to read it now, thank you!
Can someone pls help me out...I'm new to pandas. So, basically I'm doing a college project in python using pandas library where I've generated a basic healthcare database consisting of 100 entries using ChatGPT. And I wanna use pandas to read the csv file and filter out patients satisfying some required parameters for clinical trials . I'm using a dictionary to store the parameter names as keys and parameter values as values.How to I use these to filter out the patients satisfying the required criteria?Is it possible to use Classes and objects to model the patients , if so how...Thanks once again
Math scares me for Data Science 🤐
Maths Roadmap for Machine Learning
https://docs.google.com/spreadsheets/u/0/d/10spJMs0Zmv5cugfFjJVc4MudyOVjl_16Ef5z54oxqnM/htmlview
Have you successfully read the data into pandas and now you just wanna subset the df to filter out needed information ?
Also, is there any reason why you're storing the fields and their respective values in a dictionary ?
hi
i need some help
a guy helped me and sent me this code that trains models

but i dont get where the training data is brought from
@spark inlet The data is loaded from a Keras dataset mnist
how can i put my own?
Probably use Pandas to load in your dataset
whats that
Why do you find it so scary? Tbh you only need high school math to get started.
You don't learn how to play football by first learning the rules of the game. You learn by running around a field / your house with a football or anything that resembles one.
The rules of the game will come to you much later once you've started running around with a football.
I guess what I'm trying to say is, instead of using bottom-top approach to learn, just use top-bottom approach and you'll have zero worries about the math.
You will be fine if you can convince yourself that you belong here. 😊✌️
yoo
listen, does anyone have ideas for machine learning projects that are useful? and be done in 2 weeks
hard to tell how long anything will be "done" in and that depends on what you mean by "done" and also your skill level
most things you can have something working in a few hours
but then it's a question of improving performance incrementally and that can take however long you want
"Usefulness" is subjective. What do you enjoy working on, in which field do you work, what interests you in ML, what unknowns are you interested in unravelling, etc....
Once you have answer(s) to any of these questions, it'll be easier for you to come up with a personalized project idea that's 'useful' to you, and won't bore you to death.
make it so it decides if text should be white or black depending on the background color
relativly easy
not much useful
i got the raw images btw not a dataset
So images you would have to read in as a pixel array. So you can read in using the PIL package. Check this out https://pillow.readthedocs.io/en/stable/reference/Image.html
Pillow (PIL Fork)
The Image module provides a class with the same name which is used to represent a PIL image. The module also provides a number of factory functions, including functions to load images from files, a...
its already imported
and used
did u check the code?
but like i dont get how i can change the code so it gets the local images
I dont think i see your changes
i didnt change anything
its already there
Thank you for the encouragement! i like the idea of approaching it from a top-bottom perspective. Your advice means alot
line 8
@odd meteor
@sudden sparrow this is how the data is gotten how can i change it to take data from pc?

You have to upload the images to your google drive then read it from there.

is there any good guides and tutorials on AutoKeras?
Question, would it be fair to say that machine learning is just computers trying something, getting an error, and correcting itself to reduce the error?
that's a very, very simplified version, I suppose.
and it's not "getting an error" in the same way that one "gets an error" when an exception is raised in a program
is anyone familiar with IntelliBot?
Ask the question you would ask if someone said yes--don't withold information that someone would need to immediately start helping you.
Got it, right, how would you word that better?
the model gets an input, produces an output, and tries to reduce the disparity between the actual output and the expected output.
I have an interview tomorrow and the interviewer told me to familiarize myself with Intellibot. I watched a few videos check a github repository. I need help familiarizing myself with it through, syntax, or anything that would be relevant for me to know for the interview
its a prompt engineering role
That really helps, I'm trying to think of a basic function that demonstrates the "idea" of machine learning using basic math. My thought is to guess a good very simple example would be to guess/predict the next number in a sequence. Thank you.
Perhaps this is easier:
class GeniusAI():
def __init__(self):
self.correct_number = 124
def guessNumber(self,guess):
error = self.correct_number - guess
print(f"Your error is {error}")
genius = GeniusAI()
genius.guessNumber(124)
I think this is neat, because if the error goes up from the last guess, then you know to go in the other direction.
why are we trying to teach people calculus without using calculus
because everyone things calculus is "too much math for them"
Don't tell me that... haha
I'm actually down with derivatives
but not integrals
is there such a thing as "a-model-in-a-model"? so like can i have a small model that operates within a larger model but can be used on its own when compute is limited. my use case is an alphazero-style network where i alr have the implementation but i want to be more versatile in terms of inference speed as yk, speed is quite important in chess games, especially with shorter time controls. i have thought of distillation but just curious, what sorta stuff is out there
Does anyone have experience with automatic speech recognition, to text display?
I have an interview tomorrow and the interviewer told me to familiarize myself with Intellibot. I watched a few videos check a github repository. I need help familiarizing myself with it through syntax, or anything that would be relevant for me to know for the interview
its a prompt engineering role
@serene scaffold have you figured out what you want to do yet
I want to be able to eat whatever I want and get to decide what the consequences are
that's a good one

{kind=link}
you can try a YOLO algorithm

Medium
Object detection using OpenCV dnn module with a pre-trained YOLOv3 model with Python. Detect 80 common objects in context including…
does it have to be yolo?
if this was helpful remember to subscribe and SMASH that like button
uh, no, but you asked how it could be done
this is one way
ok thanks
a good starting point
Much obliged
Would you guys recommend majoring in Data Science itself as an undergradute or something like Major in stats and minor in CS or something like that?
langchain or haystack?
I've read what you send, helped me a lot! i made a simple class just so i can understand the basics of gym
class Shower(gym.Env):
def __init__(self):
self.observation_space = spaces.Box(low=np.array([0]),high=np.array([100]))
self.action_space = spaces.Discrete(3)
self.temperature = random.randrange(0,100)
self.ticks = 60
def step(self,action):
self.temperature += action - 1
reward = -abs(37-self.temperature)
done = self.ticks == 0
return self.temperature, reward,done,{}
def render(self,mode=None):
pass
def reset(self):
self.temperature = random.randrange(0,100)
self.ticks = 60
return self.temperature
but i can't undestand how do i make envs with more than one variable
tbh ive never used it. most likely action space can be expanded in two dimensions:
Box(low=np.array([-1.0, -2.0]), high=np.array([2.0, 4.0]), dtype=np.float32). EDIT: this is BS
i made this some minutes ago and forgot to update here, but thx
i can interpret this object for observation space. but for actions idk
btw the model needs adaptation to fit multiple features
the step needs to return a np array with the features

did you read
https://www.gymlibrary.dev/content/environment_creation/?
they generate N actions 1,2,3,..N and assign what they mean using dictionary
i kinda understood well the actions, just struggling with the observation thing
well... obeservation space should be like a matrix or a coordinate system. for your shower env, you can make 2 taps: one can increase temperature by big steps and other by small steps. they are x and y axis and each and coordinate point is number of turns of each tap
maybe im wrong xd. but if you go with that idea, you can define scaling for each tap and agent will try to reach goal temperature by big steps and fine-tune by small steps
ofc goal temp and agents current temp will have different coords in observation space
Is anyone playing with the 8x7b models?
Any tips or tricks
I'm trying to offload the processing from the ram onto the GPU, is that possible?
what does that mean
What part?
Mixtral 8x7b?
no, processing from ram onto the GPU
the ram doesn't do any processing
Oh yeah I worded that wrong, I'm trying to map from ram into the vram
I'm on Debian at the moment
Hey I am Sumedh!.... Can u tell me which is better and interesting data science or Machine learning
I am new here actually
I needed a suggestion from a community so
Because I know you can run hashmap algos through the graphics card, I was wondering if you could do something like that to speed up the LLM a bit
Anyone?
They go hand and hand
If your trying to start I would take CS50s course on ML (it's free on yt)
And for data science I would probably learn a bit of power bi/excel and play around with some open source projects
But they do go hand in hand after awhile depending on what you are doing
okay okay!
Free code camp ryt?
CS50s
yea i got it
Free code camp is good
And tell me last one...is it better to learn many languages or only amster one
master*
If your new to python I would do py4e
yes yess i know
Thank you for that bro !
Ye
Seee i am asking here for a suggestion
Actually confused ryt now
I am CSE undergrad 1st Year
hi
😒 @clear mica
Hello, any ideas on how I can proceed with this? I basically need to compact a dataset looking like the first table and make it look like the last table.
I currently compressed all rows with the same DrugNames are taken uninterruptedly, but now I need to figure out how to infer the overlapping period for one or multiple (indefinite number) of drugs so I can merge them and then remove the rows I summarized (or update their periods if they have non-overlapping intervals).

is there like a known dataset that is hard and still being used to test models
columns group and diff are cols that I added to help me
PatientID DrugName StartDate EndDate group diff
13 092c1 Xarelto 2019-10-07 2019-11-04 0 -28 days
0 092c1 Brilinta 2019-10-28 2020-01-23 0 -87 days
14 092c1 Xarelto 2019-11-27 2020-05-14 0 -169 days
3 092c1 Entresto 2019-12-06 2020-02-01 0 -57 days
4 092c1 Entresto 2020-02-01 2020-03-02 0 -30 days
this is an example for a single PatientID, but for other patients I kinda summarized the data in the same way
Can someone help in my ML project with hyperparameter tuning please?
nevermind, I could have added a screenshot, sorry

this is better than a screenshot. even better would be to print df.head().to_dict('list')
what is the question?
give all the information someone would need to start helping you--don't wait for a commitment.
so I wanna merge all the rows that contain overlapping periods
grouped by patient ID
I am overfitting and underfitting at the same time lol
- you'll probably want to use a split-apply-combine approach where you solve the problem in terms of dataframes for one (patient, drug) pair
- it might be easier if the rows are sorted by StartDate, so that if there is temporal overlap between two rows, those rows are adjacent.
and the merge would be like:
drug; start; end
A ; 0; 10
B; 5; 8
becomes
A; 0;5
A+B 5;8
A 8;10
they are already sorted by start
oh, that's a more challenging problem than the one I thought you were solving.
yyep
all the timestamps are days, right? nothing more fine-grained than a day (like hours)?
yep
then it might be easier to transform the dataframe so that every row is a day, and each column tells you if the patient took a given drug on that day
and then you can collapse adjacent rows that are the same
right
and get all the rows for a given day to a group, get the drug names for them and concat them
bruh yes
thanks
yw
that doesn't make any sense
somehow the training accuracy is much more
have you checked for any data mismatch or data leaks
Yes
whats the data set
fer2013 and UTK
have you balanced labels
maybe its learning to predict one expression more cos there is more of its images
no I am using onehot encoding and every label has different value
yeah but it says there are The Disgust expression has the minimal number of images – 600, while other labels have nearly 5,000 samples each
so by just outputting the more common label it increases accuracy without actually training
# Defining a function to convert class names (strings) to numerical labels
def class_to_label(class_name):
# Defining the new groups
class_names = ["negative", "fear", "positive", "neutral", "sad"]
# Mapping the original classes to the new groups
if class_name in ["angry", "disgust"]:
return class_names.index("negative") + 2
elif class_name == "fear":
return class_names.index("fear") + 2
elif class_name in ["happy", "surprise"]:
return class_names.index("positive") + 2
elif class_name == "neutral":
return class_names.index("neutral") + 2
elif class_name == "sad":
return class_names.index("sad") + 2
# Creating NumPy arrays for training data
train_images = []
train_labels = []
# Looping through the directories
for class_name in os.listdir(expression_train):
class_path = os.path.join(expression_train, class_name)
if os.path.isdir(class_path):
label = class_to_label(class_name)
for image_file in os.listdir(class_path):
if image_file.lower().endswith((".jpg", ".jpeg")):
image_path = os.path.join(class_path, image_file)
# Reading the images
image = cv2.imread(image_path, 0)
image = cv2.resize(image, (32, 32))
# Normalizing Pixel Values
exp_train_image = image / 255.0
# Appending training images and labels
train_images.append(exp_train_image)
train_labels.append(label)
# Converting lists to NumPy arrays
X_expression_train = np.array(train_images)
y_expression_train = np.array(train_labels)
# Converting the labels to one-hot encoded
y_expression_train_onehot = to_categorical(y_expression_train - 2, num_classes=5)
y_expression_test_onehot = to_categorical(y_expression_test - 2, num_classes=5)```in colab, I'm unable to save my files
Does anyone know what I should do?

in what way are you unable to save your files?
that is, what action did you perform that was intended to save your files, and what happened instead of what you wanted?
upload them each time or save them to your google drive and load from there
https://www.statlearning.com/ i came across this resource for learning machine learning (i've heard it also referred to as statistical learning). Would you guys recommend this book or are there better options?
An Introduction to Statistical Learning
Good evening everyone
I need your help anyone
I've been learning Data Science for some month now and I need good sites to learn more about it so as to get certificates... I'm already using Cisco but it seems Cisco doesn't have all the information I need
It's a great book 💯
Those certificates are almost useless in my opinion. You don't really need all those certificates to get hired, except you just like the idea of collecting certificates.
Tbh nobody really cares about certificates these days. It's more about what you've built and projects you've worked on!
Nonetheless, for courses that provides certificates, you can check out any of these
https://www.deeplearning.ai/
https://www.udacity.com/
https://www.dataquest.io/
https://DataCamp.com/
https://Udemy.com/

Learn the skills to start or advance your AI career | World-class education | Hands-on training | Collaborative community of peers and mentors

Learn online and advance your career with courses in programming, data science, artificial intelligence, digital marketing, and more. Gain in-demand technical skills. Join today!

Dataquest
97% of learners recommend Dataquest for learning AI and data skills. Better teaching = better outcomes. Take a free lesson now >>
Learn Data Science & AI from the comfort of your browser, at your own pace with DataCamp's video tutorials & coding challenges on R, Python, Statistics & more.
Of course, how can I forget https://Kaggle.com/learn
Practical data skills you can apply immediately: that's what you'll learn in these no-cost courses. They're the fastest (and most fun) way to become a data scientist or improve your current skills.
if i have the following code using opencv:
#
import cv2 as cv2
import numpy as np
def vessel_segmentation(input_image):
# Carga la imagen en escala de grises
img = cv2.imread(input_image, cv.IMREAD_GRAYSCALE)
print(img.shape)
# Aplica un desenfoque gaussiano con un kernel de 11x11
img_blur = cv2.GaussianBlur(img, (11, 11), 0)
# Aplica un umbral adaptativo con un tamaño de bloque de 21 y una constante C de 3
# Usando el método de la media (ADAPTIVE_THRESH_MEAN_C) y umbralización inversa (THRESH_BINARY_INV)
thresh = cv2.adaptiveThreshold(img_blur, 255, cv.ADAPTIVE_THRESH_MEAN_C,
cv.THRESH_BINARY_INV, 21, 3)
contours, hierarchy = cv2.findContours(thresh, cv2.RETR_CCOMP,
cv2.CHAIN_APPROX_SIMPLE)
# Encuentra el contorno más grande
largest_contour = max(contours, key=cv2.contourArea)
print(cv2.contourArea( largest_contour))
# Dibuja todos los contornos excepto el más grande
for cnt in contours:
if cv2.contourArea(cnt) != cv2.contourArea(largest_contour):
cv2.drawContours(img, [cnt], 0, (0, 255, 0), 1)
plt.imshow(img)
plt.show()
And the following result:

how do i remove the external circle?
i thought that it would be removed with the if inside the for loop
Maybe put the plt.imshow(img) and plt.show() inside the for loop to see what the first few contours look like. (sort the contours from large to small beforehand)
Could be that there is a bigger contour
okay, i will try
Is it even drawing a contour for the largest circle? You are also just showing a heatmap (or grayscale) of the original image
this is the input image:

If you turn it into grayscale and plot it in matplotlib, it will basically look like this image without the contours
I have a hard time actually seeing the drawn contour for the outer circle
oh, i will try man, thanks
i can kinda see the contours; it makes it looks like a cell-shaded image
where exactly?
I see the problem 😛
import cv2 as cv2
import numpy as np
import matplotlib.pyplot as plt
def vessel_segmentation(input_image):
# Carga la imagen en escala de grises
img = cv2.imread(input_image, cv2.IMREAD_GRAYSCALE)
print(img.shape)
# Aplica un desenfoque gaussiano con un kernel de 11x11
img_blur = cv2.GaussianBlur(img, (11, 11), 0)
# Aplica un umbral adaptativo con un tamaño de bloque de 21 y una constante C de 3
# Usando el método de la media (ADAPTIVE_THRESH_MEAN_C) y umbralización inversa (THRESH_BINARY_INV)
thresh = cv2.adaptiveThreshold(img_blur, 255, cv2.ADAPTIVE_THRESH_MEAN_C,
cv2.THRESH_BINARY_INV, 21, 3)
contours, hierarchy = cv2.findContours(thresh, cv2.RETR_CCOMP,
cv2.CHAIN_APPROX_SIMPLE)
contours = sorted(contours, key=cv2.contourArea, reverse=True)
# Dibuja todos los contornos excepto el más grande
new_img = np.zeros((*img.shape, 3), dtype=np.uint8)
for cnt in contours:
v2.drawContours(new_img, [cnt], -1, (0, 255, 0), 1)
plt.imshow(new_img)
plt.show()
vessel_segmentation("retina.png")
Run this

These are the first three contours
This code sorts the contours, then shows them added one by one onto an empty image
oh, I see the issue I guess. it sees the edge as two contours, because there's a slight halo around the edge
Yeah, so more blurring could help
so dropping the highest-area one still leaves the second.
Or simply dropping the first 2, which is easy as they are now sorted, so for cnt in contours[2:]:
oh, okay guys
i understand the problem
thanks ❤️
man you are so pros, thanks
i have the result that i wanted
Hi guys I hope this is the right place, I'm trying to build/train a model for algo trading.
I got 0 knowledge in ML but I do know python, how can I even start this kind of project?
Start with some basic project like Mnist using tensor flow
use pytorch
haha I guess I'll have to figure something out!
"# import required packages
import cv2
import argparse
import numpy as np
handle command line arguments
ap = argparse.ArgumentParser()
ap.add_argument('-i', '--image', required=True,
help = 'C:\Users\Andrew K\Downloads\aux.jpeg')
ap.add_argument('-c', '--config', required=True,
help = 'C:\Users\Andrew K\Downloads\yolov3.weights')
ap.add_argument('-w', '--weights', required=True,
help = 'path to yolo pre-trained weights')
ap.add_argument('-cl', '--classes', required=True,
help = 'path to text file containing class names')
args = ap.parse_args()
#input images
image = cv2.imread(args.image)
Width = image.shape[1]
Height = image.shape[0]
scale = 0.00392
read class names from text file
classes = None
with open(args.classes, 'r') as f:
classes = [line.strip() for line in f.readlines()]
generate different colors for different classes
COLORS = np.random.uniform(0, 255, size=(len(classes), 3))
read pre-trained model and config file
net = cv2.dnn.readNet(args.weights, args.config)
create input blob
blob = cv2.dnn.blobFromImage(image, scale, (416,416), (0,0,0), True, crop=False)
set input blob for the network
net.setInput(blob)" i am ge4tting an error which says
usage: main.py [-h] -i IMAGE -c CONFIG -w WEIGHTS -cl CLASSES
main.py: error: the following arguments are required: -i/--image, -c/--config, -w/--weights, -cl/--classes
what to do
Can anyone recommend a book to learn PCA , it's very hard to understand 😅
Is there a discord community for llama-cpp or gbnf/grammars?
hi!
i saw the episode thing when training reinforcement learning models, like, it trains for x steps and then reset and train again, how can i implement it here?
env = TradingEnv()
states = env.observation_space.shape
actions = env.action_space.n
model = Sequential()
model.add(Dense(24,input_shape=(1,states[0]),activation='relu'))
model.add(Dense(24,activation='relu'))
model.add(Flatten())
model.add(Dense(actions,activation='linear'))
agent = DQNAgent(model=model,
policy=BoltzmannQPolicy(),
memory=SequentialMemory(limit=5000,window_length=1),
nb_actions=actions,
nb_steps_warmup=20,
target_model_update=0.001)
agent.compile(Adam(lr=0.001),metrics=['mae'])
#agent.load_weights("tradingAgent-v2.h5")
agent.fit(env,nb_steps=len(df["Close"]),visualize=False,verbose=1)
agent.save_weights("tradingAgent-v2.h5",overwrite=True)
Hello Gentleman , Can anyone share the complete roadmap of how to learn machine learning along with the resources I know Sql,Python,R and NOSql
def split_dataset(dataSet, axis, value):
retDataSet = []
for featVec in dataSet:
if featVec[axis] == value: # error here
print(type(featVec)) # str
reducedFeatVec = featVec[:axis].tolist() #chop out axis used for splitting # error because str has no tolist() method
print(reducedFeatVec)
reducedFeatVec.extend(featVec[axis+1:]) # error cause it's not a string, but a dataframe column
# reducedFeatVec = reducedFeatVec.append(featVec[axis+1:].values.tolist())
retDataSet.append(reducedFeatVec)
return retDataSet
Does anyone here know some way to stream data through kafka online but for free? Evem if its just demos or something
Plz ping me if ur gonna reply to me (u can even dm)
Hello, im wondering what are the prerequisite concepts that are needed in order to start machine learning?
currently I am at Python OOP level
knowing OOP isn't super important for ML. You need to be able to identify the types of each object that you work with (strings, lists, dicts, arrays, dataframes), but you never really need to design your own class.
you also need to know the different kinds of primitive types, like ints and floats. and the difference between a 16 bit float and a 32 bit float. but that's not part of OOP, just types.
thank you!
PCA is a little tricky because you can derive it from both a statistical perspective and an algebraic/geometric perspective, and those derivations look very different from each other. you'd want a stats textbook for the statistical perspective and a linear algebra for the geometric perspective.
even the statistical approach relies on diagonalization, so looking at eigenvalue decomposition (and also singular value decomposition, because why not) is a good place to start regardless of how you plan on interpreting the result
My head got burned while understanding PCA
Covariance and all that
hello, ive discovered LM studio, where u can download free open source models and run them locally. Is there a way to download them and import them on my own python script? with keras or tensorflow?
Great point. Also when people do PCA i think they are usually thinking of it as a geometric thing moreso than a statistical model
so I have this CUDA error:

Yet my y and predicted labels have the same shape and the same type
what exactly is going wrong here?
Not sure but check if your model and data are on same accelerator. Maybe your predicted_y is on GPU and y is on CPU
figured it out but I was outputting to 1 neuron when it was a classification problem
dont know how I didnt notice that lol
are there any part time or remote jobs I can take if I'm interested in cs, more specifically data science?
Hi guys, I'm having trouble with my code. Specifically OpenCV, because whenever I launch the code the OpenCV console is very slow and laggy. My goal is making a sign language translator speaker using tensorflow action recognition. At first I thought the thing that was making my OpenCV lag was my text-to-speech code, but when I removed it, the console was still lagging. It's been weeks since I tried to find an answer for this and still haven't come to a conclusion. Yeah, If you guys can help I'd very much appreciate it thank you!!!
Here's the code of the testing in real time:
Profile it and view with something like snakeviz
Ohhhh thank you, I'll try that!
Hello is there any online tutorial on python data science
i started learning statistics resolving hackerrank problems, maybe it help you too
Didn't know hackerrank had statistics questions, that could be useful. @feral sand can you share a link to some of that?
i think this is the first one https://www.hackerrank.com/challenges/s10-basic-statistics/problem

HackerRank
Compute the mean, median, mode, and standard deviation.
https://www.hackerrank.com/domains/tutorials/10-days-of-statistics or here for all the problems
i see. that's not a bad starting place
normally i would say that focusing on code too much is a detriment to understanding statistics, but in this case it looks like the exercises are at least partially encouraging you to understand the concepts well enough to write the code yourself, which is a great check on understanding
whereas too many statistics students are given a library that already implements a large number of statistics routines, and students apply those routines without understanding much of what they're doing
hackerrank btw don't accept external libs for what i remember
does anyone know why it's complaining about OpenGL not being a thing in this code:
https://paste.pythondiscord.com/TXTA
Also its saying "LBPHFaceRecognizer_create" is not a known member of module "cv2.face"
I'm not quite sure why
Thanks for providing the code. You also need to show the whole error message to get help.
Also, it looks like you used ChatGPT to produce this. How much do you understand about how it works? If someone helped you fix it, would you understand what they are saying?
hey man short update, I instead used opencv headless and it works fine now, just having troubles with opening the camera index, its saying out of range
could I re-share my code for you to take a look at it?
Always share the full error message and the exact code that causes the error. You don't need permission--just do it.
G I fucking know I was just tryna be nice
I fixed it also
I'm just letting you know for the future. I appreciate that you're being polite, but it saves everyone a step to present all the information that people need to help you all at once.
bruv I know, thanks tho I guess
Can someone make a code on python on topic Physics
Can you be a bit more specific? Why do you need this code also?
hi, I took this transformer model
model_factory = ModelFactory(
coordinates = 6*8,
words = 70,
tokens=50258 + 1,
number_of_blocks = 1,
number_of_heads = 6,
bias = 0,
attention = "metric"# "scaled_dot_product", # or "metric"
)
and stuck a couple feed forwards on top of it, and that was enough to train it on sentiment analysis on CPU
the model is so small that it got me wondering
would a simple feedforward work from the get go ?
wait y am I asking, I can literally just try it
I just needed to make a project
try to make a simple random walker particle
have it have 3 coordinates, for each step choose a random direction and a random displacement, displace particle in that direction, repeate
hi guys, im using opencv to get retina blood vessels, i have some code but it's not working like i want:
import numpy as np
import matplotlib.pyplot as plt
def vessel_segmentation(input_image):
# Carga la imagen en escala de grises
img = cv2.imread(input_image, cv2.IMREAD_GRAYSCALE)
# Aplica un desenfoque gaussiano con un kernel de 11x11
img_blur = cv2.GaussianBlur(img, (11, 11), 0)
# Aplica un umbral adaptativo con un tamaño de bloque de 21 y una constante C de 3
# Usando el método de la media (ADAPTIVE_THRESH_MEAN_C) y umbralización inversa (THRESH_BINARY_INV)
thresh = cv2.adaptiveThreshold(img_blur, 255, cv2.ADAPTIVE_THRESH_MEAN_C,
cv2.THRESH_BINARY_INV, 21, 3)
contours, hierarchy = cv2.findContours(thresh, cv2.RETR_CCOMP,
cv2.CHAIN_APPROX_SIMPLE)
contours = sorted(contours, key=cv2.contourArea, reverse=True)
# Dibuja todos los contornos excepto el más grande
new_img = np.zeros_like(img, dtype=np.uint8)
for cnt in contours[2:]:
cv2.drawContours(new_img, [cnt], -1, (255, 255, 255), -1)
plt.imshow(new_img, cmap=plt.get_cmap('gray'))
plt.show()
return new_img
But some images show like this

and the out should bee something like this

I'm using python 2 (by force) and am not allowed to use any external lib
I've constructed a 2D Matrix class as follows:
https://paste.ofcode.org/cGzje8Ubrhx7fBysvZkX6x
However upon testing the inverse method for matrix
[2, 1, 0],
[0, 1, 1],
[1, 1, 0]
I get
[1.0, -0.0, -1.0],
[-1.0, -0.0, 2.0],
[1.0, 1.0, -2.0]
Which is incorrect to my knowledge
I've tested all the functions that inverse() calls and they seem to be working properly
Anyone has a clue why it's doing this?
This result looks correct to me.
!e as in,
import numpy as np
A = np.array([[2, 1, 0],
[0, 1, 1],
[1, 1, 0]])
print(np.linalg.inv(A))
@tidal bough :white_check_mark: Your 3.12 eval job has completed with return code 0.
001 | [[ 1. 0. -1.]
002 | [-1. 0. 2.]
003 | [ 1. 1. -2.]]
If you have ground truths, I'd just throw a CNN at it, these manual segmentation things are a nightmare to get right sometimes
UNET converges very well and was made for medical
Yeah, that's the next step
rn i have to do it with raw opencv filters
thanks bro, i save this message for the future
Just to be certain
Could the inverse of an int matrix ever have a float element?
I'm still happy about my day's work tho

Well, in this case all the elements of the inverse are integers, just represented as floats.
But also, yes. Obvious example would be the inverse of 2I - it's 0.5I (where I is identity matrix).
This makes me wonder what is the domain of applicability of transformers. In this case, a transformer is clearly overkill.
Maybe when the context window is too large the feed forward stops working ?
hi! I'm using the rl-keras + gym for reinforcment learning models, how can i train in episodes instead of just steps?

this is my coding now, i think i need to make something in the place of agent.fit, but idk what
def dot(self, matrix):
if not isinstance(matrix, Matrix2D):
raise ValueError('{} must be a 2D Matrix'.format(matrix))
if self.columns != matrix.rows:
raise ValueError('Cannot . the two matrices.')
result = [[sum(a * b for a, b in zip(row, column)) for column in zip(*matrix.matrix)] for row in self.matrix]
return Matrix2D(result)
The dot method inside the Matrix class
Am I doing this right? I feel like there's a slip up but I don't find it in the debugger
fyi the .matrix property is just a list[list[]]
anyone got tips on reducing columns in datasets? and how to distinguish which can be deleted
if you are using pandas, you can just do dataframe.pop("Column name")

no no technically i know how, i mean how to understand which ones i should in my dataset