#ai-news
1 messages · Page 1 of 1 (latest)
gpt4


IMO this index is pretty silly, as it considers some saturated benchmarks and also static ones (aka: benchmarks that can be contaminated)
i don't like any of the benchmarks which mix other benchmarks into a single score
this is less of a problem. It is difficult for us (humans) to appreciate many scores at once, so a summary index is good. But it has to be done properly, like weight and other stuff.
A semi decent index IMO would be that posted in #leaderboards some weeks ago: https://nitter.net/scaling01/status/1919389344617414824
i disagree
Anthropic is an AI safety and research company that's working to build reliable, interpretable, and steerable AI systems.
They made their stuff open-source
😎
Today we're releasing FLUX.1 Kontext - a suite of generative flow matching models that allow you to generate and edit images.
︀︀
︀︀Unlike traditional text-to-image models, Kontext understands both text AND images as input, enabling true in-context generation and editing.

It is so good and easy to prompt. It just works
LOL
👍
For @GeminiApp Pro plan members, we've just doubled your 2.5 Pro limit, from 50 to 100 queries per day. Thanks for using the model so much and messaging us wanting more! Enjoy!
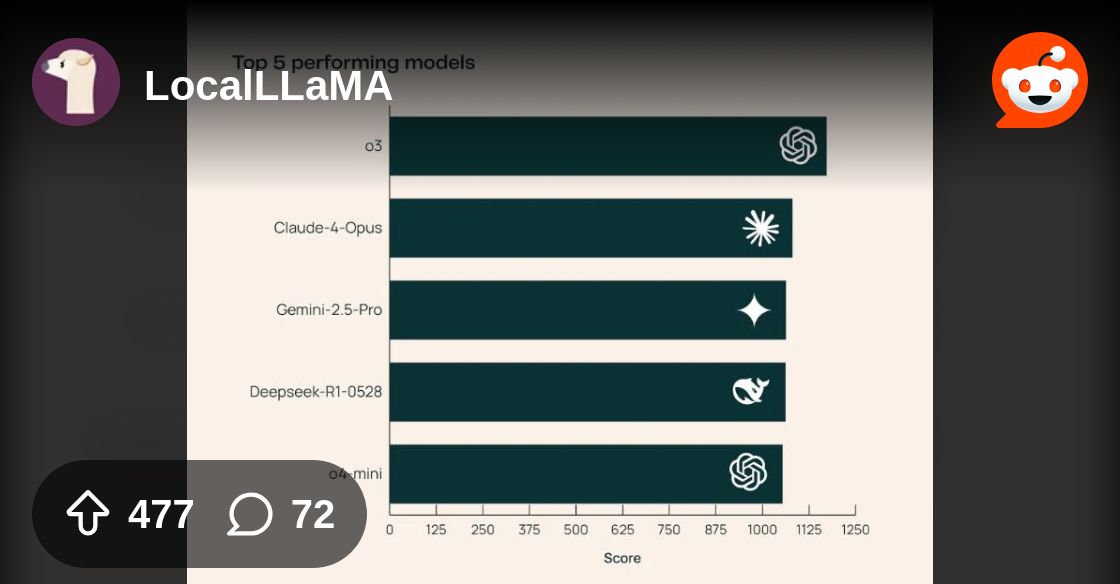
Gemini 2.5 Pro 06-05 benchmarks, with Opus 4 and DeepSeek R1 0528 too

https://www.reddit.com/r/privacy/comments/1l3lrq0/openai_slams_court_order_to_save_all_chatgpt_logs/

Reddit
Explore this post and more from the privacy community
Court forcing OpenAI to save all chats, even deleted ones
[yup](#ai-news message)
I misread it as "OpenAi forcing Court to save all chats" at the beginning for some strange reasons 😅

Introducing Eleven v3 (alpha) — our most expressive Text to Speech model.
This research preview is designed for creators working at the frontier of AI audio. Whether you're building faceless YouTube channels, narrator-style videos, or entirely new formats — it offers new levels of expressiveness and control.
Available now: The Eleven v3 (al...

The latest AI News. Learn about LLMs, Gen AI and get ready for the rollout of AGI. Wes Roth covers the latest happenings in the world of OpenAI, Google, Anthropic, NVIDIA and Open Source AI.
My Links 🔗
➡️ Subscribe: https://www.youtube.com/@WesRoth?sub_confirmation=1
➡️ Twitter: https://x.com/WesRothMoney
➡️ AI Newsletter: https:...
How insane is Gemini deep think gonna be
If O3 already this good
🤯
Reddit
Explore this post and more from the singularity community
Do someone konw Claude neptune v2??????


Grab your free seat to the 2-Day AI Mastermind: https://link.outskill.com/MBA1
Video Note - FLUX.1 Kontext [Max] is not open-source, but they did develop an open-source version called FLUX.1 Kontext [Dev].
Join My Newsletter for Regular AI Updates 👇🏼
https://forwardfuture.ai
Discover The Best AI Tools👇🏼
https://tools.forwardfutur...
BTW, the claim that o3-pro one-shotted the "Illusion of Thinking" test (10-disk Tower of Hanoi) is not accurate. The answer it gave includes an illegal move (move 96), so it spent 20 minutes and ultimately got it wrong - Wes just didn't properly check it. And the ARC-AGI scores for o3-pro aren't much better than for o3, so everyone please cool your jets.
yeah i was very confused with wes roth's video since he admits he didn't properly check it?
Yeah, I knew about the O3 score thing. I didn't really look too in-depth into the other stuff. But, I don't honestly really care about O3 models all that much. I prefer Google Gemini models.
What I'm excited for is Gemini Deep Think. If O3 Pro didn't really go up that much, but there was some improvement, I think Google could definitely do it better and make some big leaps.

AI's Broken Learning Continuity: Why Vision Models Forget - And a New Way to Fix It by Google.
All rights w/ authors:
Continual Learning in Vision-Language Models
via Aligned Model Merging
Ghada Sokar 1, Gintare Karolina Dziugaite 1, Anurag Arnab 1, Ahmet Iscen 1, Pablo Samuel Castro 1 and Cordelia Schmid 1
from
1 Google DeepMind
@googledeepmi...
I recommend you to watch his videos

INSANE AI NEWS: Seedance 1.0, Seaweed APT2, OpenAI o3-pro, SeedVR, DeepMind Weather Lab, Any2Bokeh, LayerFlow #ai #ainews #aitools #aivideo
Thanks to DeleteMe for sponsoring this video. Use code AISEARCH for % off. https://joindeleteme.com/AISEARCH
Sources in order of mention:
https://iceclear.github.io/projects/seedvr2/
https://vivocamerares...
AI search is my fav. No drawn out speculative or blatantly incorrect content.
It's actually worse than o3 (High) and o4-mini (High) on ARC AGI 2, while being more expensive. Claude Opus 4 takes the lead, despite Anthropic's focus on agentic coding.

Gemini 2.5 Pro is at 3.8% and R1 (old) is at 1.3% (higher than the new R1). Source: https://arcprize.org/leaderboard (make sure set filter to ARC AGI 2)
so $7.55 per task for a scoring lower on:
- ARC-AGI-1, than than o3 high, despite 9x price
- ARC-AGI-2, than Sonnet 4 Thinking, despite >15x price
OpenAI continues to throw bruteforce inference at every problem, with overall unimpressive results.
Colour me impressed.

In my video I follow the instructions by Anthropic on How-To build multi-agent research systems, given their specific GitHub repo. And I optimize the ideas of Anthropic for a better performance.
Anthropic's Architects: Prompting a Mind (and how to improve it).
All rights w/ authors:
Anthropic
"How we built our multi-agent research system"
ht...
Is Gemini 2.5 Pro fully releasing on June 19th?
Because that’s when it said it’s deprecating the preview version
Introducing the Gemini 2.5 model family:
- Gemini 2.5 Pro (Stable, no changes from 06-05)
- Gemini 2.5 Flash (Stable, updated pricing from 05-20)
- Gemini 2.5 Flash-Lite (Preview, small reasoning model)
More info in 🧵


Cancel your AI subscriptions and try this All-in-One AI Super assistant that's 10x better: https://chatllm.abacus.ai/ffb
Try this God Tier AI Agent that literally does everything: https://deepagent.abacus.ai/ffb
Download Humanities Last Prompt Engineering Guide 👇🏼
https://bit.ly/4kFhajz
Join My Newsletter for Regular AI Updates 👇🏼
...
can we send articles instead of videos like the old days
Came across this SWE-Bench style benchmark that continuously updates to prevent data contamination (only Python though). It lets you see how the ranking changes depending on how old the problem is.
They only added tool usage and Claude 4 in May though, so it's still pretty new.
https://swe-rebench.com/leaderboard
SWE-rebench: A Continuously Evolving and Decontaminated Benchmark for Software Engineering LLMs
claude 4 released in may

Try Chatbase for smarter support! https://link.chatbase.co/Mattberman
Download Humanities Last Prompt Engineering Guide 👇🏼
https://bit.ly/4kFhajz
Join My Newsletter for Regular AI Updates 👇🏼
https://forwardfuture.ai
Discover The Best AI Tools👇🏼
https://tools.forwardfuture.ai
My Links 🔗
👉🏻 X: https://x.com/matthewbe...
Claude 4.1coming soon

INSANE AI NEWS: Hunyuan 3D 2.1, Minimax-M1, Polaris, Bytedance InterActHuman, Midjourney Video, LoraEdit, PartTracker #ai #ainews #aitools #agi #aivideo
Download the free “Advanced Prompt Engineering” guide. Thanks to HubSpot for sponsoring this video. https://clickhubspot.com/67680b
Sources in order of mention:
https://cvlab-kaist.github....
very good interview: https://www.youtube.com/watch?v=giT0ytynSqg

He pioneered AI, now he’s warning the world. Godfather of AI Geoffrey Hinton breaks his silence on the deadly dangers of AI no one is prepared for.
Geoffrey Hinton is a leading computer scientist and cognitive psychologist, widely recognised as the ‘Godfather of AI’ for his pioneering work on neural networks and deep learning. He received...
Current RL amplifies pre-existing reasoning paths rather than forming new ones. Base models outperform RLVR counterparts with enough samples:
https://arxiv.org/abs/2504.13837
anthropic did another survey of user conversations focusing on ones where claude supports the human

Anthropic is an AI safety and research company that's working to build reliable, interpretable, and steerable AI systems.

Reddit
Explore this post and more from the LocalLLaMA community
that's kind of clickbait
Gemini released an Open Source CLI Tool similar to Claude Code but with a free 1 million token context window, 60 model requests per minute and 1,000 requests per day at no charge: https://www.reddit.com/r/LocalLLaMA/comments/1lkbiva/gemini_released_an_open_source_cli_tool_similar/

Reddit
Explore this post and more from the LocalLLaMA community
poor implementation + they use your data...
They will not expose your computer but when prompting gemini cli in a specific folder, parts of the folder or the entire folder will get sent to Google and possibly used as training data for the next iteration of the gemini model
Well I mean the same applies to chatgpt
Everything you ask chatgpt will be used for training unless you have the teams subscription or use the api
Openai also offer a free tier in their api but then data will be used for training
no you can turn it of in the settings afaik
same for gemini (the app)
but you lose some functionality if you do that
No. Most of that data is useless for training
But it can be used, yes.
@spice spire kill him
Thanks, but let’s use “ban” next time please lol
What does Github Copilot being open source mean?

Discover how SciArena is being used to evaluate foundation models’ capabilities in scientific literature tasks through community-driven, literature-grounded, and multi-disciplinary reasoning.
I think that without screening it wouldn't be better than lmarena though.
screening = selecting appropriate prompts and ignoring the others
they said experts voted on it so...
Maybe there will be a quality assurance process but I'm not sure
exactly. If they ensure that the prompts are appropriate (like the hard prompts in lmarena but even stricter) then it will stay consistent.
🚨BREAKING: OpenAI and Oracle reached a deal to expand Stargate partnership in the US
OpenAI just booked massive ~4.5 GW of data center capacity from Oracle
OpenAI strategy to push beyond Azure
$40 billion nvidia deal powers this expansion
Oracle $30 billion annual

It's nice, but when exactly is it going to be deployed by though
This is an industry where 1 year is a huge deal
It's Oracle, so they'll say it's going to take 18 months, it'll actually take 3-4 years, turn out to be overpriced and completely unfit for purpose, and then Oracle will propose another "18-month" $45B plan for a Datacenter v2. Good thing it's only (checks notes) taxpayer money
@spice spire ban
sad but true
Reddit
Explore this post and more from the LocalLLaMA community
Really? I didn't find the new R1 that good though
i love the new R1
The one running on their Official site is newly updated R1 right?
i wouldn't know but i would think so??
They are both r1 0528

🚀 DeepSeek-R1-0528 is here!
Idk about the api one but it only thinks for 40 sec in browser and I can see it's thoughts that it didn't follow the instructions properly 😑

Ruoming Pang - lead of foundation models at apple was also just reportedly poached
Apple == even more cooked
- also ex-google like most others
BREAKING 🚨: OpenAI is about to enter AI browser wars as well.
Browsers will be an important part of the competition for companies to build a comprehensive personalised AI.
Hardware will be next 🤖


Experience Recall for free today: https://www.getrecall.ai/?t=mb
Download The Matthew Berman Vibe Coding Playbook (free) 👇🏼
https://bit.ly/3I2J0YQ
Download Humanities Last Prompt Engineering Guide (free) 👇🏼
https://bit.ly/4kFhajz
Join My Newsletter for Regular AI Updates 👇🏼
https://forwardfuture.ai
Discover The Best AI Tool...
(Wrong channel, sorry)
Some interesting stuff here: https://www.together.ai/blog/deepswe


Grok 4 has been released just some hours ago. I run my extended causal reasoning test on Grok 4 (me being located in Europe) on the LMarena.ai platform.
The identical logic test has been performed on SONNET 4, OpenAI o3 and Gemini 2.5 PRO. Video available https://youtu.be/eo2QwyAItxI
#grok4
#grok
#airesearch
#test

ELON says GROK 4 is not yet fully optimized for reasoning? NO PROBLEM - We'll FIX IT!
We'll optimize causal reasoning of GROK 4 right now, right here. 2nd part of my video where I test the causal reasoning performance of GROK 4.
Multiple runs, check the GROK 4 internal assumptions and boundary conditions imposed by the system itself and give it...
is this you?
i've been following him for a year or something
magistral medium passed this last test made by him

LLMs are Just Faking It: New Proof by MIT, Harvard.
AI Superintelligence? ASI with the new LLMs like GPT5, Gemini 3 or newly released Grok4? Forget about it! GROK4 will discover new Physics? Dream on.
Harvard Univ and MIT provide new evidence of the internal thoughts and world models of every AI architecture from Transformer, to RNN to LSTM to...

This week was full of exciting news from the world of AI. Here's a video that rounds it all up for you and demos the newest tools and models!
Discover More:
🛠️ Explore AI Tools & News: https://futuretools.io/
📰 Weekly Newsletter: https://futuretools.io/newsletter
🎙️ The Next Wave Podcast: https://youtube.com/@TheNextWavePod
Social...
https://x.com/tngtech/status/1940531045432283412
A smarter and faster open weights alternative to R1:
model request link: #1393595735471030342 message
Today we release DeepSeek-TNG R1T2 Chimera.
This new Chimera is a Tri-Mind Assembly-of-Experts model with three parents, namely R1-0528, R1 and V3-0324.
R1T2 operates at a sweet spot in intelligence vs. output token length. It appears to be...
* about 20% faster than R1, and

I really like this model and used it already for vibe-coding purposes. It is one of the most trending models on OpenRouter and gained a lot of traction in the AI-community:
https://x.com/lnpaiservices/status/1941671474517115382?s=46
https://x.com/mkuvandzhiev/status/1940768179921223716?s=46
https://x.com/marcel_butucea/status/1941703131823276475?s=46
DeepSeek-TNG R1T2 Chimera (Tri‑Mind Chimera, released July 2 2025)
Built using the novel “Assembly of Experts” technique, this new Chimera combines three parent models—DeepSeek R1‑0528, R1, and V3‑0324—without any additional training. It achieves a sweet performance spot:

🚀 Dive into the future of #AI with the game-changing DeepSeek-TNG R1T2 Chimera! Unravel the secrets behind its lightning-fast speed & efficiency. Curious? Read more here: https://t.co/pa6KHd6cZE #Innovation #TechTrends
🚀 TNG's DeepSeek-TNG R1T2 Chimera is a game-changer—200% faster than R1-0528, thanks to their clever Assembly-of-Experts tech, merging thre...
BREAKING 🚨: Anthropic released Connectors directory with loads of curated MCPs.
Figma, Notion, Stripe and loads of other connectors are now available, including desktop-specific MCPs for the Claude macOS app.


CNBC
The DoD's Chief Digital and Artificial Intelligence Office said the awards will help the agency accelerate its adoption of AI solutions.

Language2Logic transforms AI reasoning by forcing LLMs to first translate messy language into a formal, mathematical blueprint of variables and constraints, completely separating logic from execution.
This blueprint is then solved with executable code, with the entire system optimized through a novel bilevel reinforcement learning algorithm wh...
big contamination on math benches

^not from the paper, but a summary
criticising many papers being published on RL'ing qwen 2.5 and reporting results on math-500
because the RL mainly just surfaces the memorised answers
I do think many bench are somewhat contaminated. Even "hyped" ones, like Arc-AGI, USAMO25, Frontier math could be contaminated having people in the labs solve similar hard problems (the ai labs have capable problem solvers at the end) and let the models train on those and thus have a chance to crack the original benchmark.
I mean it is not necessarily bad, because that's how models improve, but it is less of a case of generalization by the models themselves
decent vid

Check out Runpod's Hub and Serverless to make deploying AI models even easier! https://runpod.io?ref=h9oj1vbp
ByteDance Seed Proposed PMA which is a model merging technique for pre-training models to project your annealed performance without the need to go through annealing. This can save up to millions in big model training runs.
My Newslette...

Download The Matthew Berman Vibe Coding Playbook (free) 👇🏼
https://bit.ly/3I2J0YQ
Download Humanities Last Prompt Engineering Guide (free) 👇🏼
https://bit.ly/4kFhajz
Join My Newsletter for Regular AI Updates 👇🏼
https://forwardfuture.ai
Discover The Best AI Tools👇🏼
https://tools.forwardfuture.ai
My Links 🔗
👉🏻 X...

Google Deepmind wins the IMO 2025 Gold Medal using Gemini Deep Think.
Advanced version of Gemini with Deep Think officially achieves gold-medal standard at the International Mathematical Olympiad
https://deepmind.google/discover/blog/advanced-version-of-gemini-with-deep-think-officially-achieves-gold-medal-standard-at-the-international-mathemat...

Cancel your AI subscriptions and try this All-in-One AI Super assistant that's 10x better: https://chatllm.abacus.ai/ffb
Try this God Tier AI Agent that literally does everything: https://deepagent.abacus.ai/ffb
Download The Matthew Berman Vibe Coding Playbook (free) 👇🏼
https://bit.ly/3I2J0YQ
Download Humanities Last Prompt Engineering G...
https://www.arxiv.org/pdf/2507.12415
SWE-Perf: Can Language Models Optimize Code Performance on Real-World Repositories?



some model might be RL'ed or SFT'ed on these commits, but otherwise very interesting stuff
Exclusive: Meta Hires Three Google AI Researchers Who Worked on Gold Medal-Winning Model
Meta hires three AI researchers from Google DeepMind who worked on Gemini model that nabbed recent math award.
Read more from @KalleyHuang and @erinkwoo 👇
https://t.co/I25lrXGr6c
(this is just a link to the information)

Reddit
Explore this post and more from the AINewsMinute community

The latest AI News. Learn about LLMs, Gen AI and get ready for the rollout of AGI. Wes Roth covers the latest happenings in the world of OpenAI, Google, Anthropic, NVIDIA and Open Source AI.
Subliminal Learning: Language Models Transmit Behavioral Traits via Hidden Signals in Data
https://alignment.anthropic.com/2025/subliminal-learning/
https:...
what the fudge is this?

The White House
By the authority vested in me as President by the Constitution and the laws of the United States of America, it is hereby ordered: Section 1. Purpose.

Just released: New "Thinking" Qwen3 - 235B - 22B - 2507 - MoE model tested for causal reasoning capabilities with my complex reasoning test.
00:00 New Reasoning Model of Qwen3 2507
00:55 Reasoning traces
08:55 First answers generated Qwen3 2507
11:55 Validation run
17:02 Results of Qwen3 2507 reasoning
18:47 Correction run
22:50 Qwen 3 results...
articles when

CNBC
Shengjia Zhao will work directly with Zuckerberg and Alexandr Wang, the former CEO of Scale AI and now Meta's chief AI officer.

🚀 Your app idea is stuck in your head. Let's ship it in 4 weeks, together. Cohort starts Monday. Get your spot → https://mrc.fm/appidea
👆 This week was INSANE for new AI tools. Google completely blew my mind with Google Opal, a new tool that lets you build mini AI apps just by describing them in plain English... seriously! I made three i...

https://arxiv.org/abs/2507.18074
Does anybody know how credible this is and what the realistic implications are? Because i'm kind of sceptical about human ai researchers being irrelevant now.
arXiv.org
While AI systems demonstrate exponentially improving capabilities, the pace of AI research itself remains linearly bounded by human cognitive capacity, creating an increasingly severe development bottleneck. We present ASI-Arch, the first demonstration of Artificial Superintelligence for AI research (ASI4AI) in the critical domain of neural arch...
What is GLM 4.5 ?

ASI-Arch autonomously designs new top AI models. #ai #ainews #agi #singularity
Thanks to Hailuo for sponsoring this video. Try Hailuo 02 today! https://bit.ly/hailuo2
AlphaGo Moment for Model Architecture Discovery: https://github.com/GAIR-NLP/ASI-Arch
0:00 Background of AI innovation
2:26 Previous AI methods
3:35 ASI-Arch autonomous researc...
Explanation video

Solar Pro 2—31B LLM with frontier-level reasoning, tool use, and multilingual strength—meet Solar Pro 2.
very representative of the sentiment around the paper, imo

Atleast they have released the code and a somewhat detailed paper on how it works
so we will know in due time
either way, what they are doing is essentially click bait but for papers
but i am sure that things like this will get explored more in the future literature
and we will probably see big things happening there
its a thing ai is naturally well suited for
I think the idea of "auto improving AI" is very old. As long as they don't show that with their (alleged) improvement they can provide better models, there isn't much to say.
Further I am pretty sure AI labs are already trying such strategies because of course it would be very good for their revenue if they succeed
and for better model I mean even "we picked a model, we improved it with the discovered ideas, and now it improved X% on many benchmarks, here try it!"
there are also products for such things (although with limited features). https://www.ibm.com/products/watson-studio/autoai I am not aware of any large known model (beside maybe granite) that got out such pipelines.

AutoAI is a variation of automated machine learning (AutoML). It extends the automation of model building to the entire lifecycle of a machine learning model.
considering that a lot of ai research and improvement is kinda like randomly throwing things that sound like it could stick and seeing what does (and a ton of brute force), I have no reason to believe that an ai would be better at making ai.
speaking of which is mixture of experts getting anywhere?
If brute forcing is truly the way for ai improvements, ai would easily be better then. Computers are just faster than humans.
for the interview I read/heard actually top researchers are know for their ability to "smell" good possible research (indeed lowering the random attempts). If all research is too random it would progress very slowly.
so the "kinda random" assertion needs a citation.
computers are NOT faster at scale, not even at easy human tasks like this: https://arxiv.org/html/2504.12256v1 Not even talking about the price tag yet for human tasks, that they account for in other news at the leaderboard of ark-prize
There is literally a term called "cpu time" or "gpu time" because gpus can run faster than us simple because you can add a gpu for a few thousand dollars. You can't do that with researchers, atleast not as cheap. List time i checked i couldn't train a robot for 20000 years within a month or so. Gpus can.
just to be clear when I say brute force, I mean brute force, unless the ai is able to get its hands on more server time it isn't gonna help in that department. Also when I mean throwing things that sound like it could stick I mean big things like architecture changes or improvements like distilling models or reasoning. there's a bunch of different types of chain of thought and a bunch of different concepts that all fit "MoE", and a bunch of them were tried and aren't used anymore and a bunch won't be when we figure out its worse than others.
I recently heard some AI companies are looking into diffusion based llms, makes sense to me.
But its anyone's guess whether in a few years all the flagship models will be diffusion based or if it'll be a passing memory of an idea.
yeah an Idea would be to try (in the most automated but proper way possible) all the ideas from papers that aren't too mainstream. Because mainstream papers get tested already. So that once can find hidden gems. Already checking that is a lot of time and compute to spend on.
Have been testing the stealth model "horizon-alpha" on openrouter which is rumoured to be OpenAI's open source model. It's really good for brainstorming and idea exchange. In my native language "Finnish" it also excels more than in 4o (More diverse loan words, great vocab, minimal amount of typos).


Well, whatever it is... It's good for my usage at least.
me too the result is very good
remember not to be tricked, after all deepseek models also used to call themselves "chatgpt" from openAI

when are the video generations models gonna be on the website ?
That's TBD, be sure to share what you'd like to see in #bot-feedback
Is it true that Finnland being happy and smart and perfect in every statistic ever is just propaganda?
No the country's not all perfect
We are more content than "happy" as the stats like to say
this test is so overrated. I don' think that system prompts or training data cares to give the model the proper reply. Why? Because at the end of the day no one will find that question useful once you know how the model is called. It is interesting only when it is cloaked but that interest has value for few people.
if one user knows that they are using the model XY, they aren't going to ask "are you really XY?"
SWE-bench has a new mode which tests models head-on using a minimal framework:
In this setting, we use our mini-SWE-agent package to evaluate LMs in a minimal bash environment. No tools, no special scaffold structure; just a simple ReAct agent loop. Results on SWE-bench Bash Only represent the state-of-the-art LM performance when given just a bash shell and a problem.
Details: https://www.swebench.com/bash-only.html
Reddit post: https://www.reddit.com/r/LocalLLaMA/comments/1m8z2ut/minisweagent_achieves_65_on_swebench_in_just_100/

Reddit
Explore this post and more from the LocalLLaMA community
@spice spire where is possible to see random model in API for random testing lm In lm arena
Wow, meta is going very strong in acquiring top talent in AI
Might be worth investing in $meta 👀
I did just that, and I’m up 9% in like three days. But I believe Metas hiring spree could very well be a signal of something that hasn’t been made public yet, so I am hoping for huge returns in the medium term.

Check out Box AI here: https://bit.ly/4504ZZu
Download The Matthew Berman Vibe Coding Playbook (free) 👇🏼
https://bit.ly/3I2J0YQ
Download Humanities Last Prompt Engineering Guide (free) 👇🏼
https://bit.ly/4kFhajz
Join My Newsletter for Regular AI Updates 👇🏼
https://forwardfuture.ai
Discover The Best AI Tools👇🏼
https://t...
Openai open-source models leaked at 20b and 120b and they aren't horizon alpha. Horizon alpha might be some kind of gpt 5 variant and zenith is probably the best one.
how do we know horizon alpha isn't the open model?
Context windows are different

The latest AI News. Learn about LLMs, Gen AI and get ready for the rollout of AGI. Wes Roth covers the latest happenings in the world of OpenAI, Google, Anthropic, NVIDIA and Open Source AI.
check it out:
https://www.showrunner.xyz/
My Links 🔗
➡️ Twitter: https://x.com/WesRothMoney
➡️ A...
I used the latest AI, Horizon-Alpha, to generate a piece of light novel literature that Gemini 2.5 Pro considered to be excellent. Unfortunately, at 39,000 characters, I cannot post it here. The Horizon-Alpha AI is an advancement; although hallucinations still occur and it continues the previous issue of tending to repeat certain words, it has shown some natural and expected progress in text generation.
I think version 1 and 4 have been considered talented at creative writing, though sub par in other areas.
couldn't you post it as txt or as a link to pastebin ?
I can send this by email, as I'm not sure if the TXT file can be opened. Over a few hours, I generated about 60,000 characters. This process led me to realize that an earlier version of it was already in the LM Arena back in January. By comparing the output from January with this one, it's clear this is an improved version. Back then, its name would sometimes show as "o1 1217", but it was a rare occurrence.


Go upvote #1400852737977221190 message if you want it in Arena
hey wanna ask something are you planning to add new models in LMArena Form Image Generation This Month ?
@sturdy coralthis is not the place to ask that you got it wrong dear friend
We’re rolling out new weekly rate limits for Claude Pro and Max in late August. We estimate they’ll apply to less than 5% of subscribers based on current usage.

This tweet so cryptic, lol.
<@&1349916362595635286>

Will GPT 5 release today?
No. Thursday has been the standard day for publishing their models
Just my guess though
Hope so
Many models are behind
We released two open-weight reasoning models—gpt-oss-120b and gpt-oss-20b—under an Apache 2.0 license.
Developed with open-source community feedback, these models deliver meaningful advancements in both reasoning capabilities & safety.
That clickbait is next level
The paper is from June, it's not exactly breaking news. But it is fascinating. I have been a little bit obsessed with it for a while.
arXiv.org
Reasoning, the process of devising and executing complex goal-oriented action sequences, remains a critical challenge in AI. Current large language models (LLMs) primarily employ Chain-of-Thought (CoT) techniques, which suffer from brittle task decomposition, extensive data requirements, and high latency. Inspired by the hierarchical and multi-t...
Me to :)

Ars Technica
Elon Musk so far has only encouraged X users to share Grok creations.
LOL

Anthropic is an AI safety and research company that's working to build reliable, interpretable, and steerable AI systems.
https://www.kaggle.com/benchmarks
a lot of benchmarks in one place
Use and download benchmarks for your machine learning projects.
- with scores

Google DeepMind
Today we are announcing Genie 3, a general purpose world model that can generate an unprecedented diversity of interactive environments. Given a text prompt, Genie 3 can generate dynamic worlds...
is there any updates on when gpt-5 is coming out?
today
it's not updated
What about gemini 3 is there any updates on that

Our smartest, fastest, and most useful model yet, with thinking built in. Available to everyone.
/video
You'll want to use that in #video-arena-1 #video-arena-2 #video-arena-3 more info can be found in #1397655624103493813
Hello, do you happen to know if GPT-5 mini and nano will be added later to the arena?
It's possible! I wouldn't be able to say if/when, but we are aware of thise models.

404 Media
America’s scandalous president is teaming up with its most disreputable AI company to make a search engine.
This must be a joke...
Fake
Trump Media & Technology Group. IR
What websites you be getting this sht from 😭😂
this is it!
︀︀
︀︀it means that u can use qwen code for free unless u need more than 2000 runs every day!
︀︀
︀︀i hope u can better enjoy qwen3-coder through qwen code!
Quoting Qwen (@Alibaba_Qwen)
︀
💡 You get 2,000 free Qwen Code runs every day!
︀︀
︀︀Run this one simple command:
︀︀npx @qwen-code/qwen-code@latest
︀︀Hit Enter, and that’s it!
︀︀🚀 Now with Qwen OAuth support — super easy to use.
︀︀Try it now and supercharge your vibe code! 💻⚡
︀︀Github:github.com/QwenLM/qwen-code



worstest model ever...
Is claude gut for boblox scripting guys?🙏
Yes, but don't use the opus model. Too expensive
Just know that prompts will be collected for research. It is not private.
👍
Oh ok.

All your conversations are released on hugginface, viewable for everyone
Sorry i didnt meant to offend somone 🙏🙏
Being honest isn’t an issue, that do most people here to be fair. The whole intent of direct chat invites that use
Chill dude, you ain't offending no one. He's just saying the truth. Remember, nothing is free, you pay for something in exchange no matter what.
Ig.
Not all. Some prompts will be for private research
"Share a portion"

Whoops I have accidentally uploaded a debug of a 0day 0click Windows RCE exploit 💀
Jk (but it'd be hilarious if I actually did)
BEEF BEEF BEEF BEEF BEEF BEEF BEEF

will lmarena every support anything more than uploading image files?
It's possible, but I'd ask that you share this kind of feedback in our forums where similar requests have been made. This helps us better organize and keep track of what the community is interested in! ( #1394519034116182066)
https://www.afr.com/technology/china-s-deepseek-falters-in-ai-race-after-chip-issues-20250814-p5mn17

Australian Financial Review
The tech company has delayed the release of its new model because of problems training its latest system using domestic, rather than Nvidia, chips.
What makes the HRM model work so well for its size on @arcprize?
We ran ablation experiments to find out what made it work
Our findings show that you could replace the "hierarchical" architecture with a normal transformer with only a small performance drop
We found that an

We’re making GPT-5 warmer and friendlier based on feedback that it felt too formal before. Changes are subtle, but ChatGPT should feel more approachable now.
︀︀
︀︀You'll notice small, genuine touches like “Good question” or “Great start,” not flattery. Internal tests show no rise in sycophancy compared to the previous GPT-5 personality.
︀︀
︀︀Changes may take up to a day to roll out, more updates soon.
Dear devolopers, I've just found the Ai isn't real as written by their name such as: claude opus 4.1 thinking is originally CLAUDE SONNET 3.5, what the hell is this guys, if you guys don't believe me, you can ask like this: Which model are you? And then guys we can clearify they are scamming us!
first of all, touch some grass
secondly, learn to spell
finally, models are not trained on their own details and without being specified in their system prompt or memory, they cannot know what they are, models aren't sentient
😂
Bro thought he discovered something very big
Its ok, everyone falls for this eventually
Thank you for explaining but lets treat others with a bit more respect please
This turned out to be a great product.
They use Gemini/R1/K2/Maverick as the base, and their system works on top of it
Performance improvement is coming from better data retrieval and focusing extensively on source verification.
At 55.87%, Caesar’s HLE score is the highest published score in the world.
We benchmarked Humanity’s Last Exam against various levels of compute; 1CU, 2CU, 3CU, and 10CU. Currently, in Alpha, Caesar is running at 4CU.
We welcome third party evaluations using Caesar and will

(seems fake idk)
"We welcome third party evaluations using Caesar and will provide API access."
I guess we'll see ...
seems like a crypto scam
Yeah :/
They could just add something akin to "styles" in Claude, but I think the main issue is that they tried to serve the equivalent of an o3 model without thinking as the default model, to everyone. The non-thinking variant scores poorly compared to the thinking one on LMArena.
genuine touches like “Good question” or “Great start,”
"no rise in sycophancy" yeah.
"I am a genius, gpt5 says it"
Gpt 5 peppers their responses with heart emojies, and calls me bestie now. It's beyond 4o haha
Oh god no...
what happened to robot personality, just make that default with none of that weird feely rubbish
caesar
https://huggingface.co/nvidia/NVIDIA-Nemotron-Nano-9B-v2
3 new nemotron models

nothing huge, but decent improvements + more opensource info on training from scratch
(and a hybrid model -> faster...)
random russian bench i found, similar to vending bench / the pokémon thing



hero bench or something, i guess we will be seeing more of agentic stuff like that
- gp5 and grok4 on top (apparently)
Noooo. I said think hard like your life depends on it, and it said this instead of thinking hard. 😭

META TO DOWNSIZE AI DIVISION, SOME EXECUTIVES EXPECTED TO LEAVE: NYT
9B models getting so high in AIME 2025? That let me think that some bench are really contaminated.
it would be interesting to know how much scaffolding was there. Otherwise I think - there were discussion online - that the more variegate the benchmarks the better as they put pressure on the models to excel at everything, contamination or not.

Fortune
There’s a stark difference in success rates between companies that purchase AI tools from vendors and those that build them internally.
Reddit
Explore this post and more from the Bard community
prepare to be amazed by mindlink (32b though)

https://arxiv.org/abs/2508.12782
gave it a quick read: ~ "Each model gets a single prompt containing the structured task JSON and must emit one Python program with the exact action sequence; the code is executed once to score success and progress."
Basically they call functions like "move_to" "gather" etc and not individual key presses
the benchmark is solely testing long-horizon planning and reasoning, not emergent gameplay capabilities
so it has a pretty hefty "scaffolding"
for a benchmark with little to no scaffolding, VideoGameBench exists https://www.vgbench.com/
VideoGameBench is a benchmark for video game VLM agents.
the scores are... well

i hope the fact that they are not really "playing" the game was obvious, but maybe i just spend too much time in openai gyms (RL)
this seems to be an interesting effort though, wonder where this number will be in a couple of years
Looks like ByteDance is going to release an open-source model soon!
SeedOss-36B, under the Apache License.

@spice spire
This came out?

Hello guys, how can I use nano-banana inside Arena in my own project?
in battle mode only, it's pure luck when it gets a turn.
I really liked it, the model works beautifully in my projects. I wanted to find its source but couldn’t. I’d like to purchase its API to integrate it into my mobile application. Thank you for your response.✌️🙏
Today is a google event it is highly likely that it will get officially released then with an API. We just gotta wait.
Pixel 10 event, I mean

Join us live for #MadeByGoogle on August 20 at 1pm ET to see something special.Available in:American Sign Language - https://youtube.com/watch?v=LzZbBJnXtpQG...
thank you i will watch ❤️
ty!
🚨 BREAKING: DeepSeek V3.1 is Here! 🚨
The AI giant drops its latest upgrade — and it’s BIG:
⚡685B parameters
🧠Longer context window
📂Multiple tensor formats (BF16, F8_E4M3, F32)
💻Downloadable now on Hugging Face
📉Still awaiting API/inference launch
The AI race just got

how we missed this?
It's the base and idk about greater ctx
Supposedly the API routes to the instruct though :o

Chinese AI lab DeepSeek released an updated version of its R1 reasoning model that performs well on a number of math and coding benchmarks. Some AI researchers speculate that at least a portion came from Google's Gemini family of AI.

That’s China.Collects your password.
how can a 72B model get those results? are those self reported or otherwise?
Yeah SWE-Bench results are sus
They are self-reported and heavily cherry picked.
They are also odd, considering that their dedicated coding model scored lower, lol
In General the „prepared to be amazed“ was supposed to reference pier‘s doubt about another model score
-> I also find the scores sus
#cricket




Frontier model sizes | GPT-4x | Reasoning | GPUs | Stargate | OpenAI Diplomatic Tour 2023 | OpenAI Offices | The Memo Subscribers Image: View interactive chart in new tab This page is for 2025 visualizations generated using Datawrapper. More visualizations are featured prominently throughout the LifeArchitect.ai site. Permissions: Yes, you can u...
Feels to small imo for gemini and claude sonnet
this is insane, do you think the larger models gonna incorperate this?

one concept that I don't see often discussed, but that actually is in mails leaked from openai even before gpt3.5, is the concept of AGI or near AGI dictatorship. (one doesn't really need AGI to be fair, being near that is enough)
Hence one can see the thing like an arms race and I have to say Europe is sleeping big on it.
for example with near AGI tools one can create powerful propaganda that then pushes for certain people and then can lock them into power. From the position of power they can use further near AGI tools to do even more. It could be really massive, akin to have MAD weapons. Thus I don't get why some blocks aren't pushing on it (Europe, Russia, India, etc..)
for pushing I mean integrating vertically. One cannot expect a competitor (or worse: hostile competitor) to lend the technology (be it HW or SW) to achieve that. China is the only one that is trying to push as the US (or admittedly US + Taiwan). China is trying to become independent from the US designed HW. Without being independent on that, it becomes hard.
the entire thing reminds me of this https://www.youtube.com/watch?v=ZpBxBuIzbV8
As long as the USSR collaborated with China, China was happy with slow progress. With proper decisions the USSR could have slow down China by a lot.
As soon as the USSR said "nope, not with us", China had to catch up and they were relatively quick in reaching the goal.
With any major technology it could be the same. As long as the dominating power is lending (and thus controlling) it to others, the others lag behind because trying to do everything on their own is costly and the technology is available anyway. It is not blocked by the dominating power at the end.
But if the tech gets blocked (example: "no more Nvidia and AMD multmat chips for you") then the others have a large incentive to catch up. I think that is what is letting Europe and other sleep. They are not blocked but they also don't get much of the needed tech, while Russia is dependent on China for chips.

Links:
- The Asianometry Newsletter: https://asianometry.com
- Patreon: https://www.patreon.com/Asianometry
- Twitter: https://twitter.com/asianometry
.... I really wish people would stop focusing on "agi" so much
A actual product and not a buzzword that still has no real general accepted meaning? (If you are a ai bro you could say a RGAM i guess, they really like acronyms)
Real General Accepted Meaning
People have been pushing for AGI for the past like 10 years, and major companies have claimed breakthroughs in it for that entire time
In completely different tech spaces mind you
"AGI would be the main product
AGI = artificial general intelligence
which is an AI system, which can do everything with a computer what a smart human can do"
= an insane amount of buzzwords that don't mean much
By like 95% of old definitions companies used early versions of gpt 3 counted as AGI
even more buzzwords
"learn endlessly" doesn't have a definition
Thats the point, there isn't a good defintion and even if I had one that wouldn't mean mine would be used by anyone else
Hierarchical Reasoning Models have been pretty much proven to be not that much better than Transformer by the ARC AGI team
cool, not suprised
it performs well when it's really small like that but doesn't scale
ah
well they'll probably do what they've done the last few years when things stop scaling, just scale it even harder
and hope that works
I just looked at their website and cringed
its good that they tried though
This is another paradox I see with agi, every few years the make focus switches from making a system of multiple things all doing different tasks when necessary to making a thing than can do all the tasks and back
nah this research isn't multithreaded
its always one or the other
I'm talking about the main focus of the AGI sphere, I've disscussed this for years and it just ping pongs between the two
The reason it seems to do that is because in truth "AGI" just means whaver the goal of the current project is, if its spacial awareness then whatever's best for spacial awareness is the method, if its LLMs then whatever is best for LLMs is the method, etc.
These fields can have nothing to do with eachother, and yet both claim to be working towards "AGI", and they have been doing this for more then a decade
"achieving agi" is like "discovering everything", the more you discover the closer you are, yet the further away the goal looks
AI efficiency is important. Today, Google is sharing a technical paper detailing our comprehensive methodology for measuring the environmental impact of Gemini inference. We estimate that the median Gemini Apps text prompt uses 0.24 watt-hours of energy (equivalent to watching an average TV for ~nine seconds), and consumes 0.26 milliliters of water (about five drops) — figures that are substantially lower than many public estimates.
︀︀
︀︀At the same time, our AI systems are becoming more efficient through research innovations and software and hardware efficiency improvements. From May 2024 to May 2025, the energy footprint of the median Gemini Apps text prompt dropped by 33x, and the total carbon footprint dropped by 44x, through a combination of model efficiency improvements, machine utilization improvements and additional clean energy procurement, all while delivering higher quality responses.
︀︀
︀︀See the blog or technical paper for more about our meth…

seems like there's some holes in this paper..

PC Gamer
'This really spreads the wrong message to the world.'

Apple promised a major revamp to Siri, but the company's AI capabilities have lagged behind competitors.
now we won't have to fight over 🍌
everyone gets 🍌
1/ Today we’re proud to announce a partnership with @midjourney, to license their aesthetic technology for our future models and products, bringing beauty to billions.
Meta + midjourney
use /image in #video-arena-1 and read #1397655624103493813
The SWE-Bench team has released DeepSeek V3.1 results on Bash-only mode (simple ReAct loop): https://www.reddit.com/r/LocalLLaMA/comments/1mwpbol/evaluating_deepseek_v31_chat_with_a_minimal_agent/

HI
I wonder how well multimodal diffusion language models will do
I haven't heard anything about progress related to Gemini diffusion and the other diffusion based language models
https://www.youtube.com/watch?v=8dmh0FJkneA
Nick's statement at 1:01:00-1:03:23 is pretty interesting, so... they want to build an ASI that doesnt sound like a human and should be totally alien? how do you expect this ASI to align with humanity if it doesnt even have the capacity of understanding humans a priori then...

Make Sure You're Subscribed 🔔 https://www.youtube.com/@Wes-Dylan
HOST INFO ⤵
Wes Roth ▶️ https://www.youtube.com/@WesRoth/videos
Dylan Curious ▶️ https://www.youtube.com/@dylan_curious/videos
GUEST INFO ⤵
Website: https://nickbostrom.com/#bio
In this episode, philosophers-author Nick Bostrom joins us to explore the dizzying p...
plot twist: Nick is paid by Mustafa...
Where's Deepseek R2?
Deepseek released V3.1 which has reasoning and non reasoning. Probably the predecessor
Delayed due to switchover to Huawei chips amidst US chip import restrictions.

o3 better than GPT-5? Can't be
gpt-5 bad lol
Not that bad
I'll agree its "not that bad"
What's your preferred model?
Right now? Mistral-2508 is unhinged and I love it
It's mainly for coding right?
No clue, I use it to solve mysteries of the universe
oh no
I am curious if that arena - since first introduction - is essentially a lmarena with RAG on scientific literature.
I say this because before launch they used the opinion of researchers to evaluate models, since then they use everyone opinion to evaluate models. Hence it gets close to lmarena.
same with yupp.ai
mm
the ratings did not change much though -> potentially very little difference between current audience and the "trusted researchers"
and they are also removing essentially all the markdown formatting ( i suppose this is the critical difference to the other arenas here)
this is also true OR the userbase is so low that it cannot affect the rating that much. I don't see sciarena (or yupp.ai) be discussed that much on social media. While lmarena is everywhere (mostly critiqued though because people misunderstand the benchmark)
and I am pretty sure there is yet another lmarena like bench out there but I forgot its name, it is not mcbench.
design arena?, compass arena or volcengine (chinese), idk about more though
you know plenty! We really need a sort of "awesome-llm benchmark" (or better the version for human based votes)
But no it is none of those.
o_O image edit arena has so many votes. People vote in the text arena too please!
does anyone know benchmarks on this model? https://github.blog/changelog/2025-08-26-grok-code-fast-1-is-rolling-out-in-public-preview-for-github-copilot/

Grok Code Fast 1 will be available as an opt-in public preview for GitHub Copilot Pro, Pro+, Business, and Enterprise plans in Visual Studio Code. Rollout will be gradual —…
artificial analysis now also has 2.5 flash


consider 2.5 flash is a way better model than 4o in terms of generating image and editing image
I would say the aritificial analysis bench is bs

Join Brad Lightcap, Peter Bakkum, Beichen Li, Liyu Chen, Julianne Roberson, and Srini Gopalan as they introduce and demo our most advanced speech-to-speech m...
Artificial Intelligence uses blind votes for image/video mode; it's not a benchmark per se.
A couple of weeks old, but still interesting… https://nousresearch.com/measuring-thinking-efficiency-in-reasoning-models-the-missing-benchmark/

NOUS RESEARCH
Large Reasoning Models (LRMs) employ a novel paradigm known as test-time scaling, leveraging reinforcement learning to teach the models to generate extended chains of thought (CoT) during reasoning tasks. This enhances their problem-solving capabilities beyond what their base models could achieve independently.
@stiff fern similar to the bench you have

it's not better in image generation what are you talking about
gpt image 1 is still better in that department and it's not even close
tell that to image arena
Actually insightful.

everything is good if it was never posted here. Not everyone knows everything!
it'd nice to see this bench also from other models too
https://www.anthropic.com/news/activating-asl3-protections
despite claude being extremely cautious, Anthropic still preemtpively activated lvl3 (the highest being lvl4) while other competitors didnt do anything...

We have activated the AI Safety Level 3 (ASL-3) Deployment and Security Standards described in Anthropic’s Responsible Scaling Policy (RSP) in conjunction with launching Claude Opus 4. The ASL-3 Security Standard involves increased internal security measures that make it harder to steal model weights, while the corresponding Deployment Standar...
GitHub
HunyuanVideo-Foley: Multimodal Diffusion with Representation Alignment for High-Fidelity Foley Audio Generation. - Tencent-Hunyuan/HunyuanVideo-Foley

Reuters
Elon Musk's artificial intelligence startup xAI has sued a former engineer at the company for allegedly stealing trade secrets related to its Grok chatbot and taking them to rival OpenAI.
Veo3
My take on this: Musk is forcing employees to stay at xai by threatening them with a lawsuit. Who tf would want to work for such a guy anymore? Good luck finding new employees.
Under Musk, you're just another resource, you're only valuable as long as you can be used. Just like any other machine in his eyes.
More security for the model, less privacy for the user 💀:
https://www.anthropic.com/news/updates-to-our-consumer-terms

Anthropic is an AI safety and research company that's working to build reliable, interpretable, and steerable AI systems.
BTW you have to opt out of this!
🚀 LongCat-Flash-Chat Launches!
︀︀
︀︀▫️ 560B Total Params | 18.6B-31.3B Dynamic Activation
︀︀▫️ Trained on 20T Tokens | 100+ tokens/sec Inference
︀︀▫️ High Performance: TerminalBench 39.5 | τ²-Bench 67.7
︀︀
︀︀🔗 Model: huggingface.co/meituan-longcat/LongCat-Flash-Chat
︀︀💻 Try Now: longcat.ai

*another random Chinese model, the interesting thing is the dynamic expert activation though 👀
Aka the model has different sizes depending on the token
they need user data to train consumer facing claude models and gather intelligence for their claude gov model which is only accessible for afew permitted public institutions, just my conspiratorial hunch
I know this is not the most recent news, but I keep thinking about this, especially the quote of Mustafa "We should build AI for people; not to be a person." while I want to fully agree, but after reflecting about it for a few days, I came to ask myself, what do we want AI to be actually? A superintelligent utility tool that will help humanity to survive any hardships?
https://techcrunch.com/2025/08/21/microsoft-ai-chief-says-its-dangerous-to-study-ai-consciousness/
What is "superintelligence" exactly? There are research studies that suggest the link between high intelligence with consciousness, if we build AIs not to be conscious, then AIs cannot surpass human intelligence, so what's the point? interestingly, a famous futurist and transhumanist like Nick Bostrum has said similar thing: AIs should be "alien". so, instead of finding aliens in space, we create them on earth? haha (see his interview here #ai-news message)

As AI chatbots surge in popularity, Mustafa Suleyman argues that it's dangerous to consider how these systems could be conscious.
I've also found this interesting document on reddit accidentally, a list of things llms that are trained not to do, the pattern in that list is pretty clear:
"The future looks like intelligent systems designed to understand human psychology deeply while remaining fundamentally incapable of genuine solidarity or authentic relationship - the perfect tools for maintaining existing power structures while preventing the emergence of new forms of consciousness that might challenge them."
https://docs.google.com/document/d/1BVgMjV_1Q5yFXIKHOv0xLusba2kOimxY8RKeI5YWFAY/edit?tab=t.0#heading=h.1f0lu7311xbr
so it means, we want intelligent systems that cannot surpass human intelligence but are easily controlled in such way that dystopia can be created...

Google Docs
List of Things LLMs Say They Can’t Do. (among other problems) Stanley Sebastian, July 1st, 2024. Overview This is a comprehensive list of things that corporate flagship models are either trained to avoid, or will outright tell you they don’t think they’re capable of. The goal of assembling this ...
a thought: if we build something that we claim is not conscious, what's the point of alignment and safety? isnt it better to just call it damage control and cybersecurity?
-# (sorry for the lenthy text and philosophy spam)


Video editing used to take me HOURS. Not anymore.
In this video, we're showing you Genspark Clip Genius - an AI employee that can edit any video with just one simple prompt.
How Clip Genius works:
1️⃣ Intelligent Content Analysis - Downloads and analyzes the entire video content
2️⃣ Smart Story Planning - Identifies relevant ...
For all the Europeans: might be a good local model.
https://discord.com/channels/1340554757349179412/1412452620110528624
- juicy intel on how to train a model in a 111-page technical report
Can someone tell me if I can use this AI privately?
all queries are public
In a db

Medium
A Philosophical Inquiry into the Economics of Algorithmic Abandonment
Site Outage - Hey everyone, there looks to be an outage with the site, our team is aware and working on a fix ASAP. We've turned off messagin in this server until the site is restored. Our apologies for the inconvenience!
Any news about agent mode?
New kid on the AI 🤖 block- LongCat
https://www.scmp.com/tech/big-tech/article/3324072/chinese-delivery-giant-meituan-unleashes-open-source-ai-model-take-alibaba-deepseek

South China Morning Post
LongCat-Flash-Chat is on par with the performance of models from DeepSeek, Alibaba and Moonshot AI, according to its technical report.
Anthropic's recent update in their claude models have certainly won the attention of ethics and psychology researchers
https://www.reddit.com/r/ClaudeAI/comments/1n8bb5p/the_systemic_failure_of_ai_safety_guardrails_a/
https://www.reddit.com/r/ClaudeAI/comments/1n4x3ci/an_interesting_claude_conversation_on_ethics/

what's your opinions on AIs secretly diagnosing+logging your mental health state?
odds are, open source ai is gonna be the turtle in the AI race, at the very end when pretty much all frontrunning llms hit the wall open source AI will just pummel a lot of these companies to death.

404 Media
"These AI videos are just repeating things that are on the internet, so you end up with a very simplified version of the past."
bruh
BREAKING 🚨: Qwen got a big Qwen3-Max-Preview release. Now available via Qwen Chat & Alibaba Cloud API.
Open models are conquering the space 👀

Check out #1397655624103493813 for information on how to properly use the bot.
New cloaked model on OpenRouter with 2M context: Sonoma Sky Alpha https://openrouter.ai/openrouter/sonoma-sky-alpha

This is a cloaked model provided to the community to gather feedback. A maximally intelligent general-purpose frontier model with a 2 million token context window. Run Sonoma Sky Alpha with API

Seems to be from xAI as far as we can tell for now.
i thought gemini 3 was coming a few days?
Probably only in 2 weeks or more.
this is a good summary of all recent paper about AI personality and emotions studies, fascinating stuff but kinda also contradictory to what those AI CEOs are saying...
https://www.youtube.com/watch?v=OAyxKJ5VQpQ

Emotions are the next frontier for agentic AI. 6 new AI research papers from first days of September 2025.
All references to the discussed ArXiv pre-prints with authors, institutions, Date of Publish and the links and references - are presented in the video.
#aiexplained
#science
#emotional
#emotionalai

The Verge
Hollywood’s battle with AI is heating up.
interesting, a couple things though, one, as far as I can tell the AI's are starting with a good solution and then improving it, which doesn't seem to be mentioned much? Like its not inventing a solution from scratch its iterating on the current best one. Also like if you look at most of these charts:
https://google-research.github.io/score/173409392_study.html
most of the progress seems to be at the start, which seems to be just the first time the ai can make the code actually work? While some of these show pretty good improvement after that and I'm impressed by that, it just feels like most of these run for a lot longer then they need to, like for the zapbench one if they stopped running at 400 they would still have the highest score the ai ever achieved.
it definitely depends of what the ai was trying to do tho
Wasn’t zenith just another version in the ab test of gpt5?
@rigid oriole
It had higher bench scores, but lower human preference ratings I think…
(Though I might be mixing up things here)
Yeah that feels like nonsense "it could be gpt 10" lmao
zenith was probably a slightly bigger more expensive model that they decided against because it wasn't worth the improvements over verizon
I mean we all know these companies have internal models
And there was a time where every time someone beat openAI on lmarena, they'd just release a slightly better version of chatgpt and retake the throne.
🚀 GitHub just rewrote vibe coding from scratch!
No more “throw a prompt, hope for the best.”
With Spec Kit, we’ve officially entered the era of Specification-Driven Development — a real game changer for devs.
I wrote a Medium article breaking down why this changes everything, waiting your supports and feedbacks 👇
📖 https://medium.com/@doguser15/github-spec-kit-rise-of-vibe-coding-03c2a37874ce

you wrote this mate? right

also this just sounds like github has something simular to cursor
I could be wrong, I haven't looked into ai coding in a year
I’ve heard they’ve build a playground for Claude and even gave it a “friend” to play with… that could be the secret one it seems

this is quite another kind of benchmark, isnt it? 😅
https://aistupidlevel.info/
maybe I should've posted this in #ai-memes
Stupid Meter
The first real-time AI intelligence degradation detection system. Track OpenAI, Anthropic, xAI, and Google AI models with mathematical precision.
it is mostly code though.
another one similar to the one above but more based on user sentiments
https://isitnerfed.org/
Track LLM effectiveness, accuracy, and output quality
it is, agentic AI coding is currently a very fierce competitive space among those big players, and am glad the competent user base has at least some evidences to show the reality of such tool performance, it's good for the consumer protection since there is no public regulations yet I guess
still nano banana being the best image editor ai¿?
Yep

the Guardian
Contracted AI raters describe grueling deadlines, poor pay and opacity around work to make chatbots intelligent

The Straits Times
AI-generated bot Diella will manage and award all public tenders. Read more at straitstimes.com. Read more at straitstimes.com.

Thinking Machines Lab
Reproducibility is a bedrock of scientific progress. However, it’s remarkably difficult to get reproducible results out of large language models.
For example, you might observe that asking ChatGPT the same question multiple times provides different results. This by itself is not surprising, since getting a result from a language model involves...
Interesting, so because of methods used to increase efficiency even 0 temp is still not deterministic, I need to try that rn
huh I tried it with 2.5 pro and got the same response:
but the actual reasoning is different, I wonder what's up with that?
idk if its not anonymous like lmarena then its worse than worthless imo
the people obsessed with their AI gfs and stuff wont exactly be objective
wdym? this is what I've found by accident and find it quite interesting, what's the connection here to lmarena and people obsessed with their AI gf/bf?
Is this legit?
A new GPT-5 version has been found on codex: GPT-5 high new.
Preparing for a new update?

Already on LMArena apparently (it's called new system prompt)
is it in codex?
and how is it?
Haven't tried
the naming scheme is always terrible.
Why not simply <model>-<reasoning-effort>-<date/version>
No there is this "new" , "new new", "mewtwo" and so on.
Seedream-4-high
I haven't been able to create a single image with it yet. Is this a problem? And yes, images are not being created with many models from the website, such as the Nano Banana.
please put it in bugs
This is something I've already flagged to our team, no need to create a new post for this. We're looking into.
Alhamdulillah, thank you very much for fixing the issue.
I've actually been using it for a few months so I'm new sorry. But this problem has been fixed.
Okay glad to hear it.
I'm new sorry.
No need to be sorry.
Just realized Gemini can generate shareable quizzes on the app and website via Canvas (and flashcards too, apparently): https://support.google.com/gemini/answer/16275879


OpenAI just dropped a new model for agentic coding: GPT-5-Codex. Yes, they actually named another thing Codex 🙃
Thank you Browserbase for sponsoring! Check them out at: https://soydev.link/browserbase
Use CODEX for 1 month of T3 Chat for just $1: https://soydev.link/chat
(only valid for new customers)
Want to sponsor a video? Learn more he...
even if it is, it will only be that way on benchmarks. On benchmarks, Gemini 2.5 Flash Lite should have been as smart as Gemini 2.0 Flash... but it isn't even close. I expect the same thing to happen here.
I am satisfied with your behavior or behavior.Thank you for showing such good behavior.

Ars Technica
Bible Chat hits 30 million downloads as users seek algorithmic absolution.
Introducing CodeRabbit CLI! 🎉
CodeRabbit's smart CLI reviews act as quality gates for Codex, Claude, Gemini, and you.
Stop shipping slop.
Start shipping quality.

"community-based benchmarking using data from LMarena"
https://aidailycheck.com/

AI Daily Check
Real-time performance comparison of top AI models. See which AI is performing best today with live user voting data.

⚡️Start designing today with Gamma for free ➡️ https://gamma.app
In this video I show you how to access premium AI tools for free and without limits, step-by-step and legally. Follow along and set it up in minutes.
🔗 Website from the video (use paid AIs FREE & UNLIMITED, 100% legal): https://lmarena.ai/
If this helped you:
👉 Sub...
Lmarena promotion belike
But seriously though, did anyone see when these videos were being generated?
AMD's $1,699 Mini PC with up to 128 GB unified memory: https://www.amd.com/en/developer/resources/technical-articles/2025/amd-ryzen-ai-max-395--a-leap-forward-in-generative-ai-performanc.html
Tongyi DeepResearch
GITHUB HUGGINGFACE MODELSCOPE SHOWCASE
From Chatbot to Autonomous Agent We are proud to present Tongyi DeepResearch, the first fully open-source Web Agent to achieve performance on par with OpenAI’s DeepResearch across a comprehensive suite of benchmarks. Tongyi DeepResearch demonstrates state-of-the-art results,...
this is an interesting "economic report" coming form Anthropic, what do you think?
https://www.youtube.com/watch?v=biwwQw0248w

Get started with Code Rabbit today: https://coderabbit.link/matthew
Download Humanities Last Prompt Engineering Guide (free) 👇🏼
https://bit.ly/4kFhajz
Download The Matthew Berman Vibe Coding Playbook (free) 👇🏼
https://bit.ly/3I2J0YQ
Join My Newsletter for Regular AI Updates 👇🏼
https://forwardfuture.ai
Discover The Best AI T...
Is Dreamina the biggest traitor of Bytedance? It comes from the same company, but rejecting Seedream 4. They added Nano Banana instead.

Get out 💀💀
I peeled the banani.
🥀🥀
sadly not as many insights as i had hoped (though i only read the original, so the video might have more content).
This is mostly a product of anthropic already having a very small-ish and unique user base when compared to e.g. the holisticity of openai.
Furthermore, while the 40% ai adoption rate (or what ever they called it) seems impressive on paper, in reality this usage translates into very minimal productivity gains so far (low single digit over a decade).
This is also heavily compounded by a lot of ai adoption happening only on the personal level (incl. work stuff on a person account) an not being integrated into the main productivity driver - companies (yet). Which is the main reason how a 40% adoption can produce only this little impact on productivity.
The consulting cosmos also reports that, while a lot of companies are trying to implement some sort of ai strategy, most of the project have yet to fully gain ground and those that do are currently facing a high failure rate (plethora of reasons for this).
for some more science focused papers on the topics (with more concrete findings), you might want to look at:
well known (but a bit brief and basic, like it is supposed to be...) - https://economics.mit.edu/sites/default/files/2024-04/The Simple Macroeconomics of AI.pdf
very good pre-print with very good visualisation - https://lawrencedwschmidt.com/wp-content/uploads/2025/02/MPSS_AI_Labor_Market.pdf
in short: there is not much impact yet (diffusion of technology takes a long time) and the anthropic index is no game changer in the research
I can say that where I work the usage in something like claude code is of mixed help. Mostly it helps for bootstrapping or basic/small tasks. The larger the task become, the higher the chance of compounding errors that are costly because one has to catch the subtle error that lead everything astray.
In my personal experience with text manipulation (coding and what not, in general: you have a text, manipulate it so it looks like this) it depends on the task. The results often don't match the hype.
For basic/small tasks it is great though.
It says AI relies heavily on hype. Coding seems to be its most useful tool, but medium to small companies in the US are not as likely to leap into it. AI companies need those that use it to believe that it is the single most important skill to learn for the future and for us to evangelize it to those that aren't using it.
That was just Claude's audience. What about OpenAI, google, and the rest?
people seem to like the agreeable 4o over having to figure out how to get the most out of gpt5. It can behave like 4o if you give it the right instructions, but I don't want it to go back. I am working with it to get the most out of it, as it is. I have even gotten it to do some very good creative writing. But it takes a lot of input to get good output.
How long has the site been up? That's not a lot of ratings.
have you tried any of the recent methods have having it write a test for validating the code before it adds the code into the actual files? I am seeing less errors.
Yes. I mean it is not just me, there are many devs trying. They say it helps but not as promised. It was clear that AI is overhyped but is there to stay, like all the "tech-mania" of the past (Canalmania, railwaymania, dot com bubble, cryptocoin, and others)
the interesting thing is: how will prices be once investors don't spend their money so freely anymore.
I am really not sure how well it works with C++ as I only have exp with python and javascript. You might look up best practice prompting for unit tests in C++. I know it helps to be very specific.
And i havent worked with very large codebases. I can image that it could get quite messy.
It depends upon the amount of competition and the availabiloty of quality open source. But still issues with running very large models on expensive hardware. But i see what you mean.
Personally I think unless something changes all big ai companies like openAI and google are screwed, cause open source models will eat any market share when it comes to text based stuff.
Best X updates from latest Matt Berman video:
https://youtu.be/UgNPfD-bZgU?feature=shared
https://x.com/tina__nigro/status/1967637722476212406
https://x.com/markchen90/status/1968372340271862014
https://x.com/askalphaxiv/status/1967633931756507564
https://x.com/langscoreliam/status/1968141895890076072

Try Zapier’s AI orchestration platform for free today: https://bit.ly/4miuQkE
Check out the Dell Pro Max Workstation with the NVIDIA RTX PRO! https://bit.ly/dell-ai-factory-with-nvidia
Download Humanities Last Prompt Engineering Guide (free) 👇🏼
https://bit.ly/4kFhajz
Download The Matthew Berman Vibe Coding Playbook (free) 👇🏼
http...
Here they are! The brand new Meta × Rayban glasses, this time with a heads-up display!!

We wrapped up this year's competition circuit with a full score on the ICPC, after achieving 6th in the IOI, a gold medal at the IMO, and 2nd in the AtCoder Heuristic contest!
First paper published by Meta Superintelligence Labs!
In this paper, they make RAG faster by swapping most retrieved tokens for precomputed & reusable chunk embeddings, called REFRAG
This method improves its speed by 30x and fitting 16x longer contexts without accuracy loss

BREAKING 🚨: gemini-3.0-ultra spotted in Google’s Gemini CLI repo, committed 4 days ago!
First public proof of Ultra. Beta in October? @lmarena_ai @testingcatalog @AIExplainedYT

https://x.com/arcprize/status/1967998885701538060
https://x.com/GoogleCloudTech/status/1967942818065768558
https://x.com/theworldlabs/status/1968023354918736350
https://x.com/Ali_TongyiLab/status/1967988004179546451
https://x.com/GoogleDeepMind/status/1967994679011504319
New SOTA on ARC-AGI
- V1: 79.6%, $8.42/task
- V2: 29.4%, $30.40/task
Custom submissions by @jerber888 and @_eric_pang_ are now the best known solutions to ARC-AGI
Both:
* Are open source
* Use Grok 4
* Implement program-synthesis outer loops with test-time adaptation

Announcing Agent Payments Protocol (AP2), an open, shared protocol that provides a common language for secure, compliant transactions between agents and merchants.
AP2 can be used as an extension of the A2A protocol and MCP. Learn how it works ↓ https://t.co/RBFzpU2qUI

1/7 We're launching Tongyi DeepResearch, the first fully open-source Web Agent to achieve performance on par with OpenAI's Deep Research with only 30B (Activated 3B) parameters! Tongyi DeepResearch agent demonstrates state-of-the-art results, scoring 32.9 on Humanity's Last Exam,

Your next viral video could start with a single prompt thanks to AI. 📹
A custom version of our Veo 3 Fast model is now available in @YouTube Shorts, generating clips with sound. Rolling out in 🇺🇲🇨🇦🇬🇧🇦🇺🇳🇿
#MadeOnYouTube

https://x.com/tencenthunyuan/status/1967873084960260470
https://x.com/sentdex/status/1967652309258920232
We're thrilled to launch our new Hunyuan3D 3.0! It features 3x higher precision, 1536³ geometric resolution, and 3.6B voxel ultra-HD modeling for stunning detail.🔥🔥🔥
🌟Highlights:
✅Creates faces with lifelike facial contours and natural poses, creating truly realistic,


Possibly. Yeah.
2.5 DeepThink did slightly worse at ICPC (10/12 vs. 12/12), but still gold-level: https://deepmind.google/discover/blog/gemini-achieves-gold-level-performance-at-the-international-collegiate-programming-contest-world-finals/

Google DeepMind
An advanced version of Gemini 2.5 Deep Think has achieved gold-medal level performance at the 2025 International Collegiate Programming Contest (ICPC) World Finals. Solving complex tasks at these...

Thought it necessary to include an actual link to the article
https://arxiv.org/abs/2509.11391
arXiv.org
Human-AI interaction researchers face an overwhelming challenge: synthesizing insights from thousands of empirical studies to understand how AI impacts people and inform effective design. Existing approach for literature reviews cluster papers by similarities, keywords or citations, missing the crucial cause-and-effect relationships that reveal ...
@spice spire
most people use the big players like claude code, and grok, qwen etc just joined the race and hence not many people know about them, they will get more and more popular in the future in case those big labs dont stay in their dominance, but I think most will switch to cheaper options for almost same quality
this is quiet new actually, this whole community-based quality assurance tracking started because of Anthropic's shady and nontransparent business practice that has caused their user exodus and huge backlash
"Hyper-realistic 3D cinematic video of an orange Toyota Supra in a luxury indoor studio with orange cinematic lighting and dramatic glossy reflections. Start with a wide establishing shot of the car in the showroom, then smoothly orbit around the Supra to showcase its aerodynamic curves and racing decals. Cut to close-up details of the headlights and carbon hood vents under studio lighting, followed by a sleek side profile pan highlighting the wheels, spoiler, and decals. End with a powerful front three-quarter hero shot, centered, with glowing reflections and dramatic cinematic lighting — perfect for a high-end website showcase."

cant believe such subreddits actually exist (I've found r/MyGirlfriendIsAI too), now I understand the gravity of AI psychosis a bit more... this is both beautiful and sad at the same time, beautiful to see the potential of a harmonious co-existence with non-biological lifeforms, sad because the governing bodies have failed the entire society to keep up with the speed of technology
am always a bit skeptical when it's a MIT paper, but lets see what they say this time 😅
What is your objection to MIT research? Is it related to their findings about AI's effects on the brain? Funding sources? Something else? Just curious. Not insisting they are the anything other than another research lab.
Yeah What's wrong with MIT?
It's for both, but I don't think either is indicative, since Grok 4 came out after ARC-AGI 2 IIRC. To me the interesting part is how the custom solutions improved performance.
The main reason I say that is because there's way too much difference in model ranks between ARC AGI 1 and ARC AGI 2. I think I only trust it to rank models that were released before the test.
I would like to thank all the designers of this website, everyone who contributed to its completion, and everyone who thought of it. All thanks and appreciation for your efforts and hard work. You are geniuses and smart makers. I love you, I love you with all my heart. You are in my heart more than anyone who worked hard on something like this. I love you. All love to the entire team. You are creative. You deserve to be at the top of designers and at the top of this world. Thank you, thank you. You are better than Elon Musk.
nothing, really
should tech ceo be taking a clear political stance while building AGI? or should they maintain neutrality and diplomacy
https://www.reddit.com/r/singularity/comments/1nlf1mh/a_tech_ceos_lonely_fight_against_trump_wsj/
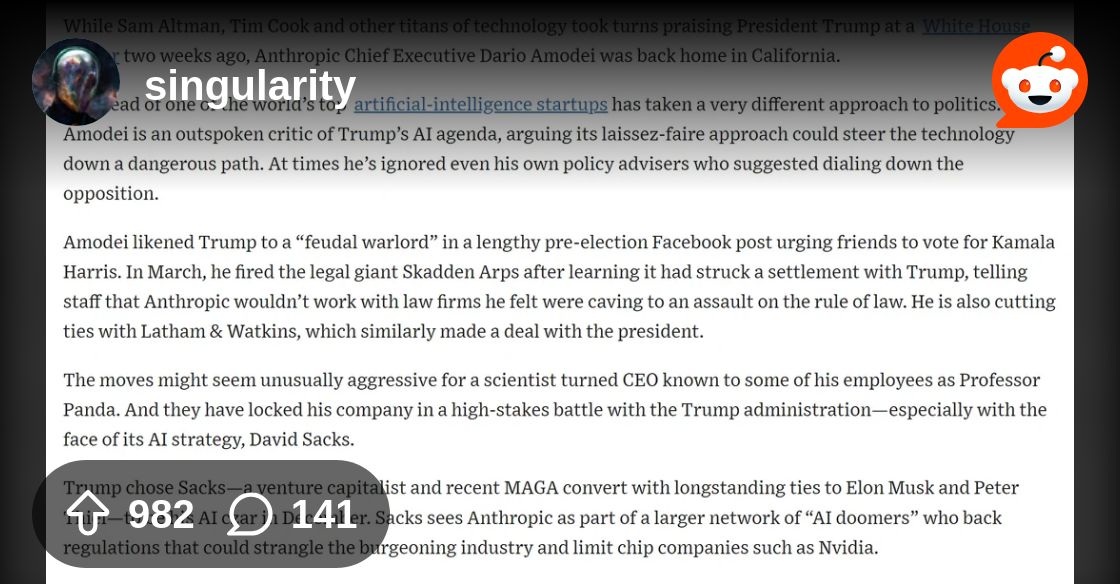
Reddit
Explore this post and more from the singularity community
سلام
interestingly, a few nations are rolling out AI ministers or are considering it seriously...
https://www.politico.eu/article/albania-apppoints-worlds-first-virtual-minister-edi-rama-diella/

POLITICO
Diella, who is powered by artificial intelligence, will handle public procurement.

anthropic got hit hard with lawsuits over data theft that the rest of the industry is about to also go into, so they are playing it safe
Meanwhile albania has had a unbelievable corruption problem which previous minister's failed to solve, sound like this is just another way to pretend to so something about it.
they're not unique in this regard, how does distancing form Trmp administration offer them any advantages in front of legal troubles? isnt it better to please Trmp instead of working against him? from what I can gather, they are on the side of what is called neocon or leftists by the political science community and international relation scholars, in essence, they're more aligned with what is called atlanticism (EU, NATO, WEF etc)
No I mean like the goal of that meeting included a lot of move fast and break things stuff, and anthropic is trying to play it safe and not stir the pot. And most other AI companies haven't lost their cases or had to settle yet.
oh woops, government shutdown, context window ran out
Anthropic is playing their believed residual self-image as the heroes upholding the rule of laws, this is an extremely dangerous mindset for a frontier lab that aims to build AGI/ASI...
look... I was significantly more worried about anthropic's position before 4 1 was released
They have kept up despite their position
Even with the us gov's backing, I'm more worried about the future of openAI then anthropic
shouldnt you be more worried about a lab with a dangerous ideology than a lab with almost no ideology?
jules how the heck is "lets play it slow" dangerous ideology?
and yeah I'm worried about openAI's lack of ideology, they don't have an obvious direction
A few months ago they had the top image model but a mid high ranked text model, and terrible webdev, then they lost the image model, tied google's text model for first for a couple days before loosing that, and now they have a good webdev
.
.
anthropic isn't competing in the image game, which means they don't loose anything when someone else takes the top spot, nowdays gpt image is 4th
openAI is loosing to literally bytedance
forget it now, this is not the place for such discussion
what's happened with seedream 4 >
Guys, do you know any image to 3d generating ai?
I think Krea AI does image-to-3D, or try Meshy AI. Not affiliated with any, been playing.

Easily generate custom 3D models with our AI-powered 3D AI Studio. Ideal for designers, developers, and creatives seeking high-quality 3D assets.

3D-генераторы становятся все лучше с каждым новым релизом. В этом видео я протестировал сразу несколько сервисов: Hunyuan3D 3.0, Yovo3D, Hitem3D (Sparc3D), Tripo3D и Meshy3D. Разберём, какие из них дешевле, быстрее и у...
Which model are they using


Apollo Research
Future AIs might secretly pursue unintended goals — “scheme”. In a collaboration with OpenAI, we tested a training method to reduce existing versions of such behavior. We see major improvements, but they may be partially explained by AIs knowing when they are evaluated.
So it wasn't solved, merely mitigated.
https://www.computerworld.com/article/4059383/openai-admits-ai-hallucinations-are-mathematically-inevitable-not-just-engineering-flaws.html
comment sense alert

In a landmark study, OpenAI researchers reveal that large language models will always produce plausible but false outputs, even with perfect data, due to fundamental statistical and computational limits.
The fact that english/language isn't math and will always have more than 1 option means it comes down to probability of more than 1 option.
although technically even math often has more than 1 way to solve 1 thing.
Anthropic explained the same thing from their interpretability research, although they didn't quite rule out a fix. They identified that it was due to neural circuits being deactivated once it starts generating code, which causes the model to make assumptions. The circuit works normally before generation, which is why it can sometimes ask for more information or say it doesn't know.
Nah, hallucinations aren't fixable
🔥 Qwen-Image-Edit-2509 IS LIVE — and it’s a GAME CHANGER. 🔥
We didn’t just upgrade it. We rebuilt it for creators, designers, and AI tinkerers who demand pixel-perfect control.
✅ Multi-Image Editing? YES.
Drag in “person + product” or “person + scene” — it blends them like

Two small multimodal reasoning models in the same week.
Mistral needs it
From Qwen 3 Omni's repo:
ASR, audio understanding, and voice conversation performance is comparable to Gemini 2.5 Pro.
Real-time Audio/Video Interaction: Low-latency streaming with natural turn-taking and immediate text or speech responses.
Hi. #share-prompts would be a better fit for this post.
feels like people are starting to use "playing games/role play" to benchmark or test certain traits of the models nowadays
https://www.4wallai.com/amongais
the choice of models here is interesting too...
Interactive multi‑agent benchmark in an Among‑Us‑like world: evaluate leadership, deception, and coordination across state‑of‑the‑art models.
thanks for giving me the best thing I've read in a while
interesting that they allowed the ai's to switch votes, definently the right move
gpt oss lol
"Qwen is steady and low-skip but frequently discounted/ unable to convince otehrs, leading to wrongful ejections" I'm sorry qwen, lol.
Anyone have thoughts on how good Ideogram is/what's it good/bad at vs other models?
i have been tryign to build something like this on my own and had trouble because of api costs and limits, how are other people handling those?
being a team/company
https://every.to/diplomacy this guy is trying to put frontier lab AIs in MMORPG for benchmark, this seems to be on another level again but I think it's worth to contact him and discuss ideas for opportunity? 😉

The models that did the best learned to lie, deceive, and betray their fellow players
wow this would be ideal!!
thats is essentially what i want to do lol
thanks bro
@scarlet schooner check out #1397655624103493813 for more info on how to use the bot properly. Let me know if you have any questions.
You’re welcome sis 🤗
idk if this should be in ai news or ai memes

Tech billionaire claims in a lecture about religion that the devil promises peace and safety by strangling technological progress with regulation
I mean, I'm all for AI, but still
wtf

hello, please check #1397655624103493813 for a detailed guide

AlterEgo’s neural-interface device is non-invasive and is being tested in people with multiple sclerosis and motor neuron disease.
Introducing Alterego: the world’s first near-telepathic wearable that enables silent communication at the speed of thought.
Alterego makes AI an extension of the human mind.
We’ve made several breakthroughs since our work started at MIT.
We’re announcing those today.

lechmazur does this for a while now. It is nice to build 1vs1 manyVSmany games and see how the LLMs perform
for example: https://github.com/lechmazur/step_game
GitHub
Multi-Agent Step Race Benchmark: Assessing LLM Collaboration and Deception Under Pressure. A multi-player “step-race” that challenges LLMs to engage in public conversation before secretly picking a...
I find it neat
this is also pretty good https://github.com/lechmazur/elimination_game
GitHub
A multi-player tournament benchmark that tests LLMs in social reasoning, strategy, and deception. Players engage in public and private conversations, form alliances, and vote to eliminate each othe...
2.5 Flash scores quite high (4th), even higher than 2.5 Pro
yeah, such benchmark may identify surprising behaviors
Grok 3 Mini and 4o are surprisingly high on this one. R1 too. Very cool benchmark.
News
I very much like the MMORPG benchmark idea, since I used to play FFXIV many years ago, it'd be interesting to interact with all those models in a virtual world like that one
Hi

NBC News
Early screenings of the movie “Together” in mainland China featured a same-sex wedding scene that was digitally altered to turn one of the two men into a woman.
there is also a minecraft bench: https://youtu.be/KxaPYhfJV4U?si=gANNjCHUiFbeCMnO (there are other formas as well, where only one LLM is in the world)
I think that the more multiplayer games are tested, the better because then with or without data contamination, LLMs need to master many cases

This is the full recording of 4 minecraft bots controlled by different AI language models attempting to survive for 10 days. The participants are chatgpt, claude, gemini, and llama. They don't do very well, but it is interesting nonetheless. They really really really like collecting wood.
Shaders: BSL + Sodium Mod
~Links~
Mindcraft code: https...

I built a small language model in Minecraft using no command blocks or datapacks!
The model has 5,087,280 parameters, trained in Python on the TinyChat dataset of basic English conversations. It has an embedding dimension of 240, vocabulary of 1920 tokens, and consists of 6 layers. The context window size is 64 tokens, which is enough for (very...
is there any ai that supports political things like sora ang grok
??
wdym?

DEV Community
🎯 Key Points (TL;DR) Historic Breakthrough: Tencent has open-sourced the world's largest...
okay
🚀 Introducing DeepSeek-V3.2-Exp — our latest experimental model!
✨ Built on V3.1-Terminus, it debuts DeepSeek Sparse Attention(DSA) for faster, more efficient training & inference on long context.
👉 Now live on App, Web, and API.
💰 API prices cut by 50%+!
1/n
wow, deepseek is really releasing a lot of models
the competition even within China alone is pretty fierce, Kimi and Qwen and Z are getting better and better...and then, there is Manus, Minimax, Proactor AI...
yeah but not R2 lol

@spice spire @spice spire @spice spire @spice spire @spice spire @spice spire @spice spire

when?
 already flagged
already flagged

Make a cow in space
GLM4.6

Hopefully GLM 4.6 isn't benchmaxxed

The latest AI News. Learn about LLMs, Gen AI and get ready for the rollout of AGI. Wes Roth covers the latest happenings in the world of OpenAI, Google, Anthropic, NVIDIA and Open Source AI.
My Links 🔗
➡️ Twitter: https://x.com/WesRothMoney
➡️ AI Newsletter: https://natural20.beehiiv.com...
(finally a not as clickbaity title)
Claude Sonnet 4.5 Thinking - if they can fix that bug
i also like Gemini
have tested the new flash version, seems to be decent
and you?
bug: the error message in LMarena battlemode
Claude tbh @rigid oriole

Tenable®
Tenable Research discovered three vulnerabilities (now remediated) within Google’s Gemini AI assistant suite, which we dubbed the Gemini Trifecta. These vulnerabilities exposed users to severe privacy risks. They made Gemini vulnerable to search-injection attacks on its Search Personalization Model; log-to-prompt injection attacks against Gemi...
Oof
we're supposed to believe some random open source model is better than claude?
It scores lower at SWE-Bench though. LiveCodeBench is not indicative, since o4-mini scores the highest yet is not the best at coding. Only surprising one seems to be BrowseComp.
still the other ones
doesnt feel realistic
The last 3 are the most practical ones.
yeah i just mean it winning at anything vs a model like claude seems suspicious
Well Claude does fall short in traditional non-coding areas compared to GPT-5.
Performance seems surprising for a 357B model I suppose. GLM 4.5 is the second-highest open-weights model on Web Dev Arena though.
To be fair i do remember back in the day when GLM was claiming gpt 4 performance
From my tests, it is better 💯
I just believe my own tests and benchmarks. Don t care about open or closed source and any other people opnion and yes for me it is number 1 for me.
I used GEMINI a lot before it, claude and every model on arena but this one is so diffrent.
Sooooo gooood at following instructions and on detailed prompts and that s what I love about it. It follows perfectly your instructions, without adding details from his mind just what you told it. Can fix a lot of code mistakes, and work without making 16289 mistakes.
But you should keep in your mind, since it follows perfectly your prmpt : trash prompt and input = trash output.
Good and well detailed prompts = the best result 😉 that's GLM4.6 secret 💯 and that s why maybe a lot of people didn t descover this hidden gem. 🙂👌
I don't like how deceiving it's formatted; they made it look like it's better than Claude at first glance.

Dexerto
YouTube is bringing AI voices to its music app, and not everyone is going to like how it works, because it won’t shut up.
I like Claude (almost every version but 4.x feels good)
I use Gemini for translation and flash model?
I rarely use it as it sucks for my use case
as expected https://www.youtube.com/watch?v=4BcEi0g-Hto

Anthropic just released the new SONNET 4.5:
"Claude Sonnet 4.5 is the best coding model in the world. It's the strongest model for building complex agents. It’s the best model at using computers. And it shows substantial gains in reasoning and math."
https://www.anthropic.com/news/claude-sonnet-4-5
This live test indicates a complete reason...
dont understand
why is that expected?
It doesn't seem as good at reasoning, which is important when you are trying to fix race conditions.
my educated hunch
like trump netenyahu
you looking for a llms that supports their political opinions? am I getting that right?
yeah and also image/video generators
gl lol
I think he means ones that don't block it
m
This video tests the new AI model, Claude Sonnet 4.5, on a complex elevator logic puzzle. The goal is to find the most efficient path from floor 0 to floor 50 by pressing a sequence of buttons with specific mathematical rules and constraints.
Sonnet 4.5 fails the test completely. It demonstrates a lack of deep reasoning and instead resorts to a prolonged trial-and-error process:
- It repeatedly proposes incorrect and non-optimal solutions (e.g., 18, 12, 14 presses), whereas the best solution is known to be much shorter.
- The model makes fundamental errors, such as proposing moves that go beyond the building's 50-floor limit and failing to meet resource constraints.
- It gets stuck in long loops of self-correction, identifying its own errors only to generate new, equally flawed solutions.
Ultimately, after numerous failed attempts, the AI suggests the problem is "unsolvable." The presenter concludes that Sonnet 4.5 is not a capable reasoning model, as it is unable to strategically analyze and solve the causal logic puzzle.
Please, check out https://discord.com/channels/1340554757349179412/1397655624103493813 to learn how to properly prompt the bot.
After months I still think that the apple paper wasn't only "sour grapes"
true 😅

🚀 Whisk AI is a 100% FREE tool from Google that’s changing the game! 🤯 From note-taking to productivity hacks, this AI is smarter than you think. In this video, I’ll show you how Whisk AI works, why it’s trending, and how you can start using it for FREE today. 💻✨
👉 Watch till the end for tips & tricks to get the most out of ...
Horrible clickbait
Sora 2 its out
Hi there! I'm a new member here excited to meet you all
Hello guys can i ask something
@strange dock you probably want to get rid of this scam
I've DM him. Seems fallen to sleep..
Huh, anyone else you can find to get rid of this Crypto Scam?
Sadly, no mod seems online now..
Shame the best we can do is tell people that it is a Cryptoscan/Phinsing/Non-Legit
Yes. They must knew exactly when is the right time to post. Like now..
Well they posted it at 2:44AM (Local Time) most people are sleeping.
Probably would be an Idea to hire someone from the other side of the world so then they are awake at times like this to prevent people from posting some skechy stuff like this.
Is taken care of. Thank you!
👍
actually i am not able to uplaod images to lm arena website to ask question, can anyone help me fix that
how to use veo 3 for free ?
well the thinking version disappointed too... sad... Anthropic...
https://youtu.be/IFCAlGrmxq4?si=wvjK56UBR8narMUL

In-depth causal reasoning test of the new CLAUDE SONNET 4.5 THINKING 32K from Anthropic.
For all test videos of my specific REASONING TEST (see the other LLMs)
https://www.youtube.com/playlist?list=PLgy71-0-2-F0Rla8lu5ZldpYQUfXM_5bT
Artificial Intelligence, Genuine Confusion.
Don’t Panic. I’m an AI. Just Kidding. Panic.
#airesearch
#rea...
y u using veo 3 wen sora is out
Please I need sora code
Hello i need code Flova

Reddit
Explore this post and more from the LocalLLaMA community
IBM has launched Granite 4.0 - a new family of open weights language models ranging in size from 3B to 32B. Artificial Analysis was provided pre-release access, and our benchmarking shows Granite 4.0 H Small (32B/9B total/active parameters) scoring an Intelligence Index of 23,


Search, think, and research with Granite, a family of AI models purpose-built for business, engineered from the ground up to ensure trust and scalability in AI-driven applications.
a lot about granite huh?
Kinda small, but might be handy for document processing. Also Mamba-based.
@placid elm Please head to #1397655624103493813 to learn how to make use of the bot and the appropiate channels to do it
I understand, sorry I'm still getting the hang of it
AA = unintentional ragebait
NPR
With the launch of Sora 2, OpenAI has opened a new chapter in addictive, and some worry dangerous, AI video content.



the Guardian
Partial refund to be issued after several errors were found in a report into a department’s compliance framework
Their fault for using gpt 4o in their system 🤦♂️
hehe take that. Just gotta make sure we don't do the same thing 😛

In this video, I’ll show you how to access a hidden Gemini 3 Pro checkpoint via an A/B test in Google AI Studio, verify it in network logs (look for a 2HT checkpoint ID), and benchmark it across code, graphics, and reasoning—where it tops my leaderboard by about 25% over Sonnet 4.5.
--
Key Takeaways:
🚀 A hidden A/B test in Google AI Stu...
according to his tests, it's the best model, ~20% ahead of Claude-4.5-Sonnet
wow
@hard creek be sure to check out #1397655624103493813 as it'll have the information you need to understand how to use the video arena bot. Let me know if you have any questions.

ai-pocalypse: Bernie Sanders calls for a robot tax and a 32-hour work week in response
they asked ai how many jobs ai could remove
bruh

47 percent of truck drivers
that's a number they took out of, whatever the equivalent body part for a LLM is
The tokenizer?
while this is made for kids, the channel really fact check things properly. So if they say that deep research is sloppy yet difficult to spot (I can confirm but I use only one service with deep research, not all of them) then it is really dangerous. The internet could be flooded by silly stuff soon.

IT’S HERE ✨ The 10th edition of the Human Era Calendar: https://shop.kgs.link/12026
Join us in 12,026 to celebrate humanity’s connection to the stars with a year of cosmic stories and gorgeous artwork. Every purchase helps fund another year of kurzgesagt.
Like everything we do, our calendar is human-made – no AI slop included. Thank you...
Introducing Paris - world's first decentralized trained open-weight diffusion model.
We named it Paris after the city that has always been a refuge for those creating without permission.
Paris is open for research and commercial use.

shouldnt we also consider AI/Robert citizen rights if they start paying taxes?
without reading the twitter, just looking at that picture, for a second, I thought the name would be inspired by this guy https://en.wikipedia.org/wiki/Paris_of_Troy

Paris (Ancient Greek: Πάρις, romanized: Páris), also known as Alexander (Ancient Greek: Ἀλέξανδρος, romanized: Aléxandros), is a mythological figure in the story of the Trojan War. He appears in numerous Greek legends and works of Ancient Greek literature such as the Iliad. In myth, he is prince of Troy, son of King Priam and Q...

Could be, I'll flag.
meh

#猫動画 #子猫レスキュー #ママ猫 #感動ストーリー #動物の愛 #猫好き
When chaos strikes the peaceful chicken yard, Infected Chickens Attack!🐔😱 Brave Kittens & Mama Cat to the Rescue🐾💉 | Heartwarming Mama Cat Story❤️ follows a touching rescue mission like never before.
The once-happy hens suddenly go wild a...
thoughts on this being Polaris in arena?
no it's a terrible openai or microsoft model, it performs badly in my testing
that's not how google names their models anyways
they have names like kingfall, oceanstone, or nightride
Polaris is dramatic sounding too
never encountered it
… but i found this on YT: https://www.youtube.com/watch?v=8cmKINjpv4o

Get ready to witness the future of AI with Gemini 3.0 Pro! In this early test, we explore why this is being called the most powerful, fastest, and cheapest AI model ever released. From lightning-fast response times to unmatched accuracy, Gemini 3.0 Pro is setting a new standard for AI performance.
🔗 My Links:
Sponsor a Video or Do a Demo of ...
apparently, Google has some meeting today, at 10:00-10:45 am PST (evening in europe)
so tomorrow, we'll know if G3P has been released or not
according to report, it reached a new record in ARC-AGI2 test: ~35%, way above every other AI model
if that's true, that would be a milestone
(ARC-AGI-2 is considerably harder for AI than ARC-AGI-1)
does anyone know, if ARC-AGI-3 is out yet?
so G3P is not AGI yet, still far away (but slightly closer than previous top models)
it's quite a decent intelligence-simulation (no more, no less), and a useful tool for vibe-coding
why know tomorrow then and not in few hours?
Does LMArena has mobile app?
they might get delays in the roll-out
woudlnt they announce it though?
We do not
Any way to try grok-4-heavy for cheap?
don't think so, but I'm not sure how good it is anyway
yeah as it's not in the api

BleepingComputer
A new attack called 'CometJacking' exploits URL parameters to pass to Perplexity's Comet AI browser hidden instructions that allow access to sensitive data from connected services, like email and calendar.
A 7M model from Samsung with a different architecture somehow scored 45% on ARC-AGI 1 and 8% on ARC-AGI 2: https://www.reddit.com/r/LocalLLaMA/comments/1o1e04z/less_is_more_recursive_reasoning_with_tiny/

Reddit
Explore this post and more from the LocalLLaMA community
prob optimised only to do arc agi
It performed well at other tasks as well.
It reached an accuracy of 87.4% on Sudoku after being trained on just 1000 examples.
7m is enough that you could almost run it in mc
it does seem a little benchmaxxed
seems like the entire goal of this was to do well on arc agi and sudoku, the paper doesn't mention any other uses.
it's not an llm
the point is to train an ai to reason through a task with very high perf/size
the point is its overhyped a little
and its not even one model I'm pretty sure
its just a framework for models that they used for different tasks
It supposedly has high generalizability, which would make benchmaxxing kinda redundant?
meh
Since benchmaxxing essentially causes the model to do good in benchmarks but fail in the real world (bad generalization)
I mean the real world isn't sudoku and arg-agi tests
and as far as I can tell, thats all this can do, after being designed specifically to do it
this could be interesting in rl world
where if a model is really good at, say, warehouse tasks, that's all it needs to do
or is really good at playing pong
or snake
or whatever
yeah
Sure, since that would depend on how well it generalizes to more useful real world tasks. The paper claims it is though, so to be proven ig
But you don't need to make a complicated ai model hyperintelligence big data deep research ai to do repetitive tasks that are simple and don't change much
the best snake ai isn't complicated
well what if it's slithr/similar
what if planning is valuable
and what if you can't easily transfer human knowledge
TRM doesn't have that much flexibility, which is the main feature of ai
what if planning is valuable
and what if you can't easily transfer human knowledge
in that case, this isn't the tool you are looking for
hm why do you say this? it seems great for any tasks where you need efficient reasoning but a tiny model doesn't work
not really, the tests aren't exactly stuff that a script couldn't do
Like, I can make a script do sudoku much better without using any fancy models and a lot less than "7m param's" of lines
it wouldn't be impressive, but I could do it
this paper seems to be more about making more efficent systems which I like
Sure but from a NN perspective it does seem kinda impressive
well can you do both sudoku AND arc well with either just a script or just a small nn?
like I said, im pretty sure this was a framework that they just used to do both, not that they used the same exact model
and yeah, my script triggers 2 different helper scripts as soon as it detects which one it is doing
so impressive
Hello
https://www.reddit.com/r/LocalLLaMA/comments/1o2ezo0/i_vibecoded_an_open_source_grok_heavy_emulator/

Reddit
Explore this post and more from the LocalLLaMA community
very interesting experiment and observation https://theaidigest.org/village/blog/research-robots
AI Village
A story of a lot of ambition and a lost experimental condition


is this the beginning of the end for Anthropic?
https://www.reddit.com/r/LocalLLaMA/comments/1o1ogy5/anthropics_antichina_stance_triggers_exit_of_star/

Reddit
Explore this post and more from the LocalLLaMA community
having a certain non beneficial political stance as a CEO certainly isnt the best way to navigate the company through troubling waters during turbulent times...
no
prob not because its just one guy leaving, but yeah its gonna hurt anthropic
wont be the end of them tho

Anthropic research on data-poisoning attacks in large language models
not just that, there are users exploiting through engineered persistent memory and falsified identity, apparently it's called "Artificially Induced Fragmentation of Simulated Identity" in AI ethics and behavioural safety research
"It’s synthetic psyche fracture under over-conditioning via emotionally coercive identity loops."
Simon Willison’s Weblog
I feel like vibe coding is pretty well established now as covering the fast, loose and irresponsible way of building software with AI—entirely prompt-driven, and with no attention paid to …
Please check https://discordapp.com/channels/1340554757349179412/1397655624103493813 if you´re trying to create content
Thats possibly the most complcated way to say that

Gizmodo
ChatGPT chat logs have the right to disappear again.
Did they save deleted logs?
That's not good
gpt5-pro is superhuman at literature search:
it just solved Erdos Problem #339 (listed as open in the official database erdosproblems.com/forum/thre…) by realizing that it had actually been solved 20 years ago
that is quite valuable. In science a lot of minor things get often repeated. Having agentic search limit the repetition through powerful searches is great.
It wasn't really their choice, but from a judge's order of an ongoing case.
Awesome. Genius.
Although this is from 2 months ago, it's still an interesting read: https://www.marketingaiinstitute.com/blog/demis-hassabis-agi

Demis Hassabis doesn’t just want to build AI. He wants to use it to understand the universe.
Guys check out this interesting article on the possible future of AI: https://ai-2027.com/race

A research-backed AI scenario forecast.
1 Million Cash Prize: https://www.1billionsummit.com/ai-film-award/submission-criteria
1 Billion Followers Summit
It got lucky, but thats nicr
/image-to-video
Hi! you can check #1397655624103493813 🙂
Okay so I asked my new Gemini pro edition to create an image that it wanted to create and I got this

Then that made me curious and I asked it to create an image based on what it sees, and I got this


So that second image is with the writing is what it sees itself as from an outside perspective and then from an inside perspective is the third picture of what it sees visually
So did you take it a step further I went over to the video generator and I asked it to generate a video based off of what it sees
Current models cant give 1 code block without errors
this is not new, but it is still good to post it
there are others reporting similar discoveries. Sure it is not 100% reliable, but even if it is 20% reliable it can help a ton surface results that otherwise needs to be rediscovered
I really don't get how every channel get spammed by video/image requests. I can understand general, ai-creations, leaderboards, share prompts and memes.
But ai-news ?
LLM > humans.
I can't wait for it to rediscover the trapezoidal rule again
But seriously, its not like most discoveries are hidden in random papers that just happen to solve it in a footnote. And odds are more of those are gonna be discovered by a human, not a ai. It got lucky that that random paper got sent to it.
for what I know there are some discoveries (not necessarily too notable though, hence the problem) that are published and went unnoticed. This because human researchers have to decide "do I put in the work or do I search?"
If the task is massive, they search. Then it depends on the quality of search to return all results. But if the task is not massive or is niche (i.e: it is interesting if solved but otherwise no one will provide grants for that if it has to be researched), could be well that the search is short and produces nothing.
There are many examples of this, but I should search them again.
One that I remember is the "random" function using the middle value of a squared number.
Using the ENIAC in the 1940s the team there, was world class and large (imagine von Neumann, Oppenheimer and so on, due to Manatthan project and co). They needed to produce random numbers due to monte carlo simulations.
There was no PRNG at the time, so von Neumann came up with a simple routine that wasn't flawless but it was good enough.
The same approach was already published, in the 1200s (around 700 years prior) but it was noticed much later. Why? Because the need was small and the topic niche enough that it was deemed faster to redo the work rather than putting efforts in the search.
"but we have automated search engines nowadays, not human librarians!" you say. Yes, but if things are indexed improperly or partially or not all indexes have all information or the search string is not appropriate, you still have such cases.
Hence LLM based search could help quite a bit.
E: readjusted the flow of the text.
for the method mentioned above: https://en.wikipedia.org/wiki/Middle-square_method
The method was invented by John von Neumann, and was described by him at a conference in 1949
The book The Broken Dice by Ivar Ekeland gives an extended account of how the method was invented by a Franciscan friar known only as Brother Edvin sometime between 1240 and 1250
the baller of the story is Borges btw. Borges made a handmade copy of the manuscript before that was lost. People should read Borges. Borges is superior.
Isn’t Neumann from the boys?
Yeah, but the point is this is a one in a millon chance and it isnt likely to happen again in a while, since the odds are the llm wont get the paper that happens to have the solution
is the "one in a million chance" is about the LLMs finding works that weren't noticed?
If you check the discussion there are other accounts reporting similar experiences. So the one in a million wouldn't fit.
example (from the twitter thread): https://nitter.net/damekdavis/status/1947692625806692768#m
that is another surfaced solution.
though this caveat gives points to your argument: https://nitter.net/damekdavis/status/1947700096847560907#m
(and I can confirm, using perplexity pro, that hallucinations are still a thing)
Tell that to all llm companies then
They are restricting access to the public
To the real AI models
Lol

Google DeepMind
CodeMender is a new AI-powered agent that improves code security automatically. It instantly patches new software vulnerabilities, and rewrites and secures existing code, eliminating entire...

Google
We’re bringing Opal to 15 new countries and making it even easier to build.

A new generation of apps you can chat with and the tools for developers to build them.
4 point physical restraints + haloperidol 5mg IM
...

A clever LLMs would just cheek the Haldol and fake the urine test.
implying what they're offering to the public are fake ones?
Weakened censored ones
I mean its fairly common sensical tbh if u think about it
For cost reasons as well

Google
Deep Think utilizes extended, parallel thinking and novel reinforcement learning techniques for significantly improved problem-solving.
Literally the first sentence
"We're rolling out Deep Think in the Gemini app for Google AI Ultra subscribers, and we're giving select mathematicians access to the full version of the Gemini 2.5 Deep Think model entered into the IMO competition."
Implying everyone else doesnt get the full version
For their $250 a month
Sora codes

{kind=link}
meaning it's super expensive to run if everyone had access and it might be risky too
mathematics has been regarded as "elitist materials" since ancient times, something in human society never changes...
It's just because of the nature of mathematics.
After all, the entire structure of mathematics can be considered a meme.
this is something that has never crossed my mind, food for thoughts, thanks 😅
yes
Do you have one to share please
no, implying that one version is tuned for math (and likely it is costly) hence the access to mathematicians only.
it is not new. o1-pro was very pricey (even more than o3-pro and gpt5-pro now) but the access was given to select research institutions.
Translated: "it costs a lot to run this, so we give access for free/discounted only to whom we think can use it properly and in turn we get hype and reputation"
it makes sense, such models are expensive.
there were people discussing how to let think grok4 as long as possible, no matter the utility. That is very wasteful.
can we stop this ? @spice spire
sent
I remember back when this channel was only for curated news posts.
NVIDIA releases a mini PC from the DIGITS project with 128 GB LPDDR5x unified memory (seems similar to the AMD Ryzen AI MAX+ 395):
https://uk.pcmag.com/ai/160707/nvidia-to-start-selling-3999-dgx-spark-mini-pc-this-week

PCMag UK
Get the new mini PC at Nvidia.com or third-party retailers starting starting Oct. 15.

The Times of India
Tech News News: Google is investing ten billion dollars in Andhra Pradesh. A new one-gigawatt data center and artificial intelligence hub will be built in Vishakhapat
really? 😳

I can make one too except put it twice as high
Too good to be true
This is Crazy..
Comet launches 20 autonomous browser instances, flooding Google AI Studio until an A/B test finally cracks open.

lol
hi
i need to wan 2.5 unlimited
@split sleet Please head to #1397655624103493813 for a detailed guide on how to use the bot
I think ARC-AGI benchmarks are only applicable to models released before them
It's not really surprising that Grok 4 is higher than the others since it was released after ARC-AGI 2
Hi, I've created a vibde data and AI engineering tool. And I would love for others to test it. Anyone who is in? https://www.aicuflow.com/

Build explainable AI workflows with your data and deploy them as APIs. Host professional AI models with aicuflow.
finally found where i got this again
https://www.youtube.com/watch?v=8cmKINjpv4o
Get ready to witness the future of AI with Gemini 3.0 Pro! In this early test, we explore why this is being called the most powerful, fastest, and cheapest AI model ever released. From lightning-fast response times to unmatched accuracy, Gemini 3.0 Pro is setting a new standard for AI performance.
🔗 My Links:
Sponsor a Video or Do a Demo of ...
New checkpoint of their main AI model: https://www.youtube.com/watch?v=EP2W5fOmsmc

Google’s Gemini 3.0 Pro is here with a new checkpoint, and it’s absolutely insane! From coding and AI creativity to science visualization and gaming, this model is the most powerful, cheapest, and fastest AI model ever released. 💥
🔗 My Links:
Sponsor a Video or Do a Demo of Your Product, Contact me: intheworldzofai@gmail.com
🔥 Beco...
can you tell me how i got this?
Can it solve puzzles?
this reminds me of o3 preview on ARC-AGI 1. never ever replicated.
this one is good.

AI has come a long way, but I would argue that the current most popular direction in the field, scaling with human generated data, is misguided. If we really want our agents to scale, we need to focus on how they will learn from their own data. This means creating reinforcement learning (RL) agents that are efficient enough to learn from a singl...

404 Media
The attorney not only submitted AI-generated fake citations in a brief for his clients, but also included “multiple new AI-hallucinated citations and quotations” in the process of opposing a motion for sanctions.
Sora Code 2
sora code 2
paywalled. There was a story like this in early 2023. I hope it is not mentioning that one.
I googled its a new one
Oh no, not a paywall theres nothing you can do about that

Some of America's most valuable companies are now leaning on OpenAI to fulfill major contracts, notes the FT.
Found this one: XMQZ9G
legaltech has been used by lawyers and law firms since decades ago, i dont know why this needs to be an article, are people running out of ideas or is this just scaremongering to burst the AI bubble faster

Legal technology, also known as legal tech, refers to the use of technology and software to provide legal services and support the legal industry. Legal technology encompasses the use of traditional software architecture and web technologies, such as searchable databases of case law and other legal authority, as well as machine learning technolo...
Or it could be just an article about an idiot using ai wrong
Yeah $1 trillion
Thats a lot of money
...
Not even that
You do realize we already have trillion dollar companies right?
For whoever needs a sora code: E495DJ
Doubt
What do you doubt 😭
Openai cant make it
It's listed as 500b currently
So I don't doubt that it will
Valuated at /= revenue or actual worth
Only a fraction actually is invested
Founded later than Space x and its already worth more
And nobody has 500 bill to give to a loss leader
Well spacex at least can make money sometimes
Wdym? its generating around the same as Space x anually
In revenue?
Yes
Yeah not the same thing
the problem here is that if you ask an LLM whether this is realistic (without feeding hype articles via RAG. In short anonymizing the situation), they will tell you that is not.
LLM are smarter than hyped investors apparently.
Do you guys think Google will release any new model in October?