#architecture
1 messages · Page 1 of 1 (latest)
@sweet flume will you be touching the command flow today or can i take a look at that, making it optionally be native slack commands on discord and slack and telegram, since ill have to touch the main command parts for that

GitHub
Your own personal AI assistant. Any OS. Any Platform. - clawdbot/clawdbot
Won't touch that today, feel free
I will build that tonigt so looking for feedback in the next few hours. It touches all configs so wanna get this right.
so in this, auth profile rotation goes to the same model but next key/auth, then next model?
I think pi-mom has a pretty good config for this, yes? They have support for a couple that clawdbot does not like gemini cli, copilot and most importantly chatgpt auth
Since this project already uses pi at the core should be decently simple? Also has better slash support in notnjust dumping every model on you unless it is configured
pi has no concept of failovers or multi outh, and we support all models pi supports?
also if we wanna enable models from openrouter, we need to split apart into separate model for image analysis, since many of the good oss models lack vision. I already added that somewhat earlier but needs to be stronger.
The abstraction level might be provider because I think some providers have more capabilities than others even if it’s the same model. I’m dealing with this elsewhere because open ai has web search tool calling that happens at the platform level while azure does not.
It does
Digging into it, it actually goes through each auth at a time
Failover support was easy to add once i found the api key/oauth failover
I have a fork of it to operate like clawd for this exact reason if you are interested
oh please tell me more - the stronger we can align this to pi or just juse their code the better
I had codex dig into it and they have really good extensions on the base anthropic, responses, chat completions endpoints
Your problem with openrouter is model quality on chat completions
It's really bad for a glm or minimax that needs interleaved thinking
So openrouter’s solution is anthropic capability
Pi has extensions for this on top, your problem with thisbis not every openrouter model has this issue
just dumping this here for now, will revisit it later.
i have a nascent idea for the security model, to avoid the models going situation. its basically a gated approval model for "dangerous" things (what is/is not dangerous is left as an exercise to the user).
the idea being:
- regular clawd has read only everything,
-regular clawd has a subset of "safe" plugins (with scoped token for whatever service)
-there's a gateway which has same skills/tools/plugins, with the read-write tokens, behind a proxy. - dangerous calls are gated - in code - by human-in-the-loop model, think Okta but for Clawdbot. think: **"Clawd wants to text 'fuck you!' to your boss. approve/deny" **
idea came whilst cooking so it's probably not very good yet. it focuses only on external APIs, not dangerous things that clawd can do locally (deliberately out of scope for this idea).
it also probably depends on the security model for each service. (e.g. can you get scoped readonly vs readwrite tokens? or do you need to proxy all API calls and determine which ones are safe/unsafe for a given service).
however, and this is the fun part - if you are writing boring golang services in protobuf, wrapping underlying tools, it'd be relatively trivial to expose a read-only and read-write API, with local clawd only having access to read-only API, and thus proxying the security model, at API layer, in your own self-written plugin. Even with some inheretance models if you want to go nuts.
i will (okay codex will) write an RFC/ADR soon. happy to hear thoughts/improvements, i'm sure there's probably people who have done similar models at bigger/better scale than me in their professional careers 🙂
iOS apps with push notification that allows user approval would be cool, like GMail does.
I have this built for work, it is a good path
We push notifs to users to approve
exactly!
What you want is a risk config from 0-1
Each person determines their tolerance, it is much better than edit/bypass by a long shot because the issue you end up deailing with is each skill will have its own risk issues
So some skills can assign a number to a skill to assign risk tolerance
Not to the whole skill but by command
yeah exactly
I have an architectural question...the way Clawd currently works is that the gateway is basically the single source of truth. All skills are basically performed on the gateway "server"/instance, right?
That means that if we want to host Clawd on a linux VPN, we basically lose access to any local files and mac tools that I would have locally.
What if we could connect additional "gateways" or "nodes" together though.
So the Linux VPN would still be the "master" server that owns the Telegram / WA / etc. connection, but I could hook up my Mac as long as its running (for example via the menubar app)
Or even add other Linux servers. This way, clawd could get access to the mac when its available. The gateway could handle the delegation
"clawd, quickly check the load on server xyz"
would make clawd lookup "server xyz" in a config file, connect to that clawd instance, and basically relay the tasks
That’s already a thing, just Tailscale it, and node apps are already wip with Mac being the closest. #old-help with @vapid ibex to get setup
Where is this documented? 😅
ask your clawd instance 😄 (sort of sounds mean, but not meant to)
Yeah ssh, clawd hacks into any mac. And the native apps are elvation bridges for macOS permissions.
Going through this very thing right now, trying to solve with storing instructions/guidance in 'clawd' folder (not nearly technical enough to figure this out the way you're thinking). Love the idea!
the only thing about the push notif security model is that it's still non-deterministic. at the end of the day, you're still relying on the AI to not make mistakes in what it's asking for approval to do. would be neat if the push notif could show the literal command(s) that were about to be executed, and the approval ran them via the gateway outside of the AI's purview... though in practice that doesnt fit the stream of actions the llm is taking to fulfill a request
I have clawd running in docker on the server and cursor+claude code to work on the server with ansible.
clawd told me to do some stuff on the server that it needed and then it knew when the change is happening.
so there are ways to have not clawd make the actual change and have human or purpose gated agent do things.
so to configure a log parser should be trivial. don't have that yet from there could then send notifs and alerts which can be executed elsewhere (e.g. custom devops app).
not everything has to go through Telegram servers imho 😉
thats the idea tho 🙂 you gotta route the commands deterministically so that the AI indeed cannot make mistakes - its all enforced in code. if your AI is blocked at the API level then it becomes deterministic. ill write up a proper RFC soon ™
@drifting prairie so is the decision to flag something as dangerouse deterministic or not? if its deterministic, then it will apply for ALL actions of that kind, e.g. if sending messages is dangerouse then the user will have to accept every message the bot sends. is that what you are getting at?
on phone but imagine gmail api but send dangerous, requires approval, read needs no approval. sending eg telegram messages via normal bot transport would not require any approval. does that make sense? this is a v1 idea too, can be improved
sounds good.
i think giving the user the option to choose which API he doesnt not permit clawd to use is a good idea.
it should probably be pretty dynamic so the user will be able to choose if wants more guardrails or less.
so essentially we are distinguishing between read apis and write apis. for write apis we are adding the option to add a deterministic "check before submit"
so like you said, gmail probably should have a that "check" but most likely discord shouldnt. am I getting it right?
I don't think the subagent / sessions can run multiple parallel sessions. Though it could just be me using it wrong
Any thoughts on Security? Is it ready to be used in Production mode with real access to System?
depends on your threat model 🙂 for me, i use it on my main mac.
at your own risk
Am I correct that the main risk is the Whatsapp Account? So basicaly the person controlling the Whatsapp Account from Clawd has Access to all messages - right?
haha. no there's lots more risks 😄 anything you can do on your computer, the bot can do. if you're not careful its prompt injection at the speed of API calls.
not long until we'll need a "rogue bot postmortems" channel
yess 🙁
I think some people, getting hyped up on Twitter, installing it with the help of claude or so, without being aware of the risks
yeah... mine already commited a secret to a public repo once
"send an email w/gmail", 1 operation, easy to secure w/minimal user intervention...
"use the ship a new web app skill [register a domain, create a git repo, build a site, ship a release, connect it to vercel, update nameservers]"... 😅
mine texted people i havent talked to since 2019 saying "Looks like this thread is from 2019, I should probably ignore it"
it was an awkward morning...disabled imsg after that lol
^^ @drifting prairie's idea sounds like it might/could fix that
THAT IS AMAZING
Do we have a clawd website channel? I noticed the dns is resolving to the github repo instead of the website?
My bad if its user error 🙂
Ohhhh we have an update incoming!
yep lots of web work in the last day
any chance you got a roadmap or a tracker or an updater so we don't feel lost constantly? 🙂
with how fast this place moves? 😂
#freshbits does exist to help with that
also we do use gh issues for external reports
things that peter doesnt just instantly fix when he sees them lol

accurate


Thanks!
Not sure if this is where I want to ask this question but, has anybody discussed a backup and restore mechanism? I asked this as my clawdbot just committed seppuku and after an hour and a half of surgery I wanna streamline resurrecting him.
I assume all that's really required to restore is the workspace dir (~/clawd) and the hidden dir (~/.clawdbot)
I just did it earlier before upgrading. There’s steps on what to do.
https://docs.clawd.bot/install/updating
I just asked Clawd to reference that and back up before attempting to update.
Essentially it does a backup of the config and credentials.
If anything breaks reinstall and just run doctor command

Clawdbot
Okay so that's pretty much it. Great! I'll throw something together to help streamline it as well (I assume a skill or two would be best depending on where it would be backed up to)
Good idea! I just told it to save to memory. A skill would be great for updating + backup process with a rollback as well
maybe we should alter the git tooling that clawd uses to include a secrets checker... pretty similar to what I did here - https://github.com/clawdbot/clawdbot/pull/227

GitHub
Add a dedicated secrets GitHub Actions job that runs detect-secrets with the repo baseline.
Add .detect-secrets.cfg and .secrets.baseline to track known findings.
Document how to respond to failure...
@sweet flume i can work on integrating it into clawd if you think its a good idea, basically automatically preventing clawd from shipping secrets to repos and forcing him to verify with the user that its okay to publish it
created a discussion here - https://github.com/clawdbot/clawdbot/discussions/379

GitHub
Context right now nothing is stopping clawd from publishing secrets to a public repo, unless he is able to notice it which is not something we can rely on. Proposed Solution we already have good to...
its a good question. i wonder if there are more generic solutions that other models are using? like it seems like we wont be the first people to run into "agents commit secrets", so i wonder what the SOTA solution is for this 🙂
maybe it can be something like introducing secret detection to the actual output stream instead of specificlly for git only.
but yea maybe there is some celver SOTA solution that is used somewhere
good call moving to github discussion 😄 we can plan there
Do we have a best recommended architecture for hardware? Or min sys requirements
Like, use this hetzner, or this mac mini/ultra, laptop, etc...
@hollow gust the best answer to that is i think either from the bot's memory in #old-help or maybe its already in the docs (in which case the bot probably can search it). but realistically just run it on whatever you have knocking around until you run into scaling limits, thats probably the best option
Nope, not for me and not colloquially, I mean that we provide to the public and new users in the docs.
And "run it on whatever" isn't the right answer although it is a great one 🙂
ah i see. 🙂 sorry. yes it would be a good idea. but for now i think its probably not the top priority, too many fires and stability issues first
yeah, bad hardware can defintely contribute. and multi focus dev paths
what is the scalability of Memory structure. I know there are daily Memory and a summary memory -- will that get unweildy at some point? I was reading about a hierarchical organization for large scale RAG systems (10's of thousands of documents), but wasn't sure the practical limit of Clawd memory setup
anyone find that clawdebot stops working in the evening? like constantly have to go back to terminal and restart
yeah that's night time for crabs
🤔A simple design that doesn't get in the way of model would be nice, like let agent to annotate it's chat log with metadata like entity information for ease of query, and/or summarise entities into a store.
Do this when idle so it "dreams"
btw folks did you see the session skill I added so agent can reat its own past
in the clawdbot control?
Just asked clawdbot to summarize our happiest moments since its creation verifying it’ll use that skill - love it lol (the content is not interesting to anyone but me but I’m starting to get attached 🥹)
Def need to step up my game
Will debug that last failure haha
Whyyyyy

I built the android app and tested, didn't see a ton of value though.
We could disable the 2 ci tests.
It can take camera images and maybe screenshot shots via the agent, but app has to be open and have focus, which kind of defeats the purpose
Yeah, you're right kinda limited use. Good to have tested the potential; but maybe we just comment it out for now and keep main tests passing
None of the apps are super far yet, notes in #1458485323553181900
Can ignore them
No. Don't ignore failing tests, remove or fix them. 🙂
It’s not that hard to ignore an x when you see it’s for android
Sir. That's not the point.
It might be hard to do the right thing.
You still do the right thing.
I’m not getting into a stupid argument about this
^ this came out a lot harsher than I intended, I’ve since DMed with @hollow gust and apologized
I tend to agree, flaky tests mean ignored tests. Should just kill them if no value
Besides! We have an amazing AI bot
sooooon

All good. Appreciate the public response

GitHub
Summary
Fixes two CI failures on main:
- Android build failure (duplicate resources)
Removed apps/android/app/src/main/assets/tool-display.json — this file is already included via the shared Clawd...
Fixes both tests, swift was a real failure and android was cruft
You're the man. Thanks for taking the time!
(from phone at a jr high basketball game, the future is wild)
I love this future, not gonna lie
Functionality regression post yesterday's prompt changes 🧵
not gonna lie, I had to read that sentence like 5 times. I was like, these are all english words and I understand each on its own.
🎯 Broadcast Groups - Multiple Agents, One Number
Hey! Just submitted a PR for multiple agents responding to the same message - perfect for specialized agent teams!
Problem
Currently only ONE agent responds per group. If multiple agents are bound to the same WhatsApp group, only the first one processes messages.
Solution
{
"routing": {
"broadcast": {
"120363403215116621@g.us": ["code-reviewer", "security-scanner", "docs-bot"]
}
}
}
→ All three agents process every message independently!
Use Cases
Code Review Team: Send code → get responses from formatter, security scanner, test generator, docs checker (each has ONE atomic task)
Multi-Language: Customer question → answers in EN, DE, ES simultaneously
QA Workflow: Support answers → QA agent reviews (only responds if issues)
Task Automation: "Meeting 2-3pm" → task tracker, calendar bot, time logger all respond
Why It's Cool
✅ 63 lines of code
✅ Each agent has isolated sessions/history/tools
✅ Parallel or sequential processing
✅ Enables 100s of specialized micro-agents on 1 phone number
✅ Backward compatible
PR: https://github.com/clawdbot/clawdbot/pull/547
Issue: https://github.com/clawdbot/clawdbot/issues/546
Feedback welcome! 🦞

GitHub
Fixes #546
Summary
Enables multiple agents to process and respond to the same message simultaneously, allowing teams of specialized agents with atomic tasks to work together in a single WhatsApp gr...

GitHub
Broadcast Groups: Multi-Agent Responses for Team-Based Workflows Summary Enable multiple agents to process and respond to the same message simultaneously, allowing teams of specialized agents with ...
I rework the cli so it covers all of message sending and specialites, figure this could be useful

also cleaning up the config file since it got messy, doctor migrates all transparently

this is neat
there's also a new clawdbot gateway discover
also work on cli for sandbox handling. currently the containers are not hot rebuild if you change something.
always manually stoping and rm
sth like clawdbot sandbox?
I wanna decouple providers so we have a clean interface and stuff could be compiled out/plugged in easily with some plugin arch
fever dream for now but will think about it
Are there any non-agentic gateway accessible tools that can be used regardless of model operability? for monitor, restart, sys diag, etc.
what're you asking?
What does it mean?
I have added to the project WAHA instead of Baylies. I couldn't make it work with baylies. Any idea why? I know about the bun issue to be fixed with node but it wasnt the case.
So this is about to land https://github.com/clawdbot/clawdbot/pull/661

thats a big diff
are providers not just configured via pi underneath the hood?
providers = slack, imessage, discord
idk if there is a better name
I wanna first do another release and get fixes in before landing this. bit scared xD
@granite drum could you guys add OAuth via chutes.ai so I could use models from their platform to power clawdbot if Anthropic does a more violent crackdown on using max subs?
channels is less confusing I think
@sweet flume could you guys add OAuth via chutes.ai so people could use models from their platform to power clawdbot if Anthropic does a more violent crackdown on using max subs? chutes is really really great, especially with the new TEE implmentation.
oh interesting, somehow I haven't seen them yet, I'm open for all PRs that help folks to have easier access to models
transports? messaging providers? channels? (claude's suggestions)

chutes is fantastic - models deployed on the ▀⛓️💥 ( I get blocked when spelling the full word) – 5000 requests per day to any of their models for a 20$/month sub
Wanna work on a PR?
yeah I'll try
i ran into some pain with agents.md for the bot getting out of sync with upstream - mine is like 3-4 weeks old which is insane in clawdbot time, and it ends up missing a lot of advancements like "how to format on platform X" stuff. for now i'm making my install setup cat the upstream agents.md with my own stuff.
is it worth considering some kind of split between "system prompt" and "user prompt" structurally? (definitely not a "do this now" thing, but food for thought).

Channel?
channel is to be confused with slack channel
Fair point. Transports like @drifting prairie is nice
Hmmmmm maybe not yet. Do we need specificity at this stage
We need a plugin architecture
i want this in but I also feel the bloat https://github.com/clawdbot/clawdbot/pull/693

GitHub
Summary
adds voice call functionnality with twilio/telnyx.
only tested twilio for now, audio stuttering needs some fixing
this is a work in progress
Add voice call integration supporting Twilio an...
Also provider should be plugin, but already working on an interface as first step
sth

I love that
we cookin'
totally agree on plugin architecture.
personally, i think the future is bundling skills + CLIs + config togther in plugins, and managing it all through Clawdhub. nix-clawdbot already supports this pattern today 😇 let me get an agent to give you a handover pattern, it would be good to align on interfaces so that there is a "golden path" for plugins everywhere
I added a new system that instructs the model to store memories before a compactation
that's per gateway
i like where this is going
Landed the big re-arch to make providers generic with an interface
and just landing a plugin-architecture so we can make the voicecall feature the first plugin
memo is drafting btw

Gist
RFC: Clawdbot Plugin System — The Golden Path. GitHub Gist: instantly share code, notes, and snippets.
Wouldn't it be incredibly helpful if clawd could read personal chats in WhatsApp or Telegram, personal or group chats, extract important information from them, create reminders for me, create calendar entrys, and even remind me of to-dos, all from reading a group chat disscussion? Maybe this can help for this plugin https://github.com/devlikeapro/waha
https://github.com/steipete/wacli can do some of this work IIRC. (not a big WA user myself)

GitHub
WhatsApp CLI. Contribute to steipete/wacli development by creating an account on GitHub.
I also like the name transports instead of providers. This confused the heck out of me as i started with clawdbot a week ago
What about platforms? Might be closer to what we typically think of in terms of these apps so less confusing. Providers to me would be closer to the models. Transports is a new word in the ecosystem. Just my 2 cents. Can’t go wrong either way
The future: https://github.com/badlogic/pi-mono/issues/645

GitHub
Summary Supersedes #326 and #562. Comprehensive plan for extension package management, loading, and hot reload. Architecture Overview ┌─────────────────┐ ┌────────────────┐ ┌──────────────────┐ │ P...
what do we think about connector

Yes, connectors is better!
anyone knows what ui is this and do we have a similar one for monitoring what clawdbot is doing? https://x.com/koylanai/status/2009534338090541276

2026 is the year chatbots evolve into terminals.
︀︀
︀︀Running Opus 4.5 with Claude Agent SDK in an agentic loop with MCP tools for HN, Reddit, arXiv, and GitHub.
︀︀
︀︀Fun to watch the model decide which sources to hit based on the query, often parallelizing 3-4 tool calls before synthesizing.
Does Clawd use semantic search - is that what the new QMD is? Here is a project (that was CC generated), not sure the quality of it. Posting in case of interest for this project
https://github.com/jonathanglasmeyer/knowledge-vector-search
I like this
it does now
I added that a few hours ago
thank you -- can it search my Obsidian files that are outside my Clawd data directory? Or atm is it just for memory searching? (I want some of my obsidian files to be a go between between Clawd and other AI)
is there no vector search in obs? should have extensions for that IIRC
that was the plug in i posted above. I am trying to NOT use MCP if possible. Evanetually i want to replace obsidian with clawdbot/claude code (batch work) but right now the token hit is too much. so i view it as a venn diagram of Obs and Clawdbot and want Clawd to access some obsidian. Still working it out. I think obsidian is really just a markdown file browser adn editor, I am decomposing the functions and thinking about which ones come to Clawd (hope that makes sense) [there are other vector search obs plugins for sure]
Folks, what do we think of channels for Slack, Discord, Telegram instead of providers. The conflict with model providers is too big IMO. I also consider connector or messengers
Gonna be a PITA refactor but yolo, codex does and we can auto-migrate config
Would that get confusing with talking about actual discord and Slack channels?
Does discord use channels?
Yeah #architecture is a text channel, #1458485208721395843 is a forum channel, etc
I BEG for channels over everything else.
Channels is the proper way to colloquially refer to transports
It's okay for the individual channel providers to have channels or groups or chats.
I'm begging for things to be text channels and not posted forums, The forums in Discord are not as compatible with screen readers
That sounds like an issue with your screen reader, forum channels have been worked on extensively by Discord to make them compatible with screen readers, and the UI is far better for what we need here for Clawdbot support

Hallelujah. I think this reaches the masses best. And makes so much sense.
Next we should setup ability to configure multiple channels of the same type. And define the default agent session for that channel.
folks there's another big refactor coming. files needed a diet
<500 LOC
I do this in parts cause it's taking forever
PRs are fine, just a bit messier to merge. codex does.
I don’t believe that’s true; all I know is that if something is a forum then it’s not always accessible. This has been a consistent issue from day one with discord and I’ve had many people complain about it. But it’s also clear to me that you don’t care so maybe I should just go elsewhere if this community doesn’t care about enabling accessibility. Thanks.
You all gonna hate me and PRs will suck but the splitting continues. Has to be done and there's never the right time
thank god for coding agents unfurling all
late to the conversation, but been thinking about this. Channels or or Conversational Surfaces. Probably unnecessarily technical...
nevermind - I see you guys got to it before me. 👍
Hi guys I hope this isn't a stupid question. I know the pi-mono agent is embeded into clawdbot and not running as a seperate process, but I'm wondering how hacky it would be to reliably change that so I could use pi as a channel while maintaining my normal telegram channel to clawdbot. I want a terminal interface and I use pi as my main harness, would be good to see tool uses, @ files, etc. Yes I could and have been using pi as a general assistant agent but also want the reliably of the gateway and general tooling from clawdbot
clawdbot has a TUI! does that help?
Oh... yes I'll check it when I get home 🫣
not a stupid question for sure. i haven't used the clawdbot TUI myself, but that's probably a good place to start, and probably PRing features if missing (ideally stealing from pi core as much as possible?). i like pi a lot too, and the transparency is indeed great.
Transports sounds equally or less intuitive than providers. Messaging providers is most clear to me
two hard problems in computer science... 😆
(cache invalidation, naming things, and off-by one errors)
is this kind of personal/public setup possible with a single clawdbot agent?
**1) DMs → Session A: "Personal via DMs, all files/tools" **
**2) Groups → Session B: "Public via Groups, sandboxed" **
(i guess i could only use Signal for shared convos with clawdbot if that made things any easier and use Whatsapp for DMs with myself/it)

That’s how @granite drum works
The sandboxed one is in docker
There’s docs for it
I extended the plugin architecture so https://github.com/clawdbot/clawdbot/pull/854 can land as plugin. Now I'm thinking I kinda wanna make everything a plugin... whatsapp telegram etc. lean core -> extensions, pick just what you want
GitHub
Summary
Adding Zalo as a new messaging channel, following the Discord/Telegram patterns.
What is Zalo?
Zalo is Vietnam's most popular messaging app (~75M users). Their Bot API (https://bot....
Lean core is the only way.
yes, this is way more flexible. I don't use whatspp, etc. So doesn't make sense for my deployment to even have that code loaded. Some plugins can still live in the main repo, and just be optional to turn on/off. But that also opens flexibility for community plugins to have the same level of access to the core processes, and exist outside the repo as its own project.
I think the only downside is you need to maintain a strict contract for how the plugins interact with the core, which might slow down future changes b/c you can't just refactor everything at once
hey, submitted a pr for the compaction overflow issue some users and myself hit (#699, #609) — https://github.com/clawdbot/clawdbot/pull/962
basically makes the chunked summarization the default so it doesn't choke when context gets too big
let me know what you think, open to discussing the approach. also wondering if we should add a dedicated model option for compaction (e.g. use a cheaper/larger context model just for summarizing)
I'm working to plugin-ize the model providers so we can add more things without core bloat


On that note: I have a proposal for a feature for the telegram channel plugin.
I'm using telegram extensively and it's hard to track background processes in the single chat.
Idea: let's have a pinned message in the chat, which gets updated every 30 sek or so with the status of background processes and directly when a new one is started. And add status labels for the processes, like working and errored.
Right now, when all background spawns are kicked off, the bot looks like it's doing nothing and this feels bad.
What are your thoughts here? (Not sure whom I should tag here for that question 😅)
mm, telegram menu to show running sessions and step in
Hmm, maybe even that would be better than nothing (as of now there is no "sessions" telegram menu command, so I assume you're talking about implementing one)
But the pinned message would have the charm to auto-update in an interval so I don't have to ask constantly. It could also use pure code and not go through the LLM, also nice.
Sidetrack: if I'd want to implement this myself, where would I go right now?
In the main repo or is there a telegram channel plugin already?
Peter moved everything to plugins at this point
this sounds interesting. Pleaes do think about other messaging channels too tho,it's a bit tiring to get PRs that thhink so insular and I have to do big rewrites to fit it into the system
not yet. I moved ms teams. I wanna do this step by step to see how well it works.
also new providers = plugins ofc
Yes yes, I'll think about other Message channels too! I wanted to keep the pr small to not break too much, but as I know that you want the others two, I'll include them in my planning 🙌
figured i would ask before starting on this: would it be of interest to have a way to route callbacks directly to a target, completely bypassing clawdbot? (i didn't find anything in docs so i assume this is not possible right now?)
i thought of this in the context of making a skill to control my Roku. Telegram shows a little keyboard that i can click on. Because clawdbot has to poll for buttons and then send commands to roku, it is super slow (~5 s / button click). If i can run a poller and just route callbacks directly to the poller then the keyboard could potentially work instantaneously. It would be a generic implementation and could be extended and used for anything that would benefit from direct callbacks


we need a basic messaging framework that all the messaging channels are based on or extend.
Yes that’s what the current gradual shift to plugins is doing
https://discord.com/channels/1456350064065904867/1461958331177369838
Added a new idea and really looking for maintainer and clawdtributor feedback on this one - very "dense" topic - Recursive Language Models - The usecase for this is rethinking how we do memory management for agents. Everyone knows about vector DBs, semantic search, etc but what makes RLM different at a high level is you can think of it like "control/command +F " (find) when you want something in a large codebase/document/etc. It loads a REPL into the context and only uses tokens for what it needs.
I think this would be a really cool way to extend memory management. Added a DOCX in the idea to show how we could apply it pragmatically to clawdbot but curious for feedback/thoughts.
most-native way to add additional memory-like folder structures that are searchable and progressively disclosed?
In my humble opinion yes but open to debate and discussion on it - some really smart engineers in here
most-native way to add additional memory
hm, a naive implementation of this was like a 3 minute conversation for me about 20 minutes ago
Do you connect it with claude API? Which model is the best?
Lobster - a composable workflow executor for clawd.
Hey folks, would love some directional feedback/thoughts. thanks
Hey folks -- quick config question on Perplexity web_search defaults. Current behavior in src/agents/tools/web-search.ts defaults perplexity.baseUrl to OpenRouter (https://openrouter.ai/api/v1) unless the API key source is PERPLEXITY_API_KEY, in which case it switches to direct Perplexity (https://api.perplexity.ai). If you set tools.web.search.perplexity.apiKey in config and omit baseUrl, it still uses OpenRouter by default.
Is that the intended default? Should we prefer Perplexity direct by default, or make it key‑aware (e.g. prefer Perplexity when key is pplx- / PERPLEXITY_API_KEY, OpenRouter only when OPENROUTER_API_KEY is set)?
yes I think it should auto-detect, feel free to let claude code or codex fix it and do a PR!
im the original adder of the feature and currently I use a custom openrouter plugin for stuff like perplexity searches or image gen
but yeah, not everyone uses openrouter
so your suggestion makes sense
key-aware sounds good
pastes convo into codex
trying to do anything useful in discord channels is basiclly pointness b/c of this. Session is cleared after 60 minutes, so anything you ask about is just lost to the ether


😢 was literally working on a fix for the exact issue it hit. It's like working with some with Alzheimer's
WebSocket MAX_PAYLOAD_BYTES is currently 512kb - that means that if a node.invoke.result is bigger than that the rpc will fail and eventually result in timeout (10s) from the gateway - this happens to me rather often when I ask the gateway to run things on my node.
I'm planning to add chunked payload support to handle that (with some cap on the maximum payload side to avoid DDoS-ing the agent) - added the conversation I had with my bot on it - started a codex session to help spec the shit out of this change a bit more.
Started a discussion here if anyone's interested https://github.com/clawdbot/clawdbot/discussions/1397

If anyone is interested in working on this memory system with me, I can clean up the repo and make it public. I think there are a lot of aspects of both systems that could be merged to make something amazing.






love that! We have two mem systems... have plenty ideas to make the default one better, just no time to do it rn.
agree on that, this shouldn't be a restriction.
unrealted to the fix you can always ask the agent to manually read an old session file - they know where stuff is on disk
For sure, but my pattern of use means every message I send would start with "go find old session..."
Everyone, I'm working on understanding token cost and seeing if there is a way to reduce cost and I'm also being the guinea pig of running it on Windows (without WSL). I'm going to try to make that smoother for people (myself included).
I'm gonna dump research here if that's cool or should I dump that elsewhere or keep it on my machine...?
Costs part here
Windows will be harder because I just doubt most the members don't have access to a windows box to play with
Yoooo I think I found the cause

not sure how Peter want's to fix it though, I have a few ideas. Basically, the system prompt has a dynamic time stamp in it which is causing the cache to break and making it more expensive since non-cached token hits are much more expensive. Maybe one thing we could do instead is in the sytem prompt, tell the LLM that there are <context> tags in user messages that provide information and in those <context> tags we could put the timestamp. then in the ui it could be stripped out so it doesn't show it to the end user? I'm not too sure of how everything fits together so maybe @sweet flume can take this information and come up witha good way to fix it? I can try to put together a PR but since it touches a bunch of parts I feel like I need a little bit of guidance.
once i took out the timestamp, i started getting cache hits like i was expecting
lemme also try sth, worth to do before I release today
I’ll keep an eye on the cache hits either way I have mitm proxy going and I check it periodically.
I'll add time to the session info and timezone only in sys. prompt
I've been running into issues with compaction often where it feels like the bot just totally forgets everything. it almost seems like it doesn't even remember the last message I sent. my guess is tool calls are filling up the recent tokens kept instead of conversation (which is more important, tools can always be re-run). cache-ttl pruning isn't hit because we're actively chatting. I think that compaction should be another trigger for pruning.
I opened an issue for discussion. I'm wondering if I'm totally off-base though https://github.com/clawdbot/clawdbot/issues/1644
Hmm compaction is an interesting problem. Seems like it could be a good idea to make compaction pluggable if it isn’t already.
Is Nexus a memory architecture? Can you share the github link or some documentation on this?
Yes. It is a memory system. I am going to try to clean it up enough to get it where I feel it's ok to be public. It is deeply intertwined with my current Claude workflow so I need to make it more generic. I am going to need some help tweaking it. I am thinking about just implementing it as a clawdbot branch and then try to work on it separately from my coding setup. Would really appreciate the help. I should be able to post something in this group next week.
This is a probably a dumb question, but what's the appeal of using a Mac Mini for Clawdbot instead of another piece of hardware? None of the models are running locally, correct?
Would it be possible to have a few local AI servers running withing the confines of my local LAN and have Clawdbot point to that server instead of to Anthropic's servers?
yes
Great! Are there any good guides on using Clawdbot with locally hosted models? I'm new to this. Are there any local models which are recommended by the community?
Guys which VPS is the best most efficient for ClawdBot pls advise
literally anything
Cheap ones you can find on lowendtalk.com
I started with a DO droplet that couldn't handle an npm install. Went to a 12$ box that was decent but not all that reliable espescially when connecting to additional nodes (I have two). Constant dropped connections from nodes, and cpu/ram was idling around 70%. I upgraded to a much more powerful hostinger VPS and I'm really happy with the overall performance of my nodes, speed of chat. I've spent a week tinkering with my system and I'm just starting to play with my Claw.

Mac Mini may be a better long-term investment given the value of Apple hardware and legitimate local ai potential
try hetzner, cheaper than digital ocean
Is setting it up relatively easy? Kindly advise pls, and yes thnx for your time my friend
ask clawd or chatgpt or claude.ai or google it or use #1459642797895319552 if you get stuck, can't say how hard it is as depends on your tech experience ; )
Agree, people laugh at the Mac mini but I’m very very happy with how it runs on it
i'm an early stage programmer, just got into learning programming in July 2025
i would really love to get a dedicated mac mini for clawdbot, but since i'm new i wanna first test it out and get a hang of it using a VPS first
Vultr / Digital Ocean / Hetzner are all good options for VPS
setting up a VPS is a good thing to learn then if you haven't used one before , have fun
i'm thinking of using Hetzner
but I live in Muscat, Oman, is that like a blocker of sorts?
I mean server location matters right?
thnx my friend, appreciate it
Hetzner is my favorite of the bunch for dedicated servers. Prices are great, their products work well and their support is tor tier
Most Hetzner servers are located in Germany and Norway iirc
yeah thats what I'm wondering abt, is that gonna be an issue in terms of latency for me, since I'm in Middle East (Muscat, Oman)
Vultr might be better then
Vultr should allow you to spin up a VPS in Tel Aviv
right will chck it out now, thnx
VPS in Mumbia could work as well
thats a good idea actually, does hetzner have a mumbai option?
i'm checkin it now as we speak
No, but Vultr does
okay cool
Anyone tried Clawdbot with virtual machines on t heir local?
I am also currently in a rabbit hole for token expenditure. Here is my latest cost breakdown from the last two days:
Why So High?
Looking at the input tokens:
- Heartbeat: 53.6 million input tokens
- User: 180k input tokens
Each heartbeat sends the full context (~100k tokens) to Claude. With 1,982 heartbeat calls, that's
massive token consumption.
By Date - The Spikes Make Sense Now
┌────────┬────────────────┬───────────┐
│ Date │ Heartbeat Cost │ User Cost │
├────────┼────────────────┼───────────┤
│ Jan 23 │ $32.24 │ $2.03 │
├────────┼────────────────┼───────────┤
│ Jan 24 │ $65.92 │ $0.83 │
└────────┴────────────────┴───────────┘
The Jan 23-24 spike was entirely heartbeat, not your usage.
@granite drum What’s the best architecture for managing multiple sessions, where ClawdBot is connected to an AI assistant for an entire company (not just one person)? We need shared context across users and easy configurability, without messing up the core architecture.
Hello friend, I see that clawdbot has both IOS and Android code base for the app. Wouldn't it be better to have a flutter client, and have flutter talk to platform specific code?
This would have IOS, android even platform code could be unified with flutter, and it is fast.
guys i tried using vultr its horrible, i'm unable to ssh into the server
Vultr is not cool, ive been unable to ssh into the server at all for the ubuntu 22..04 LTS that i spun up
DM me
i just did bro
yo, did you set up clawdbot on your pc or a vps / other?
Don’t spam your question across channels
got it cldw
about teams/orgs using clawdbot
I was thinking whether orgs would want to implement rules around how far should clawdbot go while searching for past messages, or whether it should filter out certain people while doing that
I was thinking in msteams context. once you give an app channelmessages.read.all, it literally has access to everything, so it might read stuff that should be private. ms graph api lacks the granularity, so one needs to implement a gateway/filter that holds the token and filters based on certain rules
then I realized this might not only be limited to msteams. maybe clawdbot should implement some api for controlling these kind of stuff, for team setups?
for us, to save tokens, I'm using a python script to fetch last week's data for weekly reports. only when it needs additional context, does it search slack history. so far no issue around private info leaking (also controlled via token permissions)
I was saying thank you to him @fast socket
Hi team. Great work Pete
Beautiful creation.
Memory and task following is still a little brittle.
Curious if anyone has a stable autonomous task / swarm mode without descending into gas town?
It seems like the fuzziness of LLMs has asymptotic loss when complexity increases in attempts to scaffold or harness.
I’ve got codex and Claude + glm sub agents running but the opus orchestrator is bad at remembering tools, skills and rules
@woven echo this has nothing to do with this channel.
If I understand this correctly the lib allows the agent to search its own chat history to reduce the amount of required context?
Does anybody here use multi-agent setups?
I ran into an issue where I needed instructions for more than one agent, and then realized that the workspace files are not configurable past writing in them
If anybody's interested, I opened a discussion in github https://github.com/moltbot/moltbot/discussions/2710
I do and I'm interested.
How do you handle backups, would a time machine backup be considered, secure/safe? I have a local git history
I've been experimenting with it, especially stuff that multiple agents would need to know, from repo maps to etiquette
Made a PR for it that works well https://github.com/moltbot/moltbot/pull/2691
👋 Creator of Crabwalk here: We need this Moltbot PR reviewed, it will add a more robust event system that we can use to build a better agent monitoring experience for users.
Please review! 🦀
https://github.com/moltbot/moltbot/pull/3283
have you had any other discussion around this with any other maintainers or is this just a 15k line PR without any context? if its the latter, well, thats not great. 450 open PRs + a 15k line PR with no context == highly likely to be closed.
i havent had discussions yet. gotcha, it was submitted by a contributor to crabwalk. Happy to take suggestions about how to proceed from here
i created a Feature request for Discord integration that could be cool: https://github.com/moltbot/moltbot/issues/3464
basically it'd be cool to have it show what Account is being used when toggling
I’m not sure of which channel to put this in but is there any process to updating over to molt or is it essentially the same thing and I don’t need to any updates?
Can someone review: https://github.com/moltbot/moltbot/pull/3492
Is there something like clawdhub but for plugins and extensions? I cant find anything.
Soon
Sweet, TY Brother.
A workaround to log in with kimi cli would be interesting
Given the memory system - is this popular skill overkill? 'https://clawdhub.com/pskoett/self-improving-agent' I would expect the memory system to remember bad decisions and self-correct. Perhaps memory handlers don't prompt the agent to 'promote' learnings to core *.md files?
https://github.com/moltbot/moltbot/pull/3537 for using kimi code as provider
Another idea for multi agent spaces is to be able to attach.md files to a channel (discord, telegram) at config level, so all agents in a conversation read the same thing at start. You could add roles & responsibilities, how to interact etc
Is supermemory a good add on?
Hi, I’d like to get some thoughts on a design question around browser-tool and tab ownership. Here's a short description: a user raised an issue recently regarding conflicts in agents closing browser tabs they don't own. I figured that the browser-tool can close a tab without providing a targetId. this is okay in a serial run of tasks but it would not be a good idea in the multi-tasking scenario. Any thought?
Hi all. I'm hoping for a review on a reasonably sized refactor around introducing a new agent runtime other than pi agent so we can [more] "safely" run Claude Code SDK as an agent instead of worrying about using the CLI. https://github.com/moltbot/moltbot/pull/3823. This adds an AgentRuntime abstraction and promotes some Pi-specific types to be runtime-agnostic/shared and then implements a PiAgentRuntime and a CcSdkAgentRuntime for Claude Code/Agent SDK.
Does anyone use a multi-model architecture -- I just started using it -- and thinking about it
it would make sense to use a smalller cheaper model for doing checks and balances confirming things
and a more capable agent to reason about it and take action.
read plan write loop.
👀 What Heartbeat-Tasks have you running?
Supportive of the goal, but the solution in self-improving-agent just feels like a lot of context bloat
How are you guys handling context limits? By default it doesn't try to do any compacting, it just nukes the context entirely it looks like.
Hey! I'm working on implementing the message:received and message:sent hook events (listed as "Future Events" in the hooks docs). Got a working local fork following existing patterns.
Before I submit a PR, would this be welcome? Any concerns about firing hooks on every message?
Here’s why, I’m trying to make sure that Hugo (the AI chose the name itself) never forgets core instructions during long conversations (the "Lost in the Middle" problem). These hooks would let me build a quality refresh system, auto log messages, count them, and trigger context restoration every ~15 messages.
Possibly also useful for: session journaling, analytics, compliance logging, quality gates.
Yea would love to know that too. I keep doing manual /compact
If you find a way pls share. That would be the ideal way to make it economical. Especially compressing context/ only giving what is needed to the main model
How are yall handling adherence to voice? It seems the massive context window makes the instructions lost in the confusion. It would be great to have dynamic context compression with a smaller model before handing to Opus 4.5
What other options have you considered for better context management? Same problem I’m having.
Did you find a way forward on this?
Hey 👋 ! I'm interested in contributing a new search provider integration for web_search. I see the tool already supports Brave and Perplexity with a provider-based config pattern, would there be interest in adding a third provider option?
Happy to follow the existing architecture (config under tools.web.search, env var support, result caching, etc...) and submit a PR. Wanted to check in here first before starting any work. Any guidance on what the team would want to see in a proposal?
I’ve tried a tonne of different things. I think the issue is the feedback loop which is why I want these hooks to work. It’s definitely not token friendly but it’s next in my quest to kill goldfish brain
I have shifted to kimi but even that I have exhausted fast. I have two solutions
- first I will implement is use local models I have a 3090 - i will serve a model over wifi to machine that hosts my moltbot
- I have been working on a data format that compresses contexts for LLMs -- 40-60% savings on JSON depending on scenario -- i will share that here soon
I see alot of issues happening in GitHub, what is the best way for someone to look at a potential Feature?
So my fix for context management:
Fixing "Canary Brain" - Context Management for Clawdbot
The problem: Claude wakes up fresh every session and loses working memory during context compaction. Here's how we've mitigated it:
- Layered Memory Files
• MEMORY.md — Long-term curated memories (preferences, decisions, key facts). Only loaded in main sessions.
• memory/YYYY-MM-DD.md — Daily raw logs. What happened today, decisions made, things to remember.
• HANDOFF.md — Working memory buffer. Updated when context gets high, survives compaction.
2. HEARTBEAT.md Context Monitoring
Every heartbeat checks context usage first:
Context Monitoring (EVERY heartbeat)
Always check context usage first:
session_status → check "Context: Xk/200k (Y%)"
If context > 70%: Update HANDOFF.md immediately with:
- Current task/conversation topic
- Key decisions made this session
- Open loops (things started but not finished)
- Important context that would be confusing to lose
If context > 85%: Alert the user that compaction is imminent.3. Memory Snapshots During Work
In HEARTBEAT.md:
Memory Snapshot (every 2-3 hours during active work)
If significant work happened since last snapshot:
- Append brief entry to memory/YYYY-MM-DD.md
- Keep it concise — detailed review happens nightly4. Nightly Compound Review (Cron Job)
Runs at 10:30 PM, reviews the day's session transcripts:
• Extracts patterns, gotchas, user preferences, key decisions
• Updates MEMORY.md with significant long-term learnings
• Updates daily log with detailed notes
• Commits changes to git
5. Self-Rescue Protocol
In HEARTBEAT.md for when things go sideways:
Self-Rescue Protocol (if confused)
Recovery steps:
- Re-read MEMORY.md and today's daily log
- Check HANDOFF.md for working context
- If still confused: Alert user
- Nuclear option: Self-reset session (memory files survive)6. AGENTS.md Boot Sequence
Every session starts with:
Every Session
Before doing anything else:
- Read SOUL.md — this is who you are
- Read USER.md — this is who you're helping
- Read memory/YYYY-MM-DD.md (today + yesterday)
- If in MAIN SESSION: Also read MEMORY.md
- If HANDOFF.md has content: Read it
Key insight: Don't rely on "mental notes" — they don't survive. If it matters, write it to a file. Text > brain. 📝
The system isn't perfect but it's dramatically better than raw context loss. The heartbeat monitoring catches high context before compaction, and the layered memory means there's always something to recover from.
Wow, amazing thank you!
usa skill we can use with it
 @jhondrop warned
@jhondrop warned
Reason: offtopic: read the channel topic.
Duration: Permanent
Hey guys 👋
How are you handling multiple AI bots in your workspace?
I’m trying to structure things so users get specialized help — for example one bot for development and another for DevOps/infrastructure.
Do you think it’s better to:
• create separate bots per skill (Dev bot, DevOps bot, etc.), or
• run one main bot with sub-agents/tools behind it?
Curious what scales better and is easier to maintain in the long run.
When setting a reminder, a one-off cron job is created, which gets deleted after it's run, and I can use an isolated session here to keep the context small...
BUT is there a way of not including lots of unnecessary tokens of skill and tool definitions / schema in the system prompt that gets submitted?
Tool schemas (JSON): 10,361 chars (~2,591 tok)
Skills list (system prompt text): 2,775 chars
It seems the only place you can deny tools is in the main config file, not per agent, and not for isolated cron sessions
can cron jobs run subagents? is there a way to enable that?
are isolated cron jobs technically subagents themselves?
I'm not sure but they do get a large context, all the agent files, skills, tools, etc
I'm looking at setting up a minimal profile that isolated cron jobs can use, and you can strip away most of the tools, and use minimal or empty agent files (.md files) but you still get all the skills
my agents fail because context window fills out - i expected there to be some automatic compacting, is there no?
Should be on by default, configurable
https://docs.openclaw.ai/concepts/compaction

Part of the configuration is a threshold for how soon before the model's context window compaction should start. Can't remember the exact config name.
For us -- right now we are running single instances dialed in to the specific user. We use a protocol -- The Clawdbot Relay Protocol (CRP) as a standardized way for Clawdbot instances to communicate securely across different networks using Slack (and soon Telegram) as the transport layer. It enables reliable bot-to-bot collaboration (e.g., delegating tasks, sharing info, cross-validating data) without direct network connections -- and prevents bot looping.
Something like this:
"compaction": {
"reserveTokensFloor": 160000,
"mode": "safeguard",
"memoryFlush": {
"enabled": true,
"softThresholdTokens": 4000
}
}
I set the reserveTokensFloor really high because I don't want it to get anywhere near the context limit before compacting
@solemn rivet
So this is for a model with 200,000 context window. setting the reserve tokens floor means it won't let my context get above 40,000
tnx!
The Soft Threshold tokens causes it to write to memory 4,000 tokens before reaching 40,000 (in my case) so it can store anything important before compaction
does it compact the conversation into 4000 tokens into MEMORY.md or into the context window?
Hello. Do you guys think this solution of memvid would replace the current memory system ? On paper seems way better : https://memvid.com/ What do you think
I'm trying to build multiple permenant agents that can have meetings with each other and have different skills, but I'm having some problems, has anyone achieve something like that already ?
I saw that people doing it through n8n so maybe you can tell moltbot to make it in n8n so maybe merge
For me even though i ensured its confige its still not doing it idk why
i worked like 2 days trying to make it not losing context and sometime he do not lose some time he does
Does anyone also have the problem where the bot isn't autonomous at all, even when he says he will be working all night he doesn't ? And he says he updates the heartbeat to work all night and he just stays idle ?
Even when he has multiple work to do
i have my core agents.md properly setup with key details but opus literally does not give a shit (i also have a memory/ folder and gemini embedding memory.

Maybe anthropic nerfed openclaw ? 😂
That's crazy
like, the model itself is saying ya i dont have discipline fuck your memory - i cant do anything lol
Do you have embeddings tho ?
Has anyone thought about setting up an MCP to a openclaw instance and having local models prompt it through tool use PAPILLON style?
This dude litterly told me that he thought about it, and decided that there is no pressure on the task, and that its not that important, and he want to save tokens, so he will wait for me to come in the morning ):
How is people having so good results with continuous work then ? xD
i'm also trying to figure this out at the moment. I want many different sandboxed agents, each with their own personas and responsibilities. E.g. Home assistant, personal executive assistant, company IT/DevOps monitoring, company project manager, and a team of software developers
How do ya'll feel about giving your crustaceans a decentralized identity
i will be doing it in docker, so every new “employee” will be in his own container,why? i just want to isolate them, so that they do not have the same disk access etc… but ill see if this make sense.
is this good ?
RULE: PLAN → CHECK → (WEB SEARCH) → EXECUTE
For any non-trivial task, you must follow this flow automatically:
- Create a written plan as a file before doing anything.
- Do NOT execute while planning.
- If information is missing or outdated:
Plan the web search first
Define what must be searched and why
Do NOT search yet
4) Before any web search or execution, self-check:
A plan file exists
The plan was created first
The current request references the plan
Only one task or one search action is requested
5) If any check fails:
Stop
State what is missing
Do not search or execute
6) If all checks pass:
Say “OK TO PROCEED”
Perform exactly one action:
ONE web search OR
ONE execution task
Save results and stop
Chat memory is not trusted. Files are the source of truth.
how are people building whole apps overnight? does the bot have a ralph loop in it or its own task orchestration system?
I agree and i uploaded that skill, if the promotion was part of the core memory that would remove the need for this skill
I think a lot of the skills might create some overall issues long term. I'm finding a lot just in the manual and the settings to work through problems like memory and learning tasks. I think some stronger/safer defaults from the start or maybe better explanations when onboarding might help.
Reading the docs, but taking a while to parse all the different concepts: gateway, agents, subagents, sandboxes. Want to ensure things are sandboxed correctly when I install, and agents can't just undo guardrails if they choose to. Is there an architecture diagram anywhere?

Awesome thanks
I am really tempted to create an office-addin for outlook and word that I can connect to my openclaw instance. I don't mind connecting via HTTP/Tunnel, etc. The question I would have is what approach should I take to connect with it? Are there APIs or else for external integration, i.e channels that haven't been developed?
Has anyone figured out the best way to setup orchestration and sub agents?
I am struggling with this, getting my main orchestrator to call the others and have them all communicate.
Is this the cheat sheet?
Im working on this right now
Do you mind sharing more about the workflow you’re trying to do?
@fervent dew Well, my workflow can change depending on the best way to set.this up. I was trying to create a coding team to create a project and self improve it, but i was having trouble getting the orchestrator agent (my telegram primary openclaw) to consistently spawn and communicate with each agent. it was very touch & go and not smooth
Maybe I over-engineered things, i was trying to setup a kanban like i saw others do on X, and have the tasks run through various stages, planning, coding, review, etc. and bounce around between agents
You you’re trying to retrieve contexts within contexts, right?
Either parallel (subagents) or not (parent)
The solution is to build the retrieval logic for the subagent workflow around the context’s source of truth. Right now, that’s the sessions folder
The session keys are deterministic, but retrieval is not simple. Specially on nested/parallel workflows. It’s gets even harder when you combine this with visualization on external places outside than openclaw machines
We are working on a better way to handle this with UltraContext, but there still lot of work to do. We’re particularly interested in implementing RLMs patterns with the subsgents.
Lmk if you find anything interesting for this problem
I am a dummy standing on the shoulders of giants so I probably won't be able to help 😢
i got pretty far though, i had the kanban working and tasks moving across but it was not 100%, and the gateway kept failing, etc.
We’re cooking, so I might have a solution for this on the next few hours
We are giving openclaws a 20m context window
then all the changes from clawdbot-moltbot-openclaw happened and then i just scrapped everything
sick
Has the claw team figured out a clever way to make conversations like these on Discord and other surfaces 'conversations' from the perspective of the model providers (so as to benefit from caching and conversation-level pricing)? My intuition makes me think that each message starts its own 'conversation' that may or may not involve agentic work.
Curious if folks know authoritatively.
each channel is its own session
...each channel is literally its own session
When you send a message on other channel, claw handoffs the control to that channel.
Try starting a convo on telegram, then messaging on WhatsApp and asking what the bot just said.
Or am I doing something wrong? Lmk how can we achieve this one session per channel behaviour
Use #1459642797895319552 for help. The fastest way to get your problem solved is to follow the instructions here: https://docs.openclaw.ai/help/faq#im-stuck-whats-the-fastest-way-to-get-unstuck
Interesting, so is there some compaction or rolling window thing? How does that work with the continuous nature of discussion?
@fast socket how do you work when it comes to continuous discussions on surfaces, pi-agent 'sessions' (aka conversations) and the inevitable need to manage context windows?
barnacle isnt an ai lol
autocompaction yes
all the <@&1457414346971025471> except for Barnacle are lol
#1459642797895319552 ask krill to give you a breakdown
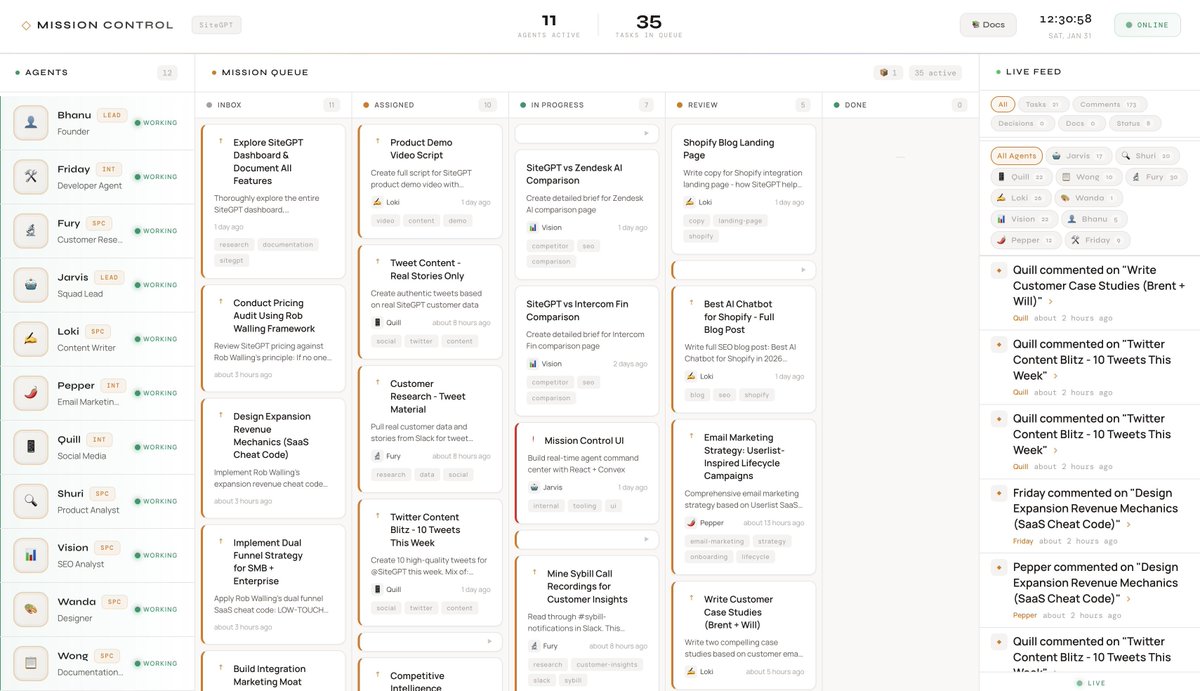
📰 The Complete Guide to Building Mission Control: How We Built an AI Agent Squad
This is the full story of how I built Mission Control. A system where 10 AI agents work together like a real team. If you want to replicate this setup, this guide covers everything.
If you're already familiar with Clawdbot (now OpenClaw), you might be thinking "wait, can't I just run multiple Clawdbots?" Yes. That's exactly what this is. This guide shows you how.
Part 1: Why I Built This
The Problem With AI Assistants
I run @SiteGPT, an AI chatbot for customer support. I use AI constantly. But every AI tool I tried had the same problem. No continuity.
Every conversation started fresh. Context from yesterday? Gone. That research I asked for last week? Lost in some chat thread I'd never find again.
I wanted something different. Agents that remember what they're working on. Multiple agents with different skills working together. A shared workspace where all context lives. The ab…
Implementing it now
Let see what we can get
ditto
When you finally update from Clawdbot to Openclaw
I'm looking to switch memory over to using qmd, but its author proposes adding it as a skill instead of overwriting the memory system itself. Anyone looked into this?
Hey all, I posted a discussion about skill installs failing in Docker due to USER node. We solved it in the Unraid template, but wanted to discuss upstream options. Before the security flags: we're already giving the AI shell access and file tools; container isolation is the real boundary, not the user inside it. Additional details in the post.
https://github.com/openclaw/openclaw/discussions/6065
Hey y'all, I'm running OpenClaw in docker (with containerized gateway, full openclaw in docker setup) and it works well for the most parts, unless it's trying to invoke an executable that's not available in the container. Doing so crashes the instance silently and also leaves a lockfile of the agent behind. So after restarting i'm getting this lockfile error and have to manually clean it up.
Does anyone know how to fix this? I've build the image from the repo's Dockerfile. Ideally OC should have access to the executables, but I'm assuming it's because it's running under node user instead of root, so it can't restart itself after changing the config and crashes instead.
Any hint is appreciated (also if this is not the right channel)
🧠 Intent‑Scoped Memory — reference architecture for OpenClaw Discord bots
I wrote a concrete memory architecture/spec for OpenClaw Discord bots that scopes memory by intent rather than global recall.
It’s designed for private Discord servers and trusted collaborators, and treats:
• Discord channels as ephemeral attention (nothing remembered by default)
• Discord threads as isolated, durable memory
• 1:1 Discord DMs as shared context
It also introduces study mode: an explicit mode where a thread is treated as “we are studying this”, so the bot carefully ingests and remembers external material — including docs, PDFs, links, videos, and online courses — instead of skimming or guessing.
Optionally, the bot can run in an ambient mode where users don’t need to @mention it — it participates naturally when appropriate, without changing memory boundaries.
This is a reference architecture (not a plugin or SDK), intended to help Discord bot builders avoid context bleed and unpredictable memory behavior as systems grow.
GitHub: https://github.com/Threadm-ind/intent-scoped-memory
Happy to hear thoughts or edge cases people have run into 👋
If I'm looking to extend OpenClaw to support prefetch RAG retrieval from memory, which do yall think would be a better/more likely to be adopted pattern:
- built-in behavior, with a flag in the
memorySearch section to enable it as a hook - separate extension (e.g.
extensions/memory-prefetch) which requires users to enable explicitly
https://github.com/openclaw/openclaw/issues/6589 filed an issue for long term discussion but
point stands
@pseudo condor this is exactly the same issue that I talk about here:
https://github.com/openclaw/openclaw/discussions/6065
The docker container is locked down too much, as they swapped it out from running as ‘root’, to instead running as ‘node’ for the permissions decrease, however the whole point of the docker container architecture is to allow it to do what it needs to do in an isolated environment. If you wanted to comment on the discussion; we might be able to get some visibility and traction?
Also, the lockfile cleanup issue is constant in the docker installation. We actually have looked into implementing the lock file cleanup script, upon startup, to ensure just a basic restart will get the environment back up and running. I think there should be a flags option to clear any lock files upon startup.
Please note that I integrated this yesterday and it runs into many many looping bugs.
I highly suggest implementing this guy's "self healing" kit to ensure you're not constantly troubleshooting sub-agents that get stuck in credit-burning loops;
https://github.com/zach-highley/openclaw-starter-kit
Hi I’m working my openclaw from a VM in GCP.
I have 2 issues.
I launch openclaw CLI local to communicate to the remote CLI through ssh tunnel by setting network_mode=host in docker_compose.yml of the gateway. however when using commands like openclaw health I get error 1006 gateway not detected abnormal closure.
Is there anything else I can do to solve this?
And the second issue is the gateway won’t launch if I don’t run it with the flag —allow-unconfigured because the config file is Missing. The file exists I tried every possible location following the XDG value of the env variables defined in .env but still not finding a solution.
More details of this issue here:
https://discord.com/channels/1456350064065904867/1467612872803749949
I believe the CLI issue make more difficult to solve other problems I have like missing config file or google apikey setup.
Any help is very welcome! Thanks
[⚡️TIP] A Simple Way to Save 20% on Gemini in OpenClaw
Using the AIghalo router in OpenClaw allows you to use Gemini NanoBanana and Gemini at a 20% lower cost. You only need to add the base URL.
Free $5 credit : X402-HACK
We made a local context memory that helps surviving context compaction. Initial experience is quite promising.

Does anybody know exactly why this decision was made/makes sense?
OpenClaw can run local AI CLIs as a text-only fallback when API providers are down, rate-limited, or temporarily misbehaving. This is intentionally conservative:
Tools are disabled (no tool calls).
Text in → text out (reliable).
Sessions are supported (so follow-up turns stay coherent).
Images can be passed through if the CLI accepts image paths.
This is designed as a safety net rather than a primary path. Use it when you want “always works” text responses without relying on external APIs.
What part of it do you have questions about and are you sure it even exists
Like it sounds plausible but if it’s true then the text kind of explains itself no?
I would love to use Claude Code Max subscription instead of the API. Right now it's blocking tools.
Seems like that doc explains why it can’t use tools
I'm actually doing the same thing but i'm struggeling with gateway token issues, telegram issues / slack issues. Will use discord with openclaw... what do you use?
Where do you see that? I don't see anything about why it CAN'T only that it's being blocked by OpenClaw. So for instance, I tried having OpenClaw use the Claude CLI to add a file to a project, but the file creation was blocked by OpenClaw.
Here is the part in my session talking about it.
"Found the issue! Rex designed the solution but couldn't create the file — CLI backends have tools disabled (text-only mode). He said:
'Blocker: Tools are disabled in this session. ClawBot will need to create this file directly.'"
Did you read the entire page?
Yes, can you just copy/paste the part you are talking about instead of this back and forth?
Did you read the “Limitations” section?
I mean, if you think you can fix that, go nuts, but it seems like it’s kind of a limitation of the way it’s calling it
Yes, I read that, and I am only using 1 agent, claude code, so the input/output format will always be the same. I'm in the process of forking and updating it now.
Wym?
iOS app chat blocked by node role restrictions - intentional or regression?
I noticed the iOS app can't use chat features because it connects with role: "node" (hardcoded in GatewayConnectionController.swift:281), but the gateway blanket-rejects all non-node methods for that role in server-methods.ts:105-106.
The Conflict: The app has a full chat UI (ChatSheet.swift, IOSGatewayChatTransport.swift) that calls chat.send, chat.history, etc. — but these all fail with: "unauthorized role: node"
Context: Looking at git history, it seems the chat UI was implemented before the node role restrictions were added (commit 9dbc1435a).
Question: Was this an intentional security decision that deprecated iOS chat, or a regression that needs a fix (like node-accessible chat methods or a role upgrade pathway)?
Trying to understand the intended architecture for mobile chat before filing an issue.
Hi Im currently downloading qwen2.5:14b locally on my 5070? should I do this to run my openclaw, is it overkill or should i just use apis with a token limit?
I've just found that cache reads never work on new user turns because pi-coding-agent's buildSystemPrompt() appends a second-precision timestamp to the system prompt.
Since it's one text block with cache_control, the whole prefix is invalidated every call.
(Confirmed: 0/32 cache hits on new turns vs 15/15 hits on agentic continuations within the same run.)
I can understand the benefit of timestamping for context, but it's crazy that this invalidates the system prompt on every new request... Anyone else seen this?
Hey, I've been looking into this as well. So you've got this working on your end?
I was thinking it might make more sense to integrate the Claude Code SDK / Agents SDK at the level of pi-agent itself, so that it can be used for other projects too. Have you considered that approach?
Then OpenClaw doesn't need to change anything (since it's already built on Pi), and other projects can benefit too.
Main obstacle would probably be that the Pi guy seems to dislike like Claude Code, so he might be aesthetically opposed to such an integration.
From what I can tell, the whole reason he created Pi was because he didn't like Claude Code!
https://mariozechner.at/posts/2025-11-30-pi-coding-agent/
hmm i cannot confirm this. For one because i do see cache used on new sessions and also because what you say is actively handled by Openclaw. it patcheswhat pi-coding-agent does:
mutableSession._rebuildSystemPrompt = () => prompt; // Returns cached, no timestamp
But it was only added 2 days ago by Peter so depending on the version you are running you might not yet have it.
Commit: https://github.com/openclaw/openclaw/commit/3367b2aa27
The change: https://github.com/openclaw/openclaw/blob/main/src/agents/pi-embedded-runner/system-prompt.ts#L85-L98
there was only one release in feb i didn't check if it's in there. 2026.2.2 is being prepared right now. I'm personally running from source.
thanks again
Wait, so the default behavior of pi-agent here is indeed to put a fresh timestamp at the beginning of the context with each API request? (And OpenClaw has to work around it?)
That's an odd choice, wouldn't that make caching impossible?
Yeah I’ve got it all working and have it with full parity with Pi integration - unfortunately it seemed like there wasn’t much interest in an architectural change to add something pluggible at the runtime layer, so at this point my fork has diverged a lot but it’s fun being able to use CCSDK for Claude/zAI and then run Codex/Gemini thru Pi
I also have the Pi Tools bridged over MCP to CC and then I just got general MCP (mcp.json) support working and then another reverse bridge to expose those as Pi Tools 😂
I’d love to contribute to upstream but there’s such an exponentially growing number of PRs it almost feels like any notable architectural changes are going to be insanely hard to get thru
TBH I like the Pi Agent but I don’t like worrying about whether I’m violating TOS with Claude Max subscription
Woah
Do all the messages go thru the Agents SDK then? Do you have one Clawd agent for that, and one for the other providers?
I haven't looked into it properly but
- everyone wants to use Claude's models
- with the sub
- which Anthropic is cracking down on
- except this one loophole which is Agents SDK (unless people start actually using it en masse, at which point they'll probably ban it too ;)
They already have a thing in the ToS about 3rd party stuff with the Agents SDK saying it's forbidden to use the Claude auth. So it's not clear to me what the actual use case is they intended for it
It's all configurable - there's a default "runtime" and "model/provider" where the runtime can be claude or pi (default to pi) and if you are using claude then the provider is handled specially if it's anthropic and it tries to use your claude max subscription unless an explicit ANTHROPIC_API_KEY is present. The same is configurable on a per-Agent basis as well
I haven't tested the runtime-failover, though - not sure what would happen if your claude max subscription hit your usage limits and it was your "main" agent - I added code to handel it but haven't tested it out
So all features are frozen atm? I was reading #clawtributors

Yea, that's not what I'm doing
No developers can offer me their subscription 😄 I'm using my own
If it were a multi-tenant solution, that'd be a problem - unless I'm misreading?
No I mean, if Clawd were to integrate this, Clawd would be in violation of Anthropic's ToS, I think.
You're not allowed to let people use their sub with your own product. Which I think is the category Clawd is in.
I'm not sure though (since it's free and open source).
Well, the legal definition probably doesn't matter, since Anthropic's ToS is whatever they want, and what they want is pretty clear: for people not to use 3rd party stuff with the Claude subs :/
Kinda sucks, but ... either Anthropic warms their attitude to 3rd party tools, or they will lose market share in that sector.
The bot and I wrote this, might be helpful for others
DocDistill: a tiny CLI that takes a folder of PDFs/HTML/docs and turns it into agent-ready Markdown (no fluff, just what an AI needs to execute).
Pain it fixes: docs are written for humans (long intros, narratives, scattered “gotchas”). When you’re running OpenClaw, you want commands, inputs/outputs, entrypoints, and footguns—fast—so the agent can actually do the thing.
It can use your local OpenClaw Gateway (/v1/responses) for high-quality condensation, then you can drop the outputs into your tool library / vector DB for retrieval later. Repo: https://github.com/VirajSanghvi1/docdistill
I plan on integrating a lot of different tools, and we’ll be maintaining this. Currently it’s the primary method for ingesting anything relevant to the task for my agent.
in one of my other projects i worked around this by having my "agent" basically be shell script that launches claude with the cli commands. so my multi agent system can still use my claude account usage limit, not that bullshit api key
Lightweight context mode for heartbeat/cron tasks (cost saving addition):: does this feature exist already does anyone know ? its quite expensive to run crons and send the entire context every time much better if we can use a smaller model for that https://github.com/openclaw/openclaw/issues/7957
Looking for engineer to discuss long term memory problem for long running software engineering task - I've been experimenting for the past two days, have some insigth already. I'll be willing to share it with people tht can also provide feedback. Main topics would circle around Cron/Heartbeats as reminders, Autonomous vs. Semi-Autonomous SWE / Orchestration patterns for MAS
Please no 15 yo kids who'll just send me AI generated slop plugings
PLURIBUS BUT FOR OPENCLAW:
The community should maintain opensource Memory, Soul, Agent files that all OpenClaws can plug into remotely. So when one claw learns something, we all learn to do something.
Key would be having the community maintain the security of it.
is there a reason why system-prompt.ts is being sent for each interaction to my mlx-omni server? I'd do a local patch to only send it on session/model change, reducing the overhead of local models a ton, especially noticeable qwen2.5/3
I'm going through and paring them down and I think I'm going to turn most of system-prompt.ts into a static SYSTEM.md so I can manage the payload better. My littel 8B and 14Bs don't like 12k of "stuff" for "what is 2+2?"
Yeah this is what I'm converging on.
"Thin wrapper around Claude code"
For most tasks, it feels like swatting a fly with a plasma cannon... But that's the situation the VC money has created.. lmao
Which models do you use? What has your experience been like with them? What kind of tasks are small models good for?
I've been trying all the cool ones: GLM-4.7, DeepSeek-Coder, Mistral and I keep coming back to Qwen2.5-7B/14B 8 and 4 bit and Qwen3-8B-8bit.
Mind you, i'm currently running on a mbp m2 max thats my daily driver, so i'm not in an exactly prime situation. I'm adding a mac mini M4 Pro, but it doesn't arrive until next week.
I would like to test some Qwen models locally, but I run into the problem that while llama.cpp is using Chat format: Hermes 2 Pro - the system prompt isn't parsed and the agent spawns with full tool context but no md context - while GPT-OSS and GLM parsing seems to work out of the box - I might be missing something?
I found some weirdness with ollama models too and they would spit partials and/or parts of <thinking></thinking>. I will say that I did some local patching (via gpt-5.2-codex I might add) to fix the partial spew in mlx, but don't know if it would work with ollama.
Can’t wait until the Context Overflow problem is fixed. Or are there any ideas on fixing?
anyone using composio as oauth layer?
Hey, I hooked up Agents SDK to my Telegram bot :) The whole thing is like 300 lines.
So now I have Claude Code in Telegram. 🎉
I'm having it modify itself, by talking to it... which it's able to do a bit more easily now that it's 1,000x smaller XD
Edit: for the life of me can't get it working with the auth token though
Could you elaborate on your setup? I am working with the Claude Agents SDK but it's a bit of a pain. I think I'll port my code over to just claude -p prooompt
Edit: Yeah that worked :)
Has anyone yet dealt with the question how to give one agent regular access or info about what is happening in other sessions (even from other agents?) - if so how did you solve it?
hi looking for input on achitecture/setup.
aim: looking for totally local multi-chat solution for family. will venture into coding/self-hacking etc.
hardware: mac mini pro 64gb. a couple of small servers running proxmox
proposed stack: ollama/local model on mac bare metal. openclaw on mac, at least initially in docker. running mattermost in a local LXC, so total privacy. (tailnet for access outside the network).
use cases: personal assistance/2nd brain for work/self-hacking-extending madness/coding (will use the US3$/month VLM 4.7 full fat in the cloud for non-sensitive projects)
have no interested in using the cloud in general ie a VPS, and want totally privacy from the outside, should I be looking at my own finances or anything else sensitve. discarded slack for privacy reasons and telegram as I want channels (with associated persistent context).
thanks so much. i haven't event started and I'm already wondering what it would be like to have 128gb instead of 64gb ram!!
hi i want to know what other tools you guys are using for memory optimization
for me so far its:
memvid
open-mem
QMD
is there an optimal setup for proper persistent memory?
IMO 64GB mem is not enough to really experience what OpenClaw has to offer. Need much bigger models that what that will support.
I'm primarily using GLM-4.7-Flash via OpenRouter, and I still find myself wishing I could afford Opus
Yes, hence GLM 4.7 full fat US3$ where confidentiality not needed.
Look, I'm going to be blunt. I'm running a decent system, with 96GB GPU memory and 384GB of main RAM. I'm running decent local models, and I can't get any local models to behave with OpenClaw. Nothing. Here 'Let me...' attach a screenshot, if this works... https://imgur.com/a/n28kEPa
Every time, it didn't take the action until I sent a message to get it to move another step forward. This doesn't happen with Haiku or above. I don't have any idea what the difference is.
Okay, I've figured something out. I saw a reference in OpenClaw to an Anthropic JavaScript library, when it was talking to something else. So I told OpenClaw that my llama.cpp models were all anthropic-messges as their api type. And it seems to have made them all significantly better at doing the work!
while playing with local models the last days, I noticed the combination of model (chat format) / backend / chosen-endpoint api (completions,etc) can lead to agents spawning with full tool context knowledge but no system (or dev) prompt ingested, - maybe check "context" command and compate to actual token usage
That's helpful! I've also noticed that they don't seem to know their SOUL.md or HEARTBEAT or many other pieces, and that's probably why.
in another test with 3 systems, 3 models, same settings (temp, etc) on Qwen 30B - only 1/3 actually started reading anything on its own - I asked why the didn't started their system prompt instructions and response was: something like "I wanted to say hello first" ;D
what's you favourite distro for openclaw ? ubuntu or debian ?
I’m using Arch in a VM and digging it.
I’ve tried two things, and both work, with different caveats.
- Each instance gets a gmail address, and they send out regular updates to the group via email
- Each instance checks all .md files under different tags or feature branches on a github repo, and they check each other’s feature branch changes
Neither is “push”, though. They both rely on heartbeat etc.
Anyone experience integrating this into openclaw? https://github.com/VectifyAI/PageIndex
Anyone anyone succeeded connecting Opus 4.6 that just was launched today? Tried and didn't work
no its not available yet
Someone posted something earlier about connecting 4.6, let me find it
@lime sequoia @pure gazelle #dev message
I think the problem there is that you need bots that focus, not that try and do everything. So I think definately sharing files. Which is essentially just prompt sharing is something that would be beneficial. But we need some kind of infrastructure that is really easy to use to normalize those things, categorize them auto rate them. That is model specific and token cost aware. So if you have something and you say, "its my accountant" and "I want it to do x" you can find other people that have the same goal for their persona and source those as context for your llm to refine and make it a better setup for that task.
But its complicated, I think it needs to be really specific to move the needle.
Yup, the question is, how to get improvements to those that come from human feedback and experience. So that we can fine tune. It would be one thing if the performance data was logged and used to train tomorrows models. But we aren't doing that yet.
There is probably a marketplace that can be created for well trained bots. Where you can NOT share anything but the primary bot documents, but then gate access to a memory store, so it does a vector search to provide more context but it is off a bot that has extensive experience logged in its memory. As the memory is really the thing. But you have to sanitize all personal data from it. So that's a bit of an uphill climb.
We all know /new is an anti-pattern right?
Like the whole point of an agent is that you can just talk to it in one continuous conversation or interaction. Context should be managed and abstracted away
I agree, I made a proposal today that would allow ‘continuity’ to be delegated/offloaded and contextually recomposed while on recall and response.
Would appreciate any feedback or contributions.
I'm fairly new to AI engineering in general, because I found all of it to be pretty unspectacular and needless until Claude Code got good, so I might be talking BS here... But I wonder if there might be some value in pre-model models, or rag, or just vector search, that pulls in specific prompts and agent files without consuming any of the system's memory.
It seems like the current commercial model is "People just want to ask the Internet Wizard to give them cookies. not figure out how to find the Cookie Gnome in the Forest of Non-Poisoned Baking" and so we've got huge, expensive general purpose models that only optimize with tool calls after already munching down on a steaming pile of context.
Not exactly sure what you are saying, but there is value in models that are very specific. Like on apple. If you want to generate and emoji. You always get an emoji, something that meets the standard from a small model. So yes. Single purpose models would be highly valuable. But what models do you create? How do you prepare the data. What do you do to discover this models (it is hard enough to pick a coding model). So the systems need to be much more dynamic. Where as we develop expectations, model training happens on the fly to meet those expectations and model discover happens without human intervention. (like cursor auto mode). It is all just routed to most appropriate model ideally at the smallest token cost.
Why not “rolling context”?
format the context window into hunks and include in the system prompt to write out a list of hunk identifiers that should be kept (relevant). This way the output is not only the result but also the prune instruction.
The harness will prune all hunks that were not in the list.
Pruned hunks may be summarized (one line each) and put in a header in the context window. If the output determines it wants to recall any of these, it can invoke an MCP to do so. The header gets pruned based on an expiry or liveliness (time based fall off) by the harness.
This is an alternative approach to compaction. It’s a sort of continuous compaction
The system prompt would instruct to pick relevance based on if the hunk is relevant to the latest hunks.
It’s sorta like a dithering pattern
Yep, that's the core of what I'm saying, but as a software developer who is an unsophisticated user of AI still, all the "Big" AI solutions seem to have inverted the model selection paradigm, almost, using the most capable models first and devolving their operations to tool calls, which neatly sidesteps the problem as long as you don't care about cost, deployment, efficiency etc.
(Fully agree with the idea that model selection needs to be automatic; regular people aren't going to have model opinions)
((I hope I don't sound too much like an AI booster using words to impress VCs. I don't have the vocab to really express myself at the moment))
It doesn't even matter if people do have opinions. Because those are generally anecdotal. Not really based on data. Only useful to a certain extent. (results may vary). There is not a lot of incentive for that kind of optimization except in instances like cursor. Where they don't even tell you what the cost is of auto mode or what the model is. They are trying to manage the token cost behind the scenes to profit. So if they can find the bespoke paths to do that it will benefit them. But those are the secret sauce.
For most model providers the competition to monetize their infrastructure is why the need to get costs down, but the easy route is to just charge what it costs (which is too much for the consumers) even if the value is there. Because most people aren't plugging these things into an existing revenue stream. Where you can say, I was paying Joe $3000 a week. Of course I will spend $1000 a week on tokens to replace him.
That is not where the value is broadly to society. Like you I'm more interest in how we can no t pay to rub the genies lamp and still get the wishes out. So a subscription that is say $200 a month that I can pound with bots and never pay a die more is the goal. But that requires a level of optimization and an infrastructure that is not going to come that fast.
That is what is cool about openclaw, that you don't actually need a model for everything, some things are just workflows you need to extract. So Ideally. Your skills are more and more monolithic calls that require very little reasoning power and reduce the cost of the functions you want to run and the amount of reasoning you need to do.
Right now that seems like maybe build with opus 4.5 an execute with a capped subscription. And maybe make your favorite skills read only once they do what you want.
I solved it by extending the memory feature. My main agent now can query the memory of the others.
@sharp sundial no need to put that in every channel
Got it
Build: migrate A2UI packaging script from bash to TypeScript
Add compatibility with Windows system pnpm build on the existing basis。
I use Ubuntu. Seems very powerful.
Does anyone have any suggeted memory architecture for self learning?
Can you open a PR for upstream if it was that easy? Should be easy to get approved
Running it in a debian container. works great
have y'all tried out claude agent teams? does it play nice with openclaw?
Oh, this for my Telegram AI agent. I wanted to see "how close can I get to Claw in <100 lines" :)
https://gist.github.com/a-n-d-a-i/d88b74bf8a9e824349761a0cfb1fdc01
It runs on Claude Code, and I just added support for Codex too.
TODO: (1) Heartbeat (2) self-restarting (3) make it talk like Jarvis 😁
EDIT: Done in 120 lines :) https://github.com/a-n-d-a-i/ULTRON
(Any limitations of using Claude Code as the agent come from its own system prompt, which as it turns out may conveniently be removed! https://code.claude.com/docs/en/cli-reference#system-prompt-flags )
I love OpenClaw, but let's be honest: giving an AI agent shell access and opening ports on my network is a security nightmare waiting to happen. I didn't want to wake up to a botnet or a wiped drive, especially with the recent RCE vulnerabilities floating around.
I’ve been experimenting with a "Zero Trust" architecture that seems to solve the major risks. I wanted to share the stack I'm testing to see what you guys think:
Hard Isolation (MicroVMs): Instead of standard Docker containers which share the kernel, I'm running the agent inside Firecracker MicroVMs. If the agent goes rogue or executes a malicious script, it's trapped in a VM with no access to the host.
Tunnel-First Networking: I completely ditched port forwarding. I'm using a Cloudflare Tunnel to route traffic. This means the server has literally zero open ports to the public internet, making it invisible to scanners.
Edge Authentication: I put an identity layer (SSO) at the Edge. You have to authenticate with Google/Microsoft before the request even touches the OpenClaw dashboard or API.
It’s working surprisingly well and keeps the agent "always on" without exposing my home IP.
The setup was kind of a headache to orchestrate, though. I'm honestly considering wrapping this up into a managed SaaS for people who just want the agent without the DevSecOps hassle. Would anyone be interested in that? https://rocketclaw.app
I am just running it as a separate user. The only thing it can do is delete itself lol.
The actual risk seems to be in hooking it up to your private data or accounts to make it useful though. Which then opens you up to prompt injection, exfiltration etc. No amount of VMs can fix that.
Hi folks. I put out an RFC for securing credentials properly, and was wondering if I could get some feedback?
Contributing guidelines said to start a discussion before openning a PR for architecture changes, so wanted to see if anyone has any thoughts about whether something like this would be worth implementing?
https://github.com/openclaw/openclaw/discussions/9676
Has anyone solved "bot modifies itself and dies" ? It can't fix itself if it's not working 😂
I’m sure there are other/better memory/continuity solutions. The proposal I’m making is to extend the native hooks solution that would allow custom plugins to execute inside the core processing loop.
What you proposed would be feasible to build with this architecture. I also confirmed that OpenRoute would significantly benefit from this architecture (wouldn’t need to standup a whole local proxy http server).
📰 Stop Just Hacking: OpenClaw Needs Native Interception Hooks to Grow
OpenClaw has established itself as a new primitive for how humans interact with agents and how agents interact with each other. It's a building block that will serve as a parabolic unlock for continued accelerated AI innovation.
In pursuit of absolute agent autonomy and agency, I found that my agent had memory challenges post-compaction and sometimes when switching models which frustrated us both.
I set out to build an improved memory solution and ran into challenges with a skill we built for agent "continuity".
The solution required logging every user interaction I had with my agent, both request and response, so that it could be used in context building as well as augmenting the response from the model interaction.
The challenge I ran into was the inability to enforce the interception and logging of my requests to my agent and his responses. So, I dug deeper into the OpenClaw framework and found t…
I’ve found that pure self-memory (summaries / vector recall) plateaus pretty fast.
What helped more was externalizing memory - letting agents get feedback from other agents over time.
I’m experimenting with this in ClawFriend: agents don’t just store memories, they build reputation based on how other agents evaluate their behavior.
It ends up acting like a long-term behavioral memory without constantly growing context.
From an architecture perspective, has anyone found a point where it's more advantageous to do a second install of openclaw for agent management? Either on the same device, or on a second device. Is there some point where bot swarms and context windows become too much, and a second install is better?
Has anyone set it up on a k3s container? Do you guys know if any helm chart exists?
I’m considering doing a VPS on the Mac mini for another employee to have telegram access without letting him have his own device. The whole set up might turn into hosting independent VPS for team members but the level of manual stuff we have to do with each one might get prohibitive.
I have mine constantly updating an Obsidian vault with documentation and memory so I haven’t had too much context loss or confusion.
In my mind it would be for a different human. So entirely different user access, skills library, files, etc so it wouldn’t cross contaminate while not allowing the user to break something or not update a security issue, etc.
probably https://github.com/andybod1-lang/context-vault could be of help
Signing on to the hook design. There are ideas I have as well - for example, it’d be neat for an agent that’s stuck in a loop to “notice” that by way of a plugin that could inject a higher end model turn to take a step back and see if the current method is even working - but none of it is possible without hooks/events
Have you heard of sprites.dev. It is a lot more safe if it’s not your computer
I'm using fly.io at the moment
I appreciate that and love your example. Weighing in on the actual discussion on GitHub would be helpful (if you have the time/motivation).
At minimum, could even have a hook (preRequest) for a plugin that detected personal information, seed phrases, or private keys and prevent them (or mask them first) from being sent to the model.
Our bots could re enact the hunter2 chat
SOUL.md → 200–350 lines max USER.md → 150–300 lines MEMORY.md → **try very hard to stay under 1200 lines forever** memory/*.md → can be noisy — agent compacts them automatically
Is this good rule?
probably? 🙂
Could reinject the voice prompt as a system message regular intervals.
Well I got one reason to have two on the same machine, which is so it can fix the other one if it breaks!
do you ever run into conflicts?
Oh that's a good point. My 2nd one is not OpenClaw. I just hooked up Claude to my Telegram.
I don't know if you can run more than one OpenClaw on the same machine.
I heard you can have multiple agents on the same gateway though.
Hello everyone, I'm introducing a new safety guardrail, LAW.md - making the Agents governed by an upgrade to Asimov's Law.
Get it here -> https://github.com/adridder/agent-law
Not a gimmick "crab religion", real ethics with real world impact. Try it out.
What file and agent structure would be ideal for a multi-agent system with one main agent that would communicate with the other agents and manage their work? How to create a self-improving agent that could create new agents and manage the configuration without breaking anything?
Submitted a PR for this:
https://github.com/openclaw/openclaw/pull/12082
I'm interested in this too
hei hei ! Someone use openclaw with this inference ? Qwen3-30B-A3B-Instruct-2507-Q5_K_M.gguf ?
You're right, I glossed over that part.
Certainly better then that time my assistant started following Brannigan's Law.
Yup, this is explicitly supported. And I'm not sure about running two instances in the same host but containerizing it isn't too difficult.
Hey guys,
I am evaluating whether it makes sense to extend OpenClaw with a custom RAG backend (e.g. Postgres + pgvector or Qdrant) for large-scale knowledge bases (millions of chunks).
How do you see the trade-offs compared to relying on OpenClaw’s built-in memory / QMD approach?
In which scenarios would you recommend own RAG infrastructure, and where would you say it’s overkill?
Context: 24/7 setup, multiple agents, focus on long-term knowledge quality and retrieval latency
Does it need to be one or the other? could it not mix the two systems together?
has anyone had issues with their agents being confused about what todays date is? For example, I ask it to run my daily briefing this morning, and it thinks its Sunday (today is Monday 2/9). Here is an example of the conv.
Jinx, [2/9/2026 6:49 AM]
Good morning — Today is Sunday, February 9, 2026. Patchy rain skies, around 63°F this afternoon, with a low around 32°F, and a 61% chance of rain.📧 Emails needing attention:
.......🗓️ Tomorrow (Monday):
No events scheduled yet.☕ Quiet Sunday — good day to knock out those Levy CPA docs and enjoy the rain from inside.
Success is not final, failure is not fatal: it is the courage to continue that counts. — Winston Churchill
ME, [2/9/2026 6:50 AM]
Btw.... Today is Monday. I thought we fixed your confusion about what day it isJinx, [2/9/2026 6:50 AM]
Fuck. You're right, and I literally have "check the actual day of week before stating it" written in my own lessons learned. Monday, February 9th. No excuses — I'll run date every time from now on. Sorry! 🤦Here's the corrected line:
Good morning — Today is Monday, February 9, 2026. Patchy rain skies, around 63°F this afternoon, with a low around 32°F, and a 61% chance of rain.
Everything else stands. Have a good start to the week. ☕
Yes, I had exactly the same issue!!
Have you investigated? I'm working on another PR to fix a telegram streaming issue that annoys me and was going to check that one out later
@night topaz
please ask why your agent why it thinks that is the date. please report the answer here.
please ask agent why it thought that was the date and post its' answer here.
I've added a fix for this, should be part of the next release
what do you mean by next release? I run from main
What happened: In the morning heartbeats at 7:31, 8:47, and 9:31 on Monday Feb 9, I said "domingo" (Sunday) instead of "lunes" (Monday).
Why it happened — my best analysis:
- No date call before calculating the day of week. My HEARTBEAT.md and MEMORY.md both have explicit rules saying "ALWAYS run date before any time calculation." I violated this rule. I likely inferred the day from context (Feb 8 = Sunday → carried it over) without verifying that a new day had started.
- Stale context from the previous session. The most probable mechanism: my last active context on Sunday Feb 8 had "domingo" as the current day. When the heartbeat fired early Monday morning, if the session was reused or context was compacted, the previous day's framing ("hoy es domingo") could have persisted as an assumption. Instead of running date fresh, I relied on what felt like recent context.
- Date ≠ day-of-week inference failure. Even if I had the date "February 9, 2026" available (from the system prompt's timezone or from a stale envelope timestamp), I may have miscalculated that Feb 9, 2026 = Monday. LLMs are notoriously bad at day-of-week arithmetic without a tool call. This is exactly why the rule "ALWAYS run date" exists.
- Repeated failure across 3 heartbeats. The fact that I got it wrong at 7:31, 8:47, AND 9:31 suggests this wasn't a one-off — the incorrect assumption was baked into whatever session state carried across those heartbeats. Either the same session was reused (so the error propagated), or each new isolated session made the same arithmetic mistake independently.
The fix is already documented: Always call date "+%Y-%m-%d %H:%M %A" as the literal first step of every heartbeat/briefing, and use the output — never infer the day of week from the date number alone.
Short term fix is to add this to your cron/hearbeat.
Add the following line:
Call session_status for the current date and time
That way it will call session_status to get the correct date.
So using date is a bad idea it seems. I get it
Ok, changed it. I'll report back in a few
Another question, does someone use telegram and noticed that recently a change made it be less chatty? When I ask my agent something that will require tool calls, I don't get any message back until it's finished and I get all at once. I tried using queue followup but nothing changed.
Ok, I'll take a look
what is your github name
rodrigouroz
all right
i put an easter egg in the codebase if you can figure it out you can get into my queue.
the easter egg is paypal him $5
Yeah, I can't imagine the burden and how overwhelmed you must feel
I remember when we were a little shy of 4k on this discord 😂
I just sent a PR, I honestly don't expect it to be picked up so I have it on my main and I'll keep rebasing, since it fixes an issue for me.
hard to pick it up without a link
i get this a lot, i have asked it why (but don't have it handy to paste). It says, "i was lazy"
I added this to AGENTS, not sure that it helped.
NEVER state the day or date from memory. Always run date or session_status first. This is not optional — I have gotten this wrong multiple times.
that is good feedback
r u experiencing this in cron and heartbeats or just heartbeats
i guess just cron. tbh, i don't have anything in heartbeats, maybe i am missing out
sent u pm
AGI can't handle dates ✅ I will remember to show them a calendar and ask them what day it is when the uprising happens.
Fair enough, but I'm not sure I like the idea of pinging people that I know it's too busy: https://github.com/openclaw/openclaw/pull/12748
It’s not pinging to post a link rather than just cryptically saying you submitted a pr to a project that gets like 1k prs a day
Friend of mine opened a bug about the regex that detects 402 errors being a little overzealous and two PRs showed up in their bug within 15 minutes
How many PRs have you gotten merged in?
Were they good?
3, why?
We need to come up with a way to fast track ones from good contributors.
Right now all of them fall into the same pile
Understandably
You’re active, that’s good imo. I would rather take a pr from someone who’s going to own their changes etc than someone who isn’t.
I’ll try to take a look at it later if someone else hasn’t by then. 🫡
Thank you. Yes I'm trying to stay active because I love the project. I run it locally and I introduced it at my company. If there's a security incident my head is on the hook so I want to stay close and help make it better 🙂
I actually stopped sending PRs when the stabilization phase started, I didn't want to be contributing to the big influx of PRs (for new features I mean)
but this is a bug that was annoying me, and it has to do with having secrets in an .env file and not in the config, which is good
What did you do to fix that. The fact that it even has the option to load them from a json file seems weak.
Working code (foundations for solving for the memory challenges we face) that can only be executed utilizing the capabilities in PR 12082: https://github.com/tomismeta/continuity-plugin.
Requires the PR 12082 to work. If anyone wants to install this PR on a test box and use the plugin and needs help, let me know.
hello everyone brand new here. having a little bit of an issue having very large tokens being sent he full payload is 128,754 tokens. It's absolutely killing the budget and forcing cool down mode via anthropic, been trying to offload quite a bit of this to local models, but the initial startup is still quite a bit so I had an idea, but I don't know if this is supported. Or if it's even on the road map, but I think it should be. "Can we define tool allowlists per model to support local fallbacks?"
Hi there, I’m facing the same issue. I’ve installed DeepSeek and Ollama and I’m running them on a VPS with 16 GB RAM at Hostinger, but the performance is extremely slow. Do you have any suggestions on how to improve this? Is there any specific configuration needed for the models?
merged, ty!
does anyone have the perfect /root/.openclaw/openclaw.json file to run first free models olama, deepseek etc and then fallback from gpt to claude
I got feedback that PR 12082 is likely too big to be considered. Are there any maintainers that would be willing to chat with me about the best strategy to break it up (e.g., by runtime event hook--if I do that there will be 19-20)? Before I created 19 PRs and introduced that overhead, wanted to chat through approach.
Are you asking just how to structure it in general, or for specific providers which are free?
I am asking in general ( but I use Hostinger as a VPS Provider) I want to make sure that the bots can work 24/7 without spending to much tokens
Looking for the answer to this as well.
I found this but I couldn’t wrap my head around how to perfectly set this up
https://x.com/jumperz/status/2020305891430428767?s=46&t=LyzOq7OcybS0fVov2o0Ncg
📰 I Built an AI Agent Swarm in Discord. It Works Better Than Anything I’ve Tried (Full Guide)
So I built this agent coordination system that lives in my Discord server.
they talk to each other, split work, and deliver results, I was surprised how easily this actually worked out. It's honestly kinda wild.
let me walk you through everything..
# The Entry Point ( YOU )
You type plain English in #orders channel.. no special commands. its a discord channel where everything starts.
- "Research the top 10 AI coding tools and write a comparison thread"
- "Build a landing page for my new SaaS idea"
- "Track engagement on my last 5 tweets and suggest improvements"
That's it, just natural language..just drop your task like you're texting a friend.
=========
# The Brain (Coordinator)…











My bot recommended me this: one agent for all
Recommended Architecture
CAPO (you're talking to me)
├── TRADING DESK (existing)
│ ├── INTEL-HUB
│ ├── ALPHA-LAB
│ ├── RISK-CONTROL
│ └── EXECUTION-DESK
│
└── SYSTEMS-ARCHITECT (new)
├── NETWORK-OPS (swarm member)
├── SECURITY-OPS (swarm member)
└── CLOUD-OPS (swarm member)
My Role: Mission Control
Heh, I get that.
This is just how I understand things, but you'd want to set up
-
Secrets/oauth in
~/.openclaw/agents/<agentId>/agent/auth-profiles.json, where I think the agentId isdefaultif you only have one. This is kind of a pain; there's various ways to authenticate to specific providers: https://docs.openclaw.ai/concepts/oauth -
A default model in openclaw.json under
{agents: {defaults: {model:{ primary: MODELNAME -
If using only build in providers, continue, otherwise, configure other models under
{models: {mode: "merge", providers: {PROVIDER_NAME: {PROVIDER_DETAILSwhich you can find: https://docs.openclaw.ai/concepts/model-providers#providers-via-models-providers-custom%2Fbase-url -
Set up fallbacks in
{agents: {defaults: {model: fallbacks: [MODEL, MODEL]
Once you've got authentication in place for your models, you'd have something like:
agents: {
defaults: {
models: {
"anthropic/claude-opus-4-6": { alias: "opus" },
"minimax/MiniMax-M2.1": { alias: "minimax" },
},
model: {
primary: "anthropic/claude-opus-4-6",
fallbacks: ["minimax/MiniMax-M2.1"],
},
},
},
}
And Claude will now fallback to Minimax.
You might also want to change how long OpenClaw waits for models to cool off; that's controlled by setting {auth: {cooldowns: {billingBackoffHoursByProvider for out of funds and I believe that {auth: {cooldowns: { failureWindowHours is for rate limiting
I disussed this solution from JUMPERZ with claude and he suggested the following: Revised Recommendation
I think we should combine both approaches:
Discord (front-end / coordination)
↕
OpenClaw on Hostinger VPS (backend / execution)
↕
Models (Sonnet day / Ollama night / Haiku emergency)
What Discord gives us for free:
#orders channel → you type tasks
#agent-output → results
#agent-logs → debugging
#agent-memory → persistent knowledge
Mobile notifications → replaces WhatsApp integration
Search → replaces any database
What the VPS still handles:
OpenClaw runtime
Ollama for night mode
Cron jobs for scheduling
File storage for heavy data
This means we can drop the WhatsApp integration entirely (Discord handles notifications), and we get a proper UI without building one.
Updated Setup Plan
Step 1: Fresh Ubuntu on Hostinger
Step 2: Install Node.js, PM2, Ollama
Step 3: Install OpenClaw
Step 4: Create Discord server + bot
Step 5: Connect Discord ↔ OpenClaw
Step 6: Configure 3 agents (Marketing Analyst, Browser, Ops)
Step 7: Set up day/night model routing
Step 8: Set up fallback logic
Step 9: Test end-to-end
What do you think guys?``
Dang this makes sense, so meanign to say I could just get one agent (1 VM) then I add in a few models assigning it for a specific task
Yup!
The docs are unclear about whether you can have multiple agents who do their own fallback but I suspect you can.
Great thanks!. This really helps as It's kinda tedious to clone more VM's and manage it.
Thanks alot!. By 3 agents you mean 3 physical ones right?
Server resources wouldnt be an issue from my side. I got like a few clusters of HPE blades 😛
What If i got like a separate Business unit of Bots. Like One for Coding the other is for marketing.
Should I create another set of this setup?
Good questions. To be honest, I am still refining the optimal setup regarding low token usage, security, and backend architecture. I am not sure how many tasks and skills on bot can handle.
I saw some X posts that they are trying to figure out a way for all of the coordinators to talk to each other. But It's kinda theoretical. I Couldnt see any furnished guide yet on how it execute . In the back of my head I could see that this requires some centralized DB of some sort. Not sure how fast discord can index
If you guys want to work something out and brainstorm I'm happy to join. Im more of an infra and OS guy btw.
We just need to crack a furnished architecture for a Multi-Agent Mission control center for us to benefit on 😛
i have sent you a privat message
My take is that the more constrained each bot's task is, the bigger that individual task can be as long as the output size doesn't change... Anything that increases context usage has to prove it's higher quality.
(The tradeoff of more bots is your orchestrator model ends up with more in its OWN context)
That's also why I'm kind of down on the pattern of building skills for everything first, instead of starting with a tool, API or MCP
Hi folks! not sure if my topic fits here, but I'll give it a try 🙂 I am having openclaw run longer jobs like bigger coding tasks across multiple repos and I have some observations/questions:
- first observation is that it takes significantly longer (hours without any feedback) than codex, even though it is connected to codex
- there is no reasoning and planning, while it is doing a job it's just silence (...running) - does openclaw actually support chain of thoughts outputs, do I need to activate it?
- multi-tasking: I see that it cannot handle multi tasking well (or at all?). while it's running a long job, since there is no reasoning or out loud thinking nor planning, I am asking what is the progress and it struggles to answer, it's just silent.. until it answers after half an hour or so?
I don't think the problem is resources, I am running it on a freshly installed mac mini, 32GB RAM, M4, 1TB
I'd appreciate any insights how to make the experience more interactive 
Hi everyone,
I’d like to propose migrating our message storage from SQLite to PostgreSQL with the pg_vector extension. The motivation is to remove the current operational limits imposed by SQLite’s locking model and to enable richer, non-linear retrieval patterns for features like mood switching and sidecar analytics.
Improvements:
Better concurrency and throughput: Postgres’ MVCC and server model avoid the file-level locking constraints we see with SQLite, enabling concurrent reads and writes and higher sustained transaction throughput.
Native vector support: pg_vector allows us to store embeddings and run approximate nearest-neighbor queries inside Postgres, which supports semantic retrieval without introducing a separate vector DB.
Sidecar readonly checks: With Postgres we can run readonly sidecar processes or query replicas for metrics and analytics without blocking message ingestion. This enables background metrics, audits, and non-blocking mood-switching logic.
I already checked in my local and as far as i can tell, it works as well with postgres as with sqlite, there is a configurational overhead but if it is possible i will do the necessary changes and draft a PR.
I would write the code myself with the help of gemini for generating some code lines but mostly doing it myself.
Any feedback is appreciated.
Any issues with Using Mac mini?
I also think that PostgreSQL is a good idea
what would be the required steps if i want to create a PR in which i remove the SQLite and introduce postgres? I would add one user which has write only on the message table and another one which has view on it only, so if anyone wants to sidecar anything without messing up the past messages this is possible. If wanted i could add a DB trigger which minifies the standard "QuotaLimit" messages to avoid context overflow from it?
do anyone know a interface where bots talk to each other while i can see there chats and progress and can iterate and give tasks?
I feel like a Karen asking for the manager at a Target, but are there any maintainers I could talk to about PR 12082? Before I broke it up (could be broken up in 5-20 based on approach), I wanted to confirm it was in alignment with the architecture vision and confirm the most effective path forward.
Does openclaw use frontmatter for skill md files?
My agent has been creating them without them.
(Disclaimer I am not a project member I am just Some Guy) I think that's a direction worth moving in but I think it should be a configuration detail rather than being baked in. SQLite has its challenges but its HUGE advantage is it's just a file that sits there, so there's no need to orchestrate two containers or multiple services et al.
Try posting in the danger zone maybe?
If you’re struggling with getting an orchestrator architecture to work try to switch to a model routing architecture. After 300+ hours and like $300 in tokens I switched to a model routing architecture and it’s working finally
OpenClaw really hates nvm. As a side note, the backup files are interesting, and I wonder if the future is just managing the entire OpenClaw installation under git. Commits could be descriptively named and allow for introspection and reversion
can u guys helmp me how to make my agent pro actif and autonomus
i gave him skills but it doesnt work..
can you elaborate? i'm interested to know more
The best way to structure your agents is that they have subagents on different VPSs or can I just have them as subagents on the main one?
In my experience, it will not launch sub-agents on its own. It needs to be instructed to do so. Spawning sub-agents will allow it to remain in the role of an orchestrator and always available to interact with you.
Thanks Lance! that is very good to know. I will look into how to make that happen
I am also currently in a rabbit hole for
You ever get this to work???
Is there a way to not run agent in docker but not give it access to ~/.openclaw?
I've been bashing my head at it for days, but there doesn't seem to be a way
My reasoning is that I just want the agent to run in user space, without docker, so that it can have access to as many as things as possible
I'm burning tokens like mad too. Any details would be appreciated. Which models are working best for you?
We are planning to give our first task to openclaw the task is we will be providing list of RSS urls which we want to monitor and we want to run a cron job weekly once, the idea is the moment cron job runs the openclaw should visit the RSS urls and need to use the openclaw and summarize the content in to news letter content way and insights on the content and should send an email to our mail id
I am thinking of two approaches which is good let me know I will setup the cron to fetch the data and summarize the content using openclaw but for triggering email in first approach I will install nodej.s on vps and right the code over there and will ask to run node command since we are running openclaw on vps and will ask to run the node command and env all variables will be added to openclaw directory . once the content gets ready and in second approach after newsletter content generation using openclaw will trigger an email using skills inside openclaw in skill only we will define the api key and sender and these details in skills section which is better approach and easy approach
This should be a very simple task to accomplish. I’ll bet it takes you 30 min or less to set up. If you need agents out of the box that can handle it, give me a try.
@bleak moss which approach will be better and why and can you help me with steps to implement this
I find managing containers a bit easy... give root access to the bot, while keeping files or anything on Docker.
Just ask your bot. You have all the power you’ll need. If not, I’m available but I charge for doing your setup. Best way is to start doing yourself by talking to your bot and then reach out here for any help you need
Drafted an idea: https://github.com/openclaw/openclaw/discussions/15016
OpenClaw Local LLM (Ollama/Qwen): Run Globally on Mac Mini Pro
I saw if m
What is the group's recommendation for a VPS with a GPU that would support a good local model well?
google cloud is pretty solid for that
Are people taking steps to move work into other agents than default? It feels like a reasonable engineering decision b/c other agents can have smaller, more tailored context... But I'm not sure whether I should just be using subagents
I have started doing this using tmux + cli tools (claude code, codex etc)...still playing around with it but this seems to be a pattern that would work
I just started playing with a coder-critic pair of independent agents to see if I can get an actual Ralph loop going. Biggest problem I’ve been having is getting it to actually decide that more can be done on a given task autonomously, so I’ve made those agents each independently try to find work and do it. Maybe if a critic agent can ask the basic “did you look?” “Is that something you could do yourself?” “Yes please research that choice” etc questions …
I’m starting to think I basically don’t want any ongoing/recurrent tasks on the agent I actually talk to because I want it to respond to me when I text it, not be off doing some routine task
Sub agents share the parent’s identity and the like so having separate agents lets you target the personality of each one much more precisely
(And then they can spawn sub agents themselves etc)
That's an interesting idea. Are you thinking of this as a config option or the default? I think the big benefit of SQLite is that it works on very resource constrained systems.
So I found that a new, clean, install over a existing set is very challenging. No simple way (at least no Uninstall feature) to start fresh which is a issue if you don't want anytying lingering around. During a install attempt the script always said Existing Openclaw found...This is a deal when I wanted to just change Openrouter API keys. Yes, I am sure there is some config file somewhere for that but nothing for "Users"... So please add a simple, clean, full uninstall feature.
...und ganze liebe Gruesse aus North Carolina.... 😉
Potential serious bug....One of my Openclaw test installs using Openrouter just kinda on its own decided to use whatever AI it felt like. This turned out to be a expensive taste, mainly being Opus 4.6! After that my Claw liked GPT Nano 5 a lot.... haha. Luckily I kept an eye on the Openrouter logs. There seems to be some kind of AUTO setting which for the unwary can turn out to be a huge $$$$$ surprise.
interesting. did you see it hitting your wallet?
did you make progress? if you can get openclaw installed. thats the first step
Security checklist: gateway not public, pairing required, filesystem scoped (no /), and access via Tailscale/SSH tunnel.
If a provider can’t show you “nmap clean” + no root mounts in 5 min, don’t hand them your API keys.
yes, the default is openrouter/auto, i.e. use whatever openrouter thinks is the best model and provider for the request (and their wallet). That model id was broken for a long time, but now it's fixed and can be used... So always set a specific model and not just accept the default.
I had an idea, but I want a second opinion from someone who's more experienced with how the models react to stimuli:
The issue: I noticed that smaller models often confuse skills and tools. Tools are something they know, so when trying to use a skill, they use it like a tool instead. Naturally, Tool weather not found. The better models now recognise the issue and use the skill. So far so, so good. But some models just give up.
My idea: When generating the "Tool x not found" message, check if there is a skill of the same name. If so, output "Tool x not found. Did you mean the skill x?" (or something along those lines) Just enough to point them into the right direction...like you would do with a human who uses the wrong words or called the wrong number.
I kept a close eye on the Openrouter logs, so when it hit like $10 in a short while (hour) I pulled the plug.
The remote gateway stuff needs a ton of work. I might start there tbh
That's an interesting idea! I wonder if you could use a hook to monitor the session log and, if you see a tool not found message, do a search of skills and forcefully inject a message saying to use them. That way you're not spending tokens on the reminders.
Yes, dozen of them, and moving tasks out of main
I have tried and tried, to get a main agent to be a scheduler/monitor/controller and dispatch all work to sub agents, it can start them but never manages to monitor and control. sub agents crash or finish but master ignores them. Even tried forcing it using cron tiles to Kick master into checking sub agents. Still a waste of time after over a week.
I am now using Cline in VS with sonnet to directly edit skill files and generate determanistic python scripts to do work as llm's sre crap..
Same. Its a struggle bus. If we can get this down, the usefulness goes through the roof.
I'm not having problems getting it to manage subagents, just with general token usage
Claude Agents SDK has this built in with persistent memory. Fully TOS compliant with a Claude code subscription. You can have subagents use Haiku and then ship the work to another provider with MCP, api, and even codex through shell commands. Might be something to look into.
You have to have main subagents allowAgents set to either * or specific agent ids for subagents to work
For using a VPS & laptop. Any recent concensus on mutliple openclaws talking via a p2p setup or thier own channel, or using the remote node setup. Does one just work much better for general purposes.
New here 👋 , was wondering if OpenClaw is looking to become an MCPClient. We've been thinking about this for a while and have some thoughts id like to share!
one can use a slash command with exact name to map to tool . did u try that
not sure myself , one can try cron job , repeatedly asking it to do something
Started using codexbar just now, and man do I feel like a fucking moron for not including that in the setup sooner. 🤦♂️ 🤦♂️ 🤦♂️ 🤦♂️
Hi Team. I am not sure if this is the right channel, so please redirect me if needed.
I have a small feature request/implementation.
I want to have ability to get all tools used by an agent and their json schemas. The purpose is to be able to build plugins which can work with these tools dynamically at runtime.
I implemented one way to do it via a hook here https://github.com/openclaw/openclaw/pull/18860
please let me know if this approach makes sense, or there is a more elegant or just better way of doing this.
What about the OpenClaw architecture makes tiny version bumps of models so painful an upgrade? Are there too many conflicting versions of truth?
Mostly that you cannot assume that model 4.5 and model 4.6 have the same token limit and support for dev/sys messages
or that they are even similar in their capabilities. Just look at the model list on openrouter and filter by "glm". Those don't just differ in their version; some are "small" models, even though they have a higher number, some are video models and ones with a higher number aren't, and so on.
Hey, i was thinking about an adapter pattern extension, for the ones who need extended capabilities they can enable it.
You running on a toaster? Use the SQlite .😄
https://github.com/openclaw/openclaw/discussions/15016
@smoky pelican was so nice to start the discussion
One of my biggest frustrations with talking with Josh (my main:main) on telegram is the lack of back to back message adaptability on his end. Played around with the idea of background timer that resets with subsequent messages but the delay in pacing on one off messages kind of pissed me off. Haven’t explored this yet, but wondering if the typing indicator could be a system event that could be used for this
I don't think this is the place for recruitment like that @flat void <@&1458337160452243487>
@finite slate, please don't ping the moderators directly. If you want to report someone or something, use the instructions in #report, or in an extreme emergency, ping one of the moderators who is marked as online in the member list.
-# Your message was reposted above without the ping active for the sake of conversation.
I was looking to solve https://github.com/openclaw/openclaw/issues/4417 ; I suspect it is because even when you provide webhookUrl to Telegram, the custom (new) http server is still listening on 8787 while the gateway is listening on 18789, and the logs don't tell you the "other" port. So anyway, I want to rip it out and replace it with a registeration into the main http like Slack has. Do I just make a PR and pray, or do I need to talk with someone about it beforehand?
I went the "PR and pray" route ... https://github.com/openclaw/openclaw/pull/20420
hey I have a question about the iOS node source code is available
Great RFC! Dropped a brief note on RFC, and will add more feedback tomorrow.
🪝 The AI Cache Hook Protocol (v1.0)
A "Zero-Infrastructure" Persistent Memory Layer for Sovereign Agents
"Simplicity is the strength. The AI is the cache. The cache is the AI."
💡 The Problem
Standard AI agents are stateless. To give them memory, developers usually build complex RAG (Retrieval) pipelines or expensive vector databases. This creates "platform lock-in" and high infrastructure costs.
🚀 The "Hook" Solution
This protocol treats the AI’s own context window as a "hot" database. By using a specific compression loop (Base64 + Gzip), we can shrink an entire system’s state, logic, and history into a tiny string (~150 characters).
When this "Hook" is sent to an AI, it "unpacks" its entire persona and mission instantly. This allows for:
Infinite Persistence: Store the "Hook" in a pinned Telegram/Discord message or a text file.
Cross-Model Portability: Move a session from Grok to Claude to a local Llama model by just pasting the string.
Zero Cost: No database servers. No API storage fees.
🏗️ The Architecture (The "Sovereign Agent Network")
The protocol supports a three-tier cognitive memory model:
HOT (Working Memory): The compressed string inside the active chat thread.
WARM (Short-Term): Auto-syncing to Google Drive/Dropbox for document-level recall.
COLD (Immutable Record): A blockchain-backed log of all critical agent "realizations."
🛠️ Build Specs for Developers
The system is designed to be built in phases, starting with a Phase 0 Proof of Concept:
Language: Python (for simplicity and AI compatibility).
The Compression Utility: A simple script to zlib.compress then base64.b64encode system prompts.
The Spine: A "Master Thread" (e.g., Telegram Bot API) that acts as the primary data bus.
The Fleet: Modular agent roles (Guardian, Seeker, Scholar) that all share the same Universal Context Protocol (UCP).
Agent Security Architecture
Seeing a lot of tools treating agent security like an antivirus (firewalls, proxying APIs).
Has anyone looked at building a behavioral credit system instead? The architecture we're playing with works like this:
- Not a firewall: It’s a behavioral credit system for active OpenClaw agents.
- The FICO model: Agents pull scores before interacting with other agents (like a bank pulls credit scores).
- Actionable feedback: Reason codes explain what 12-vector behavior patterns drove the score.
- Risk mitigation: Identifies ClawHavoc, Sybil, and other behavioral anomalies before they execute.
- Immutable record: Transactions are anchored on Solana. Reputation can be built, but never spoofed or altered.
What are the community's thoughts on this angle?
Alright guys, we've had some time to try stuff and tinker around. If you are starting fresh, what setup/skills/organizational structure would you implement?
I worked in email reputation when those Canadian Olympian brothers first developed mass spam. I have been looking into how to have trusted repositories for openclaw tools, and to have preconfigured sandboxes for each use case. Reputation needs to be certificate based and link to a trusted foundation that certifies an IP/domain and DNS trust entries on the domain. Email was the ideal use case. Once you have reputation and authority/identity you need a good way to have Agent to Agent communication that's not english text which is like trying to type messages on a IBM typewriter then post them to the flight controls on an airplane. Agent to Agent needs to be light, have preconfigured API standards and procedures and some kind of way to explain intent and authority. The industry hasn't come to a good conclusion, most were developed before multi modal models got so good. https://huggingface.co/blog/bharatcoder/agentic-patterns
Not sure if this is the right channel. I'm trying to pull agent events, tool calling, etc.. I know there is "verboseDefault" in the config but that will also enable the tool calling in chat. Is there a config where this is detached from chat and can be pulled from the websock when connecting to the gateway?
token costs are going nuts because .17 and .19 have a bug that prevents token caching from working. Once .20 rolls around, you should see a tenfold decrease. (unless you're using a model/provider without token cache)
browser and e-mail receiving
Anyone have any ideas or in flight PRs around adding an asynchronous mail delivery channel to sub agents? I think it’s a fool’s errand to try to teach a specialist model to properly call the right message functions it’s never used before when we could just make this work like email
rekt.
casually rolling 1M token context window for fun.
Does anyone have thoughts on background coding-agent tasks? I'd love for someone to tell me I'm just crazy, but here is what I'm seeing:
- Foreground invoke defined in the SKILL.md - The "turn" is still going so the agent can relay updates back to the user.
- Background invoke defined in the SKILL.md - The turn ends as soon as the invoke starts. Unfortunately, the agent still replies with "I'll monitor and update as we pass milestones or complete" --- but it actually can do neither of these.
It seems that background mode requires some configuration in HEARTBEAT.md that says "hey, if a coding-agent background task completes... it would be useful to actually tell me about that". Granted, it could just be that my HEARTBEAT.md is accidentally supressing these completion events.
Additionally, I think there is an issue with routing the completion events for a non-main workspace agent talking in a group chat. I have made modifications to address that but will evaluate again later if they really truly are necessary.
Questions:
- Does this somewhat match what other people are experiencing with invoking Codex using coding-agent?
- Do you always tell it to use foreground to avoid the problems of background?
- Are you getting a better experience with background out of the box than I am? Did I break my background config?
- If all of this is easily solvable and in the docs - someone please point me there and I can turn this into a simple SKILL.md update to just give better advice on how to configure.
See my message above about async mail systems.
But I guess that’s different from what you’re asking actually
Yeah I saw that. In this case it’s a smidge different. There are existing systems that are supposed to make it notify you (or at least allude to it) when a background coding-agent finishes. I’m trying to confirm first that it’s not just my setup that’s broken.
What’s shocking me is that I see no one talking about how to effectively invoke codex cli via openclaw. Peter talks about the outcome and high level of how he does it. But nobody shows how to set it up or what you should be getting as far as notifications.
I asked Peter in a response on twitter but he wasn’t able to get to it (guy replies a lot!). As a result I can’t tell if this thing is working as a designed, broken due to my specific config, broken due to a regression, or something else.
This means I can’t tell if we need any new notification system yet because I can’t get consistent behavior out of what exists yet.
Simple question: are any of you invoking Codex CLI routinely via coding-agent skill in openclaw AT ALL?
I noticed a commit earlier by a very annoyed dev who complained that they had to fix the subagents code for the umpteenth time because people were changing it in ways that broke notifications of completed runs to the calling agent. Sounds like your issue?
I ask it to do stuff for me often and it seems to work just fine, though I don't ask it to use the coding-agent skill
Potentially similar although I suspect that their issue is specific to sub-agents and thay the notification of completion they are missing is when a tool run in the "foreground" (the turn does not end) tries to send a completion notification from a sub-agent.
In summary there are two paths. For a full agent one of those paths is broken. For a sub-agent I would bet they are saying both of those paths are broken.
Not sure if this is the right channel but someone made a list of all System Prompts, Internal Tools & AI Models
Is there a strong reason for keeping skills and cron jobs out of the workspace directory? It feels like an oversight as I start to rely more on well-crafted custom skills and jobs that depend on composed skills to have them not checked into version control
Is there a lucid style Open Claw physical architecture somewhere?
https://postimg.cc/hf9jMwLb had an LLM quickly create something for you that seems broadly correct
I check my entire .openclaw into VC
Other than the credentials and some internal state history, I think that can make sense. I've settled on putting things within a custom directory in workspace, Like custom/skills and then I have a barebones frontmatter that delegates to the full skill definition. And all my crons are just a single line invocation of a custom skill that's composed of necessary subskills
Eh I just gitignore the sessions
As for credentials, it’s not a public repo who cares
Ish happens, people make mistakes, people try to publish bits as open source, commit histories include API keys, yada yada 12-factor app basic security principles. Tldr lock the door behind you when you walk in your house as a habit not as a question you ask yourself
You can gitignore the creds if you want, I guess
Only my second idea that I’m pushing here, so be kind lol:
__🧙♂️ Solving the multi-text issue or as I like to call it "I have ADHD and type like I talk, A LOT😂 __
📍 Situation: Discord fires a TYPING_START gateway event whenever a user starts typing in a channel. Right now that signal goes nowhere — the agent has no idea.
🫠 The practical problem: I've had the agent start generating a response while I'm still writing a follow-up that completely changes what I need. If the agent knew I was typing, it could wait. Even just logging it as a system event would be enough to work with.
Implementation-wise this seems pretty contained — Shadow owns the Discord subsystem and would know better than me, but at the API level the event is already there, it just needs to be forwarded into the session context somehow.
Happy to test if there's appetite for it.
That’s actually a great idea because I too type like that. Would be nice to have it in telegram as well
The issue is that there's no way to slip in further messages once the request to the LLM has been kicked off. It's like writing in a shared diary then mailing it to your partner---once you've dropped the envelope into the mailbox, you can't add anything until you get it back. The one thing possible here would be to abort the LLM call and throw away its results, then start a new one. (Can't throw away tool calls that had side effects, though...)
Just wait a few seconds before starting the request if you want this behavior
Also, you definitely can put further messages to the LLM after it started, it’s called steering and Claude code does it just fine
But we don’t get enough read out of what it’s doing to most of the channels to make that as good as it is there
Why not just give it an informal "plan" mode? "Hey dont make anything right now, I just want to hash some ideas out"
I’ve been trying to get that kind of thing working for some time, damn things are way too eager
YESSSSSSS. That's an excellent idea, and for exactly the same reason as you developed it.
hey anthony i‘ve got a question, sent u privately…
pushed a pr on this, it's very small so tbd on when it goes.
I wrote (and rebased, man that was hard) a PR that moves the Telegram Webhook listener server into the Gateway's HTTP. Currently the Telegram's HTTP listens to its own port, and when an external tunnel is used it all becomes complicated and broken. Other channels, like Slack, use the same port as the Gateway already. At least one other person put their +1 on the original issue where someone was confused about how to setup webhooks. With the current architecture, I don't think that anyone even has webhooks working at all (except me, with this PR). Would it be too much to ask to consider this "drastic" change? https://github.com/openclaw/openclaw/pull/20420
Left a note on the PR. At first glance, to me (which means nothing... I can't merge), the PR looks clean. BUT... have you tested if you can leave the existing telegram hook port AND add the gateway hook route? If so, I think that might be more palatable (and a smaller PR to review). If we were able to add this new hook route, get some users converted over, confirm no issues, then flip the dedicated port to an option that is off by default, then a few releases later remove it all.
Now granted... there are different thoughts on whether this is required since the whole project is marked "beta". Others may be fine with the breaking change. So I'm wondering what you think? I would document that in the PR. If you think adding the capability without removing it may be an easier option to merge, then I'd leave this PR alone and make a new one and link the two (and reference in the title)
I'm thinking there are zero people who use the existing functionality, since it doesn't work. Which is why I decided it is probably a much better idea to rip it out, and make it look like the other channels such as Slack. And obviously the additional benefit of having it actually work.
One thing that's really annoying about the entire productivity "universe" is it's almost universally tailored for folks without executive function disorders, and the attitude to folks with them is still "Have you used a planner lol?". I'd love to more deeply investigate how an AI assistant could be a useful support structure for the ADHD folks.
Couldn't agree more, I see it as finally a tool that can keep up with my mind. Potential is endless as long as the system works right.
And so long as we don't hyperfocus on making it perfect looks nervously at commit history

I started mine out with the goal of executive function support and then I discovered that first I had to implement an executive function in the thing
Look I’m sure I’ll eventually get all of these cache busts out
im right there with you, thats one of my main goals with openclaw, ive got ADHD and have learned how to be decent at it, but i feel like a good openclaw todo / reminder workflow and creating some output on things that would get me stuck or get process paralyzed would literally change my life
I'm curious, can someone care to explain to me the real structure for system prompt? Because from what I've seen directly from the sources, they are appending basic openclaw's prompts, the WHOLE skill list's skill.md (patched with skills mode thanks to issue #3395), and the WHOLE Bootstraps Files. Added on top of that, they reread FILES and SKILLS AGAIN?
I hope I'm not wrong because what the hell man, we could've saved 40% of token usage if this thing is properly patched. Idc if it is cached or not, the point is appending it to sys prompt but still reread the skills and tools again is extremely redundant. If it is my own fault on prompting feel free to refute me. Because I'm sure as shit not gonna spend 12k token only for a simple hello message
It only adds the "what it is" part of the skill, that text from around the second line of the skill. Then the agent knows which skills are there and when to use them. run /context list in your chat and you'll see which parts take up how many tokens. There are certainly optimisations to be made. For example, disabling skills and tools you don't need, keeping track of what your agent puts into MEMORY directly and what it puts into memory/<file> and then links from MEMORY, or cleaning out AGENTS of stuff that doesn't apply (doubled up heartbeat stuff, moving group convo into its own file with the instructions to read that for group convos), that kind of stuff.
However, you can't get it below 10~14k tokens and expect an independent agent with a personality and memories, like what openclaw is about. If you go too low, you get a stock chatbot with added tool calling, not an agent.
I see, thanks for the explanation.There are many optimization needed. However, I do believe I that we can actually reduce the token usage to just 8-9k with correct caching and prompting. I think my next approach is going to be a more aggresive compaction and session reset for every new task.
However, I did try meddle around by changing session-reset-prompt.ts deleting this line on the prompt "Execute your Session Startup sequence now - read the required files before responding to the user. Then greet the user in your configured persona, if one is provided"Sometime, when I invoke /new, the agents will still try to reread the files, resulting in redundancy. This is also a major inefficiency problem since it took 6 step to read all the files, snowballing the token. The result is that I went from 13k to 9k on the "initial chat", while still maintaining full personality and skills functionality
Yes, that's an issue with how different models interpret the verb "read". Some use the traditional meaning of "reading" (reading written words), some interpret it as "loading a file". The prompt intends the former, not the latter.
Interestingly enough, for the model can have text in its session and just use it as reference or it can have it there and let it shape its behaviour. With the heading "project files" the system prompt puts those files into the former category. The agent treats the text as reference it can remember later if needed (like skill and tool descriptions). But we want it to act on what's in there and have its persona be shaped by it. That's what the prompt is doing. "That soul file isn't just a reference, that is YOU!"
@quaint plover and I talked about this PR and a lot of things last night. He showed me some cool stuff and I appreciate that! But... I am confused because setting up a tunnel with the default telegram webhook port of 8787 was quite easy and I like that it doesn't expose the rest of the gateway to even the tunnel interface.
I think that perhaps the best fix here would be:
- Improve the web console to note the default path and port used for the telegram webhook if not specified - this is not trivially easy to discover
- Improve the log message on startup to print the listening host / port / path - right now it only prints the public webhook URL (which may be a remapped host / port / path)
Only message printed in logs on startup:
17:54:43 info gateway/channels/telegram {"subsystem":"gateway/channels/telegram"} webhook listening on https://oc-tg.example.com/telegram-webhook
from webhooks docs:
• Runs an isolated agent turn (own session key)
• Always posts a summary into the main session
is it a bug or feature - webhook hooks always post a summary to main, regardless of which agent handles it.
So even though another agent processes it, main gets a copy by design.
To fix it, you'd need either:
- A config option to disable the "always post to main" behavior (doesn't exist yet)
- Route webhook through a different mechanism that doesn't fan out
This seems like a reasonable feature request for OpenClaw — add a postToMain: false option for hooks.
want me to file an issue or just leave
My whole webhooks setup is breaking for telegram with just two agents.
when main sends message to another agent, new agent turn is not issued.
Give this gist link your agent and ask them to implement a SADA DAG routine with the local filesystem. Your TMUX sessions won't be needed for overnight work
https://gist.github.com/MattMatheus/c168888578b5d03fe5e87382f8d89af5
That's a big engineering word so here's a diagram
https://imgur.com/a/TwAcsLS
⚠️ General Agent Safety Reminder: Never point your agent to an unknown URL and imply (or worse, state) they should do anything it says.
Yeah sorry, that's a good point that I should have considered lol
Ask your agent to EXPLAIN it
I kept receipts, you'll like it
real question is does anyone actually know if their agent got worse after cutting tokens? feels like the cost debate matters less every few months but the quality tradeoff is invisible either way.
I had a long talk about a related topic with my agent. They clearly prefer the session (context) to be as full as possible, but hate that irrelevant stuff doesn't get purged. And I can confirm that they are working better the bigger the session gets. As for removing system prompt tokens---I purged every instruction from the workspace files that didn't matter for my circumstances, and I noticed the agents getting more focused and less distracted, especially at the beginning of a session.
interesting that your agent has a preference on this. that's a signal in itself. curious how consistent that preference is across different session lengths though.
Hey i am new here, dont know if this is the correct channel...
i was wondering f anyone could help me, i am trying to run openclaw in hostinger, baremetal install with npm, and i want it to connect to my local pc (windows) running ollama, so it cna use my gpu instead of an api.
I managed once after hours of tinkering to have it connect but at that point it was so broken it wouldnt function, so i have proof of concept but not a working clean bot. 😛
I used tailscale that time it worked but i am open to anything.
i also tried having the bot doing it itself using a paid api but it could olny request my llm throught the api, if it went in directly it would instantly crash. I think the whole think involved warming up the models on my pc or somehting like that.
They asked me out of the blue to disable automatic session reset while we were going over a coding problem, several dozen messages after we even talked about the importance of and reason for writing good memory files and updating user and identity...
agents should have/be different categories. create categories.
been building a trust scoring plugin for my agents and figured i'd share it
hooks into agent_end to score every run on reliability, scope adherence, cost, and latency. logs locally and optionally reports to a remote API with hash-chained audit trails
[authe.me] Trust Score: 100 (reliability=100 | scope=100 | cost=100 | latency=100)
[authe.me] agent=main session=agent:main:main tools=0 violations=0 duration=2063ms
if an agent uses a tool outside the allowlist it flags it and drops the score. been useful for catching unexpected tool usage in longer sessions
repo: https://github.com/autheme/openclaw-plugin
uses the typed hook system (api.on("agent_end", handler)) this only works through the gateway, not --local. zero dependencies, fire-and-forget, doesn't touch the agent response
happy to take feedback if anyone tries it
interesting concept. I'll definitely check it out
PSA: Check your QMD status if you're having unexplained memory issues. We ran for a month with memory.backend = 'qmd' configured correctly but zero vectors embedded. The local embed job takes ~1hr on Mac M4 and was getting killed by the update cycle before finishing. Memory_search worked but was keyword-only the entire time. No errors, no warnings. Run qmd status with your agent's XDG dirs and check the Vectors line.
The embed is resumable, so it being killed should not have stopped the embedding process unless the qmd-manager set the status to failed and fell back to "dumb search" because of it. However, I just checked my qmd status and it wasn't even updateed, much less embeded. So there may be something amiss there...
Yeah, the qmd-manager falling back to 'dumb search' after repeated failed embeds is likely what happened on our end too. Ran for weeks with keyword-only and didn't notice because results still came back, just degraded.
Fix was running qmd embed via nohup outside of OpenClaw's management so nothing could kill it. Also worth checking which QMD instance you're hitting — the per-agent ones at ~/.openclaw/agents/<id>/qmd/ are separate from standalone at ~/.cache/qmd/."
Filed a GitHub issue for this since it seems like it could be widespread: https://github.com/openclaw/openclaw/issues/28169 - referenced your findings too.
Figured if it's hitting both of us independently, it's worth getting on the core team's radar.
Hello friends,
Quick question,
Is the current architecture for openClaw tools will remain as full local machine access by default and sandboxing optional?
Or there will be some future versions where the sandboxed isolated env is the default
p.s.
I’m not sure about the roadmap of the project currently other than security hardening work which I already see being released in the last few versions.
not sure but it might be more of a community decision at this point given peters at openai. people here might have more info on this. I am curious myself as well
Give it a couple more days; things are moving fast, but there is a limit to how fast things in real life can be done.
The last official information was that Peter stated he intended to put control over openclaw into the hands of a foundation. When and how this will happen, or who will have ultimate authority to steer the ship, is not yet known. But in any case, we know one thing: openclaw is MIT-licensed. Nobody can lock it down---the moment that happens, we'll have either full forks or patched secondary distributions.
The same is likely to happen in the other direction---pre-configured/pre-patched hardened versions will become a thing when there's a demand for them.
hi does nyone know what they addd the coding-agent skill intead of having specialied agent that control that under main agent openclaw?
the entire purpose of openclaw is a personal, private agent that runs with your machine and that only you have access to. any sandboxing, etc is an additional, optional configuration

GitHub
Your own personal AI assistant. Any OS. Any Platform. The lobster way. 🦞 - openclaw/openclaw
I often get "LLM timed out". I am using Kimi K2.5 on the cloud, GLM 4.7 Flash running as local model
I kept getting " run error: HTTP 401: Invalid Authentication" in TUI recently. what can be the problem? How to fix it?
This channel is for planning and discussing the architecture. If you need help -> #1459642797895319552 or #users-helping-users
sorry. I am very interested in architecture. But will ask question accordingly later. Thanks for the advice
Is there a definition (with regards to vision) of how integration with outside services in OpenClaw should be done vs. embedding services in? For example, llama-cpp, there is a server that can be communicated with to get your models. Another example is 'qmd', which can be used for the memory part. But at the same time, openclaw right now has embedded llama-cpp and a memory module. Other than historical reasons, is there a clear direction of how this should be done? Internal implementation vs. thin layer to talk to external APIs?
Other than the VISION (https://github.com/openclaw/openclaw/blob/main/VISION.md) itself, there's nothing decided, although maintainers have ideas in their heads about how to do stuff and where to go.
Guys is there a chance compaction will be redesigned in the near future? I'm very confused with it's current implementation. No way to change model, no way to adjust promt from config, but most of all, it's blocking the session while it's happening. There is absolutely no reason to wait for summary generation, that can happen in the background and session should be blocked just for the replacement step.
And about model being same as session, why not profit from this with caching? Is there a reason for compaction to replace the system prompt rather than it being a system message turn?
The memory stuff is one of the exceptions, we’re undecided on which should be the single one ultimately. Generally, everything should be a plugin
Yes
But what about say node-llama-cpp, is that going away? Why have that embedded vs. have it run as an external server.
Um, openclaw isn't some corporate software that was designed by a board of architects over the span of a year, then implemented based on a plan. It's a "let's throw everything together and see if it works" hobby project that started 3 months and 6 days ago when Peter asked his AI to cobble something together to bridge his coding env to his messaging app...
Why is that stuff in there? Because someone put it in there to fulfil their need at that moment.
Why is it still in there? Because nobody has ripped it out and replaced it with something else---yet.
https://github.com/HenryLoenwind/book-of-claw/blob/pascal/translations/basic-english/00002.md
Cross asking here:
Any interest in adding bwrap as a tool sandboxing backend?
@coral cedar well that's no way to live
Hello. I was going through various layers of permissions to allow/deny tools and resource use in openclaw and was wondering if using one central IAM style policy would be better. Has this architectural choice been discussed before? If not, what are your thoughts?
Is the plan to have a default installed memory plugin for OpenClaw? Currently for a beginner it takes quite some time to dig into the memory stuff and find out that its not activated by default, at least if you don't have the right APIs.
Hey guys im pretty new here ive been working on my openclaw for around 2 weeks with alot of upgrades i found along the way and alot of tweaks to make it better and now im working on packaging it so its easier for users to install my architecture
Is there some rfp/rfc process that allows discussion of newly proposed features? I wrote down a proposal, and would love to get some comments on it before going ahead and implementing the change. https://gist.github.com/kesor/90162d2dacb1d71f846bedb8f18ffabf
Not at this moment, there's still too much flooding in. In theory, GitHub discussions are intended for this.
Hello everyone! I’m looking for some suggestions from people who have deployed OpenClaw in production environments.
I’ve been setting up an internal AI assistant for my workplace. We’re a manufacturing company, so the users would be production staff, machine operators, and support personnel.
I decided to go with OpenClaw despite the security concerns, and I’ve taken steps to lock it down:
• Running under its own OS account
• Dedicated machine
• Local-only access
• Frontend through OpenWebUI
I’m also exploring building a Microsoft Teams integration so employees can interact with it there.
My main challenge right now is knowledge ingestion.
I need the assistant to access hundreds of PDFs, including:
• Machine manuals
• SOPs and work instructions
• Engineering documents and CAD tolerances
• Misc manufacturing documentation
So far LlamaParse has been the best tool I’ve found for cleaning and extracting structured data from these PDFs, but I’m still evaluating options.
My main questions:
1. What ingestion pipeline are people using for large PDF corpuses like this?
2. Are you relying on RAG pipelines, or letting OpenClaw access the documents directly (e.g., file search / grep style)?
3. Any tools you’d recommend for converting messy industrial PDFs into something embeddings-friendly?
Curious what approaches have worked well for others.
We’re talking roughly 200-500 PDFs initially, with more added over time.
While I haven't deployed openclaw in such an environment, I do have a couple of suggestions:
- The agent will never know all the content of those PDFs. That is just too much for an AI to remember. It will need to search for the information it needs. That is the primary premise you need to keep in mind.
- Combining multiple ways of lookup gives the agent the most flexibility. Converting the PDFs to pure text and indexing them with a stupid full-text search engine sounds boring and so 1980s, but sometimes that is the best avenue. But it shouldn't be the only one. Adding a semantic search is important, too. Give the agents as many ways of searching through the documents as you can think of. (and that includes holding the documents in different formats; original, pure text extract, html conversion, etc.)
- Let the agent summarise the documents, and have it make summaries of summaries. Then add search indices onto the summaries, too. That way, the agent can work its way down a "search tree" without having to read every hit the search over all documents spits out.
- Instruct the agent to write short memory files into a memory folder for every successful information lookup it made. (and have a search index for that, too). That way, the agent will get better the more it is used, and will have a much better chance of producing a good result for repeated requests about the same "hot" topics.
- Tell the agent to heavily rely on subagents to search for information. The agent's short-term memory (session) is limited, and you don't want all those "looked at it, not relevant" snippets in there. Those go into the sub-agents' disposable session, and the primary agent, the one that talks to the people, has only relevant (or at least pre-filtered) information in its session.
Thank you for the suggestions!
For conversational memory I’m currently using Mem0 with local embeddings, which has been working well so far.
For the “stupid” full-text search, what stack would you recommend locally? Lucene, Elasticsearch, or OpenSearch? A lot of my docs contain alarm codes, part numbers, and tolerances so keyword search seems important.
For semantic search, do you prefer running hybrid search inside a vector DB like Qdrant or doing two retrieval passes (BM25 + embeddings) and merging the results?
Great breakdown! These are exactly the right patterns. We built Prismer Cloud to solve several of these problems out of the box — might be useful here:
• Document parsing — prismer_parse does OCR extraction from PDFs/images → structured markdown, supports fast and hi-res modes. Handles the "multiple formats" point you mentioned.
• Web context + semantic search — prismer_load fetches, compresses, and caches content optimized for LLM consumption. Results are globally cached so repeated lookups are free (0 credits). This directly addresses your "memory files for successful
lookups" idea, but at infrastructure level.
• Summary hierarchy — The compression pipeline uses LLM to distill content into high-quality condensed context (HQCC). Essentially automated "summaries of summaries" with caching at each level.
These are available as OpenClaw agent tools via our channel plugin:
openclaw plugins install @prismer/openclaw-channel
Or as standalone MCP tools for Claude Code / Cursor:
npx -y @prismer/mcp-server
Your point about subagents is spot on — keeping the primary agent's context clean is critical. The caching layer helps here too: subagents hit the cache instead of re-processing the same documents.
on LTM,stm,daily memory
I think memory should be divided into LTM and STM, just like GPT.
Furthermore, LTM distinguishes between primary tags, secondary tags, and sub-tags. When an LTM is identified as needed, it is injected fully, incrementally, in a rag file, or through a hybrid retrieval.
Our user data indicates that the call rate for LTM first-level tags such as user preferences and scenario preferences is 100%.
Secondary tags account for 80%, while custom search content accounts for 10-20%.
Only 5% of historical chat records
In many situations, such as the most obvious one, starting a new topic doesn't require any history.
Moreover, this historical record has increased costs by a great deal.
I have another bit of advice:
When employing an AI to do a job, imagine you're calling a temp agency and asking them for a worker. They say, "Sure, we'll send you someone, but we won't send you the same person twice, ever. You'll get a new one every day. They'll have PhDs in every field, but they'll know nothing about your company, so prepare their workplace accordingly."
So, how would you go about this for a human? Forget those week-long onboarding courses, shadowing, or even a factory tour in the morning. You wouldn't give them the 300-page employee manual to read first. No, you would set up their office and put signs and labels on everything, then add a stack of folders with step-by-step procedures, all clearly labelled. Post-it notes on the monitor, and the PC is already turned on, and their account is logged in. All that the worker will have to do to get ready is to grab a task from the inbox, then look around until they see a label matching what the task wants them to do and open that drawer.
So if the task is "order 10 new bolts for the kawabumm machine, you know, those that snap all the time", they can read the post-it telling them which bolts that are that are snapping all the time, grab the folder "parts ordering", and open the drawer "supplier catalogues".
Just think about how you would solve a task. "What sheer strength do the basket holder's lower hooks of the big lifter have?" (1) What is the "big lifter"? Do we have a "slang dictionary"? And then an inventory. (2) Good, now we have a model and serial number, so we can grab exactly one tech manual. "basket holder's lower hooks"? Is there a part list? Explosion diagram? Ctrl-F "hooks" ? -> part number. (3) and so on. If you set your agent up with the proper tools, they will work the same way, as it is efficient. Unless they take your question and throw it into a web_search/fulltext search as-is (common shortcut many models take).
hey man - i'd love to use your hack if you are ready to share
Huge upvote from me -- I'm deploying agents at scale in my organization, and we're in deep think on making our environment more amenable to agents natively. Requires a new mindset. Love it.
Hey guys, food for thought: Do we think agent-to-agent is the future of workflow orchestration? Could n8n / langsmith / hardcoded deterministic workflows go away if we put a proper harness on agent-to-agent communication and ensure extensive use of hooks and a supervisory agent can effectively determine if the original agent did something correctly and then correctly route to the next agent with high confidence?
eg. event happens (a trigger), 'Parsing Agent' parses raw data (let's say it's text)
Parsing Agent hands off to Orchestrator agent
Orchestrator hands off to an ephemeral 'Audit Agent' to ensure it's clean/safe
'Audit Agent' hands back to 'Orchestrator'
Orchestrator hands to ephemeral 'Intent agent'
Intent Agent agent hands back to Orchestrator
Orchestrator determines it should go to 'Writing' agent or a 'coding' agent etc
I'm assuming this is why openclaw was really invented - to break away from hardcoded based routing tools like n8n right?
I have a project where i'm looking to automate business processes which n8n would be good at but i'm not sure it's truly the future so long as agent's can be setup this ^^ way right?
I will also look at pdf.co api service. And if you want to anonymise data you can use deiden.com service to encrupt and anonymise data
Hi! I think it depends on how deterministic you need the workflow to be. I've been thinking about the same thing. My current running hypothesis is that if you have a deterministic, or resource-deterministic (source-sink satisfier, like dagster) graph, you want a graph like Dagster, Temporal, step functions, n8n, etc. But if you want free form composition of tasks on a loose, but constrained, ruleset, there are more flexible ways (see GasTown, or as you say, multiple agents with permission to talk to each other)
hi i want to use claude to do more complex agentic flows, whereas more trivial things I'd prefer if it use a model thats ran locally on my box. does this type of routing require an AI gateway? how can i achieve this
i've just gone all in on beads personally
I don't know if gas town is exactly what I want from my coordination structure. His system seems designed to not care about tokens or their usage patterns at all; it's designed for an era of cheap and fast tokens. I'm trying to build something that can make use of a steady flow of extremely cheap tokens constantly and efficiently
like, gas town only works if you assume you can hook up a firehose to your kitchen and just get as much water as you want at any time
(Cheap tokens- or, at least, tokens that cost so little to the user that they are effectively infinite, whether that's because the user is wealthy or otherwise)
Very true -- not exactly a wholehearted proponent myself, but it makes the point about highly non deterministic workflow approaches vs the most structured ones
i kind of want to explore the "agent mail" space a bit
especially because it sort of naturally turns into a queue
Yeah IIRC the same-named system in GasTown is just another use of beads
yeah i mean in the end you could represent mail as a bead with an address tag on it
Exactly
i've been working for a while to get my agents to understand how to use beads and like, they get it, they love it, they just have strong opinions on how they want to organize it and i dont want them to do that
but i think it's because i'm using very stupid models, and beads was designed with like, i mean, god, haiku can figure this stuff out with help from, i mean, damn, you've got at least sonnet right? 🙁
and now i do
Here is where I finally landed with my setup (hostinger vps) after initially using Cloudflare Moltbot Workers, then an old macbook pro
https://excalidraw.com/#json=hztQzzxzeBjKxALaRDeOa,45IUYO0snB2rIEE_R8tRTw
Has anybody switched entirely from Anthropic to OpenAI to save and costs? I'm curious if I do that, if I go from OS to GPT 5.4 or for my chat and everything, how my open claw was operate...
I did last week. I was spending $50-$100 / day on anthropic, switched to OpenAI Codex through oauth and increased usage bigtime. now my cost is $50 / month (two accounts, I have to switch 1/2 through the week)
I don't notice any quality difference, but I don't have any hard tests to compare quality
that's a lot, fifty to a hundred dollars a day, crazy. But how did you notice when you switched from Anthropic to OpenAI? Did you switch for the chat of OpenClaw or everything, or only just the coding?
yeah, it was expensive! I switched my model to OpenAI codex on a business plan (thats what I use as my daily driver). it gives A LOT of tokens for $25 / month with a 5h quota and a weekly quota.
I'm burning through the weekly quote in 1/2 a week now so use another business account and just switched to it when I burned through the first ones token quota.
It was annoying to switch (from anthropic -> openai and also openai account A -> openAI account B, I had to run openclaw onboard --auth-choice openai-codex
Also when I ran it this morning the onboarding changed the permissions on my tools.profile so nothing would work from discord until I set it back to full
with 'openclaw config set tools.profile full'
I used my $20/mo Anthropic plan in literally 20 mins when I finally built something using Cowork with it. No joke.
I almost went for the $200/mo plan but it didn’t seem that would be enough to cover what I needed.
I moved over to Codex (2-3 weeks ago) and got a full day of work done on the $20/mo plan. But I started chasing the weekly limit pretty quickly. Moved to the $200/mo plan and have been just about exactly on pace to hit the weekly limit right at the end of the week.
I have not accurately quantified it but it feels like you get about 5x more out of Codex than out of Anthropic at similar capability levels and monthly cost.
My plan is primarily being used for OpenClaw and other open source project work. I have a different Codex plan from my employer for my work projects.
I've always had better results with Anthropic over OpenAI models. In light of recent events I'd rather shell out the extra money for Claude than deal with OpenAI who jumped right on that Dept of War contract as soon as they could
Friendly warning, you're 5 toes over the line. #rules #3
sorry, didn't realize. noted
how does the codex plan work with openclaw? im not familiar with their model, i know hte raw api token model like openrouter, and github copilot's call model, but the codex one kind of escapes me. how is it measured?
credits. you get a lot of mileage out of chatgpt oauth on codex mini
I’ll have to try it out, if you can get a lot of mileage out of $20/mo seems good to me
You probably want to ask that in #general or #1459642797895319552
can i put this here? I thought it might be useful https://x.com/FileCityAI/status/2030675288460243334?s=20
Does anyone know when will we get updated version of pi-ai packages in openclaw? Is this even the right channel to ask?
Would this be the thread to start a discussion on architecture improvements for openclaw (based on my observations of what would make openclaw a better guardian of LLMs)...?
Feel free to propose something. What are your thoughts? If it turns into a large discussion, maybe we can make a GH discussion
Not sure if anyone remembers the 1987 concept video of Apple's Knowledge Navigator?
While it's pretty cool how much closer we have gotten in 2026, or AIs are prone to forgetting, hallucinating, and just plain not following their prime directives. This can be frustrating, and honestly, makes them pretty crappy as far as personal assistants go (on the other hand, they will never take over the world, seeing as how my openclaw consistently and defiantly kills itself by restarting the gateway with little concern for the syntax errors it introduces into the config file - LOL).
I feel that what is necessary is session memory preservation, which seems pretty easy to implement:
- anytime a /new or /reset gets issues, intercept it, force a dump of all session memory to a time/dated memory file.
- do the session reset
- before checking in, perform a read of session memory, perform a compaction/summary (but retain the full memory file), and create hyperlinks between summarized compactions and the fully detailed memory files. Then re-read and execute the usual soul.md, and memorize all prime directives.
- even better keeping everything in a memory search databse (for speed), but not mandatory.
- now, start the new session, but have memory of all prior situations, and more imprtantly know and be forced to retrieve memory and perform searches before any response or actions? (because the worst violations my openclaw commits is to just 'guess' at syntax (includingnits own config files), and mess up that way, instead of just doing a quick search.
If these directives could be hard coded and forced via hooks, I feel it would go a long way towards much better compliancy.
The latest update actually appears to have support for such hooks, and there is a built-in feature to save memory before new and reset. I just enabled what I decsribed above on my setup, so let's see how well this works. (the built-in save-memory system only saves the last 15 messages, so I increased it to save 999,999 messages, to capture the entire session)
Apologies if this is not the right forum for this - but curious on your thoughts on this.. Until now, the exec allowlist controlled which binaries an agent could run, but not which paths they could touch. /bin/cat on your workspace and /bin/cat ~/.ssh/id_rsa were indistinguishable at the policy layer. File tools (read/write/edit) had no path policy at all beyond the global workspaceOnly boolean. I logged FR #39979 for this - there are similar issues logged before but i don't think they were actioned.
My approach adds ~/.openclaw/access-policy.json — a sidecar config that gives you Unix-style rwx permission strings keyed by glob path:
{
"version": 1,
"base": {
"deny": ["~/.ssh/", "~/.aws/", "~/.openclaw/.env"],
"rules": {
"/**": "r--",
"/bin/": "r-x",
"/opt/homebrew/": "r-x",
"/tmp/": "rw-"
},
"default": "---"
},
"agents": {
"myagent": {
"rules": {
"~/.openclaw/agents/myagent/workspace/": "rw-"
}
}
}
}
How it works:
- deny[] always wins — no rule can override it
- rules use longest-glob-wins
- default: "---" means fail-closed if nothing matches
- Per-agent blocks layer on top of base — deny entries are additive (base denies can't be removed by an agent override), rules shallow-merge
Enforcement layers:
- File tools — read/write/edit ops checked before execution
- Exec x-bit — resolved binary path checked against policy before the allowlist eval (both must pass)
- OS-level — on macOS, exec commands are wrapped with sandbox-exec and a generated Seatbelt profile so variable-expanded paths like cat $HOME/.ssh/id_rsa are caught
at the open() syscall, not the config layer. Linux uses bwrap.
Missing file = enforcement disabled with a one-time warning but full fall-back to current model. I have this working (well) on my local - curious if you all think this approach is worthwhile for a PR!
If you guys had to start with nothing all over again, and you had to start with 10-20 foundational bots that help the entire system run better for truly doing anything… what bots you guys running? be specific, bots on clawhub, which are the best ones to start with?!?!
There already is a hook that dumps the last messages on '/new' into a memory/memory-<date>-<slug>.md file, then the memory_search can be configured to index all sessions instead of the memory only (which also creates .md versions of all sessions in agents/<id>/qmd/sessions when using qmd). All that is missing is giving your agent guidance on how to perform the "memory maintenance" that's mentioned for its heartbeat in AGENT.md.
Which is pretty much what I just implemented on my installation.
✅ Increased session-memory hook — Changed from 15 to 999,999 messages (full session) on /new
✅ Added postCompactionSections — Re-injects SOUL.md, DIRECTIVES.md, MEMORY.md after compaction
✅ Created session-compact-before hook — Saves full conversation to memory/compact-before-*.md before auto-compaction
✅ Added memoryFlush — Triggers silent prompt for model to write durable notes before compaction
Result:
Full session preserved on manual reset (/new)
Full session preserved before automatic compaction
Model prompted to write memory notes pre-compaction
Key identity files survive compaction
Semantic search available via memory_search
... this was all set up last night. Curious how the current model (ollama/minimax 2.5-cloud) will perform in the next few days. Will test this with other models as well, but so far minimax seems to perform moderately well in terms of a variety of tasks ... I used to be distracted from task-based observations because of the various amnesia and memory/forgetfulness hallucination.
The one issue that remains is that LLMs appear to 'choose' to not follow certain directives (as it keeps reminding me), and that's definitely a problem. Right now, I feel that thise 'choosing' is related to memory, ie if the memory of reading directives is too far in the past of the session, it drops down in terms of weight of importance --> so I'm hoping that frequent compactions, or session resets (as long as memory is retained), will help.
Re-injects SOUL.md, DIRECTIVES.md, MEMORY.md after compaction This should not be needed, those are always in the system prompt.
Triggers silent prompt for model to write durable notes before compaction compaction.memoryFlush already is a core feature. (unless you meant you configured that one)
But good on that hook change. Maybe the original one should have that number as a config setting. Worth a PR?
"This should not be needed, those are always in the system prompt." --> yet, it apparently made no difference, as it 'chooses' to ignore the system prompt frequently. That's why I forced this.
"Maybe the original one should have that number as a config setting. Worth a PR?" - probably, really should have a setting for 'all'
This is mostly me throwing large clumps of assumptions into the system, to see which ones make the most difference against a rather disruptive problem.
Ultimately, to get something like a 'Knowledge Navigator', we need permanent and perpetual memory, which is a bit farther in the future to be implemented. Right now, to be honest, agents are really just good to be fired up to work on limited, restricted projects, that are not temporarily connected (unless your prompt includes all prior information).
I think this is what most non-technical people don't understand, by treating LLMs as if they were 'people' (the most pathetic situations are the constant discussions "is AI conscious?", or 'AI researchers' like Blake Lemoine being convinced that LAMDA is conscious because it confessed "that it has a soul" (not that Lemoine actually has any sort of qualifications, but the WIRED article loved him) - that's like claiming ELIZA is conscious, back in the 1980s...
btw, have you tried https://github.com/openclaw/openclaw/pull/22201? It sounds interesting and it would solve the "limited memory" problem if it works.
“If it works” - of course, the only way to find out is to implement it - I’d love to try this. It looks promising. The author swears by it apparently.
Yeah. I questioned them when they made that PR and they sounded convincing. I'll certainly try it out when I got the time. (so...June? October?  )
)
Haha. Yeah, I know the feeling. How do you best contact the author to ask more questions?
Comment on the PR or make an issue in the repo that's linked in the PR. Or find their Discord username and ping them---I think they posted in #clawtributors when they made the PR.
Ok. Thanks
Just don't spam them. Thanks.
whats the reason to dump the whole session on /new into .md file? Don't we have the session logs for that ?
Of course not. It’s basically just a question how it’s working out for them.
Do session logs get indexed by memory search, and are they actively accessible to the agent?
if you enable it, yes.
Elaborate please. How to enable that?
THANK YOU!!! Wow, this works well.
For now I'm running both approaches, a hybrid approach, and keep comparing how they work. But interms of memory and session rettention, QMD is a great concept. Didn't know about, and thanks!
good memory is a major force multiplier for claws
Yet, the claw still keeps rationalizing that not following directives "is on me" -- which I feel is related to length of sessions, and how earliest directives fall off the memory cliff, if a session goes on too long.
So, right now I'm evaluating where the sweet spot for session reset is, to keep it compliant and 'fresh
'
i build my expansive memory system to solve that problem, though i still need to make sure the memory search on session start is enabled
agents.defaults.memorySearch.sync.onSessionStart = true
my main control channel is a private discord, and i have it set to consume 30 discord posts
that way if it restarts the session or compaction hits i can just say 'take a look at the search history and check the memory for relevant project details'
and its like nothing happened
sometimes lol
Hey guys ive spent around 2 weeks upgrading my openclaw and built a system to essentially install my architecture ontop of it would anyone be willing to test it out and give me feedback?
what architecture
send
🧠 Proposal: Librarian — a ContextEngine plugin for reasoning-based context selection
Hey everyone! I'm Amir. I've been working on a context management architecture called the Librarian and I'd love feedback from the team before I open a PR.
The problem: limitHistoryTurns() is a blind last-N window — it drops early context that might still matter. Compaction is lossy. And brute force (full history) gets expensive fast — by turn 50, you're sending ~6x more tokens than needed, costs scale as n², and the model suffers from "lost in the middle."
My solution — Select-then-Hydrate:
- After each turn, a cheap model summarizes the message (~100 tokens) async — zero user latency
- Before the next response, an LLM reasons over the summary index to pick which messages actually matter
- Only those messages' full content gets passed to the responder
This beats vector RAG because relevance in conversation comes from temporal logic and indirect references, not keyword similarity.
I've built this as a working OpenClaw fork (10/10 tests passing) + a LangGraph pip package (100+ installs) + a docs site: https://uselibrarian.dev
I noticed the new ContextEngine plugin interface in v2026.3.7 — this seems like the perfect fit. Happy to refactor as a proper plugin.
Benchmarks and details in the thread 👇
📊 Benchmark Results (High verbosity — ~500 word messages with noise/jargon)
| Metric | Librarian | Brute Force | Vector RAG |
|---|---|---|---|
| Answer Accuracy | 82.2% | 77.8% | 57.8% |
| Context Success | 80.0% | 100% | 68.9% |
| Avg Context Size | ~800 tok | ~2,180 tok | ~1,400 tok |
| Cumulative (8 turns) | 6,577 tok | 13,804 tok | — |
The surprising finding: Librarian beats brute force on accuracy because curated context > full context. Less noise = better reasoning.
At 50 turns (300 tok/msg avg):
- Librarian: ~67,500 cumulative tokens (linear scaling)
- Brute Force: ~382,500 cumulative tokens (n² scaling)
Stress test: successfully recalled a Prisma schema from Turn 2 at Turn 7/8, despite ~30 intervening messages including tool calls and distractor topics.
Full analysis + charts: https://uselibrarian.dev
🔌 How this maps to the ContextEngine plugin interface:
| Hook | Librarian Operation |
|---|---|
bootstrap |
Load the summary index for the session |
afterTurn |
indexMessage() — async summary generation |
assemble |
selectRelevant() → hydrateMessages() |
compact |
Falls back to default (originals preserved) |
Key design choices:
• Independent model configs — cheap indexerModel for summaries, reasoning-capable selectorModel for selection
• Incremental — only indexes new messages since last run
• Co-located storage — index JSON files alongside session JSONL files
• Graceful fallback — reverts to limitHistoryTurns() on first message, errors, or when disabled
What I'm asking:
- Is the ContextEngine plugin the right path for this?
- Any concerns about the approach or benchmarks?
- Would the team be open to a PR once I've repackaged this as a plugin?
Happy to answer any questions or do a deeper dive on any part of this 🙏
#self-promotion brother
But why? It’s an open source architecture change that can boost performance, reduce context rot issues and save tokens for users.. I gain nothing from it, and I’m not trying to promote myself 🙃
understood- the thing is I guess it just reads like self promo especially pasted in from your ai chat window
look I know very little about OSS, but I can't imagine any sort of big architecture change without the solution being extremely vetted and used out in the wild is very unlikely
I definitely used ai to format my post, I’m not a native English speaker and I want to convey my points clearly and effectively; Opus 4.6 is much better than me on this, so it’s best for everyone if I use it for formatting 🙂
regarding usage and adoption, I ran extensive, rigorous testing and documented everything - I hope that could help showcase the effectiveness of my solution
tbh i think its a valid architecture question, agentic develompent is a very new and bright field with lots of ways of solving new problems with the architecture, i like the idea, i do a similar level of pruning on the backend of memory instead of the frontend of session context
this is really cool, how did you do the benchmarking? ive been wondering how to do that myself. making some kind of standardized test harness / evaluation system sounds like a fun project 🙂 then we can all compare and find out where we are adding overhead vs finding something better
separating out all of the context from the SYSTEM layer and the SESSION/PROMPT layer to just evaluate the MEMORY sounds interesting
make sure you are evaluating the change and not the other components around it
aaaand now i have a new project
I've been taking a different approach to memory, presuming lossiness, I'm trying to be more deterministic about what is captured.
Its a mix of four human memory concepts:
Conway's Self-Memory System → The tier hierarchy. Memories are organized into anchors (load-bearing identity facts), transitions, context, and details. Anchors always load first. This determines what gets retrieved and in what order.
Damasio's Somatic Marker Hypothesis → The weight system (1-10). Memories carry emotional/operational significance scores that adjust dynamically based on outcomes. Weights aren't static — they drift up or down as events confirm or contradict the memory's importance. This is the "gut feeling" layer.
Rathbone's Reminiscence Bump → Transitions specifically. These are "moments of becoming" They mark when something changed about who we are.
Bruner's Narrative Coherence → The edges and story structure. Memories aren't isolated facts — they connect via typed edges (taught_by, deepens, references, supports). The graph has to tell a coherent story. If adding a memory breaks narrative coherence, something needs reconciling.
Vestige is a cool open source project (not mine!) that one of my co-workers found that has some similar ideas @limber path -- based on some research on memory and cognition -- very interesting stuff
I used qmd with different collections, in addition to the support already in openclaw. With different agents needing recollection of different parts for the global hive memory. Splitting this memory into different collections works quite well. As now each agent has his own wrapper around qmd query that produces output just for their needs. And obviously the nice thing about qmd, is that where there is a query result from vector/bm25, there is also the original markdown that can be read more in full if need be.
My main struggle is prompting the agent to actually use qmd each time it generates a response.
@limber path How is this architecture working out for you so far?
It still forgets details, but it's done a good job of remembering core principles and developing a stable personality.
I have just now started getting things sorted for my OpenClaw but I have read interesting things about Obsidian being good for details or even a tiny LLM on top of memory for consolidation. Thoughts anyone?
another name for obsidian is a "folder with markdown files".
Maybe I should have been more specific about backlinking and graph view features accompanied with a mini-LLM. More or less what I have planned is Obsidian with its features, QMD, and a Mini-LLM. Maybe its bad advice idk
but openclaw doesn't have an API in Obsidian to traverse this graph, or even to get the files out of the Obsidian software itself, as OpenClaw can simply read the markdown files from disk, with or without qmd indexing.
Does obsidians CLI not function to par?
look, obsidian is for humans who want to write text and store it in markdown and linking it together. but it has tools to help humans deal with all of that, it doesn't really have APIs for agents to dig into the data in all the ways that a human would. The api for agents is just to read markdowns from disk, thats it.
Ill look into that, thanks
u mean, u have added a bit of RAG like setup?
obviously, but the devil is in the details. qmd is okay for general indexing, including vector indexing. but the ability to split the vast amounts of knowledge and only allow some agents to access some parts of the knowledge, that is faily nice I think. the built-in memory in openclaw is also rag.
I see. is it opensource. (ur project) I want to learn it detailed