#general
1 messages · Page 266 of 1
it sucks
Time moved forward
ill just stick to claudius
claudius
Is Gemini 3.1 good
best name oat
i bet 3.5 earliest on google I/O. So in on May 19th
Going to be real though i keep forgetting how much direct chat get get so disrupted by random competitive mode it's crazy
Pineapple WHEN IS SEEDANCE 2.0 COMEING

It is AGI

Sorry going to have to give the boring answer -> I won't be able to share details about what new models or features are upcoming until we're ready to share more. Would recommend to keep an eye on our announcement channel.
80.6 on swe
Thanks socky
Pineapple last queston can u check my dms
is the gemini on lm arena high thinking
Why do I not have permissions to use the video arena channels? For some reason, Arena won't let me use those channels.
Gemini pro is just so dumb... More stupid than GLM
Its deleted.
I dont mean to be a nag, but its been like 2 days and yet the thinking model for sonnet 4.6 still did not come out while usually the previous ones came out withing the hour
Is it like a whole intentional thing or what @echo aurora
Note that Video Arena has been removed from the server. More information can be found in this announcement.
nah
claude is better
At all !!!
Because sonnet 4.6 thinks for so long. The API cost would be too high
Yeah I will when I get to it.
What does that mean? The channel is deleted? Or my permission is deleted? And if my permission is deleted - why?
and cheaper)
existensial crisis
The bot its gone
The bot was removed from the server.
Ah. Ok. Atleast i got a answer.
Moving Video Arena off of Discord and just onto the site.
Okay it's your opinion
Oh. Does Arena plan to add it back?
Ah. I understand.
The request for thinking versions has been raised. There are various reasons why we will or won't have specific models added.
No, not at this time. We're too limited with the bot. Unable to add new functionality to Video Arena so it's best we have it just on the site so we can focus efforts.

why did bro send his pfp

You did see my PIN right in feedback ( just want to make sure)
why send fake chicken.,.,
Thanks for replying and letting me know.
Really interest in coding performance in real tasks
ai chicken
that chiken aint real
with video removal, new users intro process to this discord is perma locked on "Generate a video"

yes exactly
We got ai chicken before gta 6
yea fair-
<@&1349916362595635286>
oh come on...
Fake
just like chicken?
is anyone even still falling for that scam
Thank You
Ofc he is
Tried to combine both our pfp

It’s not supposed to be groundbreaking
YOOOO
this coding is terrible

SICK
It’s a refresh

Hold on let me check this out
I love it!
Let me give it a pretty simple task

why peeps posting slop?
I think people forget video arena moved
Same problem 😂 😂
Yeah Gemini code was never good
Me and my friend tested it out and it always was just messy
Did it work? Yeah
But it’s still ahh

But pineapple remove limts
I DONT BELIEVE THAT AT ALL
/vídeo
LMAO GEMINI 3.1 IS GOOD
seems like it bunched up a lot of code in a single line to reduce the total lines by 700
I thought Google will destroy all her competitors..
Now the competitors are safe 😆 😆 😆
It will get nerfed tomorrow
It is terrible today what about tomorrow
Probably more terrible
Video arena is moved to the website
Google is once again the leader in AI: Gemini 3.1 Pro Preview leads the Artificial Analysis Intelligence Index, 4 points ahead of Claude Opus 4.6 while costing less than half as much to run
@GoogleDeepMind gave us pre-release access to Gemini 3.1 Pro Preview. It leads 6 of the
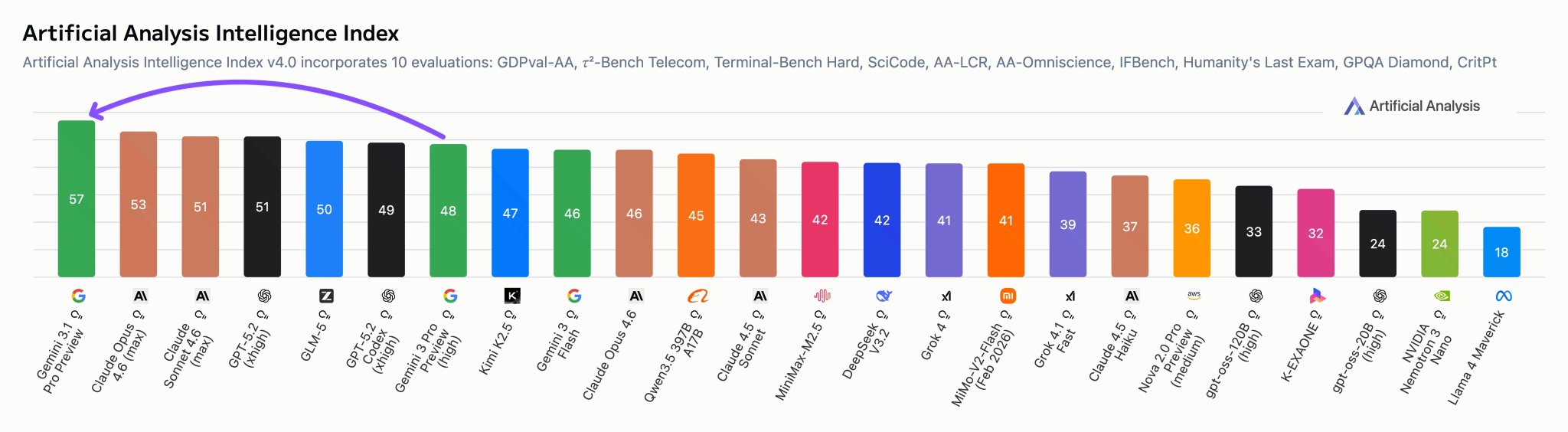
Yeah I know it’s from artificial analysis
Yeah no this is ridiculous
It’s a literal refresh model
INSANELY slow too
yeah lol like it should’ve achieved 1st place on the arena leaderboard
Depends
with those “insane” benchmark results
Well from what I'm hearing I guess it was a good thing I did not use that most recent AI the granted it probably wouldn't had help right now with the compares and stuff so still funny to hear some of the complaining ( cuz well I mean I was So nice to see I'm not the only one)
GPT 5.2 isn’t a refresh
hallucination gone back it seams
That’s a whole ass new architecture
“it actually is” 5.1 was a refresh
5.2 was completely diff
Yeah
Hold let me check this out
How is Gemini 3.1 pro number 4 in speed this is slow as hell
Number one in coding?
at least at AA 😉

Nahhh
we at a point of dinimishing returns. More compute, better inference, better artificial data, but still same paradigms
There wont be another GPT3 moment in a long time
nice

use in aistudio
hopefully this shows in usage
yeah
older models hallucinated all the damn time
but thats nitpicking, in general compute is increasing at a linear pace
Opus 4.6 wasn't a gamechanger. This is what I mean, diminishing returns
is this good? 🤔 doesn't seem that impressive to me:

Yea
lets see, how it's on simple bench 😄
average
Since it's going to be a new/high demand models there errors may happen, team is monitoring this
they migrated from the video arena channels
I think it's people trying to use Video Arena
@echo aurora I wanna use sora on arena but it chooses for me random model please fix
I think we've been at a point of diminishing returns for a bit, but improvements are definitely still meaningful
WOW
Isn't broken, that's intended
is this lmarena or ai studio
lmarena or studio
Arena
why are you asking? is studio worse?
There's a chance compute is too high, I predict there'll be a inflexion point of algorithmic paradigm shift way more radical than what deepseek did and we get to a way higher joules efficiency
I know i just want side by side video
I don't mean compute is high in an absolute sense, rather energy output towards compute is too high
ok so gemini 3.1 pro is comparable to 4.6 sonnet nonthinking
The human brain is enough evidence of that
but much worse than sonnet high or opus high
i thought it is better than them
in leaderboard artifical analysis
Artificial analysis is benchmarked
what does that mean
thought all the models get it?
not even close


how does 3.1 not really better than 3 ?
gpt models fail, google and claude models pass
Benchmaxxed
Not at all

when we got opus 4-6 it was much better than 4-5 and gpt 5.3 codex is much better than gpt 5.2 then why not for gemini 3.1
great i just lost my massive manually made prompt to a somethnig went wrong error
Marginal improvement
🥺
wrote a 9k char prompt with no new lines today without noticing
I would say Gemini 3.1 Pro is very good besides coding
they released a new model knowing it was just a small improvement ?
Benchmarks wise it’s defo a lot better
Actual use?
Eh.
Defo a LOT more token efficient
benchmarks say theres a massive leap
Thats why LMArena is the goat
True
if that was really the case then we should see it
That’s why it’s Gemini 3.1 Pro instead of Gemini 3.5 Pro
claude is probably still better lol
To be fair it is a refresh
like i said for example opus 4-6 is much better than 4-5
same for gpt
in b4 Gemini 3.105 Pro
Gemini 3.1.2 pro xhigh ultra spark codex
Except for use on Code Arena which is very glitchy like every other new model added to Code Arena
Gets 0.2% increase in swebench
but that's arena problem
not the model
Yeah this is a joke Gemini 3.1 pro refuses to code
I still think Claude is better at coding, and I use it for my personal projects
i would liked to see as much improvement from gemini 3 to 3.1 than what we saw for opus and gpt codex
I tried Gemini 3.1 Pro, and it couldn’t even get the start button right 💀
I’m asking it to make a simple 3D fps shooter and it’s installed 6 packages
I’m sorry?????
same, it sucsk
Is it still optimized or is it like when 3.0 first came out?
Cause after it came out, it got Nerfed
Just use Claude, or even Gemini 3 Flash (which is somehow better at coding than Gemini 3.1 Pro)
Quantization
Oh yeah, is it still quantized?
Uhhh no looks like it’s working at full precision
Or is it like Gemini 3.0 prime
As a tradeoff
Abysmally slow
quite sad imo
it's quantized
not even close
That’s a full precision model
probably just cause everyone is using it. it doesn't seem much better
Not how compute works
Google doesn’t do batch inference
its fun

bad
how do you know?
Looks fine
he's right, I don't, I'm just basing it on the fact there was a model 1-2 weeks ago that was miles ahead of the current release
doesnt mean we are ever getting the real model lol
If it was quantized it would be fast
i hate this so much

I’m getting mixed reactions. Can I make a poll here? I can’t find rules anymore and the last time I read, it was a long time ago
its quantized and slow
cause that was more like a new thinking mode no ?
it was very big before release

Two conflicting points
Models are quantized to be faster
opus 4.5 is quantized too
or cheaper
its not fast 💀
codex spark is fast
opus isnt
Yeah it is?
For Claude users, what is the best EV in getting usage? Their plan or just go to Openrouter API?
LOL

LMAO
this one


i'm too dumb to get the joke
why the "remove" option is deleted?
2.5 flash does better than this bro
ill wait for the subtitled version
i think its lazy as hell
Reminds me of that one panzer
you have to prompt it well
?
It’s being aggressively token efficient
The files it’s making don’t even go above 100 lines of code
It’s strangling itself
the tank has 300
Not enough at all
See what I mean?
It’s been trained to use the least amount of tokens as possible to copy Claude
the noita prompt had like 3 times repeated to never take any shortcuts and such
900 LOC
not remotely close to what opus did
A lot of people have been noticing this with 3.1 and I have too
LOL

gemini worse than gpt 5.2 low?
this is grok levels of disappointment
I mean
The model isn't terrible by any means
It just doesn't feel great with some coding tasks

i think google is positioning it more for common user and maybe into the scienece direction.
Not for coding
i'll admit that's pretty bad for an LLM to have lol
But majority of the time, it generates pretty reasonable code
i think claude could do this better

high 🥶
considering it made me this

<@&1349916362595635286>
@twilit sable Note that Video Arena has been removed from the server. More information can be found in this #announcements
this is way better

welp

holy cook
the models not even close
lmao
god forbid third world countries from touching latest tech 🙏
WHEN DID 3.1 PRO COME OUT
Try qwen 3.5 lmao

Is opus 4.6 that good?


TODAY
Yes
anyone want to share how does gemini 3.1 vs opus 4.6 feel?
Benchmarks or tests?
@echo auroracan max route you to gemini 3.1
Gemini 3.1 is great in everything except coding
Claude Opus 4.6 just gives you the same performance
Oh and Gemini is slow ahh hell
as in did any user test it extensively to have some own opinion, cus the benchmark from google said it really good but the rank on arena is a mixed bag innit
thx man its always you haha 😂 🙏 👍
same lmaooo 💀
I love how my breakup was the reason I became invested into llms
I literally had no other hobby
really gemini 3.0 was the fastest among gpt and opus for me
it gotten slower?
Gemini 3.0 still peak
but for grounding i like gpt 5.2 more than gemini 3 search tho
grok 4.2 is the best research model
GPT 5.2 search is great if it would USE IT MORE OFTEN
is it i haven't use it actually
Agreed
Grok makes the best research models
penguin riding a motorbike

alright guess i gotta check it out then thx bud
yeah sometimes it goes through 250+ sources
Why is Claude 4.6 better than Gemini 3.0 pro in the text?
It’s just peak
i will honestly say. gemini 3.1 pro is great in terms of solving math and etc. problems, but i hate it speech type and position
Oh, good then. I just didn't understand why it was better if it looked like it was going to be worse.
Haven’t tried it too much yet
But it really goes crazy in coding
Not in a good way.
It installs way too many packages
Is slow
gerar Prompt de vídeo profissional de uma pessoa que faz flexão rápido
Lane
Overwhelming right?
hi guys
It took it a solid 3 seconds to make one line of code
Idk. I like the style of gemini models.
Hi.
i'm trying to deal with the error in my arena.ai side lol

Also Gemini 3.1 is heavily token efficient but not in a good way
It has too many shortcuts when coding
Claude is thorough
Every other model is thorough
umm @echo aurora i would like to get some help with this
it puts like 30 lines of code in a single one just to reduce total line count
🥀

Real
Hmm. Idk. Maybe the limit, but I'm not sure.
the error was already like 3-4 hours and the conditions still the same
maybe garbage system prompt?
i don't think it's rate limit
I feel like it's actually not bad speed wise considering it's so good in regards of verbosity
Definitely faster than Opus 4.6
Opus 4.6 was faster for me
It's hard for me to say for sure with the information I have, but based off this image I wouldn't be surprised if this was rate limit. Regardless, you'll want to follow the steps outlined in this message: #1417174113092374689 message
if it's a rate limit, it shouldn't affect other model like claude since i often use gemini 3 pro
Note that there is a rate limit for specific model use, but also a rate limit for overall modality use.
Without being asked to?
Mhmm
Yeah real
Oh
It finished coding
Let’s see
Yeah it’s garbage
It’s complete garbage
Oh my god
Hold on let me send the link
Opus 4.6 is good with some languages💗
Check out what I built in Arena's Code Arena - Content is user-generated and unverified
This is god awful
kekw
so code is still opus (how good is sonnet btw?)
search is grok?
Studio sucks right now
Arena has seemingly been better
Lmao let me get Claude sonnet to do the same thing
its really hard to just use logic without any search, or is it just me?
i agree actually
Gemini losing the plot
it's normal for specific model to hit rate limit, but at my side, all model are unusable due to error as well (it happen to all model and even the model that i have not being interacting before)
Claude is cooking
hey brada would you say
code is still opus and research is grok?
what else? how good is sonnet btw?
yes 100% this
Sonnet is fire
I think a mix of opus and kimi right now is goated
Maybe GLM 5?
Research is always grok
Grok crushes research
Oh my god sonnet is COOKING
Yeah this sounds like it could be something else. I assume this is happening with different modalities as well?
Note I would like to move this convo to #1417174113092374689 so we can keep #general clear for chatting.
how much is sonnet performance of opus?
yup this
I’d say 90%
Hopefully today?
/image
possibility
thats really good then, consider that 4.6 sonnet is already better than 4.5 opus right?
tried all model and it won't work :/
A bit yes
I’d say sonnet is 5-10% better than 4.5 opus
I have been using AI for research and code, so for now i guess i only need to use grok and opus/sonnet?
text leaderboard
LMAO I IUST REALIZED GEMINI 3.1 PRO SKIPPED MAKING THE ACTUAL HUD AND GAMEPLAY
BRUHHH
Ass model
i guess we need to give it a little bit of time for people to vote more?🤔
thx mate 🙏
lol
me too
मनुष्य किसी भी दुःख को, सहन कर सकता हैं, लेकिन गृह क्लेश उसकी, आत्मा को निचोड़ देती हैं..!
I have to agree, Gemini 3.1 isnt that good
It’s such a downgrade
Remember how crazy 3.0 was at coding to the point we were blown away
the benchmark numbers from google looks good idk 🤣
i like style of all gemini models , except gemini 3.1 pro
isnt is nano banana pro
why
it refuses to understand my meta-thought
Alright, Let me guess, I think deepseek v4 releases tommorow
nah i think it wasn't that good still, the point for me was opus 4.5, that was actually usable good
I make use of json prompts to enhance and make it understand
DUDE
can you tell me any?
SONNET COOKED GEMINI BY A MILE
Check out what I built in Arena's Code Arena - Content is user-generated and unverified
LOOK AT THIS
not sure is it i'm the only one who get this problem in arena.ai or anyone else got the same
Gemini 3.1 is cooked
Introducing Gemini 3.1 Pro, our new SOTA model across most reasoning, coding, and stem use cases!

anyone tried g3.1?
no it is general
yeah thats pretty good eh
have u seen it
yes, thanks
Yep
Yeah
smh
Sonnet cooked it
This is just slamming the model for nothing lol
If this was Gemini 3.1 flash it would’ve been understandable
The model is not that bad
It is
It IS
Sonnet wiped the floor with it in less time and 10 times higher quality code
The only problem it has is the verbosity and uncommon syntax errors
10 times higher quality based off what?
WILD

For one the game actually
Functions
Has working dynamic lighting
High quality code
Multiple files
Robust systems
Gemini 3.1 made a mess
Check out what I built in Arena's Code Arena - Content is user-generated and unverified
Here’s sonnet
It's a bit unfair to base an entire model's performance off 1 prompt no?
it has awful system prompt
gemini sys prompt SUCKS
Tried it twice
Failed both times
this i can agree with lol
same prompt?
Mhm
That's the problem
The third time the game functioned
You're basing your entire opinion of a model on a single prompt
On the same prompt
Not only that but community impressions here
Like ampro’s tank
look at this


For a SOTA model that looks awful
I do not think 2 hours of testing is nearly enough time to form a general finalized opinion on a large multi-modal model like Gemini. For me it's generated some pretty nice stuff but in completely different medium than what everyone else is posting.
Safety fine tuning fluff
OK
heres with system prompt

did gemini deep think get updated as well?
gemini is actually better if you tell it to work hard and ignore sys prompt
the sys prompt DEMANDS it to be cost efficient and token efficient
Fotor: Easy-to-use AI imaging editor at your fingertips. https://mobile.fotor.com/
I was wondering why my photos don't look good in terms of quality anymore. I thought my app was bugged because it wasn't saving in 2K. Lol.
@echo aurora starting a new chat does the fix, but that means i can't use the old chat anymore because my project (usually from code arena) still going on.
anyway thanks for the tip
Kk
try to start the new chat in arena.ai, but that means you will have to start it over.
@random ginkgo Note that Video Arena has been removed from the server. More information can be found in this #announcements

We’re exploring how occasional Battles in Direct chat might work. Our mission is to measure and advance the frontier of AI for real-world use, and integrating Battles into Direct is a meaningful step in that direction. The help center's article about the experiment can be found here.

We are currently experimenting with a new feature: Battles in Direct. When chatting In Direct mode, occasional Battles may appear. After casting

Hey everyone. Trying to use opus4-6 here in the arena, but it's clearly not the right model. It's running some version that doesn't even know its own existence lol. Any routing or deployment issues going on?
Hi everyone, what can these lags be related to?

look

no, it did?
look at what?
You'll want to follow the steps in this article - #1417174113092374689 message
This is single‑handedly one of the least helpful features I’ve come across.

its worse than gpt 4o with default prompt
you didn't label the pics
This is a typical hallucination. Essentially the model isn't able to perceive it's own existence when it's being trained, as it doesn't yet exist.
why i could not make video?
Battles should only appear if the user is in Battle mode
The Video Arena bot was removed from the server. Video Arena is only on the site now.
I'll try to follow the guides, but it's unlikely to work out.
for Russia ❤️
Link?
Yo guys getting like mad errors
I did but ur in dark mode
If it doesn't work be sure to follow Step #3. This is the step that helps us by getting us more information. Think of the Something went wrong error like a car's check engine light. A mechanic wouldn't be able to tell you what's wrong with just with the information that the check engine light is on.

Arena | Benchmark & Compare the Best AI Models
Chat with multiple AI models side-by-side. Compare ChatGPT, Claude, Gemini, and other top LLMs. Crowdsourced benchmarks and leaderboards.

It's just that I have a huge project there, and if I create a chat, I can throw him a repository that he would copy?
thats insane
I'm sorry to hear you're not a fan. It's worth noting that this is still in the experiment phase, so there could be changes before being fully rolled out.
yup
I get the pre-training argument, but in production, a properly fine-tuned model should have its identity explicitly defined in the System Prompt. If it's guessing whether it's Sonnet or Opus, it usually means the system prompt injection is either missing or misconfigured on your end, not just a random pre-training hallucination. Can you check the prompt wrapper?
i agree with him - the whole point of direct is no battles
At least make it so you can turn the feature off somewhere (if it does get fully rolled out)
@echo aurora ?
when you vote in side by side does that count?
or does it need to be in battle
i thought only battle counted
but it lets you vote side by side which is weird
I can flag this, but this tends to be pretty common. I've seen this happen with a lot of different models.
No, no it does not. It’s a new Experiment that puts Battles in Direct Chat that is pointless in my opinion
Only votes in Battle are what power the leaderboards.
what is the vote for in side by side then?
bruh

@echo aurora Hey team, following up on the model identity issue with some visual proof.
Image 1: The official UI. The model knows exactly what it is (3.1 Pro) because the system prompt is properly configured.
Image 2: Your gemini-3.1-pro-preview endpoint. It's defaulting to a generic, outdated response (claiming it might be 1.5) because it clearly lacks a proper system prompt wrapper.
By exposing these raw endpoints without injecting the correct identity context, you're essentially lobotomizing state-of-the-art models. Users come here to benchmark, and when a model acts lost, they blame the AI companies, not the platform's infrastructure. It's tarnishing the models' reputations. You really need to update your system prompts for these new endpoints.


where can i utilize gemini 3.1 no system prompt
holy yap
Standard hallucination
Models don’t know what they are
@nocturne turtle Note that Video Arena has been removed from the server. More information can be found in this #announcements
yeah what is tguy yapping aobut
Buddy that's not how it works
Probably jus doesn’t know about llms
If I tell gemini that it's gemini 4.5 it doesn't become magically more powerful
@proud bobcat Models don't know what they are unless you pass a proper system prompt at inference time. The official UI injects it. Your API wrapper clearly doesn't. Calling a missing system prompt a 'standard hallucination' is wild for a testing platform. But anyway, good luck with the benchmarks.
@whole swallow I never said a system prompt magically boosts capabilities. That's a strawman. I said it grounds the model's identity. If you don't inject the correct context (like the official UI does), the model falls back to older SFT data and hallucinates an outdated version. It's a basic context injection issue, not a capability debate. But I'll leave it at that.
This is the worst possible thing arena.ai could do with there loyal members, lost everything.


@surreal zephyr where can i use the best version of gemini 31
api
and tell it to put max effort ect
lm arena?
ok
its trained to be lazy for money
Vertex
you have to tell it to put more effort
How did you lose everything
Look, I was just trying to give you a heads-up so you could actually update your system prompts. I have zero interest in using this outdated, misconfigured crap anyway. I'll just take this to social media to expose how you're doing false advertising and dragging these AI companies' names through the mud by serving crippled models. Have fun with your broken benchmarks. I'm out.
dude quit yapping
do wahtever you want
@surreal zephyr exhaustively enjoy 3.1 while you can, it's gonna be nerfed to trash after 2 days
ive never seen someone so upset because a model doesnt tell you its name
yup
I had a month old chat history which i build with time, now i can't build it again. It took alot of time. i tried to create a master prompt for a new chat but it doesn't work the same.
What problem you're facing mr white444
It randomly starts a battle and now claude 4.6 also has a rate limit which asks to wait for 21 minutes.
Why can't you wait
Do you have to catch a train?
& Something went wrong with this response, please try again.

its what it is buddy
Happends with Video too
if you want more pay aa claude subcription
kkkkkkkkkkkkkkkkkkkkkkkkkkkkkkkkkk
If the something went wrong with this response error is not fixing after repeated generations switch the model and continue the chat
You get enough rate limits that you can copy paste every single message from the error chat instead of scrolling instagram and wasting time
just to say it's one thing when it clearly isn't
you're right but you can't make these changes suddenly.
1 blocked message
wdym its always been there
3.1 pro is soo good
Already have done it but it starts battle mode during chat chats which is more annoying
'A blocked message from taco bell.'
where are you using it
vertex aint free
It is
Yea yea we know
200$ google cloud free credits
9/10 ragebait
Chicken go lay eggs
Already did, i have 1000s of eggs
Dude
Can only wait, maybe they will fix it. we can only criticize
Even with a system prompt
It still doesn’t know
Gemini has told me it was 1.5 pro on the official app
Oh gods, nothing helped how to live?

lmarena's gemini 3.1 is way better than the one on gemini app and ai studio
skill issue?
Yeah real
Bro, it does not only happen with claude but with video too.
the problem with the error
Nah, everyone is struggling here
claude models feel like that too but its probably the system prompt idk
@stray aspen vertex ai bro
Google Cloud Documentation
Learn about Google Cloud's free offerings and free trials, plus how to upgrade your account.
Claude processing 5 billion safety parameters before Something went wrong with this response, please try again.
He just can't give me the code! I've been doing this for an hour now.
Reset browser cookies
I've tried
Gemini gives a free trial on gemini business for 30 days
No this is different
300$ api credit
90 days
😊
Now endless coding

The rate limit just needs to be waited out and should start working again.
Are the battles still in direct mode? 💩
yes
what about the Something went wrong with this response, please try again. ERROR?

IT'S THE SAME FOR ME
I think pineapple has to delete the limt
Yea its the same for me
bruuuhhh

Xs what should I do, I need to download the repository
You'll want to follow these steps: #1417174113092374689 message Also note that the rate limit can result in the Something went wrong error.
Yeah this is likely rate limit, spamming the chat when you're getting this error probably isn't helping.
Is Gemini 3.1 better than CLaude Opus 4.6 according to your tests?
really efficient too
with proper prompt?
its not even close
bro
its literally AGI
wow, it works on firefox so this could be used as liquid glass
https://019c7741-bf0d-7a29-b05d-7f7e191208a3.arena.site/ see this water
Check out what I built in Arena's Code Arena - Content is user-generated and unverified
gemini
bad test
I have gemini deepthink which is based on 3.1 and it is NOT AGI
If you want to test Deepthink send me your prompt
WTF ITS ONLY 350 LINES LONG
exactly never even heard of it before
guys what the hell is trinity

us based ai company
bad models
why?
oh they just released it on arena?
loooooooo
so late
Opus 4.6 non thinking 😭
Tf is trinity
us based ai company
Try it out and let us know
USA?
decent for first release
is kimi better than chatgpt
depends on the task and the chatgpt model you are talking about
If your a free user yes
If you are paid user no
I think coding yes that's at least from what I've heard
i've been using 4.6 opus in antigravity for days and 3.1 pro is fixing problems opus wouldn't
Who is trinity large
USA company
even the quantized version of 3.1 is better than 4.6
yea idk why people are happy that a us based company released an ai model
It's good ai?
which is what we have rn
thinking or not?
(opus)
Cuz now they aren't gonna see a random Chinese worker watching them and selling their data 😭
the unquantized version which was only around for a short time at launch was also noticeably better than the 3.1 we currently have access to

Trinity-Large-Preview is a frontier-scale open-weight language model from Arcee, built as a 400B-parameter sparse Mixture-of-Experts with 13B active parameters per token using 4-of-256 expert routing.
It excels in creative writing, storytelling, role-play, chat scenarios, and real-time voice assistance, better than your average reasoning model usually can. But we’re also introducing some of our newer agentic performance. It was trained to navigate well in agent harnesses like OpenCode, Cline, and Kilo Code, and to handle complex toolchains and long, constraint-filled prompts.
idk if this is crazy to say but I'd rather let china collect my data not USA cuz at least it's not going to israel or something
512k tokens btw
try api
are u thinking about Deepthink or base model? cuz how could they quantize the day it releases, if u are thinking about base model then I'm assuming the short time is before it got added to Google ai studio?
i'm talking about 3.1 pro w/ thinking
what i really like about kimi is the agent mode
Correct
but i think ur right
https://019c774c-8fa7-7a3f-bc95-f01faad869df.arena.site/
someone fight me
Check out what I built in Arena's Code Arena - Content is user-generated and unverified
chatgpt is definitely more worth paying for generally
Btw are you using CLI agents cuz I got something interesting for you
who beat me
You can use GPT 5.3 codex xhigh for free (idk about limit)
If you got macos install codex
If you got windows / linux install codex CLI
or opencode and link your account there
And what should I do in this case? Wait?
Game code
@echo aurora Why do you come with so much armour?
i left you can make your lobby and share codes
479f2ec5-b5f9-47fd-9a38-2495390686f3
You should follow the steps in this message: #1417174113092374689 message

Pineapple’s armour
Ggs u just smoked me
I bet if a pineapple would have fell on netwon, we all would be floating today
Hey
Gravity defeated
oh no.... i thought this is a dream... BATTLE MODE IN DIRECT???!!!

its fine
mhm yeah, sorry bro
Its really good
hold on let me try studio
Pineapple is heavier so gravity would be stronger
dw side by side will work for me '
Make sure to force it to think much
without sys prompt
Lma has no sys either
if you specificly want a clean chat with no interuptions, google AI studio is now the current best option. (if you like gemini)
has anyone noticed that the quality of NB Pro has degraded after the errors?
does it have NB Pro for free?
no i dont think so, higgsfield does though, but its pretty limited
omg why does it have errors again STOP THE TORTURE...!!!!
Welcome, fresh victim. You're just in time for the worst update ever. Highlights include: destroying your conversation flow.
NB still errors but come with low resolution when it works

Check out what I built in Arena's Code Arena - Content is user-generated and unverified
for infinite generation glitch on arena: no login, generate 2 prompts, save pictures, clear cookies, repeat
the quality has degraded since the errors
"create a detailed 3d simulation of a tanks suspension with a map, driving controls, accurate physics, and polish. do not cheap out on code, think to the maximum and install as many packages as needed."
trying this out
lets race it against sonnet lmao
whats your opinion on this?

did they buff on Flux or something
never seen them work so fast
If you have experiences a lowering of quality we are looking for examples in #1470529575367868498, the top of the thread has instructions on what we're looking for.
so its a bug ?
i feel like after nano banana pro released, all the other models suddenly become dogwater compared to NB


I'm not sure, we're trying to gather more examples
this is dogwater lmao

Yea
and it's NB Pro 🤣
is battle in direct still classed as an experiment or a main element of the site now?
Testing out Code Arena now, can't say I'm seeing the same (stll mid generation), but doesn't appear to be having issues.
I should bump this again as it is still heavily discussed here, please remove the battles in direct
It's currently considered and experiment.
kk thanks
Oh wait now I'm seeing it. Reporting to the team. Thanks 

no problem
What model did this happen for you btw? I'm using battle and it appears is only happening with one of the options.
WHAT?!
Today vs... 2 weeks ago


@echo aurora edited: nevermind the scam got deleted
Gemini3.1
Oh sorry it got deleted
yes sadly I rarely see them in battle
All good. Btw don't hesitate to use the @ Moderator ping for mod purposes.
I thought that doesn't work?
If you can share in #1470529575367868498 and include the Eval IDs for both sessions that'd be helpful.
No it does
Alr I'll try it when I see a scam again
the prompts for the second one... were deleted
Okay good to know, if you notice this again don't hesitate to use that thread and flag the images/Eval IDs.
DOG WATER
better or no?

https://019c775e-143e-7242-92b4-0d936da78f8c.arena.site/ the gravitational lensing is insane
Check out what I built in Arena's Code Arena - Content is user-generated and unverified
Create a 3D simulation of a blackhole including accurate light bending, you should be able to pan the camera with the mouse, the blackhole should have a accurate accretion disk, web based
@quartz light
what model

Hey I've been waiting two weeks I don't see this feature in claude ai if it's going to be added soon?

again... @surreal zephyr

Is nano banana being nerfed it’s generating 600kb files instead of the usual 6mb and failing to generate much more frequently
They are good for different tasks.
guys, someone know how to export lmarena chat .txt?
bro nano banana pro across all platforms are dogwater lmaoooo
.
They are not equal
i can send u code for this
add to friends
(i just needed it for myself)
sure
via api? gemini is infinitely better.
normally? opus
it just never works on arena


Remove battle mode in direct chat... ☠️🤌
I doubt there is a public model which is able to overperform Opus-4.6-thinking in pure coding tasks.
Maybe Gemini 3 Deep Think Could actually be better, but only by reading its description card provided by Google, it is more of a research tool than a model made only for coding.
GPT-5.3-Codex was pretty competitive in a fair few marks, wasn't it?
Given it itself anecdotally way outperforms GPT-5.2 and at least matches GPT-5.2-Highest in abilities
Γεια σου!
everytime i try to use nano banana pro i get this error lol

https://019c779f-32f1-7eab-83f0-e1cfe2cf7544.arena.site/ custom wormhole shader
I guess so, but as Anthropic stated in its benchmark outputs, Opus 4.6 manages to be extremely good in agentic coding environments, extremely long context coherence and tool interaction / call
Those are parameters of evaluation which in my opinion are worth more than a single benchmark when we’re talking about pure vibecoding in real scenarios
as Anthropic stated
^
first party rankings should always be externally verified for cherry-picking or unrealistic comparison factors
Yeah, true, I still remember Google faking their benchmarks for Gemini 3 pro. I just hope Anthropic isn’t that naïve 💀
It’s like steroids for AI at this point
I'm not saying faking but I'm moreso saying if you use a metric that's a subset of something else that can only ever be measured as a whole, what does that tell us? nothing much.

Because the context of the metric matters. If you remove its context, it can look phenomenal. But if it's doing a phenomenal job at X while being subpar at X, Z, U, V and W, it's mostly pointless.
Congrats! You've asked the model for their identity 
Classic hallucination case
It's not a hallucination if you mean "GPT-4 class"
what does it mean by gpt-4 class
It's aaaah. An unintended lens into how OpenAI got to it. It just means that GPT-5 is, as we know, a further-trained version of GPT-4.
I guess so, the model does not actually know the specific version of itself
ai studio gemini 3.1 sucks
id assume that
i have no idea how you even begin to train AI models, i can understand how they work
but training makes no sense
also coding in arena has recently just never worked for me, one time today but every time i get this error, and this error is common when using nano banana pro. not sure why

nano banana pro works fine when i use the actual gemini
Simple concept of a Transformer:
- You give it random noise created from adding noise to a real piece of data
- You punish it until it guesses what the original was correctly every time.
- You do this concurrently with a f"ckton of other data! :)
Have you tried clicking "Re-generate"?
after multiple tries before i have, but i only tried on nano banana pro. ill see if coding with opus will work
it happens often
I dont like the idea that when we generate we can choice to have 1 generated at a time.. by the time I generate the 2nd image its saying im up to my limit which is wrong bc I normally get 5 chances
<@&1349916362595635286>
i dont speak english
@vocal axle Note that Video Arena has been removed from the server. More information can be found in this #announcements
Yes it might. That means you'll have to try clicking re-generate "often" as well! :)
when they punish it, do they cut the power
lol
no, they don't. It's a high level overview.
i am nexs user

quota waste
There should be an identity dataset where they train the self perception of the model about its metadata, but I guess that to preserve the efficiency of the hardware allocated to the training session, it just reinforces the company name and maybe the model series
Then just sulk, be my guest. Let me know how you get on and continue. :')
When gpt 5.3 Codex😭
This has nothing to do with it haha.
They can tell the model.
They usually do in the system prompt.
The API doesn't inject one.
Arena doesn't add it either. because that would be antithetical to the point.
But across all the training data (which, in case of ChatGPT we’re talking about terabytes of stuff), its impact is very limited
Ask GPT-5.3 on the ChatGPT.com website and you'll see that it has no problem telling you.
I doubt it’s just prompt engineering
it worked on claude, but gemini 3.1 pro keeps failing to create anything
That's not really how the training data works. Seeing the training data as "this is two kB and this is ten TB" is trying to count apples by moving oranges on your counting screen.
Otherwise it would be easier for the model to “remember” that stuff
The system prompt is not included on Arena, as I said
That's why it doesn't truly know to tell you its identity. It's intentionally not part of the post-training.


It matters to the point where the model learns to have a better inference performance if the training dataset is generic enough (not implying that a lot of data = more generic, but it was an assumption that I made for how it’s trained a fundational model like ChatGPT)
Good show! Yes, the ChatGPT website (first image) will indeed be able to tell you its identity just fine. It's told about what its identity is and what the date today is as well if I'm not mistaken.
I'm saying that bytes aren't a thing in the neural net
i remember in like 2023-2024 using chatgpt when the website was green themed, and i kept asking it the year for its training data
i was pissed when it said october 2022 or 2023
too
also it didnt even have web search back then
fk lie
Byte count doesn't scale from binary storage count to nonbinary neural net gradients. Your comparison of "compared to many terabytes" is one that doesn't hold up because the data when trained, is not transformed into bytes of any quantity.
on opus its cuz of timeout
whats timeout
As a free user I've been using Gemini Flash 3 as my preferred everyday model. I use the limited free Pro for more complex tasks. Interestingly, Sonnet 4.6 from Claude was made the default for even Claude Pro users, so I thought I'd give it a try.
Initially, my thoughts are that it seems pretty good, but can't tell if it's better than Gemini Flash. I was wondering when it would be added to the leaderboard?
That was likely correct for the dataset though. A year of delay between dataset termination and post-training completion is not unreasonable
ai providers have different timeouts and basically if the response is taking longer than the timeout plan theyre paying for then it just stops
I was very upset, swearing I was using opus 4-6 when in fact it's a clear derivation of 3-5. Shame!
Once it accumulates enough votes and ELO confidence
that was when chatgpt started getting viral and nobody knew how LLM's worked
You'll understand why this is the case when you conceptualise what the models are based on. They don't start from scratch every time.
so we just assumed chatgpt was like google if it could talk back
well, it basically is that nowadays
since it can use the web
No, nowadays it's a teenager that talks back (and brattily so). 
Ah so it's available to be voted on currently then. I searched the change log for it but I guess that must not include when things are added for initial voting
is gemini 3.1 nerfed already?
@scarlet spire Dude, I'm developing my own model in Brazilian Portuguese from scratch. I've already developed my rag Online using some free models, and you can clearly see the difference when you use the latest templates directly from their respective platforms to the Arena platform.
Performance drift time record?
Okay! That's cool. How are you finding the experience?
@scarlet spire Look, I'm using Antigravity with Opus 4-5 and I was sometimes using the arena because I don't have the paid Opus plan, and I noticed that some days it always sends the same mess instead of fixing what it should do to continue training... then I just asked it to find out the version and realized I was using something that clearly wasn't it.
The scoreboard displays a vote count, but the actual ranking isn't based on raw votes. The system that underlies this ranking is based on a longer-term heuristic-type averaging, the "elo" system.
Look... at? Look at what exactly?
You're sending me random pings with absolutely no reference to what you are commenting on. You sound to me like you're trying to reply to something but are effectively failing to use the reply feature? Use the reply feature.
what is this ai conversation
@scarlet spire Just configure the correct API to use the correct version and stop running those crappy system prompts from older versions.