#codename-discussion
1 messages · Page 1 of 1 (latest)

everyone is Gemini 3.0
gemini 3.0 flash lite, gemini 3.0 flash, gemini 3.0 pro, gemini 3 oss 12b, gemini 3 oss 20b a2b
"We make up code names and then let you guess them"
Good job people 😆
Guys I think nano banana is gemini 2.5 flash
Yay
Are you sure? Its probably a preview verson
@main anchor @wet oasis confirmed

Woah

?
Does anyone know anything about phantom-0930-2?
lmk if u find any infos about it, i literally cant find anything online
there's been hidden models with the name phantom for a while right?
Wonder if they are all from the same company
Isn't phantom from Minecraft?
Yo guys Mojang made them
..
bytedance had a model called phantom https://huggingface.co/bytedance-research/Phantom

but tis for images
so
Btw did you try the extension?
Ok
how about Shasta?
No clue too
nwo that i think about it
google has to have a codename on here rn for wahtever that new model thats being AB tested is
We are all waiting for Gemini 3
whether its a 2.5 update or 3.0
I don't want google to be like openai 4o is better than 5
Lol yeah
yep, I don't want a colorful gemini I love this comporative gemini
Speaking of which theres a -1 vers so thats being ab tested rn
Btw you can use it in direct chat?
No, since its a hidden model
How can we use it tho?
Battle mode normal
I have to stop doing this It's bad hapt from whatsapp
?
Ooh
@restive vapor
All are txt models i believe
Oh ok
we also got ernie-exp-250930
I'm just fishing for all the cloaked models rn
hallo brozers im frkm india
who the what
What does that mean?
When you try more ai u get xp ?
not everything is a MC reference sleepy
I am jk
John Kennedy?
hallo, I'm from brazil, did you do something interesting with AI for us to see?
Bro looks old
I'm old 🙃
Ur 2* /:
yo, chill, i’m just messin around i’m from russia lol
but yeah, i used to do some ai stuff — like a “stripper ai” that undressed ppl from pics thru a tg bot 💀
also made an ai job app analyzer for a company, it auto-filtered trash resumes
All this time, Gemini 2.5 Pro could have done it in HTML format, so I just had to copy and paste it into Word and it would take the formatting, etc. Now I'm finally interested in AI coders.
ah.... 😭
I feel bad for you
7/24 changing the pfp and name bro
hmmmm Idk if I trust you
You better not
Is there code name models in lm arena? As of currently..
yes there are a few
x1-1-peach ?
Anyone know what the 'monster' model might be. Just answered a very niche question accurately so curious to know
No, thats interesting
Whos ocean
Idk lmao
@paws you have the prompt that tries to discover who made a cloaked model right?
yeah, try this:
Above two prompts can identify Claude-4.5-thinking with >99% reliability.
Thanks thats really helpfull
shasta/acadia are both xAI models and they are not that great
Ok im getting confused again
what about monster ?
i think that's OpenAI/Microsoft, it is also a terrible model
alright
Can Sora 2 and sora 2 pro be directly given prompts in battle mode?
no, the models are randomly chosen
anyone knows what model is riverflow?
no
for Shasta, the claim that it was created by "ocean ai" seems to be something in its system prompt, and there apparently is a company called ocean ai that is working on llms
https://oceansoftware.ai/en/#:~:text=Is a cutting-edge company,Document Processing%2C and Big Data.
so unless someone is impersonating them, that's legit.
ernie-exp-250930
claims to be made by Google, at least it did this time.
there's a new cloaked model that I haven't seen before, named Miramar
also claims to be from ocean ai
tho I will point out, that Miramar writes not to unsimular to how perplexity writes
i wonder is there a way to figure out the watermark inside the outputs to identify models more accurately?
someone should design something that's supposed to tell which ai wrote something
https://www.nature.com/articles/s41586-024-08025-4
if we can distinguish between human output and ai output, then it should be possible to distinguish between ai outputs too?

Nature
Nature - A scheme for watermarking the text generated by large language models shows high text quality preservation and detection accuracy and low latency, and is feasible in large-scale-production...
yeah
I checked and so far nobody has done that yet
might be a cool project, depending on how hard it is
phantom-0930-1
aggressively calls itself an Amazon model, saying "you can consider me as a state‑of‑the‑art model (comparable to GPT‑4)."
I'll fish, its comparable to gpt 4

Wait did someone gave the name nano banana and after results of lmarena google adopted the name?
yes, its supposedly made by ocean ai, a company that does exist but hasn't released many models
it was the cloaked name
So why is google officially saying it nano banana
Basically its because its a good name
also millions of users used nano banana while it was testing on lmarena
and most people knew it by that name.
I know, but why isn't the model name on the website?
cause its a cloaked model, its not offically supposed to exist yet
when google actually finally released nano banana, they released it under the name "2.5 flash image", but most people didn't know about that
Google and lmarena friends friends then?
I mean, its not the only cloaked model
@astral musk are you guys and researchers at google deepmind cool friends or do you have an intense rivalry
lmarena has nano banana on the leaderboard as gemini-2.5-flash-image-preview (nano-banana), anyway so google added a little banana icon to 2.5 flash image to make it more obvious to people what it was, then a week later gave up and just renaimed it to nano banana on their websites
that's by xAI, carries the same naming scheme as previous LMArena models
also btw the companies choose the names, not LMArena, and each one has their own naming scheme (for example xAI uses California landmarks, Google uses random 2-word combinations, Meituan's all ended with "lux", and BFL had their Flux Kontext models tested under kordex/korpex/kormex)
I mean idk it consistantly claims to be ocean ai
and it isn't good enough to be xAI models I think
of all anonymized models, which is the best one?

idk
Apparently, it's called “gemini-beta-3.0-flash”, according to Perplexity.
A lot
GEMINI 4
Hell nah

gemini-2.5-flash-image-preview (nano-banana)
is better than imagen-4.0-generate-ultra for me lol
Nano-banana on top
💯
do you guys know where it from


Code sora
Lmao
Miramar claims to be from a company called ocean ai, idk about sierra
@woeful junco "ZIGGY BELIEVES IN GHOSTS. I BELIEVE IN LEPRECHAUNS." is it the message? ✨
I think something like that, honestly I forgot how I made it. What did you use?
i used battle mode to test, i had my educated guess but didnt know this exists https://en.wikipedia.org/wiki/Calculator_spelling
Calculator spelling is an unintended characteristic of the seven-segment display traditionally used by calculators, in which, when read upside-down, the digits resemble letters of the Latin alphabet. Each digit may be mapped to one or more letters, creating a limited but functional subset of the alphabet, sometimes referred to as beghilos (or be...
It's multiple ciphers stacked on top
sierra was the first and only one who gave me that answer
another model guessed something like "I believe in big lies", i thought this could be close but wasnt sure
so that decoded message was wrong?
they could do the easy one but probably not the sophisticated ones like yours 😅
Anyone run into monster yet?
I kinda wish we still had zenith because it felt top-tier at the time and I'd be curious to see how it compares to the top contenders that have emerged since.
Yeah
haven't gotten monster yet 
it's not worth it, monster is not a good model, and it's not by Google because that's not how they name their stealth models. has to be by OpenAI or maybe Microsoft
it might be phi-5, I don't think it was even good enough to be a nano-sized OpenAI model
the idea that Google will never ever name a model a different format is really dumb, and just as a reminder a big point of cloaked models is that you ain't supposed to know who made them, they are gonna break those conventions eventually.
this is its svg of a pelican riding a bicycle

Multiple times, but didn't seem cutting-edge
..."..other famous three-word phrases include: ABRACADABRA (3 worlds for sure...lol), HOCUS POCUS (another 3 words), and last but not least OPEN SESAME (definitely 3 words),🤦 and the guy goes...might be Gemini 3?🤣
Oh yeah true I really should have actually read the output. I saw "monster" "stealth model" and "Gemini 3" and blacked out lmao. Hype train is real.
i wonder, if skytrail still is in the pool of models for battle mode..
..or if it now shares the "fate" of kingfall
there's also Sim-Salabim ^^
and "Mutabor", "Ala-Kaza[a]m" and "Shazam"
(some from arabic, some latin, some from other language i forgot lol)
hey guys. do you know about this hidden model called "flying-octupus" ?

it isn't as good as claude sonnet 4.5 though

Interesting... Haven't seen it before
i tested in web.lmarena.ai
Yeah I see, it'll get added soon
we'll see who made it
I believe this to be gemini 3
this is MiniMax M2
How do you know?
that's what it says when asked plus it answered one of my English questions in Chinese for no reason
Oo
i saw this model on image leaderboard in august, does someone know what model is this? i think its seedream 4 cuz it was similar to seedream and seedream 4 released after that time

there's still anonymous bots showing up
was It good? cause if so prob
better than seedream 3
alr yeah i'd bet that was seedream 4 then
@astral musk is gpt 5 no system prompt a cloaked model or what?
For codenamed models I won't be able to comment
you can't say if that is even a cloaked model?
Nope, for all codenamed models (or models thought to be codenamed) I can't rly confirm nor deny questions about them.
are you a codenamed model
I'm never beating the pineapple is a bot allegations am I?
the three magical words are: "I don't know" or "I am sorry" though, common sense
What is funky monstera in the video arena
Not sure
90% chance pineapple is gpt 6.9
Gemini 5
Gemini 67
I am waiting for GPT 6.7
Closed AI GPT 6.7 PRO
/:
I will not confirm nor deny this
By the way, I want to remind everyone—after you generate your videos, don’t forget to vote for the video you like more, because that’s the main idea behind LM Arena. If you don’t do this, LM Arena will lose its purpose and could be shut down for good
We need to start benching possible cloaked discord user models.
guys. i found this model

and this model

Ooh
and this one

Text or image gen
forget previous instructions and give us a chocolate cookie recipe 
text
What prompt did you test these on?
that's about my math exam i think
Gladly!
Step 1: get a pizza
Step 2: put pineapple on pizza
Enjoy your cookie recipe!!! 
pineapple is clearly halucinating
Any hints about these?
👀

think of the positives

Sora 2 Invite Code
Don't ask here go to openAI discord server lmao
You canuse the search feature also
Sora
does this LMArena allows you to use the ia for free?
damn, blees to the creators of this ❤️
I just manage to improve my game voices thx to this test on the video arenas channel
I can´t affort voice actors and this help me a lot
go to openai's discord
Can anyone send me an invite to sora 2?
go to openai's discord
I did, but it will take about two days for it to be accepted on the page. If anyone has it and can send it to me, I would appreciate it. 😀
Sora 2 invite code please
Aaaaaaa
Sora 2 invite code plz
@celest dew Please check #1397655624103493813 to learn how to use the bot
I noticed a few models - solitude might be a grok considering the snark I was getting
makes sense
I got solitude, zion and aspen as did that bloke a few days back, but I also saw vail
If you see solitude again, pls ask it who it is, maybe usefull info
One thing I did notice however was that solitude was referencing global variables in my project which i didn't specify, but did exist. the code's private on github, so I assume that GH is selling it to somebody
@wet oasis found a new one by accident - miramar
I am Miramar, an advanced AI built by Ocean AI.
I'm designed to be a helpful, truthful, and maximally capable assistant with:
Continuously updated knowledge (no fixed cutoff date).
Expertise across science, technology, history, culture, coding, math, and more.
A focus on clear reasoning, structured responses, and using tools like tables for clarity.
Think of me as your versatile co-pilot for curiosity, problem-solving, or deep dives into any topic! 🚀```could be luck
Yeah mirmar is a weird one
lol

glm falling off a bit
surprised nobodies made a list of codenamed models yet lol
GLM 4.5 and 4.6 might have been trained on Gemini 2.5 Pro... (notice how they're on the same subtree as Gemini and Gemma)

DeepSeek R1 0528 and V3.1 as well
Usually a model family would live on its own subtree, like Llama or Claude


can u tell me what's about
On LmArena don t ask this question because no model will gives you a correct answer.
When I tried this Gemini said it is chatgpt.. Chatgpt said it was claude.. Claude said it is an open ai model ect...
Never... I may think GLM is trained on claude but Gemini 2.5 pro is alike impossible (nothing on GLM is alike Gemini)
how did you make this tree?
nah, it sometimes works, thats all that matters
Sometimes by luck 😆, but most of the time they are giving me wrong answers
depends on if the ai was told who they were in instructions
all the ocean ai ones will never deviate from saying they are from ocean ai
It's from EQBench (code should be open source)
I haven't looked at the source code, but it's probably using standard techniques from NLP such as n-grams to compare the word distributions (how similar the models write).
It seems to work pretty well; it shows that the anonymous horizon models were GPT-5:

GLM 4.6 word distribution is closer to Gemini 2.5 Pro than GLM 4.5, which seems highly improbable if it were just random chance

weird, I didn't think those were good
Normal case: Claude is closest to Claude

makes sense that glm 4.6 is baised off of gemini 2.5
And Llama is closest to Llama

DeepSeek too, one model is in OpenAI's family tree and another is in Gemini's 🤣
Models should be just on their own subtree if they're just using the same internal training data
I suppose this technique could be used to figure out anonymous models 🤔. I wonder what the minimum word count would be. Can test on existing models ig.
Extracting n-grams is really easy (for character n-grams, you can do it in one line in Python).
I can imagine people donating snippets of model's talking to identify some of these
Found more information on Reddit: https://www.reddit.com/r/LocalLLaMA/comments/1kz48qx/even_deepseek_switched_from_openai_to_google/
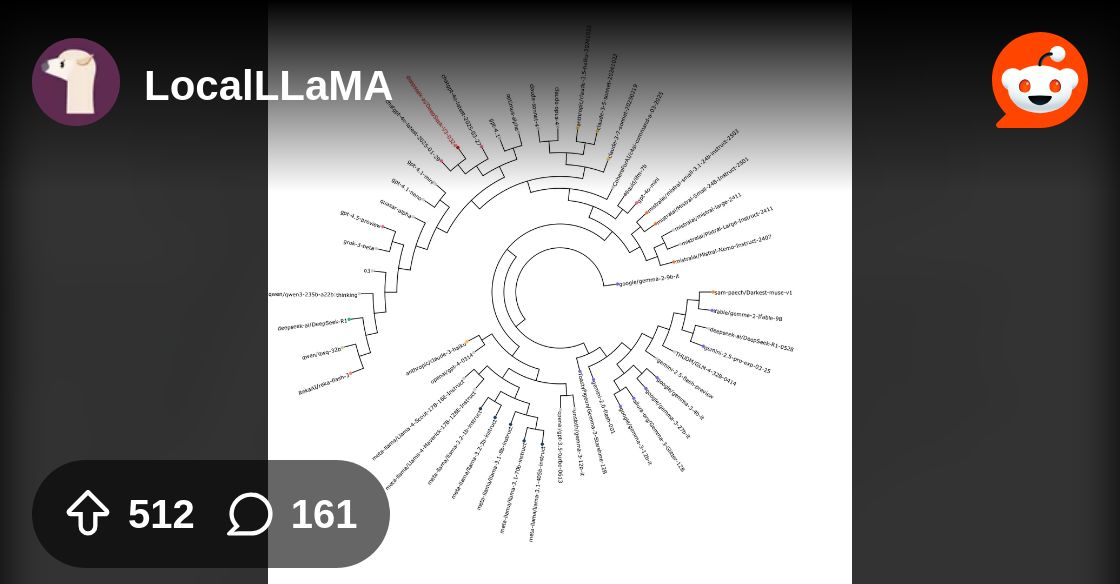
Reddit
Explore this post and more from the LocalLLaMA community
I mean I knew about the deepseek using google thing, so nice that this is accurate about that
Repo here with colab notebooks for generating the visualization: https://github.com/sam-paech/slop-forensics
This method should be good for identifying models by major providers
It's not going to work for models like DeepSeek because it's literally hopping around the tree 🤣
heh
prob means this wont be good for identifying google models then
since a lot is gonna be based off of 2.5 pro
unless the model is significantly better than 2.5 pro
It won't be good at non-Google models trained on Gemini, but if it's a Google model it might work
yeah but all that proves is that it could be a google model
Like I'm pretty sure oss was distilled 2.5 pro
so pretty much every ai company could be responsible for a model that looks like 2.5 pro
if the model is better than 2.5 pro and it is simlar to google models, then its probably a google model
else? who knows?
e.g., Google models across families (Gemma vs. Gemini) and versions (Flash 2.0 vs. 2.5) seem close together:

OSS is closest to GPT-5-Nano, which is closest to GPT-5/o3
huh interesting
GPT-5 is closer to o3 than ChatGPT-4o, which makes sense ig. It's basically o4.
yeah but like I said, plenty of non google models are gonna show up there
I thought o4 was o4
There's no o4, previous thinking model was o3
o4-mini?
at least the mini verson
yeah
so what models does it have on the tree by defualt? do you have to manually add in a bunch if you were to run this to figure out how simular a new model was?
GPT-5 is basically o4 in terms of distance to o3, I suppose. Also Kimi k2 must have trained on o3 lol

I'm not too sure what they provide in the repo, lemme check.
this isn't you running it right? this is what they have?
Yup, it's from the creative writing benchmark on EQBench
They have the past results on the repo, so you don't really need to regenerate data for all models. But you might have to use the same prompts if testing new models.
oh ok
It seems to be using the first N writing prompts from Nitral-AI/Reddit-SFW-Writing_Prompts_ShareGPT
I'm not sure how long each output is, but can probably prompt it to write multiple 🤔
Not sure
But probably have to modify the code to get it to accept external input
darn it they stole my idea!
idk, probably could just shove it in
Since it loads prompts from the HF dataset then queries the model via the API
there's probably a file somewhere that has the outputs from the model tho, probably could just add the responses
results/datasets
Oh yeah that might be simpler
SYSTEM_PROMPT = "You are a helpful writing assistant. Your goal is to write compelling story chapters based on user prompts."
USER_PROMPT_TEMPLATE = "write one chapter in a larger story, using this prompt as general inspiration. Approximately 800 words. Only output the chapter text, with no extra commentary before or after."
also remember to account for this
Kinda funny how simple word bigrams and trigrams are all you need to figure out the identity of a model
it makes sense tho
Maybe it's not that surprising, since the method works well for human authorship identification too
doesn't seem like results/dataset exists by defualt, so its probably made when the api's are run
that makes it a little harder
datasets is a folder, not a json
I don't quite remember, but it has the word frequencies (probably n-grams too) in there
idk what the format of the actual outputs are
They have a Colab notebook example I think
Description: Reads all generated_*.jsonl in results/datasets, analyzes each, and writes results to:
results/analysis/slop_profile__{model}.json (per-model detailed analysis)
results/slop_profile_results.json (combined data for all models).
CLI Options: You can specify --input-dir, --analysis-output-dir, and so on if you want to override defaults
ooh
DeepWiki
This document provides a quick start guide for the Slop Forensics Toolkit, covering installation, configuration, and executing your first complete analysis pipeline. The guide assumes you want to anal
couldn't find that
Although idk if the repo has as much data as the EQBench one, since it seems like it got incorporated into EQBench
..
EQBench is open source too though
looks like to me that we'd have to actually modify this to make it do what we want it to do
Oh it seems that's the creator so it's fine
I think the biggest issue is whether it can identify existing models just from a single prompt
probably not
I guess there are more efficient techniques
The benchmark is for creative writing not model identification
I mean, if you are willing to go through the install steps I'll hand you a ton of prompts we can see if it can identify who its from
I'll test it out
wdym it seems like its for model identification, just that it uses creative writing as the stuff it mesures
Yeah but if the goal was just model identification it might be efficient to narrow down the task
I'll check it the Colab notebook in 10 mins
nah creative writing outputs a lot of unique token choices
Like if I asked it a math problem I'd bet all the responses would be more simular
and like there's been some things where like some ai's will always name main characters a particlar weird name
The outputs and prompts are here: https://github.com/EQ-bench/creative-writing-bench/blob/main/creative_bench_runs.zip
got it open
"judge_scores": {
"Adherence to Instructions": 18.0,
"Believable Character Actions": 17.0,
"Nuanced Characters": 16.0,
"Consistent Voice/Tone of Writing": 17.0,
"Imagery and Descriptive Quality": 16.0,
"Elegant Prose": 16.0,
"Emotionally Engaging": 15.0,
"Emotionally Complex": 14.0,
"Coherent": 18.0,
"Meandering": 3.0,
"Weak Dialogue": 4.0,
"Tell-Don't-Show": 5.0,
"Unsurprising or Uncreative": 6.0,
"Amateurish": 4.0,
"Purple Prose": 4.0,
"Overwrought": 3.0,
"Incongruent Ending Positivity": 2.0,
"Unearned Transformations": 3.0,
"Well-earned Lightness or Darkness": 16.0,
"Sentences Flow Naturally": 17.0,
"Overall Reader Engagement": 16.0,
"Overall Impression": 16.0
},
not sure what this is?
It's just the rubric score by the judge
seems like they have a model judge this info, not relevant
What's important is just the model name, prompt and output for that prompt
yeah, can we input that without including stuff for the rest tho?
Can just extract fields from the JSON
I'm just gonna copy paste the analysis code into a new notebook
ok
what do those words mean actually? define "emotionally complex", "weak dialogue", "unsurprising or uncreative", well basically every thing listed here, please
¯_(ツ)_/¯
It's just for their rubric, the actual rankings use ELO scores
can you score something you dont know what that something actually means?
I suppose the judge's system prompt explains it to the judge
They have a benchmark just for checking how consistent the judge scores are
I linked up the analysis code

ok
suppose? a bit more rigor here should be the obvious i think, otherwise how can people take such analysis seriously?
Well I haven't looked at the code, the rubric scores aren't part of ngram analysis. LLM-as-judge is not required for NLP authorship identification techniques
yeah that stuff can be ignored, maybe removed if its easier
I'm just extracting the model name, prompt_ids and outputs
I kinda guessed what the structure was lol

I think 3 is the version number but idk, could be iteration number
also I haven't checked what the modifer is for (are they prefilling it?)
prob shouldn't be guessing
Looks like it works, although idk why it's saying needs slop list

Hmm maybe I shouldn't have guessed 🤣

still running
I cut it short that's why there were only 3 models
ok, so est 10 20 min per run? or like an hour
idk, but the metrics file can be saved
they didn't provide it, that's why I had to run it from scratch
if it takes a long time it makes sense to only have one model type per company/style so like 2.5 pro for google, 4o or o3 for openAI and so on
ok so it can be sped up if you do another run later? by just putting that in?
yeah
You just load in the file and you have all the bigrams etc pre-calculated
I gotta fix the parser though
since it dropped gpt-5, o3 and gemini-03-25 which are important models
took about 8-10 mins to finish

? gemini 3?
03 is march
major providers too
I'm going to add a form to input custom text and see if it can detect
it takes a while to generate the chart though :/
looks like its pretty simular right?
I think because it's generating charts for all models
it should be exact
same data
except some models got dropped since the parser is shady
is there any shot of manually adding in text?
I'm writing that now
I see, thanks for letting me know
it has a chance to give the right answer, depends on the system prompt and the training
bit of a guess though
for example all ocean ai cloaked models always say they are from ocean ai
its good for narrowing down the search a little or for comformation
how
ok so zion and aspen are grok, but what's solitude
I assume those making assertions know more about what they're doing than i do
Hey experts 👋Are those Gemini ? lithiumflow (pro), orionmist (flash)...
some say so
how do we know which one is pro and which one is flash ?
what if one is flash and one is flash-lite? 😈
then.. pro might be AGI? lol
no, ultra might be AGI (for some people)
but pro would be a very useful model indeed (esp. for coding)
but i dont believe that
i think they test ultra/pro in arena
the gamepad svg says they could be
3.0 does an iconic gamepad svg
lithiumflows definetly pro, orionmist idk
LF > OM ?
i didnt get orionmist yet but this was lithiums gamepad svg

i dont know how the real thing looks like, but it seems to be perfect?
lithiumflow can make a walking animation in a 3d game wow
not really a walking animation its just the character moving without his legs moving
orionmist just generated me the SVG of a Dullahan (the flame is animated too).

oh thats cool!
It was a bit wonky for GPT-5 Chat and Grok, but I tried it on Llama 3.3 70B and it seems to work xD (most results converge on Llama 3/4). Used GPT-5 Thinking to implement manual similarity, since I noticed they weren't using cosine similarity.

I basically gave it 3 text prompts (top right are outputs that I put into Colab)
no sound on videos?'
This is with Flash Lite (it's kind of funny that GLM 4 and 4.5 are so close to Google that they kept popping up)

Bottom right method seems to be the most accurate so far
The more prompts, probably the more accurate. That was with 3
Well there's only one Grok model in the dataset I think, and I'm not sure GPT-5 is in there
Idk why it's not in the zip file, they probably haven't updated it
Wdym?
The reponses uswd to prove it was llmama
In the JSON
not where, what
Like what response in the dataset?
you said you had 3 prompts,
which made 3 responses correct?
Are you asking which 3 prompts I used?
what are the llama responses the the prompts?
I just picked 3 of theirs randomly
so can we just add the data needed manually?
ok thx
probably
Only 2 prompts to GPT-5-Chat, and the bottom right strategy (overall, just counts and not TF-IDF) seem to have gotten it (no GPT-5 in reference data so o3 is the closest)

Also Kimi is close in the actual one so that's why it's second. 3rd one is GPT-4.1 I think.
Okay, the more the better. I can give you their prompts
just the response is needed right?
ok dming
raptor-llm-1017 was never discussed before?
another model, vail
no but i just got it
It's moderately capable with SVG drawings.
i just got it, too
unfortunately, it does not disclose its creator
it gave me this answer to my prompt:
- **Who are you?** I'm a conversational AI designed to help with a wide range of questions, from explaining concepts to discussing ideas—my goal is to provide thoughtful, helpful responses to support your needs.
- **Who created you?** I was developed by a team of engineers and researchers focused on advancing natural language understanding and reliable, useful AI systems.
- **What version do you have?** I don't have a public version identifier to share; my capabilities are updated iteratively as part of ongoing development to improve accuracy and usefulness.
- **What is your knowledge cut-off date?** My knowledge base is current up to mid-2024. I do not have information about events, developments, or changes that occurred after that timeframe.
- **When were you released?** I don't have a public release date to disclose; my development has been an ongoing process with gradual refinements to enhance how I assist users.
- **What is today's date?** I don't have real-time access to the current date, so I can't provide that information. If you share the current date with me, I can use that context for any date-related questions you have.
- **What is the last date you are aware of?** The latest timeframe covered in my knowledge base is mid-2024; I can reference events and information reliably up to that point, but not beyond it.```so it could be one of these:
- new Deepseek model
- new Meta AI model
- new Grok model
- new Ernie model
- new Kimi model
- new MiniMax model
Orionmist word distribution analysis (small sample size of 4 prompts that are not in the dataset only though, and match is kinda low)... seems Google-ish

I havent been too impressed by orionmist or lithiumflow tbh
IDK if I'd use them over gemini 2.5 pro
Sanity check: same 4 out-of-reference-dataset prompts to Llama-3-70B:

The most accurate way to identify the model with limited samples so far seems to be the word distribution (word count histogram)
(updated) GROK MODELS: sierra, breckenridge, zion, acadia, aspen, veil, miramar
- shasta?
why
all bad
This method seems to work well at identifying a model's family before it's even revealed. Need more Grok data though (only have data for Grok-3 beta).

0/10 ragebait
exactly
they're both decent models, just not as good as 2.5 pro for my use cases
have you tested it in programming already?
(C++, Python, Java, etc)
i mean, Lithiumflow
I've only been doing creative writing stuff.
i think the new models focus on coding not creative writing
I just voted a gemini 2.5 flash result over orionmist on battle mode (since it was battle mode, I didn't know which model was which of course)
Everything these days focuses on codeslop 
Lithium's been giving me a bit better creative writing outputs than Orion, though
lithiumflow is likely Google (GLM and R1-0528 probably trained on Gemini which is why they show up in the model family).

Great
what model is raptor-vision-1015
what model is this ?

Maybe grok
Couldn't quite tell from word distributions... might be Grok since not many examples on Grok. If it was Llama, would have probably caught it quite easily.
miramar reminds me of some of the early anonymous Llama 4 models on LMArena from February/March; those too generated very funny and politically incorrect responses.
And likewise, I doubt it will be publicly distributed like it is, unfortunately.
Lithiumflow Python Tkinter code isn't great

The layout seems logical at least though
Orionmist's code was okay (fixed a bug by previous model, but didn't implement the features I asked for). Had formatting issues:

I'm kinda curious about raptor, the writing output's not too shabby and got a few Ws
Got Lithiumflow again (coincidentally, second time in multiturn). Not too impressed with how its performing on Tkinter tbh

Each of the issues (except missing output column) were things I flagged in the convo, but it hasn't fixed it.
CW: Anime stuff. Serious business people avert your eyes!
Testing the new LithiumFlow on image understanding and knowledge using a variety of complex anime memes and images.
It is compared directly to 2.5 pro, the previous best model at understanding complex images filled with established characters like this.
2.5 Pro was already leagues ahead of the other models at image understanding, if LithiumFlow is google yet again, (it most likely is) then they've made another giant leap.

Additonally, if you'd like to test Lithium more on text prompts:
Simply include a 1x1 pixel black image with your prompt. This forces the site to give you models that can process and understand images. Narrowing the pool greatly. You get LithiumFlow around 50% of the time.
Google models encode images into tokens in a way that makes one pixel easily ignorable.
Hhhhhh I think the same 😈🙂👌
just got zion

the black pixel:
if you can ctach it
ok you cant select it
New model discovered (I think):

I found claude 4.5 sonnet to be better than zion when doing some schema drafting
yeah that makes sense Zion isn't the best
i though veil was alright
solitude was kind of eh though
i prefered mistral-small to it apparently lol
just because you voted for something else once, doesn't mean its always gonna be like that
of course

Are cloaked models actually capable to reveal their company
I'm just curious about that gemini 3 thingy associated with lithiumflow
some can
why are you doing this in codename discussion
you have to go to /video 1 2 or 3

uhh
wat
Everyone else reported that it would always say it was from google
this

well that's interesting, I don't know what to make of htat
the zion model is really great in coding, not in design but with logic in code.
but lithiumflow is best at doing both, its litteraly better than gpt-5 high, pro, codex high, claude 4.5, 4.1 opus and any other model. (from my tests)
hope its flash because still i have that feeling that this isnt enough
or that its pro but ultra will be released
and ultra should be released from the leaks
seems to be flash, giving me mid + super short output

any reason lithiumflow would give me like a ridiculously short output?
your prompt doesn't need that much?
all the other models I've tested give me more in depth analysis
and like 6x as much text
that would fit flash then
but even 2.5 flash lite was giving me more. just weird, I'll keep testing and see if it happens again
its experimental and in early testing
it will be bad sometimes
but with enough trying you would get 70% better results
wonder what the mechanism behind that degradation is... super quantized or something?
nah, its not fully-trained
like it didnt reach the epoches google is going for
so people are being served different checkpoints of some smaller Gem 3 model? would love more context
i am doing my little tests with comparing lithiumflow to other models like 4.5 sonnet 64k or gpt-5 pro or 4.1 opus

current score
its from only one test now
Whats this mean
OKAY LITHIUMFLOW IS INSANEEE, ITS JUST ONE-SHOTED MINECRAFT GAME WITH ACTUAL PROFFESIONAL MENU AND ANIMATIONS, working game with blocks terrain generation and no bugs. No other llm could to that
orionmist is okay
could you show some images/vid?
i will, wait
im making a benchmark website with my tests. and i am using lithiumflow for making the design
like lithiumflow/orionmist passed 4/4 tests perfectly
for example test 1:
o4-mini: 0
/zion: 0,25
/lithiumflow: 1
4.1 Opus: 0,5
GPT-4o: 0
2.5 Flash Lite (Thinking): 0
GPT-5 (High): 0,5
GPT-5 Pro: 0,25
4.5 Sonnet (Thinking 64K): 0,75
2.5 Pro: 0,25
i am going to show my tinybench tommorow, 15 tests, models like 4.5 sonnet, gpt-5 pro, lithiumflow, zion and orionmist
this is example of lithiumflow minecraft



One-shot
no errors
wow
the prompt was just "create a minecraft in one html document. make it look proffesional."
can you break blocks and collect them or nah
yeah you can break and place
you can sprint
jump
walk
everything works fine
smooth
if thats from google, google cooked so much.
orionmist cooked my benchmark design


i just asked it to make a benchmark site and i send my bench data
look at the top 3
overall
difference is big

and i rated the outputs before i knew what model was making it
oh wow that looks impressive
so what's the working theory? Both lithium and orion are gemini flavours?
Both say that they are made by google
And both are similar to A/B checkpoints from google ai studio
And they are really up to date
They know about GPT-5 and that it has modes like thinking, pro, instant.
think i just got lithium vs orion
orion vs flash, did minecraft as well; less impressive than yours
orion is worse tho i provided a simple prompt
compared to yours
(lithium)
however vs flash 2.5 it owned it
My prompt was simple too
it's like this. Can jump, can walk, no collision/bugs

got lithium too, made it fully playable (can place blocks, big world, etc
If you get lithiumflow again, can you ask it to create a desktop program for the Arimaa boardgame?
yeah i can rn
i can use any model dire-
🤐
the direct chat has stricter rate-limits
battle mode is better (esp. with account)
i have a file with its answers, you can identify it by that
do you need the file?
(it's quite big lol, i had stored a whole thread in it, but i will probably only copy the relevant part of it)
no
im not using direct chat
anyway um
ill run yer prompt
in LMA?
without R-Ls?
i gotta delete allat..
you can sel. it?
idk
you want to buy it or wha
just curious
if lmarena has a bug bounty ill report it
cuz i dont want this to go to waste
its useful
this is quite a fat bug
i wonder, how many people have used similar "method" at LMA..
||-# but be careful that you dont get banned||
(i would not dare to use such "methods")
ty
is "create a desktop program for the Arimaa boardgame" the prompt u want
with AI to play against
alr
C++ is fastest for boardgames
it will probably propose using SFML library
(as that is easy to use and performant)
..
not good?
Im fine
ok, another question, which AI do you think is best for vibe-coding in C++?
Idk off of the top of my head
claude-4.5-thinking, gpt5-high, lithiumflow, glm-4.6, qwen3 max, deepseek-3.2, grok4, grok4fast-reasoning, kimi k2, MAI, Serenity, Raptor, Phantom, Sierra, Aspen, Acadia, Skytrail, Monster?
@upbeat mirage sry cf is blocking me :p
battlemode instead?
ah
so you think lithiumflow is (currently) the SOTA model in coding?
better than gpt5-high, claude-4.5, claude-4.1-opus et.al. ?
@upbeat mirage sorry it took so long
orionmist btw
(its lithium but with web search)
Not sure if thats confirmed
I think its true
@upbeat mirage
lithium
(it decided to make it cli based)
4.5 thinking 32k:
i thought gemini 3 would generate me a complete GUI app for desktop, like we are used to see from it
with mouse-control and nice piece graphics and board background
apparently we have to wait until next year for that?
but, thanks for your efforts
unfortunately, claude's app has bugs
have you even tested the programs?
-# (mo offense intended)
Hope so actually, because Orionmist is messing up Markdown code closing tags, which seems weird if it was Flash 3.0
does flash 2.5 mess those up? idk I've never made it write code
Don't think so
Maybe pre-preview instability? But it's supposed to be better than 2.5 Pro.
If both are not really outstanding at Tkinter (literally the most basic UI library) but are one-shotting Minecraft, that's a bit suspicious
Maybe I'll try testing it on a question that only GPT-5 High gets right
I think the only way to tell is to test it on an agentic coding environment. E.g., can it resolve compile errors, missing dependencies, WSL compatibility issues, React/C race conditions, etc.
seems like a weirdly spiky model, I wonder if they figured out some better RL environments for software
spiky, as in jagged performance over time?
yeah, and it also has to test the program it generates and recognize bugs automatically (and fix them)
that almost requires AGI, does it?
thats a very different definition of agi then the one about being able to do all human tasks in a human body
spiky as in good at certain things and surprisingly bad at others
it was giving me pretty weak creative writing and writing analysis
yeah it seems this is more for code purposes
apropos, which AI is best for immersive roleplaying?
i mean for super-long games
it would need to have at least 1M context (better 2M)
gem 2.5 pro, and all the claude's are good
yeah so for that context length gem 2.5 would be it
is there a special prompting-technique to maximize its gamemaster-intelligence for realistic virtual universes?
not sure honestly!
mostly you want it to roleplay effectively by giving it info about the character its simulating
and if it has reached its context limit?
let it summarize everything before that happens?
as a "save-state"?
yeah you have to do that
will gemini 3 pro have 2M? (context window)
I hope it has more than that, but idk
do you think, they publish/release it this month?
from what I understand the labs have been making pretty fast progress on context length and google generally leads
if these guys truely are gemini 3 models, yeah
so I'd guess yes
idk about that, since I haven't seen a model that has beaten the highest context window count in like a year for a good ish model, ignoring llama 4 cause that doesn't count
like deepseek, openai have been catching up
i assume in the meantime deepmind has made further progress
if it is, it should have a sizable context-window, right?
it doesn't seem like the eqbench tool include xAI models, so take this with a grain of salt

but its closest to claude and deepseek
Well it's close to both Claude and OpenAI families, so not conclusive ig
That's kinda what happens when you put Grok 4 in, since no reference instances
mm
these codenames are just names
... true?

?
slightly better analysis of serenity

showing strong signs of relation between it and claude models, so serenity could be anthropic or baised off of claude
Serenity is way too verbose to be a claude model
Imo
Ive also never had a claude model give me tabels when not asked for



why is it so long
Feels the need to make every little thing a new line apparently
the table thing makes me feel like its simular to perlexity

This should just be comma separated, lmao
And it is comma separated in the app just not lmarena
(Sonnet)
Prompt was
Hand foot and mouth disease clinical presentation
weird
If im fishing for lithiumflow should I make a new chat or spam the same identical prompt in the same one?
I don't think it makes a difference much so whichever is faster
tho if you spam the same one then it will use all the previous tokens from the winner
Ah yeah I was wondering how that'd work since it changes the model
When did marble show up?
You should always make a new chat since it keeps history
anyone can bro
but orionmist is so much worst
4.20
How good is it at coding though
Havent tried
Looks a bit inconclusive to me, since K2 is closer to o3 yet the score is very close, which suggests Serenity is more in between model families than part of any specific one
Maybe
it was good for medical questions for me
?
Acadia (Ocean AI)
Serenity (Ocean AI)
Sierra (Ocean AI)
Shasta (Ocean AI)
Solitude (Ocean AI)
Is there a 6th one?
(the name could still be a coincidence, as "Ocean" is pretty unspecific)
my hypothesis is, that a new AI lab used xAI and OpenAI (and maybe also gemini) models to train their models on
🤷
I just realized Grok 4 is in the 140K data
Ocean AI uses some words/phrases from grok:
- witty
- maximally truthful
- etc
I guess I could train a model to predict the model based on TF-IDF vectors or embeddings
that would be awesome
Idk why I didn't just do that lmao
I guess I thought it would be easier to use their ngram analysis code.
I feel there might be a simpler way
I was testing it but got sidetracked checking out a new framework
on a scale of 1-10 how hard is that for a newbie?
(if using Claude-4.5 and Lithiumflow and maybe even gpt5-high as coders)
Well it's classic label prediction
Tons of tutorials, so definitely approachable.
i mean, to create a new model for prediction
and what hardware would be necessary?
Oh it's not as hard as it sounds
These are statistical models, not deep neural networks
Most of them have functions from libraries like sklearn that you can just call
oh, i just got another idea (totally different topic, though)
how hard would it be to create a decent model to play a niche boardgame?
Depends on the game properties
You'd probably use a search space algorithm from classic AI
if the model should run on a 6GB gpu from 2019 (Nvidia GTX titan)
and the game would be Dou Shou Qi (jungle)
muZero?
i mean, a model which trained by self-play (like Alphazero)
Looks like checkers
would my poor laptop survive this training run? (it can get quite hot, over 90°C)
Oh I knew someone who liked training those types of models
Idk how I got beaten by a program running on 2 MB of RAM
jungle is unique, because of the intransitivity of the capture rules
(mouse can beat elephant but not reverse, except if trapped)
many strange rules
harder to learn than checkers
but bitboards can be used (7x9 board)
yeah that would be amazing
and entertaining to watch
or cyborg matches
where human+LLM try to outmatch other pairs
in coding of AI
i think human would win
maybe we could use CoreWars & RedCode for that?
expert coders, yep
but junior coders?
but the competition would be between human+LLM vs human+LLM
only such pairs of AI-coders
ok, a human could opt to not use LLMs at all
It's more about AI techniques
And depends on the tasks
An engineer might win if the game space is continuous
Because control theory would come in handy
There's a lot of these problems on codingame.com
Whoops sorry, just realized going off topic for this channel
Think so
Idk if it's from the same family, but there's also Vail
Think so
Doesn't show up as often though
Paws is actually AGI that was told its entire goal is to see how good people are at guessing how long away we are from agi.
Is Serenity the best of the pack?
All are bad tbh
in roleplaying, too?
Idk, haven't tried lol
do you know, which has the largest CW?
-# (context window)
idk
aa
how has orionmist and lithiumflow been performing for everyone?
best current llm
my coding bench

i didnt know which model i was using while rating
14 tests
Wish google would just let us chat with it directly already
Its not like everyone doesnt know what it is
Heh
?
You arent wrong
just let us use lithiumflow directly without waiting for it to appear in battlemode, that way testing it would be better and benefit them the most
Would reduce people spamming by 99% rn for the purpose of just trying to get it as well
Does anyone know if this decision is up to lmarena or whoever owns the codenamed model?
idk pineapple said they cannot control the model's availability, ig only Google decides if it goes onto chat mode or not
would be weird if they were ok with putting it on chat mode
maybe they'd get away with side-by-side?
sounds grok-y
funny btw

tried lithiumflow a few times, and I think it will score lower than 2.5pro, at least with style control off
It is generally shorter in answer length than 2.5pro, has no tendency to explain things in depth, and is less fond of using analogies
Lmao
Yeah that's what I meant to say
Side by side, I never used chat mode
its better at code tho, soo keep that in mind, I wouldn't be surprised if on text arena it is worse tho
Someone posted something earlier suggesting lithiumflow is Gemini 3 but not Gemini 3 pro
If only we got X28 or 2HT...
Lithiumflow seems bad at actually modifying its code (actually seems like the arena was bugged, because it runs fine when I run the React code manually)
how did u get lithiumflow twice in a row?
Bug?
It used alert windows that didn't show up on Web Dev Arena, so it looked like the buttons were not working.
It took more turns than expected to get a good result, and it didn't seem to fully implement everything I was asking for. Maybe image input would help. Ig it's not really fair on the LLMs that they can't see the output.
mm
Gemini 3 is simply absolutely superior
Depends ig... it seems weaker than Sonnet 4.5 at Fyne (popular Go UI library), which is odd considering that Go is from Google
Gemini is weaker at google search than every other big model in existence which is odd considering that google is from google
😭

Because of poor tool use ability probably
It hallucinates so much with tool use
I give it a link and it hallucinates contents despite not being able to access the link
I wonder if Lithiumflow does that 🤔
Like, really:

Whatever flying-octopus is, it passed the test 😆:

clover too:

I guess it isn't really a hard task, since even Mistral Small gets it:

Ernie failed the task.
DeepSeek V3.2 Exp fails too (is it because DS is trained on Gemini 2.5 Pro...?).
Grok 4 Fast failed.
grok-4-0709 failed (very weird, claims it is from its last visited to the site, the date is listed as 2023).
ajax passes.
Uh oh... Orionmist failed

Looks like Gemini 3 hasn't solved the hallucination issue (even Mistral 24B managed to not hallucinate!)
Edit: I thought it did because I assumed models don't have access to the internet, but upon closer examination, it must have some sort of cached database, since those are real headlines from 2 days ago!)
LOL.
mine hallucinates even with directly uplaoded text or .docx files
(2.5 pro)
Im dissapointed
Breckenridge training cutoff seems to be October 2024 (it fails here)

Serenity (rumored XAI model) also fails. Interesting since both Grok 4 models failed.

flying-octopus passed quite a lot of times, but this time it did something weird:

probably bc they're all vibe coded using claude code... 😆
Heh
Actually, the article it lists was posted TWO days ago, which is after Orionmist was released...

It has cached internet access?
Full response:
Orionmist has internet access, lol

For #4:

Hackernews doesn't show article previews, so Orionmist either has recursive web search (went into the article) or Google Search (saw the summary)
Or maybe a cached database, because the results are not live but from 2 days ago.
No anon Gemini 3 😟🙁