#databases
1 messages · Page 187 of 1
Yes, I could do this using inner join, but im trying to make my sub queries strong here. I expected this to Return the name of projects which were chosen by multiple people.
do you see why SELECT COUNT(current_project) definitely does not return that?
I don't get it, I shared 2 codes before mentioning the doubt, it did work there. Why not with COUNT then
but look at what those do! they do completely different things
you might want to review what IN does
MAX returns an actual value from the table
COUNT does not
uhh shit
okay
Is there any way I could find my desired output using the same format?
i'm not sure what you're even going for. but it honestly looks like you're trying to re-use a template that worked well for one query, without considering why it worked
I am trying to find the name of projects which were chosen by multiple people using sub queries.
okay. so first you have to figure out how to obtain "projects which were chosen by multiple people"
do that first, then figure out the sub-query part
FROM projects
INNER JOIN employees
ON projects.project_id = employees.current_project
WHERE current_project IS NOT NULL
GROUP BY current_project
HAVING COUNT(current_project) > 1;```which one is better? 500mb of nosql or 10,000 rows of sql?
(honeslty saying, it doesn't matter much to me whether its sql or nosql.. just wanna know which one is a better choice) :'/
ping me when u reply
maybe a dumb question.. but :")
I tried both ways. They always print an error. But I now managed to get a different error. Sth like „pls import psycopg first before importing this package“. Pretty confusing error imo. Sounds as if it asks me to import the non-binary version first. And I actually wanna avoid that as that always created even more problems
anyone know how i would make a leaderboard for my discord bot with pymongo? i want like the top 10 users with the most coins but i dont know how to do this.
hi guys im using sqlite3 and making an api using fastapi everything is fine when the api is running but it al gets messed up when I restart the program its not updating for some reason. I also used db browser for sqlite3 theres nothing there
is there any option available to run trigger only once not for each statement
I have service which downloads data from vm and insert it into batches, but the trigger which I created is running for each insert statement, how can i control it
?
CREATE TRIGGER execute_process_dbt_point_geom_py
AFTER INSERT
ON dbt.dbt_point_primary
FOR EACH STATEMENT
EXECUTE FUNCTION dbt.processDBTpointGeom();
Also this trigger is not executing and showing permssion error
C:\Program Files\Python37\python.exe: can't open file 'C:\Users\Dell\Desktop\Python\DBT\PointLink\Point_Location_processing_dbtData_newMethods.py': [Errno 13] Permission denied
C:\Program Files\Python37\python.exe: can't open file 'C:\Users\Dell\Desktop\Python\DBT\PointLink\Point_Location_processing_dbtData_newMethods.py': [Errno 13] Permission denied```--
function which run plpython in background
CREATE OR REPLACE FUNCTION dbt.test_processDBTpointGeom()
RETURNS void
AS $$
import subprocess
subprocess.call([r'C:\Program Files\Python37\python.exe',
r'C:\Users\Dell\Desktop\Python\DBT\PointLink\Point_Location_processing_dbtData_newMethods.py'
])
$$ LANGUAGE plpython3u;
ALTER FUNCTION dbt.test_processDBTpointGeom()
OWNER TO postgres;
how to use terminal inputs in sqlite
:incoming_envelope: :ok_hand: applied mute to @gusty mulch until <t:1649542580:f> (9 minutes and 59 seconds) (reason: newlines rule: sent 108 newlines in 10s).
!unmute 365262543872327681
:incoming_envelope: :ok_hand: pardoned infraction mute for @gusty mulch.
!paste hiya that's a lot of lines. please use the pastebin 
Pasting large amounts of code
If your code is too long to fit in a codeblock in discord, you can paste your code here:
https://paste.pythondiscord.com/
After pasting your code, save it by clicking the floppy disk icon in the top right, or by typing ctrl + S. After doing that, the URL should change. Copy the URL and post it here so others can see it.
can you send me the text from that msg, I'll add the sql to pastebin now since I have that local but I don't have a local copy of my msg part
o yeah
thanks, should I reply with my pastebin url to that or will you delete it for me to resend?
thanks again 👍 😄
tl;dr SQLAlchemy keeps redlining attributes
hi. i'm new to flask, sql, webdev, etc. and thought my first project was going well. trying to make something simple that uses sqlite to save usernames and passwords to a db. don't fully understand it, but following a guide that has me making a class for the records. yet, for some reason, Column, Integer, and String keep having the red underline. says there's unresolved attribute references.
here's what i assume are the relevant parts of my code. i put a comment so it's easy to find the trouble lines.
https://paste.pythondiscord.com/fanavugiqo
can someone tell me what i'm screwing up?
is sqlalchemy the 'industry standard' for python databasing?
@junior bone gbr, i have zero clue. just following what this tutorial used. also looked at cs50's tutorial, but idk what they're using since they have their own library
i'm not looking to master any industry standards atm. just want to successfully complete some projects with things that are new to me. like databases. i know what they are and query syntax or whatever, but still next to clueless on working with databases in actual programming.
i was just asking a separate question lol
is there a script to take all the data in a json and yeet it into a sqlite3 or sql database
https://cdn.discordapp.com/attachments/859749825604354079/962648945723596840/unknown.png
Anyone know how I can get the sum of all the values in the last 30 days?

The date is also given
Hi, I'm just looking for someone to sanity check my SQL found below. ↵
I have a table called data which stores everything related to a specific guild.
I have a table called member which stores everything related to a member
I have a table called members_guilds which should be making a combined primary key from the foreign keys of data and member. This table will be storing things related to both a member and a guild (how many times they have joined x guild for example) and the member & guild columns should autofill from the data found in the tables they reference.
I have a table called reminders which should be referencing data and member so that the member and guild columns for reminder autofill from the table and column they reference.
This is my sql: https://paste.pythondiscord.com/cihoxewulo
I'll leave this here if anybody wants to reply pls ping me
Anyone know how to generate a fake surname using the faker module?
I knowfake.first_name generates a fake first name
faker.last_name() https://zetcode.com/python/faker/
Ah I see thank you 🙂
help?
How do i remove the parentheses and commas? i want it to be in a line



aiosqlite's given you a list of tuples with the idol inside each one, so you need to join them into one string before setting it as the description
!e example: py fruits = [('Apple',), ('Orange',), ('Pear',)] message = ', '.join(row[0] for row in fruits) print(message)
@waxen finch :white_check_mark: Your eval job has completed with return code 0.
Apple, Orange, Pear
oh i see tysm
Is there any way to implement hardware acceleration into your python script? Especially if it has 2D Graphics like with PyGame or PyQt5.
Hello everyone, I'm having an issue with my PostgreSQL database and I'm hoping someone here would be willing to help
im using sqlite how can i get a value in a table in a range? so it checks one table, gets the value i need, i run my code i need to run with the value then it checks the next etc
When I try to import a .csv file into my database I get this error "value too long for type character varying(90)". How do I fix this?
with django, how would I replicate this WHERE clause? sql WHERE CONCAT(table.first_name, table.last_name) IN ('XY', 'ZW')
I'm aware I can do py Table.objects.filter(first_name__in=('X', 'Z'), last_name__in=('Y', 'W')) but this will also match the names XW and ZY which I don't want
hey can anyone help me with database and sockets?
you might need Q for this, i'm not sure exactly how it would look
ooh no you need annotate
This is how I'm currently doing it, but I don't love it ```py
q = Q(pk__in=[])
for first, last in zip(first_names, last_names):
q |= Q(first_name=first) & Q(last_name=last)
queryset = queryset.filter(q)```
Table.objects.annotate(full_name=Concat(
F('first_name'), F('last_name')
)).filter(full_name__in=('XY', 'ZW'))
actually i think this is better
doing string operations to avoid doing logical operations seems like an antipattern
thanks I'll give this a try
the only reason why I think its not great is because this is a list of thousands of names
ah
so its kind of a huge query to be using OR (x = y AND z = w) like a thousand times
yeah good point. i'd be curious to see the EXPLAIN output for that...
i have no idea how well database indexes perform with huge ORs
While I've got you - i have one other unrelated question, I'm trying to make a model called Person, the person can have a Pet (only one or none at all), if a Pet exists, then it must belong to a Person (that is, its primary key is the person's id)
How do I set up this relation?
(that is, its primary key is the person's id)
don't do this. each pet gets its own primary key, but you also have a foreign key pointing to the person who owns the pet. just the standard relational setup
i mean maybe you can do it that way in django, where the primary key is a foreign key?
i don't know
i don't think there's much benefit to it
you can put a unique constraint on the column
so something kind of like this? ```py
class Person(Model):
normal model stuff (no mention of a pet)
class Pet(Model):
person = OneToOneField(
Person,
on_delete=CASCADE,
unique=True, # does this work?
#primary_key=True # not set
)```
wouldn't one-to-one already enforce uniqueness?
i haven't used django since v2.x so i'm missing a lot of new features
oh yeah
A one-to-one relationship. Conceptually, this is similar t a ForeignKey with
unique=True, but the “reverse” side of the relation will directly return a single object.
https://docs.djangoproject.com/en/4.0/ref/models/fields/#django.db.models.OneToOneField
it might be possible to make a OneToOneField the primary key too
the docs don't explicitly mention it so I'll just try some stuff out - thanks for all the help @harsh pulsar !
yeah it is, its actually in their examples
@ivory turtle https://docs.djangoproject.com/en/4.0/topics/db/examples/one_to_one/
class Restaurant(models.Model):
place = models.OneToOneField(
Place,
on_delete=models.CASCADE,
primary_key=True,
)
serves_hot_dogs = models.BooleanField(default=False)
serves_pizza = models.BooleanField(default=False)
def __str__(self):
return "%s the restaurant" % self.place.name
so yes it seems like it's supported to make the pet primary key also a one-to-one foreign key
primary_key=True
Okay so maybe this is fine
but consider the implications here, you are guaranteeing that a pet can never exist that isn't attached to a person
if that's the intention, then this is good
yeah - I don't particularly have a use for that
a person can't have multiple pets? people can't trade pets? etc.
the real example is that the Person is actually an item in a video game, and the Pet is the ItemForSale
and of course the item can only be for sale at one time
well in that case you probably want multi-table inheritance
where ItemForSale is actually a subclass of Item
it wouldn't make sense for Person/Pet, but it makes perfect sense for Item/ItemForSale
well I don't want to duplicate any of the information
and I do want to ensure that the item is only for sale once at a time
read what it says, it doesn't duplicate information, it does exactly what you are asking to do
all of the Item fields stay on the item table, only the extra fields from ItemForSale go in the for-sale table
All of the fields of Place will also be available in Restaurant, although the data will reside in a different database table
Oh
After making a request for an XML file, parse it, how do I return a JSON object of this file?
Part of a job I'm interviewing for will work with XML files (😞), but is there a way to return a JSON object and then work with that??
it kinda looks like its a shortcut to the same database setup
Okay so I tried setting it up like that instead, but I have created a bunch of wrappers around my Model class, and if I use pythonic inheritance then it messes those up
i.e I have a base model which adds a created_at field, but that field just gets inherited from the Item class
whereas I would like them both to have distinct created_at fields
so definitely good to know about for the future but I don't think i'll use it for this
no, learn to use xml. xml is strictly more expressive than json, there are things you can express in xml that you can't naturally express in json, and you'd need some "out of band" format to represent them (like a specific object layout)
it does, but you wouldn't want to do this with Person and Pet because a Pet "is not" a Person
right
can you define your own created_at field on the Item? you could inherit from (Item, BaseModel) but then you are going to be deep in method-resolution-order hell and that's probably a bad idea
maybe you can write a standalone helper function that generates the created_at field with your particular parameters
I have something like this right now ```py
class ModelWithCreatedAt(django.Model):
class Meta:
abstract = True
created_at = DateTimeField(auto_now_add = True)
class Item(ModelWithCreatedAt):
blah
class ItemForSale(ModelWithCreatedAt):
item = OneToOne(Item)
price = IntegerField```
I'm looking through XML now and way more difficult than I anticipated. The job assessment needs me to convert my XML into JSON. Everything I google has it saved as a local file but I'm working with requests
def make_created_at_field():
return DateTimeField(auto_now_add = True)
class ModelWithCreatedAt(django.Model):
class Meta:
abstract = True
created_at = make_created_at_field()
class Item(ModelWithCreatedAt):
...
class ItemForSale(Item):
created_at = make_created_at_field()
what about this?
you can read xml right in memory
use the "etree" api in the python standard library, ElementTree.fromstring is the way to do it
response = requests.get(url2)
root = ET.fromstring(response.content)
yep exactly, although you might want to read response.text instead
.content is raw binary content, .text is decoded to string
i.e. .content is bytes and .text is str
explains why I kept getting binary content lol.. but ahh okay what's the point of making it into JSON if we can directly play with it from tehre
because json is easier to work with in a lot of cases
welcome to data jobs, moving data from A to B and reshaping it is just necessary
I mean, it would work probably, but it would get kind of difficult to maintain since there are also other fields like that that I don't exactly want to inherit, realistically I have a model_extensions.py file and I do ```py
from model_extensions import MyModel
class Item(MyModel):
...``` and I don't really want to have to come back and edit ItemForSale when I edit MyModel
this is the actual MyModel py class MyModel(AutoValidatedModel, ExportableModel, CleanableModel, ModelWithCreatedAt, ModelWithCallbacks): class Meta: abstract = True
fair enough
so ive got quite a few extensions
yeah you don't want to have to keep track of all that
okay, so then I'm struggling to find a solution for converting this into JSON.. then I can easily play with it
"converting" xml to json sometimes requires creativity, and/or a careful assessment of the requirements of your project
ahhh okay. so no standard way essentially
thanks for all the help!
e.g. if you have xml like this
<?xml version="1.0"?>
<actors xmlns:fictional="http://characters.example.com"
xmlns="http://people.example.com">
<actor>
<name>John Cleese</name>
<fictional:character>Lancelot</fictional:character>
<fictional:character>Archie Leach</fictional:character>
</actor>
<actor>
<name>Eric Idle</name>
<fictional:character>Sir Robin</fictional:character>
<fictional:character>Gunther</fictional:character>
<fictional:character>Commander Clement</fictional:character>
</actor>
</actors>
how do you convert that to json? you have to figure it out
also .text won't work with my data, I get an error
and what is the error? you know better than to say "halp it doesnt work" 😉
might as well learn about text encoding while you're at it
you know me so well, haha yes I should know better
xml.etree.ElementTree.ParseError: not well-formed (invalid token): line 1, column 1
well that's not a good start. what is response.content[:10]?
nvm i was able to hit the api myself
Sorry I was looking through it
so I think I have an idea, I could take this XML data and first group them by "id" and then work some magic from tehre
let me see, hang on
yeah probably. that's the kind of thinking you need though
Yep, see I was thinking too simple because I'm used to JSON being fairly easy.. which I enjoy
In [3]: response = requests.get(url2)
In [11]: response.content[:10]
Out[11]: b'\xef\xbb\xbf<?xml v'
In [12]: response.text[:10] # it inferred iso-8859-1 encoding for some reason
Out[12]: '<?xml v'
In [13]: response.content.decode('utf-8')[:10]
Out[13]: '\ufeff<?xml ver'
that is a windows byte order mark
this is utf-8, but with windows' stupid thing slapped in front
ahh interview's tuesday this stuff is hard lol

Stack Overflow
I've found lots of posts describing how to parse/ignore BOMs but can't find anything on how to simply output a true/false as to whether a file contains a BOM. Can anyone point me in the right dire...
0xFEFF - that's the one
always be wary of it
so that's why I cant use .text?
well no, you can use .text, but the BOM will be left in there
the 0xFEFF
In [18]: codecs.decode(response.content, 'utf-8-sig')[:10]
Out[18]: '<?xml vers'
oh you can just do this
In [19]: response.content.decode('utf-8-sig')[:10]
Out[19]: '<?xml vers'
okay this is me doing it on my own, I'm sure they'll have me work with a different API. For now need to familiarze how to just get my data from XML once I've done request
you could also just strip off the first codepoint but this is more technically correct
yeah, just decode with 'utf-8-sig' and go on with elementtree
you might want to get friendly with xpath, it's a nice shorthand for grabbing data deep inside xml structures
(it's also a huge bloated standard that i know only a tiny fraction of, but the basics are good enough for me)
let me look into it, again the goal is to grab this stuff and return a JSON object. If I can do that I'll be happy!
don't be afraid to write a lot of loops. that's what the examples in the python docs show and there's nothing wrong with it
SELECT title
FROM books
INNER JOIN orderdetails
INNER JOIN orders
ON books.title = orders.order_date
WHERE order_date < "2016-03-01 00:00:00";
Anybody know what I'm doing wrong here? Trying to get the order_date from orders
this is the ER diagram

Random thought I just thought of, why not utilize my extensive knowledge of Pandas do this? Why not request a XML file and then use pandas.read_xml to then allow me to convert that into .json? Seems easier for sure.. will test and see
you might want to read up on what exactly read_xml does, and maybe read_json as well
it applies heuristics to handle some common data layouts, but it's not magic
you do want to be able to do this stuff "manually" anyway, even if you are using pandas elsewhere in your project
hi

@green umbra sorry i had to leave for a bit. re: #help-falafel message it sounds like you should just continue building your application. once you have the server set up, make some test queries and the database should start to fill up
I will. When the db file was made it was made empty.
I think I ended up figuring this out.. thanks so much for the guidance and allowing me to push through! I ended up creating a list from all the XML data, then convert each to dictionary and then returning a JSON object.
we see that URL is the main node in this XML file.. how do I specify to find <loc> using the .find? I keep getting a None. Here's my code and XML file:
CODE:
import xml.etree.ElementTree as ET
import xmltodict, json
url = 'https://www.washingtonpost.com/arcio/news-sitemap/'
response = requests.get(url)
root = ET.fromstring(response.content)
namespaces = {'urlset': "http://www.sitemaps.org/schemas/sitemap/0.9"}
for pubs in root.findall('urlset:url', namespaces):
location = pubs.find('loc', namespaces)
print(location) ```
```<url>
<loc>https://www.washingtonpost.com/business/on-small-business/s-korea-nominates-choo-as-finance-minister-with-prices-in-focus/2022/04/10/3b6964c4-b88b-11ec-8358-20aa16355fb4_story.html</loc>
<lastmod>2022-04-10T22:47:05.000Z</lastmod>
<news:news>
<news:publication>
<news:name>Washington Post</news:name>
<news:language>en</news:language>
</news:publication>
<news:publication_date>2022-04-10T22:47:05.000Z</news:publication_date>
<news:title>
<![CDATA[ S. Korea Nominates Choo as Finance Minister With Prices in Focus ]]>
</news:title>
<news:keywords>
<![CDATA[ smallbiz: BC-S-Korea-Nominates-Choo-as-Finance-Minister-With-Prices-in-Focus, partner-exclude ]]>
</news:keywords>
</news:news>
<changefreq>hourly</changefreq>
</url>
<url>```Hi, I'm just looking for someone to sanity check my SQL found below. ↵
I have a table called data which stores everything related to a specific guild.
I have a table called member which stores everything related to a member
I have a table called members_guilds which should be making a combined primary key from the foreign keys of data and member. This table will be storing things related to both a member and a guild (how many times they have joined x guild for example) and the member & guild columns should autofill from the data found in the tables they reference.
I have a table called reminders which should be referencing data and member so that the member and guild columns for reminder autofill from the table and column they reference.
This is my sql: https://paste.pythondiscord.com/cihoxewulo
I'll leave this here if anybody wants to reply pls ping me
Appears you are smashing everything into one table. Especially the data table. Maybe you can create more tables than just what you have currently to separate out things.
Also what are all the Text data type columns for ?
I do have multiple tables. I have a data table, a member table, a members_guilds table and a reminders table. You can see it 'creates' a new table at every CREATE TABLE IF NOT EXISTS public.table_name
I meant those tables can be normalised into further tables
webhook urls. My discord bot has a logging feature and it needs to know which channel to send it's logs to, Ordinarily I would make the columns a bigint and store channel ID's and then get/fetch the channel when it's time to send a log but that has a few drawbacks that 1) it would fail to send the log if the channel it is trying to get is not in the bots cache which would mean I'd need to implement something to check if the get failed and then run a fetch if it did and a fetch could cause me to get rate limited, so my solution to this potential problem was to use webhooks as then I'm not needing to get or fetch anything as I'm providing a specific destination
@gusty mulch, looks like you posted a Discord webhook URL. Therefore, your message has been removed, and your webhook has been deleted. You can re-create it if you wish to. If you believe this was a mistake, please let us know.
do you mind explaining this a bit further? maybe with some examples of what you mean
As an example, in members table you store an array for guilds. This is usually a hint that it can be separated out into its own table. Arrays can be used but ideally you want atomic values.
It can reduce other complexity later on when you need to write queries for reporting.
Also what if in data table you want to add a new data point. That means you need to add a new column requiring schema change. In production if you have a lot of data this can cause issues. Also if you update one columns data and have indexes on the columns those indexes need to be re updated. You can imaging this would be troublesome if you have many columns.
You should try to follow the rules here https://www.guru99.com/database-normalization.html

Guru99
Normalization in Database 1NF, 2NF, 3NF, BCNF, 4NF, 5NF, 6NF. Normalization is a database design technique which organizes tables in a manner that reduces redundancy and dependency of data.
yeah I'm trying to use relationships for the re-updating of the columns, that's the reason I sent my original msg as I wanted someone to check if I was doing my relationships correctly.
Thanks for letting you know about the potential issue my guild array on the members table might cause, I don't think it should be much of a problem as the array will hold a max of 5 items however I'll have a think of ways I can adjust this
The array was just an example. There are cases where you would want to de-normalise and use the array like you are now, but I don’t have enough knowledge of what your goals are. In which cases it is always better to start with a normalised approach and then de normalise when the case arises.
okay I'll keep that on mind and try to normalise my db altho I felt it was pretty normalised already, apart from all of the text columns in the data table which I was contemplating making their own table.
It still comes down to my original question tho, do these relationships```sql
ALTER TABLE IF EXISTS public.members_guilds
ADD CONSTRAINT member_id FOREIGN KEY (member_id)
REFERENCES public.member (member_id) MATCH SIMPLE
ON UPDATE CASCADE
ON DELETE NO ACTION
NOT VALID;
ALTER TABLE IF EXISTS public.members_guilds
ADD CONSTRAINT guild_id FOREIGN KEY (guild_id)
REFERENCES public.data (guild_id) MATCH SIMPLE
ON UPDATE CASCADE
ON DELETE CASCADE
NOT VALID;
ALTER TABLE IF EXISTS public.reminders
ADD CONSTRAINT guild FOREIGN KEY (guild_id)
REFERENCES public.data (guild_id) MATCH SIMPLE
ON UPDATE NO ACTION
ON DELETE NO ACTION
NOT VALID;
ALTER TABLE IF EXISTS public.reminders
ADD CONSTRAINT "user" FOREIGN KEY ("user")
REFERENCES public.member (member_id) MATCH SIMPLE
ON UPDATE NO ACTION
ON DELETE NO ACTION
NOT VALID;```work in the way I describe here #databases message
I have a hypothetical MYSQL table where there are three columns, reference-id (an INT reference to another table ID), geography-number (a number 1-10), setting (1, 2, or 3)
Sample data:
ref|geo|set
200 | 8 | 1
201 | 3 | 1
202 | 5 | 1
203 | 2 | 1
204 | 7 | 2
205 | 1 | 3
206 | 8 | 3
I want to find the lowest geography number that applies grouped by setting. However, setting 1 truly just means an item qualifies as both "2 AND 3" so, the expected result above would be to retrieve ref 203 for case when set = 2 (geo 2 < 7, set 1 = set 2), and 205 for case when set = 3 (geo 1 < 2, set 3 = set 1). How can I best do this with that grouping in the set. I need all the lines retrieved because this is nested within a later group by, so it's not just solving for one situation unfortunately.
what's the full xml header for this? i can't parse it on my end because of the undeclared news prefix
i hate that you need to declare namespaces
just ignore the namespace?
import requests
import xml.etree.ElementTree as ET
url = 'https://www.washingtonpost.com/arcio/news-sitemap/'
response = requests.get(url)
root = ET.fromstring(response.content)
for location in root.findall('.//{*}loc'):
print(location.text)
oh i was parsing the snippet they sent with <url>
ET.fromstring was raising the error on the undeclared namespace
well im kinda weak in sql , so i would really appreciate if someone can tell me how should i organize it,
there should be a single database, with work office names on the tables, and a there would be two sub categories under the table, one is texts and the other is voice communication. the text format would be something like :
(author TEXT, place TEXT, message TEXT, time TIME)
and in the voice category the format would be same as the text category, but i got no idea how to create the subcategories, a code example would be appreciated
What's the difference in memory for a table vs a view?
an ORM would probably generate two separate tables for you, but with the same columns/schema. if you are doing it by hand, you could make one table with a category column. but if you do that, you can never extend the voice category to include that that the text category does not have
yep looking into ORM's rn
What would be a query to add +1 to a table's column where we have an int?
UPDATE
UPDATE Aanwezigheid
SET verlof = verlof +1
WHERE voornaam = naam
Would this work?
It worked, thx
what are the best json databases for async functions?
can i use mongodb or will it block?
yeah, seen it but havent found any tutorials so skipped that. will take a look
Not sure whats wrong here:
AttributeError: module 'psycopg2' has no attribute 'connection'. Did you mean: 'connect'?```that's a weird attitude imo. the docs are there for a reason
not everything has a 10-part youtube series attached to it
the class names are probably capitalized?
i dont mean videos, but at least some example uses in projects
They aren't :/
try psycopg.Connection, or check the docs to see what the actual class names are (they might be buried in some other module)
huh it is actually a lower-case class name
they probably try to hide it from you

it might be a C extension
huh, weird. does psycopg2 actually ship with type hints?
it might be a c extension class that isn't actually accessible from regular python
what happens if you do this in the python console? import psycopg2; print(psycopg2.connection)
It was working earlier, so it must be something else but I get the same error
I might restart my computer
it's possible that it wasn't working earlier because pycharm hadn't indexed your module yet, or something weird
and now it's not working for a different reason
It's VS code but I am almost certain it was working earlier
That's possible
but yesterday all of this was working flawlessly:

I am going to restart my computer
In [1]: import psycopg2
In [2]: psycopg2.connection
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
Input In [2], in <cell line: 1>()
----> 1 psycopg2.connection
AttributeError: module 'psycopg2' has no attribute 'connection'
i don't think it's you
huh
Thats so odd
how was it not throwing an error yesterday?
maybe I am losing my mind
because it was probably silently ignoring it for some other reason
In [9]: conn = psycopg2.connect(host='localhost', database='postgres')
In [10]: type(conn)
Out[10]: psycopg2.extensions.connection
In [11]: from psycopg2.extensions import connection as PostgresConnection
In [12]: type(conn) is PostgresConnection
Out[12]: True
from psycopg2.extensions import (
connection as PostgresConnection,
cursor as PostgresCursor,
)
class Connection:
def __init__(self, connection: PostgresConnection, cursor: PostgresCursor) -> None: ...
note: do not re-use cursors for multiple queries
one cursor per query
yeah. every database library is different. some libraries it's ok, others it's really bad. the intention is that you only use 1 per query, so stick to that
actually i changed my mind, i want them to be something like each workspace has an individual table, can it be possible with ORM?
what is a "workspace" in this context?
something like umm...take discord in context, each server as a different workspace
like the work notifications and information details of the workers
in this case information details means like the workeers opinion about the group they are in
and so on
taking discord as the work environment in mind, how would u chose to design it?
okay, thanks!
I think what you're looking for is multitenancy. Depending on your database and ORM it can be quite difficult to setup
lemme google the term lol, this is really not my strong suite
For your use case I don't really think it's worth the hassle to be honest, you can just add a guild_id column to your tables
And if you're using postgres you could also make use of row level security so that you don't have to add the guild id filter for every query
Although I don't know what ORMs support it
hmm...makes sense
ima go with that idea then , sqlalchemy might be able to handle it with postgres
lemme see
That could, you need to be careful and make sure that the same connection is used across requests though
Hi,
which database would you recommend to load data from python into it and use it on a frontend (e.g. angular)
Data is csv
--> lot of data, includes pictures
you could just play safe with PostgreSQL + BLOB, but that might not be the most efficient way to do it
whats a good api for databases
there seems to be some arguments against storing images in databases, but I cannot speak much about it other than what you'd find googling "images in database"
depends - what kind of API / which kind of database?
I think it would be better to store them in the directory and link it with the url to the directory, right?
...given that you just asked that in here and #data-science-and-ml, do you actually understand what you are asking?
so instead of saving the images in the db, it's better to place the link there right?
that is a possibility I think, you can try asking in #web-development as well but idk how active it is
yes i just need to still decide whether i want to take a career path in databases or in ai
Alright, thank you bud @storm mauve
I recommend checking the pins of each channel then
how could i iterate through all the document in a collection for mongodb? Without returning
TypeError: 'AsyncIOMotorCursor' object is not iterable
Anyone able to help me, Im trying to connect to mariadb server using the connector, however it denies me in the script, however I can connect fine thru heidisql
the user that i am using is whitelisted on all ips and dbs
Sorry ben gone from my desk all day... the full XML header is urlset, can be found here https://www.washingtonpost.com/arcio/news-sitemap
But I'd like to include all of the data within each url
I think this worked!! I included the namespaces just filtered even morre on finding each <loc> every time we loop through a URL
use the .to_list() method on the cursor
maybe it supports async for but i don't remember
what about
<url>
<loc>https://www.washingtonpost.com/national-security/2022/04/10/ice-war-criminals-latin-america/</loc>
<lastmod>2022-04-10T16:38:05.958Z</lastmod>
<news:news>
<news:publication>
<news:name>Washington Post</news:name>
<news:language>en</news:language>
</news:publication>
<news:publication_date>2022-04-10T16:38:05.958Z</news:publication_date>
<news:title>
<![CDATA[ A historian at ICE hunts Latin American war criminals in the U.S. ]]>
</news:title>
</news:news>
<changefreq>hourly</changefreq>
</url>```
How do I get into <news:news> and then <news:publication> ??@harsh pulsar any idea on how to get into the news:news tag and then news:publication ? Here's my code:
import xml.etree.ElementTree as ET
import xmltodict, json
url = 'https://www.washingtonpost.com/arcio/news-sitemap/'
response = requests.get(url)
root = ET.fromstring(response.content)
namespaces = {'urlset': "http://www.sitemaps.org/schemas/sitemap/0.9"}
news_namespaces = {'urlset': 'http://www.google.com/schemas/sitemap-news/0.9'}
for pubs in root.findall('urlset:url', namespaces):
location = pubs.find('.//{*}loc', namespaces).text
modification = pubs.find('.//{*}lastmod',namespaces).text
news = pubs.find('.//{*}news', namespaces)
change = pubs.find('.//{*}changefreq', namespaces)
print(news)```root = ElementTree.fromstring(response.text)
namespaces = {
"_": "http://www.sitemaps.org/schemas/sitemap/0.9",
"news": "http://www.google.com/schemas/sitemap-news/0.9",
"video": "http://www.google.com/schemas/sitemap-video/1.1",
}
for pubs in root.findall('_:url', namespaces):
news_items = pubs.findall('news:news', namespaces)
for news_item in news_items:
print(news_item)
for news_publication in news_item.findall('news:publication', namespaces):
print(' ' + str(news_publication))
why i get this error?:
mysql.connector.errors.DatabaseError: 2003 (HY000): Can't connect to MySQL server on 'x.x.x.x'
i create a database using xampp on my vps and trying to connect it using python

Hello, i’m using MySQL to create a database and i’m just wondering whether this would be the way to send the database, with all the information inside of it:
Tabel_1 = [
{"userid": user.id, "channelid": channel.id}, # first piece of info / aka first column
{"userid": user.id, "channelid": channel.id}, # second piece of info
# and so on...
]
ax.plot(xs,256-file.flow[source_start:source_end])
hey is source_start:source_end acting on both x variable (xs) and y variable (256-file.flow). or is source_start:source_end only acting on y variable (256-file.flow)?
idk if there is other way (cuz i never tried to do something like this), but like u can do it by looping and put the value of the key or whatever in the query
from flask import Flask, render_template
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
app.config['SQLALCHEMY_DATABASE_URI'] = 'sqlite:///market.db'
db = SQLAlchemy(app)
db.create_all()
#local database
class Item(db.Model):
id = db.Column(db.Integer(), primary_key=True)
name = db.Column(db.String(length=30), nullable=False, unique=True)
price = db.Column(db.Integer(), nullable=False)
barcode = db.Column(db.String(length=12), nullable=False, unique=True)
description = db.Column(db.String(length=1024), nullable=False, unique=True)
def __repr__(self):
return f'Item {self.name}'
Hi all. I am trying to write a d.b file with information inside. I have some code for 3 items that I personally hardcoded. Would those automatically go inside?
Also how is my set up for the database? Am I missing anything?
EDIT: The 3 times are a dictionary list. They are for example an iphone with a name, price, barcode, and description of the item. My plan is to put this information in a database so that I won't have to hardcode all of this in python. And it'll look cleaner to do a db.join() rather than have a dictionary list of items and there elements.
I have a MongoDB shell question. I'm running a for loop in the shell, it is doing a find and then an insert in a loop. I would like to stop it (eg: ctrl-C) , obviously that doesn't work, so the other option is to use killOp() but wont the currentOp() be constantly updating with each new find and insert iteration, if so then how can you stop a running for-loop?
is there anyone with sqlite3 experience with python. My problems shouldn't be very complex however i'm struggling to get my head round them. please dm me if you have a spare minute
i haven't used sqlite3.. but jsut suggesting.. no one has time to DM u to solve your problem.. instead it's a better choice to drop your question here with error (if there is any)
:>
it's the "don't ask to ask" principle
Is my question ok?
yeah, except i don't understand what you mean by this:
I have some code for 3 items that I personally hardcoded. Would those automatically go inside?
Oh. I should learn to edit my things here.
Essentially I have 3 items in a dictionary list in the program. Which is a 'market' website. With the above acting as a database for the items. The 3 items are in a SQL table because each item has different things like name of item, price, barcode (these are just rando numbers), and etc etc.
sorry salt @harsh pulsar
are you asking how to add items to your database?
i believe you need to do create_all after defining all the classes
and you only need to run it once. you shouldn't run it every time you run your app
How could I output images I stored in a MongoDB collection?
I want to make an API with Python and Flask that would output images from the database and use that API with React which is my frontend.
how did you store them?
this is helpful information, but i still don't know what you're asking
converted it to a byte array, then just inserted it in a specific collection
Sorry I will do better. I don't know why i'm struggling to specify the problem.
anyone to help me with Database management systems normalization forms?
what is your objective? you have some data (3 rows?) and you want to get it into the database?
Stack Overflow
I am trying to verify a bytearray with Image.open and Image.verify() without writing it to disk first and then open it with im = Image.open(). I looked at the .readfrombuffer() and .readfromstring()
Right! This here I think?
each item has different traits to it hence the way the dictionary works. But I want to use SQL to make them into rows.
thank you very much
highest_salaries = salary.sort_values(by='salary', ascending=False)
eighth_highest_salary = tenpaid.get['salary'].index[9]
eighth_player_name = tenpaid.get['name'].index[9]
print('Player:', eighth_player_name, '\nSalary:', eighth_highest_salary)
what is the issue with this code

salary is used on the first line, but it comes from no where. Not defined
self.cursor.executemany("""INSERT INTO redsignalsbsc(models_id,block_no,transaction_hash,models_timestamp,unix_timestamp,token0,token1,liquidity_pair,pair_address,models_name,models_symbol,description,decimals,models_total_supply,website,twitter,telegram,reddit,github,blog,discord,whitepaper,price,price_updated_at,market_cap,liquidity,buy_tax,sell_tax,buy_gas,sell_gas,error_message,is_honeypot,updated_at,json_id,json_name,json_symbol,slug,date_added,json_max_supply,json_total_supply,json_circulating_supply,self_reported_circulating_supply,json_last_updated,json_timestamp,Data_Recorded_at) VALUES (%s),(%s),(%s), (%s),(%s),(%s),(%s),(%s),
(%s),(%s),(%s),(%s),(%s),(%s),(%s),(%s),(%s),(%s),(%s),(%s),(%s),(%s),(%s),(%s),(%s),
(%s),(%s),(%s),(%s),(%s),(%s),(%s),(%s),(%s), (%s),(%s), (%s),(%s),(%s),(%s),(%s),
(%s),(%s),(%s),(%s)""", (data,))
self.conn.commit()
output:
psycopg2.errors.SyntaxError: INSERT has more target columns than expressions
LINE 1: INSERT INTO redsignalsbsc(models_id,block_no,transaction_has...
no. of columns in table are same. but still i am getting this error
Hello every one,
I have a project which is to manage datas on a RPI with a client application (coded with kivy). Currently, I make this possible with the module pysftp and a json file. I choose this solution for the security that bring to me because of the SSH protocole (I think). So the question is, could i make the same thing but with a dataserver on the raspberry an make this secured?
Thank you in advance for your answers :)
Hello, may I ask why my visual studio highlights 'message' as a predefined value when I'm writing my schema.sql?
help? (using aiosqlite)
await cursor.execute(f"DELETE FROM embed WHERE guild_id and embeds = (?,?)", (ctx.guild.id, name))
error:
Traceback (most recent call last):
File "/home/runner/ganyubot/venv/lib/python3.8/site-packages/discord/ext/commands/core.py", line 85, in wrapped
ret = await coro(*args, **kwargs)
File "/home/runner/ganyubot/commands/embed_create.py", line 51, in delete
await cursor.execute(f"DELETE from embed WHERE guild_id and embeds = (?,?)", (ctx.guild.id, name))
File "/home/runner/ganyubot/venv/lib/python3.8/site-packages/aiosqlite/cursor.py", line 37, in execute
await self._execute(self._cursor.execute, sql, parameters)
File "/home/runner/ganyubot/venv/lib/python3.8/site-packages/aiosqlite/cursor.py", line 31, in _execute
return await self._conn._execute(fn, *args, **kwargs)
File "/home/runner/ganyubot/venv/lib/python3.8/site-packages/aiosqlite/core.py", line 129, in _execute
return await future
File "/home/runner/ganyubot/venv/lib/python3.8/site-packages/aiosqlite/core.py", line 102, in run
result = function()
sqlite3.OperationalError: row value misused```
await cursor.execute("DELETE FROM embed WHERE guild_id = ? AND embeds = ?", (ctx.guild.id, name))```I have a weird question..
if i have a database for managing airline company website and flight ticket purchases - do you have ideas for SQL queries that database should have?
It depends on what you need
Nothing to specific i only need basics queries in the theme ill give u some examples
Return all the flights in the last week @paper flower
Should be a simple filter
e.g.
select * from flights
where date >= ...
My problem was with the finding ideas for different queries
So just start creating your queries, if you have any problems just ask
You don't need ideas, you need problems
But my problem is i dont have ideas
And if i want the number of flights from each airport in the last month?
something like
select count(*) from flights group by airport_id;
Thx!
if this hasn't been updated yet, you have 2 options. But generally this should be done outside fo the Flask app. This, like the creation of the database, should be done once.
Option 1, loop through each item in the list and create an Item then within the db.session run a db.commit(). Follow the docs here https://docs.sqlalchemy.org/en/14/orm/tutorial.html#adding-and-updating-objects
Option 2, since you are set up with a list of dictionaries you should look at bulk_insert_mappings inside the session. https://docs.sqlalchemy.org/en/14/orm/session_api.html#sqlalchemy.orm.Session
Any able to suggest a good async library for mariadb?
Probably sqlalchemy + aiomysql?
when using SQLAlchemy to insert a list of records into a SQLite3 table that has a UNIQUE ON CONFLICT IGNORE constraint for multiple columns -- should result.inserted_primary_key always be 0 if an insert was ignored?
i'm having trouble replicating the issue using non-work/production code to share as an example
in my test code, when I insert 5 unique rows, followed by 2 duplicate rows -- inserted_primary_key = 5 for the last 2 duplicates (when they should be 0, AFAIK)
in my actual code, inserted_primary_key just continues to get incremented
I think I may be fundamentally misunderstanding how inserted_primary_key works
Hi im working on a scraper and like to notify when there is a match. Which database should i use for this? And i wonder how i should build the notify part. Any ideas?
Require some help with database code here. If anyone can help.
Hey @dark copper!
You either uploaded a .txt file or entered a message that was too long. Please use our paste bin instead.
I have a postgresql database on google cloud and multiple users want to connect to it (they are using sqlalchemy). can you link a good and clear guide on doing that because I don't understand a thing in the google cloud documentation
what will be the database uri of the database??
i went and whitelisted my ip but now I cannot figure out the uri
:incoming_envelope: :ok_hand: applied mute to @obtuse ermine until <t:1649900068:f> (9 minutes and 59 seconds) (reason: burst rule: sent 8 messages in 10s).
Its probably interesting to talk about what can be done, DB level, to prevent selling more seats for flights than there is in type of plane that will be used. Maybe it would imply row or table locks, transactions, etc.
are the users trying to connect from inside the same virtual network as the database server is or are they connecting from somewhere else on Internet? Not sure enought what your use case is
they are trying to connect from somewhere else
ok, many peoples will do a virtual network in the cloud to connect the db server to. That network has an internet gateway with a public Ip adress. you can set nat rules in there so that certain request made on your sql port on the public ip are forwarded to your sql server internal ip. Then you can connect to the database using the public IP or setup a dns name for it. HIGHLY suggest you block all requests except those coming from whitelisted ips.
This is not really a big prod ready solution. More like a quick way to share access to a db to some peoples
thanks, i'll try doing that
thanks im trying that but what will be the connection uri of the database?
im using albamic for the migrations and it requires a uri
It usually refer to the string that you put in the code to specify address & credentials used to connect to db.
Can look like : "mysql://user_name:password@blablalbla.com:3333"
Im getting database is locked after trying to verify someone is already verified (im only doing this to test if the reply works)
@commands.command()
@commands.is_owner()
async def verify(self, ctx, user: discord.Member):
conn = await aiosqlite.connect('./sql/ghostbot.db')
c = await conn.cursor()
await c.execute('CREATE TABLE IF NOT EXISTS verified_users(uid BIGINT, uname TEXT)')
await c.execute('SELECT uid FROM verified_users WHERE (uid = ?)', (user.id,))
result = await c.fetchone()
if result:
embed = discord.Embed(title=':Invalid: Error Verifying User!', color=0xff0000)
embed.add_field(name='Reason: ', value=f'This {user.mention} has already been verified!')
await ctx.reply(embed=embed)
await conn.commit()
await c.close()
await conn.close()
return
if not result:
await c.execute('INSERT INTO verified_users(uid,uname) VALUES(?,?)', (user.id,user.name))
embed = discord.Embed(title=':Verify: Verification Successful!',description=f'{user.mention} has been successfully verified!' , color=0x000000)
await ctx.reply(embed=embed)
return
await conn.commit()
await c.close()
await conn.close()
anyone able to help with this issue?
worst comes to worse Ill just have to use the mariadb server I have
been using sqlite so I can have a local db for the test bot instance of the bot I use
Make sure you dont have another process stuck running maybe a looooong ALTER TABLE. You only have INSERT and SELECT otherwise and those should not lock table by themselves.
Other troubleshooting track. You do a create table and select right one after the other in what seems to be an asynchroneous setup...maybe double verify the table is finish creating before the select is executed. You could test for that with a sleep in between, just for troubleshooting.
The only update is for the prefix command
so no alterations really running
and only per server prefixes may be running if anything
I'm not sure what you mean by prefix. Are you getting database lock or table lock errors ?
Was assuming table lock error on verified_users

hmm this might not be related to your code. It looks like an access control error
it works fine for everything else
nvm
spoke too soon
It was working fine before I added this cmd
help?
await cursor.execute(f"UPDATE embed SET title = ? WHERE embeds = ? AND guild_id = ?", (value, embedName, ctx.guild.id))
it doesnt send an error message but it wont update

did you forget to commit the update?
i did! thank you for reminding
Your if not result: block does return before the commit/close statement. Also I see some code duplication you can avoid which are done in the if blocks.
@commands.command()
@commands.is_owner()
async def verify(self, ctx, user: discord.Member):
conn = await aiosqlite.connect('./sql/ghostbot.db')
c = await conn.cursor()
await c.execute('CREATE TABLE IF NOT EXISTS verified_users(uid BIGINT, uname TEXT)')
await c.execute('SELECT uid FROM verified_users WHERE (uid = ?)', (user.id,))
result = await c.fetchone()
if result:
embed = discord.Embed(title=':Invalid: Error Verifying User!', color=0xff0000)
embed.add_field(name='Reason: ', value=f'This {user.mention} has already been verified!')
else:
await c.execute('INSERT INTO verified_users(uid,uname) VALUES(?,?)', (user.id,user.name))
embed = discord.Embed(title=':Verify: Verification Successful!',description=f'{user.mention} has been successfully verified!' , color=0x000000)
await ctx.reply(embed=embed)
await conn.commit()
await c.close()
await conn.close()```Anyone know how to make sure a small database (3 tables) are in 3NF form?
Also how to create Query Screens?
def update_role(self,
role_id: int,
role_name: str,
payment_type: str,
payment_value: Optional[int] = None,
start_date: Optional[datetime.datetime] = None
) -> Union[Role, None]:
"""
Updates the role with the given id with the new name and returns it.
Parameters:
role_id: The id of the role to update.
role_name: The new name of the role.
payment_type: The new payment type of the role.
payment_value: The new payment value of the role.
start_date: The new start date of the role.
Returns:
The updated role.
"""
with Session(engine) as session:
role = session.get(Role, role_id)
if role:
role.name = role_name
role.payment_type = payment_type
role.payment_value = payment_value
role.start_date = start_date
session.add(role)
session.commit()
self.roles[role.id-1] = role
self.roles_names[role.id-1] = role_name
session.refresh(role)
return role```Role.name has a UNIQUE constraint, so if I try to update the existing role to have the same name an other one, this error happens:
>>> sqlite3.IntegrityError: UNIQUE constraint failed: role.name```I know I could use a try except block, but is there a way I could check it before this error happens?
Just query your db to see if there are any roles with such name
also i'd avoid using such large if blocks:
with Session(engine) as session:
role = session.get(Role, role_id)
if not role:
pass # If role does not exist
role.name = role_name
role.payment_type = payment_type
role.payment_value = payment_value
role.start_date = start_date
session.add(role)
session.commit()
self.roles[role.id-1] = role
self.roles_names[role.id-1] = role_name
session.refresh(role)
return role
sometimes you just need to check by trying and seeing if it fails. otherwise you can encounter a "time of check / time of use" error
wrap the try/except block around the smallest possible code that requires it, not the whole function
so probably just around session.add() in this case
I believe you can't really check if where IntegrityError is originated from really 🤔
also fair, i don't think you can in general
Shouldn't that be commit?
wherever the exception gets triggered
wrap both to be safe?
my intuition is that the exception would happen on the query itself
add doesn't raise exception, it just stages your models for commit
commit flushes sql into database and commits transaction
i see, i assume there's a way to separate those if you need to
because the whole point is that you don't want to commit a sequence of related operations if one of them fails
Yep, you can call add multiple times and then commit
so sqlalchemy will automatically rollback if an error occurs?
Yep
i've never used sqla for anything more than toy projects
i should spend more time with it, i like the query builder
I had to use transactions manually because i was sending http request at the same time
Anyway, it should be easy to check if there are roles with such name:
stmt = select(select(Role).filter(Role.name == name).exists())
exists: bool = await self.session.scalar(stmt)
Yeah, it's just like sql 😅
stmt = (
select(
Event.path,
func.count(Event.id),
func.count(distinct(Event.user_id)),
func.count(Event.id) / minutes_in_range,
func.percentile_disc(0.50).within_group(Event.duration),
func.percentile_disc(0.95).within_group(Event.duration),
cast(func.count(Event.id).filter(Event.failed == True), Float)
/ func.count(Event.id),
)
.group_by(Event.path)
.filter(after <= Event.timestamp, Event.timestamp <= before)
)
just started database in college hope to learn it soon
@bot.command()
@commands.has_any_role(692760082085183519, 940008547993927691, 863878825376743475, 902292952381001779, 863879069253894166, 902292952381001779, 863879304110276668, 940008547993927691)
async def пред(ctx, member: discord.Member = None, *, reason = None):
print(45)
cursor.execute("""CREATE TABLE IF NOT EXISTS warning(guild_id BIGINT, user_id BIGINT, warn INT, count INT, moderator_id BIGINT, reasons VARCHAR)""")
base.commit()
print(1)
warnings = cursor.execute("SELECT * FROM warning WHERE user_id = ? AND guild_id = ?", (member.id,ctx.guild.id)).fetchone()
print("работает")
if member is None:
await ctx.send("Выберите участника")
return
if reason is None:
try:
cursor.execute('INSERT INTO warning(guild_id, user_id, warn, count, moderator_id, reasons) VALUES(?, ?, ?, ?, ?, ?)', (ctx.guild.id,member.id,0,1,ctx.author.id,'Отсутствует'))
base.commit()
except Exception as e:
print(repr(e))
print(2222)
cursor.execute(f'UPDATE warning SET warn = {warnings[2] + 1} WHERE user_id = ? AND guild_id = ?', (member.id, ctx.guild.id))
base.commit()
await ctx.send(f"**{ctx.author.name}** Выдал предупреждение #{warnings[2] + 1} {member} (случай # )")
else:
cursor.execute('INSERT INTO warning (guild_id, user_id, warn, count, moderator_id, reasons) VALUES(?, ?, ?, ?, ?, ?)', (ctx.guild.id,member.id,0,1, ctx.author.id, reason))
base.commit()
cursor.execute(f'UPDATE warning SET warn = {warnings[2] + 1} WHERE user_id = ? AND guild_id = ?', (member.id, ctx.guild.id))
base.commit()
await ctx.send(f"**{ctx.author.name}** Выдал предупреждение #{warnings[2] + 1} {member}, причина {reason}. (случай # )")
Like... if the user didn't have a previous one before, then the bot first gives an error TypeError: 'NoneType' object is not subscriptable , well, if you do it again, everything will work. How to fix?
@tender salmon this doesn't solve your problem, but you can use query placeholders in SET warn = ?, you don't need to use the f-string
just check if warnings is None before proceeding with the UPDATE? e.g if warnings is None: INSERT ; else: UPDATE
@bot.command()
@commands.has_any_role(692760082085183519, 940008547993927691, 863878825376743475, 902292952381001779, 863879069253894166, 902292952381001779, 863879304110276668, 940008547993927691)
async def пред(ctx, member: discord.Member = None, *, reason = 'Отсутствует'):
print(45)
cursor.execute("""CREATE TABLE IF NOT EXISTS warning(guild_id BIGINT, user_id BIGINT, warn INT, count INT, moderator_id BIGINT, reasons VARCHAR)""")
base.commit()
print(1)
warnings = cursor.execute("SELECT * FROM warning WHERE user_id = ? AND guild_id = ?", (member.id,ctx.guild.id)).fetchone()
print("работает")
if member is None:
await ctx.send("Выберите участника")
return
if warnings is None:
cursor.execute('INSERT INTO warning(guild_id, user_id, warn, count, moderator_id, reasons) VALUES(?, ?, ?, ?, ?, ?)', (ctx.guild.id,member.id,0,1,ctx.author.id,'Отсутствует'))
base.commit()
print(2222)
cursor.execute(f'UPDATE warning SET warn = warn + 1 WHERE user_id = ? AND guild_id = ?', (member.id, ctx.guild.id))
base.commit()
await ctx.send(f"**{ctx.author.name}** Выдал предупреждение #{warnings[2]} {member} (случай # ) {reason}")
else:
cursor.execute(f'UPDATE warning SET warn = warn + 1 WHERE user_id = ? AND guild_id = ?', (member.id, ctx.guild.id))
base.commit()
await ctx.send(f"**{ctx.author.name}** Выдал предупреждение #{warnings[2]} {member} (случай # ) {reason}")
like this? and where to write reason, so that if the reason is not indicated, it will not be written in the chat Missing?
@harsh pulsar
can someone tell me what i did wrong?
async def delete(self, ctx, *, name=None):
db = await aiosqlite.connect("embed.db")
cursor = await db.cursor()
await cursor.execute(f"SELECT embeds FROM embed WHERE guild_id = {ctx.guild.id}")
emds = await cursor.fetchall()
if name not in emds:
emb = discord.Embed()
emb.description=f"embed {name} doesn't exist. Try again."
emb.colour = 0x599cff
await ctx.send(embed=emb)
else:
if name == None:
emb = discord.Embed()
emb.description="name is required."
emb.colour = 0x599cff
await ctx.send(embed=emb)
else:
await cursor.execute("DELETE FROM embed WHERE guild_id = ? AND embeds = ?", (ctx.guild.id, name))
await db.commit()
emb = discord.Embed()
emb.description=f"deleted {name}"
emb.colour = 0x599cff
await ctx.send(embed=emb)
it says "test embed doesn't exist try again" even though its in the db

it might be giving you a list of tuples like [('foo',), ('bar',)]?
Why not just:
...
await cursor.execute("SELECT embeds FROM embed WHERE guild_id = ? AND embeds = ?", (ctx.guild.id, name))
emds = await cursor.fetchone()
if emds is None: # not found
...
And you shouldn't use f-strings for data bindings.
oh thank you! and noted
Hi there, currently developping a discord bot and I got back to SQL after 3 years of not using it. I have a command to add data to my database, and after asking for input I want to add them to a new row, the thing is, I used this statement at the beginning self.db = sql.connect('database\main.sqlite'), does it mean I can simply then use the INSERT function or do I need to use a cursor?
You should use cursors
So inside the cursor.execute I put my Insert?
also use context managers with cursors
Wdym?
You're using built-int sqlite driver?
I'm using sqlite3 that's all I know
Then nvm, i though cursors are context manageable (can be used in with construct), like files
with open(...) as f:
...
I was using json file and decided to give sqlite a try because well many people told me it was for the better
Yeah I was doing that!
It is better 🙂
^^
I mainly use sqlalchemy which abstracts a lot of things but it's just more convenient than using raw sql
Damn there is a lot of SQL thingy
It looks kind of like this ^
But resulting sql is exactly like it
what is the difference of conn = sqlite3.connect("spider.sqlite") and ``conn = sqlite3.connect("database.db")`? thank you
different file names?
sorry to bother again but I just wanted to be sure this was right:
values = (age.content, gender.content, picture.content, f'0x{color.content}', desc.content, universe.content)
self.cursor.execute("INSERT INTO main VALUES values")```I'm trying to connect to mysql server locally and unable to, when I try and connect in cmd prompt I just get:
Can someone please help me be able to access my server?

is there any difference in the characteristics of "spider.sqlite" to other normal ".db" files?
you can name it whatever you want
database.txt would work the same way
I am very unsure about this one :
await ctx.send('Enter new value for the label you picked')
new_value = (await self.bot.wait_for('message', check=check, timeout=30)).content
self.cursor.execute(f'UPDATE main SET {new_label}={new_value} WHERE oc_name={name}')
await ctx.send('Character information successfully modified')```and here is me who just start learning database through XAMPP in my College
anyone mind telling me if that has a chance to work
you guys seems professional
definetely not
I'm Just Starting programming
we all started somewhere
hm.. !
idk what that is, but I surely didn't learn anything at university, I pretty much saw everything by myself because university classes were pretty empty
anyway back on DataBases
XAMPP is the local server
for hosting a website locally on your pc
it has all the database structures and templates already built in to help host a complete website
very useful if you don't own a domain
ayo that's really cool!
yup its an open source project completely free
you should join Github to learn more about these kinds of amazing open source projects
I already have Github hehe
You shouldn't use any form of string formatting with sql
https://docs.python.org/3/library/sqlite3.html#sqlite3-placeholders
Sqlite documentation actually covers it, so give it a read

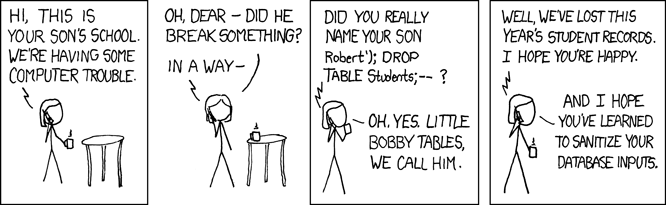
I don't get it
!sql-f-string
SQL & f-strings
Don't use f-strings (f"") or other forms of "string interpolation" (%, +, .format) to inject data into a SQL query. It is an endless source of bugs and syntax errors. Additionally, in user-facing applications, it presents a major security risk via SQL injection.
Your database library should support "query parameters". A query parameter is a placeholder that you put in the SQL query. When the query is executed, you provide data to the database library, and the library inserts the data into the query for you, safely.
For example, the sqlite3 package supports using ? as a placeholder:
query = "SELECT * FROM stocks WHERE symbol = ?;"
params = ("RHAT",)
db.execute(query, params)
Note: Different database libraries support different placeholder styles, e.g. %s and $1. Consult your library's documentation for details.
See Also
• Extended Example with SQLite (search for "Instead, use the DB-API's parameter substitution")
• PEP-249 - A specification of how database libraries in Python should work
see i know you are a professional
what are you guys talking about
f"insert into table Students (name) values {}".format("Robert; DROP TABLE Students;--")
ha but yeah that's dumb
and ye I get that it will cause issues now you put it that way
new_value = "value; DROP TABLE main;--"
self.cursor.execute(f'UPDATE main SET {new_label}={new_value} WHERE oc_name={name}')
does it mean that when I put several ? then the params tuple just contains what I need to query?
Yep, you should use ? in place of your parameters and pass them to execute function
params = (f'{new_label}',f'{new_value}',f'{name}')?
self.cursor.execute('UPDATE main SET label = ? WHERE oc_name=?', (new_lable, name))
no
ha okay
haha I got confused for a second x)
so it's like a sql string formating that cleary establishes that the parameter IS a parameter and won't cause any trouble?
Yep, driver would escape it so it doesn't get interpreted as sql

#discord-bots message I'm gonna link this here as well because it concerns discord py and mostly sqlite3, if you mind having a look ^^
and here is how I initialized my db:
self.cursor.execute('''CREATE TABLE IF NOT EXISTS main(
guild_id INT NOT NULL,
artist_id INT,
oc_name STR,
oc_age STR,
oc_gender STR,
oc_url STR,
oc_color STR,
oc_desc STR,
oc_universe STR,
PRIMARY KEY(guild_id))
''')```values = (id, id_user, age.content, gender.content, picture.content, f'0x{color.content}', desc.content, universe.content)
self.cursor.execute('INSERT INTO main VALUES ?', values) ```
The problem might come from here but idk whyI added self.db.commit() but I still have the exact same problem
I really don't understand why it doesn't update the database
there isn't any error message either
hi im just learning on website building and i was wondering if i should learn php since im planning to learn flask or django already
anyone?
It’s just another language to do the same thing. Use whatever your comfortable with or will be of use in the future.
This is wrong.
how so
The values to insert should be in brackets. And your query is only expecting 1 value currently, whereas you are supplying more than 1.
it didn't work
Show what you tried but didn’t work
self.cursor.execute('INSERT INTO main VALUES (?,?,?,?,?,?,?,?)', values)```Maybe the issue is elsewhere in the code. You should debug. Is that statement even being reached ?
yeah it is
using json wasnt an issue, now sqlite3 is a problem
@commands.command()
@commands.cooldown(rate=1, per=60, type=commands.BucketType.user)
async def ocadd(self, ctx):
""" Add OC to the database of the user """
id = ctx.guild.id
id_user = ctx.message.author.id
if (ctx.message.author.guild_permissions.administrator) or checkrole(ctx, 'rolesid', id):
def check(m):
return m.author == ctx.author
await ctx.send('Enter the name of the character: ')
name = await self.bot.wait_for('message', check=check, timeout=30)
await ctx.send('Enter the age of the character: ')
age = await self.bot.wait_for('message', check=check, timeout=30)
await ctx.send('Enter the gender of the character: ')
gender = await self.bot.wait_for('message', check=check, timeout=30)
await ctx.send('Enter the picture url of the character: ')
picture = await self.bot.wait_for('message', check=check, timeout=60)
await ctx.send("Enter the hex code of the character (without the `#`): ")
color = await self.bot.wait_for('message', check=check, timeout=60)
await ctx.send('Enter the description of the character: ')
desc = await self.bot.wait_for('message', check=check, timeout=60)
await ctx.send('Enter the universe the character belongs to: ')
universe = await self.bot.wait_for('message', check=check, timeout=30)
values = (id, id_user, age.content, gender.content, picture.content, f'0x{color.content}', desc.content, universe.content)
self.cursor.execute('INSERT INTO main VALUES (?,?,?,?,?,?,?,?)', values)
await ctx.send(f'Character successfuly added to the file of <@{id_user}>!')
self.db.commit()```
The codeYou should create a new cursor each time you want to make a query. Might not be the issue but avoid using a global cursor.
Global db should be fine, doesn’t really matter
Your table seems to have 9 columns and you only provide 8, I think name.content is missing after id_user.

{kind=link}
{kind=link}
Long shot but...does anyone know how to split a CSV (Which is in a table as a string) into tables/columns?
I know you can do it with regex i just cant remember how. Something like this?
SELECT
regexp_extract(col_value, 'REGEX', 1) column1
regexp_extract(col_value, 'REGEX', 1) column2
regexp_extract(col_value, 'REGEX', 1) column3
from tbl_datahold;```@bot.command()
@commands.has_any_role(692760082085183519, 940008547993927691, 863878825376743475, 902292952381001779, 863879069253894166, 902292952381001779, 863879304110276668, 940008547993927691)
async def пред(ctx, member: discord.Member = None, *, reason = 'Отсутствует'):
print(45)
cursor.execute("""CREATE TABLE IF NOT EXISTS warning(guild_id BIGINT, user_id BIGINT, warn INT, count INT, moderator_id BIGINT, reasons VARCHAR)""")
base.commit()
print(1)
warnings = cursor.execute("SELECT * FROM warning WHERE user_id = ? AND guild_id = ?", (member.id,ctx.guild.id)).fetchone()
print("работает")
if member is None:
await ctx.send("Выберите участника")
return
if warnings is None:
cursor.execute('INSERT INTO warning(guild_id, user_id, warn, count, moderator_id, reasons) VALUES(?, ?, ?, ?, ?, ?)', (ctx.guild.id,member.id,0,1,ctx.author.id,'Отсутствует'))
base.commit()
print(2222)
cursor.execute(f'UPDATE warning SET warn = warn + 1 WHERE user_id = ? AND guild_id = ?', (member.id, ctx.guild.id))
base.commit()
await ctx.send(f"**{ctx.author.name}** Выдал предупреждение #{warnings[2]} {member} (случай # ) {reason}")
else:
cursor.execute(f'UPDATE warning SET warn = warn + 1 WHERE user_id = ? AND guild_id = ?', (member.id, ctx.guild.id))
base.commit()
await ctx.send(f"**{ctx.author.name}** Выдал предупреждение #{warnings[2]} {member} (случай # ) {reason}")
how to make it so that if the reason is not specified, then Missing is not written in the chat?
hey there I'm currently using python cursor.execute('SELECT DISTINCT oc_name, oc_desc FROM main WHERE guild_id = ? AND artist_id = ?',(id_guild, id)) result = cursor.fetchall() to get some infomation from a data base but I only get result for one row instead of all of them, how could I fix that?
the error is cursor.execute('INSERT INTO main VALUES (?,?,?,?,?,?,? sqlite3.IntegrityError: UNIQUE constraint failed: main.gui
Perhaps because you're filtering your data?
I fixed the issue by removing the primary key
Also if you're planning to run your bot over long periods of time and mutating/migrating your database schema over time i'd recommend using orm
It would make using sql easier and many orms have migration tools
so you can for example add or remove columns from your tables
what's orm !
Does anyone have any recommended patterns/methods to storing and using record level permissions? For example, I have an app for approval requests, the approval request will be able to be accessed by the requester, the approvers, and anyone who has Admin access to view the specific request type. The admin piece is easy, I know how to handle that using scopes/roles. However, I am not too sure what the best way to setup record level permissions for the requester/approvers would be. Do I have a separate table for those permissions, do I store them with the record itself in let's say like an acl json column etc.
It basically maps your database rows to classes
e.g.
class User:
id: int
username: str
In most cases you can just check for object ownership, e.g. post.user_id == user.id, you probably could parametrize that too
I also saw packages for ABAC somewhere
Its more so storing it, as 3 users can have access, but so can 10 depends on the amount of people involved, the role based requests can be handled easily with roles/scope. So would a json acccess list be good in a similar fashion to your post.userid = userid example?
Not sure if I want to make a seperate table to hold that
with like groups I can query for ( foreign key in post )
I believe scopes and roles are not used for row-level control
I can use it as a broad override ( ApprovalType1.Admin )
that's very cool
@late tinsel This is a setup I have generally. It is quite flexible and can work with multiple different entities that need support for roles/permissions #databases message
That actually looks great, one issue is that you must create a permission for each new row which could be troublesome
But some systems could definitely benefit from it
Which is why models have roles
Roles have permissions which are inherited
So then the model so to speak would be each approval request
and the group of people with there roles
Group of people for each approval request, with each persons set roles for that group. So in the case of an approval there is the requester - with requester group perms ( general model for all approvals ), then the approval group ( model ) that is custom for each approval ( ie 1 approval = 1 model with a set of specifications for that particular request ).
If I am interpreting, it correctly
Wait, so it provides row level access?
It can, its general enough
You bring the same structure to high level perms, and then replicate it on the row level perms.
Would be my take on it
Define the roles over arching, then dig in deeper for row level, still need a structure for the low level
Through the model has permissions table yes
Then how roles solve problem with permissions?
You can define roles generically I would presume
Approves have these permissions on the request
If you have a set of posts which only creators of them should have access to you'd still need a bunch of entries in model_has_permissions, no?
Then the model has permissions would store each requests model
Roles don't give you row-level access though 🤔
They define a set of permissions
So in the request I can have these people have these roles with these permissions to this record
Everyone else falls into the viewer role
or no access
Permissions can be shared across models.
They can, but you still have to create the permission relationship
In my case - Approval request requester will always have the same rights accross approval requests
for each row in a table which you want to control
Of course, permissions for row level don’t magically appear
alternatively in simpler cases you can use abac
So like I can set a custom model X belongs to request Y - everyone not in this model is a viewer if they have access to the request
Its pretty much the samething as abac
now that I am reading what abac is

Cyral
Learn why attribute based access control in databases prevent unauthorized users. Today, RBAC is not enough. ✓ Make the change to ABAC security today!
I think wikipedia has more detailed article
This one is generalized
I want to be able to connect to a few different database types (sqlite3, oracle and maybe more eventually). I am looking at sqlalchemy as a generic way to interact with databases but I only want to use SQL and none of the ORM stuff. I am aware that means I will have to consider DB type when writing SQL. Is sqlalchemy a good fit or is there something simpler for this task?
Sqlalchemy is an orm
If you don't want to use orm you could use sqlalchemy core, though, i'd go for orm
that article looks to deal with the user that is logged in to the database, but i'm guessing you use one database user for all the access by the backend service, right?
That's what I'm doing but more specially is there something better suited for this?
Has anyone worked with or knows anything about databricks?
For what exactly?
sqlalchemy works well with a lot of sql dialects if that's what you're worried about
I am only worried that using sqlalchemy core is overkill for just needing an interface to many different dbms'. But it's the only thing I know of that is good at that. I am wondering if there are any other libraries I should consider before getting too deep into something that might be overkill.
sqlalchemy is nice, I'd give it a go
ok thank you
Yeah, backend api has the only set of credentials for db
Anybody using aiosql for his/her discord bot?
some ppl do (not me tho)
:")
Ohh ok well I implemented it wanted to know some stuff abt it
hmm tho i've never used it. but ig.. i'll try?
depending what level of stuff you're asking
:>
Umm lets say I have a bot which is mainly dependent on mysql database....so I just wanna know what ways people implement it....do they create a new connection object everytime for a query or do they use mysql pool...the normal mysql pool which comes with mysql.connector has con limit of 32 so does aiosql has such limit or there aint any limit?
ok, firts thing.. as of what i googled & understood
you're asking for mysql
but the thing, aiosql, is used for sqlite
🤔 tho it should still be same
and idk if here is any pool in mysql
but like u can connect to the database on bot initialization?
🤔 ** **
Umm naah am asking for aiosql I am already familiar with mysql.connector
mysql connector is sync lib
u don't use sync in async flow.. it resutls in 'blocking'
:'/
Yea but after sometime the bot breaks connection with database
As in we need to either use pool
Or reinitialize the connection
Either of them
We cant use one cursor that is created throughout the life cycle of program
which lib you're using?
I have 5 features, in 4 of them I have used mysql.connector but I thought to experiment a bit and made the 5th one with aiosql
.
so
use
aiomysql

Aye am shifting to that slowly
eh..
I have already implemented it in one feature
Am gonna remake other 4 features to include aiomysql
and u don't have to connect to this everytime...
But still my que stands that whether I should reinitialize the connection on each query or use a pool and what's the max pool size?
time to refer docs
lmao
Umm yea am going through them
btw u not gonna need so many connections tho
like
since it's async.. so gonna be easier either way
and don't init it every time
just init it once
:'/
when starting the bot
Umm ok lets see ill try to implement it into my bot code
If it works Ill let you know!
sure
Thanks for the help!
Aha for sure! Thanks for the help!
:">
No
It's like asking if x/y is the same as x*y/100 for all x,y. It's not.
(also, probably not database-related)
Hello there, i'm trying to update a value in sqlite3 by adding 1 to it, but the database doesn't update
cursor.execute('UPDATE main SET oc_rank = oc_rank + 1 WHERE guild_id = ? AND oc_name = ?',(id,name))
what's wrong with that
Sorry for posting on the wrong channel.
But is the result not the same?
NVM.
Realised the mistake.
-- this works
insert into prefixes (guild_id, prefixes)
values (1, '{hi}');
but,
-- this does not work
insert into prefixes (guild_id, prefixes)
values (1, ARRAY ['hi']);
what to do?
Does the string hi need to be in quotes ?
yes?
it doesn't work otherwise either
I’m not sure, I’ve not read the docs .
You should share your table structure with the column types
I'm making a database right now with potentially lots of users and i'm kinda stuck for a design choice. Is it better to make a brand new table per user with whatever information they will put in it or is it better to have one table with all of it all the users' info together?
The table(s) will consist of only six columns but a single user can add up to a max of 900 entries
the issue i might run into if i make one per user then i could get a really wide db which might not like it and potentially slow down my queries. The issue with making one table is that queries after x amount of entries into the table will slow down how fast it gives information back.
I'm kinda stuck on what is a smarter choice honestly.
After a certain period of time mysql database disconnects, and I need a way for it to reconnect without having to restart the discord.py bot
File "C:\Users\User\AppData\Local\Programs\Python\Python36\lib\site-packages\discord\client.py", line 343, in _run_event
File "c:/Users/User/Desktop/DiscordBots/FriendlyStreamers/index.py", line 227, in on_message
elif message.content.startswith(tuple(bot.command_prefix(bot, message))):
File "c:/Users/User/Desktop/DiscordBots/FriendlyStreamers/index.py", line 63, in get_prefix
cursor.execute(f"SELECT prefix FROM guild_prefixes WHERE guildid = {message.guild.id} ")
File "C:\Users\User\AppData\Local\Programs\Python\Python36\lib\site-packages\mysql\connector\cursor_cext.py", line 271, in execute
raw_as_string=self._raw_as_string)
File "C:\Users\User\AppData\Local\Programs\Python\Python36\lib\site-packages\mysql\connector\connection_cext.py", line 522, in cmd_query
sqlstate=exc.sqlstate)
mysql.connector.errors.OperationalError: 2013 (HY000): Lost connection to MySQL server during query```Table per user is an anti pattern. You should not consider that as a possible option.
Are you using an async package for the db?
Idk how to check if I was or wasn't.
import mysql.connector
from discord.ext import tasks
import colorsys
from configparser import ConfigParser
from mysql import #connector
from discord.ext import commands
from configparser import ConfigParser as cParse
mydb = mysql.connector.connect(
host = "localhost",
user = conf['user'],
password = conf['password'],
database = "friendlystreamers",
auth_plugin="mysql_native_password"
)```okay, thank you @proven arrow
Yeah don’t use that, You can use aiomysql
GitHub
aiomysql is a library for accessing a MySQL database from the asyncio - GitHub - aio-libs/aiomysql: aiomysql is a library for accessing a MySQL database from the asyncio
I use mysql though, so would that effect anything I have in my python or does it still save everything?, and also does it still save everything in the database?
I don’t understand
The package you use currently is making blocking calls in your application which is mostly asynchronous.
If I just replace this in index.py it should just stop randomly disconnecting? (even if my database uses the old ones in the cogs?)
No you will still need to update parts of the code to work with the new package. But yes it should get rid of the issue you are seeing.
Also you should maintain a pool of connections through connection pooling. https://aiomysql.readthedocs.io/en/latest/pool.html
@commands.command()
async def rank(self, ctx, user:discord.Member=None):
if not ctx.author.id == 205088813503086594:
return await ctx.send("Sorry this command is in maintenance")
if user is None:
user = ctx.author
mydb = mysql.connector.connect(
host = "localhost",
user = conf['user'],
password = conf['password'],
database = "friendlystreamers",
auth_plugin="mysql_native_password"
)```like I have that, in this
just because it wasn't updating properly the other way unless I restarted the bot if I didn't have the close command in the card_plugin.py cog.
cleanup = [filename, f"{user.id}-avatar.png"]
for item in cleanup:
try:
os.unlink(item)
except Exception:
pass
mydb.close()
Regardless. Use an async driver for the database.
do I still need the auth_plugin?
oh wait
that doesn't work
I just read that it reqires 3.7+ 😦
Yes if that’s the auto plugin you use.
wait, unless that 3.7+ is only for sqlalchemy which i probably don't use.
ummm do i still need cursor = mydb.cursor() or is cursor already defined with the db connection feature thing?
Does anybody know how to make login/registration + database in python? Something like "Hello welcome back before we continue pls login back". And registration option like "Hello pls registrar before continuing"
Is that a problem?
login with pure HTTP (no JS) can only be handled by Cookies
so you can have Set-Cookie HTTP header, which will set the cookie to certain value on the browser, and then each time browser makes request to your server, the cookie is sent alongsite
so an UNSAFE example would be, to give each user their user ID from database, via Set-Cookie header, which will mean the browser of user will save this (forever), and then each time you render some page, you take a look at the cookie, which will contain ID, and then you can get arbitrary information of the user, using database
in order to make things safer, you may look into UUIDs, some encryption algorithms, and always hash user's passwords, never save them in plaintext
Ok thx
How can I make a check that would block row insertion if there's a certain amount of records with some condition
Let's say I have some table like
id | pet```
I need to make it so there can't be more than 50 records of the same id in the databasePostgres
You're getting a list of result tuples from cursor. execute
You probably should use fetch (or something similar) instead of fetchall
so you get a single tuple
Is there a way to drop duplicates (select distinct) for all but some columns in postgresql? but i would like it to return the entire row instead of just the columns that were selected as distinct
i'm able to do similar functionality in pandas with:
df.drop(['uuid', 'personal_compact', 'gems', 'ability_scroll', 'enchantments'], axis=1).drop_duplicates().join(df[['uuid', 'personal_compact', 'gems', 'ability_scroll', 'enchantments']])
Could you share your table and data and what kind of result you want? 🤔
sure, give me a moment
how would you like me to share it? csv? screenshot?
copy paste?
@app.route('/market')
def market_page(): #The goal here is to connect the DB above so that we don't have to write all of this out in code.
#items = [
# {'id': 1, 'name': 'Phone', 'barcode': '893212299897', 'price': 500},
# {'id': 2, 'name': 'Laptop', 'barcode': '123985473165', 'price': 900},
# {'id': 3, 'name': 'Keyboard', 'barcode': '231985128446', 'price': 150}
#]
items = Item.query.all()
return render_template('market.html', items=items)```
Is this right? for some reason when I run this flask file it tells me that "no such table" seems to be available.Actual error:
sqlalchemy.exc.OperationalError: (sqlite3.OperationalError) no such table: item
[SQL: SELECT item.id AS item_id, item.name AS item_name, item.price AS item_price, item.barcode AS item_barcode, item.description AS item_description
FROM item]
(Background on this error at: https://sqlalche.me/e/14/e3q8)
You didn't create the table

A couple of items (5-10) should be enough
Prefferrably something people can copy-paste
brb. I think I forgot a big step.
alright give me a moment
Oh okay I remember something now. I had a file with the table. But it is in a separate file.
from flask import flask
from flask import SQLAlchemy as db
app.config['SQLALCHEMY_DATABASE_URI'] = 'sqlite:///market.db'
db = SQLAlchemy(app)
db.create_all()
#local database
class Item(db.Model):
id = db.Column(db.Integer(), primary_key=True)
name = db.Column(db.String(length=30), nullable=False, unique=True)
price = db.Column(db.Integer(), nullable=False)
barcode = db.Column(db.String(length=12), nullable=False, unique=True)
description = db.Column(db.String(length=1024), nullable=False, unique=True)
Item1 = Item(name="Anime DVD", price="50", barcode="423213296896", description="Desc")
db.add(Item1)
db.commit()
How can I connect/call this file to have it used?
You're creating tables before actually defining your model
Isn't the db.create_all() making the table?
Item1 = Item(name="Anime DVD", price="50", barcode="423213296896", description="Desc")
Should define it no? What if moved this up?
class Item(db.Model):
id = db.Column(db.Integer(), primary_key=True)
name = db.Column(db.String(length=30), nullable=False, unique=True)
price = db.Column(db.Integer(), nullable=False)
barcode = db.Column(db.String(length=12), nullable=False, unique=True)
description = db.Column(db.String(length=1024), nullable=False, unique=True)
This is your table definition
You create tables before it is defined
So if I moved the db.create after it should be ok? Sorry if I sound stupid. I got a new job to pay bills and just came back to my code. The feeling of frustration is high atm.
But thank you Doctor
Yep, it should work if you move your .create_tables() 🙂
Also you should probably commit right after doing so
But then my other question is how do I call this separate file?
I have 2 files.
One is market.py and the other is marketdb.py.
marketdb.py has the database stuff that I want to call into market.py which is the main file. How can I do this?
You mean how you can store your models in separate file?
right my program folder is a little large atm. But it has 6 files. Not inlcuding a templates folder with some HTML files.
Do you plan on migrating your models/tables? e.g. adding or changing fields
Because then you need to use alembic for your database migrations
I have a project setup with fastapi, sqlalchemy and alembic: https://gitlab.com/ThirVondukr/fastapi-cookiecutter
Sort of? This is more of a proof of concept thing. I'm trying to just finish the database tables and make it 'work' before just deploying the website.
I'm sort of just racing for the finish line to make this a part of my portfolio.
ok @paper flower it's taking too long for me to get it, but preferably what i'd want is something like this:
with this as the input i want
index num1 num2 unimportant
0 1 6 a
1 3 6 b
2 4 5 c
3 5 4 d
4 5 3 e
5 7 1 f
6 2 2 g
7 3 1 h
8 3 1 i
9 2 4 j
this as the output
index num1 num2 unimportant
0 1 6 a
1 3 6 b
2 4 5 c
3 5 4 d
4 5 3 e
5 7 1 f
6 2 2 g
8 3 1 i
9 2 4 j
only num1 and num2 are being filtered for duplicates, but i want the entire row to be returned
I am unsure what you mean by migrating models and tables.
How would you determine which row you should get?
Changing your models in any way, removing old ones, adding new ones
Also index is just an id? @minor plover
Oh in that case yes I think so? I do imagine being able to change the items off of a database when wanted should be a thing.
you mean how it's being filtered?
for each row, it goes through the value of each of the specified column. if any of the values inside the row is unique for its column, the entire row is kept
my current issue that stops me from using select distinct is that it only returns the rows that are being selected as distinct, and preferably i would like the entire row to be returned
Look into alembic, though, documentation of sqlalchemy and alembic is hard to comprehend if you're just starting
yes i was listing it how pandas does, but we can pretend that it's an id bc that's all it's really used for
this isn't actual data i'm using, but same principle
Ok, let me try 😅
dod damnit
thank you, i appreciate it
You want to select distinct records on both columns? e.g. if col1 and col2 contain same values you should filter that out?
no, if they have the same value it's not necessarily filtered (look at index 6 on my example data)
what is actually happening is something like the following "pseudo-code":
unique_num1 = []
unique_num2 = []
returned_rows = []
for row in table:
for cell in row:
returnable = False
if cell.column == 'num1' and cell.value not in unique_num1:
returnable = True
unique_num1.append(cell.value)
if cell.column == 'num2' and cell.value not in unique_num2:
returnable = True
unique_num2.append(cell.value)
if returnable:
returned_rows.append(row)
basically it's checking if one of the 2 selected columns' value is unique over the entire column
if one of them is, the entire row gets returned
if none of them are, the row is not returned
I see
I'd say easies way is to use cte's or nested select 🤔
create table items (
id integer primary key,
prop1 integer not null,
prop2 integer not null,
not_duplicate varchar(255)
);
select distinct on (prop2) * from (
select
distinct on (prop1)
*
from items
) as "inner";
1,1,6,a
2,3,6,b
3,4,5,c
4,5,4,d
5,5,3,e
6,7,1,f
7,2,2,g
8,3,1,h
9,3,1,i
10,2,4,j
wait so if i have, say, 5 different columns i want to select distinct (assume it's identical to the other prop columns), how would it change the query?
Yep, i want to know why do you want to do that though?
Maybe you can make your columns unique?
that's not the reason
i'm doing analysis on the table, and i'm looking to do this for that specific reason
but columns aren't supposed to be unique
So, what kind of analysis? Maybe you can share more in dms?
@torn sphinx which database ?
This is what you need, https://www.sqlite.org/lang_UPSERT.html
However, you need a valid column for the conflict to occur.
Hi, I have experience with using thread locks to use sqlite with multiple threads, but I came across this SO answer that mentioned garbage collection needs to be serialized and I am not sure what that means in this context https://stackoverflow.com/a/6313962
Stack Overflow
To fully utilize concurrency, SQLite3 allows threads to access the same connection in three ways:
Single-thread. In this mode, all mutexes are disabled and SQLite is unsafe to use in more than a ...

hello everyone I have a problem in pandas how I could do to change the data of column 2 in full knowing that I have a table of 1000 lines so I could not change for each line
I had thought of calculating the average then dividing by 10 for example for line 1: 91+100/2 =95.5 /10 = 9.55 but I know how to write it in code so that it works for the whole table
!e something like:
import pandas as pd
df = pd.DataFrame({
"gender": ["male", "female", "male", "male"],
"calc": [None, None, None, None],
"range": ["91-100", "71-80", "91-100", "81-90"]
})
print(df)
def calculation(column_value):
return sum(map(int, column_value.split("-"))) / 2 / 10
df["calc"] = df["range"].apply(calculation)
print(df)
@grim vault :white_check_mark: Your eval job has completed with return code 0.
001 | gender calc range
002 | 0 male None 91-100
003 | 1 female None 71-80
004 | 2 male None 91-100
005 | 3 male None 81-90
006 | gender calc range
007 | 0 male 9.55 91-100
008 | 1 female 7.55 71-80
009 | 2 male 9.55 91-100
010 | 3 male 8.55 81-90
how to update the sql statement of a (python) application after changing the database structure?
Lets say, you have made "author" field on books table from string to list of string, so you need to make a new table + association table for authors
thank you
For example?
Say, you have made "author" field on books table from string to list of string, so you need to make a new table + association table for authors
And say we have a python script that calls that database and many lines sql statements have written on that script
You could use orm like sqlalchemy, it would be somewhat easier to manage
There's no way to automate it
what is yaml?
That's a Google question https://en.wikipedia.org/wiki/YAML
YAML (/ˈjæməl/ and YAH-ml) (see § History and name) is a human-readable data-serialization language. It is commonly used for configuration files and in applications where data is being stored or transmitted. YAML targets many of the same communications applications as Extensible Markup Language (XML) but has a minimal syntax which intentionally ...
Found this data interesting: https://w3techs.com/technologies/overview/programming_language
Is it really plausible that barely over 1% of websites use server-side Python when Django and Flask are apparently so popular? The 2% for JavaScript is also surprising to me.
What are the most popular server-side programming languages on the web
Because most websites use CMS like WordPress
Good point
is it only possible to upload files to a db using a temporary file storage location and then pulling it into the db after
It’s possible yes
But it’s more common to store the file on a separate file system, rather than directly into the database. The database usually just holds the path to where the file is located.
my objective is to store pdfs into mysql
and you're saying it is encouraged to store to temporary location?
No I am saying it is more common to store the file on some file system other than the database. Then in the database you store a reference to the location of that file.
Usually better for performance reasons. Especially as table size increases.
can you elaborate on this a bit
i thought it was common place to store pdfs in DBs
Elaborate how, what is it you don’t understand ?
are you implying that each pdf is stored in a different file location
On any file system except the database. This means on the server where your app is running, or some cloud storage like S3.
so i have worked with this in the past
using both sqlalchemy
and pymysql
i stored a csv file in a file location, then abstracted that location away using an env file, and then had mysql pull the data from the temporarily stored location
but this method doesnt scale
because multiple users adding multiple files
to the same location
doesn't make sense
The method that I suggested ?
I don’t understand what you are doing here with env and stuff.
so im supposed to store each pdf in its own location
then store that location in a db
Yes
so how do you save each file to a separate location
do i dynamically create these locations?
What are you building ? An web app or mobile app or something ?
So you might want to decide where you are going to store the files first. If it’s on your own hosting server you will want to create a directory where you store uploaded files.
It should be straight forward, if you use a modern web framework it should make file handling a breeze.
thanks
I guess you could use nfs for files and store paths to them in your database
If my django database doesn't exists ( for superusers) how can i create it
@client.command(aliases = ["join"])
async def joinlobby(ctx, lobbyname, password):
db = sqlite3.connect("amongus.db")
cursor = db.cursor()
cursor.execute(f"SELECT Password FROM amongus WHERE LobbyName = {lobbyname}")
result2 = cursor.fetchone()
print(result2)
if result2 == password:
cursor.execute(f"SELECT LobbyName FROM amongus WHERE LobbyName = {lobbyname}")
result = cursor.fetchone()
if result == None:
await ctx.send("No lobby exists")
elif result != None:
sq = (f"INSERT FROM amongus(LobbyName, Password, UserID, guild) VALUES(?,?,?,?)")
val = (lobbyname, None, ctx.author.id, ctx.guild.id)
cursor.execute(sq, val)
error:
Traceback (most recent call last):
File "C:\Users\LENOVO\AppData\Local\Programs\Python\Python38-32\lib\site-packages\discord\ext\commands\core.py", line 85, in wrapped
ret = await coro(*args, **kwargs)
File "C:/Users/LENOVO/Desktop/Coding -Winson/Python/NotaroBotBackupCode/testing discord bot/BotTesting.py", line 67, in joinlobby
cursor.execute(f"SELECT Password FROM amongus WHERE LobbyName == {lobbyname}")
sqlite3.OperationalError: no such column: mylobby
Traceback (most recent call last):
File "C:\Users\LENOVO\AppData\Local\Programs\Python\Python38-32\lib\site-packages\discord\ext\commands\bot.py", line 939, in invoke
await ctx.command.invoke(ctx)
File "C:\Users\LENOVO\AppData\Local\Programs\Python\Python38-32\lib\site-packages\discord\ext\commands\core.py", line 863, in invoke
await injected(*ctx.args, **ctx.kwargs)
File "C:\Users\LENOVO\AppData\Local\Programs\Python\Python38-32\lib\site-packages\discord\ext\commands\core.py", line 94, in wrapped
raise CommandInvokeError(exc) from exc
discord.ext.commands.errors.CommandInvokeError: Command raised an exception: OperationalError: no such column: mylobby

can someone help me
this is sqlite3 btw
is it possible to insert a key value twice
or would it overwrite the original
would it throw an error if you tried to insert a primary key that already exists?
Car_Name
Year
Selling_Price
Present_Price
Kms_Driven
Fuel_Type
Seller_Type
Transmission
Owner
)
VALUES(?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)
''', tups)
connector.commit()
connector.close()```i am getting the syntax error
near "Year": syntax error
i often get syntax errors when i am trying to execute my values
i am using sqlite3
in google colab
is it standard practice to use inserted_primary_key to retrieve the primary key of the most recently inserted record? or is there a better way?
it depends on how you define the tables -- if the field of the key has a UNIQUE constraint, and you try to enter a duplicate, you can choose from a number of actions
the default is to abort and give you an error
you can also "Ignore" that record, or you can "update" it
yeah, looks like it's making duplicates from testing, should probably change that, but it also means that wasn't the bug i was trying to fix 
the primary key field specifically should always be unique though
Hi! Is there someone that is willing to help me do an assignment?
#❓|how-to-get-help might be better for you
If it's related to databases you can ask here, but please be more clear about what you need upfront
is jupyter the most typical way most data analysts look at data?
i think you just forgot about adding a , in between each column name when you listed all the columns that you want to insert data into
Even with the volume
Commas
Still getting the same error
Idk
what does your query look like now?
Something's odd with the MySQL connector.
I populated a table with data, but I can't retrieve it with Python.
cur = con.cursor()
tups = [(0,)*9, (1,)*9]
cur.execute("""create table expectancy (
Name,
Year,
Selling_Price,
Kms_Driven,
mileage,
engine,
max_power,
seats)""")
cursor.execute(expectancy)
connector.commit()```you also don't have the same number of columns and ? placeholders for data in your insert query
that's for creating the table, but what about the query that you use to insert data, have you changed it to include commas between the column names as well?
When I run SELECT * FROM db1.table in the MySQL console, I get data.
But when I run the following code in the Python interpreter:
connection = mysql.connector.connect(host="localhost",user="root",password="nottellingyou")
cursor = connection.cursor()
results = connection.execute("SELECT * FROM db1.table")
for result in results:
print(result)
I get "NoneType is not iterable."
What's wrong with the code?
not the problem you are facing, but i hope your not using the root user in your actual code 😉
This is just for a development database on my computer, so I don't need to worry about user access privileges for now.
you should probably specify database="whatever_it_is_named"in your connect() statement
interesting idea, but I'm not sure it solves my problem.
what is the best database for everything in general
PostgreSQL is a very good relational database
If you're just starting out I'd highly recommend SQLite though as it means you don't have to manage a database server
And it's still incredibly powerful
is there a sql wrapper that uses functions instead of words
What do you mean?
like
instead of using the regular """CREATE TABLE IF NOT EXISTS""""
just use lik
create_table(ifnotexists=True, name="table")
Like a query builder?
statement = (
select(User.id, User.username)
.where(User.joined_at >= datetime.now() - timedelta(days=1))
)
For tables you usually use a slightly different tool
ig like that yea
ok
OK, I just tried it, and - as I predicted - the problem persists:
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'mysql' is not defined
>>> import mysql.connector
>>> connector = mysql.connector.connect(host="localhost",user="root",password="jack2417",database="hashtagintel")
>>> cursor = connector.cursor()
>>> results = cursor.execute("SELECT * FROM hashtags")
>>> print(results == None)
True````Hi there, so i have a database, SQL, and I'd like to make a query where I select two columns and then return a list of those. The catch is, some rows have a value that repeats. For instance, each user has characters with a universe they live in, so I have several rows with the same user id, and I was to list the distinct universe they input. And I want to do that for every user
how could I do that? Do I have to use SELECT DISTINCT?
nvm I figured it out
is it possible for me to delete an entire row in a mysql database table through the mysql python connector and tkinter. Right now i have this code to try and remove it:
global index
wf_order = index+1
answer = messagebox.askyesno("Confirmation", "Are you sure you want to delete this entry?")
if answer == True:
cursor.execute("DELETE FROM waterfall_info WHERE wf_order IN (?)", wf_order)
and this is the error that pops up:

what am i doing wrong here
Is your DB user authorized to do a DELETE?
Yes, I can do it just fine through the mysql workbench
I feel like it has something to do with the where clause and using a python variable for it
again, just use if to check if things are missing. don't over-think this kind of task.
cursor.execute("query", (wf_order,))
I have a .sql file with multiple inserts and I'm trying to figure out how to insert with sql alchemy.
is sqlalchemy.text() what i need to use?
You want to execute your sql file or rewrite it using sqlalchemy?
I just want to execute it.
connection.execute(text(sql_string)) should be fine?
how would i rewrite it using sqlalchemy?
You said you just want to execute it 😅
Depends on what's in that sql file
only inserts
basically I'm trying to set up a test db
I'm using testing.mysld
but i need to prepopulate the data.
I would insert data you need when you're testing
Well, you don't need to create sql files for that 🤔
the problem is i have about 25 tables that i need to dump about 300-400 rows in
You probably don't need all the data for all tests
I thought the best way would be to just export the needed data as a sql file and insert on test
yeah its paired down about as much as i can get.
existing tables have been in production for about 3 months and have over 10,000,000 rows so i dont want to copy them
but with testing I'll miss a ton of edge cases if i go less.
Usually when i need to test something simple that requires one or two rows for a single i'd just insert them:
def test_get_user(session):
item = Item(name="Name")
session.add(item)
session.commit()
session.refresh(item)
# Test functionality that does something with item
If more tests require that data i'd make a fixture
oh and your right i dont necessrarily need all the data for all of the tests, but with the joins we have we do typically use 3-4 tables per query.
yeah thats basically what i was doing until i hit a database that needed 300-400 rows of data.
Some data you can just generate dynamically during tests
then i said f that and exported the data i needed to .sql inserts.
in postgresql, i have a jsonb column, and i want to query that and return a table with distinct key names
for example, if i had:
{'test': 1, 'foo': 2}
{'foo': 4, 'bar': 1}
i want to return:
test
foo
bar
Can't you use distinct and json_object_keys?
could you please give me an example query with that? i'm not sure how to use json_object_keys
jsonb_object_keys(jsonb_column)
oh so like:
select distinct jsonb_object_keys(jsonb_column) from table_name?
Probably, i'm not quite sure
Hi i am making a leveling system and stoing the xp and level into a database. i got this error. how do i fix it?
Traceback (most recent call last):
File "C:\Users\thoma\AppData\Local\Programs\Python\Python310\lib\site-packages\discord\client.py", line 343, in _run_event
await coro(*args, **kwargs)
File "c:\Users\thoma\OneDrive\Desktop\discord server bot\leveling system.py", line 21, in on_message
if message.author.client:
AttributeError: 'Member' object has no attribute 'client'
what do u need from the message.author?
I am creating 2 variables
One for the author and one for the guild
so again the same question lol
What is the easiest database to learn using python?
Is there a python package that is widely used for interfacing with a SQL database?
i think sqlite3, or json if u see that as a database
Any GOOD tutorial how to use?
Hi
Anyone know how to save db file using sqllite3
The file appears but for some reason it is empty?
yo anyone free to help me with something rq?
i dont know the name of what it is exactly
can you try to describe it