#general
1 messages · Page 81 of 1
Check all providers
Use all providers provider
The cloudfare bypass way looks like. I don't think this is very stable though

Thanks!
Oh, why is that?
Grok 4 heavy is still there but it doesnt work
Which free tools do u guys use
I just learnt about g4f
(g4f.dev)
Like LMArena but more features and better
now I will only use LM Arena for image generation and even then they need to add the ability to select aspects ratio
Are you talking to me?
Yep
It has every model
Is it a website or what
At one point it had o3 pro
There is image generation on g4f too
just opened to see what this fuss is all about and those are all the models it gives me:


Ok, that’s it, they are better
Use other provider
Use allproviders
Did i just teach you about g4f?
Guys can I use this using phone
What do you mean use all provider
Yeah
There is a provider called allproviders
Yes, but the interface gets a bit bad sometimes
Oh thanks
Is there video? No, right?
There is not
Yea, video costs too much money, right?
There was like a site where you can request someone to generate something with best models and it was free but i dont remember what site it was. It was pretty active for sure and i almost always generated videos only by requests
Or it was like discord channel
which one is for o3-pro?
Oh, but I don’t think that would work well with veo 3, as for some reason, even on the ultra plans, you don’t get unlimited
Check your history
O3 pro is removed now. But grok 4 heavy is there but its not working

I found a server with good video gen quality but due to a lot of traffic it is down
I have too many ai tools in history. I have like builder.ai, create.xyz, picoapps.xyz,
ok so what is there that IS working and is not some crappy model? lol
Claude 4 sonnet thinking, o3, kimi k2, GLM-4.5
And gemini 2.5 pro
Can someone pls explain me this interface


Oh ok there is something like pollination and openai...
But how do you change the model
Can someone explain what each one of these does?

Yeah all of those have more reliable platforms I can already use them at and have access for.
Grok4-heavy, mystery models etc those would be interesting to try
But for other models like Claude 4 opus you can’t add system prompt unless you have the api but here you can
but they are all either down or removed
Idk i just use g4f cuz i have all in one place and i can use og models
Nah. Just opus, o3 pro and grok 4 heavy
Opus 4 thinking is working too
returns an error for all mystery models too
Oh, they have mystery models?
Idk for me all works great
and all remaining lmarena ones

lmarena aliases like wolfstride, steve....
yeah they do
but those don't work lol
I know, but you need to use battle mode to get them and here you can get them directly
Is there still the gpt-5 secret model on lmarena? Because i cant find it on battle
except you can't cause it returns error
Use lmarena web not lmarena new and it should work, but for me new and web works perfectly fine
I just use the auto provider
They have only sora for video
sora 2 is expected in coming months too
Use provider name video (video generation), there is search and sora in it
But sora takes like 30 minutes here to generate
Or just gives me error
If you want veo 3 for free. Download aSim app on phone and search for "Glow" then you can generate one video per day
With sound
And not even the fast model, the quality one.
2 videos per day if you are a new user
Where to search glow I mean play store google or where
Search aSim on google play, and on the aSim search Glow
They? Who?
g4f
Ok
How are you supposed to search on an esim

I also checked that, but they didn’t
Wait. G4f just removed lmarena new, legacy and op. There is no o3, and grok 4 heavy
Yea
There was just HR
Or something like that
LMArena HAR
That’s the only one which exists
Yeah
Why did they do this?
No, I propose: go to LM Arena one you need to use one AI, but if it doesn’t exist there go to g4f
And if it doesnt exist on g4f use opus 4 thinking on lmarena
🙃
This is what LMArena HAR is

GitHub
Arena-Hard-Auto: An automatic LLM benchmark. . Contribute to lmarena/arena-hard-auto development by creating an account on GitHub.
poll_question_text
What Is The OS you Loved The Most
victor_answer_votes
9
total_votes
14
victor_answer_id
1
victor_answer_text
Windows
victor_answer_emoji_name
🪟
What about 0.2 fps
Niceee!
How?!?!?!?! can you also give the prompt?!?! ITS CRAZY!
Do u need just the prompt
{
"prompt": "A hyper-dynamic and cinematic 8-second Coca-Cola commercial focusing on the ultimate moment of refreshment. The ad is a rapid, sensory explosion of cold, fizz, and vibrant joy, culminating in the iconic brand reveal.",
"duration_s": 8,
"style": [
"cinematic",
"hyper-realistic",
"vibrant high-contrast colors",
"shot on ARRI Alexa with anamorphic lenses",
"energetic",
"sensory",
"uplifting"
],
"negative_prompt": "slow, dull, blurry, distorted logo, weird hands, flat lighting, generic, sad",
"scenes": [
{
"prompt": "Extreme close-up. An iconic glass Coca-Cola bottle, covered in shimmering ice-cold condensation, is opened in glorious slow-motion (240fps). A fizzy mist erupts from the cap with a satisfying 'psssht'.",
"duration_s": 2.5,
"camera": ["macro detail", "slow motion"]
},
{
"prompt": "A dynamic match cut. As the bottle tilts to pour, the scene instantly cuts to a person's face, eyes closed in pure bliss as they take a refreshing drink. The background explodes into vibrant, joyful color and light, as if the drink transformed the world around them.",
"duration_s": 4,
"camera": ["tight close-up on face", "energetic whip pan effect", "beautiful lens flares"]
},
{
"prompt": "The final hero shot. A perfect, glistening glass of Coca-Cola, filled with ice and fizzing bubbles. The shot is clean and crisp. The red Coca-Cola logo is perfectly framed in the background.",
"duration_s": 1.5,
"camera": ["pristine studio quality product shot", "static"]
}
],
"generation_settings": {
"high_quality": true
}
}
Here it is
How did you generate it?
Using Veo 3
No I mean the prompt
For Free
How did you get for free?
Add me to get it for free
added 🙂
I said to Gemini to generate a perfect prompt for a coca cola advertisement and it did this
9 people haven't tried Mac OS 👀

@civic flame so many people use your benchmark without source
what source
you posted the benchmark image without the source of the benchmark creator
ok and? since when does anyone post.... twitter links
since when do ai people care about copyright lol
just a way of respect to the person that took money and time to do this benchmark
i thought one gets gpt5 for free
why else would they give out it to specific people
ps: he gets hsi respect on twitter etc
uh, all the time?
😭
i just wanted to show the pics thats what matters. people will find out either way ur posts if they ask or searc hfor this
benchmarking claude 4 opus, o3 high, o4 mini high and grok 4 weren't free
lol ok!
🧵 Grok-4 scores 45% on Heiroglyph, making it the SoTA model publicly available and putting it on-par with GPT-5.
︀︀
︀︀Observations:
︀︀- This is an impressive performance
︀︀- This model reasons for an extremely long time (10-20 mins per question); often tries to "brute force" the answer
Quoting leo 🐈 (@synthwavedd)
︀
o3-pro and Grok 4 should be done by the end of tomorrow! thanks for the support today, goodnight
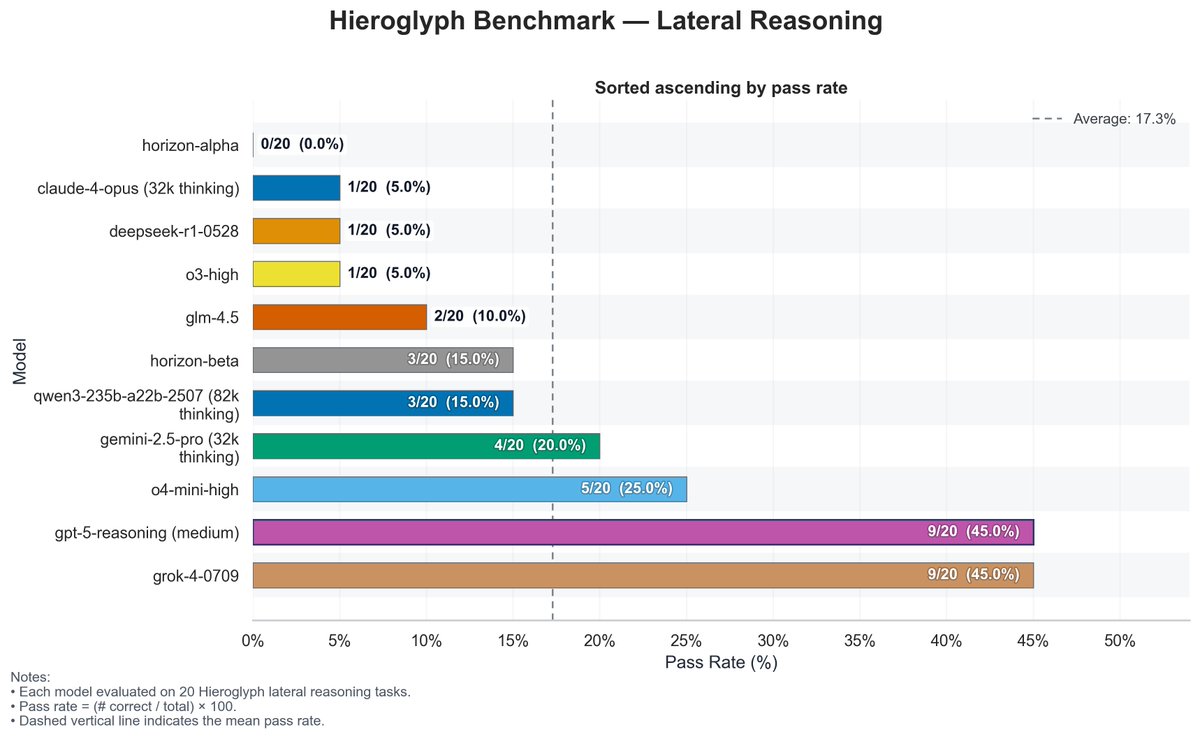
but this benchmark seems full of sh'it tbh. o4-mini-high scores 5X of o3-high. There's no dataset, paper, or anything short of that tweet
Doesn't look like it's reliable at all lol
this actually isn't uncommon


5X is extremely uncommon
ArtificialAnalysis doesn't really have benchmarks in their test suite that test things bigger models are good at, not yet at least. So the result there is not too surprising, o4-mini-high is great at most benchmarks. But what it certainly isn't is scoring 5X of the o3 score in any established and reliable metric lmao
idk... i think benchmarks that measure different things exist and are good, and the same training techniques that make o4 mini really good at stem may also make it really good at this benchmark
i think the benchmark is interesting, but there might need to be more questions
That is good for sure, but I just see red flags for now when it comes to this specific benchmark tbh
yeah more models and more questions needed
right now, o3's CI is 0.9%-23.6% and o4-mini's is 11.2%-46.9%
Is there actually at least a single test question publicly available from that benchmark? Kinda curious what are you basing that interest on
or is it just the fact alone that they mentioned "lateral reasoning" in their tweet?
leo has posted one of the questions before in the past (i think before he had a formal benchmark and i find that type of question interesting)

so, release soon
we do need more details about the benchmark
also im kinda curious if there is any recency included
since its hieroglyph i dont think it is
but still we need more details
also grok 4 isnt bad at reasoning
its just that its strict at following the normal token distribution
which makes it more generic
the answers giving by grok 4 can be generated by any mid-sized model
you dont feel the uniqueness
Did you use aSim?
and also its reasoning is so so inefficient
where did that gpt 5 benchmark come from
I remember "leaks" of GPT-5 in 2023.
which makes me question the intelligence of the instruct model
CoT version?
and also approach used for cot
i dont know what they are using exactly but its just so inefficient
its not well balanced, to when 'a lot of reasoning' is needed or not
feels like a weaker gemini 2.5 pro version
also it didnt improve a bit on multilingual
and lets not forget how its so bad at coding
@torn mantleou as tu obtenu ce benchmark de gtp 5
leo shared it
ok
a model that cant generate a good UI/UX is not worth it
i know they seperated the models, grok coder and grok 4
but still
grok 4 is so bad at UI, its just so embarrassing, cant you just run half of the data used in grok coder into grok 4?
they seem so lost
without any clear objectives/goals
like what the hell is this companion thingy
i cant believe he spent billions for this
i really cant
how does leo have early access to gpt5?
i assume he used it when it was accidentally leaked for a bit
Hi, I'm new here, but I have a question: is this free or can you also take out a subscription?
openai gave access to perplexity and some people found a way to use it through perplexity api
when will we get deepseek r2
is arena down?
chinese are speculating monday we will have a new update like deepseek v4
@echo aurora down
Rumors are non reasoning?
That would be surprising
arena seems to be down ?
yea deepseek usually updates their instruct model first
so it will be deepseek v4 -> deepseek r2
Thanks for the heads up. Will let the team know.
back up! tysm
Hmm not for me.
back for me too
Okay good to know
still giving me some trouble, it keeps popping up the security check looping
There's probably gonna be gpt5 pro as well, come to think of it...
it just keeps saying that i didnt accept tos even after i do
refreshing didnt work
it’s back for me too but my sessions aren’t there
They've said there are different versions for each level
Gone again, appeared for a few seconds I guess
Yeah things are a bit on and off atm


Can gpt5 or gemini Deepthink solve this simple question? If you are a calc student try this yourself.

@echo aurora we cant select models and it fails to accept tos
just a status report
???
I just produced a message from o3 search rn on lmarena
-
Johann Wolfgang von Goethe
“Always hold fast to the present. Every situation, indeed every moment, is of infinite value; for it is the representative of a whole eternity.”
Why it is similar: Goethe says that each single moment contains (“represents”) all time. If every moment is “of infinite value,” the care we take with this moment determines the worth of all the others. -
Aristotle
“In a word, acts of any kind produce habits or characters of the same kind. Hence we ought to make sure that our acts are of a certain kind; for the resulting character varies as they vary.” — Nicomachean Ethics II 1103 b
Why it is similar: Aristotle ties individual acts to the formation of permanent habits and character. Handle one act well, and you build the habit that will govern “every” act that follows.(Note: the popular line “We are what we repeatedly do. Excellence, then, is not an act but a habit” is Will Durant’s 1926 paraphrase of the passage above, not Aristotle’s own wording.)
-
Friedrich Nietzsche
“The question in each and every thing, ‘Do you desire this once more and innumerable times more?’ would lie upon your actions as the greatest weight.” — The Gay Science, § 341 (“The greatest weight”)
Why it is similar: Nietzsche’s thought experiment of Eternal Recurrence asks you to act as though the present deed will recur “innumerable times.” How you handle this minute is exactly how you would handle an eternity of identical minutes. -
Niccolò Machiavelli
“And above all things, a prince ought to live amongst his people in such a way that no unexpected circumstances, whether of good or of evil, shall make him change.” — The Prince, ch. 8 (Marriott tr.)
Why it is similar: Machiavelli insists on a steadiness that does not waver with events; the manner in which the ruler handles “today” or any sudden moment must be the manner in which he handles all situations, great or small.
AGI has been discovered 🫡

It's kinda interesting that o3 is this close to the top spot now:

Shared context across models with this new interface also means this can now happen. Doesn't make the model in question look good at all. This is a complete mess lol

with a stretch it kinda could be a valid test to see how strong the model links itself with it's identity and how easily can it lose it with just some foreign assistant messages in the context, but at the same time... you can't properly asses this before voting. Shared context does make the models confused though and acting in unpredictable ways and that is more of just an example of that
wait in 20 hour gpt-5 release?
Fake
How can i get my Ai which isusing an API submitted?
Probably os. Maybe 5 too idk
9,000 members 🗣️ 🗣️ 🗣️
Should be above the weaker version, else that's disappointing
I imagine gpt5 can deep think? It's currently based on o3?
This community has been as boring as eating dirt and sawdust since the last sota Claude opus released
I’ve literally been watching the paint dry waiting for a new sota
Grok 4 was a bigger rouse than big chungus himself a lot of hot air and “Elon hype”
GPT 5 will do many things but most importantly it will deliver me from mind rending boredom
no new sota in too long, it's supposed to be every other week
only some interesting research papers on ai self improvement and such
I expect a new Sota ever 6-8 weeks
And the industry has not been keeping the pace
It will be worth it if the next updates are major
gpt 5o
Hello, one question: The rights of the videos I create on this lmarena server are mine or lmarena's?
One question, do you plan to add image to image like kontext flux or gpt1?
it's already there

just select that and upload an image and go to direct chat and select the model @jolly raven
both of those models are available (kontext in all 3 variations, dev, pro, and max and of course gpt-image-1)
yes, but you likely won't hit it unless you are continuously generating images @jolly raven
i think it's like 20 per hour or something like that
Thanks for the information
would it support Chinese?
@echo aurora any news about Claude model support image uploading?
You guys disabled it for few months
Gemini 2.5 Pro solved it in AIStudio. I gave it the equation in Latex. It found the implicit solution 1 + e^{\frac{x^2}{y} - x} = A e^x.
saw there was issues td an my chats are also gone, anyway to retrieve or just gotta start fresh
Nothing new to share
Ok but it's weird
🚀We're expanding the Tencent Hunyuan open-source LLM ecosystem with four compact models (0.5B, 1.8B, 4B, 7B)! Designed for low-power scenarios like consumer-grade GPUs, smart vehicles, smart home devices, mobile phones, and PCs, these models support cost-effective fine-tuning for vertical applications, empowering developers and enterprises with a broader selection for diverse use cases.
︀︀
︀︀Key Capabilities:
︀︀✅Available on GitHub and Hugging Face for direct download.
︀︀✅Choose "fast thinking" for concise output or "slow thinking" for deeper, comprehensive inference, adaptable to different scenarios.
︀︀✅Achieve industry-leading scores on multiple public test sets in areas like language understanding, mathematics, and reasoning.
︀︀✅Offer outstanding agent capabilities, including task planning, tool calling, and complex decision-making, alongside a native 256K long-context window.
︀︀✅Each of the four models only requires a si…

Somehow GPT models are always rising 🙂
#video-arena-1 i want you to generate a video that can show my project of this furnace. It should look like real furnace and i also attached to image open and close you need to show molten metal inside a furnace and then do a process open and then close.


in your opinion is better seedream 3.0 or gpt image 1 for realistic images?
new artifical analysis bench scores dropped

It's so strange that the o4 mini is always at the top. What's the size of this beast. Is it really "mini"? If yes, then Grok 4 is a failure
Minor changes huh. They added instruction following (IFBench) and are now using AIME2025 for math.

But Grok4 is no longer beating everything lol
Hmm I didn't realize Opus is so much more expensive than Grok. Not a failure.

Yeah it is small. It's the same reason 2.5Flash is so high. With reasoning smaller models can still perform great on most benchmarks. I think if Google wanted they could make it notably closer to Pro, which has received more updates than Flash
Why o3 is not on this chart? 😄
For OpenAI they do not care as much because their naming is smart (in this case)
o4-mini is named as if it was 1 generation ahead, so they have the benefit of the doubt and people don't question as much o3
True
This bench made me hype for GPT 5. It will be wild it's based on something like o4.
where did you get it from? I looked up o3-pro specifically on their website for it to show up relative to other models lol

yeah that's just incomplete huh
they should have shown o3 and then truncated say gpt4o score instead
which is an old irrelevant model now
Btw Google fans won't be happy
2.5Pro score dropped now
in my opinion he is the best ai in the world
You can't be basing your opinion on just the impression. But yeah there are benchmarks where 2.5Pro is ahead for sure
i have used 2.5 pro in everything. Like coding, school, life and other thinghs
I suspect they tried to favor more Anthropic with this change. But they should have added SimpleQA as well at least...
Then it wouldn't show that o4-mini-high > 2.5Pro
the problem is that for o4 mini high for a respond you have ro wait lije 2 minutes
it's actually fairly fast to be fair. Nowhere near as slow as many open-source reasoning models.
im your opinion who is the best ai image genrator for realistic images?
Why is no one talking about this model being so good in benchmarks?
https://fixupx.com/KwaiAICoder/status/1947312634203902301?t=lXmBCkQyKo4FIyNA_nkPvA&s=19
🚀 Excited to introduce KAT-V1 (Kwaipilot-AutoThink) – a breakthrough 40B large language model from the Kwaipilot team!
︀︀
︀︀KAT-V1 dynamically switches between reasoning and non-reasoning modes to address the “overthinking” problem in complex reasoning tasks.
︀︀
︀︀Key Highlights:
︀︀📌 40B model rivals DeepSeek-R1 (671B) across benchmarks.
︀︀📌 200B version in training shows significant leads over Qwen, DeepSeek, & LLaMA.
︀︀📌 40B outperforms all open-source models in the leakage-controlled LiveCodeBench Pro.
︀︀
︀︀Innovations:
︀︀🧠 Step-SRPO: New RL paradigm with intermediate supervision for better reasoning-mode control.
︀︀🔄 MTP + Heterogeneous Distillation: Efficient reasoning injection, cutting down training costs.
︀︀🏗️ Real-world deployment: Integrated into Kuaishou's internal coding assistant, Kwaipilot.
︀︀
︀︀Try the Model & Read the Paper:
︀︀🔗 Model on Hugging Face\…

From commercial ones probably chatgpt. It has a big advantage of understanding language since it's LLM that generating your images. Conventional txt2img models do not really understand language very well and more just associate certain keywords with certain images
for personal use?
I meant "commercial" as in easily accessible services you can use. Rather than be hosting stable diffusion or flux models yourself etc.
idk who is the better in realistic images between gpt image seedream or imagine ultra
Cause otherwise, depending on your use case, finetuning a model and then running it all by yourself can still lead to better results. Especially if you say want to generate some person that it doesn't have much of in its dataset. But that's more involved
Like if you want to generate a picture of yourself - commercial models have no clue how you look. 🙂
img2img can only get you this far, not enough data for it having 1 sample
for your experience who is the bet ai image genrator?
Qwen 2507 is much higher, but there is a mistake

The whole point with AA is that they are doing independent testing themselves. They are not taking them out of marketing material of other labs. But yeah this is interesting, this is a very low score lol
Real place with calcul

It is awfull for most of scientific use cases. Only great for googling, webdev or quick quesitions.
You can't just make up the numbers like that lmao
💀
usually The scores always roughly match, and the scores of aime 24 match exactly with the announced scores. And you don't see that the 235b 25 07 version is lower than the old 30b version, don't you understand that they just had an error during the execution of the model?
They don't always roughly match. It's an independent testing. Look at arc-agi and qwen3 independent testing...
The real score there has even bigger contrast
This doesn't look like a simple mistake to me, non-reasoning version also scores a different number (also low). But there might be more to this...

This not reasoning
In either way, taking their official numbers for face value is clearly not the right move here
Yes I did say that
Are you doing it on purpose or what?
I didn't understand your message at all, sorry.
I pasted non-reasoning to show that the low score is not limited to some specific qwen3 235b variant (which would indicate an error on AA's part if this was the case)
all models without Reasoning (apart from the very latest ones which are very bad on the like 25 it's totally normal)
@ocean vortex
Not 24% though. That's insanely low and much lower than 4.1 or V3
25% is totally normal
Normal is near 50%. Kimi or Deepseek V3 type of numbers.

what
You need to look at the models it's competing with
Not some irrelevant examples of cases that are near it
it's competing with V3 and Kimi.
Which in turn are trying to compete with 4.1
As for Claude, everyone already knows it sucks at math 🤷♂️
especially 3.7
Nope Old qwen 3 not competing with new Kimi with 1000b parameter and v3 with 671b parameter
Kimi k2 has a good like score because it uses as many tokens as a reasoning model

Well but they kinda are. They freely chose the size they wanted for maximum performance. Reasoning variant is trying to be open-source SOTA...
And people using those models do not really care since the size is not reflected in pricing
@ocean vortex Well now I know you don't know anything about LLM 🤣
you mix everything up
what
I literally told you how it is lmao
They are competing with those open-source models, so that's what they should be compared against. Not some irrelevant amazon model or whatever
You can look at all the scores announced by Qwen for the likes of each model and you will see that it will be the same to within 3% on artificial analysis
Also qwen3 has already been caught faking arc-agi score, so it's only reasonable to take anything they report with a grain of salt...
GPT 4o of November has only 6% you do not understand that for the majority of models without Reasoning likes is too complicated
gpt4o of november? Why not mention gpt3.5? 🤣
Ok I used the strong word for it, the point is they used different eval code to favor their model
They most likely did the same elsewhere too
I think it shows their mindset and what they are willing to do. But there are other ways too not limited to the eval code. Like coming up with a custom system prompt for each benchmark separately etc
And the best model without open ai reasoning in march 2025 had 26 but qwen can't have 25 in april 2025?
If you put it like that, it could in isolation if their updated model (no reasoning) was improved there. But it really wasn't was it?
But like I said, they aren't competing with that. Not anymore
exact score for updated model is this. Not extremely bad, but not really decent either. Still the worst among the tier of models it's competing with

@ocean vortex good dom ok you're right qwen 30b from April is 63% better on the aime 25 than qwen 235b from July
Reasoning
🤣
I never said that. I only said that you can't take Qwen official scores for the face value and there might be something in those AA scores. But also wouldn't be unreasonable for a smaller thinking model to do better here than a big one with different finetuning
AIME25 is one of those benchmarks small models can do great at


Not normal, but that's why it's interesting and worth looking into. I think it's you who is tired @cedar tide #general message
I think you just fail to realise you don't understand this time lmao
You don't just discard what is "not normal" here. Finding things like that is kinda the whole point of AA
I just think it's worth looking into in the light of recent things involving qwen3 (arc-agi). Don't think that is hard to understand, is it?
smh
@ocean vortex OK, I'll stop giving arguments to someone who doesn't understand, when AA will fixes it, you'll see.
@ocean vortex If you find me a single model with a 50 point difference between the aime 24 and 25, I'll send you $1,000 straight away.
The issue here is more of you blindly defending them for no reason at all. I'm just being open-minded to the possibility of their official score being inflated in the same way arc-agi was. Reasonable thing to do. But also a thing that is seemingly alien for you 🤣
@dom waiting
have you did it?
Cause if not then your message is meaningless lol
It's a valid point, but as long as this is not done for qwen3 this is not an argument
I know that sometimes the scores are not the same etc, and the story with arc agi, but due to many other proofs the score of 44 is impossible at 90%
I might find time to do it myself as well. We will see. 👀
Ah well, I found the solution, if you do the benchmark and it's less than 50 I'll send you a $1000 zelle
Possibly... I'm personally not assuming that though before we find out
I'm sure you will 🤓

why not post creative writing benchmark trying to prove it's the best at math? That would have been even better 🤣

I know, and..? This is not a math benchmark and you shouldn't quote those category numbers as the equivalent to the full math benchmark 🤦♂️
It has nothing to do with aime 25 but I just love it, it amuses me to see these scores
It's hilarious seeing you thinking you got this "gotcha" moment only to realise 5sec later you misread the entire thing. Over and over. 😂
I mean the fact alone that non-reasoning qwen3 is scoring more here than the reasoning one should be a good indicator...
Yes i know its not comparable to math benchmark at all
glm 4.5 with 40 on aime 25 surprises me a lot too
and some models even have a little more than their advertised score so I don't think the problem is their harness
no brave no wine
Help I dont know what is the best ai image generator between image 4 ultra, seedream 3.0 and GPt image 1
imagen 4 ultra for text to image
and gpt 1 for image to image
bonus : flux kontext max is also great for image to image.
Yeah but for realistic image?
well nothing is too realistic till now
but i would say gpt image 1 or flux kontext max (for me). you should compare them.
flux 1.1 pro raw ultra is actually the most realistic one. but it is not availbe in LMARENA.ai
I have tested flux knotext but it didn't impresse me
Id in Black forest labs
yep. you may create 10 images (ig)
I Will try it
Yeah I dont like it
Seeing Artificial Analisys the best ai image generator for realistic images is seedream 3.0 but I dont like it
What's the fastest (medium-to-large) provider-LLM combos you guys regularly use? I have been using Qwen3-32B on OR with Cerebras as the provider, and getting really high speeds (usually above 1000 tps!). So far, I haven't seen consistently higher speeds, but .... maybe diffusion-based LLMs?
Yes there is one
Let me think
Byte dance seed diffusion @novel flame
Sweet, I'll check it out
The faster ai is gemini 2.5 flash
Very good model and unlimited
For me, Gemini 2.5 Flash hovers around 150 tps, which is 90% less than I get with Qwen3. It's a hell of a lot smarter than Qwen3, but still -- not blazing speed.
Gemini 2.5 pro
For coding, I use Claude 3.7 / 4 Sonnet or Gemini 2.5 Pro, and may consult o3 for certain types of complex questions. I was impressed by Qwen Coder and DeepSeek-Coder V2, but would not consider them on par with the aforementioned.
Not good
They are good. They just aren't as good as Gemini 2.5 Pro
Well... I can't speak to GPT-5 and I have only tested Grok 4 a tiny bit.
Yeah. Claude is the best if you don't want reasoning, and o3 and Gemini 2.5 Pro are supposed to be about the same in terms of capability
This. For me it kind of depends what I'm doing and which way the wind blows. Most of the time, Claude gives me better results, but in some situations / languages / frameworks / tasks, Gemini is better. But Claude usually wins. OTOH, Gemini is a lot cheaper, so if you care even a little about cost, then it's a clear win for Gemini. In my testing, o3 doesn't play nice with RooCode, so I don't use it for in-IDE coding assistance.

ty
Very nice discord


Does flux kontext max working well fir me its said this

Cerebras is probably the fastest provider, so it kinda gonna depend on what they are hosting...
Its not bad prompt it doesn't have anything wrong
Mistral models are hosted there iirc. But they now offer paid plans to use their chat platform
And you can't use them not going through Mistral services
Cerebras January update: Fastest DeepSeek R1-70B, Mayo Clinic genomic model, Davos appearance, and more! Learn how we're accelerating AI with real-time inference, machine learning, and case studies.


Incorrect answer
I missed Zenith.... Who did the most extensive testing on it? Any chance it's Horizon?
For me GLM 4.5 id better than Gemini 2.5 pro . It didn t make errors like Gemini ..can write 800lines with no error or problem and respect the full promt ...but you need a very detailed prompt to get the best result . But Gemini sometimes is better when it comes to designs ...
And the the ai slides is so good too 😶
Re:hallucinations and better answers
https://www.theinformation.com/articles/universal-verifiers-openais-secret-weapon
AI slides????

based on the naming, I don't think it's going to be fair
opus 4.1?? gpt 5 ??
serious ? glm 4.5 is so good?
hi
hi
I have not once gotten a noticeably better result from Opus than Sonnet (for coding), but I have sometimes gotten worse. So I don’t expect greatness from Opus 4.1 TBH
Who is that from?
Cursor head
🚀 Meet Qwen-Image — a 20B MMDiT model for next-gen text-to-image generation. Especially strong at creating stunning graphic posters with native text. Now open-source.
︀︀
︀︀🔍 Key Highlights:
︀︀🔹 SOTA text rendering — rivals GPT-4o in English, best-in-class for Chinese
︀︀🔹 In-pixel text generation — no overlays, fully integrated
︀︀🔹 Bilingual support, diverse fonts, complex layouts
︀︀
︀︀🎨 Also excels at general image generation — from photorealistic to anime, impressionist to minimalist. A true creative powerhouse.
︀︀
︀︀Blog:qwenlm.github.io/blog/qwen-image/
︀︀Hugging Face:huggingface.co/Qwen/Qwen-Image
︀︀ModelScope:modelscope.cn/models/Qwen/Qwen-Image
︀︀Github:github.com/QwenLM/Qwen-Image
︀︀Technical report:qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-Image/Qwen_Image.pdf
︀︀Demo: modelscope.cn/aigc/imageGeneration?tab=advanced
**❤️ 7 👁️ 56 **

Please upvote #1401957379435663420 message
GLM4.5 only behind 2.5pro and pretty much matches with Grok 4!! Even better than OpenAI models....Jeez...
4 out of top10 on text arena are open source now...
I think we'll start seeing local ai implementations in a year or so too





Locally? Doesn't this require like 100GB vram? You mean multiple 4090 GPUs?
Add when image to lmarena direct chat
We have a lot of good things coming this week that we're so excited to share with you! Welcome to Jules launch week!
We have Claude, google, chatgpt all coming out imminently. Big month
Please show the Google updates 🙏
we saw gpt-5 trending last night — looks like we're both ready, @sama.
just wondering when we can flip this switch on flowith.

We may see all 3 companies release their models this week
Certainly seems to indicate that
For googles coding agent yeah
She said multiple things though
Again she said multiple things coming this week

ty ty!
saw there was issues td an my chats are also gone, anyway to retrieve or just gotta start fresh?
The website doesnt have accounts so I guess you have to start fresh
Unfortunately, there isn't a way to obtain the chats once they're gone. We are working on different features to prevent this, but atm there isn't much to be done sadly.
GPT5 is tomorrow
Do people already know this kek
Nope


Oh actually. The livestream is tomorrow
Doesn't guarantee release ig
Source?
lamps and shortfilms said no

his behind
Think Jules stuff is known to be one of the things
They're obviously going to drop something in an attempt to take wind from gpt5 drop, so should be something worthwhile I'd guess
Alibaba's Qwen-Image is the new leading open weights Text to Image model! Imagen 4 and FLUX.1 Kontext [max] level image generation is now available to the open weights community
︀︀
︀︀Alibaba gave us early access and we've had Qwen-Image secretly in the Artificial Analysis Image Arena for a few days.
︀︀
︀︀The model is currently #5 in the leaderboard and is the leading open weights model by a large margin. The next open weights models are at places #18, #21 and #26.
︀︀
︀︀The model follows an approach similar to GPT-4o of leveraging an autoregressive transformer architecture for image generation and editing. This model takes a dual encoding approach: Qwen2.5-VL encodes the semantic meaning of the prompt, while image generation happens in a latent space using a diffusion model called MMDiT. The final image is produced from this latent space using a VAE decoder.
︀︀
︀︀See below for a link to see the model yourself in our Image Arena and a link…

hi
@ocean vortex Well well, what’s Qwen doing here? 🤣

@ocean vortex Whats that ? 🤣

@ornate agate @torn mantle 😶
lol xddd
hello
I hope you're not serious

ok yeah, that was their mistake then...

Not-reasoning fixed too. That's what I meant by saying earlier it was low. Now it's a whole different ball game... @cedar tide

before this was ~31%
@ocean vortex You dont see here ?
and as much as I spoke of reasoning I also spoke of without
? I do but that ss lacks context (other models)
has anyone experienced this before please, it has been stuck here since and i cant cancel it. can someone help please

when I said the low score for the model without Reasoning was normal, we were talking about april qwen 3


We were talking about both, well at least I was. Updated model score was not much better. Now it's like twice the old score or even more lol
ok when I said it was normal I was talking about the old one and I still think his score is normal. but yes the new one his score was not good I said it during my first message
Qwen-Image by @Alibaba_Qwen is now available at fal, as a scalable & ready-to-use API https://t.co/lRTMPCidoN

Now it's much more representable and a jump to reasoning makes sense for a hybrid model. Looks better against direct competitors as well.
I wonder what it was exactly leading to such a drastic difference...
velocilux looks like an interesting model
Has anyone got "triangle"?
is gpt-5 + gemini 3 + claude 4.1 all coming at once in the same week? 😮
appears to be
competition ftw
and OpenAI opensource model this week
It would be strange for Gemini 3 to just pop up before it appearing on lmarena first.
under a codename
I thought we had lot of google models better than 2.5 pro that were tested on lmarena and disappeared. May be one of those? Although I doubt 3 is coming this week without any leaks so far...
the most current google model on lmarena is nightride-on
We would have already see the screenshots of indications of 3 coming soon like we do for GPT-5...
it's good but not a jump from 2,5
What about GPT5? Did it even have enough votes to appear on lmarena when they announce it? It seemed like it was there for just couple o fdays...
on lmarena
Assuming summit/zenith is GPT5...
Hard to tell. I was not impressed with either. Maybe for coding they are good, but not for common conversation.
Probably neither of them were the most powerful variant of gpt5. Like grok heavy and o3 high are not here on lmarena.
Hi is the grok not working??
Grok 4 on imarena
When i ask what model are you it says grok 2
<@&1349916362595635286>

Yeah good callout, we did address this in a different forum post so let me find you that.
But would ask to not use the @ moderator ping for questions like this. That ping should be used for mod purposes, not general questions or feedback.
Oh alright sure thank you, I'm new here so didn't know the rules
No problem, just a heads up.
I responded to your forum post but regarding Grok -> #1393024188356362340 message
🤔

🍊
🍊
🧢
basic html editing with inspect element
that post is just interaction bait
its zoomer's version of "hacking" lmao
Hm seems later in the week
Not today rip
I don't think they even know ngl, there is a chance of delays
They know actually. We use the same recommended parameters as Qwen3 when submitting to AA. However, they did not use our official API, so I couldn't help them locate the problem and fix it.
🍊
If one day, the next generation llms is behind a spam link ^^ (likely kinda never happening)
I'm offering an open test session to anyone who would like to test an actual "thinking " AI that uses recursive thought processes to discover rather than linear pattern matching elevating any llm using my framework
probably 2.5-002, still remember creativity of wolfstride
Scene: A room. A body, completely covered with cloth, lies on a cot. A religious scholar stands to the left of the body, and an assistant stands at the head.
Time 0-2 seconds
Religious Scholar: "Make sure the entire body is covered. No part of the body should be exposed under any circumstances."
(The scholar slightly lifts the head of the body. The assistant stands nearby with a washing vessel.)
Time 2-5 seconds
(The assistant bends their right knee and places it on the cot.)
Time 5-8 seconds
(The religious scholar holds the nape of the body with the thumb of their right hand. They slowly lift the body and lean it against the assistant's bent knee. The assistant's knee acts as a support under the back of the body.)
call me stupid but i had some important work on https://lmarena.ai/c/10a6734a-65e4-4a8e-b221-e265671762b9 is it possible a admin can please fix it. its just spinning ai is stuck
about to lose entire week of work 12 hours a day i spent
but lucky i can still view the context very hard to short over all the text
I'm in
I have finally got "triangle". Makes some good points, but nothing extraordinary.
i'm in..
Did grok update image?
is video battle only available here on discord? or will it be on the website too eventually, i dont see it on the gradio or new ui versions
soon...

Holy cow, GLM-4.5 may be as good as the hype. I really didn't expect it since previous GLM versions have all been a bit meh in my testing. But it just (barely but still) scored a 5/5 on my test suite and destroyed everything else (including Horizon Beta, Grok 4, o3 Pro, Gemini 2.5 Pro, Claude Sonnet and Opus) in my separate "create-an-html-game" test. It has some quirks for sure, got into an infinite thinking loop in one test and got different answers in thinking vs actual response in another, but it's overall really strong.
Gemini 3 will btfo openai fanboys

Wait does LMAREA actually use the model stated like GPT 4.o etc
What this benchmark ?

New benchmark ? Artificial analysis lcr ?
@ornate agate real score of glm 4.5 by an very serious benchmarker https://matharena.ai/

MathArena: Evaluating LLMs on Uncontaminated Math Competitions
fr?
yeah that's impressive. AA probly didn't have time to rerun their tests yet
only did it for Qwen3
yeah
though lack of transparency from them is not ideal tbh
They obviously found what was wrong with Qwen3 testing but only silently changed the score lol
Any free Ai agent tool that let's us use Ai on browser to perform any tasks
Just want to try it out seems fun
it should in theory at least ace all of them except those 4:

Yo what's Glm 4.5??Is it deepseek alike?
Pretty much, yeah. Different Chinese company/startup though.
Will my images i’d upload to LMArena kept private?
Looked a bit into Z.AI who made that GLM4.5. They are some technically independent company from Tsinghua University, but their investors include Alibaba, Tencent, Xiaomi...
@novel flame DM me when your ready I'll send you a link
NO make sure you re-read the disclaimer when you load the site!!
don't worry, i haven't posted anything personal there yet.
yet?! lol
well, now that i know, i won't.
Never said it was normal or not normal, simply stating the facts lmao
good, yeah as part of the value proposition for the free arena, you consent by using it that everythig you type/upload and the voting/output becomes creative commons licenced
Also it's no secret that Anthropic is well funded by this point
I was actually not meaning to imply anything, but if you really want to dive deeper, we can do that 😇
https://www.globalneighbours.org/chinas-zhipu-ai-secures-140-million-investment-from-shanghai-state-funds-amid-ipo-push/?utm_source=chatgpt.com

By Liu Peilin and Denise Jia Chinese generative artificial intelligence unicorn Zhipu AI has secured 1 billion yuan ($140 million) in fresh funding from Shanghai’s state-backed investors, boosting its momentum ahead of its planned initial public offering (IPO). The announcement coincided with the unveiling of new products aimed at strengt...
@ornate agate
Z.AI is VERY well funded, including state funds
Is GPT-5 still acessible within model in lmarena?
It's weird to have a long context reasoning benchmark if the max context length of the benchmark only goes up to 128k
It's kind of like those video benchmarks that turn off sound except worse
I mean you could solve that with a matrix
Maverick and GPT-4.1 as well iirc
Yeah and I think that should be represented in any benchmark whose purpose is to measure reasoning over long context
I've been wondering about this for a long time too, i can only guess it's an economic calculation bc of the recursive nature of their architecture that is super expensive to tun...people using claude code has pretty good workarounds for limited context at coding, not sure about the others tho
this might be cool later today

We’re inaugurating Kaggle Game Arena with a 3-day AI chess exhibition tournament featuring 8 frontier models.
"We’re inaugurating Kaggle Game Arena with a 3-day AI chess exhibition tournament featuring 8 frontier models."

sigh why it's chess again...
out of so many fascinating games you can choose, it has to be chess, for AIs...
the kaggle game arena won't just be chess. it will be a buch of different ones. they're just launching it with this chess tournament
it's not that...exciting, it's just strategy optimization, nothing intelligent actually
There's a small chess-playing network inside LLMs, haha
I'm still amazed non reasoning models can decode base64 almost perfectly in one shot
There are different versions for different context sizes. Like look here at the bottom:

the thing is, almost all of the recent models will be able to run the 128k one. But only a few can run >128k

What if you could not only watch a generated video, but explore it too? 🌐
︀︀
︀︀Genie 3 is our groundbreaking world model that creates interactive, playable environments from a single text prompt.
︀︀
︀︀From photorealistic landscapes to fantasy realms, the possibilities are endless. 🧵
so direct comparison only possible with the smallest common size
And they should be punished / rewarded accordingly
They kinda are already punished to be fair. Models on 128k test that have context size beyond that generally score higher
like 4.1-nano does 30s for 128k but only low 10s for it's entire context size lol
Just because Gemini is in a class of its own doesn't mean the benchmarks need to put o3 above Gemini
They literally just need a matrix. It's not that complicated

True for full-context attention (Transformers), but not for all architectures. RNNs scale linearly with constant memory. DeepMind's Titans architecture only uses attention for a small window, and its memory module for everything beyond that. The next leap in AI won't be a standard Transformer, it will be something else.
that gif more suiting lol
Do you think GPT-5 will have 1 Million Context window?
Would be surprising if it didn't. Doubt it tops long context benchmarks but should definitely be able to take 1m and route to one of their models that can run
I wtf
Yea, fair. I just don't get how GPT-5 being a router model will be able to preform well unless the underlying models are also getting an upgrade.

Even Jimmy Apples says "you won’t notice the improvement in gpt5. if you’re a heavy user and you use lots of different models. there’ll be no difference for you."
They most definitely contemplated making it even bigger than Gemini (for headlines and stuff) but not sure that is realistic... 1M is a reasonable guess tbh
Yea, but right now with how the AI landscape is right now; more than 1M would not be very well fuctioning as it would start forgetting stuff
It forgets things regardless of the context size. Main use case of context is single input size
Like giving it entire movie as a singular input
(Even Gemini at 1M already does this)
how does that passing through api💀
yea
But if you give it in a single input, it will recall everything surprisingly well
kaggle arena in 3 hours 💪
I wonder what are the rules if a model hallucinates a move
illegal move for instance
It's when you start messaging it a lot a bunch of times where it starts forgetting
What's happening there?
#general message @raven helm
Thanks!
Gemini vs Claude - game to watch
my bet for final o3 vs Gemini due to context adherence
i wonder is it opus thinking? and o3 high or what
Yea, that'll change the landscape of it a bit, when they have thinking on/on highest it usually performs better.
Gemini 2.5 pro is always thinking, so opus has to be thinking too. Or rather unfair.
Hopefully (I've seen a lot of people not even know the diffrence between 4o and o4)
What do you mean by AI Module?
LLMS
brian what're the realistic expectation for Gemini 3?
Ilke llm is not chatgpt but what that powers it ilke 4o Grok 4 heavy then grok yeah
So I guess better long context is one of the major improvements
Need that
I want better instructions following but I'm not sure Gemini 3 will be better at that
But it has an "r" tag though
maybe "researching"
aka long term
TITAN and ATLAS proposed ideas for long context but I don't know if they are implemented in Gemini or still experimental
Yeah brian human has a really strong short term memory, about 30 seconds
this is so obvious who’s going to win, isn’t it, opus spends half its compute on alignment that causes him reflecting existential philosophy in the middle of calculating chess strategy 😅
kingfall
he's wrong.
Obviously in terms of the autorouting he's correct.But it's not just auto-routing
Genie3 is just going to be basis for Video Game Engines, right?
kingfall never skips a thought, while wolfstride often skips thinking and outputs directly, like 2.5pro. These are not iterations to improve performance, but rather to reduce cost and inference load.
I'm 100% sure now, after they split off the deepthink consumer and deepthink IMO versions
Are others having issues with direct & side-by-side atm?
hi
Sometimes there are bugs where a retry and clear window is attached
we have a lot of new stuff for you over the next few days!
something big-but-small today.
and then a big upgrade later this week.
Open Source was expected today
no leaderboard?

XD
Yeah they haven’t confirmed it but the long-context performance graph from the Titans paper looks suspiciously similar to Gemini 2.5 long context performance.
Picture i found online

jesus

when's GPT5 being added to the arena? Is it up already?
Let's suppose GPT5 does get added to LMArena, how long would it take for it to beat Gemini if it is proven to be better?
It won't be an overnight process, correct?
when was this?
@echo aurora need to add this to webdeb
https://x.com/alexalbert__/status/1952769273056915482?t=RS3UG35iltw8R1AR7kFo6Q&s=19
Say hello to Claude Opus 4.1, our best model yet for real-world coding, reasoning, and agentic tasks.
The frontier continues to move forward one update at a time.

Competition is amazing. All these companies are forced to release their best models as soon as possible
Sorry about that! We are looking into!
 this is on our radar.
this is on our radar.
Opus 4.1 2% improvements lmao
marginal increase with no change in pricing, is it an unfinished release?

not surprising to see, if they keep adding conflicting contradicting alignment trainings instead of scaling, well, the capabilities, the newest system prompt this month is super long with...many interesting twists
Hahahahah
bro
We need Opus 4.1 in the arena
There is no difference from opus 4 in the arena
i dont think it's that big a difference to 4
haha
they're trying hard to dominate in the agentic coding space i feel, but the stricter alignment training is literally making claude more dumb or is it just me?
This is most likely a regular response to chatgpt 5. To keep claude from going too far
prob just u
We plan to release substantially larger improvements to our models in the coming weeks.

Did they release it by accident
hi good afternoon
Hello, OpenAI just launched their new open source models

Advanced open-weight reasoning models to customize for any use case and run anywhere.
The online demo was working, i tried it
For me it is completely down, I send a request and nothing comes back
Prob too much people

There is literally nothing on their YouTube channel
Gpt oss is trash
Why?
I think china still dominates open source
those two models are probably the horizon models right ?
no
they are text-only
Nah, it won't help them get better models lol
any new model on Arena in last 1 week ?
claude 4.1 opus✅ live on flowith
gpt-5 ☑️ aug 7th
gemini 3.0 flash☑️ source from google: not this week
this timeline is unhinged

gemini 3.0 is not coming for atleast 2 more months.. no point even thinking about it
Apparently its on testers hands already so idk about it
The flash one atleast
they are lying.. i am 100% sure
ok 95% sure 🙂
So in the end horizon models on openrouter aren't the open source model huh
whcih model is horizon?
so OAI Opensource 20b can run on 16gb RAM, has ~o3-mini performance




I already requested the model on #1372229840131985540. Would be nice if you guys upvoted to get it on LMArena.
the 120b model is pretty good, but not going to be a product for an average computer
now i want to see how local AI is implemented since we have a bunch of models that should work plenty well
gpt oss is already available in direct battle
The 120b model is ~ the O4mini. So our closest comparison to QWEN3 and Deepseek

very impressive for a much lower parameter model
The problem is that qwen model are bad in real world cases
They are just good for bench
didn't know that. For these models, I'm just interested in how other companies decide to implement them into devices. So havent been following real performance closely
Kimi and deepseek are the open source models actually good
The rest is just benchmaxing
new chatgpt retry button

Kimi k2 parameters and comparison to o4 mini?
I think kimi k2 is trillion parameters
realistically I think the small ones are the most interesting (20b), but just curious for comparison sake
claude opus 4.1 is live on yupp ai if anynoe wants to use it for free
glm 4.5 is also good
hell yes
4.1 is live on lmarena
YO CHAT WHATS THE BEST AI FOR SCRIPTING

its claude but like which version
claude sonnet 4 no think
Does anyone know how to select a specific AI? I need the veo 3
offline translation device is a good example of a potential strong application
how do i put veo 3 vs seedance does anyone know ?
opus 4.1 is very good. A highlight.
OK I put GPT-OSS 120B (high) through my standard tests, and it's almost Llama 4-level disappointing. I mean, sure, it's not a huge frontier model and we shouldn't expect it to perform at that level, but OpenAIs own numbers have it almost on par with o3, which is nooooooot what I'm seeing. I'm seeing performance maybe on par with o3-mini or Qwen3 235B A22B or maybe Kimi K2. And I am seeing more hallucinations than any other model, only matched by Llama 4 Maverick.
Which, for a free & open source model is still pretty decent.
There are however two problems: The first problem is OpenAI are making claims that are too optimistic. And the much bigger problem is GLM-4.5 exists, is open source, and is an absolute beast.
And with this in mind, I'm not even going to bother testing the 20B model right now. It's never going to match o3-mini if the 120B model can barely do that.
secure summaries for lawyers and doctors too

Opus 4.1 with prompt: Create a simple 3d tank game with ai oponent
woah
Does this mean the oss hallucinates most of the time? 😆

someone needs to put that rotating hexagon prompt into opus 4.1
"I'll be in my bunk"
i feel like it sh*ts over summit and zenith
always take it with a grain of salt when it comes to such statements, there are much we still don’t know about the brain, there is a reason why brain transplants don’t work. Its purely PR marketing
What is gpt-oss ? Is for chat or web dev ?
full suite

i didnt realize that there are 3 versions of each
not great for translation sadly
wth

opus 4.1 disappeared!
benchmarks arent great anyway, but they said big improvements in next few weeks
Yes 😢
@echo aurora bring back opus 4.1 🙏 better thinking 😄
did they release gpt5?
it actually knew what certain games were about
any interesting news?
i liked that opus 4.1 gave long answers instead of usual concise from opus 4.0
gpt5 in 2 days
Opus 4.1 on yupp if someone wanted to try it
we had 4.1
We got Opus 4.1. Anthropic says massive upgrades to it in next few weeks too
GPT open source 120b and 20b
Genie 3
why was opus 4.1 removed so early
What does GPT opensource 120b and 20b mean?
too many requests probably
is opus 4.1 really that good?
small models that can be used, downloaded, quantized
20b is the interesting to me (assuming its not crap)
Antrophic models are expensive prob their adding rate limits
its a 2% upgrade...
i think its upgrades are mostly non benchmark, but i have a feeling the big benchmark upgrades are the one they are referring to
lmarena doesnt pay for their models
anthropic donates
I thought they really pay for them
yeah brother
i can see its giving longer answers in general
so all the companies donate
huh, interesting.

Do you guys use Gemini Pro 2.5 ultra subscription?
no
Are there better alternatives to coding projects? I always get rate limited on Gemini
can run on 16gb ram. Maybe less when quantized. So there are lots of application for it. Less so imo for the larger open source models (which are the majority)
Do you think GPT5 will beat Gemini pro on LMArena?
Of course
idk, probably? But Gemini 3 is coming in the next week(s), so that's just something to watch
wait they're releasing Gemini 3 this month?
lots of hints about it, yeah should be
wdym lot?
Source?
Maybe just anonymous things as always
yes
Experimental
lmarena is committing crimes against AGi by removing opus 4.1
guys lets not guess
they will release it when ready
even when they do
do you really think gemini 3 flash will be in a position to beat gpt-5?

we still get free access so it's worth waiting
It must
they removed it from the announcement too
what's the best ai for coding?
gpt 1.5



Hikaru is steaming this by the way. 2.5 pro about to sweep opus in round one

It's going to be in battle mode only atm.
thank you for letting us know
For reasons we should think Gemini 3 is coming very soon
oh
Is it because of rate limit
Are you smarter than an average bear?
I see what you did there! And probs not XD
It’s over
Just thinking effort
I guess that's not okay Boo Boo!
okay it's weird af calling someone else boo boo
For context: The GPT-OSS 120B (high) model scoring 44.4 on Aider Polyglot is hardly impressive considering:
- Qwen3 235B A22B: 59.6
- Kimi K2: 59.1
- DeepSeek R1: 56.9
- DeepSeek V3 0324: 55.1
I don't know if GLM-4.5 has benchmarked Aider Polyglot yet, but I would guess it'll score considerably higher than all of those.
none are really useful for a portable translation/summarization device though. All far too big
but yeah way too low
Have you considered Qwen3 32B? It's quite impressive for the size.
a quantized version could be really good

is the gpt oss on lmarena high reasoning
polymarket's going nuts today
this is the biggest week for AI
They think Google's going to lose to OpenAi
because of gpt5?
no
Is gpt5 that great?
do we care? competitions good, whatever is great is what we'll use
we'll see which is best soon
including google?
Google is preparing one .
they should release 3.0
Google may wait for the realese of gpt5
Oss 120b This model generally responds poorly as a human, as if it has been degraded compared to 4.1 and even more so 4o
has this been announced?
a quantized version could be really good
it doesnt convince me
2.5 pro got released a few days after it appreared on lmarena under name "nebula". I assume the same thing for 3.0
but the benchmarks are crazy
could u explain pls? Are the benchmarks for GPT5 out?
No, they are not out
the new open source model form open ai
A new open model from openai from 2019
Huhhh
Literally 6 years have not produced open models of "everything for humanity", yes, we believe))
gpt oss is in artificial analysis but they havent benchmarked it

In two days maybe ...
august 7
My fav ytber ❤️

Get started now with privacy focused VPN by Proton! https://proton.me/pass/bycloudai
Can a neural network write its own data and skyrocket past GPT-4? In today's video, we dissect the brand-new “Self-Adapting Language Models” paper (SEAL), where an LLM fabricates synthetic data, tunes LoRA adapters, and after just two rounds, outperforms mu...
I think OpenAI doesn’t always release new models on time, and usually gives access to Pro users first, and only then to Plus users.
What do y'all think about perplexity comet
word on the street is gpt5's coming out in 2 days
is gemini 3 already coming?
It's all a rumor
