#data-science-and-ml
1 messages · Page 64 of 1
np where was almost instant, str contains was the bottleneck
do you mean to use regex here? if not, try passing regex=False to str contains
otherwise the comparison isn't very good
by using some dtype stuff and then numba, I managed to make it 2 and 8 times slower respectively 🥴
Not yet, but I should also test regex maybe.
np.where() with in is now way ahead
can you show?
but anyway yeah, str contains is a super general function with regex, nan replacement, etc by default, so the comparison will be bad unless you turn all of that off
you're seeing the numpy and pandas tax: a fixed overhead to prepare for large data with weird properties

^ that's np.where() with in , str.contains() doesn't have regex=False yet
clear winner lol
str.contains() takes the same time with regex=False
str.contain s does have regex=False
can you show the code?
I don't believe this np.where result is right.
Ah, let me inspect the df. I used:
np.where('char' in df['column'], 'thing', 'some')
'char' in df['column'] is just a single True, since of course it's there
yeah i was afraid you'd do something like that
i can't think of a sensible way of using np where for this case
short of ==, you kinda have to use str contains or one of the other methods you listed to generate the bools
Ah yep, thanks for that 🤦♂️
if we do this, for example
# np.where
start_time = time.time()
np.where(df['column'] == 'char', 'thing', 'some')
results.loc['np.where'][f'Test {i+1}'] = time.time() - start_time
``` we get this plot
which would kinda be the ideal case
Nice thanks. I'll try to refine that to better match some use-cases
this also makes sense
# np.where
start_time = time.time()
np.where(df['column'].apply(lambda x: 'char' in x) , 'thing', 'some')
results.loc['np.where'][f'Test {i+1}'] = time.time() - start_time
``` and yields the plot:
I think I might have finally got an overengineered solution that's a bit faster
%%cython
import pandas as pd, numpy as np
cdef int cont(str a, str b):
return a in b
def str_contains_cython(arr: np.ndarray, sub: str):
n = len(arr)
result = np.zeros(n,dtype=np.bool_)
for i in range(n):
result[i] = cont(sub, arr[i])
return result
200ms on my set, ~10% faster than the listcomp
Is anyone familiar with building input output hidden Markovs?
a-ha, I got <100ms by cythoning it entirely:
cpdef void str_contains_cython(np.ndarray arr, str sub, np.ndarray res):
n = len(arr)
for i in range(n):
res[i] = cont(sub, arr[i])
%timeit str_contains_cython(df["column"].values,"char", np.zeros(len(df["column"]),dtype=bool)) # 82ms
ah yes, python't
my least favorite part of cython is the C type syntax
why, oh god why
last time I tried using cython I realised it would be faster and less painful to rewrite it all in rust
that's probably not true either
that's what I ended up doing though :p
sunken cost fallacy
I'm using a regular jupyter notebook, is there anything I need to install to run your function definitions in cython? I'm not familiar with it sorry
nvm ill read the docs x)
You'd need to install cython, then do %load_ext cython, and then a cell with %%cython should compile the contents as cython.
then you'll have to rewrite the python as cython 😛
ah yeah... not convinient
not sure what you mean, that function is meant to be self-contained
like, cpdef means it's callable from python.
yeah but does that look like python? that was my point
ah, that's true. it's only useful in situations where you are okay with writing a weird function to speed up a process 2x
occasionally it's a lot more useful when you're doing something really weird and the weird function speeds it up dozens of times (e.g. calculating some complicated cumulative function over the df, so you need to iterate)
Thanks, I'll try to use that. I've seen worse boilerplate for the time gain.
has anyone used a jetson nano for object detection?
I'm stealing this phrase hahaha
also if you don't want to do Cython but are dealing with relatively common types, you can use Numba
YMMV tho
How common it is to try to implement an algorithm from a paper and it doesn't work?
I feel like every image generation algorithm I try to implement solely based on the original paper ends up failing...then I have to make adaptations until it works 
Except for DCGAN. DCGAN is cool 
But those papers that use MSE Loss for Variational AutoEncoders...I really don't get their trick. My VAEs only work with Gaussian Log Likelihood
If you don't have access to the same data that they used, you can't say for sure that you've replicated their experiment and demonstrated that it isn't reproducible.
But it's probably a more common problem than we'd like to think
I've only implemented the algorithm from a paper once, and it performed well on my data, which was different.
Aw, that's sad...
I wouldn't want to reproduce the algorithm using the exact same data, though(most VAEs, GANs and Diffusion Models papers use CelebA dataset, which I find meh).
But I suppose that changing the data from CelebA to a CIFAR100 might be catastrophic...which is also sad, since a good model should be able to overcome such things...I guess... 
Common. 😦
(And huge waste of my time)
Yeah, I've wasted quite some time in GANs because of that...
Strange... I thought math was supposed to be exact sciences 
Math is not science, nor is science engineering.
and python is not perl.
Math - You know what you are doing because you made up the rules.
Engineering - You know what you are doing and are trying to figure out the best way to do it.
Science - You don't know what is going on and are trying to figure it out.
ML tends to bounce around all three.
Now it makes sense now
Which one is "You don't know what is going on, but you're happy to be here"?
Art?
Engineering - You think you know what you are doing
I thought some of the most profound and impactful art is made by the depressed and mentally ill
Like my GANs
Art - You don't know what is going on, and are **trying** to be happy to be here.
!otn a squiggle the philosopher
:ok_hand: Added squiggle-the-philosopher to the names list.
Just based on the equations? Kinda common for generative algos ig, if you don't use their data then often it doesn't work out. Dcgan, cycle-gan, ragan, wgan have worked and a few others. I'm currently working on implementing LDMs, let's see how that turns out 🥲
And they say engineers aren't artists and software isn't our canvas...smh
Software not canvas? Oh, my. Oh my oh my.
I'm always skeptical unless said method has a lot of adoption. There's more incentive to publish than there is to publish stuff that actually does really well / generalises broadly to many problems
If for my research I'd implement everything that looks remotely good I'd be busy forever. Half of the implementations are in Matlab 💀💀💀, way more than half doesn't share code/data and all of them seem to crush the existing benchmarks

Can somebody explain why my test accuracy is so bad (8.7%) and my loss isn't decreasing at all
I get that I should be using a CNN (idk how to implement CNNs though) but this test accuracy is just crazily bad
that link is not public
0.5 in everything?

0.5 dropout as well?

also not 100% sure if it is fine or not to reuse the same layer, it would probably give a warning if it was a problem though
yea i was just doing the medium
i dont think the dropout helps me anyways because im far from overfitting 💀
you are dropping way too much
okay i think ill lower it to 0.3 then
yea im doing some research on them
if you feel like it is overfitting, you can increase it back later
do you think my low test accuracy is just because im using an rnn (i think thats what its called??)
not sure if it has a name besides just being a neural network, but a CNN would likely work much better
maybe also try using Adam instead of just SGD
i heard about adam before
all i know is that itsthe combination of momentum and rmsprop
but ill read more into it on the math and its function
thank you so much !! 🙏 🙏
Dropout, batchnorm, ... are things you should add after you've got a network that works but is overfitting
Anyone who have a quick way to make this model into text/latex form? Or something similar?

you could try to type it in graphviz/plantuml/mermaid?
Any webpage that does this thing?
Depends on how beautiful it needs to be, draw.io could work
It's web based but you can also install it
It doesnt have to be beautiful, As long as GPT understand it 😛
Yeah, draw.io (https://app.diagrams.net/) works for that
Ehm. It looks like this page can only create the outlook of the model, not in textform
Oooh, you want to give this diagram as text. I don't think GPT will understand that
I remember I got a suggestion earlier here one time but I don`t remember the name of it. Some kind of latex of two dimentional matrix
anyone can explain to me what is difference between sequence_length and vocab_size from this code?

sequence_length relates to the length or size of the input sequence, while vocab_size relates to the number of unique tokens in the vocabulary. These parameters serve different purposes in the code and are used to configure and shape the embedding layer accordingly.
In your code, the , sequence_length and vocab_size are two parameters used in the Embeddings class
I try to run that code as:
emb=Embeddings(5, 5, 256)
emb_out=emb(test_input)
print(emb_out)
print(emb_out.shape)```
why did I still get ``shape`` as (1, 5, 256) instead of (5, 5, 256)?I recommend reviewing the implementation of the Embeddings class and checking if there are any batch-related operations or configurations that might be causing the discrepancy in the output shape
Sorry for late reply @bold timber
I have an array alphas = alpha ** np.arange(1, X.shape[1]+1)] that I multiply with X as such y_pred = np.dot(alphas, X.T). Now my question is, how would you guys optimize alpha wrt. the MSE? This is a non-convex problem. Right now I used simulated annealing because that's what I'm most conversant with from school. Can I just throw BFGS on such a problem instead? It's been a while but afaik 2nd order methods will just go to a saddle point.
So it's a 1d optimization task, you are only tweaking α? Maybe differential evolution would work well, too.
what shape is X?
Exactly
#num_pts x #num_variables.
I hadn't heard of differential evolution yet! I'll try it on my data
ok, was just making sure it was a matrix and not something else
actually, wait... isn't this exactly quadratic by α? ah, nevermind, **
i would point out that no method has guarantees of finding the global optimum btw, so a heuristic like sim annealing also has no guarantee of finding it
I'm OK with not finding the global optimum. I just defaulted to sim annealing because I was unsure how my go-to (BFGS) would behave here
0 < alpha < 1
ok
I'm reading about differential evolution and at a glance it looks like a special case of genetic algorithms
Both being population-based metaheuristics that use crossover, mutation and selection. Am I missing anything @tidal bough ?
Like, you can express genetic algos in terms of real-valued vectors and pick a specific mutation operator and then it's differential evolution?
Yup, it's a fancy genetic algorithm and local searches for refining the results. I've had good results with it in high-dimensional optimization, but plausbily it's less interesting in 1d.
Genetic algorithms were some of my favourite coursework 🙂 Good to know scipy has a very easy-to-use implementation
anyone know of a good text summarizer model on github?
kind of an ed-techy tool that can summarize large texts
not cgpt
in the interest of saving money not using their api
do your matrix X and data y have any special properties?
the problem is not convex in general, but one could plot the second derivative vs alpha and see if anything special happens
It's just an exponentially weighted moving average so X are lags
so all the entries of the matrix are positive?
Yes
if the matrix and y are fixed, there's a good chance the problem is convex after all
But they might not be in the future - I might swap the task from predicting y_t to predicting delta_y_t
aha
once I label my dataset, are there any good tutorials for object detection?
i want to draw a bounding box
Running YOLO through open-cv is pretty plug and play: https://opencv-tutorial.readthedocs.io/en/latest/yolo/yolo.html
it's gotta be a custom object detection model, any yt vids for that?
You'll have to look for that yourself 🙂
you can consult the docs of YOLO, they have a tutorial there on how to train their model
Guys, I got a trained model from github but I wanna run it using my test dataset.
it is an image steganography project
but the code just keeps giving me results from the training data
If there are any kind souls present who would be willing to spend some time to read this project, I would deeply appreciate your effort. It is getting kind of desperate. I need help. please.
hey everyone, im trying to remove the outliers from my data using pandas
Im using the following code rn:
lower_limit = df.column.mean() - 3* df.column.std()
upper_limit = df.column.mean() + 3* df.column.std()
df = df[df[column] > lower_limit]
df = df[df[column] < upper_limit]```
The error being raised is that the database doesn't have a column objectHow can I resolve this? Im kinda a beginner with pandas and this is the easiest method to remove outliers I found
try df[column].mean()
GAs can vary. Some are used in Neural Nets; however, some can be as simple as an array depending if the use case is static or not.
This server really isn't the place for you to promote your youtube channel.
Sorry about that, will remove the post
Huh I don't see the connection between GANs and the conversation we were having before (differential evolution vs genetic algorithms)
GANs?
I think JTexpo meant to make a general comment on GAs, in that they can be used to train neural networks
what would be the best way to measure a plants bio mass with ai to accuratly measure a plant from the soil up in a single pot, guestimating the root biomass is also important but if i could get a accurate reading of the upper plant i could guestimate the roots possibly. the goal is to measure how much the plant is growing, has grown and esitmate how much water it has uptaken and also possibly transpired. if the system could be embeded into a cheap micro controller like esp32 or arduino it could help with a watering system im working on
what?...
ai biomass estimation. i was thinking white dots around plant like in green screen movie animation
sounds a bit like a regression problem, but you would need of a lot of data to train a model for that
after the edit: do you understand how models actually work?
a little bit but no real world hands on
hey guys
- you must have well defined inputs and outputs
- the model itself is used to approximate a function, but you must model your problem in a way such that you can "teach" it how to get better at approximating that function
ive been recomended open cv and plant cv from gpt

forget about using GPT if you do not understand the subject of the discussion well enough to verify whenever or not the output makes sense, seriously
does anyone know?
ok, i was just asking for guidence on where to start and maybe there is similar projects i could learn from. i see it as a possible highly valuable tool for automating watering for plants and robots but ive only found bit of info here and there regarding the subject, nothing precise like i would like. i would def need somone with experience and thats another story
it looks like there is some research on it (e.g. https://www.frontiersin.org/articles/10.3389/fpls.2022.758818/full), and that plant cv is an actual thing, but I had never heard about that area before
wow such a well documented article thank you. the arduino system i built for water plants is basically the blueprint that would work great with a accurate biomass estimate software. would just need to patch them together somehow. i can show u my code if interested
the biggest issue you would have to tackle first is finding a dataset containing the biomass of the plant, with the features you want to use to estimate the biomass
mainly for cannabis plant to start, mainly for vegging. all edible plants one day too
I don't know much about plants, but I highly doubt that data about one species would work for other species unless they are extremely similar/close
to get it to work with and high edible plants would be an accomplishment
or any valued plant
i water plants based on weight so the ai would be a compliment to my setup
watering can be a challenge for a lot of people, under watering over watering ect. if the ai can do it all then can help humans with labor costs
yeah interesting problem to solve but you need to define it as an ML problem first
along the lines of what etrotta said, identify your inputs, why those inputs will give you valuable modeelling information, identify your outputs, study whether such a system even is possible, identify what kind of statistical modelling task it fits into (regression maybe), etc.
Good luck!
anyone knows a reliable Midjourney API provider?
Why is my test accuracy so bad and not increasing at all? (5.6%) for my multiclass task?
😦
There are a lot of Stable Diffusion API providers and OpenAI offers Dalle-2 via API, but Midjourney does not offers an official API and you should not trust anything that claims to offer an API for it - It would be either a scam using a different model or violate ToS
I think that your Backprogagation step is in the wrong order?
also the normalisation with everything in 0.5 might (still) be doing you a disservice
yeah i think ill chagne that then
what do you mean the backpropagation step is in the wrong order
the order of these lines

compared to https://pytorch.org/tutorials/beginner/introyt/trainingyt.html in which they zero grad before all others
I would also recommend taking a look at the images yourself after your code resizes them to make sure that they remain identifiable at all
thank you
okay let me try putting the zero_grad first and hen check the images after resize
(like, if the original images are wallpaper sized, you might want to keep them a bit larger or crop the faces first)
@agile cobalt thanks for that awesome site and your help
loss.backward() is what accumulates the gradients that zero_grad() clears, so both are equivalent no?
np!
I have no idea tbh
ah okay
the model is also fairly large so you might need to let it train for a bit longer than 2 epochs, specially with the learning rate you set
Both would be equivalent
i trianed for 5 epochs and the accuracy didnt change at all
looking at the dataset... a lot of these images are not like each other at all
I would recommend testing your model on a more conventional dataset first

including inverted images in the dataset is also weird af imo
specially considering that it looks like they were not even consistent on it? some of the characters have inverted images while others don't
yeah you're right il use a different dataset this one is way too hard
ill find one iwht more consistent images
it might work well enough if you fine-tune an existing model, but I don't think that training one from scratch on that data set is a good idea
yea i probably took too hard of a dataset for a starting learning project 😭
thank you very much!! 🙏
A few things. Check if 64x64 image size contains enough information for you to do the classification you're trying to do, look at the dataset for this
Though these probably aren't significantly responsible for keeping it at 5%:
Try a lower kernel size. Your image is 64x64, a kernel size of 5 is probably too much
Try more filters, instead of 3->6 try 16,32,64. More filters give the model the ability to capture/model more features
Report train accuracy as well and compare train and test accuracy to get a sense of bias/variance
Check the data distribution and balance across classes
Lots of things are possible, you just keep eliminating what isn't the problem to keep making your method better and eventually find out a solution
Albumentations could be useful too once your model is learning better
So much successive pooling with such a small image-size to start with is rapidly reducing the size of your feature map, and combined with you having few filters could mean a lot of relevant information is available for very few parameters to learn
Hi! I am trying to use TargetEncoder from sklearn so as to apply mean encoding to some of my features. But i cant find any info about it, especially examples. Any one knows how to use it?
well, they really have a reason for delaying the release of their own API, so people like me that rely on their bot are pretty much stuck if they want to create bigger projects. I, for example, need it for a video generation tool, but without an API it's useless. others like DALEE2 don't work as well. I've found mjapi.io, thenextleg.io and others, might just try them, but I was curious if there's anyone that had already tried them and has anything to share. ofc, this is just a proof of concept, and I'm well aware that it's safer to use a burner account
I'll just recommend using Stable Diffusion instead and request for you to avoid discussing that sort of alternative in this server 🤷
if something requires using proxies, burner accounts or such, we will not assist it
this is my device map for "HuggingFaceH4/starchat-alpha" model , can anyone tell what values should i pass inside no_split_module_classes to make the same layers in one device.

Im hoping I could get some help on a problem that I have been having. I have been trying to implement the paper HiPPO https://arxiv.org/abs/2008.07669 and accomplished this here: https://github.com/Dana-Farber-AIOS/HiPPO-Jax. However since then I have been trying to re-implement it with different design choices. The big difference is that HiPPO is basically a layer that behaves recurrently. Its common practice, atleast with RNNs, that you implement the RNN Cell and then call the RNN Cell within a skelaton RNN that accepts arbitrary RNN Cells, i.e. LSTM, GRU, etc. I wanted to do the same with HiPPO where the two different cells are HiPPOLSICell and HiPPOLTICell. I have found that when I try to initialize my parameters such that the flax module knows the learnable weights, the way I am doing it doesnt work and will fail when I try to set the weight matrices as self.param. I will provide the code for all of this in a moment.
My experience with PPO(not HiPPO) says that initializing the network weights the way they suggest(which is, if I remember correctly, through an invertible matrix) makes the model rubbish
and that's a standard for most algorithms I've tried so far
At least my model tends to produce the same outputs and get stuck on local optima more easily with such initialization
hi everyone, im have a problem, i have to generate a dataset for fine tune gpt from documents, but i have no idea how to do 🥲
Who told you to do this, and why do they want you to do it?
my instructor and he want to fine tune chat gpt to question answering about the document
I suppose it's to decrease the chance of misinformation
you can't fine-tune ChatGPT, because the actual model is not available. you can only interact with it over their website.
You can download GPT-2 (in a certain sense, ChatGPT is GPT-3.5), but I think that's as close as you can get. And GPT-2 isn't conversational the way ChatGPT is.
If your instructor doesn't know this, but they gave you this assignment anyway, you should see if you can get a refund for the course.
if I'm reading this other article right, it looks like you can fine-tune GPT-3 via OpenAI's API, but that the actual model is never turned over to you.
if they did not specify it has to be exactly chatgpt, there are some open source models you can use - overall they are significantly worse than openai's gpt, but should work well enough with fine tuning
GPT-2 is on huggingface
I'm thinking more like the ones released earlier this year than however long ago gpt 2 was
edit; 2019
everyone and their grandma wants their own LLM
How come my model test accuracy is just the same accuracy as pure guessing and is not improving at all? (10% with 10 classes)
I've used three different datasets and my test accuracy has been the same as guessing each time
😦
you are still using that?
transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
I have a question about this code:
def compute_mask(inputs, mask=None):
mask = tf.math.not_equal(inputs, 0)
mask1 = mask[:, :, tf.newaxis] # column vector
mask2 = mask[:, tf.newaxis, :] # row vector
attention_mask = mask1 & mask2
return attention_mask
That code is the code for masking in Transformers. But I'm confused about why do we need to set mask= None ?
you shouldn't have to, specially if you always overwrite it later
I don't understand what you mean. Can you elaborate, please?
:incoming_envelope: :ok_hand: applied timeout to @tulip wyvern until <t:1685075660:f> (10 minutes) (reason: newlines spam - sent 157 newlines).
The <@&831776746206265384> have been alerted for review.
!unmute 494283724373098529
:incoming_envelope: :ok_hand: pardoned infraction timeout for @tulip wyvern.
if you were doing something like ```py
if mask is None:
mask = tf.math.not_equal(inputs, 0)
use the pastebin
yeah sorry 😭
i printed out the num correct guesses and the corresponding y label and found that my model is always guessing 9. Anybody have any idea why?
try shuffling your input data
for the train or test, or both?
both
okay i will try that 🙏
just remember to keep the images and their corresponding labels together
either bundle them in a 2-D array and only sort in the first axis, or just generate a random order to grab indexes from
i have the label and the image as attributes in my dataset class
as lists
and for getitem i return the object at the selected index for the image and label list
okay i shuffled my training and test set and i got 37% test accuracy
Do you think this is just because I have a bad model architecture or is it a product of another dumb mistake?
are you still using 0.5 for all in the normalisation?
yep
but either way that was definitely a big whoopsie 
your model was pretty much only seeing one type of 'target' on each batch
yeah I can't believe i missed that 😭
okay it looks my model can finally learn
ill just work on finding better normalizaiton parameters and architecture
thank you very much i really appreciate it
taking a quick look at https://paperswithcode.com/sota/image-classification-on-cifar-10 it looks like at least 80% accuracy should be reasonable to achieve

The current state-of-the-art on CIFAR-10 is VIT-L/16 (Background, Spinal FC). See a full comparison of 228 papers with code.
any more than that might require some more delicate tweaking, but even 95% should still be reachable if you put time into it
yeah im definitely gonna put in some time to play around with it
Guys, who can help me with Python simple thing, im new in it.
Can somebody explain why the RNN performs so much better than the CNN (which is not improving at all)
I don't know why I keep getting this issue 😭 😭
recall = True Positive / Total Positive
you have 516 False Positives and 79 true negatives, so you identified correctly 79 / (519 + 79) of the examples labeled 1 = 0.13277310924369748
your classes are extremely unbalanced, so it predicts false positives more often than false negatives
*I might have messed|mixed up the names ; do double check it
I assume so
(so that it supports cases in which you have three or more categories instead of just binary classification)
tbh I would recommend trying to use a slightly more high level library like fastai
I would guess underfitting, since your CNN network has wayyy more params than the other one, but I feel like even then it should improve at least a little more than it is right now
also you left the other one with 10 outputs?
Fastai is higher level?
I was considering learning it but I didn't know people actually use it
Wait if my cnn network has more params how come that causes the cnn network to underfit?
not enough data to adjust all the params
but never mind, that does not makes much sense
I'm kinda sleepy
i think i will try to grind and figure this out
even though it is extremely painful
hopefully im learning something 💀
thank you for all the help youve given me 🙏
maybe play a bit with the learning rate (both increasing and decreasing)
the loss going up in the last epoch for the 'rnn' is also a bit suspicious
im going to do everything imaginable
hi guys, i recently got interested in data science..... can you share some really good resources to study....also how much time would it take before i could make a decent project and land an intership?
error: mp_drawing = mp.solutions.drawing_utils
AttributeError: module 'mediapipe' has no attribute 'solutions'
Hello, so i have a question about an onnx models, im new to this and i'm not finding enough documentation on the internet.
So i have two models i exported as onnx and they work fine. One is called splitpost and the other nosplitpost. They take as input a mask of shape [1,88,44,60]
i wanted to create an onnx model where i have an if else statement and a split boolean value.
If split is true, we use the first model on the image else we use the second one.
This is my code: https://codeshare.io/Lw4en6
Obviously this isn't working but i don't know why. i'm getting this error on the check model:
onnx.onnx_cpp2py_export.checker.ValidationError: Unrecognized attribute: axes for operator ReduceSum
==> Context: Bad node spec for node. Name: OpType: If
Can anyone please help me solve this?
.
can anyone tell which libraries can i use for automatic license plate recognition
You can prolly use ChatGPT retrieval plugin and connect it to a vector DB of your knowledge base
But that's reliant on getting access to chatgpt plugins
Check your filenames. They shouldn't be the same as the module name (mediapipe)
Basically, if you're using a file named mediapipe.py, change the name
One approach would be to use yolo for detection and then extract that and use an ocr model to get the license plate number
Many other approaches are possible depending on the kind of data, compute, and what exactly you want to do
Also, that won't be fine-tuning. You can't fine-tune chatgpt because the model isn't publicly available.
But for the use-case your prof seems to be going for, retrieval plugin with vector-db is how a lot of teams do it
Hello, I am trying to make a CNN to predict whether an image of an eye is open or closed, and it seemed to train very well over 50 epochs:
Epoch 50/50
9/9 [==============================] - 7s 816ms/step - loss: 0.0044 - accuracy: 1.0000 - val_loss: 0.0119 - val_accuracy: 1.0000
When I predict images using the model, it always looks something like this:
array([[0.00796265, 0.9920373 ]], dtype=float32)
where the second class is much larger than the first.
Also, I tried predicting Images that are in the training set and it still outputted the same, incorrect prediction.
I'm not sure how I could fix this. If anyone could help that would be great.
u sure something isnt swapped around?
why do you have two output values for the prediction if its a binary classification?
Check the data distribution across your classes to ensure it's not heavily imbalanced
For example if you had 990 images - class A, 10 images - class B.
In this case even if your model learns to just predict A everytime, it gets 99.9% accuracy, even tho it's not learning anything valuable.
What is the sample size you are using of both open and closed eyes?
I have 12 5-second videos of my friends where they move their heads around, 6 with their eyes open the whole time, and 6 with their eyes closed. I used every frame from the videos to train my model, so theres an equal amount of data for each class.
Just to double check, are you making sure to shuffle your data and not train eye open first then eye closed?
both ways is fine
i really thought you were answering my earlier question 😢 . Thanks for the clarification anyway
I believe so. I have this code: X,Y = shuffle(img_data_list,target_column_hotcoded,random_state=2)
I’m not familiar with that shuffle. I usually see people do it with a zip of their input list and their output list and then unzipping the object
Something like this ^
anyone here familiar w/ pygsheets or google api auth? I had a project I was working on a while ago, I was using a service account to connect and could access my spreadsheet fine. I went to run it today but it just keeps giving me a timeout error. Nothing has changed in the code since or on my console account
Anyone here competing in Kaggle?
I think sometimes the IAM permissions have an expiry after which you have to reinstate them. Maybe that, but not very plausible
Yeah?
What kind of competition you are, @potent sky ?
The last one was on RL
I'm in competing in the "playgrounds", to learn more
oh great! That should be useful
Past competitions are also useful to learn, you can also observe the discussions by the top submissions and even their code if they've made it public
Good luck!
I'm trying this competitions because there are a lot of people in there!
Oh yeah community is very important too, lots to learn from our peers
But I feel 'alone' in the competitions. I think that talking with other about the competitions can acelerate the apprenticeship
For the reason, I decided be more participative here
stargazer always here responding! I did go back into the console and adjusted scopes, made a new service account, everything I could think of but couldn't get it to work unfortunately
don't know if this helps narrow down how to troubleshoot but running the code in my editor (PyCharm) works fine - it will connect and print the data from the sheet - the issue is when it's trying to display this data in streamlit. Is this a network related issue? It did work previously w/ streamlit when I was originally working on it a few months back.
do you know how to create a column for start of week's date for all the value in the Date column?
that's your first order of business.
In Pandas, is it possible to take a list of the data from rows like [A, B, C]
and have it output like
0 | Header A | Header B | Header C|
1 | A1 | B1 | C1
1 | A2 | B2 | C2
1 | A3 | B3 | C3
Got it! Thanks 🙂
What was your solution?
Hello! I´ve been learning python basics for almost 2 months and I want to improve my skills related to python for data analytics, does anyone know about any course that could be helpful?
In pytorch, what is the difference between nn.Conv2d() and nn.MaxPool2d()? Both take in the "kernel_size" and "stride" arguments, so wont they perform the same function of decreasing the analysis area of the data?
where did you even read about them?
Doing the "learnpytorch.io" tutorial on CNN's
their inputs and outputs are similar, but the operation they perform on the data is completely different
could you explain?
MaxPool, as the name suggests, grabs the maximum value present in the kernel region, and ignores the rest
a Convolution has weights for each of the kernel positions, and will take all values into consideration at least until an activation layer like relu negates some of them
There's this course by freecodecamp that's..well, free
https://www.freecodecamp.org/learn/data-analysis-with-python/
This is very code-orientated
There's also a few courses by mit ocw if you want to get into the math behind it (recommended)
https://ocw.mit.edu/courses/15-075j-statistical-thinking-and-data-analysis-fall-2011/
Datacamp is considered a very good resource so here's a datacamp course:
https://www.datacamp.com/tracks/data-analyst-with-python
But datacamp is paid. I think you get a free 3 month trial so use it wisely
There are some other great courses as well on udemy, Coursera and ofc YouTube
Good luck!
so a maxpool is more specific than cnn's
They perform different operations
maxpool and convolution both involve operations on a sliding region of the array, yes? is there a term that encompasses both?
maxpool as the name suggests, activates the maximum from the kernel region
A convolution operation activates each element, with some weight, from the kernel region and adds them up
I'm taking a look at their website... I seriously hope that the website is meant to be used as complement to videos, not just on it's own?
Thank you so much! I´m going to save this links and try them later!
but specifically for CNNs, do take a look at the https://poloclub.github.io/cnn-explainer/ page that they link in their website if you haven't yet
it also explains convolutions and pooling layers
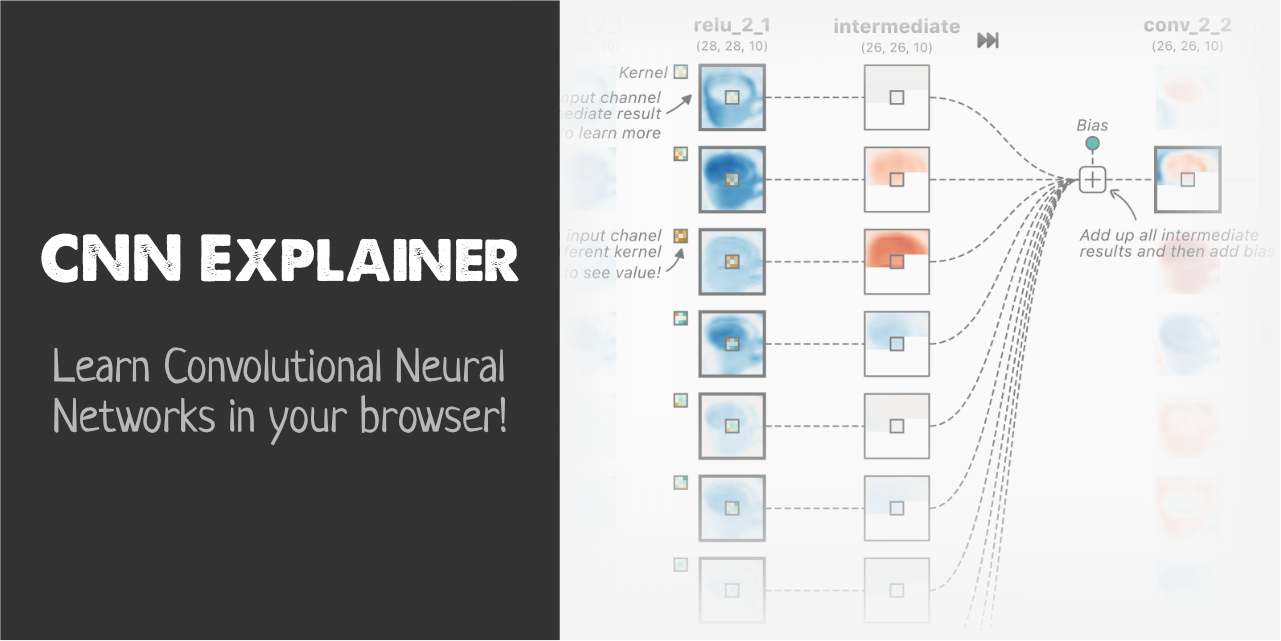
An interactive visualization system designed to help non-experts learn about Convolutional Neural Networks (CNNs).
Interesting, I'm not so sure. Streamlit's limited customisability annoyed me so I've not used it for ages. I generally just use flask or smtg else
Grpc support for streamlit was also messed up iirc
no problem, and good luck!
Ig maxpool can also be seen as a sort of convolution operation no? The max element is weighted to one and the others to zero
Hello, am trying to install mediapipe, does anyone know why is this error?
I can think of a lot of formatting
Formatting the keys and values to form a dataframe from a dictionary
Broadly speaking, there are no versions that would work in your environment. Check the library's supported OS and Python versions
Aight, i was using conda, maybe is that
Anybody have any ideas on how I can reduce overfitting (Train: 100%, test: ~65%)
On a multiclass image task
I've done:
Normalization
Batchnorm
Random horizontal flip (0.5 chance)
Random grayscale (0.2 chance)
Dropout regularization (0.4 chance on each layer)
What other techniques are there?
undersampling
not enough train data?
how much training data do you have
840 * 3 (for each class)
did you figure out why was it stuck on 33% the other day?
yeah my model was just really bad
yeah
0.4 dropout sounds a bit high to me, not sure what is the standard though, and you are applying it pretty late in the process?
using Norm layers like BatchNorm comes with a few things you have to pay attention to, did you look into that?
idk how you set up your code but ill explain the basics of undersampling if you want to try it, basically you make it so that the number of classes you have for each target is approximately the same, and you can do that by removing samples randomly of a row that has the target class where there is more of. so lets say you have 1000rows of data where the target value is of class a and 200 rows of data for target class b. you randomly remove 800 of those rows where target value is a so that you end up with 200 rows for each target; if you implement that properly you can probably reduce the number number of convolutions, normalizations and dropouts you do significantly
0.4-0.6 is normal
oh wow
The default in pytorch is 0.5 so I just used 0.4
What do you mean I'm applying it late in the process? I thought you were supposed to apply it right after each linear layer
I haven't looked into the things that batchnorm brings along with it, but upon a quick google search it says that too small of a batch size could negatively affect it, and that batchnorm can also affect the laerning rate?
The dataset I used from kaggle is already balanced
never mind about dropout, from looking it up it sounds like that is about right (batch norm between conv layers and dropout between linears)
you should try looking at a classification_report then on your test and the predictions to see how your model is working
I've never heard of classification_report, I will look into it
xgboost_classifier = xgb.XGBClassifier()
xgboost_classifier.fit(X_train, y_train)
y_pred = xgboost_classifier.predict(X_test)
report = classification_report(y_test, y_pred, output_dict=True)
print(classification_report(y_test, y_pred))``` here is a simple exampleguys i keep trying to do knn classifier
but i keep getting error about ''ValueError: Unknown label type: 'continuous'
anyone know the problem?
Knn is used for classification task where the target variable is discrete. Your dataset might require a regression algorithm. Try using linear regression or SVR
Your target variable should be divided into classes
It is and everything seems discrete so im quite confused
could anyone throw me a link to a good guide on feature engineering? Feels like it's a big deal yet I see little coverage for it in guides and tutorials.. I get that domain knowledge is often key here, but what are some ways you could get an idea of what to do without any domain knowledge? The kaggle tutorial on PCA shows that it can be used for feature extraction, but it's not very well explained. Anyone know where I could read about PCA, not about how it's calculated (there's plenty info on that), but on how to interpret and use the results? And/or other popular feature engineering techniques?
What helped for me was just doing Kaggle competitions. Do a notebook, submit and then look at other people's solutions.
There's also well-documented things you can try for canonical problems like creating lags in time series. Specifically for linear models: interactions terms, B-splines, ...
do you think putting a kaggle notebook into ur portfolio is a good or bad idea? I see many mixed opinions on the matter
Is this information from Reddit? I feel like they say a lot of stuff there that is demonstrably fake or at least coming from people that are in a different country or even continent so it might not apply to you 🙂
oh I've seen it everywhere, on youtube, reddit, random chat groups. Some say recruiters love kaggle, some say they've seen all kaggle notebooks and that they're sick of it and putting them on your resume is a bad idea.. I'm thinking of doing the House price prediction one and putting that on my resume, but..
I'm European and the voices on those platforms are all dominated by the US so I take them with a massive grain of salt
I think someone having code I can gloss over is great. It's nice if they've actively worked on things so I'd see experience on Kaggle as a plus. I also value experience in internships, student jobs as well but that's not mutually exclusive with sideprojects like Kaggle
For me the big thing is that none of these are mutually exclusive and most discussions treat them as if they were lol. You can get a degree, do Kaggle/sideprojects and get internships etc. Personally that's what I did
but when ur time is limited and u r in a big hurry to get a job quick - u gotta choose 😅
I don't have a degree (not CS at least, I have a bachelors in Economics), and an unpaid internship is.. not really something I'd want to spend time on (if its a paid internship then sign me up lol). I have a few ideas for sideprojects, but one is massive and I'm unsure if I'm qualified to even approach it, and I haven't even checked if I can get the appropriate data for the second one I had in mind.. 💀 If everything works out as planned, I'll put one kaggle and 2 side projects on my resume, and hope for the best. I just hope my antisocial introvertness doesn't kick in during interviews.. 🗿 First step is to get the interview tho.. Storytelling is a big deal in DS, it seems.. and my storytelling skills are.. lacking
You could also just get an analytics type job and do that for a year or two. A lot of the skills are transferable.
For what it's worth, my bachelors was from the economics faculty as well, but not pure econ
Hello, does anyone know how to do classification on univariate, muticlass, and imbalanced time series dataset? I would like to know that what i'm doing is right or not.
I think Kaggle NBs are useful in the sense that they can demonstrate your ability to work with code like a lot of the industry does, much like GitHub but toned down
However I think there could be a case for recruiters being tired of seeing the same things again and again. Like house price prediction is an overdone project, everyone does it, it's available easily, you could've just copy pasted it onto your resume.
Don't do something like that.
Do something new. Use Data Science to actually solve an interesting problem. It might be useful, or it might be silly, doesn't matter; you can do analysis of Pokemon for all they care
As long as it's something new and interesting
I have heard this from recruiters at some top companies. The same overdone kaggle projects don't help you.
Demonstrate that you can identify a problem and then use Data Science to bring it to a solution
Well said
Whenever you get to see this, do know that I am data scientist willing to participate in machine learning / DS projects . My main goal is to build my experience in solving real world problems using machine learning algorithms.
Whether it is a virtual internship, unpaid role, paid role, hackathon I am willing to contribute as much as my current resources would allow me to
Good morning!
I plan to be a machine learning engineering, but don't know if I need to learn machine learning from scratch without software development tool or It's better to use libraries and frameworks in this process? What should I analyze and consider on this choice?
If I will learn from scratch, what should I learn, only the logic or more structured and complex things like algorithms or similars?
Here's a roadmap that you can use as a reference: https://whimsical.com/machine-learning-roadmap-2020-CA7f3ykvXpnJ9Az32vYXva

2020 machine learning roadmap built in Whimsical. View for detailed mind map on: machine learning resources and the machine learning process for projects.
Hey @grand minnow
Heyyyy

You've been scammed and don't even know it.

Just because you don't know it doesn't mean it doesn't exist.
What do you guys think of this channel, and what guidance could you give someone who's trying to make it in machine learning engineering or data science?
@narrow crane I watched the first one. I think he's mostly right, but might be over-stating a few things for dramatic effect. like with portfolio projects--they aren't useless necessarily, but no number of portfolio projects can make up for a lack of "real" experience.
he's also right that "learning Python or R" isn't a strategy for getting an AI role. No one gets hired into AI because they "know python". They get hired because of demonstrated knowledge and application of AI.
His videos somewhat startled me because I realized my understanding and path is a lot more shakey than I imagined.
My plan was to just go through kaggle courses, then try to do the machine learning bootcamp, and hopefully do some projects while learning NLP and SQL.
you will not get a job in AI doing that.
unless you have industry experience in another STEM field.
I watched both. What he's saying, especially in the second video doesn't apply to say Western Europe
I'm watching the second video now. He seems weirdly preoccupied with SQL.
Because for old school data professionals data = tabular data
I agree that SQL is very important. it's just weird that he keeps saying "3 years of SQL"
If you start your career making Power BI dashboards good luck pivoting to anything ML heavy in the future I think...
he just said "excel is not a big boy data tool"--is this the guy who keeps posting that starbucks barista pic on quora??
done with the second video. does he ever talk about getting a masters in CS? because that's probably the most straightforward way to get a job in ML.
Getting a bit off-topic on my part but I'ma be honest and say that what matters the most is just a solid university degree.
I think he's mostly right when he says "there are no entry level jobs in ML" in the sense that the only ML jobs that will take you based only on your degree, require that you did something tangible with ML during that degree
this is on-topic.
Well according to his videos I have to start with an entry level role preferably data analyst. So what do you think I should be doing to get there and then eventually to a machine learning engineer role?
Should I consider changing my study plans?
Are you based in the US?
Yeah I am.
I think you should plan to get a masters in CS.
(I'm assuming you're a young person who doesn't have professional experience. tell me if I'm wrong.)
You’re not wrong. But my current degree is in cyber security.
Which is..different yeah. I was trying to learn two skill sets in one.
one that you're currently pursuing, or that you've finished?
Currently pursuing. I’m in my freshman year right now. But I was just very interested in data science.
Then I don't know how your job market looks like. In our case, you're not getting hired to do ML with a bachelors. Amongst masters level candidates there's tons of degrees (CS, bio-informatics, quant business (my first one), statistics, ...) that all can/want to work in ML/AI so you need to be able to "compete"
If you're interested early you have a ton of time to do relevant internships, projects, ... I think
I got hired into ML with only a bachelors, but I had to cultivate a very niche skillset that only made me viable for a handful of roles. and there was also some luck involved.
Yeah I think I may have made a few mistakes with my goals.
If you're a freshman, then you have lots of time. You should pursue a STEM degree of some sort (math, CS, physics, chemistry, engineering, econometrics, etc.), and you should plan to get a master's degree.
"data science" is really an umbrella term, rather than a specific thing. but if you can take ML courses during your current program, or get into an ML-focused masters after you finish this program, someone who knows about ML and cybersec would be very valuable.
Take it from someone that studied in the economics / business faculty. You have time.
I did a lot of internships in data, learnt Python, ... while I was in my 2nd year I think
Really I would say that the important thing is to do well in your courses. Any student with a 3.9 GPA is more appealing than any student with a 2.5 GPA.
Got it.
Yeah I was doing courses and studying data science on my own whilst being in clsss for cyber security.
If you can pick good electives you should
Idk how math / statistics heavy your program is but for us those 2 were the cornerstone of the degree which made grokking "data science" concepts easier
I have to go, so Kyle and zestar can fight over who gets to be in charge.
So is it realistic for me to continue as I am and be able to land a good career or do I need to change a few things?
What courses, practices, or anything do I need to learn practical data science skills?
Btw should I do courses for the sake of certification or actually learning the skills?
Well I don’t think he’s ever discouraged anyone from getting a degree but he treats the idea very harshly. He stated that degrees won’t teach you the real world necessary skills.
Considering you're a freshman just work on getting the skills you need on the side and do internships, summer jobs, ... in data
the way I see it - you don't get a degree to learn anything. U just get it so you would attract recruiters, so you could get hired. Once you are hired, then you actually start to learn (obv u should learn on ur own before that, else you won't get hired even with a degree, cus u won't have any knowledge, but what I mean is that a degree won't give you much.. didn't give me much at least)
Everything is learnable without a degree sure but if your uni / profs are good it helps. Massively.
I appreciate the advice. But still I’m curious as to whether or not current study plan of using kaggle resources, the google collab boot camp, and then trying to do my own projects is sufficient for me to get those skills on the side. Will definitely start looking into internships. Also how do you feel about coding boot camps?
Like maybe I could do a boot camp for a summer to get the data skills
There’s a lot of programs for data science and cyber security
Job experience >>>> bootcamp
Alr, will the job experience teach me? Better than the boot camp at least?
Or is it just better for people to hire me with
Jobs taught me a lot I didn't learn in school nor didn't pay enough attention to
Reading and doing something are different
It depends on what you want to do. If you want a thorough understanding of ML theory, then you will not get it this way. That requires a master's degree in statistics (at a minimum). A boot camp will teach you how to use existing ML packages in elementary ways.
They're complementary
I see
Boot camps are fine if you want to just use ML techniques as a black box.
I wish I could say mine were good.. they weren't 💀 I want to get a masters at MIT, but.. if I ever get the chance, I'll probably be 30 by then, so waaay in the future some time.. :/
I took DB courses in school and also spent the summer doing data engineering a few years back
The DE jobs taught me so much about working in data environments, what the pitfalls were, and just practical SQL and more
Okay so it would be preferable to do both but if I can only do one, pick job experience and internships?
Let me put it this way. Given your situation, planning on a boot camp seems unwise. You would probably be better served by taking relevant courses. After all, you're already paying to go to school; you may as well learn some things while you're there!
The uni perspective was way broader and explained a lot of concepts that people take for granted in industry
True that’s a good point.
What you don't usually get in university courses are practical skills, like how to use SQL or various ML packages.
I’ll have to consider a lot after this conversation
You can get those in a boot camp, but you get them faster and better with a job.
I think they're reasonable in some situations. They give you something specific you can put on a resume. Like, maybe you start to do data stuff at some job, but it's not an official part of your job duties, and you decide you want to do it full-time. A boot camp might smooth that transition for some people.
That said, I think they are often oversold.
I think they have some value, but not as much as the boot camps' marketing would have you believe.
Don’t mean to interrupt but I have one final question. Are the Kaggle and collab courses good enough or are they irrelevant or bad or whatever
I really do appreciate you guys being patient enough to talk to me about these things btw
I don't know; I've never looked at them myself.
But yeah currently I was on the Kaggle course for machine learning introduction, which I did right after I finished the Kaggle course for pandas
That’s fine
I did Kaggle a bit because my degree was very theoretical
Do you think it was actually helpful? Is it sufficient for a person like me who’s not currently going for a degree in computer science or data science?
I think right now I may have to focus on just being able to use these things like how Kyle said
Yes, there's a series of competitions called "tabular playground", make your own notebook. Submit it and then look at how other people solved theirs
Part of me is scared but at the same time the capability of learning and growing over time is interesting.
Imagine I’m 30 or something and just a cyber wizard.
When you're 30, you'll probably not feel like a wizard no matter what you do. Either you won't be that good; or you really will be that good but you'll know how much you don't know!
RIP. Higher ed in NA is so expensive
If you like an adventure you could just do it in Europe for a fraction of the price
I kinda want the prestige that comes with the letters M.I.T :3 Also they're supposed to have high quality material and innovative stuff.. I'm interested in timeseries and stock analysis as well as robotics, and that's the place to go for that.. Will probably settle for a cheap online masters eventually tho
determinate came up in my study, ad - bc is kind of abstract for me, this something i should spend much time studying if i want to market myself in DS fields?
thank you for the resource. i have no idea why this message didn't load on my phone
Its true that an overwhelming majority of jobs in ML Engineering/Research require you to have atleast a bachelor's.
However, it's definitely possible to get one with just a bachelor's, just very difficult. You have to be either very highly skilled ina specific area, or have solid demonstrable expertise well rounded
Don't you generally have the option to pick your major till end of sophomore year in US universities?
I mean, yeah there's many different paths to whatever role you want 🙂 I'm just talking about the path of least resistance?
A lot of what you learn during a degree isn't directly applicable, but what matters is that it's what employers want to see in someone who doesn't have industry experience.
If you have enough industry experience, that can eventually eliminate the need for a degree. But then, that experience is hard to get if you didn't have the degree.
No you pick your major first before you start studying.
Tbh here you either do bachelors + masters at a research univ or a bachelors in applied science. The latter has 0 math in their applied comp sci programs.
Correlation != causation but employers do think so, so if you don't have a masters you're looked at unfavourably (at entry level). This doesn't apply to the US so I'd say my most important piece of advice is actually not to give too much weight to stranger's advice on the internet (not me, Reddit, Youtube or otherwise) and to understand your local job market tbh
Yep yep I agree with your point, was just supplementing it
Atleast you can change it till end of sophomore year? I'd advise you to maybe check this again with your uni administration
**atleast have a master's
I have followed this tuto https://ubuntu.com/tutorials/enabling-gpu-acceleration-on-ubuntu-on-wsl2-with-the-nvidia-cuda-platform#4-compile-a-sample-application for install wsl but how use gpu with vsc ?

Ubuntu
Ubuntu is an open source software operating system that runs from the desktop, to the cloud, to all your internet connected things.
You don't use the GPU with VSC. VSC is just the editor.
Are you trying to use pytorch, or what?
tensorflow
So you need to look into how to install tensorflow with CUDA. That you're using VSC isn't relevant.
So I must install an anaconda framework ?
You don't need to install anaconda, no. You can if you want to. But anaconda is mostly for academic types who don't consider themselves programmers.
Also there is no "anaconda framework". It's just anaconda.
WSL2 is a type-1 hypervisor. Just install tensorflow with cuda and cudnn for Linux in the subsystem and it should ideally work
I have never tried it myself tho
Yes, TF and Pytorch support WSL2 better than actual Windows 🤣
Is that surprising?
I have installed cuda like in the tuto but i don't know how install cudnn and i tried to install tensorflow with pip but it doesn't work
Be sure to never say that something "doesn't work". Show what you did, and the result.
How so? Or dym only for cuda?
i have did this

"GPU support on native-Windows is only available for 2.10 or earlier versions, starting in TF 2.11, CUDA build is not supported for Windows. For using TensorFlow GPU on Windows, you will need to build/install TensorFlow in WSL2 or use tensorflow-cpu with TensorFlow-DirectML-Plugin"
Yeahh I read about this.
Thankfully, non cuda is well supported
And there's always pytorch xd
How do you run TF without CUDA? ROCm? CPU?
Afaik torch.compile doesn't work on Windows either
I meant cpu yeah
Hmm I haven't experimented much with 2.0 yet
But for there rest, you're good to go
Can you describe what you've done and what error you're facing exactly.
Unfortunately the only thing I can make out here is a pip install keras that returns requirement already satisfied
Getting anything to run on WSL2 is easier anyway I think
Probably, I'm not very familiar with the windows scene rn esp for CUDA
i have this problems but keras and tensorflow are already installed

Also why not just dual-boot but let's not get off topic
reload your window (CTRL + SHIFT + P and type reload)
What happens if you run the code? As long as it runs it's only an autocomplete issue
And yes, tf and keras has been having autocomplete issues since 2.9.0 iirc, only recently released a fix after 2.11.0 that seems to work ig
thank you this problem seems resolved but when i run this code it doesn't found gpu

It says there're some missing libraries. Also gives a link to follow steps to ensure you have everything setup. Try that
a link ?
hey folks,
anyone please help me out with this issue 🙏
I am making a data science text-code generating bot by finetuning https://huggingface.co/HuggingFaceH4/starchat-alpha this model on my own dataset which is having about 3000 text-clean code conversations.
i have loaded the model checkpoint shards successfully on my colab with the help of hugging face acclerate , BitsAndBytesConfig nested quantization for memory efficiency.
This is how my data science text to code data is structured.
DatasetDict({
train: Dataset({
features: ['input_ids', 'attention_mask', 'labels'],
num_rows: 2384
})
validation: Dataset({
features: ['input_ids', 'attention_mask', 'labels'],
num_rows: 666
})
})
I am facing a error while training this model with this code:
trainer = Trainer(
model = model,
args = training_args,
train_dataset = lm_datasets["train"],
eval_dataset = lm_datasets["validation"],)
trainer.train()
and getting this error :NotImplementedError: Cannot copy out of meta tensor; no data!
Please someone help me out in resolving this error, it will be a great help to me.
this is the full error message


hey anyone here experience with bert word tokenizer? basically it generates word vectors for a word in a sentence so if bert doesnt have an embedding for a word suppose overweight, then it sub divides it as "over" and "##weight" and then produces word embeddings for these two sub words instead, now would it be okay to define the embedding of the complete word overweight as the average of these two?
no, not at all?
it isn't an average by any means. It is divided into two tokens, but each of these tokens has it's own individual meaning
Those are called subtokens, or word pieces. They aren't because BERT doesn't have embeddings for them--they are intentional.
"over" and "weight" both have discrete meanings that contribute to the overall meaning of "overweight".
Anyone please tell the reason of this error , if would be very helpful 🙂

For large models hf accelerate loads your model and weights in shards on each device.
For this it first instantiates a meta tensor, which contains only shape and dtype information and doesn't consume any memory.
Then it moves different layers of this model to different devices
And then loads the corresponding weights from the state dict in each part of the model
Your error seems like you're trying to move the meta tensor to some device directly without any data, which can't be done since there's no data to move
I think there's an empty_like() method you can try using to do that and later load the model weights in
Or, more simply. You can just load the corresponding shard of weights into the meta tensor and then move it to the device of your choice
See if that helps. Meta tensors are still a relatively new feature last I checked and support is still maturing
anyone have any good decision Tree tutorials?
the sklearn documentation should explain it fairly well
they also have a free course/mooc with publicly available materials you can take a look at
It's there in the error message
Awesome
i have a lot of these words in my data I was wondering what could i do represent them as a single word vector? Is this possible to do without training your own vocabulary or model ? I need to do this with a pre trained model only like with Gensim's word2vec or bert or any other...
so i have a vector for over and for weight but is there no way to estimate the vector for overweight? I'm working on a data from reddit and it has a lot of slangs like this
iirc the way bert encodes it is not even a vector at all, it is just one number per word segment
why do you want to "represent them as a single word vector"?
and how would you even define what is and isn't one word?
no? i believe word produces a 768 dimensional word vector for every word if you give it a sentence based on the contextual meaning of the sentence
i meant in cases where it subtokenizes one word into many is bad for me like consider a statement
"All men are overweight these days" then if i pass it to Bert then it will generate 768 dimensional vectors for every word from "all" to "days".... except for overweight, in this case I'll get two word vectors one for "over" and one for "##weight" and that's the issue i need to resolve
see by finding the word vector or "overweight" i can account for biases in my data whether overweight is more associated to words like He, Him or male or She, Her or females
what I was thinking off are the Tokens like on https://platform.openai.com/tokenizer, does it later uses these for making the vector you are talking about?

(I know that Bert and GPT are not the exact same thing, but as far as I know, the way they tokenize is more or less the same)
Computerphile has a few great videos on byte-pair encoding and it's worth looking at if you want to understand tokenization
is this the right place to talk about scipy?
yes
can I do integration in scipy?
Don't know. Can you?
i have to see
one thing can I read about how to use scipy from the help section of python IDE?
You could or you go its official doc
both works
Also depends on your IDE
whatever that is
python's own IDLE
And I assume help section of it is just help(scipy)?
Bro, being more specific, I want to dive into neuro science and social psychology studies using AI (Like Elon Musk's Neural Chip projects for example), can you or anyone here give me an orientation and advices more specific for it?
i have to check
University 🙂
What course or courses to do?
The masters program I did (AI) had multiple courses in computational neuroscience. I didn't do them but I assume that's the way to go.
Actually I already am in a University, but I do Data science, so I need to know the areas and subjects that cover this path to guide me trough my career, otherwise I am wasting my time studying some useless or less important things, you know?
not helping
can someone confirm if i want to use azure for training the models i have to create the virtual machine there?
No, you can also use "serverless" compute through azure machine learning or databricks. You don't need to create a VM
ok thx, finally someone answers! so i will figure that out a bit later and if i later would have a question can i ask you again?
what kind of help are you looking for? Can't you refer to the official docs instead?
Just in case, a thing you must know: there is nothing intelligent in AI. It's pure math: for prediction and classification. There are two types of tasks AI can solve:
- classification
- math regression (prediction)
All amazing AI things and wonders of past years are built because those tasks were applied to particular domain areas.
What about Complex systems and data science application for it? Nowadays data science just use till Calculus 2 sporadically, but there still Calculus 3 and 4 available for further researches on the area.
are those university subjects or what?
actually gradient descent is Calculus 3, I believe
how can i do some basic machine learning to make a snake ai
like where would i start
so I would be so ultimatively stating it is only Calculus 2
Anyways this is just subject names. When Newton invented Calculus, he didn't have 1 2 3 and 4
Of course bro, They are essential for everything, complex systems studies not only on neuroscience, psychology or social areas, but anything that has a system representation, like biology, telecommunication, including ANN itself (artificial neural networks). This area will discover and solve AI extreme low explainabilities for example and beyond things
i think its to wean you onto the concepts of it
im gonna go ask chatgpt my question
Yes, but Why Chat GPT is the best for what it does, and don't bypass Calculus 2 I think?
I think That they even won't willing to use gradient descent
ChatGPT is also prediction. Prediction of which of the many answers is the most appropriate.
It's not only matter of difficulty, having more deep calculus is good and is the trend for the development, but I talk about complexity too, Complex systems
It's slight different
The more subjects you know well the better. You know, they are not isolated from each other. Knowing what is positive feedback and negative feedback might help you in your AI work.
How Calculus 1 or simple things in general communicates with the more complex?
Thanks, I know that no one here is a specialist on my area of interest, but I expected for someone that already is in the career and knows things related
There is no Math 1 2 3 4, so there is no Calculus 1 2 3 4. This is just conventional dividing into smaller parts. In math the more complex things are always built upon more simple things. As in many other subjects.
So the AI of Elon Musk's neurointerface is also either prediction or classification. E.g. classification of what particular signal could mean.
And you're right, complex systems is so new and "experimental" let's saying, that it lacks so much of information, so that I discovered it accidentally. Only the best universities like Stanford, MIT and related has the most of the research results and projects at the moment.
Yes I treated it like that just as title of understanding, representation and simplification. Cause are real examples that I know
have you a tuto who is simple and works for using tensorflow gpu ?
you might see if you can turn off wordpiece tokenization in the tokenizer. but BERT isn't for getting vectors of each token individually.
dont think it is possible i dont see any argument for this and even if i turned it on Bert would then probably give bad results or something, I think it's better to work with the complete sentence embeddings rather than just the word embeddings
I think it's better to work with the complete sentence embeddings rather than just the word embeddings
that's what I'm saying
Try the official doc. It has everything including using GPU
yep now im thinking to form the problem around this instead ty for the help
Maybe I wasn't so clear too and misunderstanding, Complex systems are no related to hardware and software although it has applications based on that, an example of Complex system is climate, it doesn't nothing to do with hardware, software or IT, but as the mainly purpose of IT itself, I can use it as a technology or tool for understand climate systems (And I believe that it's the next researches studies steps after discovering human brain functions, to go understand it systems).
I said it so meaning not as a merely of software or hardware only, I talk about more fundamental things, next to the core, more structural and "symbolic", how Elon's Neural chips works as a system (a complex system type) on the sense of interactions and communication, like how a neural network works. Unfortunately the actual neuroscience focus and fame isn't on what I said and should be, it's on health solutions only (That's isn't a bad thing but maybe exclude other important scientific areas, like sociology that's so but so underrated and poorly explored till nowadays I think)
Your initial question was about AI, right?
Yup
So you've got answers about AI, don't you
No, I don't know What I have to study, only a more superficial advice thought for studying computacional neuroscience at a unversity
https://www.tensorflow.org/install/pip#windows-wsl2_1 maybe this'll help
read carefully, it has links to guides on setting up nvidia for gpu on wsl2, etc.
TensorFlow
specific to wsl2
have been wondering how valuable it might be to move my python install to wsl
you'd get a list of courses available right? It's difficult to suggest anything without knowing what is actually available to you
other than that, generic suggestions you know already, neuroscience, computational neuroscience etc.
I exactly mean on how use data science and AI for it...
maybe ot but why not just dual boot
would throw out a lot of OS familiarity
on windows you might have problems with CUDA, esp with tensorflow
fair
tf gpu and jax are only available on windows through wsl, and also docker requires it
it's worthwhile to look into
short of using a proper vm, it's the easiest way of getting started with linux too
jax as well? damn I've really been blissfully unaware using linux
Thanks, I know, but the problem is that as I said is a new area, It's more on "experimental phasis", like Data science on the past, there no course for that. So I decided to search by informed people here..

Look for it, just 4 pages about it! hahaha
I can find courses, but again, so superficial I think
Not a Degree for it
wait so are you looking to choose what courses to take at your uni or
what courses to take online or what to refer to?
None, I want to be a professional on this area whatever I have to do, I only said that it isn't so structured to be on a university yet

hahahahaha
It's like more a additional course, there isn't anything directed and complete for, It's more like "coaching" let's say
You have to study:
- Math statistics (probability and statistics).
- Linear algebra (matrixes).
- Programming in Python.
- How to create neural network via pure math.
- Other types of machine learning which also exist (not only neural networks).
- Common Python libraries in data science: for data manipulation, visualization and ML.
- Jupyter / Anaconda
How to create a neural network via pure math
One does not simply become professional. You need to spend 10'000 hours doing it.
Super super questionable advice you're getting here but OK
after exactly 10k hours, your skin immediately turns gold and music chimes from within you, heralding the unlocking of an achievement
if god == ("true")
print("Fear me mortal")
else:
print("nah I'm capping")
I know that it isn't your fault or responsibility to instruct me on this case, on how to discover the covered subjects for this scientific area, but actually I don't have any methods for it...
How you'd do to study one professional career that don't have any course about yet guys, is on "experimental phasis" and isn't well structured educationally saying, but it is full of concepts (They surged in 1950's, next to AI concept), you know that it's viable study and work on it? Like Its a low explored scientific area and there's no learning materials, but you know there's some core areas involved although not knowing which exactly and can do a self-taught on it?
Yes
I already know these things
i missed he beginning of the conversation, are we talking about AI/ML or something else?
Yep, How to apply AI/ML for Complex systems science
what's complex systems science? AI/ML degrees are widely available at all education levels
hey guys had a question, so if a word reappears again and again in a sentence than how to modify it's word embedding? like say it appears in two completely different sentences but the word has pretty much the same meaning (I'm only talking about pronouns in my case) so for a big data set how can i calculate the embeddings of these words in Bert
Yes, not kidding, I really am Willing for it
To sum up all our talk and simplify on a lay way, complex systems science, is the study of systems, climate and even the entire universe is one.
We can use Data Science or AI, to understand these systems, which can solve the extreme low explicability of ANNs and everything on IT and on the world furthermore...
sounds very wishy-washy
but in the direction you're pointing lies physics-informed AI, so maybe read up on papers related to the topic
What point you didn't get?
No course? You do your own research then. Or explore other researches (you don't have to have PhD for that, but you would want to know how to learn without complete trainings or step-by-step tutorials).
- information theory
there's interseciton but I think it deserves to be mentioned separately
"Complex systems". Is it something from the 80s? You said it's something new. I don't think it's new. Maybe it develops more rapidly last years (as almost any subject), but it is definitely something from 1980s. Or even 70s.
I have encountered people who bill themselves as experts on "complex systems" and I have not been impressed.
My advice is that the fundamentals are the same regardless of the subject area: Math, statistics, computer science, physics, and so on are useful everywhere.
If you understand those well, then you can apply them to whatever problem interests you.
So so, This area is so general, but majority is based on physics approaches. I am willing to go to social science systems and they are the less physics related actually
Like we have complex systems even in generic electronics (not microelectronics).
Social science systems... What the heck is this?
No, it's from 50's, but as study is new
You are speaking some bird language I don't understand.
I don't think he's a very fluent English speaker. But I also believe that's not the biggest problem here.
Yep hahahaha
same
Me neither a native speaker. And subject names could differ from country to country. Anyway I have no clue what Social Science Systems is.
Sad that this isn't maintained anymore: https://github.com/dswah/pyGAM
If only I had 5x more time than I do
You have a pen (AI). You have an apple (domain area). Boom! PPAP
Although this journey is not always that linear.
And that's why science exist, and scientific researches exist.
You could investigate history of text-to-speech technologies to see what was the evolution in this particular domain area
It's just systems present on around the world with an social science approach: friendship, family are ones
Remember your School biology class about biological organization levels, from atom to biosphere, between them we have systems
Guys, is there a method to calculate how complex an operation is and how to use a method which may provide similar performance?
I'm currently making some experiments on GANs and I've noticed that, from previous experiments I've made, the best one (contrary to what is recommended) was the one where the Generator used no Transposed Convolutions for upsampling, but simply applied bi-linear upsampling operations followed by a residual block with 3 convolution layers + a single convolution layer to get an output with 3 channels.
I've done this to generate, in a single generator, images 4x4, 8x8, 16x16 and 32x32. However, for the 32x32 images, I've also applied, after the convolution, another residual block with the idea that the model could, then, "apply small enhancements" to the image.
The results: 4x4, 8x8 and 16x16 images are fine, but 32x32 have a tendency of showing model collapse or even collapsing the discriminator(there's one discriminator for each dimension, so the collapse of 32x32 discriminator doesn't affect the others). I was thinking that, of course, since 32x32x3 images are more complex than 16x16x3, this could be expected. But I'm not thinking: is this instability really caused just by the complexity of data, or is it because I added too many layers? Or maybe too few for such complex data? Is it possible to estimate whether I added too many parameters or too few for a given data sample?
(PS: Transposed Convolutions in Pytorch are simply the gradient of a normal Convolution with respect to the convolution input. So I suppose Transposed Convolutions and Convolutions in Pytorch should be the same operations, I guess the only difference is that TransConv might add way more padding)
Wait...then I suppose that...if I apply a Bilinear Upsampling...the model will have a better idea on which transformations it should apply to the data than in the case of a Transposed Convolution, since this one is equivalent to padding the input...so the model will just receive 0s and have no idea on what it should do...relying solely on the bias...
Yes, that's true, we have complex systems on electronics too...
A complex system is a system composed of many components which may interact with each other. Examples of complex systems are Earth's global climate, organisms, the human brain, infrastructure such as power grid, transportation or communication systems, complex software and electronic systems, social and economic organizations (like cities), an e...
Please, consider reading this
@pseudo spire , @past meteor , @queen cradle , @wooden sail and @cold osprey .
If any of you help me on this, I'll be thankful
tbh i dont even follow the initial question
This. I think I can't help more.
@tepid parcel please do not ping people to ask for help. If they're online and have time to answer questions, they'll look at this channel. Otherwise, no one is on-call to answer questions.
ok.
Oh, ok, thanks anyway
I found this useful
Nobody here has any experience with AI for the social area studies and so?
I'd like to know about the experience too, know more about it before get into...
this is something really wide why dont you search for it?
It's not that simple, I talked about even more specific things, created all this talk and nobody could understand and help.
What I can to is try to generalize a little bit more to find something out.
I dont understand you
Did you follow the conversation bro?
still dont get you
What is the problem? My English is so weird at that point?
think so
I mean it looks like that you already got an answer.
first i am trying to do with stationary. Then with moving cars, like extracting images from video and then training ml model.
Can u plss tell other approaches?
For videos you could add a detection module with model chaining so that one model will detect whether there is a vehicle in the frame and only then the rest of the models will run to extract the car and license num. This will save a lot of processing.
You could also add an object tracking module to ensure each vehicle is processed only once
For static images YOLO + OCR is quite a solid and standard approach
An E2E model would not work as well for this even if you could somehow get a suitable dataset.
Same for a ViLT model fine-tuned for VQA, it wouldn't work as well imo
You can use some traditional image processing techniques to preprocess the images so that the license plate numbers become more prominent and then run OCR on that
You could also try segmentation but that'd be overkill since detection is the right task here
thanks for the explanation, can u pls provide any documentation
One simpler way could be to detect contours and extract the probable license plate regions from there, tho I don't think this would perform very well
Since it has to be in cars and cars will probably be upright you could also design specific kernels or structuring elements to detect these license plates
I mean, yolo, tensorflow, pytorch docs are available online but here you go:
https://docs.ultralytics.com/
If you're asking for a tutorial then maybe this'll help
https://medium.com/saarthi-ai/how-to-build-your-own-ocr-a5bb91b622ba

Explore Ultralytics YOLOv8, a cutting-edge real-time object detection and image segmentation model for various applications and hardware platforms.
Medium
In this article, you will learn how to make your own custom OCR program with the help of deep learning, to read text from an image. I will…
You could try RPNs, greedy selection algos etc. too but Yolo is better in both speed and performance
i explored pre-trained OCR tools for the first time in a while recently. before that, i'd been so disappointed with tesseract that i figured paying for google's vision module was my only hope for any ocr-reliant project. but this time i found paddleocr pretty impressive -- though even then I had to preprocess the input images a little to get useful outputs
there's a HF space that lets you try it out somewhere. will look to find it unless you're looking to train your own tool?
YOLO is a model for computer vision. OpenCV is a library/module/package/idk to work with computer vision in Python(and I guess in C too)
The problem is... Judging from your questions, it is very likely that you try to find a ready-to-use recipe in a particular domain area (or areas). This judgment can be wrong, but as you are unable to came up with more practice-oriented questions, it very seems so.
Also, it might happen that in those particular domain area (or areas) a ready to use recipe either doesn't exist, or it's not made public. So... yeah.
Also, it there was a publicly available ready-to-use recipe, then you (as an AI professional, lets imagine that) would not be needed at all. Any person who knows how to operate computer to some extent, would be able to follow a ready-to-use recipe and achieve a needed result.
So.. .Step-by-step guides are not an option when you want to create something new / breakthrough. However, step-by-step guides can be used on some stages of learning... It's important though, that the learning path must include something else aside following step-by-step guides, otherwise the learning would not be complete.
So I previously mentioned AI is the best in solving the following practical tasks:
- Classification
- Math regression
Actually I was wrong (I am learning as well), and there are more tasks/computational methods which can be well executed with AI:
- Classification
- Math regression
- Clustering
- Dimensionality reduction
- seq2seq
So as an AI professional, you start to think can you apply any of the mentioned methods to a particular domain area. If yes - how exactly. E.g., the "clustering" task/method is very relevant to social connections, I believe.
Yes, AI projects with ML are experimental, testing and failing, and all else. Maybe I was misunderstood, I know that nobody know exactly what of Data science and AI subjects cover Complex System science, It's because I just didn't dive into this area before to know something about so I want to know it better before start to studying it, I thought that would hear something like "Dude, if you want to be not only a professional but a real researcher, study x, w, y, z subjects" maybe "on x subject you can start with this or that, on w together with y you will learn something".
To complement my doubt, I need know about the career too, the experiences, opportunities, specializations, future prospection and etc.
One must not only "know", but also be able to apply this knowledge. This is usually achieved via extensive practice in a particular domain area and gaining practical experience.
I hardly recommend you to stop this right here. It is just weird.
Why broo?
This is what we do in Universities, isn't it? It's not only reading about x, w, y, z. But also some practical work. Or more precisely scientific work (especially for candidates to PhD). There is a disctinct difference between practical work and scientific work. And this difference is novelty, pushing forward borders of science.
you are getting answers arent you?
Because you have to do some practice bro
Interesting
Tesseract didn't work that well for me either but then I had a bit of a niche use case
I ended up training a model myself
Yep this
And C++ actually
Yolo is more like a set of techniques by now rather than one single model, but fair enough
We're at YOLOv8 now
my domain was reading timestamps from screenshots of the game league of legends. surprisingly, even though these timestamps were way more well-structured than the canonical challenge for an OCR system (e.g. handwriting), this was too hard for tesseract and the failure rate was at least 10% (didn't actually measure)
Surprising, tesseract is pretty popular
yeah i can't help but think i was doing something wrong. but either way, paddleocr proved easier to get working
Did you do preprocessing on the images? Game screenshots can be kindof flashy
yeah! i think i did some transformations to increase contrast and whatnot. what ended up being important for getting performance on paddleocr to work was to basically make sure the parts of the image i snipped from these screenshots to read were superimposed on larger images -- e.g. a 150x150 image of black pixels. My guess is that if the ratio of "text" to background is unusual wrt to its training set, the model can be thrown off.
Not really, how with this advice I will get an PhD on Complex System?
This are advices aren't directed enough, I think, I know that this server don't have any label of areas to apply AI, but I am asking for. Great part form what was said here, just being honest, clear and direct, I already know. But I am happy to know that I am one the right path!
You will not get PhD with an advice. Full stop.
Not really PhD, I exaggerated, but apply AI knowledges
Hmm yes possible. I observed this when building a handwriting recognition model
okay, im living in an english speaking country, but I swear to god I dont understand you.
it's really interesting how janky these AI models are. Felt like negotiating with an alien
What academic year are you in at the university?
You mentioned I think social sciences and complex systems. These are pretty broad fields and like you said most of the advice we can give in this setting are things you already know: explore relevant courses, understand the ML math deeply, consult books on the topic etc.
What other advice are you looking for? /gen
I hope this doesn't come off as harsh, I'm genuinely trying to understand what other advice you're expecting
Maybe I missed something in between, quite possible
Just a student.
Which year student?
Second year
Yes, all of you are right
I meant that: if there's anyone that study that or something near to that who can give me theses advices, I though that it'd simpler too, just asking here I'd find something more consistent
Fair enough. I don't think I specialise in those fields so there's not much more I can say.
Except that combining ai-ml with any other field will demand a deep understanding, so it is really recommended that you dive deep into the math behind it and how things work under the hood (esp for complex systems ig)
GL!
Ok, I don't know how can I find people in the area, perhaps I will struggle a lot in this case.
Search up courses on this online by other universities, see the professors who're taking the class, maybe contact them and ask for advice? Or the students enrolled in those courses?
Or people in the industry working in related positions, can get that through a LinkedIn search
Is there any way to use opencv to render footage live
from an api or a server hosted
using google colab
Ugh... GANs are already annoying enough, and then when I search for a way to make a Variational AutoEncoder that doesn't generate blurry images...the papers around this tells me to use a VAE with a GAN configuration 
I guess I'll just turn to huggingface and use a pretrained VAE, then...
Hierarchical VAEs with extra constraints work pretty well (e.g. diffusion).
Fun fact: I'm trying to make a research on GANs using exactly the same idea of the stable diffusion. But for that, I need a pretrained VAE.
But I'm having some trouble in getting a trained VAE
And I'm having a hard time trying to find the architecture of the VAE they used for Stable Diffusion.
Oh... Hierarchical... I've seen some comparisons about "eye recovery" with Stable Diffusion and the VAE...
I suppose that's the trick to avoid blurry, then...reducing the complexity of the data.
I also see folks commenting about MSELoss... Really, I don't know how they manage to make a VAE work with colored images using a MSE Loss. At least my VAEs only work with colored images when I use Gaussian Log Likelihood
Interesting... I knew this for GANs, the Progressive Grow, but I didn't expect that this would be necessary for VAEs, too.

Thanks, Squiggle! I'll run some tests.
But first, just a single VAE in 8x8 or 16x16 images...just to make sure
Hm... The targets for the Encoding Loss isn't just a Normal Distribution for each encoder? It could be a distribution of a more complex features?
Now this got even more interesting...I'm already thinking about information entropy. Too bad it tends to make things too computationally expensive
Yes iirc, but they change this often so better consult a tutorial. But there used to be ways
It seems that with 16x16 images the VAE (non-hierarchical) generates quite the same quality of output.
But at least it's easier to notice that...the secret ingredient is probably many, many, many, many iterations and running time.
Even when the loss appear to have stabilized, after 3 or 4 epochs it decreases some 3 or 4 points, then stabilizes again, and so on...
Too bad I still don't know enough about how to implement Genetic Algorithms...it may be interesting to use stochastic gradient descent for a VAE and, when the model begins to take too much time to get better, maybe perform some evolutionary optimization in parallel...
does gpu parallelism in pytorch just means:
send model to each gpu
devide input into n parts
nothing else?
Pretty much yea, and the gradients get merged in some master process and get broadcasted to the gpus. There are some nitty gritty details about how this exactly works, but generally the idea is as you have stated
okay, do you recommend any source i can go through? i am unable to kind to find something simple.
I am working on movies dataset on kaggle link here https://www.kaggle.com/datasets/rounakbanik/the-movies-dataset and I am practicing data cleaning. So there is a column named production_countries which tells all the countries where movies produced. There are a lot of NaN values in this column so I decided to replace all of these with the most occured city names (like US, FR,GB). And I cannot do this by fillna() because it want a scaler or dictionary value but the values that I have are in lists form. So i found another way which is using random() function. prod_countries_nans = movies4['production_countries'].isna() prod_countries_nans_length = sum(prod_countries_nans) replacement = random.choices([['US','DE'],['GB','FR']], weights=[.5 , .5], k=prod_countries_nans_length) movies4.loc[prod_countries_nans,'production_countries'] = replacement . So this function try to evenly distribute the countries and stores them in replacement. But I am receiving an error Must have equal len keys and value when setting with an ndarray . The length of both prod_countries_nans_length and replacement is same 6206 and the same thing I applied for genre and production companies worked fine. Can anyone tell??

Metadata on over 45,000 movies. 26 million ratings from over 270,000 users.
You can probably do a one liner replacing all your NaNs with a random choice
can you put the code in a normal codeblock with the python tag on it?
!code
choices = [...]
df['column'] = [random.choice(choices) if pd.isna(x) else x for x in df['column']]
This will replace all NaNs in your column with a random choice from list choices
I was thinking about something interesting after seeing AUTO-GPT. How is it possible to use an AI agent that can control your entire operating system, open application files, and perform various tasks?
Hello, could I ask for help? It's about a question concerning a MLP. I have just started my journey into the wide land of ml, so I'm fairly new which is why I'd like to ask some more advanced pogrammers if they could help me spot the error in my code
This is maybe not exactly how it's being implemented. But when you have an AI agent like ChatGPT write a script for you, you are already having it specify a sequence of system operations that achieve a desired result. So from there, the only additional step you haven't automated is the execution of that script on your system. To use an AI agent that can control your entire operating system, you just automate that step too.
Thank you for your answer but with what technology, it can be a simple CLI and this app has the permission to execute various commands on the user's computer?
show your code and we'll do our best 🙂
Sure. So one scripting language for controlling operating systems is bash. ChatGPT can write bash scripts to execute system operations. You can make an app that the user grants system access, prompts ChatGPT to create scripts that suit a specified need (e.g., through an API call), and then executes that script.
I assume if I want to use APIs I should go with python and some low level languages.
so like extend python with c.
I guess it depends on your project-specific needs. But you can mostly stick to Python for this. Python will talk to ChatGPT through an API, and then initiate system commands based on ChatGPT's responses. Python's os library supports issuing system commands.
chatgpt is an idiot though. could do crazy irreversible things. careful!
The idea is to write a CNN but I seem to struggle with just implementing a MLP
Your forward method (line 5) seems to be wrong already
I also don't think writing a MLP from scratch and manually computing gradients is a good exercise.
If you're going to implement neural nets from scratch you should implement automatic differentation (aka autograd) https://en.wikipedia.org/wiki/Automatic_differentiation by yourself and then use that yo make your neural network library
In mathematics and computer algebra, automatic differentiation (auto-differentiation, autodiff, or AD), also called algorithmic differentiation, computational differentiation, is a set of techniques to evaluate the partial derivative of a function specified by a computer program.
Automatic differentiation exploits the fact that every computer pr...
I mean it should be able to communicate and handle every applications, since linux is open source and every-sofware on it, maybe a model could be trained on those softwares, and knows exactly how to deal with things.
Yeah i accidentally typed self.weight, self.bias instead of self.weight, self.input
There's some C++ pseudo-code in the wiki page. There's also minimal autograd implementations from Andrej Karpathy on Github (https://github.com/karpathy/micrograd)
Appreciate it, will read through it
But yeah, if you want to use an MLP on an image you'd have to flatten the 100x100 matrix into a 100,00 vector and feed that to your MLP
Just as you wrote
I've done everything it says but it doesn't work
hi
currently doing my project, and these are the project suggested steps

shouldn't missing value imputation be before train and test split?
and the transformation of numerical variables using proper transformation methods be after the train test split?
would appreciate anyone's help here 🙂
Is this some kind of homework?
its an assignment apparently
the lecturers suggested these steps
and i felt that the arrangement was kinda flawd
flawed
unless im wrong
What's flawed in yoru opinion?
shouldnt missing values imputation be before the train and test split?
o?
You want to estimate the performance of your method on truly unseen data. If you explore it with .describe() and remove outliers from it, it is not truly unseen
Hmm why? Data cleaning before split is perfectly reasonable
Moreso because you might have to drop records in data cleaning and that might skew the train test split, not maintaining the ratio selected
You're just introducing bias into your results
That would be, but this is simply handling missing data, and it is being performed anyway
The question is whether before or after split
Measure the performance of your methods like you would if you deploy them into production
it also stated that the transformation methods are done before the train test split
That's bogus
shld it be after split?
Hmm that should be done after
^
Ideally everything is done after. In reality this is not the case but you should postpone as much as possible unless you can't
mmm alright
Imagine your split makes it such that all the outliers are in your test set? If you split after removing outliers you've manipulated your test set
Which means your test set is not truly unseen. You saw it and you touched it.
such a good example, oof
makes sense
then what about the missing value imputation?
what happens if i perform it before the train test split
The same
Imputation will also have similar problems. The values filled in will be representative of the whole dataset
So the imputed values in your train set will have been influenced by the test set, rendering it not unseen
Only dropping records or features is fine before split I think
You're most likely doing some mean value imputation right? You're information from unseen data to determine the mean and using that to impute the values
It's a tough judgement call but I think yes you can drop records before the split. But ideally you define the rules for which you will drop records before looking (extensively) at the data
so it means i should do the transformation methods such as logarithm transformation before the splitting?
so sorry for pestering too much yeah, im pretty new to this mb
no, you split first and then do all the rest
No no, this is a good discussion tbh because this is something some of my colleagues struggle with 💀
Another thing to notice is that the transformations your lecturer wants you to do are linear regression specific
Yes exactly
However I think there's 2 different concepts at play here.
Exploring the data and being selective about what rows to drop will deteriorate the quality of the data.
But, it will not introduce bias
By my understanding
You can either 1) Eyeball the data and determine you need a log / box-cox / ... transform beforehand OR 2) make your linear regression model and study the residuals. If the residuals have any structure then you apply a transform afterwards (easier)
Try to do everything after splitting as a thumb rule
As you get more experienced you might try dropping rows and columns before splitting (but in a rule based manner as zestar75 mentioned) so as to maintain stable split proportions
Removing outliers are something you should do immediately though yeah
Because linear regression is very sensitive to outliers. I'll look for an image, sec
so after i performed my train test split, lets say i want to use a mean value imputation. since im going to split it 70% and 30%, so the missing values in the 70% are going to be replaced by the mean of the values of that 70%?
If it was based on all the 100% then some information is "leaking" from the test set to the train set
Which means the test set isn't exactly "unseen" anymore.
Obviously we want the test set to be unseen
To answer this, I think it all goes back to measuring the performance on truly unseen data. You're free to drop rows based on "basic" rules that you're sure of your model will not see in reality. For example if Y is missing you'd drop it, that's fine.
Because information is not leaking from your test set to your training set (google leakage)
Mhm I might drop rows that it may see in reality. That will be bad data processing. I'll be a bad data scientist. The data will be lower quality and the model will be worse.
However, I believe that it won't be introducing bias
if you wanted to do a fair imputation, you'd do it based only on the 70%, which would introduce some amount of bias unless you have a fair amount of knowledge on the statistics of the problem you're dealing with
It won't lower the quality of your model, it'll just reduce the fidelity of the estimate of the performance of your model
This is a good clear example of leakage btw. Ngl a lot of times it's very difficult to spot leakage in complex data pipelines
Like, the whole point of this is having a high fidelity estimate of how your model will perform in the wild
I was referring to performance in the wild. That it will probably have lower performance since I've removed rows that I know would occur in reality
Still not 100 % correct imo, really focus on this part
My point is only that it's different to bias
thanks so much for ur support and answers anyway guys, hope to see you all next time when i have more queries. really nice learning more from y'all!
Wait before you go
No problem! We sure get to learn too. Atb!
Do the box-cox or log transforms after step 8
So load in the data, split immediately, explore it, remove outliers, impute missing values, one hot encoding, make features and then make a model
yep gotcha!
Step 9 is investigate the residuals (the error you're making) with respect to all of your variables. Afterwards if you see "structure" in these residuals then you go for box-cox, log transform or binning
yes sirrrr
So bias in statistics is just that the estimate you have is different to that of the actual quantity. So even if your sample is infinite you do not converge to y_true. The quantity you're trying to estimate in model evaluation is "how well is my model performing in the wild". If you remove a certain % of the data it may see in the wild you will converge to an estimate that is "biased", it will not accurately reflect the performance it should have had
I think you're mixing it up a bit with "if I drop valid rows my model will get less data and be worse"
Eep mb. I used the full sentence here. "Introducing bias". By which I mean biasing the training set towards the test set, and the model as a result
I think in the limit the problem I described is worse. Why? Companies like Zillow lost billions of dollars because they deployed bad ML models. This can likely be ascribed to not having high fidelity estimates of how well the model is performing.
I don't think I can explain it any differently or better than I have now 😅 . It's a bit unintuitive and poorly taught in school so it might take a while for this to make sense idk
I agree. I was talking about something else though, perhaps I didn't convey it very well
Ensuring fidelity in model estimates has multiple aspects. One is to have test data representative of real data. Another is to ensure the model is not biased towards the test data.
Different things
What does "biased towards the test data" mean?
I was referring to the second aspect and how dropping records or features will not lead to this.
It might lead to the first one
The test data is not representative of entirely unseen data
Dropping records will not lead to the latter but imo that's a moot point
So learning in the training data biases model towards the train data distribution. This is why we need a test data to have a good fidelity estimate.
Hence we must ensure the training data (and the model by extension) isn't biased towards the test data
Scenario #2 is a lesser of both evils yes
It'll lead to your estimates not necessarily being higher than they're supposed to be (which happens if you leak from test -> train) but they'll still be off
Unless maybe you dropped the rows at random
Mhm I think I interpreted this as stating that selectively dropping records before split will introduce the second kind of bias
Okay so a concrete example from my work 😄
We have multiple time series. For now our independent variables (X) are lags. We use the last n lags to predict n+1. If there is an interruption in our time series longer than for example 45 minutes between any of the lags we can drop that observation
This is a rule we made before looking at the data. The 45 min etc. is arbitrary, it could've been 2 hours or something else
In the real world if we deploy our system I don't think we'd make any prediction in these cases, we don't have enough information. In that sense dropping them does not lead to any bias
I'm a bit "annoying" in this respect, before we start modelling I always want to have a meeting where everyone sits together (tech/non-tech) where we discuss how we evaluate and how we'll drop rows, ...
Precisely. I agree.
My point was that if you had set it to 10 secs, it would introduce the first kind of bias, in that you would have to make those preds on deployment but you're dropping those records from your data
However it wouldn't introduce the second kind of bias, i.e. biasing the model towards the test data
We would still have low fidelity estimates tho. This becomes the problem of our test data distribution not being representative of the deployed data distribution
Yup, makes sense. It's a rough subject
Maybe I exaggerate as well, idk
I'm jealous that other "engineering" disciplines like mechanical engineering etc. take the evaluation of their products so much more seriously.
Ahaha it's difficult to convey the entire sense over text, that too without math
In the ML Engg/ DS industry, some more rigorousness before jumping into building a deep neural network would help xd
It's normal there to have a meeting on product / material evaluation before you even start building the pieces. You don't want to test the brakes of a car in different situations than it will be used on the road etc. in data science it's less common to be very very rigorous about this
Exactly
Some more preparation than "throw a black-box at the problem and pray it works" lol
Anyw, fantastic discussion! gtg now tho

is there a discord server related to data science?
Here I googled "confusion matrix" for you:
https://www.v7labs.com/blog/confusion-matrix-guide
anyone online now?
quick question, are you able to check for r square and mse if there are columns that contain categorical data in your dataset
Huh
You compute the rmse between your predictions and the target, not on your variable itself
oh, because the lecturer asked us to like, for instance, the transformation methods
he asked us to like for each numerical variable
try out the different methods
and see which one gives the best score or smth
but i still have some categorical data, so shld i js encode it first, and then do some transformation, and then use the r aquare and mse test?
You try out the different methods, make predictions and compare the rmse they were making on the test set
So method 1 -> predictions_1 -> rmse_1 vs method 2 -> predictions_2 -> rmse_2
aite
Hello fellas
I’m new in Data science
What ur suggestions for better understanding..?🙏🏽
Very hard question to answer because it depends on what you already know
what numerical imputation should i use for this case?
i feel that mean wld be good here as the data is quite evenly distributed without any form of extreme values
or maybe median
I know, but I literally just understand basics python and now want to learn Data science
How is your math / statistics?
If it's rusty I'd start there tbh
And then pick up a canonical data science book and proceed from there
Not good🥲
What u mean bout rusty..?
Being not good
That’s me😂
https://mml-book.github.io/book/mml-book.pdf this book covers most of the math that is frequently used
Thanks❤️
math statistics is a vital skill, so if you are in university pay attention to it
is target encoding often used in the field, and is it something one should necessarily know? Every way I look at it looks like the whole idea is a target leakage hazard.. I don't like it...
As they said it depends.. and for me i will study it for machine learning
Is it right to start understanding Data science for machine learning..?
I think it can work for very very high dimensional input
Like if a few of your columns have very high cardinality if you'd one hot them
I mean, if your target feature are classes like ["dog", "cat"], then even just converting the output from your neural network from 1 or 0 or otherwise index positions to the names when using a normal classification model is already a form of encoding, isn't it?
Target encoding is something else
It's encoding a level your feature (a categorical variable) by say the mean of the target when that categorical variable appears
No
oh wait I see
[{"colA" : "foo", "target": 1}, {"colA" : "bar", "target": 2}, {"colA": foo" : "target":7}] colA gets replaced with 4 in case it's foo and 2 in case it's bar
Bit handwavy but one hot "retains" information better but it sucks, so much, for high cardinality stuff sometimes
hello folks! hope you are having a great day! We are working on writing a ml pipeline for a bunch of models, in Rust and Python . So, we have looking at various inference engines. So far we have tried OnnxRuntime and tflite. While working with Onnx we noticed that it also has a bunch of ExecutionProviders. It has support for CoreMl on Apple devices. We also noticed another package coremltools by Apple. Both can give us inference results. Can any body give me some differences between the two? Do they call same backing code or are there any significant differences ?