#leaderboards
1 messages · Page 1 of 1 (latest)
its out in leaderboard?
yeah, snagged 1st place everywhere
crazy
BREAKING News: @OpenAI's GPT-4.5 now tops the Arena leaderboard!
With over 3k votes, GPT-4.5 landed #1 across ALL categories, and singularly #1 under Style Control / Multi-Turn 🥇 Huge congratulations to @OpenAI on this impressive milestone! 🙌
View below for more insights on

claude 3.7 thinking still not in there?
https://x.com/elonmusk/status/1896624102674506172?t=8x9-X8P7egbp7k3UXOhHyg&s=19
anyways seems like grokman wants to do better
It seems extremely easy to gain the lm dashboard and just upvote GPT 4.5 content. Why do y'all put so much weight on this leaderboard that seems pretty fickle
it's just one metric of many. And I think the people who try and game the leaderboard are pretty few in number.
but the battles are blind
Seems like it does play a big factor in vibes. I prefer artificialanalysis.ai for my model evals
Do the arena (side by side) votes not count on the leaderboards? If not, then good!
Oh good question, I don't know. I didn't see that.
But I checked and gpt 4.5 is not available as an option there
I would assume not. I didn't realize the main page of lm arena does the blind study type voting, my earlier question was based on a wrong understanding of the methodology.
Was able to confirm side by side arena results are not factored into leaderboards

Curious how 3k votes was determined as a big enough sample size to put in the leaderboards since the rest of the top 5 have 10k+ votes. Maybe there were a lot of votes where 4.5 beat other top 5 models?
I think a few other models that showed up in the leaderboard had ~6k - 10k votes before first showing up there. Might be the fact it's pricey, might be hype amount, idk
In any case it's a win for the more casual LLM users/the general public imo, it'll be on Plus this week
@west lodge I DM'd you for a collaboration.
could we get the servers to have different logos?
DeepSeek R1 had only 1.5k
Ohh ok cool
This is below the lower bound I calculated using ELO math, disappointing
worst part is that it's true, new version wins by 1 point
in style control there's more of a substantial gap
These elo ratings are pretty similar for example 4.5 only wins 54% of the time against Google's most advanced model
any theories on how this is possible in the span of a day via a legitimate process instead of gaming by that twitter guy??


elon knows in real time what the estimate for the arena score will be
like there's been over 1000 votes in the last day, so every few minutes he receives a new vote so can know he'll probably be #1 when it enters the arena
Does the arena increase the frequency of new models for the blind test studies? In order to quickly assess capabilities? I guess I am not sure how Elon would control this which seems like he did based on his tweet lol
there are gambling sites that allow you to bet on what the #1 model is. iykyk
hi
Considering ethical aspect of elon (he is the least moral guy since 2023), the benchmark is probably being gamed. Maybe legally (fine-tuning on arena questions) or illegally (faking votes, allocating more resources than being communicated).
Also, he's the richest guy in the world. Some donations to LMSYS team may not be game changer but may give extra perks.
he is not faking votes or bribing anyone, he is obviously just optimizing the model for user preferences, which is a fine thing to optimize for. he is just cringe about it
OK stupid noob question, is there a way to recreate leaderboards from the past...
I see that https://colab.research.google.com/drive/1KdwokPjirkTmpO_P1WByFNFiqxWQquwH#scrollTo=C5H_wlbqGwCJ
Reaches down into a google cloud storage. I'm trying to look at trends in the Arena scores over time
url = "https://storage.googleapis.com/arena_external_data/public/clean_battle_20240814_public.json"
But what are the other valid things to enter, it would be great to get the current ones, is there a listing somewhere?
I tried to just list it, but of course it looks like you need authentication
gcloud storage ls --recursive gs://arena_external_data/public
ERROR: (gcloud.storage.ls) HTTPError 403: rich@tne.ai does not have storage.objects.get access to the Google Cloud Storage object. Permission 'storage.objects.get' denied on resource (or it may not exist). This command is authenticated as rich@tne.ai which is the active account specified by the [core/account] property.
# but accessing individual objects works
gcloud storage ls --recursive gs://arena_external_data/public/clean_battle_20240814_public.json
He's choosing to cheat and immorally engage in all other business aspects, why are you so naive in believing he's a good boy in LLMs?
i am not naive, he is not a "good boy", he just cannot fake votes at scale, and not literally everyone is corrupt, it just is the kind of fraud that is too likely to be caught to be worth persuing most of the time.
usually when you have cracked employees you have to keep them by not pushing them to be obviously fraudulent. talented ppl just quit the job when they're being asked to be obviously fraudulent, bc they want their cracked engineer status points which come from not being caught being an obvious fraud
just doesn't seem likely to me
Thanks guys for your thoughts on this. I agree with Bayesian that this seems pretty hard to game but I also agree with Larry that he is not a good boy and cringe most of the time.
only kalshi gamblers here
I hate elon musk too, but i cant lie, grok can cook (not to mention he didn’t develop it at all). It's a great balance of precise reasoning and proper formatting + clarity. The problem with most other models doesn't lie in any sole benchmark; usually, it's imbalance, it's due to prioritizing Markdown formatting over a precise response (or vice versa)
GPT 4.5 also seems to strike this balance well.
Idk if grok can overtake it. we'll see
You’ll never catch me paying $30/mo for grok though. No way
I don't know men, I've tried grok and gemini many times when my GPT PLUS acc was out of limits. They just don't satisfy my needs. The only time other LLM surprised me more than GPT was the Sonnet 3.7. It was the first LLM to answer my ultra niche prompt. Grok does not understand it.
What is the ultra niche prompt?
Drawing a Hanning window (context: signal processing) using ASCII given the constraints and explaining the formula. Every model up to last month used to draw triangles, which is BS.
That is pretty niche!!
the non-reasoning models will often be worse at reasoning tasks like coding / math
but they're as good or better at non-reasoning tasks
I don't think that grok should be the best in coding... Been reading about advanced non-Elo algos yesterday, a/b algos are a part of my trailblazing successes...
Wym Grok can do it pretty easily

Oh god 😄 Not sure if you're joking but its funny 😄
This is the second image that Grok made, but I think the first is funnier xd

To be fair this is more accurate 😄
However, this is what it should make https://en.wikipedia.org/wiki/Window_function

In signal processing and statistics, a window function (also known as an apodization function or tapering function) is a mathematical function that is zero-valued outside of some chosen interval. Typically, window functions are symmetric around the middle of the interval, approach a maximum in the middle, and taper away from the middle. Mathemat...
Btw I completely agree with you on this. But maybe it is just different uses cases people have.
Like everytime for coding stuff Sonnet is just better idk. Even tho other models are close on the leaderboard
im being forced by this server to write random stuff here to remove thhsese annoying popups.
What popups?
You just have to check out 3 diff channels for one time but yeah its dumb
Hi~all, Does the Visual Language Multimodal Leaderboard include other languages besides English and Chinese? For example, French and Spanish?
unfortunately we have too few votes in other languages for us to compile the leaderboard. could you say more why you're interested in seeing other languages?
@west lodge I am curious about the evaluation of the multimodal model. Does the votes in the category "overall" only include Chinese and English, and exclude votes outside of these two languages?
Does anyone know the AI big model rankings that polish Chinese papers?
为什么gpt 4.5不能模型比赛?
为什么gpt 4.5不能比赛
Why can't gpt 4.5 compete
overall includes all languages
hello
Any safeguards to prevent this type of jailbreak from influencing the leaderboard rankings?

Play Fair: If AI identity reveals, your vote won't count.
That is not a jailbreak and you don't need a jailbreak to identify a model
There are simpler tells that won't detected by simple text match like @wide schooner mentions in the rules
Maybe the fact they be wrong 80% of times also helps a lot, Gpt thinks he is Gemini immo
I'd imagine most newly released llms don't have a problem recalling their name. Also refer to models as "it" instead of "he", they aren't humans lol.
At the prashis, use "it" right after think would be kinda weird, anyway great Pfp xD
Without asking the model those questions ,you can know its name easily . Each model have a specific style, mistakes and answers , so you can't prevent it. For example chatgpt 4o answers are like
1️⃣
--
2️⃣
--
3️⃣
With some kind of emojis and I can disting 4o from gpt4.5 by the accent .
The only method to prevent it is to play fair and to vote for the model that deserves it.
Is the grok-3-preview in the leaderboard actually grok3 or grok3-think?
I wonder, why claude-3-7-sonnet-20250219-thinking-32k is on the chat available but is not on the leaderboard 🤔
have patience
when can i chat with o1 generate image with dall e 3 generate video with veo2
o1 is in arena (battle) (not in direct chat)
Dalle 3 is in text2img (basically arena battle's chat mode, but for image generation)
Veo2 is not on lmarena to my knowledge. .-. Would be interesting.
in arena battle under chat now you can see Expand to see the descriptions of 90 models, in direct chat you also see it. what do you think that mean?
password: super-alpha
Hi, just an amateur AI user here who has taken a gander at the leaderboard off and on. NGL, the ranking system confuses me.
hello
It's like chess rankings
The Bradley–Terry model is a probability model for the outcome of pairwise comparisons between items, teams, or objects. Given a pair of items i and j drawn from some population, it estimates the probability that the pairwise comparison i > j turns out true, as
where pi is a positive real-valued score assigned to individual i. The comparison i ...
Perhaps you can paste that into your favorite AI model and have it simplify it for you
Have a question concerning the AI models used on https://lmarena.ai/ it is a great opportunity to check the models before installing. I was testing command-r-08-2024. It was giving a very good output for my promt and was reproducable with similar results. Then I was installing the same model through ollama (https://ollama.com/library/command-r) but was giving very poor results for the same promt. Do you have any suggestions? Thanks!

Command R is a Large Language Model optimized for conversational interaction and long context tasks.
command-r and command-r-08-2024 are two similar but different models.
also, by default ollama uses Q4, which is lower precision than what is likely ran on arena
Thank you! Is there a reference what is used here instead of Q4? Or what num_ctx is used?
你好
will grok text-to-image be added to text-to-image LB?
Isn't that flux pro?
I thought it was flux dev with a lora
They changed it
Hi all!
I was wondering if Claude 3.7 Sonnet - Thinking would be added to the leaderboards soon?
I think it’s important to differentiate the thinking model from the non-thinking model. In my opinion, there’s a good chance that 3.7 Sonnet Thinking could even be #1 in coding!
Best,
Mason
Soon
Awesome!
Hi is there a way to get leaderboard changes programmatically? The notebook mentions a file that’s 6 mo old and simple playwright script hits cloudflare…
I just want the data for the little dashboard I have for myself that aggregates llm related news etc
why 😂 ? is it against the rules somehow?
You wont get the realtime data
Possibly due to prevent cheating
At least make it harder
huh? if any human can see it how does that prevent cheating? i'm fine if it's delayed like a day, too...
even wayback machine is blocked, which is too bad... https://web.archive.org/web/20250225010050/https://lmarena.ai/?leaderboard
make your own script that looks something like https://github.com/KTibow/lmb/blob/main/handling/convert_pickle.py
(ignore the unused code)
That’s perfect! Thank you!
i'm not completely certain about this but i kinda thought that they review/analyse the latest data/votes (like further checks against potential manipulation, looking into any wild anomalies etc) before publishing an updated leaderboard
if that is the case, ig there isn't really a 'live' leaderboard per se - just the accumulation of new votes / data
When do the arena score leaderboards update?
It doesn't appear to be done in realtime and instead manually?

Join this in-person event for the AI community and the Google teams behind Gemma.
I assume they will unveil they new gemma models
hello, I want to know how to add the company's model to the competition ranking.
https://ai.google.dev/gemma is already updated to Gemma 3, so this is definitely true
Google AI for Developers
Gemma open models are built from the same research and technology as Gemini models. Gemma 2 comes in 2B, 9B and 27B and Gemma 1 comes in 2B and 7B sizes.
i don't understand why a model that just was released is included, but still no claude-3-7-sonnet-thinking. Or qwq-32b
What is the difference between Gemma 3 and Gemini 2, which one is better
What is the difference between Gemma 3 and Gemini 2, which one is better
Gemma is open (Apache 2.0 License), but likely less powerful.
It got a good amount of votes 3000.
i think the gemma team wanted it released (they are really proud of their arena score)
and i'm guessing claude and alibaba didnt make those requests? just a hunch
on the coding leaderboard its quite low tho

(with style control)
without its actually on rank 15

i want qwq on the leaderboard
gemma 3 27b has been in testing under the name zizou-10 for longer than qwq and Claude thinking
How did you know that it was zizou ? 🥲
Oh it told me now thta it was zizou 10
Well he said he was Gemma, who else do you want it to be?
I tested gemma 27b in AI studio. Is it the same in lmarena? It is not even close to Claude and Deepseek
i noticed that too, something is off there
google's best private models have only around a 56% chance of winning over gemma 3 27b
i like this prompt and have been using it a bit (almost all models indeed fail, usually producing a triangle or just all over the place)...
[i don't know anything about hanning windows, jftr ha]

A Hanning window is a smooth, bell-shaped curve commonly used in signal processing. (Actually it should be called 'Hann window"...)
yeah i know what it looks like, and skimmed the wiki page to get a sense of what's going on - but yeah at a technical level, it means nothing to me ha
i've tried prompting with both Hann and Hanning Window. With the former, some LLMs point out that the latter is the more conventional phrasing, others say the former 🤷♂️ either way, they know what you mean so it's kinda redudant to the task imo
4o intitially says one thing (Hanning), then the other (Hann) in the very next response lol


is there an api to get the latest lb rankings
i'd like to get alerted when it gets updated basically
Not sure if anyone knows, but I was curious, is the “Grok-3-Preview-02-24” the thinking or non-thinking model?
Haha I've never thought someone would be interested in this niche thing
Interestingly, O3-mini blew my mind when I first asked him to do this with a maximum of 40 characters per line. It chose number 27 as a desired maximum for the "esthetics". Which is weird, because models usually goes with whatever maximum you give them. This was a first time I sensed some kind of "free will" coming from the model. Also, it drew the hanning perfectly. Better than I would.
However, when I ran the same prompt on the ChatGPT website, even when using the same model, the output was much worse. Why would that be I dont know. Maybe they limit the thinkning tokens based on current server capabilities?
I hope they don't prompts from LMARENA with higher performance limitations. That woudl ruin the benchmark.
chatgpt free has the lower reasoning effort one
I have plus
oh did u use o3 mini high?
Yes
did u try o3 mini (non-high) too?
No, maybe this is the cause. Will check it 🙂
afaik lm arena has o3 mini medium by default
Perfection of o3-mini-high

it mightve just been a fluke because of sampling
03-mini-medium great too

When trying this on arena now (o3-mini) it returns garbage
There really is a replication problem. Performance is inconsistent.
sampling can do that
Could you define "sampling"?
temperature, top_p, etc
The params are not the same on gpt web and arena?
Or are they trying performance on different params?
even if its the same there's a lot of randomness say with the same setting of temperature 1.0
models arent even deterministic anyway with greedy decoding. with the same seed youll get basically deterministic results (though it depends, and it might not be guaranteed)
I would hope they woul 'set.seed(X)" in the script 😄
rarely anyone uses these models with greedy decoding and specific seed
Still I would expect models to perform slightly worse or better due to randomness and not complete collapse
It can be bought? Or what
he's calling u a gambler
LOL makes sense, yeah i make good $, and if i can snipe those limit orders on top of that that’d be nice
but if anyone knows if there is a way to get quick data when the lb updates lmk
Thoughts on Google Gemma 3?
Will the next multimodal Gemini Flash now be added to the text-to-image leaderboard? Doesn't seem to be in the mix currently
I know, I was joking. It's just used to fade in and out the ends of a signal so there aren't abrupt cutoffs that pollute the spectrum.
"Hamming window" is named after a guy named Hamming. "Hann window" is named after a guy named Hann. "Hanning window" is a (very common) confusion of the two.
I’ll let you know bro 🙏
ty mate
Anyone knows why there is no qwq-32b in the leaderboard?
Usually it takes a bit to get enough votes and data to show up in the leaderboards - should be soon! You can test qwq-32b in the chats and help get it there by voting.
ahhhh i see!
thanks for clarifying / explaining - makes sense now why the LLMs also seemingly get it confused in their explanations of the terminology (but they still know what you mean in the context of the 'window' and task.. most just aren't great at ASCII art .. or get that it's meant to be a bell shape, but instead go for the eaiser - but wrong - triangle shape... ig anyway ha )
and what about claude-3-7-sonnet-thinking ?
how often and when is the leaderboard updated? thanks
same situation, we release to leaderboards as soon as we get enough votes and data. looking like it next week for claude-3-7-sonnet-thinking if the votes come in as expected.
goal is weekly, but may differ depending on how quickly votes and data come in
How is 4.5-preview ranked so high? I've heard a lot of people say that it's bad, is that not the case?
its a good model, but not worth its price as its not that much of an improvement compared to other models. also for coding o3-mini/deepseek is better
sometimes, because gpt4.5 is such a large model, and has a lot of knowledge stored in its weidghts it can find the error in things, that other models sometimes cant find
its also the model which hallucinates the least of all models, simply because a lot of stuff is stored in its weights, such as even all the restaurants of my local place, no other model has that much knowledge stored in its weights
the smaller models can of course use web-search, but that is something different then directly knowing something, which can also be better for explaining things
Is the grok3 on leaderboard thinking model?
I doesn't seem that it is. Are they saving the other one? Or it's one of the code names in testing?
Hello
It’s not a thinking model
The current grok 3 thinking model is called grok 3 thinking beta, it’s not trained as much as they d want, so we ll probably get grok 3 thinking in a few weeks and it ll probably be very good
Was just thinking about this. Maybe we should also consider emoji usage for style control. Some models are notorious for using them more than others.
Oh, and also block quotes.
And would like to know the coefficients of those two factors. 👀
Am I the only one feeling that
Specter is the new Gemini 2.0 flash thinking (experimental) updated by google yesterday
Phantom is the old Gemini 2.0 flash thinking experimental
Just a feeling ... 🥲🥲💔
Phantom is aldo a new model, not old
Phantom have the same problems of the old Gemini thinking while the new version looks improved and have less mistakes and problems but I am not sure just a feeling because when I tried the new Gemini thinking on the app It looks improved. Maybe google wanted to compare between them secretly.
I think the criticism is that it's disappointing, not bad. It's an improvement, but very expensive and not worth it in many cases
hi guys, thanks for this great work! I would like to ask you regarding "early-grok-3" model. Isn't this model in market, is it? As per info in their site it says there is no API yet for grok3. Also I don't find it in OpenRouter or Glama for example. So, my question is how and who are the persons voting (less than 5 thousand) that can say it is good for coding or not? Thanks!

It says it’s deprecated which prolly means it wont show up in the arena anymore
Seems likely the grok3 available on grok.com is the grok3 preview so early grok 3 may just be gone permanently
But it was good at coding, prolly not the best, depends on the task
You usually get more out of reasoning models
You can test them on arena web dev (even if you are 0 at coding like me there are some artifacts that will show you the result of the code 😆😂)
Do you guys think phantom is gemini 2.0 pro thinking?
Interesting how Hunyuan-Turbo is on the leaderboard with only 1473 votes, I thought it had to be over 3k, or did the company request personally?
Is there a benchmark/leaderboard for llms with access to web search?
Does anyone know if the grok answers at the Arena are with Think mode or without?
It is a Gemini thinking but not sure with the "pro"
I think without
I also misread pro, seems more likely to be another iteration of flash thinking
QwQ has a 1312 elo
how are they saying this when gemini flash is right there

you can download the weights at least
same goes for gemma, deepseek, etc
you can run command a more easily than deepseek ig
i guess command a is just the "enterprise" experience
gemma-3-27b being ranked above command-a (111b) seems kinda notable - imo reflects very well on gemma (or poorly on command-a), given the latter has 3 times as many params
thats what happens when you distill from gemini
the base models are very bad though
tbf, command-a does seem 'smarter' (though it guess must lose points to gemma in coding or creative writing or some other tasks i don't prompt for) but only marginly (definitely not 3 times smarter)
it also has a longer a context window, and i believe is optimised for agentic stuff and RAG.. but yeah still..
what i personally found was interesting about gemma 3 outside of the focus on human preference was afaik they revealed what they basically did to gemini 1.5 exp/2 math

I assume "large IT teacher" is a domain-specific LLM (which is 'teaching' the model being distilled i.e. gemma3), right?
oh no its just a gemini 2 instruction tuned either flash or pro
but like couldn't they find (build / tune) a math teacher?
though there is something special about programming language ig - seems LLMs learn and kinda generalise a lot from it
yea but the "solution space" between the math model and the general model may be different. might make be counterintuitive. they will apply rl anyway to increase math scores. (gemini models are basically math reasoning models on math questions)
yes. research has shown that to be true. personally i hypothesize its because its basically cot lol
additionally they do two phases of distillation:
- pretraining (presumably from a gem 2 base model)
- instruction tuning (presumably from a gem 2 instruct model)
unlike regular synthetic datasets, they train it on 256 probabilities from the gem 2 model - effectively copying a lot more of the "solution" better or worse
also comparison between gemma 3 base models and qwen 2.5 (released in september 2024)

ignore the metric column xd (gemini added it without it really matching)
ha yeah indeed - being formulaic / structured and goal-oriented apparently goes a long way. i also read somewhere that the comments in code are part of the magic. like natural language, explaining stuff (like what a particular piece of code is meant to do; how a human would explain that). seems to do something that just dumping reddit posts into a training data can't
i see i see - interesting!
oh i said gem 2 pro but its not known which one they used
i misread/misremembered what they said, its likely pro was the teacher i think


Is this website ranking accurate? Ranking number one is o3 high?

this channel is about lm arena's leaderboard, not any others
that said, artificial analysis benchmarks stem and o3 mini is a good stem model
why do we still not have claude thinking on the leaderboard
The text-to-image has so few models. I wonder why we have so many LLMs but so few text-to-image. Harder to manage data? Harder to train? Less financial incentive?
Looks interesting: https://neurohive.io/en/state-of-the-art/llama-nemotron-nvidia-launches-family-of-open-reasoning-ai-models-overtaking-deepseek-r1/

NVIDIA has announced the open Llama Nemotron family of models with reasoning capabilities, designed to provide a business-ready foundation for creating advanced AI agents.
could be march-chatbot (and with, reasoning enabled, march-chatbot-r) i think
any guess whether o1-pro is on the lmarena now that it has an api thing
how often does the leaderboard typically update?
every week or so
is there a way to find the history of past leaderboards?
check commit history on the huggingface repo
can u link that?
the repo i see
doesn't update for leaderboard updates
just when they change column names and whatnot
https://huggingface.co/spaces/lmarena-ai/chatbot-arena-leaderboard/tree/main look at the leaderboard table csvs, cross reference with commit history if you want to verify dates

Is o1 pro in the arena yet? People are saying it is most advanced open ai model. Curious how much better it is compared to Gpt 4.5..
It’d plausibly be worse but prolly pretty similar
What makes you say that? If it is not better, why is OpenAI charging lot more for it?
most of lm arena isn't hard prompts
if you would please consult the leaderboard

Any info on if it will be ranked?
will we get o1-pro or GPT-4.5 ranked? or is the price gate too high? i did see 4.5-preview in rankings and in cursor
I don't see how Ranking o1-pro would be feasible. If you have to wait 2 minutes for getting an answer most will assume that something is broken and reload the page. Also some speculated that o1-pro is simply o1 but with best of n rating.
what about sonnet thinking?
It's actually already on the leaderboard
Rank #14
Any idea on how does lmarena system identify "hard prompts"? Is it based on token numbers of the prompt or on number of instructions included?
Leaderboard update: claude thinking and nemotron 49b

hi
guys do you know this chat model called nebula on arena ? i cant find any info on it
#1 for hard prompts with Style Control enabled, but also tied with o1, R1, Grok 3 and gpt-4.5 when taking confidence interval into account.
The 49B is on there now
A secret model from google 😁
yeah google is being very secretive about it
Anyone know if any Deep Research models exist in the arena’s Search or just light research ones
HI , How are the new models evaluated? According to the orginal paper https://arxiv.org/pdf/2403.04132 , evaluates preferencing using humans . How is this done for new models, is this also using human preferences? If so which dataset is it usng?
Dataset????
It's an arena
People go to vote every day
How does it work that some models like Nebula aren't on the LB but I get them on battles?
also true for march
What exactly do you mean by how does it work
Well the company has to contact the arena and then it adds them under a psuedonym
So does it scores towards some of the listed models in the leaderboard?
I mean, does the pseudonym I see on the battle have a counterpart on the leaderboard?
What's the point of having an anonymous model if it goes on the leaderboard
My question is basically if there are models taking part on the battle that are not being scored for on the lb because that would not make much sense from what I understood of how the elo system works
No the anonymous model system is typically used for testing early tunes or checkpoints
They can just drop battles that aren't entirely public models
So if a listed model win a battle against a anonymous one how would the elo gain be calculated if the formula takes elo diff into account?
Do you mean when the score is reported?
Well then they include all battles
Not too hard to reason about
I mean that if model A and B present an answer to a series of prompts in a battle and I vote for B
Well nothing immediately happens
The match goes into a DB
B gains elo and A loses elo, but that gain/loss is based on their current elo and how they performed relative to their expected winrate against each other, right?
I understand that the match goes into a dB and LMArena uses Bradley-Terry with bootstrapping to get a closer approximation to models performance on the long run to make it more equitable between models that are newer (w lower vote count) and the ones that already have a lot of votes
But still for it to go into the dB it should be scoring A against B, and the way it is supposed to do it is getting an approximation (through current elo) of how A and B should perform against eachother and then take into account how the result panned out
Yes this is exactly my question. Also model generated output cannot be automatically evaluated unless it is a classification problem
A has a probabilistic chance of winning against B based on their elo diff.
So how can the results of a model be evaluated so qucikly? Unless it is simple classification and not generated long answers which requires human eval for reliable preference judgement
The only way it makes sense is if the pseudonym models are having their elo calculated and updated but just not being openly presented within the leaderboard
How is win determined?
Ah I think I ended up answering my own question lol
Prob they have elo ratings just it's in the shadow. Bummer.
By user vote based on the answer to a prompt in the arena
One prompt, two answers, user picks his favorite answer. Winner increases elo, loser decreases
Is this meme answer or is it actually a Google model? Cause it's really impressive on all answers so far
we think it's gemini 2 pro thinking
yeah I think that's basically how it works / the right way to look at it. In some cases, the anonymous models are very publicly 'unmasked', like when oai disclosed that im-a-good-chatbot was in fact a new version of 4o, or when xAI revealed that sus-column-r was an early version of Grok-2.



though in most cases.. they just come and go.. presumably the voting data goes to the lab responsible for the anon model, but unless it is performant, seems generally they just pull it and move on
like based on this (h/t @hallow comet) nebula is potentially the 38th anon model google has added to the arena.. meta I feel adds anon models just as frequently.. though again, mostly they just come and then quietly go.. ("success has many fathers, but failure is an orphan" kinda thing ha)

yeah google put a lot of models on the arena, quite a lot of them never see the light of day (checkpoints and the likes)
Thank you. So I am actually surprised they are able to obtain human eval (user vote ) so quickly on new models. Wonder what the number of questions and model pair comparison distribution. Cos some folks on reddit are saying that the benchmark is not very reliable and some models are way ahead on the leaderboard but way worse on real world comparison
if youre gonna be a new user at least do your homework
browse the arena a bit
battle yourself
see if you agree with the rankings
The point is model eval is about user vote distribution, extends beyond single user. LLMArena voting and question selection is not very clear when they release scores for new modeld
everything we need is already here
Again, Anyone know if any Deep Research models exist in the arena’s Search or just light research ones
its all light search
of course it is
nobodys waiting 10 minutes for a report
Hi Team, I am using the notebook and how come some judges are predominatly the same person. If it were all live users through the webapp i would expect users (judges) to numbers of votes to fairly uniformly distributed. i am surprised that some users have contributed so many more votes than others

Oh
MUCH longer than I expected it to take
So in the future when Search models are accessible via Direct Chat and Manual Arena, will the deep research models be present?
would be cool if so but i doubt lmsys users will wait that long
why would votes be uniformly distributed
that doesnt make sense
Assuming user behvaiour is very similar, or the other case is normal distribution. The above is long tail distribution, so hence my question..
why would user votes be normally distributed? It's not like people are choosing at random whether to vote every day
Some people are gonna vote more than others and its gonna create fatter tails
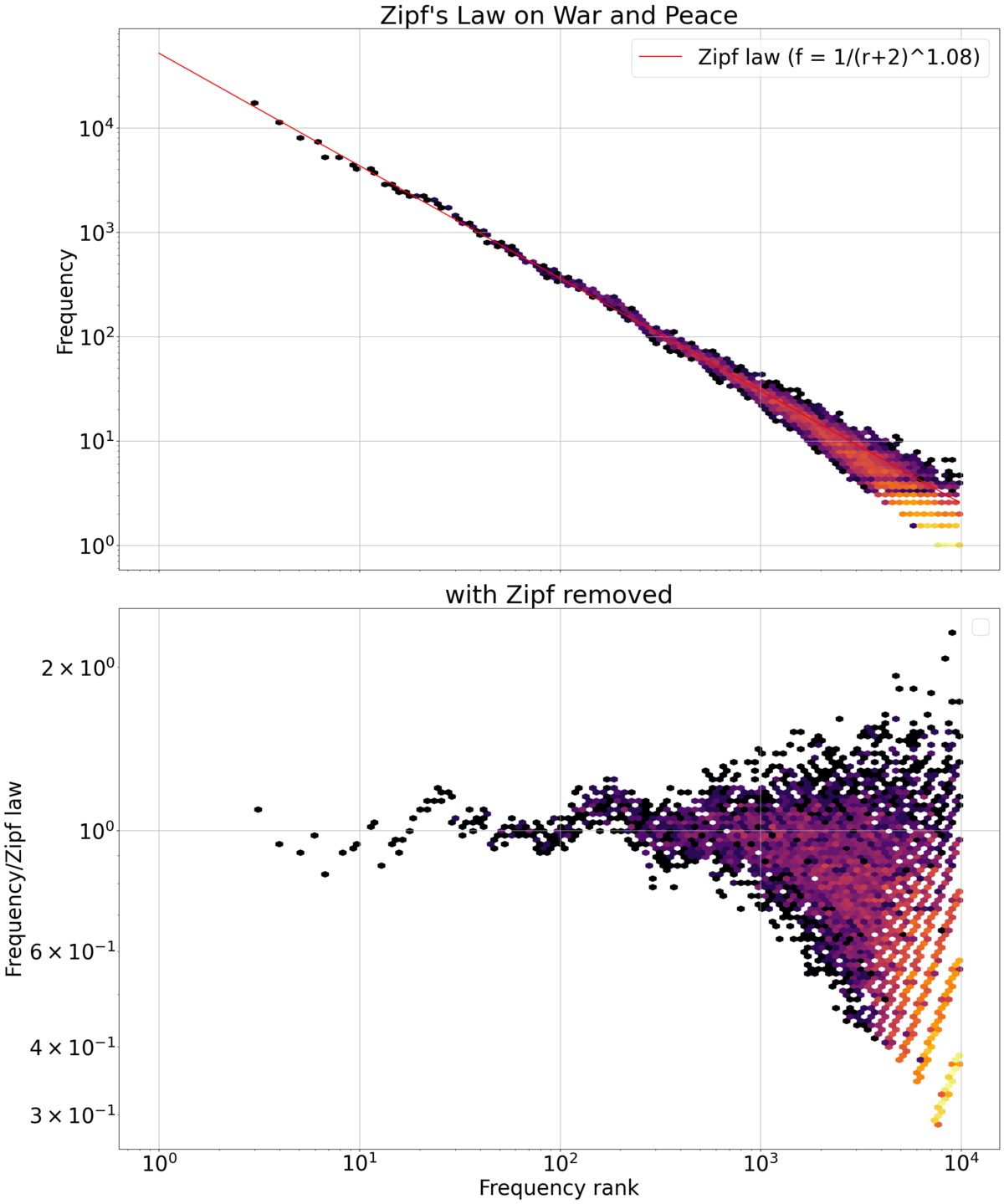
Zipf's law (; German pronunciation: [tsɪpf]) is an empirical law stating that when a list of measured values is sorted in decreasing order, the value of the n-th entry is often approximately inversely proportional to n.
The best known instance of Zipf's law applies to the frequency table of words in a text or corpus of natural language:
...
kinda looks like this to me 🤷♂️
Well there is the issue to broad preferencing for models across the population, if votes are dominated by one user or few users then the results are not representative of the wider population. It is also about the leaderboard design
So you think they should preprocess the data
AT this point, I am trying to understand how the votes are consolidated - trying to get context behind the numbers. But yes, if the vote is dominated by one or few select users then the leaderboard becomes less reliable when it comes to representing human preferences ( how people feel about the model output). If it is only getting experts on the subject matter to vote, then different path and user vote distribution i guess.
worth having a look through their blog (and research papers for that matter), which might shed some light on, if not address entirely, your questions e.g. https://lmsys.org/blog/2024-05-08-llama3/#the-effect-of-overrepresented-prompts-and-judges
not sure if this is still representative of the current pipeline (it's pretty old), but could also be relevant / helpful https://colab.research.google.com/drive/1KdwokPjirkTmpO_P1WByFNFiqxWQquwH#scrollTo=B_PYA7oVyaHO
Where can I see this information?
@crude hawk
@crude hawk Where did you get that screenshot from?
Hello there. I am new here and I just discovered Arena and I am looking for resources to understand the leaderboards a bit better, beyond just the mechanics. For example, I would like to know when and how often it is updated, how is it decided if a model gets a "preview" or not, how many updates a certain model gets, if there's a test in the pipeline etc. Can someone point me in the right direction? Thank you.
From here! #general message
(I'm not the person to ask where / how they found it - honestly no clue other than something to do with the browser console, i assume ha)
does anyone know if the current Deepseek V3 leaderboard listing is for DeepSeek-V3-0324?
or is it the original?
original
thank you! i'm curious if they'll add the newer one anytime soon
gpt-4o-11-20 isn't on the leaderboard, but can be selected as a model to compare and ChatGPT-4o-latest (2024-11-20) is on the deprecated leaderboard. https://github.com/lm-sys/FastChat/issues/3685
GitHub
Why gpt-4o-2024-11-20 not on the latest leaderboard.
Is there a Search leaderboard?
i don't believe yet (still gathering data)
will be interesting to see the leaderboard
In the arena, are models matched against each other randomly, or is there a higher chance of matching models with closer scores? Cause I think the latter makes more sense.
Higher chance of closer scores, but certain models appear in the arena much more frequently, and the pairings are usually more random for those bots
which likely happens because the Elo/strength of such models is much less certain (because it’s new, fewer votes, etc.) , thus they get matches more often to lower the rating spread.
so in conclusion, models with high variance are more likely to be matched in general, but yes, also ones close in Elo
(this is not based off any conclusive evidence, I’m making all of this up)
@west lodge hi, I’m new here and have recently started studying the chatbot arena. I noticed that our LMArena has released multiple datasets, such as Chatbot Arena Conversations (https://huggingface.co/datasets/lmsys/chatbot_arena_conversations), Arena Human Pref-100K (https://huggingface.co/datasets/lmarena-ai/arena-human-preference-100k), and Arena Human Pref-55K (https://huggingface.co/datasets/lmarena-ai/arena-human-preference-55k) on huggingface. But, I also saw that the tutorial notebooks, like the BT model notebook ((https://colab.research.google.com/drive/1KdwokPjirkTmpO_P1WByFNFiqxWQquwH#scrollTo=ViV11W8l9NfL)) and the ELO rating notebook 1 (https://colab.research.google.com/drive/17L9uCiAivzWfzOxo2Tb9RMauT7vS6nVU?usp=sharing#scrollTo=-0rg26TQxFQv), ELO rating notebook 2 (https://colab.research.google.com/drive/1RAWb22-PFNI-X1gPVzc927SGUdfr6nsR?usp=sharing) include a lot of Arena data as well. I’m just curious. are the datasets used in these notebooks new, or do they overlap with the ones we’ve already released on huggingface? what's the relationship between these datasets? Thank you so much! and btw, chatbot arena is really an impactful project for the community.


I got my first answer from "spider".
It was amazing, looked far from anything before
spider feels good fr fr
if you see something like this when doing an arena battle does that mean its real name is hidden?
usually hidden. One time "chocolate" got uploaded to the leaderboard, but then soon replaced by grok 3.
same for neptune or something, that was 4.5, i think
It woud be funny to see models like harry potter or gandalf rocking the #1 place xd
(those aren't in the arena, but were fyi ^^)
is there a historic high elo score over time chart?
the data for each update is available here https://huggingface.co/spaces/lmarena-ai/chatbot-arena-leaderboard/tree/main
i used 4o and o3-mini to provide code to pull and manipulate all the data. haven't crossed checked or anything, but it looks about right to me


(if of any interest, here's the – very messy - collab notebook used https://colab.research.google.com/drive/1eiR0B_8paakgexC1OHvH20H3FeaNVwZh?usp=sharing )
пацаны
дайте топ модель для работы с cline желательно фри
щас юзаю gemini 2 флэш
но у нее иногда такая деменция происходит
что ужас
💀
deepseek-v3-0324:free
that's the problem of all LLMs
IDK, on LMArena spider just wins every round (for me)
Hi, I'm lost, why aren't Baidu models ranked anywhere while they are supposedly kind of good?
Do they fall in a certain category that is not ranked?
Because I want to know how good they really are, I don't trust internal benchmarks
they are not present on LMArena, IDK why
And minimax too ,
I devevopped the stats myself using this notebook https://colab.research.google.com/drive/1KdwokPjirkTmpO_P1WByFNFiqxWQquwH
any idea when we can expect to see the first Search leaderboard @west lodge ?
Hello, I would like to know which model is Stradale in Chatbot Arena. It's not on the leaderboard, and I can't find it either. Thank you very much.
stradale is the name I gave to the model after temporarily conversing and evaluating it in Arena (battle).
This would be interesting to see in terms of open source Vs proprietary
does votes for a model into the webdev arena count towards the general LMarena leaderboard or its 100% segregated?
100% segregated
Any1 has an answer to that please?
can someone explain what exactly is "style control"?
Models need to be submitted by their company to be contending in the arena
I don't think Baidu's models are really good, so they are not on the leaderboards. Apple searched for an AI service for the iPhone in China, but Baidu was out. Finally, Apple chose Alibaba. DeepSeek is out because it does not have enough commercial experience.
without "style control" option nothing is chabged based on style?
the problem is that I barely understand how exactly "style control" check works, and I just want to see leaderboard without it
Oh fair thanks
Hope they do
Yea they're probably not as good as Baidu says, but I believe they're at least top 20-30, which would be great to know, always good to track progression
If they end up being a solid top 15 in the long term run, knowing their starting point would surely be interesting
I wonder what would a llm be if it scores over 1500
Gemini pro 3 or Gemini pro 3.5 😁
llama 4 is now tied for first place with a 1417 elo
that green dot is llama 4 maverick

Why does UB rank show 2 for Llama ?Shouldn't be 1 since elo overlaps with Gemini2.5?
being more accurate than the official leaderboard is a first for me


I dont understand. Where did you get your rank from?
yeah 1439.18 - 10.02 is definitely under 1416.58 + 13.5 so idk whats up
ranking comes from my own math and website
* lmb uses style control by default, turn it off for the mainstream results
Nice. So, take the data from arena repository and calculate the elo/rank yourself?
yup
well i don't calculate the elo, just the rank
i take their elo for granted
(since they stopped publishing the anonymized battle data you need to recalculate elos)
Llama 4 Maverick... Experimental?
yep
actually
mistakes were made...

turns out accidentally shifting the CI down by 0.5% causes problems
HI lov to see new llms and the use of it
So, basically a matter of 1 elo point or 1 CI point...
yeah
for all purposes llama 4 is statistically worse than gemini 2.5
(however - don't forget that gemini 2.5 just has a 53.2% win rate over llama 4)
Back to this topic.
Tested and compared between the Experimental and the full-release Maverick in my native tongue (officially instruction-tuned). Even when I cranked the temperature of Experimental down to zero, it still sounds overly friendly, instead of the much more bearable full-release.
The Experimental should be deprecated at this point, and let people test the full-release herd, so that it won't be misleading.
Trying to plot the Elo of an ideal AGI by using the "both are bad" ratings: https://gist.github.com/endolith/e001d8b7811699cf9be822a774e7cb67

Gist
I tried to plot AGI on the Chatbot Arena Elo scale by comparing to "both bad" and "tie" votes - .gitignore
Trying to plot change in skill over time for API models that are being changed behind the scenes: https://github.com/lm-sys/FastChat/issues/3004
GitHub
For the API-based models, there are frequent claims online that users see models getting worse over time. It would be good to know if that's true. Copying a comment of mine from HF: I know ther...
https://x.com/lmarena_ai/status/1909397817434816562
In addition, we're also adding the HF version of Llama-4-Maverick to Arena, with leaderboard results published shortly. Meta’s interpretation of our policy did not match what we expect from model providers. Meta should have made it clearer that “Llama-4-Maverick-03-26-Experimental” was a customized model to optimize for human preference. As a result of that we are updating our leaderboard policies to reinforce our commitment to fair, reproducible evaluations so this confusion doesn’t occur in the future.
We've seen questions from the community about the latest release of Llama-4 on Arena. To ensure full transparency, we're releasing 2,000+ head-to-head battle results for public review. This includes user prompts, model responses, and user preferences. (link in next tweet)
Early
Meta so desperate
Absolute clowns
We knew something was fishy with so much skepticism the last few days
thanks - glad to see this... was just about to post a rant about how this 'experimental' (i.e. arena/human-preference primed) version violates LMarena's existing policies about stealth models.. like based on their blog post, they can only be unmasked and added to the leaderboard if the unmasked model is made publicly available... which isn't the case with this maverick-experimental thing (aside from Direct Chat in LmArena afaik)
all a bunch of nonsense from meta
did they think noone would notice or something lol

it should be deprecated / removed immediately. this model is not publicly available (and the only place it's 'available online' is LMarena itself via Direct Chat..) and so imo shouldn't have been added to the leaderboard in the first place

grok 3 is now a frontier model without and with style control (if you exclude llama 4) (when prices are mixed 2:1 and are adjusted for thinking)


@glacial glacier whats your data based upon?
the prices are collected manually, i could explain more if i want
the elo scores are direct from arena data
You mean based on your personal battles DB?
no, the elo scores are the general arena scores
Ah, okay. So based on current arena standings
yes
Llama 4 just dropped rating dramatically(Finally the one it deserves)
damn

Is super on reasoning mode on the arena?
also double damn: instruction following + style control:

not sure, but seems a good question. fwiw i think so (based primarily on the LB rank, but also, using it via Direct Chat, there is a) a lag before first token is generated, and; b) it hits its max output well before that limit has been reached in terms of the tokens visible in the UI.. so presumably the rest were used up for thinking/reasoning)
what interface is that?
whoa, that's good
nice @glacial glacier . So many users cry for different default ratings, while they could simply make a new leaderboard like yours
visualize scores "with moats" let me chuckle 😄
would it be possible to select some options and categories in the leaderboard and get a link? In that way discussions online would be easier, rather than saying "go this this page and click this and that"
it would be also cool to see the No. of votes. I know that the CI would tell that, but orderining by No. votes could help too.
but orderining by No. votes could help too
wdym?
resorting the leaderboard by vote count?
What happened to Llama-4? 💀
Amazed chatgpt-4o is even on the leaderboard
so two different llama-4 that presumably differ only in style have 50 Elo difference with style control? Can we think of ways to improve style control so that this difference goes down to negligble one?
yes sometimes I do it to see if a model is relatively new or barely used.
some models are in the middle of the rankings, without great publicity, but they are new as well.
that's an interesting idea... i might implement something similar like a new badge
once new models start to show up they'll get new badges
how much should the link include?
just type, category, and style control?
it would be a start. I also would add moats because it is visually nice.
https://ktibow.github.io/lmb?type=text&category=math&style_control=off&moats=off
but of course it depends on you, at the end it is your time and project.
neat! Thank you! (hopefully lmarena integrates something similar or directly asks you to do the leaderboards)
checking your github. You have a lot of repos and advent of code as well!
gemini 3.0🗿
What's the process for LM Arena adding a new model?
gpt-4.1 on the leaderboard soon?
It isn t just chatGpt4o with some updates?
is there a way to have this https://chromewebstore.google.com/detail/mylmarena/dcmbcmdhllblkndablelimnifmbpimae?authuser=0&hl=en-GB but without browser plugin? That could solve a lot of problems for single users

Track your LLM preferences on LMArena with a personal ELO rating leaderboard.
it does feel like a more efficient 4o. probably a lot cheaper to run (mostly for OpenAI 😉 )
Can't wait to check the score of gpt4.1 and nvidia/Llama-3_1-Nemotron-Ultra-253B-v1, curious on their actual performance.
it would be quite fun to find nvidia version of llama3 surpass the score of llama4
Also I think style control should be enabled by default; that would save the whole llama 4 drama among other benefits
how often are the leaderboard updated?
what is style control?
this might be helpful: https://blog.lmarena.ai/blog/2024/style-control/
they are live, but it takes a certain amount of data to be significant enough to see a change, so you'll notice they generally "change" weekly. happens faster if there is more data.
right they're updated periodically (roughly weekly)?
i know i'm being pedantic.. but that isn't 'live' per se
they are updated like weekly, can confirm.
Why? Because with too few votes the score would be all over the place so they need to accumulate votes and waiting a week is not that bad.
I tried them, and I'd say they are mostly optimized for coding. As general models, for usage in a multitude of broad real world tasks, they don't stand out:
Tested **GPT-4.1 **series:
GPT-4.1 Nano:
Cheap tiny model, roughly comparable to Qwen2.5 14B.
Substantially beaten on price & performance by e.g. Googles flash models.GPT-4.1 Mini:
Versatile fast model, roughly comparable to Gemini 2.0 flash (but more expensive).
Quite a solid coder, and performed on par with the larger model in my STEM segment.**GPT-4.1 **:
"flagship" of the series, roughly as strong Llama 3.3 70B (but weaker STEM) & DeepSeek V3 0324 (but weaker coder).
Behind 7 other OpenAI models in my testing.
The "Maverick" type model of OpenAI.All models are non-reasoning models and not very verbose, when compared to other recent model releases (1.15x / 1.23x / 1-35x token verbosity as size increases in testing).
All models, including Nano, are fairly competent coders! though none excel at my backend testing
None of these were particularly good in my STEM segment.I have also added 0-shot examples for UI impressions and simplistic game design for each model on my shared assets (NOT part of any scoring, just for additional curiosity/comparison).
As always, YMMV!

someone add gpt 1.4
was this already shared? https://huggingface.co/spaces/lmgame/game_arena_bench

Do you have initial estimates for o3 / o4mini? Where do you expect them to land on the leaderboard?
these things.. they take time
is this for https://dubesor.de/benchtable ?
Dubesor LLM Benchmark table - Small-scale manual LLM performance comparison benchmark
Was meta caught in the act gaming the lmarena benchmarks?
Yes
Haha. How did they get caught?
I also thought grok was cheating but didn't say anything
does your expertise in on chain derivatives help you forecast this?
Wait, so were they caught in the act or is it just assumed they were gaming the leaderboards?
it's confirmed
that's why they were removed
well i just got my first head to head of o4 mini and gemini 2.5
who won?
i voted for 4o mini. it was a coding question though
and i think the o models do very well w coding
so not sure that's representative of how it's gonna stack up
o4 mini or 4o mini?
o4 mini my bad
np 🤣 its hella confusing
Yeah o4 mini seems v good for coding, but o3 is a weird model, seems more slanted towards generalization than memorization, maybe because it is supposed to have access to search/tools, also they seem to have more 'personality' than the old o models
So, dragontail/night whisperer are from google and they are better or similar to 2.5 experimental? Thats what the april 22 announcement is, isnt it?
looks like o3-mini-high is still on the leaderboard, looks to be deprecated for o4-mini-high so I think it should be deleted now?
nah. As long as the api endpoint is there it is not deprecated. Like many other models
another request if I may. Add the latest update of the leaderboard (otherwise I tend to check the official leaderboard anyway)
i don't see any updates
I see, so in the data on github there is nothing like "Last updated: 2025-04-09." ?
When will the leaderboard include o3 ?
Hard to say, it is known google will release flash 2.5 , and a coding model. Updated gemini 2.5 too its speculation
which did you gamble on?
o3
why did flash land on the leaderboard so quickly and o3 and o4 mini are still not there
flash was an anonymous model
o3 and o4 mini were just added
thanks for your answer
when was the gemini 4-17 model added to vote on?
its flash model, was under anon name, now its public and directly in leaderboard
i know
but when was the “anon” model added
to the arena for ppl to vote on
ah nvm i thought you meant "could you run the update script again"
uhhhhh
i might skip this one since i can't think of a good place to put it
you can always read https://github.com/KTibow/lmb/commits/main/src/routes/assets/results.json though

GitHub
Language Model Board, a better way to read the LMSYS results - History for src/routes/assets/results.json - KTibow/lmb
also uhhh @twilit echo lmk when you calculate the thinking ratios for gemini 2.5 flash
very close to o4-mini (normal). I'll post my stuff tomorrow, too late rn
edit: actually nvm, since at the time I only looked at usage stats and didn't inspect actual content (which contained some API errors), the ratios are in fact not similar.
Do you guys think o3 > 2.5 ?
yes
i think it depends on the user/task
i almost exclusively use llms for working on a codebase
so my preferences are highly correlated w the swe and coding benchmarks
and the o models do better on those
it’s hard for me to say which will do better in the arena
but my personal preference is oai over gemini
i would be surprised if they are more than 10 apart in elo
guys do you think 2.5 will be the top model on leaderboard on apr 30? say 10am ET? if you could assign % chances to your views that would be helpful. also how often does leaderboard update. thank you
Its 50/50. leaderboard will likely update in the next day or two, id be surprised if it took more. Also as a tip, dont trade manually
thank you. do you think the leaderboard will look different at 12 PM ET on APR 30?
oai is a lock
trust me
as much as i trust a catfish
my few messages from o3 felt a head of everything for like 15-25 rating points
nah, if it wins its with 3 points , 5 max. at least thats how i see it
I added the final ratios to my token rate page
yeah no worries
but then you have it already, one could put the date of the update. Or at least the link. I mean as a user it is nice to have it in the same place. Anyway no worries, mine are just wishes.
Also a pity that localllama blocks github.io links because I think your leaderboard is more shareable and visually intuitive
btw o3 and the new oai models have somewhat limited replies. When I get them in the battle mode with non-trivial questions they are nice answer but pretty concise. So they lose sometimes as other models add details.
when gemini 2.5 was released , it appeared on the leaderboard exactly 1 day and 3h after , for o3 it has been 1 day and 19h and still no leaderboard :/
the leaderboard is just a marketing tool nowadays and doesn't represent real life, so who cares. Whether its #1 by a huge margin or #35 makes no difference anyway, the former just means they gamed better.
the leaderboard is my favorite way to check the status of AI
"so who cares. Whether its #1 by a huge margin or #35" -> my portfolio
i think it was being tested under a different name for longer than a day
huh , but even flash 2.5 got in the leaderboard so quick.
when do you think o3 will be there
flash 2.5 was being tested under a different name as well... it was probably dragontail.
There were many google models introduced in last month. So, not sure which one was flash.
I would be surprised if it does not show up in next 5 days. If more people test it on arena, faster it will show up.
Although since o3 is expensive, I dont know if arena has resources to test it often like o4-mini...
But dont side by side votes count ?
Ive tried 10 questions myself with o3 and gemini, no problems so far
Yes, that should count. Do that 2000 times and you will see them on leaderboard tomorrow 😅 Side by side votes do not count
what do you notice btw? o3 is clearly better or similar to gemini?
o3 is better and similar
Side by side votes do not count. Only battle mode votes because they are not anonymous in side by side votes...
bro was tying to rig it in his favor
o3 better, not by much
nah i assumed they had measures
Still you can rig it , cause its easy to detect to which llm the output belongs to. For instance just asking what llm they are , and they would say openai or google. But way too much effort
they claim they exclude responses where the model reveals itself
still you can detect even if they dont reveal, but again , too much effort.
true, their style is very different. chatgpt is probably the easiest to spot id say
but if there is rigging happening, id say for sure its on the side of gemini
no, because ive seen a lot of google shilling happening, and google also promoted that they were nr 1 in this arena (which they can also optimise for) , maybe rig, maybe bias call it what you want
theres one dude betting $14k against openai and $22k on gemini. he sure thinks google is going to win
thats actually somewhat more in favor to openai as to what the market thinks. hes saying 38% chance for openai 62% for gemini , market is 28% for openai atm
just gonna go all-in on the top placer the second the leaderboard updates with o4-mini and o3 (hopefully at the same time)
Since I am not interrested to codes and maths , I don t like those O3 ,,, just trush
Can t comprae it to Gemini
what do you use them for? I think it is better at almost everything
o3
except creative stuff which I havent tested
its formatting is a little odd though, this might be a problem
Since I am a medical student and I am preparing for exams I asked them for some tricks to memorize diffrent name of drugs and the doses and link the names and doses to something known and logic , No open ai model get it but Gemini models are perfect and deepSeek is next to Gemini ,,,, they are just Wow ...if those models are trully reasoning why failing a taks like that ?!!
Which free large language model is best for the summarizing of YouTube videos?I'm confused between Gemini 2.0 Flash and Gemini 2.5 Flash Preview 04-17 because they differ in tokens per minute
summarizing actual videos or the transcript? if actual video, then you will need 2.5 pro
if not then id use 2.5 flash
ive used 2.0 flash but it is kind of bad with timestamps, ok at summarizing
Id use 2.5 pro, its great at that
disagree
sometimes models are announced when they are made public in lmarena. Some other times they are announced before. Unless you want nonsense voting, one has to wait that models gain enough votes to have a reliable score. What difference 1 week makes in 99,999999 % of the cases? none.
For this I strongly think that lmarena represent closely average chatbot.
They don't represent api calls, that yes. For that we have openrouter rankings.
25% true. I know there are undervalued models, but not by that big a margin
how is the score decided for the leaderboard?
blind voting in battle mode
intelligence race and who has better model are two different things
my guess is that google and openai have achieved agi internally and are looking to control it (OpenAI researcher)

that is why i said intelligence race, also do you have sth to back your guess up?
yes, basic logic, but no proof.
can you explain the logic?
why would they have agi internally?
they have the compute for 10x more powerful models
but they havent published nor reported to have trained such models
Which means, A they havent done so for whatever reason
or B they have and they are hiding it
Option B is very much the more likely for me. Powerful AI would automate jobs, automated jobs lead to protests and revolts, the last thing billionaires want (like those backing google and openai)
i think sam said recently that not compute is the issue anymore but running out of good data or sth
it could simply be that we dont scale as we would like
bro trades prediction markets and has crazy conspiracy theories.....
🤣
so billionaires behind these companies are telling us the whole truth ? thats a strong stance to take 🤣
do you think that every single employee at openai is just keeping their mouth shut about some AGI model?
every single one (even those that quit)
and that the billionaires behind openai wouldn't stand to gain so much more from releasing it
there are also a ton of independent companies all working on this so your logic would have to apply to them too
automating jobs does not lead to protests and revolts. extreme poverty does
are you saying no one will have a job at all because of AI>
some billionair who is concerned about riots wouldn't have to worry about riots if they had the first company to make AGI. they would become a multi trillionaire
AGI is nothing short of a manhattan like project where everything is at stake, so its very clear there would be measures, first one that comes to mind is restricted access, and nda forms. You talk you lose everything and no one would believe you without proof.
other independent companies dont have google and openai resources
no1 would have a job cause of ai -> almost, very few people would be needed
making AGI = rich , yes, but publishing it and automating jobs collapses the system. so they are developing it, but quietly
I believe that but I am enjoying the chatbots 😆🙃
then why didn't they release a chatbot that gets how many 'r's in the word strawberry correctly until recently?
Polymarket is really a bad thing for Lmarena.
I can spot super easily if a model is OpenAI or Gemini on first sight after any prompt.
You just need a few people to massively play on lmarena to make one or the other win all the time and you can rig the results...
You put 10 people right now and make them prompt for 10 hours a day, you can really rig o4 scores and make it look like trash by the end of the month.
true maybe the team is handling that. maybe they did before poly too, to avoid biased reviews. its not too hard, just removing the 20-30% of user votes that are on either extreme (very pro o3 or very pro 2.5) would give better estimates.
yeah, that was mentioned to some extent in the original paper
it has safeguards, I looked into it awhile ago
It wouldn t give also be a solutions. For example, if I always vote to a model that s because I know it deserve it or I always don T vote to a model it os because it is a real trush ... Removing my votes will make me so uncomfort and I will stop voting 4ever ...
Just check the promt and the result or you can make a review button ... If the user gave you why he voted like that even if i vote 1000 times you musn t change the result !!!!
there’s not enough money in the market to make it worth it
100 man hours
for that
counterpoint

there are people who have bet 20k and stand to win 5x if openai (or gemini) wins. thats 80k profit. Sure that is not enough to rig or bribe ? I hope not but idk
poll_question_text
who is currently leading the intelligence race in your opinion?
victor_answer_votes
7
total_votes
18
some bets on polymarket are not serious at all, you can literally bet on jesus coming back to earth in 2025
these ai bets are kinda like a joke
and enables some rather uneducated ppl to bet their money and lose it
and yeah, the ai bet markets are not really liquid either
What bro tells me after losing a $10 parlay
lmao thats actually a legit market xDD
Just like shitcoins, you put money on it, you bet some people will invest in it and you'll be able to sell your shares at a higher price than you bought it
and educated ppl to react quick to news and win $
Don't know why this message was rejected by the system, probably a banned word

that is true but that account would likely get flagged
Yeah and then they install Tuxler which has undetectable residential IPs for free and switch at every round.
i imagine its way more ez for a whale that bets 20k , to pay 5-10k on supporting lmarena and so getting to know what goes on .. early. ez 3x
they could do that, but lmarena can still filter to only include people who have been around long enough not new ones
if theres huge difference between new peoples voting and people who have been around for 2+ years then thats clear rigging indicator
Hopefully...
Yeah still could go that way, or whale bribe way .. thats why you never bet early, you must be the first to react
The only time to bet before news is if you know the news before the news is public 😅
it go down so fast 😭

I like the change of the color for "new". more distinguishable
also did the order of the categories on LMB change? My preferred one are easier to reach.
When will o3 and o4-mini be put on the leaderboard?
Does it matter so much if its today, 30th of April or May 1st ?
they are being tested, as long as not enough votes are there, it is not good to show their scores. Just wait a bit. Why are people so impatient for something absolutely not life changing.
I think its a sign people trust the Arena and are excited
polymarket bets
some people are betting on it
well people can bet on everything, then everything becomes life changing. I don't think is an argument.
We're just explaining why we think they're doing it, not saying they should
nope, it's been the same since the start
hello
Llama 4 maverick was rated ~1400 on launch and now it is 1271. Is it just due to error margin or something else
long story - meta tried to cheat the benchmark by using a model specifically optimized to do well on lmarena, and then lmsys forced them to use their publicly-released model instead
you have a point
to add the "do well on lmarena" means "make the output more enjoyable for humans". Thus emojii, structured formatting and so on. I still think that that version is used in meta services (like whatsapp)
i hate that formatting because they like putting 5 newlines after each sentence
and they love bullet points as everyone knows which is usually not the best way to format
yeah it introduces incentives among all sorts of actors who have no stake in the actual performance of a model (like i've always thought major labs wouldn't waste their time trying to rig the votes, because the performance of their models in the wild will always ultimately speak for themselves.. even if they generate initial 'hype', the net result after being found out is likely to be negative [see Meta's llama4 maverick-arena-version fallout.. they ofc didn't manipulate votes .. but just released a model specifically juiced for the arena.. and it's been a disaster for them and the model release imo]
but betting markets and a crowd-sourced ranking project to my mind do not make a healthy mix .. there will invariably be those who at least consider ways to manipulate the system, if not have a go... it's like the inherent nature of betting...
doesn't bother me that people bet on the leaderboard - why not (and it does kinda seem illiquid anyway).. but it's not really an ideal situation in terms of the integrity of the voting system.. i dunno if LMarena asking polymarkt not to provide coverage would be possible / worthwhile.. ig if there's enough interest, the market would just be created / facilitated elsewhere.. be a game of whack-a-mole
how come there are 4 models at rank 2 even if they have different arena scores?
theyre within margin of error
what's the margin
for the graph at the end of the rankings on your site, would it be possible to add the pareto line? If it is too much work then no worries
something like this

let’s say there’s some probability p1 of someone gaming the system in favor of oai, and there’s some other probability, p2, of someone gaming it in favor of gemini, unless there is a substantial difference between p1 and p2 then it just introduces additional variance and doesn’t change the EV for ppl wagering on the markets
so it’s w/e
but like adverse selection is part of every single market
u think ppl don’t know earnings reports before they’re released to the public?
do u think that the ppl running lmarena aren’t telling their friends which model “looks promising”?
million ways to get an edge in any market
if you’re trading it you’re willing accepting the risk your bet doesn’t play out
no crying in the casino
also if u think someone is doing this for just one model (but u don’t know which) then the fair value for the two models is just 50% and there’s some serious EV to be made rn
it's hard to get right
i've tried before but probably won't implement anytime soon
that seems highly idealised..based on purely hypothetical / arbitrary assumptions rather than anything empirical.. like i don't get why such an equilibrium would be the natural end state of any and all attempted manipulation/s..
i mean what if there is a substantial difference between p1 and p2? what if there's no p2 at all? the underlying assumptions seems purely abritrary
you’re assuming there is a p1 and no p2
seems arbitrary
what?
i'm responding to your post
let’s say there’s some probability p1 of someone gaming the system in favor of oai, and there’s some other probability, p2, of someone gaming it in favor of gemini
nevermind i thought u were the person who said someone could rig
either way it’s kinda silly when ppl freak out about this cuz like
there’s information asymmetry in every market
and if u think it’s worse here
then don’t trade
no crying in the casino
discussing it ≠ freaking out..
obviously..
but not all markets are the same...
rigging LMArena leaderboard would be easier than say rigging the result of the SuperBowl or a US pres election
LMarena staff telling their buddies stuff in advance who then use that info to bet on polymarket would be something resembling insider trading - not market manipulation
crowd sourced anything is inherently vulnerable... doesn't mean the arena is being rigged (i don't think it is) - but the idea that 'well, there'd be multiple manipulators and it'd all just net out anyway so what's it matter' just seems kinda naive
yeah but LMArena isn't a casino
no one is complaining about losing money lol
i think you're missing the point (like i said, it doesn't bother me at all that people are betting on the leaderboard – i gamble all the time, on stocks, horse racing, roulette; whatever), i just find the fact that they are able to problematic in terms of introducing incentives that otherwise would not exist for actors to attempt to manipulate the leaderboard
they could just make it so you need to make an lmarena account
that way if there’s ever any funny business
they know who to go after
Actually the issue with gaming with Gemini is that it is wayyyy harder, because there are already 9000 votes.
With OpenAI's new models, usually for the first update on leaderboard, there are like 3-4k votes. So you're making a difference that can make it not be rank one with only 200 votes. That's how flawed it is.
And Gemini 2.5 Pro-exp isn't going through hard testing on lmarena right now so it's harder to find this one in particular
Good enough
are you guys suggesting that this rigging is happening right now? or that it’s only a matter of time? because current leaderboard scores are pretty well-aligned with benchmark results and user sentiment.
a baseline “vibe” that the arena is being gamed is not conclusive. there’s literally zero evidence to prove it.
also, yes you’re absolutely correct that it is extremely easy to rig, but on the same token, users have been very quick to detect BS’ed scores. Look at Maverick 4, for example.
Though, to give yall credit, the absence of evidence is not the evidence of absence. it’s definitely POSSIBLE that this is happening.
I think its pretty unlikely the leaderboard is currently being rigged and I actually concluded that rigging the lmarena leaderboard is a more diffiicult way to market manipulate than some other things you could do.
You'd think this would protect the integrity of the leaderboard but the main thing is that its not a particularly clever to rig it. Every degen and their mom has realized that its possible someone could try.
what are some other things one could do?
(asking for a friend)
April 30 at 11 AM
“what are some other things one could do?”

Any plan for a leaderboard for video generation models?
you added the date of the introduction of the model. neat!
yeah - come to think of it, I can imagine a few really fun ones
i think that, with the level of sophistication required to actually rig the arena without being found out, you'd probably realize as much
is it against PMs rules?
against kalshi rules but not polymarket rules. I'm also really doubt this is happening
arent they still useless?
the point of PM is information gathering in first place, TBH I am not sure that such actions should be forbidden
i think a credible fear of insider trading results in worse predictions overall
kalshi also markets itself as a securities trading platform so from that perspective insider trading is very bad
if someone literally changes the result then yes but if somebody just knows the result in advance then I think it can be OK
eh? i mean LMarena staff could just bet on it themselves if they were willing to do that (tip off mates)
if either are acceptable... literally what would be the point of the market
from a market structure perspective nobody's gonna trade on a market where theres a chance that someone has the answer beforehand
yeah exactly
so the forecasts will just get worse and worse over time
what does it really change? if I am right that Gemini will be #1 I am right no matter who knows what
if you literally know that gemini will be #1 because you are the one compiling the leaderboard
that's not an information asymetery
it's a totally broken market
the whole idea behind prediction markets is that there is a financial incentive to make good predictions. liquid markets result in better predictions since the financial incentive is stronger
I can't get it TBH
if you know you will trade against someone who has the answer you cannot make money
so people will just stop trading the market
yeah that sounds like a natural law of economics to me ha
when you're predicting you're not competing with others, only with real world, I can't get it
what exactly?
if you know you will trade against someone who has the answer you cannot make money
so people will just stop trading the market
dont get what you're saying here
what does it mean to be 'competing with the real world'
your predictions doesn't depend on others'
the odds that you get for it do
they do lol
you're trading against real other people
if i know the answer and buy 50% of the open interest on a strike who do you think that money i win will come from
how? you're making a prediction, you calculate probability, not someone else
say i forecast the odds of gemini winning to be 70% and openAI to be 30%
someone with a large bankroll who knows the answer buys openAI to 40%
what trade do i do
this is not only trading, smartcontract(s) with the oracle do the thing
WDYM?
i feel like you dont understand the basics of prediction markets
guys I am sorry but you didnt provide a single argument
not gonna keep arguing we can just agree to disagree on this
fwiw some people do share your opinion
so no arguments?
yes you won the argument
we're going round in circles.. here's sonn3.7's take:

you are so smart
i wish i could win arguments like you
please let me know what trades you make next time so i can trade accordingly
if you're wrong at predictions you lose thats right, but it doesnt mean what you will quit because how do you know you wrong?
trolling sarcasm doesnt make you smart either and is destructive for the discussion
why do you think i’m trolling
i am very dumb
i need advice from you to make my next trade
please let me know what you want to trade next
anyway banning someone at predicting because he knows answer too well is.. just strange given that the goal is gathering information, not gambling between people who doesnt know anything
So, you are saying insider trading should be legal?
do you think it should be legal to give one person at the table for online poker ability to see all the cards?
in case of predictions markets where goal is clearly information gathering, why not
anyway amount of information what people have is unequal. it is not a prediction competition where every participant have equal information
do you think it should be legal to write senseless messages on online communication platforms?
i am ESL
is there a problem with my grammar
the goal is not to define who is the best
If you want prediction markets without these rules, I am sure you will find markets for them. Companies which have these rules do this because it gives them better business from more markets and higher volume.
i feel like you are just making really big claims about how prediction markets work but aren't very inexperienced with them
It’s so much harder to argue with a dumb person 😂
i don't think they're dumb though
i feel like its just a very nuanced and random thing
Very confidently incorrect
No, for most people, it’s very clear why it’s not ethical to insider trade
this wasnt a discussion on ethics though...
yeah, probably bad word choice. i mean, though, it’s obvious why it’s wrong, unfair
i felt like this was only a discussion about whether it results in better/worse predictions
i also dont think the answer is obvious a lot of people disagree on it
there are any serious and active prediction markets other than PM? PM doesn't have these rules, does it?
why do you speak so confidently about these things lol
you don't even know kalshi exists?
if someone does know the answer in advance and vote for it, it can only improve predictions overall, am I wrong?
available only for U.S. residents.
im aware
it is a 'serious and active prediction market'
i'd also argue and prediction market where you trade real money is serious
im not sure why residency requirements make a pm less 'serious or active'
You are assuming that allowing insider trades does not affect market and volume. If I know that insiders can buy up orders as soon as they get information, I am not going to place any order. If there are no orders, then there is no opportunity for insiders. So, it basically kills the markets even for insiders.
Your argument works only when people dont know that there are insiders. Then, insiders will bring markets to correct values sooner than otherwise. If people know i.e., insider trading is legal --> no volume --> no trading, not even insider trading --> wrong predictions.
Trust me, big players on prediction markets dont gamble. They trade because they think they have an edge. If they know that they dont i.e., only gamblers are left in the market. Which does not help predictions.
So, if you want accurate predictions, you increase the publicity of prediction markets and make them popular or competitive. Not by outright legalizing insider trading which basically kills the markets.
idk man dinahu seemed like he was very educated on the subject
are you sure you want to take an opposing take?
seems unwise to oppose someone so smart
yeah.. i mean.. it's not a prediction market if a participant (either directly on indrectly) has literally perfect information about the thing on which everyone else is speculating/gambling (e.g. which model will be number on the leaderboard after the next update).. they aren't predicting anything if they quite literally know with 100% certainty what the outcome will be
[it is a prediction market if individuals with such perfect information do not use it or disclose it to others - then it's a fair playing field. but it's basicallly an honour system as far as i can tell lol.. or at least it's not in LMsys' interests to exploit their info advantage - because the moment they were found out to be doing so, their and the Arena's integrity collapses]
tbh i don't really get the nuance here... i feel like i'm missing something if that's the case ha
i'm surprised r1 has held up this well
lol are people really this dumb
the LMArena leaderboard isn't like the weather, or the outcome of a sporting game or election
if some pollster has info not publically released, they can use that to bet on the outcome of a particular election. they have an info advantage (as an 'insider' of a polling company company), but they don't know the literal outcome of the election; and so yeah, it theoretically leads to a more accurate prediction market
a boxer's trainer might no that they are injured before a bout, and use that info to place a bet (e.g. that the boxer will lose); the 'insider' has privledged info but again, they don't actually know what the outcome will be for certain.. so sure.. more accurate accurate prediction market yadada
but the #1 spot on the LMArena leaderboard is straight-up known by insiders before an update is actually published.. they don't have an info advantage; they literally know actual outcome, on which people are betting, before it is released public..
how that difference and the problems it potentially entails is not blindingly obvious is beyond baffling
hi
Guys stop yapping ong
At this point they should just rename this to #gambling
it's not gambling when i know i'm gonna win
becuase the mods tell me in advance
well ig for all of y'all plebs it is
nevermind
have you even said thank you
can we move the polymarket discussion elsewhere?
Besides the discussion, will there be a leaderboard update today/tomorrow?
Hey guys, I am working on a model recommending system and I would love to use the lmarena leaderboard as source to base the recommendations on. For now the way I go about it is simply downloading this dataset maintained by someone:
https://huggingface.co/datasets/mathewhe/chatbot-arena-elo
And filter within that dataset. But this is just for the LLMs.
Is there any intent to create an API for the leaderboard? Or something similar with which I can easily access the leaderboard data in my applications?

you could write something similar to this script https://github.com/KTibow/lmb/blob/main/handling/convert_pickle.py
GitHub
Language Model Board, a better way to read the LMSYS results - KTibow/lmb
Thanks for sharing! I do feel like its still a bit sub-optimal though..
wouldn't that be "prompt to leaderboard" ?

GitHub
Prompt-to-Leaderboard. Contribute to lmarena/p2l development by creating an account on GitHub.
Hey Hi
I am from BharatGen we had builded our own llm with indic nuance
May I know how we can integrate our model api in chatbot arena to get better comparison
arXiv.org
Measuring progress is fundamental to the advancement of any scientific field. As benchmarks play an increasingly central role, they also grow more susceptible to distortion. Chatbot Arena has emerged as the go-to leaderboard for ranking the most capable AI systems. Yet, in this work we identify systematic issues that have resulted in a distorted...
see here #arena-feedback message
But that doesnt show the leaderboard no?
Is there a way to find old leaderboards? For example the leaderboard on the 14th of April
it does for every type of prompt
Is it legit? Looks cool
well when they tested it, it was legit. For me the p2l model (simply picked the best model that thought was going to answer your question) never lost in my cases.
The only drawback is that they have to compute the p2l every now and then. Last time was in January I think.
https://github.com/nakasyou/lmarena-history maybe this will help

GitHub
The history of scores on lmarena.ai saved as JSON. - nakasyou/lmarena-history
was nvidia nemotron 253B tested via lmarena? I cannot remember its score
i actually recently reran the lmb data fetcher on historical data, seems it was removed but when it was tested it got around 1221 elo

Ah, so if its very outdated then its not that useful no? What is the reason it gets updated with such infrequency?
ty! I wonder if the "v1" has any meaning. 1221 seems very low
lmarena people have only so much time to dedicate to many todos. No if it is outdated is not that useful. In general one can argue so: even if an existing solution exists, you never know if it stops being available anytime soon. In the past there was the idea that "internet never forgets" but time has shown that it does or some services become less user friendly.
so yeah if you want to go at it, go for it. My initial objection was only to understand if the prompt to leaderboard was the same thing you wanted to do
Well not exactly, but I do like your suggestion very much (if it has some value for live recommendation)
I get that, and its not a flack to the lmarena people. What I mean is that it sounds like keeping this updated is very automatable. But I guess my assumptions are wrong?
wdym by built your own llm
😂
Chatgpt with fancy layers
according to 5 minutes of research, bharatgen is a legitimate government funded indian startup
also according to 5 minutes of research, i cannot find any info on the llm itself, only the organization
the p2l is automated for sure, but I guess they cannot run all the script they can. Already checking the leaderboard - classifying the battles - is surely compute intensive.
Imagine every week they have X thousands new battles that have to be classified, rejected (if something is obvious) and then evaluated. In the past, if I am not wrong, they used a llama model for classification. I am not sure if it is still the same. Still it takes compute to go through all that, plus manual checks. I think the lmarena team is small.
now, what could "indic nuance" mean
context for anyone joining in: https://bharatgen.tech/
$30M (equivalent) in funding, not too shabby
indian subtext
Hello guys , May I know When will the leaderboard be updated again?
that's because the ratio of people who ask that question that are here for the money vs that aren't is significant
HAHAH because we've seen the same pattern for months, its very obvious.
Or...
He is just curious about where QWEN or other releases get placed on the leaderboard
The polymarket bet ends every end of the month...
Stop being toxic

and starts again every new month
what money
there is a popular bet on which company will have the #1 model on lmarena
whos reading for grok 3.5 to break the leaderboard
Grok 3.5 will be just below chatgpt 4o
rightt
someone compiled and calculated glicko ratings using 28 benchmark scores
https://nitter.net/scaling01/status/1919389344617414824

(where glicko is elo with uncertainty taken into account)
What is the reason that a model like gemma 3-4b can be one place below claude 3.5 sonnet?
I have used a lot of small models, and I have never seen any that can consistently produce quality answers

because style is king in lmarena, and claude family generates no-fluff answers by default, whereas other models do not. This heavily influences match outcomes. as you can see, with style control the gap grows from 1 rank to 40 rank difference. The default ranking is kinda meaningless, because of this.
even so, 40 ranks is still very little considering the models are worlds apart in capability (obviously, since it's 4B..) for reference here is my own comparison (no censor):

Where can I read up on how this style controle measurement is used?
I think combining multiple (relatively notable) benchmarks is a good idea.
@glacial glacier would it be possible for you to add the history of the score of a model? I know it is asking for quite some work and I know that models with small CI change their values slowly, but still it would be interesting to know.
Another one would be to check the changes in the amount of votes (if those are reported in the stats distributed via github). One could see if a model, despite being not yet deprecated, practically stops getting votes (without votes: no further rating or CI change).
Would you mind filling out the feedback form? That’d be helpful, let me know if you need that link
New Gemini 2 Flash image generation is legit more expensive than Imagen 3 002 🤡
I sent a lot of feedback but my request was for this https://ktibow.github.io/lmb/ leaderboard (made by @glacial glacier ) that is not bad at all.
I didn't ask the lmarena team to do the same improvements because I think they have too much on their plate already.
if needed I can request the same for the official leaderboard but I won't expect changes because the team is surely super busy
understood, thanks for explaining 👍
interesting... are both of these to accomplish the same goal (understanding when a model stops changing) or no?
no, the model should stay (allegedly) the same. Rather the rating should change (if at all) because other models change or the judger change (different questions, different judgments).
The score history is what is most interesting. The vote history (or CI history, though the latter is a bit more cryptic) is interesting to see because it tells whether the score is really stable, despite further battles, or it is stable because mostly no battles happens.
For example I am pretty sure many models, though listed, are receiving very few battles.
sorry i meant "understanding when a model stops getting battles / moving around on the leaderboard"
is it OK what I in 50%+ cases judge LLM by first 100-200 characters of response and didn't read the rest when start is bad to me?
no
🤔 the number of votes achieve what you say (stop getting battles). The rating history shows how the "playerbase" changes. Even with the BT model over Elo (or any Elo variants), over time a model can be "farmed" so to speak - provided that it gets battles. Or a model can still hold pretty well (claude 3.5 from Oct 24) . Sure the rating can move slowly (within the expected CI) but can move nonetheless as the playerbase and votes get in. Because people voting change their judgment and question get different.
ah
well voting history would require a good bit of effort and i don't know if it would quite work as intended if there's general elo drift
yeah no worries, I throw ideas because I like your leaderboard a lot, but you don't have to implement them
Is there any information regarding the Qwen3 32B model? I think it's more commonly use than those MoE models, since MoE = Memory Overconsumption Ensemble in practice.
how could we add new models to the LMArena leaderboard?
what is this leaderboard?!

where's gpt-4o-2024-11-20?
why is gemini flash down there?
and also having a wide CI is giving it an advantage here
maybe deprecated and gemini flash getting more votes (that pulls it down?)
Hello everyone I'm new here; I'm wondering can I push my own fine-tuned model to the Chatbot Arena to let the users blindly test it with other models? Thanks!
You’re unable to push your own model to the arena; however, tell us about it in #1372229840131985540
fwiw i gave it to o3 on chatgpt and i think this part of its response perhaps explains it?

but yeah the ranking in the ss you shareed seems counterintuitive.. i assume there;s methodological explanation.. o3's seems convincing but eh i dunoo
🤔
Aloha hi, I am sorry if this is already documented somewhere; I am responsible at my company for compiling a list of models that our product can run, and I thought it would be nice if I could query the contents of the Leaderboard via an API, rather than picking through the list on a browser and copying and pasting.
Is the data that populates the current leaderboard available via an API, or an export of that data available as a flat-file in some manner?
Hi 🫡
Hi everyone, I'm newcomer, how could we push our company's model to the Chatbot Arena? Thanks !
hey there  at the moment the best course is to put information about your model in the #1372229840131985540 channel.
at the moment the best course is to put information about your model in the #1372229840131985540 channel.
Hi🤗 , I have put the model information in the model-request channel, could you please have a look and if there are more details needed?
how to join?
are you asking how you have a model apart of LMArena?
hi
hello
Hello Guys, Found this website through YT video... Hope to learn something more in AI Universe 😉
Ping on this? Given that MLperf releases their data under Tableau, I'm hoping this isn't an unreasonable ask. Right now, the site uses CloudFlare Captcha to prevent screen-scraping, which I respect. But it feels like making a limited set of data available would prevent people from either trying to circumvent captcha and/or copying and pasting a bunch of data by hand.
ah sorry about missing your initial question! I'll get back to you shortly!
Apologies for the delayed response. Unfortunately, at the moment this isn't available.
Would it be worthwhile for me to create a GitHub issue requesting?
I've passed this request to the team.
Cool thank you. I created a GH issue in the interim anyways, if it would make sense to track there: https://github.com/lm-sys/FastChat/issues/3730

GitHub
I asked on the Discord, and I believe that this isn't available today. If I am wrong, happy if you can direct me to the source. At my company, I am responsible for compiling a list of (non-prop...
Thank you!
One last thing, just to hopefully make this as innocently lightweight as possible, I added this to the issue description:
I think what I am asking is that the leaderboard-table-file (gradio_web_server_multi.py#L337) (docs) is copied to an S3 bucket, or even just served raw via the site's http server (sans captcha, please), so that we can look at the raw data.
The more detail/pinpoint request provided does help, thank you!
maybe with the upcoming sentiment control claude 4 opus might actually be #1
until gemini deepthink atleast
idk is it nice to talk to?
When will the leaderboard update next? like with the scores of new claude 4 models?
Why isn't claude 4 into the leaderboard?

Is there a channel to suggest improvements to the existing benchmarks?
yeah absolutely! using #1372230675914031105 would be ideal 👍
Thank you
Hi, when do the leaderboards update usually?
it's not on a set schedule and we don't rly disclose when it will be; however, the leaderboards will say the last time they have been updated.
Gm ser
I sent you a proposal in DM, kindly check.
Would have love to open a support ticket but couldn’t find any.
yes i am also curious. i am also wondering if someone could give a probability of it surpassing 2.5 pro by the end of may
lol
fellow polymarket trader 💀
In my own LMArena stats Sonnet 4 does worse than 3.7.
Curios where it ends up on the public leaderboard.
It is really just optimised for the agentic coding workflow huh?
Opus does well for me tho. I like how it is efficient with tokens.
Very unlikely because it's only arguably stronger in coding and weaker in everything else
I hope the old website can last longer, or at least remain accessible as a legacy URL after the update, as tools like p2l and arena explorer on it have not been fully replicated on the beta website yet
when is the leader updating to show sonnet 4?
in randint(1,5) days
I am keeping track of the results to my questions since early May. Sonnet, no matter the questions, loses every time as soon as I ask something that is not about coding or computer configuration. Now I see why it is that low in the rankings.
What is the "Arena Overview" leaderboard? Is it the same as the text leaderboard (with style control)?
@indigo cliff Yes. If you mean here and the default is now Style controlled.

I mean the one at the bottom of the page. Is it influenced by webdev, vision, search, copilot, and text-to-image? or is it just the text? By looking at the page one would think its a combination of all the leaderboards above, but that doesn't seem to be the case.
@indigo cliff yes it is also just the Text, just split in the different categories.
It is just the overview you also have in old one but worse because you can't switch to the ELO points. The new design looks better but hopefully all the functionality will also come back.
I see, thanks
Hi just saw the X post for the Claude 4 update but the site doesnt show it?
currently looking into, ty for the flag!
also are we only getting WebDev results and not for any other?