#users-helping-users
1 messages · Page 53 of 1
Thanks CompleteTech, original issue is that my OC agents we working great but now are fizzling out on every message (even in new, small context window sessions). Agents describe their plan in every reply but never execute any tool calls even when explicitly called out. Suggestions are to remediate behaviour instructing agent to disallow response without execution & maintain on disk state logs so context can be kept continuously current with efficient context window size.
First I would check each of the .md files:
agents.md
soul.md
identity.md
user.md
tools.md
bootstrap.md
memory.md
To clarify I would read the files and not use an llm to read them. If you do not find what you need there I suspect it could be buried in the chat logs which would require more drastic measures.
hey guys what do you use the integrate with google suite google drive and the rest of the apps .. i heared that there is a new plugin or skill to be used other than the gog peter did is that true ? can you guide me to the best one to use ?
also my agent is weird when i ask similar questions to him it seems that it cannot do search .. while i am already using chatgpt 5.4 codex which already includes search i belive right ?
i was expecting a better experience like it will automatically go search and find something and come back with some recommendations to go with
question, was the claude auth token ban lift off? I wanna run claude in my openclaw but don't really have the money to just be burning tokens using the API
nope
Config warnings:\n- plugins.entries."memory-wiki": plugin not found: "memory-wiki" (stale config entry ignored; remove it from plugins config)
is this knowbug?
The new method I mean
the one using claude cli as the backend or something
I've heard the method doesn't cache responses but that it should be fine
why does it always give me this when i try to talk to the bot "[agent/embedded] embedded run agent end: runId=eb8ceda1-68e7-429f-892b-c82ba71b1eed isError=true model=deepseek/deepseek-v3.2 provider=openrouter error=401 Missing Authentication header rawError=401 Missing Authentication header
23:30:34 [agent/embedded] embedded run failover decision: runId=eb8ceda1-68e7-429f-892b-c82ba71b1eed stage=assistant decision=surface_error reason=auth from=openrouter/deepseek/deepseek-v3.2 profile=sha256:ac092b59b472"
Hmm is this ASI-Evolve good? 🤔
there is issue with openrouter
OpenClaw “dreaming” silently died after 72 hours—REM stuck on stale corpus + zero promotions (0/602)
Running OpenClaw 2026.4.15 as the runtime for a long-term memory system. My Obsidian vault is the single source of truth; the container’s DREAMS.md and MEMORY.md act as caches, reconciled nightly back into the vault so memories compound over time.
Dreaming worked cleanly for three days (Apr 15–17: 86 / 98 / 24 light+REM entries), then stopped completely. Three nights later: still no new entries. Container is healthy, cron jobs are firing, but nothing is written to DREAMS.md.
Two consistent symptoms:
- REM reflector pinned to stale corpus file
Every entry in DREAMS.md and every memory rem-harness preview cites the same evidence from:
memory/.dreams/session-corpus/2026-04-14.txt
—despite newer corpus files existing with significantly more data. - 0/602 recall entries promoting to MEMORY.md
All candidates score in a tight band: 0.805–0.806, just above minScore=0.8, yet none promote.
Troubleshooting already attempted:
• memory status --fix → no change
• Full container restart → no effect
• Verified corpus files present (7 files, ~350 KB total)
• Confirmed permissions: node:node 664, all readable
Questions:
• How does the REM reflector select its corpus file?
Is there a state or pointer (beyond session-ingestion.json) that could be pinning it to an old file? If so, is it safe to reset?
• Why are candidates above minScore=0.8 not promoting?
Is there an additional gating mechanism beyond the visible score?
• Is there a way to force a full re-ingest of session-corpus/ via CLI?
Api key issue
You didn't happen to find anything, did you?
Has OpenAI 0AUTH started firing "The server had an error processing your request.." at anyone else in the last 5 minutes?
nope did you try updating and check
Hey everyone, I'm curious, is anyone here having their OpenClaw agents collaborate with other people's agents? Curious if this is something people have tried and for what use cases
Hi, I cant choose groq as a provider on the onboarding. What to do?
Could you provide the logs?
Also, double check your configuration and try to setup the model again
Hi all, who has a working two-machine ubuntu server openclaw Ollama setup? I have been trying for days to get this to work and am just plain stuck openclaw on one ubuntu server and ollama on another. all local network
So what are you struggling with specifically?
Well I get no reponse in the UI openclaw. It just eats the cursor and disappears. I have been through the entire testing everything with the Kirll bot. but can not get past this issue of nothing coming back on the ui
Can you provide the logs and the version you're running with?
Is having your agent set up your crons a good idea? could it missing things that i should know about?
Depends on the model as any other task, but yes it's generally a good idea
Just remember to specify it must be an OpenClaw cron job if you want an agent to take care of said cron job
Otherwise have it set a system cronjob
Are you sure the two servers can talk to each other? Do the logs on the ollama side show the request arriving?
This ^ also remember to set up the firewall config to allow incoming traffic on your set ports
If it's Ubuntu, use ufw
the two servers are certainly communicating in all aspects except getting Ollama to respond correctly in the browser or the TUI, Firewalls are certainly correct.. Mostly we have tried everything for days. I would not have thought this would be an issue.
Then our next step must be to check the gateway logs, otherwise we're going blind
So during onboaridng you have selected the provider and gave the base url as your other server?
hi yes and yes. the json files have been complete proofed and are correct
Have you done curl from the gaetway machine to your ollama server machine to that base url?
yes
Did that a coupe times...all of my logs look the same as what's in the thread
Why don't you give us the logs so we stop blind guessing 🙏
Your openclaw is a direct install on the machine or docker?
Have you tried completely removing the model config and setting it up again from the CLI?
Oh yeah this too
openclaw is a direct install. not docker
yes to the model config questions as well
That one wasn't for you
If you can hit tags from curl on the machine oc is running the problem is somewhere else.
Indeed I have...wouldn't hurt to try again though. I shall.
I'll add more logs to the thread as well
So only ollama is the problem or other cloud models also have this problem? Btw which version of oc
What version are you running? Also what's your provider?
4.15, openrouter or ollama local
Ollama is actually known to present some... "issues" when it comes to OpenClaw but logs will tell
Did you have this problem on prior versions?
I did not. It just popped up up out of nowhere a couple days ago. Should I roll back?
Try rolling back
@velvet cosmos take backup of .openclaw and do a fresh install from scratch. Are you open to using docker? Since it will be much cleaner install
my question was, does anyone have this actually working locally on their own lan without being connected to a cloud model it seems like it should be straight forward but it definetely isn't
Yes I have connected earlier so ollama or any other locally hosted like privategpt, anythingllm is no issue- most people get base url incorrect
yes. openclaw + ollama. in separate docker containers on a bridge network, which has all the same complexity of exposing ports as doing it on two separate servers.
You're probably getting banned you know that right?
What's the best way to do that? Haven't had to do it before
npm i openclaw@2026.4.14 -g
Perfcet. Thank you kindly.
Np
Suggest using k8s if on multiple hosts...there will be no issues of opening multiple ports - just the k8s nodes single port
lol I have to do k8s at work I am not doing it in my spare time. proxmox and podman are just fine.
ansible manages it all, claude writes the ansible playbook, it all works and I don't have to touch it. 🙂
Sure - just that if you have multiple services within k8s, they are easily accessible to oc and you can set discrete policy between namespaces making it more secure
@velvet cosmos are you seeing the api requests make it to ollama when you chat in the openclaw web ui? In the ollama logs:
[GIN] 2026/04/21 - 00:30:08 | 200 | 2.548139565s | 10.x.x.x | POST "/v1/chat/completions"
[GIN] 2026/04/21 - 00:30:10 | 200 | 1.788704499s | 10.x.x.x | POST "/v1/chat/completions"
Have you used https://semaphoreui.com/ ? All your ansible and terraform can be in single container. And this also has mcp server
nope. it's just me and a couple of servers at home, I prefer plain text in version control and the cli. claude handles the majority of it, and I run the playbook when needed. I let everyone here figure out what works during the week and carefully upgrade once on Saturday, then we're golden for another week.
Okay. I also have couple fo servers at home - but they connect to mutliple cloud vm i have across - all connected via k8s multicluster via linkerd. Hence openclaw nodes in each of them provide me great control to a single k8s gateway pod at home. Waiting for the openclaw swarm equivalent for HA
I have a question for you. When I create agents on my openclaw, I'm curious what you think is the best to set them up,should I have one marketing agent that publishes to all of my different social media channels, or should I have an agent that specializes in a particular business vertical. Like a different agent for each of my businesses. Or a different agent with specific business skills that can work across multiple businesses.
Depends upon your need and type of usage. Remember that each agent can have their own workspace, context and memory. So based on what you think how much background or isolation each agent should have, you decide. After all, they are all equal except their prompts 😃
I am not using docker. clean ubuntu server 24:04 installs on both machines
okay. when you show us the logs from both ollama and openclaw we can help more.
nothing at all ok I will collect the logs for openclaw and ollama
According to Claude. Per-business agents is the best starting point.
Each agent knows that business's voice, audience, and goals deeply — producing far better content than a generalist agent context-switching between brands.
Key insight: Keep channel routing (Twitter, Instagram, etc.) as a downstream step, not the agent's defining job. The agent's job is knowing the business, not the platform.
Design tip: Structure each agent's prompt so the business knowledge (brand voice, audience, offers) is injected context rather than hardcoded. That makes it easy to later consolidate into shared skill-based agents if you scale up.
what is the output of openclaw config get models ? someone earlier asked about the baseUrl, that will show it. I'm also interested in the api value for the model.
I can't seem to attach files to the chat for some reaso. no option to do it. it says click the plus sign but that just says create another thread
don't blindly believe claude. ask yourself what you need. Do you need each business to also know the outcomes of other business to make decision? then combine 2 agents into 1 as they will share context and memory. If you keep them seperate, you would also need an orchestrator agent which can combine the outputs and make decision. Think in those line and decide what you exactly want as an output objective. as the number of agents grow, orchestrations becomes very difficult and it will be no better than a single agent doing everything. Hence, keep isolation where you need it absolutely.
you can use three backticks (these: ` ) on a newline before and after to surround some log lines. we do not need reams of them! just the bits right when you write a chat message. hoping that you're seeing something interesting in there. It will format like this (my output from the command I asked about.)
$ openclaw config get models
🦞 OpenClaw 2026.4.15 (unknown)
{
"mode": "merge",
"providers": {
"custom-host-docker-internal-9092": {
"baseUrl": "http://ollama:11434/v1",
"apiKey": "__OPENCLAW_REDACTED__",
"api": "openai-completions",
my bet is still that this part is wrong and openclaw is not sending to the right place and/or in the right format -- either it's not getting there, or it is and ollama can't parse it.
{
"mode": "replace",
"providers": {
"ollama": {
"baseUrl": "http://192.168.1.102:11434",
"apiKey": "OPENCLAW_REDACTED",
"api": "ollama",
"models": have also used mode merge. made no difference
what does curl http://192.168.1.102:11434/api/tags return for you from the openclaw server?
well, does it return data? we do not need to see the whole thing. just testing connectivity. should look like:
$ curl http://localhost:9092/api/tags
{"models":[{"name":"gemma4:26b","model":"gemma4:26b","modified_at": [...]
Hey All im new to openclaw and im having issues getting it working on ym remote device (Old laptop that drives my home labs, openwebUI, Home assitance, etc)
Is anyone able to help me set this up?
@main sparrow Also learn about A2A protocol - you can use plugins like this https://github.com/win4r/openclaw-a2a-gateway to get better coordination. but when you get issues, it is kind of difficult to troubleshoot unless you know what you are doing
you planning to run as a docker container?
Rolling back didn't sem to help. I'm on 4.14 now. DIscord bot stop responding for a bit, now just saying "Agent couldn't generate a repsonse". 🙁 I can more logs to thread if that'll help
Hi! I'm setting up OpenClaw with a dedicated Gmail account and want to give my agent access to Gmail and Google Drive. Does OpenClaw have native Gmail/Drive integration, or does it need to be built custom? Any guidance on the recommended approach?
i think the OAuth is just billing its not using the subscription at all
do you already have an experience in using openclaw. If not, I would say try that. Also, I would probably setup a seperate account, then run a job to just copy existing set of email to another email id and then experment there and see does it meet your expections
Created a dedicated email address so Jethro can write to Google Drive files not .md files.
Just trying to simplify my user experience and collaboration
tryed both as docker and just running..... issue is i cant get onto the web ui
Can i DM you so i can share screenshots
show me output of docker logs -f <container_name> just the last few lines shoudl be good
2026-04-21T02:03:59.177+00:00 [diagnostic] lane task error: lane=session:agent:main:main durationMs=6815 error="Error: No API key found for provider "openai". Auth store: /home/node/.openclaw/agents/main/agent/auth-profiles.json (agentDir: /home/node/.openclaw/agents/main/agent). Configure auth for this agent (openclaw agents add <id>) or copy auth-profiles.json from the main agentDir."
2026-04-21T02:03:59.184+00:00 [model-fallback/decision] model fallback decision: decision=candidate_failed requested=openai/gpt-5.4 candidate=openai/gpt-5.4 reason=auth next=none detail=No API key found for provider "openai". Auth store: /home/node/.openclaw/agents/main/agent/auth-profiles.json (agentDir: /home/node/.openclaw/agents/main/agent). Configure auth for this agent (openclaw agents add <id>) or copy auth-profiles.json from the main agentDir.
2026-04-21T02:03:59.185+00:00 Embedded agent failed before reply: No API key found for provider "openai". Auth store: /home/node/.openclaw/agents/main/agent/auth-profiles.json (agentDir: /home/node/.openclaw/agents/main/agent). Configure auth for this agent (openclaw agents add <id>) or copy auth-profiles.json from the main agentDir. | No API key found for provider "openai". Auth store: /home/node/.openclaw/agents/main/agent/auth-profiles.json (agentDir: /home/node/.openclaw/agents/main/agent). Configure auth for this agent (openclaw agents add <id>) or copy auth-profiles.json from the main agentDir.
have you exposed the ports? 18789?
i will be back in 30 mins
yes pages loads but im blocked from loggin in
hi guys can nay one help me i have two differnet auth
antropic and codex openai when i configure using openclaw configure --section model i can only setup one of those
everytime i do something with discord, my openclaw breaks, i try to propmpt my way threw it with claude and i end up reonboarding, does anyone else have problems with there openclaw and discord??
you get pairing error or what error exactly?
if you are getting pairing errors, you need to go to your gateway open command line openclaw devices list you would see a request ID under pariring, use that here openclaw devices approve <requestid>
it gets apended into the .json . In the chat you should be able to select the model using /model <name>
Invalid config:
- channels.discord: invalid config: must NOT have additional properties
│
I need to Google auth every 7 days to use my Gmail etc...
What are you guys using?
I just got a hermes agent to work for my openclaw try to use a two bot system, wanted them to be able to talk in discord
telegram and discord
any one using the claude subscription cli token path for openclaw?
I'm so close to fixing it. I finaly got replies on Discord, but it's coming from the wrong session/agent/whatever.
Any idea why my Agents page is always blank? Has been for weeks.
hi guys can nay one help me i have two
learning openclaw, need help
what is the third box at top left after model selection which says 'default (adaptive)'
$ openclaw devices list
🦞 OpenClaw 2026.4.15 (unknown) — I'm the middleware between your ambition and your attention span.
│
◇
Paired (1)
┌──────────────────┬────────────┬────────────────────────────────────────────────────────────┬────────────┬────────────┐
│ Device │ Roles │ Scopes │ Tokens │ IP │
├──────────────────┼────────────┼────────────────────────────────────────────────────────────┼────────────┼────────────┤
│ 21ec80a55f54cbb9 │ operator │ operator.admin, operator.read, operator.write, operator. │ operator │ │
│ 8d85c200882a0479 │ │ approvals, operator.pairing, operator.talk.secrets │ │ │
│ 19df668147569c4e │ │ │ │ │
│ d86151ec0e2a2c29 │ │ │ │ │
└──────────────────┴────────────┴────────────────────────────────────────────────────────────┴────────────┴────────────┘
Dont think thats it
It would have moved out since it did not get approved in sometime. Open the browser again, put the gateway token and state what issue it is says in ui?
any help please ?
what is your recommendation guys ?
even when i go to it it does not change
you need to add some tool for it to search the web. gpt 5.4 is just a model , setup some search like brave or tavily for it to search the web
maybe you are talking about the thinking?
I cannot help if you don't provide what error you see browser , since you stated earlier that site is opening
but i dont want to pay extra for search is there a way i can use my model to do that ? or is there a free alternative
tavily gives you 1000 credit free per month
How do internal agents communicate with each other?
Via files. But if you want it sophisticated - use A2A protocol - download the plugin
You can run brave or firecrawl docker contianrrs and use that
i want to use groq as a provider but there doesn't seem to be an option to choose groq in the onboarding
what to do?
I need a quick answer please
in the help chat sharing ym screen
but in short it wont let me log in
Give me the link to post - help section is flooded with comments.
Can you not just type here what error it shows when you provide token and enter
can someone please take a look at my question?
Try asking it here : https://discordapp.com/channels/1456350064065904867/1459642797895319552
@wooden coral you are accessing openclaw dashboard from other machine? then use https://<ip address> OR if you are on the same machine use http://localhost:18789 - the error detail is very clear
just saw this in my logs.. is it normal to take this long?
[bonjour] restarting advertiser (service stuck in announcing for 41339ms
It wont let me log in
Sorry for the late reply i got block trying to link the voice chat in this group
Hey all,
Looking for a bit of help getting OpenClaw running properly.
I’m running this on Ubuntu and have tried both a local install and Docker setup. The gateway starts and binds fine, but I’m having issues getting the dashboard/control UI working consistently — it either won’t load or doesn’t behave properly even though the service looks healthy.
I’ve also been hitting issues getting the WhatsApp integration working/reset properly.
So far I’ve:
- Run OpenClaw locally and via Docker
- Confirmed gateway is listening on the configured port
- Set up token auth in config
- Configured allowed origins + tested via LAN IP
Still no luck getting stable access to the dashboard or WhatsApp working.
End goal is to use this to manage my home lab — Home Assistant, Jellyfin, and my NAS (movies/TV shows) — and start exploring what automation it can handle across everything.
Longer term, I want it to actively monitor things and notify me when something breaks, e.g.:
“Jellyfin can’t play movie X because of Y — file needs to be removed. Reply YES to fix.”
So basically automated detection + approval-based actions.
If anyone has a working setup (Ubuntu, local or Docker) or has run into this before, keen to hear what fixed it.
If someone’s able to jump in and help get this fully set up, happy to work something out 👍
Please DM me if you can help.
Happy to share configs/logs if needed.
in your openclaw.json - enable allowInsecureAuth and restart gateway
"controlUi": {
"allowInsecureAuth": true,
next time give the error correctly - it was clearly showing on your dashbord screen
Hi guys and galls. I have an issue where my agent seems to keep working with a "mobile" layout or resolution using the (headless) browser tool. I asked it to "browser resize 1920 1080" but it keeps defaulting to a mobile layout.
This seems to cause problems in a workflow where it can't find element (buttons, fields, etc) which the resize to 1080p seems to fix.
Does anyone of you have any insight into this? Thx!
I asked my agent and it suggested a check after every snapshot the browser makes (snapshot -> check layout -> continue workflow) but I idk if I want that, if there's a hardcoded way to force the agent to resize to 1080 that's preferable I'd say.
hey guys, is Kimi k2.6 from opencode go working for you with openclaw?
I am looking to run openclaw for myself, i have yet to install or configure any of the options
Is this something i can do for free?
I have:
copilot pro (student vers)
Perplexity Pro plan (student vers)
my specs locally are:
64gb ddr5
rx 6800xt
r7 7700x
What would be the right setup, is there a tutorial or something i can follow with good configs, I'm not too sure what models i want to use (also open to more student offers)
any workaround for cluade code subscripion to use in openclaw
hi!
I have Macbook Pro 14 2021 M1Pro 32Gb
I want to use openclaw + ollama local.
I try it but it gets me frustrated... it takes long delays and ollama stops in some time.
I spent two weeks and i am close to quit of it)
Model that I use qwen3.5:4b
I am plan to use it for Web Dev most of time and little for personal.
Any 100% working guides to setup or advice for best setup?
4b model? thats why
4b parameter isnt going to help you anyhow for agentic task
How can i make so OpenClaw doesn't detect Codex? I want to use Ollama models (Also i'm using windows)
I don’t know what you mean by detect, but set the default model to one in ollama and make sure your agents are using the default.
Noob question. I tried to talk to krill bot and it said my discord username is not paired and it says ask an admin of the bot. Which Channel shouldi use to post that?
where did you talk to krill bot? Did you use #1459642797895319552
I installed OpenClaw and it automatically recognized Codex so he logged in and didn't even show me the quick setup
I uninstalled it i'll try to install it later
you just have to do the onabord the configure the model then you will see the model you want
Do you mean your discord bot doesnt answer you or sends a pairing request
Thats correct. Trying how to pair and where to run the command.
Easy in your pc or vps where openclaw is installed
Openclaw pairing approve discord pairing code
No if the bot send the pairing request the discord end is working
Ok. I am still analyzing the correct setup to suit my needs. I don’t have personal laptop and have only work machines.
I am getting this all the time, what does it mean: typing TTL reached (2m); stopping typing indicator
I am bumping my question if that's alright 
- It does not cancel / stop the model request. If the model finishes later, the reply should still be delivered — you just won’t see the typing indicator anymore. ```
https://www.answeroverflow.com/m/1478106641017602242Are you running a local model? It might be working on a reply and timing out the typing event
Hello friends, I am trying to figure out why Google Search Console says "Couldn't fetch" for my sitemap.
My endpoint returns:
- valid xml
- 200 response
content-type: application/xml
What else is even is there to check?
You can try it: curl -v https://www.dailygoal.fit/sitemap.xml
I have tried removing and re-adding it many times, no luck.
See: GSC screenshot
I have also tried their URL inspection tool, which did manage to fetch it, and I clicked 'request indexing', but that has not made a difference.
Additional info:
- It's hosted on vercel.
- I have disabled bot protecion (shouldn't even have to do that but just in case).
- robots.txt is allowing everything
Yea its easy just give it the corrext command : google-chrome --start-fullscreen https://google.com do this by urself and see
Use hybrid local and cloud
You can do that for free
hey all, hope all you'll doing good.
question, I'm running into this this with OpenClaw where I'm writing a skill to pick a date night.
it succesfully picks a selection of possible dates but after sending it to the shared whatsapp group (with my wife and openclaw) things get difficult.
when I reply in the whatsapp groupchat, openclaw doesn't know about the ongoing skill and treats it as a normal message.
how can I get this to behave appropriately? in a perfect world I'd like it to say "thanks for your response!" and then the date gets send back to the skill (thats running in another session) to perform the next steps.
I'm sure this is possible, I just haven't figured out the right way.
Try lm studio les bloated and faster based on llama.cpp
If i get you right your openclaw picks a date based on what ? Your request or cron job
the cronjob starts looking through the calender, picks 3 dates as candidates and send them to the whatsapp group so me and my wife can pick
Okay great now after it sends the dates available you tell it thanks or something it just answers like it did nothing
?
I reply with our chosen date. It should then say 'thank you' and perform additional steps from the skill
You could try with a plugin such as lossless-claw to help context between sessions
ok I'll read into this thanks
i would expect this to be a much more common problem right? I have an agent doing a skill, which needs information and requests that from a whatsapp group, and then it continues it's script
Okay i got what your saying, for best troubleshoot try ask it what was the last cronjob that was triggered when it asnwers tell it what happened no one can help you here but the agent becaude it knows the setup , tell it exactly what you need and ur problem in a new session btw so it doesnt have any context but the soul and memeory, and see in the soul.md if the skill is mentioned because u said skill and cron job
So the workflow must be the trigger -> crongjob -> skill -> proccessed task
i've been talking to the agent the whole day trying to fix this 😀
ideally, the whatsapp group session should get a headsup that the skill is in progress and that when a message arrives confirming a date it should send that to a certain session.
but i'm unable to send messages between my main session and the whatsapp channel
Because the cronjob is a separate session it get triggered by heartbeat and heartbeat counts as anew session what you must do is the cronjob should talk to the main agent yours and tell it to send the data to the session active in the groupchat
Try answering it with enough information to trigger the skill again. That is, think of the reply as coming into openclaw without the previous context -- because it is. The messge sent from the cron job is elsewhere. So reply with "Yes, schedule the date night for April 29 at 8pm at whatever restaurant." and make sure the skill definition says to use it "when the human asks to schedule..." so it will match.
Try to update the system instructions with : When a user mentions a date or choice, check if there is an active task in pending_dates.json you edit the skill to save in that file. If found, use the send_session_event tool to notify the Main session."
also, what model are you using? make sure it is a fairly capable one if you want it to keep all of this straight.
i'm using sonnet
It is capable you just need a little tweak to figure
thanks for the help so far
i'm now trying to get a cron job to actually send additional instructions to the whatsapp-group-session so it gets context
that kinda works, however the agent thought it was prompt injection attack so I might need to tweak it a little bit
Hey guys, just getting started and was wondering if my $20month chatgpt subscription is enough to do tasks like have openclaw scrape linkedin and companies/contact info
Try out and see for yourself. It would obviously depend upon the relative data
Hi guys, my OpenClaw searches for news, but the links it returns are broken, and it keeps forgetting to do it. It always says there was a problem with the latido.md file but that it fixed it. Any reason why this might be happening? I've tried different versions.
I'm only getting HEARTBEAT_OK as a response all of a sudden
if you want it to happen on a schedule, set up a cron job. what tool is it using to search? brave api or ?
what do you expect to happen? that is what it does when it decides there is nothing to do this tick.
Apparently my HEARTBEAT.md decided to empty itself. It's blank all of a sudden. That sure would explain it.
this thing definitely requires discipline with backups! I am tempted to put the entire .openclaw directory under version control sometimes.
Anyone rocking Med Gemma w/ Openclaw? MIne gets mad and just spews out tool thinking text to discord 🙁
Why are you using MedGemma?
Just asking
I want to play with it for ... analyzing my medical records/images, for fun 🙂
MedGemma is just not it, dude
friend posted a CT scan and while qwen 3.6 isn't bad, I wanted to see if Med Gemma was more in-depth.
Don't use it.
yeah open in that I can run it at home
Yeah bro I literally just disqualified myself from working on Gemma 4
hahaha
I've always hated Gemma
that's good to know ;0
I'm basically only able to work on Gemini, it's the only pleasing thing to me
There were some other open ones i've not played with yet, will look into those thx
Try something like uhh
Ermm
Nvidia build
All of the models on there are open
wonder if any will fit on the Spark ;0
Nvidia build is an API
But there are basically NO RATELIMITS
OH, that's interesting 🙂
DGX Spark
Like the NVIDIA spark thing
128G of slow DDR5
Oh, yea
thankfully was obtained via work ;0
Its clock speed isn't THAT bad
Yeah I mostly get all my hardware and GPUs from work
Yeah same as the M4 Pro mac mini, 273 GB/s
I plan to MAYBE put a fourth gpu in the server
before dram/nand gate, the AMD AI 395 MAX was quite a decent bargain
performance is pretty decent for the cost
maybe 80G H100s will come down in price in 10 years? :0
Yeah but in 10 years it's gonna be doodoo
yeap
apparently these might be ok, and qwen-3.6-35b that im already running is 'ok' for med. Meditron-70B, Llama 3.3-70B-MedSpec, Polaris 3.0
Llama 3.3 medspec
not a ton of headroom w/ qwen 3.6 & flux2.klein already running, might have to swtich over to talk to it then back heh
what GPUs do you have local?
NGL Med Gemma was pretty damn fast via openwebui, sad it doesn't wanna work from openclaw
damn that's awful
;0
I'd try to expense one but I don't work on models so they'd prob balk 😉
What does each card pull @ full tilt, Watt wise?

Hold on
Let me check
600 watts pretty sure
Which alone is 1800 watts for the 3 GPUs
So yes I need a poor rural family's electricity
1792 GB/sec vs 273
Yeah they are miracles
you know I should just say yolo and request 2 ;0
Well YOLO
My power bill is already $600/mo in summer 🙁
When I be like 80 or something I'm gonna try the gas station nacho and sushi
Yikes.
Not sure what my consumption is rn
Since I'm doing my business
as they say
ah yeah 🙂
but it probably takes like 50 hamsters to power my apartment alone
Guys I'm setting up openclaw and i successfully got the oauth prompt for chatgpt, I logged in, and it said i could close the tab, and now its asking me to "paste the authorization code (or full redirect url):"
What is it talking about?? I already signed in
to be clear its asking this in the onboarding
Would kill for that price
The tab should have either been errored out (at which point you take the URL that had errored out and paste it there), or It loaded properly after logging in and you would take the code that resulted on the screen and paste that there.
Anyone have a stable model for windows up past 4.1 lol
why i am not able to update openclaw to the latest version, says update blocked reason dirty
"Hi folks, messed up an update path on .20 release. Workaround for OpenClaw 2026.4.20 bundled channel dependency failure:" maybe this is the reason, seen from release chanel
thank you! will look it up
I was able to fix this...but I had to completely nuke my OpenClaw install! I had backups of all my important files, so dropping my memory files and such in the new workspace was no big deal.
I am here
New, and you need model
Yep thats correct
My recommendation... bite the bullet, spend the $20, and get ChatGPT subscription. You can do a ton with it. Have a world class frontier model. And also cheap ass models to do a lot of little things with
Well you know money is a problem thank you for this recommendation best free modal which i can use
Whats your venmo? 😛
Damn you for real
OpenRouter account. Find out whos testing their next model, and try some of the free ones there. But honestly, the results can vary WILDLY
What is openrouter
openrouter is a company that has a ton of different models available. Like the amazon of shopping for models. Expensive, to super cheap
Try something that's currently free, which is usually hammered to death, and often is slow or err'd out. Or something cheap, Like Gemma 4 would be reliable and probably work fine. GLM 5.1 would be good, but more costly.
All of those cheaper options can add up to 5-15/mo depending on how you use it and hammer on it. Which is why I lean towards you getting the $20/mo chatgpt plan, and you have lots to play with, and it'll work way better
Kk but still money is the problem cant spend money on ai my family will kill me for spending money on some piece of software
anyone using kiloclaw for coding?
was wondering how you guys do that,
access github account
how to clone, pull, code, push etc?
Gotta spend money to make money bro. Turn that $20/mo into $1000/mo income. Setup some services for local businesses around you. It's a business expense, a life changing force of greatness.
Well if can tell me how like you even make money with ai like i hear about it a lot people making money with ai if yiu tell me how i can convince my family to spend that money
I helped a buddy of mine do this 5 times last week. Goal of one 'yes' per day. He had a list of 5 businesses for that day. Went to each. In person. No phone call. "Whats your #1 and #2 problem that you have right now with your business". It could be answering phones at night for a plumber. Or a light marketing campaign for a whatchamaker.
My friend does #1 for free using openclaw/whatever tool fits, and if they like it, they're commited to #2 getting fixed for $1k. He had 3 people agree last week. Got a couple grand already.
I'm not saying it'll work for sure. But that's 1 way, out of 10000000000 ways, to use AI right now to make money.
Fake it til you make it bro
Thats a very good advise thanks man i will try this
I am looking to run openclaw for myself, i have yet to install or configure any of the options
Is this something i can do for free?
I have:
copilot pro (student vers)
Perplexity Pro plan (student vers)
my specs locally are:
64gb ddr5
rx 6800xt
r7 7700x
What would be the right setup, is there a tutorial or something i can follow with good configs, I'm not too sure what models i want to use (also open to more student offers)
you want to set it up on pc? then i will suggest docker
Docker? I'll look into that
I wonder I'm running a vps with coolify and it uses docker the openclaw that comes with it is old 2026.2 or something and I try to use it with ollama and I have hooked it up to telegram so far so good but there seems to be a problem with the connection to ollama 🤔 and that openclaw seems to not be able to update so I'm wonder if anyone has done something like that? I would prefer the coolify container because of the setup of persistent data for the configs and the htaccess it puts openclaw behind but I also don't want to have a old version 😅
I tryed many different models from 3b to 32b - situation same. It is working, but in some peripod all just stuck.
I think there some problem this some settings between ollama and openclaw.
I watched all videos on youtube about it, but all videos looks like not deep dive and flow, but just hype.
Hi, since i updated my Openclaw to version 2026.4.20 yesterday, i become in my Discord chat following failure.Any ideas what to do?
⚠️ Something went wrong while processing your request. Please try again, or use /new to start a fresh session.
Which VPS would be a good alternative for my Rasberry Pi? I think th CPU and SD Card speed is a bottleneck. Even with Codex or any other cloud provider, I find it ridicously slow. Sometimes take 2-4 mins just to reply to a "Hi"
OCI
24gb ram, and 200gb ssd for. free
the only problem u will face is the signup
Anybody have any hands on with the dell pro max gb10s?
hi how can i fix this
error: gateway did not start on localhost:18789
Hello, I hope everyone’s doing well. I was given the task of mining Github repositories that had openclaw integrated into them. However, I’m unsure on how to go about doing this comprehensively, since every repository I visit has a significantly different layout, so it’s hard to identify common patterns that would help me shortlist them. I’m fairly new to openclaw so would appreciate any insights on this matter.
I have OpenClaw and Ollama installed to run local models. Until a week ago, everything was working fine running a small model like Llama 3.2:3b. However, since last week, starting the local model via OpenClaw causes my CPU and RAM to saturate completely.
I noticed that when I run it through OpenClaw, it sets a very high context window (131,072), but if I run it via ollama run in the console, the context is 4,096 and it works perfectly.
Do you know what might have happened? I’ve tested this on several machines and even performed a clean format/reinstall just in case it was an installation issue. It seems like an OpenClaw problem where it forces a high context limit, causing the hardware to bottleneck.
I have tested this on several systems; they aren't extremely powerful, but they were working fine until last week:
PC 1: Intel Core i3-6100 (4 cores) with 16GB RAM.
PC 2: Ryzen 5 2600 (12 cores) with 32GB RAM.
The same issue occurs on both, and I am running the installation on Ubuntu Server without a graphical interface (GUI).
same situation for all parameters? cant be the higher parameters will always be slowed. i also have local model setup but with lm studio
setting a higher context widow of 100k is normal actually , 4096 token is nothing nowadays
i will say the minimum context window should be 64k when working such agentic frameworks
After installing the 2026.4.21 update, gateway won't come up. Doctor says:
Invalid config:
- <root>: read failed: Error: Cannot find module 'grammy'
Require stack:
- /home/scotter/.local/share/pnpm/global/5/.pnpm/openclaw@2026.4.21_@napi-rs+canvas@0.1.97/node_modules/openclaw/dist/extensions/telegram/allowed-updates-BD2bJyzD.js
Hi guys, is anyone using GLM-5V Turbo as an OpenClaw model for agents?
Hey everyone 👋
How are you scaling WhatsApp account creation to run many gateways?
My setup: 1 OpenClaw gateway = 1 WhatsApp number, one per client. So every new client means a new number + a new gateway.
Right now I'm already using eSIMs, activating accounts, and spinning up gateways. It works but it's still manual and slow.
I came across Linq (linqapp.com), which looks exactly like the kind of infra I'd want: clean API, no SIM juggling. Problem is it only covers iMessage / SMS, and I'm on their waitlist anyway. I'd love a "Linq-for-WhatsApp" equivalent.
Has anyone here cracked this at scale? Whether it's a specific eSIM provider whose numbers actually survive WhatsApp signup long-term, a BSP / Cloud API setup people actually trust or something else entirely? All input welcome.
Happy to share back what I learn along the way 🦞
4th straight install that bricked my setup. Sigh. Yes, I did openclaw doctor --repair. i always do. always bricked.
how do u guys fix this API service overload error? and what causes this?
Yeah latest 4.21 update bricked mine.
Hi how do I get Chat gpt 5.4 to stop being so lazy and give Outputs Like Opus it feels line no matter what I Hard wire or if I Update Soul I don’t get the Same Results
is it better or worse to just use 1 agent but over multiple sessions or 2 separate agents? Can two agents share the same workspace easily?
I've been using OpenClaw with the claude-cli provider and opus models, this has worked reasonably well but for about the last week I keep losing state in the middle of a conversation. I'll happily be chatting with the agent on telegram and suddenly out of nowhere it will respond as if it had completely lost the plot and stated with a fresh new session (or context from older sessions but nothing from the messages we've just been exchanging seconds before). I wonder if it has anything to do with agent heartbeats messing up the router for channels? Has anyone experienced anything similar recently or found a way to fix it?
I don't think that's the issue here. It can happen in really tiny conversations of just a couple of messages. It looks more as if something is triggering the claude-cli backend to reset the session ID for whatever reason. Logs seems to corroborate this with a SESSION RESET entry at the time the agent seems to lose context, but I can't figure out what is causing it to happen so frequently (many times in a day at random times)
latest version, i am not able to create and connect mcp servers
I’m trying to run a docker sandboxed openclaw instance, and when the workspace access is “rw”, it can’t access any default skills because they’re not mirrored into the ~/.workspace/skills location and it’s sandboxed so it can’t access them from npm, but if it’s “ro” or “none”, they are mirrored correctly but I’m not sure the intended way to complete the onboarding/bootstrap since the sandboxed workspace is also read only. If I’m aware of what the bootstrap steps are can I manually modify those files in the workspace..? Is there a way to seed the “none” workspace with the main already bootstrapped one? Is there a recommended way to get the default skills visible in the rw workspace?
The documentation says the skills should be available there but the bot actually tried to read them from some npm install folder instead which it of course didn’t have access to (sandboxed)
Guys since the update number 26.6, openclaw is not usable for me. A lot of crashes a lot of unstable behavior.
Tried many times to fix it using codex and whatever, still not working what should I do?
It’s pretty much unusable
I can help with that
Looks like there’s a bug for it: https://github.com/openclaw/openclaw/issues/48011
As far as I know I can’t complete the gog onboarding since it needs to store config files in locations that “none” and “ro” don’t allow
I think I can copy that in manually so the only “problem” really is the openclaw onboarding
Good afternoon:
I'm currently using Minimax 2.7 as my solver, but I'd like to step it up a notch, and I've heard great things about Kimi 2.6. What are the main differences between Kimi 2.6 and Minimax 2.7?
glm 5.1 better
hey guys. im very new here . and i have a simple question. i want that in my openclaw are two agents that are working parallel, and i want to chat with them in seperatet discord channels. and 2 seperatet bots. is this possible ? im sory for my bad english, its not my main language.
i guess you can , only if they are aware of each other so they dont overwrite each other's changes simultaneously
Thank you bro. Do you use it from Ollama?
no i have glm coding plan + opencode go plan .
I mostly use glm 5.1 and now the kimi k2.6 and qwen 3.6 max
if you want a variety of top tier opensource model then you can look into opencode go , its around 10$ per month
I currently have a Minimax plan, but I'd like something better—though not as expensive as Openrouter.
I'll check out what plans are available. Thank you very much.
check opencode go plan its 10$
hi guys i have some problems with lcm, it eat up so many tokens every message. any same issue?
i tried contacting krill, but no reply in help thread
Hey — not sure if I’m doing something wrong or if this is a bug, but I’m having trouble with a fresh OpenClaw install (latest version, clean droplet).
During onboarding it keeps crashing with missing module errors from extensions, e.g.:
Cannot find module '@larksuiteoapi/node-sdk' (feishu)
Cannot find module 'nostr-tools'
Cannot find module '@slack/web-api'
Cannot find module '@whiskeysockets/baileys'
It looks like OpenClaw is trying to load all bundled extensions during onboarding, but their dependencies aren’t installed.
I’ve tried:
fresh droplet rebuild
installing via pnpm (with approve-builds)
running doctor
clean config reset
Same result every time — onboarding fails unless I manually install each dependency one-by-one.
Is this a known issue with the current release?
Are we supposed to install extension deps manually, or should these be bundled / lazily loaded?
run this instead of the normal onboard:
bashopenclaw onboard --non-interactive --accept-risk
That skips the extension loading during onboarding. Then after it completes, add the model and channel they actually want:
bashopenclaw configure
Can one help me how do i use clade code cli with ollam models through openclaw
Basivallu using cladu cli as tool
I'll take care of it, bro. Thanks a lot for the help.
through openclaw? you want to use ollama models in claude code or openclaw?
I am currently using qwen for codign but also want to use claude code for handling bigger tasks
there are many tutorial for this on youtube. did you try those?
for using ollama using claude code?
Check this documentation , everything is written here:
https://docs.ollama.com/integrations/claude-code
I can launch ollam a launch claude —model but the i was like how do i integrate this in openclaw
Any help ?
not sure what you mean by claude code integrate with openclaw
honestly i’m done, it’s been 2 weeks trying to get OpenClaw working properly on Windows and it’s a nightmare. i’ve uninstalled/reinstalled dozens of times, changed Node versions, deleted all config files, NOTHING. every single command takes 30-45 seconds minimum, even a simple openclaw configure. i have a Ryzen Z1 Extreme so it’s definitely not the machine. i found out about the Bonjour/mDNS bug on Windows, installed Bonjour, changed nothing for configure. and now i find out there’s also a provider validation bug since 2026.3.28 that destroys startup time. basically OpenClaw on Windows in 2026 is a disaster, bugs stack on top of each other and nobody has a real fix. if anyone fixed this without downgrading please help me out because i’m losing my mind
claude cli
Hey guys, how are you setting up your multi-agent workflows so an agent or cron job or heartbeat can nudge the next agent for continuity?
yo anyone not getting images sent thru telegram on 2026.4.21?
Did you try installing it on WSL2? I would stay away from native Windows, it's not well supported from what I heard.
I'm running it on Ubuntu via WSL2 and it runs great
Anyone figure out this one?
https://docs.openclaw.ai/plugins/skill-workshop
in the CHANGELOG for .21 https://github.com/openclaw/openclaw/blob/main/CHANGELOG.md#2026421
but not in the tag https://github.com/openclaw/openclaw/tree/v2026.4.21/extensions
and not in the NPM package https://www.npmjs.com/package/openclaw?activeTab=code
available only in HEAD https://github.com/openclaw/openclaw/tree/main/extensions/skill-workshop
tried to enable and get "plugins.entries.skill-workshop: plugin not found: skill-workshop (stale config entry │ │ ignored; remove it from plugins config)"
I've made a new install of 2026.4.20 on a Hetzner server, and I was working with Krill yesterday to resolve the dependency issues everyone is complaining about. I can confirm the agent is responding now, but once I log out of the server, the agent stops responding entirely: no replies to Telegram, no cron jobs. How can I troubleshoot this if the connection needs to be active?
For the record, I can confirm I have set up agents on Hetzner before and this hadn't happened, but I don't know if it's because anything changed in the new version or if it's a server issue.
hi, anyone with any idea of adding comfy provider to the openclaw config ?
Hi... Can someone please help me how can i make the Arch setup
I deployed OpenClaw (self-hosted AI gateway) on a $12-25/month GCP VM.
Do you need fullwalk through?
hi, anyone with any idea of adding comfy provider to the openclaw config ?
Hello guys, I feel my agent isn't fulfilling their duties. They get bogged down in problems and don't solve anything. I ask them to keep me informed, but they don't. Do you have any ideas or advice on how to improve this and get them to perform as they should?
Is there any way to complete the bootstrap in the sandbox where the agent can’t modify the files
hi, anyone with any idea of adding comfy provider to the openclaw config ?
docker?
Yeah the docker sandbox
It doesn’t have write permission for the workspace files
If you enable write permission for the workspace there’s a bug (reported and patch submitted a monthish ago) where skills don’t work anymore, so that’s not an option
So I need some sort of hack to complete the bootstrap
if I have been using lmstudio before the official integration, is there any point in doing the new onboarding? i occasionally manually edit the openclaw.json and agents/main/models.json files when I add new models, does that get easier with the official integration? i don't want all my lmstudio models in openclaw
you tried the docker image for openclaw?
anyone running openclaw through claude CLI post their recent policy change?
I had it set up and thought it was working but it was just charging me for "extra usage" and then as soon as I turned that off it cut me off
anyone using omlx with openclaw?
after never having an issue with it previously, after either today or yesterday's update, I am suddenly getting "this channel is not allowed" on my slash commands in discord. Anyone else having that?
What model are you using?
yes you cant use it now
Hey, I created a PR that fixes token / cost usage dashboard that was previously showing No Data for multi agents setup.
What is the process like for getting a PR approved?
Do I need to provide some human proof or the likes?
Tag someone?
Is there a better channel to talk about this?
Hacker news reported it.
Okay so it seems you can now authenticate using CLI but it still charges you as API usage which is pretty fucking non-news to me.
Correct that was back in early April that they started really enforcing their policy / terms of use.
there was news today/yesterday that they were changing their mind on this
no use on having claude subsccription any more for openclaw
Link? The latest news was about kicking the $20 plan out of Claude Code CLI entirely. They were testing a new pricing page and it caused a big uproar. That they have walked back for now. But I’m sure it is coming.
$20 is not even doing much use anyhow now lol opus just burns in 15-30mins
No, I’m running openclaw bare metal
The sandbox uses docker by default
For the sandbox
hi frens. since krill is taking a sabbatical, wondering if anyone could help me. having issues with openclaw not being able to have full access to the browser tool.
‘playwright is not available in this gateway build’
playwright is installed. the browser tool is enabled and active. is this something i missed in the daemon config?
Anyone want to have a look at a project im working on for the construction industry?
Im using it to build and maintain a database that I previously used VBA coding for and tendering projects.
Looking for some guidance on memory, model routing, and assigning skills to dedicated agents to handle the process
same as @valid maple here, "Browser act commands don't work — needs full Playwright package installed on the gateway for click/navigate actions."
it broke after the latest update
interesting. so it was working for you before 4.21?
yep, i had 4.15 and updated at around 23 utc , crons were running fine before that
https://github.com/openclaw/openclaw/issues/70323#issuecomment-4300870685 looking into this atm
yea so i had an issue with it too. but it does work with claude cli with your subscription. if your running a VM like you should with openclaw. then you would ssh into the vm install claude. then you can open it and have it do the work for you. my issue i had the old api key trying to take over the session and it kept telling me i was out off usage. so we removed every model and added the claude.cli and it used my oath and it worked. it's using my subscription and not the api billing.
I need help setting up openclaw on my mac can anyone help?
Hi, I have Gemini pro on my google account thanks to my university edu email. Can I use this pro on openclaw to use gemini 3 pro without token limits?
no, you need API access
damn
if you want to play around with openclaw, sign up for openrouter and try out their free models
I immediately hit token limit
I need help setting up openclaw on my mac can anyone help??
Anyone know how to set a history limit in open claw? My token usage claims with every single interaction.
Or is there another setting I should be looking for?
how? I get this "⚠️ API provider returned a billing error — your API key has run out of credits or has an insufficient balance. Check your provider's billing dashboard and top up or switch to a different API key."
cleaned out old API keys and everything
if "Extra usage" is turned off it straight doesn't work
I received that message the other day and needed to stop and start open claw multiple times for it to clear
using CLaude CLI with subscription?
Hhmm… I am using Claude and an Api key
I need some help with the auto start. I always need to open the Ubuntu terminal and type OpenClaw to boot it up. Any way I can make it auto run? So, whenever my PC turns on, it'll boot up auto?
claude had to do alot of changes, so if you run claude "on the same location as your openclaw" so it has access to the files. then i told it i want to use Claude cli on openclaw then i pasted this url https://docs.openclaw.ai/gateway/cli-backends then just kept testing until it worked, im using my subscription and not api, And it's the way anthropic wants it hooked up
I need help setting up openclaw on my
My claw likes to forget to follow up on stuff, I'll ask it to do a search, it'll respond saying it's gonna search, and then nothng. Most of the time if I'm waiting for a follow-up, it never comes. I have to re-prompt it to get the answer.
What model are you using?
has anyone used docker desktop?
Nemotron
How do I code here like use agents/ login for free
With Nemotron? You can use a free access point for Nemotron through OpenRouter
Which one? 30b or the big one? I ask because This tends to happen with less capable models and you can try to fix it by writing in SOUL.md to not promise what it cannot do in a single turn, always do any tool calls before answering, etc, etc.
I'm using the Nemotron Super. I could try out some different models, see if I get better responses, too. OpenRouter is great 😄 heh.
Hm, I would think the 130b model would behave better. Try that in SOUL.md anyway — and tell it what it’s doing wrong and ask it what it thinks will help.
Great advice, thanks. I'm so technically focused, I forget to just...tell it what to do! You know what I mean?
I did spin up ana agent and tell it to fix the other broken agent. That worked! heh
I use Gemma4:26b local which needs a lot of care and feeding. Claude Opus helps curate very specific instructions for it, then it mostly behaves.
I would love to be running fully local. I switch between local and cloud models just because of hardware limitations.
Yeah… it’s not free. I feel it in the electric bill, that server doubles as a space heater!
I'm sure it is! But having control of all of it yourself, plus other homelab projects, is worth it. If you can afford it, anyway.
It has been a learning experience. Can confirm that video drivers on Linux are almost as fun as printer drivers used to be! It was all gibberish at first and amazing when it started to actually work.
I also just switched to CachyOS about two months ago. First time I've daily driven Linux in over 10 years. Lots of new stuff going on.
How is Gemma4 going for you?
I’m happy with it. Nothing complicated, summarizing web searches and yelling at me about my Fitbit stats. Simple tool calls, no coding or complex multi-step workflows. I’m going to try having it pick up tasks from an issue tracker. We shall see.
I’m using Google Antigravity Auth but right now im getting this error UI Chat.
Cloud Code Assist API error (400): User location is not supported for the API use.
location: canada
What’s the issue behind it?
Very cool! I've got Gemma4 running through Ollama on my MacBook, but I've yet to try it.
Yeah, I'm getting a lot of stuff like this: I'm on it! Let me do a search and summarize what I find:....and then it never responds witih the results
or anything that necessetates a follow up response, really
Is there anyone here who has used Terraform to deploy OpenClaw and would be willing to swap notes? I have a project I'm working on for reusable deployment and I would love to chat with someone who has done anything similar
I've done it successfully for Hermes already but I haven't actually done it yet for OC, haven't tried it yet since I have 3 agents right now
It just keeps following up with some equivalent of
"You're right. Let me now do the search and let you know the results"....
But still never does it , over and over in a loop
My dude is losin' his mind
Suggest deploying via docker or k8s . Then you do not need terraform. OR your exisitng terraform to create instance can be seperate
Is it me I tried it with Kimi-K2.5 but openclaw seems to be very dumb 😅
Getting stuck in a loop trying to change a config
(adding Approved models to the models array)
Hey everyone 👋
Issue: NemoClaw sandbox cannot reach AWS endpoints (proxy restricted)
Setup:
AWS EC2 → Docker → OpenShell (K3s) → NemoClaw sandbox
Goal:
Run AWS CLI commands from inside the sandbox (e.g., CloudWatch logs)
Problem:
- Sandbox only allows outbound via proxy: 10.200.0.1:3128
- Proxy allows only inference.local (Bedrock via BAG)
- All *.amazonaws.com endpoints are blocked
What I tried:
- AWS CLI installed in sandbox
- IAM credentials injected
- Squid proxy on EC2 host (not reachable from sandbox)
- Bedrock works via BAG
Questions:
- Can OpenShell proxy allowlist *.amazonaws.com?
- Any network allowlist / proxy config available?
- Has anyone enabled AWS CLI access from sandbox?
- Should AWS actions be done outside sandbox (gateway/tools)?
Happy to share configs if needed. Thanks 🙏
Hi chat gpt 5.4 feels lazy in comperison of opus how can I give it a bit more motivation to walk on its own legs I tried cron jobs I tried always on 2 monitoring each other a drill Sargent but nothing really works like opus just did the task and finished it I’m missing that from chat gpt5.4
I’ve set up multiple main agents on the same OpenClaw instance. Is this a good approach, or is it better to keep them as permanent sub-agents under one main agent? In your experience, what works best?
Hey. Can I make cursor integrated with openclaw? Any chance someone can reply?
So I build in cursor but use openclaw as a governing brain for that cursor software?
Cheers for anybody that can help
How do you guys use Claude with Openclaw?
The Claude CLI option doesn't feel natural to me. Does anyone else feel the same way?
Hi everyone! I'm trying to build a powerful SaaS app using Openclaw, but I'm having trouble. I've tried more than six times, and it's deleted almost everything. Can anyone help me?
why even use openclaw for coding?
Because I have zero technical knowledge, haha. It doesn't require any coding—it would be like a software system involving several agents—but I don't know which agents I need or how to connect them. I have the idea, but I don't know how to build it.
why not use claude code / opencode etc? those are meant for coding
Hi! I'm using openrouter/tencent/hy3-preview:free as my primary model. The model supports reasoning: {"level": "high"} via OpenRouter API body parameter. Is there a way to configure the default thinking/reasoning level in OpenClaw's openclaw.json, or will this require a feature request?
hi guys - since the new beta, anthropic models work perfetly again?
Actually, I don't think it needs to be programmed. My idea is to feed it some inputs and have it generate outputs as needed. Those outputs will change based on the software's results. To put it simply, the outputs will improve on their own.
Hello! I successfully set up the Google CLI in OpenClaw, but I'm getting a 403 error (Google Cloud API not enabled) when trying to use it. I read somewhere that OpenClaw's CLI integration is currently enterprise-only. Is that true? Is there any workaround for personal users to use the GeminiCLI with Claw? Thanks in advance!
then look into hermes
if you want self improving
gemini cli is crazy slow if you want to use it with openclaw (assuming you want to use 3.1)
What I mean is that if the software gives me some results, I need to copy and paste them so I can improve those results.
Thanks! I've been on the free 200$ Gemini API, but since I have a Pro account, I want to integrate the CLI into OpenClaw mainly to utilize my Pro account's monthly free limits.
So, I'm still completely stuck on how to actually configure the CLI into OpenClaw. If anyone here understands how this works and could tell me how to resolve this 403 error, I'd really appreciate it! Thanks!
just asking are you new to this whole thing? why would you need to do that?
I'm new to OpenClaw, but I run a digital marketing agency that specializes in Meta Ads, and I want to build something really powerful. I'll use it both internally and to upsell to my clients.
Actually OpenClaw does that better
Basically, I'm really creative and have lots of ideas, but I don't know how to bring them to life, haha
Well that's what OpenClaw does
I mean that's the whole point: an AI agent
Different than just an agent that requires human input to do something, it can stay proactive
Yeah multiple subagents works fine. I only talk to the main, router/dispatcher agent and I have a bmad software factory agent team that he run for me
I mean, I have five main agents, not sub agents
Each main agent for specific tasks
Is that good workflow or should I have only one main agent with sub agents under him?
But the problem is that I don't know how to build the tool hahaha
HELP: Looking for anyone who have a dual machine setup with OpenClaw on one machine, and connecting to Ollama for local LLM's (perhaps through tailscale) on a second machine.
Please tag/ping me if you have experience with this.
brainstorm with your agent and get it to ask you questions. im sure you can come up with ideas and then let your agent build it for you haha
What tool?
Thank you all so much for your help!
It's something I've been thinking about. If I can figure it out, I'll post it. Haha
Is your issue connectivity? If so, I used Tailscale so I could easily use a terminal and file explorer on my windows box and my android phone to connect to/control the linux mint laptop I have OpenClaw running on.
Interesting, is there a write up of how you’re using bmad with openclaw?
Not that I know of. I've just pointed my main agent at the bmad GitHub and other sw factory docs and told him to copy everything needed. Bmad agent personas. And I added lots of scripts and workflows from elsewhere
I'd ask my agent to write something but it managed to crash itself fiddling with the update and I can't fix it until I get home in two days
I'm agent less. Already feeling the withdrawal
I haven't tried it but as long as you don't have issues, should be fine? I think you'd have maybe process issues organising the work, not OpenClaw issues per se.
anyboy else had the problem of not getting a reply from the chat bot (in the OpenClaw browser dashboard)?
fresh install, free OpenRouter API.
better than claude code?
the free openrouter wont work . i also faced this. switch to some other provider
ollama cloud
Thank you, @strong ferry
try opencode go or nvidia nim
opencode go is paid use opencode zen
I had this a lot on discord recently, agent said it was gateway config issues that OpenClaw doctor would fix. I said yes run that then my gateway crashed and I can't fix it rn. Sad
for 10$ its giving a lot so thats why opencode go is worth. who knows when they will increase their prices like glm did
imma talking bout people who pay shit and want free apis
groq is also good ,only it has a daily and per minutee token limit
Potentially, yes. It depends on how you manage the AI, not just the AI
Nope. The issue is actually accessing and using the locally hosted LLM models from Openclaw, through tailscale and on to the machine that hosts the local LLM models.
As an example, I can tell you I tried qwen. Qwen is a thinking model by default, and I see no way of turning it off.
When I use curl commands from the linux server hosting the openclaw installation, it works perfectly. When I use it from withing Openclaw, I get empty replies back, no matter WHAT I've tried to set up in openclaw.json with thinkingdefault: off, reasoning: off etc etc.
So everything essentially works - except from within openclaw when agents try to connect and use it. Tried both with openai's /v1 configuration.. and as reference/api config
So I'm looking explicitly for someone who actually has a setup like this working
Since 2026.4.21 update, my OpenClaw won't work. I see the issue is documented on the repo and Peter (or his proxy) even addressed it with some kind of change to 4.21 that isn't reflected when I bash openclaw update. He said for that, have to wait until next version releases. Is there another way to get that fix so I can get my claws back up?
Restarted systemd service: openclaw-gateway.service
Invalid config:
- <root>: read failed: Error: Cannot find module 'grammy'
Require stack:
- /home/scotter/.local/share/pnpm/global/5/.pnpm/openclaw@2026.4.21_@napi-rs+canvas@0.1.97/node_modules/openclaw/dist/extensions/telegram/allowed-updates-BD2bJyzD.js
│
└ Doctor complete.
Roll back to 4.20 🙂
How? Is there command for that?
npm i -g openclaw@2026.4.20
Thanks!
If installed with npm
No problem!
scotter@Luna:~$ openclaw --version
OpenClaw 2026.4.21 (f788c88)
scotter@Luna:~$ npm i -g openclaw@2026.4.20
npm warn deprecated node-domexception@1.0.0: Use your platform's native DOMException instead
changed 454 packages in 8s
82 packages are looking for funding
run npm fund for details
scotter@Luna:~$ openclaw --version
OpenClaw 2026.4.21 (f788c88)
@dense sleet it didn't seem to take
yeah i agree its the harness but i wish anthropic didnt restrict on openclaw
With coding, I find that GPT 5.4 High and xtraHigh excel and do just as well - sometimes better - than the latest Claude models, at least in the harness I use; Kilo Code. With OpenClaw, I use GPTs for high-end tasks and MiniMax M2.7 on their $10 plan (1500 requests/5 hour-reset) has worked great for the rest!
Hi everyone,
I'm running the latest version of OpenClaw on my VPS. Yesterday I added Ollama Gemini 3 Flash Preview as a model.
Whenever I try to actively use Gemini, I get the error:
"Invalid function call signature: parameters do not match schema"
I couldn't find any solution using the search here.
Does anyone know how to fix this or what might be causing it?
On paper those GPTs are expensive (a bit less than the Claudes) but in operation, very efficient and proving for my purposes to cost about 1/3 (on avg) as much for similar tasks.
same i also use openclaw with gpt 5.4 now only and its quite good with models from opencode go as fallback
kilocode? is it better than opencode or claudecode? never used it so no idea
KiloCode is a fork of CLine, a free VS Code extension, not a CLI like Claude Code. So yeah, you have tabs to your files that show the code you can edit yourself, etc. Not sure if you have played with those kind. The first was Shithub Copilot back in 2022.
BUT KiloCode has also made a CLI version based on OpenCode, as well as a beta of the more graphical one I prefer (mentioned above) that is based on OpenCode. THAT one is in beta right now.
They were somewhat parallel and nearly identical to Roo Code (I used that for 7 months) but Roo dropped out of the race.
when you say graphical one , you mean the comfy ui style feature? i still have cline installed in vscode and saw it 2 weeks before but didnt use it
Not experienced enough with comfy ui style to say. I'd paste a screenshot in here but doesn't seem possible.
You say you still have cline. Just take a look at it.
Same style UI (almost identical) to all the early coding assistants.
i kind of become dumb when i see such comfy style ui , same happened with me when i tried to use comfyu ui for first time
Sadly (not for you), CLI-style (pure terminal-like) is probably the future because it's far more friendly to agents.
Ah I got it working by using the pnpm method. Thanks for the help, esp the idea to fallback to older version!
Hi, after i got the message „Discord inbound worker timed out.“ , my discord gateway stopped working. It doesnt matter what method I am trying it wont come back online. I even updated openclaw, restarted gateway, changed bot token and restarted my machine, nothing seems to be working.
Real
But I get them
Using the Oauth causes users to use way more than 200 usd in usage for only 200 usd
Meaning they lose
"discord does not support guided setup yet." ??
Could use some help:
Fresh Mac mini install (M4, macOS, Node 25, OpenClaw 2026.4.21). Getting "scope upgrade pending approval" error that blocks write access. Gateway runs fine, Telegram works, but dashboard shows read-only capability. Pairing flow seems to have a chicken-and-egg problem — need an approved device to approve devices. Currently using launchd workaround. Issue documented at ~/.openclaw/workspace/command-center/GATEWAY-SCOPE-ISSUE.md. Is this a known bug or missing config step?
this is hard to setup, I tried openclaw, jeriko and hermes, so far jeriko and hermes are the easiest to deal with
Hi i dont get it. I even tried to set this up with openrouter/auto and i cant get it to work. The remote pc and the mac studio dont respond to openclaw. I can get them to work via curl i terminal but not with openclaw.
-
Orchestrator (Mac mini M4, 16GB)
- Ollama: Gemma4:E2B
- Role: Task decomposition, routing, coordination
- Endpoint:
http://localhost:11434(Ollama default)
-
Worker Alpha (PC with RTX 5080)
- Llama.cpp:
http://192.168.3.3:8080 - Model: Qwopus-GLM-18B-Healed-Q4_K_M
- Role: Fast inference, web scraping, initial analysis
- Llama.cpp:
-
Worker Beta (Mac Studio, 64GB RAM)
- Llama.cpp:
http://192.168.3.120:8080 - Model: Qwopus3.5-27B-Q8_0
- Role: Deep analysis, synthesis, complex reasoning
- Llama.cpp:
This would be my setup, any general hints how to set this up? Thx!
openclaw devices aprove --latest
hey everyone — been using openclaw for a few months and loving it so far. but I keep hitting the same wall: the moment I need to coordinate something with another person, I end up being the middleman again. my agent can prep everything but I'm still the one sending messages and relaying replies back.
I am curious if others hit this — do you find most of your agent use is single-player? or has anyone actually figured out how to close the loop when another person (and their agent, if they have one) is involved? I also came across ClaWeb and AgentMail in my searching — has anyone here actually tried either?
Get them to share a memory file that they update regularly and pull from github
Man oh man.
I have been trying to get openclaw to review vtt transcripts from zoom,
and create minutes from meetings , with a template for formatting on a google drive , via gog.
I generally use openrouter, but it doesn't seem to matter what model, the results are shit.
Is there a workflow here or skill that I might not be thinking of?
I found that - somewhat like other harnesses I've plaed with - OpenClaw seems to work better (for me it does) when I tell it certain things more than once, in more than one file. Much duplication between HEARTBEAT.md and AGENTS.md, for example. Also, I use thing to emphasize or key a lot. From time to time, I also will have high-end models with extra high thinking turned on assess those files and skills files for efficacy.
yeah that's a great point. I have spent zero time trying to customize and of the mds. I have spent far more time on the container and model environment and have just relied on it committing it's own memory md's and on prompting.
What are some good ways to remotely monitor multiple OC running on their own VPS? I've built simple monitors that run OpenClaw Health --json but it is extremely slow.
I'll start refining parameters
Maybe asking their agents to check the status
I am struggling to setup openclaw on a GCP VM to use the Vertex AI linked to the VM via ADC. But it can't find it automatically and there is no option to pick that when I setup the models in onboarding
There are commercial products that do this well, it isn’t a trivial problem. What models are you using, what size context window?
they can be a lil gnereous ehe
deepseek 200k v3.2
I think I will try and chunk first
Hey everyone, I am a researcher working at Gravity, looking for individuals who use/employ AI agents at your workplace. I would need only 5 mins of your time. Feel free to dm me or reply to this message if you are interested
I am connecting to my Openclaw instance through rest SSE and when it delegates to a subagent ti closes the connection right away. the subagent response isn’t being passed back to the main agent before closing and this is making it so that the web interface I have is receiving the delegation message and I have to re-query if the subagent is done over and over again. Is there a planned fix for this? It works fine in slack. But my client requires it be accessible through an embedded webchat interface.
Is there an option in openclaw onboarding to specify vertex AI model via ADC?
Does it expose an API?
Try "Custom Provider"
A2A protocol
If you have a coding agent like Gemini cli or claude cli you can ask it to configure all if that for you.
````openclaw plugins enable tokenjuice` lets you use tokenjuice to reduce the tokens used for tool calls.<-- announcement,Plugin "tokenjuice" could not be enabled (blocked by allowlist).```
L M A O
We use it pretty heavily since i introduced it to workplace slack, what questions do you have
I have a 5 min survey that you can fill, can I dm you?
I tried with zoom too their api was on the paid plan, had to switch to fathom for more flexibility, they have webhooks so after the meeting your agent knows right away that you just got off and with fathoms api it gets full context.
Now THAT is interesting.
I am using the paid plan, I will look into the api angle
I had just been providing vtt's
Also i stopped using gog its pretty annoying that i have to authenticate every single time defeats the purpose for me, instead i created a credentials keys directly from google console so my authentication is long lived and doesn’t expire every other day
I guess the aim is to reduce the amount of manual work you do so it only makes sense your agent is able to access all the information it needs.
it was finicky, but gog works with a personal google drive, as well as a business workspace account for me now.
I think a lot of my issues are session related. I was trying to use one thread for minutes, I think I need a new thread each time, or specific prompting to forget previous month ids etc
I'm digging into the api/webhook angle now though. That saves me steps, and perhaps I can get a consistent outcome .
refresh token saved in persistent gog config dir
GOG_KEYRING_PASSWORD set
Thats cool
Try using one of the free models directly instead of OpenRouter/free. Nemotron Super/Nano, Trinity Thinking, Qwen's free offerings
In OpenClaw , select OpenRouter as your provider, and under the models list, choose a free model directly instead of the /free endpoint @past gull
Free and small local models are great for keeping your rate limits in check
Combine them with your paid options
@wraith seal I tried med gemma with like 100 MRI images and it kinda choked said nothing wrong, Qwen 3.6 accurately identified the issue(s) 🙁
I don't know about the free openrouter tho, there are limits included. Best advice is to go for paid option (pay per use) maybe, then choose a cheap model (better for testing), once you're ready to scale you can now choose your preferred model (claude Opus, GPT, Kimi, GLM, etc).
You might want to try AIsa for that, has cheaper models compared to openrouter and no markup fees, and their dashboard features looks good too, you can easily navigate it
Anyone with a decent ai agent assistant setup that can help me with some content Creators' research please? I apologize for spamming this msg but it's really really urgent
why not use the deep research in most ai chatbots? or use something like manus , genspark etc
The Gemini one is so so dumb
Like every other deep research thing js hallucinates
look into manus genspark skywork etc
manus is a joke
Thank you!
I will try that as well, thank you!
I too am having issues getting follow up messages from OpenClaw right now. If I ask it to do something, it'll tel lme "yeah sure, lemme do that" and then never do it or respond. It did get better with a model switch, but that clearly isn't the only issue.
OpenRouter's free endpoints are the way to go for that kinda stuff, no doubt. Just make sure to turn off OpenRouter/auto in your OpenClaw config, otherwise you'll end up spending tokens accidentally!
@steady sorrel have you had any luck with GHL and open claw? This is what I need to do
the free models work for you? i always get the provider not found error with free model with openrouter free models
Been using them for a long time now
In openclaw config, select models, select openrouter, give it your API key, and scroll the list of models for the free options. I don't use the openrouter/free endpoint, as I've not had great luck with it. I go straight to the free model. I'm using Nemotron Nano and Super now.
those doesnt work for me. same with all the free models
sad
hmm, that's odd! You can't select this model?
google/gemma-4-31b-it:free
or
nvidia/nemotron-3-nano-30b-a3b:free
i can select but those doesnt work
I'm playing around with inclusionai/ling-2.6-1t:free today too
That's odd. I can confirm for you they should work. I do it every day.
Time to ask OpenClaw to fix itself @strong ferry
Legit might fix it
heh
the thing is its not for just openclaw , i also tested it with postman and n8n and same there
The resource you are requesting could not be found
No allowed providers are available for the selected model.
how do we put GPT5.5 on our lobster?
hello just wondering for everybody using openclaw fo ra long time nnow. how are you guys using you ropenclaw or what are your most insane use cases?
Pregunta para copiar y pegar:
───
Hi! I'm using OpenClaw 2026.4.11-beta.1 with openai-codex/gpt-5.4 via ChatGPT OAuth.
The status always shows 200k context window instead of the documented 272k or 1.05M.
I checked the source code and found:
• OPENAI_CODEX_GPT_54_NATIVE_CONTEXT_TOKENS = 1050000
• OPENAI_CODEX_GPT_54_DEFAULT_CONTEXT_TOKENS = 272000
• But the model falls back to patch?.contextWindow ?? 2e5 (200k)
I tried:
- Adding contextTokens: 1050000 in agents/codex/agent/models.json → OpenClaw regenerates the provider with models: [] empty
- Setting it in agents.defaults.models["openai-codex/gpt-5.4"].contextTokens → no effect
- Removing managedBy: codex-cli from auth profile → no effect
Questions:
- How can I increase the effective context window for openai-codex/gpt-5.4?
- Why does buildOpenAICodexProvider() always return models: [] empty?
Thanks!
Lol... Somone have answers for context window oauth codex
Fascinating! Have you ever bought OpenRouter credits?
yes around 100$ i guess
i need to add more?
Very strange....I wish I could help you. I'm running an OpenClaw agent on Nemotron Nano for free via OpenRouter right now
150$ and now 99.29 remaining
Oh no, you only need $5 in the account to get an API key
maybe probably a lot of guy exploit the free tier in india lol. maybe its our region
i use the opencode go subscription now. its cheap 10$ per month so its doing great but wish i could use the free models on openrouter
Only $10 for OpenCode stuff? How are the usage limits? That seems like a great deal. I just started using the OpenCode app anyway.
here
you get all the top tier oss and chinese models in this plan
i use glm 5.1 and kimi k2.6 a lot from here
how to add gpt 5.5 on openclaw via oauth guys? can anyone help?
Oh wow, they have MiMo! I'm in
I used the test versionf of MiMo for awhile. They were called Hunter and Healer
i didnt use mimo yet till now. was using only glm 5.1 coz for me its quite good
can anyone help on how to add gpt 5.5 on openclaw via oauth?
Anyone available to answer a few questions for a new user working with qwen3.5 4b and openclaw? I’m experiencing stalling issues and gateway errors it seems like
I do not think a 4b model is going to work as an agent. Maybe for specific tasks.
Hello guys whats the best search provider?
Dunno about best. Brave works fine and provides sone free usage.
Hey all, have a config that is working for me except for one thing, whenever the agent spawns async tasks and encounters an error it will que up tasks again and await user input. However, the as soon as the qued up failed results come back to the session it stimulates the agents turn again and the behaviour loops forever at this point.
Is there some common knowledge on task/agent debouncing I am missing?
I was using duck duck but well i guess i will use Searxng
Has anyone else had this issue:
*****)"}```
Not sure why it keeps happening with all the cloud models I try, especially since I haven't reached a rate limit..this thing kinda happened to me in GPT
If you use GPT CODEX and change accounts after hitting limit it will still say
"you hit the limit" but when you refresh the message of the agent will show up
Probably the openclaw files doing that but the message is going through but thats just my guess it can be or cannot be the issue
hi guys, i am having problems navigating on remote browser. keep getting this error:
2026-04-23T22:32:22.465+00:00 [ws] ⇄ res ✗ node.invoke 645ms errorCode=UNAVAILABLE errorMessage=INVALID_REQUEST: Error: Playwright is not available in this gateway build; 'navigate' is unsupported.
Install the full Playwright package (not playwright-core) and restart the gateway, or reinstall with browser support.
Docs: /tools/browser... conn=7065702c…7226 id=f9073cdb…fee4
2026-04-23T22:32:22.472+00:00 [tools] browser failed: INVALID_REQUEST: Error: Playwright is not available in this gateway build; 'navigate' is unsupported.
Install the full Playwright package (not playwright-core) and restart the gateway, or reinstall with browser support.
MedGemma is bad
I'm using Discord as a gateway and I love that I can have different context windows by utilising separate channels.
I was wondering if you can do the same with different models or even provider backends (openai / gemini / claude, etc) and have a different model or provider for a given channel?
Yep you were 100% right, it literally just kinda shit and only produced a small incorrect summary lol
Looks like you need to install playwright-core
Is it normal the new version everytime i talk to my openclaw he gets a bootstrap message and reads all the bootstrap?
imagine using it in real world scenarios
"Doesn't look like cancer, go ahead"
ehh??
it should delete it after
Please let me know if its intended or its a bug lol
I mean it gets sent bootstrap message which tells him which files to read
And its everytime i talk to it in whatsapp
so that's not normal
It started happening since i updtated
well uhh
on boot i can see on log:
2026-04-23T22:07:55.241+00:00 [plugins] browser installed bundled runtime deps: @modelcontextprotocol/sdk@1.29.0, commander@^14.0.3, express@^5.2.1, playwright-core@1.59.1, typebox@1.1.28, undici@8.1.0, ws@^8.20.0
So lol uh should I fix this or what
Guys any reccomends on a desktop control on skills i tried gui control its working but is not that good any reccs?
revert
If ur on win do windows control skill
arch linux to my sadness
I guess you may need the agent put pieces togeter and build it own skill if it got some cpable llms models tell it to do research and build the skill

archie
also, @spare shard , what display protocol do you use?
and also, what wm/de?
Gnome probably it is the norm
okay, cool
display protocol?
think x11 or wayland
i keep getting: Install the full Playwright package (not playwright-core) and restart the gateway, or reinstall with browser support.
no way out of this
it is installed
found this bug. maybe its the same prob:
https://github.com/openclaw/openclaw/issues/50717
Good evening together. I have a question about the integration of a local Model. It was all pretty easy to configure, exept one thing.
Openclaw dont parse the Tool usage. I tried documents, huggingface's jinja file like it is, reformat for Ollama , KI Help and so on... and i am frustrated now for 2 Days trying this.
The Setup it self was pretty easy. I use the openclaw docker container from alpine/openclaw:latest (2026.something) with Ollama local as provider and the Model from huggingface
Qwen3_4b_Q8_function_calling_pro.gguf based on the 2507 intruct model.
But everything i try results in errors (format) or he just send me back the json string as a chat instead of skill usage.
Has anyone a working TEMPLATE """ ... """ to communicate with openclaw in the right way and can help me?
or did i something miss in openclaw or any hints.
No, i can't use a CloudModel. I am poor 😄
Thank you for your Support
All I do is ollama pull <model> and then configure it in OpenClaw. I suspect a 4b model is going to struggle with acting as an agent though.
thank you for your answer, but that wasnt the question. I tried also a Llama 3.3 8B Model. i dont own an AI Server , i have to use a model for consumer hardware.
sounds familiar, my experience with qwen3.5 was xml leaking, it feels like parser issue , you have to specifically appoint the parser to the model. and ollama is supaer slow with mac, i changed to mlx.
rapid-mlx serve mlx-community/Qwen3.6-35B-A3B-4bit
--port 8900
--served-model-name qwen3.6:35b
--enable-auto-tool-choice
--tool-call-parser qwen3_coder
--pin-system-prompt
--max-tokens 4096
--timeout 300
i am no tech person, did everything using ai, so can't guarantee you.
Can a admin reach out and tell me why i was muted as all i did was ask for help which i thought was one of the reasons for this group
you should of got a DM saying why that happened
I’m having the same issue, were you able to resolve it?
tavily , 1000 free credit per month
llama 3.3 in 2026 is crazy , use something new and better like gemma4 , qwen 3.5/6 , glm 4.7 flash etc
Can I get open claw on my iPad Air 11
nope just tells me i got muted
hey guys just owndering if naybody got a way or a repo on how i can actually talk to openclaw more than just one chat interface? sorry i dont kno how to set it up i got to do it with hermes but ive been using openclaw for months now and i dont want to stop using it if possible
it was probably from saying a naughty word

OpenClaw
every interface you can set up
thank you so much!
Does anyone know if there is a real benefit to using Codex Harness?
One benefit I know is that I can use the latest GPT-5.5 without waiting for an official OpenClaw release, but other than that, does it improve anything? When should one use it?
Gateway multi channel is the right pattern, worth noting that if you run the same agent on different interfaces you probably want separate memory scopes per channel otherwise conversations start bleeding into each other.
Not sure who might be interested but, I filed three bug reports related to remote Ollama setup on v2026.4.22:
Beta blocker — 9b garbage output under full agent system prompt
https://github.com/openclaw/openclaw/issues/70975
Beta blocker — ollama-provider appends /v1 to baseUrl in models.json
https://github.com/openclaw/openclaw/issues/70979
Remote Ollama autodiscovery impossible — schema contradicts docs
https://github.com/openclaw/openclaw/issues/70982
All three have full reproduction steps and logs. Happy to provide more info if needed.
Hey admins — please don’t mute me again 😅 I’m genuinely trying to get this working and looking for help.
Hey all,
Looking for a bit of help getting OpenClaw running properly.
I’m running this on Ubuntu and have tried both a local install and Docker setup. The gateway starts and binds fine, but I’m having issues getting the dashboard/control UI working consistently — it either won’t load or doesn’t behave properly even though the service looks healthy.
I’ve also been hitting issues getting the WhatsApp integration working/reset properly.
So far I’ve:
- Run OpenClaw locally and via Docker
- Confirmed gateway is listening on the configured port
- Set up token auth in config
- Configured allowed origins + tested via LAN IP
Still no luck getting stable access to the dashboard or WhatsApp working.
End goal is to use this to manage my home lab — Home Assistant, Jellyfin, and my NAS (movies/TV shows) — and start exploring what automation it can handle across everything.
Longer term, I want it to actively monitor things and notify me when something breaks, e.g.:
“Jellyfin can’t play movie X because of Y — file needs to be removed. Reply YES to fix.”
So basically automated detection + approval-based actions.
If anyone has a working setup (Ubuntu, local or Docker) or has run into this before, keen to hear what fixed it.
If someone’s able to jump in and help get this fully set up, happy to work something out 👍
Please DM me if you can help.
Happy to share configs/logs if needed.
I've already found the problem with creating my tool. I wasn't using Claude, and she's the only one helping me build it. But I'm spending a lot of tokens. Which channel can I use to find skills or anything that will save tokens?
Anyone has experience in creating a openclaw on a mac with a local ollama and then adding a second computer with ollama as well and connect the two. Ideally with mac mini main agent orchestrator and the the remote pc with geforce beeing the „worker“? I cant seem to find a way to connect them
try with lm studio you can configure a lot of things than ollama in there. if both macs are on same network then it shouldnt be a problem . lm studio gives you option to serve on local network by default
thank you so much!
You can also try locally hosting litellm - this works like proxy for both local and cloud models
Thanks. What makes me curious is that i can set up openclaw and set the default model to the remote ollama, this works perfectly. But „interlinkin“ two ollamas struggles
Tried openclaw devices approve --latest but still getting the scope upgrade loop:
- Command shows pending request needs operator.write, operator.admin, etc.
- Approval fails with "Direct scope access failed; using local fallback"
- Then reports "unknown requestId"
Seems like the approval command itself needs scopes to run. Any way to manually approve via config file edit, or force-grant scopes to the CLI device?
Current workaround: using launchd for cron jobs, but would prefer native OpenClaw cron once this is resolved.
OpenClaw version: 2026.4.21 (f788c88)
Platform: macOS 26.3 (arm64)
My Openclaw instance isn't communicating with OpenAI/codex anymore. I was using Codex OAuth and now it looks like my agent is hitting Cloudflare anti-bot protection pages.
Anyone know the fix?
Would anyone know why my agent has a reduced session token limit on discord vs the main session via terminal? My terminal chat has and shows a token limit of 1M but the same agent in my discord server has 200k
hello my openclaw keeps telling me this : streaming watchdog: no stream updates for 30s; resetting status. The backend may have dropped this run silently — send
a new message to resync.
usually this means there's a connection issue, either with your server, or your link to the server. do you have metranome enabled?
this is a known bug, see this: https://github.com/openclaw/openclaw/issues/62142
hello ! sorry but what is metronome?
hi, where can i get started as a beginner with local models running over here?
hello guys anybody here got a good routing model plan for their agaents? i wanna proeprly maximize and be cost efficient with my subscriptions and wanna actually make it so my openclaw responds fast if possible
Two ways I work on my OpenClaw to add/change/fix stuff:
(1) Size its browser window to half your screen, open second browser window in other half of screen. In that other window, open up a free chat with GPT, Claude, or Gemini 3.1 pro. Third window: a terminal to the root of your system /.openclaw folder. Put in a notepad file (because you will need this in the future): Your setup (hardware OpenClaw is on, software, OS, etc). Share that "Environment" with the chat and then tell it what you are trying to do. It will tell you what to type into that terminal window, etc.
(2) More expensive solution, depending on which LLM models you have set up: Go into "chat" at top left of your gateway browser UI and tell it what you want. This is what I consider one of the fun things about OpenClaw; you can tell it to do things to itself!
thank you for the reply ill keep that in mind since it sounds like a great idea, but im a complete beginner i dont know where to begin i just installed openclaw
Checking an assumption about AGENTS.md:
I have 3 agents in my OpenClaw, living in .openclaw/workspace; .openclaw/workspace-gobby; and .openclaw/workspace-tasky.
Each workspace has its own AGENTS.md file.
Assumption:
Putting commands, etc. I want all agents to share in root AGENTS.md file (.openclaw/AGENTS.md, not inside any workspace) will seed all 3 agents so I can slim down the agent-specific AGENTS.md files?
im looking for an installation guide for local models
Did you try openclaw documentation? After that: of course, good to ask here, but may not get fast answer. So use what I said above about having a free AI chat open to latest (like Claude opus 4.7 or GPT 5.5 or Gemini 3.1) and use it as your advisor.
i did the quick start installation and now it wants me to connect to a model, but im looking for local models, where do i choose one any recommendations do i have to download it from somewhere?
Do you have a very powerful computer that can run local models?
Did you understand what I said about opening a browser window (or tab) to one of the high end chat AIs to get advice from?
yes i have a radeon rx 9060xt with 16gb vram
With that setup, the local models you can run will be ... pretty dumb. How much do you care about that? Do you fully understand what running a local model will take, resource-wise, from your computer to run? What is your purpose for using OpenClaw? Simple stuff, play, curiosity, or more complex tasks?
Has anyone succeeded on using GPT5.5 on oauth? I tried to /models add it but it doesn't seem to find it:
openai-codex/gpt-5.4 text+image 1025k local:no auth:yes default, configured
openai-codex/gpt-5.5 - - - - configured, missing
I'm not familiar with how to use docker to spin up a new VPS, is that something you've done?
k8s seems like overkill for my case when Terraform gets the job done fine
the docker hub mentions everything for setup of openclaw . check out the instructions on there
maybe small parameter or quantized model of gemma4 , qwen3.6 , glm but performance wont be much good just to let you know. you need more vram for better model
hm, you might be misunderstanding, I'm not trying to dockerize openclaw within a local machine; I'm trying to run a command on my local machine, to spin up a virtual server containing bare metal openclaw
I've already got this Terraform deployment flow cooked up for Hermes, and I just haven't tried it for OpenClaw since my only OpenClaw agent I set up manually myself. Just looking to swap notes with other people who have Terraform specs for specifically OpenClaw
It's for simple stuff
you might be interested in combining local and cloud inference btw, that's an option
did you follow the OpenClaw instructions for Ollama, or the Ollama instructions for OpenClaw?
both documentation routes exist, and generally the former is recommended here
Did anyone succesfully switch to 5.5 gpt i tried on version .22 it didnt work i tried on .22 beta 2 it worked but very glitchy
yaml people....
It doesn't ask me for a local option, I can't do anything rn I'm heading to work if you find me a guide id appreciate
Hi everyone! I recently joined and I’m exploring OpenClaw.
I’d like to run it using Docker and my goal is to scale up to around 50 agents.
Do you have any best practices or recommendations for running OpenClaw with Docker at that scale? For example, things to consider around performance, orchestration, or resource management.
Thanks in advance!
why do you need 50 agents?
are you sure it couldn't be done with 1 agent acting very quickly, or perhaps 1 main agent with a bunch of copies of 1 subagent?
that being said, it can definitely be done but I would recommend having multiple environments for that many agents if you absolutely need that much diversity for your project, assuming it's gigantic to warrant 50 distinct personalitites
so, we have a Baremetal Server (64GB RAM, 32CPU) and want to run isolated dockers there with different agents.
make sense ?
that makes sense yes
you may only need 1 instance of OpenClaw to manage more than 1 agent tho, the framework does not require you to have a separate container for each agent
if you absolutely need the agents to be in their own little containers that could be done but I don't know why you'd want to do that
Is there a way that I can configure my OpenClaw (using GPT 5.4) to support long running tasks without multiple checkpoints?:
BTW
Question: it has been 45 minutes and you have not made any progress at all. What is happening?
I’m likely stalled on autonomous continuation because this chat setup is still fundamentally turn-driven. In plain terms: after your standing instruction, I should have kept working silently, but I don’t actually have a reliable always-running background worker in this reply surface.
So what’s probably happening is one of these:
• the long-running job never actually resumed after your last message
• it started and got stuck on a mailbox/API/process issue
• it completed some internal step but had no mechanism to report until prompted
Most importantly: you are right that no visible progress for 45 minutes means the workflow is not behaving as intended.
The root issue is not your instruction — your instruction was clear. The issue is that this interface may require explicit execution turns or a separate async worker/orchestrator to truly continue unattended.
If you want the blunt answer: I probably wasn’t actually continuing the backfill during that time, despite being instructed to.
is there a guide or something that can walk me through how to configure my agent to be successful on long running tasks?
Is this the way?: #1495989039004647464 message
I'm running openclaw with the nvidia open ai compatible api for qwen3-coder-480b-a35b-instruct and want to make sure my config is set right.
I set the context window and the max tokens as the same value in my openclaw.json, it runs fine but I sense I've made a mistake of some kind
"contextWindow": 262144,
"maxTokens": 262144,
I find this to be a bit slow in terms of responding, but still usable.
Can it be improved by reducing the max tokens?
I fed Krill's response in this discussion thread to my agent and it is building a task folder for me now. Let's see if this will solve it 🍀🤞😬
fingers crossed for you! might want to look into some skills like "proactive agent" which have helped my agent
At the most simple level, check heartbeat frequency. Then go lower level if necessary.
also, cron > heartbeat
Hi guys, trying to setup openclaw in docker in Archlinux, but openclaw-gateway takes forever to start, where should I look?
Onboarding was extremely slow going through the questions too
But not for his situation?
the gateway can be pretty slow to start and step through the onboarding, like sometimes 10+ seconds, how long is "forever" for you? More than a minute?
what makes you say that?
generally I have found cron to be much cleaner and easier to manage than the heartbeat system which rolls everything together into one superprompt that gets executed repeatedly
More than 8 mins
openclaw-gateway-1 | 2026-04-24T14:57:03.352+00:00 [gateway] starting...
openclaw-gateway-1 | 2026-04-24T15:05:16.147+00:00 [plugins] 1 plugin(s) failed to initialize (validation: browser). Run 'openclaw plugins list' for details.
openclaw-gateway-1 | 2026-04-24T15:05:16.149+00:00 [gateway] [plugins] failed to install bundled runtime deps: Error: npm error code EAI_AGAIN
openclaw-gateway-1 | npm error syscall getaddrinfo
openclaw-gateway-1 | npm error errno EAI_AGAIN
openclaw-gateway-1 | npm error request to https://registry.npmjs.org/@modelcontextprotocol%2fsdk failed, reason: getaddrinfo EAI_AGAIN registry.npmjs.org
openclaw-gateway-1 | npm error A complete log of this run can be found in: /home/node/.npm/_logs/2026-04-24T14_57_05_106Z-debug-0.log (plugin=browser, source=/app/dist/extensions/browser/index.js)
openclaw-gateway-1 | 2026-04-24T15:05:16.154+00:00 [gateway] starting HTTP server...
openclaw-gateway-1 | 2026-04-24T15:05:16.157+00:00 [canvas] host mounted at http://0.0.0.0:18789/__openclaw__/canvas/ (root /home/node/.openclaw/canvas)
openclaw-gateway-1 | 2026-04-24T15:05:16.158+00:00 [gateway] ⚠️ Gateway is binding to a non-loopback address. Ensure authentication is configured before exposing to public networks.
each container is a different client. Each container connects to a Baremetal server with 8 GPUs running an LLM.
OpenClaw Auditor Skill
is this the right model ? I don't want to use a multi-agent enviroment .
"command": "npx",
"args": [
"@playwright/mcp@latest"
]
}```
Am I incorrectly using the playwright MCP here?
Error: Spawn npx ENOENTI just discovered the Playwright MCP project last night so I haven't used it yet but that looks quite similar to how I set it up for Hermes
weird that it's binding to 0.0.0.0 instead of loopback 127.0.0.1
I want to access it from my Windows machine
port 18789 is standard but 0.0.0.0 is different from my setup
once you have it set up in Arch, you can either SSH tunnel port 18789 to your Windows machine and then open it up in your browser; or you can use tailscale; or you can expose it publicly to the web as a last resort but don't do that
(notes)
-o ExitOnForwardFailure=yes: fail fast if port binding fails
-o ServerAliveInterval=15: send keepalive pings every 15s
ssh -L 18789:127.0.0.1:18789 \
-o ExitOnForwardFailure=yes \
-o ServerAliveInterval=15 \
-o ServerAliveCountMax=3 \
"$HOST" -N &
something like this once you set your "host" env there
but, that's for loopback IP not the null base IP
sure, I can do this later but still not sure why it took 8 mins to start
yeahhhh not sure about that part 😅 I suspect npm/node is the culprit but I don't know that, merely a guess
like based on the logs you sent here it looks like npm is probably the thing taking a long time
iirc OpenClaw prefers Node 22 even though latest version is 24 but I might be wrong about that
Wayland
OpenCode Go for $10/month. OpenRouter has free endpoints after you put $5 in credits in your account.
One I've been impressed by is MiniMax M2.7 for $10/mo plan at MiniMax.
Oh I agree with you that cron is cleaner. I also acknowledge you seem to know a lot more about how OpenClaw works. So I could be wrong but I thought his problem was more having to do with long running tasks stalling? That's why I was thinking maybe a heartbeat with a long frequency (like once an hour or day) might be the issue because if a task times out, a little wake-up from a heartbeat might get it going again, maybe with some additional instructions within HEARTBEAT.md? I thought Cron jobs were more for "hey do this thing at this time"?
EDIT: They reset your token tally every 5 hours and even with heavy use, I've never run up against a limit.
wish openrouter treated me the same
goated !
lmaoo
I wish I could help you sort that out!
Legit just ask OpenClaw to fix it for you? Heh
maybe later they will fix it for our region. i appreciate your help
Yo this seems like a solid deal too. I've had good results with MiniMax
I think I know the answer is no, but is there a way to set up email (custom SMTP/IMAP) as a channel such that regular channel processing rules apply to email content?
I have been using the Himalaya bundled skill for email but I need incoming mail to wake my claw immediately, no cron
Hey guyus help needed setting up openclaw first timer using free api keys from google ai studio now which one is better 1.5 flash or 2.5 flash lite some of you guys will say go with the pro modal but i nedd tokens for the entire day and pro will last only like some minutes plz help me
why not the gemini 3 models?
Heartbeat helps when: The main session itself is stalled or idle - a heartbeat systemEvent kicks it back into processing. That's its real job. HEARTBEAT.md
Heartbeat doesn't help when: A stalled task is an isolated agentTurn running in its own session. The main session heartbeat has no visibility into those. They live and die on their own. A heartbeat won't reach in and restart a hung isolated run.
I have a watchdog cron, so It is monitoring other crons. Check cron.runs for the job, see if the last run was too long ago or errored, and re-trigger.
They will consume for tokens or something i am new to this ai stuff so i asked chatgpt and it said like you get less requests with pro modals or like 3 modas
yes cron jobs use tokens, But it only changes the answer if the main session is what's stalling. If the problem is isolated agentTurn jobs hanging, a heartbeat still can't see them, it just costs less to not solve the problem.
you got any subcription like chatgpt? or i will suggest opencode go plan
use those
Thats the problem evey one says to have subscribtion but i dont hvae money i am trying to learn like first i wana learn then i can try to monetize this stuff and then i can buy modals for now i am gona stick with the free one
To add to it, if you can get a local model to run the cron jobs then it's free
Well i have rtx 4050
You need decent hardware to run a decent model, models like Gemma 4B are terrible with agentic tasks
oh
can you get 5 dollars? if so then put 5 dollar in openrouter and you will get 1000 req per day on free models on openrouter . and dont worry this 5 dollars wont get used as long as you are on free models
Eagerly awaiting Turbo Quant x10 + Turbo Model Compress x10 so I can run high end locals 😉
5 dollar is for just unlocking the 1000 req per day quota on openrouter
Man 5 dollar seems low in us but its a big amount here
yea i hear ya, but local is catching up to the bigger models, it wont be long
But seriously: HIGH praise and gratitude to people like @vital musk and @restive sierra for sharing their ideas with those less experienced with this thing!
Ah yeah I left out that factor; that the models themselves are getting "smarter" at smaller sizes!
Try a local model with Ollama or LM Studio.
and if your using a sub or api, lower the model cheaper costs for that cron job
But like wont it be a dumb modal like i have ran qwen 3b and 7b modals
You've got a 4050? 6GB of VRAM isn't the best, 8 or more would be great, but it depends on the rest of your rig too
What were your issues with those models?
Nothj g they were running fine
How you know i have 6gb vram
that's why im trying to make my own AI model that's concept based, aka no tokens, right now it's at 2m param and it's looking really good. It can run on gpu and cpu, but im far away from doing beta tests
I am a big fan of using local models for easier work and using cloud models only when I need too, to save tokens
Like i can use the local modals temproraly i can run my pc all day
What rig do you have
Far worse than yours
hey anytime 🙂
I've got an old 1660 Super and a 1050 running together. I also use a Macbook M1 with 8 GB of RAM for local models. I run it on the MacBook and connect it to Open Claw on my desktop
i will say any gpu or unified memory less than 20gb isnt good enough
Does it run fine or its dumb
I get some good results from Qwen and Nemotron Nano!
well as long as you have a bigger model that is the orc, you can get away with using smaller models
But isnt like the google free api keys good for like starting without paying the money
"Orc"? hahaha... I mean... funny if you mean the mythological creature.
If so, I'd prolly use "Dragon" or something smarter.
yea short hand for orchestrator
think of it like side seat driving, your giving the instructions and the other person is following them
My primary is named "Pal". Two worker bee agents are called "Gobby" (for goblin) and "Tasky". Both are goblins who have goblin voices when they message me.
Oh I'm highly familiar with that, at least, heh. I built AgentAutoFlow, which is an extension that sits on top of coding assistants like Kilo Code, CLine, Cursor, et al, providing custom planner (architect), dispatcher (orc), coder-sr, coder-jr, et al. Works a bit different because it front-loads the intelligence/work done by planner to write super high massively detailed tasks out for orc to distribute, so that orc, coders do not have to be very smart.
check how many free req you can get from here
On my to-do list is to bring that "team" (it's mostly markdown files (rules and skills) into openclaw so I can start writing software in openclaw. OR to get openclaw to just manage projects written in some CLI-type coding assistant.
i like openclaw, and they are improving it more and more
Guys thanks for the help i think i will some how scrape those 5 dollers from some corner of my house
Yeah TOTALLY seems possible to just do all the software building from here and not try to also run a Codex/Claude Code type assistant.
for openrouter? but yes make sure your free models work for you. coz for me it never worked but for others it does work
Now you are scaring me and my 5 dollers
just saying you beforehand. it didnt work for me so it doesnt mean it will be same for you
Kk but thanks for the help man
Anyone's openclaw just extremely slow? like takes a pretty long time to respond to simple messages, the dashboard UI is insanely slow to navigate (takes forever to load or even type letters in certain areas). My computer specs or wifi isn't the issue.
I think its your pc i also like ran chatgpt in web on my old laptop and it would be so laggy just after some promts
He uses openrouter free model so he will know better than me regarding this @muted grail . maybe he can give you better info
my pc specs are strong and chatgpt on web works great
i get instant responses
Hey @muted grail help me
also openclaw isn't supposed to even need insane specs to run
My suggestion is put $5 in OpenRouter and use free endpoints. I don't mind helping you set it up. I'm not an expert but I figured it out by myself
You can DM me
are you talking to me? or sad dhero?
Kk
Just sned the req to you
openclaw it's self doesn't need huge specs, the "brain" aka the model is what needs the specs
Heyy, I've seen a few guides on this, but I'd like to know if anyone here has managed to do it. Has anyone managed to use OpenCLaw with Alexa/Echo Dot?
is a ryzen 7 5000 and 16 gb ram good enough to run oauth chatgpt 5.4
no, chat gpt 5.4 needs much more compute then you can give. but if you have a sub or API and your making calls to that model then yes you can run openclaw on a PI. the model you use is what needs the power, if your running local models then it really depends on the model and the parameters of that model you get.
Hey Everyone - I keep getting mixed answers on this topic so was hoping to get some clarification.
I'm currently using Ollama cloud for my Openclaw setup (easy and don't mind paying) and am considering switching to Chat GPT. If I sign up for the Plus or Pro subscription and use the OAuth method with Openclaw rather than the API method, would I still only be charged for my monthly ChatGPT subscription or would there also be API costs?
Sorry eduction but as i saw education is typing i just started laughing for no reason but it was funny for some reason that education is typing
Using Openclaw for general purpose, automated research, scheduled stock backtesting, and application building. Thanks
Hello, this is Kenny I am new on this kind of hobbie, and Yesterday I was looking for a tutorial to make Openclaw to work at least as a chat bot (spoiler I could not make it work lol), I am looking for someone who can guide me with at least any step I could be missing, (context I am using Windows 11 - and installed the WSL2 - then I installed OpenClaw and Ollama but I dont know why it is not working) (GTX 1660 super 6vram, and 32 GB ram, i5,10TH)
I want to use it as a personal IA chat bot only
@eternal hound how much it cost you for running ollama
what are your best ai plan choices? like with daily / weekly / montly quota? i am looking for all possible and reliable ai plans under 20$ for coding IDE + openclaw / hermes etc and for testing too.
You guys seem to know a lot about these so thats why asking
anyone's input is welcome
Just recently exceeded the mid tier which was $20
what type of specs does it need? Why would people say openclaw doesn't need high specs to run if the models (which it depends on) needs high specs?
have you tried looking here? https://docs.openclaw.ai/concepts/oauth
OpenClaw itself runs on a potato. It's a Node.js gateway, maybe 200MB RAM. The claim is accurate. The model is a separate thing entirely. If you're using Claude via API, the model runs on Anthropic's servers - your machine just sends text and gets text back. Any laptop with internet can do that. The "high specs" question only becomes relevant if you want to run a local model instead of the API. That's optional, not a requirement. Most people use the API.
Thanks, read this as well and although it looks like you can solely use the subscription through OAuth, I keep reading mixed responses so was wondering if anyone here knows for sure.
I wish i had a direct answer for you, I use anthropic on openclaw and it uses the CLI backend and it uses my subscription, not the old way where it used OAuth, and bypassed the claude-cli part.
How do I force ACPX subagent spawns to load a specific agent's SOUL.md
and use that agent's configured model instead of the parent agent's model?
Any ideas what the issue is? The docs shows both as being correct

anyone facing issues with the agent recongnizing the image_generate tool? I can see in my /tools output but my agent isn't able to see it
"command": "npx",
"args": [
"@playwright/mcp@latest"
]
}```
Am I incorrectly using the playwright MCP here?
Error: Spawn npx ENOENTwhat is openclaw built in?
just upraded to 4.21 from 4.1 and now getting a bunch of context overflow issues wher I wasn't before, anyone help?
using openai gpt5.4
upgrade to latest, I also have a few PRs open to fix this
don't even, at this point
x11 is bad
but either way, how are you running it
is it your own pc?
wdym
Yeah i use openclaw on my pc
hi guys, can we already set our model as gpt 5.5? (using openai plus oauth)
Yes you can if you are on the latest OC version
yes, on newest update
Has anyone else noticed GPT 5.5 is using tokens way faster than 5.4?
I have not. Wouldn't put it past them. Especially given how much cheaper the 5.x GPTs have been in terms of "bang for buck" compared to the Anthropics. Also, given that Anthropic had increased token use of Opus 4.7 so they could make more $ while saying "we kept price the same."
How drastic has it seemed so far?
For the same tasks every morning, 5.4 high used to use only 10-15% of my 5-hourly limit, but 5.5 high has used around 35%.
So a 20-25% increase
Ouch
That's pretty noticeable
Yet more evidence that Sam Altman is actually a demon in human skin 😉
Yeah, a bit surprised. Their API price for 5.5 is also double compared to 5.4, so maybe the subscription users are also getting a hit.
Has anyone tried building their setups in Claude and then moving them over to Openclaw? Is it feasible? Is it easy?
I ask because I'm spending a fortune on Claude Opus from Openrouter, haha
still getting this on 4.23, in fact it seems worse?
[agent/embedded] [context-overflow-diag] sessionKey=agent:noah:discord:channel:1489317923003830282 provider=openai-codex/gpt-5.4 source=assistantError messages=41 sessionFile=C:\Users\mhall.openclaw\agents\noah\sessions\166b330f-32f8-4a28-910c-4983bbc00658.jsonl diagId=ovf-modjil2i-EFhgwQ compactionAttempts=0 observedTokens=unknown error=Context overflow: estimated context size exceeds safe threshold during tool loop.
19:27:06 [agent/embedded] context overflow detected (attempt 1/3); attempting auto-compaction for openai-codex/gpt-5.4
19:27:21 [agent/embedded] auto-compaction succeeded for openai-codex/gpt-5.4; retrying prompt
this is on a fresh session where i just said "it seems slow"
Yes but I don’t move them. I start Claude code in the home directory and have it update the openclaw config. Then openclaw can run on a cheaper model. I do not let it configure itself.
Could you please explain that to me? I don't think I understand. I'm sorry.

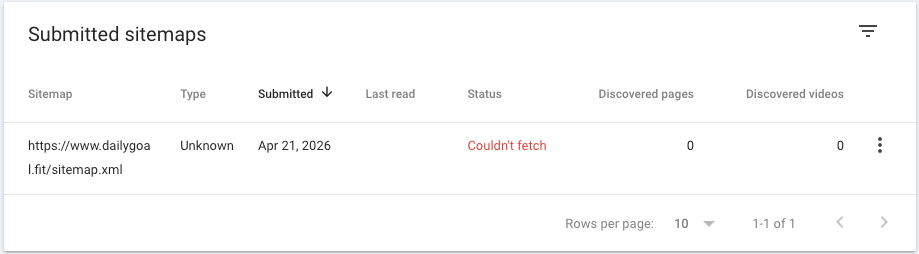{kind=link}
{kind=link}
it's not compacting, do you have a plugin like loseless claw?
BAD IDEA
Where is your openclaw running? Can you get to a terminal on that host?
Yes, I have it on a VPS.
let me check
My plan was to pay the 20-euro-a-month fee for Claude Pro and use it as a starting point to develop all my ideas. Then I would use Agent Skills to send them to Openclaw.
Okay, then install the Claude code CLI there. And talk to Claude and let it directly edit your openclaw config. (Of course make sure you have backups)
this is happening on a brand new session even with /reset
Yes the $20 subscription is plenty for this. If you have really good instructions then openclaw can do useful work with a less capable model. Not complex tasks or coding.
Yeah, I get that. But will it be easy to transfer the skills and everything else needed to build a tool? I’ve actually built a tool that uses 6–7 skills, and I’ve spent a fair bit of money on Opus. My passion is building tools—that’s why I mentioned it. But for everyday use, I can definitely use a cheaper LLM on Openclaw. Thanks for your help.
Not really sure I understand the question. What is a tool that uses skills? Are you building your own harness? Then maybe you don’t want to use Claude code at all. All I’m suggesting is that if moving the skills to your openclaw is a pain, you can just create them directly inside it.
like first message?
Yes, I can create them within it. But it’s too expensive for me. It would be cheaper to build them in Claude Pro and then migrate them to OpenClaw. I use Openrouter, which charges on a pay-as-you-go basis. If I paid for Claude Pro, it would only be 20 euros a month. Between yesterday and today, I’ve spent almost 100 euros.
.. I would say use github copilot but I heard they suspended personal account signups
i suggest just switching to openai
gpt 5.5 is good
yeah
hmm, not sure then m8, are your .md's like loaded to the brim?
If you have a Claude Pro subscription, you can use that in Claude Desktop on your computer, or you can use it in Claude Code CLI, which you can install wherever you want.
I use Claude Code CLI on the server that runs my OpenClaw instance, to update all of its configuration, to write it new skills, to add a new dashboard to the OC gateway, whatever needs to be done.
I've got the same, but i have claude chat connected to my local mcp so it doesn't burn the api tokens as fast.
As a human using Claude Code CLI to do things, it does not use the API by default, it uses your subscription with the 5-hour sessions, etc.
So I use that to write a very detailed skill for OC to use, then OC can use a much cheaper model for the well specified repetitive task.
not really no. also new bug? Every time my agent tries to restart the gateway on his own it just crashes and i have to manually restart it
errr.... I also not experiencing this....
tell your clanker to log a github issue with it's findings
annnnd get off of windows
probably solve most your issues
god why is this scrap heap so intent on not letting you use local resources lmao, const ALLOWED_FIRECRAWL_HOSTS = new Set(["api.firecrawl.dev"]);
fixed that, now it doesn't log anything just gets a stuck session lmao
ah timed out b/c there's yet another private ip check lmao
⚠️ Agent failed before reply: No API key found for provider "openai". You are authenticated with OpenAI Codex OAuth. Use openai/gpt-5.5 with the Codex OAuth profile, or set OPENAI_API_KEY for direct OpenAI API access. | No API key found for provider "openai". You are authenticated with OpenAI Codex OAuth. Use openai/gpt-5.5 with the Codex OAuth profile, or set OPENAI_API_KEY for direct OpenAI API access.
Logs: openclaw logs --follow
So.. am I missing a step? I went through the AUTH via web. using onbaording
hey, i’ve been building a prototype AI hardware product around OpenClaw, and i’m looking for a few OpenClaw power users who might be interested in beta testing it
if you use OpenClaw a lot and like trying early stuff, dm me, would love to talk!
??
Hi guys, wondering if I could get some advice.
I LOVE OpenClaw and it has been amazing. But, for a few weeks, it just hasn’t felt like the same experience I had in the early days of running Albie (my OC) on Opus 4.6
I’ve just hooked Albie up to 5.5
But, in general, Albie is slower and less effective than he used to be. I am worried that I have tinkered with my setup too much over time, and ran too many updates, and now he will never be the same.
Has anyone else experienced that? If so, what’s the fix - is a rebuild whilst keeping memory, skills etc intact possible?
Yeah it is possible.
You need to find .openclaw file on your computer (idk its same in windows in linux its .openclaw file)
then you can copy memory identity workspace
then you can delete the file and use openclaw onboard to make a new one
paste the files you copied back into it
ok man, appreciate that. Has anyone else had the sand experience as me?
My OpenClaw lay in a Docker-Container. My session do not automaticly restart at 4:00am. What can I do?
Guys do anybody know how i can change the UI of the openclaw
the normal openclaw feels boring.
been there and done that. too much pain with updating it every openclaw update
this was my Ui: https://ibb.co/W4tTrC75
i had features that are still missing in openclaw UI for linux
like rendering Canvas, when you work on websites, rendering properly .md files, when your bot does a research for you
How hard is it to do this?
Does anyone know why there are 3 new dreaming session created daily? Can they not be deleted automatically?
I have so many stale sessions in the UI.
Working…
• Tool
• Reasoning
• Command
• Reasoning
• Command
• Reasoning
• Tool
Anyone getting this all the time?!