#data-science-and-ml
1 messages · Page 41 of 1
The idea is pretty straight forward. If the discriminator can't tell apart the expert from the novice, then the novice has mimicked the expert.
Interesting... I'll take a look. Thanks!
If you are not trying to do IRL. Are you trying to use a generative model to maybe make the problem a bit easier (e.g. a generative model that reduces dimensionality)? Maybe do rollouts?
im trying to do sentiment analysis of buisness articles. Ive tried to use both textblob and vaderSentiment but neither seem to work very well. Is there any alternatives?
Efficient topic modelling in Python
thanks you ill try these
Could someone recommend a data set? I'm seeking images that contain a single subject on a transparent background
@fleet sapphire Per Rule 6, your invite link has been removed. If you believe this was a mistake, please let staff know!
Our server rules can be found here: https://pythondiscord.com/pages/rules
There's Fashion MNIST, but it's grayscaled
hmm, ok I saw this one on pytorch guide today
Take a look as tensorflow and Pytorch's Datasets pages
They might give you some ideas
i wanna try feeding saliency based segmented data to model, would pre-trained model be fine for that? if so, are there any recommendation of what model to use?
i am using plotly with a scatter plot. How can i prevent the x-axis from showing the gaps between ticks where no values are present? I tried setting the tickvals and ticktext.. but the result is not what i expected..
fig2.update_layout(
xaxis = dict(
tickmode = 'array',
tickvals = dff2.Auftragnummer.sort_values().unique(),
ticktext = dff2.Auftragnummer.sort_values().unique(),
)
)

Is it possible by any chance if anyone can help me with this? https://stackoverflow.com/questions/75108957/assertionerror-the-algorithm-only-supports-class-gym-spaces-box-box-as-acti

Stack Overflow
So basically I tried converting this custom gym environment from https://github.com/Gor-Ren/gym-jsbsim to use farama foundation's gymnasium api. This is my repo whih I am working on: https://github...
I wrote some pytorch code to fit models once and for all. Introducing '𝙩𝙤𝙧𝙘𝙝𝙮', a PyTorch wrapper that preserves all of the functionality and code writing conventions of PyTorch, while adding the convenience of the '𝙢𝙤𝙙𝙚𝙡.𝙛𝙞𝙩()' method directly to the nn.Module class. With 'torchy', you can devote your time to making good models and preprocessing the data, while your training process becomes more efficient. Additional utility functions are also included in nn.Module and in torch.utils.data to make your PyTorch experience even more seamless.
You can find the torchy module on:
GitHub at https://lnkd.in/dDj3vV5r
PyPI at https://lnkd.in/dRn-BgQH
Docs at https://lnkd.in/dmnQHmJd
I hope you find torchy as useful as I do and I would love to hear your feedback.
PS: torchy is also my first python module in production.
When dealing with a dataset where the differences between each input are subtle, should I use a network with more features per layer or should I use more layers?
(I really don't want to make a monster with billions of parameters)
I need a power bi partner
im editing source code from https://github.com/alxschwrz/dalle2_python
ive changed the function open_urls_in_browser to open a new qt window but i dont know how to display the image in it
def open_urls_in_browser(self, image_urls=None):
if image_urls is None:
image_urls = self.image_urls
for url in image_urls:
app = QApplication(sys.argv)
win = QMainWindow()
win.setGeometry(512,512,500,500)
win.setWindowTitle("Dall:E")
label = QLabel()
pixmap = QPixmap(url)
label.setPixmap(pixmap)
win.show()
sys.exit(app.exec())
GitHub
DALLE2 in the command line. Contribute to alxschwrz/dalle2_python development by creating an account on GitHub.
Hello everyone, I have a problem while practicing the fundamentals, why is this not working?? I wrote a name, and a seed=42, Ive tried importing tensorflow and numpy as well, and still didnt work.

I have a global and operational variable
help por fi
hey thanks, I'm working on doing that preprocessing step I missed to normalize the data.
The error message is pointing to the object not_shuffled
It's not a variable you've created anywhere, so python couldn't find it. Ensure you declared the variable / there's no typo in the variable name.
@odd meteor okay will check, thanks
train_dataloader = DataLoader(training_data, batch_size=64, shuffle=True)
for epoch in range(10):
for images, masks in train_dataloader:
is it correct to say that images is a batch of 64 single images (which my get returns a single image and mask) that are then passed to the model? how is this different from one image at a time?
and is it safe to say if all my images are the same size, and one "batch" or iteration of the inner loop takes for example 10 seconds, than the total time I must wait for the model to finish running is total number of (images / 64) * the time it took for one batch
or am I misunderstanding entirely
are you using a CPU or a GPU?
In either case, the amount of math to be done per training instance is the same no matter what batch size you're doing. but a larger batch size means that there are fewer iterations of the for images, masks in train_dataloader loop and that more math is being done per pytorch operation. and letting pytorch do more work, and doing less pure Python work, is faster. And if you're using a GPU, the pytorch work is also being done in parallel.
but you also keep in mind how many training instances you want to account for before you adjust the weights.
thanks, that clears some up. right now I noticed it's only using my cpu. I'll have to figure that out soon so I can use gpu. doesn't seem to be detected.
Did you define your device?
what GPU do you have?
device = "cuda" if is_available() else "cpu"
Oh, ok
Usually, the tensors aren't initialized in your defined device, so you have to use .to(device)
if you do nvidia-smi at the terminal, you can see what your cuda version is. you might have the wrong pytorch wheel for your cuda version.
also device needs to be an instance of torch.device, not a string.
I think I should determine if my OS is utilizing my gpu to begin with since I reformatted
I'm not confident it is
oh hmm
@feral hedge did you do nvidia-smi at the terminal? what happened?
i don't have it so I'm just installing the drivers now.
just had a hellish time trying to enable nvidia drivers. saving it for tomorrow. will update if you're around
650k to go but will 78ish be the highest it'll get?

oh it's going higher
Hi~~
I'm editting Awesome ComputerVision.
Current content created includes Image Classification, Semantic Sementation, Object Detection, Fine grained Visual Categorization.
Unlike the existing Awesome, Kaggle and colab running code were added.
Thanks for lot of attention...!
https://github.com/kalelpark/Awesome-ComputerVision
GitHub
Awesome-ComputerVision. Contribute to kalelpark/Awesome-ComputerVision development by creating an account on GitHub.
how to get saliency based segmented image of dataset? i see most of the literature on "detecting saliency" but not segmenting it
One popular method is to use a saliency detection model, such as a deep neural network, to predict the saliency map of an image.
Once the saliency map is obtained, it can be thresholded to create a binary mask that segments the salient regions from the background.
actually the current model is transformer for video action recognition
Does that mean incorporating saliency based segmentation mean i will feed human with black backgroud to transformer?
any good toturial for polars yet?
i think taking datacamp/dataquest/<insert favorite vendor> and duplicating the questions using polars is my next step.
looks like you're promoting your own channel?
if you're going to drop links, at least say why they're interesting. no one is just going to click random links.
True . I can explain it
YOLOv8 is the newest version of the You only look once (YOLO) family . YOLO is a state-of-the-art, real-time object detection system and is used object detection, image classification, and instance segmentation tasks.
Here is a video i made about it
YOLO v8
https://youtu.be/jMvLCZBXbtc

YOLOv8 is the newest version of the You only look once (YOLO) family . YOLO is a state-of-the-art, real-time object detection system and is used object detection, image classification, and instance segmentation tasks.
@serene scaffold check it out now
Good afternoon everyone, I'm new to the channel. I'm researching time series for an academic project. I have to create a model. I didn't get to work with it, if anyone can give me a direction to start I'd appreciate it.
Hi friends, I need a little help on how to build my classification model in TensorFlow using Python.
I have 7 classes and I want to identify each individual with one of them, but if it doesn't belong to any class mark it as Unidentified.
I would be very grateful 😭

Data science has three parts
Data engineering
Data analysis
Machine learning
Most companies want you to do all three
So it would make sense to start from data engineering and analysis
But if you want to go straight to ML
There are good courses on YouTube and...
You could see this as having 8 classes, 7 different kind of cats and "other"
As long as the data is balanced that should make it easier
Could also have a model to see if it is a cat, and then one to differentiate between different types of cats
Any good introduction to numpy?
I see
Ok
I can't even understand this , to me this looks like Schrodinger's cat
You can also check out edx and Coursera
Some big tech have courses there
Does anybody use alpa and jax?
ChatGPT (Generative Pre-trained Transformer)[1] is a chatbot launched by OpenAI in November 2022. It is built on top of OpenAI's GPT-3 family of large language models, and is fine-tuned (an approach to transfer learning[2]) with both supervised and reinforcement learning techniques. I made a video on some cool Facts about ChatGPT https://youtu.be/AiwjiSrMg0c

ChatGPT enables users to submit questions using a natural language interface and receive responses written in conversational, if somewhat stilted, language.
The bot will respond based on the context of your conversation, considering your previous queries and answers. Its results come from analysing vast amounts of data collected from the World ...
I installed jax and jaxlib from alpa rep and jax functions like jax.random.PRNGKey(0) throw an error
?
wow
ChatGPT is OP
SOP?
It's pretty awesome
I want one like it but BUT BUT he answer everything
and Don't say its unethcal or something
You can use ChatGPT iself
I asked him how to hack he told me fuck off
Don't use it for that. It will report you and ban you
sad
@lapis sequoia I'm going to have to ask you to stop positing your own videos.
Three in four hours is pretty excessive.
can i do saliency detection without finetuning?
Can you explain what fine tuning is?
making a pretrain model learn to do similar task on similar dataset different to one is was trained on
actually i ask because i dont have ground truth for my video dataset
i wanna have a fixed backbone for saliency based segmentation
Are there any?


what does "Instead, open Anaconda3 with the Windows Start menu and select Anaconda(64-bit)" mean?
what am i supposed to do
@heavy basin adding a directory to PATH means that Windows will look in that directory for executables to run commands
Like, if you run a python command, the operating system needs to find an executable program named python that can do the command.
It says that it's not recommended. (And I don't recommend anaconda.)
idk im trying to do a project with pandas and it recommended me to use anaconda
Just use pip install pandas in the command prompt
It'll install pandas to your python directory and won't fulfill your computer with garbage
is anaconda bad
I think it's antiquated and that the data science community needs to let go of it.
k
Yes. It makes things way more complicated than it should be, and might also mess up with your IDLE because it'll install another Python
i will uninstall
> using idle
ty
VS Code fan here 
hello everyone, any suggestions on methods to deal with imbalanced data..?
i personally use conda since it handles cuda very well but I'm probably gonna switch over to a more classic env manager at some point
do i ask pandas questions here
yes
i want to create a dataframe and this is the txt file for each person's grade percentage, grade letter, and student ID

is the student ID on a separate line, or is it just wrapping?
separate line
that's really annoying
yeah
if you can read that file in as a string, and flatten each data point into one line, you can use pd.read_table
who gave you this data?

oh okay
actually i can ask my friend to send me the text of that
that's data cleaning for you, I guess.
the other thing you could use is a regular expression.
you could also replace every other \n with a
wait this is smart
ill try it ty
hello everyone Im trying to solve this fundamental problem, I expected this to work in Google colab

probably an issue with you not running the cells in order
please don't do screenshots of text. you can copy and paste it into the chat.
okay
if not_shuffled was defined in another cell that you didn't run yet then it wouldn't be defined
common mistake with notebooks
Okay I see... Thank you
gonna try and solve it now
any way to do this inplace?
all the tutorials ive seen they create a list, do the .replace() and then write it back
no. strings are immutable, so in-place operations are impossible.
ok
@serene scaffold can you help me i kinda have no clue what im doing

i fixed the file and did pd.read_csv('newgrades.txt', delimiter = ' ') and this is what the dataframe looks like rn
try pd.read_csv('newgrades.txt', delimiter='\s+', header=None, names=['percent', 'grade', 'student_id'])
a problem you're having is that it's interpreting the first row as the header
beyond that, what do you want to do with the data, now that you have it?
i want to sort the dataframe by the percent column
so once you do df = pd.read_csv('newgrades.txt', delimiter='\s+', header=None, names=['percent', 'grade', 'student_id']), you can do df.sort_values('percent')
wow! tysm
now
nvm
@serene scaffold how do i get the student IDs to be the row names
pd.read_csv('newgrades.txt', delimiter='\s+', header=None, names=['percent', 'grade', 'student_id']).set_index('student_ids')
How does a Conv2D works when the number of feature maps is reduced?
I know that, when I have a grayscaled image and I want to generate 64 feature maps, then my Conv layer will make 64 convolutions using 64 different kernels, right?
But what if I have 64 feature maps and I want to achieve a grayscaled image?
I just noticed that ResNet and Inception are way deeper than VGG, yet they have few parameters, so I got this curiousity...
I was determined to figure out how to make this whole table without any loops or using .apply

that's crazy
every element is the result of calculations several dataframes deep. and I couldn't afford for there to be any mistakes. it probably took 50+ hours.
(but only because I didn't know pandas prior to that.)
so impressive
my goal isn't to talk myself up, mind you. just that I learned-by-doing in a high-stakes setting.
whenever you want to do something with pandas, try to find a way to do it that doesn't involve loops, or apply.
and eventually you'll learn it pretty well.
ok
bumping your question. does the fact that the image is greyscaled here matter, beyond there not being color channels (thus reducing the dimensionality of the image)?
Nah, it doesn't matter, it's just an example
Just to illustrate that from 1 channel to 64 channels, I'd have to make 64 convolutions(I guess)
Then, how is the process done when I have 64 channels and I want just 1 as output?
hmm? 64 channels?
I even have an idea of trying to combine a Conv to generate multiple images and then use a separate layer and a softmax to decide which image will be my output
But depending on how the Conv layer works, I suppose this would be redundant
I'm clearly out of my lane. going back to playing with words.
Don't you use convs when working with words, too?
At least the original idea of Transformer used Convs, too. I guess Conv2D with kernels 1x1
speaking/writing are sequences of symbols, so most neural NLP techniques involve RNNs, not CNNs.
RNNs are lame. I always get vanishing gradients with them 
That's why I love attention layers
an annoying bit here with tf is that it doesn't explicitly say what it does across channels when you do a 2d conv.
every 2d conv layer takes k matrices (k channels) of size m x n and spits out as many matrices as filters you specify, with sizes that depend on m,n and the filter sizes. the output is of size l x m x n, with l channels = l filters. not quite a 2d conv, but a sum or average of 2d convs. stack overflow says its just a sum, but it's the same thing modulo a scaling factor
this is what"s done if you use only 1 filter
as mentioned above, num filters = new num of channels
Does channels mean something different in this case than the RGB "layers"?
past the 1st layer yes, since they no longer represent color after averaging
but also nothimg stops you from doing a 2d conv on data that isnt an age, where there is no color to speak of in the first place
i find calling it "channels" is misleading and hides the generality of the operation, but the name stuck due to people wanting to make networks accessible to people that dont wanna deal with the math
like calling it the "time axis" in rnns, space and channels in cnns, etc
Hello, idk if that question fits in this channel (though it's about astrophysics), but does anyone know how to actualize the color of points in a 3D scatterplot in an animation please ? I'm having a hard time understanding why it doesn't work when i update the points of the scatterplot, even though it works fine if i replot the scatterplot each frame (which takes a lot more time and saving the animation keep all the previous plots, which isn't what i'm looking for)
For instance, i'm currently making an HR diagram (Luminosity VS Temperature) where the points change in color depending on the value of the temperature.
It looks like this if i replot every frame :
def updatefig_full(*args):
global j
if (j<len(logTe[:,0])-1):
j += 1
else:
j=0
index = np.where(logTe[j]!=0)[0]
if (j>0 and np.size(index)!=0):
Te_no_zeros = Te[j,index]
L_no_zeros=L[j,index]
size_no_zeros=size[j,index]
scatplot = ax.scatter(Te_no_zeros, L_no_zeros, s=size_no_zeros,
c=Te_no_zeros,edgecolor='k',linewidth=.5,cmap='rainbow_r')
else:
scatplot = ax.scatter(Te[j], L[j], s=size[j],c=Te[j],edgecolor='k',linewidth=.5,cmap='rainbow_r')
time_text.set_text('t = %.3f Myr'%round((10**Age[j])*1e-6,3))
return scatplot,time_text
As you can see the c parameter needs the temperature array.
If i do it by updating the parameters of each point, i'll use this instead to generate the RGBA array (which, if i understand correctly, is automatically done by the ax.scatter function)
colormap = cm.rainbow_r
normalize = mcolors.Normalize(vmin=np.min(Te[j]), vmax=np.max(Te[j]))
s_map = cm.ScalarMappable(norm=normalize, cmap=colormap)
cmap=s_map.to_rgba(Te[j])
scatplot.set_sizes(size[j])
scatplot.set_facecolor(cmap)
with j the frame.
Could anyone explain to me what's wrong with that last portion please ?
The color change should be like this, but the other case keeps the color of each point (as if the temperature was the one at the first frame)
what if you call scatplot.draw() after updating the oarams
Right in the updating function ?
I think i should show the function i'm using for the 2nd case :
def updatefig(*args):
global j
if (j<len(logTe[:,0])-1):
j += 1
else:
j=0
index = np.where(logTe[j]!=0)[0]
if (j>0 and np.size(index)!=0):
Te_no_zeros = Te[j,index]
L_no_zeros=L[j,index]
size_no_zeros=size[j,index]
pos = np.array([[Te_no_zeros[i],L_no_zeros[i]] for i in range(len(Te_no_zeros))])
normalize = mcolors.Normalize(vmin=np.min(Te_no_zeros), vmax=np.max(Te_no_zeros))
s_map = cm.ScalarMappable(norm=normalize, cmap=colormap)
cmap=s_map.to_rgba(L_no_zeros)
scatplot.set_sizes(size_no_zeros)
scatplot.set_facecolor(cmap)
else:
pos = np.array([[Te[j,i],L_no_zeros[j,i]] for i in range(len(Te[j,i]))])
normalize = mcolors.Normalize(vmin=np.min(Te[j]), vmax=np.max(Te[j]))
s_map = cm.ScalarMappable(norm=normalize, cmap='rainbow_r')
cmap=s_map.to_rgba(Te[j])
scatplot.set_sizes(size[j])
scatplot.set_facecolor(cmap)
scatplot.set_offsets(pos)
scatplot.draw() #Scatplot Draw here
time_text.set_text('t = %.3f Myr \n n = %i'%(round((10**Age[j])*1e-6,3),j))
return scatplot,time_text
This returns me an error :
TypeError: draw_wrapper() missing 1 required positional argument: 'renderer'
hmm maybe i'm thinking of fig.canvas.draw() instead
do you have the figure stored in a variable?
Still no change in color
I do
fig,ax=plt.subplots()
fig.suptitle('Hertzsprung-Russel Diagram')
and how about
renderer = fig.canvas.renderer
scatplot.draw(renderer)
No change again
For some reason the program doesn't want to renormalize with each frame
and you're calling draw every frame? i would maybe try animation, but otherwise i'm not sure what the matter is
I am
And i am animating
if fig_update: #Generate the figure each frame
anim = animation.FuncAnimation(fig, updatefig_full,frames = len(Te[:,0]),
interval = 10, blit=True)
else: #Actualize the parameters of the points each frame
anim = animation.FuncAnimation(fig, updatefig,frames = len(Te[:,0]),
interval = 10, blit=True)
Writer = animation.writers['ffmpeg']
writer = Writer(fps=30, bitrate=1800)
@wooden sail Found the issue
I had to use scatplot.set_array(Te[j]) instead of scatplot.set_facecolor(Te[j])
As it seems facecolor doesn't change the color of the points
Anyway thanks for your help 😳
oof, aight
Hi guys
I am Mohit Narwani, A senior data analyst
I worked at tableau(sales force)
we generally used c++ at tableau but libraries like seaborn, matplotlib and plotly are very good for visualization. So I have decided to make a whatsapp group where i can add plots based on user's demand and also they can also help
https
@shell sequoia We block WhatsApp links for a reason. Please get permission from the server admins before advertising or promoting within the server. Thanks.
okay
You can contact the admins by DMing @sonic vapor
no i am not here to advertise, I am just here to make data vis more strong. I am not going to earn any money from it
if someone is interested can dm e
me

hmm?
Isn't a convolution, like... You pass a kernel(mxn array) through your input, column by column, row by row, applying element-wise multiplications which are summed to get your final feature map pixel?
So, I can imagine that, if your input is an array 1xHeightxWidth, and you want 64 feature maps, you'll just create 64 kernels and apply 64 convolutions, one for each kernel.
But what if you have 64 feature maps and you want as output a single array 1xHeightxWidth, how is this done?
as i said, you add them up
note that this is not the only way of doing it, you're asking for an operation that can be defined in more than one way
tensorflow adds them up
So...it's a single convolution through each feature map, using the same kernel, and in the end tensorflow adds all the 64 outputs together, element-wise?
yes
no idea
It's just that, in my GANs, it seems that Conv2D layers that output fewer channels than the input has much, much more parameters than Conv2D layers that output the same number of channels, or even more channels...
aha, in pytorch there's an extra "groups" parameter with which you control this
it could also be that tf makes different kernels per channel and adds up those results
i do know it just adds up the results in the end. idk about the per channel behavior
Uh... I couldn't understand a single word in that "groups" parameter
you should be able to test it out
well, all of the math there is pretty clear tbh. the pytorch documentation is a lot better
but as you noticed, you need to understand the math to read it 😛
tf makes decisions for you to make it easier to use
Tensorflow seems way more complicated, though
all inputs are convolved to all outputs.
What does it mean?
Each convolution through the input = each output, directly?

each line there is a convolution
(the question still remains whether converging lines are the same kernel in tf)
Regular convolution...makes a convolution through the Red channels to determine the output Blue channels?

I could understand this for YUV channels, but...RGB?
the names there R' don't actually mean color, as i said to stelercus
Oh...
after the convolution layer, the outputs are no longer colors
even if you specify you want 3 output channels
that's because you then go out of your way to put the channels into the RGB channels of an image
that's your doing, not the network's
from the network's perspective, none of the inputs nor outputs have any interpretation other than being in vector spaces or manifolds
Still confused on why my Conv2d with 400 input channels with 3 output channels has so much more parameters than the ones with 3 inputs and 400 outputs
what sizes do they have
any good introduction to numpy?

most important would be the one with the highest GINI, no?
ohh so is it most impt: meanfun , least impt: sp.ent
something like that
idk, i haven't worked with Gini index before, thats just from what i heard
Hello, I am trying to train myself to perform text clustering with gensim.Word2Vec and KMeans.
The vectorization and creation of clusters are both happening as expected. What I don't understand is that my dataframe has 900 rows, but my model generates 1700 vectors.
I thought it would generate a vector for each row, and as a result it is impossible to add them to my dataframe since the length is not the same.
Some people tell me not to worry and create the clusters from these vectors even if the length is different, but I would like to understand and even better have everything "organized" in my dataframe.
Any ideas ?
self.transconv1 = nn.ConvTranspose2d(100, 1000, 4, 1, 0, bias=False)
self.transconv2 = nn.ConvTranspose2d(1000, 800, 4, 2, 1, bias=False)
self.transconv3 = nn.ConvTranspose2d(800, 600, 4, 2, 1, bias=False)
self.transconv4 = nn.ConvTranspose2d(600, 400, 4, 2, 1, bias=False)
self.transconv5 = nn.ConvTranspose2d(400, 200, 4, 2, 1, bias=False)
self.transconv6 = nn.ConvTranspose2d(200, 3, 3, 1, 1, bias=False)
Just a DCGAN with many, many feature maps
According to torchsummary:
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
ConvTranspose2d-1 [-1, 1000, 4, 4] 1,600,000
ConvTranspose2d-2 [-1, 800, 8, 8] 12,800,000
PReLU-3 [-1, 800, 8, 8] 1
ConvTranspose2d-4 [-1, 600, 16, 16] 7,680,000
PReLU-5 [-1, 600, 16, 16] 1
ConvTranspose2d-6 [-1, 400, 32, 32] 3,840,000
PReLU-7 [-1, 400, 32, 32] 1
ConvTranspose2d-8 [-1, 200, 64, 64] 1,280,000
PReLU-9 [-1, 200, 64, 64] 1
ConvTranspose2d-10 [-1, 3, 64, 64] 5,400
Tanh-11 [-1, 3, 64, 64] 0
================================================================
Total params: 27,205,404
Trainable params: 27,205,404
idk what convtranspose is
Transposed Convolution
what's that supposed to mean
it's certainly not a deconvolution
https://pytorch.org/docs/stable/generated/torch.nn.ConvTranspose2d.html#torch.nn.ConvTranspose2d
This module can be seen as the gradient of Conv2d with respect to its input. It is also known as a fractionally-strided convolution or a deconvolution (although it is not an actual deconvolution operation as it does not compute a true inverse of convolution).
In a nutshell: a Convolution, but bigger

However, while Convs with 2 strides usually make you get feature maps with half the height and width of your input, the Transposed Convolution with 2 strides make you double the height and width
idk, after reading about it, i'd just call it upsampling, but ok
and which layers are you troubled by
I'm troubled by the fact that my first layer, which converts a random noise with sizes (Batch, 100, 1, 1) to (Batch, 1000, 4, 4) Has more than 10x more parameters than the second layer, which simply takes this (Batch, 1000, 4, 4) and converts to (Batch, 800, 8, 8)
I mean, ok, there's the upsampling, but...wow... 10x more parameters?
If I were to use a ConvBlock where the number of channels is all 1000, I could probably pile like 8 Conv layers until I reach 12 million parameters
so i would just recall the image i posted earlier
this one
and we're working with the case on the left, with groups = 1
that means every single input channel is involved in generating an output channel, and one convolution kernel is applied in doing each of these operations
that means in the first layer you will have 100*1000 filters of size 16
in the next one, you will have 800*1000 filters of size 16
yep
So... I just have to use kernels with size 1x1
Meh... I can't simply upsample because GAN things.
But I found Conv 1x1 a bit lame...I mean...you multiply element-wise a single number by your input array...wouldn't it be better if you just defined an array of weights and then multiplied element-wise your input?
as i said, a conv 1x1 is the same as multiplying the whole input by a scalar lol
There are some models that use that, though, like Self-Attention GAN
probably because the API has no other built-in function for scalar multiplication
but as you say, that's what attention does
take some inputs, scale each of them, and add them up
that's the same as pytorch and tf decide to do by default when you do convolutions
Fun fact: the model was made in tensorflow
this is the type of thing where using built-in layers obscures what you're doing. it's no longer a convolution at that point. you'd write clearer code if you wrote the math more directly
this whole "let's make AI accessible to everyone" has its downsides
They might have made some fancy things that just complicated things...seems like most research papers do this.
Unless the chinese guys...they're op.
it's not "fancy things", it's "exploiting the API to do what we actually want it to do"
Doubt
def _get_d_real_loss_KL(discriminator_on_data_logits):
loss = tf.nn.softplus(-discriminator_on_data_logits)
return tf.reduce_mean(loss)
this is where i'd just say using jax is better. but that's neither here nor there. regarding the issues and questions you usually ask, i'd suggest to review the maths a bit more
hmm?
Just one of the functions they made for SAGAN
Which is...simply applying the loss from tensorflow
that's like sum(exp(-inputs) + 1)
i would much rather read it that way
but they were limited by the api
They're literally using the API...
that's exactly what i'm saying 👁️
it looks dumb because they're using the API
it is much easier and simpler than it looks there
but they have to write it in a specific way that looks dumb (e.g. 1x1 2D convolution kernel) because the API has a fixed set of tools
But... tensorflow is such a low-level API, they surely would be able to create a customized operation
they COULD. but they aren't doing it
That's why I don't read the official codes on GitHub anymore
Now I'm slightly curious, though...what if, instead of a Conv2D, I simply created an array with graphs with the same height and width as my input and simply multiplied element-wise this array of weights by each channel to get an output with the same number of channels?
Would it be at least as efficient as a Conv2D that returns an output with the same sizes as the input? Maybe even in a less expensive, faster, way?
yes, but you lose the effect of having neighboring pixels affect each other, or being able to detect something regardless of where it is located in an image
which is the whole point of using convolutions
i.e. the network no longer enforces a "spatial invariance prior"
Not even through backpropagation?
indeed
Sad. I'm getting annoyed by how much time it takes to make a conv that returns many channels
At least this appear to be a pattern in GANs...starting with a Conv that outputs like, 1024 channels, then the next layers filter those channels until you get 3
SRGAN uses a ResNet architecture, but I'm afraid fixed channels, height and width aren't effective for generating images, just for SuperResolution
Or I did something wrong, which is quite likely
In the Asynchronous variant for n-step dqn I notice that they use theta instead of theta' when Initializing the network gradients. Does this mean they use one shared network gradient vector? Or is it separate for each thread?

Which part are you referring to?
Initialize network gradients dtheta <-- 0
I suppose that, if theta' is a target parameter, then it's the parameter the network must achieve
So there's no gradients to be initialized for theta'
theta' is the thread-specific parameters
Oh, ok, there's theta' and theta-
the way I understand it the threads don't necessarily update the main network at the same time hence why it's called asynchronous
Correct
it just says "Perform asynchronous update of theta using dtheta" but that's really vague imo
I have no idea what that means
so do we like sum up the gradients then average them?
From what I'm seeing, theta' is more or less a variable to synchronize the networks, so theta' gradients is actually theta gradients
well the way it works is you have multiple threads running at the same time exploring different parts of the state space right
Theta is the parameters of a specific thread, those parameters will be optimized.
After finishing the episode/state/idk, those parameters are synchronized to be theta'.
I suppose that, being an Asynchronous actor-learner, the better thread will provide the parameters for all threads
my understanding was that different threads could encounter an episode termination at different times
That's correct. And this is why their parameters must be synchronized
i'm confused on the Asynchronous update part though
If your thread A finishes your episode after 10 minutes, and thread B finishes only after 15 minutes, then thread A will be kept "dormant" until thread B finishes the episode
so it's accumulating gradients... does it average them?
yeah
No, it sums all gradients and applies them during the optimization step
But this isn't exclusive to asynchronous algorithms, most RL algorithms do that
that's interesting so then after summing all the gradients does it multiply it by the learning rate after?
Yes. In Stochastic Gradient Descent, yes.
If you use Adam, then it does its mathmagics there when applying gradients
well the optimizer part is even more confusing because when I looked at how they implemented SGD with momentum into the algorithm
they said you keep separate gradient and momentum vectors for each thread
let me just find the section
The optimization occurs separately, probably

The optimization occurs separately, indeed
that is confusing
The optimization doesn't have to occur after you finish your episode
It can happen after certain number of steps, after your agent took certain number of actions
so why does each thread have a separate momentum and gradient vector
Because you're actually training different networks at once to get the best parameters faster
oh I see
I sort of understand it
so wait let's say for simplicity we perform an update on the main network after the episode terminates
so thread A performs an update on the main network after 10 minutes right
You're testing different networks in different configurations(different momentum, different learning rate).
After you had enough training(aka: the episode has ended), you see which one performed better, than applies that one parameters to all of them. Then restart training
oh we're using different configurations for each thread?
No, thread A finishes episode after 10 minutes. If thread B is still running its episodes, thread A will have to wait.
Yes, the image you sent say that they try different momentum vectors
And there's different gradients
why does thread A have to wait though?
Because you don't know if thread B will actually perform better than A
If you update thread B based on A, you might sabotage thread B and lose performance
Thread B might even get confused, as it might have reached a state that thread A didn't manage to reach
but thread A is updating the global network not thread B?
all threads are updating the global network
If thread A finished its episodes, it's not updating anymore
Think like this: you're playing a match of...idk... Valorant.
This match can have a duration of 10 minutes, 15 minutes or even 1 hour.
Your friend is playing a match of Valorant, too, but you both want to play together.
So, if her match ends after 10 minutes, but yours is still running, he'll have to wait.
If thread A finishes its episodes after 10 minutes, it finished its match, while B is still playing its match, so A have to wait until B finishes so they can synchronize(update parameters)
but looking at the psuedocode it seems like after performing the asynchronous update it clears the gradients, synchronizes the thread-specific parameters with the global network parameters then sets t_start to t and gets state s_t
it doesn't seem to wait for the other thread
there is thread-locking though I think although I don't really understand it
it says it performs an asynchronous update meaning 2 updates cannot happen at the same time right?
from what I understand thread-locking might be used to prevent 2 threads updating the global network at the same time
Hm... "Asynchronous update" might refer to thread being updated
It refers to theta, not theta'
right and theta refers to the global shared parameter vector
Oh, sure
It might be possible, then, that they actually try updates in real time
But it doesn't seem to make sense to me, though.
Asynchronous actors usually are for getting the best parameters, but you can't know which one is the best if one of them is still running and getting optimized
I was confused on the thread-locking part because the only place where it sorta made sense to me was in the update part to prevent 2 threads updating the global shared parameter vector at the same time
I think the point of asynchronous actors were for speeding up training not getting the best parameters
wait
It might be just because of that...avoid 2 updates at once.
And if the threads indeed update the main network in real time, then there might be a way to filter which one is better
unless you're referring to the same thing?
wait you're saying parameters and not hyperparameters right
ok i'm just getting confused
It's more or less the same thing
Parameters are the weights
(I guess...Q-Learning models tend to be crazy)
lol
but then it says in the sgd with momentum implementation it uses no thread-locking
which is another thing i'm confused about
There's an SGD optimizer for each thread, and there's an SGD optimizer for the global net
The global one has no locks, as it seems
that is confusing
but if each thread has a separate SGD update why does it use theta?
If I understood it, then it's more or less
see it defined theta as "the parameter vector that is shared across all threads"
The SGD for each thread is to apply the gradients in that thread and optimize the thread.
The global SGD is simply to apply the parameters you got from the threads.
Shared across all threads upon initialization and upon synchronizing, not every moment
right so this is the same thing as the global network right?
Yes
It seems you apply the parameters to the global network, and, upon synchronizing threads, you apply the global parameters to every thread
so each thread is accumulating its own gradients then independently applies the SGD momentum update
Yep
I see where I'm getting confused now
Each thread is optimized independently, they're autonomous. The synchronization is the only intervention they suffer
it is possible for each thread to be using a different "version" of the global network correct?
No. Synchronization doesn't allow that
Unless the synchronization occurs while a thread didn't finish its episodes, which I find unlikely
it says to repeat until terminal state or t - t_start == t_max

this seems to imply that it could be possible
That is for the thread
I guess the global thing would be the part if T mod I target == 0 then
no that's for updating the global target network
This part you remarked is simply a normal step
Select action, check consequences, get reward, get grads, update
so do they synchronize at the same time? that doesn't sound like it
This happens within a single thread
Each thread will perform the loop Get state --> get action ---> get new state ---> get reward ---> get grads ---> update if condition
right
I am confused now
I'm pretty sure synchronization can happen while another thread is still running an episode
Well, it normally doesn't. But check the paper, perhaps they say something about that.
Synchronization while a thread is running an episode can be troublesome. You can't know if that thread will perform better than the others and that thread will change its parameters so abruptly that it can get unstable
And Reinforcement Learning is already remarked by unstability
this is strange

so in this algorithm for one-step dqn it accumulates the gradients with respect to the global shared parameters
but in the one for n-step it accumulates gradients w.r.t the thread-specific parameters
The thread specific parameters are used as a basis to update the global shared parameters
As I said, probably the best thread gives origin to the global parameters
It's in the pseudocode
d0 < ---- d0 + ?(R-Q(s,a;0')²/?0''
I suppose that ?(R-Q(s,a;0')²/?0' would be the d0'
But I'm not so sure, now
As I said, Q-Learning algorithms tend to be crazy
That's why I prefer policy gradients and actor-critic
it's adding gradients to d0 which are calculated w.r.t the thread-specific parameters
but then at the top of the repeat until T > T_max loop it has clear gradients dtheta <-- 0
so I'm assuming that if the gradients were cleared while another thread was accumulating gradients that wouldn't be good
I am confused
so then this goes back to my original question is d_theta shared or for each thread
the section where they implement SGD with momentum in an asynchronous setting implies that it was a shared vector
if it's global then there is no way the gradients should be cleared while another thread is accumulating gradients
then is it like you said it halts the thread until the other thread is done with the episode?
but that didn't make sense to me because it didn't mention that in the psuedocode
any good introduction to numpy?
There's this introduction to numpy and the rest of the data science stack: https://colab.research.google.com/github/yandexdataschool/Practical_RL/blob/coursera/week1_intro/primer/recap_ml.ipynb
(it's part of this course, but the rest of it is on RL: https://github.com/yandexdataschool/Practical_RL)
thank you
I can't install openai I keep getting something wrong
if you need help, be sure to say what you did, and how you know that it's wrong.
Hi everyone, I'm on 35% of a DataScience career path, looking to find ppl to share ideas and some code reviews too, greetings!
so guys, for few days im in middle of trying to create unsupervised training algorithm
rn im stuck on creating network itself. I wanted to have rather simple inputs and outpus but it had issue with shape of tensor, so i checked it and it outputed "torch.Size([3, 81269])"
but this code is a little overkill, right? I belive inputs shouldnt be that big
def __init__(self):
super(Transformer, self).__init__()
self.fc1 = nn.Linear(81269, 4).float()
self.fc2 = nn.Linear(4, 3).float()
self.fc3 = nn.Linear(3, 1).float()```what u mean by 35% 🗿, how can u be so precise
for a Codecademy certification I mean
Which tensor has shape 3, 81269?
The inputs?
numpy array i created with bunch of ebooks
Also, you don't really need to use .float() in the linear layers. Pytorch initializes all floats in float32 by default
If it's a numpy array, then you need to convert it to a torch tensor with torch.from_numpy(). Then things should run fine.
(Though I suppose that, considering how much time passed since you posted that, you might've figured that out already)
I don't know if it's an overkill, actually. You probably would have to check through trial and error
you are right, i dont have this problem anymore but well
i have bunch of others
can someone help me with pandas please
please always ask your actual question right away, without asking for a commitment, so that someone who knows the answer can start answering right away, with no follow-up questions.
to show the dataframe, do print(df.head().to_dict('list'))
i have a dataframe df (sorted by percentage) that looks like this

i also have gender_grp = df.groupby('gender')

i tried sorting the thing by sorting the original dataframe and then doing sort=false
but that didnt fix the issue where B+ is under B
i think a possible solution would to be sort with percentages, but not show in the table. but i'm unsure how to do that
so you just want this, but where the letter index is sorted by grade order?
yeah
I might be able to answer in a bit.
👍
though I need to know if the expression in that screenshot is a DataFrame or a Series. if you had given the code as text, I could tell you how to figure that you.
I think i am trying to chew more than i am able to.
so this is my script, very crude attempt at unsupervies learning```import numpy as np
import torch
import torch.nn as nn
from numpy.core._simd import targets
from torch import Tensor
from torch.nn import MSELoss
load the input data
input_data = np.load("train_data.npy")
convert the input data to a torch tensor
inputs: Tensor = torch.from_numpy(input_data)
define the model
class Transformer(nn.Module):
def init(self):
super(Transformer, self).init()
self.fc1 = nn.Linear(81269, 20).float()
self.fc2 = nn.Linear(20, 5).float()
self.fc3 = nn.Linear(5, 1).float()
def forward(self, x):
x = self.fc1(x)
x = torch.relu(x)
x = self.fc2(x)
x = torch.relu(x)
x = self.fc3(x)
return x
model = Transformer()
define the loss function
criterion: MSELoss = nn.MSELoss()
define the optimizer
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
train the model
for epoch in range(100):
# Forward pass
outputs = model(inputs)
loss = criterion(outputs, targets)
# Backward and optimize
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (epoch + 1) % 10 == 0:
print('Epoch [{}/{}], Loss: {:.4f}'.format(epoch + 1, 100, loss.item()))
torch.save(model.state_dict(), 'model_checkpoint.pth')
gender letter
boy A 0.095238
B 0.190476
B+ 0.142857
B- 0.142857
C 0.095238
C+ 0.095238
C- 0.190476
D/I 0.047619
girl A 0.090909
A- 0.272727
B 0.181818
B- 0.181818
C 0.181818
C+ 0.090909```do type(gender_grp.value_counts(['letter'], normalize = True, sort = False))
series
and i get this errors "```
Traceback (most recent call last):
File "C:\Users\Reny\PycharmProjects\crossoverwriter\trener.py", line 43, in <module>
outputs = model(inputs)
File "C:\Users\Reny\PycharmProjects\crossoverwriter\venv\lib\site-packages\torch\nn\modules\module.py", line 1194, in _call_impl
return forward_call(*input, **kwargs)
File "C:\Users\Reny\PycharmProjects\crossoverwriter\trener.py", line 24, in forward
x = self.fc1(x)
File "C:\Users\Reny\PycharmProjects\crossoverwriter\venv\lib\site-packages\torch\nn\modules\module.py", line 1194, in _call_impl
return forward_call(*input, **kwargs)
File "C:\Users\Reny\PycharmProjects\crossoverwriter\venv\lib\site-packages\torch\nn\modules\linear.py", line 114, in forward
return F.linear(input, self.weight, self.bias)
RuntimeError: mat1 and mat2 must have the same dtype
i belive line 43 is about input trying to get 2d tensor and reciving 3d tensor, but when i tried to convert my input data into 2d on it was saying "tulpe out of range" so it is 2dThe error says it's a dtype problem, so maybe your layer is dealing with float32 type and your input is in float64
anyone familiar with polars can explain to me what Expressions means?
@heavy basin as soon as df is created, before you make gender_grp, do this:
df['grades'] = df['grades'].astype(pd.CategoricalDtype('A+ A A- B+ B B- C+ C C- D+ D/I'.split(), ordered=True))
Pytorch uses by default float32, but I guess numpy uses float64 by default
@drifting wagon
So converting from numpy directly to pytorch can cause those errors
At least I know that when I convert a list of indices(int64) from numpy to Pytorch I get those errors
holy sh*t you are my savior
thank you 🙏
ive spent so many hours today trying to like add an invisible character with a unicide between + and - 😭
how come u needed to know if it was a series or not
what is a standard deviation?
Wikipedia Search Results
Standard deviation
statistics, the standard deviation is a measure of the amount of variation or dispersion of a set of values. A low standard deviation indicates that the
Geometric standard deviation
preferred to the more usual standard deviation. Note that unlike the usual arithmetic standard deviation, the geometric standard deviation is a multiplicative
Page 1/5
·
whats a bulldog request
There's a geometric version?
all these "what is x" questions are really better answered by Google.
i managed to train it for the 1st time, thanks
i had some code for supervised learning which caused problems
@serene scaffold do you have to do something different if it's another datatype?
gender_grp.value_counts(['letter'], normalize = True, sort = False) looks kind of like a dataframe with three columns. but it's actually a series with two levels of indexing. I'd have to experiment to figure out how one would change the dtype of the letter index level
but you should do things like this as early in the process as possible. if the letters are categories, and they have an order, you should make them that way when the dataframe starts.
In the fine-tuning?
What happened?
i use chatgpt as my deep learning mentor and he well, sometimes he spews bullshit straight into my face.
well, don't do that.
Oh, then I guess you'll have to try filtering it
I don't know how to use teacher-student learning...never tried it because of the crazy things I'd have to do...
there's no point using chatgpt to get factual information if you have to fact-check everything that it says
he is not that bad, i m in middle of watching "Learn PyTorch for deep learning in a day." by daniel Bourke, but in all honestly a lot of lessons i watched from him gpt summarized in few paragraphs without losing information
and with use of davinci-code and davinci 3 i can get actually a lot of troubleshooting right away.
everytime i run my program in remote server I get this error, F external/org_tensorflow/tensorflow/tsl/platform/default/env.cc:74] Check failed: ret == 0 (11 vs. 0)Thread host_executor creation via pthread_create() failed
but it works fine on my machine
I dont understand, I think it has to do with how multiprocessing process are created ig?
It's a bit sad how ChatGPT can make some things so much easier to understand than listening to a specialist...
I only managed to learn how to implement a Reinforcement Learning algorithm after going to ChatGPT
But then... I guess this is the curse of knowing too much.
My biochemistry teacher at the college can't do a rule of 3 calculation, for instance...despite it being useful to calculate some variables used in biochemistry
i tried asking chatgpt my problem but it didnt work
but that's probably since i dont understand it enough to ask it good
There's this problem. Once I asked ChatGPT about SRGAN structure and it gave me a vague answer...and it was wrong
trying to learn new stuff from chatgpt is a pretty bad idea
its notion of correctness is good grammar and text appearing together with high likelihood in the wild. nothing to do with factual correctness. that means it's very difficult to catch its mistakes if you're not already familiar with a topic
its made to be convincing and nothing else
well, gpt is limited to knowledge from 2021 and if he doesnt know something he makes it up.
But there is plugin that makes him utilise web search results and he can summarise online articles with it
getting correct answers is just coincidence
I guess if it makes web search it might do it only if you correct it and appoint the mistake.
ChatGPT will give you elegant nonsense. If you tell it what is correct, it will just accept it as fact, which can be used, for example as shown in Wolfram's recent blog post: https://writings.stephenwolfram.com/2023/01/wolframalpha-as-the-way-to-bring-computational-knowledge-superpowers-to-chatgpt/

Accessing Wolfram|Alpha's computational knowledge with ChatGPT--an ideal combination of precise computation with human-like expression of ideas. Stephen Wolfram explains how.
it confused the INEOS 1:59 marathon with the legit 2:01:39 berlin marathon

it's not that smart
Oh, you don't have to go that far. Ask it about Diffusion Models and Stable Diffusion
no no, it's pretty good. but not at what people are using it for
it's not meant to give you factually correct answers
that's not what it was trained for. that's the user's own fault
There might be a bunch of employees at OpenAI at this moment having to label millions of ChatGPT answers according to degree of "correctness" 
Poor guys...labeling a dataset is so boring...and prone to tendonitis
same question but with web results enabled

oh ok
It needs to be combined with something that does have the facts. But ChatGPT is not that on its own. You can think of ChatGPT as being the human-computer interface, but it's just that. With something else to provide reasoning (and world knowledge beyond just the text it had) it could be one of the best tools ever made.
as a text model, what it values is the likelihood of certain chunks of text occurring together. whether those chunks really belong together is a different matter (that it does not care about). you literally depend on how biased the training data is.
though extending it with wolfram searches would be great
still, it has no notion of correctness, so 😛
One of the reasons ChatGPT does better than previous models is injection of MORE bias into it. But it's just human preferences, there is not an actual world model.
(Wolfram Alpha can function as such a world model for math/science)
I want my hot takes to be part of the world model
🥞 hot cakes
If programming in English is what you want, nothing comes even close to Wolfram Alpha, but it's not open source...
I thought that was COBOL
COBOL is if you want to program by committee.
(made up of people that never did any programming)
my hot takes for the world model would be a set of propositions in the format "x is y, but bad".
"COBOL is executable English, but bad."
openai has english to python finetuned model
that's not very difficult considering python is essentially pseudocode in english
(i'm kidding about it not being difficult)
"finetuned" has a specific meaning in machine learning, and it's not "very good at a narrow task".
Don't say that... I'm trying to make an Unsupervised reward model fine-tuned with supervised learning
But yes, it isn't working
The reason Wolfram Alpha does so well is because it spits out Wolfram Language code, which is very high level (much more high level than Python) and much easier to generate. It also does not spit out text, but rather the abstract syntax tree directly, removing an entire layer of complexity and errors when compared to using a text model for programming.
damn, now i want to check it out
Even higher level than Python? Damn...
I have a coworker who calls Wolfram his secret weapon
Wolfram Language is probably the most high level language ever made that actually works and is not just a gimmick.
It's also been around for a very long time.
(Older than Python IIRC)
Interesting...
Now I know what to do every time I have to calculate some integral...specially if there's geometric functions involved
Its major downside is that it's not open source and costs a lot.
Upside is that they give you a lot in return, cloud compute, giant database of algorithms for everything, datasets for everything updated in real time, etc.
This approach works, but there will always be some gaps, where open source could help out. Like how Python has a library for even obscure things that maybe only 1 other person is doing.
I would like to see some kind of open source Wolfram Alpha like thing though. I think it helps a lot with the discoverability problem, which is what ChatGPT seems to be mainly used for. That is, knowing which things are available and the general way things are done with X (this is a barrier to entry for any new framework or project being worked on / with). Autocomplete in IDEs are a weak form of this (what are the available functions/methods and a brief description of them in their comments).
Hello, does anyone know what is the easiest way to return the coordinates of points such that those with the largest sizes are closest to the origin (pos (0,0,0)) in 3D please ?
I've been trying spherical coordinates but it keeps returning me a totally uniform distribution while totally neglecting the condition on size. Here is the code i'm using :
for i,mass in enumerate(initial_masses):
for j,pos_mass in enumerate(positions['Mass'][0]):
if pos_mass == mass:
positions['size'][:,j] = data_matrix_object['size'][:,i]
# Generate random spherical coordinates
theta = np.random.uniform(0, 2*np.pi)
phi = np.random.uniform(0, np.pi)
R = 1/positions['size'][0,j]
#Generate positions
positions['X'][:,j] = R*np.sin(theta)*np.cos(phi)
positions['Y'][:,j] = R*np.sin(theta)*np.sin(phi)
positions['Z'][:,j] = R*np.cos(phi)
i = 0 corresponds to the greatest size and the higher the value of i, the smaller the size.
With this, i get that plot (purple dots = greatest size, red dots = smallest size) :

I'm pretty sure i missed something but i can't tell what exactly
@wooden sail let's talk about mathmagic again.
When I pass an image through a Conv2D layer, that layer will create feature maps based on the convolution through the image, right?
People use to say that the first conv layers, in the complete image, usually extracts the shapes and objects in the image and the deeper ones extracts relations between pixels.
My question is: are those feature maps related to each other? If I pass an image through a conv layer, generating 64 feature maps, are those 64 feature maps related somehow in a way that, if I try to work with 10 of them separately, I might get bad results?
I'm thinking about making a GAN that, despite using conv layers to generate many feature maps, I'd also like to make it extract some of the best feature maps generated according to certain input
it's almost 4 am, maybe later
Okay. Sweet dreams
Yeah what a lot of people don't quite understand about these types of language models in general is that they're not trained based on correctness or clarity, they're purely trained to mimic human language. Even during training, if the model says something that's completely incorrect, but the dataset also included this incorrect statement, it will be told it's correct. There's nothing that distinguishes fact from fiction other than the idea that the data it's trained on tends to have correct statements, although that's not always the case.
I have a question that might not be for this space but Ill try as someone doing analytics maybe has encountered it. In excel you can generate a map a that shows statistics, but it requires a connected to the internet to setup. Does anyone know what data is shared while doing this check?
Hello Everyone, I am working on Hands-On-Machine-Learning-with-Scikit-Learn-Keras-and-Tensorflow book version 2. In chapter 10 page 294, there is an example about MNIST dataset and my result and the book result are far from each other. We are using same dataset and model but our result are completely different, one of the reason can be we are using different Tensorflow version but just this can create such a this difference? Another difference is I limited epochs up to 70 but in the book is 50. Is everything is related to epochs then why at the begging they are the same? Thank you


Your initial accuracy seems to be very high. What is your validation accuracy by epoch 50?
I ran the same code on Colab (took about 5min with Colab free GPU) and got the graph you can see below. Colab uses TF 2.9.2 and keras 2.9.0. Colab reports this as the epoch 50 training step:
Epoch 50/50
1719/1719 [==============================] - 5s 3ms/step - loss: 0.1636 - accuracy: 0.9420 - val_loss: 0.2978 - val_accuracy: 0.8936
There might be some randomness in the state which could be further sorted out

I have a bunch of high-dimensional embeddings (well, millions in fact) that each represent an image, does anyone know of some examples I could use as inspiration for making cool visualizations from them, like in terms of libraries used and stuff like that? But i dont mean something like Tensorboard but more like a nicely formatted image or video I could post on r/dataisbeautiful or something
Thank you so much for the response. It is about %89 at epoch 50. In your view, when is a good time stop the training? at epoch 20?
hi guys , I need help . how can ı accessing the coordinates of the bounding boxes ?

I'm trying to get the labeled coordinates of the test data of the model we trained in yolov5.
ı saw this code . the use torch.hub.load() but with github code and yolov5s own dataset labels . but we have our own model and own dataset label txt . so ı dont know how to use . Sorry for the poor english ı am still learning

Whenever the validation accuracy does not increase, and for you it seems flat so I don't see any benefit :\
pseudocode from: https://arxiv.org/pdf/1602.01783.pdf
what does t_max mean? is it the maximum number of steps per episode? or is it the value for n-steps? if it was the value for n-steps that wouldn't make sense because it's performing an asynchronous update right after accumulating gradients, which would mean it would be updating the weights sequentially (experiences right next to each other are highly correlated)

if it wasn't referring to the value for n-steps, why is it called n-step Q-learning then?
Hey @spiral tangle!
It looks like you tried to attach a Python file - please use a code-pasting service such as https://paste.pythondiscord.com
I'm a newbie so my apologies if something I ask might be to obvious and my english is not quite good. I'm stuck in doing a custom grid search with cross validation with LightFM which does not come with those functions. Here the code https://paste.pythondiscord.com/agukakibad. It seem the way I split the dataset is wrong but I do not understand why since I've replicated the code of the function random_train_test_split https://making.lyst.com/lightfm/docs/_modules/lightfm/cross_validation.html#random_train_test_split to get the folds. The error I get is Incorrect number of features in item_features. I'm glad if someone could give me some tips or suggest some platform even paying to get this thing done since it is driving me crazy.
what is the first AI related project I should start on?
the youtube video i posted above shows you how to make a recommendation engine for research articles, it's pretty simple and works as a nice introduction to AI and NLP
okay thanks
Can someone help me to filter some feature maps from a convolution in Pytorch?
I have an input with sizes (Batch, 3, 64, 64) which is passed through a Conv2D, providing an output (Batch, 1000, 64, 64)
Then, I have 1000 indices obtained through a FeedForward layer and a logsoftmax function, from which I extract the 3 ones with highest value, providing me a variable with sizes (Batch, 3)
Now, I want to use this variable to get 3 channels from the Conv2D outputs, batch by batch, but I'm having some hard time figuring out how to do this.
I tried so far variations of
x = conv_output
channels = torch.ones((conv_output.size(0), conv_output.size(1))
selected_channels = self.logsoftmax(self.fc(channels))
_, indices = torch.sort(selected_channels, 1, descending=True)
indicesA = indices[:, 0]
indicesB = indices[:, 1]
indicesC = indices[:, 2]
for batch in range(x.size(0)):
selected_features[batch] = torch.cat((x[batch, selected_channelA[batch]], x[batch, selected_channelB[batch]], x[batch, selected_channelC[batch]]), 1)
However, this throws the following error:
RuntimeError: The expanded size of the tensor (32) must match the existing size (96) at non-singleton dimension 2. Target sizes: [3, 32, 32]. Tensor sizes: [32, 96]
And I simply don't get why the function is concatenating the height and width dimensions, not the channels
Does anyone know about AI machine learning?
I need help with a python project, if anyone has the time and is willing to help me I would be happy to talk
be sure to always ask your actual question(s). no one is a universal expert, so there's no way to know if someone will want/be able to help until they know what the question is.
does one know if theres a custom made solution to use linear regression within multioutputregressor
linear regression is a widely-applicable concept in ML, so your question is probably under-specified.
got 2n_features and n_targets and i wanted to use LR for it to better understand and reproduce parameters instead of KNN or RF
does anyone already did th snake game with NEAT algortihm ?
My model learns very badly, I think I don't have the right inputs, i take :
the distance from the head to each of the walls (4 inputs)
distance from head to food (x_distance and y_distance) (2 inputs)
Hi can someone help me with decision tree please
I am trying to use grid search for model improving
the direction of the snake, up, down, left, right (4 inputs)
Not working
You could alrdy make it simpler by only considering forward, left and right. The snake can only go 3 directions at every timestep. as inputs you could do distance to wall/snake body in the same 3 directions. Then you could have the x and y offset of the candy relative to the head and orientation.
oke i see, do you mean the distance between head and food ?
For the last part yeah
okey so it is a total of 3 (wall) + 3 (snake body) + food (2)
jup
but the snake need to know in whoch direction it goes ?
right, left, up or down ?
Well the information you supply is based on the current orientation yes
It doesn't if it's all relative to its heading
hmm i see
https://pola-rs.github.io/polars/py-polars/html/reference/api/polars.Config.set_fmt_str_lengths.html
does anyone know how this method of polars work?
it's supposed to help with changing the amount of data dataframe shows when calling it
I have to apply conditions to calculate each input? for example to calculate the distance from the wall in front of the head, it is calculated in 4 different ways depending on whether the snake goes up, down, goes right or goes left
and it's the same for each input, I have to calculate according to the direction of the snake
direction = ''
if direction == 'up' :
input1 =
input2 =
...
if direction == 'down' :
input1 =
input2 =
...
if direction == 'left' :
input1 =
input2 =
...
if direction == 'right' :
input1 =
input2 =
...```You could also base your calculations more on vectors
I think that could work because even if each set of input is calculeted in a different way, each set of input have the same meaning
ie. transform your heading into a vector
that change a lot ?
the point is to reduce the code
but if your current solution works, don't mind me 🙂
but it gives me a super big line of code?? I'd rather have multiple lines than one big line of code
It wouldn't give you super big lines of code. But I am starting to think it would be a distraction for you at this stage. You can always revisit that later
I haven't tested it yet! but it should work I think since even if each variable of each condition is calculated in a different way, ultimately regardless of the conditions, they all express the same thing
I don't understand 😅
but thank you for your help, i am gonna try this solution tomorrow
👋 hey, I want to auto-classify pytest failures. Anybody have recommendations for the approach? I'm planning to do bert sentence similarity https://www.kaggle.com/code/eriknovak/pytorch-bert-sentence-similarity/notebook but I'm afraid that the logs are much bigger then just sentences and it will not work well.. 😆
Any suggestions would be greatly appreciated!
omg, this didn't work well 😆 pretty terrible classificaion
If I were to use a Variational AutoEncoder with a GAN...would it help my Generator and my Discriminator to converge?
I think I've seen that VAEs can be used to generate specific noise for the generator to generate specific images(kinda like Conditional GAN, but I suppose it's more stable), but I don't know exactly how I could make this to make my Discriminator be less efficient
Even the most rubbish of rubbishest discriminators I can make turns out to simply laugh at my generator useless attempts to fool him
I shall make a discriminator with only 3 conv layers. If he still manage to properly differentiate fake images from real images, then I'll give up for the Diffusion Models...
or not. Diffusion Models are boring to train
And spectral normalization, which was supposed to help, actually makes things even worse
hello, can anyone recommend a website to search for deep learning projects by "theme"?
Not looking for complete projects, but just something to give me a list of possible ideas
also, theme is business-oriented so the usual ideas I find generally are not usable
Hi, i'm starting to learn stable disfution and wanted to make a server with stable difusion, anyone know where to start?
Hello I wanna start like data scientist but I know whether to start studying mathematics, statistics or Python.
But I alredy know programming until OOP
In c++
And I know some descriptive statistics and calculus (of one variable).
I would recommend:
- Make sure you have a CS degree. The more advanced positions would even go as far as looking for masters
- There are some nice introduction books to get started like
Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems
i would just note that it doesn't have to be a CS degree. there are other programs that cover more math (but less programming)
But before all that isn't more basic things necessary? I'm in 3rd semester
Before what?
a job? able to program something? To do basic statistics? etc.
I mean, is it not necessary to have some basis to start in ML?
You can do anything you want
Probably the conceptual bit
Hey @late shell!
It looks like you tried to attach file type(s) that we do not allow (.docx). We currently allow the following file types: .gif, .jpg, .jpeg, .mov, .mp4, .mpg, .png, .mp3, .wav, .ogg, .webm, .webp, .flac, .m4a, .csv, .json.
Feel free to ask in #community-meta if you think this is a mistake.
@split cedar Per Rule 6, your invite link has been removed. If you believe this was a mistake, please let staff know!
Our server rules can be found here: https://pythondiscord.com/pages/rules
Yes. Sometimes it can even perform better than in supervised learning
Yep
I think there's also something related to the Neural Network trying to decrease the entropy in the data
But, from what I remember reading, there's not really a definitive explanation, just some hypothesis
I don't remember how clustering works, but the NN identifies patterns in the input and tend to assign it to the closest labels as possible.
I think GPT-2 works through Unsupervised Learning in text. And there's also Neural Networks for labeling data
https://d4mucfpksywv.cloudfront.net/better-language-models/language-models.pdf
https://lilianweng.github.io/posts/2021-12-05-semi-supervised
When facing a limited amount of labeled data for supervised learning tasks, four approaches are commonly discussed.
Pre-training + fine-tuning: Pre-train a powerful task-agnostic model on a large unsupervised data corpus, e.g. pre-training LMs on free text, or pre-training vision models on unlabelled images via self-supervised learning, and the...
In fact, I learned about unsupervised learning in NNs exactly because I wanted to make one to label my datasets
You might see more about that in the Pseudo-labeling part of this blog post, as it seems that working with pseudo-labels(labels generated by unsupervised learning, including NNs) rather than actual labels(human-made) tend to generate better results.
Curious... Using more discriminators and making them duel against each other makes things work surprisingly well.
I shall now make a GAN called The Good, The Bad and the Generator
@serene scaffold since you're the NLP guy, tell me...
How does the Transformer works in eval mode?
Since the Decoder requires both the input sentences and the target sentences, training is ok, but what about evaluation mode, when I don't have the target sentences?
I couldn't find a link that explains this clearly. The best explanation I could find was "the Transformer predicts many possible outputs and selects the best one based on a language score"
I suppose that if I use BERT's version, since it tries to predict words from masked values, this might be easier to deal with...I'd just have to pass a mask as target in eval mode, right?
!mute 691597752345296957 "1 day" This server is not a place for you to promote your YouTube channel. You will likely be removed from the server if this continues after your mute expires.
:incoming_envelope: :ok_hand: applied mute to @lapis sequoia until <t:1674056667:f> (1 day).
Hey guys, i’m running into a keyerror trying to .at a specific index that I know is valid. This specific column has 4409 rows of data, but i can only .at up to index 3559 without getting a keyerror, anyone know why? This is so bizarre
are you sure it exists in the index?
!e example of when it's missing, note i have more than 4 rows.
import pandas as pd
df = pd.DataFrame({"x": [1,2,3,4,5]}, index=[1,1,1,2,3])
df.at[4, 'x']
@boreal gale :x: Your 3.11 eval job has completed with return code 1.
001 | Traceback (most recent call last):
002 | File "/snekbox/user_base/lib/python3.11/site-packages/pandas/core/indexes/base.py", line 3803, in get_loc
003 | return self._engine.get_loc(casted_key)
004 | ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
005 | File "pandas/_libs/index.pyx", line 138, in pandas._libs.index.IndexEngine.get_loc
006 | File "pandas/_libs/index.pyx", line 162, in pandas._libs.index.IndexEngine.get_loc
007 | File "pandas/_libs/index.pyx", line 197, in pandas._libs.index.IndexEngine._get_loc_duplicates
008 | KeyError: 4
009 |
010 | The above exception was the direct cause of the following exception:
011 |
... (truncated - too many lines)
Full output: https://paste.pythondiscord.com/owijamerol.txt?noredirect
oh actually i just figured it out what the issue is
so when i import the dataframe into a csv, i can see the index of the dataframe vs the index on the excel sheet, and the index of the data frame is actually messed up, its not incrementing by 1, but there is some random pattern thats extremely weird. is there any way to reset that index on the actual dataframe?
df.reset_index(drop=True)
beautiful thanks so much
technically it is a world model - just modelling the 1D world of tokens. So from its POV, everything it says is totally correct. However, we interpret those tokens in the context of the real world which it isn't capable of
Better idea: using the same mask wouldn't make that much sense. So what if I passed an input from 0 to len(vocab_size) to a feedforward layer and the output would become the target sequence?
(I still didn't manage to discover how the Transformer generates sentences in eval mode)
I wrote something like this in a previous message.
(by "actual" I really mean "physical world model," I should have clarified)
(sensory fusion with text or via other means)
(Or maybe at least something like Wolfram Alpha, just math and science)
@worldly dawn Hi, I have coded the distances to the walls in each direction but I cannot calculate the distance from the head to the body, for example if to the right of the head there is no body, what do I put cmme input because the distance does not even exist
Hi! I have Raspberry Pi 4 Model B 4 gb Ram 64-bit model. I am trying to use raspberry camera but it doesn't work. I guess 64 bit doesn't support camera yet. I installed 32 bit os to it. When I enabled legacy camera from configuration, a problem occurs that "Can't show the desktop". Is there any solution for this problem?


It does not only depend on data, it may also depend on the algorithm you are planning to use. Some algorithms desire input data that is normalized, others standardized, and some don't even care.
I plan to use a TensorFlow NN as my baseline
I know models like XGBoost doesn't really care about the data in that sense
So if you want to be on the safe side, normalization is often a pretty good pre-processing step. It is mostly important to not have extremely high/low values, and so that every feature is in the same range.
If you have very extreme outliers, you may want to think about dealing with those though, as they can heavily affect normalization
Having a single point with a feature value 99999 could make all other values very low after normalization f.e.
What's the best way to go about figuring out what outliers to remove (if any)? Here is the box plot for the top data or example:

I know some people bin data to help deal with some of those extreme values
This seems fine already, I'm more so talking about close to a magnitude higher than most other points
Like this? lol

That's the second set of data from my first pic ^
Imo still fine, but I don't know if there is a objective way to tell if an outlier is too much for the normalization to have a bad impact on the network.
So the first set of data is "Age" and second set is "MonthlyIncome". Obviously those have very different scales. Do I need to normalize both then standardize or just standardize?
Just normalize would be fine
Why so? I'm fairly new and get really confused between the difference lol
in terms of when to use which ^
Normalization is mostly used for NNs to get different features on the same scale. In your case the price is quite a few magnitudes bigger, so it could be biased to use that more over the age.
Standardization is used when your data seems normally distributed, and some algorithms expect your data to be normal and standardized.
So I should normalize the data first (if it isn't already). If it is normal already, I should should standardize it instead?
Your data is not normalized, as the age ranges between 0 and 60 ish and the income betwen 0 and 20k
Normalized is between 0 and 1
I know I'm saying in general
And I'm not sure when you would use standardization for neural networks. It seems to differ case by case when looking at projects

Yeah that would probably be a good idea
Is it just best to drop them (I think it's like 5 points or something)? Or is there a better way to handle them?
ehh, I'm not sure. If 5 points is not a lot of points you could just drop them. You could maybe also clamp them if you think they contain very useful info.
It might also still give good results if you simply just normalize anyways.
What's clamping?
Basically just saying everything above value x will now be value x and everything below value y will now be y
For chosen x and y
anyone knows how to make the graph in matplotlib fixed size and not flexible to the line?
But this will treat every value above and equal to x the same
https://www.geeksforgeeks.org/change-plot-size-in-matplotlib-python/ fig size you mean?
Gotcha! Last question lol. Do I need to normalize each column by itself or everything at once? Guessing each individually
,,,
You should normalize every column separately
tysm
Kk thanks for the help!
As a quick note, you should also normalize the test data according to min and max of the training data
So you should separate train and test before normalizing
And the normalize the training data according to train_max and train_min for each column
and use those for test as well
Yea 😄 although, this is for a Kaggle contest and I've heard it's fine to concat the two and preprocess them together since there won't be anymore data coming in. Is this true?
Ehh, it is a bit more involved, I'll explain in a bit, bit busy atm
Sure np! Just @ me when you have time to explain a bit
no wait it didnt quite work
Why not?
its still flexible to the line
but the size of the image itself
changes
but like the measurements are the same
Send me a pic? Idk what you mean xD
oke

dont mind the numbers
see, the measurements are the same
but the size of the picture is different
Measurements as in what?
like
y and x axis?
yeah
Try using plt.xlim(__, __) plt.ylim(__, __)
So the reason you want to normalize just based on the training data is because you want to have a fair judgement of how well your model will perform on new/real world data. If you normalize based on all data, this means you are using information from data that you are testing on, which makes your performance measure on the test data less meaningful. It's a bit like cheating, your model will seem to perform better than it actually does.
It's also the reason why you only test on your test data once, and not modify the model anymore after getting the final performance measure on the test data
There won't be any new data though since they give a train/test set. Obviously in a real world application I would need to but wouldn't it be alright in this case?
Would your model eventually be tested on other data to compare your model with others?
If so, then yes it could matter. In any case, your performance on the test set will be less meaningful if you normalize using your entire dataset, instead of just your training data.
This is the note for the leaderboard: This leaderboard is calculated with approximately 20% of the test data. The final results will be based on the other 80%, so the final standings may be different.
Eventually you would want to train on both train and test if you have done all steps of designing your model.
So I'm not sure if they use an extended set of test data or a completely different dataset
Different datasets it seems
Of which 20% will be used for leaderboard, and 80% for actual score
So in that case I should normalize only the train data first
When designing the model yes
Let's say I normalize the train data + fit the model on the train test split data and it performs well. I'm guessing I need to then perform the same normalization on the test data that I did for the train data before I fit it to that?
Same normalization as in on the same columns
You would fit on training, then probably use validation data to make decisions about your model like architecture and amount of layers etc.
Then after done you could test on tests set to see how well the final model does
Gotcha 😄 thank you for the help!
is there any good tutorial on spacy?
Beam search... I've studied this, but I had forgot...
Seems a technique a bit meh, though

(For a moment while he was processing the answer, I thought it would interpretate my input as if I was offended...this memory system it has is surely quite a thing)
Do you know if sklearn's MinMaxScaler normalizes each column individually or the whole dataset when you feed it a dataframe?
It looks like it does each column individually but I can't tell for sure.
scikit-learn
Examples using sklearn.preprocessing.MinMaxScaler: Release Highlights for scikit-learn 0.24 Release Highlights for scikit-learn 0.24 Image denoising using kernel PCA Image denoising using kernel PC...
individually "each feature individually"
thank you 😅

{kind=link}
Guessing one of your columns is a string insterad of int
Possible for gender?
all of them are string
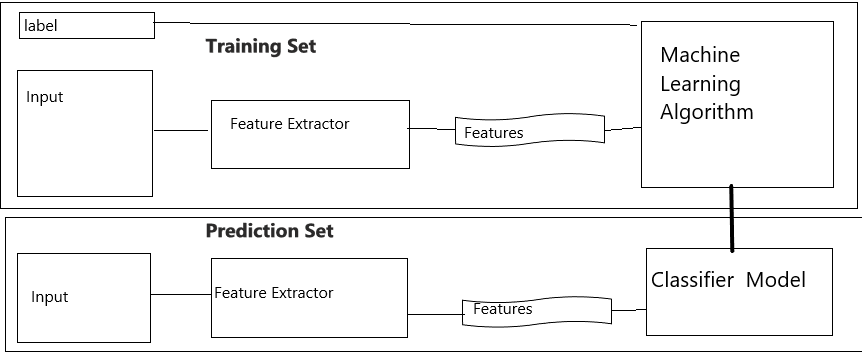
GeeksforGeeks
A Computer Science portal for geeks. It contains well written, well thought and well explained computer science and programming articles, quizzes and practice/competitive programming/company interview Questions.
thats my "inspiration"
yeah
Have you heard of one-hot-encoding before?
In your case, "gender" is a categorical feature (i.e. you're either male or female). One way to handle this is to turn the columns into integers (0 and 1). One-hot-encoding is a way to do this.

This is what it looks like
alright but can i ask one more question
could you explain how does nltk.NaiveBayesClassifier.train() exactly work
ik it uses Bayes theorem to classify
but what does it mean
ik the theorem but like how it works
Honestly I'm not sure I've never used it before xD
It uses Bayes' theorem that's all I know too lol
welp one last question about my code
sure
why does the same thing work herehttps://www.geeksforgeeks.org/python-gender-identification-by-name-using-nltk/
GeeksforGeeks
A Computer Science portal for geeks. It contains well written, well thought and well explained computer science and programming articles, quizzes and practice/competitive programming/company interview Questions.
but not for me
Can you print test_set?
your labeled_names has part of the code wrong
You have ([(name, "name)]) when in the example it's name, "male" and name, "female"
oh
Also you're missing this line py featuresets = [(gender_features(n), gender) for (n, gender)in labeled_names]
Oh nvm I see you just called it "features" instead
what happens now if you print test_set after you changed it?
It doesn't seem like you need to
let me download the dataset and try it's hard to do it with no code xD sec
oh um you want me to send txt files?>
no it's ok I see it in the geeksforgeeks page
Can you copy and paste your code?
!code
Here's how to format Python code on Discord:
```py
print('Hello world!')
```
These are backticks, not quotes. Check this out if you can't find the backtick key.
sure
import random as r
from nltk.corpus import names
import nltk
def genderFind(word):
return(word[-2])
MaleNames = open("/content/Male.txt").readlines()
FemaleNames = open("/content/Female.txt").readlines()
labeled_names = ([(name, "Male") for name in MaleNames] + [(name, "Female") for name in FemaleNames])
r.shuffle(labeled_names)
features = [(genderFind(n), gender) for (n, gender) in labeled_names]
train_set, test_set = features[500:], features[:500]
classifier = nltk.NaiveBayesClassifier.train(test_set)
Ok I downloaded sec let me look through it
ok
Change the function you have in line 4
to this
def genderFind(word):
return {'last_letter':word[-1]}```Works for me now
😄
Yea I think it's due to the way you're reading the lists
if you print either of the male names or female names you can see there's a \n in every name string
is there a way to say that its wrong when its wrong so it learns more?
and so it remembers it somehow
btw tysm for the help
forgot to say ity
It's predicting the test name based on how you trained it
It's only showing male names for me I think because of the way you're reading files
if you print either the MaleNames or FemaleNames, you can see that the names haven't been stripped of the new line from the txt file py 'Wilson\n', 'Wilt\n', 'Wilton\n', 'Win\n', 'Windham\n', 'Winfield\n', 'Winford\n', 'Winfred\n', 'Winifield\n', 'Winn\n', 'Winnie\n',...
Replace the 2 lines where you're reading in the file with this:
with open("/content/Male.txt", "r") as file:
MaleNames=file.read().splitlines()
with open("/content/Female.txt", "r") as file:
FemaleNames=file.read().splitlines()```You could write a function to do it in less than 2 lines but I'm too lazy to figure that out rn xD
Based on the training data you gave it should be accurate now
@cunning flame
Np let me know if it works 😄
alr it became more accurate but im actually doing it for a n order so i need like 95-99% so ill have to go ask a very smart guy i know
but again thank you so much
Np 😄
also can you tell me what was changed?
gl with your model
like what was the problem?
For the reading files part?
yeah
https://media.geeksforgeeks.org/wp-content/uploads/male.txt see how in the file each name is on a new line? Well python recognizes that so for each name in the file it added \n which means new line
Splitlines tells python to ignore the new lines and only focus on the words
You could also get it more accurate by using different datasets
The male/female dataset provided seems kind of bad
yeah
imma go find like a 10 thousand line one or smthn
also, do you know if there is a way for ai to remember its training so it doesnt have to redo it everytime?
i found a dataset with 240000 names
You shouldn't have to retrain it every time
Oh that's because you're running everything again
google colab
Split up the lines of code into chunks so that way you only have to rerun the cell that has the name
or actually just keep it as is
and move this to a new chunk py print(classifier.classify(genderFind('Walt')))
ih thats smart
then you only have to run that chunk of code
hello, I am currently learning how to work with time series data, v this is a sample of the data I am working with, there is no "periodicity" can you suggest how I should do time series analysis on this ?

are you trying to smooth it out or?
atm I havent thought about that, I can try that, but I want some advice on algorithms that I can try
the data I have worked with in the past is clearly seasonal/periodic, so I just use arima, but I dont think that will give good perf on this dataset
i need to first fully understand what you are trying to do
if you want some more detail, this is a custom/real life sales data set
my trainer has asked me to do sales forecasting
yeah
so just do that
it doesn't look like there's any sort of correlation for regression
that was my thinking also