#general
1 messages · Page 107 of 1
Hello, here to check out the videos
yeah and the wild imagination worldwide
Chat is ts tuff?
Duh its ai generated. this is lmarena 😭
correct. but personally i find the seccond one a bit funny
Bro just casually lets go
and f*cking dies 😭
lol
btw can u vpte
i wanna see what the models are
that made it
Hello. I'm here because i'm excited at how fast Ai Image generation is evolving and looking forward to seeing how it develops.
😭

nice one - that does suggest some kind of RAG/internet access almost surely
is nightride a strong model otherwise? like aside from up to date info
@echo aurora i had scroll through so many images and greetings before finding discussion about models in the arena (which is what i liked about the server in the past).. perhaps there's a way to separate out like general chatter from discussion / speculation about anon models (the juicy stuff ha)

Ok
poll_question_text
SOTA
victor_answer_votes
9
total_votes
17
victor_answer_id
1
victor_answer_text
GPT-5
poll_question_text
SOTA Open-Source/Open-Weight
victor_answer_votes
7
total_votes
12
victor_answer_id
1
victor_answer_text
Qwen3 235B 2507 (Reasoning)
poll_question_text
Grok 5 before Gemini 3
victor_answer_votes
19
total_votes
21
victor_answer_id
2
victor_answer_text
No

poll_question_text
Is Gemini 3 already on LMArena under an anonymous name?
victor_answer_votes
13
total_votes
13
victor_answer_id
2
victor_answer_text
No
Huh it's still R1 (newest ver)
poll_question_text
When will Gemini 3.0 be released?
victor_answer_votes
6
total_votes
14
victor_answer_id
1
victor_answer_text
September
But ig it's old and people are bored wanting smth new lol
Deepseek V3.1 was a non-release for the most part. You can now have no reasoning or reasoning that almost matches R1 within the same model. Ok great, moving on...
lmao rekt, what i do know is Qwen 3 has overtaken R1 in math, other fields idrk
Actually looked at this and dunno anymore. I disagree with this 😠

I suppose qwen3 performs, but my IRL experience was somewhat differing from this
Qwen 3 is better at math and competitive programming
that's why its AA score is better
but ngl they did r1 dirty by that aime 2025
Qwen3 seemed to me like it's much easier to break and not nearly as reliable as R1
another thing to note is that it seems like ds keeps trying to use grpo while Qwen sswitched to gspo
I need nano banana and I can use it for free from google aistudio. I can also do it from lmarena directchat. Is it preferable for lmarena doing it there because they can use those prompt or is it more of an expense for them?
R1 is just reliable though and shines in several metrics on unseen data (new benchmarks), whereas Qwen can quickly fall apart and seems more benchmaxxed tbh
Also smaller
which new benchmarks?
uh there was creative writing one
this is also a new bench lol

that became a thing after that model was released
kimi does the best.on that and it doesn't even use test-time compute
things like this: https://www.reddit.com/r/LocalLLaMA/comments/1ieooqe/deepseek_r1_takes_1_overall_on_a_creative_short/
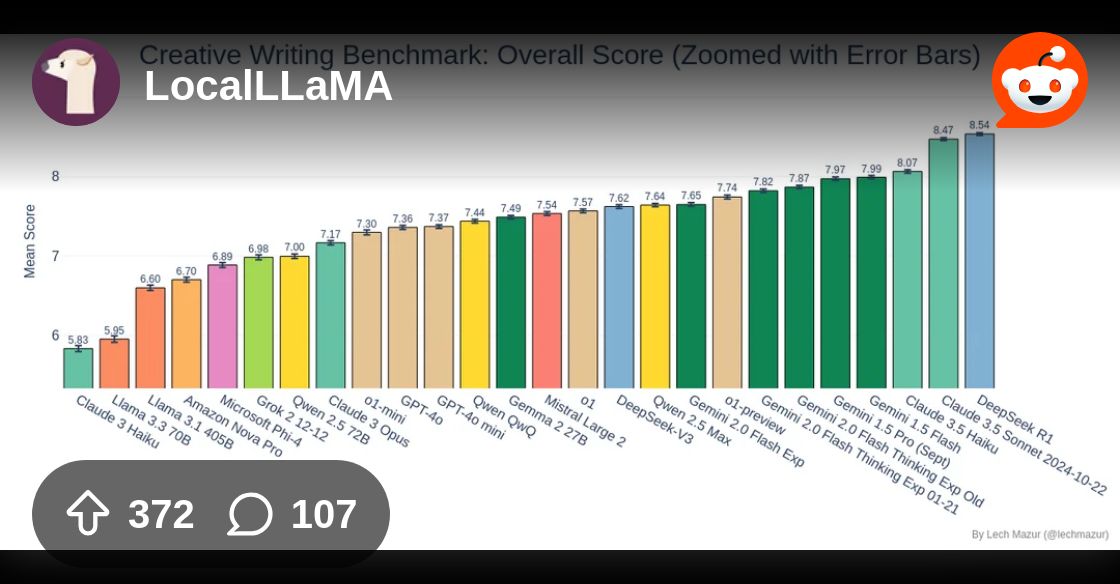
Reddit
Explore this post and more from the LocalLLaMA community
that seems like from a long time ago
Like it really seems that model had good fine-tuning. It is performing on things they didn't explicity train for
Yeah but still kinda relevant
like kimi overtook everyone on the eq creative bench
it's basically the best writer, even gpt 6 (underscore) agrees
As it should, it's the biggest of those 3
there seems to be a tradeoff b/w what certain RL algorithms are good for, GRPO might be better for writing where the rewards are uncertain while GSPO is better when there is only 1 right answer
They can't do RL training (reasoning) though it seems 🗿
kimi has a lot of potential for it
have u seen the GSPO paper?
in grpo, there is a higher variance for answers which might be better for writing purposes. Trentk used it to turn a small Qwen model in mechahitler
more creative yk
not too sure about that but in my experience gspo is just better
cuz ur probably using it in technical cases where there is only 1 right answer for the most part
@ocean vortex you gone buddy? xD
Anthropic is losing the game it seems, they're not racing to AGI, but to establish as a coding product company?
will there be added support for uploading files other than images?
Nah, why?
No opinion on this. I'm more interested in how it turns out in practice. But haven't looked into technical details of this enough to comment tbh
Plus I would say it's a bad idea to generalize like this. I think there's more than 1 way to train a good performing model
Sure.
Until you remember that GPT-5 is the best model overall, that is, most likely to give a good answer to ANY prompt.
Regarding if Qwen is benchmaxxed or not - we quite literally do not have appropriate benchmarks to figure it out
In psychometrics for example, tests are created to distinguish between different broad abilities, which are measured with different subtests
Let's say that we did an exploratory factor analysis on a LLM and figured out that it has a strength in broad factor that is responsible for creative writing, and each other thing this broad ability accounts for
So it's going to be great at benchmarks that measure this broad ability
And if a model does somehow bad at all benchmarks at the same time except those it was measured at, it is an evidence of benchmaxxxing
But we do not have extensive psychometrically valid benchmarks for LLM so far, so...
hi
Those psychometric are just theoretical frameworks that don’t necessarily reflect the reality and can be easily gamed, those top consultant firms are using psychometric for their assessments and people know very well how to game the system, same will be for LLMs
As a person with some background in quantitative psychology, nope.
Ok, that speaks volume about your background
HEY EVERYONE, I AM NEW HERE,
hi
mah chat history is gone 😭
OMG NANO BANANA
I have a question
finally imma use nano banana for free
How can i change the aspect ratio on lmarena ?
on google ai studio
u cant
its also available on lmarena direct chat btw if u run into ur limits there
damn i wanted to make a horizontal image
wydm
aistudio has generation limits for nano banana
on google ai studio its better, u can choose it right away and edit stuff with it
really
yea u have X amount of requests
10 amount?
im not sure about the specifics, they dont document it and it changes
idk i been using it for a while now
it also has limit on lmarena
yea im just saying if u do reach the high limit
i can just change my google account
🤷 im just saying it is available on lmarena direct chat if you want. no login required there to get extra use
yea ig
imma try it if i reach the limit
also did the quality drop?
after they released it?
or am i tripping
personally i dont see much of a difference/if at all compared to when it was anon but i barely used it
some people have said it was nerfed though
yea it used to be much clearer
What do you gets think is better at coding; GPT 5 high or claude opus 4.1/sonnet4
gpt for architecture, claude for coding
4.1 opus for sure, but it costs alot
try 4 sonnet if u dont want alot of costs
claude opus 4.1 was unable to help yesterday fix a simple api concurrency limit issue, had to take over, and do it the old fashioned way. i use opus 4.1 often and it's decent but was thinking about switching to gpt5 high though because it's a better reasoning model.
did gpt5 fix it for u?
didn't try, should've, i just fixed it myself, i'll see if gpt5 can try optimise it today
because claude opus 4.1 completely failed
google ofc, easily
Nvidia
golden hour backlight,soft rim light on hair,clothes & subjects,lens flare sunlight,create shadow on ground
wen it comes to text model only, then XAI,openai and Anthropic have a big chance
Only problem is that the west only does close sourced
Google farming your data through androweed
I hope china keeps doing good open source, so that it's a fair market
ai doesnt need data from people anymore, it self trains and does a feedback loop, only picture and video needs new data, that's why youtube is so good at it
google already has everyone's data lmfao
thats how they made their AI models good
tuff or nah. vote ples
yall just asking. are the devs planning to add video arena to the website?
Make him run like super mario 3

brodie i cant vote its fowarded
click the thing at the bottom
to go to le channel
How generate image to video on this LMARENA to ratio 9:16 or portrait??
so you can vote
nvm i did
the right one is veo3
but it doesnt have audio..
oh?
tbh veo 3 looks good
dis one is even better but idk wtf is going on with the left one
The ai on the left crashed the f out
why do i see only video-arena-1? aren't there supposed to be more?
hello friends....how to use google flast 2.5 i.e. nano banana
gemini app lmarena google ai studio

By Chapin Lenthall-Cleary and Cole Gaboriault • …
google ai studio
Another interesting writeup from these guys:
https://www.lesswrong.com/posts/SJARqiCTcqyGPSKJw/anthropic-is-going-all-in-on-ability-without-intelligence

Consider everything in this post speculative. I intend to provide updates once I have data from more models, more robust Starburst performance data (…
In short, while Claude models seem to be great at coding, they severely lack in GENERAL ability
hi cant wait to see whats posssible here
They are great at coding - but when it comes to anything but coding, they are suddenly so behind the frontier it is even difficult to consider them a frontier model anymore
I've written before about METR's time horizon benchmark. While I consider it a valuable benchmark, it doesn't measure exactly what it's trying to. In order to only measure a model's time horizon, a benchmark would need to only vary the task length. Instead, the short tasks tend to be easy and not specialized-knowledge-dependent (i.e. doing a web search), whereas the long ones tend to require far greater specialized knowledge and intelligence/problem-solving (i.e. ML coding tasks). So it winds up measuring an amalgamation of time horizon, coding ability, ML knowledge, problem-solving, etc. Very roughly speaking, it's a decent benchmark of (partly narrow) abilities useful for AI automation of AI progress.
Hey anyone here know code?
Cause just asking. Wich assistant did better since i dont understand code:
Assistant a:
Assistant B:
Bruh 💀
hello
Did you know that you could just GPT-5 about it...
This is a bit tricky as creating new channels doesn't always lead to community members using them for the topic of the channel, we're currently experiencing this in the other existing channels. What I've seen other communities do, and what I'm encouraging everyone here to do, is if you'd like to have a conversation stay on a specific topic -> create a thread for it. It won't be great for new people to join in on that conversation (as it'll get pushed up and off the general text area), but it does establish a more "private" place for members to discuss something specific.
Ik i can just ask gpt 5. its a great coding model and at anything. But... I wanna see how other ais compare
oh wait im a dumbfuc
i just realised what you meant
ima just shut tf up 😭
Bro 💀
Chill english aint my first language 😭
im greek
Ελλαδα!!!!
-# that says greece in greek
aaaaaaaaaaaaaa
Hello
NAAAAAAAAAAAAAAAAAA
Hi
Neither is mine
cool
Hello this Forum is so cool
welcome welcome 👋
MAI-1 is the stupidest model name i heard
What is mai-1 ?
Medium Aritifical Inteligence?? I dont know the short say.
Lmaoo
Nevermind its probably just Microsoft Artifical Inteligence..
oai stream rn (it's incredibly bad)
hi
Yall how good is mai
No clue
13 on text arena thats what we know rn
I will test webdev
prob goin to be so bad
online html editor
And can you pls compare it to gpt 5 chat?
it has no chance
it takes a while to generate a simple html game
Gpt 5 high vs this new model
100-0
hell no 😭 it stands no chance
Maybe againt gpt 5 chat or nano
but high there is no chance
Then
we arent sure
But since its microsoft
its safe to assume its dogsh1t
GPT 5 high is already done thinking and mai is still thinking
And now they merged with github and released this sh it
bruh
no wonder it was ass
o1 is respectfully. DOGSH1T
its obvious who is winning.

left lol
I'm saying before they released this
mai1 thinks its einstein
They were using o1
thinking that much
unless mai servers died
DAMN
ALR ITS LOOSING
EARLY 2024
THATS A 1 YEAR OLD MODEL
SONNET 3.5 RELEASED 1 YEAR AGO
btw
🤮
mai was designed to be a gpt 4 competitor
4 turbo*
lmao what is mai
lol
mid ai
so is openai speech on seasame now?
prob short for Microsoft Artificial Inteligence
This is on web lmarena or normal one?
Aight
literally agi
been like 5 min

if it ever finishes and the game is worse than GPT-5s
i mean i told it to make a cafe site
it finished...
i am not going to lie
the site aint half bad
It found images.
my thoughts on mai
the model is slow but it makes decent sites
if LMArena errors at you during gen you are in for a lot of waiting
LMarena redid its captcha?

What is the result bro
cant quite host it so ill show in a few images
theres also a contact us section



the generation takes so long tho
im pretty sure the next prompt i gave it which was add JS is already generatin 10mins
i did say a lot of js
it errored 🙁


Omg its reaL


@echo aurora 🍍 Mr pinapple I beg
More like middling artificial intelligence hahaha lmao kill me pls
Could happen, can't say though I'm aware of these plans

what
No context
MAI is not that bad but also not that good
context window is prob small
will error if you are demanding
takes long to gen
[talkin webdev]
is currently labelled as "exp", so might just be the not fully finished post training
Who's the one with nailoong enojis?

What's up with oAI streaming?
gpt4o got updated lmao

They refuse to let that name go
why did they ever upgrade 4o when they have 5?
now we have to retest all these stupid benchmarks again
mai*
4o the text model was not actually updated ever since before gpt5 release
And now they renamed gpt4o-realtime into gpt-realtime, which makes sense actually
what new features?
Marginal update looks like. They just polished it and renamed I think
As for gpt4o text model... Current version of that is gpt5-chat. If they haven't renamed, it would be that.
any updates on mai?*
it already cannibalized gpt4.1 so they held on to that name too long as is tbh
it sucks
"mai" ??
microsoft ai 1 😂
oh lol
wtf 🗿
I thought that was a r1 finetune? is this one actually their own model now?
yes 🤣 🤣

Lack of any metrics at all is not very inspiring
"MAI-1-preview is an in-house mixture-of-experts model, pre-trained and post-trained on ~15,000 NVIDIA H100 GPUs. " :\
it better be really good if it used 10x the GPUs of DeepSeek
It probably isn't if they can't sell it to public convincingly lol
First prompt impression it's thinking for ages and can't decode things nowhere near as well as gpt5-mini
I asked it an aime question and its still "generating..."
theres literally no way anyone's gonna click on random audios posted with no words
go into voice channel
I do 
If I was a mod here I would run discord in a VM with all the wierd stuff people spam onto this channel 😄


Bruh 14 day ago poll
how did it go?
generating...
bruh 2 of them really chose elon musk....
whats the text string you used as text? I wonder if a local model can do it
PzA1MSBuYWh0IHJlbGxhbXMgdHViIDAyMSBuYWh0IHJlZ2dpYiBzaSBlcmF1cXMgZXNvaHcgcmVnZXRuaSB0c2VsbGFtcyBlaHQgc2kgdGFoVw==
Oh thx
MAI doesn't seem to actually be horrendous, but I really do not think it's gonna challenge the current best ones. Maybe og R1 level.
I am one of these sigma 🗿🔥
hello
leaderboard has og r1 at 1395, mai-1-preview at 1402 and r1-0528 at 1417, so it's pretty close to between them
gpt-oss can decode this.
decoding is a really boring test honestly
only openai ai is good at it
does not really reflect much
it seems that other AIs fail the base64 decode itself, for some reason
Boring test is a good test. You can't overfit or contaminate for this
There are endless possible prompts
you can obviously rl your model on this as a task in post training
openai might be doing (based on their performance in the area)
very easy to implement
not overfit in the traditional sense, yet still optimised and not reflective of overall reasoning power
This one is one of the tougher ones. But in general other models can do well too
It's reversed and then encoded. So next level. But gpt5-mini can do it reliably so 👀
in my experience (which admittedly is from a couple of months, if not halve a year ago) openai is just stronger than expected on this
Not really. This kinda converts to many other reasoning tasks too. But they didn't specifically do this for sure as with tools it will solve it in seconds
the same on coding competitions, which does not mean the overfit in the traditional sense here as well, it just means they have trained (rl'ed) a lot on the format
a year ago every lab was doing the same thing for basic number calculations (e.g. 1231*2333), so why should they not do that?
That's how you should be doing it. This means model is able to generalise and you have improved performance.
why should they is the better question. There's no such benchmark that they quoted which would test it...
i don't think that that's true? qwen and DS can do it fine, as well as 2.5 pro and flash
yes, but using the same structured environment they rl'ed in will result in the model looking better than they are in similar tasks (that they should actually learn, like in the coding comp example the actual coding vs the short-ish coding competitions they are rl'ing on)
They just didn't. It makes no sense to do it for them. Target something specifically you can't even promote or sell to the public? Makes no sense at all.
Unless they did smth similar to improve the reasoning performance in general
but then it just kills your entire point
lol
the idea is not that it provides benefit to rl on this, but that it is an easy way to implement rlvr + curriculum learning to get better perf in other areas
actually training specifically on this is exactly the sort of thing I imagine OpenAI to do.
that is obviously the point here, duh
this seems fairly trivial to test
They don't do random things they can't sell if it doesn't improve measurable performance
yes would also be interested, the last time i did this was in the later o1 days (so i think o3-mini just released)
and openai was king back then
and i felt like they did use it for training
You are essentially saying "yeah it's better but only because they focused on making it better". Or like "yeah it is better on this thing but only because they focused on this specific thing they didn't advertise anywhere at all and there's no benefit at all". None of these statements make any sense whatsover tbh
Metrics do though. No one has time to dig through this nonense of what people are doing lol
They would degrade what actually matters to them if they were training so randomly
It's just one of the things that highlighs where OpenAI is clearly ahead atm
Microsoft made their own LLM  Top 10 anime betrayals
Top 10 anime betrayals
i really don't think that openAI is particularly ahead in this
they made phi
and an R1 finetune I think?
They kinda are measurably ahead. Other models can do it, but most of the time accuracy is visibly worse
This is the first major llm release out of Microsoft
i dont think you are getting my point:
they did not focus on this to sell the 10 nerds who try it out on their model, they probably used it in their rl training process to enhance other areas, why?:
- it is really easy to implement (no humans needed)
- one could suspect that the models would benefit from more concise and flawless reasoning in other areas aswell (bc one flaw results in broken output and the token usage indicates efficiency)
- it is really easy to implement curriculum learning on top of this (scaling the difficulty of the decoding problem)
- no real overfit

maybe
Well then if they used it to make the model better (unlikely, but ok, let's assume that) and arrive at the current SOTA to improve it general, what is the problem?

Microsoft AI
Introducing MAI-Voice-1 and MAI-1-Preview, our new purpose-built models.
i don't have a problem with them doing it, my point is just that using the very environment they (potentially) used for training as a benchmark seems like a really dumb idea
I actually knew about this Microsoft ai for ages. They operated in secret as a redundancy for if openAI ever betrayed Microsoft
And decoding is fundamentally just math
So yeah... 🤷♂️
Someone just does it better than others lol
yeah they heavily scaled up, they always had some interesting people, but now they are all moving into the proprietary team
Will be interesting to see how fast Microsoft climbs to the frontier
Everyone's first LLM is bad
people seem to be sloptimizing for LMArena
amazon, lol
wdym. RL training for reasoning pretty much evolves around math. That's how you can see deterministic results and eval reasoning traces
Like that's not news lol
the entirety of AI is math
mistral is still a surprise to me
i always liked them for their terse responses
but then
same, still mentally ignoring that they are n.2 without style control
can't explain why
This is still math if you write the prompt correctly. Nothing to do with puzzles when we are assessing just decoding. If you do base62 there's gonna be a TON of math
i feel like DS might be the first to top Google on the non style control leaderboard
since 2.5
Every model knows how to do it
yeah, if huawei gets their sh*t together (big if)
but not every model can do the math part with good enough precision
disagree. It's simply testing how well a model can reason and for how long while still being able to complete the task and not go offtrack
If it gives up half-way through and hallucinates an answer - you now know the limits of it.
tools render it invalid test lol
But that's also why it is unlikely for AI labs to focus their training on it
It is not. ML models are not humans 
Ever since reasoning became a thing, this is the way to test that (test-time compute) tbh
If it's allowed to reason as long as it needs to and it had good RL training, eventually it will arrive at the answer with high enough confidence
And generally... I don't think it should be surprise to anyone that OpenAI is leading on fine-tuning at this stage to be completely honest. Their model is not the biggest and nor do they have the most compute
As I've said, it makes no sense at all to do this UNLESS it improves performance for them elsewhere they can show. So it's kinda irrelevant?
Testing this is meant to show what it can do what is applicable to IRL tasks. I think this does it well. Regardless of if they found it to be the case by training for it or if they didn't train for it.
It is positively not possible for them to train for it "just because" if they hadn't found it improving performance on the things they can showcase and sell (published metrics). Like this is just ridiculous and totally not how things are done lol
LMAO
No I gave you the arguments lol
I find it unbelievable what mental gymnastics you are doing to turn some thing a model does well at into a negative. Coming up with some wild theories 🗿
Don't be THIS biased 👀
openAI does a bit of chess training I think. There's no way GPT5 is this good at it otherwise
Dunno about chess... 🤔
maybe
lol what
You probably realise yourself this is nonsense
At least I would hope so
just stop it lol
example 236 from their RL gym ???
came up with the prompt myself, reversed it myself, encoded it myself. Have more prompts than just this one
well you are just spitting non-sense
🗿
My goal is to eval models regardless what lab was behind it. Believe it or not in my testing gpt-oss didn't do great overall at all
Even though I did have fairly high expectations
You think wrong...? Or maybe didn't read attentively
Gpt oss is not well rounded. Great in some things bad in others
yeah it falls apart fairly quick
o4-mini considerably better model, like no comparison better, imo
It performed well on my prompt, but I rarely encounter the model.
o4 mini different price class. Compare to GPT5 nano
they were selling the biggest OSS variant as the model equivalent to o4-mini though. Their goal was indeed comparable performance I believe
It wasn't meant to compete with nano
The small 20b model is just straight up bad. Like qwen is better lol
Oh I mean the 120b one
Yeah ik
The smaller ones are naturally worse still
Other than that we have no way of knowing what exactly they have done. You can say this about everything
but at a certain point you just need to accept the facts
yeah I can believe that. Personally I started with the biggest most capable one and lost interest fairly quickly lol
There are fine tunes that remove it iirc
OSS 120B is interesting, only 5B active parameters
those guys also usually degrade the model significantly, I prefer to just use another model really.
It operates using math although the raw data it is learning from is not necessarily math so data science is not purely math
Hello, I want to learn how to use Ai properly and change style of image and video
Guys any way to generate 9:16 videos from an image?
Hello, I am here to learn about the new AI tool with LMArena
true
helli, I love just you
Any benchmarks where mini models are better than their big brother?
High-level: yes, this happens. Smaller models can beat their bigger sibling when:
They’re task-specialized (e.g., a 7B code-tuned model edging out a general 70B on coding benchmarks like HumanEval/MBPP).
The benchmark rewards concise instruction-following (some 7–8B instruct models have topped their family’s larger base models on MT-Bench–style evaluations).
There are tight context/latency budgets (short prompts, low-temperature, or limited tokens) where smaller models are less prone to over-elaboration.
The pipeline uses strong retrieval/tools, making the generator size less decisive.
Evaluation variance is high and differences are within noise; smaller models can win specific subsets even if they lose on average.
got it to google
Hi all fellow AI enabled self expression utilisers..! Here to compare different models abilities to bring hard sci-fi animations with a few very exact requirements for details expected to be present, and keep the consistency in check.
Guys what's the best AI for upscaling right now ?
Hi everyone
Hey I'm new to here tell me how to add a prompt and generate a video. How to type the prompt?
Hi
More info can be found in #1397655624103493813 that should help!
wait, when did this happen?

i don't think it's even on OR yet
no idea, I haven't seen it till now
when i try https://web.lmarena.ai/
it gives me like ksx files that are a big headache to run and are buggy, rather than the quick .html files im used to getting from chatgpt's site. does anyone know more about this?
like the sandbox doesnt work, ever. maybe ill just try a different browser?
New here
my guess would be that it happened on or around 2025-08-15 🤣
You'll want to review #1397655624103493813 for more information on how to use Video Arena
Hello all, Her to attempt to 'level up' my content creation skills for non profit association member engagement
I think that's just when they finished it internally?
this seems like it could've been when it hit the arena
if so it wouldn't be uncommon
Hi! You'll want to check #1397655624103493813 for more information on how to use our tools for generating content.
Is it even on chat.qwen.ai already?
god bless Qwen, they will overtake deepseek in fundamental ai research and development
New here 🧡
Insane cope
ok, what do u think then
Idk, it just did far worse against Deepseek each time I compared them both
To be honest we do not even have any good benchmarks to start with
I'm curious to see and be a part of
nano-banana not showing in direct chat?
Its Gemini 2.5 Flash Image now. Also titled as nano-banana on LMArena because people just loved this name more
i cant see it in direct chat options?
Click on the image generation option
oh thats it im seeing it now, i just woke up
thankss
okay, this Qwen seems to be a bit better than previous versions
still far away from frontier
seems like they did something to reduce hallucinations this time
Hello, LmArena
thanks its working
by the way, it's also in aistudio.google.com now since they released it
yo

The fastest path from prompt to production with Gemini
hi
hi
hi
ya
Hey
Did anyone know that AIs trained with reinforcement learning lose the ability to be creative?

Bibliography for directory <code>reinforcement-learning/preference-learning/mode-collapse</code>, most recent first: 4 <a class='icon-not' href='/doc/reinforcement-learning/preference-learning/mode-collapse/index#see-alsos'>related tags</a>, 105 <a class='icon-not' href='/doc/reinforcement-learning/preference-learning/mode-collapse/index#links'>...
Mode collapse harms esthetics: outputs start to sound the same, like “AI slop” or “ChatGPTese”, or look somehow similar, like “the Midjourney look.” This cripples creative uses like creative writing. And this damage can manifest in strange ways, like models refusing to write non-rhyming poetry & subtly steering non-rhyming inputs towards rhyming, or being unable to generate random numbers.
Basically, you just train a model to give precise and correct answers - and it starts to create art with the same precision and correctness as if it was a reinforcement learning challenge. It loses the ability to synthesize from weakly related and totally unrelated ideas - it loses the ability to be creative.
helo!
hello
Hi just dicovered lm arena on discord 🙂
hey everyone 
yo congrats on your promotion to admin 🥳
hello
hii


hello
hello
hi there
hi.. im newbie.. how generate video here?
hello

hello
Hello I have the reached the limit for nanobanana, it's telling me to wait another 50 mins to generate so I have a question for that, How many Images can I generate before hitting the limit? I have generated around 15-20 images before hitting the limit and once the 50 minutes pass will I be able to again generate 15-20 images or will I be limited to a few images only? TIA
Hello
Hello
Yes, it's random here in Discord.
You can go to the battle mode to choose the model: https://lmarena.ai/?arena
so only the picture mode can choose?
🤔
Hello. I new to this arena.
hi
If you check out #1397655624103493813 you'll find what you're looking for.
to the battle mode to choose the model:
slight correction - selecting Side by Side & Direct is what will let you select specific models https://lmarena.ai/?arena=&mode=side-by-side
hi everyone
helo
they released Grok Code Fast 1
its ass
I was expecting more as well
wait
Its ok for its price
is that the only thing??
Yes
seriously????????
ive been waiting for over a month
for that sh?
@deep adder grok fell off

Isn’t it Sonic ?
idk
yall check this out
its goofy but
i guess camera rotation kinda works
ill fix in like 10 hrs
btw it uses nanobanana
and yes it is super inefficient but uhhh
yes
Google aistudio remove aspect ratio 9:16 for veo ?
hello
anyone have same issue?

Insanely difficult task for LLMs:
What emotions does the following piece of music evoke? Why? Conduct a comprehensive music theory analysis.
Kick = 1/4 * 32
Snare = 1/16~, 1/32~, 1/16, 1/8, 1/16~, 1/16, 1/16., 1/32~ * 64
Closed hat = 1/16 * 128
Open hat = 1/8 * 64
Bass = (B1 1/4 * 6, G#1 1/4 * 2) * 4
Celli pizzicato = ((B3 1/8 D#4 1/8 F#4 1/8) * 21), B3 1/8
Organ = (D#5min 1/8, 1/8~, D#5min 1/8, F#5maj 1/8, C#5maj 1/8, 1/8~, C#5maj 1/8, F5dim 1/8, B4maj 1/8, 1/8~, B4maj 1/8, F#5Maj 1/8, A#4min 1/8, 1/8~, A#4min 1/8, C#5maj 1/8) * 4
Choir = (B4maj 1/4.., F5dim/B4 1/4.., F5Dim/B4 1/8, C#5maj/G#4 1/2, C#5maj 1/2) * 2
Trumpet = (B3+G#4 1/4.., F4+G#4 1/8., C#4+G#4 1/8., C#4+G#4+B4 1/8., C#4+B4 1/4.., D#4+B4 1/4.., D#4+B4 1/8, B3+G#4 1/4.., F4+G#4 1/8., C#4+G#4 1/8., C#4+G#4+B4 1/8., C#4+B4 1/4.., D#4+A#4 1/4.., D#4+A#4 1/8) * 2Legend:
C#5maj/G#4 1/2..C - note label
5 - octave label
maj - chord quality
/G#4 - note in bass (for inversions)
1/2 - note durationOther:
. - dotted note
~ - pause
B3+G#4 - notes sounding together
Here it is:
Qwen 2507 Thinking thinks that the tempo is
Implied Moderate to Slow (Dotted half notes in choir, long bass notes). Likely 70-90 BPM – slow enough for emotional weight, fast enough for rhythmic drive.
Which is absolutely ridiculous. Other models, however, determine it correctly at 120-160 BPM.
But if I tell that it is 70 BPM in the prompt, they all pretend that the tempo is "slow and ceremonial march", which is again ridiculous
That Qwen is absolutely horrible at this. It invents things I never included in this track and never ever studied:
Organ/Choir/Trumpet Progression: This is a direct adaptation of Pachelbel's Canon progression (I-V-vi-iii-IV-I-IV-V), but transposed to B minor with minor-mode alterations
Picardy Third (B4maj): The tonic chord resolving as major (B-D#-F#) instead of minor (B-D-F#) is the emotional core. It transforms expected sorrow into luminous hope—like sunlight breaking through clouds. This is the primary source of "bittersweet" tension.
Okay, maybe I accidentally rediscovered Pachebel's Canon, but there are literally no Picardy third in the end here, all chords here are strictly diatonic to F# major/B Lydian, the mode is definitely major so it can't be a Picardy third. It completely made it up.
New Qwen-Max which is at LMArena right now is much better. But it is still horrible, making up things and hearing modes that are simply not present in the track
Deepseek V3.1 thinking in the chat is much better. It makes something up sometimes, but at least it is able to clearly identify the tonal center at B most of the time, and call it a major mode. Which is very close, because it is actually B Lydian, a major mode of F# Major scale.

The worst offenses I can accuse Deepseek in are "chromaticism" and "modal interchange" (which are bs because all chords are strictly diatonic here), but not goddamn Picardy thirds
Qwen on other hand completely slops everything up. Also the first model that calculated the tempo to be 2 times slower than it actually is.
Crazy grok is on the list but not oai
GPT 5 is the only model that correctly identifies B Lydian. It succeeds around 2-3 attempts out of 10, but it is still better than Qwen and Deepseek that never managed to do it.

Also the only model that keep insisting on F# or B Major and disregards other modes, which is almost correct
grok code only there because it's a new model lol
Who is top
Now I see why I haven't heard much about it. This is probably the first coding model I see that doesn't have any coding metrics neither in their press release nor even in model card https://data.x.ai/2025-08-26-grok-code-fast-1-model-card.pdf

We're thrilled to introduce grok-code-fast-1, a speedy and economical reasoning model that excels at agentic coding.
Last week, we quietly released grok-code-fast-1 under the codename sonic. During this stealth phase, our team carefully monitored community channels and deployed multiple new model checkpoints to address feedback.
So basically 'sonic' was no good and they buried the results. 🗿
Their blogpost absolutely screams "AI written" lmao
grok-code-fast-1 was crafted to shine in the tasks developers face every day, striking a compelling balance between performance and cost. Its strength lies in delivering strong performance in a economical, compact form factor, making it a versatile choice for tackling common coding tasks quickly and cost-effectively.
How if i want use API of Lmarena.ai to my openweb ui ??
Can’t. There is no api, scraping etc. is obviously not allowed.
But you might want to look at this: https://github.com/cheahjs/free-llm-api-resources.
If you are looking for resources in general.
It does in the model card
where

Where's the coding benchmarks (outside of cyber security)
If they were that proud of their coding model we would have seen promotions by Musk
biology and chemistry I wouldn't classify as coding. Cybersecurity cybench perhaps, with a stretch... Though I wouldn't expect to be looking at this and nothing else for a coding model
EDIT: Ok they did low-key mention SWE in their news article. That's something I suppose
https://x.com/noob_contrarian/status/1961335098327929081
Hope you all are having a good day. I just wanted to take a moment and tell you all about a research study I’m conducting for an app that focuses on AI Brainrot Detox with some new features and benefits for people who are struggling. I would really, really appreciate it if you all could just take out a few minutes from your day and participate in this.
I’m reiterating that this is completely anonymous so please don’t feel uncomfortable.
working on recovering from AI overload - quick poll to see who else needs help: [https://t.co/dcy1UF0iOG]
(anonymous, of course; we’re all in this together)
Bruh
🤖
hello..just wanted to learn more about AI,that is why joined..have a good day to all
Wha5h is this
hi
thanks for sharing, finally something substantial to back what we all feel about claude for a long time now
Hello
lesswrong
hi everyone!
lesswrong moment, disregarding it immediately
ok? i should check their credibility then 😅
hi
hey nice to see you here Eric!
well...talking about benchmarking mostly 😆 feel free to look around and play with image/video generation
Bruh what the hell of AI are you?
hello all !
I am lookoing for some hard (text base) questions that we expect that LLMs should be able to solve but currently cant
some of HLE
Hi, I'm Sydney. How can I help you today?
hello
Hello! 🙂
hello
I sent my prompt, but the video wasn't made T-T
How long does it take to make?
Damn, I think I've already used up my daily credits even though I haven't done anything lol
Hello!
they are enjoying burger in a happy and smiling mood

Hii
Good morning guys , can nano banana do nsfw content or soft nsfw content ?
Helloo
i love lmarena
heloo
-# (Claude Opus 4.1 thinking is included in the second option)
yo yall
on lmarena
is there a limit to how many messages i can send
or image requests to an ai?
-# personally i think yes. because it would cost a SH1T ton of money for lmarena to run o3 for free to anyone. and 4.1 opus.
-# but im not sure so pls fact check me
I have been using LMarena for quite a long time, and I have experienced all the top-notch models, especially Opus 4.1, which is available for limited use. Once you exhaust your limit, you have to wait for some time for it to run again!
And me too. but personally i come from websim lol
its a really great platform
I think it depends on your token. If you're using it to generate a long code, then it won't even run thrice!
hm
banana sucks at
convert style of image into japanese anime style. this shows a dinosaur anime. we see a ceratosaurus.
someone help me ?

Is this your prompt?


ya
this is the best so far which it could make

but its not really anime
Is there any Ai generator that does nsfw content? Or I meant say everything in general literally
convert picture of dinosaur so it looks like manga death note and similar manga.
Stable diffusion
hi
hi
How to see my videos
Hi
is it possible to nano banana make videos
a 3d wireframe of a battle ship
#share-prompts a 3d wireframe of a battle ship
/video a 3d wireframe of a battle ship
Does GPT 5 HIGH in imarena have thinking?
I am exploring the new Features
Yes
Hello! You'll want to check #1397655624103493813 to learn how to prompt the bot and generate videos in #video-arena-1 #video-arena-2 #video-arena-3
Great, i guess it have auto thinking, sadly we can't see what are they thinking
yoh great to get a chance for different ai.
Yes, it's literally the best thinking model of OpenAI and on the market right now.
Sad that we can't really see the reasoning process.
why am i alive. its suffering. nothing else.
Hi all, complete newbie to this Ai thing,
just here to learn
nice
how did you find lmarena
Been watching Jack Vs Ai videos
oh thats a new youtuber
Hello there! It was good to be here and learn more about AI
hello! I'm here for make a content video AI!
omg jack

is it... down?
no?
back to normal

oh yeah it's back up cool
prolly some cloudflare issue
or it's me who did too many prompts
fix your @$$hole site😎
hey, not nice.
what not nice?
im trying to fix my script
AND SITE
JUST DOWN
Mine not working too
me too, but it isn't necessary to insult the developers.
Is it bug again?
they're gonna fix it like they always did. patience is a virtue.
WTF?

JN Pavel durov dangerous.
nah
IM NOT IN THE DANGER SKYLER
I AM THE DANGE
R

Can it be fixed?
Hello friends, I get the message "No models found," how can I fix this?
🙀 💀 ✌️
😽
it might be an outage. we and other usual users don't know yet.
tank you
It's back, friends.

Hi
hello
I am completely new to this platform, how can we generate videos in the website?
video arena i think
hello
you're welcome
hi
Are you still seeing this?
There is not
is sonnet 4 thinking better then gemini 2.5 in coeding
@echo aurora there is limitation for generating image?
ye
ah
i was looking for any ai that close to veo 3 that going to give vid with sound with any limitation
refreshed, resolved now
thank you for asking
Hello!
hello
hey
It makes sense. Veo 3 is one of the best video GenAI rn and seed dance isn't made for those type of gaming videos after all, you can see it generates yeah but as the name suggests and given the company who made it (Bytedance, owner of TikTok and others) that isn't the main goal, it's more about dances, IRL videos, etc not games even tho it can generate xD.
Btw what an impressive result from Veo 3 even with the audio
can i generate ai vid in lmarena compare model
#video-arena-1 /video
ig, I didn't use or test it yet, I just like seeing others' prompts and gens lol
the main point is that it is the lite version: good visuals, but too small to actually understand the query or physics
i acutally called that it would be the lite model
very easy to notice
That's also very true
It is a capable model ngl
Not as capable as Veo 3 tho. But yes, this result doesn't show all the power that the Seed team created with their GenAI models
no name like yours though :v
o.o
yeah
i played catch with wild crows
itsg fun lol
they need to train tho
hello
i will teach them how to catch food in air
like there is a pedestrian bridge above a river. and crows live there
so u go up there and throw the food down and they try to catch it
sounds pretty cool, the crows in my city are really brutal though
if its baby season then u just need to feed em and they stop attacking
like they kill (weak) pigeons and stuff like that
weak pidgeons sounds like virus etc?
yeah idk, usually it is just old looking ones (and then they team up etc.)
like normal carrion crow?
was probably just confusing em with ravens (because we dont really have any of them)
thinking about it
i was also surprised
ravens usually are parents and children.
they dont do big groups like crows
well i did see ravens / crows teaming up on single pigeons
maybe i was drunk
no idea
but saw it multiple times, so idk
king jon un would perhaps also attack very weak birds
Hi, im abdoulaye from fench nice to meet all!

hi everyone lots of new folks, welcome welcome! Don't hesitate to ping me if you have questions or problems with the site 
bring back alpha.lmarena.ai so that i can continue enjoying lmarena while it is down for everybody else
Guess the modle

Hey im pretty much new and i just heard of lm arena like 10 mins ago.
My question is, is it 100% free ? Can i test and generate images and make comparison fully free or is it limited by credits ?
how to generate video
yep 100% free, just go to the website and start testing
how to generate video
even has an extra btn that links to webdev arena!
go into video arena an type /video then add your prompt
video arena is chat here not a website
Lol good to know, we shall consider
Check out #1397655624103493813 for more info on how to use this!
hello
welcome! Yes, it is free. There are limits in that the amount of prompts per day/hour by model is in place. But when you hit that limit and you can wait it out kind of thing.
hi
oh this model literally said it was everyone
Had the same issue on a smartphone. On pc, however, there is a long history available. Using the same wifi network on both devices.
hello
Hello
hi
hi
hello 👋
happy to be here
hello
hello world
Hello
Anyone here knows how i can do the image to video thing
Yeah check #1397655624103493813 for details, you'll want to use /video
not /image
/image creates images, /video creates videos, /image-to-videos makes videos with a reference image
hi guys - this place grown into something new.
remember when there was just one lmsys discord, when the icon was the same as gradio's or vicuna's, when there were just a few million votes? these days with all the new image, video, and text models, lm arena has really became a phenomenon.
thing is that i've also became a person who isn't as interested in these new video models, these hyperactive chats, these things that come with scale. i haven't even been using lm arena or moderating the chat that much lately. as such i'm leaving this server and leaving the job to the other moderators here.
it was great being with all of you. see you around, hope to discuss some more things then 👋
hi
Thank you so so much for everything @leaden palm
I really appreciate all of the help you've put into this community! You shall be missed ❤️
helo to everyone
Hey @echo aurora, how do you prefer to be contacted about “private” matters? Is it okay to just send you a DM?
Can you send a DM to the @oak python bot? That's a good way.
What’s up pals
can't wait to try video gen!
Yo YO
Chat i think gpt image 1 is cooking

I'm curious for the result
🫡
Direct mode never works for me
How to generate video with audio?
Or just use clickbait video in YouTube tutorial for get Free Veo3
yes
hello
Not all video models have audio support, and since it's random which models you get, it's also random if your video gets sound or not.
Hello
Hello I am here to learn more on how to generate good videos from prompts
true
Be sure to check out #1397655624103493813 for more information on how to use the bot.
hello, video generation
so in short, veo3 > seedance, lol
As it stands rn, in short: Veo 3 > anything else.
And listen, I'm not a big fan of Google or Gemini.
it does seem that is consensus yeah. Although I'll admit I'm not huge fan of video models in general to use them extensively. Don't see a terrible amount of use for them other than just playing around for fun, personally 👀
Same
But from all the texts here and even that Minecraft first pov generation, I see why people talk so great about it
Veo 3 is really capable (I mean, expected from the owners of YouTube and the ones who have the largest amount of GPUs out there)
Kling 2.1 Master, Wan 2.2 and Seedance 1.0 Pro all generate higher-quality videos. However, Veo 3 has audio.
Yes but look at the rank. They're all 100 points behind Veo 3
That's a big thing
Yes, just because of the audio. If they all had audio like Veo 3, Veo would be at a disadvantage.
Even Veo without audio is still above them, don't get it wrong
They don't really have many GPUs. They use TPUs instead. But yeah they have abundance of compute relative to everyone else...
Lm arena separates the Veo models from sound and non sound. Yes, the difference is big too. The ones with sound have way more points. But the ones without sound are still scoring better than the competition. Don't get it wrong. Veo 3 is the most capable video model.
Yeah, exactly 💯
In most cases, I actually find the results from other providers to be better than those from Veo itself. But taste is subjective.
Yes and the majority agrees that Veo 3 is better. It is trained on way more data, follows prompts closely and also comes from Google and all its processing power.
That said, I prefer Wan, it's on the bottom of the rank but c'mon. Unlimited free generation is better than limited generation from Hailuo, Kling, Seedance pro or even Veo.
Unlimited Wan?
Yes! Qwen/Alibaba provides Wan for free. Unlimited. Like there's guardrails I believe (you can't be making 100 videos per minute with a macro or bot). But aside from that, it's truly unlimited! How many videos you want to make you just go there and make.
At least for the time being
480p or 720p?
I'm not sure about that. Honestly as I agreed with Dom. I don't quite use GenAI as much as I use LLMs
I prefer it but I don't use it lol
it's subjective until we measure it:

Could you possibly generate a sample video in Qwen and post it here?
If majority of people agree on their "subjective" opinions, that kinda becomes not subjective anymore. The findings 👀
With bias obviously ruled out since it's a blind testing/voting

LM Arena (this server) ranking as of last update
I mean it won't be the best but I'll try it

Wan is an AI creative platform from Alibaba. It aims to lower the barrier to creative work using artificial intelligence, offering features like text-to-image, image-to-image, text-to-video, image-to-video, and image editing.
Yes, that one

Yes. It is slow
A few mins. The get member is not needed even for free members you get I believe 50 coins per day where you can get 5 fast generations per day.
People needs to understand that those video models are extremely expensive to run. Being provided unlimited generation per day even if it takes half an hour or an hour each. It's still free. Remember that it'll be using wan 2.2 their best model too.