#databases
1 messages · Page 7 of 1
In that case even if results: may be sufficient
Not with how it's setup right now. It's a leaderboard command that creates a temp table of all members ordered by points, limit 10. Then I fetchall and start assigning variables. So I think I can make len() work in my favor because then the leaderboard could be any length Less than 10 if the db isn't long enough
well, a list counts as truthy if there's at least one item, so if results: and if len(results) > 0: are equivalent to each other
With len() though I can do >1 and >2 etc to make the resulting message different in size if there's, say, 4 entries
that sounds a bit like a code smell
preferably one block of code should adapt for 1-10 items, unless you require some extravagant styling changes
I'll toy with it more tomorrow if I get time, thanks for the help
Hey, I have a question about SQL. I don't understand why we use ALTER and add CHECK constraint instead of SELECT and WHERE or perhaps even SELECT and CHECK

This is my professor's exam preparation note.
SELECT * FROM ACCOUNT WHERE ACCOUNT_CK_BALANCE <= 1000
Won't that work as well? Is it one of those things that "there are many ways to get the same result" thing?
SELECT * FROM ACCOUNT
ADD CONSTRAINT ACCOUNT_CK_BALANCE
CHECK (ACCOUNT_CK_BALANCE <= 1000)
Anyone?
Uh...

SQLite does not support to add constraint in alter table. this must be done at create table. And a constraint is defined for a column or a table as a whole, a select can't have a constraint. A CHECK constraint is done for each insert or update and if it fails it's raising an error where a where statement just don't display data which does not match.
I see
Thank you!
from typing import Optional
from sqlmodel import Field, BigInteger, Column, SQLModel, JSON
from engine import engine
class Hero(SQLModel, table=True):
__tablename__ = "tage"
name: Optional[str] = Field(default=None, primary_key=True)
secret_name: str
age: Optional[int] = Field(sa_column=Column("age", BigInteger))
wives: Optional[dict | list] = Field(sa_column=Column("wives", JSON))
class Config:
arbitrary_types_allowed = True
class Subhero(Hero, table=True):
pass
def create_db_and_tables(): #
SQLModel.metadata.create_all(engine) #
create_db_and_tables()
Why subhero table is not creating???
What I want is create a new subhero table with column same as hero
Hello! I am planing to build a chat application in a few days but I am pretty confused when it comes to Database.
Can you guys suggest me a fast, noSQL database? (Except Firestore and Cassandra)
The only one I've really used is Mongo
Scylla and Cassandra are probably the top performers
well, Scylla is probably the fastest you can get outside of in memory redis

Probably yes, it depends on exactly what you're trying to do. If the history table just needs to store search terms, user IDs, and timestamps that's simple enough
Makes sense to me
That's what foreign keys are for
If you want to know the search history of user 1, you query the history table for user 1's records
Just a basic SELECT ... WHERE
Anyone familiar with models in django?
Don't ask to ask, just ask
In django i've created 3 models ['participants', 'team1', 'team2'] i just simply want to move the data from participants to either team 1 or team 2 when I press the button correlating to the team the player needs to go too. im using django with sqllite3, and html/css. Im even willing to hop on a call if someone can help me, i've spent hours with this issue
I suspect you'll need to share your code for anyone to understand what you're trying to do. #❓|how-to-get-help
class Participant(models.Model):
name = models.CharField(max_length=22)
def __str__(self):
return self.name
class Blue_team(models.Model):
name = models.CharField(max_length=22)
def __str__(self):
return self.name
class Red_team(models.Model):
name = models.CharField(max_length=22)
def __str__(self):
return self.name

Question: If I were to use df.queries() on this and wanted to write a program where it prints out the total expenses given that the region == West and the sales are greater than 50,000 , how would I do so?
this sounds like a homework assignment?
no
I am doing a project
but am stuck in this particular place
the project contains names of individuals in an organization and therefore cannot share their names.... so I used this crappy example off the internet as a similar situation
but I wanted to know the logic since I have been trying for ages
@harsh pulsar
hi guys!
I tried to make SQL proxy and I need to manipulate the raw query using python, my goal is encrypt the value based on column name, for example:
confidential_column = ["name", "emp_number"]
and the query:
SELECT id, name, emp_number, created_at
FROM public.employee
WHERE name = 'testing' AND
emp_number = '123' AND
created_at = "2022-26-10"
expected_result:
SELECT id, name, emp_number, created_at
FROM public.employee
WHERE name = '*encrypted_testing*' AND
emp_number = '*encrypted_123*'
created_at = "2022-26-10"
is there's any best practice for doing it? thanks in advance 🙏🏻
Hey guys , anyone use mysql workbench?
like so?
confidential_column = ["name", "emp_number"]
query = f'SELECT {", ".join(confidential_column)} FROM ...'
@queen rose not like that, only the WHERE statement but from the vonfidential column, I need to change the value
I've never seen someone using a Year-Day-Month format for a date, that's just wrong.
I've seen every stupid date format imaginable, but if you have any choice in the matter, ISO or GTFO
ISO 8601 is good
I was referring to your example: created_at = "2022-26-10"
Can someone help me understand the difference between a primary key and foreign key
The primary key is the key for the record on a given table, a foreign key relationship ties to the primary key on a different table.
What would be an example of a foreign key?
The SQLite docs have a nice foreign key introduction: https://www.sqlite.org/foreignkeys.html (with examples)
ID, let's say ID. that is a good sample of foreign key! a sub item taking id of an item, ie.
Hey everyone! I'm making an application for a list of judo tournaments. I need to be able to save the IDs of participated tournaments for every user, and the number of points received for it. How can I implement this, and what will my DB look like in this case?
Sounds pretty straightforward, what's the question exactly?
I am trying to build out an ER diagram in mysql workbench. I have one employee table with an employee_id and standard data about that employee. Then a doctor table with employee_id as a FK. Then, I try to add a nurse table with employee_id as a FK and it tells me duplicate FK. Can you not use the same FK name in multiple tables?
Can anyone explain the flow of serving data through Restful APIs? For example If I have a custom data set that I want my team to have access to via an API endpoint. How would I store that custom data set? (In a db, locally etc..)
In most cases you'd go with a database
Thanks!
You can assign doctor_id to your nurses' table and use it to access the patient ID from the doctors table. It also makes more sense since different than doctors, nurses don't actually have patients, they are assigned to help doctors who have the patients.
I am having trouble with my flask-sqlalchemy. The details are in #help-lemon so please help me if you can
When I want to import some MySQL dumps via Python, should I be using subprocess.run() and mysqlimport for that task? From what I understand, importing entire dumps is not what the MySQL connector for Python is made for.
The question is why you want to do that from python?
It's part of a larger program and I wanted to do everything with a central tool. That might not be the most elegant but I think it's better than doing some parts with Python and other parts via Shell scripts or something like that
should I do conn.commit() after dropping a table or view in Sqlite3?
from my understanding the only benefit for declaring a column as PK or FK is performance, is there any other functionality that changes with that?
DDL commands autocommit
thats great to know
so I will remove the commit from all the CREATE and DROP commands in my script
I think that should work
It also helps with data integrity.
If you have a user and a user_inventory table the user_inventory will get automatically delete if you delete the user and have set the FK to cascade on delete.
Otherwise you'll need to do it manually and you might overlook one table and get ghost entries (or if the userid will get reused some old entries for a new user).
interesting, I didnt think about this
ensuring integrity is the primary purpose of foreign keys
write performance can decrease as a result of foreign keys, as the database has to do extra work to verify that integrity is maintained according to the constraint
this is all new to me, is good to know the reasons as to why we do certain things
guys smoll question
how can i add multiple values to the "things" column? (not at once) like for example an inventory command, when buying things it gets added to it

you want to insert several rows? you can just do multiple INSERTs
most python database libraries also have an "executemany" function that will do a bunch of inserts for you
several rows ? do you mean in 1 colmun ?
are you trying to put multiple values into a single database cell?
yes
that's not recommended
how else can i do it ?
there are some specific use cases for it. but in general the best option is to have 1 row per "thing"
your inventory table can look like this:
| user_id | item_id | quantity |
there is a DELETE statement
no, you'll have to look up how to use it
you know like the code ?
it's part of standard SQL, but every database has its own quirks and extensions, so you'll have to read the docs for the database that you're using
("UPDATE test SET things = ? WHERE name = ?")
it's generally good to get in the habit of figuring out code for yourself 😉
yes i did for a long time cuz i didnt know servers like this existed
well, "servers like this" aren't free code resources either!
ye ik i just asked for some help but i already found it
DELETE from rental WHERE id = ? does this look good ?
like internet isnt giving much information
how do i put that in the command
with what do i start and end
do i just smack it in there in a random spot
or ?
that seems reasonable, yes
if you're using UPPERCASE for sql, you would usually capitalize FROM as well
DELETE FROM rental WHERE id = ?
ok where do i put it in here ?
async def testb(ctx, txt: str):
db = sqlite3.connect("merlyn.sqlite")
cursor = db.cursor()
cursor.execute(f"SELECT things FROM test WHERE name = {ctx.author.id}")
result = cursor.fetchone()
if result is None:
sql = ("INSERT INTO test(name, things) VALUES(?, ?)")
val = (ctx.author.id, txt)
elif result is not None:
sql = ("UPDATE test SET things = ? WHERE name = ?")
val = (txt, ctx.author.id)
cursor.execute(sql, val)
db.commit()
cursor.close()
db.close()```is it needed ?
it looks like you already know how to run sql queries, so i don't understand the question. put it where you want to use it.
no, it's purely cosmetic
ok
yes i know how but where do i put the DELETE statement
what do i remove and where do i do it
...put it wherever you want to delete something?
bruh
why are you using an f-string in the SELECT? you are using query parameters in the other queries, use the query parameter in SELECT too
?
honestly, this looks a lot like you're fumbling around and copy-pasting other people's code
even worse
what else do i do ? idk where to start
you see the ? in your queries? do you know what those mean?
the ? is a placeholder for data that gets inserted into the query
yes the "val" thing right ?
yes
you should not use "string interpolation" (f-strings, .format, or %) to insert data into a query
so whoever you copied this from was doing the right thing there
i do not understand that
ok its a good thing i guess
then don't worry about it. use ? to put data into a sql query
?
however you also copied some code that does the wrong thing
i think you might want to back up and actually learn how this stuff works...
he only put 1 ? instead of 2
let me try to find a coherent document for you to learn from
because copying stuff from videos is not going to teach you anything
i just want a "beter" database instead of json
first, i suggest learning sql itself using sqlbolt https://sqlbolt.com/
SQLBolt provides a set of interactive lessons and exercises to help you learn SQL
i am nothing with documents i have learn disabilities
sqlbolt is interactive
if you have a really hard time learning from text documents, then at least let me find a good video for you
can you just tell me where i put the "DELETE" statement in my code ? like do i switch it with the "if result" or ??
i have no idea what you want to delete! so i don't know the answer to this question.
i know enough cuz i already made a few tables that work fine
like a row with a specific item it it
explain to me in words: what do you want to delete, and when do you want to delete it?
where "things" = to ...
okay, what row? what item? under what conditions? are you trying to implement a "remove item from my inventory" command in your discord bot?
just beginning simple so i can make it harder myself
like this
i have a "things" column with "hi" in a row

how do i delete that whole row
but only that row
like this is to much text
you execute the DELETE query you showed me above, using name as the query parameter
ok but like
what happens if you read it in small pieces?
async def testb(ctx, txt: str):
db = sqlite3.connect("merlyn.sqlite")
cursor = db.cursor()
cursor.execute(f"SELECT things FROM test WHERE name = {ctx.author.id}")
result = cursor.fetchone()
if result is None:
sql = ("INSERT INTO test(name, things) VALUES(?, ?)")
val = (ctx.author.id, txt)
elif result is not None:
sql = ("UPDATE test SET things = ? WHERE name = ?")
val = (txt, ctx.author.id)
cursor.execute(sql, val)
db.commit()
cursor.close()
db.close()``` what do replace in hereits gonna take a long time
honestly, i don't see anywhere in this function where it makes sense to delete something from the table
ok wait
it looks like the purpose of this function is to insert or update data in the table
i can't imagine where or why you would run a DELETE query here
it'll be worth it! it takes people without learning disabilities a long time to learn things for the first time, too.
yes that it but I DO NOT KNOW WHERE and WHAT i have to remove to replace the DEL statement
back up and consider what i am asking you.
you are showing me a discord bot command. that bot command currently takes a "thing" and inserts a row into the database with that thing, or replaces a row in the database with that thing.
you are asking me "where do i put the delete command". i am answering you truthfully and plainly that i do not know the answer to this, because i don't understand what you want to delete.
therefore i am asking you: what do you want to delete?
i just explained what i wanted to delete but ill do it again
yes, you explained what.
so i have this
but you did not explain what the user should enter if they want to delete something
this is the only thing i know
right now a user in your discord server has no way to tell the function what operation to perform.
i remove the if and elif result thing to replace the "DEL" statement in that spot ? or what do it do
nothing
bruh
then you don't need DELETE at all?
if you do that, it will no longer UPDATE. it will DELETE instead. is that what you want?
you didn't say that before!
you just said that you wanted to delete something, you didn't say that you wanted to replace the updating behavior!
i do not KNOW where i put the "DEL" statement
yes, if you want to delete instead of update, just replace the UPDATE query with the DELETE query
remove the UPDATE and INSERT or idk what
@bot.command()
async def testb(ctx, txt: str):
db = sqlite3.connect("merlyn.sqlite")
cursor = db.cursor()
cursor.execute(f"SELECT things FROM test WHERE name = {ctx.author.id}")
result = cursor.fetchone()
if result is None:
sql = ("INSERT INTO test(name, things) VALUES(?, ?)")
val = (ctx.author.id, txt)
elif result is not None:
sql = ("DELETE from test WHERE name = ?")
val = (txt, ctx.author.id)
cursor.execute(sql, val)
db.commit()
cursor.close()
db.close()``` like this ?ill explain it 1 more time for you cuz i dont think you understand
so i begin with python db = sqlite3.connect("merlyn.sqlite") cursor = db.cursor() next i do ?? idk what i do
in general, this is how sql queries work in python libraries:
# Connect to the database
db = sqlite3.connect("merlyn.sqlite")
# Obtain a "cursor" to run a query
cursor = db.cursor()
# Execute query
query = ...
params = ...
cursor.execute(query, params)
# Fetch resutls
results = cursor.fetchall()
maybe that helps?
ah ok
query is a string containing a query, and params is a tuple or list of values to be injected into the query
i know you struggle with longer chunks of text, but i really do think you would benefit from reading something like this https://docs.python.org/3/library/sqlite3.html#sqlite3-tutorial
it is the text
take your time, do it one piece at a time
docs are even worse man
the "query" is the sql code that you would like to execute
i just dont understand docs
the "params" are data that you want to insert into the query
i can read them i just dont understand them
you are understanding what i'm telling you. the docs are not very different. some docs are better than others. the sqlite3 python docs are pretty good. you definitely seem capable (from what i can tell) of working through the "tutorial" section, with some patience.
it might help if you "follow along" in code, instead of just trying to read the docs like a book. again, this is something that people without learning disabilities often do.
docs are very different
very few people are good at reading docs when they start
i'd suggest at least trying this one
now that you've seen it explained already, maybe it will be easier to understand what the documentation is telling you
async def testb(ctx, txt: str):
db = sqlite3.connect("merlyn.sqlite")
cursor = db.cursor()
cursor.execute(f"SELECT things FROM test WHERE name = {ctx.author.id}")
query = ("DELETE from test WHERE name = ?")
params = (txt)
cursor.execute(query, params)
db.commit()
cursor.close()
db.close()```ok ill try it
does this look good ?
why is dis so bright
a couple of things about this:
-
(x)is justx. if you want to construct a tuple, you need to use(x,)-- note the,. you might want to use list[x]instead, which is maybe easier to read. -
as above,
params = (txt)is justtxtitself. you will want to writeparams = [txt]orparams = (txt,)
ah yes
so is this correct ?
no, params = txt is wrong, and f"SELECT" is wrong for different reasons
?
cursor.execute("SELECT things FROM test WHERE name = ?", [ctx.author.id])
it's the same as the DELETE query, use the ? to put data into the query
in this case, the author id
actually in this case you can just delete the SELECT entirely
ah ok
think about why you can delete it
don't just do what i'm telling you
spend a minute and think: do i need this SELECT query? what does SELECT do? is that something i need or want in this code?
yes and yes
discord.ext.commands.errors.CommandInvokeError: Command raised an exception: ProgrammingError: Incorrect number of bindings supplied. The current statement uses 1, and there are 2 supplied. cuz error
show your code. that thing about "bindings" says that there is only 1 ? in the query, but you provided 2 pieces of data.
cursor = db.cursor()
query = ("DELETE from test WHERE name = ?")
params = txt
cursor.execute(query, params)
db.commit()
cursor.close()
db.close()```the ? is a "binding", which is a fancy programming term for a "placeholder".
ah ok
you need to wrap txt in a list or tuple
in a list so [] ?
otherwise it's trying to treat each letter in txt as a separate piece of data
yes, params = [txt] for a list, or params = (txt,) for a tuple
ok
it works but it didnt delete anything in the database
ill brb
ok back
ok so i found the problem
but now how do i make it with an amount
What do you mean?
SELECT items.item_name FROM items INNER JOIN character_items ON items.id = character_items.item_id WHERE character_items.character_id = 951071923692011541 AND items.item_category = 'Weapon' AND items.item_category = 'Armor'
How can I make the item_category return one or another? bcs atm it returns none like this but if I change to OR it will show weapons and armor like I would want but from it will ignore the character_id condition
Guys I need your help```import sqlite3
import datetime
with sqlite3.connect('database.db') as db:
cursor = db.cursor()
query1 = """ INSERT INTO expenses (id, name) VALUES(1,'Комуналка') """
query2 = """ INSERT INTO expenses (name, id) VALUES('Бензин', 2) """
query3 = """ INSERT INTO expenses VALUES(3,'Интернет') """
#cursor.execute(query1)
#cursor.execute(query2)
#cursor.execute(query3)
db.commit()
def get_timestamp(y,m,d):
return datetime.datetime.timestamp(datetime.datetime(y,m,d))
def get_date(tmstmp):
return datetime.datetime.fromtimestamp(tmstmp).date()
with sqlite3.connect('database.db') as db:
cursor = db.cursor()
query = """ CREATE TABLE IF NOT EXIST payments(id INTEGER,
amount REAL,
payment_date INTEGER,
expense_id INTEGER)"""
cursor.execute(query)
db.commit()
day_str = '01-09-2020'
day_obj = datetime.datetime.strptime(day_str,"%d-%m-%Y").date()
print(day_obj,'day_obj')
new_day_string = str(day_obj.day)+'-'+str(day_obj.month)+'-'+str(day_obj.year)
print(new_day_string,'new_day_string')
drt = datetime.datetime(2020,9,1)
print(drt,'drt')
dts = datetime.datetime.timestamp(drt)
print(int(dts),'dts')
print('good read', datetime.datetime.fromtimestamp(dts).date())```


"EXISTS"
just needs parens?
SELECT
items.item_name
FROM
items
INNER JOIN character_items ON items.id = character_items.item_id
WHERE
character_items.character_id = 951071923692011541
AND (
items.item_category = 'Weapon'
OR items.item_category = 'Armor'
)
not certain
ohh will try thx
Is there a software that lets you see data from all different databases. For example, MySql, Oracle SQL, Postgres etc?
DBeaver
Oh DBeaver looks promising
there's also Jetbrain's data grip
Our team doesn't have subscription for data grip, so I'll give DBeaver a try for now.
If you have any professional version of the JB IDEs they also have the same functionality and can do inline SQL validation and checking within the code which you may find useful if you don't like dbeaver but have a JB ide
We have subscription for phpstorm.
What do you mean by inline SQL validation and checking?
hey i need help with some codes can anyone help me?
Is there any way or training for me to create a barcode scanner and have a detabase so I can see the scanned items
server.postgres.database.azure.com" to address: Unknown host i am getting this error when i try to connect my django application to azure postgres db is there any solution?
There is also the IN operator in SQL:
SELECT items.item_name
FROM items
INNER JOIN character_items ON items.id = character_items.item_id
WHERE character_items.character_id = 951071923692011541
AND items.item_category IN ('Weapon', 'Armor')
Looks like you need an UNSIGNED INT (but doesn't year return already an int?)
Yeah I managed to fix it, would u mind elaborating on the need for singed/unsigned?
It's listed in the documentation: https://dev.mysql.com/doc/refman/5.7/en/cast-functions.html#function_cast
Yeah so I wasnt sure, but I found out checks dont even work for versions until v8+
So i originally didnt have the cast, but thought that was the reason it wasnt working
Turns out checks are valid syntax but dont actually do anything
OK, didn't know that because I never used MySQL, good to know.
Sorry for the long response, but it means if you're writing SQL as part of your code, say as part of a website backend and you're retrieving some data, it can often detect that and highlight and validate the query you're writing within your code.
Looks fine to me
Yeah as long as there will always be 1 user and 1 item per search
*no more than 1
nothing
How can I optimize SQL queries?
when you SELECT and put a condition (where) can you make an AND and put a random condition? ok let me rephrase it selects an group and from that group it selects random
Unless you can be more specific, look for lists of tips like this: https://blog.devart.com/how-to-optimize-sql-query.html

Read the tutorial to learn more about SQL Server performance tuning best practices that help greater improve SQL Server query optimization.
There are numerous answers on Stack Exchange, but it obviously depends on the DB
there's no much one can say about "optimization" if you don't have a specific goal in mind, and a specific task that you are considering.
what db? what kinds of workloads/queries? how many concurrent clients? what is the performance of your current solution and how much better does it need to be? etc etc
FYI, you don't need to commit() when you're using the connection context manager: https://docs.python.org/3/library/sqlite3.html#how-to-use-the-connection-context-manager
That is not necessarily true: https://docs.python.org/3/library/sqlite3.html#transaction-control
Oh right yeah, we mostly end up concatenating queries.
But it was more so just to see what the data looks like in different columns anytime with little effort. We use MySql and MySql Workbench. It looks and works amazing. But I had to use Oracle SQL and didn't like Oracle's database management software that's why I was looking at other options and you mentioned DBeaver.
Are you missing a T there (instead of the space before it)?
Hello, I need help on a program.
Here are the instructions:
KimTay Pet Supplies is considering discounting the price of all items by 10 percent. List the item ID, description, price, and discounted price for all items. Use DISCOUNTED_PRICE as the name for the computed column.
This is the program that I wrote ```SELECT ITEM_ID, DESCRIPTION, PRICE
FROM ITEM;
@fading patrol Could you help me with my problem as well?
I think you're close but just need to apply the discount
In SQL only use caps for reserved words like SELECT, the rest should be lower case
There's no DISCOUNT_PRICE in the table. They wanted as a computed column.
Yes, good point
Do I need to create a subquery for a computed compound?
Sounds like you're on the right track
@fading patrol This is what I wrote so far ```SELECT ITEM_ID, DESCRIPTION, PRICE
FROM ITEM
WHERE PRICE IN (SELECT PRICE AS DISCOUNTED_PRICE FROM ITEM);
@fading patrol Are you still there?
you can select expressions, so to apply the discount you can multiply by 0.9

from here you can use as DISCOUNTED_PRICE to "name" the new column
Thank you very much!
@brave tree Would it be alright if I contacted you again in the future if I ever need any more help?
of course! though it would be better to ask in this channel in case im not available
ping me in here if you need
Hey, I'm working with mySQL and SQLAlchemy. I'm accessing the same database from lots of different places at the same time and changing reading values which I need to be up to date and precise - how should I go about making sure the values I'm reading are always update?
does anyone know how you could create a table that stores dates as dd-mm-yy? I cant find any info online as to how to do this from a simple CREATE TABLE way -- im very beginner so the easier the better
need to be able to store data this way

in SQL sorry
when you are storing a DATE you are storing an object.
When a user enters a date in TEXT it needs to be parsed into the DATE
And when the user wants to view the DATE it needs to be formatted to TEXT.
All database servers that have DATE and TIMESTAMP object have methods much like pythons datetime strptime and strftime functions. NOTE: p is for parse and f is for format
AHA! so ive made this so far and my dates a formatted as date in the excell but its giving me UNIQUE constraint failed but ive filtered all the dates to be unique..... any ideas? is is how ive formatted?



this was how i created the table....
Having a bit of trouble understanding we haven’t gone over parses yet
Can anyone help me with deploying sqlite3 database in postgressql heroku?
Can you try to just a SQL client (ideally something with a terminal though something like dbeaver etc) instead of excel? Excel could be causing strange issues I'm not familiar with.
Is there any client for Mysql like postgressql?
It depends, are you using ORM or Core?
Yes, what kind of client do you mean though? DBeaver is a free desktop app that supports most common DB types of that's what you want
For command line use psql
@true fjord
hey guys, why the following code is raising this error? I have no clue pls help me fix it -> Error
Traceback (most recent call last):
File "/workspace/Blue-Brain/bluebrain/bot/bot.py", line 90, in on_starting
await self.db.connect()
File "/workspace/Blue-Brain/bluebrain/db/db.py", line 43, in connect
await self.executescript(self.build_path)
File "/workspace/Blue-Brain/bluebrain/db/db.py", line 56, in wrapper
return await func(self, *args, conn=conn)
File "/workspace/Blue-Brain/bluebrain/db/db.py", line 140, in executescript
await conn.execute((await script.read()))
File "/workspace/Blue-Brain/.venv/lib/python3.10/site-packages/asyncpg/connection.py", line 317, in execute
return await self._protocol.query(query, timeout)
File "asyncpg/protocol/protocol.pyx", line 338, in query
asyncpg.exceptions.UndefinedColumnError: column "last commit" does not exist
``` And the code is here with the build.sql file ->
<https://hastebin.com/azegepufaj.py>In SQL double quotes " are used for identifiers (table names, column names, ...) and single quotes ' for string literals.
If you use "last commit" a SQL standard compliant database will look for a column named like that.
(same goes for the DEFAULT entry in your system table)
What should I do about this code ->
for guild_id, user_id in await gateway.bot.db.records(
"SELECT GuildID, UserID FROM entrants WHERE CURRENT_TIMESTAMP > Timeout"
):
``` And errir ->
asyncpg.exceptions.UndefinedFunctionError: operator does not exist: timestamp with time zone > text
HINT: No operator matches the given name and argument types. You might need to add explicit type casts.
Maybe use as Date/Time datatype for Timeout instead of text? https://www.postgresql.org/docs/current/datatype-datetime.html

Stack Overflow
I am using Django as backend and using VueJS via Vite for frontend. I currently make a GET request for data through "api/recipes". I am looking to add a button in my Vue component to make a
would you guys say that this is a database?
https://github.com/ncolyer11/huge-fungus-index
i'm not familiar with the proper definition thats all

GitHub
contains the probabilities of a stem, shroomlight and wart block generating for every individual block for every valid trunk height and hat height configuration - GitHub - ncolyer11/huge-fungus-ind...
https://pastebin.com/embed_js/fFksPTm8?theme=dark . This is my pastebin of json and I want to search element inside "patterns" using tinyDB. Also if search item found then it will return me index of object
this is a "data set". a "database" usually refers to a software application that stores data.
A set of data could be called a database too
Generally you can use term "database" for a collection of data and database management systems interchangeably
How do I filter 1 field based off another field in Tortoise/Django ORM ?
Let's say I have this model
class TestModel(Model):
updatetime = fields.DatetimeField(auto_now=True)
waittime = fields.SmallIntField()
Now I want to filter it in this logic updatetime <= datetime.utcnow() - waittime
How do i achieve this in the filter queryset?
I thought of doing
TestModel.filter(updatetime__lte=datetime.utcnow()-waittime)
But then I thought I wont be able to access waittime like that
You could probably use django's F or Q object, don't remember which one you need there 😅
Hm, it's F @vocal parrot https://docs.djangoproject.com/en/4.1/topics/db/queries/#filters-can-reference-fields-on-the-model
oh wow thats perfectly what i wanted
tysm
sqlite3 how insert values only if they not exists?
INSERT INTO table_name (...)
VALUES (...)
is there any pycharm plugins to view contents of a sqlite.db in IDE?
I googled it for you. Best solution is to have uniqueness constraint on the field but you can also just add OR IGNORE. https://stackoverflow.com/questions/57685385/how-to-avoid-inserting-duplicate-data-when-inserting-data-into-sqlite3-database
Stack Overflow
I use python 2.7 in Windows 7.
I have wrote a program to insert some data read from a text file into a SQLite3 database.
However, I found duplicate data inserted as there are duplicate data in th...
thanks
что за комуналка? Коммунальные услуги
ok thats the thing but it doesnt seem to work
any idea why this is not working? no errors?
Tortoise ORM but very similar to Django
class TestModel(Model):
updatetime = fields.DatetimeField(auto_now=True)
waittime = fields.SmallIntField()
i tried doing
test_objects = await TestModel.filter(updatetime__lte=timezone.now()-F("waittime"))
And i got nothing back. No errors. How do i fix?
I don't use tortoise / django, maybe check what sql it produces
maybe in programming in general, but in statistics and data science the terminology has drifted and the words mean different things
Isn't word "dataset" more applicable to a single collection of data? Like a table in a database
not necessarily, a data set could consist of several tables
in typical data science usage, a "data set" describes the data itself, a "database" describes how it's stored in a computer
i think there's also a colloquial use of the term "database" that's a little different from both
that would be like "a database of phone numbers" or something like that
"data set" is used to refer to some specific chunk of data, usually not updated dynamically, and something that you might perform data analysis on
whereas the abstract sense of "database" is just a collection of data more generally, maybe some thing that's updated routinely. you might construct a data set from an abstract database, and store the data set in a database server
i was tired when i wrote my first message and completely forgot about the abstract sense, which is probably what you had in mind
Yep, it's usually something that you do analysis on
Anything that you access programmatically is technically a database
it's actually really confusing now that i think about it, for the most part people intuitively use one term or another and don't consider the distinction consciously
Well, you usually get that from context, "I've upgraded our database version" is probably related to your dbms and not the data itself
right
need help in php cant insert data in a database though there is no error message but the table is just empty
Hi I'm currently trying to install the MySQL Python Connector but it fails. Can anyone help me?
Hey @gentle hedge!
You either uploaded a .txt file or entered a message that was too long. Please use our paste bin instead.
Is there a way I can automatically send an email to a specific email address when the value of a field in one of my tables changes?
I am using postgres
thank you for sharing information about your system and posting the error message. can you also show what commands you used to install this? this error output is not typical for Pip
I used the mysql community installer for that not pip https://dev.mysql.com/downloads/installer/
it's possible they have not updated their installer to support 3.11
Should be supported was in the last Patch Notes
Stack Overflow
I using pgsql to set a trigger, when update the table dataset(change the status to Finished)
it will automatic send a email to the email account using dataset email value and save this email in ser...
Are database theory questions allowed here
FROM CUSTOMER
WHERE INVOICE_DATE IN(SELECT INVOICE_DATE
FROM INVOICES
WHERE(INVOICE_DATE = '2021-11-15'));
Instructions: ```Use the IN operator to find the ID, first name, and last name of each customer for which as invoice was created on November 15, 2021.
@brave tree
is anyone familiar with dbeaver can they add me on discord temporarily for help setting it up?
or chat here
no reason why not
perhaps. I've set up all sorts of connections and have found it mostly intuitive. What is your error you are having?
@unkempt prism Can I just confirm I am using dbevear for the right purpose. If I have a database on my machine in an ide can I use dbeaver?
What do you mean by
If I have a database on my machine in an ide
I mean I am trying to access the database and information from my pc but it is not on a website . machine = pc
yes Dbeaver when installed on your Workstation can connect to your databases hosted locally.
so I have to install dbeaver on visual studio code?
nothing to do with your IDE
I wondering if it would just be faster to query the database rather then wasting the time the to setup dbeaver.
there is VS Code extensions that can connect to different database engines
what is the name
depends on your database engine you use. Postgres mysql, SQL Server etc
na. SQL Alchemy connects to your database
it is a abstraction / python binding of sorts.
If your are unsure read the front page of the sql alchemy website.
ok I will
Its getting late here I think for now I will just query the database. I just wanted it in a more organized . Thanks can I show what I am trying to connect sqlalchemy in dbeaver another day here and mention your name?
sure just remind me of the context when you get to it.
ok thanks I have one more question before I go I am using flask-sqlalchemy and typed python in the terminal and get the error .
SyntaxError: invalid syntax
> SELECT FROM * User;
> File "<stdin>", line 1
> SELECT FROM * User;
> ^
> SyntaxError: invalid syntax
> ```
Do I need to pip/conda install sql?
Below are the imports to print the database table.
from app import db ,app
from app.models import User
SELECT FROM * User```
Or an extension?
You will have more luck with
SELECT * FROM User;
and you can't mix python and sql.
Thats what sql alchemy is for
I guess I can just query it doing sqlalchemy it will just be slower to type
thanks again
is there anyway to audit what happens to a local db in pgAdmin 4? I've recently run into an issue where half of my db gets deleted and my code behaves in unexpected ways because of it. I'm using sqlalchemy in my flask app if that helps as well
I only have one delete in my entire file as well so I'm just confused how things are being deleted like this. It was a recent introduction but my new code didn't touch any db stuff so I'm just boggled
You can't just stick SQL into python file
The point of using sqlalchemy is to not write raw sql 😅
Yes shouldn't have said.
Nothing to do with pdadmin but check out the suggestions here: https://satoricyber.com/postgres-security/postgres-audit/

Satori
Learn about three ways to perform PostgreSQL auditing - log_statement=all, pgaudit, and custom triggers, understand the differences and which is right for you.
https://pastebin.com/embed_js/fFksPTm8?theme=dark
This is my pastebin of my json and I want to search element inside "patterns" using tinyDB. Also if search item found then it will return me index of object
If you want to use raw SQL, look at psycopg2
GeeksforGeeks
A Computer Science portal for geeks. It contains well written, well thought and well explained computer science and programming articles, quizzes and practice/competitive programming/company interview Questions.
here's the docs of pyscopg2
any help?
i'm using mongoengine for mongodb, it seems all field's default values work perfectly fine other than the boolean fields'. the default value of the boolean fields is just not getting set, while everything else is. is this a bug or am i doing something wrong?
class Chatbot(EmbeddedDocument):
toggle = BooleanField(defalt=False)
channel = IntField(null=True)
class StaffMembers(EmbeddedDocument):
moderator = ListField(IntField())
administrator = ListField(IntField())
## USER
class Privacy(EmbeddedDocument):
message_content = BooleanField(default=False)
## -- DOCUMENTS -- ##
class Guild(Document):
_id = IntField(required=True)
settings_locked = BooleanField(default=False)
chatbot = EmbeddedDocumentField(Chatbot, default=Chatbot())
staff_members = EmbeddedDocumentField(StaffMembers, default=StaffMembers())
class User(Document):
_id = IntField(required=True)
timezone = StringField(regex=r".+\/.+", default="Europe/Belfast")
privacy = EmbeddedDocumentField(Privacy, default=Privacy())
## -- SETUP -- ##
connect(db="new_db", host=os.environ.get("MONGO_LOGIN"), tlsCAFile=certifi.where())
Guild(_id=836495137651294258).save()
User(_id=638038115277340723).save()
When I create a temporary table, does it work like a view, in the sense that it dosent save any data but instead points at another table ? (not to confuse a temporary-table with a temporary-view)
with the following query:
CREATE TEMP TABLE AS SELECT * FROM accounts
Guys, I have made a database using python. What libraries or tools would be best for creating visual representations of the data?
Pandas dataframes are arguably the best
you can do
conn = # sql connection...
pd.read_sql_qurey('SELECT * FROM table LIMIT 20', conn)
and you get a nice table
Thanks brother, will check it out
Like plots and charts and stuff? Seaborne is nice and easy, matplotlib is more powerful
yeah i think that is more to what i was looking for. will check this out too, thank you 🙂
no worries G
@fading patrol do you by chance know if temp-tables store the data phisically?
I've never used temp tables but my guess would be that they're in memory
ok tnx will do some tests
shameless bump :)
I would define the group by column even if there is only one user with that ID. And you could use the join column instead of using the value twice (and a single equal is enough in SQL):
SELECT RegistrationDate, COUNT(SearchID)
FROM Users, History
WHERE Users.UserID = 'TaDJtRcaSXXkzYWyfUdusRUuEjAoyMsx' -- use single quotes for text literals
AND History.UserID = Users.UserID
GROUP BY RegistrationDate
i have a valid query here for asyncpg and i am passing correct parameters
await db.run_query(f"insert into blacklisted_users(userid, reason) values({user_id}, '{reason}')")
but it still throws me an error
PostgresSyntaxError: syntax error at or near ","
can someone help me please
this never happened before even when i used f strings
Well, print out the statement before you run the query and take a look. You still should change to placeholders / parameters.
alr let me see
In SQLite you can define if the temp_store to be in memory or a file. I guess that's true for other databases also.
And a temporary table has it's own data, not like a view.
the values seem correct
and this code had worked before
but suddenly its throwing this new syntax error out of nowhere
How did the statement look like?
It seems to be ok if the user_id is a number and the reason don't contain any '
user id was <@useridhere> and the reason my reason here
i think strings need to be single quoted in postgres
<@useridhere> that's not a number and will be invalid SQL.
i have run through an error like that before where i forgot the quotes for a string
oh
That's one more reason to use placeholders / parameters.
oh alrrr got it, thanks for the help, just realized i need to pass an id attribute for it to work
Thanks, exactly what I needed to know. I guess I'll just use a Temporary View then, my issue is that I then need to loop through all the rows and create a rowid column manually, what would you do in my case?
for context I need the rowid to be able to get the data by index position
Well, you can include the rowid in the select list of the view?
Im working on something like a pandas Dataframe but all the data is in the database instead of in memory
right, I could explicitly select it, but then it shows up in the SELECT * query, is there a way to do smth like:: SELECT *, rowid AS HIDDEN ?
Not that I know of.
tell me smth, why would Sqlite store the data phisically when it just points at another table, for ex:
CREATE TEMP TABLE test1 AS SELECT * FROM accounts LIMIT 10
it could just store the query and function like a regular view, what would be the advatage of storing the actual data?
Doesn't the table have an primary key? Depending on an rowid is never good.
the rowid if for a method in python Column.iloc[<index>]
you can have a look at how I implemented it here:
https://github.com/shner-elmo/pandas-db/blob/7238983b48a3198f1b01a1d38837a75c2ed25fb0/pandasdb/column.py#L305
pandasdb/column.py line 305
def iloc(self) -> IndexLoc:```but basically it gets the row using the rowid column, but for views than it uses the Sqlite function: ROW_NUMBER() to create a column with all the indexes
That's just how it is defined. A temporary table is just like any other table with its own data. The create temp table ... as <select> is just one way of doing it. You may want to manipulate the data without changing the original one, or acquire data from different tables into one temp to further processing, or ...
You do use an aggregate function which normally requires a group to work.
SQLite does support this but not all databases do.
What function can be used in case you want to show some text output in the "Messages" tab of the script output window?
SQL
For postgres within a PLPGSQL function you can use RAISE NOTICE etc as per: https://www.postgresql.org/docs/current/plpgsql-errors-and-messages.html

PostgreSQL Documentation
43.9. Errors and Messages 43.9.1. Reporting Errors and Messages 43.9.2. Checking Assertions 43.9.1. Reporting Errors and Messages Use the RAISE statement to …
I have a column in a database table that is type json, would it be better to use Postgres's built in functions for making changes to the json or importing the json object to python and making my changes there?
My guess that it depends on a few factors like size as the time it takes to transfer to another server. This assumes you are not using plpython3u as that won't have that problem.
cant seem to figure this out. running into an issue of trying to append a bigint, when doing so without type casting, i get
Command raised an exception: UndefinedFunctionError: function array_append(bigint[], bigint[]) does not exist
HINT: No function matches the given name and argument types. You might need to add explicit type casts.
"INSERT INTO word_notifs (n_words, member_id, guild_ids) VALUES ($1, $2, $3) ON CONFLICT (member_id) DO UPDATE SET word_notifs.n_words = array_append(word_notifs.n_words, $1::VarChar), word_notifs.guild_ids = array_append(word_notifs.guild_ids, $3::bigint) WHERE word_notifs.member_id = $2",
[word],
member_id,
[guild_id],
)
i then type cast like above and get
Command raised an exception: CannotCoerceError: cannot cast type bigint[] to bigint
As $1 and $3 are arrays you might want to use array_cat(word_notifs.n_words, $1) and array_cat(word_notifs.guild_ids, $3)
yeeee i figured it out thanks
Btw, the WHERE clause is not needed because the update will be done on the conflicting row.
whats the difference between casting and converting in the context of converting a text column to date (format: mm-dd-yyyy)
in a select query)
Yeah sorry I am late because I ended up using timestamps as integers rather than using datetime and now it works. But I'll send cuz I'm curious
So those models in my previous msg aren't real, but i will send the SQL for the actual model i was using in my db
SELECT "update_time","id","cooldown" FROM "gawmsgcount" WHERE "update_time"<='2022-10-30T13:42:27.715187+00:00'-"cooldown"
I removed the other columns and WHERE conditions because it works perfectly otherwise
Could use a bit of assistance
I have two dataframes old and new (records)
I want to compare the two and get a list of any of the records that share the same value in three specific columns
that list would be a dataframe, but only contain the data from the old records
then I would iterate over each row in that dataframe and delete the records that match in the database
essentially I am adding data to a database from a csv while also being sure to delete old data which has a new version, determined by a match of those three specific columns
Who can i add x rows like in my example two in the database?
1 Picture = "SELECT closed_tickets FROM s210_DeadShot.team_tickets WHERE userID = 714361420409733171"
2 Picutre = All in the databse


how to pass a locale parameter within a collation into a PyMongo count_document() function? in a valid way that actually works...
the docs say that collations should be passed as keyword arguments, but even if I don't get a syntax error, the result is incorrect because of the case sensitivity that can be "disabled" by using an english locale in a collation
I can use this solution to do find() in a case-insensitive way, but using it on count_document() has a different syntax which I can't figure out
Thanks I typed python into my terminal and get ```from app.models import User SELECT * FROM User;
-
^
SyntaxError: invalid syntax```iow's the invalid syntax is caused by user. Did I do anything wrong?
I installed psycopg2 with conda . I even tried a longer version with create_app(Config)
Read the docs for psycopg2 or look up examples of how it works
OK I will
how hard are databases ?
tooo muchhhhhhhh huhuh
hey guys btw
from django.contrib.auth.models import User
what is the function of this
it imports User class from the django.contrib.auth.models table
where is this file though django.contrib.auth.models
its like mandatory to write this line in models.py?
Stack Overflow
How do i take input from user as .csv read the data and take the row with names and catogorize it into sub catogires like manufactoring and so on
@unkempt prism
Hi you told me to remind you of why I need help. I am trying to get Dbeaver to work.
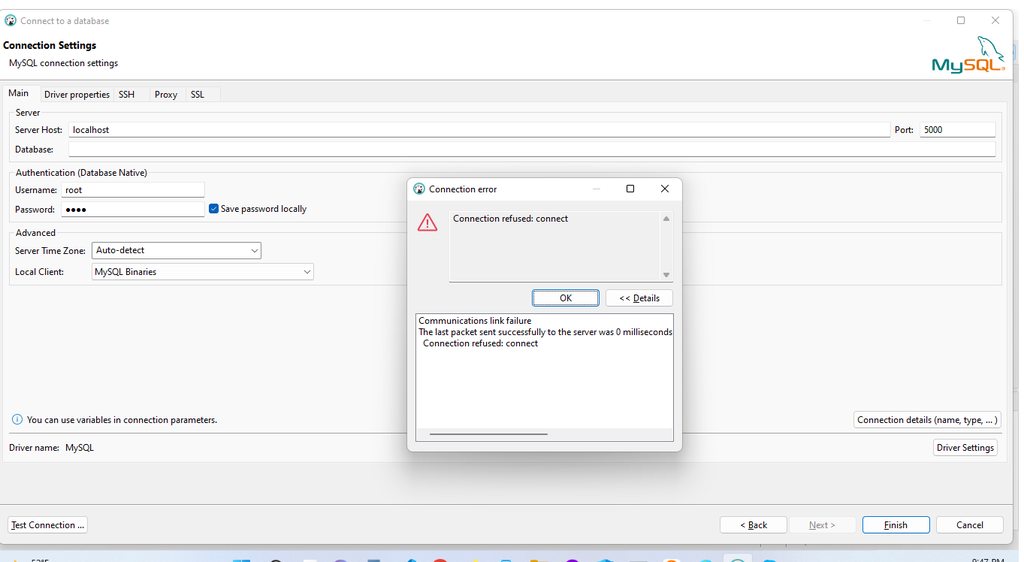
I have an image of what I tried. When I test the code I get the error in the picture https://imgur.com/a/U2pQ01t . I tried mysql database for a flask slalchemy database. Is this wrong? I even turned off my firewall in avast1. Any advice on how to fix this? Also I tried to fill out the database form and got the same error.
how to get client server lag of 2 machines running on the local network
which database do you use?
<@&831776746206265384> shitposting
!ban 509554361802948619 3d this is not a shitposting server
:incoming_envelope: :ok_hand: applied ban to @timber citrus until <t:1667632351:f> (3 days).
Please guide me why i'm getting this error? I am using sqlalchemy File "F:\pyenv\lib\site-packages\sqlalchemy\orm\decl_api.py", line 76, in __init__ _as_declarative(reg, cls, dict_) File "F:\pyenv\lib\site-packages\sqlalchemy\orm\decl_base.py", line 126, in _as_declarative return _MapperConfig.setup_mapping(registry, cls, dict_, None, {}) File "F:\pyenv\lib\site-packages\sqlalchemy\orm\decl_base.py", line 183, in setup_mapping return cfg_cls(registry, cls_, dict_, table, mapper_kw) File "F:\pyenv\lib\site-packages\sqlalchemy\orm\decl_base.py", line 333, in __init__ self._setup_inheritance(mapper_kw) File "F:\pyenv\lib\site-packages\sqlalchemy\orm\decl_base.py", line 921, in _setup_inheritance raise exc.InvalidRequestError( sqlalchemy.exc.InvalidRequestError: Class <class '__main__.Core'> does not have a __table__ or __tablename__ specified and does not inherit from an existing table-mapped class. .
Here's the code ```class Patterns(Base):
tablename="patterns"
pattern_id = Column(Integer, primary_key=True)
pattern = Column(String)
tag = Column(String)
def __init__(self , pattern_id, pattern , tag):
self.pattern_id = pattern_id
self.pattern = pattern
self.tag = tag
class Responses(Base):
tablename="responses"
response_id = Column(Integer,primary_key=True)
response = Column(String)
tag = Column(String)
def __init__(self, response_id,response,tag):
self.response_id = response_id
self.response = response
self.tag = tag
class Core(Base):
_tablename="core"
id = Column(Integer,primary_key=True)
tag = Column(String)
def __init__(self,id ,tag):
self.id = id
self.tag = tag
engine = create_engine("sqlite:///kyubi.db", echo=True)
Base.meta.create_all(engine)
Session = sessionmaker(bind=engine)
session = Session()
c1= Core("greeting")
session.add(c1)
session.commit()```
any help?
make sure the mysql service is running. Also another things to try is localhost can mean 2 things for ipv4 and ipv6. So sometimes its worth using the respective loopbacks of 127.0.0.1 or ::1 instead.
any help?
hey guys can anyone help me with the following?
I have a problem with a query in BigQuery and it looks like this:
CREATE TEMP TABLE DBL (blabla STRING, ETC) AS
SELECT
BLABLA
FROM
BLABLA;
SELECT x, y, z, case
when b LIKE '%G%' THEN 'G'
when b LIKE '%D%' THEN 'D'
when b LIKE '%F%' THEN 'F'
ELSE 'GGG' END AS b2
from asdf.asd.as as a
LEFT JOIN DBL as b
on a.x = b.x and a.y>b.h
where j > '2022-01-01'
but I get an error Invalid value: Table 'DBL' must be qualified with a dataset (e.g. dataset.table) at [82:1]
how do i solve this? do I need to use something like asdf.asd.DBL instead (if that is where the temp table is stored?)?
I'm fairly sure to name a join you don't use AS its just LEFT JOIN DBL b
i've never seen AS used there, it maybe the same thing
i'm quite sure it is but anyway the issue is not there
if I ran the create temp table bit it works fine
but if I just do afterwards:
select * from DBL
OR
select * from asdf.asd.DBL
it does not find the temp table
if i check the details of the temp table, tableid looks like this:
asdf._script47389473928749327498374929.DBL
but the inbetween bit is just the query id which i guess is dynamic?
any help?
typo in Core.__tablename_
Hi guys, seeing a very weird issue when I spin up a sqlite db for unit tests:
import sqlalchemy
from sqlalchemy import create_engine
engine = create_engine("sqlite:///test.db")
engine.execute("CREATE SCHEMA test;")
And here's the error I see:
def do_execute(self, cursor, statement, parameters, context=None):
> cursor.execute(statement, parameters)
E sqlalchemy.exc.OperationalError: (sqlite3.OperationalError) near "SCHEMA": syntax error
E [SQL: CREATE SCHEMA ss;]
E (Background on this error at: https://sqlalche.me/e/14/e3q8)
I really don't know what's wrong - The syntax is correct I can't figure why it's giving me that error 😦
Stack Overflow
I want to do the "CREATE SCHEMA IF NOT EXISTS" query in SQLAlchemy.
Is there a better way than this:
engine = sqlalchemy.create_engine(connstr)
schema_name = config.get_config_value('db', '
that method doesn't exist - idk if it's been removed
There is no CREATE SCHEMA in SQLite. https://www.sqlite.org/lang.html
Learnt that the hard way
@paper flower any help? why am i getting this error? File "F:\pyenv\lib\site-packages\sqlalchemy\engine\base.py", line 1900, in _execute_context self.dialect.do_execute( File "F:\pyenv\lib\site-packages\sqlalchemy\engine\default.py", line 736, in do_execute cursor.execute(statement, parameters) sqlalchemy.exc.IntegrityError: (sqlite3.IntegrityError) UNIQUE constraint failed: core.id [SQL: INSERT INTO core (id, tag) VALUES (?, ?)] [parameters: (1, 'greeting')]
id isn't unique ie there's already a row with that id there
so what to do?
replace it with another name?
use another id or delete the existing one
ok
Thanks , It's working .I'm facing a bit difficult in reading sqlalchemy docs. Will you suggest me any other docs for sqlalchemy?
I can't even access the sqlalchemy docs link 😦
ohk ! I got one and right now digging that
@woven dragon I wanna ask one question
sure
Actually I am working on python discord bot. If user sends the message and it contains word given in json . It will generate response as per given response in json. pastebin of my json and searching algo https://pastebin.com/embed_js/rWpLiRNQ?theme=dark (value for word in values if any([myword for myword in word['patterns'] if myword.lower() in msg.lower()]))
My question is that I want that every word of user message is being checked whether it contain any of patterns. Also it fetches from sqllite db
@woven dragon is it clear?
patterns = ['bad', 'terrible', 'horrible', 'unsafe']
message = "This is bad practice"
You want to check if any word from patterns appears in message ?
Also this is a #python-discussion question - please repost on there
@woven dragon ok but i want to fetch every pattern from my sqllite db
and then check it
but this patterns is a list which means user cannot add further after it is deployed
I want me to add further from discord
as a owner i must have a power to add more words to my bot
also i have did this eariler. Here's the code ```
val = [msg for msg in patterns if msg in message]
I'm not meaning that
please read carefully
what is your question?
My question is that I want that every word of user message is being checked by script whether my patterns table contains any of such pattern
ok what part do you need help with?
I need help in side by side searching . More clearly as it searches pattern from user message side by side it searches same word from pattern table in my sqllite db and give me tag or any other info
Anyone here is familiar with sqlmodel?
I've been wrapping my head for days trying to figure out what is wrong with my code. What I'm trying to do is to create a children of the same type/self-referencing. But I'm getting greenlet_spawn has not been called; can't call await_only() here exception.
I went through forums where the solution was to add 'lazy':'selectin' to sa_relationship_kwargs to my SQLModel Relationship, but it did not work.
Here's an example
import asyncio
from sqlmodel.ext.asyncio.session import AsyncSession
from sqlalchemy.ext.asyncio import create_async_engine
from typing import List, Optional
from sqlmodel import Field, Relationship, SQLModel, select
class LinkNodes(SQLModel, table=True):
parent_id: Optional[int] = Field(default=None, nullable=False, foreign_key="node.id", primary_key=True)
child_id: Optional[int] = Field(default=None, nullable=False, foreign_key="node.id", primary_key=True)
class Node(SQLModel, table=True):
id: Optional[int] = Field(default=None, primary_key=True)
name: str
children: List['Node'] = Relationship(
link_model=LinkNodes,
sa_relationship_kwargs={
"lazy": "selectin",
"primaryjoin":"Node.id==LinkNodes.parent_id",
"secondaryjoin":"Node.id==LinkNodes.child_id",
})
sqlite_file_name = "database.db"
sqlite_url = f"sqlite+aiosqlite:///{sqlite_file_name}"
engine = create_async_engine(sqlite_url, echo=True)
async def create_db_and_tables():
# SQLModel.metadata.create_all(engine)
async with engine.begin() as conn:
await conn.run_sync(SQLModel.metadata.drop_all)
await conn.run_sync(SQLModel.metadata.create_all)
...
Continue...
async def create_nodes():
async with AsyncSession(engine) as session:
parent_node = Node(name="Parent")
child_node = Node(name="Child")
parent_node.children.append(child_node)
session.add(parent_node)
await session.commit()
await session.refresh(parent_node)
print(parent_node)
async def select_nodes():
async with AsyncSession(engine) as session:
statement = select(Node).where(Node.name == "Parent")
result = await session.execute(statement)
node = result.scalar()
print(f"Parent: {node}")
print(f"Children: {node.children}")
async def main():
await create_db_and_tables()
await create_nodes()
await select_nodes()
if __name__ == "__main__":
asyncio.run(main())
or you can first fetch all the words from the database and then go thru every word in every message and see if it matches the pattern
that too will be okay but how to do?
I think this is better suited for #async-and-concurrency ?
result = []
patterns = fetch_patterns_from_db()
for message in messages:
for word in message:
if word in patterns:
result.append(word)
how to fetch from db?
I see, ok
def get_xp_rank(user_id):
db = sqlite3.connect('xpranks.db')
c = db.cursor()
c.execute(f'SELECT xp, rank FROM xp_rank WHERE user_id = {user_id}')
info = c.fetchone()
if not info:
c.execute('INSERT INTO xp_rank(user_id, xp, rank) VALUES(?, ?, ?)', (user_id, 0, 1))
info = (0, 1)
db.commit()
c.close()
return info
print(get_xp_rank(730793398600073317))
is anyone able to tell my why the data is being printed in the console twice? i'm sorry if this is a question that gets asked a lot here btw
I don't know what's creating each line of output but if you get rid of print does that do what you want?
can someone help me at #help-pancakes
I'd like to store some albums of pics in a DB, what would be a good host for this? that would also remove an album if the row containing the link to the album doesn't exist anymore etc
some sort of ON DELETE CASCADE for pic links
You could do that anywhere. What are you using currently?
that would only be possible if you were to selfhost OR host on a VM with direct access to the files, no?
Like, I could be using sqlite & Google Photos, but that wouldn't link them together, would it?
I definitely want my pics in the cloud
since it's for some kind of Listing
=> each listing item has an album of pics
You can store URLs to the images in your DB. I don't know if SQlite will let you store the images as blobs in your DB, but other DB engines will
yeah, storing URLs isn't the problem, it's SYNCING the deletion of a row with an existing album in the cloud
If I remove a row, it should also remove the album
and I'm not sure if storing pics as blobs is the best solution, I would like to know some alternatives
You ultimately have those 2 options: blob in the database or URL somewhere else. The somewhere else can be wherever you like.... S3 buckets are probably the most common solution
You asked where to host, this has nothing to do with it... This is application logic
I want to avoid blob in the db since that increases the size of it by a lot
having an url stored in the db is nice, but won't cascade the deletion
You can set a trigger if you don't want to handle this with application logic
I have no idea if SQlite does triggers
SQLite is an example, I'm still deciding
@unkempt prism
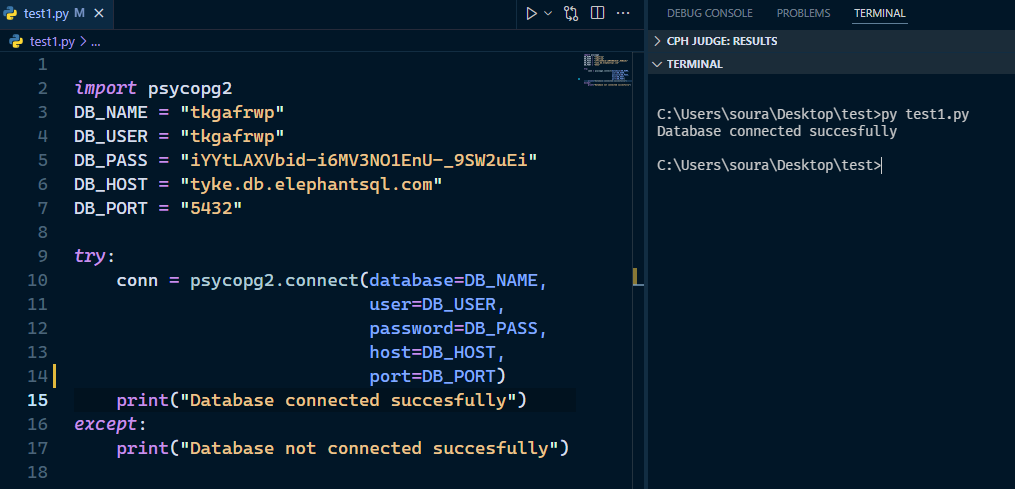
I tried what you suggested here is a picture as proof. https://imgur.com/a/csA4nf9. When I try this it just stays stuck and doesn't load . I tried localhost the default setting. I tried 127.0.0.1 and ::1 . What do you mean by "mysql service is running" ? Do you mean if I have the server running because I do.
Thanks for the help.

are you really running mysql on port 5000 that is suspiciously close to the flask default port and not the mysql default port of 3306
Hi folks, I'm facing issues in with high latency in my Postgres+SQLAlchemy stack due to partition level locking when number of concurrent writes increases.
I have a system with heavy real-time writes. The writes happen using SQLAlchemy + Celery + RMQ stack. The tables are partitioned at date level. When I perform writes using max 16 concurrent connections, it takes ~1second, but when I increase concurrency to ~64, it starts taking ~10 seconds. All fields are pregenerated, even ID using sequence generator. And number of indexes is also optimised.
The problem is my queue starts logging up with high volume of messages if I decrease concurrency, and I need all these to be consumed in near-realtime.
Does anyone have any suggestions on how to fix this issue? The code was previously Django based & we didn't face any such issues there ... Posting here as this issue seems to be specific to Python SQLAlchemy library... Please help!
How are you writing your data? Did you use any bulk create methods when working with django?
Yes, bulk_create in Django...
I'm using bulk_save_objects in SQLAlchemy
Can you share your code? 🤔 Also in 2.0 sqlalchemy would bulk orm objects creation
It could also depend on db driver you're using
Sure... Sharing in a bit...
from my_library import settings
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
# `MY_DB` uses `DATABASE_URL=postgresql://uname:pwd@dbhost:5432/dbname`
class MyBaseRepository:
_engine = create_engine(settings.MY_DB, echo=True, implicit_returning=False,
executemany_mode='batch', executemany_batch_page_size=10000,
pool_size=20, max_overflow=10,
execution_options={"isolation_level": "AUTOCOMMIT"}) # disable "echo" to disable logging
_session_maker = sessionmaker(bind=_engine)
session = _session_maker()
def __init__(self):
pass
@property
def session_maker(self):
return self._session_maker
class AppRepository(MyBaseRepository):
def __init__(self) -> None:
super().__init__()
self.session = MyBaseRepository().session_maker()
def bulk_create_records(self, objects):
with self.session.begin():
self.session.bulk_save_objects(objects)
self.session.expunge_all()
return objects
Why autocommit? 🤔
As there are certain DML actions running without with ... begin (using ORM, of course)
Why not simply commit after executing them? 🤔
using self.session.commit() at the end of code block?
So for instances like this also, I'll have to explicitly commit?
def delete_table2_records(self, category):
self.session.query(Table2).filter(Table2.sender == category).delete()
Also are you closing your connections?
not in delete_table2_records case, no ... in with .... begin it gets closed implicitly, right?
Yep, or use a contextmanager
No, you're just commiting here
how is autocommit impacting the latency/ locks?
Might be an issue with that you're not closing your connections properly tbh
self.session = MyBaseRepository().session_maker() creates a new Session
with self.session.begin(): just starts a transaction
when should i close the session then? do i have to close it inside with ... begin too?
Depends on how you use that class
Ideally you should use one connection per operation
like celery task or a REST endpoint
You're calling https://docs.sqlalchemy.org/en/14/orm/session_api.html#sqlalchemy.orm.Session.begin
There's also sessionmaker.begin() which starts transaction AND closes a connection
then {"isolation_level": "AUTOCOMMIT"} is fine, i just need to close the session?
🤷♂️
where should i close it?
Close it when you no longer need it
I mostly use settings like this:
engine = create_engine(
_db_settings.url,
future=True,
pool_size=10,
pool_pre_ping=True,
pool_use_lifo=True,
echo=_db_settings.echo,
)
sessionmaker = sessionmaker(
future=True,
bind=engine,
)
with sessionmaker() as session:
...
Classes themselves shouldn't manage their dependencies, you probably can just pass session into it:
with sessionmaker.begin() as session:
my_service = MyService(session=session)
my_service.do_stuff()
ok
Hi,
I am not able to solve a problem with connecting to Azure SQL with FastAPI using pyodbc. What I want to achieve is to make interaction with database without using ORM layer. Just simple queries or execution of stored procedures.
When I run FastAPI locally I have no problem with authorization and querying database. The only strange thing is when I make function that makes connection with database async everything works fine but when it's synchronous function freezes during execution. Which seems to me counter intuitive as Azure SQL and pyodbc is not async. The problem that I have is when I run the same code from docker container ( locally and deployed to azure app service - doesn't matter) nothing works, workers start to crash during execution and nothing happens.
This function that I run:
@app.get("/sql")
async def get_db_tables():
# Get token for Azure SQL Database and convert to UTF-16-LE for SQL Server driver
credential = DefaultAzureCredential() # system-assigned identity
token = credential.get_token("https://database.windows.net/.default").token.encode(
"UTF-16-LE"
)
token_struct = struct.pack(f"<I{len(token)}s", len(token), token)
# Connect to db using the token
SQL_COPT_SS_ACCESS_TOKEN = 1256
connString = "Driver={ODBC Driver 18 for SQL Server};SERVER=tcp:<SERVER>.database.windows.net;DATABASE=<DATABASE>;Encrypt=yes;"
conn = pyodbc.connect(
connString, attrs_before={SQL_COPT_SS_ACCESS_TOKEN: token_struct} # , timeout=1
)
# Execute query
with conn.cursor() as conn:
cursor = conn.execute(
f"select PrincipalName, ObjectName, PermissionName, PrincipalType, ObjectScope, AuthType, PrincipalId from adm.perms"
)
data = pd.DataFrame.from_records(
cursor.fetchall(), columns=[col[0] for col in cursor.description]
).to_dict()
return {"data": data}
This is Dockerfile:
FROM tiangolo/uvicorn-gunicorn-fastapi
ENV PYTHONUNBUFFERED=Y
ENV ACCEPT_EULA=Y
RUN apt-get update -y && apt-get update \
&& apt-get install -y --no-install-recommends curl gcc g++ gnupg unixodbc unixodbc-dev apt-transport-https
RUN curl https://packages.microsoft.com/keys/microsoft.asc | apt-key add - \
&& curl https://packages.microsoft.com/config/debian/11/prod.list > /etc/apt/sources.list.d/mssql-release.list \
&& apt-get update \
&& apt-get install -y --no-install-recommends --allow-unauthenticated msodbcsql18 mssql-tools \
&& echo 'export PATH="$PATH:/opt/mssql-tools/bin"' >> ~/.bash_profile \
&& echo 'export PATH="$PATH:/opt/mssql-tools/bin"' >> ~/.bashrc \
&& source ~/.bashrc \
&& apt-get install --reinstall build-essential -y
RUN exit
RUN apt-get update
RUN apt-get update && apt-get install -y locales \
&& echo "en_US.UTF-8 UTF-8" > /etc/locale.gen \
&& locale-gen
# Install Poetry
RUN curl -sSL https://raw.githubusercontent.com/python-poetry/poetry/master/install-poetry.py | POETRY_HOME=/opt/poetry python && \
cd /usr/local/bin && \
ln -s /opt/poetry/bin/poetry && \
poetry config virtualenvs.create false
# Copy using poetry.lock* in case it doesn't exist yet
COPY ./pyproject.toml ./poetry.lock* /app/
RUN poetry install --no-root --only main
COPY . /app
This is stdout during execution from docker container:
[2022-11-02 18:34:36 +0000] [1] [WARNING] Worker with pid 1288 was terminated due to signal 11
[2022-11-02 18:34:36 +0000] [1334] [INFO] Booting worker with pid: 1334
[2022-11-02 18:34:37 +0000] [1334] [INFO] Started server process [1334]
[2022-11-02 18:34:37 +0000] [1334] [INFO] Waiting for application startup.
[2022-11-02 18:34:37 +0000] [1334] [INFO] Application startup complete.
[2022-11-02 18:34:38 +0000] [1] [WARNING] Worker with pid 1265 was terminated due to signal 11
[2022-11-02 18:34:38 +0000] [1357] [INFO] Booting worker with pid: 1357
[2022-11-02 18:34:38 +0000] [1357] [INFO] Started server process [1357]
[2022-11-02 18:34:38 +0000] [1357] [INFO] Waiting for application startup.
[2022-11-02 18:34:38 +0000] [1357] [INFO] Application startup complete.
[2022-11-02 18:34:39 +0000] [1] [WARNING] Worker with pid 1334 was terminated due to signal 11
[2022-11-02 18:34:39 +0000] [1380] [INFO] Booting worker with pid: 1380
[2022-11-02 18:34:40 +0000] [1380] [INFO] Started server process [1380]
[2022-11-02 18:34:40 +0000] [1380] [INFO] Waiting for application startup.
[2022-11-02 18:34:40 +0000] [1380] [INFO] Application startup complete.
What I also did is run sqlcmd to connect to database from inside of container that was running locally and everything worked just fine I got a result from database. Maybe there is something with running the function async not right, but I run out of ideas.
Hey @sage pasture!
You either uploaded a .txt file or entered a message that was too long. Please use our paste bin instead.
Seems like your gunicorn workers are crashing
Is this a correct implementation of sessions using SQLAlchemy, instead?
https://paste.pythondiscord.com/ibugeyisoz
I'd try using python base image instead
I just don't think you need that repository class
I did the same with python 3.9 image and same results
I don't see an entrypoint in your dockerfile
FROM python:3.9
WORKDIR /app
ENV PYTHONUNBUFFERED=Y
ENV ACCEPT_EULA=Y
RUN apt-get update -y && apt-get update \
&& apt-get install -y --no-install-recommends apt-utils curl gcc g++ gnupg unixodbc unixodbc-dev apt-transport-https
RUN curl https://packages.microsoft.com/keys/microsoft.asc | apt-key add - \
&& curl https://packages.microsoft.com/config/debian/11/prod.list > /etc/apt/sources.list.d/mssql-release.list \
&& apt-get update \
&& apt-get install -y --no-install-recommends --allow-unauthenticated msodbcsql18 mssql-tools \
&& echo 'export PATH="$PATH:/opt/mssql-tools/bin"' >> ~/.bash_profile \
&& echo 'export PATH="$PATH:/opt/mssql-tools/bin"' >> ~/.bashrc \
&& apt-get install --reinstall build-essential -y
RUN exit
RUN apt-get update
RUN apt-get update && apt-get install -y locales \
&& echo "en_US.UTF-8 UTF-8" > /etc/locale.gen \
&& locale-gen
# Install Poetry
RUN curl -sSL https://raw.githubusercontent.com/python-poetry/poetry/master/install-poetry.py | POETRY_HOME=/opt/poetry python && \
cd /usr/local/bin && \
ln -s /opt/poetry/bin/poetry && \
poetry config virtualenvs.create false
# Copy using poetry.lock* in case it doesn't exist yet
COPY ./pyproject.toml ./poetry.lock* /app/
RUN poetry install --no-root --only main
COPY . /app
CMD ["uvicorn", "main:app", "--host", "0.0.0.0", "--port", "80"]
My implementation is such that one module in the library will use the corresponding Repository class only. And the BaseRepository can be used by all modules...
Maybe just
engine = create_engine(
settings.MY_DB,
echo=settings.DEBUG, # disable "echo" to disable logging
pool_size=20,
max_overflow=10,
future=True, # Use the 2.0 style Engine and Connection API.
pool_pre_ping=True,
pool_use_lifo=True,
)
session_maker = sessionmaker(future=True, bind=_engine)
class AppRepository:
def __init__(self, session: Session) -> None:
self.session = session
def bulk_create_records(self, objects):
session.bulk_save_objects(objects)
return objects
with session_maker() as session:
app_repo = AppRepository(session=session)
pool_use_lifo just cycles connections differently, single session always uses one connection
ok, thank you for sharing!
Well, you could make your repo class a context manager so you could write
with AppRepository() as repository:
...
and it would manage session inside
But I'd rather do that outside of that class
You could look into dependency injection
I don't want to invoke sessions inside my business logic module, so I'm calling it as such new_records = AppRepository().bulk_create_records(new_records)
DI kind of solves that
you should control (increase) the number of workers & threads - try using gunicorn instead of uvicorn
If you could do
business_logic = Service(
repository=Repository(
session=session
)
)
then your business logic object wouldn't know anything about your session
can you share some reference code/ repo for context management & dependency injection?
meanwhile, would the codebase i shared solve for the concurrency/latency issue so i can implement this as a hotfix?
Well, you could do manual DI, just pass all dependencies into your objects
If you want something automatic look into python di frameworks like dependency-injector, returns or di
but session=session would still need me to create a session in the business logic. in there i'm not invoking any DB level functionality - have implemeted Saga pattern to handle rollbacks in case of errors
I also have a di framework but I wouldn't recommend using it 😅
Well, not in your business logic
You must do DI in your entrypoints
like celery tasks
Ok
class Business:
...
class Repository:
...
def some_entrypoint():
with create_session() as session()
business = Business(Repository(session))
business.do_stuff()
session doesn't touch your business logic in this case
di frameworks can do plumbing work for you though:
@inject
def some_entrypoint(business: Annotated[Business, Inject]):
business.do_stuff()
@sage pasture Let me know if you still have issues after fixing connection leaks 🤔
Will implement this, thank you!
meanwhile, would the codebase i shared solve for the concurrency/latency issue so i can implement it as a hotfix?
I mean, your postrges might underperform because of connection leaking, also you're runnig it with 64 concurrency while having only 20 connections in your pool
How many records do you need to insert?
But won't implementation of with ... session ... begin solve connection leaking?
On an average, inserts for that table have a throughput of ~10000 rpm.
We're running them as k8s pods, so earlier there were 3 min replicas which had 20 connections each...
Is it records per minute or requests?
records per minute
So multiple objects per request?
Postgres shouldn't have any problems with that tbh
it's ~232 insert queries per minute with max 50 records per bulk insert, so around ~10000 records inserted per min
Same goes for sqlalchemy
Maybe it's just because of connection leaking, try fixing that first
will implementation of with ... session ... begin solve connection leaking?
without implementing DI & Context Manager
If you only use session in a context manager - yep
the with...session...begin is the context manager, right?
Well, kind of, not sure how to explain that properly 😅
This could also be useful https://docs.sqlalchemy.org/en/14/orm/session_basics.html#opening-and-closing-a-session
If you do
session = session_maker()
with session.begin():
...
you won't actually close the session, you just begin and end transaction
You should use session itself as a contextmanager:
with session_maker() as session:
...
this seems best in that case:
# create session and add objects
with Session(engine) as session, session.begin():
session.add(some_object)
session.add(some_other_object)
# inner context calls session.commit(), if there were no exceptions
# outer context calls session.close()
but it seems redundant
oh, i see
There's also a shorthand method on sessionmaker that both creates transaction and closes it too:
with session_maker.begin() as session:
...
# Commits
# Closes connection
Well, connection is't "closed" but returned to the pool, but that's not what matters now
sessionmaker is just like functools.partial with some extra methods
Like mentioned begin
but basically it just creates new session with these parameters to you don't have to specify engine each time
engine = create_engine("postgresql://scott:tiger@localhost/")
# a sessionmaker(), also in the same scope as the engine
Session = sessionmaker(engine)
# we can now construct a Session() and include begin()/commit()/rollback()
# at once
with Session.begin() as session:
session.add(some_object)
session.add(some_other_object)
# commits the transaction, closes the session
So in this case session has already begun & connection opened during the class object initialisation itself?
class MyBaseRepository:
_engine = create_engine(
settings.MY_DB,
...)
_session_maker = sessionmaker(future=True, bind=_engine)
def get_latest_message_received_at_date(self):
with self._session_maker.begin() as session:
max_date = session.query(func.max(Table1.received_at_date).label("received_at_date")).scalar()
return max_date
This should close the connection, yep
But you don't have to use begin if you don't change anything in your db
i.e. if you don't need to commit
right
so is the above implementation i shared a permanent fix (if it works) ? or should i still implement DI?
This should work
Even sqlalchemy documentation recommends to pass sessions from outside of your function/methods
This one 
Cool! Have edited the code ... Can you please verify: https://paste.pythondiscord.com/qimapopefi
Looks fine but i'd use
with self._session_maker.begin() as session:
Instead of
with self._session_maker() as session, session.begin():
Ok, thanks a lot! 🙂
Show your code, explain what it's supposed to do and show what's happening instead
Sure one second
Huhu
this is my query
rows = db.execute(
"""SELECT * FROM users
JOIN shares ON users.id = shares.user_id
WHERE user_id = ?""",
session["user_id"])
when shares is empty, it returns nothing, even though users is not empty. how can I fix this?
We don't know what DB engine you're using but I think the concept you may be looking for is LEFT JOIN (include all relevant records from users even if shares is empty
I think a FULL JOIN may also work in this instance
So SQLite maybe?
I would think left join should work... Show some sample records? Screenshot is fine


I included schema too, i hope that's what you mean by sample record
[] is the result

select * from shares? 🤔
what do u mean ?
What's inside of your shares table?
I sent the schema , it's empty
I get this error

seems like a different issue, not related to db
can someone help me with a subquery exercise problem?
Give mysql database please Men =(.
!code in general, it's hard to read code in a screenshot. please share your code as text, in a formatted code block. read below (carefully) for instructions:
Here's how to format Python code on Discord:
```py
print('Hello world!')
```
These are backticks, not quotes. Check this out if you can't find the backtick key.
# creating file path
dbfile = r'C:\Users\gabri\OneDrive\Skrivebord\swingtrading\earnings.db'
# Create a SQL connection to our SQLite database
con = sqlite3.connect(dbfile)
# creating cursor
cursor = con.cursor()
for row in cursor.execute("select * from earnings"):
print(row)
# close the connection
con.close()
thanks for sharing your code. are you sure that there is actually data in the earnings table in that database?
if the table is empty, no rows will be produced
yes i have created the file in another script (the one that produces the file itself) but want it printed out on this script, the other script prints it out fine.
and is there anyway i can read the file or check it? im very new to databases:) and ty
can you show the other script too?
conn = sqlite3.connect('earnings.db')
cursor = conn.cursor()
cursor.execute("create table earnings (Company text, Total_revenue_1 real, Total_revenue_2 real, Total_revenue_3 real, Total_revenue_4 real, Net_income_1 real, Net_income_2 real, Net_income_3 real, Net_income_4 real, Profit_margin_1 real, Profit_margin_2 real, Profit_margin_3 real, Profit_margin_4 real)")
earn = []
for i in x:
ticker_earn = yf.Ticker(i)
financials = ticker_earn.quarterly_financials
try:
net_income = financials.loc["Net Income"] + 1
total_revenue = financials.loc["Total Revenue"] + 1000
profit_margin = net_income / total_revenue
earn.append((i, list(total_revenue)[0], list(total_revenue)[1], list(total_revenue)[2], list(total_revenue)[3], list(net_income)[0], list(net_income)[1], list(net_income)[2], list(net_income)[3], list(profit_margin)[0], list(profit_margin)[1], list(profit_margin)[2], list(profit_margin)[3]))
print(i)
except:
pass
earn = tuple(earn)
cursor.executemany("insert into earnings values (?,?,?,?,?,?,?,?,?,?,?,?,?)", earn)
for row in cursor.execute("select * from earnings"):
print(row)
conn.close()
by default, sqlite3 does not actually save your data to the database after inserting. it stores it in something called a "transaction". you must commit the transaction, and then the data will be saved
you must call conn.commit() after inserting data
note also that you should not reuse a cursor for multiple queries
weird things can happen
create a new cursor every time you run a query
finally, this is a very bad idea in general:
except:
pass
this will prevent you from seeing bugs in your own code. do not try to "make the errors go away". read the error messages: they are there to help you. you can always ask here if you need help
okay thanks a lot, im not so sure how the cursors work, can you point out where i potentially reuse?
earn = tuple(earn)
earn does not need to be a tuple, a list is fine. usually we use tuples to represent individual rows, and lists to represent the entire dataset. but sqlite3 doesn't care, lists and tuples are interchangeable from its perspective.
any time that you call .execute more than once using the same cursor object
i see two executes using the same cursor that you created at the top of the script
so i should commit and close everytime and then start a new one?
no
you only need to close the database connection at the end of the script
however you need to replace cursor every time you make a query
conn = sqlite3.connect(...)
query1 = ' ... '
cursor = conn.cursor()
cursor.execute(query1)
query2 = ' ... '
cursor = conn.cursor()
cursor.execute(query2)
conn.close()
you see how i make a new cursor each time?
regarding commit, you only commit when you modify data in the database. so you need to commit after insert, but you should not commit after select.
conn = sqlite3.connect(...)
query1 = ' select ... '
cursor = conn.cursor()
cursor.execute(query1)
# no commit
query2 = ' insert ... '
cursor = conn.cursor()
cursor.execute(query2)
conn.commit()
conn.close()
oh yeah, makes a lot of sense thanks a lot.
as a convenience, sqlite3 lets you call .execute directly on the connection object, and that will create a new cursor for you
not all database libraries have this feature, but sqlite3 does
conn = sqlite3.connect(...)
query1 = ' select ... '
cursor = conn.execute(query1)
# no commit
query2 = ' insert ... '
cursor = conn.execute(query2)
conn.commit()
conn.close()
and for the sake of convenience, here's how a typical python programmer might work with sqlite3, using some more intermediate-level python features:
import sqlite3
from contextlib import closing
with closing(sqlite3.connect('...')) as conn:
query1 = ' select ... '
cursor = conn.execute(query1)
query2 = ' insert ... '
with conn:
cursor = conn.execute(query2)
-
i do not need to call
.closeanymore. thewith closing(...)does it for me, even if an error is raised inside thewithblock -
i do not need to call
.commitanymore. thewith conndoes that for me, and furthermore it rolls back the transaction if an error is raised inside thewithblock
the python docs provide an okay tutorial, but frankly i think my tutorial is better 🙂 i should write this up properly some day
you really should, gotten me a lot further in a couple of lines, ty a lot good sir
now that you know the general structure of database work in python, you'll probably have an easier time reading the official docs too
!d sqlite3
Source code: Lib/sqlite3/
SQLite is a C library that provides a lightweight disk-based database that doesn’t require a separate server process and allows accessing the database using a nonstandard variant of the SQL query language. Some applications can use SQLite for internal data storage. It’s also possible to prototype an application using SQLite and then port the code to a larger database such as PostgreSQL or Oracle.
The sqlite3 module was written by Gerhard Häring. It provides an SQL interface compliant with the DB-API 2.0 specification described by PEP 249, and requires SQLite 3.7.15 or newer.
This document includes four main sections:
Hey all! im using sqlite and i keep getting foreign key constraint failed and i cant figure out why!!! Can anyone see anything obvious?


im losing my marbles

this means that the foreign key constraint is not respected in the data. that foreign key on date looks really suspicious by the way. i would remove that
im strugglign though because this table should take the dates from the observation data table
also having a similar issue with these ones


this is how we were taught to identify foreign keys
and ive looked it up and thats what google says also
the error is about the data, not about the DDL
how are you loading this data?
so this is what the locattion data is that references country

and then this is the country data

@thorny thunder try removing the date foreign key constraint and see if that works. my guess is that one of the dates doesn't match up with the other table
can someone recommend me a site if im having trouble grasping nested sql queries
for location when i marked the iso code as a primary key instead of foreign key it worked
https://sqlbolt.com/ good sql tutorial here
SQLBolt provides a set of interactive lessons and exercises to help you learn SQL
nested queries aren't that complicated: the inner query returns a table, and you make another query from that table
ok care to entertain my dilemma?
oh i figured out my issue with the countries and locations table
lets say my inner query returns a table i don't want included. im stuck on trying to write my outer query statement in a way that excludes the inner query using NOT IN operator. if that makes sense... i can throw up a code block if you want
omg
i got it
this literally helped me because i was overthinking it
best free cloud sql database for small applications?
Please don't hesitate to file a documentation bug for issues with the sqlite3 tutorial (or docs in general). Improving the docs is super important, and input from the community is highly appreciated. Ping me on GH (@erlend-aasland) for review/merging.
I have been a big fan of the free Postgres on Heroku but they are shutting that down at the end of this month 😭 I have no good alternative that's quite comparable
Hmm, this works fine
select('*').select_from(some_subquery).join(TableA, TableB.column == 'value')
But using an and_ clause with the same column value comparison doesn't appear to.
select('*').select_from(some_subquery).join(TableA, and_(..., TableB.column == 'value'))
Any idea why there's a difference with the and_?
Is ... literally ... or some sort of condition?
A condition I just truncated for space
Well, these are two different queries
What exactly doesn't work with the first query?
any resources for datasets to practice sql? (other than kaggle)
Give free mysql database please
R/datasets on Reddit
glooks
Traceback (most recent call last):
File "/Users/ellalbrys/Library/Application Support/JetBrains/PyCharm2021.2/scratches/scratch.py", line 1, in <module>
import cx_Oracle
ImportError: dlopen(/Users/ellalbrys/PycharmProjects/EconomyDiscordBot/venv/lib/python3.10/site-packages/cx_Oracle.cpython-310-darwin.so, 0x0002): tried: '/Users/ellalbrys/PycharmProjects/EconomyDiscordBot/venv/lib/python3.10/site-packages/cx_Oracle.cpython-310-darwin.so' (mach-o file, but is an incompatible architecture (have 'x86_64', need 'arm64e'))```Can anyone help me to figure this out? I'm on a Mac with the M1 chip
I assume you're using an existing ORM (SQL Alchemy or whatever, not building your own) and then the answer yes.

The MySQL-compatible serverless database platform.

Does anyone know why I’m getting a random ServerSelectionTimeoutError? (MongoDB)
Full Traceback: https://paste.pythondiscord.com/uvuhozetut.
Looks like a network error to me. Make sure you have the right server details, are not blocked by firewall rule, etc.
I needed to refresh my IP whitelist, thanks! :)
does someone know, why i get datatype missmatch?
**Challenge: **
- NoSQL database with many-to-many relationships among people/project/organization entities.
- Every relationship match needs the ability to attribute one or multiple data sources and descriptive timestamps.
Attempted Solution:
STRUCTURE
"sources" collection - raw data source documents
"relations" collection- source <> entity relation document (one per entity)
"entities" collection - final entity documents
DATABASES
mongodb atlas & firestore
FUNCTIONS
Google Cloud functions (Python) for keeping denormalized data in sync
Asks:
- Does my current solution seem correct & efficient? (is a "relations" collection best to keep track of data sources?)
- Any recommended low/no-code ETL tools? (keboola seems promising but expensive at scale)
Any suggestions or advice very welcome (Will get to 1M+ entities this month so want to do it correctly haha)
In this SQL query, how can I compare the CURRENT_TIMESTAMP only with value of Timeout ? Currently sql is taking timeout as text but its integer. What should I do?```sql
SELECT GuildID, UserID FROM entrants WHERE CURRENT_TIMESTAMP > Timeout
What DB?
You can't normally compare an integer to a timestamp either... is this what you want? https://stackoverflow.com/questions/47336832/how-to-convert-this-string-to-timestamp
Stack Overflow
i have a column with the Data like this "08.06.2017/10:20:46". Data Type is string. i want to convert it into timestamp.
i tried CAST("08.06.2017/10:20:46" AS TIMESTAMP) but it doesn't work
Can you
Thanks! that'll help a lot!...
I'm working on a database API where almost everything was based on this horrible function called get_by
it creates a session from scratch and gets one value from the corresponding table, and calls itself recursively if it needs to match constraints. I don't know how much time I've spent reworking code based on it, because the manager insisted on only using the provided functions in that layer to do calls to the database
How should I go about making a for loop which will return every document in my collection where "suspect" == member.id? (MongoDB)
With Pymongo? https://stackoverflow.com/questions/37941610/get-all-documents-of-a-collection-using-pymongo
Stack Overflow
I want to write a function to return all the documents contained in mycollection in mongodb
from pymongo import MongoClient
if name == 'main':
client = MongoClient("localhost", 27017,
I keep getting the following TypeError:
'AsyncIOMotorCursor' object is not iterable
?
from typing import Optional #
from engine import engine
from sqlmodel import Field, SQLModel, Column, JSON
class Test(SQLModel, table=True): #
id: Optional[int] = Field(default=None, primary_key=True) #
a: str
ki: list = Field(sa_column=Column("ki", JSON))
g: str
k: str
b: str
c: str
d: str
e: str
f: str
def create_db_and_tables(): #
SQLModel.metadata.create_all(engine) #
if __name__ == "__main__": #
create_db_and_tables() #
can anyone tell me why the created column order is different than this mocel
*model
2022-11-05 21:48:02,973 INFO sqlalchemy.engine.Engine
CREATE TABLE test (
ki JSON,
id SERIAL NOT NULL,
a VARCHAR NOT NULL,
g VARCHAR NOT NULL,
k VARCHAR NOT NULL,
b VARCHAR NOT NULL,
c VARCHAR NOT NULL,
d VARCHAR NOT NULL,
e VARCHAR NOT NULL,
f VARCHAR NOT NULL,
PRIMARY KEY (id)
)
2022-11-05 21:48:02,975 INFO sqlalchemy.engine.Engine [no key 0.00201s] {}
this is the order that is generated
BUT
I want the same order as model I created
Show the code that's giving you this error?
fixed dw
Guys, can anyone explain me if it's possible to implement naming_convention for alembic migration scripts with already preexisting migration scripts?
So the naming_convention will be enforced from a specific migration script?
I think alembic docs require you to implement them for all scripts
thanks! what did you think of my presentation? i think it "cuts to the chase" a lot better than what's currently there, which i think wanders around too much
the logging docs have a similar problem
a lot of the python docs seem to be written with an "expert" end user in mind
when in reality the people reading those docs for the first time are likely to be new to the entire problem space
is SQL very important when trying to become a data/business or any sort of analyst?
Yes
Sqlite question here, if I have the following query, will the rows it produces be grouped by r.id ? I am trying to get all of the receipts and receipt items in one query, which would be much easier if the rows that come back are sorted by r.id ```sql
SELECT r.id, r.created_on, ri.product_name
FROM receipt AS r
JOIN receipt_item as ri
ON r.id = ri.receipt_id`
just add ORDER BY r.id at the end?
ahh thanks, first time seeing that keyword!
That sound like it will do the trick
in general, it's healthy to assume that database rows will be returned in an arbitrary and unknown order without ORDER BY
Got it
This channel is amazing fyi. Learning python, but i've been working with all relational db's for 17+ years. Big-tech and the like. Best way I've found to learn Python, for myself, is using it on DB related projects.
How to fix this mess py Traceback (most recent call last): File "/workspace/Blue-Brain/bluebrain/bot/extensions/error.py", line 48, in on_error raise event.exception File "/workspace/Blue-Brain/.venv/lib/python3.10/site-packages/hikari/impl/event_manager_base.py", line 667, in _invoke_callback await callback(event) File "/workspace/Blue-Brain/bluebrain/bot/extensions/gateway.py", line 368, in on_started await Synchronise(None, gateway.bot).on_boot_sync() File "/workspace/Blue-Brain/bluebrain/bot/extensions/gateway.py", line 326, in on_boot_sync for guild_id, user_ids in await self.bot.db.records( File "/workspace/Blue-Brain/bluebrain/db/db.py", line 56, in wrapper return await func(self, *args, conn=conn) File "/workspace/Blue-Brain/bluebrain/db/db.py", line 109, in records query = await conn.prepare(sql) File "/workspace/Blue-Brain/.venv/lib/python3.10/site-packages/asyncpg/connection.py", line 565, in prepare return await self._prepare( File "/workspace/Blue-Brain/.venv/lib/python3.10/site-packages/asyncpg/connection.py", line 583, in _prepare stmt = await self._get_statement( File "/workspace/Blue-Brain/.venv/lib/python3.10/site-packages/asyncpg/connection.py", line 397, in _get_statement statement = await self._protocol.prepare( File "asyncpg/protocol/protocol.pyx", line 168, in prepare asyncpg.exceptions.UndefinedFunctionError: function group_concat(bigint) does not exist HINT: No function matches the given name and argument types. You might need to add explicit type casts. the SQL query is thus ```sql
SELECT GuildID, GROUP_CONCAT(UserID) FROM entrants GROUP BY GuildID
PostgreSQL doesn't have group_concat() function, you might want to use array_agg() or string_agg():
SELECT GuildID, array_agg(UserID) FROM entrants GROUP BY GuildID;
SELECT GuildID, string_agg(cast(UserID as text), ',') FROM entrants GROUP BY GuildID;
Hey guys, i want to return with that query also the total count, how can i archieve this?

thanks!...
can i ask pandas relating questions here?
here i am trying to insert
a dict in em_feild

someting like this but

i cant add more than one dict
how can i add more than one dict
How to use programm?
what is programm
What kind of program do you use for coding?
i am making discord bots
with mongo db as database
and discord.py
Well, different parts of the docs are written by different people, so it varies; the docs for each stdlib module is very often written by the original author of the module; the Python language tutorial (https://docs.python.org/3/tutorial/index.html) OTOH is mostly Raymond Hettinger's work, IIRC. For the sqlite3 docs, they were originally written by Gerhard, the original sqlite3 (aka pysqlite before inclusion in the stdlib) author. We've been doing a lot of work with the sqlite3 docs lately, especially improving the accuracy and clarity of the reference section. The tutorial and how-to's definitely need more care.
What kind of program do you use for coding?
FTR, the new sqlite3 tutorial was written specifically with beginners in mind.
u mean my ide or language
I think your presentation was very nice; a good and concise "quickstart-ish" tutorial!
!paste
Pasting large amounts of code
If your code is too long to fit in a codeblock in Discord, you can paste your code here:
https://paste.pythondiscord.com/
After pasting your code, save it by clicking the floppy disk icon in the top right, or by typing ctrl + S. After doing that, the URL should change. Copy the URL and post it here so others can see it.
hey can anyon help me with pymongo
Are there certificates for databases?
Code:
async def add_experience(user, exp):
db = sqlite3.connect("merlyn.sqlite")
cursor = db.cursor()
cursor.execute(f"SELECT exp AND lvl FROM level WHERE id = {user.id}")
result = cursor.fetchone()
end = result + exp
sql = ("UPDATE level SET exp = ? AND lvl = ? WHERE id = ?")
val = (end, user.id)
cursor.execute(sql, val)
db.commit()```
**Error:**
```error
Traceback (most recent call last):
File "C:\Users\Jeff\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.9_qbz5n2kfra8p0\LocalCache\local-packages\Python39\site-packages\discord\client.py", line 409, in _run_event
await coro(*args, **kwargs)
File "G:\Jeff\Merlyn\Merlyn.py", line 1233, in on_message
await update_data(message.author)
File "G:\Jeff\Merlyn\Merlyn.py", line 1251, in update_data
cursor.execute(sql, val)
UnboundLocalError: local variable 'sql' referenced before assignment```
pls helpI'm trying to do a project with Tkinter, This program should be able to create new table in mysql. I want to create table-like entry boxes, I did it with a for loop, but I'm not sure how to obtain data that the user enters in that. I'll be thankful if someone can teach me how to do that.
The AWS certificate database has NoSQL. I'm looking for database that uses SQL.







i need to create the bottom half of this program
SELECT
t.teamID, t.teamName,
g.firstName, g.lastName,
c.name
FROM Gamer g
JOIN team t ON g.teamID = t.teamID
JOIN country c ON g.countryID = c.countryID
WHERE g.teamID IN (
SELECT teamID
FROM Gamer
WHERE teamPoints = (SELECT MAX(teamPoints) FROM Gamer)
)
ORDER BY t.teamID ASC;
Someone help me out
(SELECT MAX(teamPoints) FROM Gamer) <- This will select the max points of ALL gamers, not per team.
(SELECT teamID, maxPoints FROM Gamer WHERE teamPoints = (SELECT MAX(teamPoints) FROM Gamer)) <- so this will only select the teamID where the gamer has the max point of all gamers. BTW, a sub-select for an ... IN () should only select one column. I wonder why you don't get an error.
And your outer most select will select ALL gamers from the teams where a gamer has the max point of all gamers.
So it looks like one gamer from team 10 has the max points and you just select all gamers from that team.
But max points isn’t a thing
I refered to MAX(teamPoints) as max points.
You need to select the gamer in your sub-select and restrict the max() select to the team of the gamer.
SELECT t. teamID, t.teamName, g.firstName, g.lastName, c.name from Gamer g
JOIN team t ON g.teamID = t.teamID
JOIN country c ON g.countryID = c.countryID
WHERE g.teamPoints = (SELECT MAX(g2.teamPoints) FROM Gamer g2 WHERE g2.teamID = g.teamID)
ORDER BY t.teamID;```did that
and
it wants a subquery
The sub-select is a list of gamerIDs which do have the maximal points per team.
You're nearly there.
You did add the "per team" to the max() select but removed the teamID sub-select instead of changing it to the gamerID.
what would yall suggest is the best beginner interface for a sqlite3 db? im completely new to working with dbs so im not even sure of the options
whats the main ide for SQL? Does vscode work fine?
im a fan of SQLiteStudio, its got both its own interface for viewing and modifying the database, as well as an SQL Editor if you want to write your own queries by hand
https://www.sqlitestudio.pl/

o nice
ive also heard other people suggest DB Browser for SQLite
a db ide is completely seperate from my python ide right? so i dont need something that is compatible with my python ide?
you do not.
though you can find tools that work with VSCode (and likely pycharm) to help you with your SQL.
DBeaver is pretty standard
alr so ive set up and connected the db/sql studio, is it worth inputting anything that wont change (ie mob statblocks, current server ids for my bot etc) into the db through the ide rather than python ?
just wondering what is a good way to actually process the information, as i alrdy have a lot of code im going to have to move/modify; wasnt sure if theres a good way to go about it
whichever is easier for you to do
perhaps you might create the tables in sqlitestudio, then write a python script to migrate your older data to those tables
yeah atm all my info/statblocks are in instantiated classes
would i want to actually move them to the db, or just leave as is?
im not actually sure (apart from ids) what i should actually be moving to the db
the only person that was offering to go through it with me has since ghosted me
Hi folks & @paper flower ,
I tried to fix connection leaks with the attached implementation, but the insert latency went back up after a few hours. It goes down when I kill all processes but the latency issue is still there...
updated code: https://paste.pythondiscord.com/ejebilimet
PFA ss of the pg_stat_activity

Hot looking. I worked with sqlitebrowser, it would be interesting to compare them
Resolved.
one of the reasons i preferred it over my (brief) experience with DB Browser for SQLite was the export to SQL feature, although the sqlite CLI also offers this with the .schema command
Not going to use any of them for real work
But for documentation and beraucracy they are pretty fun as Excel/LibreofficeCalc alternative
For real work we need ORMs and SQL migrating libraries ;b
Migrating libraries are the most important
ORM itself is kind of double edged sword. But the stuff SQLAlchemy Core 1.4+ future 2.0 offers looks like pretty sick though
At the same time ORM and nearly native SQL in syntax
Do you use savepoints? 🤔
In one case yes... Using begin_nested as there are several sub function calls...
In one? Seems like all of these connections are waiting for sub transaction lock
@sage pasture Maybe you have some long-running transactions? They might be an issue too
These bulk save inserts are the only long running transactions (the records in ss are sorted in desc order by age of txn)
Since you mentioned savepoints... Could what's mentioned in this blog be the same issue with my system... https://about.gitlab.com/blog/2021/09/29/why-we-spent-the-last-month-eliminating-postgresql-subtransactions/

GitLab
How a mysterious stall in database queries uncovered a performance limitation with PostgreSQL.
We're using a get or create functionality too ... Will check SQLAlchemy engine logs for savepoints
I encountered that article too while searching for your problem 😅
Im using sqlite3 , i need it to sort for the UKEY , and in the same colum or like bar idk what to call it i need to tell me if it either gold , sliver , basic , etc.

I tried looking for 'savepoint' keyword in sqlalchemy.engine.log but didn't find anything... any idea how can i look for subtransactions?
I think it should be logged by sqlalchemy, just pass echo=True to your engine
You also have statement/query here, maybe you could find it in your application
I can see commit & rollback statements besides the queries with echo=True but don't see savepoint...
I'm writing an app that collects tabular data from PDFs and the user can select, filter and save desired data to excel spreadsheets.
A next step is to check values against a 'database' that is currently also an excel sheet.
I import the sheet, do some wrangling and get a dataclass
@Compound:
id
time
value
...
All dataclasses are stored in a list `compounds' and I iterate with the names from another list ```py
['id','time','value']
Is this an okay approach? Since it should be kept simple the database is likely to stay in excel so I don't have to hassle with SQL or anything which other users might not like to use or have access tocan someone recommend me a online database for discord bot
https://tutorial.vcokltfre.dev/tips/storage/
found this but still dont have a very clear idea
A tutorial to help you make better Discord bots.
Grrr I can connect to my database on my mac, but not on my PC... I think it has something to do with my universities wifi, but idk why it works on my mac
An async mariadb library that supports connection pools where I'll need to make minimal changes to my existing code?
Currently using mariadb
What exactly are you doing on your Mac and how exactly does it fail on your PC?
Legit just plugging in port, user, pass, database, etc into my IDE
It connects on my mac and it times out on my PC
Nevermind, I think my college wifi is the problem. Using a VPN fixes it
Afternoon, I'm looking for a easy MongoORM for a fastapi application. Ny recommendations?
i dont know if this is the right channel. Im currently reading rows in a csv file 1 by 1 and i want the rows to write into a database table in Postgresql. But it gives me this error (im a python newbie btw). Do anyone know how i could solve this?

If you use a dictionary as parameter you can't use %s as placeholders you must use the named one like: ... VALUES(:Bericht, :Datum, :Tijd, ...

'''INSERT INTO Tekstbestand (Bericht, Datum, Tijd, Naam, Station) VALUES (:Bericht,:Datum,:Tijd,:Naam,:Station)'''
is this what you meant ^^
Yes


It's db module dependent. It looks like psycopg2 uses a different style:
"INSERT INTO Tekstbestand (Bericht, Datum, Tijd, Naam, Station) VALUES (%(Bericht)s, %(Datum)s, %(Tijd)s, %(Naam)s, %(Station)s)"
What database can i use if im planning to make an android application that can be use offline
did not work either 😦
We'll need to see the error (traceback).
Let’s say i have a csv file with image links and i downloaded the data
I found out that some of the data needs to be cleaned because of null values and unnecessary or broken data
I want to edit the name of the images that were already named by their order in the csv file
So when I delete a value it changes their name to the new order
Can someone help me here?
Aside from find and replace with a text editor or uploading to something like Gsheets and using their editing tools, no idea here
Hi I have an interview for data engineering tomorrow, can someone please help me prepare
What code editor do you use.
what level? did you have any specific questions?
Junior
how do i convert business requirements into technical solutions using the QIDP technology stack, e.g., Azure Data Factory, MS-SQL stored procedures, views, functions and dbt
This is one of the qualifications required for this role
and I don't have experience in this
I have experience as a Junior Business Data Analyst
However, I am really enthusiastic and really want to drive value and growth to humanity through the use of technology
you are responsible for developing and managing data workflow, pipelines, ETL processes and load assurance reporting across QInsure's Data Platform (QIDP).
the thing is that you're missing a step between "business requirements" and "specific tools"
what do you mean?
the missing step is a general understanding of how to solve business problems
Yeah
understanding what a data pipeline even is, what kinds of things that one typically needs to do with data, different kinds of tasks and categories of tools used to solve those tasks
it's not like azure data factory is some specific important skill. it's what you do with it that matters

do you understand reproducibility? do you understand the general performance characteristics of different kinds of databases and other data storage locations like a azure blob store? do you feel comfortable with basic computing tools to set up data pipelines without fancy tools, just shell scripts and postgres?
this seems not truly junior
it looks like they are expecting someone with enough experience to be able to design solutions from scratch, and select among a variety of tools with some understanding of what they all do
I have a slight conceptual understanding of reproducibility
on the other hand, if this is a junior role, it's possible that they expect you to learn a lot and grow into the role
Yeah that's what I am willing to do
make that clear, but also make sure you are really comfortable with sql
I am very passionate about this field, I have already done a 6 month internship on Data Analytics.
it's always ok to admit that you don't know some specific tool, like azure whatever
Getting this job will ensure I progress in my career
it's much worse if you don't know some fundamental sql things
Yeah I have never been exposed to Azure
good then just say so
did you use some other cloud platform ever?