#data-science-and-ml
1 messages · Page 29 of 1
yeah its fun tho when it tickles your brain a bit lol
i probably need to get better at that and learn DSA coding before i even attempt another language
!warn 760895878159663166 Python Discord is not a platform for recruitment. This is stated clearly in our rules.
:incoming_envelope: :ok_hand: applied warning to @vapid crypt.
Asking for paid work isn't allowed, either.
 ima beamer boy
ima beamer boy
idk what that is.
off topic
So transform returns the operation applied to all the rows of the group?
that's quite beautiful. And thanks for your detailed explanation. I missed it yesterday
did you learn about these functions from the documentation? @untold bloom
ArrowInvalid: Casting from timestamp[ns] to timestamp[us] would lose data: 1668020216913324032
what do I about this error
I am trying to convert a numeric column to type str
but even after that it stores some numeric rows
I have tried astype(str) and .apply(lambda x: str(x) )
spotted the issue
Actually I am writing a csv and re reading it again. And in the process pandas reads "3205" as 3205 in an object column. Is there any way to turn it off?
yes it repeats what the aggregation says for each member of the group. please compare:
In [5]: df
Out[5]:
item month sales
2021-12-27 A 1 100
2021-12-28 A 2 200
2021-12-29 B 3 300
2021-12-30 A 2 100
2021-12-31 D 1 300
2022-01-01 Z 3 200
2022-01-02 Z 4 0
2022-01-03 B 2 500
In [6]: df.groupby("item")["sales"].sum()
Out[6]:
item
A 400
B 800
D 300
Z 200
Name: sales, dtype: int64
In [7]: df.groupby("item")["sales"].transform("sum")
Out[7]:
2021-12-27 400
2021-12-28 400
2021-12-29 800
2021-12-30 400
2021-12-31 300
2022-01-01 200
2022-01-02 200
2022-01-03 800
Freq: D, Name: sales, dtype: int64
```the "raw" GroupBy.sum reduces the number of rows to `grouper.nunique()` after it operates; OTOH, transform'ed version keeps the size as `len(df)` by repeating the found values (like A's 400 is repeated for every A seen in df above). GroupBy.transform is therefore favored when you want to keep the shape of the column of interest after applying a possibly-aggregator operation (and that's what we needed for `.where` above). Noting that `transform` can take any callable (and applies it to columns-of-interest *independently*); but for very common operations, like summation, it accepts string forms as well (this is also seen in some other places, e.g., `agg` accepts strings as function names). We could write `np.sum` there as well and the result will be the same (and as fast); but why type more and clutter the code instead of a beautiful string.
> did you learn about these functions from the documentation
uh, not directly, no. i spent some (probably unhealthy) time in stackoverflow's pandas tag. IMHO, after/next to documentation, popular Q&As as well as the recent ones in SO are very useful for both practice and seeing what other people have to write for learning new things. glad if it helpsIs there a way to make a graph like a box and whisker/ candlelight but without showing the std deviation etc.?
Like I basically have a list
[[5, 1.5, 1.7], [10, 1.6, 1.65], [15, 1.6, 1.60], ...] and I want the first element to be the xtick, the second to be the absolute lower bound and the last to be the absolute upper bound
No deviation or anything, more like just flying barplots
what does a fuzzy set low medium and high numbers mean
Looks like its a way to categorize your data


I have a brief question regarding a sensitivity analysis I am doing
Would you suggest this is better for analysis purposes (steps of 5)

Or do you reckon steps of 10 would be better because I cover more?

is this matplotlib?
no this is just done in Excel
Its less of a coding issue, more of a trying to get your data science opinion
Guys someone know a roadmap for data science, machine learning....deep learning?
Hello guys, i want get started with AI using python, can you help me out what i need to do most
How can i convert custom images to be fed to the keras.datasets.fashion_mnist model
this is the code i have but i do not beleive it works
drawn_image = cv2.imread(image_path, cv2.IMREAD_GRAYSCALE)
resized_drawn_image = cv2.resize(drawn_image, (28, 28), interpolation=cv2.INTER_LINEAR)
resized_drawn_image = resized_drawn_image.reshape(-1, 28, 28)
cause no matter what image i give it the model always guesses the same thing
i had a similar problem once, are the pixel values the same as the training data? i believe the values in the mnist dataset range from 0 to 255, while mine were 0 to 1
(assuming you trained on the mnist set)
yeah
wait this is weird
ohh
im such a bafoon
i did ```py
train_images_copy = train_images_copy / 255
but not for my test images
test_images_copy = test_images_copy / 255
``` this worked nowthanks
ah nice!
still guesses the same thing
what does it show if you print resized_drawn_image?
before or after resized_drawn_image = resized_drawn_image / 255 ?
after
but isn't it supposed to be 28 x 28?
looks like: ```[[[1. 1. 1. 1. 1.
1.
-
1. 1. 0.8627451 0.58823529 0.19607843
0.34901961 0.56078431 0.56470588 0.49803922 0.25882353 0.47058824
0.78823529 1. 1. 1. 1.
1.
-
1. 1. 1. ]
[1. 1. 1. 1. 1.
1.
-
0.7372549 0.36862745 0.16470588 0.03921569 0.
0.05098039 0.15294118 0.15294118 0.03921569 0.03921569 0.01960784
0.0745098 0.25882353 0.58823529 1. 1.
1.
-
1. 1. 1. ]
[1. 1. 1. 1. 1.
1.
0.42352941 0.03921569 0.03921569 0.17647059 0.21176471 0.17647059
0.16470588 0.32941176 0.35294118 0.17254902 0.15686275 0.18039216
0.14509804 0.0627451 0. 0.18431373 0.89803922 1.```
thats a small portioin
before looks like: ```py
[[[255 255 255 255 255 255 255 255 255 220 150 50
89 143 144 127 66
120 201 255 255 255 255 255 255 255 255 255]
[255 255 255 255 255 255 255 188 94 42 10 0
13 39 39 10 10
5 19 66 150 255 255 255 255 255 255 255]
[255 255 255 255 255 255 108 10 10 45 54 45
42 84 90 44 40
46 37 16 0 47 229 255 255 255 255 255]
[255 255 255 255 255 142 0 43 47 51 56 51
43 40 42 42 44
47 42 46 44 0 62 255 255 255 255 255]
[255 255 255 255 221 28 48 45 42 52 55 56
54 46 45 48 47
47 45 44 39 32 0 125 255 255 255 255]
[255 255 255 255 89 25 58 42 42 55 55 57
56 53 51 52 48
47 46 45 39 30 41 6 196 255 255 255]
[255 255 255 172 17 61 59 43 41 57 56 58
59 57 55 52 49
47 46 47 44 31 50 22 30 242 255 255]
[255 255 227 41 45 60 59 43 40 54 57 58
61 60 56 55 53
50 48 48 47 31 48 53 6 81 245 255]
[255 239 58 24 65 58 57 48 44 53 57 58
60 62 60 58 56
53 49 50 49 31 47 52 46 0 149 255]
[255 235 93 24 40 60 56 50 46 55 58 57
58 60 63 60 57
54 49 52 53 33 52 38 9 108 225 255]
[255 255 255 173 56 18 54 53 48 56 59 58
58 59 60 60 57
55 52 55 54 33 16 38 163 255 255 255]
[255 255 255 255 240 124 38 34 54 59 60 59
58 59 58 58 58
57 55 59 56 8 78 220 255 255 255 255]
[255 255 255 255 255 255 203 75 36 60 59 59
57 58 58 57 57
56 58 52 53 156 255 255 255 255 255 255]
wdym?
this is what the dataset looks like, where the white parts are 0 and the black is 1. in yours, the white parts are 1 and the black is 0

i guess a simple fix would be resized_drawn_image = abs(255 - resized_drawn_image) / 255
Using a CNN, how could you return the position of a math in an image? Like object detection
Hi all I have a very simple issue that I can't find a way to fix in Pandas.
Considering I have the following data:
infoA = [dict(user=1, infoA=20), dict(user=2, infoA=10)]
infoB = [dict(user=1, infoB=20), dict(user=2, infoB=10)]
infoC = [dict(user=1, infoC=20), dict(user=2, infoC=10)]
all_data = infoA + infoB + infoC
If add this all_data to pandas, pandas doesn't understand that each row is complementary, so it won't merge the records, and I get something like:
infoA infoB infoC
user
1 20.0 NaN NaN
2 10.0 NaN NaN
1 NaN 20.0 NaN
2 NaN 10.0 NaN
1 NaN NaN 20.0
2 NaN NaN 10.0
Can find a way to flatten this. I can groupby, but groupby would expect some sort of transformation, no?
Any ideas?
I have a model made with keras mnist
i am trying to have a custom image be predicted by the model
it is not working
it always guesses the same thing
from tensorflow import keras
from pathlib import Path
import tensorflow as tf
import cv2
image_path = fr'{Path(__file__).parents[1]}/images/dress.png'
labels = [
'T-shirt',
'Pants',
'Long sleeve shirt',
'Dress',
'Coat',
'Sandal',
'Shirt',
'Shoe',
'Bag',
'Boot'
]
label = labels(3)
""" Retrieving and loading data """
(train_images, train_labels) = keras.datasets.fashion_mnists.load_data()
train_images_copy = train_images
""" Making the image the correct format """
drawn_image = cv2.imread(image_path, cv2.IMREAD_GRAYSCALE)
drawn_image = drawn_image[0:600, 0:600]
resized_drawn_image = cv2.resize(drawn_image, (28, 28), interpolation=cv2.INTER_LINEAR)
resized_drawn_image = resized_drawn_image.reshape(-1, 28, 28)
""" Pre-processing images to be between the values of 0 - 1 """
train_images_copy = train_images_copy / 255
resized_drawn_image = abs(255 - resized_drawn_image) / 255
""" Creating the model """
model = keras.Sequential([
keras.layers.Flatten(input_shape=(28, 28)), # Input layer | here we give it information
keras.layers.Dense(128, activation='relu'), # Hidden layer | Here we manipulate information
keras.layers.Dense(10, activation='softmax') # Output layer | here we extract information
])
""" Compiling the model """
model.compile(
optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
""" Fitting the model """
model.fit(
tf.expand_dims(
train_images_copy, axis=-1),
train_labels,
epochs=10)
""" Testing the model """
test_results = list(model.predict(resized_drawn_image)[0])
""" Getting the results """
guess_index = test_results.index(max(test_results))
""" Printing the results """
if labels[guess_index] == label:
print(f'\n\n The model guessed {labels[guess_index]}, the model was correct!')
else:
print(f'\n\n The model guessed {labels[guess_index]}, the correct answer was {label}.')
please tell me why this doesnt work
that is the image i am feeding it ^ (dress.png)
your dress looks more like a bag. that's not keras' fault.
is there any way to get static typing
i would learn how to use the API faster if things were statically typed. tried mypy but it isn't the same
why do you invert the image? if you don't invert it, it seems to work.
inversion should be necessary if it has a bright background. but your input has a dark background.
i mean this part abs(255 - resized_drawn_image)
guys, i am trying to train the random forest model using a historical dataset. Then, now i wanted to predict the outcome of the users' input using what i have trained the random forest model. How do i do that?
Is there a a test that I can use to see if my back prop algorithm works, like test it against one that does or is that not possible
How to extract data from receipts using Python : https://www.youtube.com/watch?v=NrSjwk1jBy4

In this video you'll learn how to easily extract data from receipts with 🐍Python using different AI engines.
Eden AI simplifies the use and integration of AI technologies by providing a unique API connected to the best AI providers, combined with a powerful management platform: https://www.edenai.co/
Try the app for free 📲 http://app.edenai.r...
@silk garden would you like to explain why this is interesting? Because this channel isn't for "dump and run" posting of links
@serene scaffold came across this gem

hey folks, has anyone here had success running OpenAI Whisper on an M1 mac? I'm having some issues setting the device to mps:
LLVM ERROR: Failed to infer result type(s).
thanks, I'll send this to my friends!
if they ask for details, link them this https://mlops.community/why-ml-in-production-is-hard-and-solutions-to-help/
they won't have questions. they get it.
@elfin swan you asked a data science question in the wrong channel (namely #pedagogy)--it belongs here.
is anyone here have good knowledge of seaborn, good enough to be 50% of tableau
I'll be productionising via databricks
what is databricks, anyway
the rival of snowflake 
its a cool tool i believe azure bought out, lets you write ur stuff on the cloud and deploy it quite easily
u can even write jupyter notebook style stuff on it
(not that id ever want to put a notebook into production, but azure i think now lets you also make git like projects)
hosted apache spark with a bunch of extra features layered on top: "delta lake" (basically version control for parquet files), mlflow integration, their own filesystem called dbfs (instead of the typical hadoop hdfs), and a notebook interface that supports collaborative editing
it runs on azure virtual machines and dbfs can mount azure blob storage and azure data lake volumes
and of course it supports sso with activedirectory
just like how mysql is a rival of python, right? 😉
lmao you right. theyre technically different services but theres this weird rivalry narrative going on
i guess theyre both trying to become "lakehouses" in a sense
but different interpretations of the term?

databricks is fundamentally a big data computing platform with some data lake features bolted on. snowflake is a data warehouse.
any rivalry is artificial and invented in the minds of engineering managers who post on twitter

and people writing vapid Towards Data Science and Analytics Vidhya and KDNuggets articles just so they can put that on their resume
omg its true
on the practical side, most companies need a data warehouse a lot more than they need big data compute
databricks is and should remain a niche product
something like azure data factory however is awesome
yeah bigquery is said to be popular not bc of its big data processing capabilities
but its "easy-query" capabilities
you can build a pretty robust ETL system with just airflow, dbt, and snowflake python UDFs, but you still have to run and host airflow for that
oh yeah? ive heard good things about it

i haven't used it myself much, but replacing "servers" with "services" is always good in a smaller team
and also in a bigger team where the servers need to be more robust
one problem w/ bigquery apparently is that it's easy to make a mistake and cost your company $10k in a few minutes
i haven't experienced that, but i have a coworker w/ lots of bigquery war stories
snowflake is honestly just really good. their pricing is fair and the feature set is huge.
of course i'd prefer if it was open source and self-hostable but i can't blame them for not wanting to do that
snowpark is also really interesting, and that is starting to edge into databricks/spark territory a bit
it's a system where you connect from a regular python application, but it somehow pushes the computations up to the snowflake servers
the rivarly will begin if/when snowflake more explicitly moves into the "compute" space
snowflake does have streamlit
sometimes i forget about that. but maybe more data apps built on snowflake compute?
snowpark and their udf system is already robust enough to avoid the need for databricks. so if there's any rivalry, it's that the entire product category that databricks represents is somewhat obsoleted by snowflake for a lot of companies' needs
yeah
it's a smart acquisition, i'm sure streamlit having tighter integration w/ snowflake is going to be a big value add for both products
yeah for sure. i really like streamlit too. great for testing stuff
good for internal stuff too
so right now our etl/elt system consists of airflow running dbt tasks, plain snowflake sql tasks, and python tasks that run on aws ecs
but the latter requires a lot of care and feeding
we need to have an ecs cluster and ecr registries for the docker images and a lot of testing and software boilerplate in the actual python tasks
python on ecs huh? why not, what is it called aws glue
precisely, so i've been looking into options like that
iirc aws glue is the equivalent of azure data factory but i'm not sure
the thing now is that we already have an airflow+dbt setup that works, so we don't want to migrate to some proprietary managed service if we can avoid it
i think it doesnt have as many features but still relatively good. havent used it myself though but my friend that does ML monitoring has.
that makes sense
so my main interest now is looking into ways of making the python jobs themselves simpler and less needing of boilerplate
and it turns out that snowflake has great support for running python stuff directly inside snowflake
it has "batch udfs" that give you whole chunks of the data table as a pandas dataframe, built right in with 0 additional setup
and you can upload arbitrary python packages into a snowflake stage
oh shoot thats pretty dope
it even has support for a limited set of packages from the anaconda conda channel, if you don't want to deal with uploading wheels or tarballs
and that's just the built-in udf system. there's also an "external function" system that can actually send data to a remote machine running an arbitrary application, basically what we are doing now with airflow, but the whole thing is abstracted away and just looks like a plain table udf when you're writing the query. and that uses snowpark
so snowflake offers a lot of interesting options
other options include something like aws lambda or fargate instead of ecs
i can look into glue though, maybe i missed something
hm, it does look like airflow can run glue tasks
oh hey thats nifty
also im looking into fargate myself lol
for one project at work
its for a streamlit app funny enough

i still haven't used or needed streamlit
we use some data dashboard tool and i never have to make dashboards anyway
Holy. So true. Databricks is good anyways. Coming from having no idea what’s going on with other cloud products.
the databricks notebook interface was the worst thing i've ever used, but otherwise it's good 😆
Remind me again why to use airflow when you can crontab
And where to run airflow?
I built and ran streamlit and used ct exaclty for this
dependencies between tasks, determining if a task succeeded or failed, monitoring, can be distributed
Is that data analyst or data engineer
Don’t like glue for this purpose as u can’t easily clear old files out
Where does airflow actually excecute
data engineer usually handles this stuff, but data scientists might write individual airflow tasks
My company gave me da title and I did this work, lol
just a webserver, or you can pay a company to host airflow for you like aws
So, not an Ubuntu instance
yes, that would be fine
you can run it on your laptop
So it’s similarly done as in, you run it as a cmd
Do u need to launch it like spark or does it run natively bash
I’m guessing u have to start it up
bash needs to be "started" too
yes, airflow is an application and you need to run it
I like how I, a second rate analyst made a bootleg etl pipeline as I went along
Following zero best practise
I hosted my dash on heroku
And sent that shit refreshing on a vm lol
Had no idea just winged it
a crontab entry is a lot like an airflow task. cron is a lot like airflow in that it runs continuously, and runs certain tasks when certain conditions are met.
Maybe my future lies in de not ds….
frankly, you'll find a job faster in DE
there's more demand for de than for ds nowadays, and lots of aspiring ds people are flooding de job applications trying to get in the door
I’d catch way less flak too - people almost have a break down when they hear I didn’t study maths past school and still work on ml pipelines
a good data engineer needs to know some data science stuff anyway
This is interesting
almost every company could benefit from a data engineer that can also do some data analysis as needed
So I’m a analytics engineer
a data scientist/analyst without a data engineer will end up being an ad-hoc data engineer anyway a lot of the time
ok, i shouldn't say most companies
but companies that are looking to build a data team basically need: 1) a ds lead, 2) a data engineer, 3) a business/data analyst to build dashboards and stuff while (1) figures out models and (2) figures out the data warehouse
It wud be vastly more easy for me to be a DE and drop my evening maths studying for my DS work…
I’d free up alot of hours
the math can't hurt, but honestly yeah
it's probably easier than self-studying math tbh
The main thing is exposure in the work place builds it passively
self-studying math in particular is hard
I’ve noticed this to be true. Especiallly frustrating at times
I did somewhat underestimate learning calculus and linear algebra within a year, simply because there’s things that need to come before that I’ve forgotten since school
I refused to move forward until I find myself doing well on the precalc tests
And that took literally months
Defiantly not enough time for both that and a new programming language
this was an image taken straight from the data fashionmnist website
it was one of the testing images
i tried shirts, shoes,
nothing works
initially i didnt have this but someone said put it so i did, it made 0 diffrence, so i kept it in, it doesnt work with, or without
yes, i found it. hmm.
but yeah, there is no inversion necessary. earlier with the numbers your input image was inverted so you had to invert it again. but the dress.png is correct as it is.
it should always be a white object on black background.
with white i mean something like 1.0 or 255 and with black i mean something like 0.0 or 0.
when you've taken an image straight from the training/test data set it's already perfect.
but for aesthetic reasons (black on white) sometimes they are displayed with inverted colors.
Hello guys. I'm attempting to use catboost to build a classification model using UFC data. I'm trying to figure out the best way to scrap data from the UFC website to find the fighters style. I only want to scrape data from active fighters. https://www.ufc.com/athlete/aljamain-sterling for an example of the page layout. Would the most efficient way of doing this be to scrape every UFC fighters name and then format it into a url? Thanks

Aljamain “Funk Master” Sterling is an American professional mixed martial artist and the UFC bantamweight champion. Get the latest UFC breaking news, fight night results, MMA records and stats, highlights, photos, videos and more.
guys, i am trying to train the random forest model using a historical dataset. Then, now i wanted to predict the outcome of the users' input using what i have trained the random forest model. How do i do that?
model.predict(new_data)
https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestClassifier.html#sklearn.ensemble.RandomForestClassifier
scikit-learn
Examples using sklearn.ensemble.RandomForestClassifier: Release Highlights for scikit-learn 0.24 Release Highlights for scikit-learn 0.24 Release Highlights for scikit-learn 0.22 Release Highlights...
the new_data do i need to make it into a dataframe? since the new data is coming from wat the user input
Yeah it needs to be in the same format as data the model was trained on
same format as in same number of column or same type which is a dataframe?
The same features, so the same type, the same transforms applied. I think latest scikit learn ver models accept pandas so could be pandas
the dataset used pandas dataframe to train and there are 10columns, however the newdata im going to predict will be 3columns.. thats fine right?
Data to predict on must be the same shape as train data
So if you trained on 10 features you need to give 10 features for model to predict
All transforms like standardization, outliers removal etc needs to be applied in the same way as to train set
ok thanks for the help
Not sure but this repo may be interesting to you https://github.com/WarrierRajeev/UFC-Predictions/
GitHub
A web app to predict UFC fights. Contribute to WarrierRajeev/UFC-Predictions development by creating an account on GitHub.
Determine if News is Fake or Real by Urkchar
https://www.kaggle.com/code/urkchar/determine-if-news-is-fake-or-real/
I'd love to hear some feedback on this notebook that I wrote.

Explore and run machine learning code with Kaggle Notebooks | Using data from Fake and real news dataset
Interesting. Do you have link to some data on that? And about which job pays more? 😅
This might be obvious, but have you tried data augmentation, like doing random horizontal flips to increase the sample size?
Also, you mentioned that it's overfitting on some of the characters (like the MC). In that case, maybe you should stop and ask what you're actually trying to do... from the looks of it, you want to generate a new character or, to be more specific, generate the face of a new character in the ATLA style. In which case, maybe first clustering the faces (with a model/or by hand) and using that as one of the inputs for face generation could help (I'm just shooting ideas here).
it's actually underfitting which seems to be the problem
data augmentation is on by default in stylegan which helps some
but my goal is essentially this

GitHub
Contribute to RyanWu2233/Style_GAN2_TWDNE development by creating an account on GitHub.
a model that produces clear character faces, but generalizes across all avatar characters
the underfitting produces images like these

some of which could barely be considered images of humans
overfitting only happens when I reduce the dataset size dramatically
from that guy's github
"The virtual Waifu pictures are generate by AI using NVIDIA famous style GAN2 algorithm. The training set is composed of 2500 images generated by TWDNE website. Resolution of each image is 512 x 512."
Are you using a pre-trained model? Cause I don't think avatar style could be considered similar to eastern anime (it is on some level, but it also has western elements).
stylegan comes with links to pretrained models trained on large datasets of human face photos, metropolitan museum of art faces, and animals
I've tried training from scratch, as well as retraining the human faces and the animal models
retraining any model seems to converge pretty quickly to the same sort of thing
Isn't this a problem? I agree, doing it from scratch would be worse.
what do you think the problem could be?
that ryan wu guy trained his to that level of quality with just 2500 images
idk. You gotta keep trying I guess. I'll come back to you once I read some papers on the topic.
2500 seems a decent number, I think going over that would make it worse. The model just needs the right types of inputs and maybe a better loss function.
after 16 hours of training from scratch I got this
but that was on a dataset of only 800

I think that's called mode collapse?
haha
I've got 1900 now but I'm not sure I'll get much better training from scratch. worth a shot though, computer's got nothing else to do while I sleep
I feel like it'll get weirder with more abstract images, but sure you can give that a shot.
For now, I'll try downloading the package and running it locally, and stepping over the code to see how they actually implemented that.
does this really not come with a paper?
that's just someone's github. stylegan3's paper is here https://nvlabs.github.io/stylegan3/

ty. Wait, nvm, that's just the style gen model.
wait what were you looking for
like a cartoon-specific model, with style gen or any other framework. Just wanna see their transformations and hyperparameters.
this talks about it some, but sadly I don't think he goes into detail about his hyperparameters

I describe how I made the website ThisWaifuDoesNotExist.net (TWDNE) for displaying random anime faces generated by StyleGAN neural networks, and how it went viral.
thanks again, I'll come back to you once I find something useful.
thank, I appreciate you!
The moment when you question your entire life and research because results do not seem to make sense
Seeing these mfkers

Guess who thought this would mean 1198
me when I accidentally prove waves do not decay ever
yesterday while running feature extraction on video with 950 000 frames i slowed down server by utilizing 303GB, i wanted to know following:
considering there is 250 gb free memory(500+ total) and how much can i use without slowing down the server.
And, Even after using garbage collection what can cause memory usage to rise steadily?
Is there a way to just trigger a jupyter notebook (lets say example.ipynb) from another notebook(main.ipynb) so that all the cells are run in the original file (example.ipynb). %run won't do this as it will just list the outputs from example.ipynb in main.ipynb. What is the alternate solution?
Like, you want the cells to update in that notebook? Huh, interesting. Maybe jupyter run can do that, the docs for ipython's %run mention it.
is there any way to that in jupyter notebook itself instead of command line?
you can run console commands via, IIRC, !, so !jupyter run other_notebook should work
I am getting this error:[RunApp] WARNING | Config option kernel_spec_manager_class not recognized by RunApp. Did you mean kernel_manager_class?
NameError Traceback (most recent call last)
<ipython-input-1-31fa03dbdf04> in <module>
3 {
4 "cell_type": "code",
----> 5 "execution_count": null,
6 "id": "c6715233",
7 "metadata": {},
NameError: name 'null' is not defined
Traceback (most recent call last):
File "/home/ec2-user/anaconda3/envs/python3/bin/jupyter-run", line 10, in <module>
sys.exit(main())
File "/home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages/jupyter_core/application.py", line 254, in launch_instance
return super(JupyterApp, cls).launch_instance(argv=argv, **kwargs)
File "/home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages/traitlets/config/application.py", line 664, in launch_instance
app.start()
File "/home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages/jupyter_client/runapp.py", line 108, in start
raise Exception("jupyter-run error running '%s'" % filename)
Exception: jupyter-run error running 'a.ipynb'
huh, wild. That looks like it tried to execute the notebook's source as python code, which it isn't
which is very weird because that's the usage example
https://docs.jupyter.org/en/latest/running.html#using-a-command-line-interface
how can we solve the issue of no kernel name found with papermill?
I’m not sure but I would like to learn to so if u have on @ me
Hey Pythonistas, is anyone aware of a library or even a tool that's able to describe a tabular dataset in normal language after profiling it?
For e.g., if I feed in a dataset containing revenue by country, it generates "This table contains revenue by country". Perhaps a bit of a stretch but I'm wondering if machine intelligence is there yet. I can vaguely recall some BI tool having this feature, but I can seem to find or remember which one it was.
It sounds possible, but I don't see the use case.
you would need to encode the schema of the tabular data as a set of features, and then write natural language descriptions of each table, and then train a NN to learn the relationship.
The use case is for data governance
Profile a dataset -> generate a natural language description -> human uses it to assign a sensitivity classification -> sensitivity classification determines default access privileges
convergent evolution. what do you think about that?

Hey, is anyone familiar with the python pandas library and could maybe tell me why my read_csv(path) does not throw when there are problems with the file format, notably in the file I'm trying to read into a CSV file has a header with n values but the records in the file contain E.g. n+1 values, therefore it should result in a ValueError exception, but it isn't. Pictures are added for clarity. Picture number one contains the file I'm trying to convert. Picture number two contains the code snippet which is responsible for reading the file. Picture number three is the result.
Thank you in advance.



nope, just personal observation
does anyone know how to fix this error? its an error with cv2.imwrite()
cv2.error: OpenCV(4.6.0) D:\a\opencv-python\opencv-python\opencv\modules\imgcodecs\src\loadsave.cpp:737: error: (-215:Assertion failed) image.channels() == 1 || image.channels() == 3 || image.channels() == 4 in function 'cv::imwrite_'
where did you get this dataset? you should describe where it comes from and how it was collected. this is critically important in a data project. the quality of any model is entirely dependent on the quality of the data.
in this case the content of the data is potentially opinion-driven and controversial, which will be reflected in the model output.
yep this is what i was getting at. not at all surprised that this is how the market is going.
what do you mean by this?
like agents have different enviroment types
so if a program uses naive bayes classification would it be epsiodic or sequential
!e ```python
import io
import pandas as pd
buf = io.StringIO("""x,y
1,2,3
4,5,6""")
data = pd.read_csv(buf, sep=None, engine='python')
print(data)
@desert oar :white_check_mark: Your 3.11 eval job has completed with return code 0.
001 | x y
002 | 1 2 3
003 | 4 5 6
interesting. this seems like a bug in the python csv engine @hard wing . i would file a bug report with pandas
actually wait
it might be inferring that the first column is an unnamed index column
!e ```python
import io
import pandas as pd
buf = io.StringIO("""x,y
1,2,3
4,5,6""")
data = pd.read_csv(buf, sep=None, engine='python', index_col=False)
print(data)
@desert oar :white_check_mark: Your 3.11 eval job has completed with return code 0.
001 | <string>:8: ParserWarning: Length of header or names does not match length of data. This leads to a loss of data with index_col=False.
002 | x y
003 | 0 1 2
004 | 1 4 5
yeah, that's what's happening. it's treating the "extra" columns as unnamed index columns
if you pass index_col=False it simply drops the unnamed columns
i see. i don't know about reinforcement learning. naive bayes is a probability model that can be used outside of RL, so perhaps the answer is "neither".
what kind of data are you writing? the error is complaining that the image doesn't have the expected number of channels.
Right well now I'm at least getting realistic values back, I wonder what happened to the error message though, is it the python engine that doesn't have this feature or? Previously I was getting a nice exception with additional information like the line which is responsible for causing the exception etc.
I'd like to terminate because the data I'm going to be using on it is pretty important and has to be in the correct format etc
I.e. none of it can be lost in the process
Appreciate the help btw, been trying to figure this out for a day
i fixed it thans
yes, try removing engine='python'. why do you have it at all? because you want to try to infer the separator?
if the data doesn't have an index column, set index_col=False to trigger the warning and then use a warning filter to convert that specific warning into an exception
Yes, the delimiters are dynamic, known at run-time and the c engine doesn't support infering
!e ```python
import io
import warnings
import pandas as pd
from pandas.errors import ParserWarning
buf = io.StringIO("""x,y
1,2,3
4,5,6""")
with warnings.catch_warnings():
warnings.simplefilter("error", category=ParserWarning)
data = pd.read_csv(buf, sep=None, engine='python', index_col=False)
print(data)
@desert oar :x: Your 3.11 eval job has completed with return code 1.
001 | Traceback (most recent call last):
002 | File "<string>", line 13, in <module>
003 | File "/snekbox/user_base/lib/python3.11/site-packages/pandas/util/_decorators.py", line 311, in wrapper
004 | return func(*args, **kwargs)
005 | ^^^^^^^^^^^^^^^^^^^^^
006 | File "/snekbox/user_base/lib/python3.11/site-packages/pandas/io/parsers/readers.py", line 680, in read_csv
007 | return _read(filepath_or_buffer, kwds)
008 | ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
009 | File "/snekbox/user_base/lib/python3.11/site-packages/pandas/io/parsers/readers.py", line 581, in _read
010 | return parser.read(nrows)
011 | ^^^^^^^^^^^^^^^^^^
... (truncated - too many lines)
Full output: https://paste.pythondiscord.com/ikotapevub.txt?noredirect
it's helpful to know lots of python arcana once in a while!
hi is there a way i can use list comprehension to make the code more efficient?
exact_tp_coords_g, exact_tp_coords_p = [], []
for g_c in g_clusters:
for p_c in p_clusters:
if len(set(g_c).intersection(set(p_c))) > 0:
exact_tp_coords_g.append(g_c)
exact_tp_coords_p.append(p_c)
appending to a list in a loop is very nearly the same performance as a list comprehension
however if you want to use fancy python features, you can write it this way:
from itertools import product
import numpy as np
exact_tp_coords_gp = np.asarray([
(g_c, p_c)
for g_c, p_c
in product(g_clusters, p_clusters)
if len(set(g_c).intersection(set(p_c))) > 0
])
exact_tp_coords_g = exact_tp_coords_gp[:, 0]
exact_tp_coords_p = exact_tp_coords_gp[:, 1]
yeah that bundling vs. unbundling debate. looks like market is moving towards bundling of services atm
or even this:
rom itertools import product
import numpy as np
def check_gp(pair):
g_c, p_c = pair
return len(set(g_c).intersection(set(p_c))) > 0
pairs = product(g_clusters, p_clusters)
filtered_pairs = filter(check_gp, pairs)
exact_tp_coords_gp = np.asarray(map(tuple, filtered_pairs))
Hi! Theres some tutorial or example for nesting groupby in dataframe?
The ide is a to apply sucesive griupby ober every iteration
Thanks, but forgot to mention that g_clusters and p_clusters are of different lengths
Hi I just trained a language model, how to talk with it? It's Bert model
First you need to understand probability, statistics, differential calculus, and matrix multiplication
Ive got a task of identifying different whales and the way I wanted to do it is get cnn to get features and then train decision tree based on that. Now heres the question: would it be critical if whales didnt face the same side? (Some upside down, some with tail to the right side, some with tail to the left)
ahahhaha lmfaooo
what britney spears said. spend a year studying math and coding xD
THEN you will fully understand ML models
Hello, everyone, what are the requirements for someone to learn data analytics using python?
Should have prior knowledge in mathematics and statistics?
First you need to understand probability, statistics, differential calculus, and matrix multiplication
well I guess that's mostly for ML
but yes, you do need to know stats. And you need to understand what different kinds of data are.
I love how u just copy pasted
of each of those areas, matrix multiplication seems to be the smallest/fastest to learn
its literally week 2 of linalg
Can I learn python first then learn statistics later before combining both?
Are calculus, probability and matrix multiplication needed in data analytics?
for ML its related to the models, but youre gona need python, sql and other analysis tools in order to do anything
applied stats is always useful for anything related to analysis
id think that being good at python would make u stand out vs others but thats just an opinion
Hi Nancy, welcome to PythonDiscord. May I ask which country you're from?
To your question...
You don't need prior knowledge on math and statistics before learning python for data analytics. However, it's pertinent to mention that, for you to unleash your superpower as a pythonista in data analytics, you must learn stats as you progress in your journey.
As regards stats, when it comes to data analytics, you'd need to start with
- Measures of Central Tendency
- Probability
- Hypothesis Testing & Statistical Inference
- A/B Testing
- Treatment Effect & Confounding (you might not necessarily need this but it won't hurt to know it)
- Add SQL & PowerBI / Tableau for creating dashboards and you're good to go.
- Last but not the least, you'd need to learn Python for data analytics
All the best in your journey 👍🏾
This is in fact one of the tricks used when performing data augmentation on an image dataset. So, it's not a big deal if the whales aren't facing same direction.
What is the main difference between analytics and data science, that you dont need maths?
What are you trying to build or what project are you working on? In otherwords, on what task did you train the language model? NMT, Text Summarization, ASR, Sentiment Analysis, NLG, NLU, etc
probably start w watching some youtube videos?
PREREQUISITES
Machine Learning is a field of applied statistics & applied mathematics. Our statistical models are then simply implemented through computers. This means to start off, you need to learn prerequisite mathematics and statistics along with have some basic knowledge of python programming.
In particular, you need to learn multivariate calculus, linear algebra and statistics & probability theory.
Calculus
• Stewart - Calculus [Series]
A very standard introductory calculus series
• MIT OCW - 18.01 and 18.02
MIT's own calculus subjects
• 3blue1brown - Essence of Calculus
The one, the only, 3blue1brown's excellent video series. Best complimented by formal course
Linear Algebra
• Strang - Introduction to Linear Algebra
Good intro linear algebra book
• MIT OCW - 18.06 Linear Algebra
MIT's own LA course, taught by Strang
• 3blue1brown - Essence of Linear Algebra
Statistics & Probability
• MIT OCW - 18.05 Introduction to Probability and Statistics
Programming
• MITx on edX - Introduction to Computer Science and Programming Using Python
Excellent introduction to programming
MACHINE LEARNING
Before you start specialising in any particular field, it's important to learn the core theory of Machine Learning for a broad exposure to ideas and techniques that you can likely apply to any field.
Core
• Bishop - Pattern Recognition and Machine Learning
- Also check out Model-Based Machine Learning by the same author
• Tibshirani, Friedman, Hastie - The Elements of Statistical Learning
• ColumbiaX on edX - Machine Learning
SPECIALISATIONS
Computer Vision
• Stanford - CS231n: Convolutional Neural Networks for Visual Recognition
Natural Language Processing
• Stanford - CS224n: Natural Language Processing with Deep Learning
Reinforcement Learning
• Sutton, Barto - Reinforcement Learning: An Introduction
• Berkeley - CS285: Deep Reinforcement Learning
would still work, the product is all possible pairs
well then numpy array stuff might be different
but the idea is that you're looping over possible pairs and filtering them
Data scientists often work with vast stores of raw data, working as investigators to create ways to analyze and model that data using statistical analysis and heavy coding. The goal of their work is to uncover the questions the data can answer. Data science often lays the foundation for further investigation.
Data analysts leverage the modeling of the data scientist to create actionable and practical insights using a variety of tools. The work of data analytics involves using organized data to apply findings immediately.

data analysts look at data and report on data, data scientists do more technical stuff
of course, good data analysts can build models and good data scientists can report to the business
it's more about business function than anything, but data science usually implies significantly more technical skills
What sort of technical skill does DS have that a da wouldn’t
straight-up programming, as well as a more mathematical/deeper understanding of statistics and ml
probably more experience building models and designing project plans
Should a good programmer skip on da?
A lot of these job titles / differences only happen at large enough companies due to corporate structure and just having a lot of employees. They like to have separate people present things to higher up.
depends entirely on your goals @steady basalt
DA and BI is split from DS even at small companies now
usually the DAs build KPI dashboards while the DS build models
I prefer DS or de over da cause I r not once used bi
Yeah they are probably trying to split out the difference between can program and can't program.
As someone who can programme would I be over skilled as a da?
I don’t wish to peruse swe though
that and model building. obviously deep learning has become fairly accessible but you still need to know what you're doing with it
True that! 💯
Maybe, there are other skills, more business oriented. @steady basalt
Maybe sticking to ds and or de is best for my career even if da roles can look attractive and easier
not if you want to go down the DA path. being a good programmer will never be a bad skill around data
I’d suppose I’d be too limited on da path
this. DAs are expected to know the business deeply and might end up in meetings with alarmingly high-ranking people
A DA can insulate the DS from business.
that too
So, DE or MLOps, which one do you prefer most? 😀
MLOps sounds good, but what’s the difference? Is it between DS and de?
That sounds exactly like what I do to be honest, a bit of both but without the formal math training DS ask for
Today I learnt how to solve 10th grade multivariate equations with improper powers 🥹
MLOps / DevOps is like the oil in the engine / a fixer.
They just keep coming up with all these names tbh... I think anyone who's into MLOps can straight up do Data Engineering. I think MLOps is broadly Software Engineering + DE + DevOps but for Machine Learning
DE can be a subset of DevOps / MLOps (same thing?).
The people that make things happen / work out (internally).
Good path?
Don’t see many advertised
Mlops
I beleive my new company will give me the regular “data scientist” role when I ask for it after my 6 month review… probably a good move career wise
Even if I’m not a algebra genius
If your team does not have Ops people explicitly, it will have them implicitly.
Ops is fun and a lot of learning
Hey if a company rents cloud space, what is then the process of data analysis/data flow? how do we clean the data from the cloud? do we store it in a separate RDMS and then analyze the data after? just trying to understand the process
I find this MLOps article from DataCamp quite interesting https://www.datacamp.com/blog/getting-started-with-mlops
Learn about the rise of MLOps and how to get started with a comprehensive set of resources
In my own experience yes the data sits on a database you pull from
Is collected by likely JavaScript devs or whatever they built their platform on
Graphql or some thing
You can technically download it locally using sql queries or just stream it straight over to cloud based tools for analysis
I spent weeks doing just this on Aws
it's probably going to depend on the company, how much money they have to spend on cloud compute, and what compute resources they have as an alternative. One of my projects rents a VM on AWS, and we pretty much do everything for the project on that VM. Ideally, we'd be able to do more work locally, so that we could keep the cloud VM on for less time.
I'm not into MLOps yet so I don't know much about the field. More so, I think most Machine Learning Engineers can do what MLOps guys are doing.
EC2!!
Ster, u guys can just run a lambda to launch the VM when need be
If it’s a specific time
we know what our options are
Hello, I am from Kenya. Thanks for the detailed explanation. Would you mind suggesting any useful course or resources that I might use to learn data analysis. I intend to learn on my own.
Sorry…
Yeah, it's just that someone has to actually extract the value being generated by the rest of the team. Because this is so crucial, it has its own role dedicated to it.
What’s the name for the dev who codes the functions that allow Athena to pull data from a non rdb
it depends on what kind of renting you're talking about. very often you're already storing your data in a cloud platform of some kind, so if you are doing cloud compute you just pull the data from wherever it's already hosted
Cloud engineer?
Another African in the house 🇰🇪 Karibu kwenye PythonDiscord. My swahili is rusty lol but I'm from Nigeria
in bigger organizations it's also there to support the team. running systems like mlflow and even airflow, as well as making sure the data scientists have access to the computer they need
Jambo bwana
Wow are you Kenyan too? You speak Swahili?
No I’m British and we have close ties to Kenya especially in school
Stuff like school building, charity, twin school
@desert oar Can the data already be in a RDMS where it is hosted on the cloud? or is that an additional cloud service that we would have to have that requires more than just cloud storage space?
Cloud services let a company have its data on a rdbs on its own as a service, as well as pure storage
Check out s3 and dynamodb
@steady basalt even if you dont partner w them and just rent space on AWS?
Use this resources https://drive.google.com/file/d/19-LhSy30Pf1zxtk0GCmmevItl_xoob7W/view

Google Docs
Is that a thing? People rent space without partnering for services? In theory yeah nothing stopping u just renting s3 storage
Idk if that’s cost efficient
I guess if u only wanted file hosting
Ohh that's cool. 
I know but like im doing a school assignment where i have to create a process flow diagram as a data analyst and the scenario is that we just rented space on AWS for our applications and databases instead of partnering
As a analyst you’d probably wana use Athena tied with a rdbs
As well as glue between that and potentially quick sight
Or I think quicksight reads it straight up actually
No need for etl
Data stored on rdbs can be queried in sql
But for a DA u may just tell Amazon quick sight to pull data from the DB via Athena and display it
Entirely on cloud, feels very limited but will probably get ur job done
If you just use s3 I’d assume the same is possible but I never did that. You can also use boto3 to read, query and move data
👋👋👋 Another Nigerian here too
Does anyone know if azure sdk has the same abilities as boto3?
Hi D_Lone, Kedu, Bawo ni, Hafa? 😄
I dey o
Wetin dey sup?
@steady basalt How can we do this without using any additional cloud services? can we maybe access data on the cloud, clean it, store it in a seperate RDMS database and then analyze?
Are you into ML Research or Engineering?
Engineering
Hello guys
I'm doing great myself bro.
I'm very new to machine learning and deep learning, can you guide me please?
I have personally never build a rdms on the cloud you’d need software engineer help to get Tyne data from source if its live and not just csv uploads
@craggy shadow
I’d assume that’s largely what cloud use case is otherwise u can analyse locally
What of you, are into engineering or research?
Honestly I’d start by university or something or else projects will become insanely hard to self teach
my project isnt that hard
There’s no way I could have self taught everything from no code, no stats to ds
And I’m pretty resilient
I want to analyse a graph and make predictions
A graph?
Yes, a chart
can i dm you ?
I’m not sure if my account allows it so u can try
check it out
Yeah didn’t work just ask here
But analysing a graph and making predictions may not require me
Ml
And definetley not deep learning
Why not deep learning ?
let's take the sp500 index for example
Hi Artemys, welcome to PythonDiscord. Refer to this #data-science-and-ml message
Additional Resources
-
Mathematics for Machine Learning: Linear Algebra: https://www.youtube.com/watch?v=T73ldK46JqE&list=PLiiljHvN6z1_o1ztXTKWPrShrMrBLo5P3
-
Mathematics for Machine Learning: Multivariate Calculus: https://www.youtube.com/playlist?list=PLiiljHvN6z193BBzS0Ln8NnqQmzimTW23
-
https://www.reddit.com/r/MachineLearning/comments/j4avac/p_i_created_a_complete_overview_of_machine/
If these are overwhelming and you wouldn't mind making a financial commitment to learn ML, then I'll suggest checking out ML courses on any DataQuest, DataCamp, Udacity, or Udemy.
All the best 👍🏾

Welcome to the “Mathematics for Machine Learning: Linear Algebra” course, offered by Imperial College London.
Week 1, Video 1 - Introduction: Solving data science challenges with mathematics
This video is part of an online specialisation in Mathematics for Machine Learning (m4ml) hosted by Coursera. For more information on the course and to ...

YouTube
Welcome to the “Mathematics for Machine Learning: Multivariate Calculus” course, offered by Imperial College London. This video is an online specialisation i...
reddit
718 votes and 74 comments so far on Reddit
not exactly
Then?
The imperial course is absolutely not suitable for beginners, awful
And what graph analysis are you doing?
well, it has to analyse the prices doesnt it ?
I know that the ai doesnt need visual graphs
You want to visualise predictions of stock prices
Engineering & Research but I'm trying to get into NLP Research formally via Graduate School.
If ur brand new to ml this is a very very hard task because I don’t think experts could do it well, but if u just wana see what the output is I’d recommend learning timeseries analysis with python
why would it be hard ?
Because stop prices are effected by so many unknowns
There's an easy way to make it teach itself
its not quite random that is the thing
machine learning will find the patterns that are hidden
No technically not, but you need to understand that random things effect it more than what u can model
bear with me a second, there is 2 ways to teach it right ?
lol I see you bro @serene scaffold 😀
I’ve done time series on blood readings and was fairly straight forward because persons bloods are predictable
either you give it a lot of data and label it like for example show it a dog and label it a cat etc
or you just give it a picture of a dog and let it find it itself by generations
right ?
This is different to predicting totally random stock fluctuations
just bear with me
Because nothing is stopping a whale from making a random buy in and ruining ur pattern
Or a bomb going off somewhere, or a report leaking
yes exactly, but that s the exception not the rule
the rule is simple
No it isn’t
but sometimes shit happens
im saying, that the success rate of an ai that thought itself is much higher than a human
Ur basically saying u want to make something that can inform a trading algorithm
It's not customer-friendly or cool but too advance?
It’s some next level quant man
Yes for a team of experienced quants
without quantum shit
Not with new to ml skills
Why???
because i know it will work
How many data scientists have told u so?
you will see brother
😬
Are u gona sit and buy when ur model predicts a increase and sell before it predicts a drop
If it's as easy as you seem to think.
Don't you think all data scientists would be predicting stock prices and smiling to their banks?
nop, im not gonna do anything, everything will be automated
How?
I have a plan 🙂
What’s the plan
come dm
Just put it here
help me withpython basic syntax please
This is the data science channel. But if you want help, you need to ask an actual question.
what the hell. that's cool. sorta can follow. props
anyone else gone through this? https://github.com/karpathy/nn-zero-to-hero

GitHub
Neural Networks: Zero to Hero. Contribute to karpathy/nn-zero-to-hero development by creating an account on GitHub.
With Reinforced Supervised Learning Using Machine Learning On A Closed System With Say Python, Is It Possible To Link My Library From Google Books And Choose Specific Books By Sequence For The AI To Read And Store It In Memory To Go Alongside Training Data For Such A System Later.
I am trying to have a list as all the values in a df column. But it's not allowing me


Nice data input. You put a lot of thought into it @lapis sequoia
hmm. Is it sarcasm
anyways. The issue is that it's considering the list as a series object rather than something to copy along in all the elements of a series
I wanna turn it off
python?
I use VSCode dark mode so syntax color and wrapping look different from mine. Thanks
it's a jupyter notebook
Oh! That's why. I do everything on a local M.2. So anyways double check your grammars real quick.
what is this error?
ValueError: Found input variables with inconsistent numbers of samples: [106582, 1]
so i was trying to use a trained random forest model from historical dataset [532909 rows x 8 columns]
to predict the user input (so the dataframe will be just 1 rows x 8 column.
however, i am getting this error. anyone know why?
This is a simplified and trimmed down chunk of code I want to run. But it is of course insanely slow. I've a notion to stop using lists of tuples and switch to ndarrays, but I don't see any easy way to reproduce the functionality of more_itertools distince_combinations (or other itertools for that matter) Should I investigate numpy further or tackle this from a totally different angle?
from more_itertools import distinct_combinations as dCombos
from more_itertools import flatten
possExtras = [(0, 5), (0, 8), (0, 10), (0, 11), (0, 19), (0, 23), (0, 24), (0, 31), (1, 5), (1, 8), (1, 10), (1, 11), (1, 19), (1, 23), (1, 24), (1, 31), (2, 9), (2, 12), (2, 13), (2, 14), (2, 15), (2, 16), (2, 26), (2, 30), (3, 9), (3, 12), (3, 13), (3, 14), (3, 15), (3, 16), (3, 26), (3, 30), (4, 5), (4, 8), (4, 10), (4, 11), (4, 19), (4, 23), (4, 24), (4, 31), (5, 17), (5, 21), (5, 27), (5, 28), (5, 29), (6, 9), (6, 12), (6, 13), (6, 14), (6, 15), (6, 16), (6, 26), (6, 30), (7, 9), (7, 12), (7, 13), (7, 14), (7, 15), (7, 16), (7, 26), (7, 30), (8, 17), (8, 21), (8, 27), (8, 28), (8, 29), (9, 18), (9, 20), (9, 22), (9, 25), (10, 17), (10, 21), (10, 27), (10, 28), (10, 29), (11, 17), (11, 21), (11, 27), (11, 28), (11, 29), (12, 18), (12, 20), (12, 22), (12, 25), (13, 18), (13, 20), (13, 22), (13, 25), (14, 18), (14, 20), (14, 22), (14, 25), (15, 18), (15, 20), (15, 22), (15, 25), (16, 18), (16, 20), (16, 22), (16, 25), (17, 19), (17, 23), (17, 24), (17, 31), (18, 26), (18, 30), (19, 21), (19, 27), (19, 28), (19, 29), (20, 26), (20, 30), (21, 23), (21, 24), (21, 31), (22, 26), (22, 30), (23, 27), (23, 28), (23, 29), (24, 27), (24, 28), (24, 29), (25, 26), (25, 30), (27, 31), (28, 31), (29, 31)]
if __name__ == '__main__':
possCombos = [combo for combo in dCombos(possExtras, 16) if len(set(flatten(combo))) == 32]
print(possCombos)
possExtras won't be the same every time, but this is a goor represntation of what I'd be dealing with.
how can i combine the training images and training labels to the testing images because i don't need to testing images anymore?
Why should I install a Jupyter notebook environment on my computer when I can use it online for free ?
easier access
I see ! thanks for answering
any way to auto train a image recognition ml model?
There are tons of no code/low code AutoML services, if that's what you mean.
Anyone,here pls msg me if you have a grip on Anaconda,Gdal and jupyter??
Yes search tutorials for resnet50

What do you need
I've noticed that when conducting a t test using thettest_1samp function from scipy.stats, the p-value is always about 0.004 less than than doing is manually using norm.cdf, is this supposed to happen? I can't figure out what's causing it
They’re not the same calculation?
I'm just beginning to learn scipy and I'm not familiar with what caculation ttest_1samp is doing but for for norm.cdf I used the expected mean and np.std(dataset) / np.sqrt(len(dataset)) for the mean and standard deviation arguments
Right that’s for a normal distribution
T test is for a student t distribution whose tails are slightly heavier

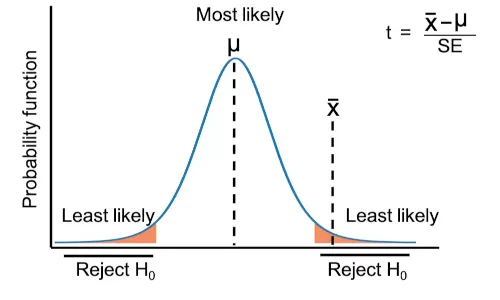
Data science blog
Calculate three types of t-test from scratch
Yes we use heavier tails of t student distribution usually for smaller samples as to not assume too much
okay that's cool. For some reason I always assumed t tests were for normal distributions
Nope that’s a z test
alright thanks for clear up the confusion
hello everyone, I need to do a sensitivity analysis for my results right now
I simulate the day-to-day logistics of offshore wind farm decommissioning in hourly steps
And I want to identify the impact of learning effects, captured through a decrease in activity durations
In your opinion, should I do that in %-steps (like -10%, normal, +10%...) because this is quite hard
Since I run in hourly steps, taking 10% of 33 hours is a bit annoying because I would have to adapt my entire model
Would it in that case be valid to just say (-10 hours, -5 hours, 0, +5 hours, +10 hours)?
Did the definition of sensitivity analysis change with the advent of ML ? My stats tutor had a really different definition
sensitivity analysis in statistics includes studies of curvature of probability density functions
e.g. the derivative of likelihood functions w.r.t. their parameters
So.. in ml it’s like, changing the model output?
that's one way to look at it
to study how much the output changes for small changes in the input
"sensitivity" is a rather broad term, so you find it in different flavors depending on the field
you'll find it being related to robustness (either to randomness or other effects), being "well conditioned", etc.
my best advice is to never do that lol. you see something, you read about it 😛
make sure you know what you're being asked for
I mean the question was just “sensitivity analysis” 5 marks
Half way down the assignment
well, and what did you learn in class about sensitivity analysis
They Didn’t explicitly mention it unless I just missed a week
This was like logistic modelling and linear modelling
And robustness
Or like “good practise” assumptions
there it is, then. robustness is probably what they meant
but yeah, better go review
What is robustness to you
depends on the context 😛 it doesn't matter what "i think" it is
pls guys i need an urgent help??
you have to ask a specific question to get help.
opt = gradient_descent_v2.SGD(learning_rate=lr, decay=lr/epochs)
NameError: name 'lr' is not defined
I got this while performing a chatbot python code,
How to clear this error?
idk what gdal is. my recommendation is to not use anaconda, and to use jupyter sparingly.
you have to define a value for lr. if you're copying from a tutorial, you must have missed the line where it's defined.
Learning rate probably takes a float !!!
@serene scaffold is it more common for people to set a lr variable? I prefer to just code it within whatever I’m making
it's just a matter of preference.
some people like to have all their hyperparameters as "constants" near the top of the file.
Fair, might make it easier to find if it’s a lot of n code
What’s this new harmonic mean joke? Since when is this a hard concept?
is there a way i can speed up the training of a image recognition model
currently using teachable and i have to manually put 800 images in the classes
any help woild be appreciated
use a GPU and use the largest batch size that can fit on the GPU
uh sorry a lil new i am, can you explain it in laymen terms?
a GPU is a graphics processing unit, which is a piece of hardware. But the thing that makes GPUs good at rendering graphics for video games also means that they can run deep learning algorithms faster than a CPU. If you don't have a GPU, there is probably nothing you can do to speed up your training that will make a substantial difference.
you can get some GPU computation for free on google colab.
The point of the batch size, in this case, is to make sure you're always using as much of the GPU as possible.
nono what i meant by training was to upload the images, is there any way to automate that?
upload the images. to where?
hi fellas. Does anyone know of a free to use library to extract text / digits from a picture?
teachable
if you know a better site for image recognition model builder pls lemme know
If I am trying to use q learning for smb1, and I want the ai to pick the action that has the maximum q value, do I need to store all possible actions like (left and run) as one action or(right jump and run)?
is anyone doing project related to deep learning?
yeah I am
on which topic specially?
You have to be more specific before anyone will commit to helping
That guy yesterday is trying to make me build him a crypto predictor @serene scaffold
And won’t tell me his secret method until I do
Said I’d be rich
Just build a model with arbitrary outputs, but with a crash every Tuesday.
Maybe there should be a pin of gambler's fallacy, inverse gambler's fallacy, gambler's conceit, gambler's ruin, and efficient-market hypothesis...
Ahh
Afaik you can't really predict the price of a crypto or a stock cause it's not really just dependent on privious prices
It's dependent on the market, the news, general public intrest etc
There are a bunch of factors other than just price
The information given to the model is incomplete and hence the output given by the model is not better than a 50/50
cringe how he said hes gona put together a team and be rich, and i asked him whats his secret ingrediant and apparnetly i wont know u ntil i finish his work
yeah its not possible, unless we had more undersatanding
I'm not sure if there is a term for this kind of thinking / fallacy, would be nice to have to reference.
Another term for "if it seems easy many have already tried it. How many of them are rich?" would be useful for reference too.
'someone whos never studied data science and thinks they somehow know better than those who have' ?
we can call them ducks
Sort of related to Dunning-Kruger effect.
would you like to write it?
We can call them Ducking Krugers. Or Dunning-Quackers.
tensorflow or pytorch for reinforcement learning?
they're basically the same, but more people are tending towards pytorch.
why's that?
I don't really know.
i've been trying to use tensorflow but i'm stuck with meaningless error messages that are like 8 calls down
tf_agents to be precise
Sorry to hear.
it this an issue with pytorch too?
are you alleging that it's an issue with tensorflow? because it's very unlikely that you've discovered a bug in tensorflow.
its not really a bug its probably somewhere i have gone wrong in my code
its more that the error is thrown in a weird place and is difficult to trace back
what im really asking is does pytorch have better input validation?
That's a great question, but I'm not sure. Sorry I can't be more helpful.
np
this is exactly why britney spears said people tending towards pytorch
what
which one are you talking about
i spent the last hour putting print statements in the tensorflow (tf_agents) code
tf where the guys got a error
honestly if u invest the time to learn pytorch for ur needs i think u wont get this error
ive never done RL tho
use pycharm
ye, pycharm + pytorch is a nice combo
im still not amazing at torch tho, takes a bit of effort to learn
but from what i can do i can feel how its much nicer for coders
if something doesn't take effort to learn, no one will pay you that much to do it.
i wonder if tensorflow will become relegated to a teaching software and pytorch will take over
for production?
i was taught tensorflow through uni
same
i struggled a lot with finding documentation
does it support jupyter notebooks?
yes. but don't give in to the notebook addiction
atm im running a remote vscode connection onto my uni machines (cos they have better gpus)
does pycharm like that?
oh. pycharm doesn't let you do remote notebooks, last I checked. but dataspell does.
I’d still rather use pycharm community than dataspell
I haven't used dataspell
I wonder if you can do remote notebooks if you use gateway
Why are notebooks so popular?
so its a good idea to ditch TensorFlow for what i'm doing and pick up PyTorch instead?
not too sure
they are alright but not revolutionary
Is it just to be able to get bearings of impact and dataframes as you go along?
because non-programmer data scientists get addicted
I mean the pros
what do you mean "the pros"?
U can run changes and see visually at each part
Dataframes in pycharm return as something very ugly in the console
notebook addicts can still be very knowledgeable and deserve top-dollar salaries.
if i was doing something in prod i wouldnt use notebooks
but we all know the real heroes are their ML-ops team
some people don't know that.
@serene scaffold how do you get nice output in pycharm like pretty dataframes that aren’t text based in console
When printed
case in point
I don't know. I only use notebooks when I'm SSHed into my prod VM and I need to make some matplotlib shit
This is one thing I like about notebooks, seeing data nicely at a certain point in code
which u cant rly do in pure ide
ud need to click on 'view df' somewher ein the debugger
well here we go
off to a good start already
Exception: You tried to install "pytorch". The package named for PyTorch is "torch"
wow, suprised that theres an error that can do that
could just download pytorch for me but nah i guess
yeah im downloading it now
probably saving time learning another framework because this isn't the first time that the error messages have been vague
gonna do the intro docs first see if its any good
never used it.
@serene scaffold I don’t think it’s impossible to make a model that could predict if a stock will move up or down the next day tbh
If u had the right data
Wudnt be totally reliable but cud come close
Above 50%
Even 52% wud be good
Have read a couple papers which suggest current work is going to be on incorporating sentiment and more economics
you can't have a model that makes non-trivial predictions with 100% accuracy.
Of course, but you beat 50% and make money
I'm pretty sure most stock trades in the world are AIs interacting with eachother
Obviously retail investors don’t hold all the power to move stocks, but I wonder if a wide reaching sentiment analysis would foreshadow moves
What do you think, @stark mulch?
Yeah, not something you could pull off if you’re not a Goldman Sachs funded lab unless you want to risk losing your savings, but I wonder if such work is being done and informing as of 2022
Not many papers
Meh
Not great
hello!
I'm doing a image classification CNN on the Standford Dog Breed dataset. My model is over fitting. I have a drop out layer, and I am doing augmentation. Model & image transformation code: https://paste.pythondiscord.com/waxokaguru. I can adjust my early stopping but what are ways I can increase validation?

Here's what the dataset loss can be if done properly.

has anyone attempted a dynamic approach to model weight initialisation
like assuming a model was finetuned to dogs and cats, can't i use both the variations to preserve the performance of each model state?
I am asking cause I am working on this topic for my final graduation project.
does anyone knows how to train multilabel multiclass classification?

{kind=link}
I'm trying to make a computer vision for measuring object with a plane/paper as reference on a mobile device, is it possible to use TFLite for this? or is there a straighforward method that I can use?
can you do supervised learning with pytorch?
Hey
Hi everyone, I'm new to matplotlib and would like to know if I can plot such a graph with it. Is there another tool that suits this task much better?

How can i merge two training data sets?
essentially something like this
train_labels.append(extra_labels)```
the images in question are from keras.datasets.fashion_mnist
this is how i am loading the dataa
```clothes = keras.datasets.fashion_mnist
(train_images, train_labels), (extra_images, extra_labels) = clothes.load_data()```would someone recommend me good tutorial about linear algebra 🙂
check out gilbert strang's course on mit ocw
but this sort of stuff requires a book as well. i'd also say gilbert strang's book is good
i second strang book but it gets into the import stuff quite late as you need to cover basis first w vectors n stuff
but thats the kind of book u want to have a second material for such as videos, rather than solo
as it could be hard to do alone
that's a fair assessment. if all you want is to pick up some tools, there are other reads that just present them. this goes more in depth, which requires building up a base slowly
i h ave all linear algebra on hold until 10 months frmo now
im ONLY calculus
not for data science but for general competence
I forgot everything i have learnt at school about liner algebra 😄
if u ddi that in school ull prob recall very fast
As much as we like to say that one needs to know linear algebra, do we really need to know more than general array arithmetic and matmul? because I don't think I've ever used determinants.
it was a long time ago haah
this ^ id feel fine just knowing such basics
my answer would be definitely yes
understanding the meaning of a transpose and a dot product is already super important
on the job? modelling for clients?
I dont think this is also that far into linalg its prety basics no?
that's exactly my point, everything from the very basics to the very end is important
can't very well understand an svd if you don't understand a dot product
and as that's linked to PCA and so forth...
i feel like its the hardest to get your head around in all areas but its also the simplest for some reason
and well, that depends. if you just want to use tools, that's fine. i do need to know all of this stuff in my job, but i understand not everyone does
I was taking linalg in spring 2020. and we all know what happened eight weeks into that semester 🙈
simplest/easiest but hardest to understand in the first place
i dont know
dropped?
@wooden sail no crown. my point is that I probably need to review at some point.
the best part is that linalg isn't even about matrices and "vectors" as arrays of numbers, so it generalizes quite far
i put a crown cuz corona means crown
ah right. in the US, we pretty much only call it covid
here covid start the nationwide lockdown end of march
uni shut down
do u guys still remember how to simplify surds
like cubed roots and stuff
do you have an example? i don't know the word "surd"
like
what is cubed root of 80 in simplest terms
then u say its cubed root of 10 times cubed root of 8
therefore answer is 2root10 or something like that
I've never heard of a surd either.
that's fine, i just didn't know that word
surd is where you have irrational number
like u cant just turn it do wn to a integer
yeah this took up 2 hours of my day last night
good old days

if you're given numbers, you usually try building something out of the prime factors
factoring took up 1 hour of my day
why?
i was going throgh this 7 hour algebra video
because i forgot a bunch of rules that basically made clac harder than it should be
like rationalising
exponents
etc
also cause its kind of fun
hey guys
i dont' have enough DevOps/MLOps knowledge here
my workflow with an IDE is a lot better than using the web ide on google colab. Can i still train a model on a cloud service but develop locally?
i'm guessing i need to deploy an app right?
i develop on a mac so no GPU. Testing locally is a pain
what IDE are you using?
and is your objection to colab the overall experience, or specifically it being a notebook environment?
yes, you'll need to run your code using ssh or equivalent
if your IDE supports remote editing, you can edit the files directly over SSH. otherwise you can write a script that runs your code by first rsync-ing it up to the cloud machine, and then invoking the run/train/whatever program on the cloud machine
e.g. you can put this in cloudrun.py:
#!/usr/bin/env python3 -u
import subprocess
import shlex
import sys
if __name__ == '__main__':
# These are example values :)
remote_user = 'user'
remote_host = 'cloudhost.example.net'
remote_path = '/path/to/cloud/working-dir'
if remote_path[0] != '/':
remote_path = f'/{remote_path}'
rsync_target = f'{remote_user}@{remote_host}{remote_path}'
rsync_cmd = ('rsync', '-av', './', cloud_target)
subprocess.check_output(rsync_cmd)
ssh_target = f'{remote_user}@{remote_host}'
cd_cmd = f'cd {shlex.quote(workdir)}'
remote_cmd = shlex.join(sys.argv)
remote_script = f'{cd_cmd} ; {remote_cmd}'
ssh_cmd = ('ssh', ssh_target, remote_script)
subprocess.check_output(ssh_cmd)
the -u option to python prevents buffering, so you see output exactly as it's produced (rather than buffered and shown to you in chunks)
you could of course build a fancier CLI around this and/or use env vars for setting things like the remote username
omg is it just me or am i finding that meme more and more relevant?
I'm trying to build a chatbot
Wdym by develop exaclty?
Also the new macs can handle deep learning decently fast
Sounds like your solution is to just develop locally and copy paste to cloud to train
Run as a python script on a gpu cluster ?
Can you guys suggest me somr good sources to learn and get into DS?
What skills should i have? I am good at python and knows somewhat pandas and numpy.
!resources data science
Resources
The Resources page on our website contains a list of hand-selected learning resources that we regularly recommend to both beginners and experts.
tensor(3.0404, device='cuda:0', grad_fn=<NllLossBackward0>)
tensor(3.1936, device='cuda:0', grad_fn=<NllLossBackward0>)
tensor(3.3188, device='cuda:0', grad_fn=<NllLossBackward0>)
tensor(3.5685, device='cuda:0', grad_fn=<NllLossBackward0>)
tensor(3.0136, device='cuda:0', grad_fn=<NllLossBackward0>)
tensor(2.9961, device='cuda:0', grad_fn=<NllLossBackward0>)
tensor(3.2644, device='cuda:0', grad_fn=<NllLossBackward0>)
RuntimeError: CUDA error: device-side assert triggered
CUDA kernel errors might be asynchronously reported at some other API call,so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
These are losses. I figure this means the gradient exploded?
Sure, if I post it here at some point then you can pin it if you want. I don't actually know how to write posts on discord with blank lines (as in the other pins) without using the triple back ticks.
If you hold control while you push enter
Testing
I mean shift + enter
I have a quick question about updating a dataframe column based on a value in an adjacent column
can you do print(df.head().to_dict('list')), give the text, and explain what is wanted?
I have a Description column and based on certain descriptions, I'm trying to update the category column
def consolidate_subscriptions(self) -> None:
for sub_cat in TransactionExtractor.subscriptions:
self.transactions.loc[self.transactions['Description']==sub_cat,'Category'] = 'Subscription'
Actually, let me paste a screen shot, that isn't formatted well
@shadow flower please follow the instructions in my previous message before you continue.
I will not accept a screenshot.
Okay
@shadow flower I will wait up to two more minutes for the result of print(df.head().to_dict('list')) as text. (where df is the dataframe in question.)
I'm trying to update it, the code was being used to process input and was being passed along somewhere else
Is there something you don't understand about what I have asked you to do?
{'Date': ['2022-11-10', '2022-11-10', '2022-11-09', '2022-11-09', '2022-11-09'], 'Description': ['PECO Energy Company
111022', 'Spotify', 'Hotel Shocard', 'Hotel Shocard', 'Walmart'], 'Original Description': ['PECO Energy Company 111022', 'SPOTIFY 877-778-1161 NY', 'HOTEL SHOCARD NEW YORK NY', 'HOTEL SHOCARD NEW YORK NY', 'WAL-MART #2167270 INDIAN EXTON PA'], 'Category': ['Category Pending', 'Subscription', 'Hotel', 'Hotel', 'Shopping'], 'Amount': [-92.43, -14.03, -500.99, -225.09, -184.92], 'Status': ['Pending', 'Posted', 'Posted', 'Posted', 'Posted']}
Thank you. Bare in mind that I asked for this over five minutes ago--next time, please have it ready when you send your first message.
Can you explain what you want to do, without using any code to explain it? @shadow flower
Who understands fuzzy c-means algorithm here?
Yeah, the Description column contains descriptions that should be in the subscription category. They are being id'd as internet category
I'm trying to update them to be of category subscription
You're more likely to get help if you just ask your whole question all at once. Put yourself in the shoes of a potential answerer and answer all their clarifying questions that you already know the answer to.
So I'm effectively trying to update category column of rows containing a specific description ie. a row with spotify in the description's category would be relabeled subscription
Can you type what you want the expected output to be exactly for these rows?
Description Category
0 PECO Energy Company 111022 Category Pending
1 Spotify Subscription
2 Hotel Shocard Hotel
3 Hotel Shocard Hotel
4 Walmart Shopping
I forgot the rules
The question is simple, can fuzzy c-means algorithm be used on one dimensional dataset?
can't find any information about it in the internet
So every data point is just one number, basically?
yes, i have frequencies, i want to cluster them.
I know it can be done with k-means but didn't find anything about fcm
Spotify was already labeled correctly in this dataset, but there are others where it isn't and the code that I have to update it isn't working

@heavy vessel in principle it should work. here's a visualization.
the data just exists on one axis, but you can still have clusters based on gaps in the data points
My apologies.
there's probably a more elegant solution than what you're currently doing
In [89]: df[['Description', 'Category']]
Out[89]:
Description Category
0 PECO Energy Company 111022 Category Pending
1 Spotify Subscription
2 Hotel Shocard Hotel
3 Hotel Shocard Hotel
4 Walmart Shopping
In [90]: descriptions_to_change = ['Spotify', 'Walmart']
In [91]: df.loc[df['Description'].isin(descriptions_to_change), 'Description'] = df['Category']
In [93]: df[['Description', 'Category']]
Out[93]:
Description Category
0 PECO Energy Company 111022 Category Pending
1 Subscription Subscription
2 Hotel Shocard Hotel
3 Hotel Shocard Hotel
4 Shopping Shopping
Yeah, actually, that is better than how I did it
I honestly not quite understand fcm itself and how to implement its algorithm with pythons.
Is there any documentation on how to do it?
Thank you so much for the help
or, if the list is actually the ones you don't want to change, you'd do ~df['Description'].isin(descriptions_to_keep). note the ~
do you just need to be able to know what the fuzzy clusters are, or do you actually need to implement the whole algorithm?
i tried to use some libraries and use my dataset pops errors all the time. In short, very much confused. :/
Based on that yeah i might need to implement it
which libraries?
Thanks for the help @serene scaffold !
i didn't find anything in sklearn and i saw github repo and didnt work
https://github.com/ranjiGT/Python-Hackerrank/blob/main/Fuzzy-c-Means.ipynb

GitHub
HackerRank practice solutions. Contribute to ranjiGT/Python-Hackerrank development by creating an account on GitHub.
Hi, I need some help making sense of some code. All I want is pointers into what to look into. Blunt question: what does this code do? It's for pytorch. Suposedely it's a custom autograd function, but looking into this tutorial (https://pytorch.org/tutorials/beginner/examples_autograd/two_layer_net_custom_function.html) I can't understand the backward method. Apparently f_forward and f_backward are functions accept and return torch tensors as well
def make_pat_func(f_forward, f_backward):
class func(torch.autograd.Function):
@staticmethod
def forward(ctx, *args):
ctx.save_for_backward(*args)
return f_forward(*args)
def backward(ctx, grad_output):
args = ctx.saved_tensors
torch.set_grad_enabled(True)
y = torch.autograd.functional.vjp(f_backward, args, v=grad_output)
torch.set_grad_enabled(False)
return y[1]
return func.apply
Please don't ask people to read screenshots of text.
!code
Here's how to format Python code on Discord:
```py
print('Hello world!')
```
These are backticks, not quotes. Check this out if you can't find the backtick key.
oh, my bad. 1se
try sklearn-extensions. you're right that sklearn itself doesn't have it
This library i think is outdated
I am getting this error even though it is in docs
module 'sklearn_extensions' has no attribute 'fuzzy_kmeans'
sorry, fixed some issues regarding this library imports.
What now, i tried this example, did i do it right with the 1d data? it seems not in my opinion, i am passing 2d array but each of it has on value.
np.random.seed(0)
batch_size = 45
centers = [[1], [-1], [-1]]
n_clusters = len(centers)
X, labels_true = make_blobs(n_samples=1200, centers=centers, cluster_std=0.3)
kmeans = KMeans(k=3)
kmeans.fit(X)
kmedians = KMedians(k=3)
kmedians.fit(X)
fuzzy_kmeans = FuzzyKMeans(k=3, m=2)
fuzzy_kmeans.fit(X)
print('KMEANS')
print(kmeans.cluster_centers_)
print('KMEDIANS')
print(kmedians.cluster_centers_)
print('FUZZY_KMEANS')
print(fuzzy_kmeans.cluster_centers_)
Output
KMEANS
[[ 0.9914344 ]
[-1.25156362]
[-0.79159916]]
KMEDIANS
[[ 0.9805198 ]
[-1.23923844]
[-0.85981725]]
FUZZY_KMEANS
[[-1.22482642]
[-0.75778351]
[ 1.00747844]]
scikit-learn k-means treats each row as one "data point", and each column as one "attribute" of that data point. so a 2-dimensional array with 1 column is completely valid input.
Thank you! 🤝
note that pretty much all machine learning algorithms are set up to work this way mathematically. so pretty much all machine learning code will be structured similarly.
Hi I have a question, epochs in training args in transformer are responsible for training time?
like more epoch, the better model but it takes more time to train?
all neural network models have "epochs", not just transformers. and essentially yes, an epoch is one complete pass over the training data. more epochs means more passes over the training data, which generally means that the model fits closer and closer to the training data each time.
sometimes you can overfit to the training data, which means that the model only works well on that specific dataset but doesn't work well on other datasets. there are many solutions to handle overfitting in machine learning, and one of them is "early stopping", training the model with fewer epochs.
ok thanks
Plotting a Bar plot where x - axis has multivalued values. So I am trying to get a bar plot that looks something like the image posted down below. I have managed to extract the required values in a form of pivot table but i can't seem to figure out a way to plot it using the seaborn library any help would be appreciated
Code Snippet:


the 2nd example looks like exactly what you want to do
the one that says "Add a second layer of grouping:"
oh ty I will definitely check that
i just searched "seaborn barplot" on duckduckgo 🙂
learning to search for things will save you a lot of time
pytorch 1.10.2 uses cuda 10.2 but idt geforce 3080's supports it 😔
does anyone know if 3060's support cuda 10
you might be able to find the right wheel for your (torch-version, cuda-version, python-version, OS) combination here: https://download.pytorch.org/whl/torch
if that's the GPU you have, do nvidia-smi to see what CUDA version it is, and make sure there's a wheel for it before giving up.
i looked into it like an hour ago
i saw a solution to use docker
b/c cuda is backwards compatable it's just that there's weird stuff
Can't Build Pytorch from Source on my MacOS, can someone guide me through the process?
does anyone know how I could fix
File "/home/user/HiFi-GAN/utils/train.py", line 87, in train
step)
File "/home/user/HiFi-GAN/utils/validation.py", line 25, in validate
sc_loss, mag_loss = stft_loss(fake_audio[:, :, :audio.size(2)].squeeze(1), audio.squeeze(1))
File "/home/user/.local/lib/python3.6/site-packages/torch/nn/modules/module.py", line 1102, in _call_impl
return forward_call(*input, **kwargs)
File "/home/user/HiFi-GAN/utils/stft_loss.py", line 130, in forward
sc_l, mag_l = f(x, y)
File "/home/user/.local/lib/python3.6/site-packages/torch/nn/modules/module.py", line 1102, in _call_impl
return forward_call(*input, **kwargs)
File "/home/user/HiFi-GAN/utils/stft_loss.py", line 91, in forward
sc_loss = self.spectral_convergenge_loss(x_mag, y_mag)
File "/home/user/.local/lib/python3.6/site-packages/torch/nn/modules/module.py", line 1102, in _call_impl
return forward_call(*input, **kwargs)
File "/home/user/HiFi-GAN/utils/stft_loss.py", line 46, in forward
return torch.norm(y_mag - x_mag, p="fro") / torch.norm(y_mag, p="fro")
RuntimeError: The size of tensor a (151) must match the size of tensor b (146) at non-singleton dimension 1```
Using https://github.com/rishikksh20/HiFi-GAN on commit 7c049f9Read my last few messages about downloading the right wheel.
could you tag me there?
also i am building from source
@thorn bobcat
Hey @woeful hedge!
It looks like you tried to attach file type(s) that we do not allow (.log). We currently allow the following file types: .gif, .jpg, .jpeg, .mov, .mp4, .mpg, .png, .mp3, .wav, .ogg, .webm, .webp, .flac, .m4a, .csv, .json.
Feel free to ask in #community-meta if you think this is a mistake.
Hey @woeful hedge!
It looks like you tried to attach a Python file - please use a code-pasting service such as https://paste.pythondiscord.com
Hey @woeful hedge!
You either uploaded a .txt file or entered a message that was too long. Please use our paste bin instead.
@serene scaffold thing is i'm trying to build from source
Why can’t you pip install or conda
i am so good at this 🧌

to run my AMD graphics card..
Why?
Wait are you sure u can’t just install it like a cuda gpu
I’d assume torch has support
seems good enough..

It is but u can also get much faster
What’s the error when u pip install?
Does rocm not work
i want to use my macos
dont wanna change my os
also i didn't pip install it, i downloaded it and then followed the guide on pytorch github
Or metal?
but still didn't work..
Metal is a Apple api
metal is too slow..