#databases
1 messages · Page 21 of 1
yeah i added a lock to my benchmark just after pool.acquire()
🌚
man that like defeats the purpose of a connection pool
well probably not because 1000/7s is still 142 executions per second, but i expected better performance from running them concurrently... i guess the alternative is carefully sharing one connection without holding it for too long
or opening an indefinite number of connections, which i found wasnt a good idea when i implemented my NullPool and attempted running 1000 queries in 1000 threads
JSON Database best
why is it such a pain in the ass to install the mysqlclient library smh
depends on the project
some projects such as dbots and traditional web apps are best suited for SQL, while others are more suited for MongoDB
then PostgreSQL will always win over MongoDB
MongoDB is a NoSQL database that stores data as documents in BSON format. Not recommended in general as most of Discord data you are storing is relational (e.g. economy things) while mongodb is for non-relational data, hence there is no reason to use NoSQL over SQL to store relational data.
^ that's the reason above
idk I never used any other DB before
other than JSON DB
try out PostgreSQL
Ok
like an actual file?
poor move right there
Leads to data corruption, file locking, file permission issues, no atomic reads/writes, loading all of the data into RAM (which is a costly mistake), and many others
wha?
funnily enough even MongoDB would be better than just a file JSON db
oh yea that's the truth on why you should never use a json file as a db
by the sound of it, you might want to look into Sqlite3, its plenty fast, and stored as a single file
SQLite works great for smaller bots
i just primarly use PostgreSQL bc i know that most of my bots will probably be running off of a PostgreSQL server instead. Primary bot uses both PostgreSQL and Redis in order to not screw over my RAM usage and Redis is used as a cache for server config values
What if I want to use database.json in replit?
just dont
Because PostgreSQL requires money in r- ok.
PostgreSQL is free and open source
and plus replit's fs is ephermal, which means that any file you saved via your bot will be overwritten when you next launch.
But replit:

pretty much meaning that your data would be gone
WHAT?
No....
oh yea that's how bad replit is
How the hilsha fish do I host my bot then
Replit's postgres db are trash anyways. I can just get a vps and just host it there instead
What's VPS?
It's called using a VPS (Virtual Private Server) provider
Please don't think of me as stupid, I'm new to coding and all.
ok
!hosting
Discord Bot Hosting
Using free hosting options like repl.it or Heroku for continuous 24/7 bot hosting is strongly discouraged.
Instead, opt for a virtual private server (VPS) or use your own spare hardware if you'd rather not pay for hosting.
See our Discord Bot Hosting Guide on our website that compares many hosting providers, both free and paid.
You may also use #965291480992321536 to discuss different discord bot hosting options.
How do I obtain one of those?
I want free
Free VPS
see the tag i just sent above. you'll need to buy it. but if you are an eligible HS student or college student, then there are deals for it
and fyi there are no such things as "free vps providers"
Please make sure you read this fully
When you look for hosting your bot, you might be tempted to use free services or providers that claim to support hosting discord bots . Do not use them. Why? Let me explain.
Free hosts and tiers always have drawbacks - The point of a free tier or a host is to get the user to use their product, and upgrade for all of the good features. Hosts such as replit use shared cpus, oftentimes will run into ratelimits, and have "gotchas" that make you tempted to upgrade to their paid tiers. They also literally remove all control out of how you run your bot. Think about it: Hosts need to make money somehow in order to either break even or gain profit. So naturally they will tempt you into upgrading in order to do that. This is basic economics and quite literally how businesses run.
If you are still looking for a host after reading this, then you have some options. And here are them:
-
Pay up - Pay up and use a VPS provider. My pick is Heznter, but see
?tag vpsfor the full list (if you are on the Python discord server, then see!hostingfor your options). More than likely if you are not an eligible HS or college student, this is your option. -
Self Host - If you are able to self host your own server, then go for it. This is really the only "free" way if you already pay for your electricity bill and have the equipment to do so. Raspberry Pis oftentimes are great for this.
-
GitHub Student Developer Pack - IF you are a enrolled student in an HS or college (you will need to either provide an valid student ID or proof of education of your HS or college), then you may apply for this deal. More info about this can be found here. The deal offers $200 free credits on DigitalOcean for 1 year, so if you are a student and need to host your bot, go for it.
ik this is more dbot related stuff but just had to put it out there
...
I'm 13
how do i clear my console on windows? i'm using the mysql shell plugin for vscode
! cls doesnt work
PowerShell? clear should do it
that's for linux mate
clear doesnt work on windows \ ! cls supposedly works
but it aint

works on the cli

as u can see
And PowerShell (on Windows), like I said... but that's not what you're using. You did say MySQL... here's the first result from a web search: https://stackoverflow.com/questions/8807836/how-to-clear-mysql-screen-console-in-windows

Stack Overflow
The title is my question. I googled and try something like
mysql> !\ clear
mysql> !\ cls
mysql> system cls
mysql> system clear
blah blah ...
but none of them works.
Anyone show me ho...
i know it was a misunderstanding on your side it's alright we're fallible
A master class in how not to get helped next time 😅
i have an almost fully functional stat bot tracker. i just need help making the data go to a database.. the time in vc resets every time i leave the call and i want all of the data to be on a database but i am unsure of how to set it up

Hello, can anyone suggest any libraries for working with large parquet datasets?
polars seems like a good package to explore
https://pola-rs.github.io/polars/py-polars/html/reference/api/polars.read_parquet.html
Looks alright, I'll give it a try
I use duckdb, can query directly from parquet, with filter push downs, and provide a pandas or arrow or polars dataframe result. It’s just: duckdb.execute(“SELECT * FROM read_parquet('myfile.parquet')”).df()
Can't find a way to stream rows with polars, duckdb doesn't appear to have any sort of streaming
Dataset is larger than memory'
Hey, I didn't use polars but quick google search yielded this: https://www.rhosignal.com/posts/polars-dont-fear-streaming/
Would that help? 🤔
I have a table with 3 columns, (a, b, c) and I want to create a new table with 2 columns ([a | b], c). - So that a query for rows with some a/b value returns the unique c values that is associated with the a/b value on the original data
# (a, b, c)
(5, 6, 7)
(8, 5, 7)
(9, 3, 5)
(8, 6, 9)
# ->
# (a|b, c)
(5, 7)
(6, 7)
(6, 9)
(8, 7)
(8, 9)
(3, 5)
(9, 5)
Guys is docker only way to use cockroachdb locally?
Docker is by far the easiest way to set it up
my potato pc cant run it even though i have docker
I mean.. Why are you using cockroach of postgres then?
wdym?
I mean if you have super low resource requirements then postgres is going to be better
i mean ill use cockroach cloud for that, i was asking so that i can run it locally and save my requests
should i use neon db for hosting?
why?
Are you actually doing anything which actually makes these alternatives useful?
neon db is postgresql for hosting , its just name not db
neon DB is not really just a postgres host
then what is it?
shoudl i use mongodb the, i dont wana use any db locally
It's complicated, but it's a cloud giving you effectively serverless postgres but has things like storage decoupling
Litterally every cloud provider and their dad has some hosted postgres offering
but neon db is free i guess
Mmm yes but you're charged per unit of a metrics (Compute, Storage, Data transfer, Data written)
For small projects though it is pretty cheap
ye, i just making a social media app for practice
do u think its fine to use for such small project or i use mongodb? i have github education
I would prefer using postgres over mongo for 99% of things, so probably neon IG if you really don't want to self-host
whats postgres of mongo?
oh, so ill use postgre, do u know a good ree hosting service fo rit?
I mean you just said neon
Neon provides a postgres API
which is all you need really
I am trying to create a simple IRC chat platform using the socket library in Python. I've got that part going well, but I want to implement encryption to ensure security. The solution I thought of for that would be to have one public key for the server and one private key for each client. The user would define a matching encryption passphrase within the server & client and matching keys could be generated individually based on that passphrase. With this logic messages could be kept within the bubble of a single server securely and the server would only have to encrypt it once and every client would be able to decrypt it with their own key. Would this work? If so, what's a good library I could use to do it or could someone send a good tutorial/documentation?
That's not really a database question
But this is
I'm making an app to track some grocery prices over time. I'm going to be tracking potentially thousands of UPCs. What's the best way to do this? I've used Parquet in the past to store stock price data but there were only a hundred or so tickers. I could use a SQL database also and have been looking at QuestDB. I have used MongoDB in the past also.
Overall I'm not super familiar with using databases so I'm wondering if anyone has any thoughts on the pros and cons of each type of database for this particular application
I would start with a SQL database like postgres
maybe with an extension for timeseries if it's really required for fancy timeseries computations. But I would suggest to keep it simple and stupid and start with something simple like postgres
(Agree with Re, too) Parquet is a fine format, but I look at it when I’m looking at massive datasets. This doesn’t sound like that case. Number of UPC’s or tickets isn’t as much an issue as rate of change (total number of records).
(it comes down to if you want to prioritize the metadata and relationships around the UPCs or the TS itself)
Ideally I'd like to build a dashboard to display charts of price trends etc
Nothing really fancy on the math side
I have used Postgres in the past and was underwhelmed with the GUI for it
But maybe this time I'll do strictly command line
The only thing I'm wondering is this: I'm only going to be storing UPC, Description, Price, and Date. With so few rows/columns wouldn't it make sense to just store everything in one table? And if that's the case does it make sense to use a relational database?
A database GUI is meant to be practical, not really pretty
If it's timeseries data, then maybe use a timeseries database, otherwise relation is probably fine.
Examples include:
- ClickHouse
- TimescaleDB (Built on postgres)
- QuestDB
Yeah I was looking at QuestDB, but really it's a timeseries for each UPC
So idk what the heck that would look like
I mean that shouldn't affect things too much, since that could just be your partition key probably
What would be
eh dw about it actually
I don't think QuestDB should really struggle with anything, or ClickHouse really.
Both take very little configuration to be performant
So here's what I'm thinking
If I did parquet I could have a parquet file for each read date (once a week) and then 6000 columns inside it (one for each upc)
oh no
nvm
Why cant it just be like this: UPC, Description, Price, and Date
and price and date are lists?
oh
like every week make a new entry for each UPC
man
Well I would just have 1 row = one price, one date, one upc
right
you can have multiple rows for a single date and upc
Yeah. Just feels like so much duplicated data
but for storage efficiency, performance and convenience, you probably shouldnt have them in nested collections
What if I added a new column each week
For TS type data though you don't really care that much, since the compression will effectively handle all the duplicated storage
Don't add columns
Quest or ClickHouse yeah
Ok it makes more sense to me now. I wasn't even thinking that you could just add another row each week for the same upc
Yeah, having them be consistent columns and flat also makes aggregation and what not easier
right just do a groupby or select where or whatever
Appreciate the help
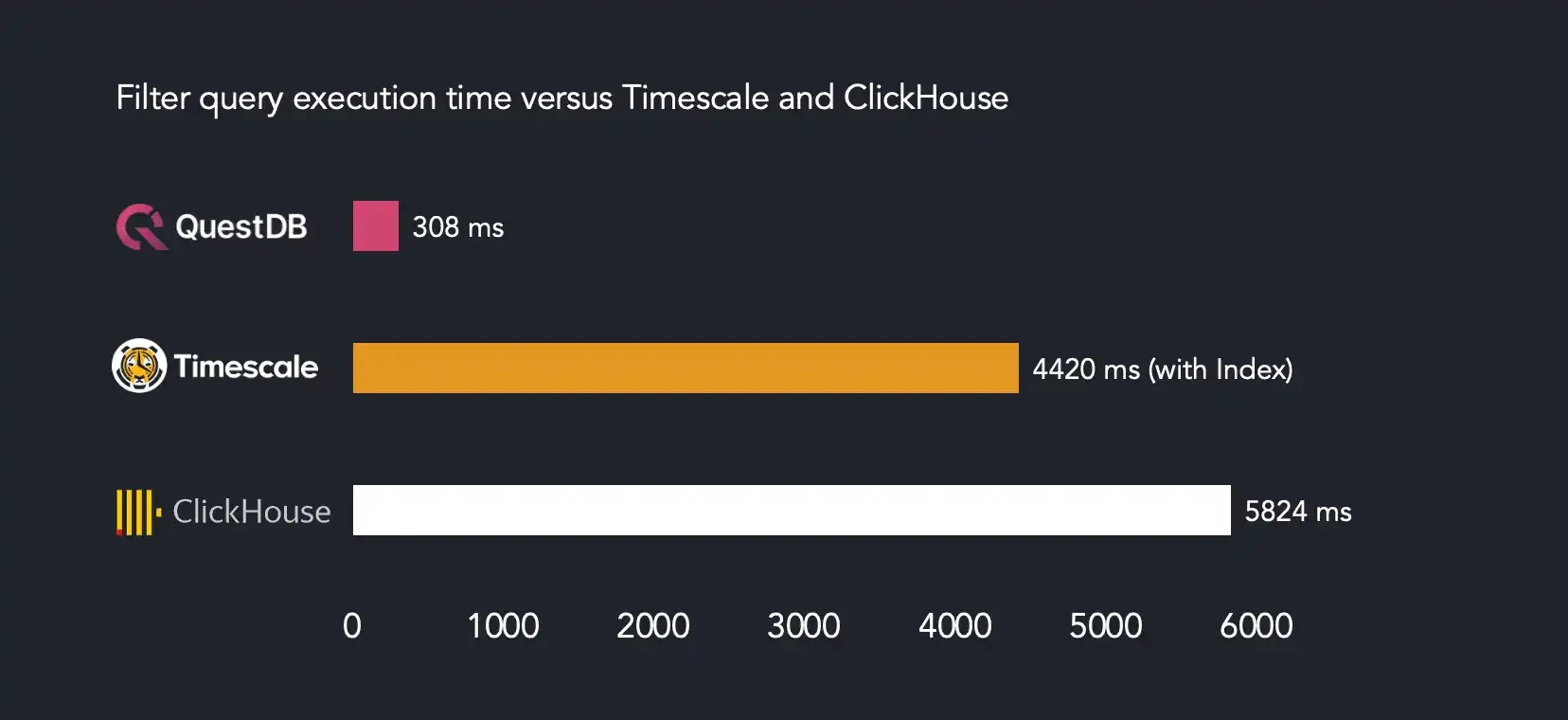
QuestDB 6.3 brings parallel filter execution optimization to our SQL engine allowing us to reduce both cold and hot query execution times quite dramatically.
They are cherry picking the query for that graph 😅
I wouldn't put too much thought into it
Yeah I figured. I also realized my math was wrong though and I need to track 325,000 products
6500 api calls * 50 products per call
fwiw, since clickhouse was mentioned, I'd also throw duckdb into the discussion. Postgres is probably fine, but if you're looking at the analytical db route, and are throwing it in parquet, then it's as simple as: ```py
import duckdb
df = duckdb.execute("select category, count(*) from 'myfile.parquet' group by category").df()
print(df)
Storing all the data in just one parquet file?
Not required, you'd partition it however you want. You don't need to use parquet, I only mentioned parquet because you did.
Yeah. I enjoyed using it in the past. Just not sure if it's the right way to go with this. Almost tempted to use something I've never used before just for the learning experience, but idk
Kind of leaning toward mongo
Really?
Dang it
I have no sense of scale. 325,000 products updated once per week is going to end up being a lot of data right?
It sounds like you have an analytical problem with a simple structured dataset. Therefore, an OLAP/columnar db is probably a good fit.
(but again, postgres is probably fine, and has columnar extensions)
If I'm going to use columnar I'll just use parquet and I'll check out duckdb
I dunno, that's not that much data... how many bytes per update?
And in a columnar store, you'll get significant compression.
Not sure. Haven't done one yet but each row would have maybe 6 columns max
Just doesn't seem like that much data to me. If it were once per hour or minute, I'd worry about timeseries.
Ok. Yeah the number just seems big to me because I don't do this often. I know databases get much much larger
Appreciate the input
It appears I should also switch to polars from pandas lol
yah, it's pretty ridiculous how bad pandas is. Although, I avoid both as much as possible and use duckdb (this is not really a popular view around here, it's just my view)
one data point per week? That's nothing for most databases
At this stage, I wouldn't worry about the database
yeah come on, you can't say that around me and expect a fight
pandas tends to bog down at around 1 million records but can scale up into the 10s of millions
if you're using pandas to process the 325k records weekly you will have no problems, although for a production app polars will probably save you some cpu cycles
for analyzing a time series dataset of millions or billions of rows, definitely don't use pandas. i believe polars can do out-of-core data processing with lazy data frames, but really you'd want to consider something like spark at that point, or an actual OLAP database
definitely do not use mongo
I'll have to see what I'm actually going to end up doing with the data. I think very rarely would I ever be accessing all the data at once
Usually it will just be plotting the price trend of one product at a time
Or possibly the averages of products in a category
sorry i missed the beginning, are you asking about how to store this data?
I was, yes
so you're writing 325 million rows / week?
I guess so. Really all I need to do is add a data point per product
(assuming some of those are updates to existing entities, but you shouldn't be throwing out historical data so it's the same either way)
thats like what, 16 million rows a year?
The API design of pandas has also been more than suspicious over the years
is it? i think the only bad decision was allowing [ to be too heavily overloaded
See that sounds like a lot to me but I guess compression takes care of all the redundancy
But honestly I think I'm going to go with parquet
for an actual data warehouse like snowflake or clickhouse, or even a regular database like mysql or postgresql, that's no big deal
hell you can put all that in a single pandas dataframe in memory and have little trouble
ive worked with 1 billion rows before completely in memory using the R data.table package
lmao\
Fwiw; my main issue with pandas (and polars) is its yet another API to learn when there’s already SQL: the one data language to rule them all.
oh yeah i remember that argument. i don't agree at all (partly because SQL is a super clunky API that you have to embed in python strings) but that's a separate discussion
(Just clarifying my earlier point)
yeah its an interesting perspective
imho, most questions related to the choice of db should start with: why is postgresql not working for you? What have you tried?
i think there might be a misinterpretation, i would have thought from their phrasing it was 325k updates weekly, not ~325k inserts
#databases message #databases message
++++
You can't do a lot of transformation with SQL can you?
my argument is that the 325k updates are inserts, you don't want to throw out historical data
ask any data analyst what they think of in-place updates
you'll get groans and head shakes
ah right, cant plot data thats deleted
I used postgres in the past to try to make a database for stock prices and the GUI (forget the name) got so bogged down I couldn't use it. I didn't bother learning to use it from the command line, but I switched to parquet for that project and it worked out really well
not just that. what if the CEO wants a report of user % with profile pics over time? i can't give them the current number, i need to know who had a profile picture every month
that would have nothing to do with the GUI
pgadmin? you probably were just loading too much data at once
@bright hound how is this data actually coming to you?
Yeah I was storing streaming data from a websocket for that one, but for this project I'm going to be making async api calls
is it a weekly dump of 325k records, or is it through an API or something?
Stocks are a special case, very separate topic from general business analytics.
6500 api calls
and I did maintain my own stock and ticks data in postgres and had zero issue either.
We should not conflate the DB with whatever admin UI was being used
It was pgadmin
And I couldn't even open it to view my database because it would take 30mins to unfreeze
honestly? save each raw request/response pair to a file and figure it out later. ideally you'd use a database but there's something to be said for storing the rawest form of data possible and cleaning it up later
Not sure what the problem was
I’d either do this, or stream to a csv, or to a daily parquet. Mainly because no matter what I do, I’ll need a record in s3
I've got the data cleaned pretty much. Whittled it down to 7 columns. Figuring out how to make pandas accept a nested list when creating the dataframe
Wdym? A list of list of rows? Or columns?
1 sec

So I have a list of lists, and the last item in each sub-list is also a list
So pandas is giving me trouble about that
So you have a list of rows, but one column has a list of product categories?
You could convert the categories to a string. Or, you could onehotencode them
So the last column needs to be of type 'object' I think
oh just make more columns
I hate that
lol I'm OCD
Yah. But if you just want this to work, convert to a str
Yeah you're right. Then just split it later
When you do ml stuff, you end up needing the ‘more columns’ case a lot.
you know honestly, JSON request/response pairs are actually an OK use case for mongo
json files in an s3 bucket do a similar job though
Yeah I've studied a little bit of ML that's how I knew what you meant lol
assuming you don't need to query this data except to process it a database
Not to be a broken record but duckdb supports lists and structs as a column type 🙂
I will need to query it though. Like if I want to track the trend of the average price of Frozen sausages I'll need to be able to get that
(That was more for srl, stick with what you’re doing
Which I still could with one hot
Oh right
Not actually querying it
I'll be loading the data as needed
import pandas as pd
data = [["a", "b", "frog, cow"]]
df = pd.DataFrame(data, columns=["col1", "col2", "col3"])
dummied = df["col3"].str.get_dummies(',')
pd.concat([df, dummied], axis=1)
0 a b frog, cow 1 1```See above.
Right. Then use loc to find where cow == 1 after you read it back in from the parquet file
Or something similar
Or idk honestly if what I'm saying even makes sense. Been coding all day. Brain fried lol
how do i make a db
that's a loaded question
what db do you need/want

just to store my keys
and restic there hwid/ip
i can only speak about SQLite, if you need anything else i can't really help
idc what is it i just neeed something
you might want to do more reading on what a database is, because if i start telling you to use SQLite without you knowing what SQL database is or how you interact with it we're both going to have a hard time understanding each other
i would recommend trying sqlite because its a simple disk-based SQL database, and what knowledge you get can be transferred to other sql databases like MySQL, PostgresSQL, etc
this should get you up to speed
https://realpython.com/python-sqlite-sqlalchemy/
In this tutorial, you'll learn how to store and retrieve data using Python, SQLite, and SQLAlchemy as well as with flat files. Using SQLite with Python brings with it the additional benefit of accessing data with SQL. By adding SQLAlchemy, you can work with data in terms of objects and methods.
you dont need sqlalchemy just yet i dont think, but it's a good thing to know and learn
guys, anyone here knows mongodb atlas?
i need help with this:
raise ServerSelectionTimeoutError(
pymongo.errors.ServerSelectionTimeoutError: encoding with 'idna' codec failed (UnicodeError: label empty or too long), Timeout: 30s, Topology Description: <TopologyDescription id: 64fe05c96c3a72c737ffff88, topology_type: Unknown, servers: [<ServerDescription ('mongodb%2bsrv%3a%2f%2fhirukarogue%3adv%40plasma123%40rpucloudserver.bscpl0p.mongodb.net%2f%3fretrywrites%3dtrue%26w%3dmajority', 27017) server_type:
Unknown, rtt: None, error=UnicodeError("encoding with 'idna' codec failed (UnicodeError: label empty or too long)")>]>
i'm with problem in idna
i have my database but i can't connect to it
in atlas mongodb
greetings
anyone here care to share there fav database ?
Depends on the requirements, but for general use probably postgresql
postgresql for serious projects in most of the time. sqlite3 for pet projects 😅
For my pet analytics projects, duckdb. Can’t believe you didn’t mention it
with docker/podman, it's so easy to get postgres up and running anyway
😅 i thought to mention it, but due to lack of personal experience i did not.
plus it is after all specialized database that requires extra library drivers, while sqlite3 works out of the box most of the time
It’s just a pip install away! Otherwise practically the same as sqlite3. No setup/config/etc.
But yes for op: PostGres is the first stop for most ppl
pet projects are things for long term maintenance to me. any extra library usage counts. and if i have less depenendecies, that's nice.
i write in advance that i will be returning from time to time year/years later to them.
Honestly even for pet projects I'd prefer posgresql - more features, no pitfalls such as disabled foreign keys by default
PostgreSQL #cal
if you dont know what the #cal reference is, look up on google where postgres was first made
Hint: It's the same university that made BSD
and berkeleydb, alluxio, spark, etc.
i mean UC Berkeley apps are open rn so feel free to apply lol
yep agreed
what db does that?
sqlite has foreign keys disabled by default If I'm not mistaken?
ay yes, DATA
Indeed, also some weird type validation if I remember right due to legacy issues.
you can enable it pretty easily though
I know, but honestly foreign keys should be enabled by default
yeah... Unfortunately backwards compatibility is a bitch
hi
i have this function
def to_datetime(_v: Optional[str]) -> datetime.datetime:
if _v is None:
return datetime.datetime.now(datetime.timezone.utc)
date = datetime.datetime.strptime(_v, "%Y/%m/%d %H:%M:%S").replace(tzinfo=datetime.timezone.utc)
return date
that returns two datetime aware objects, i pass these datetime aware objects to asyncpg and it raises:
Ignoring exception in slash command 'create':
Traceback (most recent call last):
File "asyncpg\protocol\prepared_stmt.pyx", line 168, in asyncpg.protocol.protocol.PreparedStatementState._encode_bind_msg
File "asyncpg\protocol\codecs/base.pyx", line 206, in asyncpg.protocol.protocol.Codec.encode
File "asyncpg\protocol\codecs/base.pyx", line 111, in asyncpg.protocol.protocol.Codec.encode_scalar
File "asyncpg\pgproto\./codecs/datetime.pyx", line 152, in asyncpg.pgproto.pgproto.timestamp_encode
TypeError: can't subtract offset-naive and offset-aware datetimes
but they're both offset-aware datetimes, are they?
please clarify what do you mean by "both"?
i have two variables that represent a date in the following format "%Y/%m/%d %H:%M:%S", on both i'm calling the to_datetime method and passing them to asynpg to be inserted into my table, now they should be both offset-aware datetimes
it would be beneficial to post the snippet of code where to_datetime is used as well.
and is that the entire traceback?
Pasting large amounts of code
If your code is too long to fit in a codeblock in Discord, you can paste your code here:
https://paste.pythondiscord.com/
After pasting your code, save it by clicking the Paste! button in the bottom left, or by pressing CTRL + S. After doing that, you will be navigated to the new paste's page. Copy the URL and post it here so others can see it.
what's the column type of created_at?
https://github.com/MagicStack/py-pgproto/blob/881be4cbd24ebae2fe45c79a434b2168ebb0ae6c/codecs/datetime.pyx#L152
it's failing when it's encoding your datetime object in preparation to transmit over to PG.
id SERIAL PRIMARY KEY,
created_by bigint,
starts_at timestamp,
ends_at timestamp,
winner_numbers integer,
win_goal integer,
prize text,
partecipants bigint[],
title text NOT NULL,
description text NOT NULL
codecs/datetime.pyx line 152
delta = obj - pg_epoch_datetime```is pg_epoch_datetime a tz aware object?
codecs/datetime.pyx line 17
pg_epoch_datetime = datetime.datetime(2000, 1, 1)```then isn't that the issue?
sorry, isn't what the issue?
timestamp you have in your table definition is timestamp without time zone
asyncpg/pgproto is using the encoding function for timestamp without time zone correctly, which uses tz naive pg epoch
yet you have supplied a tz aware datetime object to the query, as such it blew up with such a cryptic message in the encoding function
https://www.postgresql.org/docs/current/datatype-datetime.html
reference for
timestamp you have in your table definition is timestamp without time zone

PostgreSQL Documentation
8.5. Date/Time Types 8.5.1. Date/Time Input 8.5.2. Date/Time Output 8.5.3. Time Zones 8.5.4. Interval Input 8.5.5. Interval Output PostgreSQL supports the …
im using sql for storing the body text of my blog posts with django, is sql good for this application?
it should be fine as your database supports unlimited-length strings
you'll almost certainly never get useful help asking questions like this. it forces people to "interview" you to even determine if they can answer your question. the general principle is "don't ask to ask". just state your question.
also this is a python server, java questions aren't on topic
My bad im so sorry won't happen again
same here ! Django framework come bulit in with sqlite3 im sure other frameworks do the same thing
You should use the ORM, not raw sql.
so its wrong if i make a model then do body = models.TextField()?
That's fine
I don't know if this is the correct channel to talk about the subject. But i'm syncronizing a microsoft sql database to a mysql database. But there a some columns with file stored in base_64 in it. This is really slow to copy and bottlenecking my speed. How should i approach this to fasten it up
😅 store the files in something like s3 rather than the DB
If these are big files, you are always going to be killing your DB
Yeah, I know but I didn't start the project and have to clone the db nightly
I know it's a bad approach but i'll have to work with it :p
The other way to speed it up is to throw more money at the problem, I e. nvme disks, more memory for more caching
Hmm obviously :p
Ok thanks for the insights, i was hoping for a little magic but i guess i'll just run them in batches and cope with the long runtime
you could maybe look to see if you can incrementally update the DB? Like actually do the duplicatation to the second DB when it happens rather than doing it all at once
Or maybe... If it's supported dump MSSQL DB to a flat file like parquet, CSV, etc... and then ingest that way
ow, the csv route is actually quite interesting. I'll check to do it that way. cause there is one table already with 40K records and 4 of those columns so it's really thrashing the speed
MySQL also supports different storage engines, such as external csv files. Some thing to look into
(So you don’t have e to mount the entire dump). But yah, generally; externalize you large blobs lest you end up with an unrecoverable database
Me: I’d consider exporting to parquet files. But everything I do involves parquet nowadasys
I'll read me in on parquet! Projects like this are quite new to me, but already learned a ton thanks!
Hola
Alguien habla español?
Aqui no

La comunidad hispanohablante de Python más grande del mundo 🐍 🎉
does anyone know the right way to do declarative base in sql alchemy 2.0? I'm updating to the latest and i want to not get this warning anymore
The ``declarative_base()`` function is now available as sqlalchemy.orm.declarative_base()
do i import it differently now?
yes:
https://docs.sqlalchemy.org/en/20/changelog/migration_20.html#declarative-becomes-a-first-class-api
The
sqlalchemy.ext.declarativepackage is mostly, with some exceptions, moved to thesqlalchemy.ormpackage. Thedeclarative_base()anddeclared_attr()functions are present without any behavioral changes.
although declarative_base() is also superseded by the DeclarativeBase class
Is 15 days a plausible amount of time to develop a mobile app that can perform and update database interactions in real time from scratch?
Taking chatgpt into account too
Why is this:
@group.command(name="decree", description="Store a mayoral decree to the database")
@app_commands.checks.has_any_role(583496754712805376, 1087922383698014279)
async def decree(self, interaction: discord.Interaction, decree_name: str, decree_number: int, signed_by: str, decree_status: str, decree_link: str):
if decree_link.startswith("https://drive.google.com/file/d/") or decree_link.startswith("https://forums.stateoffirestone.com/") or decree_link.startswith("https://docs.google.com/document/d/"):
async with aiosqlite.connect("/home/pi/Documents/Arborfield_Automation/arborfield_backup.db") as db:
message = await interaction.response.send_message("Storing decree to database...", ephemeral=True)
try:
await db.execute(f"INSERT INTO decrees values('{decree_name}', {decree_number}, '{decree_status}', '{signed_by}', '{decree_link}')")
print(f'Added Mayoral Decree {decree_number} - {decree_name} to database')
await db.commit()
print('Saved')
await message.edit(content="Decree stored to database!", ephemeral=True)
except Exception as e:
await message.edit(content=f"Error: {e}", ephemeral=True)
print(f'Ignoring exception in command decree: {e}')
pass
pass
else:
await interaction.response.send_message("Use a Google Drive or Forums link", ephemeral=True)
pass
pass```Creating this error?
Traceback (most recent call last):
File "/home/pi/Documents/Arborfield_Automation/cogs/arborfield-automation-store.py", line 20, in decree
await db.execute(f"INSERT INTO decrees values('{decree_name}', {decree_number}, '{decree_status}', '{signed_by}', '{decree_link}')")
File "/home/pi/.local/lib/python3.9/site-packages/aiosqlite/core.py", line 184, in execute
cursor = await self._execute(self._conn.execute, sql, parameters)
File "/home/pi/.local/lib/python3.9/site-packages/aiosqlite/core.py", line 129, in _execute
return await future
File "/home/pi/.local/lib/python3.9/site-packages/aiosqlite/core.py", line 102, in run
result = function()
sqlite3.OperationalError: no such table: decrees```Look at the last line of your error?
sqlite3.OperationalError: no such table: decrees
It means it could not find such table

is it connecting to the same db?
It may be worth logging which db it's connecting to and listing the available tables on start
Oh...
Whoops
Bruh, today has just been one of those days
It happens. That's why it's good to have a rubber duck or to talk it out
I perfect bonking sticks
random but I've started using regex so much in my job and I'm loving it. previously I was relying on the limited LIKE operator in Snowflake lol
easy, more seductive
hi,
In psycopg2 is is possible to catch this exception type? ObjectNotInPrerequisiteState
I tried to write except psycopg2.ObjectNotInPrerequisiteState:, but PyCharm is telling me that doesn't exist
it does let me write this though: except psycopg2.OperationalError:
here's where the exception I'm talking about is listed: https://www.psycopg.org/docs/errors.html
Its the error code
not an actual type
so you need to catch the operational error
and then get the error code from that
e.g.
try:
cur.execute("LOCK TABLE mytable IN ACCESS EXCLUSIVE MODE NOWAIT")
except psycopg2.OperationalError as e:
if e.pgcode == psycopg2.errorcodes.LOCK_NOT_AVAILABLE:
locked = True
else:
raise
thanks!
seems to work fine importing psycopg2.errors.ObjectNotInPrerequisiteState
see also the part of the documentation just below this snippet showing the psycopg2.errors namespace being used

ah yeah, you're right

use types-psycopg2 from typeshed
https://pypi.org/project/types-psycopg2/
it will reveal the dynamically generated types to your editor for type checking/hinting purposes
see: https://github.com/python/typeshed/blob/main/stubs/psycopg2/psycopg2/errors.pyi
if you inspect the source of psycopg2, you will see the types are infact dynamically generated and highlights the need of using something from typeshed (or anything that provides the correct *.pyi really..)
(edit: as mentioned below, you would still need to do a import psycopg2.errors even with types-psycopg2, i forgot to mention this)
the error message says __init__.pyi so i think it is correctly using the typeshed, but there's no mention of an errors module in that type stub
i guess as a workaround you can explicitly import psycopg2.errors
Does anyone have experience using SQLServerAgent to run SSIS Packages that execute Python scripts?
Or any suggestions on a means to schedule my scripts to run regardless if my machine is online or not?
liuljhhhh,h
Hello
hi
I'm getting a sqlite3.IntegrityError: UNIQUE constraint failed: Canada.line_name error even though I'm using update
UPDATE {country} SET line_name = ?, `0-7` = ?, `8-15` = ?, `16-25` = ?, `26-40` = ?, `>40` = ?, undelivered = ?, cache_time = ?
What could be the problem?
Are there certain rules that can determine whether it makes sense to create a reference table based on the number of distinct values and the max length of those values?
You don't seem to have a where clause there? So you're setting all rows to be the same line name
what is a reference table?
Hi! Is it possible to get the inserted IDs after bulk-inserting rows using insert described at https://docs.sqlalchemy.org/en/20/orm/queryguide/dml.html#orm-bulk-insert-statements?
Simplified example of my code:
session.execute(insert(model), inserted_rows)) # inserted_rows = list of dicts
session.flush()
# return inserted_row_ids
I previously did it row by row which allowed me to access the id after each add/flush:
session.add(inserted_row) # inserted_row = SQLAlchemy object
session.flush()
return inserted_row.id
Not very familiar with sqlalchemy but that's usually done via a RETURNING clause, and looks like bulk insert statements support it: https://docs.sqlalchemy.org/en/20/orm/queryguide/dml.html#getting-new-objects-with-returning
not sure offhand how to make the ORM return only the id and not the entire object, though
Oh, thats nice. Probably returning(User.id)
returning(User.id) works. Thanks for a quick response
If you're using orm just add a model
session.add_all(models)
await session.flush()
print([model.id for model in models])
It should bulk insert them, I don't see a good reason to use raw insert there 
hmm
2.0.20
And what db?
postgresql + psycopg3
I think it should work that way already
enable echo flag on your engine and see what sql it produces to be extra sure
Looks good, thanks for the input
Hi,
i have a sqlite query as below which is working fine
query = SELECT * FROM JIMBO
WHERE emp_id IN %(emp_id)s
execute_query(query, 1)
but, when i try to query an emp_id which is not in DB,
sqlite3.OperationalError: near "%": syntax error
do guys consider the database name to be senstive info? something you would put in the .env?

tfw the reason your spark-submit was keep throwing "classNotFoundException" is because your class name had single capital letter instead of lower case along spark-submit line, and that capital letter looked like it was part of actual class name.
No.
I suppose maybe you could use a complex database name and treat it as a secret if you want that extra layer of security, but this doesn't seem to be a normal practice... probably not worth the inconvenience in most use cases
Logical database name also known as dbname? no
Domain address? may be. 🤔 but if i made proper private network setup, then no
I think a reference table is a type of table that stores data that you reference in other tables. For example, if you have a warehouse, you might have a shipping status reference table. Instead of typing in "shipped", "processing", etc for each order, you would just reference the ID of the status in the Status (reference) table. If you have lots of rows, it might save space to store integers instead of a varchar with many characters.
A few points: Many/most OLAP engines will employ various compression techniques to make this unnecessary.
Enum fields are also helpful: far more efficient than joining on a second table for the lookup
😫
Oh Interesting. I didn't know this.
Honestly I'm not too sure about what I care about most in my case: query speed, ease of writing queries, or the size of the DB. I should probably think about this.
For example, duckdb is an in memory OLAP db that employs a number of compression techniques: https://duckdb.org/2022/10/28/lightweight-compression.html. These techniques are similar to other OLAP dbs and formats like parquet
I'm still pretty new to this stuff so I'm not sure if this is related to what you are saying but I will be using MySQL on my local machine for the foreseeable future of this project.
Then look at ENUMs, if you have a lot of constant values
After reading a bit about them, it sounds like you can't add to the list of values because it is created at the time the table is created. That being said, for some of my values, it is unlikely that I will need to add to them.
You can add, see: https://dev.mysql.com/doc/refman/8.0/en/alter-table.html
ENUMs are just stored as ints, so modifying makes sense when you’re adding a new possible value
In that case, perhaps I could get some use out of ENUMs.
Changing topic. After doing some reading online I've come to the conclusion that 1:1 relationships shouldn't exist and should be merged into a single table. Would you agree with this statement? If so, why? If not, why not?
, 1:1 is often 1:[0,1], and it’s cleaner to model as two separate tables, especially if second is sparse
Logically, one giant flat table can cause performance problems in row oriented databases: the cost of retrieving each row is a factor. In OLAP, which is generally columnar, this is less of a concern
Sometimes you might just need to join against one or the other, so there potentially a cost of a giant wide table
So, it’s a good thought and worth considering: usually wide is simpler and more performance, but not as a rule
I do have a 1:[0,1]. However, I have many more that are actually 1:1. I was using this 1:1 relationship to organize attributes that were similar. Is this not necessary, or worse, inefficient?
In OLAP, we tend to go wide, in transaction, small is fast
It’s like object oriented design: start based on the classes- separate tables for separate things, not for attributes of a thing
This is a great analogy.
Hi, I have a database with which I'm accessing with Sqlite3. I can commit data into it, which I can see if I open the .db file. And I can see the data with a select query. But if I close my python file and run it again, the data is still in the database file, but I cannot select it with a query, does anybody know what's going on?
Share your code?
Kerckhoff’s Principle states: “Don’t rely on keeping secret anything you can’t easily change”. Can you easily change your database name?
what no
Depending on your setup it might not be that hard
you might put it in .env because you might use different database names in different envs, the .env idiom is not only for secrets
just pass your db name as a part of your uri connection string
i have 1 file nyp how to open ít
hi
alter user system ACCOUNT UNLOCK
Error report -
ORA-01031: insufficient privileges
01031. 00000 - "insufficient privileges"
*Cause: An attempt was made to perform a database operation without
the necessary privileges.
*Action: Ask your database administrator or designated security
administrator to grant you the necessary privileges
Nice error message you found there. Did you do what it says? If you're stuck see #❓|how-to-get-help
Hi i installed mariaDB and mySQL workbench but when i try to connect to the server i get the following error Authentication plugin 'auth_gssapi_client' cannot be loaded: The specified module could not be found. I read online and it says that the module should come with the mariaDB installation so im not sure why i get this problem.
How can I fix this error with aiosqlite?
@app_commands.commands.command(name="unrole-stript", description="nothing")
@app_commands.checks.has_any_role(owner_role, co_owner_role)
async def unroe_stript(self, interaction: discord.Interaction, member: discord.Member):
async with self.bot.db2.cursor() as cursor:
await cursor.execute("SELECT role FROM user =?", (member.id))
role = await cursor.fetchone()
await member.add_roles(role)```
what is the column name you are trying to compare with your member ID? a WHERE clause needs to be used to filter your rows
Just forget it I already fixed it
oh alright
But however
how could I fix this formatting?

@app_commands.commands.command(name="warn-check", description="checks if you have a warn or not")
@app_commands.checks.has_any_role(mod_role)
async def warn2(self, interaction: discord.Interaction, member: discord.Member):
embed = discord.Embed(
title="Warns",
description=member.mention,
color=discord.Color.red()
)
async with self.bot.db3.cursor() as cursor:
await cursor.execute("SELECT reason FROM warn WHERE user =?", (member.id,))
#mod = await cursor.execute("SELECT mod FROM warn")
warn = await cursor.fetchall()
for user in warn:
embed.add_field(name="Warns", value=user, inline=False)
await self.bot.db3.commit()
await interaction.response.send_message(embed=embed)
fetchall returns a list of records. Each record consists of multiple columns, even though you may have selected one column, so it's a tuple (the warn table record which you named user in the for loop consists of only reason so the tuple consists of one item)
You just need to use user[0] when setting the value of the embed field
The names of the variables are all wrong. warn and user are grossly misleading, leading to some of your confusion.
result = await cursor.fetchall()
for row in result:
(user, ) = row
would be much better
uggh no wait
you are selecting reason, not user
(reason, ) = row is the correct line there
hi, I am having a problem with mySQL database in Xampp, it does not start at all, have anyone know why?(apache and proftpd is working properly)
running linux
Any resource on query performance optimization?
Do you mean how databases do it? There's a number of academic papers (and industry) on this topic... the tough part is that every database optimizes differently, although for most intents and purposes, it's not so complicated.
Or do you mean, how to optimize a query that you've written? I've never seen a great text on this... there are some intros/etc on query tuning, focused on indexing and analyzing query plans. That's really where most people start.
this
yeah ive read abit on how a database plans and executes a query
Good (experts?) study their databases "explain plan" output, and in particular, the intricacies of certain paths: the subtleties of how, say, MYSQL vs Postgres handle certain optimizations do matter.
Yah, I think there's three skills involved: understanding the domain/data model - you can often do things differently (optimize upstream of the database, for instance, such as via caching/etc. Understanding indexes and the various indices available in your particular database. And, understanding the details of your databases implementation... at least at more than a superficial layer. And... for bonus: data types / layout optimization. Sometimes laying the data out differently can help with certain types of problems.
ait thanks, seems like i just need to read up and understand how a db runs the query and reading the analyze/explain
https://use-the-index-luke.com/
you might find this useful

SQL indexing and tuning tutorial for developers. No unnecessary database details—just what developers need to know. Covers all major SQL databases.
What database are you using?
postgres currently
I don’t know your skill level, but the ‘expert’ level is to understand stuff like this; https://write-skew.blogspot.com/2018/01/parallel-hash-for-postgresql.html?m=1. This is after understanding index placement, the different types of indices, etc.
- I might not really be helping with my answers because perhaps you just needed something like ry posted, rather than the advanced stuff
please can someone help me out here all my sqlmap scan

Hey I am having problem in writing SQL query for this
The public dataset of Ubereats available on BigQuery can be accessed using -
SELECT * FROM arboreal-vision-339901.take_home_v2.virtual_kitchen_ubereats_hours LIMIT 10;
It has several columns and in response column there is json data from where I have to extract endTime and startTime
This is the JSON structure I have attached.
Please if possible provide or help in sql query

Can i have 2-3 instances of an app connected to a single sqlite3 database?
For read only? Yes
For write? I think u can if u enable WAL mod
Test thoroughly that, sqlite3 is trigger happy to lock write access in case of trouble
Ideally u just should use
Postgres if u need that, it is properly multi app accessable
Thought about switching to mysql. Just gotta look into the enterprise aspect of it.
Switch to postgresql 🙂 it is superior
Ive never used anything outside of sqlite3 so im fairly maliable lmao
Sucks that I have to switch to webapp though lmao.
Best switch to Django 😄
best idiot proof decision
if u will just use Django boilerplating tools to maximum, u will be able to screw up far less
Flask newbies can screw up way worse
i would assume u need to make Rest API / JSON inputs/outputs?
Try Django Ninja, it is rather cool and will generate automatically documentation for your endpoints :). Otherwise Django Rest Framework is a more common choice.
Also... main recomendation... try to have written unit tests for your applications 🙈
applications written in python without unit tests are usually screwed up beyond recoverability always
My portfolio was made with flask so I’m somewhat familiar with it.
I’m making a management system.
I know. I’ve been pushing it off my my personal management system but now that the first window is fully functional, I’m going to go back and write some test.
what is it managing?
will it need Moderator/Administrator input to add data?
Django has an awesome feature called Django Admin
boilerplated the hell out of it, Admin web site creator
Pretty much stuff admin level access out of the box
I should’ve call it a management system. It’s more of a data collection system. I’ll have a login but it doesn’t need to be secure. Just enough of a deterrent to keep the customer from trying to log in.
Users will input two sets of data, production data or downtime data. And it will create reports based on the information in the database.
I wish I could show you but since I started working on it from a company laptop it’s their property and I have no ownership over it lol.
Sounds like u just need pure Django then
it will still benefit u greatly in comparison to Flask
because Django has FAR easier to use ORM interacting with db
everything is configured out of the box 😉 including easy to use mgirating system
I’ll look into it.
I am just starting to use databases. I currently am using mongo and creating collections of different data for stocks as far as company management team, job titles, names, company, ticker, etc. I have very little experience and after reading, I want to ask you all this. What database should I learn how to structure financial data with? I like the visualization aspect of the mongodb compass application. I want to stress I am just learning. I see this as needing to track relationships between people and companies, as well as people and their job titles as well as the companies that employ them (sometimes more than 1), companies latest: dcf, cash flow statement, revenue report, expense report, balance sheet, esg ratings, historical earnings, etc.(lots of numerical data with relation to the companies), sec fillings for each company, and lobbying information from each company (keyword search, numerical filter). Open to any suggestions on what to start with. again, I do well when I have a visual such as mongo compass. not stuck on mongo though.
can probs read data warehouse toolkit, got examples there
SQL seems be more suited for this. Most finical intuitions use SQL databases such as PostgreSQL in one way or another
if you are doing more analytical stuff, then use a analytical DB such as snowflake to do the analysis on instead. If your data is massive, then probably look into data warehouses instead
I see this as needing to track relationships
Hehe.,.. SQL databases are called Relational Databases for a reason.
Postgresql advising for real work too
It is universal database serving well for all cases until u reached TBs of data
At some point more specialized dbs for specific usage causes could be wished though
Could anyone help me to understand how to compare value from PG array with 'like' statement? SQLAlchemy 2.0
or_(
Packaging.barcode.like(q),
any_(Packaging.additional_barcodes).contains(q),
any_(ClientContactsNotification.phones).contains(q),
)
)```
So I need to check 2 arrays if any string contains symbols (param `q`)As others have said, you want a relational (SQL) database. If you have any trouble getting started with Postgres, look at SQLite which is easier to manage but not that different
Thanks! @halcyon dew @wise goblet @fading patrol
who good with excel? i got a question i can pay pm me right now
!rule 9
Can I connect to postgre over wifi?
Sure, why not. Wifi is creating local network as far as I know
And where u can make TCP connection, u can connect postgres
Sounds like I’ll have to get IT involved because that’s over my head.
yeah
you overcomplicated the explanation
poor guy got confused
I'm not confused, just working on a network I don't have that level of access to. Fairly certain the PC ill be working on is isolated on its own network as the location and thus network belongs to the customer and not my employer.
can you access the internet via wifi?
if that's a yes then you can access the postgre
Not sure, I’m not at the facility. Was just told I’ll be going there to set up a script I wrote. I know at my main location, I cannot access the wifi. Its password protected which means I would need IT to set my our devices (highly doubt they’ll just give me the password lol)
Hello, I just wanted to get an idea as to how to go about it. I'm thinking of using python to retrieve JSON data from a website and load it into postgreSQL data base. However, I want to create make it such that the new data is updated daily from the website onto my database. How should I go about it?
You could set up a cronjob (or a task scheduler job) to run your script every day.
My friend showed me a google program that could take a json dump and had a user interface that showed all of the data as intended. If you know of something else that can take this json and store it while being able to visualize the individual arrays I'd like to know. I'm probably just missing something fundamental. Here is the Json, it is different financial analysis data exported from OpenBBTerminal. earnings, cashflow, earnings estimates, balance sheet, revenue, growth, discounted cashflow, etc. total of I think like 10 tables per dump but I'm trying to start with the whole S&P500. @halcyon dew @wise goblet, suggestions?
Hello everyone!
I have to do a project using machine learning but I would like to know if anyone has an interesting dataset to share with me?
would you like to have access to the fmp pro api key for ESG Rating analysis?? @slim sleet
If you can assist me in managing the api then I can get LOADS of financial data. no real limit on usage
I'd like to know about the % of company shareholders over time as it corresponds to ESG popularity growth among institutional investors. I could also have you analyse datasets of SEC filings by vanguard that are written by the 'Alladin' model.
How fast is a Sql select count(*) compared to a Python len function?
u need to learn normalization in order to properly structure your data to SQL tables
i can recommend "The manga guide to databases" for getting started
if u will not learn proper normalization, your SQL will suck ^_^
Sqlite3Browser is great to navigate sqlite
Beekeper Studio is good universal SQL interactive GUI in general ( i use it for postgres usually, sometimes for other engines like mariadb/mysql)
I will check those out and do some learning about normalization! Thank you
until u got experienced with SQL, recommending always normalizing to 100% capacity your data. Let SQL engine work for you, don't use silly Arrays/JSONs if u don't understand normalization yet
Exception can be given to trully Enum data (very limited amount of constant value choices that is not going to be ever changed probably). This is fine to denormalize for sure
S&P500 is absolutely massive. Just as the other person responded, it's best to learn about data normalization for this
if anyone could help me solve this

and just explain what a join is in general using that above questio
i know the answer but im just really confused
BCNF is what I did with the s&p500 company name and ticker list and then used the ticker as a field in the management teams of each company. I made 2 separate collections with that idea in my head but not understanding what i was trying to do! Thanks🤯🤝
If I’m totally miss understanding bcnf lmk
That was just the format that the OpenBB Terminal(api management hub), exports the data as. I can either choose json, csv, or xlsx. But now I am starting to work directly with the financialmodelingprep api. I can export with the same name (structured as {data type}_{TICKER}.{json or csv}, so that after the data is updated and the database updates with time stamp, the old data gets overwritten, therefore only the database grows and my data for time series analysis is in the database. The export folder should end up being the same size and same structure of data everyday theoretically.
If I already have the automation to pull revenue forecasts, cash flow analysis, balance sheet, dcf cash score, earnings history, earnings estimates, and income statements… automatically format itself into a layered json dump… also maintaining each csv file that is composed in the dump… and it translates perfectly in google big query… how far off am I from getting this into a solid format? Does this, being over a period of time with a number of entries following the same data frame, normalize it in a horizontal sort of way?
so whats the answer?
(2, 4)🤞
ChatGPT:
import pytesseract
from PIL import Image
Load the image from the provided path
image_path = "/mnt/data/5C7E6F87-BB95-4915-BCD8-24E20CF98987.png"
image = Image.open(image_path)
Use pytesseract to extract text from the image
extracted_text = pytesseract.image_to_string(image)
extracted_text
The provided image contains two tables: LOAN and BORROWER.
The LOAN table has the following structure:
[
\begin{array}{|c|c|c|}
\hline
\text{LOAN_NO} & \text{B_LNAME} & \text{AMOUNT} \
\hline
\text{L-170} & \text{DELHI} & 3000 \
\text{L-230} & \text{KANPUR} & 4000 \
\hline
\end{array}
]
The BORROWER table has the following structure:
[
\begin{array}{|c|c|}
\hline
\text{CUST_NAME} & \text{LOAN_NO} \
\hline
\text{JOHN} & \text{L-171} \
\text{KRISH} & \text{L-230} \
\text{RAVYA} & \text{L-170} \
\hline
\end{array}
]
The question is: How many rows and columns will be there in the natural join of these two tables?
A natural join combines rows from two tables based on the equality of specified columns. Here, the common column between the two tables is LOAN_NO.
Let's find out how many rows and columns will be there in the natural join of these two tables.
Data for tables
loan_data = [
{"LOAN_NO": "L-170", "B_LNAME": "DELHI", "AMOUNT": 3000},
{"LOAN_NO": "L-230", "B_LNAME": "KANPUR", "AMOUNT": 4000}
]
borrower_data = [
{"CUST_NAME": "JOHN", "LOAN_NO": "L-171"},
{"CUST_NAME": "KRISH", "LOAN_NO": "L-230"},
{"CUST_NAME": "RAVYA", "LOAN_NO": "L-170"}
]
Perform natural join on LOAN_NO column
natural_join = []
for loan in loan_data:
for borrower in borrower_data:
if loan["LOAN_NO"] == borrower["LOAN_NO"]:
combined_data = {**loan, **borrower}
natural_join.append(combined_data)
Number of rows and columns in the result
num_rows = len(natural_join)
num_columns = len(natural_join[0]) if natural_join else 0
num_rows, num_columns
(2, 4)
The natural join of the two tables will have 2 rows and 4 columns.
Join:
A join operation in databases combines rows from two or more tables based on a related column between them. It allows querying data from multiple tables as if they were a single table. There are several types of joins:
- Inner Join (or simply Join): Returns only the rows for which there's a match in both tables.
- Left (Outer) Join: Returns all rows from the left table, and the matched rows from the right table. If there's no match, the result will contain NULL.
- Right (Outer) Join: Returns all rows from the right table, and the matched rows from the left table. If there's no match, the result will contain NULL.
- Full (Outer) Join: Returns all rows when there's a match in either the left or the right table. Rows that do not have matching counterparts in the other table will contain NULL values.
- Self Join: Joins a table with itself. This can be useful when the data related to one row can be found in another row of the same table.
- Cross Join: Returns the Cartesian product of the two tables. It returns every combination of rows from the two tables.
Natural Join:
A Natural Join is a type of join that is based on column(s) with the same name in both tables. When performing a natural join, the database system:
- Looks for columns in both tables with the same name.
- Performs an inner join on these columns.
- Returns only one column for each pair of columns with the same name (i.e., it doesn't duplicate columns).
For instance, given two tables with a common column "ID", a natural join will combine rows with the same "ID" value from both tables. The resulting table will have only one "ID" column.
It's important to note that while natural joins can be convenient, they can also be risky if the schema of the tables changes or if columns with the same name have different meanings in different tables. For this reason, it's often recommended to explicitly specify the columns on which you're joining, as you would with an inner join.
-openai
I know this is a db chat but does anyone use obsidianMD? thinking about starting a new vault for database definitions and relationships.
!rule 10 , this is exactly forbidden
dont post chatgpt answers lel
Basically i did this in Sqlalchemy
query = select(User, Attendance).join(Attendance, (User.id == Attendance.user_id) & (Attendance.date == date.date())) \ .where(User.designation_id != None, User.organization_id == organization_id)
suppose there is user and attendance model. user may or may not have attendance in a particular date.
now write a query that will fetch all the users of a organization along with the attendance object of a given date. if any user doesnt have attendance on given that date that user will still be listed but their attendance will be null.
how can i do it in django ?
4 columns 2 rows i figured it out tho my textboik puts it really bad
my fault, I thought since it was a hypothetical... and I wanted to know if what I was learning was correct. is the answer (2, 4)?


yep it is
would anyone know the answer
probably, but it's frowned upon to ask people for answers like this
"you're only cheating yourself"
what is thats mean? discord.ext.commands.errors.CommandInvokeError: Command raised an exception: TypeError: 'int' object is not subscriptable
thats in SQLite
it means what it says. you tried to use x[i] syntax on an int, which does not support x[i] syntax (sometimes called "subscripting"). you need to look at your code to figure out why it happened. the "traceback" part of the error message will tell you where it happened, so you can investigate.
guys have i made relationship correctly, it should delete exp if user gets deleted , i using sqlalchemy
class User(Base):
__tablename__ = 'users'
id: Mapped[int] = mapped_column(primary_key=True)
guild_id: Mapped[int] = mapped_column()
user_name: Mapped[str] = mapped_column(String(32))
avatar_url: Mapped[str] = mapped_column(String(128))
exp: Mapped["Exp"] = relationship("Exp", back_populates="user", uselist=False, cascade="all, delete-orphan", single_parent=True)
def __init__(self, id: int, guild_id: int, user_name: str, avatar_url: str):
self.id = id
self.guild_id = guild_id
self.user_name = user_name
self.avatar_url = avatar_url
def __repr__(self):
return f"<User(id={self.id}, guild_id={self.guild_id}, user_name={self.user_name}, avatar_url={self.avatar_url})>"
class Exp(Base):
__tablename__ = 'exp'
id: Mapped[int] = mapped_column(ForeignKey("users.id"), primary_key=True)
level: Mapped[int] = mapped_column()
exp: Mapped[int] = mapped_column()
user: Mapped["User"] = relationship("User", back_populates="exp", uselist=False, cascade="all, delete-orphan", single_parent=True)
def __init__(self, id: int, level: int, exp: int):
self.id = id
self.level = level
self.exp = exp
def __repr__(self):
return f"<Exp(id={self.id}, level={self.level}, exp={self.exp})>"
there is not a need for a second 1-1 table. Just include the exp within the user table
also applies to the level col
As @halcyon dew mentioned - there's probably no need for a second table, for automatic deletes you could use foreign keys though and their cascade option
Oh , k thanks
Thank u
Np
What type of structure should I use , do I need relationship in my table like relationship of user and exp?
Well, you already have a relationship there
You just need to add ondelete to your foreignkey
Is my relationship correct according to you?
guys how can i fix this error
qlalchemy.exc.ArgumentError: Error creating backref 'user' on relationship 'User.rank': property of that name exists on mapper 'Mapper[Rank(ranks)]'
class User(Base):
__tablename__ = 'users'
user_id: Mapped[int] = mapped_column(primary_key=True)
guild_id: Mapped[int] = mapped_column()
user_name: Mapped[str] = mapped_column(String(32))
avatar_url: Mapped[str] = mapped_column(String(128))
rank: Mapped["Rank"] = relationship("Rank", backref=backref("user", cascade="all, delete-orphan"))
def __init__(self, id: int, guild_id: int, user_name: str, avatar_url: str):
self.id = id
self.guild_id = guild_id
self.user_name = user_name
self.avatar_url = avatar_url
def __repr__(self):
return f"<User(id={self.id}, guild_id={self.guild_id}, user_name={self.user_name}, avatar_url={self.avatar_url})>"
class Rank(Base):
__tablename__ = 'ranks'
user_id: Mapped[int] = mapped_column(ForeignKey('users.user_id'), primary_key=True)
level: Mapped[int] = mapped_column()
exp: Mapped[int] = mapped_column()
user: Mapped["User"] = relationship("User", backref=backref("rank", cascade="all, delete-orphan"))
def __init__(self, user_id: int, level: int, exp: int):
self.user_id = user_id
self.level = level
self.exp = exp
def __repr__(self) -> str:
return f"<Rank(user_id={self.user_id}, level={self.level}, exp={self.exp})>"
i am using sqlalchemy
CREATE TABLE store
(store_name varchar (15),sales int (8),st_manager varchar (20));
INSERT INTO store
(store_name,sales,st_manager)
VALUES (colombo, 1200, Perera);
INSERT INTO store
(store_name,sales,st_manager)
VALUES (Kandy, 8000, Silva);
SELECT *
FROM store;
SELECT store_name, sales
FROM store;
WHERE sales >=6000;
SELECT store_name, sales
FROM store;
WHERE store_name = 'Silva';
UPDATE store
SET sales = 10000
WHERE store_name = 'Silva';
ALTER TABLE store
ADD (telephone int (10));
Can someone tell me if this SQL code I have written is correct?
It’s not. You have where’s by themselves. Alter table is missing ‘add column’, etc.
whdm by "where's by themselves"?
I'm a beginner so I have no idea wht u mean by tht
Semicolons divide sql into separate statements. Separate what you wrote by each semicolon and look at each statement
Can I somehow use ON CONFLICT DO NOTHING with SQLAlchemy's session.add_all()? I'm inserting multiple rows, some of the data will already exist and will trigger my UniqueConstraint set on the table. I want to ignore this data but insert the ones who are OK.
you might need to use the lower-level sqlalchemy core syntax https://docs.sqlalchemy.org/en/20/dialects/postgresql.html#sqlalchemy.dialects.postgresql.Insert.on_conflict_do_nothing
i remember looking into this kind of thing recently and i don't believe Session.add supports it
that is, you can use ORM objects, but you have to use Core syntax
Cant bulk insert then?
the docs only show it working with dicts and not ORM objects https://docs.sqlalchemy.org/en/20/orm/queryguide/dml.html#orm-bulk-insert-statements
maybe you can pass a list of ORM objects though? i never tried it
Will give it a shot at work tomorrow
If performance is not critical just filter out existing records
Anyone that can help with a difficult sql issue i've been stuck on for days. I want to create a view that has 2 CTE's. One of the CTE's uses the
sql ROW_NUMBER() window function which partitions based on two rows, with an order by. I then join these two cte's and fetch the relevant columns which have a rank 1 from the window function. The problem is that when I create this view, and I want to query & filter it on a date column, it only filters the resulting data and not the CTE's, leading to very long query times because the window function ends up ranking large amounts of data even though I only want to get a specific date. Is it possible to adjust the view to force the filters to apply to the CTE's?
Can you share the sql or a minimal reproduction?
But, it sounds like you need to move the where clauses into the CTEs.
Yeah but I can't have the where clauses hardcoded, I want to be able to query the created view with different dates/filters. I may have found a solution where the window function seems much more optimised by only selecting the columns that are used within the function, and then fetching the remaining columns from a 3rd CTE. But I can't seem to get the JOIN's properly now that theres 3 CTE's as it's returning double the amount of rows as its supposed to.
Why would it matter if the where clause is in the cte vs outside? You can parameterize eithrr.
Oh. You’re creating a view
ID,
Date,
SUM(Col1),
...
MAX(Col2)
FROM MainTable
GROUP BY ID, Date
), CTE_Rank as (SELECT
ID,
Date,
Load_Date
ROW_FUNCTION () OVER (PARTITION BY ID, Date ORDER BY CASE WHEN ID IS NOT NULL THEN 0 ELSE 1 END, Load_Date DESC) as rank
FROM MainTable
), CTE_Remaining as (SELECT
ID,
Date,
RemainingCol1,
...
RemainingCol2
FROM MainTable)
SELECT
CTE_Aggregate.ID,
CTE_Aggregate.Date,
CTE_Rmeaining.RemainingCol1,
...
FROM CTE_Aggregate
JOIN CTE_Rank ON (CTE_Aggregate.ID = CTE_Rank.ID)
AND CTE_Aggregate.Date = CTE_Rank.Date)
JOIN CTE_Remaining ON (CTE_Aggregate.ID = CTE_Remaining.ID)
AND CTE_Aggregate.Date = CTE_Remaining.ID``` This is the 3 CTE one i'm trying, with the original being 2 cte's with the CTE_Remaining cols all being in CTE_Rank. This new one seems to be much more efficient but I can't get the JOIN's properSo the first problem is that the where filter can’t one pushed down to the CTE clause because row_number is operating on the whole table: sometimes the database can optimize/push a filter down, but not in this case
Yeah I think thats unfortunately the main issue here but I think the 3 CTE sql is the compromise but I'm not sure how to join them
This would be much easier as a parameterized query, because you could parameterized the date field directly the cte. It’d perform the best.
For your issue, I’d just check each of the ctes and see which one is the problem. Just spot check the duplicates. I don’t have time right now to read through it, but not sure I’d catch the issue because it depends on the schema
All good thanks for having a look. Just with a quick test of this 3 CTE solution I went down to 4-5 minute query time down from 18-20 minutes. I'll hopefully get the JOIN's to work and have a compromise while still using a view.
And why aren’t you filtering out rank is null in cte_rank? It’ll never join in the select with a null id
I want the rows with null id's to still be ranked. Often there are two matching rows both with null Id's, in which case I just want the most recent one
But incase one is not null and the other is null I want it to prioritize the non null one, which is what I believe the function does now
Then your join is wrong, because you’re joining on cte_rank.id, which doesn’t work for nulls
Sorry I just looked at the code again and saw that it's supposed to account for nulls, heres the actual join: FROM CTE_Aggregate JOIN CTE_Rank ON (CTE_Aggregate.ID = CTE_Rank.ID OR (CTE_Aggregated.ID IS NULL AND CTE_Rank.ID IS NUL)) AND CTE_Aggregate.Date = CTE_Rank.Date) JOIN CTE_Remaining ON (CTE_Aggregate.ID = CTE_Remaining.ID OR (CTE_Aggregated.ID IS NULL AND CTE_Remaining.ID IS NULL)) AND CTE_Aggregate.Date = CTE_Remaining.ID
What db are you using?
Netezza
Oh wow, that’s a name I haven’t heard in a while. I don’t know but some dbs have null safe equality’s
(Just simplifies the code)
Well the original 2 cte solution worked fine and returned the expected amount of rows, including the ones that had null IDs, using the (one of the) JOIN from above. I've just tried to expand it to account for the 3rd CTE
Are you only interested in rank 1?
Yeah, the entire query is ended with WHERE CTE_Rank.rank =1;
So why not just filter it to the first row in the cte with a limit clause?
And drop the row number stuff
Not sure I understand, currently the row number takes the most recent one if both are null, and the nonull one if one is null and one is not null
Cte rank is just sorting and assigning a rank from the row number, and then you’re filtering to rank 1. That’s the same as sorting by same criteria and taking first row, right?
Sort and limit is (likely) much faster than window ranking
I'm not sure, not exactly sure how I would go about doing it manually without the window
I thought that even if there was manual sort logic that did the same as the window function that the performance impact would end up being equivelant but that may very well be wrong
Just sort the cte_rank by whatever you want and do a limit 1
Ok thanks I'll try it
i now understand why everyone hates mapping; especially when names of the columns change. holy cow
You mean like with MongoDB?
not necessarily. We are migrating from one data warehouse to another, and in that process the team that's doing the migration spread all the data to somewhere else with different names for columns. Some were easy and were found within minutes, but some took hours and days to figure out. Going back and forth between old and new, trying to match the data, and scratching my head why name is similar but value is different, and where did original value go, then find the expected value in totally different name.
That team should be fired for incompetence. (And I feel your pain, that’s the worst)
For Sqlite3, :memory: is what you need for a temporary database right?
yeah, if you use sqlite3.connect(":memory:") it will only be stored in memory instead of saving to / loading from a file
Alright, I think my issue is the way im using the class. Oh well, ill just make a module level script.
Nvm, its becuase my code automatically connect and disconnect to the database
very basic question here. Is this the proper way of defining the objects in a set through user input? Example; credentials = input({"enter your number: ", "enter your name: "})
Sets are mutable right? Why not just add to an empty set.
True…I’m gonna give that a try. Thank you!
D
Hi,
At work, for ETL we basically have functions (stored procedures) defined in pgadmin which are run on a daily basis by a cron job.
However, there isnt any version control for the code in these functions. Does anyone know of any tool that can integrate pgadmin with some form of version control?
Flyway, Liquibase are more language agnostic
But we are in python server, Python has really strong solutions already for that.
Django ORM has excellent migrating system
Also Alembic from SQLAlchemy is excellent migrating system
I would recommend Alembic or Django ORM. Not sure which one for sure to recommend. Both are good
thinking more towards Django ORM migrating system first perhaps, it has more features 🤔
How does Django ORM work with typical data engineering pipelines tho?
Afaik that is more for app purposes
https://docs.djangoproject.com/en/4.2/topics/migrations/
https://docs.djangoproject.com/en/4.2/ref/migration-operations/#runsql
just abuse its migrating system only
Define migrations
with runSQL (or with its other features if desired). Define migration to move forward and to revert it back just in case
and use python3 manage.py migrate
Thus u will have version controlled applyable and changable postgres procedures (as well as if desired all SQL structure changing code having version controlled pretty much 😄)
Will look into it when I get home, thanks
optionally consider same with Alembic
https://alembic.sqlalchemy.org/en/latest/tutorial.html
it has some features that may be advantageous over Django ORM
Alembic is more friendly towards being used as raw SQL migrating tool
the great thing regarding all of that... that u will be able to run
migrations applies
and having ability to revert them easily
and it will be code reviewed in pull requests
and stored in git
so...

{kind=link}
If you need to just version it, and you're using raw sql - alembic would probably be a better choice here 🤔
Thanks for the suggestion, I'll need to try them out first
What do you use to run these functions/procedures?
And also how do you change your tables?
So we define these functions in pgadmin. There's a cron job that executes these functions on a daily basis
So far I haven't had to change a table (add new col etc)
btw, as additional measure, don't forget to remove Table/Procedure structurs changing access from your users
leave SELECT/EXECUTE and etc for reading only
in order to prevent future GUI creep
Huh?
u need to stop people making manual changes via GUI
We are the only users
enforce changes via code only
GUI as in pgadmin?
yes
Ah right okok
Will be a big overhaul hahahah
Especially when we're in the middle of building more tables for more analytics
how to delete a row in mysql?
DELETE FROM table WHERE condition = ?
delete from table where id = something
The same as in any other SQL db
You shouldn't use an ORM for data engineering imo
This is definitely a place where performance matters and where you want to be in control of the exact queries
Hello
Guys
I need help
Asap
I created two tables called staff and dept
I have added primary keys to both
I wanted to make joints but i forgot to add foreign key
Now i am using alter table function to add it
But its giving some weird error
Help pls?

@stiff radish sry for the ping mate. But can you help me 😭🙏🏻
Oh i got it
Thanks tho
That's what I thought but don't know the reason
The codebase I inherited used a SQLalchemy ORM based pipeline. It was super clean, 0 comments or docs but I was able to finish the work and it ran. Yay! It scaled super super poorly though. At a certain throughput it became a massive bottleneck.
Then it became a question of digging through all the SQLalchemy docs to see what could be done. I ended up removing and rewriting critical parts without the ORM. I think if you fully master SQLalchemy you could do it but it's not worth the effort, you'll constantly be thinking at the SQL level and finding what features do what you want
For us it tends to not be an issue, if we hit a bottleneck it tends to be an expense related bottleneck where just using SQL in general for the pipeline becomes too expensive to run
Regardless of how well optimized the query is
So then it gets of loaded to spark
roughly at what point will it be offloaded to spark?
just so i can see where i currently lie on that line
idk it depends on the data
but we process several TB of data as part of single pipelines
ah ok, we more on the multiple GB scale currently
altho we do face some long runtimes
someone know a better way to access a int from the .idxmin() (pandas library) instead using .idxmin().values[0]?
thats one example of return of a .idxmin()

.iloc[0] might work
provide an example dataframe that reproduces the problem, and the exact code you used
you might be running idxmin on the dataframe but you want to just run it on one column?
!e ```python
import pandas as pd
data = pd.DataFrame({'x': [1,2,3]}, index=list('abc'))
idxmin on all columns
print( data.idxmin() )
print()
idxmin on column 'x'
print( data['x'].idxmin() )
@harsh pulsar :white_check_mark: Your 3.11 eval job has completed with return code 0.
001 | x a
002 | dtype: object
003 |
004 | a
!e ```python
import pandas as pd
data = pd.DataFrame({'x': [1,2,3]}, index=list('abc'))
print( data['x'].idxmin() )
print( data.idxmin()['x'] )
print( data.idxmin().at['x'] )
print( data.idxmin().loc['x'] )
@harsh pulsar :white_check_mark: Your 3.11 eval job has completed with return code 0.
001 | a
002 | a
003 | a
004 | a
@foggy iron
That's still a level duckDB and polars can easily handle 🙂
What is an xlmx file??
Or did the guy I heard it from mean xlsx?
Might have meant xmlx
How can i find out whats my database name and collection name from mongoDB?
According to WhatExt, it is obsolete
Someone?
I saw recently that duckdb raised a huge pile of VC funding
I don't get it
It's one thing to try to make a business supporting your open source software
But VC funding? I feel like the only possible reasonable exit scenario is acquisition
ServerSelectionTimeoutError: SSL handshake failed: ac-qb0gg1h-shard-00-00.2lrs6ai.mongodb.net:27017: [SSL: TLSV1_ALERT_INTERNAL_ERROR] tlsv1 alert internal error (_ssl.c:992),SSL handshake failed: ac-qb0gg1h-shard-00-02.2lrs6ai.mongodb.net:27017: [SSL: TLSV1_ALERT_INTERNAL_ERROR] tlsv1 alert internal error (_ssl.c:992),SSL handshake failed: ac-qb0gg1h-shard-00-01.2lrs6ai.mongodb.net:27017: [SSL: TLSV1_ALERT_INTERNAL_ERROR] tlsv1 alert internal error (_ssl.c:992), Timeout: 30s, Topology Description: <TopologyDescription id: 650ef00ec787e7cf6195619f, topology_type: ReplicaSetNoPrimary, servers: [<ServerDescription ('ac-qb0gg1h-shard-00-00.2lrs6ai.mongodb.net', 27017) server_type: Unknown, rtt: None, error=AutoReconnect('SSL handshake failed: ac-qb0gg1h-shard-00-00.2lrs6ai.mongodb.net:27017: [SSL: TLSV1_ALERT_INTERNAL_ERROR] tlsv1 alert internal error (_ssl.c:992)')>, <ServerDescription ('ac-qb0gg1h-shard-00-01.2lrs6ai.mongodb.net', 27017) server_type: Unknown, rtt: None, error=AutoReconnect('SSL handshake failed: ac-qb0gg1h-shard-00-01.2lrs6ai.mongodb.net:27017: [SSL: TLSV1_ALERT_INTERNAL_ERROR] tlsv1 alert internal error (_ssl.c:992)')>, <ServerDescription ('ac-qb0gg1h-shard-00-02.2lrs6ai.mongodb.net', 27017) server_type: Unknown, rtt: None, error=AutoReconnect('SSL handshake failed: ac-qb0gg1h-shard-00-02.2lrs6ai.mongodb.net:27017: [SSL: TLSV1_ALERT_INTERNAL_ERROR] tlsv1 alert internal error (_ssl.c:992)')>]>
i keep getting this error when i try to access my database in mongodb, ive gotten it before but fixed by adding tls=true in the uri but now its showing up again
https://paste.pythondiscord.com/2I2Q bascially, i'm having a flask run server problem here and it's database for postgresql since this text is too long for me to paste and that i don't have nitro, i have this link here that y'all can look at it my problem
Check out #❓|how-to-get-help but this is a Python server so you might have better luck on Coding Den or a PHP server. Check Disboard
Line 2 says you have a Postgres password error. Nothing will work without the correct password
can i get those server links?
Yes, you can search the web or go directly to Disboard dot com
Huh? I don’t get the point. You raise VC money because you think there’s a product/revenue opportunity. I follow duckdb closely, but am not affiliated, but my understanding is:
Duckdb is open source, owned by Duckdb labs and the funding has nothing to do it it. MotherDuck is a separate entity (with some overlap in people), which is the ventures backed entity building a cloud service around duckdb. They have a fairly active discord.
A lot of other systems I get
but DuckDB seems slightly odd in terms of how it generates revenue
They’re not trying to monetize duckdb tho, but distributed database services on top of it. They’ve been good, imo, of not contaminating duckdb.
https://motherduck.com is the $$ stuff
Yeah i suppose
my only concern is it's a bit of a hard field for them to compete with VS the other current heavyweight champions
Since effectively motherduck tries to compete with Starburst, Athena, BigQuery, Sneller, maybe ClickHouse, etc... as Comerical offerings.
And has to compete with Trino, Presto, etc... for self-hosted services.
did i do anythin wrong here idk what i did wrong
In particular, Starburst, BigQuery and Sneller are just giants with really solid products, but idk, I haven't seen MotherDuck's pricing/I cant find it?
Yah, I only care about duckdb itself: I use it for certain pipelines that fit in memory. It’s eliminated a lot of spark for me.
yeah, like DuckDB has a lot of use cases
and is a super powerful tool
but IDK how well that ends up happening in the world of datalakes
I’m doing some stuff right now with pyodide and duckdb wasm: browser based analytics, curious how far I can push this
this here is supposed to serve a flask app, room.py: https://paste.pythondiscord.com/BY2Q, but has failed to do so. config.py: https://paste.pythondiscord.com/AQ7Q



You should probably create a help thread for this, this is more than a db question: #❓|how-to-get-help
Right, there's nothing wrong with building a business around an open source project, but VC funding is such high risk high reward
It's more like Spark than a database/warehouse
Ooh, I missed your point. Yah, VC is a tough way to go: they make you run as fast as you can into a brick wall and hope you break through. And don’t care about the damage to you.
Right, which is not what i want to see when choosing vendors tbh
Fortunately it's open source so if they fuck it up the community can fork
Im not sure if apache drill and friends are comparable
But this was my point: duckdb/duckdb labs is separate. Two separate entities
Right
So no fork problem.
well yeah, but that is the premise of all the solutions I mentioned
since datalakes now days are just execution engines ontop of S3/Blobstorage
on some file format, normally parquet
right but they're optimized for different things as far as i understand
maybe you could build a data warehouse using duckdb internally but that'd be a whole project
They seem to be targetting the same things no? I don't think it's anything near capable of competing with Spark processing, i'd argue they'd have a better time trying to compete with Athena
There’s a bunch of stuff around delta lakes doing this actually
the databricks product? i actually DIYed this at a previous job 😆
the data lake was just a bunch of delta lake tables + docs
Yah, the vendors always want to make something easy hard.
I can't work out how to use their cloud product atm, but it's in beta so meh
but from what I can see in their docs its effectively:
- Attach Motherduck to S3 as a primary datalake (Other sources available but point is the same)
- In your notebook you can create queries and do processing of the files like parquet files on the lake

I guess reminiscent of how I use jupyter remote kernels.
it's your fairly standard datalake saas offering from playing around with it

Mother Duck
(never used it, but excited in advance because of their theme 😁 )
Anybody has experience with relational databases in FastAPI specifically using the sqlalchemy ORM?
Don't ask to ask, just ask.
If your actual question is too complex to ask directly here, then grab a help channel. #❓|how-to-get-help
Alright. So I just want to know if the FastAPI docs is more than enough for my needs? Should I just follow the example?
Specifically: https://fastapi.tiangolo.com/tutorial/sql-databases/

FastAPI framework, high performance, easy to learn, fast to code, ready for production
Yes, that looks like a good place to start
Alright. Thanks.
I strongly suggest starting without a database, just get HTTP requests working nicely
SQLA isn't that hard to use, but I suggest working on one element at a time because both frameworks are fairly rich in features and it will be a lot more effective with your time to learn one at a time instead of trying to learn both halfway
the one tip i have is to use fastapi Depends to obtain a database session instance from your sessionmaker. that won't make a lot of sense now, but file it away and come back to it once you start working on the SQLA stuff
fastapi also makes nontrivial use of pydantic and is a relatively thin layer over starlette's asgi implementation, so you're already looking at two additional frameworks before you get to any database interaction
I think fastapi's tutorial is not that good - it's outdated, uses legacy SQLA model definition API, uses synchronous API, specifies unnecessary aguments (e.g. Column(Integer, primary_key=True, index=True), PKeys are already indexed), uses outdated pydantic API, uses legacy SQLA query API, uses try-finally instead of with
TLDR: Don't follow that tutorial, just read sqlalchemy docs, though a lot of people find it quite hard to read/understand
Hi! But I have to use a database, that's a requirement for the task I'm doing. Also, I think starting with the database (which IMO seems like the hard part) is a better way to start
My problem is the plenty boilerplate code.
What kind of boilerplate?
I've used SQLA with Flask, and the flask wrapper makes it relatively easier
Maybe go through the link? https://fastapi.tiangolo.com/tutorial/sql-databases/
FastAPI framework, high performance, easy to learn, fast to code, ready for production
Maybe you could just tell me what you're talking about?
Nobody can read minds
Ok please hold
Also since I already picked that tutorial apart here - I had to read it 😅
I see what you mean. But would it be cool if I just remove the indexargument?
Also, what do you mean by synchronous API?
I'm using the sqla package directly, not some wrapper
There's a lot more problems than just the index argument
I kinda understand this because it's really similar to when I was working with Flask
I mean the Column stuff
That tutorial is just outdated
But it seems specific to FastAPI. Would it be easy for me to integrate with FastAPI by reading the official docs?
fastapi does not require anything specific to do
If you can use sqlalchemy you can use it anywhere
As @harsh pulsar it would be a good idea to move session creation to a dependency, so you don't have to do that by hand everywhere, that's all
But it's not required
ORM Guide: https://docs.sqlalchemy.org/en/20/orm/quickstart.html
2.0 Changes if you're familiar with sqlalchemy already: https://docs.sqlalchemy.org/en/20/changelog/whatsnew_20.html
So I think this is already in the FastAPI docs I shared
That's what they do
That could be shortened to just
async def get_session() -> AsyncIterator[AsyncSession]:
async with async_session_factory() as session:
yield session
With FastAPI, I don't need to install any package to use the async/await right? I mean, I've done it before but I've only worked with FastAPI once so I'm asking
To use async/await where?
With fastapi? No.
Sqlalchemy would require a specific DB driver depending on what DB you use
Yeah, with fast api
But I don't see the dependency that enables that feature
Something like asyncio
I can only see anyio
Is that it?
I'm using postgresql db
What do you mean specific driver? Isn't sqla the driver?
no
You need psycopg3 or asyncpg
hmmm... I see what you mean. THat's simply as a dependency I guess, not that I'm using it directly
Yep
I appreciate the help guys! I'll try my best :)
why doesnt it replace?? i get as output medium, hard and soft
import fastf1
import pandas as pd
from fastf1 import plotting
import numpy as np
import csv
from datetime import datetime
track = "Catalunya"
race = fastf1.get_session(2023, track, "R")
race.load()
point_finishers = race.drivers[:10]
print(point_finishers)
driver_laps = race.laps.pick_quicklaps()
driver_laps_view = driver_laps[["Compound", "TyreLife", "LapTime"]]
driver_laps_view["LapTimeSeconds"] = driver_laps_view["LapTime"].dt.total_seconds()
del driver_laps_view['LapTime']
driver_laps_view["Compound"].replace("SOFT", 0)
driver_laps_view["Compound"].replace("MEDIUM", 1)
driver_laps_view["Compound"].replace("HARD", 0)
driver_laps_view.to_csv("D:/Dev/Python/F1Strategy/tyre-model/tyredeg.csv", header="Compound, TyreLife, LapTime", index=False)
Tbh, I don't know how you arrived at this snippet. For instance, I can't find the async_session_factory function anywhere in the docs
The closest I've seen is async_session or something like that
I think thats why doctor say just follow sqla's docs rather than fastapi's docs.
I'm following sqla docs and that's why I asked that
The sqla docs is really hard to read :)
@paper flower I read somewhere that I don't need to specify psycopg2 when creating the engine
As sqla uses psycopg2-binary under the hood
Yoooo
For a datetime field, do I need a special data type (say DateTime from sqlalchemy.types)?
Or I can use Mapped[str]??
I need answers 😢
This is an interview task I'm building that would be submitted
just use the datetime field. that's why that exists
So would it be Mapped[DateTime]???
no clue what Mapped does
That's the new model definition syntax for version 2.0 I guess
Also, have any idea how I can provide validation for email field?
so Mapped is basically REFERENCE table (id)?
REFERENCE is supposedly a FK relationship right? No, it's not
There's the relationship() function for that
Mapped is just used for the data type mapping
You can refer to this: https://docs.sqlalchemy.org/en/20/orm/quickstart.html
i dont work with sqlalchemy so can't help you that part. only work with SQL
Alright, that's fine. Thanks for the help
the async session factory is probably an instance of sqlalchemy.ext.asyncio.async_sessionmaker
engine = create_engine(...)
async_session_factory = async_sessionmaker(engine, ...)
async def get_db() -> AsyncSession:
async with async_session_factory() as async_session:
yield async_session
app = fastapi.FastAPI()
@app.get("'/users"
async def get_users(
db: Annotated[AsyncSession, fastapi.Depends(get_db)]
):
...
or something like that anyway
that's just off the top of my head, you'll need to confirm with the docs
Yep, that's what it is
Mapped[datetime]
It's a synchronous driver
Not for async
consider I have a 2 tables in db user (with columns primary_key and id) and user_collections (with columns primary_key, some_value and user_id) why should I use foreign key in user_collection(user_id column) when i can just use the user id real value (because that value is also uniue)
does this make sense can I use either option and it's fine or 1 is better then another
Depends on what relationship you need here
like i need to create 1 to many relationships or 1 - 1 (does that matter)? for user and user_collections
Please where do I import the datetime from? The regular python datetime module? Also, is this in the official sqla docs?
You're right. I later figured. Even psycopg2 is synchronous. So I settled for asyncpg
For 1-1 using the same id as user id should work
from datetime import datetime
Sqlalchemy has a bunch of standard types already "mapped" to sql types
ints, floats, datetime, date, etc
I see... thank you
I will regularly ask for help here. Is it even okay I DM you directly?
You could but I'd prefer if you don't
Alright. I'll stick with here then
Please is this valid code?
date_created: Mapped[datetime] = mapped_column(default=datetime.now)
I mean the default argument stuff
@paper flower
Also, how can I implement the equivalent of auto_now_add and auto_now in Django for datetime fields?
I guess onupdate argument solves this?
Yes, if it's a function/something callable it would call it when constructing default value
And onupdate is called when you update the model
Nice... thanks
Please how can I add email validation at the model definition level?
I'm really sorry for the many questions :)
I don't think that's the right place to add email validation to
Also you'd be surprised what emails are valid

We're not quite sure exactly when email was invented. Sometime around 1971. We do know exactly when spam was invented: May 3rd, 1978, when Gary Thuerk emailed 400 people an advertisement for DEC computers. It made a lot of people very angry... but it also sold a few computers, and so junk email was born.
Fast forward half a century, and the rel...
Okay okay
What about FK relationships. So I have two tables, User and Todo. A user can definitely have multiple todos. Should I use a 1:M or M:1 r/ship?
My guess is that 1:M solves this even though it sounds counter-intuitive
??
1:M is the way to go there
You could take a look at docs
https://docs.sqlalchemy.org/en/20/orm/basic_relationships.html
Yeah, I'm actually looking at that part of the docs
Well, now I think about it, it doesn't sound counter-intuitive
One User to Many Todos
The docs uses List[] data type though as opposed to list[]
Does that mean I'd have to import typings module?
I thought that's not needed for pydantic v2?
They're the same, and it's not related to pydantic at all
If your python version supports list[] - use it over typing.List
Okay. Thanks. My python version does - it's 3.10+
Even in FastAPI docs, I noticed they didn't have to import typing
I have a problem

In the docs, they just used the child model in string, like "Todos"
but mine doesn't really work.you can see the editor highlight
I guess this is because the model is defined in another file
Should I just import the model, and add it as typing argument?
Without the strings?
You can't do that because of circular imports
Also model name preferrably should be Todo
You could import it in TYPE_CHECKING block
Ah, yes Todo actually
Please what's this?

Python documentation
Source code: Lib/typing.py This module provides runtime support for type hints. For the original specification of the typing system, see PEP 484. For a simplified introduction to type hints, see PE...
from typing import TYPE_CHECKING
from datetime import datetime
from sqlalchemy import String
from sqlalchemy.orm import Mapped, mapped_column, relationship
from .base import Base
if TYPE_CHECKING:
from .todos import Todo
class User(Base):
__tablename__ = "users"
id = Mapped[int] = mapped_column(primary_key=True)
email: Mapped[str] = mapped_column(unique=True)
password: Mapped[str] = mapped_column(String(10))
created: Mapped[datetime] = mapped_column(default=datetime.now)
modified: Mapped[datetime] = mapped_column(
default=datetime.now, onupdate=datetime.now
)
children: Mapped[list["Todo"]] = relationship()
def __str__(self) -> str:
return f"User: {self.email}"
Is this correct?
Yep, looks fine
replace = with : in id = Mapped...
Yes, thanks for the oversight
How do I handle creating database table and migrations
From the docs, I'm seeing something like
await conn.run_sync(meta.create_all)
Is that what that line does?
Whereas in FastAPI docs, I think they recommend alembic?
Yep, Ideally you'd use alembic
Too many moving parts. Phew
How can I improve mysql data insertion speed? I'm importing data from an xml file, but it's taking about 2 seconds to insert the data, I wanted to improve the speed at which it inserts the data...
import pymysql
db_config = {
...
}
table_name = 'intimacoes'
xml_file_path = 'my_file.xml'
conn = pymysql.connect(**db_config)
cursor = conn.cursor()
load_xml_query = f"""
LOAD XML LOCAL INFILE '{xml_file_path}'
INTO TABLE {table_name}
ROWS IDENTIFIED BY '<intimacoes>';
"""
cursor.execute(load_xml_query)
conn.commit()
cursor.close()
conn.close()
Don’t know first hand (I’ve bulk loaded to MySQL, but never xml), but how many rows? I would try, for a baseline comparison, converting to csv (or exporting/reimporting) just to compare csv vs xml load performance.
Also; local infile is going to be slower than infile (serverside), so if you can move the file to the server, that’s also help.
1.152.175 lines
I'm in a challenge between friends where we have to load data from an xml file, and whoever inserts it the fastest wins, so there are some limitations
Does your table have any indices or constraints? If so, you could disable them before load.
Second, you could transform the xml to csv before loading. I would compare xml vs csv load times for your dataset before writing any code here tho
@paper flower From the alembic docs, I can see that they modified the .ini file to add the database url. However, this is risky as the creds are exposed. I intend to read from an .env file which I'm using. Please how do I go about this?
It seems I have to edit the env.py file but I'm not very sure about this
Please, again, forgive my plenty questions
I have a deadline in less than 24 hours and this is just the backend of the task. I still have frontend and devops left
I can't afford to do things myself
I edited the run_migrations_online() function in the env.py:
def run_migrations_online() -> None:
"""Run migrations in 'online' mode.
In this scenario we need to create an Engine
and associate a connection with the context.
"""
connectable = create_engine(settings.SQLALCHEMY_DATABASE_URL)
with connectable.connect() as connection:
context.configure(connection=connection, target_metadata=target_metadata)
with context.begin_transaction():
context.run_migrations()
Does this make any sense?
I substituted engine_from_config function with create_engine
I'm just seeing this. I appreciate. I figured too
Please can someone else help with this??? Seems @paper flower is not available at the moment
Using the same config above, I get this error when I run migrations (specifically alembic upgrade head):
sqlalchemy.exc.MissingGreenlet: greenlet_spawn has not been called; can't call await_only() here. Was IO attempted in an unexpected place? (Background on this error at: https://sqlalche.me/e/20/xd2s)
If I change create_engine to create_async_engine, I get the error:
with engine.connect() as connection:
AttributeError: __enter__
Please get a help channel instead of hijacking this one #❓|how-to-get-help
Wouldn't that take long to get a response?
I just need a quick response to my problem
And I promise I might not disturb here again
That's why I suggested starting without the database stuff!
If you need help on demand, you will need to pay somebody. This server is staffed entirely by volunteers contributing in their free time
Isent 2sec for 1.1mil lines fast enough?
Maybe try pandas copy to db method?
Not sure if it supports xml though
Don't worry, I found a hack
I just needed to run alembic init -t async alembic
the -t flag was missing previously
Yep, for async you have to use async template
What tokens?