#data-science-and-ml
1 messages · Page 20 of 1
I mean, pandas for one is literally a dataframe library, that data structure sounds familiar?
sure - I just want to make sure I'm using/learning the language in the most efficient manner
for example I spent 2 years doing datascience in R without learning about the tidyverse, which I guess is the R equivalent of pandas
can someone recommend me soft or basic introduction to machine learning videos/tutorials?
you can check sklearn's MOOC or Andrew Ng's Machine Learning Specialisation course on Coursera, or look at our other !resources on the website
!resources
Resources
The Resources page on our website contains a list of hand-selected learning resources that we regularly recommend to both beginners and experts.
what's the relevance of the intercept method in linear regression
Hello there I'm looking for some datasets for some reinforcement learning models I'm working on, does anyone know any sites that have some datasets I could get? paid resources are fine I'm just looking for some places to download datasets for different models
idk if there are many specifically for reinforcement learning, but do check out Kaggle if you haven't yet
https://wesmckinney.com/book/ book from creator of pandas. Also free online.
my friends
this just came out recently

super duper valuable if your job responsibilities include deploying models

https://course.fast.ai/ starts high level, but also goes deeper later

A free course designed for people with some coding experience, who want to learn how to apply deep learning and machine learning to practical problems.
More of a general question, but I'm trying to find the usage differences between numpy's vectorize and frompyfunc
From what I'm seeing, ufncs are numpy functions that operate element by element for an entire array
vectorize is a ufunc-based class that applies some given ufunc across the provided iterables
and frompyfunc is a function to create a vectorized ufunc
Is that all correct?
hi there. I am building a search engine based on tf-idf and want to use cosine similarity for the query. Based on my understanding, say that a query "apple and orange", the cosine wants me to have a vector of tf-idf for each word in the query. What I don't get is what vector of tf-idf do I need to get for the documents I want to compare? Just the word "apple", "and", "orange" or the whole words that the document have.
Why do I need auto grad for a NN? For back prop I’m just doing a couple gradients but they are easily done by hand and it’s not like they are ever changing so I can just hard code 4 and not ever need it
and what is tensorflow used for in a real neural net
you can, but what if you modify you network and make it very complex. a lot to calculate by hand. check this great video from andrej karpathy https://www.youtube.com/watch?v=VMj-3S1tku0
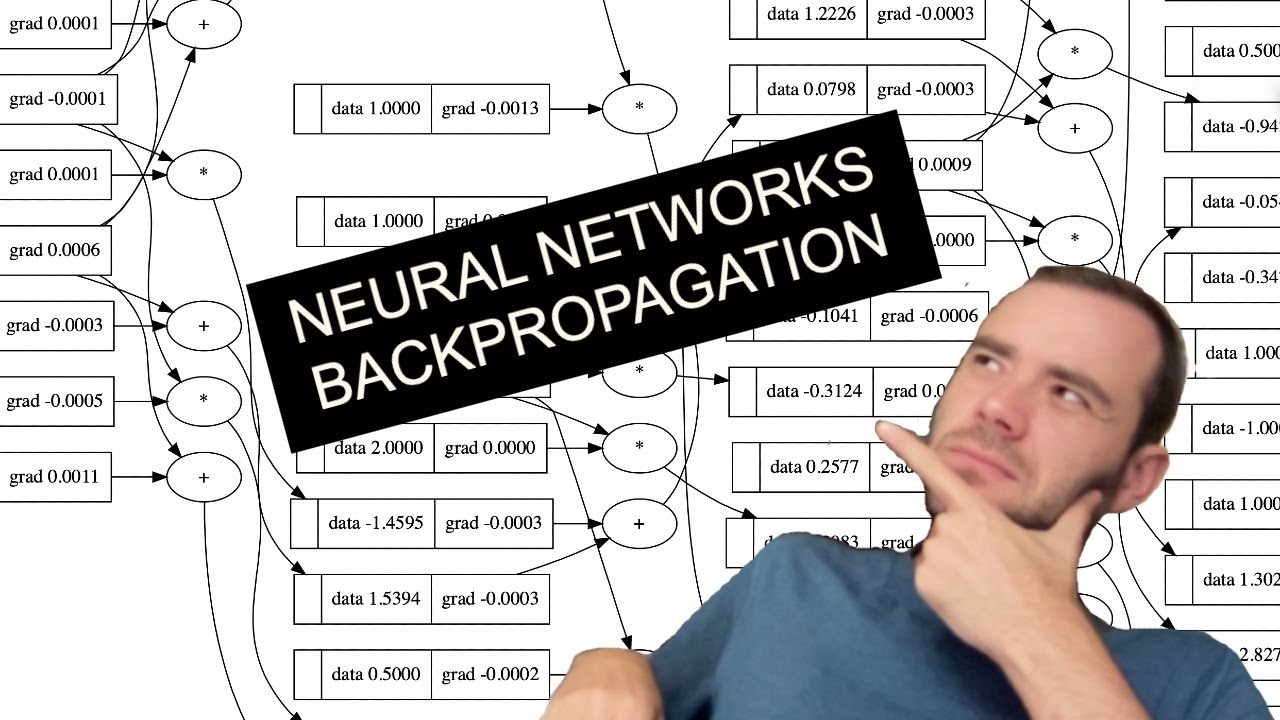
This is the most step-by-step spelled-out explanation of backpropagation and training of neural networks. It only assumes basic knowledge of Python and a vague recollection of calculus from high school.
Links:
- micrograd on github: https://github.com/karpathy/micrograd
- jupyter notebooks I built in this video: https://github.com/karpathy/nn-z...
how would making it more complex cause the need for auto diff
it is still using the same actiations
Sure don't use it. It's not mandatory 😜
its clearly a used tool, im trying to find out how/why its used
Autograd keeps track of operations performed and will auto calculate gradients needed for backpropagation to adjust the weights.
so will a simple class declarion
If you have time watch Andrejs video.
Can anyone recommend a library for AI?
scikit-learn or tensorflow. Depends on your use case
For data preprocessing, im trying to convert the date-format
dd/mm/yy to dd-mm-yy in one particular column in excel using py.
I tried using the .replace([‘/‘],’-‘)
But this isn’t working. What else can I do.
I got by with that book. Van der Plas is was one of the core dev's of Scikit-klearn.
https://composingprograms.com/
https://learnxinyminutes.com/docs/python/
Depends on how much programming you want to learn.
Learn Python the hard way was good. Someone will need to reconfirm.
also can someone know some simple projects to start learning about ai?
Thanks - I looked at the reviews on Goodreads and it seems even recent reviews say it's a good resource
I downloaded data science from scratch but it seems a lot of people say it's only good for learning why libraries work the way they do, and doesn't actually tell you about how to get the most out of them
Hey guys.
I'm making a model to predict the weight of oxen using a neural network. I made the input as follows to simulate the image and the real weight of the animal.
I'm having trouble creating the model, I've already tried some close to what I wanted but I didn't have results.
X_train = np.random.randint(256, size=(10, 720, 1280))
Y_train = np.random.randint(100, size=(10))
X_test = np.random.randint(256, size=(10, 720, 1280))
Y_test = np.random.randint(100, size=(10))
X_train = X_train.reshape(X_train.shape[0], 1, 720, 1280)
X_test = X_test.reshape(X_test.shape[0], 1, 720, 1280)
X_train = X_train.astype('float32')
X_test = X_test.astype('float32')
X_train /= 255
model = keras.models.Sequential(
[
# Dense(32, input_shape=(1, 720, 1280)),
# Activation('relu'),
# Flatten(),
# Activation('relu'),
keras.layers.Dense(units=1, input_shape=(1,720,1280))
]
)
model.compile(optimizer='sgd', loss='mean_squared_error', metrics=['accuracy'])
model.fit(X_train, Y_train, batch_size=1, epochs=100, verbose=1, validation_data=(X_test, Y_test))
The model is wrong, because I'm just showing the structure of the input for you to understand..
Could anyone explain neural networks to me? (ive tried googling it before lol, understood nothing.)
Did you watch 3b1b's NN video?
preferably using common english vocabulary, I'd like to know a scenario where it would be useful, how its better than another option, and the step by step process it works through
idk
actually that thumbnail looks very familiar
i might have.
ill watch it
actually thanks @shell crest this one image just explained the whole thing to me XD

lmao
here's what i got from that one image, say it's recognizing the number 2, it could start by seeing it's characteristics. like it has a flat line, it has a flatish curve at the top, and it has a diagonal line, it could go into those 3 nodes which would be algorithm, and then maybe slowly get closer to a number, like look at how 5 and 7 and 2 have a flat line
and how 7 2 4 and 8 have diagonal lines
and then it can slowly say "no it's not that number
cause thinking how we understand the 3, it's essentually, a line with 2 curves, so the program would have to comprehend that data to classify it as a 3
wdym by that?
I think you could transform of input weights into whether a neuron is doing edge detection, but that IMO is not at all obvious
input weights
so you're saying that it actually goes through all the nodes and has like a score on how much it resembles each characteristic?
maybe?
okay i know im using the wrong word
just pretend im using the right word lol
i think i know where a neural network could be useful though
lets say you're trying to identify a person, and they are like a black male average height
would a neural network process that like this?
white- 0.01 short - 0.5
black- 0.99 tall-0.5
or something like that
to eventually figure out what describes a certain thing, in this case a person, and in the videos case numbers, the best?
Alright, I still think it is in some weird abstract way, but thanks for telling me about the video
thanks, ill check this out.
oh nice it seems my guess was exactly correct on how it works

Features and Activations don't explain interpretability
The problem with traditional high-performing NN is that you actually don't know what feature the NN is/has found
also @shell crest explanations, i dont think they should always be this specific and precise because if you go into so much advanced detail then it gets confusing. I think it's better to focus on giving an understandable comprehendable base to start from, and then just allow the brain to build off this basic concept and explore into more advanced things over time.
It's not about detail or not
It's much easier to start from a basic concept
I think the cvpr paper is quite readable, and 3b1b's video quite accessible
NNs are made of activations and features, but it is not known what corresponds to what
That's why you can't say
white- 0.01 short - 0.5
black- 0.99 tall-0.5
because this demands an interpretable NN
Let me give you an example, even though he is doing stuff like explaining each and every detail of how the nueral networks, just a simple singular image was enough to get me started and have an idea of how they work, and now i can go onto thinking about how i could use it in a different context, explanations are just best done in 1-2 simple sentences that anyone can understand, and then letting the brain build off from there.
And I'm sure of this because it's actually how I learned how to swim, roller skate, and... something else, i forgot lol, except those learning expiriences were just 2 words, even though it had no detail and i could have completely messed it up and did it the wrong way, just building off that basic knowledge, it went much farther than any swimming class could take me.
I think what I have said so far is short
Well I think the main issue where i didn't understand is the uncommon words.
You can ask about those words. I'm not an expert of NN math and I don't intend to be
like you said demands an interpretable NN, what demands an interpretable NN?
Right
and i really don't have a clue what you mean by edge detection either, what edge?
Interpretable means we know what the neural network is looking for. So if we see certain things like noses, earrings, etc. - that's how humans identify people
But it is not clear if artificial neural networks look for the exact same things. This has issues even if the artificial neural network 'does better' than humans. - if you don't understand your tool, can you really use it?
then isn't that why you code it?
you make it look for what you desire
edges are just lines. they are the boundary of objects
in order to reach your desired outcome
LOL no you only decide an activation function and let the matrix multiplication happen. Then you let it sit there and find the local loss gradient until it converges
most of what I just said doesn't matter, what I'm saying is that you don't actually decide what goes into each neuron
gives 1st place medal
why not?
as I said, it's unsolved lol
what's unsolved?
Why does a neural network work? welll, I don't think any honest answer can say 'we know'
How do we make a neural network such that we know what it is looking for?
also i just wanna note i dont know what an activation function is, matrix multiplication, or local loss gradient
so you can make statements against/for these
don't bother, it's just computation
Isn't it because of the derivatives? 
This is the one you should care about
at it's core isn't all coding and computation a true or false? on or off?
The hot term you're looking for is
https://en.wikipedia.org/wiki/Explainable_artificial_intelligence
Explainable AI (XAI), or Interpretable AI, or Explainable Machine Learning (XML), is artificial intelligence (AI) in which humans can understand the decisions or predictions made by the AI. It contrasts with the "black box" concept in machine learning where even its designers cannot explain why an AI arrived at a specific decision. By refining t...
so doesn't it just decide yes or no, for a lot of possiblities
as I said the code only says how many layers you put out and what mechanically occurs at each stage. This doesn't mean you know what each neuron will eventually do
well yeah you wont know what each neuron will do unless you're just spamming f10 on vscode
or was it f11
indeed, and even after you do so, what's the point?
can you confidently do that for every input to the network?
there is no point lol, you're letting the computer process information faster than u can
but you still design the neurons right?
so you can have a desire for what they will do
well the idea is that eventually we'll find some neural networks that are explainable, and have features we relate to
and an expectation
but the end goal is for the computer to reach your expectations and process it in the desired pattern
not really, at a high level you decide
- architecture (how many layers, and how fat each layer is)
- activation function (function you apply to each layer)
- types of layers
the standard end goal is to see better performance in a very narrow sense of the word
then how does each neuron get designed?
in image classification in 3b1b, the end goal is to correctly classify all digits
lmao, deep question. IDK
so you're telling me it just magically appears
any architecture that does this to 99.9999999999999999% accuracy is considered good, even if we don't know wtf the neural network is doing

welcome to AI, as I said, you're looking for https://en.wikipedia.org/wiki/Explainable_artificial_intelligence
Explainable AI (XAI), or Interpretable AI, or Explainable Machine Learning (XML), is artificial intelligence (AI) in which humans can understand the decisions or predictions made by the AI. It contrasts with the "black box" concept in machine learning where even its designers cannot explain why an AI arrived at a specific decision. By refining t...
isn't each neuron like an algorithm that outputs a result of possibilities
Most AI/ML we do today aren't really explanable. Something works, and someone does the thing that works. Most (all?) people can't explain why
no, that's the whole network. Each neuron does a small thing
@noble zealot You should read this wiki article
hey can anyone help me replicating a GIMP feature in openCV?
I want to replicate the functionality of the "curves" tool provided by GIMP to make this modification on an image. If opencv is not the correct tool what should I use instead. Any suggestions?

lol then there's no point
Me and articles don't get along well unless it gets straight to the point
like Mozillas js documentation, best documentation ive read in my life
and w3 schools... their docs are alright, could use improvement, but surely good.
Actually just read the first-2 sentences in each paragraph
okay here's what i got from the first 2-3
this is how humans think...
"HUH!? HOW IS THAT A 539 IT'S OBVIOUSLY A 2 YOU DUMMY"
anyway sorry, not a CV person here. you could repost later since I think we're drowning your post
and eventually it works after being refined enough right?
This is for #media-processing, but I think openCV and/or pillow should have something in the documentation.
no, humans think if a specific part of the image curves in a certain way, it's a 3. (see the 2 curves in 3?)
if there is a certain orientation an image could be 6. Flip it and you get 9.
ye no worries, I asked like 3 times already ill ask again later
machines are just led to best performing outcomes, even though we don't know the path they are taking to those outcomes
im really dumb can you give me a few key words to search for in the docs. I get lost
and computer things "oooo pixels" so you have to make it understand what a curve is by relativity and angle, by essentially plotting almost a graph with the pixels and converting that into a math equation
kind of like plotting averages on a dot graph
uh, I will not comment on that
an while a computer cant easily understand pixels in 8 possible different spots relative to another, if you convert it into a graph function it can understand it
and that's why on something i clicked on earlier
i saw math.
cv.cvtcolor maybe
awesome ill look into it tysm
Hello, today at work I overhead some coworkers talking about a browser extension that uses a ML language model (bert?) to highlight/summarise websites. It was so early in the morning that I didn't register what they said until several hours later xDD and tbh I dont even remember who they were. Does anyone know about it? I find it quite interesting and might want to give it a try
https://keras.io/api/applications/inceptionv3/
How do I select channel_last format for my pictures in Keras?
hey im trying to divide a series by another series using pandas
TypeError: unsupported operand type(s) for /: 'str' and 'str'
a.div(bc)
example of what 'a' is: a = t_data.iloc[0]
how do I fix this error
hi, what values does a contain? number-looking strings?
a = pd.to_numeric(a) should work maybe...
in case it errors as non-convertable, you can do
num_a = pd.to_numeric(a, errors="coerce")
print(a[num_a.isna()])
```to see which values were nonnumeric, and take action dependingly...with the extra errors argument, nonconvertables will become NaN at the end; then we check from the original series which values caused NaN.
Hii, can somebody explain me when should I use tf and when should I use sklearn?
depends on what you are trying to do
sklearn supports more traditional, relatively simple models
tensorflow/pytorch supports neural networks
Noted, thanks!
I have a dataset thats very imbalanced. How would I go about fixing this?

just multiclass classification?
you can test some different metrics (e.g. balanced accuracy instead of accuracy)
Hello! wanted to Ask how can i change background on plotly since i cant use update.layout nor layout_update
Imagen
https://media.discordapp.net/attachments/705066515761987587/1025601827837841448/unknown.png

im doing very basic ML decision tree: is 60% accuracy rate any "good"?
what percent rate is the threshold for sufficient or viable?
How many classes are there? Because if there's only two classes and they're equally represented, 50% is basically the worst performance, since that's what you'd get by chance.
Depends on your use case.
I've been learning Linear Regression and came across an interesting topic of interaction term
Anyone has ideas on how to identify the columns with interactions??
Hello could someone who has some experience with tesseract dm me, I need some help, thanks.
i have some tesseract experience. but really only a little. if you find noone with real knowledge, dm me then. but again, only worked with tesseract once.
ON ANOTHER NOTE:
I can turn nonstationary timeseries into stationary data by detrending or differencing. But can I turn stationary data into non-stationary data? I know this is a stupid question, but cointegration of timeseries can only occur between nonstationary data. So if I have a stationary timeseries is there a (VALID!) way to turn it into nonstationary data and perform a cointegration test like johansen coint?
Guys am just...frustrated with Data Science cause I feel like am just making zero progress
Am thinking of taking a break from it for a while and learning something else
what are you frustrated with?
I don't know the reasons behind this, but am just not able to think of what to do next while making even simple models
I just don't know
Some might say that it's because I don't have the adequate mathematical knowledge but the things I've studied so far didn't seem to have anything too complex yet
For now I feel like I'll just continue on with my degree and learn all the maths bit that can help in DS through it and mean while try something new in computer science
Yh I shouldn't too ig
I'll follow ISLR as one last attempt
Would just read every topic in it, do every exercise and try to avoid complex shit for a while
ngl i hate reading stuff
Just stick to the basic stuff ISLR provides
Maybe it'll give me an insight
for me, following a book gives me pain
Like I still genuinely think about model building as "isn't this just doing the same old shit again and again?"
rather watch videos and do projects that involve the topics
And I just feel like cause am a rookie I just don't understand the things you can do
that's true too
Videos are easier to follow
yeah, i just cant read books as good as others - wish i could
But the problems with videos is that...it's just the same basic shit again and again
I kinda want to grow out of this
have you looked into mlops?
Uptil now no video felt to teach me something new, ISLR however did teach a lot of new stuff about Linear Regression itself
Nope
What is it?
I have only heard about it but never researched about it cause of just "lack of knowledge"
its about once you built a model, how are you going to make it scalable, how are you going to deploy it, set up CI/CD ... etc
its another side of skills needed for machine learning
So applying your ML knowledge into the real world?
so you could learn that stuff and take a break on the stuff youre doing
I guess that's where the AI bit lies
once you built a model
how are you going to deploy it for use and how are you gonna monitor the model

Coursera
Offered by Google Cloud. Advance your career as a Cloud ML Engineer Enroll for free.
im currently preparing for the google cloud certification for ML, you might be interested in this - teaches you a complete picture for ML
never done it
but people say its really good
and he is the founder of coursera i believe
so it has to be good right
You should always take a break if it gets too much.
I'll just apply for financial aid for the course and see how it goes for now
how much is the course?
Yh maybe but I truly don't want to leave this field without learning anything insightful about it
I've also had this problem. Some youtubers just blatantly copy other people works or websites.
It's pretty heavy
For my country it's about $130 which is a lot
Yh that's why I don't trust YT much for all that, except StatQuest

the first one?
Yh the first one
only 42 pounds a month for me
Yh it's around the same for me too
I've heard you can get financial aid most of the times
can anyone suggest me any good Ml or Ai project?
this isn't really specific enough for us to help you. what is the data? which part are you trying to predict?
so far, we've established that you're trying to do classification. unless you tell us what the data is (what are the columns, and what do they represent), we can't really help you
there's no one-size-fits-all solution for classification. it depends on what the data is.
which is the one you want to predict?
that kinda sounds like something what would take way longer to solve with ML than by hand
unless you have several hundreds of files
ok, now we're talking.
and they all have the same kind of data, with the wrong headers?
??
@paper rover I know you're new to this space, but we're finding it difficult to get information from you. it would help if you say exactly what your data is. What is every single column, what kind of data is in it, and what is missing?
thanks!!! I got it
i need to google... thanks everyone
hey guys, is it possible to find out which month has the highest death rate for clinic 1 or 2 from these data sets? first dataset is monthly deaths, 2nd is yearly deaths

the 2nd data set mentions the clinic, the first does not. So is it possible to infer on which month the death rate was the highest in each clinic?
if there are years where you only have data for one of the two clinics, that would be the only way.
Hello friends! I need help with this Error:
LinAlgError: 27-th leading minor of the array is not positive definite
I am trying to fit a VAR model and I am unable to understand what this means or what I have to change?
I am really at a loss here on how to debug this. I can post full traceback, code and data if that helps and if someone here is willing to help me figure this one out?
can you elaborate on this
you're using a solver that requires your model matrix or the hessian to be positive definite, but it isn't. you'd have to regularize or solve in a different way
also, dumb question but does anyone know the difference between these two? subset_one.deaths.mean() #27 - incorrect subset_one.deaths.sum() / subset_one.births.sum() * 100 #10.52
in the second dataframe, you have (year, clinic) pairs. if there's two clinics, then each year can appear at most twice. but if a year appears only once, then that means that all the data you have about that year is for only one of the two clinics.
okay. how would I get the average monthly value for that
first I would figure out if you even have years where there's only data for one clinic.
because if data is present for both clinics for every year, then you're kind of SOL.
nah present for both
so, for every year in the second dataframe, there's always a value for both clinics?
yeah
then there's really no way to work backwards. you have no idea for which month the death rate is highest for each clinic, and there's no way to figure it out.
wait, what is pct_deaths?
the monthly avg of the deaths
you mean, the percentage of births or deaths for that month that were deaths?
that doesn't really help either, unfortunately.
So is it possible to infer on which month the death rate was the highest in each clinic?
did someone tell you that it is?
What is the highest monthly death rate in clinic 1 compared to clinic 2?
Which clinic has a higher proportion of deaths?
is the death rate just your pct_deaths column?
oh
that's different than what I thought you were asking
I can help in like ten minutes
@verbal venture so df2 tells you how many deaths happened in each clinic each year. so take the sum of both clinics' deaths for each year. those numbers are going to equal the sum of the number of deaths for each year in df1
do you follow?
hmm, come to think of it, I think you still have to assume that the distribution of deaths between the two clinics is the same within a given year
does the question say that you're allowed to make that assumption?
Oh shit, I remember you. AI linguist guy - what was sent above was literally all that was provided. But yeah, let’s say we can make that assumption
you can use the first DF to calculate what percentage of annual deaths happened during each month, and you can use the second DF to calculate what percentage of annual deaths happened in which of the two clinics (so one might be 40% and one might be 60%, for example.)
can you think of what to do next?
Can someone help me with pyqt? there #help-lemon PLS!!!!
Please don't cross spam for your question
It doesn't even relate to this channel
Oh, sorry. I won’t, anymore
@worldly dawnwhere can I ask for help?
I know it. I created the channel with my question. However, what should I do after?
you wait 😉
I really need an answer)
I understand and appreciate your situation. However this is a volunteer driven community. So no one is due anything. Sometimes people may not be around or may not know the answer or may be busy or not interested in answering a specific question.
This is not a reason to go around in random channels and spamming people. If anything it will motivate them to not help you
ok
patience is key
Does anyone know the difference between these averages? subset_one.deaths.mean() #27 - incorrect b = subset_one.deaths.sum() / subset_one.births.sum() * 100 #10.52
the question was # What was the average percentage of monthly deaths after handwashing was made obligatory?
how do i get the wights fro the weights or group_weights parameters of Pool()?
wowwwwww
huh, that was a year ago?
xP, did not notice it
stelercus are you familiar with catboost?
people like to talk about GPT-* like it's the be-all-end-all of nlp
and it's not.
u.u
The power of marketing. Most of the cool stuff going on is still mostly unknown despite the internet being a thing now (the search engines don't seem to be helping at all with this, they have other priorities).
(Although idk if it's just me, but search engines seem to have gotten worse when it comes to finding actually useful information)
I find that google typically gives me better results than whatever the default browser in my linux desktop would give me, but you do have to wade through all the sponsored results, which is disappointing.
Hey guys
anyone knows how to predict different depended variables on the basis of one independent variable
Hi guys, is it possible to use K-nearest neighbors algorithm for real-time object detection? I'm searching the internet but can't find anything about it.
I'm thinking of training a model using KNN for image classification and will just manually create an algorithm for the sliding box to detect such objects on a image, but I'm thinking that can be very lousy solution (or maybe I'm wrong). Thanks!
im trying to implement kmeans clustering from scratch to seperate the lesion from the the image using 2 k clusters. .but the black corners keep getting added to the cluster with the lesion

can anyone guide me about how i can remove the black corners and only get the lesion
I'm thinking of findContour() of OpenCV, use the RETR_TREE for hierarchy and just select the content inside the circle.
due to this being a homework task i cant use the functions from opencv
have to manually manipulate the image using pixels
Guys, quick question about Conv2Ds:
If I use kernels that are too big, will I have a greater chance of having vanishing gradients problem?
Hey, is there a way to plot the decision boundary for Logistic regression which has more than 2 coefficients?
I've noticed that most NNs use kernels of size around 3, 4... I've been testing a neural network with kernels like 51, 101 because I didn't want to add that much layers.
And exploding gradients have been giving me quite a headache. Even when I use residual blocks
Im reading the book called "Introduction to Machine Learning with python"
Input:
prediction = knn.predict(X_new) print("Prediction: {}".format(prediction)) print("Predicted target name: {}".format( iris_dataset['target_names'][prediction]))
Output:
Prediction: [0] Predicted target name: ['setosa']
what does 0 means in here and how code knows the name setosa
can someone explain
It doesn't
The code tries to predict the correct index for your class. And then you simply matches the index the model predicted with your class list
If you have something like
classes = ("Class1", "Class2", "Class3")
If you use print(classes[1]), it'll return "Class2".
If you would use print(classes[predicted]), since predicted = 0, you would get "Class1"
The same goes for the iris dataset, which is in a pandas DataFrame, if I remember it right
oh I see thank you
Are you allowed to set a region of interest and then crop the image?
hey I have a question
so I'm training an MLP classifier with 6000 images, but originally I set my batch size to 64, which made the model not even finish 1 epoch in 3 hours
what would be a reasonable batch size for this
I am using adam solver and relu activation
and learning rate of .001
Maybe you should use smaller images
Or review your architecture
6.000 isn't that much, and 64 as batch size isn't that big, depending on your GPU
Use GPU
import tensorflow as tf
print(f"TensorFlow version: {tf.__version__}")
I just installed CUDA Toolkit 11.7 but I still get this warning.
2022-10-02 20:58:06.071163: W tensorflow/stream_executor/platform/default/dso_loader.cc:60] Could not load dynamic library 'cudart64_110.dll'; dlerror: cudart64_110.dll not found
2022-10-02 20:58:06.085819: I tensorflow/stream_executor/cuda/cudart_stub.cc:29] Ignore above cudart dlerror if you do not have a GPU set up on your machine.
I have a CUDA-enabled NVidia GPU on my PC so I'd like to use it.
What did I do wrong?
I'm using it with scikit learn which has no gpu support
hi guys, so I'm trying to deal with this project and I'm not so sure what's the best approach:
I have the monthly internet usage of a variety of mobile phones for 7 months only and I want to apply a model that will predict the usage for the next month based on what I have.
The thing is, I don't think it makes sense to consider every row to train a model, since each row is a complete different client and they have complete different actions. But also, I can't run a model on a single row for every row in the dataset (not sure if that's possible or would be optimal, since there would be no way to split into different sets)
Right now the only way I can think of a solution is to use the first 6 months as X, and the last month as y to see how accurate a model would be. But still, it doesn't make sense to run the model on the whole dataset.
Any suggestions?
Recurrent Neural Networks (RNNs) are designed for time-series predictions, you can look into using such models
Why not to yse lib with GPU support. That's how training is done



import keras
import numpy as np
input1 = keras.layers.Input(shape=(1,))
input2 = keras.layers.Input(shape=(1,))
merged = keras.layers.Concatenate(axis=1)([input1, input2])
dense1 = keras.layers.Dense(2, input_dim=2, activation=keras.activations.sigmoid, use_bias=True)(merged)
dense2 = keras.layers.Dense(1, activation=keras.activations.relu, use_bias=True)(dense1)
model = keras.models.Model(inputs=[input1, input2], outputs=dense2)
model.compile(optimizer='sgd', loss='mean_squared_error')
model.summary()
x1 = np.array(
[5,6,7], dtype=float)
x2=np.array(
[2,3,4], dtype=float)
xarr = np.stack([x1, x2], axis=1)
#y = 2x + 3y
ys = np.array(
[16,21, 26], dtype=float)
print(ys)
model.fit(xarr,ys, epochs=100, verbose=0)
print(model.predict([3,3])[0][0] )
print(model.predict([2,3])[0][0])
Simple NN to predict linear formula y = 2x + 3y
i am trying to give two inputs to the model, but it is throwing out error saying that only one input is given
Someone Familiar with tensorflow/keras please help
Also #🤡help-banana
Okay what do you think your input is here? as far as I can tell, there is no comma around the input
How hard it is right now to get a part time / remote job as a first experience with a Data Analyst / DS role (aside an internship) in Europe ? Is US job market accessible ? (Either as internship or contract) (looking to work with my competence aside study)
I wonder if the numbers were actually encoded as strings
also, you need to show the dataframe again in order to see if your line had any effect.
Anyone know how to translate sql to nosql query
Or experience replicating it including “joins”
Best idea to select entire tables and join w pandas?
hello, has anyone here ever used SimPy?
it's best to ask your actual questions, rather than ask if anyone knows about a question you haven't asked yet.
what is the nosql in question?
pandas is very sql-like. it's basically in-memory sql.
I have already coded a full simulation, but it does not run after a specific state, but always takes different time steps (so the weather in my model is checked after a full execution of a task which for example takes 27 hours)
In reality, the weather should be checked continuously while the task is executed. I do not know how to implement that and found SimPy so I was wondering if it allows you to keep on doing stuff while constantly checking for something else on the side
I don't have alot of CS or python knowledge, so I can't figure a way to do that in my current code
sounds more like you need multiprocessing or multithreading
you said you want to do two things at the same time on the side
Basically the company database is nosql and yet we need to bloody query it for analytics
😅😅
Dynamodb
I’m using boto3 atm
But the current plan requires having local scripts scheduled to run to a) move data to s3 and b) download data to dashboard and data processing scripts which then run locally at scheduled hours to refresh the dash
This sucks. How can I get live integration to the data?
I’m not a backend dev
Why is NumPy vectorize function flattening my array? I want to run some function per every element in my 4D NumPy array. This array contains multiple 3D elements I want to run my function on.
please tell us the shapes of the arrays in question and what the function was. because there's no way to answer your question without knowing what the inputs were and what you did.
Free code camp maybe?
Does anybody generate XML inside files in python? If so, do you have any libraries/VS Code extensions you recommend to make the process less tedious, or do you do it manually?
this is the data science channel. it seems that your question isn't about that.
I want to use it for data science, but if the specific topic pertains elsewhere, I would love to ask there
a general help channel. see #❓|how-to-get-help
It's a bit specific, so it will probably die buried in general help
I'll ask there though
#python-discussion isn't a good place to ask for things. the #❓|how-to-get-help channel describes how to open a help channel for your own dedicated help session.
Me
-
the timeout is 15 minutes.
-
you are welcome to re-post if you didn't get an answer. it's often the case that nobody who knows the answer sees your question. it's always a matter of luck to some extent, as in any help forum or channel. there is no harm or shame in re-posting if you don't get an answer the first time.
-
often questions don't get answered because they are hard to answer. maybe they don't contain enough information (see https://stackoverflow.com/help/minimal-reproducible-example) or contain too much information so that it's difficult for someone to cut to the relevant parts of the question. the #❓|how-to-get-help post contains a lot of advice for asking questions that are easier to answer, including a link to a whole webpage that this community maintains.
-
you aren't entitled to anyone's help; everyone here is helping on a volunteer, best-effort basis. lack of an answer is one channel does not give you any right to post your question in channels where it's off-topic.
I would pin this if it were in a more general channel. 🙏🏻
use docker
in all fairness, it is extremely interesting and extremely unexplored
No wonder there's a huge research effort and entire communities around it. It's not transformers per se, but all the subtle mathematical ways via which they can be manipulated and rewritten.
haha, that's a very subjective take though 😉 How goes your research? Any interesting insights?
is YOLOv7 good for image recognition(1 task) or only object detection?
Yeah, I like very non-incremental improvements and things that are very different (so if you have some wacky ideas / math, I would like to know about it). Research is progressing well, one of the main things is just yet again realizing how good ART is (and the many variants / things based on it, I think it's fair to call it its own branch as this point like how deep learning is its own thing because of how many there are now) and we have been getting results (for world modelling and RL) on a CPU, that are close to that achieved with a Nvidia DGX Station A100 (and also way less time spent training, also it's online learning). I can't say more details without giving away identifying information (or well, making it too easy) and I would prefer to stay anonymous for now.
Yeah, sure
So yeah, ART = good (like really good, and it's still way too unexplored).
Other really interesting things include grid cells (still), and Triadic Memory.
ART? I think some GOFAI people mentioned it - d'you have any handy links?
Honestly, for world modelling and RL, I feel like most approaches are far from being state-of-the-art or general enough for me to appreciate its significance for AGI. World modelling, Diffusion is all the rage - and in all honesty, the results from some of the latest models like Make-A-Video and Dreambooth are quite fantastic with an unexpected amount of fidelity.
As for RL, GATO really showed how powerful Decision Transformers are - and how potentially game changing they can be for RL especially if they demonstrative strong positive transfer at scale. The amount of tasks a simple 1B model can do is just insane to me.
On the Mathy-y side, the Anthropic papers are quite the rage. There's been a huge shift towards intepretabilty, phase transitions in transformers and Grokking (very close to the famous Double decent phenomena) which defy traditional statistical wisdom. And ofc, perhaps hinting how inefficiently we're using these architectures 😉
I feel you're locked in some sort of a competition between some other rival lab and want to minimize and leaked ideas 😄 can't blame you tbh.
does anyone know? For example, if i were to make a program to detect different hand diseases, would i use YOLOv7 or Keras?
DL is definitely using way more than it needs to, but for now they continue to just throw more hardware and more data at it, with some improvements in the more with less department. Their end results still make for good targets/goals though if you are trying to to do more with less. And in inference they are not bad in terms of speed after sparsification, but they are static then, and we are interest in life-long learning (hence online learning via stuff like ART). But they can definitely be used to initialize / give zero shot to an online learner, so we do value them, but for other reasons than usual usage (also the math). We are also heading towards explainable AI, although we find ours already much easier to reason with than DL, but we think we can take it further. We also use the term "designable AI" which is loosely the goal of being to have more exact control over how it behaves without constraining it in a way that locks it into local minimum (too much or maybe even on purpose) and it's also part of it becoming explainable. https://en.wikipedia.org/wiki/Adaptive_resonance_theory https://www.amazon.com/Conscious-Mind-Resonant-Brain-Makes/dp/0190070552
Adaptive resonance theory (ART) is a theory developed by Stephen Grossberg and Gail Carpenter on aspects of how the brain processes information. It describes a number of neural network models which use supervised and unsupervised learning methods, and address problems such as pattern recognition and prediction.
The primary intuition behind the A...

How does your mind work? How does your brain give rise to your mind? These are questions that all of us have wondered about at some point in our lives, if only because everything that we know is experienced in our minds. They are also very hard questions to answer. After all, how can a mind under...
Grossberg and Carpenter are the ART people, we have been in contact and showed them our stuff.
"defy traditional statistical wisdom." - this has been coming up for us for a long time now and it's pretty hard to make some well engineered thing when the math is not already all there yet (DL has this problem too, it's just not as bad as when one makes some very different idea and may not even be sure where to start with the math), but on the other hand, we do enjoy math, so more math to play around with and an excuse to do so.
So stuck between wanting to make something very different, but drifting back towards the more familiar because the math is there.
would anyone like to review my project (its not long at all) and suggest improvements I could've done

GitHub
Building a neural network using TensorFlow to identify different forest cover types. Practice tuning hyper-parameters . - GitHub - kjw009/Forest-Cover-Classification: Building a neural network usin...
nice little project! part 1:
-
you should include a detailed description of how to obtain this
cover_data.csvfile (presumably somewhere from the USFS website?), ideally including a script of some kind that downloads and processes it into its current form -
good job describing each variable in your data set, including units
-
use pandas
Categoricaldtype for things like class labels: https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.Categorical.html. internally it stores the data as int, and you can easily access the int values for putting them into a machine learning model. -
use pandas
booleandtype for yes/no binary values (soil types) -
normally i would say that pie charts are bad, but this "proportion of classes in dataset" chart is an okay use of it
-
it would have been good if you also displayed this "distribution of 7 forest types" the other way around in addition to what you created: one "pie" for each wilderness area, with 7 "slices" for each forest type. consider also a "small multiples" 2x2 grid of bar charts as an alternative that has more fidelity at smaller sizes: https://www.displayr.com/what-are-small-multiples/
-
excellent use of violin plots!
-
i would strongly question the interpretation of the extremes of the elevation distribution as outliers. this is just a distribution with a long tail. consider that elevation is bounded at the bottom. by comparison, if you found one or two isolated aspen stands at sea level, that would be an outlier. i see that you actually dropped these outliers from the data in your pre-processing, which i think is a big mistake, and reflects that you are over-relying on mechanical procedures. domain knowledge always supersedes textbook recipes.
part 2:
-
# We subract 1 from every class value to include 0 as a label for the softmaxyou forgot to actually subtract 1. that said, you could use pandasCategoricalhere and not worry about it. -
it might be interesting to see how well it compares to xgboost, as well as to a smaller neural network with fewer layers/parameters, and even linear regression. it's important to establish baselines!
-
good job with the heatmap of the confusion matrix.
-
did you validate these results manually? i'm surprised to see better accuracy in the test set than in the training set.
-
i don't know if there is currently any research into this kind of thing with neural networks, but in traditional statistics i would be strongly tempted to add some kind of "spatial autocorrelation" into this model: the tree cover type in any cell is almost certainly correlated with the tree cover type in surrounding cells, and the rate of change in tree cover type between cells is probably correlated with the rate of change of other features (elevation, etc). however if the accuracy really is > 90%, then perhaps the gains to adding this to your model would be marginal and only useful if you needed to improve it further (e.g. i see that there is a lot of "confusion" in your model between spruce/fir and lodgepole pine). this will depend a lot on your real-world application. perhaps this could be encoded as a CNN over several "layers" of features (equivalent to RGB in image models, called "channels"), but i'd have to do some research to see what's the established best practice here.
-
consider also that the rate of change of elevation (hillside/mountainside vs flat) might itself be a useful feature.
-
it might also be interesting to look into bayesian machine learning to obtain a probability distribution over tree cover types.
https://arxiv.org/abs/1906.04928 some relevant stuff in here
arXiv.org
With the fast development of various positioning techniques such as Global
Position System (GPS), mobile devices and remote sensing, spatio-temporal data
has become increasingly available...
Hey, I'm new to machine learning (learning by myself). I'm looking into StandardScaling (and scaling in general). I do have a question though regarding this. Let's say my dataframe looks something like this (as an example): py name John Marie AyAyRon age 27 22 69 sex 0 1 0 eyes 2 0 11 In this case, columns "sex" and "eyes" refer to the group they belong to (i.e. 0 for male, 1 for female, different integers for eye colors).
My question is: Is it necessary to scale these categorical/group information or is it only necessary on large data values? (@ me on reply if possible)
help

This is a screenshot of my tensorflow profiling session. Is there a way for me to have lower memory fragmentation? (red line is memory fragmentation)

also is there a way to reduce the peak memory usage? looks like only ~2% of the time i am using 95+% of heap memory
Post it on Reddit, this discord would hardly get you any help you help
Many machine learning algorithms perform better when numerical input variables are scaled to a standard range. The two most popular techniques for scaling numerical data prior to modeling are normalization and standardization. Normalization scales each input variable separately to the range 0-1, which is the range for floating-point values where we have the most precision. Standardization scales each input variable separately by subtracting the mean (called centering) and dividing by the standard deviation to shift the distribution to have a mean of zero and a standard deviation of one
What kind of help do you need?
You can see how i normalized my data using minMax scaler..try

someone searching for a study budy with focus on data science (kaggle)?

OMG THANK YOU!
gonna go through your review once i get home
thank you once again @desert oar
lmao! share me the full source code in Url,
I was just following the tensorflow tutorial in 7 hrs from freecodecamp

in youtube
I'm pretty sure it was the neural networks module
if you can't find it still, I'll get you the link
Was it LSTM or BERT Model they use?
sorry, I've got no idea, I was just folowing the tutorial lol
Image similarities distance .i did some project for a client in Uk

Maybe next time, ask what model they are probably using- it will serve you well because All models have built-in assumptions You need to understand each model's assumptions, and their strengths and weaknesses.
scaling isn't only for reducing the magnitude of "big" values. putting everything on roughly the same scale can be an aid to interpretation and can make it easier for the optimization algorithm to function. scaling age makes sense in this case.
scaling the binary representation of sex is maybe a good idea, but it actually makes the interpretation a little more difficult: you are now talking about hypothetical "deviations from a probability", instead of two actual categories.
under no circumstances should you attempt to scale categorical data with more than one category, like eye color. those integer values are completely misleading, because they don't actually represent numbers with a set ordering, nor do numerical operations on them like taking differences or multiplication have any meaning. ideally you should avoid encoding categorical data as numbers in order to avoid making this mistake! pandas has good support for doing this.
Ah, OK, thank you
pandas has good support for doing this. -- get_dummies()
with what, deep learning methods for spatiotemporal data?
that's one specific way of handling it. i was more thinking that in general you would want to encode this data with string or categorical dtype
yeah, even sklearn is also capable
sometimes assuming i want to do some predictive analysis on a category columnmor somthing

i was more talking about how to encode the data "at rest", starting when you first load it from a file, and before you put the data into any kind of machine learning model
that's where text and categorical data types are useful
onehot encoding and such are all techniques for encoding categorical data numerically for use in a model of some kind
ok, that is nice
I assumed it was because of the dropout layers?
as the cause for the train set acc being lower than the test set?
yes, that's possible. you should debug by disabling dropout just to make sure!
note also that usually it's not a great idea to use the "validation" set from your model fitting process as your final accuracy. in this case it's ok, but if you perform any parameter tuning or feature selection against that data, you've already "burned" that data so to speak and it's no longer a valid approximation of out-of-sample data
hello everyone
i want to ask for references that i could read for week-of-month forecasting, since its very scarce cases for this one
what do you mean by week-of-month forecasting? are you talking about forecasting with monthly cycles?
in weekly cycles, but the week cycle i used is not a week in year, but week of month
said i have data from 1st week of January and i want to forecast information for 2nd week of January
and when the data reached end of month (last week of January) it will be used to forecast 1st week of February
what happens if the week is only 2 days at the end of the month?
it sounds like maybe you want two "levels" of cycles, both weekly and monthly
i have considered that problem
maybe i will try an weekly approach from daily data then using two levels forecasting
hey guys
ok so i have this code to generate this (here's the code: https://pastebin.com/KjqMcZfd)

but now i want to add to the figure

something alike (putting a circle over the squares) and highlight every degrees shown above
0
45
90
etc
is it doable on python, if so any help appreciated as i have not a single clue how to make this up
hmm. that sounds an awful lot like a Hopfield network on steriods. You say it performs well for RL?
Also, atleast from the wiki page I can't help but draw all the similarities to attention - the comparison field can be represented as a scaled matrix product, the lateral inhibition created by the recognition field is similar to a softmax operation, the vigilance parameter are the final attention matrices (where that threshold is applied to the FF layer after) - the search procedure is what stands out though.
This is interesting as this line of work alone could be used to spin of variations of attention itself.
Lastly, that search procedure stage has quite some similarity with gated mixture-of-experts style architectures - except we don't explictly code s.t the gradients affect particular subnetworks depending upon the confidence level (i.e we don't weigh some threshold, after which its decided that some relatively untouched subnetwork gets assigned this weird class - that routing mechanism is learnt, which may be a factor for improving performance compute wise with explicit hardcoding)
I had a variation off MoEs of my own - its quite a lengthy and convoluted operation, but it makes sense theoretically. I'll post it someday if I get down to actually write it properly rather than disjointed discord threads 🙂
like this

i see thank you
can anyone explain sytnax + ML wise what's going on with these first 3 code bits?
data += 0.5 * noise data[::2] += 5 * noise[::2] data[::4] += 20 * noise[::4]
Can someone explain me what are custom types and how they can be useful?
https://docs.flyte.org/projects/cookbook/en/latest/auto/core/extend_flyte/custom_types.html
this is adding noise to the data, and doing so in a special pattern
presumably there exists a noise vector which is scaled by 0.5 and added to the data. next, dada[::2] is using slice notation to make changes to every other sample, so all even samples are modified to now have 5.5 x the noise (since we add 5 x the noise on top of the original 0.5)
lastly, slice notation is used again to add even more noise every 4 samples
for some kinds of noise, this type of multiplication in front is equivalent to changing the noise variance
like so:
In [32]: import numpy as np
In [33]: import matplotlib.pyplot as plt
In [34]: x = np.arange(0,100,dtype=float)
In [35]: y = 3*x + 5
In [36]: noise = np.random.normal(loc=0, scale=4, size=len(x))
In [37]: y += 0.5*noise
In [38]: plt.plot(y)
Out[38]: [<matplotlib.lines.Line2D at 0x1e2ce5bbd30>]
In [39]: y[::2] += 3*noise[::2]
In [40]: plt.plot(y)
Out[40]: [<matplotlib.lines.Line2D at 0x1e2ce5e8070>]
In [41]: y[::4] += 6*noise[::4]
In [42]: plt.plot(y)
Out[42]: [<matplotlib.lines.Line2D at 0x1e2ce581e50>]
In [43]: plt.show()

you can see there are clear noise spikes here and there following a particular pattern
thanks for the explanation! what's the relevance of adding noise to a sample? is that a testing sample? and why specifically to every 2nd or 4th element, and why 5x the noise or 20x the noise?
i have no clue, because you gave no further context. this alone means nothing
it's just a particular noise distribution with a special covariance matrix
the importance comes from the interpretation. even though the quantity is random and called noise, just from those 3 lines you can't even tell if the target is to estimate the noise or to denoise the data. there is no significance in the data itself, but rather in the context around it
Trying to rename my headers for a 1D dataframe but the numerical headers are staying. I don't see anything wrong. Here is my output from print(df.head().to_dict('list')) and the code to rename my headers
{'N-protein spiked lysate - Input': [25564], '40uL + Aptamer flth A': [12132], '40uL + Aptamer flth B': [12587], '40uL - Aptamer flth A': [19856], '40uL - Aptamer flth B': [20392], '60uL + Aptamer flth A': [10432], '60uL + Aptamer flth B': [10117], '60uL - Aptamer flth A': [17904], '60uL - Aptamer flth B': [18839], '80uL + Aptamer flth A': [8260], '80uL + Aptamer flth B': [7885], '80uL - Aptamer flth A': [16364], '80uL - Aptamer flth B': [10854], '40uL + Aptamer wash #1 A': [649], '40uL + Aptamer wash #1 B': [575], '40uL - Aptamer wash #1 A': [807], '40uL - Aptamer wash #1 B': [769], '60uL + Aptamer wash #1 A': [1315], '60uL + Aptamer wash #1 B': [594], '60uL - Aptamer wash #1 A': [1921], '60uL - Aptamer wash #1 B': [514], '80uL + Aptamer wash #1 A': [524], '80uL + Aptamer wash #1 B': [515], '80uL - Aptamer wash #1 A': [834], 25564: [689], 12132: [288], 12587: [190], 19856: [220], 20392: [167], 10432: [97], 10117: [77], 17904: [185], 18839: [49], 8260: [190], 7885: [182], 16364: [106], 10854: [184], 649: [39293], 575: [29479], 807: [3982], 769: [3478], 1315: [55517], 594: [47794], 1921: [8238], 514: [3414], 524: [45480], 515: [61068], 834: [10099], 689: [15114]}
My code for renaming the headers is
'25564': '80uL - Aptamer wash #1 B',
'12132': '40uL + Aptamer wash #2 A',
'12587': '40uL + Aptamer wash #2 B',
'19856': '60uL + Aptamer wash #2 A',
'20392': '60uL + Aptamer wash #2 B',
'10432': '40uL - Aptamer wash #2 A',
'10117': '40uL - Aptamer wash #2 B',
'17904': '60uL - Aptamer wash #2 A',
'18839': '60uL - Aptamer wash #2 B',
'8260': '80uL + Aptamer wash #2 A',
'7885': '80uL + Aptamer wash #2 B',
'16364':'80uL - Aptamer wash #2 A',
'10854':'80uL - Aptamer wash #2 B',
'649':'40uL + Aptamer Elute A',
'575':'40uL + Aptamer Elute B',
'807':'40uL - Aptamer Elute A',
'769':'40uL - Aptamer Elute B',
'1315':'60uL + Aptamer Elute A',
'594':'60uL + Aptamer Elute B',
'1921':'60uL - Aptamer Elute A',
'514':'60uL - Aptamer Elute B',
'524':'80uL + Aptamer Elute A',
'515':'80uL + Aptamer Elute B',
'834':'80uL - Aptamer Elute A',
'689':'80uL - Aptamer Elute B'}
df.rename(columns = headers,
inplace=True)```I truncated the part that occurred before the problem but that part of the code looked and functioned fine
I'm working with Pandas
sorry, can you explain this slice? it keeps turning an index out of range error
can you post what you're doing?
::n downsamples by a factor of n and it is computed automatically, it shouldn't give any errors
playing around in the compiler to see what it's doing
a = [i for i in range(1, 101)]
b = [i for i in range(1, 20)] #increment by 4
a[::4] += 20 * b[::4]
that fails because they're not the same length. the problem is not the slicing
you can't assign an array of one length to an array of a different length
if I make them the same length it throws me the same error
show
a = [i for i in range(1, 101)]
b = [i for i in range(1, 101)] #increment by 4
a[::4] += 20 * b[::4]
ValueError: attempt to assign sequence of size 5025 to extended slice of size 25
!e
a = [i for i in range(1, 101)]
b = [i for i in range(1, 101)] #increment by 4
a[::4] += 20 * b[::4]
@wooden sail :x: Your 3.11 eval job has completed with return code 1.
001 | Traceback (most recent call last):
002 | File "<string>", line 3, in <module>
003 | ValueError: attempt to assign sequence of size 525 to extended slice of size 25
I got the same error - 5025 was from other code
i do wonder what this is doing, since these are lists and not numpy arrays as were presumably used both in your original example and in the example i gave you
yeah I'm just testing it out so I guess it operates differently between list and numpy arrays?
super differently
for one, 20*b[::4] is not scalar multiplication, it makes 20 copies of the list b[::4]
that's where the length of 525 comes from
haha yeah
i never remember what exactly lists do when you call +=, if it makes a copy or not, but anyway, this is entirely different from the matrix operations that numpy does when using the same syntax
it adds it to the end of the list
you can probably never append to a slice of a list
but anyway, so in numpy it downsizes by the step provided in the slice, and replaces it ?
!e
a = [1,2]
a[::2] += [1]
@wooden sail :x: Your 3.11 eval job has completed with return code 1.
001 | Traceback (most recent call last):
002 | File "<string>", line 2, in <module>
003 | ValueError: attempt to assign sequence of size 2 to extended slice of size 1
yes
www.mlpredict.net Here I share these artificial intelligence models trained by me, with sets of data taken from Kaggle. I try to deploy them for easy use, so that anyone can put their data in the different models and get a clear result. So you have a small taste of the potential of handling the data with machine learning algorithms. for the moment the models only have a didactic use since the data sets are few to give highly reliable results.
You can think of it as a sort of "hard" attention mechanism. However, there are variants that soften it a bit too (ART is more of an umbrella term at this point). One can be make a transformer-like system with it (if you are interested and end up making one, please let me know). What we have now though we find better than transformers (only works well with the stability given by something like ART and sparsity) (it's not a recurrent network either, it's our own unique thing, but I can say that if you read Schmidhuber's papers for alternatives to recurrent, you might stumble upon a similar idea). The reason it's "hard" is to enforce sparsity ("hard sparsity" (it's never dense at any point, even in training)) of some amount and network stability so it can do incremental/online/life-long learning (see stability-plasticity dilemma & catastrophic interference), which also has the side effect of making it run very fast (ART's hidden layer(s) is a sparse representation, and later variants make it a sparse distributed representation (SDR), which has very nice properties (nice math)). It does perform well for RL, including online RL, but this is ongoing for us (when it comes to online RL (or online tasks in general), I have not seen better). It also has been scaling well for us (both up AND down (runs on embedded / good for robotics, but also on a bunch of GPUs)).
TLDR: ART is unexplored and can be related back to "attention". If you read Grossberg's book, it covers many of these sorts of insights (not a connection to transformers specifically, but ideas like attention in general) (has been working on it for decades and it's biologically plausible / very biologically inspired / book covers biological implementations).
*Transformers being as widely applicable as they are makes them kind of relate to everything, they get a lot right (closer to biological systems (directly, but also emergent (the better they perform the more they tend to mimic biology in many ways (e.g. mimicking grid cells (which the neocortex may be doing too))))).
"I had a variation off MoEs of my own - its quite a lengthy and convoluted operation, but it makes sense theoretically. I'll post it someday if I get down to actually write it properly rather than disjointed discord threads" - I would love to read it.
ART does sound promising in that respect; I'd have to read that book sometime - it seems quite interesting. I definitely agree with you there about the applicability of ART towards transformers - a hybrid can allow for multiple properties. However, I still doubt its expressiveness is on par with transformers, atleast for now. It would definitely learn basic patterns quickly and effectively, but that is an advantage boasted by multiple biologically inspired architectures. I suppose a more geometric approach can be taken with ART (if it hasn't been done already) the additional interpretability here is quite nice though.
Definitely - I take you say Jean Remi-King's work in comparing brain activations and DL models' activations? I wouldn't go as far as to say that these models are definitely mimicking the brain or other biological mechanisms - yet it is quite an unexpected and surprising phenomena; One'd would think models so diverged from their biological counterparts wouldn't show any similarities at all.
The original ART algorithm is very old and the systems built with ART / variations of it / the main idea of it are much better and can learn more than basic patterns. The convergent behavior of biological systems and non-biological is a hypothesis with some evidence to show it, but holds more when it's already more similar to the biology, like Transformers. I do not expect it to mimic all of biology, both because there are parts that are just an implementation detail due to constraints of how the biological systems were made and also just because it's not the same thing, just similar in part.
(It can make for a nice way to find out what some good universal and simple ways of doing things are (when both some artificial system and biology converge to the same/similar thing (it's often something more fundamental drawing them both to it, something in the math / physics) (e.g. grid cells way of encoding position))
(e.g. grid cells relation to Gaussian processes)
(And Kolmogorov complexity)
Oh yeah, someone made a survey for a bunch of ART based methods: https://arxiv.org/pdf/1905.11437.pdf
I can give you a tl;dr here - basically, its a bunch of stuff together to alleviate multiple problems simultaneously. MoEs suffer from heavy gradient issues, especially when training from scratch where experts selected may disrupt gradient flow for other experts who may be slightly better at their task thus inhibiting them.
My idea in a nutshell is for w warmup steps, one shares parameters of every corresponding expert on the dataset s.t they aren't independent until they have a better initialization much closer to a local optima and are similar to the ideal manifold; The core idea however is to model n experts in L layers as modelling a Gaussian distribution over n*L trajectories. Thus, rather than choosing an independent subnetwork at each layer whose representations may or may not align with other experts, you choose a certain sequence of experts across the whole network. Thus if you chose that 'trajectory' again, you're effectively picking the same network again with no difference - allowing for a much smoother gradient flow throughout the different trajectories, which don't have to worry about their experts being replaced.
So you have only a single router in the entire network to route through the trajectory of experts it sees fit.
The Gaussian's parameters would have to be trainable ofc; and you sample top-k trajectories as normal.
Now here comes the next part - every often so steps, you 'sync' parameters. i.e, every m steps you accumulate the gradients you calculate and average them.
Then, you apply those gradients to the experts weighed by the router distribution (The Gaussian) Effectively, its to protect against catastrophic forgetting. By averaging gradients, you do the naive trick where trajectories most commonly called upon become more general (as they're weighted in a manner to allow for a stronger averaged update) while less common trajectories (those specialized to tasks who benefit little from generalist knowledge) don't have their precious parameters disrupted to a large degree.
Those m accumulated gradients would be decayed by some hyperparameter to ensure that as the training goes own, experts become incentivized to actually specialize. I don't expect experts to be as discrete, as one for mathematics and one for handling Reddit shitposts, but that demarcation allows for implicit data filtering - namely 4chan shitposts would be forced upon a few experts preventing other specialized experts from going too far from their distribution.
So in a nutshell, providing resistance to catastrophic forgetting, introducing implicit data filtering, allowing for more specialized experts, and encouraging well behaved gradients (to an extent) and allowing experts to collectively pool their knowledge and divide it into parts to aid transfer learning (* to an extent, but atleast beter than vanilla MoEs) all in one stroke.
It's not going to be the next AGI 😉 but I feel like its going to be a decent first paper when I start my undergrad. I suppose that's what all freshmen like to think anyway.
Ok, that was a little long for a tl;dr, but atleast you get the gist.
Also, https://www.youtube.com/watch?v=Nf-d9CcEZ2w&ab_channel=Google actually visualizes trajectories very well..

Subscribe to our Channel: https://www.youtube.com/google
Tweet with us on Twitter: https://twitter.com/google
Follow us on Instagram: https://www.instagram.com/google
Join us on Facebook: https://www.facebook.com/Google
We did something very similar to pathways years ago (and prior to that, pretty much exactly pathways). We no longer use it, but if I were still into purely DL, I think it would be the best way forward. It's a very good first paper (and maybe think about what happens if you were to use ART to choose the trajectories, since ART is stable (same inputs, same trajectories) and learns very fast, especially in the beginning when it populates all the initial categories... wink).
(Choosing what parts to train (and which to leave alone to be stable / non-interference) is kind of what ART is all about (answering the question of how the brain learns so many tasks without disrupting existing knowledge))
*The explainability of routing methods is another potential paper.
My life would have been so much easier if I took maths as an A level instead of History
if anybody is actually interested in MLOps https://hackathon.redisventures.com/
Vector Search Engineering Lab
MLOps Community Engineering Lab (Hackathon) in collaboration with Redis and Saturn Cloud.
Theme is vector search with arXiv papers dataset and redis vector database
Shot in the dark here but does anyone know when will NeuRIPS 2022 papers be announced/released/etc?
Author I'm looking at says 'accepted' but no online version sadge
I wonder if I can find the paper on openreview, but I don't think NeuRIPS sends its current stuff there?
Getting an error when running the following simple code.
import tensorflow as tf
fashion_mnist = tf.keras.datasets.fashion_mnist
(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()
Hey @rugged comet!
You either uploaded a .txt file or entered a message that was too long. Please use our paste bin instead.
i am using ssh
i ran my code on small sampled data and it ran fine.
now on complete data, the terminal says killed after some time, what can be the possible reasons?
i was checking ram using free -g and it was fluctuating up and down continuously
is there a system log you can check? could be too much memory or cpu/gpu usage
my process was killed last night, can i still see it?
if the event was logged, sure
someone says dmesg | less for logs, but it gives empty screen on mine
you might need to contact your admin then
ok, is the command correct?
well, several events are logged there indeed, i can't guarantee this one should show up though
did you sudo dmesg?
i probably dont have the permission to sudo
dmesg requires elevation so that probably won't work, then
i just tried and it asked for password
i remember keeping it blank and only pressing enter when it was asked, but it says sorry try again when i just press enter
how come im getting 2 very different values when i try to calculate RMSE?

yo if i was to ask, on the premise of black box learning, what's the practical application or use cases for calculus math in machine learning.
Probably gotta check y_test and predictions. Works for me
from sklearn.metrics import mean_squared_error
import numpy as np
y_true = np.asarray([3, -0.5, 2, 7])
y_pred = np.asarray([2.5, 0.0, 2, 8])
rms=mean_squared_error(y_true, y_pred, squared=False)
rms2=np.sqrt(((y_pred-y_true)**2).mean())
print(rms)
print(rms2)
interesting, thank you
I agree, but the hard, discrete nature of ART routing would be at odds with the soft gradients required for most complex tasks. For one, you won't be able to share gradients easily if you have no way to determine how to weigh updates for each expert - leading to collapsed training with gradients going haywire
how can i get accurate floats in python
i want to make a program for my numerical computing course, since typing numbers out on my calculator takes a while and there's a possibility of error i want to make a program to check if i've done it correctly
i need scientific calculator level float accuracy
I feel as tho u can specify float detail
Google how to return float of x digits
double precision (which python uses by default) and the decimal library should carry you pretty far, and symbolic operations with sympy/symengine for the rest
what are symbolic ops
the "CAS" you see in calculator names and pay extra for that allows you to manipulate symbolic expressions, like factoring x^2 - 9, for example
i have an older scientific calc that doesnt help me factor :^)
did not help with those crazy factorizations at school
In the biological version the winner is applying a Gaussian activation/inhibition to its neighbors (Gaussian weights) (https://en.wikipedia.org/wiki/Self-organizing_map 😉) (It will take more than just using the plain old original ART implementation from the 80s).

A self-organizing map (SOM) or self-organizing feature map (SOFM) is an unsupervised machine learning technique used to produce a low-dimensional (typically two-dimensional) representation of a higher dimensional data set while preserving the topological structure of the data. For example, a data set with
p
...
Something to consider, but I would not go down this route for your first paper. Your proposed method with the Gaussian is similar to ART, it's more indirectly implemented and soft (routing methods in general, but this version in particular) (the more one goes towards ART, the less catastrophic forgetting (but DL being the way it is, can't go all in on that)).
hey guys i want to start learning about data science and machine learning im looking for udemy course specifically jose portilla ones any1 knows the diffrence between his masterclass course and bootcamp one can maybe you know other ones that you would recommend more?
@desert oar can you review my friends project? Its not that long dw
It's better to post the project in the chat and invite anyone to review it. Waiting for one person to commit to something before giving relevant information wastes everyone's time.
Why do you need the shape to be uniform?
Is this really a couple, or are we talking about more
I may be stupid, but what is y train for in model.fit()
I legitimately cannot find this information anywhere
yeah sure, mb
how do you post word documents
You can't. You'll have to put the content in the paste bin
!paste
Pasting large amounts of code
If your code is too long to fit in a codeblock in Discord, you can paste your code here:
https://paste.pythondiscord.com/
After pasting your code, save it by clicking the floppy disk icon in the top right, or by typing ctrl + S. After doing that, the URL should change. Copy the URL and post it here so others can see it.
compare the accuracy of this two results

Here is the project

the above is exploratory data analysis of the dataset
https://github.com/asadiceccarelli/horse-racing-betting the data set and the code for the model can be found in this repo => in the projects folder => bet_table.csv.
GitHub
Analysing placed horse racing bets to optimise a profit maximising strategy. - GitHub - asadiceccarelli/horse-racing-betting: Analysing placed horse racing bets to optimise a profit maximising stra...
What is the best library if I were looking to make an AI based language translation?
don't look into specific libraries. that's not how the AI ecosystem works. look into a technique, like "neural machine translation".
Alright, thanks
I’m about to start university and will have a calc class. I feel like my highschool years (especially because I graduated in 2020) were a chaotic time to learn, and as such I feel worried about retention. My major is data science and AI. I am also watching professor Leonard’s to supplement this learning.
For any of you who went through a college education for data science and Ai, how did you handle/study the math
Noted... I think I'll apply this for Audio and NLP...
The unfortunate reality is that calculus classes are often presented as a bunch of theorems to be memorized and applied, and starting with integral calculus, you're expected to memorize them more quickly than I think is reasonable.
For calc 2, all I can suggest is looking at the reviews for each professor and staying on top of the material.
Why people tend to make audio and NLP way more complicated than it is? 
"audio and NLP" is very broad. who's making it "more complicated than it is"? and how complicated is it, compared to what?
The tutorials I see about audio NNs seem to be way more complicated than those I've seen that uses image datasets. In image, people use scaling/normalizing, some data augmentation and voilá, while in audio people generate waveform, convert the audio using fourier transform, create spectrogram, scale it...
Sometimes make a multiplication to make all values positive...
there are tons of low-quality ML tutorials out there. but that's to be expected when there's no quality control 
I would make tutorials, but I think I'd spend most of each tutorial telling people not to do things that I hate. (CC @misty flint)
But even Nvidia's codes make audio preprocessing way more complicated than OpenAI's Guided Diffusion(which uses RGB images)
(Comparing Tacotron 2 and Guided Diffusion)
lol
When I post my codes into GitHub, I kinda try to explain each step, so it's kinda tutorial...
But it can be quite confusing as I usually try to do everything in a single file 👍
(Though I find this easier to understand)
you can do as much as you want in one file, as long as it's well-structured
It probably isn't 
But then... this audio preprocessing thing even made me give up trying to make audio GANs...until I realized that audios are just 2D arrays...just like a grayscale image.
everything in neural networks are arrays
Now I just need to learn some small details in NLP... and I'll be able to have my own voiced AI VTuber 
good luck with that.
Thanks, heh
don't make a model of your voice, though
Nah, I won't
It's just sad that I'll probably need to use a pretrained model. I don't feel like labeling more than 1 hour of audio.
listen. just make it your newsletter:
"5 Anti-patterns in Data Science"
bam. ok credit me at the bottom
antipattern 1: pip install jupyter

how to interpret r-squared in running linear regression models? what values or range of values is deemed good or strong?
Such a useful tool for many 📔. Without context hard to agree 🤪
https://www.tensorflow.org/tutorials/keras/classification
"Scale these values to a range of 0 to 1 before feeding them to the neural network model."
Why do we scale the values to a range of 0 to 1 before feeding them to the model? Can models only take values in this range?
no, but it makes the math nicer. it changes how the gradient behaves and also lets you use the trained model on different data, as long as it's scaled correctly
Interesting, thank you.
Best options for hosting datasets? (Currently using GitHub)
I'm thinking that maybe GitHub is not the best option for the long term. I just uploaded a 60MB JSON Lines file, and I got the large-file warning.
Kaggle might be good, but they're no longer supporting organizations, just individual accounts. And I'd like to publish datasets under my startup company's name.
Is there anything else out there? I'm thinking I might need to build something myself: a simple front-end backed by S3 or IPFS.
Or ... I'm thinking, maybe I will stay with Git and either GitHub and GitLab: but I'll figure out ways to divide up the data into smaller files.
anyone know how to stop importlib from "escaping" a virtual environment that it's located in?
I'm in a Jupyter notebook and trying to run the following cell:
import matplotlib
%matplotlib widget
from matplotlib import pyplot as plt
I'm getting the following error message
---------------------------------------------------------------------------
ModuleNotFoundError Traceback (most recent call last)
Cell In [1], line 3
1 import matplotlib
----> 2 get_ipython().run_line_magic('matplotlib', 'widget')
3 from matplotlib import pyplot as plt
File ~/.cache/pypoetry/virtualenvs/poetry-venv-py3.10/lib/python3.10/site-packages/IPython/core/interactiveshell.py:2309, in InteractiveShell.run_line_magic(self, magic_name, line, _stack_depth)
2307 kwargs['local_ns'] = self.get_local_scope(stack_depth)
2308 with self.builtin_trap:
-> 2309 result = fn(*args, **kwargs)
2310 return result
File ~/.cache/pypoetry/virtualenvs/poetry-venv-py3.10/lib/python3.10/site-packages/IPython/core/pylabtools.py:359, in activate_matplotlib(backend)
354 # Due to circular imports, pyplot may be only partially initialised
355 # when this function runs.
356 # So avoid needing matplotlib attribute-lookup to access pyplot.
357 from matplotlib import pyplot as plt
--> 359 plt.switch_backend(backend)
361 plt.show._needmain = False
362 # We need to detect at runtime whether show() is called by the user.
363 # For this, we wrap it into a decorator which adds a 'called' flag.
File ~/.cache/pypoetry/virtualenvs/poetry-venv-py3.10/lib/python3.10/site-packages/matplotlib/pyplot.py:264, in switch_backend(newbackend)
261 rcParamsOrig["backend"] = "agg"
262 return
--> 264 backend_mod = importlib.import_module(
265 cbook._backend_module_name(newbackend))
266 canvas_class = backend_mod.FigureCanvas
268 required_framework = _get_required_interactive_framework(backend_mod)
File /usr/lib/python3.10/importlib/__init__.py:126, in import_module(name, package)
124 break
125 level += 1
--> 126 return _bootstrap._gcd_import(name[level:], package, level)
ModuleNotFoundError: No module named 'ipympl'
basically, IPython is trying to import ipympl from within the Jupyter notebook using importlib, but for some reason it uses the importlib from my system Python, rather than the one found in my poetry venv
Greetings, I'm working on an art installation where I want to add some AI and realtime processing. I will be filming at some point a video of the person and I want to process that video so that I can change the person's face in the video or maybe add like a wink to the person or something like that and he needs to see it at the end so there's no time to have someone editing the video, it needs to be automated like with a deepfake model or something. Any idea where I can start?
I will be working with touch designer at some point so I can add python code and I know enough AI engineering to start this, I just don't know where to look.
💀
i'm trying to get an output for something like f a game is selected from the dataset at random what is the probability of it's score being 'awful'. trying to display the data from a csv file using pandas
sorry, i happened to have time & motivation for yours but i won't be able to do another like that. more busy with my own work now 🙂
Did you even install lib?
commands used:
conda skeleton pypi sentence-splitter
conda-build sentence-splitter
error from 2nd command:
Downloading source to cache: sentence-splitter-1.4_3d1d773d07.tar.gz
INFO:conda_build.source:Downloading source to cache: sentence-splitter-1.4_3d1d773d07.tar.gz
Downloading https://pypi.io/packages/source/s/sentence-splitter/sentence-splitter-1.4.tar.gz
INFO:conda_build.source:Downloading https://pypi.io/packages/source/s/sentence-splitter/sentence-splitter-1.4.tar.gz
Error: HTTP 404 NOT FOUND for url https://pypi.io/packages/source/s/sentence-splitter/sentence-splitter-1.4.tar.gz
Elapsed: 00:00.357711
An HTTP error occurred when trying to retrieve this URL.
HTTP errors are often intermittent, and a simple retry will get you on your way.
WARNING:conda_build.source:Error: HTTP 404 NOT FOUND for url https://pypi.io/packages/source/s/sentence-splitter/sentence-splitter-1.4.tar.gz
Elapsed: 00:00.357711
An HTTP error occurred when trying to retrieve this URL.
HTTP errors are often intermittent, and a simple retry will get you on your way.
Could not download https://pypi.io/packages/source/s/sentence-splitter/sentence-splitter-1.4.tar.gz
is there someone able to get the pypi sentence-splitter through conda?
if yes, then how?
conda-skeleton-pypi sometimes is a bit naïve about the url to fetch the package. i usually just write my meta.yaml by hand nowadays
But the conda skeleton pypi command did not give any errors
because it just constructs the package tarball url but doesn't test it. it basically guesses at the url
Ooh
if its similar to ART, that's a good thing - right? Its a decent way to combat some of the gradient issues MoE's face
however @fast rivet that url should work. it redirects to https://files.pythonhosted.org/packages/source/s/sentence-splitter/sentence-splitter-1.4.tar.gz so you can try that url instead maybe
Thanks! I’ll try it tomorrow at work since I’m at home rn
hey, just looking at creating a neural network. how should I represent a neural network in python,. using numpy arrays
nws
I have questions about stt. is there some way to use the speech recognition library without internet (recognize_google only works online). or is it possible to combine / mix models in the vosk library (e.g. polish + english)?
TTS or STT models are usually for one language.
yeah but speech recognition can detect language
but its only work online. is possible to somehow download google recognize?
to use this offline
it probably first determines which language it is, and then delegates the work of encoding it to a model that's only for that language
and I doubt Google will let you download their models. it's possible to train your own if you have a lot of annotated data.
Any data science student?
I have a question
Don't ask to ask, just ask.
Sorry, I am new to discord, so I was a bit skeptical.
Do you know about distplot?
You're still asking to ask. Just ask your question. Don't ask if someone knows about a topic before revealing the actual question.
I provided values from 0 to 5 but it is showing me negative values as well on the x-Axis. Why is it so?

can you show the code that created this?
!code
Here's how to format Python code on Discord:
```py
print('Hello world!')
```
These are backticks, not quotes. Check this out if you can't find the backtick key.
^ Here's how to paste code. Remember to never ask people to read screenshots of code.
Sns.distplot([0, 1, 2, 3, 4, 5])
it's fitting a gaussian kde to that data, which is unbounded at both ends
so, this is with seaborn
also distplot is deprecated, use displot instead https://seaborn.pydata.org/generated/seaborn.displot.html#seaborn.displot
does it just asymptotically approach 0 on both ends?
do you have any ideas how to do what i want? without training
Yeah, I know it's deprecated but first I'll have to learn about Gaussian KDE in order to get it.
you might be able to find an existing model and load it with pytorch or tensorflow
how is the value selected in a knn regressor, I understood how its done for a classifier, you take the k nearest points and choose the most common label, but just averaging in case of a regressor wouldnt really be accurate ?
is it done thru some form of extrapolation ?
oh there is a problem, i cant pytorch or ai
why not
you don't know how, or you're constrained?
from what I'm understanding, it seems like they use the distance to each point as a feature, so yes for the last question, but I'm not 100% sure
https://scikit-learn.org/stable/auto_examples/neighbors/plot_regression.html#sphx-glr-auto-examples-neighbors-plot-regression-py
scikit-learn
Demonstrate the resolution of a regression problem using a k-Nearest Neighbor and the interpolation of the target using both barycenter and constant weights. Generate sample data: Fit regression mo...
i have never used a pytorch and i dont lern ai yet
ohh, makes sense
now's the time 😛
second question, why am I learning all these algos when I can just use deep learning for everything ?
is there a type of problem where these algos (linear, clustering etc) shine at ??
the gaussian density does, yeah
https://jakevdp.github.io/PythonDataScienceHandbook/05.13-kernel-density-estimation.html
https://en.wikipedia.org/wiki/Kernel_density_estimation

In statistics, kernel density estimation (KDE) is the application of kernel smoothing for probability density estimation, i.e., a non-parametric method to estimate the probability density function of a random variable based on kernels as weights. KDE is a fundamental data smoothing problem where inferences about the population are made, based o...
so can you recommend me some tutorial or books for teach pytorch, ai? or just tutorial for stt to do what i want?
well, deep learning does have some major disvantages:
- model complexity
-- inference and training costs
-- model interpretability
-- may require a large amount of training data not to overfit
and it builds upon simpler models such as linear regression
should I go hard on learning basic algorithms or just gloss over them and directly go to neural nets
I wanna make a career in machine learning engineering
in that case all I have to say is "good luck", but you'll probably need to have at least a moderate understanding of most basic models you may get asked about in interviews
makes sense, thanks for the help
(I am totally not losing my mind learning different algorithms lmao)
an important lesson to learn is, deep learning doesn't always make sense
there are tons of classical algorithms that work just as well or better, with less data and less complexity for many tasks
deep learning is usually a data-driven approach to optimizing those same classical algos, so you anyway need to know them for DL
but, its always a valid solution XD
I dont wanna waste ur guys time, I am just burnt out from learning and wanna start actually using my knowledge
valid if you meet the conditions for it to be applicable in the first place 😛
there are conditions ???? 😩
dont tell me deep learning also has a problem with correlation :(
serious question again, kaggle is good and all, but are there any easier website where I can practice ml ??
the most restrictive ones are having enough data, and having that data be representative of what you wanna infer. and yeah, cleaning up the data and the exploratory analysis you need to do BEFORE you can do DL requires some stats, commonly uncluding correlation
kaggle competitions are a bit high level for a starter
it can literally be the difference between having a model that doesn't work at all vs one that works amazing
at the end of the day, ML (including DL) is math, so 😛 have fun
thats there, data cleaning and feature engineering are important
this
?
that i wouldn't know. why not grab a book though?
does anyone know a good explanation of how I could implement the NEAT algorithm in python?
umm, too expensive for me rn
I am a broke college kid lmao
uni library

Does speciation make a difference when finding solutions using neural nets ?
Watch the video to find out..
Music :
https://www.bensound.com/
he has a couple of videos going over all the parts of NEAT
this is just the first video
ill check it out, do you have a specific book suggestion ?
thanks for that
no problem
at how many years of experience are you expected to learn about machine learning as data analyst/engineer? (assuming you start your job at 0 years of previous experience)
so can you recommend me some tutorial or book for teach pytorch, ai? or just tutorial for stt to do what i want?
you should at least know what machine learning is and how it works. but you should focus on having a solid foundational understanding of statistics, probability, sql, excel or google sheets (i am not joking), and some linear algebra & calculus
as well as general python programming and scripting skills of course
some data visualization skills too
"machine learning" as a discipline usually doesn't require a lot of specialized knowledge. it's all the other stuff i mentioned that makes it possible to deploy "machine learning" techniques in real world applications
Yeah, catastrophic forgetting is one of the main issues with DL, and this is not a hard fix like (the original) ART, but any fix is better than just not addressing it (also it seems that to some extent some DL models can learn to work around their own catastrophic forgetting (e.g. Transformers), but only so much (and it requires a lot of training time)). The proposed method is somewhere in between the hard fix (ART, no forgetting at all), and not having any fix, while still working within DL and having nice(ish) gradients.
I am using ssh
I have realised i cannot get access to check logs.
What can probably be thè reason my process is getting killed.
My code only has to extract feature using resnext3d101 architecture on each video one by one.
so u are telling me i dont need to freak out over my thesis in data science yes? 🗿
you shouldn't freak out over anything! life is too short
i try to be

{kind=link}
but tbh im a lil bit scared of my thesis
if it makes you feel better, that's how my brain looks pretty much every day @serene scaffold
yep thats me rn
if you do have specific questions, this is not a bad place to ask
(although you should also get comfortable with asking your advisor for help)
(don't be like me: make sure you have a thesis advisor before you start writing your thesis)
am a bit afraid of the expectations in my thesis, since i have no benchmark and i actually don't come from the field of data science
It is not the general fear of a thesis, but the fear of being in a subject area where you may not fit in properly.
I am currently working my way a little into the subject and realize that a lot of it is really unclear to me.
I mean, ok, most of the publications I read are from PhD students but still
i am a little afraid of the uncertain 🗿
When you code works, but you don't know why...
are you an undergraduate? what field of study are you actually in?
yes and in chemistry
but thesis is mat science
then it's critically important to set expectations with your advisor. ask them what they think you're capable of, and have frequent check-ins to make sure that you are on track. a sensible undergrad program should have this built-into the system. but it can't hurt to make sure and be proactive.
I agree that compute requirements to allow for positive transfer as almost always over 1B parameters - though that's quite relatively cheap to train. How well does ART transfer positively? I would think that the discrete mechanism doesn't really allow for sharing/pooling representations?
The school system teaches one to be really afraid of failure, but real life out there is full of mostly failure (especially in research).
sounds like a smart thing to do
i do know that but still u wouldnt want to fail ur As with the final thesis would u 🗿
It does, that is where ARTMAP, and sparse distributed representations come in.
One can create a memory database of SDRs which can be transferred perfectly.
the publishing system doesn't exactly help 😬
(Also see fusion ART)
science is bad 🗿
Basically, Grossberg thought of this stuff.
something like this? https://arxiv.org/abs/2203.08913
arXiv.org
Language models typically need to be trained or finetuned in order to acquire
new knowledge, which involves updating their weights. We instead envision
language models that can simply read and...
basically, a KNN lookup for nearest QKV vectors and integrating them into the model
Sort of, but we work with SDRs because they are better than the regular old (dense) vectors used in most language models.
It allows for insanely large context lengths - but the transfer learning ability has to be baked into the model to be able to leverage its external memory efficiently
Right - the ones Numenta proposed, I take? Sparse, and certain operations which work nicely with sparse matrices
Numenta uses SDRs too. That is because biology uses them.
But as an example: https://www.cortical.io/science/semantic-folding/
Semantic Folding & Fingerprinting - Cortical.io has developed a new machine learning methodology inspired by the latest findings on the way the brain processes information. Semantic Folding creates a new data representation, the Semantic Fingerprint, that encodes meaning explicitly, including all senses and contexts.
(Which is based on Numenta's thing)
(Although Numenta has moved on to grid cells... 😉 )
(Still using SDRs, because they are one of the best known ways to represent things in ML)
As I understand, they're quite fundamental in how the brain passes information around
Yeah, which why one can also transfer knowledge with them and even form a database out of them (like vector search).
(And ART can produce them)
Fusion ART seems more focused on obtaining symbolical representations, which confuses me - since the main goal was to push towards more biologically plausible mechanisms?
SDRs have set operations.
Taking their intersection for example, is meaningful.
And from this, one can do GOFAI-like stuff.
Interestingly, from my quick Wikipedia skim
.. ARAM learns a predictive model (encoded by the recognition nodes in F2 that associates combinations of key features to their respective classes ... https://en.wikipedia.org/wiki/Fusion_adaptive_resonance_theory#Adaptive_resonance_associative_map
Fusion adaptive resonance theory (fusion ART) is a generalization of self-organizing neural networks known as the original Adaptive Resonance Theory models for learning recognition categories (or cognitive codes) across multiple pattern channels. There is a separate stream of work on fusion ARTMAP, that extends fuzzy ARTMAP consisting of two fuz...
It seems really similar to contrastive learning
ahh, right. but you can't really effectively parse them into KBs
just perform similarity and surface level operations
I don't imagine transformations play well with SDRs 🤔
Yeah, which is where more works come into play (including our internal stuff).
The search for the one representation to rule them all (and be able to do all the operations we want to do, and for that, we continue to look at biology for answers).
but I don't really get the obsession with controlling representations. One can't effectively manipulate biological representations - why would simulated ones succeed?
DL models have interpretable representations to an extent - atleast for smaller counterparts. https://twitter.com/neelnanda5/status/1559060507524403200
I've spent the past few months exploring @OpenAI's grokking result through the lens of mechanistic interpretability. I fully reverse engineered the modular addition model, and looked at what it does when training. So what's up with grokking? A 🧵... (1/17) https://t.co/AutzPTjz6g
Likes
1241
Retweets
210
But when you scale it up - it all breaks down. It's simply too complex to be reverse engineered - yet.
Well it's not just that they can be manipulated and understood for explainability / designability, it's understanding how biology is stable, distributed and such.
The main thing is that even if we can't manipulate it, it def. acts as a good way to pass around knowledge.
How can I get LaTeX font on my plots? 🙂
It just so happens that SDRs have set operations, which was not the goal from the beginning.
But now that we are here, and SDRs work as well as they do, we might as well ask the question of how explainable / designable / etc we can go.
(As long as it does not negatively affect the rest / limit it)
Hm. Sounds like a much different question to me. I for one, doubt we'll ever be able to actually interpret such models without high performance penaltiies atleast
Yeah, I agree. But there was a jump from dense to SDRs. Which was unexpected.
The representation is simply too information dense to be effectively interpreted. And if you simplify those, like GOFAI, then they won't really represent that information well.
With no downside yet.
in all fairness, there wasn't any theoretical results arguing against it either.
Making DL sparse has been quite an old field for a lot of time
My guess is that for explainbility some system that interprets the SDRs would have to explain it for us.
They work terrifically well for inference. Absolutely fail for training due to gradient issues.
(Before DL)
I mean, that's just putting you back into the interpretability cycle of trying to understand that system you create
It's hard to develop a truly universal (and simple) framework around it
Yeah, I don't have the answers for that.
tbf, it isn't a totally useless approach. FSD companies use GANs and autoencoder to project their latent space as close as possible to the original image distribution. They found that the learned latent actually ignores a lot of useless information
Yeah that is related to why sparsity works (sparse latent).

This is a pretty old image I found - but it demonstrates it quite nicely. notice how the reconstruction below ignores useless details like the signboard, focusing on lanelines and vehicles in immediate vicinity
Also, the traffic barrier is visualized, but the colors of the cars isn't carried through
Yup. However, SDRs can capture most of the information in there, even if it's not as important.
We have such reconstruction experiments.
One way to see this is that with an SDR as your latent, because it's sparse, it can be a massive vector.
I'm not arguing why sparse vectors are bad; but rather that using another system to interpret a black-box is only applicable to a certain degree.
Sparse latents on their own can provide insane speedups especially on CPU.
Yes, it can only be applied to so far, but SDRs certainly make it a lot better.
Well, gradient issues with SDR's is huge problem
but if someone solves it, that's pretty much a Turing-award level breakthrough to me
For example, we can pick certain "atoms" in the SDR latent space and add in certain objects / parts of objects into the scene.
And a human can do that by hand.
A human can view an SDR and learn what symbols are in it by playing around with it.
We don't use backpropagation / no gradient issues (it's not DL (as in backprop) / more biologically plausible).
This becomes better the more high-level it gets. Near the senses it's not understandable by humans (too much going on).
Hello, does anybody know where I can get examples or exercise for event in progress problems in python ?
I am trying to build a function that gets the peak number of views, given a collection of view times.
*It would be great if someone solved this somehow and would allow for the merging of things such as ART and DL, which would advance ML as a whole by a lot. And have worked on it before, we are just busy with other things (we have to play the multi-arm bandit game).
I know that; what I envision is that somehow people figure out how to use sparse matrices in DL which play nicely with gradients. It could allow the merging too, yes, but it would heavily speedup training by orders of magnitudes.
maybe read this section of the pandas docs: https://pandas.pydata.org/docs/user_guide/dsintro.html#column-selection-addition-deletion
actually that section has less info than i thought
you can select multiple columns at a time by passing a list of column names
x = data[['a', 'b', 'c']]
y = data['label']
for example
Would anyone be able to help me organize a dataset column in descending order
yes, a MLP is just a NN with fully-connected layers, what keras calls Sequential
at least... for the most part? there are probably some historical specifics in the terminology here
can you state your actual question, with specifics? don't "ask to ask", as they say.
you'll have to check the documentation, but from what i remember scikit-learn does not have a CNN implementation. MLP usually does not mean CNN or anything fancier than fully-connected/dense/sequential layers.
i'm trying to make a multi billion AI can you help me
a bot that can solve google recapcha
I want to apply RNN to a dataset I have of internet data usage over a period of 6 months for a variety of clients. My problem is that I have no idea how to approach that case because every row is a whole different "trend", such as:

those are 5 different clients, for example
I'm having trouble finding the best solution how to separate this dataset into test/train to predict for the next month
i suggest reading the docs for these. you should be able to answer questions like this if you're expected to build such models
"multi-layer perceptron" is generally synonymous with feedforward, densely-connected neural networks
do you know what a convolutional layer is?
you can't really accidentally use one. you would know if you did.
what is this class where they teach you cnns before you know what a mlp is
i wouldn't be surprised, there are a lot of people now teaching this material who appear unqualified to teach it, and their students lack the prerequisites to understand it. there seems to be a notion floating around that because this stuff was developed by "computer scientists" that any computer science student is equipped to learn and use it.
it's kind of amazing how easy keras and pytorch are, and how little you do actually need to know in order to use them. but that is more of a testament to how freakishly effective deep learning is, and how well designed those libraries are. it doesn't change the situation.
that's ridiculous
if you need decent self-study materials, look into the fast.ai course
it's free online and the material seems to be good quality from what i've seen
and the people who made the course actually do know something about deep learning
this is good for cnns http://cs231n.stanford.edu/
this is good for general ml https://www.youtube.com/playlist?list=PLl8OlHZGYOQ7bkVbuRthEsaLr7bONzbXS
what framework should i use for multi label image recognition?
how can I sort the values inside a group

I tried it today and it still gives me
Error: HTTP 404 NOT FOUND for url https://files.pythonhosted.org/packages/source/s/sentence-splitter/sentence-splitter-1.4.tar.gz
but thanks for the suggestion
Good day everyone,
I tried creating a virtual environment in my Linux terminal with ' conda create --prefix ./env pandas matplotlib numpy'
When I tried importing pandas and co, it returns error ' module not found '
did you activate the environment?
.apply(lambda df: df.sort_values(...))
i'm pretty sure both URLs worked when i tested it, and one redirected to the other
could there be something else wrong with my meta.yaml?
{% set version = "1.4" %}
package:
name: "{{ name|lower }}"
version: "{{ version }}"
source:
url: "https://pypi.io/packages/source/{{ name[0] }}/{{ name }}/{{ name }}-{{ version }}.tar.gz"
sha256: 3d1d773d07cc733ca2955aa87d0fa1c0a7274c6bdeec1daac5c5e92efb512f63
build:
number: 0
script: "{{ PYTHON }} -m pip install . -vv"
requirements:
host:
- pip
- python
- regex >=2017.12.12
run:
- python
- regex >=2017.12.12
test:
imports:
- sentence_splitter
requires:
- pytest
- pytest-runner
about:
home: "https://github.com/berkmancenter/mediacloud-sentence-splitter"
license: "GNU Lesser General Public v3 (LGPLv3)"
license_family: LGPL
license_file:
summary: "Text to sentence splitter using heuristic algorithm by Philipp Koehn and Josh Schroeder"
doc_url:
dev_url:
extra:
recipe-maintainers:
- your-github-id-here
I also tried removing the sha256 but that still gave me the same 404 error
or could it be a firewall? or conda (build) version? I don't know where to look and how to test if it has something to do with a firewall
Hey Hii I am new to this platform
@wooden sail yes
are you using pycharm or vscode by any chance?
in both of these you need to specify which venv to use as well
So basically I want to make my carrier in data science . Please anyone here can give me advise what step to be followed to become a data scientist
🙏
Pycharm and atom
pycharm will require you to activate the venv from its terminal
I did, but when I tried running python script by importing pandas.
It gives the error of module not found
you sure you activated it from inside pycharm and not on a terminal outside?
Yes, am very sure.
Am baffled because I had done this about 6 month ago, when I did an exploratory analysis on a dataset without any issue
first try downloading the file with your web browser or a cli tool like curl
set the python inside the conda env as your pycharm project interpreter
but tldr it should work unless the installation itself failed, but then you would see an error message
try invoking the env python directly, without activating
./env/bin/python or whatever
I am able to download it using firefox through this link:
https://files.pythonhosted.org/packages/20/b3/86b431fe7002ba006c08b8559d2ad78e1153bfc515a453cc96d2f55a2c40/sentence_splitter-1.4.tar.gz
but not through the pypi.io link nor files.pythonhosted.org using the firefox web browser
but changing the link in the meta.yaml file to https://files.pythonhosted.org/packages/20/b3/86b431fe7002ba006c08b8559d2ad78e1153bfc515a453cc96d2f55a2c40/sentence_splitter-1.4.tar.gz gives me the 404 error again
Thank you for the response, could you direct me on how to go about it
I am also able to download it using pip install, but I'd rather not use it this way since it could mess up my conda environment of my project
go to pypi.org for that package and look at the "Files" page. can you download the file from that link? if so, try hard-coding that link in your meta.yaml for now
hardcoding the link didn't give me a 404 error anymore!
either just leave it as-is (and remember to update it when you update versions) or try to work backwards to see if you can get it working. i remember having this issue w/ conda before as well
there might be some jank in how it follows (or doesn't follow) redirects
Hello
I'm trying to create a neural network from scratch.
So i have choosen to create a neural network that can approximate square function i.e, if input is 2 then the output of the neural network should be 4.
As I'm coding it from scratch, I have choosen to keep a 1 input neuron and 2 hidden layers with 2 neurons and 1 output layer.
Can I build a network something like above?
Or should I need to plan building something else?
Thank you
what's your goal in building it from scratch? just to learn how it all works mathematically?
Yes exactly @desert oar
you absolutely can do that from scratch. people used to do it like that for many years before tensorflow came out. you will need to work through the backprop calculations by hand, which i think is also a valuable excercise.
it's probably best to try doing it with numpy instead of "plain" python, since numpy is so ubiquitous in scientific computing and data science
numpy will also give you a lot more power to scale up to bigger neural networks more easily
i suggest starting with 0 hidden layers. just input and output layers, compute the gradient, and run sgd. this should be equivalent to a traditional linear model from statistics, and you should test your implementation by verifying that the results are the same as e.g. scikit-learn or statsmodels.
scale that up from 1 input to maybe 5 or 10, and from 1 output to maybe 5 or 10. then you can graduate to one hidden layer.
that is the progression that i recommend
it will force you to gradually increase both the level of complexity and generality
start small, build intuition and understanding, then scale up gradually. it's a tried and true method for learning things and solving problems.
if you can't do it with 1 input and 1 output and 0 hidden layers, how can you expect to do it with 30 inputs and 5 outputs and 2 hidden layers?
also the process of figuring out how to generalize from e.g. 1 input to 15 inputs, and from 1 output to 5 outputs, will i think be enlightening
Ok I'll start from scratch again
May be I directly jumped to 2 hidden layers.
Will try to code for 1 hidden layer with 1 input and 1 output
Thank you @desert oar
You are talking about the neurons in the input and output layer rite?
yes, although i think removing any notion of "neurons" from your mental model will serve you well. it's an outdated metaphor and it doesn't help you understand neural networks as they actually are implemented and used.
So how do I understand then?
Like what should i call them?
you understand them as a composition of affine and nonlinear transformations
and a basic "feedforward" neural network is just feeding the output of one linear model into another
each "layer" is basically just a linear regression (apart from the nonlinear activations)
Ok thank you!
i don't think regression is a great term there though
What is the best module for starting with machine learning?
regression usually refers to finding params, not the application of a (part of a) model
I don't know what you mean by "working backwards". All I know is that the same link doesn't work when it is not hard coded. So it looks like the problem lies in using variables in the meta.yaml for some reason. But thanks a lot! For the first time I can finally use pip packages with conda now!
i am suggesting that something is subtly different between the "variables" version and the hard-coded version
ooh
in statistics and social sciences people are pretty loose about calling linear models "regression models". i come from that world and i am guilty of doing it a lot.
oof
i would kinda recommend to look at it from the other end. start with a basic problem, its formulation, and a bird's eye view of the math. then you can use whatever lib you prefer to tackle it
I found the difference: the name of the package is sentence-splitter but the download link has sentence_splitter
ah, that's really tricky
i suspect that should be handled by http redirects. maybe conda is failing to follow them properly
good catch, that's probably affected me before as well
Most people usually would say, Andrew NG's Machine Learning course but I'd say try different approaches then settle for the one that best works for you.
What materials/modules have you tried thus far?
None, I wanted to know which to start with
Is pytorch any good?
Have you any knowledge on ML already? If yes, then I'd presume you're interested in getting into Deep Learning. PyTorch is one of the popular deep learning frameworks currently. Just think of it as React vs. Vue of Software Development but for Machine Learning.
Is PyTorch any good? Yes, it is.
Thx
Pytorch is what my team uses. Some people are moving to Jax, but that library is newer, so pytorch will have tons of books and tutorials.
Also, all my data science helper homies are in the chat today
(edd, salt, and emyrs)
it's important to keep in mind jax is just numpy with jit, parallelization, and autodiff. if you want to do ML with it, you need other stuff on top or you build it from the ground up
Aren't Jax arrays also fully immutable?
this is a feature 🙂
Where you use masks?
using masks is ok. manipulated a mask part of an array isn't, since that is of an arbitrary size
XLA no likey when you do that
iirc there's an open issue regarding masking methods
Any suggested tutorial series for pytorch - preferably available for free
pytorch has several guides and examples on their website
Don't know of much else though
Hello,
I'm not sure if this is the correct channel for that question. I need some advice what technology/libraries to use.
I have a dataset containing words in two languages. I want to create and train a model to be able to reconstruct a word in language2 when given a word in language1 (and preferably vice versa). The languages are closely related so the model would be trained to do slight changes like sound shifts, palatalization etc. Are there any libraries that could potentially help me with this or are there any works that tackle such a problem?
Are you talking about text or audio? This is a critical distinction, and most NLP is about text.
text
Then sound shifts and palatalization don't matter. Models that deal with text don't know what the words sound like.
By the way, when looking for AI solutions, don't look for libraries. Look for implementations of techniques
People don't make libraries that solve specific ai problems.
What are the two languages?
Ukrainian and Russian?
Polish and Proto-Slavic
I see
I have a dataset of reconstructed words in Proto-Slavic but it's incomplete. I want to incorporate machine learning model to do the job
I don't think you need AI for this. You can just write a program that applies the changes according to whatever the rules are.
If you wanted to incorporates other child languages of proto Slavic, and applying the sound changes to those other languages produces different results, you could use ML to decide which to listen to, or what combination of choices to listen to.
(I'm a computational linguist. But I haven't worked on proto language reconstruction.)
Is the problem that you don't know what the rules are?
I see. I considered the approach of simply making a set of rules and applying that to a word to reconstruct it, I think that would totally work. I was just really curious if this could be done using AI as this would both:
- potentially learn irregular development in a few cases
- be doable from a perspective of someone who doesn't know the rules
More or less but this is within my reach
I might, though, have a problem with picking a correct order of applying these rules
Even if one doesn't personally know what the rules for the sound changes are, someone does, because proto languages are unknown and are only based on applying sound changes that some linguist believes account for the differences in the child languages.
Forgive me if this isn't news to you.
You might look into sequence to sequence models
If you can encode each phoneme as one symbol (what it is doesn't matter as long as you can decode it later), it should be pretty straightforward. As sequence to sequence goes.
I'm aware that we don't really know what a reconstructed language sounded like. After all it's a reconstruction. I just assume those reconstructed words are correct.
Thank you, I'll look into that
No problem. It's actually a really interesting question. I'll see if my coworkers have any thoughts
what is actually happening here? overfitting?
