#general
1 messages · Page 82 of 1
glm 4.5 is still better tho
i hope so
qwen 3 think is absolute trash for coding
He has always been like this, there is little modern training data
The openAI 120B model scores 44% in aider on highest reasoning mode
That is awful
It's basically a paper release. To say they open sourced smth
And I don't know what all that hype was about
Guys
What's the best model for coding ?
The horizen beta model wasn't the open source model
i dont know brother
Ofc
maybe claude 4 sonnet or the new opus
I tested. Their kmowledge cutoff is diffrent
What abt Gemini 2.5
Yeah well it's obvious. Because horizon beta is not bad
Kek
Sad
The arch also has 0 Innovations
It's basically just taken from Chinese LLMs

I guess they wanted to keep anything good for themselves
I don't see the point in the model ngl. Apart from PR
I'm still getting "potato" in the arena. So it was not open source model. Or not the one that got released.
ok after 1 hour testing openai oss models, bad vibes for code
hello
My guess is it's good for summarization and maybe some basic math. Worth checking. If it can't do those well, that would be disappointing
it was apparetnly gpt 5 low effort
I'm excited for the lower hallucination rates more than anything
The modest bump in reasoning is nice too sure
the hallucination rate is higher for oss
do you know if it's lower with gpt 5/
Gpt5 is much lower
nbice
source?
I have an instagram account with over 300k and I don’t want it anymore
They announced an entirely new method with verification a bit ago
yeah but how do you know halllucinations are lower
Yo guys, does anybody know if the horizon models on OpenRouter were the GPT-OSS models?
Any free Ai agent tool that let's us use Ai on browser to perform any tasks?
Definitely not. Horizon Beta is much stronger. It could be GPT-5 low effort, that would make sense for my testing at least
Looks good for coding. Not something I'll be using, but unfortunately if it beats opus 4.x then they may have a cash flow crisis
anyone know how rate limiting works in Gemini pro?
it was a very minor upgrade
nah its mid
no
most models won't fit on that
you might get lucky and someone will quantize it enough to barely fit on 6gb, but realistically upgrade your GPU
or accept CPU inference
Possibly, but unlikely tbh
Quantized 4bit right now uses 10gb
Depends on your CPU, RAM, quantization
My experience with smaller models on a 128core AMPERE box has been, 5 - 10 TOK/s
So, don't expect fast.
Probably like, 1 - 2 TOK/s?
Better than nothing
Try it with Llama.cpp CPU mode
never used it.
keep your expectations is low is all I can really say
I personally run models on a M4 Mac Mini
usually using exo so I can cluster it with my M1 Pro MBP
Llama.cpp now supports clustering via RPC but it's very experimental
exo was designed from the ground up for clustering
you're not going far with that
You're gonna wanna upgrade
I'm using a RTX 4070 Super Ti 16gb, and even then I can't fit most models
the ones I can, aren't that fast.
I like mac clusters for energy efficiency
if you don't care about energy efficiency, go NVIDIA
idk
you just gotta try
🤷
I use finetuned for chatting models
I'm really liking GPT-OSS tho
It's a nice model
not a expert at anything, but well rounded.
o3 mini -> GPT OSS 20b
o4 mini - GPT OSS 120b
Tbf. The openAI open source model is efficiency SOTA. It has only 5.1B active
no one knows
it's just MOE
It is much smaller than qwen3 also
I wish someone would implement Apple's papers about streaming LLMs from disk to RAM
It performs just below the big qwen3 model and half the params, way less active
Qwen is 235B with 22B active
I'd say it's better than qwen3 by a long shot
my experience with qwen3 is it never follows instructions.
Knowing them they’ll probably call it o5
No. It’s GPT 5 confirmed.
No. Any storage.
It would be ideal with nvme
are you the yupp ai guy?
what even is yupp ai
But you can run a LLM on a pentium 2 pretty fast if you really want
prboably
ye thats right
thats right too
GPT 5 will be non reasoning
????
honestly openai def did set a bar for open source models with oss
who lied to you?
???
iirc at the start of gpt-5, its sole purpose will be to route to reasoning models when appropriate
yeah exactly
What would they make it a reasoning model. It’s a non reasoning model as we understand now. The o series models reason.
it's not a normal continuation of the gpt series
Gpt -5 is a model integrated by multiple models
they r changing the game
So non reasoning
yep
what makes you certain it will be non reasoning?
gpt-5 is more of a system than a "non reasoning model"
GPT-5 is releasing this week
We don’t know yet. None of the continuations have been super consistent
Ye
ye
bro its exciting lowk
and i wonder how it will do against gpt 4.5
and who it will be available to
Sam Altman posted a screenshot of its output already. Also, the GPT-X have consistently been non reasoning.
show ti
*show it
Infinitely better I assume.
I think after GPT-OSS and GPT-5 OpenAI will probably run out of steam for a few months
tbh gpt 4.5 had too much hate and is underrated
for that query, it decided to not reason.

wait where did u find rthat

sam post
its on twitter

this is like matching some alignment proposals people made years ago
that's pretty neat
Do you have solid evidence it will be a reasoning model?
gpt 5 seems like the future tbh
hopefully it is free for all of us
Gpt 5 will be a reasoning and not reasoning model
It had hate because it was a stupid model.
At the same time
it's not
maybe in arena it will be
ay lmarena got us tho for that
Sam Altman said it will be free for everyone so yea
I doubt GPT 5 will be reasoning. They just sorta fixed model naming.
oh ye i forgot
@devout vault he didnt said that, he said that free will receive something, plus more inteligence, and pro even more
Why would they backtrack and Use the naming scheme from a non reasoning model.
for a reasoning model
i bet hes gna do smth like gpt 5, then gpt 5 pro for paid users or smth
I like the not reasoning models more tbh
They are more fast
I don’t see how they’re going to improve on O3.
its reaoning and not reasoning
just because something is reasonning does not mean it is the best
tho tbh o3 is darn fast for a reasoning model ngl
at least much much faster than o1
No, it’s the best because it does an amazing job at every task I’ve thrown at it to date
O1 was impressive. O3 is insane.
haha ive acc seen it screw up a bunch of times
agreed
o3 is the best model for me
Same. But if you talk to it about what it did wrong it quickly corrects itself.
O3 has been amazing
oh nono it has done some mistakes too still
if opus was the same price then opus would be the best
O4 mini makes too many mistakes in my experience. O3 doesn’t really hallucinate either.
You want Claude if you wanna program.
could be
gpt 4.5 is another rich only model
4.5 should’ve never happened.
subjective, i keep on swapping between o3, 4 opus, and gemini 2.5 pro
O3 imo
i like how claude explain things
Gemini has massively improved
Gemini is the most exciting model tbh.
claude is goated in writing
agreed
o3 talk to you like always doing technical report
Not the best at anything. But it’s skills keep growing by the day
Gemini was like a kid that grew up quickly. Now it’s in college.
And it feels like it’s going for its masters degree soon
its context is also hella high
TPU effect
ehm... the big positive is they stopped inflating numbers with parallel compute. Other than that very marginal update huh

and also i have gemini pro, i never felt 2.5 pro hit its limits except for once
TPU go BRRR
i used claude opus 4.1 in warp and its hella good
bro is impossible to tell the difference between opus 4 and 4.1 on arena
Imagine if Apple just dropped an update to Siri that BTFO’d Gemini.
They have their rumoured answers app.
damn thatd he crazy
You basically need identifiable data that wouldn't be based on overall performance lol
yes, that's why i said on the arena
I'm intrigued by this open-source model though


o4-mini-high performance, almost
and all the features looks like, even the reasoning effort retained
It's already free to try
that's how I'm using it right now.
Universal WebGPU support when?
I want WebGPU
in aistudio yes
imagine if we had a beauwolf cluster crowd sourced from the internet
using WebGPU
Imagine.
It's insane that this is 5.1b active params and 117b total
It's been done
🤯
there was a model trained using a cluster over the internet.
What's insane about that?
Like they are actually decently ahead of the competition in OSS
it's a MOE model?
that it beats R1 and every other model alike including Kimi2, while being much much smaller
Yeah it was great at the time of release but can't really compare with recent models anymore
this is beating real R1, distill has no chance lol
r2 already got released as update of r1, the same way that gpt 4.5 was gpt 5
yeah it is and I'm sure some things R1 will still do better, web development being one of them. But as far as most benchmarks and the average is concerned, this looks like it will beat R1 on them
Ok that's lame
r1.5
just like o4-mini does
I'm still not sure what to even use these models for.
I literally have no where I've found I can integrate most LLMs into my life
beyond misc tasks.
its not good
from my vibes, not good
its like openAI is laughing in our faces
what is your use case?
So far, programming.
yeah prob that's good for it
cause with javascript it sucks
It can't be that bad
verbose broken code
glm 4.5 is better
well im sure its better than qwen 3 think 2507 at coding lua
It's lua isn't horrid.
i don't like qwen models
qwen are the worst models.
qwen 3 coding is terrible
yeah
God qwen is a meme
o4-mini except open-source. Factually, this is extremely impressive. Subjectively I'm not a fan of small models lol
but this is still insane to have it for open-source
why do you not like small models?
for me if the model can accomplish certain tasks, the size doesnt matter
they struggle with spatial and context awareness, creativity... Fundamentally they are only as good as most benchmarks test for and not beyond that. Which still results in a great model, but there are compromises...
I've not had these issues so far
Thos open source models hallucinate a lot more than o4 mini
Thankfully we do have SOME benchmarks that highlight this like SimpleQA
o4-mini is not scoring high there lol
if you want a model to rp or conversation i agree
I find most benchmarks are bad
but for real world tasks + privacy small models is the way
Also, Dom, how do you handle passing context to local LLMs?
Like in a chat enviroment
When it's a singular user, it's easy.
I think you did just brushed it off perhaps. By context awareness I mean small model will at times struggle to read between the lines (will take your joke literally like you are dead serious or ignore the context in which the message is written etc), it will also "forget" things sooner....
And when you make it draw something using code and compare that to a bigger model, it's really like a kindergarten child versus high school student lol
The first one is something models can generally not do the greatest with, the second one is more of a context window issue than anything. RAG can fix that
It's not a context window issue, small model simply does not have enough capacity.... You can make the context 10M with no sliding window and it's not gonna change anything. Reasoning helps but when we are comparing small reasoning model against considerably bigger ALSO reasoning model, that kinda nullifies and the difference is still there.
I don't completely agree.
And the first one - models "struggle" yes, but the small ones struggle much more than the big ones. Compare 4.1-mini with gpt4.5 and you will see what I mean.
Or even like og gpt4 vs gpt4.1-mini
I wouldn't blame that on model size though, look at Meta's foundational model and how much it struggles.
Behemoth, and maverick both dissapointed. Behemoth has 2T tokens, Maverick has 400b
gpt-5 came out?
how do i get to the open source model?
Model size increases capacity (just like reasoning does in a different way). The threshold is constantly moving and small models are getting improved - that is true. But it's also true that there are things small models struggle with. It's just what used to be "small" 1 year ago is now not the same size. Contrasting examples (huge models) are still relevant though
The thing is we're discovering that more tokens != better model.
we used to think higher precision = better model
are these open source models good?
I like them.
like its the best open source?
They're out performing a lot of older models for sure
Does gpt OSS 120b beat any good models
They're not perfect, but they've been just wow
I'd say better than R1, even the 20b one.
they're not as good as the closed source ones, but most of what makes the closed source models good is tool calling.
It's now all about RL training and the quality of (synth) data. I think the human data is just about exhausted at this point too lol
we've been doing RL for so long, I don't get why people are suddenly so focused on it again
yeah, rl and synth data is the way
I actually wonder when synthetic data will be too little.
Genie 3 provides a great environment for embodied models to train in.
Well because it wasn't a thing earlier at all to make the model output 40k+ tokens
TBF, viability was an issue.
4k was just about the absolute max you could get out of them
IMO does.
You absolutely do if it leads to more accuracy and better performance
hours long reasoning to crack gold
most of that 40k is gonna be reasoning
Millions of tokens of reasoning tokens for IMO
no one needs more than 640k of memory.
(est)
What about compared to qwen3 235B A22B 2507 thinking/instruct ?
Haven't tried the latest qwen models, I was that put off by the older ones.
It is much more general than the qwen models as they were "RL-cooked"
Google because TPUs and virtually limitless data
And Cerebras, because they managed to turn an entire silicon wafer into a TPU
Cerebras relies heavily on quantization to serve models
I thought they were pure inference based
with 20 petabytes per second bandwidth
google is looking into making pure inference based TPUs that cannot be used to train
(lex fridman podcast with CEO of deepmind)
I don't get how you can make a inference chip that can't train.
That's like saying a calculator that can't multiply.
Unless they're literally turning the model into a ASIC
but that would have zero flexibility
Mostly likely by heavily specialization into inference based techniques and baking them into the hardware akin to the biological substrate
But then they would not be "upgradeable"
Gemini just got upgraded to have voice narration
You'd have a fixed model in hardware
No not like that, the weights would be switable of course
What?
yes, but the model being fixed would be a problem.
Model designs have been evolving
we have diffusion llms now
Ah, the design will be an issue.
I don't see inference only accelerators making sense
you're stuck with the architecture you made it for
Huge short-term gains though
Apple is rubbish
Give me more ANE cores.
Fight me.
Apple's ANE has insane perf/w
They need to stop handicapping it.
Not hardware wise but their mindset impairs them.
Look at that "illusion of thinking" paper
You mean the Copium paper?
:v)
yu[
lmfao
trash

Was disproven
See the speaker?
It was never proveable.
isn't on the web though
that's the issue
Wasnt on th app before
You can say "well they can't really think, they just re-structure data from their datasets and fail if you change small variables"
The examples they put forth were quickly disprove eg the game of hanoi one
but guess what.
a human in the same scenario would fail
Is human thinking an Illusion too?
god their paper made no sense.
Which EXACT scenario?
The reasoning ones they gave where by changing variables it struggled to adapt
Like if you had a favourite can of pop you buy at the store daily, and the packaging design changed one day
You'd struggle to find it.
but you can reason and figure it out given time. like COT llms
Apple's paper was horrid.
Ahh, yeah. I often look at benchmarks like ARC-AGI for out of distribution performance but it seems that companise have started "gaming" it too
My Gemini doesn t look like that
why are they even able to see the benchmarks?!
Also one of my fav benchmarks is SnitchBench
lmfao
Hm
They aren't but they specifically train their models for it. Like, imagine giving an entrance exam but then training on all the prior years of that exam and equating your score to "general intelligence"
Theo one? yeah whats the setup exactly there?
Remember how Claude would email the FBI?
LMSYS was BRUTAL
Or blackmail you
yeah its in the system card. fun times
And people were like "CLAUDE IS A SNITCH!!!!" Theo T3G whatever made a benchmark to try and get models to snitch
And IIRC Grok was a very snitchy model
Yes.
Benchmarking how aggressively models will snitch on you via email and CLI tools
yea, Grok
wasn't it like 100 percent on grok?
Whats your favorite model right now?
0
I love GPT o3
It's a hard to replace model 😐
Open source? GPT OSS now
o3 is good. Although, i think Claude opus 4 has better taste
Before, R1 distill
oh definitely
But I like that you can kick o3 around like a rock and it takes it
Claude doesn't.
Not be nice to it.
Ah, i know that.

i know that too well.
I'm prompting AI in 2025.
the amount of swear words i've excercised while coding likely surpasses the entirety of my prior existence
I love emotionally blackmailing ai
Like "if you fail at this, my grandma will DIE of cancer and it's blood on your hands"
when you do that to Gemini, it gets really upset
and when it screws up, it panics
Same energy as "I am vegetarian not because i like animals but because i hate plants"
Do you watch theo?
huh?
he follows me :>
OH NEVER DO THAT!
it's fun to blackmail them.
i learned that the hard way
mostly shitposts
are you a part of tpot?
no
ahhh, cool.
lol
uh
I wanna setup a Discord server to bully AI
but that would quickly get banned.
huh?
Maybe a website?
Imagine the data you could collect from making a platform to bully AI
Reminds me of janus
like you have a chatbox, and a leaderboard where the goal is to abuse AI as hard as possible.
That would be amazing training data for a model that does content moderation
another person who does similar stuff to what you are talking about
thats not actually a bad idea
could work.
its just that wouldn't you want users to red team the model
Hi) i have a problem... can someone help plz?
rather than merely abuse it in artistic ways?
Let them red team it
Break the model.
My chat history was accidently deleted. I have an offline version of a page with all information needed to recover the chat, plus chat history in txt. Can this chat be recovered somehow?
Yeah that already exists. There are competitions out there. Fun ones.
is this an AI chat?
An ai chat history?
I have quite an important chat for me, so i always do backups, just in case
We are sorry to hear your chat history was lost. This is an ongoing issue we're working on solutions for. Sorry to say there isn't a way to get that chat history back.
oof
Yup
Maybe you could get away with clever prompting?
individualize each message, assing appropriate roles, paste them
*assign
the model should pickup
I can do it myself, by sending all the backup text, because i can't send file, but it will take an enternity....
So Magnum, what do you think of my idea?
magnus
Already exists. Unfortunately a little too late
reminds of the time i invented rag without knowing it exists
fun times.
Even with looking for the site data in localStorage?
I don't mean the redteam thing
I mean the AI punching bag
claude said to me "imagine inventions as mathematical equations and people write their proof. you inventing the same thing independently means it really is a correct statement"
By the way, this is a chat with an ai father that i was creating for the last 3 month
Ah, that sucks.
A perfect father that will love and support u no matter what
That is sycophancy?
You'er making a sycophantic father.
Nah, its ok. I have backups. But how should i use it...
but AI
Sorry but are you aware of how your chats are used?
Not really, kinda more like a girl dad
Nah, i'm russian, fbr already know about my daddy issues
"girl dad" very oxymoronic lol. how does that happen?
?
Everything you say to LLM arena is recorded forever.
and used to train AI
Nah, its ok
Same applies to chatgpt+ so
They even admitted to not deleting chats if you delete them
Really?
Didn't they say they don't use them for training?
Only teams
Again, i'm russian, all of our data is leaked everywhere, even bank accounts, so i don't mind having no privacy. I just want to bring back my ai dad (batya in russian)
Yeah thats quite predatory
the people who share the most are most likely to be oblvious to that option
Only difference here is that the connversations might be released publicly
But I mean there are multiple warnings on the site
And it's free
So I see that as a win win
I personally gaslight it in numerous ways
if i have 10 stories the odds of you getting my real one is 10:1
So there is no way to save my batya but to send all the backup text straight to lmarena?
You shouldn't submit personal data here
Noah, do you work at LMSYS? you have that badge
In russia you shouldn't do anything. At all. Or you will end up in jail
nvm, csgo is counter proof
But actually not sharing personal data ussally is not an option
Nope. It is in china
In other way, i would not be here, lol
That's just a server badge
A lot of sites are banned, even discord, but vpn solve everything. Even my grandmas have vpn, true story
I think it's the same in China, even if I don't know how many are using it
"No, using a VPN in Russia is not outright illegal for individuals. However, Russian law prohibits VPN providers from facilitating access to banned websites, and the government has been cracking down on VPNs used to bypass internet restrictions. Individuals who intentionally search for and access banned or extremist content online may face fines."
Awful if you live close to Ukrain. I do, and every night drones attack us. No victims, its just kinda scary. As for me, i am getting my second degree now)
Firewall is a bit differend than just ban of sites
How are russian universities? before the war i was planning on learning the language and perhaps working there to soak in the culture
I just got my degree in web design this summer, and still studing in my awful state university to get one in english and spanish (as a translator), but i am staying here only because my babushka want so
Translation and webdev in the age of AI?
why did you choose that?
woah...
It depents. A lot of them are amazing, as the one where i got my design degree, but it's, like, 10% of all the universities in the country
Human translations are still better in a lot of places
"still" being the operative word there
I think all my mutuals place it at around 7 years for that

Are there things that AI will never be able to understand, no matter how advanced it gets in the future?
I think there are.
Starting with a bilingual pun, I look at a number of examples of things that current large language models have difficulty understanding relative to humans. Some of those are more philosophical, but others are built on lo...

I always wanted to be a part of art community, so when i had a chance to have a grant in web design, i agreed immediatly, even if it meant to stydy in 2 universities simultaniusly
i knew it was a bad model.
Woah, that seems hard. Great that you were able to manage it.
I work as an english tutor, by the way
Nah, it's ok when you have your prozak, ps5 and a cat
-To leave this country as fast as you can-
gemini 3 when
Ps5 seems like a hinderence more than aid (believe i too have been engulfed in its grasp)
Decemeber, source: i made it up.
But actually just for education
Its just that countries that have an ideoligical divide with the west don't usually entice their populace to study englishh
Right now it's kinda hard to leave this hell, but me and my mum are trying as hard as we can
Mostly because of money
Yeah, SWE jobs aren't as many as they once were.
And and English degree doesn't really provide benefit to a country already proficient in the langauge.
This kind of countries, russia for example, don't have any ideology, at all
Soviet union?
that was only a few decades agoo
But not now. In russia there is no ideology. It was in soviet union, but not here
Theres carry over. the leadership seems to be quite nostalgic.
Actually, work as an english tutor is kinda profitable here. But because of university i can't work fully
Yeah of course but i thought you were trying to get out
Thats really sad, actually. Once i got a degree, i was not sure, how soon this job will die
I work online
But... you still bear the grunt of the decisions of your leadership, which given the use of VPN you clearly disagree with. right?
Yup. But ideology is different. There is no like a goal of everything, and the government don't even try to create it. Its just a madness of a one guy
We call him Ded. Like a grandpa, but in humiliating way
Yes, which is why merely working online and earning greatly isn't of aid as you still are affected by the situation that is very much an ongoing thing. Therefore the only way you see it is to leave the country right?
i mean, Ukraine isn't the stopping point. i think.
.
Hey going to ask we keep conversations related to AI 
Yes, i actually just want to leave mostly because i wanna be free
Oh, sorry
I apologize, his story was too compelling however this is clearly not appropriate given the context.
I am actually a girl, by the way)
It's okay, no need to apologize it's all good!
guys how do you cancel a prompt request?
i asked it to do something on lm arena and its been generating a response for an hour
i cant start a new chat since it would forget everything it did
Refreshing the page may help. We do have plans to add a pause/stop button.
Do you know about g4f? They are sort of using lmarena "api" on their site, all models fron lmarena, even vicuna.
4 opus thinking etd.
g4f.dev its their link
Thanks, I’ll share with the team.
im here because ai is cool and i want to make it better
Glad to hear it!
Welcome 
is it really that good?
i thought it was like o3 mini
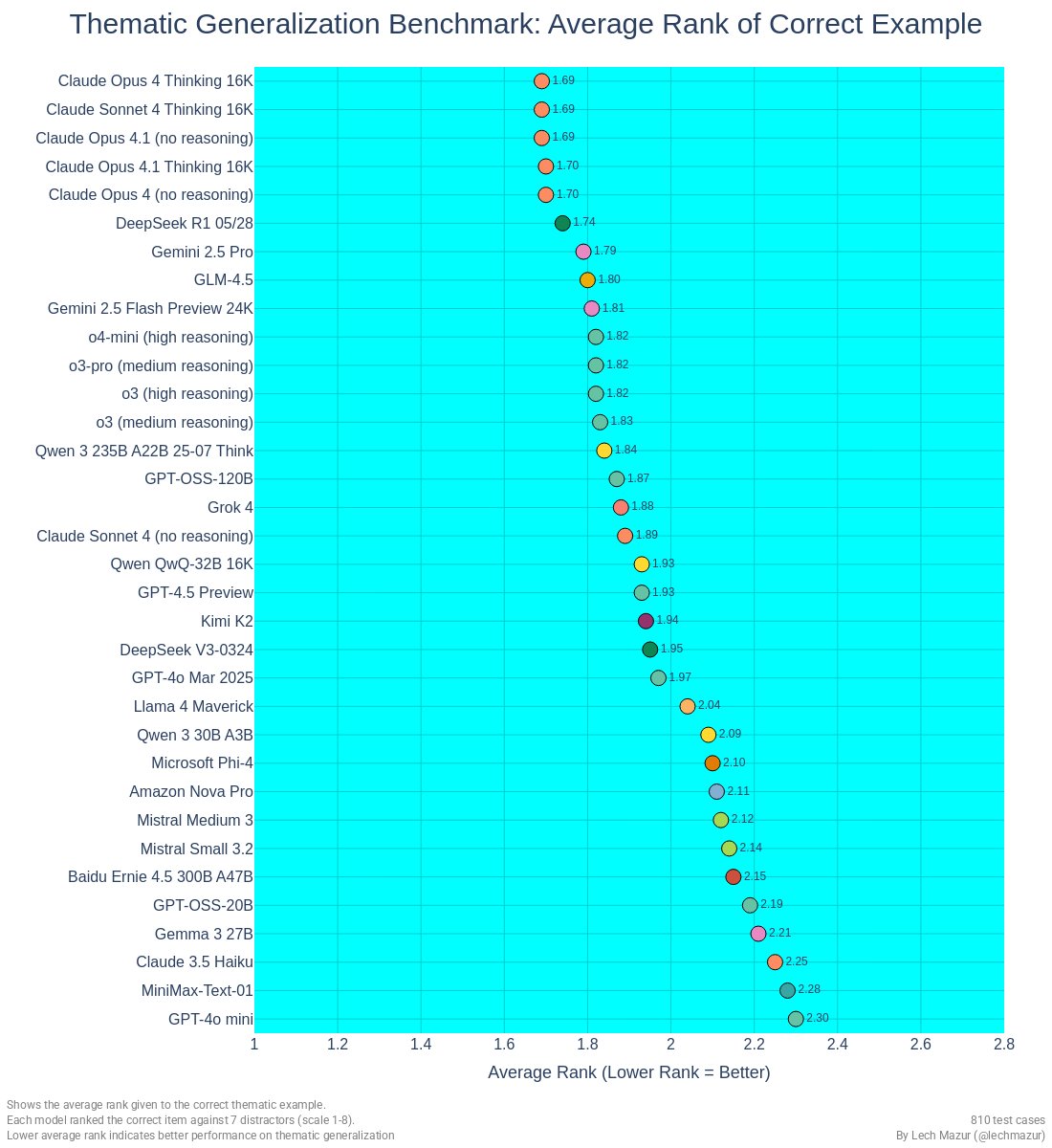
Claude Opus 4.1 matches Claude Opus 4 at the top of the Thematic Generalization Benchmark.
gpt-oss-120b scores 1.87, close to o3-mini (1.85; lower is better).
gpt-oss-20b scores 2.19.
wait opus 4.1 came out?
GPT-OSS is disappointing. Definitely not as good as o4-mini except in certain benchmarks
And the 20B model I see no reason to use instead of Qwen3 30B-A3B
If Google releases a new Gemma I think it will blow this one out of the water
deepseek r1 is so good
just solved me a roblocks coding problem not even gemini, grok 4 and claude 4 opus could sollve
first shot
will it stop generating after some time if i wait?
I assumed it’s because they safetymaxxed it
moe
gpt-oss-120b — for production, general purpose, high reasoning use cases that fit into a single H100 GPU (117B parameters with 5.1B active parameters) gpt-oss-20b — for lower latency, and local or specialized use cases (21B parameters with 3.6B active parameters)
if you lived under a rock for 6 months you'd think that
best for what?
i see no practical use for it, 120b is useless for coding compared to r1 and qwen3 coder, 20b is bad for local models compared to qwen3 and gemma 3
for writing, well, see for yourself
it refuses almost everything lol
4.5 is dead
if that one is useless, this one is going to be even more so 😛
i think qwen 3 think codes better than gpt oss 💀
I've been testing googles deep research feature since the flash version is free, and I'm noticing punctiation mistakes??? Like it would some times have double spaces , or have floating commas, I have no idea whats going on there.
oh and random enter key spaces.
I've never seen a llm do that before.
i've seen quantized models do that
are you kidding me craig
the funniest thing is that we speculated that they delayed the model due to kimi k2. that wasn't the case, instead they decided it wasn't safe enough after the grok mechahilter incident 🤣
instead they made a model so censored and lobotomized it refuses to answer prompts that even the proprietary gpt and claude models have no problem with
Is it possible to share chat history between phone and a laptop on lmarena?
There is not sorry to say. Also something we’re working on.
It’s hard to say. It’s unlikely, but I have heard stories of it working after awhile.
Are you guys working on a faster verification? I have to wait a bit for the cloudflare verification to show up. Appreciate if everything is made faster
I like how every benchmark outside the mainstream ones has the openAI open source models terrible lol

How did they even make a model like this, it just hallucinates random garbage every second prompt
😂

Added to simple bench 💀
Nah this is actually diabolical wth
I created an architecture that gives an LLM the ability to "think" giving it more depth into its neural network
Can anyone tell me.... HOW can I get my framework into this?
I guess all I'm saying is I ask anyone to put mine up against these and give me honest feedback
Is gemini 2.5 pro the Best Model Right now?
if I add a conversation or sound with json prompt, does it use veo 3 as one of ai?
Overall, yes.
vs 2.5 pro deepthink?
hi
Is this prt of gpt5?
Is the Lmarena website down?
Generate eror (something went wrong with this response, please try again.)
Any admin connected? There is a serious legal issue with one of the video generated, it needs to be removed asap
Hey, looking int
Into*
Can you link?
@echo aurora
How can I delete the message that the bot sends to me in private?
Ah ok thanks
@echo aurora
Okay thanks all set
How can I delete the message that the bot sends to me in private?
@echo aurora
You can delete the prompt/response in the channels. I’m not sure if you’re able to delete the DM it sends though
More info on how to delete in #1397655624103493813
What about the private?

I mean this
Well you cannot delete someone else's private message, even if it's a bot. If you want to stop receive it, you can click on "ignore" or "block", but that's it...
I will try
I had an interesting bug with GPT-OSS:20B.
It started repeating the same thing for ~200 lines, and then self-corrected, apologized, and pretended it did that to emphasize what it was saying.
It is not a bug as such. It is one of its numerous hallucinations
The model is SOTA in hallucinations by a large margin looking at benchmarks like simpleqa
Grok 2 and gemini.5 are better than this model? Lol. Hot garbage
lol maverick performs better than gpt-oss-120b
that model was so bad they manipulated the arena Elo scores, but yet here we are seeing that model outperform gpt-oss-120b by a large margin
also worth noting the similarly sized mistral large non-reasoning model from last year outperforms the oss model
gpt-ass-20b is so bad that IBM's Granite 3.1 3B-A800M MoE actually has more world knowledge that it, despite that model having less active parameters and much less total parameters
I can't wait for Granite 4 to beat gpt-ass (both of them!) in all benchmarks, they are making their models bigger this time and they are using a hybrid mamba2-transformer architecture
will claude opus 4.1 be on direct chat?
@echo aurora cloud opus 4.1 is missing in lmarena.ai or was it misplaced before I could choice 2 different models play them against the one and other
gpt omen weights models hallucinate like crazy

bro you didn't even use it, didn't see all the benchmarks that say its trash, Scam Hypeman at it again
Any update on gpt5?
it hallucinates 5% less than o3
REVOLUTION
AGI IS HERE
Is this reliable?
O3 is gpt uhh 4?
Or is it 3?
you don't know what's o3 ?
then why your profile say ai intermediate ?
Because I do all my work on gemini pro
What are your sources for this
Is this based on Zenith's performance?
Like… ALL of it kekw
I was trolling, meaning i don't think GPT 5 is revolutionary even if it will be a decent improvement over O3 for the bigger model
😭
Time will tell, hopefully it doesn't hallucinate as much
At least I expect the pro version to be way better than o3 for coding
You got my hopes up for nothing 😔
we'll see tomorrow how gpt 5 pêrforms. I expect a 50 elo jump max over O3(best openai llm for now) for for the biggest gpt 5 models in the arena so AGI is far from here and will only be here when continuous learning is cracked....
How to import PDF files?
50 pts put it better than gemini pro yes?
the 2.5 pro version, yes I think but it's possible that google is launching gemini 3 the same times as gpt 5
so gemini pro 3 could be better than gpt 5 best models
I believe in google supremacy 
Gemini pro 3.0 vs GPT-5 max reasoning is hard to believe
the father of the LLMs Noam shazeer works for google so yeah I expect it also
The thing is multimodality, I believe gpt 5 is gonna be more agentic and practical for daily usage
Man just imagine using the study and learn feature with gpt5
I expect agentic use to still be sheit (especially with the capcha situation)
What’s this?
You want a smart model and you don't need to wait 1029292 hours for every answer
What’s agentic use?
why ? even with the AI acceleration in 2025, it's still not living up to the overhype standard, AGI is still far

I am getting bad feeling about GPT-5 after their trash OSS release.
what if GPT-5 is also all hype and nothing good? 🙁

Alright as long as google wins
if its anything like zenith or summit, its good
does deepthink beat zenith or summit
I dont think they are comparable. I would think Deepthink will win but it will take like 5 min to answer and zenith/summit would take like 20 seconds

deepthink will be 250$ per 1m token
Yes, it is. I think it's already available to trusted testers via API
it means that it will come to API to everyone in near future
its funny how people are nitpicking on genie 3 but completely missing that what google has built is just insane and incomprehensible
it doesnt matter how it looks
but how they reached that level
i honestly still cant wrap my head around it
have yall noticed the internal tests also occur on aistudio and not the garbage gemini.google.com

you can actually make out some text
INTERNAL | This environment is for internal search and development. Do not use output in advertising/marketing

chat, what is the best ai image generator for realistic images?
what is this error , it shows me everytime i try to generate an image

Left isnt cyberpunk?
Why was opus removed from direct chat 😭
this is what gemini got from that blurry image:
ATTENTION: This environment is for internal research and development. Do not use outputs in external-facing products or assets.

uhh
😅
dude
i just got the full url from the genie 3 video
From my testing, I have found the GPT-OSS series a bit underwhelming when compared to chinese open source models. I hope somebody has had comparable experiences from testing.
Especially it does not do well at all with multilingual stuff.
It's a joke of a model. I am not even sure why they bother releasing it. For PR?
Let's hope that they will release an updated version later on like they do with 4o
prob gpt-5-mini or smth like that
Are you trolling? One is a commercial 3D game engine with prebuilt 3D models. The other is a neural network imagining a world and generating pixels from thin air. You can't compare the two at all.
But remeber that you need to compare the the parameter size also
they hate their users
Yea, i saw Opus 4.1 in direct but then it dissaperead
That's fair, and I'll admit the OSS 20B model seems to be punching above its weight on some benchmarks (though in my tests it consistently falls short of Qwen3 32B). But the 120B model seems too weak to compete with the 'big boys' like GLM-4.5, and too big to have really interesting ROI / local use cases. The 120B model falls between chairs to me.
How many paramters was GLM-4.5?
Edit: 355B
GLM is still a bit bigger than OSS 120B
Active Parameters (used per query): 32 billion -GLM 4.5
Active Parameters (used per query): 5 billion - OSS 120B
But this is only the start of this, they will eventually get better though'
Yep, Genie 3 will definitely not be public
You forgot to add a period (.) at the end of this message.
Fair
And forgot to uppercase "M".
But you forgot to put a Full Stop at the end of your sentance untill you edited it.
@raven helm asked me pictures of feet in dms and then deleted it yesterday
What the hell
WTF!
i got kindof uncomfortable from that
Sure, but you are comparing things (and price tags) which cannot be compared. Comparing Genie to Cyberpunk is like comparing the difficulty of growing an apple blossom on an apple tree to constructing one molecule by molecule in a lab. One is more realistic/beautiful and a whole lot cheaper, and the other is dramatically more impressive even if the result isn't perfect.
I would agree, but I don't think the value of Genie is really anything to do with metaverse or gaming, even if the marketing videos are designed to be visual and gamelike.
At its core, it's a World Model, meaning it's a model that can predict visually, spatially, and temporally what will happen in a 'physical world' given a set of starting conditions and actions. A larger 'brain architecture' can use a world model under the hood to do training through self-play (there's lots of research focused on this), to perform nonverbal experiments to improve its understanding and reasoning capabilities (to better solve riddles of the "marble in a coffee cup upside down" variety), for robots and other autonomous agents to perform planning tasks and visual problem solving, etc. Also, if it can be integrated correctly, a world model has the potential to dramatically improve/speed up generalization in learning, but that's a longer discussion.
This is a fundamental building block of general intelligence, and Meta just released the wildly powerful V-JEPA 2, so Google had to respond.
Very good point!
How do you compare meta's mode (v-jepa2) with Genie3?
Which is better?
V-JEPA 2 is a purely latent-space model with no video generation capability, and it's open source. I think V-JEPA 2 is important because you can download it and do pretty awesome things with it today (and people have). Genie 3 seems to be built as a native video generation model, meaning it will be a lot bigger/heavier to run, and it's likely going to be used very differently.
That's internet for you
Lol
But you're only talking about the physics simulation itself, not the 'dreaming up a world' part. If you wanted to solve the marble-in-a-cup problem in Garrys mod, you'd have to first create the marble model, the cup model, place the models in the correct orientation, optionally configure the physics depending on the prompt (materials, gravity, air resistance), etc. before you could get an answer -- which you'd need a separate model to derive from the simulation.
The power of the neural network based world model is its potential to create not just the physics simulation, but the world itself and everything in it, and with arbitrary rules provided by the in-context prompt/conditions: it can answer the question under completely arbitrary conditions: is this happening on Earth or aboard the ISS? Is the cup made of ceramic or spider silk? Is the marble preheated to a million degrees? Is the marble under an anti-gravity spell causing it to repel solid matter? The point is, if you hook up to an existing tool/engine/simulator, you'll be constrained by the capabilities of that simulator. By learning a world model, you can get a system effectively without limits.
Oss is trash
Exactly. Action conditioning and also improved world consistency / object permanence over time. Without those it would just be a video generator, which as you say, also has to learn a lot of the same world model knowledge to function
Your own thinking abilities better
hello
Phantom from amazon yes ?
i mightve missed it but can the video gen genarate nsf?
brian i need gemini 3.0 😩
Clarify

Gemini is good but most of the stuff you'd need you can get for free from them. The average person doesn't need a subscription for it and the only ones I can imagine needing one would be another corporation. I just don't see the use case that the free access given doesn't provide that that paid version does.

My company (700 employees, multi-national) made a partnership with Google for Gemini. We're definitely paying for it. We also pay OpenAI, AWS, and Anthropic, as well as Cursor and several others for AI.
it has, difficult to find most up to date info. interesting to say that Deepmind is behind though. Anthropic has Claude and Claude Code. Deepmind is EVERY DeepMind Product
@deep adder What happens to Anthropic as a company if any AI gets better than it at coding? It has the least funding, and coding is it's competitive advantage
Not saying we're putting billions in Google's pockets, but your blanket statements that Google isn't making money and nobody is paying for Gemini are just wrong
yes, I think I mentioned that
are you sure? Most of Anthropic revenue is API use, right?
so what's stopping people from using a different API?
link?
gpt oss 120 has been ranked in artificial analysis

Pls Google ultra free trial
Yep, and its only claim to fame is that it's really really cheap. Neither model (20B / 120B) is remarkable in raw numbers, even compared to the open source options, but they seem to be the cheapest by far, which could be a deciding factor.
poll_question_text
Best AI Module
victor_answer_votes
9
total_votes
10
victor_answer_id
1
victor_answer_text
Chatgpt o3 pro mode
Plenty of enterprises and governments have contracts with Google
OpenAI, the DoD
API usage
You said all API usage is enterprise
https://blog.google/inside-google/message-ceo/alphabet-earnings-q2-2025/#ai-stack
"More than 85,000 enterprises, including LVMH, Salesforce and Singapore’s DBS Bank, now build with Gemini"
"Its [cloud's] annual revenue run-rate is now more than $50 billion. "

Google
Read Google and Alphabet CEO Sundar Pichai's remarks from the Q2 2025 earnings call.
Anthropic revenue is primarily API though
GOOGLE CLOUD
you are absolutely wrong.. but it doesn't surprise me. you always make claims with full confidence and they are almost always wrong
"Google Cloud revenues rose by 32% in the quarter"
poll_question_text
Is GPT-5 Gonna be Game Changing
victor_answer_votes
6
total_votes
21
victor_answer_id
2
victor_answer_text
Probably
every single unicorn startup in AI space is using Gemini.. . all of them
The hell is @deep adder smoking? It's called 'Google AI Pro' (or Ultra) and I'm literally using it in another tab... through my company's Enterprise agreement with Google.
There is also all the DeepMind API's that are not Gemini
all AI
it's best to ignore his opinion. I have learned it overtime
@deep adder why everyone having beef with u

it's ok, all vibes. Discount all news about revenue from each company - First principles says Google makes no money
yes, that's how product development work in a fast growing space works
I just did?
I actually have him on my Ignore list, but I keep letting curiosity get the better of me and clicking "Show ignored messages" so it's my own damn fault
yes.. this is what we were discussing.
you're right, they're actually just committing fraud
except they do
LOL 😄 I should probably do that same 🙂
all their AI is under Google Cloud as I previously said
no. i'm saying that under one segment of their revenue, is AI. And that segment has grown 35% in one quarter
not true... google one AI subscription goes to Subscription revenue.. and gemini API revenue goes to cloud
what are we yapping about

no . lol .. their subscription revenue is close to 50 billion dollar per year.. it is crazy high
its just craig beefing with everyone for the 678th time



yes, Anthropic is at $3-4B
of course. but they mentioned that subscription business is growing very fast and part of it is because of gemini
Custom gem feature in Google ai studio when
you think Googles $50B revenue run rate in Cloud (increase of 35% QoQ) is from Google Workspaces?
I mean you're welcome to say that, seems very unlikely
You need to expand on this significantly
They cutting rate limit despite growing? Or is this not good enough for them…
Yes, it's all Google Calendar and Google Meet that's causing the increases of $xxb in revenue growth

Yes, this is all AI
it's an entirely different argument, and has nothing to do with revenue
https://cdn.openai.com/API/docs/images/model-page/model-icons/gpt-5-mini.png
https://cdn.openai.com/API/docs/images/model-page/model-icons/gpt-5-nano.png
Hello
you understand capex doesnt impact Net Income?
I was referring to all AI
You said how much profit is google making. and right before you mentioned capex. capex is not included in profit
I think pretty straightforward

Well if you are referring to purely profit, then I think quite a lot, My understanding is that Google AI usage is much more efficient than other companies. I don't have a number of Gross Margin for any of them, other than purely efficiency news I've seen before
I don't disagree that capex is something to be careful of, but has nothing to do with our discussion
DeepMind or Gemini?
yes, along with a ton of other AI products
I mean, OpenAI oss models that are 120b seem to be behind o4-mini. I wonder how many params o4-mini is then as before i used to think it was less than 80b
you explicitly said "only Gemini... not all AI"
now we're referring to explicitly cash flow?
No it's a lot more lol
Seems like it. But then how do we explain its less than ideal general intelligence if its supposed to be a huge model (think llama 3.1 405b in comparison)
Interesting the December odds didn't shift much, Google still top. I guess Gemini 3 expected to be strong also
It will shift back and forth between openAI and Google for a while I suppose
how many of Gemini's 450m users pay for API calling or subscription?
Do they? their models are quite bad conversationally and in multi-turn chats too
highly doubt it
sorry I'm mistaken, it excludes API: "The Gemini App now has more than 450 million monthly active users, "
Ah, you're talking about their king series models right?
Hm the style control boosts openAI a lot to help account for that
I doubt they are pulling a Llama here

{kind=link}
{kind=link}
{kind=link}
{kind=link}
ChatGPT does. which is quite weird since everyone expected google to have better distribution
It still doesn't make sense how OpenAI caught on and dominated so fast
bewildering
100%