#discordjs/ws big bot memes (old)
1 messages · Page 2 of 1
clusters are basically a process where it runs a single d.js client
threads is basically discordjs/ws spawned threads
basically imagine d.js sharder but with clustering method
similar to kurasuta if you are familiar with it
so you mixed djs/ws with djs itself?
its basically what the pr that ports djs/ws
but my own implementation
do not be confused with it doing major overwrites other than the identify thing in the ws package
its not mixed but rather a port to make djs/ws compatible with d.js
our sharder is https://github.com/Deivu/Indomitable which supports v14 stock just fine

GitHub
A lightweight (the actual ship is heavy though), performant, powerful & no dependency sharder for Discord.JS - GitHub - Deivu/Indomitable: A lightweight (the actual ship is heavy though), ...
sharder spawns clusters, which has discord.js client, which has ported discord.js/ws on it
we say clusters because each clusters handle multiple websockets (in this case, threads that is made by discord.js/ws)
each thread handles one discord.js/ws websocket connection that is mostly untouched as well
did that clear the confusion here
Surpassed 3 days of no issues now
pogging
and just when I say that a shard dies
let me get the debug logs
seems to be the same as here
this is on 0.8.0-dev.1679832251-b8b852e.0 though
shard is never seen again after this
okay, but
there's a rather large pending PR
that refactors the waitforevent logic
though the shard never being seen again is unrelated, it's mostly that's a hard error throw so the worker just died
and we don't have any auto-restarting logic in place
probably should in hindsight

though idk how that should work like
it throws cus invalid token
and i just... restart anyway? like that is
not great
i guess the alternative would be to handle the handshake timeout different
but i think i just can't
the stack trace is fully internal as you can see
genuinely don't know
i cant tell if ws is just throwing internally
or if they actually fire an error event on handshake timeout
either way i do not see an easy way to make it retry if that happens
which is lovely
and i'm gonna ask again
didn't your PR changing waitForEvent fix it
no dude
again
this is the handshake timeout
its a number I pass into the WS constructor
this is not a waitForEvent call at all for me
its literally WS internally waiting for the TCP connection being opened
before I start getting any events from the connection
I thought waitForEvent listened for error too
yes, but again
I am not calling waitForEvent at all at this point, I don't think
I'm not quite certain what WS is doing internally here
girl you dont even know your own code at this point
[DEBUG[ [Fri,03/31/23,10:19:46] (Cluster Process [ID: 3]): [[EventHandler](Discord.JS): [WS => Shard 79 => Worker] Waiting for event hello for 60000ms[
literally the log before the handshake error
so you DO call wait for event
shrug then
so you CAN handle it
aka Promise.race(once(), once(error), timeout)
oh you know what

why do we pass a handshake timeout at all
if the hello one will just fire anyway
lol
i had a review to add it in the original /ws pr because it "helped solve mainlib issues"
handshake timeouts are also node only
believe me idek why half the code in current ws exists either
current ws not /ws
side note, any word back about the big bot/currency bucketing
oh lol
the sweet sweet sounds of silence
the classic
Can we actually continue this topic? Hopefully the explanation here (#1086244458900750367 message) cleared some confusion as to why we call them clusters
its still unclear to me what your shardsPerWorker is
@sullen snow I guess
but I guess that was answered already

u dont seem v sure abt it
im sure about it
I coded the whole thing so I know it's 1
well, i cannot reproduce
so you're gonna have to get me a reproduceable code sample that I can easily run myself
did you try running it with lots of shards?
on my 100k bot this doesnt seem to happen
where does the warning actually come from
is it one of the threads or the main process
scrap that, it's def the threads
since the stack trace includes the bootstrapper
MaxListenersExceededWarning: Possible EventTarget memory leak detected. 11 message listeners added to [MessagePort [EventTarget]]. Use events.setMaxListeners() to increase limit
at [kNewListener] (node:internal/event_target:514:17)
at eventEmitter.<computed> (node:internal/worker/io:307:12)
at MessagePort.addEventListener (node:internal/event_target:623:23)
at MessagePort.on (node:internal/event_target:873:10)
at VanguardBootstrap.setupThreadEvents (/main/node_modules/@discordjs/ws/src/utils/WorkerBootstrapper.ts:83:5)
at VanguardBootstrap.bootstrap (/main/node_modules/vanguard/src/worker/VanguardBootstrap.ts:51:14)
at process.processTicksAndRejections (node:internal/process/task_queues:95:5)
how many shards is that
w/e
ill run 100
1440
well
hmm
Error: Not enough sessions remaining to spawn 1440 shards; only 986 remaining; resets at 2023-04-04T13:30:54.853Z lol
or rather 24 "threads" per cluster
@stable hatch i'll use our magic bot token
its kinda a weird bug since I'd seen this happen on my original bot, but didnt care about it
and this is on older 0.6.x master ws
its there but I'm unsure how it even emits or how it even emits
and it doesnt also seem to happen again after the initial emit anyways
yeah I see it too at 1440 shards
yeah its directly tied to the shard count
at 9 shards it doesnt happen
at 10 it does
yes
1 per worker/thread
10 total
im p sure i know why now though
not a bug as i thought
you can always causae the token to reset 
(dont)
so my guess is its not really an issue
but then again
kyoso hates seeing those errors
that was my own bot, not ours
so he's been knocking on me about it
those are not errors
and are also non issues
which is why its saying it leaks
well it could've been an actual leak vlad
but really its every thread assigning 1 listener
but there's just a bunch of threads
and the object is just shared i guess
i have no idea how that works
can't we just try to increase the event emitter based on how many shards per worker we have
i dont have any other explanation otherwise
so we can just have this error silenced
its kinda tricky i think
oh well I guess I'll just let him know
but yeah thanks for confirming it as well that its not really an issue
we know
thats also our default setting
right now
oh wait a second
let me check real quick
I think Im missing something crucial here
no wonder it was starting 1440 threads so easily
➜ node index.js
<--- Last few GCs --->
<--- JS stacktrace --->
#
# Fatal javascript OOM in GC during deserialization
#
<--- Last few GCs --->
<--- JS stacktrace --->
FATAL ERROR: Committing semi space failed. Allocation failed - JavaScript heap out of memory```
lmaoi just crashed trying to start 1440



it was all all along
"are you sure you're doing shardsPerWorker 1?" "yes we're sure"
neither is mine but at least check properly 
when r u going over my pr @stable hatch

yeah actually u can fix that urself
if you provide your own uh
workerFile
just do parentPort.setMaxListeners() somewhere in your script
lol no it means all of them in one thread
thats why I was telling it was 1
yeah I think so because the thread only runs ws
its not like its handling d.js insane class conversions
a big part of my stuff is that basically everything is async
so there's like no thread-blockers
other than zlib
if lucky, this week
and why I opted to do my own impl. of porting it to v14 using your ws when there are choices 
zlib w
i'd buy that
but you end up sending more data over the wire
in most cases
w/o zlib
receiving*
with, erlpack is much easier for zlib to compress
we used erlpack so thats maybe the reason why we are able to run 24 shards on one thread of your ws
you dont send zlib data
yeah ty, receiving
with stock d.js ws handling
you can run about 16-20 shards
with erlpack in single process
if you can remove the channels bottleneck
so soon you should be able to ditch all that ancient jank garbage

true
well tbh the main issue or main issue with d.js for me rn is
its insane class conversions and caching this class
not to mention thats a stretch dd
yeah soon is a stretch lol
we're having discussions, wont mean we even start work on it till those discussions yield a conclusion
its still soon in terms of like
how long their bot's been around for tho realistically
tldr dont listen to dd unless its ws stuff

main reason I just dont move to eris or other libs there is because d.js is just maintained and been using this since like v11
no point on moving to other libs if I can just make it work I guess

I get timely updates on parts I dont want to maintain, and just maintain the parts I want to maintain kinda thing
any ideas on what is c lose code 4200 could be @dusty dove
cant find any documents on it so you might know what that is?
oh so basically the sharder tries to reconnect then?
resume specifically, yes
tries to fresh reconnect
ok, just wondering since theres some kind of outage last night
and some shards didn't connect
same on my side but my logs is 1gb so
Probably related to previous issues, is the big™️ PR merged already?
kyra approved now
Doesn't help we got 10k+ 520's from Discord in like 40 minutes lol
Alright
i k r
We love 3500 zombie shard disconnects in ~20 minutes
Just heard news about ya boy, max_concurrency, sounds like we're handling it correctly in djs/ws 
So buckets aren't a thing at all?
You'll need to explain that buckets means to you
You need 5s between identifies for shards in the same bucket, where bucket = shard_id % max_concurrency
other than that you can do whatever order you want
not what the docs say
also yeah we're doing it correct
oh wait
but what did they confirm here, that what I said is wrong?
ugh your phrasing is so confusing
its not a bucket
its a ratelimit key
the formula is correct
and yes, you cannot do shard 0 and 16 at the same time for example
you need to wait the 5s between them
But for example, I can start 0..7 and 40..47 at the same time
Yeah yeah, but just hypthetically
So what I said was right and the docs are wrong?
Or what
yes, hypothetically you COULD spawn 0..7 and 40..47 at the same time
because they have different ratelimit keys
(which is what discord calls them, not buckets)
wait what
someone hasn't read the docs page for big sharding
what we do is we spawn shards at the same "bucket"
........?
so you spawn
that wasn't there before
is it? it was never even noticed there
it has been there for a LONG while,yeah
wouldn't be asking questions on some big bot managers guild if it was there all the time
so let me get this straight
here I'll show you the actual stuff
you're spawning shards 0, 16, 32, ... in one process?
const bucket = shardId % concurrency;
const cooldown = BASE + OFFSET;
let unlocked = await cache.redis.set(`current:lock:${bucket}`, 1, 'PX', cooldown, 'NX');
while(!unlocked) {
unlocked = await cache.redis.set(`current:lock:${bucket}`, 1, 'PX', cooldown, 'NX');
await WaitAdmiral(128);
}
return message.success(true);
basically once you set that bucket on redis
I'm confused what you're doing
it will connect allow all the shards on that bucket to connect
ok i'm confused why you're doing it
when instead you could, and should, spawn your clusters in batches of 16 (or w/e max_concurrency is)
and wait for them to ready up
we just spawn our clusters regardless, and keep them in "waiting" mode until its their ws's turn to connect
in all sense, yes
like for example, if you have 16 shards
in that cluster
it will handle that
but we don't care about the number of the shards in the cluster
I think there's still confusion between what a cluster is here
bc y'all have 50 layers of namings

just show them a code sample maybe? dunno what would help to clear things up
d.js doesnt handle max_concurrency in a way that all clusters are in sync
because we expect shards to be linear, as you should to speed up boots as much as possible
instead of spreading them around so hard
what you mean by spreading them around?
if you mean I spawn a lot of clusters with little shards on it, we don't do that
in fact we cram as much as shards as possible in a single process
well it sounds like your clusters are keyed by the ratelimit_key
instead of spawning a cluster with 0..15, one with 16..31, and so on
yall 
see dd also related
do you not read docs
i wont be confused about max_concurrency if it was there all along
on what other page other than gateway would you have looked
anyways, our system doesnt spawn shards in a cluster based on max_concurrency
that means, you can keep the clusters equal to your # of threads of your cpu
in theory i think they're right if they do stuff over the network
so that means our shard count can reach 30 shards per cluster

2 years ago
now on boot, we just start everything we dont care about it
this is why we have a redis lock
where in shards will take turns on connecting
right now with our current built in strategies things work though
welp, lmao
if you just run them just like that
also
ngl
you could probably make all shards in one process with worker strategy and 16 per worker
like with this setup, how fast our boot up time again @dim oracle
but is not efficient as I designed the code to be able to even handle 50k + guilds in single process
since that just crashed node last time
in theory 1440 shards can be up in 7,5 minutes (1440 / 16 *5)
thats why we need the redis to get them all sync up with the ratelimited identify
if you spawn shards at discords recommendations you'd have 16k guilds
which is what our version of max_concurrency does
we spawn shards on discord's recommendations
im doing too many things at once
we just control how many clusters we spawn
aka process
so each shard still has avg of 1000 guilds
you know how discord is saying this ratelimit key exists?
uh
i might have debunked that
Full boot this morning to the latest dev release took from 13:01:23 to 13:10:03 which is 8 minutes 40 seconds
let me check it again
DEBUG [Wed,04/12/23,11:10:34] ([Cluster 3 (2218313)]): Discord.JS; [WS => Proxy] [Info] Spawn settings
Shards: [ 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 100, 101, 102, 103, 104, 105, 106, 107, 108, 109, 110, 111 ]
Shard Count: 28
Total Shards: 112
like eg I did a full restart today
this is a process
it contains 28 shards
max_concurrency is set to 1
so it means even I spawn this clusters all at the same time
I don't need to worry about exceeding the ratelimit key
as they are synched process wide
idk, our impl doesn't seem right now that i see this docs page
tried with ```
shardCount: 64,
shardIds: [0, 16, 32],
yeah that should throw right?
out of the 3, shard 16 got invalid session
Invalid session; will attempt to resume: false
def did
yeah odd that its not both that got it
even tho realistically both 32 and 16 should've invalid session'd
no wait
you're wrong
just 16 should've
0 % 16 = 0
32 % 16 = 0
0 and 32 share
oh wait
off by one errors
girl
classic programmer mistsake
now i tried it again and now it was 32 that did
so
Discord's enforcement of this is
I dont
yeah but also discord is not properly handling it
like many other things
either way
waitForIdentify should give a shardId param to support allowing this properly for their cluster setup/over the network stuff
yes
and the identifythrottler needs to account for it too for our builtin strategies
finally master dd
but yes, this is why we rarely get invalid sessions even our cluster shard count is wack
or do we even get those
KINDA?
i mean
it still wont help
wut
but im fine with just passing a custom identifyThrottler
we just need to also account what ratelimit key each shard has
I mean ok, how will you account max concurrency for the shard bucket?
the devs should be the one who implement it over the network
ok dd but they spawn the same bucket in a process
so in the end there is no max_concurrency to handle, only 5s wait between identifies
it needs to be done but gl handling that, and not opening the conn before identify is available
not opening conn before identify is available?
given shardCount: 64
shards 0..15 should all start and identify at once
shard 0, 16, 32, 48 should each identify and wait 5s between each other
right now, ws opens con even ident is not available it just not identifies
yeah which might have its own side effects
no i just gave you params to test your changes
idc what you do to make it work
shardCount: 64
shardIds: the numbers there
yeah see but this makes no sense as an isolated test case with our built in strategies
thats what i was saying
it doesnt need to make sense
this is the tricky one
it needs to work
yes, but this test makes no sense with how it should work
How so?
well the way I imagine it is
well if you want to test this
It tests both ranges that wouldn't have any ratelimit_keys clashing (0..15, each element modulo 16 is a diff number), as well as spawning shards that share the same ratelimit_key (thus each id modulo 16 is 0 for example)
idk if you're missing something or i suck at explaining lmao
I recommend to just test this without exact max_concurrency values on each cluster shard count
lets say you have 16 max_concurrency.
have first process have 10 shards, second 10 shards, then remaining on last process
then spawn all the clusters at the same time.
now 10 shards 1st cluster and 6 shards on 2nd cluster should spawn at the same time
wait 5 seconds
now last shards on 2nd cluster and 3rd cluster should spawn
thats what the redis impl. solves on our case
shardCount: 64
shardIds: {start: 0, end: 16 (or 15, idfk how our range works LMAO)}
All shards should identify at once and none should invalid session
shardCount: 64
shardIds: [0, 16, 32, 48]
Shard should identify and wait 5s before the next one identifies, none should invalid session
thats what I learned on some python dev that has a big bot on what he does
waitForIdentify(shardId: number): Promise<void>
const key = formulaHere;
const shardsInKey = this.whatever.get(key); // whatever is a Map<key, number[]>
const promise = new Promise((resolve) => this.promises.set(shardId, resolve));
shardsInKey.push(shardId);
if (shardsInKey.length === 16) {
for (const shard of shardsInKey) {
this.promises.get(shard).resolve();
this.promises.delete(shard);
}
}
return promise;```but those two test cases need to work 
you get the idea?

no but what I'm saying is
thats on you
god you won't listen at all
and you're ignore me
I've read everything u sent, im just trying to tell you that
shardCount: 64 shardIds: [0, 16, 32, 48]
will literally never resolve with how I want to do it with our current strategies
our strategies have nothing to do with the identify throttler
because to make this work we need to make the IdentifyThrottler wait for all max_concurrency shards to attempt their Identify call before we send off the batch
they literally do though
well sounds like you need to redo it then
these two tests need to pass
thats all I'll say

I think you should just have
2 in built strategies
then 3rd = custom to the 3rd party dev
like
1 will use redis
1 will use not
1 will use whatever they like or make
I dont think we can cover your tests in a single strategy here
shardIds: [0, 16, 32, 48]
this does not make sense, if we want to benefit from max_concurrency then the throttling implementation needs to wait for shards 1..15 to have the full 0..16 pack before it sends off the batch
and I gave you test cases that should pass but you're worse than a brick wall
it makes sense if you had more managers on different processes/places, yes
which is what we do ^
No you wouldn't
I literally cannot test that
you'd need the identify throttler to handle it
yes you can
you give it those ids
you make it connect
??????????? dude what
you see it doesnt invalid session
you profit
whats so hard
You literally build a map of ratelimit_key -> remainingConcurrency
or well
yes
oh well, unless you have access to the "main process" of whatever sharder they use
and you're telling me
no, ratelimit_key -> 1
to connect [0, 16, 32, 48]
if its not 1, you wait 5s
so, when am I supposed to decide when to connect just 0
because 1..15 aren't coming through
which are in the same bucket
they're NOT
that is what im telling you makes no sense here
ratelimit_key = shard_id % concurrency
This puts your shards into "buckets" of max_concurrency size. When you start your bot, you may start up to max_concurrency shards at a time, and you must start them by "bucket" in order. To explain another way, let's say you have 16 shards, and your max_concurrency is 16:
0 -> 0
1 -> 1
...
16 -> 0
they do use the term bucket on the docs
okay, so let's be clear
when I say bucket
I refer to shards that need to identify at once, yes?
agreed?
no
that is literally what it says man
oh my god
do you want to argue over the english language
or semantics
do you not read the whole fucking codeblock
where they explain what a bucket is
lmao
zoomers i s2g
k
you know what
implement it yourself
im not dealing with it if this is the attitude i get
shard_id: 0, rate limit key (0 % 16): 0
shard_id: 1, rate limit key (1 % 16): 1
shard_id: 2, rate limit key (2 % 16): 2
shard_id: 3, rate limit key (3 % 16): 3
shard_id: 4, rate limit key (4 % 16): 4
shard_id: 5, rate limit key (5 % 16): 5
shard_id: 6, rate limit key (6 % 16): 6
shard_id: 7, rate limit key (7 % 16): 7
shard_id: 8, rate limit key (8 % 16): 8
shard_id: 9, rate limit key (9 % 16): 9
shard_id: 10, rate limit key (10 % 16): 10
shard_id: 11, rate limit key (11 % 16): 11
shard_id: 12, rate limit key (12 % 16): 12
shard_id: 13, rate limit key (13 % 16): 13
shard_id: 14, rate limit key (14 % 16): 14
shard_id: 15, rate limit key (15 % 16): 15
shard_id: 16, rate limit key (16 % 16): 0
shard_id: 17, rate limit key (17 % 16): 1
shard_id: 18, rate limit key (18 % 16): 2
shard_id: 19, rate limit key (19 % 16): 3
shard_id: 20, rate limit key (20 % 16): 4
shard_id: 21, rate limit key (21 % 16): 5
shard_id: 22, rate limit key (22 % 16): 6
shard_id: 23, rate limit key (23 % 16): 7
shard_id: 24, rate limit key (24 % 16): 8
shard_id: 25, rate limit key (25 % 16): 9
shard_id: 26, rate limit key (26 % 16): 10
shard_id: 27, rate limit key (27 % 16): 11
shard_id: 28, rate limit key (28 % 16): 12
shard_id: 29, rate limit key (29 % 16): 13
shard_id: 30, rate limit key (30 % 16): 14
shard_id: 31, rate limit key (31 % 16): 15
>
> In this case, you must start the shard buckets **in "order"**. That means that you can start shard 0 -> shard 15 concurrently, and then you can start shard 16 -> shard 31.or get someone actually willing to have a conversation without snarky remarks every 10 messages
maybe space or kyra
well tbh
you cant implement this easily without something that could make it lock
I tried without using redis or smth and my mind came out blank
so thats just my 2 cents here
of course, but making it work with redis is your responsibility
thats why I never added support for max_concurrency on my sharder package
considering you're using custom strategies
I mean if you're gonna spawn random shards across processes then yeah there's no way for us to keep it in sync
yes but if you can make that work with a "lock" that can substitute from redis it may work
the question is what
..unless we pull a sessionInfo and make it a method you can use?
if you want to make that work saya, you need a single dedicated process just to deal with that
dd would that work?
kinda like its own microservice
i mean that calculation we do is offloaded on a thread
and we just do a await promise() to wait for shards to connect on where discordjsws is
so the idea is
if you want to do it as efficiently as you can
you need a central place that aggregates this state
the way you should do it is like
imagine you have a message broker
and you send it a shard id
and you create a promise
and you resolve it when you get a reply through the broker
like, it sends you that shard id back

{kind=link}
yes thats how technically it works
meanwhile in the broker end
just in other layman terms on us
you have one unique consumer for the queue
and once it has all the shards of a given batch together
like [0, 15]
it fires the messages for those 16 shards
makes sense?
what do you mean
waitForIdentify?
yes that makes sense
i mean
no im asking
we could make the throttler extensible
because it already is a strategy method
exactly because of this
lol
is what i was telling you
yes thats what I was asking since we made the thread
export interface IContextFetchingStrategy {
readonly options: FetchingStrategyOptions;
retrieveSessionInfo(shardId: number): Awaitable<SessionInfo | null>;
updateSessionInfo(shardId: number, sessionInfo: SessionInfo | null): Awaitable<void>;
waitForIdentify(): Promise<void>;
}```for the built in ones that just calls an identify throttler
well
simple calls one
OK but what if you wanna use current strategies with a diff throttler
i mean we have a use case right here that answers your why
right now I "block" the original op on the worker strategy and foward it to my ws manager class which contains my custom throttler
to me your waitForIdentify() should be responsible for throtting logic
our IdentifyThrottler is its own class because we use it in 2 places
its just a sane internal impl
mostly sane, we need to handle the ratelimit_key too if someone does [0, 1, 2, 3, 15, 16, 17]
you shouldnt really need a different one with our built in strategies
like
if they need to send their identify requests over redis
that already won't work with the default worker strategy
they need to extend it
once waitForIdentify has the shardId, I can just extend the waitForIdentify function
without me doing any hacks
and give it to the sharding strategy

i'll use the term batches as to not irritate anyone
so you have numbers like
0..15
that is a batch
16..31
another batch
they go together at once
yea?
no..?
pls english
so
wait to finish what, just wait 5s and start the next
ye
so the thing is
if you create a manager with [0, 1, 2, 3, 15, 16, 17] and no other manager(s)
im never completing the 0..15 batch
and in my mind that isn't a usecase we should... support
there's 2 cases it doesn't get completed
faulty strategy - not our problem as long as its not the default ones
or 2, someone is trying to never connect X or Y shard - makes no sense to account for that
Its not a usecase we want to support but its a usecase we should gracefully handle
but shoooooould we
I feel like we might end up trading perf in some ways if we do
Girl
You don't call identify every second
because i was thinking "the promise just never resolves" lol
like, that makes sense to me
Adding on a few ms won't kill the world
.
and how do we determine what "never" means
how long?
Ok but like
One thing you're thinking differently than discord
Is in batches
Whereas discord thinks in ratelimit keys
Which is what we should also do
idk
In this case, you must start the shard buckets in "order". That means that you can start shard 0 -> shard 15 concurrently, and then you can start shard 16 -> shard 31.
Shoot away
Realistically we need to consider the concurrency and the ratelimit key
But I'll wait to see your idea
it has come to me via divine revelation
Bit early, easter is in a few days
I'm not even going to question what you mean by that
apparently there's 5
Will you share with the class or
@stable hatch yeah nvm this is unfeasible
if we could like
better guarantee the order of shards requesting identifies
it would work
otherwise this is insane
we bounce so much between incomplete batches
I'm like 99% sure its best we just do what I described where it waits for completed batches
re-iterate
map of ratelimit key and if it was used + when it resets
Get the ratelimit key from the shard id that wants to identify
If its used, wait, otherwise try sending it
Optimal? Not even by a long shot
But would it work? Probably
i think i just mind blocked
since thats basically what i was trying to do w/o having even gone over what u said again
but this doesn't feel right
oh
yeah i see now
let me tweak that
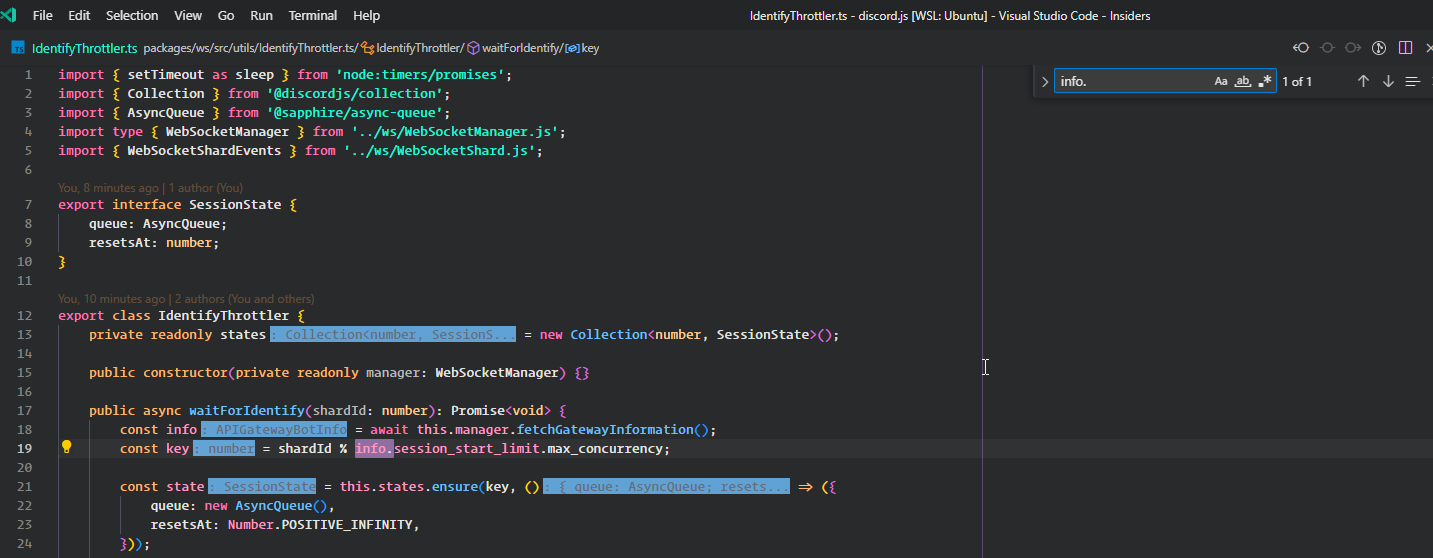
export class IdentifyThrottler {
private readonly states = new Collection<number, SessionState>();
public constructor(private readonly manager: WebSocketManager) {}
public async waitForIdentify(shardId: number): Promise<void> {
const info = await this.manager.fetchGatewayInformation();
const key = shardId % info.session_start_limit.max_concurrency;
const state = this.states.ensure(key, () => ({
queue: new AsyncQueue(),
remaining: info.session_start_limit.max_concurrency,
resetsAt: Date.now() + 5_000,
}));
await state.queue.wait();
try {
if (state.remaining <= 0) {
const diff = state.resetsAt - Date.now();
if (diff <= 5_000) {
// To account for the latency the IDENTIFY payload goes through, we add a bit more wait time
const time = diff + Math.random() * 1_500;
await sleep(time);
}
state.remaining = info.session_start_limit.max_concurrency;
state.resetsAt = Date.now() + 5_000;
}
state.remaining--;
} finally {
state.queue.shift();
}
}
}``` @stable hatch 👀test('basic case', async () => {
fetchGatewayInformation.mockReturnValue({
session_start_limit: {
max_concurrency: 2,
reset_after: 5_000,
},
});
// Those shouldn't wait since they're in different keys
await throttler.waitForIdentify(0);
expect(sleep).not.toHaveBeenCalled();
await throttler.waitForIdentify(1);
expect(sleep).not.toHaveBeenCalled();
// Those shouldn't wait either since they're in the same key and max_concurrency is 2
await throttler.waitForIdentify(2);
expect(sleep).not.toHaveBeenCalled();
await throttler.waitForIdentify(3);
expect(sleep).not.toHaveBeenCalled();
// These should wait since the key is full
await throttler.waitForIdentify(4);
expect(sleep).toHaveBeenCalledTimes(1);
await throttler.waitForIdentify(5);
expect(sleep).toHaveBeenCalledTimes(2);
});
passes
GitHub
Please describe the changes this PR makes and why it should be merged:
Status and versioning classification:
Code changes have been tested against the Discord API, or there are no code changes
I k...
@dim oracle @sullen snow this also adds the new param
you'll still need custom waitForIdentify for your cluster setup though
the default identifythrottler obviously cant deal with cross process stuff
➜ node max-concurrency-test-1.js
Hello 2
Hello 5
Hello 6
Hello 9
Hello 4
Hello 7
Hello 14
Hello 11
Hello 13
Hello 8
Hello 0
Hello 3
Hello 1
Hello 10
Hello 12
Hello 15
Ready 14
Ready 11
Ready 6
Ready 2
Ready 9
Ready 5
Ready 3
Ready 0
Ready 8
Ready 4
Ready 1
Ready 13
Ready 10
Ready 12
Ready 7
Ready 15```first test seems fine
if thats all
aaa
no this is wrong

asyncqueue is trolling me
wth
@stable hatch ok i fixed it
the 2nd case passes
What about the first
passes too
all run instantly
if i add an extra shard just that one waits
e.g. 0..16
➜ node max-concurrency-test-1.js
Hello 2
Hello 3
Hello 9
Hello 10
Hello 16
Hello 12
Hello 0
Sleeping 5875.688359300205 for shard 0
Hello 1
Hello 4
Hello 6
Hello 7
Hello 5
Hello 11
Hello 8
Hello 14
Hello 13
Ready 2
Ready 6
Ready 16
Ready 10
Ready 3
Ready 9
Ready 4
Ready 13
Ready 5
Ready 12
Ready 7
Ready 11
Ready 14
Ready 8
Ready 1
Hello 15
Ready 15
Ready 0```@stable hatch hmmm
I have a question for u
do u think its fine if i refactored this
public constructor(private readonly manager: WebSocketManager) {}
public async waitForIdentify(shardId: number): Promise<void> {
const info = await this.manager.fetchGatewayInformation();```to like
public constructor(private readonly info: APIGatewayBotInfo) {}```what's the worst that could happen
esp. considering how aggressively fetchGatewayInformation caches anyway
that would also make our class re-useable for kyoso and saya
Could make it instead take an interface that provides the fetching method for the gw info
Then we can pass in the manager, they can pass in w/e
oh wait lol
To fetch from redis or whatever
i just looked at the code
we only use uh
{kind=link}

one reference to it
and its for max concurrency
loool
can just take it in the constructor
that should be ok
Oh yeah lol
since ull always need to fully restart to change it anyway
Yeah
oh nooo
this also tries to emit a debug log
this.manager.emit(WebSocketShardEvents.Debug, {
shardId,
message: `Waiting ${time}ms before IDENTIFYing`,
});```i had just added that one

to track sleep times
oh well
its not that important
@dusty dove will check once I have time
just clarifying something, this is extendible?
yeah i need to fix some stuff up
what is
the identify throttler
cus you cant change what throttler we use internally anyway in our strategies
im just telling you that if you go the redis/message broker approach i told you about
you can use the class on the receiving end now
without having to re-invent the logic
since it doesnt take a manager in the constructor anymore
wait im confused, give me a quick rundown on how it works?
Tbf @dusty dove they'd still need to make their own
Because they want to pull from redis
yeah, but thats just the strategy
will do in a sec
like, the actual sleep() logic they can re-use from us
is what im saying vlad
they dont need to re-inevnt that anymore
I still feel like we should make our existing strategies have the ability to pass in a custom identify throttler
they just need to change where the wait requests go to
look thru the code
and ull see why that doesnt make a lot of sense
haha
no 
Having to reinvent strategies to replace just this one piece that's standalone is not ideal
Yes DD.
???
lol
because as things stand right now
the goal of Strategy#waitForIdentify and similar methods, like the session fetching ones
are to do effectively do messaging to get a reply back
for instance
public async waitForIdentify(shardId: number): Promise<void> {
const nonce = Math.random();
const payload = {
op: WorkerReceivePayloadOp.WaitForIdentify,
nonce,
shardId,
} satisfies WorkerReceivePayload;
// eslint-disable-next-line no-promise-executor-return
const promise = new Promise<void>((resolve) => this.waitForIdentifyPromises.set(nonce, resolve));
parentPort!.postMessage(payload);
return promise;
}```and on the other end
case WorkerReceivePayloadOp.WaitForIdentify: {
await this.throttler.waitForIdentify(payload.shardId);
const response: WorkerSendPayload = {
op: WorkerSendPayloadOp.ShardCanIdentify,
nonce: payload.nonce,
};
worker.postMessage(response);
break;
}```you never need to overwrite the throttler's behavior, is what I was saying
the throttler is just responsible for being that central point that figures out how long to wait
like, being able to pass in your own throttler class does not help at all
because the throttler is not responsible for messaging
they need a custom strategy because they do cross-process stuff over the network
But dd you're missing the point
The throttler sleeps
That's what hangs identifies
They want to base the info from redis
They can't do that without overriding the throttler
Which is what sleeps
well, they have to override the strategy first and foremost
to send the data over redis
?
Is when the throttler says "ya you can identify now"
since that makes it inconsistent with everything else
you literally are though, like, what im saying is, the strategies are actually responsible for throttling
straight up
the identifythrottler is just a convenient helper
Ok but you're missing the point
since we implement it in two places
I'm not. I understand what you're proposing and I wholeheartedly disagree
I don't think you are understanding, which is fine and I'm trying to explain you it
Lets go step by step
The strategy had a throttler, which waits to tell a shard it can identify, correct?
the shard asks the strategy for an identify, which internally leverages the throttler to determine, yes
past the messaging layer
We don't care about how the strategies communicate
But
The throttler in the end is what waits for n time before the strategy gets the go-ahead
And tells the shard that it can proceed
Correct?
sure
Ok now say I want to reuse the current worker strategy, but I want the locks for the shards to be stored in redis
Everything in the worker strategy is already perfectly wired up for it (messaging to / from worker to say it can proceed)
I just need to change the throttler to make it fetch from/set to redis
See what I'm hinting at now?
Then I fail to see the issue with making the throttler replaceable
We'd default to our impl and let people change it should they know what they're doing
I just see major footguns with it
That's on users side
no but
Just like how we allow custom strategies
on one hand sure, that's the case with any indirection like this that you let the user potentially implement
but you kind of need a really good reason to allow it, or if the user has no other way to accomplish it
once you give them 2 ways to do it
they're likely to not figure out what is best for their case
and create some abomination
I mean you do realize this is already doable by extending our current classes and overriding the class
I'm just asking we make it more friendly
I want to control as much of the flow as possible too
But we also want experienced users to build out their system if they know what they're doing
Remember that this is mega low level
You can decide if you want the manager to make the throttler or the strategy
ugh i broke my tests

nvm
the unit test was just wrong
lol
the ones u had me do work fine still
what a mess
Kek
ok im done w everything now
so as per vlad's moaning @dim oracle @sullen snow you now have 2 ways to go about this once the PR is merged
if you don't need a custom strategy anywhere for any other reason, then you now have the option to implement IIdentifyThrottler and pass in a buildIdentifyThrottler to the manager with a custom one
though just make sure you do it right 
I'm guessing the double I in IIdentify is a typo?
no
its an interface meant to be implemented
I prefix
just like IContextFetchingStrategy
just unfortunate it ends up being double
I see
or make an abstract class okno
thank u
i keep forgetting we can do that
lol
also @dusty dove it looks perfect, I think the only thing that looks off is something for future PRs, which is that connections are open even if we cant identify
so maybe for future, we should start the conns after we have identify available, unless we have resume available
i think that's ok
(imagine if you start like 20 conns, discord will kill those that dont identify fast enough, and uhhh, that we haven't tested yet)
still
(its also a good ratelimit bc if you open 16 conns constantly discord tends to have some conns that never respond with hello)
im curious actually
2440 shards here goes

never mind
Error: Not enough sessions remaining to spawn 2440 shards; only 1856 remaining; resets at 2023-04-14T11:35:33.799Z
we really abused our test bot today
lmao
how many do we even start with
actually never ran into this
i have while trying to help others with the ws