#discordjs/ws big bot memes (old)
1 messages · Page 1 of 1 (latest)
@sullen snow for any follow up questions
Also was the version not injected??
doesn't seems like it
what I did is mostly just inject the erlpack since d.js dont support it yet so connection flow was untouched on my version of discordjs/ws port to v14
yes I have my own impl.
I wanted to port it myself but someone already did it so I didnt
i cant debug off that lol
i need an actual repro sample
either way that looks like its heartbeating a closed connection
which doesnt sound all that related to the bubbling pr compared to some other stuff i changed
Tbf it looks like a long lasting conn issue that you can't easily repro in quick prs
I feel like this could be caused by a missed interval clean
though I'm not sure how it happens
cause seems like it doesn't happen on all the bots I did
doesnt help you dont run with --enable-source-maps
so i have no idea what index.js line 795
oh that is disabled by default?
Ye
Did we release that?
I don't remember
yea
i need to know what 795 is
its either in the interval
or its the awaited send call
also on prior discordjs versions
like my prod rn
is running on 0.6.x
has all the shards intact
so it could be isolated as 0.7.x issue
nvm its def interval now that i paid more attention
That definitely helps us debug
are you running into this consistently
795 - 798
await this.send({
op: import_v102.GatewayOpcodes.Heartbeat,
d: this.session?.sequence ?? null
});
or was this a one off earlier
right now yes
interesting
second time it has happened now
sec
You'd need debug logs for that
because the interval is cleared in destroy()
which should be called the moment we get a close event
or a payload telling us to resume
Exported the logs to a file so ignore the markdown but we get a few reconnects/resumes before (Ignore the no close code, that's on us)
[32mINFO[39m [Wed,03/15/23,12:04:47] (Cluster Process [ID: 27]): [36m[EventHandler]: Shard Reconnecting => Shard: 888 | Close Code: none[39m
[32mINFO[39m [Wed,03/15/23,12:04:47] (Cluster Process [ID: 27]): [36m[EventHandler]: Shard Resumed => Shard: 888 => Replayed Events: 1[39m
[32mINFO[39m [Wed,03/15/23,12:04:47] (Cluster Process [ID: 28]): [36m[EventHandler]: Shard Reconnecting => Shard: 914 | Close Code: none[39m
[31mERROR[39m [Wed,03/15/23,12:04:47] (Cluster Process [ID: 28]): [36mWebSocket is not open: readyState 0 (CONNECTING)[39m
err: {
"type": "Error",
"message": "WebSocket is not open: readyState 0 (CONNECTING)",
"stack":
Error: WebSocket is not open: readyState 0 (CONNECTING)
at WebSocket.send (/main/node_modules/ws/lib/websocket.js:442:13)
at WebsocketShard.send (/main/node_modules/vanguard/dist/src/ws/WebsocketShard.js:187:25)
at async WebsocketShard.heartbeat (/main/node_modules/@discordjs/ws/dist/index.js:795:5)
}
we could enable debug logs and filter things out but that would require us some time
Best case would be like a week or two lol, so not really an option I think
@dusty dove also could I request a way to inject a custom identify manager specially for multi process bots so we could implement our own identify throttler? also pass the shardId that requests for identify
the strategy handles identify throttling
so u can just write your own
the identifythrottler class is just used for our built in strategies
yes but the websocket shard dont pass the shardId
I would appreciate if it would also pass the shardid
since its needed to calculate for buckets
a sec

GitHub
A powerful JavaScript library for interacting with the Discord API - discord.js/WorkerContextFetchingStrategy.ts at 51edba78bc4d4cb44b4dd2b79e4bbc515dc46f5b · discordjs/discord.js
this one
so why do you need the shardId there
like just send the shardId as well on the payload
of the shard that asks for identify
because on big bots
its needed to properly calculate buckets of shard to identify
If this is about max concurrency, that's not how it works
You don't really need shard id to calculate it
 yeah you dont need it per api docs afaik
yeah you dont need it per api docs afaik
are you sure? seems like all the devs I asked that has big bots calculates it using the shard id and concurrency
That's bc they don't realize buckets are already just n shards based on max concurrency
If you need 64 shards and max concurrency 16, its shard 0-15, 16-31, 32-47, stc
const bucket = shardId % concurrency; like I calculate if the shards are able to login by using this formula
and if the redis lock is on this bucket it will let the shard login
We can't easily test max concurrency
yes im not asking for d.js to implement the max concurrency, but rather just pass the shardId for this to be possible
Sofor all intents and purposes you could be right, but the docs example just shows batches of max_concurrency identifies
unless this is some big bot thing only and its secret and not in the api docs no, thats not the case
theres no buckets, it just says you can identify max_concurrency shards per 5 seconds
it doesnt matter what id they have
Yknow it might, we don't know for sure
well idk
I doubt you can identify the same shard for n amount of times
the idea pisses me off
that theyd not put it in the docs
for lib devs to actually handle
so i almost dont want to in protest
but anyway ill look into it
thanks also let me know if what we are doing is wrong or right
but it was stable for like
months now
5s after shard 0 identifies you can do 16
we dont have any reidents
you need 5s between identifies for shards in the same bucket, where bucket = shard_id % max_concurrency
other than that you can do whatever order you want
Thats unrelated to max concurrency
yes I thought I just want to bring that up
since we are already talking about the ws
I'll poke some people about it later
thank you
cause personally myself
concurrency is also something I'm not sure of
if its just idc just login the shards as long as the max concurrency allows
also, kinda weird they don't allow you to have 16x to test stuff
But even the docs show that its batches of max-concurrency shards that are sequential
or there is buckets
the buckets implementation is stable so far but then again without knowing what they mean about it I'm unsure as well
is that broken for every pkg
re this, I assume you've asked before if you could?
no we dont rly have comms
well
vlad does and a few other ppl on the team
but lib devs r treated like nobodies mostly lol
same in the bot space unless you're 10m+
I wish I have 16x cause its a pain to login 112 shards with 1x concurrency
for what it's worth, if you need to test something I'm down to run it on my token
finally, next time we have an issue do I just DM you again Vladdy?
You don't need to ask to ping, feel free to, or dm, ideally just make a thread and ping me (and I'll ping dd if needed)
wth is actually happening here
so this is you hacking it into discord.js right
that makes it a bit hard to track which of those events come from /ws and what is patched up by you
because i do not have a reconnect event
yeah sorry I can't get too far on this without you listening to my debug event
iirc
we don't use it for anything besides logging/graphing @dusty dove
Hopefully this can be done without the debug listener, I'd rather not restart prod
unless i can repro it with a super clean minimal sample to get debug logs myself, probably not
I don't know too much about our ws, but the custom stuff we use is just OS (by Saya) -> https://github.com/Deivu/Vanguard
Not sure if that would help
Saya could probably answer most of you questions, but its midnight for him
cc @sullen snow
@dusty dove alright so it is happening quite often, with a few occurrences the past hour, here's what I've found so far
Here are two examples, each representing one shard having this issue, for the first one (shard 394) we try to reconnect and get the error/issue the same second, for the second shard (866) we try to reconnect but get the issue after 3 seconds.
[Fri,03/17/23,14:54:02] [EventHandler]: Shard Reconnecting => Shard: 394 | Close Code: none
[Fri,03/17/23,14:54:02] [ERROR] WebSocket is not open: readyState 0 (CONNECTING)
err: {
"type": "Error",
"message": "WebSocket is not open: readyState 0 (CONNECTING)",
"stack":
Error: WebSocket is not open: readyState 0 (CONNECTING)
at WebSocket.send (/main/node_modules/ws/lib/websocket.js:442:13)
at WebsocketShard.send (/main/node_modules/vanguard/dist/src/ws/WebsocketShard.js:187:25)
at async WebsocketShard.heartbeat (/main/node_modules/@discordjs/ws/dist/index.js:795:5)
}
[Fri,03/17/23,14:54:02] WebSocket is not open: readyState 0 (CONNECTING)
err: {
"type": "Error",
"message": "WebSocket is not open: readyState 0 (CONNECTING)",
"stack":
Error: WebSocket is not open: readyState 0 (CONNECTING)
at WebSocket.send (/main/node_modules/ws/lib/websocket.js:442:13)
at WebsocketShard.send (/main/node_modules/vanguard/dist/src/ws/WebsocketShard.js:187:25)
at async WebsocketShard.heartbeat (/main/node_modules/@discordjs/ws/dist/index.js:795:5)
}
[Fri,03/17/23,20:17:18] [EventHandler]: Shard Reconnecting => Shard: 866 | Close Code: none
[Fri,03/17/23,20:17:21] [WebSocket is not open: readyState 0 (CONNECTING)
err: {
"type": "Error",
"message": "WebSocket is not open: readyState 0 (CONNECTING)",
"stack":
Error: WebSocket is not open: readyState 0 (CONNECTING)
at WebSocket.send (/main/node_modules/ws/lib/websocket.js:442:13)
at WebsocketShard.send (/main/node_modules/vanguard/dist/src/ws/WebsocketShard.js:187:25)
at async WebsocketShard.heartbeat (/main/node_modules/@discordjs/ws/dist/index.js:795:5)
}
[Fri,03/17/23,20:17:21] [WebSocket is not open: readyState 0 (CONNECTING)
err: {
"type": "Error",
"message": "WebSocket is not open: readyState 0 (CONNECTING)",
"stack":
Error: WebSocket is not open: readyState 0 (CONNECTING)
at WebSocket.send (/main/node_modules/ws/lib/websocket.js:442:13)
at WebsocketShard.send (/main/node_modules/vanguard/dist/src/ws/WebsocketShard.js:187:25)
at async WebsocketShard.heartbeat (/main/node_modules/@discordjs/ws/dist/index.js:795:5)
}
The error originates from here + the error showing a readyState of CONNECTING just seems like we're trying to send a heartbeat while the shard is still connecting (not sure if this could cause issues). But we get the error twice per shard 
// djs/ws index.js line 795
await this.send({
op: import_v102.GatewayOpcodes.Heartbeat,
d: this.session?.sequence ?? null
});
Then finally it gets moved to Vanguard's send function https://github.com/Deivu/Vanguard/blob/master/src/ws/WebsocketShard.ts#L157
I do want to move this to high priority since it's happening often, without enabling debug on prod (for now), how can I enable you to get debug logs on your own? I'm really out of touch with Djs so I'd need you to point me to the right parts.
If needed I can even stream and we can go through this in vc or something
i didnt really hack anything, i just included erlpack on the ws build, and didnt touch any connection flow of ws package
i left that as is
i tried to mimic the old ws manager, so its mostly just discord.js package who is modified to fit into ws, not ws modified to fit into discord.js
can you.. update that send function
ive heavily changed it in ws because of certain bugs
nevermind, yours is up to date
sigh
ill see what i can do today
@dusty dove is it possible to lock into a specific commit in the current repo setup?
not easily I don't think
also, if you're around
how often were you saying you run into this
since I think I figured it out
very frequent
based on the latest news I know
50 shards are down in less than a day
mmm
no but im asking more like
time frequency on a per-shard basis
like this issue will hit all shards regardless
does it take a while before it happens the first time on a given shard
and then it keeps happening?
because if so I think I have it
no idea then lol
I'd probably figure it out instantly with debug logs but /shrug
I can't quite get it into your state locally
I just see something wrong with the code that vaguely resembles your issue
what do you think it is?
so I have an idea and see
actually I have the commit that is known to be the last stable
if you want I could give you the files
and try to compare it to latest master
"version": "0.6.1-dev.1675904160-0e4224b.0", this is the current version on my prod bot and it doesnt crash
case GatewayOpcodes.Hello: {
this.emit(WebSocketShardEvents.Hello);
const jitter = Math.random();
const firstWait = Math.floor(payload.d.heartbeat_interval * jitter);
this.debug([`Preparing first heartbeat of the connection with a jitter of ${jitter}; waiting ${firstWait}ms`]);
await sleep(firstWait);
await this.heartbeat();
this.debug([`First heartbeat sent, starting to beat every ${payload.d.heartbeat_interval}ms`]);
this.heartbeatInterval = setInterval(() => void this.heartbeat(), payload.d.heartbeat_interval);
break;
}```
as it is, that `await sleep` call isn't cancelled in any circumstances, so if your shard goes through a reconnect very soon after another one (or after the initial connect), you end up in a state where:
- you end up sending 2 heartbeats once the connection is finally fully re-established
- the old `heartbeatInterval` is never cleared and instead gets lost since there's no reference to it anymore as its overwritten by the new one
- the part that confuses me - only with very specific bad timing would you end up sending a heartbeat before the conn is actually open sometime in the future, since well, now there's just 2 or more heartbeatIntervals running, not in sync
- if that initial condition keeps occurring, the issue adds up, with more and more loose unbound intervalsso it would actually be the heartbeat jitter PR that's guilty
yeah most def.
cause I also encounter 2 reconnects on my current prod bot
I guess since your bot is big maybe your heartbeat interval is much smaller than mine
(my test bot has 45 seconds)
so I can't really trigger it
even manually
and you also just have more shards so you're more likely to run into it lol
but yeah I'll PR a fix now

 #9244 in discordjs/discord.js by didinele opened <t:1679140961:R> (review required)
#9244 in discordjs/discord.js by didinele opened <t:1679140961:R> (review required)
fix(WebSocketShard): cancel initial heartbeat in destroy
@stable hatch ^
yeah I know one of those = null assignments is redundant in some cases, I just want to be extra safe
that is...jankkkk
couldn't you have done like
what someone else suggested somewhere
in your jitter pr actually


well they mean setTimeout on that first call, first off
well ye
ignore me
nice delete
gh didn't show the method name 
ugh
this is honestly just JS sucking here lmao
I took this super async/await approach everywhere when it came to events and waiting for things
and what I did with the controller is consistent with that
but the other pattern does look nicer here i guess
you could've / should've used a try/catch/finally

LISTEN
will keep this approach but will do try/catch i guess after lunch
Do you perhaps know when this will be merged?
whenever space and kyra review it
Also (unrelated to the rest), what is now the official/best way to support Djs, I'm still subscribed to https://patreon.com/discordjs but I haven't seen Amish in eons, and iirc he's also no longer part of Djs
yeah he only really runs /voice

discord.js is the largest JavaScript/TypeScript Discord library to create bots.
you can donate there
it's all transparent and you can also see where the money is going in the Expenses tab
every so often we (contribs) can bill if we've had any significant work on the library ^^
Alright, I'll look into that
Either github sponsors, or directly on open collective, whichever is simpler for you
Seems like the GitHub sponsors are more directly to a person itself rather than the whole project, and I'd have no idea who does what

@dim oracle @sullen snow it's been merged
just wait for the next @dev release and let me know if it helps
oh, sorry about that ping
dont know if that's helpful either 
we make those automatically every 12hrs
Great thanks a ton again, we'll wait for the dev release then ^^
while you're at it, since this is gonna take a prod deploy anyway, enable debug logs so I can actually figure out what's going on if this doesn't fix it
Yeah will do that for sure, will probably release it on prod this Monday
@stable hatch @dusty dove alright so it appears the issue has not yet been resolved. Surprisingly it took over 24 hours before the first shard got hit. Here's what I can find in the debug logs for shard 873 (Once again ignore markdown)
Seems like there's... a lot going on
You can ignore the INFO lines here
Well we haven't released the fix, unless you put it in yourself in the code?
We used the dev release
Hmm
Can you npm ls it?
Just to be sure 🙏
Or yarn why, whichever package manager you use
Also HOLY did you just say shard 873
😵💫😵💫😵💫
yeah we have 1.5k shards
Damnnn
We don't have the files on disk, we run npm install in the docker file
You can access the container!
we are on 0.7.1-dev
docker exec -it name /bin/bash
package.json shows "version": "0.7.1-dev.1679184639-9842082.0"
"version": "0.7.1-dev.1679184639-9842082.0" to be precise
ill look at those logs when i have a sec
And yeah we run 1440 shards
probably will be a while
Well its definitely latest version at least
seems like an error occurred before the send error happened
Can you provide us the strategy you use too?
worker
Shards per worker?
1
I'll also take a look to see if anything jumps out but I doubt I'll figure it out as quick as dd might
thank you 
this is new though isnt it
theres no send calls erroring anymore
Yeah the previous error is not present which kinda surprised me
But it results in the same thing
Yeah no clue
cleaner version without markdown and INFO logs
i need lunch im running on 0 calories for the past 18 hours or so
i dont touch anything about ssl
nor how this ws open a connection
but the error happened after an error
also it looks like ws is trying to close something that isnt established?
could be a good clue since it means we may have been missing some checks here
yeah that's what I eye'd as well
though
why it happened
after several "error"
it could happen after the first error
but it decided not to happen on that and happened after several errors
@dim oracle yeah so, it looks like the WS docs just straight up betrayed me
Prevent the server from accepting new connections and close the HTTP server if created internally. If an external HTTP server is used via the server or noServer constructor options, it must be closed manually. Existing connections are not closed automatically. The server emits a 'close' event when all connections are closed unless an external HTTP server is used and client tracking is disabled. In this case the 'close' event is emitted in the next tick. The optional callback is called when the 'close' event occurs and receives an Error if the server is already closed.
nothing here says I can't call .close() if it's CONNECTING
but that's what happened to you
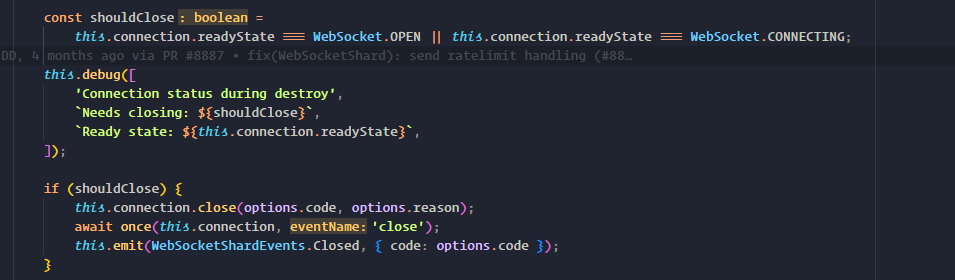
DEBUG [Mon,03/20/23,11:55:22] (Cluster Process [ID: 27]): [EventHandler](Discord.JS): [WS => Shard 873 => Worker] Connection status during destroy
Needs closing: true
Ready state: 0
ERROR [Mon,03/20/23,11:55:22] (Cluster Process [ID: 27]): [EventHandler]: Shard Errored => Shard: 873
err: {
"type": "Error",
"message": "WebSocket was closed before the connection was established",
"stack":
Error: WebSocket was closed before the connection was established
at WebSocket.close (/main/node_modules/ws/lib/websocket.js:285:7)
at WebsocketShard.destroy (/main/node_modules/@discordjs/ws/dist/index.js:638:25)
at process.processTicksAndRejections (node:internal/process/task_queues:95:5)
at async WebsocketShard.bubbleWaitForEventError (/main/node_modules/@discordjs/ws/dist/index.js:693:7)
at async WebsocketShard.connect (/main/node_modules/@discordjs/ws/dist/index.js:587:20)
at async WebsocketShard.connect (/main/node_modules/vanguard/dist/src/ws/WebsocketShard.js:79:9)
}```SSL errors = internet going dumb btw
¯_(ツ)_/¯
fricking insane
hate how poorly documented this package is
And for what it matters it seems that we handle those gracefully
yeah it looks like it was handled fine
this seems to have nothing about ws clients
only the server
lmao yeah i think you're right
yeah

there's the client one
thanks, very informative
either way, I guess like
I guess try catch connection close, assume its fine and carry on?
nuh-uh
I feel like that could leak
somehow
leaves an open connection or smth
I was thinking we make that if (this.connection.readyState === WebSocket.OPEN)
and proceed as we currently do
and else if (this.connection.readyState === WebSocket.CONNECTING)
use connection.terminate() instead
not a big deal
connection.terminate is nodejs ws only
great
anyway
this seems like the only issue kyoso ran into
DEBUG [Mon,03/20/23,11:55:22] (Cluster Process [ID: 27]): [EventHandler](Discord.JS): [WS => Shard 873 => Worker] Destroying shard
Reason: Something timed out
Code: 1000
Recover: Reconnect
DEBUG [Mon,03/20/23,11:55:22] (Cluster Process [ID: 27]): [EventHandler](Discord.JS): [WS => Shard 873 => Worker] Connection status during destroy
Needs closing: false
Ready state: 3
ERROR [Mon,03/20/23,11:55:22] (Cluster Process [ID: 27]): WebSocket was closed before the connection was established
err: {
"type": "Error",
"message": "WebSocket was closed before the connection was established",
"stack":
Error: WebSocket was closed before the connection was established
at WebSocket.close (/main/node_modules/ws/lib/websocket.js:285:7)
at WebsocketShard.destroy (/main/node_modules/@discordjs/ws/dist/index.js:638:25)
at process.processTicksAndRejections (node:internal/process/task_queues:95:5)
at async WebsocketShard.bubbleWaitForEventError (/main/node_modules/@discordjs/ws/dist/index.js:693:7)
at async WebsocketShard.connect (/main/node_modules/@discordjs/ws/dist/index.js:587:20)
at async WebsocketShard.connect (/main/node_modules/vanguard/dist/src/ws/WebsocketShard.js:79:9)
}
ERROR [Mon,03/20/23,11:55:22] (Cluster Process [ID: 27]): WebSocket was closed before the connection was established
err: {
"type": "Error",
"message": "WebSocket was closed before the connection was established",
"stack":
Error: WebSocket was closed before the connection was established
at WebSocket.close (/main/node_modules/ws/lib/websocket.js:285:7)
at WebsocketShard.destroy (/main/node_modules/@discordjs/ws/dist/index.js:638:25)
at process.processTicksAndRejections (node:internal/process/task_queues:95:5)
at async WebsocketShard.bubbleWaitForEventError (/main/node_modules/@discordjs/ws/dist/index.js:693:7)
at async WebsocketShard.connect (/main/node_modules/@discordjs/ws/dist/index.js:587:20)
at async WebsocketShard.connect (/main/node_modules/vanguard/dist/src/ws/WebsocketShard.js:79:9)
}
well this looks weird
but they got into a broken state by that point already
sooo
we'll pretend we don't see that part
#9254 in discordjs/discord.js by didinele opened <t:1679327757:R> (review required)
fix(WebSocketShard): don't close in #destroy when status is connecting
@stable hatch ^
also updated that debug log since it was a bit miss-leading after some refactors
hmmm, you should remove all listeners from the conn if its not in a should close state
👀
oh wait i see
misread
maybe add a debug message in the else for shouldClose to log that "shit broke, oh well"
the debug log there is already clear enough though if it'll enter the if or not
Needs closing: false, will mean it didn't
ugh its still pain that we cannot close while its connecting
yeah, shrug
u're right though it'll eventually just die anyway if it does end up staying open with no refs to it
WS connections due that in the first place if they don't send any payloads for a while
discord might be even faster if they see we aren't heartbeating or anything
its p rare it'll happen anyway
and leaks basically nothing realistically
it's just a tcp handle
still hate it but its the best we can do I guess because ws fucking throws on attempting to close when connecting
rofl
though I must ask
@dim oracle did the shard eventually recover w/o your intervention or
Not yet, I haven't tried doing anything with it yet either
I don't think its doing anything, after those logs the shard ID never showed up again
lmao
not the most intended of behaviors
is that the only shard that broke?
if so it sounds like we did squash the original bug and you just ran into something new that's much less likely to happen
(which seems to be trying to destroy a shard that hasn't fully connected yet)
I think it is, I don't really have a good way to check since my PC cries when I open the 8GB log file
yeah good, cool
For confirmation sake, can you patch-package it with the PR fix?
I don't really want to restart prod during peak hours tbh
Only one shard down atm after 30+ hours, so not really worth restarting prod for atm
Well you dont have to do it now
I can do it, but probably in a few days
pr was merged anyways
Just thought I'd keep you posted~ surpassed 48 hours of no issues so far
Running 0.7.1-dev.1679400254-950fc47.0 still
this one iirc
yeah so i was probs right your last issue was just a super rare thing
this should've patched that as well
either way good to know u're stable now
cc @stable hatch, looks like I nailed it the first try
Don't jinx it
too late
oh u replied to the same one
yes ok
so everything should just be good

@stable hatch @dusty dove it seems like there's another issue? Here's an example for one of the shards affected. After this it is completely radio silence and I never see that shard again.
ohlawd
cc @sullen snow as well I guess
what 1k shards does to an mf
dude ur ass got a 520 from discord
wth
yeah ok
that is insane
i have no idea what im looking at
ur logs are failing to capture smth fwiw
or not actually
nvm
i dont know why theres just radio silence after
either way that shard just completely broke
it managed to get into a state where it identified after resuming?
there is one reference to this.identify in the whole file
and its in connect()
you had 2 concurrent connect calls running
one with a session and one without

I can check if the same happened for the other 18 shards I suppose
Weird thing is, this happened on all 3 bots at the exact same time

yeah that makes a lot of sense
because you got a 520 from discord
which means this is specific breakage from them im not handling appropriately
you just keep running into the most absurd edge cases
what 1440 shards does to a mf ig
DEBUG [Fri,03/24/23,22:20:18] (Cluster Process [ID: 42]): [EventHandler](Discord.JS): [WS => Shard 1370 => Worker] Resuming session
DEBUG [Fri,03/24/23,22:20:18] (Cluster Process [ID: 42]): [EventHandler](Discord.JS): [WS => Shard 1370 => Worker] Identifying
shard id: 1370
shard count: 1440
intents: 131
compression: none```this is nonsense
nope
I think I get it
time for a third pr I guess
Though, whatever changed from 0.6.x -> 0.7.0 seems to have added a lot of edge cases
Things were running fine for weeks before we upgraded to 0.7.0
omg
that's such a cool bug
look at this
/**
* Does special error handling for waitForEvent calls, depending on the current state of the connection lifecycle
* (i.e. whether or not the original connect() call has resolved or if the user has an error listener)
*/
private async bubbleWaitForEventError(
promise: Promise<unknown>,
): Promise<{ error: unknown; ok: false } | { ok: true }> {
try {
await promise;
return { ok: true };
} catch (error) {
// Any error that isn't an abort error would have been caused by us emitting an error event in the first place
// See https://nodejs.org/api/events.html#eventsonceemitter-name-options for `once()` behavior
if (error instanceof Error && error.name === 'AbortError') {
this.emit(WebSocketShardEvents.Error, { error });
}
// As stated previously, any other error would have been caused by us emitting the error event, which looks
// like { error: unknown }
// eslint-disable-next-line no-ex-assign
error = (error as { error: unknown }).error;
// If the user has no handling on their end (error event) simply throw.
// We also want to throw if we're still in the initial `connect()` call, since that's the only time
// the user can catch the error "normally"
if (this.listenerCount(WebSocketShardEvents.Error) === 0 || !this.initialConnectResolved) {
throw error;
}
// If the error is handled, we can just try to reconnect
await this.destroy({
code: CloseCodes.Normal,
reason: 'Something timed out or went wrong while waiting for an event',
recover: WebSocketShardDestroyRecovery.Reconnect,
});
return { ok: false, error };
}
}```so there's this method, right
in your case, what happened is
the shard was trying to resume from the await this.resume() call in connect()
and it timed out for whatever reason
but since this isn't your first connection
it goes to those last 2 statements
await this.destroy({
code: CloseCodes.Normal,
reason: 'Something timed out or went wrong while waiting for an event',
recover: WebSocketShardDestroyRecovery.Reconnect,
});
return { ok: false, error };```and it awaits the destroy call
which initiates a fresh reconnect
before returning { ok: false }
so back in connect
const { ok } = await this.bubbleWaitForEventError(
this.waitForEvent(WebSocketShardEvents.Hello, this.strategy.options.helloTimeout),
);
if (!ok) {
return;
}
if (session?.shardCount === this.strategy.options.shardCount) {
this.session = session;
await this.resume(session);
} else {
await this.identify();
}```the waitforEvent call for hello fails in a connect() where connect would be called because of the state of session
and it initiates another connect because of that inner destroy call - before hitting the if (!ok) return;
so the 2nd wait for Hello on the non-resume connect goes through
and both of them end up going through, I guess?
though I still don't quite understand how, since we still eventually return ok: false
but it's def something racing there
I'm surprised you found this already
lol
my instinct for async races is crazy good since its all ive been working with in my time programming
Welp, it sure worked this time I suppose
still super odd
but yeah it's def smth to do with this given both a resume and identify fired right after a Hello came through
also, 520 is from cloudflare 
tbh, this direct line has helped a ton the past few days so glad this came to be 🙏
yeah i mean
its good you're running it in prod
because I get to iron it out like this
yea im not 100% this will do it but its a one-line diff that should improve the behavior either way
while im at it
i wanna append something to the readme
Seems like this only happens rarely so I don't really need to rush any of this
I got some of these too!
..just for 2 shards
@stable hatch https://github.com/discordjs/discord.js/pull/9276

rofl
unclear 100%
but it's def. more correct now
since before it made connect calls just kinda hang about if something timed out
until the shard fully reconnected
and that could start nesting up
lmao
not really
mocking WS even enough just for this is insane
well its not insane its just completely unmaintainable if I just hack it up like this
hrm right, you'd need to make some mock ws that just sends the 3 payloads
yeah
are versions injecting correctly yet?
btw DD
wont this throw undefined too?
if (this.listenerCount(WebSocketShardEvents.Error) === 0 || !this.initialConnectResolved) {
throw error;
}
yeah, but when would it be undefined
I mean
when an aborterror is thrown
ALSO emitting error will throw if theres no error listener
they are btw, just checked
thinking
cool
yeah, the point of the throw there is to act as control flow, mostly
in the !this.initialConnectResolved case its so the user can try..catch connect()
it is still technically able to throw undefined, right?
if an aborterror is thrown
I always destructure even if its an aborterror

ill push a fix for that into this PR as well
also why do you even emit error if its an aborterror
thats really not useful, right?
if you get an aborterror you just wanna return false, or?
well i actually dont have a good answer to this my brain was just like "anything else is an error event in the first place so i guess i should make sure abort errors also go there"
maybe rethink the whole catch block then?
no, I still want to throw
because of control flow

like
you call .connect()
the first time
I need it to throw so connect() throws
and so the user can catch it
I guess from the main ws.connect call
@dusty dove honestly tho
error = isAbortError ? error : (error as { error: unknown }).error; should be error = error instanceof Error ? error : theCast
merged already sheesh? Will just wait for dev release then
@dim oracle @sullen snow do u guys keep perf metrics
we're getting rid of zlib-sync in favor of node:zlib
and i wanna see what the impact is
oh
wth why do you use etf then
it's literally just bigger payloads in a bunch of cases if you don't zlib
used to be for performance
but nowdays
due to threaded ws
might just remove it to reduce maintenance for me or wait for your implementation
Please tell me you've installed bufferutil and utf-8-validate
discordjs/ws big bot memes
both are installed, but even with those, cpu usage without etf encoding is high
thats nuts
That's why you use zlib-stream
yeah lol
zlib has leaks on node
It wat
wait a second

I'd imagine its because abal doesn't maintain zlib-sync
I don't really know the compression stuff but we basically have no CPU usage on prod
with etf ^
Like <5%
how do you search for
messages that I sent with a specific keyword again
@stable hatch @dusty dove
surely you dont want those pauses

I'll see if I can add garbage collection pauses again
as that was my 2020 code
who knows where I even put it

@dusty dove where pr
thats why personally I used etf over compression
but then again, once this zlib issues is fixed
we may want to try it but this is prod so we don't want anything breaking like the 0.7.0 commit 
"big bot memes" 
Btw don't remove zlib-sync yet
Lets make a (dev) release with both
damn I was wrong, we hit 8% during peak hours
Discord isn't supporting etf for much longer apparently
So
how do u want me to support that
...add a new compression method called nativezlib?
Suffer

ok
anything else you want to test on a big bot before I pull the latest dev release somewhere tomorrow
If you mean big bot that's a stretch
oh that's nice
Yeah LOL so we can test max concurrency
yeah its not gonna be anything like the 'real' thing though
ye
16x or higher?
https://github.com/discordjs/discord.js/pull/9279 do w/e u want w it @stable hatch
Pls tell me you let maintainers push to it
i also split useIdentifyCompression into its own option but thats probably not how i should have done it
yes
Otherwise i will ping you every minute for the next day
i never tick that box off

do you actually know how many bots with big bot sharding use djs
Why the hell did you split the options
mostly cus of how I deal with the compression enum
You can't mix identify compression with zlib-stream
Zoomers i s2g
I'm glad its an automated system now tbh, back in the day you had to contact Discord to move you, and if you weren't running a multiple of 16 you'd have to reboot before you can access it
I pass the value as-is into the query params of the WS url
params.append('compress', compression);
Horrible
I'll look into it
Is it automated lol
it is now, if you hit 150k and have a multiple of 16 as shard count you're just moved automatically to 16x
same for 32x iirc
not sure about 64x or 128x though
Are there any bots in that range o.o
p sure rythm still is as well
yeah but dead bot so shrug
well
we still keep a gateway connection going
so they def. care lol
esp. considering the last time we did anything spicy we took the platform down

Why
to display presence, marketing things i guess 
Discord rolling in their grave
If you ever disconnect and the sessions fully shut down and you reconnect you'll be yelled at 😂
idk tho i had nothing to do w bot eng and still dont have anything to do with eng there
I do wonder what you'll come up with to support 16x if that's gonna be a thing now
Wat
We already support max concurrency
yeah i had vlad double check and we're still waiting for a response but
p sure you were wrong abt the max concurrency formula thing
there's just no such thing as bucketing on them, you can just identify max_concurrency shards at any given time regardless of their id
so we already fully support it lol
We'll see when I get an answer
Hmm, tbf I haven't actually used djs's sharding manager in a while
💀
The amount of issues it has is insane
Anyways this is what i asked discord
We do actually have a question about max_concurrency!

Is there any formula to what shards can connect concurrently? Does max_concurrency only alter the identify limit (so we could technically identify shard id 0/16 16 times), or does it alter the sequence too (so only shard 0-15 first, then 16-31)
We shall wait and see
The docs suggest the latter
(which wouldn't affect us anyways bc it works already)
We'll see, every bot dev I have contact with does say the bucketing is a thing
how many sessions does the test bot have actually? Since it scales of guild count I guess just the normal 1000
2000 total, concurrency 16
@dusty dove @stable hatch I'm not sure if this is caused by Djs, but again a shard is showing some weird things before never recovering again. Still on ws 0.7.1-dev.1679400254-950fc47.0
Again after these logs shard 162 is never seen again
aaaa
likely bc of outdated ws
why do you not run with --enable-source-maps
I mean @dusty dove
for all we know
your awaiting destroy bug fix could've solved this
Best bet is wait for them to update, and check after
which could be what you solved in https://github.com/discordjs/discord.js/commit/519825a651fe22042a73046824d12f03f56ca9e2
well
that specifically patched a race caused by uh
waitForEvent timing out while resuming
but yes, thatd typically happen from network issues
I stand by what i said 
@dim oracle
- update ws
- run with
--enable-source-maps - followup if it dies again
4. contemplate why you made a discord bot when networking is so reliable
Just making sure this isn't missed before I update ws again
i mean dd knows that better than me but its not impossible its already handled
this will end up being a cat and mouse against async race conditions
still more stable than djs's current ws which has at least 1-2 dead locks LMAO
no weird network shenanigans around that time though
your logs show networking issues
@dusty dove fyi the error seems to have been thrown in waitForEvent
yeah makes sense
probably waiting for hello?
but the handshake timeouts are def. outside of my control
ye
if its not your network its discord
that should have a debug call tied to it if it was hello
DEBUG [Sun,03/26/23,18:55:51] (Cluster Process [ID: 5]): [EventHandler](Discord.JS): [WS => Shard 162 => Worker] Waiting for event hello for 60000ms
ERROR [Sun,03/26/23,18:56:51] (Cluster Process [ID: 5]): [EventHandler]: Shard Errored => Shard: 162
err: {
"type": "Error",
"message": "The operation was aborted",
"stack":
AbortError: The operation was aborted
at EventTarget.abortListener (node:events:958:14)
at [nodejs.internal.kHybridDispatch] (node:internal/event_target:735:20)
at EventTarget.dispatchEvent (node:internal/event_target:677:26)
at abortSignal (node:internal/abort_controller:308:10)
at AbortController.abort (node:internal/abort_controller:338:5)
at Timeout.<anonymous> (/main/node_modules/@discordjs/ws/dist/index.js:650:91)
at listOnTimeout (node:internal/timers:569:17)
at process.processTimers (node:internal/timers:512:7)
}
ya dont say
no but
nvm
i missed the destroy log
thats what i was looking for
yeah it timed out on hello
Yknow, I do wonder if we can deadlock shards like that
than subsequent reconnects timed out on the TPC handshake
committed this now so I don't forget
sooo discord was just dying
imma test if shards deadlock when ws never responds with a hello
Just to make sure, ^0.8.0-dev.1679789487-b8b852e.0 would be the latest right
god rays who tf knows
theres enough async to kill an elephant
sounds correct
why did we bump major again
eh w/e
yes, its correct
Will update prod somewhere tomorrow
@dusty dove so this is fun...
{
message: 'Connecting to ws://localhost:8080?v=10&encoding=json',
shardId: 0
}
{ message: 'Waiting for event hello for 60000ms', shardId: 0 }
[WSS] Connected
Exception in PromiseRejectCallback:
file:///Users/vlad/Development/Discord/discord.js/node_modules/@vladfrangu/async_event_emitter/dist/index.mjs:305
});
^
RangeError: Maximum call stack size exceeded
node:events:958
reject(new AbortError(undefined, { cause: signal?.reason }));
^
AbortError: The operation was aborted
at EventTarget.abortListener (node:events:958:14)
at [nodejs.internal.kHybridDispatch] (node:internal/event_target:735:20)
at EventTarget.dispatchEvent (node:internal/event_target:677:26)
at abortSignal (node:internal/abort_controller:308:10)
at AbortController.abort (node:internal/abort_controller:338:5)
at Timeout.<anonymous> (/Users/vlad/Development/Discord/discord.js/packages/ws/src/ws/WebSocketShard.ts:258:65)
at listOnTimeout (node:internal/timers:569:17)
at process.processTimers (node:internal/timers:512:7) {
code: 'ABORT_ERR',
[cause]: DOMException [AbortError]: This operation was aborted
at new DOMException (node:internal/per_context/domexception:53:5)
at AbortController.abort (node:internal/abort_controller:336:18)
at Timeout.<anonymous> (/Users/vlad/Development/Discord/discord.js/packages/ws/src/ws/WebSocketShard.ts:258:65)
at listOnTimeout (node:internal/timers:569:17)
at process.processTimers (node:internal/timers:512:7)
}
Node.js v18.14.0```i.. dont know why or how theres a rangeerror from async ee
so true, how could i forget to catch the stack overflow error
what in the name of sweet lord
I logged the error that kept getting thrown
AEE ERROR Error: Unhandled 'error' event emitted, received [object Object]
at WebSocketManager.emit (file:///Users/vlad/Development/Discord/discord.js/node_modules/@vladfrangu/async_event_emitter/dist/index.mjs:213:19)
at WebSocketShard.<anonymous> (file:///Users/vlad/Development/Discord/discord.js/packages/ws/dist/index.mjs:977:51)
at file:///Users/vlad/Development/Discord/discord.js/node_modules/@vladfrangu/async_event_emitter/dist/index.mjs:297:34
at new Promise (<anonymous>)
at Object.wrappedFn [as wrappedFunc] (file:///Users/vlad/Development/Discord/discord.js/node_modules/@vladfrangu/async_event_emitter/dist/index.mjs:292:23)
at WebSocketShard.emit (file:///Users/vlad/Development/Discord/discord.js/node_modules/@vladfrangu/async_event_emitter/dist/index.mjs:224:25)
at file:///Users/vlad/Development/Discord/discord.js/node_modules/@vladfrangu/async_event_emitter/dist/index.mjs:301:30
at new Promise (<anonymous>)
at Object.wrappedFn [as wrappedFunc] (file:///Users/vlad/Development/Discord/discord.js/node_modules/@vladfrangu/async_event_emitter/dist/index.mjs:292:23)
at WebSocketShard.emit (file:///Users/vlad/Development/Discord/discord.js/node_modules/@vladfrangu/async_event_emitter/dist/index.mjs:224:25) {
context: { context: { context: [Object], shardId: 0 }, shardId: 0 }
}```I'll have to take a look at that
that might be my bad
ok so that aside, @dusty dove didnt u say that uhhh...if the hello times out it should retry?
bc it sure doesnt do that
It DOES work if the conn is closed
but not if it times out
oh no sorry
this is only if its not the initial connect, actually
im not sure why its that way
anymore
but it is on purpose

{kind=link}
{kind=link}
{kind=link}
maybe, i think its this way bcus like
First off how are you sure its only on initial connect
secondly it shouldn't even be like this ever
the idea is that connect only resolves once its ready right
hello timeouts can happen bc internet is just dead
and to accomplish that itd just
recurse down on every failure
so in practice the retry logic would need to be handled outside the shard class
the field literally being set and checked just for this
elaborate
what does "conn dies" mean
Consider a wss local server
Consider ws = the connection to the wss
When the manager spawns the shard that connects to the local wss
- if the timeout is reached, process exits with the abort error
- if the ws is closed in the wss, it tries to reconnect constantly, as it should
oh god I've found bugs in AEE too brb crying
I mean hard to test that locally
the more i think about this the more absurd i realize it is to make it so connect is catchable
so many edge cases
its why all the error handling is so dank
what version is this
latest main
and uh
ok so tbf it could be my test script
B u t uhhhhh it like breaks breaks
ill scrap the thing that makes connect throw if things timeout during the initial connects
anddd i also know a way to still guarantee it only resolves on ready
@dim oracle I tracked down a new bug related to what you ran into a couple of days ago
it seems waitForEvent calls were never cancelled by the WS shard closing regularly
I just did a massive refactor to address this and some of the janker error handling
hmm, prod is currently on the dev release I mentioned yesterday
yeah nws
I haven't even opened the PR
vlad has been toying with things and edge cases using a fancy script
import { WebSocketManager } from '@discordjs/ws';
import { REST } from '@discordjs/rest';
import { WebSocketServer } from 'ws';
let initial = true;
const wss = new WebSocketServer({ port: 8080 });
wss.on('connection', (ws) => {
console.log('[WSS] Connected');
ws.on('close', () => {
console.log('[WSS] Disconnected');
initial = false;
});
ws.close();
});
const rest = new REST({}).setToken('');
const manager = new WebSocketManager({
intents: 0,
rest,
token: '',
retrieveSessionInfo(shardId) {
if (initial) {
return {
shardId,
shardCount: 1,
sequence: 1337,
resumeURL: 'ws://localhost:8080',
sessionId: 'owo',
};
}
return null;
},
shardCount: 1,
shardIds: [0],
helloTimeout: 10000,
});
manager.on('debug', console.log);
manager.on('heartbeat', console.log);
manager.on('ready', console.log);
await manager.connect();
console.log('Connected');```we hijack the WS server it connects to using the resumeURL, lol
to test some weirder stuff like if it insta closes
interesting
if thats fancy I should be paid 7 digits
lmao
haven't touched ur branch btw
but i mean
can u try this without ws.close too
yes
worked
i'm more interested in the behavior in that condition
mostly
just a range error from AEE
lmao
➜ node --enable-source-maps vlad.mjs
{
message: 'Connecting to ws://localhost:8080?v=10&encoding=json',
shardId: 0
}
{ message: 'Waiting for event hello for 10000ms', shardId: 0 }
[WSS] Connected
Exception in PromiseRejectCallback:
file:///home/didinele/Documents/Code/didinele/discord.js/node_modules/@vladfrangu/async_event_emitter/dist/index.mjs:308
}, "wrappedFn");
^
RangeError: Maximum call stack size exceeded
Exception in PromiseRejectCallback:
file:///home/didinele/Documents/Code/didinele/discord.js/node_modules/@vladfrangu/async_event_emitter/dist/index.mjs:308
}, "wrappedFn");
^
RangeError: Maximum call stack size exceeded
Exception in PromiseRejectCallback:
file:///home/didinele/Documents/Code/didinele/discord.js/node_modules/@vladfrangu/async_event_emitter/dist/index.mjs:308
}, "wrappedFn");
^
RangeError: Maximum call stack size exceeded
{
message: 'Destroying shard\n' +
'\tReason: Something timed out or went wrong while waiting for an event\n' +
'\tCode: 1000\n' +
'\tRecover: Reconnect',
shardId: 0
}
{
message: 'Connection status during destroy\n\tNeeds closing: true\n\tReady state: 1',
shardId: 0
}
[WSS] Disconnected
{
message: 'Connecting to wss://gateway.discord.gg?v=10&encoding=json',
shardId: 0
}
{ message: 'Waiting for event hello for 10000ms', shardId: 0 }
{
message: 'Preparing first heartbeat of the connection with a jitter of 0.6635785282947928; waiting 27372ms',
shardId: 0
}
{ message: 'Waiting for identify throttle', shardId: 0 }
{
message: 'Identifying\n\tshard id: 0\n\tshard count: 1\n\tintents: 0\n\tcompression: none',
shardId: 0
}
{ message: 'Waiting for event ready for 15000ms', shardId: 0 }
{
data: {
v: 10,
user_settings: {},
user: {
verified: true,
----------- [snip] ----------
},
shardId: 0
}
Connected```huh, verified: true
what bot token have I been using
All bots have this
do they
Its not the verified bot flag
Oh it did work
Past the aee errors
Nice
 #9282 in discordjs/discord.js by didinele created <t:1679928436:R> (review required)
#9282 in discordjs/discord.js by didinele created <t:1679928436:R> (review required)
refactor(WebSocketShard): waitForEvent and its error handling
have fun
I sure love getting 5 notifications whenever a pr is open
this should really iron things out
watch there be many edge cases after this anyways
Shhh
We're just glad you're reporting these and that, overall, ws has been more stable than djs ws
Gives me more confidence for 14.10
that didn't have the send bug that caused all shards to eventually reconn loop
Running debug logs for a week straight learned me I need to set a size limit for the logfile
@dusty dove heres the thing with your emitting of error events in waitForEvent
it will ALWAYS throw the error
because just like in node, emitting an error event when theres no error listeners will throw
so the destroy call will never happen
and same with the return
wait what
I thought the throw was async on the next tick or something
not on the .emit call
its on the emit call
what's interesting is if you run simple strategy there'll always be a bound error event anyway
so the throw ends up coming from the manager
I guess I just get rid of it?
yeah, was just a consistency thing
is kinda useless
fair
I mean an abort error emitted in error events is kinda...useless?
especially since the method can reject instead
ye, done
either way
I like this solution
I'm finally actually pleased with waitForEvent
at [kNewListener] (node:internal/event_target:514:17)
at eventEmitter.<computed> (node:internal/worker/io:307:12)
at MessagePort.addEventListener (node:internal/event_target:623:23)
at MessagePort.on (node:internal/event_target:873:10)
at VanguardBootstrap.setupThreadEvents (/main/node_modules/@discordjs/ws/src/utils/WorkerBootstrapper.ts:83:5)
at VanguardBootstrap.bootstrap (/main/node_modules/vanguard/src/worker/VanguardBootstrap.ts:51:14)
at process.processTicksAndRejections (node:internal/process/task_queues:95:5) ```
@dusty dove there is a memory leak issue from event emitter on thread wsnot sure how it started, but I doubt this is from my code
can u show me ur worker src

GitHub
A drop in replacement for Discord.JS v14 websocket - Vanguard/VanguardBootstrap.ts at master · Deivu/Vanguard
there are some uneeded code there that I dont use like the extendederrordata since d.js support it already
that implies the setup method is called a bunch of times? hm
yes
not sure why as well
you can probably prepatch it by just checking if the method was initialized once, but then again that would mean this would be a patch fix rather than fixing it from the base
id rather you hacked in a trace that figures out where its being called from
not sure how I can make a trace for that
like so:
const err = new Error();
Error.captureStackTrace(err);
console.log(err);```used this trick a bunch to debug shard
is trace warnings not complete in this regard?
doesnt seem to be, since it only goes to bootstrap
but i guess an error trace wont help more either then
idk, if setup is only called in bootstrap that'd imply bootstrap is called multiple times
wait
is that the only warning u got
setup makes multiple listeners
u shouldve gotten one for each event i feel
ohhh wait
@sullen snow whats your shardsPerWorker
this might actually just not be a leak
we do actually just bind that many listeners
one per shard
1
thats why theoretically it should not emit
does this repro every startup
nope usually it emits after some time
ehh this does occur for every cluster we spawn
so if we spawn 60 clusters during startup we get the message 60 times
oh
nah directly after we spawn the cluster iirc
but only past a certain amount of shards per cluster, so e.g. for like 2 shards per cluster we don't get the message
did some testing this morning, didn't mention that to saya yet ^^
but for 3 you do?
didn't test at what point we got the message, can do in a bit though
ye would be helpful
So we get it at 10 shards per cluster, anything below that does not trigger it
And we get it instantly after we launch the cluster
lol ok then its not a leak
^
cc @sullen snow I guess
we usually run around
1 shard per worker
@dim oracle are you changing how many shards we run
worker !== cluster
@dusty dove we run the same amount of threads for our websocket
so basically if we run 32 shards
thats 32 threads
Used to be 32 per cluster, now its 24 per cluster to match the core count of the dedi
make up your minds 
probably its just confusing but
the structure is like this
master process -> cluster process -> thread for websocket
where we run 24 threads in that cluster
each thread handles 1 websocket
if you ask me why I do that is because I want each ws thread to have its dedicated event loop, and its not that expensive to spawn them once, its not like its being spawned everytime
this way heartbeats is as accurate as it can be