#databases
1 messages · Page 12 of 1
you should create a table for categories and then add a category id to the product table
don't forget about product variations (sizes, colors, etc)
don't forget that categories need to be grouped
don't forget that category groups can overlap
don't forget that product attributes will vary by category
etc, etc, etc
what do u mean by "don't forget that categories need to be grouped"?
categories are not mutually exclusive. hard drive is both a storage device and a computer accessory and a consumer electronics etc
so its many to many relation ?*
maybe. or set based or hierarchical depending on your needs
some retailers use hierarchies. some use tags (sets). it varies
so i put product as forgien key in the cat table ? or the opposite?
if you don't want to deal with product category taxonomies, then I would suggest a many-to-many relationship between categories and products
that puts the responsibility of managing product categories on the retailer. if they have only a few products, it's viable.
I did some work for saks 5th ave back in the day... they had like 500,000 product sku's
so be aware of what limitation you're putting on yourself
this is my first website so i wanna spmething simple
how do i decided for the forgien key ?
I have a table like this
class OrderItems(SQLModel, table=True):
"""
Order items table. This is basically like a cart.
"""
id: Optional[int] = Field(default=None, primary_key=True)
order_id: str = Field(default=None, foreign_key="orders.id")
product_ids: int = Field(foreign_key="products.id")
total_quantity: int
How would I go about storing multiple products in one cart?
Would List[int] work?
You need a relationship
Not sure how it is defined in sqlmodel
Something like this?
product_ids: List["Products"] = Relationship(back_populates="orderitems")
From my understanding a relationship would take a whole row and put it into one row.
So basically for each row in products that we choose, we would add it to the list of products and then at the end store them in one row on the order items table?
No, it would actually create a separate table and link it with your main table
You can look into how one-to-many and many-to-many relationships work
This is it right?
this relationship is M2M (many to many), because a cart has many products, and a product can be in multiple carts so you end up with 3 tables:
carts
products
cart_product
both carts and products table need to have an id, and then cart_product should have cart_id and product_id and corresponding foreign key constrains.
Also, nice nanachi picture
Hello, does anyone know how to create a perceptron in python? help me please
Yep, for cart you'd need a many-to-many relationship, and, potentially some additional properties in your "relationship" table
To store things like amount, position in ui (if you need something like that), etc
Last question. I'm still confused and if you could help me.
Feel like my tables are not designed well
class Orders(SQLModel, table=True):
"""
Orders table
"""
id: Optional[str] = Field(default=None, primary_key=True)
customer_phone: str = Field(foreign_key="users.phone_number")
order_status: str
order_date: datetime = Field(default_factory=datetime.now)
# order_items: List["OrderItems"] = Relationship(back_populates="order")
total_order_price: int
class OrderItems(SQLModel, table=True):
"""
Order items table. This is basically like a cart.
"""
id: Optional[int] = Field(default=None, primary_key=True)
order_id: str = Field(default=None, foreign_key="orders.id")
product_ids: List[int] = Field(foreign_key="products.id")
product_id: List["Products"] = Relationship(back_populates="orderitems")
created_at: datetime = Field(default_factory=datetime.now)
class OrderItemsProducts(SQLModel, table=True):
"""
Stores all products in an orderi
"""
id: Optional[str] = Field(default=None, primary_key=True)
order_item_id: int = Field(default=None, foreign_key="order_items.id")
product_id: int = Field(default=None, foreign_key="products.id")
created_at: datetime = Field(default_factory=datetime.now)
Why do you need both order and order items?
product_ids: List[int] = Field(foreign_key="products.id") Also you can't have that
Order is an order. Order items would be the items in the order itself
Yea the code told me that this would not work. I'll remove it
Why can't you have a list of products linked directly to an order?
It doesn't make much sense to split that into two tables here
Unless you create items separately from an order
Or have multiple OrderItems per order
This is how my order payload would be. Is it right?
{
"email": "test44@gmail.com",
"phone_number": "+254-5941025",
"products": [
{"product_name": "Test product 1", "product_id": 1, "quantity": 3},
{"product_name": "Test product 2", "product_id": 2, "quantity": 2}
]
}
You don't need a product_name here
Ok. So no product name.
Also no include products in an order like above
From there link those products to the products table right?
Instead of using an order items table
I would do something like this
class Orders:
id: int = Field(default=None, primary_key=True)
customer_phone: str = Field(foreign_key="users.phone_number")
status: str
order_date: datetime = Field(default_factory=datetime.now)
products: list["OrderProduct"] = Relationship()
class OrderProduct:
order_id: int = Field(primary_key=True)
product_id: int = Field(primary_key=True)
amount: int = 1
class Product:
id: int
...
I think this makes much more sense. Thank you doctor
@teal sparrow Also you had a total_order_price: int field
I would avoid denormalizing your tables here, in case of a total price it's easy to calculate
And it could be harmful if person adds a product to a cart, and then price changes
You'd charge a different amount of money from current product price
I was planning to calculate it using python. No SQL
That should address the issues right?
Also just started learning SQL last week. That's why I'm making a lot of mistakes 😅
No, the issue is that you persist that information
Let me read more on it so I can ask the appropriate questions
Yes all the containers are running fine and the logs show no sign of any errors
I have an issue with a django application.
So I am trying to build a library API where there couldbe multiple libraryies that carry different books games dvds and more and you can see the avaliality of different items in 1 specific library or more.
So I at the moment i have an issue where if the endpoint is /main/library/1/games
This should only show the games availiable in library with the pk of 1 but its also showing the games connected to other libraries.
Would love some help on this 😄
is it okay to use f strings when constructing sql queries???
and how to prevent sql injections
!sql
SQL & f-strings
Don't use f-strings (f"") or other forms of "string interpolation" (%, +, .format) to inject data into a SQL query. It is an endless source of bugs and syntax errors. Additionally, in user-facing applications, it presents a major security risk via SQL injection.
Your database library should support "query parameters". A query parameter is a placeholder that you put in the SQL query. When the query is executed, you provide data to the database library, and the library inserts the data into the query for you, safely.
For example, the sqlite3 package supports using ? as a placeholder:
query = "SELECT * FROM stocks WHERE symbol = ?;"
params = ("RHAT",)
db.execute(query, params)
Note: Different database libraries support different placeholder styles, e.g. %s and $1. Consult your library's documentation for details.
See Also
• Python sqlite3 docs - How to use placeholders to bind values in SQL queries
• PEP-249 - A specification of how database libraries in Python should work
ohh
Then I would attach to the containers and troubleshoot from inside. See if you are able to do queries as expected, is there network connectivity between the containers as needed, etc.
Yes sure I also tried logging into the container and doing queries on my redis cluster and everything was fine. But when I try to connect to my redis cluster with python, the script gets stuck and doesn't respond to anything. Do you have any other suggestions how I can solve this problem ?
Sorry, I'm not familiar with the redis Python library, so I could only point you to look for their documentation/support. It does sound like that's where the issue is based on what you say
That's no problem thanks for your advice
Hello, I'm a beginner in database and I would like to understand how to take the data from a GitHub database, this one in particular: https://github.com/huyszn/ClashOfClansLegendsLeagueDataset
and I would like to take all these data to be in my SQL database

GitHub
Dataset of all Legends League Seasons from the Clash of Clans API - GitHub - huyszn/ClashOfClansLegendsLeagueDataset: Dataset of all Legends League Seasons from the Clash of Clans API
git clone or look up a website that lets you download a zip from a github folder, after that either read the csv files and upload yourself (if you want to transform the data in the process / learn how to do it it with few tools), or look up some method to import CSV files into the database you're using

Just tell while using -p cmd what is the password i should enter
I entered welcome password but it showing error
heyo, I'm having an issue creating an EER diagram, is there a specific #help channel for database questions?
I want to know how to get rid of my code showing up with the data that i call in sql
Image
I dont want it to show count(distinct supplier)
how do I change what it shows?

anyone pls
do i ping someone?
??
or whatever you want to call instead of count
as i shown here
like how would I implement that into my code?
select count(DISTINCT(supplier)) from item count() as hi
like this?
select count(DISTINCT(supplier)) as count from item
^
please ping me if anyone can help in this area :). Thanks
Can you filter based on a condition you created earlier without using a WITH in SQL? Basically:
SELECT
ID,
value,
X(value) as calc_applied_on_value
FROM TABLE
WHERE calc_applied_on_value >= 10
I know above won't run, I'm just asking if there's a way to do above without encasing the first half into a WITH first, then doing a WHERE.
You can do it as a sub-select:
SELECT *
FROM (SELECT ID, value, X(value) as calc_applied_on_value FROM TABLE)
WHERE calc_applied_on_value >= 10
or do the calculation again:
SELECT ID, value, X(value) as calc_applied_on_value
FROM TABLE
WHERE X(value) >= 10
The current SQLite does allow the use of alias names in the where clause but it is not SQL standard. So your select would work with SQLite.
Thanks, found something similar earlier. Forgot to update here.
Didn't know that it would work in SQLite, good to know.
have any of you ever tried connecting Maria DB and python to develop something
And is the problems in database connection problems of python solved?
https://docs.djangoproject.com/en/4.1/ref/databases/
https://docs.sqlalchemy.org/en/20/dialects/mysql.html
officially supported by Django ORM and SQLAlchemy. Better to choose Postgresql though
They provide python connector

MariaDB
MariaDB is the leading enterprise open source database with features previously only available in costly proprietary databases. Enterprise grade, wallet friendly.
anyone here that can help me with a small influx problem?
i have a list of points (that are Point-objects, printed with __dict__):
[{'_tags': {'guild_id': 637234990404599809, 'bot': 'False'}, '_fields': {'on_message': 1}, '_name': 'events', '_time': datetime.datetime(2023, 1, 29, 12, 44, 34, 78038, tzinfo=datetime.timezone.utc), '_write_precision': 'ns'}, {'_tags': {'guild_id': 637234990404599809, 'bot': 'False'}, '_fields': {'on_message': 1}, '_name': 'events', '_time': datetime.datetime(2023, 1, 29, 12, 44, 34, 676363, tzinfo=datetime.timezone.utc), '_write_precision': 'ns'}, {'_tags': {'guild_id': 637234990404599809, 'bot': 'False'}, '_fields': {'on_message': 1}, '_name': 'events', '_time': datetime.datetime(2023, 1, 29, 12, 44, 35, 371205, tzinfo=datetime.timezone.utc), '_write_precision': 'ns'}, {'_tags': {'guild_id': 637234990404599809, 'bot': 'False'}, '_fields': {'on_message': 1}, '_name': 'events', '_time': datetime.datetime(2023, 1, 29, 12, 44, 35, 907234, tzinfo=datetime.timezone.utc), '_write_precision': 'ns'}]
and i want to insert all of thenm in my DB with that code:
def influx_decorator(func):
async def inner(*args, **kwargs):
async with InfluxDBClientAsync(url=f"http://{IU}:{IP}", token=IAT, org=IO) as influx_client:
return await func(influx_client, *args, **kwargs)
return inner
class InfluxDB:
@staticmethod
@influx_decorator
async def insert_startup(i_client: InfluxDBClientAsync, /):
data_point = Point("startups").field("startup", 1).time(datetime.utcnow())
await i_client.write_api().write(bucket=IS, record=data_point)
@staticmethod
@influx_decorator
async def insert_points(i_client: InfluxDBClientAsync, cached: list[Point]):
print([point.__dict__ for point in cached])
await i_client.write_api().write(bucket=IS, record=cached)
but the problem is that influx cuts all seconds into 10 second rows, even if theres a diff of 8 seconds between points

idk where the bottleneck is
(pls ping me if u know the answer)
can someone comment on the error

It's a bit generic, but likely here it means that the file cannot be found
https://docs.sqlalchemy.org/en/20/errors.html#error-e3q8
import pandas as pd
gym_df=pd.read_csv('gymdata.csv', index_col=['Id'])
id = 5
gym_df.at[id] = ['DV', '18', '10-01-2023', '188', '85', '32525']```Traceback (most recent call last):
File "C:\Python 10\lib\site-packages\pandas\core\indexes\base.py", line 3803, in get_loc
return self._engine.get_loc(casted_key)
File "pandas\_libs\index.pyx", line 138, in pandas._libs.index.IndexEngine.get_loc
File "pandas\_libs\index.pyx", line 144, in pandas._libs.index.IndexEngine.get_loc
TypeError: 'slice(None, None, None)' is an invalid key
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "c:\Coding\IP Project\School_Project.py", line 5, in <module>
gym_df.at[id] = ['Daanveer', '18', '10-01-2023', '188', '85', '32525']
gym_df.at[id] = ['DV', '18', '10-01-2023', '188', '85', '32525']
File "C:\Python 10\lib\site-packages\pandas\core\indexing.py", line 2442, in __setitem__
return super().__setitem__(key, value)
File "C:\Python 10\lib\site-packages\pandas\core\indexing.py", line 2397, in __setitem__
self.obj._set_value(*key, value=value, takeable=self._takeable)
File "C:\Python 10\lib\site-packages\pandas\core\frame.py", line 4207, in _set_value
icol = self.columns.get_loc(col)
File "C:\Python 10\lib\site-packages\pandas\core\indexes\base.py", line 3810, in get_loc
self._check_indexing_error(key)
File "C:\Python 10\lib\site-packages\pandas\core\indexes\base.py", line 5966, in _check_indexing_error
raise InvalidIndexError(key)
pandas.errors.InvalidIndexError: slice(None, None, None)
PS C:\Coding\IP Project>```this is the error i am getting
i dont know what is causing this error
some one please help
👀
what on earth are you trying to do?
are you trying to insert a new row or something?
the csv file has 4 rows
ok don't worry about that
and the id is index column
ok bro, use the function i told you to use, you can find more info on the pandas append method in google.
thank you@spring turtle
what about, changing values of an existing row
you can use something like dataframe.loc[row:index, ['col1', 'col2', ...]] = VALUE
or if it happens just once you can use like dataframe.replace()
should this work?
you don't need the trailing comma. only need that when there's only 1 element in the list
okay but does it still work
why does the search still return None... the data is correct fyi

Remove this. Everything else looks right.

It depends, with linters I use trailing comma is required, and it's generally a good thing, imo
Hey, im trying to connect my python code to my MariaDB, database named ‘portail_post_bts’, I found this on internet but it seems not working I don’t get the city ‘Lille’ in my table. Any help will be appreciate !

What message do you get when you run that code? Are you sure about the server details, database name, etc.? I don't know that specific library you are using or what else you have done already, but you probably need to create the database and the table first before you can insert data into it.
if its a maria database, wouldnt you want to use the mariadb connector instead of one for mysql?
https://mariadb-corporation.github.io/mariadb-connector-python/
Problem solved just used mysql.connector instead of pymysql
hello I am trying to scrape information from amazon and I see this problem

I need extreme help with a mongodb connected discord bot. I need to go into the database with my already coded connection and document files, once im into the database I need to get a leader_id when a person click the button. After it gets the leader_id I need it to get all of these: all_members and clan.name all in the database already.
my friend gave me the document.py files.
Variable "cc" is not an array, check if the xpath is correct. Also, try printing it.
I tried different xpath but it is the same
!e
for n in None:
print(n)
@somber niche :x: Your 3.11 eval job has completed with return code 1.
001 | Traceback (most recent call last):
002 | File "<string>", line 1, in <module>
003 | TypeError: 'NoneType' object is not iterable
how can i select random rows from database ,
database str.
s no | weight
1 | 100
2 | 50
3 | 70
4 | 60
I already wrote this
/help
i have a question, how can i connet to my postgreSQL database (my app is hosted and i want to connect to the db)
here is my url:
postgres://postgres:<MypassWord>@localhost:5432/<MydbName>
using aggregation with mongodb, how do I join a certain collection based on the value of a document's field from another collection please? For example, if the item's type value is 1, Weapon collection should be looked up, if 2, lookup Potion collection, if 3, lookup Food collection
I'm doing some work in SAP sqlanywhere, and it has my new favorite SQL statement, REMOVE JAVA
import pandas as pd
df = pd.read_csv('books.csv')
if df["semester"] == 1:
print(df[df["semester"]])
``` This code gives me this error: `ValueError: The truth value of a Series is ambiguous. Use a.empty, a.bool(), a.item(), a.any() or a.all().`
How will I print only the 1st semester books?pandas (unless using something like read_sql / to_sql) fits more in #data-science-and-ml than #databases
also: read the User Guides in the pandas official website, more specifically the basic usage / intro to pandas
hi
import sqlalchemy as sa
engine = sa.create_engine('sqlite:///flight.db')
connection = engine.connect()
CREATE TABLE readings (
flights,
ts,
temp,
pressure,
humidity,
accel_x,
accel_y,
accel_z
)
Cell In[8], line 1
CREATE TABLE readings (
^
SyntaxError: invalid syntax
this is the error i'm getting
Hi, you can't just mix SQL code with python
Check how it's done in sqlite documentation:
https://docs.python.org/3/library/sqlite3.html
import sqlite3
con = sqlite3.connect("tutorial.db")
cur = con.cursor()
cur.execute("CREATE TABLE movie(title, year, score)")

Python documentation
Source code: Lib/sqlite3/ SQLite is a C library that provides a lightweight disk-based database that doesn’t require a separate server process and allows accessing the database using a nonstandard ...
You can connect with whatever client you like. DBeaver is a good place to start
Can someone help me? why aiosmysql tolds me this


.
I think the self is not needed here: https://aiomysql.readthedocs.io/en/latest/cursors.html
I don't see any await
where are the databases written in .JSON???????
Usually in hell
can anyone help me with postgresql?
no matter which psql command i put into cmd.exe
i get this
C:\Program Files\PostgreSQL\15\bin>psql --port 5432
Password for user info:
so he asks me for password for user "info"
that user is my windows user name
i tried windows password and the superuser passwords
none of them work
psql: error: connection to server at "localhost" (::1), port 5432 failed: FATAL: Password-authentification for user >>info<< failed
It is the password that you set up while installing Postgres, if I remember correctly
yes but thats one of the ones i tried
both dont work
Also, there is a file called pgpass.conf in %APPDATA%\postgresql\pgpass.conf
Maybe you can find the password there

if you look at this here login/group rules
*roles
there is just one user at the bottom postgres
yet he always wants a password from me for the user "info"
how does that make sense?
You can use a flag to log in with this user
Don't remember what the flag is, but it exists
Log in with the user "postgres" and use the password you set up on install
yes sry i dont know what that means "flag"
ah i see

PostgreSQL Documentation
psql psql — PostgreSQL interactive terminal Synopsis psql [option...] [dbname [username]] Description psql is a terminal-based front-end to PostgreSQL. It …
psql --username=postgres --port 5432
try this
Connection options:
-h, --host=HOSTNAME database server host or socket directory (default: "local socket")
-p, --port=PORT database server port (default: "5432")
-U, --username=USERNAME database user name (default: "info")
oh no
i must be reta*d
i swear i did not see it yday
💀 💀 💀 💀 💀 💀 💀 💀 💀 💀
-U, --username=USERNAME database user name (default: "info")
can you explain this line to me
it means i can either do
psql.exe -U "postgres"
or i can do
psql.exe --username="postgres"
or what are the two options mean?
no need string " " things?
yep
that's the console
yep
okay then idk this seems weird
i see many sql queries where its multiline
but i cannot shift+enter to write two lines in cmd.exe?
or do i need copy+paste the queries always?
well
cmd cannot do multiline queries
but if you run \e
you'll open a text editor
that can in turn run the queries that you need
np
any recommendations how i can start
just read the docs and the man pages
is that a command u mean?
yep
anyone is using OpenVPN?
Probably millions of people are, but you should probably ask your actual question in #networks rather than here
hi
anyone knows pgadmin 4?
i'm getting 'Columns' error when importing data
none of my csv files open in it
still couldn't register a server on linux
Hey sorry I have a super quick question that I just wanted to check
Does anyone know how to sum each column individually?

because when I call .sum(axis=1, numeric_only = True), I just get a full sum of everything without preserving the date data
SELECT sum(here the column you want to sum)
FROM the table
if you want to add a filter just put a comma
sorry this is pandas I think I must've put this in the wrong channel
@client.command()
async def list(ctx):
db = sqlite3.connect('main.db')
async with db.cursor() as cursor:
cursor.execute('SELECT id FROM users WHERE guild = ?', (ctx.guild.id,))
result = cursor.fetchone()
await ctx.channel.send(f"TYPE: {str(result[0])} - REASON: placeholder")
I am trying to fetch some data
Im using sqlite
is my code correct?
if you want async sqlite connector use aiosqlite
!pypi aiosqlite

asyncio bridge to the standard sqlite3 module
I have to import aioslite in my bot?
do you want to use it?
ur using discord.py?
python yes
what library u r using to make your bot
ok, so then u should use an async connector like aiosqlite instead of sqlite3
aiosqlite is just the python connector
oh
so i do import aiosqlite in the top of the code right?
okay i did it
docs are here: https://aiosqlite.omnilib.dev/en/latest/
if you dont know about loops or functions you will need to learn those first
Could you send a example?

i tried this
You ought to save one aiosqlite.Connection object in your bot. Did you override the setup_hook function yet? You should have it save the connection object to the bot there.
Also, you forgot ctx. before member.id. Actually, I think it's supposed to be ctx.author.id
select sum(amount),program_discipline.name as pd from student_fee inner join cms_program_batch on cms_program_batch.id = student_fee.program_batch_id inner join program_discipline on program_discipline.id = cms_program_batch.program_decipline_id where student_fee.state in ('unpaid','paid') group by pd order by sum (amount) desc;
Kindly help me with query.. I want get paid and unpaid amount separate columns in output
currently it gives 1 column for both paid and unpaid with sum
Hello, I've got a piece of python code working to import excel file into mysql. However, I'm facing two problems:
- for one column called payment it's IntegerField and I set it up so null= True but when I run the python file I get
MySQLdb.OperationalError: (1366, "Incorrect integer value: '' for column 'payment' at row 1") - for another column called desc (description) I had strings that I had to combine using \r\n and I had alignment with wrapText set to True... this causes this error
MySQLdb.ProgrammingError: (1064, "You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'desc, status, donotcount, removed, removedreason, reportfloor) VALUES (15548.0e0' at line 1")
If I don't need these two columns then the python code I made worked.
''is an empty string and notNULL- hard to tell without the whole sql statement. I hope you are using binding parameters and not f-strings (or the like). Another thought would be that
descis a keyword (for descending order by) you may have to quote it (standard sql uses double quotes"but i think mysql is using backticks?).
Thanks for the response!
2) What I meant to do was to store a piece of text with enter in it. Ill tag you tomorrow the code.
I'm pretty sure it is the desc column name you are using without quoting it in the sql statement because it is a keyword.
I just finished a basic Python script for a client that I’d like to share with you. He needed an easy means of moving data back and forth between MySQL and Excel, and sometimes he needed to do a bi...
I used the code here, i fixed some bugs and it worked partially
query = """INSERT INTO orders (desc)"""
Im not sure how to quote it? @grim vault
I would just rename the column to description so you don't need to quote it. But as I said, mysql uses backticks to quote sql identifiers.
query = "INSERT INTO orders(..., `desc`, ....) ..."
👋 Hello all! I have a program I am trying to write - to convert my many notes on movies on my phone into reviews on letterboxd.com
It involves writing to a csv - if anyone wants to help, I'd really appreciate it 😄 check out #1070706066523951156 cheers! 👍
I was running a connectionless execution in SQLAlchemy 1.4:
engine.execute(f"SHOW CREATE DATABASE IF NOT EXISTS `{schema}`").fetchone()
How can I get the same result as the above statement but doing it in a way which aligns with SQLAlchemy 2.0+?
I guess I found it
connection = engine.connect()
from sqlalchemy import text
result = connection.execute(text(f"SHOW CREATE DATABASE IF NOT EXISTS `{schema}`"))
I am confused.
I have script that connects from AWS Lambda to AWS RDS.
it works to Postgresql.
it does not work to MariaDB (timeout error)
They both have same terraform code / permissions / security stuff.
Well, except on the level of database parameters of course
I can connect to MariaDB, when i have port forwarded and connecting to localhost
...
...
i think probably for final test i will just... get my access to Linux machine inside infrastructure, and try to connect to MariaDB without port forwarding with some CLI client i guess?  may be that will give me some more info
may be that will give me some more info
Nevermind. Found reason in AWS security rules
guys im using MongoDB and when i run this code
collection.insert_one({"_id": _id, "_username": username, "_balance": 0, "_wallet": 0})
all i get is this {"_id":{"$oid":"63dc0117e944ccc7c8df5f63"}}
which my only explanation is its taking the id of the dictionary

I make alliances in a bot, a participant can create as many as he wants, but there is a variable in the database, how many alliances a person has created (count) and the name of the alliances (name), is it possible to do something so as not to create many variables for 1, 2,3 and etc. alliances, and two variables output information about alliances? (postgres)
as data engineer, did you ever use any other data structure other than built-in dict and set? I once came across google answer that DE should be aware of Tree structure at least, but at the same time I found out for python users, built-in is plenty for most cases.
hey, i have a question, mysql closes the conexion automatically after use it or not?
when using python, you will not go out of your way to implement new data structures - you're just going to use the built-ins + those provided by one or two libraries
data engineers use much more than only python though, and in other places they may need to understand other data structures
(though even then you'll rarely have to implement them yourself - but it can still be important to understand how they work. For example, to make optimised queries, you must understand somewhat well how indexes work)
Considering that data engineers work with databases, which often under the hood use different forms of trees (b-tree is default index in Postgresql), we can say yes 🙂
can someone call with me to look at this database python stuff before i cry
@grim vault omg I did it!!!! Thank you so much ❤️
Just kinda curious if this would be a bad idea to do for implementing a search function that a user could use.
Let's say the user wants to find something that's red or blue in a db of 100k items. would it be alright if i did something like what's below every time someone wants to look for something? or would this be bad at scale?
db.execute("SELECT * FROM images WHERE colors='{}'".format(args))
You should not use str.format with SQL queries
how should i reformat my query then?
100k items doesn't look like much, what is colors though?
That depends on what library you're using
colors is a column of some combination of five different colors(red,blue,black,white,green). I want to make the searches more complicated so instead of getting let's say a thousand results the user can make their query more strict to only get a handful of results
It's a string?
i'm using postgresql in pgadmin and sql alchemy in python to make the requests
Why are you using textual sql with sqlalchemy? 🤔 You can use sqlalchemy core/orm instead to build queries
yes, it's written like how i wrote it above and here (red,blue,black,white,green) but I was thinking of changing it to ones and zeros separated by commas
Why not use a relationship here instead?
I haven't heard of this part of sqlalchemy before. How do you use it to build queries?
You should read sqlalchemy documentation: https://docs.sqlalchemy.org/en/20/tutorial/
how would the relationship help out here?
thanks. I'll check it out now
Storing multiple values in single column is something that's not usually done in relational databases
It should be ok if you store single color for a given item
e.g.
id color
1 black
2 green
3 blue
4 blue
etc ..
but if something is both green and blue?
Then you'd probably need a relationship 🤔 Though it's possible to use arrays in postgres
I think this is a similar question: https://stackoverflow.com/questions/2885564/ways-to-implement-tags-pros-and-cons-of-each

Stack Overflow
Related
Using SO as an example, what is the most sensible way to manage tags if you anticipate they will change often?
Way 1: Seriously denormalized (comma delimited)
table posts
+--------+------...
hmm you've given me a lot to chew on for tonight. I'll be seeing if i can fix my sql stuff up tonight but I'm still unsure on if making super specific queries available for the user will be okay at scale with only 100k entries for the db
!pypi aiomysql
MySQL driver for asyncio.
100k isn't much
iirc you need to do self.conn = await aiomysql.connect()
im not sure if you have to await the creation of a cursor as well
dont worry bro, i fixed it making a DB class xd
k
awesome. I just wanted some reassurance. I didn't think it was a lot too but I just wanted to be careful
Hi. I have a MongoDB database and want to limit X amount of docs for each distinct id. Example database: json { id: 1, value: 2.0 }, { id: 2, value: 32.4 }, { id: 1, value: 2.1 } I want for every unique id (1,2) I want a max of X documents. How do I limit each distinct thing instead of the whole request?
And I want the actual data for each doc to be available
When I create a connection to a DB that is present in another server (with SQLAlchemy), do I need to make a web request everytime I do a read/write query to the DB? or in other words, whats the overhead when the DB isnt present in the same machine?
I don't think it's technically a web request, but it does have to travel the internet which will slow things down. Ideally you want to avoid this (at least in production).
I created an economy bot with mongodb but for the bot verification i need my users to be able to get their data deleted. I just cant figure out how i could do this.. Can anyone help me?
I have to delete the entire inventory with the command. Im not a good coder so i dont know how to code this

Hmm on second thought did you look at this? https://www.mongodb.com/docs/manual/tutorial/remove-documents/
I couldnt find anything cause i didn't really know how to call the thing i was searching lol
ill look into it thx
how can I avoid this?
I I'm not very familiar with the whole AWS setup my company has, but I believe there are two different servers for the DB and the machine that executes the batch (a python script)
btw is this syntax correct for MySQL?
CREATE DATABASE test_db IF NOT EXISTS
I found the IF NOT EXISTS on the official docs but sqlalchemy is complaining:
sqlalchemy.exc.ProgrammingError: (MySQLdb.ProgrammingError) (1064, "You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'IF NOT EXISTS' at line 1")
[SQL: CREATE DATABASE test_db IF NOT EXISTS]
(Background on this error at: https://sqlalche.me/e/20/f405)
IF NOT EXISTS might not be available in mysql 🤔
Ah, nvm
CREATE DATABASE IF NOT EXISTS test_db
ohh lemme try that
now it works, thanks!
do you by chance know what this error means?
"BLOB/TEXT column 'path' used in key specification without a key length"
interestingly, I get this error when I have a PRIMARY KEY with a large TEXT field, now that I removed the PRIMARY KEY constraint it works
how do you put a ' inside a sql?
like it's
i'm trying to fetch data from a table where guildid = $1, id but I keep getting this error: discord.app_commands.errors.CommandInvokeError: Command 'restore' raised an exception: ValueError: parameters are of unsupported type
You double it, like insert into test(name) values('It''s')
keep in mind the column i'm checking is bigint
are you allowed to use double quotes like insert into test(name) values("It's") ?
Double quotes are used for SQL identifiers, so the standard does not allow it but some databases do.
In this case a standard compliant database would look for a column named It's.
If you're using AWS, then you would normally have everything (RDS + EC2 or whatever you are using) in the same Availability Zone at least. So it's not going out over the internet and the latency shouldn't be too bad. If you need extra low latency there are things you can architect / pay extra for.
@weary lantern Per Rule 6, your invite link has been removed. If you believe this was a mistake, please let staff know!
Our server rules can be found here: https://pythondiscord.com/pages/rules
how do people normally store files with mongodb? i was able to store an image by encoding it into a base64 string which i decoded in another language to show the image
would this work fine for things like audio files too?
this is the only way i was able to store an image so i'm not sure if there is a better method i feel like this probably isn't the best way
especially with large files
and i haven't even tried it with anything other than images 😅
if anyone responds to this please tag me
take a look at https://www.mongodb.com/developer/products/mongodb/storing-large-objects-and-files/ / https://www.mongodb.com/docs/manual/core/gridfs/ if you haven't yet
thank you! I didn't know about gridfs but ill definitely read up on it
Store them elsewhere, just put the URL string in your DB instead of the file
that's an option anyway
S3 bucket. AWS S3 bucket
Every big enough provider has S3 compatible analog. Even Digital Ocean has
Minio is a self hosted solution
Store only address to file in bucket in SQL/mongodb
(Link from S3 can be directly served to client. It is capable directly serving static assets. People often add to it CDN(cloudfront/Cloudflare) for additional caching if necessary)
This is what I've always been told. It's interesting though that mongodb is recommending direct storage of large files per the link from erotta. I've never tried it.
or just store to filesystem if you work with single server. filesystem is usually way more efficient again (from which your nginx server can serve content again directly)
S3 solution is for... microservices/multi server setups/too much containerized setups
I am not sure if this is completely database related, I have a table "Users", I want to be able to have a user input from the CLI like "users with name starting with foo", I want to know how I can convert this to a sql query, I am not looking into natural language stuff, I would want to support a limited number of queries
i am using sqlalchemy
other possible things I would like to have "count of users with verified emails", "users who signed up 3 months ago"
somehow I want to be able to get from "users who signed up 3 months ago" to select(Users).where(Users.created_at > "date that is 3 months")
If you're not going to process natural language then you're going to need to guide the user with menus or something I think
A GUI might be easier if that's an option
so based on the value I get in a certain dropdown, I construct that part and join together the query?
Yeah, it doesn't do joins, but I'm thinking of Salesforce Workbench for example: http://www.sfdcpoint.com/wp-content/uploads/2019/12/SOQL-Detail.png

thanks @fading patrol this seems to be along the lines of what I want, though mine is in no way going to that extensive
@little veldt Per Rule 6, your invite link has been removed. If you believe this was a mistake, please let staff know!
Our server rules can be found here: https://pythondiscord.com/pages/rules
I havent been introduced to the whole setup yet, but both servers are in the same region (Italy) and the same AWS account. In your opinion how big will the delay be for a simple read query to the DB, 100ms, 200ms?
No idea sorry
I think they shouldn't be that high for in-cloud communication 🤔
Since they would usually be in the same datacenter
100ms is a lot
oh really? so like around 50 ms?
I think you should test it
I think so too lol
For cloud we're using it's a couple ms
For example sentry shows sqlalchemy queries that take time of less than a ms for database hosted with the same cloud provider where that application is running

oh shit, thats super fast
now im really curios
but thats basically the same performance as if it was on the same machine
I started learning swift language for 2 months and I also want to learn artificial intelligence, for this, is learning Python an obstacle to learning swift?
Hey, I installed mysql-connector-python via pip in command prompt but when importing mysql.connector it throws a module not found error?
import mysql.connector
ModuleNotFoundError: No module named 'mysql'
When you guys refer to the plural of a database index, do you say indexes or indices?
The grammar nazi part of me wants to use "indices", but on the other hand, an index as a data structure is a distinct thing from the normal, more general sense of the word "index", so then in this case, it would seem that "indexes" would be appropriate.
How can I speed up my query
you start by measuring why it is slow
Use some indices ;)
You can't improve what you can't measure
I am using mongodb, and I will be removing product ids in batch, or adding them in batch. Which one is a better thing to do. In users collection, in each user document should I save product ids associated with them as products.product_id_1,products.product_id_2 etc, or just save them inside an array under products field. I don't know if mongodb uses sets or not so I am a bit hesitant.
I think one question to ask yourself is how are you planning on querying users and their associated products? What are the queries or other operations do you need to be fast? Like, are you just going to query users and return a list of associated product ID's, or are do you need to select users by product id? How many product id's will there be on average? 10 or less or possibly orders of magnitude more?
Hey @still citrus!
It looks like you tried to attach file type(s) that we do not allow (.ps1). We currently allow the following file types: .gif, .jpg, .jpeg, .mov, .mp4, .mpg, .png, .mp3, .wav, .ogg, .webm, .webp, .flac, .m4a, .csv, .json.
Feel free to ask in #community-meta if you think this is a mistake.
Hey @still citrus!
You either uploaded a .txt file or entered a message that was too long. Please use our paste bin instead.
Was it wrong for me to post here. Sorry guys for a bunch of noise.
why it gives me this error, i think im using the release method appropriately (in aiomysql)


not more than 16mb limit but can be a lot 50k something maybe? and like I mentioned previously on my question. I will have to in batch remove/add product IDs. I will not get users based on product id but get product ids based on user id.
I think removing them in batch will be too costly from an array than just removing them as field don't it?
when you're using the context manager there's no need to manually call release
has anyone used imagekit to store image
Is it possible to perform queries with python on a MS access database (.accdb)?
A quick web search says yes: https://stackoverflow.com/questions/34614070/how-to-execute-query-saved-in-ms-access-using-pyodbc
Stack Overflow
There are a lot of tips online on how to use pyodbc to run a query in MS Access 2007, but all those queries are coded in the Python script itself. I would like to use pyodbc to call the queries alr...
what graph databases are there in Python? (that have a Python API)
Neo4j is popular
https://neo4j.com/developer/python/

Neo4j Graph Data Platform
This guide provides an overview of how to connecting to Neo4j from Python.
But you can check also this interesting list

Plus i want to mention that Python is kind of awful for Graphs. (if using it without databases at least)
Too slow for them. Graphs are very CPU performance demandful topic. Bettter going Golang/C# or smth like that
wait, shouldnt the DB process the queries (in its own language)? like when I send a query to Neo4j I'm sure it processes it in a more performant language
Ergh. Sure, database resolves problem of python slowness in graphs
problem is... do you need database for each case though? Python leaves no room for in memory graph usage.
Although you know, someone probably implemented C-implemented Python library for graphs 😆 for this exactly performance problem
what do you mean for each case? I'll populate the DB slowly slowly, and then each SELECT query should return a JSON or a value, not a sub-tree or anything very large
im there is almost everything in Python 😄
Ergh. i mean, do you trully need database for your usage case of graphs?
Often enough it is enough to upload data into program memory and calculating right in it necessary stuff without usage of database
oh trust me, it is pretty large 😅
in my latest pet project i simplified it greatly and made it finished because i stopped going into too many microservices and using too many databases.
I have everything multithreaded there now and only SQLite3 is applied for some settings storage 😆 It made things way easier
Im downloading all of wikipedia's categories (and voices) and its stored in a Cyclic Graph
as of right now I'm using MySQL with a bunch of tables, but its not ideal because I encounter the same node again and again and I need to add a new record for it every time,
but if Im using an actual graph DB I could just a link to the node and thats it
its such a pain to use SQLite with multithreading
i use golang. Very very simple in it. Because three code lines add Mutex lock that prevents any multhreading data corruptions problems for me
type Records[T Deletable] struct {
records []T
mu sync.Mutex
}
func (b *Records[T]) Add(record T) {
b.mu.Lock()
defer b.mu.Unlock()
b.records = append(b.records, record)
cutterStart := len(b.records) - 10
if cutterStart < 0 {
cutterStart = 0
}
b.records = b.records[cutterStart:]
}
Although you know... wait 🤔 i haven't protected with Mutex SQlite3 queries
they aren't having this problem
wait, but SQLite dosent support multithreading
it may accept multiple queries concurrently but will process them synchronously
am I wrong?
Ergh? SQlite3 is external. It is not existing in memory of application. it is not affected by multhreading problems
well, sure. it is probably processing them syncronously. Not really a problem for me
I wont pretend like I can read your code since I have had any experience with Go yet 😅
Golang is not having single thread lock GILL 😆 Threads are trully parallel in Golang.
b.records = append(b.records, record)
is this like string = string.replace(...)
?
is b.records immutable or what
umm. no. it is ListOfValues.append(record)
so whats the assignement for?
Ergh. Golang... quirck in how it sees appending operation to list
or the = sign
if you have learned DSA you can remember Linked List structure, as a chained list of pointers?
Golang i think sees list in the same way, so.. when you want to add new value to the list
you copy pointers to the list begining and end, and appending at the end value to it
and then assigning in order to have more functional programming feeling to the code of functional operations even regarding list operations
Don't mind it. It is Golang being Golang 😆
Basically, golang treats lists like they are... ergh... Slices in Python? Immutable slices which you can cut or extend into another list at the minimal operational cost.
just imagine it is a regular list.append(value)
hmm interesting
so anyways this is too big to store in memory
so neo4j seems like the best option
Sure. if it is so.
Golang has pointers, so it allows VERY efficient in memory storage of data structures, since you can keep each object only once and making just connections between them too
plus high performance allows of course quickly going through data
so can you store 400k nodes?
So for... big enough range of Graph data... no problem to process in memory
Ergh. 400k nodes is a stretch. Very long to read at least
I think it would be still possible to process in memory, since with parallelization and vertical scaling i think you can upload such data within 4 seconds?
But still you know, it would be tricky to run queries in it 🤔 Since your solutions are usually aren't easy to write with parallelism and you are highly likely needing parallelism here for quicker processing such amount of data
Although golang makes really easy to write even paralleled queries easily
So it will depend on amount of edges in such graph to process quickly
if their amount is low, even Golang could process it within reasonable time of like less than 10 seconds
but Database is better in such case 😆
fair enough
At the end Graph databases can be highly likely written in Golang, but they are already written and mature in code 😆
Your own solution would be immature and longer to write
also for longterm storage you need a DB, otherwise I'm gonna have to make a million web-requests to Wiki's API
yes, but they are stored on disk
that too.
Just with Golang you start to get philosophy of... if you need something, question yourself throughly.. you really need library or third party solution for this
May be you can write it on your own. Language is kind of very comfortable for this
for 400'000 nodes it is justified to use Database though
thank god 😅
you can use Database even for 1000 record storage. It is only question of sanity, do you trully need fully fledged database for this 😆
some people use Distributed Databases like Cockroach, Yugabyte for smallest data, because it is easier to have HA replication of them
btw the idea of storing the object only once, and the reference multiple times is also done in relational DBs (and in graphs should be much easier).
you have one table with a PK (the reference) and whathever the content is, and then you just reference the PK in the other table...
Sure. But databases introduce complexity of their own language, and introduce biggest possible delays in form of networks delays
plus, usually they go with at disk storage, while your program in memory can do stuff way faster (like Redis in memory or Memcache, but even without network request delays!)
fair point though, that Postgresql has adjustable caching in RAM for bigger value. So you can set it to cache up to 4 GB of values too
plus database language and structure is actually a constraint you need to work within for. Fully fledged programming language always has more flexbility to fit your case perfectly (eventually)
as long as sqlite3.threadsafety == 3 and you create a connection with check_same_thread=False, the same connection/cursor should work across multiple threads (though apparently sqlite3.threadsafety was hardcoded as 1 until 3.11)
unless you meant you wanted queries to actually run concurrently, in which case i think that requires establishing multiple connections
Hey how can I sum distinct values in a column in spark.sql
i have this code
cur.execute("UPDATE thing SET sessionactive = '1' WHERE user = ?", (username))
but it gives error
sqlite3.ProgrammingError: Incorrect number of bindings supplied. The current statement uses 1, and there are 5 supplied.
i dont know about python but i only see one statement being used
(username, )
^
And I would do:
cur.execute("UPDATE thing SET sessionactive = ? WHERE user = ?", (1, username))
url = 'https://api.jsonbin.io/v3/b/63e21f90ebd26539d07820da'
headers = {
'X-Master-Key': os.environ['jsonbin']
}
req = requests.get(url, json=None, headers=headers)
squad = req.json()
guild_id = str(ctx.guild.id)
user_id = str(lbb[0])
if guild_id in squad:
if user_id in squad[guild_id]:
squad[guild_id][user_id].append(pl[0])
else:
squad[guild_id][user_id] = [pl[0]]
else:
squad[guild_id] = {user_id: [pl[0]]}
response = requests.put(url, headers=headers, json=squad)
It doesn't append to players list rather it just posts multiple data. what is the solution?
The ... requests.put(... line seems to be indented only for the outer else: part, so it will only be called if the guild_id is not in the squad dictionary.
Ty and found the solution, We dump it first then Append
Hey guys, I have a table in MySQL that has only one column which contains a path and its very long (up to 40k chars, TEXT), the issue is that since its so big I cant make it a PRIMARY KEY, which I need for fast lookup and to make sure everything is unique,
so I was thinking of adding a second column called hash_path which contains the output of: hash(path_value) in Python but the disatvantage is that I need to get the hash in python each time
fast lookup + unique? you can achieve it by creating Unique Index https://www.mysqltutorial.org/mysql-unique/

MySQL Tutorial
In this tutorial, you will learn how to use the MySQL UNIQUE index to prevent duplicate values in one or more column in a table
@wise goblet is UNIQUE INDEX the same as (..., index=True, unique=True) in SQLAlchemy?
Sigh. Let me google it for you in documentation of the library
https://docs.sqlalchemy.org/en/14/core/constraints.html#indexes
# a uniquely indexed column with index "ix_mytable_col2"
Column("col2", Integer, index=True, unique=True),
is equal to
CREATE UNIQUE INDEX ix_mytable_col2 ON mytable (col2)
yes
what I thought, so I can add the UNIQUE constraint, but when I add index=True or primary_key=True it says it cannot index more than 3000 bytes
it seems like the only option is to index the first 3k chars of each value, but thats basically useless, since the max is about 40k chars
hmm. Can you create unique CONSTRAINT at least?
or I can generate the hash in Python like I mentioned above, what do you think?
yes, only that
What is content inside this TEXT value?
Search Engine like Elastic Search sound like a potentially way to speed up searching query can be used
Or checking other existing Index types. (Default one b-tree is created in postgresql for example, but it is not the only one possible. May be some index supports bigger Text length)
this is an example with 500 chars, other will be much larger. (its a path to a category from Wikipedia's category-tree, which is actually a graph)
Letteratura italiana/Opere letterarie di autori italiani/Saggi di autori italiani/Il Milione/Luoghi di Marco Polo/Venezia/Storia di Venezia/Repubblica di Venezia/Possedimenti della Repubblica di Venezia/Dalmazia/Regione spalatino-dalmata/Comuni della regione spalatino-dalmata/Spalato/Sport a Spalato/Competizioni sportive a Spalato/VIII Giochi del Mediterraneo/Sport agli VIII Giochi del Mediterraneo/Pallavolo agli VIII Giochi del Mediterraneo
So, how searching query will be looking?
matching any word phrase in it?
Select content WHERE path = some_path?
What are parameters length of those path and content?
provide me example of content and path separately
more precisely expected query
I'm actually not sure yet, I have another table that has all the nodes of the graph,
the idea was to have the path to each node in a separate table since each node can appear in multiple paths/categories
its basically to 'cache' expensive queries
otherwise I would need to find the root of the tree and traverse trough all its childs in Python or trough an SQL recursive query
makes sense?
okay, you have Graph database of pages relantionship
you want to cache quering page content faster by path. understood
exactly
now if I want to check if a path exists in my DB, or to make sure they are all unique, I need to make it a primary key
(at least if I want O1 lookups, and inserts)
is it possible to query necessary Graph node without traversing all parent nodes?
if you have the name of the node, yes
great.
but most often you will want to have all the nodes are under a given node
because nobody is gonna know the subcategory that is 500 levels deep...
so, what do you think about, having caching table that saves only
Path -> Node Name (for accessing in Graph DB)?
its exactly what I want it to be!
but note that the name of the node is the last value of the path, so its redundant
Redis Database could be used... it has speed like 100'000(or even 1'000'000) requests of reading/writing per second
key = path
value = address to node
only questionable if it will work well enough for 400'000 elements, it is RAM constrained database.
I need something that I can store for the long term
but you know that the path IS the address to the node, since each value in the path is the name of a node
and there are different paths to the same node, since a node can appear under different nodes/categories
Redis saves data to disk though
but at this point I could just store it in the same DB? (MySQL)
i think i am missing something.
So you wish to have caching table like
node1-node2-node3 -> node3?
what is expected input and output, clarify what is query and desired result. Give me samples 😆
the path is the address, what I'm hoping to achieve, is to be able to read and write to the path column very fast (the challenge is the field being so large TEXT(32768) that I cant index it)
wait, are your obligated to use MySQL, may be you can use Postgresql?
https://www.postgresql.org/docs/current/indexes-types.html
Postgresql has different index types, i am highly sure some index like hash could match even your whole TEXT(32768)
if path is:
path = node1-node2-node3
and I want to get its node, then I do:
SELECT * FROM category_nodes WHERE category = {path.split('-')[-1]}
find = {path.split('-')[-1]} # node3?
SELECT * FROM category_nodes WHERE category = find
yeah
and path is TEXT(32768)?
the last value of the path is the category-name of the node
What will yield SELECT * in a caching table?
something like this:
A.C. Mestre | ["Allenatori dell'A.C. Mestre", "Calciatori dell'A.C. Mestre", "Presidenti dell'A.C. Mestre", "Stagioni dell'A.C. Mestre"] | [{"id": 916112, "title": "Associazione Calcio Mestre"}, {"id": 2464917, "title": "Stadio Francesco Baracca"}]
category | subcategories | voices
content basically.
okay. final requirements writing
- You wish quickly accessing content through caching database
- Where key is TEXT(32768) sized
- Key needs to be accessed in equal comparison key=key
- It should return arbitary content of different stuff
- There will be more than 400'000 nodes
- key should be checked by Unique constraint for being unique
precisely.
I would check Postgresql first for this i think
It has different index types, and probably one of them should be working for TEXT(32768), hopefully the hash one
it can have columns with specific values, or can be having as value JSON type (so any arbitary data is desired)
Pretty much universal choice for your case highly likely
Secondly, if amount of data will be very great, distributed databases can be applied like Apache Cassandra stuff. Still SQL database, but specifically intended for... ergh not relational data with search by one key only.
and thirdly, MongoDB can be considered as a choice. Fast to replicate, easy to scale stuff saved to disk too, fitting arbitary amount of data inside and accessed by hash value too. Can be worse choice since no ability to set enforced data structure
Anyway, Postgresql should be investigated first, as well supported solution, good for your small 400'000 amount of records
no point to go into other solutions i think
Postgresql will be possible if desired having enabled in bigger ram of GB caching, it will be very rapidly handling your queries then
Tbh probably default settings would be enough for this.
https://www.postgresql.org/docs/current/indexes-types.html
if primary key would not be willing, then index not in B-tree, but in Hash would work
ergh, check page for which indexes support equality operation
wait bro, but MySQL has the hash index as well
really? its documentation is kind of poor to find it. 🤔 check them too then
https://dev.mysql.com/doc/refman/5.6/en/create-index.html
Found. BTREE and HASH are supposed to be only in MEMORY/HEAP and NDB engines
https://mariadb.com/kb/en/storage-engine-index-types/
hmm, mariadb MEMORY/HEAP/ MyISAM and ARIA engines
I honestly have no idea what these even mean: MEMORY/HEAP/NDB
care to exaplain?
me three 🙂
i am user of Postgresql
not of MySQL/MariaDB
https://mariadb.com/kb/en/memory-storage-engine/
apperently it is entirely changing functionality database how it works
turning it from regular one to working in memory like Redis
NDB was deprecated, and HEAP became MEMORY
so only MEMORY engine is available for Hash key
i think Postgresql is less pain in the ass to choose 😆 it is not having such... conditions. You can use it in standard configuration working from disk like a normal database, and it will work with hashes as it is already
yeah I wish I could experiment more, but in my place of work MySQL is the standard and they rather keep it like this
does this mean that everytime the table is queried it caches the hash of a value for next time? how does in-memory hash even work
so you close the DB and the cache is cleared just like that? then whats the point of having the hash optimization
I might as well make it in Python
hey, i'm making a project, and i want to use some python orm, which is better to use?
SQLAlchemy, probably
do u know any article about choosing an orm?
no idea, but thats the most used. also Django and Flask use that
centralized storage not limited by single application constraints 🤔 the point is valid though, you can make such caching even in Redis then.
redis is at least not wiped during server restarts 😆
or do it in Python and have it stored permamently?

Why would be stored permanently in python
I mean using Python to generate the hash and store it in a seperate column
this is the model btw:
class Category(Base):
__tablename__ = 'categories'
path = Column('path', TEXT(16383)) # TEXT since the path can get very long if the node is far from the root of the tree
path_hash = Column('path_hash', VARCHAR(255), primary_key=True) # TODO convert to VARCHAR(64)?
def __init__(self, path: str, path_hash: str, **kwargs):
super().__init__(**kwargs)
self.path = path
self.path_hash = path_hash
@staticmethod
def get_path_hash(path: str) -> str:
"""
Get the hash value of the given path string
"""
return hashlib.sha256(path.encode('utf-8')).hexdigest()
@classmethod
def create_from_path(cls, path: str) -> Category:
return cls(path=path, path_hash=cls.get_path_hash(path))
and I just use Category.create_from_path()...
and to check if it exists:
with Session() as session:
stmt = select(Category).where(Category.path_hash == Category.get_path_hash(category_path))
row: Category | None = session.scalars(stmt).one_or_none()
if row:
...
what do you think?
Congratulations, you are reinventing the wheel of Postgresql in Python

Possible hash collisions can be.
no, how?
this is basically INDEX HASH but its not working with MySQL, and I dont really have the option to switch DB
You know, two values can yield same hash?
whats the probability?
Depends on hashing function quality
And constant parameters used in it
thats a non-answer 🤣
I have no idea which hashing algorithm u use xD
I'm using sha256, which from what I understand seems to be pretty reliable
or isnt it?

I guess good enough for 400000 values
Chance for collision = ( 1- chance of algorithm collision)^amount of values
close some of those goodamn 81 tabs
U will not be able to calculate such value though
Not sure how bad multiplication with float64 will fail on such operation
But i suspect it will output incorrect stuff
Or may be it will be able
bro I have no idea how to calculate it, but do you think I should search for a better algorithm ? or is this good enough?
Best decision is to be not reinventing the wheel. Which u do.
And to use database already solving it for you 🙂
It is like to implement custom encryption algorithms. Possible, but in prod only students could think to do so
Persuade to use Postgresql :b
ok but I cant switch to PostgreSQL
why not?
if you think about it, PostgreSQL, or whichever database uses some algorithm to hash each value,
so if mine isnt secure, then so is theirs ??!
that sorta depends on what you mean by "secure" doesn't it?
Provide people with made findings, that mysql does not have this functionality and u can offer only custom hashing scripts to reinvent the wheel in it
Recommend using Postgresql, if u a sane people in terms of using right stuff for prod
If they will remain deaf and all persuasions failed (made sure to record it somewhere), then implement approved silly the wheel.
And when prod will fail for some reason related to this implementatiom, u will have documented proof who is really to blame 🙂
but since I don't know the context here, your opinion matters far more than mine
well I mean faulty, specifically that the hash function will assign the same hash to two different values.
thats the only downside I see to it.
Postresql was implemented and had tested their solution for dozens of years and made by many dozens/hundreds of best developers.
Chances for your custom novice solution to compete with it? And having unexpected problem arraised during data scale which will be very high cost to fix?
but you see I'm not inventing nothing, did you see this code?
I'm using the hashlib.sha256() from the standard library to generate the hashses

postgres started out as a project by stonebraker, one of the bigwigs of relational databases (along with codd, rowe, date, et.al.) back in ye olden times. it was the next evolution from ingres (a commercial rdbms that stonebraker also led). to sum up, postgres isn't some "let's learn db's" project like mysql. it was a serious effort with a serious theoretical foundation.
Postresql struggled with correct work of hashing index until tenth major version
Guess how much custom solution by one person will struggle
here's one of the early papers on postgres (c. 1995) => https://dsf.berkeley.edu/papers/ERL-M85-95.pdf
and yeah, hashing is a much more difficult subject than it appears on the surface.
@formal cosmos
Please don't ping random people without good reason
I just see tou dont dm just ask publicly
:●
:♤
@formal cosmos , You Know The MySql?
Which databaee good for python
You don't have to ask specific people if you post publicly, there are plenty of people who can help
Ok
It depends on your use case.
class Database:
"Guys Can Help Me With asqlite or MySql??"```Can you explain more about what you are going to use the database for?
Discord bot
If you have a small number of users and will store the information directly on the host machine then you can use SQLite for it's simplicity
Yeh i found it google too
Idk not high player use my bit i think 😢
sqlite can be good
@burnt turret
is this the right place to ask about a snowflake issue i've been having? basically for the life of me, i cannot remove new lines when converting a VARCHAR to an array via STRTOK_TO_ARRAY()
SELECT STRTOK_TO_ARRAY(REPLACE(COLUMN, '\n', ''), ',')
.... still results in [ " Item1", " Item2"]
I would like ["Item1", "Item2"]
I've been on this for like 2 days now sorry if this is the wrong place to ask
https://discordapp.com/channels/267624335836053506/366673247892275221/1072734328540373083 A simple question about pandas.merge(outer)
I asked it on the data-science chatroom, but I should have asked here perhaps
File "C:\Users\porwa\AppData\Local\Programs\Python\Python311\Lib\site-packages\django\db\backends\sqlite3\base.py", line 357, in execute
return Database.Cursor.execute(self, query, params)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
django.db.utils.IntegrityError: NOT NULL constraint failed: auth_user.last_login
can anybody help me with this error, i was working with django databases and this errors appeared...
Guys I Need Help With Database How I Update The Data?```which database you are using??
Aiosqlite
ohk, you can update your data base with makemigrations and migrate function
They're not necessarily using django
Hello guys, quick question:
I'm using djongo driver in a django project.
The Djongo model queries to a mongoDB database, by translating sql queries I think.
by running this statement:
if Hotel.objects.filter(anno_fiscale=anno_fiscale).exists():
where anno_fiscale is defined as: '2019'.
I get a long traceback, where the important part i'm seeing is:
djongo.exceptions.SQLDecodeError:
Keyword: FAILED SQL: SELECT %(0)s AS "a" FROM "hotel" WHERE "hotel"."anno_fiscale" = %(1)s LIMIT 1
Params: (1, '2019')
Version: 1.3.6
Sub SQL: None
FAILED SQL: None
Params: None
Version: None
It's a long traceback, it also says:
RecursionError: maximum recursion depth exceeded in comparison```
Isn't this wrong?anyone in here doing databases for businesses with a decent amount of clients?
yeah, im kinda asking to ask, plz lemme
it might be the case
Not really, but what do you want?
well I'm looking for advice on how to setup the database/s of what would be a business.
idk what to save, what not to. since there are different products, if i should have a "master" database or a database for each product.
if u think u can help let me know and I can develop on my "issue"
Don't do databases of databases 😆 u are potentially going to regret it with high chance
Use multi schema approach
My current team uses databases of databases for thousand clients and already tries to perform this migration to schemas
Because it is better solution in terms of amount of necessary connections reopening
so a whole database that contains everything from every product?
Anyway... It totally depends on your requirements. I don't know your domain to advice further
nono it makes sense
so okay now I've another question.
I work with an api, it's gives certain data, should we store this certain data knowing that they already store it? how expensive can it be in the long run if you get a good amount of users?
also, knowing that each product manages data differently, should we have a different table for each product? if not, how can we put everything in one place?
how does realises one to many in tortoise orm?
hey y'all, any good w web scraping,
from bs4 import BeautifulSoup
import requests
url="https://www.olx.in/delhi_g4058659/cars_c84/q-swift-dzire-vdi?isSearchCall=false"
page = requests.get(url)
soup= BeautifulSoup(page.content, 'html.parser')
lists = soup.find_all('div', class_="_1H1M1")
for list in lists:
title = lists.find('div', class_="_2Gr10")
price = lists.find('span', class_='_1zgtX')
area = list.find('div', class_='_3VRSm')
year_km = list.find('div', class_='_21gnE')
info = [title, year_km, price, area]
print(info)
selenium
what do you mean
can you type it out
this isnt database related though
How can I add a row if its not present in SQLalchemy?
I'm running into an issue that I have multiple functions that are checking the DB and if the row isnt present, the will add it. The issue is that sometimes there are two functions which are both running in parallel and they add the same value, so I get the error sqlalchemy.exc.IntegrityError: (MySQLdb.IntegrityError) (1062, "Duplicate entry ...
what type of database do you recommend for business matters?
btw, what do you guys prefer, session.scalars(stmt) or session.query(...) ? (with SQLAlchemy)
Is there anyone here who is a database developer?
Sounds like you need Fault Tolerance to retry failed tasks. Celery has it
Otherwise consider may be it is correct behaviour
Technically Mutex lock can prevent them working at the same time, but it is solution only if your processes share memory of app
Multithreading
Hello, I am having some trouble with mysql in python and would appreciate some help
Here's what I am trying to do:
monthNum = '12'
Year = '2022'
sql = "SELECT Emotion, COUNT(ID) FROM DATA GROUP BY Emotion where Month(date)=%s && Year(Date)=%s;"
val = (monthNum, Year)
mycursor.execute(sql)
The error I am getting is:
ProgrammingError: 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your MariaDB server version for the right syntax to use near 'where Month(date)=%s && Year(Date)=%s' at line 1
The group clause must come after the where and it's AND in sql not &&:
monthNum = 12
Year = 2022
sql = "SELECT Emotion, COUNT(ID) FROM DATA WHERE Month(Date)=%s AND Year(Date)=%s GROUP BY Emotion;"
val = (monthNum, Year)
mycursor.execute(sql, val)
And I'm not sure if Date is a keyword and may needs quoting.
I would use integers for month and year.
Don't forget to use the val parameter in .execute()
Hello 👋, let's say that I have a municipalities DB table that has a compound Primary key: municipalityId, insertion time. The reason why it requires insertionTime as part of the PK is because its municipality can be inserted multiple times. I wouldn't do it this way, what's the point of having the same municipality inserted multiple times with different insertion times... I know that it's quite silly, but that's how they wanna do it... The thing is that, I have another DB table that references municipalityId and I cannot create a Foreign Key constraint cause it warns me that the relation cannot be established, which makes sense. Is there a way to attain this considering the restriction that I mention before?
If your primary key consists of two columns your foreign key must also consists of two columns which make it unique.
Yeah definitely
I think that my colleges they are not fully aware of that yet😅
Mm...
How am I suppose to establish a field that matches insertion times of municipalities table?
So that I can create a two column foreign key
I've never used Celere, I'm currently using SQLAlchemy and this solution works for now:
try:
with Session() as session:
session.add(new_category_record)
session.commit()
except IntegrityError as ex:
msg: str = ex.args[0]
if '(MySQLdb.IntegrityError) (1062, "Duplicate entry' not in msg or 'for key' not in msg:
raise ex
Session.query is legacy
so Session.scalars is the best way?
Yep, execute, scalars, scalar
whatever you need
and what is the difference between scalars and scalar?
Scalars returns multiple values, scalar returns one or none
ah I see, thank you!
I have some functions like get_column_names(TableClass), get_columns_with_constraints(TableClass), they just get a sqlalchemy table class and return column names or names with constraints, currently they use a global engine, should I make this non global?
I mean, should I pass the engine as a parameter to these? or should I pass a connect string and have the function create an engine?
its hard to tell without seeing what the function does
let me get a simple one
engine = create_engine(conn_str)
def get_column_names(table):
inspect_obj = inspect(table)
return [i.key for i in inspect_obj.columns]
get_column_names(Foo)
that is one example, I have many wrappers like these, "inspect" is from sqlachemy.inspect
Is there any free cloud sql database without any card
why would you want to make it engine/session dependent if it dosent even need that paramter?
the table I use is reflected, not something I define
like so
class Foo(Base):
__table__ = Table('foo', Base.metadata, autoload_with=engine)
shouldnt i have the same engine if I want to call this function?
kinda new to sqlachemy
Hello, how to make Discord bot to register timers in database?
I highly doubt it... Maybe PythonAnywhere's Beginner account has some kind of DB support but I'm not at all sure it does
I used time.time
others are too hard
Can I ask someone to host me a database? is it possible.
btw, you dont need an engine or a Session to use inspect() on a table-class
so to answer your question; no
also, if you are using the class to create tables, I would go with this method:
class User(Base):
__tablename__ = "user"
id = Column(Integer, primary_key=True)
name = Column(String)
fullname = Column(String)
nickname = Column(String)
guys i was trying out golang can somebody help me out if its fine to ask golang questions here..
You should use Mapped and mapped_column 😉
class User(Base):
__tablename__ = "user"
id: Mapped[int] = mapped_column(primary_key=True)
name: Mapped[str]
fullname: Mapped[str]
nickname: Mapped[str]
For free? You get what you pay for. Might as well self-host on your own laptop or whatever at that point.
CREATE TABLE TAGS(
id BIGSERIAL,
tag_name text UNIQUE,
user_id bigint,
guild_id bigint DEFAULT NULL UNIQUE,
points_to bigint REFERENCES TAGS(id) ON DELETE CASCADE,
content text,
created_at timestamptz,
is_global bool default false,
uses bigint not null default 0,
PRIMARY KEY (id)
);
ALTER TABLE TAGS ADD UNIQUE (is_global);
So I have this old table that was designed for tags where it allowed it to be a dm tag, a guild tag or global tag (this is if it's approved)
how would I make the queries for it or should I make it from scratch) (this is not currently in my postgresql database)
idea:
DM tag and normal tag support
So I am going to do this
1. dm -> your personal
2. normal tag support i.e. guild
3. one to be checked is global tags, which will be done by me
tags(DM based and guild tags)
4. aliases too
A.k.a having your own user tags in your dm channel, or maybe sharing them idk
Yeah I am going to share them(a.k.a you can show tags to friends)
Tag is like message autoresponse? And you want to have autoresponses that work in DM, single guild and all guilds respectively?
it seems like mapped is actually the latest method, but its only for type hints which you could declare at __init__, anyway I dont see many people use it
Not really, it's for all parameters
All columns now can use Mapped
understood
Tags are messages that people create to explain a thing
For example t.tag cats
"Cats are one of the most adorable animals and are memed a lot"
I would recommend to have a structure like
class TagType:
DM = 0
GUILD = 1
GLOBAL = 2
Alternatively you can use sep table for this enum-like class, but imho it's too much hustle.
The table can look like this
CREATE TABLE IF NOT EXISTS tags (
name VARCHAR(32) NOT NULL,
tag_type SMALLINT NOT NULL, -- here you would use that TagType
owner_id BIGINT, -- either user ID if type is DM, guild ID if GUILD and NULL if GLOBAL
);```
Then I think everything should be easy to figure out. If you need uniqueness, just add constraintsIt couldn't recognise comments too bad
that's really smart
There's also a second table
either only in your dm channel
global - for you everywhere
guild -> for that guild(guild owner only)
and then for that channel if you have proper permissions
(invalidation config a.k.a token invalidation)
\d invalidation_config
Table "public.invalidation_config"
Column | Type | Collation | Nullable | Default
-------------+-------------+-----------+----------+---------
entity_id | bigint | | not null |
bound_to | bigint | | not null | 0
entity_type | etype_enum | | not null |
mode | config_type | | not null |
invalidate | boolean | | | true
Indexes:
"invalidation_config_pkey" PRIMARY KEY, btree (entity_id, bound_to, entity_type, mode)
--
-- Name: invalidation_config; Type: TABLE; Schema: public; Owner: jdjg
--
CREATE TABLE public.invalidation_config (
entity_id bigint NOT NULL,
bound_to bigint DEFAULT 0 NOT NULL,
entity_type public.etype_enum NOT NULL,
mode public.config_type NOT NULL,
invalidate boolean DEFAULT true
);
ALTER TABLE public.invalidation_config OWNER TO jdjg;
--
-- Data for Name: invalidation_config; Type: TABLE DATA; Schema: public; Owner: jdjg
--
COPY public.invalidation_config (entity_id, bound_to, entity_type, mode, invalidate) FROM stdin;
351656397257310212 336642139381301249 user guild f
\.
--
-- Name: invalidation_config invalidation_config_pkey; Type: CONSTRAINT; Schema: public; Owner: jdjg
--
ALTER TABLE ONLY public.invalidation_config
ADD CONSTRAINT invalidation_config_pkey PRIMARY KEY (entity_id, bound_to, entity_type, mode);
This is designed to be opt in token invalidation
guys how to make barplot for each class the sum of the two other columns?

I have no idea what we're looking at, but if you're asking how to draw a basic barplot in Python, I like Seaborn: https://www.geeksforgeeks.org/seaborn-barplot-method-in-python/
GeeksforGeeks
A Computer Science portal for geeks. It contains well written, well thought and well explained computer science and programming articles, quizzes and practice/competitive programming/company interview Questions.
Would the result of a dropdown selection be stored as a string within a database (SQLite3)?
That's OK, but it's generally better to store those strings just once in their own table, and then store the indexes that correspond to those strings as foreign keys somewhere else.
ah, alright, I need to read more about that, have not heard of foreign keys yet
a list of number is considered text or bigint in postgres
im so confused with the datatype of a list of userid
its not bigint but i dont think its text as well
like [0,1,2,3]
look explain please no is correct, "incorrect" but explain only separated other separated

Look example:

should I add more info?
What is the datatype of the field? I'm pretty sure you can have text[] or bigint[] or whatever you want.
File "<frozen os>", line 679, in getitem
KeyError: 'mongodb://127.0.0.1:27017'
any idea ?
Don't ask to ask
I got recommended to have 1 database for all the services I have, instead of having 1 DB for each service.
Now the question is, should I have 1 table for each service? or try to put everything in one table?
tables represent 'objects' (in database terms, records) just like classes in OOP
if two services interact with the same 'objects', you might want for them to use the same table
you almost definitely should NOT use the same table for everything though
some databases also allow for one database 'instance' to have multiple different 'databases' - which you might want to use if your services are 100% unrelated to each other
(think of the multiple 'databases' like namespaces in this case though)
the services are all related because they are all used for one type of thing, but they might work with different data.
so it sounds like having one table per service is the right choice here, right?
are you familiar with OOP and using classes to represent different objects?
you would usually have one table per 'class' you want to store in the database
I understand the concept, I know how it works, used it a couple of times but I dont use it
makes complete sense.
but the answer would still be this, right? since they work with different data.
if you have one service that stores three different kinds of data, you'll want to have three (or perhaps even more, if you need to JOIN stuff) tables just for that service
if you had two services that use the same data, you might want to use the same table for both of these services
if you had two services that use the same data, you might want to use the same table for both of these services
absolutely
if you have one service that stores three different kinds of data, you'll want to have three (or perhaps even more, if you need to JOIN stuff) tables just for that service
three tables for one service? I think I don't understand.
if you had one service that manages people and their pets, you might want something like ```py
class User:
id: int
name: str
class Pet:
id: int
name: str
species: str
tables = [
'''CREATE TABLE user (id INT PRIMARY KEY AUTOINCREMENT, name TEXT)''',
'''CREATE TABLE pet (id INT PRIMARY KEY AUTOINCREMENT, name TEXT, species TEXT, owner INT FOREIGN KEY user.id)''',
]
(side note: treat that as pseudo-code at best)
Ok I see now 
So you in a way share databases to avoid storing the same data more than once, it seems like?
There's also a second table
either only in your dm channel
global - for you everywhere
guild -> for that guild(guild owner only)
and then for that channel if you have proper permissions
(invalidation config a.k.a token invalidation)
\d invalidation_config
Table "public.invalidation_config"
Column | Type | Collation | Nullable | Default
-------------+-------------+-----------+----------+---------
entity_id | bigint | | not null |
bound_to | bigint | | not null | 0
entity_type | etype_enum | | not null |
mode | config_type | | not null |
invalidate | boolean | | | true
Indexes:
"invalidation_config_pkey" PRIMARY KEY, btree (entity_id, bound_to, entity_type, mode)
--
-- Name: invalidation_config; Type: TABLE; Schema: public; Owner: jdjg
--
CREATE TABLE public.invalidation_config (
entity_id bigint NOT NULL,
bound_to bigint DEFAULT 0 NOT NULL,
entity_type public.etype_enum NOT NULL,
mode public.config_type NOT NULL,
invalidate boolean DEFAULT true
);
ALTER TABLE public.invalidation_config OWNER TO jdjg;
--
-- Data for Name: invalidation_config; Type: TABLE DATA; Schema: public; Owner: jdjg
--
COPY public.invalidation_config (entity_id, bound_to, entity_type, mode, invalidate) FROM stdin;
351656397257310212 336642139381301249 user guild f
\.
--
-- Name: invalidation_config invalidation_config_pkey; Type: CONSTRAINT; Schema: public; Owner: jdjg
--
ALTER TABLE ONLY public.invalidation_config
ADD CONSTRAINT invalidation_config_pkey PRIMARY KEY (entity_id, bound_to, entity_type, mode);
datatype bigint[]?
is there something like a not like for sqlalchemy?
for example i can write this out in pgadmin SELECT * FROM public.carddata WHERE game='mtg' and identity='C' and cardtype!='Land' and names not like '%Art%' and names not like '%Token%' and names not like '%Emblem%';
but can i write something like the following - and names not like '%Emblem%'
I want to use the sqlalchemy orm to make the query
@pastel wren Does that solve your problem or you still need help?
it solved it. thank you 🙂
You can find most operators on that class
And you can use custom operators using op:
SomeModel.column.op("some_operator_from_db")("value")
ooh cool. thanks
You rarely need it though 😉
i figured that it was more of a special case
can I somehow run a portable version of mongo with my python application?
conn=await conn.cursor()
it is called using Docker 🙂 (and docker-compose makes it easier)
that will be portable at the level of dev environment and linux servers at least
if u wish it being portable to desktop users... then no.
asyncpg uses auto-commit, so really, @torn sphinx can remove the function for commitment altogether.
unless you're calling an instance of the Transaction class and building the transaction that way.
then commit() is a method of the Transaction object

here's a link to the documentation for asyncpg, might come in handy as you work on your project =]
i have a question
if i have a list
maybe in excel
if 1 column maybe has group of fruits
apple
banana
strawberry
and i want it to repeat its value again but in another column without rewriting the whole column as in
if list == "apple":
print("apple")
as if its in a for loop
KeyError: 'mongodb+srv:/
any idea ??
Need more context.
Is it possible to use Postgres COPY FROM/TO commands with sqlalchemy?
anybody here who worked with mariadb aria i want to know can it provide the functionality that redis does
I'm using bcrypt to check if the user's login credentials matches the hashed password that's in the database. Whenever I try to retrieve the user's hashed password from the server's database, it retrieves the integer 1 instead and I am not sure why this is the case.


bcrypt has some randomness to it, it uses random salt, unique to each password
You need to retrieve user and password using username and check if hash matches password, your library should provide a separate function for that, e.g.:
check_password(hash, password)
Also, Line 44 in the above screenshot is only the execute. You'll also need to do a .fetchone() to get the selected column.
Hey guys, I need help with discord module and databases, I am new to Databases (never used them).
So I made slash commands, and a command where I enter some letters
And I want when I use another command, I got those letters, how to do this?
I'd like to learn how to structure databases. I can create really basic databases and I know some basic queries, but I think queries is not the most important thing, you can just google how to query X thing, I think I need to learn how to build good databases. Where should I learn from? Thanks in advance 💙
may be it is silly book, but it explains very well how to perform process of Normalization

and normalization process (1-2-3 level) is exactly important to build good relational databases
as for learn how to build good databases... ergh... i haven't encountered book advising on this topic (hmm actually encountered)...
it is more than just SQL relational databases logic to handle.
https://sre.google/books/ Site Reliability Engineering book i remember had parts regarding it i think
Probably data intensive applications book should be having important information regarding it (haven't read yet)

Discover Site Reliability Engineering, learn about building and maintaining reliable engineering systems, and read books online to learn more about SRE and other reliable engineering organizations
There are many databases.. and in it is good to learn when is the right time to apply which one. and all the cases when you aren't supposed to user noSQL databases 😆

presume to use SQL databases until you very well learned when alternatives should be used
Hello, is it posible to define date field format while creating a DB table?
create table mytable (
datefield Date as 'dd/MM/yyyy'
)
Cause I try to insert with this format dd/MM/yyyy but then Postgres converts it into what I guess is the default format yyyy-MM-dd
https://www.postgresql.org/docs/current/runtime-config-client.html#GUC-DATESTYLE:~:text=Locale and Formatting-,DateStyle (string),-Sets the display
you might want to set the option here?
omg thanks for all of this info!!!!!!!!!!!
I'm not too familiar with indexes but if I wanted to implement indexes, Am I suppose to add an index to every column in my table?
no, not to every column.
Adding and maintaining (updating) an index is somewhat expensive - you'll want to have indexes for some of your most common queries, but you should avoid having unneeded indexes
each added index adds considerable taken storage disk space proportional to amount of records 🙂 use sparingly.
Here's a table question I Have about:
either only in your dm channel
global - for you everywhere
guild -> for that guild(guild owner only)
and then for that channel if you have proper permissions
(invalidation config a.k.a token invalidation)
\d invalidation_config
Table "public.invalidation_config"
Column | Type | Collation | Nullable | Default
-------------+-------------+-----------+----------+---------
entity_id | bigint | | not null |
bound_to | bigint | | not null | 0
entity_type | etype_enum | | not null |
mode | config_type | | not null |
invalidate | boolean | | | true
Indexes:
"invalidation_config_pkey" PRIMARY KEY, btree (entity_id, bound_to, entity_type, mode)
--
-- Name: invalidation_config; Type: TABLE; Schema: public; Owner: jdjg
--
CREATE TABLE public.invalidation_config (
entity_id bigint NOT NULL,
bound_to bigint DEFAULT 0 NOT NULL,
entity_type public.etype_enum NOT NULL,
mode public.config_type NOT NULL,
invalidate boolean DEFAULT true
);
ALTER TABLE public.invalidation_config OWNER TO jdjg;
--
-- Data for Name: invalidation_config; Type: TABLE DATA; Schema: public; Owner: jdjg
--
COPY public.invalidation_config (entity_id, bound_to, entity_type, mode, invalidate) FROM stdin;
351656397257310212 336642139381301249 user guild f
\.
--
-- Name: invalidation_config invalidation_config_pkey; Type: CONSTRAINT; Schema: public; Owner: jdjg
--
ALTER TABLE ONLY public.invalidation_config
ADD CONSTRAINT invalidation_config_pkey PRIMARY KEY (entity_id, bound_to, entity_type, mode);
is there a different way of writing updates using the sqlalchemy orm? In the docs it says to do it this way but it's not working the way it's supposed to work. here's the docs https://docs.sqlalchemy.org/en/20/tutorial/data_update.html
I'm trying to figure how out the password variable has ghost initialized to it when I was trying to make storedInDatabase initialized to it.

storedInDatabase has the hash of ghost initialized to it.
how do I come up with a way to revert changes made in a db
Use ALTER
What kind of changes?
if user ran a wrong sql command
For DML operations (update, delete, insert) you can use transactions
what if the user ends the transaction and later realises the issue, then what should they be able to do to revert back progress?
No, if transaction is aborted you can't get previous state 🤔
Ideally users shouldn't run SQL directly
They should interact with some sort of api, unless that DB is stored locally (e.g. using sqlite)
I find myself constantly doing:
record_exists = any(conn.execute(f'SELECT * FROM table WHERE a = {some_values}'))
if not record_exists:
conn.execute('INSERT INTO table (a) VALUES (?)', some_values)
Is there a way of doing this all in SQL as one transaction? because this is getting very slow when I have lots of records (millions)
I've heard of INSERT IGNORE but unfortunately you cant specify the exception to ignore, so it will any error pass silently.
Then there is INSERT ... ON DUPLICATE KEY UPDATE which forces me to UPDATE something when I just want to return/pass.
And lastly REPLACE INTO which will overwrite it if it exists, which I don't really like.
Are there any other options? and is it possible to create a procedure or a function that does this?
(I'm currently averaging 1.4 ms per record, which is pretty slow)
are you using mysql?
yep
what version?
altough I'm using it rough SQLAlchemy's API
I have 8.0 but in production I'm probably gonna use 5.7
Although I could update it if there is a big difference
in general i would always use the same version as prod for dev, but that's a completely different issue.
let me go check the docs real quick.
yeah its not ideal
i am assuming your column a already has a uniqueness constraint on it?
in some tables its a PK, in others its just UNIQUE and in the third one its none of them
(in the third table I do: WHERE a = {x} AND b = {y})
Then there is INSERT ... ON DUPLICATE KEY UPDATE which forces me to UPDATE something when I just want to return/pass.
this is probably the best you can do, to mimic a "do nothing" in postgres (or as you call it "pass"), you canupdate <your-pk>=<your-pk>, at least that's what i am reading anyway
https://stackoverflow.com/a/56944420 pretty decent answer
Stack Overflow
I have a table with a unique key for two columns:
CREATE TABLE xpo.user_permanent_gift (
id INT UNSIGNED NOT NULL AUTO_INCREMENT ,
fb_user_id INT UNSIGNED NOT NULL ,
gift_id INT UNSIGNE...
as for your third type of table, i have no clue how mysql deals with that sorry! i only use postgres
So this is the exact same as using REPLACE INTO, correct?
replace into completely removes the row and insert the new one if i understood correctly
whereas INSERT ... ON DUPLICATE KEY UPDATE <your-pk>=<your-pk> doesn't actually update anything even if you are seemingly updating your PK
do I need to close sqlite's Cursor too if I already have closed the Connection?
I am using sqlite which has the db stored locally
first close the cursor, and then the connection
It should perform the UPDATE tansaction/operation, but yeah, the data will be exactly the same
what about procedures? are you familiar with them?
thanks!
you can double check the number of rows affected after you executed your query, there are people online saying if you do an no-op update, the update itself is optimised away, and no UPDATE would be issued at all.
not really, haven't found a need for them especially with mysql which i don't use regularly
Hello Everyone, I have query where it takes value from input in postgres and returns the result, while passing input to query, user have option to pass number or empty string if string is empty query should perform the other where case
SELECT tal.dtncode AS dtncode, tal.dtnname AS dtnname, tal.thncode AS thncode, tal.thnname AS thnname,
MAX(dbt.activity_group) AS activity_group,MAX(dbt.activity_group_id) AS activity_group_id,MAX(dbt.activity_group_code) AS activity_group_code,
SUM(no_of_application:: INTEGER) AS no_of_application, SUM(no_of_presanction:: INTEGER) AS no_of_presanction,
SUM(no_of_paymentdone:: INTEGER) AS no_of_paymentdone, SUM(no_of_registration:: INTEGER) AS no_of_registration,
SUM(no_of_work_completed:: INTEGER) AS no_of_work_completed,
COALESCE(SUM(no_of_village:: INTEGER), 0) AS no_of_village,
tal.geom AS geom
FROM pocra_dashboard."Taluka" tal LEFT JOIN dbt."dbt_activity_group_taluka_Farmer" dbt ON tal.thncode = dbt.taluka_code
WHERE
dbt.district_code = '515'
AND
( CASE
WHEN activity_group_id = '' THEN NULL
ELSE activity_group_id
END
) = activity_group_id ---
GROUP BY dtncode,dtnname,thncode,thnname, geom
ORDER BY dtncode, thncode
please suggest edits
activity_group_id is optional, if it equal to '' then only district_code value should be considered
I want to generate a unique primary key but I dont want to use auto increment, is there a better alternative. I see people using uuid, but does it affect the performance of the database if I have 10 million + records?
I'm no expert, but I think I would go with UUID. a) What else is there? I agree incrementing 10 mil. integers doesn't seem desirable. b) I can't imagine it would slow things down dramatically, but you could test.
would you recommend checking the uniqueness of the id given with the database ?
So, sqlite supports TEXT[] datatype when you create a table, but how do I insert into it?
what module is the best for databases? (except of sqlite)
It may depend on the use case and you may need to test, but I assume the most efficient in general would be to rely on a uniqueness constraint on the column and handle the very extremely unlikely event of an error if it occurs.
Any reason you don't want to use auto increment?
A Python module other then sqlite3? Generally I use SQLAlchemy. If you mean a database, my go-to when Sqlite is not robust enough is Postgres.

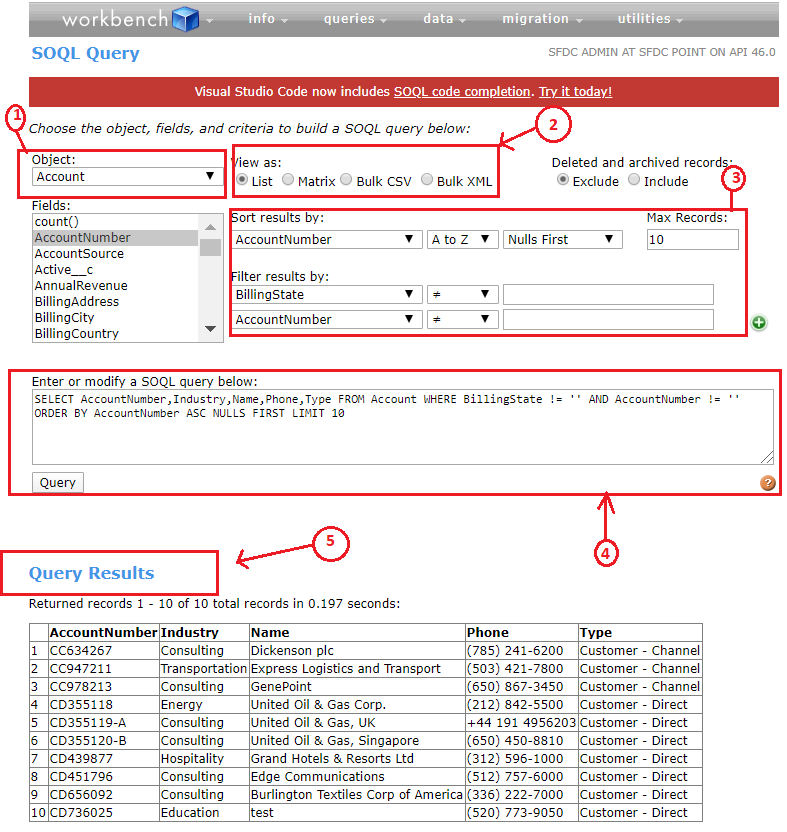{kind=link}
ok, thanks
Could you please check my questition? #1075123456116523039
Is there any better place to train sql other than sql-practice?
there are some SQL resources pinned, have you checked them out?
Oh, I will do now, thanks!
If someone wanted to set up a VM, then install MySql on it, plus do other database administration things, what kind of courses/training can someone do?
hi everyone ! İ need help on build restful api for msSQL with python. Can anyone help me ? i did not build before. There is any useful tutorial. Thank you in advance
I am trying to create a database archive, in which the archive contains the same values but has one extra (time stamp). I am trying to insert into the archive but it isnt happening. anyone can explain why?
Is there a way to check if a sqlalchemy select was successful?
besides iterating over the pointer to it
hey geis, I've switched to the dark side here and I'm asking for help on how to download python in a jpg file
please see


which bracket should i use
its a list btw
datatype = text[]
do i need to make the list a variable and put it as $2
hey guys
sql injection!
I am not exactly familiar with that but from my understanding, hackers use it.
Hey guys, what is the best way to enforce that a subclass of a Django ModelViewSet has a specific class attribute implemented? I've created a function that does so, but when should I call it? new and then call super().new?
if someone is familiar with django and has some time i would appreciate it: #1075444152222875759
Got the following problem using MongoDB;
I'm trying to remove a specific field with the given UID in this case "584u-4p75-WUR0-5Pwm". It pulls the field, yet doesn't remove it for some reason. Every necessary information is listed in the stackoverflow question, for more information either ask me here or comment on the question.
https://stackoverflow.com/questions/75463983/successfully-pulling-field-unsuccessfully-updating-it
Stack Overflow
I got the folllowing problem:
I'm successfully pulling the field with the UID "584u-4p75-WUR0-5Pwm" (the UID I'm testing it with), yet it's not updating it. The output of the prints is the
Is it possible to merge the migrations for PocketBase into a single file?
Anyone got an idea who this wouldn't remove the entry from the database:
await db.execute('DELETE FROM afk WHERE user_id = ? ',(message.author.id,))
It puts it into the database, just doesn't delete it
no errors either
why would this work, it works for my mate but wont for me, bit confused as it returns no errors

HELP NEEDED
please
Situation:
I have a raspberry pi 3b as development pratform
Write a dc bot with mariadb integration
Buy a banana pi m2 berry for deployment because Chip shortage
Setup environment on banana pi, trying to make sure I set it up the same way on rpi
It throw this error
Find and follow stack overflow advice
unable to resolve problem
and here I am

Hello,
I see that COALESCE takes the first value in a list which isn't null, i.e.
SELECT COALESCE (val1, val2, val3)
FROM some_table
WHERE id = 5
if val1 = Null, val2 = 4, val3 = Null, then this will select only the number 4.
I want to store values into a table in which there are columns according to mysql type. so let's just say a column for ints and a column for varchar
This way I can simply do a COALESCE and get whatever the correct value is.
How do I actually go about INSERTING these values? Like if I have a value that is either a string or an integer. How do I programmatically insert it into my table so it knows to insert it in the correct column?
Help needed !! I have this "Fångvaktare""" value and when I upload it to postgresql it shows int64 error. How do I remove the quotes and this is only for a few values out a 10 million value file.
@commands.Cog.listener()
async def on_message(self, message):
if message.author.bot: return
cursor = await self.bot.database.cursor()
await cursor.execute('SELECT * FROM afk WHERE user_id = ?', (message.author.id,))
data = await cursor.fetchall()
timestamp = data[0][2]
time = humanize.precisedelta(timestamp - discord.utils.utcnow().timestamp(), format='%0.f')
if data:
await cursor.execute('DELETE FROM afk WHERE user_id = ?',(message.author.id,))
else:
return
await self.bot.database.commit()
await message.channel.send(f'Welcome back, you were away for **{time}**')
if message.mentions:
for mention in message.mentions:
await cursor.execute('SELECT * FROM afk WHERE user_id = ?', (mention.id,))
data = await cursor.fetchall()
await message.channel.send(f'**{mention}** is currently **AFK**: {data[0][1]} - {time} ago')
Bot isn't sending message and not getting data from database if a person gets mentioned who is in the database.
Do you have message content intents? And you're sure the listener is working?
Yes I do, the listener works. Me and someone else in d.py discord have come to the conclusion it's either the mention.id or the cursor.execute that doesn't work properly. It returns mentions if I just try to print them after the for loop.
Hello programming guru.
I am asking you if you can help me. The circumstances were such that I had to leave my country and move to Spain, which I did not know. And now I have to start from scratch. So someone can take me as a student or assistant . I am ready to perform any tasks to gain experience and skills. I have a little knowledge in python. I understand neural networks and have been involved in cyber security for a long time in my country
Hi guys i need help with this issue. I have a table named products and i need to know if it exists before i write to it so basically there's no data in the table but i need to know that the table has already been created. So i run:
cur.execute("SHOW tables LIKE products")
print(self.cur.fetchone())
How can i do that because i think my current approach above is not working. Have also tried:
if cur.execute("SHOW tables LIKE products")
print("Validated")
I am trying to come up with a database design where in the log table the table is used to look values in the correct table. How would I do that?

How would I do?:
A. Move databases to a different database (I want to move sincorini to its own user to easily manage)
B. Does it require its own user?
Or is this for just using psql?

start() initialises connection and cursor, finish() contains conneciton commit, cursor closure and connection closure
when ran it tells me my db is locked and idk how to fix

- show what exactly you are doing in
start() - are you accessing that database from multiple files and/or using threading/multiprocessing/asyncio?
im a beginner if u cant already tell 😢

if you don't know what the last three words mean the answer to the second question is 'no'
yea the answer to the second q is no
not sure then
just making sure: are you using that with something like flask, discord.py or some other library that controls the flow of the program for you?
pygame