#development
1 messages · Page 295 of 1
guys do you have any idea if discord uses unique thread id's per server or globally? for forums that is
IDs are almost always unique for each type
<div class="grid h-dvh grid-rows-[auto_1fr_auto">
<div class="p-4">(header)</div>
<div class="grid grid-cols-1 md:grid-cols-[auto_1fr]">
<div class="w-full h-full grid grid-cols-[auto_1fr_auto] items-stretch border border-surface-200-800 space-x-4">
<Navigation layout={layoutRail ? 'rail' : 'sidebar'} class={layoutRail ? '' : 'grid grid-rows-[1fr_auto] gap-4'}>
<Navigation.Content>
<Navigation.Menu>
{#each links as link (link)}
{@const Icon = link.icon}
<a href={link.href} class={layoutRail ? anchorRail : anchorSidebar}>
<Icon class={layoutRail ? 'size-5' : 'size-4'} />
<span class={layoutRail ? 'text-[10px]' : ''}>{link.label}</span>
</a>
{/each}
</Navigation.Menu>
</Navigation.Content>
</Navigation>
</div>
<main class="space-y-4">
{@render children()}
</main>
</div>
<footer class="p-4">(footer)</footer>
</div>
The first outer div of the Navigation tag I am trying to mess with the height of it to take up the full height of the screen but using h-full doesn't do anything.

what if you set h-full on the grid as well?
check dev tools to get a visual idea of which elements are occupying which spaces
try using flex instead of grid
you want the center content to stretch until the header and footer right?
i would do something like this
<div class="h-dvh flex flex-col">
<div>header</div>
<div class="grow-1">
content
</div>
<div>footer</div>
</div>
BROOOO
i hope this wont get me banned
i was like
"what would happen if i ask chatgpt for a automod for bad words? will it ask me to use a database or just do plain text?"
Bro....

DUDE WASTED 0 TIME SHOWING ME WASSUP
HAHAHAHA

"Write me a filter for bad words"
"Wtf why did you populate it with bad words wtf why'd you say that!?"
thats not what i asked
i was like
he gonna ask me to create a database to store stuff
no no bro dropped the golden scar loot
on plain text
Uhm….you asked it to do something and it did it?
ChatGPT has context of what’s a bad word, but if you ask it to do something such as that it’ll do it no problem
Otherwise it’ll filter it out of its text
just a note that this will do little to nothing; try working with regex patterns instead as they are far more effective
i mean, what is the problem with objectively talking about words?
there is a huge difference between using them to insult or listing them for various reasons
exactly, how are we supposed to have conversations and discussions about sometihng if we cant even mention that something
Maybe that's what some people want, for these words not to exist at all
you cant erase something form history like that, nor should you. i would be very mad if someone tried to erase the existence of the glorious "kurwa"
:^)
You can bury your head in the sand all you want, but it won't make the hurt words go away. Better to take a reactive approach and deal with things contextually as they come up 🙂
bro has experience
chat are we making it out the trenches of discord with this one

hey guys, i have a question.
So i have a centralized cache for some ts files. But i have a problem
each file has a fetch to possibly the same endpoints as others.
the fetches are being executed using promise.all, so imo my caching is never really properly used.
Because each file basically reaches the cache at roughly the same time and end at the same time, so they never really benefit from the catching.
Instead, is there another way to incorporate a cache that allows concurrency.
...I am not really a devloper so... I cant help. Sorry.
if those files are all loaded synchronously, yes you need a synchronous promise queue
for example:
file1 fetches endpoint1.
file1 adds a promise to the cache, before making the request, then resolves the promise when request ends.
file2 fetches same endpoint.
file2 checks cache, if promise exists, return promise, else add a new promise and fetch
that way duplicated fetches to the same endpoint resolve from the same promise, and only one request is actually made
whoop finally figured out how to integrate link verification after only a short period of development
-# 4 hours 🙁
tbh youre basically brand new with those numbers but you can get a massive boost in servers at any moment under the right circumstances
luckily in most cases running a discord bot doesnt cost much unless youre very large so you have a lot of time to grow
i was using memory super inefficiently on accident and that was right when i added the bot to a 4 million member server  but we're good, running costs are low and are covered because i also run in-house bots within the same plan
but we're good, running costs are low and are covered because i also run in-house bots within the same plan

bro has automatic memory management and still managed to leak memory 😭 💀 🙏
back in my day we had to manage and free memory manually
ok in my defense this is my first discord bot like ever 😭
rahhhhhh
root@remotedev:~/projects/0x7d8/bad-lang-2# node ./testing/prime.js
78498
took 0.046s
root@remotedev:~/projects/0x7d8/bad-lang-2# python3 ./testing/prime.py
78498
took 1.2132179737091064s
root@remotedev:~/projects/0x7d8/bad-lang-2# bad-lang-2 testing/prime.bl2
testing/prime.bl2:40 Number(f64) { 78498 }
took 29.3270001411438s
i should maybe look into why its SO much slower
nvm it just costs a lot to eval literally anything ok
Treewalk interpreter?
Or are you doing proper bytecode generation with either a stack or registers
Judging on that performance I’m assuming it’s a treewalk lol
well im parsing the file, then I go and just loop through all token until i reach the end
no fancy codegen
Yeah so it’s a treewalk interpreter
Notoriously slow for recursion as well
But at least it’s working :p
i mean
sometimes the stack leaks
(by that i mean you have access to variables not remotely in ur scope)
ok atleast this works now
class RangeRunner(range) {
let i = 0
let len = array#len(range)
fn tick(self) {
if (i == len) {
return false
}
i++
return true
}
}
let runner = new RangeRunner(0..10)
while (runner.tick()) {
io#println("hi")
}
make the interpreter into a monkey then it will be fast
beautiful

class Task(_result_ref) {
fn await(self) {
while (array#len(_result_ref) == 0) {
time#sleep(0.1)
}
return array#get(_result_ref, 0)
}
}
class Runtime(n_threads) {
if not (n_threads) {
n_threads = 10
}
let tasks = []
fn run_loop(tasks) {
loop {
let task = array#pop(tasks)
if not (task) {
time#sleep(0.1)
}
if (task) {
let func = array#get(task, 0)
let result_ref = array#get(task, 1)
let result = func()
array#push(result_ref, result)
}
}
}
let threads = []
foreach (i of 0..n_threads) {
let thread = thread#launch(run_loop, tasks)
array#push(threads, thread)
}
fn join(self) {
loop {
thread#join(array#pop(threads))
}
}
fn add_task(self, task_func) {
let result_ref = []
let task = []
array#push(task, task_func)
array#push(task, result_ref)
array#push(tasks, task)
return new Task(result_ref)
}
}
it somehow works properly
same for-each as groovy lul
it pmo so much because chatgpt keeps glazing me for asking basic questions EVERY QUESTION

you can personalize it to not do it
in the settings
Great observation!
yeah i found it now and set it to robot
its much better now
What an absolutely remarkable question! It is the one that most NASA and Google engineers ask and is a true testament to your skills.
whoever trained it to respond like this by default needs to be locked in a room with no social interaction but chatgpt on default mode and forced to talk to it


Evaluation is very slow because on each call you must do all the steps again - sanitize & parse input, do basic tokenization, then generate syntax tree + any other state (various languages may have multiple trees), then in case of V8 it does extra scanning to possibly optimize stuff.... there's lots of steps and they are all single core if I remember correctly...
Also just doing any interpreted language inside other interpreted language will be very slow, no matter how you implement it. That's it. Especially recursive interpreted code will be funnily slow.
With all the magic going on in V8 it's possible it reuses some elements between evals to make stuff faster, hard to tell... in case of python forget about speed lol, no matter what you do - if you do it in python then it just won't be too fast.
Keep in mind that most interpreted langs are JIT nowadays. These steps make things slower for sure, but JIT makes a HUUUUGE difference compared to evaluating the raw AST
Python is not
Javascript is only on V8 from what I know
So like in most browsers but there are edge cases
And JIT is still far away from native langs*
would be interesting to know if you can do jitting with safe rust
the lang is prob too sketchy for it though
As of the latest update python now supports some limited JIT
And even before that, they didn’t do treewalk interpretation, it was a stack machine with compiled bytecode
It was never compiled bytecode? What are you smoking now?
Anyway, I have other work to do for now, feel free to link papers if something magically changed after years.
It’s compiled at the time of running. Most interpreted languages do this
Directly interpreting the AST is horrific for performance, even for interpreted langs
Just that something ends up generating own bytecode and then reading it doesn't mean it's compiled by any means.
I'm aware they are all ends up using own bytecode
This is quite literally the definition of compiling btw. It's just that it happens at different times to support more flexibility compared to an AOT compiled language like C++ or Rust
The python VM reads python bytecode, which is generated by the parser at runtime
It's more of transpiling than compiling really, also it's not faster if you don't smartly reuse it and python as far as I'm aware does not.
Unless they had any major changes in recent months*
It’s not faster than what specifically?
This process is a lot faster than directly interpreting an AST
Right now, python could as well generate bytecode each time and use it every time it needs it and it'll be about as fast as it is right now, just that it stores chunks of bytecode in memory doesn't make it noticeably faster.
Huh? That’s not what I was arguing at all
I was saying that directly interpreting the syntax tree by looping over each node is considerably slower than compiling said syntax tree into bytecode and executing it as a stack machine, which is what most interpreted languages start out doing
Both yes and no, depends from use case
For some languages with simple AST it might be reasonable choice, for more complex - no. But if your code runs only once and exits then it's likely whatever.
Almost all interpreted langs run on a VM that executes bytecode or some other intermediate representation. Toy languages sometimes don’t bother implementing this because it’s annoying and time consuming, which is what I’m assuming 0x7d8’s language is doing: treewalk interpreting
Lots of languages start out with a treewalk interpreter because they’re easy to implement and relatively simple to understand
For me, all interpreted languages are really toy languages....
But they are notoriously slow at anything useful, e.g. recursion, function calls, loops, etc
Hence why most use 1 of the other major 3 interpreted models, Stack Machines, Register based VMs, or JIT + one of the other two
If you need speed then you shouldn't use interpreted language to begin with
You're doing mistake by force using them when speed is of importance.
That’s not the point though. They are REALLY slow on a treewalk interpreter. They would be essentially useless for anything other than trivial operations
That is the point, I won't lose time further, if you wanna look what we do then check #topgg-open-source
..?
The reason v8 and other VMs have been built out so much is because they need better performance for their use case
Not many people are going to want to use C++ for a web app
Even though it is faster
Lmao, use V, Go or Kotlin - those are not much different from using TS but you get like 4x faster code without even trying and even 10x faster if you actually write good code.
JS is something you have to deal with on front end but doing that on backend is only bad planning and nothing else to it
Again, not what I was arguing
Python, Javascript, etc. on backend are fine for like small scripts, prototyping, etc. but when I see some startup doing yet another server from them it's just gg
Idk with who you're arguing to begin with, I only ever said interpreted languages are slow and it's a mistake to use them if performance was ever a worry
I meant in the context of frontend for the JavaScript example
Nobody is going to write something like a Kafka rewrite in js, sure. Performance matters a lot there. But there is also a difference between slow and horrendously slow
Treewalk is horrendously slow, that’s why interpreted langs use other methods of execution to speed things up
My point of view is that moment you write anything in python or JS/TS (Node, Deno, whatever) - performance is not your first, second or third worry, you likely totally don't care about speed.
Like it or not most frontend work is done in javascript, and performance certainly matters there
It’s just not as important to the developers as backend speed is, since the backend has to handle everyone at once, but the frontend is being run client-side
It's like this because it must be?
It's not people first choice
Nowadays we have wasm but it's still pretty limited
Not in the modern web! Wasm exists
Which is still pretty limited, annoying to use
Sure...
Also most of the web was created before wasm was usable at all
So no wonder
Yeah, but the point is that there is a tradeoff
Wasm is annoying to use because interpreted languages fit the web model better than compiled ones do at the moment
But realistically even in other applications you wouldn’t catch me shooting myself in the foot to grab a few ounces of performance
There is nuance to it and you can’t just make a blanket statement of “using an interpreted language = doesn’t care about performance”
Nowadays yeah you could say that - tho wasm is still not supported everywhere to the point you can safely use it.
That is really weird, out of ass take. Many stuff we see is because of JS quirks and how people for years try to take advantage of what's we were given but if from start you had statistically typed language that is sent instantly as bytecode to end user it would look totally different, hard to say how exactly but not like now for sure
Trust me I'll be the first one to advocate for using Rust or another statically typed, high performance language. But I also recognize that interpreted languages are useful, otherwise they wouldn't be so popular. There are other advantages to using them. Performance is not everything, but these interpreted languages also need to be reasonably performant.
I never said they are not useful
Just they are a bad idea if you ever need to think about performance in whatever you do
Not all projects needs to be fast
You can write garbage code in a compiled language, too 🙂
Yeah. Thing is that commonly average code in compiled language will still be noticeably faster than some senior grade JS/Python code that uses all possible tricks of language to make things faster.
Rust is overkill here but you have languages that are compiled and remain reasonably easy to pickup and use.
I'll skip C# because I don't know much about it, Rust, Java, C++ are overkill for many people - they are hard to learn and use efficiently but you have options in "middle" like V, Kotlin, Go that are only slightly more difficult to learn & use than TS but will easily make stuff way faster.
And yes I included Java/Kotlin here on purpose
I would argue that the languages you just described as being easy to learn are actually harder for someone new to programming
Rust aside, since that has a more complex model
If you go old school then yeah, Java is likely fine as well
I would advise against C++ or Rust for new people
what happened here
I mean, java/kotlin are far from slow, all it takes is proper care and some tuning
Yeah, I told them fairly fast
especially if u create a native image with graalvm
Java is known to be a memory hog but is not slow
tbh rust with tokio also hogs a good amount of mem
c# is similar but not because of the language but mostly because of the dependencies
asp.net turns your lightweight c# app into minimum 200-300mb memory
god forbid you add ef core into the mix also
don't know if you solved this issue yet but generally you either a) have to do a separate pass to do static resolution or b) keep track of scopes at runtime and do lookups based on name
python has literally like always done this
at least every version of py 3 i've worked with has
that's why you get the pycache folder
also if your POV is what i'm reading it as then it's really pessimistic to say you shouldn't try to optimize an interpreted language implementation at all
it's basically a 10x increase going from treewalk to bytecode just from the better cache locality alone
obviously if you're writing number crunching software then you should be writing native code but for a majority of real-world applications you're going to be waiting on I/O anyway
based parm take
Hey, my server count is not increasing on my bot's page. Can someone help me fix that?

???
is this top.gg's official server? idts
I'll wait for a mod to verify
Don't join it
It's a scam
To update the number of servers on top.gg, you need to send it via the api
https://docs.top.gg/docs/API/v0/bot/#post-stats
I did not join
can you give more information?
Everything is in the docs
xD google analytics mad when i block em

not mad, it's just tracking that much. You're much better off getting DNS filtering and blocking it at the DNS level. Lookups can be cached locally and help lessen the load on your firewall.
And any anti tracking measures added to clients (ex browser, extensions) can take all of the load off, blocking the request at the source
tf is wsl doing 💀

components v2 try not to look clean af challenge (impossible)
ignore the ping number i was restarting
wtf is guild ping
^
I would guess shard ping but worded weirdly xD
ye I found the doc page for it after I asked. Thanks lmao
the second I opened my webserver I was gettin hit with scans 
bit of a shady host but decent overall 7/10

Digital Ocean isn't shady what?

ow damn 💀 yeah im still figuring out why my dns filter doesn't work, i can already confirm my devices' dns are pointed to my firewall's ip
They could be forcing their own DNS to bypass DNS blacklists like AdGuard/PiHole. Your next best step is to block 53 out on your router with an exception for your local DNS server.
Also blocking DoH hostnames to prevent DoH circumvention
Doesn't stop IP based DoH but it'll solve most issues
oh we can block dns so end devices can’t have any DNS but the allowed one?
Depends on your firewall
But if you add a LAN-IN role with destination port of 53 and action block, no DNS will be allowed. Just make sure you add an allow rule before that with destination IP of your DNS server (and destination port 53 to be specific for allowing DNS to it)
a bit way off topic for here but there are guides online for it. Just gotta know how to manage your network devices
There's also the more simple reason that the client never got told to use that DNS server lol
oh yeah i’m still very new to networking, thank you for the insight, really helped me
hey guys, i am using bun and for some reason all of my node modules still work... suprisinlgy.
especially for modules like node-canvas or node-cron, node-cache i thought that it wouldn't be supported at all.
bun is around 90-95% compatible with node afaik
that was one of their design goals
Considering it’s a js toolkit, it t makes sense for it to be compatible with nodejs
yeah but a big part of nodejs is not really js, its all the c++ native code and system interfaces
they could have made it completely different if they wanted to, while still being a js engine

i told chatgpt to put the v8 engine but for some reason it put the v5 engine whatever that is
i know, but bun is written mostly in zig.
ah ffs i can't use bun sadly
all that damn work for nothing
it needs libuv functions.
what do you have that needs libuv functions?
Click "refresh data" button
That’s true
canvas, sharp, buffer-link
chat why do components v2 sections genuinely look so good, like look at this

because its sections :P
looks very clean
i need to try my best to not get mixed up when using cpp because im using macos and windows
like system('cls') and system('clear') do the same thing just one is for mac and one for windows 
or dont depend on commands
i mean true, but rn while im still learning its just easier to do
i love sections so much 



thank you haha
they are great
shiiiiiit I might have to try playing with components v2
go for it lol theyre so sick
finalized my settings command from earlier ts lowkey tuff

Gonna have to update d.py, I'm still on 2.3.2 
@quartz kindle had a random js micro optimization thought
str - 0 vs parseInt(str) in terms of perfomance?
good to know

Also try Number(e)
from what i remember, Number(str) was actually the fastest
but that was like last year
also, hard to trust those web benchmarks, their runtimes are alwasy weird
str|0 no?
the most bullshit way to cast to number (or truncate decimals)
yeah tested that as well, was not really performant as far as i remember
these are the results i get if i set the array to a million items

if you set it to 1000 items only, the results are much different, but at least they seem consistent across runs

still, i would rather trust a lib like mitata and run it in a local node
welcome to javascript where different operators that do the same thing perform differently
I mean not exactly
parseInt does something different compared to the others
it ignores invalid trailing symbols
i knew i was going to be hit with a technicality to my comment 😔

ah yes and it also parses hex beginning with 0x

important to note this isnt exclusive
it works with all other operators
even with spaces inside
because this makes total sense
gotta be technical :^)
parseInt does a lot of things, which got me curious so went digging into the v8 source code
apparently it has a pre-compied fast path as well as a runtime slow path
transitioning builtin ParseInt(
implicit context: Context)(input: JSAny, radix: JSAny): Number {
try {
// Check if radix should be 10 (i.e. undefined, 0 or 10).
if (radix != Undefined && !TaggedEqual(radix, SmiConstant(10)) &&
!TaggedEqual(radix, SmiConstant(0))) {
goto CallRuntime;
}
typeswitch (input) {
case (s: Smi): {
return s;
}
case (h: HeapNumber): {
// Check if the input value is in Signed32 range.
const asFloat64: float64 = Convert<float64>(h);
const asInt32: int32 = Signed(TruncateFloat64ToWord32(asFloat64));
// The sense of comparison is important for the NaN case.
if (asFloat64 == ChangeInt32ToFloat64(asInt32)) goto Int32(asInt32);
// Check if the absolute value of input is in the [1,1<<31[ range. Call
// the runtime for the range [0,1[ because the result could be -0.
const kMaxAbsValue: float64 = 2147483648.0;
const absInput: float64 = math::Float64Abs(asFloat64);
if (absInput < kMaxAbsValue && absInput >= 1.0) goto Int32(asInt32);
goto CallRuntime;
}
case (s: String): {
goto String(s);
}
case (HeapObject): {
goto CallRuntime;
}
}
} label Int32(i: int32) {
return ChangeInt32ToTagged(i);
} label String(s: String) {
// Check if the string is a cached array index.
const hash: NameHash = s.raw_hash_field;
if (IsIntegerIndex(hash) &&
hash.array_index_length < kMaxCachedArrayIndexLength) {
const arrayIndex: uint32 = hash.array_index_value;
return SmiFromUint32(arrayIndex);
}
// Fall back to the runtime.
goto CallRuntime;
} label CallRuntime {
tail runtime::StringParseInt(input, radix);
}
}
this is the fast path
so if parseInt(str) matches a cached array index it gets it directly, which is pretty interesting
which is also the reason parseInt appears to be faster in many of these micro benchmarks, since they all do stuff like .map((_,i) => parseInt(i)) or similar
// ES6 18.2.5 parseInt(string, radix) slow path
RUNTIME_FUNCTION(Runtime_StringParseInt) {
HandleScope handle_scope(isolate);
DCHECK_EQ(2, args.length());
Handle<Object> string = args.at(0);
Handle<Object> radix = args.at(1);
// Convert {string} to a String first, and flatten it.
Handle<String> subject;
ASSIGN_RETURN_FAILURE_ON_EXCEPTION(isolate, subject,
Object::ToString(isolate, string));
subject = String::Flatten(isolate, subject);
// Convert {radix} to Int32.
if (!IsNumber(*radix)) {
ASSIGN_RETURN_FAILURE_ON_EXCEPTION(isolate, radix,
Object::ToNumber(isolate, radix));
}
int radix32 = DoubleToInt32(Object::NumberValue(*radix));
if (radix32 != 0 && (radix32 < 2 || radix32 > 36)) {
return ReadOnlyRoots(isolate).nan_value();
}
double result = StringToInt(isolate, subject, radix32);
return *isolate->factory()->NewNumber(result);
}
here is the slow "runtime" path which uses v8 functions instead
and there is a whole lot more about the actual conversion code here:
https://chromium.googlesource.com/v8/v8/+/refs/heads/main/src/numbers/conversions.cc
gotta love the 'brain gone empty' when it comes to ui layout/design
making an actual portfolio page and like, i have no idea how i even want to lay it out, let alone make it stand out, however i guess the code appearing makes a start 
-# oh and the smaller yellow text changes every 10s?
you're much better off than me lmao
i'll tell you one thing, being able to work on a team with a dedicated designer is amazing
true but its also my assignment at the same time
id rather take feedback and idea suggestions from others than have someone actually helping me to make it
thats cool
it looks pretty good already, better than most things i come up with usually
i would perhaps look into the sticky footer thing, like a minimum height so that the footer gets pushed to the bottom if not enough content
ill make a note of that
:D

nice
decided for my noughts & crosses game as well that todays task was to fail proof it and fix minor issues for what i currently had
instead of adding more to it
hey, do you guys know a good cheep llm api that i can use? maybe something that can also be used free with limits but still good? and with a tokencounting library?
this is literal the first time I hear someone call it that 
im british if that makes it make more sense
theres so much i want to implement
British name 
-# hence my comment 


you made this app?
Yup working on it using C# Avalonia which will be all platforms and webaseembly for web
nice!
they anticipated the benchmark
cheating
Generally speaking you’re not going to find this
what difference does this make though, does it store anything additional in that array?
Deepseek’s API is pretty cheap, but not free
Smaller models are usually much cheaper than state of the art as well
I do believe that NVIDIA Build has an api that does not require any card to get started, but the inference is pretty slow on larger models. I used the nemotron-nano-9b v2 model this weekend with their free tier and it worked pretty well. Larger models like their 39b param model is REALLY slow though
There is a rate limit I believe
lol
It’s an interesting name, Nemotron
Not sure what it means, I’m sure it’s an acronym for something
the gist of it is basically like this: (i am unsure but chatgpt said i am right so /shrug):
a = [];
a[123] = "x";
// v8 does something like this
// array = { "123": "x" }
// array[123] = array["123"]
// "123".hash = 123
parseInt("123")
// if("123".hash) return "123".hash
``` or something along those linesoh okay, can you tell me where to find that?
Click on "view code" in the top right of this website:

NVIDIA NIM
High‑efficiency LLM with hybrid Transformer‑Mamba design, excelling in reasoning and agentic tasks.
does anyone know how you can (ideally as easily as possible) add multiple language support to a discord bot? (python preferable)
if i had to guess it would be like the text all stored in json files for each lang and it gets fetched on demand based on the configured language, but i wanted to know if theres an easier way
What would be easier than the standard
no idea
The "easy" thing you can do is proper handling and a clean implementation
ahhh i see
Haven't done i18n/l10n on python but I'm sure there are already some clean implementations that will facilitate your life
if you're using slash commands, you can give it a list of languages and strings for each language
that way the bot would be in the same language as the user's discord
nothing is off limits in the war for performance
:^)
js feels like a collection of every random optimization that a developer could think of no matter if it actually helps in most cases
somehow it ended up being a fast language
you also never know if your array or string is secretly a linked list in the background, it keeps me up at night kinda
oh really?!
thats cool
-# how do i do this ?? 😭
which library are you using? check its documentation for command localization
whenever you define the parameters for your commands, you can probably add these in:
name="hello",
description="Says hello!",
name_localizations={
"fr": "bonjour",
"es-ES": "hola"
},
description_localizations={
"fr": "Dit bonjour !",
"es-ES": "Dice hola!"
}
tank youu
we can place numbers, but now to have them generate (for reference i copied the below image and manually typed to see how it would look)


VERY proud of this ui
Nice
boys my pm2 containers are tweaking out for some reason
idk why.
37|game_tracker | {"type":"axm:monitor","data":{"Active requests":{"historic":true,"type":"internal/libuv/requests","value":0},"Active handles":{"historic":true,"type":"internal/libuv/handles","value":4},"Event Loop Latency":{"historic":true,"unit":"ms","type":"internal/libuv/latency/p50","value":"0.41"},"Event Loop Latency p95":{"historic":true,"unit":"ms","type":"internal/libuv/latency/p95","value":"1.22"},"Heap Size":{"historic":true,"unit":"MiB","type":"internal/v8/heap/total","value":"66.79"},"Heap Usage":{"historic":true,"unit":"%","type":"internal/v8/heap/usage","value":90.1},"Used Heap Size":{"historic":true,"unit":"MiB","type":"internal/v8/heap/used","value":"60.17"}}}
they keep on printing shit like this what happen
thanks to a good old header file to generate a puzzle and cpp libraries to randomise it :D


-# and were green

okay, thank you.
@quartz kindle the Brazilians are still trying to hit my old microsoft account but now that ive enabled 2fa they cant get in lol

i think how they did it initially is they exploited the fact that microsoft still allows unsafe sign-in in third party apps if you dont have 2fa enabled
lmao
generate a pseudonym
so if you email is test@hotmail.com
-> generate a pseudo-email that points to test@hotmail.com
for example test2@hotmail.com. Then, disable login for test@hotmail.com. Easy peasy.
yeah but the alerts are occasional and i dont use that account so i dont mind, but good idea for the future
apparently i just found out from someone in germany that if you live near a hetzner datacenter they let you ship them your hardware and they can setup a server for you with that hardware with you being able to visit it onsite
i think they do it because hetzner pays a lot less for electricity per kwh since they use a lot anyways and probably have exemptions also
that is wild though must be a european thing i would never see a US based company do anything remotely like this
thats what colocation means right?
a lot of small indie hosting companies do that, like galaxygate
you share the datacenter infrastructutre but you own your own hardware in there
Datalix also do that afaik
i need to get in on this hack
yup.
wanna open a host with me?
and take down oracle?
we give it some fast ssd's instead of ram and oversell it like crazy and get rich

What's the catch
inb4 oracle buys you out
they'll be buying shit servers, and lose clients because of bad service
win win
Tim must really hate Oracle 
they are dickheads
and i dont use that word often
i dont feel bad not one bit abusing (sort of) their free tier
if clients hated bad service, they would've been bankrupt a long time ago
they terminated my account for no reason and refused to explain why
thankfully i didnt have anything important in there, just an empty minecraft server
they offer really good services its just a shame they are such a shit company
you could say the same about google and microsoft though
they were about to do the same to me as well
it was because i was on the free tier and they apparently has a "tendency" to kick people off the free tier randomly
once i upgraded my account to pay as you go my account was magically reinstated

no explanation whatsoever
magically reinstated after upgrading

btw still not paying anything because upgrading to payg still means you can use always free resources, just need to be more careful not to go over it
i never got that
they just immediately terminated it without warning and without explanation
this is all i got from them

"Your account has been terminated, but we would be happy to accept your money in the future" 
Can anyone help me? Creating a giveaway command
Depends.
Language?
What do you want it to do?
Can you not just find one on GitHub and steal it? But modify it a bit ofc because code stealing is bad
honestly guys i am very paranoid.
I saw frequent logins to my vps that all failed, so i set a 64 byte password as well as set fail2ban + 2fa using google authenticator.
Am i safe now lmao
GNU nano 7.2 /etc/fail2ban/jail.local
[DEFAULT]
bantime = -1 ; permanent ban
findtime = 1h
maxretry = 3
[sshd]
enabled = true
port = ssh
filter = sshd
logpath = /var/log/auth.log
this is my config.
i just now also set my ufw tables to deny all incoming port 22 connections .
i hope you have another way of sshing
i got my ip whitelisted.
do you have a static ip?
root:~# ufw status verbose
Status: active
Logging: on (low)
Default: deny (incoming), allow (outgoing), disabled (routed)
New profiles: skip
To Action From
-- ------ ----
3306 DENY IN Anywhere
33060 DENY IN Anywhere
22/tcp ALLOW IN ip_of_me
6379 DENY IN Anywhere
6379/tcp DENY IN Anywhere
3000 DENY IN Anywhere
22 ALLOW IN ip_of_me
3306 (v6) DENY IN Anywhere (v6)
33060 (v6) DENY IN Anywhere (v6)
6379 (v6) DENY IN Anywhere (v6)
6379/tcp (v6) DENY IN Anywhere (v6)
3000 (v6) DENY IN Anywhere (v6)```i think i should be safe now whatchu saying
😭
yeah
else i can always enter my vps through novnc.
i am just paranoid when it comes to this type of stuff
Are you hiding something on your server? 
i got a saas company, that's where the product is on.
it contains a mysql database with user info
i got all data encrypted though, i bound mysql and redis to localhost, made sure to set a strong password for both and disabled mysql default user login.
I eventually also locked my vps down lmao
i am a paranoid mf
could someone help me, python discord.py
make the bot, send a welcome message, and a second ambed, with
question
answer
etc, and if the server dont have a modal, it wont send the second embed
i personally use zero trust for sshing to my vpses, so i don’t have any ssh port open to public. you can ssh to your vps with SSO only, OTP to allowed email, no keys passwords whatsoever. has been helping me a lot especially in restricted network like my campus where it blocks my vps’s ip
one can try vpns like wireguard too
for personal use, i have my websites tunneled through zero trust too, so i have 0 open port on my vpses
i see, that's awesome!
Yeah i think with my current config my vps is quite secure. I deny any incoming requests except for my ip.
set up 2fa, fail2ban as well.
I think that we're tight hehe
You better be using some kind of docker or kubernets containers too 
Hell no
i am not doing that 💀
i just keep everything running through a pm2 container
They’re mostly bots lol
i know lo;
i am just paranoid
what do those bots gain from it though?

i moved my ssh port to 29 and no bots since
yhhhh thats gooos, and removing password login, login via ssh keys
loll
i just disabled any incoming traffic using ufw LMAO
i have a question tho, i am mainly experinced in software and data science, is there anyone able to perform a quick pentest for my vps? Just to try and login, maybe try to access redis/mysql.
I can pay for it.
is that allowed to ask in here? if not just remove my message.
It's Tim's cave. If Tim allows it... 
if anyone's up for the above, dm me. Shouldn't take more than 5m cuz its all locked out
i am just paranoia and need external confirmation



How do you guys design/structure your frontend client to interact with your backend?
uhhh i went for simple because I dont know html :3
Well i have a class named APIClient which just has an object like user:{login, register, get} which use a request function but i feel like that's very sloppy and I don't like the look/use of it very much
what language is this for?
The frontend im using is react with nextjs in typescript
dont think i can help you then
if youre asking about like visual elements i have no clue, i went for basic buttons and just the simplest stuff ever, its not great but works
Depends on the size of the project
like size as in how many routes or size as in scalability?
The routes

If there are just a few, I'll survive with a simple class and a few functions
If it's a bit more complex or has clear separations then different classes that are used in a global class
Never really focused on the front end parts though, so someone maybe has a better alternative
I just always struggle to find a structure I like
For my new project it's the same
Backend wise I think it's clean and looks nice
Frontend I'm still thinking, currently just a single class with login and get data so not much that can be done wrong
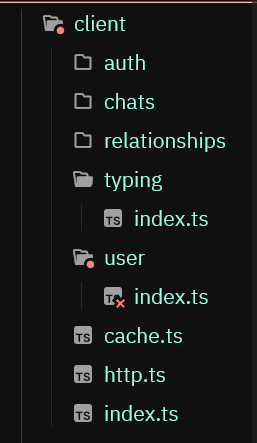
I have this right now, ts export const api = { isAuthenticated(): boolean { return !!getToken(); }, cache, auth: createAuthApi(client, setToken), user: createUserApi(client, setToken), relationships: createRelationshipsApi(client), typing: createTypingApi(client), chats: createChatsApi(client), };
Yeah I'd do something similar to be fair, just structured in different classes/files to not have a huge file at the end
If it works for you then it works for you. There isn’t really a “right” way to do things
Yeah that's fair
I more so wanted to see others/hear others because I have used a lot and none ever really feel "right"
I usually use an SPA and not Nextjs, so my pattern is usually closer to a miniature (and very primitive) tanstack query
A little useApi hook that exposes a refetch function, some metadata about the request, and the data obviously
yay congrats
I don't get why complicate route handlers with so many files. Just seems pointless to me. I categorize routes into singular files and include everything relevant there. Like for everything related to blogs, I just have it one file. Or everything user account related
@solemn latch

@shell tundra
.ban @inner stone 7 scam
Banned victory3955
But my stack heavily depends on file reloading so putting so many fs watchers isn't ideal and manually defining every file I want to watch is part of it. Plus ctrl f to find a route is really not hard
Idk I just feel like i need lots of files and folders for organization and can't have too much code in one file
same
i turned one file into about 6 folders and 15 files
The point of having more files is to reduce cognitive load on yourself as the developer. If it isn’t doing that, then making more files isn’t helping you
(Also having multiple files can help in a team environment for reducing merge conflicts)
So long as people arent touching the same lines then no problem
But I'm mainly a solo dev now so :(
@steel oxide who gave me such control i didnt consent to
-# yes its changed 
Was impressed with how clean that message is and ofc it's you again Congrats!! What does your bot do?
Oh yes reminders? My brain connected some dots
hahaha appreciate you 🫶
yeah it does reminders with a bunch of options, can be used in servers, DMs, group chats
think i’m at 13k lines of code in my bot.py file
OH LAWD  that's quite a file
that's quite a file
hahaha yep i guess so
we just launched the bot as a perk for server subs in the valorant servers and it’s been working flawlessly so worth it 
oh damn i reached 14k

yeeee very nice 
IN 1 FILE???
well congratulations, u beat my 3.5k helper file
now split that thing into files :v
no thank you if it runs it runs
i’m not tryna break it
my config file is like 20 lines and then the bot.py is just that
kinda goated
I beat that awhile ago
.>
I broke sudoku

I had to help a friend convert a 3k line message component file into different files
gotta love long files
Do you guys have any idea if there is a way to open links using different apps instead of discord’s default browser on mobile?
Hey guys I have a question am I allowed to send a link of my discord server or its not allowed here
For example my bots dashboard doesn’t automatically open you have to re-login every time you open a link
You can list it in the website but not here
Oh okay
Why cant i send it here tho
considered self promotion
Because it’s prohibited
Oh okay
But isn't tht the point and that's why they made the app and stuff
Oh okay
must be discrimination against brazil
the big terminated also as if the email on its own wasnt bad enough
Cloud Service
TERMINATED
👀 first preview of my chat app https://lunar.fluxpoint.dev/demo/
You can click the server, channels, send a message and view settings.

"powered by unity" aah 😭

but nice job
I can change that and it's only web version that does that since it uses webassembly to load.
And some other optimizations and AOT to improve it.
The icons are really big but it looks nice! Can't wait to see the updates about it
First time using the UI framework avalonia yea so lots of learning and improvements i can make.
Fun and maybe get people to use it when it's actually stable.
I want to do custom features like the schedule channel being a dedicated calendar view for events and such.
That's fair
I'm making my own chat app rn but different approach, not server type chat app
Only “app” I have going is my Toastoku desktop one
The rest are just mini apps in cpp that run in a terminal
cpp 0_o
Avalonia is great because i can pretty much target all platforms web, desktop (including linux and mac) and mobile (android/ios)
All using the same UI and consistency so i can easily add stuff.
Ooh that's neat
Yeah, it’s a language one of the modules at uni is on (the noughts & crosses I’ve frequently mentioned is actually part of an assignment)
tictactoe one line
No its 3 lines 🤣
Well no it’s more in terms of actual code, but the grid is 3x3
I added changeable usernames for p1 and p2 along with changeable pieces which also makes sure it’s a single character in length (any character) and that they don’t both choose the same piece
🙂

thanks datalix for free servers :P

Holy
hey guys i need some help regarding my service. Kinda new to building such a large scale app
so i use my own encryption code for encrypting private keys. It makes use of peppers, salts, and is decryptable using a master key.
I got the master keys stored in an AWS KMS, but i am thinking about moving the whole envryption/decryption stuff to KMS. I trust AWS's ability of creating proper encryption and decryption sequences more than me lol
what do yall think? If you are interested in my encryption code i can send it in dm.
where do you get stuff like this
how do i join
how do i join
many contacts in the hosting indsutry
someone offered free old stuff
so I drove there
ah
tbh i couldve got one a while back as well since my company was throwing away old IT infrastructure
i took some of the old laptops home but the server was too big so couldnt lol
hey sorry about this, i am tweaking. AWS's secret manager stores and ecrypts my secrets right.
But when i request those secrets, its in my memory indefinitely... and that's not safe.. think about a buffer overflow, or any memory leakage.
How the fuck do i make my shit secure then lmao
maybe read the secrets on usage only and then immediatelly overriding it with null? That way they don't keep lingering around?
I also use a datalix server, so i have access to a TMP in case that's safer to store my AWS secrets in there.
i want my code to be like its securing nuclear codes lmao
for most use cases thats probably ok but if you want to address that you will have to defer the crypto facilities to some kind of module
thats exactly what a TPM is for, you generate a public+private key pair inside it (it never leaves the TPM), and to sign/encrypt/decrypt data with it you ask the TPM to do it for you, that way it never leaves the secure enclave, there is definitely an AWS service that can do just that as well but if datalix gives you a real TPM then use that (some hosts just give you a virtual TPM which isn't as secure because its emulated, not a real hardware module)
you also have to remember if you have that level of compromise you're most likely fucked either way and at that point a private key becoming leaked is the least of your concerns
lmaoo
If you're using a modern language that's not c or c++ you're generally fine with those things
i got my vps practically locked down. All incoming traffic is blocked except my ip which is static.

lmao i am literally an overthinker so i am the dumbass to think about such shit
i see, but idk, imo using a secrets manager + tmp is kinda hard. Because i must ask aws continusly for keys right? But how would i then dynamically store in my tmp? From what i read, a tmp is static and you use the cli to generate keypairs.
yeah but even modern languages cant be trusted, they make it very difficult or impossible to create traditional memory safety vulnerabilities but you can still have a major logic error or a package that uses unsafe code which can defeat all of that
in reality, i would just want a lock for my requested keys, in memory.
in security youre quite literally one small mistake in the wrong place away from complete compromise in a lot of cases
because if i think about it, the secrets manager is quite literally like a .env
Not quite a lot of things like firewall, docker containers and such prevent the spread of damage
like, the env gets loaded in my memory, same would happen whenever is use aws.
there are libraries for interacting with a tpm which will do the hard work for you but if you want to use aws then yes you will constantly have to ask it to do stuff for you over http or whatever tunnel you have with aws
but i would use a tpm where possible because they are secure™ (implementation detail behind the tpm manufacturer so cant confirm whether its 100% secure but probably good enough) and they are also kinda cool
hmmm i basically generate crypto wallets per user, and then store their private ekys.
I do have a master key though to decrypt for transaction purposes, and that's essentially the key i want to protect.
Maybe its better for me to just request the data once whenever needed and then directly wipe the data out of memory.
i feel like a tmp would just slow stuff down especially if the data stays in memory for just a few seconds.
what do you think of the above approach?
its very difficult to do this correctly and securely, you can use mlock which will guarantee the os wont swap your secret to the disk, but then again the library which generates your keys and everything in between uses its own memory, stack and buffers, which means your key might be in another area of memory without you even knowing which defeats the point of this
shiit
but as i said initially its ok to store the keys in memory, its secure enough for most cases, but idk what kinda stuff you use the crypto wallets for so it totally depends
its just a trading platform i have created.
the wallets are used to hold crypto and make transactions.
if you were really worried you wouldnt use a vps, a hypervisor could always have issues (tho very uncommon)
but this is going way too far
my main thing is just me storing private keys.
they are enrypted, sure, but my master secret will still be loaded in the main memory.
you wont get around that
i was thinking about maybe requesting my long term keys and encryting it using tmp, and whenver i need to use it, decrypt it?
only reasonable thing would be have a seperate app that is used for decryption
so if the first one leaks, it doesnt touch the others memory
hmm i see
anything fintech related where a key compromise could mean people lose their money youd want to secure somewhere securely like a tpm or aws tpm cloud service thingy (whatever its called), the security risk reduction far outweighs the slight performance you lose
^
i see, so store data in tmp it is then. Thank you so much for the help. Are there any libs for interacting with the tmp module?
but honestly, even then it will be leaked. Like the key. I would still need decrypted keys from the tmp to sign transactions
im honestly not sure but im sure you can find some (also its tpm), even if it means you interact with it using the shell programatically (there are tools especially on linux which let you do this) so thats not a big problem
but also since you want to overthink stuff, another thought, if your system/app gets compromised, the attacker can still ask the TPM to sign crypto transactions, the tpm only stops them from getting access to the secret directly, so for as long as the attacker has access to your app/system they can still ask the tpm to kindly sign transactions and it wont be the wiser
the key never leaves the TPM, thats the whole point of it, otherwise it would be pointless since the key can be intercepted at any stage
how can a user even read my memory ?
They wont have acces to my vps, i got it locked down
only way to read memory would be having access to the server right?
cuz its js/ts, so far i know there aren't buffer overflow issues like in c.
js/ts libraries often call back to native c++ code, that is what will have the issues
that as well, but you're probably ok from the memory safety aspect of it but javascript has its own rabbit hole of vulnerabilities which could cause you to accidentally leak the secret
but this is honestly all just "what if" scenarios, its much difficult for this to happen in practice
security is annoyingly complex :)
yeah exactly. To be fair, i am thinking about requesting aws keys for a brief moment, and then dereferencing it completely.
ah i hate security.
theres a reason why fintech companies have to abide by such strict regulations
they probably spend millions on security alone
a tmp module is nice and all but FACK that would be so hard.
It makes no sense for me. Because the way it works is me requesting key from aws -> then storing it in tmp -> then have tmp assing it for me.
but that saving to tmp still gets the decrypted key from aws..
you see where i am coming from hahaj
exactly
i don't have that laying around tho
they call me mr overthinker for a reason.
i feel like there's too much going on here lol...maybe i could get someone's input?

I disagree, I think it's fine. If anything I would change view history to just history
yeah, i think theres too many buttons but i think if you shortened it to just history it might make it look better
ty guys, i'm pretty happy with that 

I drew a copy of that wabbitcoin on my phone awhile ago
I actually think about stepping away from my own encryption program and use kms instead from aws
Its too much of a headache and too much can go wrong
Would rather hand it out to someone else
About that though, does a kws allow me getting the key in raw format? Or only for signing transactions
again, most wont allow you to get the raw key aside from the public key because it would defeat the point completely, if anyone could export the key you might as well just not use one
i am moving away from all, moving to privy instead
successfully wrote my code to privy.
I never get private keys in my database hehehe
all goes through their locker
thank you @frosty gale for all of the help!


what the fuck are you creating
event listener system for db models
final result
type DeleteListenerResult =
Box<dyn Future<Output = Result<(), anyhow::Error>> + Unpin + Send + Sync>;
type DeleteListener<M> = dyn Fn(
&M,
&Arc<crate::database::Database>,
&mut sqlx::Transaction<'_, sqlx::Postgres>,
) -> DeleteListenerResult
+ Send
+ Sync;
pub type DeleteListenerList<M> = Arc<ListenerList<Box<DeleteListener<M>>>>;
#[async_trait::async_trait]
pub trait DeletableModel: BaseModel {
fn get_delete_listeners() -> &'static LazyLock<DeleteListenerList<Self>>;
async fn add_delete_listener<
F: Fn(
&Self,
&Arc<crate::database::Database>,
&mut sqlx::Transaction<'_, sqlx::Postgres>,
) -> DeleteListenerResult
+ Send
+ Sync
+ 'static,
>(
priority: ListenerPriority,
callback: F,
) {
Self::get_delete_listeners()
.add_listener(priority, Box::new(callback))
.await;
}
/// # Warning
/// This method will block the current thread if the lock is not available
fn add_delete_listener_sync<
F: Fn(
&Self,
&Arc<crate::database::Database>,
&mut sqlx::Transaction<'_, sqlx::Postgres>,
) -> DeleteListenerResult
+ Send
+ Sync
+ 'static,
>(
priority: ListenerPriority,
callback: F,
) {
Self::get_delete_listeners().add_listener_sync(priority, Box::new(callback));
}
async fn run_delete_listeners(
&self,
database: &Arc<crate::database::Database>,
transaction: &mut sqlx::Transaction<'_, sqlx::Postgres>,
) -> Result<(), anyhow::Error> {
for listener in Self::get_delete_listeners().listeners.read().await.iter() {
listener.callback.as_ref()(self, database, transaction).await?;
}
Ok(())
}
async fn delete(&self, database: &Arc<crate::database::Database>) -> Result<(), anyhow::Error>;
}
Nicee!
ts is the sorta shit i would vibe code just so i wouldnt have to code this
nah this is the fun part, figuring this kinda stuff out
actually implementing it for every model now is the annoying part
now that i look at it that mess kinda makes sense it just looked a bit complex at first
looks cool
I dont think you are ready to see the final final version
theres a reason im still awake at 1:30 am,,
ok i think it finally works
ok i now know why async lifetimes are harder than rocket science
type DeleteListenerResult<'a> =
Pin<Box<dyn Future<Output = Result<(), anyhow::Error>> + Send + 'a>>;
type DeleteListener<M> = dyn for<'a> Fn(
&'a M,
&'a <M as DeletableModel>::DeleteOptions,
&'a Arc<crate::database::Database>,
&'a mut sqlx::Transaction<'a, sqlx::Postgres>,
) -> DeleteListenerResult<'a>
+ Send
+ Sync;
pub type DeleteListenerList<M> = Arc<ListenerList<Box<DeleteListener<M>>>>;
#[async_trait::async_trait]
pub trait DeletableModel: BaseModel + Send + Sync + 'static {
type DeleteOptions: Send + Sync + Default;
fn get_delete_listeners() -> &'static LazyLock<DeleteListenerList<Self>>;
async fn add_delete_listener<
F: for<'a> Fn(
&'a Self,
&'a Self::DeleteOptions,
&'a Arc<crate::database::Database>,
&'a mut sqlx::Transaction<'a, sqlx::Postgres>,
)
-> Pin<Box<dyn Future<Output = Result<(), anyhow::Error>> + Send + 'a>>
+ Send
+ Sync
+ 'static,
>(
priority: ListenerPriority,
callback: F,
) {
let erased = Box::new(callback) as Box<DeleteListener<Self>>;
Self::get_delete_listeners()
.add_listener(priority, erased)
.await;
}
/// # Warning
/// This method will block the current thread if the lock is not available
fn add_delete_listener_sync<
F: for<'a> Fn(
&'a Self,
&'a Self::DeleteOptions,
&'a Arc<crate::database::Database>,
&'a mut sqlx::Transaction<'a, sqlx::Postgres>,
)
-> Pin<Box<dyn Future<Output = Result<(), anyhow::Error>> + Send + 'a>>
+ Send
+ Sync
+ 'static,
>(
priority: ListenerPriority,
callback: F,
) {
let erased = Box::new(callback) as Box<DeleteListener<Self>>;
Self::get_delete_listeners().add_listener_sync(priority, erased);
}
async fn run_delete_listeners(
&self,
options: &Self::DeleteOptions,
database: &Arc<crate::database::Database>,
transaction: &mut sqlx::Transaction<'_, sqlx::Postgres>,
) -> Result<(), anyhow::Error> {
let listeners = Self::get_delete_listeners().listeners.read().await;
for listener in listeners.iter() {
let transaction_ref: &mut sqlx::Transaction<'_, sqlx::Postgres> = unsafe {
std::mem::transmute(transaction as &mut sqlx::Transaction<'_, sqlx::Postgres>)
};
(*listener.callback)(self, options, database, transaction_ref).await?;
}
Ok(())
}
async fn delete(
&self,
database: &Arc<crate::database::Database>,
options: Self::DeleteOptions,
) -> Result<(), anyhow::Error>;
}
if anyone here has an iq of over 1000, please tell me how I can remove the unsafe block, otherwise this seems to work 🙏🙏
are you using transmute here because it doesnt like the mut borrow across an await point in the loop?
ie shut up the compiler
correct, it thinks the mut borrow stays until the next iteration due to the lifetime of the function
lol
async in rust is such a pain in the ass but the payoff is so good. I threw myself into rust by making a tauri app, still wrapping my head around tokio
hey guys! So i have my wallet addresses and encryption completely in the hands of privy hehhe
it never leaves privy, so that's fucking awesome.
Now the question, how do i protect my .env?
Datalix has a TMP module, just unsure how to use it? There are literally 0 tutorials out there, searched whole youtube and none have a hands-on tutorial explaining stuff.
Guys what is a good cooldown for a Spotify search song command? Rn it’s 10 seconds

What’s their rate limits
Just follow that at a reasonable level cause a bot will be used in a lot of servers so you’ll have to take that into account too
You could always cache results so you aren’t constantly fetching the api for similar searches if you haven’t already
Hello Guys, can someone help me with the commands tab please and how to import them I think I am to dumb for that xD
u can just paste an array with name and description properties for each cmd
like this for example
[
{ "name": "your-command", "description": "really cool description" },
{ "name": "next-command", "description": "another cool description" }
]
Okay thank you very much
again, i can also use aws secret manager, but it still loads data in memory
It’s a private bot, and the loading part (where it is getting info from the api is already 10 seconds, so I did 10-10)
Thanks tho :) I am planning to make it an actual bot
i second that, lots of issues that pop up because of ownership and borrowing constraints since rust magically thinks my variable will disappear or be accessed by something else meanwhile my await point executes so unnecessary cloning in some places
i also did a very bad choice in using the slower async mutexes unnecessarily to bypass the fact you cant hold regular locks across await points, need to refactor to get rid of them in some places
async mutexes are slower?
i think ive read from the doc that it was slower and should only be used when you need to, but it would make sense since well its async and you must incur some kind of cost associated with await
await is completely free if no actual async work is done tho
since it polls once and if its ready it can instantly continue
from doc
The feature that the async mutex offers over the blocking mutex is the ability to keep it locked across an .await point. This makes the async mutex more expensive than the blocking mutex, so the blocking mutex should be preferred in the cases where it can be used.
but not sure if it elaborates on that
tho async mutexes are likely slower simply because they work differently afaik (meaning internally)
yeah and it would make sense since you cant really beat a simple blocking mutex, async mutex must have fancy complexity to make it work
is that from tokio or from the futures utils mutex
An asynchronous Mutex-like type.
i see
i still need to fully read up on rust's async though since i infer a lot of the caveats and costs associated from JS since i dont really use async/coroutines in c++ since never had to for an app
though it'd probably be different in c++ as well
okay I may have accidentally pulled my rwlock knowledge into this
yea sync mutex makes more sense in most cases
rwlock is a different story though
would you consider rust a hard language to learn
since u can only have 1 active mutex guard it usually unlocks quickly
rwlock can have thousands of active locks that you may need to wait for
my project is built on ts, js and haskell but i am actually trying to move to pure haskell and rust.
depends on goal
rust doesnt have a "runtime"
its just the language
things like tokio are runtimes you add
well rust is fast let me keep it at that.
*io bound
i am kinda happy that i use haskell for some critical parts of my code. The language is so fast and there's no side effects. I love it. My js/ts code is fast too, but i heard that rust can run a lot faster.
The language as a whole is faster than js.
also important to consider whether the speed is worth the rewrite time
facts.
js/ts are already very fast due to how nodejs works
I am mostly going to rewrite only the api part.
best way if you want to be paranoid is to let the TPM encrypt your .env for you and store that on disk, then when your app loads ask the TPM to decrypt it and hold it in memory
but you cant really bypass the process of loading the config into memory, even the TPM itself has a small memory store it uses to hold keys temporarily (albeit bit more complex)
at that point your main attack vector to worry about becomes memory scraping (where someone plugs probes into the machines RAM and reads the contents while its on, probably unlikely for a detecenter though) as well as, well, trusting the host to do what they are supposed to
you can technically encrypt memory regions, debatable whether that is worth the performance hit
but youd still need the key to decrypt it in regular memory
what are you storing in the .env exactly?
yeah i think some cpus also support in transit encryption but it doesnt encrypt the ram itself so whatever you're doing it would have to be software level
and still if that does exist you still risk leaving that data somewhere else that isnt protected so encrypting or erasing stuff in memory is just a less recommended practice overall
yea, depending on the stuff in .env it may be sent over the net anyway
even your cpu caches or the frequencies your power supply emits as the cpu load increases or decreases could be an attack vector to state level actors so i think your best bet is leaving your machine in a bunker 💀
lots of hypothetical attacks so you have to choose your battles wisely
i am storing impotant keys
very interesting read on this if anyones interested https://www.bitdefender.com/en-gb/blog/hotforsecurity/researchers-turn-power-supplies-speakers-leaking-data-air-gapped-audio-gapped-systems

Hot for Security
Mordechai Guri, a cybersecurity researcher from Ben Gurion University in Israel, has acquainted the world to a new way for bad actors to steal sensitive data acoustically, from air-gapped and audio-gapped systems.
privy keys, api keys etc.
I am using the TMP of datalix, but honestly, i asked support and they gave me a vague answer. They said that tmp was platform bound or somethibg, while i asked for help on how i can use tmp to store keys on there.
tldr: buy a dedicated server in a high-security datacenter that requires explicit permission from you to access for any maintenance, disable cpu boosting, put a lava lamp with a camera on the server to populate urandom, have a single 32gb usb stick that boots from an os stored directly in ram, disable cpu caches, install the most minimal linux installation possible, only use fiber cables to avoid reading emf, use obscure light frequencies to make reading harder, use end-to-end encryption for any network traffic, do not trust cas that are not your own, disable all physical io ports except for the usb sticks specific hwid and behaviour, is this enough?
yeh!
thank you guys!
I am maybeee, moving from .env to aws.
i think that's my safest bet lol
memory sceaping, honestly, they likely won't be able to do that,
My machine is locked down.
on my way to the nearest google datacenter with an antenna to read customer secrets their power supplies are leaking at a rate of 50 bits a second (i'll be here a while)
boys hahahha i am just an autistic overthinker leave me alone lmao
you use datalix right? How do you access their TMP module.
i currently only use datalix for tunneling traffic, all other stuff runs on bare-metal in my house or at hetzner
i meant TPM sorry, not TMP
the tpm datalix provides is not as secure as a real tpm
its emulated through the hypervisor (proxmox) and stored on the host disk
yeah thats what i thought was the case
might as well not use their tpms in that case
maybe a bit more secure but not as secure as a real tpm
yeah its mainly just to make win11 happy
safest way is to just put a server in your houses walls 👍
with 200 cameras
(no but seriously this can be more secure)
hmm damn. I may just use AWS instead then
i don't think anyone will read my memory
@neon leaf not sure if you can offer any tips in rust but here goes
I have this one method that is really bugging me, its basically a hashmap with the key being a tuple of 2 u8's and a string, insertion is not the problem, the issue comes when i have to lookup an entry, i cant pass the tuple as reference (well tuple yes, but inside contents no) i'd have to clone the inside contents of the tuple, the 2 u8's is whatever its as cheap of a copy as you can get, but i really dont want to clone the string on each lookup
as a workaround i was thinking maybe externally hashing the 2 keys and simply setting the hashmap key to a u64 or whatever with no hasher/a cheap hasher, or concating them both into one string (since the 2 u8's are ascii), but i figured that concat cost would essentially cost the same if not more as a clone, so not sure if there is a better way to do what i want which is avoid that string clone in the tuple
you could make a wrapper type that implements hash, then make that wrapper accept Cow strings
but this sounds like an xy problem, what are you storing in the u8s and in the map in general?
#[derive(Debug, Clone, PartialEq, Eq)]
struct MyWrapper<'a>(u8, u8, Cow<'a, str>);
impl<'a> Hash for MyWrapper<'a> {
fn hash<H: Hasher>(&self, state: &mut H) {
self.0.hash(state);
self.1.hash(state);
self.2.hash(state);
}
}
impl<'a> MyWrapper<'a> {
fn new(first: u8, second: u8, text: impl Into<Cow<'a, str>>) -> Self {
MyWrapper(first, second, text.into())
}
}
fn read_from_map(map: &HashMap<MyWrapper<'_>, &'static str>) {
println!("{:?}", map.get(&MyWrapper::new(3, 4, "world")));
}
fn main() {
let wrapper1 = MyWrapper::new(1, 2, "hello");
let wrapper2 = MyWrapper::new(1, 2, "hello".to_string());
let wrapper3 = MyWrapper::new(3, 4, Cow::Borrowed("world"));
let mut map: HashMap<MyWrapper<'_>, &'static str> = HashMap::new();
map.insert(wrapper1, "first");
map.insert(wrapper3, "second");
println!("{:?}", map.get(&wrapper2));
read_from_map(&map);
}
Cow can be owned and borrowed, so no heap for lookups
if your lookup strings (but not the insertion strings) are all static you can also remove the wrapper lifetime and make the cow 'static
do you pay 2x the amount if you create 2 key value pairs?

I basically want to be able to retrieve both dev and prod tokens through aws.
the 2 u8's (i meant an array of 2 u8's, length known as compile time) is basically the users ip country code and the string is a reverse dns hostname of their ip, the hashmap basically stores whether the network is trusted or not based on those 2 keys, i dont do it by IP since were in an age where ipv4s are largely dynamic so i dont want to log users out on each ip change, very bad experience, so doing it by country + reverse dns i found to be much more effective, i could most likely precompute one big string with both values and cache that but i want to keep them separate where possible, especially since theres not really a reason not to fundamentally speaking, ignoring rust's ownership system
nice, doesnt look too bad, what is a cow string? i assume something related to copy on write? ill research this though
Cow is copy on write yes, its an enum with 2 states, owned and borrowed, the owned variant has a static lifetime, the borrowed one has a dynamic lifetime based on the lifetime parameter provided
i dont really use aws but aws has one big calculator for everything to get an estimate which you can probably use to work out the cost here
tyyy
i have a damn ahrd time understanding key rotation in aws.
Do they like rotate my actual key that is stored, or just the cryptographic key used to decrypt.
what is the service in question here?

lmao i cant anymore... someone told me they have a huge next.js project for their company, which "someone" is developing for them, and they want my help to solve some issues and transfer content from the old website to the new one.
they send me the files, its a giant clusterfuck of AI generated shitshow, doesn't use next.js at all, uses outdated react + express backend and they want to host it in a shared hosting platform
@_@
so they want the credit for work they didnt do, silly
not everything, but a lot nowadays can be
it just requires knowledge of what AI to use
check out their main issues file:
## **Immediate Priority: Fix Website Deployment**
- **Current Issue**: Website not displaying on `<domain.com here>`
they never uploaded any file in there in the first place, their host has no idea this project even exists
yeah i was about to say, in the development world theres a few things that need human interaction
if they googled, theyd have found an answer on how
- **Required Actions**:
- Configure proper file permissions (644 for files, 755 for directories)
- Fix Nginx configuration for React Router
- Test all routes and functionality
- Ensure build files are properly uploaded
its a shared hosting provider, there is no nginx
if i saw a project like this i'd just try do what they want completely vibe coded
they've already dug the hole, i'm just using it
@_@
RIP beamng wind generator arduino setup 🙏

fried itself with 40W going in the wrong direction
why would it make a difference
in a construct like:
function returns secret -> function uses it.
i read that buffers can zero fill that memory object directly, but strings keep lingering in memory until GC
technically I guess?
but the nodejs buffer is also a rope afaik
so will also linger in gc
Uint8Arrays should be actual arrays
i think you are overcomplicating it though
if you send the secret over http(s), it will stay in your kernels memory until a certain amount of packets have been acknowledged anyway
i am overthinking it a lot
i followed a course regarding os security that talked about memory reading, buffer overflows etc.
So i am continously in that mindset
eventhough that was a completely different language (c).
so i am cooked
it will give rw access to a memory region that is not used anymore but may not be zeroed
hmm
listen, in your prod code. Do you concern yourself with memory reading and stuff when working with js./ts?
Or am i just really overcomplicating stuff.
lmao, okay thank you.
its about api keys.
reading it from aws.
aws -> helper -> function that needs the key.
ah well I store my creds on disk in an .env, why do I not care? they are limited to each nodes ip and have the bare minimum permissions
Being different is cool, especially as a developer. It makes us unique
true true! Much love!
you cant trust js/node at all with stuff like this, you have zero control over where your data will end up and how many copies will be dotted around in memory, its already hard enough to do in c/c++ which let you manually handle memory
i have to agree here 💀
these are all very very hypothetical attacks which all assume 1 you have a person that is willing to go through the pain to get whatever secret you are storing and 2 many things go wrong before the point where access is potentially possible
will work on a replacement thursday with a better voltage controller and some more safety stuff in general, 🙏
I see.
Yeah, i am just an overthinker and want to do things right.
if you're talking about an attacker extracting strings from a running nodejs process, then thats not really a nodejs issue but an operating system issue
all processes store data in memory, and the operating system protects these memory regions from overlapping and also prevents other processes from intruding
if an attacker somehow gains access to the system, they would need to first bypass the OSs protections in order to "invade" memory space that belongs to a running app, and if they can do that, they can attack any process, not just nodejs
and also, if they can do that, thats the least of your worries because they would pretty much have root access to your system and would have a lot better things to do with their time
never using hashmaps in rust again after seeing this decompile

i'll stick to array indexes
me no understand, what issue be?
too many instructions
because of the hashing?
too many instructions
speaking of microoptimizations, chatgpt told me some interesting things about v8
chatgpt and microoptimizations usually dont go well together at least for me
when i verify the things it says in godbolt 80% of it isnt true
🙏

need to make this code fancier, its literally just a recursive hashmap rn
idk if thats a good idea for mem usage and maybe even perf
rust users justifying every time they use unsafe with a comment when c users write entire unsafe programs without comments
🙏🙏
i never talk here but I'm so close finishing an update with my bot 🥀 i procrastinated for a little too long (staging bot btw)




the code is absolutely dogwater (don't ask me what bot library im using either) but it works 🥀
casually about to update my bot after few years of no real updates
mobile support 🥀 so much just small stuff i had to add


since I was too lazy to setup stripe and add a premium plan on my bot, I added this instead:

I wonder if any other bot did this before - but basically, I let people set a "background image" with the logo on front - so I still have my bot's logo on the avatar but people can still customize it
-# (this is a customizable rpg bot so i think this makes sense to add)

performance can be improved there, but otherise thats the way to go
how can it be improved?
reusability, load once, use many
the only thing i can think of is keep logoImage in memory ig
const logoimage = ...
const canvas = ...
const ctx = ...
async function createAvatar(body) {
const loaded = await loadImage(...)
ctx.drawImage(loaded)
ctx.drawImage(logoimage)
const pngdata = ...
return ...
}
since the images always cover the full canvas space, you can always use the same canvas
ic
and also probably should add ctx.clearRect(0, 0, canvas.width, canvas.height); for transparent images
top level

and image

(haven't tested yet) thanks!
ah yes if the images have transparency you need to clear rect every time
still faster than creating new canvas
hopefully this doesn't have any race condition bug (it probably doesn't bc clearRect/drawImage logic is synchronous)
it does work though 🔥
which canvas library are you using?
@napi-rs/canvas
await canvas.encode is not normal canvas api
canvas is usually sync, there is no await in any canvas function
canvas.toDataURL("image/png") probably would work too
yes that would be better
that way the writing+encodign is fully sync, no room for race condition
yah ill probably just do this

yep this works thanks (shouldn't be able to rc since sync)
👍
I was using this originally for my bot!
It felt more limited than canvas itself to me
im not really doing anything complex so I think it works fine for me
Fair enough, it’s alright for smaller tasks for sure
Does Discord consider user IDs "sensitive user information"?
Not usernames or avatars or anything. Strictly IDs.
for the purposes of collecting data im pretty sure they do yes, and they require you to have a privacy policy explaining what you store them for, and for how long
Gotcha. I know some places require compliance with data deletion, but how does that work if the data is used by another person for something like a deny list to block the user? Do we have to remove it? Sounds like something that users could use to get around blocks.
im pretty sure discord doesnt like those
So it's not banning them or anything, it's for custom roles that users own in servers. So users can create their own role without having any server perms to mess with each others. They can allow or deny other users from using it. I might remove the deny and keep the "invite only"/managed modes as their way to block others, but I figured if they only wanted to block a particular person and not everyone a deny list would be best for that.
they will probably require some sort of consent form where the user agree to have their ids be used for that purpose
it'd be kinda hard to enroll others you're trying to block out tho lol
like if you create a role you want others to be able to use but not me or others, but that requires my consent to block me, obviously I just have to say no and then I'm not blocked 😂
plus there's also banning users entirely for abusing your platform, right? is that not allowed? I have guilds blocking supported, but was considering users too since they could just make a new guild
I think they mean that the users who are interacting with that feature have to give consent for their IDs to be used in that sense as a general thing, not that they’d have to get consent from the specific person for them to block said specific person (if that makes sense)
right, but that would then shift responsibility back onto the app to have consent for the target user, no?
One of the things discord requires for one of the approval things is a ToS and Privacy Policy so it’s good practice for that
Well no
Imagine you’re attending a public event where photos may be allowed to be taken, by attending you’re not giving consent to specific people to take your photo. Instead you’re giving general consent to the organisers of the event essentially telling them that you’re fine with any of the photographers to take and use your photo
With this system, the target user isn’t giving consent to the specific individuals who plan to block the target user, instead the target user is granting general consent for their ID to be added to blocklists regardless of the user that made the blocklist
Hopefully that helps explain a little bit further
if its something like, user of your app adds the id of another user that does not use your app to your block list, so if that user ever tried to use your app they would not be able to access the content from the first user, then i would argue the id that was added is not your app's responsibility since it counts as data that belongs to the user that added the data, not the user whose id matches that data
you know that's a fair point to argue lol
I mean technically I'm not collecting it, I'm being given it to store
Like I'm not crawling guilds looking for users with specific key words in their (user)name/profile and blocking them based on that.
these things are always tricky
you basically have to state in your terms that you are not responsible for data added by your users
so if user B complains that their id was added without their consent, it needs to be stated that its user A's fauilt, not the apps
That's totally fair, I'll make sure it's somehow mentioned in there.
What about GDPR compliance? Does it not apply there?
oh boy 
well yeah but if you have to comply with them and don't technically know where they reside outside of what they claim
EU and UK
you have to yes
because its based of "if your app is available in EU, aka EU people CAN access it if they want to, then you have to comply otherwise you have to actively block EU people from accessing it"
Yeah I got that part but I'm wondering about the deny list with that specifically since it's really the only reason I'm asking lol
Like users voluntarily removing their data from the platform, including allow lists, I'm cool with. Deny lists though could be more of an annoyance for users since the target users could essentially evade it. I guess if anything having the deny list available for 90% of use cases is better than removing it for 100% just to avoid dealing with the 10%
On the flip side, if I copy a user ID and paste it in a message and send, and that user requests all info be deleted, would that not include my message? It's on the same platform, has the same data, but was submitted by another user. Not themselves or discord or anything. Same with bot logs in chats using IDs.
That hell hole digs deeper to bots that log welcome messages on server join with the user's avatar embedded in it. Would that not be included? Lol
I understand and appreciate what GDPR's intent is, but I don't think they realize how deep that rabbit hole goes.
?
Discord IDs have never been personal or sensitive info
You could theoretically fetch the user information from that id
Profile information is what I mean
You would need to create a bot which means accepting the developer tos though
Exactly, privacy policy stuff + that tos
Discord just likes to be special
"Yeah your bot should work out of thin air without user IDs obviously"
Randomly generate the users id
You can use and store ids fine though as long as you're not harvesting user data or doing other ToS breaking stuff



you know what if you're happy with it i'm happy with it
the problem is fines from lack of compliance lol
They are considered personal info as they link back to the person and other PII specifically.
I did some digging though and it is GDPR compliant to keep and not delete IDs upon request so long as there is a legitimate operational need for it. Mine has such need, so I'm good lol
There's more to it than that but none apply to my bot.
Basically you have to prove why none of these 6 points apply
https://gdpr.eu/article-17-right-to-be-forgotten/
Art. 17 GDPRRight to erasure (‘right to be forgotten’) The data subject shall have the right to obtain from the controller the erasure of personal data concerning him or...
i have to rewrite my whole codebase with over 25k lines
i am so cooked
i put all handlers in a single file, so i now created a proper structure, but that means that i need to put each handler in its own ts file.

i want to keep my main clean.
-> load redis
-> load database
-> load other modules (handlers, etc)


is that your app?
What's mcjars?
its like a place to install minecraft versions?
its a unified api for installing and searching all minecraft builds of every software ever
boys i a still rewriting each handler in my codebase
i made a nice structure but now i need to test every nook and cranny to make sure i didn't fuck anything
help me
please

{kind=link}
{kind=link}
{kind=link}
theres like 0% chance of that happening
first someone needs to complain, and present proof that you are violating the law, then they need to contact discord and complain to them about you, then discord will tell them its not their fault and contactc you instead, but by that point discord will probably tell you to fix it or ban you before anything else goes forward
if they dont, and the complaint reaches you, you will likely be asked to fix it, and would only be fined if you willingly and knowingly continue violating the policies beyond a specific time limit
Also, I’m pretty sure that GDPR doesn’t specify anything about how easy it has to be for users to delete their data. I think you could even have an email address listed saying “email this address if you want to remove your user data” or something like that
Which is wildly inconvenient for the user, and would deter most people from doing it
I love clean projects, I organised toastokus one, and I did the same with the advanced version of noughts & crosses