#data-science-and-ml
1 messages · Page 57 of 1
yeah, that's the most basic form of "gradient descent"
Is my point of view correct?
But still don't get how I can calculate the grad for every parameter, based on the chain rule
it's multivariate 😄
Second-year maths is not that impressive 😅
Just checked the Wikipedia page.
all right. well, in many cases one doesn't actually need to use the chain rule explicitly, but it can be very helpful to formulate the computation of gradients very generally
in essence, a gradient vector is a vector whose elements are the derivatives of a function with respect to each of its parameters, treating one parameter as a variable at a time and treating the rest as constants
and then for each one of these derivatives, you apply the chain rule as needed
for now, i guess the most important thing for you is: you probably know how to take the derivative of something like f(x). but what about f(g(x))? the chain rule tells you how to do this. and more generally for f(g(h(...(x)...)))
and each of those f, g, h, etc is a layer in a network, if you wanna see it that way
so like this.

tbh i think looking at it connected to code is going to do more harm than good
the way this is done in code is actually very different from how it is done conceptually
so actually if I take the derivative of a function, I'm gonna get its grad?
the derivative with respect to each parameter
@mild salmon Nice code
the gradient vector is one generalization of the derivative to the multivariate case
derivate is just a slope which is represent the different between 2 points? or am I totally wrong?
it is a slope, but it's not the difference between two points
not if the function is not a straight line 😛
(btw) could you recommend me any sources, where I can learn about this more efficiently? if you don't mind.
these ones?

yeah
ooh gilbert strang has a calculus book
i like strang. check this out https://ocw.mit.edu/ans7870/resources/Strang/Edited/Calculus/Calculus.pdf part of MIT's OCW, so it's free
chapter 13 has partial derivatives and gradients
(you have to learn differential and integral calc in 1 variable before getting to multivariable)
okay, got it. 👍
thank you
I would like to read a course by myself in my own pace in data science (free of charge), is there any you guys can recommend to me?
there is no best course or website, just start with something small.
like programming?
wdym?
I mean yeah, you def should have very good python skills.
and write things from scratch, after that you can go with pytorch, or tensorflow.
like python?
in ML
im a beginner.
oh yeah
in machine learning, but have been using python for like 3 years.
oh yeah
i've been starting like 10 different courses but never manage to finish any
except one, but forgot most of it after the summer
maybe just "doing" it is best, i asked my professor for past lecture presentations, looking forward to getting them and past assignments, will do them then maybe kaggle
guys the course of udemy are equals course on youtube?
In your opinion, are they super basic courses that don't teach you anything?
some courses are paid and i guess are better since they are more structured
i'm poor so i dont want it
the ways i learned other fields, especially maths, have been by carefully looking at lecture notes, youtube videos, and doing a lot of practice problems
so gonna try that
Practice is always needed.
yeah
Everything else is preparation for the practice problems so you can solve them.
This page lists the class lectures plus additional material (slides, notes) associated with each lecture. Recordings of all the classes will available on the course Canvas page. Lectures from a previous offering (Fall 2019) are available on [Panopto](https://scs.hosted.panopto.com/Panopto/Pages/Sessions/List.aspx#folderID="618ea253-ca45-4b14-9...
i just found this from CMU
they litterally have lecture pdfs, lectures recorded and timestamped
seems like a great course
i am not sure exactly what kind of transformation this was, but often its because a lot of ml algorithms that are applied assume a normalized dataset
yeah it was a normalization, sorry for the unclear question, let me rephrase

here we scale our X_train data into values from 0 to 1, and only X_train to prevent data leakage
then here we apply the scaling to X_train

but we also do so to X_test

here the min and max of X_train is 0 and 1
but for X_test the min is -0.014108392024525074 and the max is 1.0186515935232023
so my question is 1) why aren't the values 0 to 1
and 2) why do we transform the X_test if we wanted to prevent data leakage
any help would be greatly appreciated 😄
I have some duplicate data in my dataframe but with different names. For example, tribal-human and human-tribal are the same thing but with different names. How can I pick one to keep and remove the other? I was thinking something like this
for value in df:
part_1, part_2 = value.split("-")
reverse = part_2 + "-" + part_1
while reverse in df:
# Remove reverse from df
I'm don't think you're supposed to loop over dataframes like this though.

Can do a replace
Would also put it in a lambda function to use apply() on instead of a for loop
pandas replace or string replace?
Iirc there's a way to replace all values in a column to another
Maybe like loop through the unique ones of the col, then check whether the reverse exists, if yes then do the replace
I'd rather not replace the duplicate values with anything. I'd rather remove them.
Yeah u can do that too just drop em
I tried this.
for tag_name in df["tag_name"].unique():
print(f"tag_name: {tag_name}")
reverse = "-".join(reversed(tag_name.split("-")))
print(f"reverse: {reverse}")
if reverse in df["tag_name"].unique():
# print(f"Droping {reverse}")
mask = df["tag_name"] == reverse
df.drop(df[mask].index, inplace=True)
But it removes both tribal-zombie and zombie-tribal for example. I think it's because I am iterating through .unique which isn't getting updated as I iterate.
Interesting idea.
so like assign it to another variable before the for loop
then as u drop, update it
i have another idea but this one seems the simplest
the other one will likely end up for hella if statements
Are you sure we're supposed to remove elements from a list as we iterate through it?
unique_list = df["tag_name"].unique()
for tag_name in unique_list:
# do stuff here
if reverse in unique_list:
# remove the reverse from main df
# remove reverse from unique_list
this was what i had in mind
i think it unique_list shud be updating right?
so like if the 1st item in the list is tribal-zombie, we remove zombie-tribal too, the for loop should never 'see' zombie-tribal
lemme try it haha
This is exactly what I did too. However, Python doesn't like it when you remove elements from a list as you're iterating through that same list.
Here's an example
nums = [1, 2, 3, 4, 5]
for num in nums:
nums.remove(num)
print(nums)
[2, 4]
The expected behavior is that all elements get removed but that isn't how it works.
unique_list = ['a-b', 'b-a', 'c-d']
for item in unique_list:
# do stuff here
reverse = "-".join(reversed(item.split("-")))
print(reverse)
if reverse in unique_list:
unique_list.remove(reverse)
ur example is diff than mine
i got what i expected to get
only 2 items gets printed out, b-a which is the reverse of the 1st element a-b
and d-c which is reverse of c-d
in ur example, when u delete the num ure currently on, num becomes the next num apparently

and when it goes to the beginning of the for loop again, it jumps to the next one
Yeah that's why I thought you weren't supposed to remove elements from a list as you're iterating over that list.
but for mine, since its deleting not the current one we r on, it should be fine i hope haha
Attempting to write a program that partly deals with second implicit derivatives so I worked one out by hand but I keep getting the wrong answer, can anyone spot my error?
I have taken the derivative of some function f(x), and got first derivative dy/dx = (-3x^2 - 4xy) / (2x^2 + 8y)
What is the second derivative at (0, sqrt(3)) I keep getting -1/2 when it should be -1/16

how do u know it is -1/16
also what was the original y?
was ur first derivative correct?
..
Does anyone know where I can find calculus problems of several variables but with solution?
But that re a little difficult
There are lots of books of this sort. Schaum's used to be a brand that did this, I think. Don't know if they're still around.
how do i convert a column with time series data like this at 5ms interval to rows with 1s interval where the related column is the mean of the value over the whole second?
2023-04-15 00:00:00.050000 2
2023-04-15 00:00:00.100000 1
2023-04-15 00:00:00.150000 2
2023-04-15 00:00:00.200000 3
should be 2023-04-15 00:00:01 2
apparently df.resample exists
most people do model training on mainframes that run linux. it's not hard to install pytorch on windows if you can find the right wheel for it, though.
ye for work deffo on servers. was thinking more personal project / smaller scale stuff
can anyone help me with designing a 3d pspnet model?
pspNetModel = sm.PSPNet(
'resnet34',
input_shape = (144, 144, 144, 3),
classes=4,
activation='sigmoid'
)
LR = 0.0001
optim = keras.optimizers.Adam(LR)
pspNetModel.compile(optimizer = optim, loss = total_loss,metrics='accuracy')
pspNetModel.fit(train_img_datagen,
steps_per_epoch=5,
epochs=3,
verbose=1,
validation_data=val_img_datagen,
validation_steps=val_steps_per_epoch,
)
This is giving me a val_loss nan
what is total_loss
used for training
wt0, wt1, wt2, wt3 = 0.25,0.25,0.25,0.25
import segmentation_models_3D as sm
dice_loss = sm.losses.DiceLoss(class_weights=np.array([wt0, wt1, wt2, wt3]))
focal_loss = sm.losses.CategoricalFocalLoss()
total_loss = dice_loss + (1 * focal_loss)
@cold osprey
any idea why it's showing an nan?
what can I try?
can you please suggest me some?
cos the ones which i checked required a model.parameters() as an arg within the loss
but the sm.pspnet does not support .parameters()
Is this the correct channel to ask questions about pandas/polars or is there a data processing channel I'm not seeing?
this is the channel for pandas and polars.
Cool, thanks.
for your general awareness, I can help with most pandas questions, but I typically require a copy-and-pasteable copy of the dataframe, like df.head().to_dict('list')
Good to know. I'll try to make a minimal example.
I want to join/merge multiple dataframes. The catch is that they don't all share the same columns I want to join on. So I want to do what I am calling a "permissive" join where dataframes are joined based on which join_on columns they share. I think the code below is working how I expect, though I don't have thorough unit tests yet. However before preceding, I was wondering if there is a better way to do this. Ideally, there would be native pandas/polars methods so I could avoiding having to write these custom functions.
import polars as pl
from functools import reduce
from typing import Iterable
def get_shared_elements(iterables: list[Iterable]) -> list[str]:
return list(reduce(lambda a, b: a & b, [set(s) for s in iterables]))
def join_multiple_dfs(dfs: list[pl.DataFrame], join_on: list[str]) -> pl.DataFrame:
return reduce(
lambda left, right: left.join(right, how="inner", on=get_shared_elements(
iterables=[left.columns, right.columns, join_on])), dfs
)
def test_join_multiple_dfs():
df1 = pl.DataFrame({"subjectkey": ["a", "a", "a"], "eventname": ["x", "z", "y"], "var1": [5,6,7]})
df2 = pl.DataFrame({"subjectkey": ["a", "a", "b"], "eventname": ["x", "y", "y"], "var2": [1, 2, 3]})
df3 = pl.DataFrame({"subjectkey": ["a", "b", "c"], "var3": ["foo", "bar", "baz"]})
dfs = [df1, df2, df3]
df = join_multiple_dfs(dfs=dfs, join_on=['subjectkey', 'eventname'])
print(df)
# FIXME need to make expected_output
# assert df.frame_equal(expected_output)
test_join_multiple_dfs()
In this example df3 does not have the column eventname so I only want to join on subjectkey.
df = join_multiple_dfs(dfs=dfs, join_on=['subjectkey', 'eventname'])
should be
df = join_multiple_dfs(dfs=dfs, join_on=get_shared_elements(dfs))
``` ?hmm wait m confused
I just started with NLP and trying to understand cosine similarly and Euclidean distance.
As cosine similarly takes direction into consideration than magnitude I always feel for all NLP tasks cosine similarly is the best.
But are there any scenario where Euclidean distance works better than cosine similarly for NLP?
the the join_on parameter necessary? hmm
I want to get the intersection of the columns of the two dataframes that are being joined and the strings passed to join_on in join_multiple_dfs. Technically, you don't need the join_on arg if the dataframes only share the columns you want to join on, but I can't guarantee that for my use case, so the arg guards against this.
cant run the code rn coz doing some shit with my envs
i dont see why join_on is necessary hmmn
get_shared_elements returns the shared columns between 2 dataframes, which we use to join
Say that df1 has column "foo" and df2 also has column "foo" but I don't want to join on "foo". I only want to join on "subjectkey" and "eventname". That is what the join_on arg is for.
yep
seems fine
altho i cant rly brain the reduce lambda in join_multiple_dfs
i assume its doing what i think its doing
type hinting isnt helping too haha coz i dont use it 
Here is the non-functional version of it, if that helps:
def join_multiple_dfs(dfs, join_on):
joined_df = dfs[0]
for df in dfs[1:]
joined_df = df.join(joined_df, how="inner", on=get_shared_elements(
iterables=[join_df.columns, df.columns, join_on]))
return dfs
Haha ok it's doing what I thought it was
It depends on your use case. If there is a natural interpretation of euclidean than you might have some motivation to choose that one. But otherwise, you are right, cosine similarity is often preferred in nlp.
any reason why my help request would just get closed with no responses?
Are there any good resource that explains when to choose which distance metrics. All the resources I referred didn't mention the reasons in depth
To my knowledge there's no great rule of thumb for choosing metrics. You usually just choose your metric if there is some conceptual motivation to do so. Incidentally, ML researchers have found that learned distance/similarity metrics perform better (for down stream tasks) than metrics chosen explicitly. Look up "metric learning" for more info.
I am currently trying out feature extraction using RESNET but I want to know if I resize the image to a smaller size, will it get affected in any way better or worse?
its an API (written on fastapi) that gives recommendations based on the input, before it would query the DB each time, but I suggested to do all of it in memory so we dont need to do a network request to the DB, and since there are only 600k records, not that much.
the point is that I'm constantly querying the DB/dataframe (filtering), mostly with SELECT ... WHERE col IN (...) or pd.DataFrame.isin(...), so I would like to do that as eficciently as possible.
I will try the suggestion from @serene scaffold when I go back to work, but Polars sounds really interesting (credit to @tidal bough ) as I've started using pyarrow quite a bit lately, and its usually very fast for this stuff (and it has a very low memory footprint).
- does your dataframe/source data change over time?
- does your input change over time?
- what is the characteristics of
col? (e.g. cardinality, data type, unique-ness, skewness/distribution) - what is the characteristics of your input?
- what is the current performance you have?
- what is the desired performance?
it's worth noting pd.Series.isin could utilise two different algorithm under the hood depending on the characteristics of your series and your input, and isin itself is already quite optimised, in most cases that's the best you can eek out of pandas. (one of two is a hashmap based algo, so using a set in python might be inferior to isin)
PermissionError Traceback (most recent call last)
Cell In[15], line 22
19 n += 1
21 im = Image.open("model.png")
---> 22 mlflow.log_image(im, "model.png")
error trace here
PermissionError: [Errno 13] Permission denied: '/c:'
Context: fitting a tensorflow model in wsl, using mlflow.tensorflow.autolog() which logs the metrics
Don't post screenshots. Post text.
model_plot = utils.plot_model(model, show_shapes=True, show_layer_names=True)
model_plot
model plot which is saved to a model.png file
# Train the model
epochs = 200
batch_size = 64
with mlflow.start_run():
history = model.fit(
X_train, y_train, batch_size=batch_size, epochs=epochs, validation_data=(X_val, y_val)
)
test_metrics = model.evaluate(X_test, y_test)
n = 0
for metric in test_metrics:
if n == 0:
mlflow.log_metric(("test_loss"), test_metrics[n])
else:
mlflow.log_metric(("test_" + metrics[n - 1].name), test_metrics[n])
n += 1
im = Image.open("model.png")
mlflow.log_image(im, "model.png")
then opens the model.png file as a pillow image and logs it as an artifact on mlflow
fixed
PermissionError suggests that something is wrong with model.png.
its not the reading of the file causing the error
its the logging with mlflow thats causing it
not familiar with linux, let alone wsl so not sure if theres a way to give it the perms it needs to write to /C: or not
Okay, I don't know anything about mlflow, so I'm afraid I can't help you.
But maybe someone else will come along who can.
In your opinion, will chatGPT or other technologies be the parameter for the development of everything from today? Are so many new artificial intelligences going to use chatGPT in their application?
and also in the applications, eg a website that summarizes books, it is no longer necessary to build the whole AI model and training, just integrate the chatGPT, do you think that the creation of new models will be replaced by just an integration with the chatGPT?
not at all.
chat gpt only does one thing: Respond to text with text
you can try to go out of your way to engineer ways to transform other tasks into text completion, but it's going to be extremely inefficient if not impossible for a lot of tasks.
it may be usable for summarising books, but how would you use it for recommending books? literally ask it directly and recommend whatever it hallucinates?
For ChatGPT's domain, it will probably be dominated by OpenAssistant based models. They have been collecting a lot of samples really fast via public community efforts.
so for example, for creation of AI in systems mainly chatGPT will be used, right, instead of having to develop all this from scratch?
No, ChatGPT is a narrow AI. For the specific task that ChatGPT does, it will be used, although it will probably be replaced soon by OpenAssistant models and/or ChatGPT itself will be trained on the OpenAssistant datasets.
but so to create an AI for a specific task, example: AI for playing fortnite, do you think this will be developed from scratch or will it be assisted with chatGPT going forward?
From scratch.
If we are to have some generic base from which AIs are created it would have to be some world model trained on the real world and/or simulation. And this is a much more difficult task than downloading a bunch of text, creating prompts, and having people go through them and rate them and such.
A text model can then be included to have a better interface with humans.
*It could be done though, especially with a public crowd effort like with OpenAssistant.
-
- With a strong enough world model your text model probably does not need to be nearly as good as ChatGPT. Humans probably know less about text than ChatGPT, but that does not matter for them because what they say probably comes mostly from their world model (this becomes especially apparent when you try to get a language model to write code for something it has not seen before, it only has learned from the shadow of reality that is language).
yeah
do you guess prompt enginner is next profission, can replace almost every areas, provided that the engineer has knowledge in these areas?
Last time I checked I did not get to be a "prompt engineer" for using Wikipedia to look up some concept.
The answer key to where I got the problem stated -1/16
it was correct according to the answer key I got it from
Saying i'm a prompt engineer is like saying i'm a "professional Googler."
High paying jobs will be the same as they always have been, having a strong world model with regards to some domain.
i really dont know
it's really true about google pro but chatGPT is more specific in the answer and parsing question fix that code google has no power to do that.
To get the correct specific answer out of a language model you need to already have a lot of knowledge about the domain. If you already have enough knowledge about the domain Google will work just fine.
(Or you probably do not need to Google anything, except a few specific easy to Google things like for example the values of some physical constants)
yes, but the chat interprets your question, while google shows possible answers to your question, but it's not something directed like the chat, you know?
The directed chat may be an improvement, but that does not suddenly make a huge difference. It's just a bit more nice.
In a few years we may have that world model I wrote about, when that happens there may not be any prompt engineers either, there may not be any engineers...
ChatGPT isn't actually significantly more sophisticated than what came before it. It's just bigger.
Bigger issues to deal with at that point.
New versions of language models will not suddenly do something they did not do before. They just do that same thing better.
The bigger gains now are probably from plugins, e.g. Wolfram Language.
yeah
*But even in that case, what is really happening is that it's being used to improve the UX for that thing. The real power is just whatever that plugin was for. Wolfram Language for example has always been amazing at what it does.
(Also it had NLP already (for a long time), you could code in English with it, this is just a better version of that)
yeah, how did you acquire your knowledge in the area of Ai?
Trying to make things.
but did you take a course, or did you follow the path of college?
Neither. I was reading papers (including old papers from the 40s, 50s, 60s, 70s, 80s).
And books, and things on the internet, following other's work.
The whole courses for AI/ML and in colleges is a recent thing. It was there, but kind of like in the dusty corner (relative to now).
oh nice
Now it has everyone's attention ( 😉 ).
do you have background in what area?
Programming and mathematics mostly I would say.
oh this is very interesting
in question of programming, do you think the time it takes to be a good programmer with all this information overload has become faster, or does it all come down to practice?
It's faster, but it's practice.
but do you think developing new solutions or studying first and then practicing?
knowing what to use, how to use it, because sometimes you create a crappy solution, but it works, you know?
I just started making things. So I guess you could say it was practice from day one.
in terms of improving as a developer, is your recommendation to read books and source code?
Reading source code, yes. And just making things. Just actively programming every day for hours.
when I came into contact with programming 1 year ago it was to manipulate data in the csv, I started without knowing anything, but in 3 weeks I managed to use this script to generate a budget for my father's company that was in the beginning, something that the budget sometimes takes 1 day depending on the size, in the script it took 5 min.
oh yeah, of course
Let me give an example. I would see something i'm interested in, like virtually evolved creatures, then I just started making that (from scratch). Repeat. Each time I would look at my code and realize that it was bad and could have been done in a more simple way. I then keep in mind next time to just directly solve the problem in the most simple way and not over-engineer a solution. I need to constantly remind myself of that or I start over-engineering automatically.
I would learn any of the mathematics and such needed for that domain as I tried to make whatever.
uhum... interesting
small things big difference
this habit make your code better each time
I am trying to create a machine learning model to classify text. Currently I have an accuracy of approximately 90%. Do you guys have any suggestions to help me increase it?
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.naive_bayes import MultinomialNB
train, test=train_test_split(cw,train_size=0.9999999999999999, shuffle=True)
# Tokenizing text
count_vect = CountVectorizer()
X_train_counts = count_vect.fit_transform(train.Text)
# Term Frequencies
tf_transformer = TfidfTransformer(use_idf=False).fit(X_train_counts)
X_train_tf = tf_transformer.transform(X_train_counts)
# Term Frequency times Inverse Document Frequency
tfidf_transformer = TfidfTransformer()
X_train_tfidf = tfidf_transformer.fit_transform(X_train_counts)
clf = MultinomialNB(alpha=0.1).fit(X_train_tfidf, train.class_label)
checking = pd.read_csv('checkworthy_eval.tsv',sep = '\t')
X_new_counts = count_vect.transform(checking.Text)
X_new_tfidf = tfidf_transformer.transform(X_new_counts)
predicted = clf.predict(X_new_tfidf)
print(predicted)
checking["Category"] = predicted
checking.drop(['Text'], axis=1, inplace=True)
checking.rename(columns = {'Sentence_id':'Id'}, inplace = True)
print(checking)
gfg_csv_data = checking.to_csv('checkworthy_eval_prediction.csv', index = False)```Is it possible to make your own chat bot AI? Like use an already existing ai, give it certain parameters to give it personailty like its background, origin, etc. and then talk with it? If it is possible can one link it to a discord bot
Kind of like how Neuro-sama the vtuber AI works
I'm pretty sure that that is not how neuro sama works
if you are serious about it, look into fine tuning OpenAI's models via their API [medium difficulty] or creating your own LLM from scratch [hard difficulty]
if you are just curious about what it could look like, see https://character.ai
bots that play video games have essentially nothing to do with what chatgpt does.
has anyone done projects with imitation learning? Would love to learn more about it
https://pytorch.org/blog/overview-of-pytorch-autograd-engine/ is it supposed to be "dw/dx, dw/dy." right at the end of the text up top?

Hey guys?
isn't your train size way too much?
I mean... with train data 0.99 and test data hardly 1e-6 or something perc, I'd say even 90 is like... uhm. You know very less data to evaluate.
Yeah i managed to find a github program that did exactly what i needed
https://github.com/drizzle-mizzle/CharacterAI-Discord-Bot/wiki/How-to-set-up

GitHub
CharacterAI for your Discord server. Contribute to drizzle-mizzle/CharacterAI-Discord-Bot development by creating an account on GitHub.
Thanks for introducing characterAI to me! 😁
I'm evaluating data from a different file
Hiya, I have a question for u Keras pros out there, so i have a model where i pass in my training data (with the labels) as a PaddedBatchDataset object, ner_model.fit(train_dataset, epochs=10)
my question then is, in my model call function how do i access the labels, i have been looking all over and cant find any examples for my case
Hi guys actually I've been trying to learn how to read scatter plots and how to make sense of the pattern. Can someone share a good resource i can look up for the same!
If your dataset's vocabulary is a common language (e.g. english) then you can use pretrained word embeddings from a large language model as your features, other wise you can learn embeddings yourself. You could try using word2vec or a BERT-like architecture to learn the embeddings. Typically, learned embeddings perform better than bag of words or tfidf features.
All that talk about ChatGPT...and I'm still struggling to make my vanilla Transformer to converge 
There's a paper about using a new parameter for scaling the residual blocks. Apparentely, the residual blocks tends to both stabilize and mess up the model...
Yet my model is indifferent to it. I hope I'm not implementing it correctly
Hey
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
from nltk.tokenize import word_tokenize
from collections import Counter
import pandas as pd
# Load and preprocess the data
data = pd.read_csv('sentiment_dataset.csv')
text = data['Text'].tolist()
labels = data['Label'].tolist()
words = word_tokenize(' '.join(text))
word_counter = Counter(words)
vocab = sorted(word_counter, key=word_counter.get, reverse=True)
word2idx = {word: idx+1 for idx, word in enumerate(vocab)}
text = [[word2idx[word] for word in word_tokenize(sent)] for sent in text]
max_seq_length = max([len(sent) for sent in text])
text = [sent + [0]*(max_seq_length-len(sent)) for sent in text]
# Split the data into train and test sets
train_X, test_X, train_y, test_y = train_test_split(text, labels, test_size=0.2, random_state=1234)
# Define the PyTorch Dataset and DataLoader for the data
class SentimentDataset(torch.utils.data.Dataset):
def __init__(self, X, y):
self.X = torch.tensor(X, dtype=torch.long)
self.y = torch.tensor(y, dtype=torch.float)
def __len__(self):
return len(self.X)
def __getitem__(self, index):
return self.X[index], self.y[index]
batch_size = 64
train_dataset = SentimentDataset(train_X, train_y)
test_dataset = SentimentDataset(test_X, test_y)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
#and more...
Traceback (most recent call last):
File "c:\Users\Salih Furkan\OneDrive\Masaüstü\Sentiment-analysis-cnn-master\model_in_torch.py", line 20, in <module>
text = [[word2idx[word] for word in word_tokenize(sent)] for sent in text]
File "c:\Users\Salih Furkan\OneDrive\Masaüstü\Sentiment-analysis-cnn-master\model_in_torch.py", line 20, in <listcomp>
text = [[word2idx[word] for word in word_tokenize(sent)] for sent in text]
File "c:\Users\Salih Furkan\OneDrive\Masaüstü\Sentiment-analysis-cnn-master\model_in_torch.py", line 20, in <listcomp>
text = [[word2idx[word] for word in word_tokenize(sent)] for sent in text]
KeyError: 'D.H'
How can i solve this?
It's telling you that D.H is not a key in the dictionary word2idx. Which means that text has a word in it that is not in your vocab. I like to make my word2indx via something like word2idx = {i: word for i, word in enumerate(text.unique())} (assuming text is a pandas Series where each element is a word) which helps prevents error like this.
Text is like that

Then it probably depends on what word_tokenize (I'm not familiar with it) is doing. I would grab the first few lines of that file and play around with word_tokenize to see how it transforms them to make sure it's doing what you think it is.

uhh I see. Lemme test it. Thanks for the help
oh
it worked
But... what prevented the code from running perfectly? The first couple of lines are okay but what's the obstacle there 🤔
oooh
Plug the line that breaks it into word_tokenizer (i.e. the line with "D.H" in it) and see what's different about that line
After removing the D.H words, it later gave a keyerror m.j. So I thought that words having 2 lengths cause errors. But now, it gives an error because of a key "DoOrk"
Weird 🤔
Anyways, thanks for your help! It made me realize the error
hi i need help on how to calculate the to compute the False positives of a confusion matrix
so the code i have so far is this:
def confusionMatrix(classified_data):
ActualClass = classified_data[1]
PredictedClass = classified_data[2]
classes = np.unique(ActualClass)
confusion_matrix = np.zeros((len(classes), len(classes)))
for i in range(len(classes)):
for j in range(len(classes)):
confusion_matrix[i, j] = np.sum((ActualClass == classes[i]) & (PredictedClass == classes[j]))
return confusion_matrix
def computeTPs(confusion_matrix): #calculated by getting this diagnals
tps = []
total_elem = len(confusion_matrix)
for i in range (total_elem):
tps = tps.append(confusion_matrix[i][i]) #confusion_matrix[i][i] will get the diagnals and append them to the tps list.
return tps
def computeFPs(confusion_matrix):
fps = []
for i in range (len(confusion_matrix)):
for j in range(len(confusion_matrix)):
sum
return fps```the fps is essentially the columns but i was just confused on how to go about calculating it if anyone can give some pointers
@forest pollen which axis is for predicted and which is for actual
ah sorry let me also show u the code for the confusion matrix:
so row is predicted, and column is actual
So each value that isn't along the diagonal is a fp for the predicted class, and a fn for the actual class.
oh so would the answer be something along the lines of me doing the sum of all the values confusion_matrix[i][j] then minusing that from the tps???
You don't need to do any subtraction
Remember that each class has its own set of true/false positive/negative values
What's the goal? To calculate the precision and recall for the whole system? (Rather than for each class?)
so we are grabbing the fps, Tps, and fns to calculate recall, precision, fmeasure and accuracy
for the whole system
e.g this is a function later on:
def computeMacroPrecision(tps, fps, fns, data_size):
precision = float(tps/(tps+fps))
return precision```see this image slightly confuses me:

because i thought it was the sum of all the columns - the diagnal as it is the TPs
You don't need to have float( ) in this.
ah i'll change that thank you
What do you find confusing about it
Also, it looks like you're computing micro precision. Because macro precision is the average of the precision for each class.
it has to be macro average, just reading through the website and i think i understand how to go about doing it
If you're calculating the macro precision, recall, and F1, then you need to calculate those individually for each class
And then take the average of thiae
Those
ah got it, i'll start working on that, i appreciate the help. felt good getting help for AI grad student haha. Thank you tho!
hi all, so I have the following line chart in streamlit. How could I go about allowing the user to select which years he wants to look at? the underlying data is a pandas df with columns for month/year/location/income

lol just realized it's literally clickable, guess that will suffice
Currently using pandas read_csv with chunk, is there a way to start from the last chunk? Chunk starts from 2019 to 2023 but i want the more recent rows
Im interested in building a software that can receive a photo of a wild berry, and based on a users given location (where they are in the world), it can determine whether the wild berry is safe to eat or not. I would assume this is a relatively simple concept. Does anyone have any guidance tips on where I should start?
^ I'm already at what I'd consider to be an intermediate level with Python, so I'm familiar with the language, just not building photo detection software like this
If you only want to read in the last n rows you can use the skiprows argument.
Most image prediction tasks involve neural networks these days, so you'd need either pytorch or tensorflow/keras. It's possible that there are models that are already trained on plants/berries, which would make things easier. As for the geo-stuff, I never dealt with geo data, but I've heard good things about geopandas.
Gotcha, Ill look into those asap, ty. Do you know if PyTorch or similar libraries tend to take awhile to get familiar with? My priority is creating quality software, of course, just curious if its a multi-month process.
The geo stuff could just be the user inputting their location manually tbh. Wouldnt have to make it automatic
Hi, can anyone help me with a project I am pursuing?
if you need help, be sure to always ask at least one complete, answerable question.
PyTorch has a bit of an initial learning curve, but once you get over that you start to notice that almost every PyTorch project has very similar structure.
why do i increase the number of layers and the number of nodes in a neural net?
It makes the model more flexible. That is, it can fit more complex patterns in the data.
so ur saying if i can train a dataset on 2 nodes in 1 layer its fine?
if i can get the loss to near 0
Yes, there's nothing stopping a model from being very simple and still performing well. It all depends on the data. If simple works, all the better.
so as long as a network is good enough to get the loss to 0, it is equal to a massive model
and the only reason to expand a model is if the loss converges before 0
Pretty much
so what happens if it gets 0 loss but does terribly on the testing data
Then your model is overfitting, which usually means it's too flexible and has just memorized the training data and can't generalize to new data (i.e. the test set)
Though it would be weird if a model with only two parameters was overfitting
How do I combat over fitting
Pytorch Vs tensorflow?
I set up tf GPU with wsl just to have mlflow not work properly. Moving to pytorch now instead 
pytorch all the way
Also it’s more likely to overfit the bigger the model is right?
Do u do ml research by any chance?
PyTorch is better than tensorflow yes
My ml PhD friend is pro pytorch too
Typically yes, however people have also discovered that if you massively overfit your data with huge models then somehow models start to work really well again.
Wait what?
Yep, I'm an applied ML researcher
TIL
The phenomena is called "double descent" because you tend to see the loss curve decrease as you add more parameters then increase as you start to overfit as you would expect, but if you just keep adding parameters eventually the loss starts to decrease again??? kinda magical. Neural nets are weird
V interesting indeed. Will read up on this
@dire field so i should start with a very small model size and if i can get it to 0 loss then there is no reason it shouldnt do well on testing data?
That's usually a good approach. Start small and build up from there. You may want to also have a validation set that you can validate your model on while you are tuning the number of parameters before you test your model on the test set.
what is a validation set
It is another partition of your dataset that is independent from your training and test set.
Typically you train your model on the train set, hyperparameter tuning on the validation set, and model assessment on the test set.
how do i make one
This is how I usually do it:
from sklearn.model_selection import train_test_split
def split_train_val_test(X, y, val_test_size, random_state):
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=val_test_size, random_state=random_state
)
X_test, X_val, y_test, y_val = train_test_split(
X_train, y_train, test_size=0.5, random_state=random_state
)
return {
"X_train": X_train,
"y_train": y_train,
"X_val": X_val,
"y_val": y_val,
"X_test": X_test,
"y_test": y_test,
}
The idea is to randomly split your dataset into three partitions. The majority of your data will be the train set (a common heuristic is 80%). Of the remaining 20%, 10% will be your validation set and the other 10% will be your test set.
how does the validation data differ from the testing set
The difference is in the way it is utilized. It is typically used to evaluate the performance of your model while you are in the experimental phase of model development (e.g. tweaking hyperparameters). If you repeatedly evaluate the performance of the model on the test set (and change hyperparameters in response to these evaluations), you risk "data leakage", which means that the model will start to overfit on the test set (just memorizing it). This causes the test set to no longer be a fair evaluation of how the model will generalize to unseen data.
The goal of the validation set is to guard you against this.
If you only tune the model on the validation set, you can avoid data leakage in the test set
ok i think i understand
i run it on 80%
i adjust the architecture
i run it on 10%
i adjust the learning rate
i run it on other 10%
i win
correct
what determines how many convolution layers i need and of what size
You can either experiment by tweaking the number of layers/size by hand and see if the performance improves on the validation set or setup a more complex hyperparameter tunning scheme (for example grid search)
train -> validation -> adjust archetecture/hyperparameters -> train -> validation -> adjust archetecture/hyperparameters -> ... -> lastly evaluate on test set.
so conv is complete guessing
Often yes. A lot of the time people will just use the same number of layers that other successful projects used.
You can do principled guessing if you setup a grid search or use Bayesian optimization, but those can get involved if you don't have a package that implements them for you.
@raven field Thanks
ok ty im sure ill be back ❤️
No stratify?
Probs doesn't matter if classes are fairly balanced and dataset is big enough
Yeah, it's usually a good idea to stratify.
good to know
I am trying to do a multi variable linear regression with batch gradient descent. My initial cost is astronomical... and I was wondering if this is normal for the first iteration?

My data is mostly floats and the range is quite large. About 58 features and ~2000 samples
I was playing around with the init W
It's certainly possible if your initial solution is very far from the optimum. You could try changing intial_w and initial_b, but if it's vanilla regression then the problem is convex and should converge to the global optimum no matter where you start. It just might take a little longer to get there if you start far away.
Thanks, I'll look more into better initial values. My fan is going off real loud 🤣

explain this, it only got 52% of the testing data right but it got near 0 loss and its a very small model trained on batches
so i dont see how it could be over fitting
it also got a lot blatantly wrong
Expected: [[1.0000, 0.0000]]```the training data was not representative of the testing one
Guys can anyone pls tell me how to use a GPU for training deep learning models in tensorflow..I have tried literally everything..but no progress yet ...my laptop has GTX 1650
What version of tf are u using and what os are u using?
Since 2.11 version, tf dropped support for gpus on native-Windows so that may be the case
Hello, I created a library to easily create bots and take them to porduction. Still early work but if you need features just shoot: https://github.com/momegas/megabots
GitHub
🤖 State-of-the-art, production ready bots made mega-easy, so you don't have to build them from scratch 🤯 Create a bot, now 🫵 - GitHub - momegas/megabots: 🤖 State-of-the-art, production read...
what does min mean in these GAN loss functions?

I don't know how GAN loss functions specifically work, but generally this notation would mean "minimal value of 𝓛_{join, adv} that can be achieved by varying D_{join, adv}".
I see, but what do you mean by varying?
Like, consider all possible values of D_{join, adv}, and take the minimum value 𝓛_{join, adv} achieves over them all.
ahh i see
It's defining the objective for both the discriminator and generator, right?
Then the Discrimintor objective(D on join, adversarial) is to minimize the loss on join, adversarial samples, where this loss is defined by:
loss(join, adv) = Error(D(join, adv(fake_images)²) + Error(D(join, adv(1 - real_images)²)
Below, it's the objective function for the generator.
loss(join, adv) = Error(1 - D(join, adv(fake_images)²)
Then you just have to check what "join" and "adv" really mean
D(join, adv(fake_images)²)
but in the screenshotjoin, advis the subscript of D; D isn't a function of two arguments.
Uh... I don't know. That's why I said to check what they really mean.
I was thinking it was something like "joined images" and "adversarial images"
It certainly isn't a classic GAN... 
It’s actually a discriminator with two heads, one being adversarial and the other is feature imitation
It certainly isn’t a classic GAN
well I was wondering if you would know what kind of loss function this is since it looks similar to the standard GAN loss functionlog D(x) + log(1-D(G(z)))except it’s switched between x (real image) and G(z) (fake image) and instead of log it’s exponent
Well, that's the thing...the loss for a GAN tends to be quite messy, so it seems that people tend to simply use E instead of something like Binary Cross Entropy.
Some people use Binary Cross Entropy, some use KL-Divergence, some use WGAN-Loss...
Personally, I recommend simply using a Binary Cross Entropy in a logits version(log softmax in the discriminator), or use a relativistic discriminator.
Oh yes...there's the relativistic discriminator, which also changes the loss slightly.
And to make things even more chaotic...there's a Google paper that says that...in the end, the loss choice doesn't matter that much 
I see
Hi everyone, we’ve been working for a few month on a Dictionary for MLOps that would cover most of the common terms in the field, give some snippets and examples when appropriate and overall cover the missing data engineering, feature store and main principles we believe MLOps is about, we’d love to get feedbacks, augmentation and suggestions !
https://www.hopsworks.ai/mlops-dictionary

Detailed explanations of every MLOps term you need to know. Get examples of essential MLOps terms to streamline your workflow and enhance collaboration.
I split the training data 80-20…..
Also what is that giant spike?
hey everyone! So, I have some points of data usage for mobile devices for 12 months, I wanted to make a model to predict the % of chance of it being higher or lower than previous month usage, what would be the best approach to that? I thought about maybe a neural network with softmax layer at the end, but not sure if that's the best solution for that because I don't know how I'd set up the previous layers
@pseudo tide yes I am using tf version 2.11+ ..I tried using GPU by installing wsl..but I get an error libdevice not found at libdevice.bc
Since it sounds like a time series a RNN or LSTM might be a good architecture to use.
yea, I used RNN before to try the exact prediction, but I'm still not sure how to set it up to give probabilities instead, I'll check if there's the possibility
What deep learning framework are you using?
I'm only familiar with pytorch, but I think you can pass the neural net output directly to BCELoss or BCEWithLogitsLoss (no need to convert them to probabilities).
There is likely similar functionality in tensorflow
ok I'll check that. Thanks a lot!
is 300 images of 2 classes each not enough? seems like enough
depends,
- which model are you using?
- from scratch or fine tuning an existing?
- how different are these two classes?
it might be enough, but if you are using a model with tens of thousands of parameters I'd expect for it to overfit quite hard
(not expecting an answer to these questions, more for you to think about it ; even if you did answer I don't think that I would have any more specific advice)
noob question
Which machine learning models are the most "important" for a newbie to know (to get their first job)?
(polynomial & multiple) linear regression
logistic regression
KNN
decision (regression) trees
random forest
support vector machines
k means clustering
Is that enough knowledge of theory to start working on a portfolio and get a first job, or do I need more theory? What have I missed, what else would you recommend learning as a "must know"
Linear and logistic regression are definitely the most important to know, but just knowing them won't be enough to land a job. If you are just starting out, I'd recommend Introduction to Statistical Learning. It's a book with a free pdf online and a corresponding lecture series on youtube.
from Stanford?
Yep
Cnn
Scratch
Elephant vs dog
The model does not have anywhere near 10000 parameters
I haven't used wsl yet, but if u keep on having problems with it, just switch to version < 2.11, u won't lose much
Idk what I’m suppose to change
The dense layer section is very small so it shouldn’t over train
Plenty of images
And the loss is minimized
varies depending on what you are doing - the loss isn't very comparable between different projects
it should never actually reach 0 (even if your accuracy reaches 100%, the loss still shouldn't be exactly 0)
the loss isn't very comparable between different projects
varies depending on what you are doing
iirc usually 'when it stops going down significantly' is a good reference
I can’t figure out why it’s not working so I’m trying to dig deep
what is not working?
probably overfit
are you sure you should be using accuracy, and not precision/recall?
(and by /, I mean and, not division)
The model is very small
how small exactly?
very small. are you doing 60 instances per class again?
A cnn part and a dense part with the dense having about 300 paramd
I'm not ultra experienced with tuning neural networks, but I wouldn't be surprised if that is in fact overfitting.
maybe try using data augmentation if you aren't using it yet?
I'd also check some of the misses to make sure it isn't misslabeled or check for patterns like X dog breed is often missclassified or Y photo angle wasn't present in the training so it gets confused about it
not sure how actionable that kind of thing is other than "must collect more data" though
With this many images and so few classes I couldn’t imagine it being an issue with the data
The images are pretty random and from google
Should cover everything
Also the fact that testing accuracy was essentially 50 50
It's funny that most machine learning courses teach all of those models...starting from linear regression, going to KNN, decision trees and then to unsupervised models.
I'd also add "Neural Networks" at the end of that list. 
Why is it funny tho? 0.o
Because you basically already know the path
I have a pandas column that contains strings that look like Python sets. I would like to convert the strings to Python sets in the column.
Here is what I tried
archidekt_df["color identity"] = archidekt_df["color identity"].apply(ast.literal_eval)
but I get the malformed node or string error. I know it's possible to use ast.literal_eval for sets because it says so in the docs. What am I doing wrong?
what happens if you do .apply(eval) (provided that you know this won't execute malicious code)
Oh it turns out I had some empty sets in my rows and ast.literal_eval can't handle that.
tfw {1} is a set and {} is not.
lol
python should become perl and make {:} the expression for an empty dict
but then ∅ can be the empty set symbol instead of {}
backwards compatibility though 🤷
no.
python must become perl.
lol
My next problem is I have rows that looks like
deck_id, ..., {card_id: quantity, card_id: quantity, ...}, ...
I need to turn it into a list of tuples like this
[
(deck_id, card_id, quantity),
(deck_id, card_id, quantity),
...
]
I basically need to expand the dictionary containing card_ids and their quantities.
I'm turning it into a list of tuples so that I can insert it into a MySQL database.
My proposed solution was to iterate over the rows of the dataframe and extract the information I need. However, the internet says that you generally shouldn't iterate over a dataframe like this. What would be the correct way to do this?
if you have a dictionary inside of a dataframe cell, you're already not complying with what you "generally should" do.
take a look at https://stackoverflow.com/questions/67336514/pandas-explode-dictionary-to-rows

Stack Overflow
I have a dataframe:
Name Sub_Marks
0 Tom {'Maths': 30, 'English': 40, 'Science': 35}
1 Harry {'Maths': 35, 'English': 30, 'Science': 25}
2 Nick {'Mat...
is 30x30 too small of image size for aminals?
my eyes can still identify a very small aminal
also i was wrong about my number of trainable parameters
i said a couple hundred
its actually 3968
- 2 small convolution layers
I know I shouldn't have multiple values in one column. That's just how the data was collected. I'm making it normalized in the database though.
But anyway. That looks like what I want.
m = pd.DataFrame([*df['Sub_Marks']], df.index).stack()\
.rename_axis([None,'Subject']).reset_index(1, name='Marks')
out = df[['Name']].join(m)
Could you please explain the parts of this to me. This chained expression is hard to follow.
Actually this is what I wanted
[(n, k, v) for (n, d) in df.values for k, v in d.items()]
Thanks for the help.
Is there an explanation to why a language model would be producing always the same output?
My Transformer tends to always generate spaces ' ' after some training.
Then, I've tried to innovate and make a Text GAN...same result.
I'm now thinking about going for a classic LSTM model...but it seems that the same result is a possibility.
Any hint?
I mean...always ' '? It doesn't generate always the same token, it always converge to generating always space tokens.
what mean
did you not see that term wherever you read about dropout layers?
https://www.geeksforgeeks.org/regularization-in-machine-learning/
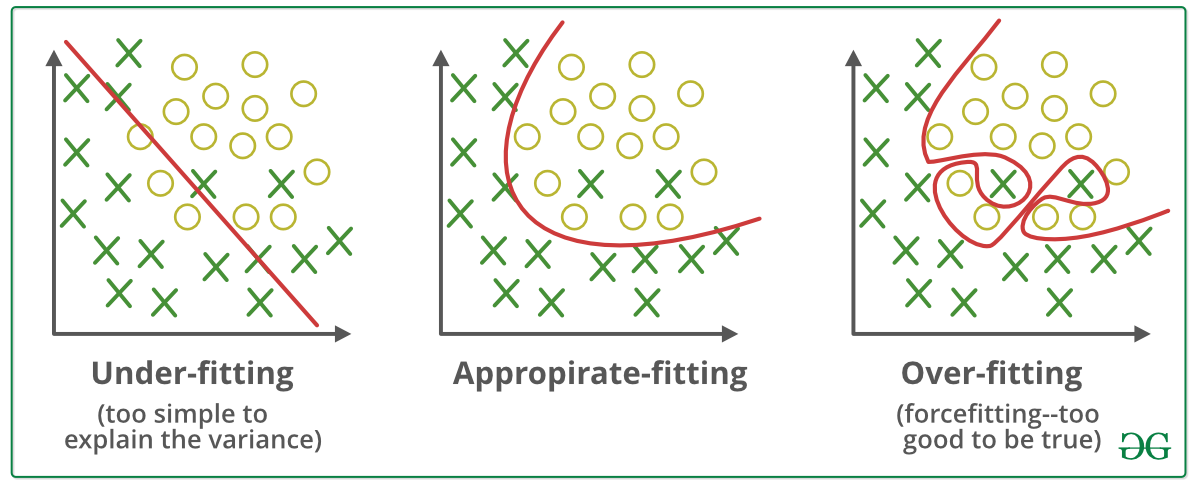
GeeksforGeeks
A Computer Science portal for geeks. It contains well written, well thought and well explained computer science and programming articles, quizzes and practice/competitive programming/company interview Questions.
no, chat gpt did not mention the word regulariszation
x-x
anyways
did you just add it without looking up what exactly they are | they do?
wasnt a complex concept
copy pasted my RELU layer with a few modifications
anyways
my model converged on 80% accuracy unseen data
i added a dropout after both denses and increased the number of dense paramaters
so now they should not be overfitting in any way
im working on a project with chatgpt api and autogpt, please dm if ur interested in help (pair or unpaid)
Bruh...
Like I said...if I were to follow what ChatGPT says without trying to double-check it, I'd be struggling for trying to train a GPT to act like a BERT model
||I'm struggling to make my vanilla Transformer work, but still...||
Chatgpt lel
If ure learning something for the first time, I wouldn't use chatgpt at all
Maybe to explain concepts and terminologies only
ChatGPT is a great assistent, but it's better to dig the fundamentals by your own
Hi, how would I filter out those tuples that contain 0, (i don't really care whether the 0 is in the first index or second index in the tuple)
holes_arr_copy = holes_arr.copy()
black_pxs = np.where(holes_arr == 0)
coords = [*zip(*black_pxs)]
coords
out:
[(0, 0),
(0, 1),
(0, 2),
(0, 3),
(0, 4),
(0, 5),
(0, 6),
(0, 7),
(0, 8),
(0, 9),..]
I find random forests fascinating.. except for the random part 😶
The way I see it, is that since samples and features are chosen randomly, there is a chance, small as it may seem, that at the end of it all, some samples and some features might end up not being used at all, which can lead to skewed and biased final results.
Is there a way to make sure that at the end, throughout the whole forest, all samples and all features would end up being used in trees on average the same amount of times, ensuring that no sample/feature would be left out? #lonely 👉👈
Separate question. When tuning hyperparameters for a random forest with a grid search using kfold cross validation with shuffle enabled, would it make sense to disable bootstrapping entirely (purely for performance reasons, to save some time), since each forest will be getting its own, slightly different dataset as is (and that kinda makes sense¿)? And then enabling bootstrapping when training the actual model with the chosen hyperparameters? Or will having the trees of the forest use the same dataset affect the choice of hyperparameters, meaning that random forests should be tuned with bootstrapping enabled?
Hello y'all, I need a good source for ARIMA and SARIMAX models that I can quote and that ideally displays equations with consistent variables. Any suggestions?
I'm not quite sure what you want, but I think it might be something like:
import numpy as np
arr = np.arange(8).reshape(4, 2)
arr[np.all(arr != 0, axis=1)]
just to get all those coordinates that dont have 0 in them in the coords variable
There is never any guarantee that a feature will be used at all. This is not necessarily a bad thing. For example, if you have two features that are perfectly correlated, then you can get away with just one of them. If the features actually provide distinct information, though, and you construct enough trees, then some tree will use them. The key assumption is that you construct enough trees. If you have three features and you construct three trees, that's very likely not enough.
I know some people have studied non-random methods of constructing forests. My recollection is that there are trade-offs. I don't know if anyone has asked the question you're asking, though.
I'm not sure I understand your second question. But shuffling (however and whenever it's performed) is a different operation from bootstrapping: In bootstrapping, you're allowed to resample the same data point multiple times. Being able to is actually important. So I would be wary of trying to replace a bootstrap by a shuffle operation.
--------d -----------|
|----------------e
--------c -----------|----|
| |
--------b -----------| | ----------f
|
--------a --------------- |
if i am trying to learn similarity between e and f, does it make sense to put loss between e and f and also c and e(representing f in way)?
its not irrelevant to do that for my use case.
what is this
a representative ppipeline
All the entries of holes_arr that don't have a zero in them? Or all the coordinates that don't have a zero? Or something else?
im talking about the py coords variable which tells me the coordinates in the py holes_arr where it is 0
think hes trying to filter coords
Like
coords = np.array(coords)
coords = coords[np.all(coords !=0, axis=1)]
maybe?
But in that case, I would rather filter black_pxs first.
this works for sure but seems like u think there could be a more efficient way to do it from then holes_arr or black_pxs var
I'm still not quite sure what he's asking. I suspect there is a faster way, but I can't tell yet.
oh i tot OP was the one who sent that msg
I guess I'm going to comment that he should probably be using np.nonzero instead of np.where, hope he notices, and leave him to figure the rest out.
heyy. So i am trying to make a model which allows a user to capture an image of his room through camera. And then click on the wall to paint it and it detects the wall and color it. So for this which ai algorithm or opencv modules can i use?
yes I think that should do it
hehe this was cute

TheStrange-007
If the replit webview doesn't work just copy and paste the URL on your browser.


How I make my model go from 80% accuracy to 95%
Image size 90 and 600 images of 2 classes each
on test set?
also i tried multiple drawn 0s and 9s and still got misclassifications
so not just cherry picking
if you ever have a question about how to improve your model, you need to say at the very least what kind of model it is, what it does, and what all the hyperparameters are. Otherwise, you are wasting everyone's time.
Image size 90 and 600 images of 2 classes each
so there are 600 images, and every image belongs to two classes? what are all the classes?
1200 images 600 dogs 600 elephants
then instead of "600 images of 2 classes each", you would want to say "2 classes with 600 images each". What you said means something else.
Oh
how long does it take to train your model currently?
Time or num epochs
time, for the number of epochs you are currently doing.
okay... I'm asking how long it takes total.
Please, in your next message, just say how long it takes to train it from start to finish, in minutes.
that would be 166.6 hours.
Hmmm
but where I'm going with this is that if it's relatively quick to train a model (less than 20 minutes), you can basically just mess with the hyperparameters and see how that affects the results.
It’s not 20 mins
It’s hours
are you using a GPU?
why are you using java
I like java more than python
what is your goal for learning all this, anyway?
Ai is cool
LEL
Java doesn’t play nicely with gpu
then dont use java?
It’s already written in java and re writing to rust will take forever
its like saying 'my car doesnt run well when its flooding'
where did rust come from now
that's probably the other language they like.
Rust is fast and modern
LEL
does it have autograd on a GPU though
I’m not using auto grad
(which is part of why it's taking so long)
No it’s taking so long because I have a really high drop rate
but he likes the language

0.4 on both dense layers
we don't mean just the number of epochs, but also the 4000ms per epoch
exactly, which means that you should try and make it run on a gpu
or using an existing library that does the hard work for you
I’m categorically against libraries
That’s why I did everything by hand in the first place
not sure how to put it nicely but that's a terrible idea
i see
what's more important here is that if you're going to ask for help in this channel, you should have things set up in such a way that you can action suggestions that are given to you in a reasonable amount of time. And you won't be able to do that if you're doing everything in pure Java.
well, doing it once for learning might be good, but if you want actual results, there's no good justification to do it all by hand
So is there no way to remove the guessing?
no
"guess and check" isn't inherently bad.
And I can’t make it educatedly guess itself?
It is when it’s blind guessing and it takes 8 hours between guesses
grid search cv
that's why we're telling you to stop using Java.
then narrow down
Rust?
if it doesn't run on a GPU, then no.
but is it machine level on a GPU?
The only reason java doesn’t is it is designed to run on any hardware by creating a cpu level virtual machine
by the way, I think that pytorch actually has Java support - or at least it lists "C++ / Java" on the homepage download tab, I haven't really looked into it
cannot say that I recommend it, but might be a reasonable compromise
Installing stuff is hard
question
Most stuff isn’t a 1 line import like it is in python
did u write the os ure using discord on by hand?
No
i see
But it was easy to install
I thought those were mainly for deploying trained models, but I'm not sure.
looking at the javadoc, I think the Java version might only support deployment?
https://pytorch.org/javadoc/1.9.0/
it's kinda barren
There is java libraries for gpu but idk how to install
you can use the 8 hours while your model is training to learn 
I just hate it so much
src/main/java/demo/App.java lines 11 to 20
Module mod = Module.load("demo-model.pt1");
Tensor data =
Tensor.fromBlob(
new int[] {1, 2, 3, 4, 5, 6}, // data
new long[] {2, 3} // shape
);
IValue result = mod.forward(IValue.from(data), IValue.from(3.0));
Tensor output = result.toTensor();
System.out.println("shape: " + Arrays.toString(output.shape()));
System.out.println("data: " + Arrays.toString(output.getDataAsFloatArray()));```example of deployment
ahh! make the bad language go away!
also archived repo
yup
Before I go to gpu which I am willing to attempt
personally I've dabbled a bit with libtorch from Rust
yes, it's in Java.
I like my defined variables and my semi colons and my curly brackets
the image size might be too small, other than that idk
90 is too small?
90x90? or 90 pixels total?
90x90
probably™️ passable then
could be small for the task
LeNet uses 28x28
(as long as they were resized in a reasonable way)
the fact it's in Java in theory isn't damning, Java is surprisingly fast for a not-really-compiled language; usually only a few times slower than Rust/C/whatever
the real problem is no GPU support - that, in any language, is a difference of 10x or more in training times
which i have no idea how to do in Java tbh, probably possible though
Why not
Java doesn’t have simd
probably should remove it from the readme then
Nobody is going to check
I’m submitting it as a final project with the goal of embarrassing everyone else in my entry to comp sci class
as you can see, I did immediately
and if someone looking at it actually knows java (and that it doesn't have simd), they won't just start searching, they'll immediately go "wait, how"
I'd probably at least use a linalg library if I decided to write an NN from scratch. Linalg libraries like BLAS are usually decades-old hyperoptimized Fortran with chunks of inline assembly, so even a C custom implementation isn't going to compare, much less a Java one. (And I don't consider it fun to implement matmul.)
Ok I’ll remove that
kek
depends how u look at it
if it was a model that a business wanted to use for deployment, this is not impressive at all
So there is nothing wrong with my data size correct?
Can I import vector libraries and do gpu?
Or is it one or the other
If I switch out my custom Matrix every single line needs to be re written
I’ll check it out
I’m mainly just here to make sure my model is conceptually correct
I can fix performance later
Does reinforcement learning use a neural network or is it completely different?
reinforcement learning is a subset of ML, not necessarily DL, so it might not involve an NN at all.
it can use neural networks, but does not necessarily have to, much like regression / classification
but there does exist deep RL, yes.
So if I was to put a model into an ant in a simulation
To give an ant a brain
What that use
Python
PyTorch
Tensowflow
Jupyter notebook
All the tools you need are in numpy + PyTorch and maybe openCV
Depending on what type of AI you want ofc, very broad term
I don't understand one thing when I calculate the loss(average negative loglikelihood ), why do I have to use the log function, I mean I know what it does but don't understand why we need this during the loss.
log_likelihood += torch.log(P[ix1][ix2])
i mean... that's why it's called the log likelihood
as for why not use the product of probabilities instead - one reason that comes to mind is that it can be so small or high as to not be representable as a float, which probably won't happen with the log likelihood.
so the log likelihood is needed because of the constant "e" -2.71? so is it like a normalization?
I'm saying that if you use normal likelihood instead, the product of all the output probabilities, it can easily be unrepresentable. say, if they're all 0.5 and there's 10000 of them, that's a product of (1/2)^10000. That's exactly 0 as far as floats are concerned (it's around 5*10^-3011 but floats don't go that low).
whereas log likelihood represents that easily - log(1/2)*10000 is only ≈ -6931.5.
hmm okay got it
I'm trying to set up object detection but when I export from CVAT to a TFrecord it warns me that it exceeds 10% of system memory before saying killed and when I export it to COCO and then convert it using the create_coco_tf_record.py script it gives me an error like "indices[0] not in [0,0]" I'm not sure if its a CVAT problem, a tensorflow problem or a config problem nothing seems to get me any closer to an answer it seems like it should work and the only idea I can think of is reinstalling linux. If anyone knows what might be the problem it would really help I've been stuck on this for a while
how to convert white lines to transparent
Having an issue with pandas loc. It returns an empty df when trying to filter for a column value and I can't see any obvious issues. I've used df.columns to make sure I was writing them as they are but it won't return anything for this specific column. Any ideas?
does anyone know opencv?
Hello, there's not enough information here to start answering your question. please do print(df.head().to_dict()) and put the result in the pastebin, and show the code that is not working in this chat.
!paste
Pasting large amounts of code
If your code is too long to fit in a codeblock in Discord, you can paste your code here:
https://paste.pythondiscord.com/
After pasting your code, save it by clicking the floppy disk icon in the top right, or by typing ctrl + S. After doing that, the URL should change. Copy the URL and post it here so others can see it.
no worries, figured it out. My strings were wrapped in " " ...lol. Didn't catch that at first
but thank you

I'm not sure if individual ants can be trained with reinforcement learning. As a whole they can be trained. Most ant simulations have individual ants be very simple.
Maybe a tiny amount.
Is viewing jupyter notebooks on github broken for anyone else on their phone, theyre clipped off like I can only see the left half
Has anyone ideas how one could type hint DataFrame contents? https://stackoverflow.com/questions/76038966/type-hinting-pandas-dataframe-content-and-columns
Stack Overflow
I am writing a function that returns a Pandas DataFrame object. I would like to have some kind of a type hinting what columns this DataFrame contains, outside mere specification in the documentatio...
there isn't an agreed upon way. you could do things like s: 'pd.Series[str]', where the type annotation is a string that's formatted like a 3.9+ style type hint.
anyone have any thoughts on this? https://stackoverflow.com/questions/76049775/matplotlib-pixel-grid-not-aligning-exactly-to-pixel
Stack Overflow
I'm using matplotlib to generate a pixel grid over an image like so:
from PIL import Image
import matplotlib.pyplot as plt
size = 20
im = Image.open("images/sunflower.jpg") # create PIL ...
Not super familiar with matplotlib but I can't find out why this is happening
Hi guys in the context of my master thesis i work on such data images for a classication ai algorithm any one knows where i can find a dataset contain these images "Ultrasonic Cscan images"

Oh man, I've looked into things like this before, and you may be in for a bad time.
it's not too big of a deal if i can't get it to work, i'll just end up using a thicker line width
The first thing to understand about matplotlib is that it does not use pixels. Never, anywhere, until the very very very end.
Any time you think you are drawing pixels, you are wrong.
What it's actually doing is drawing monochrome squares.
yeah i understand that
Your im is an image. imshow is supposed to display it. It takes each pixel of im and creates a little square whose color is the pixel color.
The first thing you have to do is make sure that the edges of the square are where you think they are.
IIRC, by default, matplotlib centers the pixels. I.e., (0, 0) in canvas space is the center of the (0, 0) pixel, not the corner.
If you want to add grid lines between the pixels, you will have to find the pixels edges.
You can do this by comparing the dimensions of the image to its dimensions on the canvas. Once you figure out the size of a pixel, you use a half-pixel offset.
That will get things very close.
i see
If you output with enough resolution then you probably won't be able to see problems.
But they're there.
The other thing that obstructs you is that canvas space is not made of pixels. I said earlier that matplotlib only uses pixels at the very end. Until the very end, it's working in canvas space, which is continuous.
To convert to pixels, matplotlib has to rasterize somehow. This can introduce subtle one pixel errors.
For example, suppose you have a checkerboard pattern with alternating swatches of color each one pixel wide and tall. It is nearly impossible to display this correctly with matplotlib.
In order for that to work, you have to get lucky when matplotlib rasterizes the image.
fortunately i don't need to be super exact but it's just slightly annoying lol
If you don't get lucky, then at some point, it will round the wrong way, and you will either skip a row or column or see the same row or column repeated.
There is a low-level matplotlib command which inserts a picture at the very end. This command is pixel-exact, but because it doesn't work in canvas space, it's very difficult to use correctly.
So your best bet is to rasterize at a higher resolution than you actually need to get exact.
how would I go about doing that?
Honestly, I don't know.
There's a lot about matplotlib that I find mysterious.
Usually it works correctly for me. When it doesn't, I have a very hard time figuring out what's wrong.
Picture sizes are one of those things that I don't know how to control.
how are activations determined for the first hidden layer in a neural network? are they based on weights and biases? if so, how are those determined?
wanted to let you know i figured it out, someone on stack overflow did at least
it's fixed by setting snap to false in the grid function
according to the docs:
Snapping aligns positions with the pixel grid, which results in clearer images. For example, if a black line of 1px width was defined at a position in between two pixels, the resulting image would contain the interpolated value of that line in the pixel grid, which would be a grey value on both adjacent pixel positions. In contrast, snapping will move the line to the nearest integer pixel value, so that the resulting image will really contain a 1px wide black line.
that's pretty annoying considering i'd have to dig thorugh the matplotlib docs to find out what was going on, odd that's default behavior
I'm not sure if this even counts as a hot take, but Matplotlib is terribly designed.
yeah i try not to work with it but unfortunately it's way too integrated with existing python libraries that not using it hurts even more
Yeah, I think matplotlib's situation is rather unfortunate. It's well established, but it has a lot of baggage.
If you try doing anything interesting with it you end up in weird territory like modifying private members (in some animation the standard method is modifying an underscore/private variable).
It's also REALLY slow (multiple orders of magnitude).
Hi all, can anyone help me regarding an issue in deployment of flask nlp app on ec2 instance? Actually this is my first time deploying an app on ec2, and i've followed several tuts, and it does works, but as you know in NLP we use heavy models like BERT having size around 1.5GB, so the endpoint let's say get_predictions takes a lot of time (as my ec2 instance is a t2.large not GPU enabled), so after like 5 minutes or less, the ssh connection disconnects throwing a Broken Pipe error and in postman i get 502 Bad Gateway error in response.
Right now i'm running the server using gunicorn with the following command from my main project directory:
In my main project dir:
/home/ubuntu/project/mlenv/bin/gunicorn -b localhost:8000 app:app --timeout 600
Now when i hit my endpoint using postman, it takes around 4-5 minutes, then the ssh loses its connection due to broken pipe error
Also, i have tested it on my local machine on dev server, it works, but as my machine is a m1 air, it runs on CPU and it takes around 5-6 minutes to give predictions.
Any help would be really appreciated!
its basically timing out. Not sure if theres a way to change the max timeout duration
u can get a better ec2 instance (with gpu)
or use a smaller model
Could anyone explain to me what the use of concatenating layers is?
wdym by concatenating layers? you mean using more than one?
I mean like the ones used in the UNet
what about them?
i don't really get their purpose?
there are 2 parts to this. the first is that neural networks get all their power from the usage of several activation functions. it's not always enough to have just 1 activation function, but the usage of several layers gives you the ability to represent any function. the second part is that the type of layer you use enforces a special behavior in a network. particularly for the U-Net, you can think of it as an autoencoder. it uses layers in such a way that the input should be close to the output, but the middle layers have very few parameters. this is the same as saying "this data can somehow be represented/encoded with very few parameters", which is very strong structural knowledge about the data.
So in other words, it gives more information to the activation function on how the data should be represented?
what is "it" in your sentence?
concatenating layers
no
just concatenating layers improves the representation power of the network
then the specific choice of which layers & activation to use makes the network behave in a certain way
hmm i see
just to confirm, to concatenate layers we use keras.layers.Concatenate() in keras and torch.cat() in pytorch?
ah ok you're talking about something else
concatenation of this kind is to take several inputs and process them together
what was the other concatenate that we were talking about?
adding more layers of a neural network
ah
what benefits are there to this?
can one concatenate several inputs of different sizes? or they should be of the exact same size?
A tensor must be homogenous, so the same shape in all dimensions but the one you concatenate them in
they NEED to share all dimensions except the concatenation dimension. otherwise the math operations on the mare not well defined
if one has designed a network in a way that specific layers represent specific things, then it can make sense to process them together
i see
Have you tried taking a look at MedMNIST library? Perhaps there might be something that suits you
That library has images from cells in optical microscopy to ultrasound exams.
Hi
Oh, concatenation is usually quite useful for conditioning outputs.
People tend to concatenate embedding arrays into certain inputs to condition the output. That's common for Conditional GAN, Diffusion Model(condition output on time_step)
How can i visualise this? https://pastecord.com/fyqijokugo.properties
Hey guys , can you recommend a good tutorial for TensorFlow with python ! Thank you
I've taken Daniel Bourke's Pytorch tutorial and found it pretty good. You may want to check out his tensorflow tutorials perhaps
I don't know witch one is better. As i have understand tensorflow it's faster or am i wrong
I didn't mean to compare these two ML libraries. I have been learning PyTorch and used Daniel Bourke's course, which were quality in my opinion and I saw that he has also tensorflow courses. That is why I wanted to suggest you to take a look at them
He explains the context pretty well
Thanks will check on that for sure !
Anytime, good luck!
Thanks may the force be with you
Hi @everyone!
Has anyone worked on multi touch attribution model using Markov Chain approach?
Let me know if anyone has worked on it, that'd be a great help!
If ure using windows n gpu, I'd suggest pytorch. Tensorflow 2.11+ doesn't natively support GPU on windows, u would need WSL
have some VM for this type of problems, but this is good to know, so Thank you !
How much math knowledge do I need to get into neural networks?
And what are some good resources to learn it?
the weights in a neuron is the connected inputs? so if the weight is 4 then its handling 4 input?
If a neuron has 4 inputs, then there will be 4 weights (or 5 including bias). Bit confused by the way you phrase your question.
Each weight value is multiplied with the output of the neuron feeded into the next neuron.

bias is just a constant which we can add to the product, like a function or distribution?
As seen here (bit unclear because of back ground srr). Every node is connected to every node in the next layer.
I got this part
A bias is just a input neuron that is always a value of 1
huu what do you mean?
can you elaborate?
then what is the point of using them?
like 1 * 27 -> 27
oh sorry maybe that is addition
So for linear regression with a single input, if you only have a weight for that input, you can get any line that goes through the origin
there are two different kinds of bias we're talking about here
one is the input feature, which has a fixed value of 1
the other one is the one used in the activation of each neuron, which is adjusted during training
So y = ax where x is the input, and a is the weight value
But often the line you want to approximate does not go through the origin
I still don't get it, what kind of origin?

the "origin" is the (0, 0) point of a 2-d graph
yes, but how comes this into the picture?
make a random guess for a y = x + b function that can generate a line like this
Now try to make one without b

I cannot?
Without a bias the function you approximate with a model with 1 input is y = a*x but a bias allows you to approximate any function that looks like y = a*x + b
hmm
which is why there is the bias feature (value = 1) is added amongst your inputs
okay how you guys understood these things, it is more like maths isn't it?
it makes no sense to me
let's say that you have a row with ```
x1 | x2 | x3 | y
0 0 0 2
bias is used so that the model can adjust it predictions even on those casesnot sure how to explain beyond that - I'll leave it for PcCamel or recommend for you to look up some videos / tutorials explaining how neural networks work
It is basically linear algebra yeah. Adding a bias allows you to perform an affine transformation, whereas otherwise you can only perform a linear transformation.
But the example etrotta showed is pretty good to see why a bias is needed in some cases.
Hello guys
Im new to apache spark
Im currently using python so ill be using pyspark for my project
I wanted some advice on how i would manage a 130GB json file and use apache spark to optimize my file reading and writing so that i can take the dataset and insert it into my mongoDB databases
(ping me with your answer)
few years ago I used to use matplotlib.
is this still used by the majority?
Yeah matplotlib is pretty popular still.
am I the only one who hates the matplotlib API?
It's a bit messed up sometimes yes. f.e. plt.xlabel(...) but ax.set_xlabel(...), it's just not always consistent.
But for most simple stuff it is easy enough to use. It gets messy when you want to customize a lot
Is the key for successful language models simply making them train for many, many, many epochs?
The way their gradients behave is a bit annoying...
1/100
Total Epoch Loss: 4.5432255665461225
Gradients Average: -1.071544155489823e-11
Current output: 1
2/100
Total Epoch Loss: 4.136872115298214
Gradients Average: 9.643897486144581e-11
Current output: 1
[...]
25/100
Total Epoch Loss: 2.6726607568243628
Gradients Average: -1.3268730558735342e-10
Current output: 1
26/100
Total Epoch Loss: 2.618607923324801
Gradients Average: -3.750404500846294e-11
Current output: 4
[...]
100/100
Total Epoch Loss: 0.4769937649512769
Gradients Average: -1.1401899563390216e-10
Current output: 10
(I got output 1 for the first 20 epochs. Only after 30 epochs the output became consistently diverse)
How sad...it seems that Transformer got it even worse...even with the warmup steps...
Sorry if I'm using the wrong channel. I have this code with sympy and it returns "TypeError: cannot determine truth value of Relational", what is the reason and how can I fix it?

Looking at the docs, you don't seem to be passing the arguments in the right format for that solver... and why are you using this solver in the first place? It's for rational inequalities - like, ratio of two polynomials ≥ (or other relationship) 0. Your inequalities all seem to be polynomial ones, so solve_poly_inequalities would do.
though unsure if it supports multivariate systems.
i think sympy straight up doesn't support nontrivial multivariate systems of equations.
We just launched https://thedrive.ai/, a context-aware storage system. If you want a ChatGPT-like system for your files and want to write content based on stored documents, you might want to try it out. I would love to hear how you would use it, and open to any feedback. This python community has been incredibly for me, and I though I would share it here. lmk if I should delete it
Has anyone installed Voice cloning Ai on local hardware?
Good evening! Quick question how would I take a sns data plot and have it filter out results from a data frame for a specific year?
For example, this code plots the occurrence of age within a df. Within that df there is a column for the year. How would I create different graphs for each year.
dataframe["age"].plot.hist()
Sorry as I am still kind of new to Python so if my question is rather simple I apologize 🙂
Can anyone please suggest me a beginner friendly book on Facial Recognition ?
please help in a neural network in the hidden layer if the activation function is the same then whats the point of having so many different nodes?

Good <time of day>,
Anyone knows a homepage that teaches ML/DL/NLP concepts? E.g. MLP or Transformers or CNN etc. Basically a platform that provides a nice learning environment.
Each neuron "represents a different proeprty of your data" play around with https://playground.tensorflow.org/

Tinker with a real neural network right here in your browser.
Hello everyone,
I am currently learning about Machine Learning and TensorFlow and I am interested in developing an app that could help detect wildfires or identify areas that have a high potential of starting a fire. Specifically, I am looking for sources for satellite thermography images that can be used to train the machine learning model.
As this is a big project, I am looking for others who are also learning about Machine Learning and TensorFlow and would like to collaborate on this project. If you are interested in joining, please let me know. All levels of expertise are welcome!
Thank you for your time
Is there anyone here who would know how to make a Latex table that is similar to the picture?

It would probably be easier to make with an online diagram maker tbh. This looks like a nightmare to do with latex.
A pandas question:
I have a list of dates with no regular intervals. How do I efficiently get the last date of both the previous and next months?
I've tried using pandas.tseriest.offsets.MonthEnd but that's taking too long on large datasets for my use case
could you post what you have tried, and potentially with some example data (e.g. a snippet to create some test data) to make the life of anyone who tries to help easier please?
I wouldn't do that as a table. The arrows on the right, in particular, would be very hard to do that way. If I had to do this in LaTeX, I'd use TikZ. It looks to me like you'd create nodes for each of the blocks of text. Some would have colored backgrounds and some would have a blue foreground. Most of this is easy. The only thing I don't know how to do is the braces used between the left three columns. If you want actual TeX brace characters then that might be difficult; I'd guess that you'd want nodes containing something like $\left{\vbox to 2in{}\right.$ but aligning the nodes properly would be a mess. On the other hand if you're happy with TikZ drawing the braces, there's probably something easier.
df = pd.DataFrame({'date': pd.date_range(start='31/01/1990', end='31/01/2023', freq='D')})
# Generate offsets; This code currently takes too long on the existing dataset
df['prev_dt'] = df['date'] + np.timedelta64(1, 'D') + pd.tseries.offsets.MonthEnd(-2)
df['next_dt'] = df['date'] - np.timedelta64(1, 'D') + pd.tseries.offsets.MonthEnd(2)
the prev_dt line currently takes a little over 24 minutes to run
how many rows are there? (in your actual dataframe, not the test one)
about 77 million
yikes. that's a lot, are there duplicates?
in terms of date yes but the rows are all unique
the way you are doing it now is already quite efficient, as far as pandas usage goes.
an alternative you could try is to get the unique dates, compute a map from date -> prev_date / next_date
and use df['date'].map(mapping) to generate the new columns, i am unsure this will be faster tbh but worth a shot?
also is it possible to generate this upstream? as in before you even read your data and generate it at the source (e.g. in your SQL or whatever source you are pulling from)
an alternative you could try is to get the unique dates, compute a map from date -> prev_date / next_date
and use df['date'].map(mapping) to generate the new columns, i am unsure this will be faster tbh but worth a shot?
Is .map faster than doing a left merge on a dataframe holding the dates? because that's my current attempt
also is it possible to generate this upstream? as in before you even read your data and generate it at the source (e.g. in your SQL or whatever source you are pulling from)
Unfortunately that'd be very unlikely, would need to ask my superiors, they'd need to talks to the data factory team, and they'd need to talk to all the other teams handing the data
ok this approach shaved off ~55 minutes
I guess that'll be as good as it gets
55 minutes 🤔 ?
Is .map faster than doing a left merge on a dataframe holding the dates? because that's my current attempt
not sure, i would think so.
previously it took 28 minutes to generate prev_dt (I did the math wrong before) and I'd expect the same time for next_dt (so 56 mins total)
now it did it in a little over a minute
I didn't know .map was fast to vectorize, TIL
sweet! that sounds good enough to me without resorting to some sort of parallelism hackily
Hi guys I would like to ask you a few questions about chatgpt I would like to create a similar assistant as my (vedal987 "neuro-sama") for twitch streaming that answers both chat and you personally via microphone. I have both of these functions but unfortunately each separate and I would need to gather them into one. If there is anyone here who understands this I would be very happy.
Thank you so much for this.
hey can any one help me with my project pls?
Does pandas no longer allow negative index usage with .iloc?
loljk, turns out there's an issue with the data pipeline, we good
how can I filter for conditions when using a pandas group and apply()?
usually you'd filter before grouping by if possible, but iirc you can use slicing inside of a lambda function - not 100% sure though
!e  ```py
```py
import pandas as pd
se = pd.Series((1, 2, 3))
print(se.iloc[-1])
@agile cobalt :white_check_mark: Your 3.11 eval job has completed with return code 0.
3
guess it does
hi there, i've got a time series analysis question which asks me to design a model that solves a 'many-to-many sequence prediction problem' -- the only further clarification to this says 'it should expect several time steps for both input and output'
i am meant to select my own dataset for this
does it imply that the prediction and dataset should be univariate, or is this multivariate?
I thought about doing it that way but I guess since I've just been self teaching pandas that I'm always wondering if my thought process/solution is the 'ideal' one. But thank you, just wanted to check if there wasn't a method I hadn't yet come across
What are some good resources to start with ML?
I've hear about Andrew Ng but I don't which course..
I think he is on coursera
If I'm not mistaken, the course is also for free
Posting my question here because someone from the help channels recommended so:
Guidance with AI in Python
Some background before the question:
I'm a beginner at AI in Python and would like to start learning. I have basic understanding of machine learning and deep learning theory (cost function, linear regression, back propagation etc.), but I don't know where to start learning the practical stuff. Specifically, I'm interested in neural networks and reinforcement deep learning. I've watched a bunch of tutorial videos on YouTube, and the libraries used vary from video to video, which includes tensorflow, pytorch and keras.
My questions are:
What are the differences between tensorflow, pytorch and keras?
Most of the time I'm blindly copying code from tutorials and feel like I've learned nothing. Any ideas on the most stripped-down basic deep learning model that I can actually try creating myself? It doesn't matter if the model has no practical application, as long as its a good warm-up exercise for a beginner. (Something other than classifying irises/handwriting like all the tutorials on YouTube)
Cant we train two models parallely on same dataset? I got some weird error and seems its process synchronizaiton error.
You should definitely find a project that you're invested in, that's the best way to learn. For me, it was working with NASA's MERRA-2 database because I had access to a ton of training data. You might want to find some cool databases online to get started, but spend a few months working with that data.
You'll learn how to code models, tune hyperparameters, visualise your training through Tensorboard or something similar, and, if you decide to write a report, documenting it.
That's how to solve the 'copying from tutorials and learning nothing' problem
Keras is basically a very abstract version of Tensorflow that makes it easy to code your first models. If you're interested in pursuing the field, I'd easily recommend either PyTorch or Tensorflow. They both have their fair share of haters and lovers, and personally, I prefer PyTorch because it has great documentation, feels very clean and straightforward to use, and is just nice overall.
Of course, they will have many technical and compatibility differences. For example, Tensorflow can train on TPUs, PyTorch can't (to my knowledge). PyTorch has ways to be deployed on mobile devices, etc. but since you're starting out, you can mostly ignore these until you actually get into more professional development
If you have any other questions, let me know
Thanks a lot for your help! I'll look into the NASA database you mentioned. Someone from the help channels also mentioned the website kaggle, I'll look into that too.
Besides working with data, do you have any pointers on reinforcement deep learning? I'm not sure if its the correct term, but I'm looking for something akin to training neural networks by trial and error in a simulated environment. I've seen deep learning tutorials on YouTube recently like balancing a cartpole and it really piqued my interest. Which library would be suitable for that? One youtuber recommends a library called stablebaselines but I've never heard of it prior to that. Preferably, I would like something with ample documentation and community support.
That's definitely an interesting field, but unfortunately, I don't have any experience in it. I've seen people make bots to play games using it.
But I'd reckon that it's definitely gonna be a lot more complex than a simple neural network. You should probably start out with a classifier or a regression problem, move onto a convolutional neural network, maybe try a recurrent network to work with audio or text. If you're interested in that, you could look into LSTMs and Transformers. Once you've built up a little experience with all that, I'm sure that you could try your hand at reinforcement learning or image generation or any of those
As for the libraries, it's probably just PyTorch and Tensorflow combined with some simulated environment. Maybe a IO library if it's a game or a 3D physics modelling library for the balancing model
You may want to look into openai gym @quartz wigeon
This contains all kind of games/challenges to be solved using (deep) reinforcement learning
Thanks for the tip! Unfortunately I'm still a student with very little time on my hands. This will be a very long learning journey for me. I'll try to learn as much as I can during my free time. Thanks a lot, I really appreciate your help!
That's sounds interesting! I'll look into it.
hey sorry but I didn't really get anything from that website
Guys, I wanted to fill all these NaN with the closest value above, is there an easy and vectorized way to do it in pandas? I only know how to do that with for loops.

ohh, now I understand what backfill does lol
that was some dumb ass question tbh, thx a lot!
if you want closest value above, wouldn't that be ffill?
yea true, ffill
Hi guys,
Any user of yolov8 on a mac M chip?
I’m trying to train a model for a instance segmentation task, and i’m trying to use MPS (Metal Performance Shaders) to make use of GPU cores. I’m assigning it to a torch device, then assigning this device to the model to be trained - this part seems to be ok. But when i start to train the model, i see ‘0’ of GPU memory.. it seems the GPU is not being allocated for this task, then my model is taking ages to be trained.
I am currently trying to make a TikZ table in jupyter notebook and I am not sure how to visualize the table now. Can someone have a look at my code and see what mistakes I am making? https://paste.pythondiscord.com/ikarafifed
when I need sequential embedding from BERT, should I do add_special_tokens=False.
by sequential embedding I mean for input sentence output shape is (batch_size, token_dim, embedding_size). compared to NON-sequential output whose shape is (batch_size, embedding_size)
How do people normally label their data? Are there programs to efficiently do this?
Hello hello to everybody i would like someone to help me with some training approaches
🤘🤘
Could someone explain how they jumped to 512 nodes in the middle 2 rows? It starts from 784 nodes from a 28x28 image at the bottom, but I don't know how it moves to 512 next

https://www.tutorialspoint.com/deep_learning_with_keras/keras_creating_deep_learning_model.htm This here also started from 784 -> 512 -> 512 -> 10, but it also doesn't explain where 512 came from
these are dense layers, so they can be any number of nodes
assuming, that is, that the first operation here (the one done on the image) is a dense layer too - usually one does convolution layers first, and 512 would indeed be a strange number of outputs for a convolution
I found this guide which seems to allow me to get to 512, except unlike what was written, I had to minus 10 instead of adding it


You'll note that it says "should", not "is". The number of neurons in hidden layers can be anything you choose.
I currently have some knowledge of pandas and some machine learning algo from the sklearn library. Have been using jupyter notebook exclusively till now. Recently I did a self project that have hundreds of thousands of rows and took hours to do even simple things. How can I get started with using my GPU for ml? How vastly would the code be for using GPU as compared to the one I've been writing till now?
There are libraries you can use to be able to use the gpu. Libraries like pytorch and tensorflow work with CUDA.
Which means that the code will not be much more complicated, just a single line with my_arr.to(device) will do
And notebooks are not great for programs that require a lot of memory and computing power
Garbage collection is garbage in a notebook (pun intended)
I have a dataframe with ~77m rows in the following format:
[key_1, key_2, start_date, end_date]
and I want to convert it to the following format:
[key_1, key_2, date] for each month interval between start_date and end_date.
How would I efficiently accomplish this? Here's the current code:
df['Date'] = df.apply(lambda x: pd.date_range(x['start_date'], x['end_date'], freq='M'), axis=1)
df = df.explode().reset_index(drop=True)
```which takes ~40 minutes. The main concern I have is the .apply function since it wouldn't be vectorized, but I don't see how I would effectively do this since pd.date_range does not accept Series parameters.this depends on use, for most data science applications notebooks are the norm even if the amount of data is very large
I guess there's a cutoff for that, since where I work we've recently had to make a policy to only use notebooks when not using the full dataset, since some users started using ~100+ GB RAM for not properly deleting unused variables they removed from the code without properly restarting the kernel
IMO that sounds like user error where ppl do not shut down their notebooks after they are done, but instead leave them running.
have you looked into a similar trick used yesterday?
i.e. get the unique dates, generate the date range with apply, explode, join it with og dataframe
unfortunately there's very few duplicate combinations of (start_date, end_date), so it wouldn't work very well
we're talking like maybe 100 records in the entire dataset
understood, let me have a quick think
usually setup a system to make annotator more efficient in annotation, sometime use multiple annotators and average them/choose median for unbiased annotations
my current best:
import pandas as pd
import numpy as np
df = pd.DataFrame(
{
"start_date": pd.date_range("2000-01-01", "2100-01-01", freq='M'),
"end_date": pd.date_range("2100-01-01", "2200-01-01", freq='M'),
}
)
full_date_range = pd.date_range(df['start_date'].min(), df['end_date'].max(), freq='M')
df['start_ind'] = np.searchsorted( full_date_range, df['start_date'] )
df['end_ind'] = np.searchsorted( full_date_range, df['end_date'] , side='right')
df.apply(lambda x: full_date_range[x['start_ind']: x['end_ind']],axis=1)
it might or might not be faster for you depending on the actual data you have
and to use every core hackily...
import pandas as pd
import numpy as np
import multiprocessing as mp
df = pd.DataFrame(
{
"start_date": pd.date_range("2000-01-01", "2100-01-01", freq='M'),
"end_date": pd.date_range("2100-01-01", "2200-01-01", freq='M'),
}
)
def get_dem_date_ranges(df_slice):
return df_slice.apply(lambda x: full_date_range[x['start_ind']: x['end_ind']],axis=1)
full_date_range = pd.date_range(df['start_date'].min(), df['end_date'].max(), freq='M')
df['start_ind'] = np.searchsorted( full_date_range, df['start_date'] )
df['end_ind'] = np.searchsorted( full_date_range, df['end_date'] , side='right')
with mp.Pool(processes=10) as pool:
res = pd.concat(pool.map(get_dem_date_ranges, np.array_split(df, 10)))
at some point it might be better to just shuffle your workload to a MPP framework e.g. spark...
I'll forward that suggestion to my boss :)
does anybody know if Pyarrow's IPC format is faster than parquet when S3 is used as the FileSystem?
I can at least confirm that on high-end servers, parquet is better for local files, not sure about S3
yeah I tested locally all the formats avaiable for ds.dataset() and parquet is the fastest and more compact
but I wonder if IPC is faster over the network, as I have this script that reads/writes 6 billion records, and when its its executed locally it takes 3 hours,
but when I run it as an AWS Batch and use S3 as the filesystem, it takes 9 hours!
what is your workload when using S3 as fs?
have you looked into S3 select?
my workload involves reading and writing (write 6 billion records, read 5.4 billion)
what is S3 select?
okay nevermind then, s3 select is basically a service for pushing some of your analytics workload to AWS instead of doing it locally, it only supports a very limited dialect of SQL.
Run a specified SQL expression against an object in Amazon S3, and return query results in response.
are you using a single parquet or multiple parquet?
did you use multipart upload?
I"m using the class from ds.dataset() to handle all the reading and writing, in total everything is splitted in 6k files
do you know if there is a better pyarrow format for interacting with S3??
When to use criterion='gini' and when to use criterion='entropy' for DecisionTreeClassifier? I'm getting conflicting results when googling.. some say that Gini is just between 0 and 0.5 and will produce the same results as using entropy (which is between 0 and 1), but Gini is more computationally efficient, so Gini should always be used.. but some state otherwise, and if it is so, then why do the other options even exist?
i don't know actually.
but to me, at the end of the day, it's just transferring data to and from S3 + CPU time used to (de)compress any data, imo just pick the one with best compression rate (provided you don't care about other characteristics of file format, e.g. predicate pushdown possibility of parquet)
i also have no idea what the heck is ds.dataset() 🤔
df.apply(lambda x: full_date_range[x['start_ind']: x['end_ind']],axis=1)
do you happen to know of a way to do this vectorized?