#databases
1 messages · Page 16 of 1
is the default
but yeah, maybe it would be worth spending some of your time reading the postgres docs 🙂
hi
so i have a file with a bunch of sqlite3 code
it's connected to another file that has a gui code in it
this sql stores names and ages and medical conditions gathered from the gui

GitHub
cs50p project. Contribute to amirreza8002/medical_recoed development by creating an account on GitHub.
i'm rather new to this
so i would really appreciate it if you could give me some feedback on this code
style wise and...
You say you're new to this... for a beginning project I'd say it's impressive!
Have you considered using an ORM like SQL Alchemy? I generally find that a lot more elegant than SQL embedded in Python.
hello can anyone suggest how do i insert emails into mysql then load it in the system in a fast way. because what i have right now is taking too long to put the emails in the database
Figure out why your inserts are slow and fix the problem. I doubt it has anything to do with them being emails.
https://seo-explorer.io/blog/twenty-ways-to-optimize-mysql-for-faster-insert-rate/

This blog post covers all the technique we used to optimize MySQL insert rate, in order to achieve sustained 50k inserts per second
Thanks!
i decided on sqlite3 because i have to submit this to cs50 and have unit test on it and...
So i thought SQLite was the way
Hi everyone, I'm currently a part of a new startup designing a modern data architecture framework (DAF) that streamlines, standardizes and centralizes the development and management of data architecture and pipelines.
DAF ingrains the process and tools that resolve Data Architecture Chaos and in doing so it includes the introduction of a Data Architecture Descriptive Language, which modernizes and eases the architecture and pipeline development process with introduction of Data as a Code, VCS, CI/CD, versioning, bundling, code reviews, easier tracking, merges, replications and other software development principles into data architecture development and maintenance practices.
We'd love to hear what data professionals have to say about our vision and would highly appreciate it if any of you could have a quick chat with me and my co-founders, feel free to pm me if you're interested 🙂
Hi!
We don't do ads nor necessarily DMs
Hi there, in my feeling this classifying as an ad is problematic since there's nothing to be sold, nor is the name mantioned
I did not mean to disrespect any rules 😅
no worries. As such, I see multiple issues:
- You talk about how you want to do X and have a call to action for people to contact you privately
- Your question/message is rather vague. No one would say no to having something that streamlines, standardize, etc. and generally makes it easier to manage your data
So that creates some problems in terms of bringing that conversation to the community rather than away from it (ie. an ad), and also in terms of value you would get from the answers (ie. product validation for an eventual market/fit).
I would suggest to pick a specific pain pain and bring it up to this community (ex: how do people solve the problem of X today? What are the best ways to achieve it today and what do you think are the remaining parts to solve?)
i'm having problem with this part:

if yet i need it
It's rather vague since we're in the very early stages and more of an exploratory discussion. And since there isn't anything concrete yet, I feel that trying to talk about it openly wouldn't be very productive.
I tried to have a discussion about the issue on a diffrent server, and it quickly devolved to "you shold just buy X or learn to use Y"
Also, sorry for the late response, osaka is distracting
okay why i can't create database or delete database?

Oof, these screenshots are hard on the eyes, you could paste the relevant text or at least crop the image...
Anyway, try closing your commands with a ; at the end

guess now i'm gonna use capture
Much better 😃
I'm not sure if it will let you create a table without any columns (https://www.postgresqltutorial.com/postgresql-tutorial/postgresql-create-table/)
This tutorial shows you how to use the PostgreSQL CREATE TABLE statement to create new tables.
i see, the problem is incorporate it through cmd (when i was learning MySQL in my IT course i was using web client, but never the terminal)
wait, now i see where it was my error
i was trying to crate a database, but i mistook with table
the right one was made:

can use pgadmin
a question, i have no idea how i will implement this thing from psycopg2:
conn = psycopg2.connect(
host="localhost",
database="suppliers",
user="postgres",
password="Abcd1234")
my plan is to create it separatedly, and it being fundamental to the bot work
if the database isn't connected or started it wouldn't allow my bot to work
That's true. What's the question?
the question is how i integrate the db into my discord bot?
I see that you're opening a connection with psycopg2. Is it working or are you getting an error?
i don't know, i'm seeing a tutorial that uses psycopg2, but someone that seems experient is teeling me to use asyncpg, well, i will need to learn it (thought it makes sense since discord bot uses asynchronous function)
Might be a question for #discord-bots
Best database for a discord bot?
If you're totally new to DBs SQLite is easiest to start with. If you need something more robust, I like Postgres
Can u view sqlite db
Whether you mean CREATE VIEW or you just mean look at your data, yes.
Any website I can see how sql works?
SQLBolt provides a set of interactive lessons and exercises to help you learn SQL
Thanks
Did anyone made an image prediction project using CNN with a notebook? If yes can someone send me their notebook
im not sure how ask this but.. why would asyncpy.Connection.transaction return None?
async with self.pool.acquire() as con, con.transaction() as trans: <- trans was None in that case
which library are you referring to? if its asyncmy i dont see any indication of a transaction() method existing
its asyncpy sorry
ah asyncpg
There is a nice open source viewer for Sqlite dbs: https://sqlitebrowser.org/
looks like thats intentional, Connection.transaction() returns a Transaction object and using it in a context manager returns None
https://github.com/MagicStack/asyncpg/blob/v0.27.0/asyncpg/connection.py#L251-L275
https://github.com/MagicStack/asyncpg/blob/v0.27.0/asyncpg/transaction.py#L57-L62
probably to prevent making the mistake of using commit()/rollback() which they will reject inside the context manager
i cant seem to find official docs for MySQL, could anyone point me to it?
yes thank you
hello, somebody here??
No
what kind of tooling do we have to execute migrations as sql scripts?
(so the use case is: I'd have a migration that I write in SQL. when server starts, it recognises there is N new migraiton files, and execute them in order?)
alembic is a popular tool to create and manage schema migrations, I don't really know if it could work with sql files though 🤔
Another option would be aerich
yeah wasn't clear from the documentation neither
what a shame
It can generate sql files, but I'm not sure it it can run them
You could ask on GitHub
people never write their migration files manually in python? 😬 I couldn't find any sort of trustful alternative to alembic
i believe with using alembic for automated migrations, you have to implement it as a revision script that it can auto-detect and import
the closest equivalent would probably be putting your statements in a separate sql file and then reading from it in your revision script, but at that point you might as well hardcode it in the upgrade/downgrade functions
indeed
and since I own the db server, I'd be as fast as not setting up anything, and just apply migrations semi-manually instead
I have this code here:
import pandas as pd
import psycopg2
from psycopg2 import OperationalError
import pg # Various functions to interface with the Postgres servers
from db_creds import * # The DB server and user creds
import sqlalchemy
#Source database
connection = pg.create_connection(sourceDB_setting[3], sourceDB_setting[5], sourceDB_setting[6], sourceDB_setting[1], sourceDB_setting[2])
#Target database
connection2 = pg.create_connection(targetDB_setting[3], targetDB_setting[5], targetDB_setting[6], targetDB_setting[1], targetDB_setting[2])
#Create a cursor to perform database operations
cursor = connection2.cursor()
#Fetch rows from source database
cursor.execute('SELECT * FROM flattened_app_data_hix168154 limit 5;')
results = cursor.fetchall()
#Create PostgreSQL connection string
postgres_str = ('postgresql://{username}:{password}@{DBhostname}:{port}/{dbname}'.format(username=targetDB_setting[5],
password=targetDB_setting[6],
DBhostname=targetDB_setting[1],
port=targetDB_setting[2],
dbname=targetDB_setting[3]))
#Create the connection
cnx = create_engine(postgres_str)
#remove columns
columns = []
for row in results:
phone, taxHousehold = row
pjrec = pd.DataFrame()
pjrec["phone"] = phone
pjrec["taxHousehold"] = taxHousehold
columns.remove(pjrec)
combined = pd.concat(columns)
print(combined)
#export data
combined.to_sql('flattened_taxhousehold_hix168154', cnx, if_exists='replace', index=False)
cursor.close()
And I want to remove Phone and TaxHousehold columns before exporting other columns to a table. How do I remove them? FYI, I use postgresql
Instead of SELECT * FROM, could you just select the columns you want?
I have 78 columns
And I just realized you're explicitly setting phone and tax household values on the data frame?
I tried to, but I got errors

Database Administrators Stack Exchange
Is there a way to SELECT all columns in a table, except specific ones? IT would be very convenient for selecting all the non-blob or non-geometric columns from a table.
Something like:
SELECT * -
You mean that the code above produces errors? What errors?
I got ValueError: too many values to unpack (expected 2)
I tried to exclude those two columns in the query but did not work so I'm trying to see if I can use Python to achieve that
Hi does anyone know a suitable database to use to find statistics on implementation of AI in carbon capture? I need some statistics for a grp research
I doubt such a thing exists. If you search for academic articles on Google scholar you'd be lucky to find a few data points, nevermind a dataset. But a place to ask for datasets is r/datasets on Reddit. You could also search Kaggle
Hi I'm trying to learn to build an app in flask using postgresql, but I can't get the database working properly. The tutorial talks about going to the terminal and importing db and then running db.create_all(), but I get an error: RuntimeError: Working outside of application context. I've tried adding the app.app_context part but noting works. how can I get this working please:
from datetime import datetime
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
app.config['SQLALCHEMY_DATABASE_URI'] = 'postgresql://postgres:password@localhost/ip_calc'
db = SQLAlchemy(app)
class Event(db.Model):
id = db.Column(db.Integer, primary_key=True)
description = db.Column(db.String(100), nullable=False)
created_at = db.Column(db.DateTime, nullable=False, default=datetime.utcnow)
def __repr__(self):
return f"Event: {self.description}"
def __init__(self, description):
self.description = description
with app.app_context():
db.create_all()
@app.route('/')
def hello():
return 'Hey!'
if __name__ == "__main__":
app.run()
There has to be a way to create a table with Flask, will anyone help please, all tutorials say to do it in the terminal, but I just get a app_context error, I cna't find a way to do this

Thank you, I will have a look at this
Hi, Does text datatype columns allow for full text search?
Hi guys
I am making a school project and I dont know what db to use for inventory management
SQLite
SQLite3 without any doubts indeed. best pet project/ school project database. Easy to use, easy to manage.
They should, what db are you using?
I'm using prisma. Suppose I have two tables in a many-to-many relationship, e.g.
model A {
id Int @id @default(autoincrement())
Bs B[]
}
model B {
id Int @id @default(autoincrement())
As A[]
}
Is there a simple way to, when inserting a new row into A, either-connect-or-create to some rows of B?
Just using create fails if the B row in question already exists. And just using connect fails if it doesn't.
I'm starting to think that's impossible because of the lack of connectOrCreate in prisma-client-python
Hey guys can I get help with this code. It's not updating to my database using this command.
It's s one to many, you just need a fk pointing from service to number... Is this a homework question or what is the problem?
can someone help me in #1110021007059734648
any way to store a image in a db using a command (aiosqlite and discord.py)
store it in filesystem 
Could you upload something onto the db using a /command if it is a image
Don't 🙂
💀
Just store path to your image and save image itself to disk
You could just store links to these images too
How would you store the links to the images
Since I've got a datbase with the items description, item value and then when I do the slash info command it shows me all the info about it
I want to add a image to it
Just as a string, you can upload images to discords own cdn so you're not sending whole image each time
Alright thanks
Can u send photos of it in like a channel and then when you go to add the image to the database you can refer back to the image in that channel?
Will that work
You can refer to that link, yes 🤔
Is there an easy way (using sqlite3) to only initialise the database once so that the subsequent runs of the script can use it. Perhaps a CREATE TABLE IF NOT EXISTS... but this seems tedious to do for each table at the start of each run.
Basically I have a template for the database that want to implement if not already implemented

Idk but just add a case when maybe
maybe:
select max(num)
from (
select num
from mynumbers
group by num
having count(*) = 1
)
doesn't max() return nothing if nothing was passed?
SQLite returns null if there is no grouping, that's why I made the sub-select. (and so does MySQL and PostgreSQL)
why is this in SQL if you can t create a table with it lol

"this" what?
create a table

it sounds like you are supposed to edit and apply the script it generates?
you tell me just made a database and trying to add a table
idk, ask in a server/community about that tool you are using (MySQL Workbench)
this channel is fit for questions about database in general or about using python to interface with them, but for specific tools unrelated to python, you're better off asking in communities focused on that specific tool
oh found it already now to mySQL as you can tell haha
And a table with no columns is most likely a syntax error.
yeah fixed it
ay guyss
i kindaa neeed helpp
does anyone of u get using python 3.6 idk it iss kindaa linux kali platform
someone just crashed into my insta acc and hella am stuck..
if anyone knows voicemaster and starboard command w/ databases on aiosqlite db please help in #1110328347940098078



Book and Author have their own table, the BookAuthor table is for which author(s) has written which book(s). It's for an n:m relationship between Book and Author so that one author can be related to more than one book (and vice versa).
Therefore it's the Writes relationship of Figure 1.4.1
What is the purpose of using the fixed length while I have variable length
I am still noob at SQL
But I am wondering
because the variable data is storage saving
i think i get it a bit
thank you
what does "implement" mean here though?
In this case it means how it (Writes) is done. So the table BookAuthor implements the Writes relationship. Or the other way around: The Writes relationship is implemented with the table BookAuthor.
ok, thank you
Hi,
I'm completely new to Discord and I
I'm just making my first steps with Python. I have experience with PHP/Laravel, but one thing I couldn't do using PHP was to convert csv to orc. Place where I'm working has implemented a python script that does this job, but I need to add to it try / catch exceptions and store it in existing database (MySQL) - is there some sort of library / plugin that reminds a little bit ORM Eloquent?
Thanks in advance for any pointers
idk how Eloquent works, but when it comes to ORMs in Python, the most popular is SQLAlchemy by a quite large margin (at least excluding Django's, but using it outside of Django projects could be a little weird)
You could use pyarrow for that usecase, maybe it's useful for you: https://paste.pythondiscord.com/avebifayig
The picture shows the result and the original csv file

By the way if they always do csv > orc > mySQL it's probably easier to skip the orc step altogether
yeah use either Arrow or Pandas (which has arrow as the backend as of v2.0) to ingest the csvs, and then there will be tons of tutorials on how to upload a Dataframe or Table to whatever db you want
I don't think that pandas uses Arrow by default even in 2.0? iirc it's optionally supported, but not the default
@frozen grotto thanks, but i need to store in SQL different data - not those that I'm processing CSV to orc
what database is the best for a beginner working on a small project?
in a group by?
usually you would just use WHERE to filter things in a select statement
if you need to filter after performing an aggregation, you can use HAVING though
How to become good at SQL?
see the pinned messages
Like anything else, practice. There are loads of sites with exercises and lessons (SQLbolt, sqlzoo, DataCamp DataQuest) but doing real projects is also important
sqlbolt website is the one for me
So, let's say i'm making a discord bot, where some commands are gonna be interacting with an sqlite database, via aiosqlite. What's best practice: opening up a connection at bot start-up, that's used for all database queries, or only opening up a connection whenever a command requiring DB access is issued?
Or well, maybe a more appropriate question is, how long should you reasonably keep a DB connection open, or can you keep it open indefinitely without worry?
both work, but best practice is to open a single connection when the bot starts up and reuse that connection for all db queries
It's better performance but comes with some downsides, as SQLite is not always thread safe, and your code base will require more error handling if the connection gets somehow closed
thread-safety and error handling are fine, i've got ideas on how to deal with that - cheers for the input! 😁
@gusty mesa id argue that multiple connections is simpler+more performant as you don't have to manage your own locks for serializing transactions, and each connection can run in parallel when allowed by sqlite's locking states
see also one of my previous discussions #databases message
if anything using multiple connections is easier because you're letting SQLite handle concurrent transactions for you (getting the same guarantees with a single connection requires much more manual labour)
fwiw sqlalchemy's decision on concurrent connections is to use a QueuePool (upto 5 concurrent connections) for synchronous sqlite3 and a NullPool (infinite connections) for aiosqlite
https://github.com/sqlalchemy/sqlalchemy/blob/rel_2_0_15/lib/sqlalchemy/dialects/sqlite/pysqlite.py#L519-L521
https://github.com/sqlalchemy/sqlalchemy/blob/rel_2_0_15/lib/sqlalchemy/dialects/sqlite/aiosqlite.py#L341-L343
(with the exception of in-memory databases, where a single connection is preferred)
SQLite3 is more thread safe if having enabled WAL

ooh alright, interesting. I came here more worried about whether there'd be certain side effects of keeping a connection open for prolonged times or not, but clearly that wasn't actually all too important. I wasn't too worried about how it'd affect concurrency, since i doubt the underlying commands will be issued ever by more than one person at a time in the first place, but i'll bear that in mind 🧐
tyvm!
Do what? Do you mean LIMIT 1?
what's N?
Oh I see it nvm
Not sure SQL server supports variables in LIMIT.
But, you can go around this. Rank the values, and filter out any value after N-1 with WHERE or HAVING
sqlite3
Hello
I already included this query from file --> open and I connect it the network or connection but, it does not working

When I created for the first time it was working
after I closed the app it is dead or does not working
what should I do
to fix it
Have you done
USE database_name;
?
are you using mysql?
then I have no clue
Or Microsoft Server

np
ask directly
I added new data for my database

but the problem is it does not show or display on query
I refresh it
and connect it by USE
but still same
I added new table and I added new data Inside AracBilgisi

what would be the easisest way to save a table from a MySQL database to an in-memory SQLite DB?
If this is a one-off case of a single table, I would probably do an export and an import in DBeaver
using sqlite,
i have a table with values like
name
type
price
data1
data2
for both entries, both data pieces will have a name, type, and price, but for one data piece it would have a data1 value and the other data piece would have data2 value. how would i achieve this?
Why? And what's a "data piece", a row in the table?
yes
some rows only require one value, some another, some both
Ok, and what's the problem?
Hey guys by definition a table that has a matching index is ordered right?
Trying to get refreshed on indexes and pointers
I am not sure if I could call the table itself ordered?
indexes may be ordered, but a table could have multiple different indexes, each ordered in a different way
it is possible that formally speaking it is accepted/defined as such though, idk
there's the concept of clustered indexes wherein the data itself is ordered on the disk
is it possible that using sqlite3, in a table when a new row is created some columns have a fixed default value
yeah https://www.sqlite.org/lang_createtable.html#the_default_clause
https://stackoverflow.com/questions/17617610/set-default-value-of-an-integer-column-in-sqlite

Stack Overflow
I am creating an SQLite database.
db.execSQL("CREATE TABLE " + DATABASE_TABLE + " ("
+ KEY_ROWID + " INTEGER PRIMARY KEY AUTOINCREMENT, "
+ KEY_NAME + " ...
How can I make so every student has a subject_name

I am doing a join on students and examinations
but I am unable to make so it does have a subject name if it doesn't exist
please show what you have tried
ok better
there are some students that haven't attended any examns from x subject

but i dont konw how to add those
okay great.
could you explain your query to me in plain english?
adding a missing ping as requested @unreal hemlock
First I select the desired columns I need, student id, subject name and the amount of exams from the table examinations
then I join the table students with examinations so I can get the student name
then I group it by student and subject so I can use COUNT(1) at the select to get the amount of exams made of each student by each subject
and then I just order it
do you mind if I ping you on reply?
no need to ping on reply, i check discord quite frequently
oki np
do you have some sqlfiddle (or alternative) you are working on? it's actually less straightforward than i originally expected
I am coding directly on the leetcode website
👍 mind if i have the link if it's public?
if you give me a couple minutes I can set up a new db with those tables in my mysql server
np

LeetCode
Can you solve this real interview question? Students and Examinations - Table: Students
+---------------+---------+
| Column Name | Type |
+---------------+---------+
| student_id | int |
| student_name | varchar |
+---------------+---------+
student_id is the primary key for this table.
Each row of this table contains the ID and ...
np, i have yanked their schema already
sorry, had to step away for a bit.
what you have here is already quite close.
one of the (maybe naive) solution is to rejoin the output you have already to a cartesian join between student/subjects, and using coalesce to fill in the blanks with 0s
a cartesian join between student/subjects is basically list of all combination between all students and all subjects
dw
Let me search some definitions you mentioned
i don't think there exists a solution that doesn't do cartesian join (it's also known as cross join) - hopefully this is enough to get you started

awesome!
letsgo

speed could be better but at least I got what I needed to do
nice!
good morning guys, new here! I am trying to connect my db, but unfornately is giving me this error
`# commit data to sql
data = prepare_data(df)
conn = sqlite3.connect(uri)
data.to_sql(table_name, conn, if_exists='replace', index=False)
create db engine
eng = create_engine(
url='sqlite:///file:memdb1?mode=memory&cache=shared',
poolclass=StaticPool, # single connection for requests
creator=lambda: conn)
db = SQLDatabase(engine=eng)**This is the error**line 77, in <module>
conn = sqlite3.connect(uri)
^^^^^^^^^^^^^^^^^^^^`
I will appreciate any help, thanks!

You typed uri instead of url

!code
Did you import sqlite3 first?
yeah, I did
Instead of using a URL, use a filepath
this is not my code, but the main feature is to deploy on :memory: due to is only when the user uses the app for short time
that's why
I was using URI
instead of url or file path
Oh interesting, I've never used that before so I'm not sure of the nuances, but then what you're doing looks ok to me
!e The sqlite:/// is SQLAlchemy specific. Remove it if you use the sqlite3 module directly. You must also specify uri=True in the connect call:
import sqlite3
uri = "file:memdb1?mode=memory&cache=shared"
conn = sqlite3.connect(uri, uri=True)
conn.execute("create table test(test_int integer)")
conn.execute("insert into test values(1), (3), (5)")
print(conn.execute("select * from test").fetchall())
@grim vault :white_check_mark: Your 3.11 eval job has completed with return code 0.
[(1,), (3,), (5,)]
!e the other version would be to just use :memory: as filename:
import sqlite3
conn = sqlite3.connect(":memory:")
conn.execute("create table test(test_int integer)")
conn.execute("insert into test values(1), (3), (5)")
print(conn.execute("select * from test").fetchall())
@grim vault :white_check_mark: Your 3.11 eval job has completed with return code 0.
[(1,), (3,), (5,)]
How would I query unique pairs of columns by most recent time stamp?
SELECT DISTINCT col1, col2, timestamp FROM table
ORDER BY timestamp desc
Is a good start
If you need to return just the most recent pairs, use a ranking function on timestamp
are you using postgres?
it has a DISTINCT ON which is closer to what I think you may want..
https://www.geekytidbits.com/postgres-distinct-on/
PostgreSQL has a really interesting and powerful construct called SELECT DISTINCT ON. No, this is not a typical DISTINCT. This is different. It is perfect when you have groups of data that are similar and want to pull a single record out of each group, based on a specific ordering.
ModuleNotFoundError: No module named 'resources'```
i made a file with variables containing all the names of all the columns but it is giving me this error?What does the file/directory structure look like here? What you probably want is a resources folder with an init.py file and a col_names.py file.
/project/resources/col_names.py and /project/databases/main_db.py and im importing col_names to main_db file

SELECT LessonSchedule.LessonDateTime, Student.FirstName, Student.LastName, Horse.RegisteredName
FROM LessonSchedule
LEFT JOIN Student
ON Student.ID = LessonSchedule.StudentID
LEFT JOIN Horse
ON Horse.ID = LessonSchedule.HorseID
WHERE LessonSchedule.LessonDateTime = '2020-02-01'
ORDER BY LessonSchedule.LessonDateTime, Horse.RegisteredName;
What am I doing incorrectly here?
Try from col_names import *
nvm
figured it out
was this line:
WHERE LessonSchedule.LessonDateTime = '2020-02-01'
Also, only the Student table needs the left outer join. The HorseID is part of the primary key, so it's not allowed to be NULL.
shows a redline below col_names and doesnt work
is there any function/extension in sqlite that has the functionality of Similarity function in postgres?
Stack Overflow
Is there a string similarity measure available in Python+Sqlite, for example with the sqlite3 module?
Example of use case:
import sqlite3
conn = sqlite3.connect(':memory:')
c = conn.cursor()
c.
Sorry, replied to wrong message
Ah, yes, because they are in different folders https://www.geeksforgeeks.org/python-import-from-sibling-directory/

GeeksforGeeks
A Computer Science portal for geeks. It contains well written, well thought and well explained computer science and programming articles, quizzes and practice/competitive programming/company interview Questions.
Yes, this works also.
ty
The Employee table has the following columns:
ID - integer, primary key
FirstName - variable-length string
LastName - variable-length string
ManagerID - integer
Write a SELECT statement to show a list of all employees' first names and their managers' first names. List only employees that have a manager. Order the results by Employee first name. Use aliases to give the result columns distinctly different names, like "Employee" and "Manager".
Hint: Join the Employee table to itself using INNER JOIN.
my incorrect answer:
SELECT Employee.FirstName AS Employee, Manager.FirstName AS Manager
FROM Employee Employee
INNER JOIN Employee Manager
ON Manager.ManagerID = Employee.ID
ORDER BY Employee.FirstName;
the actual correct solution:
SELECT e.FirstName AS Employee, m.FirstName AS Manager
FROM Employee e
JOIN Employee m ON e.ManagerID = m.ID
ORDER BY e.FirstName;
I don't understand why this is incorrect:
ON Manager.ManagerID = Employee.ID
and this is correct:
ON Employee.ManagerID = Manager.ID
Because Employee.ManagerID references the Employee.ID (of the manager of that employee). So if you want the employee data of an manager you select where the Manager.ID (because Manager is the alias for the employeedata of the manager) is the Employee.ManagerID.
Hey there! I was looking for a non blocking alternative to pymongo 🙂
i know its not the chat for it but does anyone know a good pygame tutorial or book?
i can use to learn
I think I understand better now
ty
Who can help me with this problem?
I want to send message to messaging queue of Azure Service Bus when the trigger happens in PostgreSQL.
I want to do as described in this document.
https://learn.microsoft.com/en-ca/azure/service-bus-messaging/service-bus-python-how-to-use-topics-subscriptions?tabs=connection-string#send[…]topic
I think this would be helpful to use Python code in PostgreSQL trigger function.
https://stackoverflow.com/questions/46540352/calling-restful-web-services-from-postgresql-procedure-function
Someone who has experience on Python in PostgreSQL, please help me how can I figure this out.
Stack Overflow
I have been provided RESTful web services to push data into a remote DB of another application. I need to call these services to push data from PostgreSQL DB by sending data in JSON format as GET/P...
This tutorial shows you how to send messages to Azure Service Bus topics and receive messages from topics' subscriptions using the Python programming language.
I just discovered that CREATE statements in sqlite can't be parameterised, so, does sqlite have a method for converting a python object to its SQL str representation?
is there a sql database active server on discord if anyone knows? else I want to post a question here:
Given a query
select * from table where primary_key='something';
This will give us 1 unique row consisting all the columns because of the primary key constraint.
Now, I want to add something on top of this, I want to return only columns that are not null.
the easiest intuition to do this would be:
SELECT *
FROM table
WHERE primary_key= '8000017887'
AND (column1 IS not NULL OR column2 IS not NULL OR column3 IS not NULL OR ...)
but what if the table has 10000 columns... I tried to do this via chatgpt but it's giving me a storedprocedure like solution which is a bit complicated for me atm..
Can't you just filter the data from the code side?
Alternatively, how can I convert an object into its representation in SQL?
I know None becomes Null, ints and floats can be inserted directly like f"{number}". What else?
yo
my fellow py programmer
i need help
with my website database
anyone got anyidea
plz
ideas...about what
can anyone help to import a csv file in mysql wrokbench
here is the error I get when I try to upload the csv file : Unhandled exception: 'chamap' codec can't decode byte 0x90 in position 880: character maps to <undefined>
I get some utf-8 error what is that ?
cur.execute("""INSERT INTO info (mail, ticker, wantweekly) VALUES (?, ?, ?)""" (mail, ticker, 1))
gives this error
TypeError: 'str' object is not callable
what u mean??
You're missing a comma between ...""" (mail... -> ...""", (mail...
The parser thinks you are calling a function: """whatever string"""(some, arguments)
Just a guess but maybe this: https://stackoverflow.com/a/29929677
Stack Overflow
One of the responses to a question I asked yesterday suggested that I should make sure my database can handle UTF-8 characters correctly. How I can do this with MySQL?
Hello, not sure if this is a little out of place but is anyone decent with Excel?
Im trying to find the foumla to work out the tax of an entire collum which is labelled "My Expenses"
Here's a little screenshot which hopefully makes sense

I'd like to say, work out 20% of ererything which is labelled as My Expenses
So I tried running the Load Data Infile command and I received the "Error Code: 1290. The MySQL server is running with the --secure-file-priv option so it cannot execute this statement". Okay, so I looked it up and there's a directory it mentions in which you can put files in and it allows you to use the command on those files. I did that, it still didn't work. So then I go to my.ini and check it, and the directory name is correct and all the slashes are in the right direction. I then go and just completely clear it so --secure-file-priv doesn't point to anything. I restarted MySQL and booted a new server, and now I get an error code 29 claiming that the file/directory cannot be found, because even though I completely removed that directory from my.ini it's still somehow finding it, yet somehow it deleted the slashes on the last few directory folders, which I never touched:
Error Code: 29. File 'C:\ProgramData\MySQL\MySQL Server 8.0\Data\ProgramDataMySQLMySQL Server 8.0Uploadssistercitiesuscities.csv' not found (OS errno 2 - No such file or directory)
It should be File 'C:\ProgramData\MySQL\MySQL Server 8.0\Data\ProgramData\MySQL\MySQL Server 8.0\Uploads\sistercities\uscities.csv', but as you can see in the error it's removing the last few slashes, which is probably causing the problems, but I have no clue why because as mentioned I have completely deleted that directory reference for secure-file-priv.
secure-file-priv=""
This is how secure-file-priv is set right now. There is no path, so the expected result should be that secure-file-priv is ignored and it shouldn't even be able to reference that path in an error since I deleted it.
for sqlalchemy, for your schema. is it better to use mapped_column() or Column()?
ping me pls, i don't check this discord often currently.
how can I scrap web like futbin.com
mapped_column is a newer API for ORM, you should only use Column with Table objects now 🤔
Does MySQL support the Apache Arrow Flight SQL protocol?
guys, seems that my jury rigging is not working well:

import pymongo
from pymongo import MongoClient
client = MongoClient("Connection_string"
client.list_database_names()
db = client['internal_name']
x_values = x_collections.get_x_values(db, model_id)
I've never used mongodb so this is probably a dumb question: What type of object is db? i.e. is it a dataframe?
I can't run this or have access to x_collections so I'm unable to tell.
pymongo/mongo_client.py lines 1557 to 1566
def __getitem__(self, name: str) -> database.Database[_DocumentType]:
"""Get a database by name.
Raises :class:`~pymongo.errors.InvalidName` if an invalid
database name is used.
:Parameters:
- `name`: the name of the database to get
"""
return database.Database(self, name)```hence database.Database
What would database.Database actually look like? Is it similar to a JSON format?
I'm trying to replace the MongoDB connection with a ODBC (SQL) query so I'm trying to figure out if the existing code needs changes.
Yes, you will need code changes. The documents stored in a mongo db are schemaless like JSON
But, MongoDB can be both structured and unstructured right?
e.g. doc = db["out_x_y "].find_one({"model_id": model_id}) This line looks like it maybe structured in this case?
I'm trying to gauge how much work is needed. As it was presented to me as a simple "change mongo db connection with a ODBC connection"
Structured like JSON is yes, but schemaless unlikr SQL. In other words you will have no idea what's in model_id (null, string, int, or a whole complex dictionary)
json and xml are oftentimes called semi-structured
usually your data will follow a schema to some degree, but you do not have to declare it beforehand, it is typically not enforced and fields in the schema can be missing + fields outside of the schema can be present
it is structured enough to make sense out of it, otherwise it would be nearly worthless in most of the cases, but not structured to the point of following a rigid schema like SQL
(actual unstructured data are things like freeform text, images or videos)
Yea, I'm familiar with the semi-structured JSON. I recall something like: {col : {val1,val2, }}
So I have access to the helper functions & imports. I can see the semi structure/structure as there is calls like for X in input_doc["col"]["details"]
Looks like there would have to be major refactoring for it to go from mongodb (semi-structured) to structured like SQL tables. Edit: Too many 'so'
i love cassandra db , her is my futur gf
well, if it follow a schema you can try dumping into a json or csv file then importing that from the SQL database, but if doesn't, you may need to spend some time adjusting the data
The biggest issue is that I don't have access (and will not get access) to the original MongoDB's output at all. I'm only told that there is a table in the SQL database that mirrors what is in the MongoDB. But if it's semi-structured, I still think there's probably some major changes necessary.
Could someone told why I can't create postgresql server ? (Doing a django project)

Have you installed and configured Postgres? If so is that the username and port you configured?
To be clear, that screenshot (whatever application that is) shows you trying to connect to a Postgres instance, it's not going to create one
yeah I've installed it

Using pgadmin 4 oh I got it how can I see if a postgres instance is made ?
The error seems to point to username/password as the most likely problem.
I tried changing password/username still the same error

Instead of localhost try 127.0.0.1 maybe?
Try connecting with psql and see if you get a different result or more helpful error message
got this

now trying psql way
Tried psql didnt work even harder to create since its not gui
how are you running this application? are you using any container tech (e.g. docker)?
what OS are you on?
Ok let me send you the traceback would be easier for you to understand
Fedora 36
Command I'm doing txt sudo docker-compose up --build traceback ```txt
api | File "/usr/local/lib/python3.11/site-packages/psycopg2/init.py", line 122, in connect
api | conn = _connect(dsn, connection_factory=connection_factory, **kwasync)
api | ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
api | django.db.utils.OperationalError: connection to server at "127.0.0.1", port 5432 failed: Connection refused
api | Is the server running on that host and accepting TCP/IP connections?
okay let's backtrack a little.
what's the problem you are trying to solve?
you posted something that is a django traceback and i was referring to the pgadmin screenshot you posted - so i am confused now.
Oh sorry I'm trying to make a server on pgadmin that I will use on my django project
So right now just trying to be able to make a server on pgadmin4
postgresql is a database indeed.
pgadmin4 is a tool used for administering running postgresql instances/databases, it can't "create" postgresql instances/databases
yeah I got it the word create was wrongly used
But from I've read you need to "register server" to be able to acces to your databse
yes that's correct.
do you know how you are running your postgresql database?
and how are you running this pgadmin application?
Yeah I've already used pgadmin for a school project once we had used database and pgadmin4
the only difference is that I wasn't the one making the "database connection" I've used pgadmin when all those "error connection" where already fixed
But overall I know how I'm running the database and the pgadmin app
right, please tell me how are you running the database and the pgadmin app then
(i phrased my previous question slightly wrong, i meant "can you tell me how are you running....")
I'm running the database with docker and the pgadmin app work via "connection"
My answer isn't perfect but I tried explaining
okay perfect
I'm running the database with docker
please go into more details - what network mode are you using? did you port forward?
the pgadmin app work via "connection"
not sure what you meant here, please elaborate
ok you need to use docker to be able to make your db "work" I don't get the network mode part but if you talk about host I'm using 127.0.0.1 with port 8000:8000 based on my docker-compose file
okay "8000:8000" sounds wrong. please show your docker compose file
ok
version: "3"
services:
db:
container_name: db
image: postgres:13
volumes:
- ./back-end/db-data:/var/lib/postgresql/data
env_file:
- back-end/.env
environment:
- POSTGRES_PASSWORD=postgres
api:
container_name: api
build: ./back-end
command:
- sh
- -c
- |
python back-end/pwitter/manage.py makemigrations
python back-end/pwitter/manage.py migrate
python back-end/pwitter/manage.py runserver 0.0.0.0:8000
volumes:
- .:/back-end
ports:
- "8000:8000"
env_file:
- back-end/.env
depends_on:
- db
volumes:
db-data:
.env
SECRET_KEY='SECRET_KEY'
DEBUG=True
DB_NAME=twitter-clone
DB_PASSWORD=postgres
DB_USER=postgres
DB_HOST=localhost
DB_PORT=5432```okay, and your pgadmin isn't ran with docker?
I may be wrong but I don't think it's working well
i don't know what you meant by that.
which part ?
this
but it sounds like you want to have postgres accessible on your host.
you need to port forward 5432 (the default postgres port)
yes exactly
do you know how to do that by amending your compose file?
I've used it once but I don't remember
let me google it
just that ?
did that then ```yml
version: "3"
services:
db:
container_name: db
image: postgres:13
volumes:
- ./back-end/db-data:/var/lib/postgresql/data
env_file:
- back-end/.env
environment:
- POSTGRES_PASSWORD=postgres
api:
container_name: api
build: ./back-end
command:
- sh
- -c
- |
python back-end/pwitter/manage.py makemigrations
python back-end/pwitter/manage.py migrate
python back-end/pwitter/manage.py runserver 0.0.0.0:5432
volumes:
- .:/back-end
ports:
- "5432:5432"
env_file:
- back-end/.env
depends_on:
- db
volumes:
db-data:
no
version: "3"
services:
db:
container_name: db
image: postgres:13
volumes:
- ./back-end/db-data:/var/lib/postgresql/data
ports:
- "5432:5432"
env_file:
- back-end/.env
environment:
- POSTGRES_PASSWORD=postgres
api:
container_name: api
build: ./back-end
command:
- sh
- -c
- |
python back-end/pwitter/manage.py makemigrations
python back-end/pwitter/manage.py migrate
python back-end/pwitter/manage.py runserver 0.0.0.0:8000
volumes:
- .:/back-end
ports:
- "8000:8000"
env_file:
- back-end/.env
depends_on:
- db
volumes:
db-data:
what you have here changes the api service's port forward mapping, which doesn't help expose your postgres beyond docker's internal networking (and thus make it accessible on your host)
ok I see thanks
Changed with your file got this eror now ```txt
Recreating 34698e2fba4b_db ...
Recreating 34698e2fba4b_db ... error
ERROR: for 34698e2fba4b_db Cannot start service db: driver failed programming external connectivity on endpoint db (d7251b34d93c156db5f0aaea11d26b1f3d33da37daf09439991e56bd8a13517c): Bind for 0.0.0.0:5432 failed: port is already allocated
ERROR: for db Cannot start service db: driver failed programming external connectivity on endpoint db (d7251b34d93c156db5f0aaea11d26b1f3d33da37daf09439991e56bd8a13517c): Bind for 0.0.0.0:5432 failed: port is already allocated
ERROR: Encountered errors while bringing up the project.
change the first number of "5432:5432" to something else
so that you are mapping 5432 within the postgres container to another port on your host
it seems you already have something using port 5432 on your host, this is probably some other postgres you have
ok
Worked but still got this error ```txt
api | django.db.utils.OperationalError: connection to server at "127.0.0.1", port 5432 failed: Connection refused
api | Is the server running on that host and accepting TCP/IP connections?
api |
do you understand the error?
yeah the conection failed
yes, it's connecting to "127.0.0.1:5432"
is that the correct address to be using here?
obviously no
so let's think about it, where is your postgres running? how do we reference it from within the api service/container?
my postgres is trying to run on 127.0.0.1 port 5432 , we reference it by using port we put on the service container
my postgres is trying to run on 127.0.0.1 port 5432
not quite, it's running within thedbdocker container/docker compose service, using the port 5432, which is then port forwarded to host port X (where X is the first number you have chosen)
oh ok
to access db from api service, you need to ensure api and db share the same network, which by using docker compose, i think it's already done
oh got it
you mean docker-compose does that for myself ?
oh cool
note that it's 5432 and not the first number you have chosen, because you are referencing db's port internally in its docker container and not whatever you port forwarded to your host

probably not.
I guess it's the host name/address part that is not correct

you didn't really answer how you are running pgadmin, so i assume this is what's happening
you successfully fixed the reference of db from api service, by using db:5432 which is good
now for your pgadmin, it's important to note i am assuming you are running this not within docker (mostly because you didn't have it in your compose file)
thanks
yeah
to access the now exposed postgres (running in the db docker container), you need to reference it by localhost:12345 because you are no longer in the docker compose "context"
oh ok
pgadmin uses your host's networking instead of the docker managed one, it doesn't know what is db:5432 it only knows localhost:12345
(it could, with some other tricks that you need to configure yourself, but no point doing that if localhost:12345 works)

do you understand why i chose 12345?
to don't have the same "port"
yes - now did you use 12345? in your compose file
no I'm dumb my bad

np, just making sure you understood why i typed 12345
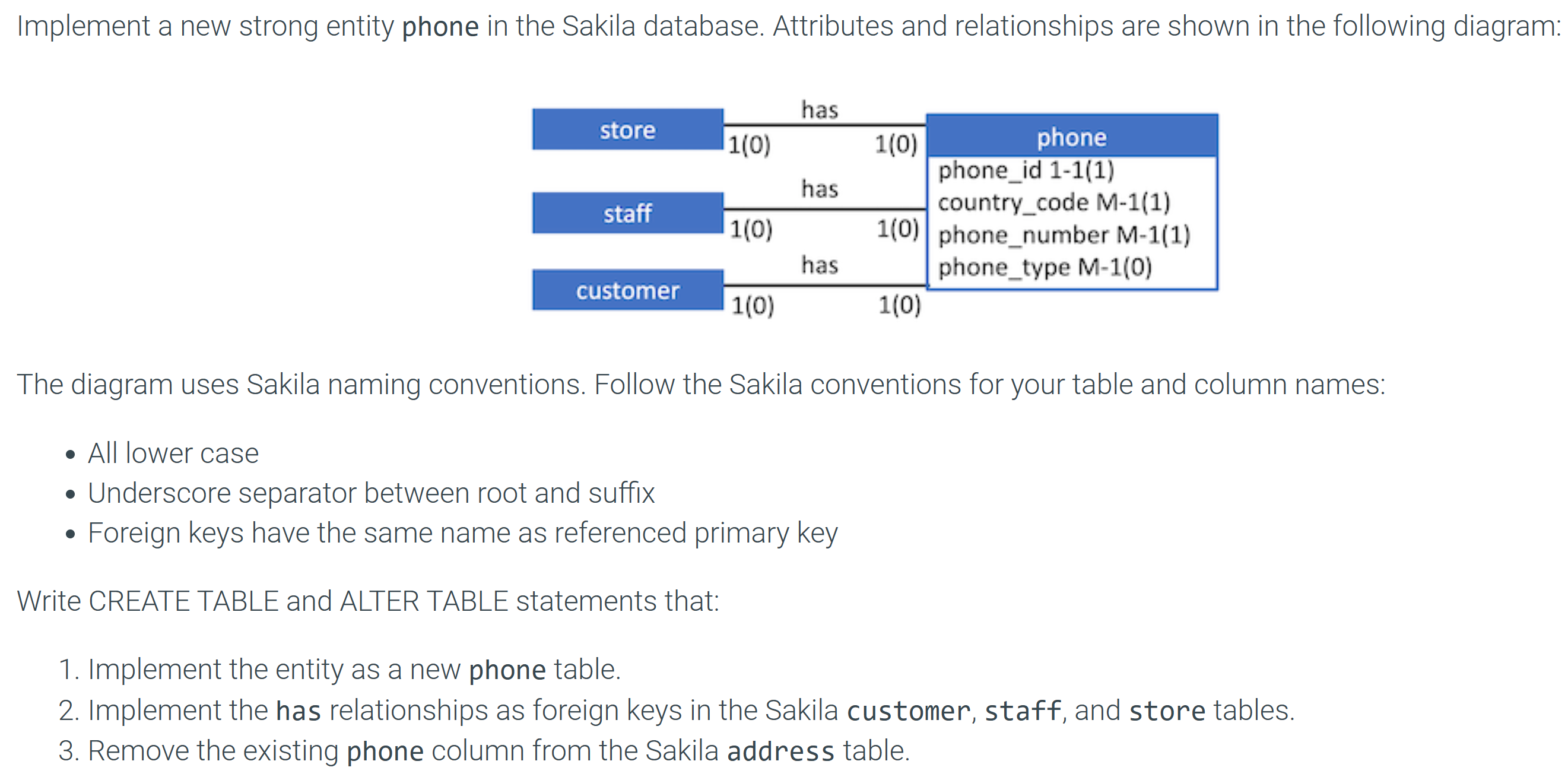
Anyone know how to do this?
I'm so confused with this topic of strong vs weak entity.
ok ok thanks
Wait I swear I'm either tired or dumb as hell is this good? ```txt
version: "3"
services:
db:
container_name: db
image: postgres:13
volumes:
- ./back-end/db-data:/var/lib/postgresql/data
ports:
- "5555:12345"
env_file:
- back-end/.env
environment:
- POSTGRES_PASSWORD=postgres
api:
container_name: api
build: ./back-end
command:
- sh
- -c
- |
python back-end/pwitter/manage.py makemigrations
python back-end/pwitter/manage.py migrate
python back-end/pwitter/manage.py runserver 0.0.0.0:8000
volumes:
- .:/back-end
ports:
- "8000:8000"
env_file:
- back-end/.env
depends_on:
- db
volumes:
db-data:```
"5555:12345" says, forward 12345 in the container to 5555 on host
which is not correct
"5555:5432" sounds more reasonable - and you need to use 5555 in pgadmin
ok ok thanks
Well well
I need to thanks you @hollow oar for all the explenation and even the draw you made for me
It worked fine
wonderful 🙌
- I understood the process well enough to be able to explain to someone if he face the same problem
that's great 😁
yep thanks
re. https://discordapp.com/channels/267624335836053506/1113391275920605275/1113391275920605275
seems like you reverted some of the changes?

hello, no I just didn't launched yesterday just tested pgadmin and when I realized it was too late to send a message so I went sleeping
I've keep the same file as they where yesterday
Just did one change like 30 minutes ago


try drawing the same picture as i did here https://discordapp.com/channels/267624335836053506/342318764227821568/1113399741162733599
but instead of just copying, fill it with what is actually happening in your app, and you should see why it's erroring.
ok thanks
How can I write a recursive query to get all data related to a row?
a good starting point is to post your schema, some example data, and what you expect from the query
I just want a generic solution. Like coping nested json or dicts.
If that's possible.
From what I have found. I don't think it is though.
the issue is we don't understand what you mean by that, there are probably more than one way to interpret your request
unless you provide some example data, i can't really comment.
Here's an example:
Lets say I have 3 tables.
user_group, user and user_posts
For a given user_group_id I want to copy the user_group, all users in that group and all posts by the users in that group.
And this is the way I have found to copy data from 1 database to another.
INSERT INTO t(a, b, c)
SELECT a, b, c FROM dblink('host=xxx user=xxx password=xxx dbname=xxx', 'SELECT a, b, c FROM t') AS x(a integer, b integer, c integer)
are these tables linked by foreign keys?
https://www.depesz.com/2023/02/07/how-to-get-a-row-and-all-of-its-dependencies/
have a look here, from one of the blog which i follow.
They are
That's a great start. I think I can work from that.
Traceback (most recent call last):
File "/Library/Frameworks/Python.framework/Versions/3.11/lib/python3.11/site-packages/discord/ext/commands/core.py", line 229, in wrapped
ret = await coro(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/Users/drake/Desktop/deadbot/cogs/mod.py", line 163, in add
async with ctx.bot.db.cursor() as cursor:
^^^^^^^^^^
AttributeError: 'Bot' object has no attribute 'db'
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/Library/Frameworks/Python.framework/Versions/3.11/lib/python3.11/site-packages/discord/client.py", line 409, in _run_event
await coro(*args, **kwargs)
File "/Users/drake/Desktop/deadbot/cogs/events.py", line 25, in on_command_error
raise error
File "/Library/Frameworks/Python.framework/Versions/3.11/lib/python3.11/site-packages/discord/ext/commands/bot.py", line 1349, in invoke
await ctx.command.invoke(ctx)
File "/Library/Frameworks/Python.framework/Versions/3.11/lib/python3.11/site-packages/discord/ext/commands/core.py", line 1023, in invoke
await injected(*ctx.args, **ctx.kwargs) # type: ignore
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/Library/Frameworks/Python.framework/Versions/3.11/lib/python3.11/site-packages/discord/ext/commands/core.py", line 238, in wrapped
raise CommandInvokeError(exc) from exc
discord.ext.commands.errors.CommandInvokeError: Command raised an exception: AttributeError: 'Bot' object has no attribute 'db'
``` my friend coded this and im not sure how to fix this error bc im new w/ dbsWould help to see the original code, it looks like somewhere in the "Bot" model the db attribute is missing or improperly defined
I'm having trouble connecting to a PostgreSQL database I have running in a docker container. It communicates with another docker container that I run a Flask application on, and I have been able to Create, Read, Update, and Delete records from the Flask app so I know that it is working. When I try to connect to it via localhost:5432 in the PSQL console, I get an error that it cannot find that host
More specifically it says: error: connection to server at "localhost" (::1) port 5432 failed: Connection refused is the server running on that host and accepting TCP/IP connections?"
hi,
i have configured the postgresql DB with the Django app. Once it is done, tried to execute the below query.
from django.db import connection
CREATE_TABLE = """
CREATE TABLE accounts (
user_id serial PRIMARY KEY,
username VARCHAR ( 50 ) UNIQUE NOT NULL,
email VARCHAR ( 255 ) UNIQUE NOT NULL,
);
"""
cursor = connection.cursor()
cursor.execute(CREATE_TABLE)
Then, the error in the console is:
django.core.exceptions.ImproperlyConfigured: Requested setting DATABASES, but settings are not configured. You must either define the environment variable DJANGO_SETTINGS_MODULE or
call settings.configure() before accessing settings.
Database is also configured in the settings.py
DATABASES = {
'default': {
"ENGINE": "django.db.backends.postgresql",
"NAME": "postgres",
"USER": "postgres",
"PASSWORD": "postgres",
"HOST": "127.0.0.1",
"PORT": 5432,
}
}
Its been a while since I used django though I think you either need to create a custom management command as per https://docs.djangoproject.com/en/4.2/howto/custom-management-commands/
Or just use existing dbshell or shell https://docs.djangoproject.com/en/4.2/ref/django-admin/#shell
::1 is the IPv6 loopback. It seems likely IPv6 isn't configured and you can try the IPv4 loopback 127.0.0.1 as its more likely to be listening.
I have 2 databases in my server, "MYDATA_TEMP" and "MY_DATA"
I have some SELECT queries I make on "MYDATA_TEMP" that I then upload to "MY_DATA"
This is done with Python using pyodbc. I execute the queries, get the data from one database and then "cursor.executemany()" on the final database
However, it seems that this part can be skipped, and directly INSERT INTO SELECT from "MYDATA_TEMP" to "MY_DATA", and Python would just execute the query
Can that be done?
@commands.command(help="whitelist a member", usage="[member]", description="antinuke")
@commands.cooldown(1, 2, commands.BucketType.user)
@commands.has_permissions(administrator=True)
async def add(self, ctx: commands.Context, *, member: discord.Member=None):
if member is None: await self.commandhelp(ctx, "whitelist add")
async with ctx.bot.db.cursor() as cursor:
await cursor.execute("SELECT * FROM whitelist WHERE guild_id = {} AND user_id = {}".format(ctx.guild.id, member.id))
check = await cursor.fetchone()
if check is not None: return await ctx.reply(embed=discord.Embed(color=0x2B2D31, description=f" {ctx.author.mention}: This user is already whitelisted"), mention_author=False)
await cursor.execute("INSERT INTO whitelist VALUES (?,?)", (ctx.guild.id, member.id))
await self.bot.db.commit()
await ctx.reply(embed=discord.Embed(color=0x2B2D31, description=f" {ctx.author.mention}: Whitelisted {member.mention}"), mention_author=False)```So in PSQL instead of connecting with the host name “localhost” use the loop back IP address instead?
yes try to replace localhost with 127.0.0.1
Peace everyone.
This will be database engine specific. For example with Postgres you would use Postgres fdw to connect one db to the other first before running the query much like the way in your example. I’m sure other db engines will have a way too.
Pleas i need someone free for helping me with phpmyadmin just to do for me a video screenshot to my base and send the video to me my pc is broken
I'm using SQL server. Thanks, I'll look that up in postgres
Seems relevant: https://stackoverflow.com/a/3502295
Stack Overflow
I want a query to insert records from one table to another table in a different database if the destination table already exists, it should append the records at the end of the table.
learningdb=> create table people(id integer primary key, name varchar(40));
ERROR: no schema has been selected to create in
why am i getting this error?
i ran set search_path to public; before this
Syntax looks wrong, what DB engine is this?
Postgres
I created the db using
createdb -U ayan learning.db
From command line
Google says you might need to grant usage https://dba.stackexchange.com/questions/106057/error-no-schema-has-been-selected-to-create-in
Database Administrators Stack Exchange
I am working on an amazon RDS postgresql database where I know there had been some issue with the public schema (maybe it was dropped). But apparently the schema exists, and anyway the problem is not
i have database dump what should i do in order to connect it to django
You haven't given us much context to go with here, is loaddata maybe what you're looking for? https://docs.djangoproject.com/en/4.2/ref/django-admin/#django-admin-loaddata
Does anyone here have experience with ontotext graphdb? If so, which web framework did you use? I was considering using Django, but I read that it's not recommended for NoSQL DBs
hi, could anyone please help me on this..
i created models.py inside Django project & it looks like below
from django.db import models
class Product(models.Model):
name = models.CharField(max_length=50)
quantity = models.IntegerField()
class Brand(models.Model):
name = models.CharField(max_length=50)
then execute the below command
python manage.py makemigrations
But, inside the app folder of the project, there is no 001_initial.py file created.
have You registered your Django app in installed apps django-project/project-name/settings.py
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'app.apps.AppConfig` # register ur app
]
I am using flask and am curious how I access the Posts column from the User table in the example below?
Please ping me if you respond.
Assume 1 to many relationship
User is 1 and Posts is many.
class User ...
id = ...
username = ...
posts = db.relationship('Posts', backref='postinfo', lazy=True)
class Posts ...
id = ...
title = ...
user_id = db.Column(db.Integer, db.ForeignKey('user.id'), nullable=False)
Access User column from the User table
user = # query the User database
user.username
Access Posts column from the User table
user = # query the User database
user. ?
Access Posts column from the Posts table
post_db = # query the Posts database
post_db.title
Access the User column from the Posts table
post_db = # query the Posts database
this is possible because of the foreign key and backref is = postinfo.
post_db.postinfo.username
Never mind I solved it
i have a .sql file which about 8MB size. It has data in it i want to make use of this file for my database or as my database for django.. i dont know much about. I used chatgpt and didt got a correct answer.
So you have no Django app and no database to connect to it? Follow the official Django tutorial to understand the basics first. Importing that SQL dump into your database will be a relatively easy part if you're starting from scratch
Hello I've done a login system for my django / react "website" but I need to check if an user is connected to access certain "pages" how can I do that ?
idk maybe set a variable that becomes true once the user logs in
I've find a solution using jwt
Now I just need to set a proper logout
And it will be good
Any suggestion on graphs that I should pick when it comes to having a lot of paramters? I have tried to make double y axis but it seems like it still looks like a mess.


shot in the dark here but I'm trying to define a table in sqlite3 to have a unique id ONLY if another column has a certain value, any suggestions how to accomplish this? here's a simplified example of the table
CREATE TABLE u_characters(
u_character_id INTEGER PRIMARY KEY,
status INTEGER NOT NULL,
character_id INTEGER)
I'd like character_id to be unique if status is > 0. would like to do this with a check, but changing the table to accomplish this can be done as well
This doesn't seem like something you actually would want to do. Why would you set a constraint on the entire table based on a single value in a single row?
If CHECK is what you actually want, that makes sense
yeah I do want to make a CHECK but not sure how to create the expression, can i just use the UNIQUE keyword on a column in it?
to clear things up say you would want to have a list of users that live at an address, if someone moves out you'd still like to retain their record, but their status would be 'disabled' or something because only one person or set of people should live at an address at the current time
I'd like to do a CHECK like CHECK (status > 0 and character_id UNIQUE)
but trying to read the documentation doesnt seem like that's possible
nm chat gpt got my back, i guess you can perform selects in checks which I guess is sufficent
guess that's not entirely true but looks like I can create a trigger ;P
How long it can take individual to learn mysql
CREATE UNIQUE INDEX ix_test_me ON "u_characters" ("character_id") WHERE status > 0;
should do
The basics? 20 minutes. But to master complex queries and all the rest? Years
Hi everyone. I need some help with why my code isn't working. I'm trying to access my firebase realtime database. My code is as follows
cred = credentials.Certificate('./admin-auth-key.json')
firebase_admin.initialize_app(cred,
{
'databaseURL': 'https://database-name.firebasedatabase.app/'
}
)
self.db = firestore.Client()
It's throwing the following error
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/path/venv/lib64/python3.11/site-packages/google/cloud/firestore_v1/client.py", line 93, in init
super(Client, self).init(
File "/path/venv/lib64/python3.11/site-packages/google/cloud/firestore_v1/base_client.py", line 135, in init
super(BaseClient, self).init(
File "/path/venv/lib64/python3.11/site-packages/google/cloud/client/__init__.py", line 320, in init
_ClientProjectMixin.init(self, project=project, credentials=credentials)
File "/path/venv/lib64/python3.11/site-packages/google/cloud/client/__init__.py", line 268, in init
project = self._determine_default(project)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/path/venv/lib64/python3.11/site-packages/google/cloud/client/__init__.py", line 287, in _determine_default
return _determine_default_project(project)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/path/venv/lib64/python3.11/site-packages/google/cloud/_helpers/__init__.py", line 152, in _determine_default_project
_, project = google.auth.default()
^^^^^^^^^^^^^^^^^^^^^
File "/path/venv/lib64/python3.11/site-packages/google/auth/_default.py", line 648, in default
raise exceptions.DefaultCredentialsError(_CLOUD_SDK_MISSING_CREDENTIALS)
google.auth.exceptions.DefaultCredentialsError: Your default credentials were not found. To set up Application Default Credentials, see https://cloud.google.com/docs/authentication/external/set-up-adc for more information.
Any help will be greatly appreciated. Thanks
have you read and follow the link quoted https://cloud.google.com/docs/authentication/external/set-up-adc ?
please post the commands you have used when following instructions on the link as well
Thank you very much. That was stupid of me.
not at all, we all are somewhat allergic to wall of text and quite often miss crucial information staring at our faces!
Indeed lol. Btw, do you know if the sdk has an asynchronous version? Thanks for your time
just firebase or other services' client as well?
i don't use firebase so i can't tell if it's legit, but give it a shot!
Year!!!!!! What
It really depends what you're trying to achieve, how focused you are, etc. If you're starting from zero worry about the 20 minutes first 😉
I have done with basic
Good, just keep going 🙂 Like anything else worth learning, there is no endpoint unless you set one
I have been told to do advance mysql will take few months
Thanks a lot once again!
So right now, I'm working on a soundboard GUI application that requires the user to upload audio files. However, I need a way to store these files persistently so that every time I open the app, the uploaded files are displayed. My two main options are to store them in a folder or a SQLite3 database. Would it be safer to store these files in a database rather than a folder?
If you're just going to be storing the audio with no other related data then you don't really need a database
Although using one in case you do decide to store relational data in the future would be more flexible
I see
However, I am planning on storing an audio file along with a name
Like for each audio file, there is a string called "name" for it
Wait
Nvm
I can just make a copy of an audio file and rename it
Not just the name, but perhaps you would want to allow the user to group certain sounds the way you would group tracks into playlists
Or more complex features where additional data needs to be stored in relation with the audio data
That's when a db would be quite useful
can someone help me setup postgre
Is there someone that could help me with creating a function that takes the average of the previous observation and the next observation to fill a NaN variable for a selection of columns that is relatively fast because the dataset is massive?
Hi
is there any one familiar with SQLalchemy tool in python.
im trying to make a connection for my localDB, but getting DB is refusing connection actively
Share your code an the error?
URI = "mysql+pymysql://%s@127.0.0.1:3306/blop" % os.environ['USERNAME']
engine_ = create_engine(URI)
conn = engine_.connect()
*Error : *sqlalchemy.exc.OperationalError: (pymysql.err.OperationalError) (2003, "Can't connect to MySQL server on '127.0.0.1' ([WinError 10061] No connection could be made because the target machine actively refused it)")
here, Blop is my DB and 'USERNAME' is my user name is singin with.... thanks in advance
Actively refused... I think that could be that the port isn't open (firewall?) or bad username/password. Are you even sending a password here?
no password, this is my localcal. Actually, i can make a connection with pyodbc module as below.
cnxn = pyodbc.connect(Driver='{SQL Server}',
Server='DESKTOP-M0S2O65',
Database='Blop',
Trusted_Connection='tcon')
but i need SQLalchemy's features
is ther an SQLalchemy's equivalent for this.
I notice this working example looks totally different... Hostname instead of IP and no port specified. Are you sure 127.0.0.1:3306 is correct?
URI = "mysql+pymysql://%s@DESKTOP-M0S2O65/blop" % os.environ['USERNAME']
i tired this, no luck still
Also, i dont know if my URI is correct. Im just going by trail and error
Why are you guessing, is the documentation unclear?
Also maybe try an fstring instead of %s, and make sure that the environment variable is set correctly.
i just couldn't find anything on ho to create engine for my local MYSQL DB
Have you tried some more like url = 'mysql://username@14.41.50.12/dbname' ? The IP should probably be your local one.
i see, im gonna try this now
isn't the username supposed to be 'root', to connect to localhost
Your ODBC code is for SQL Server and now you try to connect to an MySQL database. Which is it?
i've modified he URL for my SQL server
URL = 'mssql+pyodbc://AJ_WORK_Place@127.0.0.1/blop'
This is error im getting now :
sqlalchemy.exc.InterfaceError: (pyodbc.InterfaceError) ('IM002', '[IM002] [Microsoft][ODBC Driver Manager] Data source name not found and no default driver specified (0) (SQLDriverConnect)')
say i know database CRUD commands, and now i am upto design a database for production
now my doubt is, how can i know that everything is going well?
i mean say i created many tables with different schemas. Now i want to cross check everything, so is it like i have to check tables by commands repeatedly and note down on paper to analyse the situation
Or is there some visual way to manage and debug these databases?
Hi all, Say i were to start a data analytics consultancy. The background I have is in data analytics consulting mainly on the analytics and data science part. Im only involved in SQL logic and data warehouse design aspects of the data engineering team. My friend has experience in financial reporting which will likely be our main target for the clients.
Due to a lack of data engineering background but still wanting to set up proper data warehouses for the client instead of using data in excel/google sheets to generate dashboards in the respective dashboard tools,
Q: Are they are recommended ETL tools that are relatively easier to pick up?
i finally made it work, below is working URL
URL = 'mssql+pyodbc://DESKTOP-M0S2O65/blop?driver=SQL+Server'
thank
i think no code/low code isnt the main issue im facing, rather what tools to bring together my python and SQL skills together
In that case, Airflow seems like the default option



sus, how are you trying to connect?
in sqlalchemy for a certain query, count function returns 12, while all function returns only 6 records
there are no duplicates either
from pymongo import MongoClient
connection_string = "mongodb+srv://username:password@cluster0.mongodb.net/?retryWrites=true&w=majority"
client = MongoClient(connection_string)
db = client['your_database_name']
collection = db['your_collection_name']
packages\psycopg2__init__.py", line 122, in connect
conn = _connect(dsn, connection_factory=connection_factory, kwasync)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
psycopg2.OperationalError: connection to server at "localhost" (::1), port 5432 failed: fe_sendauth: no password supplied
I'm having an issue with my sqlalchemy connection dying after some problem happening in my flask app. I looked up the docs and this snippit seems like to fix my issue but I don't know how to particularly know to use it correctly. Do I only put it when I create my engine (this doesn't seem right to me) or do I put it before each of my queries? Also, what would the var c be used for in this context as well? does it just establish the connection to the db and not need to be used again? (this is the error i'm seeing if it helps - sqlalchemy.exc.InternalError: (psycopg2.errors.InFailedSqlTransaction) current transaction is aborted, commands ignored until end of transaction block
https://docs.sqlalchemy.org/en/14/core/pooling.html#pool-disconnects
from sqlalchemy import create_engine, exc
e = create_engine(...)
c = e.connect()
try:
# suppose the database has been restarted.
c.execute(text("SELECT * FROM table"))
c.close()
except exc.DBAPIError as e:
# an exception is raised, Connection is invalidated.
if e.connection_invalidated:
print("Connection was invalidated!")
# after the invalidate event, a new connection
# starts with a new Pool
c = e.connect()
c.execute(text("SELECT * FROM table"))

This is an example with fake info. Are you using real info?
It's telling you the password is missing
How to see username, password, host, database?
For development environments with postgres it is common to just use TRUST in the pg_hba.conf
# The same using a host name (would typically cover both IPv4 and IPv6).
#
# TYPE DATABASE USER ADDRESS METHOD
host all all localhost trust
see https://www.postgresql.org/docs/current/auth-pg-hba-conf.html

PostgreSQL Documentation
21.1. The pg_hba.conf File Client authentication is controlled by a configuration file, which traditionally is named pg_hba.conf and is stored in …
In my database and username all is written is it correct
Okay. Perhaps your issue is IPv6
The ::1 in the error:
"localhost" (::1),
indicates IPv6 loopback.
So perhaps try the IPv4 loopback of 127.0.0.1 instead of localhost
Pls give me steps to setup database and value
Sqlite or postgresql
To elaborate:
From link #1:
conn = psycopg2.connect("dbname=test user=postgres")
Well any of the connection string formats in 34.1.1.2. Connection URIs of the second link should work. I tend to use:
Put it into an environment variable. Sometimes using .env if using dotenv module.
DSN=postgresql://user:secret@localhost/mydb
Where you have replaced user secret and mydb as appropriate
And then you should be able to use:
from os import getenv
dsn = getenv("DSN")
conn = psycopg2.connect(dsn)
This is untested though it should work.
I can't understand this
i have to use one or to see two
I elaborated on this.
You need both. Link #1 from psycopg shows you how to connect if you are using mostly defaults except dbname=test user=postgres
Though link #2 from postgres section 34.1.1.2 shows all the other connection strings variables you can populate.
alsways giving error
my username is coming all
password is scram-sha-256 then also coming wrong password
am going to give up i am not able to create bot
Best to share a minimal repeatable example.
Also do you have psql on your Terminal
You should able to check that you can connect with:
psql postgresql://user:secret@localhost/mydb
where to write this
On your terminal
Server [localhost]: Best to share a minimal repeatable example.
Database [postgres]:
Port [5432]: Also do you have psql on your Terminal
Username [postgres]:
psql: warning: extra command-line argument "a" ignored
psql: warning: extra command-line argument "minimal" ignored
psql: warning: extra command-line argument "repeatable" ignored
psql: warning: extra command-line argument "example." ignored
psql: warning: extra command-line argument "-U" ignored
psql: warning: extra command-line argument "postgres" ignored
psql: warning: extra command-line argument "-d" ignored
psql: warning: extra command-line argument "postgres" ignored
psql: warning: extra command-line argument "-p" ignored
psql: warning: extra command-line argument "Also" ignored
psql: warning: extra command-line argument "do" ignored
psql: warning: extra command-line argument "you" ignored
psql: warning: extra command-line argument "have" ignored
psql: warning: extra command-line argument "psql" ignored
psql: warning: extra command-line argument "on" ignored
psql: warning: extra command-line argument "your" ignored
psql: warning: extra command-line argument "Terminal" ignored
psql: error: could not translate host name "Best" to address: Unknown host
Press any key to continue . . .
what was this
Is this the correct way to execute an UPDATE statement?
from sqlalchemy import create_engine
engine = create_engine(...)
with engine.connect() as conn:
with conn.begin() as conn2:
conn.execute(stmt, *values)
conn2.commit()
I dont understand why the object returned from engine.connect() dosent have the commit() method
I'm confused, but if I understand it correctly, engine.begin() auto-commits at the end of the with block (or rollsback)
is this the best way for executing a statement that writes to the database?
Hey guys, I'm trying to add a document to my firebase db with the below code but I get this error
from google.cloud import firestore
# self.db = firestore.AsyncClient() # this is inside a class, the below func is a method
async def process_item(self, item: dict):
item_path = f"{item['keyword']}/{item['city_id']}/{item['id']}"
item.pop('city_id')
item.pop('keyword')
doc_ref = self.db.collection(item_path)
added_resp = await doc_ref.add(item)
pprint(added_resp)
print()
return item
I get the following error
Traceback (most recent call last):
File "/path/to/venv/lib64/python3.11/site-packages/twisted/internet/defer.py", line 1697, in _inlineCallbacks
result = context.run(gen.send, result)
File "/path/to/data_scrape/data_scrape/pipelines.py", line 34, in process_item
added_resp = await doc_ref.add(item)
File "/path/to/venv/lib64/python3.11/site-packages/google/cloud/firestore_v1/async_collection.py", line 124, in add
write_result = await document_ref.create(document_data, **kwargs)
File "/path/to/venv/lib64/python3.11/site-packages/google/cloud/firestore_v1/async_document.py", line 91, in create
write_results = await batch.commit(**kwargs)
File "/path/to/venv/lib64/python3.11/site-packages/google/cloud/firestore_v1/async_batch.py", line 60, in commit
commit_response = await self._client._firestore_api.commit(
File "/path/to/venv/lib64/python3.11/site-packages/google/cloud/firestore_v1/services/firestore/async_client.py", line 990, in commit
response = await rpc(
File "/path/to/venv/lib64/python3.11/site-packages/google/api_core/grpc_helpers_async.py", line 81, in __await__
response = yield from self._call.__await__()
File "/path/to/venv/lib64/python3.11/site-packages/grpc/aio/_call.py", line 271, in __await__
response = yield from self._call_response
RuntimeError: await wasn't used with future
Thank you for your time
anyone used sqlite3 in their python code, need some help
UPDATE: When the method is run standalone( tested it by making it into a func) , it works fine
Also, I remove the await and it prints a coroutine. Coroutines is an acceptable type here. What is wrong.
just ask
ok
99% of the people here, including me
I have a python flask code where if user enters valid id card number and click on validate, it goes to verification.html page. If invalid it redirects to invalid page. I have implemented till here.
In verification page the user is sent otp and he should submit otp. If otp is valid again it is redirected to userprofile page. In user profile page user name must displayed on top right corner and some other stuff will be in user profile.
Now i have written a sql code to associate user id with a phone number and username. So that the valid id card's respective phone number will get an otp. How do i do it.
i have to use sqlite3
but for now i must send otp to respective id card number
Doesn't sound like a sqlite3 issue. Use twilio or something to send otp
@tame panther , but i have multiple id cards, for each id card they have username, phone number.
If valid card then i send otp for them
How will i send otp to that particular phone number associated with id card number
Every id card has a unique username and Phone number right, so just fetch that.
Fairly basic SQL question: suppose I have a sqlite table like this one. I'm doing queries like SELECT * FROM SavedItem ORDER BY archived_at DESC LIMIT 50 on it, and they are fairly slow (a second). Would adding an index on archived_at improve that?

(if it's not clear by the picture, the primary key is a compound one on kind and id)
Yes, it should help. Why don't you just try it out?
in general very likely yes.
i would always measure and optimise though, try explain analyze select * ... and see what the query plan shows before and after
also disclaimer: i do not work with sqlite, and it's known (at least for me) to have a few idiosyncrasies, though this is probably not one of them, but i ain't ruling it out 😑
I tried it and it made the query take 10ms instead of 1000ms, thanks. 🙂
In SQLite it's called EXPLAIN QUERY PLAN, so you take a look how tho optimizer do think with:
EXPLAIN QUERY PLAN SELECT * FROM SavedItem ORDER BY archived_at DESC LIMIT 50
SCAN TABLE SavedItem USING INDEX SavedItem_archived_at_idx now, apparently.
It's not specific to databases (although the point is mostly to preserver access to a MongoDB database), but I'm wondering, when setting up a RAID 1 on motherboard, do you guys know if when a disk fails and is replaced with another, the system will need a reboot? Does it synchronize drives asynchronously or will I have to wait for the entire disk to be mirrored?
(I know people will question the use of RAID and "hardware" RAOD in the first place, but I'm stuck on using Windows, and I can't do backup because that's what the client wants 🤷♂️ all he cares is that if a drive fails it can be replaced mostly seamlessly in less than 10 minutes)
In theory if your setup supports hot swapping, that's how it's supposed to be. https://serverfault.com/questions/73776/hot-swapping-under-raid-1
I've managed not to deal with RAID much but if that's what the customer wants it's perfectly appropriate

Server Fault
I have a server that supports hot swapping (such as HP ProLiant DL160 G6 with hot swap) (spec) and I configure it for RAID 1 mirroring across 2 disks.
Say one of the raid'ed disks then fails. Can I
Oh thank you, I couldn't find for sure whether or not it's supported by the MB's raid chip (Gigabyte H410M), but it's using Intel RST, and it looks like maybe this supports hot swap? 🤔
I'm not too worried about having to take the computer down to swap a drive, mostly just wondering if synchronisation on the brand new disk is gonna can happen during use (after reboot) or if It's gonna do it before reboot
Bit of a rookie question: If I have a Backend Server that pulls data from a public API lets say 8 times a day using a loop and a timer to compare it to a data set stored in my DB to find and store differences, does this mean my server is always running under load? Since the code execution never stops?
Is this impossible to do with a free plan of a backend server provider?
Sounds like a use case for a serverless function. Does your provider have something like AWS Lambda?
u mean like cron jobs? I don't really have one yet, but free providers probably won't offer that...
I have no idea about your unnamed provider but if this is a VPS and you're keeping it on, then cron job would work
When you say "under load", they're charging you based on CPU activity? That's not something I've encountered
As I said I don't have a provider yet. But im leaning to cron-job.org + firebase functions
both free
can you use py with mongodb
Yes
Here's one way https://pymongo.readthedocs.io/en/stable/
Is anyone using postgresql and Pgadmin 4 in Linux/Ubuntu ? for django development?
yes
I tried using pgadmin. It is good in terms of being most feature rich.
Preferring to use 🐝 bee studio https://www.beekeeperstudio.io/ as more lightweight simple universal for any SQL db alternative
Technically i could make nice and comfortable command to raise pgadmin too
I realize now best settings for comfortable usage
Beekeeper Studio
Use Beekeeper Studio to query and manage your relational databases, like MySQL, Postgres, SQLite, and SQL Server.
I will write a bit later configurational settings to have pgadmin in the best way today.
A single launch command will be to have it without resources consumption when not necessary. Comfortable to put into Linux alias or bin folder. And most simple to install
Any suggestions for active database/data management Discords/forums/etc. to lurk on? I'm green to database management and feel I'd benefit from seeing common issues folks encounter + the various approaches to testing for/solving them.
On Discord there's a Postgres server and there's a Data Engineering one (associated with r/dataengineering on Reddit... Search on Disboard and you'll probably see them
Also the DBA stack exchange
tyvm!
:incoming_envelope: :ok_hand: applied timeout to @lusty heath until <t:1686440272:f> (10 minutes) (reason: duplicates spam - sent 4 duplicate messages).
The <@&831776746206265384> have been alerted for review.
im lost
I need something to keep track of a constantly updating dataframe that I update every few seconds from an API, something like firebase. But I also don't want to first request data from an API, then send it to the database that updates it in realtime because that'd take up a lot of time.
Is there any way I can do that with Python?
Can I ask questions here regarding Firebase questions?
Hey guys, Is there any of you have source code of payroll in tkinter?

Please does anyone know how I can recreate this or refer to me any relevant article or docs to do something like this?
Thank you
What is "this'? This image doesn't make it very clear what problem you're trying to solve
So I am trying to creates a dB called add.db
But I don't know how to make the dB have things like unit options as seen in the screenshot.

Freecodecamp
Thanks
So I have two tables, store and employee with Many to many relationship. And I want to get all stores where all employee's first name is blank. How do I write an SQL query for this
SELECT s.store_name
FROM store s
LEFT JOIN store_employee se ON s.store_id = se.store_id
LEFT JOIN employee e ON se.employee_id = e.employee_id
GROUP BY s.store_id, s.store_name
HAVING COUNT(*) = 0;
I don't think this works
i want to use twilio to send otp but im getting error as : "account_sid" is not defined
i have set system's environment variables, ccreated. env file and stored sid and token but still same
from twilio.rest import Client
client = Client(account_sid, auth_token)
verification_service = client.verify.v2.services(
verification_service_sid
)
verification_service.verifications.create(
to=to,
channel=OTPChannel.SMS,
locale=locale,
)
that issue solved bro, i have another issue, could u help
This is the databases channel though
sorry, i didnt see that
can u help me with sqlite3 ?
btw thankyou for helping @covert bane
The one you finish
@commands.command(aliases=['sp'])
async def selfprefix(self,ctx:commands.Context,prefix:str):
guild_id = ctx.guild.id
db = await aiosqlite.connect("lossbot2")
c = await db.cursor()
await c.execute('''UPDATE self_prefix SET prefix=(?) WHERE guild_id=(?)''',(prefix,guild_id))
await db.commit()
embed = discord.Embed(description=f'> Changed the prefix to {prefix}', color=0x2B2D31)
await ctx.send(embed=embed)
c.close()
db.close() ``` I have my setup for a self prefix command and now when I run it I get a error returning as ```table: self_prefix doesn't exist``` when I have the db table as that??Maybe something like
SELECT s.store_name
FROM store s
LEFT JOIN store_employee se ON s.store_id = se.store_id
LEFT JOIN employee e ON se.employee_id = e.employee_id
GROUP BY s.store_id
HAVING sum(e.first_name = '') = count(e.employee_id);
with a case when it gets much simpler
Sqlalchemy currently doesnt support async orm events , so they suggest to use sync event handler. But my database is itself async.how can i use that async database session in sync event handler? whats the best approach?
Sadly I don't think you can use async session here, but what are you looking to achieve?
i need to do some db operation in that event handler
just like people do in django signals
That's obvious, can you be more specific?
okie.
suppose i have a table called Leave and Token.
now what i want is everytime when any leave object is created from anywhere of the application , i want to capture the event and i want to create a new object of Token using the data of leave
Honestly? I'd just create them in one place 🤔
Also if that's not an option maybe you can use events that don't require you to flush anything to db?
if i cant use db how can i create the new token obj
But imo first option is better because it's more explicit
You could add it to the session
What event did you want to use?
and how would i use a async session in sync functions
but committing is async
But you won't have to do that in event
where will i commit then
Give me a minute 😅
xD
for now i have been using good old function calls to create the token object , but idk if its the best approach , cause what if i need to create leave objects from multiple places ? it would be a mess, i guess
It's not a bad approach really
and i have others things too , for example i have User model. now i want to send the updated user info via rabbitmq to another service, now if use orm events life would be easier , i wont have keep track of where user data is being updated. what if another dev just casually updates user data in some functions and didnt know a function need to be called when user object updated
@shy dragon
import asyncio
from typing import Any
from sqlalchemy import event, ForeignKey
from sqlalchemy.ext.asyncio import async_sessionmaker, create_async_engine, AsyncSession
from sqlalchemy.orm import DeclarativeBase, Mapped, mapped_column, relationship, \
sessionmaker
class Base(DeclarativeBase):
pass
class Main(Base):
__tablename__ = "main"
id: Mapped[int] = mapped_column(primary_key=True)
class Dependant(Base):
__tablename__ = "dependant"
id: Mapped[int] = mapped_column(primary_key=True)
main_id: Mapped[int] = mapped_column(ForeignKey("main.id"))
main: Mapped[Main] = relationship()
engine = create_async_engine(
"sqlite+aiosqlite://",
echo=True,
)
sync_session_factory = sessionmaker()
session_factory = async_sessionmaker(sync_session_class=sync_session_factory,
bind=engine)
@event.listens_for(sync_session_factory, "after_attach")
def _after_attach(session: AsyncSession, instance: Any) -> None:
if not isinstance(instance, Main):
return
session.add(
Dependant(main=instance)
)
async def main():
async with engine.begin() as connection:
await connection.run_sync(Base.metadata.create_all)
async with session_factory.begin() as session:
main = Main()
session.add(main)
if __name__ == "__main__":
asyncio.run(main())
I'd rather just call a function, ngl
You should one place to interact with your model, in your case saving a user would add message to rabbitmq for example
But using events here doesn't seep appropriate
I'd only use events if it's something that would interact only with orm, like soft delete functionality that's presented in sqlalchemy examples 🤔
For your case I'd just split everything into layers:
"""
Service layer where we would deal with our connectors like DB and RabbitMQ
"""
class MessagingService:
...
async def send_some_message(self):
"""Sends certain message to rabbitmq"""
class UserService:
...
async def update(self, user: User, dto: UserUpdateDTO) -> User:
# Update user fields
...
self._session.add(user)
await self._session.flush()
return user
"""
Some kind of use case layer that would describe business login on a bit more higher level
"""
class UpdateUserDTO:
def __init__(
self,
messaging: MessagingService,
users: UserService,
) -> None:
self._messaging = messaging
self._users = users
async def execute(self, dto: UserUpdateDTO) -> User:
user = await self._users.update(dto)
await self._messaging.send_some_message(...)
return user
If you wonder - dto here is just an object to transfer data, could be a dataclass/pydantic model:
@dataclasses.dataclass
class UserUpdateDTO:
id: int
username: str | None = None
first_name: str | None = None
yeah its much more compact , idk if i have used the right word 🙂
thank you !!
I really hope sqlalchemy will support async event handler soon, cause i used django signals in django projects and i loved it
Honestly they could be quite messy
hey should i consider other async orm for python ? like peewee ? do they support this? i know sqlalchemy has lots of features and its mature but its documentation kinda sucks though
If you are more familiar/productive with other orms - sure
But documentation for sqlalchemy is quite extensive
nah i am familiar with others 😦 i know sqlalchemy and django orm only
yeah but its kinda all over the place. django documentation is the best
I use sqlalchemy and main complaint from my coworker is probably the documentation 😅
Otherwise sqlalchemy 2.0 is really good
xD
what web framework do you use, just curious ?
Mainly fastapi and strawberry
ahh i am also working using fastapi now , never tried strawberry
i used django mostly
It's a graphql framework
hi, feeling difficult in understanding the below code.
from unittest.mock import patch
from fetch_data_from_db import *
from unittest.mock import MagicMock
def configure_connection(mock_conections: MagicMock, mock_cursor_context_manager: MagicMock):
mock_cursor = MagicMock()
mock_cursor.__enter__.return_value = mock_cursor_context_manager
mock_conn = MagicMock()
mock_conn.cursor.return_value = mock_cursor
mock_conections.__getitem__.side_effect = {"default":mock_conn}.__getitem__
@patch("common.db.connections")
def test_manager(self, mock_connections):
mock_cursor_context_manager = MagicMock()
def execute_side_effect(query):
expected_query = """
stub_for_expected_query
"""
if query == expected_query:
mock_cursor_context_manager.description = ["column_names"]
mock_cursor_context_manager.description = ["values"]
else:
mock_cursor_context_manager.description = []
mock_cursor_context_manager.description = []
mock_cursor_context_manager.execute.side_effect = execute_side_effect
configure_connection(mock_connections, mock_cursor_context_manager)
can anyone please explain..
Hey guys, I am building a database for anime shows, and I wanted someones opinion on it.
This is how my schema looks like. am I doing it right?

At a glance this looks pretty reasonable except that a lot of tables have two fields. You may just need to keep fleshing it out but if that's really all you have then some tables might make sense to merge
For example, would a producers name field on the animes table replace the need for the two other tables? If it's worth tracking them as a many to many like that, then is there other data about the producers you will also need?
Yah, like alternative version could be removed, and anime table could have a ‘original version’ id (if it’s a one to many)
Well in producer, studios, and licensor, genres, sorces table more column will be added like description, establish date.
Good, then what you have as a start makes sense
yah that's a good idea.
I am more concerned about like alternate show where there is just two column.
You seemed to write it assuming everything is many to many, I didn’t go thru details, but think through the relations
I wrote it thinking about many to many relationship.
Or prequels and sequels: maybe have a separate table for ‘series’ which has an index and show id
Or not even a table: a series name and index in the anime table might be all you need
It is necessary because the source I am scraping data from has separate series for every season, and a series can have multiple sequels, one in the form of series a and other in movie form.
(maybe dumb) question but does shortening the keys of a big json file help reduce trafic to the db to stay below the monthly free budget?
It's an array of roughly 4000 objects all having the same 4 key-val pairs
the values obviously aren't the same
Probably not, but it would depend on how this monthly free budget works at whatever provider you're asking about... Check their documentation
it's 10gb read/write traffic
I would assume the keys are a tiny fraction of what you're sending, unless your data looks very funny
Hi guys. What is your favorite ORM to use with FastAPI that also supports PostGIS?
could be worth it, with 4000+ entries

looks like 8-10% reduction in characters if the keys would be 1 char each
I also already removed the duplicate ID
Never tried but this looks promising: https://geoalchemy-2.readthedocs.io/en/latest/
HI!
how come this works fine:
def get_users_list (self):
cursor = self.conn.cursor()
sql = """\
SET NOCOUNT ON;
DECLARE @RC int;
EXEC @RC = [dbo].[GetUserData];
SELECT @RC AS rc;
"""
cursor.execute(sql)
output_list = []
for row in cursor:
p = student_generics.StudentGenerics(row.st_id,row.fn,row.ln,row.pn,row.groupn,row.sessions,row.course_completion, row.caregiver_email,row.race,row.gender,row.total_questions,row.answered_in_pre,row.answered_in_post)
output_list.append(p.__dict__)
self.conn.commit()
return output_list
class StudentGenerics:
def __init__(self,student_id, firstname, lastname, partnership, group,sessions, course_completion, cg_mail, race,gender,total_questions,answered_in_pre,answered_in_post):
self.studentid = student_id
self.firstname = firstname
self.lastname = lastname
self.partnership=partnership
self.group=group
self.sessions=sessions
self.course_completion=course_completion
self.total_questions = total_questions
self.answered_in_pre = answered_in_pre
self.answered_in_post=answered_in_post
self.cg_mail = cg_mail
self.race=race
self.gender=gender
```CREATE PROCEDURE GetUserData
AS
BEGIN
SELECT
u.id AS st_id,
u.first_name AS fn,
u.last_name AS ln,
p.name AS pn,
pg.group_name AS groupn,
u.caregiver_email,
u.race,
u.gender,
u.sessions,
u.course_completion,
t.total_questions,
SUM(CASE WHEN t.is_pre = 1 THEN t.answered_questions ELSE 0 END) AS answered_in_pre,
SUM(CASE WHEN t.is_pre = 0 THEN t.answered_questions ELSE 0 END) AS answered_in_post,
CONVERT(date,MAX(CASE WHEN t.is_pre = 1 THEN t.start_time END)) AS pre_date,
CONVERT(date,MAX(CASE WHEN t.is_pre = 0 THEN t.start_time END)) AS post_date
but when i try to retrieve the pre_date it doesn't work?
even if i change the studentgenerics class
It’s kinda hard to help without more info. ‘It doesn’t work’ is not very descriptive.
You are right, object not serializeble I think it’s a datetime
Hey guys, how are you doing? I made my first project with Django this month and stored my database (MySQL) in AWS. However, I am looking for a better option (cheaper) because my database will have at least 10,000 registrations. I think there are better database hosting services than AWS at this moment.
I have been looking for a while, but I haven't found anything yet.
You're doing MySQL on RDS and running your Django app on EC2? I imagine it would be a lot cheaper to run MySQL directly on the same EC2 instance if you don't mind that. Or are you looking for a managed db like RDS but cheaper?
I deployed my project in PythonAnywhere and mounted the database in RDS. It's a small project, so I thought that using the AWS free tier would not incur any costs. However, I was wrong. I was charged $25 USD for using RDS for a month. T_T
I used PythonAnywhere because it was the easiest way to deploy my project, but I will try to deploy it in an EC2 instance
If you want cheap and good, don’t use managed database services. The default configurations of good databases will take you far enough that you don’t need to worry about doing DBA (outside of user / db creation) for a while
Also 10k registrations is nothing. Unless each of those stores an insane amount of data the database won’t flinch
Yah, that’s like use SQLite and be done with it
Hello I'm asking help here because I'm having troubles in understanding why result is None

I don't understand why because with this command it is supposed to update the value + 1 to the type value (positive, negative or neutral) and the fetch result to print it
def log():
# Open the JSON file
with open('data.json', 'r') as file:
data = json.load(file)
file.close()
global username
username = request.form.get('username')
password = request.form.get('password')
print(data)
# Check if username and password match
if username in data and data[username]['password'] == password:
print("Login successful!")
if data[username].get('balance') is not None:
return render_template('dashboard.html', username=username, balance=data[username]['balance'])
else:
return render_template('dashboard.html', username=username, balance='0')
else:
print("Invalid username or password.")
return render_template('login.html')
please help the login says that the password is not right even tho its pulling it out of a database
The json data base: {"w": {"password": "w", "balance": 10}, "q": {"password": "q", "balance": 10}}
I guess you don't have any row with such agent_name in database. (I don't see inserts here)
You can't update a value if it doesn't exist
print out username and password, to see if you are getting the correct values
maybe you are getting None, or some special symbols like spaces

if option.value == "add":
if type.value == "positive":
cursor.execute("UPDATE agents SET positive_rep = positive_rep + 1 WHERE agent_name = ?", (agent,))
elif type.value == "neutral":
cursor.execute("UPDATE agents SET neutral_rep = neutral_rep + 1 WHERE agent_name = ?", (agent,))
elif type.value == "negative":
cursor.execute("UPDATE agents SET negative_rep = negative_rep + 1 WHERE agent_name = ?", (agent,))
connection.commit()
cursor.execute("SELECT positive_rep, neutral_rep, negative_rep FROM agents WHERE agent_name=?", (agent,))
result = cursor.fetchone()
print(result)```our username is postgres? in postgressql?
It's your table. It doesn't mean, that you have a data in that table.
UPDATE changes value of already existing rows
You will have the username that you will create, it can be anything
how to create
how to create database
i cant create by pq admin 4
i can't say something more than google / docs, i am not using it
https://www.postgresql.org/docs/15/sql-createuser.html
https://www.postgresql.org/docs/current/sql-createdatabase.html
PostgreSQL Documentation
CREATE USER CREATE USER — define a new database role Synopsis CREATE USER name [ [ WITH ] option [ …
PostgreSQL Documentation
CREATE DATABASE CREATE DATABASE — create a new database Synopsis CREATE DATABASE name [ WITH ] [ OWNER [=] user_name …
is there any another mathod then pgadmin 4
your sql shell
what write in option
pls give example
Open your shell like this but for postgres
And create user as documentation shows
It seems
create user test;

actually on SO people do createuser instead of create user
https://stackoverflow.com/questions/30641512/create-database-from-command-line
i guess i gave the wrong docs (command not for shell but for just sql, and create user should be runned in psql it seems, but it doesn't matters actually)
anyways better to check out examples and guides in google, because i never used postgres and can't give a good information about it
i have postgresql
yes, and that‘a a complete and functional example of how to create a user in postgresql
have you tried anything that people have posted here?
Both are correct by the way - CREATE USER is the SQL statement, createuser a binary shipped with postgres that does the same
Hi
@ionic pecan
You can tell me what the problem
import requests
data = {
"chat_id": "<1001910965>",
"text": "hi"
}
token = "My token"
url = 'https://api.telegram.org/bot{token}/sendMessage'
print(requests.post(url,data=data).text)

you can help yourself and not ping random people asking for help, especially not for a telegram bot in a database channel
the error tells you everything. either the url was not found or the API responded with 404 for some other reason.
Hello,
so i am a newbie in python but i am having an issue with an interpreter in my pycharm and it is interrupting my learning
please how can i add a new interpreter
that will make my code start to debug
hi everyone,
There is one problem which i am facing and i have tried all possible measures which i could think of and search but i am unable to resolve this

wrong channel, try #1035199133436354600 or #data-science-and-ml
tag me there if you still need help.
Hi. I have segmentation fault (core dumped) error when writing to firebase with python.
What I have is a FastAPI server that receives a json request, starts another process where it writes to firebase asynchronously and does something that takes quite some time and writes to firebase again that the process completed. The FastAPI server will have returned a response by this now.
The problem is, the asynchronous calls I do before starting the process somehow crashes and I get a segmentation fault (core dumped). Why might this be? I don't know what to look for because it doesn't give any traceback. Please help
hard to say for sure. do you have some code to share?
Ill make some dummy that should probably work the same
import firebase_admin
from firebase_admin import credentials
from google.cloud import firestore
import os
from fastapi import FastAPI, Request
from multiprocessing import Process
import asyncio
import random
try:
cred = credentials.Certificate(os.environ.get('GOOGLE_APPLICATION_CREDENTIALS'))
firebase_admin.initialize_app(cred, {'databaseURL': os.environ.get('FIREBASE_DATABASE_URL')})
except ValueError:
pass
db = firestore.AsyncClient()
app = FastAPI()
async def process_run(arg1, arg2):
try:
cred = credentials.Certificate(os.environ.get('GOOGLE_APPLICATION_CREDENTIALS'))
firebase_admin.initialize_app(cred, {'databaseURL': os.environ.get('FIREBASE_DATABASE_URL')})
except ValueError:
pass
db = firestore.AsyncClient()
batch = db.batch()
batch.set(db.document('user/'+f'{random.randint(100000, 1000000)}'),
{'something': random.randint(100, 999)})
await batch.commit() # crashes here
def main(arg1, arg2):
asyncio.run(process_run(arg1, arg2))
@app.post('/run')
async def run(request: Request):
request = await request.json()
doc_ref = db.document('user/username')
await doc_ref.set({'name': 'myname'})
process = Process(target=main, args=['ag1', 'arg2'])
process.start()
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8005)```- does it crash if you don't run it in a
Processand instead run it directly in therunroute? - does it crash if you stop using asyncio in
main?
disclaimer: i don't use firebase
It doesn't crash if I don't run it in a process. Although I get RuntimeError down the line. I think that's because I'm using asyncio directly. I'm thinking it should be fixed if I create a new loop and run in it
The function in main is async function so I didn't think of it
So I turned the whole thing synchronous. Got to know that instead of setting the changes individually, i could simply create a batch object locally and commit to it and when all changes are done, commit the batch. But the problem still persists as when I try to commit the batch, the same error occurs
just so i am clear, you mean you are doing everything
- synchronous
- without
Process?
and when you commit a batch it crashes?
are you able to do anything else with firebase? i am guessing yes? you did a db.document('user/username') that seems to work
Code is running inside the process is synchronous now.
This doesn't retrieve anything from the firebase servers. It's just referencing the path. So I can't do anything with the firebase server
i would narrow down the issue first.
if it crashes only when run you firebase-related logic inside Process, then it has to do with Process.
if it crashes even when you run firebase-related logic outside Process then there is something very wrong, and you would need to re-evaluate what's happening on a deeper level.
mostly it's just about reducing your issue to a minimal and reproducible example and figure it out from there.
since you are getting seg fault when you are trying to connect to firebase, my random thought is that there is some issue with your GRPC-related tooling (which was probably brought in by the google firebase package as transitive dependency, my reasoning is: python seg fault'ing by itself is pretty rare, but with external stuff like GRPC, it's not unheard off, espeically when i looked into the code base and found mention of grpc) - this is my random stab in the dark so feel free to ignore, the correct approach is as i said, reducing your problem by removing places where it could go wrong
Does the error occur when firebase committing is done in Process? Yes. Outside Process? No
nice. then there are probably less issue than i expected
can you do firebase_admin.initialize_app(cred, {'databaseURL': os.environ.get('FIREBASE_DATABASE_URL')}) only once in your app?
i am trying to rule out that doing this twice is causing the issue
My suspicion has been the same since I read an SO answer that hinted at this. Although firebase.initialize_app throws ValueError if done already, I'm guessing the app instance being the same (for all db instances, not sure if it holds true across processes) is what is causing the problem. Let me try
Tried. The error persists
that's with initialize_app outside of Process, correct?
I've apparently fixed it! I set multiprocessing.set_start_method('spawn') inside if __name__ == "__main__" (it doesn't work if I call it first thing).
This creates a new interpreter process (from what I read). This is default in Windows and mac but not in Unix
@hollow oar Thanks a lot for all the help. I appreciate it. Have a good weekend
nice - was just about to dig into the firebase admin package and see what kind of threading magic were they doing.
Hello everyone, I'm trying to learn SqlAlchemy, I've tried to learn from their documentation but I didn't well from their documentaion can anyone suggest me the better resource for it? from should I learn it/
DM'd u a link to some examples since im not sure if im allowed to post lonks lmao
Fortunately you don't have to do that 🙂
hey so i have this json file, and it is of the form
{
name: {password: something, cart : {some things: some integers}, budget : quantity},
name2 : ..........
}
so like users would create new name entries, update the existing entries and stuff... what should be the best way to store this on the web such that i can modify it from one device and access the modified file from the other device?
i am sorry if this seems too basic i dont really know much about databases
hi, my laptop crashed can someone help with this code? import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv('exams.csv')
print(df.to_string()) read data
df.plot(kind = 'scatter', x = 'parental level of education', y = 'math score')
plt.show()
Idk how to send .csv file here
its 6 hours b4 practice😭
There’s no question there
hey, please help
I have a python project where i used sqlite3 db, the program worked fine
Now i have used the same code in different folder, as previous folder was cluttered.
In new folder I have specified path for my db to connect with python code i.e
database_path = r'C:\Users\me\Downloads\ project-07\cardsnums'
conn = sqlite3.connect(database_path)
but i get error as
File "c:\Users\me\Downloads\project_01\app.py", line 135, in <module>
cursor.execute('SELECT * FROM card_information')
sqlite3.OperationalError: no such table: card_information
should i specify the whole path in database_path ?
you can use a relative or an absolute path, and usually we'd recommend using a relative path if you want to share the project with others (be it as a github repositryo, a zip file or even trying to pack into an exe)
however, no matter which method you choose, you have to point to the right file, not a just folder
remember to include the file suffix, and double check anything like the in ...downloads\ project...
How can I improve performance of order by.
I did an EXPLAIN ANALYZE on the query and the order by is taking the bulk of the query time, like 8 seconds. I have 12 million rows in the table. And the column we are ordering by isn't indexed
Does indexing increase the performance of order by
indexing could increase the performance by orders of magnitude
maybe not orders but still by a lot
how many columns are you ordering by, and what's the cardinality?
it would be easiest to just try it if it's not mission critical.
I'm ordering by 3 columns. modified_at, created_at and id.
Well, you can guess the cardinality from that. modified_at and created_at aren't unique but are almost unique. id is of course unique
yeah an index could probably help in this case. i would try just indexing modified_at with B-Tree (the default) first, then perhaps even compound index including more columns (in the order of your order by, and in the same sort direction of your order by)
let us know what the results are 😉
So, tried it locally with just 6000 rows.
The sorting part is not displayed in the explain analyze query anymore. and execution time decreased from 7 ms to 0.3 ms
But the stop time of left join shows as 4099
Nested Loop Left Join (cost=0.70..4099.28 rows=6303 width=1878) (actual time=0.128..0.220 rows=20 loops=1)
While without the index it is 307
Hash Left Join (cost=59.35..307.88 rows=6303 width=1878) (actual time=0.378..5.401 rows=6303 loops=1)
Is that concerning.
Will that affect this when I run it with 12 million+ rows?
If this result looks promising I can test this in a staging environment that has production like data. So the results will be more representative
But the stop time of left join shows as 4099
you are looking at the cost instead of actual time here right?
cost is only for comparison within the same query plan. they are not comparable across different plans
so i would not pay it any attention here.
actual time however, is comparable
But the actual query in production has a cost of around 500K. and that's around 12million/22.
And running it for 6300 rows it has a cost of 300. Same here 6300/22 = 300
I guess I should just try it with real data then.
Since we use this same order for a lot of queries. It should speed up all those queries.
I have the results from staging now. the page load time decreased from 15 seconds to 3 seconds.
Now to the next problem. How can I optimize a multi-table column full text search query
Anyone experienced with Columnar database?
1.I want to create a database for stock prices for myself locally and then analyze over it .(gonna get the data by scraping or downloading historical price and append new data regularly to it)
2.also want to keep it updated with recent price changes means append new data to it.
3.I want an open source or free alternative
4.I have looked into KDB
and dont know much about hadoop it gives a columnar database somehow and apache is free i guess
that improvement seems rather small.. are you now bounded by IO instead of wasteful compute?
analyze over it
what kind of analysis?
.also want to keep it updated with recent price changes means append new data to it.
what sort of frequency are we talking?
.I want an open source or free alternative
sure, there is plenty to choose from.
I have looked into KDB
err.. this is likely a massive overkill. not to mention you gotta learn Q, which is... non-trivial.
No that's the page load time. The query time decreased from like 8 seconds to 120ms
oh! sweet, that's the kind of improvement i was expecting.
So I eventually wanna build a alert system for myself .....I need to pay for terminals and APIs for data
since I am also into development so thought of building it for myself as project
Analysis will be just to track price and give me an alert at a particular point and build some EMA
Database will have historical data , and for live price I am gonna use a API from a broker for the day itself and at EOD append the OHLC to my database daily
I do not know much about database performances etc wont matter much unless i am developing a product but would like to know how my choice affects the project
KDB is something I have been learning and sure overkill hence looking for alternatives and KDB license stays just for a year
PS: Do you have any experience with KDB I would like some guidance about how to get into the field
So I eventually wanna build a alert system for myself .....I need to pay for terminals and APIs for data
since I am also into development so thought of building it for myself as project
cool! 👍
Analysis will be just to track price and give me an alert at a particular point and build some EMA
okay, EMA as in exponential moving average?
Database will have historical data , and for live price I am gonna use a API from a broker for the day itself and at EOD append the OHLC to my database daily
okay, OHLC on what timeframe?
I do not know much about database performances etc wont matter much unless i am developing a product but would like to know how my choice affects the project
it really depends on your use case, query patterns, write patterns, complexity of data, etc etc.
KDB is something I have been learning and sure overkill hence looking for alternatives and KDB license stays just for a year
PS: Do you have any experience with KDB I would like some guidance about how to get into the field
i don't have experience with KDB personally, but there are people i have interacted with and trust a lot who have used KDB before/currently, and they ALL complained about KDB, and often mentioned Q being a pain in the butt.
OHLC on daily ....
Yeah KDB is pain not sure what is a right way to start just been digging into documentation ....
Can you mention name of alternatives ...like Hbase , SQL also offer columnar ...my use case is for Stock price and querrying over it none other
i would not go out of my way to use a columnar database if you are just ingesting daily OHLC.
it provides very little benefits for you when your data is that small, if anything it's just a hassle.
you can make do with a simple postgres installation for quite some time. even doing EMA in postgres would be an okay thing to do when your data is that small.
if you are ingesting higher frequency data, i would look into timescale, which is a time series database based off postgres, which could be made into a columar-ish database.
for the hardcore production usage, i would just stick it all into bigquery... which is not free nor open sourced
also, clickhouse and questdb are on my to-explore list for some time, just haven't had the time to look.
Yeah its not high frequency ....for high frequency for particular day i am just gonna use in memory value for live price
read somewhere bigquery gives 10 GB free storage above it is paid ...Dont think my data gonna be 10GB
just be careful when using bigquery.. it's very easy to rack up a massive query cost if you aren't careful
Sure thanks for the help
@rose dawn I have done the same thing you mentioned. I used a 5$ per month VPS from Digital ocean. stored in either sqlite or mysql or postgres if it's large volume of data.
And I used pandas and other timeseries anaylsis libraries for analysis.
great will come back to you after building it
Yes, I used duckdb extensively. They have a pretty active discord, in memory OLAP, columnar vectorized
Duckdb takes seconds to get going:
import duckdb
with duckdb.connect(“file1.db”) as con:
con.execute(“create table xyz as select * from ‘https://somefile.csv’”)
….
It handles gb’s, etc, easily. You’d be surprised at how much you can do on/host and in/memory, I t’s like SQLite but for OLAP sue cases. (Not an ad)
I have created a Python-MySQL project with PyQt5 GUI (a basic ticketing system for Flights which involves user creation, logging in, and displaying the details accordingly). I have uploaded the project on GitHub but I am stuck with writing the installation part of it.
The python side is not the problem, I can create a requirements.txt file for it; but for MySQL, I'm not sure on how to make users download the schema/database I have setup on my machine. I have also inserted quite a lot of data into the relations I created in the database (for example Flight details, already existing customer info, etc.)
Any solutions for this or would I need to explicitly write creation table statements and insert value statements in the installation section of the readme file?
Hey i am making a small project and need to use sqlite3 database, I have planned to make a single table for the users but there are 3 types of users in my app -> user manager admin
should i make 3 different tables for them ?
or add a role column to the users table instead ?
Add a role column
If a user can be more than one role. you can add a role table instead. Else if the role is heirarchial then a single column would be enough.
Can someone help me understand this EXPLAIN ANALYZE result
And here's the actual query.
SELECT COUNT(1) AS __count
FROM shared_flour
LEFT OUTER JOIN stores_store ON (shared_flour.store_id = stores_store.id)
LEFT OUTER JOIN stores_storegroup
ON (stores_store.group_id = stores_storegroup.id)
LEFT OUTER JOIN employment_employment
ON (shared_flour.employment_id = employment_employment.id)
LEFT OUTER JOIN workers_userprofile ON (employment_employment.user_profile_id =
workers_userprofile.id)
WHERE ((UPPER(stores_store.name::TEXT) LIKE UPPER('%West%') OR
UPPER(stores_storegroup.name::TEXT) LIKE UPPER('%West%') OR
UPPER(workers_userprofile.first_name::TEXT) LIKE UPPER('%West%') OR
UPPER(workers_userprofile.last_name::TEXT) LIKE UPPER('%West%')) AND
(UPPER(stores_store.name::TEXT) LIKE UPPER('%Rooom%') OR
UPPER(stores_storegroup.name::TEXT) LIKE UPPER('%Rooom%') OR
UPPER(workers_userprofile.first_name::TEXT) LIKE UPPER('%Rooom%') OR
UPPER(workers_userprofile.last_name::TEXT) LIKE UPPER('%Rooom%')));

The right way? https://www.educba.com/sqlalchemy-migrations/
Otherwise I guess you could provide DDL as SQL and a script to setup the database

Guide to SQLAlchemy Migrations. Here we discuss the introduction, database, and how to use SQLAlchemy Migrations along with examples.
Thanks a lot for the reference! Will check it out!
Hello guys
anyone familiar with siemens wincc 7.5 software?
I am trying to grab some data from its sql database
using python
and the framework sql-connector
I'm not, but it seems like you could go ahead and ask your question anyway
can someone help with sql?
CREATE FUNCTION GetHighEarner(dept_id INT) RETURNS TABLE (Department STR, Employee STR, Salary INT)
BEGIN
RETURN (
SELECT d.name AS Department, e.name AS Employee, e.salary AS Salary
FROM Employee e
LEFT JOIN Department d ON e.departmentId = d.id
WHERE e.departmentId = dept_id AND e.salary IN (
SELECT DISTINCT salary
FROM Employee
WHERE departmentId = dept_id
ORDER BY salary DESC
LIMIT 3
)
);
END
SELECT GetHighEarner(deparmentId) OVER (PARTITION BY departmentId) FROM Employee GROUP BY departmentId;
can someone help with sql?
yes.
what do you need help with?
(posting your query is a good start but please post you actual question upfront as well next time)
(create a db fiddle for people who try to help you would be amazing)
how can i create github repository for dsa coding + saving files for it
kindly ping me if someone helps 🙂
What format are the dsa files in? Git is generally intended for versioning text files
How can I optimize a filter and count query? I there something generic I can do?
I have a table with 12 Million + rows that needs to be joined with a few other tables with a couple thousand rows, filtered and then the result counted.
Currently the execution cost is 540K. and takes around 12 seconds to complete
The corresponding SELECT query with the same filter and limit 20 takes 118 ms to execute
What do you need count for? 🤔
It's basically for pagination
Like showing total records found and the number of pages.
It isn't super important so a rough estimate should also be good enough
But what do you need it for?
For a queryset with joins and filters.
SELECT COUNT(1)
FROM a
JOIN b ON b.a_id = a.id
JOIN c ON c.a_id = a.id
JOIN d ON d.id = b.d_id
WHERE UPPER(d.name::TEXT) LIKE UPPER('%foo%')
OR UPPER(a.name::TEXT) LIKE UPPER('%foo%')
OR UPPER(b.name::TEXT) LIKE UPPER('%foo%')
OR UPPER(c.name::TEXT) LIKE UPPER('%foo%');
But what do you need the count for?
since you mentioned pagination, obligatory link here: https://use-the-index-luke.com/blog/2013-07/pagination-done-the-postgresql-way

Fetching results in a page-wise manner: Don’t use OFFSET to avoid a performance problem also known as “The Ramp”.
What db?
That's pretty much what I'm suspecting 🙃
Postgres
I have index on the order by columns. -modified, -created, -id
The select query is comparatively fast as long as the generated result count is high.
But if I search for something that doesn't exist in the database or less than LIMIT rows exist, it takes awfully long time.
Well, less than limit makes sense, right? It has to finish scanning 100%
Your index should probably have id first, so it can be used for both order by and join (this is true in other databases, but admittedly I’m not as knowledgeable in Postgres specifics)
Look at the explain plan to confirm.
There's a separate index for id. Does that work?
I think the id is automatically indexed, either by the db or by the backend.
It might, Postgres can use multiple indices under certain cases: you’d have to look to confirm if both are being used. Regardless, I always put keys like id first in my index
Do your own testing to confirm
The index is in the same order that I use in the order by clause.
The original question was to increase the performance of the count query though
The count query always takes 12 seconds.
The first question is: are the id indices being used by the query?
I suspect not, that this is full table scans, the id probably has low selectivity..
Yup. It uses full sequential scans
Yah, so the thing to focus on is optimizing the like clause. Have you tried trigram indices?
I added GIN indices to all name columns