#databases
1 messages · Page 125 of 1
i installed aiosqlite3
but i cant import it
i am using vsc
and it says its unable to import aiosqlite3
What is fast way to remove large amounts of data from a SQLite3 Database. I tried to look online to no help.
Is there a way to bulk remove? like to bulk add to a database using 'executemany' eg. cursor.executemany(sqInsert, recordList)
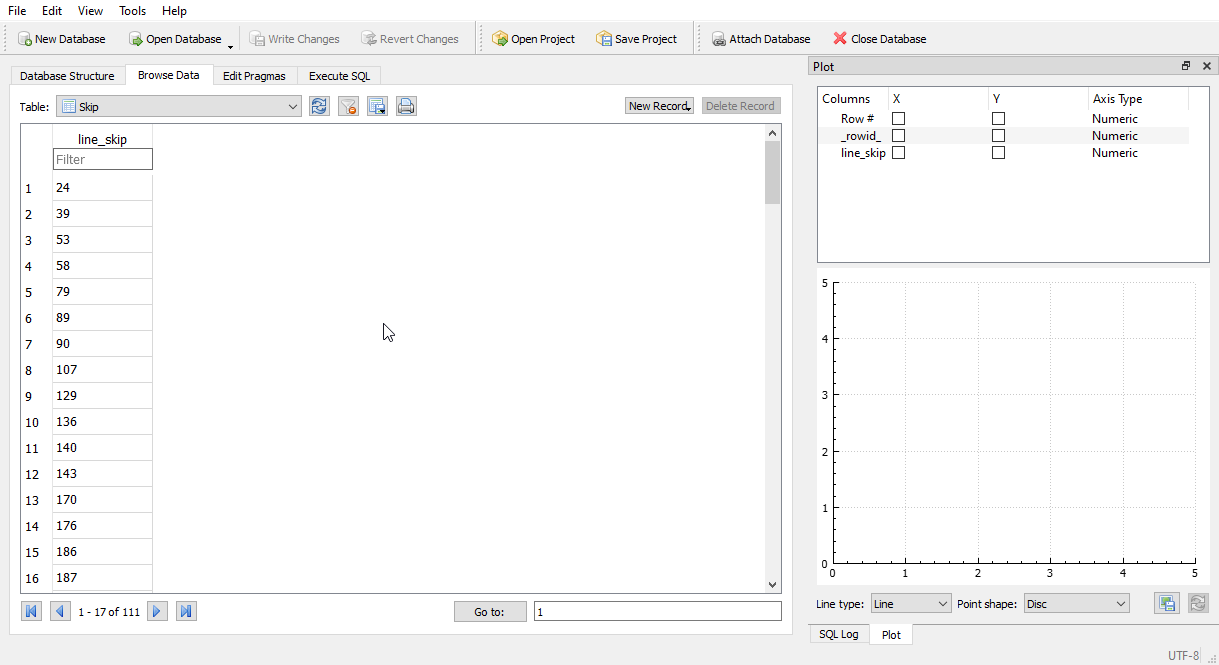
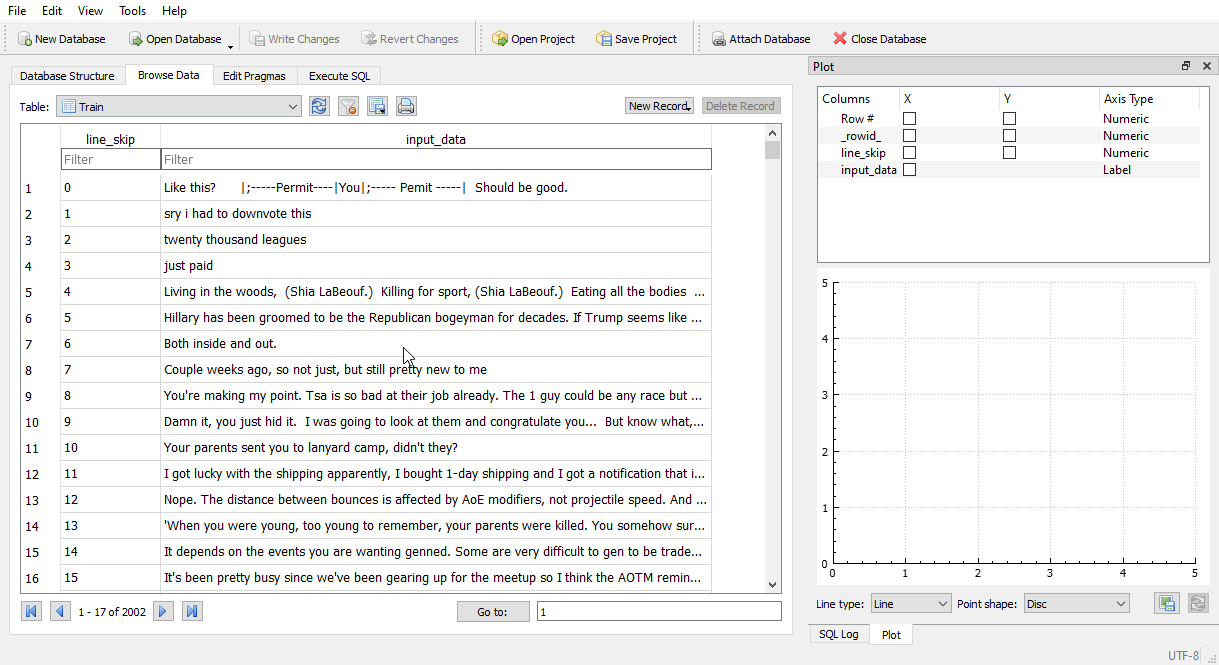
Im working with a database of 8BG. 3.5mill lines need to be removed from a total of 49mill lines. Here is the inside of the dataTest.db
https://i.imgur.com/2AyGf8x.png
https://i.imgur.com/vRWszH4.png
listToSkip = []
def readToSkip():
sqConn = sqlite3.connect(f'dataTest.db')
cursor = sqConn.cursor()
data = cursor.execute("""SELECT line_skip FROM Skip""").fetchall()
for i in data:
listToSkip.append(i[0])
cursor.close()
readToSkip()
logging.info(f'Done Load. Size to remove: {len(listToSkip)}')
#>>>INFO:root:Done Load. Size to remove: 111
def delLine(line):
cursor.execute(f"DELETE from Train WHERE line_skip={line}")
sqConn.commit()
logging.info(f"Del Line {line}")
# >>>INFO:root:Del Line 24, ext,ext
sqConn = sqlite3.connect(f'data.db')
cursor = sqConn.cursor()
for line in listToSkip:
delLine(line)
cursor.close()
don't commit after each and every delete, instead commit after every 1000 or so. It'll be much faster.
if that's still not fast enough, the next step would be to run fewer statements, and have each one delete multiple rows, using where line_skip in (1, 2, 3, 4, ...) or where line_skip=1 or line_skip=2 or line_skip=3 or something like that
also, make sure you have an index on line_skip
@radiant elbow
for number, line in enumerate(listToSkip):
if number % 1000 == 0:
sqConn.commit()
delLine(line)
then for your second Part I could use something like this
# in def delLine(line):
toRemove = len(listToSkip)
listToSkip= listToSkip[toRemove:]
for the ? ? ? places
will that work?
yes, though you'd need to have exactly as many ? placeholders as items in the list, which is annoying but doable
Do it all in one statement with WHERE IN and sub select.
Unless your dB supports join in where clause of delete. Not all do.
I'd just do the "only commit after every 1000 (and right before closing, don't forget that or you'll miss the last partial batch!) and see if that's fast enough.
Sql will do it faster than python.
yes, definitely - but that requires more changes from what they already have.
So I’d avoid looping in python
this isn't a huge number of rows - it's only a few million. Python will be slower at it than SQL, but I'd still expect it to only take a few minutes.
you can see if I'm right: move the commit out of the inner loop, only commit once every 1000 deletes, and print the amount of time since the last commit. That'll let you quickly figure out how long it will take to do all 3500 commits, and whether or not you need a faster solution.
I had a 10BG file that I needed to remove Non english from it then put it back into a .txt. So I used python to do this
Just saying that there’s no need to select then loop.
DELETE FROM Train WHERE line_skip IN (SELECT line_skip FROM Skip)
ooh, you're right
I missed that the set of rows to delete was already coming from a query
that changes my mind entirely; your approach is both easier and faster.
I was picturing needing to build up a temp table with all the rows to delete or something, which would have been much more work.
here is my code to remove non english text
took 3min when using a db
I have 2 databses
Have to remove from both
so lines are equal
@pseudo summit The list is coming from another DB
its not of the same DB
Also using
if number % 1000 == 0:
sqConn.commit()
``` does not speed it uphave to use the placeholders
how long does each commit wind up taking, out of curiosity?
and you did remove the commit that was right after the delete, right?
I'm having trouble rn
cursor.execute("UPDATE sespot SET (status = ? AND time = ?) WHERE (status = ? AND time > ?)", ('taken', 0, 'free', 60))
It returns an error: sqlite3.OperationalError: near "=": syntax error
@radiant elbow 99% of the time is taken by
cursor.execute(f"DELETE from Train WHERE line_skip={line}")
it's UPDATE sespot SET status = ?, time = ? WHERE (status = ? AND time > ?)
do you have an index on line_skip?
I dont how do I add that in sql3
CREATE UNIQUE INDEX by_line_skip ON Train(line_skip);
Also I tried py cursor.execute("SELECT * FROM sespot WHERE status = ?", ('free',)) fetch = cursor.fetchall() print(fetch)
It gave me
[]
This is a '[]' string right
listToSkip = []
def readToSkip():
sqConn = sqlite3.connect(f'data.db')
cursor = sqConn.cursor()
data = cursor.execute("""SELECT line_skip FROM Skip""").fetchall()
for i in data:
listToSkip.append(i[0])
cursor.close()
readToSkip()
logging.info(f'Done Load. Size to remove: {len(listToSkip)}')
def delLine(line):
cursor.execute(f"DELETE from Train WHERE line_skip={line}")
logging.info(f"Del Line {line}")
sqConn = sqlite3.connect(f'dataTest.db')
cursor = sqConn.cursor()
index = 'CREATE UNIQUE INDEX by_line_skip ON Train(line_skip);'
cursor.execute(index)
for number, line in enumerate(listToSkip):
if number % 1000 == 0:
sqConn.commit()
delLine(line)
cursor.close()
Traceback (most recent call last):
File "R:/Ai Bot/dataCleaner/readfile Remove.py", line 43, in <module>
cursor.execute(index)
sqlite3.OperationalError: index by_line_skip already exists
Because later after that I tried py if fetch is None: etc the etc part not working
You only need to add the index once ever. You've done it, remove that line now.
if fetchall() returned [] then there are no rows in the table where status='free'
Ye I aware of that. I want the bot to do something when there are no rows
I tried like above #databases message
fetch is None isn't true, but fetch == [] is. You want if fetch == []:

@radiant elbow
sqConn = sqlite3.connect(f'data.db')
cursor = sqConn.cursor()
index = 'CREATE UNIQUE INDEX by_line_skip ON Train(line_skip);'
cursor.execute( index )
cursor.close()
cursor.execute( index )
sqlite3.IntegrityError: UNIQUE constraint failed: Train.line_skip
adding the index has made the database maintain a list of all rows in the table sorted by their line_skip value. Now, when you want to find one of them to delete it, it can quickly find that row by binary searching. Think of a dictionary: you want to find a word, so you flip the book open to somewhere in the middle. You check whether the word you're looking for is alphabetically before or after the words for the page you're on and you either flip to a page in the half of the dictionary before or after the page you originally flipped to, and you keep cutting down the search space until you find the page you need.
hm. on that database, line_skip isn't unique - there are multiple rows with the same line_skip value
if that's an expected condition, you can just drop the word UNIQUE. If that's not expected, you need to clean up your data.
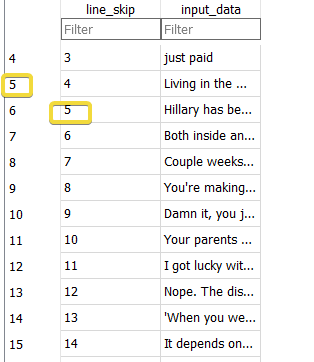
no. try doing select * from train group by line_skip having count(*) > 1
actually, make that:
select * from train where line_skip in (select line_skip from train group by line_skip having count(*) > 1)
im bad with sql how do I print that statement
if you're doing it with Python, you can do:
conn = sqlite3.connect('data.db')
cursor = conn.cursor()
query = 'select * from train where line_skip in (select line_skip from train group by line_skip having count(*) > 1);'
cursor.execute(query)
for row in cursor.fetchall():
print(row)
that worked and fixed the issue
what do you mean "fixed the issue"? It should have printed out a list of rows that violate the uniqueness constraint and stop you from being able to add the unique index.
yeah and now it runs
does the UNIQUE INDEX be stored in memory? I know .fetchall() does and make things run way faster
no, the reason an index makes things faster is that it helps the database find the rows that are being affected.
and fetchall() usually makes things slower, not faster. Reading the entire result set into memory means you can't start processing any rows until all of them are available.
@radiant elbow Thanks a lot for the help and knowledge. I help me learn a lot and understand DB more
I am getting pgconfig error while executing my postgres script on a server, I searched guthub and it says to bump pgproto, can anyone give me an idea about it?
How do I know when I should use a database
vs a CSV or JSON file
I need a simple list of accessible data to hold user accounts.
for a discord bot.
thing is a JSON file seems ideal besides being slow once I get say... 10000
Is their any magic database that is easily accessible and read/writable like JSON but faster?
There are various databases which are better than JSON, for eg SqLite3, MySQL, Postgres, etc.
Well depends on the project, I recommend Postgres but learn basic SQL before you go for it 🙂
ok.
what's data type for prefix in MySQL?
What prefix?
like i want to change prefix for bot but its in not update
DataError: 1292 (22007): Truncated incorrect DOUBLE value: '!'
Use a text type like char
i use varchar
That's fine also
after that its happen
Where is the error happening? Show the query
def update_prefix(cursor, dbs, prefix, updated_by, server_id):
cursor.execute('update prefixes set prefix = %s and updated_by = %s where server_id = %s',(prefix, updated_by, server_id))
dbs.commit()```Ignoring exception in command prefix:
Traceback (most recent call last):
File "/home/bl/.local/lib/python3.8/site-packages/mysql/connector/connection_cext.py", line 504, in cmd_query
self._cmysql.query(query,
_mysql_connector.MySQLInterfaceError: Truncated incorrect DOUBLE value: '!' ```And can you show the table structure for it
NoSQL databases allow json storage. However even sql relational databases allow it too. Also MySQL is perfectly fine, so I'm not too sure what "bad things" you heard about it.
def create_table_prefixes(cursor):
cursor.execute('''CREATE TABLE IF NOT EXISTS prefixes(
Num int AUTO_INCREMENT,
server_id varchar(255),
prefix varchar(255),
updated_by varchar(255),
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (Num))''')
async def prefix(self, ctx, *, prefix='db.get_defualt_prefix(self.bot.cursor)'):
db.update_prefix(self.bot.cursor, self.bot.dbs, prefix, ctx.author.id, ctx.guild.id)
``` its in cogI think I will use sqlite
@runic mirage Right so the error is becahse your update statement is incorrect
When you want to update multiple columns, you seperate it by a comma. You have done it by AND
Check the pinned message. It shows how to avoid this. If anything of it doesn't make sense or needs clarification then you can ask.
ok i try this one
thanks dude it's work
lmao thats amazing
what is REAL here??
It'll be a floating point number
It'll make a unique constraint on the combination of those 2 columns
So, for example
1,2 is a pair and so 1,2 combination can't exist twice. However 2,1 combination can occur (but only once)
Got that...Thanks a lot...
Does anyone know how to set the default type to a column when creating a table?
i’m looking at making a form for entering details the same as entering information through html, php and phpmyadmin but im not sure how to do it via bluetooth
im using sqlalchemy mixed with discord.py and i want to send the primary key to the person who does the command of their object in the db how do i do this?
what is the best way to represent a task that repeats every day in a database? for example, task: read 10 pages a day. the task spans 50 days for example and I want to store data on every individual day's progress? what would the models be like? i am using django but a normal sql example is fine, I am just wondering what the relation would be
Hello. I'm new to developing in general and I'm trying to set up a database for a stock trading bot. I'm using QuestDB and so far I've downloaded their tar.gz file and ran the command they specified to unpack it, but it all unpacked to the download folder where the tar file was. I'm wondering if that's not ideal, because it seems to me like I'd want those files in a more permanent place on my computer. Total beginner question but I'm brand new to this. Any help is appreciated
To clarify, the setup involved extracting the file with the -xvf command from the command line and I think it also installed something when it extracted it. I'm wondering if I can move those files now or if that would break something
Or if I need to do it over in the directory where it should be installed
You should be fine moving the extracted folder anywhere you want, about the installation part ... did it 'install' in the same directory where it was extracted to?
I'm not sure, lol
Sorry I'm not familiar with these tar.gz files so I'm not sure what happened when I ran that command
mydb = mysql.connector.connect(
host="localhost",
user="yourusername",
password="yourpassword"
)
print(mydb)```pls help i dont know what to put here it says it cant connect to the sql server 😦
i just started learning SQL so pls be patient with me
im not sure it just told me to type this
ohhhh
where should i put that?
inside or after?
like should it be inside mydb?
thanks man
sorry hehe...
DBQ.query("INSERT INTO member_table (clan_id, member_id, join_date) VALUES (?, ?, ?) ON CONFLICT(clan_id, member_id) DO UPDATE SET join_date = ? ;", [ctx.guild.id, member.id, datetime.now(), datetime.now()])
gives an error for the "ON CONFLICT"
version of python is 3.6.6. I think 3.6.6 has an updated enough version of sqlite3 to use " on conflict". can anyone assist?
sqlite3.sqlite_version spits out 3.28.0 so it should be able to use on conflict...
oh nvm.. 3.6.6 has 3.21.0 of sqlite.. i was in my 3.8 python version
Suriyawong'); DROP TABLE messages; --
How can I add date in a google database
In google docs example it said it as
data = {"date":datetime.datetime.now()}
But I am getting syntax error
What does the syntax error say and where is the documentation you are reading?
my first guess is that the document wants json so you may need to run json.dumps(data) before sending it
Hey so if i have a .sql file, is there a way to execute that file and the stuff within that file in a postgres db?
Pretty sure postgres has cli that'll do that.
If you're dead set on using python to interface with db, just read in the file and feed statements to server via execute or whatever equivalent your chosen module/library/driver offers.
Every built-in module that can be used for making mini databases:
json
csv
pickle
shelve
marshal
dbm
is there a way to do insert or ignore into table with foreign key violations in sqlite?
i know it doesn't allow for on conflict clauses for FKs but i really want the FK to just limit what data can be inserted not roll back an entire multi row insert over a FK violation.
Need company for studying..
Hey guys, sorry if i'm interrupting anything. Does anyone here have a DB certification? Is there any value in getting it? So far all of my google searches have brought up Microsoft sql server. Any advice would be greatly appreciated
i have a similar need
i need help using the mysql connector in python
@torn sphinx can you lmk if you find out?
well you'd probably need to use mysql connector too actually
yeah
like this4=
sql3lite is ew
how do you find the user
like i forgot what i put in for user and password
in mysql still

Did you find an answer? i'm on the same thing
what do you need?
@elfin talon Haven’t really found an answer. I have come across different ones like certified sql developer or db admin.Not sure what the benefits are of getting one vs the other.
Im trying to upload data into my redshift cluster using this command
pgcli -h <your-redshift-cluster> -U <your-user> -p 5439 -d <your-database> but I keep getting this error:
https://cdn.discordapp.com/attachments/668636896897007627/793602518856499240/unknown.png

First time working with aws and redshift and wasn't sure if I should ask here or one of the help channels
@client.command(aliases=['s'])
async def strike(ctx, member: discord.User = None, reason='null'):
warnid = random.randint(9000000000, 12000000000000)
post = {
"guild": ctx.guild.id,
"member": member.id,
"warnid": warnid,
"moderator": ctx.message.author.name,
"reason": reason,
"date": str(ctx.message.created_at)
}```@uneven elk (feel free to @) you responded to my thing abt databases but i didn't get to respond
basically i have created a database and i need to find the parameters user and host
i forgot what they are
also sorry for double ping
Can I connect my mongodb database to GitHub?
Could someone give me an example of creating a connection pool in asyncpg.
I don't understand the example in the docs.
QQ about the pinned message about SQL injection
How would I do that for mass populating
cursor.execute("INSERT INTO messages VALUES ("\
f"{int(message.id)},"\
f"{int(message.channel.id)},"\
f"{str(message.channel.name)},"\
f"{int(message.author.id)},"\
f"{str(message.author.name)},"\
f"{str(message.author.status)},"\
f"{str(message.author.mobile_status)},"\
f"{str(message.author.desktop_status)},"\
f"{str(message.author.web_status)},"\
f"{str(message.author.bot)},"\
f"{str(message.author.nick)},"\
f"{int(message.guild.id)},"\
f"{str(message.guild.name)},"\
f"{str(message.clean_content)},"\
f"{str(message.created_at)}"\
")")
I don't need to int/string convertions but it can't hurt besides possible a very slight performance cost
oh duh
just put all that in a variable and refrence that with a ?
... nvm sqlite3.OperationalError: table messages has 17 columns but 1 values were supplied
Do I just put a bunch of ? marks then have them all afterwards
Correct
ok thx
Ok. one other question. For asyncronus operation... should I make the cursor inside the awaited function or just use the same cursor throghout and pass it the cursor
Presently I have the cursor created at the start
but I assume one cursor can only do one thing at a time
yea other examples create cursor inside the function so that is probably correct
Cursors should not be used globally.
yea wasn't thinking so
Once you are done with it dispose of it.
They are lightweight objects anyways so its ok to recreate them
oh. do I need to close them? or just let them go away with the function end
or with cursor
Well if you use a with block, they would close automatically. Otherwise you can manually call cursor.close().
Im not sure what you mean
Reading a few other articles and they all use somewhat more complex ways of avoiding SQL injection
like passing through sql.Literal()
This is the best way i.e. prepared statements
Is their any real difference though?
like is
cursor.execute("INSERT INTO messages VALUES (?)", value)
the same as
value = sql.Literal(value)
cursor.execute("INSERT INTO messages VALUES (value)")
Really worried about injection because i'm not planning on running in a container and it will be open to literely everyone
lol
Then use prepared statements (with the ?). They are the safest way, because the query is pre compiled and sent to the database first. Your parameters will always be isolated, and can never be injected.
Ah ok thx.
Because x is a tuple, and your comparing it with a string
You can get the first element of it
if x[0] == "your code":
hewo ^w^ I feel dumb but do not know what the hell is the problem here
cur.execute(f"SELECT emoji, role, message_id, channel_id, guild_id FROM reactions WHERE guild_id = '{reaction.guild_id}' and message_id = '{reaction.message_id}' and emoji '{str(reaction.emoji)}'")
sqlite3.OperationalError: near "''": syntax error
yes but wouldnt that just get 1 row
The method fetchall() returns an list of tuples. Each tuple in that list is a row that the query matched.
x[0] just gets the first column of that row.
Its because your missing an = after the emoji
@grave eagle And dont use f strings for your queries. Instead you want to use a parameterised query.
ty ^W^
can't be injected, all thing come from discord's api and can't be "modified" by a user
Well then in that case the api is your user/client
@proven arrow
can you help me again
you're code worked but when i tried to do it with another key it didnt work
id 1 worked
but the others no\
for x in row:
if x[0] == auth_token:
return(f"<p> {json_data} </p>")
elif (x) != auth_token:
return "<p> Please enter the correct api-key.</p>"
else:
return "A error has occured."
What doesnt work?
when i do a different key
What is auth_token?
auth_token = request.args['api_key']
Then the token doesnt match.
it does
What is your goal here? What are you trying to do?
a api_key authentication
cause im making a api
and i need api to auth, and im getting the auth data from sql
db
@proven arrow
So then check if the value exists in the database using a query, instead of with python.
how
and i need to do it in python cause the api is in python
sql_data = "SELECT encoded_api_key FROM api_auth"
that the query
SELECT COUNT(*) FROM api_auth WHERE encoded_api_key = 'the_key'
This will return the count of how many rows matched. If its 0, then no result was found.
That way you dont need to loop at all, or do any comparisons in your code, because its done by the database.
error
import ipinfo
import json
import mysql.connector
import flask
from flask import request, jsonify
mydb = mysql.connector.connect(
host="freedb.tech",
user="",
passwd="",
database="freedbtech_9ine_auth"
)
app = flask.Flask(__name__)
app.config["DEBUG"] = True
@app.route('/iplookup/', methods=["GET"])
def home():
access_token = '1c1fe412af2b81'
handler = ipinfo.getHandler(access_token)
ip = request.args['ip']
auth_token = request.args['api_key']
mycursor = mydb.cursor()
sql_data = f"SELECT COUNT(*) FROM api_auth WHERE encoded_api_key = {auth_token}"
mycursor.execute(sql_data)
row = mycursor.fetchall()
details = handler.getDetails(ip)
ip1 = (details.ip)
hostname1 = (details.hostname)
city1 = (details.city)
org1 = (details.org)
region1 = (details.region)
country1 = (details.country)
postal1 = (details.postal)
country_name1 = (details.country_name)
timezone1 = (details.timezone)
json_data = ("{" + f'"ip": "{ip1}","hostname": "{hostname1}","org": "{org1}", "city": "{city1}", "region": "{region1}", "postal": "{postal1}", "country_name": "{country_name1}", "country": "{country1}", "timezone": "{timezone1}"' + "}")
for x in row:
if x[0] == auth_token:
return(f"<p> {json_data} </p>")
elif (x) != auth_token:
return "<p> Please enter the correct api-key.</p>"
else:
return "A error has occured."
app.run()
thats my code
can you please help me
Do you understand what the query SELECT COUNT(*) FROM api_auth WHERE encoded_api_key = 'the_key' does?
Well if you read what i sent maybe you would 😛
#databases message
oh ok
sorry didnt see
so how would i do a check on this
cause i dont need to get the count
i need to get the api key from db
nothing else
You already have the key, because you got it from the request? Otherwise how would you check in the database with that query if it exists?
yes but i need to do a check to see if the key exists
thats why its api key authentication
The result of that query tells you if the value exists or not.
but it didnt work
and i dont check if the value exists
i need to see if the key exists
Ive told you quite a few times now on what the query does. Maybe you need to think about this logically and then try to figure out what it is your doing/not doing.
i know im doing
but the query you send me doesnt work
i need to check for APIKEY not VALUE
Hey, I'm new to databases, and I've got a question.
I thought about working with sqlite, but I heard, that MySQL is faster, because it's online.
If I now wanted to host some application online (on a VPS or sth), then the sqlite db would be a file within the application, right? But how would I go about using MySQL for my application?
Yes it's generally faster as you scale up the number of concurrent connections
You'd need to host a mysql instance on a server and then connect to it over the network. You could host it on the same server as the rest of the application
You'd pass a connection string containing the host and credentials to a python library that will connect to the db and let you interact with it
@pure cypress can you help me with something please
Please don't unsolicitedly ping people for help
sorry
but can you help me
?
import ipinfo
import json
import mysql.connector
import flask
from flask import request, jsonify
mydb = mysql.connector.connect(
host="",
user="",
passwd="",
database=""
)
mycursor = mydb.cursor()
sql_data = "SELECT encoded_api_key FROM api_auth"
mycursor.execute(sql_data)
row = mycursor.fetchall()
app = flask.Flask(__name__)
app.config["DEBUG"] = True
@app.route('/iplookup/', methods=["GET"])
def home():
access_token = ''
handler = ipinfo.getHandler(access_token)
ip = request.args['ip']
auth_token = request.args['api_key']
details = handler.getDetails(ip)
ip1 = (details.ip)
hostname1 = (details.hostname)
city1 = (details.city)
org1 = (details.org)
region1 = (details.region)
country1 = (details.country)
postal1 = (details.postal)
country_name1 = (details.country_name)
timezone1 = (details.timezone)
json_data = ("{" + f'"ip": "{ip1}","hostname": "{hostname1}","org": "{org1}", "city": "{city1}", "region": "{region1}", "postal": "{postal1}", "country_name": "{country_name1}", "country": "{country1}", "timezone": "{timezone1}"' + "}")
for x in row:
if x[0] == auth_token:
return(f"<p> {json_data} </p>")
elif (x) != auth_token:
return "<p> Please enter the correct api-key.</p>"
else:
return "A error has occured."
app.run()
the aeron key workds
but when i do the qorrds key it dont wokr
work*
can you please help me
@pure cypress , i dont know what unsolicitedly means
@torn sphinx why you showing token
cause its on my local host
so it dont really matter for now
and there testing ones
🤣 @torn sphinx you think im dumb enough to show the actuall data that is going to be used
** Can anyone help me ? **
Unsolicitedly means that you ping me out of the blue or randomly.
its only checking for the top api key
aeron1234
but when i try qorrds1234 it dont work
What happens with the other key?
return "<p> Please enter the correct api-key.</p>"
Working key
Not working
even tho there both in the db
if x[0] == auth_token:
return(f"<p> {json_data} </p>")
elif (x) != auth_token:```You need to let your loop check all the keys before returning an error
they're two very conflicting if statements you got there
Right now you return an error if the first key you check is invalid
A for loop is fine
it does
for x in row:
if x[0] == auth_token:
return(f"<p> {json_data} </p>")
elif (x[0]) != auth_token:
return "<p> Please enter the correct api-key.</p>"
else:
return "A error has occured."
__ ** for x in row: ** __
for ...:
if equal:
return "they match"
# At this point, if the loop has ended it means none were equal
return "invalid"
It's pseudo code for the kind of loop you'd need to validate the token
idk these big words man
By "if equal" I just meant you replace that with the actual comparison of api keys
what do i put after for then
Sorry I took for granted you'd follow that.
for x in a row
Yes you need to loop over the results of your sql query
for x in row:
if auth_token == x[0]:
return "<p> It worked </p>"
return "<p> invalid </p>"
should that work
Try it
Is there a way to use to execute a statement like this
SELECT time // 86400 AS day, COUNT(*) FROM table GROUP BY day
Without having to select the day? As in only selecting the COUNT(*) but still creating the day variable to group by
maybe? I didn't know you could do that
i'll try now
no it is not
day is not an column, time is
so let me get this straight
i take it
does it matter if the groups are in numerical order in some way
if not then you can just do the math on the time coloumn then order it because it'll naturally group the times together
if it does matter
use a Self JOIN ig?
Hey everyone I Have a vague question
I am collecting some info and some of it is very obvious in length and what the answers will be, for example boolean returns or simple strings like 'orange'/'blue' etc.
I have some other data that is pulled from the same page that's a little longer and more free form in length (Descriptions)
So right now I think saving all the first stuff is easily done in a cvs, but not sure giant paragraphs should also go in that lol
How can i storage images into a sqlite column? for each product i have?
Use a BLOB column, you'll probably want to also store metadata (name, datatype, etc ...)
https://sqlite.org/datatype3.html
Generally you store the path to the image, which can just be a text type.
mongodb @torn sphinx
okey ty
Sqlite and Firebase/MongoDB are two completely different database systems. Sqlite is relational, uses SQL and has a schema, whereas Firebase/mongo do not give you this. There is no best, and each has is good for different use cases.
Hello There i have a problem:
for i in range(len(columns)):
c.execute("SELECT * FROM " + table + " WHERE " + columns[i] + " LIKE " + "%" + searched + "%")
is returning.. sqlite3.OperationalError: near "%": syntax error
how can i solve this?
@spark parrot what are you trying to do
Hello!
hellos
Im triying to search for a word in all the columns of a table and then returning all matches
do you know what query parameters are?
the "?"?
yeah
you should use that in place of searched
then
it should be in the string directly too
ok... let me try
okay
in general
you should pass a single string
not like
the result of string concatenation
and then the parameters separately
sqlite3 does it a certain way
that you can Google
that I don't remember because I don't use it but it's as a tuple I think
ok, im going to do it, give me a moment
@shell ocean c.execute("SELECT * FROM " + table + " WHERE " + columns[i] + "LIKE %?%", (searched))
sqlite3.OperationalError: incomplete input
(searched,)
oh... ok
why is table in a variable?
because i have multiple tables, so i want to be able from a tkinter optiondrop to choose in which do i wanna search the Searched variable
@shell ocean c.execute("SELECT * FROM " + table + " WHERE " + columns[i] + "LIKE %?%", (searched, ))
sqlite3.OperationalError: incomplete input
Let me see
c.execute("SELECT * FROM " + table + " WHERE " + columns[i] + " LIKE %?%", (searched,))
sqlite3.OperationalError: near "%": syntax error @shell ocean
it's mega hard to debug this kind of query
because
it's hard to see what's in table and columns
how about
you print the full query
let me try
print("SELECT * FROM " + table + " WHERE " + columns[i] + " LIKE %?%") and print(searched)
@shell ocean its not printing it, idk why, let me try another way
@shell ocean
SELECT * FROM customers WHERE first_name LIKE
sandra
i removed %?% because it was giving me an error
if i do searched="%Sandra%"
it works
so i will format it and done
@shell ocean Thanks for the help
The query needs to look like this:
query="SELECT * FROM " + table + " WHERE " + columns[i] + " LIKE ?"
And then when your executing this you need to do:
cursor.execute(query, (f"%{searched}%",))
The issue here is the query that SQLite ends up getting is:
SELECT * FROM <table> WHERE <columns[i]> LIKE %"searchterm"%
if he does %?%
@spark parrot
Oh re-reading, it sounds like you already figured that out -_- Ill show myself out
How would I do this:
await cursor.execute("SELECT clean_content FROM messages WHERE author_id=?", int(user.id))
It should select the clean_content entries (valid column name) for rows with a certain author_id
from the table "messages"
It for some reason gives an unsupported type error
even though int is correct
you most likely need to give a tuple, not just a single value. ```
await cursor.execute("SELECT clean_content FROM messages WHERE author_id=?", (int(user.id),))
that worked... do not really understand why but ok
How can I iterate through?
I tried this:
for text in list(cursor.fetchall()):
also without the List and .fetchall
Can someone help me? I've tried to convert this string to a python dict for some time now. I've converted all ' to " to see it would help. I've tried the eval() and json.loads() function but both return error. What is wrong with this string, what do i need to format to make it work?
This is the string
{"Item": {"coords": ["45.6 56.3", "45.7 56.4"], "vehicle-name": "vehicle-1", "tilt": [Decimal("89.9"), Decimal("50"), Decimal("29"), Decimal("50")]}, "ResponseMetadata": {"RequestId": "PO0B6QBL3EOA80Q2NQGNTVCBUBVV4KQNSO5AEMVJF66Q9ASUAAJG", "HTTPStatusCode": 200, "HTTPHeaders": {"server": "Server", "date": "Thu, 31 Dec 2020 03:25:27 GMT", "content-type": "application/x-amz-json-1.0", "content-length": "157", "connection": "keep-alive", "x-amzn-requestid": "PO0B6QBL3EOA80Q2NQGNTVCBUBVV4KQNSO5AEMVJF66Q9ASUAAJG", "x-amz-crc32": "1945811615"}, "RetryAttempts": 0}}
No, i'll try that! Hold on
so new_string = string_name.json()
?
Never used that function before
@torn sphinx
yes that should work
json.loads(string) should do the same though
Are you sure its valid json?
I'm not sure, not to familiar with json
Didn't work that function either, since the string isn't a json already
https://jsonlint.com/?code= pasting that there gives invalid.
JSONLint is the free online validator and reformatter tool for JSON, a lightweight data-interchange format.
Or maybe i called the function wrong
Any idea what I need to change?
Seems this line is the problem?
"tilt": [Decimal("89.9"), Decimal("50"), Decimal("29"), Decimal("50")]
Yeah so "Decimal("89.9")" would work? Probably will maybe see how to remove those Decimal from DynamoDB from the start
Yeah, was apparently a common problem
https://www.reddit.com/r/aws/comments/bwvio8/dynamodb_has_been_storing_integers_as/
But thanks for the help anyways!
reddit
11 votes and 8 comments so far on Reddit
Hmm... Probably just going to be lazy and store every number in the database as a string I guess
I would just add in regex replace to remove it
Any chance you know how to itterate through a sqlite result?
never messed around with sqllite, just some t-sql so don't think I would be of great help
ah well worth a shot
@torn sphinx Are you good with regex? How would i remove from Decimal("89.9") so only 89.9 is left?
Sorry i'm terrible at regex I'm sure I could figure it out but so could you.
your going to have to research that
Haha yeah I guess, just regex is a pain in the ass, worth a shot. Thanks anyways
Do you need to use regex?
!e ```
s = 'Decimal("89.9")'
s2 = s.strip('Decimal()"')
print(s2)
@radiant elbow :white_check_mark: Your eval job has completed with return code 0.
89.9
str.strip() removes any character from a given list of characters from the beginning or the end of a string.
I assumed that their might be parentheses elsewhere that were needed though
or other letters
and it was in the middle of the string
How could I model attributes for products?
So like when people click a page it shows all products, then they click a button it filters by for example colour red, or another button to filter by size . Like this
What is the work of 'COUNT' here?? ''''' SELECT COUNT(from_id) AS inbound, old_rank, new_rank, id, url
FROM Pages JOIN Links ON Pages.id = Links.to_id
WHERE html IS NOT NULL AND ERROR IS NULL
GROUP BY id ORDER BY id,inbound ''''''
@river vortex is counting how many values for that column like how many rows
But it's not include the null values of that column
@torn sphinx Does it select duplicates??
I think yeah
Ohh...Thanks a lot...
Im trying to design my database but im having some issues.
For each guild there will be multiple users, new users are added constantly
For each guild there will be multiple products, the guild owner can remove or add more
Each user is able to purchase products, therefor I need some way of giving each user products
Im not sure how to do that
i thought about arrays but that just seems flimsy
You need to look at many-to-many relationships
In database modeling
It seems you have 3 tables:
Guilds
Users
Products
And then various relationships between them. Which will likely need to be represented by a many to many relationships:
UsersProducts
GuildsProducts
GuildsUsers
would UsersProducts, etc be separate tables?
No
Right, the "link tables" just have 2 columns, that point to the left and right hand side of the relationship
So like UsersProducts would be like:
| user_id | product_id |
Where user_id and product_id are foreign keys to the user and product tables respectively
You can model the other relationships in the same way.
can you give me an example of what my products table may look like
with user_id be a list of users who have the product
Maybe something like:
| product_id | name | price | ... other stuff just about product ... |
and users might be:
| user_id | name |
Are you using SQL Alchemy or just hand writing?
postgres and pgadmin
but there isnt anything about the users here
Im not sure I follow
You may want to add guild id here as well. Otherwise if the user is in another guild with the same bot then their products will be global.
Yeah it depends, I figured the same product could be found for multiple guilds
or users can be in multiple guilds, if they can't then you can have simpler tables
User's Products still need to be many-many though
So are the requirements:
Guilds can have many users, and many products
Users can only have 1 guild
Products belong to 1 guild
Users can have many products
?
users can be in multiple guilds but products for this user are guild specific
and yes, each product belongs to only one guild
Alright, so this is how I would model this, (bare with me a second)
okie
Guilds
| guild_id | owner_user_id_fk | ... more data columns as needed ... |
Products
| product_id | guild_id_fk | ... more columns as needed ... |
Users
| user_id | ... more columns as needed ... |
GuildUsers
| guild_id_fk | user_id_fk |
UsersProducts
| user_id_fk | product_id_fk |```So this assumes guilds can have only 1 "owner"
When I say "more data columns" I just mean I assume you have some stuff like the guild / user name, etc ...
anything ending with _fk means "Foreign key" to one of the "core" tables
i still dont understand what UsersProducts or GuildUsers would be
because you said it wouldnt be a table right
Oh, sorry if I said that I must have misunderstood, it will be a table
GuildUsers makes a link between the users table and the guild table, UsersProducts make a link between users and products
Because you said Products are specific to only one guild, the relationship between Guilds and Products is on the products table (meaning 1 guild to many products)
No problem, this is kind of a classic db modeling problem 😄 and I like those

I have this at the top of my code db=pickledb.load("economy.db", False), but how can I set it to True, later in a command
@fading breach hard to help without some code, can you paste what you have?
its fine, I figured it out
👍
hey
im getting a qlalchemy.exc.DataError: (pymysql.err.DataError) (1406, "Data too long for column
but the model is long enough to handle the input
so idk
maybe my orm isnt updating properly?
not sure
can anyone advise on this?
hmmm i checked the db and it looks like it isnt updating it correctly
flask migrate
I am trying to created a new Dataframe from an existing one, this works for the first colum but the second colum i am trying to create always has "NaN" as its values, there are obviously values in my Original Dataframe at that space but for some reason they are not being read
my first Dataframe:
import pandas as pd
import matplotlib.pyplot as plt
df = pd.readcsv('C:/Users/andi/OneDrive/Desktop/UNI/Angew_SYS1/Projekt/2012_gwr_sprengelerg.csv', sep = ';', encoding='cp1252')
df
This is how i want to create my Second Dataframe:
dataframe = pd.DataFrame(columns=['stimm',"stimm2"])
dataframe["stimm"] = df.loc[df['ptname'] == 'SPÖ', 'stimmen']
dataframe["stimm2"] = df.loc[df['ptname'] == 'FPÖ', 'stimmen']
print(dataframe)
My output is this:
stimm stimm2
2 32 NaN
13 46 NaN
24 41 NaN
35 39 NaN
46 48 NaN
... ... ...
2939 57 NaN
2950 74 NaN
2961 82 NaN
2972 535 NaN
2983 42 NaN
Does anyone know how i should go about this?
let me refine my question
flask migrate, is not handling column datatype size changes
i read online that it doesnt handle column datatype changes, I assume this means that changing the size is also an issue
i read online that it doesnt handle column datatype changes, I assume this means that changing the size is also an issue
You got it
And that's actually because alemibic can't do it
you need to write a migration script for alembic by hand
I assume you used:
flask db revision ? probably with --auto-generate
You'll need to go into the script and add the stuff alembic couldn't do
Alembic is only able to do like 80% of stuff automatically
i see
well, I read that i could just do compare_type=True that seems to have solved the issue
i dont know what you mean by this
Oh really? That's cool
flask-migrate uses alembic underneath
well yeah
but you said write a script manually for the migration
confused about that portion
so if you don't do --auto-generate then you just get a stub alembic script with the upgrade / downgrade functions left for you to write code for
Seems type compare works for your situation, I think there are some situations alembic cannot really handle though, in which case you have to hand write the migration
And there are other reasons too, like moving data from an old table to a new table, etc ...
new to the orm and migrations in general
guess i need to do some more digging on writing migration scripts
Well sounds like you don't have to do it in this case
have just been running 3 commands, stamp head, migrate, and upgrade
but I've seen alembic fail to figure out what its supposed to do
yeah it seems kinda garbage
Well, I mean it does save you some work? But its not automagic, like we use SQLAlchemy and Alembic at work, and we always double check the scripts that alembic generates
Yeah that's the point, but it is annoying you have to go back and double check it
Well and like it kind of generates shit revision script names out of box
Yeah you can fix that
Im not sure how you specify it with flask-migrate
BTW, in the alembic section of the ini you can do:
file_template = %%(year)d%%(month).2d%%(day).2d_%%(rev)s
anywhere? or does it need a title row or something
so the name will then come out YYYYMMDD_<hash>.py
? Im talking about how to make alembic generate sequential filenames for the upgrade scripts
so the last one is the last upgrade, if you listed the directory
yeah but you said to drop that in the ini
so my ini has a bunch of "headers"
[handler_console]
class = StreamHandler
args = (sys.stderr,)
level = NOTSET
formatter = generic
[formatter_generic]
format = %(levelname)-5.5s [%(name)s] %(message)s
datefmt = %H:%M:%S```handler_console
for example
[alembic]
file_template = %%(year)d%%(month).2d%%(day).2d_%%(rev)s```Yeah
Yup?
what's the syntax for sqlalchemy?
I looked in the docs
and it was just TIMESTAMP()
but that keeps kicking back an invalid datatype
upload_timestamp = db.Column(db.TimeStamp())
AttributeError: 'SQLAlchemy' object has no attribute 'TimeStamp'
Oh
theres one specifically for like unix epoch stamp
I think its this one:
https://docs.sqlalchemy.org/en/13/core/type_basics.html#sqlalchemy.types.Time
So there's date for a date with no time stamp, datetime for date+timestamp, and then for the epoch date stamp (seconds from like Jan 1, 1970 or something) you use Time IIRC
If you use PyCharm or a similarly intelligent IDE the autocomplete can help you out for this kind of thing too.
Yeah, well I mean there's timestamp if you want it
I'd just keep type_basics open
while your working on stuff
Whats your model look like?
class Phone_Survey(db.Model):
__tablename__ = "phone_survey"
__bind_key__ = "user_data"
survey_id = db.Column(db.Integer, primary_key=True, autoincrement=True)
interviewer_id = db.Column(db.String(20), nullable=True)
first_name = db.Column(db.String(20))
last_name = db.Column(db.String(20))
upload_timestamp = db.Column(db.DateTime())
time_customer_drop = db.Column(db.DateTime)```this is the shorter version
im looking at the upload_timestamp var
WARNING in survey_form: Invalid datetime value submitted: Could not match input '' to any of the following formats: YYYY-MM-DD, YYYY-M-DD, YYYY-M-D, YYYY/MM/DD, YYYY/M/DD, YYYY/M/D, YYYY.MM.DD, YYYY.M.DD, YYYY.M.D, YYYYMMDD, YYYY-DDDD, YYYYDDDD, YYYY-MM, YYYY/MM, YYYY.MM, YYYY, W
Your model looks fine, I think where ever your getting the upload_timestamp from is an empty string
let me see
Well actually
upload_timestamp = db.Column(db.DateTime())
time_customer_drop = db.Column(db.DateTime)
yeah
That could be a problem but I don't remember exactly
that empty string i think is for the time_customer_drop
and i didnt fill that section out
the upload_timestamp is something else
upload_timestamp | datetime | YES | | CURRENT_TIMESTAMP |
hmmm maybe ill set nullable to false
Yeah I think you have an issue where like
The form being submitted back is sending '' for the timestamp
and SQLAlchemy is strick and doesn't consider that "None" (which it shouldnt)?
Maybe I don't know
Well where does it come from, that timestamp? like how are you populating it on the model
Im saying that's the problem
even if you make that column not nullable you probably will still have issues I think
(not a hundred percent sure, debugging fragments of code is not particularly easy :D)
it was working before
gonna try the null thing
then see
lol
yeah that wasnt it
ill dig some more
thank you
np
it's server side
not in python
You mean default value for the column?
yea
I didn't see you specify that on the model,
Think you have to tell SQLAlchemy to do that
I see I see, you want it to basically be the time the row was inserted, yeah I think you just need to tweak your model
Still seems like a weird error
Can someone help me use a SQL data base to store stuff for a discord bot?
@stuck raptor i suggest youtube tutorials
do you know any on mysql
I watched a corey schafer video
on building a flask app, and working with mysql db
there are also some on digital ocean
that I followed
I don't know how discord bots work
but you'd need to basically link the bot to the db
big pizza deez
Anyone know how to manipulate a csv XD
Hammer?
Can you please give me a link..
nope :/
search a column for a word, put the rows of those columsn close together
organising the csv basically
idk
but i think datascience sounds more appropriate for this
are you using pandas?
is this in a db
youd prob have to use the selector method dataframe[]
then do your manipulations
hello?
does anyone know how to make a database for saving a game
like a multiplaye rgame
Can someone help me with making a table in MySQL?
I just have the csv and then put it into Libre calc, I have never even used another program or anything so I'm not sure options etc.
Would this be the place to ask a library specific question about asyncpg?
Probably not here unless their GH Readme pointed you here
@rugged ginkgo @craggy arrow yes because asyncpg is a database module of Postgres, which is a db
Well, it is, that doesn't mean anyone here has any experience with it.
They probably have their own discord / IRC channel / mailing list / <obligatory comms channel>
Their home page actually lists it:
http://magic.io/blog/asyncpg-1m-rows-from-postgres-to-python/
magicstack is a Toronto-based team of software engineers. Feel free to drop us a line at hello@magic.io.
So he/she probably wants to emailhello@magic.io
Thanks 🙂
Anyone pymongo dev here?
I'm using PyMongo to make a DB using MongoClient and I keep getting connection refused error py pymongo.errors.ServerSelectionTimeoutError: localhost:27017: [WinError 10061] No connection could be made because the target machine actively refused it, Timeout: 30s, Topology Description: topology_type: Single, servers: [<ServerDescription ('localhost', 27017) server_type: Unknown, rtt: None, error=AutoReconnect('localhost:27017: [WinError 10061] No connection could be made because the target machine actively refused it')>]>
I don't get how it doesn't work on localhost?
I am getting pgconfig error while executing my postgres script on a server, I searched github and it says to bump pgproto, can anyone give me an idea about it?
Hey everyone a newbie to python scripting is here, I want to share my Chrome extractor version 😊, and I want you all to tell me your comments and advices to learn more about this stuff.
This Python script will extract all saved passwords from your google chrome database and save it in a hidden file chrome.txt : https://github.com/Reda-BELHAJ/Chrome-Extractor

GitHub
Python script that will extract all saved passwords from your google chrome database and save it in a hidden file chrome.txt - Reda-BELHAJ/Chrome-Extractor
I wrote the same thing awhile ago:
https://github.com/jimcarreer/tools/blob/master/crpd.py
I back up my passwords for my wife off to a thumbdrive I keep in a firebox, in case I die or something.
I just shamelessly stole most of it from:
https://github.com/priyankchheda/chrome_password_grabber/blob/master/chrome.py
😄
@craggy arrow this version is way cooler ngl
Yeah its nice, it covers Nix and Mac. I haven't been on windows for ages now.
i'm new to sql server. I want to secure my website from sql injection. What method is used to secure website. can anyone help please?
Use prepared statements is the main advice
Don't do things like:
cursor.execute(f"INSERT INTO table (column_name) VALUES ({raw_user_input})")
Do instead
cursor.execute("INSERT INTO table (column_name) VALUES (?)", (raw_user_input,))
If you're using SQL Alchemy, and don't hand write any queries, you're probably already protected @scarlet dagger
What is SQL Alchemy?
It's an object relational mapper for Python that turns class definitions in your python code into Database tables / entities:
https://github.com/sqlalchemy
It's the de-facto ORM most people use in Python.
ok Thanks @craggy arrow
I've also got a beta for a library I'm writing:
https://github.com/jimcarreer/dinao
If you like writing SQL
Do you have an any idea how to secure in php?
Its the same strategy in every language, use prepared statements, don't put user input directly into the Query strings
I'm not a fan of sprocs and don't really use them but I think the same thing applies for that.
What DB Backend you using? (MySQL, PSQL, MS ... ? )
@craggy arrow i am using sqlserver not mysql?
mssql
Its still the same, all database backends implement prepared statement functionality.
ok i try
Also if you want help with PHP, you might try a community focused on PHP instead of Python 😄 But since this is a general database question I guess its fine.
@scarlet dagger look here:
https://www.php.net/manual/en/pdo.prepared-statements.php
at Example #4 / #5, regardless of the backed the $db_handle->prepare(...) should be valid
async def create_db_pool():
client.conn = await asyncpg.create_pool(user="bot", password="Sebi2006", database="ninjamnrdb", host="127.0.0.1")```
Password is correct, asyncpg is imported.@eternal raptor would help if you posted some context, but considering there's an authorization error, you should probably check that user+pass combo with something like pgadmin
ninjamnrdb
^ When this db is specified?
database="ninjamnrdb"
NinjaaaSKDziś o 14:37
async def create_db_pool():
client.conn = await asyncpg.create_pool(user="bot", password="Sebi2006", database="ninjamnrdb", host="127.0.0.1")
Oh it says invalid password, nvm
Port 5432 ?
No I mean, is the port the db running on the standard one
5432, and are you sure you're not running 2 DB instances?
I mean unless there's a serious bug in asyncpg (I doubt it) the error is straight forward: either you're not connecting to the database server you think you are, or the password is wrong.
eee what? wait, Could you tell me how to check port?
Can you show me the settings for the database in PGAdmin?
yes, i can.
If you want to DM them to me that's fine
yup
(got him covered :D)
@maiden light can you help me with mongodb?
@fading breach Alright
Create a database user with a password that you remember, it should have all access
Well let me login I can't remember much
I apparently can't login, well allow all ip addresses or depends on you, that can access your db.
Add 0.0.0.0 as an ip to allow everyone
Create a database
Add a collection
Click on CONNECT on your cluster and then application, then set driver as Python 3.4+ and get the connection url, in that url change pass to the database user password you created, and done.
With that url you can add records, install Motor
@maiden light I have completed setup, how can I dump stuff into thew database
this is what I have for pickledb/json ```py
db.set(str(ctx.message.author.id),job+500)
db.dump()
dataclasses + sqlalchemy + active record:

{kind=link}
{kind=link}
{kind=link}
{kind=link}
Looking for feedback and pointers to similar work so I can learn about prior art in this area
Hello guys. I have a question. Is it possible to add a path and work with two work directories like in matlab?
is it possible to connect your database (from mongodb) to a website ?
Just wanted to say thanks for this
@radiant elbow lmk if u could help, you helped me last time 😛
that's not got anything to do with databases - the error there is that data is a string, and you're using 'id' as an index into it.
@radiant elbow @torn sphinx why is that tho like I have more codes that are like these? for example
data in that one is the return from fetchrow - it's the return from execute in the other.
@radiant elbow so what do I need to fix?
you probably are missing a call to some fetch* function
what is the difference between fetch, fetchrow and execute?
what library are you using?
asyncpg @radiant elbow
fetch runs a statement and returns the result as a list of records. fetchrow returns a single record, the first row of the result set.
ok 1 more question, difference between integer and bigint? @radiant elbow
integer has a maximum value it can hold, bigint is unlimited
it would work with bigint - just slower.
bigint can hold any integer, integer can hold only integers within a certain range.
I'm using PyMongo to make a DB using MongoClient and I keep getting connection refused error py pymongo.errors.ServerSelectionTimeoutError: localhost:27017: [WinError 10061] No connection could be made because the target machine actively refused it, Timeout: 30s, Topology Description: topology_type: Single, servers: [<ServerDescription ('localhost', 27017) server_type: Unknown, rtt: None, error=AutoReconnect('localhost:27017: [WinError 10061] No connection could be made because the target machine actively refused it')>]>
do you have the same problem if you remove the ( and ) from inside query1? The column list for a select shouldn't be surrounded in ()
damn u know a lot appreciated also whats fetchval?
fetch - multiple rows and columns
fetchrow - one row, multiple columns
fetchval - one row, one column (so one value)
You got the url and Motor?
from motor.motor_asyncio import AsyncIOMotorClient as MotorClient
mongo = MotorClient("Your url")
db = mongo["database name"]
record = {"id": 1234, "balance": 0, "bank": 0}
await db["collection name"].insert_one(record)
To find it
find = await db["collection name"].find_one({"id": 1234})
find["balance"] # will give balance
Also
find = await db["collection name"].find_one({"balance": 0}) # if more than 1 people have 0 balance, it will give randomly
find["id"] etc.
find instead of find_one will give all people having 0 balance, there is update_one, update_many, insert_many, you can look at docs.
To update
await db["collection name"].update_one({"id": 1234}, {"$inc": {"balance": 500}})
# Here $inc means increase, it will add 500, if you use $set it would set the balance to 500 instead of adding.
bigint also has limit
oof, so it does. My mistake for assuming.
It's weird that they call that bigint instead of int64, at least to my sensibilities...
Is it also unlimited in python or is different?
Python's int type is unlimited, as are Java and C#'s BigInteger
I find it surprising that something would be called bigint and not be unlimited - everything I've ever seen before that's called a big integer is unlimited.
I mean, the postgres bigint type is limited to 64 bits, but big integers in other languages aren't
Thats nice
!e ```py
print(2**100)
@radiant elbow :white_check_mark: Your eval job has completed with return code 0.
1267650600228229401496703205376
^ more than 2**64 🙂
So does this have anything do with IEE64
or is that for something else
nope, completely unrelated to that.
Oh yeah i remember that is for floating points right?
right. and it still has a limit
Oh so that has a limit. Ok now i see. I thought it was other way round.
IEEE-754 double precision floats (which take up 64 bits) can't represent integers above 2**53 precisely
(or below -2**53)
Understand, thanks. I thought floats were more precise befor
they have a wider range, but limited precision.
Thanks
!e ```py
print(2.053)
print(2.053+1)
print(2.0**53+2)
@radiant elbow :white_check_mark: Your eval job has completed with return code 0.
001 | 9007199254740992.0
002 | 9007199254740992.0
003 | 9007199254740994.0
^ note that line 2 isn't correct, it skipped over ...993.0 because that can't be exactly represented in an IEEE 754 64-bit float.
I see
So is this edge case ever affected in real life?
Like you cant do some things because of this?
Or there is some other way around it
that's a very large number - it's not one that typically comes up when you're dealing with integers, because you rarely have to count 9 quadrillion of something - but it does come up in various types of math, and needs to be accounted for.
Don't know where to put this question but anyone good with regex? I what to indentify the word Decimal("98.8"), the number can vary and have different length then just 00.0
I can indentify the last part ") but what to I write to tell to match everything before ") until space?
Hey, do I lose my databases if I uninstall and then re-install postgresql on Ubuntu 20.04 ?
Is the server running locally and accepting
connections on Unix domain socket "/run/postgresql/.s.PGSQL.5432"?```
psql seems to have broke after the system update, any tips?systemctl postgresql also doesn't work
I'm very new to databases in python, and I want to learn more about them. Can you guys recommend me a good database that I should start?
pymongo
thoughts on mysql?
because I'm familiar with mysql but haven't used it in python
is that like a upgraded version of mysql?
Pymongo is blocking, Motor is the way.
ok
@maiden light can you help me make the switch from pickledb to mongo
like step by step
for each command
do you have some time?
You know the basics? I mean, insert update delete ?
ok
Idk pickledb
ok
Did you make a database, and a collection?
Look at this
record = {"id": message.author.id, "balance": current_balance, }
await db["collection name"].insert_one(record)
this correct?
If it is inserting it should be 0?
But yeah it's correct
Wait you don't need the , after current_balance
@commands.command()
async def setup(self, ctx):
for member in ctx.guild.members:
record = {"id": (str(member.id)), "job": False}
await db["Scope Economy"].insert_one(record)
is this correct?
if it is, I've got the hang of it, thanks
Well, it isn't :/, you don't have balance or bank, I don't know how you do it, but that False is a SyntaxError.
Have something like "status": False
ok
Or None
You don't need the ( before str,
record = {"id": str(member.id), ..
ok
This
And this
Wait it's the same message LOL
Postgress or MySQL...
Which one should I use...?
is this correct ```py
find = await db["Scope Economy"].find_one({"id": ctx.message.author})
find["id"]
With Django
hmmm...
im not an expert or anything
Yeah you can do find["job"]
ok, thx
well Then I'll see which one of them have better
learning resources
and community support
I just see more people use mysql for web
yeah
Hey guys, looking forward to contibuting to this discord channel as I become more familar with python. I have a simple .JSON parsing question in help room chlorine if anybody could give me some input 🙂
im getting this error @maiden light InvalidDocument: cannot encode object:
#databases message anyone?
I prefer Postgres, since Oracle owns MySQL
hello
Hi, I have this error bson.errors.InvalidDocument: cannot encode object:
code: ```py
find = await db["Scope Collection"].find_one({"id": message.author})
get = find["level"]
mongodb (or any db that i know for that matter) won't support storing arbitrary python objects like that
you want to be storing/retrieving message.author.id in this case
https://pastebin.com/t9KNptAk What am I doing wrong here? Running any function gives me "Error: Commands out of sync; you can't run this command now"
Pastebin
Pastebin.com is the number one paste tool since 2002. Pastebin is a website where you can store text online for a set period of time.
message.author.id not message.author
oh
oops
silly me
get = find["level"]
TypeError: 'NoneType' object is not subscriptable
@maiden light
LOL I like how someone will 👎 an opinion but then not bother responding to the person who asked.
the dictionary find is empty
as in you're query probably had zero matches
oh
assuming you did something like find = await collection.find...
@burnt turret should I make an if statement?