#databases
1 messages · Page 186 of 1
everything accessing the connection has to stay under with
oh
ill just keep it how it is now then
i would have everything indented like 4 times
its already 2 with my code
I have an error


yeah
I followed a tutorial
but the problem is
I saw " Data "
and I tried to search what's data and else
but like I made a command to activate a module but I need to make a database to make it work

I made the database
but
I need to make my SQL connect
to the command
but I don't know how to make it
here's my table for it

@brave bridge
so anybody can help me ?
which sql engine you're using?
SQLite
💀never used it sowwy..
but wait ima search it up on gogole lmfao
import sqlite3
try:
sqliteConnection = sqlite3.connect('SQLite_Python.db')
cursor = sqliteConnection.cursor()
print("Successfully Connected to SQLite")
except sqlite3.Error as error:
print("Error while connecting to sqlite", error)
how I use this
...
bro it's py code
and that thing inside sqlite3.connect should be the name of your sqlite db
depends on how u want to do..
oh wait no I put it when the bot connects ?
wait..
idk if sqlite should be used for bto development
bot*
It can be
But it doesn’t scale well and doesn’t support high levels of concurrency
So for larger bots I would use Postgres or some other sql flavor
You can create the db connection in an overridden start or connect method
make sure to do the connection procedurally though because using a context manager will close the db connection after the queries you specify to be executed on connection to the db finish
so I am making a psql table
I have a couple of questions though
CREATE TABLE TAGS(id BIGSERIAL,
name text,
user_id bigint,
guild_id bigint,
points_to bigint REFERENCES TAGS(id) ON DELETE CASCADE,
content text,
created_at timestamp with timezone,
global bool default false,
uses bigint not null default 0,
UNIQUE (name, guild_id),
PRIMARY KEY (id))
the only issues I can think about right now about doing this, is dm tag conflicts and global tag conflicts
if I can somehow prevent them here, then I am good
{
"947688133200338985": [
"B777",
"B666"
]
}```
sorry I was doing it from my phonea question: I'm working with a MySQL database. I'm thinking of implementing a get_or_create helper function, analogous to what Django provides with its ORM - for a given id, it either gets an existing entry or creates a new one. Has anyone implemented something similar before with MySQL, and any pros/cons with that approach?


I Am stuck with the having count command. How does that help to figure out the nth highest salary ? Is there any easier way to do this ? Since I am new in sql , I feel I am not understanding the solution
Does anyone know how to get the results of "EXPLAIN ANALYZE INSERT INTO" with psycopg3? I found examples of "EXPLAIN ANALYZE SELECT" but not with "EXPLAIN ANALIZE INSERT INTO".
can we add 2 or more cities and 2 or more postal code in a single user date


like this
I ended up migrating a small discord bot from tortoise orm to prisma last night and some of today

I'm really used to the active record method of interacting with the db though so it was a bit weird to change my thinking. But the autocompletion did work well.
Ooooooh exciting! How did you find the migration process?
Glad to hear that worked for you! Yeah most other ORMs go by active record so I'm considering adding support for it as well although the only concern I have is making it even more confusing if there's multiple methods for doing the same thing
It was fairly painless. The schema being written in its own schema file is pretty cool. I had a mind blown moment when I saw the docstrings for each model's methods referencing my specific schema
Yeah the beauty of codegen :)
I'm glad you liked that, I haven't had anyone mention it since adding them
I personally would feel more comfortable with having the active record option but I'll spend some time doing it this way and see how it feels.
Yeah I think lots of other people would too, it does make it much easier for update queries
also having a queryset manager and saved queries on the models is something nice that I'm missing
now I just have a file with helper functions
but they're not well organized
is there a good way to go about saving queries and modifying them?
Yeah I realised that before but it's a difficult API to design in a type safe manner
As the queries are just standard dictionaries you can pass the dictionary around although that isn't ideal
that's true...
Something that might help is that you could subclass the models and add helper methods there
If you still want autocomplete you'll have to annotate variables to types like prisma.types.UserCreateInput which is a bit annoying but I'm not sure what a better solution would look like
I was struggling with that a little bit. I'm not well versed in python's type hinting and still need to figure out how to tell python that a dictionary is a certain shape.
I kept trying to type hint it things with prisma.types.something and then also unpacking dictionaries
ERROR 2003 (HY000): Can't connect to MySQL server on 'localhost:3306' (10061)
what to do now?
into other dictionaries. pyright wasn't happy about it

Yeah that is definitely a barrier for entry for some people, it is difficult to learn
all good though, I'm gonna keep using it. Nice library!
Yeah TypedDicts are quite strict and are more difficult to work with than normal dictionaries :/
Thank you! I really appreciate it :)
If you have any other questions about types I'm more than happy to help :)
I'm sure I'll ping you again
b r i ^
Is your MySQL server running?
i didn't realize how much of a full orm prisma-client-python was. makes me more excited to try it, i just haven't had a need for an orm in a personal project in a long time
I'm not sure, I'm not familiar with MySQL on windows
since i unchecked the option in installation like 'run server at startup'
can you pls find something similar on google, since i can't find anything relevant
Yeah even though it's new it's much more fully fledged than other new ORMs as the core functionality has already been implemented by Prisma
yeah that's really cool
have you talked to the prisma core devs at all? their website doesn't let on at all that prisma could be used cross-language
and there aren't (that i'm aware of) prisma clients/parsers in other languages beyond python and the original
I suggest reinstalling and setting that option, that's what I've found on google
Yeah I've talked a lot with the Prisma core Devs, I have a direct line with them so I can contact them if I need anything
Yeah they're focusing on their TS client at the moment
ah nice, so at least they aren't opposed to what you're doing
but isn't there any option for manual startup since i not always uses this
They had a Go client but that was deprecated because they weren't receiving enough usage
right i think you said that / i saw it somewhere
Yeah definitely not, they are very generously sponsoring me as well
i was going to say that sounds like something a Go dev could adopt for fame & glory
figure out where you installed it
find mysqld
how hard is the schema language to parse? might be an interesting project to write a parser for it in some other language
If you're just wanting to parse the schema, they've written their parser in rust so all you'd really need is FFI bindings
ahhh that is excellent news
so you can use that to do static code gen for pretty much any language already
Sort of, their whole generator concept is written in Node though unfortunately
But you can generate code for any language
yeah, that's fine for a first pass. it's the same approach that tree sitter took (much to some people's chagrin)
Yeah their whole CLI is written in Node unfortunately
I don't know if they have any plans to switch to Rust but it'd be a massive change so I'm doubtful
Tree sitter rings a bell but I can't remember, what is it?
it's a parser generator that uses some kind of super efficient incremental parsing algorithm
you specify the grammar in javascript (or compile some other language to javascript if you want), then the tool generates a single c file with no dependencies other than tree sitter itself
Ooooooh okay that sounds pretty cool
I had terribly slow syntax highlighting in vue files before I switched to treesitter in neovim
idk how it works
neovim has been starting to use it for syntax highlighting, name lookups, etc.
it also has its own query language
just thank god
yeah, it's been a really big deal
it's equivalent to LSP in terms of how useful it is, it solves another NxM problem
https://tree-sitter.github.io/tree-sitter/playground here you can mess around with it and see what syntax trees it generates.
the docs aren't great, but here is their attempt to describe the query syntax https://tree-sitter.github.io/tree-sitter/using-parsers#pattern-matching-with-queries
anyway this is off-topic for #databases and i hope your project continues to be useful and successful

Thank you :)
hi guys, would need some help on sql query and i am totally new on that, really appreciate if you can give some advise.🙏
I would like to verify a table 'account trade fee' columns field are correctly recorded based on another table 'exchange trade'.
Since I am really new to coding, would like to seek some help from yours.
Give background is now there is table account trade fee, as you see below there are column name 'fee_currency','maker_fee' and 'taker_fee'
account_trade_fee
"account_uuid","fee_currency","maker_fee","taker_fee"
c3f94bdf-8854-49d2-833d-0690eb821aa1,BTC,0.0002,0.0002
c3f94bdf-8854-49d2-833d-0690eb821aa1,USDT,0.02,0.02
c3f94bdf-8854-49d2-833d-0690eb821aa2,CRO,0.0002,0.0002
c3f94bdf-8854-49d2-833d-0690eb821aa2,USDT,0.02,0.02.`exchange_trade
"account_uuid","buy_fee_scale","buy_fee_value","buy_fee_currency","sell_fee_scale","sell_fee_value","sell_fee_currency","taker_side
c3f94bdf-8854-49d2-833d-0690eb821aa1,10,400000,BTC,8,400000,USDT,SELL
c3f94bdf-8854-49d2-833d-0690eb821aa1,10,400000,BTC,8,400000,USDT,SELL
c3f94bdf-8854-49d2-833d-0690eb821aa1,10,400000,BTC,8,400000,USDT,SELL
c3f94bdf-8854-49d2-833d-0690eb821aa1,10,400000,BTC,8,400000,USDT,SELL
c3f94bdf-8854-49d2-833d-0690eb821aa1,10,400000,BTC,8,400000,USDT,SELL
c3f94bdf-8854-49d2-833d-0690eb821aa1,10,400000,BTC,8,400000,USDT,BUY
c3f94bdf-8854-49d2-833d-0690eb821aa1,10,400000,BTC,8,400000,USDT,BUY
c3f94bdf-8854-49d2-833d-0690eb821aa1,10,400000,BTC,8,400000,USDT,BUY
c3f94bdf-8854-49d2-833d-0690eb821aa1,10,400000,BTC,8,400000,USDT,BUY
c3f94bdf-8854-49d2-833d-0690eb821aa1,10,400000,BTC,8,400000,USDT,BUY
There is equation of calculating the maker fee and taker fee from exchange trade table. If from below column 'taker_side':
if taker_side = 'BUY' refers to a maker fee, BTC would be the buy_fee_currency. which the formula would be buy_fee_value/pow(10,buy_fee_scale) = 0.00004. Since there is total five trade from BTC_USDT pair are BUY side. So the final maker fee would be 0.00004 * 5 = 0.0002 for BTC currency, which shows the same result from account trade fee above.
As BTC would be the buy_fee_currency, then USDT would be the sell_fee_curreny so then it will calculated as taker_fee and formula is like sell_fee_value/pow(10,sell_fee_scale) = 0.004 . Since there are total five trade are "SELL" side, times 5 would equal to 0.004 * 5 = 0.02
vice versa to the case if taker_side is "SELL" BTC is sell_fee_currency. USDT is buy_fee_currency.
I could only manage to write some sql query like below , but it couldn't generate the expected sum as I don't know how to control the calculation with regard to maker side or buyer side.In order to verify if the logic apply correctly, I would like to write a query to check if the sum of each currency is correctly display in maker_fee and taker_fee. Could any one kindly advise how to do so?
select sum((buy_fee_value/power(10,buy_fee_scale))) maker_fee, sum((sell_fee_value/power(10,sell_fee_scale))) taker_fee, taker_side,buy_fee_currency, sell_fee_currency ,account_uuid from exchange_trade et group by buy_fee_currency, sell_fee_currency,taker_side ,account_uuid order by account_uuid"maker_fee","taker_fee","taker_side","buy_fee_currency","sell_fee_currency","account_uuid"
0.0002,0.02,BUY,BTC,USDT,c3f94bdf-8854-49d2-833d-0690eb821aa1
0.0002,0.02,SELL,BTC,USDT,c3f94bdf-8854-49d2-833d-0690eb821aa1
0.0002,0.02,BUY,CRO,USDT,c3f94bdf-8854-49d2-833d-0690eb821aa2
0.0002,0.02,SELL,CRO,USDT,c3f94bdf-8854-49d2-833d-0690eb821aa2
How can I geo Index more than one field in mongodb which are in a nested array???
"firstName": "Lillian",
"polyclinic": [
{
"polyclinicName": "lo",
"location": {
"longitude": 56.12623,
"latitude": 0.88207
}
},
{
"polyclinicName": "jantascuz",
"location": {
"longitude": 150.48677,
"latitude": -77.29458
}
}
],
"hospital": [
{
"hospitalName": "duh",
"location": {
"longitude": -91.90766,
"latitude": -5.96207
}
},
{
"hospitalName": "na",
"location": {
"longitude": -170.75445,
"latitude": -82.66879
}
}
]
}``` this is the mongodb schemathis query is not working ```db.docgeo.find(
{
hospital:
{ $near:
{
$geometry: {type: "Point", coordinates: [-8.9667, 40.78 ] },
$maxDistance: 50000
}
}
}
)```
btw it is cosmos api for mongo db
hi, so i tried to change password into passwd but nothing changes, I don't know what i am supposed to do
here is my code
import mysql.connector
mydb = mysql.connector.connect(
host="z84xh.myd.infomaniak.com",
user="username",
passwd="password",
database="mydb"
)
print(mydb)
here is my error
Traceback (most recent call last):
File "C:\Python310\lib\site-packages\mysql\connector\connection_cext.py", line 236, in _open_connection
self._cmysql.connect(**cnx_kwargs)
_mysql_connector.MySQLInterfaceError: Can't connect to MySQL server on 'z84xh.myd.infomaniak.com:3306' (10060)
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "g:\Mon Drive\prog\parser\test.py", line 3, in <module>
mydb = mysql.connector.connect(
File "C:\Python310\lib\site-packages\mysql\connector\__init__.py", line 272, in connect
return CMySQLConnection(*args, **kwargs)
File "C:\Python310\lib\site-packages\mysql\connector\connection_cext.py", line 85, in __init__
self.connect(**kwargs)
File "C:\Python310\lib\site-packages\mysql\connector\abstracts.py", line 1028, in connect
self._open_connection()
File "C:\Python310\lib\site-packages\mysql\connector\connection_cext.py", line 241, in _open_connection
raise errors.get_mysql_exception(msg=exc.msg, errno=exc.errno,
mysql.connector.errors.DatabaseError: 2003 (HY000): Can't connect to MySQL server on 'z84xh.myd.infomaniak.com:3306' (10060)
I repeat what i said if someone read that, one of my friend success to connect with a c# script but he failed with python
https://dev.mysql.com/doc/connector-python/en/connector-python-connectargs.html password and passwd should both be valid. do you know if your server uses a nonstandard port? the default is 3306, which is the default port for mysql
and check for typos
@green sorrel see the link i posted above, both password and passwd are valid
personally i don't like mysql-connector for "casual" use. mysqlclient seems more user-friendly
i've used mysql-connector before (years ago) and i remember it was very un-ergonomic. maybe it has better performance for "industrial strength" applications, hard to say

if anything it looks like mysql-connector was slower than mysqldb back in 2015 http://charlesnagy.info/it/python/python-mysqldb-vs-mysql-connector-query-performance
There are a lot of python driver available for MySQL and two stand out the most. The one, traditionally everybody’s choice, sort of industrial standard MySQLdb. It...
(mysqlclient is a fork of mysqldb)
and since everyone wants to write discord bots nowadays, you should probably use aiomysql anyway if you are writing a discord bot
no, it's a db for a website, i wan't to automate something haha
i make my discord bot with mongodb, in js
Traceback (most recent call last):
File "g:\Mon Drive\prog\parser\test.py", line 2, in <module>
myConnection = MySQLdb.connect( host="z84xh.myd.infomaniak.com", user="*****", passwd="********", db="z84xh_dbSGCTests" )
File "C:\Python310\lib\site-packages\MySQLdb\__init__.py", line 123, in Connect
return Connection(*args, **kwargs)
File "C:\Python310\lib\site-packages\MySQLdb\connections.py", line 185, in __init__
super().__init__(*args, **kwargs2)
MySQLdb._exceptions.OperationalError: (2002, "Can't connect to server on 'z84xh.myd.infomaniak.com' (10060)")
with mysqlclient
i think it's the db, but i tried many different ports...
are the username and password correct?
have your friend share their C# code that worked
yes, I copy and paste them from phpmyadmin
i search it one moment
// Librairie
using System.Data;
using System.Data.Common;
namespace Test01
{
/// <summary>
/// Logique d'interaction pour MainWindow.xaml
/// </summary>
public partial class MainWindow : Window
{
DbProviderFactory dbPf;
DbConnection dbConn;
bool bEtatConn;
DbCommand dbCmd;
string sLigne;
public MainWindow()
{
InitializeComponent();
dbPf = DbProviderFactories.GetFactory("mySQL.Data.MySqlClient");
dbConn = dbPf.CreateConnection();
dbConn.ConnectionString = "Server= z84xh.myd.infomaniak.com; DATABASE=db ; UID=username; PASSWORD=pw";
bEtatConn = true;
DbDataAdapter dbAdapter = dbPf.CreateDataAdapter();
DbDataReader drInfos;
if (dbConn.State != ConnectionState.Open)
{
dbConn.Open();
}
// Écrire la commande SQL simple
dbCmd = dbConn.CreateCommand();
dbCmd.CommandText = "SELECT * ";
dbCmd.CommandText += "FROM tblcra; ";
// Lancer la requête crée précédemment
drInfos = dbCmd.ExecuteReader();
// Affichage de la requête dans la DataGrid
//dtgInfo.ItemsSource = drClients;
// Afficher dans une ListBox
while (drInfos.Read())
{
sLigne = drInfos["craId"].ToString() + " " + drInfos["craNom"].ToString();
lstbRes.Items.Add(sLigne);
}
dbConn.Close();
}
}
here it is
C# 😍
i'm not sure about that xd
I can’t even read the code I’m on phone lmao
np
and you are 1000% sure you have the right username and password?
it works in C# but not in python, on the same computer?
i think i remember having problems like this once when i used mysql, but it almost always was due to a typo that i missed
my friend tried his c# script and a python script on the same computer, juste the c# script worked
does it have to do with how the mysql server is configured?
Connector/Python supports authentication plugins available as of MySQL 5.6. This includes
mysql_clear_passwordandsha256_password, both of which require an SSL connection. Thesha256_passwordplugin does not work over a non-SSL connection because Connector/Python does not support RSA encryption.The connect() method supports an auth_plugin argument that can be used to force use of a particular plugin. For example, if the server is configured to use
sha256_passwordby default and you want to connect to an account that authenticates usingmysql_native_password, either connect using SSL or specifyauth_plugin='mysql_native_password'.
this is getting beyond my level of expertise with mysql though
there is something special on his c#, there is a space before the host
it's the only difference
but if i put a space on the string of the host in python, it can't found the host
i'm not sure if that's relevant, it should work without the space i think
i want to ask that suppose i making this program to connect to mysql but how would it connect to database when i will send and run my program in another pc since it may not contain mysql or root user like me with same username and password. so how can i do this task?

what to do if the bot does not add discord.py sqlite3 to the database?
Hey guys, I'd like to vizualize my datas, do u have a link to install sqlite3, bc I don't know what is the "right" sqlite3
please mention me
I don't quite understand what you're trying to say, but im guessing you want to access a SQL database from another server?
If your DB is remote you need to specify hostname at minumum. https://dev.mysql.com/doc/connector-python/en/connector-python-connectargs.html
@bot.command()
@commands.has_any_role(692760082085183519, 940008547993927691, 863878825376743475, 902292952381001779, 863879069253894166, 902292952381001779, 863879304110276668, 940008547993927691)
async def пред(ctx, member: discord.Member = None, *, reason = None):
print(45)
cursor.execute("""CREATE TABLE IF NOT EXISTS warning(guild_id BIGINT, user_id BIGINT, warn INT, count INT, moderator_id BIGINT, reasons VARCHAR)""")
base.commit()
print(1)
warnings = cursor.execute("SELECT * FROM warning WHERE user_id = ?", (member.id,)).fetchone()
print("работает")
if member is None:
await ctx.send("Выберите участника")
return
if reason is None:
try:
cursor.execute('INSERT INTO warning(guild_id, user_id, warn, count, moderator_id, reasons) VALUES(?, ?, ?, ?, ?, ?)', (ctx.guild.id,member.id,0,1,ctx.author.id,'Отсутствует'))
base.commit()
except Exception as e:
print(repr(e))
print(2222)
cursor.execute(f'UPDATE warning SET warn = {warnings[2] + 1} WHERE user_id = ? AND guild_id = ?', (member.id, ctx.guild.id))
base.commit()
await ctx.send(f"**{ctx.author.name}** Выдал предупреждение # {member} (случай # )")
else:
cursor.execute('INSERT INTO warning (guild_id, user_id, warn, count, moderator_id, reasons) VALUES(?, ?, ?, ?, ?, ?)', (ctx.guild.id,member.id,0,1, ctx.author.id, reason))
base.commit()
cursor.execute(f'UPDATE warning SET warn = {warnings[2] + 1} WHERE user_id = ? AND guild_id = ?', (member.id, ctx.guild.id))
base.commit()
await ctx.send(f"**{ctx.author.name}** Выдал предупреждение # {member}, причина {reason}. (случай # )")
error:``` OperationalError: no such column: user_id
How to fix?!sql-fstring
SQL & f-strings
Don't use f-strings (f"") or other forms of "string interpolation" (%, +, .format) to inject data into a SQL query. It is an endless source of bugs and syntax errors. Additionally, in user-facing applications, it presents a major security risk via SQL injection.
Your database library should support "query parameters". A query parameter is a placeholder that you put in the SQL query. When the query is executed, you provide data to the database library, and the library inserts the data into the query for you, safely.
For example, the sqlite3 package supports using ? as a placeholder:
query = "SELECT * FROM stocks WHERE symbol = ?;"
params = ("RHAT",)
db.execute(query, params)
Note: Different database libraries support different placeholder styles, e.g. %s and $1. Consult your library's documentation for details.
See Also
• Extended Example with SQLite (search for "Instead, use the DB-API's parameter substitution")
• PEP-249 - A specification of how database libraries in Python should work
@warped imp ☝️ that applies to SET too. hard to say if that's your problem, but you should at least try to rule it out
note that you should not re-use database cursors
one cursor per query, then the cursor is "dead"
you get unpredictable behavior otherwise
🤔
Someone knows how to install SQLAlchemy 2.0 in a conda env? I only seem able to get 1.4
did you try conda-forge?
you can use pip if it's not in either the default or conda-forge channels
actually sqlalchemy is still 1.4 in pypi too
is 2.0 even released yet? looks like it isn't
Yeah tried conda install -c conda-forge/label/prerelease sqlalchemy too which also installs 1.4.32
I was going off this page, I thought you could use it with pip install --pre SQLAlchemy but maybe I misunderstood it
https://docs.sqlalchemy.org/en/20/intro.html#installation-guide
But do I just use the latest 1.4 if I want to implement SQLAlc with 2.0 syntax?
Any recommendations on migrations tools? I'm using sqlalchemy but not a fan of Alembic.
yeah maybe it's just not in conda-forge yet
i'm not sure, you can check the 2.0 migration guide to see what 1.4 supports
I think this is what I'm looking for
https://docs.sqlalchemy.org/en/14/orm/session_basics.html#querying-2-0-style
"In the new 2.0 style of working, fully available in the 1.4 release"
In Postgres is there a way to specify all columns in a table to have the NOT NULL constraint without putting it on every column individually?
no, just add it on every column. Does not take that long does it to type few words out 🙂
no just thought there might be a dedicated way or something
You could try using Prisma Migrate
You don't need to use the client or anything, you would just have to write a minimal schema file defining your database connection and then run prisma db pull to get your current database schema in
The downside to this is that you'll then have two sources of truth, the Prisma Schema and your SQLAlchemy models
The solution to that is to have a custom Prisma Generator to create the SQLAlchemy models but that would be a decent amount of work
def additem(databasename,items):
cursor.execute("INSERT INTO {databasename} VALUES({items})")```
Anybody know what I'm doing wrong? trying to set up a sqlite3 functionSQL & f-strings
Don't use f-strings (f"") or other forms of "string interpolation" (%, +, .format) to inject data into a SQL query. It is an endless source of bugs and syntax errors. Additionally, in user-facing applications, it presents a major security risk via SQL injection.
Your database library should support "query parameters". A query parameter is a placeholder that you put in the SQL query. When the query is executed, you provide data to the database library, and the library inserts the data into the query for you, safely.
For example, the sqlite3 package supports using ? as a placeholder:
query = "SELECT * FROM stocks WHERE symbol = ?;"
params = ("RHAT",)
db.execute(query, params)
Note: Different database libraries support different placeholder styles, e.g. %s and $1. Consult your library's documentation for details.
See Also
• Extended Example with SQLite (search for "Instead, use the DB-API's parameter substitution")
• PEP-249 - A specification of how database libraries in Python should work
ooooooh
so it'd be
def additem(databasename,items):
cursor.execute(f"INSERT INTO {databasename} VALUES({items})")```i'm not sure this function is a good idea though
why not?
execute does it for you. it is redundant. what even is the point of the function?
so it's easier to do and I can do it in one line since I have to commit it as well
easier to just type "additem" than to go and copy/paste execute
well i dont think what you have rn will suffice. you might need to make tons of different helper functions for specific use cases
and take into account placeholders and parameters
an extra line for committing doesn't hurt
yeah I'll have to add more complexity in the future but for now it's all I need
Other than more datatypes, hosted, faster & bigger, are there any more benefits of PostgreSQL when compared to something like SQLite?
postgresql is also a lot more programmable, with several procedural languages: pl/pgsql, pl/python, etc.
pg has user accounts with detailed access controls, and the ability to define "schemas" which are groupings of tables within a database.
pg has several more index types, which gives you more precise control over performance properties
the sql query language itself in postgres has more features such as LATERAL
ah okay thank you
@violet marten Go to https://mongodb.com/ and create an account

MongoDB
Get your ideas to market faster with an application data platform built on the leading modern database. MongoDB makes working with data easy.
creating mongo acc free?
yes
aight

Not really, just click "build a new application"

yes
now
i am from asia near india
oh
created user
Do this
this?
Click browse connections
yep.

Add my own data

Anything, I prefer naming it discord or bot
@oak oyster im so sorry, ive hit a wall in my knowledge even when its the simplest thing.
@client.event
async def on_member_join(member):
embedVar = discord.Embed(title="HELP", description="tEXT", color=0x619491)
await client.message.send(embed=embedVar)
which part of this is incorrect? it doesnt seem to be sending to new users
await member.send(...)
name it bot (database name)

still doesnt seem to be working..
i need it to DM them, i feel like im missing a line of code
oh wow, wrong channel i ujst realised. apologies
next?
Click database access and show me what you see
hm show "Network Access"

Click add ip

Click allow access from anywhere

Click confirm

Click database > connect

Click "connect your application"


ok
copy the link, replace <password> with the password u entered earlier
Then
install motor & dnspython
!pypi motor

Non-blocking MongoDB driver for Tornado or asyncio
!pypi dnspython
DNS toolkit
no, in your shell



done both
i mean discord.py
i forgot
how can i check?
pip show discord.py
now in your main file do ```py
from motor.motor_asyncio import AsyncIOMotorClient
bot.mongo = AsyncIOMotorClient(THE_URL_FROM_EARLIER)
isnt it client.mongo?
Done. You can now insert/delete/update stuff inside your db ```py
col = bot.mongo["discord"]["test"]
await col.insert_one(...)
ye
just change client to mongo
I mean bot to client

Show line 19

Make the url a string, and put that below your client variable

put that below your client variable

client.mongo = AsyncIOMotorClient
str ('mongodb+srv://nizoki:<>@cluster0.zaut6.mongodb.net/myFirstDatabase?retryWrites=true&w=majority)```i am confused
client = ...
client.mongo = ...

Dude
Define client.mongo below your client variable

No
Can you see your client variable bere?
hm
like client = discord.Client()
yes

put client.mongo UNDER that ```py
client = commands.Bot(...)
client.mongo = ...

yes
now
don't forget to enter your password in the mongo URL
how can i sent data into db
like
if i do ?staff name how can i add him in the staff list embed
you wanna add the name into the db?
can you give a example of that

how can they store there data in db
its being complicated for me
Discord.py will be discontinued because of Discord's slash commands, use pycord lol
it's a fork of it
?
dpy is back
slash cmds were also added about a month ago
oh lol, I guess I remembered an old source, haven't been using discord.py for a while sorry for that
oh
wouldn't have known either if it wasn't for the updates ping
cursor = await db.execute('select name from cards where name like "%?%"', (card,))
File "/home/ubuntu/.local/lib/python3.10/site-packages/aiosqlite/core.py", line 184, in execute
cursor = await self._execute(self._conn.execute, sql, parameters)
File "/home/ubuntu/.local/lib/python3.10/site-packages/aiosqlite/core.py", line 129, in _execute
return await future
File "/home/ubuntu/.local/lib/python3.10/site-packages/aiosqlite/core.py", line 102, in run
result = function()
sqlite3.ProgrammingError: Incorrect number of bindings supplied. The current statement uses 0, and there are 1 supplied.
sqlite uses the ? as the placeholder and will automatically handle putting quotes around it if the argument you pass is a string
oh wait if you are looking to do a text search, i think an fts table is preferable for this
full-text search https://www.sqlite.org/fts5.html
special table that indexes the content to make matching words a lot faster
o
so I just replace first line with
CREATE VIRTUAL TABLE cards USING fts5(x);
oh wait
I need to install it?
ive only read through the docs but hadnt attempted an implementation with fts
oh
though i think fts should be built in
yes
uh?
is there a way to delete a sql table entirely or add more columns to it
like the table itself not records in the table
cause I didn't do mine right the first time
DROP TABLE to delete or ALTER TABLE to modify
consult the documentation for your specific database for usage details
Any great alternatives to Alembic? not a big fan since it's a bit clunky but I do use SQLAlchemy.
near "channels_id": syntax error``` hi! what is wrong with this?DELETE cannot delete a single field.
Correct would be:
DELETE FROM logs WHERE guild_id = 956990653336784976;
It always deletes the whole database row.
np
You could try Django (https://docs.djangoproject.com/en/4.0/topics/migrations/) which has built-in support for database migrations.
If you don't want the overhead of a complete framework, why not try EdgeDB (https://www.edgedb.com/docs/datamodel/index) which is based on PostgreSQL with a built-in Data Model including Migrations directly in the database.

I have a database having more than 10k records on local pc how can I take its backup? I used to use php admin it was easy to export sql file there is there any way to get backup through cli too?
which db yuo've in your local pc?
Traditional mysql
owo i see
Is it possible?
ok i believe that it should be possible
but, I've no experience with it, ||like i've used mysql, but never did backup stuff||. u can try this: https://dev.mysql.com/doc/mysql-backup-excerpt/5.7/en/using-mysqldump.html
mysqldump -u [uname] -p db_name > db_backup.sql I got this query but will it work for like 10k records
that's all i can do my friend.. I never tried to do backup stuff before :'/
let's hope someoen else will solve your question
:)
Aye aye no worries thanks for help!
:>
is there a better way to do this?```py
for i in range(1, 71):
cursor = await db.execute('select name from cards where loc = ? limit 1', (i,))
# some stuff with the result
You can use ‘where in (1,2,3…)’. Obviously the list would be generated by python so you don’t have to type all those values in.
But you avoid making the query in a loop
?
so it would return only 1 row from loc 1,2,3...?
No you will have to get the row you want from the list returned.
But this avoids the n+1 problem
oh
what database are you using?
aiosqlite
and what library

Stack Overflow
I am trying to use parameter substitution with SQLite within Python for an IN clause. Here is a complete running example that demonstrates:
import sqlite3
c = sqlite3.connect(":memory:")
c.execu...
wait
@uneven stream ```py
db.execute('select name from cards where loc >= 1 and loc <= 70')
oh
I needed only 1 row from each loc
That's actually not a big problem with SQLite
https://www.sqlite.org/np1queryprob.html
select name from cards where loc = 1 limit 1
select name from cards where loc = 2 limit 1
select name from cards where loc = 3 limit 1
...
smthn like this?
why?
ig I used this, but if there's a better way I would like to know
!e
import sqlite3
con = sqlite3.connect(":memory:")
con.execute("CREATE TABLE foo(id, bar)")
con.execute("INSERT INTO foo(id, bar) VALUES ('a', 1), ('b', 2), ('c', 3), ('d', 4), ('e', 5)");
con.commit()
cur = con.cursor()
cur.execute("SELECT id, bar FROM foo WHERE bar >= 2 AND bar <= 4")
print(cur.fetchall())
@brave bridge :white_check_mark: Your eval job has completed with return code 0.
[('b', 2), ('c', 3), ('d', 4)]
this way, you can fetch all the information in one query
Or is your actual code using something other than a range to select the cards?
the cards are more like this```py
(loc, card)
[(1, 'a'), (1, 'b'), (1, 'c'), (1, 'd'),
(2, 'e'), (2, 'f'), (2, 'g'),
(3, 'h'), (3, 'i'),
(4, 'j'), (4, 'k')
(5, 'l'), (5, 'm'), (5, 'n')]
what's the difference?
and I would need```py
[(1, 'a'), (2, 'e'), (3, 'h'), (4, 'j'), (5, 'k')]
why (1, 'a') and not (1, 'd')?
I need the first card of loc 1
first based on what? because 'a' comes before 'd' alphabetically?
alphabetically, but since I have the table data in alphabetical order it would be the first card for each loc
rows are not guaranteed to be returned in any particular order.
inserted them in alphabetical order
rows are not guaranteed to be returned in any particular order, including insertion order
idk abt that, returns stuff in alphabetical order for me
Yes, it happens to do that in that particular case. But it's not guaranteed to do that in all cases, and it might change in a later version
https://dba.stackexchange.com/a/5775

Database Administrators Stack Exchange
Whenever I manually insert a row into a table in SQL Server Management Studio 2008 (the database is SQL Server 2005) my new row appears at the TOP of the list rather than the bottom. I'm using iden...
oh
for now its fine ig
i think an aggregate function might be appropriate for this
e.g. sql SELECT loc, MAX(char) FROM cards GROUP BY loc; 1|d 2|g 3|i 4|k 5|n
in your case you'd use MIN() with whatever you named the column
thanks!
create_tables = """\
CREATE TABLE IF NOT EXISTS stock (
id INT,
name VARCHAR(255) NOT NULL,
amount INT,
PRIMARY KEY (id)
);
CREATE TABLE IF NOT EXISTS stock_price (
id INT,
stock_id INT NOT NULL,
price INT,
PRIMARY KEY (id),
FOREIGN KEY (stock_id) REFERENCES stock(id)
);
"""
cur.execute(create_tables, multi=True)
why doesn't it create table?
I think you have to make call to function commit() after
still doesn't
Show code
from mysql.connector import connect
con = connect(host='localhost', user='root', passwd='', database='temp')
cur = con.cursor()
create_tables = """\
CREATE TABLE IF NOT EXISTS stock (
id INT,
name VARCHAR(255) NOT NULL,
amount INT,
PRIMARY KEY (id)
);
CREATE TABLE IF NOT EXISTS stock_price (
id INT,
stock_id INT NOT NULL,
price INT,
PRIMARY KEY (id),
FOREIGN KEY (stock_id) REFERENCES stock(id)
);
"""
cur.execute(create_tables, multi=True)
con.commit()
Then I don’t know lad 🤷♂️
Try single statements, not sure if it supports multi true
i think its the multi
yea that works
wouldn't that be ... (5, 'l')?
and a window function works also:
select loc, name
from (
select loc, name, row_number() over win as "row_number"
from cards
window win as (partition by loc order by name)
)
where row_number = 1
oh
edited msg later, but yup
thanks!
With the window function you can also eg. get the 2nd or 3rd of the entries.
o
Does Pandas have a bulk update(not insert) functionality with sqlalchemy?
How to make the warn system non-global? type that on other servers were different?
sql
in relation to discord? i would suggest a compound primary key like (guild id, warn id)
!e
import sqlite3
con = sqlite3.connect(":memory:")
con.execute("CREATE TABLE cards (loc INTEGER, name TEXT)")
con.execute("INSERT INTO cards VALUES (1, 'a'), (1, 'b'), (1, 'c'), (1, 'd'), (2, 'e'), (2, 'f'), (2, 'g'), (3, 'h'), (3, 'i'), (4, 'j'), (4, 'k'), (5, 'l'), (5, 'm'), (5, 'n')")
con.commit()
sel_stmt = (
'select loc, name'
' from ('
' select loc, name, row_number() over win as "row_number"'
' from cards'
' window win as (partition by loc order by name)'
')'
' where row_number = ?'
)
cur = con.cursor()
for i in range(1, 5):
print(i, cur.execute(sel_stmt, (i,)).fetchall())
@grim vault :white_check_mark: Your eval job has completed with return code 0.
001 | 1 [(1, 'a'), (2, 'e'), (3, 'h'), (4, 'j'), (5, 'l')]
002 | 2 [(1, 'b'), (2, 'f'), (3, 'i'), (4, 'k'), (5, 'm')]
003 | 3 [(1, 'c'), (2, 'g'), (5, 'n')]
004 | 4 [(1, 'd')]
(why not use a triple-quoted string?)
I don't know. I somehow have a dislike of triple quotes.
I realized that I've never seen a window function
any resources to learn about them?
you could read about them on the sqlite docs https://sqlite.org/windowfunctions.html
or here https://mode.com/sql-tutorial/sql-window-functions/#intro-to-window-functions
Ignoring exception in command fish:
Traceback (most recent call last):
File "C:\Users\leka\PycharmProjects\Amk\venv\lib\site-packages\discord\ext\commands\core.py", line 187, in wrapped
ret = await coro(*args, **kwargs)
File "C:\Users\leka\PycharmProjects\Amk\fishergame_cog.py", line 15, in getfish
await db.execute("UPDATE exp SET FISH = ? WHERE UserID = ?", ran, alpha)
File "C:\Users\leka\PycharmProjects\Amk\db.py", line 48, in execute
await cur.execute(command, tuple(values))
File "C:\Users\leka\PycharmProjects\Amk\venv\lib\site-packages\aiosqlite\cursor.py", line 37, in execute
await self._execute(self._cursor.execute, sql, parameters)
AttributeError: 'Result' object has no attribute 'execute'
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "C:\Users\leka\PycharmProjects\Amk\venv\lib\site-packages\discord\ext\commands\bot.py", line 1234, in invoke
await ctx.command.invoke(ctx)
File "C:\Users\leka\PycharmProjects\Amk\venv\lib\site-packages\discord\ext\commands\core.py", line 923, in invoke
await injected(*ctx.args, **ctx.kwargs) # type: ignore
File "C:\Users\leka\PycharmProjects\Amk\venv\lib\site-packages\discord\ext\commands\core.py", line 196, in wrapped
raise CommandInvokeError(exc) from exc
discord.ext.commands.errors.CommandInvokeError: Command raised an exception: AttributeError: 'Result' object has no attribute 'execute'
Im not sure what the Result object is(im pretty sure its the cursor) but im getting this error:
How to make the warn system non-global? type that on other servers were different?
sql
how to insert a datatime value in a VALUES(' ') command ?
Curious, how computationally expensive is to merge values and pandas.to_sql('replace') vs sqlalchemy bulk update vs sqlachemy iterated update.
@torn sphinx answered you above
that depends on the library - if you're using sqlite3 then they automatically adapt datetimes into ISO strings when passed as a ? parameter, though you would need to connect to your database with the detect_types=sqlite3.PARSE_DECLTYPES kwarg to auto-convert TIMESTAMP columns back to datetimes (https://docs.python.org/3/library/sqlite3.html#default-adapters-and-converters)
thanks 🤗🤗
is it normal for fetching 388 objects which each contain 25 key-value data points to take around 1-2 min on mongoengine?
feel like that's a insane amount of time to fetch only 388 items, not scalable at all
Anyone know of a kind of data store that is specialized for time series data, similar to InfluxDB or Prometheus, but you can refeed it the same data series at multiple granularities and when you query it, it gives you the finest granularity it has available automatically and fills the gaps with the less granular data as a fallback?
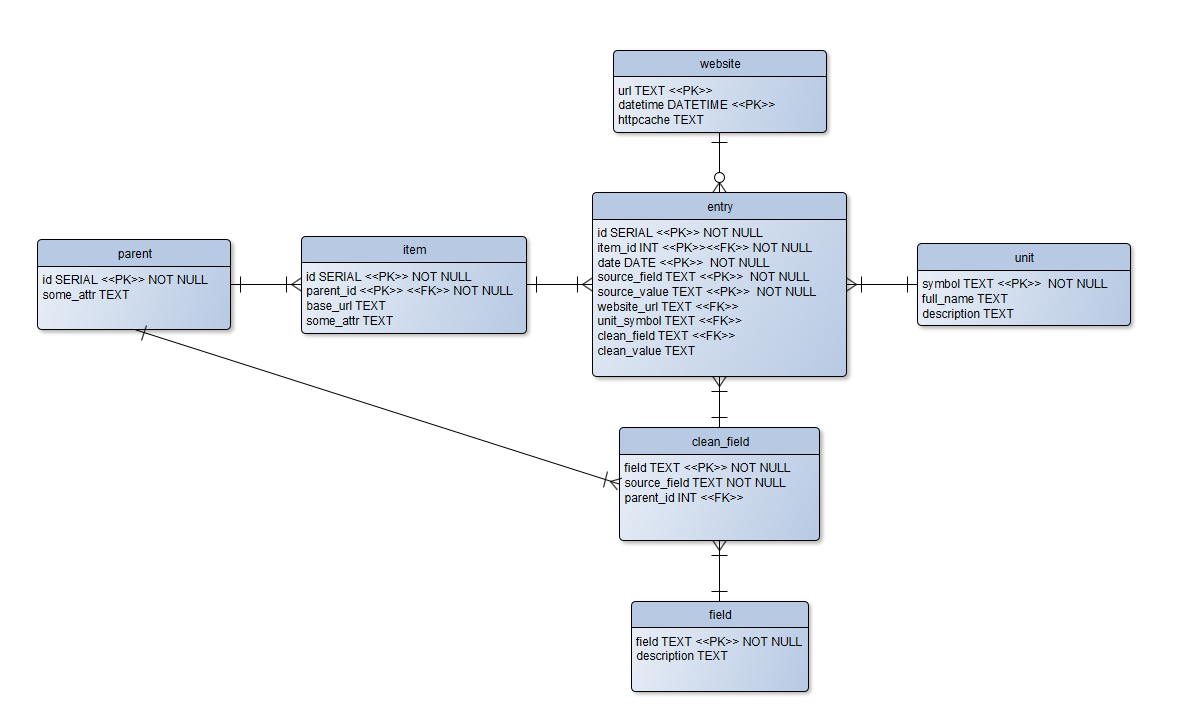
Can I ask for comment on my ER diagram here? https://i.imgur.com/XuDL5hs.png
It should let me store "dirty" data from scraped sources (scrapy; i.e. it follows crawling instructions from which HTTP responses are parsed into items (dicts really) with instructions and then into an output pipeline, say into JSON files or in this case into a postgre DB - using dicts as rows). The attribute/key values tho are not always explicitly pre-defined, so I store one target (from the response) as it's key and another target (or many, or whatever) as it's value. So I use an associations table matching scraped keys with proper keys representing a standard attribute, also with the item's parent's (companies for what I want) id. Tables unit, clean_field and the last three values of entry would be completed by a later pipeline.
Two things I'm unsure about are entry's PKs and the looping reference. For the PKs, does this look ok? For presenting I'll be using most recent (or date-targeted) entry for each combination as cells of a table (col: entry.clean_field, row: item.id).
For looping, it's something I learned to avoid back when I was taught SQL/databases. Is this kind of loop here an issue? Does it even count as such since entry.clean_field derived from a lookup of an existing value (entry.source_field) and should it be diagrammed differently?
Thanks !
How to make the warns on other servers different, otherwise it issued a varn on one server, and it is shown on all?
Sql
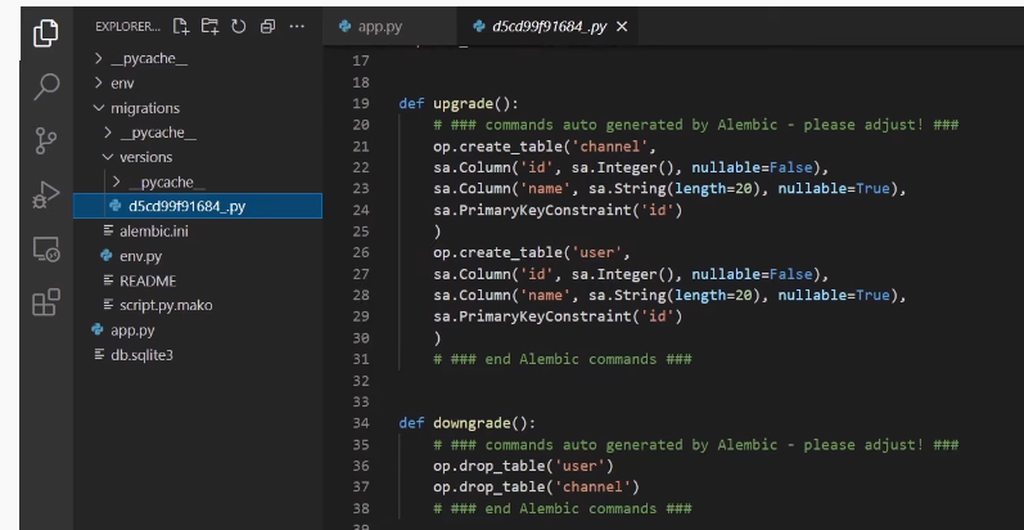
I am trying to install flask-migrate with flask-sqlalchemy but I can't update my database because the upgrade database folder is in the wrong location
When I type flask db migrate -m "Initial migration." in the versions folder there is no pyache file and there is no env.cpython-310.pyc. These files are in the migrate folder but not in the version folder.
Here is a picture.
Here is how it should look.
Notice how versions is empty and I don't have the upgrade or downgrade function or the file.
Why is this happening?
I am following this tutorial.
https://www.youtube.com/watch?v=uNmWxvvyBGU
Here is flask-migrate documentation
https://flask-migrate.readthedocs.io/en/latest/
Thanks

If you need to update your database without dropping and recreating the tables (you will need to eventually), Flask-Migrate is a great way to do so easily. It will handle everything for you, and it will even keep track of your database's video.
I cover how to use it in this video.
Get the data model design checklist here: https://prettyprinte...
You should probably clarify what you are using flask djanjo etc. This might get you started https://www.w3schools.com/sql/sql_insert.asp Or better yet https://www.freecodecamp.org/news/sql-and-databases-full-course/. If you need how to create the database I have other recommendations
W3Schools offers free online tutorials, references and exercises in all the major languages of the web. Covering popular subjects like HTML, CSS, JavaScript, Python, SQL, Java, and many, many more.

freeCodeCamp.org
In this course, Mike Dane will teach you database management basics and SQL. The course starts off with Mike helping you install MySQL on Windows or Mac. Then he explores topics like schema design, Create-Read-Update-Delete operations (CRUD), and other database fundamentals. If you've never studied databases or SQL before, this
Never heard of it
tkinter is like a library of python i think so
is like to make a interface

so this is just the code
for the insert
haha
But you know primary keys and foreign keys
yeah i know that
do you have a question currently
You should probably indent the code that is meant to be the arguments for connect
Anyone experienced with SQLModel? If so, how do you feel about it?
my boss insta-fixed a query issue the other day, and it blew my mind 
i was still trying to understand the problem the stakeholder was having
What sort of fix
she was like [Rex], try putting these few lines after the where clause
id have to look at it again for the specifics but it was basically a subquery that did many things
and like the team that was working with the dashboard brought up a list of issues previously and i applied the new query
and basically
all the issues were resolved
Did anyone here worked on BigQuery?
i am uploading data from .dta file batchwise but not all the rows are getting uploaded
It gives error ike provided scheme does not match: field chaanged type from FLOAT to INTEGER
How to make the warns on other servers different, otherwise it issued a varn on one server, and it is shown on all?
Sql
Hi, I have a problem where I have an app that is way too big if calculation is to happen locally. Therefore I want to send a request to another place where calulations will happen. How should I approach this? So for example I want the app to send information - add 20 to 50 and get result back from the server -70. Is there any good tutorial explaining this?
Hey guys is it possible to write user input data to a .json file through a MDTextField? i presume it is but i cant find any material anywhere.
When working with jsons, is there anything like .keys() that allows me to check if a certain value is attached to a key without iterating through the whole json?
Similar to me being able to do if "a" in json.keys()
!e
import json
some_json = """{
"id": 1,
"name": "bob"
}"""
s = json.loads(some_json)
if "name" in s:
print("Key 'name' exists with value: ", s["name"])
else:
print("Invalid key")
@nova cove :white_check_mark: Your eval job has completed with return code 0.
Key 'name' exists with value: bob
something like this will work, @torn sphinx. you can just do if "key" in var_holding_json_object
also if you are using JSON as a db, I would recommend using something else like an rdbms
I’m actually attempting the opposite, like querying for “bob” and getting “name” without having to iterate through all keys and comparing their values against “Bob”
It’s a pretty small thing, like 10 entries max
ah ok
hi
!e
Missing required argument
code
!eval <code>
Can also use: e
*Run Python code and get the results.
This command supports multiple lines of code, including code wrapped inside a formatted code block. Code can be re-evaluated by editing the original message within 10 seconds and clicking the reaction that subsequently appears.
We've done our best to make this sandboxed, but do let us know if you manage to find an issue with it!*
!e x = 150 print(x)
Hey @worn musk!
You either uploaded a .txt file or entered a message that was too long. Please use our paste bin instead.
!e
Missing required argument
code
!eval <code>
Can also use: e
*Run Python code and get the results.
This command supports multiple lines of code, including code wrapped inside a formatted code block. Code can be re-evaluated by editing the original message within 10 seconds and clicking the reaction that subsequently appears.
We've done our best to make this sandboxed, but do let us know if you manage to find an issue with it!*
@worn musk :x: Your eval job has completed with return code 1.
001 | Traceback (most recent call last):
002 | File "<string>", line 1, in <module>
003 | ModuleNotFoundError: No module named 'matplotlib'
I need some help with caching some data which I get from a database. So I have a database containing tracks (file_path.mp3, artist, album, etc.) and I want to my repository class to fetch tracks only once and then cache them, but in a slightly specific way. I want for the tracks to be available via key ("artist", "year", ...) and value ("Alan Walker", "2017", ...). The key and value would be a tuple which would be a key in my cached dictionary and tracks which have that value would be the value in my cached dictionary. I want the same to be done with different keys, for example "artist", and to cache tuples containing artist name and the number of songs by that artist, for example [("Alan Walker", 22), ("Coldplay", 7)]. I thought I can make that cached dict into an attribute of my repository class and to make it Singleton, so every instance would point to the same object in memory and will use the same attributes, but that only works for instances created within the same function, so once the function is finished all the instances are garbage collected and new ones will be made in the future, so this approach doesn't work. I've seen online that there exists @functools.cached_property decorator but I don't think it's the best way to solve this problem nor do I know how to solve it by using it. Is there an elegant solution to this problem?
from typing import Union, List, Tuple
from constants import *
from data_models.track import Track
from repositories.tracks_repository import TracksRepository
from utils import Singleton
class CachedTracksRepository(TracksRepository, metaclass=Singleton):
def __init__(self):
super().__init__()
self.cached_track_groups = {}
self.cached_counts = {}
def get_tracks_by(self, key: str, value: Union[str, int]) -> List[Track]:
tuple_key = (key.lower(), value)
if tuple_key not in self.cached_track_groups:
self.cached_track_groups[tuple_key] = super().get_tracks_by(key, value)
return self.cached_track_groups[tuple_key]
def get_track_counts_grouped_by(self, group_key: str) -> List[Tuple[str, int]]:
if group_key not in self.cached_counts:
self.cached_counts[group_key] = super().get_track_counts_grouped_by(group_key)
return self.cached_counts[group_key]
def cache_tracks(self):
for group_key in GROUP_OPTIONS:
for group_name, _ in self.get_track_counts_grouped_by(group_key):
self.get_tracks_by(group_key, group_name)
self.get_tracks_by(group_key, None)
def delete_cache(self):
self.cached_track_groups = {}
self.cached_counts = {}
Here's the code, TracksRepository is what actually has the alghoritms of getting tracks from the database and GROUP_OPTIONS is a list ["Artist", "Album", "Year", "Composer", ...]
is it a bad idea to create a new cursor every time i query something?
Context may matter but generally I think cursors are meant to be disposable like that.
a small discord bot
im subclassing aiosqlite to add my own methods for convenience
in the initializer i wanna do self._cursor = super().cursor()
but heard its not a great idea
Yep, just use cursor directly
also use context managers when working with cursors so you don't forget to close them 🙂
do not reuse cursors
one cursor per query
and yes use context managers
also doesn't aiosqlite allow you to invoke execute as a method on the connection itself, returning a new cursor?
yes but i was told not to do that in #python-discussion
more precisely, i was told not to directly invoke execute on a connection. perhaps, they didn't know that aiosqlite returns a new cursor
Who told you that? it's fine as long as you understand that it's still a cursor being returned
one cursor per query doesn't make sense, how would you manage transactions and such?
I'd say one cursor per operation, could be a bot command, api endpoint, etc
Hm, i thought cursor in dbapi represents connection but that's not the case
Do they store state? Why would you create new one each time?
yeah, transactions are normally invoked on the connection
Yep, just read on that
and whether or not the cursor stores state i think depends a lot on the underlying library implementation and the database itself
i just know that i have seen a ton of weird problems arising from reusing cursors
ranging from mysterious runtime errors to data seeming to disappear from the database
https://peps.python.org/pep-0249/#cursor-objects I think it does have some internal state?
You seem to be right, you should probably create individual cursors for your queries
Python Enhancement Proposals (PEPs)
dbapi required cursors i guess just as a compatibility layer
kind of annoying for queries that don't require cursors, but it is what it is
so this is why a lot of database libraries let you invoke execute directly on the connection object, to alleviate the boilerplate of creating a cursor just to call .fetchall()on it and then toss it away
i think technically you're supposed to close the cursor too, with .close(), but usually i don't bother with that unless the database library docs make a big point of it
I usually use sqlalchemy orm/core and didn't use dbapi implementations like sqlite or psycopg 🤔
sqlalchemy wraps those libraries
i dont think i understood what you meant then
Just saying that i didn't use DB API directly
ah, yeah
I don't usually write sql except for one-time query/update
Because stuff can and would suddenly break, but orm's are usually type-checkable (unlike raw sql queries), so it would break less often 😅
indeed, i like orm's a lot
i use raw sql for ad-hoc data processing scripts. for a real professional application i'd always want to use an orm if possible
if i need precise control over the query, i can always drop down to writing raw sql
I don't like active records orms, for example django orm or tortoise 🤔
I used django orm a lot, but it's a chore to write something remotely complex
i feel like sqlalchemy allows to build queries easier and is just better overall
valid. those are good for small lookups of things, not big complicated queries
I would usually use sqlalchemy for that, it allows to write anything
also true, sqlalchemy core is excellent
Django on the other hand doesn't even support cte's out of the box 🤔
fwiw i've never needed a CTE in production code
I needed a recursive cte because i have self-referential relationship in my project, but i ended up just using a for loop and a stack
i've used them to keep my sanity intact instead of writing 4-level-deep nested queries in some ETL code though. even though i know they're often an optimization fence i prefer the syntax
hm... i did have that problem once, but it was when i was a junior and didn't know about recursive cte's 😆
i chose loop deliberately because i didn't want to write any sql
if you start writing raw sql in your project it suddenly spreads everywhere
brrr
ehhh idk about that in general, but i can see how it might happen
Also query builder in django is just weird
I have three tables with around 100 mil, 80 mil and 200k records, and I performed left join between them and it take 15hrs in ADF Pipeline. I tried using non clustered index and still it didn't have much impact. Can someone please suggest some other solution to speed up the performance.
Good day everyone! Is there any way to select only existing values from row using sqlite3 + python?
I have many rows = 0, and i need to get only rowname > 0 & not null
How to make the warns on other servers different, otherwise it issued a varn on one server, and it is shown on all?
Sql

why am i getting this error
File "C:\Users\91834\Desktop\DBSM\page1.py", line 14, in <module>
mycursor.execute("INSERT INTO Worker(ecode,name,design,plevel,doj,dob) VALUES (%s,%s,%s,%s,%s,%s),(%s,%s,%s,%s,%s,%s),(%s,%s,%s,%s,%s,%s),(%s,%s,%s,%s,%s,%s),(%s,%s,%s,%s,%s,%s)",
TypeError: execute() takes from 2 to 4 positional arguments but 7 were given```mycursor.execute("INSERT INTO Worker(ecode,name,design,plevel,doj,dob) VALUES (%s,%s,%s,%s,%s,%s),(%s,%s,%s,%s,%s,%s),(%s,%s,%s,%s,%s,%s),(%s,%s,%s,%s,%s,%s),(%s,%s,%s,%s,%s,%s)",
(11,"Radhe Shyam","Supervisor","POO1","2004-Sept-13","1981-Aug-23"),(12,"Chander Nath","Operator","P003","2010-Feb-22","1987-Jul-12"),(13,"Fizza","Operator","POO3","2009-Jun-14"),
(15,"Ameen Ahmed","Mechanic","POO2","2006-Aug-21","1984-Mar-13"),(18,"Sanya","Clerk","P002","2005-Dec-19","1983-Jun-09"))
db.commit()
it depends on your dialect, PostgreSQL has Boolean True and False https://www.databasestar.com/sql-boolean-data-type/
that's T-SQL, you can use BIT https://www.mssqltips.com/sqlservertip/6447/sql-server-bit-data-type/
yea thats what i used
now i have to use Values 1 and 0
any way to change them to Yes or No
?
ah if you literally need Yes and No then you indeed need a kind of string datatype, nchar is also okay, because you know beforehand how long it will be (maximum three chars)
ah aight
you are the first person I have ever heard ask this question والله
A database's main purpose is to... store data
However there are many formats that data can be stored in, and there are different systems that can be used as an interface to that database
One common database type is a relational database, i.e. an SQL database, where data is stored in tables
Here's a video explaining more about SQL is: https://youtu.be/zsjvFFKOm3c
And to practise writing SQL yourself you can check out this interactive tutorial: https://sqlbolt.com/
In python there's builtin support for the SQLite database using the import sqlite3 module
If you also want to look into other database types you can check out this video and then search up different database libraries for python, for example PostgreSQL, MySQL, or MongoDB (a NoSQL document-based database): https://youtu.be/W2Z7fbCLSTw

Learn the fundamentals of Structured Query Language SQL! Even though it's over 40 years old, the world's most popular databases still run on SQL.
Foreign key basics https://docs.microsoft.com/en-us/sql/relational-databases/tables/create-foreign-key-relationships
#dev #database #100SecondsOfCode
Draw SQL Diagrams https://drawsql.app/
Install ...
ohhhhhhhh
thanks
btw how can i select all the orders from only 2 locations and sort them using ASC? lets assume i have a Orders table with a Location field, and i want to select only orders from NY and LA ?
can someone help me writing this query?
you can use WHERE location IN ('NY', 'LA') to check if its one of those two
ohh
i didnt know u can use multiple "locations" in this case in tha command
i coded it to select from one
but was struggling where to add the second city xD
thanks tho
the other way is combining your two conditions with OR, e.g. WHERE location = 'NY' OR location = 'LA'
tysm
implementing a scoreboard in my web game, using pymongo.
I want to find the data in my document with the highest number:
example:
{'word': 'crams', 'user': 'ethan', 'score': '19'}
{'word': 'ankle', 'user': 'ethan', 'score': '20'}
{'word': 'elate', 'user': 'ethan', 'score': '21'}
{'word': 'wagon', 'user': 'ethan', 'score': '22'}
{'word': 'clary', 'user': 'ethan', 'score': '23'}
{'word': 'darbs', 'user': 'ethan', 'score': '24'}
{'word': 'loggy', 'user': 'ethan', 'score': '25'}
{'word': 'bribe', 'user': 'ethan', 'score': '26'}
{'word': 'hempy', 'user': 'ethan', 'score': '27'}
I want to find the set of data with the highest score count.
how do I do that?
What rdbms are you using?
Azure sql
I never worked with it, but, what your query looks like?
Select with 2 left join
could you send me query plan for it?
something like collection.find().sort("score", -1).limit(1) should work i suppose
does any1 have an idea?
Hm, why do you need to cache them?

firebase = pyrebase.initialize_app(config)
database = firebase.database()
author = ctx.message.author
now = datetime.now()
data = {
'Submit by': f'{author.name}#{author.discriminator}',
'Date': now.strftime("%d/%m/%Y %H:%M:%S CET")
}
database.child(str(username)).set(data)
Does anyone know how I'll able to get a list of all the child nodes in my realtime database?
So I'm trying to get a list that would look like [user1, user2, user3, user4].
I'm using it in gui and it needs to be really fast, otherwise there will be slight lag
I don't want everything to be calculated on button click because some of it are very long lists and it makes the gui freeze for a split second which is pretty ugly
You mentioned that you tried to use singleton, it didn't work?
i doesn't work, once all the objects get destroyed, new one will be created and all of the attributes would reset, for example if i create an object in a function it will get destroyed once the function is finished so if I create it again in a new function it wouldn't point to the same object because the old one was destroyed so the new one will be created, but it would work if I create new objecta within that function although that's not what I want, I want to be able to access that object (cached data) from a lot of other methods and classes in different files
Singleton shouldn't just die or be collected by python's gc
how did you implement it?
So apologies, I am very much learning. I have a small script that builds a SQLite db to track case statistics. I can pass the input() variables into the database just fine, but I am sticking on the foreign key issue. I have two tables, a case table that tracks global data relevant to a case and then an items table that tracks individual data points to multiple items within a case.
I am having trouble finding a good video or article that describes how to generate/link a foreign key from the items table to a primary key of the case table.
since the PK is generated when a new case is inputted, how do I populate a foreign key with that number without knowing it? There has to be a way, I am just not googling the right phrasing, I think.
I'm sure at the size of the database I intend on building, I don't really need multiple tables... but I want to learn how to do it.
Hey guys, i'm not sure if this is the right place to ask but i'm trying to scrape about 900 pages of a website and i'm stuck, i'm always getting the result from the first page.
url = f'https://www.capitoltrades.com/trades?page={pg}&pageSize=50'
r = requests.get(url)
soup = BeautifulSoup(r.text, 'html.parser')
t_table = soup.find('table', class_ = 'q-table trades-table')
print(t_table.text)```What am i doing wrong?
Whats error
No error, i just get the same table (t_table) on every iteration
Is it constantly repeating printing the forst page.
yes
Hmmm
from the looks of it. Theres nothing there to say for it to go to the next page
...and so on

url is formated with pg in range(1,905)

i then use requests.get(url)
shouldn't it jump?
How to make the warns on other servers different, otherwise it issued a varn on one server, and it is shown on all?
Sql
sorry my ipad dies.
died
I know for sure for i in range(number, number) automatically goes from the first number in the range. And changes i by +1 everytime the loop starts over again. But im not familiar with pg. im assuming its just page. Try using INSIDE of the for loop. pg += 1
is there any way to get column name + row value output if cell not empty?
Using sqlite3
row value output...? can you describe the table you have and the information you're looking to get from it
hey guys, does pandas.read_html() only work on tables?
Anyone mind popping over to #🤡help-banana to answer some questions about how I should layout my db tables for my logging events for my #discord-bots
I have the same impression. There is also a jupyter-lab plugin called mito, which should help doing similar things.
I am using SQLAlchemy for not very large projects and not web applications, but I show another ORM framework, namely PonyORM: https://docs.ponyorm.org/. It looks rather intuitive, has anyone had more experience with that? Would you recommend something else, eg Django ORM? (I don't intend to build a web app though)
anyone help

i have all these arrays that come up when i run code in debug mode. but none of these arrays are in my code. i want to export values of one of these arrays to excel but whenever i do some code it says cannot find array.
Those arrays are one-dimensional numpy arrays do you wanna export them one by one to Excel or a combination of them?
just one of the arrays
my coding knowledge is not good, i dont know how
I would write something like
import pandas as pd
df = pd.DataFrame(calc2, columns='calc2')
df.to_excel(df, 'calc2.xls')
Check also here: https://saikatkumardey.com/building-pandas-dataframes-from-ndarrays

what is calc2 is it name of excel file
I see in your screenshot that your variable is named "calc2"
oh i see
So you convert this to a pandas DataFrame, named df and then you save to Excel

datamerged = df2.merge(df3, how="inner", on=["begin_date","end_date","company_id"], left_index=True)
when I am running this command on my Jupiter notebook it runs and successfully merges two-time series datasets, but when I'm doing this on google colab it returns me the following error:
MergeError: Can only pass argument "on" OR "left_index" and "right_index", not a combination of both.
Apparently, there are different pandas version. May I ask how I can execute this on google colab ?

{kind=link}
right, so before you were having a breakpoint right after print("hello"). Your code is not really there and you 'd better align it properly so that is get's executed after the print. Isn't that what you wanted?
oh so what shall i do - indent lines 285-7?
oh i think it may have worked!
can you check does this code do same as yours.

when i indented as you suggest it works
I guess it does otherwise it gets ignored as an outer block of code
BUT
Do you really want this code to get executed there?
umm im not sure to be honest. wherever you think is best. i just wanted the numbers exported to csv. i can share with you the code
!pastebin
Pasting large amounts of code
If your code is too long to fit in a codeblock in discord, you can paste your code here:
https://paste.pythondiscord.com/
After pasting your code, save it by clicking the floppy disk icon in the top right, or by typing ctrl + S. After doing that, the URL should change. Copy the URL and post it here so others can see it.
It seems good where you put it at the end. The for loop you start at line 219, should first end at line 2183, where you have print("done") and then save the file, otherwise you will just save the data from the last loop iteration. I hope it makes some sense what I 'm saying
👍 
I think sqlalchemy is pretty good
True, my main problem is that I get it for a bit, then I leave it for rather long and when I get back to it, it needs loong time and tutorial revisions to see how things should be done.
thank you so much for your help
it saved my life
I think that apply to any library or framework
It does SQLAlchemy is involved at some points, eg. relationships. Those pieces can often get complicated
You'd have same relationships with any other orm if you choose to design your db in a certain way
hey anyone know how to plot a line on an image. i have a massive list of x, y coodinates on excel
@jolly heron
- get x and y into a dataframe with pandas.read_excel
or: - get a list of x and a list of y with openpyxl/xlwings
then:py import matplotlib.pyplot as plt plt.plot(x, y) plt.show()that's the short of it, it only gets tricky when you want to customise the graph
I did this to make a data frame when I exported values to excel. Do I have to do something else so that it reads the X and y values of column 1 and 2

@swift patio
Sorry I'm bad at coding
when you use read_excel you should get the same dataframe you used to_excel with. Maybe some data types changed, but if you're only using numbers to plot it should be fine.
if you need more help with this you should open a channel for it
That's great. Noone else has been able to help. So first I will do the read excel stuff. Then I will do your code. I have many xy coordinates will it understand that I want each xy coordinates joined up
SELECT INV FROM table WHERE ID = 1 ?
Does anyone know how to run and operate a redis server on windows?
(varname) is not a tuple you need a comma at the end like: (varname,) for all the executes you have there.
cursor.fetchall() will return a list of tuples. You can't just use that as a input into the next select.
Can I assign a variable for my for loop? So when I click on the variable it runs the loop
Hi all, ive been having trouble writing a query. I have 3 tables, Table 1 has Staff Members with their ids, Table 2 has jobs with their ids and Table 3 has all the ids from other tables related to eachother. Im trying to create what i presume is a left outer join of all staff that dont have a relating job id in table 3, but to no luck
Afaik EXCEPT doesnt seem to exist in my version of SQL
So far I have tried:
SELECT `WorkTable`.`staff_id`, `table3`.`job_id`, `staffTable`.`first_name`, `staffTable`.`last_name` FROM `WorkTable` LEFT JOIN `staffTable` ON `WorkTable`.`staff_id` = `staffTable`.`id` WHERE NOT EXISTS (SELECT `jobTable`.`id` FROM `jobTable` WHERE `jobTable`.`id` = `WorkTable`.`job_id`;
but it just returns blank
How about
SELECT staffTable.id, staffTable.first_name, staffTable.last_name
FROM staffTable
WHERE NOT EXISTS (
SELECT "X"
FROM WorkTable, jobTable
WHERE WorkTable.job_id = jobTable.id
AND WorkTable.staff_id = staffTable.id
);
-- or
SELECT staffTable.id, staffTable.first_name, staffTable.last_name
FROM staffTable
WHERE staffTable.id NOT IN (
SELECT WorkTable.staff_id
FROM WorkTable, jobTable
WHERE WorkTable.job_id = jobTable.id
);
Well, that seems to have actually done the trick
thanks for that :)
been racking my brain for that XD
I'm not sure if you even need the jobTable for that.
OH
It seems like the WorkTable is enough.
Hi ... anyone tried pulling data from an excel sharepoint using python. Sharepoint with Multifactor Authentication
?
is there a microsoft sharepoint api?
oh, you can mount a sharepoint folder as a network drive and just use the filesystem
i've done that before
i see, there is a sharepoint api as well https://martinnoah.com/sharepoint-rest-api-with-python.html
and mounting it as a network drive https://bauensolutions.com/2017/01/20/how-to-map-your-sharepoint-online-library-like-a-network-drive/
to work with xlsx data, you need pandas or openpyxl
Thanks...i'll try the second one... I dont have access to sharepoint API
anyone mind popping over to #help-potato rq, I have a question about naming text files from python
I can help
but I don't know your question
I think I got an answer to my question already, not exactly what I was looking for but an answer nontheless
hey
https://paste.pythondiscord.com/ifuleyejuq i cant remember if i feed in 512 pixel height image of 256 height
can someone tell from the code which would be right
hey guys
I'm trying to sum some records and group them by their label
my problem is that I don't know how to implement the sum function (I'm using sqlalchemy in flask)
I can already group my records by their label, but I only get the first instances of each label
this snippet:
month = Expense.query.filter_by(user_id = current_user.id).filter(extract('month', Expense.date_created)==4).filter(func.sum(Expense.label)).group_by(Expense.label).all()
and this snippet:
month = Expense.query.filter_by(user_id = current_user.id).filter(extract('month', Expense.date_created)==4, func.sum(Expense.label)).group_by(Expense.label).all()
are not working. I tried to figure them out after reading documentation, but I was not succesful.
How can I implement this sum function into this code? I get an error "invalid use of group function" with each of the lines. Documentation has a little bit different way of using the query
@whole pebble does this help? https://stackoverflow.com/a/25560881/2954547
Stack Overflow
I am trying to group a few fields in a table, and then sum the groups, but they are getting double counted.
My models are as follows:
class CostCenter(db.Model):
tablename = 'costcente...
I've been there
this has a different way of querying table
base_query = session.query(
Expense.date and so on
I don't know how could I rebuild my code into fitting this way
I followed some tutorials in order to get the knowledge to build some websites and they used that way of querying tables
I do not use "session" string in querying tables in my code
when I changed it to
month = Expense.query(Expense.label, func.sum(Expense.amount)).group_by(Expense.label).all()
I got "TypeError: 'BaseQuery' object is not callable"
can anyone hellp me
I need help with an error trying to start mysql in ubuntu server:
error:
-- The process' exit code is 'exited' and its exit status is 1.
Apr 06 19:12:07 server systemd[1]: mysqld.service: Failed with result 'exit-code'.
-- Subject: Unit failed
-- Defined-By: systemd
-- Support: http://www.ubuntu.com/support
--
-- The unit mysqld.service has entered the 'failed' state with result 'exit-code'.
Apr 06 19:12:07 server systemd[1]: Failed to start LSB: start and stop MySQL.
-- Subject: A start job for unit mysqld.service has failed
-- Defined-By: systemd
-- Support: http://www.ubuntu.com/support
--
-- A start job for unit mysqld.service has finished with a failure.
can anyone help me
Anyone here a wiz with bigquery python packages?
Keep getting an error that won't let me import bigquery from google.cloud
Does importing tables into an sql database with python from a dataframe create a schema as well?
DataFrame.to_sql(name, con, schema=None, if_exists='fail', index=True, index_label=None, chunksize=None, dtype=None, method=None)```
Write records stored in a DataFrame to a SQL database.
Databases supported by SQLAlchemy [[1]](https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.to_sql.html#r689dfd12abe5-1) are supported. Tables can be newly created, appended to, or overwritten.otherwise, probably not
!pastebin
Pasting large amounts of code
If your code is too long to fit in a codeblock in discord, you can paste your code here:
https://paste.pythondiscord.com/
After pasting your code, save it by clicking the floppy disk icon in the top right, or by typing ctrl + S. After doing that, the URL should change. Copy the URL and post it here so others can see it.
Pasting large amounts of code
If your code is too long to fit in a codeblock in discord, you can paste your code here:
https://paste.pythondiscord.com/
After pasting your code, save it by clicking the floppy disk icon in the top right, or by typing ctrl + S. After doing that, the URL should change. Copy the URL and post it here so others can see it.
Guys hope you get these people help with there scripts? im just into coding not scripting sorry!!!
im off of here
I am using sqlite3 and I would like to understand how to disable auto_commit. I would like to manually do all the commit to have full control on my database. I tried to change isolation level but this is not working.
In the following example, there is an insertion into the database even though' I didn't make any commit.
connection = sqlite3.connect(path, isolation_level = None)
self.conn = self.connection(path)
self.cursor = self.conn.cursor()
try:
self.cursor.execute("""INSERT INTO _Subject (subject_id, first_name, last_name, birthdate)
VALUES (?, ?, ?, ?) """, value)
ID = self.cursor.lastrowid # get the core auto increment ID
print(f'Lastrow inserted in Database: {ID}')
return ID
except SqlError as e:
messagebox.showerror(title='Insert Subject Error', message=f"Error: {e}")
Get or set the current default isolation level. None for autocommit mode or one of “DEFERRED”, “IMMEDIATE” or “EXCLUSIVE”. See section Controlling Transactions for a more detailed explanation.
https://docs.python.org/3/library/sqlite3.html#sqlite3.Connection.isolation_level
Does that help?
But isolation_level = None IS the autocommit one.
Is there a way with heroku connected to a github repository to use database (Not mongodb)
I need help making a database, where can i learn it or how do i start( its for a website )
Not sure I understand what you're asking but you can very easily spin up Postgres on Heroku
Hey is it normal to ask SQL questions here?
What kind of database do you want and how do you plan to interact with it? Look for relevant tutorials on Postgres or maybe MongoDB if you want to go that route
yes
I'm trying to merge/join two tables.
TABLE1 (left) is the main table i am trying to join on, it contains some values in TABLE2, others that are not in TABLE2 and null values (normal in my case)
I use the following command:
SELECT * FROM TABLE1 LEFT JOIN TABLE2 ON TABLE1.UNIQUE_ID = TABLE2.UNIQUE_ID_OF_CUSTOMERS
The issue is that it drops all the rows that are not in TABLE2 and does a form of a weird join that I cannot understand how to fix
That's how LEFT JOIN is meant to work.... sounds like you want a FULL JOIN or something else
Hey.
When is the best time to remove anomalies, redundancies and inconsistencies when normalizing medium size data sets.
?
Hm,I am not sure how to do that with discord.py. I want users to be able to set their own log channel
take a look at asyncpg
for that, you would just have a table like ```
GUILD_ID | LOG_CHANNEL
267624335836053506 | 342318764227821568
... | ...
for resources on SQL overall, check the pins
Hi guys, Can someone help me out with this sql query on postgres which I have to write but I just can't come up with, I have tried my best to simplify the problem from 1 million records and more constraints to this, I know this looks easy, but I am still unable to resolve this somehow :-
Table_name = t
Column_1_name = id
Column_2_name = st
Column_1_elements = [1,1,1,1,2,2,2,3,3,]
Column_2_elements = [a,b,c,d,a,c,d,b,d]
Now I want to print to those distinct ids from id where they do not have their corresponding st equals to 'b' or 'a'.
For example, for the above example, the ouput should be [2,3] as 2 does not have corresponding 'b' and 3 does not have 'a'. [even though 3 does not have c also, but we are not concerned about 'c']. id=1 is not returned in solution as it has a relation with both 'b' and 'a'.
Let me know if you need more clarity.
Thanks in advance for helping.
these are two columns in the same table?
so you just need to filter the table to remove rows that have st in ('a', 'b'), and then get the distinct ids from the result?
try using SELECT .. WHERE and SELECT DISTINCT
Nah just did a silly mistake of putting where instead of and at the end
@harsh pulsar yes. But that would return this row too ->[1,c] and [1,d], and I don't want 1
would it? you can use SELECT DISTINCT with specific columns
you don't need to use select distinct *
select distinct id from t where st not in ('a','b') this, right?
this would return 1 ^
try it
@harsh pulsar

Hey guys, this program enables me to create a Customers Table and a Products Table. How can I implement a "Buy" function that makes the user select a Client then Products and sends this data to a "Total Sales" table ? I'm using Tkinter and MySQL
Code here : https://pastebin.com/bpciapwe any help would be amazing 🙂
Pastebin
Pastebin.com is the number one paste tool since 2002. Pastebin is a website where you can store text online for a set period of time.
I have customers & products. A customer can buy products, then you want to receive the right prices, sum them up and add them to a bill associated with the customer
bill is sent to the Total Sales where all the bills are saved
INSERT INTO total_sales (customer_id, price)
VALUES (
$(customer_id),
SELECT SUM(price)
FROM products
WHERE id IN ($(', '.join(str(e) for e in product_ids)[0:-1]))
);
this is the SQL part
I am still puzzled as how I can implement this in the GUI
meaning selecting a client and associating products to him
This should work:
select distinct id from t
where id not in (
select id from t where st = 'b'
and id in (select id from t where st = 'a')
);
Looking for some help with a MongoDB aggregation - my goal is to add total_count to the end result, but preferably without having to do 2 queries
collections = db["data"]["collections"].aggregate(
pipeline=[
{"$skip": 0},
{"$limit": 5},
{"$project": {
"_id": 0,
"slug": 1,
"website": 1,
"domain_authority": 1,
"page_authority": 1,
}},
],
allowDiskUse=True,
)
collections = list(collections)
data = {
"collections": collections,
"count": len(collections),
"total_count": db["data"]["collections"].count_documents({}),
}
How could I achieve the same, but without having to query again for the total_count (db["data"]["collections"].count_documents({}))? Perhaps using $facet?
Hello,
Problem: When I try to import psycopg-binary it says ImportError: Module not found even though I pip installed it without any error message occurring. This is psycopg3, not 2.
My setup: MacOS Big Sur (not M1) with IDE PyCharm CE and project running in virtualenv with Python 3.9.7 using PostgreSQL 14.
Notes: I’ve already had so many bugs and issues with psycopg that i’m about to look for an alternative. Wanna ask here first though. Also, the google results mostly refer to psycopg2.
Add total_count to your pipeline if that makes sense. So you want a single pipeline that does a total count, and does your other stuff.
Yeah, I'm asking how do I do that. I want to count all the documents, but without limit/skip. It will be used for pagination, so I know how many pages do I have to generate. What I have above works as expected, but I'd rather want to do it via a single DB call and create the total_count on the DB's end
oh
Stack Overflow
I am trying to find the correct combination of aggregation operators to add a field titled "totalCount" to my mongoDB view.
This will get me the count at this particular stage of the aggregation
that's the answer
but that's actually a very good question
how do you do skip and count in the same pipeline
The truth is what you've described is very tricky to do declaratively haha. But MongoDB is all about providing declarative solutions and the optimised happens in the background

near every product I have a button that ADDs the product to the TOTAL SALES table
can someone help me with the SQL statement that grabs PRICE from the PRODUCTS table and then sums it in the TOTAL SALES TABLE ?
Can I expect same queries to behave exactly the same way in postgres and sqlite3
Some of them will do, others won't 🙂
SELECT 1; should work in both
Also depends on what driver library you're using. asyncpg has a very different query substitution syntax from sqlite3
I had a rather dummy idea to locally clone my remote database in sqlite3 for caching.
Such that the cache accepts sql
Sounds like a fun project 
nobody? 🥺
do u think its possible to make a username system and keep value in the username data
with json
Why do you need a cache over PostgreSQL?
Becasue my io bound database is slow
Despite setting up a shared buffer cache
Check if:
- you're creating a connection on every request instead of using a shared connection pool
- you're running into the N+1 problem: https://stackoverflow.com/questions/97197/what-is-the-n1-selects-problem-in-orm-object-relational-mapping
can you show your code maybe?
I don't have anything slow per se, I just wanted it to be more performant rather.
I get fetch times of around ~50 ms on non-intensive queries, which is okay I believe 
Wait lemme show you my idea, please hold on a sec
are you sure this is what you're supposed to be importing?
not just psycopg ?
MMM  My average database latency is < 1ms
My average database latency is < 1ms
But that depends on your DB and disks
they said it's a remote one. depends on how remote I guess?
true
You ideally want the DB to be able to go across your intranet or at least have the datacenter peer with the other
Wouldn't a cache over PostgreSQL reduce its own caching quality?
it would
at least for large queries
But postgres does rely largely on the OS' file system cache
so it depends
but yeah generally I'd say you're better off just configuring Postgres to try use as much of the resources you want it to than having it share with a Redis store for example
also because trying to cache stuff outside of the context the DB has is really hard to do right
also cache invalidation
thats what i mean xD
ah
If you have this really really big query, that takes in all these parameters that change on a per user basis, then you're probably not gonna save much
but yeah, i'd probably start with just configuring Postgres to use your machine first before thinking about an external cache
where can i get some free db hosting servers? (preferably sql)
(ik that free server are gonna have their limits, but i'm okay with it.. just suggest me if u know any)
ping me when u reply
Railway is a okay one.
It is so cheap with a 5$ credit that it is essentially free
Could someone help with this MongoDB aggregation?
have u tried it? 👀
Yeah
owo i see
so like.. that free one.. won't cost anything right? and that $5 is granted monthly?
If you have a little bit of money there are much better hosting options though.
You don't have to give in any payment info for service if you are worried
hmm it's more like.. i don't have any of my 'own' money at least for two months
so yeah.. that's sorta issue
well, thanks for helping so far
I see, you don't have to pay anything really unless you exhaust your 5$ quota during the month.
makes sense 🤔
If I want to store a python datetime object in a postgres dB what data type do I need to set my column to? I've been reading up on working with postgres and python datetimes and know that I need to make the python dstetime aware not naive as postgres works with aware but what data type should my column be? And yes I want to store the date and time as one column (my reading of the postgres docs seemed to suggest I'd need a column for time and a column for date)
hmm
if i understood it correct
then it's basic sql, "DATETIME" type data
not related to postgres or mysql.. it's just sql :'/
I'm no longer at my laptop so I can't double check this but when I typed in date or time into a column type a singular 'DateTine' but I might have missed it
i see
alr then
let's see when u check it
:'/
when using beeline i can query my thriftserver and get results without issue, .. when using tableau/jdbc i can see tables and get fields returned, but all rows are null. .. what would cause this behavior?
how much data can the mongodb 500mb hold?
500mb
if you're just using text and numbers, that's a lot
if you try to include images/sound files or other forms of media, not as much
Hi I'm back now, these are the type that pgadmin is showing that postgres can support



💀 ok i'm not gonna lie.. i haven't used postgresql yet.. i'm only familiar with mysql at the moment
but as per what i understood by ur question..it shuold be datetime
so.. try to find something similar around it ig?
:'/
thanks for the help, it's much appreciated even tho I wasn't able to get a concrete answer and at least i now have a better idea of what I can google
eh yeah :")
so if I'm reading this right https://www.postgresql.org/docs/8.2/datatype-datetime.html then what I should be using is the timestamp with timezone for 'aware' datetimes

PostgreSQL Documentation
Yes, but there is a space between time and zone timestamp with time zone
Hello guys, is it possible to upload images to MongoDB using GridFS but to upload those files under a specific collection, not under the default fs.files one?
Hello world, how can i save variables in my pygame project? Im new here
hi
Not here
Anyone know why my SQL database wont sort in alphabetical order?
This is literally all I have
SELECT school, last_name
FROM teachers
ORDER BY school ASC, last_name ASC;
check if there's any leading whitespace?
Thanks for the response, I figured it out, it was a beginner error on my end
This is the database schema

These are the 2 queries I used and got this output(which is correct)


When I tried to use this query to find out the name of projects that were chosen by multiple people, it is giving me a blank output. Could someone assist me with this?

Do you guys know how I can maybe store something like
Value : Proof : Time in mongo? Basically need to store this in an array (multiple donations) for each document so I can retrieve the amount donated, a link to the donation and the time it was done
Ok after looking a little more I think I would need to insert an object for each donation? That can have all the details?
what does the top-level document represent?
why would the project id be in a table containing counts? also it is much easier to help if you post your code as text (in a codeblock) and not a screenshot
!code
Here's how to format Python code on Discord:
```py
print('Hello world!')
```
These are backticks, not quotes. Check this out if you can't find the backtick key.
Basically I need to be able to store each donation. When its done, proof and its value. So now I think I might make objects named "Donation1", "Donation2" etc but still not sure how I would make it work..
How will I check if the previous exists, seems messy idk
i'm still not sure what you're asking about. you said something about multiple donations for "each document" - what is "each document"?
Sec, ill show you a pic
Currently, I am storing a users id, their balance, perks redeemed, when it expires. I also now want to be able to store when they donated and how much they donated then

Each document is the donations information for 1 user

Now I would have to store it like that right?
If I wanted to store how much they donated in their first donation etc
If they make another donation, ill have to have another object to be Donation2 and then add them again. But how would I check which donation object is alr made, Donation4, Donation5 etc.
Wondering if theres a better way to do this
definitely an array of donation objects is a better choice here
Wait- you can have an object inside an array?
of course
you can have arbitrarily nested data in mongodb
that's like the one good reason to use it
oh wow
otherwise it's just a super-shitty relational database
Haha, Also, do you know if I can find any documentation for motor?
https://motor.readthedocs.io/en/stable/ like the official docs?
(hint: ignore all the "tornado" stuff)
I dont know, I cant ever find what I am looking for there 
Still pretty new with databases, not really sure how I would insert a object in the array, read from iti etc
you might want to read the actual mongo documentation then
pymongo/motor map pretty closely to mongodb operations
that said, if you're new... why are you even using mongo?
it's going to teach you bad habits and non-transferable skills
Actually, the base that I am using already uses mongo and I dont want to manage 2 databases so its easier this way
fair enough
to read, use find_one or find to fetch an object or objects
then you get a dict or cursor that returns dicts
to update, use update_one and the $push operation to append to an array
Stack Overflow
My mongoDB document looks like this
name:"XYZ"
P: Array
0: Array
0:1604647764553
1:0
I want to make it look like this
name:"XYZ"
P: Array
0: Array
0:
also, make use of https://mongoplayground.net/ and MongoDB Compass
Mongo playground: a simple sandbox to test and share MongoDB queries online
FROM projects
WHERE project_id IN(
SELECT COUNT(current_project)
FROM employees
HAVING COUNT(current_project) > 1
);```thanks... what did you expect this to do?
why would project_id be in the count of all current projects?
also you aren't doing any grouping or joining
Why not? what else could I go with, the project tab just has 4 columns and that's the only way I could perform sub queries
why would project_id be in here? SELECT COUNT(current_project)
that's a column of counts of things
and it's actually just the count of all projects since you aren't grouping or anything