#databases
1 messages · Page 15 of 1
i think u can even move the case when to this where clause
@trail rune not sure if i make sense or not haha
I don't know yet. I'm trying to fix another problem right now.
Is it possible to replace Null values in a column with the real values that I have?
yeah there should be a way
I think I have to use UPDATE but I can't figure out how to get the keys to match up.
I'm trying to figure out how to use UPDATE to fill in the Null values in a column. I originally made card_text into its own table but I realized it could go in the cards table. So I used ALTER TABLE to add a new column to cards called oracle_text. But now I'm trying to populate all the Null values in that new column with the values that I have in the card_text table. Not sure how to get the scryfall_ids to match up to make sure I get the right oracle_text associated with the right card.
Here's an example of what I have
cards table
scryfall_id,name,oracle_text,...
1,Brushwagg,Null
2,Storm Crow,Null
3,Colossal Dreadmaw,Null
card_text table
scryfall_id,oracle_text
1,Whenever Brushwagg blocks or becomes blocked, it gets -2/+2 until end of turn.
2,Flying
3,Trample
I want to fill in the Nulls in the cards table with the oracle texts that I have in the card_text table. Notice how the scryfall_ids match up.
haha this is why u design tables beforehand or use nosql
im not familiar with UPDATE at all
haha
Not sure I know exactly what you're trying to do but presumably you need to add a foreign key relationship that connects these two tables
Is that possible to do after table creation?
Actually they are already linked with a foreign key relationship.
Basically I need to take the values from card_text and put them in the oracle_text column of the cards table.
Which column is the fk?
scryfall_id is the foreign key in card_text
Then I think a simple join should allow you to update
I know how to join them on the scryfall_id but I don't know what to do after that.
you can use alter table
Can you elaborate at all?
Your question is about this right ?
Oh yeah. Thanks for answering that.
Now I'm asking how to use ALTER TABLE to update the values of cards.oracle_text with the values of card_text.oracle_text?
I'm not very familiar on that so I can't help, but try searching the docs of your database
It's MySQL by the way.
Thanks. This looks like what I want.
START TRANSACTION;
UPDATE cards
SET cards.oracle_text =
(SELECT oracle_text
FROM card_text
WHERE cards.scryfall_id=card_text.scryfall_id);
COMMIT;
By the way, am I using TRANSACTIONs correctly?
Again I don't have any experience with your db, so I don't really know
okay
Can you explain this more, please?

Stack Overflow
So I have a in my Postgresql:
TAG_TABLE
id tag_name
1 aaa
2 bbb
3 ccc
To simplify my p...
Oh okay. Thanks. I'll try it.
Guys, please, who can explain how I can create a release build of the database using either Python or simple third-party programs or just throw off the link to the guide?

too broad question having miriads of answers, you may wish to be more specific
I have a sportOrg.db file with a database written in SQLite. How can I create a database release build using either python or simple third party programs?
not understanding connection, how
I have a sportOrg.db file with a database written in SQLite.
is connected with wish for
How can I create a database release build using either python or simple third party programs?
what is creating database release build process for you
I have this task: Create a release version of the database (a release/production software so others can deploy your database)
ah. Now i get his task, probably
or not 
if he had Backend application, i would have said, he needs to build docker image ready for deployment
Sqlite3 has option to run over network
may be he needs to build Docker image that exposes Sqlite3 over network for connection then (then in single command it can be deployed anywhere)
the caveat, sqlite3 is usually not used over network though (usually stuff like postgresql used then)
it is possible to migrate Sqlite3 database easily to postgres though
just make python script, to get SQL dump, migrate to Postgresql, ergh, and write docker-compose to launch it as database instance configured for access
anyway, this is a very broad task, not really well defined ^_^ proper actions would be questioning teacher further what he meant under this
Okay, here's a more complete description of the task: Create a database for development and testing. Test any necessary data transformation. The design should be based on a client-server (can be monolithic) or similar architecture. The project should demonstrate the ability to execute SQL queries (CLI) on the client side. Create a release version of the database (release/production software for others to deploy your database)

u should have started from this, instead of making your oversimplification that lead to entirely different task description
sorry for this
Look, I've already created a python script that executes data from my database. Next, I tried to use Apache maven to create an assembly, but I got a .jar file that is written in java. This doesn't work for me as I don't know java.
Well, if i read task requirements correctly, you are asked to make Database Engine.
Developing your own database, that has network accessability (following client-server model)
And database should be connectable with client CLI to execute SQL queries
So it should be able to interpret SQL language (we can say, it is like developing programming language runner basically)
And then, it should be released in the way, that it is comfortable to run it
Possible ways to go with it:
- Writing in python and wrapping into docker container for deployment?
- writing not in python, but lets say in golang, then it will be just binary file easy to deploy anywhere
under slight question, if u are asked to reinvent SQL language interpretor though, Task does not sound like you need to do it though
it sounds like main point of task, to teach your networking communications + releasing app
so we can just use language inbuilt SQL libraries to interpret SQL for us, and having under the hood potentially just a regular Sqlite3 for example
What languages you know ^_^
python, sql
anything else? may be you are up for a challenge to learn quickly another language ^_^
idk
Does this code make sense for creating a release version of the database that is contained in the file sportOrg.db?
import sqlite3
con = sqlite3.connect('C:/sportDB/sportOrg.db')
with sqlite3.connect('sportOrg_release.db') as conn:
conn.execute('VACUUM')
with open('C:/sportDatabase/schema.sql', 'w') as f:
for line in conn.iterdump():
f.write('%s\n' % line)
with sqlite3.connect('sportOrg_release.db') as conn:
with open('C:/sportDB/sportOrg.db.sql') as f:
schema = f.read()
conn.executescript(schema)
with sqlite3.connect('sportOrg_release.db') as release_conn:
with conn:
for table in ['Athletes', 'Events', 'Results']:
cursor = conn.execute('SELECT * FROM %s' % table)
columns = [description[0] for description in cursor.description]
rows = cursor.fetchall()
release_conn.executemany('INSERT INTO %s (%s) VALUES (%s)' % (table, ', '.join(columns), ', '.join(['?'] * len(columns))) , rows)
conn.close()
release_conn.close()
you don't know what is release version of the database 😐
this is gibberish to you at the moment, right?
In fact yes)
okay, how to simplify explanation then...
... release of some program, is making it public accessable to install/download and to launch (with having some instruction how to do that)
releases of programs are made in the way, that downloading and launching your app is very easy to do (preferably end users just download one file they can run right away)
so, you are asked next thing:
- create a program, preferably compiled to one file (preferably having as least dependencies to install for its running), that will acess Sqlite3 file and expose it for access to your client program (this is Server part)
- create a CLI program, that will access over network your Server application and will be able to execute SQL commands redirected to this Sqlite3 file
make both programs preferably compiled, so they will require no dependencies for their launch and would be looking like two single files, which are easy just to download and to run
highly likely you are expected making
- Server application that exposes TCP port for connection (while binding itself to 0.0.0.0 port for network accesability), and it will execute any SQL queries to this Sqlite3 file and send answer back
- CLI client program that connects over TCP, and can send SQL queries to server and receives asnwer back
compile for easy download and running both programs
====
Then for testing you just launch Server program, it autobinds itself, lets say to 0.0.0.0:1234
Client CLI program you execute like -> client --connect 0.0.0.0:1234, it connects to server, and then you type SQL queries to query from server and receiving answers
releasing as Github Release, boom. done.
all you need learning how to use Sqlite3 library, how to use socket stuff, how to use pyinstaller to compile (if we go with python), and how to press button release in Github where u saved that, and creating Release to which you drop your binaries
- writing instruction to download two files (+third file is sqlite3 db) and to run them ^_^
Give me a minute to think about everything you wrote, please.
In fact, I only have a day to do it. As I understand it, in 1 day I will not be able to do it all?
well, it is easy enough to do in one day
u just need sockets + pyinstaller + sqlite3 lib usage
we can throw away github part, just save to USB flash ^_^ or save in google drive
I will send you a private message now
not answering private msgs
ok, so how much do you want for writing step by step how do I do it?
well, this stuff is forbidden to mention in this server, pretty much against the rules
solving other people problems like that.. uh, i did it actually during university, but i was much poorer person at that time as well
!rule 5
5. Do not provide or request help on projects that may break laws, breach terms of services, or are malicious or inappropriate.
I'm sorry, then what do you want in return for helping me explain how to do this step by step?
best learn how to do it on your own, i can link your resources how to do that ^_^
up to you to follow and to make it
Yes, you can. In fact, I wanted to suggest exactly what you would describe to me how to do it step by step so that I myself would learn. But if it's not difficult, you can give links)
I would appreciate
https://medium.com/swlh/easy-steps-to-create-an-executable-in-python-using-pyinstaller-cc48393bcc64
Pyinstaller instruction for how to make one file compiled binaries
(googled "python pyinstaller onefile)
how to use SQlite3 you already know.
https://docs.python.org/3/library/sqlite3.html (this is full ofificial docs though)
you are just missing stuff how to make simple socket connection for client server
https://www.digitalocean.com/community/tutorials/python-socket-programming-server-client
(here you go, googled "Python make socket server client")
those three resources (or google alternatives, i provided you with google examples), should be enough to finish and to make it
Okay, then thank you very much for the explanations and links. You really helped me)
be careful when you ask stuff like that ^_^
https://www.javaprogrammingforums.com/cafe/9544-problem-spoon-feeding.html
if people help too much with spoon feeding you answers (which will certainly happen if u hire someone), you will learn nothing out of it
finding answers is one of main skills of a developer. Help received should be small enough to push you forward (around stuck place) to do it on your own further, only then it is helpful to be not stagnating your skills
or preferably managing to do it without help
The gist:
Spoon-feeding is NOT helping. It robs a person of the process of solving a problem by working through it, which is not only fun but is also a crucial skill to learn. Problem solving is much harder to learn than memorizing syntax. Even if a person looks through the syntax you provide, you’ve taken away the chance to practice problem so...
during university times, i helped like 4 students to get good grades for their programming course works for a small reward? each one received good grades, but a year later they were all expelled one by one because they were not able to follow university program on their own
Well, in general, I was looking for either quick help or links, but after what you painted, it just seemed to me that it would take me a week of study, so I decided to suggest doing it to you, and then explain to me step by step, what would be simple faster as I have 1 day left. But since this is not so already and has been studied for a long time, then I will gladly do it myself, I just needed links. I have been trying to do this for quite a long time and just could not find normal sources of information on how to do this.
i feel like your potential problem because your task was received much much earlier, and you just do it at the last possible moment ^_^
do tasks earlier than in the last day of their submission
finding stuff to write programs on your own, learning it, takes some time (at least a week in advance beter to have)
Yes, I understand you perfectly. But time is my main enemy, so I have to get out somehow.
if u will cut off bad habits time like, playing computer games, watching youtube/tiktok/instagram, going through social networks and etc, you will find you have much more free time for self studies
In fact, I had only 4 days for this task, of which 1 day I was doing the database, 2 day I was trying to figure out how to release it. And so I do not play computer games at all for more than a year.
perhaps not paid attention to teacher, when he was explaining what is release then? surely he/she should have explained what it is.
don't be afraid asking dumb questions if you don't understand smth from teacher ^_^
that is that silly motto then went with me through university. better asking dumb questions and finding out answers, then not asking them and kept ignorant (and dumb)
or asking your class mates is an option too.
many tasks i was able to do only because interrogated my classmates, each tasks, is an exercise to soft skills (communicating) as well, not just hard skills (tech knowledge)
Understood. Then I went to look at your links, thanks again for them. Hope I can figure it out.
does it? i thought running a sqlite connection over nfs was setting up for disaster, unless you meant writing a webserver in front of that db https://sqlite.org/useovernet.html
i mentioned few lines later that it is not favourable choice ^_^
that better going just with migrating to postgresql in this choice
it does not matter though, his real task was entirely smth else apperently
at least if i made good guess what he was actually asked to learn and to use (with drawing from my own experience going through uni)
ye, i just didnt consider the "not usually used over network" as a caveat
technically he has student work. it would have been acceptable for him to go in this way for further simplification
task is highly likely assumes he would use self written sockets anyway though, so this is not acceptable path
anyone here knows how to make an image prediction with cnn
A web search yields examples of how it is done, so what is your question?
Can someone tell me why my server is rejecting hashlib??
Hello Can someone tell me why my server is rejecting hashlib?
Yes... I have done a project in captcha image reading
What help do you need
await self.bot.db.execute(
"""CREATE TABLE IF NOT EXISTS admin_settings(
admin_role_id bigint PRIMARY KEY,
stat_channel_id bigint NULL,
stat_message_id bigint NULL);
"""
)
So the issue is that admin_settings is supposed to only have one row. Until now I had admin_role_id set the primary key to resolve the issue, however my bot can work without that ever being specified, but I can't insert the other columns without setting admin_role_id this way. How do I solve this issue?
dump=# create table test(t int primary key default 10, d int null);
CREATE TABLE
dump=# \d test
Table "public.test"
Column | Type | Collation | Nullable | Default
--------+---------+-----------+----------+---------
t | integer | | not null | 10
d | integer | | |
Indexes:
"test_pkey" PRIMARY KEY, btree (t)
dump=# insert into test(d) values (1);
INSERT 0 1
dump=# select * from test;
t | d
----+---
10 | 1
(1 row)
dump=#
Alright, seems I resolved the issue.
What this error means in Mongo db ?

Yesterday it was working but today I woke up and see this :,/
Hello, I need a quick small help with concatenating values for Inserting values from a textbox in windows form into sql.
cmd.CommandText = "INSERT BRGYTable (lastname, firstname, middlename) VALUES (txt_lastname.Text, txt_firstname.Text, txt_midname.Text)";

I am unsure how to concatenate them properly
hello, im trying to insert a date in mongodb from a different timezone, but it always converts it into another timezone, i even specifiec the timezone with tzinfo any help?
I doubt anyone can help without seeing the code
It's network related, specifically DNS
So what should I do bruh ?
What have you tried? You should troubleshoot your network connectivity and DNS resolution, make sure the server exists, etc.
I tried only change my database on other mongo, same mistake
Considering a google cloud certification how does it compare to the AWS?
AWS is much more widely used but if you see enough jobs that ask for it, not a bad idea to target those since fewer people presumably have that focus
python remedy scracth
someone help me on this error for mongo db
please
where can i run it except replit ?
your own pc maybe ?
and it was working yesterday...
or just try connecting to the db on another device
its either replits dns system or the db
Anyone know how do I make a accuracy graph? I used cnn
wdym accuracy graph
Accuracy graph of my predictions
Yes
r u using tensorflow or pytorch
tensorflow
yeah but somehow “history isn’t defined” even tho I did defined it
show code snippets
Meh
Don't spam across channels
Have you tried verifying to get the voice chat role?
!voice
Voice verification
Can’t talk in voice chat? Check out #voice-verification to get access. The criteria for verifying are specified there.
I HONEST TO GOD HATE THIS GAH
Any specific problem with databases?
what is a data base
I have to write code for an assignment but I am so confused on how to access the data and use the data in a list because that is the chapter that we are on. I was out for health reasons and have no idea what to do and need help fast.
Where is the data stored? Or do you have to supply the data?
i have a list that i have to create for it
Oh, like a standard Python list? Or rows on a database?
I'm currently using ReturnDocument from PyMongo, but I want to switch to using Motor instead. Is it possible to achieve the same functionality using Motor?
from pymongo import ReturnDocument
counter_doc = await counter_collection.find_one_and_update({"_id": "case_counter"}, {"$inc": {"count": 1}},
return_document=ReturnDocument.AFTER)```
Yes
That is the one I'm using right now
yeah your code already matches motor's api
Python list
I could show you the requirements for the assignment
when i read data from CSV, print function on python adds an extra decimal. Also, python seems to have a row before zero. Could I be causing this?


Hello I am using Visual Studio local Sql DB implementation
This is a datagridview

and this is the data when you view the actual table

The ID in the sql table isn't showing the correct ID in the DataGridView
Any reason as to why this happens?
I deleted a few rows already from the start
hence why the ID starts at 5 on the SQL Table
But the DataGridView UI Object is not showing the correct ID from the SQL Table, it starts at 1 2 instead of 5 6
could u send first few lines of ur csv?
@obtuse magnet 1483383600 19.13 19.13 15.5001 18.999 452.99913936 25
that is what i am wondering
not sure if cp-ing will change it
@obtuse magnet will try copying file
huh?
just create a copy of ur file, delete most of the rows
and send it?
u can even send the whole file if ure ok with it
@obtuse magnet okay, that would be awesome. How can I send it to you?
its above 100 megsbytes
like 160 i think, i can zip it and get it below 100
uhh maybe not the whole file then
just some example rows will be more than enough
if its feasible for u that is
else u can dm me the full file
In the meann time, I have my own ques
General ques on data cleaning:
Background: Work in a consulting firm mainly designing dashboards for clients.
In a internal training session we have recently, we were discussing about data validation and how we ensure the data shown in dashboards etc is correct. We also built the ETL needed to get and transform the data to something suitable for analytics use. Basically most of our dashboards are built from existing manual reports our clients have, so there was always a 'source of truth' to refer to.
I then asked, what if there is no manual report we can refer to? Or even, how did they validate their manual report to begin with?
I can't really remember the answer my manager gave to this, but it was unsatisfactory for me. Could anyone share more on this from your experience?
TLDR: How do you ensure the data shown in the dashboards are accurate to what is actually in the source system?
okay, np thx

what should i need to change?

select * from a union select * from b except select * from a intersect select * from b
im using this query to find difference between 2 table. but i want to exclude a specific column but show it in the result set..
when i specify the columns in select, it wont show in result set, how can i achieve?
It's trying to read the first row as the header
is there general help channel?
There is #python-discussion and #❓|how-to-get-help for steps on opening a help post in #1035199133436354600
guys, help me pls with this error:
i make discord bot on replit and when i try to connect to Mongo db - i get this error:

@signal nacelle got it. thank you
I suspect the answer is still the same: #databases message
one guy told me to use this:
import dns.resolver
dns.resolver.default_resolver = dns.resolver.Resolver(configure=False)
dns.resolver.default_resolver.nameservers = ["8.8.8.8"]
he said it helped him, but me nope 😹
Are you certain of the server name and port? You said it was working previously but could it have changed on their end?
all correct, few hours it was working again, but now it doesnt
its only replit probs, but im nub, i cant use anything instead of it (long story why)
this might fix my problem but it gives me this error:


mysql> ALTER TABLE deck_lists ADD FOREIGN KEY (deck_id) REFERENCES decks(deck_id);
ERROR 1452 (23000): Cannot add or update a child row: a foreign key constraint fails (`mtg_pdh_db`.`#sql-1f7c_74`, CONSTRAINT `deck_lists_ibfk_1` FOREIGN KEY (`deck_id`) REFERENCES `decks` (`deck_id`))
mysql> SHOW KEYS FROM deck_lists WHERE Key_name = "FOREIGN";
Empty set (0.00 sec)
mysql> SELECT deck_id FROM deck_lists WHERE deck_id NOT IN (SELECT deck_id FROM decks);
Empty set (0.11 sec)
What do you think is going on here? I want to add a foreign key to the deck_lists table that points to the primary key deck_id in the decks table. In the second statement, I checked that the key wasn't there already. In the third statement, I checked that there were no elements in the child table that weren't in the parent table.
ALTER TABLE child_table
ADD CONSTRAINT FK_child_parent
FOREIGN KEY (parent_id)
REFERENCES parent_table(parent_id);
Can you talke about the constraint, please?
This constraint specifies that any value entered into the child_table's "parent_id" column must correspond to an existing value in the parent_table's "parent_id" column.
I thought that's what adding a foreign key does.
The query 'add' just means only 'add'. Without 'constraint', the inner logic of database can't match child' foreign_key with parent's primary_key
So then is there a point to adding a foreign key without a constraint?
If you don't add constraint, it's just same to reference.
What do you mean by "it's just same to reference"?
the column which is added as FK without constraint is equal to simple column referenced to other table.
I guess what I'm confused about is how a column with a constraint and a foreign key differs from a column with only a foreign key.
A foreign key joins a table to another table by referencing its primary key. A foreign key constraint specifies that the key can only contain values that are in the referenced primary key, and thus ensures the referential integrity of data that is joined on the two keys.
weyo i need help
Okay I think that makes sense. But why would they let you add a foreign key without a constraint? Isn't that the whole point of a relational database?
Wait do you use CONSTRAINT merely to name a foreign key?
I use it normally as that. And RDB must be has constraint in production env. So some kind of DB support that originally.
I see. Thank you.
Haha, I wish your luck
Thank you.
can I do something like this with SQL? 😭😭 the pets table is done with SQLAlchemy

it also has something to do with foreign keys, but i don't know how it'd work with a whole row→a single column
It's unclear what problem you're trying to solve. If there will never be more than 1 user per pet, you can simply list the same user_id value on both rows of the pets table.
If the same pet can belong to more then one user, that's a many-to-many relationship and you'll need a separate users-pets table
that was it!!! thanks so much!!
i like this
how do i make a data bse
couse i dont know
lol
is it like a text file
or a .db file
and how do i modefy it with python
i need this stuff in my app
as a online server that only my program can acsess
also how do i make it so that the database is like acsses able from anywhere for my app
so if app has internet the app can talk to server and then that adds a user count and adds a username and password to a database
this is very hard for me as I never did anything with servers or anything that uses external machines
if anyone has a idea please let me know
also only ping me as i wont see the messages otherwise
thank you lovely python community
can you pass the table name as a parameter with SQLAlchemy and MySQL?
SELECT a, b, c FROM %s LIMIT 10
not tried but i dont see why not
just try it and u shud have ur ans
just did with SQLAlchemy and its not working
parameter substitution usually doesnt work for tables
postgres has a quote_ident function for this, not sure about mysql
a good alternative is to have a hardcoded list of table names that you accept
@wanton matrix It sounds like you may need to learn the basics. I have a tutorial for that you might like to try: https://owencampbell.me.uk/sql_python_tutorial/
Hi, I'm trying to use Asyncpg with Quart. Here's my code:
@app.route("/dashboard/<int:guild_id>")
async def dashboard(guild_id):
global act
global efinal
data = await app.db.fetchrow("SELECT enabled_ftrs FROM guildsettings WHERE guildid = $1", guild_id)
channels = []
guild_data = {}
if not data:
ret = "nd"
return await render_template("dashboard.html", ret = str(ret))
else:
data = data["enabled_ftrs"]
if not "db" in data:
ret = "nd"
return await render_template("dashboard.html", ret = str(ret))
It raised asyncpg.exceptions._base.InterfaceError: cannot perform operation: another operation is in progress
is this only during high load or every time you< call this endpoint?
every time
the only operation running was
async def create_db_pool():
app.db = await asyncpg.create_pool(dsn = "a dsn", statement_cache_size=0)
loop = asyncio.get_event_loop()
loop.run_until_complete(create_db_pool())
loop.close()
But this loop is closed. This shouldn't be a problem, right?
ok not here
anyone?
why not just run that function normally by awaiting it
u sure ur not resigning app.db anywhere it looks like it is trying to use a connection or a single cursor
im using app.db (5th line)
the operation shouldn't go on forever ig. When I call app.db again, it should be a fresh new call
(i'm calling it twice in total with some interval)
i havent used asyncpg myself but based on https://stackoverflow.com/a/66448094, you might want to store a connection pool in your app rather than just one connection, that way each request can acquire its own connection that isnt in use by another route
so should I create a new connection for every route?
not literally creating a new connection but acquiring one from your pool, which transparently manages connection reuse
Can you please give me an usage example (if possible)
an ideal place for creating the connection pool within quart: https://quart.palletsprojects.com/en/latest/how_to_guides/startup_shutdown.html
connection pool usage: https://magicstack.github.io/asyncpg/current/usage.html#connection-pools
Thank you sooo much
this isnt a python-specific problem, but i was wondering how i could design table(s) in postgres for an rpg? for example, i'm wondering what the best practice is for storing something like a player's stat points, like how many points in strength, dexterity, defense, etc, and how many are unused. would a custom type be appropriate for this? or should each stat exist as a separate row in the database?
like:
create table player (
gold int, level int, stats Stats
)
create type Stats as (
unused int, str int, dex int, def int
)
vs
create table player (
gold int, level int, stat_unused int, stat_str int, stat_def int
)
the later
assuming that it'll be an 1-1 relationship between Player and Stats, you may as well just put the stats on the player's table
anyone here knows system design and analysis
yes, some people here know system design and analysis
lol
this is cool
and funny
i like this server
a lot
people are kind
and staff too
i like this
its fun
im not lying
MRE and traceback: https://paste.pythondiscord.com/zezeruzezu.py
how would i create an sqlalchemy (v2.0.9) integer type that serializes to TEXT on sqlite and bigint otherwise? ive tried using TypeDecorator.load_dialect_impl for this, but the above attempt fails with TypeError: Visitable._generate_compiler_dispatch.<locals>._compiler_dispatch() missing 1 required positional argument: 'visitor'
typedecorator docs which im referencing: https://docs.sqlalchemy.org/en/20/core/custom_types.html#sqlalchemy.types.TypeDecorator
if i remove load_dialect_impl the error goes away but the column type gets set to BIGINT, and integer affinity is what im trying to avoid
for context, im intending to store 64-bit unsigned integers (discord snowflakes), but sqlite's integer type only supports 64-bit signed integers
oh, i think i was meant to write my method using type_descriptor(): py def load_dialect_impl(self, dialect): if dialect.name == "sqlite": return dialect.type_descriptor(String) return dialect.type_descriptor(BigInteger)
this works too...? py def load_dialect_impl(self, dialect): if dialect.name == "sqlite": return String(20) return BigInteger()
How do you know what's the tech being used at the database layer? I know we're using Hue's Hive/Presto SQL versions to query, but what is that based on? Nvm, asked one of our DB guys.
Apache Hive + Something else?
Does a Trino have a separate/it's own ODBC or is it based on presto (Simba ODBC?)
This looks like a good model to learn from: https://github.com/jgoodman/MySQL-RPG-Schema/blob/master/create_tables.sql
GitHub
A database schema for role-playing games. Contribute to jgoodman/MySQL-RPG-Schema development by creating an account on GitHub.
ooooh thanks ill take a look at this
SELECT card_name FROM cards WHERE scryfall_id IN (
SELECT scryfall_id FROM deck_lists WHERE scryfall_id IN (
SELECT scryfall_id FROM cards WHERE oracle_text LIKE "%Unearth%"
)
);
I'm trying to find the most popular unearth cards.
The innermost statement should get the scryfall_id of all cards with Unearth. This gives 367 scryfall_ids.
The middle statement should get all records in deck_lists where the scryfall_id of that record is in the list of 367 scryfall_ids. This gives 1949 scryfall_ids.
The outermost statement should get the name of each of those 1949 scryfall_ids. So I think I should get 1949 names. But I only get 48 names.
Any idea what's going on?
I think the issue lies with the outermost statement because the two inner statements give reasonable results.
Without seeing your data it's impossible for anyone to tell you why a certain query is returning x number of records. But I would think if you look at the results of each sub query with enough columns included you should see what's happening
What data would you like to see?
I'm saying that someone would probably need access to your database to solve this for you, but I'm not offering to do that
If you think the inner query is correct, the outer query should return all records where scryfall_id is a matcn
I think the inner queries are correct. Do you agree that if the inner query returns 1949 records, that the outer query should also return 1949 records?
Only if all 1949 of those IDs from the inner query are a) unique and b) present in cards. If you get less that 1949 results from the outer query, one or both of those things are not the case
All 1949 IDs from the inner query are not unique. But that's expected.
Basically I want to return a record with the name of a card for each time the IDs show up in the inner query.
So if an ID shows up 5 times in the inner query, I want to see that name 5 times in the outer query.
Might work better if you do a join instead
Can you elaborate, please?
You're using MySQL? I think CROSS JOIN might be what you are trying to do. https://www.cloudways.com/blog/how-to-join-two-tables-mysql/

The Official Cloudways Blog
Learn joining tables in mysql in this tutorial. How Joins in MySQL are used and how you can use the query to Join two table in MySQL.
Yes, MySQL. I'll take a look.
MySQL Tutorial
This tutorial shows you how to use the MySQL CROSS JOIN clause to create the Cartesian product of rows from the joined tables.
^^° assuming I'm not leading you down a blind alley, that looks more to the point
Is it possible to add a WHERE clause at the end of a SELECT when there's a JOIN in the middle?
I tried doing
SELECT cards.card_name FROM (cards
CROSS JOIN deck_lists
WHERE cards.scryfall_id = deck_lists.scryfall_id)
WHERE cards.oracle_text LIKE "%Unearth%";
I want the second WHRE to be a part of the SELECT.
But I got a syntax error
Near the last two lines
SELECT
card_name
FROM
(SELECT
card_name, oracle_text
FROM
cards INNER JOIN deck_lists ON cards.scryfall_id = deck_lists.scryfall_id) derived_table
WHERE
derived_table.oracle_text LIKE "%Unearth%";
It looks like this is what I wanted. I'm still trying to get the hang of the derived table syntax.
Do you know why all 1949 IDs would have had to have been unique for my original method to work?
I'm.jusy guessing that maybe it's returning one result per ID
Hi @trail rune What's your problem?
I don't think you need the sub-select:
SELECT card_name
FROM cards
JOIN deck_lists ON cards.scryfall_id = deck_lists.scryfall_id
WHERE cards.oracle_text LIKE '%Unearth%'; -- should be single quotes for conforming to SQL standard
You could even let the db do the counting:
SELECT card_name, COUNT(*) AS card_count
FROM cards
JOIN deck_lists ON cards.scryfall_id = deck_lists.scryfall_id
WHERE cards.oracle_text LIKE '%Unearth%'
GROUP BY card_name
ORDER BY card_count DESC;
Given the following SQL statement I get an unexpected behaviour which might be because I misunderstood what IN clause is supposed to do.
SELECT * FROM table1 WHERE field1 in (SELECT DISTINCT field1 FROM table2)
If table two is empty it shouldn't return any record from table1, right?
yo
I have the following at the top of main.py:
from database.queries import Database
and in queries.py i have the following:
from models import Summoner, Match, Participant
and queries.py is able to pick up my models.py file when working in queries.py
but when I run main.py, I get the following error:
Traceback (most recent call last):
File "c:\...\main.py", line 2, in <module>
from database.queries import Database
File "c:\...\database\queries.py", line 3, in <module>
from models import Summoner, Match, Participant
ModuleNotFoundError: No module named 'models'
any ideas why? I am only asking here cause I was stuck even with chatgpt
nvm, my models import should be .models I think
Seems right to me
Yeah at least the logic that I'm trying to achieve looks great. I guess that there is smth behind the scenes causing the hassle
Thank for your reply
i was looking through this and i was wondering - for tables like user_type or character_type, do you know why a table is used instead of an enum custom type? to leave it open to new variants in the future?
If table2 is empty this should select nothing because the IN-list is empty so there is nothing to compare to the value of filed1 of table1.
That would be my guess https://stackoverflow.com/questions/24680744/when-to-use-an-enum-or-a-small-table-in-a-relational-database
Stack Overflow
I have a several small entities in my database that I represent as small table with two columns: id and name. Example of such entities: countries, continent.
Should I create an enum type instead,
Can anyone help with this issue?
when adding the characters "再见" to my sqlite database, I get the characters "??"
i see, thanks!
using peewee with sqlite and the following line:
summoner = Summoner.create(id=id, name=name)
and the name field is "??"
when I print name directly before it prints: "再见"
the original string is "\u518d\u89c1"
Hi, thanks for checking in. The problem is solved now.
That would make sense. It's just not the behavior I expected.
Is there a PEP but for SQL instead of Python?
I'll put it this way... If you're trying to reference data from more than one table at a time, assume you probably need JOIN.
Good to know, thanks.
nvm actually turns out my terminal is just reading it wrong
guys i am on dads laptop and I need to plot a grapgh
can someone run it and send it to me on dms ?
Your request is totally off topic here, but if you just need to run some Python quickly from a web browser there are plenty of options like Google Collab or Kaggle or Replit or PythonAnywhere
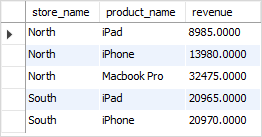
This query is giving weird results. Here's an example,
SELECT cards.card_name, COUNT(*) AS Occurrences
FROM cards
INNER JOIN deck_lists
ON deck_lists.scryfall_id = cards.scryfall_id
WHERE deck_id IN
(
SELECT deck_tags.deck_id
FROM deck_tags
WHERE deck_tags.tag_name = 'Competitive'
)
AND deck_lists.scryfall_id IN
(
SELECT card_tags.scryfall_id
FROM card_tags
WHERE card_tags.tag_name = 'Removal'
)
GROUP BY cards.card_name;
This shows Into the Roil at a count of 11. but when I individually get the count of Into the Roil in competitive decks,
SELECT deck_lists.deck_id -- Get decks that use Into the Roil
FROM deck_lists
WHERE deck_lists.scryfall_id
IN (
SELECT scryfall_id
FROM cards
WHERE card_name = "Into the Roil"
)
AND deck_id
IN (
SELECT deck_tags.deck_id -- Get decks that are tagged Competitive
FROM deck_tags
WHERE deck_tags.tag_name = "Competitive"
);
it shows 41.
Why would these two queries give different results for the same card?
how do i create a dataset of pictures and labels?
You could simply have a JSON file with filenames and labels, or you could use any database you choose
im new to Sqlite and im trying to make a database system
I want to add a dictionary into the database
how do i do this
yea but i want a numpy array
how do i do this
Sorry I didn't read your mind 😅. Then use Numpy, what's the question?
okey then i would say i am to dumb but i dont know how to add these labels (0,1) to each image. or how do i do that
In this tutorial we look at storing and retrieving JSON data in SQLite and also at how we can easily store time series data in SQLite.
Stack Overflow
I have a numpy array created such as:
x = np.array([[1,2,3,4],[5,6,7,8]])
y = np.asarray([x])
which prints out
x=[[1 2 3 4]
[5 6 7 8]]
y=[[[1 2 3 4]
[5 6 7 8]]]
What I would lik...
ohoho thank you my g
im confused as to how this works
await cursor.execute("CREATE TABLE IF NOT EXISTS inventory (user INTEGER, items LIST)")
I Want to make it so there is new table called inventory where it has the user's id and a dictionary called items in it
def make_numpy(label_of_pictures, folder_path, img_size, output_name): images = [] for filename in os.listdir(folder_path): img = cv2.imread(os.path.join(folder_path, filename)) if img is not None: img_resized = cv2.resize(img, img_size) images.append(img_resized) print(len(images)) numpy_dataset = np.array(images) labeledArray = [0, numpy_dataset]
i have it now like that but its still not working i just want to add to every images the label which is 0 or 1. (In a way it has worked by np.zeros(...)) but yea
but why the hell cant i simply add this label to every image
anyone here can help me with databases?
So i need to have 2 tables.. first one is Countrys and needs to contain id(autoincrement), name and capital city id.
Second table is Citys and needs to contain id autoincrement, name, zip_code , boolean if is capital city (i suppose self.capital = 0 as defoult?) and country_id to which country this city belongs.
i think i will have problem with circular implementing
Correct... there is no reason to have those last two columns on the second table. You can always find those values with a simple join and so no reason to store redundant data
I need to provide some data (readonly) from a postgre db using rest apis or at least json. Any ideas on frameworks to make it easier? I have used SQLAlchemy as well as Flask in the past. Wondering if there are easier ways. Would GraphQL be an option? A friend told me its quite complex to get into.
You might consider FastAPI. You probably want to stick to SQLAlchemy. I wouldn't switch to GraphQL if you don't have any specific reason to do so
This seems like a good discussion of reasons (mainly not to) do so: https://www.moesif.com/blog/technical/graphql/REST-vs-GraphQL-APIs-the-good-the-bad-the-ugly/

REST vs GraphQL APIs, the Good, the Bad, the Ugly | Moesif Blog
GraphQL adoption is exploding, but should you migrate to GraphQL?
The conclusions of the article has been my view on the matter as well.
GitHub
REST API for any Postgres database. Contribute to PostgREST/postgrest development by creating an account on GitHub.
Anyone free to help me have a 👀 at what am I failing so miserably with when trying to set up my test_db?
This is great, but I dont work with postgre sql dbs unfortunately. I'll see if there is something similar. Perhaps I can make some kind of library that converts DBT into sql alchemy and some factory method for the API.
Simply not using SQLAlchemy is an option if you feel that embedding raw SQL queries in Python is good enough for your project
Hello! Can somebody please help. I'm getting this error every time I make a HTTP get Request to my API: ```sqlalchemy.exc.ArgumentError: autocommit=True is no longer supported
It works on my laptop but not on my PC although the Python version is the same on both devices.
check if you are using the same sqlalchemy version on your pc and your laptop
you can check with pip list / pip show
ty, I'll try it out
Thank you, it was due to my SQLAlchemy version.
https://discord.com/channels/267624335836053506/1099775111063666718
could someone please give this a look
How can i create my own database?
using python
like vector database
Can i get resources for learning about more database
should I use engine.connect() or engine.begin() in SQLAlchemy if I'm doing SELECT queries?
start with relational databases (SQL), find a DB you find interesting, learn how its drivers work in Python and play around with it
you can use the library SQLAlchemy for almost all SQL databases
engine.connect should do!
engine.begin would automatically commit when you exit a context manager
ok thanks
i was wondeirng if i can limit the amount of references to a column using postgres.
my schema is similar to this:
create table user (
username varchar(20) not null,
email varchar(20) not null,
room bigint,
constraint fk_user_room foreign key room references room(id)
)
create table room (
id bigserial not null,
primary key `id`
)
how could i make it so that only 4 users can reference the same room at once?
how familiar you are with postgres? do you already know what is a trigger?
in a nutshell, a trigger is a special type of stored procedure that automatically runs in response to a specific event or change in a database.
it can be used to enforce business rules such as the one you have defined.
have a read here for more details https://www.postgresql.org/docs/current/sql-createtrigger.html

PostgreSQL Documentation
CREATE TRIGGER CREATE TRIGGER — define a new trigger Synopsis CREATE [ OR REPLACE ] [ CONSTRAINT ] TRIGGER name …
you want a before insert/update trigger that checks if there are too many users in the any room that's referenced by any existing or to-be-inserted users, and raise an exception if so to abort the insert/update
oooh ok thanks ill take a look
alternatively, you can define the check in your application, as long as you protect against race conditions by e.g. locking the room row
there are advantages and disadvantages to each approach
Seems like this belongs in #discord-bots
oh, my bad 😹
CREATE DATABASE metricity;
\c metricity;
What is the \c part?
C for "Connect" maybe? Who knows. I assume you're using Postgres. https://hasura.io/blog/top-psql-commands-and-flags-you-need-to-know-postgresql/

Hasura GraphQL Engine Blog
This post will teach you the top psql commands and flags you need to know when working with PostgreSQL.
from man psql

is there a way to make a select all columns statement using the sqlalchemy orm?
kinda like this?
resultTest = cardSession.query(pokemonInfo).with_entities("*").filter(pokemonInfo.name==(cardName)).all()
I googled it for you... https://stackoverflow.com/questions/636548/select-in-sqlalchemy
Stack Overflow
Is it possible to do SELECT * in SQLAlchemy?
Specifically, SELECT * WHERE foo=1?
I'm workin on my python project for backend i use firebase firestore and framework Flask and jinja when im tryiing to retrive data it will take around 3-4 secounds i Also use multithreading for the reduce data retrival time...
is this possible reduce more time like 1-2 seconds using any other module or anything else?.....
guys which is better i use .json files for my databases but its a little slow and hard to sort quickly
is sql worth it for python web development?if so which sql module should i learn?
can anyone help me with the database tables for phpmyadmin
def purchase():
while True:
a = int(input("Enter Company ID:-"))
b = int(input("Enter Invoice no:-"))
h = int(input("How many products:-"))
for i in range(0,h):
c = input("Enter PID:-")
d = input("Enter Medicine Type:-")
e = int(input("Enter Quantity:-"))
f = int(input("Enter Rate:-"))
insert = "insert into purchase values ('%s', %d, '%s', %d, %d, %d, Curdate());"%(c,b,d,a,e,f)
cur.execute(insert)
con.commit()
query = "Select * from purchase;"
df = pd.read_sql(query, mycon)
print(df)
i +=1
g = input("Do u want to continue adding? YES/NO: ").lower()
if g == "no":
break
purchase()```how does this code look
any suggestions on improving it
You spelled "you" wrong.
no u
If you enter a wrong number to the int() inputs, it‘s gonna crash. Add a helper function that essentially asks for a given input until the user entered it without errors.
The INSERT INTO statement is vulnerable to SQL injection. Pass the parameters you got from the user in cursor.execute separately. Never blindly format user input into an SQL query.
You should use parameter binding:
insert_stmt = "insert into purchase values (%s, %s, %s, %s, %s, %s, Curdate());"
cur.execute(insert_stmt, (c,b,d,a,e,f))
oh, and another improvement suggestion, use actual variable names 😄
@ionic pecan can u tell me more about the helper function
Something like this:
def ask_numeric_input(prompt):
while True:
try:
return int(input(prompt))
except ValueError:
print("Invalid number, please try again")
for example
>>> ask_numeric_input("Company ID: ")
Company ID: no
Invalid number, please try again
Company ID: no
Invalid number, please try again
Company ID: 33
33
a database is homogenous??
So i have sql database that keeps medical records
Using sqlite3
First column is name
Second column is age
and third is condition
How can i make it so any time a user adds more condition
It adds another column?
like
condition_2
condition_3
...
do not "add more columns"
add an id column to the users table, then create another table like id | condition and use a one-to-many relationship
Do you have a source for one to many relationship?
I'm kinda new
I recommend following some tutorial/course like the pinned Khan Acamedy intro to sql
plz help:
using mySQL
getting an error around "IF" statement
first %s and second %s are both the same word, it was working before i added the if statement, %s should be working
Not sure what you're trying to do but seems like maybe you want WHERE instead of IF
This picture is the original working version:
where each %s is a value like from the example ab1, everything except the first value is subject to change at a given moment,
but i dont want to add a new row if theres already one with the word in a column called "Word"
if the word is in the column, then i also want to set the column countdown to -1

sounds like you want upsert, i don't use mysql so i can't comment on how to do it properly.
in postgres this would be ON CONFLICT DO NOTHING, but this is definitely not how it's specified in mysql, you will need to look at the docs/google to figure out how to do it
invoice = pd.read_sql("select products.pname, sale.qty, sale.mrp, sale.amt from products, sale where products.pid = sale.pid and sale.customer_id = 4 and sale.sale_invoice= 1;", mycon)
print(invoice)```when i execute this code using python it results in empty dataframe
but in mysql it shows one record
can someone tell me a solution

@ionic pecan
import mysql.connector as mys
import check_access as c
import logging
obj = mys.connect(host = 'localhost',user='root',password = 'root',database = 'password_manager')
cursor = obj.cursor()
logger = c.create_logger()
logging.basicConfig(filename= logger, level=logging.INFO)
def store_to_db(_data):
try:
if not exists_check():
cursor.execute('insert into pwm values({},{},{})'.format(_data[0],_data[1],_data[2]))
cursor.commit()
print('Saved Successfully')
else:
print('Data Aldready exists')
except:
logging.error('error while writing to database')
def remove_from_db(_data):
try:
if exists_check():
cursor.execute('delete * from pwm where domain = %s and gmail = %s and password = %s'%(_data[0],_data[1],_data[2]))
print('Saved Successfully')
else:
print('No such data exists!')
cursor.commit()
except:
logging.error('error while removing from database')
def exists_check(_data):
try:
cursor.execute('select * from pwm where domain = %s and gmail = %s and password = %s'%(_data[0],_data[1],_data[2]))
if cursor.fetchone():
return True
return False
except:
logging.error('error while checking database')```
is there a syntax error i always get into the exception partyes there are syntax errors if you use % formatting or {} formatting like that.
"{}".format("hello") is hello as a string not 'hello' as string, only the later is correct.
!sql-f
SQL & f-strings
Don't use f-strings (f"") or other forms of "string interpolation" (%, +, .format) to inject data into a SQL query. It is an endless source of bugs and syntax errors. Additionally, in user-facing applications, it presents a major security risk via SQL injection.
Your database library should support "query parameters". A query parameter is a placeholder that you put in the SQL query. When the query is executed, you provide data to the database library, and the library inserts the data into the query for you, safely.
For example, the sqlite3 package supports using ? as a placeholder:
query = "SELECT * FROM stocks WHERE symbol = ?;"
params = ("RHAT",)
db.execute(query, params)
Note: Different database libraries support different placeholder styles, e.g. %s and $1. Consult your library's documentation for details.
See Also
• Python sqlite3 docs - How to use placeholders to bind values in SQL queries
• PEP-249 - A specification of how database libraries in Python should work
it's not advisable to use % formatting or {} formatting like you did, please read the above ☝️
ok 👍
i use mysql.connector is ? as place holder supported there?
looks like it's %s
(that is, using format or pyformat style).
do note the , between the query and the parameters, and the lack of sql % params
import mysql.connector as mys
import check_access as c
import logging
obj = mys.connect(host = 'localhost',user='root',password = 'root',database = 'password_manager')
cursor = obj.cursor()
logger = c.create_logger()
logging.basicConfig(filename= logger, level=logging.INFO)
def store_to_db(_data):
try:
if not exists_check():
cursor.execute('insert into pwm values(%s,%s,%s);',(_data[0],_data[1],_data[2]))
cursor.commit()
print('Saved Successfully')
else:
print('Data Aldready exists')
except:
logging.error('error while writing to database')
def remove_from_db(_data):
try:
if exists_check():
cursor.execute('delete * from pwm where domain = %s and gmail = %s and password = %s;',(_data[0],_data[1],_data[2]))
print('Saved Successfully')
else:
print('No such data exists!')
cursor.commit()
except:
logging.error('error while removing from database')
def exists_check(_data):
try:
cursor.execute('select * from pwm where domain = %s and gmail = %s and password = %s;',(_data[0],_data[1],_data[2]))
if cursor.fetchone():
return True
return False
except:
logging.error('error while checking database')```
i have added semicolons switched with query params, im encountering the same errorpost your error please
np 👍
also should i leave it as an empty except, or is there anything in specific i can catch
naked try/except is usually frowned upon. you will have to read the docs to find out which exception you want to catch, i don't use mysql
I usually just test with bad inputs to verify what exception type(s) I'm trying to catch
is it fine to use varchar types as primary key as long as you know it will always be unique?
invoice = pd.read_sql("select products.pname, sale.qty, sale.mrp, sale.amt from products, sale where products.pid = sale.pid and sale.customer_id = 4 and sale.sale_invoice= 1;", mycon)
print(invoice)```when i execute this code using python it results in empty dataframe
but in mysql it shows one record
can someone tell me a solution

does not work
what are ways to make databases using chatgpt
You can ask it to pretend (https://eightify.app/summary/artificial-intelligence-and-machine-learning/simulate-a-microsoft-sql-server-database-with-chatgpt) or you can ask it to tell you how to use one ("How do I use SQLite?" or whatever. But it can't "make" a real db for you
Generate summaries of YouTube videos quickly and easily with Eightify AI ChatGPT. Our Chrome extension lets you access a summary of YouTube videos and quickly find main points. Try it now and get the most out of your YouTube videos.
fair

I'm workin on my python project for backend i use firebase firestore and framework Flask and jinja when im tryiing to retrive data it will take around 3-4 secounds i Also use multithreading for the reduce data retrival time...
is this possible reduce more time like 1-2 seconds using any other module or anything else?.....
any one have any idea?..
How do you use psycopg to create a dataframe?
A foreign key reference must be unique either by being a primary key, a unique constraint column or with an unique index on the column.
What kind of query are you running to retrieve your data?
when I'm retrieving data from firebase firestore it will take 3-5 sec. so i want to reduce this time of retrieving data time
What kind of data are you retrieving? People can't help you without knowing the details
I'm workin on my python project for backend i use firebase firestore and framework Flask and jinja when im tryiing to retrive data it will take around 3-5 secounds i Also use multithreading for the reduce data retrival time...
Retrieval Data in text format , I was Retrieve data From Multiple Collection and Subcollection
class Dashboard():
def __init__(self, db):
self.db = db
def _get_employee_data(self, emp_doc):
employee_data = {'name': emp_doc.get('employeeName'),
'dob': emp_doc.get('dob'),
'doj': emp_doc.get('doj'),
'leaves': {}}
if employee_data['dob']!='':
if datetime.strptime(employee_data['dob'], '%Y-%m-%d').month == datetime.today().month:
employee_data['birthday'] = employee_data['dob']
if employee_data['doj'] != '':
doj = datetime.strptime(employee_data['doj'], '%Y-%m-%d')
if doj.month == datetime.today().month:
years = datetime.today().year - doj.year
employee_data['anniversary'] = {
'name':employee_data['name'],
'date': employee_data['doj'],
'years': years}
leaves = emp_doc.reference.collection('leaveMST')
total_leaves = 0
for leave in leaves.stream():
if leave.id != 'total_leaves':
dt2 = datetime.today().date()
dt1 = datetime.strptime(leave.id, '%Y-%m-%d')
diff = (dt2.year - dt1.year) * 12 + (dt2.month - dt1.month)
if diff < 2:
employee_data['leaves'] = leave.get('fromdate')
if leave.id != 'total_leaves':
total_leaves += int(leave.get('days'))
employee_data['total_leaves'] = total_leaves
return employee_data
def Dashboard_data(self):
users_ref = self.db.collection(u'alian_software').document('employee').collection('employee')
employee_data = []
with concurrent.futures.ThreadPoolExecutor() as executor:
for emp_doc in users_ref.stream():
employee_data.append(executor.submit(self._get_employee_data, emp_doc))
employee_on_leave, total_leaves, employee_birthday, employee_anniversary = {}, {}, {}, {}
for future in concurrent.futures.as_completed(employee_data):
result = future.result()
if 'birthday' in result:
employee_birthday[result['name']] = result['birthday']
if 'anniversary' in result:
employee_anniversary[result['name']] = result['anniversary']
if result['leaves']:
employee_on_leave[result['name']] = result['leaves']
total_leaves[result['name']] = result['total_leaves']
return employee_on_leave, total_leaves, employee_birthday, employee_anniversary
How many times is self._get_employee_data called?
it depends upon number of employee
Can you retrieve multiple employees with a single query?
for the testing purpose I'm Using 5 employees
Do it, it's better than running multiple queries
Also is there a particular reason so use firestore?
I'm just using for learning purpose
while True:
Comp_name = input("Enter Company name:-")
df1 = pd.read_sql("select Company_id from Manufacturer where company_name = '%s';"%(Comp_name, ), mycon)
Comp_ID = 0
if df1.empty == False:
Comp_ID = int(df1.loc[0, 'company_id'])
print(Comp_ID)
This code is giving keyerror 0
i can't find the mistake
I don't think you can use .loc[] to index using a number, only labels. try df1.loc['company_id'][0]
Also, two other unrelated pieces of advice: you can use if not df1.empty to make it more readable and if you are just selecting the first company_id, you can add limit 1 to the SQL.
def purchase():
while True:
Comp_name = input("Enter Company name:-")
df1 = pd.read_sql(("select Company_id from Manufacturer where company_name = '%s';"%(Comp_name, )), mycon)
Comp_ID = 0
if df1.empty == False:
Comp_ID = int(df1.Company_id[0])
print(Comp_ID)
elif df1.empty == True:
q1 = "insert into manufacturer(Company_name) values ('%s')"%(Comp_name,)
cur.execute(q1)
con.commit()
q9 = "select Company_id from manufacturer where Company_name = '%s';"%(Comp_name,)
df2 = pd.read_sql(q9, mycon)
print(df2)
Comp_ID = int(df2.Company_id[0])
print(Comp_ID)```with q1 i am insert the company_name and the comp_id is auto generated because of auto increment in sql
then with q9 i am extracting the comp_id of that company name
but it is producing empty dataframe
can anyone suggest a solution
yes it is
.loc is used to select rows based on the indexes (both the dataframe index and the dataframe columns)
you can use .loc[row_index, column] (as well as ranges, lists and a bunch of other cases) and it will work.
if you are using the default index, the row index is probably it's position (assuming that you have not filtered anything yet)
would have to see what their df looks like to tell what is happening there though
it is producing empty df
also you do realise that the way you are interpolating strings is not safe right? (as in, is prone to sql injection)
hi! this sounds so dumb but how can I assure a column is not a negative integer? as in, whenever i update 5 by subtracting 6, it will not be -6, but 0?
!d pandas.read_sql
pandas.read_sql(sql, con, index_col=None, coerce_float=True, params=None, parse_dates=None, columns=None, chunksize=None, dtype_backend=_NoDefault.no_default, dtype=None)```
Read SQL query or database table into a DataFrame.
This function is a convenience wrapper around `read_sql_table` and `read_sql_query` (for backward compatibility). It will delegate to the specific function depending on the provided input. A SQL query will be routed to `read_sql_query`, while a database table name will be routed to `read_sql_table`. Note that the delegated function might have more specific notes about their functionality not listed here.not sure tbh - did you test it using something like psql?
nah
Not sure what db you are using but for portgres you can enforce checks on columns (such as > 0) that raise an error if not met. https://www.postgresql.org/docs/current/ddl-constraints.html#DDL-CONSTRAINTS-CHECK-CONSTRAINTS I'm not sure if you can cap the overflow at 0 on the db side. would a simple max(number, 0) work?
PostgreSQL Documentation
5.4. Constraints 5.4.1. Check Constraints 5.4.2. Not-Null Constraints 5.4.3. Unique Constraints 5.4.4. Primary Keys 5.4.5. Foreign Keys 5.4.6. Exclusion Constraints Data …
@storm mauve i used py cur.fetchall() function and now it works
You could use a CASE statement:
UPDATE tabname
SET colname = CASE
WHEN colname > subvalue THEN colname - subvalue
ELSE 0
END
WHERE ...
max(colname - subvalue, 0) 🤔
There is more than one way. I'm not sure all databases support max() as a function call. You could also: (colname - subvalue) * (colname > subvalue) 🤔
I'd say max call by far is the easiest to read
i was able to solve it earlier with CHECKS (column >= 0), but it's great to learn something new. thanks!

is it fine to use varchar types as primary key as long as you know it will always be unique?
Why do you need a varchar pk? 🤔
im using username as the primary key in the users table right now
instead of a number id
and references to that table just reference the username
I'd use a surrogate key like integer or a uuid/ulid, since it would be easier to reference from other tables
imo
^
postgres has a uuid type
as in if u have tables
how would i create uuids to insert into the table?
with an integer i can see you could just make it increment
It's not auto, you have to specify a default or generate it on python side
Hey guys, i'm really new to utilising databases in my projects and was hoping someone might be able to offer some guidance on how to achieve what i'm trying to do. I'm creating a raffle system and have designed a visual for a relational database seen below.
I'm aware of how to create a database and access data using CREATE/SELECT, but i'm not really sure how to reference anything deeper than that. For example:
Raffle 1 has been generated and a ticket number has been selected, I want to access the Entrants database and find the user with the ticket number x.
How would I reference this hypothetically? If anyone's able to explain this or provide a very brief code example to get me going i'd really appreciate it.

if every user only has a single ticket then storing it on the entrants table together with the user is probably a good idea
Users are going to be able to purchase multiple tickets per raffle which is why I assumed i'd need a separate section for each entrant 😅
ahhhhh no you‘re right in that case it looks correct
just to be sure, are the columns referencing the parent table omitted intentionally?
like entrants should have a raffle_id, tickets an entrant_id and maybe also a raffle_id
oh no haha, i think that was just my poor use of the diagrams, i’ll modify that now ;P
I'm trying to design a database for a tinder-like app for academia and would love to get some feedback from some db experts here: https://dbdiagram.io/d/644127016b31947051eac144. Thanks in advance

Quick and simple free tool to help you draw your database relationship diagrams and flow quickly using just keyboard
I'm sure you'll need to add more (users email?) but as a simple starting point looks fine to me
you're right, I totally forgot about the email, which is very crucial
I want some help related to mysql
I have Ubuntu Linux
One of my professor set up Apache server in my laptop
Now, I want to learn the mysql using terminal, but I forget the password for mysql
I searched on internet tried some commands suggested, asked chatGPT, nothing worked
how to connect MongoDB with python?
can anyone help me with that?
Atlas to be specific...
I've never done that so I don't know exactly how to do that but I found this library called PyMongo that claims to do just that https://pymongo.readthedocs.io/en/stable/atlas.html and this short example on how it can be done https://stackoverflow.com/questions/45546293/pymongo-3-4-0-connecting-to-mongo-atlas
Stack Overflow
I have python 2.7, have pymongo 3.4
and im trying to connect to mongo atlas using the following :
import certifi
import ssl
import os
from pymongo import MongoClient
MongoClient(
"mongodb://...
Apache and MySQL are totally separate things so I'm not sure I follow you, but maybe this helps? https://dbschema.com/2020/04/21/mysql-default-username-password/
In this article, you are going to find the default username and password for mysql and how to reset the password.
i have two tables, lets say users and users_stats, and i want exactly (not zero, or more than) one row in users_stats corresponding to each users row. would it be better to have a field in users_stats which references a row in users, or a field in users which references a row in users_stats?
create table
"public"."woocommerce" (
"id" serial primary key,
"enabled" BOOLEAN not null default false,
"coupons_enabled" BOOLEAN not null default false,
"coupons_create" BOOLEAN not null default false,
"orders_enabled" BOOLEAN not null default false,
"orders_create" BOOLEAN not null default false,
"orders_retrieve" BOOLEAN not null default false,
"orders_update" BOOLEAN not null default false,
"orders_delete" BOOLEAN not null default false
)
Got a question. Is this a good way to go about having settings?
If not how would I? Should I have a table for each group? Like a orders table and a coupons table?
Seems fine, no need to have so many tables
I think nosql makes more sense for speed considerations but it doesn't matter ig
Hi all. I am coding a personal project to categorise my personal bank statement using ml. I wondered if anyone had any suggestions or experience in storing labels and their necessary information. I originally had a somewhat convoluted system, where I have handful of dictionaries that store different store name or categories as keys, and then information about the transactions that have been labelled as that store/category. Example: store_dict = {"wallmart": [["wallmart transaction text", 2.56, "2022-01-01"], ...], ...} and debit_categories = {"groceries": ["wallmart", ...], ...}. The "nice" thing is that it would be quick and easy to pull all (currently) possible store names or categories. But it is of course somewhat cumbersome to get all the information for a category.
Another solution is to store it in a dataframe (or similar type), where a single line is a transaction with all its information, and having a label column for its category. Put I having a problem with how to keep track of all possible categories, as it is completely possible that I haven't yet seen a transaction associated with specific category. I could store a list of possible categories in a separate list or similar, but it also feels a little clumsy to have the information stored in separate places. I have very little experience in databse management, so I don't know how one usually handles these types of problems? I am not sure if my question makes sense, I am possibly over complicating things.
if 2 tables have a 1-to-1 relationship, why aren't they just 1 table?
class UserFilter(BaseModel):
user_id: Optional[str]
is_member: Optional[bool]
joined_before: Optional[datetime]
joined_after: Optional[datetime]
@property
def search_criteria(self) -> tuple[str, list]:
criteria, values = [], []
if self.user_id:
criteria.append(f"user_id = ${len(criteria) + 1}")
values.append(self.user_id)
if self.is_member:
criteria.append(f"is_member = ${len(criteria) + 1}")
values.append(self.is_member)
if self.joined_before:
criteria.append(f"joined_at < ${len(criteria) + 1}")
values.append(self.joined_before)
if self.joined_after:
criteria.append(f"joined_at > ${len(criteria) + 1}")
values.append(self.joined_after)
if not criteria:
return "", []
return f"WHERE {' AND '.join(criteria)}", values
if there are better ways to do this I'm all ears, but I rather not change from asyncpg to sqlalchemy for example coz I'd have to rewrite everything and it's just so different to use as well
I understand this question isn't really Python-specific but rather SQL related
I want to have a table which contains two columns: userID (integer increasing by 1 starting from one) and userUUID (classic uuidv4), and the thing is I would like to be able to quickly fetch userID from a given userUUID (there will be few million users)
I know that already something like this will be efficient because of primary key indexing: sql SELECT userUUID FROM userIDmap WHERE userID = 12345 however I want this query to also be fast: sql SELECT userID FROM userIDmap WHERE userUUID='0415db9d-83e0-4592-97dc-168f3e72defd'
Just index the column, like create unique index uix_user_uuid on userIDmap(userUUID)
Yes
Pastebin
Pastebin.com is the number one paste tool since 2002. Pastebin is a website where you can store text online for a set period of time.
I want to create a simple database but don't how can i create
A simple database but how can i modify it
i got some solution like use protocolbuffer and snappy and use MurmurHash and use B-trees/hnswlib
And i have one more idea using open ai for embeding my data using text-embedding-ada-002
I am also studying tinydb database
Any advice?
ok! any advice?
don't understand how?
ohho, Ok how can i prevent this!
okay thanks!
ok how it is possible?
U have great knowledge of databases which resources do u follow for databases?
okay!
okay!
Thanks!
Thanks Bro for helping my i will try and learn new concept!
async def start(self, *args, **kwargs):
self.db = await asyncpg.connect(user=user, password=password, database=name, host=host, port=port)
for statement in SETUP_SQL.split(";\n"):
await self.db.execute(statement)
await self.db.commit()```
setup.sql:
```sql
CREATE TABLE IF NOT EXISTS blacklist (
user_id BIGINT PRIMARY KEY,
reason VARCHAR
);
error:
Traceback (most recent call last):
File "c:\Users\Admin\Desktop\Book Verse\main.py", line 79, in <module>
main()
File "c:\Users\Admin\Desktop\Book Verse\main.py", line 75, in main
AvalianBot().run()
File "c:\Users\Admin\Desktop\Book Verse\main.py", line 71, in run
super().run(TOKEN)
File "C:\Users\Admin\AppData\Roaming\Python\Python310\site-packages\disnake\client.py", line 1128, in run
return future.result()
File "C:\Users\Admin\AppData\Roaming\Python\Python310\site-packages\disnake\client.py", line 1107, in runner
await self.start(*args, **kwargs)
File "c:\Users\Admin\Desktop\Book Verse\main.py", line 57, in start
await self.db.execute(statement)
File "C:\Users\Admin\AppData\Roaming\Python\Python310\site-packages\asyncpg\connection.py", line 318, in execute
return await self._protocol.query(query, timeout)
File "asyncpg\protocol\protocol.pyx", line 338, in query
File "asyncpg\protocol\protocol.pyx", line 850, in asyncpg.protocol.protocol.BaseProtocol._dispatch_result
File "asyncpg\protocol\protocol.pyx", line 777, in asyncpg.protocol.protocol.BaseProtocol._on_result__simple_query
AttributeError: 'NoneType' object has no attribute 'decode'
Exception ignored in: <function _ProactorBasePipeTransport.__del__ at 0x0000025EACB0E7A0>
Traceback (most recent call last):
File "E:\lib\asyncio\proactor_events.py", line 116, in __del__
File "E:\lib\asyncio\proactor_events.py", line 108, in close
File "E:\lib\asyncio\base_events.py", line 745, in call_soon
File "E:\lib\asyncio\base_events.py", line 510, in _check_closed
RuntimeError: Event loop is closed```trying to use postgres in my discord bot
for some reason it gives the above error, even though I checked the db and it had executed the statement
Super quick question do I have to manually add foreign keys in a sqlalchemy db
Not sure what you mean by "manually" but the docs may help https://docs.sqlalchemy.org/en/20/orm/basic_relationships.html
I mean with the primary key I don't have to add the it to the db does the same logic apply to the foreign key? Did I explain that better
You need to explicitly define any fkeys, they don't get defined automatically (how could they?)
Thats what I thought I just wanted to confirm thanks
Hey everyone, I am working with mysql-connector for the first time and can't figure out why my query is not being executed, here is what I am trying to do
c1 = connector.cursor()
# add gpa field
c1.execute("ALTER TABLE list ADD gpa float;")
# keep only the students in grades 2, 3, 4
c1.execute("DELETE FROM list WHERE grade NOT IN (2, 3, 4);")
print(c1.fetchone())
the first ALTER command works fine but the DELETE command is doing nothing and the response is None I tried doing the exact same command on the mysql server directly and it works so I don't think the query is wrong. Anyone able to help me out here?
according to documentation, autocommmit is off by default so you need to call connector.commit() once you're finished with your transaction
https://dev.mysql.com/doc/connector-python/en/connector-python-example-cursor-transaction.html
This fixed it, thank you so much
hey guys can I get some help making sure I'm not overthinking the definition of a database schema?
From what I understand, it's a representation of the layout of a database.
I use a MySQL Database with python
My Connection gets overloaded easily
This is my python code:- https://github.com/Adnan-Jindani/cryptoPlay/blob/main/main.py

GitHub
Contribute to Adnan-Jindani/cryptoPlay development by creating an account on GitHub.
Are there any suggestions to make it work better
So that it doesn't get overloaded
Right... Basically the definitiona of the tables, fields and relationships
I guess I'm confused about whether a schema specifically is a blueprint or just the logical idea of the database structure
It can be both. DDL is a concrete blueprint that defines a schema. Don't get too caught up on the terminology, what matters is if you know how to build and use one https://hasura.io/learn/database/mysql/core-concepts/3-schema-ddl-dml/

In this section, we will look at schemas, different types of schema, DDL and DML statements to interact with the MySQL database.
hii, I'm trying to figure out a task and I was wondering if anyone knows how I know the email has already been used when creating a survey, so people don't apply the same email twice!
Thanks, I was really confused.
By checking first to see if the email has been used. You probably want a uniqueness constraint on the DB level.
To get more specific you'll probably need a help channel #❓|how-to-get-help
@fading patrol okii thank you, i will try to ask in the help channel!
Hello everyone one i hope you all good
I have a problem in my programe i devolpe some desktop application using python and i need a host to give me a database i can access it with internet
I need that because i want store in it some subscription information
My programe is have activations code and every code is have spesphic active period and then he has to put another activation code to activate the program
If anyone can help me i Will be appreciated
Am i able to ask for help w/ sql and php in this channel?
SQL yes, PHP no. (Ask php there https://github.com/mhxion/awesome-discord-communities#php )

GitHub
A curated list of awesome Discord communities for programmers - GitHub - mhxion/awesome-discord-communities: A curated list of awesome Discord communities for programmers
I don't do database stuff very often. I was wondering if someone would tell me if this is the right way to do this?
I know that it works... but for example, I am not calling conn.close() and I'm assuming that the with statement is handling that.
I'm also not individually committing changes, but instead committing everything all at once at the end.
def write_records(self, records: List[dict]):
print(f"Preparing to write {len(records)} records")
with sqlite3.connect(self.db) as conn:
for record in records:
print(f"Inserting records for {record['title']}")
c = conn.cursor()
prepared_record: tuple = self.prepare_hack_record_for_db(record)
c.execute(self.read('sql/insert_hack.sql'), prepared_record)
hack_id = c.lastrowid
for author in record['authors']:
c.execute(self.read('sql/insert_author.sql'), (hack_id, author))
for hack_type in record['types']:
c.execute(self.read('sql/insert_type.sql'), (hack_id, hack_type))
for hack_path in record['sfc_files']:
c.execute(self.read('sql/insert_path.sql'), (hack_id, hack_path))
conn.commit()
This looks good. The with statement should handle close, yes
Maybe one suggestion: read the SQL files ahead of the loop
with sqlite3.connect(self.db) as conn:
insert_hack_sql = self.read('sql/insert_hack.sql')
insert_author_sql = self.read('sql/insert_author.sql')
# ...
ah ok
good call
So I'm going to give you a hypothetical. Lets say that function is passed 2000 dicts to be entered as records, and on dict number 1208, there is an error.
Does it rollback every attempted c.execute()?
because the commit happens at the end?
Yes
Morning all. I'm struggling a bit trying to understand the SQLAlchemy documentation for working with async connections. I've got to a stage where I can read/write asynchronously, but am now struggling to work with some of the data in the database using pandas. I'm trying to recreate what I found here https://pythonspeed.com/articles/pandas-sql-chunking/ to work with the async engine. Anyone have any experience with this?
Unless you use autocommit, of course
Thanks I'm not 100% sure what is more desirable yet. Once I do the initial entry of data there should never be a large quantity entered at once again for this project.
You could use AsyncSession.stream or stream_scalars
That's what someone on another channel here said as well - I've been looking at it, but I'm not quite sure how to combine that with pandas to_sql() function like they've done in that article. My experience working with db's is limited, sorry
I don't think you can use async sqlalchemy with pandas 🤔
But I don't work with pandas, so I'm not entirely sure
Async support in sqlalchemy is relatively new, so pandas may not support it
Most of my limited experience with databases is Django apps, and then I end up putting a lot of effort into something that no one ends up using and that is pointless to keep running 😂
My latest app idea benefits from the ability to do complex selection queries tho... even if no one else is using it but me, and its just a local app, it benefits a lot from the sqlite3 structure.
I considered trying SQLAlchemy since most of my background is working with Django ORM, but I quickly kind of decided to just go with manually writing sql. While I have written SQL to do selections on an existing database this is the first time i created all the tables and insertions with it.
It's pretty simple, these are my tables
CREATE TABLE hacks (
id INTEGER PRIMARY KEY AUTOINCREMENT,
title TEXT NOT NULL,
page_url TEXT NOT NULL UNIQUE,
is_demo TEXT NOT NULL,
is_featured TEXT NOT NULL,
exit_count INTEGER NOT NULL,
rating REAL NOT NULL,
size REAL NOT NULL,
size_units TEXT NOT NULL,
download_url TEXT NOT NULL,
downloaded_count INTEGER NOT NULL
);
CREATE TABLE hack_types (
hack_id INTEGER NOT NULL,
type TEXT NOT NULL,
FOREIGN KEY (hack_id) REFERENCES hacks(id) ON DELETE CASCADE
);
CREATE TABLE hack_authors (
hack_id INTEGER NOT NULL,
author TEXT NOT NULL,
FOREIGN KEY (hack_id) REFERENCES hacks(id) ON DELETE CASCADE
);
CREATE TABLE hack_paths (
hack_id INTEGER NOT NULL,
path TEXT NOT NULL,
FOREIGN KEY (hack_id) REFERENCES hacks(id) ON DELETE CASCADE
);
and this is how I select it right now.... tbh this code is kinda confusing to me but it does what I want so.
SELECT hacks.id, hacks.title, hack_paths.path, hacks.rating FROM hacks
JOIN hack_paths ON hacks.id = hack_paths.hack_id
JOIN hack_types ON hacks.id = hack_types.hack_id
WHERE hack_types.type LIKE '%Hard%'
AND hacks.rating > 3.9;
the sad thing is... I forgot to include the dates on the records, so I have to write some type of migration code to add them 🤡
I actually have no idea how to do migrations without Django tbh
im trying to implement an buff system for a game and so far in my postgres database i have a modifiers table which has two fields, apply_on: varchar(20) (when to apply the modifier) and effect: varchar(20) (what the modifier should do). right now i have a check constraint on apply_on which makes sure that an entry to this table will match an event like start, on_attack, etc. but im stuck on how i should handle effect.
the behaviour of effects have to be programmed in the server at some point, and what ive thought of so far is having effect soft reference a function that i've programmed in the server and have no constraint within the database, which does work, but doesnt seem like an elegant solution . i could also constrain effect like i do with apply_on, but having to update it every time i add a new effect to the server doesnt seem much better.
any advice? am i even taking the right approach here?
Is there anyway to do a select on a list of values? For example if i have a list of colors [Red,Green,Blue[ can i do a select for all entries that have one of those in the color column? I'm using pgadmin 4 as well
Hopefully that field is in a JSON or JSONB field? Haven't done this in a while but that's what it's meant for https://stackoverflow.com/questions/22736742/query-for-array-elements-inside-json-type
Stack Overflow
I'm trying to test out the json type in PostgreSQL 9.3.
I have a json column called data in a table called reports. The JSON looks something like this:
{
"objects": [
{"src":"foo.png"},
...
Thank you
Is there any db to store a small amount of data like if a button was on or off , or small string values.
I want a minimalistic db, should I just use env
you can‘t persistently save values in env
just use sqlite, or some file you format yourself
Json/Yaml could be a good choice if it doesn't change often
If you need to save something for gui then why not simply store it in memory? 🤔
well the user might not want the settings to reset everytime
I think sqlite or a json/yaml could be a good choice
anything to encrypt it ?
encode?
I want to connect to my azure key vault to get secrets, every single tutorial on this ive found uses environment variables for tenant-id, client-id and client-secret. i can't use those, because my python file has to be run from the azure storage account. any ideas on how to tackle this?

„has to be run from the azure storage account“ what do you mean by this?
i want to run this as a batch job through the ADF pipeline
I see, you probably want to use Managed Identity then: https://learn.microsoft.com/en-us/azure/data-factory/data-factory-service-identity
Learn about using managed identities in Azure Data Factory.
https://learn.microsoft.com/en-us/azure/data-factory/store-credentials-in-key-vault I think this documents exactly what you need
Learn how to store credentials for data stores used in an Azure key vault that Azure Data Factory can automatically retrieve at runtime.
okay ill check it out thanks
u could just enable autocommit also if ur opening a cursor using with statement yeah that is handled
I am trying to make a "POST" from PostMan and it gives me an error in the console, I see that I also have an error in the database connection as you can see in VS but the server is running on port 5000
Does anyone know what I could be doing wrong? I leave the link of the repository and attach the images.
I am copying the code from the following video: https://www.youtube.com/watch?v=S6Yd5cPtXr4&t=1700s

Node.js E-Commerce App with REST API | MongoDB | Advanced Authentication
In this video, we'll be building an e-commerce app in Node.js with a REST API and MongoDB. We'll be using advanced authentication with a JSON web token and the mern stack. This will be a comprehensive guide that will teach you how to build an e-commerce app from scratch.
...

GitHub
Contribute to LautaroBacega/backendError development by creating an account on GitHub.



Hey guys real quick, is anyone able to spot the issue here? It says i'm giving two positional arguments but I don't see how thats the case:py next_task = await cur.fetchone('SELECT * FROM raffles WHERE NOT completed ORDER BY timeLeft LIMIT 1') #error TypeError: Cursor.fetchone() takes 1 positional argument but 2 were given
because ur sql statement shoudlnt be there
suggest u read the docs or look at an example
fixed the issue, didn't realise i'd swapped execute and fetchone, you could have just said that- but what can you expect from unsociable coders 💀

So I was working on this piece of code here the other night, the storage object is using SQLAlchemy, and the set task was to retrieve a list of Place instances within a given list of States and Cities if defined or all Place instances if otherwise; then to filter the results to only include Places that has a matching list of Amenities if defined.
The snippet from the image attached, ended up mashing Amenity instances with the list of Place I was working with, I had no idea how it happened but I would like to know WHY?
Everything works as expected until the if block where I checked if any intersections exists between Place.amenities and a_filter amenities.
I tried to inspect what had happened, when I learned that somehow a list of Amenity instances was added as a property of the very last Place instance on the list, which is weird.

Before if block >>>
[Place] (df2548db-377d-422e-b805-4e8e0c794302) {'_sa_instance_state': <sqlalchemy.orm.state.InstanceState object at 0x7f200de95a20>, 'name': 'City view, Central location, Quiet', 'description': 'Room is next to kitchen with 2 Pocket doors that open/close the space off. Private bedroom(Daybed with Trundle), private bathroom(5 steps down hallway), shared balcony, living room(has sleeper sofa) and kitchen. Basic cable, 200mb internet, pool, sauna, gym, 7 min to Downtown, 17 min to Galleria Mall, 7 min to i65, i35 and i20, gorgeous city view<BR /><BR />Daybed will sleep one and pull out trundle will sleep 2nd person, Dresser, drawers in Armoir, and closet for storage, Iron and ironing board in closet with hangers, Blowdryer in bathroom under sink.<BR /><BR />Pool, sauna, Gym, basic cable, high speed internet<BR /><BR />I may or may not be home. Most likely guests do not really see me I try to stay out of the way, Remy has free roam of place so you will see him more than me. He is friendly and does not bite, but will try to get snuggles and pets.<BR /><BR />Close to everything, inbetween a transitioning neighborhood, gas station down the street (shell) and a chevron ', 'number_bathrooms': 1, 'price_by_night': 55, 'longitude': -86.8143, 'created_at': datetime.datetime(2017, 3, 25, 2, 17, 6), 'user_id': '61302be9-4b31-4be0-92fc-d0dda253e167', 'city_id': 'f14fefb3-c6e4-42f6-8a5a-ee704a101f8b', 'number_rooms': 1, 'max_guest': 2, 'latitude': 33.4796, 'id': 'df2548db-377d-422e-b805-4e8e0c794302', 'updated_at': datetime.datetime(2017, 3, 25, 2, 17, 6)}

After if block >>>
[Place] (df2548db-377d-422e-b805-4e8e0c794302) {'_sa_instance_state': <sqlalchemy.orm.state.InstanceState object at 0x7f200de95a20>, 'name': 'City view, Central location, Quiet', 'description': 'Room is next to kitchen with 2 Pocket doors that open/close the space off. Private bedroom(Daybed with Trundle), private bathroom(5 steps down hallway), shared balcony, living room(has sleeper sofa) and kitchen. Basic cable, 200mb internet, pool, sauna, gym, 7 min to Downtown, 17 min to Galleria Mall, 7 min to i65, i35 and i20, gorgeous city view<BR /><BR />Daybed will sleep one and pull out trundle will sleep 2nd person, Dresser, drawers in Armoir, and closet for storage, Iron and ironing board in closet with hangers, Blowdryer in bathroom under sink.<BR /><BR />Pool, sauna, Gym, basic cable, high speed internet<BR /><BR />I may or may not be home. Most likely guests do not really see me I try to stay out of the way, Remy has free roam of place so you will see him more than me. He is friendly and does not bite, but will try to get snuggles and pets.<BR /><BR />Close to everything, inbetween a transitioning neighborhood, gas station down the street (shell) and a chevron ', 'number_bathrooms': 1, 'price_by_night': 55, 'longitude': -86.8143, 'created_at': datetime.datetime(2017, 3, 25, 2, 17, 6), 'user_id': '61302be9-4b31-4be0-92fc-d0dda253e167', 'city_id': 'f14fefb3-c6e4-42f6-8a5a-ee704a101f8b', 'number_rooms': 1, 'max_guest': 2, 'latitude': 33.4796, 'id': 'df2548db-377d-422e-b805-4e8e0c794302', 'updated_at': datetime.datetime(2017, 3, 25, 2, 17, 6), 'amenities': [<models.amenity.Amenity object at 0x7f200dea4a30>, <models.amenity.Amenity object at 0x7f200dea7190>, <models.amenity.Amenity object at 0x7f200dea5000>, <models.amenity.Amenity object at 0x7f200dea5ed0>,
...
<models.amenity.Amenity object at 0x7f200dea6bc0>]}

Hi Guys!
Is it better to have a database open throughout my app for like 3 uses
or is it better to open and close it each time?
if you do these operations in succession without doing much other between them, it can be fine to reuse the connection
if you do anything else unrelated to the database between these operations, close and reopen
Hey guys, I have a ORM class in sqlalchemy for a table, and i was wondering if I could reuse it for a second table that has the exact same columns and types, the only difference is ofc the table name. Is this the correct way to do it?
class Base(DeclarativeBase):
pass
class Table1(Base):
__tablename__ = 'test1'
id = Column('id', INTEGER, nullable=False)
title = Column('title', VARCHAR(255), primary_key=True)
class Table2(Table1):
__tablename__ = 'test2'
I don't think you can use it this way, you need to create a base class in this case
Also use sqlalchemy v2
is this not v2? and what is the major difference between the two
class Table(Base):
__tablename__ = "test"
id: Mapped[int]
title: Mapped[str] = mapped_column(String(255), primary_key=True)
Also weird that you have an id which is not a primary key and title primary key
oh so basically the typed mode
I just checked, I'm actually using version 2
I might use that in the future. does the linter recognize the types when youre instantiating the ORM class or when youre filtering in the query?
Yep, it would work with execute and scalar(s)
# (variable) stmt: Select[Tuple[str, int]]
stmt = select(str_col, int_col)
# (variable) stmt: ReturningInsert[Tuple[str, int]]
ins_stmt = insert(table("t")).returning(str_col, int_col)
no way
thats actually pretty sick
will defintely use it in the future, thanks for letting me know @paper flower
btw, if I have a JSON column, can I create a new record by any iterable/mapping, or does it have to be exactly either a list or dict, which is what json.dump would accept?

PK should be where the PK should be
the employee ID column would be PK in the employee table
so is the table correct?
Which db do you guys use mostly? Been using mysql for as long as i remember, but been thinking about switching to sqlite since most of my work is <=10,000 records and that's being way too generous
choose whatever database is appropriate for your use case, and use case depends on more than just row count
#databases message
for me ive used sqlite a lot for local application data
Is sqlite bad on servers?
What are the factors to consider when picking a database?
As far as I'm concerned, only size matters.
sqlite over a network drive is not exactly reliable https://sqlite.org/useovernet.html, though if you're willing to write a webserver on top of it (i.e. using sqlite as a server-side database) it'll work fine
see also https://sqlite.org/whentouse.html
Nah, if it's not reliable I'll just pick something else or stick to mysql
What do you personally prefer? Need a new db to use with fastapi
If you're used to MySQL, why change? Does it have a limitation you're trying to get around?
(I personally use Postgres which seems roughly comparable)
Not realitime. I hate sending a request every 5 seconds to my api just to get the same response.
i cant answer that question since ive only worked with mariadb and postgresql once for pet projects, of which the former was my only choice and the latter was with fastapi+sqlalchemy but i stopped halfway after getting the docker configs right
Postgres + sqlalchemy works perfectly
can you show me how to make a one to many relationship database with sqlite3?
i know what it is just don't know the syntax
I googled it for you https://stackoverflow.com/questions/7541595/how-to-create-one-to-many-in-sqlite3
Stack Overflow
How to create one to many in SQLITE3?
I have 2 tables:
Mans:
_id name
1 antony
2 fred
and
point
_id date point
1 23 77
24 99
2 25 78
5...
mmm
so is this valid
cur.execute("CREATE TABLE person(id INTEGER PRIMARY KEY NOT NULL, name VARCHAR, age INT)")
cur.execute("CREATE TABLE condition(id INTEGER, condition VARCHAR, FOREIGN KEY(id, condition) REFERENCES person)")
?
Looks fine to me, try it and find out
seems to work
just wanted to make sure
Dosn't look correct to me. You are refererencing non existant column: condition is not a column in person.
Maybe you want:
cur.execute("CREATE TABLE condition(id INTEGER NOT NULL, condition TEXT, FOREIGN KEY(id) REFERENCES person(id))")
and I normally use the table name for the FK column:
cur.execute("CREATE TABLE condition(person_id INTEGER NOT NULL, condition TEXT, FOREIGN KEY(person_id) REFERENCES person(id))")
and VARCHAR is TEXT in sqlite.
so... i made a docker container... i try and do localhost, default port for postgres... when i try and add it in pgadmin i get this error...

Check the docker logs and/or attach to the container to make sure it's running. If nothing obvious there, maybe try 127.0.0.1 instead of localhost.
did you forward the default port when you created the container? The command flag is -p 5432:5432
docker run --name postgres-db -e POSTGRES_PASSWORD=docker -p 5432:5432 -d postgres
this is what i went off of for the test db
What happens when you type in psql -h localhost -U postgres and enter the password?

it just works... ;.;
im so confused.
thats good you can connect! must be the connection config in pgadmin then
so... something in the preferences? or what?
it's a fresh install so idk what it could be
hmm maybe you need to specify the exact ip that the docker container is running in pgadmin.
hmmm ok...
you can find this using docker inspect <container name>
Got permission denied while trying to connect to the Docker daemon socket at unix:///var/run/docker.sock: Get "http://%2Fvar%2Frun%2Fdocker.sock/v1.24/containers/postgres-db/json": dial unix /var/run/docker.sock: connect: permission denied
try sudo. Is your user a part of the docker group?
I legit just was going through this step-by-step, but after i ran that line that was docker run ...
it just wouldn't do anything. I thought it was just a few steps. install docker, install postgres image, install pgadmin4. create an image, create an instance and boom, theres a db I can make and interact with.
https://dev.to/andre347/how-to-easily-create-a-postgres-database-in-docker-4moj

DEV Community
Have you ever had the problem where a tool or a piece of software works fine on your machine, but the moment you install it on someone else's you get all kinds of issues? Well, I have, and particularly for this reason Docker was invented! In this blog post we will take a quick look at what Docker is and how easy it is to run a database in a Dock...
hi, just started with database in general and I am using aiosqlite, can I use params to change which table name am I searching for? like db.execute('SELECT * from ?', (table_name,))
hey all 👋 I'm new (or at least I'd like a reminder) about the best tools to handle database migrations in Python. I'm using sqlalchemy to connect to the database
if you are already using sqlalchemy with ORM, then alembic is a pretty common choice.
heck even if you aren't using the ORM part of sqlalchemy, alembic is still pretty decent. i don't have much pain point when working with alembic.
are there any good examples of caching at the ORM level? e.g. something that sits between an API and the client when the interface returns lists of objects
okay thx you ! will have a look
oh a fellow ryan 👋
i am a little confused, your example and question doesn't seem to agree with each other.
"caching at the ORM level" seems to imply caching that happens internally in your application.
"something that sits between an API and the client when the interface returns lists of objects" seems to imply a cache like so:
your code <-> API <-> (THE CACHE) <-> client
which one are you interested in?
in general caching is a really really tough task, without a good description of the problem, i wouldn't even know how to begin to evaluate where the footguns are
its a tough problem, and its why I'm trying to work out the architecture a bit 😄
Web API with a rubbish rate limit -> Cache -> Client
Its for a consumption role, which barely any examples seem to cover well,
I've been slowly working out the details, currently all of my functions for grabbing data off the API return pydantic models that I am slowly converting to SQLModel ones (think SQL_Alchemy with Pydantic validation)
But I'm struggling with some of the concepts like partial cache hits, where I say have part of the data I need, and other related structural details

most of it is historical data relating to vehicles, e.g. positions, and other trip data, that reports run against, anything that doesnt need to be cached will be skipping the layer
oh understood. i just assumed you manages the API but that's not the case.
- what API is this?
- how do you currently know an entity is stale and should be re-fetched?
- what does partial cache hits look like in this case in your opinion?
API is for a telematics company, Its documented, and I have that layer complete,
Rate limit is 1 request per 30 seconds
Cache entries are not really stale, historical data doesnt change over time, for the small subset, e.g. a rego plate, or odometer, they have stored in there table a last requested time,
for the more historical data, so far I've been storing an extra table against each vehicle with the list of timespans (start and end time), that the data has been requested for,
A partial cache hit might be, say I'm running a daily report on something, I have out of the last 24 hours, the last 23 cached, and will need to request that last hour,
for the timespan stuff I've been trying to build a worker that slowly adds requests to the API queue to fill gaps and update that table to merge overlapping records
seems like u should have a intermediate database from which the reports run from?
that might be the better architecture, being new to this, I was treating it as the cache layer 😄
cache makes me think of redis which is when speed is required but doesnt seem like thats what u need
u just need somewhere to store the data from the api due to rate limit calls
ah okay.
i know this isn't the answer you are looking for, but something i would do first is try to contact the owner of the API and see if they have other way of dumping the data you need in other more suitable means if the API limit is that rubbish
failing that, maybe VCR (https://vcrpy.readthedocs.io/en/latest/) is of interests, ultimately you are trying to cache API responses (what you do downstream is your business logic, which could be changed, as such you should cache as upstream as possible imo), this library is fits that bill perfectly
I'll have a go through it, why I wanted to do it at the Object layer and not the request layer was so that I could try and be smarter about what I was requesting, if I was requesting the last hour every hour, it would take about 50 minutes in requests 😄 so I'm doing my best to be smart about it to request bigger chunks less often,
Sadly this is as fast as they offer, Its just I'm in a weird use case where normally someone would be requesting for maybe 100-300 vehicles, I'm requesting for about 7000,
Thanks for the suggestions
Hey i need some help with mysql. I use Planetscale and i want to connect to the db in vscode
hmm seems like there is more complexity that I originally thought. Happy to help via DM or you can try #1035199133436354600
has anyone used pythonAnywhere to run a script remotely? I have a scraping script i need to run, but will not be my computer everyday. Any advice is appreciated
okay, and whats the error?
I am not my computer everyday either. Or any day. So I'm not sure what you mean by that 😉
Scraping may require outbound access PA doesn't provide, especially free tier. It might also be considered abuse.
You might want a proper VPS, there are plenty of free options, mostly on a trial basis but I think Oracle's is permanent.
Hey guys QQ, when working with SQL, if i have an AUTOINCREMENT column, do I still need to include it in INSERT INTO statements? Like here:py INSERT INTO raffles(''' ID, username, winnerID) VALUES (?,?) ''', (username,winnerID))
||CHECK||
Hello, anyone around who's brain I could pick on incorporating composition in to a SQLA polymorphic hierarchy?
Hello i got this error
https://paste.nextcord.dev/?id=1683457131347176
I googled it for you https://stackoverflow.com/questions/74830570/planetscaledb-prisma-setup-server-does-not-allow-insecure-connections-client
Stack Overflow
I am starting a brand new PlanetScale backed project, with a Prisma setup. I followed the instruction on this official documentation (aside from changing the name of the database) and after locally
Looks like you're on AWS so details may vary but the meaning of the error is clear
In the meantime i got this error
csl = ssl.SSLContext(ssl.PROTOCOL_TLS_CLIENT)
csl.load_verify_locations(cafile={"ca": "/etc/ssl/cert.pem"})
loop = asyncio.get_event_loop()
async def connect_db():
connect = await aiomysql.connect(host=os.getenv("HOST"),
user=os.getenv("USERNAME"), password=os.getenv("PASSWORD"), db=os.getenv("DATABASE"), loop=loop, ssl = csl)```
And this short error appears:
```Traceback (most recent call last):
File "C:\Users\domin\AppData\Local\Programs\Python\Python310\lib\site-packages\nextcord\client.py", line 490, in _run_event
await coro(*args, **kwargs)
File "c:\Discord\Maja Projekt\Maja-Beta\bot.py", line 62, in on_ready
csl.load_verify_locations(cafile={"ca": "/etc/ssl/cert.pem"})
TypeError: cafile should be a valid filesystem path```So, is that a valid filesystem path? If yes, probably a permissions issue
Seems unlikely given that you have a Windows path in there too, and that's a POSIX path
I dont know how i get the right path
Wherever you put your cert.pem file
I dont know
Can't help you there. Seems like you just copied sorry code from somewhere? May need to read a tutorial and/or basic documentation to understand how to connect to your database
Nope, I went by the docs
I dont know much about ssl
But you don't know what certificate you need to connect to your DB? If you didn't save one you may need to create it again
If this is not already present in Windows
No, you need to generate a pair. This is how it would normally work if you were self-hosting: https://dev.mysql.com/blog-archive/simplified-ssltls-setup-for-mysql-community/
Not sure if you need a different approach for AWS, but probably
I just use an python bot
Meaning you're just running some code you didn't write? Talk to the developer then
I wrote it myself 😮💨
Like i said i dont know much about ssl
suggestion needed. planning to make a database that will store information about two types of users, a 'company' user, and a 'market' user. they both can login but have different data. what's the best way to design such db, separate their tables and add the username and password fields for each table or just create a third table that stores the login info?
itching to do the latter.
I worked with Aiosqlite and now switched to mysql
And you set up a MySQL database on AWS it looks like?
PlanetScale
It depends on the specific fields you need
I would probably seperate the tables, and have the userId in a 3rd table directing which table to call from for that user?
also means market and company can have different feilds if required?
yeah, thought about it and that sounded the most reasonable. i will just add a field that indicates whether a user is a company or a market.
I use aiomsql
how does this db look for a market ordering stuff from a company look?

Based on that, doesn't seem like separate tables for markets and customers makes sense. You could just have a table for contacts since that's really what you're putting there currently
Also, if you haven't checked for examples you can just reuse, there are a lot. Here's an example: https://www.mysqltutorial.org/mysql-sample-database.aspx
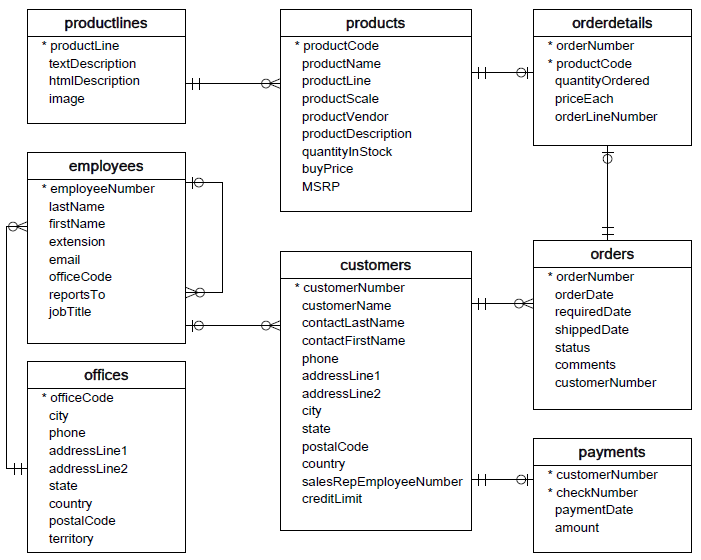
MySQL Tutorial
This page provides you with a MySQL sample database that helps you to practice with MySQL effectively and quickly. You can download the sample database and load it into your MySQL Server.
@fading patrol Where can I get the certificate from?
a need a MySQL developer to help me please
Don't ask to ask
hi there , guys does anybody know anything about (ARPO) in data and marketing?
@peak lion this tells you how to get the certificate
I dont get it
Im not asking for asking, i just need help to setup one thing un my discord bot with MySQL
Please DM me if you're familiar with postgres, I'm getting an error and I need help with it
just ask here LOL
@timber mason

Can the foreign key be mandatory or optional? For further details I have 2 tables User and Payment . Payment contains the foreign key. The reason I asked the original question is because Payment table allows donations. I want non logged in user to donate. Is that a good idea?
Please ping me on reply.
@torn sphinx check if the you are allowing the port and exposing the port
@torn sphinx https://dykraf.com/blog/how-to-connect-pgadmin4-and-postgresql-server-on-docker-container

Dykraf
Doing Web Development on a local machine requires multiple applications running together. Docker provides an os level virtualization on the host machine to have
Stack Overflow
I have created an ubuntu image with nginx, php and postgres.
I want to connect the postgres database in my current image with pgadmin located on my local machine.
I have tried using docker inspe...
I googled it for you. The TLDR is that it's probably ok. https://stackoverflow.com/questions/1723808/nullable-foreign-key-bad-practice
Stack Overflow
Let's say you have a table Orders with a foreign key to a Customer Id. Now, suppose you want to add an Order without a Customer Id, (whether that should be possible is another question) you would h...
:incoming_envelope: :ok_hand: applied timeout to @torn sphinx until <t:1683548163:f> (10 minutes) (reason: duplicates spam - sent 4 duplicate messages).
The <@&831776746206265384> have been alerted for review.
How do i make db classes
What do you mean by "db classes"?
Well I was told that this is clearer instead of reading out the db in every command
Got it .. you want to use an ORM. SQL Alchemy is most popular overall. If you want something a little simpler for a basic project, check out peewee
Django also has a good ORM built in if you want to use that
I didn't understand certain abbreviations xD
Right, I'm telling you what to look into, you can read what they are
This shows how peewee works: http://docs.peewee-orm.com/en/latest/peewee/quickstart.html#quickstart
What is ORM
You can Google that as well as I can, but it does exactly what you asked
You use its classes instead of putting raw SQL in your Python
class StartUpDB:
def __init__(self) -> None:
self.db = mysql.connector.connect(
host=os.getenv("HOST"),
user=os.getenv("MEMBERNAME"),
password=os.getenv("PASSWORD"),
database=os.getenv("DATABASE"))
self.cursor = self.db.cursor()
self.cursor.execute('''CREATE TABLE IF NOT EXISTS setup (
guild_id INTEGER,
admin_role INTEGER,
moderator_role INTEGER,
supporter_role INTEGER,
log_channel INTEGER,
global_channel INTEGER,
language TINYTEXT
)''')
self.cursor.execute('''CREATE TABLE IF NOT EXISTS moderation (
guild_id INTEGER,
user_id INTEGER,
warned_by INTEGER,
last_edit_time INTEGER,
last_edit_by INTEGER,
date INTEGER,
reason TINYTEXT,
case_id INTEGER
)''')
self.db.commit()
class SetupTable:
def __init__(self) -> None:
self.db = mysql.connector.connect(
host=os.getenv("HOST"),
user=os.getenv("MEMBERNAME"),
password=os.getenv("PASSWORD"),
database=os.getenv("DATABASE"))
self.cursor = self.db.cursor()
#await cursor.execute('SELECT guild_id FROM setup WHERE guild_id = ?', (inter.guild.id,))
def query_guild_setup_table(self, guild_id):
self.cursor.execute('''SELECT guild_id FROM setup WHERE guild_id = ?''', guild_id)
output = self.cursor.fetchone()
return output[0]```
@fading patrol is this right?You have a bunch of raw SQL there. If I understood what you're asking, then, no, you are using raw SQL instead of Python classes to create your tables
@fading patrol Thanks
Hi, how i create a deck builder for yugioh card search database? I have a card database in mysql
do you need help crafting queries?
CREATE TABLE Car
(
Pk_Car_Id INT PRIMARY KEY,
Brand VARCHAR(100),
Model VARCHAR(100)
);
CREATE TABLE Engineer
(
Pk_Engineer_Id INT PRIMARY KEY,
FullName VARCHAR(100),
MobileNo CHAR(11),
Fk_Car_Id INT FOREIGN KEY REFERENCES Car(Pk_Car_Id)
);
INSERT INTO Car ('Brand','Model')
VALUES ('Benz','GLK350');
INSERT INTO Car ('Brand','Model')
VALUES ('Toyota','Camry XLE');
INSERT INTO Engineer ('Pk_Engineer_Id','FullName','MobileNo','Fk_Car_Id')
VALUES(50,'Elvis Young','08038888888',2);
INSERT INTO Engineer ('Pk_Engineer_Id','FullName','MobileNo','Fk_Car_Id')
VALUES(51,'Bola Johnson','08020000000',1);
INSERT INTO Engineer ('Pk_Engineer_Id','FullName','MobileNo','Fk_Car_Id')
VALUES(52,'Kalu Ikechi','09098888888',1);
INSERT INTO Engineer ('Pk_Engineer_Id','FullName','MobileNo','Fk_Car_Id')
VALUES(53,'Smart Wonodu','08185555555',1);
INSERT INTO Engineer ('Pk_Engineer_Id','FullName','MobileNo','Fk_Car_Id')
VALUES(54,Umaru Suleja','08056676666',1);
SELECT * FROM Car;
SELECT * FROM Engineer;
is this how you would insert data for a one to many relationship?
Hi can anyone help me with a data structure i want for my mysql table.
The table name is groupstorage and stores guild id + group id and other configuration but isnt relevant, inside of a row that stores a set of that data for a server i want to store or verified users in that server.
Basically a table in a row
you could use a json column or create another table for users that has a one to many relationship with groupstorage
Sounds like you want an fk pointing to another table
Is there an Oracle discord server or help place?
wdym by 'is this how you would insert data for a one to many relationship?'
well i have a database with two tables having a one to many relationship
i want to insert data in it
is this how you write the query
can anyone tell me why i'm getting this error in my asp.net mvc identity framework application?
InvalidOperationException: Cannot create a DbSet for 'IdentityUser' because this type is not included in the model for the context.

i don't think anybody can help you with that here since it's a python community
Yes, engineer to car is one-to-many many here
You can easily google that error: https://stackoverflow.com/questions/46761397/invalidoperationexception-cannot-create-a-dbset-for-role-because-this-type-is
Maybe that helps?
I realized it's because i overwrote the onmodelcreate or whatever it's called of the dbcontext class
made a separate one for identity which i left alone and all is well
can anyone help with sqlite?
Don't ask to ask, just ask. #❓|how-to-get-help
General Spark Cluster Architecture
The most important thing to reenforce is that in Spark, things run in in parallel before getting aggregated together at the end.
The driver context is You. It runs the users function and executes the various parallel operations on the worker nodes.
The Cluster Manager is responsible for distributing the processing to the various worker nodes.
The worker nodes read and write data from/to data sources. They also cache transformed data in memory as RRDs (Resilient Data Sets).
Worker Nodes and the Driver Node execute as VMs in the public clouds (AWS, Google and Azure).
Is this accurate, and dose this make sense?
where would be the most relevant tab to ask about a webscraping task using API, SQL ?
Start wherever you like but web scraping gets touchy with rule #5
Check your PM
Hi, does anyone know proven ways to migrate data? I am using fastapi/sqlalchemy/postgresql. I have two databases: prod and dev. I would like to perform data modifications on the dev environment, and finally create a migration that changes the database on the prod environment. I don't want to do a dump every time, but I would like to have easy access to each version of the database. I wanted to use alembic, but I've only dug up information about the ability to perform database schema migrations, and I mainly care about just data changes between versions of the application. Does anyone know any ways, approaches or tools for this problem?
if raw SQL in your migration script is an option. Get connection by conn = alembic.op.get_bind() then run the SQL by conn.execute(["YOUR-SQL-SYNTAX"]) . AFAIK alembic focuses on schema migration and might not be able to automatically generate the raw SQL part from high-level ORM model (you need to add them manually).
Hello! I am trying to deploy my db using render.com. But When i'm trying to connect it to my postgres db created with psequel it shows me this error: unable to conect to the server: connection timeout expired. May someone help me please with this?
Make sure you have the hostname, port and other details correct and you're not behind a firewall or something that's blocking you. Beyond that you would need to ask Render what's wrong
Alembic migrator is integrated natively with Sqlalchemy
Well, alembic is exactly for SQL data changes / migrations between application versions.
SQL scheme migrations and data changes are supposed to be synonym at some point
Or at least nothing prevents using alembic for more necessary data changes than just schema migrations
As long as it is for application version migrations of anything SQL related, it is still intended usage i think
@keen minnow erm something like that maybe?
See this is what I was asking about.
I'm facing something similar but it seems like it breaks down into a lot of different types of approaches, for me a beginner to databases chose to split the historical write once data from the slow to change data, and I have a change log table of sorts on that slower table so I can roll forward or back any changes?
So my own feeling is its quite dependant on the implementation to do partial merges without more throught on locking and safely handing the transfers?
it depends on the scale of the application and DB as well as the architecture of your app.
There are various ways to go about it, from a stop-the-world-and-migrate, all the way to migrating gradually by writing to both versions.
Great! It may help to give more details about the context, your problem, what you are trying to achieve and where you are at.
@keen minnow I'm trying to make a card database that display as page for each cards on my website and deck builder also those deck builder can be categorized by deck type
You could plan out the database schema and draw a diagram first, or you could just start writing code. Have you made it that far?
What do you have so far? What is the problem? What is stopping you?
Well, I have a database but I dunno how to make it display on my website and btw I'm using wordpress
oh I don't know enough about wordpress to know how to hook it up to a custom DB.
You may want to try in #web-development
@keen minnow oh ok, thanks
is this valid sqlite3?
Hey, on my Mongo DB Atlas database, I have a document in which I store IDs
How would I add another banid2 here for example?
update_one only changes an existing one can't add a new one

I haven't done it but I think you need to insert as an array (that banid1 looks like a string) the you can use push. https://www.mongodb.com/docs/manual/reference/operator/update/push/

{kind=link}
I figured it out, I just had to use update_one() a little differently

anyone here who uses SQLAlchemy on a regular basis?
I'm trying to use a SQLAlchemy DeclarativeBase inherited class, mixed with MappedAsDataclass. Is there such a thing as post__init() like in regular dataclasses? I know I can have a mapped_column(init=False, default=some_function) as a field, but the default gets triggered only when saving to the database. I'd really like the objects to have attribute values set to the default value when instantiating them, instead of when being dumped to the database. Am I missing something?
I used sqlite before for my small webapps but as i'm going forward i got to know about postgresql database
but as a sqlite user i'm confused with this
Like in sqlite we create new files for each of project as database but in psql it's single server which listens on port 5432 and idk why but it seems like i'm doing it wrong
What i want to know is How are we supposed to work with postgresql database for creating/development new webapps (not for production)
I would appreciate any help
The short answer is that you must create a development environment. So that would mean duplicating the production database ( or part of it ) to a development one. Im not familiar with postgres itself but you can usually install a copy on your dev box and take full dump or a few tables by doing a export select as CSV or TSV. to load it into your dev db
If i understand correctly you want to have each of the fields to be programmatically set before saving to db? If so can use the __init__ function to do that..
class File(Base):
__tablename__ = "files"
id = Column(Integer, primary_key=True)
name = Column(String(200))
state = Column(String(60))
cwd = Column(String(200))
def __init__(self):
self.state = "init"
self.cwd = str(Path(".").resolve())
row = File()
row.name = blah
in this case perhaps you want to record the current dir or any other state.
You could create multiple logical databases in single postgres instance, but for large systems it wouldn't be that desirable 🤔
hey whats that first column without any name with counting? is it made by sqlite or its a feature of sqlite vscode extension?

haoe
a feature of sqlite vscode extension?
Looks that way to me. I suspect if you use any other tool to view your DB, you won't see it
alright thanks
Is it possible to both read from and write to a .txt file placed in a folder on my website?
I can give read/write permissions to this file.
I have successfully read data from this file - but my attempts to write to it results in call back error "no such file or directory"
My code:
url = "mysite_actual_url"
with open(url, 'w') as file:
file.write(data_to_write)
Any help appreciated
You may not have file permissions, or you may be unable to read and write at the same time. In any case there is probably a better way to do whatever you are trying to do
What happens when i store a value as a small int in postgres as the max value but then on accident add one to the max value? does postgres throw some error up or is there some weird things happening at this point?
I would guess it throws an error, but why don't you just try it and see?
I won't be able to do so until much later today and so I was hoping someone might know
Error message, something something out of range
not sure which database driver to use with create_engine of sqlalchemy for mysql!?
also, does anyone know if there are any sqlalchemy discord servers?
I've never done it, but presumably the official connector? https://dev.mysql.com/doc/connector-python/en/connector-python-example-connecting.html
There's a list of supported drivers in sqlalchemy docs, also aiomysql has support for sqlalchemy
Hey, I dont know if anyone here has used ibm-db-django to connect IBM databases to Django applications. But it is dead on pip repositories and it requires a minor adjustment to work with latest Python releases.
I tried to reach devs but all contact with the team is invalid. How can I report it to demand adjustment or take it down so other people can maintain?
Open an issue at https://github.com/ibmdb/python-ibmdb-django?
You can use the Google group
Link
any good batch text file editors out there that are free?
my chatgpt scripts dont work as intended
It depends on which language you want to use.
Im looking for a software with user interface, too poor with scripting I keep running into problems doing it with python
You can use a pycharm of vscode
There is a version of pycharm with money. Be sue to select the free
Sure
Do you want other options?
Not sure what you mean by "batch text file editor" but seems like #editors-ides would be the place for your question
ok thanks guys
anyone is experient with postgres? I need help

i reseted my password by putting everything on trust
but i don't know why i'm having this error
thought i backed up the file before going to put everything into trust
try psql -U postgres

Capital U
it's an uppercase U

I know because I made the exact same mistake this morning 😅
grats, you now got an active connection
You're in