#databases
1 messages · Page 29 of 1
What does "manually send requests" mean?
hi, i have an app (or, better, i am in the middle of developing an app), that will be run as a micro service. so i thought it might be a good idea to run db migrations before the start of the app to ensure that the db is always up to date. so i created that function that is suppsoed to be executed at start:
def migrate_db():
try:
if os.getenv("AUTO_MIGRATE") == 'True':
logging.info("Migrating database...")
alembic_cfg = Config("alembic.ini")
command.upgrade(alembic_cfg, "head")
logging.info("Database migration done...")
else:
logging.info("AUTO_MIGRATE not set, skipping migration.")
except Exception as e:
logging.error(f"Error during database migration: {e}")
it kinda works but for some reason it isnt "exited" when its done. so the process "hangs" when putting it in the main.py
running the same code outside the app exits it and i am back at the command line. just inside the app it doest even log the migration done log message. the output i get is:
INFO [alembic.runtime.migration] Context impl PostgresqlImpl.
INFO [alembic.runtime.migration] Will assume transactional DDL.
has anyone a tip as to what i do wrong?
Swallowing exceptions and just logging them without exiting with an error code is very bad. This will mean that incorrect migrations will fail and then your code will deploy anyway, which means your app will break.
I don't understand what you mean by "inside the app". Surely you run the migrations separately BEFORE the app itself gets deployed?
i wanted to run the migration before the actual app functionality starts but within main.py
good tipp
Not using a package to extract data from the database
Well.. yea.. you can use a SQL desktop app, or the terminal interface
Who cares if it's "within main.py"? That's irrelevant.
something does because it doesnt execute the log while it does when not run inside the main
thats the reason i am here and ask for help
but anyway, i execute it outside the app. thanks for your kind help
I think you're missing the point. Outside or inside the app isn't the point. It's BEFORE the DEPLOY that's important.
And if the migration fails, the deploy process must stop
no, i do not miss the point. i try to focus on the actual problem, not some logging and exception handling. right now it is not actually executing the migration or hangs or whatever the issue might be and thats where i am stuck and where i thought i ask for help.
What?

rn it js doesnt do anything
what do you think "js" means? you seem to write it randomly in sentences
just
Don't do that. I have never seen someone abbreviate that before.
This is a programming forum. "js" means javascript.
in england js is abbreviated a lot
i know
well not among programmers I'm sure. Just saying that no one understood you because they read "javascript" every time you wrote "js". Try reading scrolling up and reading it that way yourself.
So you can make the html but you can't make it do anything? This is for #web-development not this channel
this is not html, its python
ah its not in web
its an app
the top left icon indicates its a customtkinter app
do you need your database to be online or just offline?
the latter's easier to work with (especially with sqlite3), while the former will require hosting some backend API for your gui to make requests to (kind of beyond my knowledge)
I believe they probably need an online API/DB since they've sent a sign in screen
I have a blob in my oracle db i want to read it in chunks or as a stream than trying to get the whole thing at once
how do i go about this
What's in the blob?
a bunch of media data in binary its about 2-3mb
Like an image for example?
no audio
Delete that column and use s3
i just need it as raw bytes
i would like to but college hw
i cant use s3 only oracle
using the oracledb package? probably this:
https://python-oracledb.readthedocs.io/en/latest/user_guide/lob_data.html#streaming-lobs-read
oracle and c# to be precise i am tired too ;-;
https://docs.oracle.com/cd/B19306_01/appdev.102/b14258/d_lob.htm#i999170 i found some related docs ig i can try
Didn't know you can stream individual columns
custom tkinter
offline for now
For now?
You'll have to rewrite a lot of things when you need an online one 
ah
but
if its online, do i have to have a server running it
Yes
cant use my computer as a server otherwise it will blow up
if you were to use prisma, you could migrate from sqlite to a server database like postgres trivially.
And have unrestricted database access that's the problem
it would definitely test your ability to loosely couple the login backend to your GUI if you wanted to eventually migrate it
I mean, essentially the whole backend
imma just do offline to learn and then configure it to be online when im comfortable
There are a couple of options:
- If the app is meant to only be ran locally - you can use sqlite
- If app will be distributed and should have common data - you have to create an API
how can other people access the program locally?
Sign In system doesn't make sense in the first case
Data would be local, they can't
what about, people in my network
why?
As a simple example - notepad stores data locally, it doesn't need login system or anything like that
Because data is accessible by the user without any restrictions, since it's stored locally
just the login page and a working database
@paper flower Any sources you use to gain a better understanding of postgresql or databases in general?
Hello, I'm using flask-sqlalchemy to build a tool with a plugin system,
I'd like for plugins to be able to create new databases and add them the sqlalchemy object, I tried this but get an error in db.create_all
def init_db(app:Flask):
with app.app_context():
app.config['SQLALCHEMY_BINDS']["youtubedl_db"] = os.path.join(os.getcwd(), "sqlite:///databases/youtubedl.sqlite")
db.create_all(bind_key=["youtubedl_db"])
db.session.commit()
sqlalchemy.exc.UnboundExecutionError: Bind key 'youtubedl_db' is not in 'SQLALCHEMY_BINDS' config.
Normally I would set the db up in the flask config file but for plugins I'd like to avoid this, what's the best way to approach this problem?
A lot depends on where you're at and what you're trying to do by the official tutorial might not be a bad start: https://www.postgresql.org/docs/current/tutorial.html

PostgreSQL Documentation
Part I. Tutorial Welcome to the PostgreSQL Tutorial. The following few chapters are intended to give a simple introduction to PostgreSQL, relational …
I'm having throuble connecting into the database using Docker container. I tried changing stuffs in docker compose and even tried to give the python connection URL a user and a password but neither is working



Is 'mongo' a valid hostname? If you attach to the container, is it ping-able ?
i have no idea, cus i just copied the instructions of someone
so i added mongo
but wasn't mongo before
from what i remember
how do i check it
is there a command for that?
I’m a beginner how would a database work

SQL (Structured Query Language) is one of the most used tools by data scientists, data analysts, and data engineers.
So either your instructions are bad or you didn't follow them correctly... If you're stuck you could share the instructions and all your code (links not screenshots) in a help channel #❓|how-to-get-help
best sources to learn how sql databases function?
ERROR: Failed building wheel for llama-cpp-python...I want to build a docker image and I got this error message
Hey guys I am reading in postgres databases using SQLAlchemy with pandas read_sql_query, but I am wondering if I close out the connection right, as I keep getting connection timeouts, below is my code, would be really helpful if someone knows if there is a problem on my end (I cant find it at this point and I have looked for days..)
#Sets up the engine with the config details
f_sql_engine=sqlalchemy.create_engine("postgresql+psycopg2://"+o_sql_config_details_profile_signal["user"]+
":"+o_sql_config_details_profile_signal["password"]+
"@"+o_sql_config_details_profile_signal["host"]+
":"+str(i_postgres_port)+"/"+o_sql_config_details_profile_signal["database"])
#Connects and outputs to pandas df
f_s_sql_input='SELECT * FROM '+f_sql_table_name+''
f_df_readin = pd.read_sql_query(con=f_sql_engine.connect(), sql=sqlalchemy.text(f_s_sql_input))
#Closes engine
f_sql_engine.dispose()
usually connection timeouts mean that you are not connecting to the right domain name or port, or there is something blocking you. but also you don't need .connect() with pandas, just pass in the engine itself. con=f_sql_engine, ...
try printing the sqlalchemy uri to make sure it looks how you expect it to look
Sorry, I am a bit of a noob here, how do I print the URI? I think I am already passing the engine, in the above no?
just put the uri into a variable, print() it, and then put it into the engine
db_uri = "..."
engine = sqlalchemy.create_engine(db_uri)
data = pd.read_sql_query(con=engine, ...)
If I dont connect with pandas but just pass the engine I get an error "'OptionEngine' object has no attribute 'execute'", I know that they changed the format in SQLAlchemy 2x from 1x, I think you might need to connect now
anyone know how to add data from a csv file to a sqlite3 table? everytime I try to do so, it ends up saying the database file is malformed when I try to open it in DB Browser for Sqlite.
(nvm, I figured it out)
what was the problem?



Is it something to do with cascading deletes? Like one table has keys which are not contained in the other?
Off topic, do people actually use ms access?
okay so, the execute_fetchall return a Row
but i have no idea how to manipulate that in aiosqlite
like, how do i get the values from it?
i want to grab prefix
here

what is better than this?
where i can fetch all results
and i can manipulate them?
it looks like the result will never be None. try just wrapping result in a list?
it's not an async iterable, it's just an iterable
results_iter = await self.db.execute_fetchall(query, params)
results = list(results_iter)
return results[0] if results else None
or just
results_iter = await self.db.execute_fetchall(query, params)
return next(results_iter, None)
!d next
next(iterator)``````py
next(iterator, default)```
Retrieve the next item from the [iterator](https://docs.python.org/3/glossary.html#term-iterator) by calling its [`__next__()`](https://docs.python.org/3/library/stdtypes.html#iterator.__next__) method. If *default* is given, it is returned if the iterator is exhausted, otherwise [`StopIteration`](https://docs.python.org/3/library/exceptions.html#StopIteration) is raised.
Similar names: pdbcommand.next, 2to3fixer.next
does anyone know if sqlalchemy has a discord server?
according to their docs, they only have a gitter room and IRC channel
https://www.sqlalchemy.org/support.html#real-time
does anyone know if the example here means to do cls.__qualname__.lower()
cause __name__ isnt found
Did you use @declared_attr.directive or @declared_attr?
They're pretty quick to respond on GH discussions 🙂
the first one. but also i think my vs code was messed up temporarily or something because i switched it back to __name__ and the error didnt show up
That could be a thing 😅
am i using relationship() right?
class TableMixin:
id: Mapped["Snowflake"] = mapped_column(primary_key=True, unique=True)
@declared_attr.directive
def __tablename__(cls) -> str:
return cls.__name__.lower()
class Members(TableMixin, Base):
message_count: Mapped[int] = mapped_column(default=0)
saved_roles: Mapped[list["Snowflake"]] = relationship(default=[])
class Snowflake(TypeDecorator):
impl: BigInteger
i ditched prisma btw. im trying sqlalchemy again better prepared to tackle the docs monster
No, why are you using type decorator? 🤔
relationship should "point" to a db model, not to a column
and default=[] probably isn't right
Maybe default=list
Hey guys, I still havent managed to fix my continuous timeout using SQLAlchemy with Supabase, I have a sneaking suspicsion that I am not closing down the connection right, can any see what I am doing wrong?
#Sets up the engine with the config details
f_sql_engine=sqlalchemy.create_engine("postgresql+psycopg2://"+o_sql_config_details_profile_signal["user"]+
":"+o_sql_config_details_profile_signal["password"]+
"@"+o_sql_config_details_profile_signal["host"]+
":"+str(i_postgres_port)+"/"+o_sql_config_details_profile_signal["database"])
#Connects and outputs to pandas df
f_s_sql_input='SELECT * FROM '+f_sql_table_name+''
f_df_readin = pd.read_sql_query(con=f_sql_engine.connect(), sql=sqlalchemy.text(f_s_sql_input))
#Closes engine
f_sql_engine.dispose()
I have been having this problem for days now and the timeouts appears to be completely random, any help would be really greatly appreciated
I am using SQLAlchemy version 2.x
Why are you closing the engine here? 🤔
That disposes of all connections
this is in a function actually
no it is initiated whenever the function is run, is that bad?
Kind of, you're not using connection pooling that way
to be frank I am fairly new to postgres/sql
To correctly dispose of connection you should just use a context manager
with f_sql_engine.connect() as connection:
f_df_readin = pd.read_sql_query(con=connection, sql=sqlalchemy.text(f_s_sql_input))
Got it and then keep the engine creation outside the function
and then move dispose to the end of the script+
No
Don't call the dispose
You can call dispose once, usually when your application shuts down
okay so no dispose, but move engine creation to outside function?
Yeah sorry thats what I meant by end of script
Yep, that's if that configuration is static
it is
Yep, just move it outside then
Okay so engine outside function, no dispose and use a context manager as in above
Sweet!
yeeehaw it works
quick question, what hjappens if I dont dispose of the engine?
I think since process would close then connections would be closed anyway
But I'm not sure
Okay so they world shouldnt burn
You literally just saved me hours and hours of grief
can i get a \certificate on cluster computing for finanacial aid
Hi
Hi
<@&831776746206265384>
You should check your own site with Grammarly or something.
cause I'll use BigInts for other stuff too, i wanna keep the one for the purpose of Discord IDs distinct
You could use NewType
Snowlake = NewType("Snowlake", int)
Type decorator is a db specific thing, you wouldn't touch it in other code
ah
I was also trying to figure out how to define actual database types at the same time
What for though?
cause i originally was wanting to have my Members table have basically 1 column for each Member type, and then the member type will hold everything
but idk thats where i was stuck so im just gonna ditch that idea i think
Creating columns dynamically is almost always a bad idea
If that's waht you wanted to do 🤔
not that i mean like a table of Members. and Member is Member(id=..., message_count=1, ...)
cause that feels more like a discord library
CREATE TYPE discord.member AS
(
id bigint,
last_username text,
last_displayname text,
last_servername text,
joined timestamp with time zone,
message_count bigint,
roles discord.role[]
);
is that not a good idea
Never used them to be honest, Not sure what kind of support sqlalchemy offers in that case
basically i wanna try to mimic how discord api wrappers do it
like how you have Member and Role objects in it
I feel like when coding it'll just make more sense to interface with the db that way
but tbh this is my first time trying to use a relational db so idk what makes sense
what would be good for speed
db design feels scary cause as soon as it goes live its basically gonna be set in stone with how much data there is
there's basically like 10 events a second
Hello, looking for some advice. I have a bot that calls an API to get some data, takes that data and updates my DB. I am using Pyhon for the coding and a mySQL database for the backend. Now, for my situation, I need to read from the same table i am going to write to. I am also running many process to that do the same thing. So far, i am hitting a few deadlocks but overall it is a low percentage. The issue is because i am reading a table, getting a shared lock on that table, then some other process is wanting to write to that table, causing the deadlock. I would like to understand how others have dealt with this sort of issue
To add, i have tried indexing to make the queries more efficient, but the read query is putting a shared lock on the entire table, as it needs to do a full scan (unavoidable based on how the data is structured). For the updates, it is not doing a full scan or anything, and between processes will not update the same rows, but will update the same table.
That's what you have tables for
That sounds wrong to me. You can add columns and drop columns live.
are you saying a table for each member?
i just realized something actually. i can do the Member type thing in python. so each row of the Members table is automatically parsed as a Member type. likely with pydantic or something
or maybe sqlalchemy has something built in for that idk
i really wish i knew the best practices for this stuff. im doing a lot of guessing, finding out its bad practice, then starting over from scratch
is anyone here into this stuff professionally and able to give me a few pointers?
i mean less about columns, more about entire tables
previously i had message_count as its own table for instance. then i realized "why" when it only has 2 columns, one being a reference to the main members table
im also going to be doing a massive migration from 30 different sqlite databases just before i make this live, so thats another reason everything needs to be planned solidly
refactoring a database live doesnt seem fun
The table contains members. Each row is one member. This is how relational databases work.
You might want to use an ORM like Django or something.
yea ok.. hmm, I thought you did things manually with tables and stuff
that doesn't really matter honestly. The ORM is great to use outside of web dev too.
huh interesting
maybe in the future. ive already invested so much time into learning sqlalchemy
if youre talking about this, thats just the CREATE statement exported from PgAdmin
but idk if im gonna be using native PG types cause the sqlalchemy docs for them is really confusing
sorry im just gonna go back to not overthinking cause thats been helping me actually move forward lmao
ive remade my db like 3 times this month just trying to settle on a format
I've been curious if people do this. I've only done one project with each, but find Django so much easier to work with then SQL Alchemy that I wouldn't want to go back
hi
so i'm wondering if there is any ORM supporting psycopg3
other than django and sqlalchemy
If u use Sqlalchemy u could learn generating auto migrations with alembic. nothing is set to stone
SQL DBS are easiest to change for new app versions with keeping previous data
I think Peewee does... Which ones are left that don't?
peewee has an issue stating they are working on it
that's for about a year ago
but i don't see anything in the changelog
except one that says starting to go for it
The issue is closed and referenced in the changelog
Begin a basic implementation for a psycopg3-compatible pg database, refs issue #2473.
i'm not sure if this means it can be used in production or not
People use peewee in production?
they don't?
I've only used django ORM so i don't really know
Current required sqlite for python distribution is 3.7.15 from 2012. A LOT has happened since then. Wouldn't it make sense to bump this in the next python release to something in the past decade? e.g. 3.44.0 from nov 2023? https://www.sqlite.org/changes.html
In [4]: sqlite3.sqlite_version
Out[4]: '3.44.2'
this is my Python 3.11.6 version I have installed
right but if you make a package that does some sql then you wouldn't be able to rely on e.g. json functionality working for users as they might be on an older one, right?
I guess. You could just check the sqlite3 version in your package maybe. If someone has recompiled python with an ancient sqlite3 version instead of using the official package then yea that's a problem.
If I wanted to propose this to python devs, where would I go? https://discuss.python.org/ ?

Discussions on Python.org
Discussions related to the Python Programming Language, Python Community, and Python Software Foundation operations.
in the Ideas topic yea I think so
coolio. Thanks @shut tiger ❤️
is it possible to do this in sqlite?

Yes. it's possible
noice
Yes, sure!
Try this code -
user_id = 1
prompt_prefix = "Hi"
name = "Betty" #example name
cur = self.b.execute_fetchall(
"SELECT * FROM default_characters WHERE user_id = ? and (prompt = ? or name = ?)",
(user_id, prompt_prefix, name)
)
return cur
☝️
But you can't do it async right?
Beginners question. In order to do a join between two tables, do they have to have a column in common (like CustomerID) in order to do the join with those two tables?
You mean to say the column names themselves have to be the same to make joins?
If so, no they can have different names, just the data types have to be the same.
Some db to auto type casting when joining, but that's a different thing
Correct, I am wondering if column names have to be the same to make joins. I am use MySQL, so I assume your answer applies to that?
It does apply to mysql too
Thanks. I am going through w3schools MySQL tutorial. I just got the impression from them that the column names have to be the same name.
Some teams and orgs might have some conventions to name it same, but it doesn't matter, joins like this 100% works
table1.some_name = table2.different_name
Awesome. Thanks.
This works:
SELECT Orders.OrderID, Customers.CustomerName
FROM Orders
INNER JOIN Customers ON Orders.CustomerID = Customers.CustomerID
But, this will give me zero results:
SELECT Orders.OrderID, Customers.CustomerName
FROM Orders
INNER JOIN Customers ON Orders.CustomerID = Customers.CustomerName
Ohhh...that might be violating the has to be the same data type rule.
Ya that's because in the 2nd query the data in Orders.CustomerID and Customers.CustomerName are different
Essentially what it's doing is comparing each record from one table with the other one the particular column and if it's matching the record is displayed else it'll not
This didn't work either:
SELECT Orders.OrderID, Customers.CustomerName
FROM Orders
INNER JOIN Customers ON Orders.OrderID = Customers.CustomerID
Yes so the values themselves are different
What exactly does it mean a matching record? Does each column need to be the same info? For example, Customer ID is the info. But, this info can have two different column names as long as they are essentially both Customer IDs?
https://www.w3schools.com/sql/sql_join.asp
If you navigate to the different types of joins, the diagram makes total sense
W3Schools offers free online tutorials, references and exercises in all the major languages of the web. Covering popular subjects like HTML, CSS, JavaScript, Python, SQL, Java, and many, many more.
Yes for inner join for example, the actual value has to be same
1=1, becomes true and returns the result
1=0, becomes false and doesn't return
Hmmm...I'm going to have to find more indepth tutorials on joins.
SQL is more of hands on, see the data and try out things 😁
Yeah, I'm messing with it.
Just take out a spreadsheet and try out the comparison manually if you want
I am messing with it, but not fully understanding how it works yet. I"ll go find some tutorials that give more details. Thanks for your help.
Can I only do joins with primary and foreign keys?
Actually you can with any columns, primary and foreign key define relationship as code
okay guys so, how do i check if in SQLite something from a column contains such characters?
like, i want to check if there are elements with the characters "ardo" for example
so it would return "leonardo" and "eduardo" for example
Wildcard pattern using like clause
where column_name like '%ardo%'
like this:

also i have a dread feeling of python using % to inscript some other weird character
Make the query string raw, with r"query here"
I would say that it would be unusual for the column names to be the same even.
like this:

what are you trying to do? prompt = %?% looks wrong to me. And the await looks wrong to me too.
Yep, i think you should add single quotes around the wildcard params
is that supposed to be a LIKE query?
iut's because it uses aiosql that uses async functions
Ah yes it's like some pattern
prompt like %?% maybe?
well i could use like, but, i would have the issues with ids, but that would be just my overthinking, since ids don't repeat
yeah i was overthinking
ids? of what? in the prompt column?
it was in user_id column
but now that i observed, it was just my overthinking
yea don't use LIKE on that column. That would be wrong.
ik, i just thought in doing a thing that was actually wrong, i thought you was asking me to change where to like
until i observed it again
[and it was just in conditions
The wildcard must be part of the parameter value not the sql statement.
wrong: execute("select * from table where column like %?%", (name,))
correct: execute("select * from table where column like ?", (f"%{value}%",))
does anyone know how AsyncAdaptedQueuePool works in sqlalchemy
That's great.
just wanted to bump this thread to see if anyone has any thoughts
Not really, I know how to find the docs 😉 If it doesn't answer your question you might want to show your code in a help channel https://docs.sqlalchemy.org/en/20/core/pooling.html#sqlalchemy.pool.AsyncAdaptedQueuePool
asyncsession class cant be used concurrently so i dont get how it ties together with asyncadapted pool
there's no official examples with connection pools and async so im having a hard time understanding how to use it for the first time
well with queuepool
i need a strictly ordered queue
that handles concurrency
What does that have to do with pool? 🤔
because queue has to do with concurrency
Not really
db connections don't support concurrent operations, that's it
When you create session you get a connection from pool, you release it back to the pool when you close the session
This is why you can't execute concurrent queries on a single session
yeah exactly thats what the queue pool handles i thought
is there a boiler plate for sqlalchemy connection pooling somewhere?
You don't need any boilerplate
I just use this
engine = create_async_engine(
_settings.url,
pool_size=20,
pool_pre_ping=True,
pool_use_lifo=True,
echo=_settings.echo,
)
yeah i got that far but im trying to connect
class ConnectionPool:
def __init__(self) -> None:
self.engine = create_async_engine(
url=config.URL,
pool_size=20,
max_overflow=10,
poolclass=AsyncAdaptedQueuePool,
connect_args={"ssl": "true"},
#echo=True,
#echo_pool=True,
)
@asynccontextmanager
async def connect(self) -> AsyncGenerator[AsyncSession, None]:
async with AsyncSession(self.engine) as session:
try:
yield session
await session.commit()
except SQLAlchemyError:
await session.rollback()
raise
Again, you don't need that
engine = create_async_engine(
_settings.url,
pool_size=20,
pool_pre_ping=True,
pool_use_lifo=True,
echo=_settings.echo,
)
async_session_factory = async_sessionmaker(
bind=engine,
)
async with async_engine_factory.begin() as session:
...
You don't have to
begin already begins a transaction, rollbacks on error and closes the session
async with AsyncSession(...) closes it too
woah async_sessonmaker is a class..

i had no idea
thats why i was not trying to use it
A lot of classes are named in snake case in python 😅
i have something like this
connection = sqlite3.connect("sample.db")
cursor = connection.cursor()
cursor.execute("create table if not exists ran (data text, processed integer default 0, UNIQUE(data), PRIMARY KEY(processed, data))")
cursor.connection.commit()
extraction_path = pathlib.Path("extracted/")
for file in extraction_path.iterdir():
print(f"processing {file.name}")
with rich.progress.open(file, encoding="utf-8") as temp_file:
all_lines = temp_file.read().splitlines()
print("preparing data")
prepared = ((line.strip(),) for line in all_lines)
print(prepared)
cursor.executemany("insert into ran (data, processed) values (?, 1) ON CONFLICT DO NOTHING", prepared)
cursor.connection.commit()
file.unlink()
``` where i have inserted a few billion rows, these are simple strings, however the db is now over 30gb in size, i wonder if there's a more size efficient dbVACCUM that ish and see if it helps.
https://stackoverflow.com/questions/7682503/how-to-shrink-sqlite-database

Stack Overflow
Once done storing all of my data into sqlite, it reach 14 MB already. That's why I'm afraid that some people cannot download my application from connection slow area. Is there any way to shrink sql...
it's been running for over 40 minutes now 
Execution finished without errors.
Result: query executed successfully. Took 2580612ms
At line 1:
VACUUM;
of course as i say it, it finishes.
no changes to the db size.
i wouldnt know any alternatives, but just curious, does the size improve when you remove your two indices? you might also want to manually de/compress your data with zlib before you insert it, kind of like sqlite archives
but then the lookups i do will be much slower without the indexes.
suggesting something a bit more complicated, would it make sense to use a full-text search table alongside it instead of two indices? i.e. main table holds the data which may or may not be compressed, and you have an fts5 table to serve as your index without actually storing full copies of each line
https://sqlite.org/fts5.html
i'm not doing any search other than grabbing lines where the processed interger is 0
oh, have you considered replacing both indices with just one index on the processed column then?
just double checked, having an index on the data column itself effectively doubles the filesize (58MB -> 122MB), and you indexed it twice ```py
import contextlib, random, sqlite3, string
with contextlib.closing(sqlite3.connect("test.db")) as conn, conn:
conn.execute("CREATE TABLE job (data TEXT PRIMARY KEY, processed INTEGER DEFAULT 0)")
for _ in range(1000000):
s = "".join(random.choices(string.ascii_letters, k=50))
conn.execute("INSERT INTO job (data) VALUES (?)", (s,))
``` testing with just an index on processed, i.e. CREATE INDEX ix_job_processed on job (processed), increased it to just 68MB (+17%)
i'll take a look after i eat something, thank you
thank you, two things
- how does that
as conn, connwork the heck - is there a way i can make the data column unique? i'd like to avoid duplicates there
or does the primary key ensure #2?
ergh, the second context manager is supposed to handle BEGIN/COMMIT/ROLLBACK, but curiously it didnt rollback the CREATE TABLE when i encountered a few mistakes while writing the example
as for #2 dunno, im not aware of a way to directly store data in sqlite's b-tree implementation without having it duplicated in a table...
maybe there's another feature that would help here, but maybe an alternative is also more worthwhile
i did try fts+zlib but the index contributed a lot to the filesize (136MB), probably because it cant easily tokenize my random strings: ```py
import contextlib, random, sqlite3, string, zlib
with contextlib.closing(sqlite3.connect("test.db")) as conn, conn:
conn.execute("CREATE TABLE job (id INTEGER PRIMARY KEY, data BLOB, processed INTEGER DEFAULT 0)")
conn.execute("CREATE VIRTUAL TABLE job_fts5 USING fts5(data, content='', contentless_delete=1)")
for _ in range(1000000):
s = "".join(random.choices(string.ascii_letters, k=50))
d = zlib.compress(s.encode())
row = conn.execute("INSERT INTO job (data) VALUES (?) RETURNING id", (d,)).fetchone()
conn.execute("INSERT INTO job_fts5 (rowid, data) VALUES (?, ?)", (row[0], s))curiously zlib alone results in 66MB (+14%), and thats without any indexing:py
import contextlib, random, sqlite3, string, zlib
with contextlib.closing(sqlite3.connect("test.db")) as conn, conn:
conn.execute("CREATE TABLE job (data BLOB, processed INTEGER DEFAULT 0)")
for _ in range(1000000):
s = "".join(random.choices(string.ascii_letters, k=50))
d = zlib.compress(s.encode())
conn.execute("INSERT INTO job (data) VALUES (?)", (d,))```
yeah that's why i was using the UNIQUE index on data
How big is your data. You could add a hash column and make that unique with an good hash algorithm (eg sha-256).
though if you went with a 64-bit hash or smaller, you could save a bit of space by aliasing the rowid instead of indexing on a BLOB column, e.g.
https://docs.python.org/3/library/hashlib.html ```py
import contextlib, hashlib, random, sqlite3, string
with contextlib.closing(sqlite3.connect("test.db")) as conn, conn:
conn.execute("CREATE TABLE job (hash INTEGER PRIMARY KEY, data TEXT, processed INTEGER DEFAULT 0)")
for _ in range(1000000):
s = "".join(random.choices(string.ascii_letters, k=50))
h = hashlib.sha3_256(s.encode(), usedforsecurity=False)
h = h.digest()[:8]
h = int.from_bytes(h, signed=True)
conn.execute("INSERT INTO job VALUES (?, ?, 0)", (h, s,))``` but this resulted in 73MB (+25%), which combined with the +17% index on processed still feels like too much overhead...
the strings would be short than the generated hash in most cases.
already thought of that
I have a query where sometimes I have to request something WHERE thing is NULL and sometimes I have to request something WHERE thing = 10, how "illegal" (/bad practice) is it to just use WHERE thing is 10? cus I checked it and it works just like... why is the = operator than? :D
using sqlite3
and python to write proper queries
so like, these both work, but if I want to check sometimes for subrace where it exists


is there anything stopping me from just using "is" everywhere? :D
am I doing something dumb?
you can use is there, but keep in mind this appears to be unique to sqlite. from the docs
The IS and IS NOT operators work like = and != except when one or both of the operands are NULL. In this case, if both operands are NULL, then the IS operator evaluates to 1 (true) and the IS NOT operator evaluates to 0 (false). If one operand is NULL and the other is not, then the IS operator evaluates to 0 (false) and the IS NOT operator is 1 (true). It is not possible for an IS or IS NOT expression to evaluate to NULL.
emphasis added
IS exists in postgres as well, and works similarly.
not similarly to sqlite is the point Thuri was making. In postgres it works like the SQL spec says. In sqlite it does not.
# SELECT 1 IS 1;
ERROR: syntax error at or near "1"
--
# SELECT (1::int) IS TRUE;
ERROR: argument of IS TRUE must be type boolean, not type integer
--
# SELECT TRUE IS (1::int);
ERROR: syntax error at or near "("
--
# SELECT (1::int) IS NULL;
?column?
----------
f
Feels like javascript. Though it works fine with booleans and nulls.
It feels like sanity. Unlike JS :P
Implicit rando coercion is evil. Postgres won't do it.
Yep, that's the truth. But it's not obvious that IS TRUE is an operator itself, along with IS FALSE and IS NULL, and there's no separate IS operator.
Ah. Yea that's weird. But SQL is kinda weird always if you start to think about that stuff.
CREATE TABLE is weird. Two words for one command? eew
I'm being very confused by SQLModel/SQLAlchemy
metadata = SQLModel.metadata
table = metadata.tables["toolmaster"]
with Session(engine) as session:
statement = select(table)
results = session.exec(statement)
print(results)
print(results.all())
prints
<sqlalchemy.engine.result.ScalarResult object at 0x000002C2358D2760>
[1, 2, 3]
but
with Session(engine) as session:
statement = select(ToolMaster)
results = session.exec(statement)
print(results)
print(results.all())
correctly prints
<sqlalchemy.engine.result.ScalarResult object at 0x0000017FE496DEF0>
[ToolMaster(cage_code='CC1', type_id=1, profile_id=1, id=1, cati_code='TM1', grit='80', diameter='10.0', thickness_id=1, description='Tool 1', qty_reorder=100, num_profiles=1, profile_life=1000.0, concentration_id=1), ToolMaster(cage_code='CC2', type_id=2, profile_id=2, id=2, cati_code='TM2', grit='100', diameter='20.0', thickness_id=2, description='Tool 2', qty_reorder=200, num_profiles=2, profile_life=2000.0, concentration_id=2), ToolMaster(cage_code='CC3', type_id=3, profile_id=3, id=3, cati_code='TM3', grit='120', diameter='30.0', thickness_id=3, description='Tool 3', qty_reorder=300, num_profiles=3, profile_life=3000.0, concentration_id=3)]
In first case you're trying to select a table object, in the second - an orm model, which sqlmodel fetches all columns for
You can enable echo in your engine and see what sql it produces
Ok, that's what I thought. So what is the correct pattern to select the orm model using the models name as a string?
Why do you want to use a string?
oh yeah, @formal lintel using WITHOUT ROWID can save a bit of space too, removing the automatic index that sqlite uses for the primary key: ```py
Same script as before:
import contextlib, random, sqlite3, string
with contextlib.closing(sqlite3.connect("test.db")) as conn, conn:
conn.execute("CREATE TABLE ...")
data = [
("".join(random.choices(string.ascii_letters, k=50)),)
for _ in range(1000000)
]
conn.executemany("INSERT INTO job (data) VALUES (?)", data)
sql
-- 58MB
CREATE TABLE job (data TEXT, processed INTEGER DEFAULT 0);
-- 188MB (+224%)
CREATE TABLE job (data TEXT UNIQUE, processed INTEGER DEFAULT 0, PRIMARY KEY (processed, data));
-- 122MB (+110%)
CREATE TABLE job (data TEXT PRIMARY KEY, processed INTEGER DEFAULT 0);
-- 133MB (+129%)
CREATE TABLE job (data TEXT PRIMARY KEY, processed INTEGER DEFAULT 0);
CREATE INDEX ix_job_processed ON job (processed);
-- 60MB (+3%)
CREATE TABLE job (data TEXT PRIMARY KEY, processed INTEGER DEFAULT 0) WITHOUT ROWID;
-- 122MB (+110%)
CREATE TABLE job (data TEXT PRIMARY KEY, processed INTEGER DEFAULT 0) WITHOUT ROWID;
CREATE INDEX ix_job_processed ON job (processed);if you're willing to make some backwards-incompatible changes, you could split it into two tables which complicates reading/writing but removes any duplication from indices:sql
-- 60MB (+3%)
CREATE TABLE job_pending (data TEXT PRIMARY KEY) WITHOUT ROWID;
CREATE TABLE job_done (data TEXT PRIMARY KEY) WITHOUT ROWID;```
because I have one endpoint for each table
hey this relation b/w driver and scan is Many to One?

Guys, I want to learn some NoSQL databases through a pet project. What a simple pet project can get me familiar with some NoSQL database maybe like MongoDB?
I googled it for you: https://www.projectpro.io/article/mongodb-projects-ideas/640
Really you can do whatever simple thing you want to though. Better to do something personally interesting or useful to you based on a hobby or a problem you want to solve

ProjectPro
MongoDB Projects Ideas for Beginners with Source Code for Practice
anyone used postgres notification?
import select
def listen_notifications(engine):
connection = engine.raw_connection()
cur = connection.cursor()
cur.execute("LISTEN table_update;")
while True:
select.select([connection], [], [])
connection.poll()
events = []
while connection.notifies:
notify = connection.notifies.pop().payload
print(notify)
I am trying to see print msgs but I m not getting any
used the following in pg admin
NOTIFy table_update, 'HI'

You are missing connection.commit() between selecting the cursor and execute command
Why would they have to commit here?
Because otherwise nothing will commit, you should remember that commit is like clicking the save button here, after using all commands
Why would they have to commit before execute and while they're using listen/notify?
Ok let me explain this with a basic example, so after selecting the raw connection, you get the cursor for the connection, and then you execute the query, if u dont commit then it would be just in memory, and the queries executed will be in the pending transaction.
Commit basically adds the changes made in memory to the database.
I think you have to commit after executing listen though 🙂
But reading the docs - you have to commit to receive any events
PostgreSQL Documentation
NOTIFY NOTIFY — generate a notification Synopsis NOTIFY channel [ , payload ] Description The NOTIFY command sends a notification …
Yeah commit is used when you want your changes to be applied in db and not remain in pending transaction.
If we do something like
commit()
execute("...")
Our execute obviously wouldn't be applied
So they have to commit after cursor.execute
Yes, commit should only be used at the end, after the changes you have made in memory have to be permanently saved in db, so for this a commit should be executed.
So why would you recommend doing commit before execute?
Yeah that was a mistake from my part u wont commit before execute, u commit once you have made all changes and you want to save those changed in db.
i cant find this on their website but how do you send/recieve data with mongodb
you use a python client for mongodb
How do u check if a value is present in a column of sqlite database or not
The simplest is to just compute a count and check if the count is greater than 0
You can also use “exists” and “in” or select … limit 1
i wonder if the optimizer would short circuit a count == constant check
Would be the best to put a limit 1 though
And that's a good question, maybe I should test that 😅
i know with exists it should
So what kind of query did you have in mind then?
explain analyse select
(select count(id) from test) = 1
yeah, basically that. or some other constant. or other comparison operators
Nah, it does a full scan here
Well, index only scan, but still 🤷
Result (cost=17145.39..17145.43 rows=1 width=1) (actual time=30.290..33.007 rows=1 loops=1)
InitPlan 1 (returns $1)
-> Finalize Aggregate (cost=17145.36..17145.39 rows=1 width=8) (actual time=30.288..33.004 rows=1 loops=1)
-> Gather (cost=17144.92..17145.35 rows=4 width=8) (actual time=30.215..33.000 rows=5 loops=1)
Workers Planned: 4
Workers Launched: 4
-> Partial Aggregate (cost=16144.92..16144.95 rows=1 width=8) (actual time=14.316..14.316 rows=1 loops=5)
-> Parallel Index Only Scan using test_pkey on test (cost=0.42..15519.92 rows=250000 width=4) (actual time=0.120..9.549 rows=200000 loops=5)
Heap Fetches: 0
Planning Time: 0.058 ms
Execution Time: 33.040 ms
explain analyse select
exists(select id from test)
Result (cost=0.04..0.07 rows=1 width=1) (actual time=0.012..0.012 rows=1 loops=1)
InitPlan 1 (returns $0)
-> Seq Scan on test (cost=0.00..35405.00 rows=1000000 width=0) (actual time=0.010..0.010 rows=1 loops=1)
Planning Time: 0.057 ms
Execution Time: 0.023 ms
ouch
It's essentially the same as select id from test limit 1
thats quite a huge difference in execution times 👀
i bet that is a litle and dumb mistake but i can´t compile my code because of my library... *I alr installed the library
import mysql.connector
connection = mysql.connector.connect(
host='localhost',
database='banking_system',
user='root',
password='*******'
)
cursor = connection.cursor()
cursor.execute("SELECT * FROM login")
rows = cursor.fetchall()
for row in rows:
print(row)
cursor.close()
connection.close()
@thorny anchor

That makes no sense. Copy paste the error message.
You are sending 19 parameters. But the sql says 1.
The comma for the tuple looks out of place
Yes that was the mistake
Fixed it
The computer is always right. Your job as a programmer is to find out why your monkey brain is confused :)
Cool
Consider storing numbers as numbers by the way
I'm taking message id from a Slash command
If i take as int
It says invalid
So I have to make it a string
And cuz of that in db some are int some are text
The column in the database table says to store it as a string
That's why I made all text
Why not alter or change it to store integers instead
Fair point
Columns have one type
I know but I'm also storing role id as int which I changed to text because I thought it'll be good if everything have same datatype
I'll change the datatype to int while storing now
It is ok if it makes sense, i.e., if the ID contains letters
Discord IDs/snowflakes are all integers
The id only have numbers
Yes
Anyways can u check this https://discord.com/channels/267624335836053506/1219125904370831401
I'm not familiar with tuple maybe can u help me
I suggest you learn basic Python then
Hmm? You said above it was fixed?
That bug was fixed but I got another one
Ah. Well show the line again. You inserted a comma but you have a bad comma left.
Sorry. Read it again. That variable inside the int() call is a tuple.
Exactly as the error says
Yes that's the problem
I have to make a str
So I can use int()
But I don't know how to do that
No, you should not make a tuple in the first place.
I'm new to sqlite
Also I make the tuple into str then into int
This new problem is not sqlite related. It's just python.
No don't do that. Don't make it a tuple in the first place.
(result, ) = something()
i know about json files…should I put “5 years of database experience” in my resume :3
Are you applying for jobs that ask for years of experience with JSON?
yeah dude I can put “hello world” inside a json file
I can apply for FAANG now
I’m just that good
Maybe keep the jokes in some offtopic channel
I am trying to create a partial index in MongoDB but getting an error for the $expr operator, it seems like it's not supported with partial indexes, does anyone know any alternative for that?
{
"uid": {
"$type": "string",
"$expr": {
"$eq": [{ "$strLenCP": "$uid" }, 8]
}
}
}
error message
Error in specification { unique: true, partialFilterExpression: { uid: { $type: "string", $expr: { $eq: [ { $strLenCP: "$uid" }, 8 ] } } }, name: "uid_1", key: { uid: 1 } } :: caused by :: unknown operator: $expr

how did you install mysql connector?
no, answer in the chat like everyone else, so everyone can help
i just download the zip file
and then what did you do with the file?
I extracted the files
and that´s it
extracted where?
to my downloads
Try to work with us here...
?
Well that's clearly not going to work. Anyway, why don't you read this instead: https://dev.mysql.com/doc/connector-python/en/connector-python-installation-binary.html
The first hit on Kagi for "python install mysql driver".
i alr did this command: pip install mysql-connector-python
and still doesn´t work
try python -m pip install mysql-connector-python
assuming you run your program with python later
he is not recognized '-m'
always copy paste errors
-m : The term '-m' is not recognized as the name of a cmdlet, function, script file, or operable program. Check the spelling of the name, or if a path was included,
verify that the path is correct and try again.
At line:1 char:1
- -m pip install mysql-connector-python
- ~~
- CategoryInfo : ObjectNotFound: (-m:String) [], CommandNotFoundException
- FullyQualifiedErrorId : CommandNotFoundException
python -m pip install ... not just -m pip install ...
hmm, ok. and how do you run your program? python something.py?

it gives me this error
You didn't answer my question. And please copy paste text, don't take screenshots.
hmm.. ok, but that's a different error. So somehow the problem you asked about before was solved.
yeah this error that i just post i run with that command
Did you try googling this error? This is the first hit if you do https://stackoverflow.com/questions/50557234/authentication-plugin-caching-sha2-password-is-not-supported
is there a python pattern for mapping event names (defined by another library) to their respective repositories?
say the event name is "message_add". I want it to choose the MessageCount repo
and if its "member_update". I want it to chose the Member repo
Mapper, router?
For me, it's usually
_MAP = {
"message_add": MessageCount,
"member_update": Member,
...
}
def map_event(event):
cls = _MAP[event["type"]]
...
that was my first idea actually but im trying to find a solution thats compatible with static type checking
wait it might be.. didnt bother to actually check cause it felt too simple lol
Hello everyone, sorry to bother you (I don't really know if I'm in the right server) I'm from France and I have a homework to give in a subject called database introduction for beginners but I don't understand too much, I'm pretty bad in this matter. I'm looking for help if possible. Thank you 😄
would you suggest that I first work with MySQL workbench before I start using it with python?
You can do both. I would focus on whatever you're actually trying to accomplish rather than what tools you use
my thought process is that working with the workbench could help me grasp databases more easily. It would help me work with MySQL API in python with a bit more ease
Of course. You could build an app with Django or something and never touch SQL, but it's likely to be worth understanding your database
But also if you do use Django, try to go with the tool and not fight it.
i don't know what that means but ok!
alr thanks!
I have a pretty dumb question and I'm sure I will not use appropriate terminology so bear with me:
Generally speaking when I'm working with an existing database (for now let's assume read-only queries) - does it make sense to create a data class (or is it a model) for each type of query response I'm expecting?
I have a question... i used postgres to store my images... i got stored in bytea format...but now how can retrieve those images again??. ..like want to perform some operations on it and download it temporary from the database... How should I do that?
I think that would depend too much on specifics to be answerable. Specifics like performance requirements, number of unique queries, the amount and type of processing after the raw result is read etc.
@shut tiger Unique queries: 100-200, no intense performance requirements on the app side (though the queries themselves can be rather complex, so there would be overhead on the SQL server if that matters in this case)very little to no processing.
@shut tiger Would those questions you have be deciding factors as to whether or not classes/models should be used?
hey does anyone have any suggestions on what i should buy
to start self-hosting a database
don't really want to feel beholden to some corporation's free tier
Why would you need to buy something to self-host a database? Are you asking about hardware?
i need help with a database in https://discord.com/channels/267624335836053506/1219756076279533608, any help is appreciated!
Discord
Discord is the easiest way to communicate over voice, video, and text. Chat, hang out, and stay close with your friends and communities.
yeah
I am currently working on a project which includes yolo object detection. At the moment it is using a database using yolov5, but I would like to change it to a different database using yolov8. I have the database, I am just unsure how to implement it into my project to replace the current one. Is anybody able to help?
It depends on your budget and performance needs. You can run Postgres on a Raspberry Pi or on a high performance server and everything in between
just a lil hobby project
Then I would not purchase hardware. Whatever you're using for your app can host the database too
see i'm running my app locally on my desktop or laptop
if i host it on my desktop, then one day i'll forget to turn it on, go out, and be unable to dev on my laptop
Personally I have a Pi and a more powerful server that I keep running 24/7. If I couldn't do that I would probably pay for a VPS. You could maybe get by with a free VPS from Oracle or some other cloud service if it's just one light app
even a $5/mo VPS will probably be totally adequate + gives more reliability over free services
help
😭

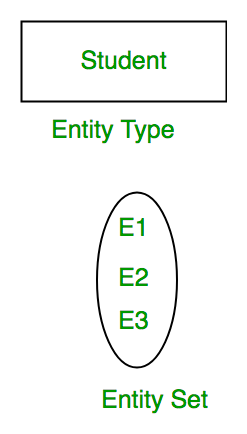
How many Entities are there and what are they?
@zealous spire
@clever musk
anyone 
I'm sure the answer is in whatever lecture and /or textbook you were supposed to read but it's here too: https://www.geeksforgeeks.org/introduction-of-er-model/
GeeksforGeeks
A Computer Science portal for geeks. It contains well written, well thought and well explained computer science and programming articles, quizzes and practice/competitive programming/company interview Questions.
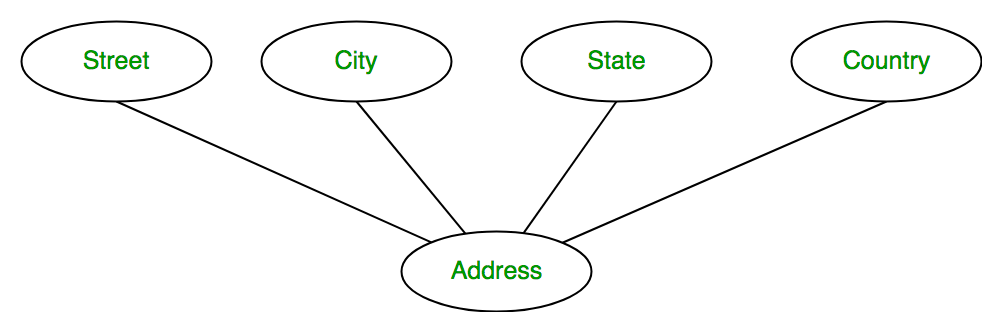
4, department, dependent, employee, job
You should develop with a local db though. Otherwise you can't develop without internet, and you will risk breaking production by local in-development experimental changes.
it's a discord bot, i can't develop without internet anyways lol
CodeWorks HQ database looks a little like this:
A login\user=test.local\password=find("91.pass")
A d(send)
terminal login
hardware wise it's like this:
in query
or so
but it looks for login\ once there in query it finds the user= and password= fromt here it takes the data reads it and compares to a folder with every possible login
after taking 18 minutes to find their login they can log in
what thier side does is take user=test.local and goes to its local folder and finds a file called test
it tastes their username from that
password is the same
folder 91
finds the file called pass
it can be shortened like this:
A login=/data.find("pass")--tran=185{data.find("user")[if login=1 do(bin-send)
Did you post this in the wrong channel? It seems to lack a lot of context, and be the wrong topic.
probably
it's related to database however
logging into one
lesson of the day: never truncate your table while insert operation is going on in airflow. I did this by mistake, in spark sql environment, though I thought there'd be no harm because table was for test.
nope, something happened to table and inserting to that table through airflow became impossible. I was still able to insert fine running in pyspark in cluster, but it just wouldn't work in airflow. In the end I had to drop the table.
hello guys, in case if i have a product name and it's parameters(parameters of the product), what kind of table i should organize?
Depends on the properties. Are the valid properties easily enumerated so you can put them as columns in a product table?
yeap, the table looks like this

and there is plenty of products with this table
ok, so all good?
differences from learning on a sqltutorial vs postgresqltutorial???
postgresql is a type of sql language
that's... sort of correct and also sort of wrong. Postgresql is an SQL compatible database engine.
Are those some sites you found?
Yes
Okay. Thanks for correcting me.
I know that postgresql is slightly different
different from what? That's the key. They are all different from each other. They normally implement the SQL ANSI standard though. Although SQLite is not great with that.
mysql has special stuff, oracle has special stuff, postgres has special stuff, etc, etc
Ahhh nevermind
I'm still new to learning about postgresql/sql so I was stumped
I did some searching around and figured out where I went wrong
Hello, is there any mongo client faster than pymongo that you guys recommend me to make queries faster?
Did you do profiling to see if there is any gains to be made there?
For one thing, you don't want to just stick random strings in the major column on the student table, because then you can't maintain normalization. Imagine if some students out "Conpurer Science" and others put "CS". By maintaining a table of majors you can keep control of that.
It also just makes sense that majors are entities which might have their own data, independent of students. So different entities get different tables and you reference connections with foreign keys
If you don't understand what someone is saying, ask. He already told you how to do it. Read it again and ask about the things you didn't understand.
given the document's wording, it looks like each school should be able to customize what races/majors/statuses they want to use for their own students
whether a particular school wants a separate category for middle eastern would be up to them
Did you get the part about foreign keys?
How to do a self join relationship in sqlalchemy?
I googled it for you: https://docs.sqlalchemy.org/en/20/orm/self_referential.html
When do you need to have a database with a server?
When you want your data to be persistent.
The data is stored in memory so if your application restarts all that data will be gone.
I don't think relationships help with my code
What does "with a server" mean?
Explain why not. We can't guess.
class Users(Base):
__tablename__ = "users"
username: Mapped[str] = mapped_column(primary_key=True)
email: Mapped[str] = mapped_column()
password: Mapped[str] = mapped_column()
profile: Mapped[str] = mapped_column(default="https://firebasestorage.googleapis.com/v0/b/discord-83cd2.appspot.com/o/default.png?alt=media&token=c27e7352-b75a-4468-b14b-d06b74839bd8")
friends: Mapped[List["Friends"]] = relationship("Friends",primaryjoin="or_(Users.username == Friends.sender,Users.username == Friends.receiver)")
def __repr__(self):
return f"Users(username={self.username},email={self.email},profile={self.profile})"```class Friends(Base):
__tablename__ = "friends"
id: Mapped[int] = mapped_column(primary_key=True)
sender: Mapped[str] = mapped_column(ForeignKey("users.username", ondelete="CASCADE"))
receiver: Mapped[str] = mapped_column(ForeignKey("users.username", ondelete="CASCADE"))
sender_user: Mapped["Users"] = relationship(foreign_keys="Friends.sender")
receiver_user: Mapped["Users"] = relationship(foreign_keys="Friends.receiver")
def __repr__(self):
return f"Friends(id={self.id},sender={self.sender},receiver={self.receiver})"```I'm trying to create a relationship between these two tables
How is that self referential? That sounds like just a foreign key.
Two of the foreign keys reference the same table. I asked the wrong question earlier.
Hmm. So what is the question?
Pls someone help
@commands.command(
name="protected_users",
description="Shows the list of protected users.",
aliases=["pu"]
)
@commands.is_owner()
async def protected_users(self, ctx):
try:
protected_users = collection.find({'name': 1})
if collection.count_documents({}) == 0: # Count on the collection
await ctx.send("No users are protected.")
else:
user_list = ""
async for user in protected_users:
user_list += f"{user['name']}\n"
await ctx.send(f"The protected users are:\n{user_list}")
except Exception as e:
await ctx.send(f"An error occurred: {e}")
In this code the error sending
An error occurred: 'Cursor' object has no attribute 'count_documents'
Pls someone help
@waxen finch
The error message is straightforward but your code is incomplete. What library is this? The documentation for it should clarify what you need to do
this is pymongo
Is anyone free for the next 2 weeks to help me out in a complex django project?
You're not showing where you declare collection but I'm guessing that's the problem. Maybe this example helps? https://www.geeksforgeeks.org/count-the-number-of-documents-in-mongodb-using-python/

GeeksforGeeks
A Computer Science portal for geeks. It contains well written, well thought and well explained computer science and programming articles, quizzes and practice/competitive programming/company interview Questions.
You're asking for volunteers? You may want to share more info about the project and how many hours you think it will take.
If you're looking to hire someone, not on this server, please read the rules
not hire someone, just a buddy to help out for my project
My project is like a collaboration tool that handles API from like Gmail to be able to view users emails
My projects also creates its own hashing techniques to hash users passwords
My project handles tasks and has its own to do list section.
Its basically combines a lot of the key features in today's collaboration and planning tool
if anyone is willing to lend out a hand, pls dm me
Is Postgres easier than it seems?
I'm used to SQL Server and it seems much easier to use and less "clunky" I'll say is the best describing word when it comes to syntax for querying data
SQL server SQL less clunky than postgres SQL? For instance?
friends = await db.execute(select(Users.profile, Users.username,Dms.id).join(Friends, or_(and_(
Friends.receiver == current_user.username, Friends.sender == Users.username), and_(
Friends.sender == current_user.username, Friends.receiver == Users.username)))
.outerjoin(Dms,or_(and_(Dms.sender == current_user.username,Dms.receiver == Users.username),
and_(Dms.receiver == current_user.username,Dms.sender == Users.username))))``` I'm trying to simplify this query and maybe relationships is the solutionI just find (keeping in mind I am brand new to Postgres) that it feels like extra steps to do the same thing.
When selecting columns I'm having to put "" around the name compared to not having to do it in SQL Server (me being lazy, not the end of the world).
But I just tried declaring a couple of variables to use in my WHERE clause in Postgres to make changing the values easier. In SQL Server I can add in the variables to my query and use SELECT statement to display the results. In Postgres I have to use Raise Notification (only way I've found so far) and the output is uglier than my grade 6 school picture 😅
Quoted identifiers should only be necessary when the column name includes capitals, operators, whitespace, or is a keyword(corrected). If sql server behaves differently for user convenience, I'd wager they were operating out of the (sql) spec.
Yeah, don't recall a syntax for variables in (raw SQL) postgres. You'd probably be directed to plpgsql for needs like that. (Caveat: My postgres experience is a little dated)
In SQL Server if there's any of what you mentioned, it requires [] around the name. As far as I can tell a column RestautantName doesn't have any keywords, operators or whitespace so I was a little confused by the need for quotations 🥴
Like a bad haircut I will get used to it no doubt. Just a little frustrating having to relearn something. But because it's one of the go to's I really wanted to get familiar with it
Oh. And uppercase. I think postgres is preferring to be conformant here.
If you're forced to use postgres, you'll probably want to adopt underscores and lower case naming patterns unless you don't mind quoting for whatever reason.
Ahhh that would make sense whenever I label a formatted column it automatically displays as lowercase unless I use "" around the label. Excellent observation and point! Thank you!
I find it easier to just query the data without using relationships
Still not a question. And it doesn't make sense either.
any VBA wizards here?
friends = select(
case(
(Friends.sender != current_user.username, Friends.sender),
(Friends.receiver != current_user.username, Friends.receiver)
).label("username")
).select_from(Users).options(joinedload(Users.friends)).join(Users.friends).filter(Users.username == current_user.username).subquery()
friends_information = await db.execute(select(Users.profile,Users.username,Dms.id)
.join(friends,friends.c.username == Users.username)
.outerjoin(Dms,or_(and_(Dms.sender == current_user.username,Dms.receiver == Users.username),
and_(Dms.receiver == current_user.username,Dms.sender == Users.username))))```friends = await db.execute(select(Users.profile, Users.username,Dms.id).join(Friends, or_(and_(
Friends.receiver == current_user.username, Friends.sender == Users.username), and_(
Friends.sender == current_user.username, Friends.receiver == Users.username)))
.outerjoin(Dms,or_(and_(Dms.sender == current_user.username,Dms.receiver == Users.username),
and_(Dms.receiver == current_user.username,Dms.sender == Users.username))))```Which query do ya'll prefer?
If ya'll could give me any advice, I'd appreciate it.
In case this wasn't answered, using a different client won't make mongo go faster.
Hello, be sure to always ask an actual question. Never ask "does anyone know about x". Ask your actual question about x.
For a social media like database where
Boards -> Posts -> Comments -> Reactions
Also
Posts -> Reactions
And i somehow need to keep a count of reactions and comments and posts on all user, board and post page, what would the way to go be ?
Initially i had a view which was calculated at each request that sounds computationally bad, one solution was either to have materialized views and scheduling an update every so often
Or track all counts on each table, i.e whenever a reaction is addedd update count at post and the user
When comment is added update count at post user and board
That sounds bad too, I'm not sure which way to go
I'm thinking something hybrid is the answer but I'm not sure how to go about it, somehow i keep track of counts where it matters like reaction to posts and comments are accurate, but reactions to user table will be scheduled update
Something like that but I'm not sure which and where count is important
You can do atomically safe updates in SQL, so that should mostly cover that. I would do the hybrid approach of storing the count and the likes in a table if it was a performance issue. Just like you said.
So go with schema that looks like
Users table
stuf
postcount
Reactionscount
Commentcount
Which counts should i be updating immediately I'm thinking ones that have direct relation
Reactions would update post and comment
Post would update board
Comment would update post
Every user count and everything else will be scheduled maybe every hour or so
Scheduled? why? You just update when you get a comment/like.
So when i get a comment
Inc post
Inc board
Inc user
And dec when delete ?
Is that good ?
Yea
Oh it sounded worse performance wise
Is there a good resources you guys recommended to someone starting new, videos or books on design and sfuff
Maybe. But selecting the total count every hour isn't free either. You are comparing two very different things and just thinking about the cost of one and not the other.
Question about how people "import" new data for databases...and do most databases work the same?
Lets say the databases have customers/patients/clients. And each person has a "profile" (the one) and then each person can have multiple visits (the many).
And let's also say that they have locations, so each person can visit multiple locations for their 'visits', including balances, time of visit, notes, etc,.
But how do most people work with / overcome accidental duplicates?
Sorry' not sure how to word this exactly.
If someone is receiving many batch files of customers, and the customer can come from different locations- there might be a chance for duplications (as in they have two unique primary keys - but some demographic informational). How do most people handle that? Do they run a query to search for duplicates?
Hopefully there is a way to enforce uniqueness in some ways. Like in Sweden we have person numbers, which are unique. So you can have that field specified as the primary key even and you then can't have two user records for the same person.
Assuming I'm understanding what you have written and are asking, are you wondering how to handle if Person A has an entry from Location X and another entry from Location Y? If the Person was generated a unique ID, than you could also maybe have the Locations have a Unique ID as well. So when Person A logs an entry from Location X and again later from Location Y you can check if the Location ID's are the same or not. Thus removing that risk of duplication.
It's all in the relatioships. My take would be one profile with all the visits and related data keyed for that location. the person + location is always unique for the visit. If we are talking bulk imports you can dump the raw data in a temp table with no enforced keys and do integrity checks as it is migrated over into the relational tables with integrity checks.
yes. ask your question
hello guys, is there any way to declare another model inside a field on sqlmodel?
on pydantic I used to do something like this:
class State(BaseModel):
name: str
class City(BaseModel):
ibge: PositiveInt
name: str
class Address(BaseModel):
zipcode: PositiveInt
city: City
state: State
But on sqlmodel the foreign key is needed?
I'm trying to do something like this:
class StateBase(SQLModel):
name: str
class State(StateBase, table=True):
__table_args__ = (UniqueConstraint('acronym'),)
id: UUID | None = Field(default=None, primary_key=True)
addresses: list['Address'] = Relationship(back_populates='state')
class CityBase(SQLModel):
ibge: PositiveInt
name: str
ddd: int | None = None
class City(CityBase, table=True):
id: UUID | None = Field(default=None, primary_key=True)
addresses: list['Address'] = Relationship(back_populates='city')
class AddressBase(SQLModel):
zipcode: PositiveInt
neighborhood: str
complement: str | None = None
city: CityBase
state: StateBase
class Address(AddressBase, table=True):
__table_args__ = (UniqueConstraint('zipcode'),)
id: UUID | None = Field(default=None, primary_key=True)
state_id: PositiveInt = Field(foreign_key='state.id')
state: State = Relationship(back_populates='addresses')
city_id: PositiveInt = Field(foreign_key='city.id')
city: City = Relationship(back_populates='addresses')
I don't want the id, state_id, city_id... in my strawberry type, because of this I'm trying to make 2 sqlmodels like that (base and table)
I need to do a class like that for use in my graphql type like this:
from strawberry import auto, type
from strawberry.experimental.pydantic import type as pydantic_type
from database.models.brazil import AddressBase, CityBase, StateBase
@pydantic_type(name='State', model=StateBase)
class StateType:
name: auto
@pydantic_type(name='City', model=CityBase)
class CityType:
ibge: auto
name: auto
ddd: auto
@type(name='Coordinates')
class CoordinatesType:
"""A coordinate consists latitude, longitude and altitude."""
latitude: float
longitude: float
altitude: float
@pydantic_type(name='Address', model=AddressBase)
class AddressType:
zipcode: auto
city: auto
state: auto
neighborhood: auto
complement: auto
coordinates: CoordinatesType | None = None
Hi everyone, I am looking for a python library that can read and write to dbase 4/ dbfIV files and works with python3... Does anyone know any solutions there?
hey guys

I'm trying to alter things from a SQL database (microsoft SQL).
Specifically, I'm trying to standardize the dates of a column
However after understanding how to read the data (in the print statement at the bottom)
i'm not sure what to do next
do I save the data from the column in a variable, and then try to alter that variable? Then reintegrate it into the SQL database? Do I write some sort of code that alters it directly?
Note that my goal is to update the table, not make a new table entirely
okay
thanks
Good morning everyone, I'm currently developing a real estate app with Firebase and have very little experience with backend. At the moment, it's like this: when a new user registers, a collection + document with their user ID is generated. Here they can now create properties that, of course, only they can see. Now I have the "problem" that sometimes there are 2 or 3 accounts that should also have access to these data. Do you perhaps have a basic idea of how I should structure the backend in this case? I'm a bit afraid to start creating hundreds of data entries and then make a mistake in the setup. Permissions or user management are not necessary for now. Thank you very much!! Best regards, Marcel
what is "a collection + document with their user ID"?
Alright!
I fixed it thats why i deleted the message 😄
In Firebase, a collection is essentially a folder that then contains various contents. For example, in my case, the collection is assigned to the user, who can then create properties in it, which are essentially generated as subfolders of the collection.
Hmm, sounds like that's what are normally referred to as "databases" then. Annoying that they use non-standard nomenclature. Anyway. Ok, so if you want the data to be accessible by others you probably want just one database with a foreign key to the relevant user on each row. Or whatever the corresponding thing is in firebase.
according to Digitalocean Documentation [ https://www.digitalocean.com/community/tutorials/how-to-move-a-mysql-data-directory-to-a-new-location-on-ubuntu-18-04]
I am changing my data directory to another path, but an error occurs when I'm trying to restart AppArmor. I get stuck in step 3.
The error is :
Job for apparmor.service failed because the control process exited with error code.
See "systemctl status apparmor.service" and "journalctl -xe" for details.
How can I solve that and
does anyone give me some knowledge about how I can change the datadir?
Does anyone have an open-source project in python where they use the ORM technique for databases? I like to take a look at it, since I'm trying to implement it for the first time in my little project.
Maybe a repository link will help.
Thanks!
All Django projects? Like sentry for example if you want something really big. If you want something very small maybe look at this tiny hobby project of mine: https://github.com/boxed/dubbningshemsidan
Thank you, for ur answear.
I first searched on this link: https://github.com/mahmoud/awesome-python-applications?tab=readme-ov-file#tag-dev.code_review
but this projects are for people with more expirience.
For the understanding: I am building a web app with flask, htmx and postgesql.
The backend logic is ready and the frontend is o.k.. Now i want to impement my sql class, and i have read some docs about orm and sql-alchemy and i thinks its the right choice for my application

GitHub
💿 Free software that works great, and also happens to be open-source Python. - GitHub - mahmoud/awesome-python-applications: 💿 Free software that works great, and also happens to be open-source Py...
SQLAlchemy is the default choice for flask yea
?
can i ask for help related to mongodb here?
just ask
im following a code along tutorial
this is my server.js file
import express from "express";
import mongoose from "mongoose";
import dotenv from "dotenv";
const app = express();
dotenv.config();
mongoose.set("strictQuery", true);
const connect = async () => {
try {
await mongoose.connect(process.env.MONGO);
console.log("Connected to mongoDB!");
} catch (error) {
console.log(error);
}
};
app.listen(8800, () => {
connect();
console.log("Backend server is running!");
});```
and i have pasted the url link for connection of the cluster in a .env file
```MONGO = mongodb+srv://abhilash:mypasswordhere@cluster0.41ged.mongodb.net/?retryWrites=true&w=majority&dbname=fiverr```
when i save my server.js file i get `backend server running` but the connection to database is not established bcuz im not getting `connected to db` msg.my user has access to read and write in the cluster

Maybe you should try a javascript/node server... mongo+python seems ok for here, but that is a bit off topic
ok thanks
I'm having an issue that I think is related to Pyodbc's behavior. Basically I have a Plotly Dash App and when I try to get new data, I end up getting the old data. Here's what I'm talking about.
df:
Letter
A
B
C
Expected df after updating:
Letter
D
E
F
What I end up getting after updating:
Letter
A
B
C
The code goes something like this:
def CheckAlphabet(dte, df):
server = XXXX
database = XXXX
username = XXXX
password = XXXX
conn = pyodbc.connect(.....)
sp = f"SET NOCOUNT ON; EXEC [dbo].[SP_Name] @Dte = '{dte}'"
df_temp = pd.read_sql_query(sp, conn)
pd.set_option('display.max_columns', None)
if not df_temp.empty:
for idx, row in df_temp.iterrows():
df.loc[len(df.index)] = [row["Letter"]]
This is just the code of the function in question (not the exact function, but an example of something similar to what I actually have). But anyways, I had another connection live in a function that calls another function and you'll have functions calling other functions until this function is called. I made sure to use cursor.close() and conn.close() once I got df via Pyodbc. Does anyone know why I still get the old data when running through this function with updated data instead of the new data from the Stored Procedure?
Update: I think I might have an idea on what's going on. It doesn't appear that dte is updating since now I'm just realizing that dte is a Global Variable. I made sure to pass the updated value of dte to see if I can get it working now. I'm running it now to see what happens.
It works now. This should've been more obvious for me to catch.
my first time at this
ok
from flask import Flask, render_template, request
import _mysql_connector as mysql
app = Flask('__init__')
@app.route("/")
@app.route("/cadastro", methods=['POST', 'GET'])
def cadastro(dados_banco):
nome = request.form.get('nome')
email = request.form.get('email')
senha = request.form.get('senha')
botao = request.form.get('cadastrar_botao')
dados_banco = mysql.connect(host="localhost",user="root",database="github", port=3306)
cursor = dados_banco.cursor()
inserir = f'''insert into users(nome, email, senha)
values ("{nome}", {email}), {senha});'''
cursor.execute(inserir)
# inserir.commit()
cursor.close()
dados_banco.close()
return render_template("index.html")
app.run(debug=True)
I think you need to do this:
ccnx = _mysql_connector.MySQL()
ccnx.connect(user='scott', password='password',
host='127.0.0.1', database='employees')
@warm igloo
now it is, thank you very much!
Always happy to help. Here's the documentation you can refer to.
https://dev.mysql.com/doc/connector-python/en/connector-python-cext-module.html
good evening people, i have a question for my data format (or more like cleaning) is about spread of sales data, when analyzing revenue.
so as i said my data project asks for variance (or spread) over time for revenue, among three methods, some customers don't buy anything, and the variance will be bigger for big revenue further from those 0 values, should i ignore values of 0 ? or does that variance is useful for revenue insights ? the percentage increase is unaffected (as i computed it) and without 00s the variance is just a stripe not so thick. But with them, the spread is huge.
What's the mistake here?
I googled it for you: https://stackoverflow.com/questions/72221346/mysql-connector-no-ciphers-available-error
Stack Overflow
I am using the MySQL connector to create a connection for my simple python app however every time I run it, it fails and returns the following error:
2055: Lost connection to MySQL server at '{
Ah thanks.
I don't understand that solution.
Did you install mysql-connector with pip? Uninstall that and replace it with mysql-connector-python
Pip uninstall “package ”
Ur using pycharm?
Vscode
.
Alr. Ty.
users can post posts with images , then like the posts and then reply or comment in them does this look alright ? This is just pseudocode ```python
pseudo-code-models
class User(model.Model):
username = textField()
profilePic = imageField()
post = oneToMany(Post)
comment = oneToMany(Comment)
reply = oneToMany(Reply)
createdAt = dateField()
class Post(models.Model):
image = imageField(...)
description = textField(...)
comment = oneToMany(Comment)
like = oneToMany(User);
createdAt = dateField()
class Comment(models.Model):
description = textField()
likes = oneToMany(User)
reply = oneToMany(Reply)
createdAt = dateField()
class Reply(models.Model):
description = textField(...)
createdAt = dateField()
please ping me immediately
@fading patrol what r u trying to say man ?
can u not underestand it too its django ORM
I don't see any obvious problem there
r u joking with me or r u serious ?
here is the real code i.e not psuedocode https://paste.myst.rs/9nu7rd30
a powerful website for storing and sharing text and code snippets. completely free and open source.
if u want me to upload sqlite3 then telll me
are u sure u r not trolling me or joking with me
I have just used char field instead of image field because I wanted to make it quickly
guys is this person joking with me ?
Hey guys. Does anyone have any examples of using sqlmodel with mysql+asyncmy? I'm having a little trouble generating the session. I wanted to see what would be a good way to do this.
Why are you even asking that?
Users don't need to have post nor reply nor comment fields
Then each post
Must be created by a user
So the post model
Should have a foreign key to the users model
But comments and likes not in the post model
We will ignore the image now for simplicity
Then
Each comment also must be created by a user
So comment model
Have a foreign key to the post model
And the same for Reply
And so on
Think of it like:
Do users must create a post when they are registering ?
Of course they don't
Also for creating a Post
Does this post must have a comment ?
Of course not
. . .
But reverse it
When a post exists
Of course there is a creator
If a comment exists
There must be a post That this comment belongs to
Something like this:
from django.db import models
from django.contrib.auth.models import User
class Post(models.Model):
user = models.ForeignKey(User, on_delete=models.CASCADE)
content = models.TextField()
created_at = models.DateTimeField(auto_now_add=True)
class Comment(models.Model):
user = models.ForeignKey(User, on_delete=models.CASCADE)
post = models.ForeignKey(Post, on_delete=models.CASCADE, related_name='comments')
content = models.TextField()
created_at = models.DateTimeField(auto_now_add=True)
class CommentReply(models.Model):
user = models.ForeignKey(User, on_delete=models.CASCADE)
comment = models.ForeignKey(Comment, on_delete=models.CASCADE, related_name='replies')
content = models.TextField()
created_at = models.DateTimeField(auto_now_add=True)
when should i close my sqlite dbs?
like rn i just open it and i leave it open forever
is that bad?
Can I not do null = true in User
I thin it can be left empty
please ping me mahmoud
This is a text file called urls.txt it contains all the urls of instagram profiles related to 'fitness' niche basically I developed a python script to extract the data using google dorks, I simply automate the process of scraping data from Google Dorks.. what you think how can I make it better

If you're asking how your script can be better, you should share a paste (not a screenshot) of the script itself (not just the output)
But try a help channel or #python-discussion if this is not actually a question about databases
thanks will this work out in the long term and with lots of data ?
@inland pawn
Of course you can
But
When you create a post
There is no reference whose post this is
Also for comments and replies
There is no reference for which post
or comment
So how would you retrieve the related posts of the user
Or the related comments of the post
And so on
This is a design consideration
And for the large amount of data
You should consider optimizing each query
Don't do
select *
Ever 😄
Specifically for production DBs
So when you make queries
For posts
Consider selecting the related ones for each user
And so on for each model
And try to think of it again
And do your search
You'll get comfortable with how the design should go
For this kind of models
Here is what I mean by 'there is no reference for related objects'

Also each one of them
Is a whole entity that has multi input value
Not a part -field- of other objects
So when you create a post within the user objects
What are the other values of the post itself ?!
I hope this makes it more clear
You should try . and , instead of newlines
It's not clear at all. The reverse mapping is trivial in an SQL database, and you get it by default and automatically in Django. You are just making everyone confused.
Why is trivial in SQL
When we are talking about
Relations already !
And what do you mean by you get it automatically in Django
I am talking about the design of these entities before anything else
How should these entities must be
And how they are related
But if you considered using NoSQL DBs
Maybe it works fine
Stop pressing enter randomly. Please. It's very annoying to read.
Really
Maybe if you don't know you shouldn't give advice to others on this :/
I want to know
How could you retrieve the
Related posts of the user
From the post model 😄
Using your suggestion
select * from posts where user_id = 3
lol, well then your model is broken. And yea, I see it's much worse than that. likes = oneToOne(User) that's super wrong.
a_list_of_things = one_thing totally wrong
Who said likes will be a oneToOne relation?
?
This is the design of the one who asked
Not from me
Yea, this advice is solid. This makes sense. You should follow this @inland pawn
I released a new versions of records tonight https://github.com/kennethreitz/records

GitHub
SQL for Humans™. Contribute to kennethreitz/records development by creating an account on GitHub.
thanks but I cant see user
how does it look now ?https://paste.myst.rs/6d2b7o42
a powerful website for storing and sharing text and code snippets. completely free and open source.
tell me
hey! I'm trying to connect a SQL Server database with PySpark however I'm getting this error when it comes to 'load()'. I tried every advice that I saw on Stack Overflow but nothing worked for me. Is there anybody who has experienced this error before?
My code:
spark.read.format('jdbc')\
.option('url','jdbc:sqlserver://[ip_address]:1433;database=Test;user=[username];password=[password];')\
.option('driver', 'com.microsoft.sqlserver.jdbc.SQLServerDriver')\
.option('dbtable', sqlQuery )\
.load()\
.show()
Error starts with:
Py4JJavaError Traceback (most recent call last)
Cell In[4], line 5
1 spark.read.format('jdbc')\
2 .option('url',sqlConnection)\
3 .option('driver', 'com.microsoft.sqlserver.jdbc.SQLServerDriver')\
4 .option('dbtable', sqlQuery )\
----> 5 .load()\
6 .show()
The last error I can't handle: (I can connect to DB with this user by using SQL Server Management Studio, and I tried 3 different users.)
Py4JJavaError: An error occurred while calling o34.load.
: com.microsoft.sqlserver.jdbc.SQLServerException: Login failed for user '[username]'. ClientConnectionId:b60537a5-bfbc-4e11-9d82-3
I am trying to get tortoise to give me a single item off of my postgres db... And it annoys me that I cannot find any documentation for it... Either I am too stupid or there is a big lack in it...
My table:
from tortoise import Model, fields
class Server(Model):
id = fields.IntField(pk=True)
server_id = fields.BigIntField()
name = fields.TextField()
created_on = fields.DatetimeField()
The code to get a server:
server = await Server.filter(server_id=guild.id).first()
I also tried out Server.get(server_id=guild.id), but neither works at all...
If you know any alternatives or can help me fix this, I would be thankful...
Do you get an error?
No, not any. Also no report on my db :/
hey guys, I have a psql table here ```py
await connection.execute("""
CREATE TABLE IF NOT EXISTS hangman_data (
wins INT DEFAULT 0,
fails INT DEFAULT 0,
words JSONB
)
""")
and my goal is to have `words` be an array of jsons, I tried multiple things like `JSON[]` but I am just not sure how I would update/insert/select the `words` column. Any advice is appreciatedDon't. Use a separate table for the words with a foreign key.
Hm? What's wrong with using json/array?
reminds me of a time where i wanted to pick random rows from a table in sqlite... if only it was as simple as one function call
...hmm, actually i think my pains came more so from other constraints than just picking a row
You are working against the tool. This is not how relational databases are supposed to be used.
Depends on the data in there and how it will be interacted with
postgres supports types (similar to classes), so why json would be different here?
CREATE TYPE inventory_item AS (
name text,
supplier_id integer,
price numeric
);
CREATE TABLE on_hand (
item inventory_item,
count integer
);
class User(Base):
__tablename__ = 'users'
id = Column(Integer, primary_key=True)
tg_id:Mapped[int] =maped_colunm(BIGINT,nullable=false,index= True)
wallet :Mapped['Wallet'] = relationship(backref="user")
class Wallet(Base):
__tablename__ = 'wallets'
id = Column(Integer, primary_key=True)
balance = Column(Integer)```
is this enough to create a 1-1 relationship where i can access users wallet ?or do i have to create a user-id foreign key in Wallet too?
Huge difference. Json is stringly types dicts. That's no way to build an app.
Normally when you think you want a 1-1, you actually shouldn't. Put the balance on the user object directly.
You could wrap them in a pydantic or similar thing, so, why not?
That doesn't solve schema migrations for when the data structure needs to change. It also doesn't solve the inherent problem of synchronization/updating being much worse for dicts. Race conditions for example.
I don't say I don't agree with that, but json could be useful sometimes
I think my coworkers used it for some kind of version history of objects
that has alot of fields omitted and later i might have to change it to 1 to many
but just wondring y this works same as if has foreign key field in wallet to?
and to make it one - to - many i just do Mapped[List['Wallet']]??
Yea that's a good use case.
Can smn tell me why when ive installed mysql connector and ive xampp and still get error called modulenotfound for mysql when i try to import mysql.connector
I see, what are foreign keys and how do I use them?
Follow any basic introduction to SQL and you will learn this
Alright
how do i pytest with mongodb based fastapi app?
Hello folks,
PostgreSQL team at Microsoft is organizing an annual free and virtual developer event, POSETTE: An Event for Postgres 2024!
This is the third time we organize this event (formerly Citus Con) and it's open for speakers and listeners with all levels of experience. If you have any ideas, stories, tips, tricks or expertise to share about using PostgreSQL in your Python projects or Postgres in general, please submit your talk idea!
All talks will be pre-recorded, and they will be live streamed during the event with live speaker Q&A.
The CFP closes this Sunday (April 7th) and the event will happen on June 11-13. It takes a title and a short description to submit. If you have ideas to share, please hurry up and submit your talk ideas soon.
You can find more information on POSETTE on the website: https://aka.ms/posette

Join us at POSETTE: An Event for Postgres (formerly Citus Con), a virtual and free developer event happening on Jun 11-13, 2024. Come learn what you can do with the world’s most advanced open source relational database—from the nerdy to the sublime. Organized by the Postgres team at Microsoft.
Don't crosspost
hey guys. I'm using 2 sqlite database in django project. one named buyer and another is named as seller. In seller database I'm using buyer as a foregin key in one model. When i run the admin page and try to access that model it throws and error. Exception Type: OperationalError at /admin/seller/bid/ Exception Value: no such table: buyer_buyer
You can't have foreign keys between databases. You should have just one database.
i tried finding the solution for this on claude and bard. they said to use database routing. And i'm already using it
but i don't want to combine seller model tables in buyer models/database
That's wrong advice. As one would expect with AI models they are fed with bad advice and then output bad advice...
true tho 🙂
so what do you suggest
to use single database ?
Yes. That's what I said, that's what is sane. That is what will actually work.
multiple databases in django is very niche, and something you should avoid
okay... and what's the storage limit in sqlite databases ???
okay I'll keep that in mind from now... Thanks bro
You probably don't want sqlite for production anyway.
i'm using it just for now... In my development phase...
I won't be using it in production
It's fine for very specific uses cases like mostly read dbs with just one thread updating the data for example.
The storage limit is not something you will likely hit. I wouldn't worry about it.
Hi everyone, I am looking for a python library that can read and write to dbase 4/dbfIV files and works with python3. Does anyone know any solutions there? Thanks.
np. Next you might want to look at something like Dokku or Caprover to make that all much nicer
Guessing you saw this already? Doesn't look promising 😔 https://stackoverflow.com/questions/70915812/python-3-writing-to-dbf-dbase-iv-with-memo
Stack Overflow
I need to write to dBase IV dbf file with memo fields in Python3, but cannot find a suitable module to do this.
Packages that I have tried:
Simpledbf - Read-only
dbf - Does not support dBase IV
dbf...
Unless https://pypi.org/project/YDbf/ does what you need

Yeah I saw this one that's why asked here in case someone else dealt with it thanks for the response. Will view the other one you posted, thanks
- This isn't the right channel for frontend questions. This is #databases
- Just ask the real question
try #web-development
Hi guys, can someone give me some pointers how I would implement a product search based on multiple search terms/texts per each article attributes that have each a confidence value based on multiple imgage to text reads. So some of the red terms might be wrong. Can I perform this just with SQL query? Everything I try works fine as long as all the terms are exactly correct? Would I need some other table structure than the standard non normalized article table?
postgres has vector search indexes built in I believe
So for example the camera reads from the product "brand": [
[ "CONTINENTAL", 0.8724173418411512 ], [ "CONTINENTALK", 0.00032810526921936076 ], [ "CONTINENTALT", 0.0003197072269859897 ]...
there are GiST and GiN indexes also, but those didn't sound like what you wanted
ah ok, thanks I will take a look at vector search indexes
What do ya'll think about the database design? It's my first time making a diagram btw

Hi there, so we have two Postgres schemas, one for QA and one for sandbox, but the sandbox schema migration is not matching with the qa schema migration when checking the diff of both the DB I am getting that in diff also, due to that queries is failing because there is one field which is not on sandbox db(schema) table, how can I keep both in sync? we are using Prisma.
Django?
express.js + prisma
Maybe you should ask on a js server? I don't think you'll find someone here who knows how that migration system works
Hey glad to see you're learning to do good ERD, so here's my feedback on it. I may sound a bit harsh though 😅
Ok, so first the relationships are all over the place. I've no clue how and where does the relationship from Server.owner_username connect to.
You should also standardise the table names, for example some names has a space in between while another doesn't (like Friend Request). It may also help to write them all in snake_case instead.
Is the DB normalised? You may have to look into normalization principles before designing a database and maintain optimal integrity of it.
Is there some feature in MySQL that is similar to vector search indexes? Or can I only achieve this with postgres?
helloSELECT * FROM "schools" WHERE "id" = ( SELECT "school_id" FROM "graduation_rates" WHERE "graduated" = 100 ); only give me one row SELECT "school_id" FROM "graduation_rates" WHERE "graduated" = 100 give me 7entry i want to get 7names
why not do a join?
no its a basic query i am learning why isnt this showing 7 names
something like this should happen ?

i am only getting one row from the query while the sub query SELECT "school_id" FROM "graduation_rates" WHERE "graduated" = 100 give 7 row
shouldnt i be getting 7 rows
problem is solved the where clause of outer subquery expects one item not a list
Any resources you recommend for learning to design a database?
Nothing in particular tbh but I can recommend the following over the top of my head:
https://youtu.be/ztHopE5Wnpc?si=lCtCHHcYtQ38QhYe
And then Google about "database normalization" and a ERD cheatsheet which uses crow's feet notations

This database design course will help you understand database concepts and give you a deeper grasp of database design.
Database design is the organisation of data according to a database model. The designer determines what data must be stored and how the data elements interrelate. With this information, they can begin to fit the data to the da...
You used = (expects one item) instead of the IN (zero, one or more items) operator.
Weird/bad that there isn't an error message for that.
I've been asked to draw a entity-relationship model (ER model).
But it's first time when I hear about this term
Can someone please let me know if this is a correct representation for it?

Do you recommend I break the database into smaller pieces. Like have separate diagrams with each group of tables that are related to each other?
What's the best way to host server on python
Yes, that's the intention of normalisation anyway. Each entity (representing a table) are it's smallest atomic unit which has certain attributes (representing the columns) referring to one another using crow's foot notations
thanks for the input
There's some redundant entity in there. You could represent the model using only a orders and pizza entity
Can you elaborate and perhaps state your well framed question at #1035199133436354600?
Is there any better way to configure this relationship?

You could remove id from Friends table
Yes by a lot, how is a user entity different from a friends entity? Perhaps if you state what your objective is, I might be to tell you how the ER Model should be like
Friends is a relationship here, e.g. user A maybe friend with user B
"friends" is a many-to-many relation. That's how you make those in SQL.
I object to the username being the primary key though :P
I have Username
?
I Have Username in Discord
So what? What do you mean?
you forgot a question
Can I use sqlite with django when hosting ?
Will it be stored on the local server and is that OK?
Pong me
Maybe. Unless you host somewhere with an emphemeral disk like heroku. Then no.
You probably shouldn't in any case.
Yes, sqlite kinda implies single server setups.
Seen it done in prod and it worked but I would avoid it if possible
heloooo guyses
Don't do that. Making multiple channels unread for all users without a question is annoying.
hey guys, I wanted to know how to save the values entered in my tkinter asktring or askfloat and then save them in my sql database. I've tried defining the variables in my database function but it doesn't work.
Is there any special relationship in sqlalchemy for a relationship like that?
Say that I have this db schema. Is it necessary to have writer's id in Chapter table as well?

if you want to associate a chapter with potentially a different writer than the story it's a part of, then sure
otherwise if the writer of a chapter will always be the writer of the story, just having a foreign key for the story's PK is sufficient to retrieve the writer of a chapter via inner join
I see, I dont plan to have multiple writer for a chapter. Much thanks

was there an update to mysql-connector-python? We used to import as "_mysql.connector" and now we are importing as "mysql.connector". The trace has been removed
{kind=link}

No, many to many is supported out of the box in sqlalchemy
_mysql probably was a private module/package
pytest has that for example (_pytest)
guys I'm having a problem
with filtering the relationship data in sqlalchemy v1.4
so for an overview I have a table something like this
class Company(BaseModel):
id: str
employ = relationship('Employees', back_populate='company')
class Employees(BaseModel):
id: str
is_laid_off: bool
company = relationship('Company', back_populate='employ')
so here I want to get the company by id and get the emplys whose is_laid_off is False.
anyone can help me with this?
help?
"is_laid_off" would be the correct English btw
lmao
that was an example
still
thanks
i have a question
you are doctor who? haha
what is a user friendly way of displaying the database to the user in python? Is there a specified library?
i think users mostly aren't meant to see databases; there can be horrors there not meant for their eyes
you could read it as a pandas dataframe and print it, I guess
I suppose
thank you
i forgot pandas existed for a second
There is a library rich
Is it alright for a database table to have no relationship with other tables at all?
sure
async def updatetable(self, table: str, conditions:int, **kwargs):
conditionslist:list[tuple] = []
items = list(kwargs.items())
for i in range(conditions):
conditionslist.append(items.pop()[i])
conditions = " AND ".join([f"{key} = '{value}'" for key, value in conditionslist])
updates = ", ".join([f"{key} = '{value}'" for key, value in items])
await self.db.execute(f"UPDATE {table} SET {updates} WHERE {conditions}")
this is saying too many values to unpack for some reason
Like I have a food menu and I construct a table for it. I just use it whenever you want the price to be changed or remove the food, etc.
I just wanna make sure that this isn't a bad practice
if you don't need a relation then...you just won't have one
ye
idk if python lists count as db but here is more people than on web channels here. someone knows how to recurse infinitely infinite tree with unknown number of items? gonna either crawl a filesystem or web manually, yk
?
be tomorrow
What?
Yup, altho -sometimes- such isolated data may be static data better suited for a json or other non-db storage.... or versioned. Using your menu example: do you want to version it? Is this something that gets developed, updated and published? But regardless: totally reasonable to have a 'current_menu' table with no relations.
hello everyone . I have a question regarding databases. I Have recently completed the fundamentals of python.So I want to learn database through it .Few days ago, I saw that python has a special package which is pymongo and through it I can store my datas directly on MONGODB which is a NOSQL database written in javascript .will it be better for me to learn pymongo?
anyone ??
No. You want SQL
MYSQL?
Any SQL db will do
Ohh .... But will it be better to learn MongoDB using pymongo ?
Better than what?
learning MYSQL??
No. People build using nosql because of hype and then they regret it.
Or they suffer in ignorance. That's an option too :)
OHH I get it. So at first I will start from MYSQL and go for others??
There is little difference between the sql databases. You can use sqlite, mysql, or postgresql. Doesn't matter in the beginning. Switching is super easy.
ohh I get it
I'm new to SQL and I built a program in Visual Studio that connects to a Microsoft SQL database. The database itself is stored on a server running on my computer. I was wondering, if my friend wanted to use their own Visual Studio to connect and edit the data, would my computer need to be on for them to connect?
Yes, otherwise your sql server wouldn't be running
Can anyone tell me about the difference between internal and non-internal Dunder functions quitely?
Cuz as I've seen, "the internal one is always being called whenever you call the object" can't be the only difference
Or can? maybe
Also one more question
How does return for Dunder functions work? I feel like it's working different compared to a regular def function
am back and still with same problem
This doesn't seem like the right channel. And you should probably cite something more specific because I don't understand what you are talking about.
That's easy. It doesn't. Dunder functions are just normal functions starting and ending with __. It's how they are USED that provides the magic. They are just normal functions when implemented though.
Pardon man, thank you for informing me
Also thanks for the respond
99% of the time, an sql database will be the right choice

I'm working on a system for managing food order receipts and I need some advice on the database structure. What fields would be most useful to capture the necessary information?
You can find examples online. This one probably has more than you need: https://mysql.tutorials24x7.com/blog/guide-to-design-database-for-restaurant-order-system-in-mysql

Tutorials24x7
A complete guide to designing a database in MySQL for restaurant ordering system based websites and applications. It provides the food order database design for restaurants. It also covers the tracking of table booking and orders placed by the customers.
Hey guys, I am a real beginner so I have a couple of questions. I hope im in the right place and that you are all having a great Sunday! I want to create a program that can use a database to sort through my music. I have a big library of likes songs and almost 100 playlist. I want this program to be able to update the databases (which would consist of one big database of likes songs and then smaller databases for each playlist). And with this check if there are songs in multiple playlists and if there are songs in my likes songs that are not yet in playlists. This I can figure out but I cant seem to find an understanble way of getting all of the information required from spotify (eg the liked songs or playlists) without it being a total mindbending file or folder. Thanks if anyone understood this rant and knows how to proceed.
fun fact: the dbf files I have are dBase III
therefore, a combination of dbfread and dbf libraries are great for reading and writing
:incoming_envelope: :ok_hand: applied timeout to @finite wasp until <t:1712512516:f> (10 minutes) (reason: duplicates spam - sent 4 duplicate messages).
The <@&831776746206265384> have been alerted for review.
!unmute 933750150344622151
:incoming_envelope: :ok_hand: pardoned infraction timeout for @finite wasp.
Please don't spam your question across several different channels @finite wasp. You can use #1035199133436354600 instead.
i recommend using sqlite since it works quite well with python (sqlite3 module) and is relatively simple to use. what you want is a table for all the songs and their attributes (song length, genre, artist, name, etc) scraped from spotify.
then a second table that will relate a playlist ID to a song ID. that way you can query all the songs for that playlist with the specific ID and add new songs by inserting new rows.
remember, you have limited tables and limited columns but you have unlimited rows so make use of them!
to view .sql and .db files i make good use of db browser for sqlite
https://sqlitebrowser.org > download > get the latest version
then for the file you want to open:
- right click it
- select “open with”
- click “another app on this pc”
- go to your downloads or wherever that file was downloaded to
- click db browser for sqlite.exe
- click okay
- reopen your file
I'm having trouble figuring out how to handle multiple items on a receipt in my food reservation system. The system also needs to consider how many tables are available at a certain period of time.
for the guys who use mongodb:
do u guys believe its necessary to use motor for asynchronous project that does something like 20 requests per second or pymongo inside a async function will be enough?
I'm trying to understand how motor works, I think it keep the client on the second plan for multiple requests while pymongo create new client for each request?
motor just runs the stuff in another thread so it doesnt block the async function
and yes 20 RPS is enough to warrant either using motor or wrapping the calls in a thread in order to not block the async runtime
make a table of tables and their availability and then query that list to see if X table is present there and if its free or not
(by food reservation service i presume you mean like booking tables at a restaurant)
__mapper_args__ = {"eager_defaults": True}``` What does this do?I would check the documentation for whatever library that is
Please forgive me lord for I have sinned: py await self.cursor.execute(""" INSERT OR REPLACE INTO configuration (key, value) ON DUPLICATE KEY INSERT INTO configuration (value) VALUES :val WHERE key = :key """, (key, value), { 'key': key, 'val': value } )
if anyone can help me my server and client server license key checks out and send to client yet client still says its invalid even though its in the database if anyone can help me in a call thanks!
send part of your code for the client check
can someone help me -> i need a site or a document where i can find every command from mysql.connector import ?